Embed Size (px)
Citation preview

Guilherme Martins Dias Batista
Túlio Tonini da Silva
Regressão para Variáveis Categóricas
Ordinais aplicado em indicadores
financeiros
CURITIBA
2009

2
Guilherme Martins Dias Batista
Túlio Tonini da Silva
Regressão para Variáveis Categóricas Ordinais
aplicado em indicadores financeiros
Trabalho apresentado à disciplina de Labora-
tório de Estatística II do curso de Estatística
do Departamento de Estatística do Setor de
Ciências Exatas da Universidade Federal do
Paraná.
Orientador: Prof. Fernando Lucambio Pérez
CURITIBA
2009

3
Sumário RESUMO ..........................................................................................................................4
1. INTRODUÇÃO ............................................................................................................5
2. MATERIAIS E MÉTODOS .........................................................................................6
2.1 Regressão Logística ..............................................................................................6
2.2 Razão Contínua .....................................................................................................7
2.3 Estereótipo ............................................................................................................7
2.4 Odds Proporcionais ...............................................................................................8
2.5 Odds Proporcionais Parciais .................................................................................9
2.6 Banco de Dados ..................................................................................................10
3. RESULTADOS ..........................................................................................................13
4. CONCLUSÕES ..........................................................................................................23
5. REFERÊNCIAS .........................................................................................................24
6. APÊNDICE....... .........................................................................................................24

4
RESUMO
Em muitos estudos as informações disponíveis são classificadas em mais do que
duas categorias, nessas situações modelos de regressão para variáveis ordinais
são interessantes.
Neste trabalho fez-se um apanhado e um resumo dos modelos existentes e
propostos na literatura, em seguida uma aplicação em dados financeiros é
mencionado com resultado e com mais detalhes sobre o modelo mais adequado
para a situação encontrada.
Palavras-chaves: Regressão Ordinal, variáveis ordinais

5
1. INTRODUÇÃO
No presente trabalho estuda-se a relação entre uma variável resposta Y com um
conjunto de covariáveis ou variáveis explicativas 1x , 2x ,..., px que podem ser contínuas
ou discretas. Discute-se aqui o caso da variável resposta Y ter mais do que dois níveis
de resposta (multinomial), caracterizando assim um modelo de regressão para variáveis
categóricas.
A ênfase deste trabalho será dada na chamada regressão ordinal, que nada mais é do que
uma extensão dos modelos de regressão logística (no qual as variáveis são dicotômicas,
univariadas).
Com a intenção de se fazer estudos que permitam trabalhar com mais do que dois níveis
para variáveis categóricas, surgem modelos como regressão logística politômica, que
permitem avaliar relações entre covariáveis e a variável resposta com mais de um nível
tanto para variáveis que não exista uma ordenação natural quanto para as que existem,
(modelos de regressão ordinais).
Quando a variável resposta possui mais de dois níveis e pela sua natureza seja ordenada,
existem algumas metodologias de análise, dentre elas o modelo de Odds Proporcionais,
modelo de Odds Proporcionais Parciais, modelo de Razão Contínua e o modelo
Estereótipo. Estes modelos pertencem à família logística, que contém uma hierarquia de
modelos tanto para dados ordenados quanto nominais.
A escolha do modelo depende de como foi construída a variável resposta e de algumas
suposições. A metodologia se encaixa tanto para X fixo e y aleatório quanto para
ambos aleatórios.
É importante comentar que a classes de modelos atualmente estudadas não cobrem
todos os tipos de problemas que surgem na prática. Apesar dessa diversidade e dessa
grande variedade de estudos sobre o assunto, a sua utilização ainda é escassa. Isto pode
ser atribuído não só a complexidade, mas especialmente à dificuldade da validação de
seus pressupostos. Outro fator que poderia estar relacionado a pouca utilização destes
modelos são as reduzidas opções de modelagem em pacotes estatísticos comerciais.
Mais a frente, para exemplificar o uso da metodologia de regressão para variáveis
categóricas ordenadas, optou-se por estudar o banco de dados ‘Financial Structure
Dataset’, que possui indicadores financeiros de vários bancos de vários países, que
medem entre outras coisas, tamanho, atividade, importância.

6
2. MATERIAIS E MÉTODOS
2.1 Regressão Logística
Segue uma pequena revisão que serve de base para o acompanhamento dos modelos
propostos na introdução (Giolo 2006). Experimentos e estudos em geral podem ser
modelados pela regressão logística quando a variável resposta de interesse é de natureza
dicotômica. Fazendo uma analogia com modelos de regressão linear podemos perceber
que [ ] +∞<<∞− xYE | e que Y é contínua e neste caso estimamos a média da variável
resposta dados as covariáveis. Na regressão Logística, [ ] 1|0 << xYE e estimamos a
probabilidade de se obter uma resposta positiva. Tem-se então o modelo:
++
+===
∑
∑
=
=
p
kkk
p
kkk
X
X
xYPx
10
10
exp1
exp
)|1()(
ββ
ββθ
Onde 1=Y significa presença da resposta e x as variáveis independentes considerando
o logito como função de ligação. Em seguida pode-se estudar a relação entre presença e
ausência de resposta através de OR (odds ratio) onde uma odds é da forma:
( )( )x
x
θθ−1
Tomando-se o logaritmo neperiano da odds acima se encontra uma equação linear:
Logito = ( )
( ) ∑=
+=
−
p
kkk X
x
x
101
ln ββθ
θ
Esse é o modelo linear para o Logito da relação acima. O Logito, pensando em modelos
lineares generalizados, é uma função de ligação canônica. A função de ligação
estabelece a relação entre a média e o preditor linear.
A estimação dos parâmetros é feita através da função de verossimilhança. Dada uma
amostra aleatória ),,( ii xy ni ,...,1= a função de verossimilhança é definida por:

7
( ) ( )[ ] ( )[ ] ii yi
n
i
yi xxL −
=
−= ∏ 1
1
1 θθβ
A solução para as equações dos valores dos coeficientes é através de métodos
numéricos como por exemplo Newton-Raphson
2.2 Razão contínua
Este modelo permite comparar a probabilidade de uma resposta igual a categoria com
determinado escore, digamosjy , JY = , com a probabilidade de uma resposta
maior,Y>J. Este modelo possui diferentes interceptos e coeficientes para cada
comparação e poder ser ajustado por k modelos de regressão logística binária. É mais
apropriado quando existe interesse em uma categoria específica da variável resposta.
( ) ( )( ) ( )
( )( )
=
==
=+++===
∑+
k
j
j
xjY
xjY
xkYxjY
xjYx
1
|Pr
|Prln
|Pr...|1Pr
|Prlnλ
( ) ( ) kjxxxx pjpjjjj ,...1,...2211 =++++= βββαλ
kαααα ≤≤≤≤ ...321
Com k categorias na resposta
2.3 Estereótipo
O Modelo Estereótipo pode ser considerado uma extensão do modelo multinomial.
Compara cada categoria da variável resposta com uma categoria de referência,
normalmente a primeira ou a última. Devido ao caráter ordinal dos dados são atribuídos
pesos aos coeficientes. Os pesos são diretamente relacionados com os efeitos das
covariáveis. Este modelo é adequado para situações que temos resposta ordinal discreta,

8
por exemplo, situação de um paciente após tomar uma medição, ele pode ter melhora,
não ter reação ou piora e neste caso seriam três níveis de resposta.
( ) ( )( )
===
xY
xjYxj |0Pr
|Prlnλ
( ) ( ) kjxxx ppjjj ,...,1,...11 =+++= ββωαλ
kαααα ≤≤≤≤ ...321
kϖϖϖϖ ≤≤≤≤ ...321
Com k cateogrias na resposta.
2.4 Odds Proporcionais
Como dito na introdução, um dos fatores que se deve levar em conta na escolha do
modelo é como foi construída a variável resposta. O modelo de Odds Proporcionais é
apropriado para analisar variáveis ordinais provenientes de uma variável contínua que
foi agrupada. Por exemplo, imagine que em um estudo a variável resposta seja renda por
família, inicialmente ela é contínua, porém, podemos agrupá-las em faixas (0-1000;
1001-2000,...) a fim de facilitar alguma análise. O pressuposto de proporcionalidade
consiste em considerar que os coeficientes das covariáveis são os mesmos em todas as
categorias da resposta, ou seja, as relação entre x e y é indepente dos níveis de resposta.
Quando nos encontramos nessa situação, o interesse está em calcular a probabilidade
acumulada até o j-ésimo nível de da variável resposta levando em consideração o
seguinte modelo.
[ ] ( )
+++
=≤ηα
ηαi
iXjYPexp1
exp|
Onde,
+= ∑
=
p
kkk X
10 ββη

9
Nesse modelo são considerados 1−k pontos de corte das categorias sendo que o
ésimoj − ( )1,...,1 −= kj ponto de corte é baseado na comparação de probabilidades
acumuladas como mostrado a seguir.
( ) ( ) ( )( ) ( )
( )
( )
=
==
=+++==++==
∑
∑
+
k
j
j
j
xjY
xjY
xkYxjY
xjYxYx
1
1
|Pr
|Prln
|Pr...|1Pr
|Pr...|1Prlnλ
( ) ( ) 1,...,1,...2211 −=++++= kjxxxx ppjj βββαλ
kαααα ≤≤≤≤ ...321
2.5 Odds Proporcionais Parciais
Como a suposição de odds proporcionais é difícil de ser encontrada na prática, pode ser
utilizado o modelo de Odds Proporcionais Parciais que permite que algumas covariáveis
possam ser modeladas sem que essa suposição seja satisfeita, colocando assim um
coeficiente γ que é o efeito associado a cada ésimoj − logito cumulativo ajustado
pelas demais covariáveis.
( ) ( ) ( )( ) ( )
( )
( )
=
==
=+++==++==
∑
∑
+
k
j
j
j
xjY
xjY
xkYxjY
xjYxYx
1
1
|Pr
|Prln
|Pr...|1Pr
|Pr...|1Prlnλ
( ) ( ) ( ) ( ) ( )[ ] 1,...,1,...... 11111 −=++++++++= ++ kjxxxxx ppqqqjqqjjj ββγβγβαλ
kαααα ≤≤≤≤ ...321

