Embed Size (px)
Citation preview

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 1/71
CENTRO FEDERAL DE EDUCAÇÃO TECNOLÓGICA DE M INAS GERAIS
PROGRAMA DE PÓS-GRADUAÇÃO EM MODELAGEM MATEMÁTICA E COMPUTACIONAL
TÉCNICAS PARA ANÁLISE DE
SENTIMENTOS DE APLICAÇÕES DA WEB
EM LÍNGUA PORTUGUESA
RENATO FREITAS MARTINS
Orientador: Prof. Dr. Adriano César Machado Pereira
Centro Federal de Educação Tecnológica de Minas Gerais
BEL O HORIZONTE
FEVEREIRO 2016

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 2/71
RENATO FREITAS MARTINS
TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE
APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
Dissertação apresentada ao Programa de Pós-graduaçãoem Modelagem Matemática e Computacional do CentroFederal de Educação Tecnológica de Minas Gerais, comorequisito parcial para a obtenção do título de Mestre emModelagem Matemática e Computacional.
Área de concentração: Modelagem Matemática eComputacional
Linha de pesquisa: Sistemas Inteligentes
Orientador: Prof. Dr. Adriano César Machado PereiraCentro Federal de Educação Tecnológica deMinas Gerais
CENTRO FEDERAL DE EDUCAÇÃO TECNOLÓGICA DE M INAS GERAIS
PROGRAMA DE PÓS-GRADUAÇÃO EM MODELAGEM MATEMÁTICA E COMPUTACIONALBEL O HORIZONTE
FEVEREIRO 2016
ii

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 3/71
Esta folha deverá ser substituída pela có-pia digitalizada da folha de aprovação for-necida pelo Programa de Pós-graduação.
iii

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 4/71
Dedico todo esforço despendido nesses lon-
gos anos à minha esposa Elaine, minha filhaMaria Luisa e a todos que estiveram comigonesta caminhada.
iv

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 5/71
Agradecimentos
Agradeço ao meu competente orientador Prof. Dr. Adriano César Machado Pereira que me
acolheu no momento de maior dificuldade nesta caminhada e pelo conhecimento adquirido
durante o processo de construção deste trabalho.
Agradeço ao amigo Joaquim Augusto pelas palavras de apoio no primeiro semestre de
aulas quando, pela primeira e última vez pensei em desistir.
Agradeço também a todos os professores, colaboradores e colegas do CEFET-MG, que
fizeram parte desta importante etapa da minha vida.
Aos meus amores, Elaine e Maria Luisa, pela compreensão e apoio nos momentos de
ausência e dificuldades.
Por fim, agradeço a Deus por me proteger por quase 200.000 km rodados para cumprir esta
missão.
v

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 6/71
“Fracassar não é cair, é recusar-se a levantar.”
(Provérbio Chinês)
vi

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 7/71
Resumo
A democratização da Internet, o aumento da interatividade entre usuários de redes sociais eo crescente uso de aplicações Web em smartphones contribuem com a produção massiva
de dados sobre diversos assuntos. Métodos de análise de sentimentos são frequentemente
usados na extração de informações que podem ser valiosas para as empresas, incluindo
opiniões de usuários sobre produtos e serviços, tendências e humor do mercado financeiro.
Métodos consagrados com abordagem léxica para classificar sentimentos possuem compor-
tamentos que variam de acordo com a base de aplicação, gerando resultados divergentes
entre si. O objetivo deste trabalho é propor novas técnicas de análise de sentimentos no
idioma português utilizando métodos de análise de sentimentos existentes com abordagem
léxica. Foram utilizadas bases de dados reais da Web no idioma português sobre notícias do
mercado financeiro e tweets relacionados a uma marca de veículos, às quais se aplicaram
as novas técnicas de análise de sentimento. Os resultados gerados pelas técnicas propos-
tas se mostraram melhores e mais estáveis que os produzidos pelos métodos aplicados
individualmente, constatando a diminuição da dependência do contexto da base analisada.
Estes também se mostraram compatíveis com ferramentas de análise de sentimentos
comerciais e gratuitas nos idiomas português e inglês. Por fim, foram detectados pontos
com possibilidades de melhoria das técnicas, que podem ser melhorias futuras.
Palavras-chave: Análise de Sentimentos. Redes Sociais. Aplicações Web.
vii

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 8/71
Abstract
The democratization of the Internet, the increased interactivity among users of socialnetworks and the growing use of Web applications on smartphones account for the mas-
sive production data on many subjects. Sentiment analysis methods are often used in the
extraction of information that may be valuable for businesses, including user opinion about
products and services, trends and moods of the financial market. Relevant methods with
lexical approach have behaviors that may vary according to the application base, generating
different results between them. The objective of this paper is to propose new sentiment
analysis techniques in Portuguese language using existing individual methods with lexical
approach. We used real database from the Web in Portuguese on financial market news and
tweets related to a specific vehicle brand, to which we applied the new sentiment analysis
techniques. The results generated by the proposed techniques proved better and more stable
results than those produced by the methods applied individually, decreasing the context
dependence of the analyzed database. These also proved compatible with commercial and
free sentiment analysis tools in Portuguese and English. Finally, we have detected some
technical issues which can be further improved.
Keywords: Sentiment Analysis. Social Networks. Web Applications.
viii

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 9/71
Lista de Figuras
Figura 1 – Mapa mental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Figura 2 – Técnica de Votação pela Maioria para análise de sentimentos. . . . . . 24
Figura 3 – Exemplo de funcionamento da técnica TVM ML. . . . . . . . . . . . . . 24
Figura 4 – Representação gráfica da técnica de análise de sentimentos SentiPipe . 26
Figura 5 – Mapa mental - Estudos de Caso. . . . . . . . . . . . . . . . . . . . . . . 30
Figura 6 – Características associadas ao conceito “celebrar ocasião especial”. . . 33
Figura 7 – Diagrama do processo de criação da base léxica SenticNet. . . . . . . . 34
Figura 8 – Abrangência e Precisão dos métodos individuais utilizados nas propostas. 39
Figura 9 – Acurácia versus Medida F1 das propostas de análise de sentimentos comos métodos individuais. . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Figura 10 – Sequência de execução dos métodos utilizados na técnica (SP ALE ) e
respectivas classificações individuais. . . . . . . . . . . . . . . . . . . . 42
Figura 11 – Medida F1 versus variação da proporção treino/teste. . . . . . . . . . . 44
Figura 12 – Média e desvio padrão da Medida F1 para a distribuição treino/teste
(80%-20%). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Figura 13 – Variação das médias e desvios padrão da Medida F1 nas distribuições
treino/teste (80%-20%) versus (99%-1%). . . . . . . . . . . . . . . . . . 46Figura 14 – Comparativo entre os métodos Semantria, iFeel, TVM ML e SP ALE . . . 48
ix

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 10/71
Lista de Tabelas
Tabela 1 – Distribuição das bases em classes. . . . . . . . . . . . . . . . . . . . . 32
Tabela 2 – Método SenticNet traduzido aplicado a texto em português. . . . . . . . 35
Tabela 3 – Método SenticNet no idioma original aplicado a texto traduzido do portu-
guês para inglês. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Tabela 4 – Emoticons e suas variações. . . . . . . . . . . . . . . . . . . . . . . . . 38
Tabela 5 – Métricas de todos os métodos nas 3 bases. . . . . . . . . . . . . . . . . 40
Tabela 6 – Contagem de instâncias processadas por métodos da técnica SP ALE . . 43
Tabela 7 – Variação da Medida F1 relativa à proporção Treino/Teste - Base de Notícias. 44
Tabela 8 – Variação da Medida F1 relativa à proporção Treino/Teste - Base de Títulos. 44Tabela 9 – Variação da Medida F1 relativa à proporção Treino/Teste - Base de Tweets. 45
Tabela 10 – Comparativo das técnicas propostas com os aplicativos Semantria e iFeel
- base Tweets. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Tabela 11 – Comparativo das técnicas propostas com os aplicativos Semantria e iFeel
- base Títulos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
x

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 11/71
Lista de Quadros
Quadro 1 – Exemplo de classificação de polaridade em nível de frase realizada por
método léxico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Quadro 2 – Regras de desempate da TVM ML . . . . . . . . . . . . . . . . . . . . 23
Quadro 3 – Matriz de confusão das classes positivo, negativo e neutro. . . . . . . . 27
Quadro 4 – Matriz de confusão adaptada às classes não negativo e negativo. . . . 28
Quadro 5 – Adaptações das saídas dos métodos de análise de sentimentos. . . . . 33
Quadro 6 – Associação de ID’s entre openWordNet-PT e SentiWordNet 3.0. . . . . 37
Quadro 7 – Matriz de confusão para base de notícias - Método SN . . . . . . . . . . 43
Quadro 8 – Matriz de confusão para base de notícias - Método SWN. . . . . . . . 46
xi

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 12/71
Lista de Abreviaturas e Siglas
AS Análise de Sentimentos
ALE Aleatório
API Application Programming Interface
DECOM Departamento de Computação
EMO Emoticons
HI Happiness Index
ID Identificação
INWeb Instituto Nacional de Ciência e Tecnologia para a Web
NB Naive Bayes
PLN Processamento de Linguagem Natural
PoS Part-Of-Speech
RDF Resource Description Framework
RLC Recurso Léxico Computacional
SN SenticNet
SP ALE SentiPipe
SS SentiStrength
SWN SentiWordNet
TVM ML Técnica de Votação pela Maioria
UFMG Universidade Federal de Minas Gerais
WWW World Wide Web (WEB)
xii

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 13/71
Sumário
1 – Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Objetivos Específicos . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Justificativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Principais Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Organização do trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 – Trabalhos Relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1 Aperfeiçoamento dos Métodos de Análise de Sentimentos . . . . . . . . . . 7
2.2 Tradução de métodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Análise de Sentimento em Diferentes Aplicações . . . . . . . . . . . . . . . 11
2.4 Combinação de Métodos de Análise de Sentimentos . . . . . . . . . . . . . 12
2.5 Diferencial deste trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.6 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3 – Fundamentação teórica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1 Aplicações Web / Mídias Sociais . . . . . . . . . . . . . . . . . . . . . . . . 153.1.1 Microblogging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Processamento de Linguagem Natural . . . . . . . . . . . . . . . . . . . . 16
3.2.1 Processamento de Texto . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2.2 Níveis de Análise Textual . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2.3 Análise Léxica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2.4 Análise Semântica . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3 Análise de Sentimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Principais Métodos de Análise de Sentimentos . . . . . . . . . . . . . . . . 20
3.4.1 Métodos Baseados em Dicionário . . . . . . . . . . . . . . . . . . . 20
3.4.2 Métodos Baseados em Aprendizado de Máquina . . . . . . . . . . . 20
3.4.3 Métodos Estatísticos e Semânticos . . . . . . . . . . . . . . . . . . 20
3.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4 – Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1 Soluções Propostas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1.1 Técnica de Votação pela Maioria . . . . . . . . . . . . . . . . . . . . 23
4.1.2 Técnica SentiPipe . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2 Adaptação dos Métodos de Análise de Sentimentos . . . . . . . . . . . . . 26
4.3 Métricas de Avaliação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
xiii

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 14/71
4.4 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5 – Estudos de Caso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.1 Classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.2 Coleta e Tratamento de Dados . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.3 Configuração Experimental . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.4 Resultados e Discussões . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
6 – Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.1 Contribuições Científicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Referências . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
xiv

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 15/71
Capítulo 1
Introdução
Muitas das decisões tomadas por indivíduos passam, em algum momento, pela opinião
de outros mais experientes ou influenciadores (PANG; LEE, 2008) e, em se tratando de
escolha, acertar na decisão é seu principal objetivo.
A World Wide Web (WWW) (DIAS, 2000) tem sido um dos principais meios de divulgação de
todo tipo de conhecimento. Sites de notícias, blogs e redes sociais concentram grande parte
da informação produzida atualmente. Devido à imensa popularidade e à grande quantidade
de informação compartilhada nesses sistemas, várias aplicações têm surgido na tentativa
de extrair opiniões e até mesmo inferir o sentimento público.
Muitos sistemas Web já possuem a maioria dos usuários usando tecnologias móveis como
smartphones , permitindo registro de novas informações a todo momento e em todo lugar. A
partir da evolução dos dispositivos e redes móveis, o uso das aplicações para smartphones
vem crescendo continuamente. A plataforma móvel do Twitter1 é utilizada por 78% dos seus
usuários. Nesta mesma aplicação, em 2014, eram criados 500 milhões2 de tweets por dia,
contra 400 milhões no ano anterior (AJMERA, 2014).
Mesmo com tanta informação, o cenário futuro é de crescimento contínuo. O próprio Twitter,apesar dos números surpreendentes, ainda possui 46% dos seus usuários sem ter criado
nenhum tweet , mostrando o quão massivo podem ser as informações criadas por usuários
em uma aplicação Web.
Números tão expressivos já fizeram com que empresas engajadas no ambiente virtual este-
jam em busca da transformação destes dados em informações que possam ser utilizadas
para agregar valor aos seus serviços. Esta façanha pode auxiliar empresas a monitorar a
intenção dos consumidores e mudanças em seus comportamentos, antecipar problemas e
criar novos produtos com menor resistência de aceitação. Outros benefícios também são
1http://www.twitter.com/ 2https://business.twitter.com/pt/basics/learn-twitter
1

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 16/71
percebidos pelos usuários que tem sua experiência nos sistemas Web melhorada com a
evolução dos mesmos.
O fato das redes sociais e microblogs, como Facebook3, Instagram4 e Twitter, possuírem
uma forma de publicação de informações mais livre e desestruturada que blogs e listas
de e-mail tradicionais, está levando muitos usuários a migrarem para este novo formato
que, apesar de limitar o conteúdo em textos mais curtos, permite a inserção de links que
apontam para notícias completas em outros sites (PAK; PAROUBEK, 2010).
O desafio da interpretação de opiniões e sentimentos expressos na forma textual motivou o
surgimento da análise de sentimentos, que é uma ferramenta popular para a mineração de
dados em redes sociais online com muitas aplicações úteis. Além de ser uma pesquisa de
opinião de grande escala, não invasiva, rápida, autêntica, barata e automática (MALHEIROS;LIMA, 2013), é comum encontrar opiniões ou comentários de produtos, serviços, eventos
e marcas em dados sociais. As pessoas são fortemente influenciadas pelos formadores
de opinião (KELLER; BERRY, 2003) que, apesar de serem minoria nas redes sociais, são
usuários influentes, que possuem argumentos fortes e compartilham-nos nesses ambientes.
De uma forma geral, existem dois tipos de métodos de análise de sentimentos: baseado em
aprendizado de máquinas e léxicos (GONÇALVES et al., 2013). Os métodos de aprendizado
de máquina são baseados em classificações supervisionadas e dependentes de dados para
treinar os classificadores (PALTOGLOU; THELWALL, 2012). Uma vantagem dos métodosbaseados em aprendizado de máquina é que eles se adaptam facilmente a contextos
específicos, e sua desvantagem reside no fato deste depender de dados previamente
rotulados que possuem alto custo de preparação, o que o deixa menos eficiente em novos
contextos.
Os métodos léxicos são criados a partir de uma lista predefinida de palavras associadas
a um sentimento ou classe (positivo, negativo ou neutro). O desempenho deste tipo de
método varia de acordo com a concordância entre o contexto da base analisada e a lista de
palavras que o compõe.
Existem vários métodos de análise de sentimentos disponíveis, mas poucos para o idioma
português, apesar deste ser o 5o mais usado na Web, de acordo com a Internet World Stats 5
e 3o mais utilizado no Twitter, atrás apenas do Inglês e Japonês (HONG; CONVERTINO;
CHI, 2011). Outro fato relevante pode ser constatado com a instalação dos escritórios das
principais empresas de aplicações sociais da Web no Brasil como Facebook, Google6,
Twitter e Instagram, demonstrando a importância deste mercado de língua portuguesa.
3http://www.facebook.com/ 4http://www.instagram.com/ 5http://www.internetworldstats.com/stats7.htm6http://www.google.com.br/
2

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 17/71
A proposta deste trabalho é a criação de técnicas de análise de sentimentos no idioma
português que melhorem os resultados obtidos por métodos existentes quando utilizados
individualmente. As técnicas propostas utilizam esses métodos de maneira combinada,
obedecendo um conjunto de regras e somente traduzindo a base léxica dos mesmos, semacrescentar ou remover palavras e suas valências de sentimento associadas.
Neste trabalho são utilizadas duas bases de dados reais da Web no idioma português,
rotuladas nas classes positivo, negativo e neutro. As novas abordagens, aqui apresentadas,
geraram resultados superiores à maioria dos métodos individualmente aplicados, o que
vem ao encontro da solução do problema descrito por Gonçalves et al. (2013), quando
verificaram que os resultados gerados pelos métodos de maneira individual dependem do
tipo de base de dados à qual estes métodos são aplicados, já que os mesmos possuem
uma base léxica diferente.
Para verificar a eficácia das técnicas, foi testado o método de aprendizado de máquina
supervisionado (LIU et al., 2004) Naive Bayes Multinomial, por ter apresentado o melhor
resultado, dentre vários métodos de classificação previamente testados. Apesar do método
supervisionado apresentar resultados um pouco melhores, as técnicas propostas se mostra-
ram superiores à medida que a quantidade de dados para treino do método supervisionado
diminuia, já que o método de aprendizado de máquina é supervisionado e demanda assim
uma base de dados para treinamento.
As técnicas também se mostraram relevantes quando comparadas a outro método de
análise de sentimentos comercial onde além da proximidade dos resultados, foi possível
classificar mais bases que a solução paga.
Além disso, as técnicas propostas permitem que novos métodos lhes sejam incorporados
facilmente, melhorando ainda mais seu desempenho.
1.1 ObjetivosEste trabalho tem como objetivo geral propor técnicas de análise de sentimentos para
o idioma português que faça uso de métodos já existentes. Tal objetivo será alcançado
extraindo o melhor destes métodos consagrados no idioma inglês, adaptando-os ao novo
idioma.
1.1.1 Objetivos Específicos
Os objetivos específicos são:
• Coletar e tratar base de dados para testes dos métodos de análise de sentimentos,
3

