Embed Size (px)
Citation preview

Slide 1
Prof. Afonso C. MedinaProf. Leonardo Chwif
Coleta e Modelagem dos Dados de Entrada
Capítulo 2Páginas 24-52
Este material é disponibilizado para uso exclusivo de docentes que adotam o livro Modelagem e Simulação de Eventos Discretos em suas disciplinas. O material pode (e deve) ser editado pelo professor.
Pedimos apenas que seja sempre citada a fonte original de consulta.

Coleta
Tratamento
Inferência
Três Etapas

1. Escolha adequada da variável de estudo
2. O tamanho da amostra deve estar entre 100 e 200 observações. Amostras com menos de 100 observações podem comprometer a identificação do melhor modelo probabilístico, e amostras com mais de 200 observações não trazem ganhos significativos ao estudo;
Coleta dos Dados

3. Coletar e anotar as observações na mesma ordem em que o fenômeno está ocorrendo, para permitir a análise de correlação ;
4. Se existe alguma suspeita de que os dados mudam em função do horário ou do dia da coleta, a coleta deve ser refeita para outros horários e dias. Na modelagem de dados, vale a regra: toda suspeita deve ser comprovada ou descartada estatisticamente.
Coleta dos Dados

Exemplo 2.1: Filas nos Caixas do Supermercado
Um gerente de supermercado está preocupado com as filas formadas nos caixas de pagamento durante um dos turnos de operação. Quais seriam as variáveis de estudo para coleta de dados? (S) ou (N).
( ) O número de prateleiras no supermercado
( ) Os tempos de atendimento nos caixas
( ) O número de clientes em fila( ) O tempo de permanência dos clientes no supermercado( ) Os tempos entre chegadas sucessivas de clientes nos caixas de pagamento
N
S
N
N
S
É resultado!!

Exemplo 2.1: Coleta de Dados
Intervalo entre chegadas de pessoas nos caixas do supermercado (100 medidas). Tempos em minutos:

Exemplo 2.1: Medidas de Posição e Dispersão
Medidas de posição
Média 10,44
Mediana 5
Moda 3
Mínimo 0
Máximo 728
Medidas de dispersão
Amplitude 728
Desvio padrão 51,42
Variância da amostra 2.643,81
Coeficiente de Variação
493%
Coeficiente Assimetria 13,80
O 728 é um outlier?

Exemplo 2.1: Outlier
Intervalo entre chegadas de pessoas nos caixas do supermercado (100 medidas). Tempos em minutos:

Outliers ou Valores Discrepantes
Erro na coleta de dados. Este tipo de outlier é o mais comum, principalmente quando o levantamento de dados é feito por meio manual.
Eventos Raros. Nada impede que situações totalmente atípicas ocorram na nossa coleta de dados. Alguns exemplos:
Um dia de temperatura negativa no verão da cidade do Rio de Janeiro;
Um tempo de execução de um operador ser muito curto em relação aos melhores desempenhos obtidos naquela tarefa;
Um tempo de viagem de um caminhão de entregas na cidade de São Paulo, durante o horário de rush, ser muito menor do que fora deste horário.

Exemplo 2.1: Outlier (valor discrepante)
Dados
com o outlier
sem o outlier
Média 10,44 6,83
Mediana 5 5
Variância da amostra
2.643,81 43,60

Identificação de Outliers: Box-plot
0
5
10
15
20
A B C Séries
Valores
mediana
outlier
Q 1
Q 3
Q1-1,5(Q3- Q1)
Q 3+1,5(Q 3- Q 1)

Análise de Correlação
Diagrama de dispersão dos tempos de atendimento do exemplo de supermercado, mostrando que não há correlação entre as observações da amostra.

Análise de Correlação
Diagrama de dispersão de um exemplo hipotético em que existe correlação entre os dados que compõem a amostra.

Exemplo 2.1: Construção do Histograma
1. Definir o número de classes:
O histograma é utilizado para identificar qual a distribuição a ser ajustada aos dados coletados ou é utilizado diretamente dentro do modelo de simulação.
2. Definir o tamanho do intervalo:
3. Construir a tabela de frequências
4. Construir o histograma

Exemplo 2.1: Histograma

Exemplo 2.1: Inferência
Qual o melhor modelo probabilístico ou distribuição estatística que pode representar a amostra coletada?
x
f (x )
1/λ
x
f (x )
µ
x
f (x )
a bm
x
f (x)
µ =1 σ=1
µ=1 σ=0,5
Exponencial?
Normal?Triangular?
Lognormal?

