Embed Size (px)
Citation preview

UNIVERSIDADE DO VALE DO ITAJAÍ
Oswaldo Cavalcanti Dantas Júnior
MODELO EVOLUTIVO PARA OTIMIZAÇÃO DE ESTIMATIVA DE ESFORÇO EM PROJETOS DE
SOFTWARE
São José
2006

UNIVERSIDADE DO VALE DO ITAJAÍ
MODELO EVOLUTIVO PARA OTIMIZAÇÃO DE ESTIMATIVA DE ESFORÇO EM PROJETOS DE
SOFTWARE
Oswaldo Cavalcanti Dantas JúniorAcadêmico
Trabalho de Conclusão de Curso apresentado como requisito parcial para obtenção do título de Bacharel em Ciência da Computação na Universidade do Vale do Itajaí, Centro de Educação São José.
São José
2006

Oswaldo Cavalcanti Dantas Júnior
MODELO EVOLUTIVO PARA OTIMIZAÇÃO DE ESTIMATIVA DE ESFORÇO EM PROJETOS DE
SOFTWARE
Este Trabalho de Conclusão de Curso foi julgado adequado para obtenção do título de Bacharel
em Ciência da Computação e aprovado pelo Curso de Ciência da Computação, da Universidade do
Vale do Itajaí (SC), Centro de Educação São José.
São José, 29 de Janeiro de 2007.
Apresentada à Banca Examinadora formada pelos professores:
Prof. Dr. Marcello Thiry
UNIVALI - São José
Orientador
Prof. Dr. rer. nat. Eros Comunello, membro da banca examinadora
Profa. MSc. Fernanda dos Santos Cunha, membro da banca examinadora

DEDICATÓRIA
À minha esposa Estela, cujo carinho, compreensão e apoio foram
essenciais para a conclusão deste trabalho, aos meus pais, que sempre
foram fonte de incentivo e inspiração, às minhas irmãs, aos familiares
e a todos que direta ou indiretamente contribuíram para formar quem
sou hoje.

AGRADECIMENTOS
Aos professores das instituições UniCEUB, onde iniciei meu Curso, e UNIVALI, onde concluí.
Em especial ao professor Marcello Thiry, por seu apoio e ajuda a manter as idéias em foco.

RESUMO
Devido a características específicas de projetos de software, modelos matemáticos complexos
podem ser utilizados para estimar a duração das atividades. Porém, para se modificar ou calibrar
um modelo é necessário coletar um grande volume de dados históricos de sua aplicação em
diferentes projetos. Estes ajustes podem tomar anos e normalmente não são realizados por
outras organizações além da responsável por dar manutenção ao modelo. Por não serem
naturais, características específicas dos softwares afetam a forma de gerenciar. Se estas não
forem corretamente observadas podem levar a problemas que se manifestam como a dificuldade
de entregar o produto no prazo acordado. Os cálculos necessários para criar um modelo
envolvem um grande número de variáveis e interações, tornando praticamente inviável a
criação ou ajuste de um modelo com muitas variáveis durante o andamento de um projeto. Este
trabalho analisa características da gerência de projetos de software, o uso das estimativas, como
os modelos são criados. Além disso, apresenta como resultados a especificação de um modelo
evolutivo capaz de automatizar este processo, realizando de forma autônoma todos os processos
de cálculo, retornando um modelo já calibrado com base nos dados e variáveis fornecidas
inicialmente ao mesmo, e um protótipo da funcionalidade básica da especificação, validado
contra uma massa de dados simulados.
Palavras Chaves: Modelos matemáticos de estimativa, estimativas em projetos de software,
algoritmos genéticos, programação evolutiva, sistemas de descoberta de equações.

ABSTRACT
Due to specific characteristics in software projects, complex mathematical models can be used
to estimate the duration of the activities. But, to modify or calibrate a model, a big amount of
historical data of it's aplication in different projects is needed. The adjustments can take years
and usually aren't done by other organizations besides the one responsible for giving
maintenance to the model. Because they are not natural, softwares have specific characteristics
that affect the way the project is managed. If this characteristics aren't correctly observed, they
can lead to problems that manifest like difficulty in delivering the product on time. A
collaborator needs knowledge in management and statistics to be able to create a estimation
model. The necessary calculations involve a large number of variables and iterations, turning
the creation or adjustment of a model during the execution of a project not viable in most cases.
This work analyses the characteristics of software project management, the use of estimates and
how the models are created. Besides, it specifies an evolutionary model that can automate this
process, autonomously working all the calculations and returning a calibrated model based on
the data and variables initially given to it.

SUMÁRIO
1 INTRODUÇÃO..........................................................................................................................7
1.1 CONTEXTUALIZAÇÃO.......................................................................................................7
1.2 PROBLEMA...........................................................................................................................8
1.3 OBJETIVOS............................................................................................................................9
1.3.1 OBJETIVO GERAL.............................................................................................................9
1.3.2 OBJETIVOS ESPECÍFICOS...............................................................................................9
1.3.3 ESCOPO E DELIMITAÇÃO DO TRABALHO..................................................................9
1.4 RESULTADOS ESPERADOS..............................................................................................10
1.5 JUSTIFICATIVA...................................................................................................................10
1.6 ASPECTOS METODOLÓGICOS.........................................................................................11
1.6.1 METODOLOGIA...............................................................................................................11
1.6.2 PLANO DE TRABALHO..................................................................................................11
1.7 ESTRUTURA DO TRABALHO...........................................................................................13
2 ESTIMATIVAS EM PROJETOS DE SOFTWARE.................................................................14
2.1 INTRODUÇÃO.....................................................................................................................14
2.2 GERÊNCIA DE PROJETOS.................................................................................................14
2.3 CARACTERÍSTICAS DE PROJETOS DE SOFTWARE....................................................18
2.4 FORMAS DE ESTIMAR UM PROJETO DE SOFTWARE................................................22
3 CRIAÇÃO DE MODELOS MATEMÁTICOS........................................................................27
3.1 INTRODUÇÃO.....................................................................................................................27

3.2 COLETA DE DADOS...........................................................................................................28
3.3 SELEÇÃO DE VARIÁVEIS.................................................................................................28
3.4 NORMALIZAÇÃO...............................................................................................................31
3.5 IDENTIFICAÇÃO DE RELAÇÕES MATEMÁTICAS.......................................................34
3.6 VALIDAÇÃO E CALIBRAÇÃO..........................................................................................37
3.7 ALGORITMOS GENÉTICOS..............................................................................................37
3.8 PROGRAMAÇÃO EVOLUTIVA.........................................................................................40
4 ESPECIFICAÇÃO DO SISTEMA PROPOSTO......................................................................42
4.1 INTRODUÇÃO.....................................................................................................................42
4.2 ARQUITETURA GERAL.....................................................................................................42
4.3 EXPERIMENTOS COM JGAP............................................................................................43
4.4 CLASSES E PACOTES........................................................................................................48
5 CONCLUSÕES E PERSPECTIVAS FUTURAS....................................................................53
5.1 CONCLUSÕES.....................................................................................................................53
5.2 PERSPECTIVAS FUTURAS................................................................................................54
6 REFERÊNCIAS BIBLIOGRÁFICAS.....................................................................................55

6

7
1 INTRODUÇÃO
1.1 CONTEXTUALIZAÇÃO
Qualquer erro de estimativa pode custar muito em termos de recursos alocados ao projeto. (PETERS;
PEDRYCZ, 2001, p. 480). Métodos de estimativa formais permitem a redução dos possíveis erros de
estimativa e um melhor acompanhamento do progresso do projeto. Com o histórico de projetos
desenvolvidos é possível constatar que não há método perfeito, que se aplique a qualquer organização.
Os métodos levam em consideração elementos que se relacionam, variáveis que afetam o
desenvolvimento de um projeto e conseqüentemente o seu prazo. O COCOMO, modelo criado por
Bohem no fim da década de 70 com base em um estudo feito sobre 63 projetos (HUGHES;
COTTERELL, 1999, p. 97), e em uma de suas versões chamada COCOMO81, o modelo
intermediário envolve desde complexidade do produto e tamanho da base de dados, atributos de
produto, até a capacidade de análise e experiência na linguagem de programação, atributos de pessoal.
Mesmo quando é usado o método de Delphi, técnica onde a estimativa é dada pelo consenso entre
especialistas (WU, 1997), e um especialista relata suas estimativas baseando-se em sua experiência,
sem ter utilizado um modelo matemático, são avaliados de forma consciente ou não, diversas
variáveis que levam a um valor estimado. Apesar da existência de modelos matemáticos como a
Análise de Ponto de Função, método de estimativa top-down que permite quantificar o tamanho de
um programa independente da linguagem de programação usada (HUGHES; COTTERELL, 1999, p.
89), ou o COCOMO, divulgados principalmente em meio acadêmico, “Em muitos casos, estimativas
são feitas usando-se a experiência passada como único guia.”(PRESSMAN, 1995, p. 57).
Com a experiência, gerentes de projetos, analistas e desenvolvedores criam métodos de estimativa
próprios. As variáveis visíveis no momento são selecionadas e arranjadas de forma a produzir
resultados que se aproximem de casos anteriores. Com a experiência e acúmulo de dados históricos da
aplicação do método em projetos anteriores, surge a possibilidade ou até mesmo a necessidade de se
fazerem ajustes às fórmulas.
O propósito deste trabalho é contribuir com a comunidade científica, mais especificamente na área de

8
projetos de software, permitindo melhor previsibilidade do prazo por meio do uso de uma ferramenta
capaz de ajustar o modelo matemático com o mínimo de interação com o usuário.
1.2 PROBLEMA
Pesquisa feita pelo Standish Group em 1994 mostra que os projetos de software estavam
ultrapassando o prazo estimado 200% em média e apenas 16,2% dos projetos de software estudados
foram concluídos com sucesso, dentro dos limites de prazo e custo. Ainda segundo a pesquisa, 52,7%
dos projetos foram concluídos depois do prazo, acima do custo e com menos funcionalidades do que o
originalmente especificado. Os 31,1% são projetos que foram cancelados em algum ponto do seu
ciclo de desenvolvimento.
Estes dados são reflexos da dificuldade que existe para se fazer uma estimativa com precisão aceitável
na área de desenvolvimento de software. Um projeto que ultrapassa a data de entrega, aumenta o risco
de ser cancelado, pois gera falta de confiança em novas estimativas.
É virtualmente impossível criar manualmente um modelo matemático genérico e perfeito, que inclua
todas as variáveis possíveis, visto que este deveria envolver desde fatores técnicos até condições
climáticas da região onde a equipe está. Isto seria inviável do ponto de vista prático, pois requer o
monitoramento de uma grande quantidade de elementos para alimentar o modelo, como probabilidade
de quedas de energia durante o projeto ou o número de defeitos bloqueantes encontrados por mês nas
tecnologias utilizadas. Ele teria um custo computacional alto para chegar à solução, nem sendo
cogitada a sua aplicação de forma manual.
Para criar um modelo viável, seleciona-se dentre as variáveis disponíveis, aquelas que tem maior
impacto sobre o esforço necessário para completar uma tarefa. As variáveis são arranjadas em uma
função que descreva a relação do que deve ser feito e o tempo necessário para fazê-lo. O histórico
acumulado permite que o modelo tenha suas constantes ajustadas, reduzindo sua imprecisão.
O ajuste do modelo por meio de constantes não altera a forma básica da curva descrita. Para isso, é
necessário modificar a relação das variáveis, mudando entre uma equação de reta ou uma parábola
por exemplo. Mesmo assim, o ganho de precisão do modelo pode não ser significativo. A inclusão de
uma nova variável pode levar a resultados melhores, mas como ela não fazia parte do modelo, ela
provavelmente não era monitorada. Portanto, alguns projetos deverão ser executados para se acumular
histórico sobre a nova variável.
Softwares de apoio à gerência de projetos normalmente possuem uma grande quantidade de variáveis
que poderiam ser utilizadas para formar o histórico que seria usado para o ajuste do modelo. Porém,

9
por exigir um grande volume de cálculos e tentativa e erro sobre massa de dados, todo esse processo é
muito custoso para ser realizado manualmente e de forma controlada.
Neste trabalho foi desenvolvida a especificação de um componente para automatizar o processo de
ajuste de um modelo. Descoberta de equações é uma sub-área do aprendizado de máquina, que por
sua vez é sub-área da inteligência artificial. Aprendizado de máquina é um método para se criar
programas de computador pela análise de um conjunto de dados, sendo fortemente ligado a estatística.
E, de acordo com TODOROVSKI (2001), “a descoberta de equações é a área que desenvolve
métodos para a descoberta automatizada de leis quantitativas, expressas na forma de equações, em
coleções de dados” (tradução livre).
Dessa forma, o diferencial deste trabalho é que o resultado poderá ser adicionado a softwares de
gerência de projetos já existentes, agregando valor. O sistema passaria a contar com um modelo de
estimativa com alta precisão, criado a partir da realidade do projeto e da empresa.
1.3 OBJETIVOS
1.3.1 Objetivo geral
O objetivo geral deste trabalho é desenvolver um modelo evolutivo para otimização de estimativa de
esforço em projetos de software.
1.3.2 Objetivos específicos
a) Fazer um levantamento dos métodos, ferramentas e técnicas utilizadas por um especialista para
criar ou ajustar um modelo matemático de estimativa de esforço em software;
b) Especificar um sistema que seja capaz de realizar ajustes a modelos matemáticos;
c) Desenvolver um protótipo que siga a especificação;
d) Validar os valores gerados pelo protótipo contra uma massa de dados histórica (dados simulados
ou reais fornecidos por empresas).
1.3.3 Escopo e delimitação do trabalho
O escopo deste trabalho se limita a especificar um modelo evolutivo para otimização de estimativa de
esforço em projetos de software, realizando pesquisa suficiente para tal. O trabalho não tem por
objetivo descrever outros assuntos relacionados à gerência de projetos ou engenharia de software nem

