Embed Size (px)
Citation preview

INE5408Estruturas de Dados
Gerência de Arquivos
-Técnicas utilizando Listas-Técnicas utilizando Árvores

Técnicas utilizando Listas• Técnicas de indexação através de listas provêem
uma solução excelente para a recuperação de chaves secundárias;
• exemplos típicos de chave secundária: CARGO, DEPARTAMENTO, IDADE, entre outros.
• Lista: estrutura de acesso inerentemente seqüencial. Não é adequada: para conjuntos de dados com somente um ou muito poucos registros por valor de chave.Situação ideal: poucos valores possíveis para umachave e muitos registros possuindo este valor de chave.

Técnicas utilizando Listas• Suportam os três tipos de solicitações de
recuperação;• se a aplicação possui uma chave tipicamente
primária (ex.: nome, cpf, id), a melhor técnicaé utilizar uma forma de indexação primária(ex.: árvore B) para a organização geral do arquivo e utilizar uma das duas técnicas de listas encadeadas a seguir para a indexaçãosomente de chaves secundárias.

Atualização de arquivos com índices em Lista
• Independentemente do tipo de indexação por lista, dois aspectos sãogerais:– um registro pode ser membro de duas ou
mais listas;– marcar um registro como excluído é aqui
muito mais prático do que atualizardiversas listas.

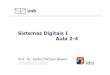
Multilista• O arquivo multilista é a implementação mais
intuitiva da idéia de se utilizar listasencadeadas para indexar chavessecundárias.
• Princípios básicos:– cada campo do arquivo de registros de dados a
ser tratado como uma chave é encadeado comouma lista, possuindo além do campo com o valor de chave, também um campo com um apontadorpara o próximo registro com o mesmo valor de chave para este campo.

Multilista

Multilista• Princípios básicos:
– além desse encadeamento, o arquivo possuirá um diretório;
– o diretório do arquivo multilista é constituído porum arquivo índice para cada campo indexado e um índice geral apontando para os índices-de-campo;
– o arquivo-índice de um campo possui umaseqüência de cabeças-de-lista contendo: o valor de chave indexado, o número de elementos nalista e o endereço do primeiro elemento da lista. Em caso de chaves contínuas, o limite superior do intervalo representado pela entrada será dado.
Multilista

Multilista• A próxima figura exibe uma visão
"pictórica" do encadeamento provocadopelas listas dos gráficos anteriores(Claybrook 77);
• os endereços (1.5, 0.7, 2.7) referem-se a uma forma de endereçamento relativomais antiga, onde um arquivo é divididoem "células".

Multilista

Formas de pesquisa• A pesquisa é realizada através da criação de
tabelas de resultados parciais, cuja união ouintersecção é calculada de acordo com o tipode pesquisa (disjuntiva ou conjuntiva) que érealizado;
• uma lista é percorrida e todos os elementos(registros de dados desta lista) são colocadosem uma tabela;
• em pesquisas simples (chave=valor) a primeira tabela gerada já é a resposta àpesquisa.

Formas de pesquisa• Em pesquisas booleanas ou por intervalo o
procedimento é mais complexo:– para todas as expressões conjuntivas escolhemos
o valor de chave com o menor número de elementos para a geração da tabela inicial. Estatabela é gerada copiando-se todos os registroscorrespondentes do arquivo de registros de dadsopara lá. Em seguida, todas as outras listas de valores-de-chave são percorridas e elementos daprimeira tabela não encontrados nestas sãoeliminados.

Formas de pesquisa• Em pesquisas booleanas ou por intervalo o
procedimento é mais complexo:– para operações disjuntivas, o procedimento
consiste em se iniciar com uma tabela gerada a partir da maior lista de elementos e incluirelementos das outras listas ainda não presentes;
– para combinações de operações conjuntivas e disjuntivas a geração de tabelas intermediárias énecessária. Claybrook sugere aqui, queinicialmente se transforme a expressão-perguntana forma disjuntiva normal, para depois iniciar o processo de busca.

Vantagens• É um método relativamente simples e
econômico em termos de espaço de se indexar arquivos por chave secundária;
• para pesquisas simples por chave secundáriaé o método mais econômico: O(m) : m < n, para devolver todos os registros quesatisfazem uma condição simples;
• suporta todos os tipos de pesquisa, mesmoexpressões booleanas complexas.

