Embed Size (px)
Citation preview

Figura 1 Tese apresentada à Pró-Reitoria de Pós-graduação e Pesquisa do Instituto
Tecnológico de Aeronáutica, como parte dos requisitos para obtenção do título
de Mestre em Ciências no Curso de Pós-Graduação em Engenharia Eletrônica e
Computação, Área de Concentração em Telecomunicações.
Mariana Olivieri Caixeta Altoé
CODIFICAÇÃO CONJUNTA FONTE-CANAL UTILIZANDO
CODIFICADORES UNIVERSAIS ADAPTATIVOS
Tese aprovada em sua versão final pelos abaixo assinados:
Prof. Dr. Marcelo da Silva Pinho
Orientador
Prof. Dr. Homero Santiago Maciel
Pró-Reitor de Pós-Graduação e Pesquisa
Campo Montenegro
São José dos Campos, SP - Brasil2007

ii
Dados Internacionais de Catalogação-na-Publicação (CIP)
Divisão Biblioteca Central do ITA/CTA Altoé, Mariana Olivieri Caixeta Codificação conjunta fonte-canal utilizando codificadores universais adaptativos / Mariana Olivieri Caixeta Altoé São José dos Campos, 2007. 90f. Tese de mestrado – Curso de Engenharia Eletrônica e Computação – Área de Telecomunicações – Instituto Tecnológico de Aeronáutica, 2007. Orientador: Prof. Dr. Marcelo da Silva Pinho. 1. Codificação conjunta fonte-canal. 2. Codificadores universais. 3. Compressão de fonte. 4. Embutindo informação extra. I. Centro Técnico Aeroespacial. Instituto Tecnológico de Aeronáutica. Divisão de Engenharia Eletrônica e Computação. II.Título
REFERÊNCIA BIBLIOGRÁFICA ALTOÉ, Mariana Olivieri Caixeta. Codificação conjunta fonte-canal utilizando codificadores universais adaptativos. 2007. 90f. Tese de mestrado – Instituto Tecnológico de Aeronáutica, São José dos Campos.
CESSÃO DE DIREITOS NOME DO AUTOR: Mariana Olivieri Caixeta Altoé TÍTULO DO TRABALHO: Codificação conjunta fonte-canal utilizando codificadores universais adptativos TIPO DO TRABALHO/ANO: Tese / 2007 É concedida ao Instituto Tecnológico de Aeronáutica permissão para reproduzir cópias desta tese e para emprestar ou vender cópias somente para propósitos acadêmicos e científicos. O autor reserva outros direitos de publicação e nenhuma parte desta tese pode ser reproduzida sem a sua autorização do autor. ___________________________ Mariana Olivieri Caixeta Altoé Rua Francisca Maria de Jesus, 67, Ap. 11 – Jardim Satélite 12246-021 – São José dos Campos – SP

iii
CODIFICAÇÃO CONJUNTA FONTE-CANAL UTILIZANDO
CODIFICADORES UNIVERSAIS ADAPTATIVOS
Mariana Olivieri Caixeta Altoé
Composição da Banca Examinadora:
Prof. Dr. David Fernandes Presidente - ITA
Prof. Dr. Marcelo da Silva Pinho Orientador - ITA
Prof. Dr. Waldecir João Perrella Membro Interno - ITA
Prof. Dr. Antônio Cândido Faleiros Membro Interno - ITA
Prof. Dr. Jaime Portugheis Membro Externo - UNICAMP
ITA

iv
Aos meus pais
Marisa e Celso

v
Agradecimentos
À minha família, sempre presente e incentivadora.
Ao meu marido pelo apoio e paciência.
Aos amigos do ITA.
Ao Professor Pinho pela confiança e orientação.
À FAPESP pelo apoio financeiro (Processo 03/09625-1).

vi
Resumo
Tradicionalmente, codificação de fonte e codificação de canal são tratados
independentemente, no que se denomina sistema de codificação em dois passos. Isso ocorre
porque o teorema da separação das codificações de fonte e canal garante que não há perdas
em termos de confiabilidade da transmissão em assim fazê-lo quando o volume de dados
gerados pela fonte cresce indefinidamente. No entanto, para seqüências finitas, foi mostrado
que pode ser mais eficiente realizar a codificação em apenas um passo, denominada
codificação conjunta fonte-canal, que faz uso das características da fonte ou do codificador de
fonte para prover proteção contra erros. Este trabalho propõe uma técnica de codificação
conjunta utilizando codificadores de fonte e canal consagrados e encontrados em aplicações
práticas. São eles o codificador universal adaptativo LZW e o codificador de canal Reed-
Solomon. O método proposto utiliza o fato do codificador de fonte não remover
completamente a redundância dos arquivos originais para adicionar bits extras, sem perda de
desempenho e sem distorção dos dados originais. A redundância remanescente no código é
então utilizada para embutir os bits de paridade do código de canal. O desempenho do método
é medido através de sua aplicação em arquivos dos corpos de Calgary e Canterbury. A
exploração da redundância remanescente no código gerado pelo LZW pode ser aplicada aos
codificadores universais LZ78 e suas variações que se baseiam no mesmo princípio de
atualização do dicionário.

vii
Abstract
Traditionally, source and channel coding have been treated independently, in what is
called separate coding system. This is because the source-channel coding separation theorem
guarantees that there is no loss in terms of reliable transmissibility provided that the volume
of source generated data increases indefinitely. Nevertheless, for finite sequences, it has been
shown that it may be more efficient to perform joint source-channel coding, which makes use
of source or source coder characteristics to provide error protection. This work proposes a
joint source-channel coding method that makes use of well-known and widely-adopted source
and channel coders. They are the LZW adaptative, universal coder and the Reed-Solomon
channel coder. The proposed method is based on the fact that LZW does not completely
remove all source redundancy to add extra bits in the codeword, with no penalty in
compression rate nor distortion in original data. The codeword remaining redundancy is then
used to embed the parity bits of the channel code. The performance of the method is measured
using the files of Calgary and Canterbury corpora. The exploration of the remaining
redundancy in LZW codeword can be applied to the LZ78 universal coder and its variants
whose dictionaries are built based in the same principle.

viii
Sumário
LISTA DE FIGURAS .........................................................................................................................................IX
LISTA DE TABELAS.......................................................................................................................................... X
LISTA DE SÍMBOLOS ......................................................................................................................................XI
1 INTRODUÇÃO ............................................................................................................................................ 14
2 CODIFICAÇÃO DE FONTE...................................................................................................................... 20
2.1 CODIFICAÇÃO COM CONHECIMENTO DA MEDIDA DE PROBABILIDADE DA FONTE ............24 2.2 CODIFICAÇÃO UNIVERSAL................................................................................................28 2.3 CÓDIGOS DE LEMPEL-ZIV.................................................................................................31 2.3.1 Codificador LZ77..........................................................................................................32
2.3.2 Codificador LZ78..........................................................................................................35
2.3.3 Codificador LZW ..........................................................................................................39
3 CODIFICAÇÃO DE CANAL ..................................................................................................................... 43
3.1 CÓDIGOS EM BLOCO LINEARES ........................................................................................48 3.2 CÓDIGOS REED-SOLOMON ...............................................................................................49 4 CODIFICAÇÃO CONJUNTA FONTE-CANAL...................................................................................... 52
4.1 TEOREMA DA SEPARAÇÃO E VELOCIDADE DE CONVERGÊNCIA ........................................53 4.2 CODIFICADOR LZRS77 .....................................................................................................56 5 CODIFICAÇÃO CONJUNTA FONTE-CANAL UTILIZANDO LZW E RS........................................ 59
5.1 EMBUTINDO INFORMAÇÃO EXTRA NO LZW .....................................................................60 5.2 CODIFICAÇÃO CONJUNTA.................................................................................................64 6 RESULTADOS............................................................................................................................................. 68
7 CONCLUSÕES ............................................................................................................................................ 88
REFERÊNCIAS BIBLIOGRÁFICAS .............................................................................................................. 90

ix
Lista de Figuras
FIGURA 1 – DIAGRAMA ESQUEMÁTICO DE UM SISTEMA DE COMUNICAÇÃO DIGITAL .......................... 14
FIGURA 2 – CANAL BINÁRIO SIMÉTRICO ............................................................................................... 16
FIGURA 3 – CODIFICAÇÃO DE FONTE .................................................................................................... 20
FIGURA 4 – ÁRVORE REPRESENTANDO O DICIONÁRIO DO EXEMPLO DO CODIFICADOR LZW ............... 42
FIGURA 5 – CODIFICAÇÃO DE CANAL.................................................................................................... 44
FIGURA 6 – CODIFICAÇÃO CONJUNTA FONTE-CANAL ........................................................................... 52
FIGURA 7 – EFEITOS DA SEGMENTAÇÃO DOS ARQUIVOS ...................................................................... 72
FIGURA 8 – COMPORTAMENTO DA RECUPERAÇÃO DE BITS AO LONGO DOS ARQUIVOS ....................... 75
FIGURA 9 – AUMENTO DA TAXA DE COMPRESSÃO QUANDO O CÓDIGO DE CANAL NÃO É EMBUTIDO .. 77
FIGURA 10 – TAXA DE ACERTO NA RECUPERAÇÃO DOS ARQUIVOS ...................................................... 86
FIGURA 11 – RESULTADOS OBTIDOS COM LZRS77 ............................................................................... 87

x
Lista de Tabelas
TABELA 1 – PROCESSO DE CODIFICAÇÃO DO LZ77 ............................................................................... 34
TABELA 2 – PROCESSO DE CODIFICAÇÃO DO LZ78 ............................................................................... 37
TABELA 3 – PROCESSO DE CODIFICAÇÃO DO LZW................................................................................ 41
TABELA 4 – EMBUTINDO BITS EXTRAS NO LZW ................................................................................... 63
TABELA 5 – BITS RECUPERADOS ........................................................................................................... 69
TABELA 6 – BITS RECUPERADOS NOS ARQUIVOS DO CORPO DE CALGARY .......................................... 70
TABELA 7 – EFEITOS DA SEGMENTAÇÃO DOS ARQUIVOS NA MÉDIA .................................................... 71
TABELA 8 – e MÁXIMO PERMISSÍVEL ................................................................................................... 76
TABELA 9 – TAXAS DE COMPRESSÃO DE BIBLE.TXT .............................................................................. 77
TABELA 10 – COMPRIMENTO MÁXIMO DO ARQUIVO COMPRIMIDO, EM BYTES, PARA TAXA DE ACERTO
IGUAL A 0,99................................................................................................................................. 79
TABELA 11 – COMPRIMENTO MÁXIMO DO ARQUIVO COMPRIMIDO, EM BYTES, PARA TAXA DE ACERTO
IGUAL A 0,90................................................................................................................................. 80
TABELA 12 – SEGMENTAÇÃO DOS AQUIVOS PARA SIMULAÇÃO ........................................................... 80
TABELA 13 – TAXA DE ACERTO NA RECUPERAÇÃO DE BIBLE.TXT DIVIDIDO EM 8 SEGMENTOS ............ 81
TABELA 14 – TAXA DE ACERTO NA RECUPERAÇÃO DE E.COLI DIVIDIDO EM 4 SEGMENTOS................. 81
TABELA 15 – TAXA DE ACERTO NA RECUPERAÇÃO DE KENNEDY.XLS DIVIDIDO EM 2 SEGMENTOS ...... 82
TABELA 16 – TAXA DE ACERTO NA RECUPERAÇÃO DE WORLD192.TXT DIVIDIDO EM 4 SEGMENTOS.... 82
TABELA 17 – MARGENS DE ERRO PARA N = 150 E COEFICIENTE DE CONFIANÇA DE 0,95..................... 83

xi
Lista de Símbolos
1nX Saída da fonte de informação
S Alfabeto da fonte de informação
α Cardinalidade do alfabeto da fonte
p Medida de probabilidade da fonte de informação
σ Fonte de informação
1nu Seqüência de entrada do canal
1nV Saída do canal
outC Alfabeto de saída do canal
inC Alfabeto de entrada do canal
errop Probabilidade de erro de bit do BSC
c Codificador de fonte
1( )nc X Palavra-código gerada pelo codificador c para 1nX
scC Alfabeto do código de fonte
*scC Conjunto de todas as seqüências finitas de símbolos de scC
nS Conjunto de todas as seqüências com n símbolos de S
( )1n
cl X Comprimento da palavra código 1( )nc X
1nx Realização de 1
nX

xii
( )1nH X
Entropia de 1nX
( )H σ Entropia da fonte de informação σ
( , )cr nσ Redundância média do codificador c com relação à fonte σ
l Comprimento do match nos algoritmos do tipo LZ
wl Comprimento da janela do algoritmo LZ77
sl Comprimento máximo do match no algoritmo LZ77
( )77 1n
LZm x Número de partições geradas pelo LZ77 para a seqüência 1
nx
iD Dicionário de padrões dos codificadores do tipo LZ78 no -ésimoi passo
iβ Cardinalidade do dicionário iD
( )78 1n
LZm x Número de partições geradas pelo LZ78 para a seqüência 1
nx
( )1n
LZWm x Número de partições geradas pelo LZW para a seqüência 1
nx
w Mensagem a ser codificada pelo código de canal
1nv Realização de 1
nV
w Mensagem estimada pelo decodificador de canal
CanalC Capacidade do canal
( )1 1;n nI U V Informação mútua entre 1
nU e 1nV
in
nC Conjunto de todas as seqüências com n símbolos em inC
noutC Conjunto de todas as seqüências com n símbolos em outC ,
( )1 1|n nH U V Entropia condicional de 1
nU dado 1nV
),( kn Código de canal com taxa de transmissão kn

xiii
*d Distância mínima
N Número de possíveis partições de 1nx com mesmo ( )1
nLZWm x
sN Subconjunto de N
ip -ésimai partição de 1nx
il Comprimento de 1( , )i ip p +
iN Número de possíveis partições de 1( , )i ip p +
t Número de segmentos de 1nx

CAPÍTULO 1 14
Capítulo 1
1 Introdução
O objetivo de um sistema de comunicação é transmitir informação de um ponto a
outro através de um canal de comunicação de forma eficiente e confiável. A Figura 2
apresenta o diagrama esquemático simplificado de um sistema de comunicação digital.
Figura 2 – Diagrama esquemático de um sistema de comunicação digital
A fonte de informação gera a mensagem a ser transmitida. O estudo aqui realizado
leva em consideração que a fonte de informação é a tempo discreto e sua saída é modelada
como uma seqüência de variáveis aleatórias discretas, 1 1 2...nnX X X X= , onde n representa o
número de variáveis na seqüência, também denominado comprimento da seqüência. Cada
variável aleatória iX , 1 i n≤ ≤ , pode assumir valores em um conjunto fixo finito S (com

CAPÍTULO 1 15
cardinalidade α ), denominado alfabeto da fonte, segundo uma medida de probabilidade, p ,
que é usualmente chamada de medida de probabilidade da fonte de informação. Sendo assim,
uma fonte de informação, σ , é totalmente caracterizada pelo seu alfabeto e por sua medida de
probabilidade e é usual representar a fonte através da seguinte notação ( ), pσ = S . Quando
1nX é uma seqüência de variáveis aleatórias estatisticamente independentes, i.e., quando a
fonte emite símbolos estatisticamente independentes, esta é dita sem memória.
O transmissor processa a mensagem de forma a produzir um sinal apropriado para a
transmissão através do canal de comunicação. Este processamento pode envolver codificação
de fonte, codificação de canal e modulação. Dependendo da fonte de informação e do canal de
comunicação identifica-se a necessidade de realizar apenas um dos possíveis processamentos
ou uma combinação deles, incluindo a realização dos três em seqüência. O objetivo do
codificador de fonte é representar de forma eficiente os dados gerados pela fonte, o que ocorre
pela redução da redundância presente nestes. O objetivo do codificador de canal é proteger os
dados contra erros introduzidos pelo canal de comunicação, o que é feito inserindo
redundância aos dados de entrada do codificador. A diferença entre a redundância retirada
pelo codificador de fonte e a inserida pelo codificador de canal é que a última segue uma
lógica que permite identificar e até corrigir erros na decodificação. O modulador representa
cada símbolo na saída do codificador de canal como um sinal analógico correspondente,
apropriadamente selecionado de um conjunto finito de possíveis sinais analógicos. Como o
objetivo deste trabalho é o estudo da codificação conjunta fonte-canal, serão considerados
apenas os processamentos relativos a codificação de fonte e codificação de canal,
isoladamente e em conjunto.
O canal é simplesmente o meio utilizado para transmissão do sinal. Para realizar o
estudo da codificação de fonte e da codificação de canal, este trabalho utilizou o modelo do
canal discreto sem memória (DMC – Discrete Memoryless Channel). Para estudar códigos de

CAPÍTULO 1 16
controle de erro, em geral, considera-se que o canal é um sistema estocástico que aceita em
sua entrada seqüências de símbolos, 1 1...n
nu u u= , i inu ∈C , 1 i n≤ ≤ , e gera como saída uma
seqüência de variáveis aleatórias 1 1...n
nV V V= , que podem assumir valores em um alfabeto
outC , segundo uma medida de probabilidade que depende da entrada. O conjunto inC é dito
ser o alfabeto de entrada do canal e outC é chamado de alfabeto de saída do canal. Estes dois
alfabetos em conjunto com a medida de probabilidade caracterizam totalmente o canal. Um
canal é dito discreto quando inC e outC são finitos. Um canal é dito ser sem memória quando
iV só depende de iu , 1 i n≤ ≤ . O canal binário simétrico (BSC – Binary Symmetric Channel),
representado na Figura 3, é um dos modelos mais simples de um DMC, mas ilustra a
complexidade do problema geral. O modelo é caracterizado pelo alfabeto binário de entrada
{0,1}in =C , pelo alfabeto binário de saída {0,1}out =C e por uma medida de probabilidade,
que estabele a probabilidade de erro de bit, errop .
Figura 3 – Canal binário simétrico
O receptor realiza os processamentos inversos aos do transmissor reconstruindo a
mensagem através do sinal obtido na saída do canal e entrega-a ao seu destino.
As duas questões fundamentais a cerca de um sistema de comunicação são [1]:
• Qual a complexidade irredutível abaixo da qual um sinal não pode ser
comprimido?

