Embed Size (px)
Citation preview

ANÁLISE DE REGRESSÃO APLICADA A DADOS LINGÜÍSTICOS DE CRIANÇAS DISLÉXICAS
Gastão Coelho Gomes (DME-IM-UFRJ)[email protected] Clara Oliveira Esteves (Lingüística-UFRJ)[email protected] Christina Abreu Gomes (Lingüística-UFRJ)[email protected]
RESUMO Esse trabalho focaliza a aplicação de métodos estatísticos para subsidiar a interpretação de dados lingüísticos que visam ao entendimento do comportamento de crianças de população clínica. Aplicação de modelos de regressão em dados de crianças disléxicas (DIS) obtidos através da aplicação de teste de nomeação com o objetivo de checar a relação entre o tamanho do léxico (quantidade de palavras armazenadas na memória) e o conhecimento fonológico da criança. O comportamento observado das variáveis indicadoras e a realização dos testes de hipóteses relativos a diferentes modelos encaixantes levaram à proposição de um modelo estatístico parcimonioso para abranger todos os tipos de respostas das crianças DIS. Os resultados obtidos pela análise exploratória subsidiaram a interpretação das hipóteses lingüísticas, motivação inicial do problema, e conduziram à observação de questões da metodologia de análise de regressão com modelos encaixantes e variáveis indicadoras. PALAVRAS CHAVE: Lingüística; Análise de Regressão; Variáveis Indicadoras.
ABSTRACT This paper focuses on the use of statistical models to give support to the interpretation of linguistic data attempting to understand the behavior of children with language disorder. Application of regression models to data from dyslexic children (DIS) through a naming test in other to check the relationship the child's lexicon size (the amount of words represented in the memory) and child’s phonological knowledge. The observed behavior of the studied dummy variables and the use of hypothesis tests related to nested models leaded to the proposition of a parsimonious statistical model to handle the types of answers from DIS children. The results obtained through exploratory analysis gave support to interpreting the linguistic hypothesis proposed, the original motivation for the study, and conducted to some methodological issues about regression analysis of nested models and dummy variables. KEYWORDS: Linguistics; Regression Analysis; Dummy variables.
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 322

1. Introdução Nesse trabalho procuramos explicar e comparar, através de modelos de análise de regressão,
o comportamento observado em crianças disléxicas (DIS) a partir de dados obtidos em situação de teste. O objetivo é avaliar hipótese lingüística sobre relação entre tamanho do léxico e representação da forma sonora das palavras na memória.
Uma hipótese corrente na literatura sobre dislexia é que o déficit de processamento no acesso à forma das palavras no léxico mental resulta de um déficit na representação das formas sonoras das palavras no léxico, embora não haja nenhuma menção na literatura de problemas de desempenho relacionados à produção das palavras pelas crianças disléxicas em fala espontânea. Baseando-nos em hipótese dos modelos baseados no uso “usage-based models” (Bybee, 2001; Pierrehumbert, 2003), segundo a qual um léxico de tamanho adequado à idade é suficiente para o estabelecimento da gramática fonológica de uma língua, procuramos defender posição contrária à da literatura, isto é, que as crianças disléxicas não apresentam problema de representação fonológica. Especificamente, nossa hipótese é a de que, se as crianças disléxicas não têm léxico deficitário, vão apresentar o mesmo comportamento que as crianças controle num teste de nomeação, que checa acesso às palavras no léxico, no que diz respeito ao tamanho do léxico e à natureza das respostas fornecidas. A análise de regressão tem sido o modelo utilizado por esse grupo em problemas relacionados à produção, percepção e processamento da linguagem (cf. Gomes, Ferreira, Gomes, 2007).
