Embed Size (px)
Citation preview

Inferência de Personalidade a partir de textos em Português
utilizando Léxico Linguístico e Aprendizagem de Máquina
Aldo M. Paim1, Ricardo S. Camati
1, Fabrício Enembreck
1
1Programa de Pós-Graduação em Informática (PPGIa)
Pontifícia Universidade Católica do Paraná (PUCPR) – Curitiba – PR – Brasil
{aldo,ricardo.camati,fabricio}@ppgia.pucpr.br
Abstract. Recent advances in automatic text analysis refer to the possibility
that computer systems are able to recognize and detect personality traits from
text. However, these methods are still in process of development and are,
mostly, specific for the English language, although there are a few studies
related to Portuguese. In this context, the paper presents a method for the
inference of the individual's personality in texts published on the social
network Facebook, written in Portuguese. The method is based on linguistic
features available in the LIWC lexicon and is processed by text mining
algorithms. The results show output values related to human personality in a
moderate scale.
Resumo. Os avanços recentes em análise automática de textos remetem a
possibilidade que sistemas computacionais sejam capazes de reconhecer e
detectar características de personalidade em texto. Entretanto, esses métodos
ainda estão em fase de desenvolvimento e são, em sua grande maioria, para a
língua inglesa, existindo escassos estudos para língua portuguesa. Nesse
contexto, o artigo apresenta um método para a inferência da personalidade do
indivíduo por meio de textos publicados na rede social Facebook, escritos em
língua portuguesa. O método é baseado em características linguísticas, por
intermédio do léxico LIWC e são processadas por meio de algoritmos de
mineração de texto. Os resultados apresentam valores de saída
correlacionados à personalidade humana em uma escala moderada.
1. Introdução
A descoberta do comportamento e esclarecimento da personalidade humana está
presente em diversas áreas de conhecimento. Estudos desenvolvidos no campo da
Neurociência e da Psicologia comprovam o papel fundamental que a personalidade do
indivíduo reflete na cognição humana, no que se refere à percepção, raciocínio,
aprendizagem, memória e tomada de decisão [Damásio, 1996].
Devido ao seu potencial de aplicabilidade, há uma grande difusão do estudo do
Reconhecimento da Personalidade por meio de Texto (RPT), utilizado em diversas
áreas: (i) na Inteligência Artificial para criar agentes mais humanos [Dimuro, 2007], (ii)
mensurar a personalidade dos usuários em redes sociais [Quercia et al., 2012], (iii)
personalização de produtos em sites de negócios (e-commerce) [Nunes et al., 2008], e
(iv) sistemas de recomendação baseados em personalidade [HU e PU 2011].
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 481

Para a inferência da personalidade por meio de texto, diversos pesquisadores,
como [Mairesse, 2007], [Quercia et al., 2012] e [Lima e Castro, 2013], utilizam o
modelo de fatores chamado “Big Five”, descreve a personalidade de um indivíduo em
torno de cinco traços [McCrae e John,1992]: Extroversão, Neuroticismo, Socialização,
Realização e Abertura à experiência. Em relação ao RPT, nota-se que a expansão de sua
aplicação para idiomas diferentes do inglês é necessária. No caso da língua portuguesa
existem poucos estudos computacionais com o objetivo de inferir a personalidade
humana [Nunes et al., 2013; Lima e Castro, 2013].
Esta pesquisa promove um modelo de reconhecimento automático de
personalidade a partir de texto, em língua portuguesa, por meio de uma abordagem
léxica, utilizando algoritmos de aprendizagem de máquina (AM). Até a publicação deste
artigo, não identificamos nenhum outro trabalho de RPT que utiliza léxico linguístico e
a rede social Facebook para a língua portuguesa. O presente artigo está estruturado da
seguinte forma: a seção 2 discute a personalidade humana e o modelo BigFive; a seção 3
expõe o método proposto de inferência; e os resultados são apresentados e analisados na
seção 4. As conclusões e direções para trabalhos futuros são oferecidas na seção 5.
2. Personalidade
Etimologicamente, a palavra personalidade deriva do latim – persona – que significa
“máscara”, isto é, como nos apresentamos aos outros indivíduos da sociedade. Em
Psicologia, o conceito de personalidade é subjetivo, existem muitas perspectivas
teóricas diferentes. Estas teorias podem ter algumas semelhanças ou serem
completamente contraditórias [Bock et al., 1999].
