Embed Size (px)
Citation preview

1
PREVISIBILIDADE NOS MERCADOS DE AÇÕES: ESTUDO DOS PAÍSES EMERGENTES APLICANDO REDES NEURAIS
Autoria: Everton Anger Cavalheiro, Kelmara Mendes Vieira, Paulo Sérgio Ceretta,
Carlos Eduardo Moreira Tavares
RESUMO O interesse pelo estudo da previsibilidade do mercado de capitais é quase tão antigo quanto o próprio mercado. Nesse sentido, a aplicação de modelos estatísticos tem se mostrado cada vez mais presentes nos trabalhos empíricos nacionais e internacionais. Recentemente o interesse pela utilização de técnicas associadas à grande área da Inteligência Artificial (AI) tem crescido, havendo um especial enfoque a aplicação de Redes Neurais Artificiais (RNA´s) na previsão destes mercados. As Redes Neurais Artificiais (RNA´s) são um conjunto de técnicas que tentam simular, em meio computacional, o funcionamento do cérebro humano de uma maneira simplificada, contudo seus algoritmos são muitas vezes “caixas pretas” que impedem o entendimento de como são processadas as informações durante o cálculo da rede. No contexto estocástico da análise de dados, encontram-se as redes Group Method of Data Handling (GMDH). As primeiras investigações foram realizadas por Alexey Ivakhnenko em 1968 e seguidas por Shankar, em 1972. As Redes Neurais Polinomais GMDH são reconhecidas como um método para solucionar problemas de estilo, identificação, predição de curto prazo de processos aleatórios e reconhecimento de padrões. Os conteúdos destes algoritmos se desenvolveram com o desejo de identificar relações lineares e não lineares entre inputs e outputs, gerando uma estrutura que tende a ótima, a partir de um processo sucessivo de várias manipulações nos dados, mediante a incorporação de novas camadas. Apesar da combinação de redes neurais e conceitos estocásticos, o que facilita sua interpretação, raros estudos nacionais e internacionais testam a eficiência das Redes Neurais Polinomiais GMDH na previsão de séries temporais financeiras. Desta forma, o objetivo deste estudo foi testar a eficiência desta ferramenta na busca de não aleatoriedade nos retornos do mercado de capitais dos países pertencentes ao BRIC´s (Brasil, Rússia, Índia e China), através do uso de redes neurais artificiais (RNA´s), polinomiais do tipo Group Method of Data Handling, em uma aproximação indutiva do retorno logaritmo mensal dos índices mais representativos destes países. Inicialmente, foi realizada uma revisão teórica sobre o tema de redes neurais e, durante o método, procurou-se a desmistificação do conceito de redes neurais, prejudicada pelo efeito “caixa preta” que impede o conhecimento do processamento e dos métodos de decisão de uma rede neural, bem como seus efeitos. Os resultados das redes demonstram uma maior, e satisfatória, previsibilidade para o mercado acionário brasileiro e menor, assim como insatisfatória, previsibilidade do retorno mensal dos demais países pesquisados.

2
1. INTRODUÇÃO
O uso de técnicas pertencentes à grande área de inteligência artificial (IA) para a previsão de séries temporais financeiras tem se mostrado cada vez mais presente no meio acadêmico, neste sentido há um especial destaque para o uso da técnica de Redes Neurais Artificiais (RNAs). O uso de tais técnicas é representativo, pois conforme cita Boose (1994, p. 30), a área de inteligência artificial é um campo de estudo multidisciplinar e interdisciplinar, que se apóia no conhecimento e evolução de outras áreas do conhecimento.
O Group Method of Data Handling (GMDH) é um uma derivação do campo das Redes Neurais Artificiais. Esse modelo é caracterizado pela sua habilidade de selecionar a combinação de variáveis exógenas mais significativas para predizer uma variável endógena, a partir da manipulação dos dados para encontrar o melhor ajuste.
Ferson (2007, p. 1), destaca que o interesse pela previsão do comportamento dos preços das ações é provavelmente tão antigo quanto os próprios mercados, bem como a literatura sobre o assunto é vasta e significativa. Neste sentido, o uso de redes neurais em modelos de previsão tem se mostrado cada vez mais presente nas modelagens empíricas nacionais e internacionais. Contudo, raros estudos têm sido desenvolvidos através de modelagens polinomiais, especialmente as do tipo GMDH. Desta forma, a pergunta de pesquisa deste artigo é: “o uso de redes polinomiais GMDH é suficientemente capaz de demonstrar não aleatoriedade no retorno mensal dos índices dos países pertencentes ao BRIC´s?”.
Para o desenvolvimento deste trabalho optou-se pela utilização de uma rede neural supervisionada, com algoritmo de seleção para frente. Dentre os modelos disponíveis, o método escolhido foi método GMDH, devido a sua característica híbrida de redes neurais e métodos estatísticos tradicionais, conforme cita Valença (2005, p. 24). A rede escolhida foi a rede multilayer pela sua possibilidade de testar uma abrangente combinação de variáveis, bem como sua inferência estatística. O cálculo de cada neurônio foi realizado através do método dos mínimos quadrados ordinários.
Kobayashi-Hillary (2007, p. 1), destaca que BRIC ou BRIC’s são termos utilizados para referir-se à combinação do Brasil, Rússia, Índia e China. O consenso geral é que o termo foi inicialmente utilizado em um relatório do banco de investimento Goldman Sachs, sendo tal sigla creditada à Jim O'Neill, economista do próprio banco. Os principais pontos destacados por Wilson e Purushothaman (2003), é que as economias dos BRICS estão em rápido desenvolvimento e que até o ano 2050 estes países representarão mais de 40% da população mundial e suas economias unidas, que somam atualmente mais de 14.951 trilhões de dólares em PIB, serão agentes representativos para a economia mundial.
Kobayashi-Hillary (2007, p. 2) comenta que o estudo do BRIC´s é significativo, pois tais economias iniciam um domínio global nos setores de serviços e industrial, os quais se pode destacar a China e a Índia. Já o Brasil e a Rússia são fontes abundantes de matérias-primas (como soja ou minério de ferro, por exemplo) e em recursos energéticos (petróleo e gás natural). A combinação destas nações poderia formar um grupo sem precedentes na economia mundial, sendo capaz de ser um rival à altura do restante do mundo atual.
Em 2004, a Goldman Sachs divulgou um relatório de acompanhamento do estudo original intitulado de “The BRICs and Global Markets: Crude, Cars and Capital”, analisando como o crescimento destas quatro nações impactaria nos mercados em geral. A Goldman Sachs afirmou que entre 2005 e 2015 mais de 800 milhões de pessoas, nestes países, terão atravessado um limiar renda anual de US $ 3.000. Em 2025, calcula-se que cerca de nada menos que 200 milhões de pessoas, destes países, terão rendimentos anuais acima $ 15.000, renda ainda baixa quando comparado aos estimados US $ 35.000 dos países pertencentes ao G6 (EUA, Japão, Alemanha, Inglaterra, França e Itália). Este crescimento, da renda per

