Embed Size (px)
Citation preview

Distribuicao Skew Normal:
Aproximacoes, Generalizacoes e Aplicacoes
Murilo Coutinho Silva
Orientador: Pushpa Narayan Rathie
Resumo
Esse trabalho trata sobre distribuicoes assimetricas advindas da distribuicao Nor-mal, alem de formas gerais para qualquer distribuicao. Utilizando-se de formulas deassimetrizacao como a de Azzalini (1986) e a de Fernandez e Steel (1998) compomosdistribuicoes assimetricas para a Normal. Esse trabalho propoe tambem generalizacoespara as formulas de assimetrizacao.
Alem disso, nesse artigo utilizaremos uma aproximacao da distribuicao Normal,proposta em ”On a new Invertible Generalized Logistic Distribution Approximation toNormal Distribution”de Pushpa N. Rathie e Prabhata K. Swamee para aproximar adistribuicao Skew-Normal em expressoes bem definidas.
1 Introducao
Nesta secao definimos algumas formulas que serao importante para o desenvolvimento destetrabalho e para uma melhor compreensao do leitor do que esta por vir.
1.1 Distribuicao de Rathie-Swamee
Queremos propor uma aproximacao inversıvel para a Skew-Normal. Para isso utilizaremosa seguinte funcao densidade de probabilidade e sua distribuicao acumulada:
f(z) =[a+ b(1 + p)|z|p]exp[−z(a+ b|z|p)]
{exp[−z(a+ b|z|p)] + 1}2(1.1)
F (z) = {exp[−z(a+ b|z|p)] + 1}−1 (1.2)
onde z ∈ ℜ, a, b, p > 0.
Essa distribuicao foi estudada em ”On a new Invertible Generalized Logistic DistributionApproximation to Normal Distribution”de Pushpa N. Rathie e Prabhata K. Swamee.
1

Para os valores a=1.59413, b=0.07443 e p=1.939 essa distribuicao aproxima muitobem a distribuicao Normal, com um erro maximo de 4.10−4 em z=0 para a funcao dedensidade e 7.757 10−5 em z=±2.81 para a funcao de distribuicao, aproximadamente.
1.2 Geracao de Distribuicoes Assimetricas
1.2.1 Formula de Azzalini
Podemos encontrar varias distribuicoes assimetricas pela seguinte formula:
h(x) = 2.g(x).G(w(x)) (1.3)
onde h(x) e a funcao densidade de probabilidades assimetrica, g(x) e uma funcao de densi-dade simetrica em torno da origem, G(x) e uma funcao de distribuicao acumulada de umaoutra funcao de densidade simetrica em torno da origem qualquer, e w(x) e uma funcaoımpar qualquer.
1.2.2 Skew Normal
Para a distribuicao Normal, podemos formar a distribuicao Skew-Normal (Sn(z)), comw(z) = c.z, c ∈ ℜ e z ∈ ℜ :
Sn(z) = 2.ϕ(z).Φ(c.z) (1.4)
onde ϕ(z) e a funcao de densidade e probabilidade da distribuicao Normal padrao e Φ(z)sua funcao de distribuicao acumulada.
Generalizando com um parametro de posicao µ ∈ ℜ e um parametro de escala σ > 0temos:
Sn(z) =2
σ.ϕ
(z − µ
σ
).Φ
(c.z − µ
σ
)(1.5)
Analogamente a Eq.(1.4), que e a Skew-Normal formada pela distribuicao N(0, 1), a Eq.(1.5)e a Skew-Normal formada pela distribuicao N(µ, σ2).
A distribuicao Skew-Normal foi primeiramente dada por O’Hagan e Leonard (1976), mas foiAzzalini (1985, 1986) que descobriu suas propriedades e demonstrou uma serie de resultadosimportantes.
Para a Eq.(1.5) temos media, variancia, assimetria e curtose dadas respectivamente por:
E[z] = µ+ σ√
2/πρ (1.6)
V ar[z] = σ2(1− 2ρ2/π) (1.7)
γ1 =4− π
2
(√
2/πρ)3
(1− 2ρ2/π)3/2(1.8)
γ2 = 2(π − 3)(√
2/πρ)4
(1− 2ρ2/π)2(1.9)
2

Onde ρ = c√1+c2
Propriedades:
Seja Z uma variavel aleatoria com distribuicao Normal Padrao. Para c ∈ ℜ, sendo v =c/√1 + c2 e Xc ∼ SN(c). Assuma tambem que W e Y sao distribuicoes Normais padrao
independentes. Entao seguem as seguintes propriedades:
(i) SN(0)=N(0,1)
(ii) X2c ∼ χ2
1
(iii) −Xc ∼ SN(−c)
(iv) A funcao geratriz de momentos de Xc e Mc(t) = 2exp[t2/2]Φ(vt)
(v) SN(c) e a distribuicao condicional de W dado que Y < cW .
(vi) Xc → |Z| quando c → ∞ e Xc → −|Z| quando c → −∞ (convergencia em distribuicao).
(vii) Se Z1 = min{Y,W} e Z2 = max{Y,W} entao Z1 ∼ SN(−1) e Z2 ∼ SN(1).
A distribuicao Skew Normal tras problemas ja que nao conseguimos fazer o calculo explıcitode Φ(c.z), e com isso tambem nao conseguimos uma formula explıcita para a distribuicaoSkew-Normal.
Posteriormente utilizaremos as funcoes dadas nas Eq.(1.1) e Eq.(1.2) para propor aprox-imacoes para a Skew-Normal.
1.2.3 Fernandez and Steel
No trabalho de Fernandez and Steel de 1998 foi apresentada a seguinte formula geradora dedistribuicoes assimetricas, utilizando-se de fatores inversos:
h(x) =2
α+ 1/αf(xαsinal[x]) (1.10)
onde α ∈ (0,∞). Generalizaremos esta distribuicao nesse trabalho e desenvolveremos muitaspropriedades.
1.3 Funcao H
A funcao H [ver Mathai e Saxena (1978)] e definida por:
3

Hm,np,q
[z
∣∣∣∣ (a1, A1), . . . , (an, An), (an+1, An+1), . . . , (ap, Ap)(b1, B1), . . . , (bm, Bm), (bm+1, Bm+1), . . . , (bq, Bq)
](1.11)
=1
2πi
∫L
∏mj=1 Γ(bj +Bjs)
∏nj=1 Γ(1− aj −Ajs)∏q
j=m+1 Γ(1− bj −Bjs)∏p
j=n+1 Γ(aj +Ajs)z−sds
onde
(1) i =√−1,
(2) z(= 0) e uma variavel complexa,
(3) zs = exp (s (ln |z|+ i arg z)),
(4) O produto vazio e interpretado como unidade,
(5) m, n, p e q sao inteiros nao negativos satisfazendo 0 ≤ n ≤ p, 0 ≤ m ≤ q (ambos n em sao nao negativos),
(6) Aj (j = 1, . . . , p) e Bj (j = 1, . . . , q) sao quantidade positivas,
(7) aj (j = 1, . . . , p) e bj (j = 1, . . . , q) sao numeros complexos dos quais, nenhum dospolos, Γ(bj + Bjs) (j = 1, . . . ,m) coincidem com os polos de Γ(1 − aj − Ajs) (j =1, . . . , n) i.e. Ak(bh + ν) = Bh(ak − λ − 1) para ν, λ = 0, 1, . . ., h = 1, . . . ,m,k = 1, . . . , n,
(8) O contorno L vai de −i∞ ate +i∞ de modo que os polos de Γ(bj+Bjs) (j = 1, . . . ,m)ficam a esquerda de L e os polos de Γ(1− aj − Ajs) (j = 1, . . . , n) ficam a direita deL.
Em Braaksma (1964), p 278, foi mostrado que a funcao H faz sentido e define umafuncao analıtica de z nos dois seguintes casos:
(i) δ > 0, z = 0 onde
δ =
q∑j=1
Bj −p∑
j=1
Aj
(ii) δ = 0, e 0 < |z| < D−1 onde
δ =
p∏j=1
AAj
j /
q∏j=1
BBj
j
Os valores da funcao H nao depende da escolha do contorno L.
Quando os polos dem∏j=1
Γ(bj −Bjs) sao simples,
4

Hm,np,q (z) =
m∑h=1
∞∑v=0
m∏j =1h
Γ
(bj −Bj
bh + v
Bh
)q∏
j=m+1
Γ
(1− bj +Bj
bh + v
Bh
) ×
n∏j=1
Γ
(1− aj +Aj
bh + v
Bh
)p∏
j=n+1
Γ
(aj −Aj
bh + v
Bh
) (−1)vz(bh+v)/Bh
v!Bh(1.12)
para z = 0 se δ > 0 e para 0 < |z| < D−1 se δ = 0
Quando os polosn∏
j=1
Γ(1− aj +Ajs) sao simples,
Hm,np,q (z) =
m∑h=1
∞∑v=0
m∏j =1h
Γ
(1− aj −Aj
1− ah + v
Ah
)q∏
j=m+1
Γ
(aj +Aj
1− ah + v
Ah
) ×
n∏j=1
Γ
(bj +Bj
1− ah + v
Ah
)p∏
j=n+1
Γ
(1− bj −Bj
1− ah + v
Ah
) (−1)vz(1−ah+v)/Ah
v!Ah(1.13)
para z = 0 se δ < 0 e para |z| > D−1 se δ = 0.As funcao H e aplicada nesse artigo na construcao dos momentos e na inversao da dis-
tribuicao.
2 Aproximacao da Distribuicao Skew Normal
O leitor ja deve ter notado que a formula da distribuicao Skew Normal dada pela Eq.(1.4)contem em sua composicao a funcao de distribuicao acumulada de Normal que infelizmentee definida por uma integral ou por funcoes especiais.
Tal formulacao e prejudicial em termos computacionais e praticos pois temos que calcularnumericamente esta integral.
Propomos uma solucao para este problema utilizando uma aproximacao quase perfeitada distribuicao Skew Normal tendo em mao a distribuicao dada pelas formulas (1.1) e (1.2).
5

