Embed Size (px)
Citation preview

Sintonia (Tuning) de Bancos de Dados
O que é?
Realizar ajustes de forma a obter um melhor
tempo de resposta para determinada
aplicação e/ou aumentar throughput =>
Garantir um desempenho satisfatório das
aplicações de banco de dados

Conhecimento para o Tuning
O tuning de SGBDs envolve o conhecimento
de muitas questões distintas:
Hardware e sistema operacional
Gerência de memória e acesso a discos
Controle de concorrência, controle de
recuperação
Uso de índices
Otimização e reescrita de consultas
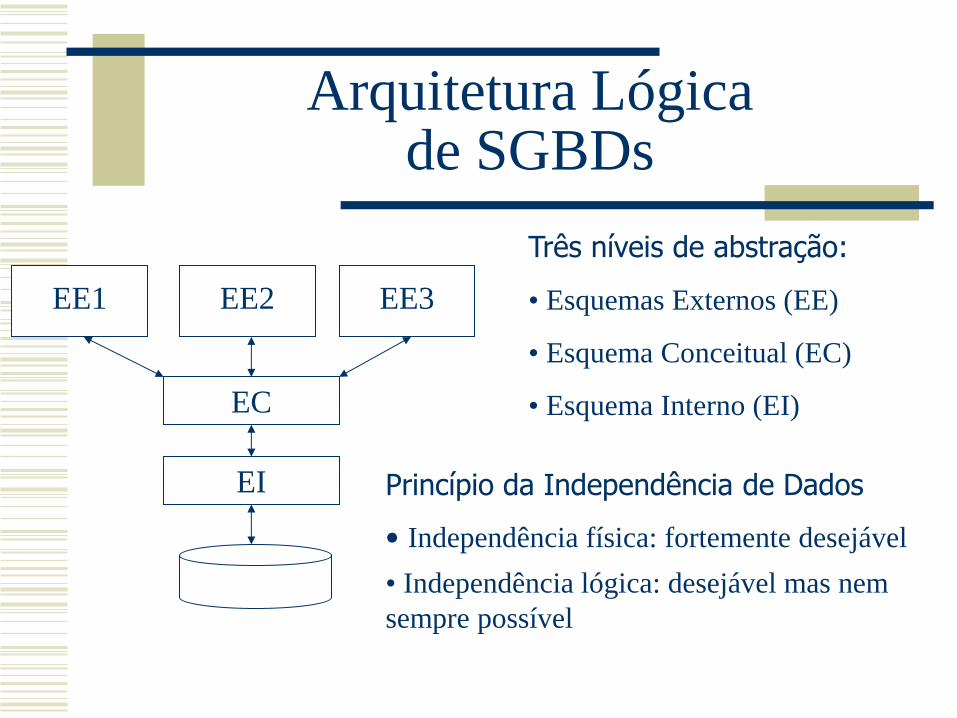
Arquitetura Lógica de SGBDs
EE1 EE2 EE3
EC
EI
Três níveis de abstração:
• Esquemas Externos (EE)
• Esquema Conceitual (EC)
• Esquema Interno (EI)
Princípio da Independência de Dados
• Independência física: fortemente desejável
• Independência lógica: desejável mas nem
sempre possível
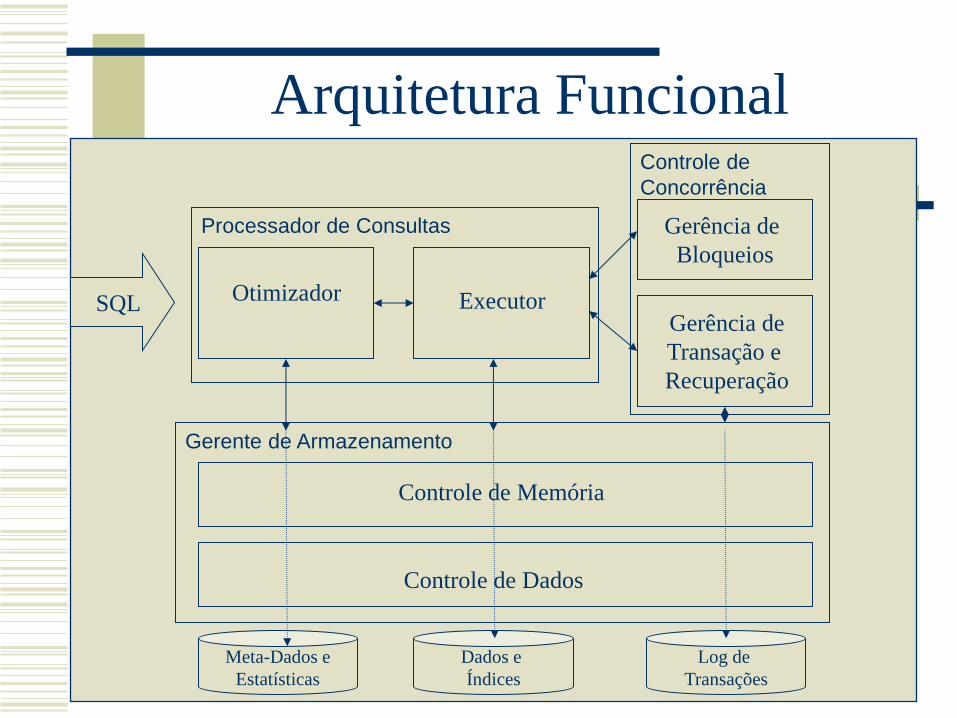
Controle de
Concorrência
Processador de Consultas
Gerente de Armazenamento
Arquitetura Funcional
Otimizador Executor
Gerência de
Bloqueios
Gerência de
Bloqueios
Gerência de
Transação e
Recuperação
Controle de Memória
Controle de Dados
Meta-Dados e
Estatísticas
Dados e
Índices
Log de
Transações
SQL

