Embed Size (px)
Citation preview

PREVISÃO DE EMPLACAMENTO DE
VEÍCULOS DE UMA EMPRESA
AUTOMOBILÍSTICA BRASILEIRA POR
MEIO DE REDES NEURAIS
ARTIFICIAIS
Isadora Andrelise Álvaro Bonfim Soares Cosme Damiã
Paulo Fernandes Sanches Junior
FELIPE DIAS PAIVA
Luciano dos Santos Diniz
O tema desse trabalho é a previsão de demanda por meio de métodos
lineares e não lineares. Assim, o principal objetivo consistiu em
realizar uma previsão de demanda da quantidade de veículos que
seriam emplacados (vendidos para o cliente final e devidamente
registrado pelos DETRANs) de uma empresa do setor automobilístico
brasileiro, no período de janeiro a agosto de 2017, através da
aplicação do método de redes neurais artificiais (RNA) e do método de
Regressão Linear Múltipla (RLM). Buscou-se utilizar das RNAs e da
RLM para comparar os resultados dos modelos com (1) a previsão
realizada pela empresa automobilística e (2) com as quantidades reais
de veículos emplacados no período, visando identificar qual método
obteve menor erro de previsão. Nessa perspectiva, o trabalho teve
como fundamentação teórica a previsão de demanda e o
gerenciamento das previsões, sucedido do modelo de regressão linear
múltipla e o modelo de redes neurais artificiais. A pesquisa foi
desenvolvida de forma descritiva e quantitativa, não-probabilística,
utilizando dados de janeiro de 2012 a dezembro de 2016, para o grupo
in-sample. Já para o grupo out-of-sample foram coletados dados de
janeiro a agosto 2017. A técnica utilizada para a coleta de dados foi
ex-post-facto, por se referir a fatos conclusos. Como técnica de análise
dos dados utilizou-se uma rede neural com arquitetura MLP
(Multilayer Perceptron) implementada a partir do algoritmo back-
propagation e, também foi empregada a regressão linear múltipla. o
método de RNAs, Concluiu-se que o método de RNA, além de
apresentar melhor resultado quando comparado com a RLM, também
mostrou-se mais preciso quando comprado com a previsão realizada
pela Empresa X. A variação total do erro absoluto das RNAs é inferior
ao erro absoluto da previsão realizada pela empresa.
XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO “Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações”
Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.

XXXVIII ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO “A Engenharia de Produção e suas contribuições para o desenvolvimento do Brasil”
Maceió, AL, Brasil, 16 a 19 de outubro de 2018.
2
Palavras-chave: Redes Neurais, Regressão Linear Múltipla, Previsão
de Demanda

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
1
1. Introdução
O tema desse trabalho é a previsão de demanda por meio de métodos lineares e não lineares.
Assim, o principal objetivo consistiu em realizar uma previsão de demanda da quantidade de
veículos que seriam emplacados (vendidos para o cliente final e devidamente registrado pelos
DETRANs) de uma empresa do setor automobilístico brasileiro, no período de janeiro a agosto
de 2017, através da aplicação do método de redes neurais artificiais (RNA) e do método de
Regressão Linear Múltipla (RLM). Buscou-se utilizar das RNAs e da RLM para comparar os
resultados dos modelos com (1) a previsão realizada pela empresa automobilística e (2) com as
quantidades reais de veículos emplacados no período, visando identificar qual método obteve
menor erro de previsão.
Nessa perspectiva, o trabalho teve como fundamentação teórica a previsão de demanda e o
gerenciamento das previsões, sucedido do modelo de regressão linear múltipla e o modelo de
redes neurais artificiais. A pesquisa foi desenvolvida de forma descritiva e quantitativa, não-
probabilística, utilizando dados de janeiro de 2012 a dezembro de 2016, para o grupo in-sample.
Já para o grupo out-of-sample foram coletados dados de janeiro a agosto 2017. A técnica
utilizada para a coleta de dados foi ex-post-facto, por se referir a fatos conclusos. Como técnica
de análise dos dados utilizou-se uma rede neural com arquitetura MLP (Multilayer Perceptron)
implementada a partir do algoritmo back-propagation e, também foi empregada a regressão
linear múltipla.
2. Previsão de demanda
A previsão de demanda consiste no ato de prever a quantidade de produtos ou serviços a serem
vendidos por uma organização, em um determinado período de tempo. De acordo com Ritzman
e Krajewski (2008), a previsão é a análise de eventos futuros, com objetivo de planejamento.
