Embed Size (px)
Citation preview


D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 2
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
SUMÁRIO
1. GENERALIDADES ...........................................................................................................................................................4 1.1. INTRODUÇÃO.................................................................................................................................................................4 1.2. DIVISÃO DA ESTATÍSTICA ..............................................................................................................................................4 1.3. MENSURAÇÃO ...............................................................................................................................................................5
1.3.1. Introdução ........................................................................................................................................................5 1.3.2. Formas de mensuração ....................................................................................................................................6
2. RESUMO DE PEQUENOS CONJUNTOS DE DADOS ................................................................................................8 2.1. INTRODUÇÃO.................................................................................................................................................................8 2.2. MEDIDAS DE POSIÇÃO OU TENDÊNCIA CENTRAL.............................................................................................................8
2.2.1. As médias ..........................................................................................................................................................8 2.2.2. A mediana .......................................................................................................................................................10 2.2.3. A moda ............................................................................................................................................................10
2.3. MEDIDAS DE VARIABILIDADE OU DISPERSÃO ................................................................................................................11 2.3.1. A amplitude.....................................................................................................................................................11 2.3.2. O desvio médio (absoluto)..............................................................................................................................11 2.3.3. A variância .....................................................................................................................................................11 2.3.4. O desvio padrão .............................................................................................................................................12 2.3.5. A variância relativa........................................................................................................................................12 2.3.6. O coeficiente de variação ..............................................................................................................................13
3. DISTRIBUIÇÕES DE FREQÜÊNCIAS.........................................................................................................................14 3.1. INTRODUÇÃO...............................................................................................................................................................14 3.2. DISTRIBUIÇÕES POR PONTO OU VALORES.....................................................................................................................14 3.3. DISTRIBUIÇÕES POR CLASSES OU INTERVALOS.............................................................................................................14 3.4. ELEMENTOS DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIAS..................................................................................................15
3.4.1. A freqüência relativa ou percentual ..............................................................................................................15 3.4.2. A freqüência acumulada simples ou absoluta................................................................................................16 3.4.3. A freqüência acumulada relativa ou percentual............................................................................................16 3.4.4. Outros elementos............................................................................................................................................16
3.5. APRESENTAÇÃO DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIAS............................................................................................17 3.5.1. Distribuição de freqüências por pontos ou valores. .....................................................................................17 3.5.2. Distribuição de freqüências por classes ou intervalos .................................................................................17
3.6. RESUMO DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIAS .......................................................................................................18 3.6.1. Medidas de posição ou tendência central .....................................................................................................18 3.6.2. Medidas de variabilidade ou dispersão.........................................................................................................21 3.6.3. Medidas de assimetria ...................................................................................................................................23
3.7. PROPRIEDADES DAS MEDIDAS ......................................................................................................................................23 3.7.1. Medidas de posição........................................................................................................................................23 3.7.2. Medidas de dispersão.....................................................................................................................................23
4. ANÁLISE BIDIMENSIONAL.........................................................................................................................................25 4.1. VARIÁVEIS BIDIMENSIONAIS QUALITATIVAS.................................................................................................................25 4.2. INDEPENDÊNCIA DE VARIÁVEIS ....................................................................................................................................26

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 3
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
4.3. DEPENDÊNCIA ENTRE VARIÁVEIS NOMINAIS .................................................................................................................28 5. VARIÁVEIS BIDIMENSIONAIS QUANTITATIVAS..................................................................................................30
5.1. O DIAGRAMA DE DISPERSÃO ........................................................................................................................................30 5.2. O COEFICIENTE DE CORRELAÇÃO.................................................................................................................................32 5.3. A REGRESSÃO..............................................................................................................................................................34
5.3.1. Determinação da linha de regressão.............................................................................................................35 6. EXERCÍCIOS...................................................................................................................................................................37
7. RESPOSTAS DOS EXERCÍCIOS..................................................................................................................................43
8. APÊNDICE .......................................................................................................................................................................47
9. REFERÊNCIAS................................................................................................................................................................48

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 4
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
1. GENERALIDADES
1.1. INTRODUÇÃO Por onde quer que se olhe ou escute uma coleção de números são normalmente enunciados
como estatísticas. Estes números referem-se aos mais diversos campos de atividades: esportes, economia, finanças, etc. Assim tem-se por exemplo:
• O número de carros vendidos no país aumentou em 30%. • A taxa de desemprego atinge, hoje, 7,5%. • As ações da Telebrás subiram R$ 1,5, hoje. • Resultados do Carnaval no trânsito: 145 mortos, 2430 feridos. Um número é denominado uma estatística (singular). No fechamento da bolsa as ações da
Vale foram cotadas a R$ 45.50. As vendas de uma empresa no mês constituem uma estatística. Já uma coleção de números ou fatos é denominado de estatísticas (plural). Por exemplo, As vendas da empresa Picuínhas totalizaram: 2,5 milhões em janeiro, 2,7 em fevereiro e 3.1 em março. No entanto o termo Estatística tem um sentido muito mais amplo, do que apenas números ou coleção de números. A Estatística pode ser definida como:
A ciência de coletar, organizar, apresentar, analisar e interpretar dados numéricos com o objetivo de tomar melhores decisões.
Assim como advogados possuem “regras de evidência” e contabilistas possuem “práticas comumente aceitas”, pessoas que tratam com dados numéricos seguem alguns procedimentos padrões. Alguns destes métodos serão vistos no que se denomina de estatística descritiva.
1.2. DIVISÃO DA ESTATÍSTICA A Estatística que lida com a organização, resumo e apresentação de dados numéricos é
denominada de Estatística Descritiva. Assim pode-se definir a Estatística Descritiva como sendo: Os procedimentos usados para organizar, resumir e apresentar dados numéricos. Conjuntos de dados desorganizados são de pouco ou nenhum valor. Para que os dados se
transformem em informação é necessário organizá-los, resumi-los e apresentá-los. O resumo de conjuntos de dados é feito através das medidas e a organização e apresentação através das distribuições de freqüências e dos gráficos ou diagramas.
Estatística Indutiva. Muitas vezes, apesar dos recursos computacionais e da boa vontade não é possível estudar todo um conjunto de dados de interesse. Neste caso estuda-se uma parte do conjunto. O principal motivo para se trabalhar com uma parte do conjunto ao invés do conjunto inteiro é o custo.
O conjunto de todos os elementos que se deseja estudar é denominado de população. Note-se que o termo população é usado num sentido amplo e não significa, em geral, conjunto de pessoas. Pode-se definir uma população como sendo:
Uma coleção de todos os possíveis elementos, objetos ou medidas de interesse. Assim, são exemplos de populações: 1. O conjunto das rendas de todos os habitantes de Porto Alegre;

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 5
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
2. O conjunto de todas as notas dos alunos de Estatística; 3. O conjunto das alturas de todos os alunos da Universidade; etc.
Um levantamento efetuado sobre toda uma população é dito de levantamento censitário ou simplesmente censo.
Fazer levantamentos, estudos, pesquisas, sobre toda uma população (censo) é, em geral, muito difícil. Isto se deve à vários fatores. O principal é o custo. Um censo custa muito caro e demanda um tempo considerável para ser realizado. Assim, normalmente, se trabalha com partes da população denominadas de amostras. Uma amostra pode ser caracterizada como:
Uma porção ou parte de uma população de interesse. Utilizar amostras para se ter conhecimento sobre populações é realizado intensamente na
Agricultura, Política, Negócios, Marketing, Governo, etc., como se pode ver pêlos seguintes exemplos: • Antes da eleição diversos órgãos de pesquisa e imprensa ouvem um conjunto selecionado de
eleitores para ter uma idéia do desempenho dos vários candidatos nas futuras eleições. • Uma empresa metal-mecânica toma uma amostra do produto fabricado em intervalos de
tempo especificados para verificar se o processo está sob controle e evitar a fabricação de itens defeituosos.
• O IBGE faz levantamentos periódicos sobre emprego, desemprego, inflação, etc. • Redes de rádio e tv se utilizam constantemente dos índices de popularidade dos programas
para fixar valores da propaganda ou então modificar ou eliminar programas com audiência insatisfatória.
• Biólogos marcam pássaros, peixes, etc. para tentar prever e estudar seus hábitos.
O processo de escolha de uma amostra da população é denominado de amostragem. Riscos da amostragem. O processo de amostragem envolve riscos, pois toma-se decisões
sobre toda a população com base em apenas uma parte dela. A teoria da probabilidade pode ser utilizada para fornecer uma idéia do risco envolvido, ou seja, do erro que se comete ao utilizar uma amostra ao invés de toda a população, desde que, é claro, a amostra seja selecionada através de critérios probabilísticos, isto é, ao acaso.
Baseado nos conceitos anteriores pode-se definir Estatística Indutiva ou Inferencial como:
A coleção de métodos e técnicas utilizados para se estudar uma população baseados em amostras probabilísticas desta mesma população.
1.3. MENSURAÇÃO
1.3.1. INTRODUÇÃO
O processo de selecionar o modelo matemático ou estatístico a ser utilizado com uma dada técnica de pesquisa ou procedimento operacional envolve algumas decisões importantes. A tomada de decisão do modelo matemático ou estatístico a ser aplicado costuma ser precedida pela mensuração do fenômeno envolvido. E uma primeira dificuldade surge na necessidade de se definir o que é mensuração. Se o termo se referir somente aqueles tipos de medidas comumente utilizados em ciências tais como a física (por exemplo: medidas de comprimento, massa ou tempo) não haverá muitos problemas na escolha do sistema matemático. Mas se o conceito de medida for amplo o suficiente para incluir certos procedimentos de categorização normalmente utilizados em Ciências Sociais, então o

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 6
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
problema torna-se mais complexo. Pode-se distinguir entre diversos níveis de mensuração e para cada um existem diferentes modelos estatísticos apropriados.
1.3.2. FORMAS DE MENS URAÇÃO
Existem quatro formas de mensuração ou tipos ou níveis de medidas ou ainda escalas que são conhecidas como: nominal, ordinal, intervalar e razão.
Nível nominal. A operação básica e mais simples em qualquer ciência é a de classificação. Na classificação tenta-se separar conjuntos de elementos com respeito a certas categorias, tomando decisões sobre quais elementos são mais parecidos e quais são diferentes. O objetivo é colocar os elementos em categorias tão homogêneas quanto possível quando comparados com as diferenças existentes entre as categorias.
Os termos nível nominal de medida ou escala nominal são utilizadas para se referir a àqueles dados que só podem ser classificados em categorias. Se bem que no sentido estrito não existe na realidade uma medida ou escala envolvida. Existe apenas uma contagem. Variáveis que podem ser colocadas nesta categoria são, por exemplo, a classificação das pessoas quanto à religião, sexo, estado civil, etc. Não existe uma ordem particular entre as categorias ou grupos e além disso duas categorias quaisquer são mutuamente excludentes, isto é, uma pessoa não pode ser ao mesmo tempo católico e protestante. Além disso as categorias são exaustivas, significando que um membro da população deve aparecer em uma e somente uma das categorias. Observe a tabela um abaixo.
Tabela 1.1 - Exemplo de variável nominal
Estado civil Número de pessoas Casado 340 Solteiro 250 Viúvo 40
Divorciado 50 Total 700
Deve-se ser salientado que as classes ou categorias podem ser rotuladas com números, mas isto não significa as operações aritméticas com estes números tenham algum significado em particular. Neste caso os números exercem a mesma função dos nomes, isto é, identificar a categoria.
Nível ordinal. O nível ordinal é o tipo nominal em que se pode ordenar as categorias. A única diferença entre os dois níveis é a relação de ordem que se pode estabelecer entre as categorias. No entanto, não é possível afirmar o quanto uma categoria é maior do que a anterior, isto é, não se pode afirmar o quanto uma categoria possui da característica. A avaliação através de conceitos é feita por uma escala ordinal. Veja um exemplo na tabela dois abaixo.
Tabela 1.2 - Exemplo de variável em escala ordinal
Conceitos Número de alunos A 4 B 6 C 15 D 3 E 2
Total 30