CAPÍTULO 1 17
• Qual é a maior taxa de transmissão para comunicação confiável sobre um canal
ruidoso?
Estas questões foram respondidas por Shannon em 1948, quando da publicação da sua
teoria da informação [2]. As respostas são, respectivamente, entropia da fonte e capacidade do
canal. Entropia, definida em termos do comportamento probabilístico de uma fonte de
informação, corresponde à menor taxa de símbolos necessária para representar a fonte de
informação sem que haja qualquer distorção nos dados. Capacidade do canal, estabelecida em
função do comportamento estatístico do canal, equivale à máxima taxa de símbolos que pode
ser transmitida através do canal tal que a probabilidade de erro seja arbitrariamente pequena.
Os processos pelos quais se busca atingir estas representações são chamados codificação de
fonte e codificação de canal, respectivamente. A codificação de fonte visa representar a saída
da fonte de forma eficiente, ou seja, aproximar a taxa de símbolos da entropia, enquanto a
codificação de canal visa reduzir o número de erros produzidos pelo canal, com uma taxa de
transmissão que se aproxime da capacidade do canal.
Quando se conhece a medida de probabilidade da fonte, é possível projetar
codificadores de fonte cuja taxa se aproxima da entropia. Em geral, a medida de probabilidade
não é conhecida a priori e precisa ser estimada sobre realizações da saída da fonte. Esta
estimação é um ponto importante, pois se o codificador for projetado com base em uma
medida de probabilidade incorreta, o código deixa de ser eficiente, ou seja, a taxa de
compressão se distancia da entropia da fonte. Em muitas aplicações, no entanto, a única
informação disponível é a seqüência de dados que se deseja comprimir, como acontece
geralmente com equipamentos que utilizam o mesmo código para comprimir diferentes tipos
de dados. Daí o interesse em codificadores universais, que se mostram eficientes para todas as
fontes pertencentes a uma determinada classe, i.e., codificadores que quando são utilizados
para comprimir a saída de uma fonte qualquer, dentro desta classe, possuem taxa de

CAPÍTULO 1 18
compressão que converge para a entropia desta fonte específica, quando o comprimento da
seqüência cresce indefinidamente.
Na prática, não se conhecem codificadores de canal que sejam capazes de atingir o
limitante da taxa de transmissão representado pela capacidade do canal com probabilidade de
erro arbitrariamente pequena. Entretanto, existe uma grande variedade de códigos eficientes,
ou seja, capazes de reduzir o número de erros produzidos pelo canal, utilizados em sistemas
de comunicação e armazenamento de dados.
A utilização de códigos (de fonte e canal) em aplicações práticas tem como objetivo
melhorar a relação de compromisso entre recursos utilizados, que pode ser a largura de banda,
a potência de transmissão ou a quantidadade de memória disponível em um dispositivo de
armazenamento, e qualidade do sistema, que no caso mais geral é dada pela taxa de erros.
É comum tratar a codificação em dois passos, como apresentado até então, pois existe
um resultado teórico que mostra que não há perda em separar o problema em codificação de
fonte e codificação de canal. Entretanto, o resultado é assintótico e, para seqüências finitas,
pode ser mais eficiente realizar a codificação em apenas um passo, ou seja, realizar uma
codificação conjunta fonte-canal, dado que a velocidade com que a probabilidade de erro
converge para zero, em alguns casos, é mais rápida quando se realiza uma codificação
conjunta.
Este trabalho propõe uma técnica de codificação conjunta utilizando o algoritmo LZW
(Lempel-Ziv-Welch) [3], que é uma variação do famoso codificador universal proposto por
Ziv e Lempel em 1978, conhecido como LZ78 [4]. Nesta proposta, a redundância
remanescente do LZW é utilizada para embutir símbolos de paridade de códigos de controle
de erro. A técnica proposta explora uma particularidade do LZW, existente na maioria das
versões do LZ78 e sendo assim, pode ser estendida para grande parte destas versões.
Diferentes códigos de controle de erro podem ser utilizados na técnica proposta. Este trabalho

CAPÍTULO 1 19
utilizou o codificador de canal Reed-Solomon [5] para avaliar o desempenho do sistema
proposto na transmissão de dados através de um canal BSC.
O trabalho está organizado da seguinte maneira. Os capítulos 2, 3 e 4 apresentam a
teoria relativa a codificação de fonte, codificação de canal e codificação conjunta fonte-canal,
respectivamente, além de soluções práticas para estes problemas. A contribuição deste
trabalho, que consiste na técnica de codificação conjunta baseada no LZW, é apresentada no
capítulo 5. Os resultados são expostos no capítulo 6 e as conclusões no capítulo 7.

CAPÍTULO 2 20
Capítulo 2
2 Codificação de Fonte
A quantidade de informação que trafega pelas redes de comunicação vem aumentando
imensamente com a expansão rápida destas redes e o aumento do número de usuários. Por
isso torna-se cada vez mais importante o aprimoramento da técnica de compressão de dados,
realizada pelo codificador de fonte, permitindo transmitir e armazenar informação de forma
mais eficiente.
A Figura 4 ilustra o problema tratado pela codificação de fonte. O codificador de fonte
codifica a seqüência de n variáveis aleatórias 1nX em uma palavra-código, 1( )nc X , que, após
armazenamento ou transmissão por um meio de comunicação, são disponibilizadas ao
decodificador. Este tem como objetivo encontrar a melhor aproximação, 1ˆ nX , da saída da
fonte, dada a palavra código 1( )nc X . Assume-se que as palavras-código não são alteradas por
ruído entre a saída do codificador e a entrada do decodificador.
Figura 4 – Codificação de fonte
Há casos em que a informação apresenta algumas distorções na saída do
decodificador, i.e., 1 1ˆ n nX X≠ , sem, contudo, prejudicar o seu entendimento por parte do
usuário, que pode até mesmo não percebê-las. É a chamada codificação com perdas, ou

CAPÍTULO 2 21
codificação segundo um critério de fidelidade. Imagem e voz são exemplos de aplicações que
aceitam pequenas distorções. Para aplicações em que distorções não são toleradas, como em
arquivos de texto, deve-se realizar a codificação sem perdas, caso em que 1 1ˆ n nX X= . Assim, a
codificação é dita sem perdas quando a representação da saída da fonte permite que os dados
originais sejam reconstruídos sem perda de informação. Neste trabalho o estudo e o
desenvolvimento são focados em codificação sem perdas.
Um código de fonte c para uma seqüência de variáveis aleatórias 1nX irá representar
possíveis realizações de 1nX através de seqüências de símbolos pertencentes a um conjunto,
scC . Na maior parte dos trabalhos em codificação de fonte, este conjunto, denominado por
alfabeto do código, é tomado por { }0,1sc =C . Neste caso, o código é chamado de código
binário. Seja *scC o conjunto de todas as seqüências finitas de símbolos pertencentes a scC (se
{ }0,1sc =C , *scC é o conjunto de todas as seqüências finitas de bits). Seja nS o conjunto de
todas as seqüências com n símbolos em S . Neste caso, é possível definir um código de fonte
c para 1nX como um mapa de nS em *
scC . Como na prática a fonte pode emitir uma
quantidade de símbolos muito grande, em geral, o código de fonte é projetado para seqüências
de comprimento reduzido e o código final é dado pela concatenação destes códigos. Quando a
concatenação de códigos permite uma decodificação perfeita, o código para seqüências
reduzidas é chamado de unicamente decodificável.
Como um código fonte, c , é um mapa de nS em *scC , é possível definir uma função
cl , associada ao código, que mapeia as seqüências de nS no comprimento de suas palavras-
código. Neste caso, cl é um mapa de nS em * (conjunto dos naturais positivos), e ( )1n
cl X
representa o comprimento da palavra-código de 1nX . É usual definir a taxa do código através

CAPÍTULO 2 22
da razão ( )1
n
cl X
n, que é a razão do número de símbolos do código pelo número de símbolos
da fonte (no caso de um código binário, a unidade é bits por símbolo da fonte).
A função do codificador de fonte é aumentar a eficiência do sistema de comunicação
através da redução da forma de representar a saída da fonte. Na maior parte das aplicações, os
símbolos emitidos pela fonte de informação não se distribuem uniformemente pelo alfabeto
da fonte. Sendo assim, um bom modelo probabilístico para estas fontes não deve gerar
variáveis aleatórias equiprováveis. Por exemplo, em textos da língua portuguesa, a ocorrência
da letra “a” é muito mais freqüente que a ocorrência da letra “z”. Sendo assim, codificar a
letra “a” usando menos símbolos que a quantidade usada para a letra “z” é uma estratégia que
torna a representação do texto mais compacta. Além disso, também é comum que um bom
modelo para a fonte de informação considere uma dependência estatística entre os símbolos
da fonte. Voltando ao exemplo da língua portuguesa, é possível observar que após uma letra
“q” sempre aparece a letra “u”, o que obviamente não ocorre com as outras letras. Isto
significa que existe também uma redundância entre os símbolos da fonte. Aumentar a
eficiência de transmissão do sinal significa retirar toda ou parte da redundância presente nos
dados provenientes da fonte de informação, fazendo com que a representação da saída da
fonte seja a mais compacta possível. Retirar o máximo da redundância da saída da fonte é
equivalente a buscar um código, c , que minimize a média de ( )1n
cl X . Quando toda a
redundância é removida, atinge-se a entropia da seqüência 1nX , no caso de codificação sem
perdas, e neste caso, o código é dito ótimo para esta fonte de informação.
A entropia pode ser entendida como uma medida da quantidade de informação média
contida na seqüência 1nX [1]. Definindo quantidade de informação como a informação obtida
após a observação do evento 1 1n nX x= , 1
n nx ∈S , como a função logarítmica

CAPÍTULO 2 23
( )1 1log ( )n np X x− = , onde 1 1( )n np X x= denota a probabilidade do evento 1 1n nX x= , a entropia
de 1nX é obtida através do operador valor esperado, i.e.,
( )( )
( ) ( )( )1
1 1
1 1 1 1
( ) log
log ,n n
n n
n n n n
x
H X E p X
p X x p X x∈
= −
= − = =∑S
(1)
A base do logaritmo é igual à cardinalidade do alfabeto do código e neste trabalho, quando
não for especificada, é assumida igual a 2. Neste caso, a entropia é dada em bits. Usualmente
a entropia da fonte de informação σ é definida por
( ) ( )11lim ,n
nH H X
nσ
→∞= (2)
se o limite existir. É possível mostrar que se σ for estacionária, i.e., se o processo estocástico
1 2...X X for estacionário, o limite existe pois pode-se provar que a seqüência ( )11 nH Xn
é
limitada inferiormente e é monótona não crescente. Por esta razão,
( ) ( )11 ,nH X Hn
σ≥ (3)
para todo n .
Outra forma de interpretar entropia é como a medida da incerteza de 1nX . O valor da
entropia representa a quantidade média de informação necessária para descrever esta
seqüência. Sabendo que a cardinalidade de nS é nα , é possível mostrar que a entropia de 1nX
satisfaz
( ) ( )10 log ,n nH X α≤ ≤ (4)
sendo que o valor mínimo é atingido se e somente se ( )1 1 1n np X x= = para algum 1n nx ∈S
(não há qualquer incerteza) e o valor máximo é atingido se e somente se ( )1 1n n np X x α −= =

CAPÍTULO 2 24
para todo 1n nx ∈S (caso em que todas as seqüências em nS são equiprováveis, indicando o
máximo de incerteza).
Um importante resultado da teoria da informação, vide [6], afirma que a entropia
fornece um limitante inferior para a média da taxa de qualquer código unicamente
decodificável, i.e.,
( ) ( )1
11 .
nc n
l XE H X
n n
≥
(5)
A desigualdade acima se transforma em igualdade se e somente se
( ) ( )( )1 1 1logn n ncl x p X x= − = para todo 1
n nx ∈S . Para uma fonte estacionária σ , uma
conseqüência direta da equação (3) é que
( ) ( )1 .
ncl X
E Hn
σ ≥
(6)
Os projetos de codificadores de fonte sem perda de informação são divididos entre os
que utilizam o modelo probabilístico da fonte (e sendo assim dependem do conhecimento a
priori do modelo) e os que não a utilizam, chamados codificadores universais. As seções a
seguir apresentam a relação entre a taxa de compressão e a entropia para os dois casos. O
princípio de funcionamento de alguns codificadores universais é apresentado na seqüência.
2.1 Codificação com Conhecimento da Medida de Probabilidade
da Fonte
Conforme pode ser observado através da equação (5), a entropia da seqüência 1nX
fornece um limitante inferior para o comprimento médio das palavras-código de qualquer
código unicamente decodificável. Para facilitar a busca por bons códigos de fonte, é comum
restringir a análise a um subconjunto dos códigos unicamente decodificáveis, chamado de

CAPÍTULO 2 25
códigos instantêneos ou códigos livres de prefixo. Um código é dito livre de prefixo se
nenhuma palavra código é prefixo de outra palavra código. Além de possuir uma estrutura que
facilita a busca por bons códigos, o decodificador de um código livre de prefixo possui uma
complexidade reduzida. É interessante observar que a restrição do conjunto de busca da
solução ótima, em princípio, poderia provocar uma perda de desempenho. No entanto,
existem diferentes algoritmos capazes de gerar códigos livres de prefixo cujas taxas atingem a
entropia da seqüência, a menos de um erro de arredondamento. Por esta razão, grande parte
dos trabalhos de codificação de fonte adota esta restrição. É importante ressaltar que tais
algoritmos necessitam do conhecimento a priori da medida de probabilidade da fonte.
Entre os códigos construídos com conhecimento da medida de probabilidade da fonte
encontram-se os códigos de Shannon, Huffman, Shannon-Fano-Elias e o código aritmético,
entre outros [6].
Analisando a desigualdade apresentada em (5) e a condição necessária e suficiente
para que ela se transforme em uma igualdade, é fácil observar que a solução ótima seria criar
um codificador tal que ( ) ( )( )1 1 1logn n ncl x p X x= − = para todo 1
n nx ∈S . No entanto, o
resultado do logaritmo nem sempre é inteiro e como o comprimento da palavra código é o
número de bits utilizados para codificar a seqüência 1nx , esta não é uma solução possível. O
código de Shannon, apresentado em [6], é um código livre de prefixo que produz palavras-
código tais que ( ) ( )( )Shannon 1 1 1logn n nl x p X x = − = para todo 1n nx ∈S , onde t representa o
menor inteio maior ou igual a t∈ . Sendo assim, é possível afirmar que

CAPÍTULO 2 26
( ) ( ) ( )( )
( ) ( )( )( )( ) ( )( ) ( )
( )
1
1
1 1
Shannon 11 1 1 1
1 1 1 1
1 1 1 1 1 1
1
1 log
1 log 1
1 1log
1 1 .
n n
n n
n n n n
nn n n n
x
n n n n
x
n n n n n n
x x
n
l XE p X x p X x
n n
p X x p X xn
p X x p X x p X xn n
H Xn n
∈
∈
∈ ∈
= = − =
≤ = − = +
= − = = + =
= +
∑
∑
∑ ∑
S
S
S S
(7)
Com a equação (5) e com o resultado da equação (7), é possível afimar que
( ) ( ) ( )Shannon 11 1
1 1 1 .n
n nl X
H X E H Xn n n n
≤ ≤ +
(8)
O algoritmo apresentado por Huffman em 1952 possibilita construir um código livre
de prefixo que é ótimo, ou seja, um código cuja média do comprimento das palavras-código é
menor ou igual à média do comprimento das palavras-código de qualquer código livre de
prefixo. Sendo assim, é possível afimar que ( ) ( )Huffman 1 Shannon 1n nE l X E l X ≤ e com este
resultado e os resultados apresentados em (5) e (7), é possível concluir que
( ) ( ) ( )Huffman 11 1
1 1 1 .n
n nl X
H X E H Xn n n n
≤ ≤ +
(9)
O esquema de codificação aritmético, baseado no código de Shannon-Fano-Elias,
permite a construção de códigos quase ótimos que apresentam comprimento médio que
satisfaz
( ) ( ) ( )Aritmético 11 1
1 1 2 .n
n nl X
H X E H Xn n n n
≤ ≤ +
(10)
O código aritmético, apesar de se basear em técnicas que datam de 1963, tornou-se
prático a partir de 1976 e desde então surgiram várias de suas versões. Apesar de apresentar
maior comprimento médio, o código aritmético é preferível ao código de Huffman quando o
alfabeto da fonte é pequeno. Nesse caso, o código de Huffman somente apresenta boa taxa de

CAPÍTULO 2 27
compressão para blocos longos de símbolos da fonte. No entanto, a metodologia de
construção do código de Huffman exige o cálculo das probabilidades de todas as seqüências
da fonte com um comprimento de bloco particular, mesmo que já se tenha construído um
código de Huffman para comprimento de bloco menor. Já o código aritmético pode ser
facilmente expandido para comprimentos de bloco maiores sem a necessidade de refazer
todos os cálculos.
Se a fonte de informação σ for estacionária, tomando o limite quando n →∞ nas
equações (8), (9) e (10), é possível notar que as médias das taxas do código de Shannon, do
código de Huffman e do código aritmético convergem para a entropia da fonte, ( )H σ . Isto
mostra que o limite fundamental (dado pela entropia da fonte) é alcançado quando se codifica
um número suficientemente grande de símbolos da fonte por vez.
A diferença entre a média da taxa do código e a razão ( )1
nH Xn
representa a
redundância do código que não foi removida pela codificação. Portanto, através das equações
(8) e (9) é possível notar que as redundâncias do codificador de Shannon e do codificador de
Huffman são menores ou iguais a 1n
e através da equação (10) é possível observar que a
redundância do codificador aritmético é menor ou igual a 2n
. É importante ressaltar que estes
valores de redundância são atingidos quando os codificadores operam em blocos de
comprimento n . Como em geral, o codificador aritmético consegue trabalhar com blocos de
comprimento elevado, na prática, existe vantagem em se utilizar este método de codificação.
Quando é considerada uma medida de probabilidade incorreta para a fonte de
informação, a eficiência destes códigos é comprometida. Considerando que uma medida de
probabilidade q seja utilizada para construção do código no lugar da distribuição correta p , é
possível mostrar que o comprimento médio de um código perfeito (i.e., um código tal que

CAPÍTULO 2 28
( ) ( )( )1 1 1logn n ncl x p X x= − = para todo 1
n nx ∈S ) , será acrescido de ( )D p q , onde
( ) ( )( )1
1 11 1
1 1
( ) logn n
n nn n
n nx
p X xD p q p X x
q X x∈
= = = =
∑S
é a entropia relativa, que, embora não seja
uma métrica, é freqüentemente utilizada para indicar uma distância entre duas distribuições. A
entropia relativa pode ser entendida como uma medida da ineficiência ao se assumir uma
distribuição equivocada. Na prática, muitas vezes não se conhece um bom modelo
probabilístico para a fonte que se deseja comprimir ou até mesmo um único codificador é
utilizado para comprimir diferentes tipos de dados. Este problema deu origem à teoria da
codificação universal, cujo objetivo é desenvolver códigos bons para todas as fontes
pertencentes a uma determinada classe.
2.2 Codificação Universal
Códigos universais são freqüentemente utilizados quando não se conhece a
distribuição de probabilidade da fonte. Tais codificadores são eficientes para todas as fontes
pertencentes a uma classe. De fato, um codificador é definido como universal com relação a
uma classe de fontes se, para todas as fontes desta classe, a taxa do codificador converge para
a entropia da fonte, segundo algum critério de convergência. Seja Σ uma classe de fontes
(p.ex., a classe de fontes sem memória). Um codificador c é dito universal para a classe Σ se
( ) ( )1n
cl XH
nσ→ , segundo algum critério de convergência, para toda fonte σ em Σ . Como o
critério de convergência não é estabelecido, este deve ser explicitado quando determinado
codificador é considerado universal.
A partir da definição de codificador universal, é possível notar que assintoticamente,
não existe penalidade em codificar uma fonte de informação utilizando um codificador

CAPÍTULO 2 29
universal ao invés de se utilizar um codificador que faz uso da medida de probabilidade da
fonte. Contudo, deve-se observar a velocidade com a qual a taxa de compressão atinge
(assintoticamente) a entropia da fonte, uma vez que, na prática, codifica-se seqüências finitas.
Se a velocidade de convergência da taxa de compressão de um determinado codificador for
muito lenta, este produzirá resultados ruins para seqüências finitas. Como qualquer
codificador unicamente decodificável satisfaz a condição estabelecida em (5), o conceito de
redundância pode ser utilizado para analisar a velocidade de convergência da taxa. Conforme
apresentado na seção 2.1, a redundância de um codificador é a diferença entre a taxa média do
código e a razão ( )1
nH Xn
. Sendo c um codificador para a classe de fontes Σ , a redundância
de c com relação à fonte de informação σ ∈Σ é definida por
( )( ) ( )1 1
, .n n
c
E l X H Xr n
nσ
− = (11)
Como o objetivo de um codificador universal é comprimir de forma eficiente todas as fontes
de uma determinada classe, é preciso que a redundância definida em (11) seja reduzida para
toda fonte σ ∈Σ . Sendo assim, um parâmetro muito utilizado para avaliar o desempenho de
um codificador universal é a máxima redundância sobre todas as fontes em Σ . Um importante
resultado da teoria da informação [7], afirma que para a classe de fontes markovianas (i.e., o
conjunto de todas as fontes tais que 1 2...X X é um processo estocástico de Markov)
( ){ }{ } ( )logmin max , ,cc
nr n O
nσσ
∈Γ ∈Σ
=
(12)
onde Γ é a coleção de todos os códigos univocamente decodificáveis e ( ).O é a função
conhecida como big-O1. Sendo assim, o melhor código universal para fontes sem memória
1 Seja n∈ e sejam ( )f n e ( )g n duas funções reais. É dito que ( ) ( )( )f n O g n= se existem uma
constante k e um inteiro 0n tais que ( ) ( ) 0k ,f n g n n n≤ × ∀ ≥ .