Desvantagens• Chave Primária: é totalmente inadequado;• operação de cópia: a técnica de pesquisa de se
copiar registros de dados para uma tabela pode se tornar cara em uma pesquisa conjuntiva, onde:– registros completos que vão mais tarde ser descartados são
copiados para uma tabela;– todas as listas que fazem parte de uma pesquisa conjuntiva
são pesquisadas completamente, mesmo que só uma fraçãomuito pequena dos dados satisfaça a expressão booleana.
• Não existe nenhum mecanismo, em pesquisas porintervalo ou booleanas, que impeça que registros quejá tenham sido visitados através de uma das listassejam visitados novamente através de outra lista.

Resumo• A Multilista é um método intuitivo. A sua
grande desvantagem é que precisamossempre copiar os registros por completopara uma tabela para podermostrabalhar com eles em pesquisas quenão sejam simples.

Lista Invertida• A organização de um arquivo Lista Invertida
consiste de um diretório contendo uma oumais listas-índice e um ou mais arquivosendereços de registros de dados, além do arquivo de registro de dados em si;
• o diretório é constituído por dois grupos de arquivos:– listas-índice para valores de chaves;– arquivo com apontadores para registros
organizado por valores de chave.

Lista Invertida• Uma entrada do índice de uma chave
possui os seguintes dados:– o valor da chave;– um indicador para a lista de registros
contendo o valor de chave;– o número de registros da lista.

Lista Invertida• Uma entrada da lista de registros
possui os seguintes dados:– um conjunto de m campos contendo
endereços de registros de dados;– um apontador para a posição do próximo
registro da lista de registros.

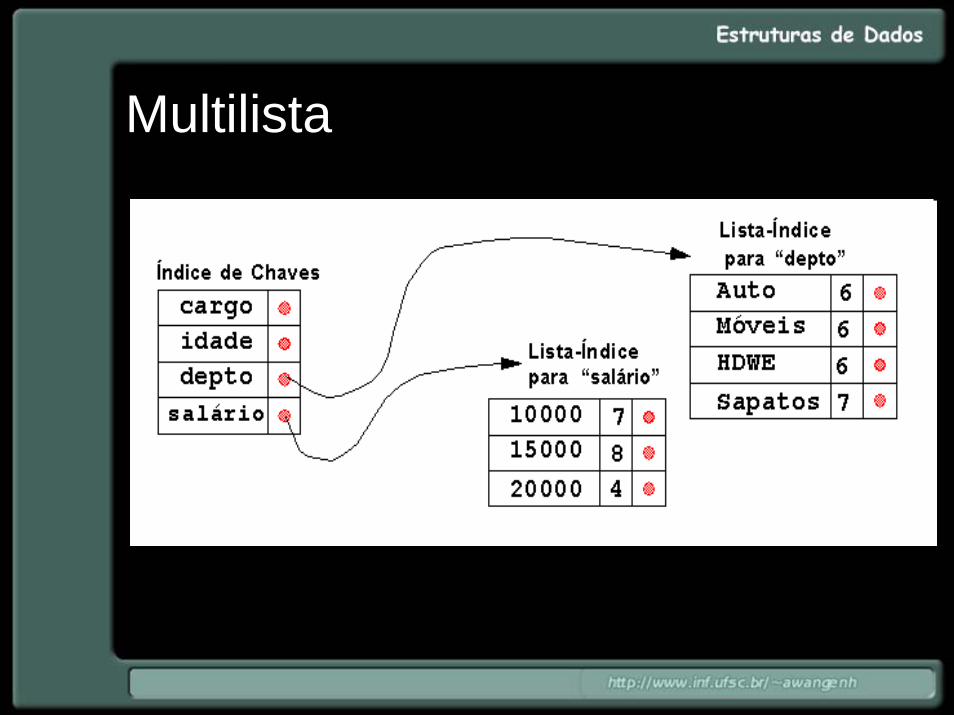
Exemplo• Na figura a seguir, as listas-índice para
cargo e depto estão omitidas, damesma forma só foram representadosendereços de registro para idade = 18 e 20 e salário = 10.000 e 20.000.

Exemplo

Exemplo• No exemplo anterior endereços de registro
dos arquivos presentes no gráfico estãorepresentados por setas, endereços de registros do arquivo de registros de dados porvalores de endereço relativo;
• evidentemente podem existir vários arquivosde endereços de registro e várias listas-índice. Alternativamente podemos colocar osregistros de endereços todos em um únicoarquivo.
Exemplo

Exemplo• Na figura anterior somente um arquivo
para listas de endereços de registro éutilizado;
• os endereços do exemplo (1.5, 0.7, 2.7) também se referem a uma forma de endereçamento relativo mais antiga, onde um arquivo é dividido em "células".

