Embed Size (px)
DESCRIPTION
Compactação de dados.
Citation preview

UNIVERSIDADE FEDERAL DE GOIÁS ESCOLA DE ENGENHARIA ELÉTRICA E DE COMPUTAÇÃO
PROGRAMA PARA COMPACTAÇÃO DE DADOS UTILIZANDO CÓDIGO DE
HUFFMAN
Diego Vidier Oda Arruda Rodrigo Silva Goes
Orientador: Prof. Dr. Getúlio Antero de Deus Júnior
Goiânia 2003
DIEGO VIDIER ODA ARRUDA
RODRIGO SILVA GOES

2
PROGRAMA PARA COMPACTAÇÃO DE DADOS UTILIZANDO CÓDIGO DE
HUFFMAN
Dissertação apresentada ao Curso de Engenharia de Computação da Escola de Engenharia Elétrica e de Computação da Universidade Federal de Goiás, como parte para aprovação na disciplina de Estágio e Projeto Final. Área de Concentração: Compactação de Dados. Orientador: Prof. Dr. Getúlio Antero de Deus Júnior.
Goiânia 2003

3
DIEGO VIDIER ODA ARRUDA RODRIGO SILVA GOES
PROGRAMA PARA COMPACTAÇÃO DE
DADOS UTILIZANDO CÓDIGO DE HUFFMAN
Projeto Final defendido e aprovado em oito de janeiro de dois mil e quatro, pela Banca Examinadora constituída pelos professores:
______________________________________ Prof. Dr. Getúlio Antero de Deus Júnior
Presidente da Banca
______________________________________ Prof. Dr. Reinaldo Gonçalves Nogueira
1º membro da Banca
______________________________________ Prof. Msc. Carlos Galvão Pinheiro Junior
2º membro da Banca

4
À Deus e aos nossos pais.

5
AGRADECIMENTOS
À Universidade Federal de Goiás, pelo aprimoramento
proporcionado nas lides da Engenharia de Computação.
Aos coordenadores, professores e funcionários da Escola de
Engenharia Elétrica e de Computação, pelo ambiente de estudos e meios
colocados à disposição.
Aos companheiros de turma, pela camaradagem e amizade.
Em especial ao nosso professor e orientador Getúlio Antero de Deus
Júnior pela dedicação, incentivo e compreensão.
À nossa família que anonimamente vem ao longo dos anos sendo o
suporte sem o qual este não seria possível.
Ao nosso Grandioso Pai Celestial.

6
SUMÁRIO
Pág.
RESUMO........................................................................ 07
ABSTRACT.................................................................... 08
INTRODUÇÃO.............................................................. 01
CAPÍTULO 1 ................................................................. 02
PREMILINARES TEÓRICAS..................................... 02 1.1 Histórico........................................................................... 02 1.2 Código de Huffman.......................................................... 07 1.3 Estrutura de Dados........................................................... 17 1.4 Compactação ................................................................... 21 1.5 Técnicas de Compactação............................................... 24
1.6 Compactação Estatística ................................................ 34 1.7 Compactação Fixa versus Compressão Auto-adaptável. 35 1.8 O código de Lempel-Ziv ................................................ 36 1.9 Codificação Lempel-Ziv ................................................ 41
CAPÍTULO 2 ............................................................... 45
O PROBLEMA.............................................................. 45
2.1 Introdução........................................................................ 45 2.2 Proposta para implementação do compactador................ 48 2.3 Desempenho do compactador implementado.................. 53 2.4 Testes realizados.............................................................. 53 2.5 Aplicações....................................................................... 55 CONCLUSÃO............................................................... 57 REFERÊNCIAS BIBLIOGRÁFICAS........................ 58

7
RESUMO
É impossível pensarmos nos dias de hoje num mundo computacional sem pensarmos nas formas de armazenamento de dados. Isto implica articularmos todos os aspectos do armazenamento. Desde como gravaremos fisicamente, como transmitiremos estes dados de formas mais eficientes até em formas de compactação destes dados.
Neste trabalho, ressaltamos o aspecto particular da compactação de dados, que busca mecanismos para reduzir o tamanho dos dados utilizando alguma lógica matemática adequada ao tipo de aplicação considerada, de tal forma que possamos na outra ponta obtermos os dados originais utilizando a lógica inversa.
Neste sentido, tratamos especificamente da compactação de arquivos textos, dando uma noção geral sobre compactadores e sua história, sobre de que se trata o Código de Huffman e finalmente permeando nossa experiência na implementação desse código e nossas conclusões empíricas, comparando inclusive com outros códigos eficientes como Lempel-Ziv, expressos através de índices de compactação.

8
ABSTRACT It is impossible think nowadays in a computational world without
think in the ways of data storing. It means to explore every aspect of storing. Since how phisically we record it, how eficientily transmit these data until ways of data compression.
In this work, we hilight especificaly this aspect, the data compression, wich looks for mechanisms to reduce these data length using some mathematical logic that fits to the type of considered aplication, in a way that we are capable on the other side get the original datas by taking an inverse logic.
On this way, we treat especificaly of text file compression, giving a general explanation about compactors and its history, as what Huffman Code talk about and finaly exchaging our implementation experience and our empirical conclusions, comparing e with another eficient codes like Lempel-Ziv.

9
INTRODUÇÃO
A compactação consiste basicamente numa forma de
armazenamento reduzido de um conjunto de dados. Primeiramente,
abordaremos a evolução da comunicação de dados tratando dos códigos que
foram desenvolvidos para que esta comunicação fosse possível. Permearemos
desde códigos primitivos como, Código Morse e Baudot, até os códigos
modernos.
Faremos um estudo detalhado sobre Código de Huffman, que é o
tema central de nosso trabalho, e suas aplicações confrontando-o com outros
códigos existentes como o de Lempel-Ziv.
Aprofundamos também nosso estudo sobre Estruturas de Dados,
tratando especificamente sobre árvores binárias, estrutura imprescindível na
construção do Código de Huffman.
Em seguida, apresentamos alguns conceitos relativos a compressão
e compactação de dados. Separando conceitualmente a definição destes
termos, inclusive com o esboço de algumas técnicas de compressão.
No capítulo, apresentamos a proposta de implementação do
algoritmo de Huffman, para demonstrarmos que ele é um algoritmo ótimo
para caracteres. Consideramos vários aspectos do compactador e viabilizamos
uma solução para a compactação de arquivos tipo texto. Com a utilização de
arquivos-entradas de prova levantamos e respondemos algumas perguntas
realizados. Além disso algumas considerações a respeito do desempenho e
discussão sobre índices de compactação foi realizado.

10
CAPÍTULO 1
PREMILINARES TEÓRICAS
1.1 - Histórico
A comunicação de dados constitui o processo de comunicação de
informações em estado binário entre dois ou mais pontos. Às vezes, a
comunicação de dados é chamada de comunicação de informática, porque a
maioria das informações trocadas hoje em dia é transferida entre dois ou mais
computadores ou entre computadores e terminais, impressoras ou outros
dispositivos periféricos. Os dados podem ser elementares como os símbolos
binários 1 e 0, ou complexos como os caracteres representados pelas teclas
em um teclado de máquina de escrever. Em todo caso, os caracteres ou
símbolos representam informações [1].
O campo de comunicação de dados representa uma das tecnologias
de mais rápida evolução. Utilizando semicondutores especializados
desenvolvidos para realizar o processamento de sinais e a compactação, estão
sento desenvolvidos vários aplicativos de multimídia que orientam a
comunicação de dados em direção ao transporte de informações, dados e
vídeo.
É importante entendermos a comunicação de dados por causa de sua
significação no mundo de hoje. A comunicação de dados é usada comumente
em negócios e está sendo cada vez mais empregada também em ambientes
domésticos. Quer seja a transmissão de informações de um computador
central para máquina de um caixa eletrônico, a seleção de um programa de
TV a cabo no sistema "pay-per-view" ou o download de um videogame desde
um BBS para um computador pessoal, a comunicação de dados está se

11
transformando em uma parte integrante de nossas atividades diárias. Na
realidade, muitos leitores dificilmente conseguirão passar um dia interiro sem
se beneficiarem de alguma atividade executada ou aperfeiçoada pelo uso da
comunicação de dados. Quanto mais moderna uma sociedade, mais ela
depende da comunicação de dados [1].
A comunicação de dados moderna envolve o uso de aparelhos
elétricos ou eletrônicos para transmissão de informações sob a forma de
símbolos e caracteres entre dois pontos. Pelo fato da eletricidade, as ondas de
rádio e as ondas luminosas serem todas formas de energia eletromagnética,
poderíamos afirmar ainda sem grande exagero que as primeiras formas de
comunicação, como os sinais de fumaça das fogueiras dos índios americanos
ou a reflexão da luz solar em espelho também eram formas do mesmo tipo de
comunicação de dados. Para levar essa idéia mais adiante, imagine as nuvens
de fumaça como símbolos discretos, exatamente como os símbolos usados
nos atuais sistemas de comunicação.
A descoberta e a utilização da eletricidade introduziram muitas
possibilidades novas para os códigos de comunicação. Uma das primeiras
propostas, apresentada em uma revista escocesa em 1753, era simples mas
teve implicações profundas para o hardware. Essa idéia era a de estender 26
fios paralelos de uma cidade à outra, um fio para cada letra do alfabeto. Um
inventor suíço construiu um sistema protótipo baseado nesse princípio de 26
fios, mas a tecnologia de fabricação de fios nessa época eliminou a
possibilidade de uso sério dessa idéia. A complexidade de estender 26 fios
para denotar as 26 letras do alfabeto indicava a necessidade de uma técnica
mais eficiente [1].
Em 1833, Carl Friedrick Gauss usou um código baseado em uma
matriz 5 por 5 de 25 letras (as letra I e J eram combinadas), para enviar
mensagens pela deflexão de uma agulha para a direita ou esquerda de uma a

12
cinco vezes. O primeiro conjunto de deflexões indicava a linha e o segundo
indicava a coluna. Essa técnica pode ser considerada equivalente a especificar
uma coluna e uma linha para denotar uma letra, permitindo o uso de uma
única linha em lugar de 26 linhas.
Um dos desenvolvimentos mais significativos em comunicação de
dados aconteceu no século XIX, quando o americano Samuel F. B. Morse
inventou o telégrafo elétrico. Embora outros inventores tenham trabalhado na
idéia de usar eletricidade para se comunicarem, a invenção de Morse eram
sem dúvida a mais importante, porque ele juntou a mente humana (a
inteligência) com o equipamento de comunicação, com a decodificação
baseado na capacidade auditiva da pessoa que recebia a mensagem, e também
de seu conhecimento do código desenvolvido por Morse [1].
Quando a tecla do telégrafo na estação A era pressionada, a corrente
elétrica fluía pelo sistema e o induzido na estação B era atraído para a bobina,
emitindo um sinal sonoro à medida que atingia o ponto de parada. Quando a
tecla era liberada na estação A, ela abria o circuito elétrico e o induzido do
receptor na estação B era forçado para sua posição aberta por uma mola,
atingindo o outro ponto de parada e emitindo um ruído um pouco diferente.
Assim o receptor do telégrafo emitia dois ruídos distintos. Se o
tempo entre cliques sucessivos do receptor era curto, ele representava um
ponto; se era mais longo, representava um traço. O operador de transmissão
convertia os caracteres das palavras de uma mensagem a ser enviada em uma
série de pontos e traços. O operador receptor interpretava esses pontos e
traços como caracteres; assim, as informações eram transmitidas do ponto A
para o ponto B.
Quando Morse desenvolveu seu código, diz a lenda que ele
examinou a quantidade de tipos nas caixas que uma tipografia usava para
armazenar caracteres ingleses e dígitos. Morse atribuiu códigos curtos a