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 18/71
eliminando pontuações e palavras desnecessárias na identificação de sentimentos;
• Adaptar métodos de análise de sentimentos, originais no idioma inglês, para o portu-
guês, adequando suas saídas para retornar resultados positivos, negativos e neutros
além da indicação de não ocorrência na base léxica do método;• Propor técnicas de análise de sentimentos no idioma português que, utilizando-se de
métodos já consagrados, possam realizar classificações de sentimento melhores que
estes aplicados individualmente;
• Implementar algoritmo das técnicas propostas que, usando bases previamente rotula-
das e tratadas, utilizem de forma conjunta os resultados gerados pelos métodos de
análise de sentimentos aplicados às bases de dados;
• Avaliar os resultados gerados pelas técnicas propostas, confrontando-os com os
gerados a partir dos métodos aplicados individualmente.
1.2 Justificativa
A importância deste trabalho se deve ao fato de existir grande quantidade de informações
no idioma português oriundas de usuários da Web, que podem possuir alto valor se tratadas
por uma ferramenta de análise de sentimentos eficiente.
Com o surgimento da Web 2.0 , a interatividade virou regra na relação sistemas versus
usuários, onde a informação é produzida de maneira intencional ou até mesmo sem opretexto de fornecer algum conteúdo relevante.
Diversos autores abordam a extração e análises destas informações oriundas das redes
sociais, como a utilização de dados do Twitter para detectar diversas informações como:
a ocorrência da dengue no Brasil (GOMIDE et al., 2011), predição da eleição ao governo
federal na Alemanha (TUMASJAN et al., 2010), aplicações do comércio eletrônico (ZHANG,
2008; DAVE; LAWRENCE; PENNOCK, 2003a), análise em bolsa de valores (BOLLEN;
MAO; ZENG, 2011), avaliação de desastres naturais (SAKAKI; OKAZAKI; MATSUO, 2010)
e até detecção de depressão (SCHWARTZ et al., 2014).
Todo este conteúdo gerado só é valioso se transformado em conhecimento. Identificar e
sumarizar os sentimentos contidos nos textos é peça chave para descobrir opiniões e fazer
previsões com maior precisão, permitindo assim a melhoria de sistemas existentes e a
criação de outros antevendo tendências. Um exemplo da importância dessas informações
foi discutida por Liu (2011), onde apresentou que consumidores se mostraram dispostos a
pagar até 99% a mais por um produto melhor avaliado. O trabalho explicita as principais
aplicações geradoras de infomações na Web , elucida o processo de análise de sentimentose demonstra a possibilidade de melhoria nos métodos já consagrados.
4

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 19/71
1.3 Principais Contribuições
As principais contribuições deste trabalho são:
• Estudo e tradução de léxicos dos métodos de análise de sentimentos no idioma inglêspara o idioma português;
• Criação de novas técnicas de análise de sentimentos baseada em métodos adaptados
para o idioma português;
• Espera-se que, utilizando métodos de análise de sentimentos existentes, seja possível
criar uma técnica que produza resultados melhores que os métodos léxicos em
estudo, diminuindo a dependência do contexto da base analisada sem necessidade
de treinamento.
1.4 Organização do trabalho
Esta seção descreve a organização do trabalho conforme mapa mental representado pela
Figura 1. O presente capítulo contempla uma breve introdução à análise de sentimentos,
caracteriza o problema e descreve a proposta de melhoria de classificações no idioma
português.
Figura 1 – Mapa mental
No Capítulo 2 são detalhados alguns trabalhos sobre classificação de sentimento, tradução,
comparação e combinação de métodos de análise de sentimentos além dos esforços
realizados para a melhoria dos mesmos.
O Capítulo 3, a fim de permitir conhecimento aprofundado do tema, apresenta os principaisconceitos do ambiente Web, processamento de linguagem natural e análise de sentimentos.
5

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 20/71
O Capítulo 4 contempla o processo de coleta e tratamento da base de dados, apresenta os
métodos de análise de sentimentos, propõe novas abordagens e descreve com detalhes o
processo de criação e execução destas. Ao final são demonstradas as métricas de avaliação
que servirão para a análise e discussão dos resultados encontrados.
O Capítulo 5 apresenta estudos de caso de aplicação da técnica proposta, juntamente
com o detalhamento dos experimentos realizados. Ao final os resultados são apresentados
e comparados ao baseline utilizando as métricas de avaliação utilizadas a fim de gerar
discussões produtivas à luz da análise de sentimentos.
Por fim, o Capítulo 6 trata das conclusões do trabalho e propostas de trabalhos futuros.
6

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 21/71
Capítulo 2
Trabalhos Relacionados
Neste capítulo são apresentados os trabalhos relacionados ao tema principal, agrupados
em abordagens distintas como a melhoria da classificação de sentimentos, comparação, tra-
dução e a combinação dos mesmos para a melhoria dos resultados de métodos existentes.
A seguir serão apresentados trabalhos relevantes da literatura que permitem a melhor
contextualização do problema estudado e, ao final do capítulo, apresentados os diferenciais
deste trabalho frente às pesquisas aqui exploradas.
2.1 Aperfeiçoamento dos Métodos de Análise de Sentimentos
Pesquisas recentes mostram o aumento no interesse pela identificação do pensamento
das pessoas e a internet tornou isso possível (LIU, 2011). O crescimento no número
de aplicações Web 2.0 , onde os usuários podem interagir entre si e com as empresas,
possibilitou a diponibilidade de grande conteúdo opinativo disputado por empresas de
diversos segmentos. Muitos trabalhos comparam métodos de análise de sentimentos com o
objetivo de avaliar as técnicas, léxicos e características que possam contribuir positivamente
para o incremento dos resultados das classificações de polaridade.
Pang, Lee e Vaithyanathan (2002) utilizaram resenhas de filmes como dados para clas-
sificação e verificaram que as técnicas de aprendizado de máquina padrão, como Naive
Bayes, Maximum Entropy e Support Vector Machine , superam os baselines rotulados por
humanos. As técnicas de aprendizado de máquina tiveram resultados entre 72,8% e 82,9%
contra o intervalo entre 58% e 64% de acurácia das classificações manuais. Neste trabalho
o baseline foi definido como o método aleatório de classificação automática, que a cada
instância sorteia uma classe aleatória, já que rotulagem humana é extremamente lenta, cus-
tosa e pode se tornar inviável devido ao tamanho da base de testes. Turney (2002) utilizouo algoritmo Pointwise Mutual Information e Information Retrieval (PMI-IR) para estimar a
orientação semântica de uma frase no texto, em qualquer ordem, onde o mesmo atingiu
7

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 22/71
uma precisão média de 74%. O algoritmo de aprendizado não supervisionado, detectou
sentimento nos textos, em inglês, à partir de informações morfológicas e classificou as
opiniões como positivas ou negativas, de maneira que o usuário que lê a avaliação de um
filme, por exemplo, saiba se o mesmo foi recomendado ou não sem a necessidade de leiturada avaliação.
Em outro trabalho, Kouloumpis, Wilson e Moore (2011) analisaram mensagens do Twitter
em inglês considerando as classes positivo, negativo e neutro. Foram analisadas diversas
características de análise de sentimentos como n-gramas, léxicos, PoS (Part-of-speech)
como verbos e características de microblogs como abreviações, emoticons e intensificadores
(texto em caixa alta).Também foram classificadas as principais hashtags , presentes no
corpus, em positivo, negativo e neutro. Os resultados como medida F foram incrementados
à medida que as características eram incluídas nas análises das mensagens atingindo seumelhor resultado de 68,0% para a base de hashtags .
Diversas tentativas de melhoria da classificação de sentimentos foram realizadas a partir
das obras de Pang, Lee e Vaithyanathan (2002) e Turney (2002). Os autores consideraram o
problema da classificação de documentos pelo sentimento geral, ou seja, se uma avaliação
ou comentário é positivo ou negativo.
Liu (2011) demonstra em seu trabalho que 81% dos usuários de internet nos Estados
Unidos realizam pesquisa online sobre algum produto ao menos uma vez e entre 73% e87% dos leitores de avaliação de serviços como hotéis, agências de viagens e restaurantes
reportaram que sofreram significante influência sobre suas compras a partir da opinião de
outros. Nesta mesma pesquisa, os consumidores se mostraram dispostos a pagar entre 20
e 99% a mais por um produto avaliado com 5 estrelas em relação a um item 4 estrelas, o
que justifica ainda mais o aprofundamento nesta área de pesquisa.
Muitas são as dificuldades na realização da AS como o uso de dialetos ou variações
no idioma, ambiguidades, uso de ironia no texto e, principalmente o uso excessivo de
abreviaturas em bases do Twitter e Foursquare1. Buscando melhores resultados, diversos
autores vem aplicando diferentes técnicas para a melhoria da análise de sentimentos
contextos diversos.
Em seu trabalho, Bermingham e Smeaton (2010) falam sobre a extração de sentimentos
em textos curtos (tweets ). Apesar de frequentes ruídos no texto, gerados pela necessidade
de abreviação de palavras pelo limite de 140 caracteres2 por tweet ou pelo excesso de
gírias no texto, foi verificado menor dificuldade de avaliação em relação a textos maiores e
foram analisados os desafios do aprendizado supervisionado na análise de sentimentos. A
1http://www.foursquare.com/ 2Desde agosto de 2015 foi extinta a limitação de 140 caracteres por mensagem no Twitter
8

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 23/71
base utilizada pelos autores foi extraída de mensagens do Twitter no ano de 2009 e, para
que esta ficasse mais homogênea foi dividida em 5 temas. As 3 classes utilizadas (positivo,
negativo e neutro) foram geradas pelos classificadores SupportVector Machine (SVM) e
Naive Bayes Multinomial (NB).
Diversas pesquisas em análise de sentimento (AVANCO; NUNES, 2014; ARAÚJO et al.,
2013; PRABOWO; THELWALL, 2009) utilizam de métodos léxicos, que permitem melhorias
como, por exemplo, o uso de conhecimento de linguística. Neste trabalho o foco será em
torno da análise em nível de documento e sentença, por métodos que utilizam técnicas de
Processamento de Linguagem Natural (NLP) para classificação de polaridade e técnicas de
aprendizado de máquina.
Avanco e Nunes (2014), em seu trabalho, apresentam resultados de classificação de senti-mentos em avaliações de produtos tecnológicos na Web escritas em português do Brasil.
Foram utilizados 3 métodos de classificação de sentimentos léxicos com diferentes abor-
dagens. Uma delas prioriza a polaridade do sentimento das palavras, outra que considera
contextos de negação e outra que acrescenta o tratamento de intensificação do contexto
além da negação. Os resultados se mostraram compatíveis e até superiores com os de
trabalhos relacionados para o mesmo tipo de base, utilizando os métodos puros.
Dentre as diversas abordagens da análise de sentimento, se destacam alguns trabalhos que
representam possibilidades promissoras como Gonçalves et al. (2013), Prabowo e Thelwall(2009), Wilson, Wiebe e Hoffmann (2005), Lertsuksakda (2014). Em seu trabalho, Prabowo
e Thelwall (2009) propõem um método combinado baseado em regras, aprendizado super-
visionado e aprendizado de máquina. Os testes foram realizados em 4 conjuntos de bases
de dados, onde os métodos foram aplicados em diversas sequências. A partir das análises
dos resultados foi possível concluir que o uso de múltiplos classificadores, de forma híbrida,
resultam na melhoria da efetividade em termos de micro e macro-F1 do que em qualquer
outro classificador individual. Como esperado, não apresentam um método que obtivesse
melhores resultados para todas as bases, mas a combinação dos mesmos gerou melhoresresultados que métodos individuais.
A polaridade de sentimentos, em nível textual, pode ser muito difícil se determinar de forma
automática devido a ambiguidades, contradições e subjetividades (RIGO; ALVES; GAZOLA,
2013). Em seu trabalho, Wilson, Wiebe e Hoffmann (2005) apresentam experimentos que
detectam, automaticamente, polaridade prévia e contextual. A polaridade prévia se refere
a alguns indícios de negatividade ou positividade como “confiança”, “bem” ou “razoável”
quando, a princípio, se referem a um texto com conotação positiva. Os autores afirmam que,
tarefas como identificação de respostas com várias perspectivas, resumos ou revisão deprodutos, requerem uma análise de sentimento por sentenças ou até mesmo frase. A identi-
ficação da polaridade se dá por pequenos fragmentos do texto que, quando combinados,
9

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 24/71
geram a classificação final do texto como o exemplo no Quadro 1.
Quadro 1 – Exemplo de classificação de polaridade em nível de frase realizada por métodoléxico.
Polaridade Texto∅ Nós+ não odiamos∅ o pecador, mas- odiamos∅ o pecado.∅ classificação final
Foi utilizado um processo de duas etapas, utilizando aprendizado de máquina e várias
características do documento. A primeira etapa classifica cada frase como neutra ou polar ea etapa seguinte efetua a desambiguidade contextual (positivo, negativo, ambos ou neutra).
Os resultados se mostraram superiores ao baseline (WILSON; WIEBE; HOFFMANN, 2005).
Apesar dos esforços da comunidade científica, as pesquisas ainda são limitadas quanto
a estudos específicos da língua portuguesa. O trabalho de Souza e Vieira (2012) está
relacionado a Silva e Team (2011), que também tiveram a intenção de realizar análise de
sentimentos em dados do Twitter para o idioma português em uma abordagem baseada em
léxicos, no entanto, não dependente de domínio específico. Foram utilizados os recursos
léxicos de sentimentos em português, Sentilex (SILVA et al., 2010) e Opinion Lexicon
(SOUZA et al., 2011). Os testes realizados contemplaram o impacto de diferentes técnicas
de processamento como modelos de negação e polaridade associada aos léxicos. Os
resultados mostraram discreta melhoria com a detecção de negação nas sentenças do que
quando as mesmas não eram consideradas. Dentre os léxicos, o Opinion Lexicon obteve
resultado pouco superior, mostrando o sucesso do corpus sem dependência de contexto
em detrimento dos adjetivos presentes no Sentilex.
Filho, Pardo e Aluısio (2013) apresentam uma avaliação do dicionário LIWC de análise desentimentos no idioma português brasileiro. Foram realizados testes com outros recursos
léxicos, Opinion Lexicon (SOUZA et al., 2011) e SentiLex (SILVA et al., 2010) onde, em suas
bases léxicas, somente foram considerados os unigramas e suas polaridades positivas e
negativas. Utilizando um corpus no idioma português sobre avaliação de livros, dois testes
foram considerados. Os resultados se mostraram superiores para o dicionário LIWC para
a classe positivo e piores que os demais na classe negativo, uma média de 51,61% de
diferença na medida F, o que demonstra oportunidade significativa de melhoria deste léxico.
Devido a variação de resultados dos mesmos léxicos aplicados à bases distintas, os valoresencontrados nos trabalhos relatados anteriormente servem como uma aproximação do
desempenho geral para determinado contexto. Em nossa proposta, são utilizadas bases
10

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 25/71
de dados reais em diferentes contextos para que os resultados fiquem mais próximos à
realidade das aplicações reais de AS.
2.2 Tradução de métodos
Devido a dificuldade de encontrar uma WordNet (MILLER, 1995) aberta a modificações no
idioma português brasileiro, Paiva, Rademaker e Melo (2012) criaram uma versão aberta e
disponível para alterações, a openWordNet-PT, que permite a melhoria da representação do
conhecimento obtida de textos em português. Este recurso léxico pode sofrer modificações
para, por exemplo, ser adaptado a um contexto específico ou como tradução da WordNet
oficial, como é feito neste trabalho no processo de tradução do método SentiWordNet.
Lertsuksakda (2014) propõe a revisão da representação computacional de emoções The
Hourglass of Emotions (A Ampulheta das Emoções) (CAMBRIA; HUSSAIN, 2012) e a cons-
trução de uma base de sentimentos rotulados em Tailandês. A base original do SenticNet
2 (CAMBRIA; HAVASI; HUSSAIN, 2012) foi traduzida para o idioma Tailandês utilizando 2
dicionários Inglês-Tailandês-Inglês e a união dos resultados das traduções resultaram em
16.478 termos, já removidas as redundâncias. Utilizando a ferramenta Protégé Research
(2013), o autor criou uma ontologia e em seguida avaliou a polaridade de sentenças e
identificou que algumas palavras, individualmente, não contribuíam para o resultado do
sentimento de uma frase geral, que o autor propõe avaliar em trabalhos futuros.
Os métodos utilizados nesta pesquisa tiveram suas bases léxicas traduzidas para o idi-
oma português (SenticNet (CAMBRIA et al., 2010b), SentiStrength (THELWALL, 2013),
Happiness Index (BRADLEY; LANG, 1999) e SentiWordNet (OHANA; TIERNEY, 2009)),
já o método (script ) Emoticons, por não ser dependente de idioma, foi mantido em sua
configuração original. Detalhes das adaptações são descritos no Capítulo 4.
2.3 Análise de Sentimento em Diferentes AplicaçõesCom a grande disponibilidade de dados de opiniões de usuários em vários serviços da Web,
vislumbra-se uma oportunidade para extrair as informações de tais bases para produzir
conhecimento antes inexistente.
Aplicações como detecção da Dengue (GOMIDE et al., 2011), predição de terremotos
(SAKAKI; OKAZAKI; MATSUO, 2010) ou resultado das eleições (TUMASJAN et al., 2010;
SILVA; TEAM, 2011) mostraram produzir bons resultados com a aplicação da análise de
sentimento.
A seguir serão discutidas algumas das principais aplicações Web da atualidade onde a
11

