Embed Size (px)
DESCRIPTION
Treinamento hadoop - dia4
Citation preview

Treinamento Hadoop
Parte 4

Alexandre Uehara
● Analista Desenvolvedor (E-commerce)
● Coordenador Trilha Big Data (TDC
2013)
http://www.thedevelopersconference.com.
br/tdc/2013/saopaulo/trilha-bigdata#programacao
● Geek e nerd, trabalha com Python,
Java, C, BigData, NoSQL, e outras
coisas mais que aparecem no dia a dia

NossaAgenda:

Dia 4!!!

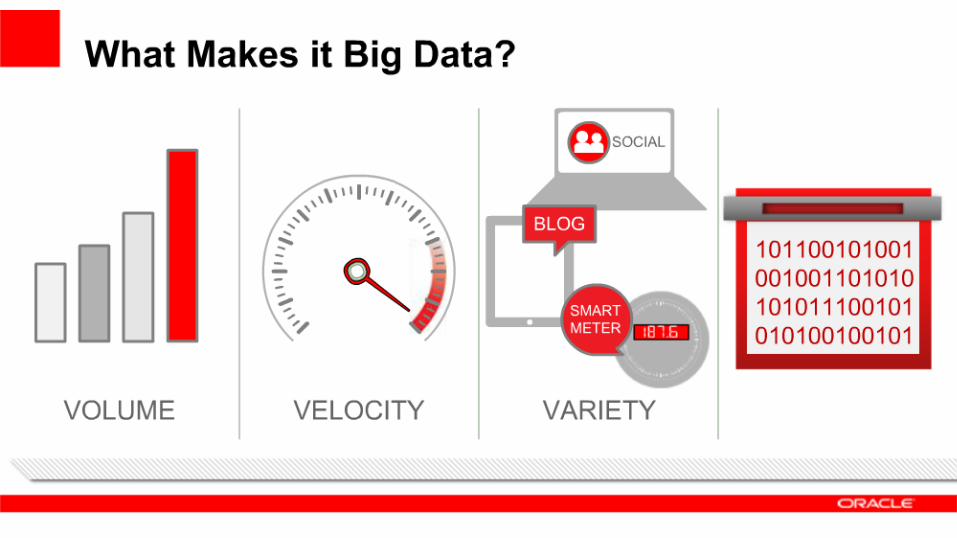
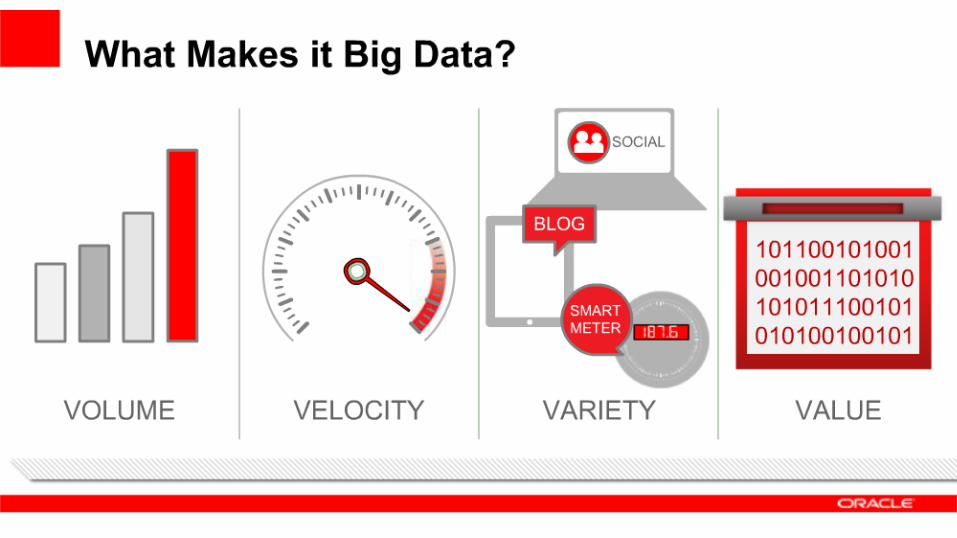
Dia 1:IntroduçãoConceitos Básicos Big Data→ O que é?→ 4 V's→ Por que agora?→ Onde Usar?
→ Desafio→ BI x Big Data→Profissional de Big Data→ Ferramentas→ Dicas

Dia 2 e 3:Map Reduce e Hadoop→ História (Google)→ ConceitoMapReduce→ Hadoop→ Cases

Dia 4Outras
Ferramentas→ Ecossistema→ Ferramentas → Distribuições Hadoop→ Hadoop na Nuvem
→ NoSQL Tipos → NoSQL Exemplos → Data Science → Machine Learning

Dia 5, 6 e 7Hands-on
→ Python→ Hadoop

Não aguento!!!