13
caracteres e dígitos que ocorriam com menor freqüência. Isso explica por que
foi atribuído um ponto à letra E, o caráter usado mais freqüentemente no
idioma inglês, e por que foi atribuído um traço à letra T, o segundo caráter de
uso mais freqüente.
Morse desenvolveu o telégrafo inicialmente em 1832, mas foi
somente bem mas tarde que ele demonstrou seu uso com sucesso. A
demonstração mais conhecida ocorreu em 1844, quando Morse transmitiu por
fios de Washington para Baltimore a mensagem: "Deus seja louvado!".
Tendo em vista que a entrega de correspondência pelo Pony Express
era o meio de comunicação típico antes do telégrafo, esse método muito mais
veloz logo se tornou um sucesso. O equipamento era simples e rudimentar: a
tecla e o receptor acústico continham cada um apenas uma peça móvel. A
força e a fraqueza do sistema (e sua única complexidade real) eram a mente
humana - os operadores de transmissão e recepção. Na época da guerra civil
americana, uma linha de telégrafo se espalhou pelo continente, cruzando as
pradarias e os desertos para conectar a Califórnia ao restante dos Estados
Unidos.
Foi a partir dessa inovação tecnológica histórica, ou seja, a criação
do telégrafo, que a Companhia Telegráfica da União Oeste (do inglês:
Western Union Telegraph Company) tornou-se conhecida. Na época em que o
telefone foi inventado, cerda de 20 anos depois, a indústria do telégrafo era
grande, com muitas empresas fornecendo serviços para quase todas as cidade
e vilas nos Estados Unidos. Em 1866, o telégrafo conectava as nações do
mundo, com a instalação do cabo de transatlântico entre os Estados Unidos e
a França.
A importância do telégrafo de Morse não é apenas histórica. Boa
parte da terminologia que se desenvolveu em torno do sistema Morse ainda é
usada atualmente. Por exemplo, considere os termos "marca" e "espaço". Se

14
um dispositivo fosse organizado de modo que o papel se movimentasse
continuamente sob uma caneta presa ao induzido do receptor telegráfico, seria
feita uma marca no papel quando o induzido fosse atraído para a bobina.
Poderíamos fazer referência ao estado de fluxo de corrente na linha,
como estado de marcação, e ao estado sem fluxo de corrente na linha como
estado de espaço. Note que isso resulta em um dispositivo de dois estados,
que pode ser considerado o precursor do sistema binário usado para transferir
informações e para controlar a operação dos computadores. Os padrões
mundiais para comunicação da dados de hoje ainda utilizam os termos marca
e espaço, com a condição de fluxo decorrente no canal de transmissão sendo
chamada condição de marcação.
O mais importante da terminologia oriunda do princípio de
operação do telégrafo foi o sistema de comunicação de dois estados. O fio
telegráfico (canal) entre os operadores encontra-se em um destes dois estados:
ou a corrente está fluindo ou não. Essa estrutura simples tem sido repetida
continuamente no desenvolvimento de sistemas de comunicação de dados.
Um sistema de comunicação de dois estados é o mais simples, o
mais fácil de construir e o mais confiável. Os dois estados podem ser ligado e
desligado (como no telégrafo), mais e menos (com o fluxo de corrente em
sentidos opostos), claro e escuro ( como ao acender e apagar uma lanterna
para transmitir código), 1 e 0 (o conceito usado nos computadores) ou alguma
outra estrutura com apenas dois valores possíveis. Um sistema de dois estados
ou de dois valores é chamado de "sistema binário".

15
1.2 - Código de Huffman
1.2.1 - Códigos
Os números 0 e 1 são símbolos do sistema binário. Um dígito
binário é comunente chamado um bit. As mudanças de linha individuais em
dados digitais (como marca e espaço) são chamadas bits, e cada bit recebe a
atribuição do valor 0 ou 1 [1].
O sistema binário emprega a notação posicional da mesma maneira
que o conhecido sistema decimal, exceto pelo fato de cada posição ter
somente dois valores possíveis, em vez de 10.
Podemos definir potências de dois no sistema posicional binário, no
qual o peso relativo de cada posição é duas vezes o peso da posição
imediatamente à direita.
Os computadores são mais eficientes se seus caminhos e
registradores internos tiverem o comprimento igual a alguma potência de dois
(2 bits, 4 bits, 8 bits, 16 bits e assim por diante). Um agrupamento comumente
usado é o de 8 bits. Um grupo de 8 bits é chamado um byte ou um octeto.
Durante o período inicial da informática, dos anos 50 aos anos 70,
foram usados agrupamentos diferentes de bits para formar um caractere de
computador. A arquitetura interna dos computadores desenvolvidos durante
esse período utilizava entre cinco e doze bits para definir caracteres únicos ou
bytes de computador. A falta de padrões sobre o número de bits que
representava um byte resultou em diversos padrões sobre o número de bits
que representações usarem o termo "octeto" em sua literatura para fazer
referência a um agrupamento de oito bits. Embora quase todos os
computadores modernos sejam projetados para grupar oito bits em um byte, a

16
maioria das organizações que criam padrões continua a usar o termo para
fazer referência a um grupo de oito bits.
Uma característica comum dos sistemas de comunicação é o uso de
um dispositivo inteligente para converter um caractere ou símbolo em sua
forma codificada e vice-versa. No sistema Morse, os "dispositivos"
inteligentes eram os operadores de telégrafo que convertiam os caracteres em
pontos e traços.
Operadores de telégrafo qualificados sempre estavam em falta, e o
trabalho era difícil e exaustivo. Por essa razão, tornou-se necessário criar um
meio elétrico ou mecânico de codificar os caracteres. Entretanto, era
essencialmente impossível automatizar as operações de transmissão e
recepção, em virtude da duração variável dos pontos e traços no código Morse
e do fato de que os códigos correspondentes aos caracteres eram formados por
diferentes quantidades de pontos e traços. Assim, surgiu a necessidade de um
código que tivesse o mesmo número de elementos de sinalização de igual
duração para cada caractere.
Códigos são interpretações padrões (combinadas com antecedência)
entre elementos de sinalização e caracteres. Os códigos usados em sistemas de
comunicação de dados já estão definidos, e o conjunto de códigos é
incorporado ao equipamento. Provavelmente, o único momento em que o
usuário poderia ter necessidade de lidar com códigos seria quando estivesse
criando a interface entre duas máquinas (como computadores e impressoras)
de fabricantes diferentes.
Caracteres são letras, numerais, os espaços, os sinais de pontuação e
outros sinais e símbolos em um teclado. Os sistemas de comunicação usam
caracteres de controle que não são impressos, mas esses caracteres também
devem ser codificados. Alguns desses caracteres de controle (por exemplo, os
caracteres de retorno de carro ou tabulação) também estão presentes no

17
teclado, embora muitos não estejam. No caso de muitos caracteres de controle
não localizados diretamente em um teclado, o usuário pode digitar seus
códigos no teclado pressionando certos pares de teclas. Por exemplo, a ação
de pressionar a tecla de controle (Ctrl) e a tecla G ao mesmo tempo (Ctrl + G)
resulta no código de tecla não-imprimível BEL, que pode ser usado dentro de
um programa para transmitir um alarme auditivo à pessoa que opera um
terminal de computador ou um computador pessoal.
Um elemento de sinalização é algo enviado através de um canal de
transmissão usado para representar um caractere. Assim os pontos e traços (ou
marcas e espaços) do código Morse são elementos de sinalização.
As definições de caracteres e elementos de sinalização ilustram o
motivo pelo qual as máquinas e as pessoas precisam de modos diferentes para
representar informações. As pessoas reconhecem com rapidez e
confiabilidade os caracteres impressos por suas formas distintas, mas é difícil
e dispendioso uma máquina fazer o mesmo. Por outro lado, as máquinas
podem manipular com facilidade longas seqüências de elementos de
sinalização de dois estados, como marcas e espaços ou uns e zeros, mas é
difícil uma pessoa conseguir o mesmo com alguma precisão.
1.2.2 - Código de Baudot
O código de Morse era inadequado para codificação e decodificação
por máquina, devido aos problemas causados pelos comprimentos variáveis
dos códigos correspondentes aos caracteres. No início do século XX, quando
se desenvolveu o interesse na substituição de operadores de telégrafo
humanos por máquinas, já existiam vários códigos adequados. O mais
proeminente desses códigos havia sido inventado na década de 1870 por um

18
francês chamado Emile Baudot. Tendo em vista que o código de Baudot,
usava o mesmo número de elementos de sinalização (marcas e espaços) para
representar cada caractere, ele era mais apropriado para codificação e
decodificação por máquina [1].
Infelizmente, o número de elementos de sinalização se limitava a
cinco, em conseqüência de problemas de sincronização dos dispositivos
eletromecânicos. O código de cinco bits só podia gerar 32 combinações
possíveis. Esse código não era suficiente para representar os 26 caracteres do
alfabeto, os 10 dígitos decimais, os sinais de pontuação e o caractere de
espaço. Para superar essa limitação, Baudot usou dois caracteres de controle
de deslocamento - o deslocamento de letras (LTRS) e o deslocamento de
figuras (FIGS) - para permitir ao conjunto de códigos representar todos os
caracteres que pareciam necessários na ocasião. Os códigos de deslocamento
não representam caracteres imprimíveis; em vez disso, os códigos selecionam
um entre dois conjuntos de caracteres, cada composto por 26 a 28 caracteres.
Embora a invenção de Baudot não tenha revolucionado
imediatamente a telegrafia (devido à dificuldade que os operadores humanos
tinham para enviar códigos de igual comprimento), ela forneceu a base para o
desenvolvimento posterior do aparelho de telex.
1.2.3 - Códigos Modernos
O código de Baudot e suas variações foram a espinha dorsal da
comunicação por quase meio século, mas claramente deixavam muito a
desejar. O pessoal da indústria jornalística considerou um problema a falta de
diferenciação entre letras maiúsculas e minúsculas. Os editores de jornais

19
inventaram um código de seis níveis para designar a diferença entre letras
maiúsculas e minúsculas. Esse era apenas um exemplo da necessidade geral.
A comunicação moderna exigia um código que pudesse representar
todos os caracteres imprimíveis e ainda deixar espaço para operações de
verificação de erros e formatação. Considerando-se as operações de
formatação, um código deve admitir os caracteres de avanço de linha e
retorno de carro, bem como o avanço de formulário e a tabulação horizontal e
vertical, porque o uso desses caracteres permite que as operações de terminal
sejam conduzidas à medida que ocorrem. O código tinha de tornar possível a
decodificação sem depender da recepção correta de transmissões anteriores, e
também tinha de permitir a decodificação por máquina. Talvez o mais
importante de tudo, o novo código precisava ser expansível [1].
Durante a década de 1960, foram desenvolvidos vários códigos de
transmissão de dados. A maioria deles caiu no esquecimento, restando três
códigos predominantes:
- O CCITT International Alphabet N 2 é um código isolado de
cinco bits que ainda é usado para transmissão de telex.
- O EBCDIC (do inglês: Extended Binary-Coded-Decimal
Interchange Code), desenvolvido pela IBM, é usado principalmente
para comunicação síncrona em sistemas conectados a computadores
de grande porte (mainframes).
- O código ASCII (do inlgês: American Standard Code for
information Interchange) foi definido pelo ANSI (do inlgês :
American National Standards Institute) nos Estados Unidos e pela
ISO (do inglês: Internacional Organization form Standardization)
em todo o mundo.