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 26/71
análise de sentimento vem sendo largamente aplicada; Mercado Financeiro (AIRES et al.,
2013; LERTSUKSAKDA, 2014), Opiniões em Aplicações de Turismo (LEITE; BENEVENUTO;
MORO, 2013) e Comércio Eletrônico (ZHANG, 2008; DAVE; LAWRENCE; PENNOCK,
2003b).
A predição do mercado financeiro vem atraindo atenção das áreas acadêmica e empresarial
nos últimos anos. Apesar do crescente interesse pela previsão dos ativos, diversos trabalhos
(FAMA, 1965), (FAMA et al., 1969) defendem a Hipótese do Mercado Eficiente (EMH), que
determina que os preços das ações estão ligadas diretamente a novas informações. Como
as notícias são imprevisíveis, os preços das ações irão seguir um padrão de caminho
aleatório e não podem ser previstas com mais de 50% de acerto.
Em seu trabalho, Bollen, Mao e Zeng (2011) questionam sobre a possibilidade de serealizar previsão do mercado financeiro. O autor propõe que o mercado financeiro nem
sempre segue o caminho aleatório podendo ter algum grau de previsão significativo e seus
resultados mostram uma acurácia de 86,7% na previsão de altas e baixas do índice Dow
Jones Industrial Average (DJIA).
Análise de sentimentos também é frequentemente utilizadas como forma de pesquisa
de opinião em eleições. Silva e Team (2011) utilizaram a AS para avaliar o sentimento
dos portugueses durante as eleições parlamentares do ano de 2011. Foram coletadas
mensagens de usuários do Twitter, que atendiam a uma ontologia específica, durante osmeses de abril e maio de 2011. Aplicando léxicos próprios associados às polaridades
positiva, negativa e neutra, foi possível classificar as mensagens e determinar a preferência
do eleitorado durante o pleito eleitoral.
Este tipo de aplicação pode ser utilizado com diferentes técnicas de AS, permitindo retratar
o sentimento dos eleitores antes, durante e após um debate político na TV, servindo de
parâmetro para auxiliar os eleitores indecisos com pesquisas mais transparentes e em
tempo real.
Em seu trabalho, Reis et al. (2015) aplicam a análise de sentimentos em manchetes
vinculadas em sites de notícias online a fim de verificar qual é o sentimento (extremamente
positivo ou negativo) predominante nas notícias, como os usuários reagem às notícias
em relação às diferentes polaridades associadas a elas, e se existe ligação entre os
comentários destes e a polaridade do título da notícia. Com a ajuda do sistema iFeel
(ARAÚJO et al., 2014), foi verificado que o sentimento do título da notícia é fortemente
conectado à polaridade da notícia
12

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 27/71
2.4 Combinação de Métodos de Análise de Sentimentos
Combinar métodos de classificação com o intuito de gerar resultados melhores que os
obtidos em abordagens individuais tem sido uma técnica bastante utilizada, atingindo bons
resultados. Em seu trabalho, Wan (2008) combina o resultado de técnicas de análise de
sentimento nos idiomas chinês e inglês. Opiniões em chinês são traduzidas para o inglês,
extraídas as polaridades e então combinadas com as polaridades obtidas em um método
de análise de sentimento na língua chinesa.
O uso combinado de métodos é abordado por muitos autores (WANG et al., 2014; FERSINI;
MESSINA; POZZI, 2014; PRABOWO; THELWALL, 2009; AUGUSTYNIAK et al., 2014;
ARAÚJO et al., 2013), onde os resultados de cada método são combinados em saída única
melhorando, por exemplo, a precisão e a Medida F1 médios comparados aos métodosutilizados individualmente.
Gonçalves et al. (2013) utilizam de métodos não supervisionados já consagrados para
análise de sentimento no idioma inglês, como PANAS-t (GOMIDE et al., 2011), Emoti-
cons, SentiStrength (THELWALL, 2013), SentiWordNet (ESULI; SEBASTIANI; MORUZZI,
2006), SenticNet (CAMBRIA et al., 2010b), SASA (WANG et al., 2012) e Happiness In-
dex (DODDS; DANFORTH, 2009), para a criação de um método combinado que analisa
a média harmônica entre precisão e revocação para todos os métodos com o objetivo de
aumentar a abrangência e melhorar a concordância para um conjunto de dados. Os autoresimplementaram esses métodos em uma ferramenta, o iFeel.
Em seu trabalho, Prabowo e Thelwall (2009) propõem um método combinado fundamentado
em classificação baseada em regras, técnicas de aprendizado de máquina (SVM) e abor-
dagem de classificação híbrida, onde os classificadores são aplicados em uma sequência,
definida pelo grau de precisão do método quando aplicado à base de testes. Após definidas
as regras de classificação, estas foram combinadas em 10 sequências. Os resultados
mostraram melhoria nos índices de precisão e revocação.
Abordagem semelhante fizeram Augustyniak et al. (2014), quando criaram um método léxico
B ag of Words (BoW) a partir da combinação de outros léxicos, onde demonstraram que a
precisão obtida a partir desta abordagem superou a de outras baseadas em léxicos.
Próximo a este trabalho estão Fersini, Messina e Pozzi (2014) e Wang et al. (2014), que
utilizaram técnica de AS em conjunto, combinando os resultados dos métodos individuais
por maioria de voto, porém não utilizando abordagens léxicas.
13

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 28/71
2.5 Diferencial deste trabalho
Até onde foi investigado, constatou-se a carência de métodos eficientes para análise de
sentimento para o idioma português. Sendo assim, a técnica aqui proposta visa trazer
benefícios na utilização combinada de alguns métodos e suas adaptações para conteúdos
em português.
Este trabalho propõe, utilizando-se de métodos de análise de sentimento já existentes,
uma abordagem voltada para a melhoria da predição de sentimentos em textos da Web no
idioma português. Além desta contribuição, a tradução para o português da base do método
SenticNet, necessário nas técnicas propostas, é um fator inovador.
Os métodos escolhidos para trabalhar em conjunto têm suas classificações combinadas
de duas maneiras, a primeira elegendo o resultado da classificação por maioria de votos
em uma polaridade (positivo ou negativo) e outra serial, onde é extraído o melhor de cada
método de acordo com sua aderência ao contexto da base aplicada.
As técnicas desenvolvidas são aplicadas a textos da Web como notícias do mercado finan-
ceiro e em outro tema específico de um microblog, e então comparadas aos métodos mais
conhecidos para o idioma português ou inglês, para fins de verificação de sua aplicabilidade
e eficiência, em termos de precisão e robustez.
2.6 Considerações Finais
Os resultados das pesquisas apresentadas neste Capítulo mostram grande variação de
acordo com a base, método aplicado ou abordagem realizada.
As combinações entre bases, métodos e abordagens exercem papel fundamental no de-
senvolvimento da análise de sentimentos e podem ser consideradas como um Estado da
Arte Empírico, também chamado de Estado da Prática, revelando a importância de cada
publicação nesta área.
14

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 29/71
Capítulo 3
Fundamentação teórica
Nesta sessão será abordada a revisão teórica relativa ao projeto de pesquisa, onde são
levantadas as principais informações relativas ao tema de Análise de Sentimentos. Assim foi
feita uma análise dos dados apresentados na literatura para proporcionar um embasamento
teórico ao trabalho.
Inicialmente serão descritas algumas Aplicações Web e as principais Redes Sociais, mos-
trando o tipo de informação disponível e sua relevância para a pesquisa. Em seguida, são
realizados alguns comentários acerca do Processamento de Linguagem Natural dando
ênfase ao Processamento de Texto, Níveis de Análise Textual e as Análises Léxicas e Se-mânticas. Por último, a Análise de Sentimentos é explicada, juntamente com suas principais
abordagens.
3.1 Aplicações Web / Mídias Sociais
A Web tem sido um dos principais meios de divulgação de todo tipo de conhecimento. A
popularização da internet ligada ao surgimento das redes sociais, resultou em um grande
volume de informações que expressam cada vez mais as opiniões e o sentimento dosusuários dessas aplicações.
3.1.1 Microblogging
Microblogging é uma forma de comunicação que vem sendo utilizada nos últimos anos
onde os usuários podem, com o uso de mensagens instantâneas enviadas pela internet
através de telefones móveis ou computadores pessoais, descrever o que estão fazendo
naquele momento ou simplesmente compartilhar seus pensamentos.
Criado em Outubro de 2006 o Twitter é uma das primeiras aplicações de Microblogging a
15

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 30/71
permitir postagens limitadas a 140 caracteres1, reduzindo a exigência de tempo e esforço
na atualização de postagens (JAVA et al., 2007).
O Twitter vem constantemente crescendo como um importante sistema onde usuários
discutem sobre tudo, expressando opiniões, visão política, orientação sexual e até mesmo
humor, como felicidade ou tristeza. Redes sociais são apontadas como locais onde usuários
influenciam e são influenciados por outros sendo, portanto, ambientes perfeitos para a reali-
zação de marketing boca-a-boca, propagandas e campanhas políticas (KELLER; BERRY,
2003).
3.2 Processamento de Linguagem Natural
O Processamento de Linguagem Natural (PLN) é uma área de pesquisa que permite aos
computadores entender e manipular textos de linguagem natural ou fala (CHOWDHURY,
2003). Um sistema de PLN, segundo Daniel e James (2000), é abordado das seguintes
formas:
• Morfológica: estuda a estrutura da construção das palavras, com seus radicais e
afixos, que correspondem a partes estáticas e variantes das palavras (e.g. inflexões
verbais);
• Sintática: estudo de como as palavras se relacionam formalmente;• Semântica: processo de mapeamento das sentenças de uma linguagem com o
objetivo de representar seu significado baseado nas construções sintáticas;
• Pragmática: estudo de como a linguagem é usada para se comunicar os objetos e
seu contexto.
3.2.1 Processamento de Texto
O pré-processamento de texto é uma parte essencial de qualquer sistema de PLN. Caracte-
res, palavras e frases identificados nesta fase são as unidades fundamentais transmitidaspara todas as outras etapas de processamento, incluindo a análise e rotulagem de com-
ponentes, tais como analisadores morfológicos e rótulos PoS, através de aplicações, tais
como recuperação de informação e sistemas de tradução automática. Pode ser divido em
dois estágios: triagem de documentos e segmentação de textos (INDURKHYA; DAMERAU,
2010).
A triagem de documentos é o processo de conversão de um conjunto de arquivos digitais em
documentos de texto bem definidos, processo que pode envolver várias etapas. Para que
qualquer documento de linguagem natural possa ser lido por uma máquina, os caracteres
1Desde agosto de 2015 foi extinta a limitação de 140 caracteres por mensagem no Twitter
16

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 31/71
devem ser representados em uma codificação de caracteres, em que um ou mais bytes em
um arquivo sejam mapeados para um caractere conhecido. Em seguida o seccionamento do
texto identifica o conteúdo dentro de um arquivo enquanto descarta elementos indesejáveis,
tais como imagens, tabelas, cabeçalhos, links e formatação HTML. O resultado do estágio detriagem do documento é um corpus de texto bem definido, organizado por linguagem, pronto
para a segmentação de texto e uma análise mais aprofundada (INDURKHYA; DAMERAU,
2010).
Segmentação do texto é o processo de conversão de um corpus de texto bem definido
em palavras e frases que o compõem. A segmentação de palavras quebra a sequência de
caracteres em um texto localizando as fronteiras das palavras, pontos onde uma palavra
termina e outra começa. Para fins de linguística computacional, as palavras assim identifi-
cadas são frequentemente referidas como tokens e segmentação de palavras é tambémconhecido como geração de tokens ou tokenização.
3.2.2 Níveis de Análise Textual
Existem muitas técnicas de Análise de Sentimentos (AS) (FELDMAN, 2013) que se aplicam
a diferentes propósitos, algumas abordagens em nível de documento (CAVALCANTI et al.,
2012), sentença (TURNEY, 2002) ou entidade (SOUZA, 2012). Classificando as diferentes
granularidades (LIU, 2012) em ordem de generalização, temos:
• Documento: nível mais geral, é voltado para a classificação de um documento como
um todo dentre as classes previamente definidas como positivo, negativo ou neutro.
Geralmente utilizado quando a base a ser classificada já foi delimitada em contexto
único como dados de uma pesquisa sobre eleições (e.g. “O pleito deste ano foi
exemplar”) (CAVALCANTI et al., 2012).
• Sentença: a fim de refinar a classificação de sentimentos, é utilizado o nível de
sentença. Neste nível é possível aprofundar o detalhe da análise quando existem
mais de um sentimento associado à uma mesma sentença (e.g. “O candidato possuiboas propostas, mas seu apoio no congresso é muito fraco”) (TURNEY, 2002).
• Entidade e Aspecto: muito utilizada para revisões de produtos e serviços, este com-
plexo nível de análise textual permite que sejam analisados aspectos de determinada
marca de um produto (e.g. “O celular X possui ótima resolução mas pouco espaço
de armazenamento, enquanto seus concorrentes tem muito espaço!”). No exemplo,
é possível vincular o conceito de resolução somente ao produto X, enquanto a ca-
racterística de armazenamento ainda fica confusa. Conseguindo realizar a análise
pela entidade (e.g. Telefone X) é possível chegar à conclusão que a característica
de espaço de armazenamento não é um ponto positivo no modelo, podendo ser
confundido caso se realize uma análise de documento (SOUZA, 2012).
17

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 32/71
3.2.3 Análise Léxica
A criação e disponibilização de recursos léxicos computacionais (RLC) é uma das atividades
compreendidas pela área de PLN, pois eles são fundamentais para processar ou analisar a
linguagem natural. Em especial, RLC’s com informações sintáticas e/ou semânticas são
importantes para tarefas como: animações de instruções em língua natural, construção
de parsers semânticos, desambiguação do sentido de palavras, dentre outras (SCARTON,
2011). Um grupo especial de RLC’s são os que tratam de verbos, pois estes possuem
uma grande carga de informação sintática e semântica, sendo possível saber, a partir do
comportamento do verbo, como a sentença se comporta.
3.2.4 Análise Semântica
Identificar a estrutura sintática de uma sequência de palavras é apenas um passo na determi-
nação do significado de uma frase; ele fornece um objeto estruturado, que é mais favorável
a uma maior manipulação e interpretação subsequente. São essas etapas subsequentes
que derivam de um sentido para a frase em questão.
Para textos longos, aplicações específicas de PLN de análise semântica podem incluir a
recuperação da informação, extração de informações, sumarização de texto, mineração de
dados, e de tradução automática. A análise semântica também é pertinente para textos
muito curtos, até o nível de uma única palavra. A análise semântica também é de altarelevância nos esforços para melhorar ontologias da Web e sistemas de representação do
conhecimento (INDURKHYA; DAMERAU, 2010).
3.3 Análise de Sentimentos
Saber “o que se passa na cabeça dos clientes” sempre foi uma importante informação
para a tomada de decisões em diversas companhias. Bem antes das informações estarem
disponíveis na Web, as pessoas já pediam a conhecidos informações sobre indicação deprodutos, serviços ou opiniões a respeito de algum tópico específico como eleições ou
tendências de mercado.
Com o surgimento da Web e suas aplicações, foi possível obter informações sobre as
opiniões e as experiências de um vasto conjunto de pessoas que nunca se ouviu falar,
aumentando consideravelmente o número de contribuições voluntárias e involuntárias sobre
todo tipo de assunto (PANG; LEE, 2008).
Sentimentos encontrados em comentários, feedbacks ou críticas fornecem indicadoresúteis para diferentes propósitos. O principal ponto na análise de sentimento é identificar a
maneira que os sentimentos são expressos em textos e se estes indicam opiniões positivas
18