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 7
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Não se pode afirmar neste caso que quem tirou A teve um número de acertos duas vezes maior que quem tirou C. A única coisa que se sabe é que quem tem A acertou mais questões do quem tem B e este de quem tem C e assim por diante. As famílias podem ser classificadas de acordo com seu estatus sócio econômico em: alta, média alta, média, média baixa, baixa. Não é possível entretanto afirmar que a diferença entre a alta e a média alta seja a mesma que entre a média e a média baixa.
Nível intervalar. No sentido estrito da palavra o termo mensuração pode ser utilizado para se referir a situações em que se pode, não somente ordenar objetos com respeito ao grau de que eles possuem certa característica, mas também indicar a exata distância entre eles. Isto é possível através de uma escala denominada de "escala de intervalos".
A escala de medida intervalar é uma escala nominal em que a distância entre as categorias, ao contrário da ordinal, é sempre a mesma. Ou seja, ela possui todas as características da escala ordinal mais o fator de que a distância entre as diversas categorias (ou valores) é sempre constante. As escalas de medir temperaturas como a Fahrenheit e a Celsius são exemplos de escalas de intervalo. No entanto, não se pode afirmar que uma temperatura de 40 graus é duas vezes mais quente que uma de 20 graus, embora se possa dizer que a diferença entre 20 graus e 40 graus é a mesma que entre 75 graus e 95 graus. Isto porque este tipo de escala não possui um zero absoluto. Ou seja o valor zero na escala é apenas um ponto de referência e não significa a ausência de calor. Escores padronizados são também exemplos deste tipo de nível de medida.
Torna-se evidente que uma escala de intervalo requer o estabelecimento de algum tipo de unidade física a qual todos concordem, isto é, um padrão, e, que seja replicável, isto é, possa ser aplicada muitas vezes e fornecendo sempre os mesmos resultados. Comprimento é medido em termos de cm ou metros, tempo em segundos, temperatura em centígrados ou Fahrenheit, renda em dólar ou reais. Por outro lado não existem tais unidades para inteligência, autoritarismo ou prestígio que sejam unânimes entre todos os cientistas sociais e que possam ser assumidas constantes de uma situação para outra.
Nível de razão. Este é o mais alto nível de medida. É caracterizado por apresentar todas as características da escala intervalar mais um zero absoluto. Aqui o zero pode ser entendido como a ausência da característica e as comparações de valor (razão) tem sentido. Um exemplo de variável deste tipo é o peso. Um valor igual a zero significa ausência de peso e um valor de 20 kg é duas vezes mais pesado que um de 10 kg.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 8
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
2. RESUMO DE PEQUENOS CONJUNTOS DE DADOS
2.1. INTRODUÇÃO Para se analisar um conjunto de valores é necessário primeiramente, para fins de notação,
distinguir se este conjunto é resultado de um censo ou de uma amostragem. A Estatística Descritiva pode ser estudada considerando os conjuntos de valores analisados
como sendo amostras ou então populações. Como o caso mais comum é a obtenção de amostras a notação apresentada será feita considerando os valores como resultados de amostragens. No entanto, convém ficar atento, com a bibliografia, pois dependendo do autor a orientação pode ser outra. A diferença, considerada do ponto de vista da descrição dos dados, é apenas notacional. Assim o tamanho de uma população (quando finita) é representado, normalmente por “N”, enquanto que o tamanho de amostra é representado por “n”. Afora algumas exceções os valores calculados na amostra são representados por letras latinas enquanto que os correspondentes na população o são pelas mesmas letras só que gregas.
Para facilitar o estudo da Estatística Descritiva os conjuntos de valores serão considerados como pequenos e grandes. Assim se um conjunto tiver 30 ou menos valores a análise será feita sem o agrupamento. Caso o conjunto tenha mais do que 30 valores então primeiramente será feito o agrupamento de acordo com o tipo de variável considerada. O valor 30 é apenas um ponto de referência escolhido arbitrariamente e dependendo da situação pode-se considerar o agrupamento com mais ou menos valores envolvidos.
Um conjunto de dados, de qualquer tamanho, pode ser resumido de acordo com as seguintes medidas:
1. Medidas de tendência central ou posição 2. Medidas de dispersão ou variabilidade. 3. Medidas de assimetria. 4. Medidas de achatamento ou curtose.
2.2. MEDIDAS DE POSIÇÃO OU TENDÊNCIA CENTRAL
Um conjunto de valores (amostra) será representada por: x1, x2, ..., xn, onde “n” é o número de elementos do conjunto, isto é, o tamanho da amostra.
2.2.1. AS MÉDIAS
(a) A média aritmética A média aritmética do conjunto x1, x2, ..., xn é representada por x e calculada por:
x = (x1 + x2 +... + xn) / n = ∑nxi
(b) A média geométrica A média geométrica dos valores positivos: x1, x2, ..., xn, é representada por mg e calculada por:
mg = nnx....xx 21 = n
ixΠ

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 9
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(c) A média harmônica A média harmônica dos valores positivos x1, x2, ..., xn é representada por mh e calculada por:
mh = ∑
=+++
=+++
x
n
x...
xx
n
nx
....xx inn
11111111
2121
Observando a expressão do cálculo da média harmônica pode-se verificar que ela é definida como sendo: O inverso da média aritmética dos inversos.
Exe mpl o : Calcular as médias dos seguintes conjuntos de dados: (a) 1 9 (b) 4 6 (c) 1/2 4/5 3/2 7/4
Para o conjunto em (a) tem-se: x = (1 + 9) / 2 = 5 mg = 19 9. = = 3 mh = 2 / (1 + 1/9) = 18/10 = 1,80
Para o conjunto em (b) tem-se: x = (4 + 6) / 2 = 5 mg = 4 6 24. = = 4, 90 mh = 2 / (1/4 + 1/6) = 24/5 = 4,80
Para o conjunto em (c) tem-se:
x = [1/2 + 4/5 + 3/2 + 7/4] / 4 = 91/80 = 1,14 mg = == 448084
47
23
54
21 ... 1,02
mh = 421
54
23
47
437784
336377
0 89+ + +
= = = ,
Relação entre as três médias As três médias mantém a seguinte relação entre elas, desde que os valores sejam positivos e
diferentes entre si. x > mg > mh
(d) A média quadrática A média geométrica dos valores positivos: x1, x2, ..., xn, é representada por mq e calculada por:
mq = n
... xxx n22
221 +++
= nxi∑
2
(e) A média aritmética ponderada A média aritmética ponderada do conjunto x1, x2, ..., xk, com pesos w1, w2, ..., wk, é
representada por map e calculada por:
map = (x1 w1 + x2 w2 +... + xn wk) / (w1 + w2 + ...+ wk) = ∑
∑
wwx
i
ii
(f) A média geométrica ponderada A média geométrica ponderada do conjunto x1, x2, ..., xk, com pesos w1, w2, ..., wk, é
representada por mgp e calculada por:

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 10
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
mgp = ∑w wwwi kxxx k....2121
(g) A média harmônica ponderada A média harmônica ponderada do conjunto x1, x2, ..., xk, com pesos w1, w2, ..., wk, é
representada por mhp e calculada por:
mhp = ∑
∑
xww
i
i
i
Exe mpl o : A média da primeira prova de Estatística da turma 135 foi de 6,0 e foi realizada por 55 alunos.
Na segunda prova compareceram 50 alunos que tiveram uma média de 6,5. A terceira prova realizada por 40 alunos teve média de 5,5. Qual a média aritmética geral das 3 provas?
mp = ∑
∑
wwx
i
ii = (6,0.55 + 6,5.50 + 5,5.40) / (55 + 50 + 40) = 875 / 145 = 6,03.
2.2.2. A MEDIANA
A mediana de um conjunto ordenado de valores, anotada por me, é definida como sendo o valor que separa o conjunto em dois subconjuntos do mesmo tamanho. Assim se “n” (número de elementos) é ímpar a mediana é o valor central do conjunto. Caso contrário a mediana é a média dos valores centrais do conjunto. Tem-se:
me = x(n+1)/2 se “n” é ímpar e me = [x(n/2) + x(n/2)+1] / 2 se “n” é par Exe mpl o : Para o conjunto:
15 18 21 32 45 46 49 A mediana é:
me = x(7+1)/2 = x4 = 32, Ou seja, a mediana é o quarto valor na seqüência ordenada de elementos. Se o conjunto acima fosse:
15 18 21 32 45 46 Então a mediana seria: me = [x(n/2) + x(n/2)+1] / 2 = [x(6/2) + x(6/2)+1] / 2 = (x3 + x4) / 2 = (21 + 32) / 2 = 53/2 = 26,50
2.2.3. A MODA
A moda de um conjunto de valores, anotada por mo, é definida como sendo “o valor (ou os valores) do conjunto que mais se repete”. Convém lembrar que a moda ao contrário da mediana e da média pode não ser única, isto é, um conjunto pode ser bimodal, trimodal, etc. ou mesmo amodal (sem moda). Se a moda existir será representada por mo.
Exe mpl o : Dado o conjunto:
1 2 2 3 3 4 4 4 7 9 15

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 11
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
A moda será: mo = 4, Pois este valor se repete 3 vezes no conjunto e qualquer outro se repete duas ou menos vezes.
2.3. MEDIDAS DE VARIABILIDADE OU DISPERSÃO
2.3.1. A AMP LITUDE
A mais simples das medidas de dispersão é a amplitude, anotada por “h”, e definida como sendo a diferença entre os valores extremos do conjunto, isto é:
h = xmax - xmin Exe mpl o : A amplitude do conjunto: -5 4 0 3 8 10, vale:
h = xmax - xmin = 10 - (-5) = 15.
2.3.2. O DES VIO MÉDIO (ABS OLUTO)
A amplitude é uma medida simples e fácil de calcular. Tem a virtude de dar uma idéia da variabilidade do conjunto. No entanto ela não leva em consideração todos os valores do conjunto como seria desejável.
Assim prefere-se, em geral, trabalhar com medidas que utilizam toda a informação disponível. Uma destas medidas é o desvio médio absoluto ou simplesmente desvio médio. O desvio médio é representado por “dma” e definido como sendo “a média das distâncias que os valores do conjunto se encontram da média”.
dma = [ |x1 - x | + |x2 - x | + ... + |xn - x | ] / n = ∑−n
xxi
Exe mpl o : Calcular o dma do conjunto:
-7 4 0 3 8 10
A média é x = (-7 + 4 + 0 + 3 + 8 + 10) / 6 = 18/6 = 3 Então o desvio médio será:
dma = [|-7 - 3| + |4 - 3| + |0 - 3| + |3 - 3| + |8 - 3| + |10 - 3|] / 6 = (10 + 1 + 3 + 0 + 5 + 7) / 6 =
26/6 = 4,33
2.3.3. A VARIÂNCIA
O desvio médio apesar de intuitivamente fácil de interpretar e simples de calcular não é muito utilizado em Estatística. O que de fato é a medida de dispersão usual é a variância e principalmente sua raiz quadrada que é denominada de desvio padrão. A variância é anotada por s2 e definida como sendo “a média dos quadrados dos desvios em relação a média aritmética.” Por desvio entende-se a diferença entre um valor do conjunto e a média.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 12
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
s2 = [(x1 - x)2 + (x2 - x)2 + ... + (xn - x)2] / n = ( )∑
−nxxi
2
Nem sempre esta expressão é a mais indicada para ser utilizada. Quando a média é um valor decimal não exato ela não é muito prática, uma vez que entrará no cálculo “n” vezes aumentando os erros de arredondamento que ocorrem. Neste caso é melhor se valer de uma expressão alternativa que pode ser derivada da expressão acima desenvolvendo o quadrado dentro do somatório e fazendo algumas simplificações.
Trabalhando inicialmente apenas com o numerador da fórmula acima vem:
=∑ − )xx( i2 )x( xxx ii
22 2 +−∑ = ∑∑∑ −− xxx ii x 22 2
Observando que ∑=n
x xi tem-se que: xnxi =∑ e ainda que: xx n 22 =∑ vem:
=∑ − )xx( i2 xxx nni
222 2 +−∑ = xx ni22 −∑
Dividindo este resultado por “n” e simplificando a segunda parcela vem:
s2 = ∑−n
)xx( i2
= xxn
i 22
−∑
Esta é uma segunda expressão para o cálculo da variância e em muitas situações é mais vantajosa de ser usada. Neste caso a variância pode ser caracterizada como sendo: “a média dos quadrados menos o quadrado da média”.
2.3.4. O DES VIO P ADRÃO
A variância por ser um quadrado não permite comparações com a unidade que se está trabalhando. Para se ter uma medida de variabilidade com a mesma unidade do conjunto utiliza-se a raiz quadrada da variância, que é denominada de desvio padrão. Assim a expressão para o desvio é:
s = ∑−n
)xx( i2
= xxn
i 22
−∑
Exe mpl o : Calcular a variância e o desvio padrão do conjunto:
-7 4 0 3 8 10 A média é x = (-7 + 4 + 0 + 3 + 8 + 10) / 6 = 18/6 = 3 Então variância será:
s2 = [(-7 - 3)2 + (4 - 3)2 + (0 - 3)2 + (3 - 3)2 + (8 - 3)2 + (10 - 3)2] / 6 = = (100 + 1 + 9 + 0 + 25 + 49) / 6 = 184 / 6 = 30,67 E o desvio padrão: s = 5,54
2.3.5. A VARIÂNCIA RELATIVA
A variância relativa, representada por g2 é o quociente entre a variância absoluta e o quadrado da média. Isto é:
g2 = s2 / x2