20
Quando surge uma necessidade clara de padronização, os padrões
passam a existir de duas maneiras. Em um modo um único fabricante (em
especial um dominante) pode definir um padrão para seus próprios produtos, e
o restante da indústria pode segui-lo. Foi isso o que a IBM fez. Ela criou o
código EBCDIC de oito bits que permitiu a representação de 256 caracteres.
O mundo provavelmente seria melhor se o EBCDIC tivesse se tornado o
padrão, porque ele incluía caracteres exclusivos suficientes para permitir
praticamente qualquer representação. Porém, só a IBM e as empresas que
montam equipamentos compatíveis com os da IBM adotaram o EBCDIC.
O código ASCII de sete bits, formalmente conhecido como ANSI
Standard X3.4-1077, pode representar 128 caracteres, mas nem todos eles
correspondem a símbolos impressos. Estão incluídos no conjunto de
caracteres todas as letras do alfabeto inglês (maiúsculas e minúsculas), os
numerais de 0 a 9, sinais de pontuação e muitos símbolos. Esse conjunto de
códigos padrão é usado em praticamente todos os computadores pequenos e
seus periféricos, como também em computadores de grande porte na maior
parte do mundo.
O código Morse tinha um número variável de elementos (pontos e
traços) para cada caractere e era bastante restrito - apenas letras, numerais e
alguns sinais de pontuação. O código de cinco bits tinha um número constante
de elementos e alguns outros caracteres especiais, mas ainda não conseguia
distinguir entre letras maiúsculas e minúsculas.
O ASCII não apenas permite o uso de letras maiúsculas e
minúsculas, mas também tem uma grande regularidade que a princípio pode
não ser aparente. Por exemplo, para converter qualquer caractere alfabético
maiúsculo (de A até Z) em minúsculo, é necessário apenas trocar o bit 6 de
zero para um. Outra característica é a de que os bits de 4 até 7 dos caracteres
numéricos (0, 1, 2, 3, 4, 5, 6, 7, 8 e 9) são os valores BCD (do inglês: Binary-

21
Coded-Decimal) dos caracteres. Outra vantagem do padrão ASCII é que
podem ser representados 128 caracteres diferentes pelos sete bits usados no
código (em vez dos 32 caracteres que podem ser representados no código de
cinco bits).
Uma variação do código ASCII, comumente chamado "ASCII
estendido", obteve ampla aceitação com a introdução do computador pessoal
pela IBM em 1981. O IBM PC e os computadores compatíveis reconhecem
um código de oito bits, com as primeiras sete posições admitindo o padrão
ANSI. A posição de bit adicional estende o conjunto ASCII do computador,
permitindo a representação de 128 caracteres adicionais. Essa extensão torna
possível o uso de códigos estendidos pelos desenvolvedores de software para
funções como marcações de fim de parágrafo e indicadores de impressão em
negrito em um sistema de processamento de textos.
1.2.4 - Código de Huffman
Supõe-se que um texto seja constituído de um conjunto de símbolos
(ou caracteres) S = {s1,...,sn), n > 1. É conhecida a freqüência fi vezes ao
longo do texto, 1 <= i <= n. Deseja-se atribuir um código a cada símbolo, de
modo a compactar o texto todo. A restrição que se coloca é que nenhum
código seja prefixo de algum outro. Ou seja, os códigos procurados são
aqueles dados por uma árvore binária de prefixo. Para cada nó interno v, a
aresta que conduz ao filho esquerdo de v é rotulada com zero, enquanto o
rótulo daquela que conduz ao direito é igual a um. Cada símbolo si está
associado a uma folha da árvore. Os códigos dos símbolos são seqüências
binárias. O código de si está associado a uma folha da árvore. Os códigos dos
símbolos são seqüências binárias. O código de si é igual à seqüência dos
rótulos das arestas, do caminho desde a raiz da árvore até a folha

22
correspondente a si. A figura 1 ilustra um exemplo de códigos de prefixo. O
código do símbolo s4 é 011, pois a seqüência dos rótulos das arestas, desde a
raiz até s4, é 011 [3].
Figura 1 – Códigos de prefixo
Uma vantagem da utilização de códigos de prefixo é a facilidade
existente para executar as tarefas de codificação e decodificação. Por
exemplo, suponha os códigos dados pela árvore da figura 1. Suponha o
seguinte texto:
s4 s3 s3 s1 s3 s1 s4 s5 s1 s3 s3 s3 s3 s3 s2 s3 s5 s2 s2 s2 s4
Utilizando-se a tabela da figura 1(a), obtém-se a seguinte
codificação:
01101010101000101000111000101010101010101010101000101101000100
0100011

23
Para decodificar o texto, basta percorrê-lo da esquerda para a
direita, ao mesmo tempo em que a árvore é percorrida, repetidamente, da raiz
para as folhas. Nesse percurso, toma-se o caminho para a esquerda ou direita,
na árvore, de acordo com o dígito correspondente encontrado no texto, 0 ou 1,
respectivamente. Toda vez que uma folha é atingida, um símbolo
decodificado foi encontrado. Nesse caso, retoma-se o processo reiniciando-se
o percurso na árvore a partir da raiz, para decodificar o próximo símbolo.
No exemplo, o texto codificado por 0. Significa que se deve tomar o
caminho da esquerda da raiz. O dígito seguinte é 1, o que conduz para a
direita desse último nó. Como o terceiro dígito é 1, a folha correspondente ao
símbolo s4 é alcançada. O texto decodificado inicia-se, pois, por s4. Retoma-
se então a raiz da árvore. O próximo dígito na codificação é 0. O caminho a
seguir é o do filho esquerdo da raiz. Em seguida, 1, após 0 e após 1. Com isso,
atinge-se a folha correspondente a s3. Assim sendo, detectou-se que o
símbolo seguinte a s4 no texto é s3. A nova subseqüência 0101 conduziria,
novamente, ao símbolo s3. O texto decodificado inicia-se, então, por s4, s3,
s3. E assim por diante, até esgotar a seqüência binária.
É imediato verificar que, uma vez conhecida a árvore de prefixo
correspondente, o processo de codificação pode ser realizado em um número
de passos linear ao tamanho da seqüência binária codificada.
Uma questão central é o comprimento do texto codificado, isto é, o
número de dígitos binários da codificação. O comprimento da seqüência
binária produzida por uma árvore binária de prefixo T é denominado custo de
T e denotado por c(T). No exemplo anterior, o custo da árvore da figura 1(b) é
igual a 69, pois a sequência binária obtida possui 69 dígitos. O objetivo
consiste, então, em minimizar c(T), ou seja, construir T de modo que c(T) seja
mínimo. Uma árvore de prefixo que satisfaça esta condição é denominada

24
mínima ou árvore de Huffman. Codificando-se o texto do exemplo anterior
com árvore da figura 2(b), obtém-se a seqüência:
110001010101110100101000001110100111111111110
que possui 45 dígitos. Logo, o custo da árvore da figura 2(b) é igual a 45.
Uma melhoria considerável em relação à arvore da figura 1(b).
Figura 2 – Árvore de Huffman.
Seja T uma árvore de prefixo correspondente a um dado texto, onde
cada símbolo si ocorre fi vezes. Seja li o comprimento do código binário do
símbolo si. É imediato verificar que cada símbolo si contribui com fi.li
unidades no custo c(T) = Somatório fi.li, para 1 < n < i . Este valor
corresponde ao conhecido comprimento de caminho externo ponderado de T.
Se todas as freqüências são idênticas, então T é uma árvore binária completa e
c(T) é o comprimento de caminho externo de T.

25
1.3 – Estrutura de Dados
O algoritmo para construir a árvore de Huffman para um dado
conjunto de n > 1 símbolos si de freqüências fi, 1 <= i <= n. O processo
utiliza a técnica conhecida como algoritmo guloso. Este consiste na
construção da árvore mínima de forma iterativa. A árvore é construída das
folhas para a raiz, ou seja, os códigos são determinados de trás para a frente.
De um modo geral, o processo corresponde a obter subcódigos para
subconjuntos de símbolos. Cada um desses subcódigos corresponde a uma
subárvore. O passo geral iterativo produz a fusão de duas dessas subárvores,
em uma única. O processo se encerra quando o número de subárvores se
reduz a um [3].
Seja T' uma subárvore binária de prefixo. Isto é, as folhas de T' são
símbolos selecionados dentre {s1, ..., sn}. Defini-se f(T'), a freqüência de T',
como sendo a soma das freqüências dos símbolos si presentes nas folhas de
T'. Por exemplo, os números às freqüências das subárvores de raiz nos
respectivos nós.
O processo de construção da árvore de Huffman é simples. Para
iniciar, definem-se n subárvores, cada qual consistindo em um único nó
contendo o símbolo si, 1 <= i <= n. A freqüência de cada uma dessas n
subárvores é, pois, igual à freqüência do símbolo a ela correspondente. O
passo geral, iterativamente, seleciona as duas subárvoes T'e T'', tais que f(T') e
f(T'') sejam as duas menores freqüências. Essas duas subárvores de custo
mínimo são fundidas em uma única árvore T, de acordo com a operação #.
Tal operação consiste em criar um novo nó cujos filhos esquerdo e direito são
as raízes de T' e T'', respectivamente, conforme a figura 3. É indiferente a
escolha dentre T'e T'' para subárvore esquerda ou direita desse nó. Observe
que a freqüência f(T'# T'') da nova subárvore T'# T'' é igual a f(T') = F(T''). O

26
algoritmo termina quando restar apenas uma única subárvore, ou seja, em n-1
execuções da operação #. A figura 4 ilustra a aplicação do algoritmo à
construção da árvore ótima para o conjunto de símbolos e freqüências da
figura 2(a). A árvore obtida pelo algoritmo é exatamente aquela ilustrada na
figura 2(b).
Figura 3 – A Operação #.
Para implementar o processo de construção da árvore de Huffman,
observe que a cada iteração é necessário determinar as duas subárvores T'e T''
da coleção de menor freqüência. As subárvores T'e T'' são então eliminadas e
substituídas pela subárvore T' # T''. Deve-se utilizar, portanto, uma estrutura
de dados que suporte as operações básicas de minimização, inclusão e
exclusão. Por exemplo, uma lista de prioridades.
#

27
S1 S2 S3 S4 S5
5 S2 S4
S5 S1
5
S5 S1
7
S4 S2
12
5
S5 S1
7
S4 S2
S3
S3
12
5
S5 S1
7
S4 S2
21
S3
Figura 4 – Aplicação do algoritmo de Huffman.
O processo de construção da árvore de Huffman é dado pelo
algoritmo 1. As freqüências f1, ..., fn, n > 1 são consideradas conhecidas,
devendo-se construir previamente uma lista de prioridades com elas. Cada
elemento desta lista corresponde a uma árvore T' composta de um único nó,
com freqüência fi, 1 <= i <= n. Os procedimentos utilizados para manipular a
lista de prioridades está invertida. Então, o procedimento mínimo retira a
menor prioridade e rearruma a lista. O procedimetno inserir (T, f, F), que

28
inclui o elemento T, de prioridade f, na lista F, é igual ao algoritmo abaixo.
Ao final, a árvore de Huffman é a correspondente àquela que restou na lista
de prioridades F.
Algoritmo 1 - Construção da árvore de Huffman.
Para i := 1, n-1 faça
Mínimo(T', f, F); mínimo(T'', f, F)
T := T' # T''
F(T) := f(T') = f(T'')
Inserir (T, f, F)
É imediato determinar a complexidade do algoritmo. Cada operação
de minimização ou inclusão na lista de prioridade pode ser efetuada em O(log
n) passos. A operação # requer apenas um número constante de passos. Há
um total de n-1 interações. Logo, a complexidade é O(n log n).
Para verificar que o algoritmo encontra a árvore de custo mínimo,
utiliza-se o seguinte lema: sejam si símbolos com freqüências fi, 1 <= i <= n,
n > 1, tais que f1 e f2 são as duas menores frequências. Então existe uma
árvore de Huffman para esses símbolos, em que os nós correspondentes a s1 e
s2 são irmãos localizados no último nível da árvore [3].
O teorema seguinte comprova a correção do algoritmo: seja T a
árvore construída pelo algoritmo de Huffman para as freqüências f1,..., fn, n>
1. Então, T é mínima.

