Embed Size (px)
Citation preview

ENTENDIMENTO E CRIAÇÃO DE UM ANALISADOR
LÉXICO
Flavio Rodrigues
ITUIUTABA - MG
2013
UEMG – UNIVESIDADE DO ESTADO DE MINAS GERAIS
ISEPI – INSTITUTO SUPERIOR DE ENSINO E PESQUISA DE ITUIUTABA
FEIT – FUNDAÇÃO EDUCACIONAL DE ITUIUTABA

ENTENDIMENTO E CRIAÇÃO DE UM ANALISADOR
LÉXICO
Flavio Rodrigues
Trabalho de aproveitamento do
Curso de Engenharia de
Computação da Fundação
Educacional de Ituiutaba-FEIT
e Universidade do Estado de
Minas Gerais – UEMG como
pré-requisito para obtenção
parcial de créditos na disciplina
de compiladores sob orientação
da Prof.ª Drª. Mônica Rocha.
ITUIUTABA - MG
2013

Resumo
Este trabalho traz as fazes de desenvolvimento e geração de um analisador léxico, sendo
este o objeto de estudo. Para tal desenvolvimento, foi escolhido o Software Gerador de
Analisadores Léxicos e Sintáticos (GALS), sendo este uma ferramenta eficaz para
geração de analisadores léxicos e analisadores sintáticos e com proposito didático
auxiliando na construção de Compiladores.

Introdução
Analisadores Léxicos e Sintáticos são importantes partes de um compilador. Sua
construção sem a utilização de ferramentas de auxílio pode levar a erros no projeto, além de
ser um trabalho desnecessário.
Existem hoje diversas ferramentas comerciais semelhantes, porém a maioria delas
gera apenas ou o Analisador Léxico ou o Sintático, o que obriga o usuário a conhecer duas
ferramentas distintas e leva a incompatibilidades no momento da utilização em conjunto dos
analisadores gerados. Muitas ferramentas geram analisadores segundo uma única técnica de
análise sintática, o que limita seu valor didático. Praticamente todas geram analisadores em
apenas uma linguagem objeto, diminuindo sua flexibilidade. Outro fator agravante é o fato
de serem ferramentas de código fechado, o que impede que se possa provar formalmente o
analisador gerado, já que não se tem acesso a seu código fonte.
Também existem ferramentas livres (gratuitas e de código aberto) para esta tarefa. A
maioria apresenta as mesmas limitações citadas acima. Mas, por se tratarem de software,
livre têm a vantagem de poderem ter seu código-fonte analisado, verificando-se assim se o
que fazem é realmente aquilo que se propõe a fazer.
O GALS tenta superar estes problemas e se tornar uma ferramenta prática e versátil,
com aplicabilidade tanto como ferramenta didática como para uso profissional, promovendo
assim o uso das técnicas formais de análise.

1. Teoria das Linguagens - Analisador Léxico
Um analisador léxico, ou scanner, é um programa que implementa um autômato
finito, reconhecendo (ou não) strings como símbolos válidos de uma linguagem. A
implementação de um analisador léxico requer uma descrição do autômato que
reconhece as sentenças da gramática ou expressão regular de interesse.
Ele lê o texto do programa e o divide em tokens, que são os símbolos básicos de
uma linguagem de programação. Eles representam palavras reservadas, identificadores,
literais numéricos e de texto, operadores e pontuações. Comentários no texto do programa
geralmente são ignorados pelo analisador.
1.1Funções de um Analisador Léxico
Um analisador léxico possui funções importantes e que caracterizam seu
funcionamento e utilização. A classificação e extração dos tokens que compõe o texto
do programa fonte é uma das principais funções de um analisador léxico
Entre a classe de tokens mais encontradas em analisadores léxicos estão:
identificadores, palavras reservadas, números inteiros, cadeias de caracteres, caracteres
especiais simples e compostos.
Espaços em branco, símbolos separadores e comentários são irrelevantes na
geração de código podendo ser eliminados pelo analisador léxico.
1.2 Classificação das gramáticas
As gramáticas foram agrupadas em quatro classes ou tipos, para facilitar seu
estudo. Esta classificação foi feita por Chomsky, de acordo com capacidade
representativa das gramáticas.
Tipo 0 (Gramática sem Restrições): Esta classe engloba todas as gramáticas
possíveis.
Tipo 1 (Gramáticas Sensíveis ao Contexto): Possui a seguinte restrição:
Para toda produção X ::= Y pertencente à gramática, |X| <= |Y| (o tamanho de X
é menor que o tamanho de Y)