CAPÍTULO 2 30
possui uma taxa que converge para a entropia com uma velocidade igual a ( )log nO
n
.
Comparando este valor com as redundâncias obtidas para os codificadores construídos com o
conhecimento da medida de probabilidade, é possível notar que a convergência da taxa de um
codificador universal é mais lenta.
Na prática, grande parte dos codificadores universais procura estimar uma medida de
probabilidade para codificar os dados, que pode ser feita a partir de uma base de dados fixa ou
de forma adaptativa ao longo da seqüência de dados que está sendo codificada. Neste trabalho
são estudados codificadores universais adaptativos que utilizam a técnica de recorrência de
padrões para comprimir a informação.
Em geral, a seqüência de dados a ser comprimida por um codificador de fonte possui
determinados padrões que se repetem ao longo desta seqüência. Sendo assim, uma forma de
se comprimir dados é através da utilização de padrões recorrentes. Para realizar a compressão,
basta identificar padrões repetidos e codificar cada padrão através de um ponteiro para sua
ocorrência anterior. Esta técnica é conhecida como recorrência de padrões.
O princípio do codificador via recorrência de padrões é criar um dicionário de padrões
a partir de uma parcela da seqüência de dados que já foi codificada e codificar o restante da
seqüência utilizando este dicionário, que é atualizado a cada passo da codificação. No início
da codificação, em que não há padrões para constituir o dicionário, existe um dicionário
inicial que pode ser formado por uma seqüência fictícia ou pelo alfabeto da fonte, por
exemplo, dependendo do codificador.
O funcionamento de um codificador via recorrência de padrões é explicado em linhas
gerais a seguir. Seja 1nx uma realização da saída da fonte que se deseja comprimir. Seja j
kx ,
1 k j n≤ ≤ ≤ , a subseqüência 1...k k jx x x+ , onde kk kx x= . Sendo assim, 1
jx corresponde a
prefixos de 1nx e n
kx corresponde a sufixos de 1nx . Em um passo genérico, supondo que os

CAPÍTULO 2 31
primeiros 1k − símbolos de 1nx tenham sido codificados, 1
1kx − representa a parte da seqüência
que já foi codificada e nkx a parte que falta ser codificada. O dicionário que será utilizado
neste passo é gerado a partir de 11kx − . O codificador encontra o bloco de símbolos k l
kx + que
será codificado neste passo utilizando o dicionário. Este bloco é então representado por uma
palavra código que referencia de alguma forma o bloco de símbolos k lkx + à sua ocorrência no
dicionário. O dicionário é atualizado com o bloco de símbolos que acabou de ser codificado e
o processo de codificação segue na busca pelo prefixo de 1nk lx + + que será codificado no passo
seguinte.
É importante notar que a compressão de um codificador via recorrência de padrões
surge a partir do dicionário, cuja construção realiza uma medida indireta da estatística da
fonte, pois o dicionário contém blocos que aparecem freqüentemente e, em geral, não contém
blocos que nunca aparecem.
Os primeiros codificadores universais adaptativos via recorrência de padrões foram
criados por Ziv e Lempel em 1977 e 1978 – LZ77 [8] e LZ78 [4], respectivamente – baseados
em resultados obtidos em [9]. No decorrer dos anos, vários algoritmos derivados destes foram
criados com o objetivo de melhorar seus desempenhos. Alguns destes algoritmos, por
apresentarem baixa complexidade computacional e bom desempenho, tornaram-se padrões
para compressão de arquivos em computadores.
2.3 Códigos de Lempel-Ziv
Os códigos de Lempel-Ziv são a base de uma boa parte dos algoritmos de compressão
de dados sem perdas utilizados na prática. Isso ocorre porque eles atingem empiricamente
boas taxas de compressão e são eficientes computacionalmente. Os algoritmos LZ77 [8], LZ78
[4] ou uma de suas variações são utilizados, entre outras aplicações, pelos codificadores de

CAPÍTULO 2 32
fonte pkzip, arj, compress e gzip e pelos algoritmos de compressão de imagens sem perdas
embutidos nos padrões png e tiff.
Dentre as variações do LZ78, a versão mais popular é o codificador LZW [3], que foi
apresentado em 1984 quando da publicação do trabalho de Terry Welch, que propôs uma
modificação ao LZ78, melhorando seu desempenho.
Os esquemas de codificação propostos por Ziv e Lempel fazem a estimativa da medida
de probabilidade da fonte de forma adaptativa via recorrência de padrões. Nestes algoritmos
universais, a partição da seqüência de dados a ser codificada é feita de acordo com o método
do maior prefixo, ou seja, a cada passo da codificação identifica-se o maior padrão possível
que possa ser relacionado a uma ocorrência prévia que pertença ao dicionário. O desempenho
é função direta da quantidade de partições encontradas, ou seja, quanto menor o número de
partições necessário para codificar a seqüência de dados, menor o código gerado para
representar a saída da fonte e, conseqüentemente, melhor a compressão.
Os codificadores LZ77, LZ78 e LZW são apresentados a seguir.
2.3.1 Codificador LZ77
Em um passo genérico da codificação, o codificador LZ77 examina a seqüência de
símbolos anteriores presente no dicionário para encontrar o match com o maior prefixo da
subseqüência que começa na posição atual. O maior prefixo é substituído por um ponteiro
com três informações: (posição, comprimento, símbolo de inovação). O funcionamento do
algoritmo é apresentado a seguir.
Supondo que os primeiros 1k − símbolos de 1nx tenham sido codificados, a
codificação segue realizando a busca pelo maior match entre o prefixo de nkx e uma
subseqüência que comece no intervalo 11kx − . Se 1j l
jx + − , j k< , é a subseqüência que começa

CAPÍTULO 2 33
em 11kx − que possibilita o maior match, a próxima subseqüência é 1k l
kx + − . O algoritmo gera o
ponteiro (j, l, k lx + ), que irá produzir a palavra código para codificação de k lkx + , e atualiza a
posição atual k para 1k l+ + . A razão de transmitir o símbolo de inovação k lx + é garantir a
continuação da codificação quando 0l = , o que é muito comum no começo do processo.
A busca pelo maior match pode se tornar muito complexa, já que o dicionário 11kx −
cresce muito rapidamente. É comum, então, utilizar apenas o passado mais recente, isto é,
uma janela de comprimento wl da seqüência já codificada: 1w
kk lx −− . Além disso, também se
costuma limitar o comprimento máximo do match a uma constante sl , ou seja, a busca pelo
maior match é restringida à porção da seqüência ainda não codificada 1sk lkx + − .
Considerando o alfabeto de saída do codificador binário, o número de bits necessários
para transmitir o ponteiro (posição, comprimento, símbolo de inovação) é dado por
log log logw sl l α+ + , onde α é o número de elementos do alfabeto da fonte S . Como
todas as partições necessitam transmitir a mesma quantidade de bits, uma vez que wl , sl e α
são constantes, e o código 77 1( )nLZc x é formado pela concatenação dos ponteiros que
representam cada partição, o comprimento do código é dado por
( ) ( )77 1 77 1( ) log log log ,n nLZ LZ w sl x m x l l α= + + (13)
onde 77 1( )nLZm x é o numero de partições necessárias para codificar 1
nx com o LZ77.
O dicionário inicial pode ser construído com uma seqüência fictícia 01wl
x− + composta
por wl símbolos iguais ( wl zeros, por exemplo), desde que este símbolo pertença ao alfabeto
da fonte.
A seguir encontra-se um exemplo do codificador LZ77.
Seja 'abacabcbaabcbaabca' a seqüência a ser codificada sobre um alfabeto binário.

CAPÍTULO 2 34
Seja { }a, b,c=S e, então, 3α = . Definindo 8wl = e 8sl = , cada palavra código terá
comprimento log log log 8w sl l α+ + = bits. O dicionário inicial é formado por 8
símbolos 'a' .
No primeiro passo da codificação, tem-se a seguinte estrutura: 07 'aaaaaaaa'x− = e
81 'abacabcb'x = . O maior match é formado por 'a' e, assim, l = 1. A posição j em que o maior
match começa em 1 07w
kk lx x−− −= pode ser qualquer valor entre 1 e 8. Escolhendo j = 8, o ponteiro
para o maior match encontrado quando k = 1 é (j, l, k lx + ) = (111, 001, 01), sendo o símbolo de
inovação 2 'b'k lx x+ = = , representado por 01. A posição k = 1 é atualizada para k + l + 1 = 3 e
a codificação segue conforme apresentado na Tabela 1. Cada linha representa um passo do
proceso de codificação, incluindo o primeiro, detalhado acima.
Tabela 1 – Processo de codificação do LZ77
k 1w
kk lx −− 1sk l
kx + − j l k lx + (j, l, k lx + )
1 'aaaaaaaa' 'abacabcb' 8 1 b 111 001 01
3 'aaaaaaab' 'acabcbaa' 7 1 c 110 001 10
5 'aaaaabac' 'abcbaabc' 5 2 c 100 010 10
8 'aabacabc' 'baabcbaa' 3 2 a 010 010 00
11 'acabcbaa' 'bcbaabca' 4 7 a 111 111 00
Ao final do processo, o código é obtido pela concatenação dos ponteiros (ou palavras-
código): 11100101 11000110 10001010 01001000 11111100. A taxa de codificação para essa
seqüência é 18
77 1( ) 40 2,2218 18
LZl x= = bits por símbolo da fonte.

CAPÍTULO 2 35
O processo de decodificação é o inverso da codificação. Faz-se a leitura dos ponteiros
(posição, comprimento, símbolo de inovação) e remonta-se a seqüência de dados original.
O LZ77 é um código universal, pois sua taxa de compressão converge em
probabilidade para a entropia da fonte para toda fonte estacionária. Com relação à
redundância, Savari mostrou em [10] que a redundância do código LZ77 para fontes
markovianas é tal que
( ) ( )( )( )77
log log, .
logLZ
nr n O
nσ
≤
(14)
Na verdade, é possível mostrar que para um grande número de fontes markovianas, a
redundância do LZ77 é da ordem de ( )( )
( )log log
logn
n. Comparando-se este resultado com a
equação (12), é possível notar que a redundância deste codificador não atinge o melhor valor
possível. Isto significa que existe uma margem para melhorar a compressão, o que pode ser
feito através da exploração da redundância remanescente no código gerado pelo LZ77.
2.3.2 Codificador LZ78
O codificador LZ78 examina os padrões (símbolos ou seqüências de símbolos em que
a parte inicial da seqüência de dados já codificada foi particionada) que compõem um
dicionário, iD , que varia de acordo com a parte já codificada, para encontrar o match com o
maior prefixo da subseqüência que começa na posição atual. O maior prefixo é codificado
como o número correspondente à posição no dicionário, iD , do padrão que proporcionou o
maior match. Ao dicionário, iD , são acrescentados novos padrões, formados pelo maior
match concatenado com cada um dos símbolos da fonte, gerando o dicionário, 1i+D , que será
utilizado no próximo passo o algoritmo. O funcionamento do algoritmo é apresentado a
seguir.

CAPÍTULO 2 36
Supondo que no -ésimoi passo, os primeiros 1k − símbolos da seqüência de dados 1nx
tenham sido codificados, a codificação segue realizando a busca pelo maior match entre o
prefixo de nkx e os padrões do dicionário iD . Se o padrão na posição j do dicionário iD ,
composto por l símbolos, é o que possibilita o maior match, o algoritmo codifica 1k lkx + − como
j e atualiza a posição atual k para k l+ . O número de bits necessário para transmitir j é
( )log iβ , onde iβ é o número de elementos do dicionário iD . O dicionário é atualizado pela
adição dos α padrões formados por 1k lkx + − concatenado com cada um dos símbolos de S , o
alfabeto da fonte. A forma como o dicionário é atualizado no LZ78 provoca um desempenho
ruim por incluir neste, padrões que não ocorreram e podem não vir a ocorrer. O dicionário
inicial é composto pelo alfabeto S .
O código 78 1( )nLZc x é formado pela concatenação das palavras código correspondentes
à posição, no dicionário, de cada padrão que proporcionou o maior match, em cada passo.
Como o dicionário inicial contém α símbolos e como a cada passo, o LZ78 inclui α padrões
novos ao dicionário, é possível observar que o comprimento da palavra-código gerada pelo
LZ78 é dado por
( ) ( )78
78 11
log ,LZm
nLZ
il x iα
=
= ∑ (15)
onde 78 1( )nLZm x é o número de partições necessárias para codificar 1
nx com o LZ78.
A seguir encontra-se um exemplo do codificador LZ78.
Seja 'abacabcbaabcbaabca' a seqüência a ser codificada sobre um alfabeto binário.
Seja { }a, b,c=S e, conseqüentemente, 3α = . O dicionário inicial é 1 {a,b,c}=D .
No primeiro passo da codificação, k = 1, o maior match entre o prefixo de 1nx e os
padrões do dicionário é dado por 'a ' , cuja posição no dicionário é j = 1 e o comprimento é
l = 1. O número de bits necessários para representar a palavra código para codificar j é
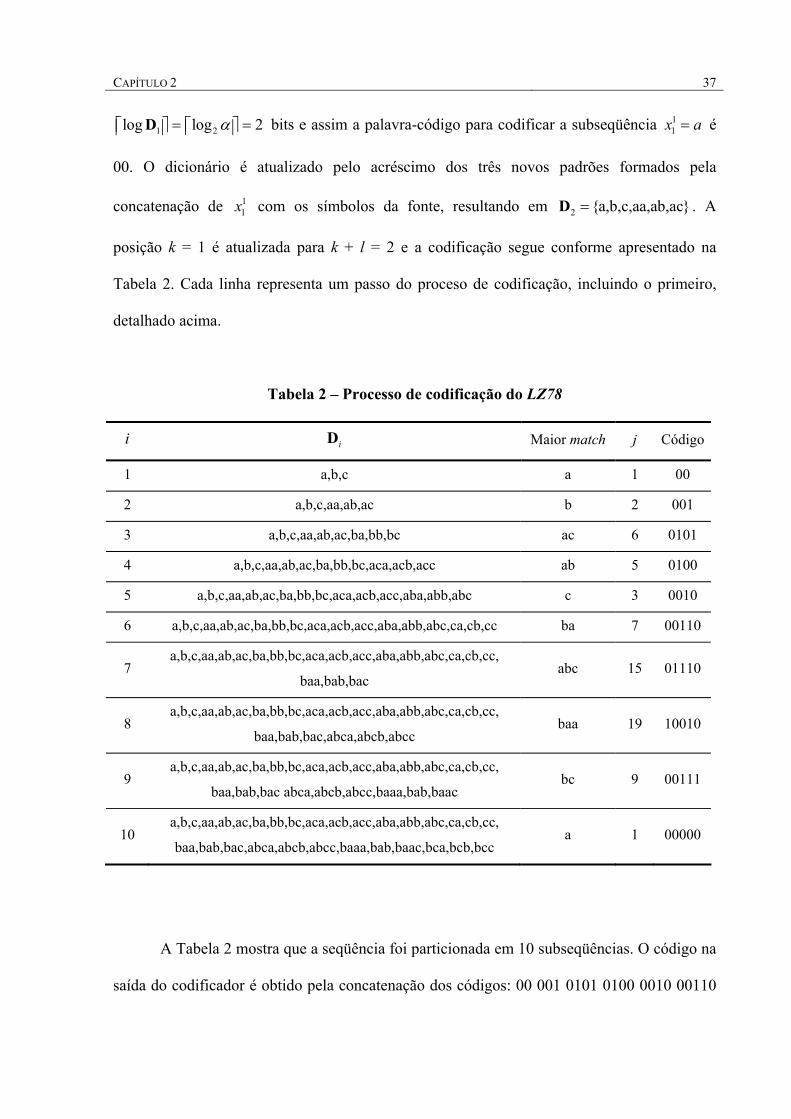
CAPÍTULO 2 37
1 2log log 2α= = D bits e assim a palavra-código para codificar a subseqüência 11x a= é
00. O dicionário é atualizado pelo acréscimo dos três novos padrões formados pela
concatenação de 11x com os símbolos da fonte, resultando em 2 {a,b,c,aa,ab,ac}=D . A
posição k = 1 é atualizada para k + l = 2 e a codificação segue conforme apresentado na
Tabela 2. Cada linha representa um passo do proceso de codificação, incluindo o primeiro,
detalhado acima.
Tabela 2 – Processo de codificação do LZ78
i iD Maior match j Código
1 a,b,c a 1 00
2 a,b,c,aa,ab,ac b 2 001
3 a,b,c,aa,ab,ac,ba,bb,bc ac 6 0101
4 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc ab 5 0100
5 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc,aba,abb,abc c 3 0010
6 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc,aba,abb,abc,ca,cb,cc ba 7 00110
7 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc,aba,abb,abc,ca,cb,cc,
baa,bab,bac abc 15 01110
8 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc,aba,abb,abc,ca,cb,cc,
baa,bab,bac,abca,abcb,abcc baa 19 10010
9 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc,aba,abb,abc,ca,cb,cc,
baa,bab,bac abca,abcb,abcc,baaa,bab,baac bc 9 00111
10 a,b,c,aa,ab,ac,ba,bb,bc,aca,acb,acc,aba,abb,abc,ca,cb,cc,
baa,bab,bac,abca,abcb,abcc,baaa,bab,baac,bca,bcb,bcc a 1 00000
A Tabela 2 mostra que a seqüência foi particionada em 10 subseqüências. O código na
saída do codificador é obtido pela concatenação dos códigos: 00 001 0101 0100 0010 00110

CAPÍTULO 2 38
01110 10010 00111 00000. A taxa de codificação para essa seqüência é dada por
1878 1( ) 42 2,3318 18
LZl x= = bits por símbolo da fonte.
O processo de decodificação segue os passos inversos aos da codificação. Lê-se os bits
correspondentes a ( )log iβ , a cada passo, e identifica-se no dicionário o(s) símbolo(s)
transmitido(s) pelo codificador. Adiciona-se ao dicionário os padrões compostos pelo(s)
símbolo(s) decodificado(s) concatenado(s) com cada um dos símbolos do alfabeto da fonte.
O LZ78 é um código universal, pois sua taxa de compressão converge com
probabilidade 1 para a entropia da fonte para toda fonte ergódica. De acordo com [11], a
redundância do código LZ78 para fontes markovianas é tal que
( ) ( )781, .
logLZr n On
σ
≤
(16)
Na verdade, é possível afirmar que para um grande número de fontes markovianas, a
redundância do LZ78 é da ordem de ( )
1log n
. Apesar da redundância do LZ78 ser menor que a
redundância do LZ77, ela ainda é maior que a redundância apresentada em (12), e mais uma
vez, existe margem para explorar a redundância do código.
Uma característica interessante ressaltada em [10] é que o número de partições em que
a seqüência de dados é dividida pelo LZ77 em geral é menor que o número de partições
gerado pelo LZ78. No entanto, como o codificador LZ78 não precisa codificar o comprimento
das partições, seu código costuma apresentar comprimento menor que o do código gerado
pelo LZ77.

CAPÍTULO 2 39
2.3.3 Codificador LZW
O codificador LZW é uma versão do LZ78, que busca melhorar o desempenho do
algoritmo original através da alteração na forma de atualizar o dicionário. O dicionário inicial
do LZW também é composto pelo alfabeto da fonte S .
O codificador LZW examina os padrões (símbolos ou seqüências de símbolos em que a
parte inicial da seqüência de dados já codificada foi particionada) que compõem o dicionário
iD para encontrar o match com o maior prefixo da subseqüência que começa na posição
atual. O maior prefixo é codificado como o número correspondente à posição, no dicionário
iD , do padrão que proporcionou o maior match. Até aqui o procedimento é idêntico ao
realizado pelo LZ78. A diferença está na atualização do dicionário, ao qual é acrescentado
apenas um novo padrão, ao invés dos α padrões adicionados pelo LZ78. O novo padrão é
composto pelo maior prefixo encontrado concatenado com o símbolo consecutivo na
seqüência ainda não codificada, que equivale ao símbolo de inovação. Supondo que 1k lkx + −
seja o maior prefixo encontrado no -ésimoi passo da codificação, o novo padrão adicionado
ao dicionário é k lkx + .
O número de bits necessário para transmitir a palavra código que representra a posição
do match no dicionário é dado por ( )log iβ , assim como no LZ78. Contudo, como neste caso
o algoritmo só inclui um novo padrão a cada passo, 1i iβ α= + − . Assim, o comprimento do
código LZW é dado por
( ) ( )( )1
11
log 1 ,n
LZWm xn
LZWi
l x iα=
= + − ∑ (17)
onde 1( )nLZWm x é o numero de partições necessárias para codificar 1
nx com o LZW.

