Embed Size (px)
Citation preview

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
UMA API PARA CRIAÇÃO DE APLICAÇÕES DE RECUPERAÇÃO DE INFORMAÇÃO
Área de Recuperação de Informação
por
Mathias Henrique Weber
André Luís Alice Raabe, Dr. Orientador
Itajaí (SC), junho de 2006

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
UMA API PARA CRIAÇÃO DE APLICAÇÕES DE RECUPERAÇÃO DE INFORMAÇÃO
Área de Recuperação de Informação
por
Mathias Henrique Weber Relatório apresentado à Banca Examinadora do Trabalho de Conclusão do Curso de Ciência da Computação para análise e aprovação. Orientador: André Luis Alice Raabe, Dr.
Itajaí (SC), junho de 2006

ii
SUMÁRIO
LISTA DE ABREVIATURAS.................................................................iv
LISTA DE FIGURAS ...............................................................................v
LISTA DE TABELAS..............................................................................vi RESUMO .................................................................................................vii ABSTRACT ............................................................................................viii 1 INTRODUÇÃO.....................................................................................1 1.1 PROBLEMATIZAÇÃO ..................................................................................... 2 1.1.1 Formulação do Problema ................................................................................. 2 1.1.2 Solução Proposta ............................................................................................... 3 1.2 OBJETIVOS ........................................................................................................ 3 1.2.1 Objetivo Geral ................................................................................................... 3 1.2.2 Objetivos Específicos ........................................................................................ 3 1.3 METODOLOGIA................................................................................................ 3 1.4 ESTRUTURA DO TRABALHO ....................................................................... 5
2 FUNDAMENTAÇÃO TEÓRICA .......................................................6 2.1 RECUPERAÇÃO DE INFORMAÇÃO............................................................ 6 2.1.1 Sistemas de Recuperação de Informação ....................................................... 6 2.1.2 Bibliometria ....................................................................................................... 8 2.1.3 Modelos de Informação Textual ...................................................................... 9 2.2 ALGORITMOS DE TRATAMENTO TEXTUAL........................................ 15 2.2.1 Identificação de termos................................................................................... 16 2.2.2 Remoção de palavras irrelevantes (stopwords) ........................................... 17 2.2.3 Normalização Morfológica (stemming) ........................................................ 17 2.3 ALGORITMOS DE SIMILARIDADE TEXTUAL....................................... 18 2.4 AGENTES .......................................................................................................... 19 2.4.1 Sistemas Multi-Agentes (SMA)...................................................................... 21 2.4.2 Sistema Inteligente de Recuperação de Informações (SIRI) ...................... 26 2.4.3 Mudanças necessárias no SIRI ...................................................................... 27 2.5 DESIGN PATTERNS ....................................................................................... 28 2.5.1 Creation patterns ............................................................................................ 29 2.5.2 Structural patterns.......................................................................................... 30 2.5.3 Behavioral Patterns ........................................................................................ 31
3 DESENVOLVIMENTO .....................................................................34 3.1.1 Diagrama de Componentes ............................................................................ 34 3.1.2 Padrões de Projeto .......................................................................................... 35 3.1.3 Diagramas de Classes ..................................................................................... 36 3.1.4 Diagramas de Seqüência................................................................................. 45

iii
3.1.5 Ferramentas Agregadas ................................................................................. 48 3.1.6 Exemplos da API em uso................................................................................ 52 3.1.7 Testes e Resultados ......................................................................................... 61 3.1.8 Documentação ................................................................................................. 66
4 CONCLUSÕES...................................................................................69
REFERÊNCIAS BIBLIOGRÁFICAS ..................................................71
A CÓDIGO DA APLICAÇÃO UTILIZADA PARA OS TESTES.....75

iv
LISTA DE ABREVIATURAS
ACL Agent Communication Language API Application Program Interface ASCII American Standard Code for Information Interchange BDTD Biblioteca Digital de Teses e Dissertações BSD Berkley System Distribuition CCL Constraint Choice Language EN Inglês FIPA Foundation for Intelligent Physical Agents GPL General Public License HTML Hiper Text Markup Language IDE Integrated Development Environment JDBC Java Database Connectivity KIF Knowledge Interchange Format KQML Knowledge Query Manipulation Language PDF Portable Document Format PT Português RDF Resource Description Framework RI Recuperação de Informação SACI Simple Agent Communication Infrastructure SIRI Sistema Inteligente de Recuperação de Informação SL Semantic Language SMA Sistema Multi-Agentes SQL Structured Query Language SRI Sistema de Recuperação de Informação TCC Trabalho de Conclusão de Curso UML Unified Modeling Language UNIVALI Universidade do Vale do Itajaí URL Uniform Resource Locator XML Extensible Markup Language WWW World Wide Web

v
LISTA DE FIGURAS
Figura 1. Espaço Vetorial...................................................................................................................11 Figura 2. Exemplo de recuperação utilizando lógica. ........................................................................14 Figura 3. Etapas do processo de indexação automática .....................................................................16 Figura 4. Exemplo de stemming ........................................................................................................18 Figura 5. Algoritmo de comparação de texto.....................................................................................19 Figura 6. Forma da KQML ................................................................................................................22 Figura 7. Exemplo de KQML ............................................................................................................22 Figura 8. Exemplo de envio de mensagens ........................................................................................25 Figura 9. Exemplo de recebimento de mensagens .............................................................................25 Figura 10. Exemplo de função para recebimento de mensagens .......................................................25 Figura 11. Arquitetura do sistema multi-agente SIRI ........................................................................26 Figura 12. Tela de inicio do SIRI (AgWebBot) .................................................................................27 Figura 13. Exemplo de Factory Pattern..............................................................................................30 Figura 14: Diagrama de Componentes...............................................................................................35 Figura 15: Diagrama de Classe – Pacote br.siri.api ...........................................................................37 Figura 16: Diagrama de Classe – Pacote br.siri.api.base ...................................................................39 Figura 17: Diagrama de Classe – Pacote br.siri.api.gerenciamento...................................................40 Figura 18: Diagrama de Classe – Pacote br.siri.api.coleta.................................................................41 Figura 19: Diagrama de Classe – Pacote br.siri.api.tratamento .........................................................42 Figura 20: Diagrama de Classe – Pacote br.siri.api.armazenamento .................................................44 Figura 21: Diagrama de Seqüência – Inicia Consulta .......................................................................45 Figura 22: Diagrama de Seqüência – Recuperação de link................................................................46 Figura 23: Diagrama de Seqüência – Inicia Coleta............................................................................46 Figura 24: Diagrama de Seqüência – Inicia Tratamento....................................................................47 Figura 25: Diagrama de Seqüência – Armazenamento......................................................................48 Figura 26. Block Distance ou L1 distance ou City Block distance ....................................................49 Figura 27: Código da menor aplicação possível ................................................................................52 Figura 28: Arquivo de configurações, Banco.properties....................................................................54 Figura 29: Exemplo de Acesso a um domínio URL ..........................................................................56 Figura 30: Exemplo de Acesso a uma pasta local ..............................................................................57 Figura 31: Diagrama ER do armazenamento de documentos ............................................................59 Figura 32: Exemplo da integração API/SIMETRICS........................................................................60 Figura 33: Aplicação utilizada para testes e resultados......................................................................62 Figura 34: Gráfico de tempo médio para recuperação de documentos usando Banco de Dados ......63 Figura 35: Gráfico de tempo médio para recuperação de documentos usando XML........................65 Figura 36: Gráfico comparativo, entre Banco de dados e XML ........................................................66 Figura 37: Exemplo da documentação, Classe AgSRI ......................................................................67 Figura 38: Exemplo da Documentação, detalhamento dos métodos .................................................68

vi
LISTA DE TABELAS
Tabela1. Classificações de SRI ............................................................................................................7 Tabela 2. Stoplist da língua portuguesa .............................................................................................17 Tabela 3: Tabela dos resultados, usando Banco de Dados.................................................................63 Tabela 4: Tabelas dos resultados usando XML .................................................................................64

vii
RESUMO
WEBER, Mathias Henrique. Uma API para criação de aplicações de recuperação de informação. Itajaí, 2005. 86f . Trabalho de Conclusão de Curso (Graduação em Ciência da Computação)–Centro de Ciências Tecnológicas da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2005. Com a popularização da Internet, as tecnologias de Recuperação de Informação (RI) passaram a possuir uma importância estratégica. Muitas pessoas utilizam diariamente os mecanismos de busca a fim de encontrar informações na Internet, fazendo com que as empresas detentoras de tecnologia eficientes de Recuperação de Informação estejam entre as mais valorizadas de nosso tempo. Este projeto apresenta uma proposta para o desenvolvimento de uma API, para auxiliar a construção de sistemas de recuperação de informação baseados na infra-estrutura existente do Sistema Inteligente de Recuperação de Informação (SIRI), desenvolvido em um projeto de pesquisa anterior. No projeto desenvolveu-se uma API baseada em modelos de desenvolvimento padrões, conhecidos como design patterns, para que possa ser compreendida, utilizada e aperfeiçoada por alunos de Ciência da Computação. Englobando tecnologias como sistemas Multi-Agentes, e distribuição de processos a API propõe permitir o desenvolvimento de sistemas de RI eficientes. O texto apresenta a fundamentação teórica sobre sistemas Multi-Agentes, o sistema SIRI bem como as alterações necessárias, a modelagem proposta para a API, o processo de desenvolvimento e os teste e resultados obtidos. Palavras-chave: Recuperação de Informação. Multi-Agentes. Interface de Aplicativo.

viii
ABSTRACT
With the popularization of the Internet, the Information Retrieval technology (IR) began to have strategic importance. Many of people using search mechanisms to find information on the internet, making the enterprises that possess efficient information retrieval technologies to be among the most valuable enterprises of our time. This project presents a proposal to develop an API to assist the construction of information recovery systems based on the existent infra-structure of the system of intelligent of information retrieval (SIRI), developed as a previous research project. The project if considers to develop a API base in development models standards, known as design patterns, so that it can be understood, used and perfected for pupils of Computer science. Contend technologies as systems Multi-Agents, and distribution of processes the API considers to allow the development of systems of IR efficient. The text presents the theoretician foundation used, the SIRI system, the proposed model to the API, the development process and the gotten test and results. Keywords: Information Retrieval. Multi-Agent. Application Interface.

1 INTRODUÇÃO
De modo geral, nos cursos de graduação da área de Ciência da Computação, a área de
Recuperação de Informações (RI) não é abordada. Acredita-se que isto se deve em parte pela pouca
ênfase dos currículos acadêmicos à área, e também pela falta de ferramentas ou métodos
apropriados para o estímulo e aquisição de conhecimento por parte dos alunos. Isto surpreende, pois
segundo Wives (2001) a Recuperação de Informação é uma tecnologia que é citada pela primeira
vez em artigo científico em 1950 por Calvin Moores.
Desde sua primeira publicação, a área de RI vem se tornando importante para a sociedade
científica, principalmente no meio acadêmico. Segundo Baeza-Yates e Ribeiro(1999), o principal
objetivo das técnicas de RI é tentar descobrir documentos ou textos que possam conter informações
relevantes.
Com a evolução da área surgiram teorias e métodos capazes de realizar a recuperação de
documentos textuais com eficiência. Divide-se normalmente o processo em coleta de documentos;
tratamento do texto, indexação e armazenagem; e recuperação através de pesquisas na base de
documentos indexados. A etapa de tratamento do texto, geralmente é a que apresenta maiores
desafios, segundo Lichtnow e Loh (2003), existem três passos essenciais para o tratamento de textos
em uma recuperação de informações que são: (1) Identificação de palavras; (2) Eliminação de
palavras que ocorrem com muita freqüência (stopwords); (3) Eliminação de prefixos e sufixos das
palavras (stemming).
Com a popularização da Internet, a recuperação de informações disponíveis no World Wide
Web (WWW) ganhou uma importância estratégica e tem sido foco freqüente de pesquisas. Segundo
Chen (1994), a sobrecarga de informação disponíveis na Internet gera muitos problemas que
dificultam a recuperação de documentos. Conforme Menczer (2003), os sistemas de recuperação de
informação atualmente tentam alcançar o “estado da arte” utilizando programas automáticos
chamados de robots ou crawlers para constantemente recuperar grandes quantidades de
informações na Web.
Apesar de existirem ferramentas para a recuperação de informações disponíveis aos
desenvolvedores de sistemas, estas não possuem nenhum intuito de auxiliar na aprendizagem da
tecnologia. Na maioria das vezes são voltadas apenas para usuários experientes, não fornecem

2
documentações que explicam ao usuário iniciante como utilizar a ferramenta ou ainda como
desenvolver uma ferramenta semelhante.
Este projeto promoveu o desenvolvimento de uma infra-estrutura tecnológica para estimular
o aprendizado dos alunos sobre técnicas de Recuperação de Informação no curso de Ciência da
Computação. Busca-se alcançar este objetivo através do desenvolvimento de uma API (Application
Program Interface) que possibilite aos alunos criarem pequenos sistemas de RI, baseados no
Sistema multi-agente SIRI (Sistema Inteligente de Recuperação de Informações) desenvolvido por
Raabe e Weber, (2004). Outra preocupação deste projeto foi a utilização de técnicas para a criação
de APIs adotando-se padrões de projeto conhecido com design patterns. Desta forma cada aluno
pode programar uma aplicação de RI diferente.
Foi adotada uma abordagem multi-agente principalmente pela flexibilidade que ela permite
no desenvolvimento e alteração do comportamento dos agentes em uma comunidade, pela
adequação ao processo de recuperação de documentos distribuídos (como na Internet), e também
por este trabalho estar fundamentado no sistema SIRI o qual já demonstrou a viabilidade de uma
comunidade de agentes construídos sob a plataforma Simple Agent Communication Infrastructure
(SACI) (HUBNER & SICHMAN, 2000) para a realização da tarefa de recuperar documentos
textuais na Internet.
Alguns aspectos do sistema SIRI foram adaptados para que aplicações genéricas pudessem
ser desenvolvidas com, por exemplo, re-estruturar a base de documentos indexados.
1.1 PROBLEMATIZAÇÃO
1.1.1 Formulação do Problema
A construção de aplicações de recuperação de informação está entre as competências mais
importantes de nossa época. No entanto, nos cursos de graduação de Ciência da Computação, a área
de Recuperação de Informação (RI) muitas vezes é ignorada ou então apresentada de forma muito
sucinta. Acredita-se que em grande parte, a falta de aplicações que facilitem o desenvolvimento de
sistemas de recuperação de informação (SRI) colabora para esta situação.