Tipo 2 (Gramáticas Livres de Contexto): Possui a restrição das gramáticas
tipo 1, e suas produções devem ser da forma A ::= Y, com A N, e Y (N
ÈT)*
Tipo 3 (Gramáticas Regulares): Além das restrições das gramáticas tipo2, as
tipo 3 só podem ter produções das formas:
A ::= aB, com A e B N, e a T, ou
A ::= a, com A N, e a T.
Vale a pena notar que em gramáticas tipo 2 e 3, produções do tipo A ::= são
permitidas, mesmo que elas quebrem a regra das gramáticas tipo 1 (o tamanho de e é 0,
que é menor que o tamanho do lado esquerdo da produção). Isto é possível graças a um
teorema que prova que para toda gramática tipo 2 ou tipo 3 com este tipo de produção,
pode-se escrever uma equivalente sem este tipo de produção.
1.3 Expressões Regulares
Expressões regulares podem ser expressas através da teoria de linguagens
formais. Elas consistem de constantes e operadores que denotam conjuntos de cadeias
de caracteres e operações sobre esses conjuntos, respectivamente. Dado
um alfabeto finito Σ, as seguintes constantes são definidas:
(conjunto vazio) ∅ denotando o conjunto ∅
(cadeia de caracteres vazia) ε denotando o conjunto {ε}
(literal) a em Σ denotando o conjunto {a}
As seguintes operações são definidas:
(concatenação) RS denotando o conjunto { αβ | α em R e β em S }. Por exemplo,
{"ab", "c"}{"d", "ef"} = {"abd", "abef", "cd", "cef"}.
(alternância) R|S denotando o conjunto união de R e S. Usa-se os
símbolos ∪, + ou ∨ para alternância ao invés da barra vertical. Por exemplo, {"ab",
"c"}∪{"dv", "ef"} = {"ab", "c", "dv", "ef"}