10
métodos de estimativas baseados em simulação como o Método de Monte Carlo, que é usado para
solucionar problemas matemáticos com muitas variáveis que não seriam facilmente solucionados por
métodos numéricos como cálculo de integrais por exemplo.
1.4 RESULTADOS ESPERADOS
O principal resultado deste trabalho será a especificação de um modelo evolutivo para otimização de
estimativa de esforço em projetos de software. Outro resultado importante é um protótipo seguindo a
especificação que demonstre capacidade de realizar ajustes que aumentem a precisão em relação ao
modelo original.
1.5 JUSTIFICATIVA
Ao contrário de outros projetos, como os encontrados na engenharia civil, onde é possível estimar
com um grande grau de certeza quanto tempo um trabalhador leva para construir uma parede, as
tarefas de um projeto de software tem apresentam uma dificuldade muito maior para serem estimadas.
Normalmente, além de envolverem um número maior de artefatos, as tarefas tem uma duração menor
e são afetadas por fatores externos além de fatores humanos.
Os modelos matemáticos de estimativa divulgados no meio acadêmico acabam sendo pouco
utilizados nas organizações ou por serem tão genéricos que não conseguem apresentar resultados com
uma precisão aceitável pela organização ou por exigirem um esforço tão grande que torne inviável a
sua utilização durante todo o projeto. Isso faz com que os responsáveis por estimar uma tarefa criem
fórmulas simplificadas, envolvendo as variáveis que em sua visão tem mais relevância.
Uma vez criados, os modelos podem levar anos para serem ajustados ou simplesmente não serem
ajustados de forma alguma, devido ao esforço necessário para tal sem o apoio de uma ferramenta que
automatize o processo. O processo de ajuste de um modelo matemático requer um especialista com
grande conhecimento tanto sobre o negócio onde a tarefa está inserida quanto sobre a matemática
necessária para criar um modelo mais preciso.
Um sistema de inteligência artificial que tivesse acesso ao modelo atual, dados históricos e todas as
variáveis que tiverem relação com as tarefas (que podem vir de uma ferramenta de apoio a gerência
de projetos por exemplo) mesmo que estes não façam parte do modelo atual, teria dados suficientes
para automatizar os ajustes. O novo modelo poderia ser utilizado então para se ter estimativas mais
precisas durante a execução de um projeto, sem esperar por seu pos-mortem.

11
Segundo LUGER (in DURKIN, 1994, p. iii), inteligência artificial é tanto uma disciplina de
engenharia quanto uma ciência no sentido que busca explicação da natureza do conhecimento,
entendimento e habilidade. É proposto nesse trabalho a especificação de um modelo evolutivo para
otimização de estimativa de esforço em projetos de software.
1.6 ASPECTOS METODOLÓGICOS
1.6.1 Metodologia
A pesquisa desenvolvida para este trabalho se enquadra na classe de pesquisa exploratória aplicada,
pois gera conhecimentos de aplicação prática e envolve levantamento bibliográfico e entrevista a
especialistas da área. Gerentes de projetos serão entrevistados para verificar a utilização de modelos
matemáticos de estimativa em seus projetos. Os que possuírem modelos de criação própria serão
questionados quanto ao processo que levou à construção do mesmo.
Com base na bibliografia e entrevistas, será criada uma especificação e um protótipo que será
validado contra uma massa de dados históricos. A massa de dados poderá ser real, cedida por
empresas, ou gerada por simulação. A especificação será feita na linguagem UML e o protótipo será
escrito sobre a plataforma Java.
1.6.2 Plano de trabalho
Primeira Fase: Pesquisa e Análise (Atividades que atendem ao objetivo específico “a”):
1. pesquisar sobre o uso de modelos matemáticos para estimar esforço em tarefas de
desenvolvimento de software;
2. pesquisar sobre os métodos ferramentas e técnicas utilizadas para a criação de um modelo
matemático a partir de uma massa de dados;
3. documentar técnica e algoritmos a serem utilizados no protótipo.
Segunda Fase: Especificação (Atividades que atendem ao objetivo específico “b”):
1. realizar de levantamento de requisitos funcionais e não funcionais do sistema;
2. projetar o sistema segundo o paradigma da orientação a objetos, utilizando diagramas de classe,
caso de uso e diagramas de seqüência.
Terceira Fase: Codificação (Atividades que atendem ao objetivo específico “c”):

12
1. codificar protótipo segundo a especificação criada;
2. codificar testes de unidade;
3. realizar prováveis correções.
Quarta Fase: Validação (Atividades que atendem ao objetivo específico “d”):
1. Desenvolver gerador de massa de dados*;
2. validar funcionamento do protótipo contra uma massa de dados;
3. validar funcionamento do protótipo na visão de especialistas.
*Ao longo da primeira, segunda e terceira fase, gerentes de projetos serão questionados quanto a
possibilidade de cederem os dados das estimativas de seus projetos e quais modelos estão utilizando
para formar a massa a ser usada na tarefa 2 da quarta fase. Caso os dados não sejam disponibilizados,
a massa será gerada por meio de simulação. Nesse caso, o desenvolvimento de um sistema que gere a
massa ocorrerá na tarefa 1 na quarta fase. Caso contrário, a tarefa 1 não será realizada, aumentando o
tempo disponível para utilização na tarefa 3.

13
1.7 ESTRUTURA DO TRABALHO
Este é o capítulo de introdução, onde pode-se destacar a contextualização, definição do
problema e objetivos, que darão base para os capítulos seguintes.
No capítulo 2, são introduzidos conceitos de gerência de projetos, a importância das estimativas
em projetos de software e explorará o cenário atual, indicando que métodos estão sendo
utilizados pelas organizações. O levantamento do cenário atual será realizado por meio de
entrevistas e enquetes on-line.
O capítulo 3 aborda os métodos, ferramentas e técnicas disponíveis para a criação de um
modelo matemático. Será descrita também a lógica usada por um especialista quando cria um
novo modelo, detalhando os passos e os motivos que levaram a eles.
No capítulo 4 é apresentada a modelagem do sistema, segundo o paradigma da orientação a
objetos. Neste capítulo constam os diagramas de classe e caso de uso que descrevam por meio
de UML o componente proposto pelo trabalho. São apresentados também, resultados de alguns
experimentos realizados para melhor embasar o modelo.
São apresentadas no capítulo 5 as conclusões encontradas com o desenvolvimento do trabalho e
perspectivas futuras, discutindo tanto a aplicação dos seus resultados na área de gestão de
projetos, auxiliando na criação de métodos de estimativa mais preciso, quanto em outras áreas
que possuam a mesma característica de possuir grande volume de dados que possam ser
descritos por uma equação.
Por fim, o capítulo 6 apresenta a bibliografia utilizada para a confecção deste trabalho.

14
2 ESTIMATIVAS EM PROJETOS DE SOFTWARE
2.1 INTRODUÇÃO
Um projeto é uma seqüência de atividades compondo um conjunto não rotineiro, visando um
objetivo, que pode ser desde a implantação de um serviço à criação de um novo produto. Uma
característica de um projeto é ter um fim definido, tendo atendido ao seu objetivo ou não. A
linha divisória entre rotina e projeto é muito tênue pois, se uma atividade é realizada repetidas
vezes ela não é um projeto. Porém, em um projeto de desenvolvimento de um sistema muito
similar a sistemas anteriores haverão muitas atividades de rotina (HUGHES; COTTERELL,
1999, p.2).
Este capítulo não pretende se aprofundar em todas as questões inerentes à gerência de projetos,
mas apresentar os conceitos relacionados, características comuns a projetos de software e como
são feitas as estimativas. Desta forma, este capítulo oferece a base necessária para a execução
do trabalho.
2.2 GERÊNCIA DE PROJETOS
Na gerência de projetos, é necessário aplicar conhecimentos técnicos e habilidades específicas,
na criação e acompanhamento de tarefas que envolvem diferentes tipos de recursos, como
financeiros e materiais, mas principalmente recursos humanos. A gerência chega a ser
considerada como sendo a arte de conseguir que as coisas sejam feitas através das pessoas.
Por motivos como participação em concorrências públicas ou obter maior controle e
previsibilidade em seus projetos, organizações buscam consultorias, treinamentos e
certificações na área de gerência de projetos. Reflexo disso é a forte aceitação do que é proposto
pelo PMI (Project Management Institute) no PMBOK Guide (A Guide to the Project
Management Body of Knowledge, 2004). O PMBOK não é considerado uma metodologia, pois

15
identifica os processos e suas áreas de conhecimento de uma forma genérica, sem definir
modelos de documentos a preencher nem peculiaridades de tipos de projetos.
As áreas de conhecimento definidas no PMBOK são os aspectos que devem ser observados na
gerência de um projeto. Cada área é formada por um conjunto de processos que interagem entre
si para permitir que o projeto transcorra de forma controlada. As áreas são: Gerência de
Aquisição, Gerência de Comunicação, Gerência de Custo, Gerência de Escopo, Gerência de
Integração, Gerência de Qualidade, Gerência de Recursos Humanos, Gerência de Risco e
Gerência de Tempo.
Figura 1: Visão geral das áreas de conhecimento em gerenciamento de projetos e os processos de gerenciamento
de projetos

16
Os processos são divididos em cinco grupos, que contém processos de diferentes áreas de
conhecimento. Estes grupos possuem forte dependência e são encontrados no ciclo de vida de
qualquer projeto, independente da área de aplicação ou do foco do setor. Por ter um
comportamento finito, os projetos passam por processos de iniciação e de encerramento,
delimitando seu ciclo de vida. Após iniciado, o projeto entra numa alternância entre processos
de planejamento e execução até que possa ser encerrado. Durante toda a sua vida, são
executados processos de monitoramento e controle, para permitir uma gestão efetiva. Por isso,
na figura abaixo retirada do PMBOK (PMI, 2004), a área representando monitoração e controle
envolve os outros grupos de processos.
Dentre todos os processos existentes em cada área de conhecimento, o que terá maior benefício
dos resultados deste trabalho será o de estimar a duração das atividades, processo 6.4 da
gerência de tempo. Este processo consiste em determinar a duração de cada atividade com base
na quantidade de esforço, recursos e jornadas de trabalho necessárias para completá-las. (PMI,
2004).
Os processos de iniciação, são aqueles que definem ou autorizam o início do projeto ou de uma
fase do mesmo. Estes processos geram documentação sobre os requisitos ou necessidades de
negócio, as alternativas para atendê-los, a alternativa selecionada e o escopo da solução.
No grupo de processos de planejamento, os objetivos e o escopo são refinados e as atividades
Figura 2: Grupos de processos de gerenciamento de projetos (PMI, 2004, p.40)

17
necessárias para atende-los são agendadas. As atividades são distribuídas pelo tempo
respeitando uma série de fatores, como dependências entre as mesmas, disponibilidade de
recursos e restrições de custo ou prazo. A medida que o projeto segue, o melhor entendimento
do escopo, das atividades e dos riscos envolvidos podem levar a uma repetição dos processos de
planejamento ou até dos de iniciação.
Processos de execução são os que envolvem a coordenação de pessoas e recursos para realizar
as atividades previstas no plano de gerenciamento do projeto desenvolvido no grupo de
processos de planejamento. Durante estes processos, podem ser encontradas situações que
levam a algum esforço de replanejamento, como detecção ou realização de um risco que não
havia sido identificado anteriormente.
Delimitando e formalizando o término de um projeto o grupo de processos de encerramento.
Nele são encerradas todas as atividades do projeto ou fase, desalocados os recursos e entregues
os resultados, caso o projeto não esteja sendo encerrado por ter sido cancelado.
Envolvendo todos os outros, o grupo de processos de monitoramento e controle observam o
desenvolver do projeto, identificando possíveis problemas no tempo adequado para que ações
corretivas possam ser tomadas. Por exemplo, um atraso identificado na execução de uma
atividade pode fazer com que seja revisada parte do planejamento para que não haja um atraso
na entrega do projeto, conseqüentemente provocando uma mudança nas atividades a serem
executadas. Esse ciclo entre processos de planejamento e execução devido a eventos nos
processos de monitoramento e controle podem ser visualizados na figura 2 apresentada
anteriormente.
Normalmente, um dos principais objetivos de se gerenciar um projeto é garantir a entrega dos
seus resultados dentro do prazo. Produtos para datas comemorativas por exemplo, dão ainda
mais importância para o fator prazo pois, não seria um grave problema entregar um produto
criado especificamente para o natal com um mês de atraso. Por esta razão, as estimativas são de
importância vital para a gerência de projetos. Com base nelas, os gestores podem verificar o
andamento do projeto e tomar ações corretivas ou preventivas. Com estimativas confiáveis
pode-se chegar até mesmo a concluir que um projeto é inviável para um determinado prazo,
evitando grandes prejuízos e problemas judiciais.
Apesar de ter uma seção de ferramentas e técnicas para cada processo, o PMBOK não
determina especificamente quais métodos devem ser utilizados na prática. Alguns métodos de