Crianças com dislexia se caracterizam por apresentar dificuldades na aprendizagem da leitura. Constitui o conjunto de observações para o grupo de crianças disléxicas e respectivos controles: 1. a variável dependente, y=%R, as percentagens de respostas correspondentes ao alvo, as substituições semânticas e as substituições fonológicas realizadas. 2. as variáveis explicativas o tamanho do léxico da criança e as variáveis indicadoras, representando os três tipos de resposta, a saber: de acordo com o alvo (Ac) (p.ex., alvo = telefone, resposta = telefone); substituição semântica (SS) (p.ex. alvo = jipe, resposta = carro); substituição fonológica (SF) (p.ex. alvo = sela, resposta = fivela). 1. 1 Descrição do Experimento
Para o grupo de crianças DIS, os dados foram coletados através da aplicação de um teste de nomeação elaborado para as finalidades da pesquisa. O teste de nomeação consistiu de 36 itens lexicais. As figuras do teste representam palavras que diferem em tamanho e freqüência de token (ocorrência). Foram 18 dissilábicas e 18 polissilábicas. Metade dos itens de cada categoria de tamanho era de alta freqüência de token e metade de baixa freqüência de token. O tamanho da palavra foi definido em função do número de sílabas, embora o tamanho das palavras seja semelhante também quanto ao número de segmentos para a maioria dos itens de cada categoria. Tomou-se o cuidado de que haja uma divisão clara entre as palavras de menor tamanho (SL) e as de maior tamanho (LL). Por exemplo, os itens SL são todos dissilábicos ao passo que os itens LL são todos de quatro sílabas, com exceção de um item com 5 sílabas. A freqüência de token e o vocabulário das crianças foi considerado na seleção dos itens lexicais a serem examinados. A contagem de freqüência dos itens foi obtida de um corpus de 130 milhões de palavras e agrupada nas duas categorias de alta e baixa freqüência (www.projetoaspa.org). O conjunto de estímulos está apresentado em anexo (tabela A1). Cada criança foi entrevistada individualmente em uma sessão. As crianças eram instruídas a olhar cada figura e dizer o nome do objeto. Se a criança não conseguisse dizer a palavra alvo, ou apresentasse uma substituição de qualquer tipo, a aplicadora do teste apresentava pistas semânticas e em seguida fonológicas, sempre nessa ordem. Para as análises conduzidas nesse trabalho, foram consideradas somente as primeiras respostas fornecidas, sem qualquer tipo de pista. As respostas foram classificadas em corretas, se iguais ao alvo. As respostas
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 323

diferentes do alvo, as substituições, foram classificadas quanto ao tipo: substituição semântica, se o alvo era espingarda e a criança falou arma; substituição fonológica, se a palavra resultante é semelhante do ponto de vista sonoro, mas não pertence ao campo semântico do alvo, como a substituição de harpa por arca; pseudopalavra, quando a substituição sonora resulta em uma palavra possível, mas não existente na língua, como ‘iblu’ por iglu; substituições mistas, que conjugam mais de um tipo de substituição. Foram calculados, então, para cada criança, os percentuais de acerto e os percentuais dos diferentes tipos de substituição, agrupando-se as substituições fonológicas e pseudopalavras. Não foram considerados na análise de regressão os percentuais obtidos para as substituições mistas. É possível que uma criança não tenha apresentado todos os tipos de substituição.
O desenho do experimento segue um dos modelos aplicados e consagrados nas pesquisas psicolingüísticas experimentais. Uma mesma lista de estímulos é apresentada a uma determinada quantidade de sujeitos para se estabelecer um padrão comportamental.
O grupo experimental é formado por 11 crianças de classe sócio-econômica média, na faixa etária de 8 a 11 anos. As crianças do grupo controle totalizam 13 e cursavam a mesma escola particular de classe sócio-econômica média, na faixa etária de 9 e 10 anos. Conforme descrito, na pesquisa outras variáveis foram utilizadas para observar o comportamento das crianças a partir do teste de nomeação, no entanto, serão discutidos no presente trabalho somente aqueles resultados relativos ao tamanho do léxico.
O tamanho do léxico da criança foi obtido através do teste Peabody, que é um teste padronizado adaptado para o português e utilizado com aplicação clínica. O teste de vocabulário receptivo de Peabody (Dunn & Dunn, 1997) é um teste de compreensão que visa quantificar o conhecimento do vocabulário em crianças (a partir de 2 anos e meio) e adultos. Consiste de uma série de cartões, cada qual contendo 4 gravuras diferentes, num total de 204 cartões. A criança é solicitada a identificar a gravura que melhor representa o significado da palavra enunciada pelo examinador. O teste foi administrado conforme as instruções especificadas no manual, com as palavras traduzidas para o português, e os scores já estabelecidos para cada idade utilizados como referência para a análise (ver tabela A2 em anexo). Para a faixa etária das crianças da amostra, o score esperado para as crianças com desenvolvimento típico está entre 51 e 79 pontos. O score pode estar adequado, abaixo ou acima do esperado.