Exemplos
a|b* denota {ε, a, b, bb, bbb, ...}
(a|b)* denota o conjunto de todas as cadeias de caracteres que contém os
símbols a e b, incluindo a cadeia vazia: {ε, a, b, aa, ab, ba, bb, aaa, ...}
ab*(c|ε) denota o conjunto de cadeias de caracteres começando com a, então com
zero ou mais bs e opcionalmente com um c: {a, ac, ab, abc, abb, ...}
A definição formal de expressões regulares é concisa e evita a utilização dos
quantificadores redundantes ? e +, que podem ser expressados respectivamente
por (a|ε) e aa*. Por vezes o operador de complemento ~ é adicionado; ~R denota o
conjunto das cadeias de caracteres de Σ* que não estão em R. Esse operador é
redundante, e pode ser expressado usando outros operadores, apesar da computação
para tal representação ser complexa.
2. Gals – Gerador de Analisador Léxico
GALS é uma ferramenta para a geração automática de analisadores léxicos e
sintáticos. Foi desenvolvido em Java, versão 1.4, de 10 de março de 2003. Utilizado em
qualquer ambiente para o qual haja uma máquina virtual Java. É possível gerar-se
analisadores léxicos e sintáticos, através de especificações léxicas, baseadas em
expressões regulares, e especificações sintáticas, baseadas em gramáticas livres de
contexto. Pode-se fazer os analisadores léxico e sintático independentes um do outro,
bem como fazer de maneira integrada. Existem três opções de linguagem para a geração
dos analisadores: Java, C++ e Delphi. O GALS tenta ser um ambiente amigável, tanto
para uso didático como para o uso profissional.
O objeto de estudo em questão foi desenvolvido no GALS, utilizando toda a
teoria estudada em sala de aula.