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 33/71
(favoráveis) ou negativas (desfavoráveis) em relação ao assunto em foco. Prabowo e Thelwall
(2009) citam que estes sentimentos também podem ser categorizados em uma escala de
vários pontos (e.g. muito bom, bom, satisfatório, ruim ou muito ruim). Assim, a análise de
sentimentos envolve a identificação de:
• Expressões de sentimento;
• Polaridade e intensidade dos sentimentos;
• Seu relacionamento com o assunto.
Estes elementos estão interligados. Na frase “Time AA é muito melhor que time BB”,
por exemplo, a expressão melhor indica um sentimento positivo em relação a AA e um
sentimento negativo sobre BB . A palavra muito indica a intensidade do sentimento, que
pode ser aplicada tanto ao sentimento positivo quanto o negativo.
A classificação de sentimento também pode ser considerada como classificação de polari-
dade. De uma forma geral, as polaridades são definidas como classes positivo ou negativo ,
apesar da classe neutro frequentemente ser utilizada. A fim de melhorar a robustez das
classificações, pode-se fazer o desdobramento das classes em subclasses como muito-
Positivo ou poucoPositivo , que permite melhor sensibilidade na análise das classificações
encontradas. Diversos métodos de AS como SentiWordNet (OHANA; TIERNEY, 2009),
SentiStrength (THELWALL, 2013) e Happiness Index (BRADLEY; LANG, 1999) retornam
diferentes graus de intensidade, em intervalos numéricos que representam graus de intensi-dade para cada classe (BECKER; TUMITAN, 2013).
Diversos trabalhos (WANG et al., 2014; GONÇALVES et al., 2013; ARAÚJO et al., 2013)
e aplicações dispensam as classes neutro com o objetivo de aumentar a qualidade dos
resultados, já que a classificação em instâncias sem sentimento é mais difícil de ser realizada
e geralmente sua classificação é menos relevante que, por exemplo, classes positivo e
negativo . Quando um texto possui características que não permitam sua classificação como
erros ortográficos, uso excessivo de gírias ou textos incompletos, o mesmo é classificado
como neutro , o que também ocorre quando existe equilíbrio entre as classes opostas
positivo e negativo .
Os desafios da classificação de polaridade apresentam mais ou menos intensidade de
acordo com a base, dos quais pode-se citar:
• O uso de expressões que não contêm obrigatoriamente um sentimento, quando uma
opinião não possui viés positivo ou negativo;
• O sentimento pode ser dependente do contexto e do ponto de vista do leitor: Um
produto pode ser avaliado como “Geladeira pequena” e ser vista como uma polaridade
positiva para quem precisa de um refrigerador pequeno e negativo para quem tem a
19

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 34/71
família grande (HU; LIU, 2004);
• Uso de ironias ou sarcasmo, onde se diz exatamente o oposto do que realmente se
deseja expressar (TURNEY, 2002);
• Questões relativas ao idioma (BECKER; TUMITAN, 2013).
Diversas tentativas de novas abordagens das técnicas de análise de sentimentos vem
contribuindo para melhoria das mesmas, criando novas referências para o estado da arte,
que neste caso pode ser chamado de “estado da prática”.
3.4 Principais Métodos de Análise de Sentimentos
3.4.1 Métodos Baseados em DicionárioMétodos baseados em dicionário, ou léxicos, são muito usados na análise de sentimentos.
Somente um léxico de sentimentos, composto por um termo e sentimento associado, é
necessário para que a classificação ocorra.
De aplicação mais simples, permite novas implementações com a finalidade de aumentar
a qualidade das classificações. O uso de informações adicionais ao dicionário como a
classificação sintática e categoria gramatical podem contribuir para esta melhoria.
Recomendado para textos com pequena granularidade, quando existe uma entidade bemdefinida, é ideal para análises em textos curtos como de redes sociais. Porém, o uso
excessivo de gírias e abreviações comprometem o desempenho da abordagem, que requer
outros tratamentos como a correção automática de palavras, proposta futura deste trabalho.
3.4.2 Métodos Baseados em Aprendizado de Máquina
O uso de técnicas baseadas em aprendizado de máquina permite extrair sentimento de
grandes volumes de textos. Os algoritmos de aprendizado de máquina são divididos em
supervisionados e não supervisionados. O primeiro constrói um modelo de distribuição
das categorias, ou classes, em função de uma base de treino já classificada dentro do
próprio domínio. Este modelo é que permite, em um segundo momento, a classificação
de novos textos a partir do treino realizado. Dentre os principais algoritmos utilizados na
área de análise de sentimentos estão o Naive Bayes (NB) (MCCALLUM; NIGAM, 1998),
Support Vector Machine (SVM) (DAVE; LAWRENCE; PENNOCK, 2003a) e Maximum
Entropy (TURNEY, 2002).
20

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 35/71
3.4.3 Métodos Estatísticos e Semânticos
Utiliza métodos probabilísticos para inferir uma relação. Uma técnica muito utilizada nesta
categoria é a Pointwise Mutual Information (PMI) (TURNEY; LITTMAN, 2002), que identifica
a probabilidade de determinada palavra pertencer a uma classe devido à frequência de
ocorrência desta junto a termos positivos como “super” para positivo ou “péssimo” para
negativo. Uma das vantagens em relação ao método supervisionado, é que esta abordagem
não depende de um conjunto de treino previamente classificado.
Esta abordagem foi utilizada por Wiebe (2000) para resolver o problema de classificação de
subjetividade, onde foi identificada a presença de expressões subjetivas em uma sentença
para determinar a subjetividade da mesma.
3.5 Considerações Finais
Nesta seção foram apresentados os principais fundamentos teóricos necessários ao en-
tendimento da abordagem de análise de sentimentos, tais como, introdução às aplicações
Web, técnicas de processamento e análise textual, além dos principais métodos de análise
de sentimentos e seus desafios. Na próxima seção são detalhados os passos necessários
à construção da proposta central deste trabalho.
21

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 36/71
Capítulo 4
Metodologia
Este trabalho contempla pesquisa de natureza qualitativa, bibliográfica e experimental
(BOGDAN et al., 1994) em torno do tema Técnicas de Análise de Sentimentos no Idioma
Português.
A seguir serão discutidos o planejamento da construção das técnicas propostas e as
métricas de avaliação de desempenho das mesmas.
4.1 Soluções Propostas
Objetivando técnicas que obtenham resultados mais uniformes quando aplicadas a diferen-
tes bases de dados no idioma português, são propostas duas abordagens que possuam
abrangência total independente da base de dados. A proposta básica é a realização da
análise de sentimentos utilizando métodos já consagrados na literatura com o objetivo de
melhorar a classificação média em um conjunto heterogêneo de bases de dados. Esta ideia
partiu do fato de que diferentes métodos de análise de sentimentos (AS) possuem variado
comportamento em bases de diferentes contextos. Toma-se como exemplo dois métodos de
AS (A e B) e duas bases (X e Y), o primeiro método possui bons resultados na base X, e osegundo se sai melhor na base Y. A intenção deste trabalho é utilizar os resultados dos dois
métodos para cada base, chegando assim a um resultado de classificação de sentimentos
igual ou melhor que os dos métodos individuais.
Duas frentes de trabalho são analisadas: a primeira utiliza um sistema de votação que
elege a melhor classificação para determinada entrada oriunda de uma base de dados
qualquer, que gerou a Técnica de Votação pela Maioria (TVM). A segunda abordagem
dá preferência de classificação aos métodos com melhor desempenho no contexto a
ser classificado. Esta última frente é chamada de SentiPipe (SP). As abordagens aquipropostas tiveram inspiração em Araújo et al. (2013).
22

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 37/71
Para ambas as técnicas, caso nenhum dos métodos consiga obter sucesso na classificação,
é invocado um método auxiliar com abrangência total para desempate, ou seja, é garantido
100% de classificação das instâncias analisadas. Os detalhes das mesmas são discutidos
nas subseções seguintes.
4.1.1 Técnica de Votação pela Maioria
Com o intuito de melhorar a análise de sentimentos, foi construído um arcabouço de vários
[2..N ] métodos de análise de sentimentos que retorna, como classificação, a polaridade do
texto analisado a partir da concordância entre os resultados individuais de cada método.
A fonte de dados é separada em treino e teste, tratada com a remoção de stopwords 1 e
pontuações desnecessárias.
Quadro 2 – Regras de desempate da TVM ML
Situações Possíveis AçãoNenhum método consegue classificaro texto
Método NB é invocado e sua classificação éconsiderada
Existe maioria de uma mesma classi-ficação
A classificação com maior ocorrência é consi-derada
Empate entre uma ou mais classescom maior ocorrência
Método NB é invocado e sua classificação éconsiderada
O texto tratado é distribuído a todos os métodos que compõem a abordagem e retornam
“1” para positivo, “-1” para negativo, “0” para neutro ou “2” caso não consiga efetuar a
classificação. De posse dos resultados dos métodos, é iniciado o processo de avaliação de
voto da maioria ou através do resultado fornecido pelo algoritmo de aprendizado de máquina
Naive Bayes Multinomial (MCCALLUM; NIGAM, 1998), conforme regras de desempate no
Quadro 2.
A fim de garantir total abrangência da técnica TVM ML, foi utilizada uma técnica de apren-
dizado de máquina, o classificador probabilístico Naive Bayes Multinomial (NB). Esteclassificador constrói um modelo baseado nas probabilidades de cada ocorrência das pala-
vras por classe (MCCALLUM; NIGAM, 1998). Outros métodos também foram avaliados tais
como SVM (DAVE; LAWRENCE; PENNOCK, 2003a), Random Forest (BREIMAN, 2001),
Maximum Entropy (TURNEY, 2002) e outras variações de Naive Bayes , porém obtiveram
resultados inferiores ao método escolhido NB .
Após a construção do modelo a partir da base treino, em cada instância do teste, é calculada
uma probabilidade para cada classe e a vencedora é a que faz a rotulação. Este método
sempre retorna uma classe, ou seja, sendo assim a abrangência é de 100%.
1Palavras que não contribuem com o significado do texto como artigo, rejeição e preposição.
23
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 38/71
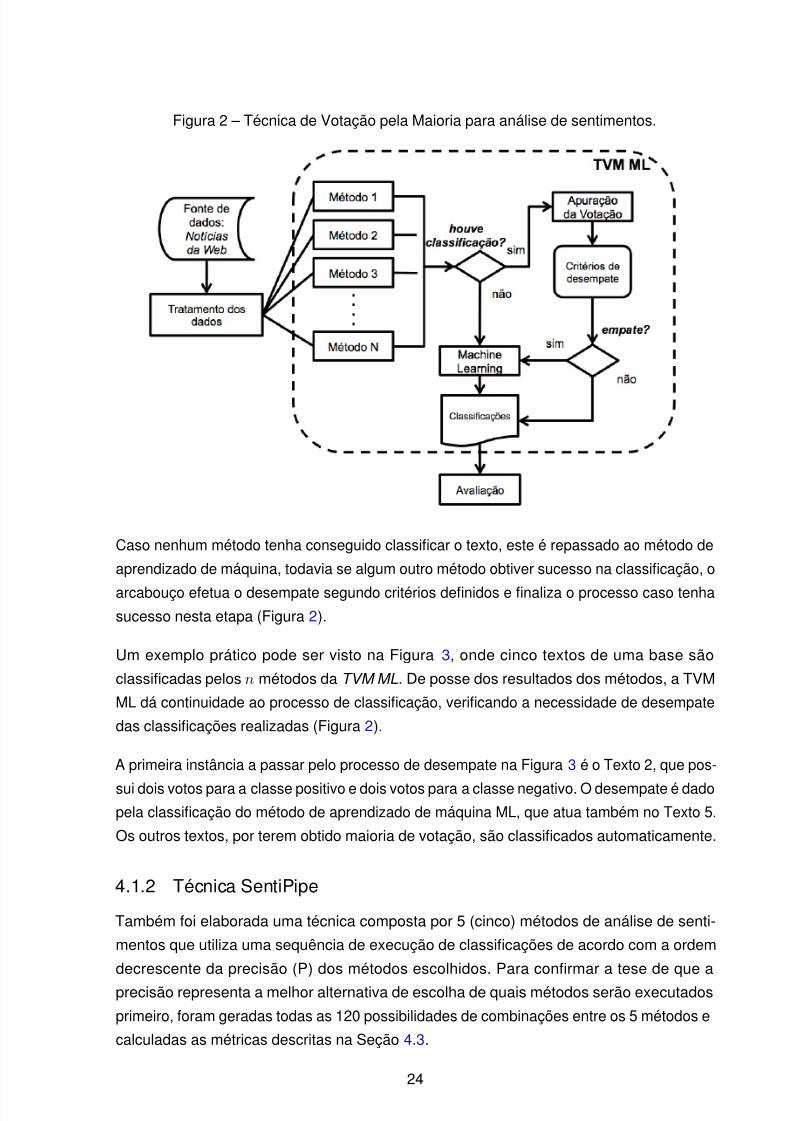
Figura 2 – Técnica de Votação pela Maioria para análise de sentimentos.
Caso nenhum método tenha conseguido classificar o texto, este é repassado ao método de
aprendizado de máquina, todavia se algum outro método obtiver sucesso na classificação, o
arcabouço efetua o desempate segundo critérios definidos e finaliza o processo caso tenhasucesso nesta etapa (Figura 2).
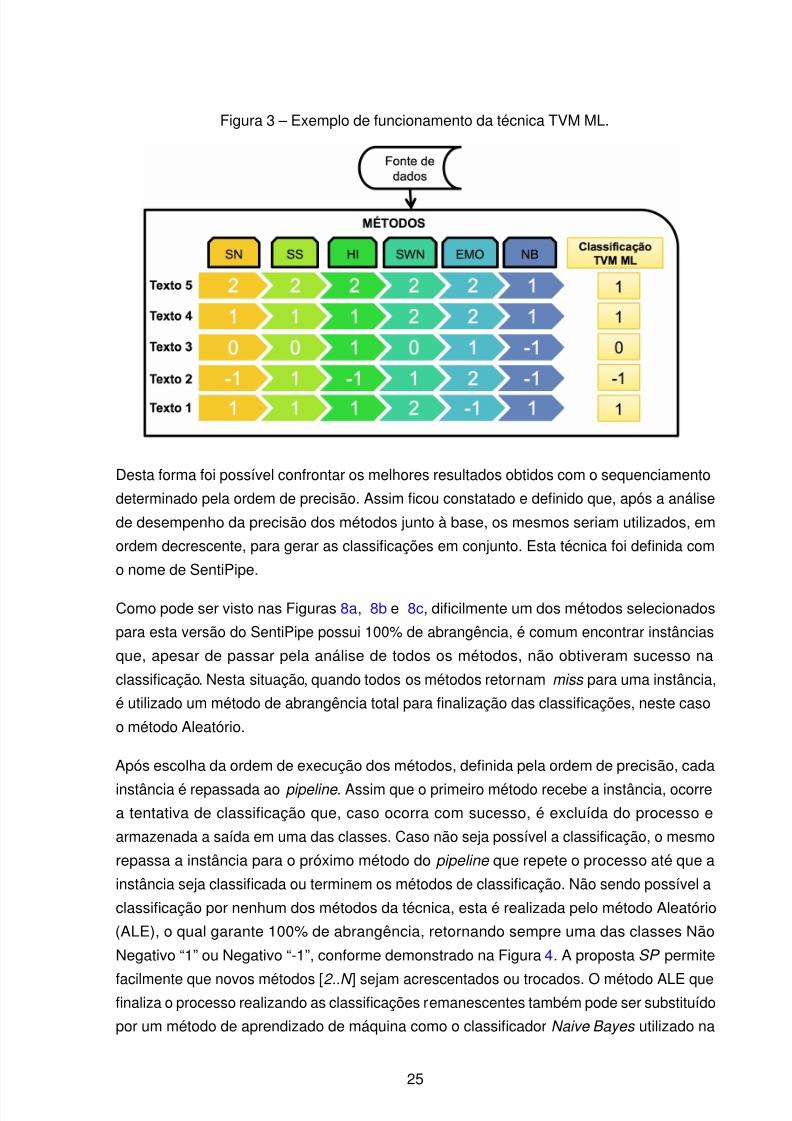
Um exemplo prático pode ser visto na Figura 3, onde cinco textos de uma base são
classificadas pelos n métodos da TVM ML. De posse dos resultados dos métodos, a TVM
ML dá continuidade ao processo de classificação, verificando a necessidade de desempate
das classificações realizadas (Figura 2).
A primeira instância a passar pelo processo de desempate na Figura 3 é o Texto 2, que pos-
sui dois votos para a classe positivo e dois votos para a classe negativo. O desempate é dadopela classificação do método de aprendizado de máquina ML, que atua também no Texto 5.
Os outros textos, por terem obtido maioria de votação, são classificados automaticamente.
4.1.2 Técnica SentiPipe
Também foi elaborada uma técnica composta por 5 (cinco) métodos de análise de senti-
mentos que utiliza uma sequência de execução de classificações de acordo com a ordem
decrescente da precisão (P) dos métodos escolhidos. Para confirmar a tese de que a
precisão representa a melhor alternativa de escolha de quais métodos serão executados
primeiro, foram geradas todas as 120 possibilidades de combinações entre os 5 métodos e
calculadas as métricas descritas na Seção 4.3.
24
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 39/71
Figura 3 – Exemplo de funcionamento da técnica TVM ML.
Desta forma foi possível confrontar os melhores resultados obtidos com o sequenciamento
determinado pela ordem de precisão. Assim ficou constatado e definido que, após a análise
de desempenho da precisão dos métodos junto à base, os mesmos seriam utilizados, em
ordem decrescente, para gerar as classificações em conjunto. Esta técnica foi definida com
o nome de SentiPipe.
Como pode ser visto nas Figuras 8a, 8b e 8c, dificilmente um dos métodos selecionados
para esta versão do SentiPipe possui 100% de abrangência, é comum encontrar instâncias
que, apesar de passar pela análise de todos os métodos, não obtiveram sucesso na
classificação. Nesta situação, quando todos os métodos retornam miss para uma instância,
é utilizado um método de abrangência total para finalização das classificações, neste caso
o método Aleatório.
Após escolha da ordem de execução dos métodos, definida pela ordem de precisão, cada
instância é repassada ao pipeline . Assim que o primeiro método recebe a instância, ocorrea tentativa de classificação que, caso ocorra com sucesso, é excluída do processo e
armazenada a saída em uma das classes. Caso não seja possível a classificação, o mesmo
repassa a instância para o próximo método do pipeline que repete o processo até que a
instância seja classificada ou terminem os métodos de classificação. Não sendo possível a
classificação por nenhum dos métodos da técnica, esta é realizada pelo método Aleatório
(ALE), o qual garante 100% de abrangência, retornando sempre uma das classes Não
Negativo “1” ou Negativo “-1”, conforme demonstrado na Figura 4. A proposta SP permite
facilmente que novos métodos [2..N ] sejam acrescentados ou trocados. O método ALE quefinaliza o processo realizando as classificações remanescentes também pode ser substituído
por um método de aprendizado de máquina como o classificador Naive Bayes utilizado na
25
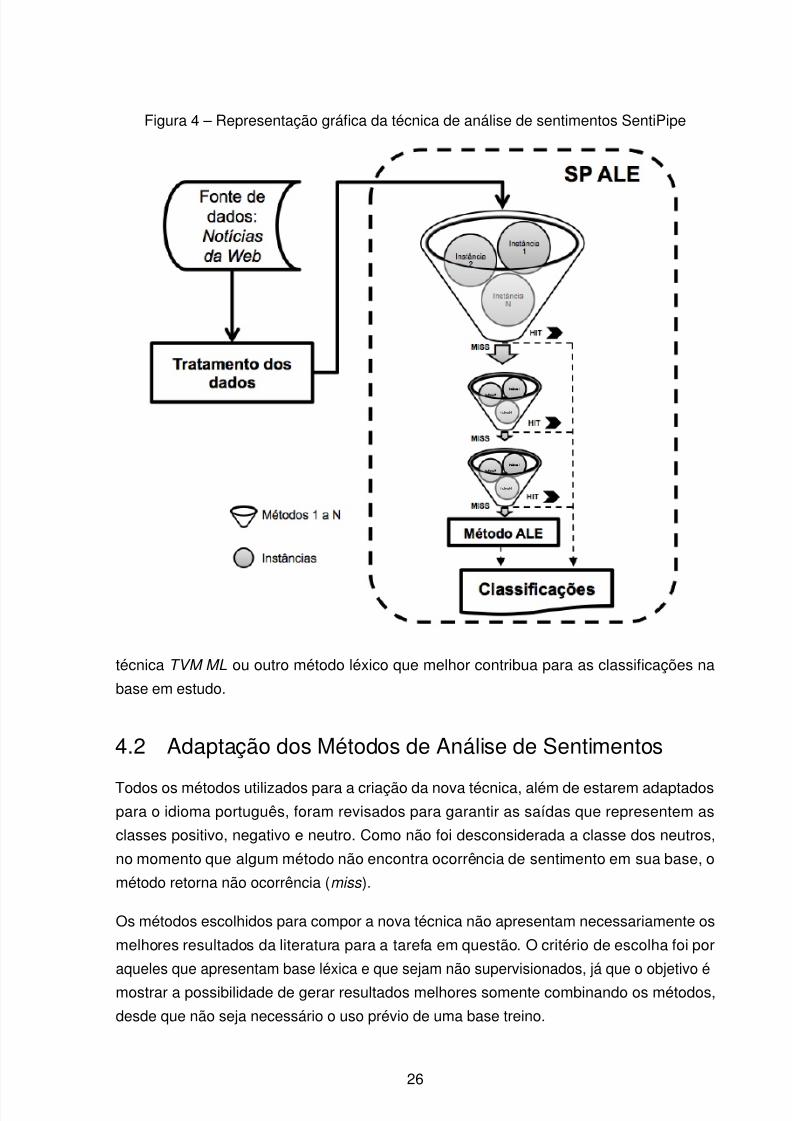
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 40/71
Figura 4 – Representação gráfica da técnica de análise de sentimentos SentiPipe
técnica TVM ML ou outro método léxico que melhor contribua para as classificações na
base em estudo.
4.2 Adaptação dos Métodos de Análise de Sentimentos
Todos os métodos utilizados para a criação da nova técnica, além de estarem adaptadospara o idioma português, foram revisados para garantir as saídas que representem as
classes positivo, negativo e neutro. Como não foi desconsiderada a classe dos neutros,
no momento que algum método não encontra ocorrência de sentimento em sua base, o
método retorna não ocorrência (miss ).
Os métodos escolhidos para compor a nova técnica não apresentam necessariamente os
melhores resultados da literatura para a tarefa em questão. O critério de escolha foi por
aqueles que apresentam base léxica e que sejam não supervisionados, já que o objetivo é
mostrar a possibilidade de gerar resultados melhores somente combinando os métodos,
desde que não seja necessário o uso prévio de uma base treino.
26