Calma…
Último dia
teórico

Big data
Big data ferramenta
Big data Hadoopferramenta
Big data Hadoopferramenta
A partir dele criou-se
Big data Hadoop
MapReduce
ferramenta
A partir dele criou-se
Big data Hadoop
MapReduce
ferramenta
A partir dele criou-se
Criou
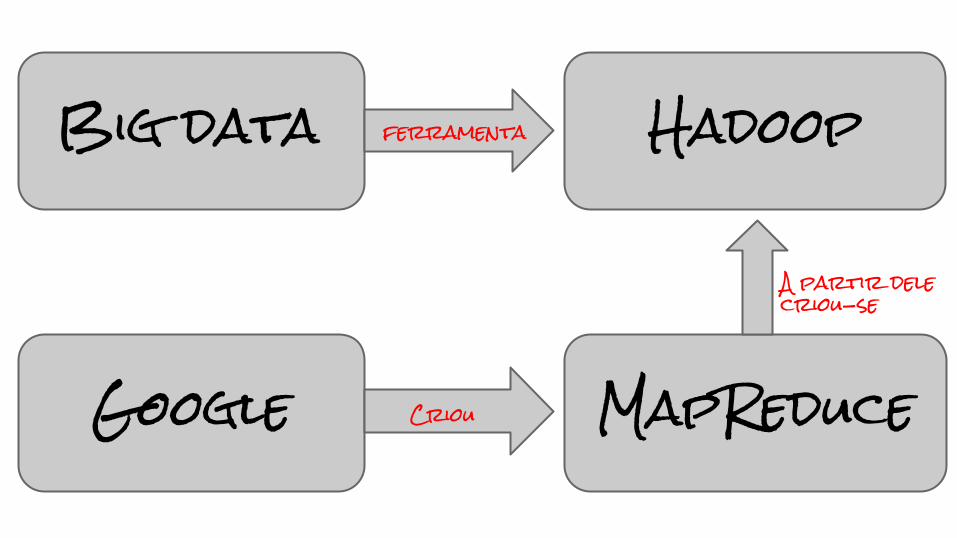
Big data Hadoop
MapReduceGoogle
ferramenta
A partir dele criou-se
Criou

Map ReduceGoogle
FileSystem
Google Map Reduce