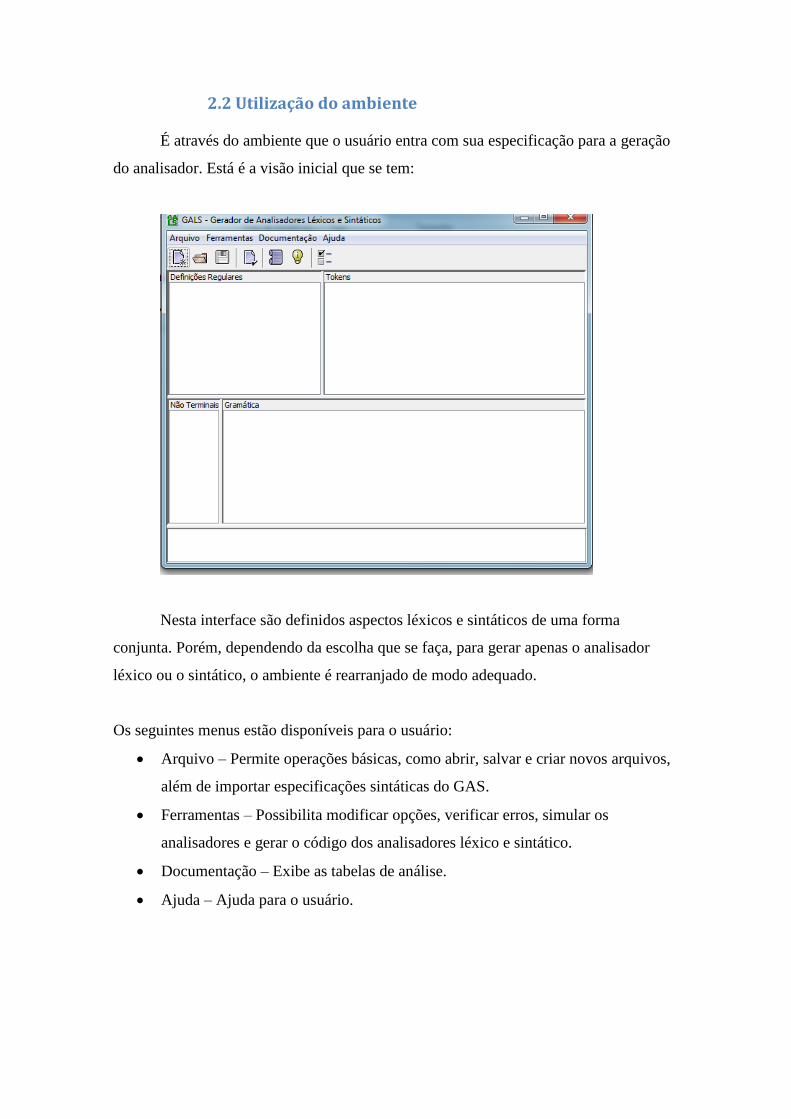
2.2 Utilização do ambiente
É através do ambiente que o usuário entra com sua especificação para a geração
do analisador. Está é a visão inicial que se tem:
Nesta interface são definidos aspectos léxicos e sintáticos de uma forma
conjunta. Porém, dependendo da escolha que se faça, para gerar apenas o analisador
léxico ou o sintático, o ambiente é rearranjado de modo adequado.
Os seguintes menus estão disponíveis para o usuário:
Arquivo – Permite operações básicas, como abrir, salvar e criar novos arquivos,
além de importar especificações sintáticas do GAS.
Ferramentas – Possibilita modificar opções, verificar erros, simular os
analisadores e gerar o código dos analisadores léxico e sintático.
Documentação – Exibe as tabelas de análise.
Ajuda – Ajuda para o usuário.
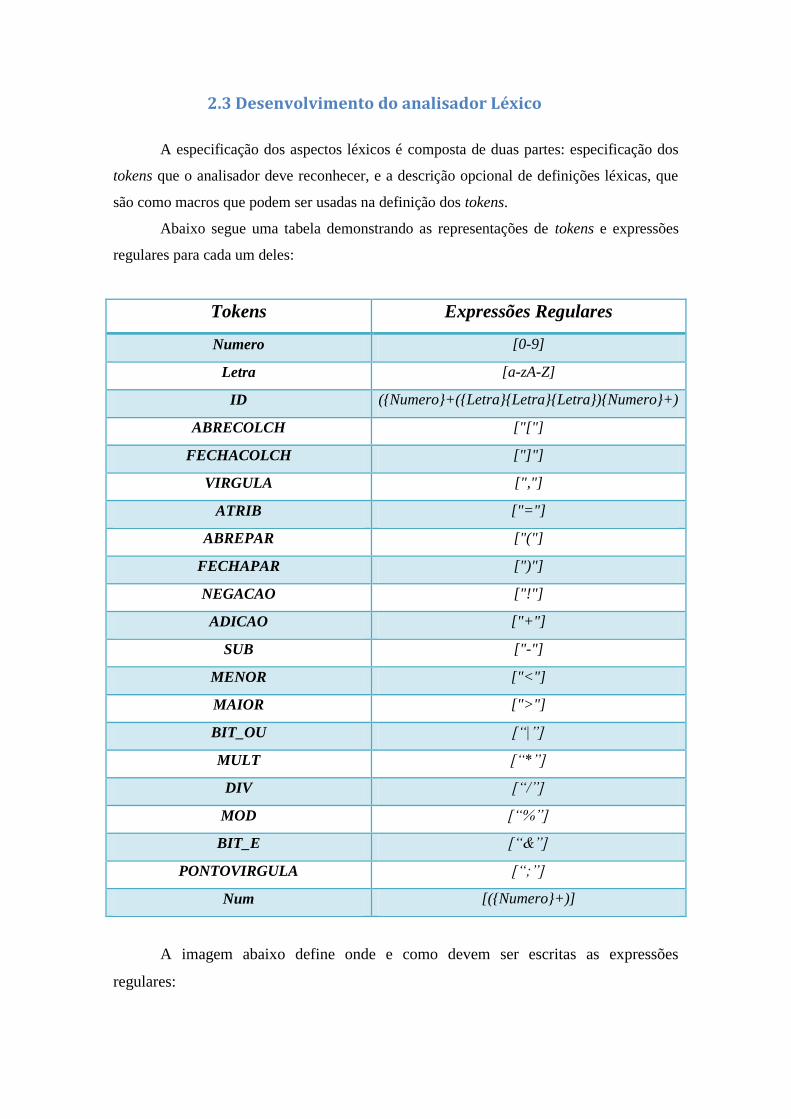
2.3 Desenvolvimento do analisador Léxico
A especificação dos aspectos léxicos é composta de duas partes: especificação dos
tokens que o analisador deve reconhecer, e a descrição opcional de definições léxicas, que
são como macros que podem ser usadas na definição dos tokens.
Abaixo segue uma tabela demonstrando as representações de tokens e expressões
regulares para cada um deles:
Tokens Expressões Regulares
Numero [0-9]
Letra [a-zA-Z]
ID ({Numero}+({Letra}{Letra}{Letra}){Numero}+)
ABRECOLCH ["["]
FECHACOLCH ["]"]
VIRGULA [","]
ATRIB ["="]
ABREPAR ["("]
FECHAPAR [")"]
NEGACAO ["!"]
ADICAO ["+"]
SUB ["-"]
MENOR ["<"]
MAIOR [">"]
BIT_OU [“|”]
MULT [“*”]
DIV [“/”]
MOD [“%”]
BIT_E [“&”]
PONTOVIRGULA [“;”]
Num [({Numero}+)]
