Embed Size (px)
Citation preview

Universidade Federal de Pernambuco
Centro de Informática
Pós-graduação em Ciência da Computação
AGRUPAMENTO DE DADOS
SIMBÓLICOS USANDO ABORDAGEM
POSSIBILISTIC
Bruno Almeida Pimentel
Dissertação de Mestrado
Recife
Fevereiro de 2013

Universidade Federal de Pernambuco
Centro de Informática
Bruno Almeida Pimentel
AGRUPAMENTO DE DADOS SIMBÓLICOS USANDO
ABORDAGEM POSSIBILISTIC
Trabalho apresentado ao Programa de Pós-graduação em
Ciência da Computação do Centro de Informática da Uni-
versidade Federal de Pernambuco como requisito parcial
para obtenção do grau de Mestre em Ciência da Computa-
ção.
Orientadora: Profa. Dra. Renata Maria C. R. de Souza
Recife
Fevereiro de 2013

Catalogação na fonte Bibliotecária Monick Raquel Silvestre da Silva, CRB4-1217
Pimentel, Bruno Almeida Agrupamento de dados simbólicos usando abordagem Possibilistic / Bruno Almeida Pimentel. - Recife: O Autor, 2013. xii, 94 f.: il., fig., tab. Orientadora: Renata Maria Cardoso Rodrigues de Souza. Dissertação (mestrado) - Universidade Federal de Pernambuco. CIN, Ciência da Computação, 2013.
Inclui bibliografia. 1. Inteligência computacional. 2. Análise de dados simbólicos. 3. Análise de agrupamento. I. Souza, Renata Maria Cardoso Rodrigues de (orientadora) II. Título. 006.3 CDD (23. ed.) MEI2013 – 021

Dissertação de Mestrado apresentada por Bruno Almeida Pimentel à Pós-Graduação
em Ciência da Computação do Centro de Informática da Universidade Federal de
Pernambuco, sob o título “Agrupamento de Dados Simbólicos usando Abordagem
Possibilistic” orientada pela Profa. Renata Maria Cardoso Rodrigues de Souza e
aprovada pela Banca Examinadora formada pelos professores:
______________________________________________
Prof. Ricardo Bastos Cavalcante Prudêncio
Centro de Informática / UFPE
______________________________________________
Prof. Getúlio José Amorim do Amaral
Departamento de Estatística / UFPE
_______________________________________________
Profa. Renata Maria Cardoso Rodrigues de Souza
Centro de Informática / UFPE
Visto e permitida a impressão.
Recife, 25 de fevereiro de 2013.
___________________________________________________
Profa. Edna Natividade da Silva Barros Coordenadora da Pós-Graduação em Ciência da Computação do
Centro de Informática da Universidade Federal de Pernambuco.

Dedico esse trabalho aos meus pais, por
terem ensinado o verdadeiro valor dos estudos.
E à professora Renata, por me apresentar a ciência
e pesquisa e me guiar nessa jornada de descobertas.
iii

Agradecimentos
Agradeço à minha família por ter me ajudado a chegar nesta etapa da minha vida, com incentivo
e compreensão, em especial aos meus pais que estão me acompanhando e orientando em todos
os momentos. Por terem me ensinado o valor do estudo e que a busca pelo conhecimento e pela
verdadeira vocação devem ser características essenciais presentes em qualquer cidadão.
À professora, orientadora e amiga Renata de Souza, que desde os primeiros semestres do
curso de Ciência da Computação me auxiliou nessa construção do conhecimento, permitindo,
primeiramente, o ingresso na monitoria de Estatística, a qual deu ocasião a ajudar outros co-
legas e aprender mais sobre a disciplina. Em seguida, a participação de pesquisas através da
iniciação científica, atividade que me fez ficar ainda mais admirado pela ciência. Recentemente
me guiou no programa de mestrado desta instituição, o que resultou no desenvolvimento deste
trabalho.
Agradeço, também aos meus colegas de turma, com os quais debatemos idéias e discutimos
sobre os mais diversos temas ajudando na minha formação acadêmica e profissional. Aos
amigos de pesquisa, que antes mesmo do Mestrado estamos adquirindo conhecimentos juntos.
Finalmente ao Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq) pelo
auxílio financeiro.
iv

Uma jornada de duzentos quilômetros começa com um simples passo.
—PROVÉBIO CHINÊS

Resumo
Este trabalho relata sobre os diferentes métodos de agrupamento presentes na literatura atual
e introduz métodos de agrupamento baseado na abordagem possibilística para dados interva-
lares. Tem como objetivo estender os métodos clássicos de agrupamento possibilístico para
dados intervalares simbólicos. Além disso, é proposto uma nova abordagem possibilística em
que há um grau de pertinência diferente para cada variável e classe. A abordagem possibilística
considera a pertinência como possibilidades dos objetos a classes e a partição resultante dos
dados pode ser entendida como uma partição possibilística. O algoritmo conhecido dessa cate-
goria é o Possibilístic C-Means (PCM). No PCM, a otimização da função objetivo em alguns
conjuntos de dados pode ajudar a identificar outliers e dados ruidosos. A Análise de Dados
Simbólico (ADS) surgiu para lidar com variáveis simbólicas, que podem ser do tipo interva-
los, histogramas, e até mesmo funções, a fim de considerar a variabilidade e/ou a incerteza
inata aos dados. As técnicas de ADS tornam-se uma poderosa ferramenta quando usadas em
métodos de agrupamentos, o que causa um constante crescimento em pesquisas para o aprimo-
ramento destas técnicas usadas nos mais variados algoritmos, tais como em K-Means, Support
Vector Machine (SVM) e Kernel. Objetivando avaliar o desempenho dos métodos propostos e
os presentes na literatura, um estudo comparativo destes métodos em relação ao agrupamento
de objetos simbólicos do tipo intervalo é realizado. Foram planejados experimentos com dados
sintéticos, usando o experimento Monte Carlo, e dados reais. O índice corrigido de Rand (CR)
e a taxa de erro global de classificação (OERC) são usados para avaliar os métodos.
Palavras-chave: Análise de Dados Simbólicos, Dados Intervalares, Método de Agrupamento
Possibilistic C-Means, Ruido, Outlier.
vi

Abstract
This work reports on different clustering methods present in literature and introduces cluste-
ring methods based on possibilistic approach for interval data. It aims to extend the classical
methods of possibilistic clustering for symbolic interval data. Furthermore, it is proposed a
new approach in which there is a different possibilistic membership degree for each variable
and cluster. The possibilistic approach considers the relevance and possibilities of the clas-
ses and objects resulting partition of the data can be understood as a possibilistic partition. The
known algorithm of this category is the Possibilistic C-Means (PCM). In PCM, the optimization
of the objective function in some data sets can help identify outliers and noisy data. Symbolic
Data Analysis (SDA) appeared to handle symbolic variables, which may be intervals, histo-
grams, and even functions, in order to consider the variability and/or the uncertainty inherent
data. SDA techniques become a powerful tool when used in clustering methods, which causes
a constant growth in research to improve these techniques used in various algorithms, such as
in K-Means, Support Vector Machine (SVM) and Kernel. In order to evaluate the performance
of the proposed methods and the methods of literature, a comparative study of these methods in
relation to the clustering of symbolic objects of type interval is performed. We planned experi-
ments with synthetic data, using the Monte Carlo experiment, and real data. The adjusted Rand
index (CR) and overall error rate of classification (OERC) are used to evaluate the methods.
Keywords: Symbolic data analysis, Interval data, Possibilistic c-means clustering method,
Noise, Outlier.
vii

Sumário
1 Introdução 1
1.1 Motivação 1
1.2 Objetivos 4
1.3 Organização da dissertação 4
2 Métodos de Agrupamento 6
2.1 Introdução 6
2.2 Métodos Sequenciais 8
2.2.1 Esquema de Algoritmo Seqüencial Básico 8
2.2.2 Esquema de Algoritmo com Dois Limiares 9
2.3 Métodos Hierárquicos 11
2.3.1 Algoritmo Aglomerativo 13
2.3.2 Algoritmo Divisivo 16
2.4 Métodos de Particionamento 17
2.4.1 Algoritmos Rígidos 18
2.4.2 Algoritmos Difusos 22
2.5 Outros Métodos 23
3 Métodos Fuzzy C-Means 28
3.1 Introdução 28
3.2 Algoritmo FCM 29
3.2.1 Função Objetivo 30
3.2.2 Protótipo 31
3.2.3 Grau de Pertinência 32
3.2.4 Algoritmo 37
3.3 FCM com Distância Adaptativa 39
3.3.1 Distância Global 39
3.3.2 Distância por Classe 42
3.3.3 Algoritmo 45
viii

3.4 FCM Robusto 46
4 Métodos de Agrupamento Possibilístico para Dados Simbólicos do Tipo Intervalo 49
4.1 Introdução 49
4.2 Grau de pertinência por Classe 50
4.2.1 Algoritmo 57
4.3 Grau de pertinência por Classe e Variável 59
4.3.1 Algoritmo 65
5 Experimentos e Resultados 67
5.1 Introdução 67
5.2 Dados Sintéticos 68
5.3 Dados Reais 75
5.3.1 City-temperature 76
5.3.2 Amanita 80
6 Conclusão e Trabalhos Futuros 84
6.1 Conclusão 84
6.2 Trabalhos Futuros 85
Referências Bibliográficas 87
ix

Lista de Figuras
1.1 Configuração com duas classes de dados intervalares 3
2.1 Exemplo de agrupamento de dados 7
2.2 Exemplo das técnicas de agrupamento 12
2.3 Exemplo do algoritmo aglomerativo 14
2.4 Dendrograma 15
2.5 Aplicação de Algoritmos Genéticos 24
2.6 Rede Neural do tipo SOM 26
2.7 Agrupamento hierárquico e piramidal 27
3.1 Posições dos elementos A, B e C. 35
3.2 Diferença entre a Função Indicador e o grau de pertinência. 36
3.3 Variação do grau de pertinência em função do somatótio para diferentes valores
de m. 37
4.1 Comportamento da função não-exponencial para a atualização do grau de per-
tinência 54
4.2 Comportamento da função exponencial para a atualização do grau de pertinência 55
4.3 Configuração com dois objetos simbólicos intervalares 56
4.4 Gráfico de superfície dos graus de pertinência para os métodos IPCM e IPCM-E 57
4.5 Gráfico de contorno dos graus de pertinência para os métodos IPCM e IPCM-E 57
4.6 Gráfico de superfície dos graus de pertinência para os métodos IPCM-V e
IPCM-VE 62
4.7 Gráfico de contorno dos graus de pertinência para os métodos IPCM-V e IPCM-
VE 63
4.8 Configuração com dois objetos simbólicos intervalares com variáveis correla-
cionadas 63
4.9 Gráfico de superfície dos graus de pertinência para os métodos IPCM-V e
IPCM-VE com variáveis correlacionadas 64
x

4.10 Gráfico de contorno dos graus de pertinência para os métodos IPCM-V e IPCM-
VE com variáveis correlacionadas 64
5.1 Conjunto de sementes 1 e 2 69
5.2 Conjunto de sementes 1 e 2 com 30% de outliers 70
5.3 Conjunto de dados intervalares 1 e 2 com 30% de outliers 71
5.4 Índice CR versus percentual de outlier dos métodos para a Configuração 1 74
5.5 Índice CR versus percentual de outlier dos métodos para a Configuração 2 75
5.6 Grupos 1 e 2 de acordo com o método Zoom Star para o conjunto City-temperature 80
5.7 Grupos 3 e 4 de acordo com o método Zoom Star para o conjunto City-temperature 80
5.8 Grupos 1 e 2 de acordo com o método Zoom Star para o conjunto Amanita 83
5.9 Grupo 3 de acordo com o método Zoom Star para o conjunto Amanita 83
xi

Lista de Tabelas
2.1 Tipos de ligação 12
2.2 Tipos de distância 13
5.1 Parâmetros para o conjunto de sementes 1 e 2 69
5.2 Parâmetros para outliers na configuração de sementes 1 e 2 70
5.3 Comparação dos métodos de agrupamento para dados intervalares para a Con-
figuração 1 72
5.4 Comparação dos métodos de agrupamento para dados intervalares para a Con-
figuração 2 73
5.5 Temperaturas mínimas e máximas das cidades em graus centígrados 76
5.6 Resultado dos agrupamentos para o conjunto de dados City-temperature 78
5.7 Índices CR e OERC dos métodos executados para o conjunto de dados City-
temperature 79
5.8 Variáveis intervalares do conjunto de dados Amanita 81
5.9 Resultado dos agrupamentos para o conjunto de dados Amanita 82
5.10 Índices CR e OERC dos métodos executados para o conjunto de dados Amanita 82
xii

CAPÍTULO 1
Introdução
Aprender é a única de que a mente nunca se cansa, nunca tem medo e
nunca se arrepende.
—LEONARDO DA VINCI
1.1 Motivação
Com o crescente interesse em automaticamente compreender, processar e resumir dados, diver-
sos domínios de aplicação, como reconhecimento de padrões, aprendizado de máquina, minera-
ção de dados, visão computacional e biologia computacional usam algoritmos de agrupamento
[1]; [2]. O objetivo da análise de agrupamento é agrupar um conjunto de elementos em grupos
tais que os elementos dentro de um cluster tem um elevado grau de semelhança, ao passo que
os elementos pertencentes a diferentes grupos têm um alto grau de dessemelhança. Técnicas
de agrupamento podem ser divididos em hierárquicos e de particionamento: no hierárquico,
os grupos de objetos se apresentam como uma seqüência de partições de modo que um grupo
inicial contenha todos os indivíduos e se divide até obter tantos grupos quanto for o número
de indivíduos ou o processo inverso, enquanto particionamento divide diretamente o conjunto
de objetos em um número fixo de clusters com nenhuma estrutura hierárquica [3] e faz essa
divisão baseada na otimização de uma função objetivo adequada.
Além disso, os métodos de agrupamento podem ser classificados em rígido (hard) e di-
fuso (fuzzy). O agrupamento rígido associa cada elemento dos dados um a uma única classe,
enquanto que no agrupamento difuso cada elemento dos dados está associado com todas as
classes da partição, os elementos não pertencem a um único cluster e, por esse motivo, os
graus de pertinência são calculados. Um método difuso assume que os graus de pertinência
devem ter valores entre 0 e 1 e a soma de todos os graus de pertinência de um elemento rela-
tivos às classes deve ser igual a 1 [4]. O método Fuzzy C-Means (FCM) é o algoritmo do tipo
difuso mais popular, entretanto a restrição da soma ser igual dos graus de pertinência para uma
determinada classe nem sempre corresponde aos conceitos de pertinência, já que elementos em
1

diferentes posições podem ter a mesma chance de pertencer aos grupos. Além disso, o FCM é
um método de agrupamento de dados sensível a ruído e outlier [4].
Outra categoria de métodos de agrupamento é a que usa a abordagem possibilística proposta
por Krishnapuram e Keller [5] que não usa a restrição da soma. A abordagem possibilística con-
sidera a pertinência como possibilidades dos pontos a classes e a partição resultante dos dados
pode ser entendida como uma partição possibilística. O algoritmo conhecido dessa categoria
é o Possibilístic C-Means (PCM). No PCM, a forma como os graus de pertinência e protóti-
pos são calculados usando o conceito de possibilidade podem, em muitos conjuntos de dados,
ajudar a identificar outliers e dados ruidosos [4].
A maior parte da literatura sobre clusters discute agrupamento envolvendo somente da-
dos numéricos. Na análise de agrupamento clássico, os dados são muitas vezes representados
como matrizes de valores quantitativos ou qualitativos, onde cada coluna representa uma va-
riável. Em particular, cada indivíduo tem um único valor para cada variável. No entanto, essa
representação pode não ser adequada para modelar informações mais complexas encontradas
em problemas reais [6]. Portanto, a Análise de Dados Simbólico (ADS) surgiu para lidar com
variáveis simbólicas que podem ser do tipo intervalos, histogramas, e até mesmo funções, a fim
de considerar a variabilidade e/ou a incerteza inata aos dados [6]. O principal objetivo da ADS
é modelar informação usando dados simbólicos descritos por regras, distribuições de probabi-
lidade ou intervalos e estender a análise de dados clássica e técnicas de mineração de dados,
tais como, clustering, técnicas fatoriais, árvores de decisão e outro para dados simbólicos.
Em ADS, uma observação simbólica quantitativa pode ser representada por um intervalo
interpretado como vários valores pertencentes a [a,b], a< b. Assim, uma variável simbólica in-
tervalar tem a variabilidade inerente e vários autores têm abordado o problema de agrupamento
para dados intervalares simbólicos. Com relação ao agrupamento rígido, Bock [7] propôs vá-
rios algoritmos de agrupamento para dados simbólicos descritos por variáveis intervalares com
base em um critério de agrupamento e tem, portanto, generalizado abordagens semelhantes
na análise de dados clássicos. Souza e Carvalho [8] propuseram métodos de particionamento
para dados intervalares baseados em distâncias City-Block, também considerando as distâncias
adaptativas. De Carvalho et al. [9] apresentou método de agrupamento para dados de intervalos
baseados em distância L2. De Carvalho e Souza [10] introduziram o uso de distâncias adaptati-
vas de Hausdorff em agrupamento de dados do tipo intervalo. De Carvalho e Lechevallier [11]
apresentaram métodos de agrupamento para dados intervalares baseados em distâncias adapta-
tivas single. De Carvalho e Lechevallier [12] apresentaram os algoritmos de agrupamento para
dados simbólicos intervalares baseados em distâncias quadráticas adaptativas. Em relação à
abordagem fuzzy, De Carvalho [13] apresentou a versão adaptativa e não-adaptativa do método
2

de agrupamento FCM para o particionamento de dados simbólicos intervalares e De Carvalho
e Tenorio [14] introduziram o método Fuzzy C-Means baseado em distâncias quadráticas adap-
tativas para dados intervalares. No entanto, todos estes métodos de agrupamento são sensíveis
a dados ruidosos e outliers.
Este trabalho tem como objetivo estender os métodos clássicos de agrupamento possibilís-
tico [5], [15] para dados intervalares simbólicos. Além disso, é proposto uma nova abordagem
possibilística em que há um grau de pertinência diferente para cada variável e cluster. A idéia
deste método é apresentado na Figura 1.1. Considere dois clusters C1 e C2 de elementos des-
critos por duas variáveis simbólicas intervalares y1 e y2. Considere os elementos 3 e 8 desta
figura serem os protótipos dos clusters C1 e C2, respectivamente.
Figura 1.1 Configuração com duas classes de dados intervalares
De acordo com a abordagem fuzzy apresentado em [13] é esperado que o elemento 5 tenha
um valor de pertinência para o grupo 2 ligeiramente maior que o valor de pertinência para o
grupo 1 uma vez que a distância entre os itens 3 e 5 é maior do que a distância entre os itens
5 e 8. No entanto, analisando a variável y2 separadamente, podemos esperar que o grau de
pertinência ao cluster 1 do item 5 tenha um valor próximo a 1 e o grau de pertinência para o
grupo 2 tenha um valor próximo de 0. Investigando a variável y1 separadamente, o grau de
pertinência ao cluster 2 do item 5 tem valor próximo de 1, mas o grau de pertinência ao cluster
1 não é perto de 0, pois a variável y1 tem maior dispersão. Neste caso, uma abordagem que
calcule o valor do grau de pertinência para cada variável é necessário.
3

1.2 Objetivos
Nesta dissertação, serão apresentados dois algoritmos para o agrupamento de conjunto de dados
simbólicos do tipo intervalo utilizando a abordagem possibilística. Inicialmente é apresentada
uma extensão dos métodos Possibilistic C-Means propostos por Krishnapuram e Keller [5] para
intervalos. Estes métodos se caracterizam pela função que calcula os graus de pertinência, a
qual pode ser exponencial e não-exponencial. Segundo os autores, o método cuja função de
atualização do grau de pertinência é do tipo exponencial possui um melhor desempenho com
configurações onde os clusters estão próximos.
Além da extensão dos métodos possibilisticos clássicos para dados intervalares, é proposto
uma nova abordagem para lidar com graus de pertinência por classe e variáveis intervalares.
Assim, existe uma matriz de graus de pertinência para cada indivíduo neste método. O objetivo
é tratar separadamente cada variável e construir a partição final usando informações de várias
partições possibilísticas. Semelhantemente ao método clássico, os métodos que tratam sepa-
radamente as variáveis também tem a função de atualização dos graus de pertinência do tipo
exponencial e não-exponencial.
Com o objetivo de avaliar o desempenho dos métodos propostos e os presentes na literatura,
um estudo comparativo destes métodos em relação ao agrupamento de objetos simbólicos do
tipo intervalo usando o experimento Monte Carlo é realizado. Foram planejados experimentos
com dados sintéticos e reais e o índice corrigido de Rand (CR) e a taxa de erro global de
classificação (OERC) são usados para avaliar os métodos.
1.3 Organização da dissertação
A dissertação segundo os capítulos está organizada da seguinte forma:
Capítulo 2 - Métodos de Agrupamento
Neste capítulo, uma breve descrição do estado da arte da Análise de Cluster é apresen-
tada. Em resumo, três principais categorias de métodos: os seqüenciais que criam os grupos
avaliando um elemento do conjunto de dados por vez até que todo o conjunto seja avaliado;
os hierárquicos que é caracterizado por formar seqüencias de partições; e os de partição que
analisam todos os elementos da base de dados não-seqüencialmente e encontram, segundo uma
função objetivo, grupos cujo número é definido a priori.
4

Capítulo 3 - Métodos Fuzzy C-Means
O capítulo descreve o tradicional método Fuzzy C-Means. Em seguida, a versão na qual
usa distâncias adaptativas single e por classe do tipo L2 para particionar dados simbólicos do
tipo intervalo. Estes métodos são capazes de encontrar um partição fuzzy e tem a propriedade
de identificar clusters com diferentes formas e tamanhos. Entretanto, são sensíveis a dados
ruidosos e outliers. Finalmente, uma versão do Fuzzy C-Means para dados intervalares robusta
a ruidosos é descrita.
Capítulo 4 - Métodos de Agrupamento Possibilístico para Dados Simbólicos do Tipo In-
tervalo
Neste capítulo, os métodos propostos serão apresentados. Inicialmente, os métodos rela-
tivos à extensão dos métodos clássicos presentes na literatura para dados simbólicos do tipo
intervalo. Em seguida, novos métodos serão descritos referentes ao tratamento isolado do grau
pertinência para cada variável.
Capítulo 5 - Experimentos e Resultados
Nesta parte da dissertação, serão tratados experimentos com os métodos propostos e os pre-
sentes na literatura para dados simbólicos do tipo intervalo usando experimento Monte Carlo.
Na primeira parte, os métodos serão avaliados através de diferentes configurações de dados
artificiais. Na segunda parte, o desempenho será avaliado para conjuntos de dados reais. Como
métricas para a avaliação, serão usados o índice corrigido de Rand (CR) e a taxa de erro global
de classificação (OERC) .
Capítulo 6 - Conclusão e Trabalhos Futuros
Nesse capítulo, serão apresentadas as conclusões, considerações finais e possíveis trabalhos
futuros que poderão ser realizados baseados no estudo realizado nesta dissertação.
5

CAPÍTULO 2
Métodos de Agrupamento
O saber é saber que nada se sabe. Este é a definição do verdadeiro
conhecimento.
—CONFÚCIO
2.1 Introdução
Uma das mais básicas habilidades dos seres vivos envolve o agrupamento de objetos similares
para produzir uma classificação. Desde os primórdios do seu surgimento, o homem, por exem-
plo, obteve habilidades para identificar que muitos objetos possuíam certas propriedades, tais
como a comestibilidade de alimentos, a usabilidade de ferramentas, a ferocidade de animais,
entre outros. Desta forma, surge a idéia de agrupamento (cluster ou classe), no qual os objetos
são reunidos de modo que a semelhança entre eles é maior do que qualquer outra classe exis-
tente. O conceito de agrupamento está relacionado a diversos ramos do conhecimento, fazendo
parte das pesquisas de muitas áreas, tais como Reconhecimento de Padrões, Estatística, Ma-
temática, Engenharia e Física, sendo usado em várias aplicações, como medicina, psiquiatria,
serviços sociais, pesquisa de mercado, educação e arqueologia.
A Análise de Agrupamentos (Clustering Analysis) objetiva separar um conjunto inicial de
objetos em um determinado número de agrupamentos, de modo que os elementos pertencen-
tes ao mesmo agrupamento possuam mais semelhanças (similaridades) entre si, e sejam mais
diferentes (dissimilares) aos pertencentes a outros agrupamentos. O processo de separar ou
identificar grupos a partir de semelhanças entre objetos é comumente realizada por seres hu-
manos e envolve um processo de aprendizagem. Por exemplo, uma criança pode associar as
palavras cão e gato através da observação da diferença que existe entre estes dois animais.
Desta forma, Análise de Agrupamentos é normalmente considerada uma sub-area de estudo
de Reconhecimento de Padrões e Inteligência Artificial. Um importante conceito utilizado em
Análise de Agrupamento é partição, a qual é caracterizada por conter um defenido número de
grupos, tais que um elemento em cada grupo não pode pertencer a qualquer um outro, isto é,
6
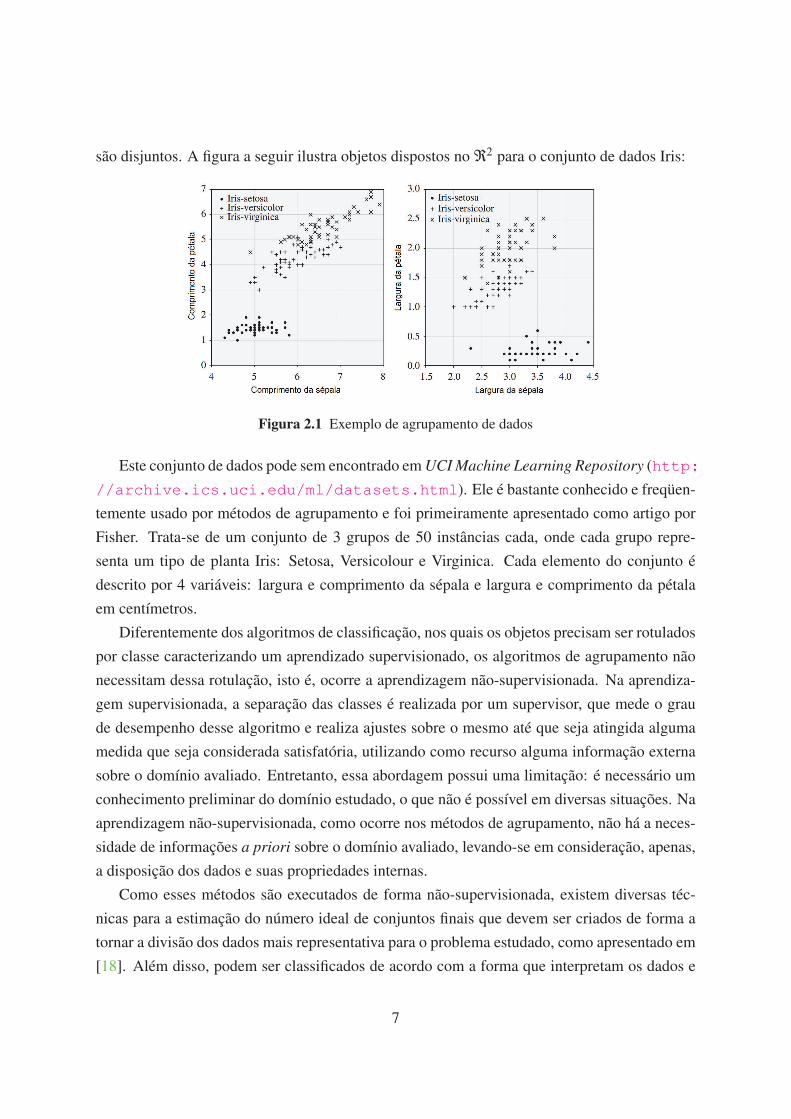
são disjuntos. A figura a seguir ilustra objetos dispostos no ℜ2 para o conjunto de dados Iris:
Figura 2.1 Exemplo de agrupamento de dados
Este conjunto de dados pode sem encontrado em UCI Machine Learning Repository (http:
//archive.ics.uci.edu/ml/datasets.html). Ele é bastante conhecido e freqüen-
temente usado por métodos de agrupamento e foi primeiramente apresentado como artigo por
Fisher. Trata-se de um conjunto de 3 grupos de 50 instâncias cada, onde cada grupo repre-
senta um tipo de planta Iris: Setosa, Versicolour e Virginica. Cada elemento do conjunto é
descrito por 4 variáveis: largura e comprimento da sépala e largura e comprimento da pétala
em centímetros.
Diferentemente dos algoritmos de classificação, nos quais os objetos precisam ser rotulados
por classe caracterizando um aprendizado supervisionado, os algoritmos de agrupamento não
necessitam dessa rotulação, isto é, ocorre a aprendizagem não-supervisionada. Na aprendiza-
gem supervisionada, a separação das classes é realizada por um supervisor, que mede o grau
de desempenho desse algoritmo e realiza ajustes sobre o mesmo até que seja atingida alguma
medida que seja considerada satisfatória, utilizando como recurso alguma informação externa
sobre o domínio avaliado. Entretanto, essa abordagem possui uma limitação: é necessário um
conhecimento preliminar do domínio estudado, o que não é possível em diversas situações. Na
aprendizagem não-supervisionada, como ocorre nos métodos de agrupamento, não há a neces-
sidade de informações a priori sobre o domínio avaliado, levando-se em consideração, apenas,
a disposição dos dados e suas propriedades internas.
Como esses métodos são executados de forma não-supervisionada, existem diversas téc-
nicas para a estimação do número ideal de conjuntos finais que devem ser criados de forma a
tornar a divisão dos dados mais representativa para o problema estudado, como apresentado em
[18]. Além disso, podem ser classificados de acordo com a forma que interpretam os dados e
7

a maneira com que esses objetos se organizam em agrupamentos. As principais categorias de
métodos não-supervisionados para criar grupos são descritos nas seções a seguir.
2.2 Métodos Sequenciais
O algoritmo de métodos seqüenciais possuem uma descrição simples e, conseqüentemente, fá-
cil de entender. Os dados são apresentados poucas vezes e o número de classes não é conhecido
a priori, apenas um número limite q de clusters definido pelo usuário, assim como um único
limiar Θ, para o Esquema de Algoritmo Seqüencial Básico (BSAS), ou mais, para o Esquema
de Algoritmo com Dois Limiares (TTSAS). Além disso, é necessária a medida de proximidade
d tal que d(x,C) mede o quão próximo um objeto x está de um conjunto C (esse conjunto pode
estar sendo representado por um protótipo, de forma que d pode ser calculado entre o objeto e
o representante de C).
2.2.1 Esquema de Algoritmo Seqüencial Básico
O algoritmo é caracterizado por fazer uma única leitura dos dados, tornando-se simples e rá-
pido. Entretanto, esses algoritmos possuem a desvantagem de serem sensíveis a ordem de
apresentação dos elementos estudados, uma vez que a representação dos conjuntos por meio de
protótipos pode mudar a cada iteração e com isso a relação de proximidade entre o elemento e
o grupo seja alterada. O esquema de algoritmo seqüencial básico pode ser definido como [19]:
O algoritmo começa criando um grupo com o primeiro elemento do conjunto de dados
e a partir deste grupo, os n− 1 objetos restando são alocados para o grupo mais adequado
segundo o limiar definido a priori. Portanto, o custo computacional é da ordem de O(n).
A distância d utilizada é importante para o resultado final da partição, uma vez que ela irá
definir se o elemento atual pertencerá ao conjunto Ck ou se será necessário criar outro. Outro
fator importante que pode definir a partição é o limiar Θ, já que ele tem efeito direto sobre o
número de conjunto formados: se for pequeno, conjuntos desnecessários serão criados; ser for
grande, serão poucos conjuntos criados, podendo ser insuficiente para representar a partição
ideal dos dados. Uma outra versão do algoritmo é caracterizado pela adição de um parâmetro
K. Este número K defini o limite de grupos que podem ser criados. Enquanto m < K, existe
a possibilidade de o algoritmo criar um grupo, entretanto caso m = K, todos os elementos
restantes serão alocados a um dos grupos anteriormente criados.
Existe uma modificação do algoritmo BSAS chamado Modified BSAS (MBSAS), que é
8