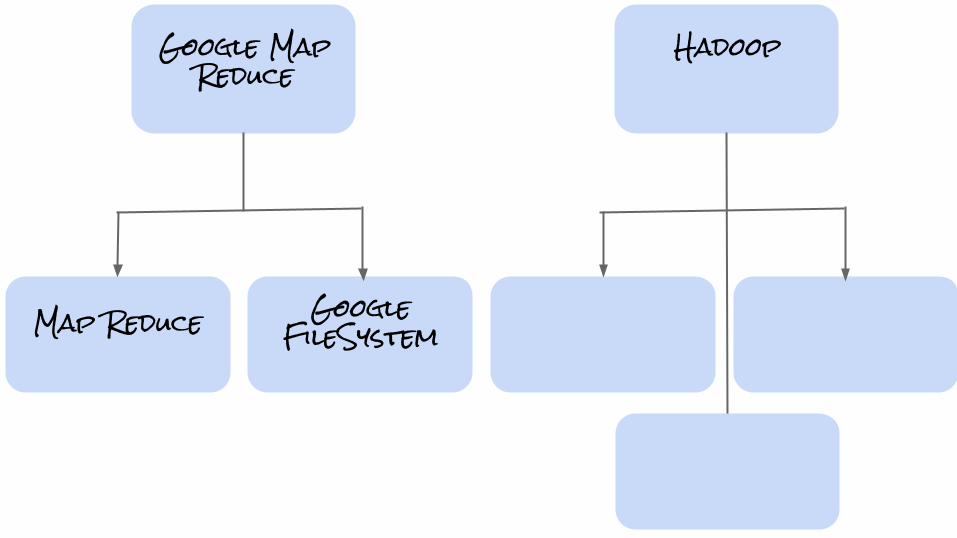
Map ReduceGoogle
FileSystem
Google Map Reduce
Hadoop
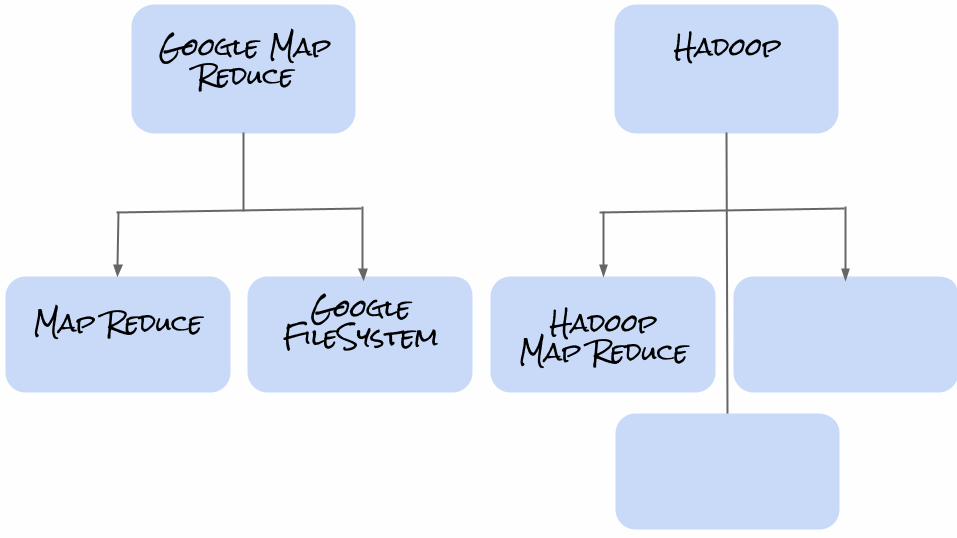
Map ReduceGoogle
FileSystem
Google Map Reduce
HadoopMap Reduce
Hadoop
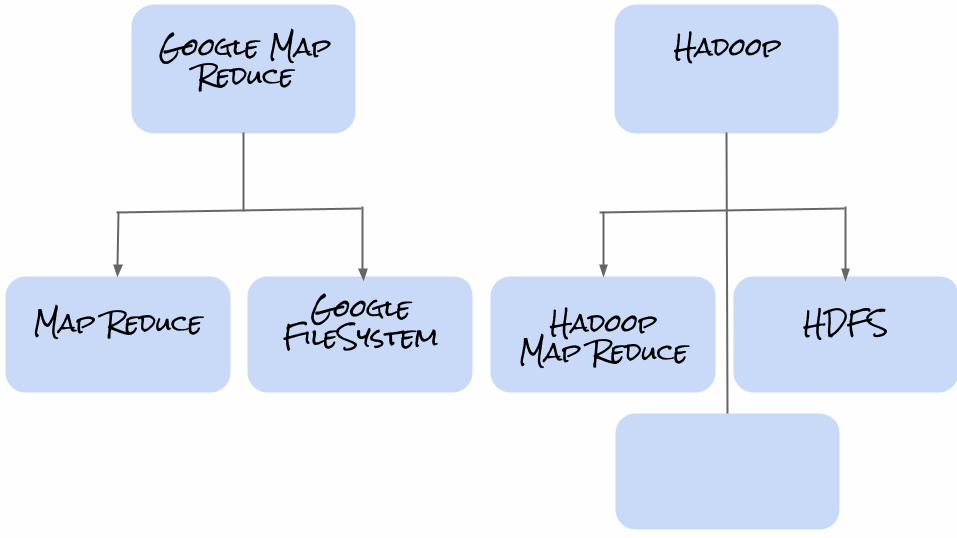
Map ReduceGoogle
FileSystem
Google Map Reduce
HadoopMap Reduce
HDFS
Hadoop
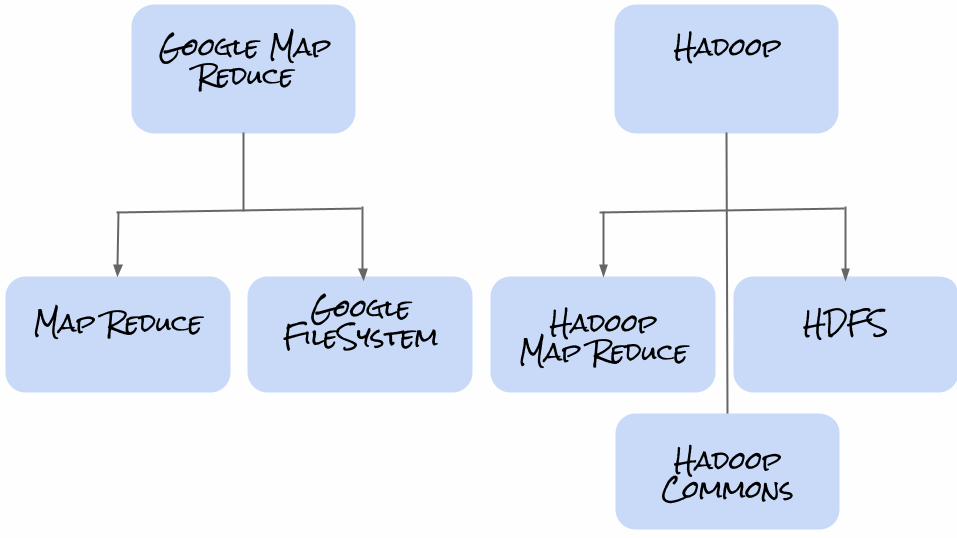
Map ReduceGoogle
FileSystem
Google Map Reduce
HadoopMap Reduce
HDFS
Hadoop
HadoopCommons