2.1 Aplicando a formula de Rathie Swamee na formula de Azzalini
Para aproximarmos a Skew-Normal fazemos g(x)=f(z)(Eq.(1.1)) , e G(x)=F(z)(Eq.(1.2)),na Eq.(1.3) obtendo assim:
h(z) = 2.f(z).F (c.z) =2.[a+ b(1 + p)|z|p].exp[−z(a+ b|z|p)]
{exp[−z(a+ b|z|p)] + 1}2.{exp[−cz(a+ b|cz|p)] + 1}(2.1)
Generalizando com um parametro de posicao µ ∈ ℜ e um parametro de escala σ > 0 temos:
Sna(z) =2.[a+ b(1 + p)| z−µ
σ |p].exp[− z−µσ (a+ b| z−µ
σ |p)]σ{exp[− z−µ
σ (a+ b| z−µσ |p)] + 1}2.{exp[−c z−µ
σ (a+ b|c z−µσ |p)] + 1}
(2.2)
Notamos entao que temos uma aproximacao na qual conseguimos nos livrar da integraloutrora presente. Lembramos ao leitor que a, b e p sao constantes dadas na secao 1.1. Comoos erros da aproximacao da normal sao muito pequenos temos erros muito pequenos para adistribuicao Skew Normal tambem. Mais a frente no trabalho iremos comparar melhor essasdistribuicoes.
2.1.1 Momentos
Vamos calcular agora os momentos de h(z), para isso considere o caso geral:
E(xn)=
∫ ∞
−∞xn.h(x)dx=
∫ ∞
−∞xn.2.f(x).F (cx)dx=
=
∫ 0
−∞xn.2.f(x).F (cx)dx+
∫ ∞
0
xn.2.f(x).F (cx)dx=
=
∫ ∞
0
(−x)n.2.f(−x).F (−cx)dx+
∫ ∞
0
xn.2.f(x).F (cx)dx=
=
∫ ∞
0
(−1)n.xn.2.f(x).F (−cx)dx+
∫ ∞
0
xn.2.f(x).F (cx)dx=
=
∫ ∞
0
2.xn.f(x)[(−1)n.F (−cx) + F (cx)]dx
Usando a identidade 1-F(-cx)=F(cx), temos para n par:
=
∫ ∞
0
2.xn.f(x)[F (−cx) + F (cx)]dx=
∫ ∞
0
2.xn.f(x)dx
Ou seja os momentos pares sao iguais aos momentos da distribuicao simetrica f(x). Essesmomentos ja foram calculados em ”On a new Invertible Generalized Logistic DistributionApproximation to Normal Distribution”e sao dados por:∫ ∞
0
2.xn.f(x)dx = 2∞∑r=0
(−1)r(r + 1)[aIn + b(1 + p)In+p] (2.3)
Onde:
6

Iβ = [a(1 + r)]−β−1
∞∑k=0
[− b
(1 + r)pap+1
]k.Γ[β + 1 + (p+ 1)k]
k!=
= [a(r + 1)]−β−1H1,11,1
[(r + 1)pap+1
b
∣∣∣∣ (1, 1)(1 + β, p+ 1)
](2.4)
Para n ımpar, teremos:
∫ ∞
0
2.xn.f(x)[−F (−cx) + F (cx)]dx=
∫ ∞
0
2.xn.f(x)[2.F (cx)− 1]dx=
=
∫ ∞
0
4.xn.f(x).F (cx)dx-
∫ ∞
0
2.xn.f(x)dx
O resultado da segunda integral e o mesmo que o dado em (2.3), ja a primeira integraltemos que calcular, para isso utilizaremos as series:
(y + 1)−1 =
∞∑j=0
(−1)j .yj (2.5)
(x+ 1)−2 =∞∑r=0
(−1)r.(r + 1)xr (2.6)
Com y=exp[−cz(a+ b|cz|p)] e x=exp[−z(a+ b|z|p)]∫ ∞
0
zn.f(z).F (cz)dx=
∫ ∞
0
zn.[a+ b(1 + p)|z|p].exp[−z(a+ b|z|p)]{exp[−z(a+ b|z|p)] + 1}2.{exp[−cz(a+ b|cz|p)] + 1}
dz=
=
∫ ∞
0
zn.[a+ b(1 + p)zp].
∞∑r=0
(−1)r.(r + 1)exp[−z(r + 1)(a+ bzp)]
∞∑j=0
(−1)j .exp[−cjz(a+
b(|c|z)p)]dz=
=
∞∑r=0
∞∑j=0
(−1)r+j .(r + 1)
∫ ∞
0
zn.[a+ b(1 + p)zp]exp[−z(a.(r + 1 + c.j))− b.zp+1.(r + 1 +
j.c.|c|p)]dz=
=∞∑r=0
∞∑j=0
(−1)r+j .(r + 1)[a.Jn + b(1 + p)Jn+p] (2.7)
Onde:
Jβ =
∫ ∞
0
zβexp[−z(a.(r + 1 + c.j))].exp[−b.zp+1.(r + 1 + j.c.|c|p)]dz=
7

=
∫ ∞
0
zβexp[−z(a.(r + 1 + c.j))].∞∑k=0
(−b(r + 1 + jc|c|p))k
k!.z(p+1)kdz=
=∞∑k=0
(−b(r + 1 + jc|c|p))k
k!.
Γ(β + (p+ 1)k + 1)
(a(r + 1 + cj))β+(p+1)k+1=
= [a(r + 1 + cj)]−β−1H1,11,1
[(a(r + 1 + cj))p+1
b(r + 1 + cj|c|p)
∣∣∣∣ (1, 1)(1 + β, p+ 1)
](2.8)
Portanto, para n ımpar temos:
E(zn) = 2.∞∑r=0
(−1)r(r + 1)
2.
∞∑j=0
(−1)j [a.Jn + b(1 + p)Jn+p]
− [a.In + b(1 + p)In+p]
(2.9)
2.2 Caso particular quando c=1
O caso particular quando c = 1 e muito interessante pois podemos calcular explicitamentea funcao de distribuicao acumulada da Skew Normal aproximada.
Considerando c=1 nas Eq.(2.1) e Eq.(2.2), com z ∈ ℜ, a, b, p, σ > 0 e µ ∈ ℜ, obtemos:
h(z) = 2.f(z).F (z) =2.[a+ b(1 + p)|z|p].exp[−z(a+ b|z|p)]
{exp[−z(a+ b|z|p)] + 1}3(2.10)
Sna(z) =2.[a+ b(1 + p)| z−µ
σ |p].exp[− z−µσ (a+ b| z−µ
σ |p)]σ{exp[− z−µ
σ (a+ b| z−µσ |p)] + 1}3
(2.11)
Conseguimos facilmente obter a distribuicao acumulada fazendo a substituicao u={exp[-z(a+b|z|p)]+1} e calculando a integral, que por fim obtemos:
H(z) = {exp[−z(a+ b|z|p)] + 1}−2 (2.12)
E portanto:
SNA(z) =
{exp
[−z − µ
σ
(a+ b
∣∣∣∣z − µ
σ
∣∣∣∣p)]+ 1
}−2
(2.13)
Podemos tambem calcular z em funcao de H o que e muito importante em varios casoscomo no calculo de quantis. De (2.12) e facil concluir que:
z =1
aln
( √H
1−√H
)− b
az|z|p (2.14)
8

E usando a inversao de Lagrange obtemos:
z =
−
∞∑n=0
(− ba)n.Γ(np+ n+ 1)
n!Γ(np+ 2)
[1
aln
(1−
√H√
H
)]np+1
, H ≤ 0.25
∞∑n=0
(− ba)n.Γ(np+ n+ 1)
n!Γ(np+ 2)
[1
aln
( √H
1−√H
)]np+1
, H ≥ 0.25
z =
−(a
b)1/p 1
pH1,1
1,2
[( ba)1/p 1
aln(
1−√H√
H
) ∣∣∣∣ (p+1p, p+1
p)
(1p, 1p), (0, 1)
], H ≤ 0.25
(ab)1/p 1
pH1,1
1,2
[( ba)1/p 1
aln( √
H1−
√H
) ∣∣∣∣ (p+1p, p+1
p)
(1p, 1p), (0, 1)
], H ≥ 0.25
2.2.1 Momentos
Calcularemos agora o n-esimo momento de h(z). Para o caso em que c = 1 temos umaforma mais compacta nao precisando separar os momentos pares e ımpares, para realizaresse calculo precisaremos separar o problema em duas integrais, uma para z>0 e outra paraz<0, do seguinte modo:
E(zn)=
∫ ∞
−∞zn.h(z)dz=
∫ 0
−∞zn.h(z)dz+
∫ ∞
0
zn.h(z)dz=
=
∫ ∞
0
(−z)n.h(−z)dz︸ ︷︷ ︸II
+
∫ ∞
0
zn.h(z)dz︸ ︷︷ ︸I
Para o Calculo de I utilizaremos a serie binomial:
(x+ 1)−3 =∞∑r=0
(−1)r(r + 2)(r + 1)
2xr (2.15)
Para z>0 na equacao (2.10) temos:
h(z) =2.[a+ b(1 + p)zp].exp[−z(a+ bzp)]
{exp[−z(a+ bzp)] + 1}3(2.16)
9