A imagem abaixo define onde e como devem ser escritas as expressões
regulares:
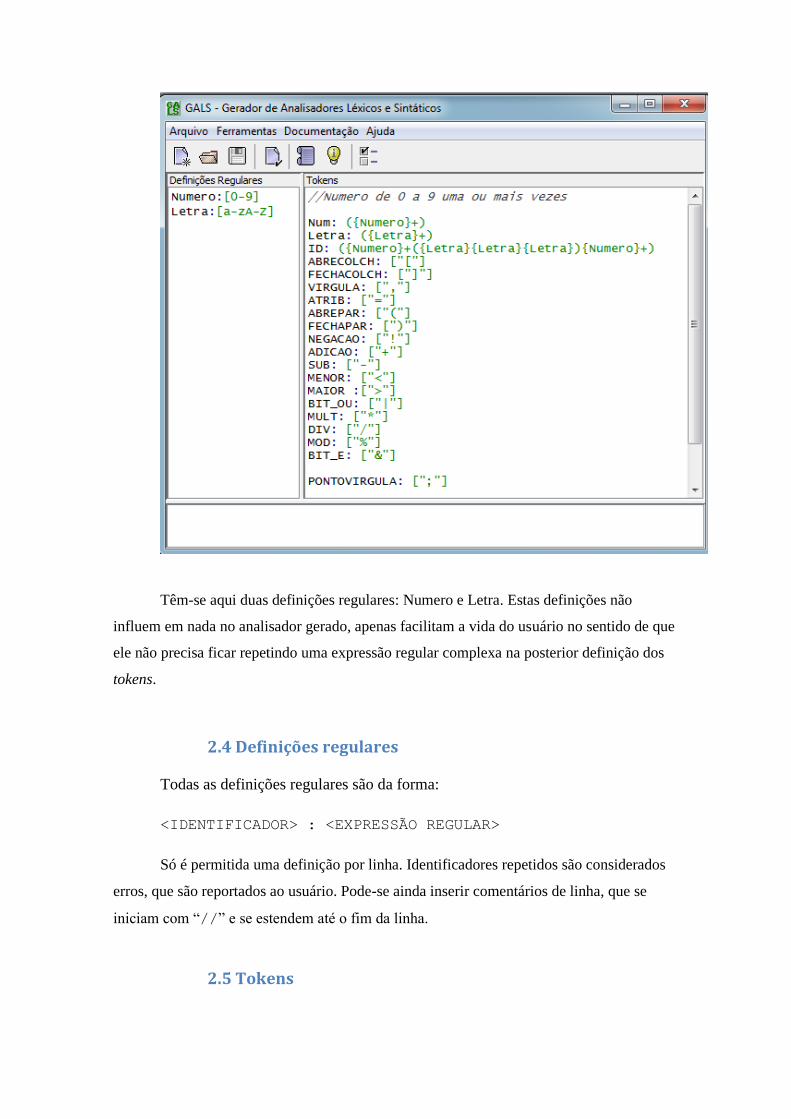
Têm-se aqui duas definições regulares: Numero e Letra. Estas definições não
influem em nada no analisador gerado, apenas facilitam a vida do usuário no sentido de que
ele não precisa ficar repetindo uma expressão regular complexa na posterior definição dos
tokens.
2.4 Definições regulares
Todas as definições regulares são da forma:
<IDENTIFICADOR> : <EXPRESSÃO REGULAR>
Só é permitida uma definição por linha. Identificadores repetidos são considerados
erros, que são reportados ao usuário. Pode-se ainda inserir comentários de linha, que se
iniciam com “//” e se estendem até o fim da linha.
2.5 Tokens
A forma geral da definição de um token é:
<TOKEN> : <EXPRESSÃO REGULAR>
Só é permitida a definição de um token por linha. São aceitos comentários, da
mesma forma que nas definições regulares.
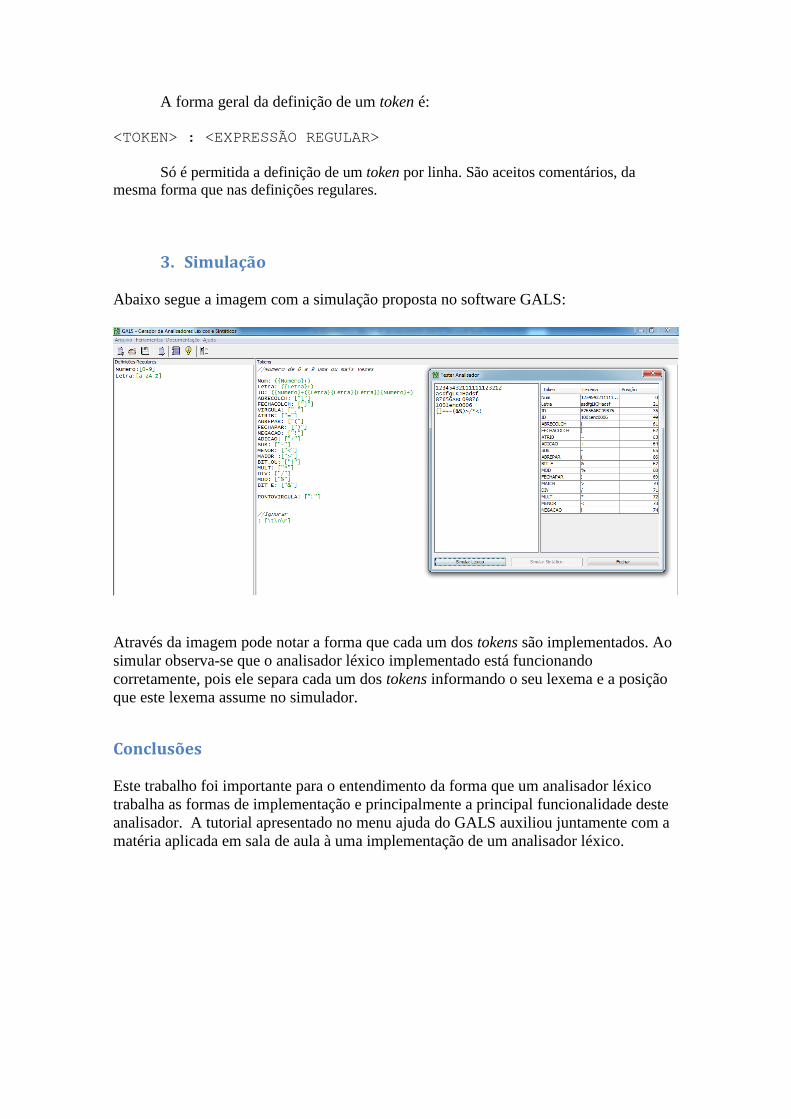
3. Simulação
Abaixo segue a imagem com a simulação proposta no software GALS:
Através da imagem pode notar a forma que cada um dos tokens são implementados. Ao
simular observa-se que o analisador léxico implementado está funcionando
corretamente, pois ele separa cada um dos tokens informando o seu lexema e a posição
que este lexema assume no simulador.
Conclusões
Este trabalho foi importante para o entendimento da forma que um analisador léxico
trabalha as formas de implementação e principalmente a principal funcionalidade deste
analisador. A tutorial apresentado no menu ajuda do GALS auxiliou juntamente com a
matéria aplicada em sala de aula à uma implementação de um analisador léxico.