2.1 Teorias da Personalidade
Variantes de três métodos científicos são usualmente utilizados para a construção de
uma teoria da personalidade: o método clínico (utiliza estudos de casos de pacientes), o
método experimental (inclui a observação objetiva e sistemática em um ambiente
controlado) e o método correlacional (avalia a relação entre variáveis). Entre as
principais teorias da personalidade, podemos classificar uma parte importante delas
como: psicanalítica, neopsicanalítica, behaviorista, humanista e genética. Estas teorias
investigam a influência de um ou mais dos seguintes fatores na personalidade: genético,
ambiental, aprendizado, parental, desenvolvimento, consciência e inconsciência [Shultz
e Shultz, 2003].
A primeira teoria da personalidade, chamada “teoria psicanalítica”, implicou na
descoberta do inconsciente. Esta teoria foi inferida por meio do método psicanalítico
(uma especialização do método clínico), criado por Freud (1903). O inconsciente é uma
instância mental, regida pelo princípio do prazer, que busca a satisfação imediata de
seus impulsos. Em contraposição ao inconsciente, o consciente é regido pelo princípio
da realidade e utiliza mecanismos de defesa contra os impulsos considerados não
apropriados, vindos do inconsciente. Os psicanalistas usam a metáfora do complexo de
Édipo para enfatizar o fator parental, considerado o principal pilar formador da
personalidade que ocorre por volta dos cinco anos de idade. A partir do complexo de
Édipo, a personalidade é classificada em três tipos distintos, de acordo com o
mecanismo de defesa utilizado. O tipo neurótico usa o recalque, reprimindo os impulsos
não adequados; o psicótico faz uso da foraclusão, encontrando fora os impulsos que
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 482

deveriam ser reprimidos (o sujeito perde o contato com a realidade). A perversão faz uso
da denegação, em outras palavras, aquilo que para um neurótico é inconcebível para o
perverso pode provocar satisfação. O legado do inconsciente motivou o aparecimento de
outras teorias complementares à teoria psicanalítica, um exemplo é o inconsciente
estruturado como uma linguagem de Jacques Lacan que aproxima a psicanálise da
lógica formal [Nasio, 1992].
As teorias neopsicanalistas foram influenciadas pela psicanálise, mas divergiram
de algum fundamento da teoria freudiana original. Carl G. Jung postulou a existência de
arquétipos (representações herdadas de antepassados) em um inconsciente coletivo.
Essas representações interagem com o inconsciente pessoal e com a consciência,
formando complexos que ditam o modo de funcionamento mental. Ele identificou os
tipos de personalidade como introvertido e extrovertido [Jung, 2002]. Erik Erikson
(1968), outro neopsicanalista, afirmou que a personalidade era formada por uma
sucessão de oito estágios (teoria life-span), que evidenciam um conflito de sentimentos
específicos (um positivo e um negativo) em um contexto social. Para Erikson o
desenvolvimento da personalidade era gradual e por toda a vida.
Em sua teoria da motivação, Maslow (1853) criticou as teorias inferidas pelo
método clínico, pois achava que apenas o estudo dos melhores espécimes resultaria em
uma psicologia livre de defeitos. Ele acreditava que a psicoterapia deveria ser um
processo de autoconhecimento e não um processo de tratamento de doenças mentais.
Iniciou suas perspectivas teóricas com pessoas que admirava, e depois com pessoas que
ele considerou emocionalmente saudáveis. Seu método humanístico e otimista
considerava que o livre arbítrio poderia moldar da personalidade. Uma de suas maiores
contribuições foi classificação hierárquica das necessidades humanas, representadas em
forma de pirâmide. Na base da pirâmide estavam as mais básicas (fisiológicas) e as mais
elaboradas no topo (autorrealização). Apenas depois das necessidades mais básicas
satisfeitas é que as mais elaboradas poderiam ser alcançadas.
Em 1913, Watson desenvolveu o behaviorismo metodológico (teoria
comportamental). Em sua ótica, o comportamento humano é análogo a uma função, que,
ao receber um estímulo de entrada, produz um comportamento na saída. Skinner autor
do behaviorismo radical, notou que certos comportamentos poderiam ser condicionados
por meio de estímulos que recompensam ou punem (conceito de comportamento
operante) [Bock et al., 1999]. No behaviorismo, a personalidade é o comportamento
resultante da interação entre o ambiente e o indivíduo.
Muitas teorias da personalidade deram importância aos processos cognitivos.
Estes processos são as diferentes percepções do ambiente por meio de pensamentos.
Albert Bandura afirmou que os comportamentos não são aprendidos apenas por reforço,
mas também por observação. Para George Kelly, cada indivíduo tem um sistema de
padrões cognitivos usados para interpretar o ambiente e moldar a personalidade [Shultz
e Shultz, 2003].
Allport e Allport (1921) admitiram um conjunto de padrões de resposta inato de
cada indivíduo que interage com o ambiente social nas dimensões afetivas, cognitivas e
comportamentais, dando origem a psicologia dos traços, evidenciando o fator genético.