Observar se há relação entre o tamanho do léxico e a porcentagem de acertos e substituições semânticas e fonológicas para as crianças DIS pode subsidiar a discussão da hipótese lingüística segundo a qual o conhecimento fonológico emerge das formas fonéticas das palavras armazenadas no léxico. De acordo com Bybee (2001) e Pierrehumbert (2003), postula-se que há dois níveis de representação da informação sobre a forma sonora das palavras armazenadas no léxico mental. Um nível fonético fino, em que memórias extremamente detalhadas da experiência de produzir e perceber os itens são estocadas, e um nível de categorias abstratas (estrutura da palavra em termos de números de segmentos, tipos silábicos, etc) que vai emergir da representação fonética fina dos itens estocados no léxico mental. O aumento gradativo do léxico, dentro dos padrões esperados por idade, permite o aumento da acuracidade no desempenho das crianças, já que uma quantidade maior de itens vai demandar um refinamento da informação fonética, ao mesmo tempo em que permite abstrações de mais padrões estruturais. Esses padrões, por sua vez, serão utilizados na interpretação e incorporação de novos itens lexicais. Portanto, mais itens estocados possibilitam mais abstrações de tipos estruturais fonológicos e representação de acordo com a língua. No caso das crianças DIS, o percentual de respostas de acordo com alvo pode ser indicativo de problema de acesso às formas das palavras no léxico.
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 324

2. Análise Estatística A técnica estatística que usamos é Análise de Regressão, sendo a %R, percentagem de respostas
de acordo com o alvo, a variável a explicar. As variáveis explicativas são o tamanho do léxico (x) e algumas variáveis indicadoras, ou seja, variáveis que assumem o valor um quando a característica está presente e o valor zero quando ela está ausente. Um bom exemplo do uso de variáveis indicadoras pode ser visto em Weisberg (1985, pag. 177-183). As 5 variáveis indicadoras aqui usadas são:
� I1 para indicar se a observação corresponde à resposta de acordo com o alvo - Ac, � I2 para indicar se a observação corresponde à substituição semântica - SS, � I3 para indicar se a observação corresponde à substituição fonológica - SF, � ID para indicar se a observação corresponde à criança Disléxica. � IC para indicar se a observação corresponde à criança do Grupo Controle.