Algorithm 1 BSAS (Ω,Θ)
Require: Um conjunto de dados Ω e um limiar Θ.Ensure: Retorna uma partição P = C1,C2, . . . ,Cm dos elementos do conjunto.
1: m← 12: Cm ←x13: for i = 2→ n do
4: Encontre Ck: d(xi,Ck) = min j d(xi,C j)5: if d(xi,Ck)> Θ then
6: m← m+17: Cm ←xi8: else
9: Ck ←Ck∪xi10: Se d for calculada a partir de protótipos, atualize o protótipo do conjunto Ck
11: end if
12: end for
return Partição P
executado fazendo a leitura dos dados duas vezes. Ela supera a desvantagem de um conjunto
final de uma única amostra ser decidida antes de todos os grupos serem criados. A primeira
fase do algoritmo cria clusters (tal como em BSAS) e atribui uma única amostra de cada cluster.
Então a segunda fase percorre as amostras restantes e as classifica para os grupos criados.
2.2.2 Esquema de Algoritmo com Dois Limiares
A principal desvantagem dos algoritmos BSAS e MBSAS é a ordem com que os exemplos são
apresentados, bem como o verdadeiro valor de Θ. Estes inconvenientes podem ser reduzidos
pela utilização de dois limiares Θ1 e Θ2. Distâncias menores que o primeiro valor Θ1 denotam
que a amostra em questão provavelmente pertence ao cluster do qual a distância foi calculada.
Por outro lado, distâncias maiores que Θ2 denotam que o objeto não pertence ao cluster. Va-
lores entre esses dois limiares estão uma faixa chamada "zona cinzenta"e devem ser avaliados
em uma fase posterior ao algoritmo.
Considerando clas(x) um booleano indicando se uma amostra foi classificada ou não e
assumindo que não existe limites para o número de clusters, o esquema do método seqüencial
básico de dois limiares pode ser descrito como no algoritmo a seguir.
A variável delta_alteracao verifica se o último elemento do conjunto de elementos foi clas-
sificado na passagem atual do loop while. Se nenhum foi classificado, o primeiro exemplo não
classificado é usado para gerar uma nova classe e isso tenta garantir que, no máximo, n passa-
gens pelo loop while foram executadas. De acordo com a complexidade teórica computacional
9

Algorithm 2 BSAS (Ω,Θ1,Θ2)
Require: Um conjunto de dados Ω, limiares Θ1 e Θ2.Ensure: Retorna uma partição P = C1,C2, . . . ,Cm dos elementos do conjunto.
1: m← 02: ∀x ∈Ω, clas(x) = False
3: alteracao_anterior← 04: alteracao_atual ← 05: delta_alteracao←−1;6: while delta_alteracao 6= 0 do
7: for i = 1→ n do
8: if clas(xi) = False E i = 1 then
9: m← m+110: Cm ←xi11: clas(xi)← True
12: alteracao_atual ← alteracao_atual +113: else if clas(x) = False then
14: Encontre Ck: d(xi,Ck) = min j d(xi,C j)15: if d(xi,Ck)< Θ1 then
16: Ck ←Ck +xi17: clas(xi)← True
18: alteracao_atual ← alteracao_atual +119: else if d(xi,Ck)< Θ2 then
20: m← m+121: Ck ←xi22: clas(xi)← True
23: alteracao_atual ← alteracao_atual +124: end if
25: else
26: alteracao_atual ← alteracao_atual +127: end if
28: end for
29: delta_alteracao← |alteracao_atual−alteracao_anterior|30: alteracao_anterior← alteracao_atual
31: alteracao_atual ← 032: end while
return Partição P
10

deste algoritmo, o custo é da ordem de O(n2).
2.3 Métodos Hierárquicos
Nos algoritmos de agrupamento hierárquicos, os dados não são particionados em um deter-
minado número classes ou clusters em um único passo. Nestes métodos, o objetivo é obter
uma informação mais completa sobre o conjunto de objetos por meio de um conjunto hierar-
quicamente aninhado de partições. Em taxonomia, por exemplo, um objeto pode pertencer
sucessivamente a uma espécie a um gênero, uma família, uma ordem, etc. O agrupamento con-
siste de uma série de partições, as quais podem possuir apenas uma classe contendo todos os
indivíduos, ou n clusters, cada um contendo apenas um elemento.
As técnicas de agrupamento hierárquicos podem ser divididos em duas categorias: algorit-
mos aglomerativos e algoritmos divisivos. Os aglometativos reduzem os dados em um único
cluster contendo todos os elementos, enquanto que a técnica divisiva irá dividir o conjunto de
entrada em n grupos, onde cada um contém apenas um indivíduo. Com isso, surge a necessi-
dade de decidir em qual estágio do algoritmo irá parar, uma vez que é preciso encontrar uma
solução com um número "ótimo"de classes.
O agrupamento hierárquico pode ser representado por um diagrama bidimensional conhe-
cido como dendograma, o qual ilustra a união ou divisão realizada nos sucessivos estágios de
análise. Considere P(Ω) o conjunto das partes de Ω, um dendograma pode ser considerado
um conjunto D de subconjuntos Ω = x1,x2, . . . ,xn satisfazendo as seguintes condições:
1. D⊆P(Ω);
2. D 6= /0;
3. ∀xi ∈Ω,xi ∈⋃
D;
4. If A,B ∈ D then A∩B ∈ /0,A,B.
A primeira condição garante que qualquer subconjunto de D é uma das possíveis combi-
nações de elementos do conjunto Ω. Por outro lado, embora D seja um conjunto de P(Ω), D
não pode ser um conjunto vazio. O terceiro item garante que qualquer elemento do conjunto
de dados também faça parte da união de todos os subconjuntos de D. Finalmente, qualquer
que sejam dois subconjuntos A e B de D, uma das opções é verdadeira: não existem elementos
em comum entre A e B ou um todos os elementos de um conjunto estão presentes no outro. A
imagem a seguir exemplifica a relação entre as duas categorias de algoritmos hierárquicos:
11

Figura 2.2 Exemplo das técnicas de agrupamento
De acordo com a figura, a abordagem de aglomerativa começa com grupos individuais e
iterativamente pares de grupos semelhantes são unidos até encontrar um único grupo. Por
outro lado, a abordagem divisiva começa com um grupo em um par de grupos diferentes até
que o algoritmo encontre n grupos que contem apenas 1 elemento. Um critério importante para
determinar a similaridade entre dois grupos é chamado ligação (linkage). A tabela a seguir
mostra os tipos mais conhecidos de ligação de acordo com a medida de dissimilaridade d:
Tipo ExpressãoMaximo (ou complete linkage) d(A,B) = maxd(a,b)|a ∈ A,b ∈ B,A,B ∈ DMinimo (ou single linkage) d(A,B) = mind(a,b)|a ∈ A,b ∈ B,A,B ∈ D
Media (ou average linkage, UPGMA) d(A,B) = 1|A||B| ∑a∈A ∑b∈B d(a,b)
Mediana d(A,B) = 2|A||B||A|+|B|d(mA,mB), mA,mB são medoids
Metodo de Ward d(A,B) = 2|A||B||A|+|B|d(cA,cB), cA,cB são centroids
Centroid (ou UPGMC) d(A,B) = d(cA,cB), cA,cB são centroids
Tabela 2.1 Tipos de ligação
A medida do tipo complete linkage é baseada na maior distância entre quaisquer par de ele-
mentos pertencentes a diferentes conjuntos. Ela conduz o algoritmo a encontrar muitos grupos
cuja dissimilaridade entre os elementos de cada um é baixa. De forma semelhante, o single lin-
kage procura pela menor distância entre este par de elementos. O primeiro tipo produz grupos
compactos ou bem encadeados e tem a propriedade de deixar elementos relativamente simila-
res em grupos diferentes. Por outro lado, o segundo produz grupos mais alongados pelo fato
de sempre procurar os elementos mais similares possível. No agrupamento de médias de gru-
pos, a dissimilaridade é obtida a partir da média das distâncias entre todos os pares de objetos,
12

sendo cada um pertencente a um grupo diferente. Este tipo de ligação tenta balancear as vanta-
gens e desvantagens da ligação simples e completa: produzir grupos relativamente compactos
e que são também afastados. Existe o agrupamento por centróides (Método de Ward), onde
cada grupo é representado por um centróide (vetor de médias) e a distância é medida entre
os centróides de cada grupo. No agrupamento de medianas, o processo é semelhante ao por
centróides, entretanto a distância é obtida a partir de vetores de medianas.
A distância d(A,B) entre dois conjuntos A e B pode ser calculada de diversas maneiras
dependendo da aplicação do problema. Ela é fundamental para definir qual par de grupos
deve ser unido (aglomerativo) ou separado (divisivo) e, conseqüentemente, irá determinar a
forma dos clusters. Considere que cada elemento a ∈ A é descrito por variáveis contínuas tal
que a = (a1, . . . ,a j, . . . ,am)T . A tabela a seguir mostra alguns dos mais usadas medidas de
dissimilaridade:
Nome da distância ExpressãoManhattan d(a,b) = ∑ j |a j−b j|
Euclidiana d(a,b) = ∑ j(a j−b j)2
Minkowski d(a,b) = p
√
∑ j |a j−b j|p
Mahalanobis d(a,b) =√
(a−b)T S−1(a−b), S−1 é a matriz de covariância
Tabela 2.2 Tipos de distância
A distância de Manhattan, também conhecida como distância City-block, é equivalente ao
espaço L1, a distância Euclidana corresponde ao espaço L2 e Minkowski ao espaço Lp. Esta
última pode ser considerada uma generalização das duas anteriores. Quando p→∞, a distância
é a de Chebyshev e pode ser calculada como d(a,b) = max|a1−b1|, |a2−b2|, . . . , |am−bm|
[20].
2.3.1 Algoritmo Aglomerativo
Um método de agrupamento hierárquico aglometativo produz um série de partições do conjunto
de dados, Cn,Cn−1, . . . ,C1. O primeiro, Cn, consiste de n classes com um único membro. O
último, C1, consiste de um único grupo contendo todos os n elementos. Para executar o método
hierárquico, comumente é utilizado uma matriz de dissimilaridade M entre pares de grupos.
No início da execução do algoritmo aglomerativo, como todos os grupos são constituidos de
1 elemento, a matriz de dissimilaridade entre os grupos é a mesma obtida quando calcula-se
essa métrica por pares de elementos. Uma operação básica do método pode ser representada a
seguir:
13

Algorithm 3 Aglomerativo (Ω)
Require: Um conjunto de dados Ω;Ensure: Retorna um dendograma D;
1: Inicialize um conjunto de grupos P = C1,C2, . . . ,Cn, onde Ci é um grupo contendo umelemento de Ω;
2: Inicialize um dendograma D← P;3: Inicialize a matriz de dissimilaridade M = [mi j], onde xi e x j são elementos do conjunto de
dados Ω e mi j é a dissimilaridade entre estes elementos;4: numGroupos← n;5: while numGroupos > 1 do
6: Selecione dois grupos Ai∗ e A j∗ tais que (i∗, j∗) = argmin1≤i≤numGroups, j<iM(i, j);7: Crie um grupo B = Ai∗ ∪A j∗ e adicione-o a P e a D;8: Remova Ai∗ e A j∗ de P;9: Atualize a matriz M usando as distancias entre os grupos pertencentes a P;
10: numGroupos← numGroupos−1;11: end while
return Dendrograma D.
A cada iteração do algoritmo, um novo grupo é criado formado pela união dos dois grupos
mais similares e é adicionado ao dendrograma D. O conjunto P é usado para armazenar a
partição atual e para calcular a matriz M. A figura a seguir ilustra as operações realizadas na
matriz M para 5 elementos usando average linkage:
Figura 2.3 Exemplo do algoritmo aglomerativo
14

Inicialmente, os grupos formados pelos elementos D e E são selecionados para formarem
um novo conjunto, uma vez que a dissimilaridade entre esses elementos é a menor dentre
qualquer outro par de objetos, e em seguida a matriz é atualizada. Esse processo de seleção,
união e atualização é realizado até que exista apenas um grupo. O correspondente dendograma
é mostrado na imagem a seguir:
Figura 2.4 Dendrograma
Uma importante propriedade do algoritmo hierárquico é sua monoticidade [21], isto é, a
dissimilaridade entre dois grupos que são agrupados é monoticamente crescente de acordo com
o nível que essa junção acontece. Isso implica que, para dado um grupo, a dissimilaridade de
seus filhos é maior que as dissimilaridades entre os sub-grupos de cada um dos dois filhos. Isso
permite que o agrupamento seja representado usando uma estrutura de arvore. Isso pode ser
visto pelo figura acima: os grupos singulares são dispostos na parte inferior da arvore onde
representa a distancia 0 e a junção desses grupos são representados mais acima dos sub-grupos,
de modo que o grupo final ocupe a posição mais afastada da linha onde d = 0.
A representação gráfica por meio do dendograma dos grupos e sub-grupos após a execução
do algoritmo hierárquico permite-se fazer análise estatística e comparações entre estes gru-
pos, a principal característica que torna os métodos de agrupamento hierárquicos populares e
atraentes. Embora, o agrupamento hierárquico não possa fornecer somente uma, mas sim um
conjunto de partições, é possível encontrar uma partição dos dados usando o dendrograma.
Cada "corte"horizontal no dendograma representa uma partição. No exemplo, a árvore pode
ser cortada nas alturas indicadas de acordo com a medida de distância. Para a distância d1, a
partição resultante é P1 = A,B,C,D,E. Por outro lado, para a distância d2, encontra-se
a partição P2 = A,B,C,D,E.
15

2.3.2 Algoritmo Divisivo
Os métodos hierárquicos divisivos são caracterizados por reunir todos os n elementos da base
em uma única classe e progressivamente separá-los de modo que no final da execução tenham-
se n classes com apenas um elemento em cada uma. Os algoritmos divisivos podem ser divi-
didos em dois principais grupos: monotéticos (monothetics), que dividem o conjunto de dados
de levando-se em conta apenas um único atributo, e politéticos (polythetics), cujas divisões são
realizadas a partir dos diversos atributos que um padrão pode ter.
No contexto de métodos de agrupamento, uma potencial vantagem dos métodos divisivos
sobre os métodos aglomerativos pode ocorrer quando o objetivo é encontrar uma partição dos
dados em um relativamente pequeno número de clusters [21].
Estes métodos podem funcionar em conjunto com métodos de particionamento tais como
K-Means ou K-Medoids aplicados recursivamente na função de dividir o grupo anterior em dois
grupos distintos fazendo-se K = 2. Entretanto, essa modificação irá depender da configuração
inicial em cada etapa do método hierárquico divisivo. Porém, isto não produz necessariamente
uma separação cuja propriedade de monoticidade do dendograma aconteça. Isto é, a altura de
cada nó não é proporcional para o valor da dissimilaridade intergrupais entre as seus dois filhos
[21].
Para evitar esse problema, uma versão do algoritmo hierárquico divisivo foi proposta por
Macnaughton Smith et al. (1965) [22]. O algoritmo começa colocando todos os elementos
em um único grupo C1. Em seguida, ele escolhe o elemento cuja média de dissimilaridades
entre todos os outros elementos é a maior. Este elemento, então, irá formar um novo grupo C2.
Iterativamente, o processo continua selecionando os elementos restantes no primeiro grupo C2
através do maior valor de médias de dissimalidades e colocando no conjunto C2. Isto termina
quando a diferença entre as médias de dissimilaridades entre os dois grupos seja considerada
iguais. O resultado é uma divisão do conjunto contendo todos os elementos em outros dois
filhos. Selecionando grupos com os maiores diâmetros ou médias de dissimilaridades, o algo-
ritmo segue recursivamente até que grupos contendo apenas um elemento cada sejam encontra-
dos. O esquema do algoritmo para a abordagem proposta por Macnaughton Smith et al. (1965)
é mostrada no pseudocódigo seguinte.
A propriedade de encontrar partições usando dendrogramas é um ponto forte dessa aborda-
gem hierárquica quando comparadado com os algoritmos de particionamento ou seqüenciais,
por exemplo. Entretanto, algoritmos hierárquicos são mais custosos em termos de espaço e
tempo. Desta forma, quando se conhece o numero de grupos no conjunto de dados, é preferível
que se use métodos de particionamento. Estes métodos são descritos na seção a seguir.
16

Algorithm 4 Divisivo (Ω)
Require: Um conjunto de dados Ω;Ensure: Retorna um dendograma D;
1: Inicialize o conjunto de grupos P= C1, onde C1 é um grupo contendo todos os elementosde Ω. Faça ε > 0;
2: Inicialize um dendograma D← P;3: Inicialize a matriz de dissimilaridade M = [mi j], onde xi e x j são elementos do conjunto de
dados Ω e mi j é a dissimilaridade entre estes elementos;4: numGroupos← 1;5: while numGroupos 6= n do
6: Selecione o grupo Ci∗ tal que i∗ = argmin1≤i≤numGroups1|Ci|
∑xl∈Ci∑xm∈Ci
M(l,m);7: Crie um grupo C j = /0 e adicione-o a P e a D;8: numGroupos← numGroupos+1;9: di f ← 1;
10: while di f > ε do
11: Selecione o elemento xs∗ tal que s∗ = argmax1≤s≤|C j|∑xs∈C j∑xt∈C j
M(s, t);12: C j ←xs∗;13: media1 = ∑xl∈Ci∗
∑xm∈Ci∗M(l,m);
14: media2 = ∑xl∈C j∑xm∈C j
M(l,m);15: di f = |media1−media2|;16: end while
17: end while
return Dendrograma D.
2.4 Métodos de Particionamento
O uso de métodos de agrupamento tornou-se um assunto muito relevante e a análise de clus-
tering tem sido utilizada em diversos domínios de aplicações tais como mineração de dados,
reconhecimento de padrões e bioinformática. Esses métodos podem ser divididos em méto-
dos hierárquicos e de particionamento [1] [3]. Os de particionamento possuem dois principais
tipos: os rígidos (hard), onde cada padrão pertence a uma única classe, e os difusos (fuzzy),
possibilitando que elementos tenham diferentes graus de pertinência entre as classes. Os méto-
dos difusos, por sua vez, geram partições usando a abordagem crisp, probabilística (ou fuzzy)
ou possibilística. Um dos métodos de particionamento fuzzy amplamente usado é o Fuzzy C-
Means (FCM), mas possui problemas com dados ruidosos e com o número de classes, já que
os graus de pertinência consideram todos os agrupamentos da partição durante o cálculo, difi-
cultando a interpretação desse valores [5]. Para resolver esses problemas, em [5] foi proposto
o método Possibilistic C-Means (PCM), tornando um caso mais geral das abordagens crisp e
17

probabilística.
Esta seção tratará de métodos não-hierárquicos mostrando, em resumo, as principais carac-
terísticas das duas grandes categorias de algoritmos de particionamento.
2.4.1 Algoritmos Rígidos
Consistem em obter uma partição a partir de um determinado conjunto de n elementos agru-
pados em um número pré-definido de k classes, onde k 6 n, de forma que cada classe possua
pelo menos um elemento e cada elemento deve pertencer unicamente a uma classe, isto é, não
admitem a existência de grupos vazios e que estes não tenham elementos em comum.
Existem versões desse tipo de algoritmo onde, além de encontrarem a partição composta
por n elementos e k classes, fazem uso da otimização de função de custo: algoritmos de nuvem
dinâmica. Estas funções se caracterizam por analisar as classes em cada iteração e usar métricas
para fornecer informações sobre o particionamento. O problema da otimização de funções de
custo consiste em fazer uso da função e encontrar a melhor solução dentre todas as possíveis
soluções objetivando minimizar um critério antes estabelecido.
K-Means
Um dos mais populares algoritmos de particionamento é o K-Means [2] proposto por Mc-
Queen (1967) [27], no qual grupos homogêneos são identificados, minimizando o erro do agru-
pamento definida como a soma das distâncias euclidianas quadradas entre cada conjunto de
dados e os correspondentes centros dos aglomerados (centróides). Isto é:
E =K
∑k=1
∑xi∈Ck
d(xi,yk) (2.1)
onde K é o número de grupos que deseja-se encontrar, d(xi,yk) é a distância entre o objeto xi e
o centróide yk da classe Ck. Essa distância é a Euclidiana e pode ser calculada como definida
na tabela 2.2, enquanto o centróide para a variável j é calculado da seguinte forma:
yjk =
1|Ck|
∑xi∈Ck
xji (2.2)
onde |Ck| representa o número de objetos pertencentes ao grupo Ck.
A cada iteração do algoritmo, dois principais passos são executados: representação e alo-
cação. No primeiro, os representantes de cada grupos são recalculados de acordo com os
18

elementos presentes nesse grupo buscando minimizar a função objetivo. Enquanto no segundo
passo, objetos são atribuídos às classes cuja distância entre o objeto e o representante da classe
seja mínima dentre todas as distâncias para as demais classes da partição. O processo é repe-
tido até que não haja mais alterações nas classes, isto é, elementos não sejam realocados, ou
até que a diferença entre o critério atual e o calculado na iteração imediatamente anterior seja
considerada pequena. O algoritmo a seguir ilustra as principais operações do K-Means:
Algorithm 5 K-Means (Ω,K)
Require: Um conjunto de dados Ω e o número de grupos K;Ensure: Retorna uma partição P;
1: Faça ε > 0. Selecione aleatoriamente K elementos de Ω (y1,y2, . . . ,yK) para serem osrepresentantes iniciais dos grupos;
2: Construa K grupos (C1,C2, . . . ,CK) tal que cada elemento xi ∈ Ω é alocado para o grupoCk∗ onde k∗ = argmin1≤k≤Kd(xi,yk). Atualize a partição como P = C1,C2, . . . ,CK;
3: t ← 0;4: Et ← 0;5: Et+1 ← ∑K
k=1 ∑xi∈Ckd(xi,yk);
6: while |Et+1−Et |> ε do
7: Atualize os representantes dos grupos usando a equação 2.2, 1≤ k ≤ K e 1≤ j ≤ m;8: Aloque cada elemento xi ∈Ω para o grupo Ck∗ onde k∗ = argmin1≤k≤Kd(xi,yk);9: Et ← Et+1;
10: Et+1 ← ∑Kk=1 ∑xi∈Ck
d(xi,yk);11: t ← t +1;12: end while
return Partição P.
O K-Means é um caso particular dos algoritmos de nuvens dinâmicas, o qual reconhece
apenas regiões esféricas devido a sua distância fixa. A versão adaptativa desses algoritmos, por
outro lado, é capaz de associar uma distância diferente para cada classe a cada nova iteração,
resultando em um reconhecimento de formas e tamanhos variados entre as classes, sendo isto
uma vantagem sobre os métodos que usam distâncias fixas [8, 10, 11, 12]. A principal diferença
entre o tradicional K-Means e os algoritmos com distância adaptativa é que estes usam pesos
para cada variável de forma que o cálculo final da distância é balanceada pela dispersão de
cada variável (estes métodos com distância adaptativa são mais detalhadamente discutidos no
próximo capítulo). Além disso, os vetores de pesos podem ser globais ou por grupos, isto é,
a distância pode variar de acordo com conjunto. Desta forma, em geral, os protótipos podem
melhor representar os grupos e a partição final encontrada é melhor que a do método que usa
distância não-adaptativa.
Xiong et al. [23] realizou experimentos com o algoritmo para investigar o seu comporta-
19

mento avaliando o tamanho dos grupos e as medidas de validação das partições encontradas
pelo método. Jain [24] fez um breve resumo dos algoritmos de agrupamento, entre eles o K-
Means. No artigo, é discutido os principais desafios dos métodos e emergentes abordagens
como classificação semi-supervisionada ou seleção de múltiplas variáveis.
Além disso, diversas extensões do algoritmo K-means foram propostas em diferentes for-
mas. Por exemplo, a idéia principal do algoritmo proposto por Yi e K. Sam [25] é agrupar
todas os elementos do conjunto de dados de acordo com as suas incertezas de agrupamento
calculadas usando múltiplos algoritmos de agrupamento. Girolami [26] desenvolveu o Ker-
nel K-means que é capaz de produzir hiper-superfícies não-lineares que podem separar grupos
transformando o espaço de entrada para um espaço de características de mais alta dimensão e,
em seguida, realizar a agregação dentro deste espaço de características.
K-Medoids
Outra técnica popular de particionamento é o método K-Medoids propostos por Kaufman
e Rousseeuw (1987) [28] em que os grupos homogêneos são identificados através da minimi-
zação do erro de agrupamento definido como a soma dos quadrados das distâncias euclidiana
entre cada ponto de ajuste de dados e o protótipo agrupamento correspondente. Uma importante
característica deste método é sua robustez ao ruído e outliers, em comparação com K-Means
uma vez que ele procura elementos centrais, ao contrario do K-Means que sintetiza represen-
tantes de classes através de médias [29]. Entretanto, o custo computacional para executar o
K-Medoid é maior que o K-Means, por exemplo, o que caracteriza sua maior deficiência. Vá-
rios autores propuseram versões do K-Medoids para tentar reduzir o tempo de processamento
[30, 31, 32].
Uma realização muito comum de K-Medoid agrupamento é o Partitioning Around Medoids
(PAM) proposto por Kaufman e Rousseeuw (1987) [28]. O algoritmo inicialmente define uma
partição com base numa seleção aleatória de objetos para serem os protótipos iniciais. Depois,
o algoritmo passa em duas fases principais: definição de protótipos em que o elemento mais
representativo (medoid) de cada grupo é selecionado com base nas diferenças emparelhadas e o
passo de alocação onde os objetos são trocados para agrupar tal que a distância entre o objeto e
o representante correspondente minimiza o critério. Este processo termina quando não houver
alteração no medoid ou a diferença entre o critério da partição atual e o critério de partição
imediatamente anterior é inferior a um limiar definido a priori.
O critério de otimização do método K-Medoids é, portanto, semelhante ao do K-Means.
Entretanto a principal diferença está na forma que os protótipos do grupos são definidos:
20

yk = argminxi∈Ω ∑xl∈Ck
d(xi,xl) (2.3)
desta forma, o medoid da classe Ck é o elemento pertencente ao conjunto de objetos Ω tal que a
soma das distâncias entre esse medoid e todos os elementos da classe Ck é a menor. O algoritmo
PAM é descrito como:
Algorithm 6 PAM (Ω,K)
Require: Um conjunto de dados Ω e o número de grupos K;Ensure: Retorna uma partição P;
1: Faça ε > 0. Selecione aleatoriamente K elementos de Ω (y1,y2, . . . ,yK) para serem osrepresentantes iniciais dos grupos;
2: Construa K grupos (C1,C2, . . . ,CK) tal que cada elemento xi ∈ Ω é alocado para o grupoCk∗ onde k∗ = argmin1≤k≤Kd(xi,yk). Atualize a partição como P = C1,C2, . . . ,CK;
3: t ← 0;4: Et ← 0;5: Et+1 ← ∑K
k=1 ∑xi∈Ckd(xi,yk);
6: while W ′−W > ε do
7: for i = 1→ |Φ| do
8: max←−19: for l = 1→ |Ω|(xl 6= yi) do
10: sum← ∑x′l∈Ci
d(xl,xl′);11: if sum > max then
12: max← sum;13: yi ← xl;14: end if
15: end for
16: end for
17: Aloque cada elemento xi ∈Ω para o grupo Ck∗ onde k∗ = argmin1≤k≤Kd(xi,yk);18: Et ← Et+1;19: Et+1 ← ∑K
k=1 ∑xi∈Ckd(xi,yk);
20: t ← t +1;21: end while
return Partição P;
De acordo com o algoritmo, existe um loop a mais em comparação com o método K-
Means. Desta forma, o PAM torna-se mais custoso computacionalmente e, em termos práticos,
é aplicado em conjunto de dados onde o número de elementos e grupos é relativamente pequeno
[31]. Para resolver este problema, o método Clustering LARge Applications (CLARA) foi
proposto por Kaufman e Rousseeuw [33] podendo ser aplicado a grandes conjuntos.
21