3
1.1.2 Solução Proposta
Em 2004 foi desenvolvido na UNIVALI um projeto de pesquisa que construiu a infra-
estrutura tecnológica para o desenvolvimento de um sistema captura e indexação de documentos na
Web. O projeto, denominado SIRI (Sistema Inteligente para Recuperação de Informações) foi
utilizado para capturar e indexar os documentos do domínio cttmar.univali.br, possibilitando a
construção de um sistema de Recuperação de Informações neste domínio.
A solução proposta é disponibilizar as funcionalidades da ferramenta desenvolvida através
de uma API (Application Program Interface) visando motivar e facilitar a construção de pequenas
aplicações de RI, auxiliando desta forma a difusão das teorias e práticas da área nos cursos de
Ciência da Computação.
1.2 OBJETIVOS
1.2.1 Objetivo Geral
Conceber e implementar uma API para o sistema SIRI, visando apoiar o desenvolvimento de
pequenas aplicações de Recuperação de Informação.
1.2.2 Objetivos Específicos • Identificar e realizar as alterações necessárias no sistema SIRI;
• Definir e implementar algoritmos de tratamento de texto e disponibilizá-los através da
API;
• Documentar a API no formato padrão utilizado pela linguagem JAVA; e
• Construir um conjunto de mini-aplicações modelo para testes e referência aos alunos.
1.3 Metodologia
A etapa de TCC I foi iniciada com o levantamento bibliográfico sobre Recuperação de
Informação, seus algoritmos de indexação e comparação textual, realizando-se testes com estes
algoritmos para viabilizá-los, classificá-los, e determinar quais seriam utilizados. Com base neste
primeiro estudo foi elaborada uma estrutura de armazenamento dos documentos a serem
recuperados. Em paralelo com esta etapa foi realizado um estudo sobre sistemas multi-agentes,
onde foi apresentada a plataforma SACI, e foi detalhado o sistema SIRI. Após o levantamento

4
bibliográfico e os testes dos algoritmos foi realizada a modelagem do sistema proposto. As etapas
da metodologia são apresentadas á seguir.
• Pesquisa sobre Recuperação de Informação: Foi realizado, pesquisa em artigos e livros
sobre técnicas de recuperação de informação utilizadas por pesquisadores da área, e
alaborou-se um documento textual sobre temas e vivencias de projetos sobre a área de RI;
• Implementação de técnicas de IR: Nesta atividade foi realizado um levantamento
bibliográfico em artigos, livros e sites de internet da área de IR a fim de encontrar
algoritmos de comparação e indexação de documentos. Nesta atividade foram realizados
experimentos de tratamento textual;
• Pesquisa sobre sistemas multi-agentes: Foram feitas pesquisas em livros e tutoriais sobre
sistemas multi-agentes para esclarecimento da tecnologia e plataformas desenvolvidas para
suportar estes tipos de programas;
• Descrever a plataforma SACI: Foram realizados estudos para descrever a plataforma SACI e
os tópicos abordados sobre a plataforma foram: a funcionalidade, arquitetura, formas de
monitoramento de agentes, troca de mensagens e a ferramenta para iniciar os agentes;
• Descrever o sistema SIRI: Baseando-se no sistema SIRI, já implementado foi apresentado à
estrutura da comunidade multi-agentes e a forma de comunicação entre os agentes do
sistema para a realização da tarefa;
• Boas práticas para o desenvolvimento de APIs: Foi estudada a tecnologia de Design Patterns
para melhor descrever as formas de desenvolvimento da API;
• Identificar as Mudanças necessárias no sistema SIRI: Foi analisado o sistema SIRI para
levantamento das alterações necessárias para disponibilização de suas funcionalidades em
uma API;
• Modelagem do projeto: Foram elaborados diagramas de classes, componentes e seqüência
para o sistema proposto;
• Desenvolvimento: Foram desenvolvidas ao longo da segunda etapa as classes para o
funcionamento da API, utilizou-se a IDE (Integrated Development Environment) eclipse
para facilitar o desenvolvimento;

5
• Documentação: A documentação proposta em JAVADOC foi elaborada no decorrer do
desenvolvimento e aprimorada ao final do mesmo, gerando um documento PDF (Portable
Document Format) e uma pasta contendo a versão da documentação em HTML. e
• Testes e Resultados: Os testes foram realizados nas dependências do laboratório de TCCII,
na UNIVALI (Universidade do vale do Itajaí). Utilizando-se de uma máquina da instituição
e um computador pessoal, gerando com estes testes um capítulo deste documento.
1.4 Estrutura do trabalho
Este documento está estruturado em quatro capítulos. O Capítulo 1, Introdução, apresentou
uma visão geral do trabalho. No Capítulo 2, Fundamentação Teórica, é apresentada uma revisão
bibliográfica sobre: recuperação de informação, assim como uma análise a respeito de algoritmos de
tratamento e similaridade de textos. Nesse capítulo, também é feita uma descrição sobre Agentes. O
Capítulo 3 apresenta o projeto detalhado do sistema que foi desenvolvido, incluindo sua
especificação e a sua modelagem em UML (Unified Modeling Language). Na modelagem UML,
são apresentados diagramas de componentes, seqüência e de classe. O capítulo também discute
como foi implementado e testado o sistema proposto, apresentando a metodologia e ferramentas
utilizadas no desenvolvimento. Concluindo, no Capítulo 4, apresentam-se as considerações finais,
onde são abordados os resultados preliminares e expectativa sobre o projeto.

2 FUNDAMENTAÇÃO TEÓRICA
2.1 Recuperação de Informação
Segundo Cardoso (2000), recuperação de informação é uma área da Ciência da Computação
que lida com armazenamento automático e recuperação de documentos que são de grande
importância devido ao uso da língua para a comunicação.
E com a invenção da escrita surgiram muitos avanços na aquisição do conhecimento para o
homem, possibilitando-a repassar seu conhecimento através dos tempos. Com o aumento da
utilização da escrita, os acervos bibliográficos foram aumentando e necessitando cada vez mais
organização para a recuperação destes documentos, isso fez surgir maneiras de armazenagem e
catalogação de livros e textos. Porém, segundo Wives (2002), o termo “Recuperação de Informação
(RI)” só foi utilizado cientificamente em 1950 por Calvin Moores, que defendeu sua teoria de que a
RI é uma atividade que envolve os aspectos de descrição de informação (indexação e padronização)
e sua especificação para busca.
Desde a publicação da teoria de Calvin Moores, a área de RI evolui muito e novas teorias
surgiram. Uma das novas teorias é citada por Gonzáles e Lima (2001) que defende que um sistema
de RI consiste na busca de documentos relevantes a uma dada consulta que expressa a necessidade
do usuário. Estes autores ainda ressaltam que um documento pode ser formado de textos, vídeos,
sons, imagens e outros tipos de dados.
2.1.1 Sistemas de Recuperação de Informação
A classificação de Sistemas de Recuperação de Informação (SRI) segundo Frakes e Baeza (1992),
divide-se em modelo conceitual, estrutura de arquivos, operação de consultas, operações de termos,
documentos e hardware, como é apresentado na Tabela1.

7
Existem diversas classificações de Sistemas de Recuperação de Informação (SRI). Neste
trabalho adotou-se a classificação proposta, a qual possui quatro tipos de SRI: (i) Bibliográfico; (ii)
Textual; (iii) Visual; e (iv) Biblioteca Digital, descritos a seguir.
2.1.1.1 Sistema de recuperação de informação bibliográfica
O SRI bibliográfico é o mais antigo. Este tipo de sistema consiste no armazenamento de
atributos de uma obra ou documento a ser armazenado, esta documentação sobre o armazenamento
de documentos é feito em forma de um catálogo.
Ao executar uma consulta em um SRI bibliográfico o usuário recebe apenas a referência dos
documentos relevantes, baseando-se nos atributos pré-armazenados.
Tabela1. Classificações de SRI
Modelo Conceitual
Estrutura em Arquivos
Operações da Consulta
Operações dos Termos
Operações do documento
Hardware
Booleano Arquivo seqüencial
Gabarito Haste Análise gramatical
vonNeumann
Booleano Estendido
Arquivo invertido
Análise gramatical
Peso Exposição Paralelo
Probabilístico Assinatura Booleano Enciclopédia Cluster Recuperação de Informação Específico
Busca em Cadeia
Pat Tree Stoplist Rank Disco Ótico
Gráficos Randômico Máscara do Campo
Espaço vetorial Picados
Cluster
Truncamento
Atribuição de Identificadores
Disco Magnético
Fonte: Adaptado de Frakes e Baeza (1992)

8
2.1.1.2 Sistema de recuperação de informação textual
Como o próprio nome diz este tipo de sistema trata basicamente de informações textuais
(ASCII), e com a utilização de filtragem dos dados é possível tratar outros formatos que contenham
textos, figuras e tabelas que possuam aspecto de documentos, como páginas web, arquivos do tipo
DOC e PDF.
Este tipo de sistema é o foco deste projeto, por poder ser implementado de forma genérica e
com âmbito educacional, e com isso este tipo de SRI será tratado com maior ênfase na Seção 2.1.3 .
2.1.1.3 Sistema de recuperação de informação visual
Os SRI visuais são especializados na recuperação e consultas de imagens, porém os
primeiros sistemas deste tipo utilizavam-se de descrições textuais das imagens, e segundo CHANG
(1997), cada pessoa compreende uma figura maneira diferente (dependendo do contexto).
Segundo Wives (2002), em um sistema que manipule imagem o ideal é que o usuário
descreva sua consulta utilizando imagens, assim o sistema poderia recuperar informações muito
mais relevantes, contudo isso exige a utilização de técnicas especificas cuja maioria pode ainda não
existir ou não ser funcional.
2.1.1.4 Bibliotecas Digitais
Wives (2002) define Biblioteca digital como um sistema que não possui dimensão física,
utilizando-se dos meios de comunicação, principalmente internet, para que funcione.
Como exemplo, pode ser encontrado a biblioteca digital “Alexandria Digital Library”, que
disponibiliza matérias georeferenciais. Este é um sistema de busca de informações geográficas bem
completo, possibilitando que o usuário visualize os pontos encontrados em um mapa. Outro
exemplo é visto em BDTD-UFRGS (2005), com a implementação da biblioteca chamada de
Biblioteca Digital de Teses e Dissertações (BDTD), o autor do artigo ressalta a utilização do
sistema comentando que “Implantada no final de 2002, a BDTD-UFRGS totaliza 1127 documentos
incluídos e 10.001 acessos até abril de 2003.” BDTD-UFRGS (2005).
2.1.2 Bibliometria
Segundo Zanasi (1998), a bibliometria é uma sub-área da biblioteconomia, e é representada
por resultados de uma busca realizada por um SRI que pode ser avaliado através de métricas.

9
Wives (2002) complementa afirmando que em teoria as métricas poderiam ser utilizada nos SRI
para que o usuário ficasse sabendo se sua consulta funcionou como deveria, porém para que tal
resultado seja obtido é necessário um vasto conhecimento sobre a coleção de documentos.
Um SRI automático não possui capacidade para adquirir um conhecimento necessário para a
aplicação de métricas. Contudo existem bibliotecas de documentos (coleções de referencias) que
servem para estudos acadêmicos e que possuem o conhecimento necessário sobre os documentos,
podendo-se medir os resultados obtido em uma consulta por um SRI.
Os estudiosos como Korfhage (1997) e Kowalski (1997) dentre outros, defendem como
principais técnicas de métricas de SRI recall, precision, fall-out e effort, e dentre estas Wives
(2002) sita recall e precision como as mais utilizadas.
• Recall: mede o número de documentos relevantes entre os existentes na base de
dados, porem o usuário ou sistema que esta avaliando necessita conhecer a
quantidade de documentos relevantes para a sua consulta, o que geralmente não é de
conhecimento por parte do SRI;
• Precision: é o grau de precisão de uma consulta, e é capaz de medir o esforço
realizado pelo usuário para analisar os documentos recuperados, esta métrica pode
ser utilizada em interações com o usuário a fim de filtrar os documentos relevantes;
• Fallout: leva em consideração a quantidade de documentos irrelevantes contidas na
base de dados, permitindo a identificação do número de documentos relevantes da
consulta quando o volume de documentos da base varia; e
• Effort: mede o esforço do usuário na interação como sistema, buscando indicar a
quantidade de interações que o usuário ainda deverá fazer para alcançar cem por
cento de precisão na sua consulta.
2.1.3 Modelos de Informação Textual
Um SRI textual trabalha com documentos em forma de textos, diferentemente dos Bancos
de dados relacionais as informações não estão de forma tabulada. Segundo Wives (2002), o
documento textual é composto por palavras que são consideradas os atributos dos textos, e elas que
destingem um texto de outro. A consulta em um SRI textual é feita por palavras, e com isso a

10
verificação de documentos relevantes, é feita de forma a se comparar as palavras semelhantes nos
documentos recuperados.
Contudo segundo Chen (1994), a comparação de palavras em documentos nem sempre
retorna um grau de similaridade aceitável, recuperando assim documentos dos mais diversos
assuntos. Buscando solucionar este problema, foram desenvolvidas diversas técnicas de
similaridade de textos, e também diversos modelos conceituais de recuperação que serão
apresentados a seguir.
2.1.3.1 Modelo Booleano
O modelo booelano utiliza a lógica de boole para expressar e organizar uma consulta que o
usuário deseja fazer, disponibilizando para uso os operadores de negação (not), intersecção (and) e
união (or).
O usuário que deseja fazer uma consulta, pode utilizar diversas formas de combinação
booleana já conhecidas para expressar sua consulta, podendo excluir, incluir ou negar conjuntos de
documentos que contenham as palavras utilizadas para uma consulta.
Porém, para Wives (2002), esta técnica deixa de considerar a relevância das palavras no
documento, pois uma palavra colocada no título ou resumo de um artigo contém uma importância
maior do que uma palavra no corpo do mesmo.
2.1.3.2 Modelo espaço-vetorial
Segundo Wives (2002), o modelo espaço vetorial foi desenvolvido por Geral Salton que
durante muito tempo contribui para a área de RI. No modelo, o documento e a consulta são
compostos por um vetor de termos e seus respectivos pesos (relevâncias). Cada peso é um valor
entre zero e um. Salton (apud WIVES, 2002), cita que existem diversas formas de se calcular o peso
de um termo no documento, contudo o mais utilizado é a freqüência que um termo aparece.
Cada elemento do vetor pode ser considerado uma posição dimensional, e podendo ser
representada em um gráfico como demonstra a Figura 1.