Map Reduce
● Decompõe tudo em ???

Map Reduce
● Decompõe tudo em Pares - chave :
valor
● Depois???

Map Reduce
● Decompõe tudo em Pares - chave :
valor
● Depois sumariza os resultados

Nó Master
Nó Slave

Nó Master
Nó Slave
● NameNode

Nó Master
Nó Slave
● NameNode
● SecondaryNameNode

Nó Master
Nó Slave
● NameNode
● SecondaryNameNode
● JobTracker

Nó Master
Nó Slave
● DataNode
●
● NameNode
● SecondaryNameNode
● JobTracker

Nó Master
Nó Slave
● DataNode
● TaskTracker
● NameNode
● SecondaryNameNode
● JobTracker

Por que um elefante amarelo?
Por que Hadoop?

Vamos….
vamos!!!

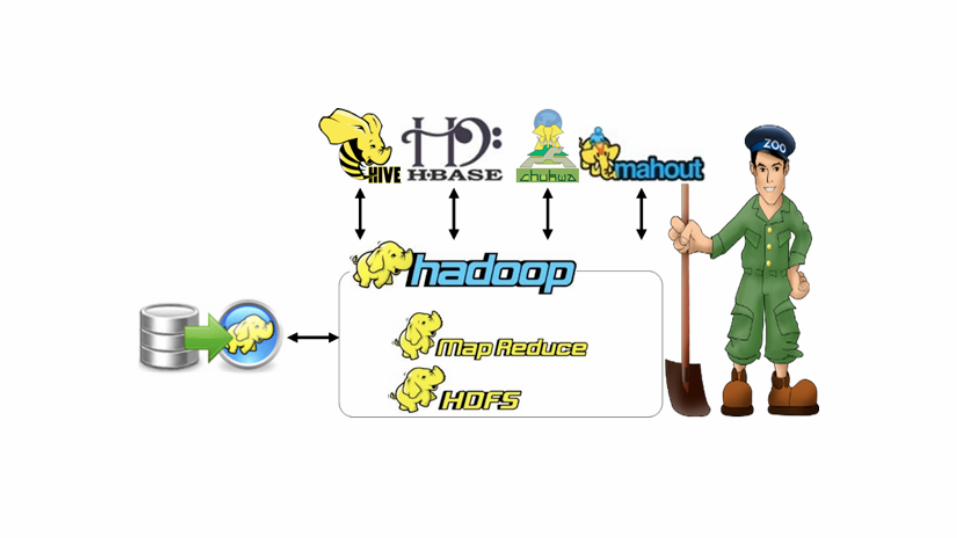
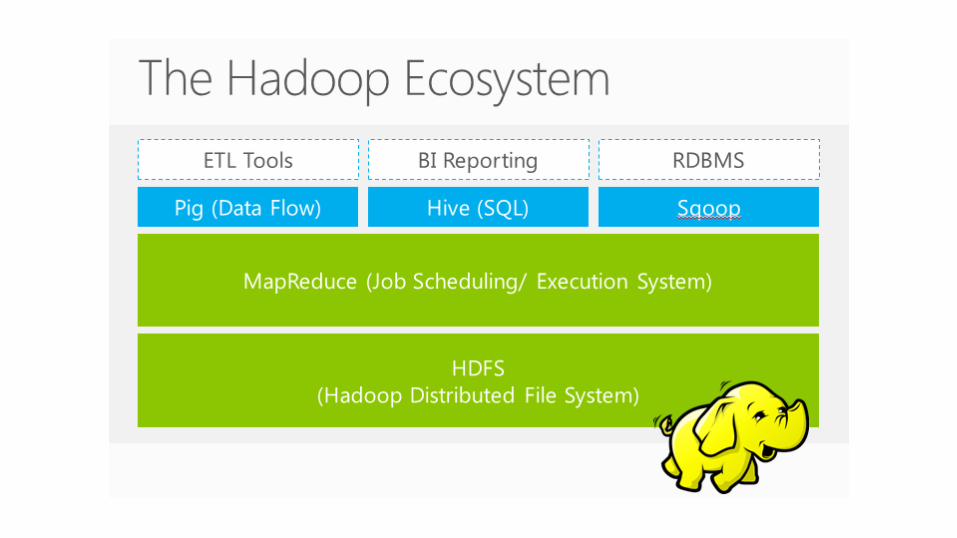
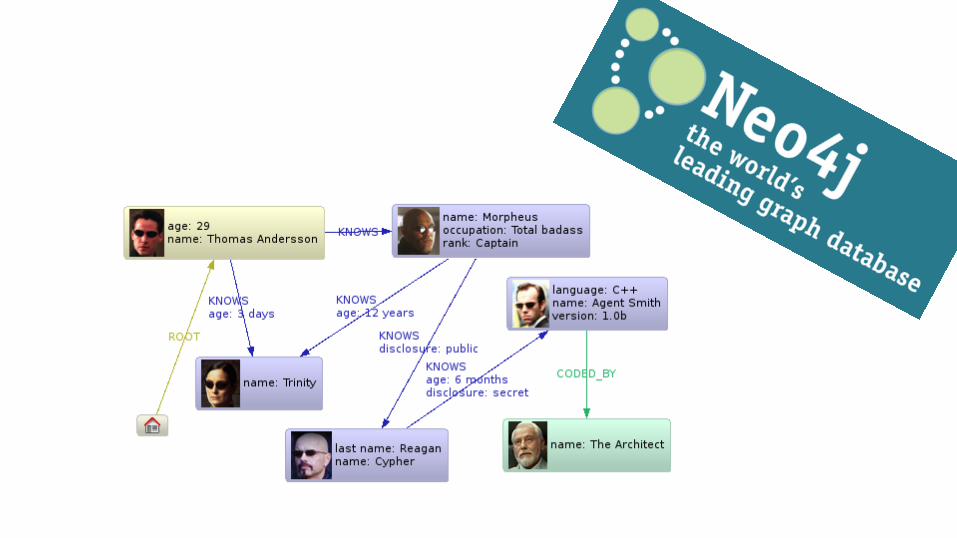
Ecossistema Hadoop
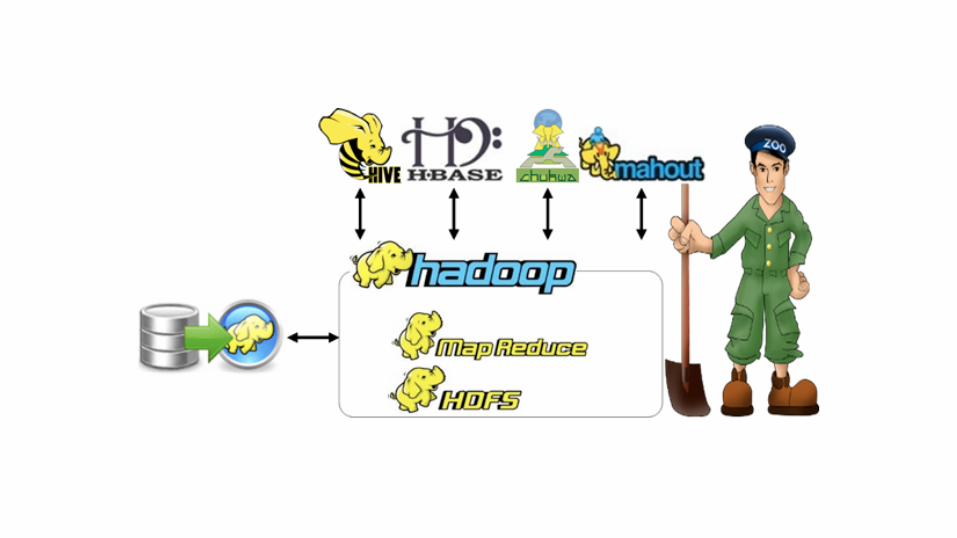