As indicadoras I1, I2, I3 são excludentes entre si: quando para uma observação uma delas assume o valor um, as outras assumem o valor zero.
2.1 Análise Exploratória A seguir apresentamos, para efeito descritivo das observações, os gráficos de cada um dos tipos de resposta para o grupo das crianças DIS e para o grupo das crianças controle (CON). Foram tomados alguns cuidados para facilitar a comparação entre os grupos em cada caso. No eixo vertical, em que é medida a variável resposta, %R, foi padronizada a mesma escala, de 0 a 100. Em todos os três gráficos dos dois grupos, DIS e CON, as retas de mínimos quadrados foram ajustadas aos pontos e traçadas. Conforme pode ser observado nos gráficos abaixo, o percentual de respostas de acordo com o alvo (Ac) e o de substituições semânticas (SS) não é influenciado pelo tamanho do léxico tanto para as crianças DIS quanto para o grupo controle. Já as substituições fonológicas (SF) entre as crianças DIS apresentam-se com uma diminuição conforme aumenta o tamanho do léxico da criança. Além disso, observa-se que os níveis dos percentuais são diferentes entre os dois grupos, sendo o percentual de acertos entre as crianças DIS inferior ao das crianças CON. 2.1.1 Gráficos de %R versus Tamanho do Léxico para o grupo DIS
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 325
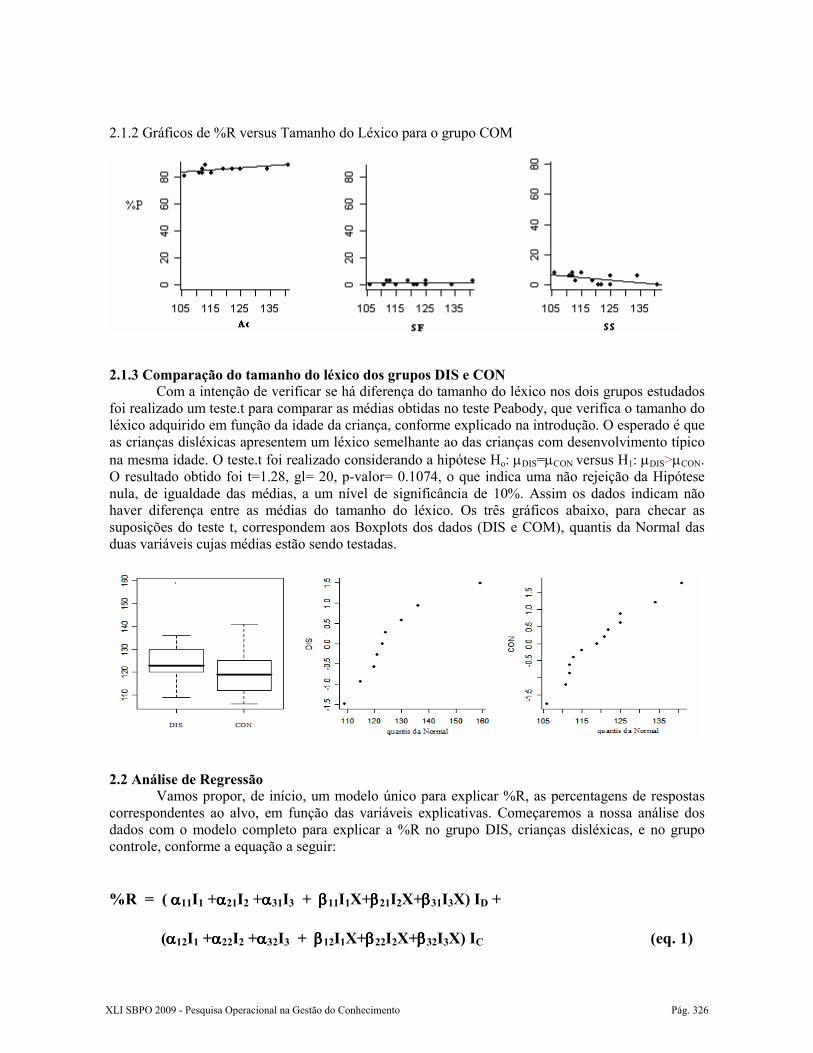
2.1.2 Gráficos de %R versus Tamanho do Léxico para o grupo COM
2.1.3 Comparação do tamanho do léxico dos grupos DIS e CON
Com a intenção de verificar se há diferença do tamanho do léxico nos dois grupos estudados foi realizado um teste.t para comparar as médias obtidas no teste Peabody, que verifica o tamanho do léxico adquirido em função da idade da criança, conforme explicado na introdução. O esperado é que as crianças disléxicas apresentem um léxico semelhante ao das crianças com desenvolvimento típico na mesma idade. O teste.t foi realizado considerando a hipótese Ho: µDIS=µCON versus H1: µDIS>µCON. O resultado obtido foi t=1.28, gl= 20, p-valor= 0.1074, o que indica uma não rejeição da Hipótese nula, de igualdade das médias, a um nível de significância de 10%. Assim os dados indicam não haver diferença entre as médias do tamanho do léxico. Os três gráficos abaixo, para checar as suposições do teste t, correspondem aos Boxplots dos dados (DIS e COM), quantis da Normal das duas variáveis cujas médias estão sendo testadas.