Para os autores, os traços são reais e não o produto de uma teoria (podendo ser
observados). Os traços possuem mecanismos entrelaçados e podem ser evidenciados
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 483

simultaneamente em um determinado momento ou variar de acordo com determinada
situação. Gordom Allport detectou dois tipos principais de traços: aqueles que são
comuns a membros de uma cultura e os que são individuais. Ele chamou de traços
centrais aqueles que são os mais expressivos em uma personalidade, se contrapondo aos
traços secundários (menos expressivos). A próxima seção discute o problema do cálculo
da personalidade.
2.2 Cálculo da personalidade
Existem diferentes métodos usados por psicólogos para investigar a personalidade: a
entrevista clínica; as avaliações de comportamentos; as amostras de pensamentos; os
inventários de personalidade; e os testes projetivos. A presente pesquisa optou pelos
inventários de personalidade, por serem aceitos pela comunidade de computação afetiva
no problema de RPT [Vinciarelli e Mohammadi, 2014].
Optamos por usar um tipo específico de inventário de personalidade (baseado na
teoria dos traços), chamado de modelo dos cinco grandes fatores, ou Big Five
[McDougall, 1932]. Este inventário se baseia na hipótese léxica, incluindo as diferenças
de personalidade dos indivíduos de uma determinada cultura na linguagem. O Big Five
começou a ganhar expressão a partir da década de 1980, quando as pesquisas de
McCrae e John (1992) começaram a comprovar a existência destes traços em indivíduos
de diferentes culturas e faixas etárias: extroversão (diz respeito a uma pessoa sensível,
assertiva, ativa, impulsiva, sociável e que expressa entusiasmo); neuroticismo (descreve
uma pessoa insegura, ansiosa, mal-humorada, autopunitiva e dimensões do afeto
negativo); socialização (define uma pessoa como amigável, cooperativa, cordial,
prestativa, altruísta e confiante); realização (caracteriza uma pessoa autodisciplinada,
organizada, metódica e persistente); abertura à experiência (descreve uma pessoa com
abertura ao novo, intelectual, criteriosa, liberal e tolerante).
A crítica, no uso deste tipo de inventário, é justamente que o indivíduo pode
mentir sobre a sua verdadeira personalidade, dando pistas falsas sobre seus traços. Os
Testes projetivos (baseados no mecanismo de projeção freudinano) como o teste
Rorschach e o teste das relações objetais não possuem estas interferências [Ocampo et
al., 1999], mas desconhecemos qualquer trabalho em computação que faz o uso destes
testes (provavelmente devido aos detalhes mais subjetivos em sua aplicação). Entre os
inventários de personalidade baseados no Big Five, optamos pelo NEO-IPIP 120
[Johnson, 2014]. Esta escolha é justificada por ele possuir 120 questões, mantendo a
precisão na inferência de personalidade sem ser cansativo.
3. Método de Inferência de Personalidade a partir de Texto em Língua Portuguesa
Nessa seção é apresentado um método detalhado para a inferência da personalidade do
indivíduo por meio de textos regidos em língua portuguesa. O método é composto pelas
seguintes etapas: (i) mensuração explícita da personalidade via inventário, cujo
resultado será utilizado para a avaliação do método computacional, (ii) montagem da
base textual, a partir de publicações da rede social Facebook (iii) pré-processamento,
responsável pela limpeza e representação dos dados, e (iv) mineração dos dados, por
intermédio de algoritmos de regressão para a geração de modelos de reconhecimento da
personalidade. Para melhor entendimento do modelo proposto, na Figura 1 são
ilustradas as fases do projeto e como elas estão relacionadas.
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 484

Figura 1. Visão geral do modelo para inferir a personalidade a partir de texto
A seguir, as etapas do método serão discutidas.
3.1. Mensuração Explícita de Personalidade via Inventário
A aplicação do questionário NEO-IPIP 120 contou com a consultoria de um
psicólogo. Ela tem o intuito de auxiliar a avaliação do método proposto e rotular os
exemplos do conjunto de treinamento, caracterizando uma aprendizagem
supervisionada. Os voluntários do estudo responderam a todas as questões do
inventário, selecionando uma das cinco opções de resposta formatadas em uma escala
Likert (discordo totalmente; discordo parcialmente; nem discordo nem concordo;
concordo parcialmente; concordo totalmente) representando seu nível de concordância
para cada pergunta.
Após o término do preenchimento do questionário, os valores atribuídos a cada
uma das indagações são utilizados para contabilizar o resultado. No cálculo, é atribuído
ao resultado um valor entre 1 a 100 para cada um dos itens do BigFive, segundo método
desenvolvido por Johnson (2014). O valor 1 corresponde ao nível mais baixo do traço e
o valor 100 ao nível mais alto do traço.