Ela se torna necessária, a partir do momento em que auxilia na determinação, programação e
aquisição dos recursos necessários a serem utilizados. Nesse sentido, Tubino (2000), acrescenta
que a função da previsão de demanda é fornecer subsídios para o planejamento estratégico da
organização. O autor ainda afirma que atividades como: planos de capacidade, vendas, fluxo de
caixa, estoques, mão-de-obra e compras são todos baseados na previsão de demanda. De uma
maneira mais simples Bowersox e Closs (2001) afirma que “as previsões são projeções de
valores ou quantidades que provavelmente serão produzidas, vendidas e expedidas.”.
A estimativa de vendas futuras é essencial para as empresas diante um cenário econômico cada
vez mais competitivo e incerto. O autor Lin (2000) comenta que esse processo é um dos pontos
mais importantes, uma vez que minimiza os custos da empresa e auxilia na satisfação dos

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
2
clientes, ajudando na redução dos riscos e na tomada de decisão. Cavalheiro (2003) afirma que
“estas informações são vitais para qualquer empresa que se preocupa com o planejamento de
suas operações”. Dessa maneira Bowersox e Closs (2001) relata que “a programação e o
controle da produção e o planejamento das capacidades das instalações exigem previsões
precisas.”
Ragsdale (2009) afirma que analisar qual a melhor ferramenta a ser aplicada é imprescindível
para se conseguir melhores resultados. Existem vários tipos de classificação para a previsão de
demanda. O autor Tubino (2000) classifica em dois tipos os conjuntos de métodos: métodos
qualitativos e quantitativos. Os métodos qualitativos são os que privilegiam dados subjetivos,
os quais são difíceis de representar numericamente. Já os métodos quantitativos envolvem
análise numérica de dados já ocorridos, desconsiderando opiniões pessoais. Dentre esses
últimos, os métodos mais difundidos de previsão de demanda quantitativos de séries temporais,
modelos causais e de inteligência computacional são: Média móvel, Suavização exponencial,
Box-Jenkins, Regressão linear, Métodos econométricos, Redes neurais artificiais e Métodos
baseados em Lógica Fuzzy.
2.1. Gerenciamento das previsões
No desenvolvimento do processo de previsão de demanda é essencial que ocorra sinergia entre
os departamentos, onde cada unidade organizacional deve trabalhar em conjunto para alcançar
um objetivo maior, independente das diferenças pessoais. Segundo Bowersox e Closs (2001)
“o gerenciamento de previsões inclui aspectos organizacionais, motivacionais, pessoais, de
procedimentos e também a integração desses aspectos com outras funções da empresa”. Nesse
sentido, Corrêa e Corrêa (2011) comentam que a “previsão, principalmente de demanda, é, em
geral um dos assuntos mais controversos dentro das organizações e um dos que mais suscitam
polêmica entre setores”. Se as relações ou dependências entre as variáveis do sistema de
previsão são lineares, tem-se que, a análise destas através de medidas de relações lineares, como
critérios de informação ou coeficiente de correlação serão suficientes (Sharma, 2000). Porém,
se o sistema envolve relações não-lineares, como acontece na maioria dos problemas reais, uma
aproximação linear pode fornecer como resultado um modelo pouco eficiente e por isso, faz-se
necessário a utilização de medidas que considerem estas características na escolha das
variáveis, para definir os estados associados, ou pelo menos, a maior parte destes.
2.2. Regressão Linear Múltipla
A regressão linear múltipla é o estudo da relação entre diversas variáveis. Segundo Devore
(2011, p.433) “A análise de regressão é a parte da estatística que investiga a relação entre duas

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
3
ou mais variáveis de maneira não-determinística”. Os autores Bryman e Cramer (2003) afirmam
que o processo de regressão linear consiste em um poderoso instrumento para fazer previsões
acerca dos valores da variável independente.
“Temos uma regressão linear múltipla quando admitimos que o valor da variável dependente
seja a função linear de duas ou mais variáveis explanatórias” (HOFFMANN, 2006, p.120). De
acordo com Devore (2011, p.511) o objetivo da regressão linear múltipla é “elaborar um modelo
probabilístico que relacione uma variável dependente Y a mais de uma variável independente
ou de previsão.” Nesse sentido Devore (2011), define o modelo como:
A equação do modelo de regressão linear múltipla aditivo geral é Y=〖β_0 + β〗_1+
β_1 x_1+ β_2 x_2+⋯+β_k x_k+ϵ. Onde E (ϵ) = 0 e V(ϵ) = σ^2. Além disso, para
testar hipóteses e calcular ICs ou IPs, supõe-se que ϵ seja normalmente distribuído.