Entao usando (2.15) em (2.16), com x = exp[−z(a+ bzp)], temos:
h(z) = [a+ b(1 + p)zp]
∞∑r=0
(−1)r(r + 2)(r + 1)exp[−z(r + 1)(a+ bzp)] (2.17)
Utilizando-se de (2.17), realizamos o calculo de I:∫ ∞
0
zn.h(z)dz =∞∑r=0
(−1)r(r + 2)(r + 1)[aI(n;r+1) + b(1 + p)I(n+p;r+1)] (2.18)
Onde:
I(β;θ) =
∫ ∞
0
zβexp[−zθ(a+ bzp)] (2.19)
Calculando (2.19):
I(β;θ) = [aθ]−β−1
∞∑k=0
[− b
θpap+1
]k.Γ[β + 1 + (p+ 1)k]
k!=
= [aθ]−β−1H1,11,1
[θpap+1
b
∣∣∣∣ (1, 1)(1 + β, p+ 1)
](2.20)
Para o calculo de II, faremos o mesmo processo feito no calculo de I, mas primeiramente,fazendo z=-z para z>0 na equacao (2.10) temos:
h(−z) =2.[a+ b(1 + p)zp].exp[z(a+ bzp)]
{exp[z(a+ bzp)] + 1}3=
=2.[a+ b(1 + p)zp].exp[−2.z(a+ bzp)]
{exp[−z(a+ bzp)] + 1}3(2.21)
Usando novamente a serie (2.15) em (2.21), com x = exp[−z(a+ bzp)], obtemos:
h(−z) = [a+ b(1 + p)zp]∞∑r=0
(−1)r(r + 2)(r + 1)exp[−z(r + 2)(a+ bzp)] (2.22)
Utilizando-se de (2.19),(2.20) e (2.22) realizamos o calculo de II:∫ ∞
0
(−1)n.zn.h(−z)dz =∞∑r=0
(−1)r+n(r + 2)(r + 1)[aI(n;r+2) + b(1 + p)I(n+p;r+2)] (2.23)
Como o resultado desejado e I+II, temos portanto o n-esimo momento:
E(zn) =∞∑r=0
(−1)r(r+2)(r+1)[aI(n;r+1)+b(1+p)I(n+p;r+1)+(−1)n(aI(n;r+2)+b(1+p)I(n+p;r+2))]
(2.24)
10
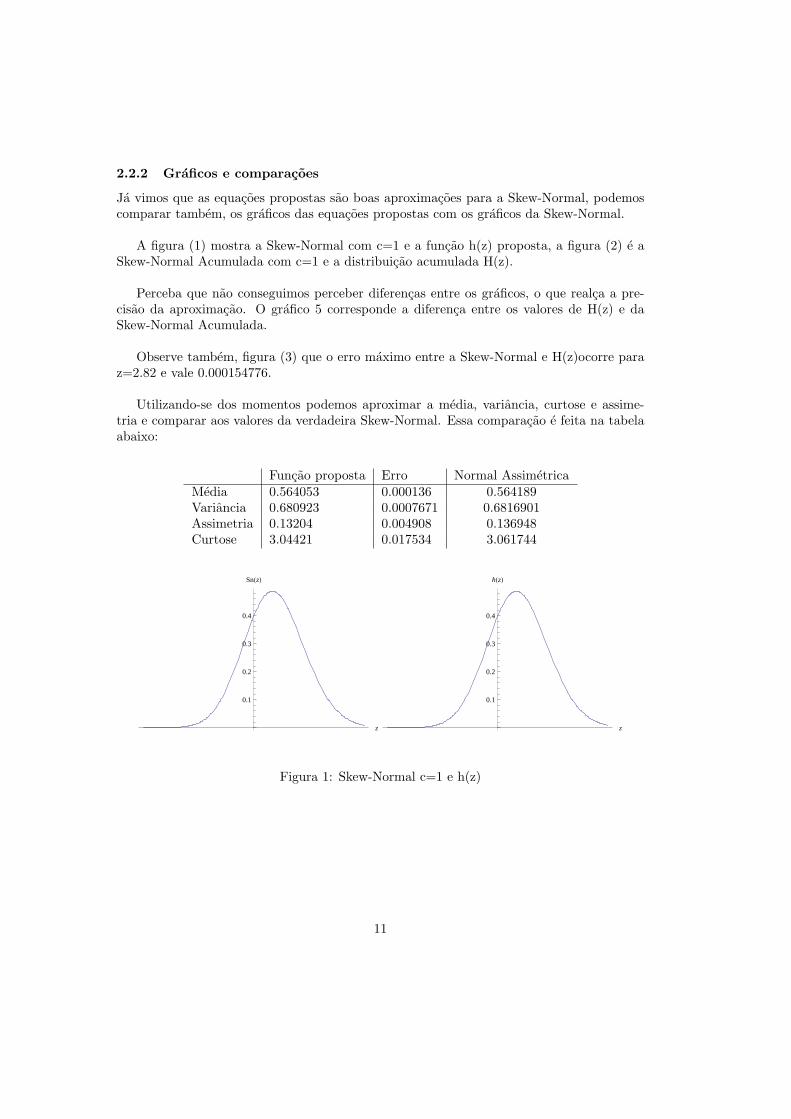
2.2.2 Graficos e comparacoes
Ja vimos que as equacoes propostas sao boas aproximacoes para a Skew-Normal, podemoscomparar tambem, os graficos das equacoes propostas com os graficos da Skew-Normal.
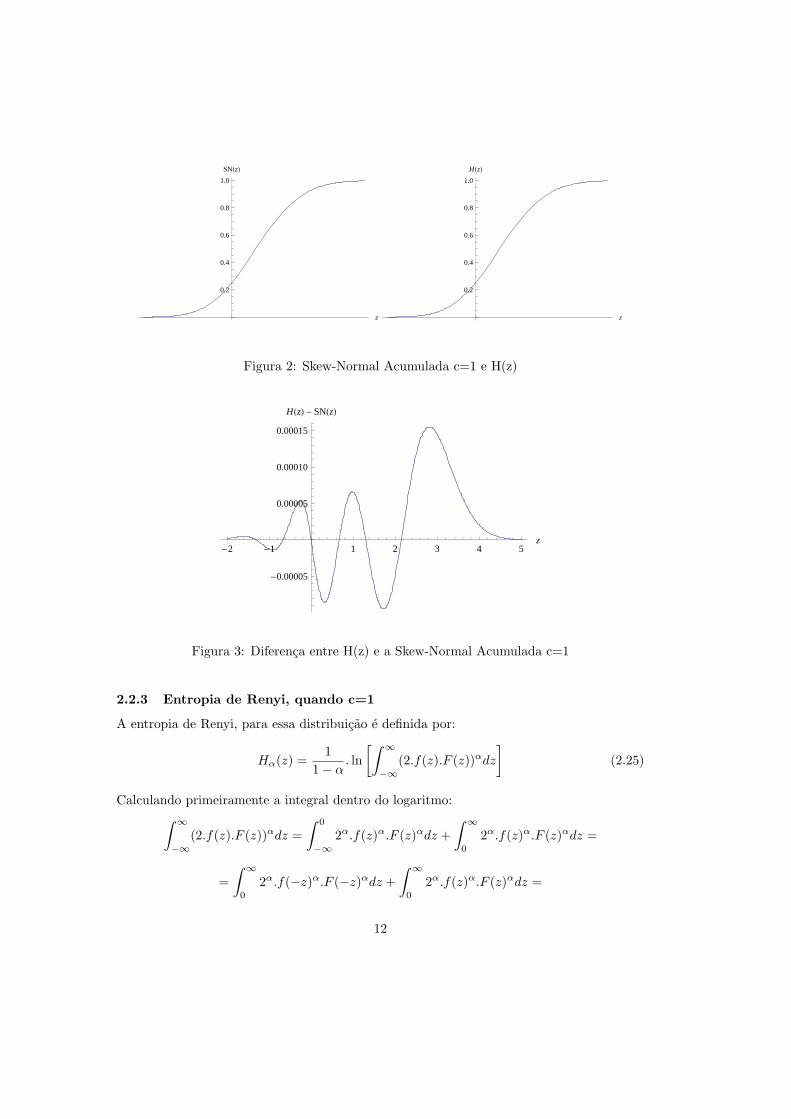
A figura (1) mostra a Skew-Normal com c=1 e a funcao h(z) proposta, a figura (2) e aSkew-Normal Acumulada com c=1 e a distribuicao acumulada H(z).
Perceba que nao conseguimos perceber diferencas entre os graficos, o que realca a pre-cisao da aproximacao. O grafico 5 corresponde a diferenca entre os valores de H(z) e daSkew-Normal Acumulada.
Observe tambem, figura (3) que o erro maximo entre a Skew-Normal e H(z)ocorre paraz=2.82 e vale 0.000154776.
Utilizando-se dos momentos podemos aproximar a media, variancia, curtose e assime-tria e comparar aos valores da verdadeira Skew-Normal. Essa comparacao e feita na tabelaabaixo:
Funcao proposta Erro Normal AssimetricaMedia 0.564053 0.000136 0.564189Variancia 0.680923 0.0007671 0.6816901Assimetria 0.13204 0.004908 0.136948Curtose 3.04421 0.017534 3.061744
z
0.1
0.2
0.3
0.4
SnHzL
z
0.1
0.2
0.3
0.4
hHzL
Figura 1: Skew-Normal c=1 e h(z)
11
z
0.2
0.4
0.6
0.8
1.0
SNHzL
z
0.2
0.4
0.6
0.8
1.0
HHzL
Figura 2: Skew-Normal Acumulada c=1 e H(z)
-2 -1 1 2 3 4 5z
-0.00005
0.00005
0.00010
0.00015
HHzL - SNHzL
Figura 3: Diferenca entre H(z) e a Skew-Normal Acumulada c=1
2.2.3 Entropia de Renyi, quando c=1
A entropia de Renyi, para essa distribuicao e definida por:
Hα(z) =1
1− α. ln
[∫ ∞
−∞(2.f(z).F (z))αdz
](2.25)
Calculando primeiramente a integral dentro do logaritmo:∫ ∞
−∞(2.f(z).F (z))αdz =
∫ 0
−∞2α.f(z)α.F (z)αdz +
∫ ∞
0
2α.f(z)α.F (z)αdz =
=
∫ ∞
0
2α.f(−z)α.F (−z)αdz +
∫ ∞
0
2α.f(z)α.F (z)αdz =
12