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 41/71
No Capítulo 5 são apresentados os métodos em detalhe e demonstradas as alterações
necessárias para a construção das técnicas propostas neste trabalho.
4.3 Métricas de Avaliação
Para melhor representação das métricas utilizadas neste trabalho, é utilizada a matriz de
confusão representada no Quadro 3. As colunas representam classificações realizadas por
especialistas e as linhas indicam as geradas pelos métodos de AS.
Para a classe rotulada manualmente como Positivo, são separadas as instâncias correta-
mente classificadas pelo método (TP - True Positive ), bem como as classificadas como
Negativo (FNpos - False Negative - Positive ) e como Neutro (Fnpos - False Neutral - Positive ).
O mesmo se repete nas outras colunas para as classes Negativo (FPneg - False Positive -
Negative ), (TN - True Negative ), (Fnneg - False Neutral - Negative ) e Neutro (FPneu - False
Positive - Neutral ), (FNneu - False Negative - Neutral ) e (Tn - True Neutral ).
Quadro 3 – Matriz de confusão das classes positivo, negativo e neutro.
Rotulação humana
Positivo Negativo Neutro
Rotulação
Método
Positivo TP FPneg FPneuNegativo FNpos TN FNneu
Neutro Fnpos Fnneg Tn
São utilizadas medidas tradicionais de desempenho de classificação para múltiplas classes:
abrangência (AB), acurácia (A), precisão (P), revocação (R) e medida F1 (F1). Seguindo a
notação do Quadro 3, a seguir serão demonstradas as fórmulas para a classe positivo, de
cada uma das medidas (SOKOLOVA; LAPALME, 2009).
A abrangência (1) mostra a fração de mensagens classificáveis por cada método:
AB = mensagens classificaveis
todas as mensagens (1)
A acurácia:
A = T P + T N + T n
T P + F P + T N + F N + T n + F n (2)
mede o desempenho dos métodos considerando os acertos realizados em relação a todas
as classificações e não considera as classes positivas, negativas ou neutras.
27

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 42/71
A precisão:
P = T P
T P + F Pneg + F P neu (3)
mostra a quantidade de acertos em uma classe, considerando todas as instâncias classifi-
cadas como pertencentes à mesma classe. Já a revocação:
R = T P
T P + F Npos + F npos (4)
mede a relação entre as instâncias classificadas como pertencentes a determinada classe
e o total de instâncias que realmente fazem parte desta classe. Por último, a medida F1:
F 1(classe) = 2 ∗ P (classe) ∗ R(classe)
P (classe) + R(classe) (5)
é a média harmônica entre precisão (P) e revocação (R), esta medida é importante para
avaliar o desempenho dos classificadores em medida única. A medida F1 final é dada pela
macro-F1 (SEBASTIANI, 2002), que é a média da medida F1 para as classes de mensagens
positivas e negativas.
Quadro 4 – Matriz de confusão adaptada às classes não negativo e negativo.
Rotulação HumanaNão Negativo Negativo
RotulaçãoMétodo
Não Negativo TnNeg FNegNegativo FnNeg TNeg
Existem divergências entre diversos autores quando se trata de avaliações neutras, alguns
a consideram (CABRAL; HORTACSU, 2010; AUGUSTYNIAK et al., 2014; CAVALCANTI
et al., 2012; EVANGELISTA; PADILHA, 2013; KHAN; QAMAR; JAVED, 2014; SPENCER;
UCHYIGIT, 2012) e outros a ignoram (ARAÚJO et al., 2013; WANG et al., 2014).
No trabalho de Cabral e Hortacsu (2010), foram analisados comentários de compradores
da plataforma de vendas online eBay2, as opiniões classificadas como neutras não foram
vistas como tal pelos compradores. Grande parte dos usuários as percebem como opiniões
negativas, ou seja, apesar do classificador não ter detectado qualquer polaridade no texto,
verifica-se que estas classificações são relevantes e não devem ser descartadas, apesar dos
resultados melhorarem artificialmente com somente duas classes. Por isso, neste trabalhoa classe neutro é agrupada à classe positivo, formando novas classes não negativo e
2http://www.ebay.com/
28

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 43/71
negativo. Esta adaptação pode ser vista no Quadro 4, que é a representação simplificada
do Quadro 3.
4.4 Considerações Finais
Esta seção permitiu entender o processo metodológico utilizado no desenvolvimento das
técnicas propostas e suas possíveis adaptações a novas abordagens de AS desde que
estas atendam a alguns requisitos.
Na próxima seção são apresentados os estudos de caso, experimentos, resultados e suas
discussões.
29

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 44/71
Capítulo 5
Estudos de Caso
O presente Capítulo apresenta os estudos de caso realizados nesta dissertação, as configu-
rações experimentais dos métodos utilizados e os resultados. Ao final, estes são discutidos
e confrontados com outras técnicas utilizadas pelo meio acadêmico e empresarial, conforme
mapa mental representado na Figura 5.
Figura 5 – Mapa mental - Estudos de Caso.
5.1 ClassificaçãoOs estudos de caso propostos neste trabalho podem ser classificados como explanatórios,
pois visam explicar as relações de causa e efeito considerando uma determinada teoria (YIN,
2011).
Os estudos de caso deste trabalho se referem a diferentes aplicações da Web em contextos
distintos. Para esta análise foram escolhidas bases do mercado financeiro com padrão de
escrita formal (Notícias da Web compostas por título e corpo) e Tweets sobre veículos da
marca Fiat.
A primeira base possui características de escrita formal, conteúdo mais extenso e, con-
30

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 45/71
sequentemente, vários tópicos analisados em um mesmo texto. Esta base foi dividida em
duas, separando o título do corpo da notícia a fim de realizar análise de sentimentos sobre
sentença.
Já a segunda base possui limite de caracteres imposto pelo aplicativo Twitter, resultando
em textos com muitas abreviações, o que dificulta o processo de classificação.
São utilizados métodos de análise de sentimentos já consagrados na literatura para a
criação de novas técnicas com o objetivo de melhorar as classificações.
Os resultados são comparados a abordagens de referência no meio acadêmico e comerci-
almente usando métricas descritas na Seção 4.3.
5.2 Coleta e Tratamento de Dados
Neste trabalho são utilizadas bases de dados reais de notícias do mercado financeiro e
tweets sobre automóveis. As notícias foram subdivididas em duas bases, uma contemplando
o título e o corpo das notícias e outra base formada somente pelo títulos da mesmas. Foram
extraídas 2.132 notícias do mercado financeiro de diversos sites de notícias e 11.027 tweets,
notícias relativas ao ano de 2014 e tweets de 2012. Os dados foram rotulados por no mínimo
3 especialistas do domínio da aplicação e classificados como pertencentes a uma das
classes positivo (POS), negativo (NEG) ou neutro (NEU).
A base de Tweets foi extraída diretamente da aplicação utilizando a API (Interface de
Programação de Aplicativos) gratuita de acesso da mesma, filtrando somente o intervalo de
data desejado e as mensagens dos Tweets relacionadas à marca “Fiat” que na sequência
foram rotuladas entre uma das 3 classes estudadas.
Os dados de Notícias utilizados foram obtidos através de um processo de coleta e tratamento
realizado por uma equipe da UFMG do projeto INWeb (Instituto Nacional de Ciência e
Tecnologia para a Web). Este conjunto de dados faz parte de uma base do mercado
financeiro, que está relacionado às empresas que fazem parte do principal índice de ações
da BM&FBovespa, o Índice Bovespa.
Os especialistas rotularam as notícias sob o ponto de vista do investidor. Assim, mensagens
que influenciam positivamente o mercado financeiro, ou ativos específicos, são classificadas
como positivo, as que deixam o investidor inseguro ou demonstre algum revés que afete o
mercado recebem o rótulo negativo e as que não representam qualquer polaridade, neutro.
Mesmo sabendo que os resultados são um pouco piores utilizando o neutro, já que esta
classe é a mais difícil de ser identificada pelos métodos, esta não foi descartada. De acordo
com a experiência dos especialistas que rotularam a base de notícias deste estudo de caso,
31

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 46/71
Tabela 1 – Distribuição das bases em classes.
(a) Base de Notícias
com neutro não negativo
POS 928 1381NEG 751 751NEU 453 -
2132 2132
(b) Base de Títulos
com neutro não negativo
POS: 925 1377NEG: 746 746NEU: 452 -
2123 2123
(c) Base de Tweets
com neutro não negativoPOS: 4435 6641NEG: 4388 4388NEU: 2206 -
11029 11029
agrupou-se os neutros à classe positivo, formando uma nova classe não negativo (NNEG),
como se verifica na nova configuração nas Tabelas 1a, 1b e 1c. Além do peso para notícias
negativas ser maior que as positivas para o cenário do mercado financeiro, uma notícia
neutra pode contribuir mais como sendo uma notícia não negativa do que negativa.
Mantendo os neutros na base, garante-se maior confiabilidade nos resultados gerados
pelas classificações dos métodos em estudo, enquanto retirar os neutros pode mascarar os
resultados, já que as opiniões neutras fazem parte do universo das classificações estudadas.
5.3 Configuração Experimental
Os resultados de métodos de análise de sentimentos, principalmente os léxicos, são muito
dependentes do contexto aplicado e de alterações em seus dados paramétricos, já que
o objetivo é comparar as técnicas propostas com os métodos individuais, e não gerar os
melhores resultados para todos eles. Por isto, neste trabalho são utilizados os métodos em
sua configuração padrão, sem nenhuma alteração que interfira no desempenho original
do método. Apesar disto, algumas adaptações em relação ao idioma e suas saídas foram
realizadas, mas sem alterar o desempenho das classificações. Algumas das adaptações
realizadas nas saídas dos métodos são relatadas no Quadro 5.
A seguir serão apresentados os métodos, sua origem e características principais:
SenticNet (SN) - O SenticNet (CAMBRIA et al., 2010b; CAMBRIA et al., 2010a) é um
recurso semântico para análise de sentimentos cuja base de conhecimento do senso
comum afetiva é gerada a partir da Sentic Computing (CAMBRIA; HUSSAIN, 2012), que é
um paradigma que aborda ontologias afetivas e ferramentas de raciocínio de senso comum.
A Sentic Computing também envolve técnicas de Web Semântica, Inteligência Artificial,
32

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 47/71

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 48/71
ao conteúdo dos módulos essenciais a adaptação. Foi verificado que, devido ao fato de não
ter acesso ao processo integral do SenticNet, seria viável neste momento somente traduzir
os termos do arquivo RDF do inglês para o português brasileiro (PT-BR), ajustando alguns
sinônimos para manter o mesmo significado das palavras em relação à polaridade definidapelo método.
Figura 7 – Diagrama do processo de criação da base léxica SenticNet.
Fonte: SenticNet
A fim de avaliar a melhor maneira de traduzir a base gerada pelo modelo, foi realizado
o levantamento do custo de tradução manual. O autor traduziu 1% da base com 14.244
termos e 5.777 semantics que são encontrados como conceito principal, totalizando 20.021
instâncias. A tradução foi realizada utilizando dicionários online como Babylon1, Infopédia2,
Linguee3 e Google Tradutor4 juntamente com o dicionário físico Longman - Contempo-
rary English (SUMMERS, 1995).
Para traduzir os 142 conceitos principais manualmente foram gastas duas horas. Em seguida
os 710 semantics foram traduzidos em 5 horas e meia, totalizando 852 termos, com custo
de 7,5 horas de tradução, que resultaria em aproximadamente 750 horas de trabalho. Em
face de uma projeção tão custosa, ficou decidido utilizar a ferramenta gratuita Goslate (Free
Google Translate API ) para verificar a eficiência da tradução automática.
1http://www.babylon.com2http://www.infopedia.pt3http://www.linguee.com.br4https://translate.google.com.br/
34