Tuning
Dificuldades:
Perceber que um recurso está sendo mal utilizado
=> monitoramento é parte fundamental do
processo
Localizar e entender a verdadeira fonte do
problema => Mais de 90% do tempo para
resolução de problemas de desempenho é gasto
no diagnóstico.

Alguns conceitos...
Plano de acesso: caminhos e formas de
acesso que serão utilizados pelo SGBD para
atender a uma requisição SQL
Otimizador: componente do SGBD
responsável por montar o plano de acesso aos
dados => independência da consulta com
relação ao formato de armazenamento dos
dados

Otimização e Execução de Consultas
Envolve
Reescrita da consulta
Determinação do melhor plano de acesso
Após otimização, ocorre a execução da
consulta

Otimização e Execução de Consultas
Parse Query
Check de Semântica
Query Rewrite
Otimização do Plano de Acesso
Geração de Código

O Otimizador
Problema “difícil”: muitas alternativas de
planos
O otimizador de consultas determina o plano
de acesso através de:
Heurísticas (otimização por regras, RBO)
Busca de plano de melhor custo (otimização por
custo, CBO)

Estatísticas
A otimização por custo demanda estatísticas,
tais como: de tabelas: número de linhas, blocos, tamanho de registro
médio
de colunas: número de valores distintos, número de
NULLs, histograma
de índices: número de folhas, níveis, clustering
de sistema: utilização típica de I/O e de CPU
A coleta de estatísticas pode ser automática
em alguns SGBDs

Planos de Execução
É o resultado da otimização
É especificado no plano de execução: Ordem de acesso às tabelas
Ordem de operações de seleção, projeção e junção
Índices utilizados
Tipos de junção
Ordenações
Tabelas intermediárias

Plano de Execução
Exemplo:
SELECT ender, datanasc
FROM empregado
WHERE nome = ‘Gal Costa’
Execution Plan
---------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMPREGADO'
2 1 INDEX (UNIQUE SCAN) OF 'PK_EMP' (UNIQUE)

Planos de Execução
Existem dois tipos básicos de operação:
Métodos de Acesso (varreduras seqüenciais,
indexadas, por rowid)
Outras operações (junções, uniões, eliminação de
duplicatas)

Índices
Estruturas auxiliares para permitir acesso
mais rápido dados
Sem índices, para obter uma informação de uma
tabela, todas as linhas devem ser lidas do arquivo
Com índice, pode ser feito acesso direto
Índices em livros permitem que passemos diretamente para o capítulo desejado

Índices
Podem ser de diversos tipos:
Árvore B+ - Cluster ou não-cluster
Bitmap
...
Alguns SGBDs permitem:
índices com valores em ordem reversa
índices em resultados de funções

Métodos de Acesso – SQL Server
Principais métodos de acesso:
Table Scan: percorre toda a tabela
Index Scan/Clustered Index Scan: percorre todo
o nível folha do índice
Bookmark Lookup: procura uma linha na tabela
ou índice baseado em seu rowid
Index Seek/Clustered Index Seek: percorre parte
do índice recuperando informações de algumas
chaves

Métodos de Acesso – Oracle
Principais métodos de acesso: Full Table Scan: leitura seqüencial de todas as páginas de
uma tabela
Index Unique Scan: acessa uma única linha, garantido
por constraint
Index Range Scan: acessa subconjunto dos dados de
forma ordenada
Index Skip Scan: acesso indexado quando as colunas que
prefixam o índice composto não são especificadas
Fast Full Index Scan: usado quando o índice cobre a
consulta