3
capita, terá impacto positivo no consumo de produtos, no comércio interno e na riqueza dos países, influenciando diretamente no mercado de capitais.
O objetivo geral do trabalho é comparar a previsibilidade dos mercados de capitais dos principais países emergentes, através do uso de redes neurais GMDH para séries de dados do retorno mensal dos índices dos países pertencentes ao BRIC´s. Secundariamente, procura-se desvelar o conceito de redes neurais polinomiais, pouco difundidas no Brasil, e desmitificar o conceito de “caixa preta” que prejudica o entendimento de como são tomadas as decisões durante o cálculo de uma rede neural.
A seguir, após esta breve introdução, é realizada uma revisão de literatura sobre Inteligência Artificial e Redes Neurais. A próxima seção destaca os aspectos metodológicos da pesquisa. Na seqüência são apresentados e discutidos os resultados e por fim, são realizadas as considerações finais.
2. INTELIGÊNCIA ARTIFICIAL E REDES NEURAIS ARTIFICIAIS
A palavra “inteligência” vem do latim inter (entre) e legere (escolher). De acordo com Fernandes (2005, p. 2), inteligência significa aquilo que permite ao ser humano escolher entre uma coisa e outra. Inteligência é a habilidade de realizar de forma eficiente uma determinada tarefa. A palavra “artificial” vem do latim artificiale, significa algo não natural, isto é, produzido pelo homem. Portanto, Inteligência Artificial (IA) é um tipo de inteligência produzida pelo homem para dotar as máquinas de algum tipo de habilidade que simula a inteligência humana.
Simons (1988, p. 37) apontou duas abordagens para o desenvolvimento da IA: a abordagem cognitiva e a abordagem conexionista. A abordagem cognitiva, também denominada de descendente ou simbolista, dá ênfase aos processos cognitivos, ou seja, a forma como o ser humano raciocina. Objetiva encontrar uma explicação para comportamentos inteligentes baseados em aspectos psicológicos e processos algorítmicos. Os pioneiros desta corrente de estudo foram John Mc Carthy, Marvin Minsky, Newell e Simon. A abordagem conexionista, também denominada de biológica ou ascendente, dá ênfase no modelo de funcionamento do cérebro, dos neurônios e das conexões neurais. Os pioneiros desta corrente de pesquisa foram McCulloch, Pitts, Heldo, rosenblatt Widrow.
Em 1943 surgiu a representação e formalização matemática dos neurônios artificiais, que fez surgir os primeiros modelos de redes neurais artificiais. A corrente conexionista sofreu grande impacto quando os cientistas Marvin Minsky e Seymour Papert publicaram, em 1969, o livro chamado de Perceptons, no qual criticavam e sustentavam que os modelos das redes neurais não tinham sustentação matemática suficiente que lhes fosse possível atribuir alguma confiabilidade. Apesar das pesquisas nesta área não terem parado, foi apenas na década de 1980 que o físico e biólogo John Hopfield conseguiu recuperar a credibilidade da utilização de redes neurais.
As Redes Neurais Artificiais (RNAs) são um conjunto de técnicas que tentam simular, em meio computacional, o funcionamento do cérebro humano de uma maneira simplificada. Elas são capazes de reconhecer padrões, extrair regularidades e detectar relações subjacentes em um conjunto de dados aparentemente desconexos. Além disso, elas apresentam capacidade de lidar com dados ruidosos, incompletos ou imprecisos. Sua capacidade de prever sistemas não lineares torna a sua aplicação no mercado financeiro muito objetiva. Para Haykin (2001, p. 28), rede neural pode ser definida como um processador maciço e paralelamente distribuído, constituído de unidades de processamento simples, que têm a propensão natural para armazenar conhecimento experimental e torná-lo disponível para uso. A rede neural assemelha-se ao cérebro, em dois aspectos: (1) o conhecimento é adquirido pela rede a partir

4
de seu ambiente através de um processo de aprendizagem; (2) forças de conexão entre neurônios (pesos sinápticos) são utilizadas para armazenar o conhecimento adquirido.
Já para Lippmann (1987, p. 6), as RNAs são sistemas físicos que podem adquirir, armazenar e utilizar conhecimentos experimentais, adquirindo uma boa performance, devido à sua interconexão entre os nós da rede. Basicamente há dois tipos de Redes Neurais Artificiais: feedforward e feedback. Nas redes feedforward, os sinais se propagam em apenas uma direção a partir da unidade de entrada, passando pelas camadas intermediárias até a saída. Nas redes feedback, os sinais de entrada podem propagar da saída de qualquer neurônio para a entrada em um outro neurônio.
As RNAs apresentam duas fases distintas em sua metodologia que são denominadas de aprendizagem e teste. Na fase de aprendizagem, são apresentados estímulos de entrada, denominados padrões de treinamento que farão com que a rede aprenda com os dados. Na fase de teste é demonstrada a capacidade de generalização da rede, pois seus resultados deverão ser significativos após seus pesos terem sido ajustados na fase anterior.
Fernandes (2005, p. 62) cita que a propriedade mais importante das Redes Neurais Artificiais é a habilidade de “aprender de seu ambiente” e, com isso melhorar o seu desempenho. Segundo Ackley, Hinton e Sejnowski (1985, p. 153), a habilidade de aprender ocorre através de um processo interativo de ajustes aplicado aos pesos, o treinamento. O aprendizado ocorre quando a rede neural atinge uma solução generalizada para uma classe de problemas. Outro fator importante é a maneira pela qual uma rede neural se relaciona com o ambiente. Nesse sentido Fausett (1995, p. 280) cita que existem três formas de treinamento: a supervisionada, a não supervisionada e a híbrida.
2.1. Redes Neurais Supervisionadas
Segundo a autora de Ré (2000, p. 30), redes neurais supervisionadas caracterizam-se pela utilização de um conjunto de treinamento composto por dados de entrada previamente classificados. O ajuste dos pesos ocorre através da apresentação dos estímulos de entrada, disponíveis no conjunto de treinamento, para o cálculo da resposta utilizando como parâmetros os valores dos pesos atuais. Faz-se, então, uma comparação entre a resposta oferecida pela rede atual e a desejada aos estímulos e, com base na similaridade entre as duas respostas, os pesos são ajustados. Esse procedimento perdura até que ocorra a classificação mais adequada possível. Esse tipo de rede fornece uma resposta mais razoável baseada em uma variedade de padrões de aprendizado, isso ocorre porque em uma rede supervisionada é possível o usuário mostrar à rede como fazer predições e classificações ou como tomar decisões, fornecendo a ela um grande número de classificações corretas ou predições das quais pode-se aprender.
2.2. Redes Neurais Não Supervisionadas
De acordo com Fausett (1995, p. 165), as redes neurais não supervisionadas aprendem sem que exista um conjunto de resposta esperadas como referência para as saídas. Os pesos são ajustados à medida que a rede vai sendo renovada de padrões de entrada selecionados como representativos de cada classe, isto é, de acordo com sua similaridade aos padrões de entrada apresentados à rede. Normalmente, a distância Euclidiana entre ambos é calculada, e o neurônio representando o peso mais próximo de vetor de entrada é considerado como o vencedor tendo, então, seus pesos ajustados. A taxa de aprendizado deve diminuir com o tempo de treinamento.
2.3. Redes Neurais Híbridas
De acordo com Towell e Shavlik (1994, p. 120), os métodos híbridos usam conhecimento teórico de um domínio e um conjunto de exemplos para desenvolver um