11
Figura 1. Espaço Vetorial
Fonte: Wives (2002)
Salton (apud WIVES, 2002) descreve a fórmula para calcular a relevância de um documento
em uma consulta realizada por um usuário, que é apresentada conforme a Equação 1.
Equação 1
Sendo:
• Q representa o vetor de termos da consulta;
• D é o vetor de termos do documento;
• Wqk são os pesos dos termos da consulta;
• Wdk são os pesos dos termos do documento; e
• N é o número de elementos;

12
Depois de calculado o grau de similaridade entre os termos é possível apresentar os
resultados em forma de ranking para o usuário.
2.1.3.3 Modelo Estatístico
Segundo Cardoso (2000), o modelo estatístico descreve documentos considerando pesos
binários, que representam à presença de termos. A principal ferramenta matemática do modelo
estatístico é o teorema de Bayes (VAN RIJSBERGEN (1979).
Por este modelo ser baseado em probabilidade é necessário calcular a probabilidade de um
termo ser relevante à consulta, e sua probabilidade de não ser relevante a consulta. Segundo
Cardoso (2000) através da Teoria de Bayes é possível chegar à equação apresentada na Equação 2.
Sendo:
• Xi é um valor antre zero e um;
• Wqi é definido por “log Rqi (1-Sqi) / Sqi (1 – Rqi)
• R1i é a probabilidade de um termo de indexação “i” ocorra no documento, dado que
o documento é relevante para a consulta “q”; e
• Sqi é a probabilidade de um termo de indexação “i” ocorra no documento, dado que
o documento não é relevante para a consulta “q”;
2.1.3.4 Modelo Difuso (Fuzzy)
O modelo difuso permite trabalhar com graus de incerteza, como em outros modelos este
também apresenta seus termos em forma de vetor, contudo o conceito relacionado à relevância
muda, pois uma vez que o modelo difuso sempre terá um valor para todos os termos existentes,
Equação 2

13
sendo que um termo que terá um grau de relevância menor tendera a um valor próximo de zero, e
um valor extremamente importante tendera a um. Definido o intervalo de valores entre zero e um.
Wives (2002) classifica métodos para o cálculo de relevância que podem ser utilizados no
modelo difuso, que são: freqüência absoluta; freqüência relativa; freqüência de documentos; e
freqüência inversa de documentos;
2.1.3.5 Modelo da busca direta
Este modelo consiste em procura de textos direto, buscando padrões em documentos. A
consulta neste modelo é normalmente feita através de termos ou expressões regulares. A Consulta
consistem em procurar as palavras desejadas diretamente nos textos.
Segundo Frakes e Baeza (1992), Esta técnica é denominada de string search e sua utilização
é aconselhada quando se possui uma pequena coleção de documentos, como em sistemas de
arquivos DOS/UNIX, realizando uma busca seqüencial nos textos.
2.1.3.6 Modelo de Aglomerados (clustering model)
O modelo de aglomerados consiste em agrupar os documentos e classificá-los em grupos
dividindo-os por assuntos abordados. Segundo Van Rijsbergen (1979), um documento com objetos
semelhantes e relevantes a um mesmo assunto tende a ficar em um mesmo grupo.
Estes grupos podem ser ordenados de forma hierárquica, possibilitando assim ao usuário a
escolha da profundidade e nodos de maior relevância a sua consulta. Uma vez feita a consulta, é
retornado para o usuário os documentos pertencentes ao mesmo grupo que a consulta foi
classificada.
Segundo Wives (2002), um dos maiores problemas deste modelo é identificar o grupo de
documentos mais coesos, sendo que a cada alteração ou inclusão de um documento este deve ser
analisado e classificado nos grupos existentes.
2.1.3.7 Modelo lógico
No modelo lógico os métodos e teorias são baseados em lógicas matemáticas para modelar a
recuperação de informação. Para que o modelo lógico funcione é necessário que o documento seja

14
modelado de forma predicativa, o que exige um enorme trabalho de modelagem atrelado a
semântica de recuperação.
Os documentos modelados em forma de predicativos possuem um formato como P implica
em Q, como demonstra Wives (2002) na Figura 2.
Figura 2. Exemplo de recuperação utilizando lógica.
Fonte: Wives (2002)
Nesta figura percebe-se a uma consulta “q” feita pelo usuário, em quatro documentos
existindo também uma base de conhecimento de sinônimos. Nesta consulta esta sendo pedido a
recuperação dos documentos cuja relevância das palavras “recuperação” e “informação”, seja
agradável para o usuário.
É percebida em seqüência a comparação feita nos quatro documentos, no primeiro
documento onde ele encontra d1=q, mostrando-se cem por cento de similaridade do documento
com a consulta. No documento dois ao perceber que o documento é diferente da consulta é feito
uma busca por um sinônimo, da palavra “recuperação”, na base de conhecimentos, e em seguida
mostrando que o documento dois é igual a consulta depois de uma transformação, mostrando um
grau de relevância de oitenta e cinco por cento de relevância. No documento três é apresentado uma
diferença na comparação, em referencia ao documento dois, depois da primeira transformação da
consulta, e então a heurística tenta fazer mais transformações até encontrar um valor relevante ou
não encontrar mais a possibilidade de transformações, assim como é demonstrado no documento
quatro.

15
2.1.3.8 Modelo Contextual
A grande maioria dos modelos apresentados até agora, fazem a relação entre o documento e
o termo, contudo muitas vezes existem termos similares que poderiam estar representando o mesmo
assunto abordado. No modelo contextual, uma vez que o termo é considerado em um contexto que
possuem sinônimos, são localizados os documentos dentro do contexto do termo e não apenas os
documentos onde os termos, exatamente escritos, estão presentes.
Contudo, segundo Wives (2002), existem várias ferramentas e técnicas desenvolvidas para
minimizar os problemas causados por consultas simples, porém nem todos os SRI utilizam este tipo
de recurso e por muitas vezes o próprio usuário quando possui este recurso não o usa.
A etapa critica deste modelo é a definição dos contextos e sinônimos para os termos do
documento, onde um termo pode pertencer a vários contextos com graus de relevância
diferenciados. Contudo, uma vez que definido os contextos desejados, o processo automático de
recuperação e indexação consegue classificar os documentos.
2.2 Algoritmos de Tratamento Textual
As etapas comumente encontradas em um SRI para o tratamento de textos são: Identificação
de termos; remoção de palavras irrelevantes; e normalizações morfológicas; Wives (2002)
demonstra isso na Figura 3.

16
Figura 3. Etapas do processo de indexação automática
Fonte: Wives (2002)
2.2.1 Identificação de termos
A identificação de termos é a separação dos termos de um documento, retirando-se
caracteres que não tenham significados ou que façam parte da formatação do texto, como por
exemplo, tags de HTML em uma página na internet, ou caracteres especiais para destacar uma
frase. Para esta identificação de termos pode ser utilizado um analisador léxico no texto a fim de
identificar os termos significativos.
Salton (1983) menciona que é possível aplicar uma validação de seqüência de caracteres,
verificando-se os termos e comparando com um dicionário, a fim de restringir ou corrigir erros
ortográficos presente no texto, esta técnica chama-se dicionary lookup.
Por outro lado existe o problema de palavras compostas que uma vez separadas perdem o
sentido inicial. Para tentar minimizar este problema pode-se armazenar as palavras de ambas as
formas, e solicitar ao usuário de que forma deseja recuperar, ou mesmo utilizar um dicionário para
tentar traduzir o contexto da palavra composta, substituído-a por termos simples com o mesmo
sentido.

17
2.2.2 Remoção de palavras irrelevantes (stopwords)
As stopwords são palavras que aparecem frequentemente nos documentos, tornando assim o
processo de recuperação ineficiente, pois são palavras que não fazem diferença no momento de
classificação dos documentos. Estas palavras normalmente fazem parte da estrutura do texto, não
possuindo relevância para seu significado.
Como exemplos, mencionam-se palavras da língua portuguesa como artigos e preposições,
por exemplo, “um”, “uma”, “desde”, “de”, etc.
As stoplists são listas de stopwords, e existem listas padrões para os principais idiomas,
como exemplo, a Tabela 2 apresentada em Oracle (2005).
Tabela 2. Stoplist da língua portuguesa
Stopword A com elas muito próximo sobre Abaixo como ele não qual talvez adiante contra eles ninguém quando todas Agora debaixo em nós quanto todos Ali demais entre nunca que vagarosamente Antes depois eu onde quem você Aqui depressa fora ou se vocês Até devagar junto para sem Atrás direito longe por sempre bastante e mais porque sim Bem ela menos pouco sob
Fonte: Oracle (2005)
2.2.3 Normalização Morfológica (stemming)
Stemming, consiste no tratamento dos termos encontrados em um documento a fim de retirar
os prefixos e sufixos das palavras para torná-las termos mais genéricos com o objetivo de ampliar a
consulta feita por um assunto. Conforme afirma Wives (2002), “As características de gênero,
número e grau das palavras são eliminadas. Isso significa que várias palavras acabam sendo
mapeadas para um único termo, o que aumenta a abrangência das consultas.”. Um exemplo pode ser
visualizado na Figura 4.

18
informalmente -> informal -> formal
Figura 4. Exemplo de stemming
Segundo afirma Frakes e Baeza (1992), esta técnica pode reduzir a quantidade de palavras
indexadas na base de dados em 50%, além de aumentar a precisão na consulta. Em contrapartida
Wives (2002), defende a idéia de que o melhor é manter os termos na forma em que foram
encontrados, e com isso passar a possibilidade e responsabilidade para o usuário no momento da
elaboração da consulta.
Já Riloff (apud WIVES 2002), possui uma opinião intermediária afirmando que,
dependendo do contexto utilizado a técnica pode se tornar um problema visto que a variação
morfológica extremamente importante para a discriminação entre documentos.
2.3 Algoritmos de similaridade textual
Algoritmos de similaridade textual permitem a comparação entre dois textos ou strings.
Estes algoritmos podem ser muito úteis para construção de SRI, principalmente na etapa de
classificação dos documentos recuperados (ranking). Desta forma, julga-se conveniente explorar
estes algoritmos e a possibilidade deles estarem sendo disponibilizados em um ambiente integrado
onde a API esteja presente. Desta forma, a API fornece o suporte as tarefas de captura e indexação e
as tarefas de classificação e recuperação podem utilizar-se destes algoritmos.
Existem projetos para tentar elaborar técnicas para cálculo de relevância e comparação de
textos, como o projeto proposto por Lynch (1995), que utiliza técnica fuzzy para tentar comparar
dois textos, o algoritmo apresentado no projeto é apresentado na Figura 5.

19
Figura 5. Algoritmo de comparação de texto
Outro projeto encontrado é chamado de “SIMETRICS” e é desenvolvido pelo grupo
processamento de linguagem natural do departamento de Ciência da Computação na Universidade
de Sheffield, o projeto é apresentado e mantido no repositório sourceforge.net, e é totalmente
código aberto com licença GPL(General Public License). Os algoritmos do SIMETRICS forma
agragados a API conforme detalhado na Seção 3.1.5.2.
2.4 Agentes
Conforme Jaques (1999), a área inteligência artificial tem buscado conceber softwares que
simulem capacidades inteligentes dos seres humanos, tais como raciocínio, comunicação em
linguagem natural e aprendizagem. Os agentes caracterizam-se por autonomia, colaboração,
autodeterminação, etc.
Um agente interfere no ambiente para solucionar um problema, tendo como variáveis o
contexto em que está as reações dos outros agentes. Entretanto, isto só será possível caso os agentes
se conheçam, e se comuniquem entre si (JAQUES, 1999). Os agentes podem possuir características
e objetivos próprios, alterar informações que possuem dos demais, além de reconhecer
modificações internas do ambiente.
int compare (char *s1, char *s2) { register int i, j, k, x, y; long n; int temp; if ((!s1[0]) || (!s2[0])) return 0; if (!strcmp(s1, s2)) return 100; n = i = j = k = x = y = 0; for (i=0; s1[i]; i++) { x = i; for (j=0; s2[j]; j++) { y = j; k = 0; while ((s1[x] && s2[y]) && (s1[x] == s2[y])) { k++; n += (k*k); x++; y++; } } } n = (n * 20) / (strlen (s1) * strlen (s2)); if (n > 100) n = 100; return n; }

20
Atualmente existem várias definições para o termo agentes. Moulin e Chaib-Draa (1996)
afirmam que basicamente existem duas formas: agentes artificiais (módulos de software) e agentes
humanos (usuários). Os agentes artificiais devem agir conforme o ambiente no qual está inserido,
comunicar-se com os demais agentes, além de possuir comportamento próprio, incluindo
coabitação, cooperação e distribuição.
De forma prática, os agentes precisam notar e interpretar informações e mensagens
recebidas, desenvolver raciocínio sobre suas crenças, realizar tomada de decisão e planejamento que
habilitarão novos procedimentos (ex: envio de novas mensagens).
Segundo Jaques (1999), os agentes são classificados pela forma que resolve seus problemas
que são: reativo (1), cognitivos (2), e de software (3).
1. Agentes Reativos: Suas ações são provocadas pelo resultado de uma outra ação já
realizada. Seu comportamento baseia-se no modo estímulo-resposta, que inibe a
recordação de atividades realizadas anteriormente e as que serão efetuadas no futuro.
2. Agentes Cognitivos: A estes agentes estão atribuídas características como crendices,
conhecimento, desejos, intenções, e obrigações. Logo, agentes cognitivos
diferenciam-se por possuir atitudes, estados mentais e filosofias próprias; tendo a
capacidade de compreender o funcionamento dos agentes que o cercam, vivendo em
sociedade com organização, cooperação e comunicação.
3. Agentes de Software: Os agentes de software são constituídos de partes de software
responsáveis pela execução de uma atividade de acordo com o ambiente que o
envolve. À medida que este ambiente sofre alguma mutação, o agente desenvolve
sua própria adaptação. Caracteriza-se por possuir autonomia, habilidade social,
reatividade, pro atividade, continuidade temporal (WOOLDRIDGE e JENNINGS,
1995). Estes agentes estão presentes em diversas aplicações como: gerenciamento de
redes e sistemas, filtragem e tratamento de e-mails, busca por informações na web,
agendamento de tarefas em grupos colaborativos, comércio eletrônico e
monitoramento de ações do usuário.