2.2 Análise de Regressão
Vamos propor, de início, um modelo único para explicar %R, as percentagens de respostas correspondentes ao alvo, em função das variáveis explicativas. Começaremos a nossa análise dos dados com o modelo completo para explicar a %R no grupo DIS, crianças disléxicas, e no grupo controle, conforme a equação a seguir: %R = ( αααα11I1 +αααα21I2 +αααα31I3 + ββββ11I1X+ββββ21I2X+ββββ31I3X) ID +
(αααα12I1 +αααα22I2 +αααα32I3 + ββββ12I1X+ββββ22I2X+ββββ32I3X) IC (eq. 1)
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 326
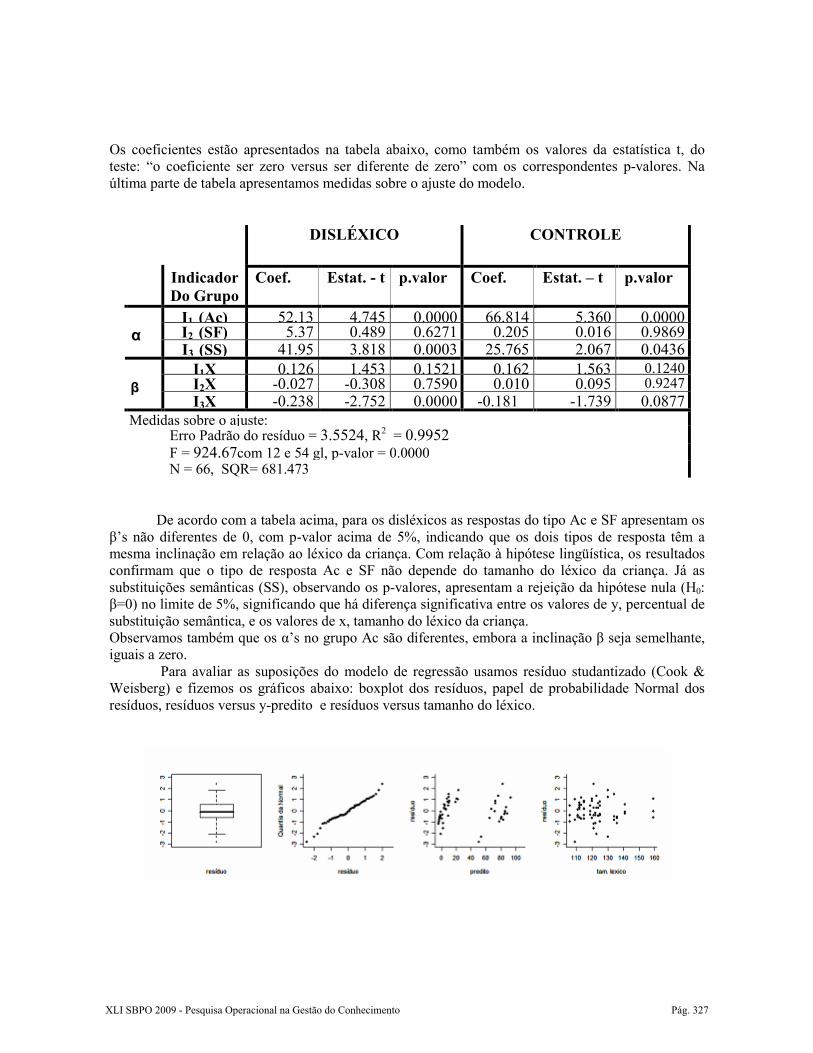
Os coeficientes estão apresentados na tabela abaixo, como também os valores da estatística t, do teste: “o coeficiente ser zero versus ser diferente de zero” com os correspondentes p-valores. Na última parte de tabela apresentamos medidas sobre o ajuste do modelo.