18
estimativa serão discutidos no item 2.3 deste capítulo. Como o PMBOK reúne um conjunto de
conhecimentos genéricos e, na prática é necessário conhecimento específico do tipo de projeto,
serão expostas algumas das peculiaridades que devem ser consideradas no gerenciamento de um
projeto de software.
2.3 CARACTERÍSTICAS DE PROJETOS DE SOFTWARE
Os projetos de software tem muitas características em comum com os de outras indústrias,
porém, algumas de suas peculiaridades requerem técnicas específicas para possibilitar uma
gestão efetiva. Hughes e Cotterell (1999, p.3) indicaram três características que afetam a forma
de gerenciar um projeto de software: invisibilidade (pois um software não apresenta resultados
que possam ser visualmente acompanhados dando um indicativo de seu progresso),
complexidade (para cada valor gasto, um produto de software possui mais complexidade do que
outros artefatos de engenharia) e flexibilidade (por serem mais facilmente modificados do que
um sistema físico ou organizacional, artefatos de software normalmente devem se adaptar às
necessidades destes outros componentes, ficando expostos a um alto grau de mudança).
Como exemplo, se um projeto de um software prevê a implementação de 10 interfaces gráficas,
ter implementado 5 não implica em dizer que o projeto está 50% concluído, pois as interfaces
podem ter apenas os componentes visuais posicionados e alguns controles sobre os mesmos, o
que não é suficiente para a utilização do software. A não ser que o planejamento do projeto
divida as tarefas de forma a ter uma tela totalmente funcional após a outra, as interfaces gráficas
não são indicativo do andamento do projeto.
Os softwares não só são utilizados em computadores, mas numa crescente variedade de
dispositivos com os mais diferentes fins, e nestes as características de invisibilidade,
complexidade e flexibilidade se tornam ainda mais evidentes. Os telefones celulares por
exemplo, são dispositivos criados para permitir mobilidade ao usuário, que pode fazer e receber
chamadas onde estiver (estando ao alcance de uma antena que possa completar a chamada) mas
que podem ser integrados a grandes sistemas.
Os softwares embarcados nos primeiros celulares, não permitiam ao usuário armazenar nome e
número para cada pessoa por motivos como a inexistência de memória para persistir as
informações ou devido aos visores disponíveis serem projetados apenas para a exibição de
números. Com a evolução de tecnologias como armazenamento, processamento e

19
miniaturização, é possível desenvolver celulares com muito mais funcionalidades. O próprio
mercado começa a rejeitar telefones que sirvam apenas para telefonar.
Os celulares se tornaram semelhantes aos computadores pessoais em muitos aspectos,
possuindo até mesmo sistema operacional, como o Windows Mobile da Microsoft ou o
Symbian OS, que é desenvolvido por um consórcio pertencente à Nokia, Motorola, Panasonic,
Sony Ericsson, Psion e Siemens. Projetos de software para celulares devem levar em
consideração quais aparelhos serão suportados.
Caso seja específico para um cliente com aparelhos do mesmo modelo, pode-se optar por
desenvolver na tecnologia nativa do mesmo. Mas se o projeto tiver como objetivo atender a um
público mais amplo, é indicado optar por uma tecnologia multi plataforma como o Java ME,
onde a mesma implementação pode ser instalada em qualquer sistema que tiver suporte à
máquina virtual Java.
A tendência de que todos os dispositivos se comuniquem, utilizando redes com ou sem fio,
permite a criação de projetos de sistemas que possam interagir com os usuários em seu
computador, celular ou até mesmo por meio de seu aparelho de televisão. Parte dos novos
televisores fabricados com suporte à tecnologia de TV digital, também possuem uma máquina
virtual Java, de forma que podem ser obtidos e instalados softwares na mesma. Essa tecnologia
está sendo conhecida como Xlets e foi introduzida pela Sun na especificação JavaTV.
Com a possibilidade de criar sistemas multiplataforma, o escopo do projeto deve estar bem
definido para se possa verificar que artefatos devem ser produzidos, que atividades serão
necessárias para produzi-los, aumentando a importância de se estabelecer um cronograma que
permita acompanhar o projeto sem que as características de invisibilidade complexidade e
flexibilidade se tornem problemas. Bechtold (1999) destaca outras dez características comuns
aos projetos de software:
• Software não é natural: Leis da natureza, usadas em outras engenharias, não se aplicam ao
software pois, não sendo natural, ele não envelhece, quebra, derrete, evapora, vibra ou
flutua.
• Sem limites de complexidade: Em software, é comum a atitude de que nada é complicado
demais, levando a decisões que envolvem uma complexidade que seria considerada
exagerada se fosse em outra área.

20
• Os principais tomadores de decisão sobre o problema praticamente não tem
entendimento ou experiência no domínio do problema: Em um projeto de software de
contabilidade por exemplo, o domínio do problema incluiria contas a pagar, contas a
receber, folha de pagamento, gerenciamento de ordens de compra e pagamento, entre
outros.
• Os principais tomadores de decisão sobre a solução praticamente não tem
entendimento ou experiência no domínio de solução: O domínio de solução de um
problema pode, por exemplo, incluir desenvolvimento usando JavaScript e PERL.
• Técnicos ou especialistas em ferramentas entendem muito pouco além de sua
especialidade: Com o tempo, um mesmo desenvolvedor pode ser alocado a diferentes
projetos que requerem o uso de uma ferramenta conhecida por ele, e aos poucos ele vai se
tornando super especializado na ferramenta, tendo pouca ou nenhuma exposição a outras.
• Os responsáveis por montar a equipe confiam excessivamente em especialistas
(especialmente com relação a ferramentas de desenvolvimento): Um dos motivos para
isso é que é mais fácil para os setores de recursos humanos e para os gerentes de projetos
determinar se um profissional tem dois anos de experiência com uma ferramenta do que
determinar se ele é um “engenheiro de software sênior”.
• Teoricamente, não há virtualmente nada “impossível” de ser implementado em
software: Em desenvolvimento de software, se algo parece ser possível, então acredita-se
que é possível, mas sem se perguntar para quando ou quanto custara com a complexidade
associada. Observando alguns projetos que resultaram grandes fracassos, a combinação de
características como alta complexidade, magnitude, duração, mostram que alguns projetos
são sim impossíveis.
• As necessidades do cliente mudam mais rápido que as ferramentas de
desenvolvimento: Os desenvolvedores de ferramentas de desenvolvimento de software
estão sempre buscando atender as crescentes necessidades de seus clientes desenvolvedores,
que por sua vez estão tentando atender as ainda maiores necessidades de seus clientes
compradores de software.
• Ferramentas de desenvolvimento de software mudam mais rápido do que os métodos
de desenvolvimento: Novas ferramentas permitem executar processos e métodos de
engenharia de software de novas formas, de forma otimizada ou até mesmo ser

21
incompatível com o antigo processo.
• Os métodos de desenvolvimento de software mudam mais rápido que as disciplinas de
gerência: Para tentar atender aos problemas decorrentes das outras características citadas,
os princípios de gerência de software também estão mudando. Porém, historicamente essa
evolução tem sido mais lenta que a dos métodos de desenvolvimento. Em parte, isso é
devido à crença de que um bom gerente gerencia qualquer grupo fazendo qualquer coisa,
mas as taxas de fracasso são evidência de que essa crença pode ser fatal para projetos de
desenvolvimento de software.
Pode-se dizer que todas as características apresentadas tem algum grau de impacto sobre a
estimativa de duração de um projeto. Mudanças de escopo devido a crescentes necessidades do
cliente, diferenças entre habilidades entre membros da equipe, invisibilidade que leva a falsas
percepções sobre a real dimensão do software, e várias outras dificuldades acabam
determinando se o projeto utilizará uma forma mais ou menos formal para realizar suas
estimativas.
Por exemplo, uma organização pode estar desenvolvendo um sistema monousuário para
cadastro de tarefas com base em análise feita em momento anterior com o cliente. Para acertar
um prazo e preço, foram identificadas atividades com base nessa análise inicial e estimadas as
suas durações e custos, que levaram ao preço informado. Durante o desenvolvimento, riscos vão
sendo realizados e o monitoramento constante do andamento das atividades permite ao gerente
tomar decisões como aumentar a equipe para recuperar o tempo tomado pelos riscos. O
aumento da equipe faz com que todo o planejamento daquele ponto em diante seja refeito,
redistribuindo as atividades e refazendo as estimativas, já que os novos integrantes da equipe
provavelmente terão produtividade diferente dos que já estavam no projeto.
Ainda no mesmo exemplo, o cliente pode informar que é imperativo que o sistema final deve
poder ser acessado em qualquer computador conectado à web, modificando totalmente o escopo
original. A equipe montada pode não ter conhecimento suficiente sobre as tecnologias
envolvidas para que a solução se adapte ao novo escopo e, dependendo da forma utilizada pela
organização para realizar as estimativas, as incertezas levarão a estimativas menos precisas.
Constantes erros de estimativas fazem com que a organização perca a credibilidade do cliente,
que pode pedir o cancelamento do projeto, principalmente se as estimativas sempre são para
menos tempo que o realizado.

22
Com isso, pode se observar que existe uma forte ligação entre a estimativa e a “vida” do
projeto. Todas as características apresentadas afetam o projeto direta ou indiretamente desde seu
início até seu encerramento e podem representar problemas dependendo das formas utilizadas
pela organização gerar as estimativas.
2.4 FORMAS DE ESTIMAR UM PROJETO DE SOFTWARE
A criação de estimativas de esforço ou custo em projetos de software dependem diretamente de
se conhecer o domínio do problema e da solução. O estudo aprofundado do problema ao qual o
software se propõe a solucionar e a definição dos recursos, ferramentas e técnicas a serem
utilizados, permitem dividir o projeto em partes menores. Isto normalmente é feito nas fases
iniciais do projeto e é necessário para que ele possa ser gerenciado e para que fiquem claras as
atividades necessárias para sua conclusão.
Como partes menores tem menor complexidade, as estimativas tendem a ser mais precisas.
Porém, esta divisão deve ocorrer até um nível de detalhe em que os executores e coordenadores
das atividades compreendam o que deve ser feito, evitando chegar a níveis de detalhamento
excessivos, que podem levar a um esforço de gerenciamento desnecessário.
Uma técnica amplamente utilizada para dividir um projeto em partes é o WBS (Work
Breakdown Structure). Um WBS é usado para definir os deliverables (produtos e resultados) de
um projeto e fazer a decomposição destes em componentes, sendo base para estabelecer o
necessário em esforço, custo, e a responsabilidade associada para cumprir e coordenar o
trabalho (PMI, 2001, p. 1). Por exemplo, um projeto de desenvolvimento de um software de
calculadora, sem entrar em detalhes específicos e sabendo que a estrutura pode mudar bastante
de organização para organização, pode ser representado pelo seguinte WBS:
1 Projeto Calculadora
1.1 Análise
1.1.1 Analisar funções necessárias
1.1.2 Avaliar necessidades do cliente
1.1.3 Definir escopo da solução
1.1.4 Aprovar escopo com cliente

23
1.2 Projeto
1.2.1 Prototipar telas
1.2.2 Criar diagramas de classe
1.2.3 Criar diagramas de seqüência
1.2.4 Validar modelagem com o analista
1.2.5 Realizar ajustes
1.3 Codificação
1.4 Testes
Além de identificar as atividades, é necessário associar os recursos necessários a cada uma. No
exemplo anterior poderia ser identificado que para realizar a atividade 1.2.2 seria necessário
alocar um colaborador com bons conhecimentos de orientação a objetos e adquirir um software
de diagramação caso a organização não o tenha. As durações variam de acordo com a
produtividade dos recursos alocados. Suas datas de início podem estar condicionadas à outros
fatores como a disponibilidade de um recurso ou ao calendário de feriados locais. Uma vez
feitas estas definições, pode-se iniciar o processo de estimar as durações das atividades.
Como pode ser visto na figura 3, o PMBOK indica cinco técnicas que podem ser utilizadas no
processo de estimativa de duração de atividade: Opinião especializada, estimativa análoga,
estimativa paramétrica, estimativa de três pontos e análise das reservas (PMI, 2004). As
abordagens para estimativa de esforço e prazo podem também ser divididas em: modelos
paramétricos, modelos baseados em atividades, analogia e relações simples de estimativas
(McGarry, apud AGUIAR, 2004).