ANEXO A
Códigos fonte – SyntaticError
public class SyntaticError extends AnalysisError { public SyntaticError(String msg, int position) { super(msg, position); } public SyntaticError(String msg) { super(msg); } }
Códigos fonte – LexicalError
public class LexicalError extends AnalysisError { public LexicalError(String msg, int position) { super(msg, position); } public LexicalError(String msg) { super(msg); } }
Códigos fonte – SemanticError
public class SemanticError extends AnalysisError { public SemanticError(String msg, int position) { super(msg, position); } public SemanticError(String msg) { super(msg); } }

Códigos fonte – Lexico
public class Lexico implements Constants { private int position; private String input; public Lexico() { this(new java.io.StringReader("")); } public Lexico(java.io.Reader input) { setInput(input); } public void setInput(java.io.Reader input) { StringBuffer bfr = new StringBuffer(); try { int c = input.read(); while (c != -1) { bfr.append((char)c); c = input.read(); } this.input = bfr.toString(); } catch (java.io.IOException e) { e.printStackTrace(); } setPosition(0); } public void setPosition(int pos) { position = pos; } public Token nextToken() throws LexicalError { if ( ! hasInput() ) return null;

int start = position; int state = 0; int lastState = 0; int endState = -1; int end = -1; while (hasInput()) { lastState = state; state = nextState(nextChar(), state); if (state < 0) break; else { if (tokenForState(state) >= 0) { endState = state; end = position; } } } if (endState < 0 || (endState != state && tokenForState(lastState) == -2)) throw new LexicalError(SCANNER_ERROR[lastState], start); position = end; int token = tokenForState(endState); if (token == 0) return nextToken(); else { String lexeme = input.substring(start, end); return new Token(token, lexeme, start); } } private int nextState(char c, int state) { int next = SCANNER_TABLE[state][c]; return next; }

private int tokenForState(int state) { if (state < 0 || state >= TOKEN_STATE.length) return -1; return TOKEN_STATE[state]; } private boolean hasInput() { return position < input.length(); } private char nextChar() { if (hasInput()) return input.charAt(position++); else return (char) -1; } }
Código Fonte – Token
public class Token { private int id; private String lexeme; private int position; public Token(int id, String lexeme, int position) { this.id = id; this.lexeme = lexeme; this.position = position; } public final int getId() { return id; } public final String getLexeme() { return lexeme; }

public final int getPosition() { return position; } public String toString() { return id+" ( "+lexeme+" ) @ "+position; }; }
Código fonte – Constantes public interface Constants extends ScannerConstants { int EPSILON = 0; int DOLLAR = 1; int t_Num = 2; int t_Letra = 3; int t_ID = 4; int t_ABRECOLCH = 5; int t_FECHACOLCH = 6; int t_VIRGULA = 7; int t_ATRIB = 8; int t_ABREPAR = 9; int t_FECHAPAR = 10; int t_NEGACAO = 11; int t_ADICAO = 12; int t_SUB = 13; int t_MENOR = 14; int t_MAIOR = 15; int t_BIT_OU = 16; int t_MULT = 17; int t_DIV = 18; int t_MOD = 19; int t_BIT_E = 20; int t_PONTOVIRGULA = 21; }
























![Analisador de Redes - UFPR]](https://img.document.onl/doc/110x75/61946898bc4c990ab107039e/analisador-de-redes-ufpr.jpg)