● Banco de Dados Hadoop
● Baseado no Google BigTable
● NoSQL - Orientado a
Colunas
● Leitura e Escrita em Real-
Time
● Funciona sobre o HDFS
● HSQL para quem sabe SQL


● Sistema de exportação de logs
contendo grande quantidade de dados
para o HDFS
● Um loader em tempo real para
transmissão de seus dados para o
Hadoop
● Armazena dados no HDFS e HBase


● Ferramenta de exportação de dados de
SGBDs
● Fornece transferência de dados
bidirecional entre o Hadoop e seu
banco de dados relacional
● Usa JDBC


● Biblioteca de algoritmos de
aprendizado de máquina (Machine
Learning) e data mining
● Principal objetivo: ser escalável para
manipular grandes volumes de dados

O Mahout é utilizado quando se é preciso
trabalhar com:
● Matrizes e vetores
● Estruturas esparsas e densas
● Agrupamento
● Cobertura
● K-Means
● Análise de densidade de funções
● Filtragem colaborativa


● "Coordenador" de serviços
● Permite que os processos
distribuídos em sistemas de grande
porte sincronizem informações um
com o outro sem falha, de modo que
todos os clientes que fazem
solicitações recebam dados
consistentes


● monitoramento e coleta de dados
de sistemas distribuídos


● Gerencia o fluxo de trabalho do
Hadoop
● um "Workflow scheduler"
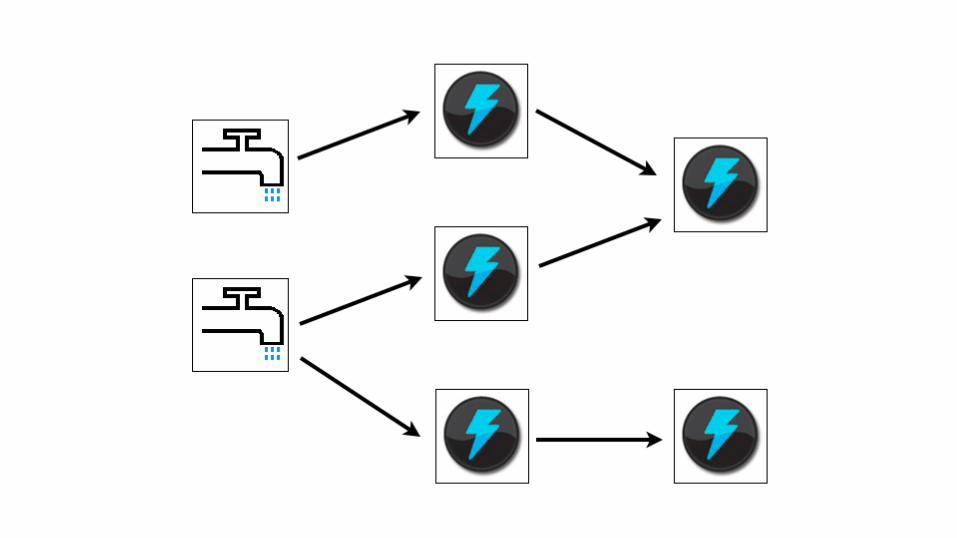

Storm
● Para processamento em tempo real
distribuído
● Independente de linguagem
● Desenvolvido pelo Twitter

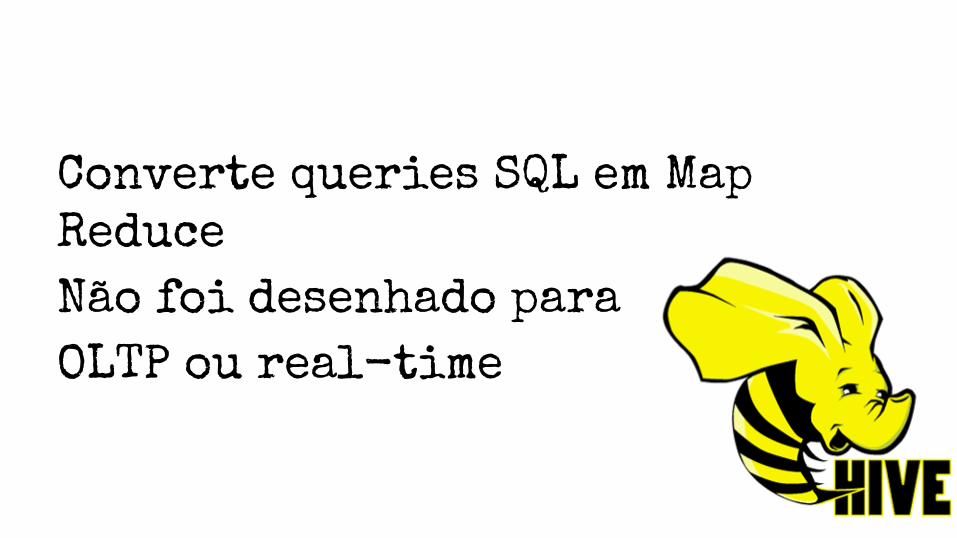
Converte queries SQL em Map
Reduce
Não foi desenhado para
OLTP ou real-time