2.4.2 Algoritmos Difusos
Os conjuntos fuzzy foram introduzidos simultaneamente em 1965 por Kadeh [34] e Klaua [35]
como uma nova maneira de representar imprecisões do cotidiano [36]. Esta teoria fornece um
conceito para aproximar e descrever as características de um sistema que é muito complexo
ou mal definido para admitir análise matemática precisa. Admite-se que a forma com que o
pensamento humano trabalha com conceitos-chave não são apenas números, mas também uma
aproximação de conjuntos difusos. Assim, este conceito pode ser aplicado a diversos domínios,
tais como reconhecimento de padrões, comunicação de informação ou abstrações relacionadas
a cognição.
Os algoritmos do tipo difuso estendem o conceito de associação de cada elemento em uma
classe, isto é, um indivíduo pode pertencer a diversas classes de acordo com uma função de
pertinência capaz de associar cada padrão a cada um dos clusters assumindo valores no inter-
valo [0,1]. Neste caso, cada classe é um conjunto nebuloso de todos os objetos. Cada elemento
do conjunto de dados possui um grau de pertinência para uma classe da partição, de forma que
a soma de todos os graus relativos a essa elemento é necessariamente igual a 1, sendo por esse
motivo essa abordagem de algoritmo também pode ser chamado de probabilísticos. Em geral,
os algoritmos rígidos são um caso particular do algoritmos difusos onde o grau de pertinência
dos objetos possui como valor um dos elementos do conjunto 0,1.
Uma desvantagem desse tipo de algoritmo é a definição da função de pertinência. Diferen-
tes funções são usadas, entre elas estão as baseadas em centróides de clusters. Outra desvan-
tagem é a dependência da escolha inicial dos protótipos das classes, como ocorre no algoritmo
rígido K-Means. O algoritmo difuso mais usado é o Fuzzy-C-Means (FCM) proposto por Bez-
dek em 1981 [37], onde os elementos mais próximos das bordas dos grupos possuem um menor
grau de pertinência, enquanto aqueles mais próximos ao centróide têm uma pertinência maior
e o centróide é obtido fazendo-se uma média ponderada do grau de todos os indivíduos daquele
grupo. O algoritmo FCM é semelhante ao K-Means, onde a principal diferença é uma etapa
extra para o cálculo do valores de pertinência. Outro aspecto que difere do K-Means é que o
algoritmo encontra um agrupamento, e não uma partição; para determiná-la cada elemento é
aloca ao grupo cujo grau de pertinência é o maior.
O método FCM proposto por Bezdek, assim como o K-Means, não é eficiente para a iden-
tificação de grupos não-esféricos devido a distância Euclidiana usada no cálculo dos protótipos
e dos valores dos graus de pertinência. Pelo mesmo motivo, configurações com grupos de di-
ferentes formas, tamanhos e orientações permitem que o FCM encontre agrupamentos pouco
representativos. Para resolver esses problemas, diversos autores tem trabalhado para propor
22

métodos que combinem os pontos fortes da abordagem difusa com outras técnicas. Por exem-
plo, Lin e Wang [39] introduziram uma versão de Support Vector Machines (SVM) utilizando
graus de pertinência. Zhang e Chen [38] propuseram métodos que unem o conceito de Ker-
nel as abordagens difusa e possibilística. De Carvalho [13] fez a extensão do método FCM
para dados simbólicos do tipo intervalo e propôs medidas de qualidade da partição permitindo
interpretar a homogeneidade desta segundo uma variável ou grupo.
2.5 Outros Métodos
Os métodos descritos nas seções anteriores são os mais utilizados para encontrar agrupamen-
tos de dados. Entretanto, outras técnicas buscam compreender automaticamente os dados e
identificar padrões. Desta forma, os métodos descritos a seguir também são utilizados para
extrair informações sobre os dados e podem trabalhar de forma híbrida com outros algoritmos
de agrupamento.
Algoritmos Evolutivos
Estes tipos de algoritmos se baseiam em mecanismos da evolução biológica, tais como
reprodução, mutação, recombinação e seleção. O conjunto de dados representa a população
sob evolução e esta é simulada através de repetidas operações associadas às mutações genéticas
comuns na evolução. Usam a idéia de que os indivíduos mais aptos têm mais chances de deixar
informações sobre o seu código genético para as próximas gerações do que outros indivíduos
menos preparados. Os algoritmos evolutivos são aplicados para aproximar funções com bom
desempenho e, desta forma, são usados em diversos domínios como engenharia, economia,
genética e robótica. Sub-grupos dos algoritmos evolutivos foram criados de acordo com a
aplicação para as quais são destinados.
O mais popular é o algoritmo genético cujo termo foi primeiramente utilizado por Holland
[40]. Esse algoritmo caracteriza-se pela busca de solução através de operações (como mutação)
sobre cadeias de números, geralmente binários. Cada objeto do conjunto de dados (fenótipo) é
descrito por uma seqüência de cromossomos (ou um genótipo). Inicialmente, a primeira gera-
ção de indivíduos é determinada aleatoriamente e as gerações posteriores irão ser influenciadas
pela seleção do indivíduo mais apto e das mutações nas seqüências de cromossomos. A aptidão
dos individuos está relacionada a uma função de adequação determinada a priori, desta forma,
a cada geração, a função se aproxima de um valor ótimo. Assim , o algoritmo genético pode
23

ser dividido em três grandes operações: inicialização, mutação e determinação da próxima ge-
ração. O algoritmo pára se a função de adequação aplicada a geração atual atingiu um valor
satisfatório ou se foram criadas um numero definido a priori de gerações. A figura a seguir
ilustra um exemplo de aplicação de algoritmo genético. Rajan et al. [41] propuseram uma ver-
são de algoritmos genéticos para encontrar a forma, tamanho e topologia de telhados de ferro
buscando reduzir o custo com o material:
Figura 2.5 Aplicação de Algoritmos Genéticos
QT (Quality Threshold)
É uma alternativa de método de agrupamento feito especialmente para ser usado em banco
de dados com informações sobre genes [42]. Neste algoritmo, cada elemento é comparado em
pares com todos os outros e é calculado um coeficiente de correlação. Elementos são agrupados
de modo que todos os elementos dentro de um cluster devem ser mais fortemente correlacio-
nadas com um único elemento central do que o limite de qualidade de entrada (threshold).
Elementos são acrescentados a esse cluster enquanto esse limite é satisfeito. Se o limite for
ultrapassado, cria-se outra classe agrupando-se elementos próximos de forma que respeitem o
limite.
Uma vantagem desse método é que não são sensíveis à ordem dos dados apresentados,
todas as informações na base de dados é considerada. Outra vantagem é que o algoritmo pode
facilmente identificar e ranquear os conjuntos de genes que são mais correlacionados de acordo
com uma determinada característica. Além disso, o numero de grupos não precisa ser definido
a priori como K-Means ou K-Medoids. Entretanto, QT é mais custoso computacionalmente
do que o tradicional K-Means, já que todo elemento é comparado com todos os outros da
24

base. Outro ponto negativo do método está relacionado a necessidade de escolha do valor do
threshold.
Redes Neurais
Uma rede neural artificial consiste de conexões de diversos neurônios artificiais (ou nós)
cujo termo foi primeiramente utilizado por Hopfield [43]. São algoritmos que tentam repre-
sentar as redes neurais biológicas por meio de grupos de unidades as quais se comunicam para
chegarem a uma resposta final. Existem três importantes parâmetros que definem uma rede: (1)
o padrão de conexão entre diferentes camadas de neurônios, (2) o processo de atualização dos
pesos das conexões entre os nos e (3) a função de ativação do neurônio que converte os sinais de
entrada em sua saída de ativação fazendo uso dos pesos. Cada unidade faz o processamento dos
sinais recebidos advindos de outras possíveis ligações, as quais possuem pesos com a finalidade
de simular a sinapses presentes nas atividades cerebrais. De acordo com o processamento, é
possível dizer a saída fazendo uso de um limiar e função de ativação. As saídas combinadas
entre as unidades da rede neural artificial dão respostas a respeito de um determinado problema,
geralmente classificando elementos de um conjunto de dados. São modelos muito usados onde
é difícil criar um comportamento matemático bem definido para um problema, ou que a estru-
tura da informação a qual irão analisar são bastante complexos se fossem usados por outros
modelos computacionais.
Existem diversas versões de redes neurais dependendo da finalidade para as quais são des-
tinadas. De acordo com a topologia, podem ser do tipo feedforward, onde os sinais de entrada
sempre chegam através de conexões de camadas anteriores da rede ou da própria entrada. Ou-
tra topologia é a recorrente, na qual os sinais de saída podem ser usados como entrada da rede,
realimentando com conexões de feedback. E as construtivas que se caracterizam por poderem
criar neurônios entre a camada de entrada e a saída de acordo com os dados analisados com o
objetivo de reduzir ao máximo o erro final entre a resposta desejada e a obtida. Desta forma,
redes neurais são usadas em diversas categorias, uma delas está relacionada com as funções
de aproximação, como análise de regressão e séries de previsão de tempo; outra está relacio-
nada com a classificação, reconhecimento de padrões e tomadas de decisão; e uma terceira com
processamento de dados, tais como filtragem, compactação e clustering.
As redes neurais auto-organizáveis (self-organizing map - SOM) é um importante tipo de
rede que caracteriza-se por utilizar aprendizagem não-supervisionada (isto é, os padrões de en-
trada não precisam de rótulos de classes) e objetiva treinar neurônios dispostos em uma malha.
Essas redes também podem ser chamadas de Mapas de Kohonen devido a sua estrutura e nome
25

do autor idealizador [44]. Uma importante característica dessa rede é que é possível produzir
uma representação de baixa dimensão do espaço de entrada (normalmente 2 dimensões) per-
mitindo que dados descritos em alta dimensão possam ser visualizados após a classificação. A
figura a seguir ilustra a topologia da rede SOM:
Figura 2.6 Rede Neural do tipo SOM
O objetivo do algoritmo de treinamento é diferenciar partes da malha para melhor classificar
os padrões de entrada, desta forma, padrões serão associados a determinadas parte da camada
de saída de acordo com os atributos que o descrevem. Muitas aplicações utilizam redes SOM
para encontrar agrupamentos dos dados. Por exemplo, Isa et al. [45] usaram redes SOM para
identificar grupos de documentos de texto. Mostafa [46] fez um estudo usando SOM para
examinar o efeito de vários fatores psicográficos e cognitivos sobre a doação de órgãos no
Egito.
Classificação com Sobreposição
Em muitos métodos de agrupamento, existe o processamento de dados de forma que não
haja sobreposição de dados ou de classes, isto é, os grupos são disjuntos entre si. Entretanto,
na abordagem de classificação com sobreposição, há a possibilidade de um elemento pertencer
a mais de uma classe, sendo bastante útil para muitas aplicações onde o conceito de sobreposi-
ção é importante [47, 48]. Assim, segundo essa definição, o FCM também pode ser classificado
como um método de classificação com sobreposição, uma vez que os elementos podem perten-
cer a diferentes grupos de acordo o seu grau de pertinência. Na biologia, por exemplo, genes
26

participam simultaneamente de vários processos. Desta forma, quando for necessário agrupar
os genes de acordo com suas expressões gênicas fazendo uso de micro-arrays, é conveniente
atribuir a esses genes a sobreposição de classes, de forma que a consulta de genes pode está
associada a diversas características importantes.
Alguns dos métodos que usam esse conceito de sobreposição são o Bk e o de pirâmides. O
método Bk é caracterizado pelas classes poderem ter no máximo k− 1 elementos em comum.
Quando se faz B1, ou k = 1, o método fica equivalente ao método hierárquico aglomerativo de
ligação simples. A construção das classes é feita utilizando-se teoria dos grafos, onde cada ele-
mento é representado por um vértice e as arestas estão associadas à dissimilaridade em cada par
de elementos. Enquanto no do tipo pirâmide, o agrupamento é feito hierarquicamente levando
em conta a ordenação das classes, de forma que a pirâmide assume uma forma generalizada do
dendrograma, uma vez que pode ser obtida a partir de um método hierárquico aglomerativo.
Enquanto o dendogama encontrado pelo método hierárquico é formado por uma seqüência
de partições, o método do tipo pirâmide encontra uma lista de grupos sobrepostos. A figura a
seguir ilustra um exemplo de possíveis agrupamentos de cinco elementos usando os métodos
hierárquico e piramidal, respectivamente:
Figura 2.7 Agrupamento hierárquico e piramidal
27

CAPÍTULO 3
Métodos Fuzzy C-Means
Os que se encantam com a prática sem a ciência são como os timoneiros
que entram no navio sem timão nem bússola, nunca tendo certeza do seu
destino.
—LEONARDO DA VINCI
3.1 Introdução
O conceito de fuzzy set foi inicialmente explorado por Zadeh [34] e posteriormente aplicado a
métodos de agrupamento por Ruspini [49]. Recentemente, trabalhos com aplicações de fuzzy
set em Análise de Agrupamento tem sido desenvolvidos em diferentes campos do conheci-
mento [50]; Chen et al. elaborou diversos trabalhos a respeito da utilização do conceito de
nebulosidade em variados métodos [51, 52, 53, 54, 55].
A partir dos trabalhos de Zadeh, Dunn [56] desenvolveu e Bezdek [37] melhorou o mé-
todo Fuzzy C-Means (FCM). Atualmente, o método FCM é o mais conhecido da abordagem
difusa para particionamento de dados amplamente usado em Reconhecimento de Padrões. Sua
principal característica é encontrar um conjunto de grupos tal que cada objeto possui graus de
pertinência para cada classe. A partição final dependerá desses valores de graus de pertinên-
cia, desta forma, o cálculo desses valores torna-se importante para esta abordagem difusa. Um
importante parâmetro que influencia a performance desse método é o expoente ponderador m,
chamado fuzzificador. Yu [57] e Wu [58], por exemplo, propuseram técnicas para tratar este
parâmetro.
Existem muitos artigos com trabalhos relacionados à teoria e à aplicação do algoritmo FCM
como teoremas numéricos, teoremas estocásticos, processamento de imagens, estimação de
parâmetros e muitos outros [50]. Por exemplo, Hathaway et al. [59] apresentou versões do
métodos FCM usando vários distâncias LP, cujo principal objetivo é aumentar a robustez a
outliers. Jajuga [60] apresentou o algoritmo de agrupamento difuso baseado na norma L1. Gro-
enen e Jajuga [61] apresentaram um novo agrupamento difuso com base na distância quadrada
28

Minkowski. Oh et al. [62] propôs um novo algoritmo de agrupamento difuso para dados cate-
góricos multivariados. Xu e Wunsch [63] apresentaram uma substituição da norma euclidiana
por uma nova métrica robusta no c-agrupamento objetivando diminuir as fraquezas do FCM
clássico. Zhang e Chen [64] propôs a substituição de uma certa métrica de distância do kernel
induzido para a distância original euclidiana no FCM que permite realizar o mapeamento não-
linear de um espaço de características de alta dimensional. Kummamuru [65] mostrou uma
versão modificada do algoritmo proposto por Oh et al. onde esta versão pode ser aplicado em
conjuntos de dados que contem grande número de documentos ou palavras. Pal et al. [66]
mostrou o cálculo de graus de pertinência simultaneamente, a fim de evitar vários problemas
do FCM. De Carvalho et al. [67] apresentou métodos de agrupamentos nebulosos baseados em
diferentes distâncias adaptativas quadráticas definidas por matrizes de covariância difusa. Liu e
Xu [68] obteu um método de agrupamento com atributo kernelizado usando distância de kernel
induzida.
Uma vantagem deste método sobre o K-Means, por exemplo, é sua capacidade de encontrar
resultados mais satisfatórios quando os dados são disposto com sobreposição, isto é, objetos
de diferentes classes possuem características similares. Entretanto, semelhante ao K-Means, o
FCM pode levar a um mínimo local. Neste capítulo, o método Fuzzy C-Means será descrito
com maior detalhe e tratará de versões deste método que utilizam a abordagem clássica ou
dados simbólicos.
Para as seções a seguir, considere uma partição de objetos P = C1, . . . ,Ci, . . . ,Cc e um
conjunto de objetos Ω = x1, . . . ,x j, . . . ,xn onde cada objeto é descrito por uma lista de variá-
veis x j = (x1j , . . . ,x
kj, . . .x
pj ), isto é, x j ∈ ℜp onde p é o numero de variáveis. Para cada grupo
de objetos Ci existe um protótipo correspondente tal que L = y1, . . . ,yi, . . . ,yc é o conjunto
de protótipos onde yi = (y1i , . . . ,y
ki , . . .y
pi ). O valores dos graus de pertinência são disposto na
matriz U = [ui j]c×n, onde ui j é a probabilidade do objeto x j pertencer ao grupo Ci.
3.2 Algoritmo FCM
O algoritmo herda características do K-Means como a escolha do parâmetro que determina o
número de grupos a priori e o uso da distância Euclidiana para o cálculo da dissimilaridade
entre objetos. Entretanto, a principal particularidade desse algoritmo está na forma como a
pertinência dos elementos do conjunto de dados é calculada e representada. A idéia chave do
trabalho de Zadeh é representar a similaridade (ou dissimilaridade) que um objeto compartilha
com cada grupo através de uma função cujos valores estão entre zero e um. Assim, a fun-
29

ção objetivo do método e o cálculo dos protótipos são diferentes do K-Means. Além disso o
algoritmo possui uma etapa de processamento importante: o cálculo do grau de pertinência.
A função objetivo, o protótipo e o grau de pertinência medidos pelo algoritmo da abordagem
difusa serão descritos a seguir.
3.2.1 Função Objetivo
Sendo o FCM um método de particionamento (assim como K-Means ou K-Medoids), o pro-
blema é encontrar uma partição P de um conjunto de objetos Ω tal que minimize (ou maximize)
uma função objetivo. Além de computação, este tipo de função também pode ser aplicado a
diversos outros campos como mecânica, economia e sistemas de controle. Em Análise de
Agrupamento, diversas tipos de funções objetivo podem ser utilizadas em métodos de parti-
cionamento, por exemplo, interno, externo, híbrido e baseado em grafos [69]. Na abordagem
interna, o cálculo da função leva em conta a relação entre objetos do mesmo grupo. Por outro
lado, a abordagem externa considera o ponto de vista inter-grupos, de forma que o método
tentar maximizar a separação entre os grupos da partição. No híbrido, existe a combinação
de diferentes funções objetivo. Enquanto na abordagem baseada em grafos, definições de nós,
arestas e cut são utilizados para o cálculo da função. No método FCM, a função objetivo é ba-
seada na soma-de-erros-quadrados (sum-of-squared-errors ou SSE), uma versão da abordagem
interna. Desta forma, o problema torna-se minimizar a soma de distâncias entre cada elemento
do grupo e o respectivo representante. Quanto menor o valor da função, mais próximos os
elementos estarão dos seus protótipos. O cálculo dessas distâncias é feita para todos os grupos
da partição e é definida como:
J =c
∑i=1
n
∑j=1
(ui j)md(x j,yi), (3.1)
onde d(x j,yi) é a distância Euclidiana calculada como:
d(x j,yi) =p
∑k=1
(
xkj− yk
i
)2. (3.2)
A complexidade de tempo teórica para calcular o valor de J é O(cnp), isto é, varia line-
armente em função do número de elementos na base, do número de variáveis que descrevem
esses elementos e do número de grupos da partição.
O cálculo de J depende do protótipo yi, do grau de pertinência ui j e do valor do parâmetro
m. A cada iteração do algoritmo, os dois primeiros são recalculados buscando minimizar a
30

função objetivo até que se atinja um mínimo local. A forma como o protótipo e o grau de
pertinência são calculados é descrita a seguir.
3.2.2 Protótipo
O FCM pertence a uma categoria de métodos que são baseados em protótipos [70]. Estes são
importantes para descrever os grupos em uma forma resumida (permitindo uma interpretação
mais detalhada da partição) e influenciam no cálculo do grau de pertinência de objetos. Os
protótipos são calculados através de informações a respeito dos grupos como a dispersão ou
posição dos elementos aos quis pertencem, desta forma, existirão tantas categorias de repre-
sentantes de grupos quanto forem as forma de avaliar as estatísticas da partição. No tradicional
K-Means, os protótipos são elementos centrais dos grupos medidos através de médias; no K-
Medois, utilizam-se medianas; e no Fuzzy C-Means, o parâmetro fuzzificador m e os graus de
pertinência são importantes para determinar os representantes. A expressão a seguir mostra
como os protótipos na abordagem difusa são calculados:
yi =∑n
j=1(ui j)mx j
∑nj=1(ui j)m
, (3.3)
Proposição 3.2.1. Os protótipos expressos pelas Equação 3.3 minimizam a função objetivo
descrita pela Equação 3.1, para todo i = 1, . . . ,c.
Prova 3.2.1 A Equação 3.1 pode ser reescrita como J =∑ci=1 ∑n
j=1(ui j)m ∑
pk=1
(
xkj− yk
i
)2(usando
a equação da distância Euclidiana) e sendo aditivo, minimizar J é equivalente a minimizar cada
termo definido como:
Jik =n
∑j=1
(ui j)m(
xkj− yk
i
)2. (3.4)
Assim, o problema torna-se encontrar um valor de yki que minimize Jik. Logo, é preciso
resolver a equação ∂Jik(yki )
∂yki
= 0, isto é:
∂Jik(yki )
∂yki
= 0⇒∂
∂yki
[
n
∑j=1
(ui j)m(
xkj− yk
i
)2]
= 0⇒n
∑j=1
(ui j)m(
xkj− yk
i
)
= 0.
A última igualdade permite chegar ao resultado:
yki =
∑nj=1(ui j)
mxkj
∑nj=1(ui j)m
. (3.5)
31

Este resultado mostra que o valor yki leva a um ponto crítico de acordo com a variação de
Jik, entretanto não indica se esse ponto é um mínimo. Para verificar isto, é necessário usar a
segunda derivada:
∂ 2Jik(yki )
∂yki
2 =∂
∂yki
[
−2n
∑j=1
(ui j)m(
xkj− yk
i
)
]
= 2n
∑j=1
(ui j)m.
Uma vez que os valores de ui j indicam uma probabilidade, isto é, ui j ∈ [0,1] (em especial,
∑ci=1 ui j = 1), a última sentença é positiva. Portanto, a função objetivo Jik atualizada por yk
i leva
a um ponto de mínimo.
3.2.3 Grau de Pertinência
O valor do grau de pertinência é associado a uma função de pertinência de acordo com a teoria
de Conjuntos Difusos (Fuzzy Set) e pode ser compreendido como uma generalização da Função
Indicador [71]. Formalmente, a Função Indicador de um subconjunto A de um conjunto X é
uma função 1A : X →0,1 definida como:
1A =
1, se x ∈ A
0, se x /∈ A.(3.6)
A expressão 1A também pode ser dita como IA. Em Análise Matemática, tal função é geral-
mente chamada de Função Característica e denotado por χA(x). Esse conceito pode ser adap-
tado como: seja P uma declaração,então I(P) leva ao valor 1 se a sentença P seja verdadeira,
ou leva ao valor 0 caso seja falsa.
Essa função pode ser usada em muitos métodos de agrupamento [72, 73, 74, 75, 76]. Uma
aplicação pode estar no processo de alocação do algoritmo, onde cada objeto x j será associada
a um grupo Ci caso IΩ(P) = 1, onde P = ”i = argmin1≤i′≤c(d(x j,yi′)” e Ω é o conjunto de
objetos. Isto é, o objeto será alocado ao grupo cuja distância entre ele e o protótipo desse grupo
é a menor dentre todos os outros clusters. Métodos que utilizam essa função são do tipo rígidos
(ou hard).
Uma generalização dessa função é o grau de pertinência de um elemento x para um grupo
difuso. Isto é, um conjunto difuso é um par (C,u) tal que u : U → [0,1]. Em Análise de
Agrupamento, o grau de pertinência (ou a probabilidade) de um elemento x j pertencer a um
grupo Ci é expresso por ui j e esses valores para todos os objetos e grupos da partição podem
ser arquivados em uma matriz difusa da forma U = [ui j]c×n, i = 1, . . . ,c; j = 1, . . . ,n. O cálculo
32

do grau de pertinência ui j, de acordo com o tradicional Fuzzy C-Means de Zadeh, é feito da
seguinte forma:
ui j =
[
c
∑h=1
d(x j,yi)
d(x j,yh)
1m−1
]−1
. (3.7)
Proposição 3.2.2. Os graus de pertinência expressos pelas Equação 3.7 minimizam a função
objetivo descrita pela Equação 3.1, para todo i = 1, . . . ,c e j = 1, . . . ,n.
Prova 3.2.2 Suponha que o parâmetro m e o protótipo yi(i = 1, . . . ,c) estejam fixos e que
u j = (u1 j, . . . ,ui j, . . . ,uc j)T seja um vetor de graus de pertinência para um dado objeto x j, a
prova pode ser formulada usando o multiplicador de Lagrange a cada termo u j. Assim, seja a
função κ(u j):
κ(u j) =c
∑i=1
(ui j)md(x j,yi), (3.8)
de forma que minimizar κ(u j) implica em minimizar J sob a restrição ∑ci=1 ui j = 1. O lagran-
giano de κ(u j) pode ser formulado como:
F(µ ,u j) =c
∑i=1
(ui j)md(x j,yi)−µ
(
c
∑i=1
ui j−1
)
. (3.9)
A função F(µ,u j) torna-se estacionária quando o gradiente for igual a zero, isto é, ∇F = 0.
Desta forma, tem-se a seguintes situações:
∂
∂ µF(µ ,u j) =
(
c
∑i=1
ui j−1
)
= 0, (3.10)
∂
∂ui jF(µ,u j) =
[
m(ui j)m−1d(x j,yi)−µ
]
= 0. (3.11)
Usando a segunda igualdade da Equação 3.11, tem-se a seguinte sentença:
ui j =
[
µ
md(x j,yi)
] 1m−1
. (3.12)
Pela Equação 3.10 e pela condição dita anteriormente, tem-se que ∑ci=1 ui j = 1. Assim,
pode-se fazer:
33

c
∑h=1
uh j =c
∑h=1
(µ
m
)1
m−1[
1d(x j,yi)
] 1m−1
=(µ
m
)1
m−1
c
∑h=1
[
1d(x j,yi)
] 1m−1
= 1,
o que implica em:
(µ
m
)1
m−1=
1
∑ch=1
[
1d(x j,yi)
] 1m−1
, (3.13)
e sabendo que a Equação 3.12 é equivalente a:
ui j =(µ
m
)1
m−1[
1d(x j,yi)
] 1m−1
. (3.14)
pode-se usar a Equação 3.13 nesta Equação 3.14, obtendo o seguinte:
ui j =
1
∑ch=1
[
1d(x j,yh)
] 1m−1
[
1d(x j,yi)
] 1m−1
=1
∑ch=1
[
d(x j,yi)d(x j,yh)
] 1m−1
=
[
c
∑h=1
d(x j,yi)
d(x j,yh)
1m−1
]−1
.
Este resultado mostra que o grau de pertinência ui j calculado pela Equação 3.7 corresponde
a um valor de extremo da função objetivo J descrito pela Equação 3.1. Entretanto, é necessário
avaliar se este extremo corresponde a um mínimo. Assim, usando-se a segunda derivada, tem-
se:
∂ 2
∂ (ui j)2 κ(u j) = m(m−1)(ui j)m−2d(x j,yi). (3.15)
Uma vez que m ∈]1,+∞[, ui j ∈ [0,1] e d(x j,yi)≥ 0, a expressão m(m−1)(ui j)m−2d(x j,yi)
34

sempre será não-negativa, isto é, ∂ 2
∂ (ui j)2 κ(u j) ≥ 0. Além disso, ∂ 2
∂up j∂uq jκ(u j) = 0 ∀p 6= q, o
que permite construir a Matriz Hessiana a partir de κ(u j) da seguinte forma:
H(κ(u j))=
[m(m−1)(u1 j)m−2d(x j,y1)] 0 · · · 0
0 [m(m−1)(u2 j)m−2d(x j,y2)] · · · 0
......
. . ....
0 0 · · · [m(m−1)(uc j)m−2d(x j,yc)]
Como a matriz é definida e positiva e segundo as propriedades deste tipo de matriz, a função
será estritamente convexa [81]. Portanto, o valor de ui j expresso pela Equação 3.7 minimiza a
função objetivo J dada pela Equação 3.1.
Em resumo, o grau de pertinência ui j de um objeto x j para um grupo Ci segue as seguintes
restrições:
1. ui j ∈ [0,1] ∀i, j;
2. 0 < ∑nj=1 ui j < n ∀i;
3. ∑ci=1 ui j = 1 ∀ j.
O primeiro item garante que o grau de pertinência será um valor entre 0 e 1, qualquer que
seja o objeto ou o grupo do agrupamento. A segunda restrição confirma a primeira onde o
somatório será n se todos os n objetos tiverem uma chance de 100% de pertencerem a um
mesmo grupo, e 0 para os outros grupos. O último item afirma que a soma dos graus para todos
os grupos fixando um objeto é necessariamente 1, qualquer que seja esse objeto.
Como exemplo da variação do grau de pertinência usando a Equação 3.7, considere três
objetos A, B e C e dois grupos unitários: um contendo o elemento A e outro o B. Nesse
exemplo, será calculado o grau de pertinência do objeto C para o grupo de B enquanto ele parte
de A até B. O esquema com os elementos e suas posições é apresentado a seguir:
Figura 3.1 Posições dos elementos A, B e C.
Para o cálculo, considere m = 2, os protótipos sendo os próprios elementos A e B e as
distâncias entre A e C como dAC e entre B e C como dBC. O valor do grau de pertinência
35

do elemento C pertencer ao grupo de B é dado como uBC =[
dBC
dAC+ dBC
dBC
]−1= dAC
dAC+dBC. Como
dAC + dBC = dAB é constante, então o valor de uBC varia linearmente em função de dAC. Na
figura a seguir, a linha com crescimento gradual mostra a variação do valor de uBC a medida
que C se aproxima de B e a linha em forma de degrau representa a Função Indicador:
Figura 3.2 Diferença entre a Função Indicador e o grau de pertinência.
Pode-se notar que é indiferente o elemento C estar perto de −10 ou 0: ele sempre irá
pertencer ao grupo do elemento A, uma vez que a distância para este grupo é menor quando
C está no intervalo [−10,0[ e o grau pertinência será invariante. De forma análoga, C irá
sempre pertencer ao grupo de B estando no intervalo ]0,10] permanecendo constante o grau
de pertinência. Por outro lado, o grau de pertinência difuso indicará uma maior incerteza
do elemento C pertencer a algum dos grupos estando perto do ponto 0 (região eqüidistaste
dos centros das classes). E a medida que se aproxima dos protótipos, o valor do grau de
pertinência se aproxima ou de 0 ou de 1. Desta forma, os métodos difusos podem fornecer
mais informações a respeito da pertinência dos objetos quando os grupos estão próximos ou
sobrepostos tornando-se mais eficientes, nesta situação, do que os métodos do tipo rígidos [1].
Como o parâmetro m faz parte do expoente aplicado ao cálculo do grau de pertinência, esse
valor influi no valor final de ui j e determina o grau de fuzzificação: quando m→ 1 a função do
grau de pertinência torna-se equivalente a Função Indicador; por outro lado, quando m→ ∞ a
função é totalmente difusa. A figura a seguir mostra curvas de graus de pertinência em função
do somatório das razões entre as distâncias
(
∑ch=1
d(x j,yi)d(x j,yh)
1m−1
)
e de diferentes valores do
parâmetro m (1,1, 1,5, 2, 3 e 5).
36