=
∫ ∞
0
2α.f(z)α.[F (−z)α + F (z)α]dz =
=
∫ ∞
0
2α.f(z)α.exp[−zα(a+ b.|z|p)] + 1
{exp[−z(a+ b.|z|p)] + 1}αdz =
=
∫ ∞
0
2α.[a+ b(1 + p)zp]α.exp[−zα(a+ b.zp)].{exp[−zα(a+ b.zp)] + 1}{exp[−z(a+ b.zp)] + 1}3α
dz
Temos entao a soma de duas integrais:∫ ∞
0
2α.[a+ b(1 + p)zp]α.exp[−2zα(a+ b.zp)]
{exp[−z(a+ b.zp)] + 1}3αdz (2.26)
∫ ∞
0
2α.[a+ b(1 + p)zp]α.exp[−zα(a+ b.zp)]
{exp[−z(a+ b.zp)] + 1}3αdz (2.27)
Para o calculo dessas integrais, consideraremos que α e um numero natural e as series:
[a+ b(1 + p)zp]α =
α∑i=0
(αi )aα−i[b(1 + p)zp]i (2.28)
(1 + x)m = 1 +∞∑k=1
m(m− 1)...(m− k + 1)
k!xk (2.29)
Tomando entao, m = −3α e x = exp[−z(a+ b.zp)] e jogando em (2.27):∫ ∞
0
2α.α∑
i=0
(αi )aα−i[b(1 + p)]i.zpi].exp[−zα(a+ b.zp)] x
x
[1 +
∞∑k=1
(−1)k3α(3α+ 1)...(3α+ k − 1)
k!.exp[−zk(a+ b.zp)]
]dz =
= 2α.
α∑i=0
(αi )aα−i[b(1 + p)]i[
∫ ∞
0
zpi.exp[−zα(a+ b.zp)]dz +
+
∞∑k=1
(−1)k3α(3α+ 1)...(3α+ k − 1)
k!.
∫ ∞
0
zpi.exp[−z(α+ k)(a+ b.zp)]]dz =
= 2α.α∑
i=0
(αi )aα−i[b(1 + p)]i
[Ipi;α +
∞∑k=1
(−1)k3α(3α+ 1)...(3α+ k − 1)
k!.Ipi;α+k
](2.30)
Onde Iβ;θ e o mesmo que o dado em (2.19). E analogamente temos para (2.26):
13

2α.α∑
i=0
(αi )aα−i[b(1 + p)]i
[Ipi;2α +
∞∑k=1
(−1)k3α(3α+ 1)...(3α+ k − 1)
k!.Ipi;2α+k
](2.31)
Portanto a entropia de Renyi e:
Hα(z) =1
1−α ln
[2α.
α∑i=0
(αi )aα−i[b(1 + p)]i
][Ipi;α + Ipi;2α+
+∞∑k=1
(−1)k3α(3α+ 1)...(3α+ k − 1)
k!.(Ipi;α+k + Ipi;2α+k)] (2.32)
2.3 Caso particular para c=-1
Considerando agora c=-1 em (1.4) podemos achar uma boa aproximacao para a Skew-Normalcom c=-1, do mesmo modo que fizemos anteriormente tendo em mao as Eq.(2.1) e Eq.(1.5),z ∈ ℜ, a, b, p, σ > 0 e µ ∈ ℜ:
h(z) = 2.f(z).F (−z) =
=2.[a+ b(1 + p)|z|p].exp[−z(a+ b|z|p)]
{exp[−z(a+ b|z|p)] + 1}2.
1
{exp[z(a+ b|z|p)] + 1}=
=2.[a+ b(1 + p)|z|p].exp[−2z(a+ b|z|p)]
{exp[−z(a+ b|z|p)] + 1}3(2.33)
E analogamente:
Sna =2.[a+ b(1 + p)| z−µ
σ |p].exp[−2 z−µσ (a+ b| z−µ
σ |p)]σ{exp[− z−µ
σ (a+ b| z−µσ |p)] + 1}3
(2.34)
Para obter H(z) faremos a substituicao u={exp[-z(a+b|z|p)]+1}:∫−2(u− 1)
u3du = 2u−1 − u−2 =
2u− 1
u2
E portanto:
H(z) =2{exp[−z(a+ b|z|p)] + 1} − 1
{exp[−z(a+ b|z|p)] + 1}2(2.35)
Analogamente:
SNA(z) =2{exp[− z−µ
σ (a+ b| z−µσ |p)] + 1} − 1
{exp[− z−µσ (a+ b| z−µ
σ |p)] + 1}2(2.36)
14

Para calcular z em funcao de H, voltamos primeiramente a (2.35) com a sub-stituicao u={exp[-z(a+b|z|p)]+1}:
H =2u− 1
u2⇒ H.u2 − 2u+ 1 = 0 ⇒ u =
2±√4− 4H
2H
Mas u =2−
√4− 4H
2Hnao convem na situacao em questao, portanto ficamos com:
{exp[−z(a+ b|z|p)] + 1} =1 +
√1−H
H⇒
⇒ z =1
aln
(H
1 +√1−H −H
)− b
az|z|p (2.37)
E usando a inversao de Lagrange obtemos:
z =
−
∞∑n=0
(− ba)n.Γ(np+ n+ 1)
n!Γ(np+ 2)
[1
aln
(1 +
√1−H −H
H
)]np+1
, H ≤ 0.75
∞∑n=0
(− ba)n.Γ(np+ n+ 1)
n!Γ(np+ 2)
[1
aln
(H
1 +√1−H −H
)]np+1
, H ≥ 0.75
z =
−(a
b)1/p 1
pH1,1
1,2
[( ba)1/p 1
aln(
1+√1−H−HH
) ∣∣∣∣ (p+1p, p+1
p)
(1p, 1p), (0, 1)
], H ≤ 0.75
(ab)1/p 1
pH1,1
1,2
[( ba)1/p 1
aln(
H1+
√1−H−H
) ∣∣∣∣ (p+1p, p+1
p)
(1p, 1p), (0, 1)
], H ≥ 0.75
O erro maximo, em valor absoluto, entre H(z) e a Skew-Normal Acumulada, para c=-1,e 0.000154776, e ocorre em z=-2.82. Alguns graficos foram tracados para a visualizacao daSkew-Normal com c = −1, e mais um grafico dos erros entre H(z) e a distribuicao Skew-Normal acumulada, que podem ser vistos nas figuras (4) e (5).
2.3.1 Momentos
Os momentos de (2.33) sao muito similares aos momentos de (2.10), de fato podemos observarque se h(z) e dado por (2.10) entao h(-z) e igual a funcao proposta em (2.33). Entao,observando a relacao:
15

z
0.1
0.2
0.3
0.4
hHzL
z
0.2
0.4
0.6
0.8
1.0
HHzL
Figura 4: h(z), Aproximacao da Skew-Normal com c=-1
-5 -4 -3 -2 -1 1 2z
-0.00015
-0.00010
-0.00005
0.00005
0.00010HHzL - SNHzL
Figura 5: Erro entre H(z) e a Skew-Normal Acumulada, com c=-1
E(zn)=
∫ ∞
−∞zn.h(−z)dz=
∫ 0
−∞zn.h(−z)dz+
∫ ∞
0
zn.h(−z)dz=
=
∫ ∞
0
(−1)n.zn.h(z)dz+
∫ ∞
0
zn.h(−z)dz =
= (−1)n[∫ ∞
0
zn.h(z)dz +
∫ ∞
0
(−1)n.zn.h(−z)dz
]Concluımos que o n-esimo momento de (2.33) e igual ao n-esimo momento de (2.10) vezes(−1)n, ou seja, para (2.33):
E(zn) =∞∑r=0
(−1)r(r+2)(r+1)[(−1)n(aI(n;r+1)+b(1+p)I(n+p;r+1))+aI(n;r+2)+b(1+p)I(n+p;r+2)]
(2.38)
16

Onde Iβ;θ e o mesmo dado em (2.19).
2.4 Distribuicao Z2
Sabe-se que a distribuicao Z2 para a Skew-Normal tende a uma distribuicao Qui-Quadradocom 1 grau de liberdade. Vamos entao calcular a distribuicao Z2 para h(z), para descobrir-mos se Z2 tendera de fato a uma Qui-Quadrado:
Chamando y=z2 temos z = ±√y, entao:
g(y) = h(z)
∣∣∣∣dzdy∣∣∣∣z=
√y
+ h(z)
∣∣∣∣dzdy∣∣∣∣z=−√
y
=
=2[a+ b(p+ 1)y
p2 ]
2√y
(exp[
√y(a+ by
p2 )]
(exp[√y(a+ by
p2 )] + 1)3
+exp[−√
y(a+ byp2 )]
(exp[−√y(a+ by
p2 )] + 1)3
)
g(y) =[a+ b(p+ 1)y
p2 ]
√y
.exp[
√y(a+ by
p2 )]
{exp[√y(a+ byp2 )] + 1}2
(2.39)
Que e uma otima aproximacao para a Qui-Quadrado com 1 grau de liberdade. E essaaproximacao tambem e inversıvel:
G(y) =1− exp[−√
y(a+ byp2 )]
{exp[−√y(a+ by
p2 )] + 1}
(2.40)
Comparada a Qui-Quadrado, essa distribuicao tem um erro maximo de 0.000156087 emy=7.9, como se pode observar na figura (6).
5 10 15y
-0.00010
-0.00005
0.00005
0.00010
0.00015
GHyL -QHyL
Figura 6: Diferenca entre G(y) e a Qui-Quadrado
17

