Embed Size (px)
Citation preview

UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE EDUCAÇÃO SUPERIOR DE CIÊNCIAS
TECNOLÓGICAS, DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
DESENVOLVIMENTO DE UMA FERRAMENTA DE MINERAÇÃO DE
DADOS APLICADA À MEDICINA
Área de Inteligência Artificial
Rodrigo Gomes Prieto
Itajaí (SC), Julho de 2004.

UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE EDUCAÇÃO SUPERIOR DE CIÊNCIAS
TECNOLÓGICAS, DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
RELATÓRIO DO TRABALHO DE CONCLUSÃO DE CURSO II
DESENVOLVIMENTO DE UMA FERRAMENTA DE MINERAÇÃO DE
DADOS APLICADA À MEDICINA
Área de Inteligência Artificial
Rodrigo Gomes Prieto
Relatório apresentado à Banca
Examinadora do Trabalho de Conclusão
do Curso de Ciência da Computação para
análise e aprovação.
Itajaí (SC), Julho de 2004.

i
EQUIPE TÉCNICA
Acadêmico
Rodrigo Gomes Prieto
Professor Orientador
Kathya Silvia Collazos Linares, Dra.
Coordenadores dos Trabalhos de Conclusão de Curso
Anita Maria da Rocha Fernandes, Dra.
Cesar Albenes Zeferino, Dr.
Coordenador do Curso
Luiz Carlos Martins, Esp.
i

ii
DEDICATÓRIA
Dedico este trabalho, em especial, aos
meus pais, que acreditaram na minha
capacidade desde o início da minha
vida e sempre me apoiaram na
conquista dos meus ideais e lutaram
dia após dia para que conseguisse
chegar até aqui.
ii

iii
AGRADECIMENTOS
Aos meus pais, Fernando e Socorro, pelo incentivo, apoio e carinho em todos os
momentos.
Ao meu irmão Fernando, e sua esposa Néia, que me deram muito apoio e ajuda em
momentos importantes e conseguiram me descontrair em momentos difíceis.
A todos os professores que de alguma forma contribuíram para o meu crescimento
profissional e pessoal.
A todos que tiveram uma participação direta neste trabalho.
Aos meus amigos que souberam agüentar os momentos de stress total e que também
auxiliaram em muitos momentos no desenvolvimento desse projeto.
Aos parentes que sei que sempre torceram por mim e que tenho certeza que estão
vibrando comigo neste momento.
A todos aqueles que não citei aqui, mas que me ajudaram nesta caminhada.
iii

iv
SUMÁRIO
LISTA DE ABREVIATURAS E SIGLAS .................................. vii
LISTA DE FIGURAS ................................................................... viii
LISTA DE TABELAS ..................................................................... x
RESUMO ......................................................................................... xi
ABSTRACT .................................................................................... xii
I - INTRODUÇÃO ........................................................................... 1
1. APRESENTAÇÃO.......................................................................................1
2. JUSTIFICATIVA.........................................................................................1
3. IMPORTÂNCIA DO TRABALHO ...........................................................2
4. OBJETIVOS.................................................................................................2
4.1 Objetivo Geral ............................................................................................2
4.2 Objetivos Específicos .................................................................................2
5. METODOLOGIA ........................................................................................3
II – REVISÃO BIBLIOGRÁFICA ................................................ 6
1. INTELIGÊNCIA ARTIFICIAL.................................................................6
2. BANCOS DE DADOS..................................................................................6
2.1 Modelo Físico ..............................................................................................8
2.2 Modelo Lógico ............................................................................................8
3. DESCOBERTA DE CONHECIMENTO EM BASE DE DADOS........10
3.1 Classificação..............................................................................................15
3.2 Associação .................................................................................................17
3.3 Agrupamento ............................................................................................18
3.4 Algoritmos de Mineração de Dados .......................................................19 iv

v
3.5 Exemplos da Utilização de Mineração de Dados ..................................22
4. RISCO CARDIOVASCULAR: DIABETES & HIPERTENSÃO ........25
4.1 Diabetes Mellitus.......................................................................................25
4.2 Hipertensão Arterial ................................................................................29
I I I – DESENVOLVIMENTO ..................................................... 32
1. O SISTEMA DE ANÁLISE DE DADOS.................................................32
1.1 Fonte de Dados .........................................................................................34
1.1.1 Formulários do HU para Diabetes Mellitus ............................................34
1.1.2 Formulário da Unidade de Saúde da Família e Comunitária da Univali 35
1.1.3 Projeto do Banco de Dados .....................................................................35
1.1.4 Ingresso das Informações........................................................................38
1.2 Pré Processamento ...................................................................................40
1.3 Mineração de Dados.................................................................................44
1.4 Pós-Processamento...................................................................................47
1.5 Avaliação ...................................................................................................51
2. DA INSTALAÇÃO DE FERRAMENTAS..............................................52
3. MODELAGEM ..........................................................................................52
3.1 Modelo Ambiental ....................................................................................53
3.1.1 Lista de Eventos ......................................................................................53
3.1.2 Diagrama de Contexto.............................................................................53
3.2 Modelo Comportamental.........................................................................54
3.2.1 Diagrama de Fluxos de Dados ................................................................54
3.2.2. Modelo Entidade-Relacionamento.........................................................55
3.2.3. Especificações dos Processos.................................................................57
3.2.4. Dicionário de Dados...............................................................................58
3.3 Modelagem dos Módulos do Sistema .....................................................59 v

vi
4. APLICAÇÃO..............................................................................................63
I V – CONCLUSÕES E RECOMENDAÇÕES .......................... 68
BIBLIOGRAFIA............................................................................ 71
APÊNDICE..................................................................................... 76
ANEXOS ......................................................................................... 97
vi

vii
LISTA DE ABREVIATURAS E SIGLAS
AVE Acidente Vascular Encefálico
BD Banco de Dados
DM Data Mining
DW Data Warehouse
E-R Entidade Relacionamento
FC Freqüência Cardíaca
HAS Hipertensão Arterial Sistêmica
HU Hospital Universitário
IA Inteligência Artificial
IAM Infarto Agudo do Miocárdio
IMC Indice de Massa Corporal
KDD Knowledge Discovery in Database
MBR Memory-Based Reasoning
RNA Redes Neurais Artificiais
RBC Raciocínio Baseado em Casos
UCI University of California, Irvine
USFC Unidade de Saúde da Família e Comunitária
vii

viii
LISTA DE FIGURAS
Figura 1. Modelo E-R............................................................................................................. 9
Figura 2. Visão resumida das fases do processo de KDD.................................................... 12
Figura 3. Árvore de Decisão ID-3 ........................................................................................ 20
Figura 4. Redes Neurais Artificiais. ..................................................................................... 22
Figura 5. Programa de Mineração de Dados Rosetta. .......................................................... 25
Figura 6. Processo de Descoberta de Conhecimento do Sistema Desenvolvido.................. 33
Figura 7. Diagrama E-R inicial............................................................................................. 36
Figura 8. Diagrama E-R baseado no formulário Diabetes & Hipertensão ........................... 38
Figura 9. Tela de Coleta de Dados ....................................................................................... 39
Figura 10. Tela de Coleta de Dados Resumida .................................................................... 40
Figura 11. Tela de Entrada de Parâmetros............................................................................ 41
Figura 12. Select das informações dos pacientes.................................................................. 42
Figura 13. Select após o pré-processamento......................................................................... 43
Figura 14. Select dos registros selecionados ........................................................................ 45
Figura 15. Resultado da Mineração...................................................................................... 46
Figura 16. Relatório de Regras Geradas Após Mineração ................................................... 48
Figura 17. Tela de Consulta de Dados Minerados ............................................................... 49
Figura 18. Tela de Gráficos de Quantidades ........................................................................ 50
Figura 19. Diagrama de Contexto ........................................................................................ 54
Figura 20. Diagrama de Fluxo de Dados Geral .................................................................... 55
Figura 21. Diagrama E-R – Modelo Lógico......................................................................... 56
Figura 22. Diagrama E-R – Modelo Físico .......................................................................... 57
Figura 23. Módulos Gerais ................................................................................................... 60
Figura 24. Consulta Pesquisa ............................................................................................... 66
Figura 25. Tela de Login ...................................................................................................... 85
Figura 26. Tela de Apresentação do Sistema ....................................................................... 86
Figura 27. Tela de Coleta de Dados ..................................................................................... 87
Figura 28. Tela de Coleta de Dados Resumida .................................................................... 88
viii

ix
Figura 29. Tela Manter Paciente........................................................................................... 89
Figura 30. Tela Cadastro de Parâmetros de Mineração........................................................ 90
Figura 31. Tela de Controle de Valores................................................................................ 91
Figura 32. Tela Entrada de Parâmetros ................................................................................ 92
Figura 33. Tela de Geração de Gráfico de Barras ................................................................ 93
Figura 34. Relatório de Geração de Regra ........................................................................... 94
Figura 35. Tela de Consulta de Pesquisa com Novo Intervalo............................................. 95
ix

x
LISTA DE TABELAS
Tabela 1: Modelo hierárquico de banco de dados ................................................................ 10
Tabela 2: Modelo hierárquico............................................................................................... 10
Tabela 3: Dados brutos exemplo de classificação. ............................................................... 16
Tabela 4: Dados brutos exemplo de associação ................................................................... 17
Tabela 5: Tarefas e Técnicas de KDD.................................................................................. 19
Tabela 6. Descrição das Tabelas de Dados utilizadas no Sistema........................................ 58
Tabela 7. Módulos de Cadastros........................................................................................... 61
Tabela 8. Módulos de Consultas. ......................................................................................... 62
Tabela 9. Módulos de Relatórios.......................................................................................... 62
Tabela 10. Módulos de Rotinas. ........................................................................................... 63
Tabela 11: Parâmetros selecionados..................................................................................... 64
Tabela 12. Dicionário de Dados da Tabela Paciente. ......................................................... 106
Tabela 13. Dicionário de Dados da Tabela Guia Exame.................................................... 107
Tabela 14. Dicionário de Dados da Tabela Histórico Pessoal............................................ 111
Tabela 15. Dicionário de Dados da Tabela Histórico Familiar. ......................................... 111
Tabela 16. Dicionário de Dados da Tabela Histórico Patológico....................................... 112
Tabela 17. Dicionário de Dados da Tabela Exames Gerais. .............................................. 113
Tabela 18. Dicionário de Dados da Tabela Histórico Paciente. ......................................... 115
Tabela 19. Dicionário de Dados da Tabela Dados Minerados. .......................................... 116
Tabela 20. Dicionário de Dados da Tabela Controle Valores. ........................................... 118
Tabela 21. Dicionário de Dados da Tabela Dados Diabetes Wrk. ..................................... 118
Tabela 22. Dicionário de Dados da Tabela Parâmetros Entrada. ....................................... 119
Tabela 23. Dicionário de Dados da Tabela Internação....................................................... 119
Tabela 24. Dicionário de Dados da Tabela Forma Tratamento.......................................... 120
x

xi
RESUMO
Este trabalho apresenta o desenvolvimento de uma ferramenta de Análise de Dados
aplicada ao estudo de pacientes com riscos cardiovasculares devido a Diabetes e/ou
Hipertensão Arterial. A ferramenta utiliza a metodologia de Mineração de Dados, técnica
da Inteligência Artificial. A Medicina é uma área em que a tomada de decisão precisa estar
alicerçada em argumentos baseados em conhecimentos médicos, assim como na
regularidade das informações e tendências extraídas dos dados estatísticos e/ou
epidemiológicos. Sendo assim, o desenvolvimento desta ferramenta pode ser de grande
utilidade para a Medicina. O objetivo do trabalho desenvolvido é buscar, no banco de dados
de pacientes diabéticos e/ou hipertensos, informações que possam indicar as relações
existentes entre Diabetes Mellitus e/ou Hipertensão Arterial e o aparecimento de problemas
cardiovasculares. O trabalho foi desenvolvido utilizando o banco de dados ORACLE e suas
ferramentas de desenvolvimento para a construção da base de dados, a criação da interface
com os usuários e a geração dos relatórios de saída dos resultados. A validação da
ferramenta foi realizada utilizando uma base de dados de 186 pacientes, consultados na
Unidade de Saúde da Família e Comunitária da UNIVALI. Como resultado da validação
pode-se destacar o índice de prevalência de sobrepeso encontrado nos pacientes diabéticos
e/ou hipertensos atendidos no ambulatório. Os resultados permitirão: realizar ações para
melhorar a condição dos pacientes atendidos, análise das características dos pacientes,
estudo de casos reais em sala de aula, entre outros.
xi

xii
ABSTRACT
This work presents the development of a tool of Data Analysis applied to the
patients' study with cardiovascular risks due to Diabetes and/or Arterial Hypertension. The
tool uses the methodology of Data Mining, technique of the Artificial Intelligence. The
Medicine is an area in that the decision-making needs to be founded in arguments based on
medical knowledge, as well as in the regularity of the information and the tendencies
extracted of the statistics data and/or epidemiology data. So, the development of this tool
can be of great usefulness for the Medicine. The objective of the developed work is to look
for in the diabetic and hypertension patients' database information that can indicate the
existent relationships between Mellitus Diabetes and/or Arterial Hypertension and the
emergence of cardiovascular problems. The work was developed using the ORACLE
database and their development tools for the construction of the base of data, the creation of
the interface with the users and the generation of the exit reports of the results. The
validation of the tool was accomplished using a base of data of 186 patients, consulted at
the Unidade de Saúde da Família e Comunitária of the UNIVALI. As result of the
validation the index of overweight prevalence found in the diabetic and/or hypertension
patients assisted at the clinic can be stood out. These results could be used: as for
accomplishing actions that allow to revert this condition of the patients assisted, as for the
analysis of these characteristics, study of true case inside of classroom, between others.
xii

I - INTRODUÇÃO
1. APRESENTAÇÃO
Este trabalho apresenta o desenvolvimento de uma ferramenta de Análise de Dados
aplicada ao estudo de pacientes com riscos cardiovasculares devido a Diabetes e/ou
Hipertensão Arterial. A ferramenta desenvolvida utilizou para a construção do banco de
dados formulários específicos desenvolvidos pelo especialista de Medicina. Assim, para a
implementação do software foi necessária a informatização da coleta de dados. A análise de
dados baseia-se nas informações contidas nesses formulários. A validação da ferramenta foi
realizada utilizando uma base de dados de 186 pacientes, consultados na Unidade de Saúde
da Família e Comunitária da UNIVALI, no período de Janeiro a Março de 2004. Diabetes e
Hipertensão Arterial são muito estudadas, pois elas são doenças prevalentes e consideráveis
fatores de risco para doenças cardiovasculares.
A área da Saúde produz uma grande quantidade de informações diariamente a qual é
armazenada em uma base de dados. Sendo assim, apenas a disponibilização desses dados
não é suficiente para um melhor aproveitamento das informações. É vital que se possa
interpretar, analisar e relacionar estes dados para desenvolver estratégias de ação.
Como exemplo destas estratégias, pode-se citar: a caracterização sobre o
comportamento de um paciente para prever visitas, identificação de terapias médicas de
sucesso para diferentes doenças, busca por padrões de novas doenças, etc.
2. JUSTIFICATIVA
Apesar da grande quantidade de projetos desenvolvidos que utilizam Mineração de
Dados, ainda existem muitas opções dentro da área da Saúde. Nessa área existem bases de
dados repletas de informação que podem ser transformadas em conhecimento útil. Assim,
há a necessidade do desenvolvimento de sistemas que possam obter esses conhecimentos.

2
Nesse contexto, o presente trabalho teve por objetivo criar uma ferramenta que
utilizasse métodos de Mineração de Dados para descoberta de conhecimento em Medicina,
propiciando a aplicação dos conhecimentos adquiridos nas disciplinas de Banco de Dados e
Inteligência Artificial, e a aquisição de novos conhecimentos ao se tratar de uma área de
aplicação que é a Medicina.
3. IMPORTÂNCIA DO TRABALHO
O sistema auxilia na análise de dados em Medicina, permitindo quantificar a
prevalência de doenças e conseqüentemente auxiliar na prevenção das mesmas.
Além disso, a ferramenta pode servir de base para o desenvolvimento de outros
métodos de Mineração complementares ao que foi implementado no presente trabalho.
O trabalho pode servir como ferramenta de apoio aos responsáveis pela área de
estudo na tomada de decisões que possam atingir ou influenciar no número de ocorrências
da doença em estudo. O sistema já se encontra implantado na USFC (Unidade de Saúde da
Família e Comunitária) da UNIVALI.
4. OBJETIVOS
4.1 Objetivo Geral
Desenvolver uma ferramenta para análise de dados, para pacientes atendidos na
USFC com diagnóstico de diabetes e/ou hipertensão, que utilize a metodologia de
Mineração de Dados.
4.2 Objetivos Específicos
Os objetivos específicos são:

3
• Identificar a forma de coleta e os tipos de dados utilizados em Medicina para
pacientes Diabéticos e/ou Hipertensos, a partir dos formulários de Diabetes Mellitus
(MONTELLO et al, 1999) e Diabetes & Hipertensão da UNIVALI (PINTO, 2004);
• Modelar a base de dados segundo o padrão do formulário a ser informatizado
(Diabetes & Hipertensão da UNIVALI);
• Identificar a metodologia para análise de dados e a técnica de Mineração de Dados a
ser utilizada no projeto;
• Desenvolver o protótipo do projeto;
• Realizar testes para a validação do protótipo.
5. METODOLOGIA
Foi realizado um estudo dos formulários de coleta de dados para: Diabetes Mellitus
do Hospital Universitário (HU) de Florianópolis (MONTELLO et al, 1999) e Diabetes &
Hipertensão da USFC da UNIVALI, desenvolvido pelo Profº. Luiz Gustavo Pinto
especificamente para a coleta dessas informações (Anexo IV). Identificou-se que a coleta
de dados era ainda manual, no caso da USFC que não possuía um sistema informatizado
para a coleta de tais dados. Este fato não favorecia o desenvolvimento de ferramentas
computacionais para análise de dados. Também foi verificado que os tipos de dados eram:
numéricos e alfa-numéricos (específicos e de texto livre).
Com base nas informações obtidas dos formulários realizou-se a estruturação da
base de dados. Desenvolveu-se um diagrama E-R seguindo o padrão dos formulários.
Foram consideradas as informações presentes nos formulários e foram definidas entidades
que suportassem essas informações. Também foi desenvolvida uma interface para a coleta
de dados, já que a coleta ainda era manual.

4
O estudo da metodologia de Descoberta de Conhecimento em Base de Dados
permitiu identificá-la como a metodologia a ser utilizada para o desenvolvimento da
Ferramenta proposta neste trabalho. De outro lado, o objetivo de descobrir perfis dentro da
base de dados dos pacientes foi associado à técnica de mineração de dados denominada
Agrupamento. Nesta técnica, o algoritmo cria classes com atributos semelhantes pré-
estabelecidos ou não. Neste trabalho as classes foram criadas através de atributos pré-
estabelecidos e para tal fim utilizou-se um algoritmo estatístico.
A seguir foi realizado todo um projeto de modelagem, de definições e
documentação do sistema a ser desenvolvido, com o intuito de se ter uma maior facilidade
de implementação. Ao final foram realizadas as etapas de definição de interface, onde foi
necessário também conversar com os responsáveis pelo ambulatório da UNIVALI, para que
se pudesse validar a forma da interface, tanto de entrada de informações quanto da saída de
resultados, finalizando o projeto com as etapas de implementação, testes e validação do
sistema desenvolvido.
A base de dados foi toda desenvolvida em Oracle, já que o mesmo é conhecido
como o melhor Banco de Dados relacional da atualidade e pelo fato da UNIVALI, local
onde foi implantado o sistema já possuir a licença do mesmo.
Todas as ferramentas utilizadas para o desenvolvimento são ferramentas da própria
Oracle. Para a modelagem e o desenvolvimento da base de dados, foi utilizado o Oracle
Designer, ferramenta case que auxilia e agiliza em muito o desenvolvimento de projetos de
Banco de Dados. Já para a interface foram utilizadas o Forms Builder, para o
desenvolvimento de todas as telas do sistema e o Reports Builder para os relatórios de saída
dos resultados. A escolha das ferramentas ocorreu, porque o conjunto delas é um ambiente
completo e integrado que combina ferramentas de desenvolvimento de aplicativos com a
integração da Base de Dados em Oracle de forma muito mais simples e consistente.
Também porque o mercado de trabalho para pessoas capazes de trabalhar com tais
ferramentas vem crescendo muito em nossa região, principalmente na cidade de Blumenau.
A Seara Alimentos em Itajaí, a Bunge Alimentos em Gaspar, a Quicksoft e a Elosoft em

5
Blumenau, e a HBTech em Florianópolis, são apenas alguns exemplos de empresas de
médio à grande porte, que utilizam tais ferramentas para o desenvolvimento de seus
projetos.
Quanto à linguagem de programação utilizada, em todo o desenvolvimento foi
utilizado o PL/SQL, ou como é mais conhecido o SQL estruturado, inclusive tendo sido
utilizada para o desenvolvimento do algoritmo de mineração. A escolha da linguagem
ocorreu porque é a linguagem nativa das ferramentas utilizadas e padrão mundial para
desenvolvimento de trabalhos que lidem com Bancos de Dados.

