Embed Size (px)
Citation preview

MARCELO OZAWA DE SOUSA
ANÁLISE DE SENTIMENTOS POR CLASSIFICAÇÃOMULTIRRÓTULO INDEPENDENTE DE ALGORITMO
LONDRINA–PR
2018


MARCELO OZAWA DE SOUSA
ANÁLISE DE SENTIMENTOS POR CLASSIFICAÇÃOMULTIRRÓTULO INDEPENDENTE DE ALGORITMO
Trabalho de Conclusão de Curso apresentadoao curso de Bacharelado em Ciência da Com-putação da Universidade Estadual de Lon-drina para obtenção do título de Bacharel emCiência da Computação.
Orientador: Prof. Dr. Bruno Bogaz ZarpelãoCoorientador: Prof. Dr. Sylvio Barbon Ju-nior
LONDRINA–PR
2018

Marcelo Ozawa de SousaAnálise de Sentimentos por Classificação Multirrótulo Independente de Algo-
ritmo/ Marcelo Ozawa de Sousa. – Londrina–PR, 2018-51 p. : il. (algumas color.) ; 30 cm.
Orientador: Prof. Dr. Bruno Bogaz Zarpelão
– Universidade Estadual de Londrina, 2018.
1. Análise de Sentimentos. 2. Classificação Multirrótulo. I. Prof. Dr. BrunoBogaz Zarpelão. II. Universidade Estadual de Londrina. III. Curso de Ciênciada Computação. IV. Análise de Sentimentos por Classificação MultirrótuloIndependente de Algoritmo
CDU 02:141:005.7

MARCELO OZAWA DE SOUSA
ANÁLISE DE SENTIMENTOS POR CLASSIFICAÇÃOMULTIRRÓTULO INDEPENDENTE DE ALGORITMO
Trabalho de Conclusão de Curso apresentadoao curso de Bacharelado em Ciência da Com-putação da Universidade Estadual de Lon-drina para obtenção do título de Bacharel emCiência da Computação.
BANCA EXAMINADORA
Prof. Dr. Bruno Bogaz ZarpelãoUniversidade Estadual de Londrina
Orientador
Prof. Dr. Sylvio Barbon JuniorUniversidade Estadual de Londrina
Prof. Dr. Evandro BacarinUniversidade Estadual de Londrina
Londrina–PR, 7 de fevereiro de 2018


AGRADECIMENTOS
Em primeiro lugar, agradeço aos meus pais, Joaquim e Tereza, pelo contínuo apoiodado em toda minha vida pessoal e acadêmica.
Agradeço também aos meus professores e a todos os funcionários da universidadeque trabalham para criar um bom ambiente de aprendizado.
Em especial, agradeço aos meus orientadores Prof. Dr. Sylvio Barbon Jr. e Prof.Dr. Bruno Bogaz Zarpelão pela paciência e por me ajudarem neste trabalho.
E finalmente, agradeço a todos os meus amigos que eu conheci aqui na universi-dade, que me ajudaram tanto durante toda essa caminhada, e que fizeram estes últimosanos serem tão especiais na minha vida.


“O sucesso é ir de fracasso em fracasso sem perder entusiasmo.“
Winston Churchill


SOUSA, M. O.. Análise de Sentimentos por Classificação Multirrótulo Indepen-dente de Algoritmo. 51 p. Trabalho de Conclusão de Curso (Bacharelado em Ciênciada Computação) – Universidade Estadual de Londrina, Londrina–PR, 2018.
RESUMO
A Análise de Sentimentos pode ser considerada uma ferramenta indispensável hoje emdia, servindo como uma importante fonte de informações. Com seu uso, é possível obterinformações que podem ser úteis em diversas situações, como na definição de uma es-tratégia de marketing, na tomada de decisões que busquem uma melhora no sucesso deuma campanha política, ou na busca por um melhor serviço de atendimento ao cliente.Esse trabalho propõe um modelo de classificação multirrótulo para realizar a análise desentimentos sobre um conjunto de dados composto de notícias. O objetivo é classificarquais os sentimentos de uma pessoa ao ler uma determinada notícia. A escolha por umaabordagem multirrótulo foi feita porque uma única notícia pode despertar mais do queum sentimento em seu leitor. Foram utilizadas diferentes técnicas independentes de al-goritmo, para que pudesse ser feita uma comparação e análise de seus desempenhos natarefa da Análise de Sentimentos. Para a análise do desempenho das técnicas utilizadas,foi utilizado o algoritmo de aprendizado de máquina Random Forest.
Palavras-chave: Análise de Sentimentos. Classificação Multirrótulos. Aprendizado deMáquina.


SOUSA, M. O.. Sentiment Analysis by Multi-label Problem TransformationMethods. 51 p. Final Project (Bachelor of Science in Computer Science) – State Univer-sity of Londrina, Londrina–PR, 2018.
ABSTRACT
Sentiment analysis can be considered a very important tool nowadays, being used as animportant source of information. Through its use, it is possible to obtain informationthat can be useful in a variety of situations, such as when defining a marketing strategy,making decisions that seek to improve the success of a political campaign, or to providebetter customer service. This work proposes a multi-label classification model to performsentiment analysis on a dataset composed of news articles. The goal is to sort out aperson’s feelings when reading a particular piece of news. A multi-label approach waschosen because a single news article can arouse multiple feelings in its reader. Differentproblem transformation methods were used in order to make a comparison and analysisof their performance in sentiment analysis. Random Forest machine learning algorithmwas used to evaluate the performance of each method used.
Keywords: Sentiment Analysis. Multi-Label Classification. Machine Learning.


LISTA DE ILUSTRAÇÕES
Figura 1 – Exemplo de árvore de decisão [Fonte: autor] . . . . . . . . . . . . . . . 31Figura 2 – Técnicas para classificação multirrótulo . . . . . . . . . . . . . . . . . . 37Figura 3 – Resultado do percentual de acerto (acurácia) usando a técnica BRC na
classificação de 7 classes de emoções . . . . . . . . . . . . . . . . . . . 41Figura 4 – Resultado da acurácia de cada uma das técnicas utilizadas (Primário e
Completo) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42Figura 5 – Resultado da acurácia de cada técnica (Primário e Completo combinados) 42Figura 6 – Comparação dos resultados obtidos com os experimentos primário e
completo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43Figura 7 – Comparação entre os métodos de representação de texto . . . . . . . . 43Figura 8 – Comparação entre os métodos de representação de texto (LV1 e LV2) . 44Figura 9 – Comparação LV1 e LV2 . . . . . . . . . . . . . . . . . . . . . . . . . . 44


LISTA DE TABELAS
Tabela 1 – Os níveis sentic do Modelo Hourglass . . . . . . . . . . . . . . . . . . . 27Tabela 2 – Emoções de segundo nível do Modelo Hourglass . . . . . . . . . . . . . 28Tabela 3 – STREN-LV1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Tabela 4 – STREN-LV2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Tabela 5 – TFIDF-LV1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Tabela 6 – TFIDF-LV2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Tabela 7 – WORDS-LV1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Tabela 8 – WORDS-LV2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Tabela 9 – Transformação Baseada nos Rótulos das Classes - Tristeza . . . . . . . 37Tabela 10 – Eliminação de Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . 38Tabela 11 – Criação de Rótulos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Tabela 12 – Eliminação de Rótulos . . . . . . . . . . . . . . . . . . . . . . . . . . . 39


LISTA DE ABREVIATURAS E SIGLAS
IA Inteligência Artificial
AM Aprendizado de Máquina
MD Mineração de Dados
RF Random Forest
NBR Norma Brasileira
BRC Baseado em Rótulos de Classes
EE Eliminação de Exemplos
ER Eliminação de Rótulos
CR Criação de Rótulos


SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 FUNDAMENTAÇÃO TEÓRICA . . . . . . . . . . . . . . . . . 252.1 Análise de Sentimentos . . . . . . . . . . . . . . . . . . . . . . . . 252.2 Aprendizado de Máquina . . . . . . . . . . . . . . . . . . . . . . . 292.3 Classificação Multirrótulo . . . . . . . . . . . . . . . . . . . . . . . 32
3 MATERIAIS E MÉTODOS . . . . . . . . . . . . . . . . . . . . 333.1 Base de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.2 Metodologia Proposta . . . . . . . . . . . . . . . . . . . . . . . . . 343.2.1 Transformação do Problema . . . . . . . . . . . . . . . . . . . . . 363.2.2 Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 RESULTADOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5 CONCLUSÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . 49