Sejam, x_1^*,x_2^*,…,x_k^* os valores particulares de x_1, …, x_k.
μ_y.x_1^*,…,x_k^*= β_0+ β_1 x_1^*+ …+β_k x_k^* . Logo, assim como β_0+β_1
x descreve o valor de Y médio como uma função de X na regressão linear simples, a
função de regressão real (ou populacional) β_0+ β_1 x_1+⋯+β_k x_k fornece o valor
de Y como uma função de x_1,…,x_k. Os β_1 S são os coeficientes de regressão reais
(ou populacionais). O coeficiente de regressão β é interpretado como uma mudança
esperada de Y associada com um aumento de uma unidade em x_1, enquanto
x_2,…,x_k são mantidos fixos. Interpretações análogas valem para β_2,…,β_k.
(DEVORE, 2011, p.511)
O método de regressão linear múltipla pode ser aplicado em diversas áreas. Isso pode ser visto
quando Abbad e Torres (2002) comentam que as pesquisas na área de psicologia organizacional
vêm trabalhando com o modelo para analisar relações complexas nas organizações. Embora, a
principal aplicação do método seja “produzir valores para a variável dependente quando se têm
as variáveis independentes (cálculo dos valores preditos)” (SASSI et al., 2011).
2.3. Redes Neurais
Os métodos de Redes Neurais Artificiais (RNAs) são modelos que assemelham-se à mesma
forma de aprendizado de um cérebro humano. “As redes neurais artificiais ou simplesmente
redes neurais, são modelos que vêm sendo desenvolvidos nos últimos anos, e que têm como
metáfora o funcionamento do cérebro humano com suas redes neurais biológicas.”
(VALENÇA, 2009). As Redes Neurais Artificiais são sistemas computacionais que imitam as
habilidades do sistema nervoso biológico, usando um grande número de neurônios artificiais
interconectados.
2.3.1. Aprendizado
Uma das principais características das RNAs é a capacidade de aprendizado. O conhecimento
aqui é adquirido através de ajustes de intensidade das conexões entre os neurônios. Valença
(2009) explica essa forma de aprendizado em:
Dentre as importantes características de similaridade destas redes com o cérebro
humano, está à capacidade de aprender. Portanto, essas redes neurais artificiais

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
4
possuem alguma forma de regra de aprendizagem que são responsáveis pela
modificação dos pesos sinápticos, em função dos exemplos de entrada que são
repetidamente apresentados. (VALENÇA, 2009)
O processo de aprendizado está diretamente relacionado com a melhoria do desempenho da
rede segundo algum critério estabelecido. Segundo Braga, Carvalho e Ludemir (2016) “Há
vários algoritmos diferentes para treinamento de redes neurais, podendo o mesmo ser agrupado
em dois paradigmas principais: aprendizado supervisionado e aprendizado não
supervisionado.” Nessa situação, Valença (2009) define o aprendizado supervisionado como
aprendizado: “[...] feito com o conhecimento prévio do resultado desejado, ou seja, são
fornecidos para a rede, o conjunto de exemplos de entradas e respectivas respostas. Já o
aprendizado não-supervisionado: a rede aprende com os próprios dados de entrada. ”
2.3.2. Perceptron
O perceptron segundo Valença (2009) é “o modelo mais simples de Rede Neural, no qual várias
unidades de processamento estão conectadas unicamente a uma unidade de saída, através dos
pesos sinápticos”. Nesse sentido, Braga, Carvalho e Ludemir (2016) lembram que o modelo
linear, corresponde ao modelo clássico de MCP (McCulloch e Pitts), conhecido como modelo
linear ou perceptron simples de RNAs, tem capacidade computacional limitada a função
linearmente separáveis. Esse, possui n terminais de entrada (dendritos) que recebe os valores
x1,x2,x3...,xn (que representam ativações dos neurônios anteriores) e apenas um terminal de
saída y (representando o axônio). Para representar o comportamento das sinapses, os terminais
de entrada do neurônio tem pesos acoplados w1,w2,...,wn, cujos valores podem ser positivos
ou negativos, dependendo das sinapses correspondentes serem inibitórias ou excitatórias. Uma
descrição do modelo está representada na Figura. 1.
FIGURA 1 – Neurônio de McCulloch e Pitts, representação de um neurônio artificial.