3 Generalizacao da distribuicao Skew Normal
Nessa secao vamos demonstrar uma formacao da Skew-Normal de Azzalini a partir da Nor-mal bivariada. Com a mesma logica, queremos propor uma nova formula que generaliza aSkew-Normal de Azzalini.
3.1 Skew-Normal a partir da Normal Bivariada
Considere que (x, y) tenha distribuicao normal bivariada com vetor de medias µ=(0,0) e
matriz de variancia-covariancia Σ=
(1 ρρ 1
), onde ρ e o coeficiente de correlacao entre x e y.
Considere agora a restricao:
x > 0
Pergunta: Qual a distribuicao de y dado que x > 0?Temos:
P{y|x > 0} = P{x>0,y}P{x>0}
Mas P{x > 0}=1/2, entao:
P{y|x > 0} = 2P{x > 0, y} = 2
∫ ∞
0
1
2π√1− ρ2
exp
[− 1
2(1− ρ2)
{x2 + y2 − 2ρxy
}]dx
Completando quadrados obtemos:
= 2
∫ ∞
0
1
2π√1− ρ2
exp[−y2/2
]exp
[− 1
2(1− ρ2)(x− ρy)2
]dx =
Fazendo a substituicao: z = − x−ρy√1−ρ2
; Obtemos:
= 2ϕ(y)
∫ ρ√1−ρ2
y
−∞
1√2π
exp[−z2/2
]dz =
= 2ϕ(y)Φ
(ρ√
1− ρ2y
)(3.1)
Ou seja temos a distribuicao de y dado que x > 0 e Skew-Normal com c = ρ/√1− ρ2.
3.2 Aplicacao: O problema da distribuicao de pesos no exercito
Nesta secao mostraremos uma possıvel aplicacao da Skew Normal por simulacao apenas parater uma nocao de possıveis aplicacoes interessantes. Mais a frente neste trabalho utilizare-mos dados reais para ajustar a distribuicao Skew Normal e para a generalizacao que iremospropor.
18

Podemos pensar nesta formulacao da distribuicao Skew Normal baseada da distribuicaoNormal Bivariada dada anteriormente para uma aplicacao como a seguir.
Numa cidade 10.000 jovens compareceram para o alistamento no exercito nacional.Porem por um problema de tempo e recursos, nao seria possıvel avaliar todos os jovenspara a selecao, por isso decidiu-se dispensar os rapazes com altura abaixo da media popula-cional para a avaliacao. Depois, com os jovens restantes, fizeram-se varios testes e medicoes,dentre eles o peso de cada indivıduo.
Considerando que a distribuicao de pesos e alturas segue uma distribuicao Normal Bivariada
com vetor de medias µ = (85; 1.75) e matriz de variancia-covariancia Σ=
(1 ρρ 1
), pergunta-
se:
a) Qual a distribuicao estatıstica dos pesos dos rapazes que serao avaliados?b) Qual a probabilidade de algum dos selecionados pesar menos do que 80kg?c) Deseja-se estimar a correlacao existente entre peso e altura, mas o exercito so possui asobservacoes dos pesos dos jovens que serao avaliados. Como estimar o coeficiente de cor-relacao baseando-se nessa amostra e utilizando a Skew Normal?
Considere tambem para a resolucao do problema que o valor real do coeficiente de cor-relacao e ρ = 1/
√2, valor que foi usado para a geracao dos dados.
Resolucao do item a:
Tendo o que foi feito na secao 3.1, podemos concluir que considerando a distribuicao condi-cional dos pesos dados que a altura e maior que 1.75m e uma Skew-Normal com c = ρ√
1−ρ2.
Portanto se Y e a variavel peso e X a variavel altura, temos:
P{Y |(x > 1.75)} = 2f [y]F [y]
Podemos observar na figura (7) o que ocorre. Foi gerada uma amostra de 10.000 elementosda Normal Bivariada com vetor de medias e matriz de variancia-covariancia dados, depoisdisso dessa amostra foram retirados os elementos com altura menor que 1.75m sobrandoassim 4932 elementos. O histograma e composto pelos valores dos pesos dos 4932 elementosrestantes e foi comparado a Skew-Normal com c = 1.
Resolucao do item b:
Como temos uma Skew-Normal com c = 1, podemos entao usar a aproximacao propostanesse trabalho, o que facilita enormemente as contas. De fato podemos dispensar o uso de umcomputador usando apenas uma calculadora cientıfica. Queremos entao achar P{Z < 80}onde Z tem distribuicao Skew-Normal com c = 1, parametro de posicao 85kg e parametro deescala 10kg. Entao usando a Eq.(2.13) com z = 80, µ = 85, σ = 10, a = 1.59413, b = 0.07443e p = 1.939, temos:
P{Z < 80} = SNA[80] = 0.095
19
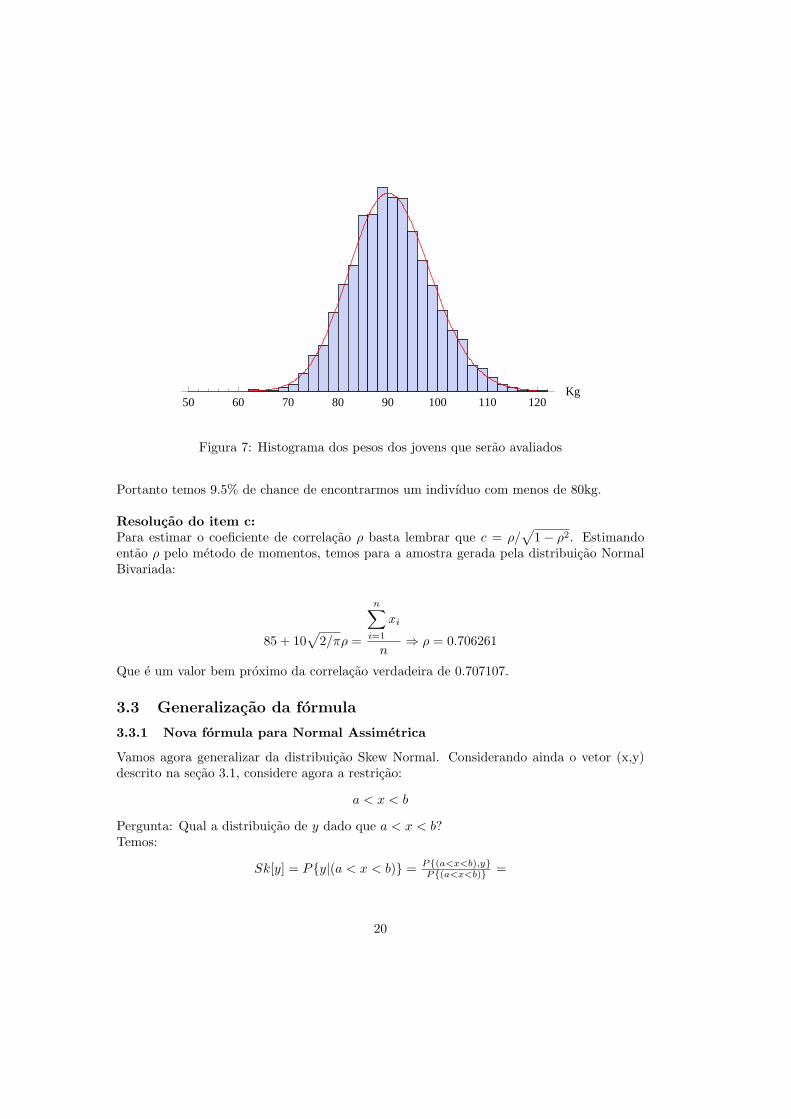
50 60 70 80 90 100 110 120Kg
Figura 7: Histograma dos pesos dos jovens que serao avaliados
Portanto temos 9.5% de chance de encontrarmos um indivıduo com menos de 80kg.
Resolucao do item c:Para estimar o coeficiente de correlacao ρ basta lembrar que c = ρ/
√1− ρ2. Estimando
entao ρ pelo metodo de momentos, temos para a amostra gerada pela distribuicao NormalBivariada:
85 + 10√2/πρ =
n∑i=1
xi
n⇒ ρ = 0.706261
Que e um valor bem proximo da correlacao verdadeira de 0.707107.
3.3 Generalizacao da formula
3.3.1 Nova formula para Normal Assimetrica
Vamos agora generalizar da distribuicao Skew Normal. Considerando ainda o vetor (x,y)descrito na secao 3.1, considere agora a restricao:
a < x < b
Pergunta: Qual a distribuicao de y dado que a < x < b?Temos:
Sk[y] = P{y|(a < x < b)} = P{(a<x<b),y}P{(a<x<b)} =
20