5
método de exemplos classificados corretamente, não vistos durante o treinamento. O desafio do sistema de aprendizado híbrido está em usar a informação proporcionada por uma fonte de dados para compensar a perda de informação de outra. Dessa forma, um sistema híbrido deve aprender mais eficientemente do que um sistema que usa somente uma fonte de informação. Knowledge-Based Artificial Neural Networks (KBANN) é um sistema híbrido, construído sobre técnicas de aprendizado conexionistas, que mapeia problemas específicos representados em lógica proposicional em rede e, então, refina os conhecimentos reformulados utilizando backpropagation, sendo que, conforme cita Kovács (2006, p. 83), o método backpropagation caracteriza-se pelo fato de se retroceder o erro do modelo, a fim de melhorar o desempenho da rede.
2.4. Redes Polinomiais GMDH No contexto estocástico da análise de dados, encontra-se a rede GMDH. As primeiras investigações foram realizadas por Alexey Ivakhnenko em 1968 e seguidas por Shankar, em 1972, o qual apresentou o algoritmo do mesmo nome como um método que permitia descobrir de forma sucessiva um sistema complexo de relações a partir de simples operações matemáticas. Trata-se de um método para solucionar problemas de estilo, identificação, predição de curto prazo de processos aleatórios e reconhecimento de padrões. O conteúdo deste algoritmo se desenvolveu como veículo para identificar relações lineares e não lineares entre inputs e outputs, gerando uma estrutura que tende a ótima, a partir de um processo sucessivo de várias manipulações dos dados, mediante a incorporação de novas camadas.
De acordo com Schneider e Steiner (2006, p. 20), os algoritmos da rede GMDH apresentam-se mais poderosos que os modelos estatísticos tradicionais devido aos seus procedimentos auto-organizáveis. Estes algoritmos extraem informação dos dados existentes utilizando-se da complexidade obtida através de modelos matemáticos flexíveis, ademais quebram o conceito de caixa preta, característicos das redes neurais.
O modelo GMDH pode ser analisado como uma combinação de redes neurais e conceitos estocásticos, conforme cita Valença (2005, p. 24). As redes GMDH são implementadas com funções de ativação nos neurônios das camadas escondidas e um critério de seleção para decidir quantas camadas serão construídas. Na formulação original, cada neurônio da camada escondida, a ser construída, recebe duas entradas e tem como função de ativação um polinômio de segundo grau. Portanto, através da combinação de cada par desses neurônios de entrada, será gerada uma função de saída polinomial cuja complexidade será função do numero de camadas, isto é, se existir duas camadas, tem-se uma função polinomial de quarto grau, para três camadas, uma função polinomial de oitavo grau. Desta forma, tais redes são chamadas de redes polinomiais, pois o modelo resultante é uma função polinomial.
2.5. Algoritmo GMDH
Algoritmo é um processo de cálculo em que se estipulam, com generalidade e sem restrições, regras formais para a obtenção do resultado ou da solução do problema. Nas redes GMDH são desenvolvidos, entre outros, o proposto por Ivakhnenko (1971, p. 364), em que os neurônios gerados nas camadas intermediárias são funções polinomiais de segundo grau compostos de duas variáveis. A equação [1] exemplifica o caso de uma saída (y) gerada a partir de três entradas (x1, x2 e x3).
.2
393822726325314213
22110 1
xxxxxxxxxxxxy [1]
Em [1], y é a saída estimada, 1x , 2x e 3x as variáveis de entrada, i seus pesos e ξ o
erro. Valença (2005, p. 26), destaca que cada camada construída terá uma quantidade de neurônios que depende do número de variáveis de entrada. Supondo que o número de

6
variáveis de entrada é n, o número de neurônios na primeira camada será de nC2 . Esses neurônios terão seu desempenho avaliado através de uma função objetivo com limiar que decidirá quais os neurônios deverão continuar e quais neurônios deverão parar. Este processo é então repetido até que reste apenas um neurônio escondido, ou então quando as camadas adicionais não provocarem nenhuma melhoria.
Valença (2005, p. 27) salienta que um importante aspecto a ser considerado no algoritmo GMDH é o uso de um critério externo de seleção dos melhores neurônios em cada camada construída. Vários são os critérios de seleção que podem ser utilizados para decidir sobre a qualidade de cada modelo testado, de tal forma que o autor detalha alguns deles: i) regularidade, que utiliza o erro quadrático médio sobre o conjunto de validação; ii) critério de mínima tendência, que tem por objetivo minimizar a diferença entre os valores calculados para os conjuntos de dados A e B; iii) critério de predição, sendo indicado quando o conjunto de dados é suficientemente grande para ser dividido em três conjuntos (A, B e C) e; iv) critério de balanço de variáveis, sendo este mais indicado para previsões de longo prazo.
2.6. Algoritmo Combinatorial
O aspecto básico do algoritmo combinatorial é a sua estrutura em uma única camada e, de acordo do com Valença (2005, p. 29), funções de soma são geradas para todas as combinações de variáveis de entrada de forma similar a uma busca polinomial. Esse algoritmo se torna eficiente pela utilização de uma técnica recursiva dos mínimos quadrados, uma vez que os modelos gerados são lineares em relação aos parâmetros.
Para um melhor entendimento, supondo-se uma função com três variáveis de entrada ( 1x , 2x e 3x ), e uma variável de saída (y), haverá uma busca polinomial do melhor modelo até
o segundo grau, devendo se começar pelo modelo mais simples ( 0y ) até o mais
complexo, semelhante ao demonstrado na Equação [1]. A seguir, demonstra-se o incremento gradual da complexidade para este algoritmo contendo uma variável:
0y , [2]
11xy , [3]
22 1xy , [4]
…
239xy . [5]
Como demonstrado nas Equações [2, 3, 4 e 5], existirão 10110 C neurônios, sendo os
pesos determinados pelo método dos mínimos quadrados, com um conjunto de treino. Na sequência, os erros obtidos por cada equação são comparados a um limiar estabelecido para cada função objetivo (complemento externo), utilizando-se um conjunto de dados teste. Finalmente, as unidades selecionadas, ditas sobreviventes serão consideradas aptas para terem sua complexidade evoluída.
Num segundo momento, todos os neurônios com duas variáveis são determinados, totalizando 452
10 C equações parciais.
110 xy , [6]
220 1xy , [7]
...
23938 xxy . [8]