Fonte: BRAGA; CARVALHO e LUDEMIR, 2016, p.8

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
5
2.3.3. O algoritimo de aprendizado do percpetron
O perceptron assim como os demais modelos de RNAs, necessitam de uma regra de
aprendizado. “Uma RNA é composta por um conjunto de neurônios, com capacidade de
processamento local, uma topologia que define a forma como estes neurônios estão conectados
e uma regra de aprendizado”. (BRAGA; CARVALHO; LUDEMIR, 2016). De uma forma
geral, esse modelo de RNA possui uma regra de aprendizado, que permite a adaptação dos seus
pesos de forma que a rede execute uma determinada tarefa, Valença (2009) explica tal fato em:
Treinar uma RNA consiste em ajustar os pesos através de uma regra de aprendizagem
até que esta forneça respostas satisfatórios ao problema analisado. Para realizar o
treinamento do perceptron faz-se necessário um conjunto de exemplos com os valores
das entradas e suas respectivas saídas (valores desejados). Logo, o aprendizado do
perceptron é dito supervisionado também chamado de aprendizado com o professor,
pois são apresentados à rede os exemplos de entrada e suas respectivas saídas. O
treinamento supervisionado é aquele que utiliza um conjunto de exemplos, de tal
maneira que para cada exemplo de entrada é fornecido um exemplo de saída desejado.
Esse processo é continuamente repetido para todo o conjunto de exemplo, até que o
erro esteja dentro de um valor considerado satisfatório. (VALENÇA, 2009)
O algoritmo de treinamento do perceptron sempre chega, em um tempo finito, a uma solução
para o problema de separação e duas classes linearmente separáveis. A expressão para a regra
de atualização dos pesos, pode ser escrita como a equação geral para atualização dos pesos de
um neurônio de um perceptron simples, que se dá por w (n+1) = w(n)+ἠex (n). (BRAGA;
CARVALHO; LUDEMIR, 2016)
2.3.4. Redes Perceptron de múltiplas camadas
O perceptron de múltiplas camadas é composta por neurônios com funções de ativação
sigmoidais nas camadas intermediárias. (BRAGA; CARVALHO; LUDEMIR, 2016). Segundo
Valença (2009) “o perceptron de múltiplas camadas (MLP) é uma generalização da rede
perceptron simples pela adição de pelo menos uma camada intermediária (também conhecida
como camada escondida)”. “As múltiplas camadas têm a função de transformar o ”problema”
(como calcular ou estimar o erro das camadas intermediárias), em uma representação tratável
para a camada de saída de rede.” (BRAGA, CARVALHO; LUDEMIR, 2016).

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
6
FIGURA 2 - Arquitetura de uma rede MLP com duas camadas ocultas
Fonte: ALMEIDA, 2014, p. 25
Segundo Valença (2009) as redes MLP tradicionais apresentam as seguintes características
principais:
Uma camada de entrada (onde cada neurônio representa uma variável considerada
como entrada para o problema). Ao menos uma camada intermediaria. É a camada
responsável pela não linearidade da rede e que permite que as redes MLP sejam
capazes de resolver problemas reais (funções não linearmente separáveis). Os
neurônios desta camada possuem em geral uma função de ativação sigmoidal que
pode ser a logística ou a tangente hiperbólica. Uma camada de saída. Esta camada é
responsável pela resposta da rede e representa a variável desejada (em geral a variável
que se quer prever ou classificar). Os neurônios também possuem uma função de
ativação normalmente sigmoidal (logística, tangente hiperbólica) ou uma simples
função linear. (VALENÇA, 2009).
Nesse sentido, Braga, Carvalho e Ludemir (2016) afirmam que “o algoritmo de treinamento de
redes MLP mais popular é o back-propagation que, por ser supervisionado, utiliza pares de
entrada e saída (x,y_d) para, por meio de um mecanismo de correção de erros ajustar o peso
da rede.
3. Resultados da Aplicação da Regressão Linear Múltipla
A priori as variáveis utilizadas no primeiro modelo de previsão foram triadas por meio do
coeficiente de correlação entre elas, com o intuito de evitar o efeito de multicolinearidade.