21
1 INTRODUÇÃO
As emoções e opiniões da população podem ser consideradas informações muitovaliosas na atualidade, ajudando na tomada de decisões de pessoas e empresas [1, 2].Sempre que uma pessoa demonstra interesse na compra de um produto, como uma te-levisão por exemplo, ela procura por opiniões de outras pessoas, seja na Internet, emsites especializados em análises de produtos, ou diretamente com amigos, para que essainformação possa ajudá-la na decisão de qual produto escolher. Saber o que o outro pensapode influenciar também na hora de escolher em qual candidato votar em uma eleição.Empresas também podem se beneficiar com essas informações, descobrindo o que seusclientes acham de seus produtos, ou de suas campanhas publicitárias, para que possam seajustar e, com isso, obter maior sucesso.
O aumento cada vez maior do uso das mídias sociais pela população resulta emuma quantidade imensa de informações escondidas em e-mails, comentários, tweets e emanálises de produtos. O grande desafio é saber manipular toda essa fonte de dados paraque se possa extrair informações que podem ser úteis para uma determinada situação. É aíque entra a Análise de Sentimentos, que pode ser definida como o processo de identificar ecategorizar opiniões expressas em um fragmento de texto, em especial para determinar sea atitude do escritor em relação a um tópico ou produto é positiva, negativa ou neutra [1].Com seu uso, é possível descobrir as opiniões e experiências de pessoas ao redor de todo omundo [2]. Uma das principais fontes de informação usadas na Análise de Sentimentos é oTwitter, devido à natureza dos microblogs, em que pessoas postam mensagens em temporeal contendo suas opiniões sobre uma grande variedade de tópicos [3, 4, 5, 6, 7, 8].
As informações obtidas com a Análise de Sentimentos podem ser aproveitadasem uma grande variedade de situações. É possível, por exemplo, verificar o efeito dasmídias sociais na performance de uma empresa no mercado de ações [9], descobrir aopinião de clientes sobre um determinado produto ou serviço, através de análises feitaspor compradores e usuários [10, 11, 12], ou até mesmo investigar quais as preferênciaspolíticas da população [13].
Embora a maior parte das pesquisas nesta área tenha como foco a abordagemsimples-rótulo, onde cada exemplo só pode ser classificado utilizando um único rótulo, hásituações em que é mais adequado o uso da classificação multirrótulo. Esse geralmente éo caso quando são considerados dados textuais, como notícias, documentos e páginas daInternet. Uma notícia que trate sobre uma briga entre torcedores em um jogo de futebol,por exemplo, pode ser considerada tanto uma notícia relacionada à violência, como umanotícia esportiva. Caso este exemplo estivesse presente em um problema simples-rótulo,teria que ser feita uma escolha por um dos dois rótulos (violência ou esporte). É isso que

22
faz da categorização de dados textuais a principal aplicação da classificação multirrótulos.
Em [14], Liu propôs uma abordagem multirrótulo para Análise de Sentimentosem microblogs. Foram realizados experimentos com diferentes métodos de classificaçãomultirrótulo, para analisar suas performances na classificação em dois conjuntos de dadosde microblogs. Segundo Liu, até então ainda não haviam sido realizados experimentos comclassificação multirrótulo de microblogs e, consequentemente, ainda não havia respostassobre qual seria a performance de métodos multirrótulo neste tipo de problema. Por isso,a busca por essas respostas é muito importante na construção de ferramentas inteligentespara a Análise de Sentimentos multirrótulo em mídias sociais.
Em [15], Huang propôs um modelo de classificação multi-task multi-label(MTML),que realiza a classificação não só de sentimentos, mas também de tópicos, de forma si-multânea. O modelo incorpora os resultados de cada tarefa dos passos anteriores parapromover e reforçar a outra tarefa iterativamente. Os resultados mostraram que o MTMLobteve bons resultados tanto na classificação de sentimento quanto na classificação detópicos.
A maioria dos trabalhos na mineração de opiniões é direcionada a textos subjetivos,como análises de produtos ou filmes. Autores deste tipo de texto expressam suas opiniõesde maneira livre. A situação é diferente quando se trata de notícias. A principal diferença éque em uma análise de um filme, por exemplo, o alvo dos sentimentos é claramente definido(filme), e é único no decorrer de todo o texto. Além disso, a maioria dos jornais geralmentebusca evitar usar um vocabulário claramente positivo ou negativo, dificultando a tarefada Análise de Sentimentos neste tipo de texto [16]. Em seu trabalho, Balahur abordao problema da mineração de opiniões utilizando notícias na língua inglesa. Ele testa aeficácia de diferentes dicionários de sentimentos, e procura separar opiniões positivas ounegativas de notícias boas ou ruins.
Em [17], Bhowmick apresentou um modelo de classificação utilizando o métodoensemble chamado de RAKEL, um algoritmo específico para problemas multirrótulo. Abase de dados utilizada continha 1305 notícias. Para a classificação dos sentimentos, foramutilizadas os rótulos desgosto, medo, felicidade e tristeza.
Em [18], Li também trata do assunto da Análise de Sentimentos multirrótuloem notícias. Diferente de modelos anteriores que tratam os documentos de treinamentode maneira uniforme, Li propôs um modelo de classificação multirrótulo baseado empesos, introduzindo o conceito de "concentração emocional"para estimar os pesos de cadadocumento de treinamento, além de abordar o problema de amostras ruidosas para cadaemoção.
Neste trabalho, foram utilizadas técnicas independentes de algoritmo, que trans-formam problemas originalmente multirrótulos em um ou mais problemas simples rótulo,

23
possibilitando o uso de algoritmos tradicionais de aprendizado de máquina. Suas perfor-mances foram analisadas e comparadas para avaliar a eficácia das técnicas que utilizamessa abordagem na resolução de problemas de classificação multirrótulo.
No Capítulo 2 é apresentada a fundamentação teórica, contendo os conceitos maisimportantes necessários para o entendimento do trabalho realizado. No Capítulo 3 estão osmateriais e métodos, onde são apresentadas as características da base de dados utilizada,além de todo o processo executado para a realização dos experimentos. No Capítulo4 é feita a apresentação e discussão dos resultados obtidos. Por fim, no Capítulo 5, éapresentada a conclusão deste trabalho.


25
2 FUNDAMENTAÇÃO TEÓRICA
Neste capítulo serão apresentados os conceitos fundamentais para o entendimentodeste trabalho.
2.1 Análise de Sentimentos
A Análise de Sentimentos, às vezes também chamada de Mineração de Opiniões,pode ser definida como o estudo computacional das atitudes, emoções e opiniões de umapessoa em relação a uma determinada entidade, que pode ser um evento, indivíduo outópico [19][20]. É uma maneira de avaliar a linguagem escrita para determinar a atitudede seu autor, seja ela favorável, desfavorável ou neutra, e qual a sua intensidade. Coma tecnologia disponível atualmente, as ferramentas de análise de sentimentos conseguemlidar com volumes enormes de comentários de clientes, em fontes como blogs e redessociais, possibilitando que seja feita uma análise da opinião de um indivíduo sobre umagrande variedade de tópicos diferentes [21].
Embora, com muita frequência, as duas expressões sejam utilizadas como sinôni-mos, alguns pesquisadores afirmam que elas representam noções ligeiramente diferentes[22]. A Mineração de Opiniões foca na aplicação específica de classificar opiniões quanto àsua polaridade (positiva ou negativa), enquanto a Análise de Sentimentos identifica qualo sentimento expresso em um texto (alegria, tristeza, medo).
A Análise de Sentimentos é utilizada atualmente por empresas em diversas aplica-ções. Ela pode ser aplicada na busca de uma melhoria no gerenciamento do relacionamentocom clientes, em sistemas de recomendações através do feedback, tanto positivo quanto ne-gativo de clientes, e no desenvolvimento de estratégias de marketing, através da avaliaçãoe previsão das atitudes do público direcionadas à sua marca [23].
Há três níveis de classificação principais na análise de sentimentos [1]:
1. Nível de documento: busca verificar se um documento expressa uma opinião positivaou negativa. Por exemplo, dada uma análise de um produto, o sistema determinase essa análise expressa uma opinião positiva ou negativa sobre um determinadoproduto ou serviço. Este nível de análise assume que cada documento expressauma opinião sobre uma única entidade (como a análise de um produto). Por isso,não é aplicável em situações onde os documentos avaliem ou comparem múltiplasentidades;
2. Nível de sentença: Classifica o sentimento expresso em cada sentença. Primeiro é