CAPÍTULO 2 40
Embora 1i iα α+ − < para 2i ≥ , não é possível comparar os desempenhos do LZ78 e
do LZW porque ( )78 1 1( )n nLZ LZWm x m x≠ e, em geral, 78 1 1( ) ( )n n
LZ LZWm x m x< .
A seguir encontra-se um exemplo do codificador LZW.
Seja 'abacabcbaabcbaabca' a seqüência a ser codificada sobre um alfabeto binário.
Seja { }a, b,c=S e, então, 3α = . O dicionário inicial é 1 {a,b,c}=D , como no LZ78.
No primeiro passo da codificação, 1i = , o maior match entre o prefixo de 1nx e os
padrões do dicionário é dado por 'a ' , cuja posição no dicionário é j = 1 e o comprimento é
l = 1. O número de bits necessário para representar a palavra código para codificar j é
( ) ( )1log log 1 2iβ α= + − = bits e assim a palavra-código para codificar a subseqüência
11x a= é 00. O dicionário é atualizado pelo acréscimo de um novo padrão formado pela
concatenação de 11x com o símbolo seguinte da seqüência de dados, resultando em
2 {a,b,c,ab}=D . A posição k = 1 é atualizada para k + l = 2 e a codificação segue conforme
apresentado na Tabela 3. Cada linha representa um passo do proceso de codificação, incluindo
o primeiro, detalhado acima.
A seqüência foi particionada em 11 subseqüências. A saída do codificador é dada pela
concatenação dos códigos: 00 01 000 010 011 010 0100 0111 1001 0001 0110. Portanto, a
taxa de codificação é 181( ) 36 2
18 18LZWl x
= = bits por símbolo da fonte.
Uma possível forma de representar o dicionário, tanto para o LZW quanto para o LZ78,
é através de uma estrutura em árvore cujos nós iniciais são os que compõem o dicionário
inicial. Os novos padrões que são adicionados ao dicionário correspondem a novos nós na
árvore. No LZW, a cada passo é criado um nó “filho” do nó que corresponde ao maior match,
representando o símbolo inovador. No LZ78, a cada passo são criados α nós “filhos” do nó
que coresponde ao maior match. A busca pelo maior match começa sempre no nível mais

CAPÍTULO 2 41
baixo da árvore (nós iniciais). Cada nó recebe o número correspondente à sua posição no
dicionário. Ao final da codificação do exemplo acima, a estrutura apresentará a forma
representada na Figura 5. Esta estrutura permite uma implementação mais eficiente tanto do
codificador quanto do decodificador.
Tabela 3 – Processo de codificação do LZW
i iD Maior match j Código
1 a,b,c a 1 00
2 a,b,c,ab b 2 01
3 a,b,c,ab,ba a 1 000
4 a,b,c,ab,ba,ac c 3 010
5 a,b,c,ab,ba,ac,ca ab 4 011
6 a,b,c,ab,ba,ac,ca,abc c 3 010
7 a,b,c,ab,ba,ac,ca,abc,cb ba 5 0100
8 a,b,c,ab,ba,ac,ca,abc,cb,baa abc 8 0111
9 a,b,c,ab,ba,ac,ca,abc,cb,baa,abcb baa 10 1001
10 a,b,c,ab,ba,ac,ca,abc,cb,baa,abcb,baab b 2 0001
11 a,b,c,ab,ba,ac,ca,abc,cb,baa,abcb,baab,bc ca 7 0110
O processo de decodificação segue os passos inversos aos da codificação. Lê-se os bits
correspondentes a ( )log iβ e identifica-se no dicionário o(s) símbolo(s) transmitido(s) pelo
codificador. Adiciona-se ao dicionário o padrão composto pelo(s) símbolo(s) decodificado(s)
mais o símbolo de inovação, que será conhecido apenas na decodificação do(s) próximo(s)
símbolo(s). Atualiza-se o símbolo de inovação do padrão adicionado ao dicionário na
decodificação anterior como o primeiro símbolo decodificado no passo atual.

CAPÍTULO 2 42
Figura 5 – Árvore representando o dicionário do exemplo do codificador LZW
O LZW, assim como o LZ78, é um código universal, pois sua taxa de compressão
converge com probabilidade 1 para a entropia da fonte para toda fonte ergódiga. A
redundância do código LZW é a mesma do LZ78, i.e., ( ),lzwr nσ é da ordem de 1log n
para
fontes markovianas [11]. Com isso, este codificador também é ineficiente se for comparado
com o resultado apresentado na equação (12). A contribuição deste trabalho consiste
justamente em explorar a redundância remanescente no código gerado pelo LZW, não para
melhorar a taxa de compressão, mas para embutir informação extra. Mais especificamente,
parte da redundância remanescente neste código é utilizada para embutir um código para
correção de erros introduzidos pelo canal. É importante mencionar que a técnica proposta
neste trabalho também pode ser estendida para o codificador LZ78 e para outras versões deste
método.
As observações feitas para o LZ78 em comparação ao LZ77 na seção 2.3.2 também
são válidas para o LZW, que em geral gera mais partições que o LZ77, mas o comprimento do
seu código costuma ser menor.
Nó 1 a
Nó 2 b
Nó 3 c
Nó 4 b
Nó 6 c
Nó 5 a
Nó 7 a
Nó 8 c
Nó 9 b
Nó 10a
Nó 12 b
Nó 11 b
Nó 13c

CAPÍTULO 3 43
Capítulo 3
3 Codificação de Canal
Sinais recebidos em sistemas de comunicação são sempre contaminados por
imperfeições do processo de comunicação, tais como o ruído térmico, as interferências, o
desvanecimento e a dispersão do sinal no meio de comunicação. Para garantir confiabilidade
na recepção dos sinais, faz-se uso da codificação de canal, que introduz redundância de forma
lógica aos dados. Apesar da taxa de dados aumentar, a largura de banda e a potência de
transmissão podem ser mantidas pequenas dado o aumento na confiabilidade proporcionado
pela estrutura elaborada das mensagens em sistemas de comunicação e armazenamento
modernos. Isto é obtido a troco de maior esforço computacional no transmissor e no receptor,
o que, contudo, é considerado factível com a tecnologia eletrônica moderna.
A Figura 6 ilustra o problema tratado pela codificação de canal. O codificador de canal
codifica uma mensagem w , que pode assumir valores em um conjunto com 2k elementos, em
uma seqüência, 1nu , com n símbolos do alfabeto de entrada do canal, inC . Esta seqüência é
aplicada na entrada do canal dando origem na saída a uma seqüência aleatória, 1nV , de acordo
com a medida de probabilidade do canal. A função do decodificador é estimar qual a
mensagem w foi transmitida a partir de uma seqüência observada 1nv , que é uma realização
de 1nV . Dependendo da medida de probabilidade do canal e do código, irá existir uma
probabilidade da mensagem estimada, w , ser diferente da mensagem original, w . Transmitir
uma mensagem que assume valores em um conjunto com 2k elementos é equivalente a

CAPÍTULO 3 44
transmitir k bits. Sendo assim, a taxa de transmissão atingida pelo código de canal é definida
pela razão kn
e é dada em bits por utilização do canal.
Figura 6 – Codificação de canal
A função do codificador de canal é aumentar a confiabilidade do sistema de
comunicação através da redução da taxa de erros ao mesmo tempo em que busca maximizar a
taxa de transmissão de símbolos por utilização do canal. Shannon mostrou em [2] que se a
taxa de transmissão é menor que a capacidade do canal, CanalC , então existe uma técnica de
codificação que possibilita projetar um sistema de comunicação para este canal com
probabilidade de erro tão baixa quanto desejada. Este teorema é conhecido como teorema da
codificação de canal e é demonstrado em [6].
Para calcular a capacidade de um dado canal, é necessário utilizar o conceito de
informação mútua. Sejam 1nU e 1
nV duas seqüências de variáveis aleatórias que podem
assumir valores nos conjuntos inC e outC , respectivamente. A informação mútua entre estas
duas seqüências é definida por
( ) ( ) ( )( ) ( )1 1
1 1 1 11 1 1 1 1 1
1 1 1 1
,; , log ,
n n n nin out
n n n nn n n n n n
n n n nu v
p U u V vI U V p U u V v
p U u p V v∈ ∈
= = = = = = =
∑ ∑C C
(18)
onde in
nC e noutC são os conjuntos de todas as seqüências com n símbolos em inC e outC ,
respectivamente. A partir da definição da informação mútua, é possível encontrar o
relacionamento desta com a entropia das seqüências 1nU e 1
nV . De fato, as seguintes relações
podem ser obtidas a partir de (18):

CAPÍTULO 3 45
( ) ( ) ( ) ( )( ) ( )( ) ( )
1 1 1 1 1 1
1 1 1
1 1 1
; ,
|
|
n n n n n n
n n n
n n n
I U V H U H V H U V
H U H U V
H V H V U
= + −
= −
= −
, (19)
onde ( )1 1|n nH U V é a entropia condicional de 1nU dado 1
nV .
Considerando um canal discreto sem memória com entrada 1nU e saída 1
nV , a entropia
da entrada do canal, ( )1nH U , depende apenas de 1
nU e representa a incerteza em relação a que
seqüência de símbolos 1 in
n nu ∈C será transmitida. A entropia da saída do canal, 1( )nH V ,
depende de 1nU e dos erros de transmissão e representa a incerteza em relação à seqüência de
símbolos 1n n
outv ∈C que será recebida. Conhecendo as estatísticas da entrada 1nU e do canal
ruidoso conhece-se a entropia conjunta ( )1 1,n nH U V , que representa a incerteza sobre a
transmissão de 1nu e a recepção de 1
nv .
Supondo a seqüência 1nu conhecida, a entropia condicional 1 1( | )n nH V U representa a
incerteza de receber 1nv quando 1
nu é enviada, ou seja, é a incerteza média do emissor em
relação ao que será recebido. Por simetria, supondo a seqüência 1nv conhecida, a entropia
condicional 1 1( | )n nH U V representa a incerteza sobre 1nu ter sido enviada quando se recebe 1
nv ,
ou a incerteza média do receptor da mensagem em relação ao que foi realmente enviado. Em
outras palavras, é a incerteza sobre a entrada que resta depois da saída ter sido observada. A
diferença 1 1 1( ) ( | )n n nH U H U V− representa, então, a incerteza sobre a entrada que é eliminada
após a observação da saída. Assim, a informação mútua 1 1 1 1 1( ; ) ( ) ( | )n n n n nI U V H U H U V= −
pode ser interpretada como uma redução na incerteza de 1nU devido ao conhecimento de 1
nV .
A capacidade do canal, que representa a quantidade de informação que um canal pode
transferir, para um canal discreto sem memória é definida como

CAPÍTULO 3 46
1
1 1
( )
( ; )maxn
n n
Canalp u
I U VCn
=
(20)
Como o canal é fixo, a maximização é feita sobre todas as possíveis distribuições de entrada
1( )np u . Para um DMC, 1 1 1 1( | ) ( | )... ( | )n nn np v u p v u p v u= , de forma que a capacidade do canal
pode ser expressa como
11 1
( )max ( ; )
nCanalp u
C I U V= (21)
O codificador de canal busca, então, maximizar a taxa de transmissão e minimizar os
efeitos do canal que deterioram a mensagem transmitida. Isto é feito pela inserção de
redundância aos dados.
Códigos que aumentam a redundância da seqüência de dados antes desta ser
transmitida pelo canal são divididos em duas classes: códigos em bloco e códigos em árvore.
Um código em bloco ),( kn representa um bloco de k símbolos como uma palavra código de
n símbolos e taxa de transmissão kn
. Um código em árvore, apesar de também representar k
símbolos como uma palavra código de n símbolos, utiliza para isso uma memória que
armazena os últimos m segmentos de k símbolos. A palavra código é gerada por operações
entre os mk símbolos da memória, o que permite a representação do código em árvore,
caracterizando a dependência da palavra gerada com os símbolos de entrada anteriores. A
principal diferença entre estes códigos é que no código em árvore um segmento de k
símbolos pode influenciar todas as palavras código que o sucedem, enquanto no código em
bloco um bloco de k símbolos influencia apenas a próxima palava código de n símbolos.
Os códigos em árvore mais importantes são os códigos convolucionais. Estes códigos
satisfazem as propriedades de linearidade e invariância no tempo. Assim, um código em
árvore ),( kn linear e invariante no tempo é um código convolucional ),( kn . Códigos
convolucionais podem ser gerados por registradores de deslocamento lineares [5]. A

CAPÍTULO 3 47
seqüência de dados de entrada é quebrada em segmentos de k símbolos. Por considerações de
implementação, k é usualmente muito pequeno, geralmente igual a 1. O codificador
armazena m segmentos de dados de entrada e, a cada pulso do relógio de sincronismo, um
novo segmento de k símbolos é deslocado para dentro do codificador e o mais antigo é
deslocado para fora e descartado. Ou seja, a cada pulso do relógio de sincronismo o
codificador armazena os mk símbolos de entrada mais recentes. O codificador computa,
também a cada pulso do relógio de sincronismo, um segmento de códigos composto por n
símbolos. Assim que o próximo segmento de dados de k símbolos é deslocado para dentro do
codificador, o segmento de códigos de n símbolos é deslocado para fora e transmitido através
do canal de comunicação. Um algoritmo muito popular para decodificação seqüencial de
códigos convolucionais de complexidade moderada é o algoritmo de Viterbi [5], desenvolvido
em 1967. Devido às limitações de implementação, a taxa do código convolucional é limitada.
Não é possível implementar um código convolucional com taxa próxima a 1, o que pode ser
obtido utilizando um código em bloco.
Em geral, dá-se maior ênfase à análise de códigos lineares devido à sua simplicidade.
Esta classe de códigos é caracterizada por impor uma propriedade estrutural forte aos códigos,
o que facilita a busca por bons códigos e ajuda a tornar práticos os codificadores e
decodificadores. No entanto, os melhores códigos possíveis não são necessariamente lineares.
A busca por bons códigos em bloco normalmente se limita a códigos lineares porque grande
parte das técnicas teóricas mais fortes se aplica apenas a esta classe de códigos. Além disso,
ainda não foram encontrados métodos gerais para se encontrar bons códigos não lineares.

CAPÍTULO 3 48
3.1 Códigos em Bloco Lineares
A linearidade de um código em bloco garante que a soma (ou a diferença) de duas
palavras código resulta em uma outra palavra código. Em um código linear, a palavra
composta apenas por zeros é sempre uma palavra código.
A eficiência de um código de canal, ou o número de erros que este é capaz de corrigir,
é dada pela distância mínima deste código. A distância de Hamming entre duas seqüências de
n símbolos é dada pelo número de símbolos diferentes entre elas. A distância mínima *d de
um código de canal é dada pela menor distância de Hamming entre duas palavras código.
Para garantir que o código corrija e erros, é necessário que 12* +≥ ed [5]. Significa
que, para que um padrão recebido com erro seja detectado e corrigido por um código com
distância mínima *d , não mais que e símbolos podem ser diferentes da palavra código que
foi transmitida. Caso 1e + símbolos sejam diferentes, a palavra código escolhida como sendo
a transmitida pode ou não ser a correta, uma vez que outra(s) palavra(s) código pode(m) distar
e do padrão recebido com erro. O mesmo vale para padrões que tenham mais de 1e+
símbolos diferentes da palavra transmitida, sendo que a probabilidade de se decodificar
corretamente certamente diminuirá com o aumento do número de símbolos diferentes, pois
aumentará a probabilidade do padrão recebido com erro apresentar menor distância de
Hamming em relação a outra palavra código que não a transmitida na codificação.
Um código é dito perfeito quando todas as palavras de comprimento n distam no
máximo e de uma palavra código e uma palavra que dista e de uma palavra código apresenta
maior distância em relação a qualquer outra palavra código. Códigos perfeitos são raros, o que
reduz sua importância em aplicações práticas.
Além disso, qualquer código linear ),( kn satisfaz 1* +−≤ knd , que significa que o
código deve ter no mínimo dois símbolos de paridade por erro a ser corrigido. Este limitante é

CAPÍTULO 3 49
conhecido como Singleton Bound [5]. No caso em que a distância mínima do código atinge o
limitante superior, ou seja, 1* +−= knd , o código é dito de distância máxima e possui
exatamente dois símbolos de paridade por erro a ser corrigido.
Pela forma como são geradas as palavras-código de um código linear, a distância
mínima do código de canal pode ser determinada pela distância de Hamming entre a palavra
formada por n zeros e a palavra código mais próxima a ela. Definindo o peso de um vetor
como o número de elementos diferentes de zero presentes neste, a distância mínima de um
código linear é dada pelo menor peso entre as palavras código, exceto a formada por n zeros.
Códigos de Hamming [5], primeiros códigos em bloco desenvolvidos e introduzidos
em 1950, são códigos em bloco lineares perfeitos capazes de corrigir um erro. São códigos
simples cujo principio serve de base para a construção da vários outros códigos lineares. Para
cada m existe um código de Hamming binário )12,12( mmm −−− com distância mínima
igual a 3.
Ainda dentro da classe de códigos em bloco lineares encontram-se os códigos cíclicos.
Estes levam a procedimentos de codificação e decodificação algoritma e computacionalmente
eficientes. Códigos BCH e Reed-Solomon [5] são exemplos de códigos cíclicos para correção
de múltiplos erros. Atenção especial é dada aos códigos Reed-Solomon por estes fazerem
parte da solução apresentada no capítulo 5.
3.2 Códigos Reed-Solomon
Códigos Reed-Solomon são muito utilizados na prática. Dentre as várias aplicações,
podem ser citadas a correção de erros em CDs (Compact Disks), DVDs (Digital Video Disks),
modems e nos três padrões de televisão digital implantados atualmente – americano (ATSC),
europeu (DVB) e japonês (ISDB).

CAPÍTULO 3 50
Códigos Reed-Solomon são um subconjunto do conjunto de códigos BCH em que o
comprimento da palavra-código é dado por 1−= qn , onde q é o número de símbolos do
alfabeto. São também códigos de distância máxima ( 1* +−= knd ), o que significa que
possuem exatamente dois símbolos de paridade por erro a ser corrigido [5]. Portanto, para
),( kn fixos, nenhum código tem distância mínima maior que um código Reed-Solomon. O
número de símbolos de paridade é dado pela diferença entre o comprimento da palavra
código, n , e o número de símbolos na entrada do codificador que dá origem a uma palavra
código, k . Assim, para um código Reed-Solomon, ekn 2=− , onde e é o número de
símbolos com erro em um bloco que o código é capaz de corrigir e, conseqüentemente,
* 2 1d e= + . Um código Reed-Solomon ),( knRS pode ser escrito como )2,( ennRS − .
Um codificador para um código Reed-Solomon pode ser sistemático ou não
sistemático, dado que todo código em bloco linear pode ser representado de forma
sistemática. Um código é dito sistemático quando os primeiros k símbolos da palavra código
de comprimento n são exatamente os símbolos que chegam ao codificador e os demais kn −
símbolos de paridade são escolhidos de forma a legitimar a palavra código. O código é não
sistemático quando os k símbolos da seqüência de dados que foi codificada não são
imediatamente reconhecidos no início da palavra código de comprimento n .
No caso em que o alfabeto é composto por 256q = símbolos, que podem ter
representação binária, por exemplo, em que cada símbolo é composto por 8 bits, como é o
caso da tabela ASCII (American Standard Code for Information Interchange), tem-se
255=n . O código é então definido de acordo com o número de erros que se deseja corrigir
por bloco. Se 3=e , tem-se )249,255(RS , ou seja, a cada bloco de 249 símbolos que
chegam ao codificador de canal são adicionados 6 símbolos de paridade, resultando em uma
palavra código de 255 símbolos.