= ϕ(y)P{a<x<b}
∫ b
a
1√2π√1− ρ2
exp
[− 1
2(1− ρ2)(x− ρy)2
]dx =
Fazendo a substituicao: z = x−ρy√1−ρ2
; Obtemos:
= ϕ(y)Φ(b)−Φ(a)
∫ b−ρy√1−ρ2
a−ρy√1−ρ2
1√2π
exp[−z2/2
]dz
Sk[y] = ϕ(y)
Φ
[b−ρy√1−ρ2
]− Φ
[a−ρy√1−ρ2
]Φ(b)− Φ(a)
(3.2)
A Eq.(3.2) e uma generalizacao da Eq.(1.4).
Relacoes:
Considere c = p√1−ρ2
, a, b, c ∈ ℜ. Seja Z uma variavel aleatoria com distribuicao Nor-
mal Padrao. Considere ainda que Xc ∼ Sk[c] e X−c ∼ Sk[−c], onde Sk[c] e a Skew-Normalde Azzalini dada pela Eq.(1.4), e que X(a,b) ∼ Sk[a, b] onde Sk[a, b] e a nova distribuicaoassimetrica proposta pela Eq.(3.2), entao:
(i) a = 0 e b → ∞ ⇒ X(a,b) → Xc. (Convergencia em distribuicao).
(ii) b = 0 e a → −∞ ⇒ X(a,b) → X−c. (Convergencia em distribuicao).
(iii) ρ = 0 ⇒ X(a,b) → Z,∀a, b ∈ ℜ (Convergencia em distribuicao).
3.3.2 Media
Vamos agora calcular a media da nova distribuicao proposta:
E[y] =
∫ ∞
−∞ySk[y]dy =
∫ ∞
−∞yP{y|(a < x < b)}dy =
=
∫ ∞
−∞y
1
P{a < x < b}
∫ b
a
1
2π√1− ρ2
exp
{− 1
2(1− ρ2){x2 + y2 − 2ρxy}
}dxdy =
= 1P{a<x<b}
∫ b
a
ϕ(x)
∫ ∞
−∞y
1√2π√
1− ρ2exp
{− 1
2(1− ρ2)(y − ρx)2
}dydx =
Fazendo a substituicao z = y−ρx√1−ρ2
, obtemos:
= 1P{a<x<b}
∫ b
a
ϕ(x)
∫ ∞
−∞(z√1− ρ2 + ρx)ϕ(z)dzdx =
21

= 1P{a<x<b}
∫ b
a
ϕ(x)
∫ ∞
−∞ρxϕ(z)dzdx =
ρ
P{a < x < b}
∫ b
a
xϕ(x)dx =
=ρ[exp{−a2/2} − exp{−b2/2}]√
2π[Φ(b)− Φ(a)](3.3)
3.3.3 Funcao geratriz de momentos
Vamos agora calcular a FGM da nova distribuicao proposta:
E[exp{ty}] =∫ ∞
−∞exp{ty}Sk[y]dy =
∫ ∞
−∞exp{ty}P{y|(a < x < b)}dy =
=
∫ ∞
−∞exp{ty} 1
P{a < x < b}
∫ b
a
1
2π√1− ρ2
exp
{− 1
2(1− ρ2){x2 + y2 − 2ρxy}
}dxdy =
= 1P{a<x<b}
∫ b
a
ϕ(x)
∫ ∞
−∞exp{ty} 1
√2π√1− ρ2
exp
{− 1
2(1− ρ2)(y − ρx)2
}dydx =
Fazendo a substituicao z = y − ρx, obtemos:
= 1P{a<x<b}
∫ b
a
ϕ(x)
∫ ∞
−∞exp{t(z + ρx)} 1√
2π(1− ρ2)exp
{− 1
2(1− ρ2)z2}dzdx =
exp{
12 (1− ρ2)t2
}Φ(b)− Φ(a)
∫ b
a
exp{ρtx}ϕ(x)dx
Portanto:
My[t] =exp{t2/2}
2(Φ(b)− Φ(a))
[Erf
[b− ρt√
2
]− Erf
[a− ρt√
2
]](3.4)
Ou equivalentemente:
MX [t] = exp{t2/2}Φ(b− ρt)− Φ(a− ρt)
Φ(b)− Φ(a). (3.5)
Na figura (8) o leitor pode observar os graficos da distribuicao Skew Normal Generalizadadada pela Eq.(3.2) comparados com o grafico da distribuicao Normal Padrao.
22

-3-3 -1 1 2 3y
0.1
0.2
0.3
0.4
-3-3 -1 1 2 3y
0.3
0.6
0.9
Figura 8: Skew-Normal Generalizada com parametros a = −1, b = 2 e ρ = 0.95 (a esquerda)e a = 1, b = 2 e ρ = 0.95 (a direita)
3.3.4 Distribuicao X2(a,b), Generalizacao da distribuicao Qui-Quadrado
Ja mencionamos que se um variavel aleatoria X tem distribuicao Skew Normal, entao X2
tem distribuicao Qui-Quadrado com 1 grau de liberdade, portanto podemos generalizar adistribuicao Qui-Quadrado descobrindo a distribuicao de probabilidade de X2
(a,b) onde X(a,b)
tem distribuicao Skew Normal Generalizada dada pela Eq.(3.2).Entao, considerando ainda o vetor (x,y) descrito na secao 3.1, e chamando z=y2 onde y temdistribuicao Skew Normal Generalizada, temos y = ±
√z, e portanto:
g(z) = h(y)
∣∣∣∣dydz∣∣∣∣y=
√z
+ h(y)
∣∣∣∣dydz∣∣∣∣y=−
√z
=
g(z) = P (y|{a < x < b})∣∣∣∣dydz
∣∣∣∣y=
√z
+ P (y|{a < x < b})∣∣∣∣dydz
∣∣∣∣y=−
√z
=
=1
P ({a < x < b})ϕ(√z)
2√z
∫ b
a
(exp
[− 1
2(1−ρ2) (x− ρ√z)]+ exp
[− 1
2(1−ρ2) (x+ ρ√z)])
√2π(1− ρ2)
dx =
SkQ[z] =
ϕ[√z]
(Φ
[b−ρ
√z√
1−ρ2
]− Φ
[a−ρ
√z√
1−ρ2
]+Φ
[b+ρ
√z√
1−ρ2
]− Φ
[a+ρ
√z√
1−ρ2
])2√z(Φ[b]− Φ[a])
(3.6)
Relacoes:
Se X ∼ SkQ(a, b, ρ) e Z ∼ χ21, entao:
(i) a = 0 e b → ∞ ⇒ X → Z (convergencia em distribuicao).
(ii) b = 0 e a → −∞ ⇒ X → Z (convergencia em distribuicao).
(iii) ρ = 0 ⇒ X → Z (convergencia em distribuicao), ∀a, b ∈ ℜ
23

3.4 Outras generalizacoes
Existem mais duas restricoes que valem a pena serem explicitadas, sao elas:
x > k, k ∈ ℜ
Usando a Eq.(3.2) com a = k e b → ∞, obtemos a distribuicao Skew Normal estendida deBirnbaum (1950):
Sk[y] = ϕ(y)
Φ
[ρy−k√1−ρ2
]1− Φ(k)
(3.7)
Usando a Eq.(3.3) obtemos:
E[y] =ρ[exp{−k2/2}]√
2πΦ(−k)(3.8)
Usando a Eq.(3.4) obtemos:
My[t] =exp{t2/2}2Φ(−k)
[1− Erf
[k − ρt√
2
]](3.9)
Ou equivalentemente:
MY [t] = exp{t2/2}Φ(ρt− k)
Φ(−k). (3.10)
E para:
x < k, k ∈ ℜ
Usando a Eq.(3.2) com a → −∞ e b = k obtemos:
Sk[y] = ϕ(y)
Φ
[k−ρy√1−ρ2
]Φ(k)
(3.11)
Usando a Eq.(3.3) obtemos:
E[y] = −ρ[exp{−k2/2}]√2πΦ(k)
(3.12)
Usando a Eq.(3.4) obtemos:
My[t] =exp{t2/2}2Φ(k)
[1 + Erf
[k − ρt√
2
]](3.13)
Ou equivalentemente:
MY [t] = exp{t2/2}Φ(k − ρt)
Φ(k). (3.14)
24