DISLÉXICO CONTROLE
Indicador Do Grupo
Coef. Estat. - t p.valor Coef. Estat. – t p.valor
I1 (Ac) 52.13 4.745 0.0000 66.814 5.360 0.0000 I2 (SF) 5.37 0.489 0.6271 0.205 0.016 0.9869
α I3 (SS) 41.95 3.818 0.0003 25.765 2.067 0.0436
I1X 0.126 1.453 0.1521 0.162 1.563 0.1240 I2X -0.027 -0.308 0.7590 0.010 0.095 0.9247
β
I3X -0.238 -2.752 0.0000 -0.181 -1.739 0.0877
Medidas sobre o ajuste: Erro Padrão do resíduo = 3.5524, R2 = 0.9952 F = 924.67com 12 e 54 gl, p-valor = 0.0000 N = 66, SQR= 681.473
De acordo com a tabela acima, para os disléxicos as respostas do tipo Ac e SF apresentam os β’s não diferentes de 0, com p-valor acima de 5%, indicando que os dois tipos de resposta têm a mesma inclinação em relação ao léxico da criança. Com relação à hipótese lingüística, os resultados confirmam que o tipo de resposta Ac e SF não depende do tamanho do léxico da criança. Já as substituições semânticas (SS), observando os p-valores, apresentam a rejeição da hipótese nula (H0: β=0) no limite de 5%, significando que há diferença significativa entre os valores de y, percentual de substituição semântica, e os valores de x, tamanho do léxico da criança. Observamos também que os α’s no grupo Ac são diferentes, embora a inclinação β seja semelhante, iguais a zero. Para avaliar as suposições do modelo de regressão usamos resíduo studantizado (Cook & Weisberg) e fizemos os gráficos abaixo: boxplot dos resíduos, papel de probabilidade Normal dos resíduos, resíduos versus y-predito e resíduos versus tamanho do léxico.
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 327

2.3 Análise visando à identificação dos tipos de respostas com comportamento equivalente Além desta formulação geral temos também como interesse juntar tipos de respostas que apresentam comportamentos equivalentes conforme sugerido pela análise exploratória precedente aliada às hipóteses lingüísticas referidas anteriormente na introdução. Para isso consideraremos modelos aninhados (Weisberg, 1985). Para decidirmos sobre a semelhança dos dois modelos em questão, o completo e o reduzido, com menos variáveis explicativas, será testada uma hipótese de igualdade dos parâmetros (inclinação e/ou intercepto) para as diferentes respostas. A estatística de teste F estará baseada nas SQR (soma dos quadrados dos resíduos) dos modelos em questão com os seus respectivos gl (graus de liberdade):
( ) ( )
CC
CRCRCR gl/SQR
glgl/SQRSQRF
−−= (eq. 2)
onde o índice C significa modelo completo e o R significa reduzido. O objetivo é juntar grupos sem que aumente significativamente a SQR, sendo a medida para esta verificação a estatística CRF acima. A tradução de FCR foi expressa numa função, apresentada em
anexo, feita no software “R”. Procuraremos identificar os tipos de resposta para os quais haja uma grande proximidade
dos s'β (inclinação), o que indicaria o mesmo comportamento em relação ao tamanho do léxico da
criança. Testaremos então a hipótese de que os s'β correspondentes a essas respostas são iguais.
Caso a hipótese nula (de igualdade dos s'β ) seja aceita, poderemos concluir que o modelo reduzido é mais indicado que o modelo completo para aquele particular Problema. O p-valor correspondente à estatística CRF acima mencionada é o instrumento que nos permitirá decidir pela aceitação ou pela
rejeição dessa hipótese. O mesmo tipo de raciocínio também foi tentado com relação aos s'α (intercepto), porém,
como estes são muito sensíveis a pequenas variações dos s'β , neste caso obtivemos pouco sucesso
em termos da redução dos modelos. 2.3.1 Em Busca de um modelo reduzido mais adequado. Sugerido pela análise dos gráficos 2.1.1 e 2.1.2, procuramos checar se as inclinações observadas dos processos Ac e SF podem ser consideradas iguais no modelo reduzido. Depois de várias tentativas o modelo reduzido mais parcimonioso é o seguinte:
%R = ( 68.00 I1 + 38.98 I3) ID + (86.25 I1 + 29.82 I3) IC -- 0.2144 I3 X (ID + IC) (eq. 3)
Os resultados obtidos com a função f.encaixante foram: F = 1.355 com 53 e 60 graus de liberdade, correspondendo a um p-valor = 0.2437, o que
indica que o modelo reduzido é equivalente ao modelo completo.