CAPÍTULO 3 51
Para decodificar um código Reed-Solomon pode-se utilizar qualquer decodificador de
códigos BCH ou códigos lineares, como o decodificador de Peterson-Gorenstein-Zierler, o
decodificador de Meggitt e o decodificador de Berlekamp-Massey [5].

CAPÍTULO 4 52
Capítulo 4
4 Codificação Conjunta Fonte-Canal
O estudo da codificação conjunta combina os conceitos de codificação de fonte e
codificação de canal apresentados nos capítulos anteriores. O problema é similar ao
apresentado na Figura 4 para codificação de fonte com a diferença de que o codificador e o
decodificador de fonte são conectados por um canal ruidoso e, neste caso, os blocos que
representam o codificador e o decodificador de fonte podem também considerar o codificador
e o decodificador de canal. A Figura 7 ilustra o problema tratado pela codificação conjunta
fonte-canal, em que a informação gerada pela fonte deve ser transmitida através de um canal
ruidoso.
Figura 7 – Codificação conjunta fonte-canal
A codificação pode ser feita em um ou dois passos, ou seja, com um código que
mapeia a saída da fonte diretamente em palavras código a serem transmitidas pelo canal ou
com o emprego de um codificador de fonte, que independe do canal, seguido de um
codificador de canal, que independe da distribuição da fonte. Independentemente de qual dos
métodos é empregado, o objetivo da codificação conjunta consiste em representar os dados na
saída da fonte da forma mais eficiente possível e garantir a confiabilidade da sua recepção,
permitindo que os dados sejam recuperados com probabilidade de erro extremamente baixa.

CAPÍTULO 4 53
4.1 Teorema da Separação e Velocidade de Convergência
O teorema da codificação conjunta fonte-canal apresentado em [6] afirma que, para
um processo estocástico 1 1 2, ,...,nnX X X X= , se
( ) CanalH Cσ < , (22)
então existe um código fonte-canal que faz com que a informação da fonte seja transmitida
através do canal com uma probabilidade de erro arbitrariamente baixa. Reciprocamente, se
( ) CanalH Cσ > , não é possível enviar a informação através do canal com baixa probabilidade
de erro. Este teorema foi primeiramente apresentado por Shannon em [2].
O teorema acima é válido para uma grande variedade de pares fonte-canal, mas
existem modelos bem particulares de fontes e canais não estacionários em que o teorema não
mais se aplica, como mostrado em [12]. Desde que a condição do teorema da codificação
conjunta seja satisfeita, tanto o esquema de codificação em um passo quanto o esquema em
dois passos podem ser empregados. Tradicionalmente, o esquema em dois passos é
empregado e os codificadores de fonte e canal são projetados separada e independentemente
para seqüências de n símbolos da fonte, com n suficientemente grande de forma que a
probabilidade de erro do canal convirja para zero quando n →∞ . De fato, [2] e [6] mostram
que a codificação em dois passos é tão eficiente em termos de confiabilidade da transmissão
quanto qualquer outro método para transmissão da informação da fonte sobre um canal
ruidoso. Por isso o teorema da codificação conjunta é também conhecido como teorema da
separação.
Entretanto, quando a velocidade de convergência é considerada, a codificação em um
passo mostra-se mais eficiente que a codificação em dois passos. Csiszár mostrou em [13]
que, para fonte e canal discretos sem memória, a probabilidade de erro converge mais
rapidamente para zero quando n →∞ quando a codificação é feita em apenas um passo do

CAPÍTULO 4 54
que quando codificadores de fonte e canal independentes são colocados em série. Vale
ressaltar que fonte e canal discretos sem memória constituem um caso muito simples de par
fonte-canal e, mesmo assim, há vantagem em se fazer a codificação conjunta.
Em [14], [15] e [16] são acrescentados alguns resultados a [13] para pares fonte-canal
arbitrários. Em [13], [14], [15] e [16] são feitas comparações entre os expoentes de erro para
codificação conjunta em um passo, ( , )JE Q W , e em dois passos, ( , )TE Q W , que dependem
apenas da distribuição da fonte Q e da distribuição do canal W (são mantidas as
nomenclaturas usadas em [14], [15] e [16]). O expoente de erro E é um número com a
propriedade de que a probabilidade de decodificar erros de um código bom é
aproximadamente 2 En− para códigos com grande comprimento de bloco n [16].
O resultado ( , ) ( , )J TE Q W E Q W> , quando aplicável, fornece suporte e justificativa
teóricos para o projeto da codificação conjunta em um passo ao invés da popular codificação
em dois passos, uma vez que a taxa de decaimento da probabilidade de erro é mais rápida para
a primeira. Isso também se traduz em redução de complexidade e redução de atraso para
sistemas de comunicação reais [16]. Em [16] também é mostrado que ( , ) 2 ( , )J TE Q W E Q W≤ .
Assim, para uma mesma probabilidade de erro, o atraso provocado pela codificação conjunta
é em torno de metade do atraso provocado pela codificação em dois passos para pares fonte-
canal discretos sem memória.
É importante ressaltar que a codificação conjunta em um passo pode combinar os
processos de codificação de fonte e canal em um único passo realmente, mas também pode
realizar codificação de fonte e codificação de canal em seqüência. A diferença em relação à
tradicional (em dois passos) é que os dois processos de codificação não são independentes,
mas buscam se complementar a partir do momento que um codificador é projetado levando
em consideração características do outro. A partir deste ponto o termo codificação conjunta
fonte-canal será utilizado para representar a codificação conjunta realizada em um passo, ou

CAPÍTULO 4 55
seja, aquela em que os codificadores de fonte e canal são dependentes, não importando se são
combinados ou colocados em série.
Explorar a redundância remanescente na saída do codificador de fonte para prover
proteção contra erros inseridos pelo canal de transmissão de forma a permitir correta
decodificação no receptor, além de mais eficiente do ponto de vista teórico, também pode ser
mais interessante do ponto de vista prático. Isso porque utilizar um codificador de canal sem
considerar o codificador de fonte pode não proteger os dados adeqüadamente, uma vez que
erros em arquivos codificados por diferentes codificadores de fonte produzem efeitos
diferentes. Dependendo da localização do erro e do codificador de fonte utilizado, um erro
pode ser pouco notado ou pode inutilizar todo o arquivo.
Vários trabalhos foram publicados sobre implementação de codificação conjunta
fonte-canal empregando técnicas de codificação específicas. Dentre eles estão [17], [18] e
[19], sendo o último o que mais influenciou no desenvolvimento deste trabalho.
Em [17] são apresentas duas formas de se utilizar a estrutura na saída do codificador
de fonte para correção de erro. A primeira abordagem realiza uma combinação convencional
de codificador de fonte e codificador de canal convolucional, enquanto a segunda substitui o
codificador convolucional convencional por um codificador convolucional não binário, que
utiliza a redundância residual na saída do codificador de fonte com maior eficiência. Esta
abordagem é estendida a códigos de comprimento variável em [18]. Os codificadores
apresentados utilizam-se do conhecimento de propriedades da fonte ou do codificador de
fonte para detectar erros do canal e compensar seus efeitos.
Em [19] é apresentado um algoritmo para codificação conjunta denominado LZRS77
que permite corrigir erros no código gerado pelo codificador de fonte LZ77 com praticamente
nenhuma degradação na taxa de compressão. Para tal, a redundância remanescente no código

CAPÍTULO 4 56
gerado pelo LZ77 é explorada. O codificador de canal empregado é o Reed-Solomon. O
método é descrito a seguir.
4.2 Codificador LZRS77
Em [19], é primeiramente apresentado um método para explorar a redundância
remanescente no codificador LZ77 e recuperar os bits extras onde podem ser embutidos bits
de uma seqüência de dados qualquer, como seqüências para autenticação ou correção de erro.
Em seguida, é apresentado um método para realização da codificação conjunta fonte-canal,
onde os bits extras recuperados são utilizados para embutir o código de canal.
A redundância remanescente no codificador LZ77 é explorada pela possibilidade de
codificar os símbolos da seqüência de dados como mais de um ponteiro (posição,
comprimento, símbolo de inovação), ou seja, pode haver mais de uma subseqüência na
seqüência de dados já codificada que proporciona o maior match. Na prática, se existem r
subseqüências iguais aos símbolos da seqüência de dados, obtém-se 2log r bits redundantes
pela escolha de um dos r ponteiros, onde t representa o maior inteiro menor ou igual a
t∈ .
Para encontrar os bits adicionais a serem usados para codificação de canal, o LZ77 foi
levemente modificado. O algoritmo resultante, denominado LZS77, permite que alguns bits de
um texto T sobre o alfabeto {0,1} sejam embutidos no código. É possível embutir bits apenas
quando 1r > . Especificamente, os próximos 2log r bits de T determinam a escolha de um
dos r ponteiros.
Uma vez identificados os bits redundantes do LZ77, pode-se explorá-los para a
codificação de canal. Foram escolhidos os códigos Reed-Solomon )2255,255( eRS − ,
pertencentes à família de códigos BCH. Esse código acrescenta e2 bytes de paridade a

CAPÍTULO 4 57
e2255 − bytes de dados, formando um bloco de 255 bytes. Erros até e bytes em qualquer
lugar do bloco podem ser detectados e corrigidos.
Os bits redundantes do LZS77 podem ser usados para embutir os e2 bytes extras. Se
for escolhido valor alto de e , pode não haver bits redundantes suficientes para embutir os bits
de paridade.
O codificador que realiza a codificação conjunta, LZRS77, comprime a seqüência de
dados de entrada usando o LZ77 padrão. Os dados são divididos em blocos de tamanho
e2255 − . Depois, os blocos são processados na ordem reversa, começando pelo último.
Quando o bloco i está sendo processado, o codificador computa os bits de paridade do Reed-
Solomon para o bloco 1+i e os embute nos bits redundantes do bloco i , utilizando o
algoritmo LZS77. Os bits de paridade do primeiro bloco não são embutidos, mas salvos no
começo do arquivo comprimido.
O decodificador LZRS77 recebe a seqüência de ponteiros precedida pelos bits de
paridade do primeiro bloco. A seqüência de entrada, retirados os bits de paridade do primeiro
bloco, é dividida em blocos de tamanho e2255 − bytes. Em seguida, os bits de paridade no
começo da seqüência comprimida são usados para checar, e possivelmente corrigir, o
primeiro bloco. Uma vez corrigido, o primeiro bloco é decodificado pelo LZS77, que além de
reconstruir a porção inicial do texto original, também recupera os bits extras embutidos pelas
escolhas de ponteiros específicos. Esses bits extras são os bits de paridade para o segundo
bloco e o decodificador pode corrigir possíveis erros neste bloco. O segundo bloco é então
decodificado e os bits de paridade para o terceiro bloco são recuperados. O processo continua
até que todos os blocos tenham sido decodificados.
O motivo de o codificador processar os blocos na ordem reversa é que os bits de
paridade do Reed-Solomon não podem ser computados antes que os ponteiros tenham sido
finalizados. Os bits de paridade do bloco atual são embutidos no bloco anterior, já que o

CAPÍTULO 4 58
decodificador precisa conhecer os bits de paridade de um bloco antes de tentar decodificá-lo.
Isto tem o efeito indesejável de tornar o codificador off-line, pois precisa que o codificador
mantenha todo o conjunto de buffers na memória principal.

CAPÍTULO 5 59
Capítulo 5
5 Codificação Conjunta Fonte-Canal Utilizando LZW e RS
A contribuição deste trabalho consiste em uma metodologia para codificação conjunta
fonte-canal que utiliza a redundância remanescente no código gerado pelo codificador de
fonte LZW para embutir os bytes de paridade do código de canal Reed-Solomon. O trabalho é
motivado pelos resultados teóricos apresentados no capítulo 4 que mostram que a taxa de
decaimento da probabilidade de erro é mais rápida quando é realizada a codificação conjunta.
A metodologia aqui proposta é possível porque os codificadores universais não
conseguem retirar toda a redundância presente em uma seqüência de dados finita, conforme
apresentado na seção 2.3. O LZW foi escolhido por apresentar, assim como o LZ78 e outras
variações deste, menor redundância que o LZ77 e suas variações. O objetivo é melhorar o
processo de codificação fonte-canal minimizando a taxa de dados por aproveitar parte da
informação inútil na saída de um bom compressor para proteger os dados contra imperfeições
do canal. O Reed-Solomon foi escolhido por ser um código de canal de distância máxima,
muito utilizado em aplicações práticas e de implementação relativamente simples.
A apresentação da metodologia começa por explicar como informação extra é
embutida no código LZW através da exploração de bits redundantes. Em seguida, explica-se
como realizar a codificação conjunta de fato.
É importante ressaltar que a exploração de bits redundantes apresentada para o LZW
pode ser estendida para o LZ78 e suas variações que mantém o princípio de atualização do
dicionário. O método não é válido para a variação do LZ78 criada por Gallager e apresentada
em [11].

CAPÍTULO 5 60
5.1 Embutindo Informação Extra no LZW
Parte da redundância remanescente neste código de fonte se deve ao fato do método do
maior prefixo, empregado pelo LZW, não fornecer a partição ótima. A partição ótima equivale
ao menor número possível de partições para codificar a seqüência de dados e,
conseqüentemente, à menor taxa de compressão possível. Como a função de um codificador
de fonte é retirar a redundância dos dados, se a partição encontrada não é ótima, significa que
ainda existe redundância neste código.
O método proposto encontra alternativas de partições de uma seqüência de dados de
entrada do codificador, utilizando os conceitos aplicados no algoritmo proposto em [20] para
melhorar o desempenho da partição.
O princípio do método é, dada uma seqüência 1nx particionada em ( )1
nLZWm x
subseqüências pelo codificador LZW padrão, encontrar todas as N partições possíveis de 1nx
com a mesma quantidade de subseqüências, ( )1n
LZWm x . Dependendo de 1nx e à medida que n
cresce, a quantidade de partições diferentes com o mesmo número de subseqüências, em
geral, também cresce. A determinação de todas as possíveis partições de 1nx com ( )1
nLZWm x
subseqüências é um problema complexo e, devido à semelhança deste problema com o
problema de se encontrar a partição ótima, talvez não exista nem mesmo um algoritmo
seqüencial capaz de solucionar esta questão. Assim, a solução implementada busca as sN ,
onde sN é um subconjunto de N , possíveis partições de duas subseqüências consecutivas a
partir do encurtamento da primeira, ou seja, relaxando o método do maior prefixo.
Sendo ( )11( ,..., )n
LZWm xp p a partição de 1
nx gerada pelo LZW padrão, para cada par de
subseqüências 1( , )i ip p + , ( )11 nLZWi m x≤ < , de comprimento il são encontradas iN possíveis

CAPÍTULO 5 61
partições que produzem um par de subseqüências com comprimento il . Para computar iN , o
primeiro passo consiste em retirar o último símbolo de ip , caso esta subseqüência seja
formada por mais de um símbolo, e verificar a existência da nova subseqüência '1ip + formada
pela concatenação do símbolo retirado de ip com 1ip + no dicionário. Caso este exista, iN ,
inicialmente igual a um, é incrementado e o novo par ' '1( , )i ip p + , onde '
ip é ip encurtado de
um símbolo, é arquivado. 'ip sempre existe no dicionário devido à forma como este é
construído, o que fica muito claro pela observação da árvore construída para representá-lo. O
passo seguinte consiste em repetir o procedimento para ' '1( , )i ip p + , começando por encurtar
'ip , e assim sucessivamente, até que a primeira subseqüência seja composta por apenas um
símbolo. Neste ponto, tem-se o valor final de iN e todos os possíveis pares de partições
derivados de 1( , )i ip p + que pertencem ao dicionário arquivados. Incrementa-se i e realiza-se
o mesmo procedimento para o par de partições seguintes, 1 2( , )i ip p+ + .
Ao final da seqüência 1nx , tem-se ∏
−
=
=1
1
m
iis NN possibilidades de partições diferentes.
Isso permite que sN2log bits, que representam os bits redundantes recuperados, de uma
seqüência de dados qualquer sejam embutidos no código LZW de 1nx pela escolha adequada
das partições a serem transmitidas.
A atualização do dicionário continua sendo feita como no LZW padrão, ou seja, toda
subseqüência ip encontrada que representa o maior match pertencente ao dicionário é
concatenada ao símbolo de inovação que a segue e adicionada ao dicionário
independentemente de qual tenha sido a partição escolhida para transmissão, o que garante a
manutenção da taxa de compressão.