Os participantes da pesquisa são 256 estudantes universitários (115 homens e
141 mulheres) com a média de 25 anos de idade, pois possuem assiduidade nas mídias
sociais e responderam de forma voluntária o inventário NEO-IPIP 120, por meio do
documento online ou impresso. Ainda, ressalte-se que esta pesquisa foi aprovada pelo
Comitê de Ética em Pesquisa da Pontifícia Universidade Católica do Paraná. A próxima
subseção tratará as minúcias da montagem da base textual.
3.2. Base de Dados
Com base nos dados coletados, obteve-se um conjunto textual composto por
2.590.034 palavras, não exclusivas, presentes em 187.488 publicações realizadas pelos
usuários participantes do experimento na rede social. A Tabela 1 apresenta outras
informações da base textual coletada.
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 485

Tabela 1. Informações sobre a base de dados
Informações Total
Usuários 256
Publicações 187.488
Média de publicações por usuário 732
Palavras 2.590.034
Média de palavras por usuário 10.117
Posteriormente à etapa de seleção e criação da base de dados, o processo avança
para a etapa de pré-processamento, responsável pela limpeza e representação dos dados.
Essa etapa será detalhada na próxima subseção.
3.3. Pré-processamento
Essa etapa é responsável pela preparação do texto para a mineração dos dados, e
também, realiza a extração de características linguísticas empregadas nos textos, criando
uma matriz de termos relevantes para a inferência.
Os indutores (algoritmos de AM) exigem como entrada um vetor de
características, o qual contém n atributos (características) e um atributo-classe (classe).
Os valores para a classe deste vetor serão baseados no resultado do inventário aplicado
aos participantes. Por sua vez, os atributos serão baseados nas características textuais
extraídas por meio do léxico psicolinguístico LIWC [Pennebaker et al., 2007],
disponibilizado para idioma português pelo estudo de [Balage Filho et al.. 2013]. A
versão portuguesa do léxico possui mais de 127 mil palavras catalogadas em 64
categorias, dentre elas: palavras relacionadas à família, palavrões, verbos e outras.
Baseado no modelo de aplicação do léxico LIWC, feita por Mairesse (2007) para
a língua inglesa, o vetor de característica contém o percentual correspondente ao número
de palavras categorizadas no léxico e presente nas publicações dos usuários nas redes
sociais, conforme demonstrado na equação (1).
d
dt
dttt
tfLIWC
100,
),(
(1)
Na equação, dttf , corresponde a ocorrência do termo t em um documento d. O
valor dtt é o total de palavras empregadas no documento d.
Ao conjunto padrão de 64 categorias, disponibilizado para o português
brasileiro, foram acrescentadas cinco novas categorias, inspiradas no léxico LIWC de
língua inglesa [Pennebaker et al., 2007]. Essas categorias são independentes de idiomas,
em razão de ser apenas contagem de características textuais, sendo tais categorias
formadas pelo total da quantidade de: palavras, termos encontrados no léxico, palavras
com mais de seis letras, palavras por frase e frases contidas no texto. Na Figura 2 são
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 486

ilustradas as etapas do processo de pré-processamento da base textual, bem como a
estrutura das cinco bases de treinamento.
Figura 2. Estrutura da base de treinamento
As bases de treinamento são criadas a partir das características linguísticas
extraídas dos textos com o auxílio do léxico LIWC. Essa estrutura de modelo permite
comprovar a hipótese inicial desta pesquisa que questiona se o reconhecimento da
personalidade pode ser mensurado por meio de trechos escritos por seus autores.
Observe-se que para construir um modelo de classificação com o intuito de
categorizar os traços de personalidade de um indivíduo utilizando o BigFive, esbarra-se
em um problema de classificação multi-rótulo, visto que no modelo BigFive uma pessoa
sempre terá os cinco traços quantificados. Dessa forma, optou-se por decompor o
problema multi-rótulo em cinco modelos pertencentes a cada traço do modelo BigFive.
Todavia, a base de dados do usuário e o vetor de característica linguística são utilizados
para todos os modelos de treinamento, alterando apenas o atributo-meta conforme cada
traço de personalidade.
Na próxima subseção serão apresentados os algoritmos de mineração de dados
utilizados para criar o modelo de inferência de personalidade e validação do método.