II – REVISÃO BIBLIOGRÁFICA
1. INTELIGÊNCIA ARTIFICIAL
O presente trabalho visa desenvolver uma ferramenta de Mineração de Dados para a
área de Medicina. Para tanto foi necessário saber que Mineração de Dados é uma forma de
se utilizar a Inteligência Artificial (IA), ou pode-se dizer que seja apenas um dos ramos da
IA.
A Inteligência Artificial é uma área da informática que tenta fazer com que o
computador realize coisas que somente os homens são capazes, como tomar decisões e
aprender, o que pode ser percebido na seguinte definição: “a IA busca prover máquinas
com a capacidade de realizar algumas atividades mentais do ser humano” (NASCIMENTO
JR & YONEYAMA, 2000).
Outros autores possuem definições um pouco diferentes, mas tentam passar de certa
forma a mesma idéia, como a seguinte que diz que “IA é o estudo de como fazer os
computadores realizarem coisas que, no momento, as pessoas fazem melhor” (RICH,
1993).
O próprio nome já sugere que o intuito da IA é o de fazer com que os computadores
de alguma forma adquiram ou demonstrem inteligência.
2. BANCOS DE DADOS
Segundo Fanderuff (2000), um Banco de Dados pode ser definido como “uma
percepção do mundo real, que consiste em uma coleção de objetos básicos, chamados de
tabelas, e em relacionamentos entre estes objetos”.

7
Segundo Pacheco et al. (1999), pode-se definir Banco de Dados “como uma coleção
de dados relacionados”. Estes dados podem ser definidos como “fatos conhecidos que
podem ser armazenados e que possuem significado explícito” .
Pacheco et al. (1999) também diz que os bancos de dados possuem as seguintes
propriedades:
Um banco de dados representa algum aspecto do mundo real, algumas vezes
chamado de mini-mundo ou Universo de Discurso. Mudanças no mini-mundo
são refletidas no banco de dados. Um banco de dados é uma coleção logicamente
coerente de dados como algum significado herdado. Uma ordenação aleatória de
dados não pode ser corretamente referenciada como um banco de dados. Um
banco de dados é modelado, construído, e povoado com dados para uma proposta
específica. Ou seja, existe um grupo de usuários e algumas aplicações pré-
concebidas as quais esses usuários estão interessados.
Na área da Medicina, os sistemas de informação têm se transformado em
instrumentos vitais para a resolução de problemas de saúde, ou para evitar outros. Já é
possível a criação e manutenção de grandes bancos de dados com informações sobre
sintomas, resultados de exames, diagnósticos, tratamentos e curso das doenças para cada
paciente.
As estruturas dessas bases de dados tornam-se de difícil acesso, por estarem
baseadas em grande parte em cima de termos técnicos. Portanto, o estudo e utilização
dessas bases de dados devem ser acompanhados pelos especialistas da área da saúde, que
possam esclarecer os termos e tentar demonstrar qual a importância do mesmo para o
assunto estudado.
Os bancos de dados podem ser definidos segundo Korth & Silberschatz (1995),
seguindo três níveis.
O nível físico é o nível mais baixo de abstração e descreve como os dados estão
realmente armazenados.

8
O nível conceitual descreve quais dados estão armazenados de fato no banco de
dados e as relações que existem entre eles.
Por fim o nível de visões que é o nível mais alto de abstração e descreve apenas
parte do banco de dados.
2.1 Modelo Físico
Os BD’s podem ser classificados segundo a sua estrutura física em BD operacional,
que é aquele que possui as informações brutas, e o Data warehouse (DW) que é esse
mesmo banco, porém de uma forma mais organizada, tratada para atender as necessidades
específicas da área estudada.
2.2 Modelo Lógico
Segundo Korth & Silberschatz (1995), o modelo lógico de bancos de dados é usado
nas descrições de dados nos níveis conceitual e visual. Dentre vários modelos existentes
pode-se citar:
• Modelo Entidade-Relacionamento (E-R): Este modelo estrutura a base de dados
seguindo uma percepção de um mundo real e separando-a em coleções de objetos e
relacionamentos. A Figura 1 seguindo o padrão de Korth & Silberschatz (1995),
apresenta o exemplo de um modelo E-R.

9
Figura 1. Modelo E-R
Fonte: adaptado de Korth & Silberschatz (1995)
• Modelo Relacional: representa dados e relacionamentos entre dados por um
conjunto de tabelas, cada uma tendo um número de colunas com nomes únicos
(ibidem).
• Modelo Hierárquico: neste modelo, os dados e relacionamentos são representados
por registros e ligações, respectivamente (ibidem).
A Tabela 1 de Korth & Silberschatz (1995) apresenta um exemplo de banco de
dados hierárquico.
SINTOMA
FORMA DETRATAMENTO
INTERNACAO
HABITO COMPLICACAO
PACIENTE
POSSUIPERTENCE
UTILIZAPODE SER UTILIZADA
POSSUI
PODE SER
PODE SOFRERPERTENCE
PODE SOFRER
PODE AFETAR

10
Tabela 1: Modelo hierárquico de banco de dados
Nome Idade Sexo Código
João 23 Masculino 900
Maria 25 Feminino 801
Pedro 36 Masculino 647
Fonte: adaptado de Korth & Silberschatz (1995)
Segundo esse modelo hierárquico, a Tabela 1 pode ser complementada pela Tabela
2 do mesmo autor. Cabe ressaltar que o ponto que o autor tenta demonstrar no exemplo é a
ligação existente entre a Tabela 1 e a Tabela 2, no caso o campo código:
Tabela 2: Modelo hierárquico
Fonte: adaptado de Korth & Silberschatz (1995)
3. DESCOBERTA DE CONHECIMENTO EM BASE DE DADOS
A noção de descobrir padrões úteis (ou parte de informação valiosa do
conhecimento) em dados não processados recebeu diversos nomes, entre os quais
Knowledge Discovery in Database (KDD, ou em português, Descoberta de Conhecimento
em Base de Dados), Data Mining (DM, ou em português, Mineração de Dados), extração
de conhecimento, descoberta de informação, coleta de informação, arqueologia de dados,
processamento de padrões de dados. “O termo KDD foi criado em 1989 para se referir ao
amplo processo de descoberta de conhecimento em dados, e para enfatizar a aplicação de
alto nível do método particular de DM” (MANNILA, 1996; 1997).
Segundo Collazos e Barreto (2003):
Código Nº Internações
900 2
647 1
801 4

11
O KDD é uma metodologia que possibilita a análise de grandes conjuntos de base
de dados, utilizando métodos aproximados, o que é uma característica intrínseca
dessa metodologia. Isso permite flexibilidade no raciocínio, o que é desejável na
análise de dados clínicos, os quais quase sempre são imprecisos e incertos. A
metodologia do KDD baseia-se em dois pilares fundamentais, o armazém de
dados e a Mineração de Dados. De um lado é necessário e fundamental criar um
armazém de dados de forma organizada e com suficientes dados sobre o assunto a
analisar e de outro é importante contar com métodos aproximados que permitam
minerar os dados, assim organizados, para a descoberta das relações existentes
em tais dados.
Conforme afirma Pacheco et al. (1999), “o processo de KDD pode ser dividido em
cinco etapas: o Data Warehousing, o Pré–processamento, o Enriquecimento, a Mineração
de Dados e o Pós Processamento”.
Essas etapas são mostradas a seguir na Figura 2, segundo Pacheco et al. (1999).

12
Figura 2. Visão resumida das fases do processo de KDD
Fonte: Pacheco et al. (1999).
1-Data Warehousing (DW): Ou dito em português Armazém de dados, “é um
conjunto de dados baseado em assuntos, integrado, não volátil, e variável em
relação ao tempo” (Pacheco et al., 1999). Pode-se, portanto entender DW como o
processo de organização das bases de dados em uma forma mais ordenada e
estruturada para o assunto que está se tratando ou como sendo um banco de dados
no qual os dados foram processados e organizados. A etapa de DM depende
fundamentalmente do método utilizado para o tratamento dos dados. Na verdade é a
etapa em que se permite que os dados possam estar limpos, agregados e
consolidados. Uma das características marcantes do DW é a orientação por assunto,
pois toda a modelagem será voltada em torno desses principais assuntos. As
I NT E G R A Ç A O
DW
Dados
Dados
Pré Proc.
MD Pós Proc.
Conhecimento

13
principais características do DW são: integração, variação no tempo, não
volatilidade, localização e a credibilidade dos dados.
2-Pré-Processamento: Etapa responsável por consolidar as informações relevantes
para o algoritmo minerador, buscando reduzir a complexidade do problema
(PACHECO et al, 1999). Pode-se dividir em três sub etapas:
• A limpeza dos dados, responsável por realizar a consistência dos dados, a correção
de possíveis erros e o preenchimento e eliminação de valores nulos e redundantes;
• A seleção dos dados é quem irá definir ou escolher os atributos relevantes de todos
os atributos existentes na base de dados e;
• A codificação dos dados divide os valores contínuos dos atributos em uma lista de
intervalos representados por um código, ou seja, converte valores quantitativos em
valores categóricos.
4-Mineração de Dados: Segundo Fernandes (2003 apud GROTH, 1998), a
Mineração de Dados ou "Data Mining é o processo de descoberta automática de
informações". Já de acordo com Tenório Jr (2001) a Mineração de Dados
“caracteriza-se pela existência do algoritmo que diante da tarefa especificada será
capaz de extrair eficientemente conhecimento implícito e útil de um banco de
dados”. Segundo outro autor, DM refere-se ao “exame de grandes quantidades de
dados, procurando encontrar relações entre dados não explícitos que possam ser
utilizadas em modelos do mundo real com capacidade preditiva e explanatória”
(BARRETO, 2001).
A etapa de DM depende fundamentalmente do método utilizado para o tratamento
dos dados. Este é o passo onde os padrões freqüentes e de interesse são descobertos nos
dados. Os objetivos primários de DM segundo Fayyad et al. (1996), são:

14
• Predição, a qual envolve o uso de algumas variáveis ou campos na base de dados
para predizer valores futuros ou desconhecidos de outras variáveis de interesse;
• Descrição, a qual procura encontrar padrões que descrevam os dados.
5-Pós-Processamento: Esta fase “envolve a interpretação do conhecimento
descoberto, ou algum processamento deste conhecimento” como definiu
PACHECO et al. (1999). A principal meta dessa fase é melhorar a compreensão do
conhecimento descoberto pelo algoritmo minerador validando-o através de medidas
da qualidade da solução e da percepção de um analista de dados.
Em alguns casos, quando a mineração não traz resultados satisfatórios é necessária
uma outra etapa de Enriquecimento, que segundo Pacheco et al. (1999), consegue
“agregar mais informações de forma que essas contribuam no processo de
descoberta de conhecimento”.
Na Medicina, Biologia e outras ciências, a Mineração de Dados vem ganhando
importâncias cada vez maiores, auxiliando no processo de extração de relações escondidas
em dados experimentais e em prontuários médicos.
A Mineração de Dados nas bases de dados voltadas para a Medicina pode vir a
fornecer conhecimento novo, como a relação entre algumas doenças e certos perfis
profissionais, sócio-culturais, hábitos pessoais, ou local de moradia.
A extração dessas informações não é uma tarefa simples, principalmente por essa
base possuir um volume gigantesco de dados de onde se podem extrair conhecimentos
diversos. Em meio a essas montanhas de dados podem se esconder informações valiosas e
por isso é de extrema importância que existam ferramentas capazes de auxiliar a extração
dessas informações.

15
Enfim pode-se entender DM como um meio para exploração e análise dos bancos de
dados com o objetivo de encontrar padrões, ou regras, ou ainda como um conjunto de
técnicas de Inteligência Artificial para a descoberta de conhecimento novo, não facilmente
visível a olho nu, que possa estar presente em grandes massas de dados.
DM pode ainda ser classificada segundo dois tipos: Descoberta direta, onde fica
explícito o que se deseja buscar da base de dados e Descoberta Indireta, onde se faz uma
espécie de busca aleatória, tentando encontrar quaisquer tipos de combinações que possam
representar algum conhecimento.
Segundo Pacheco et al. (1999), as tarefas KDD que funcionam como bases das
técnicas de DM são: Classificação, Associação, ou Agrupamento. Estas tarefas podem
utilizar técnicas de DM baseadas em Raciocínio Baseado em Casos (RBC), Redes Neurais
Artificiais, Árvores de Decisão, Estatística, Computação Evolucionária, entre outros.
Existem outras tarefas do KDD que são utilizados em menor escala, como exemplo
pode-se citar: as queries, a descoberta de dependência e a regressão (ibidem).
3.1 Classificação
Classificação é uma das técnicas mais utilizadas de DM. Segundo Carvalho (2001),
classificar um objeto é “determinar com que grupo de entidades, já classificadas
anteriormente, este objeto apresenta mais semelhança”. A definição abaixo (Souza, 2000
apud GROTH, 1998) relata que a Classificação “provê um mapeamento prévio a partir de
atributos para grupamentos especificados”.
Como exemplo podem-se classificar previamente pessoas como sendo bebês,
crianças, adolescentes, adultos ou idosos, nos baseando apenas no atributo idade (SOUZA,
2000).

16
Segundo outra definição, na classificação “cada tupla pertence a uma classe em um
conjunto pré-definido de dados” (PACHECO et al., 1999), cabe salientar que uma tupla
nada mais é que um registro de dados.
E pode-se utilizar a Tabela 3, de Pacheco et al. (1999 apud FREITAS &
LAVINGTON, 1998), que mostra a entrada das informações e define a seguir as regras de
classificação que puderam ser descobertas.
Tabela 3: Dados brutos exemplo de classificação.
SEXO ETNIA IDADE DIABÉTICO
Masculino Branco 25 Sim
Masculino Negro 21 Sim
Feminino Branco 23 Sim
Feminino Negro 34 Sim
Feminino Branco 30 Não
Masculino Moreno 21 Não
Masculino Moreno 20 Não
Feminino Moreno 18 Não
Feminino Branco 34 Não
Masculino Branco 55 Não
Fonte: adaptado de Pacheco et al. (1999).
Alguns exemplos de regras de classificação descobertas dos dados da Tabela 3 são
apresentados a seguir:
Se (ETNIA = Moreno) então DIABÉTICO = Não
Se (ETNIA = Negro) então DIABÉTICO = Sim
Se (ETNIA = Branco e IDADE <= 25) então DIABÉTICO = Sim

17
Se (ETNIA = Branco e IDADE > 25) então DIABÉTICO = Não
3.2 Associação
As regras de associação tentam manter uma relação entre os dados já existentes e o
dado atual, ou conforme a definição a seguir, “preocupa-se em descobrir que elementos dos
eventos têm relações no tempo” (CARVALHO, 2001). Podem também ser definida, como
“expressões que indicam afinidade ou correlação entre dados” (SOUZA, 2000). Ainda
seguindo o mesmo autor, pode-se citar o trecho do algoritmo a seguir como um exemplo
simples para as regras de associação:
“se hábito = fumante e exercício = falso então diabetes = sim”.
Para um melhor entendimento das regras de associação pode-se citar um exemplo
como o utilizado na Tabela 4 (Pacheco et al, 1999 apud FREITAS & LAVINGTON, 1998),
que mostra a entrada das informações e as regras de associação formadas depois do estudo
e da análise da base de dados.
Tabela 4: Dados brutos exemplo de associação
ID LEITE CAFÉ CERVEJA PÃO MANTEIGA ARROZ FEIJÃO
1 Não Sim Não Sim Sim Não Não
2 Sim Não Sim Sim Sim Não Não
3 Não Sim Não Sim Sim Não Não
4 Sim Sim Não Sim Sim Não Não
5 Não Não Sim Não Não Não Não
6 Não Não Não Não Sim Não Não
7 Não Não Não Sim Não Não Não
8 Não Não Não Não Não Não Sim
9 Não Não Não Não Não Sim Sim
10 Não Não Não Não Não Sim Não
Fonte: Pacheco et al. (1999).

18
Regras descobertas:
• Conjunto de itens freqüentes: CAFÉ, PÃO. FSup = 0.3
Regra: Se (CAFÉ) então (PÃO). FConf = 1.
• Conjunto de itens freqüentes: CAFÉ, MANTEIGA. FSup = 0.3
Regra: Se (CAFÉ) então (MANTEIGA). FConf = 1.
• Conjunto de itens freqüentes: PÃO, MANTEIGA. FSup = 0.4
Regra: Se (PÃO) então (MANTEIGA). FConf = 0.8.
Regra: Se (MANTEIGA) então (PÃO). FConf = 0.8
• Conjunto de itens freqüentes: CAFÉ, PÃO, MANTEIGA. FSup = 0.3
Regra: Se (CAFÉ e PÃO) então (MANTEIGA). FConf = 1.
Regra: Se (CAFÉ e MANTEIGA) então (PÃO). FConf = 1
Regra: Se (CAFÉ) então (PÃO e MANTEIGA). FConf = 1.
3.3 Agrupamento
O agrupamento é o método que tenta, “baseado em medidas de semelhança, definir
quantas e quais classes existem em um conjunto de entidades” (CARVALHO, 2001).
Segundo outro autor, o “agrupamento (Clustering) ou segmentação, é um método no qual
dados parecidos são grupados juntos” (Souza, 2000 apud BERSON, 97). Como exemplo
Souza (2000) cita o exemplo de um estudo de reivindicações fraudulentas, neste caso, os
registros seriam separados em duas classes, uma para os fraudulentos e outro para
reivindicações normais, ou seja, seriam agrupados de acordo com suas características
comuns.
Logo se chega à conclusão de que no caso da utilização de agrupamento, a intenção
ou meta principal da técnica é a de:

19
Criar classes através da produção de partições do banco de dados em conjuntos de
tuplas. Essa partição é feita de modo que tuplas com valores de atributos
semelhantes, ou seja, propriedades de interesse comuns, sejam reunidas dentro de
uma mesma classe. Uma vez que as classes sejam criadas, pode-se aplicar um
algoritmo de classificação nessas classes, produzindo assim regras para as
mesmas (PACHECO et al, 1999).
3.4 Algoritmos de Mineração de Dados
Para a execução do trabalho foi utilizada a técnica Estatística para realizar o
Agrupamento de dados, por representar o interesse de pesquisa do especialista. O algoritmo
desenvolvido gera ao término da execução os agrupamentos encontrados segundo a
característica fornecida em percentuais como também as regras de associação que
representam tais agrupamentos.
A Tabela 5 de Pacheco et al. (1999) apresenta o relacionamento das técnicas com os
algoritmos de mineração:
Tabela 5: Tarefas e Técnicas de KDD.
TAREFAS DE KDD TÉCNICAS (ALGORITMOS)
Associação Estatística e Teoria dos Conjuntos
Classificação
Algoritmos Genéticos, Redes Neurais e
Árvores de Decisão
Clustering (Agrupamento) Redes Neurais e Estatística
Fonte: Pacheco et al. (1999)
Cabe salientar que os algoritmos não são somente os citados na tabela acima e que
os mesmos podem ser utilizados em diversas tarefas.
Segundo Romão (2002), os algoritmos podem até ser divididos em grupos de acordo
com suas características, podendo ser dos seguintes tipos: de algoritmos de aprendizagem
simbólica, de métodos baseados em regras, de estatística tradicional, de estatística moderna,

20
baseados em Redes Neurais Artificiais (RNA) e algoritmos genéticos, para citar alguns
tipos.
A seguir tem-se uma breve definição dos principais algoritmos de mineração de
dados:
• Regras de Associação: A técnica de descoberta de regras de associação estabelece
uma correlação estatística entre certos itens de dados em um conjunto de dados
(Dias, 2001 apud GOEBEL & GRUENWALD, 1999).
• Árvores de Decisão: “A árvore de decisão é uma ferramenta completa e bastante
conhecida para classificar dados e apresentar os resultados em forma de regras”
(Oliveira, 2001 apud BERRY & LYNOFF, 1997).
A Figura 3 mostra a estrutura de uma árvore de decisão do tipo ID-3.
Figura 3. Árvore de Decisão ID-3
• Raciocínio Baseado em Casos (RBC): Também conhecido como MBR (Memory-
Based Reasoning – raciocínio baseado em memória), o raciocínio baseado em casos
tem base no método do vizinho mais próximo. “O MBR procura os vizinhos mais
próximos nos exemplos conhecidos e combina seus valores para atribuir valores de
classificação ou de previsão” (Dias, 2001 apud HARRISON, 1998).

21
• Algoritmos Evolucionários (Algoritmos Genéticos): Segundo Carvalho (2001), os
algoritmos genéticos surgiram de uma metáfora com a Teoria da Evolução das
Espécies de Darwin, ele explica que a idéia principal dessa técnica é a de se prever
ou entender o que será gerado, quando da combinação de dados de duas espécies
diferentes.
• Regras de Produção: Segundo Carvalho (2001), as regras de produção são a
representação simbólica dos operadores, capazes de criar e alterar os símbolos, que
agora estão representados pela base de dados. Seu formato segue a seguinte forma:
“SE um conjunto de condições é satisfeito ENTÃO realize uma dada operação”
(ibidem).
• Redes Neurais Artificiais (RNA): Segundo Pilla et al.(2003), redes neurais são:
Arquiteturas de rede multi camadas que aprendem como resolver um problema
baseado em exemplos e tentativas anteriores. As redes neurais podem ser de dois
tipos: supervisionadas ou não supervisionadas. Redes neurais supervisionadas são
algoritmos usados para criar modelos preditivos que capturam interações não
lineares entre fatores. Redes Neurais não supervisionadas são usadas para dividir
dados em agrupamentos de acordo com certas regras pré-definidas.
A Figura 4 de Pacheco et al. (1999) exemplifica um modelo de redes neurais
artificiais.