Figura 3.3 Variação do grau de pertinência em função do somatótio para diferentes valores de m.
Devido a sua importância para os métodos de agrupamento, variados trabalhos propõem
modificações do tradicional Fuzzy C-Means a respeito do cálculo do grau de pertinência. Por
exemplo, Krinidis e Chatzis apresentaram um método para superar algumas das desvantagens
do FCM aplicado a imagens [77]. Coppi et al. propuseram alterações para a quantificação do
grau de pertinência para os métodos Fuzzy C-Means e Possibilistic C-Means [78]. Kannan et
al. fez a combinação da função objetivo do FCM com as funções entropia, de tolerância e de
Kernel, além de modificar a etapa de inicialização para torná-la mais rápida [79]. Huang et al.
propôs o FCM com múltiplos kernels usando pesos e adaptando o grau de pertinência [80].
3.2.4 Algoritmo
O algoritmo é semelhante ao do método K-Means e, por isso, herda algumas características
como possuir quatro principais etapas: Inicialização, Representação, Alocação e Critério de
Parada. A primeira define os valores dos graus de pertinência para todos os objetos do con-
junto e todos os grupos seguindo as restrições, além de inicializar alguns parâmetros usados ao
decorrer do algoritmo. Na Etapa de Representação, os protótipos são recalculados. A Etapa
de Alocação, a matriz difusa é atualizada. Finalmente, no Critério de Parada, é verificado se
o algoritmo deve continuar ou não; normalmente, há três opções de fazer a verificação: (1) o
algoritmo pára se a diferença entre o valor da função objetivo calculado na iteração atual e o
da iteração imediatamente anterior é manor que um varepsilon definido a priori, (2) não existe
uma diferença significativa entre a matriz difusa atual e a anterior, ou (3) o algoritmo atingiu
um número de iterações máximo. Assim como K-Means o FCM também precisa definir a pri-
37

ori o número de grupos que o método irá usar para encontrar o agrupamento. O esquema do
algoritmo é mostrado a seguir:
Algorithm 7 Fuzzy C-Means (Ω,c,m)
Require: Um conjunto de dados Ω, o número de grupos c e o parâmetro fuzzificador m ∈]1,+∞[;
Ensure: Retorna um agrupamento difuso P;1: Faça ε > 0. Inicialize aleatoriamente os valores da partição U = [ui j], para i = 1, . . . ,c e
j = 1, . . . ,n tal que ui j ∈ [0,1] e ∑ci=1 ui j = 1;
2: t ← 0;3: Et ← 0;4: Et+1 ← ∑c
i=1 ∑nj=1(ui j)
md(x j,yi);5: while |Et+1−Et |> ε do
6: Atualize os representantes dos grupos usando a Equação 3.3, i = 1, . . . ,c;7: Atualize a matriz dos graus de pertinência U usando a Equação 3.7;8: Et ← Et+1;9: Et+1 ← ∑c
i=1 ∑nj=1(ui j)
md(x j,yi);10: t ← t +1;11: end while
return Agrupamento difuso P.
A complexidade de tempo do algoritmo pode ser calculada analisando a complexidade de
cada parte. Na Etapa de Inicialização, o objetivo é calcular os graus de pertinência para todos
os n objetos e todas as c classes, assim a complexidade é O(nc). Na Etapa de Representação,
é necessário calcular os c protótipos, onde o cálculo para cada um requer n operações de p
processos (para cada distância), o que leva a uma complexidade de O(ncp). Para construir
a matriz difusa na Etapa de Alocação serão necessários cp etapas para calcular cada grau de
pertinência e uma vez que a dimensão da matriz é n× c, então a complexidade desta parte
do algoritmo será O(nc2 p). No Critério de Parada, são requeridos nc cálculos de distância,
totalizando ncp operações, isto é, O(ncp). De uma forma geral, o algoritmo tem complexi-
dade de O(nc+ ncp+ nc2 p+ ncp) o que é equivalente a O(nc2 p). Portanto, a complexidade
de tempo do algoritmo Fuzzy C-Means é O(nc2 p). Kumar e Sirohi [82] fizeram uma compa-
ração da performance do Fuzzy C-Means e do Hard C-Means (método da abordagem rígida)
para o conjunto de dados Iris [83] mostrando que o método da abordagem difusa requer mais
processamento.
38

3.3 FCM com Distância Adaptativa
Uma versão do tradicional FCM para dados clássicos foi proposta por De Carvalho et al. [11]
onde os métodos usam distância adaptativa proposta por Diday [84, 85]. A principal idéia da
distância adaptativa é usar ponderadores que retratem as dispersões dos grupos e que mudem
a cada iteração do algoritmo. Assim, os métodos tornam-se capazes de diferenciar grupos de
diferentes tamanhos e formas, aumentando a qualidade da partição quando comparado com
o tradicional FCM. Os pesos que ponderam as distâncias podem ter duas abordagens: global
ou por classe. Para cada abordagem, existe uma matriz de covariância que pode ser de dois
tipos: cheia ou diagonal. O método baseado em distância de Mahalanobis e de Gustafson-
Kessel adaptativa será mais detalhadamente descrito a seguir. Para isto, considere as definições
de partição, conjunto de objetos, protótipos e matriz difusa citados na parte introdutória do
capítulo.
3.3.1 Distância Global
Este tipo de distância usa pesos que variam de acordo com a dispersão de cada variável sob
a suposição de que todos os grupos sejam indiferentes quanto a essa dispersão, isto é, não há
diferenciação de pesos para cada grupo. A distância usa uma matriz de variância e covariância
que pode ser cheia ou diagonal. O método que utiliza distância com matriz cheia tem a seguinte
função objetivo:
J =c
∑i=1
n
∑j=1
(ui j)md2
M(x j,yi), (3.16)
onde a distância d2M(x j,yi) é quadrática e calculada a partir de uma matriz positiva simétrica
definida M que é a mesma para todos os grupos:
d2M(x j,yi) = (x j−yi)
T M(x j−yi). (3.17)
A matriz simétrica definida positiva M faz uso de mais duas outras como mostrado na
equação abaixo:
M = [det(Q)]1p (Q)−1, (3.18)
onde a matriz Q é o somatório de todas as matrizes Ci:
39

Q =c
∑i=1
Ci, (3.19)
e Ci é a matriz de covariância difusa para o grupo i:
Ci =n
∑j=1
(ui j)m(x j−yi)(x j−yi)
T . (3.20)
Os protótipos, por sua vez, são calculados e provados que minimizam a função objetivo da
mesma forma que o tradicional FCM como mostrado a seguir.
yi =∑n
j=1(ui j)mx j
∑nj=1(ui j)m
. (3.21)
O grau de pertinência é semelhante ao do tradicional FCM. A principal diferença está no
tipo de distância que a equação usa para calcular o seu valor:
ui j =
c
∑h=1
d2M(x j,yi)
d2M(x j,yh)
1m−1
−1
=
c
∑h=1
(x j−yi)T M(x j−yi)
(x j−yh)T M(x j−yh)
1m−1
−1
. (3.22)
A prova de que o grau de pertinência é um valor que minimiza a função objetivo é seme-
lhante ao que foi mostrado na seção anterior.
Quando o método usa a distância calculada a partir de uma matriz diagonal, a função ob-
jetivo, o cálculo dos protótipos, o grau de pertinência e as provas de que estes minimizam a
função objetivo são semelhantes as do tradicional FCM. Entretanto, para este tipo de método,
a matriz assume um caso particular como mostrado a seguir:
M =
λ1 · · · 0...
. . ....
0 · · · λp
onde agora a matriz Ci é calculada como a seguir:
Ci = diag
(
n
∑j=1
(ui j)m(x j−yi)(x j−yi)
T
)
, (3.23)
Uma vez que d2M(x j,yi) = (x j−yi)
T M(x j−yi) é possível simplificá-la da seguinte forma
quando a matriz é diagonal:
40

d2M(x j,yi) =
(
(x1j − y1
i ),(x2j − y2
i ), . . . ,(xpj − y
pi ))
λ1 · · · 0...
. . ....
0 · · · λp
(x1j − y1
i )
(x2j − y2
i )...
(xpj − y
pi )
=(
λ1(x1j − y1
i ),λ2(x2j − y2
i ), . . . ,λp(xpj − y
pi ))
(x1j − y1
i )
(x2j − y2
i )...
(xpj − y
pi )
= λ1(x1j − y1
i )2 +λ2(x
2j − y2
i )2 + . . .+λp(x
pj − y
pi )
2
=p
∑k=1
λk(xkj− yk
i )2.
Assim, o cálculo do grau de pertinência para este tipo de método é dado semelhantemente
ao do FCM:
ui j =
c
∑h=1
∑pk=1 λk(x
kj− yk
i )2
∑pk=1 λk(x
kj− yk
h)2
1m−1
−1
, (3.24)
ainda minimizando a função objetivo que pode ser reescrita como a equação expressa por:
J =p
∑k=1
λk
c
∑i=1
n
∑j=1
(ui j)m(xk
j− yki )
2. (3.25)
Os pesos na diagonal da matriz M seguem a restrição ∏pk=1 λk = 1 e λk > 0,∀k = 1, . . . , p,
ou seja, det(M) = 1. Eles são atualizados pela equação:
λk =
∏ph=1
[
∑ci=1 ∑n
j=1(ui j)m(xh
j − yhi )
2] 1
p
∑ci=1 ∑n
j=1(ui j)m(xkj− yk
i )2
(3.26)
Proposição 3.3.1. Os pesos λ1,λ2, . . . ,λp calculados pela Equação 3.26 minimizam a função
objetivo descrita pela Equação 3.16.
Prova 3.3.1 Fixados o parâmetro m, os protótipos e os graus de pertinência, a função objetivo
em termos dos valores dos pesos pode ser reescrita como:
41

J(λ1,λ2, . . . ,λp) =p
∑k=1
λkJk =p
∑k=1
λk
c
∑i=1
n
∑j=1
(ui j)m(xk
j− yki )
2. (3.27)
A função J sendo aditiva, o problema torna-se minimizar Jk(k= 1, . . . , p). Seja g(λ1,λ2, . . . ,λp)=
∏pk=1 λk−1 = λ1×λ2× . . .×λp−1. O objetivo é determinar os extremos de J com a restrição
g(λ1,λ2, . . . ,λp) = 0. Para isto, é utilizado o multiplicador de Lagrange. Depois de alguma
algebra, conclui-se que o extremo de J é atingido quando:
λk =
∏ph=1 Jh
1p
Jk
. (3.28)
Substituindo os termos Jh e Jk da equação anterior, tem-se o seguinte:
λk =
∏ph=1
[
∑ci=1 ∑n
j=1(ui j)m(xh
j − yhi )
2] 1
p
∑ci=1 ∑n
j=1(ui j)m(xkj− yk
i )2
(3.29)
3.3.2 Distância por Classe
Esta distância também varia a cada iteração do algoritmo, diferentemente do tradicional FCM,
onde a distância é fixa. Além disso, existe uma ponderação por variável e classe (ou grupo),
de forma que o método que usa esse tipo de distância pode identificar conjunto de elementos
de diferentes formas e tamanhos. Assim como a distância adaptativa global, a por classe pode
ser diferenciada de acordo com o tipo de matriz que usa: cheia ou diagonal. Para o método que
usa distância adaptativa por classe com matriz cheia, o problema é encontrar um conjunto de
protótipos, uma matriz difusa e vetores de pesos tais que minimizem iterativamente a função
objetivo descrita como:
J =c
∑i=1
n
∑j=1
(ui j)md2
Mi(x j,yi). (3.30)
A principal diferença para o método descrito anteriormente é o uso da matriz Mi (ao con-
trário de M), onde, para cada grupo, existe uma matriz de variância e covariância. Assim, a
distância para este método é dada da seguinte forma:
d2Mi(x j,yi) = (x j−yi)
T Mi(x j−yi), (3.31)
onde a matriz Mi não faz uso da matriz Q (que é a soma das matrizes Ci) e é calculada como:
42

Mi = [det(Ci)]1p C−1
i , (3.32)
tal que a matriz Ci é dada pela equação a seguir:
Ci =n
∑j=1
(ui j)m(x j,yi)(x j,yi)
T . (3.33)
Os protótipos são calculados da mesma forma que o tradicional FCM e a prova que minimi-
zam a função objetivo é similar a apresentada na seção anterior. Semelhantemente ao método
com distância adaptativa de matriz cheia, o método por classe calcula o grau de pertinência
como a seguir buscando minimizar a função objetivo dada pela Equação 3.30:
ui j =
c
∑h=1
d2Mi(x j,yi)
d2Mh
(x j,yh)
1m−1
−1
(3.34)
Por outro lado, quando a matriz Mi é diagonal, existirá um vetor de pesos de tamanho p
para cada grupo:
Mi =
λ 1i · · · 0...
. . ....
0 · · · λpi
e o cálculo de cada matriz Ci será como:
Ci = diag
(
n
∑j=1
(ui j)m(x j,yi)(x j,yi)
T
)
. (3.35)
De forma semelhante ao cálculo da distância do método de matriz diagonal apresentado na
seção anterior, a dissimilaridade entre o objeto x j e o protótipo yi do grupo Ci é dada por:
d2Mi(x j,yi) =
p
∑k=1
λ ki (x
kj− yk
i )2. (3.36)
Desta forma, a Equação 3.30 pode ser reescrita como:
J =p
∑k=1
c
∑i=1
λ ki
n
∑j=1
(ui j)m(xk
j− yki )
2. (3.37)
43

Assim, o cálculo do grau de pertinência quando a matriz é diagonal é expressa pela seguinte
equação:
ui j =
c
∑h=1
∑pk=1 λ k
i (xkj− yk
i )2
∑pk=1 λ k
i (xkj− yk
h)2
1m−1
−1
. (3.38)
Os pesos na diagonal da matriz Mi também seguem a restrição de que ∏pk=1 λ k
i = 1∀i =
1, . . . ,c e λ ki > 0,∀i = 1, . . . ,c;∀k = 1, . . . , p, ou seja, det(Mi) = 1. Eles são atualizados pela
equação:
λ ki =
∏ph=1
[
∑nj=1(ui j)
m(xhj − yh
i )2] 1
p
∑nj=1(ui j)m(xk
j− yki )
2(3.39)
Proposição 3.3.2. Os pesos λ 1i ,λ
2i , . . . ,λ
pi calculados pela Equação 3.39 minimizam a função
objetivo descrita pela Equação 3.37.
Prova 3.3.2 Fixados o parâmetro m, os protótipos e os graus de pertinência e seja o vetor de
pesos para o grupo Ci dado por λλλ i = (λ 1i ,λ
2i , . . . ,λ
pi ), a função objetivo em termos dos valores
dos pesos pode ser reescrita como:
J(λλλ 1,λλλ 2, . . . ,λλλ c) =c
∑i=1
Ji(λλλ i), (3.40)
onde:
Ji(λλλ i) = Ji(λ1i ,λ
2i , . . . ,λ
pi ) =
p
∑k=1
λ ki Jk
i , (3.41)
e o termo Jki é:
Jki =
n
∑j=1
(ui j)m(xk
j− yki )
2. (3.42)
A função J sendo aditiva, o problema torna-se minimizar Ji(i= 1, . . . ,c). Seja g(λ 1i ,λ
2i , . . . ,λ
pi )=
∏pk=1 λ k
i −1 = λ 1i ×λ 2
i × . . .×λpi −1. O objetivo é determinar os extremos de Ji(i = 1, . . . ,c)
com a restrição g(λ 1i ,λ
2i , . . . ,λ
pi ) = 0. Novamente, é utilizado o multiplicador de Lagrange e
conclui-se que o extremo de Ji é obtido quando:
λ ki =
∏ph=1 Jh
i
1p
Jki
. (3.43)
44

Substituindo os termos Jhi e Jk
i tem-se o seguinte:
λ ki =
∏ph=1
[
∑nj=1(ui j)
m(xhj − yh
i )2] 1
p
∑nj=1(ui j)m(xk
j− yki )
2 (3.44)
A principal diferença entre o método que usa distância adaptativa do tipo global e o que
usa a por classe está na forma que eles interpretam a dispersão dos grupos: no primeiro, existe
apenas uma ponderação por variável e considera que todos os grupos tem a mesma variabili-
dade; por outro lado, o segundo faz essa diferenciação de dispersão entre os grupos. Assim, a
distância adaptativa global é mais eficiente, em muitos casos, quando os grupos tem a mesma
dispersão, e a por classe é melhor quando os grupos possuem diferentes tamanhos. Além disso,
quando a distância usa a matriz cheia, o método torna-se mais eficiente quando as variáveis
estão correlacionadas, enquanto que a matriz diagonal é mais apropriada quando não existe
correlação entre as variáveis.
3.3.3 Algoritmo
O algoritmo do método que usa distância adaptativa é semelhante ao algoritmo do tradicional
FCM. Existem quatro principais etapas (Inicialização, Representação, Critério de Parada), en-
tretanto a principal diferença está na Etapa de Alocação: existe uma sub-rotina que atualiza a
matriz de variância e covariância. Quando a distância é global com matriz cheia, para calcular
a matriz Ci são necessárias np2 operações e para a matriz Q isto repete-se mais c vezes, assim
a complexidade de tempo é O(ncp2); Quando é global com matriz diagonal, os pesos requerem
ncp, mas como existem p pesos, tem-se O(ncp2). Quando a distância é por classe com matriz
cheia, cada matriz Mi tem np2 operações, assim para atualizar M são necessárias ncp2 passos,
ou O(ncp2). Finalmente, quando a distância é por classe e do tipo diagonal, existem cp pesos,
onde cada um faz np processos, portanto obtendo a complexidade de tempo O(ncp2). Desta
forma, nesta etapa do algoritmo, a atualização da matriz de variância e covariância tem uma
complexidade de O(ncp2) qualquer que seja o tipo de distância adaptativa. O algoritmo para o
método FCM com distância adaptativa é descrito a seguir:
45

Algorithm 8 Fuzzy C-Means com Distância Adaptativa (Ω,c,m)
Require: Um conjunto de dados Ω, o número de grupos c e o parâmetro fuzzificador m ∈]1,+∞[;
Ensure: Retorna um agrupamento difuso P;1: Faça ε > 0. Inicialize aleatoriamente os valores da partição U = [ui j], para i = 1, . . . ,c e
j = 1, . . . ,n tal que ui j ∈ [0,1] e ∑ci=1 ui j = 1;
2: t ← 0;3: Et ← 0;4: Et+1 ← ∑c
i=1 ∑nj=1(ui j)
mΨ(x j,yi), onde Ψ(x j,yi) = d2M(x j,yi) caso a distância seja global
ou Ψ(x j,yi) = d2Mi(x j,yi) caso a distância seja por classe;
5: while |Et+1−Et |> ε do
6: (Fixe os graus de pertinência e a matriz de covariância) Atualize os representantes dosgrupos usando a Equação 3.3, i = 1, . . . ,c;
7: (Fixe os graus de pertinência e os protótipos) Atualize a matriz M usando a Equação3.18 (caso a distância seja global) ou a matriz Mi(i= 1, . . . ,c) usando a Equação 3.32 (casoa distância seja por classe);
8: (Fixe os protótipos e a matriz de covariância) Atualize a matriz dos graus de pertinênciaU usando a Equação 3.22 (caso a distância seja global) ou Equação 3.34 (caso a distânciaseja por classe);
9: Et ← Et+1;10: Et+1 ← ∑c
i=1 ∑nj=1(ui j)
mΨ(x j,yi);11: t ← t +1;12: end while
return Agrupamento difuso P.
3.4 FCM Robusto
Este tipo de método tem duas principais características que até então não foram apresentados
neste trabalho e foi proposto por D’Urso e Giordani [86]. O primeiro ponto importante é a
extensão do tradicional FCM para dados simbólicos do tipo intervalo. Uma variável simbólica
pode representar o resumo de banco de dados a partir de um valor categórico, ou a síntese
de informações que possuem características em comum e essa representação pode ser feita
utilizando listas, intervalos, distribuições ou funções mostrando a variabilidade contida na in-
formação original. O objetivo da Análise Simbólica de Dados (ADS) é generalizar mineração
de dados e estatística para unidades de mais alto nível descritas por dados simbólicos [6]. A
principal motivação de ADS é reduzir a dimensão da tabela de dados original e criar objetos
simbólicos a partir destes dados de forma que a perda de informação seja mínima, haja uma
diminuição do espaço de armazenamento e um aumento da velocidade de processamento deste
46

dados simbólicos.
Outra característica deste método é a sua robustez a dados ruidosos. Em muitas aplicações
de dados reais existem elementos que podem ser considerados ruidosos por apresentarem um
comportamento diferenciado em relação ao restante dos dados. Existem muitos motivos que
proporcionam o seu surgimento, por exemplo, falha no armazenamento dos dados por máqui-
nas ou humanos e erro no processamento da informação (como em reconhecimento de voz).
Além disso, grupos de pessoas, animais ou plantas podem possuir indivíduos que se com-
portam diferentemente do normal tornam-se valores atípicos (outliers) e em geral apresentam
um afastamento em relação aos demais da série. Tanto dados ruidosos quanto outliers podem
prejudicar a performance dos métodos de reconhecimento de padrões, inclusive o tradicional
FCM.
No método FCM robusto para dados intervalares, o algoritmo busca minimizar a seguinte
função objetivo:
J =c
∑i=1
n
∑j=1
(ui j)md2(x j,yi)+
n
∑j=1
σ2
(
1−c
∑i=1
ui j
)m
, (3.45)
A primeira parcela da equação é semelhante ao do FCM tradicional, enquanto a segunda
parcela garante que os graus de pertinência terão que ser maximizados para que a função atinja
um valor mínimo. A distância d2(x j,yi) mede a dissimilaridade entre o objeto x j e o protótipo
yi do grupo Ci e é dada por:
d2(x j,yi) =[
‖ci− c j‖2 +‖ri− r j‖
2]=p
∑k=1
[
(cki − ck
j)2 +(rk
i − rkj)
2]
, (3.46)
A dissimilaridade leva em consideração a distância entre os centros e o ranges dos objetos
e protótipos para todas as variáveis intervalares. Um intervalo representa a variabilidade de um
conjunto de dados quantitativos onde os limites representam o mínimo e o máximo dos valores
desta observação. A partir do intervalo, duas informações podem ser obtidas: o centro e o range
. A relação entre os limites de um intervalo para a variável k de um objeto x j é dado a seguir:
[akj,b
kj]→ ak
j = ckj− rk
j e bkj = ck
j + rkj , (3.47)
onde ckj é o centro e rk
j é o range. A partir desta relação, estes valores podem ser obtidos da
seguinte forma:
ckj =
akj +bk
j
2e rk
j =bk
j−akj
2. (3.48)
47

Assim, cada objeto x j pode ser representado por um par de vetores, isto é, x j = (c j,r j),
onde c j = (c1j ,c
2j , . . . ,c
pj ) e ri = (r1
j ,r2j , . . . ,r
pj ).
Outra importante característica deste método é a restrição do grau de pertinência. A pro-
posta é que o algoritmo calcule estes valores de forma que ∑ci=1 ui j ≤ 1. Assim, existe um
tratamento diferenciado para conjuntos com dados ruidosos e valores atípicos uma vez que ele-
mentos deste tipo receberão um valor de grau de pertinência menor que outros padrões da base
de dados. Para isto, o grau de pertinência é calculado como a seguir:
ui j =
c
∑h=1
[
d2(x j,yi)
d2(x j,yh)
]
1m−1
+
[
d2(x j,yi)
δ 2
]
1m−1
−1
, (3.49)
onde cada protótipo yi, assim como objeto, pode ser representado por um par de vetores (ci,ri).
O vetor de centros ci = (c1i ,c
2i , . . . ,c
pi ) é dado por:
ci =∑n
j=1(ui j)mc j
∑nj=1(ui j)m
(3.50)
e o vetor de ranges ri = (r1i ,r
2i , . . . ,r
pi ) é calculado como:
ri =∑n
j=1(ui j)mr j
∑nj=1(ui j)m
. (3.51)
Finalmente, a constante δ garante que o grau de pertinência seja menor do que 1 e pode ser
interpretada como uma "distância de ruido". A constante é dada por:
δ =
√
∑nj=1 ∑
pk=1 ck
j
np+
√
∑nj=1 ∑
pk=1 rk
j
np(3.52)
48

CAPÍTULO 4
Métodos de Agrupamento Possibilístico para
Dados Simbólicos do Tipo Intervalo
A mente que se abre a uma nova idéia jamais voltará ao seu tamanho
original.
—ALBERT EINSTEIN
4.1 Introdução
O estudo dos métodos de agrupamento é de domínio da Análise de Agrupamentos (Clustering
Analysis). Este tipo de análise objetiva separar um conjunto inicial de objetos em um deter-
minado número de agrupamentos, de modo que os elementos pertencentes ao mesmo agrupa-
mento possuam mais semelhanças (similaridades) entre si, e sejam mais diferentes (dissimila-
res) aos pertencentes a outros agrupamentos. Como esses métodos são executados de forma
não-supervisionada, existem diversas técnicas para a estimação do número ideal de conjuntos
finais que devem ser criados de forma a tornar a divisão dos dados mais representativa para o
problema estudado, como apresentado em [18]. Além disso, podem ser classificados de acordo
com a forma que interpretam os dados e a maneira com que esses objetos se organizam em agru-
pamentos. Assim, podem ser Métodos Seqüenciais, que analisam os elementos em uma ordem
pré-definida; Métodos Hierárquicos, cujos dados não são agrupados em um único passo e de-
pendendo da interpretação podem existir diversas classes; e os Métodos de Particionamento,
caracterizados por utilizarem funções objetivo para minimizarem um critério de otimização do
algoritmo, e podem ser do tipo rígidos (hard) ou difusos (fuzzy). Este projeto objetiva utilizar
os Métodos de Particionamento do tipo difusos.
Os métodos difusos, por sua vez, geram partições usando a abordagem crisp, probalilística
(ou fuzzy) ou possibilística. Um dos métodos de particionamento fuzzy amplamente usado é o
Fuzzy C-Means (FCM), mas possui problemas com dados ruidosos e com o número de classes,
já que os graus de pertinência consideram todos os agrupamentos da partição durante o cálculo,
dificultando a interpretação desse valores [5]. Krishnapuram e Keller [5] proporam uma nova
49

abordagem para interpretação dos dados e usaram a teoria das possibilidades como uma ferra-
menta para a construção das partições, criando o método Possibilistic C-Means (PCM). Assim,
cada elemento passa a ter uma possibilidade de pertencer a uma classe, superando alguns dos
problemas presentes em FCM. O método Possibilistic C-Means (PCM) é um caso mais geral
das abordagens crisp e probabilística.
O método de agrupamento clássico possibilístico (PCM) é diferente do método FCM, por-
que, principalmente, a soma dos graus de pertinência de um ponto de dados para todas as classes
não é necessariamente 1, o que torna o método capaz de atribuir possibilidades menores a ele-
mentos mais afastados dos grupos diminuindo a influência destes para o agrupamento. Assim,
o algoritmo PCM é capaz de identificar outlier e os pontos ruidosos [4]. Considerando as van-
tagens obtidas a partir do conceito de possibilidade, o projeto propõe métodos de agrupamento
usando a abordagem possibilística.
Portanto, o objetivo desse projeto é fazer uso das técnicas de Análise de Dados Simbólicos
e incorporá-las em algoritmos de Métodos de Particionamento destinados a tratar conjuntos de
dados de forma que criem grupos de elementos usando conceitos de nebulosidade, desta forma,
criando uma extensão dos métodos de agrupamento fazendo uso de dados simbólicos de tipo
intervalo e usando a abordagem possibilística.
Para as próximas seções, considere as seguintes definições. Seja cada item xk de Ω descrito
por p variáveis simbólicas intervalares xk = (x1k, . . . ,x jk, . . . ,xpk) onde p é o número de variá-
veis indexada por j e x jk = [a jk,b jk]. Considere o vetor de intervalos yi = (yi1, . . . ,yi j, . . . ,yip)
como os protótipos do cluster Ci (i = 1, . . . ,c) onde yi j = [αi j,βi j].
4.2 Grau de pertinência por Classe
De acordo com o método clássico possibilístico introduzido por Krishnapuram e Keller [5], o
algoritmo de agrupamento PCM para dados simbólicos intervalares (chamado aqui IPCM) visa
minimizar o critério de agrupamento dado como:
J =c
∑i=1
n
∑k=1
(uik)mφ(xk,yi)+
c
∑i=1
ηi
n
∑k=1
(1−uik)m (4.1)
Uma vez que a não existe a restrição de que a soma dos graus de pertinência para todas
as classes seja necessariamente 1, é importante que estes sejam maximizados. Para isso, o
segundo termo da equação garante que os graus de pertinência sejam mais próximos de 1 quanto
possível. Enquanto o valor de ηi foi introduzido na equação para garantir que tanto a primeira
quanto a segunda parcela tenham a mesma ordem de grandeza.
50