Testes de Aderência (não paramétricos)
Testa a validade ou não da hipótese de aderência (ou hipótese nula) em confronto com a hipótese alternativa:
H0: o modelo é adequado para representar a distribuição da
população.
Ha: o modelo não é adequado para representar a distribuição
da população.
Se a um dado nível de significância (100)% rejeitarmos H0, o modelo testado não é adequado para representar a distribuição da população. O nível de significância equivale à probabilidade de rejeitarmos a hipótese nula H0, dado que ela está correta. Testes usuais:
Qui quadrado
Kolmogorov-Sminov

Teste do Qui-quadrado

P-value
Valor Critério
p-value<0,01Evidência forte contra a hipótese de aderência
0,01p-value<0,05 Evidência moderada contra a hipótese de aderência
0,05p-value<0,10 Evidência potencial contra a hipótese de aderência
0,10p-value Evidência fraca ou inexistente contra a hipótese de aderência
Parâmetro usual nos softwares de estatística. Para o teste do qui-quadrado no Excel, utilizar:
=DIST.QUI (valor de E; graus de liberdade)

Distribuições discretas: Binomial
Exemplo:
Suponha que numa linha de produção a probabilidade de se obter uma peça defeituosa (sucesso) é p=0,1. Toma-se uma amostra de 4 peças para serem inspecionadas. Qual a probabilidade de se obter uma peça defeituosa, nenhuma peça defeituosa, 2 peças defeituosas, 3 e 4 peças defeituosas?
Pela tabela, vemos que as probabilidades de se obter uma peça defeituosa é de 29,16%, nenhuma peça defeituosa é de 65,61%, e de se obter duas peças defeituosas é 4,86% e para mais que mias que três é menos que 1%.

Distribuições discretas: Binomial

Distribuições discretas: Poisson
Distribuição discreta de probabilidade aplicável a ocorrências de um evento em um intervalo especificado
TAXA
Exemplos
usuários de computador ligados à Internet
clientes chegando ao caixa de um supermercado
acidentes com automóveis em uma determinada estrada
Número de carros que chegam a um posto de gasolina
Número de falhas em componentes por unidade de tempo
Número de requisições para um servidor em um intervalo de tempo t
Número de peças defeituosas substituídas num veículo durante o primeiro ano de vida

Distribuições discretas: Poisson
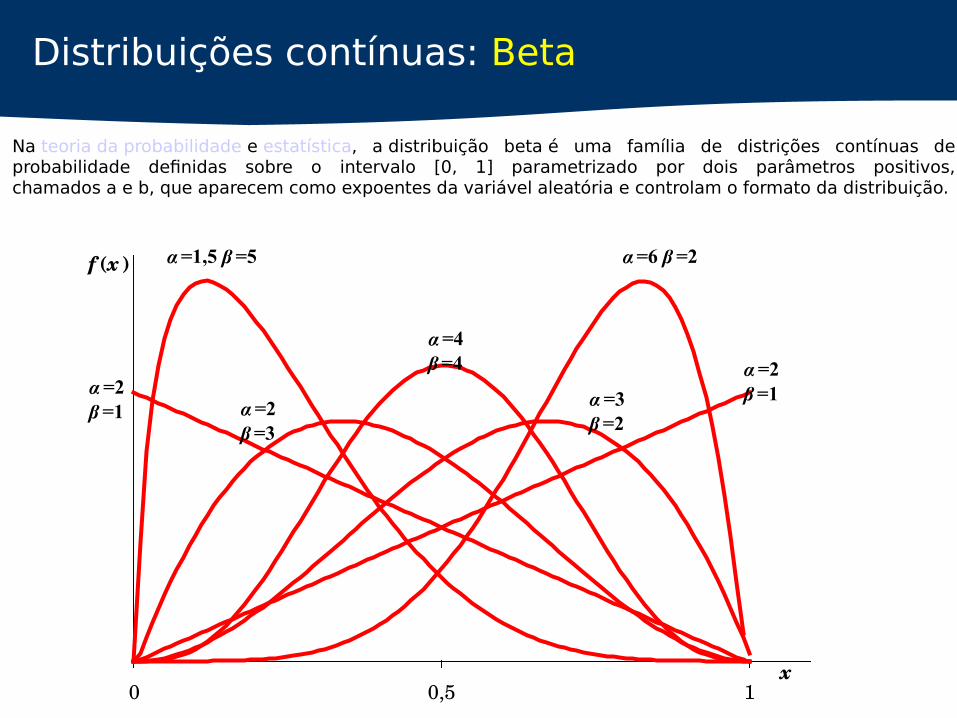
Distribuições contínuas: Beta
0 0,5 1x
f (x )
α=2 β=1α =3
β =2
α=4 β=4
α=2 β=3
α=1,5 β =5 α=6 β =2
α=2 β =1
Na teoria da probabilidade e estatística, a distribuição beta é uma família de distrições contínuas de probabilidade definidas sobre o intervalo [0, 1] parametrizado por dois parâmetros positivos, chamados a e b, que aparecem como expoentes da variável aleatória e controlam o formato da distribuição.