10
2.6 Banco de Dados
Neste capítulo, estuda-se o banco de dados utilizado no desenvolvimento do presente
trabalho, dissertando sobre sua estrutura, objetivos e descrevendo alguns dos principais
indicadores existentes.
O banco de dados aqui utilizado foi desenvolvido por Thorsten Beck, Asli Demirgüç-
Kunt e Ross Levine, tendo sido publicado inicialmente no ano de 1999, sofrendo
atualizações com o passar dos anos. Esses pesquisadores encontravam dificuldades em
encontrar informações referentes à estrutura de mercado dos variados países, bem como
a inexistência de diversos indicadores. O objetivo ao desenvolver tal banco de dados era
permitir aos analistas econômicos uma ampla visão sobre tamanho, atividade e
eficiência dos variados mercados financeiros, numa visão macroeconômica, permitindo
uma avaliação global do desenvolvimento, estrutura e desempenho do setor financeiro.
Para tanto, buscaram informações no IFS (International Financial Statistics) do FMI
(Fundo Monetário Internacional) e a partir disso construíram 22 indicadores financeiros,
de 211 países. Na versão utilizada neste estudo, encontravam-se dados dos anos de 1960
até 2005. Além dos indicadores, foram associadas aos países suas respectivas
classificações quanto ao grupo de renda, de acordo com os critérios do Banco Mundial.
A seguir, será apresentado de uma maneira mais detalhada a estrutura do banco de
dados, dividindo os indicadores em grupos e detalhando a classificação quanto ao grupo
de renda.
2.6.1 Indicadores da dimensão e atividade financeiras
Este grupo de indicadores tem como objetivo definir como se dá a distribuição do total
de ativos de um determinado país entre suas instituições financeiras. Esses ativos são
então divididos em três grupos:
• Ativos do Banco Central: correspondem a ativos pertencentes ao Banco central e
instituições que exerçam funções de autoridade financeiras;
• Ativos depositados em bancos: O total depositado em bancos é definido como o
total de ativos de instituições financeiras na forma de depósitos transferíveis por
cheque ou outro meio de pagamento;

11
• Ativos de outras instituições financeiras: são referentes aos ativos de todas as
instituições não compreendidas nos dois primeiros grupos. Como exemplo,
seguradoras integram esse grupo de instituições.
A partir desta definição, são construídos indicadores, conforme exemplos:
- Central Bank Assets: razão entre os ativos do Banco Central pelo total de ativos do
país
- Deposit Money Bank Assets: razão entre ativos depositados em bancos pelo total de
ativos do país.
Outra forma de analisar os ativos é construir indicadores utilizando o PIB (Produto
Interno Bruto) como denominador.
- Central Bank Assets to GDP: razão entre os ativos do Banco Central pelo PIB
- Deposit Money Bank Assets to GDP: razão entre ativos depositados em bancos pelo
PIB
2.6.2 Indicadores de eficiência e estrutura de mercado dos bancos comerciais
Neste grupo de indicadores encontram-se informações a respeito da estrutura bancária
das nações. Seguem alguns exemplos:
- NIM (Net Interest Margin): medida da diferença entre os juros gerados por bancos ou
outras instituições financeiras menos o montante pago aos seus credores.
- Concentration: refere-se à razão da soma dos ativos depositados nos três maiores
bancos do país pelo total de ativos depositado, medindo assim a concentração bancária.

12
2.6.3 Indicadores de outras Instituições Financeiras
Nesta seção, deseja-se ter uma visão mais ampla sobre o grupo de indicadores referentes
a “outras instituições”, conforme descrito no primeiro grupo de indicadores.
Primeiramente defini-se essas instituições em sub-grupos, conforme descritos a seguir:
• ‘Banklike’: integram esse grupo Bancos Cooperativos, Bancos Hipotecários, etc.
Essas são especializadas em atividades específicas, seja por seu histórico ou por
razões fiscais;
• Seguradoras: empresas de seguros, divididas entre companhias de seguro de
vida e demais companhias de seguro. Não inclui os seguros de fundos de
instituições governamentais;
• Fundos de Pensão e Previdência Privada: assim como empresas de seguro de
vida, servem para agregação de risco e acumulo de riqueza. Não incluem fundos
de pensão que fazem parte do sistema de segurança social do governo.
• Investimento Conjunto: instituições que investem em nome de seus acionistas
em um determinado tipo de ativos
• Bancos de Desenvolvimento: instituições financeiras cujos fundos provêm
principalmente do governo ou organizações supranacionais. Tem como principal
objetivo fomentar o desenvolvimento econômico.
Para todos os cinco grupos descritos acima foram construídas medidas relativas ao seu
tamanho em relação ao PIB.
2.6.4 Indicadores de tamanho, atividade e eficiência da Bolsa de Valores
Por fim, observam-se indicadores relativos ao mercado de ações. Como exemplo
podemos citar:
- Stock Market capitalization to GDP: razão entre o valor da cotação das ações pelo PIB
- Stock Market turnover ratio: razão entre o total de ações negociadas na bolsa e no
mercado de capitalização

13
2.6.5 Classificação em Grupos de Renda
Outra variável importante é o Grupo de Renda. Para fins analíticos e operacionais, o
Banco Mundial utiliza como critério de classificação das economias o Rendimento
Nacional Bruto (RNB) per capita. O PIB corresponde ao valor da riqueza criada
anualmente no país, e o RNB corresponde ao valor que permanece no país ao fim do
mesmo período, adicionando-se ao PIB os rendimentos recebidos dos demais países e
subtraindo os rendimentos pagos ao exterior. Sendo assim, as economias são
classificadas em seus respectivos grupos de renda conforme tabela abaixo:
Tabela 1: Classificação dos Grupos de Renda pelas faixas de RNB per capita
3. Resultados
Tendo conhecimento do banco de dados, o objetivo foi utilizar os indicadores
financeiros disponíveis na criação de um modelo que pudesse classificar os países em
seus grupos de renda de acordo com o definido pelo Banco Mundial.
Para tal fim, trabalhou-se no ajuste de um modelo de Regressão Ordinal de Odds
Proporcionais, tendo os indicadores como covariáveis e o grupo de renda como a
variável resposta. A utilização de um modelo de Regressão Ordinal de Odds
Proporcionais se justifica pela natureza de sua variável resposta, sendo esta categórica
de quatro níveis e construída a partir de uma variável contínua (RNB per capita).
Primeiramente, foi realizada uma análise das informações contidas nos indicadores, e
percebeu-se rapidamente que alguns destes não se encontravam disponíveis,
especialmente em países pequenos ou de menor economia. Sendo assim, decidiu-se por
excluir da análise aqueles países que encontravam poucas informações e também
indicadores não observados em muitas situações. Desta forma iniciaram-se as
verificações dos resultados com 88 países e 10 indicadores como covariáveis. Foi
Grupo de Renda RNB per capita Low Income < $ 935 Lower Middle Income $ 936 - $ 3705 Upper Middle Income $ 3706 - $ 11455 High Income > $ 11455