● Criado pelo Yahoo!
● Linguagem de script
(alto nível) para
MapReduce
● Script com SQL
● A linguagem Pig é
chamada Pig Latin
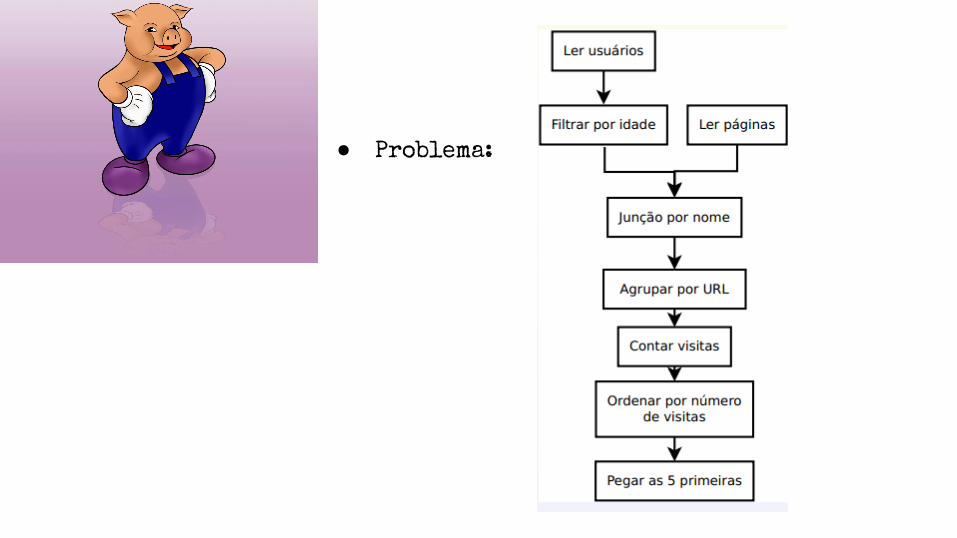
● Problema:

● Exemplo Código PIG:
Users = load `users' as (name, age);
Fltrd = filter Users by age >= 18 and age <= 25;
Pages = load `pages' as (user, url);
Jnd = join Fltrd by name, Pages by user;
Grpd = group Jnd by url;
Smmd = foreach Grpd generate group,
COUNT(Jnd) as clicks;
Srtd = order Smmd by clicks desc;
Top5 = limit Srtd 5;
store Top5 into `top5sites';

Em 2010, tarefas MapReduce geradas pelo
Pig correspondiam a 70% das tarefas
executadas no Yahoo!
O Pig também é usado pelo Twitter,
LinkedIn, Ebay, AOL, etc.

Usos comuns:
● Processamento de logs de servidores web
● Construção de modelos de predição de
comportamento de usuários
● Processamento de imagens
● Construção de índices de páginas da web
● Pesquisa em conjuntos de dados “brutos”

http://thoughtworks.fileburst.com/assets/technology-radar-jan-2014-pt.pdf

Distribuições Hadoop

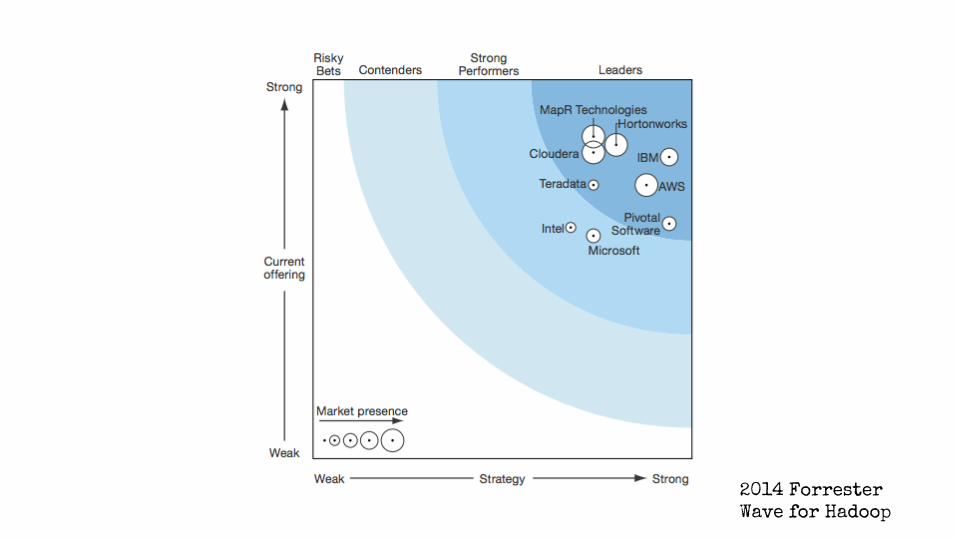
2014 Forrester
Wave for Hadoop

● Custo acessível.
● 5 a 10 anos atrás era impossível
● Apenas para grandes empresas. Hoje startup, consegue

● Custo acessível.
● 5 a 10 anos atrás era
impossível
● Apenas para grandes
empresas. Hoje startup,
consegue


● Amazon Elastic MapReduce (Amazon
EMR)
● Distribui os dados e processa em um
cluster redimensionável de
instâncias do Amazon EC2
● Hive, Pig


● 2007
● Converteu para PDF todos seus os
artigos publicados entre 1851 e 1980
● O Hadoop foi utilizado para converter
4 TB de imagens TIFF em 11 milhões de
arquivos PDF

● Duração 24 horas
● 100 instâncias EC2 da Amazon
● Gerado 1,5 TB de arquivos PDF
● Custo aproximado: US$ 240,00