24
Figura 3: Estimativa de duração da atividade: Entradas, ferramentas e técnicas, e saídas
Os modelos baseados em atividades, também são conhecidos como bottom-up, consistem em
estimar o esforço de cada uma que compõe o projeto. As outras formas de estimativa podem ser
combinadas com esta ou não. Por exemplo, um projeto pode aparecer como uma atividade de
um projeto maior, e ser estimado por um modelo paramétrico, enquanto outro projeto tem todas
as suas atividades estimadas individualmente por meio de opinião de especialistas, chegando à
duração total do projeto a partir da criação de um cronograma com as estimativas feitas.
Com a experiência, os profissionais se especializam, acumulam conhecimento e histórico. Isso
permite que eles tenham a capacidade de estimar a duração das tarefas com uma precisão
melhor do que alguém sem experiência prévia com atividades similares àquela que se pretende
estimar. Por isso, a falta de uma opinião especializada pode levar a estimativas com maior grau
de incerteza.
No caso de haverem dados históricos armazenados sobre a duração de tarefas anteriores, estes
podem ser utilizados para a estimativa análoga. Nela, dados de atividades similares às que estão
sendo estimadas fornecem um indicador de sua provável duração, identificando também as
diferenças que implicam em ajustes na estimativa. Esta técnica de estimativa se torna ainda
mais confiável se for utilizada em conjunto com a opinião de especialistas, ou seja, quando a
equipe realizando as estimativas tem experiência atividades similares às envolvidas no novo
projeto.
Para aumentar ainda mais a precisão das estimativas, pode se utilizar a estimativa de três
pontos. Esta técnica consiste em estimar o cenário otimista, pessimista e mais provável. A
média entre as três estimativas normalmente será um valor com maior possibilidade de se
aproximar da duração real que a atividade terá.

25
Quando uma atividade apresenta fatores que dificultem a sua estimativa, como maior
complexidade, risco ou incerteza, pode ser usada a opinião de mais de um especialista. Uma
forma de se obter isso é utilizando o método Delphi, “técnica para a busca de um consenso de
opiniões de um grupo de especialistas a respeito de eventos futuros” (WRIGHT;
GIOVINAZZO, 2000).
As organizações que utilizam o método Delphi normalmente fazem adaptações para suas
necessidades, mas a sua forma básica pode ser descrita da seguinte forma: Primeiro é marcada
uma reunião para discussão das estimativas. Cada participante prepara suas estimativas, listando
as tarefas que achar necessárias para a realização da atividade e anotando as estimativas, riscos
e qualquer premissa que foi imaginada como condição para aquela estimativa. No dia da
reunião, todas as estimativas são analisadas e comparadas de maneira anônima e imparcial.
Depois das discussões podem ocorrer outras rodadas de estimativas até se encontrar uma
condição de parada.
A condição para se encerrar uma reunião no método Delphi também varia a cada organização.
Pode-se por exemplo optar por encerrar quando as estimativas começarem a convergir a um
valor ou o moderador pode encerrar a reunião após um número fixo de rodadas, cabendo a um
estimador criar um documento final com base no que foi discutido.
Dependendo do grau de incerteza e riscos associados às atividades, pode-se usar a técnica de
análise das reservas. São acrescentadas ao projeto tempos comumente chamados de reservas de
contingência ou buffers. Estes tempos podem ser parcial ou totalmente consumidos, mas, com o
aumento do entendimento das atividades e dos riscos, existe a possibilidade de que eles sejam
reduzidos ou até eliminados.
A estimativa paramétrica é aquela que se utiliza de modelos matemáticos que descrevem
relações entre tamanho, esforço e prazo considerando a produtividade associada. A
produtividade pode ser considerada a quantidade produzida por unidade de trabalho, como por
exemplo a quantidade de linhas de código que um programador produz por hora. As relações
podem ser encontradas por meio de suposições teóricas ou a partir de dados históricos. Um dos
modelos nessa categoria muito aplicado pela indústria de software é o COCOMO II. É possível
encontrar implementações on-line do modelo, onde o usuário fornece os parâmetros e o
resultado é demonstrado na tela.
Os modelos paramétricos são criados para se aplicar a diferentes cenários. Para isso, levam em

26
consideração um grande número de parâmetros e constantes de ajuste, relativos à equipe, à
empresa e ao produto. Os modelos e suas constantes de ajuste são modificados a medida que o
grupo responsável pelo modelo recebe feedback dos usuários, dados do valor estimado e
realizado para cada atividade. Mesmo assim, os ajustes podem não ser suficientes para que o
modelo se aplique com precisão aceitável em 100% dos projetos.
Por isso, os responsáveis por estimar a duração das atividades podem ainda optar por criar seus
próprios modelos com base em dados históricos da própria organização, identificando relações
simples de estimativas. Estes modelos podem produzir estimativas mais precisas do que os
paramétricos, porém, esta simplificação normalmente não permite que os modelos sejam
utilizados em cenários diferentes daqueles para onde foram criados.
O sistema proposto por este trabalho poderá ser utilizado tanto para otimizar modelos
paramétricos quanto relações simples de estimativa. A partir do estudo sobre a criação de
modelos matemáticos, que será detalhado no capítulo 3, será feita a especificação do sistema
proposto, foco dos capítulos seguintes.

27
3 CRIAÇÃO DE MODELOS MATEMÁTICOS
3.1 INTRODUÇÃO
O conteúdo desse capítulo servirá de base para a especificação do sistema proposto. Nele será
discutida a criação de modelos matemáticos, como identificar as variáveis e suas relações
matemáticas. Discutirá também as alternativas existentes dentro da área de inteligência artificial
que poderiam ser utilizadas, definindo qual será utilizada na especificação.
Estimativa paramétrica é a técnica que desenvolve estimativas baseadas no exame e validação dos relacionamentos que existem entre as características técnicas, programáticas, de custo e de recursos consumidos de um projeto, durante seu desenvolvimento, manufatura, manutenção e/ou modificação (International Society of Parametric Analysts, 2003, p.1, tradução livre).
O processo de criação de um modelo requer do responsável, experiência com a matemática
necessária e, preferivelmente, experiência com a questão sendo modelada. Independente da área
fim, é possível identificar algumas atividades básicas que ocorrem nesse processo, como pode
ser visto na figura 4.
Figura 4: Atividades básicas no processo de criação de um modelo matemático

28
3.2 COLETA DE DADOS
A criação de um modelo matemático depende fortemente da disponibilidade de dados
históricos. Sistemas de informação como ERPs (Enterprise Resource Planning), sistemas de
apoio a gerência de projetos, formulários preenchidos por membros da equipe, documentação
sobre os projetos, equipe e recursos utilizados são exemplos de possíveis fontes de dados para
um modelo de estimativa de esforço de atividades.
Pouco histórico pode levar a conclusões incorretas. Por exemplo, caso seja monitorada uma
variável que está em um momento de comportamento anormal, como a produtividade dos
programadores em uma época em que parte da equipe está se recuperando de uma virose, os
valores coletados podem estar abaixo da média real.
Além disso, manter histórico de poucas variáveis pode deixar alguma de grande impacto sem
monitoramento. Por exemplo, ter os dados de produtividade de uma equipe de programação
sem verificar a experiência da mesma com a tecnologia usada. Caso a equipe seja monitorada
em projetos onde foi obtida alta produtividade, mas as tecnologias envolvidas eram bem
conhecidas, um modelo baseado nesse cenário pode criar estimativas de esforço insuficientes
para a mesma equipe realizar um projeto onde tecnologias pouco conhecidas estejam
envolvidas.
Para se obter um modelo mais genérico, é necessário coletar dados de diferentes cenários. Isso
permite identificar por exemplo se o peso de uma variável muda em determinadas condições.
No COCOMO por exemplo, em sua versão de 1981 foram utilizados dados de 63 projetos, e
para o COCOMO II foram 83 projetos (DEVNANI-CHULANI et al, 1998).
3.3 SELEÇÃO DE VARIÁVEIS
Muitos sistemas computacionais necessitam de um grande número de variáveis fornecidas pelo
usuário para o seu funcionamento. Muitas delas poderiam ser utilizados para a criação de um
modelo paramétrico. Sistemas que incluem gráfico de Gantt, como por exemplo o Microsoft
Project (MICROSOFT) ou o ODYSSEA PMS (SENSYS), demonstram graficamente tarefas
distribuídas no tempo, indicando sua data de início, data de fim e recursos alocados, como pode
ser visto na figura 5. Estas variáveis já seriam suficientes para criar um modelo simples que
estimasse a duração das tarefas de acordo com os recursos alocados.

29
No universo de desenvolvimento de software, existe um elevado número de fatores que
exercem efeito direta ou indiretamente na duração das tarefas, e monitorar todos eles seria
inviável, tanto com relação ao custo em armazenamento quanto em esforço necessário para
alimentar e dar manutenção a uma base de dados tão complexa. Selecionar quais variáveis
devem ser monitoradas para futuro uso na criação de um modelo requer experiência e bom
senso do estimador. No modelo COCOMO II é utilizada a seguinte fórmula para estimativa de
esforço:
(1)
Algumas variáveis dessa fórmula são resultado de outras fórmulas, como Fre-eng e Ci. A variável
Ci por exemplo, representa o produto dos níveis de influência encontrados para os
“direcionadores de custo”, que são calibrados e divulgados pelo Centro de Pesquisas da
Universidade do Sul da Califórnia. Cada publicação é conhecida pelo seu ano e um número
seqüencial, com zero sendo a primeira publicação do ano. Para exemplificar, publicação 1999.0
os direcionadores de custo assumem os seguintes valores:
Figura 5: Gráfico de Gantt
EHM
=aTamanhob CiF re-eng

30
Sigla Descrição Nível de Influência
Atributos do produto
RELY Confiabilidade requerida pelo software de muito baixo (0,82) a muito alto (1,26)
DATA Tamanho da base de dados de baixo (0,90) a muito alto (1,28)
CPLX Complexidade do software de muito baixo (0,73) a extra alto (1,74)
DOCU Documentação de muito baixo (0,81) a muito alto (1,23)
RUSE Reusabilidade requerida de baixo (0,95) a extra alto (1,24)
RCPX Confiabilidade e complexidade do software de extra baixo (0,73) a extra alto (2,38)
Atributos da plataforma
TIME Restrições relativas ao tempo de maquina de nominal (1,00) a extra alto (1,63)
STOR Restrições quanto ao uso de memória de nominal (1,00) a extra alto (1,46)
PVOL Mudanças de plataforma de baixo (0,87) a muito alto (1,30)
PDIF Dificuldades com a plataforma de baixo (0,87) a extra alto (2,61)
Atributos da equipe de desenvolvimento
ACAP Capacidade dos analistas de muito baixo (1,42) a muito alto (0,71)
AEXP Experiência na aplicação de muito baixo (1,22) a muito alto (0,81)
PCAP Capacidade dos programadores de muito baixo (1,34) a muito alto (0,76)
PEXP Experiência com a plataforma de muito baixo (1,19) a muito alto (0,85)
LTEX Experiência com a linguagem e ferramental
de muito baixo (1,20) a muito alto (0,84)
PCON Continuidade do pessoal de muito baixo (1,29) a muito alto (0,81)
PERS Capacidade do pessoal de extra baixo (2,12) a extra alto (0,50)
PREX Experiência profissional de extra baixo (1,59) a extra alto (0,62)
Atributos do projeto
TOOL Uso de ferramentas de software de muito baixo (1,17) a muito alto (0,78)
SITE Desenvolvimento multi-local de muito baixo (1,22) a extra alto (0,80)
SCED Prazo requerido para o desenvolvimento de muito baixo (1,43) a muito alto (1,00)
FCIL Instalações de extra baixo (1,43) a extra alto (0,62)
Quadro 1: Direcionadores do COCOMO II