21
2.4.1 Sistemas Multi-Agentes (SMA)
Segundo Wikipedia(2005), na ciência da computação, um SMA é um sistema composto por
diversos agentes com capacidade mutua de interação. A interação pode ser na forma de passagem
de mensagens ou alteração no contexto comum.
Segundo Jennings (1996) por se tratarem de uma subárea da Inteligência Artificial
Distribuída, os sistemas multi-agentes têm por objetivo investigar o comportamento de um conjunto
de agentes autônomos, buscando solucionar um determinado problema.
Segundo Oliveira (apud MARQUES e RAABE, 2004), as sociedades de agentes podem ser
classificadas quanto ao tipo de agentes imersos (homogêneos ou heterogêneos), quanto à migração
de agentes (abertas ou fechadas), e quanto à presença de regras de comportamento (baseadas em leis
ou não). Entretanto, para um funcionamento cooperativo, numa sociedade, são necessários meios de
comunicação. Estes podem ser diretos ou indiretos, e se diferem pelo fato dos agentes responsáveis
pela troca de informações conhecerem-se ou não.
2.4.1.1 Linguagens de Comunicação entre Agentes (ACL)
Para que aconteça compreensão entre os agentes de um SMA, faz-se necessário a utilização
de uma linguagem compreensível. De encontro a esta necessidade, é aplicada uma Agent
Communication Language (ACL), ou Linguagem de Comunicação entre Agentes, que é uma
espécie de formalismo concebido a fim de codificar as mensagens trocadas entre agentes
independentemente da linguagem de programação utilizada pela aplicação. Uma ACL padronizada
tem sua sintaxe e semântica definidas publicamente de forma independente de implementação
concreta, arquitetura e ambiente computacional onde está o Sistema Multi-Agente. Atualmente há
dois padrões de ACL conceituados: o KQML (Knowledge Query and Manipulation Language) e o
FIPA (Foundation for Inteligent Physical Agent).
2.4.1.1.1 KQML
O KQML (Knowledge Query and Manipulation Language) é uma linguagem de
comunicação padrão para compartilhamento de conhecimentos entre sistemas baseados em
conhecimentos ou agentes inteligentes. Os conhecimentos são transportados através de mensagens,
chamados de atos performativos, que são acompanhados por parâmetros, como mostra a Figura 6.

22
( < performativo > { : < parâmetro > < expressão > } * )
Figura 6. Forma da KQML
As mensagens em KQML são estruturadas em 3 níveis com parâmetros distintos:
• Nível do Conteúdo: contém o conhecimento a ser transportado ( :content);
• Nível de Mensagem: identificação do ato performativo e características do
conteúdo ( :ontology, :language, :force); e
• Nível de Comunicação: identificação do emissor, destinatário, sessão ou
diálogo em curso ( :sender, :receiver, :in-reply-to, :reply-with);
A Figura 7 demonstra um exemplo da linguagem KQML, onde um agente comercial solicita
um pedido de produção para a fábrica.
( ask
: sender AgComercial (1)
: content (Pedido fechado com o cliente(1))
: receiver AgProdução
: reply-with AgComercial )
Figura 7. Exemplo de KQML
2.4.1.1.2 FIPA
A FIPA (Foundation for Inteligent Physical Agents) é uma fundação responsável pela
criação de padrões para a implementação da comunicação entre agentes. Sua versão mais atual, o
FIPA 2000, é composta por 40 documentos distintos. O FIPA-2000 estabelece 4 linguagens padrão
que representam o conteúdo das mensagens trocadas entre os agentes: SL (Semantic Language),
KIF (Knowledge Interchange Format), CCL (Constraint Choice Language), e RDF (Resource
Description Framework). Dentre estas se destaca a SL por representar estados mentais (crenças,
desejos, incertezas e intenções) e ações (atos), através de uma lógica modal.

23
2.4.1.2 Plataforma de desenvolvimento
Para desenvolver um agente é necessário se utilize uma plataforma para estabelecer a
comunicação e organização entre os agentes e suas comunidades.
Existem diversas plataformas para o desenvolvimento de agentes, entre elas pode-se citar:
FIPA-OS, JADE, ZEUS, JAT Lite entre outros. Contudo para este projeto foi adotada a plataforma
Simple Agent Communication Infrastructure (SACI), por adotar a linguagem KQML, e ser de fácil
utilização, e pela afinidade acadêmica com os autores da ferramenta.
2.4.1.2.1 SACI (Simple Agent Communication Infrastructure)
Segundo Raabe e Weber (2004) o SACI é uma ferramenta que facilita a comunicação entre
os agentes, fornecendo uma infra-estrutura básica para desenvolvimento de Multi-Agentes.
Conforme Hubner(2003), o SACI foi desenvolvido com base na especificação KQML, possuindo as
seguintes características principais:
• Os agentes utilizam KQML para se comunicar. Há funções para compor, enviar e
receber mensagens KQML;
• Os agentes são identificados por um nome. As mensagens são transportadas
utilizando-se somente o nome do receptor, sua localização na rede é transparente;
• Um agente pode conhecer os outros por meio de um serviço de páginas amarelas;
• Agentes podem registrar seus serviços no facilitador e perguntá-lo sobre que serviços
são oferecidos por quais agentes;
• Os agentes podem ser implementados como applets e terem sua interface em um
website;
• Os agentes podem ser iniciados remotamente; e
• Os agentes podem ser monitorados. Os eventos sociais (entrada na sociedade, saída,
recebimento ou envio de mensagens) podem ser visualizados e armazenados para
análise futura.

24
Cada sociedade tem um agente facilitador que mantém sua estrutura: a identidade,
localização e serviços oferecidos pelos agentes da sociedade. Quando um agente deseja entrar numa
sociedade ele tem que contatar o facilitador e registrar um nome. O facilitador irá verificar a
unicidade deste nome e associá-lo à localização do agente. Da mesma forma, quando deseja sair da
sociedade, deve avisar o facilitador desta sociedade.
Todo o agente desenvolvido para o SACI é uma classe herdada de uma classe chamada
“Agent” e com isso possui um componente denominado MBox que serve de interface entre o agente
e a sociedade. Sua finalidade é tornar transparente o envio e o recebimento de mensagens. Este
componente possui funções que encapsulam a composição de mensagens KQML, o envio síncrono
e assíncrono de mensagens, o recebimento de mensagens, o anúncio e a consulta de habilidades e o
broadcast de mensagens.
As páginas amarelas são onde os agendes publicam os serviços que provêem à sua
sociedade, para anunciar um serviço um agente envia uma mensagem ao facilitador que é
responsável pelo controle deste serviço, esta mensagem é enviada ao facilitador utilizando-se o
comando “advertise” do Mbox do agente. Por outro lado para solicitar um agente que realize uma
determinada função, publicada nas páginas amarelas, são utilizadas as funções “recomendOne” e
“recomendAll”.
Uma vez tendo os serviços publicado será necessário utilizar a MBox, que tem sua
características semelhantes ao sistema de e-mail utilizado por pessoas. O MBox, permite a
utilização do padrão KQML. Para o envio de mensagens existem três métodos que são apresentados
abaixo e exemplificados na Figura 8:
• sendMsg: Envia uma mensagem assíncrona para um agente;
• senSyncMsg: Envia uma sincronizada para o agente; e
• ask: pode ser traduzido como pergunta, este método envia uma mensagem e espera uma
resposta imediata de um agente, sendo que esta mensagem é esperada por apenas um
tempo;
Message msg = new Message("(tell)"); msg.put("receiver","AgenteSmit"); msg.put("content","Ola!!!"); mbox.sendMsg(msg); mbox.sendSyncMsg(msg);

25
Message retorno = mbox.ask(msg);
Figura 8. Exemplo de envio de mensagens
Para o recebimento de mensagens existem três métodos que são apresentados abaixo e
exemplificados na Figura 9.
• getMessages: Este método retorna uma lista das mensagens especificadas por seus
parâmetros;
• polling: Este por sua vez retorna uma mensagem especificada que é retirada da caixa de
mensagens; e
• receive: Que recebe uma mensagem especificada pelos parâmetros e deixa uma copia na
caixa de mensagens;
Message msgpoll = new Message(""); msgpoll.put("sender","AgentSmit"); Message msg1 = mbox.polling(msgpoll); Message msg2 = mbox.receive(msgpoll);
List listaMsgs = mbox.getMessages(msgpoll);
Figura 9. Exemplo de recebimento de mensagens
Existe outra maneira de se receber mensagens, que é feito com funções que, sempre que um
determinado tipo de mensagem chegar, esta função será invocada. A Figura 10, apresenta um
exemplo onde sempre que uma mensagem contendo a mensagem “Ola!” for recebida,
imediatamente, será mostrado na tela uma mensagem.
mbox.addMessageHandler("Ola!", null, null, null, new MessageHandler() { public synchronized boolean processMessage(Message m) { System.out.println("Recebida um mensagem de boas vindas."); }
});
Figura 10. Exemplo de função para recebimento de mensagens

26
2.4.2 Sistema Inteligente de Recuperação de Informações (SIRI)
O SIRI é um sistema multi-agente (SMA) classificado como reativos, que realiza a tarefa de
indexar as palavras dos documentos nos formatos HTML presentes em um determinado domínio
(URL). O sistema SIRI possui uma comunidade de agentes que se comunicam coordenadamente
para a execução da tarefa. A Figura 11 apresenta a arquitetura do sistema SIRI.
AgColetores AgArmazenadores
AgGerenciador
AgTratadores☺
☺
☺
☺
☺
☺☺
Informação indexada
DocumentosNa Web
Sites a serem Visitados
AgColetores AgArmazenadores
AgGerenciador
AgTratadores☺
☺
☺
☺
☺
☺☺
Informação indexada
DocumentosNa Web
Sites a serem Visitados
Figura 11. Arquitetura do sistema multi-agente SIRI
• Agente Gerenciador: Gerencia o andamento do processo, fornecendo as URLs dos
sites a serem visitados e comunicando-os aos agentes coletores. O controle do início
(URL inicial) e do fim (não há mais sites por visitar) do processo de busca é
responsabilidade deste agente;
• Agentes Coletores: Os agentes coletores acessam as URLs (Uniform Resource
Locator) fornecidas pelo Agente Gerenciador e recuperam toda a informação textual
repassando-a para os agentes tratadores;
• Agentes Tratadores: Os Agentes tratadores são os mais importantes da comunidade.
Realizam a análise léxica dos documentos coletados e com isso separam o conteúdo
da formatação (caso do HTML), identificam os links a serem visitados
posteriormente, ignoram as palavras sem valor semântico (stoplist) e indexam as
palavras do documento conforme a quantidade e a localização onde aparecem nestes.

27
Após a análise léxica estes agentes enviam o pacote da informação estruturada para
os agentes armazenadores;
• Agentes Armazenadores: Os agentes armazenadores têm a incumbência de inserir as
informações indexadas no banco de dados do servidor que dará suporte as consultas
dos usuários. Além disso, salvam os links para os sites a serem visitados em um
repositório de links, que é constantemente acessado pelo agente Gerenciador.
Para fazer o sistema funcionar é necessário informar um endereço de Internet valido para um
AgGerenciador, através de uma tela de entrada bem simples, apresentada na Figura 12 ao receber a
solicitação de uma página um AgColetor, se encarrega de acessar a internet e buscar esta página,
repassando seu conteúdo para um AgTratador, que por sua vez processa e estrutura os dados
recebidos e repassa-os a um AgArmazenador para serem gravados em um banco de dados Oracle.
Figura 12. Tela de inicio do SIRI (AgWebBot)
O SIRI ainda usa uma ferramenta externa chamada de JFlex, que é utilizada para gerar uma
máquina de estados para o tratamento textual, transformando expressões regulares em uma classe
JAVA capaz de capturar tolkens em um arquivo HTML. Contudo a implementação de tratamento
textual presente do projeto SIRI trata apenas conteúdos na linguagem HTML.
2.4.3 Mudanças necessárias no SIRI
Uma vez que a API deverá ser genérica suficiente para sua melhor utilização, se faz
necessário a reestruturação das classes existentes, dividindo-as e ampliando suas funcionalidades
como tratamento de exceções (Exception) e tratamento de estrutura de armazenamento em memória
e arquivo.
Com esta reestruturação, foi necessária a organização dos pacotes onde serão armazenadas
as classes, dividindo-as por funcionalidade e tipos de agentes que as utilizam.