22
Figura 4. Redes Neurais Artificiais.
Fonte: Pacheco et al. (1999).
Existem diversos outros algoritmos de implementação para ferramentas de
Mineração de Dados, tendo sido citados apenas alguns.
3.5 Exemplos da Utilização de Mineração de Dados
O processo de busca de conhecimentos em banco de dados tem se tornado cada dia
mais importante, devido a descobertas relevantes conseguidas, e entre tantos casos pode-se
citar o exemplo utilizado por Barreto (2001) onde o autor conta que um programa de
Mineração de Dados previu a subida de preços das memórias de computador devido a um
incêndio em uma fábrica de tintas no extremo oriente, Dois fatos aparentemente sem
correlação: um incêndio e a subida de preços de memórias de computador. Qual a razão? A
fábrica era quem produzia a tinta para pintar todos os chips fabricados na região.

23
Mas, um dos exemplos mais famosos de um DM diz respeito ao utilizado pela
cadeia americana Wal-Mart, que identificou um hábito curioso dos consumidores. Há cinco
anos, ao procurar eventuais relações entre o volume de vendas e os dias da semana, o
software de Mineração de Dados apontou que, as sextas-feiras, as vendas de cervejas
cresciam na mesma proporção que as de fraldas. Uma busca mais específica mostrou que
ao comprar fraldas para os bebês, os pais aproveitavam para abastecer o estoque de cerveja
para o final de semana (PILLA et al., 2003).
No Brasil, outros tantos projetos já foram implementados para a área de Medicina,
como os citados a seguir:
• “Mineração de Dados de um plano de saúde para obter regras de associação”: esta
dissertação utiliza o algoritmo apriori para descobrir informações úteis em bases de
dados e com isso gerar regras de associação para o mesmo. Este projeto ficou
bastante centrado no algoritmo utilizado, no caso o apriori e segundo o autor, foram
geradas regras de associação ao final que demonstraram situações que os
especialistas da área já supunham que fossem acontecer (SOUZA, 2000).
• “Aplicação de Data Mining em Casos de Recém Nascidos com Malformação”: este
trabalho de conclusão de curso foi desenvolvido com o intuito de descobrir
informações que poderiam mostrar as causas ou motivos, do nascimento de crianças
com má formação, utilizando para isso regras de classificação e de agrupamento
(RUECKERT, 1999).
• “Aplicação de Data Mining na Busca de um modelo de Prevenção de Mortalidade
Infantil”: Este trabalho de pesquisa faz busca por conhecimentos novos nos bancos
de dados existentes, como o que controla a quantidade de nascidos vivos (SINASC)
e o que controla a quantidade de mortalidades (SIM), para tentar identificar algum
relacionamento entre a morte de crianças antes de completarem um ano de idade, e
algum aspecto relevante na vida desta criança. Esse trabalho utilizou para isso o
método de classificação aplicando técnicas estatísticas, através do Teste do Qui-

24
Quadrado e técnicas de Mineração de Dados, partindo-se da base de dados do
SINASC, no ano de 1996, do município de Florianópolis, Santa Catarina, Brasil, e
da ocorrência ou não de óbito no primeiro ano de vida. O objetivo foi detectar as
variáveis associadas a essas mortes, gerar regras de classificação do processo de
descoberta de conhecimento em base de dados que pudessem traçar o perfil dos
recém-nascidos em risco de óbito no primeiro ano de vida. Os resultados alcançados
revelaram a associação estatística entre o óbito de menores de um ano e algumas
variáveis do SINASC. As regras de classificação permitiram traçar o perfil dos
recém-nascidos que devem receber assistência eficaz e auxiliar o planejamento na
tomada de decisão, contribuindo para a redução da mortalidade infantil
(OLIVEIRA, 2001).
Além desses um sistema muito interessante e que pode ser utilizado como base para
o desenvolvimento de projetos de mineração é o software Rosetta, que é um programa que
foi desenvolvido por dois grupos, o Knowledge Systems Group, Dept. of Computer and
Information Science e o Logic Group, Inst. of Mathematics, e que permite a mineração de
informações, deixando ao término se obter regras de associação, dados estatísticos, entre
outros. Trata-se de um software bem completo com diversas opções de mineração,
utilizando diversas variáveis ou com valores fixos, podendo se definir intersecções (OHRN,
2004). A Figura 5 mostra uma das telas de resultados do Rosetta.

25
Figura 5. Programa de Mineração de Dados Rosetta.
Fonte: Ohrn (2004).
4. RISCO CARDIOVASCULAR: DIABETES & HIPERTENSÃO
O presente trabalho foi desenvolvido com base em um banco de dados de pacientes
com Diabetes e/ou Hipertensão Arterial. Assim, para se ter uma visão, é colocado de forma
resumida os conceitos dessas doenças.
4.1 Diabetes Mellitus
Diabetes Mellitus pode ser definido conforme Almeida (1997) como:
um grupo heterogêneo de doenças que diferem quanto à etiologia e patogênese e
que alteram a homeostase do homem, caracterizadas por distúrbios no

26
metabolismo de carboidratos, proteínas e gorduras, secundários a uma
deficiência ou ausência de produção de insulina pelo pâncreas e/ou diminuição
de sua ação nos tecidos-alvo.
Segundo Oliveira (2003), a Diabetes Mellitus é uma anormalidade caracterizada por
uma quantidade de açúcar em excesso no sangue e na urina. O pâncreas é um órgão situado
na região do abdome e uma de suas principais funções é a produção de insulina. Existem,
disseminados por todo o órgão, pequenos agrupamentos celulares denominados ilhotas de
Langerhans, onde é produzida a insulina, hormônio responsável por regular o nível de
açúcar no sangue e transformá-lo em energia. Se o pâncreas for afetado por uma infecção,
por exemplo, esta prejudicará a produção de insulina e o nível de açúcar no sangue
aumentará, provocando os sintomas de diabete melito. Uma outra doença, bastante
diferente da diabete melito é a diabete insípida, caracterizada pelo excesso de excreção
urinária, devido a um distúrbio dos rins. Existem dois tipos de Diabetes:
• Diabetes Tipo 1
Segundo Oliveira (2003), no tipo 1 o pâncreas não produz insulina ou produz uma
quantidade muitíssimo pequena. O pâncreas produz muito pouca ou nenhuma insulina. Não
consegue produzir insulina porque o sistema imunológico do corpo destruiu as células
produtoras de insulina. Geralmente atinge crianças ou adultos jovens, mas pode ter início
em qualquer idade. Sem a insulina é impossível o organismo controlar o nível de açúcar no
sangue e sem a insulina as pessoas tendem a morrer. Assim as pessoas com este tipo de
Diabetes necessitam injetar em si mesmas pelo menos uma dose diária de insulina. A
insulina é injetada sob a pele (região subcutânea) para que isso funcione. Não é possível
ingerir pílulas com insulina porque os sucos gástricos iriam destruí-las antes que elas
passassem a funcionar. Pesquisas avançadas estão estudando outras formas de aplicação de
insulina, mas atualmente as injeções são o único método. Para os portadores desse tipo de
Diabetes os médicos costumam definir a quantidade e tipo de insulina que poderá baixar as
taxas de glicose no sangue, e alimentos que evitem altas acentuadas e repentinas da taxa de
glicose no sangue. Um nutricionista poderá adequar uma dieta pessoal determinando

27
quanto, quando e o que comer, de forma que o paciente não precise se privar de uma
refeição rica e prazerosa, e exercícios que baixem os níveis de glicose no sangue, além de
trazer uma vida mais saudável.
• Diabetes Tipo 2
Já na Diabetes do tipo 2, Oliveira (2003) cita que o pâncreas produz insulina mas
em quantidade insuficiente para a quantidade de glicose presente no sangue. É o tipo mais
comum de Diabetes. Geralmente ocorrem em pessoas com mais de 45 anos e obesas. Os
médicos especialistas não sabem a causa exata da Diabetes do tipo 2 além do fato de ela ser
hereditária e disparada por um ou mais fatores. Os sintomas podem aparecer de forma
muito leve e de forma que o doente não perceba sua existência. Pessoas de idade podem
confundir estes sintomas com problemas de envelhecimento e devido a isso não buscar
ajuda médica. Estima-se que por volta da metade dos diabéticos não sabem que possuem
Diabetes. A Diabetes do tipo 2 pode ser controlado com dieta, exercícios e medicação,
incluindo comprimidos e injeções de insulina. Estes tratamentos podem ser aplicados
sozinhos ou em conjunto. Acontece em muitos casos de pessoas obesas que apresentam
Diabetes do tipo 2 que ao perderem peso, ao seguir controle alimentar e ao realizarem
exercícios físicos com regularidade, conseguem chegam a parar de tomar medicações. Os
médicos tendem a testar os níveis de açúcar no sangue, através de exames de sangue,
regularmente. O teste determinará se a Diabetes está sob controle.
Os cientistas não sabem por que o sistema imunológico, que permite o combate às
doenças e a outras substâncias "estrangeiras" que podem invadir o corpo, ataca e destrói as
células produtoras de insulina. Uma combinação de fatores pode estar envolvida, incluindo
exposição a vírus comuns ou a outras substâncias durante os primeiros períodos de vida,
assim como riscos herdados de Diabetes.
Pesquisadores podem agora fazer testes com membros da família de pessoas
diabéticas para identificar aqueles com maiores riscos de adquirir Diabetes. Sendo que os
cientistas esperam ainda encontrar uma forma de se prevenir a Diabetes.

28
A Diabetes pode surgir de algumas formas, podendo, por exemplo, ser hereditário
no caso da Diabetes do tipo 1, acredita-se que fatores genéticos possam estar envolvidos no
processo que leva a este quadro. Parentes de primeiro grau de pacientes diabéticos tipo 1,
como irmãos, pais, filhos, etc., correm um risco muito maior de se tornarem diabéticos
(também do tipo 1) do que as pessoas que não possuam casos na família. No caso da
Diabetes do tipo 2 também existe um importante componente hereditário. Portanto, uma
pessoa que tem histórico familiar de Diabetes tipo 2 tem maior propensão a desenvolver
este quadro.
Outro fator a ser levado em consideração é o fator emocional. Mas segundo
especialistas a Diabetes não deve aparecer devido a este fator, ela pode vir a aumentar os
níveis glicêmicos, em resposta ao estresse emocional, em indivíduos já diabéticos ou
propensos à doença. Nesta situação, são liberados alguns hormônios que têm a capacidade
de elevar a glicose.
O uso constante de bebidas alcoólicas também pode provocar a Diabetes. Existe um
tipo de Diabetes específico, decorrente do uso de bebida alcoólica de forma crônica. Isto
pode levar a um quadro de pancreatite e eventual destruição das células beta pancreáticas,
local de produção da insulina. Vale lembrar que, mesmo nos casos em que o álcool não foi
o causador direto da Diabetes, o seu uso excessivo pode levar ao descontrole da glicose.
Quanto a incidência da Diabetes em pessoas que consomem muito açúcar, não
funciona como se ouve falar muito. O uso de açúcar não causa Diabetes. No entanto, é
importante frisar que o açúcar é totalmente contra-indicado para indivíduos diabéticos, uma
vez que pode levar a grandes elevações nos níveis de glicose circulante.
A obesidade é importante fator de risco para a Diabetes do tipo 2. O excesso de
peso, sobretudo em pessoas com histórico familiar de Diabetes tipo 2, aumenta de forma
significativa o risco de surgimento desta disfunção. Indivíduos com estas características
podem diminuir o risco em cerca de mais da metade segundo pesquisas realizadas, caso
modifiquem hábitos alimentares, percam peso e pratiquem atividade física sistemática.

29
Estima-se que cerca de 85% dos diabéticos do tipo 2 apresentam excesso de peso ou
obesidade.
Quanto a incidência da Diabetes, pode ser classificada da seguinte maneira: a
Diabetes do tipo 1 ocorre igualmente em pessoas do sexo masculino e feminino. O pique de
incidência é na infância, sobretudo entre 4 e 6 anos de idade e na puberdade, especialmente
entre os 11 e os 16 anos. Já na Diabetes do tipo 2, as mulheres tem discreto predomínio no
número de casos deste tipo de Diabetes, talvez justificado pela maior prevalência de
obesidade neste sexo. Ocorre, sobretudo a partir dos 40 anos de idade.
Um último fator a ser levado em consideração, seguindo o mesmo autor Oliveira
(2003), quanto a Diabetes diz respeito ao fato de uma vida sedentária favorecer o
aparecimento do Diabetes, e em indivíduos com predisposição para o Diabetes, a atividade
física sistemática pode ajudar na prevenção, além de auxiliar na manutenção do peso ideal.
4.2 Hipertensão Arterial
Segundo Nobre & Lima (2000), “a hipertensão arterial não pode ser entendida
somente como uma condição clínica de cifras tensionais elevadas, mas como quadro
sindrômico, incluindo alterações hemodinâmicas, tróficas e metabólicas”, ou seja, deixou
de ser vista como uma doença ligada somente a tensão, para ser vista como um dos graves
fatores para doenças cardiovasculares. Essas alterações possam ter base genética, influência
ambiental ou do estilo de vida.
A hipertensão arterial nada mais é do que a conhecida pressão alta ou pressão
sanguínea elevada conforme definiu Almeida (2000). Segundo o autor a pressão, ou a força
da corrente sanguínea é mantida dentro de limites seguros pelo organismo. Porém em boa
parte da população, o sangue pressiona as artérias com uma força acima do normal. Essa
porcentagem corresponde ao grande contigente dos chamados hipertensos.

30
A Hipertensão Arterial pode ainda ser classificada de duas formas, segundo Nobre
& Lima (2000):
• Hipertensão Primária: hipertensão sem uma única causa definida, com múltiplos
fatores envolvidos e importantes componente genéticos (familiar).
• Hipertensão Secundária: elevação pressórica ocorrendo como manifestação de uma
doença conhecida, doenças renais, por exemplo, ou do uso de medicação com
marcada ação hipertensiva.
O III Consenso de MAPA (Monitorização Ambulatorial da Pressão Arterial) de
1998, publicado pela Sociedade Brasileira de Cardiologia, Hipertensão e Nefrologia definiu
como normais os valores de média de pressão arterial em um período de 24 horas que
estejam entre 130X80mmHG para pressões que tem comportamento normal e entre 130-
135X80-85mmHg para pressões com variação. Há ainda a medida domiciliar que
considera o limite de 135X85mmHG como normal.
Já Amodeo (2000), afirma que o acompanhamento a longo prazo dos candidatos a
desenvolverem hipertensão arterial primária, sofrem com o passar do tempo um aumento
progressivo da pressão arterial. Segundo pesquisas realizadas pelo mesmo, a incidência de
pressão arterial aumenta de 10% aos 30 anos para 30% aos 60 anos. Outra pesquisa mostra
ainda que a hipertensão arterial afeta cerca de 20% dos adultos em populações
industrializadas. Se não tratada a hipertensão arterial determina alterações em todo o
sistema cardiovascular, principalmente em órgãos como o cérebro, o coração e os rins.
Doenças crônicas como a hipertensão arterial, conhecida como pressão alta, e a
diabetes representam um dos grandes desafios para a saúde mundial. As estatísticas sobre
essas doenças são alarmantes. Só no continente americano, a hipertensão ataca cerca de
140 milhões de pessoas. Metade delas desconhece ser portadora da doença, por não
apresentar sintomas e não procurar serviço médico. Dos que descobrem serem hipertensos,
30% não realizam o tratamento adequado, por falta de motivação ou recursos. No Brasil,

31
estima-se que 22% da população adulta sofram de hipertensão e 8% tenham diabetes (SGB,
2004).
De acordo com o governo, doenças do aparelho circulatório como diabetes,
hipertensão, derrame, infarto e arteriosclerose lideram o ranking de mortalidade no Brasil a
cerca de quatro décadas. Cerca de 80% dos casos de acidente vascular encefálico (AVE),
mais conhecido como derrame, acontecem em pessoas hipertensas (ibidem).
Segundo uma abordagem conjunta realizada, a Diabetes Mellitus e a Hipertensão
Arterial Sistêmica tem como fundamento alguns dos aspectos citados a seguir (ibidem):
• Fatores de risco em comum: obesidade, dislipidemia e sedentarismo;
• Tratamento não medicamentoso: mudanças propostas nos hábitos de vida são
semelhantes;
• Facilmente identificadas na população;
• Alguns medicamentos em comum;
• Cronicidade: doenças incuráveis, necessitam de acompanhamento eficaz e
permanente.
O Anexo VII apresenta mais informações sobre a doença segundo cartaz do órgão
de saúde do governo.

I I I – DESENVOLVIMENTO
Este capítulo mostra como foi realizada toda a etapa de desenvolvimento da
ferramenta de Mineração de Dados.
O Desenvolvimento teve início com o estudo dos formulários utilizados como base
para o sistema, primeiro com os três formulários do HU de Florianópolis, e depois com o
formulário do USFC da UNIVALI. Com base nesses formulários, principalmente do último
foi desenvolvida a base de dados. Para carregar os dados no Banco foi implementada uma
tela de coleta de dados, que faria o papel de permitir aos profissionais da saúde colocar as
informações existentes nos prontuários em papel dentro do Banco de Dados. Foi realizada
uma etapa de organização e de limpeza dos dados existentes. Em seguida foi implementada
uma etapa de mineração e uma de visualização dos resultados. Ao final foi realizada uma
aplicação e os resultados foram validados pelo especialista.
1. O SISTEMA DE ANÁLISE DE DADOS
A Figura 6 mostra todas as etapas necessárias para a realização do processo de
descoberta do conhecimento e/ou Mineração de Dados do sistema desenvolvido.

33
Figura 6. Processo de Descoberta de Conhecimento do Sistema Desenvolvido
Para esse processo de descoberta de conhecimento, o sistema seguiu os seguintes
passos, na ordem em que estão, salvo alguma tela da etapa de pós-processamento que foi
desenvolvida antes:
• 1–Fonte de Dados: É a fase de coleta das informações para sua inserção na base de
dados desenvolvida, isto é, através da interface desenvolvida, foram carregados os
dados existentes nos prontuários do ambulatório para o banco de dados.
• 2–Pré-processamento: Nesta etapa os dados são organizados e limpos de acordo
com os parâmetros escolhidos para a mineração.
• 3–Mineração de Dados: Nesta etapa os dados são agrupados através de estatísticas
segundo os intervalos pré-definidos para os parâmetros escolhidos.
1 Fonte
De Dados
2 Pré-
Process.
3 Mineração de Dados
4 Pós-
Process.
5 Avaliação

34
• 4–Pós-processamento: Nesta etapa são gerados relatórios, diagramas de barra e
pizza, e telas de consultas para os resultados obtidos.
• 5–Avaliação: Nesta etapa o especialista avalia os resultados para a validação do
conhecimento.
1.1 Fonte de Dados
A etapa 1, Fonte de Dados é composta pela fase de entrada das informações, ou
seja, a passagem das informações presentes nos prontuários em papel da USFC para a base
de dados.
Para o desenvolvimento do BD, foi estudada a forma da coleta de dados em
Medicina, através de dois formulários: o utilizado pelo Hospital Universitário de
Florianópolis, e o formulário desenvolvido para o ambulatório da Univali (PINTO, 2004),
ver Anexo IV.
1.1.1 Formulários do HU para Diabetes Mellitus
O formulário consta de três documentos, o primeiro é o Diabetes – Primeira
Consulta (Anexo I), que mantém um ponto de vista geral, buscando informações referentes
ao paciente em um primeiro contato do mesmo com um exame para identificar a Diabetes.
Alguns indicadores utilizados neste formulário são: forma de tratamento quando sofreu da
doença, se teve algum fator como peso maior do que 4kg ao nascer, se teve viroses, ou
estresse, etc.
O Exame Físico (Anexo II) trata de informações sobre o paciente, que podem ser
observadas e ou descobertas através de exames um pouco mais detalhados, como a pressão
arterial do paciente, o ritmo cardíaco, o tipo de distribuição de gordura do mesmo, e até se
possui nas extremidades inferiores problemas como varizes, infecções ou micoses, por
exemplo.