14
escolhido o ano de 2005 para análise, por conter as informações mais recentes. Neste
momento foi decidido um nível de significância de 10%, e todas as análises foram
realizadas utilizando o software R.
Com o banco de dados ajustado, fez-se uma breve análise descritiva dos dados, onde se
pode observar algumas tendências, mas nada conclusivo, conforme observado nos
gráficos Box-plot abaixo:
Gráfico 1: Box-plot do indicador DMBAD por Grupo de Renda
Gráfico 2: Box-plot do indicador LL por Grupo de Renda

15
Gráfico 3: Box-plot do indicador CBA por Grupo de Renda
Gráfico 4: Box-plot do indicador DMBA por Grupo de Renda
Gráfico 5: Box-plot do indicador PCDMB por Grupo de Renda

16
Gráfico 6: Box-plot do indicador PCDMBOFI por Grupo de Renda
Gráfico 7: Box-plot do indicador BD por Grupo de Renda
Gráfico 8: Box-plot do indicador FSD por Grupo de Renda

17
Gráfico 9: Box-plot do indicador BOC por Grupo de Renda
Gráfico 10: Box-plot do indicador NIM por Grupo de Renda
Na sequência realizou-se uma análise de correlação entre as covariáveis. Como pode ser
visto no gráfico 11, algumas covariáveis eram altamente correlacionadas. Uma das
explicações para isso seria justamente o modo como os indicadores foram construídos,
sendo estes muitas vezes complementares aos outros.

18
Gráfico 11: Correlograma das covariáveis em estudo
Sendo assim, iniciou-se a construção de modelos com o cuidado de não utilizar
covariáveis que fossem correlacionadas. Utilizou-se para tanto a função polr do pacote
MASS do software R. Esta função é utilizada para ajustar modelos de regressão ordinal
de odds proporcionais entre outras, com uma determinada função de ligação. Aqui
utilizou-se as funções logito, probito ou complemento loglog.
Foram ajustados diversos modelos, com diferentes funções de ligação para cada
conjunto de covariáveis. Definiu-se como melhor modelo aquele que apresentasse um
menor valor no Critério de Akaike (AIC). E com um valor de AIC de 176,34, o melhor
modelo foi construído foi:
IncomeGroup~CBA+DMBA+NIM
Com funçã de ligação probito.

19
Onde:
IncomeGroup – Grupo de Renda, nossa variável resposta;
CBA – Central Bank Assets
DMBA – Deposit Money Bank Assets
NIM – Net Interest Margin
A partir disso, verificou-se na tabela 2 os coeficientes do modelo e a significância das
três covariáveis em conjunto. Na tabela 3 vemos a significância dos denominados
“saltos” entre os níveis da variável resposta, ou seja, se faz sentido existir o número de
níveis estabelecido.
COVARIÁVEL COEFICIENTE P-VALOR
CBA -3,19 0,02
DMBA 3,28 < 0,01
NIM -7,12 0,17
Tabela 2: Teste t para significância das covariáveis do modelo
GRUPOS ALFA P-VALOR
Low – Lower mid. -0,143 0,97
Lower mid.- Upper mid. 1,034 0,03
Upper mid. - High 2,449 < 0,01
Tabela 3: Teste t para significância das classificações da variável resposta
Conforme observado, o teste t mostrou não ser significativa a contribuição da covariável
NIM no modelo. O mesmo teste também demonstrou não ser significativo o valor de
α para os níveis ‘low’ e ‘lower middle’. Em outras palavras, segundo o modelo
sugerido não haveria evidências da necessidade de classificar os países pertencentes a
esses dois grupos de maneira diferenciada. Mas como se observou uma covariável não
significativa no modelo, foi realizado outro modelo apenas com os indicadores CBA e
DMBA. Desta forma, foram observados os valores para o teste t nas tabelas seguintes:
20
COVARIÁVEL COEFICIENTE P-VALOR
CBA -3,23 0,02
DMBA 3,66 < 0,01
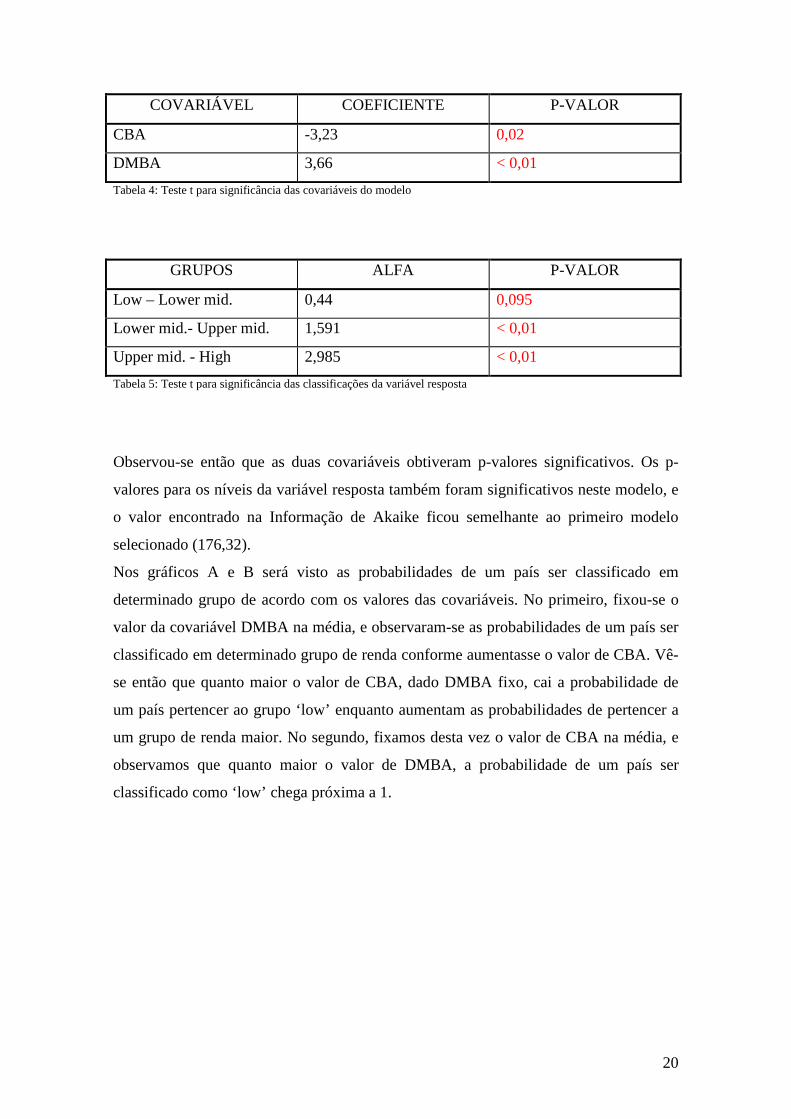
Tabela 4: Teste t para significância das covariáveis do modelo
GRUPOS ALFA P-VALOR
Low – Lower mid. 0,44 0,095
Lower mid.- Upper mid. 1,591 < 0,01
Upper mid. - High 2,985 < 0,01
Tabela 5: Teste t para significância das classificações da variável resposta
Observou-se então que as duas covariáveis obtiveram p-valores significativos. Os p-
valores para os níveis da variável resposta também foram significativos neste modelo, e
o valor encontrado na Informação de Akaike ficou semelhante ao primeiro modelo
selecionado (176,32).
Nos gráficos A e B será visto as probabilidades de um país ser classificado em
determinado grupo de acordo com os valores das covariáveis. No primeiro, fixou-se o
valor da covariável DMBA na média, e observaram-se as probabilidades de um país ser
classificado em determinado grupo de renda conforme aumentasse o valor de CBA. Vê-
se então que quanto maior o valor de CBA, dado DMBA fixo, cai a probabilidade de
um país pertencer ao grupo ‘low’ enquanto aumentam as probabilidades de pertencer a
um grupo de renda maior. No segundo, fixamos desta vez o valor de CBA na média, e
observamos que quanto maior o valor de DMBA, a probabilidade de um país ser
classificado como ‘low’ chega próxima a 1.