26
identificado se a sentença é subjetiva ou objetiva. Caso a sentença seja subjetiva,será então determinado se a sentença expressa uma opinião positiva ou negativa;
3. Nível de aspecto e entidade: Tanto o nível de documento quanto o de sentença nãosão suficientes para descobrir exatamente o que uma pessoa gostou ou não. O nívelde aspecto realiza uma análise mais detalhada, baseando-se na ideia de que umaopinião consiste de um sentimento (positivo ou negativo) e um alvo (da opinião).Em muitas aplicações, os alvos das opiniões são descritos por entidades e/ou seusdiferentes aspectos.
Um dos indicadores mais importantes de sentimento em textos são calculados combase em algumas palavras comumente usadas para indicar sentimentos positivos ou ne-gativos, chamadas de palavras de sentimento (sentiment words) [1]. Por exemplo, “bom”,“ótimo”, “maravilhoso” e “excelente” são palavras que claramente expressam sentimen-tos positivos. Como exemplos de palavras que expressam sentimentos negativos temos“ruim”, “péssimo” e “terrível”. Apesar dessas palavras serem importantes para a Análisede Sentimentos, elas não são o suficiente. Para exemplificar isso, abaixo são listados algunsdos problemas mais comumente encontrados:
∙ Uma frase contendo palavras de sentimento não necessariamente expressa um sen-timento. Este fenômeno acontece com muita frequência. Sentenças interrogativas esentenças condicionais são dois bons exemplos: “Você pode me dizer qual televisãoda Samsung é boa?” e “Se eu encontrar uma boa televisão na loja por um bompreço, vou comprá-la”. As duas frases contém a palavra “boa”, mas em nenhumadelas a palavra “boa” expressa algum sentimento negativo ou positivo em relação àuma televisão específica;
∙ Frases contendo sarcasmo são difíceis de serem analisadas, como por exemplo: “Queótima geladeira! Parou de funcionar depois de dois dias.” Embora sarcasmo não sejamuito comum em análises de produtos, pode ser um grande problema em discussõespolíticas, dificultando a análise de opiniões políticas;
∙ Muitas sentenças que não contêm palavras de sentimentos também podem sugerirsentimentos. Muitas dessas sentenças são na verdade sentenças objetivas usadas paraexpressar algum tipo de informação. Por exemplo, a frase “Esta máquina de lavarusa muita água” sugere um sentimento negativo sobre a máquina de lavar, já queela usa muita água. Esta é uma frase objetiva, já que ela apenas constata um fato.
As emoções humanas vem cada vez mais sendo compreendidas como um aspectocrucial no desenvolvimento de sistemas inteligentes. Com o decorrer dos anos, a adoção demodelos psicológicos de emoções tem se tornado uma prática comum entre pesquisadores

27
trabalhando na área da computação afetiva. Por exemplo, em [24], Ekman identificouseis emoções básicas (medo, desgosto, tristeza, raiva, surpresa e alegria), baseado em umestudo realizado com pessoas da tribo Fori na Papua-Nova Guiné em 1972. Os membros datribo foram capazes de identificar as seis emoções em fotos mostradas a elas. Depois, foramtiradas fotos de expressões faciais das pessoas da tribo Fori que foram posteriormentemostradas para pessoas de outras raças e culturas ao redor de todo o mundo. Eles tambéminterpretaram as emoções nas fotos corretamente. Gradualmente, diversos pesquisadoresconfirmaram que essas seis emoções são universais para todos os seres humanos.
No entanto, muitos desses modelos desenvolvidos não se mostraram apropriadosem projetos de aplicações no campo da Análise de Sentimentos. Por causa disso, em[25], Cambria propôs um novo modelo de categorização de emoções, chamado de ModeloHourglass.
O Modelo Hourglass organiza as emoções primárias ao redor de quatro dimen-sões independentes, mas concomitantes, cujos diferentes níveis de ativação compõem ototal estado emocional da mente. As quatro dimensões afetivas são Prazer, Atenção, Sen-sibilidade e Aptidão. Cada dimensão afetiva é caracterizada por seis níveis de ativação(medindo a intensidade de uma emoção), chamados de níveis sentic, que representam oslimiares de intensidade de uma emoção expressa/percebida. Estes níveis podem tambémser rotulados como um conjunto de 24 emoções básicas, seis para cada dimensão afetiva,que permitem que o modelo especifique a informação afetiva associada a um texto. As24 emoções básicas podem ser observadas na Tabela 1. As emoções primárias do ModeloHourglass podem ser combinadas para formar as emoções de segundo nível. Diferentesníveis concomitantes de ativação dão origem a diferentes tipos de emoções compostas. Asemoções de segundo nível podem ser observadas na Tabela 2.
Prazer Atenção Sensibilidade Aptidãoêxtase vigilância fúria admiraçãoalegria antecipação raiva confiança
serenidade interesse aborrecimento aceitaçãointrospecção distração apreensão tédio
tristeza surpresa medo desgostoaflição espanto terror repugnância
Tabela 1 – Os níveis sentic do Modelo Hourglass
Um dos principais problemas na mineração de textos é a sua representação, algofundamental e indispensável para o processamento inteligente de informações contidas emum documento. Diferente da mineração de dados, que lida com dados bem estruturados,a mineração de textos trabalha com uma coleção de documentos semi-estruturados, ouaté mesmo sem qualquer estrutura. Por isso, uma das tarefas na mineração de textos é arepresentação de textos, que consiste em transformar textos em vetores numéricos [26].

28
Atenção>0 Atenção<0 Aptidão>0 Aptidão<0Prazer>0 otimismo frivolidade amor regozijoPrazer<0 frustração desaprovação inveja remorso
Sensibilidade>0 agressividade rejeição rivalidade desprezoSensibilidade<0 ansiedade temor submission coerção
Tabela 2 – Emoções de segundo nível do Modelo Hourglass
Para a recuperação de informações, os documentos geralmente são identificadospor conjuntos de termos ou palavras-chave, que são usados de maneira coletiva pararepresentar seus conteúdos. Geralmente, há dois tipos de tarefas na representação detextos: a indexação e o cálculo dos pesos de cada termo (weighting). A indexação consisteem atribuir termos de indexação para os documentos, e o cálculo de pesos consiste ematribuir pesos para cada termo, que medem a importância de um termo em um documento[26].
Na tarefa de classificação de textos, que inclui a recuperação de informações e acategorização de textos, há duas propriedades importantes de um termo de indexação:qualidade semântica e qualidade estatística. A qualidade semântica é relacionada com osignificado de um termo, ou seja, o quão bem o termo de indexação consegue descrever oconteúdo do texto. Já a qualidade estatística tem relação com a capacidade de um termode indexação de identificar a categoria do documento no qual o termo ocorre [26].
Há diversos métodos de cálculo de pesos, que são derivados de diferentes suposi-ções para as características dos termos em textos. Um destes métodos é o IDF (inversedocument frequency), que considera que um termo que aparece em vários documentosnão pode ser considerado um bom discriminador, e por isso, deve ter um peso menor queum termo que apareça em poucos documentos. Uma variação do IDF é o RIDF (residualinverse document frequency), que assume que a importância de um termo deve ser medidapela diferença entre sua real frequência de ocorrência nos documentos e sua frequência deocorrência prevista pela distribuição de Poisson (ocorrência aleatória) [26].
O TFIDF [27] é uma evolução do IDF. A fórmula que o TFIDF utiliza no cálculodos pesos de cada termo é:
𝑤𝑖,𝑗 = 𝑡𝑓𝑖,𝑗 × 𝑙𝑜𝑔
(︃𝑁
𝑑𝑓𝑖
)︃(2.1)
onde 𝑤𝑖,𝑗 é o peso do termo 𝑖 no documento 𝑗, 𝑁 é a quantidade de documentos nacoleção, 𝑡𝑓𝑖,𝑗 é a frequência do termo 𝑖 no documento 𝑗 e 𝑑𝑓𝑖 é a frequência de documentosdo termo 𝑖 na coleção. Com o cálculo do TFIDF, é possível medir qual a importância deum termo em uma coleção de documentos.
Outro método de representação de textos bastante conhecido é o Bag of Word(BOW). Na representação BOW, um documento é codificado como um vetor de caracte-rísticas, com cada elemento no vetor indicando a presença ou ausência de uma palavra