35
O documento Diabetes – Evolução (Anexo III) busca saber o que está acontecendo
com o paciente durante o decorrer da doença, tentando acompanhar quais são os sintomas
que o paciente vem sentindo como emagrecimento, dor nas pernas, entre outros, se tem
realizado exercícios físicos regularmente, ou ainda alguma complicação que o paciente
possa apresentar.
1.1.2 Formulário da Unidade de Saúde da Família e Comunitária da Univali
O formulário foi desenvolvido pelo Profº. Luiz Gustavo Pinto, especificamente para
a coleta dos dados de pacientes com Diabetes e Hipertensão Arterial.
O documento traz informações dos pacientes atendidos no ambulatório da Unidade
de Saúde da Família e Comunitária da Univali com diagnóstico confirmado de Diabetes
e/ou Hipertensão Arterial. O formulário é utilizado com a finalidade de elucidar os riscos
para doenças cardiovasculares de tais pacientes, valendo-se para tal análise dos dados
coletados. O formulário consta de informações tais como Identificação: nome, idade, cor;
Exame Físico: peso; altura; IMC (índice de massa corporal, dado obtido da altura e peso);
Histórico Familiar do paciente referente à existência de doenças como hipertensão arterial
ou morte súbita de familiares; Histórico pessoal: tabagismo, etilismo; Bioquímica: glicose,
colesterol total; Medicação em uso; entre outros.
1.1.3 Projeto do Banco de Dados
Após o estudo dos formulários mostrados, foi criado o Banco de Dados que o
sistema utilizará. Ele foi baseado no formulário Hipertensão & Diabetes da Univali,
incluindo duas entidades que se baseiam na estrutura do Formulário do HU: Forma de
Tratamento e Histórico do Paciente. Tais entidades permitem fazer o acompanhamento do
paciente, evento que ainda não é realizado no ambulatório da Unidade de Saúde da Família
e Comunitária da Univali, entretanto poderá vir a ser utilizado mais adiante.

36
Na primeira fase do projeto, durante o TCCI tinha-se feito um pequeno modelo E-R
da Base de Dados, baseado nos formulários do HU, conforme mostrado na Figura 7.
Figura 7. Diagrama E-R inicial
Entretanto, devido à dificuldade de se obter dados para preencher as informações do
formulário do HU, e seguindo a recomendação da banca que julgou a primeira parte do
projeto, decidiu-se procurar o ambulatório da Univali para implantar o sistema. O mesmo
possuía informações suficientes para validar o sistema e apresentou interesse em possuir
uma ferramenta desse tipo.
Essa mudança ocorreu também porque a idéia de se utilizar os dados
disponibilizados na internet (UCI, 2003), não foi possível devido à pequena quantidade de
informações existentes.
Para a modelagem do BD, seguindo o formulário da UNIVALI, foram utilizadas as
seguintes entidades ou tabelas:
• Paciente: informações básicas sobre o paciente, por exemplo, sexo, idade, cor, etc.;
SINTOMA
FORMA DETRATAMENTO
INTERNACAO
HABITO COMPLICACAO
PACIENTE
POSSUIPERTENCE
UTILIZAPODE SER UTILIZADA
POSSUI
PODE SER
PODE SOFRERPERTENCE
PODE SOFRER
PODE AFETAR

37
• Guia Exame: armazena o formulário exatamente como estava no papel, esta tabela é
à base da mineração.
• Histórico Familiar: contendo as informações referentes a diabetes que tenham
ocorrido nos familiares dos pacientes.
• Histórico Patológico: com informações referentes ao paciente quanto a fatores que
podem ter influência no aparecimento das doenças.
• Forma de Tratamento: onde se guardam as formas de tratamento utilizadas no
paciente, para poder analisar quais foram mais eficientes e em quais tipos de
pacientes, esta tabela foi desenvolvida com base na estrutura do HU de
Florianópolis.
• Histórico Pessoal: armazena os costumes, vícios ou hábitos do paciente para
verificar qual a influência dos mesmos sobre a doença.
• Histórico Paciente: para apenas controlar se o paciente sofreu diabetes, qual foi a
forma de tratamento utilizada e quais os resultados após o tratamento, também foi
desenvolvida com base na estrutura do HU de Florianópolis.
• Exames Gerais: algum outro exame mais específico que possa ter sido feito no
paciente.
• Internação: controle de internações do paciente devido a diabetes, hipertensão
arterial ou sintomas das mesmas.
O diagrama E-R do BD desenvolvido é mostrado na Figura 8.

38
Figura 8. Diagrama E-R baseado no formulário Diabetes & Hipertensão
1.1.4 Ingresso das Informações
Tendo a base de dados desenvolvida, foi implementada uma interface, para facilitar
a inserção das informações presentes nos prontuários em papel à base de dados criada. A
Figura 9 mostra a tela de coleta de dados desenvolvida. Da tela apresentada inicialmente
aos usuários, praticamente nada foi alterado, já que mostrou-se amigável e teve aceitação
por parte dos mesmos.

39
Figura 9. Tela de Coleta de Dados
Porém, para o teste e validação do sistema nem todos os atributos foram
preenchidos por falta de tempo. Assim, foi necessária a criação de uma nova tela de coleta
que contém somente os atributos pré-determinados pelo especialista. Também foram
incluídas novas fórmulas para o cálculo de campos que são o resultado de outros valores do
prontuário do paciente. Por exemplo o campo VL_IMC (valor que controla o Índice de
Massa Corporal) é resultante da altura e do peso do paciente. A Figura 10 mostra a tela de
coleta de dados resumida.

40
Figura 10. Tela de Coleta de Dados Resumida
Cabe ressaltar que a etapa de Data Warehousing embora faça parte do processo de
Mineração de Dados, não foi utilizada no sistema, porque a base de dados desenvolvida é
específica para o objetivo da mineração: pacientes com diagnóstico de diabetes e/ou
hipertensão.
1.2 Pré Processamento
Esta etapa, foi realizada através de uma escolha dos registros existentes nas tabelas a
serem mineradas, selecionando apenas aqueles que possuíssem todos os parâmetros de
entrada informados pelo usuário devidamente preenchidos, excluindo dessa forma os
registros inconsistentes que poderiam influenciar no resultado da pesquisa. A seleção dos
parâmetros desejados pelo usuário é feita na tela apresentada na Figura 11.

41
Figura 11. Tela de Entrada de Parâmetros
Este pré-processamento funciona da seguinte forma: o usuário seleciona os
parâmetros desejados, após essa escolha, é executada uma rotina que lê os registros dos
pacientes, e insere em uma nova tabela somente os registros que possuam aqueles campos
preenchidos. A Figura 12 mostra diversos registros das tabelas paciente e guia_exame.

42
Figura 12. Select das informações dos pacientes
A estrutura PLSQL da seleção realizada no pré-processamento funciona
basicamente conforme mostrada abaixo:
SELECT g.vl_imc, -- Valor de Retorno
p.qt_idade, -- Parâmetro de Entrada 1
p. id_sexo -- Parâmetro de Entrada 2
FROM paciente p,
guia_exame g
WHERE p.cd_paciente = g.cd_paciente
AND p.qt_idade IS NOT NULL
AND p.id_sexo IS NOT NULL
AND g.vl_imc IS NOT NULL
ORDER BY 1;

43
Após o pré-processamento, dos 186 registros originais, apenas 143 registros foram
inseridos, isto ocorreu porque nem todos os pacientes possuíam o campo VL_IMC
preenchidos. A ordenação dos registros também foi realizada nessa etapa já que a forma
como será feita a mineração exige que os dados estejam ordenados corretamente pelo valor
pesquisado. A Figura 13 abaixo mostra a estrutura dos registros inseridos.
Figura 13. Select após o pré-processamento
Para essa etapa e para a etapa de mineração outras três tabelas foram criadas, devido
à necessidade de se armazenar as informações do processo. Estas tabelas são explicadas a
seguir:
• Controle Valores: tabela auxiliar apenas para controle dos campos que poderão ser
utilizados na mineração.

44
• Dados Diabetes Work: tabela auxiliar temporária, que facilitará o processo de
mineração.
• Dados Minerados: responsável por armazenar todas as informações obtidas durante
a etapa de mineração, contém os dados que serão apresentados ao especialista, para
sua análise.
1.3 Mineração de Dados
Após o pré-processamento, surge à etapa de Mineração de Dados, que no caso do
projeto realiza um agrupamento através de estatísticas sobre as informações mineradas. Os
dados minerados são somente numéricos. Isto se deve ao fato do especialista só possuir
interesse nos dados numéricos. Assim, não há um procedimento para mineração de dados
alfa-numéricos.
Nesta etapa, são lidos os registros da tabela temporária e selecionados somente os
que estejam dentro do intervalo selecionado pelo especialista. No caso dos 143 registros
que existiam anteriormente, apenas 88 são selecionados, como pode ser visto na Figura 14.

45
Figura 14. Select dos registros selecionados
Nesse momento é realizada uma inserção na tabela de resultados da mineração,
quando são inseridos os parâmetros de entrada da mineração, os valores encontrados para o
campo selecionado como retorno, e é realizada uma contagem do número de repetições de
cada valor encontrado.
O passo seguinte diz respeito aos cálculos que são realizados para se guardar os
índices percentuais da pesquisa. Os cálculos realizados são os seguintes:
• Percentual de fichas válidas: é realizada a divisão do número de fichas com todos os
parâmetros selecionados devidamente preenchidos pelo número total de prontuários
existentes na base de dados.

46
• Percentual de fichas dentro do intervalo solicitado: é realizada a divisão do número
de fichas dentro dos intervalos informados pelo usuário pelo total de fichas válidas.
• Percentual do Valor: é realizada uma divisão do número de vezes que o valor
retornado apareceu pelo total de fichas dentro do intervalo, para se identificar qual o
percentual de um valor específico em relação ao total de fichas.
O resultado da pesquisa pode ser visto na Figura 15.
Figura 15. Resultado da Mineração
Esta etapa pode ser expressa nos seguintes passos:
1- Seleção dos registros já limpos e ordenados que estejam dentro dos intervalos
informados pelo especialista para os parâmetros;

47
2- Inserção dos registros minerados na tabela de resultados;
3- Contagem do número de repetições do parâmetro de retorno selecionado, caso
tenha sido informado;
4- Busca pelos números totais de fichas;
5- Cálculos estatísticos para os resultados.
A rotina SMDS0400 que é responsável por esse processo, pode ser vista no
APÊNDICE I.
1.4 Pós-Processamento
Esta etapa é responsável pela transformação das informações já existentes na tabela
de dados minerados de forma que possam ser analisadas. Seria a forma da apresentação da
informação para o especialista. No projeto esta apresentação pode ser feita de diversas
formas:
• Através de relatórios: foram desenvolvidos relatórios, como o da Figura 16 que
mostra esta informação através da geração de regras, e permite ver as informações
de forma organizada, não da forma como estão estruturadas na base de dados.

48
Figura 16. Relatório de Regras Geradas Após Mineração
• Através da tela de consulta: a forma mais utilizada, pode-se ver a tabela de uma
forma um pouco mais estruturada, facilitando ao especialista tentar identificar
algum fator considerável. A Figura 17 mostra esta tela.

49
Figura 17. Tela de Consulta de Dados Minerados
O sistema permite ainda após a visualização desses dados selecionar um novo
intervalo para a variável de retorno, podendo dessa forma conseguir um resultado ainda
mais simples e específico.
• Através de telas de gráficos: Não muito utilizada, pode somente dar uma aparência
um pouco mais clara a uma pesquisa e mostrar de uma forma diferente o resultado
da pesquisa. Veja na Figura 18 uma das telas de geração de gráficos do sistema.

50
Figura 18. Tela de Gráficos de Quantidades
A estrutura dessas formas de apresentar os resultados são simplesmente consultas
simples à base de dados. Abaixo se pode ver a estrutura de consulta do relatório de regras
mostrado na Figura 17.
SELECT cd_pesquisa,
id_pesquisado,
id_entrada_1,
id_entrada_2,
id_entrada_3,
id_entrada_4,
id_sinal_1,
vl_entrada_1_1,
vl_entrada_1_2,

51
id_sinal_2,
vl_entrada_2_1,
vl_entrada_2_2,
id_sinal_3,
vl_entrada_3_1,
vl_entrada_3_2,
id_sinal_4,
vl_entrada_4_1,
vl_entrada_4_2,
vl_pesquisado,
qt_repeticao_valor,
nr_perc_valor,
qt_total_guias,
qt_total_validas,
qt_total_guias_lim,
nr_perc_fichas,
nr_perc_fichas_lim
FROM dados_minerados
WHERE cd_pesquisa = :cd_pesquisa;
1.5 Avaliação
Quando se chega à etapa de avaliação, o sistema já não pode e não deve realizar
mais nada. É o especialista quem interpretará e avaliará os resultados apresentados pelo
sistema e validará ou não o conhecimento obtido. Esta validação o especialista faz
utilizando-se dos relatórios e das telas de consultas sobre diversas pesquisas realizadas,
unindo ao seu conhecimento sobre o assunto abordado, para poder chegar a conclusões, que
poderão considerar viáveis ou não os resultados apresentados.

52
2. DA INSTALAÇÃO DE FERRAMENTAS
Foi necessário já em um primeiro momento fazer a instalação de algumas
ferramentas que seriam utilizadas tanto para a implementação do sistema quanto para a sua
execução. No laboratório de TCC e extensão do curso de Ciência da Computação, foi
necessária a instalação da ferramenta case responsável pela modelagem, o Oracle Designer,
que foi a responsável por toda a modelagem lógica e física do banco de dados e por sua
criação física, pela modelagem dos módulos a serem desenvolvidos pelo sistema, e pelo
fluxo das informações entre a base de dados e o sistema. Infelizmente não foi possível se
fazer à geração dos módulos automaticamente pelo programa, devido a um erro que ocorreu
entre a versão do mesmo e a versão das ferramentas de implementação Oracle Forms e
Report Builder que também foram implantadas na máquina de desenvolvimento. Caso essa
geração estivesse funcionando poderia ser gerado o sistema tanto para sua utilização local
quanto para a WEB já que a ferramenta permite a geração dos executáveis de três formas
distintas: para a ferramenta Forms Builder (escolhida para a implementação), para a
ferramenta Visual Basic, e para Forms Web, gerando uma página que se comunica com o
Banco de Dados através da linguagem de programação JAVA.
A seguir foi instalado um Client do Oracle (Cliente de serviços do banco) na USFC,
no computador onde está implantado o sistema, de forma que se pudesse ver a base de
dados desenvolvida no banco do CTTMAR. Também foi instalada uma versão do Forms
Runtime e do Reports Runtime para se conseguir executar os programas no local.
3. MODELAGEM
Para o desenvolvimento do projeto foram necessárias diversas definições do sistema
que viriam a facilitar a implementação do mesmo. A modelagem do sistema foi feita
através da Análise Essencial por apresentar certa velocidade na especificação, já que na
mesma é construído o modelo necessário para que o sistema satisfaça os requisitos do
usuário, utilizando-se o Modelo Ambiental e o Modelo Comportamental. Também foram

53
utilizadas: a Modelagem Física do Banco de Dados e a Modelagem dos Módulos (ou
programas) que foram implementados.
3.1 Modelo Ambiental
O Modelo Ambiental mostra como o sistema interage com o ambiente externo, sem
descrever o comportamento do sistema. É composto por uma Lista de Eventos e por um
Diagrama de Contexto.
3.1.1 Lista de Eventos
A Lista de Eventos é uma lista textual das entradas do ambiente externo, que
requerem uma resposta do sistema. A Lista de Eventos do sistema, é apresentada a seguir:
Evento 1 – Usuário entra com informações do Paciente;
Evento 2 – Usuário entra com informações da Guia Exame;
Evento 3 – Usuário entra com parâmetros de Mineração;
Evento 4 – Gerar tabela de comparação e;
Evento 5 – Emitir relatórios percentuais ou gráficos de comparações.
3.1.2 Diagrama de Contexto
É um diagrama de fluxo de dados composto por um único processo que representa
todo o sistema, conforme pode ser observado na Figura 19. Este diagrama foi desenvolvido
na ferramenta Power Designer, já que a ferramenta ORACLE Designer não possuía este
tipo de diagrama.

54
Figura 19. Diagrama de Contexto
3.2 Modelo Comportamental
Descreve o interior do sistema, mostrando como o mesmo interage com o ambiente
externo. É composto pelo desenvolvimento dos diagramas de fluxos de dados, do modelo
entidade-relacionamento, das especificações de processos e do dicionário de dados.
Esta modelagem mostra qual a ligação entre os usuários do sistema, a base de dados
desenvolvida e o sistema propriamente dito.
3.2.1 Diagrama de Fluxos de Dados
O Diagrama de Fluxo de Dados (DFD) é uma ferramenta de modelagem usada para
descrever a transformação de entradas em saídas. A Figura 20 demonstra o DFD básico
gerado pela ferramenta ORACLE DESIGNER somente para visualização.

55
Figura 20. Diagrama de Fluxo de Dados Geral
3.2.2. Modelo Entidade-Relacionamento
Para modelar o banco de dados do sistema utilizou-se o Modelo Entidade-
Relacionamento (E-R), dividido em modelo lógico (conceitual) e modelo físico. Para a
construção deste modelo utilizou-se a ferramenta Oracle Designer. A Figura 21 abaixo
mostra o diagrama E-R lógico desenvolvido para o sistema.

56
Figura 21. Diagrama E-R – Modelo Lógico
Após a geração física do modelo lógico apresentado, surge um outro modelo de
Entidade-Relacionamento, na Figura 22 pode-se observar o diagrama do modelo físico
gerado após a transformação do modelo lógico.

57
Figura 22. Diagrama E-R – Modelo Físico
3.2.3. Especificações dos Processos
A Especificação de Processos determina os passos a serem seguidos para a
transformação de entradas em saídas.
Visando-se simplificar o entendimento, optou-se pela descrição textual dos
processos.
• Processo 1 - Manter Paciente: este processo é responsável pela manutenção dos
atributos referentes ao paciente.

58
• Processo 2 – Manter Guia Exame: este processo é responsável pela manutenção dos
atributos referentes a guia de exame, base das informações utilizadas na mineração;
• Processo 3 – Entrar com parâmetros de Mineração: nesta etapa após o
preenchimento da base, o especialista informa que informações devem ser coletadas
e sobre quais parâmetros e valores;
• Processo 4 – Gerar tabela de comparação: o algoritmo minerador gera a tabela final
que contém as informações organizadas e filtradas pelos parâmetros entrados;
• Processo 5 – Emitir relatórios percentuais: esta etapa consiste da saída das
informações coletadas para o especialista de forma estruturada, através de relatórios,
gráficos das informações ou da geração de regras.
3.2.4. Dicionário de Dados
Após a construção do DFD e da Especificação dos Processos foi desenvolvido o
Dicionário de Dados, o qual consiste na descrição de todas as tabelas que compõem a base
de dados, bem como seus itens de dados. A Tabela 6 descreve quais foram às entidades
desenvolvidas.
• Descrição das tabelas
Tabela 6. Descrição das Tabelas de Dados utilizadas no Sistema.
NOME DA TABELA DESCRIÇÃO
Paciente Pacientes que realizaram exames de Hipertensão e Diabetes
Guia Exame Guia de Exame de Hipertensão e Diabetes
Histórico Pessoal Históricos Pessoais do Paciente, demonstrando seus vícios,
costumes ou problemas

59
NOME DA TABELA DESCRIÇÃO
Histórico Familiar Históricos Familiares do Paciente, demonstrando quais doenças os
familiares tiveram
Histórico Patológico Históricos Patológicos do Paciente, demonstrando que tipo de
problemas ou doenças o paciente possui
Exames Gerais Outros Exames Realizados Sobre o Paciente
Histórico Paciente Histórico do Paciente após receber uma forma de tratamento
Dados Minerados Tabela que guarda os resultados da mineração
Controle Valores Tabela que guarda os domínios utilizados pelo sistema
Dados Diabetes Wrk Tabela temporária que auxilia no processo de mineração
Parâmetros Entrada Tabela que guarda os parâmetros permitidos para mineração
Internação Internações do Paciente
Forma Tratamento Formas de Tratamento para Pacientes Diabéticos
Já as Tabelas de 7 a 19 (Anexo VI) apresentam quais campos compõem todas as
tabelas de dados descritas na Tabela anterior.
3.3 Modelagem dos Módulos do Sistema
Esta modelagem mostra a forma como estão estruturados os programas do sistema.
A Figura 23 apresenta como estão estruturados os programas no nível mais alto segundo
este modelo.