Técnica de pesquisa• Pesquisas de chaves em arquivos Lista Invertida
são realizadas também através da geração de tabelas;
• ao contrário da multilista, aqui as tabelas podem ser bem mais simples e a pesquisa para a construçãodestas pode ser bem mais efetiva, sem realmente leros registros de dados;
• pesquisas de chave simples geram uma tabela de saída com todos os registros com o valor de chavepara aquela chave, depois de ter sido gerada umatabela de endereços de registros com o valor de chave.

Técnica de pesquisa• Pesquisas booleanas são as mais complexas. Nestas
pesquisas, várias tabelas de endereços são geradas, iniciando-se sempre pelo valor de chave com o menor número de ocorrências;
• em pesquisas conjuntivas, endereços nãoencontrados para outras chaves são retirados.Em pesquisas disjuntivas, são adicionados. Com a tabela de endereços resultante é criada a tabela de registros de dados definitiva. Assimsomente os registros realmente necessários vão ser lidos do arquivo de registros de dados.

Exemplo

Exemplo• Se fizermos a pesquisa (idade = 18 & salário
= 10.000) para descobrir quem são os filhosdos donos da empresa, vamos ter comotabela inicial (103, 205, 101), pois salário = 10.000 tem só 3 registros na sua lista de endereços de registros;
• a seguir a lista de endereços de registros de idade = 18 é percorrida e todos os nãoencontrados são eliminados da tabela;
• pesquisas mais complexas vão dar origem a tabelas mais complexas.

Vantagens• Bom suporte para todos os tipos de
pesquisas, desde que o campo pesquisadoseja indexado;
• uma das melhores técnicas para chavessecundárias com altas taxas de redundânciade valor de chave;
• o fato de podermos realizar todas as pesquisas de chaves que possuam índicesdiretamente nas tabelas de endereços provêuma vantagem imensa sobre a multilista.

Desvantagens• Em pesquisas booleanas onde pelo menos
dois dos elementos procurados não estãoindexados, temos de criar tabelas contendocópias de todos os registros que satisfizerama parte indexada da consulta;
• se mais de um elemento não está indexado e a pesquisa é conjuntiva, isto pode gerartabelas grandes e se tornar caro;
• atualização é complexa, pois todos osarquivos de índices devem ser atualizados.

Técnicas utilizando Árvores• Árvores podem também ser utilizadas
para a gerência de arquivos;• possibilidade de indexação:
- Chave Primária (Árvores Binárias e Árvore B);- Chave Primária e Secundária (ÁrvoreK-D).

Duas opções• Arquivo Único: utilizamos uma árvore
diretamente, colocando tanto a chavequanto os dados em um nodo daárvore.
• Vantagem: economia de espaço.• Desvantagem: dados misturados com
informação de indexação. Só um índiceé possivel.

Duas opções• Utilizamos a árvore como Arquivo de
Índices. Cada nodo da árvore possuiinformação sobre a chave e ponteirospara um outro arquivo, o arquivo de registros de dados, que contém osreais registros de dados completos.

Duas opções• Vantagens: dados independentes do arquivo de índices.
Arquivo de índices pode ser jogado fora. Registros de dados copiados independentemente de seus índices ou novo arquivode índices pode ser gerado indexando os dados por outra chave.Vários arquivos de índices para um mesmo arquivo de dados são possíveis simultaneamente, indexando-o por diferenteschaves.Podemos gerar um novo arquivo de índices enquanto o velhocontinua disponível para usuários.
• Desvantagem: desperdício de espaço - chaves do arquivo de registros de dados utilizadas para indexação replicadas no arquivo de índices.Conjunto de dados indexado por uma chave longa (ex.: nome, endereço) terá arquivo de índices extremamente grande.

Aspectos gerais• Vantagens
– Aplicação imediata: supondo-se a possibilidadedo endereçamento relativo por registros de arquivos, algoritmos de gerência de árvorespodem ser (quase todos) diretamente aplicados a arquivos. Ao invés de ponteiros para áreas de memória, utiliza-se campos inteiros com endereços relativos de registros;
– Pesquisa rápida: árvores oferecem tempos de acesso a registros relativamente curtos, com caminhos de busca O(log n).

Aspectos gerais• Desvantagens
– Desperdício de espaço: indexação porchave secundária impõe (com exceção dasárvores K-D) necessidade de váriosarquivos de índices, um para cada índice;
– Redundância de valor de chave cara: quando um valor de chave tem altaredundância (índices de chave secundária -ex.: cargo em um arquivo de departamentopessoal) muitos registros do arquivo de índices têm de ser lidos.