3.4. Mineração dos Dados
Para a tarefa de construir um modelo de predição capaz de reconhecer os traços de
personalidade de um indivíduo por meio de texto, um conjunto de algoritmos candidatos
para essa tarefa foi analisado e testado. A base de treinamento é composta pelas
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 487

instâncias e atributos previamente rotulados (aprendizagem supervisionada), por meio
do vetor de característica apresentado na subseção anterior. Essa base de treinamento
tem por objetivo construir um indutor que possa determinar corretamente o atributo
meta de exemplos ainda não rotulados (base teste). Para a validação de cada algoritmo,
foi escolhida a técnica de k-fold cross-validation (validação cruzada), em que o valor de
k é igual a 10.
Os valores possíveis para o atributo meta serão representados pelo nível (0 a
100) correspondente ao traço de personalidade do indivíduo, caracterizando, assim, um
problema de regressão. Para a execução do método foram adotados diferentes modelos
de indutores de regressão, a saber: Linear Regression [Witten e Frank, 2005], SMOreg
[Shevade et al., 2000], M5P [Wang e Witten, 1997] e LWL [Atkeson et al. 1997].
Para a estimativa e precisão dos algoritmos na etapa de mineração dos dados,
foram utilizados métodos de avaliação de correlação de Pearson e teste estatístico não-
paramétrico de Friedman. Em caso de rejeição da hipótese nula do teste, pode-se
prosseguir com um teste post-hoc de Nemenyi [Corder e Foreman, 2011] para detectar
quais são as diferenças entre os classificadores. Esse teste permite ranquear os
algoritmos utilizados nos experimentos e obter a resposta sobre quais possuem o melhor
comportamento.
Na sequência são apresentados os resultados do método proposto.
4. Experimentos e Resultados
Essa seção descreve os experimentos realizados para a validação e avaliação de
desempenho do método proposto. Para a tarefa foi utilizada a ferramenta WEKA
[Witten e Frank, 2005] que conta com todos os algoritmos adotados para este estudo.
Com o propósito de comparar o desempenho do método, foram utilizados como
referência (baseline) os melhores resultados de correlação (r) por meio da abordagem
TF-IDF (Term Frequency – Inverse Document Frequency) [Salton e Buckley, 1988],
para cada traço de personalidade, tendo em vista que o método TF-IDF é amplamente
aplicado no reconhecimento de personalidade por meio de texto em outros idiomas.
Com a utilização da abordagem TF-IDF, obteve-se uma lista de termos
relevantes que são capazes de se correlacionar com os traços de personalidade de seus
autores. Desse modo, com o propósito de determinar o melhor conjunto que se
correlaciona com o traço de personalidade (atributo-meta), optou-se por extrair vários
conjuntos, por meio da ferramenta WEKA, variando o número de termos para cada
conjunto (68, 150, 200, 250, 300, 500, 750, 1000, 1500, 2000 e 3000 termos). A Tabela
2 apresenta os conjuntos de termos que atingiram maiores correlações com os traços de
personalidade.
Os experimentos com o LIWC são apresentados na Tabela 3. Observa-se que
com esse léxico os traços Neuroticismo, Realização e Abertura, obtiveram coeficientes
de correlação superiores aos da baseline, conforme destaque. Para os demais traços,
obtiveram-se resultados próximos aos da baseline. Entretanto, a correlação se apresenta
no intervalo interpretado como fraco, com resultados entre 0,11 a 0,30.
Ressalte-se que os valores de correlação obtidos demonstram resultados
superiores aos estudos de inferência de personalidade em língua portuguesa já
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 488

publicados, como o de [Nunes et al., 2013] que obteve o valor de 0,12 como maior
correlação. A correlação fraca, presente nos experimentos e nos trabalhos de RPT para a
língua portuguesa, indica que obter um modelo de inferência de personalidade não é
trivial, especialmente em ambientes virtuais, em que o vocábulo utilizado é informal.
Tabela 2. Melhores correlações de Pearson com a abordagem TF-IDF para com
todos os traços de personalidade.
Traço Algoritmo Correlação de
Pearson (r)
Quantidade de
termos TF-IDF
Extroversão Linear Regression 0,264 1500
Neuroticismo LWL 0,162 68
Realização IBK (k=1) 0,112 500
Socialização LWL 0,123 300
Abertura IBK (k=1) 0,185 250
Tabela 3. Resultados de correlação de Pearson utilizando léxico LIWC para
todos os traços de personalidade (* correlação significante ao nível de 0,05).