21
Gráfico 12: Probabilidade de pertencer a um determinado grupo de renda conforme variação de CBA, tendo DMBA
fixo na média
Gráfico 13: Probabilidade de pertencer a um determinado grupo de renda conforme variação de DMBA, tendo CBA
fixo na média

22
Para analisar a precisão do modelo, construiu-se uma tabela de concordância, onde
podemos observar um bom nível de acerto entre a classificação predita pelo
modelo(coluna) e o observado na classificação do Banco Mundial (linha) em quase
todos os níveis, porém no nível ‘upper middle’ obteve-se 36,4% de acerto, o que pode
indicar problemas na classificação nesse determinado grupo.
Low Low Mid. Upper Mid High
Low 78,3% 15,4% 9,1% 0,0%
Low Mid. 13,0% 65,4% 45,5% 5,9%
Upper Mid. 8,7% 15,4% 36,4% 17,6%
High 0,0% 3,8% 9,1% 76,5%
Tabela 6: Tabela de concordância entre valores preditos (colunas) e observados (linhas)
3.1 Análise de Resíduos
Depois do modelo construído uma validação é necessária e isso se faz através da análise
dos resíduos.
A análise dos resíduos para dados categóricos ordinais ainda é escassa e abre portas para
novos estudos. Embora ainda não se tenha um método claro e completo para analisar os
resíduos foi utilizado a proposta de McCullagh, P. (1980), que considera como resíduo a
a contribuição para a verossimilhança da i-ésima observação do banco de dados. A
verossilhança do modelo nulo é subtraída da verossimilhança do modelo com as
covariáveis sem a i-ésima observação, a diferença é considerada como resíduo. Esse
resíduo será sempre positivo.
Abaixo segue o gráfico de resíduos onde pode-se observar homocedasticidade
inidicando assim que o modelo ajustado tem grandes possibilidades de bom ajuste e
pressupostos satisfeitos.

23
Gráfico 14: Gráfico de Resíduos propostos por McCullagh, P. (1980)
4. Conclusão
Considerando todos os procedimentos percebe-se a importância de se trabalhar com
modelos que consideram em suas análises o fator de ordenação em variáveis categóricas
ordinais, tratá-las sem levar em conta este fato certamente levará à perda de informações
prestigiosas acerca do seu objeto de estudo
O modelo ajustado tem uma boa assertividade como mostrado na tabela 6, porém não
deixa de ser apenas uma maneira descritiva de análise. Numa primeira etapa o modelo
de odds proporcionais parece se encaixar bem para descrever a relação entre a variável
resposta e as covariáveis embora ainda alguns testes sejam necessários.
Nas próximas etapas serão feitos testes para o pressuposto de proporcionalidade além de
análise de resíduos mais profunda, ambos com poucas referências em artigos e literatura
em geral, por fim, um estudo mais aprofundado sobre o motivo da baixa proporção de
acerto na classe upper middle deve ser realizado.