Aspectos gerais• Desvantagens
– Manutenção cara: em aplicações com freqüentes inserções e exclusões de registrose chaves, a manutenção de um arquivo de índices em uma árvore balanceada éextremamente cara.Solução:
• registros excluídos são somente marcados;• registros novos incluídos são sempre incluídos como
folhas;• rebalanceamento com exclusão definitiva realizado
periodicamente.– Problema: deterioração rápida da árvore.

Aspectos gerais• Desvantagens
– Listagem seqüencial cara: listagem de registros em ordem de chave implica emvisitas repetidas a todos os nodos daárvore que não são folhas.Solução: colocar o próprio registro napilha.
– Problema: estouro de pilha pararegistros grandes ou árvores profundas.

Resumo geral• Árvores são indicadas para aplicações
onde uma pesquisa rápida é muitoimportante, poucas alterações ocorremem um período de tempo e a atualização da árvore(rebalanceamento) pode ser feita embatch em períodos em que a estruturanão é utilizada.

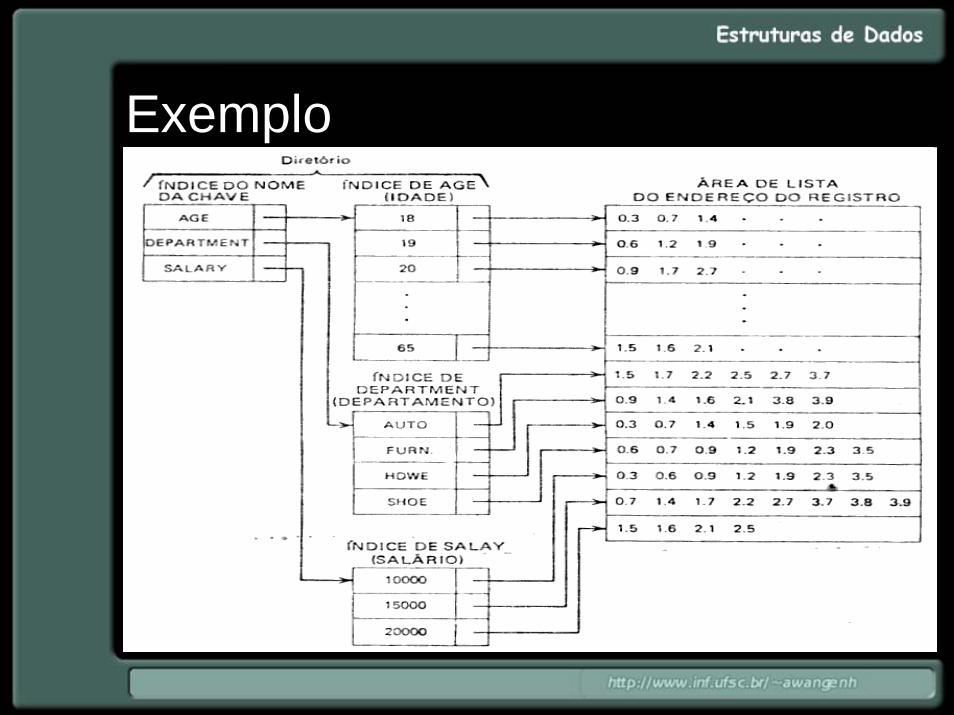
Árvore Binária Paginada• Subárvores são concatenadas em um único
registro;• adequado para árvores com nodos pequenos:
- árvores onde o nodo possui um ponteiropara o arquivo de registros;- árvores com registros de dados realmentepequenos;
• a nível de arquivo de índices, um registro do arquivo possui vários nodos da árvore.
Árvore Binária Paginada

Árvore Binária Paginada• Vantagem:
– muito menos acessos a disco sãorealizados.
• Desvantagens:– todos os algoritmos sofrem alterações;– rebalanceamento fica muito mais
complexo.

Árvore B• Árvores B (Bayer&MCCreight 1972), às vezes
também chamadas Árvores Bayer ou ÁrvoresMultivias, foram originalmente concebidaspara a implementação de mecanismos de indexação por chave primária em memóriasecundária;
• permite um número menor de nodos (menoraltura) e por conseguinte menos acessos a disco;
• implementações comuns utilizam arquivo de índices com ponteiros para arquivo de registros de dados.

Árvore B• Vantagens:
– mais adequada a arquivos voláteis do que árvoresbinárias; inclusão: redistribuição de chaves pode ser efetuada em tempo de operação;
– nodos com muitas chaves tornam paginaçãodesnecessária;
– economia de espaço: poucos ponteiros entrenodos;
– algoritmos são os mesmos que para árvore B emmemória principal.