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 13
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
2.3.6. O COEF ICIENTE DE VARIAÇÃO
O coeficiente de variação é a raiz quadrada da variância relativa. Isto é: g = s / x
Exe mpl o : Calcular a variância relativa e o coeficiente de variação do conjunto:
-7 4 0 3 8 10 A média é x = (-7 + 4 + 0 + 3 + 8 + 10) / 6 = 18/6 = 3 Então variância será:
s2 = [(-7 - 3)2 + (4 - 3)2 + (0 - 3)2 + (3 - 3)2 + (8 - 3)2 + (10 - 3)2] / 6 = = (100 + 1 + 9 + 0 + 25 + 49) / 6 = 184 / 6 = 30,67
O desvio padrão será: s = 5,54 Então a variância relativa será:
g2 = (184/6) / 9 = 3,41
E o coeficiente de variação será: g = s / x = 5,54 / 3 = 184,59%

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 14
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
3. DISTRIBUIÇÕES DE FREQÜÊNCIAS
3.1. INTRODUÇÃO Para se trabalhar com grandes conjuntos de dados é necessário inicialmente agrupar estes
dados. O agrupamento é feito em tabelas, denominadas de distribuições de freqüências. Para se construir uma distribuição de freqüências é comum fazer a distinção entre dois tipos de variáveis. A variável (ou conjunto) discreta (valores que são resultados de contagem) e a variável (ou conjunto) contínua (valores que são resultados de uma medida). Em geral variáveis discretas são agrupadas em distribuições por ponto ou valores e variáveis contínuas em distribuições por classes ou intervalos. A separação não é rígida e depende basicamente dos dados considerados. Poderá ser necessário usar uma distribuição por classes ou intervalos mesmo quando a variável é discreta.
3.2. DISTRIBUIÇÕES POR PONTO OU VALORES. Considere-se um conjunto de valores resultados de uma contagem. Poderia ser, por exemplo,
o número de irmãos dos alunos da turma U, disciplina de Estatística.
Número de irmãos dos alunos da turma U - disciplina Estatística 0 1 1 6 3 1 3 1 1 0 4 5 1 1 1 0 2 2 4 1 3 1 2 1 1 1 1 5 5 6 4 1 1 0 2 1 4 3 2 2 1 0 2 1 1 2 3 0 1 0
Esta coleção de valores não constitui informação mas pode ser transformada em informação mediante sua representação em uma distribuição de freqüências por pontos ou valores. Para tal, coloca-se o conjunto em uma tabela em que a coluna da esquerda é representada pelos diferentes números ordenados (os pontos ou valores) e a coluna da direita pelo número de vezes que cada valor se repetiu (as freqüências simples ou absolutas). Para o exemplo, na tabela três, tem-se:
Tabela 3.1 - Distribuição de freqüências por ponto ou valores do número de irmãos dos alunos da turma U. Disciplina Estatística.
Número de irmãos Número de alunos 0 7 1 21 2 8 3 5 4 4 5 3 6 2
Total 50
3.3. DISTRIBUIÇÕES POR CLASSES OU INTERVALOS Considere-se um conjunto de valores resultados de uma medida. Poderia ser, por exemplo, a
idade dos alunos da turma U da disciplina de Estatística.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 15
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Idade (em meses) dos alunos da turma U - Disciplina Estatística 230 234 276 245 345 240 270 310 368 369 334 268 288 336 299 236 239 355 330 247 287 344 300 244 303 248 251 265 246 266 240 320 308 299 312 324 289 320 264 275 252 298 315 255 274 264 263 230 303 281
Este conjunto de valores, obviamente não pode ser apresentado da mesma forma que o anterior, pois quase não há repetições. Neste caso é necessário construir uma tabela denominada de ”distribuição de freqüências por classes ou intervalos”. Evidentemente haverá perda de informação neste processo, mas o ganho obtido pela facilidade compreensão dos dados compensa.
O procedimento para construir esta distribuição envolve os seguintes passos (algoritmo): ���� Determinar a amplitude dos dados: h = xmax - xmin. ���� Decidir sobre o número de classes “k“ a ser utilizado. Recomenda-se um número de
classes entre 5 e 15. Para que a decisão não seja totalmente arbitrária pode-se usar a raiz quadrada do número de valores como o número de classes, ou seja, k ≅≅≅≅ n .
���� Determinar a amplitude de cada classe. Sempre que possível manter todas as amplitudes iguais. Para tanto deve-se dividir a amplitude dos dados “h” pelo número de classes “k”, arredondando para mais, ou seja, hi ≅ h / k.
���� Contar o número de valores pertencentes a cada classe. Em geral, utiliza-se a simbologia (|--- ), para indicar um intervalo fechado à esquerda e aberto à direita. Também poderia ser utilizado o intervalo aberto à esquerda e fechado à direita (---|), aberto de ambos os lados ( --- ) ou ainda fechado de ambos os lados (|---|).
Um exemplo de uma distribuição por classes ou intervalos é apresentado na tabela 04.
Tabela 3.2 - Idades dos alunos da turma U - Disciplina Estatística.
Idades Número de alunos 230 |---- 250 12 250 |---- 270 9 270 |---- 290 8 290 |---- 310 7 310 |---- 330 6 330 |---- 350 5 350 |---- 370 3
Total 50
3.4. ELEMENTOS DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIAS Além da freqüência simples ou absoluta pode-se definir ainda:
3.4.1. A F REQÜÊNCIA RELATIVA OU P ERCENTUAL
A freqüência relativa simples ou percentual é definida como sendo o quociente entre a freqüência simples “fi” e o total de dados “n”.
fri = fi / n

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 16
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Exe mpl o : Na tabela três tem-se:
fr3 = 8 / 50 = 0,16 = 16%, significando que 16% dos alunos da turma possuem 2 irmãos. Na tabela quatro tem-se:
fr2 = 9 / 50 = 0,18 = 18%, significando que 18% dos alunos possuem idades maiores ou iguais a 250 meses porém menores do que 270 meses.
3.4.2. A F REQÜÊNCIA ACUMULADA S IMP LES OU ABS OLUTA.
A freqüência acumulada simples ou absoluta da linha “i” é definida como sendo a soma das freqüência simples ou absolutas até a linha “i “.
Fi = f1 + f2 + ... + fi Exe mpl o : Na tabela três tem-se: F4 = f1 + f2 + f3 + f4 = 7 + 21 + 8 + 5 = 41, significando que 41 alunos da turma possuem até 3 irmãos.
3.4.3. A F REQÜÊNCIA ACUMULADA RELATIVA OU P ERCENTUAL
A freqüência acumulada relativa ou percentual da linha “i” é definida como sendo a soma das freqüência relativas ou percentuais até a linha “i “.
Fri = fr1 + fr2 + ... + fri , ou então, como sendo o quociente da freqüência acumulada simples pelo total de dados. Fri = Fi / n
Exe mpl o : Na tabela quatro tem-se: Fr2 = (12 + 9) / 50 = 42%, isto é, 42% dos alunos possuem idades menores do que 270 meses.
3.4.4. OUTROS ELEMENTOS
(i) Na tabela três os valores da coluna da esquerda são denominados de pontos ou valores. Cada um deles é representado por xi , onde “i” varia de 1 até k, sendo “k” o número de linhas da tabela.
(ii) Na tabela quatro os valores da coluna da esquerda são denominados de classes ou intervalos. As classes, também, variam de 1 até k.
(iii) Limite inferior da classe “i“. Anota-se por lii. Na tabela 4 o limite inferior da terceira classe é: 270.
(iv) Limite superior da classe “i“. Anota-se por lsi. Na tabela 4 o limite superior da quinta classe é: 330.
(v) Amplitude da classe “i”. Anota-se por hi e é calculada como a diferença entre os limites superior ou inferior da classe “i”. Assim hi = lsi - lii.
Na tabela quatro a amplitude da classe quatro é: h4 = ls4 - li4 = = 310 - 290 = 20 meses.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 17
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(vi) Ponto médio da classe. Como não é possível trabalhar com classes é necessário escolher um representante da classe. Este representante é denominado de ponto médio da classe. É representado por xi e calculado por: xi = (lii + lsi) / 2 ou então xi = lii + hi / 2.
Na tabela quatro o ponto médio da terceira classe é: x3 = (li3 + ls3) / 2 = (270 + 290) / 2 = 280 meses.
Exe mpl o : Na tabela 05, abaixo, estão ilustrados os cálculos das freqüências relativas percentuais, da
freqüência acumulada simples e da freqüência acumulada percentual.
Tabela 3.3 - Exemplos de freqüências
Número de irmãos Número de alunos fri Fi Fri 0 7 14 7 14 1 21 42 28 56 2 8 16 36 72 3 5 10 41 82 4 4 8 45 90 5 3 6 48 96 6 2 4 50 100
Total 50 100 ---- ----
3.5. APRESENTAÇÃO DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIAS
3.5.1. DIS TRIBUIÇÃO DE F REQÜÊNCIAS P OR P ONTOS OU VALORES.
Uma distribuição de freqüências por pontos ou valores é apresentada graficamente através de um diagrama de linhas ou colunas, onde a variável “xi” é representada no eixo das abcissas (horizontal) e as freqüências (que podem ser de qualquer tipo) no eixo das ordenadas (vertical). Veja-se um exemplo de diagrama de colunas simples na figura 01.
Tabela 3.4 - Diagrama de colunas simples da variável "número de irmãos dos alunos da turma U - Disciplina de Estatística"
0
5
10
15
20
25
0 1 2 3 4 5 6
3.5.2. DIS TRIBUIÇÃO DE F REQÜÊNCIAS P OR CLAS S ES OU INTERVALOS
Uma distribuição de freqüências por classes ou intervalos é apresentada graficamente através de um diagrama denominado de histograma. Um histograma é um gráfico de retângulos justapostos onde a base de cada retângulo é a amplitude de cada classe e a altura é proporcional a freqüência

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 18
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(simples ou relativa) de modo que a área de cada retângulo seja igual a freqüência considerada. Desta forma a altura de cada retângulo será igual a: fi / hi ou então fri / hi. Veja-se o cálculo das alturas na tabela 06 e o exemplo na figura 02. Também pode ser construído um histograma utilizando-se as freqüências acumuladas. Neste caso o diagrama resultante é denominado de ogiva. Se os pontos médios de cada classe de um histograma forem unidos através de segmentos de retas teremos então um diagrama denominado de polígono de freqüências.
Tabela 3.5 - Cálculo das ordenadas do histograma
Idades Número de alunos fi / hi 230 |---- 250 12 0,60 250 |---- 270 9 0,45 270 |---- 290 8 0,40 290 |---- 310 7 0,35 310 |---- 330 6 0,30 330 |---- 350 5 0,25 350 |---- 370 3 0,15
Total 50 ---- Tabela 3.6 - Histograma de freqüência simples da variável "idades dos alunos da turma
U - Disciplina de Estatística"
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
230 |--- 250 250 |--- 270 270 |--- 290 290 |--- 310 310 |---330 330 |--- 350 350 |--- 370
fi / hi
3.6. RESUMO DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIAS
3.6.1. MEDIDAS DE P OS IÇÃO OU TENDÊNCIA CENTRAL
(i) A média aritmética A média aritmética de uma distribuição de freqüências por pontos ou valores ou ainda por
classes ou intervalos é dada por:
x = (f1x1 + f2x2 +... + fnxn) / (f1 + f2 + ... + fn) = ∑nxf ii
Exe mpl os: A média da distribuição da tabela três, utilizando a tabela 07 para fazer os cálculos será:

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 19
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Tabela 3.7 - Cálculo da média de uma distribuição por pontos ou valores
Número de irmãos Número de alunos fixi 0 7 0 1 21 21 2 8 16 3 5 15 4 4 16 5 3 15 6 2 12
Total 50 95
x = ∑nxf ii = 95 / 50 = 1,90 irmãos.
Ou seja, o número médio de alunos da turma U, de Estatística, é de 1,90. Já para a tabela quatro é necessário primeiro obter os valores dos pontos médios de cada
classe ou intervalo. Fazendo os cálculos na tabela 08, vem:
Tabela 3.8 - Cálculo da média de uma distribuição por classes
Idades Número de alunos xi fixi 230 |---- 250 12 240 2880 250 |---- 270 9 260 2340 270 |---- 290 8 280 2240 290 |---- 310 7 300 2100 310 |---- 330 6 320 1920 330 |---- 350 5 340 1700 350 |---- 370 3 360 1080
Total 50 ---- 14260
Deste modo a média das idades será:
x = i ixn
f∑ = 14 260 / 50 = 285,20 meses, ou seja, 285 meses e 6 dias.
(ii) A mediana (a) A mediana de uma distribuição de valores ou pontos é obtida da mesma forma que para
dados não agrupados, isto é: me = x(n+1)/2 se “n” é ímpar e me = [x(n/2) + x(n/2)+1] / 2 se “n” é par Observação: Neste caso deve-se trabalhar como se o conjunto não estivesse agrupado.
Exe mpl o : Para os valores da tabela três a mediana é: me = [x50/2 + x(50/2)+1] / 2 = [x25 + x26] / 2 = (1 + 1) / 2 = 1, pois da oitava posição até a
vigésima oitava posição todos os valores são iguais a um, e a mediana é a média entre os valores que se encontra na vigésima quinta e vigésima sexta posição.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 20
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(b) A mediana de uma distribuição de freqüências por classes ou intervalos é dada pela seguinte expressão:
me =
−+
fF
hlii
1-iii
n2 , onde
lii = limite inferior da classe mediana, isto é, a classe que contém o ou os valores centrais;
hi = amplitude da classe mediana;
fi = freqüência simples da classe mediana;
Fi-1 = freqüência acumulada simples da classe anterior à classe mediana.
Exe mpl o : Considerando que a classe mediana, na tabela quatro, é a que contém os valores x25 e x26, isto
é, a terceira classe, vem:
me =
−+
fF
hli3
233
n2 = 270 + 20[(25 - 21) / 8] = 270 + 10 = 280 meses.
(iii) A moda (a) A moda de uma distribuição de valores ou pontos é obtida da mesma forma que para dados
não agrupados, ou seja, observando o valor ou os valores que mais se repetem. mo = valor da linha com maior freqüência (se existir apenas uma).
Exe mpl o : Para os valores da tabela três a moda é: mo = 1, pois este valor com uma freqüência de 21 é o que mais se repete. (b) A moda de uma distribuição de freqüências por classes ou intervalos é dada pelas
seguintes expressões:
mo = i ii+1
i-1 i+1li h f
f f+
+
, denominada de moda de King, ou
mo = i ii i-1
i i-1 i+1li h f f
2f f f+ −
− −
, denominada de moda de Kzuber, onde:
lii = limite inferior da classe modal, isto é, a classe de maior freqüência;
hi = amplitude da classe modal;
fi = freqüência simples da classe modal;
fi-1 = freqüência simples da classe anterior à classe modal;
fi+1 = freqüência simples da classe superior à classe modal.
Exe mpl o : Considerando que a classe de maior freqüência, a classe modal, na tabela quatro, é a primeira,
vem:

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 21
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
mo = 1 12
2li h f
f+
= 230 + 20 = 250 meses.
mo = 1 11
1 2li h f
2f f+
−
= 230 + 20[12 / (24 - 9)] = 230 + 16 = 246 meses.
(iv) Relação entre as três medidas de posição Karl Pearson estabeleceu a seguinte relação aproximada entre as três medidas de posição:
x - mo = 3 ( x- me), Ou seja, em uma distribuição de freqüências à diferença entre a média e a moda é 3 vezes
maior do que a diferença entre a média e a mediana.
3.6.2. MEDIDAS DE VARIABILIDADE OU DIS P ERS ÃO
(a) A amplitude A amplitude de uma distribuição de freqüências é definida como sendo a diferença entre os
valores extremos da distribuição, isto é: h = xmax - xmin, para a distribuição por pontos ou valores e h = lsk - li1, para a distribuição por classes ou intervalos.
Exe mpl o : A amplitude da distribuição da tabela três é:
h = xmax - xmin = 6 - 0 = 6 irmãos Já a amplitude da distribuição da tabela quatro vale:
h = ls7 - li1 = 370 - 230 = 140 meses
(b) O desvio médio (absoluto) O desvio médio absoluto de uma distribuição de freqüências é dado por:
dma = [ f1|x1 - x | + f2|x2 - x | + ... + fk|xn - x | ] / n = ∑−
nxxf ii
Exe mpl o : O dma da distribuição da tabela três utilizando a tabela 09 para os cálculos, vale:
Tabela 3.9 - Cálculo dos desvio médio absoluto
Número de irmãos Número de alunos fi|xi - x | 0 7 7|0 - 1,90| = 13,30 1 21 21|1 - 1,90| = 18,90 2 8 8|2 - 1,90| = 0,80 3 5 5|3 - 1,90| = 5,50 4 4 4|4 - 1,90| = 8,40 5 3 3|5 - 1,90| = 9,30 6 2 2|6 - 1,90| = 8,20
Total 50 64,40

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 22
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
dma = ∑−
nxxf ii = 64,40 / 50 = 1,29 irmãos
(c) A variância A variância de uma distribuição de freqüências pode ser avaliada por qualquer uma das
expressões abaixo.
s2 = [f1(x1 - x)2 + f2(x2 - x)2 + ... + fk(xk - x)2] / n = ∑−
n)xx(f ii
2
= xxf 2
nii −∑
2
(d) O desvio padrão O desvio padrão de uma distribuição de freqüências é determinado extraindo-se a raiz
quadrada da variância. Assim, do desvio padrão é:
s = ∑−
n)xx(f ii
2
= xxfni i 2
2
−∑
Exe mpl o : A variância e o desvio padrão da distribuição da tabela 04, utilizando a tabela 10 para os
cálculos vale:
Tabela 3.10 - Ilustração do cálculo da variância
Idades Número de alunos xi fixi fix2 230 |---- 250 12 240 2880 691200 250 |---- 270 9 260 2340 608400 270 |---- 290 8 280 2240 627200 290 |---- 310 7 300 2100 630000 310 |---- 330 6 320 1920 614400 330 |---- 350 5 340 1700 578000 350 |---- 370 3 360 1080 388800
Total 50 ---- 14260 4138000
A variância da distribuição será:
s2 = xxf 2
nii −∑
2
= 4 138 000 / 50 - 285,202 = 82760 - 81339,04 = 1420,96
O desvio padrão vale:
s = xxfni i 2
2
−∑ = 37,70
A variância relativa: g2 = s2 / x2 = 0,0175
O coeficiente de variação vale: g = s / x = 0,132 2 = 13,22%

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 23
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
3.6.3. MEDIDAS DE AS S IMETRIA
A assimetria de um conjunto de dados, agrupados ou não, pode ser avaliada através da seguinte relação devida a Karl Pearson:
a1 = 3( x - me) / s Se a1 for igual a zero então a distribuição (ou conjunto) é dito simétrico. Se a1 > 0 então a
assimetria é positiva significando que o gráfico da distribuição tem uma cauda alongada à direita. Caso a1 seja negativo a cauda do gráfico será alongada à esquerda.
Se uma distribuição de freqüências é simétrica então as 3 medidas de posição coincidem, isto é:
x = me = mo. Se a distribuição é positivamente assimétrica então x > me > m0
E se a distribuição é negativamente assimétrica então x < me < mo
3.7. PROPRIEDADES DAS MEDIDAS
3.7.1. MEDIDAS DE P OS IÇÃO
(i) Se todos os valores de um conjunto de dados forem somados a uma constante então as medidas de posição aumentam desta constante. Em símbolos. Dado um conjunto de dados x e somando a este conjunto uma constante “c”. Então para y = x + c, tem-se:
y = x + c O mesmo acontece com a mediana e a moda. (ii) Se todos os valores de um conjunto de dados forem multiplicados a uma constante então
as medidas de posição ficam multiplicadas por esta constante. Em símbolos. Se um conjunto de dados x for multiplicado por uma constante “c”. Então para y = cx, tem-se:
y = cx
O mesmo acontece com a mediana e a moda.
3.7.2. MEDIDAS DE DIS P ERS ÃO
(i) Se todos os valores de um conjunto de dados forem somados a uma constante então as medidas de dispersão não se alteram. Em símbolos. Dado um conjunto de dados x e somando a este conjunto uma constante “c”. Então para y = x + c, tem-se:
sy = sx O mesmo vale para a variância e para o dma. O coeficiente de variação e a variância relativa
são exceções, pois são medidas derivadas, que combinam uma medida de posição a média no denominador que se altera e uma medida de dispersão o desvio padrão ou a variância no numerador que não se altera.
(ii) Se todos os valores de um conjunto de dados forem multiplicados a uma constante então as medidas de posição ficam multiplicadas por esta constante, sendo que a variância fica multiplicada pelo quadrado desta constante. Em símbolos. Se um conjunto de dados x for multiplicado por uma constante “c”. Então para y = cx, tem-se:

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 24
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
sy = csx O mesmo vale para a o dma. Já a variância que é um quadrado fica multiplicada pelo
quadrado da constante. O coeficiente de variação e a variância relativa são exceções, pois são medidas derivadas, que combinam uma medida de posição, a média no denominador que se altera, e uma medida de dispersão, o desvio padrão ou a variância no numerador, que também se altera. Como tanto o numerador quanto o denominador se alteram na mesma proporção, então a razão entre as duas alterações passará a ser um. Portanto tanto a variância relativa quanto o coeficiente de variação são indiferentes a uma multiplicação do conjunto de valores por uma constante.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 25
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
4. ANÁLISE BIDIMENSIONAL
4.1. VARIÁVEIS BIDIMENSIONAIS QUALITATIVAS Até agora foi visto como se pode organizar, descrever e resumir informações representadas
por uma única variável, mas este é apenas uma das situações possíveis. Pode-se ter 2, 3, ou mais variáveis. Neste caso a distribuição de freqüências conjunta das variáveis vai representar um papel importante na análise. Este estudo vai se deter basicamente nas variáveis bidimensionais, mas a extensão para mais de duas variáveis é imediata.
Exe mpl o Suponha que se queira analisar o comportamento conjunto das variáveis X = Grau de
Instrução e Y = Região de procedência. Neste caso, a distribuição de freqüências é apresentada como uma tabela de dupla entrada, que esta apresentada na Tabela 4.1.
Tabela 4.1 - Distribuição conjunta das variáveis X e Y
X Y
Primeiro Grau Segundo Grau Superior Total
Capital 4 5 6 15 Interior 11 4 3 18 Outra 2 3 2 7 Total 17 12 11 40
Cada elemento do corpo da tabela fornece a freqüência observada da realização simultânea das variáveis X e Y. Neste caso, foram observados 4 moradores da capital com primeiro grau, 6 com instrução superior, 7 moradores do interior com instrução do segundo grau e assim por diante.
A linha dos totais fornece a distribuição da variável X (grau de instrução) enquanto que o total das colunas fornece a distribuição da variável Y (região de procedência). As distribuições separadas (das margens) são chamadas de distribuições marginais enquanto que a tabela 1.1 forma a distribuição conjunta das variáveis X e Y.
Ao invés de se trabalhar com as freqüências absolutas, pode-se obter as freqüências relativas (proporções), como foi feito no caso de uma única variável. Mas aqui existem 3 possibilidades de expressarmos a proporção de cada célula da tabela: (1) em relação ao total geral, (2) em relação ao total de cada linha e (3) em relação ao total de cada coluna.
A Tabela 4.2 apresenta a distribuição conjunta das freqüências relativas expressas como proporções do total geral. Neste caso pode-se afirmar que 10% dos empregados vem da capital e tem instrução de primeiro grau. Os totais das margens fornecem as distribuições (em percentual) de cada uma das variáveis, consideradas individualmente. Assim 37,5% dos pais vem da capital, 45% são procedentes do interior e os restantes de outros estados. Da mesma forma pode-se constatar que 42,50% os pais tem primeiro grau, 30% o segundo grau e os restantes possuem formação superior.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 26
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Tabela 4.2 - Distribuição conjunta das variáveis X e Y
X Y Primeiro Grau Segundo Grau Superior Total
Capital 10,0 12,5 15,0 37,5 Interior 27,5 10,0 7,5 45,0 Outra 5,0 7,50 5,0 17,5 Total 42,50 30,0 27,5 100,0
A Tabela 4.3apresenta a distribuição das proporções (em percentual) em relação ao total das colunas. Assim, pode-se afirmar que 25,53% dos pais com instrução de primeiro grau vem da capital, 64,71% vem do interior e 11,76% vem de fora do estado. Quantos aos pais com grau superior 54,55% vem da capital, 27,27% o interior e 18,18% de fora do estado. Este tipo de distribuição serve para comparar a distribuição da procedência das pessoas conforme o grau de instrução. De forma análogo, pode-se construir a distribuição das proporções em relação ao total de linhas.
Tabela 4.3 - Distribuição conjunta das variáveis X e Y.
X Y Primeiro Grau Segundo Grau Superior Total
Capital 23,53 41,67 54,55 37,5 Interior 64,71 33,33 27,27 45,0 Outra 11,76 25,00 18,18 17,5 Total 100,0 100,0 100,0 100,0
4.2. INDEPENDÊNCIA DE VARIÁVEIS Um dos principais objetivos de se determinar a distribuição conjunta é descrever a associação
existente entre as variáveis, isto é, quer-se conhecer o grau de dependência existente entre elas, de modo que se possa prever melhor o resultado de uma delas quando se conhece o resultado da outra.
Por exemplo, se for desejado estimar qual a renda média de uma família moradora de Porto Alegre, a informação adicional sobre qual a classe social que ela pertence permite que a estimativa seja mais precisa, pois se sabe que existe dependência entre os dois tipos de variáveis. Ou ainda, suponha que se queira advinhar o sexo de um estudante da cidade de PUC sorteado ao acaso. Como se sabe que aproximadamente metade dos estudantes da universidade são homens, não teríamos preferência em sugerir um ou outro sexo. No entanto, se for informado que este aluno estuda Pedagogia, então seremos inclinados a optar pelo sexo feminino, pois é que os alunos deste curso são quase que exclusivamente do sexo feminino. Agora se a informação fosse de que o aluno estuda Engenharia a sugestão seria outra, pois a grande maioria dos estudantes de Engenharia são do sexo masculino.
Vamos ver, então, como identificar se existe dependência entre duas variáveis.
Exe mpl o Quer-se identificar se existe ou não dependência entre sexo e curso escolhido, baseado em
uma amostra de 200 alunos de Economia e Administração. Estes dados estão agrupados na Tabela 4.4.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 27
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Tabela 4.4 - Distribuição conjunta dos alunos segundo o sexo (X) e o curso (Y)
X Y
Masculino Feminino Total
Economia 85 35 120 Administração 55 25 80
Total 140 60 200
De início pode-se perceber que não é fácil tirar alguma conclusão, devido a diferença nos totais marginais. Desta forma, deve-se construir proporções segundo as linhas (ou colunas) para se poder fazer comparações. Vamos supor que foram fixados os totais das colunas. Os resultados estão apresentados na Tabela 4.5.
Tabela 4.5 - Distribuição conjunta dos alunos segundo o sexo (X) e o curso (Y)
X Y
Masculino Feminino Total
Economia 61 58 60 Administração 39 43 40
Total 100 100 100
Desta tabela pode-se observar que, independentemente de sexo, 60% dos alunos preferem Economia e 40% Administração (Pode-se ver pela coluna do total)
Não havendo dependência entre as variáveis, seria esperado as mesmas proporções para cada sexo. Observando a tabela, pode-se constatar que as proporções estão muito próximos do que seria esperado, isto é, do sexo masculino 61% preferem Economia e 39% Administração, enquanto que do sexo feminino estas proporções são 58% e 42% respectivamente. Estes resultados parecem indicar que não existe dependência entre as variáveis sexo e curso escolhido. Suponha agora um mesmo tipo de exemplo, só que envolvendo alunos dos cursos de Física e Serviço Social, cuja distribuição conjunta está na Tabela 4.6.
Tabela 4.6 - Distribuição conjunta dos alunos segundo o sexo (X) e o curso (Y)
X Y
Masculino Feminino Total
Física 100 (71) 20 (33) 120 (60) Ciências Sociais 40 (29) 40 (67) 80 (40)
Total 140 (100) 60 (100) 200 (100)
Observe que as tabelas das porcentagens já foi calculada e colocada junto com a das freqüências absolutas. As percentagens foram calculadas, conforme exemplo anterior, em relação ao total das colunas.
Comparando agora a distribuição das proporções pelos cursos, independentes do sexo (coluna de total), com as distribuições diferenciadas por sexo (coluna de masculino e feminino), parece haver uma maior concentração de homens no curso de Física e de mulheres no de Serviço Social. Portanto, neste caso, as variáveis sexo e curso escolhido parecem ser dependentes. Quando existe dependência