Nessa etapa, foram descartadas variáveis que apresentavam coeficientes com o valor de módulo
de |0.7|. Além disso, para evitar qualquer possibilidade do efeito, também calculou-se por meio
do software SPSS, as estatísticas de colinearidade, como podemos ver abaixo:

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
7
TABELA 01 - Análise de Multicolinearidade
Modelo Estatísticas de colinearidade
Tolerância
Comerciais Leves 0,539
Taxa de Crescimento do PIB 0,385
Inflação – IPCA 0,66
Nível de confiança dos empresários 0,271
Preço da gasolina comum 0,306
Vendas no varejo 0,739
Produção manufatura 0,367
Produção industrial 0,436
Variação de estoque 0,696
Gastos públicos 0,393
Crescimento dos empréstimos 0,456
Fonte: Elaborado pela autora (2017)
Mais uma vez, a possibilidade de ocorrer o efeito de multicolinearidade é descartada, pois todos
os índices de tolerância são maiores que 0.1. É importante ressaltar que nesse modelo as
defasagens utilizadas anteriormente, também foram consideradas.
Com o intuito de confirmar a normalidade dos resíduos e consequentemente a relevância da
regressão, elaborou-se um histograma, no programa estatístico SPSS, apurando então que os
resíduos das variáveis consideradas, apesar de não se caracterizarem como uma distribuição
perfeita, obedecem uma distribuição normal Gáfico.01.
Gráfico 01 – Regressão resíduos padronizada
Fonte: Elaborado pela autora (2017)
Ainda com o objetivo de averiguar a relevância da regressão, foram realizados mais dois testes.
O primeiro, de Durbin-Watson, obtendo-se 1.625, confirmando a presença de independência

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
8
nos resíduos da regressão e sua relevância. E o segundo, o teste de homocedasticidade,
verificando-se que não se trata de uma relação linear (Gáfico.02).
Gráfico 02 – Regressão valor predito padronizado
Fonte: Elaborado pela autora (2017)
Para a previsão referente ao período de janeiro/2017 a agosto/2017, foram utilizadas as
seguintes variáveis: comerciais leves; taxa de crescimento do PIB; inflação - IPCA; nível de
confiança dos empresários; preço da gasolina comum; vendas no varejo; produção manufatura;
produção industrial; variação de estoque; gastos públicos; crescimento dos empréstimos.
Nesse processo, obteve-se um R-quadrado ajustado de 0,805, com a seguinte intercessão e seus
coeficientes da reta:
Tabela 02 - Coeficientes RLM
Variáveis Coeficientes
Interseção 131809,2969
Comerciais leves 0,029714675
Taxa de crescimento do PIB 2214,248619
Inflação – IPCA -118,0130839
Nível de confiança dos empresar. 256,8595379
Preço da gasolina comum -30372,64277
Vendas no varejo 590,7647858
Produção manufatura -157,1989432
Produção industrial -259,5082358
Variação de estoque 0,010882202
Gastos públicos -0,163832202
Crescimento dos empréstimos 720,5521632
Fonte: Elaborado pela autora (2017)
Na tabela abaixo é possível visualizar o resultado da simulação referente ao período descrito: Tabela 03 - Previsão RLM
JANEIRO FEVEREIRO MARÇO ABRIL MAIO JUNHO JULHO AGOSTO
17.560 10.485 16.586 20.810 20.763 24.245 20.369 20.043
Fonte: Elaborado pela autora (2017)
-3
-2
-1
0
1
2
3
4
-2,5 -2 -1,5 -1 -0,5 0 0,5 1 1,5 2
Reg
ress
ão R
esíd
uo
s
pad
roniz
ado
s
Regressão Valor predito padronizado

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
9
3.1. Previsão da Regressão Linear Múltipla x Realizado x Previsão Empresa X
Ao analisar a previsão por RLM juntamente com o “realizado” e a “previsão da empresa X”,
nota-se rapidamente a grande variação que a RLM possui diante as demais. No início, a previsão
apontava erro médio de variação de aproximadamente 5.550 automóveis, mantendo-se esse
mesmo valor até março, deste mês em diante a média do erro teve crescimento constante,
chegando ao mês de agosto com média em torno de 31.995 automóveis. No gráfico abaixo,
visualiza-se melhor tal situação:
Gráfico 04 – RLM x Realizado x Empresa X
Fonte: Elaborado pela autora (2017)
É perceptível as deficiências do método de regressão linear múltipla, para descrever a relação
indireta existente entre as variáveis. Identifica-se que as variações da variável dependente não
são explicadas pelas variações das variáveis independentes.
4. Redes neurais artificiais – RNAs
Ao todo foram realizadas 110 mil simulações. Para melhor descrever essas tentativas, é
apresentado abaixo uma estatística descritiva do erro absoluto dos dados, referente ao período
de previsão, janeiro/2017 até agosto/2017.