3.5 Aplicacoes
3.5.1 Temperatura na reserva ecologica do IBGE
Nos usamos dados de temperatura na estacao climatologica do IBGE para aplicacoes dadistribuicao Skew Normal. Primeiramente nos ajustamos a distribuicao Normal aos dadosobtendo o histograma da Figura (9). Alem disso, plotamos o QQPlot dos dados, que podeser visto na Figura (11). Podemos ver que a distribuicao Normal nao resulta em um bomajuste devido ao fato de que a cauda esquerda da distribuicao real dos dados e mais longado que a cauda da distribuicao Normal.
Figura 9: Histograma dos dados e a distribuicao Normal estimada.
Notamos entao que a distribuicao Normal nao e o melhor ajuste para os dados devidoa assimetria dos mesmos. Deste modo, aproximando os parametros µ, σ e c para a dis-tribuicao Skew Normal por µ = 28.155517, σ = 3.276348 e c = −1.883828, conseguimosuma ajuste muito melhor do que usando a distribuicao Normal. Podemos notar essa mel-horia de ajuste nos graficos da distribuicao empırica da dados comparados aos graficos dasrespectivas funcoes de distribuicao na figura (10), e pelo QQPlot da distribuicao Skew Nor-mal dado na figura (12).
Para a distribuicao Normal o desvio absoluto medio em torno da distribuicao empırica e0.0257 e o desvio absoluto maximo e 0.0683. Ja para a distribuicao Skew Normal, o desvioabsoluto medio em torno da distribuicao empırica e 0.01499 e o desvio absoluto maximo e0.0561. Usamos o teste de Kolmogorov-Smirnov para testar a qualidade do ajuste a 1% e5% de significancia.
25
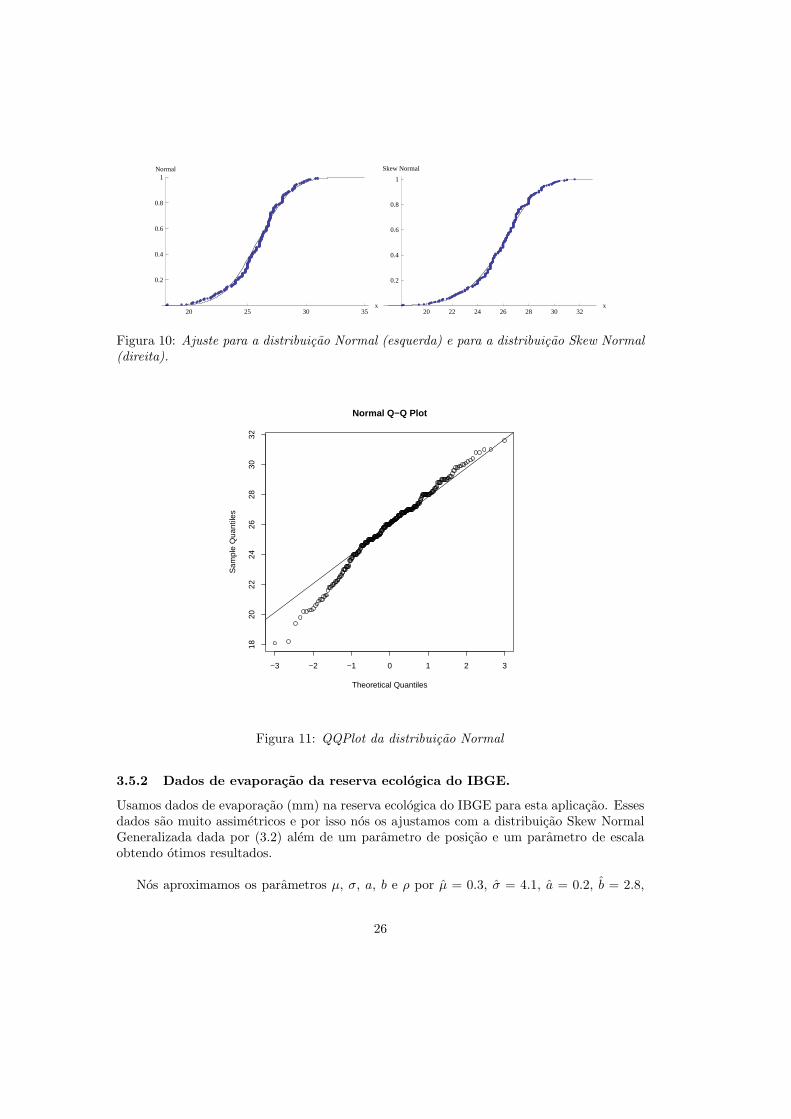
20 25 30 35x
0.2
0.4
0.6
0.8
1Normal
20 22 24 26 28 30 32x
0.2
0.4
0.6
0.8
1
Skew Normal
Figura 10: Ajuste para a distribuicao Normal (esquerda) e para a distribuicao Skew Normal(direita).
−3 −2 −1 0 1 2 3
1820
2224
2628
3032
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Figura 11: QQPlot da distribuicao Normal
3.5.2 Dados de evaporacao da reserva ecologica do IBGE.
Usamos dados de evaporacao (mm) na reserva ecologica do IBGE para esta aplicacao. Essesdados sao muito assimetricos e por isso nos os ajustamos com a distribuicao Skew NormalGeneralizada dada por (3.2) alem de um parametro de posicao e um parametro de escalaobtendo otimos resultados.
Nos aproximamos os parametros µ, σ, a, b e ρ por µ = 0.3, σ = 4.1, a = 0.2, b = 2.8,
26

−3 −2 −1 0 1
1820
2224
2628
3032
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Skew Normal Q−Q Plot
Figura 12: QQPlot da distribuicao Skew Normal.
ρ = 0.99. Na figura (13) podemos ver o ajuste da distribuicao Skew Normal Generalizadapara a distribuicao empırica dos dados. O desvio absoluto medio em torno da distribuicaoempırica dos dados e 1.214 10−2, o desvio absoluto maximo e 4.087 10−2 e o erro medioquadratico e 2.21 10−4. Usamos novamente o teste de Kolmogorov-Smirnov para testar oajuste a 1% e 5% de significancia.
x
0.2
0.4
0.6
0.8
1Generalized Skew-Normal
Figura 13: Ajuste para a distribuicao Skew Normal Generalizada
27

4 Generalizacao da formula de Fernandez and Stell
4.1 Generalizacao
Podemos tentar generalizar a Eq.(1.10) para dois parametros quaisquer a e b, ao invez deconsiderarmos apenas os recıprocos α e 1/α.Desse modo terıamos:
h(x) = c.f(x.a|x|/x+1
2 .b−|x|/x+1
2 ) (4.1)
onde a, b > 0, x ∈ (−∞,∞) e f(x) e uma funcao de densidade de probabilidade simetrica.
Sabemos que devemos ter
∫ ∞
−∞h(x)dx = 1, entao podemos determinar c:
1 = c.
∫ ∞
−∞f(x.a
|x|/x+12 .b
−|x|/x+12 )dx =
= c.
∫ 0
−∞f(x.b)dx+ c.
∫ ∞
0
f(x.a)dx =
Substituindo u = xb; dx = du/b; v = xa; dx = dv/a:
= c.
∫ 0
−∞f(u)/bdu+ c.
∫ ∞
0
f(v)/adv = c.[1
2b+
1
2a] ⇒
⇒ c2 [1/b+ 1/a] = 1 ⇒ c.[a+b
ba ] = 2
Portanto:
c =2ab
a+ b(4.2)
Temos entao nossa distribuicao:
h(x) =
{2ab/(a+ b)f(x.a
|x|/x+12 .b
−|x|/x+12 ), x = 0
2ab/(a+ b)f(0), x = 0
(4.3)
4.2 Propriedades
i) Se a = 1b , temos:
h(x) = (2a. 1a )/(a+ 1a )f(x.a
|x|/x+12 .a
|x|/x−12 ) =
= 2α+1/αf(α
sinal[x])
28

Que e a funcao de Fernandez and Steel dada em (1.10).
ii) Se a = b temos:
h(x) = (2a2/(2a)f(x.a|x|/x+1
2 .a−|x|/x+1
2 ) = a.f(ax)
Considerando a = 1σ , temos h(x) = f(xσ)
σ , onde σ e o parametro de escala. A distribuicaoh(x) nao e assimetrica nesse caso.
4.3 Momentos
Vamos agora calcular o n-esimo momento:
E(xn) =
∫ ∞
−∞xn.2ab/(a+ b)f(x.a
|x|/x+12 .b
−|x|/x+12 )dx =
= 2ab/(a+ b)
∫ 0
−∞xnf(bx)dx+ 2ab/(a+ b)
∫ ∞
0
xnf(ax)dx
Fazendo as substituicoes adequadas para a resolucao das integrais e colocando os termoscomuns em evidencia, obtemos:
E(xn) = 2ab/(a+ b)[(−1)n
bn+1 + 1an+1
] ∫ ∞
0
xnf(x)dx =
2((−1)n.an+1 + bn+1)
(a+ b)(ab)n
∫ ∞
0
xnf(x)dx (4.4)
Portanto temos o primeiro momento (media) e o segundo momento:
E(x) =2(b− a)
ab
∫ ∞
0
xf(x)dx (4.5)
E(x2) =2(a3 + b3)
(a+ b)a2b2
∫ ∞
0
x2f(x)dx =(a3 + b3)
(a+ b)a2b2(V ar(x)) (4.6)
Onde V ar(x) e a variancia de f(x).Podemos tambem calcular a Variancia de h(x) pela formula:
V ar(x) = E(x2)− (E(x))2.
4.4 Funcao de distribuicao acumulada
Considere h(x) e a, b > 0, queremos:∫ X
−∞h(x)dx = H(x)
Para X < 0:
29

= 2ab/(a+ b)
∫ X
−∞f(bx)dx = 2a/(a+ b)
∫ bX
−∞f(u)du = 2a/(a+ b)F (bX)
Para X > 0
= 2ab/(a+ b)
∫ X
−∞h(x)dx = 2ab/(a+ b)
[∫ 0
−∞f(bx)dx+
∫ X
0
f(ax)dx
]=
= 2ab/(a+ b)
[12b +
1a
∫ aX
0
f(v)dv
]=
= 2ab/(a+ b)[
12b +
1a (F (aX)− 1/2)
]Podemos entao juntar, em uma unica expressao, para formarmos a funcao de distribuicaoacumulada:
H(x) =2ab
a+ b
[1
bF
(b
2(x− |x|)
)+
1
aF(a2(x+ |x|)
)− 1
2a
](4.7)
4.5 Entropias de Renyi e Shannon, e Informacao de Fisher
A entropia de Shannon Entropy para (4.1) e
Sh(x) = −∫ ∞
−∞h(x). lnh(x)dx
Sh(x) = Sh(z)− ln(c) (4.8)
onde Sh(z) e a entropia de Shannon para a distribuicao f(z).A entropia de Renyi para (4.1) e dada por
Rα(x) =1
1−α ln
[∫ ∞
−∞h(x)αdx
]Rα(x) = Rα(z)− ln(c) (4.9)
onde Rα(z) e a entropia de Renyi para a distribuicao f(z).
A informacao de Fisher (4.1) e para um parametro θ de f(X) e
I(θ) = E[(
ddθ lnh(x)
)2]=
∫ ∞
∞c
(d
dθln f(x.a
1+|x|/x2 .b
1−|x|/x2 )
)2
f(x.a1+|x|/x
2 .b1−|x|/x
2 )dx =
30