31
A quantidade de parâmetros utilizados no modelo COCOMO II permite que ele gere estimativas
com precisão aceitável numa grande variedade de cenários. Existem outros modelos porém que
envolvem um número menor de parâmetros, limitando assim sua aplicação. O modelo Walston-
Felix por exemplo possui como variável apenas o KSLOC (milhares de linhas de código) como
pode ser visto na fórmula:
(2)
Supondo que uma mesma equipe realizou, em diferentes projetos, algumas atividades muito
semelhantes. No segundo projeto o tempo das atividades foi, em média, três quartos do tempo
do primeiro. No terceiro, o tempo se reduziu a quatro quintos do segundo. Um modelo que leve
em consideração apenas o número de linhas de código e ser produzido não apresentaria
diferença no resultado a medida que a equipe ganha experiência.
A dimensão de um software, seja medida por linhas de código ou por pontos de função, é
visivelmente a variável de maior impacto para se estimar a duração das atividades do projeto.
Mas percebe-se que outros parâmetros podem afetar as estimativas. Estes parâmetros podem ser
até mesmo questões qualitativas como o grau de experiência profissional da equipe.
3.4 NORMALIZAÇÃO
Os dados coletados para cada variável devem passar por um processo de normalização. Isto é
necessário pois podem haver dados redundantes, inconsistentes, corrompidos, em escalas
diferentes e outros problemas que impedem a correta construção de um modelo. O intuito da
normalização seria então tornar o conjunto de dados homogêneo ou consistente (International
Society of Parametric Analysts, 2003, p.5).
Primeiro deve ser feita uma limpeza dos dados, eliminando registros inconsistentes,
corrompidos ou valores anormais. Um valor muito distante do padrão que pode ser visto ao
desenhar os dados em um gráfico, pode indicar um valor incorretamente coletado ou coletado
em uma situação anormal que dificilmente se repetirá e deve ser desconsiderada para não levar
a distorções no modelo.
E=5,2 KSLOC0,91

32
As unidades de cada variável também deve ser verificada. Por exemplo, a duração das tarefas
de um projeto pode ter vindo medida em dias a partir de uma fonte, e um projeto de outra fonte
pode ter a duração das tarefas medida em meses. As unidades deverão ser convertidas para a
que for mais conveniente para o objetivo do modelo.
Podem ser feitos outros ajustes nos dados como remover variáveis inteiras por serem
irrelevantes ao modelo ou serem correlacionadas a outras. Um dos métodos para verificar a
correlação linear entre duas variáveis é o coeficiente de correlação de Pearson. O coeficiente
varia entre -1 e 1, onde 0 representa a inexistência de associação linear entre as variáveis e 1 ou
-1 indicam que todos os pontos caem em uma linha reta (RIBEIRO JR). Porém, um alto valor
do coeficiente não necessariamente indica uma relação de causa e efeito, podendo ser apenas a
tendência que aquelas variáveis apresentam quanto a sua variação conjunta (COSTA NETO,
1977, p.183).
(3)
Onde :
• n: Número de pares.
• r: Coeficiente de correlação de Pearson
Durante a normalização, valores contínuos podem ser discretizados para serem utilizados como
r=n∑ xi yi−∑ xi∑ y i
[n∑ x i2−∑ xi ² ]⋅[n∑ yi
2−∑ y i ² ]
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
5,5
6
6,5
7
7,5
8
Figura 6: Valor isolado a ser descartado

33
parâmetros do modelo, como pode ser observado por exemplo nos direcionadores de custo do
COCOMO. Eles possuem nomes que vão do “extra baixo” ao “extra alto”, mas cada nome tem
um valor associado.
Por fim pode ser executado o processo matemático chamado normalização. A normalização
permite regularizar a importância relativa de cada variável, transformando-as de forma a
garantir que todas sejam equivalentes em termos de magnitude (LOPES). Mean centering,
auto-scaling, sigmoidal, zscore e amplitude são algumas das formas de normalização. A
normalização de amplitude é uma das mais comuns sendo utilizada por exemplo em redes
neurais. Ela é feita com a seguinte fórmula:
(4)
Onde:
• m: Valor mínimo escolhido
• M: Valor máximo escolhido
• mx: Valor mínimo no vetor x
• Mx: Valor máximo no vetor x
• zi: Variável normalizada
Para o caso especial de normalização de amplitude para m=0 e M=1, a fórmula é simplificada
para:
(5)
Após estas verificações e ajustes nos dados coletados para as variáveis, elas estão prontas para
serem usadas na criação do modelo. Dados de melhor qualidade possibilitam a criação de
modelos mais precisos. Em teoria, utilizar dados que venham de outras aplicações, como um
ERP, tem a vantagem de ter passado pelas validações do mesmo.
zi= M−m x i−mx
M x−m x
+m
zi=x i−mx
M x−m x

34
3.5 IDENTIFICAÇÃO DE RELAÇÕES MATEMÁTICAS
A relação matemática entre duas variáveis pode se linear ou não linear. Por meio de análise de
regressão é possível identificar a relação entre duas ou mais variáveis, caracterizando-a como
uma expressão matemática. Além de descrever, a expressão permite predizer o valor de uma
variável (variável dependente) a partir das outras (variáveis independentes).
A seguir, serão apresentadas algumas fórmulas utilizadas na regressão linear simples,
polinomial e múltipla (COSTA NETO, 1977, p. 191-209). Com a regressão linear simples,
obtém-se uma linha reta teórica, na forma:
(6)
Onde α e β são estimados com base nos dados, obtendo a reta estimativa na forma:
(7)
Sendo:
a: estimativa do parâmetro α
b: Também conhecido como coeficiente de regressão linear, é estimativa do parâmetro β
ŷ: Valores dados pela reta estimativa
O procedimento chamado mínimos quadrados, determina o valor das variáveis a e b de forma a
tornar mínima a soma dos quadrados das diferenças entre os valores na reta estimativa e os
valores nos dados. Isso é feito usando o seguinte sistema:
(8)
A regressão polinomial segue o mesmo princípio dos mínimos quadrado s, porém são estimados
k + 1 coeficientes. Por exemplo, os parâmetros de uma parábola com valores igualmente
espaçados por exemplo, são estimados resolvendo o sistema:
(9)
Para que sejam consideradas duas ou mais variáveis independentes para estimar uma variável
y= x
y=ab x
{b=∑ xi−x y i
∑ xi−x 2 =
S xy
S xx
a=y−bx
{∑ y i=nac∑ x i−x
2
∑ xi−x y i=b∑ xi−x 2
∑ xi−x 2 y i=a∑ x i−x
2c∑ x i−x
4

35
dependente é usada a regressão múltipla. Para simplificar o sistema de equações pode-se utilizar
os dados normalizados por mean centering, onde a média de um vetor é subtraída de cada um
de seus valores. Isso permite a utilização do seguinte sistema:
(10)
Que pode ser condensado como:
(11)
Sendo:
(12)
(13)
Por exemplo, é possível imaginar criar um modelo que estime o valor de um veículo de acordo
com o seu comprimento e motor. Para esta demonstração da aplicação da regressão múltipla,
foram selecionadas estatísticas de alguns carros nacionais conforme tabela abaixo:
Observando os gráficos percebe-se uma relação entre as variáveis:
{S 1y=b1 S11b2 S 12⋯bk S 1k
S 2y=b1 S 21b2 S 22⋯bk S 2k
⋮
S ky=b1 S k1b2 S k2⋯bk S kk
S iy=∑l
k
bl S il i=1,2 , , k
S iy=∑j
n
x ij y j−
∑j
n
x ij∑j
n
y j
n
S il=∑j
n
x ij xlj−
∑j
n
x ij∑j
n
xlj
n
Tabela 1: Estatísticas sobre veículos (Fonte: Folha de S. Paulo, 14/03/1999, apud BUSSAB; MORETTIN, 2003, p. 489)
Veículo Comprimento (m) Motor (CV) Preço (US$)4,11 110 10.532,004,6 106 16.346,00
3,73 60 6.176,004,47 110 13.140,004,16 76 6.700,004,39 127 12.923,003,64 57 5.257,003,73 61 6.260,00
Chevrolet AstraChevrolet BlazerChevrolet CorsaChevrolet VectraFiat FiorinoFiat MareaFiat Uno MilleFiat Palio
36
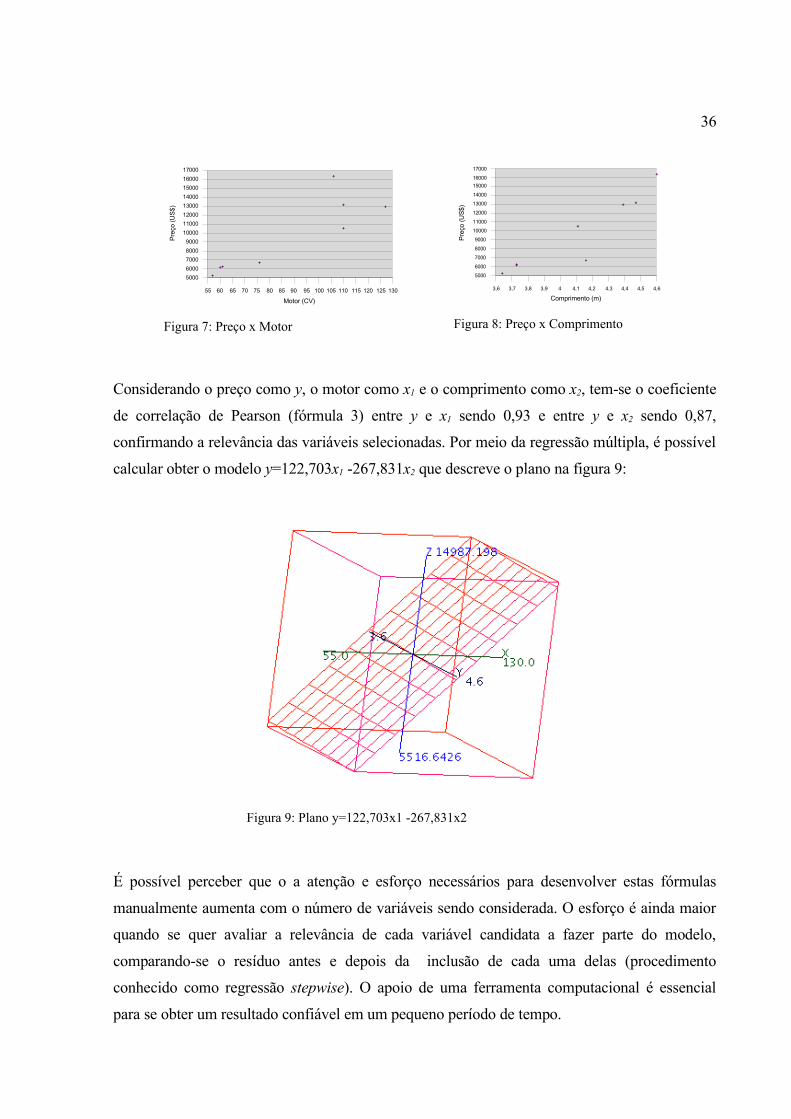
Considerando o preço como y, o motor como x1 e o comprimento como x2, tem-se o coeficiente
de correlação de Pearson (fórmula 3) entre y e x1 sendo 0,93 e entre y e x2 sendo 0,87,
confirmando a relevância das variáveis selecionadas. Por meio da regressão múltipla, é possível
calcular obter o modelo y=122,703x1 -267,831x2 que descreve o plano na figura 9:
É possível perceber que o a atenção e esforço necessários para desenvolver estas fórmulas
manualmente aumenta com o número de variáveis sendo considerada. O esforço é ainda maior
quando se quer avaliar a relevância de cada variável candidata a fazer parte do modelo,
comparando-se o resíduo antes e depois da inclusão de cada uma delas (procedimento
conhecido como regressão stepwise). O apoio de uma ferramenta computacional é essencial
para se obter um resultado confiável em um pequeno período de tempo.
Figura 7: Preço x Motor
55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130
5000
6000
7000
8000
9000
10000
11000
12000
13000
14000
15000
16000
17000
Motor (CV)
Pre
ço (
US
$)
Figura 8: Preço x Comprimento
3,6 3,7 3,8 3,9 4 4,1 4,2 4,3 4,4 4,5 4,6
5000
6000
7000
8000
9000
10000
11000
12000
13000
14000
15000
16000
17000
Comprimento (m)
Pre
ço (
US
$)
Figura 9: Plano y=122,703x1 -267,831x2

37
3.6 VALIDAÇÃO E CALIBRAÇÃO
Depois de formulado com base em dados históricos, um modelo matemático pode ser utilizado
para predição, aplicando-o durante o planejamento de um novo projeto para se obter
estimativas, como foi visto no item 2.4 deste trabalho, no que se refere a estimativa paramétrica.
Espera-se que, ao aplicar um modelo concebido para um cenário similar sejam obtidos
resultados similares, dentro de uma margem de erro conhecida.
Após a conclusão de um projeto, fazendo-se uma análise pos-mortem é possível aferir, dentre
outros elementos, quanto foi o erro médio obtido, comparando o previsto pelo modelo com o
realizado na execução das tarefas. Com isso, é feita a validação do modelo, permitindo verificar
se ele possui a precisão adequada ou se houve mudança na precisão em comparação a um
modelo utilizado anteriormente.
O modelo pode então ser calibrado utilizando os dados do novo projeto executado, repetindo
algumas das atividades desenvolvidas em sua criação. Dependendo das conclusões tiradas na
validação do modelo, pode-se decidir por apenas modificar algumas constantes ou até mesmo
acrescentar e remover variáveis. Portanto, a calibração pode ter custo semelhante ao empregado
para a criação do primeiro modelo.
Percebe-se que a criação e manutenção de um modelo paramétrico de estimativa envolve
processos complexos, que exigem esforço de profissionais com conhecimentos de estatística e
muita atenção ao grande volume de dados envolvidos. O desenvolvimento destas atividades
sem o apoio de ferramentas computacionais fica inviável na maioria dos cenários.
A solução proposta por este trabalho assume todos os processos mostrados na figura 4, exceto o
de coleta de dados, que fica a cargo da ferramenta na qual a solução for integrada. Desta forma,
toda a complexidade dos processos fica encapsulada na solução, que avalia continuamente os
dados disponíveis, indicando quando modelos mais precisos forem encontrados. A técnica
selecionada para realizar esta tarefa foi a de programação evolutiva, que tem sua origem nos
algoritmos genéticos, que serão discutidos na seção seguinte.
3.7 ALGORITMOS GENÉTICOS
As técnicas de inteligência artificial permitem desenvolver soluções mais flexíveis,
apresentando semelhanças com assuntos mais ligados à biologia como a inteligência humana e