Os parâmetros para as 110 mil simulações foram:
• alpha = 0.001;
• hidden_layer_sizes = gera uma variável randômica por meio de sorteio, para definir a
quantidade de neurônios na primeira camada oculta, podendo variar de 10 a 59. Em
seguida, é gerado uma nova variável randômica, para segunda camada oculta,
condicionada a ser menor do que a anterior;
17.560
28.044
44.630
65.440
86.203
110.448
130.817
150.860
11.511
22.630 36.340
47.354
62.968
80.20595.116
113.415
12.752
25.907
40.136
53.322
69.079
85.804
103.847
124.314
0
20.000
40.000
60.000
80.000
100.000
120.000
140.000
160.000
JAN FEV MAR ABR MAI JUN JUL AGO
PREVISÃO
REALIZADO
EMPRESA X

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
10
• solver= 'adam';
• max_iter = 5000;
• activation = gera uma variável randômica por meio de sorteio, para definir qual será a
função de ativação da camada oculta. Podendo ser identity, logistic, tanh ou relu;
• verbose = 'True';
• learning_rate = gera uma variável randômica por meio de sorteio, para definir qual será
a taxa de aprendizado para atualizações de peso. Podendo ser constant, invscaling ou
adaptive.
Dentre essas simulações de todo o grupo, “out-of-sample”, destaca-se a de número 18.457 a
qual teve uma das menores taxas de erro absoluto: 9.494 automóveis, referente ao período de
janeiro a agosto de 2017. As variáveis de entrada utilizadas nessa simulação em especifico são:
crédito ao setor privado, vendas no varejo, licenciamento total de automóveis, produção de
veículos comerciais leves, vendas de veículos do tipo comerciais leves (até 1.0), capacidade de
utilização, número de emplacamentos comerciais leves, data, vendas de veículos comerciais
leves (acima de 2.0), gastos públicos, venda de automóveis (até 1.0) e taxa de empréstimo
bancário.
Quanto as configurações processadas pela interação 18.457 vale esclarecer os seguintes
parâmetros: primeiro o “activation” utilizou-se a função “tanh” para ativação da camada oculta;
segundo “learning_rate” empregou-se a função “invscaling”, como taxa de aprendizado para
atualização dos pesos; terceiro “hidden_layer_sizes” usou-se para a primeira camada 20
neurônios e para a segunda camada 18 neurônios e, por fim os demais parâmetros
permaneceram constantes.
Na tabela abaixo é possível visualizar o resultado da simulação referente ao período descrito:
Tabela 05 - Previsão RNA
JANEIRO FEVEREIRO MARÇO ABRIL MAIO JUNHO JULHO AGOSTO
13.123 11.391 13.753 14.422 12.846 17.146 15.862 17.950
Fonte: Elaborado pela autora (2017)
4,1. Previsão Redes Neurais x Realizado x Previsão Empresa X
Na tabela abaixo, observa-se as mesmas operações aritméticas descritas anteriormente, mas
agora comparando o realizado com o previsto pela empresa X.
XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