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 28
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
entre variáveis, sempre é interessante quantificar esta dependência, que é que será visto adiante. Observe-se, também, que se teria chegado as mesmas conclusões se tivesse sido utilizado o total de linhas ao invés do total de colunas.
4.3. DEPENDÊNCIA ENTRE VARIÁVEIS NOMINAIS De um modo geral, a quantificação do grau de dependência entre duas variáveis é realizada
pelos chamados coeficientes de correlação ou associação. Estas medidas descrevem através de um único número a dependência entre duas variáveis. Para que a interpretação se torne mais fácil e intuitiva estes coeficientes normalmente variam de zero a um (ou de –1 a +1), e a proximidade de zero indica que as variáveis são independentes.
Existem várias medidas que medem a dependência entre duas variáveis nominais. Uma delas é o denominado coeficiente de contingência, devido a Karl Pearson.
Exe mpl o Determinar o grau de dependência entre as variáveis da Tabela 4.6.
A análise da tabela já mostrou que existe dependência entre as variáveis. Caso houvesse independência entre elas seria esperado que cada sexo apresentasse 60% de estudantes Física e 40% de estudantes de Ciências Sociais. Neste caso, o número esperado de estudantes masculinos de Física seria: 140x0,60 = 84 e o número esperado de estudantes masculinos de Ciências Sociais seria 140x0,40 = 56. Calculando os demais valores esperados poderíamos formar a tabela dos valores esperados. Tabela 4.7.
Tabela 4.7 – Valores esperados na Tabela 4.6, caso as variáveis fossem independentes X
Y Masculino Feminino Total Física 84 (60%) 36 (60%) 120
Ciências Sociais 56 (40%) 24 (40%) 80 Total 140 60 200
Pode-se comparar as duas tabelas, isto é, os valores esperados com os observados, determinando-se os desvios existentes entre eles. Os resultados estão Tabela 4.8.
Tabela 4.8 – Desvios obtidos caso as variáveis fossem independentes
X Y
Masculino Feminino
Física 100 - 84 = 16 20 - 36 = -16 Ciências Sociais 40 - 56 = -16 40 – 24 = 16
Uma vez obtidos os desvios de cada célula da tabela, pode-se obter os desvios relativos de cada célula. Para isto eleva-se cada resultado ao quadrado (para eliminar os valores negativos) e divide-se o resultado pelo valor esperado, isto é:
(Oi – Ei)2 / Ei
Assim, para a célula Física e Masculino, vai-se obter:

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 29
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(-16)2 / 84 = 3,0476 e para a célula Física e Feminino obtém-se: (-16)2 / 36 = 7,1111.
Juntando os resultados de cada célula, tem-se uma medida do grau de afastamento, isto é, de dependência entre as duas variáveis. Esta medida é representada por χ2 e lida qui-quadrado. Para este exemplo, o valor desta medida seria:
χ2 = 3,0476 + 7,1111 + 4,5714 + 10,6667 = 25,3968. Quanto maior for este valor, maior será o grau de associação entre as duas variáveis. De um modo geral a expressão para avaliar o grau de dependência entre as duas variáveis é
dado por: χ2 = ∑(Oi – Ei)2 / Ei No entanto, julgar a associação pelo expressão acima não é muito fácil, porque não se tem um
padrão de comparação, para saber se este valor é alto ou não. Por isto, utiliza-se uma outra medida, devida a Karl Pearson, e denominada de Coeficiente de Contingência C, definida por:
Cn
=+
2
2χ
χ, onde n é o número de observações (tamanho da amostra).
Teoricamente este coeficiente é um número entre zero e um, sendo zero quando as variáveis forem independentes (não estiverem associadas). No entanto, mesmo quando existe uma associação perfeita entre as variáveis este coeficiente pode não ser igual a 1. Uma alteração possível é considerar o coeficiente:
C* = C/[(t – 1)/t]1/2, onde t é o valor mínimo entre o número de linhas e colunas da tabela. Para o exemplo acima o coeficiente de Pearson será:
Cn
=+
2
2χ
χ = 25 3968
25 3968 200,
, + = 0,3357 = 0,34.
C* = 0,4747 = 0,47.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 30
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
5. VARIÁVEIS BIDIMENSIONAIS QUANTITATIVAS
5.1. O DIAGRAMA DE DISPERSÃO Quando as variáveis envolvidas são do tipo quantitativo, pode-se usar o mesmo tipo de análise
apresentada para as variáveis nominais e ordinais. A distribuição conjunta pode ser apresentada em tabelas de dupla entrada e através das distribuições marginais pode-se verificar se as variáveis estão ou não relacionadas. Também em certos casos será necessário agrupar os dados em classes ou valores da mesma forma que foi feita no estudo de uma única variável. No entanto, além desta forma de análise é possível a utilização de outros métodos quando as variáveis envolvidas são quantitativas.
Um procedimento bastante útil para estabelecer a associação entre duas variáveis quantitativas é o diagrama de dispersão, que nada mais é do que a representação dos pares de valores num sistema de eixos cartesianos.
Exe mpl o Na Tabela 5.1 são apresentados os dados correspondentes ao número de anos de escola (X)
dos pais e o número de anos de escola (Y) dos filhos de uma amostra de 6 habitantes da capital.
Tabela 5.1 – Anos de escola do pai e anos de escola do filho
Pai (X) 12 10 6 16 8 9 12
Filho (Y) 12 8 6 11 10 8 11
Fazendo o diagrama de dispersão destes valores obtém-se o gráfico abaixo.
Figura 5.1 – Relacionamento entre os tempos de estudo de pai e filho
02468
101214
0 2 4 6 8 10 12 14 16 18x = anos de estudo do pai
y =
anos
de
estu
do d
o fil
ho
Observando o diagrama de dispersão é possível ver que os dados estão seguindo uma
dependência aparentemente linear com um relacionamento direto entre os anos de estudo do pai com o tempo de estudo do filho. Assim à medida que a variável X aumenta a variável Y também aumenta.
Exe mpl o Considere-se, agora, a Tabela 5.2 que retrata os valores da renda bruta mensal (em salários
mínimos) de 10 famílias da classe média e o percentual desta renda gasto com assistência médica.
D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 31
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Tabela 5.2 - Renda bruta mensal e % de gastos com saúde
X = Renda bruta (s.m.) 12 16 18 20 28 30 40 48 50 54
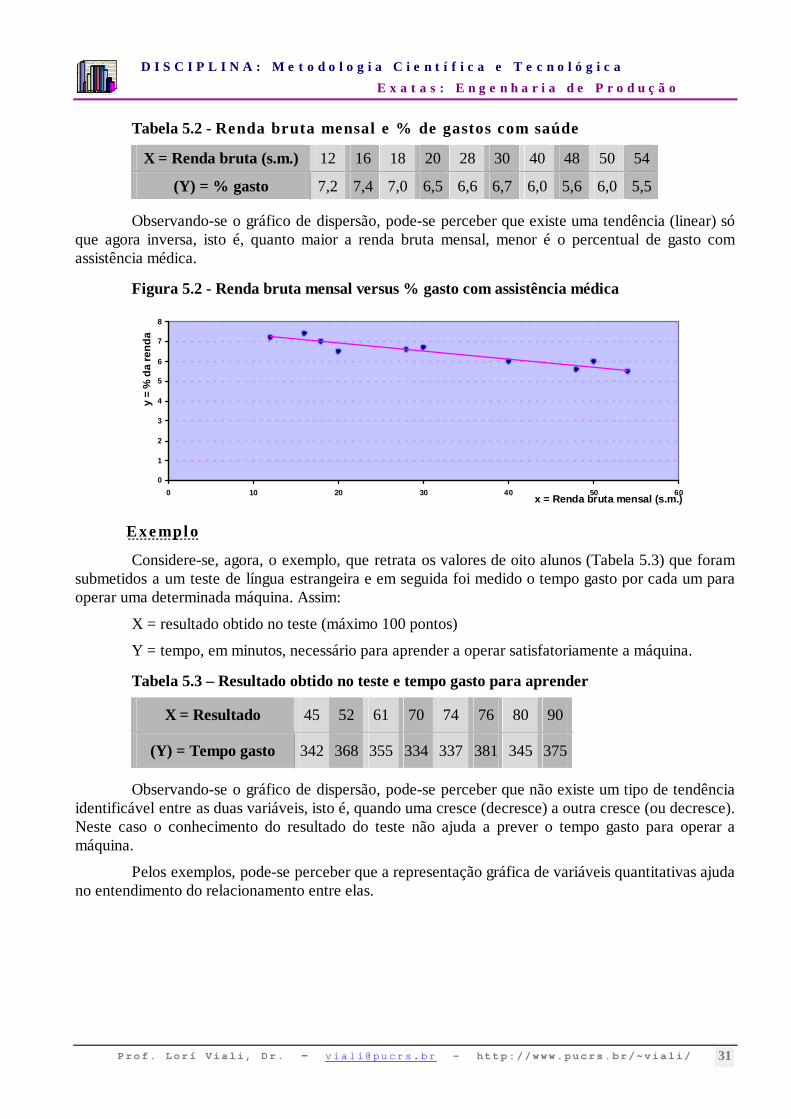
(Y) = % gasto 7,2 7,4 7,0 6,5 6,6 6,7 6,0 5,6 6,0 5,5
Observando-se o gráfico de dispersão, pode-se perceber que existe uma tendência (linear) só que agora inversa, isto é, quanto maior a renda bruta mensal, menor é o percentual de gasto com assistência médica.
Figura 5.2 - Renda bruta mensal versus % gasto com assistência médica
0
1
2
3
4
5
6
7
8
0 10 20 30 40 50 60x = Renda bruta mensal (s.m.)
y =
% d
a re
nda
Exe mpl o Considere-se, agora, o exemplo, que retrata os valores de oito alunos (Tabela 5.3) que foram
submetidos a um teste de língua estrangeira e em seguida foi medido o tempo gasto por cada um para operar uma determinada máquina. Assim:
X = resultado obtido no teste (máximo 100 pontos)
Y = tempo, em minutos, necessário para aprender a operar satisfatoriamente a máquina.
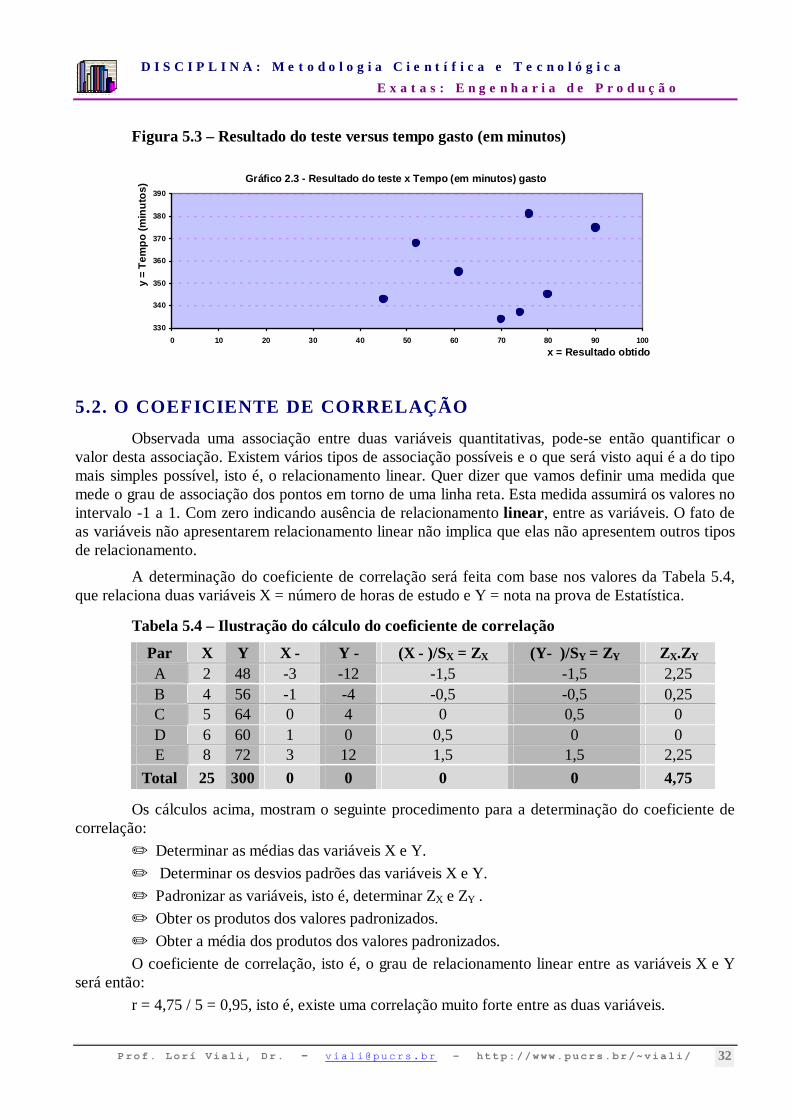
Tabela 5.3 – Resultado obtido no teste e tempo gasto para aprender
X = Resultado 45 52 61 70 74 76 80 90
(Y) = Tempo gasto 342 368 355 334 337 381 345 375
Observando-se o gráfico de dispersão, pode-se perceber que não existe um tipo de tendência identificável entre as duas variáveis, isto é, quando uma cresce (decresce) a outra cresce (ou decresce). Neste caso o conhecimento do resultado do teste não ajuda a prever o tempo gasto para operar a máquina.
Pelos exemplos, pode-se perceber que a representação gráfica de variáveis quantitativas ajuda no entendimento do relacionamento entre elas.
D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 32
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Figura 5.3 – Resultado do teste versus tempo gasto (em minutos)
Gráfico 2.3 - Resultado do teste x Tempo (em minutos) gasto
330
340
350
360
370
380
390
0 10 20 30 40 50 60 70 80 90 100x = Resultado obtido
y =
Tem
po (m
inut
os)
5.2. O COEFICIENTE DE CORRELAÇÃO Observada uma associação entre duas variáveis quantitativas, pode-se então quantificar o
valor desta associação. Existem vários tipos de associação possíveis e o que será visto aqui é a do tipo mais simples possível, isto é, o relacionamento linear. Quer dizer que vamos definir uma medida que mede o grau de associação dos pontos em torno de uma linha reta. Esta medida assumirá os valores no intervalo -1 a 1. Com zero indicando ausência de relacionamento linear, entre as variáveis. O fato de as variáveis não apresentarem relacionamento linear não implica que elas não apresentem outros tipos de relacionamento.
A determinação do coeficiente de correlação será feita com base nos valores da Tabela 5.4, que relaciona duas variáveis X = número de horas de estudo e Y = nota na prova de Estatística.
Tabela 5.4 – Ilustração do cálculo do coeficiente de correlação
Par X Y X - Y - (X - )/SX = ZX (Y- )/SY = ZY ZX.ZY A 2 48 -3 -12 -1,5 -1,5 2,25 B 4 56 -1 -4 -0,5 -0,5 0,25 C 5 64 0 4 0 0,5 0 D 6 60 1 0 0,5 0 0 E 8 72 3 12 1,5 1,5 2,25
Total 25 300 0 0 0 0 4,75
Os cálculos acima, mostram o seguinte procedimento para a determinação do coeficiente de correlação:
✏ Determinar as médias das variáveis X e Y. ✏ Determinar os desvios padrões das variáveis X e Y. ✏ Padronizar as variáveis, isto é, determinar ZX e ZY . ✏ Obter os produtos dos valores padronizados. ✏ Obter a média dos produtos dos valores padronizados. O coeficiente de correlação, isto é, o grau de relacionamento linear entre as variáveis X e Y
será então: r = 4,75 / 5 = 0,95, isto é, existe uma correlação muito forte entre as duas variáveis.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 33
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Definição Dados n pares de valores de duas variáveis X e Y, o coeficiente de correlação entre elas, será
anotado por r e calculado por:
rn
X XS
Y YSX Yi
n= −
−
∑
=
11
, ou seja, a média dos produtos dos valores padronizados (reduzidos)
das variáveis X e Y. Esta definição não é muito prática. Então na maioria das vezes é melhor utilizar a seguinte
expressão alternativa para o cálculo do coeficiente de correlação.
( )( )r
nX XS
Y YS
XY nXY
X n X Y n YX Yi
n= −
−
∑
−∑
−∑ −∑=
11 2 2 2 2
=
Exe mpl o Na Tabela 5.5 estão os dados referentes à percentagem da população economicamente ativa
empregada no setor primário e o respectivo índice de analfabetismo para algumas regiões metropolitanas brasileiras. Verificar se existe correlação entre as duas variáveis.
Tabela 5.5 – População economicamente ativa empregada no setor primário e índice de analfabetismo
Regiões metropolitanas
Setor Primário Índice de analfabetismo
São Paulo 2,0 17,5 Rio de Janeiro 2,5 18,5
Belém 2,9 19,5 Belo Horizonte 3,3 22,5
Salvador 4,1 26,5 Porto Alegre 4,3 16,6
Recife 7,0 36,6 Fortaleza 13,0 38,4
Fonte: Indicadores Sociais para Áreas Urbanas – IBGE – 1977
Os cálculos necessários para a determinação do coeficiente de correlação estão ilustrados na Tabela 5.6.
Tabela 5.6 - Cálculos para a determinação do coeficiente de correlação
Regiões Setor (X) Índice (Y) XY X2 Y2
A 2,0 17,5 B 2,5 18,5 C 2,9 19,5 D 3,3 22,5 E 4,1 26,5 F 4,3 16,6 G 7,0 36,6

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 34
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
H 13,0 38,4
( )( )r XY nXY
X n X Y n Y= −∑
−∑ −∑2 2 2 2 =
Uma das possíveis interpretações do coeficiente de correlação é:
-1,00 – correlação negativa perfeita.
-0,95 – correlação negativa forte.
-0,50 – correlação negativa moderada.
-0,10 – correlação negativa fraca.
0,00 – ausência de correlação.
0,10 – correlação positiva fraca.
0,50 – correlação positiva moderada. 0,95 – correlação positiva forte. 1,00 – correlação positiva perfeita.
Determinação do coeficiente de correlação Para a determinação do coeficiente de correlação de Pearson entre duas variáveis X e Y as
seguintes condições devem ser levadas em consideração:
� O coeficiente de correlação de Pearson mede somente o relacionamento linear entre as variáveis;
� As variáveis devem ser mensuradas, no mínimo, a nível intervalar, de forma que se possa trabalhar com escores;
� Os valores utilizados devem ter sidos retirados aleatoriamente de uma população, a menos que não se tenha interesse em testar a significância deste coeficiente.
� Se for necessário testar a significância do coeficiente de correlação é necessário que as variáveis X e Y tenham sido extraídas de populações com distribuição normal.
5.3. A REGRESSÃO A regressão e a correlação são duas técnicas estreitamente relacionadas. A análise de
correlação fornece um número que traduz o grau de relacionamento linear entre as duas variáveis, enquanto que a análise de regressão fornece uma equação (linear ou do primeiro grau) que descreve o relacionamento entre as duas variáveis. A equação pode ser usada para estimar ou predizer valores de uma das variáveis (variável explicada) conhecidos os valores da outra variável (variável explicativa)
Duas características da equação linear (parâmetros) precisam ser determinadas para que se possa conhecer qual é a equação que relaciona duas variáveis X e Y. Uma equação linear tem a forma:
Y = a + bX
onde b é o coeficiente angular (parâmetro de regressão) da reta e a é o coeficiente linear (parâmetro linear). O primeiro fornece a inclinação da reta em relação ao eixo dos X e o segundo informa o ponto em que a reta corta o eixo dos Y. O coeficiente angular (b) indica a variação da

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 35
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
variável Y por unidade de variação da variável X. Assim se o coeficiente angular de uma reta for 3, isto quer dizer que para unidade de variação de X, Y vai variar em 3 unidades.
A primeira providência a ser adotada antes de se tentar determinar uma equação de regressão é construir o diagrama de dispersão para verificar se os dados estão mais ou menos alinhados em torno de uma linha reta. Nem todo o relacionamento entre duas variáveis é do tipo linear. O relacionamento linear é apenas um dentre muitos outros possíveis.
5.3.1. DETERMINAÇÃO DA LINHA DE REGRES S ÃO
Vamos supor que foram coletados “n” de valores das variáveis X e Y e que o relacionamento entre as duas variáveis seja do tipo linear, isto é:
Y = a + bX + E, onde E = termo erro.
O método para obter a equação de regressão é denominado de método dos mínimos quadrados e consiste em encontrar uma linha que passe pelos pontos de forma que as distâncias verticais de cada ponto dado até a linha seja mínima. Suponhamos que a equação desta linha seja:
Yc = a + bX,
então a afirmação acima consiste em resolver a equação:
∑(Y - Yc)2 = mínimo,
onde Y é um valor observado de Y e Yc é um valor calculado de Y, através da linha dos mínimos quadrados. Os valores de a e b que satisfazem a equação acima são obtidos através das seguintes expressões:
( )b
X= n XY - X Y
n X2
∑∑∑
−∑ ∑2
e a bX= Y −
Exe mpl o Determine a equação que descreve a relação entre a freqüência de acidentes e o nível de
esforço preventivo educacional com base nos dados da Tabela 5.7.
Tabela 5.7 – Freqüência de acidentes e esforço educacional
Homens/Horas por mês com educação 2 5 4,5 8 9 1,5 3 6
Acidentes por milhão de homens/hora 7,0 6,4 5,2 4,0 3,1 8,0 6,5 4,4
A Tabela 5.8 resume os cálculos necessários para determinar a equação de regressão dos acidentes em função das horas gastas em educação.