CAPÍTULO 5 62
Outra grande vantagem deste método, além de não alterar a taxa de compressão do
LZW padrão, é a capacidade de embutir bits de uma seqüência de dados qualquer sem
distorcer os dados originais, uma vez que a informação extra está no código LZW e não nos
dados de entrada do codificador.
A obtenção de partições diferentes se deve à forma de atualização do dicionário do
codificador. Como o dicionário do LZ78 e de suas variações, exceto a criada por Gallager e
apresentada em [11], se baseiam no mesmo princípio, o método para embutir informação
extra no LZW pode ser aplicado a estes compressores.
O exemplo seguinte ilustra o funcionamento do algoritmo para embutir bits extras no
código LZW:
Seja 1 0001001010010nx = .
O LZW padrão particiona 1nx em 1 2 3 4 5 6 7 8( , , , , , , , ) (0,00,1,001,0,10,01,0)p p p p p p p p = .
O algoritmo apresentado procura outras possíveis partições para os pares 1( , )i ip p + ,
81 <≤ i , encurtando ip . Os pares 1 2( , )p p , 3 4( , )p p e 5 6( , )p p não podem ser particionados
de forma diferente, já que as subseqüências 1p , 3p e 5p não podem ser encurtadas. O par
2 3( , )p p também não permite outra partição, apesar da subseqüência 2p poder ser encurtada.
Isso porque, neste passo, o padrão 01 não pertence ao dicionário. O par 4 5( , ) (001,0)p p =
pode ser particionado em ' '4 5( , ) (00,10)p p = . 6 7( , )p p permite a partição ' '
6 7( , ) (1,001)p p = e
7 8( , )p p permite '' '7 8( , ) (0,10)p p = . Dessa forma, 2,1,2,1,1,1 654321 ====== NNNNNN
e 27 =N . Então, 87
1
==∏=i
is NN e 3log2 =sN bits podem ser embutidos no código LZW
de nx através da escolha de uma das oito possíveis combinações obtidas com as partições
citadas. A Tabela 4 mostra uma classificação dessas opções em relação aos bits embutidos no
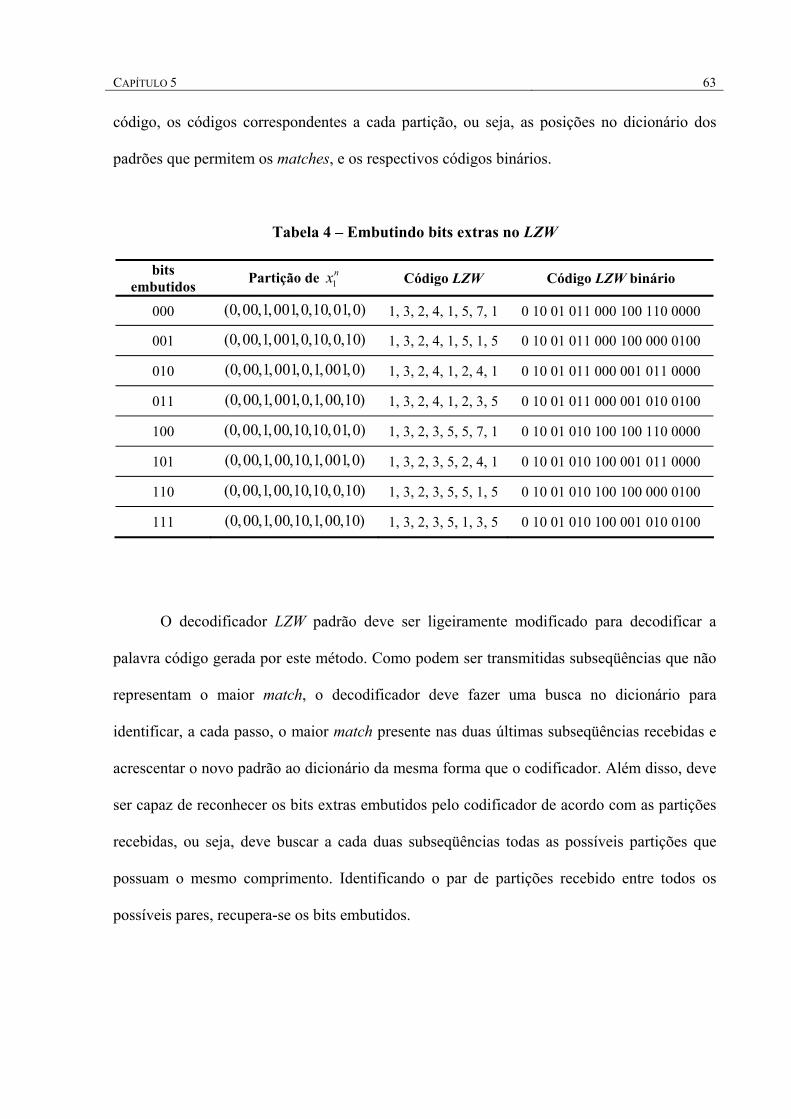
CAPÍTULO 5 63
código, os códigos correspondentes a cada partição, ou seja, as posições no dicionário dos
padrões que permitem os matches, e os respectivos códigos binários.
Tabela 4 – Embutindo bits extras no LZW
bits embutidos Partição de 1
nx Código LZW Código LZW binário
000 )0,01,10,0,001,1,00,0( 1, 3, 2, 4, 1, 5, 7, 1 0 10 01 011 000 100 110 0000
001 )10,0,10,0,001,1,00,0( 1, 3, 2, 4, 1, 5, 1, 5 0 10 01 011 000 100 000 0100
010 )0,001,1,0,001,1,00,0( 1, 3, 2, 4, 1, 2, 4, 1 0 10 01 011 000 001 011 0000
011 )10,00,1,0,001,1,00,0( 1, 3, 2, 4, 1, 2, 3, 5 0 10 01 011 000 001 010 0100
100 )0,01,10,10,00,1,00,0( 1, 3, 2, 3, 5, 5, 7, 1 0 10 01 010 100 100 110 0000
101 )0,001,1,10,00,1,00,0( 1, 3, 2, 3, 5, 2, 4, 1 0 10 01 010 100 001 011 0000
110 )10,0,10,10,00,1,00,0( 1, 3, 2, 3, 5, 5, 1, 5 0 10 01 010 100 100 000 0100
111 )10,00,1,10,00,1,00,0( 1, 3, 2, 3, 5, 1, 3, 5 0 10 01 010 100 001 010 0100
O decodificador LZW padrão deve ser ligeiramente modificado para decodificar a
palavra código gerada por este método. Como podem ser transmitidas subseqüências que não
representam o maior match, o decodificador deve fazer uma busca no dicionário para
identificar, a cada passo, o maior match presente nas duas últimas subseqüências recebidas e
acrescentar o novo padrão ao dicionário da mesma forma que o codificador. Além disso, deve
ser capaz de reconhecer os bits extras embutidos pelo codificador de acordo com as partições
recebidas, ou seja, deve buscar a cada duas subseqüências todas as possíveis partições que
possuam o mesmo comprimento. Identificando o par de partições recebido entre todos os
possíveis pares, recupera-se os bits embutidos.

CAPÍTULO 5 64
5.2 Codificação Conjunta
Após identificar a forma de embutir bits extras no código gerado pelo LZW, o objetivo
passa a ser embutir o código de canal. O código de canal escolhido é o Reed-Solomon
)2255,255( eRS − , para correção de até e símbolos errados por bloco de 255 símbolos.
Cada símbolo é representado por 8 bits, ou seja, um byte. Erro em um símbolo pode ser
ocasionado por erro em um bit ou em até 8 bits do byte. Os e2 bytes de paridade gerados pelo
codificador de canal para cada bloco de e2255 − bytes de dados devem ser embutidos no
código de fonte para que a taxa de compressão não seja diminuída.
A seqüência de dados a ser codificada é primeiramente dividida em grandes
segmentos. O último segmento é então comprimido pelo codificador de fonte LZW padrão ou
pela modificação deste apresentada acima que permite embutir bits extras. Neste momento,
contudo, não há dado algum a ser embutido e o codificador modificado opera como o LZW
padrão, escolhendo sempre a partição que equivale à encontrada pelo método do maior
prefixo.
Em seguida, este segmento comprimido é dividido em blocos de e2255 − bytes. O
codificador Reed-Solomon gera os e2 bytes de paridade para cada bloco de e2255 − . Os
bytes de paridade de todas as palavras-código de um segmento comprimido são concatenados
e formam um cabeçalho. Este cabeçalho é composto por mais uma informação, que representa
o comprimento do segmento comprimido. Os bytes que carregam esta informação são
concatenados ao início da seqüência de bytes de paridade. O conhecimento do comprimento
do segmento comprimido é muito importante para a decodificação.
O penúltimo segmento é então comprimido pelo LZW modificado e o cabeçalho do
último segmento é embutido no código de fonte resultante conforme descrito na seção 5.1. O
codificador de fonte comprime este segmento de forma independente da compressão do

CAPÍTULO 5 65
último segmento, começando uma nova árvore/dicionário. Em seguida, o segmento
comprimido é dividido em blocos de e2255 − bytes, o codificador Reed-Solomon gera os
bytes de paridade e o cabeçalho deste segmento é formado. O procedimento é repetido até o
primeiro segmento, sendo que o cabeçalho deste não é embutido. A seqüência codificada é
composta pela concatenação do cabeçalho do primeiro segmento e de todos os segmentos
codificados, começando pelo primeiro.
A codificação começa a ser feita pelo último segmento para que os bytes de paridade
dos blocos de um segmento estejam disponíveis antes da sua decodificação. Isso permite que
o decodificador decodifique os dados na ordem direta. A desvantagem do método, assim
como no LZRS77, é a necessidade de armazenar todos os segmentos comprimidos antes de
iniciar a transmissão dos dados, tornando o codificador off-line.
Quando um segmento está sendo codificado e o cabeçalho do segmento seguinte, que
está sendo embutido, é menor que o número de bits recuperados neste segmento, parte do
segmento comprimido seguinte é também embutida no código do segmento atual. Isto
melhora um pouco a taxa de compressão e aumenta a probabilidade de recuperação do
arquivo original.
A razão para aumentar a probabilidade de recuperação se deve ao fato de partes da
seqüência codificada, geralmente o começo de todos os segmentos comprimidos, exceto o
primeiro, não mais estarem susceptíveis a erro. O Reed-Solomon corrige erros em e símbolos
por bloco de comprimento 255=n simbolos. Por embutir os e2 símbolos de paridade e
considerando que estes são corretamente recuperados pela decodificação do segmento
anterior, a capacidade de correção de erros aumenta para correção de e símbolos por bloco de
e2255 − símbolos. Quando o começo do segmento comprimido é embutido, pode acontecer
de um ou mais blocos de e2255 − bytes serem completamente embutidos e/ou parte de um
bloco de e2255 − bytes de comprimento c ser embutida. No caso em que todos os bytes do

CAPÍTULO 5 66
bloco de e2255 − são embutidos, nenhum byte do bloco de comprimento 255=n simbolos
será corrompido por erros e a proteção do código de canal passa a ser indiferente. Quando c
bytes do bloco de e2255 − símbolos são embutidos, a capacidade de correção de erros neste
bloco aumenta para correção de e símbolos por bloco de ce −− 2255 símbolos.
O decodificador recebe a seqüência codificada e separa os bits correspondentes ao
cabeçalho do primeiro segmento. Como o cabeçalho carrega a informação relativa ao
comprimento do segmento comprimido, o número de blocos de e2255 − bytes e,
conseqüentemente, o número de bits de paridade são conhecidos. Os bits de paridade são
utilizados para checar e corrigir eventuais erros no primeiro segmento, desde que o número de
símbolos errados por bloco seja menor ou igual a e .
Em seguida, o primeiro segmento é decodificado pelo decodificador modificado
apresentado na seção 5.1, que, além de reconstituir a parte inicial da seqüência de dados
original, recupera os bits embutidos no código. Dos bits recuperados é extraído o cabeçalho
do segmento seguinte. Se o cabeçalho for menor que o número de bits recuperados, o começo
dos dados codificados do segundo segmento, que foi recuperado na decodificação do primeiro
segmento, é concatenado ao restante da seqüência de dados codificados para permitir a
continuação da decodificação.
Assim como para o primeiro segmento, o segundo segmento é checado e corrigido, se
necessário, e depois decodificado. O processo de decodificação de um segmento é
independente da decodificação dos demais, havendo construção de nova árvore. Os bits
embutidos no segundo segmento são recuperados e o processo se repete até o último
segmento, onde não há bits embutidos.
Apesar do processo de codificação conjunta proposto ser off-line por processar os
segmentos na ordem reversa e armazenar todos eles antes de iniciar a transmissão para

CAPÍTULO 5 67
permitir a decodificação na ordem direta, a seqüência de dados é codificada pelo codificador
de fonte uma única vez.

CAPÍTULO 6 68
Capítulo 6
6 Resultados
O codificador LZW foi implementado em software e em seguida modificado para
calcular o número sN2log de bits redundantes recuperados nos arquivos comprimidos
através do método apresentado na seção 5.1. As medidas foram feitas para arquivos do Corpo
de Canterbury [21]. Este conjunto de dados é freqüentemente utilizado para avaliar o
desempenho de compressores. Os testes foram realizados com os arquivos do corpo que
apresentam maior comprimento. São eles: bible.txt, E.coli, world192.txt e kennedy.xls. Os três
primeiros pertencem ao Large Canterbury Corpus e o último pertence ao Standard
Canterbury Corpus.
A Tabela 5 apresenta o nome do arquivo, o tamanho n do arquivo em bytes, a taxa de
codificação 1( )nLZWl x
n em bits/bytes, o número de bits redundantes recuperados sN2log e a
razão entre o número de bits recuperados e o número de bytes do arquivo n
N s2log.
A quantidade de bits que podem ser embutidos nestes arquivos seria suficiente para
incluir uma marca d’água, um código para verificar a autenticidade da informação, como uma
assinatura digital, ou um código para proteção contra erros introduzidos pelo canal, entre
outras aplicações. Em todos os casos, a informação adicional é embutida no código gerado
pelo codificador de fonte e não nos dados de entrada deste, o que significa que nenhuma
distorção é introduzida ao sinal original. Além disso, a taxa de compressão do codificador é
mantida inalterada.
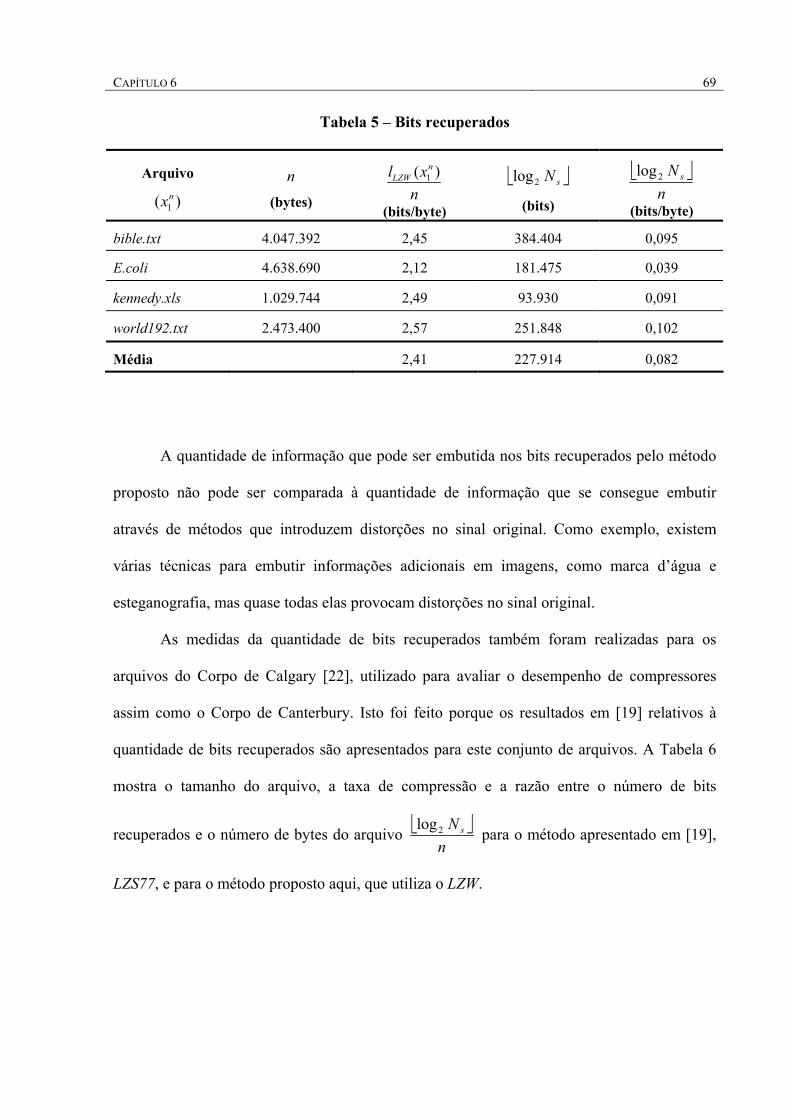
CAPÍTULO 6 69
Tabela 5 – Bits recuperados
Arquivo
1( )nx
n
(bytes)
1( )nLZWl x
n (bits/byte)
sN2log
(bits)
n
N s2log
(bits/byte)
bible.txt 4.047.392 2,45 384.404 0,095
E.coli 4.638.690 2,12 181.475 0,039
kennedy.xls 1.029.744 2,49 93.930 0,091
world192.txt 2.473.400 2,57 251.848 0,102
Média 2,41 227.914 0,082
A quantidade de informação que pode ser embutida nos bits recuperados pelo método
proposto não pode ser comparada à quantidade de informação que se consegue embutir
através de métodos que introduzem distorções no sinal original. Como exemplo, existem
várias técnicas para embutir informações adicionais em imagens, como marca d’água e
esteganografia, mas quase todas elas provocam distorções no sinal original.
As medidas da quantidade de bits recuperados também foram realizadas para os
arquivos do Corpo de Calgary [22], utilizado para avaliar o desempenho de compressores
assim como o Corpo de Canterbury. Isto foi feito porque os resultados em [19] relativos à
quantidade de bits recuperados são apresentados para este conjunto de arquivos. A Tabela 6
mostra o tamanho do arquivo, a taxa de compressão e a razão entre o número de bits
recuperados e o número de bytes do arquivo n
N s2log para o método apresentado em [19],
LZS77, e para o método proposto aqui, que utiliza o LZW.
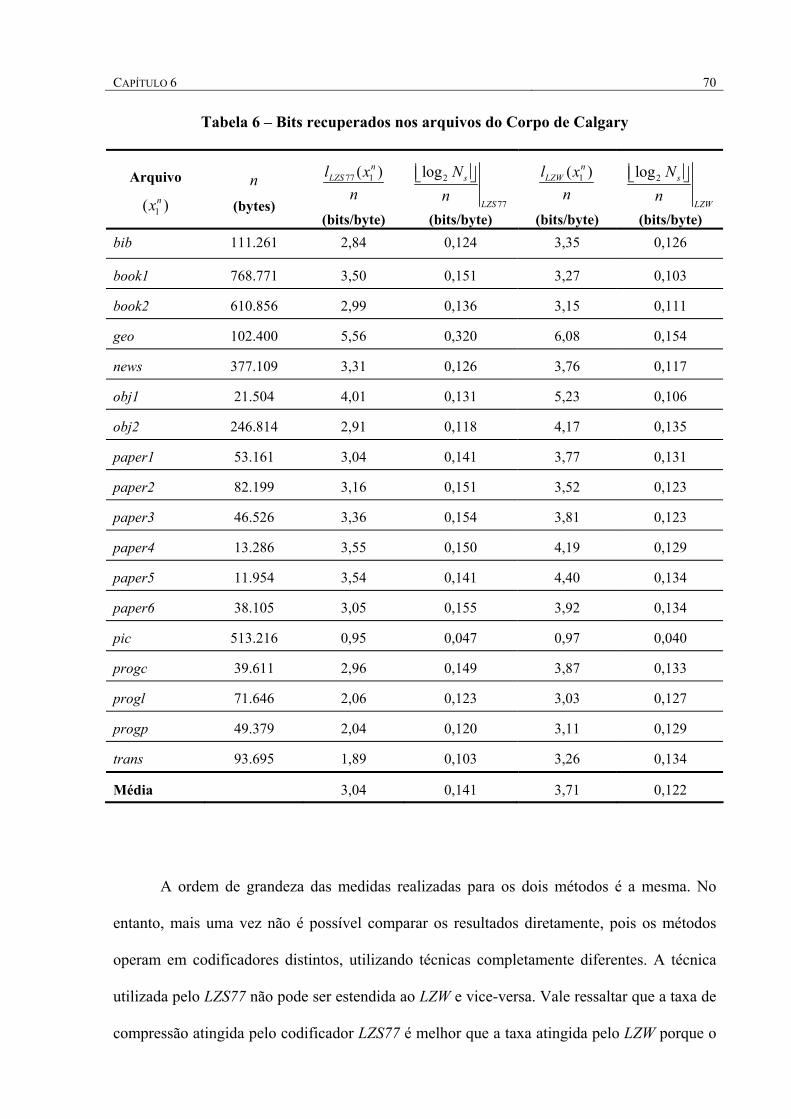
CAPÍTULO 6 70
Tabela 6 – Bits recuperados nos arquivos do Corpo de Calgary
Arquivo
1( )nx
n (bytes)
77 1( )nLZSl x
n
(bits/byte)
2
77
log s
LZS
Nn
(bits/byte)
1( )nLZWl x
n
(bits/byte)
2log s
LZW
Nn
(bits/byte)
bib 111.261 2,84 0,124 3,35 0,126
book1 768.771 3,50 0,151 3,27 0,103
book2 610.856 2,99 0,136 3,15 0,111
geo 102.400 5,56 0,320 6,08 0,154
news 377.109 3,31 0,126 3,76 0,117
obj1 21.504 4,01 0,131 5,23 0,106
obj2 246.814 2,91 0,118 4,17 0,135
paper1 53.161 3,04 0,141 3,77 0,131
paper2 82.199 3,16 0,151 3,52 0,123
paper3 46.526 3,36 0,154 3,81 0,123
paper4 13.286 3,55 0,150 4,19 0,129
paper5 11.954 3,54 0,141 4,40 0,134
paper6 38.105 3,05 0,155 3,92 0,134
pic 513.216 0,95 0,047 0,97 0,040
progc 39.611 2,96 0,149 3,87 0,133
progl 71.646 2,06 0,123 3,03 0,127
progp 49.379 2,04 0,120 3,11 0,129
trans 93.695 1,89 0,103 3,26 0,134
Média 3,04 0,141 3,71 0,122
A ordem de grandeza das medidas realizadas para os dois métodos é a mesma. No
entanto, mais uma vez não é possível comparar os resultados diretamente, pois os métodos
operam em codificadores distintos, utilizando técnicas completamente diferentes. A técnica
utilizada pelo LZS77 não pode ser estendida ao LZW e vice-versa. Vale ressaltar que a taxa de
compressão atingida pelo codificador LZS77 é melhor que a taxa atingida pelo LZW porque o

