Embed Size (px)
Citation preview

Desempenho de computação paralela o paralelismo existente na aplicação
decomposição do problema em subproblemas menores
a alocação destes subproblemas aos processadores
o modo de acesso aos dados: – a existência de uma memória global
– ou distribuída ! comunicação por trocas de mensagens
a estrutura de interconexão entre os processadores
a velocidade dos processadores, memórias e rede de interconexão.
Em ambientes distribuídos, a meta é de explorar e tirar proveito ao máximo do potencial computacional, sendo assim questões relacionadas ao gerenciamento de recursos do sistema muito importante

Escalonamento de Aplicações
Um algoritmo que estabelece como executar um algoritmo paralelo em um determinado sistema de computadores
Para implementar um escalonador, o problema tem que ser especificado: – As características da aplicação devem ser especificadas – As características cruciais do sistema de processadores em questão
devem ser estabelecidas

Modelagem Representação do problema
– Algoritmo paralelo composto por processos/threads que sincronizam parcialmente (comunicação/dependência)
– Conjunto de threads/processos independentes
Representação do ambiente de solução
Simplificação, sem omitir as características que afetam o desempenho em geral

Qual o objetivo? Escalonar aplicações em um sistema paralelo e distribuído tal que o
tempo de execução seja minimizado
Escalonar aplicações em um número limitado de processadores tal que o tempo de execução seja minimizado, considerando custo de comunicação
Escalonar aplicações em um número limitado de processadores tal que o tempo de execução seja minimizado considerando tempos limites (deadline), considerando custo de comunicação
⇓ o objetivo deve estar especificado

Questões de projeto Alocação de processos a processadores
Processos podem ser alocados a certos processadores e não mudar até o seu término – Exemplo: processo Px é associado ao núcleo Ny até o seu término – Escalonador de curto prazo é aplicado (pode ser preemptivo ou não)
– Vantagem: • menos overhead/sobrecarga • Escalonamento meio que estático

Questões de projeto Alocação de processos a processadores (alocação estática de processos a processadores)
– Desvantagem: • Associar em um determinado momento vários processos a um processador (núcleo) e
outro processador se tornar ocioso – não explora a ociosidade de processador
Solução para minimiza a ociosidade de processadores – um processo pode ser alocado a diferentes processadores durante sua vida – Pode ser vantajoso em um ambiente de memória compartilhada devido a uma
menor sobrecarga na troca de contexto – No entanto pode aumentar chache miss
• Por que?
Questões de projeto Paradigmas de alocação De qualquer forma, quem associa? Como pode ser o modelo? Duas abordagens: mestre/trabalhador e peer

Paradigmas de alocação Mestre/trabalhador As funções de escalonamento executam em um processador: o mestre Os outros processadores executam os processos de usuário (os
trabalhadores) Abordagem é simples e as políticas de uniprocessador podem ser mais
facilmente adaptadas Conflitos ficam mais fáceis de serem resolvidos pois o mestre tem visão
de toda a memória e todos os dispositivos de I/O Desvantagem:
– Falha do mestre – Mestre pode ser tornar um gargalo

Paradigmas de alocação Mestre/trabalhador As funções de escalonamento executam em um processador: o mestre Os outros processadores executam os processos de usuário (os
trabalhadores) Abordagem é simples e as políticas de uniprocessador podem ser mais
facilmente adaptadas Conflitos ficam mais fáceis de serem resolvidos pois o mestre tem visão
de toda a memória e todos os dispositivos de I/O Desvantagem:
– Falha do mestre – Mestre pode ser tornar um gargalo

Paradigmas de alocação Peer ou escalonador distribuído O núcleo pode ser executado em qualquer processador Cada processador faz self-scheduling de um pool de processos
disponíveis Vantagem:
– melhor otimização do problema e visão global
Desvantagem: – complicação de implementação – Necessidade de sincronização de diferentes processadores
Escalonamento de processos Tradicionalmente em sistemas de multiprocessadores, processos não
estão alocados exclusivamente a um processador Em geral:
Fila única
P1
P2
P3
P4