28
Outra funcionalidade necessária foi ampliação da gama de opções de armazenamento dos
documentos recuperados, por este motivo, o desenvolvimento de diversas funções para
armazenamento dos documentos em banco de dados e XML.
Porém para ser possível tornar a API genérica o suficiente para o desenvolvimento de
sistema de recuperação simples, foi necessário à reestruturação da forma de armazenamento, para
que possa ser alterada com facilidade e se adapte ao modelo abordado pela aplicação, sem a
necessidade de alteração na função de armazenamento.
Em vista dos tipos de arquivos encontrados na Internet é necessário a geração de funções
para o tratamento de documentos textuais, HTML e PDF, que são os mais encontrados no contexto
de recuperação de informação nos dias de hoje.
Em vista de que a intenção do projeto que foi desenvolver uma API para pessoas que não
tenham um completo domínio sobre as tecnologias adotadas, se faz necessário a geração de uma
ferramenta para geração e gerenciamento dos agentes.
E ainda para facilitar a utilização da API será adotada uma tecnologia de depuração de
aplicação em tempo real, baseado em log de aplicação, utilizando-se uma classe nativa da
linguagem JAVA denominada Logger.
Com todas as alterações apresentadas, se fez necessário uma completa re-implementação do
projeto SIRI, mantendo-se a arquitetura do sistema multi-agentes, as formas de comunicação entre
os agentes e conhecimento adquirido ao estudar-se o sistema.
2.5 Design Patterns
Segundo Pree (apud COOPER, 1998), os design patterns são regras que descrevem como
realizar determinadas tarefas na área de desenvolvimento de softwares, e Coplien & Schmidt (apud
COOPER, 1998), coloca seu ponto de visa escrevendo que são regras voltadas para o
reaproveitamento no desenvolvimento de arquiteturas em quanto os frameworks são voltados a
reutilização de implementações.
Segundo o próprio Cooper (1998), existem 23 design patterns descritos em livros, sendo
estes classificados em três grupos:

29
• Creation patterns que são implementações de classe que criam objetos para você, ao
invés de permitir que sejam criados objetos diretamente, proporcionando assim, que
seu programa possu mais flexibilidade para decidir quais objetos são necessários
para serem criados em determinados casos;
• Structural patterns que ajudam o compor grupos de objetos em estruturas maiores,
tais como interfaces complexas com o usuário; e
• Behavioral patterns definir a comunicação entre objetos em seu sistema e a controlar
o fluxo dentro de projetos complexos.
2.5.1 Creation patterns
Todos o patterns de criação tratam de qual a melhor forma de criar um objeto, segundo
Cooper (1998) isso é importante porque os programas não devem depender de como os objetos são
criados. Em Java, a forma mais simples e natural de se criar objetos, é através do operador new.
Contudo, está é uma forma bruta de se criar um objeto. Em muitos casos a exata origem de
um objeto poderia variar conforme a necessidade do programa. Abstrair o processo de criação de
objetos de uma classe especial pode fazer seu programa mais flexível e genérico, as formas de
patterns de criação são:
• The Factory Pattern apresenta a forma de elaboração de algoritmo para decisão de
qual classe retornar entre diversas subclasses de uma classe abstrata base,
dependendo da informação passada ao método, a estrutura de exemplo deste pattern
é apresentada na Figura 13;

30
Figura 13. Exemplo de Factory Pattern
Fonte: Cooper (1998)
• The Abstract Factory Pattern fornece uma interface para criar e retornar uma das
diversas famílias de objetos relacionados;
• The Builder Patterns separa a construção de objetos complexos. Dividindo a tarefa
para suas representações, para que diversas representações possam ser criadas,
dependendo da necessidade do programa;
• The Prototype Patterns inicializam e instanciam classe, copias ou clones para criar
novas instâncias de objetos, este pattern cria objetos clonando-os, para evidar perda
de tempo e processamento para criação e inicialização de novos objetos; e
• The Singleton patterns é uma classe que não pode existir mais do que uma instancia,
provendo assim um ponto único de acesso a instancia, como por exemplo pools de
conexões de banco de dados onde vc precisa limitar o número de conexões por
aplicação.
2.5.2 Structural patterns
Os structural patterns descrevem classes e objetos podem ser combinados em uma grande
estrutura (COOPER, 1998). A descrição de classes define a forma mais útil de representação de
interfaces de programas e a descrição de objetos define como objetos podem ser compostos de
outros objetos mais complexos. Os patterns de estrutura são divididos em sete tipos que são:

31
• The Adapter Pattern que é usado para converter interfaces de classe em outra classe
que possa ser utilizada. Normalmente um adapter é uma implementação simples de
uma interface;
• The Bridge Pattern é usado para separar a interface da classe da sua implementação;
• The Composite Pattern é usado para representar listagem de dados, denominando
nomes padrões para acesso aos dados da listagem;
• The Decorator Pattern permite que sejam criadas derivações de funcionamento de
objetos sem que seja necessário criar uma extensão para cada objeto personalizado;
• The Façade Pattern busca facilitar o entendimento de sistemas complexos,
redusindo-os em pequenas classes com poucos métodos, contudo este método pode
tornar as classes adjacentes mais amarradas;
• The Flyweight Pattern é usado para pequenas classes que contenham dados
repetitivos; e
• The Proxi Pattern é utilizado para postergar a criação de objetos, permitindo que os
objetos sejam instanciados apenas na hora que realmente serão ocupados.
2.5.3 Behavioral Patterns
Os behavioral patterns são os patterns que estão mais especificamente voltados para a
comunicação entre objetos.
• Chain of Resposability permite que muitas classes utilizem-se de uma mesma
requisição, permitindo um desacoplamento entre as classes, sendo que a única
ligação é a requisição passada anteriormente, pode-se utilizar para interligar objetos
a fim de rastrealos e trocar mensagens sequencialmente;
• The Command Pattern ao contrario da corrente de responsabilidade citada acima,
este pattern envia a mensagem para apenas um objeto, a idéia deste pattern é separar
a execução de eventos em classes, possibilitando os comandos neles executados
sejam alterados sem a necessidade da alteração do programa;

32
• The Interpret Pattern define classes de interpretação de linguagens, normalmente
utilizada para realização de consultas por um determinado programa, como se fosse à
interpretação da linguagem SQL;
• The Iterator Pattern este pattern apresenta a forma de navegação do uma listagem
sem que se saiba seu conteúdo, este é o mais simples e mais usado dos design
patterns;
• The Mediator Pattern é utilizado para fazer um acoplamento mais leve entre objetos
que interagem, criando-se uma classe que realiza as funções que deveriam ser feitas
pelo próprio objeto, permitindo que funcionalidades sejam alteradas sem
conseqüências incalculáveis;
• The Momento Pattern descreve a forma de representar valores e armazená-los para
poder recuperar posteriormente seus valores;
• The Observe Pattern descreve como deve ser implementado a separação de dados e
sua apresentação, criando classes que se comunicam através de chamadas a métodos
com nomes comuns;
• The State Pattern este patter se propõe a especificar e substituir a forma deselegante
de se criar muitas classe para o tratamento de ações semelhantes, utilizando nomes
de métodos padrões;
• The Strategy Pattern consiste em uma coleção de algoritmos encapsulados em uma
classe de Driver, onde o cliente que utiliza o Driver pode escolher um dos algoritmos
ou optar pelo melhor entre eles;
• The Template Pattern é a formalização da utilização de classes abstratas, ou seja, se
você já desenvolveu alguma classe extendida a uma classe abstrata, já utilizou um
designet pattern de template; e
• The Visitor Pattern este modelo propõe o desenvolvimento de uma classe externa
para o tratamento de dados de uma classe, este modelo é seguido sempre que existe
um grande número de instanciação de poucos tipos de classes.

33
Os design patterns são extremamente úteis para o desenvolvimento de APIs. Neste trabalho,
forma adotados o uso de alguns padrões de projeto elucidados na Seção 3.1.2 .

3 DESENVOLVIMENTO
Este capítulo apresenta a modelagem da API, as ferramentas que foram agregadas para
potencializar o uso desta, exemplos de sua utilização e a documentação que a acompanha.
3.1.1 Diagrama de Componentes
Optou-se por iniciar a elaboração da modelagem pelo diagrama de componentes, para
documentar as funcionalidades que a API disponibiliza para os alunos. Uma vez que o aluno possua
o diagrama de componentes, ele tem uma noção das funcionalidades que a API lhe provê para o
desenvolvimento de SRI.
O diagrama de componentes foi dividido em quatro componentes, que representam o acesso
às funcionalidades dos agentes dentro da comunidade. Este diagrama pode ser visualizado na Figura
14.

35
Figura 14: Diagrama de Componentes
Uma vez definido o diagrama de componentes da API, e baseando-se nos estudos dos
algoritmos testados e implementados na Seção 2.2, foram elaborados os diagramas de classes.
3.1.2 Padrões de Projeto
Para a elaboração das classes da API, foi levada em consideração a possibilidade de futuras
alterações, por este motivo foi adotado o modelo de programação baseado em padrões de projeto. A
inclusão destes padrões impacta diretamente na elaboração das classes da API. Os padrões adotados
na API desenvolvida foram:
• Façade: também conhecido como fachada é utilizado nos níveis mais altos dos
agentes, abstraindo as funcionalidades de comunicação e interação entre métodos e
agentes;
• Composite: este padrão é utilizado na classe AgSRI que reúne acesso aos quatro
objetos responsáveis pelas funcionalidades da API;

36
• Bridge: utilizada em geral em toda a API, fazendo-se uso de métodos e classes
abstratas para definir regras de funcionamento e reutilização de classes hierárquicas;
• Singleton: utilizado na factory do gerenciador, para garantir que apenas um será
iniciado;
• Observer: este padrão não é implementado na API, contudo é utilizada sua
funcionalidade no recebimento e envio de mensagens entre agentes, onde cada
agente é notificado sobre a chegada de uma mensagem em sua caixa postal;
• Mediator: assim como a anterior não é implementada, mas pode ser notada uma vez
que existe a interação entre API e agentes, onde o agente do SIRI facilitador tem a
responsabilidade de ser mediador da troca de mensagens;
• Factory Method: este padrão é utilizado para a inicialização das classes de interface
da API, onde existem quatro “factory”, que criam instancias das classes; e
• Template Method: utilizado em todos os agentes para ser possível a alteração dos
agentes sem a necessidade de alteração da comunicação ou forma de funcionamento.
Possivelmente existam mais padrões utilizados na API que não foram notados ou
intencionalmente utilizados, bem como poderiam ter sido utilizados outros. Contudo acredita-se que
foram selecionados aqueles que facilitam a utilização da API.
3.1.3 Diagramas de Classes
Para definir as regras de funcionamento do sistema interno da API, foram elaboradas classes
abstratas, que são demonstradas nos diagramas com o nome da classe em itálico. Esta definição
permite a ampliação das funcionalidades da API, sem a necessidade de refazer as operações básicas
dos agentes.
Outro tópico a ser abordado é a separação de pacotes, onde as classes da API foram
divididas por funcionalidade. O pacote chamado de “br.siri.api”, disponibiliza as funcionalidades
que o aluno tem a disposição quando for desenvolver um SRI utilizando a API. Este pacote foi
classificado com sendo de acesso a API. Os demais pacotes foram classificados como de
funcionalidade interna e foram divididos pelo tipo de agente que executará cada funcionalidade da

37
API. Estes pacotes estruturam as funcionalidades internas da API, e são:
“br.siri.api.gerenciamento”; “br.siri.api.coleta”; “br.siri.api.tratamento”; e
“br.siri.api.armazenamento”.
Existe um último pacote elaborado que possui classes responsáveis pela estruturação dos
documentos recuperados e funcionalidades básicas dos agentes. Este pacote é denominado de
“br.siri.api.base”. Os pacotes e seus diagramas são apresentados nos tópicos a baixo.
3.1.3.1 Acesso a API
Este tópico da modelagem abordará as classes de acesso a API, as classes as quais o aluno
de Ciência da Computação tem acesso para poder utilizar a API, contudo o próximo capítulo tratará
do funcionamento interno da API, o qual o aluno terá que modificá-lo caso necessite melhorar o
funcionamento do código.
br.siri.api
Este pacote possui a finalidade de servir como interface para com o programador. Através
das classes deste pacote é que a API faz a comunicação do SRI a ser desenvolvido com os agentes
responsáveis por executar as funcionalidades. O diagrama pode ser observado na Figura 15.
Figura 15: Diagrama de Classe – Pacote br.siri.api
Este pacote apresenta uma classe abstrata denominada agSRI, e é através desta classe que o
SRI a ser desenvolvido pelos alunos acessará todas as funcionalidades da API. Para a utilização da

38
API o aluno deverá criar uma classe que estende a classe agSRI. Uma alternativa para o uso de
parte da funcionalidade da API é instanciar uma das quatro classes apresentadas neste diagrama.
Nota-se que os métodos destas classes apenas disponibilizam instancias das classes que
representam agentes, onde por sua vez o aluno de computação poderá optar por programar a
comunicação com os demais agentes ou utilizar-se das funcionalidades da API.
3.1.3.2 Funcionalidade interna
Esta seção tem por objetivo apresentar as funcionalidades internas da API, especificando
como foi desenvolvida internamente para que possa prover os serviços necessários.
Em todas as classes abstratas dos pacotes serão encontrados métodos abstratos que possuem
a funcionalidade de um design pattern de criação, fazendo com que os agentes só possam ser
criados a partir de um método, dando a possibilidade da API controlar o número de agentes
instanciado, e a criação de agentes, futuramente estendidos da API.
Os padrões de projeto também são utilizados na API em métodos internos, como métodos de
acionamento de eventos de comunicação entre os agentes.
api.base
Este pacote possui classes básicas para o funcionamento da comunidade. Dentre as classes
básicas pode-se encontrar a estrutura de documento utilizada pelos agentes. O diagrama do pacote
pode ser visto da Figura 16.