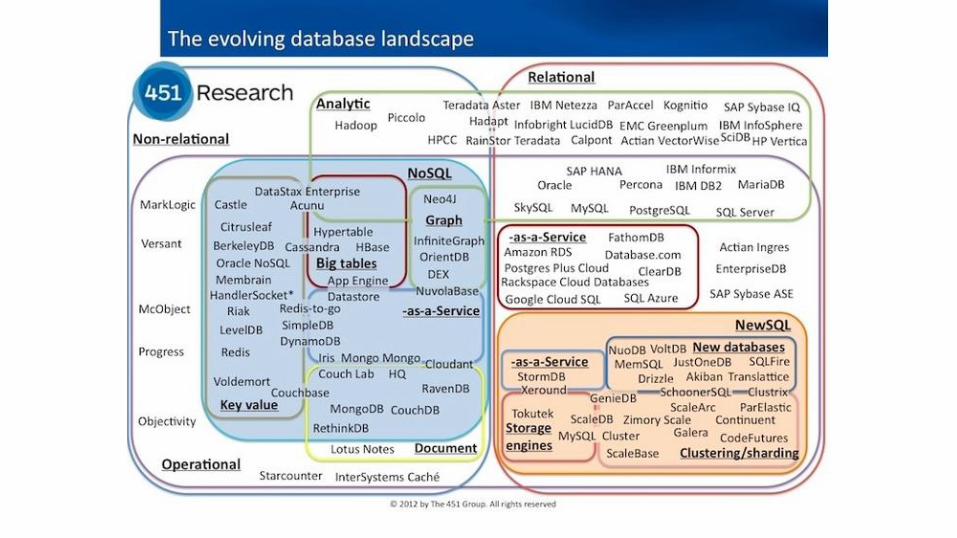
noSQL



Por que agora?
● Dados crescendo exponencialmente
● Dados não estruturados
● Arquitetura


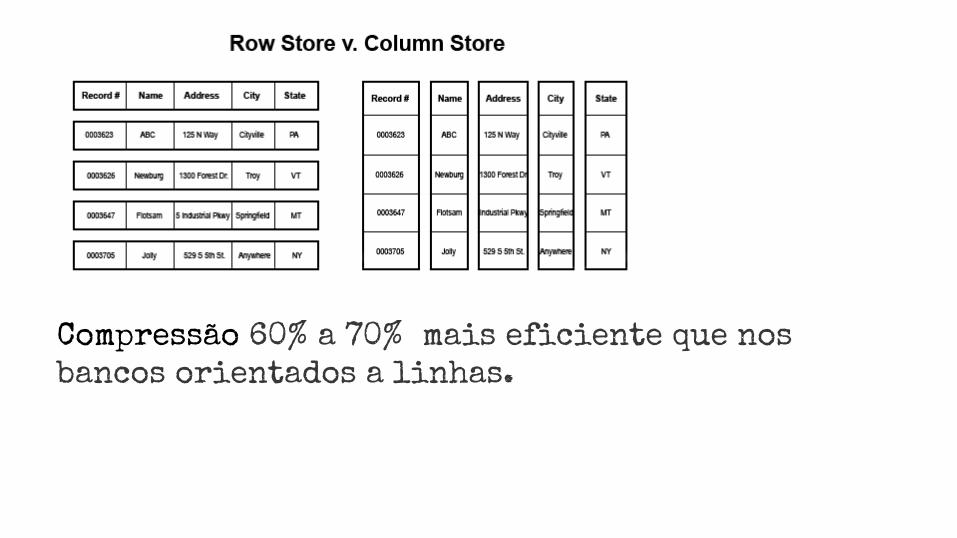
Compressão 60% a 70% mais eficiente que nos
bancos orientados a linhas.
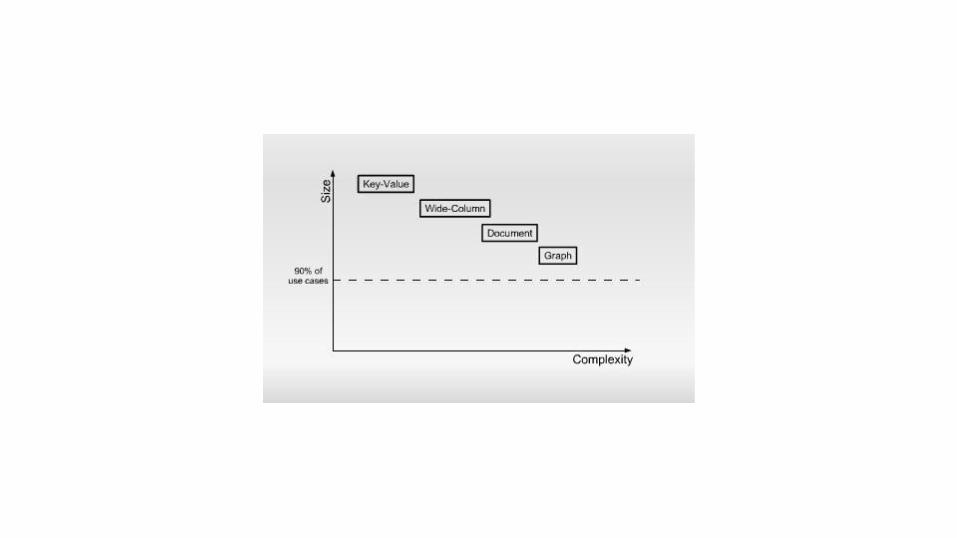


Principais benefícios
● Acesso rápido a dados (desde que você
possa manter tudo na memória);
● Rápida replicação de dados /
distribuídos por vários nós;
● Esquema flexível (você pode adicionar
novas colunas instantaneamente);

Que problemas
podem ser
resolvidos (ou as
pessoas acham que
podem resolver)
com a ajuda de
NoSQL e Big Data?