7
Os neurônios serão construídos até que no último passo obtenha 10
10C = 1 combinações, que é o
polinômio completo demonstrado na Equação [1]. É importante notar que, dependendo se o número de entradas for grande, irá ocorrer uma explosão de combinações, pois o número de modelos que devem ser testados aumenta rapidamente com o número de variáveis de entrada, como demonstra: M=2n-1. No exemplo de três variáveis de entrada ( 1x , 2x e 3x ) acrescida de
uma constante, que se desdobraram em 10 variáveis. 2.7. Rede Multilayer
De acordo com Valença (2005, p. 32), a rede multilayer é uma estrutura paralela, constituída por um polinômio de segundo grau como função de ativação. O número de neurônios gerados, em cada camada escondida, depende do número de variáveis de entrada. Neste modelo, cada duas variáveis são combinadas para gerar um neurônio escondido, por exemplo: ix e jx são passados para a unidade k que pode ser construída por uma função como
demonstrado em [9]. 2
43210 ijii xxxxxyj . [9]
Os pesos são estimados utilizando-se um conjunto de treinamento e um dado valor de limiar, um critério de erro é usado para avaliar o ajuste destes neurônios gerados. Quando se tem n variáveis de entrada, a primeira camada gerará nC2 , isto é, n(n-1)/2 neurônios parciais. Desses, escolhem-se os que são superiores a um dado valor de limiar estabelecido, que passarão a compor a próxima camada. Este processo é repetido para sucessivas camadas até que o mínimo global para um dado critério de erro seja encontrado. Os critérios utilizados para finalizar o treinamento, citados por Valença (2005, p. 27), são: i) a camada de saída possuí apenas um neurônio, ii) a camada adicionada não fornece ganhos significativos em relação à anterior.
3. ASPECTOS METODOLÓGICOS
Neste estudo foram utilizadas como variáveis o retorno mensal, na forma logarítmica, dos índices Ibovespa (Brasil), RTSI Index (Rússia), Bombay Stock Exchange (Índia) e Hang Seng Index (China), na forma da primeira diferença em t-1 t-2 e t-3, isto é, r t-1, r t-2 e r t-3
que formarão 1x , 2x e 3x , respectivamente. A escolha dos índice deu-se pelo fato de serem
considerados o mais importantes indicadores do desempenho médio das cotações do mercado de ações dos mercados emergentes pertencentes aos BRIC´s. Foram utilizados, na fase de treinamento, os retornos mensais de janeiro de 2000 até fevereiro de 2007, perfazendo 86 observações, a exceção do RSTI Index (Rússia) o qual foram utilizados 33 observações referente aos retornos mensais de julho de 2004 até fevereiro de 2007. Na fase de teste foram simuladas 28 novas observações, ou 25% do tempo de treinamento, entre março de 2007 até junho de 2009.
Tsay (2002, p. 2), cita que a maioria dos estudos de séries temporais financeiras utiliza os retornos, em vez dos preços dos ativos em questão, neste sentido o autor comenta que existem duas razões principais para o uso dos retornos em estudos financeiros: em primeiro lugar, para a média dos investidores, o retorno dos ativos é uma medida adequada para a comparação entre oportunidade de investimentos e, em segundo lugar, as séries de retorno são mais fáceis de lidar do que uma série de preços, porque os primeiros apresentam propriedades estatísticas mais atraentes. Dentre tais propriedades se pode citar a ausência de tendenciosidade comum em séries de dados não estacionados. Tsay (2002, p. 11) comenta que

8
a utilização de log-retornos em estudos financeiros é indicada pela hipótese de que os retornos dos ativos são independente e identicamente distribuídos (i.i.d.) com média e variância 2 .
Com capitalização contínua, o preço de um título é dado por rtt ePP 1 (uma vez que
se está utilizando apenas um período, ou seja, 1t ), onde r é a taxa de retorno; Pt é o preço da ação na data t e Pt-1 é o preço da ação na data t-1. A expressão pode ser reescrita na forma pt/pt-1 = er. Extraindo-se o logaritmo natural dos dois lados obtêm-se r = ln(pt/pt-1).
De acordo com Soares, Rostagno e Soares (2002, p. 8), ao extrair o logaritmo natural da razão 1/ tt PP , a curva representativa da distribuição de frequência torna-se menos
assimétrica. Isto ocorre porque o logaritmo natural de números situados entre zero e um é negativo, e o logaritmo natural de números maiores que um é positivo. Desta forma, quando tP
for menor que 1tP , o logaritmo natural de 1/ tt PP tende a −∞ , e se tP for maior que 1tP , o
logaritmo tende a ∞. Como existem infinitos resultados possíveis para a razão 1/ tt PP , assim
como infinitos números maiores que um, a curva relativa à distribuição de frequência dos retornos, seria uma distribuição mais simétrica, tendendo à centrar em zero.
Inicialmente, às variáveis puras, 1x , 2x e 3x serão acrescidas de uma constante. Na
sequência, estas variáveis formarão a uma nova combinação multiplicando-se duas a duas, formando as novas variáveis: 2
33222323121
21 ,,,,,,,,,1
1xxxxxxxxxxxx .
3.1. Cálculo Da Primeira Camada Da Rede
Para iniciar o cálculo da primeira camada, definindo o número de neurônios a serem testados, será utilizado o conceito do algoritmo combinatorial (COMBI). Haverá o desenvolvimento de combinações entre as dez variáveis, citadas anteriormente. Na equação [10], é apresentado o modelo de cálculo do total de combinações que serão testadas na camada, onde N é o número de neurônios que formará a primeira camada da rede.
N = 1
10C + 2
10C + 3
10C + 4
10C + 5
10C + 6
10C + 7
10C + 8
10C + 9
10C + 10
10C . [10]
Posteriormente, haverá uma busca polinomial, semelhante ao método stepwise. A diferença básica está no critério de decisão que será adotado no modelo. O critério de decisão a ser adotado será o Predict Squared Error (PSE), pois este além de levar em consideração o erro médio quadrático (MSE), leva em consideração a variância do erro e uma penalidade para os modelos mais complexos o que pode evitar o problema de overfitting. O método de cálculo do PSE é definido pro [11].
.min/22
ˆ2
2
1
np
n
yyPSE
N
ii
[11]
Em [11], 2 é a variância do erro; p é o número de parâmetros; n o número de
observações no arquivo de treinamento da rede; iy são os valores tabelados da variável
endógena e iy são os valores calculados de acordo com o modelo.
Serão selecionados os três melhores neurônios nesta camada segundo o critério PSE. Como o PSE apresenta uma relação direta entre o erro médio quadrático e a variância do erro, quanto menor o valor calculado em cada neurônio, maior será o ajustamento da variável estimada ( iy ) com a variável observada ( iy ).