29
no documento. A principal limitação do BOW é que ele guarda apenas a frequência daspalavras no documento, perdendo as informações sobre a sequência dos termos [28].
O SentiStrength é outra alternativa na tarefa de representação de um texto. Ele éum dicionário com 2310 palavras sentimentais, onde cada palavra possui uma pontuaçãopositiva (de 1 a 5), ou negativa (de -1 a -5). Seu uso é muito simples: quando o SentiS-trength lê um texto, ele o divide em palavras, ao mesmo tempo em que as separa de sinaisde pontuação. Para cada palavra, é feita uma verificação se foi encontrado um termo sen-timental correspondente. Quando isso acontece, a pontuação deste termo é armazenada.A pontuação total de uma sentença é composta pela maior pontuação positiva, e pelamaior pontuação negativa das palavras presentes na sentença.
2.2 Aprendizado de Máquina
O Aprendizado de Máquina aborda a questão de como construir computadoresque melhoram automaticamente através da experiência [29]. A adoção de métodos deaprendizado de máquina pode ser encontrada na ciência, tecnologia e comércio, levandoa um aumento na tomada de decisão baseada em evidências nos mais diversos setores,como saúde, educação, modelagem financeira e marketing [30].
Atualmente, o campo do Aprendizado de Máquina é organizado em três focosprimários de pesquisa [31]:
∙ Estudos orientados a tarefas: o desenvolvimento e a análise de sistemas de aprendi-zagem para uma melhor performance em um conjunto pré-determinado de tarefas;
∙ Simulação cognitiva: a investigação e a simulação de processos de aprendizagemhumana;
∙ Análise teórica: a exploração teórica do espaço de possíveis métodos de aprendiza-gem e algoritmos independentes do domínio da aplicação.
Dentro do campo da IA, o Aprendizado de Máquina emergiu como a principal esco-lha no desenvolvimento de softwares utilizados na Visão Computacional, Reconhecimentode Fala, Processamento de Linguagem Natural, controle de robôs, entre outras aplicações.Muitos desenvolvedores de sistemas de IA reconhecem que, para muitas aplicações, é maisfácil treinar um sistema com exemplos, mostrando comportamentos entrada-saída espe-rados do que programá-lo manualmente na tentativa de antecipar as respostas desejadaspara todas as entradas possíveis.
Uma solução de Aprendizado de Máquina pode ser dividida em 4 estágios [32]:

30
1. Coleta de dados: Dados são recebidos como entrada no processo. Estes dados ser-virão como base para toda a aprendizagem futura. O processo de aprendizagem damáquina tende a ser melhor quando há maior volume, densidade e variedade dosdados;
2. Preparação dos dados: O sucesso de qualquer processo analítico depende da qua-lidade dos dados utilizados. É preciso verificar a qualidade dos dados e tomar asmedidas necessárias para corrigir problemas como dados faltantes e o tratamentode outliers;
3. Treinamento e avaliação de um modelo: Este passo consiste da escolha de um al-goritmo apropriado e de um método de representação dos dados na forma de ummodelo. Os dados são divididos em duas partes: treinamento e teste. Os dados detreinamento são utilizados no desenvolvimento do modelo, e os dados de teste sãousados como referência, para testar a acurácia do modelo. Isto determina a precisãona escolha do algoritmo com base nos resultados;
4. Melhora do desempenho: Este passo pode envolver a construção de um modelodiferente, ou a modificação dos parâmetros, buscando uma melhor eficiência.
Os algoritmos de aprendizado de máquina se dividem em duas categorias [32]:
∙ Aprendizado supervisionado: os algoritmos de aprendizado supervisionado são trei-nados com exemplos rotulados, que são amostras que já possuem seus valores desaída conhecidos.
∙ Aprendizado não supervisionado: os algoritmos de aprendizado não supervisionadosão usados com dados não rotulados, ou seja, o sistema não tem conhecimentoprévio da resposta certa. O algoritmo deve descobrir o que lhe está sendo mostrado,explorando os dados e tentando encontrar alguma estrutura dentro deles.
Os problemas de aprendizado supervisionado podem ser agrupados em problemasde classificação e de regressão:
∙ Classificação: Em problemas de classificação, a variável de saída é um rótulo oucategoria, apresentando um número finito de classes. Exemplo: um problema ondedeve ser avaliado se um e-mail é spam ou não.
∙ Regressão: Em problemas de regressão, a variável de saída possui um valor contínuo.Exemplo: uma tarefa onde deve ser feita a predição do valor de uma casa.
Classification and Regression Trees (CART) é um algoritmo utilizado em proble-mas preditivos para classificação ou regressão. O CART serve como base para outros

31
importantes algoritmos, como o Random Forest. Seu modelo é representado por umaárvore binária, onde cada nó raiz representa uma variável de entrada e as arestas repre-sentam os limiares da variável nó conectada. Os nós folha da árvore contêm uma variávelde saída, que é utilizada para realizar a predição. Na Figura 1, é possível observar umexemplo simples de árvore de decisão. Neste exemplo, dado um conjunto de dados depessoas, contendo como atributos a altura e o peso, o algoritmo prediz se a pessoa é dosexo masculino ou feminino, percorrendo a árvore de decisão, de acordo com os valores dosatributos de entrada, até chegar em um nó folha, contendo a resposta para o problema, asaída do algoritmo.
Figura 1 – Exemplo de árvore de decisão [Fonte: autor]
Neste trabalho foi utilizado o algoritmo de aprendizado de máquina Random Fo-rest, um método ensemble de aprendizado utilizado em problemas de classificação e re-gressão. Os algoritmos do tipo ensemble utilizam uma abordagem de dividir e conquistarpara obter uma melhor performance. Para isso, são criados múltiplos modelos que, quandocombinados, apresentam melhores resultados [33].
O Random Forest utiliza um conjunto de árvores de decisão para encontrar aresposta final. Então, usando os termos descritos acima de um algoritmo ensemble, cadaárvore de decisão é um descritor fraco, e o conjunto dessas árvores forma a random forest,o preditor forte. Quando uma nova entrada é apresentada ao sistema, ela percorre portodas as árvores de decisão. O resultado final pode ser uma média de todos os valoresencontrados nos nós terminais de cada árvore, para problemas de regressão; ou, em umproblema de classificação, pode ser a resposta que obteve o maior número de votos dentretodas as árvores [34].

32
2.3 Classificação Multirrótulo
Em problemas tradicionais de classificação, ou simples-rótulo, o processo de apren-dizado é realizado usando um conjunto de exemplos que estão associados a um único rótulo𝑙, pertencente a um conjunto de rótulos disjuntos 𝐿, |𝐿| > 1. Quando |𝐿| = 2, temos umproblema de classificação binário e, quando |𝐿| > 2, temos um problema multiclasse [35].
Na classificação multirrótulo, cada exemplo está associado a um conjunto de rótu-los 𝑌 ⊆ 𝐿. Embora no passado, a classificação multirrótulo fosse motivada principalmentepor tarefas de categorização de textos e diagnósticos médicos, hoje é possível perceber queestes métodos são solicitados por outras aplicações, como na classificação de proteínas emBioinformática [36] e na categorização de músicas [37].
Os métodos utilizados na classificação multirrótulo se dividem em duas categorias:transformação do problema e adaptação de algoritmo [38]. O primeiro grupo de métodossão independentes de algoritmo. Eles transformam o problema multirrótulo original emum ou mais problemas de classificação simples-rótulo, permitindo o uso de algoritmostradicionais de aprendizado de máquina, capazes de resolver problemas simples-rótulo[39]. O segundo grupo de métodos modifica algoritmos de aprendizado de máquina paraque eles possam lidar com dados multirrótulo diretamente [40].