Que problemas
podem ser
resolvidos (ou as
pessoas acham que
podem resolver)
com a ajuda de
NoSQL e Big Data?
Mais
desempenho e
mais esquemas
flexíveis

SQL x NoSQL● Consistência e
integridade
● Normalização para
evitar dados
redundantes
● Linguagem
padronizada de
consulta (SQL)
● Escalabilidade
● Tolerância a Falhas
● Modelo de
consistência fraco

Machine
Learning

É um ramo da inteligência
artificial, onde o aprendizado é
feito a partir de dados.

Machine Learning - como?
1. dados são obtidos e armazenados
2. um modelo de análise é criado
3. quando novos dados chegam, o modelo é
capaz de fazer predições uteis
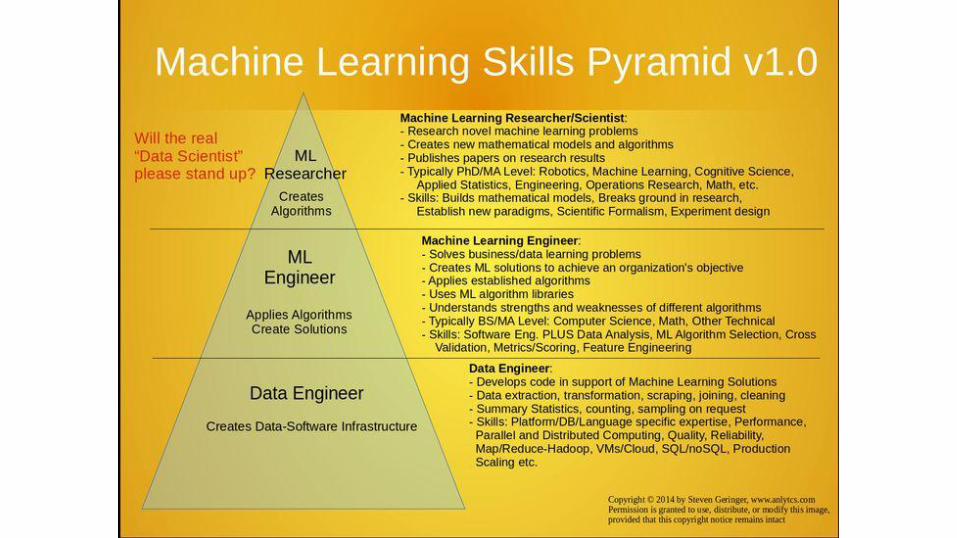

Benchmark - Statistcs Programming Language



Linguagem R
● É a linguagem mais usada para Data Scientist (Pesquisa O'Reilley - Janeiro
2014)
● 70% dos Data Miners usam R (Pesquisa Rexer - Outubro 2013)
● R está na 15a posição das linguagens de programação mais
usadas (RedMonk ranking - Janeiro 2014)
● R está crescendo mais que qualquer outra linguagem de Data
Science (Pequisa KDNuggets - Agosto 2013)
● R é a linguagem número 1 no Google Search para Advanced
Analytics Software (Google Trends - Março 2014)
● R tem mais de 2 milhões de usuários no mundo (Estimativa Oracle - Fevereiro
2012)

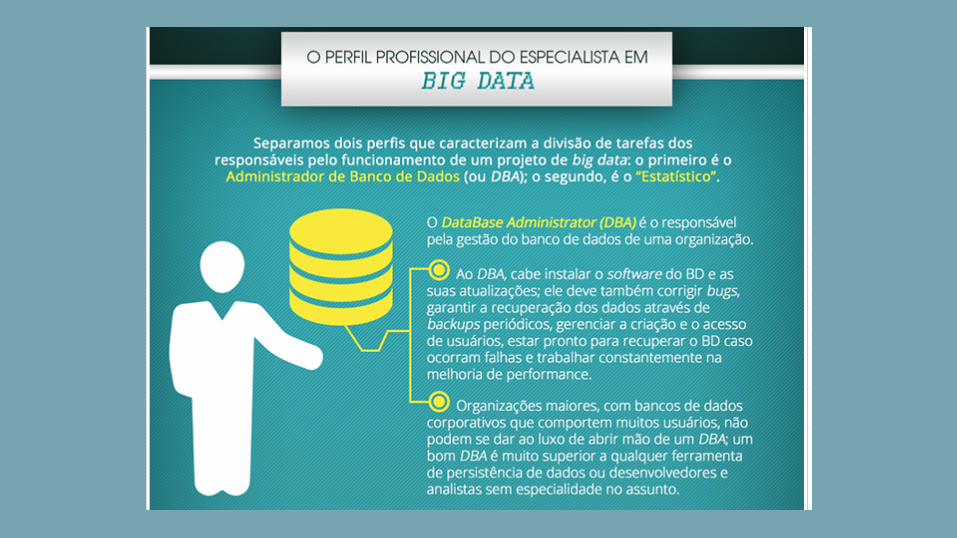
Data
Scientist


As principais habilidades para os
cientistas de dados são:
● algoritmos,
● programas de back-end como JAVA,
● estatísticas Bayesiana,
● método de Monte Carlo,
● ferramentas como Hadoop para
dados massivos,
● negócios,
● estatísticas clássicas,

● manipulação de dados como SAS,
● programas de front-end como
HTML,
● modelos gráficos como análise
estrutural de redes sociais,
● machine learning como árvore de
decisões e clustering,
● matemática como álgebra linear,
● otimização,
● desenvolvimento do produto,
● design experiencial,

● simuladores,
● estatísticas espaciais,
● dados estruturados como SQL,
● marketing e pesquisa,
● sistemas administrativos,
● estatísticas temporais como
previsão,
● e dados não estruturados como
mineração de textos e
visualização de dados




Alexandre Uehara
@AleUehara
linkedin.com/in/aleuehara
slideshare.net/aleuehara