29
1.4 – Compactação
1.4.1 - Compactação
Suponha que se deseje armazenar um arquivo de grande porte em
algum tipo de memória, primária ou secundária. Para melhor utilizar os
recursos disponíveis, deseja-se também minimizar, de alguma forma e na
medida do possível, o espaço de memória utilizado. Uma forma de tentar
resolver esse problema consiste em codificar o conteúdo do arquivo de
maneira apropriada.
Se o arquivo codificado for menor do que o original, pode-se
armazenar a versão codificada em vez do arquivo propriamente dito. Isto
representaria um ganho de memória. Naturalmente, uma tabela de códigos
seria também armazenada, para permitir a decodificação do arquivo. Essa
tabela seria utilizada pelos algoritmos de codificação e decodificação, os
quais cumpririam a tarefa de realizar tais operações de forma automática.
O problema descrito é conhecido como compactação de dados. A
sua importância foi muito importante nos primeiros anos de computação.
Naquela época, a questão de economia de memória era crítica, devido ao seu
elevado custo. Com o passar do tempo, a memória foi se tornando cada vez
mais abundante, como relativo decréscimo de custo. Entretanto, alguns
programas de aplicação atualmente utilizados requerem muita memória. Entre
esses, por exemplo, encontra-se programas que oferecem recursos visuais aos
seus usuários.
O problema de economia de memória ainda permanece na
atualidade. O advento e larga utilização de redes de computadores para a
importância da compactação de dados. Além da economia de memória,
procura-se também diminuir o custo da transmissão dos arquivos na rede:
uma maior compactação dos dados de um arquivo corresponderia a um

30
número menor de dados a transmitir, o que implicaria um custo de
transmissão menor. A hipótese concreta, nesse caso, é que o custo de
transmissão é proporcional à quantidade de dados a transmitir.
Ao contrário do que possa parecer, compactação não é somente
reduzir o tamanho de um arquivo: há várias outras aplicações que utilizam a
compactação de dados.
A redução do espaço físico é mais comumente utilizada em bancos
de dados que, incorporando a compressão no projeto de seus registros,
permite um significativo ganho em termos de ocupação em disco e velocidade
de acesso.
Como foi mencionado anteriormente, a utilização mais conhecida
da compactação de dados é a redução do espaço ocupado por arquivos. De
fato, esta é aplicação mais comum e mais difundida comercialmente. Afinal,
dado um dispositivo restrito de armazenamento que é um disquete, e um
grande depositório de arquivos que é um disco rígido, faz-se evidente a
necessidade de muitas vezes realizar-se a redução do tamanho de arquivos
para transportá-los ou simplesmente armazená-los.
A compactação também é utilizada para agilizar a transmissão de
dados basicamente de duas formas: alterando a taxa de transmissão e
permitindo o aumento no número de terminais de uma rede.
Se possuímos um modem que opera a 9600 bps (bits por segundo),
é possível que ele transmita como se estivesse a 14400 bps? Sim! Basta que
ele permita a compressão de dados transmitidos, ampliando sua capacidade de
transferência de informação. Na verdade, o modem continuará transmitindo a
uma taxa de transmissão de 9600 bps, mas a taxa de transferência de
informação estará ampliada para 14400 bps. A compressão de dados permite,
portanto, o aumento na velocidade de transmissão de dados.

31
Outra vantagem da compactação em comunicação, derivada do
aumento de velocidade, é a possibilidade de expansão de uma rede de
computadores. Como uma ampliação do número de terminais de uma rede
baixa o desempenho, dado o aumento do tráfego de dados, torna-se necessária
uma transmissão mais rápida de dados. Há, portanto, duas alternativas: trocar
os modem, utilizando modelos mais velozes, ou incorporar um chip com
algoritmo de compressão aos modens existentes. Como a primeira alternativa
é mais cara, a segunda permite que se alcance o mesmo desempenho com
muito menor custo. A compactação de dados, neste caso, permite a ampliação
de uma rede de computadores de uma forma alternativa mais barata.
1.4.3 - Tipos de Compactação
A compactação lógica refere-se ao projeto de representação
otimizada de dados. Um exemplo clássico é o projeto de um banco de dados
utilizando seqüências de bits para a representação de campos de dados. No
lugar de seqüências de caracteres ou inteiros, utiliza-se bits, reduzindo
significativamente o espaço de utilização do banco de dados.
Este tipo de compactação é possível de ser efetivada em campos
projetados para representar dados constantes, como datas, códigos e quaisquer
outros campos formados por números. A característica lógica da compactação
encontra-se no fato dos dados já serem comprimidos no momento do
armazenamento, não ocorrendo sua transformação de dados estendidos para
comprimidos.
A compactação física é aquela realizada sobre dados existentes, a
partir dos quais é verificada a repetição de caracteres para efetivar a redução

32
do número de elementos de dados. Existem dois tipos de técnicas para
sinalizar a ocorrência de caracteres repetidos:
- Um deles indica o caracter (ou conjunto de caracteres) repetido
através da substituição por um caracter especial;
- Outras técnicas indicam a freqüência de repetição de caracteres e
representam isto através de seqüências de bits.
1.5 – Técnicas de compactação
1.5.1 - Seleção de Caracteres Indicadores
Antes da discussão das técnicas propriamente ditas, é necessário o
esclarecimento de como são codificados os caracteres especiais a serem
substituídos pelos caracteres repetidos neste tipo de compressão física. Há
basicamente 3 formas de representação denominadas run-length , run-length
estendido e inserção e deleção.
1.5.1.1 - Codificação run-length
Quando temos um arquivo onde ocorre uma repetição contínua de
determinado caracter, por exemplo AAAAAAAAAAAA, é possível sua
representação através da codificação run-length , da seguinte forma:
Ce 12 A
onde A é o caracter repetido 12 vezes, o que é indicado pelo caracter especial
Ce. O caracter especial é um daqueles caracteres não-imprimíveis que
conhecemos no código ASCII, por exemplo.

33
Cabe salientar que esta codificação ocupa somente 3 bytes. Ora,
como representar um inteiro como um byte? Deve-se ter a consciência que em
um byte pode ser armazenado um valor de 0 a 255, ou seja, pode-se indicar,
como apenas um byte até 256 ocorrências de caracter. Caso ocorra mais do
que isso, deve utilizar outra representação mais eficiente.
Como representaremos um número de repetições maior que 256?
Utilizando o run-length estendido. A diferença deste para o run-length
simples é que há caracteres delimitadores no início e no fim da seqüência de
codificação:
SO R A 980 SI
onde SO (do inglês: shift out) é um caracter especial indicador de início de
uma seqüência de caracteres definida pelo usuário até que SI (do inglês: shift
in) seja encontrado. Esta é uma propriedade de códigos de caracteres, como o
ASCII e EBCDIC. O caracter R indica a compressão run-length, onde o
caracter A é indicado como repetido 980 vezes. Como o valor 980 ultrapassa
o limite de 256 de um byte, torna-se necessária a utilização de mais um byte
para a representação do valor.
1.5.1.2 - Codificação por inserção e deleção
O que fazer quando não for possível a colocação de caracteres
especiais? Há determinados casos que os caracteres especiais utilizados
conflitam com outros aplicativos, de transmissão de dados, por exemplo.
Desta forma, utiliza-se um caracter convencional como indicador de
compactação.

34
Como na língua portuguesa utiliza-se muito pouco as letras K, W,
Y, pode-se, por exemplo, indicar a compressão de um arquivo de texto na
forma:
K 12 A.
1.5.2 - Exemplos de Técnicas de Compressão Orientada a Caracter
As técnicas de compressão orientadas a caracter não são as mais
eficientes ou as mais sofisticadas. Pelo contrário, em geral elas são utilizadas
num primeiro nível de compressão multinível, onde os demais níveis podem
ser técnicas estatísticas de compressão.
Aqui serão analisados 8 técnicas de compressão orientada a
caracter, de modo a dar uma noção das possíveis aplicações deste tipo de
compressão.
1.5.2.1 - Supressão de Caracteres Nulos
Nesta técnica, temos como objetivo comprimir apenas os caracteres
nulos ou brancos. Em geral, são comprimidos caracteres correspondentes ao
espaço em branco.
Para a compactação, utiliza-se a seguinte seleção de caracteres
indicadores: Ce N , onde Ce é um caracter especial e N é o número (em
binário) de caracteres brancos repetidos seqüencialmente.
Então, por exemplo, uma seqüência do tipo:
...vazio. Exatamente o que...
Pode ser comprimida como sendo:
...vazio.Ce8Exatamente o que...

35
o que demonstra uma redução de 6 bytes no trecho apresentado.
Outras formas de indicação de compressão podem ser utilizadas,
com visto na seção anterior. Como trata-se de uma compressão de brancos,
não há necessidade de explicação do caracter comprimido.
1.5.2.2 - Mapeamento de Bit
Quando é sabida a existência de múltiplas ocorrências não
consecutivas de determinado caracter no arquivo a compactar, utiliza-se a
compressão por mapeamento de bit. Esta técnica utiliza-se de um byte no
arquivo comprimido para indicar, através dos bits, a ocorrência do caractere
repetido.
Desta forma, caso desejarmos comprimir todos os caracteres "a" de
um texto, devemos indicá-lo no mapa de bits. Cada mapa descreve 8 bytes,
um por bit do arquivo manipulado. Portanto, para letra encontrada a cada
trecho de 8 bytes, será assinalada no mapa de bits. Por exemplo:
... abacate ...
será descrito como:
... Mbbcte...
onde Mb é o mapa de bits correspondente à compressão do caracter "a" . Este
mapa é composto, para o exemplo, dos bits:
0 1 0 1 0 1 1 1
onde o primeiro zero indica a presença de um caracter "a" na primeira
posição, valor um em seguida indica um caracter diferente, e assim por diante,
até completar o mapa. Convenciona-se, portanto, que o bit 0 indica a presença
do caracter a compactar e o bit 1 a sua ausência.