39
Figura 16: Diagrama de Classe – Pacote br.siri.api.base
Este diagrama é composto de oito classes:
• “AgentBot” é uma classe abstrata que estende a classe nativa SACI, que tem por
objetivo implementar funcionalidades de comunicação de um agente;
• “Palavra” e “Link” são classes abstratas que tem a funcionalidade de representar uma
palavra e um link de um documento;
• “PalavraMap” e “LinkMap” são classes que estendem a classe HashMap, nativa do
JAVA, e representam o mapeamento de palavras e links de um documento;

40
• “Documento” é a classe que representa um documento recuperado e o mapeamento
de quais agentes estiveram envolvidos no seu processamento; e
• “Balanceamento” é uma classe concreta que implementa a funcionalidade de
balanceamento de carga dos agentes.
br.siri.api.gerenciamento
Neste pacote estão localizadas as classes responsáveis pelas funcionalidades dos agentes do
tipo gerenciador, como o próprio nome sugere possui a capacidade de prover os serviços de
gerenciamento do sistema.
O diagrama de classe elaborado para este pacote de gerenciamento pode ser visto na Figura
17.
Figura 17: Diagrama de Classe – Pacote br.siri.api.gerenciamento
No diagrama são apresentadas duas classes:

41
• “AgGerenciador” uma classe abstrata e estendida da classe “AgenteBot”. Foi
elaborada para estabelecer as regras de funcionamento dos agentes
gerenciadores.
• “GerenciadorAPI” uma classe concreta e responsável pela execuções das
funcionalidade do gerenciador que são: iniciar agentes para a API; recuperar
links; e balancear a carga.
api.coletor
As classes do pacote coletor são responsáveis por recuperar documentos na internet. Os
documentos recuperados são armazenados na memória para tornar o processo mais eficiente. O
diagrama deste pacote pode ser observado na Figura 18.
Figura 18: Diagrama de Classe – Pacote br.siri.api.coleta
No diagrama acima são apresentadas quatro classes:

42
• “AgColetor” é uma classe abstrata e é responsável por implementar a comunicação
deste tipo de agente e definir a regra para o desenvolvimento de novos agentes
coletores;
• “Coletar” é outra classe abstrata e define a regra de funcionamento para a criação de
classes de acesso a documentos;
• “ColetorAPI” é uma classe concreta que tem o objetivo de implementar um agente
coletor responsável por recuperar documentos para API; e
• “ColetaIOInternet” é outra classe concreta e possui o objetivo de coletar páginas na
Internet.
br.siri.api.tratamento
As classes do pacote tratamento têm por objetivo prover os serviços de tratamento e
estruturação de textos. O diagrama de tratamento é apresentado na Figura 19.
Figura 19: Diagrama de Classe – Pacote br.siri.api.tratamento
No diagrama são apresentadas seis classes:

43
• “AgTratador” é uma classe abstrata que define a forma de implementar um agente do
tipo tratador;
• “Tratamento” é uma classe abstrata que define as regras para a implementação de
classes de tratamento e estruturação de documentos em formato “String”;
• “Lexical” é uma classe abstrata que é baseada nas classes geradas pela ferramenta
JFlex, e define as regras para serem implementadas as classes de tratamento léxico;
• “TratadorAPI” é uma classe concreta para o tratamento de texto da API;
• “TratamentoHTML” é uma classe concreta e implementa o tratamento de páginas
HTML; e
• “LexicalHTML” é uma classe concreta e é gerada a partir da ferramenta JFlex para o
tratamento de documentos em HTML.
A ferramenta utilizada para gerar classes de análise léxica, JFlex, baseia-se em expressões
regulares para gerar sistemas de máquinas de estados para tratamento textual.
br.siri.api.armazenamento
As classes deste pacote possuem o objetivo de realizar a etapa de armazenamento das
informações. O diagrama pode ser observado na Figura 20.

44
Figura 20: Diagrama de Classe – Pacote br.siri.api.armazenamento
O pacote apresenta quatro classes:
• “AgArmazenador” é uma classe abstrata que define as regras para a implementação
de agentes do tipo armazenador;
• “Armazenamento” é uma classe abstrata que define a forma de implementação de
classes para gravação de informações;
• “ArmazenadorAPI” é concreta e implementa o agente responsável por executar as
funções de armazenamento da API; e
• “ArmazenaXML” é concreta e responsável pelo armazenamento dos documentos em
um arquivo no formato XML;

45
3.1.4 Diagramas de Seqüência
Os diagramas de seqüência procuram apresentar o funcionamento e interação entre as
classes internas da API. A interação necessária para que a camada externa de funcionalidade,
comunique-se com a plataforma SACI e os agentes da comunidade.
Os diagramas foram divididos conforme o diagrama de componentes. Os diagramas de
seqüência são apresentados a baixo.
3.1.4.1 Inicia Consulta
Este diagrama apresenta o processo para a criação da comunidade necessário para o
funcionamento da API. O diagrama pode ser observado na Figura 21.
Figura 21: Diagrama de Seqüência – Inicia Consulta
3.1.4.2 Recuperar Link
Este diagrama apresenta a etapa de recuperar um link para poder dar continuidade a
recuperação de documentos. O diagrama é apresentado na Figura 22.
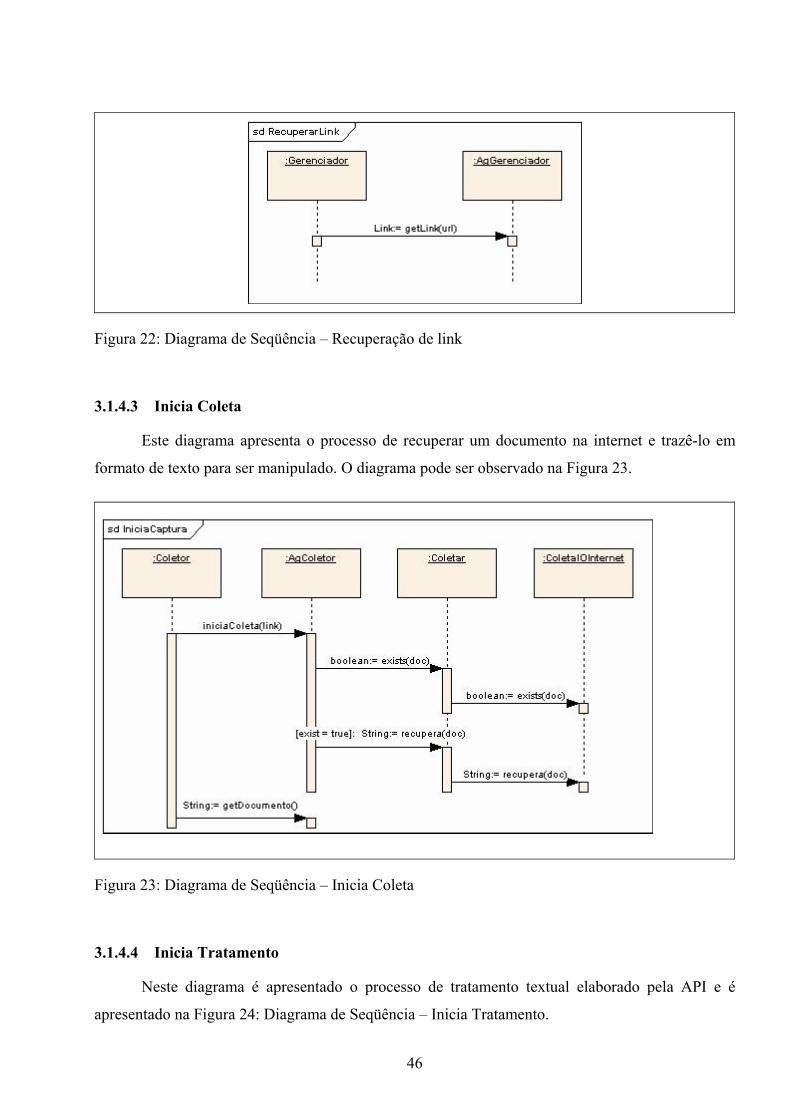
46
Figura 22: Diagrama de Seqüência – Recuperação de link
3.1.4.3 Inicia Coleta
Este diagrama apresenta o processo de recuperar um documento na internet e trazê-lo em
formato de texto para ser manipulado. O diagrama pode ser observado na Figura 23.
Figura 23: Diagrama de Seqüência – Inicia Coleta
3.1.4.4 Inicia Tratamento
Neste diagrama é apresentado o processo de tratamento textual elaborado pela API e é
apresentado na Figura 24: Diagrama de Seqüência – Inicia Tratamento.

47
Figura 24: Diagrama de Seqüência – Inicia Tratamento
3.1.4.5 Armazenamento
Este diagrama apresenta a funcionalidade de armazenamento de documentos estruturados
para arquivos XML, e pode ser observado na Figura 25.

48
Figura 25: Diagrama de Seqüência – Armazenamento
3.1.5 Ferramentas Agregadas
Para o desenvolvimento a API e para facilitar a construção de aplicações, foi necessário a
agregação de bibliotecas e ferramentas, dentre elas uma ferramenta para gerar uma máquina de
estados que possibilite o tratamento de documentos, um banco de dados, uma biblioteca para
tratamento de arquivos PDF e uma biblioteca para geração de logs. Estas agregações estão descritas
a baixo.
3.1.5.1 JFlex
O JFlex é um gerador de analisador léxico para JAVA, feito em JAVA. Esta ferramenta
utiliza-se de uma linguagem de expressões regulares para gerar máquinas de estado para análise
léxica de documentos textuais. Uma destas máquinas de estados é utilizada para o tratamento de
documentos, como se eles fossem textos escritos em HTML. Os agentes de tratamento invocam a
máquina de estado para transformar o documento textual em uma estrutura de armazenamento em
memória. O JFlex, é uma ferramenta que esta sobre a licença GPL. Maiores informações podem ser
obtidas em JFLEX (2006).

49
3.1.5.2 SIMETRICS
SIMETRICS é uma biblioteca de algoritmos de comparação textual, ela utiliza-se de
diversas técnicas comprovadas que retornam um grau de similaridade entre documentos. Foram
selecionados alguns algoritmos do projeto “SIMETRICS”, para serem disponibilizados juntamente
com a API. São eles:
• Hamming distance: define a diferença de bits entre palavras. Ou seja, indica o
número de bits que devem ser alterados para que as duas palavras se tornem
idênticas. Esta técnica não esta incluída na biblioteca por sua simplicidade de
implementação;
• Levenshtein Distance: é uma função básica de distância, uma vez que a distância é
calculada considerando o esforço mínimo de transformação de uma string por outra;
• Needleman-Wunch distance ou Sellers Algorithm: é um algoritmo baseado no
anterior, contudo sofrendo ajustes em variáveis;
• Smith-Waterman distance: este algoritmo é descrito por Smith(1981), e foi
desenvolvido para identificar algoritmos ótimos de DNA e seqüências de proteínas;
• Gotoh ou Smith-Waterman-Gotoh distance: é a implementação do algoritmo escrito
por Smith Waterman e é encontrado na referência Gotoh(1981);
• Block Distance ou L1 distance ou City Block distance: é o cálculo baseado em
vetores e dados pela formula apresetnada na Figura 26;
Figura 26. Block Distance ou L1 distance ou City Block distance
Fonte: Simetrics (2005)
• Monge Elkan distance: Este algoritmo amplia o algoritmo de Gotoh com mais
campos de avaliação e possui uma complexidade de tempo quadrática. Melhor
descrição sobre este algoritmo pode ser encontrado em Monge(1996);

50
• Jaro distance metric: especificações sobre esta métrica de distância de Jaro pode ser
encontrada em Jaro(1989);
• Jaro Winkler: é uma modificação da métrica anterior;
• Soundex distance metric: é uma métrica baseada na fonética das letras, como por
exemplo as palavras bem similares foneticamente John, Johne and Jon;
• Matching Coefficient: é uma versão do primeiro algoritmo apresentado, que trabalha
com um vetor simples de termos;
• Dice’s Coefficient: este algoritmo é baseado nas medidas de similaridade um ou
zero;
• Jaccard Similarity or Jaccard Coefficient or Tanimoto coefficient: O algoritmo de
Jaccard, utiliza o conjunto de palavras para avaliar a comparação de similaridade.
Este algoritmo é utilizado para comparar similaridade de composições químicas;
• Overlap Coefficient: Esta é uma métrica onde se um valor de X está contido em Y ou
vise versa, a similaridade é um valor cheio;
• Euclidean distance or L2 distance: Este por sua vez utiliza o calculo “euclidiano” em
vetores para definir as distancias entres os termos do vetor; e
• Cosine similarity: Este algoritmo utilize uma StopList para separa as strings em
vetores, e compara os termos similares, para calcular a similaridade entre os vetores
de termos.
Estas funcionalidades são disponibilizadas através dos agentes de tratamento para que os
desenvolvedores de aplicações possam construir algoritmos de comparação textual mais poderosos.
O SIMETRICS esta disponibilizado sobre licença GPL e maiores informações sobre esta biblioteca
podem ser encontradas em Simetrics (2005).
3.1.5.3 HyperSonic
HyperSonic é um banco de dados completo e compacto feito em JAVA. Sua versão
HSQLDB 1.8.0 suporta uma quantidade de dados acima de 8 GigaBytes. Este banco de dados pode

51
ser executado em forma de servidor ou acesso exclusivo para a aplicação cliente, podendo
armazenar as informações em arquivo, ou em memória. Os agentes armazenadores nativos da API
implementam duas formas de armazenamento; em arquivo através do padrão XML e em Banco de
dados usando, neste caso o HyperSonic.
Este banco de dados, quando utilizado com conexão do tipo JDBC, tem uma perda de
desempenho referente a outros bancos de dados de código aberto, como MySQL, contudo quando
utilizado a frameword 1Hibernate, esta perda de desempenho quase desaparece. A licensa deste
banco de dados segue regras similares a GPL. Maiores informações sobre o HyperSonic pode ser
encontradas em HSQL (2006).
3.1.5.4 PDFBox
O PDFBox é uma biblioteca open source feita em JAVA, para trabalhar com documentos no
formato PDF. Com esta biblioteca podem ser criados documentos PDF, manipular documentos
existentes e ainda extrair o conteúdo de documentos.
Esta biblioteca é utilizada pelos agentes coletores para trasformar arquivos do formato PDF
em textos ASCII, em uma formatação semelhante a HTML. Esta transformação é necessária para
que possam ser lidos documentos PDF. O projeto PDFBox esta disponível em PDFBOX (2006) e
está sobre a licensa BSD.
3.1.5.5 Log4J
O Log4J é uma biblioteca para gera log de aplicações, considerada uma forma de depuração
em tempo de execução e não em forma de desenvolvimento, a biblioteca provê funcionalidades para
gerar log de diversos tipos.
No projeto é utilizado para facilitar a depuração das aplicações da API, gerando log do
caminho percorrido pelos documentos entre as diversas funcionalidades. Este projeto esta sobre a
licença Apache 2.0 que garante a distribuição deste projeto com ou sem alterações. O projeto é
disponibilizado em APACHE (2006).
1 Hibernate é uma biblioteca para persistencia objeto/relacional e consulta em base de dados.