Distribuições contínuas: Erlang
x
f (x )
λ =0,5 k= 3
λ =0,5
λ =0,2 k= 10
A distribuição Erlang é uma distribuição de probabilidade contínua com uma ampla aplicabilidade, principalmente devido à sua relação com a distribuição exponencial e a distribuição gama. A distribuição Erlang foi desenvolvida por Agner Krarup Erlang para analisar o número de chamadas telefônicas que poderiam ser feitas simultaneamente aos operadores das estações de comutação. Atualmente esta distribuição é utilizada em várias áreas que aplicam processos estocásticos.

Distribuições contínuas: Exponencial
x
f (x )
1/λ
Esta é uma distribuição que se caracteriza por ter uma função de taxa de falha constante. A distribuição exponencial é a única com esta propriedade. Ela é considerada uma das mais simples em termos matemáticos. Esta distribuição tem sido usada extensivamente como um modelo para o tempo de vida de certos produtos e materiais. Ela descreve adequadamente o tempo de vida de óleos isolantes e dielétricos, entre outros.

Distribuições contínuas: Gama
x
f (x )
α =0,
α =1
α =2

Distribuições contínuas: Lognormal
x
f (x )
µ =1 σ=1
µ=1 σ=0,5

Distribuições contínuas: Normal
f (x )
µ

Distribuições contínuas: Normal
f (x )
µ

Distribuições contínuas: Uniforme
ba
1/ (b-a )
x
f (x )

Distribuições contínuas: Triangular
x
f (x )
a bm

Distribuições contínuas: Weibull
x
f (x )
α=0,5 β=1
α=1 β =1 α=2 β =1
α=3 β =1
α=3 β=2

Modelagem de dados... Sem dados!
Distribuição Parâmetros Características Aplicabilidade
Exponencial MédiaVariância altaCauda para direita
Grande variabilidade dos valoresIndependência entre um valor e outroMuitos valores baixos e poucos valores altosUtilizada para representar o tempo entre chegadas sucessivas e o tempo entre falhas sucessivas
TriangularMenor valor, moda e maior valor
Simétrica ou nãoQuando se conhece ou se tem um bom “chute” sobre a moda (valor que mais ocorre), o menor valor e o maior valor que podem ocorrer
NormalMédia e desvio-padrão
SimétricaForma de sinoVariabilidade controlada pelo desvio-padrão
Quando a probabilidade de ocorrência de valores acima da média é a mesma que valores abaixo da médiaQuando o tempo de um processo pode ser considerado a soma de diversos tempos de sub-processosProcessos manuais
Uniforme Maior valor e menor valor
Todos os valores no intervalo são igualmente prováveis de ocorrer
Quando não se tem nenhuma informação sobre o processo ou apenas os valores limites (simulação do pior caso)
Discreta
Valores e probabilidade de ocorrência destes valores
Apenas assume os valores fornecidos pelo analista
Utilizada para a escolha de parâmetros das entidades (por exemplo: em uma certa loja, 30% dos clientes realizam suas compras no balcão e 70% nas prateleiras) Quando se conhecem apenas “valores intermediários” da distribuição ou a porcentagem de ocorrência de alguns valores discretos





