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 328

3. Discussão da metodologia 1. Modelo único versus 6 modelos separados Uma alternativa à abordagem aqui utilizada teria sido ajustar 6 modelos diferentes, um para cada tipo de resposta e para cada grupo de crianças - DIS e desenvolvimento típico. Caso isso tivesse sido feito, os valores estimados dos coeficientes de cada reta teriam sido exatamente os mesmos aqui obtidos. Qual seria então a diferença entre essas duas possíveis abordagens? • A abordagem obtida neste trabalho pressupõe que a variabilidade dos pontos em torno de cada
uma das retas de regressão é sempre a mesma. Evidentemente não haveria nenhuma razão para que isso acontecesse caso tivéssemos optado pelo outro caminho.
• Optamos por construir um modelo único devido à nossa intenção de testar a igualdade dos coeficientes (linear e angular) para diferentes processos, o que era um objetivo importante do trabalho.
2. A Premissa de Normalidade do erro. A validade dos testes de hipótese realizados neste trabalho depende da suposição de que o
erro segue uma distribuição normal. Dado que esses testes eram o núcleo principal de interesse da pesquisa, foi importante verificar a validade dessa premissa com base na análise dos resíduos. Os plots de resíduos contra os quantis da normal se revelaram satisfatórios. 3. Questionando a independência entre as observações.
Dado que no nosso caso uma mesma criança foi observada em vários tipos de respostas em função do seu score de tamanho do léxico, assim era natural que surgisse uma certa preocupação com a possibilidade de ocorrência de autocorrelação no erro. Entretanto esse questionamento fica amenizado na medida em que foram consideradas réplicas (9 no grupo DIS e 13 no grupo CON), o que deve ter concorrido para minimizar esse possível desvio em relação às premissas da modelagem. 4. Importância da Análise dos resíduos
Vale a pena ressaltar que neste estudo, se não tivesse sido feita uma análise criteriosa dos resíduos, não teria sido detectado o comportamento atípico de uma das observações. 4. Conclusões Do ponto de vista da análise estatística, a busca dos modelos mais adequados para explicação da %R, a variável resposta, revelou um modelo reduzido mais parcimonioso que os modelos completos em função das regressões apresentadas em um único modelo, juntando todos os tipos de resposta dos dois grupos de crianças analisadas.
A análise estatística permitiu identificar, através dos coeficientes angulares β’s um comportamento semelhante em relação ao tamanho do léxico tanto para as crianças DIS como para as crianças CON. Em ambos os grupos não há relação entre o tipo de resposta de acordo com o alvo (Ac) e as substituições fonológicas e a quantidade de palavras armazenadas pelas crianças. Para as respostas relativas à substituição semântica (SS), a inclinação observada também é a mesma para os dois grupos, mas com sinal negativo, isto é, conforme o tamanho do léxico aumenta, diminui o percentual de substituições semânticas.
Complementarmente, os coeficientes lineares de α revelaram que o %R é o mesmo (zero) para os dois grupos, DIS e CON, para as respostas com substituição fonológica e diferente de zero para as respostas Ac e SS, sendo %R maior entre as crianças disléxicas, embora essa diferença não tenha relação com o tamanho do léxico.
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 329

Os resultados comparativos dos tamanhos dos léxicos dos dois grupos e o menor percentual de acertos entre as crianças disléxicas sustentam a hipótese levantada na introdução de que essas crianças apresentam problema de acesso à forma das palavras e não um problema de representação. Não existe evidência na literatura de que crianças com o tamanho do léxico adequado para a idade não consigam desenvolver abstrações fonológicas suficientes para dar conta da representação da forma sonora das palavras. Além disso, o comportamento observado para as substituições fonológicas mostra que ambos os grupos utilizam essa estratégia da mesma maneira.