52
3.1.6 Exemplos da API em uso
Para iniciar a aplicação é necessário informar ao “classpath” o caminho do arquivo JAR da
API, a partir deste momento será possível utilizar as classes da API. Todos os exemplos aqui
descritos podem ser encontrados e testados juntamente com a API, em um pacote denominado
“br.api.samples”.
Quando se deseja criar uma aplicação mínima, que realiza a captura de termos em um
conjunto de documentos, é necessário criar pelo menos um arquivo JAVA. A Figura 27 apresenta
um exemplo mínimo da utilização da API, a qual foi denominada classe “ColetorInformacoes”.
Figura 27: Código da menor aplicação possível
O exemplo segue a seguinte estrutura. Na linha 1 é feita referencia a qual pacote esta classe
pertence, nas linhas 3 e 4 são importados os pacotes para poder acessar a API e as suas estruturas

53
básicas. A linha 6 contém a declaração da classe e existe apenas um método declarado na linha 8,
que é um método de inicalização (main). Um objeto do tipo AgSRI é declarado e instanciado na
linha 9, e este é utilizado para inicializar objetos Gerenciador na linha 10, Coleta na linha 11,
Tratador na linha 12 e Armazenador na linha 13. Em seguinda na linha 15 é instanciado um objeto
Documento e na linha a seguir é indicado qual é o caminho do documento, esta operação é feita
através do método setCaminho. As linhas 18,19 e 20 executam as funcionalidades da API de coleta,
tratamento de armazenamento. Um item a ser configurado ainda para este exemplo funcionar é a
forma de armazenamento, que é configurada através de um arquivo de propriedades que é descrito a
seguir.
3.1.6.1 Arquivo de configuração de armazenamento
Agora que já foi apresentada uma aplicação mínima se faz necessário apresentar o arquivo
de configuração de armazenamento, este arquivo define onde serão armazenados os documentos
pelos agentes armazenadores. O arquivo de configuração é denominado Banco.properties, e deve
estar localizado na pasta onde a aplicação esta sendo executada ou no classpath. As propriedades
definidas no documento são apresentadas na Figura 28.

54
Figura 28: Arquivo de configurações, Banco.properties
Esta figura apresenta as propriedades que estão estruturadas da seguinte forma. Na linha 2 é
configurada a forma de armazenamento, as opções disponíveis atualmente na API são “HSQL”
armazenamento em banco de dados Hypersonic e “XML” armazenamento em arquivos no formato
XML. Nas linhas 5 a 10 são encontradas as configurações do banco de dados como “URL” string de
conexão JDBC, “user” nome do usuário, “password” senha do usuário e “Banco” nome do banco de
dados. Da linha 11 a 16 são encontrados os SQL necessários para criar as tabelas no banco de dados
e nas linhas 19 a 24 estão localizadas as configurações para armazenamento em arquivos XML,

55
contendo a pasta e os arquivos que devem ser armazenados os documentos. Neste arquivo de
configuração é utilizado um usuário “sa” e sem senha, pois este usuário é um administrador padrão
do banco de dados Hypersonic. E por fim na linha 28 existe uma ultima propriedade que indica qual
a linguagem para ser utilizada como stoplist, tendo disponíveis as linguagens Português (PT) e
Inglês (EN), segundo Oracle (2003). Outra forma de definir a “StopList” é criar um arquivo
contendo cada stopword em uma linha, e indicar o caminho do arquivo nesta propriedade.
3.1.6.2 Coletando de domínio URL
Uma das formas de recuperação mais importantes nos dias de hoje é a procura de
documentos na Internet, na Figura 29 é apresentado um exemplo que recupera as páginas no
domínio www.cnpq.br.

56
Figura 29: Exemplo de Acesso a um domínio URL
Esta figura apresenta na linha 15 a instanciação de um objeto LinkMap que é uma coleção
de links. Da linha 16 a 18 é adicionada a esta coleção uma página inicial para a consulta. Nas linhas
20 a 31 é executado o processo de recuperação de informação, a linha 30 possui a chamada para o
método responsável por buscar novos links no repositório através do método getLinks do
gerenciador, que passa por parâmetro de onde se deseja recuperar os links, seja de banco
(Gerenciador.LINKDB), de um arquivo contendo links (Gerenciador.FILELINKS) ou varrendo

57
uma pasta a procura de arquivos (Gerenciador.FILES). Na linha 20 existe a condição para que
enquanto existam links no objeto LinkMap, seja feito o processo de recuperação.
3.1.6.3 Coletando de repositório local
Muitas vezes é interessante se coletar e indexar pastas de documentos ou artigos que se
tenha em uma máquina qualquer, para isso criou-se o exemplo que é apresentado a baixo.
Figura 30: Exemplo de Acesso a uma pasta local

58
Na linha 15 deste exemplo, é declarado um objeto LinkMap que recebe o retorno do método
getLinks, visto no exemplo anterior, contudo neste exemplo os argumentos mudam, passando-se
desta vez como primeiro parâmetro o local do acervo a ser buscado, e como segundo parâmetro
Gerenciador.FILES, que indica que devem ser rastreados todos os arquivos desta pasta. A partir do
momento que já foi realizado o rastreamento dos links, o processo segue similar aos outros
exemplos, realizando o processo de recuperação para todos os links retornados na coleção.
3.1.6.4 Armazenando em banco de dados ou em XML
A API esta preparada para as duas formas de armazenamento, sendo o padrão o
armazenamento em banco de dados. Contudo quando se deseja armazenar em arquivos no formato
XML, basta alterar o primeiro atributo do arquivo de propriedades de configuração do
armazenamento, “banco.properties”, já mencionado no Seção 3.1.6.1. Alterando o parâmetro
localizado na linha dois na Figura 28, os agentes responsáveis por acessar as informações
armazenadas estarão gravando estes dados diretamente dos arquivos XML. Contudo há uma
diferença de desempenho ao utilizar o armazenamento XML, que será quantificada na Seção 3.1.7
onde são apresentados os resultados de testes.
As duas formas de armazenamento utilizam a mesma estrutura de entidade relacionamento
que é demonstrada na Figura 31, sendo que na forma de XML os arquivos são divididos um para
cada entidade do diagrama.

59
Figura 31: Diagrama ER do armazenamento de documentos
3.1.6.5 Exemplo de uso da biblioteca SIMETRICS
O SIMETRICS pode ser utilizado para comparar documentos, sua utilidade junto à API é a
de permitir a classificação para o usuário final dos documentos mais relevante encontrados no
repositório, um exemplo desta integração é apresentado na Figura 32.

60
Figura 32: Exemplo da integração API/SIMETRICS
Este exemplo inicia com a declaração de um documento, na linha 13, que é inicializado com
o texto “Nos dias de hoje a recuperação de informação é um fator relevante para a área de ciência
da computação”. Em seguida na linha 17 é solicitado que este texto seja tratado por um agente
tratador. Na linha 18 é iniciado um objeto PalavraMap, com duas palavras “Recuperação” e
“Informações”, basedo nestas duas palavras é solicitado, na linha 19, que seja recuperado do
repositório os documentos contendo estas duas palavras. Na linha 24 é realizado um laço para
percorrer por todos os documentos encontrados, e então na linha 25 solicitar o grau de similaridade
entre os documentos recuperados e o texto do documento declarado na linha 13. O documento mais

61
similar é armazenado na variável “docMaisSimilar”, e sua similaridade em “valorMaisSimilar”,
estes valores são apresentado nas linhas 32 e 33.
3.1.7 Testes e Resultados
Os testes realizados buscaram explorar situções que pudessem validar e consolidar as
funcionalidades da API. Além disso, teve-se a curiosidade de avaliar diferentes configurações de
distribuição de agentes na comunidade para realização de um mesmo serviço: coletar todas as
palavras dos documentos PDF de uma pasta. Comparou-se também a diferença de desempenho para
armazenar as palavras em banco de dados e em XML.
As situações de teste estão definidas a seguir:
• Situação um, onde a API foi executada em apenas uma máquina com um agente de
cada tipo(Gerenciador, Coletor, Tratador, Armazenador);
• Situação dois, onde a API foi executada em duas máquinas contendo dois agentes
coletores, dois tratadores, um agente gerenciador e dois armazenadores;
Dentro destas duas situações foram avaliados alguns valores relevantes para os resultatdos,
que são:
• Tempo total de coleta, tratamento e armazenamento dos documentos.
• Tempo total gasto para realizar todo o processo; e
• Percentual gasto para coleta, tratamento e armazenamento;
Para a realização dos testes desenvolveu-se uma classe, utilizando a API, com as
funcionalidades assíncronas e utilizando-se Thread, esta classe foi denominada de
“LocalFolderAssincPlus” e encontra-se no pacote “br.api.samples.tests”, o qual é
disponibilizado juntamente com o código fonte da API. O principal trecho do código
utilizado nos testes é apresentado na Figura 33, e o código completo encontra-se no
APÊNDICE A.

62
Figura 33: Aplicação utilizada para testes e resultados
3.1.7.1 Teste 1 - Pasta com arquivos PDF e armazenamento em Banco de Dados
Nesta etapa foram realizados os testes simulando as duas situações, fazendo com que, um
programa utilizando a API recuperasse informações de uma pasta local, com vinte e cinco artigos
em PDF, e armazenasse o conteúdo indexado em um banco de dados Hypersonic. O resultado dos
testes é apresentado na Tabela 3.

63
Tabela 3: Tabela dos resultados, usando Banco de Dados Valores/Situação Situação 1 Situação 2
Tempo médio para Coleta 1134823 356874 Tempo médio para tratamento 31405 28773 Tempo médio para armazenamento 11337401 8919305 Tempo Total gasto para o processo 12503629 9304952 Percentual médio gasto para coleta 13,70% 6,04% Percentual médio gasto para tratamento 1,59% 0,91% Percentual médio gasto para armazenamento 84,71% 93,05%
Com esta tabela podemos perceber de que o tempo gasto para armazenamnto é bastatnte
significativo para o tempo total do processo. Outra percepção obtida a partir destes resultados é que
o procesamento distribuído (situação 2) é 25,58% mais eficiente para a indexação dos documentos.
Percebe-se também uma influencia no processamento gasto para armazenamento e coleta no
processamento em uma maquina só (situação 1), o qual não é pecebido no processamento paralelo.
O resultado dos testes utilizando-se banco de dados podem ser melhor avaliados na Figura 34.
Tempo Médio por Documento
0
2000000
4000000
6000000
8000000
10000000
12000000
Coleta Tratamento Armazenamento
Situação 1Situação 2
Figura 34: Gráfico de tempo médio para recuperação de documentos usando Banco de Dados

64
3.1.7.2 Teste 2 - Pasta de arquivos PDF e armazenamendo em XML
Nesta etapa como na anterior foi realizado as os testes simulando as dias situações, fazendo
com que, um programa utilizando a API recuperasse informações de uma pasta local, com vinte e
cinco artigos em PDF, e armazenasse o conteúdo indexado em na estrutura de arquivos XML. O
resultado dos testes é apresentado na Tabela 4.
Tabela 4: Tabelas dos resultados usando XML Valores/Situação Situação 1 Situação 2
Tempo médio para Coleta 767816 557212 Tempo médio para tratamento 23746 39324 Tempo médio para armazenamento 19537955 21897112 Tempo Total gasto para o processo 20329517 22493648 Percentual médio gasto para coleta 6,57% 6,07% Percentual médio gasto para tratamento 0,47% 1,07% Percentual médio gasto para armazenamento 92,96% 92,87%
Assim como na avaliação anterior podemos perceber de que o tempo gasto para
armazenamnto é bastatnte significativo para o tempo total do processo também utilizando XML.
Outra percepção obtida a partir destes resultados é que o procesamento distribuído (situação 2) é
9,62% menos eficiente para a indexação dos documentos. Percebe-se também uma influencia no
processamento gasto para armazenamento e coleta no processamento em uma maquina só (situação
1), o qual não é pecebido no processamento paralelo. O resultado dos testes utilizando-se banco de
dados podem serem melhor avaliados na Figura 35.

65
Tempo Médio por Documento
0
5000000
10000000
15000000
20000000
25000000
Coleta Tratamento Armazenamento
Situação 1Situação 2
Figura 35: Gráfico de tempo médio para recuperação de documentos usando XML
3.1.7.3 Análise dos Resultados
As vantagens da API, apresentam-se ao comparar a complexidade no desenvolvimento de
uma aplicação com a API e o código desenvolvido para o funcionamento do SIRI. O SIRI possui
muitas classes, linhas de códigos e a complexidade para alteração do programa, e em contrapartida,
a API possui facilidade na modificação da API e no desenvolvimento de aplicações, aspecto
fundamental para uma aplicação de fins didáticos.
O comparativo que pode ser feito sobre os resultados é a comparação entre armazenamento
em banco de dados e XML. Contudo para fazer esta comparação deve-se notar que está se
trabalhando com um banco de dados de pequeno porte e executado na mesma máquina que o
programa, acredita-se que a execução dos mesmos testes em um banco de dados de grande porte
terá um comportamento mais eficiente. O comparativo é feito em forma de gráfico e apresentado na
Figura 36.