9
3.2. Cálculo Nas Camadas Subsequentes Os três neurônios selecionados formarão as novas variáveis de entrada para a próxima
camada, isto é, w1, w2 e w3. Haverá um novo desdobramento das variáveis e após haverá uma busca polinomial, entre as próximas combinações de variáveis, selecionando os três melhores neurônios a fim de diminuir o critério de decisão PSE. Esse processo de treinamento e seleção será então repetido para cada nova camada.
3.3. Critério Para A Finalização Do Treinamento E Análise Da Previsão Conforme destaca Valença (2005, p. 27), os critérios utilizados para finalizar o treinamento são: a camada adicionada não oferece ganhos significativos em relação à anterior ou o valor do MSE para o conjunto de treinamento é superior ao MSE da camada anterior.
Nesse caso, o modelo ótimo estará na camada anterior. Para avaliar o sucesso das previsões, conforme citam Ivakhnenko, Ivakhnenko e Müller (1993, p. 420), será utilizado a Equação [12]. Os resultados inferiores, ou iguais, à 0,5 serão considerados como adequados, os que estiverem entre 0,5 < 2 < 0,8 serão considerados satisfatórios, os maiores que 1 serão
considerados como desinformação sendo as modelagens consideradas como falhas.
.minˆ
2
1
2
12
N
i
N
iii
yy
yy
[12]
Conforme destacam Ivakhnenko e Ivakhnenko (1995, p. 532), com essa abordagem, cada modelagem a ser realizada em redes GMDH usará dois critérios. Em um primeiro momento, haverá uma exaustiva pesquisa entre todos os neurônios candidatos, conforme as combinações citadas no subitem 3.2, e um pequeno número de modelos cuja estrutura está perto de ótima são selecionados, neste caso será adotado o PSE, conforme é demonstrado na equação [11]. Então, apenas o neurônio selecionado como ótimo na última camada será testado em sua conformidade com um especial critério discriminatório, sendo, neste artigo, demonstrado na equação [12].
3.5. Análise Dos Erros E Comparação Entre Mercados
A fim de se comparar a previsibilidade dos mercados, serão utilizados o coeficiente de determinação amostral R2, pois este procura medir a proporção ou percentual de variação de y previsto pelos modelos, conforme demonstrado na equação [13].
.ˆ
1 2
1
2
12
N
i
N
i
yy
yR
[13]
Outros dois indicadores serão utilizados: o erro quadrático médio (MSE) e o erro absoluto médio (MAE), que são demonstrados nas equações [14] e [15].
.ˆ1 2
1 N
ii yyN
MSE
[14]
.ˆ1 22
1 ii
Nyy
NMAE
[15]
Adicionalmente, serão analisados os coeficientes de desigualdade de Theil, também chamado de U. O numerador de U é o MSE, mas a escala do denominador é tal que U estará sempre entre 0 e 1. Se U=0 há um ajustamento perfeito da previsão com o valor observado. Se U=1, o desempenho da previsão do modelo é o pior possível. O coeficiente de desigualdade de Theil é demonstrado na equação [16].