5. Referências Bibliográficas Beckman, M, Munson, E. Edwards, J. (2007) Vocabulary growth and the developmental expansion of types of phonological knowledge. To appear in Laboratory Phonology 9. Bybee, J. (2001) Phonology and Language Use. Cambridge, Cambridge University Press. Cook, R. D. & Weisberg, S. (1982) Residuals and Influence in Regression, Chapman and Hall, New York. Dunn, L. M., Dunn, D., Capovilla, F. C. & Capovilla, A.G. S. (1997). Teste de Vocabulário por Figuras Peabody – Versão Brasileira. São Paulo: Casa do Psicólogo. Gomes, G. C., Ferreira, A. de A., Gomes, C. A. (2007) Um Modelo em Análise de Regressão para Avaliar o Desempenho Fonológico de Crianças com Distúrbio Específico da Linguagem In: XXXIX Simpósio Brasileiro de Pesquisa Operacional, 2007, Fortaleza. Anais do XXXIX Simpósio Brasileiro de Pesquisa Operacional. Rio de Janeiro: SOBRAPO, 2007. v.1. p.1 - 12 Lamprecht, R. (org) (2003) Aquisição Fonológica do Português, Porto Alegre, Artes Médicas. Montgomery, D. C. & Peck, E. (1982) A. Introduction to Linear Regression Analysis, John Wiley and Sons. Pierrehumbert, J. (2003) Probabilistic Phonology: discrimination and robustness. In: R. Bod, J. Hay, S. Jannedy (eds). Probabilistic Linguistics. Cambridge/Massachussets, MIT Press. Weisberg, S. (1985) Applied Linear Regression, 2nd ed, John Wiley and Sons.
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 330

ANEXO Função de FCR realizada no “R” f.encaixante=function(xc, xr, y){ reg.c=lsfit(xc, y,int=F) #Modelo Completo reg.r=lsfit(xr, y, y,int=F) #Modelo Reduzido rss.c=sum(reg.c$resid^2) rss.r=sum(reg.r$resid^2) gl.c=length(y)-dim(xc)[2]-1 gl.r=length(y)-dim(xr)[2]-1 f=((rss.r-rss.c)/(gl.r-gl.c))/(rss.c/gl.c) pvalor=1-pf(f, gl.r-gl.c, gl.c) c(f, pvalor)
} TABELA A1. Lista das Palavras do Teste de Nomeação Palavras dissilábicas Palavras Polissilábicas
Palavras de Alta Freqüência de Token Cama Geladeira Mesa Telefone Maçã Pirulito Bala Borboleta Mala Sabonete Milho Televisão Bolo Dinossauro Vela Detetive Gato Escorrega
Palavras de Baixa Freqüência de Token Bule Pirâmide Leque Cogumelo Jipe Binóculo Sino Ferradura Lupa Alfinete Rolha Envelope Harpa Espingarda Sela Rinoceronte Iglú Espantalho
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 331

Tabela A2. Peabody – Tabela de Idades IDADE EQUIVALENTE A PONTUAÇÃO
Pontos Idade Média Pontos Idade Média Pontos Idade Média
Pontos Idade Média
0-22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
<1-09 1-9 1-10 1-11 2-00 2-01 2-02 2-04 2-05 2-06 2-07 2-08 2-09 2-10 2-11 3-00 3-00 3-01 3-02 3-03 3-04 3-05 3-06 3-07 3-08 3-09 3-10 3-11 3-11 4-00 4-01 4-02 4-03 4-04 4-05 4-05 4-06 4-07 4-08
61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
4-09 4-10 4-10 411 5-00 5-01 5-02 5-03 5-03 5-04 5-05 5-06 5-07 5-08 5-08 5-09 5-10 5-11 6-00 6-01 6-01 6-02 6-03 6-04 6-05 6-06 6-06 6-07 6-08 6-09 6-10 6-11 7-00 7-01 7-02 7-02 7-03 7-04 7-05
100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138
7-06 7-07 7-08 7-09 7-10 7-11 8-00 8-01 8-02 8-03 8-04 8-05 8-06 8-07 8-08 8-09 8-10 8-11 9-00 9-01 9-02 9-03 9-04 9-06 9-07 9-08 9-09 9-11 10-00 10-01 10-03 10-04 10-05 10-06 10-08 10-09 10-11 11-00 11-02
139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177
11-04 11-05 11-07 11-09 11-11 12-00 12-02 12-04 12-06 12-08 12-11 13-01 13-03 13-05 13-08 13-10 14-01 14-03 14-06 14-09 15-00 15-03 15-06 15-09 16-01 16-04 16-08 17-00 17-05 17-09 18-02 18-07 19-01 19-09 20-04 20-11 21-10 22+ 22+
XLI SBPO 2009 - Pesquisa Operacional na Gestão do Conhecimento Pág. 332