38
outros aspectos da natureza. Estes assuntos serviram de base para a criação de tais técnicas, que
podem ser aplicadas virtualmente a qualquer tipo de problema. Reconhecimento de caracteres
por meio de redes neurais e seleção de produtos a serem apresentados a um visitante de um
portal de compras aplicando raciocínio baseado em casos em seu perfil são alguns exemplos.
Charles Darwin desenvolveu no século XIX a teoria da seleção natural. Segundo a teoria, os
indivíduos passam características a seus descendentes e os mais adaptados teriam maior chance
de sobrevivência (LADD, 1994, p. 2). No século seguinte, cientistas conseguiram isolar a
molécula de DNA (acrônimo do inglês deoxyribonucleic acid ou ácido desoxirribonucléico em
português) e, por meio de experimentos com raios X, provaram que os cromossomos, grandes
cadeias de DNA presentes no núcleo das células, eram responsáveis por transmitir as
características entre indivíduos e seus descendentes.
A técnica de algoritmos genéticos foi desenvolvida com base nestas descobertas, trazendo para
a computação muitos conceitos e vocabulário originalmente da biologia. Nesta técnica,
possíveis soluções de um problema são indivíduos dentro de uma população. Cada indivíduo
tem seu cromossomo, estrutura formada por uma cadeia de genes. Cada gene é responsável por
uma característica, uma variável do problema. Os alelos são os valores que um gene pode
assumir, e a informação contida em um cromossomo, denomina-se genótipo.
LADD (1994, p. 8) afirma que um algoritmo genético cria um conjunto de soluções que se
reproduzem com base no seu grau de adaptação a um determinado ambiente (normalmente
chamado de fitness), e que este processo segue os passos:
1. Cria-se uma população inicial de soluções aleatórias.
2. Dá-se um valor de fitness a cada indivíduo, avaliado frente ao problema.
3. Soluções com maior valor de fitness tem mais probabilidade de reproduzir e originar novas
soluções.
4. O novo conjunto de soluções substitui o anterior, completando uma geração e retornando ao
passo 2.
Esta sequência é uma simplificação da teoria da seleção natural. Agregando conhecimentos
sobre o DNA, a técnica inclui dois outros processos importantes que ocorrem durante a
reprodução, no passo 3, conhecidos como operadores genéticos: mutação e crossover. A
mutação consiste em se modificar o alelo de um gene selecionado outro aleatoriamente,

39
enquanto o crossover é a troca de material genético entre dois cromossomos.
Dependendo do problema a ser solucionado, pode-se especificar uma condição de parada, como
por exemplo atingir um tempo limite, um determinado valor de fitness ou encontrar a solução
ótima, o que normalmente é muito difícil dada a natureza estocástica dos algoritmos genéticos.
Durante a busca por uma solução, o algoritmo pode convergir em direção a um máximo local e
não ao máximo global, que seria a solução ótima do problema.
A complexidade da técnica reside em codificar o problema em um cromossomo, definir a
função fitness, que afeta a chance de reprodução dos indivíduos, definir o algoritmo a ser usado
para a seleção natural, definir o número e probabilidade de mutações, definir como ocorre o
crossover entre os cromossomos e definir uma condição de parada. Todas estas definições
dependem de tentativa e erro, não existindo uma regra geral que as oriente.
As únicas restrições que podem ser feitas são com relação à probabilidade de mutação e à
proporção de alelos trocados no crossover. Se houver muita mutação, perde-se a idéia de
evolução e as soluções encontradas se tornam aleatórias, dificilmente convergindo a algo útil.
Se não houver mutação, as gerações deixam rapidamente de apresentar novas soluções. Quanto
ao crossover, se for trocado 100% dos alelos entre dois cromossomos tem-se como resultado os
mesmos cromossomos, eliminando o objetivo do mesmo.
A função fitness é totalmente ligada ao problema que se pretende solucionar. O resultado desta
função é utilizado para realizar a seleção natural dos indivíduos de uma população para outra.
Existem alguns algoritmos conhecidos para realizar a seleção natural, mas estes também podem
sofrer adaptações de acordo com o problema. Porém, todos utilizam o fitness calculado para um
genótipo, avaliando os alelos que representam uma solução codificada no cromossomo.
A forma mais comum e estudada de codificação de problemas em algoritmos genéticos é a
codificação binária, onde cada posição de um vetor é um gene e os alelos possíveis para cada
um são 0 ou 1, representando se uma característica está presente ou não. A mutação de um gene
na codificação binária consiste em alternar um alelo dada uma probabilidade. O crossover é
feito seccionando-se dois cromossomos na mesma posição escolhida aleatoriamente e trocando
os alelos das duas metades.
Davis (apud MICHALEWICZ, 1996, p. 5) observou um franco descrédito por parte de outros
pesquisadores quanto a um sistema desenvolvido por ele ser um algoritmo genético, pois ele
não usou a codificação, mutação e crossover binários. Portanto, para alguns pesquisadores só

40
pode ser considerado algoritmo genético aquele que usa a codificação binária e os operadores
tradicionais. Porém, percebe-se que esta estrutura pode limitar as soluções para problemas
complexos, com estruturas dinâmicas, fazendo-se necessárias outras formas de codificação,
utilizando estruturas como vetores de inteiros, caracteres ou até mesmo árvores no lugar de
vetores.
Abstraindo-se da discussão se algo é ou não um algoritmo genético, MICHALEWICZ (1996)
optou por chamar de programação evolutiva os programas que compartilham das características
básicas dos algoritmos genéticos, independente de sua codificação, implementação de
operadores genéticos ou lógica de seleção natural. Devido às características do sistema proposto
por este trabalho, uma codificação binária não permite a flexibilidade necessária para a criação
e ajuste dos modelos de estimativa, portando seu projeto e implementação pode ser melhor
descrito como um exemplo de programação evolutiva.
3.8 PROGRAMAÇÃO EVOLUTIVA
Não é possível prever o número de variáveis que fará parte de um modelo, tampouco a
disposição e operadores matemáticos entre eles, logo uma estrutura de vetor dificilmente
poderia ser utilizada. Uma codificação em árvore por outro lado, permite uma representação
muito mais natural de modelos matemáticos e por isso foi selecionado para este trabalho.
Neste tipo de codificação, uma mutação não significa simplesmente inverter um bit em um
vetor. Os alelos passam a ser operações matemáticas, caracteres representando variáveis e
constantes numéricas. A ocorrência de uma mutação significa então selecionar aleatoriamente
um alelo no conjunto de alelos possíveis. Porém, isto pode levar a mutações fatais, tornando um
indivíduo inviável. Por exemplo, uma mutação em um genótipo “5 ^ 2” pode originar “5 ^ *”, o
que não representa um modelo matemático válido.
Figura 10: Árvore de (8-3)^2

41
Logo, alguma providência deve ser tomada no algoritmo para tratar esta situação. Como
alternativas, pode-se:
• desfazer e repetir o operador de mutação até que o genótipo seja válido;
• modificar o operador de mutação para que este avalie quais são os alelos válidos naquele
contexto ou para aquele gene específico e selecionar um aleatoriamente deste sub-conjunto;
• criar um operador genético específico para realizar “ajustes” a indivíduos que sofreram
mutações fatais, tornando-os válidos (no exemplo anterior, inserir constantes numéricas
aleatórias à esquerda ou à direita de operadores poderiam tornar o cromossomo “5 ^ *” em
“5 ^ 2 * 2”);
• retornar um fitness que impeça a reprodução dos indivíduos que sofreram mutações fatais,
para que a característica não se dissemine nas gerações seguintes.
Ainda sim, uma estrutura de tamanho fixo não permite a criação de modelos complexos, logo,
outra característica que pode ser usada para diferenciar algoritmos genéticos de programação
evolutiva é a possibilidade de estruturas dinâmicas, sem tamanho fixo, permitindo que um
indivíduo “5 ^ 2” dê origem a um “23 * ( X + 40 ) - 2 ^ 2”. Maiores detalhes sobre a
codificação, algoritmos e operadores genéticos adotados para a solução serão discutidos no
capítulo seguinte.

42
4 ESPECIFICAÇÃO DO SISTEMA PROPOSTO
4.1 INTRODUÇÃO
Para completar o escopo deste trabalho, neste capítulo será feita a especificação de sistema
aplicando técnicas de programação evolutiva com base na bibliografia estudada. Este sistema
foi especificado visando o desenvolvido sobre a plataforma Java, devido à grande
disponibilidade de componentes de software de código aberto na mesma que podem ser
utilizados para reduzir o tempo necessário para o desenvolvimento do protótipo.
O sistema foi especificado como um componente que poderá ser integrado a outros sistemas,
mas também terá a capacidade de funcionar de forma independente. Na forma de componente, a
comunicação com o sistema onde ele estará contido se dará por meio de interfaces Java com
métodos onde o sistema poderá fornecer os dados a serem analisados e o modelo matemático
atualmente sendo utilizado. Há outro método para que o sistema possa recuperar o melhor
modelo encontrado até o momento pelo componente.
Em sua forma independente, o sistema é instalado em um servidor de aplicação como o JBoss
Application Server (JBOSS) ou o GlassFish (SUN), e disponibilizará os mesmos métodos como
web services. Desta forma, qualquer aplicação com acesso ao servidor web onde o sistema
estiver ativo, poderá se integrar a ele.
4.2 ARQUITETURA GERAL
A representação dos modelos matemáticos que chegam e saem do sistema é feita usando um
padrão aberto, como o MathML (W3C) ou o OpenDocument Formula (OASIS). A utilização de
um destes padrões, baseados em XML (W3C), permite uma maior facilidade de integração com
outros sistemas. Com uma arquitetura modular, é possível adicionar suporte a outros formatos
caso necessário. Assim, o sistema tem a seguinte divisão:

43
O analisador de modelo poderá ter uma implementação para cada formato. Para o primeiro
protótipo, os modelos serão passados para o núcleo do sistema diretamente pela interface
especificada para tal. O núcleo do sistema é onde ocorrerá a análise dos dados e do modelo
atual. Os dados recebidos deverão ser das variáveis existentes no modelo inicial e, caso
disponível, variáveis que ainda não façam parte do modelo. Para atender aos objetivos deste
trabalho, apenas o núcleo do componente foi especificado, deixando o detalhamento de outros
componentes para trabalhos futuros.
4.3 EXPERIMENTOS COM JGAP
O núcleo do sistema foi projetado para que utilizasse a técnica de programação evolutiva,
descrita no capítulo anterior. Durante a pesquisa para o desenvolvimento deste trabalho, foi
encontrado um framework para a plataforma Java chamado JGAP. Conforme descrito em seu
endereço na internet, este framework fornece os mecanismos básicos para aplicar princípios
evolutivos a solução de problemas. Com mais de seis anos de desenvolvimento e atualmente em
sua versão 3.01, ele possui uma arquitetura bem definida, facilitando sua utilização. Outro
motivo que levou à escolha deste framework é o fato de ele possuir suporte a programação
evolutiva, incluindo classes e interfaces para tal fim.
Figura 11: Divisão do sistema