A medida φ(xk,yi) é usada para medir a dissimilaridade (heterogeneidade) entre o elemento
xk e o protótipo yi. Quando xk e yi são objetos simbólicos e suas variáveis são intervalos,
a medida de dissimilaridade φ(xk,yi) pode ser calculada pela distância Euclidiana entre os
pontos 2p-dimensional no ℜ2p [9]. A medida de dissimilaridade é dada por:
φ(xk,yi) =p
∑j=1
[
(
a jk−αi j
)2+(
b jk−βi j
)2]
. (4.2)
Desta forma, φ(xk,yi) é equivalente à distância entre xk e yi dada por d2ik. Similarmente ao
PCM clássico, o protótipo do cluster Ci é definido como:
yi =∑n
k=1(uik)mxk
∑nk=1(uik)m
. (4.3)
Proposição 4.2.1. O protótipo definido pela equação 4.3 minimiza o critério de agrupamento
J na equação 4.1.
Prova 4.2.1 O protótipo pode ser entendido pela representação dos limites inferior e supe-
rior de cada intervalo. Logo, a equação 4.3 pode ser reescrita usando outras duas como:
yin fi =
∑nk=1(uik)
mxin fk
∑nk=1(uik)m e y
supi =
∑nk=1(uik)
mxsupk
∑nk=1(uik)m , onde y
in fi = (αi1, . . . ,αip), x
in fk = (a1k, . . . ,apk),
ysupi = (βi1, . . . ,βip) e x
in fk = (b1k, . . . ,bpk). Além disso, sendo J aditivo, minimizar J quanto
ao protótipo significa minimizar segundo cada limite de yi, isto é:
Jin fi j =
n
∑k=1
(uik)m(a jk−αi j)
2 +ηi
n
∑k=1
(1−uik)m (4.4)
similarmente, para o limite superior:
Jsupi j =
n
∑k=1
(uik)m(b jk−βi j)
2 +ηi
n
∑k=1
(1−uik)m (4.5)
Fazendo a derivada de em relação a αi j, tem-se:
∂Jin fi j
∂αi j= 0⇒
n
∑k=1
(uik)m(−2)(a jk−αi j) = 0
n
∑k=1
(uik)m(a jk) =
n
∑k=1
(uik)m(α jk)
α jk =∑n
k=1(uik)m(a jk)
∑nk=1(uik)m
, j = 1, . . . , p
51

Isto prova que o valor representa a mudança do comportamento da curva. Para saber se este
valor é um mínimo, é necessário fazer a segunda derivada em relação a αi j. Então:
∂ 2Jin fi j
∂ (αi j)2 =n
∑k=1
(uik)m(−2)(−1)(a jk−αi j)
0,
o que resulta na seguinte expressão:
∂ 2Jin fi j
∂ (αi j)2 =n
∑k=1
(uik)m. (4.6)
Uma vez que uik > 0,(i = 1, . . . ,c;k = 1, . . . ,n), então a equação 4.6 sempre será positiva,
o que leva a dizer que αi j minimiza a função objetivo J.
De forma semelhante, o critério pode ser minimizado em relação ao limite superior.
O parâmetro m ∈]1,∞[ é um expoente de ponderação, chamado fuzificador, que controla a
nebulosidade do grau de pertinência: quando m→ 1, a função de pertinência é rígida (hard);
por outro lado, quando m→∞, a função de pertinência é ao máximo nebulosa. O parâmetro ηi
determina a importância do segundo termo da função de critério em relação ao primeiro termo
e é calculado por:
ηi = K∑n
k=1(uik)mφ(xk,yi)
∑nk=1(uik)m
. (4.7)
Em geral, o valor K é 1 e uik é o grau de pertinência do objeto xk em relação ao cluster Ci.
Existem duas versões para o cálculo do valor uik na literatura para o método clássico que foi
apresentado em [5] e [15]. Elas são, respectivamente, dados como:
uik =1
1+(
φ(xk,yi)ηi
) 1m−1
(4.8)
Proposição 4.2.2. O grau de pertinência uik definida pela equação 4.8 minimiza o critério de
agrupamento J na equação 4.1.
Prova 4.2.2 O critério de agrupamento J sendo aditivo, o problema torna encontrar o grau de
pertinência uik tal que minimize:
Jik = (uik)mφ(xk,yi)+ηi(1−uik)
m. (4.9)
Jik mede o critério em relação ao objeto xk e o protótipo yi. Tem-se:
52

∂Jik
∂uik
= 0⇒ m · (uik)m−1φ(xk,yi)−m ·ηi(1−uik)
m−1 = 0
uik =
(
ηi
φ(xk,yi)
) 1m−1
(1−uik)
uik
[
1+
(
ηi
φ(xk,yi)
) 1m−1
]
=
(
ηi
φ(xk,yi)
) 1m−1
uik =
(
ηi
φ(xk,yi)
) 1m−1
1+
(
ηi
φ(xk,yi)
) 1m−1
uik =1
1+
(
φ(xk,yi)
ηi
) 1m−1
Com isso, sabe-se que uik é o valor correspondente ao ponto crítico, mas basta saber se o
valor uik leva a um mínimo. Assim, fazendo-se a segunda derivada:
∂ 2Jik
∂ (uik)2 = m(m−1) · (uik)m−2φ(xk,yi)−m(m−1) ·ηi(1−uik)
m−2
e desenvolvendo esta equação semelhantemente ao processo anterior, chega-se na seguinte ex-
pressão:
∂ 2Jik
∂ (uik)2 =1
1+
(
φ(xk,yi)
ηi
) 1m−2
,
assim, a segunda derivada será um valor positivo, garantindo que uik seja o mínimo de J.
Neste trabalho, o método possibilístico para dados intervalares que usa a função não-
exponencial será abreviado por IPCM, enquanto o que tem função de atualização do grau de
53
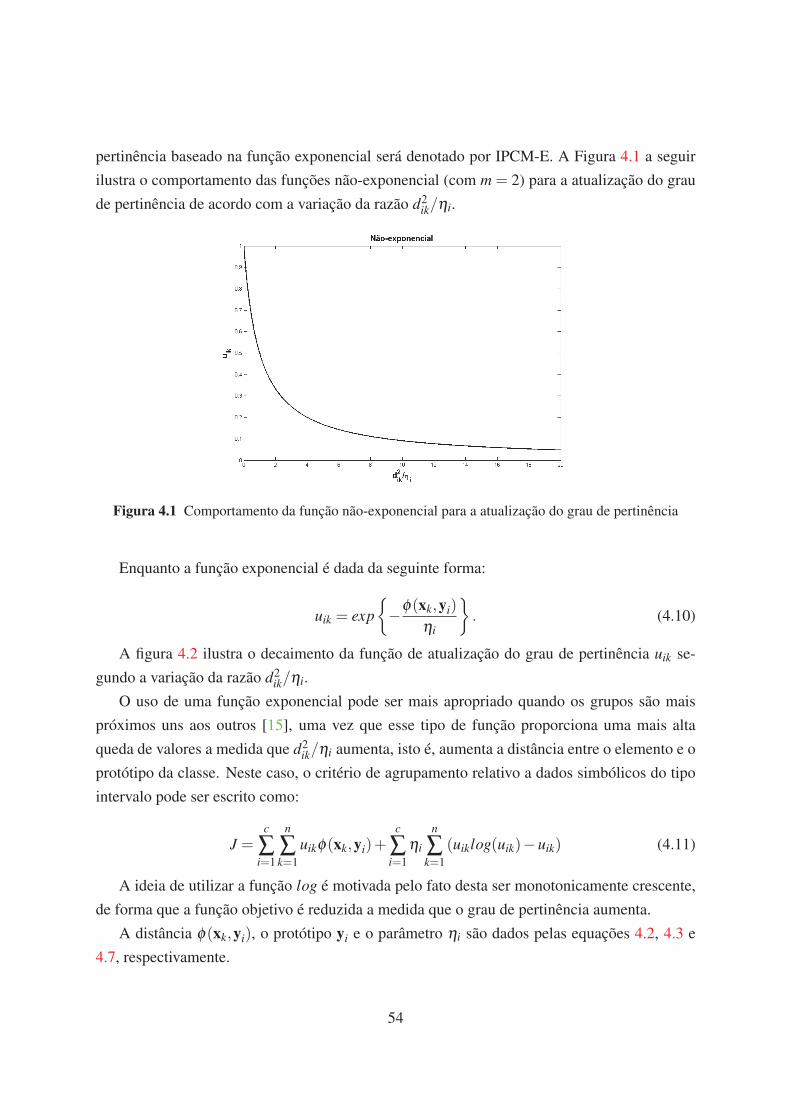
pertinência baseado na função exponencial será denotado por IPCM-E. A Figura 4.1 a seguir
ilustra o comportamento das funções não-exponencial (com m = 2) para a atualização do grau
de pertinência de acordo com a variação da razão d2ik/ηi.
Figura 4.1 Comportamento da função não-exponencial para a atualização do grau de pertinência
Enquanto a função exponencial é dada da seguinte forma:
uik = exp
−φ(xk,yi)
ηi
. (4.10)
A figura 4.2 ilustra o decaimento da função de atualização do grau de pertinência uik se-
gundo a variação da razão d2ik/ηi.
O uso de uma função exponencial pode ser mais apropriado quando os grupos são mais
próximos uns aos outros [15], uma vez que esse tipo de função proporciona uma mais alta
queda de valores a medida que d2ik/ηi aumenta, isto é, aumenta a distância entre o elemento e o
protótipo da classe. Neste caso, o critério de agrupamento relativo a dados simbólicos do tipo
intervalo pode ser escrito como:
J =c
∑i=1
n
∑k=1
uikφ(xk,yi)+c
∑i=1
ηi
n
∑k=1
(uiklog(uik)−uik) (4.11)
A ideia de utilizar a função log é motivada pelo fato desta ser monotonicamente crescente,
de forma que a função objetivo é reduzida a medida que o grau de pertinência aumenta.
A distância φ(xk,yi), o protótipo yi e o parâmetro ηi são dados pelas equações 4.2, 4.3 e
4.7, respectivamente.
54

Figura 4.2 Comportamento da função exponencial para a atualização do grau de pertinência
Proposição 4.2.3. O grau de pertinência uik definida pela equação 4.10 minimiza o critério de
agrupamento J na equação 4.11.
Prova 4.2.3 Novamente, o critério de agrupamento J sendo aditivo, o problema torna-se en-
contrar o grau de pertinência uik que minimize
Jik = uikφ(xk,yi)+ηi(uiklog(uik)−uik). (4.12)
Jik mede o critério em relação ao objeto xk e ao protótipo yi. Tem-se que:
∂Jik
∂uik
= 0⇒ φ(xk,yi)+ηi
[(
log(uik) ·1+uik ·1
uik
)
−1
]
= 0
log(uik) =−φ(xk,yi)
ηi
uik = exp
−φ(xk,yi)
ηi
O termo uik leva a um ponto crítico, mas basta saber se o valor uik leva a um mínimo. Assim,
fazendo-se a segunda derivada:
∂ 2Jik
∂ (uik)2 =∂
∂uik
= φ(xk,yi)+ηilog(uik) =ηi
uik
e desenvolvendo esta equação semelhantemente ao processo anterior, chega-se na seguinte ex-
55
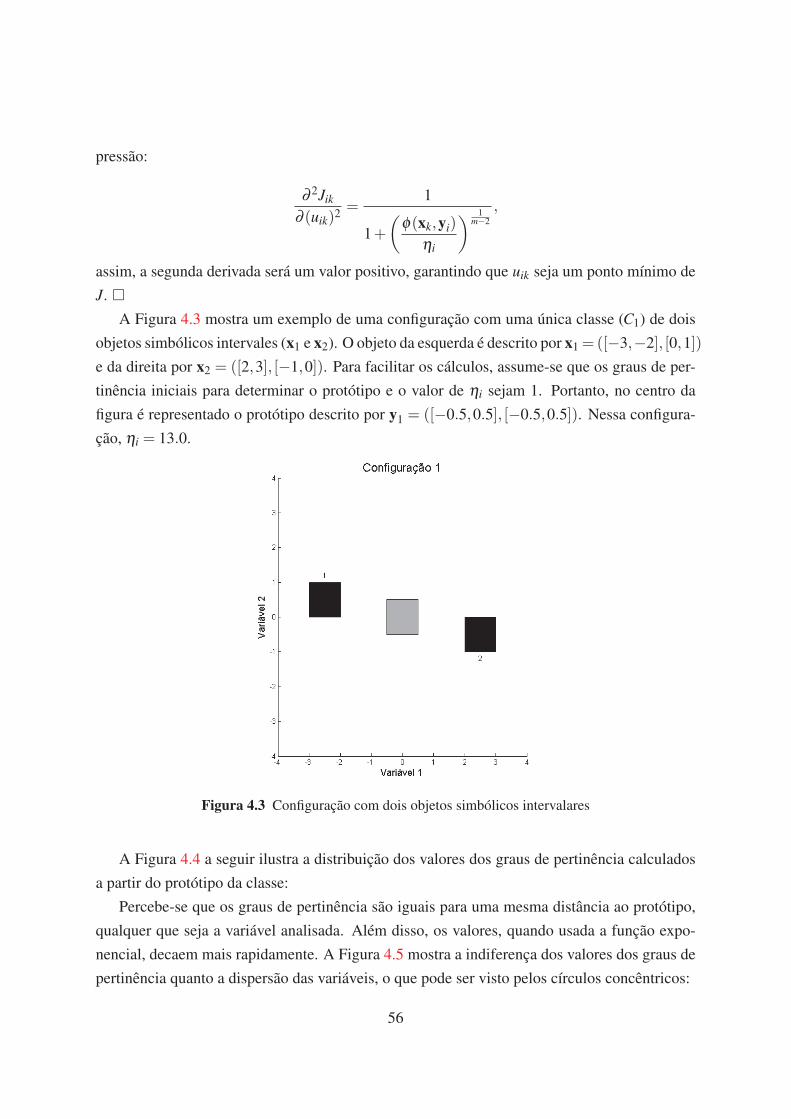
pressão:
∂ 2Jik
∂ (uik)2 =1
1+
(
φ(xk,yi)
ηi
) 1m−2
,
assim, a segunda derivada será um valor positivo, garantindo que uik seja um ponto mínimo de
J.
A Figura 4.3 mostra um exemplo de uma configuração com uma única classe (C1) de dois
objetos simbólicos intervales (x1 e x2). O objeto da esquerda é descrito por x1 =([−3,−2], [0,1])
e da direita por x2 = ([2,3], [−1,0]). Para facilitar os cálculos, assume-se que os graus de per-
tinência iniciais para determinar o protótipo e o valor de ηi sejam 1. Portanto, no centro da
figura é representado o protótipo descrito por y1 = ([−0.5,0.5], [−0.5,0.5]). Nessa configura-
ção, ηi = 13.0.
Figura 4.3 Configuração com dois objetos simbólicos intervalares
A Figura 4.4 a seguir ilustra a distribuição dos valores dos graus de pertinência calculados
a partir do protótipo da classe:
Percebe-se que os graus de pertinência são iguais para uma mesma distância ao protótipo,
qualquer que seja a variável analisada. Além disso, os valores, quando usada a função expo-
nencial, decaem mais rapidamente. A Figura 4.5 mostra a indiferença dos valores dos graus de
pertinência quanto a dispersão das variáveis, o que pode ser visto pelos círculos concêntricos:
56
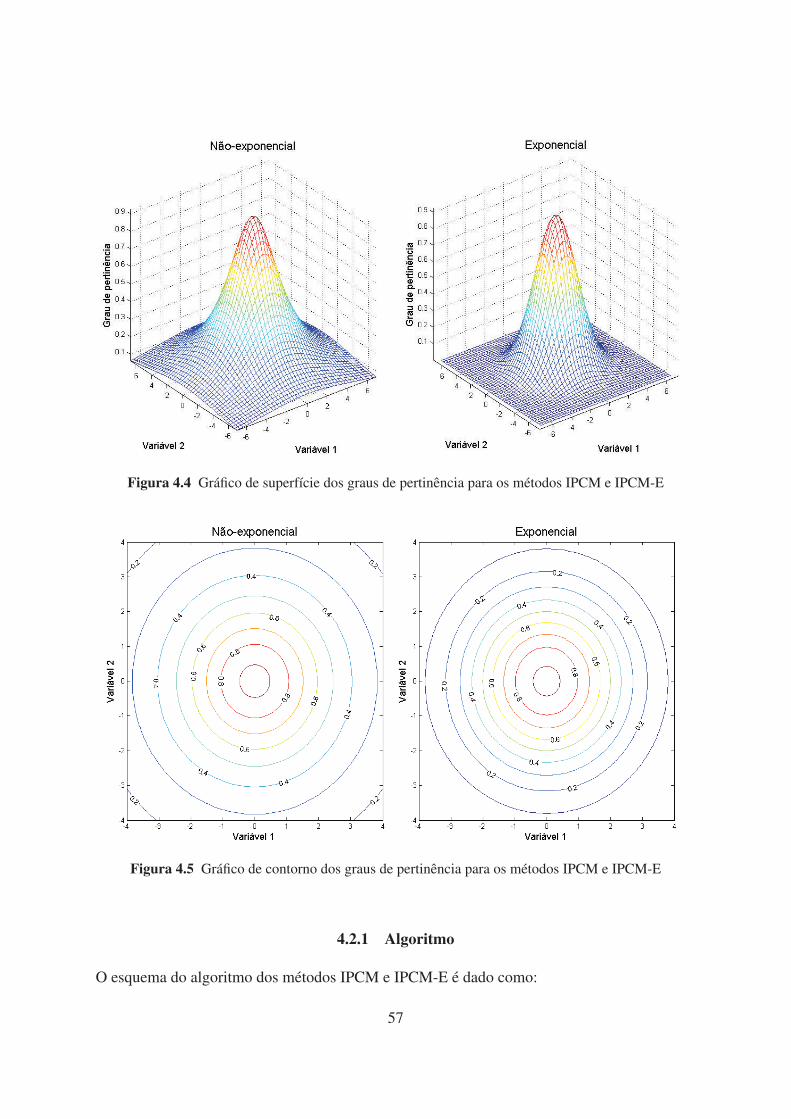
Figura 4.4 Gráfico de superfície dos graus de pertinência para os métodos IPCM e IPCM-E
Figura 4.5 Gráfico de contorno dos graus de pertinência para os métodos IPCM e IPCM-E
4.2.1 Algoritmo
O esquema do algoritmo dos métodos IPCM e IPCM-E é dado como:
57

Algorithm 9 IPCM ou IPCM-E (Ω,c,m)
Require: Um conjunto de dados Ω, o número de grupos c, 2≤ c≤ n, e o parâmetro fuzzifica-dor m ∈]1,+∞[;
Ensure: Retorna um agrupamento difuso P;1: Estabeleça T; e faça ε > 0; Inicialize aleatoriamente uik(i= 1, . . . ,c e k = 1, . . . ,n) do objeto
k pertencente ao cluster Ci tal que uik ∈ [0,1], 0 < ∑nk=1 uik < n e maxiuik > 0, para todo i
e k. Estime ηi usando a equação 4.7;2: t ← 0;3: Et ← 0;4: Et+1 ← valor da equação 4.1 ou 4.11;5: while |Et+1−Et |> ε do
6: (Fixe o grau de pertinência uik do objeto k pertencente ao cluster Ci) Calcule o protótipoyi do cluster Ci(i = 1, . . . ,c)usando a equação 4.3.
7: (Fixe o protótipo yi) Atualize o grau de pertinência fuzzy uik do objeto k pertencenteao cluster Ci (i = 1, . . . ,c) usando a equação 4.8 ou 4.10;
8: Et ← Et+1;9: Et+1 ← valor da equação 4.1 ou 4.11;
10: t ← t +1;11: end while
return Agrupamento difuso P.
A complexidade de tempo deste algoritmo depende da complexidade de cada etapa. Na
etapa de inicialização, é necessário definir o grau de pertinência para os n padrões e c grupos,
assim temos a complexidade O(nc). Ainda nessa etapa, é preciso estimar o valor de ηi, isto é,
para c grupos é feito o processo n vezes relativo aos padrões e p para o cálculo da distância,
resultando na complexidade O(ncp). Portanto, para essa etapa, a complexidade é O(ncp). Na
Etapa de Representação, o cálculo dos c protótipos é feito levando em conta os n padrões, por-
tanto, para esta etapa, a complexidade de tempo é O(nc). Na Etapa de Alocação, a atualização
do grau de pertinência tem complexidade O(1), uma vez que é um cálculo simples para valores
computados em etapas anteriores, entretanto é necessário que sejam calculados para todos os
n padrões e c grupos, assim temos a complexidade O(nc). No Critério de Parada, o cálculo do
critério J pode ser feito em um tempo O(ncp), já que no primeiro termo da equação o cálculo
da distância que envolve p variáveis é processado nc vezes. Em conclusão, a complexidade de
tempo do algoritmo é O(ncp).
58

4.3 Grau de pertinência por Classe e Variável
Neste método, o objetivo é calcular os graus de pertinência levando em conta a influência das
variáveis simbólicas no critério de agrupamento. Assim, uma nova versão do agrupamento
possibilístico por variável para dados simbólicas do tipo intervalo é introduzido. Minimizar
a função objetivo para este método é equivalente a maximizar a qualidade do agrupamento
segundo cada variável:
J =c
∑i=1
n
∑k=1
p
∑j=1
[
(ui jk)mφ j(xk,yi)+ηi j(1−ui jk)
m]
(4.13)
onde φ j(xk,yi) segue o mesmo raciocínio apresentado na seção anterior e pode ser entendido
como a distância Euclidiana para a variável j:
φ j(xk,yi) =[
(
a jk−αi j
)2+(
b jk−βi j
)2]
. (4.14)
Em relação à variável j, o protótipo é dado como:
yi j =∑n
k=1(ui jk)mx jk
∑nk=1(ui jk)m
(4.15)
Proposição 4.3.1. O protótipo yi j definida pela equação 4.15 minimiza o critério de agrupa-
mento J na equação 4.13.
Prova 4.3.1 A prova pode ser similarmente formulada como a apresentada em 4.2.1.
O termo ηi j também determina a importância do segundo termo da função de critério
quando comparado com o primeiro termo, entretanto neste caso somente para a variável j.
Este parâmetro mede a dispersão dos clusters com respeito à variável j e pode ser calculado
como:
ηi j = K∑n
k=1(ui jk)mφ j(xk,yi)
∑nk=1(ui jk)m
. (4.16)
O parâmetro ui jk é o grau de pertinência do objeto k no cluster Ci em relação à variável j.
Este importante parâmetro determina a influência de cada variável para o valor final do grau
de pertinência, uma vez que é descrito por φ j(xk,yi) e ηi j. Como no método anterior, as duas
versões para calcular os graus de pertinência de cada variável são adotadas:
59

ui jk =1
1+(
φ j(xk,yi)ηi j
) 1m−1
(4.17)
ui jk = exp
−φ j(xk,yi)
ηi j
(4.18)
A função exponencial por variável é também mais apropriada para conjuntos de dados onde
clusters são próximos uns aos outros. Neste caso, o critério de agrupamento é dado por:
J =c
∑i=1
n
∑k=1
p
∑j=1
[
ui jkφ j(xk,yi)+ηi j(ui jklog(ui jk)−ui jk)]
. (4.19)
Nesta versão, os valores φ j(xk,yi), yi j e ηi j são calculados como nas equações 4.14, 4.15
e 4.16, respectivamente. Para ambas as versões, o grau de pertinência ui jk satisfaz a seguinte
restrição:
1. ui jk ∈ [0,1] para todo i, j e k,
2. 0 <n
∑k=1
ui jk ≤ n para todo i e j,
3. maxi
ui jk > 0 para todo j e k.
A primeira restrição garante que o grau de pertinência ui jk representa valores de graus de
compatibilidade ou possibilidade, qualquer que seja o cluster Ci, a variável j e o objeto xk. A
segunda é uma conseqüência da primeira. A última restrição garante que cada objeto xk deva
ser atribuído a no mínimo um cluster para a variável j.
Proposição 4.3.2. O grau de pertinência ui jk definida pela equação 4.17 minimiza o critério de
agrupamento J na equação 4.13.
Prova 4.3.2 A prova pode ser similarmente formulada como a apresentada em 4.2.2 para o caso
em que o cálculo da dissimilaridade e o parâmetro ηi é por variável.
Proposição 4.3.3. O grau de pertinência ui jk definida pela equação 4.18 minimiza o critério de
agrupamento J na equação 4.19.
Prova 4.3.3 A prova pode ser similarmente formulada como a apresentada em 4.2.3 para o caso
em que o cálculo da dissimilaridade e o parâmetro ηi é por variável.
60