36
1.5.2.3 - Comprimento de Fileira
Esta técnica aplica a indicação semelhante à run-length de
compressão. O formato permite a determinação do caracter repetido:
Ce C N,
onde Ce é o caracter especial, C é o caracter repetido e N é o número (binário)
de repetições. Como podemos perceber, esta técnica também permite apenas a
compressão de um caracter por vez.
1.5.2.4 - Compactação de Meio Byte
Este tipo de compactação é utilizado quando encontramos uma
seqüência de bits em comum nos caracteres de determinado arquivo. Um tipo
de repetição de bits de grande ocorrência é a que acontece em caracteres
numéricos. Por exemplo, o conjunto binário da tabela ASCII para os
caracteres numéricos é dado pela tabela 1.
Tabela 1 – Conjunto binário da tabela ASCII.
Decimal Binário 0 0011 0000 1 0011 0001 2 0011 0010 3 0011 0011 4 0011 0100 5 0011 0101 6 0011 0110 7 0011 0111 8 0011 1000 9 0011 1001

37
Se isolarmos os primeiros 4 bits de cada byte de caracter numérico,
veremos que há uma constância de valores. Estes valores constantes são um
exemplo de objetos de compactação de meio byte.
A compactação de meio byte propriamente dita consiste na seguinte
seqüência de caracteres indicadores:
Ce N C1 C2 C3 C4 C5...
onde Ce é o caracter especial, N é o número (binário) de caracteres
comprimidos e Cn é a metade do caracter comprimido. Na seqüência de
caracteres indicadores apresentada são apresentados 5 caracteres porque este é
o mínimo para que a compressão seja válida, uma vez que até 4 caracteres ela
necessita um número de byte igual ou maior. Observe também que o número
de repetições está ocupando apenas meio byte. Isso significa que ele pode
indicar apenas até 16 caracteres, ou seja, este formato permite a compactação
de uma seqüência de, no máximo, 16 caracteres.
Mas então surge a pergunta: não há como estender este formato para
permitir a compactação de uma seqüência maior de caracteres? A resposta é
sim, existe a compactação de byte inteiro, onde o número N ocupa 1 byte, ao
invés de meio. Neste formato estendido, o restante dos caracteres indicadores
permanecem os mesmos, sendo alterado apenas a representação do número de
caracteres. Com a representação de byte inteiro, a capacidade de compressão
aumenta para 256 caracteres, o que permite um ganho expressivo em se
tratando de longas seqüências de caracteres.
1.5.2.5 - Codificação Diatômica
Esta técnica de compactação permite a representação de um par de
caracteres em apenas um caracter especial. Normalmente utilizam-se tabelas

38
com pares de caracteres e sua freqüência de ocorrência em determinado tipo
de arquivo. Obviamente procura-se substituir os caracteres de maior
freqüência, associando a cada dupla um caracter especial.
Em texto da língua portuguesa, por exemplo, duplas de ocorrência
freqüente são a letra "a" acentuada com til seguido da letra o "ao" e a letra "e"
com acento agudo seguido de um espaço em branco "é". A cada uma dessas
seqüência deve-se atribuir um caracter especial para nos permitir a
compactação através da codificação diatômica. Obviamente, estes são apenas
dois exemplos de duplas de caracteres, numa tabela normal para compactação
utilizam-se mais de 20 duplas para que seja obtida uma compressão razoável.
1.5.2.6 - Substituição de Padrões
A substituição de padrões é semelhante à codificação diatômica,
pois também ocorre a substituição de um conjunto de caracteres por um
caracter especial.
PALAVRA => Ce
O processamento desta técnica é semelhante ao da substituição de
padrões, com a diferença de que são avaliados um número maior de
caracteres. Desta forma, são estabelecidas tabelas de palavras de maior
freqüência de ocorrência para substituição com o caracter especial.
A utilização mais comum para este tipo de compactação é a de
arquivos de programas de linguagens de programação. Uma vez que as
linguagens contém diversas palavras que se repetem freqüentemente em
programas, utiliza-se esta característica para a sua compactação.

39
Uma variante da substituição de padrões para permitir a codificação
de um maior número de palavras é a utilização de dois caracteres para
indicação da ocorrência de determinada palavra:
C N,
onde C é um caracter escolhido para indicar a compactação e N é o número
(binário) da palavra a substituir. Isso permite a codificação de até 256
palavras reservadas, o que anteriormente era limitado ao número de caracteres
especiais que poderíamos utilizar.
Por exemplo, as palavras reservadas begin e end da linguagem
Pascal poderiam ser, por exemplo, substituídas pelos códigos $1 e $2. As
demais palavras reservadas da linguagem também poderiam ser codificadas
desta maneira, permitindo uma compactação considerável de um arquivo de
programa.
Como esta técnica assemelha-se muito à da codificação diatômica,
deve tomar como base para a programação o algoritmo e o fluxograma
apresentados para aquela técnica. Desta forma não serão apresentados formas
distintas de programação.
1.5.2.7 - Codificação Relativa
Esta técnica de compactação é realizável quando existe a
transmissão de seqüências de caracteres numéricos. Estas seqüências podem
ser valores dentro de intervalos definidos ou valores binários.
A transmissão de valores intervalares pode ser exemplificada por
transmissões de dados provenientes de sinais de sensores. Um exemplo de
transmissão binária é o fax. Nestes dois casos, suas transmissões podem ser
comprimidas através da codificação relativa. Para cada um dos casos existe

40
um processamento adequado aos tipos de valores envolvidos, por isso,
veremos como é o processamento para a codificação de valores intervalares e
para valores binários.
1.5.2.8 - Valores Intervalares
Neste primeiro tipo, a compactação somente é válida se existe um
intervalo definido de valores, caso contrário não ocorre uma compressão
satisfatória. Isso porque este tipo de compressão baseia-se na colocação da
variação numérica de um valor a outro, desta forma:
Val Var1 Var2...
onde Val é o primeiro valor da seqüência, VarN é a variação do valor anterior
para o atual. Exemplificando de forma numérica, seja a seguinte seqüência de
caracteres numéricos:
10.3 10.1 10.8 10.4 10.4 10.9 10.2,
pode ser compactada através da codificação relativa, ficando os caracteres na
forma:
10.3 -.2 .7 -.4 0 .5 -.7,
ou seja, numa seqüência dentro de um intervalo definido entre 10.0 e 10.9, foi
possível a compressão de um conjunto de 34 para 24 caracteres.
A implementação desta técnica resume-se a apenas no
processamento da gravação direta da diferença entre os dois valores anteriores
no campo atual a comprimir. Não há nenhum outro esquema a seguir para
descrever o processo.
1.5.2.9 - Valores Binários

41
Como afirmado anteriormente, o fax utiliza-se desta forma de
compactação, portanto a comparação existente não será mais entre um valor e
outro, mas entre uma linha e a seguinte. Cada linha é um vetor de valores
binários, que representam o mapa de bits do desenho da página. O que ser
quer é transmitir apenas a variação de uma linha para outra, evitando-se a
transmissão de toda a linha.
Então, um trecho de linha binária poderia ser:
... 01001011100010101...
e a sua seguinte:
... 01001011111100001...,
a diferença seria em 5 bits:
... _________MMMM_M__... .
A representação da transmissão dessa diferença entre linhas pode
ser feita de duas formas: indicando a posição da mudança a partir do início ou
a posição a partir da mudança anterior. Além da posição da mudança,
normalmente indica-se a quantidade de mudanças de ocorreram.
Para o trecho de linha apresentado anteriormente, pode-se
representar como ponto fixo da mudança seguido da quantidade de bits
alterados:
529 4 534 1,
caso se fosse esta a única alteração na linha, que normalmente possui 1728
bits, seria uma compactação expressiva.
Compactando-se a partir do cálculo do deslocamento, o número de
bits a transmitir se reduz ainda mais:
529 4 5 1,
supondo que não há nenhuma alteração anterior a que está apresentada, a
posição inicial é fixa e as demais relativas umas às outras, contabilizando-se
apenas o numero de bits de distância de uma a outra.

42
1.6 - Compactação Estatística
A idéia da compressão estatística é realizar uma representação
otimizada de caracteres ou grupos de caracteres. Caracteres de maior
freqüência de utilização são representados por códigos binários pequenos, e
os de menor freqüência são representados por códigos proporcionalmente
maiores. Neste tipo de compactação portanto, não necessitamos saber qual
caracter vai ser compactando, mas é necessário, porém, ter o conhecimento da
probabilidade de ocorrência de todos os caracteres sujeitos à compressão.
Caso não seja possível a tabulação de todos os caracteres sujeitos à
compressão, utiliza-se uma técnica adequada para levantamento estatístico
dos dados a compactar, formando tabelas de probabilidades.
Esta Teoria baseia-se no princípio físico da Entropia. A Entropia é a
propriedade de distribuição de energia entre os átomos, tendendo ao
equilíbrio. Sempre que um sistema físico possui mais ou menos quantidade de
energia que outro sistema físico em contato direto, há troca de energia entre
ambos até que atinjam a entropia, ou seja, o equilíbrio da quantidade de
energia existente nos sistemas.
Ao atingir o estado de equilíbrio, sabe-se que estes sistemas estão
utilizando o mínimo de energia possível para sua manutenção, e assim se
manterão até que outro sistema interaja sobre eles.
Aplicada à informação, a Teoria da Entropia permite a concepção
de uma teoria da Harmonia, ou seja, um ponto de equilíbrio onde a
informação pode ser representada por uma quantidade mínima de símbolos.
Para chegarmos a esta representação ideal, basta que tenhamos a quantidade
de símbolos utilizada e a probabilidade de ocorrência deles. Com base nisso, é
possível calcular a quantidade média de bits por intervalo de símbolo.

43
1.7 - Compactação Fixa versus Compressão Auto-adaptável
Caso as probabilidades nas quais foram concebidos os códigos da
tabela forem distintos para determinado arquivo a compactar, este será
prejudicado na compactação. Para resolver este caso utiliza-se uma tabela
adaptável.
A tabela adaptável consiste na mesma tabela que conhecemos,
contendo o caracter e seu código, acrescida de mais uma coluna contendo a
contagem de ocorrência do caracter no arquivo a compactar. Efetua-se,
portanto, uma contagem de quantos caracteres ocorrem no arquivo, e ordena-
se a coluna dos caracteres em ordem crescente a partir desta coluna da
contagem, mantendo a coluna de código inalterada. Como resultado, obtém-se
uma tabela com os caracteres de ocorrência mais freqüente sendo codificados
com menos bits.
Tabela 2 – Caracter, código e a contagem.
Caracter Código Contagem
C1 0 0 C2 10 0 C3 110 0 C4 1110 0 C5 1111 0
Considere a tabela 2, contendo o caracter, o código e a contagem.
Caso o caracter C3 ocorra 21 vezes, o C2 18 vezes, C1 10 vezes, o C5 3 vezes
e o C4 2 vezes, a tabela 3 mostra a nova configuração.