IC - UFF 12
Escalonamento de Processos
Exemplo de estudo comparativo S1 - sistema com um processador S2 - sistema duo-processador
● Supondo ■ taxa de processamento de cada processador em S2 = ½ taxa processamento
do processador de S1
■ Então, a pergunta é: é melhor ter dois processadores mais lentos do que um mais rápido?
IC - UFF 13
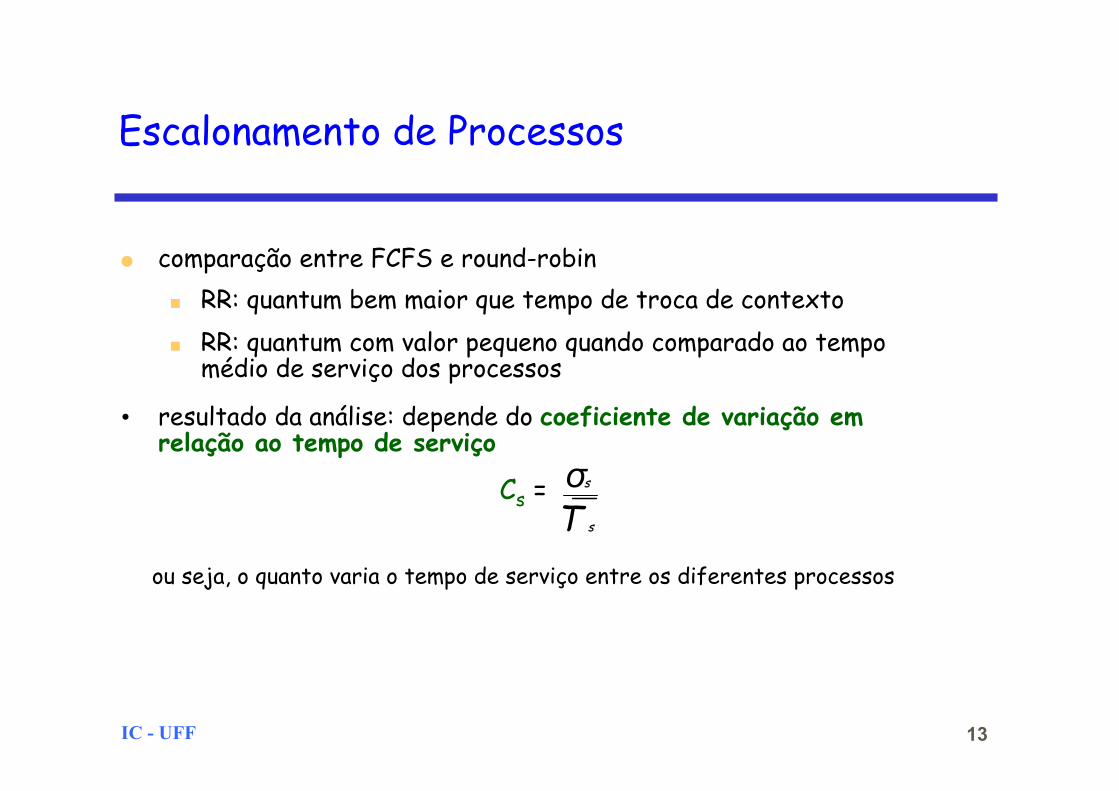
● comparação entre FCFS e round-robin ■ RR: quantum bem maior que tempo de troca de contexto ■ RR: quantum com valor pequeno quando comparado ao tempo
médio de serviço dos processos
• resultado da análise: depende do coeficiente de variação em relação ao tempo de serviço
Cs =
ou seja, o quanto varia o tempo de serviço entre os diferentes processos
Escalonamento de Processos

IC - UFF 14
• σs - desvio padrão do tempo de serviço
• - tempo médio de serviço
• Cs
• se Zero: os tempos de serviços são similares
• pode ser alto: muita variação entre os tempos de serviço
Escalonamento de Processos

IC - UFF 15
• FCFS pode ser problemático quando comparado com RR em um processador. Mas....
• FCFS em S2 (duo processado) é amenizado:
• enquanto um processo longo que chegou primeiro está sendo executado por um processador, outros processos são executados no outro
• pode ser tão bom quanto round-robin, principalmente se o número de processadores aumentar
Escalonamento de Processos