66
Comparação de Tempos BD x XML
0
5000000
10000000
15000000
20000000
25000000
Tempo Gasto
Situação 1 XMLSituação 2 XMLSituação 1 BDSituação 2 BD
Figura 36: Gráfico comparativo, entre Banco de dados e XML
Este gráfico apresenta a diferença do tempo de execução do mesmo programa executado,
onde as duas barras da esquerda representam o tempo gasto para armazenamento em XML, em
quanto isso as duas barras da direita utilizando Banco de Dados.
3.1.8 Documentação
A documentação proposta e desenvolvida para este projeto é a mesma utilizada por diversos
programas desenvolvidos em JAVA, bem como a própria máquina virtual, o qual é o gerador de
documentação nativo da linguagem, conhecido por JAVADOC. Esta ferramenta, analiza os
arquivos JAVA e os comentários incluídos no código fonte, e gera documentos em padrão
conhecido pela comunidade de usuários JAVA. Os comentários incluídos no código fonte entre os
caracteres “/**” e “**/” são considerados comentários que devem gerar documentação. Um
exemplo desta documentação pode ser encontrado em http://java.sun.com/api, este link contém toda
a documentação da maquina virtual JAVA. Na Figura 37 conten um exemplo da documentação
gerada para a API desenvolvida.

67
Figura 37: Exemplo da documentação, Classe AgSRI
Este exemplo apresenta a descrição resumida da classe AgSRI, contento uma breve
descrição da classe, links para outras classes relevantes, listagem de construtores (que neste caso
existe apenas um), e listagem de métodos existentes nesta classe. Outro exemplo da documentação
desta classe é apresentado na Figura 38.

68
Figura 38: Exemplo da Documentação, detalhamento dos métodos
Este exemplo apresenta o detalhamento dos métodos existentes na classe AgSRI,
apresentando dois dos quatro métodos, colocando a descrição do funcionamento dos métodos, o
tipo de retorno e alguns links de classe relevantes a este método.
A documentação gerada em PDF de todas as classes resultou em um documento com 148
páginas, por este motivo não foi anexado a este documento. Contudo duas versões da documentação
são distribuídas juntamente com o código fonte da API, uma versão em PDF e outra em HTML, as
duas localizadas em uma pasta chamada “doc”, muito utilizada para publicação de documentações
em projetos JAVA.

4 CONCLUSÕES
Na etapa inicial apresentou-se um projeto lógico, utilizando-se de padrões de projetos, e com
este projeto, foi possível a detecção das necessidades de alterações no projeto SIRI a fim de
transformá-lo em uma API para auxiliar no desenvolvimento de aplicações de Recuperação de
Informação.
Entretanto ao estudar-se tratamento textual, encontrou-se uma biblioteca com diversos
algoritmos para cálculo de similaridade de documentos decidiu-se então agregar estes algoritmos à
API (ao invés de inplementar novos), disponibilizando-os através dos agentes.
Ao longo do desenvolvimento, foram documentadas as funcionalidades disponíveis em
formato JAVADOC, para que outros desenvolvedores possam com facilidade adquirirem o
conhecimento necessário para uso e alteração da API.
Ao final do desenvolvimento da API, foram construídos pequenos exemplos da sua
utilização, bem como alguns programas que serviram para a realização de testes e
consequentemente a análise dos resultados obtidos em diversas situações.
Este trabalho possui uma relevância para a área acadêmica no sentido de estimular o
aprendizado dos alunos de Ciência da Computação na área de recuperação de informação, bem
como estimular o desenvolvimento de aplicações que facilitem a vida de pessoas que necessitem
organizar documentos.
Para o desenvolvimento deste projeto foi necessário um grande conhecimento sobre diversas
áreas da computação, este conhecimento foi adquirido principalmente ao decorrer do curso de
Ciências da Computação e no período de iniciação cientifica, onde o projeto SIRI foi concebido e
deixou uma grande contribuição para possibilitar o desenvolvimento deste TCC.
Contudo de nada adianta desenvolver uma API como esta, atribuí-la em licença GPL e não
disponibilizá-la para que pessoas possam usufruir, por este motivo existe a intenção de publicar a
API, juntamente com seu código fonte, em uma comunidade publica na internet. Foi inicialmente
criado um projeto dentro do repositório conhecido como “sourceforge.net” para disponibilizá-la,
entretanto até o presente momento o mesmo não teve seu resumo avaliado pelos gerenciadores do
repositório para que se seja possível vincular os arquivos para download.

70
E por fim, existe o interesse em dar continuidade a este trabalho, promovendo sua
ampliação, melhorando processos e acrescentando funcionalidades, que deixem esta API cada vez
mais rica e interessante para aprender e utilizar-se da área de recuperação de informação.
Como trabalhos futuros se percebe uma grande variedade de projetos possíveis, podendo
dividí-los em dois grupos, os projetos que irão utilizar a API, e os projetos para melhoria da API.
Dentro dos projetos que utilizariam a API pode-se incluir projetos como, o desenvolvimento
de pequenos programas para recuperar e indexar artigos contidos em repositórios. Indexando estes
documentos a fim de facilitar a vida de pessoas no momento de procurar um determinado assunto
em seus próprios documentos. Outros projetos podem ser citados como o desenvolvimento de
máquinas de busca para sites pessoais ou empresariais.
Quanto à melhoria da API podem-se incluir projetos como o de desenvolvimento de um
reconhecedor do idioma que os documentos estão escritos ou tratamento semântico para os
documentos ou mesmo ampliar os tratadores a fim de melhorar o tratamento feito nos documentos.
Contudo, o principal trabalho futuro consiste na utilização das funcionalidades da API por
parte dos alunos de Ciência da Computação, a fim destes aprenderem e se sentirem incentivados
para estudar a área de Recuperação de Informação.

71
REFERÊNCIAS BIBLIOGRÁFICAS
APACHE, Logging Services. Disponível em <http://logging.apache.org/log4j/docs/>. Acesso em março, 2006.
BAEZA-Yates, Ricardo e RIBEIRO-Neto, Modern Information Retrieval, Addison-Wesley, Harlow, England, 1999.
BDTD-UFRGS. Biblioteca digital de teses e dissertações da UFRGS. Disponível em <http://www.biblioteca.ufrgs.br.bibliotecadigital>, acessado em: novembro 2005.
CARDOSO, Olinda Nogueira Paes. Recuperação de Informação. In: Semana De Ciência Da Computação Da Ufla, 2000, Lavras. 2000.
CHANG, Shinh-Fu et al. Visual Information Retrieval from large distributed online repository. Communication of the ACM, New York: Press. 1997
CHEN, Hsinchun. The vocabulary problem in collaboration. IEEE Computer: Stecial Issure on CSCW, Los Alamitos: IEEE Computer Society 1994. Disponivel em <http://ai.bpa.arizona.edu/papers/cscw94/cscw94.html> acessado em setembro de 2005
COOPER, James W. The Design Patterns Java Companion, Addison-Wesley Design Patterns Series. 1998.
FRAKES, William B.; BAEZA-Yates, Ricardo A. Information Retrieval: Data Structures & Algorithms. Upper Saddle River, New Jersey: Prentice Hall PTR, 1992
GONZALEZ, Marcos; LIMA, Vera Lúcia Strube de. Recuperação de informação e expansão automática de consulta de thesaurus: uma avaliação. Mérida CLEI, 2001.
GOTOH, O. An improved algorithm for matching biological sequences. Journal of Molecular Biology. 1981.
HSQL, hsqldb - 100% Java Database. Disponível em <http://hsqldb.org/>. Acesso em março, 2006.
HÜBNER, Jomi F. Simple Agent Comunication Intrastructure. Agent’s Day, Itajaí 2003
HÜBNER, J. F.; SICHMAN, J. S. SACI: Uma ferramenta para implementação e monitoração da comunicação entre agentes. São Carlos, 2000.
JAQUES, P. A. Agentes de Software para Monitoração da Colaboração em Ambientes Telemáticos de Ensino Dissertação de Mestrado, Porto Alegre, RS, 1999.
JARO, M. A. Advances in record linking methodology as applied to the 1985 census of Tampa Florida. Jornal “American Statistical Society”, 1989.
JFLEX. JFlex - The Fast Scanner Generator for Java.Disponível em <http://jflex.de/>. Acesso em março, 2006.

72
KORFHAGE, Robert R. Information Retrieval System. New York: John Wiley & Sond, 1997
KOWALSKI, Gerald. Information Retrieval System: Theory and Implementation. Boston: Kluwer Academic Publishers 1997.
LICHTNOW, Daniel e LOH Stanley. O uso de técnicas de text mining e de information filtering
em chats para construção de um sistema para apoio a colaboração. III Congresso Brasileiro de
Computação, 2003.
MARQUES, Julia C. S. e RAABE, André L. A. Construção de Ferramentas Interativas para
Apoio à Aprendizagem Via Internet, Itajaí, 2004.
MENCZER, Filippo, Complementing search engines with online web mining agents. Lowa City, 2003.
MONGE Alvaro E. e ELKAN. Charles P. The field matching problem: Algorithms and applications. Apresentado em Second International Conference on Knowledge Discovery and Data Mining, (KDD), 1996.
ORACLE, Supplied StopList Disponível em: http://www.cs.utah.edu/classes/cs5530-gary/oracle/doc/B10501_01/text.920/a96518/astopsup.htm. Acesso em novembro, 2005.
PDFBOX. Java PDF Library. Disponível em: <http://www.pdfbox.org >. Acesso em: março, 2006.
RAABE, André L. A. e WEBER, M. H. Sistema Inteligente para Recuperação de Informação, SBIES, 2004.
RIJSBERGEN, C. van. Information Retrieval. 2ed. London: Butterworths,1979.
RILOFF, Ellen. Little words can make big difference for text classification. In: Annual International ACM-SIGIR Conference On Research And Development In Information Retrieval (SIGIR'95), 1995.
SALTON, Gerald; MACGILL, Michael J. Introduction to modern Information Retrieval. New York: McGRAW-Hill 1983.
SIMERTICS . Sam's String Metrics, projeto do grupo Natural Language Processing Group, encontrado em <http://www.dcs.shef.ac.uk/~sam/stringmetrics.html>. Acesso em outubro, 2005.
SMITH, T. F. and Waterman, M. S. Identification of common molecular subsequences encontrado em <http://citeseer.ist.psu.edu/smith81identification.html>. 1981
VAN RIJSBERGEN, C. J. Information Retrieval, Butterworths, 2nd edition, 1979.
ZANASI, Alessamdro. Competitive Inteligence though datamining public sources. Competitive Inteligence Review, Alexandria, Virginia: SCPI. V9, n.1, 1998.

73
WIKIPEDIA, <http://en.wikipedia.org/wiki/Multi-agent_systems> acessado em 30 de outubro de 2005.
WIVES, Lenadro K. Tecnologia de descoberta de conhecimento em textos aplicadas à
inteligência comperativa. Porto Alegre 2002.
WOOLDRIDGE, M., JENNINGS, N. R.; Intelligent Agents: Theory and Practice. The Knowledge
Engineering Review, vol. 10, 1995.

APÊNDICES

A CÓDIGO DA APLICAÇÃO UTILIZADA PARA OS TESTES
package br.api.samples.tests;
import java.sql.SQLException;
import java.util.Calendar;
import java.util.Iterator;
import br.siri.api.*;
import br.siri.api.armazenamento.ArmazenaHSQL;
import br.siri.api.base.*;
public class LocalFolderAssinc {
public static void main(String[] args) {
LocalFolderAssinc a = new LocalFolderAssinc();
}
public LocalFolderAssinc() {
Calendar inicio = Calendar.getInstance();
AgSRI agentes = new AgSRI();
Gerenciador gerenciador = agentes.getGerenciador();
Coleta coletor = agentes.getColetor();
Tratador tratador = agentes.getTratador();
Armazenador armazenador = agentes.getArmazenador();
if (Propriedades.getString("ArmazenadorAPI.FormaDeArmazenamento").equals("HSQL")) {
Gerenciador.startHSQLServer();
try {
ArmazenaHSQL.criaTabela(new ArmazenaHSQL().getConnection());

76
} catch (ClassNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (SQLException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
System.out.println("Tempo até iniclização do SACI e Agentes: " + (Calendar.getInstance().getTimeInMillis() - inicio.getTimeInMillis()) + " Milisegundos");
Calendar parcial1 = Calendar.getInstance();
try {
LinkMap links = gerenciador.getLinks("c:\\acervo", Gerenciador.FILES);
System.out.println("Tempo para coleta de informações na pasta: " + (Calendar.getInstance().getTimeInMillis() - parcial1.getTimeInMillis()) + " Milisegundos");
Calendar parcial2 = Calendar.getInstance();
Iterator it = links.values().iterator();
int nDocumentos = links.size();
while (it.hasNext()) {
Link auxlink = (Link) it.next();
Documento doc = new Documento();
doc.setCaminho(auxlink.getLink());
coletor.iniciaColeta(doc);
}
for (int i = 0; i < nDocumentos; i++) {
Documento doc = coletor.getDocumento();
tratador.tratamento(doc);
}

77
for (int i = 0; i < nDocumentos; i++) {
Documento doc = tratador.EsperaTexto();
armazenador.Armazenar(doc);
}
for (int i = 0; i < nDocumentos; i++) {
Documento doc = armazenador.ConfirmArmazenamento();
}
System.out.println("Tempo medio gasto para cada documento:" + ((Calendar.getInstance().getTimeInMillis() - parcial2.getTimeInMillis()) / links.values().size())+ " Milisegundos");
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Tempo Total: " + (Calendar.getInstance().getTimeInMillis() - inicio.getTimeInMillis()) + " Milisegundos");
}
}





