24
5. Referências Bibliográficas
Anderson, J.A. (1984). Regression and ordered categorical variable. Journal of the
Royal Statistical Society, Series B, vol. 46, Nº 01, PP. 1-30.
McCullagh, P. (1980). Rgression models for ordinal data. Journal of the Royal
Statistical Society, Series B, vol. 42, Nº 02, PP. 109-142.
David G. Kleinbaum, Mitchel Klein (2002) Statistics for Biology
Revista de saúde pública 2008. Mery Natali Silva Abreu, Arminda Lucia Siqueira,
Waleska Teixeira Caiaffa.
GIOLO, Suely Ruiz. Introdução a Análise de Dados Categóricos, 2006
The World Bank, disponível em: < http://www.worldbank.org/>.
6. Apêndice
Comandos Utilizados:
#
# Leitura dos dados
#
dados=read.table('dados.dat',h=T)
#
require(relimp)
names(dados)
#
# Eliminando variaveis com poucas observacoes
#
dados1=dados[,1:12]
#
# Eliminando observacoes faltantes
#
dados2=na.omit(dados1)
#

25
showData(dados2)
attach(dados2)
names(dados2)
#
# Variaveis de interesse: Resposta=IncomeGroup
# Explicativas: DMBAD, LL, CBA, DMBA, PCDMB, PCDMBOFI, BD, FSD, BOC, NIM
#
# Definindo a ordem dos niveis de IncomeGroup
#
IncomeGroup=factor(IncomeGroup,levels=c('Low','Lower middle','Upper middle','High'),labels=c("Low","Lower \n middle","Upper \n middle","High"))
levels(IncomeGroup)
#
# Estudo descritivo
#
X11()
par(mfrow=c(2,2),mar=c(5,4,1,1),pch=16)
plot(DMBAD~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
plot(LL~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
#
plot(CBA~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
plot(DMBA~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
#
# Observamos que quanto maiores os valores de DMBAD e LL maior a categoria de IncomeGroup
# e que quando maior o valor de CBA menor o IncomeGroup e quanto maior o DMBA maior o IncomeGroup
#
X11()
par(mfrow=c(2,2),mar=c(5,4,1,1),pch=16)
plot(PCDMB~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
plot(PCDMBOFI~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
#
plot(BD~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
plot(FSD~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))

26
#
# Observamos que quanto maiores os valores de PCDMB, PCDMBOFI, BS e FSD maior a categoria de IncomeGroup
#
X11()
par(mfrow=c(2,2),mar=c(5,4,1,1),pch=16)
plot(BOC~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
plot(NIM~IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
#
# Observamos que quanto maiores os valores de BD e FSD menor a categoria de IncomeGroup
#
plot(IncomeGroup,col=c('salmon','purple1','plum1','sienna'))
box()
#
# A quantidade de observacoes por categoria e aprox. igual
#
# Funcoes auxiliares
#
panel.hist = function(x, ...){
usr = par("usr"); on.exit(par(usr))
par(usr = c(usr[1:2], 0, 1.5) )
h = hist(x, plot = FALSE)
breaks = h$breaks; nB = length(breaks)
y = h$counts; y = y/max(y)
rect(breaks[-nB], 0, breaks[-1], y, col="cyan", ...)}
#
panel.cor = function(x, y, digits=2, prefix="", cex.cor, ...){
usr = par("usr"); on.exit(par(usr))
par(usr = c(0, 1, 0, 1))
r = abs(cor(x, y))
txt = format(c(r, 0.123456789), digits=digits)[1]
txt = paste(prefix, txt, sep="")
if(missing(cex.cor)) cex.cor = 0.8/strwidth(txt)
text(0.5, 0.5, txt, cex = cex.cor * r)}
#

27
# Correlacoes entre as variaveis
#
X11()
pairs(cbind(DMBAD,LL,CBA,DMBA,PCDMB,PCDMBOFI,BD,FSD,BOC,NIM), pch=24, bg='light blue', lower.panel=panel.smooth, upper.panel=panel.cor, diag.panel=panel.hist)
#
# Observamos que a correlacao entre algumas das variaveis explicativas e quase perfeita ou perfeita,
# isso inviabiliza o modelo. Por esse motivo devemos escolher quais delas devem permanecer
#
# DMBAD: e altamente correlacionada com quase todas as outras variaveis, logo podemos prescindir dela
#
X11()
pairs(cbind(CBA,FSD,NIM), pch=24, bg='light blue', lower.panel=panel.smooth, upper.panel=panel.cor, diag.panel=panel.hist)
#
# MODELOS
#
require(MASS)
#
# Explicativas: CBA, FSD, NIM
#
ajuste01 = polr(IncomeGroup ~ CBA+FSD+NIM, method='logistic')
#
ajuste02 = update(ajuste01, method = "probit")
#
ajuste03 = update(ajuste01, method = "cloglog")
#
AIC(ajuste01,ajuste02,ajuste03)
#
summary(ajuste02)
#
# Explicativas: CBA, FSD, BOC
#

28
ajuste04 = polr(IncomeGroup ~ CBA+FSD+BOC, method='logistic')
#
ajuste05 = update(ajuste04, method = "probit")
#
ajuste06 = update(ajuste04, method = "cloglog")
#
AIC(ajuste04,ajuste05,ajuste06)
#
# Explicativas: LL, CBA, BOC
#
ajuste07 = polr(IncomeGroup ~ LL+CBA+BOC, method='logistic')
#
ajuste08 = update(ajuste07, method = "probit")
#
ajuste09 = update(ajuste07, method = "cloglog")
#
AIC(ajuste07,ajuste08,ajuste09)
#
# Explicativas: LL, CBA, NIM
#
ajuste10 = polr(IncomeGroup ~ LL+CBA+NIM, method='logistic')
#
ajuste11 = update(ajuste10, method = "probit")
#
ajuste12 = update(ajuste10, method = "cloglog")
#
AIC(ajuste10,ajuste11,ajuste12)
#
# Explicativas: DMBAD, LL, BOC
#
ajuste13 = polr(IncomeGroup ~ DMBAD+LL+BOC, method='logistic')
#
ajuste14 = update(ajuste13, method = "probit")
#
ajuste15 = update(ajuste13, method = "cloglog")