Junções
Os principais algoritmos utilizados em
junções são:
Loops Aninhados (Nested Loops Join)
Ordenação/Intercalação (Merge Join)
Hashing (Hash Join)

Ordenação
Operação básica para diversas outras
operações físicas
Resolve (usualmente) várias cláusulas: Order
By, Group By, Distinct, Union, Minus, …
Operação cara
Se o conjunto a ser ordenado não cabe em
memória, esta operação pode ser ainda mais
cara

Fator de Filtro
Fator de filtro de um predicado: percentual de linhas da tabela que satisfazem
determinado predicado.
Utilizado pelo Otimizador para:
estimar tamanho da tabela resultado
decidir sobre uso de índices e outras estratégias de acesso
Calculado com base nas estatísticas existentes

Fator de Filtro
Fator de filtro de um predicado:
número entre 0 e 1:
0 FF 1
FF 0 poucas linhas
FF 1 todas as linhas da tabela

Fator de Filtro
Estatísticas:
Tabela de Empregados com 10.000 linhas
Coluna Sexo: 2 valores distintos.
Estimativas: FF(M) = 0.5, FF(F) = 0.5
Select nome
from empregados
where sexo = ‘M’
Estima retorno
de 5000 linhas
Select nome
from empregados
where sexo = ‘F’
Estima retorno
de 5000 linhas
Não usa
índice

Fator de Filtro
Estatísticas com a presença de Histograma: otimizador pode
perceber distribuição não-uniforme:
tabela de Empregados com 10.000 linhas:
coluna Sexo: distribuição não uniforme.
estatísticas de distribuição não uniforme:
M: 9.000 empregados
F: 1.000 empregados
FF(F) = 0.1
Para consulta “sexo = `F`”, otimizador pode decidir utilizar o índice da coluna sexo

Fator de Filtro x Índices
O fator de filtro influencia diretamente na
utilização de índices => quando consulta
retorna poucas linhas e existem índices
adequados, otimizador pode utilizar índices;
“Poucas linhas” depende de SGBD para
SGBD e de versão para versão.

Fator de Filtro
Predicado composto: AND
select * from empregados
where dept = ‘600’
and sexo = ‘m’ and cargo = ‘pgmr’
FF(sexo) = 0.9
FF(dept) = 0.2
FF(cargo) = 0.1
FF = 0.9 * 0.2 * 0.1 = 0.018
Estimativa para a tabela resultado: 180 linhas

Fator de Filtro
O Otimizador pode ser enganado em alguns casos em predicados correlacionados:
select * from empregados where cidade = ‘ rio de janeiro’
FF = 1 / 1.000 R = 100.000 / 1.000 = 100 linhas
select * from empregados where cidade = ‘ rio de janeiro’ and estado = ‘ rj’ and pais = ‘ brasil’
FF = (1 / 28) * (1 / 1.000) * (1/10) R = 100.000 / 28.000 = 3,5 linhas

Tuning
Se o problema está em uma consulta
apenas...
Tentar primeiro métodos com impactos locais:
reescrita da consulta
Criação de índices, desnormalização do
esquema e reordenação de transações, por
exemplo, podem afetar todo o sistema.

Reescrita
Evitar having se pudermos utilizar where.
Where elimina linhas antes da operação de
agrupamento e facilita a utilização de índices
na comparação
Select max(salario)
From empregado
Group by depnum
Having depnum = 100
Select max(salario)
From empregado
Where depnum = 100

Reescrita
Exemplo Oracle:
------------------------------------------------------------------------
| Operation | Name | Rows | Bytes| Cost
------------------------------------------------------------------------
| SELECT STATEMENT | | 1 | 16 | 360
| FILTER | | | |
| SORT GROUP BY | | 1 | 16 | 360
| TABLE ACCESS FULL |EMPREGADO | 100K| 1M| 102
Select max(salario) From empregado
Group by depnum Having depnum = 100

Reescrita
Exemplo Oracle
-------------------------------------------------------------------------
| Operation | Name | Rows | Bytes| Cost
-------------------------------------------------------------------------
| SELECT STATEMENT | | 1 | 16 | 2
| SORT AGGREGATE | | 1 | 16 |
| TABLE ACCESS BY INDEX RO|EMPREGADO | 100 | 1K| 2
| INDEX RANGE SCAN |IDX_EMP_DEPNUM | 100 | | 1
Select max(salario)
From empregado
Where depnum = 100
Custo cai de 360 para 2!
Queda para apenas 0,5% do
original!!!