60
Figura 23. Módulos Gerais
Esta é apenas uma visão geral dos módulos. Cada grupo mostrado acima pode ser
definido da seguinte forma:
• Módulos de Cadastros: considerados como os programas padrões, aqueles
responsáveis pela entrada das informações nas tabelas do banco de dados, ou seja
responsáveis pelas cargas das tabelas. No nosso processo de mineração seria o
responsável pela Fonte de Dados.
• Módulos de Consulta: Responsáveis pela visualização das informações existentes
na base, inclusive das pesquisas realizadas, ou seja onde podem ser vistos os
resultados do processo. Cabe ao mesmo cumprir a função de Pós-processamento.
• Módulos de Relatórios: Criados para permitir ao especialista gerar e imprimir os
resultados das pesquisas ou as informações presentes na base de dados.
Desenvolvidos da mesma forma como os módulos de consulta também exercem a
função de Pós-processamento.
• Módulos de Rotinas: São os programas responsáveis pelos processos internos da
mineração. As etapas de Pré-processamento e de Mineração de Dados são realizadas

61
através desses programas que realizam as alterações e as consultas necessárias na
base de dados, ou seja nessas estruturas estão os algoritmos.
Cada um dos grupos de módulos mostrados acima possui diversos programas, que
podem ser vistos nas Tabelas 7 a 10.
Tabela 7. Módulos de Cadastros.
NOME DO MÓDULO CÓDIGO FUNÇÃO
Manter Paciente SMDS0105 Tela responsável pelo preenchimento
da tabela PACIENTE
Manter Guia Exame SMDS0100
Tela responsável pelo preenchimento
das tabelas GUIA_EXAME e
PACIENTE
Manter Guia Exame Resumida SMDS0101
Tela responsável pelo preenchimento
das tabelas GUIA_EXAME e
PACIENTE
Entrar com Parâmetros de Mineração SMDS0108 Tela responsável pela seleção dos
parâmetros de pesquisa
Manter Histórico Pessoal SMDS0106 Tela responsável pelo preenchimento
da tabela HISTORICO_PESSOAL
Manter Histórico Familiar SMDS0107 Tela responsável pelo preenchimento
da tabela HISTORICO_FAMILIAR
Manter Histórico Patológico SMDS0109
Tela responsável pelo preenchimento
da tabela
HISTORICO_PATOLOGICO
Selecionar Percentuais da Pesquisa SMDS0120
Tela responsável pela consulta e
entrada de um novo intervalo para
uma pesquisa já realizada.
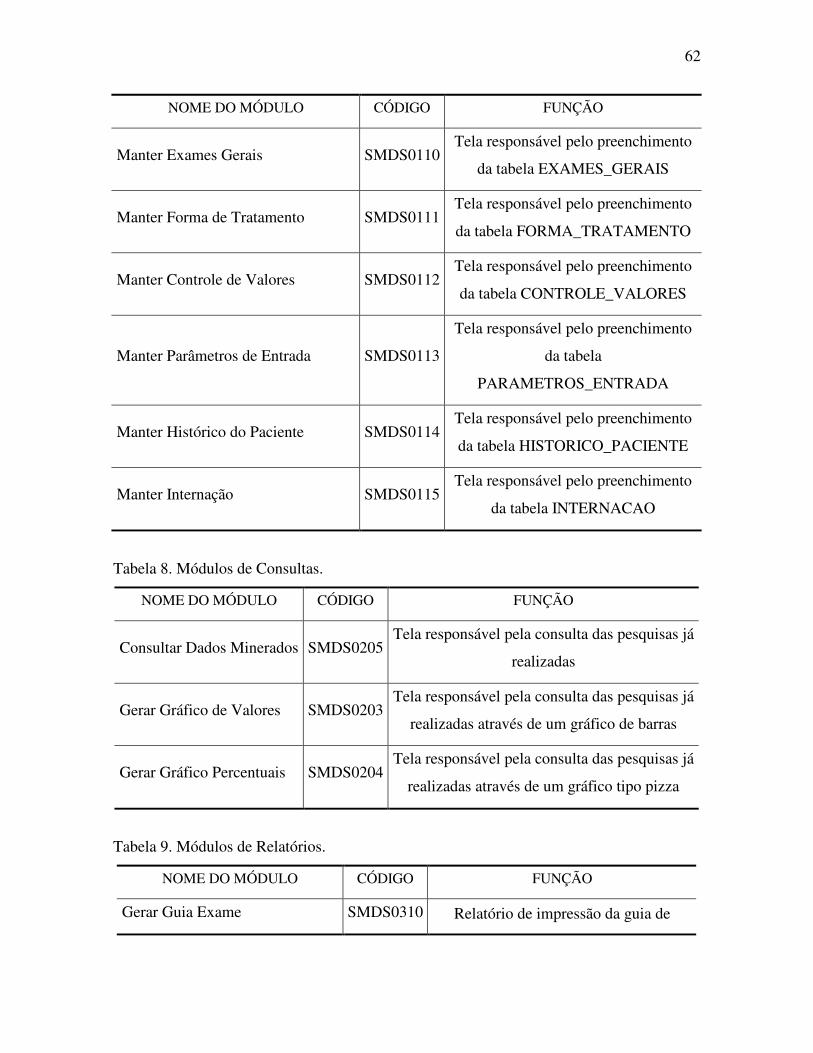
62
NOME DO MÓDULO CÓDIGO FUNÇÃO
Manter Exames Gerais SMDS0110 Tela responsável pelo preenchimento
da tabela EXAMES_GERAIS
Manter Forma de Tratamento SMDS0111 Tela responsável pelo preenchimento
da tabela FORMA_TRATAMENTO
Manter Controle de Valores SMDS0112 Tela responsável pelo preenchimento
da tabela CONTROLE_VALORES
Manter Parâmetros de Entrada SMDS0113
Tela responsável pelo preenchimento
da tabela
PARAMETROS_ENTRADA
Manter Histórico do Paciente SMDS0114 Tela responsável pelo preenchimento
da tabela HISTORICO_PACIENTE
Manter Internação SMDS0115 Tela responsável pelo preenchimento
da tabela INTERNACAO
Tabela 8. Módulos de Consultas.
NOME DO MÓDULO CÓDIGO FUNÇÃO
Consultar Dados Minerados SMDS0205 Tela responsável pela consulta das pesquisas já
realizadas
Gerar Gráfico de Valores SMDS0203 Tela responsável pela consulta das pesquisas já
realizadas através de um gráfico de barras
Gerar Gráfico Percentuais SMDS0204 Tela responsável pela consulta das pesquisas já
realizadas através de um gráfico tipo pizza
Tabela 9. Módulos de Relatórios.
NOME DO MÓDULO CÓDIGO FUNÇÃO
Gerar Guia Exame SMDS0310 Relatório de impressão da guia de
exame digitada.
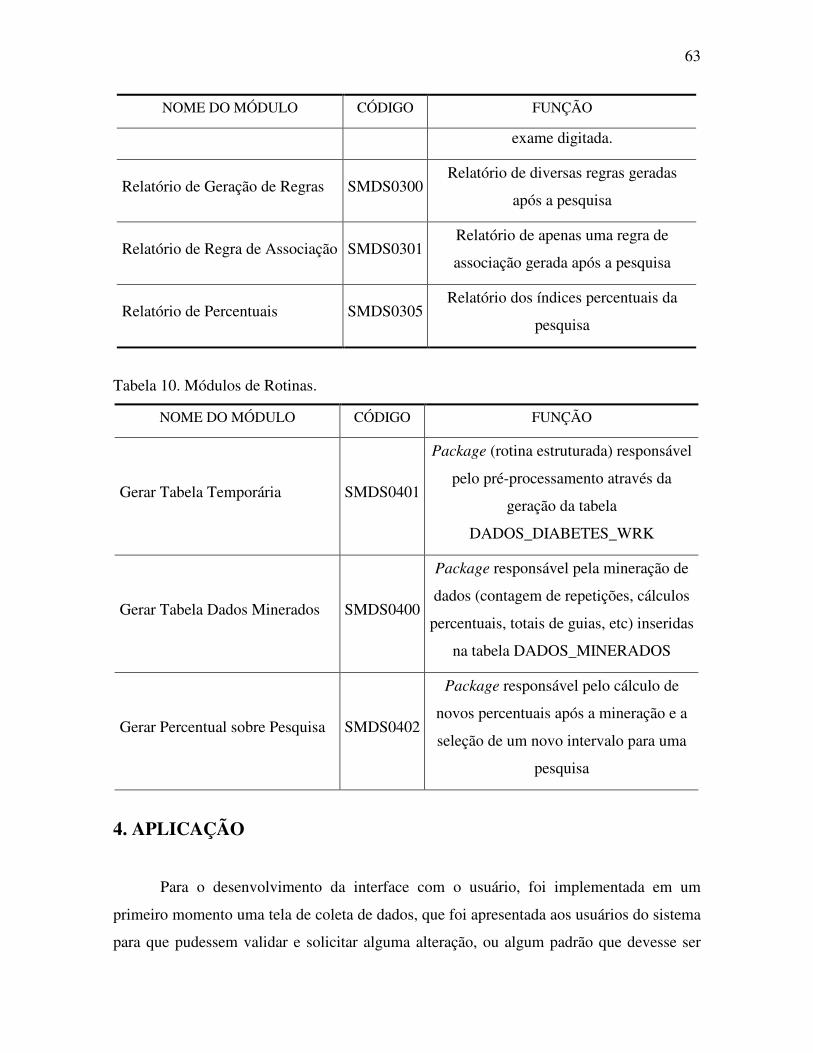
63
NOME DO MÓDULO CÓDIGO FUNÇÃO
exame digitada.
Relatório de Geração de Regras SMDS0300 Relatório de diversas regras geradas
após a pesquisa
Relatório de Regra de Associação SMDS0301 Relatório de apenas uma regra de
associação gerada após a pesquisa
Relatório de Percentuais SMDS0305 Relatório dos índices percentuais da
pesquisa
Tabela 10. Módulos de Rotinas.
NOME DO MÓDULO CÓDIGO FUNÇÃO
Gerar Tabela Temporária SMDS0401
Package (rotina estruturada) responsável
pelo pré-processamento através da
geração da tabela
DADOS_DIABETES_WRK
Gerar Tabela Dados Minerados SMDS0400
Package responsável pela mineração de
dados (contagem de repetições, cálculos
percentuais, totais de guias, etc) inseridas
na tabela DADOS_MINERADOS
Gerar Percentual sobre Pesquisa SMDS0402
Package responsável pelo cálculo de
novos percentuais após a mineração e a
seleção de um novo intervalo para uma
pesquisa
4. APLICAÇÃO
Para o desenvolvimento da interface com o usuário, foi implementada em um
primeiro momento uma tela de coleta de dados, que foi apresentada aos usuários do sistema
para que pudessem validar e solicitar alguma alteração, ou algum padrão que devesse ser

64
seguido. Porém pouco foi alterado da tela inicialmente mostrada para os usuários. A forma
de utilização do sistema pode ser mais bem entendida, observando o Apêndice II, que
mostra as principais telas do sistema, e inclui um tutorial para o uso do sistema.
Para a validação do sistema, o especialista determinou o uso de uma quantidade
menor de parâmetros devido ao tempo para se carregar à base. Foram selecionadas doze
variáveis, que fazem parte do objetivo da pesquisa inicial do especialista. Os demais
campos da base ficaram pendentes, para preenchimento posterior. Cabe salientar que o
algoritmo permite a mineração sobre todos os campos numéricos. A questão da escolha de
doze variáveis diz respeito somente ao fato de se carregar à base de dados para a validação.
Os parâmetros escolhidos podem ser vistos na Tabela 11.
Tabela 11: Parâmetros selecionados
CAMPO DESCRIÇÃO TABELA
QT_IDADE Idade do Paciente Paciente
ID_SEXO Sexo do Paciente Paciente
ID_ETNIA Cor do Paciente Paciente
DS_PROFISSAO Profissão do Paciente Paciente
VL_IMC Índice de Massa Corporal Guia Exame
VL_FC Valor de FC Guia Exame
VL_LDL Valor de LDL Guia Exame
VL_HDL Valor de HDL Guia Exame
VL_GLICOSE Valor de Glicose Guia Exame
VL_COLESTEROL Valor de Colesterol Guia Exame
VL_TRIGLICERIDIOS Valor de Triglicerídios Guia Exame
VL_PRES_BRACO_D_SENT Valor da Pressão Arterial Guia Exame
Com base nesses parâmetros foram selecionadas as informações do primeiro
trimestre do ano de 2004 de todos os pacientes que realizaram o exame de Diabetes e
Hipertensão no ambulatório da USFC, ao todo foram selecionados 186 prontuários de
pacientes que foram carregados na base.

65
Os passos realizados para a utilização do sistema com o acompanhamento do
especialista foram:
• Determinação dos Parâmetros de Entrada e Valor Pesquisado:
Os parâmetros de entrada utilizados foram: VL_IMC, QT_IDADE,
VL_TRIGLICERIDIOS, VL_LDL, ID_SEXO, em diversas combinações. Para a entrada
destes parâmetros e seus intervalos foi utilizada a tela mostrada na Figura 15.
• Mineração de Dados:
Foram gerados agrupamentos segundo o parâmetro pesquisado, para o exemplo
abaixo, o campo ID_SEXO obteve dois agrupamentos, onde cada um deles continha um
intervalo previamente especificado para cada um dos parâmetros de entrada. A Figura 24
mostra a tela dos resultados para este caso.

66
Figura 24. Consulta Pesquisa
• Conhecimento Obtido
Após o processo de mineração, o especialista, verificou os agrupamentos obtidos
para as diversas combinações realizadas, através da tela de consulta. Também foram
gerados relatórios dos resultados, para facilitar a análise um pouco mais detalhada das
informações obtidas. Um conhecimento preliminar de consideração indicado pelo
especialista é a prevalência de sobrepeso e obesidade entre os pacientes consultados nos
primeiros três meses do ano de 2004 na Unidade de Saúde da Família e Comunitária da
Univali. Valor que não está muito distante dos percentuais obtidos em outras pesquisas de
nível nacional.
Outra observação diz respeito ao preenchimento dos prontuários no ambulatório,
ficando constatado, que ao serem preenchidos, é necessário uma atenção um pouco maior

67
para informações consideradas fundamentais, como o peso e a altura, no caso dos idosos, já
que se verificou com a pesquisa que muitos prontuários não possuíam estas informações.
• Decisões Tomadas:
Baseado no conhecimento obtido, no caso do índice elevado de sobrepeso e
obesidade, já está sendo previsto, o desenvolvimento de um projeto para monitorizar e
promover um melhor controle desses definidos fatores de risco para doenças crônicas, caso
o resultado dessa mesma pesquisa em um período maior, como o de um ano, apresente os
mesmos resultados.
Também surgiu a perspectiva de um monitoramento para o correto preenchimento
dos prontuários dos pacientes, devido à outra observação feita pelo especialista quanto ao
preenchimento do índice de massa corporal (IMC), cálculo que utiliza o peso e a altura,
fundamentais para o resultado da pesquisa.

I V – CONCLUSÕES E RECOMENDAÇÕES
A ferramenta permite visualizar as características dos pacientes, facilitando o
entendimento do comportamento da doença nesse grupo humano em particular. Sendo
assim, ela servirá de apoio ao ensino e pesquisa de riscos cardiovasculares em pacientes
diabéticos e/ou hipertensos.
Os resultados obtidos com a ferramenta mostram que o agrupamento foi apropriado
para o objetivo do especialista: obter o perfil dos pacientes consultados no ambulatório.
Porém para projetos futuros seria interessante a utilização das outras técnicas de mineração
para identificar se apesar de mostrar o resultado desejado, o algoritmo é o que melhor
desenvolve a função de geração de perfis.
A ferramenta desenvolvida será de utilidade na análise de pacientes diabéticos e/ou
hipertensos atendidos na USFC da Univali, podendo ser utilizada como material
pedagógico na ministração de aulas, no estudo de aspectos epidemiológicos, e no
desenvolvimento de teses e artigos relacionados a diabetes e hipertensão
A descoberta de perfis, a partir de atributos pré-estabelecidos, objetivo do
especialista, foi realizado com sucesso. O algoritmo estatístico implementado obteve o
agrupamento dos pacientes e apresenta as classes com índices relativos à população da qual
foi extraída. O uso de índices é muito utilizado em medicina.
A idéia de utilizar redes neurais que havia sido citada na banca de TCCI, não foi
implementada porque levaria um tempo maior para o desenvolvimento, além do fato da
técnica trabalhar com muitas variáveis. Cabe salientar que segundo o especialista a
mineração deve ser com no máximo 5 parâmetros de cada vez, pois com mais do que isso a
análise da informação se torna confusa.

69
Quanto à utilização das bases de dados da UCI, para o teste do trabalho, não foi
realizada por ter uma base de casos reais e o suporte do especialista da área, além do fato da
base não possuir informações suficientes para a validação do projeto.
Todas as metas definidas para o projeto foram satisfeitas, salientando-se que foram
realizadas até tarefas que não estavam nos planos, como a utilização da própria base de
dados desenvolvida para a validação, utilizando as informações que existiam em
prontuários já preenchidos no ambulatório. O único ponto em relação à etapa de validação
foi referente à seleção de alguns parâmetros específicos, já que o preenchimento de todos
os parâmetros ficou inviabilizado devido ao prazo do projeto.
A etapa referente ao sistema de mineração foi concluída com sucesso, contando com
um banco de dados que armazena os dados dos pacientes. Além disso, esta etapa foi testada
e validada pelo especialista, conforme descreve o item Aplicação na parte de
Desenvolvimento.
A base de dados desenvolvida poderá ser utilizada como referencia para a criação
da coleta de dados de diabetes & hipertensão, fazendo parte de um projeto maior, que é a
informatização do prontuário do paciente do Ambulatório da Univali.
A interface para a entrada de dados foi validada pelos usuários do sistema, que
solicitaram apenas pequenas alterações na tela inicialmente apresentada, para satisfazer um
ou outro caso específico, já que o especialista concordou com a estrutura da tela e
considerou a sua funcionalidade simples.
Como já foi citado, a base de dados foi toda desenvolvida em Oracle pelo fato da
UNIVALI, local onde foi implantado o sistema já possuir a licença do mesmo. Porém isso
torna a utilização do sistema em outro local complicada, já que a licença do Oracle tem um
preço um pouco elevado. Este pode se considerado o ponto negativo da utilização do
Oracle, já que a sua utilização pode ser considerada um ponto positivo no trabalho, pois se
trata do que existe de melhor em matéria de Bancos de Dados. Quanto às ferramentas, são

70
próprias para se integrar com o Oracle e estão surgindo como diferenciais para profissionais
de informática, devido à necessidade de mão-de-obra qualificada.
Com o desenvolvimento do sistema foram utilizados diversos conhecimentos,
conseguidos nas disciplinas do curso de Ciência da Computação, como Banco de Dados,
Inteligência Artificial, Análise de Projetos e Sistemas, entre outros, realizando a integração
dessas disciplinas em um projeto único.
Como trabalhos futuros, sugere-se:
• A implementação do algoritmo de mineração que inclua dados alfa-numéricos;
• A migração da ferramenta para uma estrutura WEB, que pode ser na própria
linguagem utilizada e utilizando a mesma ferramenta Forms Builder que permite a
geração dos mesmos programas em uma espécie de aplicativo Java, quando gerada
via ferramenta case Oracle Designer, tendo sido inclusive realizado alguns testes da
geração dessas telas, ficando como dificuldade implementar somente a forma como
ocorre a integração do aplicativo WEB com a base de dados.
• Um acompanhamento sobre as formas de tratamentos utilizadas nos pacientes,
desde que o ambulatório passe a realizar este processo.
• A integração do sistema ao projeto de informatização do prontuário do paciente da
USFC que deverá estar sendo implantado até o início do ano de 2005.
• Embora acredite que a mineração sobre os prontuários da USFC não tornarão o
processo demorado, afirmação tirada devido a experiência profissional da área e
pelo fato da busca ser realizada em cima de apenas duas tabelas, fica a necessidade
de um acompanhamento sobre a performance do sistema quando forem inseridos
uma quantidade maior de registros.

BIBLIOGRAFIA
ALMEIDA, H. G. G. Diabetes Mellitus: uma abordagem simplificada para
profissionais de saúde. São Paulo: Editora Atheneu, 1997.
ALMEIDA, F. A. Hipertensão Arterial: conheça o inimigo, 5ª Edição. São Paulo:
Cultura Editores Associados, 2000.
AMODEU, C. Artigo: Hipertensão Arterial: Prognóstico e Epidemiologia, Sociedade de
Cardiologia do Estado de São Paulo (SOCESP) : Ari Timerman, Luiz Antonio Machado
César. São Paulo: Editora Atheneu, 2000.
BARRETO, J.M. Inteligência Artificial no Limiar do Século XXI, 3a Edição.
Florianópolis- SC: ρρρ Edições, 2001.
BERRY, Michel J. A.; LINOFF, G. Data mining techniques for marketing, sales,
and customer support. New York, John Wiley & Sons, 1997.
BERSON, A. Data Warehousing, Datamining, and OLAP. USA: McGraw-Hill, 1998.
CARVALHO, L.A.V. Datamining - A Mineração de Dados no Marketing, Medicina,
Economia, Engenharia e Administração. São Paulo : Érica, 2001.
COLLAZOS, K., BARRETO, J. “KDD Ferramenta Para Análise de Dados
Epidemiológicos”, Anais do III Congresso Brasileiro de Computação - III Workshop
de Informática aplicada à Saúde - CBCOMP'2003, Itajaí, p. 2226-2236, 2003.
DIAS, M. M. Um Modelo de Formalização Do Processo de Desenvolvimento de
Sistemas de Descoberta de Conhecimento em Banco de Dados. Trabalho de Pós-
graduação. Florianópolis – SC: UFSC, 2001.