33
3 MATERIAIS E MÉTODOS
Esta seção apresenta a base de dados utilizada nos experimentos e descreve ametodologia empregada no trabalho.
3.1 Base de Dados
A base de dados utilizada neste trabalho é composta de 2000 notícias extraídas dediversos sites de notícias online brasileiros. Como exemplo, a seguir, são apresentadas as5 primeiras notícias presentes na base de dados:
1. “Dupla assalta posto de combustíveis no Centro de Pitangui e foge em moto. Sus-peitos ameaçaram frentista com uma arma e levaram dinheiro do caixa. Políciainformou que fez rondas, mas ninguém foi preso até o momento.”
2. “Farc asseguram respeito ao cessar-fogo. As Forças Armadas Revolucionárias daColômbia (Farc) asseguraram neste domingo seu respeito ao cessar-fogo anunciadopelo comando rebelde há seis dias, mas reforçaram seu direito de se defender casoseja necessário.”
3. “Tigre branco mata tratador na frente de visitantes em zoo da Nova Zelândia:Ataque ocorreu quando dois tratadores limpavam a jaula do animal. Santuário defelinos foi fechado, e o tigre foi sacrificado.”
4. “PSOL entra no STF com pedido de explicações contra Paulo Duque: Presidente doConselho de Ética afirmou que partido ’não existe’. Após interpelação, PSOL podetomar outras medidas contra peemedebista.”
5. “Chinês fica preso na Coreia do Sul após filho rabiscar seu passaporte. Menino de4 anos fez desenhos em todo o documento. Homem foi impedido de viajar pelasautoridades no aeroporto.”
As notícias foram classificadas por dois voluntários. Para cada notícia, os voluntá-rios indicaram até duas emoções que eles sentiam ao ler a notícia: o sentimento primário(mais predominante) e o sentimento secundário (opcional). Para a classificação das notí-cias, foram utilizados sete rótulos. Os rótulos são baseados nas seis emoções primárias deEkman (medo, desgosto, tristeza, raiva, surpresa e alegria) [24], com a adição do rótuloneutro.
Foram utilizados dois conjuntos de atributos:

34
∙ Nível 1 (LV1) - Os atributos correspondem às 24 emoções de primeiro nível do mo-delo Hourglass: êxtase, alegria, serenidade, introspecção, tristeza, aflição, vigilância,antecipação, interesse, distração, surpresa, espanto, raiva, ira, aborrecimento, apre-ensão, medo, terror, admiração, confiança, aceitação, tédio, desgosto e repugnância;
∙ Nível 2 (LV2) - Os atributos correspondem às 16 emoções de segundo nível domodelo Hourglass: otimismo, frivolidade, amor, frustração, agressividade, ansiedade,desaprovação, rejeição, admiração, inveja, rivalidade, submissão, regozijo, remorso,desprezo e coerção.
Para o cálculo do valor de cada um dos atributos, foram usados três dos métodosde representação de texto citados na seção 2.1:
∙ STREN(SentStrength): calcula a força sentimental de cada palavra no texto;
∙ TFIDF: faz um cálculo da importância de cada um dos termos do texto;
∙ WORDS(Bag of Words): frequência das palavras no texto.
Com isso, a base de dados original utilizada é composta de seis conjuntos dedados: STREN-LV1, STREN-LV2, TFIDF-LV1, TFIDF-LV2, WORDS-LV1 e WORDS-LV2. Todos os seis conjuntos de dados são compostos pelas mesmas 2000 notícias citadasanteriormente. A diferença está nos atributos (LV1 e LV2) e no método utilizado paracalcular o valor dos atributos (STREN, TFIDF e WORDS). As Tabelas de 3 a 8 mostramos 5 primeiros exemplos de cada um dos conjuntos de dados. LB1, LB2, LB3 e LB4 são osrótulos escolhidos pelos voluntários. LB1 (primário) e LB2 (secundário) são os rótulos dovoluntário 1; e LB3 (primário) e LB4 (secundário) são os rótulos escolhidos pelo voluntário2. Como LB2 e LB4 são opcionais, quando um dos voluntários não atribuiu um sentimentosecundário, ‘NA’ estará presente no conjunto de dados.
ID Êxtase Alegria Serenidade ... LB1 LB2 LB3 LB41 0.86 0.00 0.06 Desgosto Medo Medo NA2 0.72 0.63 0.14 Tristeza Medo Neutro Alegria3 0.00 0.00 0.04 Tristeza NA Surpresa Desgosto4 0.00 0.00 0.02 Tristeza NA Neutro NA5 1.87 0.00 0.08 Surpresa NA Surpresa Desgosto
Tabela 3 – STREN-LV1
3.2 Metodologia Proposta
A metodologia proposta neste trabalho consiste em:
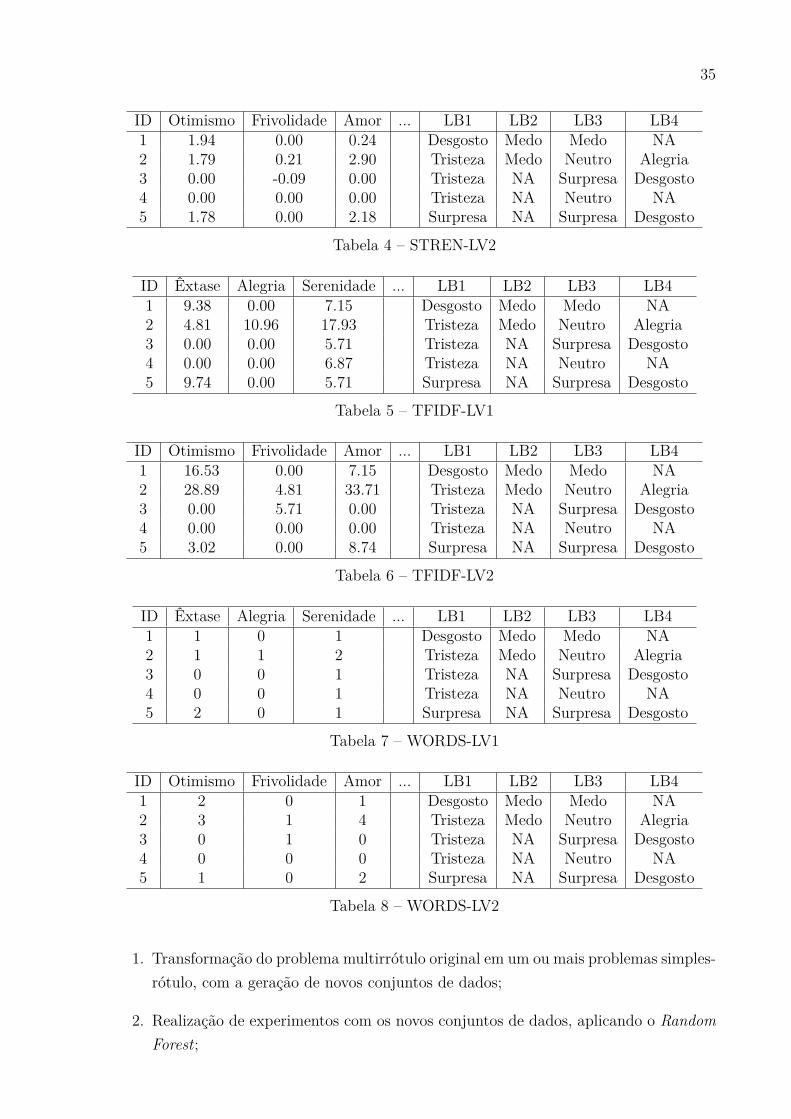
35
ID Otimismo Frivolidade Amor ... LB1 LB2 LB3 LB41 1.94 0.00 0.24 Desgosto Medo Medo NA2 1.79 0.21 2.90 Tristeza Medo Neutro Alegria3 0.00 -0.09 0.00 Tristeza NA Surpresa Desgosto4 0.00 0.00 0.00 Tristeza NA Neutro NA5 1.78 0.00 2.18 Surpresa NA Surpresa Desgosto
Tabela 4 – STREN-LV2
ID Êxtase Alegria Serenidade ... LB1 LB2 LB3 LB41 9.38 0.00 7.15 Desgosto Medo Medo NA2 4.81 10.96 17.93 Tristeza Medo Neutro Alegria3 0.00 0.00 5.71 Tristeza NA Surpresa Desgosto4 0.00 0.00 6.87 Tristeza NA Neutro NA5 9.74 0.00 5.71 Surpresa NA Surpresa Desgosto
Tabela 5 – TFIDF-LV1
ID Otimismo Frivolidade Amor ... LB1 LB2 LB3 LB41 16.53 0.00 7.15 Desgosto Medo Medo NA2 28.89 4.81 33.71 Tristeza Medo Neutro Alegria3 0.00 5.71 0.00 Tristeza NA Surpresa Desgosto4 0.00 0.00 0.00 Tristeza NA Neutro NA5 3.02 0.00 8.74 Surpresa NA Surpresa Desgosto
Tabela 6 – TFIDF-LV2
ID Êxtase Alegria Serenidade ... LB1 LB2 LB3 LB41 1 0 1 Desgosto Medo Medo NA2 1 1 2 Tristeza Medo Neutro Alegria3 0 0 1 Tristeza NA Surpresa Desgosto4 0 0 1 Tristeza NA Neutro NA5 2 0 1 Surpresa NA Surpresa Desgosto
Tabela 7 – WORDS-LV1
ID Otimismo Frivolidade Amor ... LB1 LB2 LB3 LB41 2 0 1 Desgosto Medo Medo NA2 3 1 4 Tristeza Medo Neutro Alegria3 0 1 0 Tristeza NA Surpresa Desgosto4 0 0 0 Tristeza NA Neutro NA5 1 0 2 Surpresa NA Surpresa Desgosto
Tabela 8 – WORDS-LV2
1. Transformação do problema multirrótulo original em um ou mais problemas simples-rótulo, com a geração de novos conjuntos de dados;
2. Realização de experimentos com os novos conjuntos de dados, aplicando o RandomForest;