c
∫ 0
−∞
(d
dθln f(x.b)
)2
f(x.b)dx+ c
∫ ∞
0
(d
dθln f(x.a)
)2
f(x.a)dx ⇒
I(θ) = IF (θ) (4.10)
onde IF (θ) e a informacao de Fisher para o parametro θ da distribuicao f(z).
A informacao de Fisher para o parametro a da distribuicao h(x) dada por (4.1) e
I(a) = k2 + 2kc
∫ ∞
0
d
daf(ax)dx+ c
∫ ∞
0
[d
daln f(ax)
]2f(ax)dx (4.11)
onde k = ba(a+b) e c e dado por (4.2).
A informacao de Fisher para o parametro b da distribuicao h(x) dada por (4.1) e
I(b) = k2 + 2kc
∫ 0
−∞
d
dbf(bx)dx+ c
∫ 0
−∞
[d
dbln f(bx)
]2f(bx)dx (4.12)
onde k = ba(a+b) e c e dado por (4.2).
A informacao de Fisher para x da distribuicao h(x) dada por (4.1), e
I(x) = abIF (z) (4.13)
onde IF (z) e a informacao de Fisher para a distribuicao f(z).
4.6 Caso especial: Normal
Definimos a distribuicao Normal por:
ϕ(x) =e−x2/2
√2π
(4.14)
Desse modo, utilizando a formula (4.3) temos a distribuicao assimetrica:
h(x) =2ab
a+ bϕ(x.a
|x|/x+12 .b
−|x|/x+12 ) (4.15)
Se a=b, temos:
h(x) = aϕ(ax) = ae−x2a2/2/√2π
Portanto temos uma distribuicao Normal com media 0 e variancia 1/a2.Momentos de h(x), utilizando (4.4):
31

E(xn) =2((−1)n.an+1 + bn+1)
(a+ b)(ab)n
∫ ∞
0
xn e−x2/2
√2π
dx =
=2n/2((−1)n.an+1 + bn+1)
(a+ b)(ab)nΓ((n+ 1)/2)√
π(4.16)
A funcao geratriz de momentos para (4.15) e
Mx(t) =a
a+ bet
2/2b2[1− erf
[t√2b
]]+
b
a+ bet
2/2a2
[1 + erf
[t√2a
]](4.17)
Ou equivalentemente
Mx(t) =2a
a+ bet
2/2b2Φ(−t/b) +2b
a+ bet
2/2a2
Φ(t/a) (4.18)
Utilizando-se de (4.16), temos:
E(x) =2(b− a)
ab
∫ ∞
0
xe−x2/2
√2π
dx =2(b− a)√
2πab(4.19)
E(x2) =a3 + b3
(a+ b)a2b2(4.20)
V ar(x) =1
a2b2
[a3 + b3
a+ b− 2(b− a)2
π
](4.21)
4.6.1 Estimadores de Maxima Verossimilhanca
Considere que nos temos uma amostra x1, x2, ..., xn e queremos estimar a e b, para faz-ermos isso primeiramente colocamos os dados em ordem crescente. Deste modo temos asobservacoes negativas x1, x2, ..., xn′ , e as observacoes positivas xn′+1, ..., xn. Assim, o esti-mador de maxima verossimilhanca a para a e solucao da equacao
a3n′∑i=0
x2i + a2b
n′∑i=0
x2i = nb (4.22)
E o estimador de maxima verossimilhanca b para b e solucao da equacao
b3n∑
i=n′+1
x2i + b2a
n∑i=n′+1
x2i = na. (4.23)
32

4.6.2 Entropias de Renyi e Shannon, e informacao de Fisher para a distribuicaoNormal Assimetrica
A entropia de Shannon para essa distribuicao, usando (4.8) e
Sh(x) =1
2ln(2πe)− ln(c) (4.24)
A entropia de Renyi para esta distribuicao, usando (4.9) e
Rα(x) =1
2ln(2π)− ln(α)
2(1− α)− ln(c) (4.25)
A informacao de Fisher para a, b e x, usando (4.11), (4.12) e (4.13) e
I(a) =b(3a+ 2b)
a2(a+ b)2(4.26)
I(b) =a(3b+ 2a)
b2(b+ a)2(4.27)
I(x) = ab (4.28)
Nos calculamos a informacao de Relativa de Fisher que e definida para duas funcoes dedensidade e probabilidade ρ1(x) e ρ2(x) por
I(p1, p2) =
∫R
f1(x)
[d
dxln
(f1(x)
f2(x)
)]2dx. (4.29)
se ρ1(x) = h(x, a, b) and ρ2(x) = h(x, c, d), entao temos a informacao relativa de Fisher
I(ρ1, ρ2) =a3(b2 − d2
)2+ b3
(a2 − c2
)2a2b2(a+ b)
(4.30)
Nos plotamos as informacao relativa de Fisher para os parametros a, b, c, d na figura 16 e nafigura 17 . Alguns graficos da distribuicao dada pela Eq. (4.15), para alguns valores de a eb, sao dados nas figuras (15) e (14).
33

-3 -2 -1 1 2 3x
0.1
0.2
0.3
0.4
0.5
0.6
hHxL
-3 -2 -1 1 2 3x
0.2
0.4
0.6
0.8
1.0
H@xD
Figura 14: Normal Assimetrica (FDP e Funcao de distribuicao) a = 3 and b = 1
-3 -2 -1 1 2 3x
0.1
0.2
0.3
0.4
0.5
0.6
hHxL
-3 -2 -1 1 2 3x
0.2
0.4
0.6
0.8
1.0
H@xD
Figura 15: Normal Assimetrica (FDP e Funcao de distribuicao) a = 1 and b = 3
0 2 4 6 80
3
6
9
12
15
a
I@hHx
,a,2L
,hHx
,1,1LD
0 2 4 6 80
3
6
9
12
15
b
I@hHx
,1,bL
,hHx
,2,0
.5LD
Figura 16: I(ρ1, ρ2) para b = 2, c = 1, d = 1, e I(ρ1, ρ2) para a = 1, c = 2, d = 0.5
34

0 2 4 6 80
3
6
9
12
15
c
I@hHx
,6,2L
,hHx
,c,2LD
0 2 4 6 80
3
6
9
12
15
d
I@hHx
,2,5L
,hHx
,1,dLD
Figura 17: I(ρ1, ρ2) para a = 6, b = 2, d = 2, e I(ρ1, ρ2) para a = 2, b = 5, c = 1
35

Referencias
[1] Swamee, P.K.; Rathie, P.N. Invertible Alternatives to normal and Lognormal distribu-tion, J.Hydrol. Eng.(2006) ASCE, Accepted for publication.
[2] Swamee, P.K.; Rathie, P.N. On a new Invertible Generalized Logistic Distribution Ap-proximation to Normal Distribution,J.Hydrol. Eng., 2006
[3] Kotz, S.; Read, B.C.; Balakrishnan, N.; Vidakovic, B. Encyclopaedia of StatisticalSciences. 16 Volume Ser. 2nd Edition. John Wiley & Sons. 2005
[4] Luke, Yudell L. The Special Functions and their Approximations. Volume 1.Kansas City. Academic Press. 1969)
[5] Mathai, A. M., Saxena, R.K., The H-Function with Applications in Statistics anOther Disciplines. New Delhi. Wiley Eastern Limited. 1978.
[6] Springer, M. D. The Algebra of Random Variables. University of Arkansas. JohnWiley & Sons. 1978.
[7] Bickel, P.J.; Doksum, K.A. Mathematical Statistics: basic ideas and selected topics.Vol.1. Segunda Edicao. Pearson Prentice Hall
[8] Kotz, S.; Balakrishnan, N.; Johnson, N.L. Continuous Univariate Distribu-tions.John Wiley & Sons
[9] Thomas, J.A.; Cover,T.M. Elements of Information Theory. Segunda Edicao. JohnWiley & Sons. 2006
[10] Coutinho, M. et.al. H-Functions and Statistical Distributions. Ganita. Vol.59. pgs 23-37. 2008.
[11] Yanez,R.J. et.al. Fisher information of special functions and second-order differentialequations. Journal of Mathematical Physics. 2008
[12] Adelchi Azzalini, Pagina pessoal . Disponıvel em:http://azzalini.stat.unipd.it/SN/ .
[13] Azzalini, A.; Capitanio,A. Applications of the Multivariate Skew Normal Distribution.Journal of the Royal Statistical Society. Vol 61. Blackwell Publishing for the RoyalStatistical Society. 1999.
[14] Liseo, B.; Loperfido, N. A Bayesian interpretation of the multivariate Skew-Normaldistribution. Statistic and Probability Letters. Vol.61. Issue 4. Pgs 395-401. 2003
[15] Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Statit.pgs 171-178. 1985
[16] Lin,T.I.; Lee,J.C.; Yen, S.Y. Finite Mixture Modelling Using the Skew Normal Distri-bution. Statistical Sinica. pgs 909-927. 2007.
36

[17] Gomez, H.W. et.al. A new class of skew normal distributions. Communications inStatistics: Theory and Methods.vol 33, pgs 1465-1480. 2003.
[18] Ferreira, J.T.A.S.; Steel, M.F.J. A constructive Representation of univariate SkewedDistributions. Journal of the American Statistical Association. 2006.
[19] Fernandez,C.; Steel, M.F.J. On Bayesian modelling of fat tails skewness. J. Amer.Statist. Assoc. pgs 359-371. 1998.
37





























![4 Distribui%E7%E3o[1]](https://img.document.onl/doc/110x75/5571fb00497959916993b04c/4-distribuie7e3o1.jpg)