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 49/71
À base completa foi aplicada a tradução automática, que resultou em uma abrangência de
79,70%. Em seguida foi realizada uma revisão manual e ajustados os 20,30% dos termos
não traduzidos com a utilização da ferramenta.
Após a tradução, o arquivo RDF original foi substituído pela versão em português e feitas
as devidas alterações no script do SN que varre os termos encontrados no tweet indivi-
dualmente, confronta com os léxicos da base SN e retorna a polaridade associada ao
mesmo. Como classificação geral do texto, é realizada uma média aritmética dentre os
termos encontrados, como mostram os exemplos nas Tabelas 2 e 3.
Foi levantada a possibilidade de se traduzir somente a base a ser analisada pelo método SN
em sua configuração original no idioma inglês. Para analisar a viabilidade desta abordagem,
foi realizada uma investigação aprofundada de alguns tweets aleatoriamente e escolhido oseguinte tweet: “boa tarde Brasil covardia o casal de idoso que foi roubado, em pleno um
pais de copa do mundo cade a segurança o Presidente Dilma cade vc?” com rotulação
manual negativa “-1”. Aplicando o método SN a esta frase, foi obtida polaridade negativa,
igual à classificação realizada por humanos.
A mesma frase foi traduzida para o idioma inglês usando a Goslate API e aplicado sobre ela
o método SN em inglês, resultando em uma polaridade negativa como mostra a Tabela 3. A
divergência entre a classificação realizada pelo método original e o traduzido é percebida
pela ocorrência da palavra good com polaridade 0,883, mas a mesma não foi encontradana base no idioma original, dando um viés positivo ao texto.
Tabela 2 – Método SenticNet traduzido aplicado a texto em português.
Termos Identificados (PT) Polaridade
sem peso com pesotarde -1 -0,032covardia -1 -0,545
casal 1 0,09idoso 1 0,233roubado -1 -0,094segurança 1 0,147presidente 1 0,063
Polaridade Total -0,020
SentiStrength (SS) - Este método é baseado em abordagens de aprendizado de máquina,
e classifica mensagens combinando métodos de classificação supervisionadas e não
supervisionadas (THELWALL, 2013).
Algumas palavras positivas e negativas foram utilizadas para reforçar os sentimentos, como
“muito bom” para intensificar ou “pouco claro” para enfraquecer um conceito. Também foram
35

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 50/71
inclusos uma lista de emoticons , reconhecimento de pontuação repetida (ex.: “maravilha!!!”)
e uma lista de negação que inverte ou anula a polaridade de um texto (THELWALL, 2013).
Neste trabalho é utilizada a versão do método no idioma português (THELWALL, 2015).
Happiness Index (HI) - Consiste de uma escala de sentimentos que utiliza o popular
Affective Norms for English Words (ANEW) (BRADLEY; LANG, 1999) e calcula a quantidade
de felicidade existente em um texto usando a frequência em que cada palavra do ANEW
aparece no texto, computando o peso médio encontrado (DODDS; DANFORTH, 2009).
A saída padrão do método HI retorna valores reais no intervalo [1,9] conforme Tabela 5.
Após a adaptação foi considerado 0 (neutro) o valor 5, -1 (negativo) o intervalo [1,5) e 1
(positivo) os valores no intervalo (5,9]. As classificações que não encontram ocorrência na
base léxica do ANEW são classificado como 2 (miss ).
O dicionário original do ANEW, originalmente em inglês, foi traduzido para o idioma portu-
guês e revisado pelos próprios autores com auxílio de dois especialistas.
SentiWordNet (SWN) - É uma ferramenta de mineração de opinião baseada no dicionário
léxico WordNet (MILLER, 1995). A SentiWordNet associa agrupamentos de adjetivos, verbos
e outras classes gramaticais, chamados de synsets . A partir dos termos encontrados no
WordNet, a ferramenta associa valores que denotam a polaridade do texto em relação aos
sentimentos: positivo, negativo ou neutro (ESULI; SEBASTIANI; MORUZZI, 2006).
Para que a associação ocorra com sucesso, as palavras são classificadas em suas classes
gramaticais utilizando o POS tagging (Part-of-Speech tagging ) da biblioteca NLTK (BIRD;
KLEIN; LOPER, 2009) que, em seguida, são associadas às classes da WordNet (a →
adjetivo, v → verbo, n → substantivo e r → adverbio) para que fiquem alinhadas à
SentiWordNet.
Tabela 3 – Método SenticNet no idioma original aplicado a texto traduzido do português
para inglês.
Termos Identificados (EN) Polaridade
sem peso com pesogood 1 0,883cowardice -1 -0,545elderly 1 0,233couple 1 0,09stolen -1 -0,094full 1 0,176
security 1 0,38president 1 0,058
Polaridade Total 0,147
36

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 51/71
A saída padrão da ferramenta SWN, descrita na Tabela 5, retorna valores reais no intervalo
[-1,1]. Para que a saída fique padronizada, foi considerado -1 (negativo) para qualquer valor
entre [-1,0), 1 (positivo) para valores entre (0,1], 0 (neutro) para valores nulos (0) e 2 ( miss )
quando não existir ocorrência no dicionário.
Como tradução do léxico WordNet, é utilizado o openWordNet-PT (PAIVA; RADEMAKER;
MELO, 2012), que é um WordNet aberto para o idioma português brasileiro. Os termos são
pesquisados no openWordNet-PT e o identificador (ID) da palavra é associada ao ID do
SentiWordNet, permitindo a recuperação da polaridade de acordo com a classe gramatical
classificada anteriormente pelo POS tagging , como demonstrado no Quadro 6. No exemplo,
a palavra “tristeza” é um substantivo (n - noun ) e sua associação com o SWN é dada pelo
Synset-ID em conjunto com o POS , que a identifica como a mesma classe gramatical.
Quadro 6 – Associação de ID’s entre openWordNet-PT e SentiWordNet 3.0.
openWordNet-PT SentiWordNet 3.0SYNSET_ID PALAVRA POS ID PosScore NegScore04629604-n frialdade n 4629604 0,5 0,504629604-n frieza n 4629604 0,5 0,504629604-n frio n 4629604 0,5 0,504631470-n tristeza n 4631470 0 0,875
Emoticons (EMO) - Estão cada vez mais presentes em sistemas de mensagens eletrônicascomo SMS (mensagens de celulares), microblogs (Twitter), programas de conversa online
(WhatsApp5) e muitos outros. Neste artigo, são utilizados os mesmos emoticons descritos
por Goncalves e Benevenuto (2013) como na Tabela 4. O uso deste recurso se mostrou
muito eficiente, gerando resultados de acurácia em torno de 70% em suas predições (READ,
2005), por isso a escolha deste método para compor o arcabouço. Como o método não
possui variação de acordo com o idioma, não foram necessárias adaptações com exceção
do acréscimo da classe miss como parte das saídas, já que as classificações deste método
se limitam a “-1” negativo e “1” positivo.
Para garantir total abrangência da técnica de análise de sentimentos SentiPipe (SP ), foi
utilizado o resultado do método Aleatório (ALE), que classifica automaticamente um texto
distribuindo igualmente as classes positivo, negativo e neutro dentre o número total de
mensagens. As métricas para este método são obtidas após 30 execuções do mesmo, para
cada base, e gerada a média dos resultados para que fique mais confiável. Após cada
execução, as classificações são convertidas em não negativo e negativo , para que fique
alinhado com a proposta apresentada. Este método sempre retorna uma classe, ou seja, a
abrangência é de 100%.
5http://www.whatsapp.com/
37