Traço Baseline M5P Linear
Regression
SMOReg SMOReg
(kernel=Puk)
LWL
Extroversão 0,264 0,17* 0,1331* 0.1297* 0.2085* 0.058
Neuroticismo 0,162 0,1918* 0,1503* 0.1375* 0.0735 0.1738*
Realização 0,112 0,1131 0,087 0.0503 0.1514* 0.1376*
Socialização 0,123 -0,0087 -0,0456 -0.0248 0.0405 -0.113
Abertura 0,185 0,1618* 0,1092 0.1693* 0.2008* 0.2031*
Ainda, o conjunto de treinamento, composto pelas categorias do LIWC, foi
submetido ao seletor de atributos Wrapper [Kohavi e John, 1997] e ao método de
pesquisa Greedy Stepwise [Witten e Frank, 2005]. Para cada algoritmo obteve-se um
subconjunto de atributos que possui maior correlação com o atributo-meta. Esses
subconjuntos foram utilizados para criar novas bases de treinamentos, contendo apenas
as categorias do LIWC que possuem maior ligação com os traços de personalidade.
A Tabela 4 apresenta os resultados do conjunto de treinamento LIWC
submetidos ao seletor de atributos, utilizando k-fold cross-validation, em que o valor de
k é igual a 10. Ainda, a tabela destaca o melhor resultado para cada traço.
Note-se que com a utilização desse método, os resultados superaram a baseline
para a todos os traços e o coeficiente de correlação aumentou, chegando a uma escala
moderada, com valores entre 0,27 a 0,39.
Para determinar a existência de diferença estatística significativa entre os
algoritmos do experimento, utilizou-se o teste de Friedman (todos contra todos) e post-
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 489
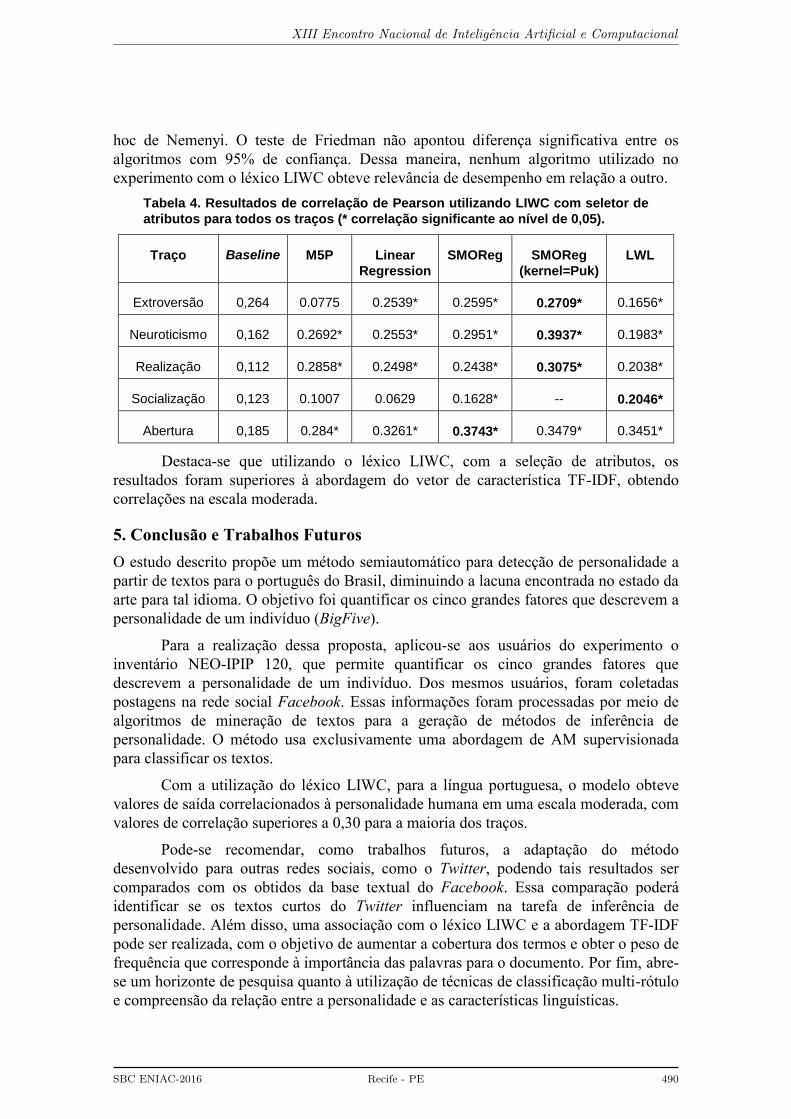
hoc de Nemenyi. O teste de Friedman não apontou diferença significativa entre os
algoritmos com 95% de confiança. Dessa maneira, nenhum algoritmo utilizado no
experimento com o léxico LIWC obteve relevância de desempenho em relação a outro.
Tabela 4. Resultados de correlação de Pearson utilizando LIWC com seletor de
atributos para todos os traços (* correlação significante ao nível de 0,05).