29
#
AIC(ajuste13,ajuste14,ajuste15)
#
# Explicativas: DMBAD, LL, NIM
#
ajuste16 = polr(IncomeGroup ~ DMBAD+LL+NIM, method='logistic')
#
ajuste17 = update(ajuste16, method = "probit")
#
ajuste18 = update(ajuste16, method = "cloglog")
#
AIC(ajuste16,ajuste17,ajuste18)
#
# Explicativas: CBA, DMBA, BOC
#
ajuste19 = polr(IncomeGroup ~ CBA+DMBA+BOC, method='logistic')
#
ajuste20 = update(ajuste19, method = "probit")
#
ajuste21 = update(ajuste19, method = "cloglog")
#
AIC(ajuste19,ajuste20,ajuste21)
#
# Explicativas: CBA, DMBA, NIM
#
ajuste22 = polr(IncomeGroup ~ CBA+DMBA+NIM, method='logistic')
#
ajuste23 = update(ajuste22, method = "probit")
#
ajuste24 = update(ajuste22, method = "cloglog")
#
AIC(ajuste22,ajuste23,ajuste24)
#
# Explicativas: CBA, PCDMA, BOC
#

30
ajuste25 = polr(IncomeGroup ~ CBA+PCDMB+BOC, method='logistic')
#
ajuste26 = update(ajuste25, method = "probit")
#
ajuste27 = update(ajuste25, method = "cloglog")
#
AIC(ajuste25,ajuste26,ajuste27)
#
# Explicativas: CBA, PCDMA, NIM
#
ajuste28 = polr(IncomeGroup ~ CBA+PCDMB+NIM, method='logistic')
#
ajuste29 = update(ajuste28, method = "probit")
#
ajuste30 = update(ajuste28, method = "cloglog")
#
AIC(ajuste28,ajuste29,ajuste30)
#
# Explicativas: CBA, PCDMBOFI, BOC
#
ajuste31 = polr(IncomeGroup ~ CBA+PCDMBOFI+BOC, method='logistic')
#
ajuste32 = update(ajuste31, method = "probit")
#
ajuste33 = update(ajuste31, method = "cloglog")
#
AIC(ajuste31,ajuste32,ajuste33)
#
# Explicativas: CBA, PCDMBOFI, NIM
#
ajuste34 = polr(IncomeGroup ~ CBA+PCDMBOFI+NIM, method='logistic')
#
ajuste35 = update(ajuste34, method = "probit")
#
ajuste36 = update(ajuste34, method = "cloglog")

31
#
AIC(ajuste34,ajuste35,ajuste36)
#
# Explicativas: CBA, BD, BOC
#
ajuste37 = polr(IncomeGroup ~ CBA+BD+BOC, method='logistic')
#
ajuste38 = update(ajuste37, method = "probit")
#
ajuste39 = update(ajuste37, method = "cloglog")
#
AIC(ajuste37,ajuste38,ajuste39)
#
# Explicativas: CBA, BD, NIM
#
ajuste40 = polr(IncomeGroup ~ CBA+BD+NIM, method='logistic')
#
ajuste41 = update(ajuste40, method = "probit")
#
ajuste42 = update(ajuste40, method = "cloglog")
#
AIC(ajuste40,ajuste41,ajuste42)
#
# CONCLUSAO: ajuste mais adequado ajuste23
#
# Intervalos confidenciais dos estimadores dos parametros
#
ajuste23.hess = update(ajuste23, Hess=TRUE)
#
ajuste23.profile = profile(ajuste23.hess)
#
confint(ajuste23.profile)
#
# Verificando a significancia das covariaveis
#

32
2*pt(abs(coef(ajuste23)[1]/sqrt(solve(ajuste23.hess$Hessian)[1,1])),ajuste23$df.residual,lower.tail=F)
2*pt(abs(coef(ajuste23)[2]/sqrt(solve(ajuste23.hess$Hessian)[2,2])),ajuste23$df.residual,lower.tail=F)
2*pt(abs(coef(ajuste23)[3]/sqrt(solve(ajuste23.hess$Hessian)[3,3])),ajuste23$df.residual,lower.tail=F)
#
# Observamos que a variavel NIM nao e significativa, logo nao contribui para o modelo
#
step(ajuste23)
#
ajuste23a = polr(IncomeGroup ~ CBA+DMBA, method = "probit")
#
summary(ajuste23a)
#
ajuste23a.hess = update(ajuste23a, Hess = TRUE)
#
# Verificando a significancia das covariaveis
#
2*pt(abs(coef(ajuste23a)[1]/sqrt(solve(ajuste23a.hess$Hessian)[1,1])),ajuste23a$df.residual,lower.tail=F)
2*pt(abs(coef(ajuste23a)[2]/sqrt(solve(ajuste23a.hess$Hessian)[2,2])),ajuste23a$df.residual,lower.tail=F)
#
# Verificando a significancia dos niveis da resposta
#
2*pt(abs(ajuste23a$zeta[1]/sqrt(solve(ajuste23a.hess$Hessian)[3,3])),ajuste23a$df.residual,lower.tail=F)
2*pt(abs(ajuste23a$zeta[2]/sqrt(solve(ajuste23a.hess$Hessian)[4,4])),ajuste23a$df.residual,lower.tail=F)
2*pt(abs(ajuste23a$zeta[3]/sqrt(solve(ajuste23a.hess$Hessian)[5,5])),ajuste23a$df.residual,lower.tail=F)
#
# Significa que todos os niveis esta bem preditos
#
# Preditos. Variaveis fixadas nos seus valores medios
#
CBA.m = mean(CBA)