10
.
ˆ11
ˆ1
2
1
2
1
2
1
N
i
N
i
N
ii
yN
yN
yyNU
[16]
Além do coeficiente de desigualdade de Theil, é possível se determinar as proporções UM e US que são denominadas respectivamente de proporção da tendenciosidade e proporção da variância que permitem decompor o erro em suas fontes características.
Conforme Pindyck e Rubinfield (2004, p. 244), a proporção de tendenciosidade (UM) é uma indicação do erro sistemático, pois mede quanto os valores médios das séries simulada e efetiva se desviam uns dos outros. Qualquer que seja o valor do coeficiente de desigualdade (U), espera-se que UM seja próximo de 0. Um valor elevado de UM (acima de 0,1 ou 0,2) seria preocupante porque indicaria a presença de tendenciosidade sistemática, de modo que seria necessário rever os modelos. Nas equações [17] e [18] são demonstradas a proporção de tendenciosidade e proporção de variância, respectivamente.
.
/12
2
A
t
S
t
AS
M
yyT
yyU
[17]
./1
2
2
A
t
S
t
ASS
yyTU
[18]
Em [17 e 18] S
y ,A
y , S e A são as médias e os desvios padrão dos valores
estimados e observados, respectivamente. A proporção de variância US, conforme citam Pindyck e Rubinfield (2004, p. 244), indica a capacidade de replicar o grau de variabilidade na variável que interessa. Se US é alto, significa que a série efetiva flutuou muito enquanto a série simulada mostrou pouca flutuação, ou vice-versa. Isso também seria preocupante, e poderia levar à revisão dos modelos.
3.5. Volatilidade dos mercados A fim de se verificar possíveis diferenças de volatilidade entre os retornos mensais de
cada um dos mercados, utilizou-se a Equação [19].
.
1
1
1
2
N
XXN
[19]
Em [19] é a volatilidade mensal dos mercados, N o número de meses, X o retorno
mensal de cada ativo e
X a média dos retornos de cada índice.
4. RESULTADOS Todos os cálculos foram realizados em planilha eletrônica Excel®
. O método dos mínimos quadrados foi calculado através de álgebra matricial. Foram calculadas até 9 camadas nas redes para cada uma das 28 previsões (somente t+1) dos índices dos países
11
pertencentes ao BRIC´s e um total de 513.546 neurônios foram testados, sendo 132.990 testados na previsão do Bovespa, 151.404 neurônios na previsão do índice da China, 122.760 neurônios na previsão do índice Bombay Stock Exchange (Índia) e 106.392 neurônios testados na previsão dos 28 meses do RTSI Index, da Rússia.
4.1. Resultados Da Fase De Teste
Na Tabela 1 são demonstrados os resultados das previsões para t+1 do índice RTSI, da Rússia.
Tabela 1 – Resultados das previsões para o índice RTSI Camada R2 Correlação Sinais MSE MAE U UM US Ivakhnenko
Camada 1 0,00001 -0,00239 0,42857 0,03939 0,14804 0,14267 0,00348 0,00079 1,66156
Camada 2 0,01450 -0,12043 0,42857 0,04505 0,15664 0,16049 0,00308 0,00059 1,90050
Camada 3 0,04212 0,20524 0,46429 0,03135 0,13599 0,11931 0,05074 0,00193 1,32251
Camada 4 0,01924 0,13871 0,50000 0,03465 0,13994 0,12706 0,02899 0,00112 1,46145
Camada 5 0,07085 0,26618 0,53571 0,02725 0,12206 0,10463 0,00486 0,00171 1,14947
Camada 6 0,07524 0,27429 0,53571 0,02828 0,12807 0,10415 0,00202 0,00100 1,19309
Camada 7 0,07527 0,27434 0,53571 0,02843 0,12772 0,10402 0,00106 0,00090 1,19926
Camada 8 0,07579 0,27531 0,53571 0,02828 0,12683 0,10379 0,00115 0,00095 1,19280
Camada 9 0,07407 0,27216 0,53571 0,02984 0,12967 0,10554 0,00011 0,00049 1,25877
Analisando-se os resultados do indicador de sucesso da previsão para o índice russo
obtido pelo critério de Ivakhnenko, demonstrado na Equação [12], todos os resultados foram considerados insatisfatórios e, de acordo com este critério, os resultados são considerados como desinformação, resultado corroborado pela baixo R2, bem como baixa correlação e baixo percentual de acerto de sinais. Apesar dos demais indicadores terem melhorado ao longo das camadas houve ineficiência na previsão deste índice.
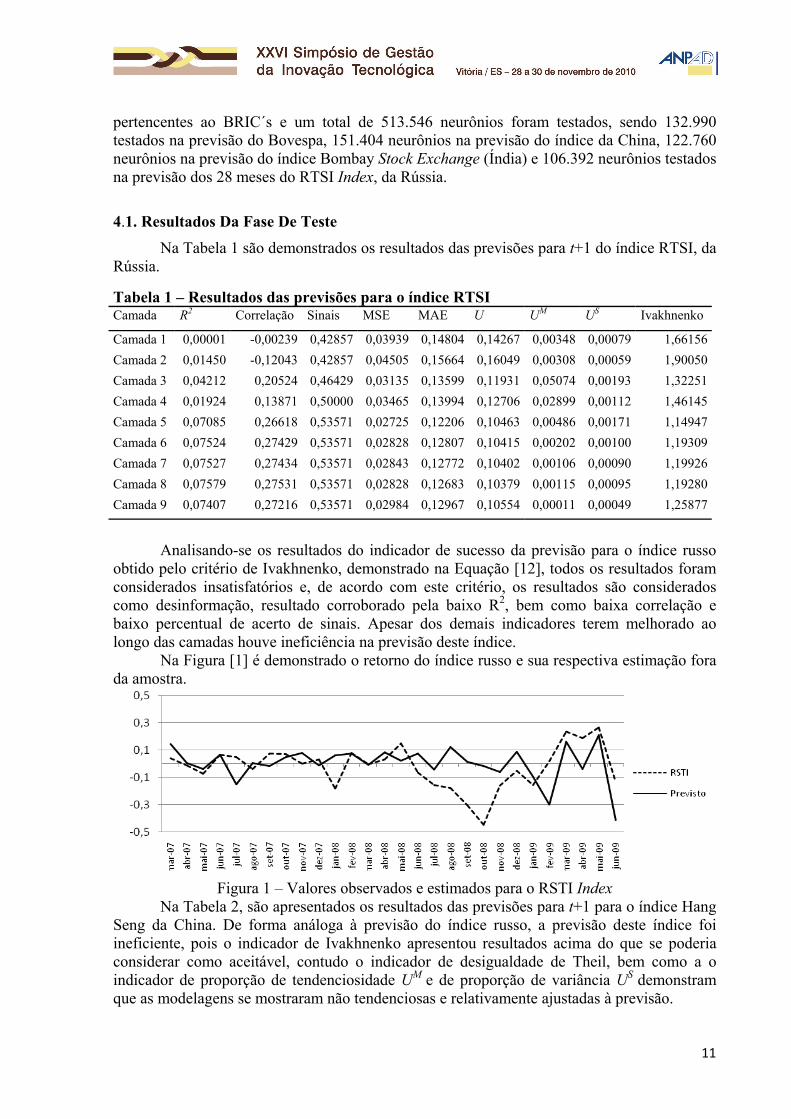
Na Figura [1] é demonstrado o retorno do índice russo e sua respectiva estimação fora da amostra.
Figura 1 – Valores observados e estimados para o RSTI Index
Na Tabela 2, são apresentados os resultados das previsões para t+1 para o índice Hang Seng da China. De forma análoga à previsão do índice russo, a previsão deste índice foi ineficiente, pois o indicador de Ivakhnenko apresentou resultados acima do que se poderia considerar como aceitável, contudo o indicador de desigualdade de Theil, bem como a o indicador de proporção de tendenciosidade UM e de proporção de variância US demonstram que as modelagens se mostraram não tendenciosas e relativamente ajustadas à previsão.