36
3. Análise e comparação dos resultados.
Os experimentos foram divididos em:
∙ Primário: Foram consideradas apenas os rótulos primárias (LB1 e LB3). Com isso,cada notícia foi associada com 1 ou 2 rótulos;
∙ Completo: Além dos rótulos primários, foram consideradas também os rótulos secun-dários (LB1, LB2, LB3 e LB4). Assim, cada notícia foi associada com um máximode 4 rótulos diferentes.
Para a realização deste trabalho foi utilizada a linguagem de programação R1 e oambiente RStudio2 na execução dos experimentos, com o uso do pacote randomForest.
3.2.1 Transformação do Problema
Para a transformação de um problema multirrótulo para um ou mais problemassimples rótulo, foram utilizadas quatro técnicas independentes de algoritmo apresentadasem [41], que criam novos conjuntos de dados a partir da base de dados original. Umfluxograma com a divisão das técnicas é apresentado na Figura 2.
∙ Transformação Baseada nos Rótulos das Classes: Nesta técnica, são utilizados 𝐿
classificadores, sendo 𝐿 o número de classes envolvidas no problema. Cada um dosclassificadores é associado a uma classe, e é treinado para resolver um problema declassificação binária.
Para o problema apresentado neste trabalho, foram necessários 7 classificadores,um para cada um dos 7 possíveis rótulos (medo, desgosto, tristeza, raiva, surpresa,alegria e neutro). No caso do classificador associado à classe ‘Alegria’, por exemplo,o classificador precisa responder se cada exemplo da base de dados foi classificadoou não com o rótulo ‘Alegria’ por um dos voluntários. Com isso, o problema originalmultirrótulo se transforma em sete problemas simples-rótulo.
Para o uso desta técnica, foram criados sete novos conjuntos de dados a partir decada um dos conjuntos de dados originais. A Tabela 9 apresenta um exemplo da cria-ção de um novo conjunto de dados para o classificador associado ao rótulo ‘Tristeza’.No novo conjunto de dados, as 4 colunas contendo os rótulos dados pelos voluntáriossão substituídas pela coluna ‘Tristeza’, que tem como possíveis resultados ‘TRUE’ou ‘FALSE’.
1 <https://www.r-project.org/>2 <https://www.rstudio.com/>

37
Figura 2 – Técnicas para classificação multirrótulo
LB1 LB2 LB3 LB4 —–> TristezaDesgosto Medo Medo NA FALSETristeza Medo Neutro Alegria TRUETristeza NA Surpresa Desgosto TRUETristeza NA Neutro NA TRUESurpresa NA Surpresa Desgosto FALSENeutro NA Surpresa NA FALSEAlegria NA Neutro NA FALSE
Surpresa Desgosto Tristeza Desgosto TRUENeutro NA Neutro Alegria FALSETristeza NA Neutro Desgosto TRUE
Tabela 9 – Transformação Baseada nos Rótulos das Classes - Tristeza
∙ Eliminação de Exemplos: Com esta técnica, os exemplos multirrótulo são elimina-dos do problema original, restando apenas os exemplos associados a apenas umaclasse. Esta estratégia simplesmente transforma o problema original em um maissimples, simples-rótulo. O número de exemplos do problema é reduzido de maneiraconsiderável.
A Tabela 10 apresenta um exemplo de como é feita a transformação do problema.Todos os exemplos da base de dados original que estavam associados a mais de umrótulo são eliminados.

38
LB1 LB2 LB3 LB4 —–> ClasseMedo NA Medo NA Medo
Neutro NA Neutro NA NeutroSurpresa NA Surpresa NA SurpresaNeutro NA Neutro NA Neutro
Surpresa NA Surpresa NA SurpresaRaiva NA Raiva NA RaivaNeutro NA Neutro NA NeutroTristeza NA Tristeza NA TristezaNeutro NA Neutro NA NeutroAlegria NA Alegria NA Alegria
Tabela 10 – Eliminação de Exemplos
∙ Criação de Rótulos: Todas as classes associadas a um exemplo são combinadas emuma nova classe. No exemplo da Tabela 11, o primeiro exemplo está associadoaos rótulos Desgosto e Medo. Com o uso da técnica da Criação de Rótulos, seunovo rótulo será DesgostoMedo. Para a criação das novas classes combinadas, todosos rótulos associados a cada notícia são concatenados (sem repetição e em ordemalfabética) em uma única palavra. Com esta técnica, há um aumento considerávelno número de classes em relação ao problema original, e algumas das novas classescriadas podem terminar com poucos exemplos;
LB1 LB2 LB3 LB4 —–> ClasseDesgosto Medo Medo NA DesgostoMedoTristeza Medo Neutro Alegria AlegriaMedoNeutroTristezaTristeza NA Surpresa Desgosto DesgostoSurpresaTristezaTristeza NA Neutro NA NeutroTristezaSurpresa NA Surpresa Desgosto DesgostoSurpresaNeutro NA Surpresa NA NeutroSurpresaAlegria NA Neutro NA AlegriaNeutro
Surpresa Desgosto Tristeza Desgosto DesgostoSurpresaTristezaNeutro NA Neutro Alegria AlegriaNeutroTristeza NA Neutro Desgosto DesgostoNeutroTristeza
Tabela 11 – Criação de Rótulos
∙ Eliminação de Rótulos: Quando um exemplo possui mais de um rótulo, um deles éescolhido de forma aleatória para representar o exemplo, e os outros são elimina-dos (Figure 12). Assim como na eliminação de exemplos, essa técnica simplifica oproblema original.
A partir dos seis conjuntos de dados originais, com a aplicação das técnicas detransformação do problema, no total foram gerados 114 novos conjuntos de dados, queforam usados nos experimentos (84 para a Técnica Baseada nos Rótulos das Classes, 12

39
LB1 LB2 LB3 LB4 —–> ClasseDesgosto Medo Medo NA DesgostoTristeza Medo Neutro Alegria AlegriaTristeza NA Surpresa Desgosto TristezaTristeza NA Neutro NA NeutroSurpresa NA Surpresa Desgosto SurpresaNeutro NA Surpresa NA NeutroAlegria NA Neutro NA Alegria
Surpresa Desgosto Tristeza Desgosto TristezaNeutro NA Neutro Alegria AlegriaTristeza NA Neutro Desgosto Tristeza
Tabela 12 – Eliminação de Rótulos
para a Eliminação de Rótulos, 12 para a Criação de Rótulos e 6 para a Eliminação deExemplos).
3.2.2 Experimentos
Para cada um dos 114 conjuntos gerados na fase anterior, será aplicado o algoritmodo Random Forests, com 30 repetições para cada conjunto de dados, sendo armazenadosos valores de acurácia em um novo conjunto de dados para posterior análise e comparaçãodos resultados.