44
Com o código fonte, que pode ser encontrado a partir de seu endereço na internet, estão
inclusive classes de exemplo, que permitem o entendimento de cada uma de suas características
e funcionalidades. Com base na classe examples.gp.MathProblem, foram feitos testes para
verificar a validade da idéia proposta por este trabalho. A classe gera 20 valores aleatórios para
uma variável X e executa a função X 4X 3
X 2−X=Y armazenando em uma tabela o X de
entrada e o Y resultante. Depois disso, o JGAP cria uma população de 1000 genótipos montados
aleatoriamente e dá início à evolução por 800 gerações, originando genótipos capazes de dar
resultados cada vez mais próximos da função que deu origem à tabela.
Em sua implementação, o exemplo usa a técnica conhecida como elitismo. Ela serve para evitar
que o melhor indivíduo seja perdido, passando uma cópia do mesmo para as gerações seguintes
até que seja encontrado outro de melhor fitness. Durante a execução, são mostrados na tela
avisos a cada 25 gerações passadas e mensagens indicando quando um novo melhor indivíduo
foi encontrado.
A literatura apresenta mais comumente, problemas onde o maior valor de fitness representa o
indivíduo mais adaptado. No caso de uma função matemática que deve se aproximar de uma
massa de dados, um indivíduo mais adaptado pode ser interpretado como uma função de maior
precisão, ou menor erro. Logo, utilizando o erro como fitness, tem-se que um indivíduo com
fitness zero representa uma solução ótima para o problema, com base na massa de dados
recebida.
Como são utilizados números aleatórios, cada execução do programa apresenta um resultado
diferente. Para avaliar o comportamento desse resultado em diferentes execuções, foi criada
uma nova classe (MathProblem2) com algumas adaptações. A primeira delas foi adicionar um
laço de repetição para que se pudesse executar várias rodadas, indo da primeira à última
geração, em uma mesma execução, armazenando o melhor fitness encontrado em cada rodada
em um arquivo texto que pudesse depois ser aberto em uma planilha eletrônica, permitindo uma
análise mais simplificada dos dados.
A nova versão da classe também foi desenvolvida de forma a aceitar o número de rodadas e o
número de gerações em cada uma como parâmetros fornecidos por linha de comando. Devido
às restrições de se tomar um tempo considerável para completar cada rodada e ter, no momento
em que o teste foi realizado, apenas uma CPU disponível para o seu desenvolvimento e
execução, o número de gerações foi reduzido de 800 para 500. Realizando o teste com 180
rodadas usando os algoritmos originais da classe MathProblem, os resultados deram origem ao

45
seguinte gráfico após 115 minutos de processamento:
Este gráfico mostra a distribuição dos valores divididos em 10 classes, sendo estas intervalos
iguais entre os valores de erro mínimo de 14,3 e o máximo de 53,52. Calculou-se também o
valor de média como sendo 30,37. Este teste demonstra que a técnica de programação evolutiva
pode ser utilizada para se criar funções que descrevam uma determinada massa de dados.
Contudo, é necessário obter-se uma função com erro aceitável para o problema que foi
modelado.
No caso proposto por este trabalho, imaginando um projeto que teve todas as suas tarefas
modeladas em dias, um erro médio de 30,37 pode levar ao encerramento do projeto com um
mês de atraso. Com o objetivo de fazer com que houvesse uma convergência mais rápida dos
indivíduos a cada geração em direção a um melhor fitness e utilizando-se da arquitetura
modular do JGAP, foi criada uma nova implementação da interface INaturalGPSelector, que
determina os métodos que uma classe deve conter para que seja usada pelo framework para
realizar o processo de seleção natural.
A classe foi chamada de ScalingSelector por ter sido pensada inicialmente para implementar a
técnica de fitness scaling. Esta técnica consiste em aplicar uma escala aos valores de fitness para
aumentar a probabilidade de que os indivíduos mais adaptados sejam selecionados para
reprodução. Esta técnica foi selecionada pois, durante depuração do código em execução, foi
Figura 12: Frequência dos resultados em 180 rodadas
18,22
22,15
26,07
29,99
33,91
37,83
41,76
45,68
49,6
53,52
0
2,5
5
7,5
10
12,5
15
17,5
20
22,5
25
27,5
30
Frequência por Intervalo
Original

46
visto que havia uma evolução rápida nas 50 primeiras gerações (descendo de fitness 600 para
100 numa sucessão de 6 indivíduos por exemplo).
Depois, no mesmo teste, a velocidade com que eram mostrados os novos melhores indivíduos
caía, mostrando apenas 3 em 250 gerações, chegando a um fitness de 30. Por fim, as últimas
gerações dificilmente produziam algum indivíduo melhor. Isso ocorre pois, com o passar das
gerações, diminuía a diferença entre o fitness dos indivíduos da população a tal ponto que
provocava uma alta probabilidade de se selecionar um indivíduo com o pior genótipo. Por
exemplo, numa primeira geração em uma população de 3 indivíduos temos os fitness 1.000,
10.000 e 1.000.000 mas depois de centenas de gerações temos indivíduos com 100, 110 e 111.
Antes de aplicar a escala ao fitness de todos os indivíduos, elevando seus valores ao quadrado,
foi necessário multiplica-los por -1 e somar a eles o maior valor encontrado anteriormente.
Desta forma, o melhor indivíduo passa a ser o de maior valor de fitness e, após a aplicação da
escala, a diferença entre os indivíduos quanto à probabilidade de seleção para reprodução é
aumentada. Outra consequência é que neste momento, o fitness zero passa a indicar um
indivíduo sem chances de ser selecionado para reprodução. Ao iniciar os testes com a classe,
foram encontrados dois casos especiais de valor de fitness decorrentes da plataforma Java e do
modo no qual o JGAP foi projetado e implementado.
O primeiro caso é com relação a genótipos que representam funções que não podem ser
solucionadas no conjunto dos números reais. Na plataforma Java, ao se tentar calcular a raiz de
um número negativo, ou elevar um número negativo a um expoente fracionário, o resultado
retornado é a constante NaN, que na plataforma é conhecido como “not a number”, indicando
que o resultado “não é um número”. Um resultado NaN não é considerado maior, menor ou
igual a qualquer outro valor, incluindo outro NaN. Por isso, para o modelo proposto, um
indivíduo que retorne NaN pode ser considerado inválido e a lógica da classe implementada
trata estes casos colocando-os com fitness zero, retirando suas chances de serem escolhidos para
reprodução.
Nas populações encontradas nos testes, também existiam genótipos retornando infinito como
valor de fitness. Lembrando que originalmente este valor indica o erro da função em
comparação à massa de dados, estes indivíduos de erro infinito também foram considerados
inválidos. Em conjunto com esse tratamento, e ainda com o objetivo de acelerar a convergência
no decorrer das gerações, a técnica de threshold foi agregada ao algoritmo implementado na
classe, fazendo com que todos os indivíduos com erro maior que 5000 não tivessem chance de

47
reprodução. Este valor foi arbitrado com base em observações feitas durante a depuração dos
testes.
Um valor maior de threshold deixaria que muitos indivíduos com genótipos prejudiciais
tivessem chance de reprodução, enquanto um valor muito reduzido poderia impedir a
participação de um indivíduo que contivesse uma parte extremamente benéfica de ser utilizada
em uma operação de crossover. O valor arbitrado fez com que em média, 300 indivíduos da
população de 1000 tivessem chances de reprodução. A determinação de um valor ideal tomaria
um tempo maior do que o disponível para a conclusão deste trabalho, e o valor atual foi
suficiente para as conclusões tiradas a seguir.
Com a nova classe, verificou-se que a média foi reduzida de 30,37 para 0,0097. Outro resultado
que deve ser destacado é a presença de 19 rodadas que chegaram à solução ótima, ou seja, em
menos de 500 gerações foi descoberta a função que deu origem aos dados, provando a
aplicabilidade da abordagem. O tempo de processamento subiu de 115 para 16183 minutos,
porém o algoritmo foi implementado sem fazer modificações no JGAP que pudessem aumentar
seu desempenho, logo, existe margem para que ajustes sejam feitos no algoritmo ou no próprio
JGAP, mas isto não afeta o objetivo deste trabalho, podendo ser realizado em trabalhos futuros.
Estes experimentos foram necessários tanto para provar o conceito quanto para adquirir o
Figura 13: Frequência dos resultados para 180 rodadas
usando a classe ScalingSelector
0,04
0,07
0,11
0,15
0,18
0,22
0,26
0,3 0,33
0,37
0
20
40
60
80
100
120
140
160
180
Frequência por Intervalo
ScalingSelector

48
conhecimento prático para se criar uma especificação coerente do sistema proposto. No sub-
capítulo seguinte serão apresentados os diagramas de classe desenvolvidos, explicações sobre o
objetivo das mesmas e sobre a organização de pacotes.
4.4 CLASSES E PACOTES
Como foi dito no sub-capítulo 4.1, a especificação apresentada será do núcleo do componente,
onde os conceitos pesquisados serão aplicados. Devido a isso, dentro de um pacote chamado
“nucleo”, se encontram os pacotes “model”, “control” e “jgap”. O pacote “model” representa o
modelo de dados do sistema. Nele estão as interfaces ITarefa, IVariavel e IRegistro. Estas
interfaces permitem que o componente possa ser integrado a qualquer outro sistema, recebendo
os dados necessários do mesmo, que devem estar organizados em instâncias de implementações
destas interfaces.
Figura 14: Classes e sub-pacotes do pacote "nucleo"

49
Visto que diferentes sistemas ter seus modelos de dados projetados da forma que seus analistas
acharem conveniente, a utilização de interfaces permite a flexibilidade para que sejam criadas
classes que integrem o sistema proposto como um componente, sem a necessidade de alterações
no código existente.
A interface ITarefa define o conjunto mínimo de atributos que uma tarefa deve ter para ser
utilizada com o sistema, tendo uma implementação padrão chamada TarefaImpl. Os atributos
são o nome da tarefa, que funciona como um identificador único, e o esforço realizado na
execução da tarefa. Como não é possível modelar todos os outros atributos que podem estar
associados a uma entidade chamada tarefa nos diferentes sistemas existentes no mercado, existe
uma composição com a interface IRegistro.
A interface IRegistro permite adicionar todas as outras variáveis relacionadas à tarefa,
agregando uma coleção da interface IVariavel, e para facilitar a integração, já existirão as
classes RegistroImpl e VariavelImpl implementando as interfaces. Por exemplo, em um sistema
de gestão de projetos pode haver uma entidade tarefa possuindo, entre outros, os atributos
“dificuldade” e “equipe”. Supondo ainda que este sistema tenha “equipe” como entidade com
um atributo “experiência”, para que as tarefas desse sistema e os atributos mencionados sejam
passados para o componente proposto nesse trabalho, poderá ser criada uma instância da classe
TarefaImpl para cada tarefa, associada a uma instância de RegistroImpl contendo uma
VariavelImpl representando o atributo “dificuldade” e outra para o “experiência”.
A interface IVariavel, como já pode ter sido deduzido com o exemplo anterior e pelo seu nome,
define uma variável que foi medida no projeto e que pode afetar a tarefa de alguma forma. Ela
não necessariamente é um atributo da entidade que representa uma tarefa no sistema onde o
componente está sendo integrado, mas pode vir de outra entidade, como a “equipe” do exemplo
anterior, ou até mesmo direto de um campo em um banco de dados, já que o sistema não
necessita de ter sido projetado usando orientação a objetos.
O pacote “control” contém as classes de controle do componente, que serão chamadas pelo
sistema externo. São elas FuncaoDelegate, VariavelDelegate, RegistroDelegate, StatusDelegate
e BaseControl. A maioria delas recebeu o sufixo Delegate em referência ao padrão de projeto
BusinessDelegate. “A função do BusinessDelegate é proporcionar controle e proteção para o
serviço de negócios” (ALUR; CRUPI; MALKS, 2002, p. 224).
A classe FuncaoDelegate permite ao sistema informar qual modelo matemático é utilizado no

50
momento. Este modelo deverá vir como um genótipo utilizando as classes fornecidas pelo
JGAP para representação de um modelo matemático, para que possa ser inserido na primeira
geração. A VariavelDelegate permite a adição, modificação e remoção das variáveis que serão
avaliadas pelo componente. O RegistroDelegate permite adicionar modificar ou remover tarefas
e seus registros associados.
Como o componente deverá fazer seu processamento paralelamente ao sistema onde ele se
encontra utilizando multithreading, todo momento que um novo modelo de melhor precisão for
encontrado, ele informará o sistema por meio da interface ICallbackControl, também contida no
pacote “control”. Para que o sistema possa consultar o estado do componente e qual o último
melhor modelo encontrado, existe a classe StatusDelegate. Os estados que podem ser retornados
são os seguintes:
O estado “Normalizando Registros” indica que o componente está verificando se todos os
registros possuem variáveis em comum para que possam ser consideradas durante o estado
“Analisando”. Caso uma variável possua valor apenas em uma tarefa e esteja sem valor ou
simplesmente não exista no registro de outras tarefas, esta variável poderá ser descartada do
registro ou a tarefa e seu registro serão descartados da base, dependendo de configuração que
Figura 15: Estados possíveis do componente