12
Tabela 2 – Resultados das previsões para o índice Hang Seng Camada R2 Correlação Sinais MSE MAE U UM US Ivakhnenko
Camada 1 0,00004 0,00644 0,50000 0,01158 0,08899 0,06696 0,01377 0,00110 1,23438
Camada 2 0,01054 0,10267 0,57143 0,01106 0,08539 0,06411 0,00647 0,00109 1,17892
Camada 3 0,00044 -0,02102 0,53571 0,01483 0,09737 0,08471 0,00786 0,00096 1,58051
Camada 4 0,00032 -0,01801 0,57143 0,01554 0,10125 0,08975 0,00728 0,00106 1,65578
Camada 5 0,00036 0,01908 0,57143 0,01496 0,09893 0,08695 0,00687 0,00111 1,59418
Camada 6 0,00054 0,02316 0,57143 0,01487 0,09834 0,08569 0,01070 0,00105 1,58488
Camada 7 0,00593 0,07700 0,60714 0,01423 0,09667 0,07843 0,01201 0,00070 1,51705
Camada 8 0,00600 0,07743 0,60714 0,01423 0,09660 0,07840 0,01185 0,00070 1,51644
Camada 9 0,00598 0,07734 0,60714 0,01423 0,09653 0,07838 0,01244 0,00070 1,51640
O ponto significativo destes resultados é a evolução dos indicadores ao longo das
camadas da rede, indicando que houve um ganho significativo na capacidade de previsão da rede na medida em que se foram adicionadas mais camadas na modelagem (respeitando os critérios citados nos sub-itens 3.1. e 3.2. deste artigo). Na Figura [2] é demonstrado o retorno do índice chinês e sua respectiva estimativa na fase de teste.
Figura 2 – Valores observados e estimados para o índice Hang Seng
Quando analisado a Figura [1] e a Figura [2], evidencia-se que a rede teve dificuldade para encontrar padrões para a previsão dos índices russo (RSTI Index) e chinês (Hang Seng Index), o que corrobora com o baixo valor para os índices R2 e do critério de Ivakhnenko.
Na Tabela 3, são demonstrados os resultados das previsões para t+1 para o índice Bombay Stock Exchange da Índia, o plot é realizado na Figura 3.
Tabela 3 – Resultados das previsões para o índice Bombay Stock Exchange Camada R2 Correlação Sinais MSE MAE U UM US Ivakhnenko
Camada 1 0,01360 -0,11662 0,57143 0,01744 0,10004 0,10082 0,01377 0,00110 1,46488
Camada 2 0,00013 0,01134 0,50000 0,01570 0,09868 0,09098 0,00647 0,00109 1,31848
Camada 3 0,01326 0,11515 0,60714 0,01454 0,09755 0,08306 0,00786 0,00096 1,22137
Camada 4 0,01221 0,11051 0,60714 0,01440 0,09672 0,08320 0,00728 0,00106 1,20964
Camada 5 0,02124 0,14576 0,64286 0,01382 0,09365 0,08032 0,00687 0,00111 1,16052
Camada 6 0,01576 0,12554 0,64286 0,01423 0,09536 0,08201 0,01070 0,00105 1,19550
Camada 7 0,00102 0,03201 0,60714 0,01654 0,10293 0,09113 0,01201 0,00070 1,38933
Camada 8 0,00080 0,02836 0,60714 0,01660 0,10299 0,09145 0,01185 0,00070 1,39402
Camada 9 0,00119 0,03449 0,60714 0,01651 0,10270 0,09092 0,01244 0,00070 1,38640

13
Analisando-se o resultado da Tabela 3 é possível se perceber que os valores da previsão do índice indiano não foram significativos, conforme critério de Ivakhnenko, embora o critério de desigualdade de Theil, bem como a o indicador de proporção de tendenciosidade UM e de proporção de variância US demonstram que as modelagens se mostraram não tendenciosas e relativamente ajustadas à previsão.
Figura 3 – Valores observados e estimados para o índice Bombay Stock Exchange
Na Tabela 4 são destacados os resultados para a previsão do índice IBOVESPA, o plot é realizado na Figura 4. Tabela 4 – Resultados das previsões para o IBOVESPA Camada R2 Correlação Sinais MSE MAE U UM US Ivakhnenko
Camada 1 0,23387 0,48360 0,67857 0,00655 0,06372 0,05763 0,02761 0,00237 0,83473Camada 2 0,25718 0,50713 0,67857 0,00628 0,06408 0,05463 0,01530 0,00217 0,79962Camada 3 0,27278 0,52228 0,67857 0,00618 0,06389 0,05348 0,01501 0,00210 0,78708Camada 4 0,17357 0,41661 0,67857 0,00661 0,06656 0,05679 0,01096 0,00200 0,84191Camada 5 0,21512 0,46381 0,67857 0,00632 0,06516 0,05329 0,00932 0,00178 0,80477Camada 6 0,40904 0,63956 0,67857 0,00480 0,06087 0,03604 0,00182 0,00084 0,61138Camada 7 0,41157 0,64153 0,67857 0,00478 0,06064 0,03588 0,00184 0,00084 0,60915Camada 8 0,41069 0,64085 0,67857 0,00479 0,06075 0,03595 0,00170 0,00084 0,61001Camada 9 0,41069 0,64085 0,67857 0,00479 0,06075 0,03595 0,00170 0,00084 0,61001
Os resultados do teste de Ivakhnenko demonstram uma evolução significativa à
medida que foram incrementadas novas camadas na rede. Todos os resultados, deste critério foram considerados satisfatórios, fato que pode ser evidenciado pela evolução de todos os demais indicadores, destacando-se o R2 que evoluiu de 0,23 para a primeira camada para 0,41 na última camada da rede. A correlação entre os valores observados e os valores previstos evoluiu durante a criação da rede, corroborando com a eficiência da rede em prever encontrar não aleatoriedade nos dados do retorno mensal do índice, neste período.
Figura 4 – Valores observados e estimados para o IBOVESPA

14
Na Tabela 5, é demonstrado o resumo dos resultados das modelagens para a previsão de cada um dos índices, bem como sua volatilidade mensal.
Tabela 5 – Volatilidade mensal dos retornos e resultados das previsões dos índices País Volatilidade R2 Correlação Sinais MSE MAE U UM US Ivakhnenko
Brasil 0,1052 0,4107 0,6409 0,6786 0,0048 0,0608 0,0360 0,0017 0,0008 0,6100Rússia 0,1374 0,0758 0,2753 0,5357 0,0283 0,1268 0,1038 0,0012 0,0010 1,1928Índia 0,1100 0,0012 0,0345 0,6071 0,0165 0,1027 0,0909 0,0124 0,0007 1,3864China 0,1305 0,0060 0,0773 0,6071 0,0142 0,0965 0,0784 0,0124 0,0007 1,5164
Na Tabela 5, evidencia-se que o método foi mais eficaz para encontrar não-aleatoriedade para o índice brasileiro (IBOVESPA), fato que pode ser parcialmente explicado pela menor volatilidade do retorno mensal deste índice, quando comparado com os demais países. A Figura 5 evidencia a evolução, em pontos dos índices analisados.
Figura 5 – Evolução, em pontos, dos índices brasileiro, russo, indiano e chinês
Na Figura 5 é possível evidenciar que o índice brasileiro apresentou maior crescimento em pontuação, quando comparado com os demais índices dos países pertencentes ao BRIC´s. Esta tendência altista é destacada a partir de janeiro de 2003, período com coincide com a posse do novo governo federal e com o decréscimo do risco país, assim como uma maior abertura do mercado brasileiro e de um crescimento representativo da participação de pessoas físicas investindo no mercado acionário brasileiro. Este cenário, de tendência altista mais proeminente, e de menor volatilidade dos dados brasileiros, poderia ajudar a explicar parcialmente a eficiência do método em encontrar não-aleatoriedade nos dados da série temporal.
5. CONSIDERAÇÕES FINAIS
As redes neurais, em especial as redes auto-organizáveis, apresentam uma capacidade de encontrar padrões em dados ruidosos e imprecisos e aparentemente desconexos. Essa característica pode ser utilizada em pesquisas financeiras, em especial de séries temporais. Neste sentido, a tentativa de utilização do método Group Method of Data Handling GMDH apresentou resultados significativos na previsão do índice IBOVESPA e não significativos para os demais índices, conforme critério específico para a avaliação deste tipo de rede neural. A maior previsibilidade do índice brasileiro pode ser, parcialmente, explicada pela maior tendência altista do mercado brasileiro, quando comparado com os demais índices dos países pertencentes ao BRIC´s. O deslocamento da pontuação do mercado acionário brasileiro, a partir de janeiro de 2003, é contemporâneo a mudanças políticas e macro-econômicas do país,