Uma comparação entre o IPCM e IPCM-E e outros métodos foi realizado por Pimentel e
Souza [16] com configurações contendo grupos separados e próximos entre si e com dados
aberrantes, mostrando a importância da função exponencial e da abordagem possibilística.
Recentemente, Pimentel e Souza [17] propuseram um grau de pertinência por classe e va-
riável para dados clássicos como uma nova versão do FCM apresentando experimentos com
diferentes situações onde o método proposto mostra ser mais adequado. Além disso, foi feita
a comparação do comportamento do grau de pertinência do método proposto e de diferentes
métodos presentes na literatura com conjuntos de dados reais.
Observação 1. Depois da convergência do algoritmo, cada objeto de Ω tem p× c graus de
pertinência e é necessário agregá-los com o objetivo de calcular os graus de nebulosidade de
cada objeto do cluster. Isto é, associar cada objeto xk de Ω ao grupo i∗ de acordo com o maior
valor do grau de pertinência uik de forma que i∗= argmax1≤i≤cuik. Aqui, a regra de agregação
é dada por:
uik =1p
p
∑j=1
ui jk. (4.20)
A razão 1/p garante que a soma não seja maior que 1. No caso especial onde ui jk = 1, j =
1, . . . , p, o grau de pertinência uik será igual a 1. Uma vez que ui jk ≥ 0(1, . . . , p), a desigualdade
uik ≥ 0 é verdadeira pela própria Equação 4.20. Assim, uik ∈ [0,1].
A solução dada para agregar os graus de pertinência usando a Equação 4.20 considera
que todas as variáveis possuam o mesmo nível de importância no agrupamento. Entretanto,
é possível que se atribua pesos para cada variável, alterando a interpretação dada ao grau de
pertinência final. Outra proposta para o cálculo de ui j é selecionar os graus de pertinência
segundo a variabilidade da variável usando autovalores, por exemplo.
Neste trabalho, o método possibilístico para dados intervalares que trata isoladamente cada
variável e que usa a função não-exponencial será abreviado por IPCM-V, enquanto o que tem
função de atualização do grau de pertinência baseado na função exponencial será denotado por
IPCM-VE.
Novamente, considere a configuração ilustrada na Figura 4.3. Para facilitar os cálculos,
os graus de pertinência ui jk foram inicializados como 1. Assim, para os métodos IPCM-V e
IPCM-VE, o protótipo por variável usando a equação 4.15 é o mesmo apresentado na seção
anterior. A Figura 4.6 ilustra a distribuição dos valores dos graus de pertinência calculados a
partir do protótipo da classe e usando informação de cada variável.
Observando a imagem, nota-se que as distribuições dos valores dos graus de pertinência
61
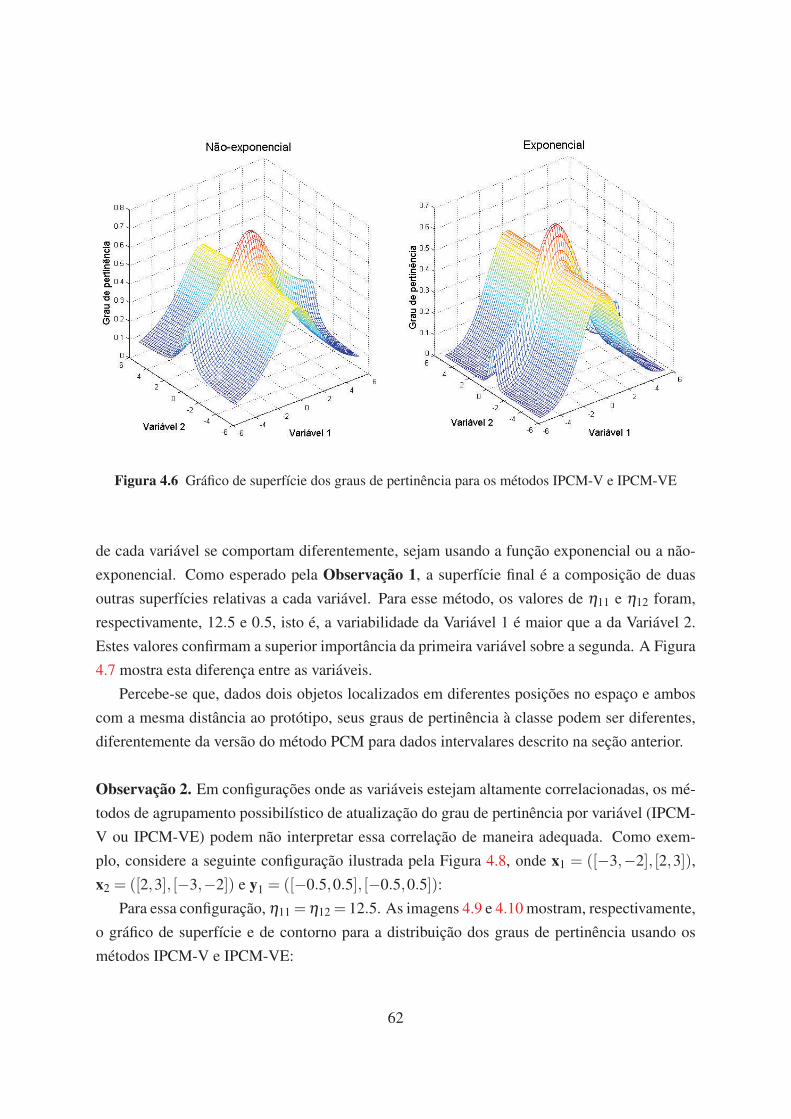
Figura 4.6 Gráfico de superfície dos graus de pertinência para os métodos IPCM-V e IPCM-VE
de cada variável se comportam diferentemente, sejam usando a função exponencial ou a não-
exponencial. Como esperado pela Observação 1, a superfície final é a composição de duas
outras superfícies relativas a cada variável. Para esse método, os valores de η11 e η12 foram,
respectivamente, 12.5 e 0.5, isto é, a variabilidade da Variável 1 é maior que a da Variável 2.
Estes valores confirmam a superior importância da primeira variável sobre a segunda. A Figura
4.7 mostra esta diferença entre as variáveis.
Percebe-se que, dados dois objetos localizados em diferentes posições no espaço e ambos
com a mesma distância ao protótipo, seus graus de pertinência à classe podem ser diferentes,
diferentemente da versão do método PCM para dados intervalares descrito na seção anterior.
Observação 2. Em configurações onde as variáveis estejam altamente correlacionadas, os mé-
todos de agrupamento possibilístico de atualização do grau de pertinência por variável (IPCM-
V ou IPCM-VE) podem não interpretar essa correlação de maneira adequada. Como exem-
plo, considere a seguinte configuração ilustrada pela Figura 4.8, onde x1 = ([−3,−2], [2,3]),
x2 = ([2,3], [−3,−2]) e y1 = ([−0.5,0.5], [−0.5,0.5]):
Para essa configuração, η11 =η12 = 12.5. As imagens 4.9 e 4.10 mostram, respectivamente,
o gráfico de superfície e de contorno para a distribuição dos graus de pertinência usando os
métodos IPCM-V e IPCM-VE:
62

Figura 4.7 Gráfico de contorno dos graus de pertinência para os métodos IPCM-V e IPCM-VE
Figura 4.8 Configuração com dois objetos simbólicos intervalares com variáveis correlacionadas
Nota-se que, apesar das variáveis estarem correlacionadas, os métodos não conseguiram
identificar essa importante característica da configuração. Segundo essa interpretação, a possi-
bilidade de um objeto pertencer a essa classe estando perto do ponto (4,4) é menor do que se
ele estivesse no ponto (0,4), por exemplo, o que deveria ser o contrário para essa configuração.
63
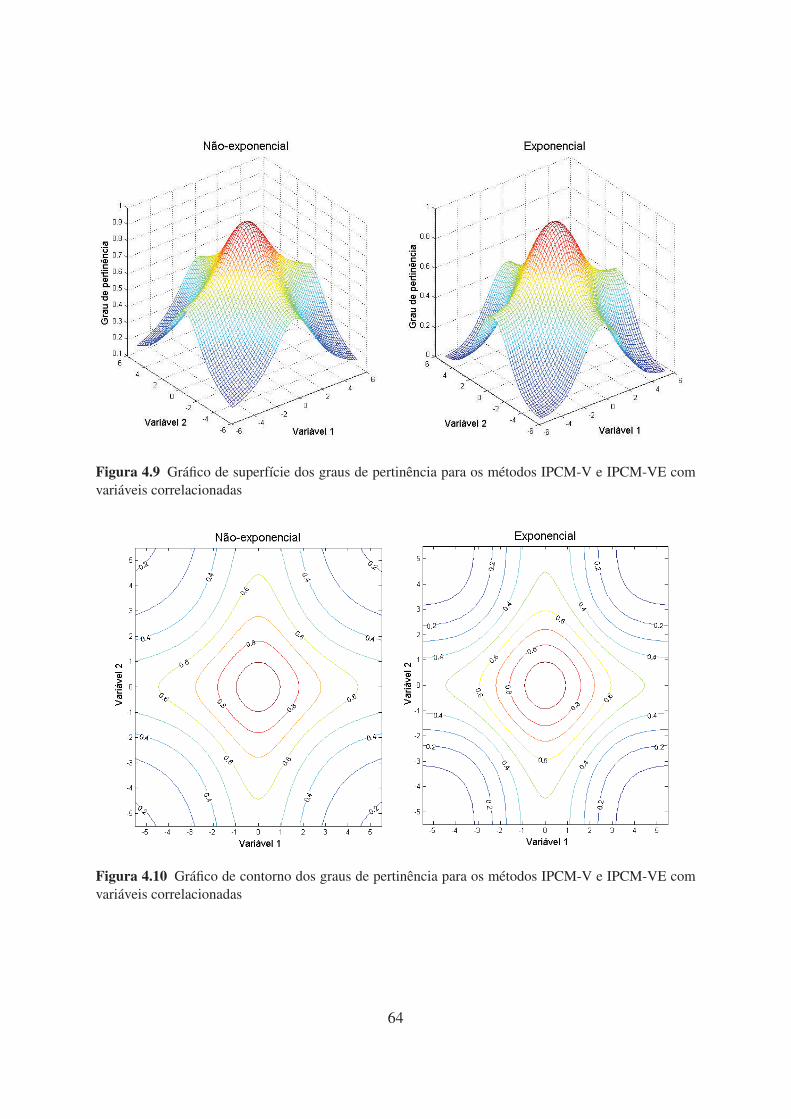
Figura 4.9 Gráfico de superfície dos graus de pertinência para os métodos IPCM-V e IPCM-VE comvariáveis correlacionadas
Figura 4.10 Gráfico de contorno dos graus de pertinência para os métodos IPCM-V e IPCM-VE comvariáveis correlacionadas
64

4.3.1 Algoritmo
O esquema do algoritmo dos métodos IPCM-V e IPCM-VE é mostrado a seguir.
A complexidade de tempo deste algoritmo pode ser calculada com a análise da complexi-
dade de cada etapa. Na etapa de inicialização, o objetivo é definir o grau de pertinência relativos
aos n padrões, c grupos e p variáveis, assim temos a complexidade O(ncp). Além disso é ne-
cessário estimar o valor de ηi j, isto é, para c grupos e p variáveis repetidas n vezes, o que nesse
caso a complexidade também é O(ncp). Portanto, para essa etapa, a complexidade é O(ncp).
Na Etapa de Representação, o cálculo dos c protótipos e para as p variáveis é feito levando em
conta os n padrões, portanto, para esta etapa, a complexidade de tempo é O(ncp). Na Etapa
de Alocação, a atualização do grau de pertinência tem complexidade O(1), já que é um cálculo
simples para valores já definidos, entretanto é necessário que sejam calculados para todos os n
padrões, c grupos e p variáveis, assim temos a complexidade O(ncp). No Critério de Parada, o
cálculo do critério J pode ser feito em um tempo O(ncp). Em conclusão, as etapas possuem a
mesma complexidade, assim, a complexidade de tempo do algoritmo é O(ncp).
65

Algorithm 10 IPCM-V ou IPCM-VE (Ω,c,m)
Require: Um conjunto de dados Ω, o número de grupos c, 2≤ c≤ n, e o parâmetro fuzzifica-dor m ∈]1,+∞[;
Ensure: Retorna um agrupamento difuso P;1: Estabeleça T; e faça ε > 0; Inicialize aleatoriamente o grau de pertinência ui jk(i = 1, . . . ,c;
j = 1, . . . , p e k = 1, . . . ,n) do objeto k pertencente ao cluster Ci para a variável j tal queui jk ∈ [0,1], 0 < ∑n
k=1 ui jk < n e maxiui jk > 0, para todo i, j e k. Estime ηi j usando aequação 4.16;
2: t ← 0;3: Et ← 0;4: Et+1 ← valor da equação 4.13 ou 4.19;5: while |Et+1−Et |> ε do
6: (Fixe o grau de pertinência ui jk do objeto k pertencente ao cluster Ci e a variável j)Calcule o protótipo yi do cluster Ci(i = 1, . . . ,c) para a variável j usando a equação 4.15.
7: (Fixe o protótipo yi) Atualize o grau de pertinência fuzzy ui jk do objeto k pertencenteao cluster Ci (i = 1, . . . ,c) e a variável j usando a equação 4.17 ou 4.18;
8: Et ← Et+1;9: Et+1 ← valor da equação 4.13 ou 4.19;
10: t ← t +1;11: end while
return Agrupamento difuso P.
66

CAPÍTULO 5
Experimentos e Resultados
Uma teoria é algo que ninguém acredita, exceto a pessoa que a fez. Um
experimento é algo que todos acreditam, exceto a pessoa que o fez.
—ALBERT EINSTEIN
5.1 Introdução
Com o objetivo de avaliar o desempenho dos métodos propostos neste trabalho, dois conjun-
tos de dados intervalares sintéticos e duas configurações de dados reais foram consideradas.
Nos dados sintéticos, foram produzidos diferentes proporções de dados ruidosos onde estes se
caracterizam por ter tanto intervalos quanto médias atípicas do restante dos elementos. En-
quanto os dados reais são constituídos de variáveis naturalmente intervalares: mushroom and a
city-temperature.
A comparação é feita com os métodos FCM com distância adaptativa com matriz diagonal
para dados intervalares propostos por [11]. Aqui o método do tipo global é abreviado por
IFCM-G e o do tipo por classe tem a abreviação IFCM-C. Outro método presente na literatura
que foi apresentado neste trabalho e que é comparado com os métodos propostos é o FCM
robusto para dados intervalares introduzido por [86] e tem a abreviatura IFCM-R. Os métodos
propostos, por sua vez, são referenciados como IPCM (PCM para dados intervalares), IPCM-V
(grau de pertinência por classe e variável), IPCM-E (PCM com grau de pertinência atualizado
pela função exponencial) e IPCM-VE (equivalente ao IPCM-V, mas com grau de pertinência
atualizado pela função exponencial).
A avaliação dos agrupamentos resultantes da execução dos métodos é baseado no cálculo
de um índice externo de qualidade de grupo (CR) e na taxa de erro global de classificação
(OERC). O índice CR [87] tem valores no intervalo [−1,1] onde o valor 1 indica uma perfeita
correspondência entre a partição original e a obtida pelo método de agrupamento, valores perto
de 0 correspondem a uma correspondência aleatória e valores negativos indicam uma insufi-
ciência do método em reconhecer as propriedades da configuração de dados avaliada. Uma
67

importante característica deste índice é que ele não é sensível ao número de grupos usados
no agrupamento e à distribuição dos elementos nos grupos [88]. Seja Q = q1, . . . ,qc, . . . ,qC
uma partição obtida depois de executar os métodos de agrupamento e R = r1, . . . ,rd, . . . ,rD
a partição a priori. O índice CR e definido por:
CR =∑C
i=1 ∑Dj=1
(ni j
2
)
−(
n2
)−1∑C
i=1
(
ni·2
)
∑Dj=1
(n· j2
)
12
[
∑Ci=1
(
ni·2
)
+∑Dj=1
(n· j2
)
]
−(
n2
)−1∑C
i=1
(
ni·2
)
∑Dj=1
(n· j2
)
, (5.1)
onde ni j é o número de objetos que estão nos grupos qi e ri, ni· é o número de objetos que estão
no grupo qi, n· j é o número de objetos que estão no grupo r j e n é o número de objetos total.
O índice OERC [89] tem seus valores no intervalo [0,1] onde o valor 0 indica uma perfeita
correspondência entre a partição original e a obtida pelo método de agrupamento, por outro
lado valor 1 representa que a partição original e a obtida são totalmente diferentes. Ele tem
como objetivo medir a abilidade de um algoritmo de agrupamento achar os grupos a priori
presentes na configuração e é calculado por:
OERC = 1−∑C
i=1 max1≤ j≤Cni j
n(5.2)
Em todos os experimento, utilizou-se o parâmetro dos métodos possibilísticos K igual a 1
segundo [5] e o parâmetro de nebulosidade m igual a 2 normalmente utilizados na literatura
[90].
5.2 Dados Sintéticos
Neste estudo, dois conjuntos de dados intervalares sintéticos contendo valores atípicos são
adotados. Eles são gerados a partir de sementes de dados contendo valores aberrantes baseadas
em dados clássicos (não intervalares), onde cada semente é um ponto (y1,y2)∈ℜ2. O conjunto
de sementes 1 tem três classes de tamanhos diferentes 100, 50 e 50, respectivamente, e as
variáveis não são correlacionadas (ρ = 0). O conjunto de sementes 2 tem também três classes
de tamanhos diferentes 100, 100 e 50, respectivamente, e as variáveis são correlacionadas (ρ 6=
0). O objetivo de usar correlação na segunda configuração é avaliar o desempenho do método
possibilístico com grau de pertinência por classe e variável (IPCM-V e IPCM-VE) e comparar
com os métodos IPCM e IPCM-E. Cada classe é desenhada de acordo com uma distribuição
normal bi-variada. A Tabela 5.2 mostra os parâmetros e tamanhos das classes para ambos as
configurações:
68
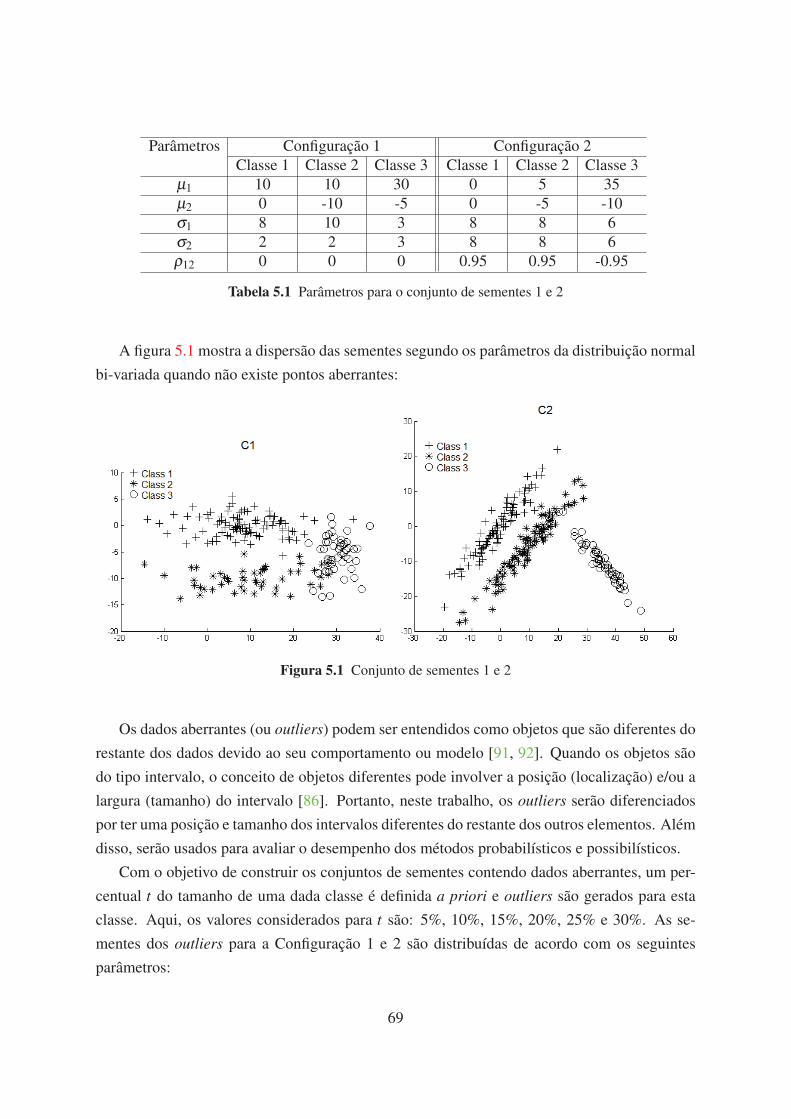
Parâmetros Configuração 1 Configuração 2Classe 1 Classe 2 Classe 3 Classe 1 Classe 2 Classe 3
µ1 10 10 30 0 5 35µ2 0 -10 -5 0 -5 -10σ1 8 10 3 8 8 6σ2 2 2 3 8 8 6ρ12 0 0 0 0.95 0.95 -0.95
Tabela 5.1 Parâmetros para o conjunto de sementes 1 e 2
A figura 5.1 mostra a dispersão das sementes segundo os parâmetros da distribuição normal
bi-variada quando não existe pontos aberrantes:
Figura 5.1 Conjunto de sementes 1 e 2
Os dados aberrantes (ou outliers) podem ser entendidos como objetos que são diferentes do
restante dos dados devido ao seu comportamento ou modelo [91, 92]. Quando os objetos são
do tipo intervalo, o conceito de objetos diferentes pode involver a posição (localização) e/ou a
largura (tamanho) do intervalo [86]. Portanto, neste trabalho, os outliers serão diferenciados
por ter uma posição e tamanho dos intervalos diferentes do restante dos outros elementos. Além
disso, serão usados para avaliar o desempenho dos métodos probabilísticos e possibilísticos.
Com o objetivo de construir os conjuntos de sementes contendo dados aberrantes, um per-
centual t do tamanho de uma dada classe é definida a priori e outliers são gerados para esta
classe. Aqui, os valores considerados para t são: 5%, 10%, 15%, 20%, 25% e 30%. As se-
mentes dos outliers para a Configuração 1 e 2 são distribuídas de acordo com os seguintes
parâmetros:
69

Parâmetro Configuração 1 Configuração 2Classe 1 Classe 3 Classe 1 Classe 3
µ1 - 10 20 40 10µ2 -30 10 0 -25σ1 2 2 2 2σ2 2 2 2 2ρ12 0 0 0 0
Tabela 5.2 Parâmetros para outliers na configuração de sementes 1 e 2
Em ambas as configurações, os pontos atípicos estão presentes nos grupos 1 e 3. A dis-
posição das sementes diferenciadas por classe e com um percentual de 30% é representada na
seguinte figura:
Figura 5.2 Conjunto de sementes 1 e 2 com 30% de outliers
Após gerar as sementes, os dados intervalares são construídos baseando-se na idéia de
centro e largura. Cada centro será a posição de cada semente, enquanto o tamanho do intervalo
é determinado aleatoriamente seguindo uma distribuição uniforme. Assumindo que um objeto
simbólico é dado por um par de intervalos (x1,x2), a construção deste objeto é feito como:
(x1 = [y1− γ1/2,y1 + γ1/2],x2 = [y2− γ2/2,y2 + γ2/2]) (5.3)
70
onde, neste trabalho, γ1 ∼ U [1,5] e γ2 ∼ U [1,5]. Por outro lado, para os dados aberrantes,
γ1 ∼ U [1,10] e γ2 ∼ U [1,10]. A figura a seguir mostra as duas configurações após usar a
Equação 5.3:
Figura 5.3 Conjunto de dados intervalares 1 e 2 com 30% de outliers
Para obter os índices CR e OERC, foram realizados experimentos Monte Carlo e 100 re-
plicações de cada uma das configurações 1 e 2 foram geradas usando o processo descrito ante-
riormente. Para cada replicação e método, foram executadas 100 repetições variando aleatori-
amente os valores da matriz difusa na etapa de inicialização do método. Em cada repetição o
método é executado até sua convergência e o valor da função objetivo é armazenado. Após as
100 repetições a melhor partição é selecionada a partir do menor valor da função objetivo e os
índices CR e OERC são calculados usando esta partição. Ao fim das 100 replicações, existirá
100 valores de CR e OERC, então a média e o desvio-padrão são calculados através desses
valores. Além disso, este processo é realizado para cada percentual de outlier: 5%, 10%, 15%,
20%, 25% e 30%.
As tabelas 5.3 e 5.4 mostram os valores da média e do desvio-padrão (em parênteses) dos
índices CR e OERC obtidos pelos métodos baseados na abordagem Fuzzy (IFCM-C, IFCM-
S e IFCM-R) e na abordagem Possibilística (IPCM, IPCM-V, IPCM-E, IPCM-VE) para os
diferentes percentuais de outliers:
71

Méthodo Percentual de outlier
5% 10% 15% 20% 25% 30%
CR
IFCM-C 0.7938 0.6679 0.5664 0.4697 0.3497 0.0816(0.0169) (0.0196) (0.0234) (0.0281) (0.0492) (0.1114)
IFCM-S 0.7840 0.6626 0.5766 0.4973 0.4348 0.3077(0.0184) (0.0210) (0.0229) (0.0197) (0.0340) (0.0706)
IFCM-R 0.7722 0.6716 0.5958 0.5070 0.4415 0.3741(0.0212) (0.0204) (0.0236) (0.0202) (0.0212) (0.0241)
IPCM 0.7128 0.6399 0.5831 0.5311 0.4990 0.5143(0.0232) (0.0243) (0.0210) (0.0291) (0.0541) (0.0673)
IPCM-V 0.8394 0.7954 0.7774 0.7541 0.7477 0.7294(0.0235) (0.0283) (0.0275) (0.0305) (0.0298) (0.0314)
IPCM-E 0.71610 0.64742 0.58529 0.52694 0.48284 0.44751(0.02364) (0.02453) (0.02162) (0.02459) (0.03708) (0.05943)
IPCM-VE 0.88323 0.85177 0.82405 0.79488 0.77548 0.75953(0.01673) (0.02540) (0.02156) (0.02483) (0.02423) (0.02673)
OE
RC
IFCM-C 0.0738 0.1181 0.1543 0.1894 0.2380 0.3518(0.0072) (0.0090) (0.0097) (0.0120) (0.0228) (0.0453)
IFCM-S 0.0767 0.1181 0.1488 0.1768 0.1994 0.2532(0.0071) (0.0093) (0.0098) (0.0082) (0.0148) (0.0334)
IFCM-R 0.0803 0.1145 0.1401 0.1729 0.1960 0.2212(0.0083) (0.0090) (0.0092) (0.0086) (0.0097) (0.0095)
IPCM 0.1009 0.1263 0.1456 0.1645 0.1784 0.1772(0.0085) (0.0091) (0.0085) (0.0109) (0.0183) (0.0240)
IPCM-V 0.0582 0.0737 0.0802 0.0887 0.0895 0.0952(0.0078) (0.0097) (0.0104) (0.0114) (0.0099) (0.0109)
IPCM-E 0.10015 0.12365 0.14530 0.16545 0.18120 0.19505(0.00867) (0.00959) (0.00956) (0.00993) (0.01149) (0.01933)
IPCM-VE 0.04320 0.05470 0.06470 0.07455 0.08145 0.08650(0.00662) (0.00979) (0.00897) (0.00949) (0.00925) (0.00955)
Tabela 5.3 Comparação dos métodos de agrupamento para dados intervalares para a Configuração 1
A Tabela 5.3 mostra, tanto para o índice CR quanto para o OERC, que os métodos baseados
na abordagem possibilítica (IPCM, IPCM-V, IPCM-E e IPCM-VE) mostraram uma melhor
qualidade da partição resultante do que os métodos baseados na abordagem difusa (IFCM-C,
IFCM-S e IFCM-R) para dados simbólicos do tipo intervalos quando o percentual de dados
aberrantes é superior a 10%. A mesma conclusão pode ser dada com os resultados presentes na
Tabela 5.4 mostrada a seguir:
72