CAPÍTULO 6 71
primeiro não se limita à codificação propiciada pelo LZ77 padrão, mas utiliza também outras
técnicas para melhorar a compressão.
Para implementar a codificação conjunta proposta na seção 5.2, os arquivos do Corpo
de Canterbury de maior comprimento foram divididos em segmentos. Os arquivos foram
divididos até que cada segmento apresentasse comprimento próximo a 150 kB. Os gráficos da
Figura 8 mostram a taxa de compressão, 1( )nLZWl x
n, e o número total de bits recuperados,
sN2log , para os arquivos quando divididos em t segmentos.
A Tabela 7 mostra a média do aumento da taxa de compressão e do aumento do
número de bits recuperados a cada aumento do número de segmentos em que os arquivos
foram divididos, de acordo com os valores de t encontrados no eixo horizontal dos gráficos
da Figura 8 aplicáveis a cada arquivo.
Tabela 7 – Efeitos da segmentação dos arquivos na média
Arquivo Média da variação de 1( )n
LZWl xn
a cada segmentação
Média da variação de sN2log
a cada segmentação
bible.txt 4,07 % 4,41 %
E.coli 0,93 % 6,34 %
kennedy.xls -3,16 % 14,94 %
world192.txt 8,11 % 5,50 %
O número de bytes do arquivo original por segmento é aproximadamente nt
e o
número de bits recuperados por segmento é aproximadamente 2log sNt
.
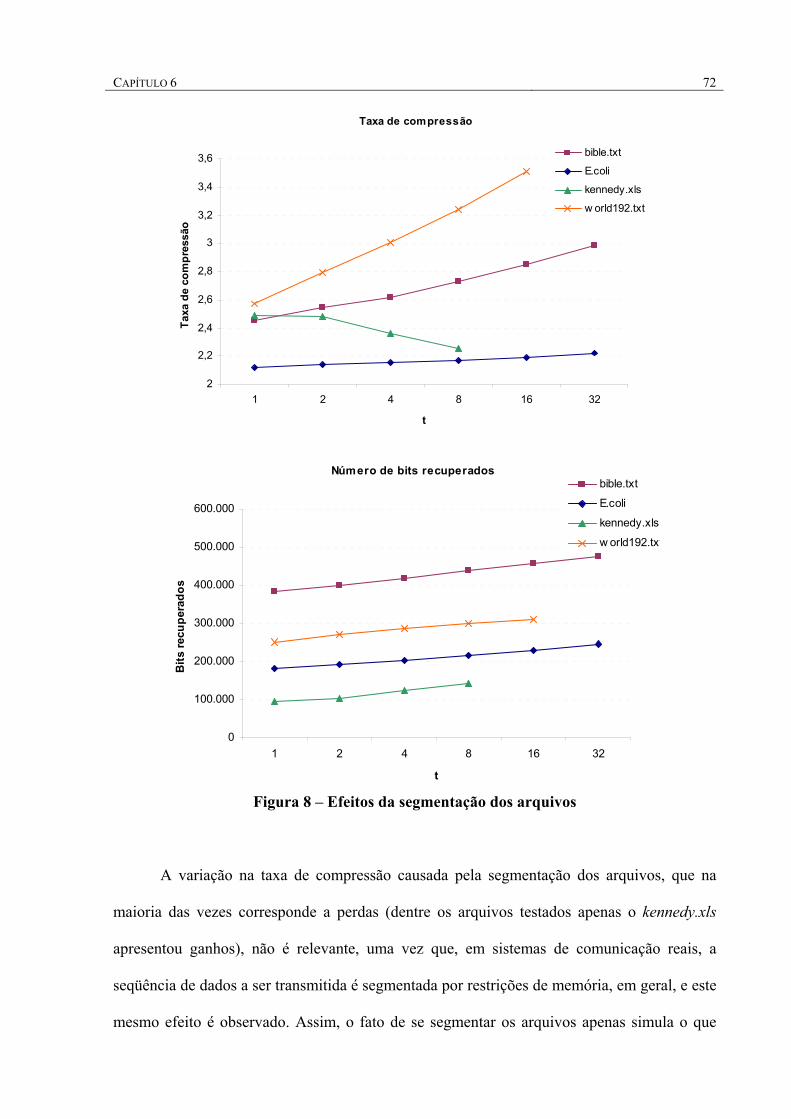
CAPÍTULO 6 72
Taxa de compressão
2
2,2
2,4
2,6
2,8
3
3,2
3,4
3,6
1 2 4 8 16 32
t
Taxa
de
com
pres
são
bible.txt
E.coli
kennedy.xls
w orld192.txt
Número de bits recuperados
0
100.000
200.000
300.000
400.000
500.000
600.000
1 2 4 8 16 32
t
Bits
recu
pera
dos
bible.txt
E.coli
kennedy.xls
w orld192.txt
Figura 8 – Efeitos da segmentação dos arquivos
A variação na taxa de compressão causada pela segmentação dos arquivos, que na
maioria das vezes corresponde a perdas (dentre os arquivos testados apenas o kennedy.xls
apresentou ganhos), não é relevante, uma vez que, em sistemas de comunicação reais, a
seqüência de dados a ser transmitida é segmentada por restrições de memória, em geral, e este
mesmo efeito é observado. Assim, o fato de se segmentar os arquivos apenas simula o que

CAPÍTULO 6 73
ocorre em sistemas de comunicação na prática. Em um satélite de sensoriamento remoto, por
exemplo, na medida em que os dados vão sendo capturados, estes são enviados para uma
estação para que sejam processados, ou seja, independentemente de ter-se chegado ao fim de
uma imagem, os dados são transmitidos porque o sistema não possui memória suficiente para
armazenar grande quantidade de informação, pois este não é seu objetivo. Outra limitação de
memória diz respeito à construção da árvore. Em algumas aplicações, a árvore que representa
o dicionário cresce até um limite pré-determinado e é então descartada e dá-se início a uma
nova codificação, baseada em um novo dicionário. Isto também equivale a segmentar o
arquivo, pois a cada segmento uma nova árvore é construída.
O número de bits recuperados aumentou em todos os arquivos testados quando
segmentados. Para analisar este fato, foram traçados os gráficos da Figura 9, onde as curvas
contínuas representam os dados reais e as retas pontilhadas, que unem o ponto inicial ao ponto
final de cada curva de dados reais, são traçadas apenas para facilitar a análise. Observando
estes gráficos, percebe-se que na parte inicial dos arquivos a derivada do número de bits
recuperados por bytes do arquivo original é maior que na parte final, ou seja, recupera-se mais
bits no começo da construção da árvore que representa o dicionário. Provavelmente,
segmentar os arquivos explora melhor esta característica, já que se tem uma nova árvore para
cada segmento. Este fenômeno, no entanto, precisa ser investigado com mais profundidade
em trabalhos futuros.
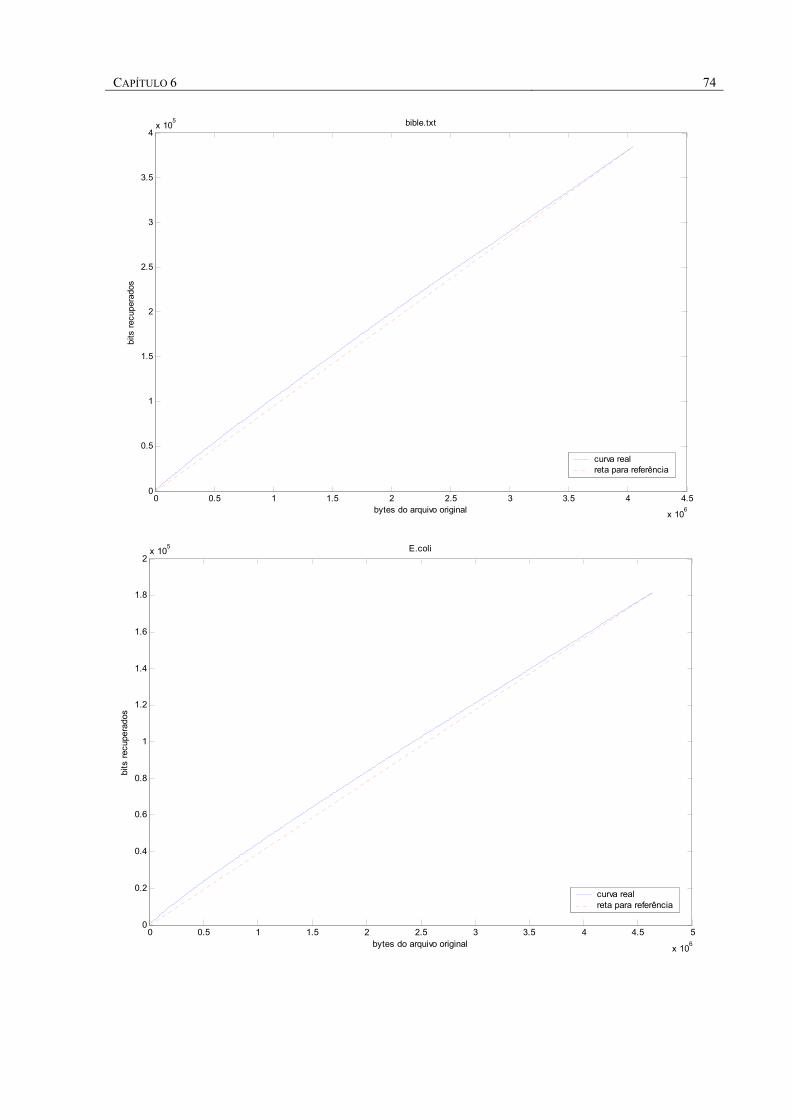
CAPÍTULO 6 74
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5
x 106
0
0.5
1
1.5
2
2.5
3
3.5
4x 10
5
bytes do arquivo original
bits
recu
pera
dos
bible.txt
curva realreta para referência
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
x 106
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2x 105
bytes do arquivo original
bits
recu
pera
dos
E.coli
curva realreta para referência

CAPÍTULO 6 75
0 2 4 6 8 10 12
x 105
0
1
2
3
4
5
6
7
8
9
10x 10
4
bytes do arquivo original
bits
recu
pera
dos
kennedy.xls
curva realreta para referência
0 0.5 1 1.5 2 2.5
x 106
0
0.5
1
1.5
2
2.5
3x 105
bytes do arquivo original
bits
recu
pera
dos
world192.txt
curva realreta para referência
Figura 9 – Comportamento da recuperação de bits ao longo dos arquivos

CAPÍTULO 6 76
Com o número de bits recuperados nos arquivos, foi calculado o número de bytes que
poderiam ser embutidos em cada um dos arquivos sem que a taxa de compressão fosse
alterada, desconsiderando-se o cabeçalho que é concatenado no começo da seqüência
comprimida no caso de se embutir o código de canal por segmentos. Como o objetivo é
embutir um código Reed-Solomon, o parâmetro utilizado para determinar a quantidade de
bytes a embutir foi o número de erros e que o código de canal é capaz de corrigir por bloco
de 255 bytes, uma vez que o número de bytes que deve ser embutido em um segmento é dado
pela multiplicação do número de blocos de e2255 − bytes do segmento seguinte por 2e
bytes. Independentemente do número de segmentos em que o arquivo foi dividido, o valor
máximo permissível de e para construção do código de canal para cada um dos arquivos
utilizados para teste é expresso na Tabela 8.
Tabela 8 – e máximo permissível
Arquivo bible.txt E.coli kennedy.xls wold192.txt
e máximo 4 2 5 4
Simulando a implementação do código de canal )2255,255( eRS − , foram verificadas
as taxas de compressão quando este código é embutido e quando ele é apenas concatenado à
seqüência de dados codificada, ou seja, quando não é feita a codificação conjunta. A média de
aumento da taxa de compressão para todos os valores de e permissíveis quando é realizada
codificação em dois passos em relação ao método de codificação conjunta proposto é ilustrada
na Figura 10 para todas as segmentações testadas. Para mesmo número de segmentos, códigos
de canal que corrigem de um erro até o valor máximo permissível apresentado na Tabela 8
para cada arquivo apresentam pouca variação na taxa de compressão. Para ilustrar este fato, a
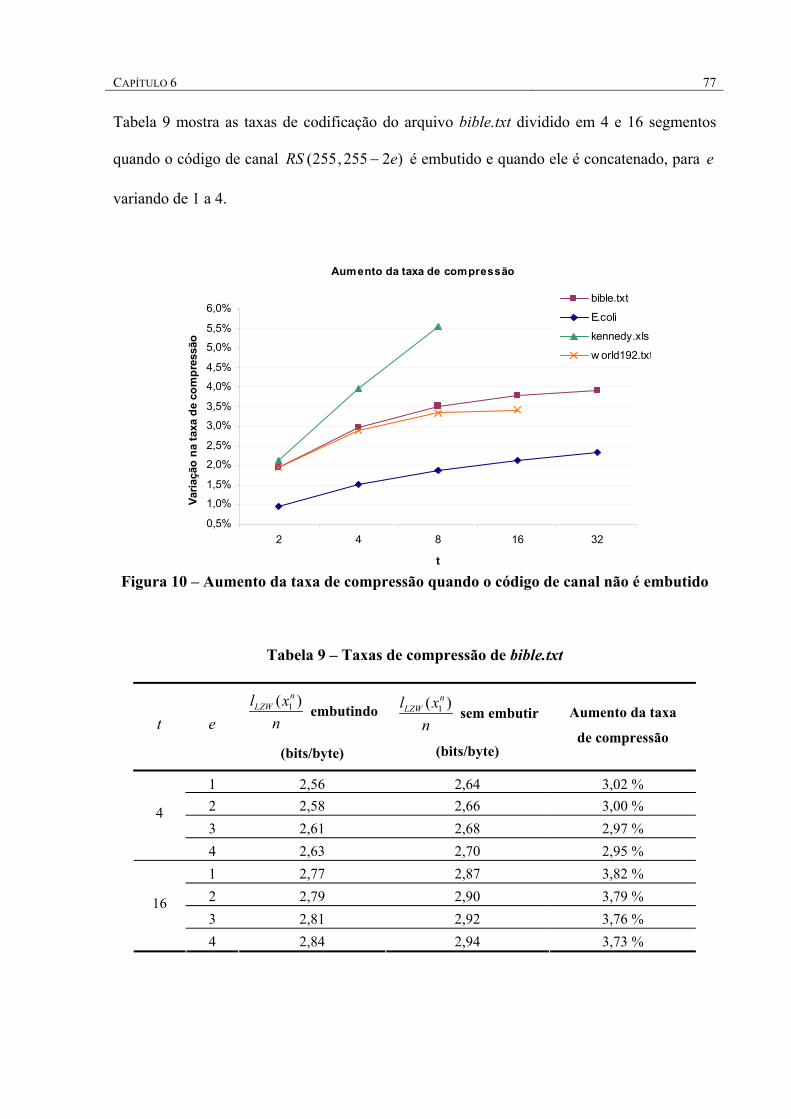
CAPÍTULO 6 77
Tabela 9 mostra as taxas de codificação do arquivo bible.txt dividido em 4 e 16 segmentos
quando o código de canal )2255,255( eRS − é embutido e quando ele é concatenado, para e
variando de 1 a 4.
Aumento da taxa de compressão
0,5%
1,0%
1,5%
2,0%
2,5%
3,0%
3,5%
4,0%
4,5%
5,0%
5,5%
6,0%
2 4 8 16 32
t
Varia
ção
na ta
xa d
e co
mpr
essã
o
bible.txt
E.coli
kennedy.xls
w orld192.txt
Figura 10 – Aumento da taxa de compressão quando o código de canal não é embutido
Tabela 9 – Taxas de compressão de bible.txt
t e 1( )n
LZWl xn
embutindo
(bits/byte)
1( )nLZWl x
n sem embutir
(bits/byte)
Aumento da taxa
de compressão
1 2,56 2,64 3,02 % 2 2,58 2,66 3,00 % 3 2,61 2,68 2,97 %
4
4 2,63 2,70 2,95 % 1 2,77 2,87 3,82 % 2 2,79 2,90 3,79 % 3 2,81 2,92 3,76 %
16
4 2,84 2,94 3,73 %

CAPÍTULO 6 78
A taxa de compressão é menor quando é feita a codificação conjunta porque os bytes
adicionados, correspondentes ao código de canal, são embutidos – a menos dos bytes do
código de canal referentes ao primeiro segmento, que são concatenados ao restante da
seqüência comprimida. Além disso, quando o número de bytes do código de canal obtido para
um segmento é menor que o número de bytes recuperados no segmento anterior, a parte
inicial da seqüência de dados deste segmento é também embutida no código do segmento
anterior. O aumento da taxa de compressão quando se realiza a codificação em dois passos
nos casos testados é de 3%, calculando-se a média entre todos os arquivos, chegando a 5,5%
para o arquivo que equivale ao melhor caso. Dependendo da aplicação, este valor é
significativo.
A manutenção da taxa de compressão do código de fonte após a implementação do
código de canal proporcionada pela codificação conjunta proposta traz vantagens aos sistemas
de comunicação reais. Para aplicações em que é realizada apenas codificação de fonte, pode-
se proteger os dados sem custo adicional de potência ou banda de transmissão, já que a taxa
de compressão não é alterada. Para aplicações em que é realizada codificação de canal que
independe da codificação de fonte, a adoção da codificação conjunta pode proporcionar
economia em banda de transmissão ou potência, uma vez que a taxa de compressão é
melhorada.
Dada a probabilidade de erro de bit do canal BSC, errop , e o código
(255,255 2 )RS e− , é possível determinar o comprimento máximo da seqüência codificada à
qual são inseridos erros que permite recuperar o arquivo original com taxa de acerto
específica. Como a probabilidade de acerto de um bit é dada por (1 )acerto errop p= − , a
probabilidade de acerto de um byte é 8_ (1 )acerto byte errop p= − e, conseqüentemente, a
probabilidade de erro de um byte é dada por 8_ 1 (1 )erro byte errop p= − − . A probabilidade de
acerto de um bloco RS de 255 bytes capaz de corrigir até e erros é dada por

CAPÍTULO 6 79
255_ _ _
0
255( ) ( )
ei i
acerto bloco RS acerto byte erro bytei
p p pi
−
=
=
∑ . A probabilidade de se recuperar um
arquivo formado por bn blocos RS de 255 bytes é _ _( ) b
b
nacerto n blocos acerto bloco RSp p= . Assim, tem-
se o comprimento máximo da seqüência codificada dado por
_
_
log( )255 255
log( )bacerto n blocos
bacerto bloco RS
pn n
p= = . Definindo a taxa de acerto _ bacerto n blocosp , foi possível
construir a Tabela 10 ( _ 0,99bacerto n blocosp = ) e a Tabela 11 ( _ 0,90
bacerto n blocosp = ) em função de
errop e e . Vale ressaltar que os comprimentos máximos encontrados nas tabelas representam
o pior caso, uma vez que são considerados blocos RS de 255 bytes, ou seja, nenhum byte é
embutido. Quando bytes são embutidos, o comprimento máximo do arquivo aumenta, pois
estes bytes não estão susceptíveis a erros.
Os dados das Tabela 10 e Tabela 11 permitem estabelecer sobre que canal, definido
por errop , determinado arquivo pode ser transmitido com sucesso e o número de segmentos
em que este deve ser dividido.
Tabela 10 – Comprimento máximo do arquivo comprimido, em bytes, para taxa de
acerto igual a 0,99
errop e 2 3 4 5
0,001 6 15 45 146
0,0006 19 71 313 1.622
0,0003 105 725 6.151 62.407
0,0001 2.131 42.737 1,0 106 32,2 106
0,00006 9.292 309.180 12,8 106 645,7 106
0,00003 71.046 4,7 106 391,9 106 39,2 109
0,00001 1,8 106 369,5 106 92,0 109 27,6 1012