41
4 RESULTADOS
Nesta seção são apresentados os resultados obtidos neste trabalho.
Figura 3 – Resultado do percentual de acerto (acurácia) usando a técnica BRC na classi-ficação de 7 classes de emoções
Com os resultados obtidos nos experimentos com os 7 classificadores binários datécnica BRC (Baseada nos Rótulos de Classes) exibidos na Figura 3, é possível analisaras taxas de acerto individuais de cada uma das 7 classes. Os experimentos indicam queo rótulo Raiva foi o que obteve a maior taxa de acerto (acima de 90%). A seguir vemAlegria, com cerca de 85%. No gráfico pode ser observado que houve uma grande variaçãona acurácia dos rótulos Desgosto e Medo. As emoção mais difícil de ser reconhecida foiTristeza (aproximadamente 60%).
A Figura 4 mostra o gráfico com a comparação entre as técnicas utilizadas nosexperimentos. É possível visualizar os resultados dos testes Primário (considera apenas osrótulos primários) e Completo (rótulos primários e secundários). No caso dos testes feitoscom a Eliminação de Exemplos, não há distinção entre Primário e Completo, pois nãohaveria diferença nos conjuntos de dados gerados.
Na Figura 5, é feita a mesma comparação, mas com os resultados dos experimentosPrimário e Completo combinados. Os melhores resultados apresentados são da técnica

42
Figura 4 – Resultado da acurácia de cada uma das técnicas utilizadas (Primário e Com-pleto)
Figura 5 – Resultado da acurácia de cada técnica (Primário e Completo combinados)

43
Figura 6 – Comparação dos resultados obtidos com os experimentos primário e completo
Figura 7 – Comparação entre os métodos de representação de texto
44
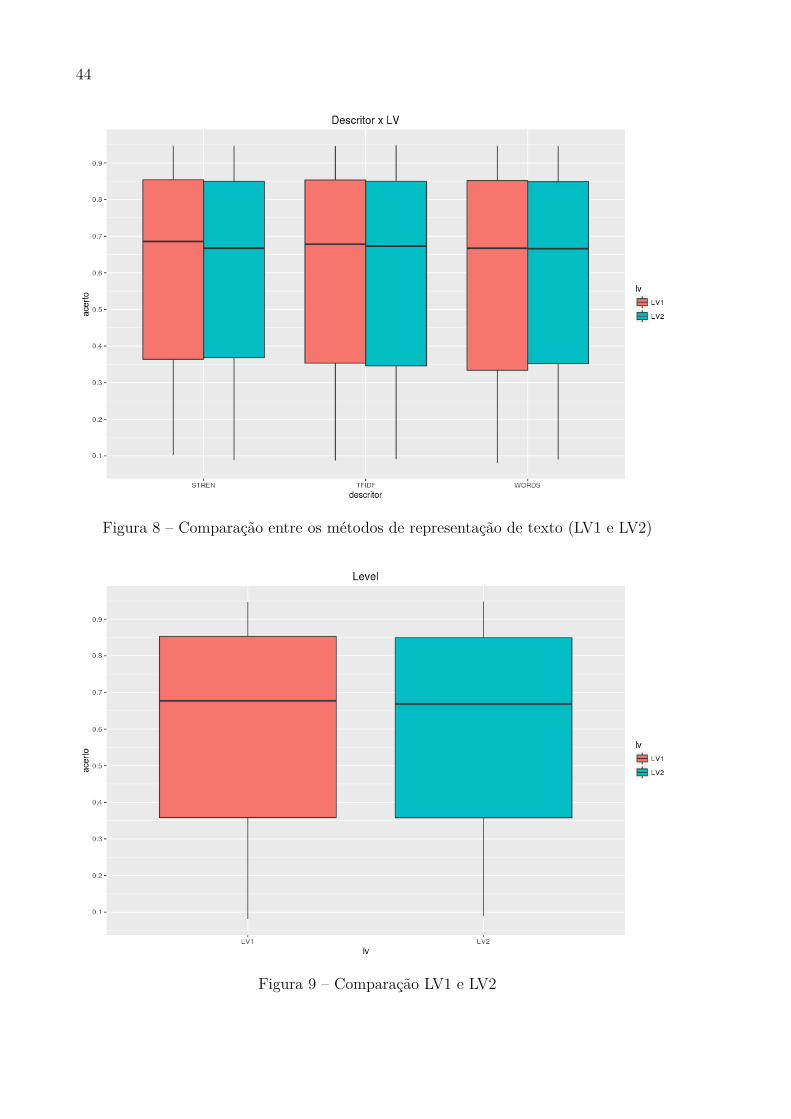
Figura 8 – Comparação entre os métodos de representação de texto (LV1 e LV2)
Figura 9 – Comparação LV1 e LV2

45
Baseada nos Rótulos das Classes, que apesar de apresentar grande variação nos resultados,alcançou taxas de acerto entre 65 e 85%. O desempenho superior do BRC em relaçãoàs outras técnicas pode ser explicado pelo fato desta técnica transformar o problemaoriginal em um simples problema binário. Na sequência, vem a Eliminação de Exemplos,com aproximadamente 35% de acurácia, e a Eliminação de Rótulos, com cerca de 20%no Completo e 30% no Primário. Por fim, com os piores resultados está a técnica daCriação de Rótulos. Isso pode ser explicado pelo grande aumento no número de classes comrelação ao problema original, ainda mais acentuado com o uso das bases do experimentoCompleto (apenas 10% de acurácia), pois neste caso são criadas classes combinadas de ummáximo de até quatro das sete classes originais. Com exceção do BRC, que apresentougrande variação em seus resultados, os experimentos indicam que as 3 outras técnicas(Criação de Rótulo, Eliminação de Exemplos e Eliminação de Rótulos) apresentaramresultados estáveis. Em todos os casos, os experimentos com as bases do Primário (emazul) apresentaram melhores resultados.
Na Figura 6, foi feita uma comparação entre os experimentos Primário e Completo,com as bases do Primário obtendo resultados superiores, apesar de apresentarem umamenor estabilidade.
As Figuras 7 e 8 evidenciam a pequena diferença entre os métodos de represen-tação de texto STREN, TFI-DF e WORDS, com todos alcançando acurácias entre 35e 85%. Apesar da pequena diferença, o STREN pode ser considerado o método com osmelhores resultados, por se mostrar ligeiramente mais estável que os outros. Também nãofoi verificada muita diferença entre os experimentos Nível 1 e Nível 2 (Figura 9).
Os bons resultados do BRC indicam que a divisão do problema original em pro-blemas de classificação binária pode ser considerada uma boa estratégia na resolução deproblemas multirrótulo. Apesar do método da Eliminação de Exemplos ter apresentado omelhor desempenho depois do BRC, ele não seria uma solução viável, pois a maior partedos exemplos do conjunto de dados original são eliminados. Isso não resolve o problema,apenas o transforma em um mais simples. Quanto ao método da Eliminação de Rótu-los, seu desempenho inferior aos já citados pode ser explicado pela perda de informaçõesimportantes presentes no problema original, ocasionadas pela seleção aleatória de apenasuma das classes associadas a cada exemplo. Por fim, o grande aumento no número de clas-ses resultantes do uso do método da Criação de Rótulos inviabiliza seu uso na resoluçãodo problema.


47
5 CONCLUSÃO
Com o aumento na quantidade de conteúdo criado e compartilhado na Internet,através de redes sociais, blogs e sites de análises de produtos, aumenta também a necessi-dade de métodos que consigam, a partir de toda esta enorme quantidade de informaçõesdisponíveis online, extrair informações que possam ser úteis.
Como há situações em que a mais tradicional classificação simples-rótulo não semostra como a alternativa mais adequada, principalmente quando se trata de dados tex-tuais, é essencial também a busca por técnicas que usem uma abordagem multirrótulo.
Neste trabalho foi proposta a análise de técnicas independentes de algoritmo, méto-dos que transformam um problema originalmente multirrótulo em um ou mais problemasde classificação simples-rótulo, possibilitando o uso de algoritmos tradicionais de apren-dizado de máquina, como o Random Forest.
Os resultados encontrados por meio dos experimentos realizados neste trabalhomostram que as técnicas multirrótulo utilizadas apresentaram resultados inferiores aosresultados normalmente esperados em tradicionais problemas de classificação simples-rótulo, evidenciando que ainda há uma maior dificuldade na tentativa de resolução deproblemas que necessitem de uma abordagem multirrótulo.
Para trabalhos futuros, propõe-se analisar outros algoritmos de aprendizado demáquina além do Random Forest, além de verificar o desempenho de outros métodos declassificação multirrótulo, incluindo métodos de adaptação de algoritmo, que são modelosque, ao invés de realizar uma transformação no problema, utilizam algoritmos modificados,adaptados para tarefas multirrótulo.