72
FANDERUFF, D. Oracle 8i. SQL*PLUS e PL/SQL. São Paulo: Makron Books do Brasil
Editora Ltda, 2000.
FAYYAD, U.M., PIATETSKY-SHAPIRO, G., SMYTH, P. “From data mining to
knowledge discovery: an overview”, In: Advances in Knowledge Discovery, Eds.: Usama
M. Fayyad, Gregory Piatetsky-Shapiro, Smyth Padhraic, Ramasamy Uthurusamy,
Massachusetts: AAAI Press/The MIT Press, capítulo 1, p.1-34, 1996.
FERNANDES, A. M. R. Inteligência Artificial noções gerais. Florianópolis – SC, Visual
Books Ltda., 2003.
FREITAS, A. A.; LAVIGNTON, S. H. Mining Very Large Databases with Parallel
Processing. Kluwer Academic Publishers. 1998.
GOEBEL, M.; GRUENWALD, L. A survey of data mining and knowledge discovery
software tools. In: SIGKDD Explorations, June 1999.
GROTH, R. Data Mining: a hands–on approach for Business Professionals. New
Jersey: Editora Prentice Hall PTR, 1998.
HARRISON, T.H. Intranet data warehouse. Editora Berkeley, 1998.
KORTH, H. F.; SILBERSCHATZ, A. Sistema de Bancos de Dados, 2ª Edição. São Paulo:
MAKRON Books, 1995.
MANNILA, H. “Data Mining: machine learning, statistics, and databases”, Proceedings of
Eight International Conference on Scientific and Statistical Database Management,
Stockholm-Sweden, p. 1-8, Junho, 1996.

73
MANNILA, H. “Methods and problems in data mining (a tutorial)”, Proceedings of
International Conference on Database Theory ICDT'97, Eds.: F. Afrati, P. Kolaitis,
Springer-Verlag, Delphi-Greece, p. 41-55, Janeiro, 1997.
MONTELLO, M. V.; MARQUES, J. L. B.; BARRETO, J. M. Sistema especialista para
predição de complicações cardiovasculares integrado a um sistema de controle de
pacientes portadores de diabetes mellitus – Dissertações. Florianópolis: Universidade
Federal de Santa Catarina, 1999.
NASCIMENTO JR, C. L.; YONEYAMA, T. Inteligência Artificial em Controle e
Automação. São Paulo: Edgar Blucher Ltda; FAPESP, 2000.
NOBRE, F.; LIMA, N. K. C. Artigo: Hipertensão Arterial: Conceito, Classificação e
Critérios Diagnósticos, Sociedade de Cardiologia do Estado de São Paulo (SOCESP) :
Ari Timerman, Luiz Antonio Machado César. São Paulo: Editora Atheneu, 2000.
OLIVEIRA, I. C. Aplicação de Data Mining na Busca de um Modelo de Prevenção da
Mortalidade Infantil. Trabalho de Pós-graduação. Florianópolis – SC: UFSC, 2001.
OLIVEIRA, J. E. P. Informações para Pacientes Diabéticos. URL:
http://www.diabetes.org.br/Diabetes/info_pacientes/infopac_set.html. Sistema Brasileiro de
Diabetes (SBD). Acessado em 11-2003.
OHRN, A. Rosetta Software. URL: http://rosetta.lcb.uu.se/general/. Knowledge Systems
Group, Dept. of Computer and Information Science, Norwegian University of Science and
Technology, Trondheim, Norway; Group of Logic, Inst. of Mathematics, University of
Warsaw, Poland. Acessado em 05-2004.
PACHECO, M. A.; VELLASCO, M.; LOPES, C. H. Descoberta de Conhecimento e
Mineração de Dados, Notas de Aula em Inteligência Artificial. Rio de Janeiro, ICA –

74
Laboratório de Inteligência Computacional Aplicada, departamento de Engenharia Elétrica
– PUC-RIO. URL:http://www.ica.ele.puc-rio.br, 1999.
PILLA, A. D.; CAPRETZ, A. L. A.; ALBERTO, G. G. Data Mining. Modelos de Data
Mining. URL:http://www.igce.unesp/br/igce/grad/computacao/cintiab/datamine/home.html
Acessado em 11-2003.
PINTO, L. G. Formulário de Coleta de Dados Hipertensão & Diabetes. Itajaí – SC:
UNIVALI, 2004.
RICH, E. Inteligência Artificial. Florianópolis - SC: Editora Da UFSC, 1993.
ROMÃO, W. Descoberta de Conhecimento Relevante em Banco de Dados sobre
Ciência e Tecnologia, Trabalho de Pós-Graduação. Florianópolis – SC: UFSC, 2002.
RUECKERT, L. Aplicação de Data Mining em Casos de Recém Nascidos com
Malformação, Trabalho de Graduação. Florianópolis – SC: UFSC, 1999.
SOUZA, O. R. M. Mineração de Dados de Um Plano de Saúde Para Obter Regras de
Associação. Trabalho de Pós-graduação. Florianópolis – SC: UFSC, 2000.
TOMÁZ, S. M. Protótipo de Data Mining para Decisões Estratégicas em Investimentos
Turísticos. Trabalho de Conclusão de Curso. Itajaí – SC: UNIVALI, 2000.
TENORIO JR, N. N. Análise de Desempenho das Funções de Avaliação de um
Algoritmo Genético aplicado ao processo de KDD, Trabalho de Pós-graduação.
Florianópolis – SC: UFSC, 2001.
SGB. Informativos do governo sobre Diabetes e Hipertensão.
www.portal.saude.gov.br/saude. Acessado em 07-2004.

75
UCI. Repository of Maching Learning Databases and Domain Theories.
ftp.ics.uci.edu:pub/machine-learning-databases. Acessado em 08-2003.

APÊNDICE
APÊNDICE I – Estrutura da procedure pl sql que lê informações da tabela
temporária e insere na tabela de Dados Minerados.
CREATE OR REPLACE PACKAGE BODY SMDS0400 IS
-- Variáveis Globais
pcd_pesquisa NUMBER(08);
w_vl_pesq_1_1 NUMBER(10,2);
w_id_sinal_1 VARCHAR2(05);
w_vl_pesq_1_2 NUMBER(10,2);
w_vl_pesq_2_1 NUMBER(10,2);
w_id_sinal_2 VARCHAR2(05);
w_vl_pesq_2_2 NUMBER(10,2);
w_vl_pesq_3_1 NUMBER(10,2);
w_id_sinal_3 VARCHAR2(05);
w_vl_pesq_3_2 NUMBER(10,2);
w_vl_pesq_4_1 NUMBER(10,2);
w_id_sinal_4 VARCHAR2(05);
w_vl_pesq_4_2 NUMBER(10,2);
w_ds_erro VARCHAR2(300);
-- Procedure Principal que minera informações
PROCEDURE controle(pcd_pesquisa IN NUMBER
,pvl_pesq_1_1 IN NUMBER
,pvl_pesq_1_2 IN NUMBER
,pvl_pesq_2_1 IN NUMBER
,pvl_pesq_2_2 IN NUMBER
,pvl_pesq_3_1 IN NUMBER
,pvl_pesq_3_2 IN NUMBER
,pvl_pesq_4_1 IN NUMBER
,pvl_pesq_4_2 IN NUMBER
,pcd_erro OUT VARCHAR2
,pds_erro OUT VARCHAR2) AS
-- Cursor Principal

77
CURSOR c0001 IS
SELECT vl_retorno retorno
FROM dados_diabetes_wrk
WHERE vl_pesquisa_1 BETWEEN pvl_pesq_1_1 AND pvl_pesq_1_2
AND nvl(vl_pesquisa_2, 0) BETWEEN nvl(pvl_pesq_2_1, 0) AND
nvl(pvl_pesq_2_2, 0)
AND nvl(vl_pesquisa_3, 0) BETWEEN nvl(pvl_pesq_3_1, 0) AND
nvl(pvl_pesq_3_2, 0)
AND nvl(vl_pesquisa_4, 0) BETWEEN nvl(pvl_pesq_4_1, 0) AND
nvl(pvl_pesq_4_2, 0)
AND cd_pesquisa = pcd_pesquisa
ORDER BY 1;
r0001 c0001%ROWTYPE;
-- Declaração de variáveis
w_id_pesquisado VARCHAR2(30);
w_id_pesquisa_1 VARCHAR2(30);
w_id_pesquisa_2 VARCHAR2(30);
w_id_pesquisa_3 VARCHAR2(30);
w_id_pesquisa_4 VARCHAR2(30);
w_cont_linha NUMBER(08) := 0;
w_total_val NUMBER(08) := 0;
w_total_reg NUMBER(08) := 0;
w_total_limite NUMBER(08) := 0;
w_cd_mineracao NUMBER(08) := 0;
w_cd_pesquisa NUMBER(08) := 0;
w_vl_anterior NUMBER(10,2);
w_cont_valor NUMBER(08) := 0;
-- Processo Principal
BEGIN
pcd_erro := 'SMDS-0000';
-- Seleciona o código de mineração
BEGIN
SELECT max(d.cd_pesquisa)+1
INTO w_cd_pesquisa
FROM dados_minerados d;
EXCEPTION

78
WHEN no_data_found THEN
w_cd_pesquisa := 1;
WHEN OTHERS THEN
pcd_erro :='SMDS-0001';
w_ds_erro :='SMDS0400-Erro Busca Código da Pesquisa
'||SQLERRM;
END;
IF w_cd_pesquisa IS NULL THEN
w_cd_pesquisa := 1;
END IF;
-- Selecionando dados da tabela temporária
BEGIN
SELECT id_pesquisado
,id_pesquisa_1
,id_pesquisa_2
,id_pesquisa_3
,id_pesquisa_4
INTO w_id_pesquisado
,w_id_pesquisa_1
,w_id_pesquisa_2
,w_id_pesquisa_3
,w_id_pesquisa_4
FROM dados_diabetes_wrk d
WHERE d.cd_pesquisa = pcd_pesquisa
AND rownum = 1;
EXCEPTION
WHEN no_data_found THEN
pcd_erro :='SMDS-0002';
w_ds_erro :='SMDS0400-Não localizou pesquisa na tabela
temporária';
null;
WHEN OTHERS THEN
pcd_erro :='SMDS-0003';
w_ds_erro :='SMDS0400-Erro ao buscar pesquisa na tabela
temporária'||SQLERRM;
END;

79
-- Abrindo cursor
BEGIN
OPEN c0001;
EXCEPTION
WHEN OTHERS THEN
pcd_erro :='SMDS-0004';
w_ds_erro :='SMDS0400-Erro Open Cursor c0001 '||SQLERRM;
END;
-- Descobrindo o sinal
IF pvl_pesq_1_1 = pvl_pesq_1_2 THEN
w_id_sinal_1 := '=';
ELSE
w_id_sinal_1 := 'Entre';
END IF;
IF pvl_pesq_2_1 = pvl_pesq_2_2 THEN
w_id_sinal_2 := '=';
ELSE
w_id_sinal_2 := 'Entre';
END IF;
IF pvl_pesq_3_1 = pvl_pesq_3_2 THEN
w_id_sinal_3 := '=';
ELSE
w_id_sinal_3 := 'Entre';
END IF;
IF pvl_pesq_4_1 = pvl_pesq_4_2 THEN
w_id_sinal_4 := '=';
ELSE
w_id_sinal_4 := 'Entre';
END IF;
-- Laço para inserção na tabela de dados minerados
BEGIN
LOOP

80
FETCH c0001 INTO r0001;
EXIT WHEN c0001%NOTFOUND;
w_cont_linha := w_cont_linha+1;
IF NVL(w_vl_anterior, -1) <> NVL(r0001.retorno, -1) THEN
IF r0001.retorno IS NOT NULL THEN
BEGIN
INSERT INTO DADOS_MINERADOS
VALUES (w_cd_pesquisa, -- Código da pesquisa
w_id_pesquisado,
w_id_pesquisa_1,
w_id_pesquisa_2,
w_id_pesquisa_3,
w_id_pesquisa_4,
pvl_pesq_1_1,
w_id_sinal_1,
pvl_pesq_1_2,
pvl_pesq_2_1,
w_id_sinal_2,
pvl_pesq_2_2,
pvl_pesq_3_1,
w_id_sinal_3,
pvl_pesq_3_2,
pvl_pesq_4_1,
w_id_sinal_4,
pvl_pesq_4_2,
r0001.retorno, -- Valor da variável
1, -- Contador
0, -- Percentual
0,
0,
0,
0,
0,
sysdate, -- Data de Atualização
user );-- Usuário
EXCEPTION
WHEN OTHERS THEN
pcd_erro := 'SMDS-0006';

81
w_ds_erro := 'SMDS0400-Erro Insert Dados
Minerados '||SQLERRM;
END;
END IF;
w_cont_valor := w_cont_valor + 1;
ELSE
BEGIN
UPDATE DADOS_MINERADOS
SET qt_repeticao_valor = qt_repeticao_valor + 1
WHERE cd_pesquisa = w_cd_pesquisa
AND id_pesquisado = w_id_pesquisado
AND id_entrada_1 = w_id_pesquisa_1
AND vl_entrada_1_1 = pvl_pesq_1_1
AND vl_pesquisado = r0001.retorno;
EXCEPTION
WHEN OTHERS THEN
pcd_erro := 'SMDS-0007';
w_ds_erro := 'SMDS0400-Erro Update Dados Minerados
'||SQLERRM;
END;
END IF;
w_vl_anterior := r0001.retorno;
END LOOP;
EXCEPTION
WHEN OTHERS THEN
pcd_erro := 'SMDS-0008';
w_ds_erro := 'SMDS0400-Erro Fetch Cursor c0001 '||SQLERRM;
END;
IF w_cont_linha = 0 THEN
pcd_erro := 'SMDS-0005';
w_ds_erro := 'SMDS0400-Não foram encontradas informações para os
parâmetros informados';
END IF;
-- Fechando Cursor
BEGIN
CLOSE c0001;
EXCEPTION

82
WHEN OTHERS THEN
pcd_erro := 'SMDS-0009';
w_ds_erro := 'SMDS0400-Erro Close Cursor c0001 '||SQLERRM;
END;
IF pcd_erro = 'SMDS-0000' THEN
-- Verificando o total de fichas
BEGIN
SELECT count(*)
INTO w_total_reg
FROM guia_exame g,
paciente p
WHERE g.cd_paciente = p.cd_paciente;
EXCEPTION
WHEN NO_DATA_FOUND THEN
pcd_erro := 'SMDS-0007';
w_ds_erro := 'SMDS0401-Não foram encontradas informações
nas tabelas paciente e guia_exame';
WHEN OTHERS THEN
pcd_erro := 'SMDS-0008';
w_ds_erro := 'SMDS0401-Erro Geral busca quantidade de
guias '||SQLERRM;
END;
-- Verificando o total de fichas válidas
BEGIN
SELECT count(*)
INTO w_total_val
FROM dados_diabetes_wrk d
WHERE d.cd_pesquisa = w_cd_pesquisa;
EXCEPTION
WHEN NO_DATA_FOUND THEN
pcd_erro := 'SMDS-0011';
w_ds_erro := 'SMDS0401-Não foram encontradas informações
na tabela dados_diabetes_wrk';
WHEN OTHERS THEN
pcd_erro := 'SMDS-0012';
w_ds_erro := 'SMDS0401-Erro Geral busca quantidade de

83
guias válidas '||SQLERRM;
END;
-- Verificando o total de fichas válidas e dentro do limite passado
BEGIN
SELECT sum(qt_repeticao_valor)
INTO w_total_limite
FROM dados_minerados d
WHERE d.cd_pesquisa = w_cd_pesquisa;
EXCEPTION
WHEN NO_DATA_FOUND THEN
pcd_erro := 'SMDS-0013';
w_ds_erro := 'SMDS0401-Não foram encontradas informações
na tabela dados_diabetes_wrk (2)';
WHEN OTHERS THEN
pcd_erro := 'SMDS-0014';
w_ds_erro := 'SMDS0401-Erro Geral busca quantidade de
guias válidas e no limite '||SQLERRM;
END;
-- Alterando totais
BEGIN
UPDATE DADOS_MINERADOS
SET nr_perc_valor = ROUND((qt_repeticao_valor /
nvl(w_total_limite, 1)), 4),
qt_total_guias = w_total_reg,
qt_total_validas = w_total_val,
qt_total_guias_lim = w_total_limite,
nr_perc_fichas = ROUND((w_total_val /
nvl(w_total_reg,1)), 4),
nr_perc_fichas_lim = ROUND((w_total_limite /
nvl(w_total_val,1)), 4)
WHERE cd_pesquisa = w_cd_pesquisa
AND id_pesquisado = w_id_pesquisado
AND id_entrada_1 = w_id_pesquisa_1
AND vl_entrada_1_1 = pvl_pesq_1_1;
EXCEPTION
WHEN OTHERS THEN

84
pcd_erro := 'SMDS-0009';
w_ds_erro := 'SMDS0400-Erro Update Percentual -
DADOS_MINERADOS '||SQLERRM;
END;
END IF;
-- Salvando informações
IF pcd_erro = 'SMDS-0000' THEN
commit;
ELSE
pds_erro := w_ds_erro;
rollback;
END IF;
END CONTROLE;
END SMDS0400;

APÊNDICE II – Tutorial do Sistema de Mineração de Dados da Saúde -
SMDS.
Entrada no Sistema
Para utilizar o sistema apenas é necessário possuir uma conta no banco de dados
Oracle e fazer o login conforme mostrado na Figura 25, que mostra a tela aberta ao tentar
se acessar a base de dados.
Figura 25. Tela de Login

86
Tela Inicial
Após o login no banco de dados, entra-se em uma tela inicial de apresentação do
sistema, neste ponto basta entrar com o módulo desejado no campo “Módulo” ou selecioná-
lo através do menu para acessar as telas do sistema. Veja na Figura 26 como está
estruturada esta primeira tela do sistema.
Figura 26. Tela de Apresentação do Sistema
Telas de Coleta de Dados
A Figura 27 mostra a tela de coleta de dados (SMDS0100) desenvolvida a partir dos
formulários em papel que foi implantada no ambulatório para a entrada das informações.

87
Nesta tela o usuário informa todos as informações pessoais obrigatórias para o paciente e as
informações que possuir sobre a sua consulta.
Figura 27. Tela de Coleta de Dados
Para a entrada das informações existe ainda a tela de coleta de dados resumida
(SMDS0101), que funciona como a tela anterior, porém com uma quantidade menor de
atributos. A Figura 28 mostra esta tela.