44
Tabela 3 – Nova configuração.
Caracter Código Contagem C3 0 21 C2 10 18 C1 110 10 C5 1110 3 C4 1111 2
Comparando-se a tabela 2 e 3, a codificação continuou a mesma,
mas a correspondência foi alterada para a situação específica do arquivo
comprimido em questão. Observamos, portanto, a necessidade de realizarmos
um processamento de leitura e cálculo anterior à compressão propriamente
dita, o que implica em maior tempo gasto do que com a utilização da tabela
fixa.
Com a compactação auto-adaptável ganha-se, obviamente, uma
compactação mais eficiente. Por outro lado, há um problema pela própria
variabilidade da tabela: para a descompactação, há a necessidade de se anexar
a tabela ao arquivo compactado, para que os códigos correspondentes possam
ser devidamente decodificados.
1.8 - O código de Lempel-Ziv
Um código alternativo é o código de Lempel-Ziv. Por volta de1977,
Abraham Lempel e Jacob Ziv desenvolveram uma classe de compactação de
dados com dicionário adaptativo chamado de Lempel-Ziv.
Posteriormente, Terry Welch, melhorou o código de Lempel-Ziv,
criando o hoje chamado de código LZW que constrói um dicionário dos
grupos de caracteres mais freqüentemente usados. É importante ressaltar que
antes que o arquivo seja descompactado é necessário que se envie o dicionário
de compactação. Este método é melhor para compactação de arquivos textos

45
cujo conteúdo é de caracteres ASCII, mas não tão bom para arquivos de
imagens, cujo conteúdo possui amostras repetitivas de dígitos binários que
podem não ser múltiplos de 8 bits [3].
O algoritmo LZW é organizado por uma tabela de tradução,
chamada de tabela de seqüência de caracteres, que mapeia esta seqüência de
dados de entrada em códigos de tamanhos fixos. O uso de códigos de 12 bits é
comum. A tabela de seqüência de caracteres LZW tem uma propriedade pré-
estabelecida que para toda seqüência de caracteres já tabulada sua seqüência
de caractres anterior já esteja na tabela. Isto é, se uma seqüência de caractres
ωK, composta de uma string ω e algum único caracter K, estiver na tabela,
então ω está na tabela. K é chamado de caracter extendido da seqüência de
caractres ω . A tabela de seqüência de caracteres é inicializada para conter
todo o conjunto de caracteres únicos [3].
Abaixo o algoritmo LZW de compactação proposto por Terry
Welch:
Inicializar tabela que conterá caracteres
Ler a primeira entrada de caracteres – prefixo ω
Passo: Ler próxima entrada de caracter K
Se K não for suficiente (entrada esgotada): código(ω) -> saída; SAI
Se ωK existir na tabela de strings: ωK – ω; repetir Passo.
Senão ωK não está na tabela: código(ω) -> saída;
ωK-> tabela de strings;
K-> repetir Passo.
Abaixo o algoritmo LZW de compactação proposto por Terry
Welch:
Descompactação:
Leia código primeira entrada -> CÓDIGO ->VELHOcódigo;

46
Com CÓDIGO = codigo(K); K->saída;
Próximo Código:
Leia próxima entrada de código -> CÓDIGO ->INcódigo;
Se não há código: Saia.. senão
Próximo Símbolo:
Se CÓDIGO = código(ωK); K->saída;
código(ω) -> CÓDIGO;
Repetir próximo símbolo
Senão se CÓDIGO = código(K): K-> saída;
VELHOcódigo, K-> tabela de string
INcódigo->VELHOcódigo;
Repetir próximo código.
Colocamos na figura 5 abaixo uma tabela que será utilizada no
exemplo da figura 6.
TABELA DESTRINGS
TABELA ALTERNATIVA
abc
abc
abc
abc
abbaabccbbabbabaaaaaaaaa
456789101112
1b2a4c3b5b8a1a10a11a
456789101112
Figura 5 – Tabela de Strings
Esta tabela é inicializada com três valores de código para três

47
caracteres. Utilizamos esta tabela de strings para codificarmos os símbolos de
entrada mostrados na figura 6 abaixo.
a b a b c b a b a b a a a a a a a
4
1 2 4 3 5 8 1 10 11 1
5 7 9 11
6 8 1210
Símbolos de entradaCódigos de saídaNovas stringsadicionadasà tabela
Figura 6 – Um exemplo de compactaçaõ
Nesta figura, os dados de entrada estão sendo lidos da esquerda para
direita, começando pelo caracter “a”. À medida que vão sendo encontradas
seqüências de caracteres diferentes, um novo código é atribuído à seqüência e
adicionado à tabela.
Na figura 7 temos um exemplo de descompactação utilizando LZW.
Códigos de entrada
Dados desaída
Strings adicionadosà tabela
1 2 4 3 5 8 1 10 11 v v v v v v v v v a b 1b c 2a 5b a 1a 10a v v v v v a b 2a a 1a v v b aa b ab c ab bab a aa aaa
4 6 8 10
5 7 9 11
Figura 7 – Exemplo de descompactação.
Nesta figura temos que o código é traduzido por realocação
recursiva do código com um código de prefixo e seu caracter extendido
proveniente da tabela de strings, figura 5. Por exemplo, o código 5 é

48
substituído pelo código 2 e “a”, e então o código 2 é substituído por “b”.
Existe também o VLC (do inglês: Variable-Length-Code) LZW que
usa uma variação do algoritmo LZW onde códigos de tamanho variado são
usados para sobrescrever amostras detectadas dos dados originais. Ele usa um
dicionário construído a partir de trechos encontrados nos dados originais.
Cada novo trecho semelhante é inicializado no dicionário e um endereço
indexado é usado para substituir a faixa compactada. O trasmissor e o
receptor mantém o mesmo dicionário.
A parte VLC do algoritmo é baseada num tamanho de código inicial
(o código inicial de LZW), que especifica o número inicial de bits usados para
compactação. Quando o número de amostras detectadas pelo compactador no
stream de entrada exceder o número de amostras codificáveis então o número
de bits do código LZW é acrescido de um. O tamanho do código é
inicialmente transmitido para que o receptor saiba o tamanho do dicionário e
o tamanho das palavras-código.
Em 1985 , o algoritmo LZW foi patenteado pela Sperry Corp. Ele é
usado no formato de arquivo GIF e é similar a técnica usada para compactar
dados no V.42bis modems.
O código de Lempel-Ziv, assim como o código de Huffman, possui
algumas desvantagens. A compressão LZ substitui as amostras repetitivas
detectadas através de referências ao dicionário. Infelizmente quanto maior o
dicionário, maior o número de bits necessários para a referência. O valor
ótimo do dicionário também varia quanto aos diferentes tipos de dados.
quanto mais variável os dados, menor será o valor ótimo para o dicionário [3].
1.9 - Codificação Lempel-Ziv
A compactação Lempel-Ziv é um tipo de compactação de cadeia
que forma strings de caracteres a partir de sua ocorrência, criando tabelas de

49
strings conforme vão acontecendo. Dada a interessante abordagem utilizada
nesse tipo de compactação, melhor do que as anteriormente estudadas, a
codificação Lempel-Ziv foi aprimorada e tornada padrão para a compressão
de dados transmitidos via modem. Esta técnica padrão baseada na Lempel-Ziv
é a recomendação V. 42 bis do CCITT (do inglês: Consultative Committee for
International Telephone and Telegraph).
A codificação Lempel-Ziv utiliza probabilidades de cadeias de
caracteres ao invés de apenas um caracter. Qual a vantagem disso?
Em primeiro lugar, vamos analisar qual é a influência da
probabilidade sobre o número teórico de bits para representação de
determinado conjunto de caracteres. Para tanto, vamos pegar os caracteres C1
e C2 para verificar a relação entre probabilidade e número teórico de bits.
Para sabermos este número teórico de bits precisamos calcular a harmonia,
que nos dá o número de bits por intervalo de símbolo. Assim, se C1 tiver
probabilidade 0,8 e C2 tiver 0,2, sua entropia será 0,72, e assim
sucessivamente, conforme mostra a tabela 4.
Tabela 4 - Entropia.
C1 C2 Entropia 0,8 0,2 0,72 0,7 0,3 0,88 0,6 0,4 0,97 0,5 0,5 1
Comparando os de C1 e C2 na tabela 4, quanto mais distinta for a
pordentagem, maior é o aproveitamento de bits. Para aproveitarmos isso como
forma de compactação, basta criarmos conjuntos de caracteres de forma a
acumular porcentagens.

50
Assim, podemos acumular os caracteres em cadeias do tipo C1C1,
C1C2, etc. Para verificarmos se há ganho no comprimento médio de bits,
vamos iniciar analisando as probabilidades de cadeias de 2 caracteres na
tabela 5 , onde foi estabelecido C1 com probabilidade 0,7 e C2 com 0,3.
Tabela 5 – Probabilidade de ocorrência.
C1 C2 0,49 C1 C2 0,21 C2 C1 0,21 C2 C2 0,09
A probabilidade de ocorrência da cadeia C1C1 é de 0,7*0,7 = 0,49,
ou 49%. O mesmo raciocínio aplica-se às demais combinações. Utilizando a
codificação Huffman, podemos estabelecer o tamanho médio ocupado pelo
grupo de cadeias da tabela anterior.
Tabela 6 – Tamanho médio de bits
C1 C1 0 C1 C2 10 C2 C1 110 C2 C2 111
Obtendo-se os códigos binários, que podem ser observados na
tabela 6, pode-se calcular o tamanho médio de bits ocupado, dado por:
T = 0,49*1 + 0,21*2 + 0,21*3 + 0,09*3 = 1,81 bits
O valor de 1,81 bits para representação da cadeia pode parecer
grande, mas se dividirmos por 2, teremos 0.905 bit por caracter, menor que 1
bit por caracter no caso de codificarmos o bit 0 para C1 e bit 1 para C2.

51
Seguindo este raciocínio, podemos ampliar a idéia para um número maior de
caracteres e chegaremos à conclusão de que, quanto maior a cadeia, mais
caracteres serão passíveis de compactação.
Desta forma, a Lempel-Ziv utiliza um conjunto de regras para
analisar as cadeias de um conjunto de caracteres pré-definido. As cadeias são
montadas e codificadas à medida em que são lidos os caracteres a codificar. A
forma de composição destas cadeias está descrita na técnica V. 42 bis descrita
a seguir.
A Lempel-Ziv foi melhorada e é utilizada como uma técnica padrão
para transmissão através de modens. Esta técnica possui um tamanho máximo
de cadeia que pode variar de 6 a 250 caracteres para formação de cadeia.
Existe um dicionário com 512 cadeias básicas codificadas, mas este não é
restrito a elas.
O dicionário de cadeias é dinâmico e pode ter cadeias acrescentadas
e retiradas em tempo de compactação. A formação de novas cadeias é baseada
na comparação das cadeias lidas com as existentes no dicionário. Se a cadeia
lida não existe, ela é acrescentada e recebe um código que a representa como
cadeia compactada.
Como o modem transmissor é o que faz a compactação e o
dicionário é dinâmico, como o modem receptor irá decifrar os códigos para
descompactá-los? Simples, a cada nova cadeia formada no transmissor são
enviados os caracteres ou a primeira subcadeia que a compõe e o código
correspondente à nova cadeia, para que exista uma réplica do dicionário no
receptor.
É utilizada uma estrutura de dados em árvore para implementação
do dicionário de cadeias. A partir de uma cadeia pré-definida é formada uma
árvore para processamento das cadeias. Seja a cadeia pré-definida DA , a