11
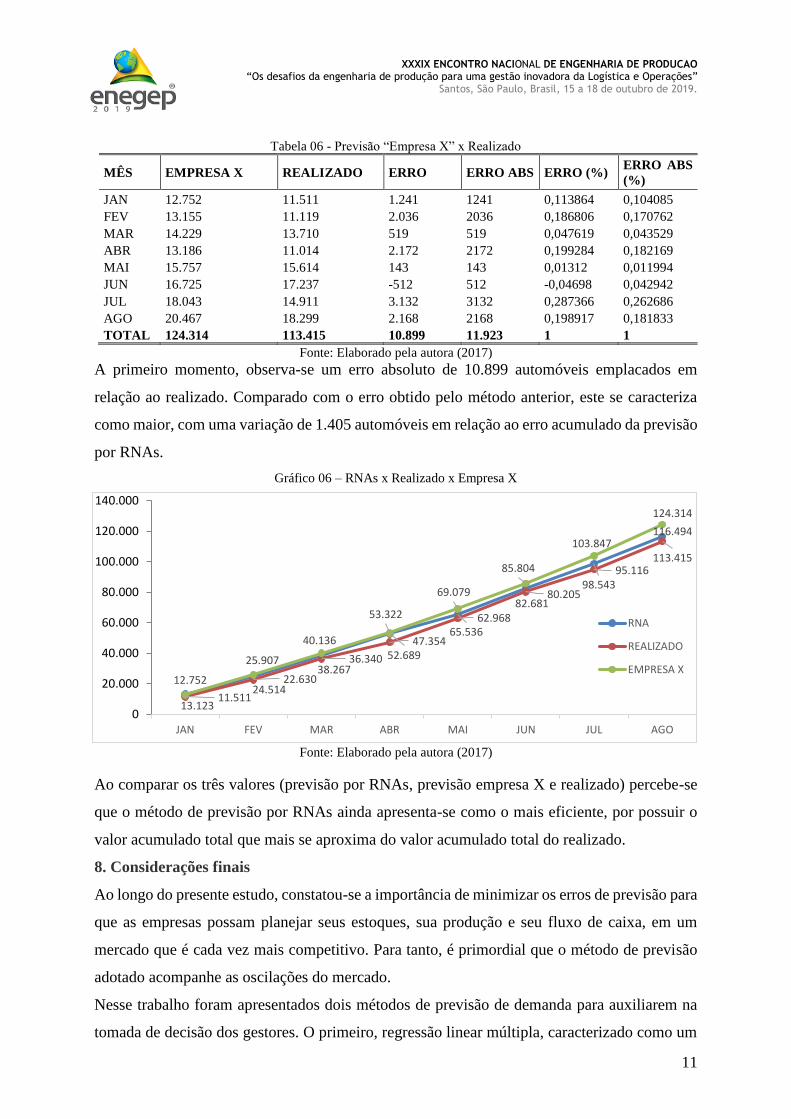
Tabela 06 - Previsão “Empresa X” x Realizado
MÊS EMPRESA X REALIZADO ERRO ERRO ABS ERRO (%) ERRO ABS
(%)
JAN 12.752 11.511 1.241 1241 0,113864 0,104085
FEV 13.155 11.119 2.036 2036 0,186806 0,170762
MAR 14.229 13.710 519 519 0,047619 0,043529
ABR 13.186 11.014 2.172 2172 0,199284 0,182169
MAI 15.757 15.614 143 143 0,01312 0,011994
JUN 16.725 17.237 -512 512 -0,04698 0,042942
JUL 18.043 14.911 3.132 3132 0,287366 0,262686
AGO 20.467 18.299 2.168 2168 0,198917 0,181833
TOTAL 124.314 113.415 10.899 11.923 1 1
Fonte: Elaborado pela autora (2017)
A primeiro momento, observa-se um erro absoluto de 10.899 automóveis emplacados em
relação ao realizado. Comparado com o erro obtido pelo método anterior, este se caracteriza
como maior, com uma variação de 1.405 automóveis em relação ao erro acumulado da previsão
por RNAs.
Gráfico 06 – RNAs x Realizado x Empresa X
Fonte: Elaborado pela autora (2017)
Ao comparar os três valores (previsão por RNAs, previsão empresa X e realizado) percebe-se
que o método de previsão por RNAs ainda apresenta-se como o mais eficiente, por possuir o
valor acumulado total que mais se aproxima do valor acumulado total do realizado.
8. Considerações finais
Ao longo do presente estudo, constatou-se a importância de minimizar os erros de previsão para
que as empresas possam planejar seus estoques, sua produção e seu fluxo de caixa, em um
mercado que é cada vez mais competitivo. Para tanto, é primordial que o método de previsão
adotado acompanhe as oscilações do mercado.
Nesse trabalho foram apresentados dois métodos de previsão de demanda para auxiliarem na
tomada de decisão dos gestores. O primeiro, regressão linear múltipla, caracterizado como um
13.123
24.514
38.26752.689
65.536
82.681
98.543
116.494
11.511
22.630
36.340
47.354
62.968
80.205
95.116113.415
12.752
25.907
40.136
53.322
69.079
85.804
103.847
124.314
0
20.000
40.000
60.000
80.000
100.000
120.000
140.000
JAN FEV MAR ABR MAI JUN JUL AGO
RNA
REALIZADO
EMPRESA X

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
12
método tradicional de previsão e ensinado na maioria dos cursos de graduação do país, indicou
resultados insatisfatórios para o objetivo proposto com um erro de previsão de 38.714 unidades
(automóveis). Já o segundo, redes neurais artificiais, apontou melhor desempenho, uma vez que
o método acompanha as oscilações do mercado e apresentou um erro de previsão de 9.494
veículos quando confrontado com a quantidade efetiva de emplacamento realizado naquele
período. Outro dado importante a ser levado em consideração, é a desigualdade de 29.220
unidades entre ambos os erros, constatando novamente a insensibilidade e as limitações do
primeiro método.