88
Figura 28. Tela de Coleta de Dados Resumida
Telas de Cadastros
As telas de cadastros são telas básicas de manutenções das tabelas. Embora o
sistema trabalhe basicamente em função de apenas duas tabelas principais, PACIENTE e
GUIA_EXAME, o sistema possui as outras tabelas desenvolvidas, e até mesmo a tabela de
pacientes possui outras informações que podem ser de alguma importância para o cadastro.
Dessa forma as telas de manutenção também foram criadas até mesmo para facilitar a
utilização da base atual, quando for ser implantada a base de dados definitiva que está
sendo desenvolvida para a Unidade de Saúde da Família e Comunitária. A Figura 29,
mostra uma dessas telas de manutenção (SMDS0105), sendo que todas seguem o mesmo
padrão.
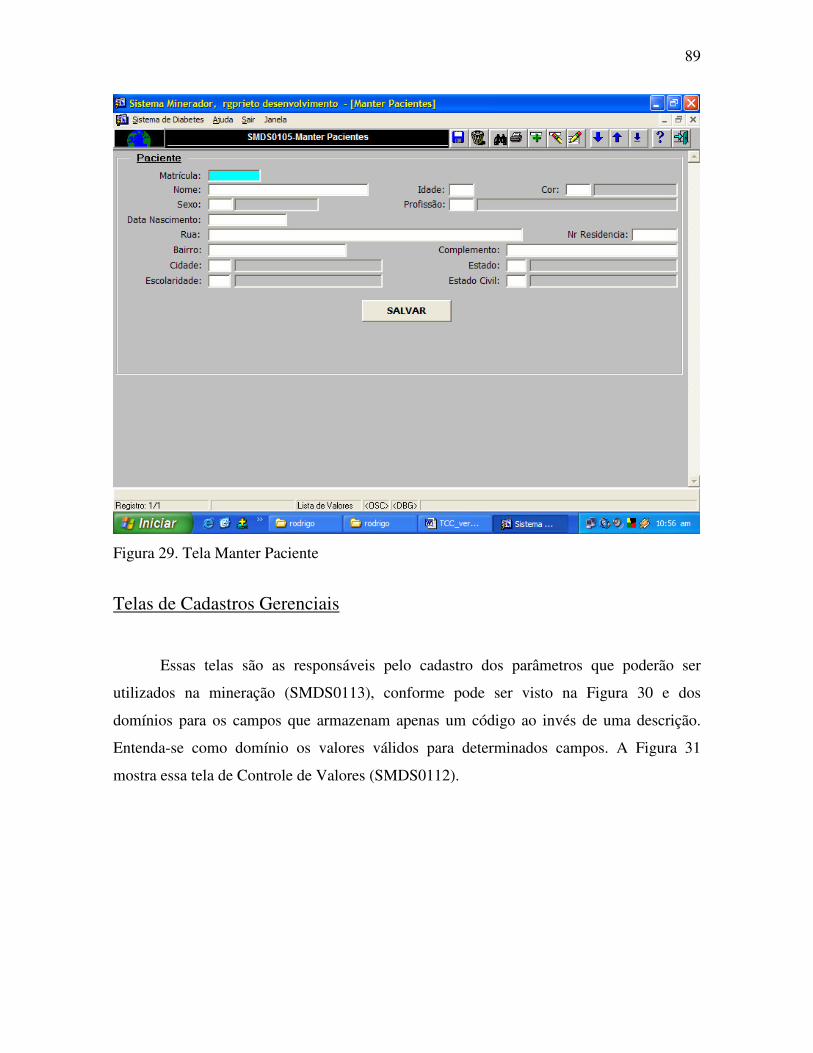
89
Figura 29. Tela Manter Paciente
Telas de Cadastros Gerenciais
Essas telas são as responsáveis pelo cadastro dos parâmetros que poderão ser
utilizados na mineração (SMDS0113), conforme pode ser visto na Figura 30 e dos
domínios para os campos que armazenam apenas um código ao invés de uma descrição.
Entenda-se como domínio os valores válidos para determinados campos. A Figura 31
mostra essa tela de Controle de Valores (SMDS0112).
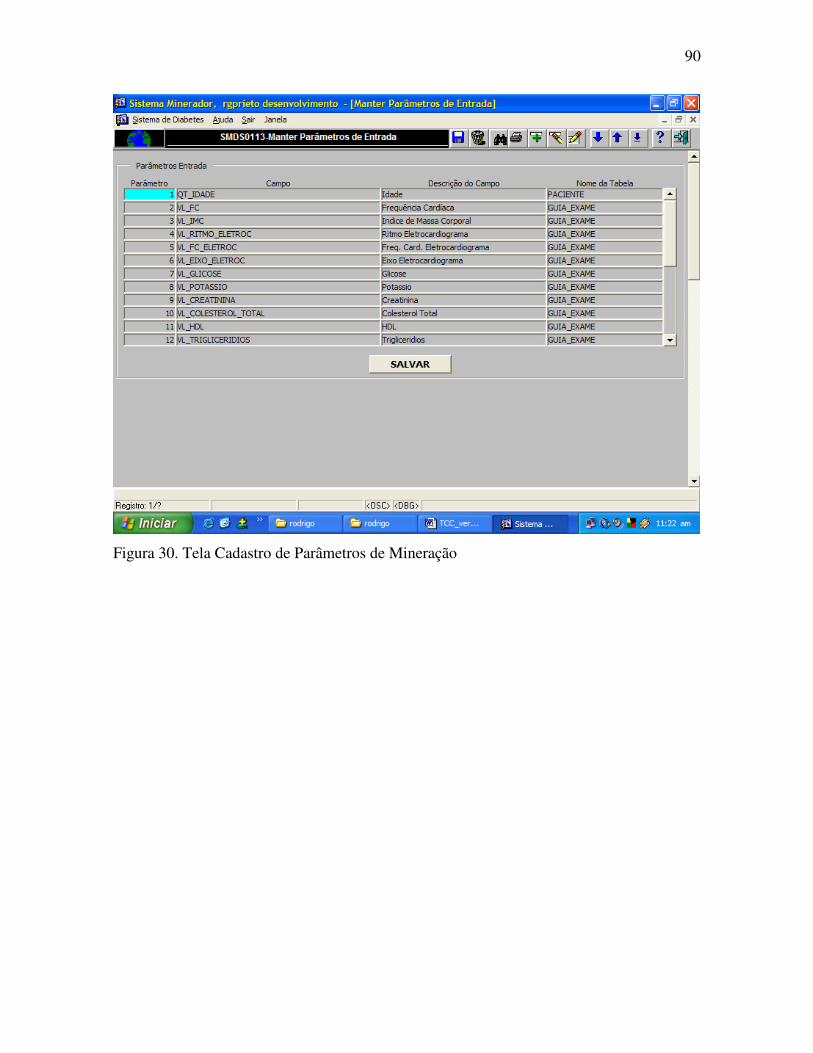
90
Figura 30. Tela Cadastro de Parâmetros de Mineração
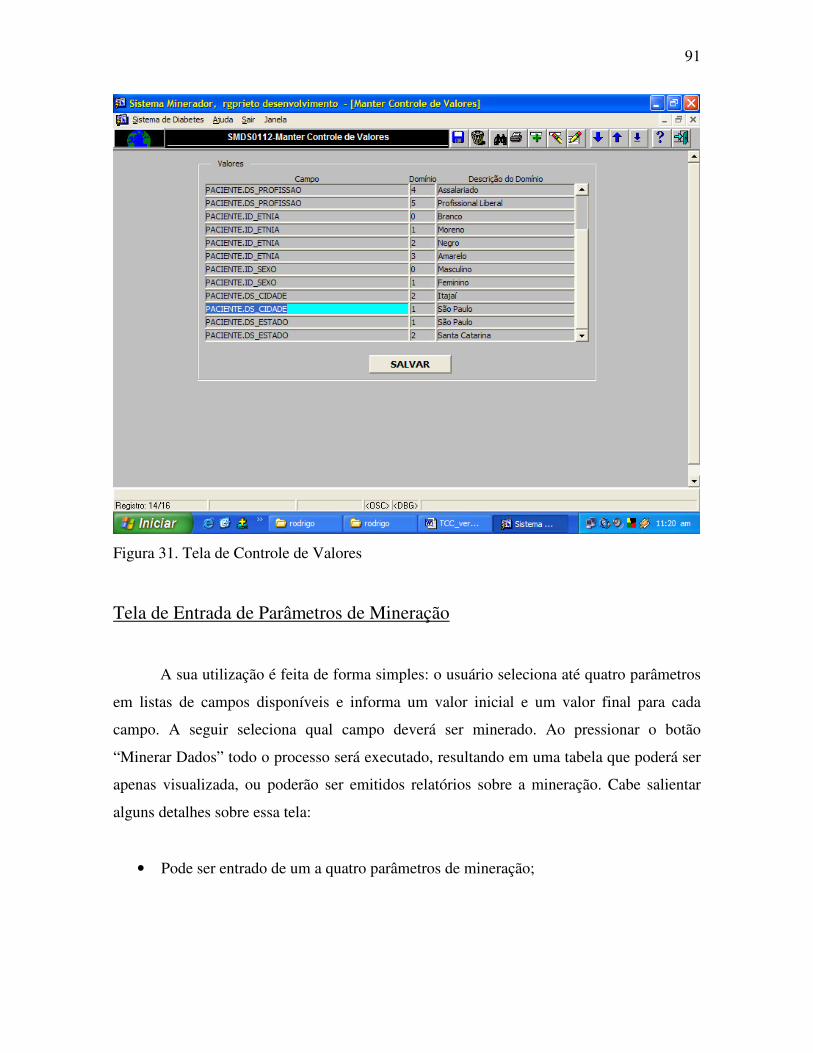
91
Figura 31. Tela de Controle de Valores
Tela de Entrada de Parâmetros de Mineração
A sua utilização é feita de forma simples: o usuário seleciona até quatro parâmetros
em listas de campos disponíveis e informa um valor inicial e um valor final para cada
campo. A seguir seleciona qual campo deverá ser minerado. Ao pressionar o botão
“Minerar Dados” todo o processo será executado, resultando em uma tabela que poderá ser
apenas visualizada, ou poderão ser emitidos relatórios sobre a mineração. Cabe salientar
alguns detalhes sobre essa tela:
• Pode ser entrado de um a quatro parâmetros de mineração;

92
• Caso não queira minerar um campo específico, poderá ser escolhido um retorno
“DEFAULT”, que trará apenas os resultados percentuais da mineração;
• Caso na entrada do intervalo for selecionado apenas o intervalo inicial, o sistema
identifica que o usuário está querendo apenas o valor especificado, no caso trará
somente os registros que tiverem o valor exatamente igual ao valor informado.
• Os valores para todos os campos são entrados através de números, portanto mesmo
para parâmetros como sexo, entra-se como 0 – Masculino ou 1 –Feminino. Para
campos que possuam regras desse tipo o sistema possui listas de valores válidos.
A Figura 32 apresenta a tela de entrada de parâmetros (SMDS0108) citada.
Figura 32. Tela Entrada de Parâmetros
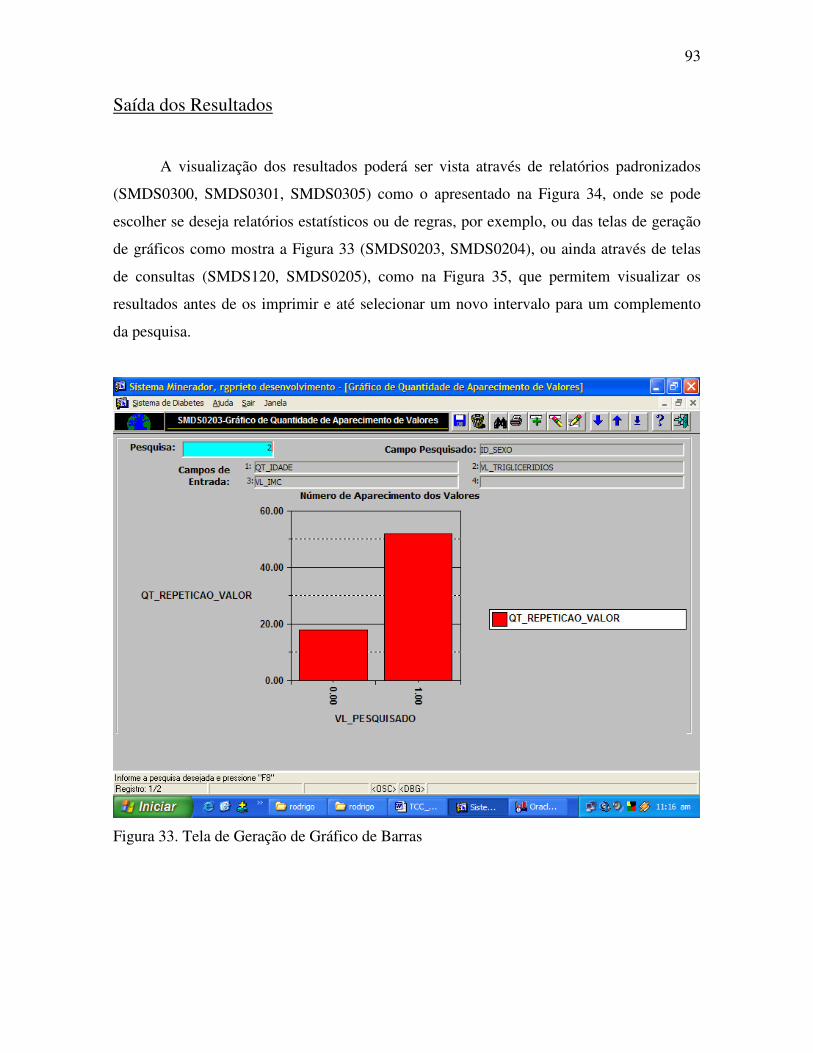
93
Saída dos Resultados
A visualização dos resultados poderá ser vista através de relatórios padronizados
(SMDS0300, SMDS0301, SMDS0305) como o apresentado na Figura 34, onde se pode
escolher se deseja relatórios estatísticos ou de regras, por exemplo, ou das telas de geração
de gráficos como mostra a Figura 33 (SMDS0203, SMDS0204), ou ainda através de telas
de consultas (SMDS120, SMDS0205), como na Figura 35, que permitem visualizar os
resultados antes de os imprimir e até selecionar um novo intervalo para um complemento
da pesquisa.
Figura 33. Tela de Geração de Gráfico de Barras
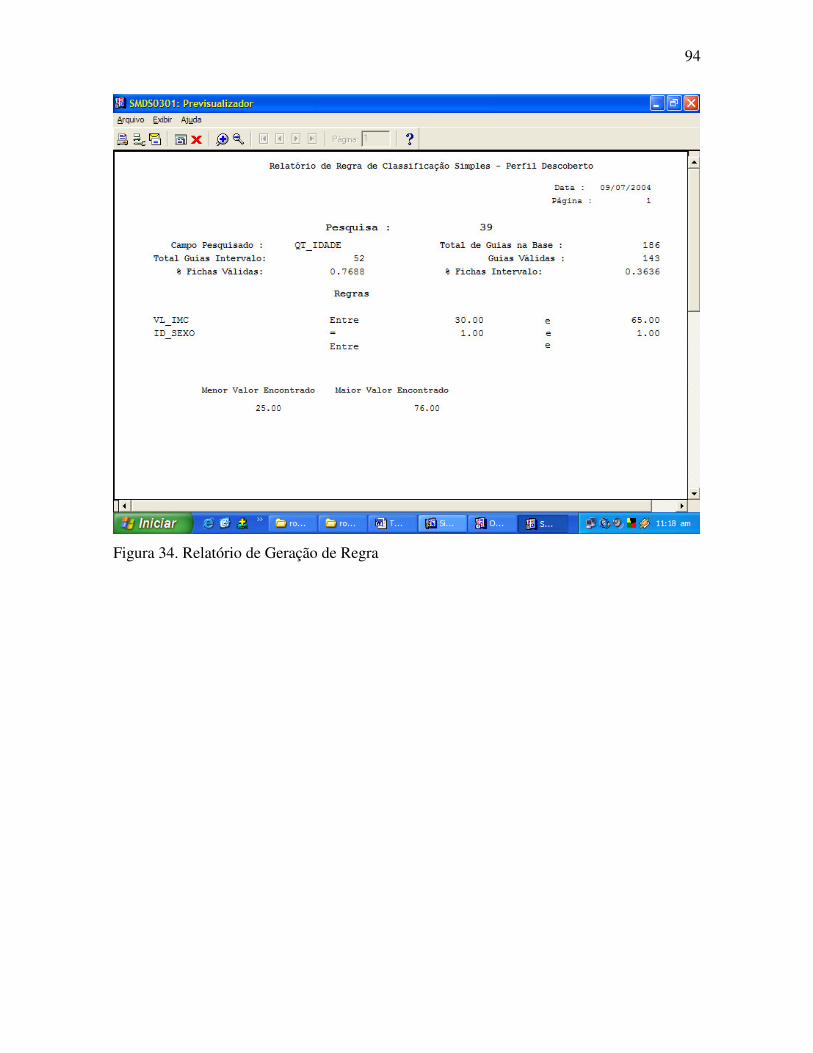
94
Figura 34. Relatório de Geração de Regra

95
Figura 35. Tela de Consulta de Pesquisa com Novo Intervalo
Funcionalidade
A seguir pode-se ver uma pequena descrição dos principais botões padrões do
sistema, facilitando o entendimento de sua funcionalidade, e as teclas de atalho para os
mesmos.
Botão salvar: utilizado para gravar as informações na base de dados (F10).
Botão excluir: utilizado para deletar registros da base de dados (Shift + F6).

96
Botão consultar: utilizado para colocar o programa em modo de consulta (F7) e para
selecionar os registros da base de dados (F8).
Botão incluir: utilizado para iniciar a inserção de um novo registro na base de dados
(F6).
Botão LOV: utilizado para abrir uma lista de valores válidos para um determinado
campo do programa (F9).
Botão fechar: utilizado para terminar a execução de um programa ou sair do modo
de consulta (Alt + F4).

ANEXOS
ANEXO I, II, III - Formulários de Diabetes Melittus do HU de Florianópolis.

98

99

100

101

102
ANEXO IV - Formulário de Diabetes & Hipertensão da Univali.

103
PROGRAMA DE HIPERTENSÃO & DIABETES
������������������ ���������������������������������������������������������������������������������������
�NOME: _____________________________________________IDADE : _______ COR : _________
SEXO: _________ PROFISSÃO: ________________________
�������������� ���������������������������������������������������������������� �������������������������������������������������� !������������"#������������� ������������$#�#�����������%�&����'(�����������#�����"��&�%��������� #)���������������%#�*������������������������*������������������ ���
������������ � ��������������"#����������+�����������������,&-� �����������������#��.$������������������� �������������$�*�������������#��%�����������������#�����������������������������������������������#���/�0 �������1��������������*����%2������������������#�# ��������������� !"������������ ��/� )%����3�������������+���4 ����������� ��� 1����������� ��/�#��#���"��#�%2�������������#��� *#���� � �#�� ���%��������� ���#�������
�$�%%!"��$&�$��'������������������������(�)������������������������������������������(�)����
%���*������������+���������� � ����,��������������������+���������� � ���
�����������������5���������66+0��7��������������������5���������66+0�
����������������������896 ���$�������������96 ������������������-'%"�������������
����������� .����*��/���� ������������������������������������������������������������� .��$���������������������������������������������������������������������0*�� ����������������������������������������������������������������������������� 0����1���������������������������������������������������������

104
Exames Complementares
��������� �����*����� �����������������6 ������������������)���������#�: ����������������;� ��/������������������������������06 ��� ���/�����������������������������������������������������������������81�������������������������������������������������������������������������������������������������������������������������������������������������������������������������*����������� ��������#���#����# ������#���%������*����
���������������������&<��# ����/"������%3*�������*����������������2����3�����"$$�4����5����+%-��&"%�$�&�6��6"%���24����3�
�����������2����3������'��������24��73�
�������$+�������� ��������1� ����������������������������������������������������������������������������������������������������������������������������������������������������������������%����������������#� .������������+#���.�������������# �����#���������9+��������(��8�#� ��������*�� 1������������ �=11� ������������������������������ 1���������������������������� ��1��� ���� ���������������+�%�������������0������� 1�����������������*���)9����� �����.������9��:�*��0������;<� ���������������������������������������������������������=<� ������������������������������������������������������������><� �����������������������������������������������������������?<� ���������������������������������������������������������@<� ��������������������������������������������������������A<� ��������������������������������������������������������B<� ��������������������������������������������������������
� �%&�4����6&"�� �
��������� �������� ����2�� � ��3� ���*����� ����2�� � ��3�6�� � � >�?@A� >BA�
�6�/���� ?@A�C�?DE� BA�C�BE��������9������� �
� �
���C����;� ;?D�E�;@F� FD�E�FF����C����=�� �G��H�;AD�� �G��H�;DD��

105
ANEXO V – Declaração Dr. Luiz Gustavo Pinto – especialista responsável
pelo sistema junto ao ambulatório do Centro de Saúdes da Família da
UNIVALI.
��� ��)9������/� �*�)9��*����0� .��*����� ��9��*��������
����"��F ���;G1���1���� �1 6 �����;����� ���8�F ���� ���1� ������1 �� �� �6 �� �� ���0 �* 6 �1������ H� 6 ��68G6 �9�8���I=/� ���0���J/� �9�� ��:���������8�F ���1��; �;�� K�������6 H�L���1��; �;�6 ��� �����6 �����6 �������6 ������ ������ 1�9��� �M�6 �����NH�;�6 ������ ��� � 6 �1���G�1�����1�9�������6 �������6 ������� 6����=����6 � �F����6 ��F ��� 111��1���1�1���������6 ��� K����;G1����1�����8�F �9 ����6 1�������� 11 ���1��; �;�6 ��� ����9�1O��1��9���6 � �P0��������9�����1�F�9�����1 1�����8G�� 1H�9��9 1���� �6 ������69��6 ����6 1�6 ����1����9��;���� ���9� 6 �� ����1Q���81�� 1�� 1���1���� 1�6 ����� 1���L� 11��������NK���G6 ���11 H��68G6 �1��=�Q����9��6 ���1���6 1���1���9�8������8�F 1��9���6 � �P0� 1��6 �;=��1�=��1���1Q��K������� �K�%��I�*�1�; ����� �� ������C�&��;��K�

106
ANEXO VI – Dicionário de Dados das tabelas que compõem o Banco de
Dados.
Tabela 12. Dicionário de Dados da Tabela Paciente.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave Primária.
NM_PACIENTE Alfanumérico / 30 Nome do Paciente
QT_IDADE Inteiro / 3 Idade do paciente (anos completos)
ID_ETNIA Inteiro / 1 Código da Raça (Cor) do Paciente segundo
lista de valores válidos
ID_SEXO Inteiro / 1 Código do Sexo do Paciente segundo lista
de valores válidos
DS_PROFISSAO Inteiro / 3 Código da Profissão do Paciente segundo
lista de valores válidos
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
DT_NASCIMENTO Data Data de Nascimento do Paciente
NM_LOGRADOURO Alfanumérico / 30 Rua da residência do Paciente
NR_RESIDENCIA Inteiro / 6 Número da residência do Paciente
NM_BAIRRO Alfanumérico / 20 Nome do Bairro do Paciente
DS_COMPLEMENTO Alfanumérico / 15 Complemento do endereço do Paciente
DS_CIDADE Inteiro / 5 Código da Cidade do Paciente segundo
lista de valores válidos
DS_ESTADO Inteiro / 5 Código do Estado do Paciente segundo
lista de valores válidos

107
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
lista de valores válidos
ID_ESCOLARIDADE Inteiro / 1 Nível de Escolaridade do Paciente
ID_ESTADO_CIVIL Inteiro / 1 Código do Estado Civil do Paciente
Tabela 13. Dicionário de Dados da Tabela Guia Exame.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_GUIA Inteiro / 8 Código da Guia – Chave Primária
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave
Secundária
ID_DOR_TORACICA Inteiro / 1 Dor Torácica
ID_DISPNEIA Inteiro / 1 Dispnéia
ID_AVE Inteiro / 1 Acidente Vascular Encefálico
ID_IAM Inteiro / 1 Infarto Agudo do Miocárdio
ID_DIABETES Inteiro / 1 Diabetes
ID_CLAUDICACAO Inteiro / 1 Claudicação
ID_PERDA_VISUAL Inteiro / 1 Perda Visual
ID_NEFROPATIA Inteiro / 1 Nefropatia
ID_ALERGIA Inteiro / 1 Alergia
ID_ASMA Inteiro / 1 Asma
ID_GOTA Inteiro / 1 Gota
ID_ARRITMIA Inteiro / 1 Arritmia
ID_AVE_FAMILIAR Inteiro / 1 Acidente Vascular Encefálico
Familiar
ID_HAS Inteiro / 1 Hipertensão Arterial Sistêmica