52
partir da qual derivam-se as cadeias DATA e DADO. Para esta seqüência, a
estrutura será dada pela figura 5.
Figura 8 – Árvore para processamento das cadeias
Os valores ao lado de cada caracter é o código correspondente à
cadeia composta até aquele nó da árvore, ou seja, a cadeia DA possui código
300, a cadeia DAT possui código 342, e assim por diante. Desta forma,
amplia-se o dicionário sem prejudicar as codificações existentes e permite, ao
mesmo tempo, a verificação de variações deste códigos.
Existe ainda, a possibilidade de substituição de códigos pouco
utilizados. Uma vez definida um número N de códigos possíveis, ao atingir
este número, procura-se um código que corresponda a um nó folha que não
esteja sendo utilizado na compactação em curso. Caso exista, a nova cadeia
utiliza o código da cadeia antiga não utilizada. Ocorre, portanto, eliminação
de códigos do dicionário. Esta é a técnica padrão V. 42 bis utilizada para
compressão na transmissão de dados via modem. Ela baseia-se na codificação
em cadeia de Lempel-Ziv, utilizando-se da multiplicação das probabilidades
de ocorrência de caracteres, para, em cima das estatísticas de cadeias, permitir
a compressão de bits utilizados na transmissão de dados.
342 T
343 A
DA 300
D 378
O 379

53
CAPÍTULO 2
O PROBLEMA
2.1 - Introdução
Basicamente compactar dados significa reduzir o seu tamanho
original de tal maneira que possamos reconstituí-lo originalmente sem perda
de informação. Ela pode ser aplicada em arquivos de dados, documentos,
imagens, etc. A figura 6 mostra o processo de compactação.
Figura 9 - Ilustrando compactação de Dados
COMPACTAÇÃO
DESCOMPACTAÇÃO
MEIO
SÍMBOLOS
DE ENTRADA
SEQUÊNCIA
DE
CARACTERES
SAÍDA DE
SÍMBOLOS
DADOS
DADOS
COMPACTADOS CÓDIGO
DADOS ARMAZENADOS/ LINHA DE COMUNICAÇÃO

54
As duas técnicas mais utilizadas é a de código estatístico e a de
supressão de seqüências repetitivas. Vamos fazer uma digressão sobre estas
duas técnicas.
O mais popular método de compactação que utiliza código
estatístico é o Código de Huffman que consiste em traduzir pedaços de
tamanho fixo em símbolos de tamanho variável. Ele procura uma maneira de
gerar códigos para os símbolos de entrada cujo tamanho destes código em bits
é aproximadamente log2(probabilidade do símbolo), onde a probabilidade do
símbolo é a freqüência relativa de ocorrência de um símbolo dado expresso
em probabilidade. Por exemplo, se o símbolo “Y” é encontrado 0,1 por cento
do tempo, então ele será representado por 10 bits. Na implementação de nosso compactador utilizando Código de
Huffman, tomamos um arquivo .txt que desejamos compactar e geramos um
arquivo .huf cujo conteúdo é inteligível apenas quando aplicamos o processo
inverso o que chamamos de descompactação.
Como propósito de pesquisa, optamos por fazer uma filtragem do
arquivo texto inicial, que consiste basicamente em considerar somente
caracteres maiúsculos; ou seja, qualquer texto que utilize nosso programa só
poderá ser processado, para nível de pesquisa, se todos seus caracteres forem
maiúsculos. Entretanto, o compactador de Huffman implementado funciona
tanto para caracteres maiúsculos como para caracteres minúsculos.
Um formulário no programa implementado a partir da leitura de um
texto retorna uma estatística de freqüência de caracteres.
Para obter uma estatística fixa, fizemos uma compilação de cem
arquivos textos diferentes das mais diversas fontes, em língua portuguesa,
aplicando o programa implementado, cujos resultados foram tabulados e cuja
tabulação será utilizada para se estimar a média em percentagem de caracteres
de um texto qualquer em língua portuguesa.

55
Tabela 7 - Estatística Fixa.
Caracter Cadeia de bits Huffman Percentagem
espaço 000 16,90%E 101 11,40%A 111 8,53%O 0011 7,88%S 0111 6,77%R 1001 5,36%U 1101 4,10%M 00101 4,00%N 01001 3,90%I 01000 3,80%D 01011 3,47%P 01101 2,99%T 10001 2,87%C 10000 2,69%Q 001001 2,14%L 010101 1,66%. 110011 1,13%Ã 110010 1,00%, 0010001 0,90%| 0101001 0,90%| 0101000 0,90%
G 0110011 0,75%Ê 0110010 0,70%F 1100001 0,63%H 00100001 0,48%B 01100001 0,48%Á 01100011 0,40%Ç 01100010 0,35%É 11000001 0,30%Z 001000001 0,25%I 011000001 0,23%X 110000001 0,15%- 110000000 0,12%Ó 0010000001 0,12%Í 0110000001 0,10%Â 0110000001 0,0005%W 01100000000 0,00025% K 001000000001 0,00025% “ 0010000000000 0,00025% ! 001000000011 0 00025%

56
A estatística fixa obtida para a língua portuguesa poderá ser
utilizada para que possamos montar a árvore de Huffman, utilizando sempre
as freqüências padrões, o que pode gerar uma compactação não ótima.
Evitamos armazenar uma tabela de correspondência de caracteres com sua
seqüência de bits montada dinamicamente pela árvore de Huffman gerada ao
se compactar o arquivo. A tabela 7 terá que ser de alguma forma armazenada,
ou como cabeçalho do arquivo compactado, ou como algum arquivo anexo.
2.2 - Proposta para implementação do compactador de Huffman
Como proposta para implementação do compactador de dados
dividimos o programa em dois formulários principais. O primeiro formulário
é mostrado na figura abaixo.
Figura 10 – Formulário Huffman
57
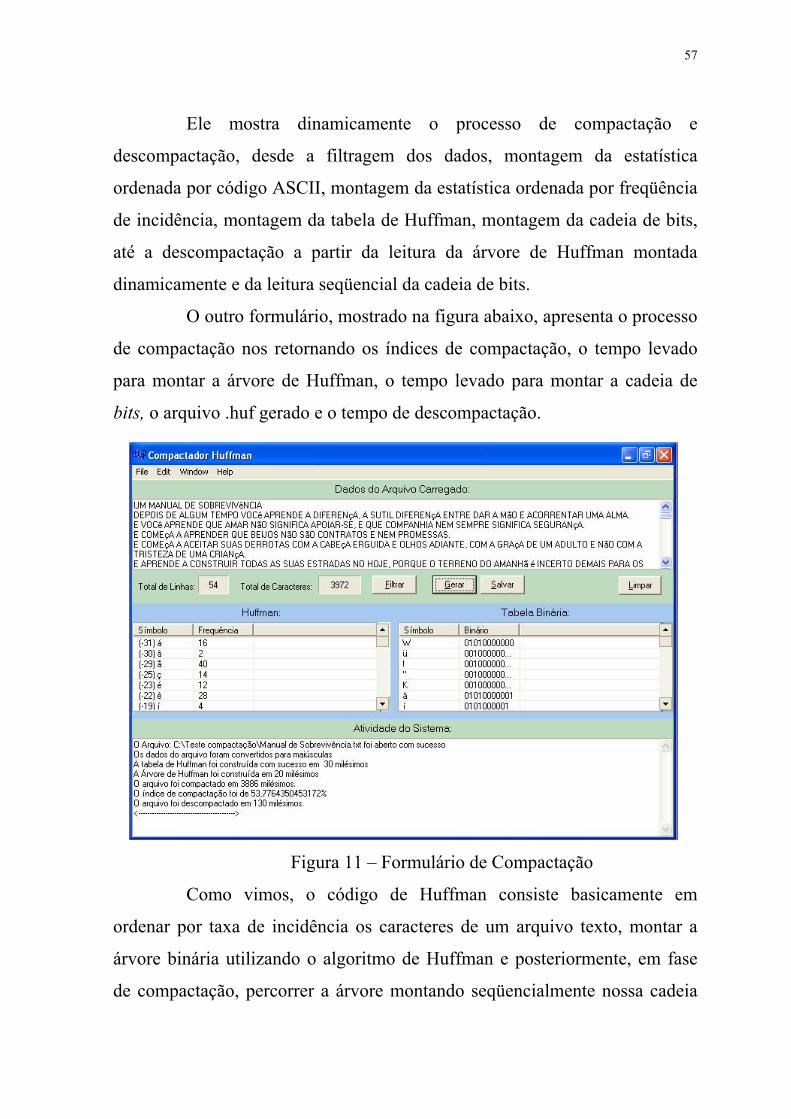
Ele mostra dinamicamente o processo de compactação e
descompactação, desde a filtragem dos dados, montagem da estatística
ordenada por código ASCII, montagem da estatística ordenada por freqüência
de incidência, montagem da tabela de Huffman, montagem da cadeia de bits,
até a descompactação a partir da leitura da árvore de Huffman montada
dinamicamente e da leitura seqüencial da cadeia de bits.
O outro formulário, mostrado na figura abaixo, apresenta o processo
de compactação nos retornando os índices de compactação, o tempo levado
para montar a árvore de Huffman, o tempo levado para montar a cadeia de
bits, o arquivo .huf gerado e o tempo de descompactação.
Figura 11 – Formulário de Compactação
Como vimos, o código de Huffman consiste basicamente em
ordenar por taxa de incidência os caracteres de um arquivo texto, montar a
árvore binária utilizando o algoritmo de Huffman e posteriormente, em fase
de compactação, percorrer a árvore montando seqüencialmente nossa cadeia

58
de bits. Esta cadeia de bits será gravada como um arquivo .huf, em binário,
para que possamos conseguir fisicamente um arquivo final reduzido.
A linguagem utilizada para implementação do compactador
implementado foi a Linguagem C++, utilizando o Builder como compilador.
Esta linguagem é poderosíssima no que tange a recursos oferecidos de
orientação a objeto, permitindo-nos utilizar uma filosofia que está
modificando os paradigmas da programação, o conceito de "reutilizar,
reutilizar, reutilizar".
Nesse sentido, utilizamos uma ferramenta de muito impacto em
C++ para implementação inicial de nosso código de Huffman: as STL's (do
inglês: Standart Template Library). A STL é uma biblioteca padrão de
gabaritos e foi desenvolvida por Alexander Stepanov e Meng Lee na Hewlett-
Packard. Baseada na pesquisa de campo da programação genérica e teve
também contribuições significativas de David Musser.
Além de se utilizar de gabaritos, uma STL gera códigos que o
programador não necessariamente precisa digitar, combinando a
generalização de gabaritos com a disponibilidade de bibliotecas padrões. As
STL's possuem três componentes-chaves, contêineres, iteradores e algoritmos.
Em nosso projeto, utilizamos um conteiner chamado de multimap
que possui as seguintes características: mapeamento um para muitos,
duplicatas não-permitidas e pesquisa rápida usando chaves. Está na classe de
contêineres associativos. Contêineres associativos da STL destinam-se a
fornecer acesso direto para armazenar e recuperar elementos via chaves. Ao
todo existem quatro contêineres associativos: multiset, set, multimap e map.
Em cada contêiner, as chaves são mantidas em ordem classificada.
Iterar através de um contêiner associativo percorre o mesmo em uma ordem
classificada para aquele contêiner. As classes multiset e set fornecem
operações para manipular conjuntos de valores nos quais os próprios valores