15
destacando-se a posse de um novo governo federal, do decréscimo vertiginoso do risco país e de uma maior abertura econômica, bem como uma nova postura da bolsa brasileira que promoveu ações que incentivavam uma maior participação do capital oriundo de pessoas físicas na bolsa. Cabe, portanto, sugerir o uso destas variáveis em futuros estudos associado a esta temática. A qualidade do método de encontrar padrões para a previsão do índice brasileiro pode ser explicado, fundamentalmente pela menor volatilidade dos dados deste índice, no período analisado. É de se esperar que, em havendo menor volatilidade nos dados maior será a capacidade de uma rede neural encontrar padrões entre dados que aparentemente são desconexos e, desta forma de demonstrar possíveis resultados não aleatórios nas séries. A força desta modelagem pode ser expressa pela excelência na previsão em t+1 do sinal (decréscimo ou aumento do retorno do mercado para o próximo período), sendo aparentemente ineficaz em modelagens para períodos posteriores a t+1. A expectativa de queda ou crescimento de um índice para o próximo período pode ser utilizada em estratégias de curto prazo na alocação de ativos. Cabe ressaltar ainda o fato de a modelagem ter sido realizada somente em planilhas eletrônicas permitiu um melhor entendimento de como os procedimentos internos de uma rede são realizados, bem como os padrões são identificados. Neste sentido é possível sugerir o uso de redes neurais polinomiais GMDH em estudos de séries temporais, pois se trata de uma ferramenta que elimina o conceito de “caixa preta” existente em outras técnicas de redes neurais artificiais. Como sugestões é possível indicar, o uso de modelos com aprendizagem por correção de erros ou aprendizagem baseada em memória, ou ainda modelos de redes recorrentes já que esta modelagem foi feita através de redes alimentadas diretamente com múltiplas camadas. Para a criação de modelagens com aprendizagem por correção é possível indicar ainda a regra delta, ou regra de Widrow-Hoff. Para a modelagem com aprendizado baseada em memória é possível indicar o uso de conceitos da lógica difusa na determinação de padrões dos dados de entrada.
REFERÊNCIAS BIBLIOGRÁFICAS ACKLEY, D. H.; HINTON, G. E. ; SEJNOWSKI, T. J. A learning algorithm for Boltzmann machines. Cognitive Science, vol. 9, PP. 147-169, 1985. de RÉ, Angelita Maria. Um método para identificar características predominantes em empreendedores que obtiveram sucesso utilizando um sistema neurodifuso. Tese (Doutorado em Engenharia da Produção) Programa de Pós Graduação em Engenharia da Produção. Universidade Federal de Santa Catarina, 2000. BOOSE, J. H. Personal construct theory and the transfer of human expertise. Proceedings of AAAI- 84, p. 27-33. California, American Association for Artificial intelligence, 1984. FAUSETT, L. V. Fundamentals of neural networks: architectures, algorithms and applications. New Jersey: Prentice Hall International. New Jersey, 1995. FERNANDES, A. M. R. Inteligência artificial: noções gerais. Visual Books. Florianópolis, 2005. FERSON, W. in Forecasting Expected Returns in the Financial Markets, Ed. Elsevier, San Diego, Califórnia, 2007.

16
HAYKIN, Simon. Redes Neurais: princípios e prática. Segunda edição, Editora Bookman. Porto Alegre, 2001. IVAKHNENKO, A. G. Polynomial theory of complex systems. IEEE Transaction on Systems, Man, Cybernetics, Vol. 1, pp 364-378, October, 1971. IVAKHNENKO, A. G.; IVAKHNENKO, G. A.; MULLER, J.A., Self-Organization of Optimum Physical Clustering of the Data Sample for Weakened Des cription and Forecasting of Fuzzy Objects, Pattern Recognition and Image Analysis, 1993, vol. 3, no. 4, pp. 415-422. KOBAYASHI-HILLARY M. Building a Future with BRICs: The Next Decade for Offshoring, NY, New York City: Springer, 2007. KOVÁCS, Z. L. Redes neurais artificiais: fundamentos e aplicações. Física, 2006. LIPPMANN, R. P. An introduction to computing with neurals nets. IEEE ASSP, 1987. PINDYCK, R. S.; RUBINFELD, D. L. Econometria: Modelos e previsões. Editora Elsevier. Rio de Janeiro, 2004. SCHNEIDER, S.; STEINER, M. Conditional Asset Pricing: Predicting time varying Beta-Factors with Group Method of Data Handling Methods. SSRN-ID667468. 2006. SIMONS, G.T. Introdução a inteligência artificial. Classe, 1988. SOARES, R. O.; ROSTAGNO, L. M.; SOARES, K. T. C. Estudo de evento: o método e as formas de cálculo do retorno anormal. Enanpad, 2002. TOWELL,G.; SHAVLIK,J. Knowledge-based artificial neural networks, Artificial Intelligence, v.70, n.1-2., p.119-165, 1994. TSAY, R. S. Analysis of financial time series. Ed. Wiley, New York, 2002. VALENÇA, M. Aplicando redes neurais: um guia completo. Editora Livro Rápido, Olinda, 2005. WILSON, D.; PURUSHOTAMAN, R. Dreaming with BRICs: The Path To 2050. Goldman Sachs, 2003.





