Reescrita
Eliminar “DISTINCT”
Verificar a lógica da aplicação
Para consultas em uma única tabela, verificar se
o resultado da consulta contém alguma coluna
definida como chave única
Para consultas com junções verificar o tipo de
junção, as colunas da junção e as colunas
resultado

-------------------------------------------------------------------------
| Operation | Name | Rows | Bytes| Cost
-------------------------------------------------------------------------
| SELECT STATEMENT | | 100K| 2M| 937
| SORT UNIQUE | | 100K| 2M| 937
| TABLE ACCESS FULL |EMPREGADO | 100K| 2M| 102
Reescrita
Exemplo Oracle: select distinct ident, nome from empregado;
select ident, nome from empregado; Custo = 102

Junções e Sub-Consultas
select E.Ident, E.nome from empregado E where exists ( select * from dependente D where D.Idemp = E.Ident )
Execution Plan
----------------------------------------------------------
SELECT STATEMENT Optimizer=CHOOSE
FILTER
TABLE ACCESS (FULL) OF ‘EMPREGADO'
INDEX (RANGE SCAN) OF 'IDX_DEPENDENTE_IDEMP' (NO N-UNIQUE)
Sem estatísticas

Junções e Sub-Consultas
Sem estatísticas
select E.Ident, E.nome from Empregado E, Dependente D where D.Idemp = E.Ident
Execution Plan
----------------------------------------------------------
SELECT STATEMENT Optimizer=CHOOSE
NESTED LOOPS
TABLE ACCESS (FULL) OF 'DEPENDENTE'
TABLE ACCESS (BY INDEX ROWID) OF ‘EMPREGADO'
INDEX (UNIQUE SCAN) OF 'IDX_EMPREGADO_ID' (UNIQUE)

Junções e Sub-Consultas
Sem estatísticas
select E.Ident, E.nome from Empregado E where E.Ident in ( select IdEmp from Dependente D)
Execution Plan
----------------------------------------------------------
SELECT STATEMENT Optimizer=CHOOSE
NESTED LOOPS
VIEW OF 'VW_NSO_1'
SORT (UNIQUE)
TABLE ACCESS (FULL) OF 'DEPENDENTE'
TABLE ACCESS (BY INDEX ROWID) OF ‘EMPREGADO'
INDEX (UNIQUE SCAN) OF 'IDX_EMPREGADO_ID' (UNIQUE)

Junções e Sub-Consultas
Com estatísticas
select E.Ident, E.nome from Empregado E where exists ( select * from Dependente D
where D.Idemp = E.Ident )
Execution Plan
----------------------------------------------------------
SELECT STATEMENT Optimizer=CHOOSE (Cost=10 Card=1640 Bytes=173840)
HASH JOIN (SEMI) (Cost=10 Card=1640 Bytes=173840)
TABLE ACCESS (FULL) OF 'EMPREGADO' (Cost=5 Card=2200 Bytes=226600)
INDEX (FAST FULL SCAN) OF 'IDX_DEPENDENTE_IDEMP' (NON-UNIQUE) (Cost=2
Card=3000 Bytes=9000)
select E.Ident, E.nome from Empregado E where E.Ident in ( select IdEmp from Dependente D)

Junções e Sub-Consultas
Com estatísticas
select E.Ident, E.nome from Empregado E, Dependente D where D.Idemp = E.Ident
Execution Plan
----------------------------------------------------------
SELECT STATEMENT Optimizer=CHOOSE (Cost=8 Card=3000 Bytes=318000)
HASH JOIN (Cost=8 Card=3000 Bytes=318000)
INDEX (FAST FULL SCAN) OF 'IDX_DEPENDENTE_IDEMP' (NON-UNIQUE) (Cost=2
Card=3000 Bytes=9000)
TABLE ACCESS (FULL) OF 'EMPREGADO' (Cost=5 Card=2200 Bytes=226600)

Tuning
Métodos de impacto com maior abrangência:
Criação/destruição de índices
Utilização de índices cluster
Visões materializadas
Escolha do tamanho adequado de bloco
Posicionamento dos arquivos em disco
Particionamento de objetos
Ajuste das áreas de memória
Ajuste dos parâmetros do SGBD
...

