Embed Size (px)
Citation preview

Estruturas de Dados Probabilísticas para lidar com
DADO PRA CARAMBA
Juan Lopes@juanplopes


Bloom Filters (1970)Hit Counting (1990)HyperLogLog (2007)

Detectar duplicações
indexar(documento): se documento não está indexado: lucene.indexar(documento)

Detectar duplicações
indexar(documento): se documento não está indexado: lucene.indexar(documento)

Consultar no disco?

Consultar no disco?

Consultar em memória?
HashSet<T>

Consultar em memória?
100M ids

Consultar em memória?
100M ids × 32 chars / id

Consultar em memória?
100M ids × 104 bytes / id
> 10GB

Consultar em memória?
100M ids × 104 bytes / id
> 10GB

Bloom Filters
I had a big data problem,"I know, I'll use a bloom filter."
Now I'm not sure how many problems I have, but I know
which ones I don't.

Bloom Filters
Adicione!(item)
Contém?(item)

Bloom Filters
Contém?(item)não 100%sim ~95%

Bloom Filters0
0
1
0
0
0
0
0
xh(x)

Bloom Filters1
0
1
0
0
0
0
0
xh(x)
yh(y)
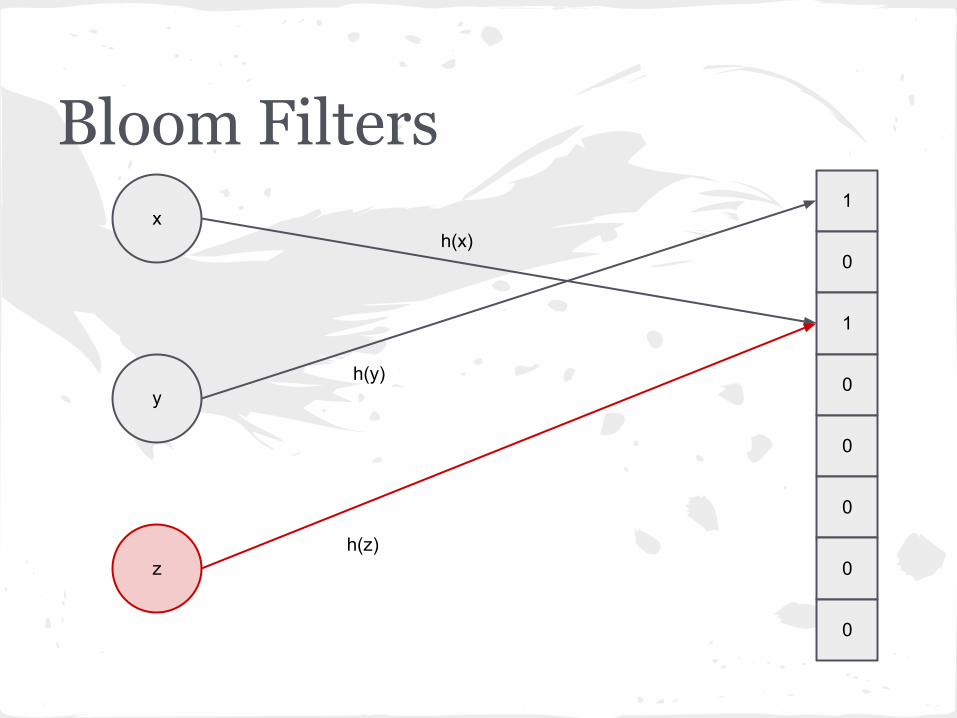
Bloom Filters1
0
1
0
0
0
0
0
xh(x)
yh(y)
zh(z)

Bloom Filters
adicionar!(item): V[hash(item)] ← 1
contém?(item): retorne V[hash(item)] = 1

Bloom Filters
100M itens2Gbits (256MB)
5% de erro

Bloom Filters1
0
1
0
0
1
0
1
xh(x)
y
h(y)
z
h(z)
g(x)
g(y)
g(z)

Bloom Filters
adicionar!(item): para cada hash em hashes: V[hash(item)] ← 1
contém?(item): para cada hash em hashes: se V[hash(item)] = 0: retorne falso retorne verdadeiro

Bloom Filters
100M itens4 funções de hash625Mbits (78MB)
5% de erro

Bloom Filters
100M itens5 funções de hash
1Gbit (128MB)1% de erro

Bloom Filters
100M itens7 funções de hash
2Gbit (256MB)0.01% de erro

Bloom Filters
Probabilidade de falso positivo:

Cardinalidade
Quantos ips distintos acessaram o site na
última hora?