59
são as chaves, isto é, não há um valor separado associado a cada chave. A
principal diferença entre um multiset e um set é que um multiset permite
chaves duplicadas e um set não permite. As classes multimap e map fornecem
operações para manipular valores associados com chaves (estes valores às
vezes são referidos como valores mapeados). A principal diferença entre um
multimap e um map é que um multimap permite chaves duplicadas com
valores associados.
Em nosso projeto utilizamos o multimap, para armazenagem e
recuperação rápidas de chaves e valores associados (pares chave/valor).
Quando se insere em um multimap, um objeto pair, que contém a chave e o
valor, é usado. A ordenação das chaves é determinada por um objeto função
comparadora. Por exemplo, em um multimap que usa inteiros como tipo de
chave, as chaves podem ser classificadas em ordem ascendente ordenando as
chaves com o objeto função comparadora less<int>. Chaves duplicadas são
permitidas em um multimap, de modo que valores múltiplos podem ser
associados com uma chave única. Isto é chamado freqüentemente de um
relacionamento um para muitos. Um multimap suporta iteradores
bidirecionais mas não iteradores de acesso aleatório.
Depois dessa breve incursão sobre STL's, voltemos ao algoritmo de
Huffman. Nosso primeiro passo, é contar quantos caracteres de cada símbolo
aparecem no texto e ordená-los por critério de aparição. Conseguimos isso
processando a cadeia de strings (texto inicial), caracter por caracter na
implementação do compactador, linha por linha e a medida que processamos
este texto alimentamos o multimap, que com o objeto função comparadora
adequado nos retornará a lista completamente ordenada.
A segunda fase do Código de Huffman consiste em montar a árvore
de Huffman da estatística concluída. É imprescindível que se utilize uma
árvore binária. Somente com esta estrutura de dados é que iremos conseguir

60
um código unicamente decodificável.
Uma árvore binária é uma N-ary tree cujo N seja igual a dois. Há
algumas características interessantes que provem da limitação de N = 2. Por
exemplo, há um interessante relacionamento entre árvores binárias e o sistema
de números binários. Árvores binárias são úteis para representação de
expressões matemáticas envolvendo operações matemáticas, tais como adição
e multiplicação.
Uma árvore binária T é um conjunto finito de nós os quais possuem
as seguintes propriedades. O conjunto pode estar vazio;
Ou o conjunto consiste em uma raiz, r, e exatamente duas árvores
binárias TL e TR distintas, T = {r, TL, TR}.
A árvore TL é chamada subárvore de T, e a árvore TR é chamada
subárvore de T.
Árvores binárias são quase sempre consideradas árvores ordenadas.
Então, subárvores TL e TR são chamadas subárvores da esquerda e da direita,
respectivamente.
Para implementação de árvores binárias temos uma classe em C++
cuja hierarquia é mostrada na figura 9. São inclusas General Trees, N-ary
trees e Binary Trees. Os vários tipos de árvores são vistas como classes de
contêineres.
Figura 12 – Estrutura hierárquica de classes da árvore binária
GeneralTree
NaryTree
BinaryTree
Ownershipe
Object
Container Tree

61
2.3 - Desempenho do compactador de Huffman implementado
Para arquivos textos maiores que 40 KB, o compactador de arquivos
implementado, apresentou uma ligeira demora na compactação, e na
descompactação que tende a crescer exponencialmente com o aumento linear
do arquivo. Isso porque ao compactarmos, temos que fazer sucessivas leituras
na árvore de Huffman para montarmos a cadeia de caracteres. Ao
descompactarmos, temos que fazer o processo inverso com a sobrecarga das
comparações com o cabeçalho.
Constatamos um problema inerente ao Código de Huffman: a
complexidade de descompactação. O método básico para interpretar cada
código é ler cada bit da seqüência. Operacionalmente, uma decisão lógica é
feita para cada bit. Em geral, descompactação com símbolos de tamanho
variável provê um custo/desempenho em decadência à medida que o volume
de dados aumente.
2.4 - Testes realizados
Realizamos alguns teste s comparativos utilizando três compactadores
comerciais e o nosso programa que utiliza o Código de Huffman, afim de que
possamos comparar os índices de compactação.
Os compactadores utilizados foram: Gzip [7], Winrar [8], Winzip [9] e
Huffman. Utilizamos dois arquivos para teste: Manual de Sobrevivência.txt - um
arquivo texto cujo tamanho original é de 3.972 bytes - e Programa.cpp que é
arquivo código-fonte do compactador de Huffman implementado. Os resultado
obtidos estão na tabela 8.

62
Tabela 8 - Comparação índices de compactação médios.
Nº Arquivo Tamanho
(bytes)
Gzip
(bytes)
WinRar
(bytes)
Winzip
(bytes)
Huffman
(bytes)
1. .txt 3.972 1.721 1.827 1.855 3.715
2. .cpp 4.105 1.469 1.529 1.575 2.557
3. .log 16.497 1.541 1.578 1.664 9.842
4. .htm 5.419 1.809 1.879 1.909 1.075
5. .obj 6.642 2.103 2.205 2.256 2.450
Para o primeiro arquivo (Manual de Sobrevivência.txt) obtivemos o
melhor índice de compactação para o programa Gzip [7], exatamente 43,33 %.
Em seguida, vem o Winrar [8] com 45,50%, depois o Winzip [9] com 48,92% e
o Huffman com 93,53%.
Para o segundo arquivo (Programa.cpp) tivemos um índice de
compactação para o código de Huffman de 62,28%. Em seguida, vem o Gzip [7]
com índice de 35,78%, depois o Winrar [8] com 37,25% e o Winzip [9] com
38,37%.
Percebemos que, no primeiro caso, o Código de Huffman teve um
índice de compactação em termos absoluto e relativo pior que no segundo caso.
Isto se deve a dois motivos: primeiramente quanto menor a quantidade de
símbolos diferentes entre si, melhor será o índice de compactação para o
Compactador de Huffman. Não é o que acontece no primeiro arquivo, cujo texto
está repleto de símbolos diferentes num universo total de caracteres
relativamente pequeno, algo como 3.972 caracteres. Em segundo lugar, o código
de Huffman, estabelece a menor cadeia de bits para o símbolo que apareceu a
maior quantidade de vezes. Obtemos um arquivo com índice de compactação
menor, quanto maior for a quantidade de vezes que esse símbolo apareça. Isto é

63
o que ocorre num arquivo.cpp, pois neste arquivo, temos uma espantosa soma de
espaços que o compactador de Huffman reduziu extraordinariamente bem.
2.5 - Aplicações
Muitos programas de compactação atualmente utilizam programas
que usam Lempel-Ziv ou Huffman, ou ainda as duas técnicas. As duas
técnicas são sem perda de dados. Em geral, Huffman é o mais eficiente,
porém, requer dois passos sobre os dados, enquanto Lempel-Ziv usa somente
um passo. Este mecanismo de um único passo é obviamente importante no
momento em que gravamos num disco rígido ou quando a decodificação ou
decodificação dos dados ocorre em comunicações em tempo real. Uma das
variantes mais utilizadas é o LZS, pertencente a Stac Eletronics (que foi a
primeira companhia a produzir um driver compactado, chamado de Stacker).
A Microsoft incluiu uma variação deste programa, chamada de DoubleSpace
no DOS versão 6 e Drive-Space no Windows 95.
A técnica LZS é tipicamente usada em dispositivos de recuperação
de dados de massa, tais como dispositivos de fitas, onde a compactação pode
tanto ser implementada em hardware como em software, o que permite que o
dispositivo de fita armazene pelo menos duas vezes sua capacidade física.
O volume de compactação depende do tipo de arquivo que está
sendo compactado. Arquivos aleatórios, tais como programas executáveis ou
arquivos de código objeto, tipicamente possuem baixa compactação,
resultando num arquivo que está entre 50 a 95% do arquivo original. Ainda,
imagens e arquivos de animação tendem a tem uma alta compactação e
normalmente resulta num arquivo que está entre 2 a 20% do arquivo original.
Devemos ressaltar que um arquivo já compactado não há virtualmente ganho
algum em compactá-lo novamente, a menos que uma nova técnica seja usada.

64
Tipicamente arquivos produzidos pelo método de compactação
LZ77/LZ78 são ZIP, ARJ, LZH, Z, entre outros. Huffman é usado em
utilitários ARC e PKARC, e em comandos UNIX.
DriveSpace e DoubleSpace são programas utilizados em sistemas
PC para compactação de arquivos em drives de disco rígido. Eles se utilizam
de uma mistura de códigos Huffman e Lempel-Ziv, onde o Código de
Huffman é utilizado para diferenciação entre dados (valores literais) e o LZ é
usado para referências.
O Gráfico de Interfaces Gráficas (GIF) utiliza um algoritmo de
compactação baseado no Lempel-Ziv-Welsh (LZW). Ao compactar uma
imagem o programa de compactação mantém uma lista de parcelas de cadeias
de caracteres foram achadas previamente. Quando uma amostra repetida é
encontrada, o item referido é substituído por um ponteiro ao original. Desde
que imagens tendam a conter muitos valores repetidos, o formato GIF é uma
boa técnica de compactação.
Os programas UNIX compactam e descompactam utilizando o
código adaptativo de Lempel-Ziv. Esta é, em geral, uma opção melhor do que
os programas baseados no Código de Huffman. Quando possível, o programa
de compactação adiciona um .z no arquivo compactado. Este arquivos podem
ser originariamente recuperados usando o descompactador ou programas zcat.
O utilitário freeware zôo baseado em UNIX aplica o algoritmo de
Lempel-Ziv. Ele pode armazenar e extrair seletivamente gerações múltiplas
do mesmo arquivo.

65
CONCLUSÃO
Como conclusão de nosso trabalho ressaltamos a importância dos
compactadores. Através destes poderosos instrumentos que diminui o tempo
de transmissão de dados e diminui o espaço ocupado por arquivos. Este
trabalho enfocou duas vertentes de compactadores que são utilizados
atualmente: compactadores estatísticos e compactadores com dicionários, o
primeiro, é representado pelo Código de Huffman e o segundo, pelo LZW.
Quanto ao nosso compactador Huffman implementado, vimos que
existem alguns problemas que são inerentes ao próprio Código de Huffman:
tais como a expressiva queda na performance do compactador para arquivos
grandes, e a ineficiência do código ao trabalhar com árvores binárias com
leituras recursivas para formação do Código de Huffman e montagem da
cadeia de bits e sua leitura acompanhado pela árvore de Huffman para
executar o processo de descompactação. Aliás, este é um dos motivos pelo
qual o Código LZW é mais usado.
Em nosso compactador implementado, por exemplo, temos que para
arquivos maiores que 15KB, temos uma demora de até cinco minutos para
executar o processo de compactação e descompactação.
Para trabalhos futuros, podemos propor a junção do Código LZW e
o Código de Huffman numa estrutura híbrida que será aplicada para cada tipo
de arquivo em particular, aplicando um ou outro algoritmo ou os dois
simultaneamente em maior ou menor proporção.

66
REFERÊNCIAS BIBLIOGRÁFICAS
[1] HELD, Gilbert, Comunicação de Dados. Rio de Janeiro: Editora Campus,
1999.
[2] SZWARCFITER, J. L. & MARKENZON, L. Estrutura de dados e seus algoritmos. Rio de Janeiro: Editora LTC, 1994.
[3] TERRY A. Sperry Research Center. A Technique for High-Performance
Data Compression. IEEE, 1984.
[4] DEITEL, H. M. e DEITEL, P. J. C++: como programar. Porto Alegre: Editora Bookman, 2001.
[5] PREISS, B. R. Data Structures and Algorithms with object – oriented desing patterns in C++. New York: Editora John Wiley & Sons, Inc, 1999.
[6] ZIV, J. e LEMPEL A., “Compression of individual sequences via variable-rate coding”. IEEE Transactions on Information Theory, Vol. it-24, n 5. september 1978, 530 a 536.
[7] www.gzip.org
[8] www.rarlab.com
[9] www.winzip.com





