IC - UFF 16
• processo = conjunto de threads • em um processador
• threads são vantajosas devido a E/S
• em vários processadores • dividir a funcionalidade do processamento entre
processadores leva a um maior ganho
• threads + multiprocessamento = exploração do grau de paralelismo da aplicação
– granularidade fina ! paralelismo não tão vantajoso – alto grau de interação entre threads
Escalonamento de Threads

● Escalonamento é mais complexo quando várias CPUs se tornam disponíveis
● Processadores Homogêneos dentro de um mesmo multiprocessador ■ no entanto, já se inicia uma tendência de
heterogeneidade: big and small CPUs
Escalonamento de Threads

Algumas classes:
● Compartilhamento/balanceamento de carga ● Gang scheduling ● Alocação a processadores específicos ● Escalonamento dinâmico
Escalonamento de Threads

Balanceamento de carga
● O escalonador supervisiona a carga dos processadores, e divide a carga
● Não deixa processador ocioso – toda vez que um processador está ocioso, a rotina do SO o seleciona para executar a próxima thread
● Uma fila global pode ser definida e as threads a serem executadas são incluídas ■ Conforme a chegada do processo, as suas threads são inseridas na
ordem FCFS ■ Ordenadas de acordo com prioridade, ou pelo número de threads que
cada processo tem
Escalonamento de Threads

Balanceamento de carga
● Alguns problemas com uma fila única ● Gargalo ● Se as threads sofrerem preempção podem ser depois
associadas a processadores diferentes com caches diferentes
● Threads que compartilham informações podem ser associadas a processadores distintos com espaço de memória distinto (cache ou memória principal)
Escalonamento de Threads

Gang Scheduling
● Tem sido aplicado ao conceito de escalonar simultaneamente um conjunto de threads que compõem um processo
● O conceito é bastante vantajoso quando threads dependem uma das outras e não podem esperar sem perder desempenho de execução
Escalonamento de Threads

Gang Scheduling
● Melhora a performance de uma aplicação se as threads correlatas estiverem em execução
■ T1 e T2 são duas threads de um mesmo processo
■ T1 está sendo executada: precisa sincronizar com T2
■ T1 fica em espera até que T2 seja executado em algum processador
● seria melhor T2 já estar executando em outro processador
Escalonamento de Threads

IC - UFF 23
Gang Scheduling
• N processadores, M aplicações com N ou menos threads cada aplicação
– cada aplicação poderia receber 1/M do tempo disponível, utilizando os N processadores
– nem sempre isso é eficiente
– alocação de tempo uniforme:
1 thread A2 4 threads A1 N = 4 ocioso
P1 P2 P3 P4
100%/8 = 12,5% 12,5% X 3 = 37,5% ocioso
½ ½
Escalonamento de Threads

IC - UFF 24
Escalonamento de Threads
Gang Scheduling
• uma solução: dar pesos aos processos de acordo com o número de threads
– considerando todos os processos
– A1 tem 4/5 das threads – 80%
– A2 tem 1/5 das threads - 20%
– Cada thread tem 20% do tempo ocioso
P1 P2 P3 P4
100%/20 = 5% 5% X 3 = 15% ocioso
4/5 1/5

Uma Classe de Problemas Escalonamento de Aplicações em um Sistema de Computadores Distribuídos
classe de aplicações – especificada pelo modelo da aplicação
a arquitetura enfocada constitui em um sistema de processadores de memória distribuída que se comunicam por trocas de mensagens – modelo arquitetural apresenta as características importantes a
serem consideradas

Escalonamento de Aplicações Alguns conceitos Tarefa – uma unidade de computação
job = conj. de tarefas com objetivo comum
aplicação paralela ! tarefas que seguem uma ordem parcial

Escalonamento de Aplicações Escalonamento local X global global ! tarefas são associadas a processadores ! mapeamento, task placement, matching local ! várias tarefas em um processador
No escalonamento global: - migração – custoso e nem sempre usado (sala contexto, trasfere
contexto para o novo processador, reinicializa tarefa) - geralmente se refere a balanceamento de carga

Balanceamento de Carga
sender-initiated
P1 P2 P1 P2
receiver-initiated

Mais conceitos preempção ! tarefas/jobs em execução podem ser transferidas
(migradas) – mais custos
não preempção ! geralmente em relação às tarefas – tarefas não são interrompidas – migração somente para tarefas ainda por executar