Cardinalidade
Qual a cardinalidade do stream S?

Consultar em memória?
HashSet<T>

Usando HashSet
adicionar!(item): S ← S ∪ { item }
quantos?: retorne |S|

Consultar em memória?
>10K eventos/s

Consultar em memória?
> 10K eventos/s × 3.600s/h × 100 bytes / evento
> 3GB/h

Consultar em memória?
> 10K eventos/s × 3.600s/h × 100 bytes / evento
> 3GB/h

Hit Counting
-c log (z/c) n/10 bits2% de erro

Hit Counting
-c log (z/c) n/10 bits2% de erro
36M eventos3.6Mbits450KB

Hit Counting
adicionar!(item): V[hash(item)] ← 1
quantos?: z ← número de zeros em V c ← tamanho de V retorne -c × log(z/c)

HyperLogLog
Contar até 1 bilhão de elementos usando 1.5KB


Hash
"To hash" é "espalhar"

Hash
04 = 0000010008 = 0000100012 = 0000110016 = 00010000

HashIt is theoretically impossible to define a
hash function that creates random data from non-random data in actual files. But in practice it is not difficult to
produce a pretty good imitation of random data.
Donald Knuth

HyperLogLog
Qual a probabilidade dos n
primeiros bits serem 0...01?

HyperLogLog
1xxxxxxx -> 50%01xxxxxx -> 25%001xxxxx -> 12.5%0001xxxx -> 6.25%

HyperLogLog
Dado que existe uma palavra com os n
primeiros bits 0...01, qual a
cardinalidade provável?

HyperLogLog
1xxxxxxx -> 201xxxxxx -> 4001xxxxx -> 80001xxxx -> 16

HyperLogLog
Multiplas funções de hash?

HyperLogLog
Dividir o stream em "m" substreams
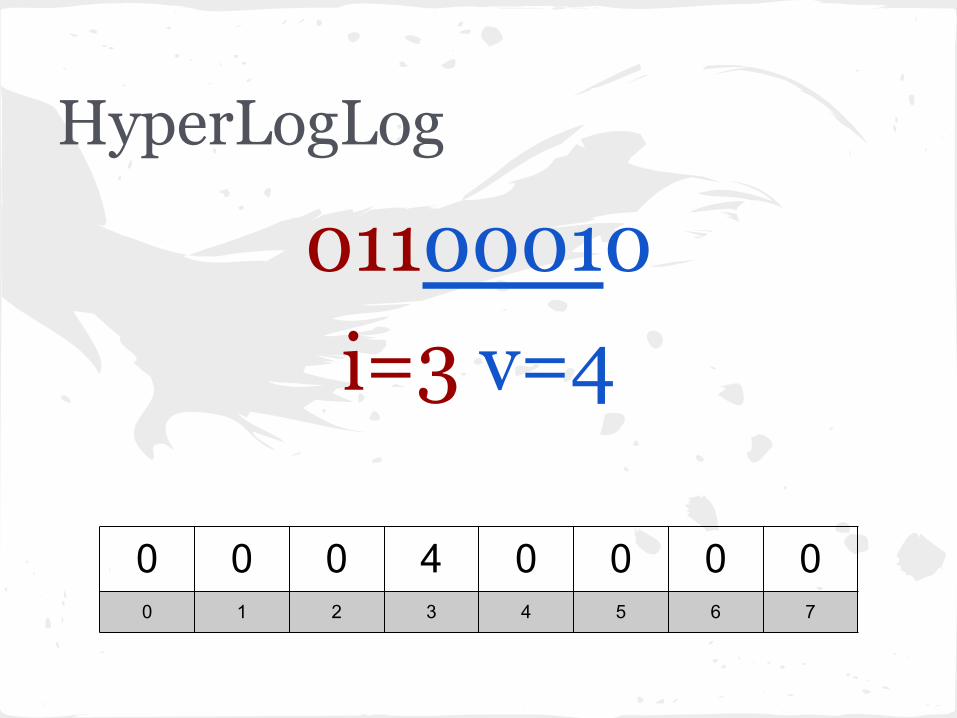
HyperLogLog
01100010i=3 v=4
0 0 0 4 0 0 0 00 1 2 3 4 5 6 7