51
poderá ser feita em um arquivo texto externo ao componente. No estado “Analisando”, o
componente está realizando os processos de programação evolutiva, buscando um modelo
otimizado. Por fim, o estado pode se tornar “Encerrado” caso ocorra uma das condições de
parada indicadas no diagrama.
A classe BaseControl tem como objetivos representar uma base de dados, onde será feito o
controle da persistência das tarefas, registros, variáveis e modelos encontrados, e fornecer os
mesmos para as outras partes do componente. Para um primeiro protótipo, esta classe poderia
armazenar as informações apenas em memória, utilizando as estruturas de dados já existentes na
API de coleções da plataforma Java, como as classes HashTable ou Vector.
O último pacote, chamado “jgap” contém as classes desenvolvidas para que o framework JGAP
seja utilizado pelo componente para realizar o seu objetivo final, que é utilizar programação
evolutiva para otimizar modelos de estimativa de tarefas de software. As classes deste pacote
são VariavelGA, VariavelFitnessFunction, ModeloGP, ModeloFitnessFunction e
ScalingSelector.
A classe ScalingSelector é a já apresentada no item 4.3 deste trabalho. O ModeloGP é a classe
que utilizará o ScalingSelector em conjunto com a parte de programação evolutiva do JGAP,
para evoluir populações de modelos matemáticos com um conjunto de variáveis selecionado
pela classe VariavelGA. Os modelos serão codificados em árvore e será utilizada a classe
ModeloFitnessFunction para isolar a lógica já descrita de utilizar o erro do indivíduo como
fitness.
Finalmente, a classe VariavelGA utiliza a parte do JGAP que implementa algoritmos genéticos
da forma tradicional, com codificação binária, para selecionar quais das variáveis disponíveis
serão utilizadas pelo ModeloGP. Com isso surge a oportunidade do componente criar modelos
mais otimizados, incluindo variáveis que tragam melhoria ou removendo variáveis irrelevantes
e, desta forma, atingindo o objetivo deste trabalho. As funcionalidades descritas até o momento
podem ser divididas nos seguintes casos de uso:
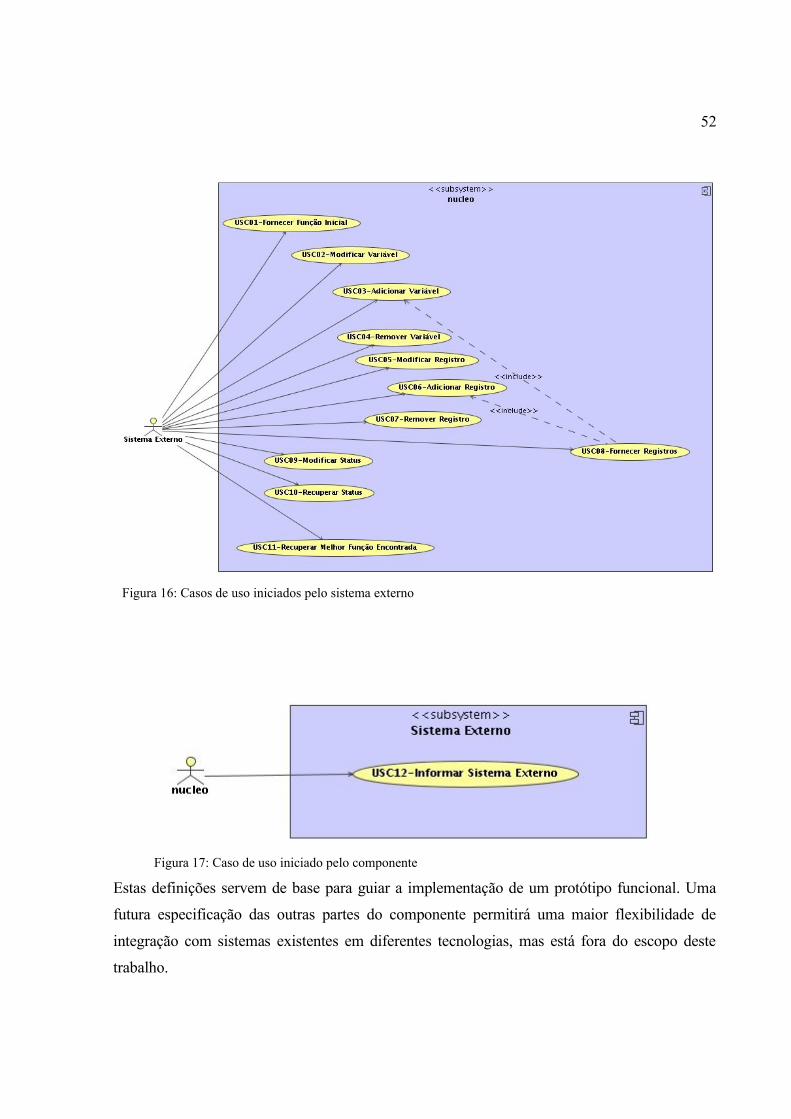
52
Estas definições servem de base para guiar a implementação de um protótipo funcional. Uma
futura especificação das outras partes do componente permitirá uma maior flexibilidade de
integração com sistemas existentes em diferentes tecnologias, mas está fora do escopo deste
trabalho.
Figura 16: Casos de uso iniciados pelo sistema externo
Figura 17: Caso de uso iniciado pelo componente

53
5 CONCLUSÕES E PERSPECTIVAS FUTURAS
5.1 CONCLUSÕES
Os objetivos específicos definidos no item 1.3.2 deste trabalho foram atingidos, visto que foi
mostrado no capítulo 3 o processo para criação de modelos matemáticos, atendendo ao objetivo
específico “a”. Depois foi feita a especificação de um sistema capaz de realizar ajustes a
modelos matemáticos (objetivo “b”). E, por fim, implementado um protótipo seguindo esta
especificação, que foi validado contra uma massa de dados simulados, contemplando os
objetivos restantes.
Foram apresentados os conceitos e dificuldades que atuam desde a criação até a aplicação de
modelos de estimativa de esforço para tarefas de software. Com base nas técnicas de algoritmos
genéticos e programação evolutiva, o modelo especificado é capaz não apenas de otimizar
funções matemáticas, mas também de criar funções originais que descrevem com mais precisão
o comportamento da massa de dados histórica recebida.
O componente foi especificado de forma altamente modular, permitindo sua futura extensão
para que possa ser integrado a outros sistemas. A especificação, feita com foco na plataforma
Java, se concentrou principalmente no núcleo do componente, onde se encontram as classes que
desempenham o objetivo do modelo proposto.
Com a implementação do modelo proposto, cada organização poderá utilizar uma função criada
especificamente para sua realidade, capaz de fornecer estimativas muito mais precisas. Funções
que, sem a solução proposta, poderiam levar anos para serem ajustadas com base em dados
históricos acumulados de vários projetos e necessitando de um grande esforço de especialistas
de diversas áreas como estatística e gestão.

54
5.2 PERSPECTIVAS FUTURAS
Com os experimentos realizados, foi possível observar que muitas técnicas podem ser
combinadas para se chegar a resultados cada vez mais precisos, porém, à medida que os
algoritmos se tornam mais complexos, cresce a necessidade de otimizá-los, podendo ser
necessário modificar até mesmo o framework que foi utilizado contendo os mecanismos de
algoritmos genéticos e programação evolutiva.
Outra forma de melhorar o desempenho do sistema seria combinar técnicas de processamento
distribuído, permitindo que vários equipamentos dividam a carga e, conseqüentemente, reduzam
o tempo necessário para se atingir um determinado valor de erro, ou para que se possa aplicar
algoritmos ainda mais complexos que levem a resultados mais precisos.
A especificação do sistema pode ser mais detalhada para fornecer uma arquitetura que facilite
ainda mais a integração a outros sistemas independente de suas plataformas tecnológicas. Com
isso poderão ser criados servidores que forneçam o serviço de otimização de estimativas. No
momento em que houverem organizações diferentes utilizando o serviço, e caso estas estejam
dispostas a disponibilizar seus dados, estes podem ser analisados, comparando os diferentes
modelos criados em busca de informações que possam melhorar ainda mais o modelo proposto
por este trabalho.
Por fim, as técnicas aqui apresentadas podem ser transportadas para outros cenários, como por
exemplo, criar uma função capaz de estimar com maior precisão o possível crescimento do
produto interno bruto de um país dada uma determinada massa de dados históricos de
indicadores econômicos do país e mundiais. Ou para estimar quantas toneladas de uma
determinada cultura serão produzidas dado o histórico de variáveis climáticas e quantidade de
insumos.

55
6 REFERÊNCIAS BIBLIOGRÁFICAS
AGUIAR, Mauricio. Estimando os projetos com COCOMO II.Rio de Janeiro: tiMÉTRICAS. 2004. Disponível em: <http://www.metricas.com.br/Downloads/Estimando_Projetos_COCOMO_II.pdf> Acesso em: 20/05/2006
ALUR, Deepak; CRUPI, John; MALKS, Dan. Core J2EETM patterns: as melhores práticas e estratégias de design. Rio de Janeiro: Campus, 2002. ISBN 85-352-1004-0
BUSSAB, Wilton de O.; MORETTIN, Pedro A. Estatística básica. 5. ed. São Paulo: Saraiva. 2003. ISBN 85-02-03497-9
Computational Science Education Project. Introduction to Monte Carlo Methods Disponível em: <http://www.phy.ornl.gov/csep/CSEP/MC/NODE1.html#SECTION00010000000000000000> Acesso em: 17/05/2006
COSTA NETO, Pedro L. Estatística. São Paulo: Edgard Blücher. 1977. ISBN 85-212-0097-8
DEVNANI-CHULANI, Sunita et al. Calibration approach and results of the COCOMO II post-architecture model. 1998. Disponível em: <http://sunset.usc.edu/Research_Group/Sunita/down/ispadoc.pdf> Acesso em: 04/06/2006
DURKIN, John. Expert systems: design and development. New York : Macmillan Publishing Company, 1994. ISBN 0-02-330970-9
DŽEROSKI, Sašo; TODOROVSKI, Ljupčo. Discovering Dynamics: From Inductive Logic Programming to Machine Discovery. Journal of Intelligent Information Systems, Boston, p. 89-108, 1994.
HUGHES, Bob; COTTERELL, Mike. Software Project Management. New York: McGraw Hill, 1999.
International Society of Parametric Analysts. Parametric estimating handbook. 2003. Disponível em: <http://www.ispa-cost.org/PEIWeb/Third_edition/Handbook/Finalized.zip> Acesso em: 02/06/2006
JBOSS. Jboss Aplication Server. Disponível em: <http://www.jboss.org/products/jbossas> Acesso em: 18/06/2006
LADD, Scott. Genetic Algorithms in C++. New York: M&T Books, 1995. ISBN 1-55851-459-7.
LOPES, João. Normalização. Disponível em: <http://bsel.ist.utl.pt/2004/PortalQuimiometria/Contents/procdados/node7.html> Acesso em 06/06/2006
Machine Learning. Disponível em: <http://en.wikipedia.org/wiki/Machine_learning> Acesso

56
em: 05/04/2006
MICHALEWICZ, Zbigniew. Genetic algorithms + data structures = evolution programs. New York : Springer, 1996. ISBN 3-540-58090-5.
MICROSOFT. Microsoft Office Online: Project. Disponível em: <http://office.microsoft.com/pt-br/FX010857951046.aspx> Acesso em: 14/06/2006
Monte Carlo Method. Disponível em: <http://en.wikipedia.org/wiki/Monte_Carlo_method> Acesso em: 10/05/2006
OASIS. OpenDocument – Formula. Disponível em: <http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=office-formula> Acesso em: 18/06/2006
PETERS, James F.; PEDRYCZ, Witold. Engenharia de Software: Teoria e Prática. Rio de Janeiro : Campus, 2001. ISBN 85-352-0746-5.
PRESSMAN, Roger S. Engenharia de Software. São Paulo : Makron Books, 1995.
Project Management Institute. A Guide to the Project Management Body of Knowledge (PMBOK® Guide). 3. ed. Newton Square: Project Management Institute. 2004. ISBN 193069945X.
Project Management Institute. Practice Standard for WBS. Newton Square : Project Management Institute, Inc. 2001. ISBN 1-880410-81-8.
RIBEIRO JÚNIOR, Paulo J. Correlação. Disponível em: <http://www.est.ufpr.br/~paulojus/CE003/ce003/node8.html> Acesso em: 06/06/2006
SENSYS Consultoria e Sistemas. ODYSSEA PMS. Disponível em: <http://www.sensys.com.br/index.php?option=com_content&task=view&id=14&Itemid=28> Acesso em: 14/06/2006
SUN. GlassFish. Disponível em: <https://glassfish.dev.java.net/> Acesso em: 18/06/2006
The CHAOS Report (1994). Disponível em: <http://www.standishgroup.com/sample_research/chaos_1994_1.php> Acesso em: 05/04/2006
TODOROVSKI, Ljupčo. Equation Discovery. Maio. 2001. Disponível em: <http://www-ai.ijs.si/~ljupco/ed/> Acesso em: 05/04/2006
W3C. World Wide Web Consortium. Disponível em: <http://www.w3.org/> Acesso em: 18/06/2006
WRIGHT, James Terence Coulter; GIOVINAZZO, Renata Alves. Delphi – Uma ferramenta de apoio ao planejamento prospectivo. In: Caderno de Pesquisas em Administração. São Paulo. v.01. n°.12. 2000. Disponível em: <http://www.iea.usp.br/iea/futuro/delphi.pdf> Acesso em: 02/06/2006
WU, Liming. The Comparison of the Software Cost Estimating Methods. Disponível em: <http://www.computing.dcu.ie/~renaat/ca421/LWu1.html> Acesso em: 10/05/2006





