Gráfico 07 – RNAs x Realizado x RLM x Empresa X
Fonte: Elaborado pela autora (2017)
Deve-se salientar ainda que a RLM deixou lacunas logo na fase inicial. Como já foi dito, esse
método não conseguiu explicar a relação entre as variáveis independentes com a variável
dependente. Todavia, ele não foi descartado em detrimento do segundo método (RNAs), pois
era necessário para fins comparativos.
Tabela 08 - Previsão “Realizado” x “RLM” x “RNA” x “Empresa X”
Data Realizado RLM Erro (Abs) RNA Erro (Abs) Emp. X Erro (Abs)
JAN 11.511 17.560 6.049 13.123 1.612 12.752 1.241
FEV 11.119 10.485 634 11.391 272 13.155 2.036
MAR 13.710 16.586 2.876 13.753 43 14.229 519
ABR 11.014 20.810 9.796 14.422 3.408 13.186 2.172
MAI 15.614 20.763 5.149 12.846 2.768 15.757 143
JUN 17.237 24.245 7.008 17.146 91 16.725 512
JUL 14.911 20.369 5.458 15.862 951 18.043 3.132
AGO 18.299 20.043 1.744 17.950 349 20.467 2.168
TOTAL 113.415 150.861 38.714 116.494 9.494 124.314 11.923
Fonte: Elaborado pela autora (2017)
0
20.000
40.000
60.000
80.000
100.000
120.000
140.000
160.000
JAN FEV MAR ABR MAI JUN JUL AGO
REALIZADO
RLM
RNA
EMPRESA X

XXXIX ENCONTRO NACIONAL DE ENGENHARIA DE PRODUCAO
“Os desafios da engenharia de produção para uma gestão inovadora da Logística e Operações” Santos, São Paulo, Brasil, 15 a 18 de outubro de 2019.
13
Por fim, o método de RNAs, além de apresentar melhores resultados quando comparado com a
RLM, também mostrou-se mais preciso quando comprado com a previsão realizada pela
Empresa X. A variação total do erro absoluto das RNAs é inferior ao erro absoluto da previsão
realizada pela empresa, ou seja, quando a empresa opta por utilizar um método diferente do
proposto assume um erro absoluto de 2.429 veículos, resultando na redução de seus lucros.
REFERÊNCIAS
ABBAD, G.; TORRES, C. V. Regressão múltipla stepwise e hierárquica em psicologia organizacional:
aplicações, problemas e soluções. Instituto de Psicologia da Universidade de Brasília. Brasília, DF, 2002.
BOWERSOX. D. J.; CLOSS, D. J. Logística empresarial: o processo de integração da cadeia de suprimentos.
São Paulo: Atlas, 2001.
BRAGA, A. de Pádua; CARVALHO, André P. de Leon F.; LUDEMIR, T. B. Redes neurais artificias: teoria e
aplicação. 2. ed. Rio de Janeiro: LTC, 2016.
CAVALHEIRO, Darlene. Método de previsão de demanda aplicada ao planejamento da produção de
indústrias de alimentos. 2003. 137 f. Dissertação (Mestrado) - Curso de Engenharia Mecânica, Departamento de
Programa de Pós - graduação em Engenharia Mecânica, Universidade Federal de Santa Catarina, Florianópolis.
CORRÊA, L. H.; CORRÊA, A. C. Administração de produção e operações: manufatura e serviços: uma
abordagem estratégica. 2. ed. São Paulo: Atlas, 2011.
LIN, Tamy Ymei; JR, José B. C. Estudo de modelos de previsão de demanda. Fundação Getúlio Vargas. São
Paulo, 2000.
RAGSDALE, C. T. Modelagem e análise de decisão. São Paulo: Cengage Learning, 2009.
RITZMAN, Larry P; KRAJEWSKI, Lee J. Administração da produção e operações. São Paulo: Pearson
Prentice Hall, 2008.
SASSI, Cecília P.; PEREZ, Felipe G.; MYAZATO, Letícia ; YE , Xiao, FRANCISCO, Paulo H. Ferreira-Silva .
Modelos de regressão linear múltipla utilizando os softwares e estatística: uma aplicação a dados de
conservação de frutas. 2011. ICMC – USP – CP668 São Carlos/SP.
SHARMA, A. Seasonal to internannual rainfall probabilistic forecasts for improvedwater supply
management: Part 1 – A strategy for system predictor identification, Journal of Hydrology 239, 2000.
TUBINO, D. Ferrari. Manual de planejamento e controle da produção. 2. ed. São Paulo: Atlas, 2000.
VALENÇA, Mêuser. Fundamentos das redes neurais: exemplo em Java. 2. ed. Olinda, PE: Livro Rápido, 2009.