Método Percentual de outlier
5% 10% 15% 20% 25% 30%
CR
IFCM-C 0.2857 0.2204 0.1700 0.1143 0.0730 0.0326(0.0303) (0.0219) (0.0305) (0.0262) (0.0263) (0.0250)
IFCM-S 0.2799 0.2144 0.1581 0.1069 0.0656 0.0378(0.0326) (0.0235) (0.0279) (0.0241) (0.0261) (0.0615)
IFCM-R 0.8556 0.7638 0.6792 0.5842 0.5182 0.4401(0.0241) (0.0192) (0.0192) (0.0202) (0.0246) (0.0231)
IPCM 0.8395 0.7672 0.7070 0.6412 0.5724 0.5124(0.0224) (0.0218) (0.0186) (0.0258) (0.0277) (0.0276)
IPCM-V 0.4567 0.3886 0.3400 0.2818 0.2298 0.2135(0.0349) (0.0303) (0.0309) (0.0294) (0.0344) (0.0460)
IPCM-E 0.78917 0.77238 0.73434 0.70269 0.65641 0.62270(0.02794) (0.02753) (0.02165 (0.02513) (0.02328) (0.02467)
IPCM-VE 0.38462 0.36062 0.33354 0.30216 0.27566 0.26806(0.04341) (0.03804) (0.03843) (0.03321) (0.03195) (0.04103)
OE
RC
IFCM-C 0.2640 0.2950 0.3180 0.3443 0.3656 0.3881(0.0145) (0.0114) (0.0149) (0.0138) (0.0160) (0.0140)
IFCM-S 0.2675 0.2969 0.3238 0.3476 0.3681 0.3818(0.0147) (0.0113) (0.0134) (0.0142) (0.0152) (0.0287)
IFCM-R 0.0510 0.0845 0.1149 0.1518 0.1771 0.2073(0.0085) (0.0073) (0.0065) (0.0077) (0.0101) (0.0096)
IPCM 0.0542 0.0781 0.0969 0.1190 0.1437 0.1623(0.0083) (0.0079) (0.0081) (0.0111) (0.0115) (0.0137)
IPCM-V 0.1969 0.2232 0.2440 0.2660 0.2861 0.2889(0.0144) (0.0128) (0.0146) (0.0133) (0.0189) (0.0243)
IPCM-E 0.07432 0.08156 0.09656 0.10960 0.12780 0.14236(0.00955) (0.00922) (0.00744) (0.00907) (0.00866) (0.00982)
IPCM-VE 0.21996 0.23392 0.24820 0.26488 0.27812 0.28188(0.01754) (0.01496) (0.01611) (0.01387) (0.01387) (0.01993)
Tabela 5.4 Comparação dos métodos de agrupamento para dados intervalares para a Configuração 2
Em ambas as configurações, os métodos baseados na abordagem possibilistica mostraram
ter um melhor desempenho quando existe dados aberrantes, mas a principal diferença entre elas
está na presença ou não de correlação entre as variáveis. Pode-se observar que os métodos com
o grau de pertinência por variável IPCM-V e IPCM-VE mostraram-se melhores que IPCM e
IPCM-E, respectivamente, na Configuração 1 quando as variáveis não estão correlacionadas.
Por outro lado, IPCM e IPCM-E tiveram um melhor desempenho do que os métodos IPCM-V e
IPCM-VE, respectivamente, para a Configuração 2 quando as variáveis estão correlacionadas.
A figura a seguir ilustra o decaimento do índice CR para todos os métodos em função do
acréscimo de dados aberrantes:
73
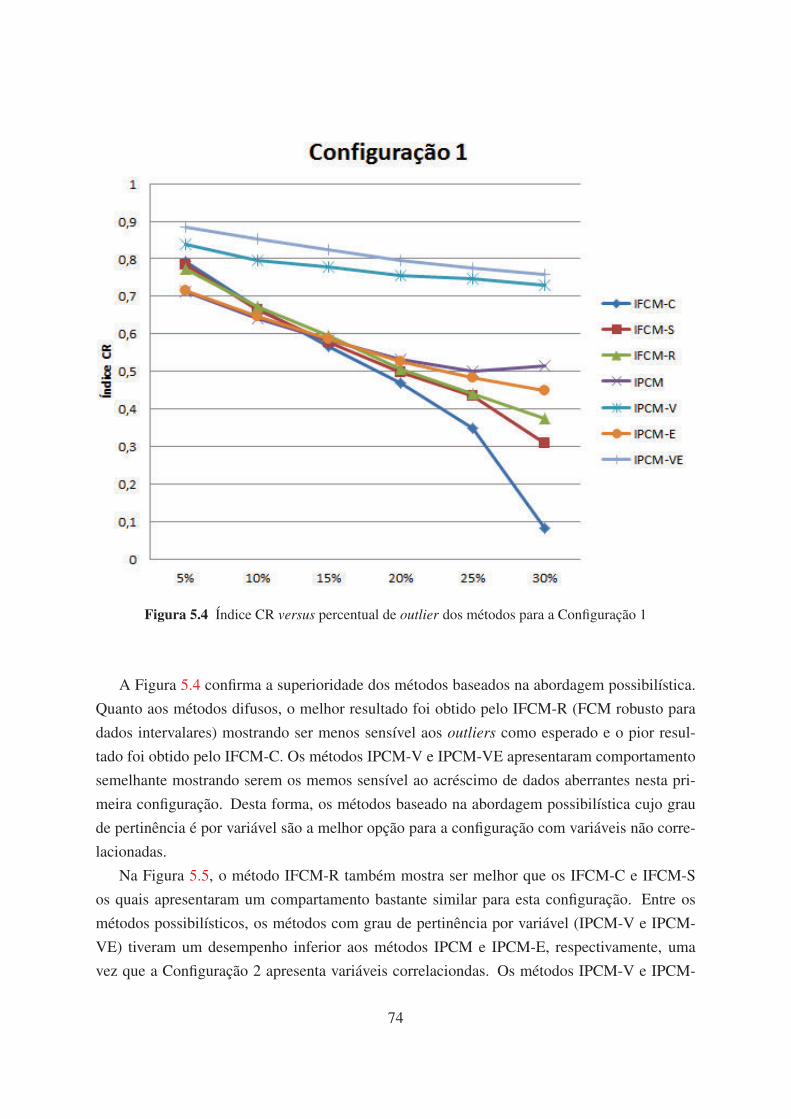
Figura 5.4 Índice CR versus percentual de outlier dos métodos para a Configuração 1
A Figura 5.4 confirma a superioridade dos métodos baseados na abordagem possibilística.
Quanto aos métodos difusos, o melhor resultado foi obtido pelo IFCM-R (FCM robusto para
dados intervalares) mostrando ser menos sensível aos outliers como esperado e o pior resul-
tado foi obtido pelo IFCM-C. Os métodos IPCM-V e IPCM-VE apresentaram comportamento
semelhante mostrando serem os memos sensível ao acréscimo de dados aberrantes nesta pri-
meira configuração. Desta forma, os métodos baseado na abordagem possibilística cujo grau
de pertinência é por variável são a melhor opção para a configuração com variáveis não corre-
lacionadas.
Na Figura 5.5, o método IFCM-R também mostra ser melhor que os IFCM-C e IFCM-S
os quais apresentaram um compartamento bastante similar para esta configuração. Entre os
métodos possibilísticos, os métodos com grau de pertinência por variável (IPCM-V e IPCM-
VE) tiveram um desempenho inferior aos métodos IPCM e IPCM-E, respectivamente, uma
vez que a Configuração 2 apresenta variáveis correlaciondas. Os métodos IPCM-V e IPCM-
74
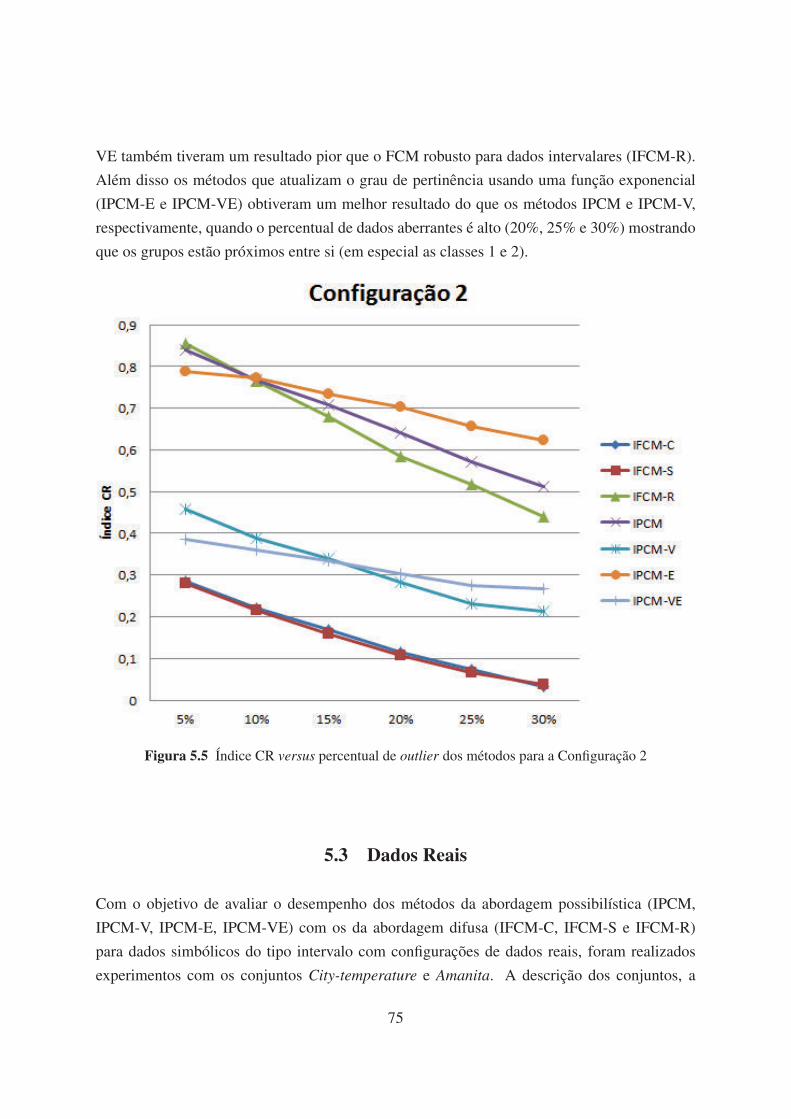
VE também tiveram um resultado pior que o FCM robusto para dados intervalares (IFCM-R).
Além disso os métodos que atualizam o grau de pertinência usando uma função exponencial
(IPCM-E e IPCM-VE) obtiveram um melhor resultado do que os métodos IPCM e IPCM-V,
respectivamente, quando o percentual de dados aberrantes é alto (20%, 25% e 30%) mostrando
que os grupos estão próximos entre si (em especial as classes 1 e 2).
Figura 5.5 Índice CR versus percentual de outlier dos métodos para a Configuração 2
5.3 Dados Reais
Com o objetivo de avaliar o desempenho dos métodos da abordagem possibilística (IPCM,
IPCM-V, IPCM-E, IPCM-VE) com os da abordagem difusa (IFCM-C, IFCM-S e IFCM-R)
para dados simbólicos do tipo intervalo com configurações de dados reais, foram realizados
experimentos com os conjuntos City-temperature e Amanita. A descrição dos conjuntos, a
75
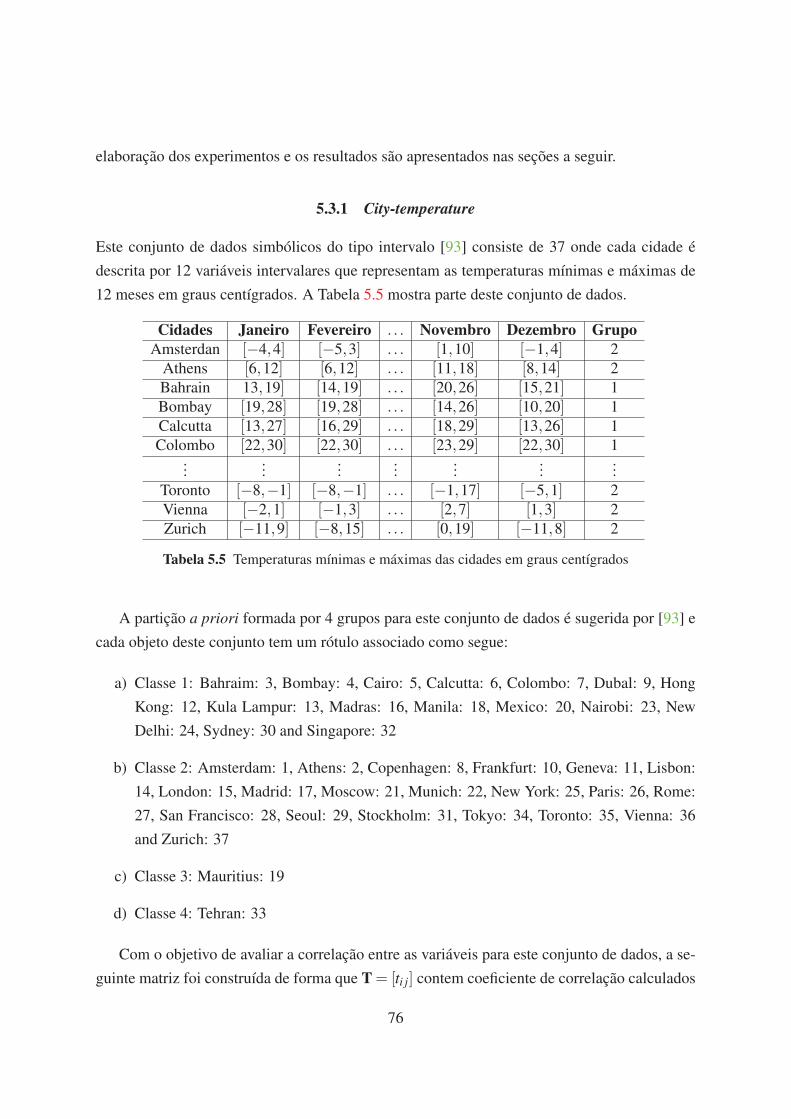
elaboração dos experimentos e os resultados são apresentados nas seções a seguir.
5.3.1 City-temperature
Este conjunto de dados simbólicos do tipo intervalo [93] consiste de 37 onde cada cidade é
descrita por 12 variáveis intervalares que representam as temperaturas mínimas e máximas de
12 meses em graus centígrados. A Tabela 5.5 mostra parte deste conjunto de dados.
Cidades Janeiro Fevereiro . . . Novembro Dezembro Grupo
Amsterdan [−4,4] [−5,3] . . . [1,10] [−1,4] 2Athens [6,12] [6,12] . . . [11,18] [8,14] 2Bahrain 13,19] [14,19] . . . [20,26] [15,21] 1Bombay [19,28] [19,28] . . . [14,26] [10,20] 1Calcutta [13,27] [16,29] . . . [18,29] [13,26] 1Colombo [22,30] [22,30] . . . [23,29] [22,30] 1
......
......
......
...Toronto [−8,−1] [−8,−1] . . . [−1,17] [−5,1] 2Vienna [−2,1] [−1,3] . . . [2,7] [1,3] 2Zurich [−11,9] [−8,15] . . . [0,19] [−11,8] 2
Tabela 5.5 Temperaturas mínimas e máximas das cidades em graus centígrados
A partição a priori formada por 4 grupos para este conjunto de dados é sugerida por [93] e
cada objeto deste conjunto tem um rótulo associado como segue:
a) Classe 1: Bahraim: 3, Bombay: 4, Cairo: 5, Calcutta: 6, Colombo: 7, Dubal: 9, Hong
Kong: 12, Kula Lampur: 13, Madras: 16, Manila: 18, Mexico: 20, Nairobi: 23, New
Delhi: 24, Sydney: 30 and Singapore: 32
b) Classe 2: Amsterdam: 1, Athens: 2, Copenhagen: 8, Frankfurt: 10, Geneva: 11, Lisbon:
14, London: 15, Madrid: 17, Moscow: 21, Munich: 22, New York: 25, Paris: 26, Rome:
27, San Francisco: 28, Seoul: 29, Stockholm: 31, Tokyo: 34, Toronto: 35, Vienna: 36
and Zurich: 37
c) Classe 3: Mauritius: 19
d) Classe 4: Tehran: 33
Com o objetivo de avaliar a correlação entre as variáveis para este conjunto de dados, a se-
guinte matriz foi construída de forma que T = [ti j] contem coeficiente de correlação calculados
76

para dados intervalores como proposto por Bilard [94], onde cada valor ti j é o coeficiente de
correlação para as variáveis intervalares i e j. A partir destes valores, a média entre os coefi-
cientes para todas as combinações de variáveis é 0.798, mostrando que, para este conjunto de
dados, as variáveis estão corelacionadas.
T =
1.00 0.99 0.98 0.94 0.81 0.63 0.40 0.44 0.70 0.89 0.97 0.99
1.00 0.98 0.95 0.82 0.65 0.42 0.46 0.72 0.90 0.97 0.97
1.00 0.98 0.88 0.72 0.49 0.54 0.78 0.94 0.98 0.96
1.00 0.94 0.81 0.58 0.62 0.84 0.96 0.97 0.93
1.00 0.92 0.75 0.76 0.91 0.95 0.88 0.80
1.00 0.89 0.89 0.96 0.88 0.75 0.62
1.00 0.97 0.87 0.70 0.54 0.38
1.00 0.91 0.74 0.57 0.41
1.00 0.92 0.81 0.69
1.00 0.95 0.88
1.00 0.96
1.00
Além disso, para verificar a dispersão entre os grupos da partição a priori do conjunto
de dados reais, o índice de heterogeneidade entre-grupos é considerado. Ele é dado por D =c
∑i=1
ni ∑pj=1(α
ji −α j)2 +(β
ji −β j)2, onde ni é o tamanho da classe Ci e [α j,β j] é o protótipo
global (centro) do conjunto Ω para a variável j dado por α j = 1n ∑n
k=1 ajk e β j = 1
n ∑nk=1 b
jk. A
contribuição relativa D(i) da classe Ci é medida pela razão Di/D, onde Di mede a contribuição
absoluta para a classe Ci com:
Di = ni
p
∑j=1
[(αj
i −α j)2 +(βj
i −β j)2], (5.4)
onde e [αj
i ,βj
i ] sendo o protótipo da classe Ci para a variável j. Valores de D(i) perto de
1 significa que o protótipo da classe Ci está longe do representante global. Por outro lado,
valores perto de 0 significa que a classe Ci está perto do centro do conjunto de dados.
Os valores de D(i), i = 1, . . . ,4 calculados da partição a priori do conjunto de dados City-
temperature são D(1) = 0.4977, D(2) = 0.4171, D(3) = 0.0433 e D(4) = 0.0418. Estes valores
sugerem que os grupos 3 e 4 estão próximos do centro do conjunto e consequentemente estão
próximos entre si.
A Tabela 5.6 mostra as classes (com os indivíduos rotulados) de acordo com a partiçãoa
priori e com a variável categórica, bem como os grupos obtidos pelos métodos relativos ao
77
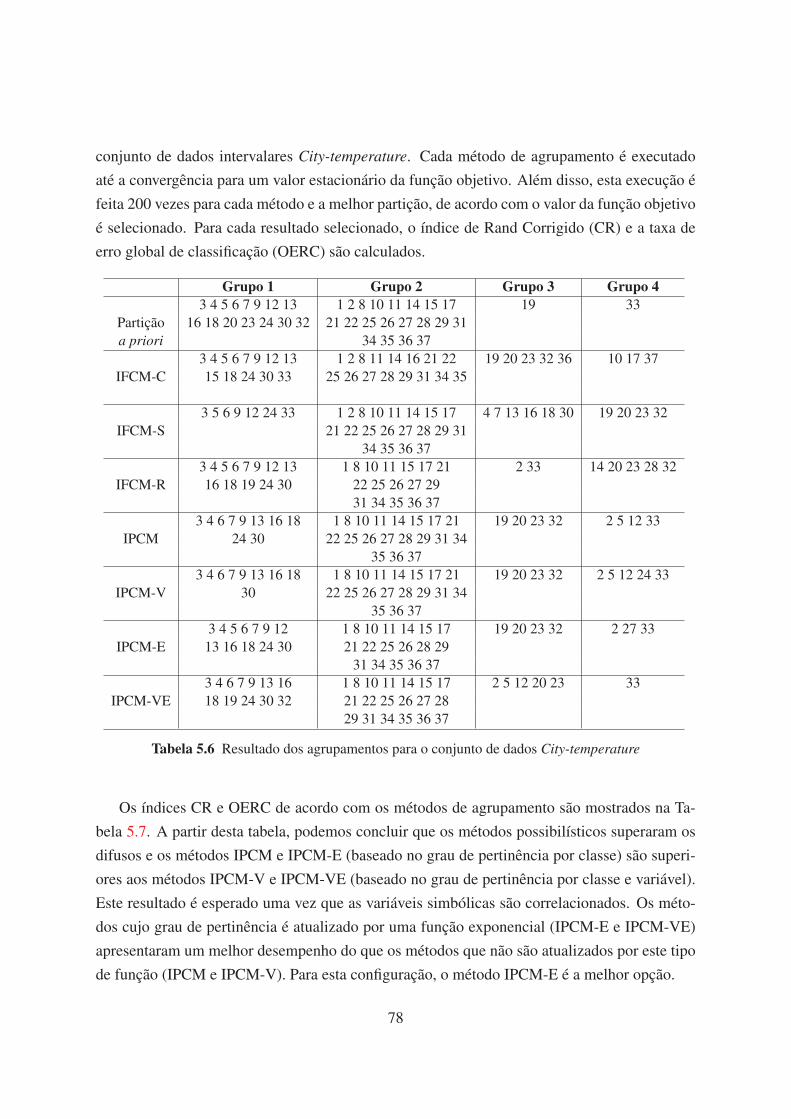
conjunto de dados intervalares City-temperature. Cada método de agrupamento é executado
até a convergência para um valor estacionário da função objetivo. Além disso, esta execução é
feita 200 vezes para cada método e a melhor partição, de acordo com o valor da função objetivo
é selecionado. Para cada resultado selecionado, o índice de Rand Corrigido (CR) e a taxa de
erro global de classificação (OERC) são calculados.
Grupo 1 Grupo 2 Grupo 3 Grupo 4
3 4 5 6 7 9 12 13 1 2 8 10 11 14 15 17 19 33Partição 16 18 20 23 24 30 32 21 22 25 26 27 28 29 31a priori 34 35 36 37
3 4 5 6 7 9 12 13 1 2 8 11 14 16 21 22 19 20 23 32 36 10 17 37IFCM-C 15 18 24 30 33 25 26 27 28 29 31 34 35
3 5 6 9 12 24 33 1 2 8 10 11 14 15 17 4 7 13 16 18 30 19 20 23 32IFCM-S 21 22 25 26 27 28 29 31
34 35 36 373 4 5 6 7 9 12 13 1 8 10 11 15 17 21 2 33 14 20 23 28 32
IFCM-R 16 18 19 24 30 22 25 26 27 2931 34 35 36 37
3 4 6 7 9 13 16 18 1 8 10 11 14 15 17 21 19 20 23 32 2 5 12 33IPCM 24 30 22 25 26 27 28 29 31 34
35 36 373 4 6 7 9 13 16 18 1 8 10 11 14 15 17 21 19 20 23 32 2 5 12 24 33
IPCM-V 30 22 25 26 27 28 29 31 3435 36 37
3 4 5 6 7 9 12 1 8 10 11 14 15 17 19 20 23 32 2 27 33IPCM-E 13 16 18 24 30 21 22 25 26 28 29
31 34 35 36 373 4 6 7 9 13 16 1 8 10 11 14 15 17 2 5 12 20 23 33
IPCM-VE 18 19 24 30 32 21 22 25 26 27 2829 31 34 35 36 37
Tabela 5.6 Resultado dos agrupamentos para o conjunto de dados City-temperature
Os índices CR e OERC de acordo com os métodos de agrupamento são mostrados na Ta-
bela 5.7. A partir desta tabela, podemos concluir que os métodos possibilísticos superaram os
difusos e os métodos IPCM e IPCM-E (baseado no grau de pertinência por classe) são superi-
ores aos métodos IPCM-V e IPCM-VE (baseado no grau de pertinência por classe e variável).
Este resultado é esperado uma vez que as variáveis simbólicas são correlacionados. Os méto-
dos cujo grau de pertinência é atualizado por uma função exponencial (IPCM-E e IPCM-VE)
apresentaram um melhor desempenho do que os métodos que não são atualizados por este tipo
de função (IPCM e IPCM-V). Para esta configuração, o método IPCM-E é a melhor opção.
78

Índice IFCM-C IFCM-S IFCM-R IPCM IPCM-V IPCM-E IPCM-VECR 0.644 0.636 0.638 0.717 0.675 0.735 0.722
OERC 0.189 0.297 0.216 0.162 0.189 0.135 0.162
Tabela 5.7 Índices CR e OERC dos métodos executados para o conjunto de dados City-temperature
A fim de avaliar os graus de pertinência para cada variável e grupo, Figura 5.6 e 5.7 apre-
sentam uma visualização utilizando o método de Zoom Star [94] para este conjunto de dados.
Este método permite a visualização da área entre os limites superiores e inferiores de interva-
los que, quando ligados, formam polígonos. Aqui, cada eixo representa os limites inferiores e
superiores dos valores de grau de pertinência (formando um intervalo de grau de pertinência)
assumido uma determinada variável para um determinada classe. O método Zoom Star permite
analisar os valores do grau de pertinência para todas as variáveis ao mesmo tempo para um
determinado grupo. Estes valores são obtidos a partir do método IPCM-V. Além disso, este
gráfico mostra os valores das medianas para os valores dos graus de pertinência representados
por uma linha em cada polígono. Intervalos de graus de pertinência com uma grande largura
(ou espalhamento) indicam que o método encontrou valores de graus de pertinência mais di-
ferentes do que um intervalo com um espalhamento baixo. Portanto, dois intervalos de graus
de pertinência são diferentes quando os valores dos graus de pertinência, resumidos por esses
intervalos, têm dispersões diferentes. Espalhamentos diferentes mostram que a interpretação
dos dados pode mudar de acordo com diferentes variáveis e isso pode dar mais informações
para o método de agrupamento.
As variáveis para o grupo 3 tem intervalos de graus de pertinência com um maior espalha-
mento do que para outros grupos enquanto que as variáveis para o grupo 4 tem intervalos de
graus de pertinência com um menor espalhamento. As variáveis para os grupos 1 e 2 têm os
espalhamentos médios. A variável Agosto tem o mais alto espalhamento em relação aos grupos
1, 2 e 4. Em geral, os dados dos graus de pertinência são assimétricas, exceto para o grupo 4.
Em conclusão, dado um grupo, as variáveis têm intervalos de graus de pertinência diferentes e
entre os grupos das variáveis também têm espalhamentos diferentes.
79

Figura 5.6 Grupos 1 e 2 de acordo com o método Zoom Star para o conjunto City-temperature
Figura 5.7 Grupos 3 e 4 de acordo com o método Zoom Star para o conjunto City-temperature
5.3.2 Amanita
Este conjunto de dados foi extraido de [95] e contém informações de espécies de fungi. Amanita
é um gênero de cogumelos de porte entre médio a grande. O mais famoso memro do gênero é
"fly agaric"de capa avermelhada. Este conjunto consiste de 16 espécies cogumelos do gênero
Amanita, na qual cada espécie é descrita por 5 variáveis intervalares: largura do píleo, largura
80

Espécies Largura Largura Espessura Altura Largura Grupo
do Píleo da Estipe da Estipe do Esporo do Esporo
Aprica [5.0,15.0] [3.3,9.1] [1.4,3.5] [9.5,13.0] [6.5,8.5] 2Constricta [6.0,12.0] [9.0,17.0] [1.0,2.0] [9.5,11.5] [8.5,10.0] 1Franchetii [4.0,12.0] [5.0,15.0] [1.0,2.0] [8.0,12.0] [6.0,8.0] 3Gemmata [3.0,11.0] [4.0,15.0] [0.5,2.0] [8.0,11.50] [6.0,9.0] 2
Lanei [8.0,25.0] [10.0,20.0] [1.5,4.0] [8.0,11.0] [5.0,6.0] 1Magniverrucata [4.0,13.0] [7.0,11.5] [1.0,2.5] [8.1,12.7] [5.5,8.3] 3
Muscaria [6.0,39.0] [7.0,16.0] [2.0,3.0] [9.0,13.0] [6.5,9.5] 2Novinupta [5.0,14.0] [6.0,12.0] [1.5,3.5] [7.0,8.5] [5.5,6.0] 1Ocreata [5.0,13.0] [10.0,22.0] [1.5,3.0] [9.0,12.5] [7.0,9.0] 2
Pachycolea [8.0,18.0] [10.0,25.0] [1.0,3.0] [11.5,14.0] [10.0,12.0] 1Pantherina [4.0,15.0] [7.0,11.0] [1.0,2.5] [9.5,13.0] [7.0,9.5] 2Phalloides [3.5,15.0] [4.0,18.0] [1.0,3.0] [7.0,12.0] [6.0,10.0] 2Protecta [4.0,14.0] [5.0,15.0] [1.0,3.0] [10.0,12.0] [8.50,10.0] 1
Smithiana [5.0,17.0] [6.0,18.0] [1.0,3.5] [8.5,12.0] [6.0,8.0] 2Vaginata [5.5,10.0] [6.0,13.0] [1.2,2.0] [8.0,11.5] [7.5,10.0] 1Velosa [5.0,11.0] [4.0,11.0] [1.0,2.5] [8.5,12.0] [7.0,11.0] 1
Tabela 5.8 Variáveis intervalares do conjunto de dados Amanita
da estipe, espessura da estipe, altura e largura de esporos. Tabela 5.8 mostra este conjunto de
dados. Ele é agrupado em 3 classes: Comestível (1), Não-comestível (2) e Desconhecido (3).
A matriz T mostra os coeficientes de correlação para as variáveis intervalares que descre-
vem o conjunto de dados Amanita. A partir destes valores na matriz, é possível verificar que
a média dos coeficientes entre as variáveis simbólicas é 0.255. Tal resultado indica que as
variáveis intervalares são não-correlaciodas.
T =
1.000 0.511 0.461 0.212 -0.011
1.000 0.474 0.2279 0.274
1.000 0.020 -0.120
1.000 0.499
1.000
Os valores de D(i), i= 1, . . . ,3 calculados da partição a priori do conjunto de dados Amanita
são D(1) = 0.0566, D(2) = 0.4391 e D(3) = 0.5043. Estes valores sugerem que os grupos são
afastados entre si, uma vez que somente o grupo 1 está perto do protótipo central.
A tabela 5.9 mostra os grupos obtidos pelos métodos para o conjunto de dados intervalares
Amanita. Tal como no conjunto de dados reais anterior, cada método de agrupamento é exe-
cutado até a convergência para um valor estacionário da função objetivo 200 vezes e o melhor
resultado, de acordo com o menor valor da função objetivo é selecionado. Para cada resultado
selecionado, o índice de CR e a taxa de erro global de classificação OERC são calculados.
81
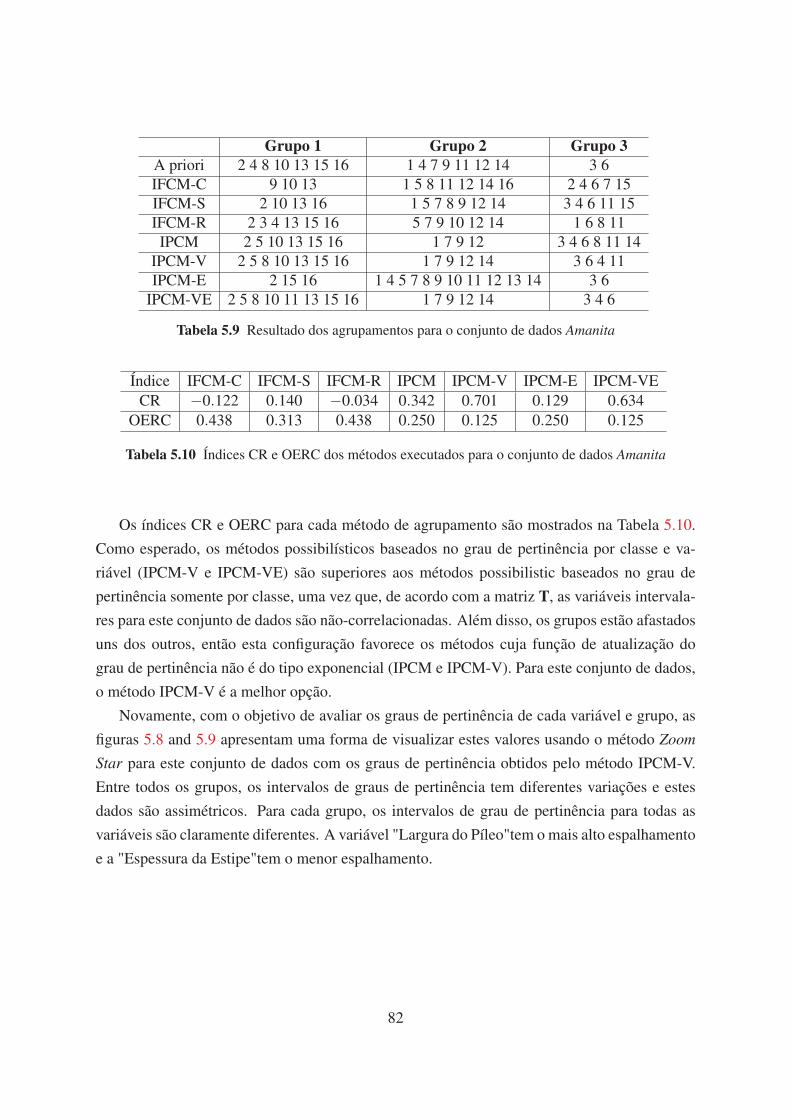
Grupo 1 Grupo 2 Grupo 3
A priori 2 4 8 10 13 15 16 1 4 7 9 11 12 14 3 6IFCM-C 9 10 13 1 5 8 11 12 14 16 2 4 6 7 15IFCM-S 2 10 13 16 1 5 7 8 9 12 14 3 4 6 11 15IFCM-R 2 3 4 13 15 16 5 7 9 10 12 14 1 6 8 11IPCM 2 5 10 13 15 16 1 7 9 12 3 4 6 8 11 14
IPCM-V 2 5 8 10 13 15 16 1 7 9 12 14 3 6 4 11IPCM-E 2 15 16 1 4 5 7 8 9 10 11 12 13 14 3 6
IPCM-VE 2 5 8 10 11 13 15 16 1 7 9 12 14 3 4 6
Tabela 5.9 Resultado dos agrupamentos para o conjunto de dados Amanita
Índice IFCM-C IFCM-S IFCM-R IPCM IPCM-V IPCM-E IPCM-VECR −0.122 0.140 −0.034 0.342 0.701 0.129 0.634
OERC 0.438 0.313 0.438 0.250 0.125 0.250 0.125
Tabela 5.10 Índices CR e OERC dos métodos executados para o conjunto de dados Amanita
Os índices CR e OERC para cada método de agrupamento são mostrados na Tabela 5.10.
Como esperado, os métodos possibilísticos baseados no grau de pertinência por classe e va-
riável (IPCM-V e IPCM-VE) são superiores aos métodos possibilistic baseados no grau de
pertinência somente por classe, uma vez que, de acordo com a matriz T, as variáveis intervala-
res para este conjunto de dados são não-correlacionadas. Além disso, os grupos estão afastados
uns dos outros, então esta configuração favorece os métodos cuja função de atualização do
grau de pertinência não é do tipo exponencial (IPCM e IPCM-V). Para este conjunto de dados,
o método IPCM-V é a melhor opção.
Novamente, com o objetivo de avaliar os graus de pertinência de cada variável e grupo, as
figuras 5.8 and 5.9 apresentam uma forma de visualizar estes valores usando o método Zoom
Star para este conjunto de dados com os graus de pertinência obtidos pelo método IPCM-V.
Entre todos os grupos, os intervalos de graus de pertinência tem diferentes variações e estes
dados são assimétricos. Para cada grupo, os intervalos de grau de pertinência para todas as
variáveis são claramente diferentes. A variável "Largura do Píleo"tem o mais alto espalhamento
e a "Espessura da Estipe"tem o menor espalhamento.
82
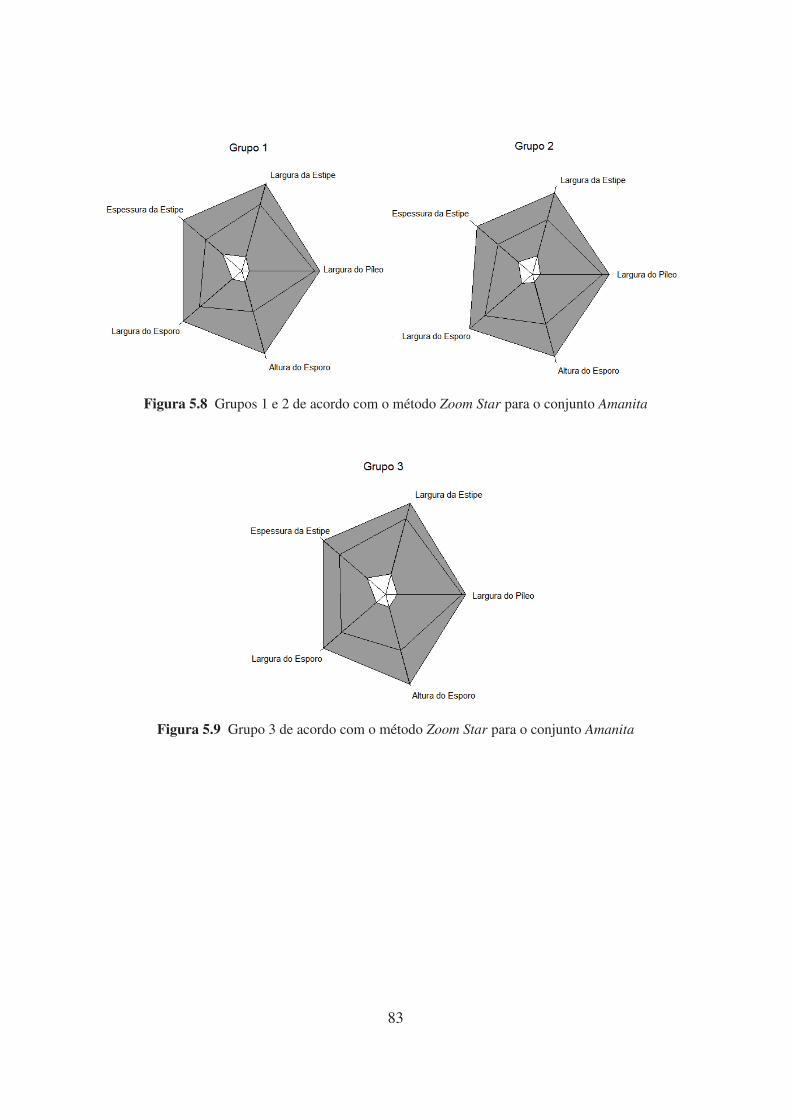
Figura 5.8 Grupos 1 e 2 de acordo com o método Zoom Star para o conjunto Amanita
Figura 5.9 Grupo 3 de acordo com o método Zoom Star para o conjunto Amanita
83