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 52/71
Tabela 4 – Emoticons e suas variações.
Emoticon Polaridade Símbolos:) :] :} :o) :o] :o} :-] :-) :-} =)
=] =} =^] =^) =^} :B :-D :-B :^D
Positivo :^B :^D :^B =B =^B =^D :’) :’] :’}
=’) =’] =’} <3 ^.^ ^-^ ^_^ ^^ :*
=* :-* ;) ;] ;} :-p :-P :-b :^p
:^P :^b =P =p \o\ /o/ :P :p :b
=b =^p =^P =^b \o/
D: D= D-: D^: D^= :( :[ :{ :o(
:o[ :^( :^[ :^{ =^( =^{ >=( >=[
>={ >=( >:-{ >:-[ >:-( >=^[ >:-(
Negativo :-[ :-( =( =[ ={ =^[ >:-=( >=[
:’( :’[ :’{ =’{ =’( =’[ =\ :\
=/ :/ =$ o.O O_o Oo :$:-{ >:-{
>=^( >=^{ :o{
:| =| :-| >.< >< >_< :o :0 =O :@
Neutro =@ : ^o : ^@ - .- - .-’ -_- - _-’ : x
=X =# :-x :-@ :-# :^x :^# :#
Fonte: Goncalves e Benevenuto (2013)
Apesar deste método não ser indicado para classificação de sentimentos devido à baixa
precisão, ele foi escolhido para finalizar a técnica SP , de agora em diante chamada de SP
ALE , por cobrir todas as instâncias e para provar que mesmo um método com desempenhotão baixo pode contribuir para o aprimoramento da técnica. Este também é considerado o
baseline dentre os diversos métodos de análise de sentimentos por ser o mais elementar
método automatizado para este fim. Outro método utilizado para garantir abrangência total
foi o Aprendizado de Máquina (ML) utilizando o algorito Naive Bayes Multinomial .
Para todos os métodos, são desconsiderados níveis intermediários de positividade e ne-
gatividade (ex.: 0,023 - pouco positivo / -0,973 - muito negativo), representando todos os
intervalos que compreendem as classes positivo e negativo para “1” e “-1” respectivamente.
Além desta mudança, para todas as abordagens, a classe neutro “0” juntamente com asnão ocorrências na base léxica, miss - “2” são contempladas, como descrito na Tabela 5.
5.4 Resultados e Discussões
Após aplicar todos os métodos individualmente e as técnicas propostas às mesmas bases,
foram calculadas as métricas de avaliação definidas na Seção 4.3 e seus resultados são
apresentados na Tabela 5.
A precisão dos métodos aplicados às bases se mostram superiores ao método aleatório,
o que mostra a relevância deles em sua função de classificação de polaridade como
38
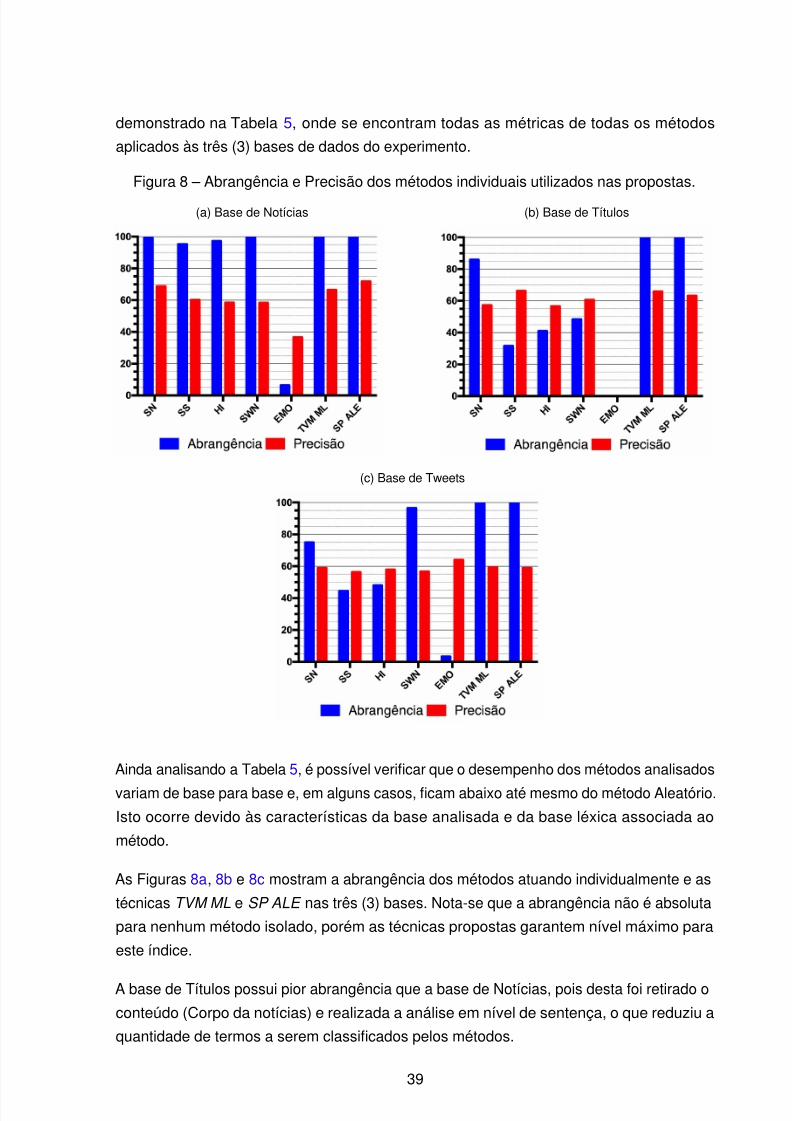
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 53/71
demonstrado na Tabela 5, onde se encontram todas as métricas de todas os métodos
aplicados às três (3) bases de dados do experimento.
Figura 8 – Abrangência e Precisão dos métodos individuais utilizados nas propostas.
(a) Base de Notícias (b) Base de Títulos
(c) Base de Tweets
Ainda analisando a Tabela 5, é possível verificar que o desempenho dos métodos analisados
variam de base para base e, em alguns casos, ficam abaixo até mesmo do método Aleatório.
Isto ocorre devido às características da base analisada e da base léxica associada ao
método.
As Figuras 8a, 8b e 8c mostram a abrangência dos métodos atuando individualmente e as
técnicas TVM ML e SP ALE nas três (3) bases. Nota-se que a abrangência não é absoluta
para nenhum método isolado, porém as técnicas propostas garantem nível máximo para
este índice.
A base de Títulos possui pior abrangência que a base de Notícias, pois desta foi retirado oconteúdo (Corpo da notícias) e realizada a análise em nível de sentença, o que reduziu a
quantidade de termos a serem classificados pelos métodos.
39
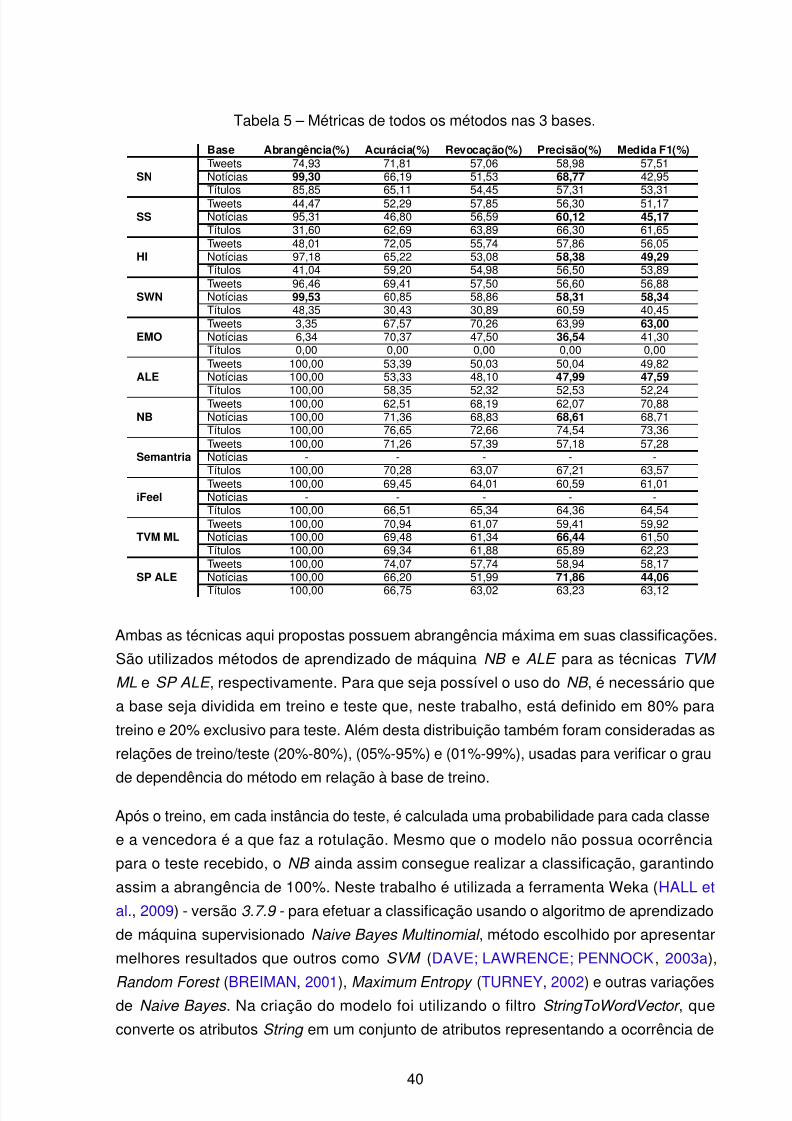
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 54/71
Tabela 5 – Métricas de todos os métodos nas 3 bases.
Base Abrangência(%) Acurácia(%) Revocação(%) Precisão(%) Medida F1(%)
SNTweets 74,93 71,81 57,06 58,98 57,51Notícias 99,30 66,19 51,53 68,77 42,95Títulos 85,85 65,11 54,45 57,31 53,31
SSTweets 44,47 52,29 57,85 56,30 51,17Notícias 95,31 46,80 56,59 60,12 45,17Títulos 31,60 62,69 63,89 66,30 61,65
HITweets 48,01 72,05 55,74 57,86 56,05Notícias 97,18 65,22 53,08 58,38 49,29Títulos 41,04 59,20 54,98 56,50 53,89
SWNTweets 96,46 69,41 57,50 56,60 56,88Notícias 99,53 60,85 58,86 58,31 58,34Títulos 48,35 30,43 30,89 60,59 40,45
EMOTweets 3,35 67,57 70,26 63,99 63,00Notícias 6,34 70,37 47,50 36,54 41,30Títulos 0,00 0,00 0,00 0,00 0,00
ALETweets 100,00 53,39 50,03 50,04 49,82Notícias 100,00 53,33 48,10 47,99 47,59
Títulos 100,00 58,35 52,32 52,53 52,24
NBTweets 100,00 62,51 68,19 62,07 70,88Notícias 100,00 71,36 68,83 68,61 68,71Títulos 100,00 76,65 72,66 74,54 73,36
SemantriaTweets 100,00 71,26 57,39 57,18 57,28Notícias - - - - -Títulos 100,00 70,28 63,07 67,21 63,57
iFeelTweets 100,00 69,45 64,01 60,59 61,01Notícias - - - - -Títulos 100,00 66,51 65,34 64,36 64,54
TVM MLTweets 100,00 70,94 61,07 59,41 59,92Notícias 100,00 69,48 61,34 66,44 61,50Títulos 100,00 69,34 61,88 65,89 62,23
SP ALETweets 100,00 74,07 57,74 58,94 58,17Notícias 100,00 66,20 51,99 71,86 44,06
Títulos 100,00 66,75 63,02 63,23 63,12
Ambas as técnicas aqui propostas possuem abrangência máxima em suas classificações.
São utilizados métodos de aprendizado de máquina NB e ALE para as técnicas TVM
ML e SP ALE , respectivamente. Para que seja possível o uso do NB , é necessário que
a base seja dividida em treino e teste que, neste trabalho, está definido em 80% para
treino e 20% exclusivo para teste. Além desta distribuição também foram consideradas as
relações de treino/teste (20%-80%), (05%-95%) e (01%-99%), usadas para verificar o grau
de dependência do método em relação à base de treino.
Após o treino, em cada instância do teste, é calculada uma probabilidade para cada classe
e a vencedora é a que faz a rotulação. Mesmo que o modelo não possua ocorrência
para o teste recebido, o NB ainda assim consegue realizar a classificação, garantindo
assim a abrangência de 100%. Neste trabalho é utilizada a ferramenta Weka (HALL et
al., 2009) - versão 3.7.9 - para efetuar a classificação usando o algoritmo de aprendizado
de máquina supervisionado Naive Bayes Multinomial , método escolhido por apresentar
melhores resultados que outros como SVM (DAVE; LAWRENCE; PENNOCK, 2003a),
Random Forest (BREIMAN, 2001), Maximum Entropy (TURNEY, 2002) e outras variaçõesde Naive Bayes . Na criação do modelo foi utilizando o filtro StringToWordVector , que
converte os atributos String em um conjunto de atributos representando a ocorrência de
40
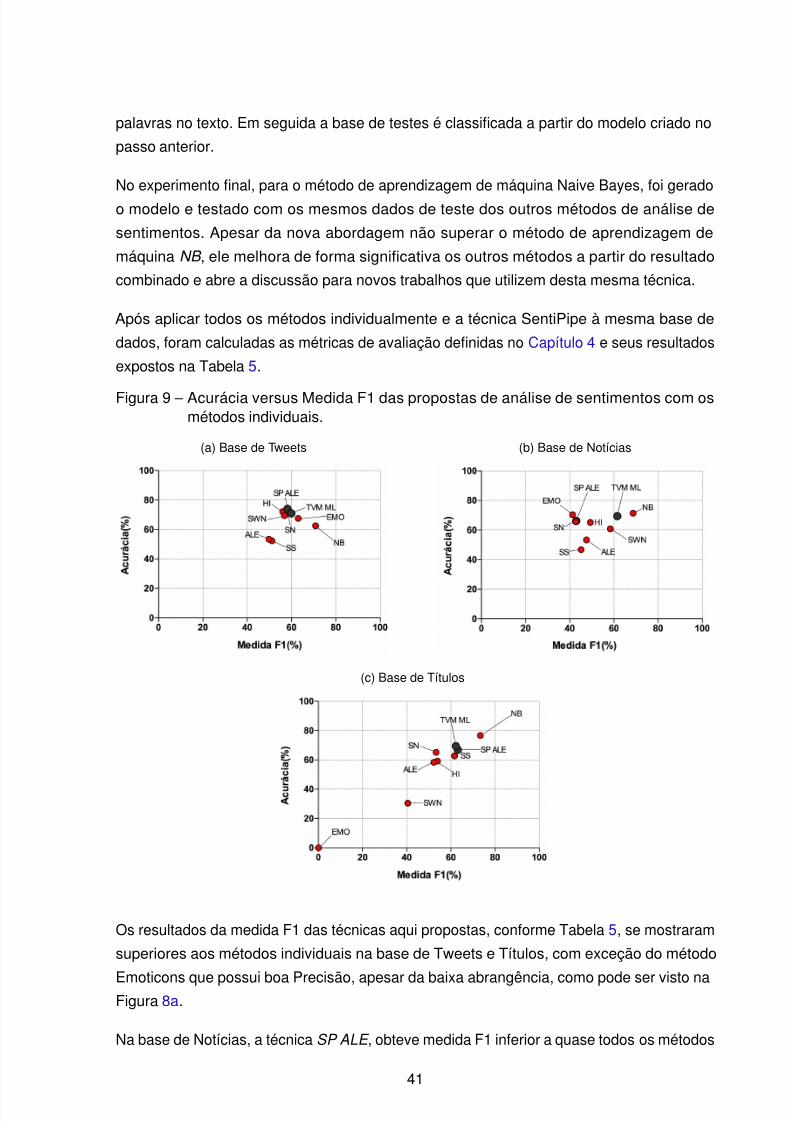
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 55/71
palavras no texto. Em seguida a base de testes é classificada a partir do modelo criado no
passo anterior.
No experimento final, para o método de aprendizagem de máquina Naive Bayes, foi gerado
o modelo e testado com os mesmos dados de teste dos outros métodos de análise de
sentimentos. Apesar da nova abordagem não superar o método de aprendizagem de
máquina NB , ele melhora de forma significativa os outros métodos a partir do resultado
combinado e abre a discussão para novos trabalhos que utilizem desta mesma técnica.
Após aplicar todos os métodos individualmente e a técnica SentiPipe à mesma base de
dados, foram calculadas as métricas de avaliação definidas no Capítulo 4 e seus resultados
expostos na Tabela 5.
Figura 9 – Acurácia versus Medida F1 das propostas de análise de sentimentos com osmétodos individuais.
(a) Base de Tweets (b) Base de Notícias
(c) Base de Títulos
Os resultados da medida F1 das técnicas aqui propostas, conforme Tabela 5, se mostraram
superiores aos métodos individuais na base de Tweets e Títulos, com exceção do método
Emoticons que possui boa Precisão, apesar da baixa abrangência, como pode ser visto naFigura 8a.
Na base de Notícias, a técnica SP ALE , obteve medida F1 inferior a quase todos os métodos
41
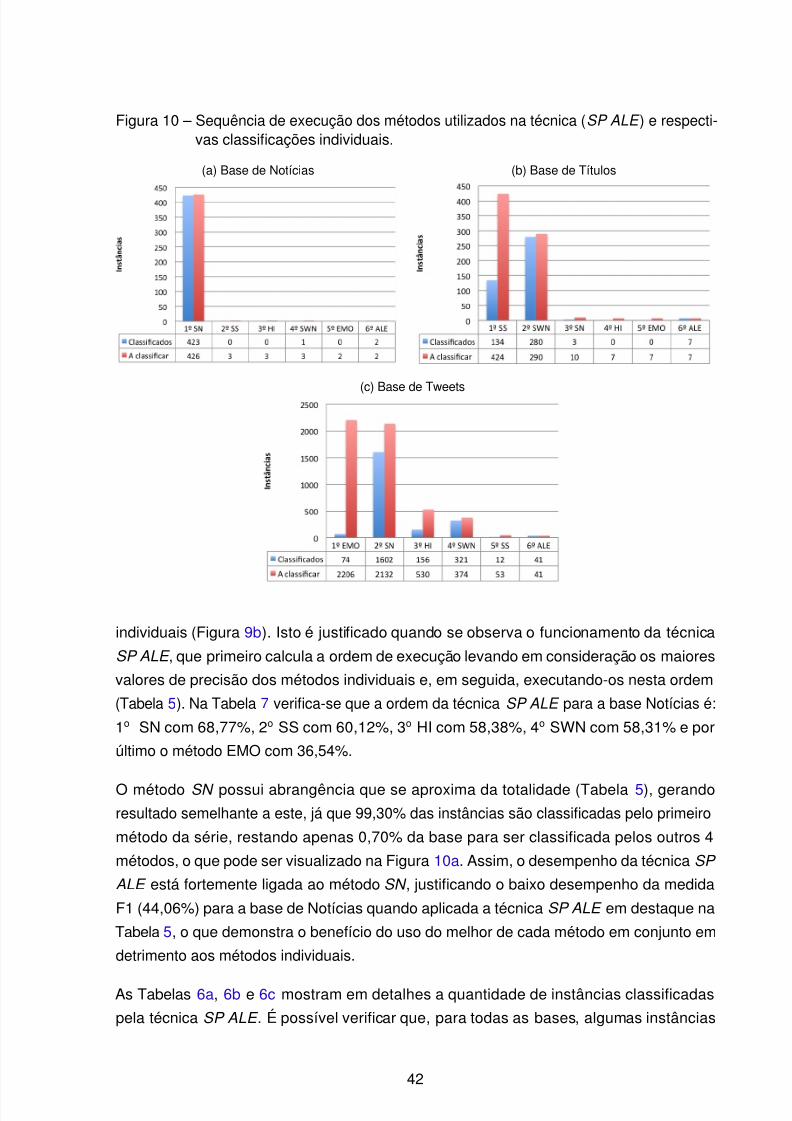
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 56/71
Figura 10 – Sequência de execução dos métodos utilizados na técnica (SP ALE ) e respecti-vas classificações individuais.
(a) Base de Notícias (b) Base de Títulos
(c) Base de Tweets
individuais (Figura 9b). Isto é justificado quando se observa o funcionamento da técnica
SP ALE , que primeiro calcula a ordem de execução levando em consideração os maiores
valores de precisão dos métodos individuais e, em seguida, executando-os nesta ordem
(Tabela 5). Na Tabela 7 verifica-se que a ordem da técnica SP ALE para a base Notícias é:
1o SN com 68,77%, 2o SS com 60,12%, 3o HI com 58,38%, 4o SWN com 58,31% e por
último o método EMO com 36,54%.
O método SN possui abrangência que se aproxima da totalidade (Tabela 5), gerandoresultado semelhante a este, já que 99,30% das instâncias são classificadas pelo primeiro
método da série, restando apenas 0,70% da base para ser classificada pelos outros 4
métodos, o que pode ser visualizado na Figura 10a. Assim, o desempenho da técnica SP
ALE está fortemente ligada ao método SN , justificando o baixo desempenho da medida
F1 (44,06%) para a base de Notícias quando aplicada a técnica SP ALE em destaque na
Tabela 5, o que demonstra o benefício do uso do melhor de cada método em conjunto em
detrimento aos métodos individuais.
As Tabelas 6a, 6b e 6c mostram em detalhes a quantidade de instâncias classificadas
pela técnica SP ALE . É possível verificar que, para todas as bases, algumas instâncias
42
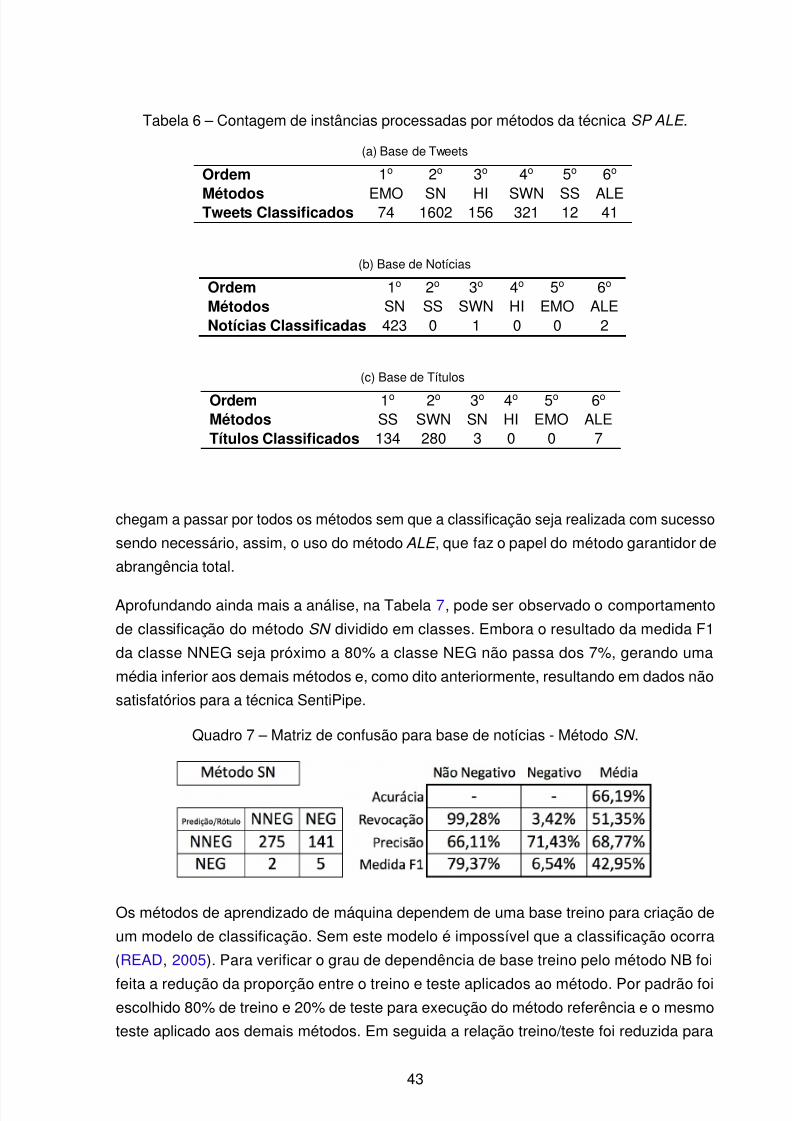
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 57/71
Tabela 6 – Contagem de instâncias processadas por métodos da técnica SP ALE .
(a) Base de Tweets
Ordem 1o 2o 3o 4o 5o 6o
Métodos EMO SN HI SWN SS ALETweets Classificados 74 1602 156 321 12 41
(b) Base de Notícias
Ordem 1o 2o 3o 4o 5o 6o
Métodos SN SS SWN HI EMO ALENotícias Classificadas 423 0 1 0 0 2
(c) Base de Títulos
Ordem 1o 2o 3o 4o 5o 6o
Métodos SS SWN SN HI EMO ALETítulos Classificados 134 280 3 0 0 7
chegam a passar por todos os métodos sem que a classificação seja realizada com sucesso
sendo necessário, assim, o uso do método ALE , que faz o papel do método garantidor de
abrangência total.
Aprofundando ainda mais a análise, na Tabela 7, pode ser observado o comportamento
de classificação do método SN dividido em classes. Embora o resultado da medida F1
da classe NNEG seja próximo a 80% a classe NEG não passa dos 7%, gerando uma
média inferior aos demais métodos e, como dito anteriormente, resultando em dados não
satisfatórios para a técnica SentiPipe.
Quadro 7 – Matriz de confusão para base de notícias - Método SN .
Os métodos de aprendizado de máquina dependem de uma base treino para criação de
um modelo de classificação. Sem este modelo é impossível que a classificação ocorra
(READ, 2005). Para verificar o grau de dependência de base treino pelo método NB foi
feita a redução da proporção entre o treino e teste aplicados ao método. Por padrão foiescolhido 80% de treino e 20% de teste para execução do método referência e o mesmo
teste aplicado aos demais métodos. Em seguida a relação treino/teste foi reduzida para
43
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 58/71
(20%-80%), (05%-95%) e (01%-99%), como demonstrado nas Tabelas 7, 8 e 9.
Figura 11 – Medida F1 versus variação da proporção treino/teste.
(a) Base de Notícias (b) Base de Títulos
(c) Base de Tweets
Nas Figuras 11a, 11b e 11c pode-se verificar que a medida F1 do método NB decai
sensivelmente à medida em que é reduzida a disponibilidade de treino para efetuar as
classificações, enquanto o SentiPipe permanece estável. O mesmo pode ser observado nas
Tabelas 7, 8 e 9, justificando a escolha da técnica SentiPipe em um cenário onde existam
poucos ou nenhum dado para treino.
Tabela 7 – Variação da Medida F1 relativa à proporção Treino/Teste - Base de Notícias.Treino/Teste (%) NB (%) TVM ML (%) SP ALE (%) Sequência Execução80/20 68,71 61,90 44,06 SN->SS->SWN->HI->EMO
20/80 69,48 61,92 59,00 SWN->HI->SS->SN->EMO
05/95 63,35 58,32 59,35 SWN->HI->SS->SN->EMO
01/99 48,26 52,54 59,46 SWN->HI->SS->SN->EMO
O pequeno desvio padrão representado na Figura 12 mostra melhor estabilidade do método
TVM ML proposto em relação aos métodos léxicos utilizados em sua criação, já que estes
não possuem comportamento estável devido a mudança de contexto nas três (3) basesanalisadas.
44
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 59/71
Tabela 8 – Variação da Medida F1 relativa à proporção Treino/Teste - Base de Títulos.
Treino/Teste (%) NB (%) TVM ML (%) SP ALE (%) Sequência Execução80/20 73,36 66,79 63,12 SS->SWN->SN->HI->EMO
20/80 68,78 65,23 66,61 SS->SWN->HI->SN->EMO05/95 61,47 63,30 65,47 SS->SWN->HI->SN->EMO
01/99 48,77 59,66 64,96 SS->SWN->HI->SN->EMO
Tabela 9 – Variação da Medida F1 relativa à proporção Treino/Teste - Base de Tweets.
Treino/Teste (%) NB (%) TVM ML (%) SP ALE (%) Sequência Execução80/20 70,88 59,92 58,17 EMO->SN->HI->SWN->SS
20/80 68,39 60,44 63,92 SS->EMO->HI->SN->SWN
05/95 57,83 59,43 63,86 SS->EMO->HI->SN->SWN
01/99 52,46 58,00 63,81 SS->EMO->HI->SN->SWN
Ainda na Figura 12 é possível verificar que o método SP ALE possui média da Medida F1
semelhante à dos outros métodos, porém elevado desvio padrão se comparado à proposta
TVM ML, o que pode ser confirmado examinando a Tabela 5 e o Quadro 7. Uma justificativa
para o baixo desempenho do método SP ALE reside no fato do método SN possuir baixa
capacidade de classificação para a classe negativo , característica também verificada por
Gonçalves et al. (2013).
O método SN possui precisão de 68,77% para a base de Notícias, medida que o elege
primeiro da sequência de execução, resultando apenas 0,70% da base de Notícias a ser
analisada pelo segundo método da sequência criada para o método na Tabela 7, já que a
abrangência deste método é de 99,30%, resultando em uma baixa medida F1.
Quando o primeiro método da técnica SP ALE deixa de ser o método SN , Tabela 7, e
passa a ser o método SWN , alterando a sequência de execução, a medida F1 melhora
consideravelmente. Mesmo a abrangência do método SWN sendo superior ao método SN a
média da medida F1 é superior a deste outro. Isto se deve ao fato do método SWN realizar
classificações mais homogêneas entre as classes não negativo e negativo como visto noQuadro 8.
Como já visto nas Figuras 10a, 10b e 10c, à medida em que diminui a disponibilidade de
treino em uma base, as técnicas propostas (TVM ML e SP ALE ) demonstram constância
em seu desempenho, afirmação esta reforçada pela Figura 13, que mostra menor variação
da medida F1 nas 3 bases, com exceção da técnica SP ALE já justificada anteriormente, e
uma menor oscilação nos resultados para as duas técnicas propostas neste trabalho.
Apesar da nova abordagem não superar o método de aprendizagem de máquina quando sedispõe de treino, ele melhora de forma significativa os outros métodos a partir do resultado
combinado, permite que sejam analisados dados sem que haja necessidade de treino,
45
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 60/71
Figura 12 – Média e desvio padrão da Medida F1 para a distribuição treino/teste (80%-20%).
Figura 13 – Variação das médias e desvios padrão da Medida F1 nas distribuiçõestreino/teste (80%-20%) versus (99%-1%).
Quadro 8 – Matriz de confusão para base de notícias - Método SWN.
abrindo a discussão para novos trabalhos que utilizem técnica semelhante.
Existem diversas soluções comerciais pagas para a mineração de textos e análise de
sentimentos, como é o caso da aplicação Semantria6 que cobra a partir de US$ 999,00
mensais e que foi escolhida por fornecer um período de uso para avaliação gratuito. Os
6http://www.semantria.com/
46
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 61/71
testes foram conduzidos utilizando a API disponibilizada no site do fabricante e aplicados às
bases de notícias, títulos e tweets, mas não foi possível classificar a primeira base devido
a limitação do Semantria de 1.500 caracteres por frase. Outra limitação é em relação à
quantidade de frases a serem analisadas em um arquivo, o que obrigou a fracioná-losem conjuntos de 200 instâncias e só então aplicar o método Semantria. Mesmo assim,
durante o processo de execução da aplicação, alguns problemas como travamento e falha
em autenticação foram percebidos.
Resultados como os apresentados nas Tabelas 10 e 11 justificam ainda mais as técnicas
propostas, que não possuem limitação pré-definida quanto ao número de instâncias a serem
analisadas e nem em relação ao tamanho das mesmas, sendo estas impostas apenas pela
capacidade do hardware utilizado.
Tabela 10 – Comparativo das técnicas propostas com os aplicativos Semantria e iFeel -base Tweets.
iFeel TVM ML SP ALE SemantriaAbrangência 100,00 100,00 100,00 100,00Acurácia 69,45 70,94 74,07 71,26Revocação 64,01 61,07 57,74 57,39Precisão 60,59 59,41 58,94 57,18Medida F1 61,01 59,92 58,17 57,28
Tabela 11 – Comparativo das técnicas propostas com os aplicativos Semantria e iFeel -base Títulos.
iFeel TVM ML SP ALE SemantriaAbrangência 100,00 100,00 100,00 100,00Acurácia 66,51 69,34 66,75 70,28Revocação 65,34 61,88 63,02 63,07Precisão 64,36 65,89 63,23 67,21Medida F1 64,54 62,23 63,12 63,57
Outra ferramenta, porém não comercial, com bons resultados na classificação de sen-
timentos é a iFeel. Apresentada por Araújo et al. (2014), esta realiza classificações de
sentimento em textos no idioma inglês a partir da combinação de diversos métodos, ge-
rando uma classificação que é a representação média de todos os métodos7 utilizados em
sua construção.
As mesmas bases referenciadas nas Tabelas 1a, 1b e 1c (20% de teste) foram aplicadas
ao iFeel e os resultados de precisão e medida F1 obtidos ficaram muito próximos aos das
propostas TVM ML e SP ALE , como evidenciado nas Figuras 14a e 14b.
Utilizar tantos métodos pode se tornar uma desvantagem. Em testes realizados na ferrameta
online foi verificado que a ferramenta iFeel não conseguiu classificar a base de Notícias, que7Em agosto de 2015, 21 métodos faziam parte da ferramenta iFeel
47
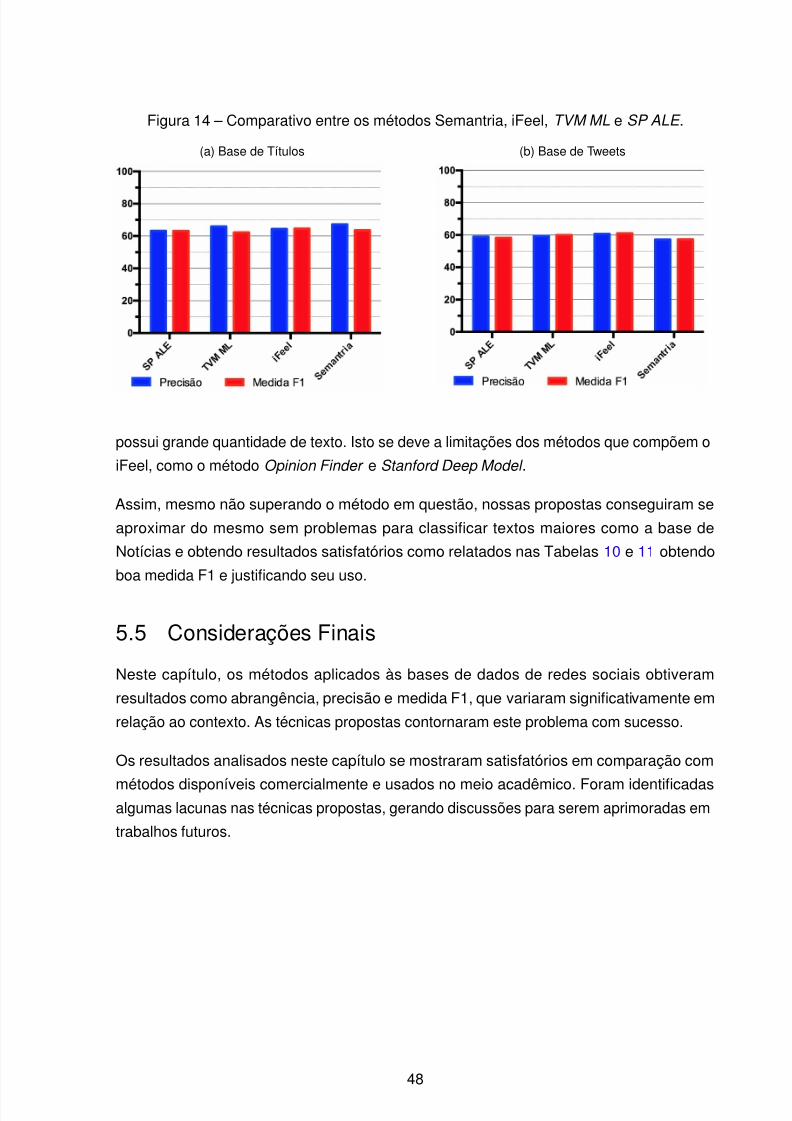
8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 62/71
Figura 14 – Comparativo entre os métodos Semantria, iFeel, TVM ML e SP ALE .
(a) Base de Títulos (b) Base de Tweets
possui grande quantidade de texto. Isto se deve a limitações dos métodos que compõem o
iFeel, como o método Opinion Finder e Stanford Deep Model .
Assim, mesmo não superando o método em questão, nossas propostas conseguiram se
aproximar do mesmo sem problemas para classificar textos maiores como a base de
Notícias e obtendo resultados satisfatórios como relatados nas Tabelas 10 e 11 obtendo
boa medida F1 e justificando seu uso.
5.5 Considerações Finais
Neste capítulo, os métodos aplicados às bases de dados de redes sociais obtiveram
resultados como abrangência, precisão e medida F1, que variaram significativamente em
relação ao contexto. As técnicas propostas contornaram este problema com sucesso.
Os resultados analisados neste capítulo se mostraram satisfatórios em comparação com
métodos disponíveis comercialmente e usados no meio acadêmico. Foram identificadasalgumas lacunas nas técnicas propostas, gerando discussões para serem aprimoradas em
trabalhos futuros.
48