Distribuição de Arquivos
I/O paralelo => diminui a disputa por disco.
Dividir arquivos de maior acesso em
diferentes discos.
Manter em discos separados:
Tablespaces do sistema;
Arquivos de dados com tabelas muito acessadas;
Arquivos de índices para tabelas muito
acessadas;

Equilibrando I/O
Mapeamento entre tabelas / índices e os data
files
Tabela
Índice
Índice
Tablespace
Tablespace

Estrutura de Armazenamento
Tabelas e índices alocam um espaço no
banco de dados quando são criados =>
tamanho inicial.
A medida que crescem, podem surgir
extensões, que podem não ser contíguas;
Fragmentação pode gerar problema de
desempenho;

Row Migration
page n
F/V 1 F/V 2 F/V 3 F/V 4 L1 L2 L3 L4 header update t1 set c1 =
....
page p
F/V 1 F/V 2 F/V 3 F/V 4 L1 L2 L3 L4 header
page n
header
ANTES
DEPOIS

Row Chaining
page k page p page t
F/V 1 F/V 2 L1 L2 F/V 3 F/V 4 L3 L4 header
Representação lógica page k
page p
page t
Armazenamento físico F/V 3 L3 F/V 4 L4 header
F/V 1 header L1
F/V 2 header L2

Eliminando Fragmentação
Aloque o espaço adequado na criação do
objeto
Recrie o objeto, possivelmente movendo para
novo tablespace => crie o objeto com o
espaço adequado;
Exporte e reimporte a tabela

Particionamento
Decomposição de grandes objetos em objetos
menores =>partições.
Cada partição física possui seus próprios
atributos físicos => podem ser armazenadas
até mesmo em tablespaces diferentes!
Pode ser realizado com dados e com índices.

Particionamento
Exemplo: CREATE TABLE vendas (idVenda NUMBER(5),
data DATE, ValorTotal NUMBER(15,3)) PARTITION BY RANGE (data) (PARTITION data1 VALUES LESS THAN TO_DATE('01/04/2004','DD/MM/YYYY') TABLESPACE ts1, PARTITION data2 VALUES LESS THAN TO_DATE('01/07/2004','DD/MM/YYYY')
TABLESPACE ts2 . . . PARTITION data4 VALUES LESS THAN TO_DATE('01/01/2005','DD/MM/YYYY')
TABLESPACE ts4)

Particionamento
Pode ocorrer por intervalos de valores (de uma ou mais colunas), hash e lista.
Sub-particionamento => partições para cada partição.
Exemplo: partição por estados e, para cada estado, sub-partição por intervalo de datas

Particionamento
Otimizador pode acessar somente uma partição na realização de consultas.
Em tabelas com mesmas chave de particionamento e pontos de quebra, as junções podem ser realizadas por partições

Utilização da Memória
SGBDs utilizam a memória para armazenar:
Dados mais recentemente acessados. Operações de
atualização realizadas por usuários podem fazer com que
existam em memória várias versões da mesma
informação;
Informações sobre árvores de execução de comandos
SQL;
Informações sobre a instância utilizada e a base de dados
acessada;
Processos do servidor e seus parâmetros de controle;

Utilização da Memória
Para melhorar desempenho:
Aumentar memória principal: nem sempre é a
solução => realocar memória
Aumentar memória para o SGBD: concorrência
com outros programas no servidor
Manter na memória as informações que são
realmente necessárias

Estruturas de Memória
Database Buffer Cache
Contém cópias de blocos de dados lidos de
arquivos
Único para os processos de todos os usuários
conectados
Buffers organizados em listas - geralmente LRU

Estruturas de Memória
Quando uma informação é acessada, SGBD procura essa informação no database buffer cache.
Se encontra (cache hit) os dados são utilizados diretamente da memória.
Se não (cache miss), o bloco de dados é copiado do arquivo de dados para o database buffer cache e, então, utilizado.
Um alto número de cache misses pode ser um indicador de problemas de desempenho

Buffer Cache
Finalidade:
manter páginas mais usadas em memória
reduzir operações de I/O
Leitura lógica
página desejada pode estar ou não no BP
Leitura física
necessário realizar operação de I/O

Buffer Cache
Eficiência do Buffer Pool: hit ratio
%100l
l
readsogical
readsphysicalreadsogicalratiohit
• Desejável:
hit ratio > 95%
depende das características do sistema

Tuning
Regras básicas x experiência
Algumas regras indicam o caminho a tomar.
O otimizador pode gerar situações ilógicas...
Experiência e criatividade ajudam muito!
Sempre testar as soluções adotadas em ambiente
de simulação!
• Sintonia automática: será a solução?

Auto-Sintonia (Self-Tuning)
Capacidade de auto-ajuste dos SGBDs ao
ambiente existente para obtenção de melhor
desempenho
Alguns SGBDs comerciais já possuem
mecanismos implementados
























![Junções celulares[1]](https://img.document.onl/doc/110x75/5572027d4979599169a39d66/juncoes-celulares1.jpg)