CAPÍTULO 6 80
Tabela 11 – Comprimento máximo do arquivo comprimido, em bytes, para taxa de
acerto igual a 0,90
errop e 2 3 4 5
0,001 66 167 475 1.536
0,0006 201 748 3.288 17.004
0,0003 1.102 7.600 64.491 65.423
0,0001 22.342 448.020 11,2 106 338,4 106
0,00006 97.419 3,2 106 135,0 106 6,7 109
0,00003 744.800 49,4 106 4,1 109 411,4 109
0,00001 19,5 106 3,8 109 965,3 109 289,8 1012
Para testar a capacidade de decodificar os arquivos sem erro no receptor, foram feitas
simulações de transmissões dos arquivos por canais binários simétricos com diferentes
probabilidades de erro de bit errop , após terem passado pela codificação conjunta fonte-canal
utilizando LZW e )2255,255( eRS − . Os resultados das simulações são apresentados para
apenas uma segmentação de cada arquivo. A Tabela 12 mostra o número de segmentos em
que cada um dos arquivos foi dividido e o comprimento médio dos segmentos antes e após a
compressão.
Tabela 12 – Segmentação dos aquivos para simulação
Arquivo Número de
segmentos
Comprimento
médio do segmento
(bytes)
Comprimento médio do
segmento comprimido
(bytes)
bible.txt 8 505.924 172.816
E.coli 4 1.159.673 312.113
kennedy.xls 2 514.872 159.341
world192.txt 4 618.350 232.665

CAPÍTULO 6 81
As Tabela 13, Tabela 14, Tabela 15 e Tabela 16 mostram a taxa de vezes em que os
arquivos foram decodificados sem erro no receptor, onde errop é a probabilidade de erro de bit
do canal e e é o número de erros que podem ser corrigidos por bloco de 255 bytes. Foram
feitas 150 simulações de transmissão de um mesmo arquivo, mantendo errop , e e t
constantes, para obtenção da média da taxa de acerto na recuperação apresentada nas tabelas.
Estes mesmos dados são utilizados para compor os gráficos da Figura 11, que ilustram o
comportamento da recuperação dos arquivos para diferentes errop e e .
Tabela 13 – Taxa de acerto na recuperação de bible.txt dividido em 8 segmentos
Perro e = 3 e = 4
0,0001 80,67% 100,00%
0,0002 2,00% 78,00%
0,0003 0,00% 19,33%
0,0005 0,00% 0,00%
Tabela 14 – Taxa de acerto na recuperação de E.coli dividido em 4 segmentos
Perro e = 1 e = 2
0,00001 44,00% 100,00%
0,00003 0,00% 86,67%
0,00006 0,00% 34,00%
0,00010 0,00% 0,00%

CAPÍTULO 6 82
Tabela 15 – Taxa de acerto na recuperação de kennedy.xls dividido em 2 segmentos
Perro e = 3 e = 4 e = 5
0,0001 97,33% 100,00% 100,00%
0,0003 2,00% 62,67% 94,67%
0,0006 0,00% 0,00% 15,33%
0,0010 0,00% 0,00% 0,00%
Tabela 16 – Taxa de acerto na recuperação de world192.txt dividido em 4 segmentos
Perro e = 3 e = 4
0,0001 82,00% 98,67%
0,0003 0,00% 26,00%
0,0006 0,00% 0,00%
Para analisar a margem de erro dos resultados apresentados nas Tabela 13, Tabela 14,
Tabela 15 e Tabela 16, seja ap a probabilidade do arquivo ser recuperado sem erro.
Definindo a variável aleatória iX , que assume o valor 1 se o arquivo for recuperado
corretamente e o valor 0 se o arquivo não for recuperado corretamente, tem-se que
[ ]i aE X p= e ( ) (1 )i a aVar X p p= − . Fazendo 1
1 n
ii
Y Xn =
= ∑ , tem-se [ ] aE Y p= e
(1 )( ) a ap pVar Yn−
= , onde n é o número de simulações ( 150n = ). Aproximando Y de uma
variável aleatória gaussiana de média ap e variância (1 )a ap pn− (aproximação motivada pelo

CAPÍTULO 6 83
teorema do limite central), tem-se que (1 ) 1 2 ( )a aa
p pp Y p Qn
α α −
− < = −
, onde
2 21( )2
zQ e dzα
απ
−
−∞= ∫ .
Obtem-se α para determinado coeficiente de confiança, dado por 1 2 ( )Q α− , e
calcula-se os valores limites de ap , denominados _1ap e _ 2ap , pela equação
( )2 2 (1 )a aa
p py pn
α −− = , onde y , uma realização de Y , é o resultado encontrado na
simulação. Assim, ( ) ( ) ( )
( )
22 2 2 2
_1,2 2
2 2 4 1
2 1a
y n y n y np
n
α α α
α
+ ± + − +=
+. A margem de erro é
dada por _1 _ 2 100%a ap p− × . A Tabela 17 mostra as margens de erro encontradas para
coeficiente de confiança igual a 0,95, sendo 150n = e y variando de 0 % a 100 %.
Tabela 17 – Margens de erro para n = 150 e coeficiente de confiança de 0,95
y Margem de erro de y
0 % 2,50 %
10 % 9,69 %
20 % 12,73 %
30 % 14,52 %
40 % 15,49 %
50 % 15,80 %
60 % 15,49%
70 % 14,52 %
80 % 12,73 %
90 % 9,69 %
100 % 2,50 %

CAPÍTULO 6 84
Analisando a Tabela 10 (ou a Figura 11), vê-se que o comprimento máximo do
segmento comprimido que permite recuperar o arquivo com taxa de acerto de 0,99 (quando
não há bits embutidos) com 0,0001errop = e 4e = é de 1 MB e para 3e = é de 42,7 kB. O
comprimento do segmento comprimido do arquivo bible.txt é de aproximadamente 172,8 kB.
Como previsto, a recuperação do arquivo nas simulações com 0,0001errop = e 4e = foi
realizada com sucesso em todas as 150 vezes (com margem de erro de 2,5%), conforme
apresentado na Tabela 13. Já para 0,0001errop = e 3e = , como o comprimento do arquivo é
maior que o comprimento máximo indicado na tabela (e também o é no caso em que bits do
bloco RS são embutidos, já que a diferença entre eles não é tão significativa), a taxa de
sucesso na recuperação é inferior a 0,99. O mesmo pode ser verificado pela análise da Tabela
11. O comprimento máximo para 0,0003errop = e 4e = é de 6,1 kB e para 3e = é de 725 B
com taxa de acerto de 0,99. O segmento comprimido em questão é maior que os valores da
tabela para mesmo errop e e e, mais uma vez, as taxas de acerto na recuperação foram
inferiores a 0,99 nos dois casos. Quanto maior o comprimento do segmento comprimido em
relação ao máximo ilustrado na tabela, menor a taxa de recuperação com sucesso. Análise
similar para os demais arquivos permite validar os resultados encontrados nas simulações.
Quando os dados não são protegidos por um código de canal, a probabilidade de se
decodificar o arquivo sem erro após transmissão por canal ruidoso pode se tornar
extremamente baixa, dependendo da probabilidade de erro do canal e do comprimento do
arquivo. Por exemplo, para 0,0001errop = , a probabilidade de se decodificar corretamente o
arquivo bible.txt quando este é comprimido pelo LZW e o código de fonte transmitido é
composto por 1.241.873 bytes é igual a 1.241.873 8 4320,9999 3 10× −× .

CAPÍTULO 6 85
Os resultados apresentados em [19] relativos à recuperação de arquivos codificados
pelo LZRS77 sem erro foram compilados nos gráficos da Figura 12. Os dois primeiros
gráficos mostram a probabilidade de se recuperar o arquivo sem erro para diferentes errop e e ,
sendo que no primeiro o arquivo testado tem 2,5 kB e no segundo, 25 kB. O terceiro gráfico,
construído com os dados relativos a 2e = , permite a constatação de que quanto maior o
arquivo, menor a probabilidade de decodificá-lo corretamente. No entanto, é de se esperar que
exista um comprimento de arquivo a partir do qual a probabilidade de decodificar
corretamente não seja tão sensível ao aumento do comprimento. Isto foi observado nos testes
realizados com o método proposto neste trabalho, onde as probabilidades de recuperar os
arquivos corretamente não variaram para as segmentações apresentadas, que apresentavam o
menor comprimento próximo a 150 kB. Assim, as probabilidades de recuperação de arquivo
obtidas em [19] possivelmente serão reduzidas para arquivos de maior comprimento, como os
testados aqui.

CAPÍTULO 6 86
Recuperação de bible.txt dividido em 8 segmentos
0%
20%
40%
60%
80%
100%
0,0001 0,0002 0,0003 0,0004 0,0005
e = 3
e = 4
Recuperação de E.coli dividido em 4 segmentos
0%
20%
40%
60%
80%
100%
0,00001 0,00003 0,00005 0,00007 0,00009 0,00011
e = 1
e = 2
Recuperação de kennedy.xls dividido em 2 segmentos
0%
20%
40%
60%
80%
100%
0,0001 0,0003 0,0005 0,0007 0,0009 0,0011
e = 3
e = 4
e = 5
Recuperação de world192.txt dividido em 4 segmentos
0%
20%
40%
60%
80%
100%
0,0001 0,0002 0,0003 0,0004 0,0005 0,0006 0,0007
e = 3
e = 4
Figura 11 – Taxa de acerto na recuperação dos arquivos

CAPÍTULO 6 87
Recuperação de arquivo de 2,5 kB
0%
20%
40%
60%
80%
100%
0 0,0005 0,001 0,0015 0,002 0,0025 0,003
p
Prob
abili
dade
do
arqu
ivo
ser r
ecup
erad
o
e = 1
e = 2
Recuperação de arquivo de 25 kB
0%
20%
40%
60%
80%
100%
0 0,0001 0,0002 0,0003 0,0004 0,0005
p
Prob
abili
dade
do
arqu
ivo
ser
recu
pera
do
e = 1
e = 2
Recuperação de arquivos com diferentes comprimentos
0%
20%
40%
60%
80%
100%
0 0,0005 0,001 0,0015 0,002 0,0025 0,003
p
Prob
abili
dade
do
arqu
ivo
ser
recu
pera
do
n = 2,5 kB
n = 25 kB
Figura 12 – Resultados obtidos com LZRS77

CAPÍTULO 7 88
Capítulo 7
7 Conclusões
Este trabalho apresentou uma técnica para embutir bits extras no código gerado pelo
codificador de fonte LZW, através da exploração da redundância remanescente no código
gerado por ele. Este algoritmo explora o fato de existirem diferentes formas de particionar
uma mesma seqüência de dados em padrões recorrentes sem alterar a taxa de compressão.
Escolhendo a partição de acordo com a seqüência de bits extras que se pretende embutir no
código, o algoritmo atinge o objetivo proposto sem reduzir o desempenho do codificador e
sem introduzir qualquer distorção nos dados originais. Este algoritmo também pode ser
aplicado ao LZ78 e aos demais algoritmos derivados deste que mantenham a forma de
atualização do dicionário.
Os testes mostraram que a quantidade de bits recuperados permite aplicações como
inclusão de marca d’água, código para verificar a autenticidade da informação ou um código
para proteção de erros introduzidos pelo canal. A quantidade de informação extra embutida
por este método não pode ser comparada à quantidade que se pode embutir com métodos que
introduzem distorções aos dados originais. Devido aos resultados que mostram que a taxa de
decaimento da probabilidade de erro é mais rápida quando é realizada a codificação conjunta,
este trabalho foi direcionado ao desenvolvimento de uma técnica de codificação conjunta
baseada na utilização dos bits recuperados no código gerado pelo LZW para embutir um
código de canal.
A técnica proposta para realização da codificação conjunta, faz uso do codificador de
canal Reed-Solomon (255,255 2 )RS e− , onde e é o número de símbolos com erro que o

CAPÍTULO 7 89
código é capaz de corrigir por bloco de 255 bytes. A seqüência de dados codificada pelo
LZW é dividida em segmentos e o código de canal gerado para proteger um segmento é
embutido nos bits recuperados no segmento anterior. Para os arquivos testados, os bits
recuperados permitiram que códigos que corrigem até 5 erros fossem embutidos. Foi
verificada também a variação da taxa de compressão quando realizou-se a codificação
conjunta proposta ou a codificação em dois passos, em que a codificação de fonte é realizada
de forma independente da codificação de canal. Esta variação não foi muito expressiva, mas
pode ser significativa em algumas aplicações.
A manutenção da taxa de compressão do código de fonte após a implementação do
código de canal proporcionada pela codificação conjunta proposta traz vantagens aos sistemas
de comunicação reais. O objetivo da utilização de códigos de fonte e canal é melhorar a
relação de compromisso entre os recursos utilizados nestes sistemas, que pode ser a largura de
banda ou a potência de transmissão, e a sua qualidade, normalmente interpretada como a
confiabilidade na recepção dos dados. Para aplicações em que é realizada apenas codificação
de fonte, a adoção da codificação conjunta permite aumentar a confiabilidade do sistema sem
custo adicional de potência ou banda de transmissão, já que a taxa de compressão não é
alterada. Para aplicações em que as codificaçãoes de fonte e canal são realizadas
independentemente, a adoção da codificação conjunta pode proporcionar melhorias na relação
de compromisso entre os recursos utilizados no sistema, uma vez que a taxa de compressão é
melhorada.
Para trabalhos futuros, sugere-se investigar e mensurar a quantidade da redundância
remanescente nos códigos de fonte gerados por codificadores universais derivados do LZ78
que é explorada pelo método proposto.

REFERÊNCIAS BIBLIOGRÁFICAS 90
Referências Bibliográficas
[1] HAYKIN, S. Communication Systems. [S.l.]: Wiley, 2001. [2] SHANNON, C. E. A mathematical theory of communication. Bell System Technical Journal, v.27, p. 379-423, 1948. [3] WELCH, T. A. A technique for high-performance data compression. IEEE Computer, v. 17, n. 6, p. 8-19, 1984. [4] ZIV, J.; LEMPEL, A. Compression of individual sequences via variable-rate coding. IEEE Transactions on Information Theory, v. 24, p. 530-536, 1978. [5] BLAHUT, R. E. Algebraic Codes for Data Transmission. Cambridge: Cambridge University Press, 2003. [6] COVER, T. M.; THOMAS, J. A. Elements of Information Theory. [S.l.]: Wiley, 1991. [7] RISSANEN, J. Complexity of strings in the class of Markov sources. IEEE Transactions on Information Theory, v. 30, p. 629-636, 1984. [8] ZIV, J.; LEMPEL, A. A universal algorithm for sequencial data compression. IEEE Transactions on Information Theory, v. 23, p. 337-343, 1977. [9] LEMPEL, A.; ZIV, J. On the complexity of finite sequences. IEEE Transactions on Information Theory, v. IT-22, p. 75-81, 1976. [10] SAVARI, S. A. Redundancy of the Lempel-Ziv string matching code. IEEE Transactions on Information Theory, v. 44, p. 787-791, 1998. [11] SAVARI, S. A. Redundancy of the Lempel-Ziv incremental parsing rule. IEEE Transactions on Information Theory, v. 43, p. 9-21, 1997. [12] VEMBU, S. VERDÚ, S. The joint source-channel separation theorem revisited. IEEE Transactions on Information Theory, v. 41, p. 44-54, 1995.

REFERÊNCIAS BIBLIOGRÁFICAS 91
[13] CSISZÁR, I. On the error exponent of source-channel transmission with a distortion threshold. IEEE Transactions on Information Theory, v. 28, p. 823-828, 1982. [14] ZHONG, Y.; ALAJAJI, F.; CAMPEL, L. L. When is joint source-channel coding worthwhile: an information theoretic perspective. In: BIENNIAL SYMPOSIUM COMMUNICATIONS., 22., Canadá, 2004. Proceedings... Canadá: [s.n.], 2004. [15] ZHONG, Y.; ALAJAJI, F.; CAMPEL, L. L. On the computation of the joint source-channel error exponent for memoryless systems. In: IEEE INTERNATIONAL SYMPOSIUM INFORMATION THEORY (ISIT), Chicago, IL, July 2004. Proceedings...Chicago: [s.n.], 2004. [16] ZHONG, Y. ; ALAJAJI, F.;. CAMPEL, L. L. On the joint source-channel coding error exponent for discrete memoryless systems. IEEE Transactions on Information Theory, v. 52, p. 1450-1468, 2006. [17] SAYOOD, K.; LIU, F.; GIBSON, J. D. A constrained joint source/channel coder design. IEEE Journal on Selected Areas in Communications, v. 12, p. 1584-1593, 1994. [18] SAYOOD, K.; OUT, H. H.; DEMIR, N. Joint source/channel coding for variable length codes. IEEE Transactions on Communications, v. 48, p. 787-794, 2002. [19] LONARDI, S.; SZPANKOWSKI, W. Joint source-channel LZ’77 coding. In: IEEE DATA COMPRESS CONFERENCE, 2003. Proceedings... [S.l.]: IEEE, 2003. [20] PINHO, M. S.; FINAMORE, W. A.; PEARLMAN, W. A. Fast multi-match Lempel-Ziv. In: IEEE DATA COMPRESS CONFERENCE, 1999. Proceedings... [S.l.]: IEEE, 1999. [21] ARNOLD, R.; BELL, T. A corpus for the evaluation of lossless compression algorithms. In: IEEE DATA COMPRESS CONFERENCE, 1997. Proceedings... [S.l.]: IEEE, 1997. p. 201-210. [22] BELL, T. C.; CLEARY, J. G.; WITTEN, I. H. Text Compression. [S.l.]: Prentice-Hall, 1990.

FOLHA DE REGISTRO DO DOCUMENTO
1. CLASSIFICAÇÃO/TIPO
TM
2. DATA
13 de abril de 2007
3. DOCUMENTO N°
CTA/ITA-IEE/TM-002/2007
4. N° DE PÁGINAS
91 5. TÍTULO E SUBTÍTULO: Codificação conjunta fonte-canal utilizando codificadores universais adaptativos
6. AUTOR(ES):
Mariana Olivieri Caixeta Altoé 7. INSTITUIÇÃO(ÕES)/ÓRGÃO(S) INTERNO(S)/DIVISÃO(ÕES): Instituto Tecnológico da Aeronáutica. Divisão de Engenharia Eletrônica – ITA/IEE
8. PALAVRAS-CHAVE SUGERIDAS PELO AUTOR:
Codificação conjunta fonte-canal; codificadores universais; compressão de fonte; embutindo informação extra 9.PALAVRAS-CHAVE RESULTANTES DE INDEXAÇÃO:
Codificação concatenada; Codificadores; Codificação redundante; Compressão de dados; Códigos de correção de erros; Transmissão de sinais; Telecomunicações; Engenharia eletrônica
10. APRESENTAÇÃO: X Nacional
Internacional ITA, São José dos Campos, 2007, 91 páginas
11. RESUMO:
Tradicionalmente, codificação de fonte e codificação de canal são tratados independentemente, no que se denomina sistema de codificação em dois passos. Isso ocorre porque o teorema da separação das codificações de fonte e canal garante que não há perdas em termos de confiabilidade da transmissão em assim fazê-lo quando o volume de dados gerados pela fonte cresce indefinidamente. No entanto, para seqüências finitas, foi mostrado que pode ser mais eficiente realizar a codificação em apenas um passo, denominada codificação conjunta fonte-canal, que faz uso das características da fonte ou do codificador de fonte para prover proteção contra erros. Este trabalho propõe uma técnica de codificação conjunta utilizando codificadores de fonte e canal consagrados e encontrados em aplicações práticas. São eles o codificador universal adaptativo LZW e o codificador de canal Reed-Solomon. O método proposto utiliza o fato do codificador de fonte não remover completamente a redundância dos arquivos originais para adicionar bits extras, sem perda de desempenho e sem distorção dos dados originais. A redundância remanescente no código é então utilizada para embutir os bits de paridade do código de canal. O desempenho do método é medido através de sua aplicação em arquivos dos corpos de Calgary e Canterbury. A exploração da redundância remanescente no código gerado pelo LZW pode ser aplicada aos codificadores universais LZ78 e suas variações que se baseiam no mesmo princípio de atualização do dicionário.
12. GRAU DE SIGILO:
(X ) OSTENSIVO ( ) RESERVADO ( ) CONFIDENCIAL ( ) SECRETO





