CAPÍTULO 6
Conclusão e Trabalhos Futuros
A coisa mais indispensável a um homem é reconhecer o uso que deve fazer
do seu próprio conhecimento.
—PLATÃO
6.1 Conclusão
Este trabalho buscou discorrer o campo de estudo conhecido como Análise de Dados. Este
ramo do conhecimento tem como finalidade inspecionar, limpar, transformar e modelar os da-
dos objetivando extrair informações úteis podendo ser utilizado no processo de apoio e tomada
de decisão. Devido a esses importantes aspectos, a Análise de Dados está em freqüente estudo
e desenvolvimento mediante o surgimento de novas técnicas e domínios de aplicações. Reco-
nhecimento de padrões, aprendizagem de máquina, mineração de dados, visão computacional
e biologia computacional são exemplos de importantes aplicações usadas em muitos sistemas
que usam técnicas de Análise de Dados. Análise de Agrupamento faz parte da Análise de Da-
dos e é muito utilizada em Inteligência Artificial com o propósito de processar os dados e tentar
organizá-los em grupos.
Os principais métodos utilizados na Análise de Agrupamento foram descritos neste traba-
lho. Além disso, foram referenciados vários trabalhos que propuseram novas técnicas e aplica-
ções baseados nos métodos abordados em capítulos anteriores. Os métodos de agrupamento po-
dem ser divididos em três grandes categorias: seqüenciais, hierárquicos e de particionamento.
Os de particionamento, por sua vez, podem ser categorizados em rígidos (também conhecidos
como hard) ou em difusos (ou fuzzy), onde o primeiro tem como principal representante o K-
Means, enquanto o segundo é representado pelo método Fuzzy C-Means (abreviado por FCM).
O Possibilistic C-Means (PCM) é um método também pertencente a categoria difusa que surgiu
com o propósito de resolver o principal problema do FCM: a sensibilidade a dados aberrantes.
Visto a importância do PCM, um estudo foi feito a respeito deste método e novas versões
foram propostas. A primeira é a extensão do tradicional PCM para o método que considera
dados simbólicos do tipo intervalo usando a abordagem possibilística. A segunda versão propõe
84

a utilização de tantos graus de pertinência quanto forem o número de variáveis no conjunto
de dados intervalares e o número de grupos na partição. Desta forma, é possível obter uma
melhor representação do conjunto de dados, mas com a suposição de que as variáveis não
estão correlacionadas. Adaptações no cálculo dos protótipos e do parâmetro η também foram
analisadas. Em ambas as versões, o grau de pertinência pode ser atualizado por uma função
exponencial ou não.
Para avaliar a performance dos métodos propostos, duas configurações de dados interva-
lares com a presença de diferentes níveis de dados aberrantes foram criadas. Os métodos da
abordagem possibilística foram comparados com versões do FCM para dados intervaleres: duas
usam distâncias adaptativas e uma é robusta à presença de dados ruidosos. Na primeira con-
figuração, as variáveis não estão correlacionadas e os grupos estão relativamente afastados, o
que favoreceu o método cujo grau de pertinência é por grupo e variável e não é atualizado
por uma função exponencial. Na segunda configuração, as variáveis estão correlacionadas dois
grupos estão próximos entre si, favorecendo a performance dos métodos que possuem os graus
de pertinência apenas por grupo e que usam função exponencial. Em ambas as configurações,
os métodos da abordagem possibilística mostraram ser menos sensíveis ao acréscimo de dados
aberrantes.
Na segunda parte dos experimentos, utilizaram-se dois conjuntos de dados que foram cole-
tados (1) de observações feitas das temperaturas de cidades e (2) das dimensões de espécies de
cogumelos de forma que as variáveis são intervalares. Os coeficientes de correlação intervalar
medidos entre todas as combinações de pares de variáveis de cada configuração indicam que
o primiro conjunto possui variáveis correlaciodas, enquanto o segundo não tem. Além disso,
existem dois grupos próximos entre si nos dados de temperaturas, diferentemente das espécies
de cogumelos onde os grupos estão afastados. Estas características favoreceram o método da
abordagem possibilística cujo grau de pertinência é apenas por grupo e com função exponen-
cial no primeiro conjunto, enquanto no segundo o melhor resultado foi obtido quando o grau
de pertinência é por grupo e variável e a função é não-exponencial.
6.2 Trabalhos Futuros
Embora os métodos da abordagem possibilística apresentam vantagens em relação aos da abor-
dagem fuzzy na presença de dados ruidosos, existem aspectos importantes que ainda não foram
devidamente explorados e que podem melhorar a performance dos métodos. Além disso, a
nova versão do PCM para dados intervalares com grau de pertinência por grupo e variável pos-
85

sui uma desvantagem. Portanto, a seguir estão listados sugestões de estudos mais aprofundados
a respeito das observações feitas neste trabalho:
• Cálculo do parâmetro K: este valor é normalmente fixo e vale 1 nos métodos possibi-
lísticos. Entretanto, ele pode influenciar o valor final de η e conseqüentemente no valor
da função objetivo. Este parâmetro poderia variar de uma configuração para outra e se
adaptando a cada iteração buscando minimizar a função objetivo. Também pode ser feito
um cálculo para cada variável, criando um vetor do tamanho da dimensão do conjunto;
• Uso da distância de Mahalanobis: embora os métodos possibilísticos de grau de pertinên-
cia apenas por grupo tenham encontrado um bom resultado em conjuntos com variáveis
correlacionadas, a performance poderia ser melhor com uma distância de Mahalanobis
onde usa as informações de correlação entre as variáveis. Um raciocínio análogo pode ser
feito para os métodos com grau de pertinência por grupo e variável, tornando-se menos
sensíveis à correlação das variáveis;
• Cálculo do parâmetro m: este importante parâmetro controla o quão similar os métodos
difusos serão dos métodos rígidos. Além disso, influenciam o cálculo dos graus de perti-
nência, o que determinam a organização da partição final. Normalmente utiliza-se m = 2,
mas este valor não precisa ser necessariamente o mesmo para os métodos FCM ou PCM
e para diferentes configurações de dados. A proposta é tornar este parâmetro variável de
acordo com a configuração e com a iteração do algoritmo tentando minimizar a função
objetivo.
86

Referências Bibliográficas
[1] Jain, A. K.; Murty, M. N. and Flynn, P. J. Data clustering: a review. ACM Computing
Surveys, 31(3): 264-323, 1999. 1.1, 2.4, 3.2.3
[2] Duda, R. O.; Hart, P. E. ; and Stork, D. G. Pattern Classification, John Wiely and Sons,
2001. 1.1, 2.4.1
[3] Xu, R.; Wunsch, D. I. I. Survey of clustering algorithms. IEEE Transactions on Neural
Networks, 645-678, 2005. 1.1, 2.4
[4] Nikhil, R. Pal; Pal, K.; Keller, James M.; Bezdek, James C. A Possibilistic Fuzzy c-
Means Clustering Algorithm. IEEE Transactions on fuzzy Sysyems, 2005. 1.1, 4.1
[5] Krishnapuram, R.; Keller, James M.. A possibilistic approach to clustering. IEEE Tran-
sactions Fuzzy Syst, 1993. 1.1, 1.2, 2.4, 4.1, 4.2, 4.2, 5.1
[6] Diday, E. and Noirhomme-Fraiture, M. Symbolic Data Analysis And The Sodas Soft-
ware. Wiley-Interscience Publishers, 2008. 1.1, 3.4
[7] Bock, H. H. Clustering algorithms and kohonen maps for symbolic data. J. Japan. Soc.
Comp. Statist. 15: 217-229, 2003. 1.1
[8] Souza, R. M. C. R. and De Carvalho, F. A. T. Clustering of interval data based on city-
block distances. Pattern Recognition Letters, 25(3): 353-365, 2004. 1.1, 2.4.1
[9] De Carvalho, F.A.T; Brito, P. and Bock, H.-H. Dynamic Clustering for Interval Data
Based on L2 Distance. Computational Statistics, 21(2): 231-250, 2006. 1.1, 4.2
[10] De Carvalho, F.A.T.; Souza, R.M.C.R.; Chavent, M. and Lechevallier, Y. Adaptive Haus-
dorff distances and dynamic clustering of symbolic data. Pattern Recognition Letters,
27(3): 167-179, 2006. 1.1, 2.4.1
[11] De Carvalho, F.A.T. and Lechevallier, Y. Partitional clustering algorithms for symbolic
interval data based on single adaptive distances. Pattern Recognition, 42(7):1223-1236,
2009. 1.1, 2.4.1, 3.3, 5.1
87

[12] De Carvalho, F.A.T. and Lechevallier, Y. Dynamic Clustering of Interval-Valued Data
Based on Adaptive Quadratic Distances. IEEE Transactions on Systems, man, and Cy-
bernetics, 39(6): 1295-1306, 2009. 1.1, 2.4.1
[13] De Carvalho, F. A. T. Fuzzy c-means clustering methods for symbolic interval data.
Pattern Recognition Letters, 28(4): 423-437, 2007. 1.1, 1.1, 2.4.2
[14] De Carvalho, F.A.T. e Tenorio, C. P. Fuzzy K-means clustering algorithms for interval-
valued data based on adaptive quadratic distances. Fuzzy Sets and Systems, 161(23):
2978-2999, 2010. 1.1
[15] Krishnapuram, R. e Keller, J. M. The Possibilistic C-Means Algorithm: Insights and
Recommendations. 4(3): 385-393, 1996. 1.1, 4.2, 4.2
[16] Pimentel, B. A. e Souza, R. M. C. R. Possibilistic Approach to Clustering of Interval
Data. In: 2012 IEEE International Conference on Systems, Man, and Cybernetics (IEEE
SMC 2012), Seoul, Korea, 190-195, 2012. 4.3
[17] Pimentel, B. A. e Souza, R. M. C. R. A Multivariate Fuzzy C-Means Method. Applied
Soft Computing, 3: 1592-1607, 2013. 4.3
[18] Sergios, Theodoris e Koutrombas, Konstantines. Pattern Recognition. Academic Press,
3a ed., 2006. 2.1, 4.1
[19] Ball, G. H. e Hall, D. J. A Clustering Technique for Summarizing Multivariate Data.
Behavioral Science, 12: 153-155, 1967. 2.2.1
[20] Souza, R.M.C.R. e De Carvalho, F. A.T.: Dynamical clustering of interval data based on
adaptive Chebyshev distances. IEE Electronics Letters, 40(11): 658-659, 2004. 2.3
[21] Hastie, Trrevor; Tibshirani, Robert e Friedman, Jerone. The Elements of Statistical Le-
arning. Springer, 2a ed., 2009. 2.3.1, 2.3.2
[22] Macnaughton Smith, P., Williams, W., Dale, M. and Mockett, L. Dissimilarity analysis:
a new technique of hierarchical subdivision, Nature, 202: 1034-1035, 1965. 2.3.2
[23] H. Xiong, J. Wu, and J. Chen. K-Means Clustering Versus Validation Measures: A Data-
Distribution Perspective. IEEE Trans. Syst., Man, Cybern. B, 39(2): 318-331, 2009.
2.4.1
88

[24] A. K. Jain. Data clustering: 50 years beyond K-means. Pattern Recognition, 31(8): 651-
666, 2010. 2.4.1
[25] H. Yi and K. Sam. Learning Assignment Order of Instances for the Constrained K-Means
Clustering Algorithm. IEEE Trans. Syst., Man, Cybern. B, 39(2): 568-574, 2009. 2.4.1
[26] M. Girolami. Mercer kernel based clustering in feature space. IEEE Transactions on
Neural Networks, 13(3): 780-784, 2002. 2.4.1
[27] J. McQueen. Some methods for classification and analysis of multivariate observations.
In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Proba-
bility, 281-297, 1967. 2.4.1
[28] L. Kaufman and P. J. Rousseeuw. Clustering by means of Medoids, in Statistical Data
Analysis Based on the L1-Norm and Related Methods, edited by Y. Dodge, North-
Holland, 405-416, 1987. 2.4.1
[29] J. Han, M. Kamber, and A. Tung. Spatial clustering methods in data mining: A survey.
In Geographic Data Mining and Knowledge Discovery [Miller, H.J, and Han, J., Eds].
London: Taylor and Francis Inc, 2001. 2.4.1
[30] M. J. van der Laan, K. S. Pollard and J. Bryan. A new partitioning around medoids
algorithm. Journal of Statistical Computation and Simulation, 73(8): 575-584, 2003.
2.4.1
[31] Q. Zhang and I. Couloigner. A new and effecient k-medoid algorithm for spatial cluste-
ring. Lecture Notes in Computer Science, 3482, 181-189, 2005. 2.4.1, 2.4.1
[32] H. Park and C. Jun. A simple and fast algorithm for k-medoids clustering. Expert Sys-
tems with Applications, 36(2): 3336-3341, 2009. 2.4.1
[33] L. Kaufman and P. J. Rousseeuw. Finding Groups in Data: An Introduction to Cluster
Analysis. John Wilsy and Sons, 1990. 2.4.1
[34] L. A. Zadeh. Fuzzy sets, Information and Control, 8(3): 338-353,1965. 2.4.2, 3.1
[35] D. Klaua. Über einen Ansatz zur mehrwertigen Mengenlehre. Monatsb. Deutsch. Akad.
Wiss. Berlin, 7: 859-876, 1965. 2.4.2
[36] Mitra, Sushimita e K. Pal, Sankar. Fuzzy sets in pattern recognition and machine intelli-
gence. Fuzzy Sets and Systems, 381-386, 2005. 2.4.2
89

[37] J. C. Bezdek. Pattern Recognition with Fuzzy Objective Function Algorithms, 1981.
2.4.2, 3.1
[38] D. Q. Zhang e S. C. Chen. Kernel based fuzzy and possibilistic c-means clustering. in
Proc. International Conference Artificial Neural Network, Istanbul, Turkey, 122-125,
2003. 2.4.2
[39] C.-F. Lin e S.-D. Wang. Fuzzy support vector machines, IEEE Trans. Neural Networks,
13: 464-471, 2002. 2.4.2
[40] J. H. Holland. Adaptation in Natural and Artificial Systems, University of Michigan
Press, Ann Arbor, Michigan; re-issued by MIT Press, 1992. 2.5
[41] S. D. Rajan, B. Mobasher, S- Y. Chen e C. Young. Cost-Based Design of Residential
Steel Roof Systems: A Case Study. Struct Eng Mech, 8(2): 165-180, 1999. 2.5
[42] Heyer, L. J.; Kruglyak, S.; Yooseph, S. Exploring expression data: identification and
analysis of coexpressed genes. Genome Research, 1999. 2.5
[43] J. J. Hopfield. Neural networks and physical systems with emergent collective computa-
tional abilities. Proceedings of the National Academy of Sciences, USA, 79: 2554-2558,
1982. 2.5
[44] T. Kohonen. Self-Organized Formation of Topologically Correct Feature Maps. Biolo-
gical Cybernetics 43(1): 59-69, 1982. 2.5
[45] D. Isa, V. P. Kallimani e Lam Hong Lee. Using the self organizing map for clustering of
text documents, Expert Systems with Applications, 36: 9584-9591, 2009. 2.5
[46] M. M. Mostafa. A psycho-cognitive segmentation of organ donors in Egypt using Koho-
nen’s self-organizing maps, Expert Systems with Applications, 38: 6906-6915, 2011.
2.5
[47] E. Segal, A. Battle e D. Koller. Decomposing gene expression into cellular processes. In
PSB, 2003. 2.5
[48] Banerjee, A.; Krumpelman, C.; Ghosh, J.; Basu, S. e Mooney, R. J. Model-based over-
lapping clustering. Proc Eleventh ACM SIGKDD International Conference on Kno-
wledge Discovery and Data Mining (KDD), 532-537, 2005. 2.5
90

[49] E. H. Ruspini. A new approach to clustering. Information and Control, 15: 22-32, 1969.
3.1
[50] M.-S Yang. A Survey of Fuzzy Clustering. Mathl. Comput. Modelling, 18(11): 1-16,
1993. 3.1
[51] C.-W. Chen. The stability of an oceanic structure with T-S fuzzy models. Mathematics
and Computers in Simulation, 80(2): 402-426, 2009. 3.1
[52] C. Y. Chen, J. W. Lin, W. I. Lee, and C. W. Chen. Fuzzy control for an oceanic structure:
A case study in time-delay TLP system. Journal of Vibration and Control, 16(1): 147-
160, 2010. 3.1
[53] Chen C. W. Modeling and fuzzy PDC control and its application to an oscillatory TLP
structure. Math. Problems in Engineering. An Open Access, 2010. 3.1
[54] Yeh K., Chen C. W. Stability analysis of interconnected fuzzy systems using the fuzzy
Lyapunov method. Mathematical Problems in Engineering. An Open Access Journal,
2010. 3.1
[55] Chen C. W. Application of fuzzy-model-based control to nonlinear structural systems
with time delay: an LMI method. Journal of Vibration and Control, 16: 1651-1672,
2010. 3.1
[56] J. C. Dunn. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact
Well-Separated Clusters, Journal of Cybernetics 3: 32-57, 1973. 3.1
[57] J. Yu, Q. Cheng, H. Huang. Analysis of the weighting exponent in the FCM, IEEE
Transactions on Systems, Man, and Cybernetics - Part B, 34: 634-639, 2004. 3.1
[58] K.-L. Wu. Analysis of parameter selections for fuzzy c-means. Pattern Recognition, 45:
407-415, 2012. 3.1
[59] R. J. Hathaway, J. C. Bezdek, Y. Hu. Generalized Fuzzy c-Means Clustering Strategies
Using Lp Norm Distance. IEEE Transactions on Fuzzy Systems, 8(5): 576-572, 2000.
3.1
[60] K. Jajuga. L1-norm based fuzzy clustering. Fuzzy Sets and Systems, 39: 63-83, 2001.
3.1
91

[61] P.J.F. Groenen, K. Jajuga. Fuzzy clustering with squared Minkowsky distances. Fuzzy
Sets and Systems 120: 227-237, 2001. 3.1
[62] C.-H. Oh, K. Honda, H. Ichihashi, Fuzzy clustering for categorical multivariate data,
in: Joint Ninth IFSA World Congress and Twentieth, NAFIPS International Conf, 4:
2154-2159, 2001. 3.1
[63] K.-L. Wu, M.-S Yang. Alternative c-means clustering algorithms. Pattern Recognition,
35: 2267-2278, 2002. 3.1
[64] D.-Q. Zhang, S.-C Chen. Kernel-based fuzzy and possibilistic c-means clustering. Proc.
ICANN, Istanbul, Turkey, 122-125, 2003. 3.1
[65] K. Kummamuru, A. Dhawale, R. Krishnapuram. Fuzzy co-clustering of documents and
keywords, in: Twelfth IEEE International Conf. on Fuzzy Systems, 2: 772-777, 2003.
3.1
[66] N. R. Pal, K. Pal, J. M. Keller, J. C. Bezdek. A Possibilistic Fuzzy c-Means Clustering
Algorithm. IEEE Transactions on Fuzzy Systems, 13(4): 517-530, 2005. 3.1
[67] F. A. T. De Carvalho, C.P. Tenorio, N. L. C. Junior. Partitional fuzzy clustering methods
based on adaptive quadratic distances. Fuzzy Sets and Systems, 157: 2833-2857, 2006.
3.1
[68] J. Liu, Meizhi Xu. Kernelized fuzzy attribute C-means clustering algorithm. Fuzzy Sets
and Systems, 159: 2428-2445, 2008. 3.1
[69] Y. Zhao, G. Karypis. Criterion Functions for Document Clustering: Experiments and
Analysis, Machine Learning, 2001. 3.2.1
[70] R. N. Dave, R. Krishnapuram. Robust Clustering Methods: A Unified View, IEEE Tran-
sactions on Fuzzy Systems, 5(2): 270-293, 1997. 3.2.2
[71] H. U. Gerber, B. P. K. Leung, E. S. W. Shiu. Indicator function and Hattendorff theorem.
North American Actuarial Journal, 7(1): 38-47, 2003. 3.2.3
[72] R. Zhang, A. I. Rudnicky. A large scale clustering scheme for kernel k-means, in: The
16th International Conference on Pattern Recognition, 289-292, 2002. 3.2.3
[73] K.-L. Wu, M.-S. Yang. Alternative c-means clustering algorithms. Pattern Recognition
35: 2267-2278, 2002. 3.2.3
92

[74] D. Tarlow, R. Zemel, B. Frey. Flexible priors for exemplar-based clustering. In Uncer-
tainty in artifficial intelligence (UAI), 2008. 3.2.3
[75] A. Finamore, M. Mellia, M. Meo. Mining unclassified traffic using automatic cluste-
ring techniques, in TMA 2011, third International Workshop on Traffic Monitoring and
Analysis, Vienna, Austria, 2011. 3.2.3
[76] F. Nazarov, M. Sodin. Correlation functions for random complex zeroes: Strong cluste-
ring and local universality. Communications in Mathematical Physics. 310: 75-98, 2012.
3.2.3
[77] S. Krinidis, V. Chatzis. A Robust Fuzzy Local Information C-Means Clustering Algo-
rithm. IEEE Transactions on Image Processing, 19(5): 1328-1337, 2010. 3.2.3
[78] R. Coppi, P. D’Urso, P. Giordani. Fuzzy and possibilistic clustering for fuzzy data. Com-
putational Statistics and Data Analysis, 56: 915-927, 2012. 3.2.3
[79] S. R. Kannan, S. Ramthilagam, R. Devi, Y.-M. Huang. Novel Quadratic Fuzzy c-Means
Algorithms for Effective Data Clustering Problems, The Computer Journal, 2012. 3.2.3
[80] H.-C. Huang, Y.-Y. Chuang, C.-S. Chen. Multiple Kernel Fuzzy Clustering. IEEE Tran-
sactions on Fuzzy Systems, 20(1): 120-134, 2012. 3.2.3
[81] R. A. Poliquin, R. T. Rockafellar. Generalized hessian properties of regularized nonsmo-
oth functions, SIAM Journal on Optimization, 6(4): 1121-1137, 1996. 3.2.3
[82] P. Kumar, D. Sirohi. Comparative Analysis of FCM and HCM Algorithm. International
Journal of Computer Applications, 5(2): 33-37, 2010. 3.2.4
[83] E. Anderson. The Irises of the Gaspe peninsula, Bull. American Iris Society, 59: 2-5,
1935. 3.2.4
[84] E. Diday e J. J. Simon. Clustering Analisys. K. S. Fu (ed), Digital Pattern Recognition,
47-94, 1976. 3.3
[85] E. Diday e G. Gouvaert. Classification Automatique avec Ditances Adaptatives. R. A. I.
R. O. Informatique Computer Science, 11(4): 329-349. 3.3
[86] P. D’Urso, P. Giordani. A Robust Fuzzy K-Means Clustering Model for Interval Valued
Data. Computational Statistics, 21: 251-269, 2006. 3.4, 5.1, 5.2
93

[87] L. Hubert e P. Arabie. Comparing Partitions. Journal of Classification. 2: 193-218, 1985.
5.1
[88] G. W. Milligan. Clustering validation: results and implications for applied analysis.
Clustering and Classification, Singapore, Word Scientific, 341-375, 1996. 5.1
[89] L. Breiman, J. Friedman, C. J. Stone e R. A. Olshen. Classification and Regression Trees,
Chapman and Hall/CRC, Boca Raton, 1984. 5.1
[90] N. R. Pal e J. C. Bezdek. On Cluster Validity for the Fuzzy c-Means Model. IEEE Tran-
sactions on Fuzzy Systems, 3(2): 370-319, 1995. 5.1
[91] J. W. Han and M. Kamber. Data Mining: Concepts and Techniques. Morgan Kaufmann,
San Francisco, 2001. 5.2
[92] V. Chandola, A. Banerjee e V. Kumar. Anomaly detection: A survey. ACM Computing
Surveys, 9: 1-72, 2009. 5.2
[93] D. S. Guru, B. B. Kiranagi and P. Nagabhushan. Multivalued type dissimilarity mea-
sure and concept of mutual dissimilarity value for clustering symbolic patterns. Pattern
Recognition, 1203-1213, 2004. 5.3.1, 5.3.1
[94] M. Noirhomme-Fraiture. Visualization of large data sets: The Zoom Star solution. Elec-
tronic Journal of Symbolic Data Anal. 0: 26-39, 2002. 5.3.1, 5.3.1
[95] M. Wood and F. Stevens. Amanita. http://www.mykoweb.com/CAF/genera/
Amanita.html. Acessado em Julho, 2012. 5.3.2
94


![Pré-processamento de Dados · 8. Atributos Intervalares ... Tabela 2: Base de Dados. Engenheiro Professor Gerente Conceito Nota ... toObj [w1, w2, w3]=(read w1::Profissao,](https://img.document.onl/doc/110x75/5be3790409d3f233038bc4ba/pre-processamento-de-dados-8-atributos-intervalares-tabela-2-base-de.jpg)


