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 36
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Tabela 5.8 – Cálculos para a determinação da equação de regressão
X Y XY X2 Y2
2 7,0 5 6,4
4,5 5,2 8 4,0 9 3,1
1,5 8,0 3 6,5 6 4,4
Determinada a equação de regressão pode-se determinar o erro padrão da regressão, que é o desvio padrão dos erros da regressão. O erro é a diferença entre o valor dado de Y e o valor calculado Yc, isto é, E = Y - Yc. Este valor informa o quanto os pontos dados estão alinhados. Quanto menor o valor do erro padrão mais próximo da linha de regressão estão os pontos dados.
Tabela 5.9 – Cálculos para a determinação do erro padrão da regressão
X Y Yc E = Y - Yc E2
2 7,0 5 6,4
4,5 5,2 8 4,0 9 3,1
1,5 8,0 3 6,5 6 4,4

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 37
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
6. EXERCÍCIOS 1. Identifique os tipos de escalas utilizadas para cada uma das seguintes características das unidades de observação, retiradas de uma tabela do Guia do Usuário do aplicativo Microsoft Excel: mês, tipo de produto, vendedor, região do país, unidades vendidas e total de vendas. 2. É possível encontrar a seguinte série de desvios tomados em relação a média aritmética: 4, -3, 2, -7 e
5? Justifique. 3. Dados dois grupos de pessoas, o grupo A com 10 elementos e o grupo B com 40 elementos. Se o
peso médio do grupo A for de 80 kg e o do grupo B for de 70 kg então é verdade que o peso médio dos dois grupos considerados em conjunto é de 75 kg? Justifique.
4. Um concurso realizado simultaneamente nos locais A, B e C, apresentou as médias: 70, 65 e 45, obtidos por 30, 40 e 30 candidatos, nessa ordem. Qual foi a média geral do concurso?
5. Para um dado concurso, 60% dos candidatos eram do sexo masculino e obtiveram uma média de 70 pontos em determinada prova. Sabendo-se que a média geral dos candidatos (independente de sexo) foi de 64 pontos, qual foi a média dos candidatos do sexo feminino?
6. Determinar a moda dos seguintes conjuntos: (6.1) 1, 6, 9, 3, 2, 7, 4 e 11 (6.2) 6, 5, 5, 7, 5, 6, 5, 6, 3, 4 e 5 (6.3) 8, 4, 4, 4, 4, 6, 9, 10, 10, 15, 10, 16 e 10 (6.4) 23, 28, 35, 17, 28, 35, 18, 18, 17, 18, 18, 18, 28, 28 e 18
7. Determinar a mediana dos seguintes conjuntos: (7.1) 9 14 2 8 7 14 3 21 1 (7.2) 0,02 0,25 0,47 0,01 -0,30 -0.5 (7.3) 1/2 3/4 4/7 5/4 -2/3 -4/5 -1/5 3/8
8. Para os conjuntos abaixo, determinar com aproximação centesimal, as seguintes medidas: (a) A amplitude (b) O desvio médio (c) A variância (d) O desvio padrão (e) O coeficiente de
variação. (8.1) 0,04 0,18 0,45 1,29 2.35 (8.2) -7/4 -1/3 3/5 7/20 1 4/3
9. Dados os seguintes conjuntos de valores: (a) 1 3 7 9 10 (b) 20 60 140 180 200 (c) 10 50 130 170 190. Calculando a média e o desvio padrão do conjunto em (a), determinar, através das propriedades, a média e o desvio padrão dos conjuntos em (b) e (c).
10. Quarenta alunos da PUC foram questionados quanto ao número de livros lidos no ano anterior. Foram registrados os seguintes valores:
4 2 1 0 3 1 2 0 2 1 0 2 1 1 0 4 3 2 3 5 8 0 1 6 5 3 2 1 6 4 3 4 3 2 1 0 2 1 0 3
(10.1) Organize os dados em uma tabela adequada. (10.2) Qual o percentual de alunos que leram menos do que 3 livros. (10.3) Qual o percentual de alunos que leram 4 ou mais livros.
D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 38
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(10.4) Classifique a variável e o tipo de distribuição utilizada.
11. O conjunto de dados abaixo representa uma amostra de 40 elementos: 3,67 1,82 3,73 4,10 4,30 1,28 8,14 2,43 4,17 2,88 5,36 3,96 6,54 5,84 7,35 3,63 2,93 2,82 8,45 4,15 5,28 5,41 7,77 4,65 1,88 2,12 4,26 2,78 5,54 6,00 0,90 5,09 4,07 8,67 0,90 6,67 8,96 4,00 2,00 2,01
(11.1) Agrupe os dados em uma distribuição de freqüências, considerando o limite inferior igual a zero, o superior igual a 10 e utilizando cinco classes de mesma amplitude.
(11.2) Construa um histograma de freqüências relativas. (11.3) Una os pontos médios de cada retângulo, obtendo o polígono de freqüências relativas e classifique o conjunto quanto à assimetria.
12. A tabela registra simultaneamente 200 aluguéis de imóveis urbanos e 100 de imóveis rurais. (12.1) Calcule e interprete fr2 para cada caso. (12.2) Calcule e interprete F3 para cada caso. (12.3) Calcule e interprete Fr4 - Fr2 para cada caso.
13. O histograma abaixo representa os salários, em unidades monetárias (u.m.) dos 100 empregados de uma empresa: (13.1) Que percentual de empregados recebem 8
u.m. ou mais? (13.2) Quantos empregados recebem de 4 a 16 u.m.? (13.3) Quantos empregados recebem menos que 4 u.m. ou mais que 12 u.m.?
00,010,020,030,040,050,060,070,080,09
0 |-- 4 4 |-- 8 8 |-- 12 12 |--16 16 |--20
fri/hi
14. Um livro com 50 páginas apresentou um número de erros de impressão por página conforme tabela:
(14.1) Qual o número médio de erros por página? (14.2) Qual o número mediano de erros por página? (14.3) Qual o número modal de erros por página? (14.4) Qual o desvio padrão do número de erros por página?
Aluguéis Zona Urbana Zona Rural 1 |----- 3 10 30 3 |----- 5 40 50 5 |----- 7 80 15 7 |----- 9 50 05 9 |----- 11 20 00
∑∑∑∑ 200 100
Erros Número de páginas 0 25 1 20 2 3 3 1 4 1
Total 50

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 39
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
15. Durante certo período de tempo o rendimento de 10 ações foram os que a tabela registra. (15.1) Calcule o rendimento médio. (15.2) Calcule o rendimento mediano. (15.3) Calcule o rendimento modal. (15.4) Calcule o desvio padrão do rendimento. (15.5) Calcule o coeficiente de variação do rendimento.
16. Uma região metropolitana tem 50 quarteirões com os seguintes números de casas por quarteirão: 2 2 3 10 13 14 15 15 16 16 18 18 20 21 22 22 23 23 25 25 26 27 29 29 30 32 36 42 44 45 45 46 48 52 58 59 61 61 61 65 66 66 68 75 78 80 89 90 92 97
(16.1) Construa, com os dados, uma distribuição de freqüências por intervalos fazendo com que as classes tenham amplitudes igual a 14.
(16.2) Calcule o número médio de casas por quarteirão. (16.3) Determine o número mediano de casas por quarteirão. (16.4) Calcule a variância do número de casas por quarteirão. (16.5) Calcule, pêlos dois processos, o número modal de casas por quarteirão.
17. De um levantamento feito entre 100 famílias resultou a tabela ao lado. Determine: (17.1) O número médio de filhos. (17.2) O número mediano de filhos. (17.3) O número modal de filhos. (17.4) O desvio padrão do número de filhos.
18. As informações abaixo dizem respeito a distribuição de três variáveis. Indique, justificando, qual delas tem média mais representativa. Distribuição A Distribuição B Distribuição C n = 200 n = 50 x = 8 ∑fx = 5000 ∑fx = 500 ∑fx = 3200 ∑fx2 = 130000 ∑fx2 = 5450 ∑fx2 = 32000
19. Identifique, justificando, qual a variável mais homogênea. Distribuição A Distribuição B n = 100 x = 50 ∑fx = 5000 ∑fx = 10000 ∑fx2 = 256400 ∑f(x - x )2 = 7200
20. Uma variável x tem média igual a 10 e variância igual a 16. Calcule a média e a variância da variável dada por y = (3x + 5) / 2
Ação Taxa (%) 1 2,59 2 2,64 3 2,60 4 2,62 5 2,57 6 2,55 7 2,61 8 2,50 9 2,63 10 2,64
Número de filhos Número de famílias 0 18 1 23 2 28 3 21 4 7 5 3
Total 100

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 40
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
21. Uma variável x tem média igual a 5 e desvio padrão igual a 3. Calcule o coeficiente de variação da variável y = 4x + 4
22. Uma variável x tem média igual a 6 e coeficiente de variação igual a 0,50. Calcule o coeficiente de variação da variável y = (5x - 2) / 2
23. Os operários de um setor industrial têm, em uma época 1, um salário médio de 5 salários mínimos (sm) e desvio padrão de 2 sm. Um acordo coletivo prevê, para uma época 2, um aumento linear de 60%, mais uma parte fixa correspondente a 70% de um salário mínimo. Calcule a média e o desvio padrão dos salários na época 2.
24. Uma variável x assume valores no intervalo [10; 30]. (23.1) Sabendo que x tem uma distribuição assimétrica positiva você diria que a média de x é: 20, menor que 20 ou maior que 20. Justifique. (23.2) E se x tiver uma distribuição simétrica?
25. O que se pode dizer se fosse dada a informação de que o salário mediano de um conjunto de profissionais é de 6 sm?
26. Um a comunidade A tem 100 motoristas profissionais cujo salário médio é de 5 sm. A comunidade B, com 300 desses profissionais, remunera-os com uma média de 4 sm. (25.1) É correto afirmar que A remunera melhor seus motoristas profissionais que B? (25.2) Diante das informações disponíveis há garantia que os 100 salários individuais de A são maiores que os 300 de B? Por que?
27. Abaixo você encontra duas distribuições que refletem os comportamentos de x e y (tamanhos de famílias) em duas comunidades, sendo que uma de base cultural alemã e outra italiana. Utilize tais informações para uma análise que indique qual das duas comunidades tem famílias maiores.
X f Y f 2 25 3 48 3 30 4 51 4 48 5 48 5 111 6 41 6 98 7 32 7 88 8 14 9 6
28. O departamento de pessoal de um certa firma fez um levantamento dos salários dos 120 funcionários do setor administrativo, obtendo os resultados da tabela: (28.1) Determine o salário médio dos funcionários (28.2) Determinar a variância e o desvio padrão dos salários. (28.3) Determinar o salário mediano. (28.4) Determinar o salário modal pêlos critérios de King e Czuber. (28.5) Se for dado um aumento de 20% para todos os funcionários, qual será o novo salário médio e o novo desvio padrão dos salários? (28.6) Se for dado um abono de 0,5 s.m. a todos os funcionários como fica a média e o desvio padrão dos salários?
29. O que acontece com a média e o desvio padrão de um conjunto de dados quando:
(29.1) Cada valor é multiplicado por 2.
Faixa salarial (s.m.) % de funcionários 1 |---- 3 0,25 3 |---- 5 0,40 5 |---- 7 0,20 7 |--- 10 0,15 Total 1,00

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 41
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(29.2) Soma-se o valor 10 a cada valor. (29.3) Subtrai-se a média de cada valor. (29.4) De cada valor subtrai-se a média e em seguida divide-se pelo desvio padrão
30. A média aritmética entre dois valores é igual a 5 e a média geométrica igual a 4. Qual a média harmônica entre estes dois valores?
31. De um estudo numa determinada comunidade foram extraídas as seguintes informações: ✏ A proporção de pessoas solteiras é 0,4. ✏ A proporção de pessoas que recebem até 10 salários mínimos é 0,2. ✏ A proporção de pessoas que recebem até 20 salários mínimos é 0,7. ✏ A proporção de pessoas casadas entre os que recebem mais de 20 salários mínimos é 0,3. ✏ A proporção de pessoas que recebem até 10 salários mínimos entre os solteiros é de 0,3.
(31.1) Construa a distribuição conjunta das variáveis "estado civil" e "faixa salarial" e as respectivas distribuições marginais. (31.2) Você diria que existe relação, entre as duas variáveis?
32. Uma amostra de 200 habitantes de uma cidade foi escolhida ao acaso para analisar a atitude frente a um certo projeto do governo. O resultado está apresentado na tabela abaixo:
Local de residência
Opinião Urbano Suburbano Rural Total A favor 30 35 35 100 Contra 60 25 15 100 Total 90 60 50 200
(32.1) Calcule as proporções em relação ao total das colunas. (32.2) Você diria que a opinião independe do local de residência? (32.3) Encontre uma medida de dependência entre as variações.
33. A tabela, abaixo, mostra os resultados de um questionário para saber se adultos moradores nas proximidades de centros esportivos construídos pela prefeitura participam ou não das atividades programadas. Baseado nos resultados seria possível dizer que a participação depende da cidade sendo considerada?
Cidade Participa Porto Alegre Caxias do Sul Pelotas
Sim 150 75 115 Não 250 225 235
34. Uma pesquisa para verificar a tendência dos alunos a prosseguir os estudos, segundo sua classe social, mostrou os seguintes resultados:

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 42
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
Classe social Pretende continuar Alta Média Baixa
Sim 200 220 380 Não 200 280 720
(34.1) Você diria que a distribuição das respostas afirmativas é igual a de respostas negativas? (34.2) Existe dependência entre os dois fatores? Dê uma medida que quantifique esta
dependência. (34.3) Se dos 400 alunos da classe alta 160 escolhessem continuar e 240 não, você mudaria sua conclusão? Justifique.
35. Uma amostra de oito casais foi colhida em um determinado bairro e seus salários anuais (em milhares de reais) estão na tabela abaixo.
Casal 1 2 3 4 5 6 7 8 Salário Homem (X) 10 13 15 17 20 22 24 25 Mulher (Y) 9 10 13 13 15 16 19 20
(35.1) Encontre o salário anual médio dos homens e o desvio padrão do salário anual dos homens. (35.2) Encontre o salário anual médio das mulheres e o desvio padrão do salário anual das
mulheres. (35.3) Construa o diagrama de dispersão. (35.4) Encontre a correlação entre o salário anual dos homens e das mulheres. (35.5) Qual o salário médio familiar? E o desvio padrão? Qual a relação entre os desvios
individuais? (35.6) Se o homem é descontado em 8% e a mulher em 6%, qual o salário líquido anual médio
familiar? E a variância?
36. Com relação aos valores da tabela em 35 determine: (36.1) A equação de regressão do salário das mulheres em função dos salários dos homens (36.2) Faça uma previsão de quanto ganharia uma mulher cujo homem está ganhando 22000
anuais. (36.3) Determine o erro padrão da regressão.
37. Com relação aos valores do apêndice: (37.1) Construa uma tabela de dupla entrada do estado civil em relação ao número de filhos. (37.2) Determine qual o percentual de pais que são casados e possuem 3 filhos. (37.3) Determine o percentual de pais solteiros. (37.4) Dentre os casados qual o percentual dos que não possuem filhos. (37.5) Determine o percentual de pais com 2 ou mais filhos.
38. Com relação aos valores do apêndice, construa uma tabela de dupla entrada do estado civil em relação à educação e verifique se as variáveis são dependentes e quantifique esta dependência.
D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 43
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
7. RESPOSTAS DOS EXERCÍCIOS (01) Mês (Qualitativa ordinal) ; Tipo de produto (Qualitativa nominal); Vendedor (Qualitativa nominal); Região do país (Qualitativa ordinal); Unidades vendidas (Quantitativa discreta); Total de vendas (Quantitativa contínua). (02) Não, pois a soma dos desvios é diferente de zero. (03) Não, pois o cálculo deve ser realizado através da média ponderada e não da média aritmética simples. (04) 60,50 (05) 55 (06) (6.1) Amodal (6.2) 5 (6.3) 4 e 10 (6.4) 18 (07) (7.1) 8 (7.2) 0,02 (7.3) 7/16 (08) (8.1) (a) 2,31 (b) 0,77 (c) 0,74 (d) 0,86 (e) 99,90%
(8.2) (a) 37/12 = 3,08 (b) 149/180 = 0,83 (c) 1,03 (d) 1,02 (e) 508,01% (09) Observe que o conjunto em (b) é igual ao conjunto em (a) multiplicado por 20 e o conjunto em (c) é igual ao conjunto em (a) multiplicado por 20 e subtraído de 10 unidades.
(10) (10.1) Número de livros Número de alunos (10.2) 24/40 = 60% 0 7 1 9 (10.3) 9/40 = 22,5% 2 8 3 7 (10.4) Distribuição por ponto ou valores 4 4 5 2 6 2 8 1 Total 40
(11.3) Assimétrica positiva
0 ,0 0 0 00 ,0 3 0 00 ,0 6 0 00 ,0 9 0 00 ,12 0 00 ,150 00 ,18 0 00 ,2 10 0
- 1 1 3 5 7 9 11
(11) (11.1) Variável Freqüências (11.2) 0 |----- 2 5 2 |----- 4 12 4 |----- 6 14 6 |----- 8 5 8 |----- 10 4 ∑∑∑∑ 40
0,00000,03000,06000,09000,12000,15000,18000,2100
0 |--- 2 2 |--- 4 4 |--- 6 6 |--- 8 8 |--- 10
fr / h

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 44
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(12) (12.1) Zona urbana: fr2 = 0,20 ⇒ 20% dos aluguéis observados estão entre 3 e 5. Zona rural: fr2 = 0,50 ⇒ 50% dos aluguéis investigados ente entre 3 e 5.
(12.2) Zona urbana: F3 = 130 ⇒ 130 aluguéis investigados são menores do que 7. Zona rural: F3 = 95 ⇒ 95 aluguéis investigados são menores do que 7.
(12.3) Zona urbana: Fr4 - Fr2 = 0,90 - 0,25 = 0,65 = 65% dos aluguéis estão entre 5 e 9. Zona rural: Fr4 - Fr2 = 1,00 - 0,80 = 0,20 = 20% dos aluguéis estão entre 5 e 9.
(13) (13.1) 64% (13.2) 76 (13.3) 56 (14) (14.1) 0,66 erros (14.2) 0,50 erros (14.3) Zero erros (14.4) 0,84 erros (15) (15.1) 2,60% (15.2) 2.60% (15.3) 2,64% (15.4) 0,04% (15.5) 1,63%
(16) (16.1) Número de casas por quarteirão Número de quarteirões 02 |----- 16 8 16 |----- 30 16 30 |----- 44 4 44 |----- 58 6 58 |----- 72 9 72 |----- 86 3 86 |----- 100 4 ∑∑∑∑ 50
(16.2) 41,76 casas (16.3) 33,50 casas (16.4) 686,86 casas (16.5) 20,67 e 21,60 casas (17) (17.1) 1,85 filhos (17.2) 2 filhos (17.3) 2 filhos (17.4) 1,30 filhos (18) É a variável A cujo coeficiente de variação é 0,20, o menor dentre as 3. (19) É a variável B cujo coeficiente de variação é 0,12, o menor dentre as 2. (20) x = 17,50 s2 = 36 (21) g = 50% (22) g = 0,5357 = 53,57%
(23) x = 8,70 sm s = 3,20 sm (24) (24.1) Deve ser maior que 20. (24.2) Seria 20, pois 20 é o centro da distribuição. (25) Que 50% dos profissionais recebem até 6 sm. (26) (26.1) Sim, em média. (26.2) Não. (27) A comparação pretendida deve ser feita pelas médias. As famílias de base cultural alemã tem, em
média, 5,23 membros, enquanto que as de base italiana tem 5,10. Então as de base alemã tem o hábito de ter famílias maiores.
(28) (28.1) 4,58 sm (28.2) 4,51 e 2,12 sm (28.3) 4,25 sm (28.4) 3,89 sm e 3,86 sm (28.5) 5,49 e 2,55 sm (28.6) 5,08 e 2,12 sm
(29) (29.1) A média e o desvio padrão ficam multiplicados por 2. (29.2) A média fica somada de 10 e o desvio padrão não se altera. (29.3) A média fica igual a zero e o desvio padrão não se altera. (29.4) A média fica igual a zero e o desvio padrão fica igual a um.
(30) 3,2

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 45
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(31.1) Renda Estado Civil Até 10 Até 20 Mais de 20 TOTAL Casado 0,14 0,37 0,09 0,60 Solteiro 0,06 0,13 0,21 0,40 TOTAL 0,20 0,50 0,30 1,00
(31.2) Sim, pois os casados representam mais do que o dobre dos que ganham até 20 salários, mas menos do que a metade dos que ganham mais do que 20 salários.
(32.1) Local de residência
Opinião Urbano Suburbano Rural Total A favor 33,33 58,33 70,00 50 Contra 66,67 41,67 30,00 50 Total 100,00 100,00 100,00 100
(32.2) Não, pois os que moram na zona urbana tendem a ser mais contra (67% contra 33%) enquanto que o morador da zona rural acontece o contrário a maioria é a favor (70% contra 30%).
(32.3) C = 0,22 e C* = 0,31
33. Depende, pois Caxias é a cidade com menor participação (25%), enquanto que Porto Alegre é a cidade com maior participação (37,50%)
34. (34.1) Não, as afirmativas totalizam 40% enquanto que as negativas 60%.
(34.2) C = 0,13 e C* = 0,18 (Existe uma pequena dependência entre as duas variáveis) (34.3) Neste caso C = 0,08 e C* = 0,12 (Ainda existe uma leve dependência)
35. (35.1) R$18,25 e R$5,04
(35.2) R$14,38 e R$3,67 (35.3)
0
5
10
15
20
25
0 5 10 15 20 25 30
(35.4) r = 0,9803 (35.5) R$18,250 + R$14,385 = R$ 32,62 Desvio = 8,67 (35.6) Média = R$30,30 Variância = 64,85
36. (36.1) x7,035,1Y +=

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 46
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
(36.2) R$17052 (36.3) R$ 0,84
37. Utilizar tabela dinâmica (Excel)
38. Utilizar tabela dinâmica (Excel)

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 47
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
8. APÊNDICE Tabela 3.1 - Informações sobre o estado civil, grau de instrução, número de filhos, renda, idade e procedência de uma amostra de 40 pais dos alunos do Educandário dona Virgulina Travessão.
Número Estado Civil Educação Filhos Renda Idade Procedência 01 Casado Primeiro 4 4,00 40 Interior 02 Casado Primeiro 3 5,55 29 Capital 03 Solteiro Segundo 1 6,60 25 Capital 04 Viúvo Primeiro 3 3,75 58 Outro 05 Desquitado Segundo 2 2,90 36 Outro 06 Divorciado Superior 1 8,85 37 Interior 07 Casado Primeiro 3 2,25 34 Interior 08 Casado Primeiro 2 3,20 39 Capital 09 Casado Segundo 2 7,20 28 Capital 10 Casado Superior 1 6,60 27 Capital 11 Casado Superior 3 8,78 49 Outro 12 Casado Primeiro 5 6,15 68 Interior 13 Desquitado Segundo 6 6,00 58 Interior 14 Desquitado Superior 2 9,10 47 Capital 15 Casado Primeiro 1 8,60 32 Capital 16 Casado Primeiro 2 3,45 36 Interior 17 Solteiro Superior 2 4,88 41 Capital 18 Casado Superior 6 5,45 46 Interior 19 Casado Superior 3 4,30 37 Outro 20 Casado Superior 3 6,00 49 Interior 21 Divorciado Superior 2 5,00 31 Capital 22 Outro Primeiro 4 3,65 44 Interior 23 Casado Segundo 1 3,68 43 Capital 24 Casado Superior 3 7,60 35 Capital 25 Divorciado Primeiro 3 3,30 29 Interior 26 Outro Segundo 1 2,50 29 Outro 27 Outro Segundo 2 3,58 24 Interior 28 Casado Primeiro 3 1,90 30 Interior 29 Casado Segundo 3 6,78 58 Capital 30 Casado Segundo 5 5,80 51 Interior 31 Casado Superior 2 9,50 53 Capital 32 Casado Primeiro 3 5,40 45 Interior 33 Casado Primeiro 3 9,93 38 Interior 34 Solteiro Segundo 2 8,80 28 Capital 35 Outro Segundo 1 4,45 25 Outro 36 Divorciado Primeiro 1 4,68 44 Interior 37 Desquitado Segundo 2 3,56 33 Interior 38 Casado Primeiro 3 4,87 29 Interior 39 Casado Primeiro 2 2,44 44 Capital 40 Casado Primeiro 3 3,25 38 Outro
Fonte: Dados hipotéticos

D I S C I P L I N A : M e t o d o l o g i a C i e n t í f i c a e T e c n o l ó g i c a
E x a t a s : E n g e n h a r i a d e P r o d u ç ã o
Prof. Lorí Viali, Dr. −−−− [email protected] - http://www.pucrs.br/~viali/ 48
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10
9. REFERÊNCIAS [BUS86] BUSSAB, Wilton O, MORETTIN, Pedro A. Estatística Básica. 3° ed. São Paulo: Atual,
1986. [HOF80] HOFFMAN, Rodolfo. Estatística para Economistas. São Paulo: Pioneira, 1980. [NET74] NETO, Pedro Luiz de Oliveira Costa. Estatística. São Paulo: Edgard Blücher, 1977. [MAS90] MASON, Robert D., DOUGLAS, Lind A. Statistical Techniques in Business And
Economics. Boston (MA): IRWIN, 1990. [STE81] STEVENSON, William J. Estatística Aplicada à Administração. São Paulo: Harbra, 1981. [WON85] WONNACOTT, Ronald J., WONNACOTT, Thomas. Fundamentos de Estatística. Rio de
Janeiro: Livros Técnicos e Científicos, 1985.





