HyperLogLog
21 22 20 24 20 25 20 20
1 2 0 4 0 5 0 00 1 2 3 4 5 6 7

HyperLogLog
2 4 1 16 1 32 1 11 2 0 4 0 5 0 00 1 2 3 4 5 6 7

HyperLogLog
2M(i), i<m

HyperLogLog
Ê = média(2M(i), i<m)

HyperLogLog
Ê = m × média(2M(i), i<m)

HyperLogLog
Ê = αm × m × média(2M(i), i<m)
αm=

HyperLogLog
Ê = αm × m × média(2M(i), i<m)
αm=
αm= (0.7213 / (1 + 1.079 / m))

HyperLogLog adicionar!(item): x ← hash(item) i ← log2m primeiros bits de x
v ← pos. do primeiro 1 nos bits restantes de x M(i) ← max(M(i), v)
quantos?: retorne αm × m × média(2M(i), i<m)

HyperLogLog
média aritmética:(M(0) + M(1) + ... + M(m-1)) / m
média geométrica:(M(0) × M(1) × ... × M(m-1))1/m
média harmônica:m / (M(0)-1 + M(1)-1 + ... + M(m-1)-1)

HyperLogLog
Registradores Erro
m (104/√m) %
m = 2048 (1.25KB) 2.3%
m = 65536 (40KB) 0.4%
m = 1048576 (648KB) 0.1%
Cada registro de M tem 5 bits. Por isso "LogLog":log2(log2(232)) = 5

HyperLogLog
Para baixas cardinalidades, o erro
relativo aumenta.

HyperLogLog
quantos?: Ê ← αm × m × média(2M(i), i<m)
se Ê < 2.5 × m: z ← número de zeros em M retorne -m × log(z/m) senão: retorne Ê

HyperLogLog
1 2 2 4 0 5 0 00 1 2 3 4 5 6 7
5 0 1 0 5 2 3 10 1 2 3 4 5 6 7

HyperLogLog
1 2 2 4 0 5 0 00 1 2 3 4 5 6 7
5 0 1 0 5 2 3 10 1 2 3 4 5 6 7
5 2 2 4 5 5 3 10 1 2 3 4 5 6 7

ReferênciasSpace/Time Trade-offs in Hash Coding with Allowable Errors (Bloom Filters)http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.20.2080
A Linear-Time Probabilistic Counting Algorithm for Database Applications http://dblab.kaist.ac.kr/Publication/pdf/ACM90_TODS_v15n2.pdf
HyperLogLog: the analysis of a near-optimal cardinality estimation algorithmhttp://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
Hashing Explained - Google Guavahttp://code.google.com/p/guava-libraries/wiki/HashingExplained
StreamLibhttps://github.com/clearspring/stream-lib


![Active Sessions [0] - html5 vs Flash](https://img.document.onl/doc/110x75/540464398d7f72aa768b4745/active-sessions-0-html5-vs-flash.jpg)





















![[FLISOL] Android Faixa Branca (Iniciando no Android) – 2013](https://img.document.onl/doc/110x75/5404d97c8d7f72a6768b48b2/flisol-android-faixa-branca-iniciando-no-android-2013.jpg)