Traço Baseline M5P Linear
Regression
SMOReg SMOReg
(kernel=Puk)
LWL
Extroversão 0,264 0.0775 0.2539* 0.2595* 0.2709* 0.1656*
Neuroticismo 0,162 0.2692* 0.2553* 0.2951* 0.3937* 0.1983*
Realização 0,112 0.2858* 0.2498* 0.2438* 0.3075* 0.2038*
Socialização 0,123 0.1007 0.0629 0.1628* -- 0.2046*
Abertura 0,185 0.284* 0.3261* 0.3743* 0.3479* 0.3451*
Destaca-se que utilizando o léxico LIWC, com a seleção de atributos, os
resultados foram superiores à abordagem do vetor de característica TF-IDF, obtendo
correlações na escala moderada.
5. Conclusão e Trabalhos Futuros
O estudo descrito propõe um método semiautomático para detecção de personalidade a
partir de textos para o português do Brasil, diminuindo a lacuna encontrada no estado da
arte para tal idioma. O objetivo foi quantificar os cinco grandes fatores que descrevem a
personalidade de um indivíduo (BigFive).
Para a realização dessa proposta, aplicou-se aos usuários do experimento o
inventário NEO-IPIP 120, que permite quantificar os cinco grandes fatores que
descrevem a personalidade de um indivíduo. Dos mesmos usuários, foram coletadas
postagens na rede social Facebook. Essas informações foram processadas por meio de
algoritmos de mineração de textos para a geração de métodos de inferência de
personalidade. O método usa exclusivamente uma abordagem de AM supervisionada
para classificar os textos.
Com a utilização do léxico LIWC, para a língua portuguesa, o modelo obteve
valores de saída correlacionados à personalidade humana em uma escala moderada, com
valores de correlação superiores a 0,30 para a maioria dos traços.
Pode-se recomendar, como trabalhos futuros, a adaptação do método
desenvolvido para outras redes sociais, como o Twitter, podendo tais resultados ser
comparados com os obtidos da base textual do Facebook. Essa comparação poderá
identificar se os textos curtos do Twitter influenciam na tarefa de inferência de
personalidade. Além disso, uma associação com o léxico LIWC e a abordagem TF-IDF
pode ser realizada, com o objetivo de aumentar a cobertura dos termos e obter o peso de
frequência que corresponde à importância das palavras para o documento. Por fim, abre-
se um horizonte de pesquisa quanto à utilização de técnicas de classificação multi-rótulo
e compreensão da relação entre a personalidade e as características linguísticas.
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 490

Referências
Allport, F. H., Allport, G. W. (1921) “Personality Traits: Their Classification And
Measurement”, In Journal Of Abnormal And Social Psychology, v.16, p. 6–40.
Atkeson, C. G.; Moore, A. W.; Schaal, S. (1997) “Locally weighted learning for
control”, In Artificial Intelligence Review, v. 11, p. 75-113.
Balage Filho, P. P., Pardo, T. A., Aluisio, S. M. (2013) “An Evaluation of the Brazilian
Portuguese LIWC Dictionary for Sentiment Analysis”, In 9th Brazilian Symposium
in Information and Human Language Technology, Fortaleza, Ceará, p. 215-219.
Bock, A. M. B., Furtado, O., Teixeira T. M. (1999) “Psicologias: Uma introdução ao
estudo da psicologia”, 13ª. ed., São Paulo, Saraiva.
Corder, G.; Foreman, D. (2011) “Nonparametric Statistics for Non-Statisticians: A Step-
by-Step Approach”, Hoboken, NY, John Wiley & Sons.
Damásio, A. R. (1996) “O erro de Descartes: emoção razão e o cérebro humano”, São
Paulo, SP: Companhia das Letras.
Dimuro, G. P., Costa, A. C. R., Gonçalves, L. V., Hübner, A. (2007) “Centralized
Regulation of Social Exchanges between Personality-based Agents”, In
Coordination, Organizations, Institutions, and Norms in Agent Systems II, Berlin,
Heidelberg, Germany, Springer Verlag, p. 338-355.
Erikson, E. H. (1968) “Identidade, juventude e crise”, Rio de Janeiro, Zahar.
Freud, S. (1901 – 1905) “Um caso de histeria, três ensaios sobre a sexualidade e outros
trabalhos”, Edição Standard das Obras Psicológicas Completas de Sigmund Freud,
volume VII, Rio de Janeiro, Imago Editora, Tradução de 1969, p. 235-240.
Hu, R., Pu, P. (2011). “Enhancing Collaborative Filtering Systems with Personality
Information”, In Proceedings of the Fifth ACM Conference on Recommender
Systems, New York, NY, ACM, p. 197-204).