Escalonamento de Aplicações Estático conhecimento de características associadas às aplicações antes da
execução desta (estimativas) relação de precedência entre os componentes da aplicação
Dinâmico estimativas são conhecidas antes da execução e não as características
reais. a especificação do escalonamento é feita ao longo da execução da
aplicação – balanceamento de carga, por exemplo

Escalonamento Estático de Aplicações O Problema de Escalonamento de Tarefas em um conjunto de
processadores é, em sua forma geral, NP-completo.
Uma variedade de heurísticas de escalonamento foram propostas, principalmente para um conjunto de processadores homogêneos, considerando ou não custo de comunicação associado à troca de mensagens
Alguns heurísticas que consideram um conjunto de processadores homogêneos foram analiticamente avaliadas, e foi concluído que escalonamento produzidos estão dentro de um fator do ótimo.
Algumas instâncias do problema possuem solução ótima

Modelo da Aplicação uma aplicação da classe de aplicações abordadas é constituída por um
conjunto de tarefas, ordenadas parcialmente por uma relação de precedência
a classe de aplicações aqui discutida pode ser representada por um grafo acíclico direcionado (GAD) G = (V,E, ε, ω), onde – as tarefas da aplicação são representadas pelo conjunto de n
vértices V = { v1 , v2 , ... , vn }
– as relações de precedência que correspondem a dependência de dados são representadas pelo conjunto de dados
E = { (vi , vj ) }

Modelo da Aplicação
o peso de computação ε(vi) pode estar associado a cada tarefa de G (estimativa) correspondendo ao número de unidades de tempo necessários para executar a tarefa vi
o peso de comunicação ω(vi, vj ) pode estar associado a cada arco (vi,vj) de G (estimativa) correspondendo à quantidade de dados a serem enviados da tarefa vi para a vj
seja pred (vi) o conjunto de predecessores imediatos da tarefa vi , ou seja,
pred (vi) = {vj / (vj ,vi ) ∈ E } seja succ (vi) o conjunto de sucessores imediatos da tarefa vi , ou
seja, succ (vi) = {vj / (vi , vj ) ∈ E }

Modelo da Arquitetura
definição de características que afetam o desempenho
processadores homogêneos e heterogêneos
número limitado ou não de processadores
memória distribuída ou compartilhada
topologia da rede de interconexão
modelo de comunicação
– latência de comunicação
– sobrecargas de envio e recebimento
– etc

Heurísticas de Escalonamento Heurísticas de Escalonamento Estático heurísticas de construção: um algoritmo polinomial no tamanho
da entrada que a cada iteração, especifica para uma tarefa o seu escalonamento – tupla (tarefa, processador, tempo de início) – ao final, uma só solução foi formada – escalonamento deve ser válido (respeitar as relações de
precedência e as características do modelo arquitetural) difícil classificação
– técnica empregada – modelo considerado

Heurísticas de Escalonamento
Heurísticas de Escalonamento Estático
List Scheduling
Algomeração de Tarefas
Minimização de Caminho Crítico
Replicação de Tarefas

Restrições de Escalonamento Seja um DAG: G(V,E) e uma modelo arquitetural • Tempo de início (start time): st(vi , pk) • Tempo de fim (finish time): ft(vi , pk) • Alocação do processador: proc (vi)
Restrições: • De processador: pk = proc(vi)=proc(vj)
⇒ st (vi , pk) >= ft (vj , pk) OR st (vj , pk) >= ft (vi , pk)
• de precedências: ∀ vj ∈ pred( vj ), st (vj , pk) >= ft (vi , proc(vi)) + comm (vi, vj )

List Scheduling Estratégia (extremamente) gulosa tradicional e bastante conhecida (utilizada) devido a sua
simplicidade (baixa complexidade) – escalonamento de instruções em unidades funcionais – escalonamento em processadores heterogêneos (em número
limitado) Alguns conceitos importantes tarefa livre - todos os seus predecessores imediatos já foram
escalonados; processador ocioso - em um determinado instante tk , não
existe nenhuma tarefa sendo executada neste instante;

List Scheduling Framework
Definição da prioridade das tarefas vi ∈ V;
Enquanto ( existir vi não escalonado ) faça {
vi = a tarefa livre de maior prioridade;
pj = o processador ocioso onde vi começa mais cedo;
escalone vi no processador pj ;
determine as novas tarefas livres;
}