49
REFERÊNCIAS
[1] LIU, B. Sentiment analysis and opinion mining. Synthesis lectures on humanlanguage technologies, Morgan & Claypool Publishers, v. 5, n. 1, p. 1–167, 2012.
[2] PANG, B.; LEE, L. et al. Opinion mining and sentiment analysis. Foundations andTrends R○ in Information Retrieval, Now Publishers, Inc., v. 2, n. 1–2, p. 1–135,2008.
[3] AGARWAL, A. et al. Sentiment analysis of twitter data. In: ASSOCIATION FORCOMPUTATIONAL LINGUISTICS. Proceedings of the workshop on languages insocial media. [S.l.], 2011. p. 30–38.
[4] KOULOUMPIS, E.; WILSON, T.; MOORE, J. D. Twitter sentiment analysis: Thegood the bad and the omg! Icwsm, v. 11, n. 538-541, p. 164, 2011.
[5] WANG, H. et al. A system for real-time twitter sentiment analysis of 2012us presidential election cycle. In: ASSOCIATION FOR COMPUTATIONALLINGUISTICS. Proceedings of the ACL 2012 System Demonstrations. [S.l.], 2012.p. 115–120.
[6] TAN, C. et al. User-level sentiment analysis incorporating social networks. In: ACM.Proceedings of the 17th ACM SIGKDD international conference on Knowledgediscovery and data mining. [S.l.], 2011. p. 1397–1405.
[7] SAIF, H.; HE, Y.; ALANI, H. Semantic sentiment analysis of twitter. The SemanticWeb–ISWC 2012, Springer, p. 508–524, 2012.
[8] HU, X. et al. Exploiting social relations for sentiment analysis in microblogging. In:ACM. Proceedings of the sixth ACM international conference on Web search anddata mining. [S.l.], 2013. p. 537–546.
[9] YU, Y.; DUAN, W.; CAO, Q. The impact of social and conventional media on firmequity value: A sentiment analysis approach. Decision Support Systems, Elsevier,v. 55, n. 4, p. 919–926, 2013.
[10] JO, Y.; OH, A. H. Aspect and sentiment unification model for online review analysis.In: ACM. Proceedings of the fourth ACM international conference on Web searchand data mining. [S.l.], 2011. p. 815–824.
[11] GRÄBNER, D. et al. Classification of customer reviews based on sentiment analysis.[S.l.]: na, 2012.
[12] GAMON, M. Sentiment classification on customer feedback data: noisy data,large feature vectors, and the role of linguistic analysis. In: ASSOCIATIONFOR COMPUTATIONAL LINGUISTICS. Proceedings of the 20th internationalconference on Computational Linguistics. [S.l.], 2004. p. 841.
[13] CERON, A. et al. Every tweet counts? how sentiment analysis of social media canimprove our knowledge of citizens’ political preferences with an application to italyand france. New Media & Society, Sage Publications Sage UK: London, England,v. 16, n. 2, p. 340–358, 2014.

50
[14] LIU, S. M.; CHEN, J.-H. A multi-label classification based approach for sentimentclassification. Expert Systems with Applications, Elsevier, v. 42, n. 3, p. 1083–1093,2015.
[15] HUANG, S. et al. Sentiment and topic analysis on social media: a multi-taskmulti-label classification approach. In: ACM. Proceedings of the 5th annual ACMweb science conference. [S.l.], 2013. p. 172–181.
[16] BALAHUR, A. et al. Sentiment analysis in the news. arXiv preprint arXiv:1309.6202,2013.
[17] BHOWMICK, P. K. Reader perspective emotion analysis in text through ensemblebased multi-label classification framework. Computer and Information Science, v. 2,n. 4, p. 64, 2009.
[18] LI, X. et al. Weighted multi-label classification model for sentiment analysis of onlinenews. In: IEEE. Big Data and Smart Computing (BigComp), 2016 InternationalConference on. [S.l.], 2016. p. 215–222.
[19] MEDHAT, W.; HASSAN, A.; KORASHY, H. Sentiment analysis algorithms andapplications: A survey. Ain Shams Engineering Journal, Elsevier, v. 5, n. 4, p.1093–1113, 2014.
[20] LIU, B.; ZHANG, L. A survey of opinion mining and sentiment analysis. In: Miningtext data. [S.l.]: Springer, 2012. p. 415–463.
[21] SERRANO-GUERRERO, J. et al. Sentiment analysis: A review and comparativeanalysis of web services. Information Sciences, Elsevier, v. 311, p. 18–38, 2015.
[22] TSYTSARAU, M.; PALPANAS, T. Survey on mining subjective data on theweb. Data Min. Knowl. Discov., Kluwer Academic Publishers, Hingham, MA,USA, v. 24, n. 3, p. 478–514, maio 2012. ISSN 1384-5810. Disponível em:<http://dx.doi.org/10.1007/s10618-011-0238-6>.
[23] CAMBRIA, E. et al. New avenues in opinion mining and sentiment analysis. IEEEIntelligent Systems, IEEE, v. 28, n. 2, p. 15–21, 2013.
[24] EKMAN, P.; FRIESEN, W. V. Constants across cultures in the face and emotion.Journal of personality and social psychology, American Psychological Association,v. 17, n. 2, p. 124, 1971.
[25] CAMBRIA, E.; LIVINGSTONE, A.; HUSSAIN, A. The hourglass of emotions.Cognitive behavioural systems, Springer, p. 144–157, 2012.
[26] ZHANG, W.; YOSHIDA, T.; TANG, X. A comparative study of tf* idf, lsi andmulti-words for text classification. Expert Systems with Applications, Elsevier, v. 38,n. 3, p. 2758–2765, 2011.
[27] JONES, K. S. Idf term weighting and ir research lessons. Journal of documentation,Emerald Group Publishing Limited, v. 60, n. 5, p. 521–523, 2004.
[28] BAEZA-YATES, R.; RIBEIRO-NETO, B. et al. Modern information retrieval. [S.l.]:ACM press New York, 1999. v. 463.

51
[29] MITCHELL, T. Machine Learning. McGraw-Hill, 1997. (McGraw-Hill InternationalEditions). ISBN 9780071154673. Disponível em: <https://books.google.com.br/books?id=EoYBngEACAAJ>.
[30] JORDAN, M. I.; MITCHELL, T. M. Machine learning: Trends, perspectives, andprospects. Science, American Association for the Advancement of Science, v. 349,n. 6245, p. 255–260, 2015.
[31] MICHALSKI, R. S.; CARBONELL, J. G.; MITCHELL, T. M. Machine learning:An artificial intelligence approach. [S.l.]: Springer Science & Business Media, 2013.
[32] WITTEN, I. H. et al. Data Mining: Practical machine learning tools and techniques.[S.l.]: Morgan Kaufmann, 2016.
[33] DIETTERICH, T. G. Ensemble learning. The handbook of brain theory and neuralnetworks, MIT Press: Cambridge, MA, v. 2, p. 110–125, 2002.
[34] BREIMAN, L. Random forests. Machine learning, Springer, v. 45, n. 1, p. 5–32,2001.
[35] TSOUMAKAS, G.; KATAKIS, I. Multi-label classification: An overview.International Journal of Data Warehousing and Mining, v. 3, n. 3, 2006.
[36] ELISSEEFF, A.; WESTON, J. A kernel method for multi-labelled classification. In:Advances in neural information processing systems. [S.l.: s.n.], 2002. p. 681–687.
[37] LI, T.; OGIHARA, M.; LI, Q. A comparative study on content-based music genreclassification. In: ACM. Proceedings of the 26th annual international ACM SIGIRconference on Research and development in informaion retrieval. [S.l.], 2003. p.282–289.
[38] TSOUMAKAS, G.; KATAKIS, I.; VLAHAVAS, I. Mining multi-label data. Datamining and knowledge discovery handbook, Springer US, p. 667–685, 2010.
[39] SPOLAÔR, N. et al. A comparison of multi-label feature selection methods usingthe problem transformation approach. Electronic Notes in Theoretical ComputerScience, Elsevier, v. 292, p. 135–151, 2013.
[40] ZHANG, M.-L.; ZHOU, Z.-H. A review on multi-label learning algorithms. IEEEtransactions on knowledge and data engineering, IEEE, v. 26, n. 8, p. 1819–1837,2014.
[41] CARVALHO, A. de; FREITAS, A. A tutorial on multi-label classification techniques.Foundations of Computational Intelligence Volume 5, Springer, p. 177–195, 2009.













![O Xamanismo e as Técnicas Arcaicas do Êxtase - Eliade Revisitado[1]](https://img.document.onl/doc/110x75/5571f81849795991698c9d80/o-xamanismo-e-as-tecnicas-arcaicas-do-extase-eliade-revisitado1.jpg)