108
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
ID_DOENCA_ISQUEMICA Inteiro / 1 Doença Isquêmica
ID_MORTE_SUBITA Inteiro / 1 Morte Súbita
ID_TABAGISMO Inteiro / 1 Tabagismo
ID_ETILISMO Inteiro / 1 Etilismo
ID_STRESS Inteiro / 1 Stress
ID_DIETA Inteiro / 1 Dieta - Gordura e Sal
ID_DROGAS Inteiro / 1 Drogas Ilícitas
ID_SEDENTARISMO Inteiro / 1 Sedentarismo
ID_ANTI_INFLAMATORIO Inteiro / 1 Anti-Inflamatórios
ID_HORMONIO Inteiro / 1 Hormônios
ID_ANTI_DEPRESSIVO Inteiro / 1 Anti-Depressivo e Lítio
ID_DESCONG_NASAL Inteiro / 1 Descongestionante Nasal
ID_OUTROS_MEDICAM Inteiro / 1 Outros Medicamentos
DS_OUTROS_MEDICAM Alfanumérico / 50 Descrição outros Medicamentos
DS_EXAME_FISICO Alfanumérico / 30 Exame Físico
VL_PRES_BRACO_D_SENT Alfanumérico / 10 Pressão Arterial Braço Direito
Sentada
VL_PRES_BRACO_E_SENT Alfanumérico / 10 Pressão Arterial Braço Esquerdo
Sentada
VL_FC Inteiro / 3 Freqüência Cardíaca
VL_IMC Decimal / 8,2 Índice de Massa Corporal
DS_OBS_APAR_CARD Alfanumérico / 30 Aparelho Cardiovascular: ( ictus,
ritmo, sopros )
DS_OBS_APAR_RESP Alfanumérico / 30 Aparelho Respiratório: ( ruídos
adventícios )

109
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
adventícios )
DS_OBS_ABDOME Alfanumérico / 30 Abdome: ( visceromegalias,
sopros )
DS_OBS_MEMBRO_INF Alfanumérico / 30 Membros Inferiores: ( edemas,
empastamento, pulsos, parestesias)
VL_RITMO_ELETROC Inteiro /4 Ritmo Eletrocardiograma
VL_FC_ELETROC Inteiro / 4 Freqüência Cardíaca
Eletrocardiograma
VL_EIXO_ELETROC Inteiro / 4 Eixo Eletrocardiograma
VL_INTERV_PR_ELETR Inteiro / 4 Intervalo P-R Eletrocardiograma
DS_SEGM_ST_T Alfanumérico / 30 Segmento ST-T
DS_OBS_ELETROC Alfanumérico / 30 Observação Eletrocardiograma
ID_ESTR_ART_FUNDOSC Inteiro / 1 Estreitamento Arteriolar ( G I)
ID_CRUZ_AV_FUNDOSC Inteiro / 1 Cruzamento A-V Patológico ( G
II)
ID_HEMORRAGIA_FUNDOSC Inteiro / 1 Hemorragia e/ou Exsudatos
Retinianos ( G III)
ID_PAPILEDEMA_FUNDOSC Inteiro / 1 Papiledema ( G IV )
DS_OBS_RX_TORAX_PA Alfanumérico / 30 Raio X Tórax em PA
DS_OBS_RX_TORAX_PERF Alfanumérico / 30 Raio X Tórax em Perfil
ID_PROTEINURIA Inteiro / 1 Proteinúria
ID_HEMATURIA Inteiro / 1 Hematúria
ID_MICROALBUMINURIA Inteiro / 1 Microalbuminúria
VL_GLICOSE Inteiro / 6 Glicose

110
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
VL_POTASSIO Inteiro / 6 Potássio
VL_CREATININA Inteiro / 6 Creatinina
VL_COLESTEROL_TOTAL Inteiro / 6 Colesterol Total
VL_HDL Inteiro / 6 HDL
VL_TRIGLICERIDIOS Inteiro / 6 Triglicerídios
VL_HEM_GLICOSILAD Inteiro / 6 Hem. Glicosilado
DS_MEDICACAO_1 Alfanumérico / 30 Descrição Texto Livre da
Medicação 1
DS_MEDICACAO_2 Alfanumérico / 30 Descrição Texto Livre da
Medicação 2
DS_MEDICACAO_3 Alfanumérico / 30 Descrição Texto Livre da
Medicação 3
DS_MEDICACAO_4 Alfanumérico / 30 Descrição Texto Livre da
Medicação 4
DS_MEDICACAO_5 Alfanumérico / 30 Descrição Texto Livre da
Medicação 5
DS_MEDICACAO_6 Alfanumérico / 30 Descrição Texto Livre da
Medicação 6
DS_MEDICACAO_7 Alfanumérico / 30 Descrição Texto Livre da
Medicação 7
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao
Banco de Dados)

111
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
VL_LDL Decimal / 8,2
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao
Banco de Dados)
Tabela 14. Dicionário de Dados da Tabela Histórico Pessoal.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_HIST_PESSOAL Inteiro / 8 Código do Histórico Pessoal – Chave
Primária
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave Secundária
ID_TABAGISMO Inteiro / 1 Tabagismo
ID_ETILISMO Inteiro / 1 Etilismo
ID_STRESS Inteiro / 1 Stress
ID_DIETA Inteiro / 1 Dieta - Gordura e Sal
ID_DROGAS Inteiro / 1 Drogas Ilícitas
ID_SEDENTARIO Inteiro / 1 Sedentarismo
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
Tabela 15. Dicionário de Dados da Tabela Histórico Familiar.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_HIST_FAMILIAR Inteiro / 8 Código do Histórico Familiar –
Chave Primária
CD_PACIENTE Inteiro / 8 Código do Paciente

112
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
ID_AVE_FAMILIAR Inteiro / 1 Acidente Vascular Encefálico
Familiar
ID_HAS Inteiro / 1 Hipertensão Arterial Sistêmica
ID_DOENCA_ISQUEMICA Inteiro / 1 Doença Isquêmica
ID_MORTE_SUBITA Inteiro / 1 Morte Súbita
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao Banco
de Dados)
DS_TIPO_HAS Alfanumérico / 30 Tipo da Hipertensão Arterial
ID_PARENTES_DIABETES Inteiro / 1 Parentes com Diabetes
NR_GRAU_PAR_DIABETES Inteiro / 1 Grau de Parentesco do Parente
ID_DOENCA_MACROVASC Inteiro / 1 Doença Macrovascular
Tabela 16. Dicionário de Dados da Tabela Histórico Patológico.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_HIST_PATOLOGICO Inteiro / 8 Código do Histórico Patológico – Chave
Primária
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave Secundária
ID_DOR_TORACICA Inteiro / 1 Dor Torácica
ID_DISPNEIA Inteiro / 1 Dispnéia
ID_AVE Inteiro / 1 Acidente Vascular Encefálico
ID_IAM Inteiro / 1 Infarto Agudo do Miocárdio
ID_DIABETES Inteiro / 1 Diabetes

113
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
ID_CLAUDICACAO Inteiro / 1 Claudicação
ID_PERDA_VISUAL Inteiro / 1 Perda Visual
ID_NEFROPATIA Inteiro / 1 Nefropatia
ID_ALERGIA Inteiro / 1 Alergia
ID_ASMA Inteiro / 1 Asma
ID_GOTA Inteiro / 1 Gota
ID_ARRITMIA Inteiro / 1 Arritmia
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
ID_VIROSES Inteiro / 1 Viroses
QT_PESO_NASCER Decimal / 4,3 Peso ao Nascer
ID_CIRURGIA Inteiro / 1 Cirurgia
Tabela 17. Dicionário de Dados da Tabela Exames Gerais.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
DT_EXAME Data Data do Exame – Chave Primária
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave
Secundária
ID_ESTR_ART_FUNDOSC Inteiro / 1 Estreitamento Arteriolar ( G I)
ID_CRUZ_AV_FUNDOSC Inteiro / 1 Cruzamento A-V Patológico ( G
II)
ID_HEMORRAGIA_FUNDOSC Inteiro / 1 Hemorragia e/ou Exsudatos
Retinianos ( G III)

114
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
ID_PAPILEDEMA_FUNDOSC Inteiro / 1 Papiledema ( G IV )
ID_PROTEINURIA Inteiro / 1 Proteinúria
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao
Banco de Dados)
QT_PESO Decimal / 7,3 Peso do Paciente
QT_ALTURA Decimal / 4,2 Altura do Paciente
QT_CINTURA Decimal / 6,2 Medida da Cintura do Paciente
QT_QUADRIL Decimal / 6,2 Medida do Quadril do Paciente
VL_PRES_ART_DEIT_DIR Alfanumérico / 10 Pressão Arterial Braço Direito
Deitada
VL_PRES_ART_DEIT_ESQ Alfanumérico / 10 Pressão Arterial Braço Esquerdo
Deitada
VL_PRES_ART_PE_DIR Alfanumérico / 10 Pressão Arterial Braço Direito em
Pé
VL_PRES_ART_PE_ESQ Alfanumérico / 10 Pressão Arterial Braço Esquerdo
em Pé
VL_PRES_BRACO_D_SENT Alfanumérico / 10 Pressão Arterial Braço Direito
Sentada
VL_PRES_BRACO_E_SENT Alfanumérico / 10 Pressão Arterial Braço Esquerdo
Sentada
VL_FC Inteiro / 3 Freqüência Cardíaca
VL_IMC Decimal / 8,2 Índice de Massa Corporal

115
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
DS_OBS_APAR_CARD Alfanumérico / 30 Aparelho Cardiovascular: ( ictus,
ritmo, sopros )
DS_OBS_APAR_RESP Alfanumérico / 30 Aparelho Respiratório: ( ruídos
adventícios )
VL_RITMO_ELETROC Inteiro /4 Ritmo Eletrocardiograma
VL_FC_ELETROC Inteiro / 4 Freqüência Cardíaca
Eletrocardiograma
VL_EIXO_ELETROC Inteiro / 4 Eixo Eletrocardiograma
VL_INTERV_PR_ELETR Inteiro / 4 Intervalo P-R Eletrocardiograma
DS_SEGM_ST_T Alfanumérico / 30 Segmento ST-T
DS_OBS_ELETROC Alfanumérico / 30 Observação Eletrocardiograma
DS_OBS_RX_TORAX_PA Alfanumérico / 30 Raio X Tórax em PA
DS_OBS_RX_TORAX_PERF Alfanumérico / 30 Raio X Tórax em Perfil
VL_POTASSIO Inteiro / 6 Potássio
VL_CREATININA Inteiro / 6 Creatinina
VL_COLESTEROL_TOTAL Inteiro / 6 Colesterol Total
VL_HDL Inteiro / 6 HDL
VL_TRIGLICERIDIOS Inteiro / 6 Triglicerídios
VL_HEM_GLICOSILAD Inteiro / 6 Hem. Glicosilado
VL_POTASSIO Inteiro / 6 Potássio
Tabela 18. Dicionário de Dados da Tabela Histórico Paciente.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave
Primária Composta

116
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
ID_DIABETES_ANTERIO Inteiro / 1 Índice da Diabetes antes do
Tratamento
ID_DIABETES_POS_TRAT Inteiro / 1 Índice da Diabetes após o
tratamento
ID_NIVEL_MELHORA Inteiro / 1 Nível de Melhora
CD_FORMA_TRATAMENTO Inteiro / 8
Código da Forma de Tratamento
Utilizada – Chave Primária
Composta
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao
Banco de Dados)
Tabela 19. Dicionário de Dados da Tabela Dados Minerados.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_PESQUISA Inteiro / 8 Código da Pesquisa – Chave Primária
ID_PESQUISADO Alfanumérico / 30 Campo Pesquisado – Chave Única
ID_ENTRADA_1 Alfanumérico / 30 Descrição do Campo de Entrada 1 –
Chave Única
ID_ENTRADA_2 Alfanumérico / 30 Descrição do Campo de Entrada 2–
Chave Única
ID_ENTRADA_3 Alfanumérico / 30 Descrição do Campo de Entrada 3–
Chave Única
ID_ENTRADA_4 Alfanumérico / 30 Descrição do Campo de Entrada 1–
Chave Única

117
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
VL_ENTRADA_1_1 Decimal / 10,2 Valor do Campo de Entrada 1 Inicial
ID_SINAL_1 Alfanumérico / 5 Sinal do Intervalo 1 ( = ou Entre)
VL_ENTRADA_1_2 Decimal / 10,2 Valor do Campo de Entrada 1 Final
VL_ENTRADA_2_1 Decimal / 10,2 Valor do Campo de Entrada 2 Inicial
ID_SINAL_2 Alfanumérico / 5 Sinal do Intervalo 2 ( = ou Entre)
VL_ENTRADA_2_2 Decimal / 10,2 Valor do Campo de Entrada 2 Final
VL_ENTRADA_3_1 Decimal / 10,2 Valor do Campo de Entrada 3 Inicial
ID_SINAL_3 Alfanumérico / 5 Sinal do Intervalo 3 ( = ou Entre)
VL_ENTRADA_3_2 Decimal / 10,2 Valor do Campo de Entrada 3 Final
VL_ENTRADA_4_1 Decimal / 10,2 Valor do Campo de Entrada 4 Inicial
ID_SINAL_4 Alfanumérico / 5 Sinal do Intervalo 4 ( = ou Entre)
VL_ENTRADA_4_2 Decimal / 10,2 Valor do Campo de Entrada 4 Final
VL_PESQUISADO Decimal / 10,2 Valor Encontrado – Chave Única
QT_REPETICAO_VALOR Inteiro / 8 Numero de Repetições do Valor
NR_PERC_VALOR Decimal / 8,4 Percentual de Aparecimento do Valor
QT_TOTAL_GUIAS Inteiro / 8 Número Total de Prontuários
QT_TOTAL_VALIDAS Inteiro / 8 Número Total de Guias com os
Parâmetros Solicitados Preenchidos
QT_TOTAL_GUIAS_LIM Inteiro / 8
Número Total de Guias com os
Parâmetros Solicitados Preenchidos e
Dentro do Intervalo Solicitado
NR_PERC_FICHAS Decimal / 8,4 Percentual de Fichas Válidas em
Função da Quantidade de Prontuários
NR_PERC_FICHAS_LIM Decimal / 8,4 Percentual de Fichas Dentro do
Intervalo Solicitado em Função do

118
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
Intervalo Solicitado em Função do
Número de Fichas Válidas
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
Tabela 20. Dicionário de Dados da Tabela Controle Valores.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
DS_CAMPO Alfanumérico / 30 Descrição da tabela e do campo do domínio
VL_DOMINIO Alfanumérico / 3 Valor do domínio
DS_DOMINIO Alfanumérico / 20 Descrição do domínio
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
Tabela 21. Dicionário de Dados da Tabela Dados Diabetes Wrk.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_PESQUISA Inteiro / 8 Código da Pesquisa – Chave Primária
ID_PESQUISADO Alfanumérico / 30 Campo Pesquisado
ID_PESQUISA_1 Alfanumérico / 30 Descrição do Campo de Entrada 1
ID_PESQUISA_2 Alfanumérico / 30 Descrição do Campo de Entrada 2
ID_PESQUISA_3 Alfanumérico / 30 Descrição do Campo de Entrada 3
ID_PESQUISA_4 Alfanumérico / 30 Descrição do Campo de Entrada 3
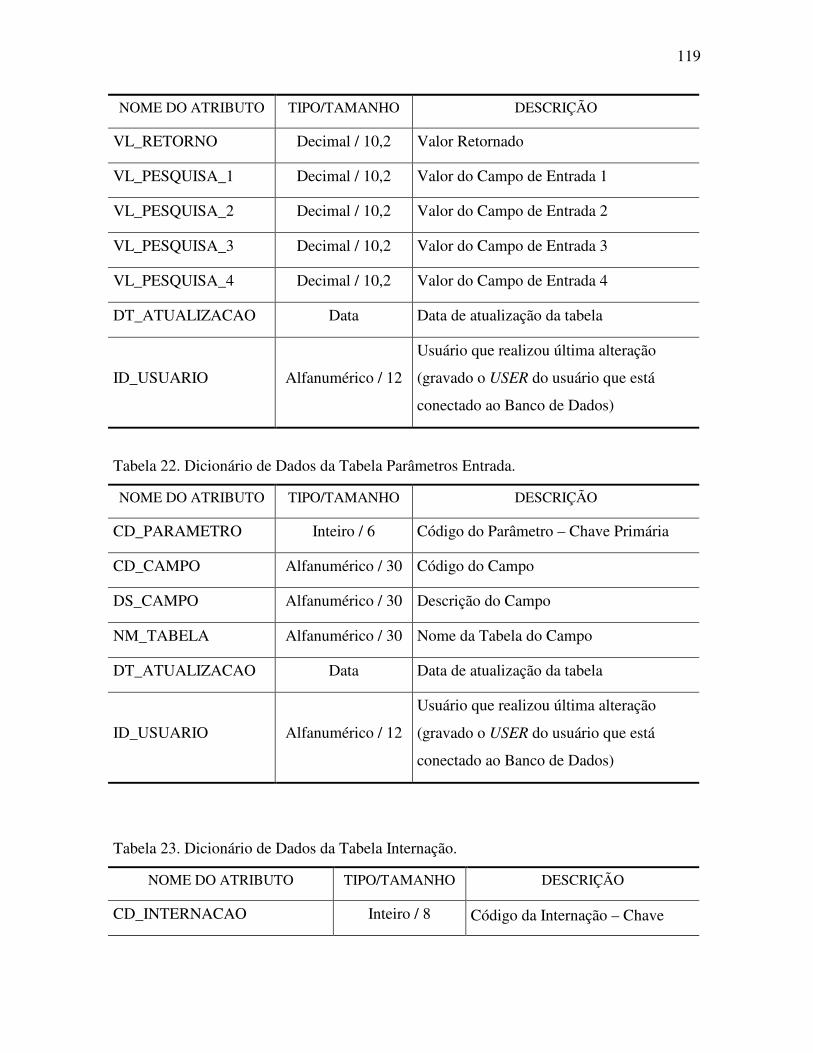
119
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
VL_RETORNO Decimal / 10,2 Valor Retornado
VL_PESQUISA_1 Decimal / 10,2 Valor do Campo de Entrada 1
VL_PESQUISA_2 Decimal / 10,2 Valor do Campo de Entrada 2
VL_PESQUISA_3 Decimal / 10,2 Valor do Campo de Entrada 3
VL_PESQUISA_4 Decimal / 10,2 Valor do Campo de Entrada 4
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
Tabela 22. Dicionário de Dados da Tabela Parâmetros Entrada.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_PARAMETRO Inteiro / 6 Código do Parâmetro – Chave Primária
CD_CAMPO Alfanumérico / 30 Código do Campo
DS_CAMPO Alfanumérico / 30 Descrição do Campo
NM_TABELA Alfanumérico / 30 Nome da Tabela do Campo
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última alteração
(gravado o USER do usuário que está
conectado ao Banco de Dados)
Tabela 23. Dicionário de Dados da Tabela Internação.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_INTERNACAO Inteiro / 8 Código da Internação – Chave
Primária

120
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
Primária
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave
Secundária
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao
Banco de Dados)
ID_CAD Inteiro / 1 CAD
ID_HIPOGLICEMIA Inteiro / 2 Hipoglicemia
ID_PATOLOGIA_ASSOCIADA Inteiro / 3 Outras Patologias Associadas
DS_AVALIACAO Inteiro / 4 Avaliação Médica da Internação
Tabela 24. Dicionário de Dados da Tabela Forma Tratamento.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
CD_FORMA_TRATAMENTO Inteiro / 8 Código da Forma de Tratamento –
Chave Primária
CD_PACIENTE Inteiro / 8 Código do Paciente – Chave
Secundária
DT_ATUALIZACAO Data Data de atualização da tabela
ID_USUARIO Alfanumérico / 12
Usuário que realizou última
alteração (gravado o USER do
usuário que está conectado ao
Banco de Dados)
ID_SU Inteiro / 1 SU
ID_ACARBOSE Inteiro / 1 Acarbose

121
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
ID_BI Inteiro / 1 BI
ID_INSULINA Inteiro / 1 Insulina
ID_DIETA Inteiro / 1 Dieta
ID_EXERCICIO Inteiro / 1 Exercícios
DS_MEDICACAO_1 Alfanumérico / 30 Medicação 1
DS_MEDICACAO_2 Alfanumérico / 30 Medicação 2
DS_MEDICACAO_3 Alfanumérico / 30 Medicação 3
DS_MEDICACAO_4 Alfanumérico / 30 Medicação 4
DS_MEDICACAO_5 Alfanumérico / 30 Medicação 5
DS_MEDICACAO_6 Alfanumérico / 30 Medicação 6
DS_MEDICACAO_7 Alfanumérico / 30 Medicação 7

122
ANEXO VII – Formulário do Governo sobre Hipertensão e Diabetes.





