Prioridades associada às tarefas Caminho crítico
– Caminho no grafo com o maior “comprimento” bottom-level, top-level, etc....
Medidas para definir a importância dum nó ! a ordem em que as tarefas são escalonadas é muito importante

Um Exemplo de GAD
6
3 2 1
0
pesos de execução em
pesos dos arcos em
5
4
4
5 2 7
6
6
3
2 4 8
1 3 2
5 4

Replicação de Tarefas Papadimitriou e Yannakakis (PY) – princípio da replicação
grafo acíclico direcionado G = (V, E) (UET-UCT)
– pesos de execução das tarefas: unitários
– pesos dos arcos: unitários
latência de comunicação L é o custo mais relevante
número ilimitado de processadores

Replicação de Tarefas Papadimitriou e Yannakakis (PY) – princípio da replicação
para cada tarefa vi , o cluster de tarefas vi é construído
o tempo mais cedo de início possível é calculado
– earliest start time e(vi )
não necessariamente a tarefa vi pode ser escalonada no tempo mais cedo e(vi )
explora a sobreposição de computação das tarefas com a comunicação de mensagens
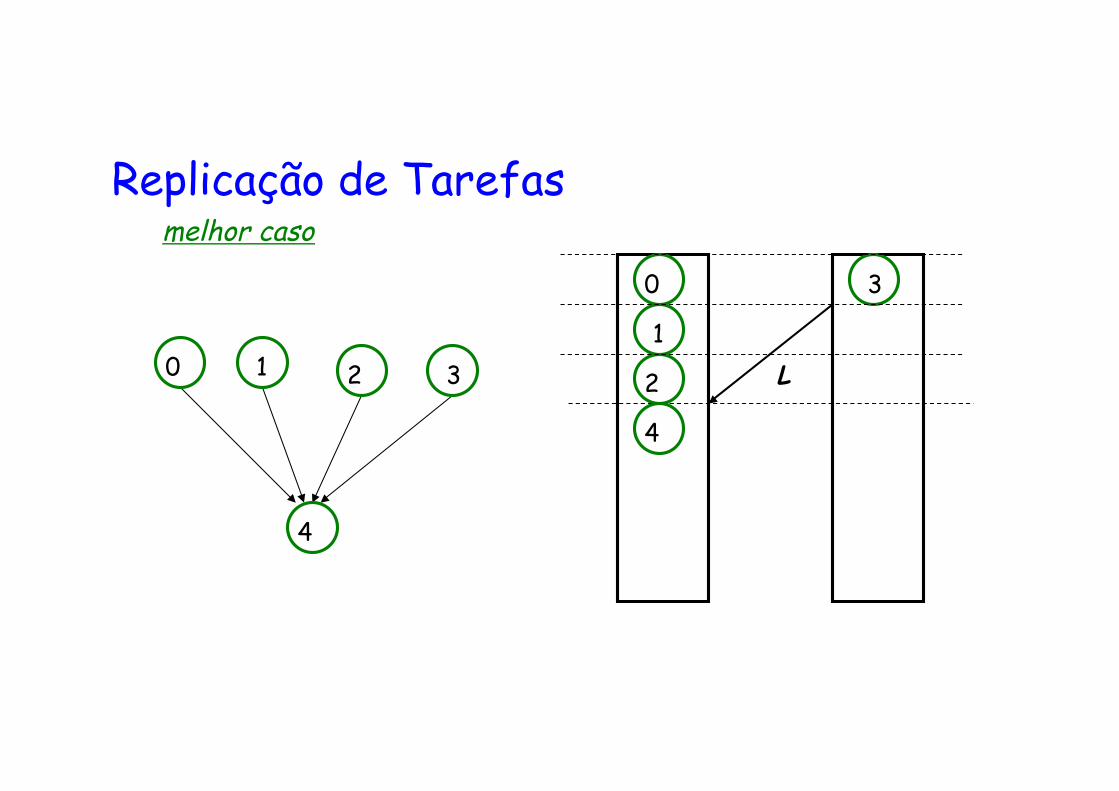
Replicação de Tarefas melhor caso
4
3 2 1 0
0
1
2
3
4
L





