Árvore B• Desvantagens:
– não oferece solução econômica para indexaçãopor chave secundária ou com alta redundância de valor de chave;
– exclusão com marcação e redistribuição offline;– não oferece solução barata para problema de
percurso por seqüencia de chave;Performance de busca por chave é idêntica à daárvore binária, se só ponteiros para nodos sãoempilhados.Problema: nodo não-folha com m chaves évisitado m vezes.

Árvore B+• Nas árvores de índices, os nodos só possuem, além
da chave, um ponteiro para o registro de dados emoutro arquivo. Isto pode ser levado ao extremo, se nós concentramos os ponteiros para o arquivo de registros nas folhas.– Nodos internos servem só como referência para o percurso;– chaves de nodos internos são repetidas nas folhas.
• Árvore é dividida em Index Set e Sequence Set.• Nodos do Sequence Set (folhas) são encadeados.

Árvore B+

Árvore B+• Vantagens:
– mecanismo para percorrerseqüencialmente o arquivo de registros de dados sem que seja necessário visitar todaa árvore;
– mecanismo para percorrerseqüencialmente o arquivo de registros de dados sem que seja necessário ordenar o arquivo de registro de dados.

Árvore K-D• Árvore binária para indexação
multichave - também chamada Árvorede Pesquisa BináriaMultidimensional.
• "Redescoberta" pela InteligênciaArtificial como mecanismo de indexaçãode Casos em Raciocínio Baseado emCasos (CBR - Case-Based Reasoning).

Árvore K-D• Estrutura:
– uma árvore K-D é uma árvore onde K é o número de chavespara cada registro. Assim, chamamos uma árvore com trêschaves de árvore 3-D (tridimensional);
– cada registro em uma árvore K-D possui, além dos dados e ponteiros, um conjunto ordenado de K valores de chaves(v0,...,vk-1);
– associado a cada nodo P está um discriminador DISC(P), que é utilizado para especificar qual chave da K-tuplav0,...,vk-1 será utilizada neste nodo para tomar uma decisãode ramificação. Geralmente o discriminador é função daprofundidade do nodo (resto da divisão da profundidade pelonúmero de chaves).

Árvore K-D• Estrutura:
– o filho à esquerda é chamado loson(P) e o à direitahison(P);
– caminhamento e inserção (nas folhas) sãorealizados seguindo-se a seguinte regra de decisão (dados Q = chaves do registro procuradoou registro a ser incluído e P = nodo):
• SE Kj(Q) < Kj(P) ENTÃO o registro Q está em loson(P)• SE Kj(Q) < Kj(P) ENTÃO o registro Q está em loson(P)

Árvore K-D• Estrutura:
– se dois valores de chave são iguais, a decisão étomada com base nos demais valores de chave naseguinte ordem (superchave):
Sj(P) = Kj(P),Kj+1(P),...,Kk-1(P),K0(P),...,Kj-1(P)
– Se incluirmos o conjunto de registros com 3 chaves abaixo em uma árvore 3-D teremos a árvore mostrada a seguir.

Árvore K-D

Árvore K-D• Estrutura:
– a primeira decisão de ramificação (raiz) étomada com base na chave primária (8), no nível 1 com base na segunda chave e no nível 2 com base na terceira chave. No nível 3 voltamos a usar a chave 0 comocritério de decisão.

Árvore K-D• Vantagens:
– árvores K-D podem ser utilizadas diretamente para todos os3 tipos de pesquisa: simples, com limites e booleana;
– o tempo médio de acesso a um registro não é pior do que o da árvore binária. Todas as características de tempo de pesquisa, complexidade, etc. da árvore binária valem, no quediz respeito à pesquisa, também para a árvore K-D:
O(1,4 log2 n)– Inserção (não balanceada) de um nodo requer também
tempo O(log2 n);– flexibilidade: aplicável a qualquer tipo de aplicação onde se
queira fazer recuperação de chaves secundárias ourecuperação multichaves.

Árvore K-D• Desvantagens:
– gera árvores de profundidadeextremamente grande. Solução: pode ser resolvido através dapaginação.
– Inserção balanceada é extremamente cara.– Rebalanceamento (após várias inserções
ou exclusões) também extremamente caro.

Árvore K-D• Resumo:
– boa técnica de indexação para arquivos somentecom muitas chaves secundárias (ex.: bases de casos em CBR);
– boa técnica para aplicações onde há poucasmodificações;
– utilização da árvore K-D como árvore de índicescom paginação é sugerida para implementaçõesem disco.Sugestão para facilitar buscas booleanas: pelomenos uma subárvore com K níveis em cadapágina.