Johnson, J. A. (2014) “Measuring Thirty Facets of the Five Factor Model with a 120-
item Public Domain Inventory: Development of the IPIP-NEO-120”, In Journal of
Research in Personality, c. 51, p. 78-89.
Jung, C. G. (2002) “Os arquétipos e o inconsciente coletivo”, 2ª. ed, Petrópolis, Editora
Vozes.
Kohavi, R.; John, G. (1997) “Wrappers for Feature Subset Selection”, In Artificial
Intelligence, Amsterdam, v. 97, n. 1-2, p. 273-324.
Lima, A. C. E. S., Castro, L. N. (2013) “Multi-label Semi-supervised Classification
Applied to Personality Prediction in Tweets”, In Computational Intelligence and 11th
Brazilian Congress on Computational Intelligence (BRICS-CCI & CBIC), 2013
BRICS Congress on. IEEE, p.195-203.
Mairesse, F., Walker, M. A., Mehl, M. R., Moore, R. K. (2007) “Using Linguistic Cues
for the Automatic Recognition of Personality in Conversation and Text”, In Journal
of Artificial Intelligence Research, v. 30, p. 457-500.
Maslow, A. (1954) “Motivation and Personality”, NewYork, Harper.
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 491

McCrae, R. R., John, O. P. (1992) “An Introduction to the Five‐factor Model and its
Applications”, Journal of Personality, v. 60, n. 2, p. 175-215.
McDougall, W. (1932) “Of the Words Character and Personality”, In Character
Personality, v. 1, n. 1, p. 3-16.
Nasio, J. D. (1992) “Cinco lições sobre a teoria de Jacques Lacan”, Rio de Janeiro,
Zahar.
Nunes, M. A. S. N. (2012) “Computação Afetiva personalizando interfaces, interações e
recomendações de produtos, serviços e pessoas em ambientes computacionais”,
Projetos e Pesquisas em Ciência da Computação no DCOMP/PROCC/UFS, v. 1, p.
115-151.
Nunes, M. A. S. N., Teles, F. R., De Souza, J. G. (2013) “Inferindo personalidade via
tweets”, In GEINTEC-Gestão, Inovação e Tecnologias, v. 3, n. 3, p. 045-057.
Nunes, M. A. S. N., Cerri, S. A., Blanc, N. (2008) “Towards User Psychological
Profile”, In Proceedings of the VIII Brazilian Symposium on Human Factors in
Computing Systems, Sociedade Brasileira de Computação, p. 196-203.
Ocampo M. L. S., Arzeno M. E. G., Piccolo E. G. (1999) “O processo psicodiagnóstico
e as técnicas projetivas”, 9ª. ed, São Paulo, Martin Fontes.
Pasquali, L. (2001) “Técnicas de exame psicológico – TEP”, São Paulo, Casa do
Psicólogo.
Pennebaker, J. W.; Chung, C. K.; Ireland, M.; Gonzales, A.; Booth, R. J. (2007) “The
Development and Psychometric Properties of LIWC2007”, [software manual],
Austin, TX, LIWC. Net.
Quercia, D., Lambiotte, R., Stillwell, D., Kosinski, M., Crowcroft, J. (2012) “The
Personality of Popular Facebook Users”, In Proceedings of the ACM 2012
Conference on Computer Supported Cooperative Work, p. 955-964.
Salton, G., Buckley, C. (1988) “Term-weighting Approaches in Automatic Text
Retrieval”, Information Processing & Management, v. 24, n. 5, p. 513–523.
Schultz, D. P., Schultz, S. E. (2003) “Theories of Personality”, 8th
ed., Belmont, CA,
Wadsworth.
Shevade, S. K., Keerthi, S. S., Bhattacharyya, C., Murthy, K. R. K. (2000)
“Improvements to the SMO Algorithm for SVM Regression”, IEEE Transactions on
Neural Networks, v. 11, n.5, p. 1188-1193.
Vinciarelli, A., Mohammadi G. (2014) “A Survey of Personality Computing”, IEEE
Transactions on Affective Computing, v.5, n.3, p. 273-291.
Wang, Y., Witten, I. H. (1997) “Induction of Model Trees for Predicting Continuous
Classes”, In Poster Papers of the 9th European Conference on Machine Learning.
Witten, I. H., Frank, E. (2005) “Data Mining: Practical Machine Learning Tools and
Techniques”, The Morgan Kaufmann Series in Data Management Systems, 2nd
ed.
San Francisco: Elsevier.
XIII Encontro Nacional de Inteligencia Artificial e Computacional
SBC ENIAC-2016 Recife - PE 492





