33
DMBA.m = mean(DMBA)
#
CBA.x = seq(min(CBA),max(CBA),by=0.01)
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.m
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
X11()
par(mfrow=c(2,1),mar=c(5,4,1,1))
#
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab='CBA',col=c('green','sienna','purple','navy'),lty=1:4)
legend(0.0,0.8,legend=c('Low','Low middle','Upper middle','High'),ncol=2,lty=1:4,col=c('green','sienna','purple','navy'))
#
DMBA.x = seq(min(DMBA),max(DMBA),by=0.01)
eta = coef(ajuste23a)[1]*CBA.m+coef(ajuste23a)[2]*DMBA.x
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(DMBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab='DMBA',col=c('green','sienna','purple','navy'),lty=1:4)
#
# Preditos. Variaveis fixadas no primeiro e terceiro quantis
#
CBA.q = quantile(CBA,c(0.25,0.75))
DMBA.q = quantile(DMBA,c(0.25,0.75))
#
CBA.x = seq(min(CBA),max(CBA),by=0.01)

34
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.q[1]
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
X11()
par(mfrow=c(2,2),mar=c(5,4,1,1))
#
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab='CBA, DMBA fixa no seu primeiro quantil',col=c('green','sienna','purple','navy'),lty=1:4)
#
CBA.x = seq(min(CBA),max(CBA),by=0.01)
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.q[2]
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab='CBA, DMBA fixa no seu terceiro quantil',col=c('green','sienna','purple','navy'),lty=1:4)
legend(0.0,0.8,legend=c('Low','Low middle','Upper middle','High'),ncol=1,lty=1:4,col=c('green','sienna','purple','navy'))
#
DMBA.x = seq(min(DMBA),max(DMBA),by=0.01)
eta = coef(ajuste23a)[1]*CBA.q[1]+coef(ajuste23a)[2]*DMBA.x
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(DMBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',

35
ylab='Probabilidades estimadas',xlab='DMBA, CBA fixa no seu primeiro quantil',col=c('green','sienna','purple','navy'),lty=1:4)
#
DMBA.x = seq(min(DMBA),max(DMBA),by=0.01)
eta = coef(ajuste23a)[1]*CBA.q[2]+coef(ajuste23a)[2]*DMBA.x
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(DMBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab='DMBA, CBA fixa no seu terceiro quantil',col=c('green','sienna','purple','navy'),lty=1:4)
#
# Podemos perceber que as probabilidades estimadas nao diferem muito quando mostradas em relacao a DMBA,
# mas sao de comportamento muito diferentes quando comparadas em relacao a CBA. Ou seja, o valor de DMBA
# influencia bastante no comportamento dos resultados, nao sendo assim com os valores de CBA.
#
DMBA.q = rep(0,4)
DMBA.q[c(1,2,4)] = quantile(DMBA,c(0.25,0.50,0.75))
DMBA.q[3] = mean(DMBA)
DMBA.q
#
CBA.x = seq(min(CBA),max(CBA),by=0.01)
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.q[1]
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
X11()
par(mfrow=c(2,2),mar=c(5,4,1,1))
#

36
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab=paste('CBA, DMBA = ', DMBA.q[1]),col=c('green','sienna','purple','navy'),lty=1:4)
#
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.q[2]
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab=paste('CBA, DMBA = ', DMBA.q[2]),col=c('green','sienna','purple','navy'),lty=1:4)
legend(0.0,0.7,legend=c('Low','Low middle','Upper middle','High'),ncol=1,lty=1:4,col=c('green','sienna','purple','navy'))
#
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.q[3]
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',
ylab='Probabilidades estimadas',xlab=paste('CBA, DMBA = ', DMBA.q[3]),col=c('green','sienna','purple','navy'),lty=1:4)
#
eta = coef(ajuste23a)[1]*CBA.x+coef(ajuste23a)[2]*DMBA.q[4]
Low.pred = pnorm(ajuste23a$zeta[1]+eta)
LowM.pred = pnorm(ajuste23a$zeta[2]+eta)
UppM.pred = pnorm(ajuste23a$zeta[3]+eta)
High.pred = 1-UppM.pred
#
matplot(CBA.x,cbind(Low.pred,LowM.pred-Low.pred,UppM.pred-LowM.pred,High.pred), type='l',

37
ylab='Probabilidades estimadas',xlab=paste('CBA, DMBA = ', DMBA.q[4]),col=c('green','sienna','purple','navy'),lty=1:4)
#
# Residuos
#
ajuste0 = update(ajuste22, .~ 1, method = "probit")
LR.geral = anova(ajuste0,ajuste23a,test='Chisq')$"LR stat."[2]
#
n = dim(dados2)[1]
LR.ind = seq(1,n)
for(i in 1:n){
ajuste0i = update(ajuste22, .~ 1, method='probit', data=dados2[-i,])
ajuste23ai = update(ajuste23a, method='probit', data=dados2[-i,])
LR0.ind = anova(ajuste0,ajuste23ai,test='Chisq')$"LR stat."[2]
LR.ind[i] = LR.geral-LR0.ind
}
#
plot(sqrt(LR.ind),pch=19,xlab='Observação',ylab=as.expression(substitute(sqrt('Razão de verossimilhanças'))))
#





