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 63/71
Capítulo 6
Conclusão
Recentes pesquisas utilizam métodos de análise de sentimentos para extrair informações
relevantes de comentários e notícias da Web. Apesar dos bons resultados apresentados
por esses métodos, a detecção de sentimentos no idioma português ainda possui poucas
técnicas e desafios a serem trabalhados para obtenção de melhores resultados.
Neste trabalho foram apresentadas novas abordagens para a melhoria da detecção de
sentimentos em textos no idioma português a partir da criação de técnicas que utilizem
métodos consagrados de análise de sentimentos em conjunto. Para a criação de ambas
as abordagens, foram utilizados os métodos de base léxica SenticNet (SN ), SentiStrength(SS ), Happiness Index (HI ) e Emoticons (EMO ).
Estes métodos foram aplicados a bases de dados de redes sociais no contexto do mercado
financeiro e automóveis. Resultados como abrangência, precisão e medida F1 apresentaram
significativa variação em função do contexto.
Aplicando as técnicas às bases da Web no idioma português, foram obtidos resultados
superiores aos métodos individuais, originalmente criados para o idioma inglês. Além
disso, os resultados da medida F1 se mostraram superiores aos do método Naive Bayes Multinomial quando a base de treino oscila entre 0% e 5%.
Foi visto que, utilizando métodos de base léxica individualmente, as classificações realizadas
pelo mesmo método mudam drasticamente de uma base para outra. Aplicando as novas
técnicas foi reduzida a dependência do contexto da base de dados analisada, gerando
resultados mais homogêneos e de qualidade.
As técnicas TVM ML e SP ALE também se mostraram superiores quando comparadas a
outro método de análise de sentimentos comercial que, além da proximidade dos resultadosalcançados, foram capazes de classificar grandes textos sem dificuldades, o que também
foi verificado em testes com outra aplicação de análise de sentimentos robusta disponível
49

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 64/71
na Web que utiliza a combinação de métodos de AS no idioma inglês.
Para a base de Tweets, nossas técnicas apresentaram medida F1 superiores às da ferra-
menta Semantria. Na base de Títulos, estas apresentaram resultados muito próximos e para
a base de Notícias, foram as únicas técnicas que conseguiram realizar as classificações.
Esta capacidade de analisar textos grandes é um diferencial que permite que estas técnicas
sejam aplicadas em outros contextos com grande quantidade de dados por frase.
6.1 Contribuições Científicas
Como contribuição científica, foram apresentados um arcabouço de métodos de análise
de sentimentos que combina seus resultados individuais e uma proposta que combina
aplicação de métodos de análise de sentimentos por ordem de precisão (P). Também
tivemos um artigo completo aceito para publicação no Simpósio Brasileiro de Sistemas
Multimídia e Web (WebMedia 2015).
6.2 Trabalhos Futuros
Como trabalho futuro, pretende-se investir na identificação de palavras chave no corpo das
notícias para melhorar a classificação e analisar questões de linguística específicas do
idioma português, como o valor morfológico das palavras com a identificação de adjetivos,
negação e outras regras específicas do idioma.
Outra ação que pode gerar bons resultados é a utilização de um corretor ortográfico com o
intuito de aumentar a cobertura dos métodos em bases com variações de ortografia e grafia
incorretas como os tweets . Ambas abordagens podem ser aplicadas às técnicas TVM ML e
SP ALE .
Além dessas abordagens, também é possível aprimorar a identificação da melhor ordem
de execução dos métodos da técnica SentiPipe levando-se em conta o desempenho dasclasses não negativo e negativo.
50

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 65/71
Referências
AIRES, A. et al. Análise do sentimento coletivo presente em mensagens do Twitter para aprevisão de índices do mercado de ações. 2013. Citado na página 11.
AJMERA, H. Social media 2014 statistics–an interactive infographic you’ve been waitingfor! lithium. com/State-Of-Social-Media,[Online]. Available: http://blog. digitalinsights.in/social-media-users-2014-statsnumbers/05205287. html, 2014. Citado na página 1.
ARAÚJO, M. et al. Métodos para análise de sentimentos no twitter. In: Proceedings of the19th Brazilian symposium on Multimedia and the Web (WebMedia’13). [S.l.: s.n.], 2013.Citado 5 vezes nas páginas 9, 12, 19, 22 e 28.
ARAÚJO, M. et al. ifeel: a system that compares and combines sentiment analysis methods.In: INTERNATIONAL WORLD WIDE WEB CONFERENCES STEERING COMMITTEE.Proceedings of the companion publication of the 23rd international conference onWorld wide web companion. [S.l.], 2014. p. 75–78. Citado 2 vezes nas páginas 12 e 47.
AUGUSTYNIAK, L. et al. Simpler is better? lexicon-based ensemble sentiment classificationbeats supervised methods. In: IEEE. Advances in Social Networks Analysis and Mi-ning (ASONAM), 2014 IEEE/ACM International Conference on. [S.l.], 2014. p. 924–929.Citado 3 vezes nas páginas 12, 13 e 28.
AVANCO, L. V.; NUNES, M. d. G. V. Lexicon-Based Sentiment Analysis for Reviews ofProducts in Brazilian Portuguese. In: 2014 Brazilian Conference on Intelligent Systems.[s.n.], 2014. p. 277–281. Disponível em: <http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=6984843>. Citado na página 9.
BECKER, K.; TUMITAN, D. Introdução à mineração de opiniões: Conceitos, aplicações edesafios. Simpósio Brasileiro de Banco de Dados, 2013. Citado na página 19.
BERMINGHAM, A.; SMEATON, A. F. Classifying sentiment in microblogs: is brevity an advan-tage? In: ACM. Proceedings of the 19th ACM international conference on Informationand knowledge management. [S.l.], 2010. p. 1833–1836. Citado na página 8.
BIRD, S.; KLEIN, E.; LOPER, E. Natural language processing with Python. [S.l.]: "O’ReillyMedia, Inc.", 2009. Citado na página 36.
BOGDAN, R. C. et al. Investigação qualitativa em educação: uma introdução à teoriae aos métodos. [S.l.: s.n.], 1994. Citado na página 22.
BOLLEN, J.; MAO, H.; ZENG, X. Twitter mood predicts the stock market. Journal of Com-putational Science, Elsevier, v. 2, n. 1, p. 1–8, 2011. Citado 2 vezes nas páginas 4e 12.
BRADLEY, M. M.; LANG, P. J. Affective norms for English words ({ANEW}): Stimuli,
instruction manual, and affective ratings. Gainesville, Florida, 1999. Citado 3 vezes naspáginas 11, 19 e 36.
51

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 66/71
BREIMAN, L. Random forests. Machine learning, Springer, v. 45, n. 1, p. 5–32, 2001.Citado 2 vezes nas páginas 23 e 40.
CABRAL, L.; HORTACSU, A. The dynamics of seller reputation: Evidence from ebay*. The
Journal of Industrial Economics, Wiley Online Library, v. 58, n. 1, p. 54–78, 2010. Citadona página 28.
CAMBRIA, E.; HAVASI, C.; HUSSAIN, A. Senticnet 2: A semantic and affective resourcefor opinion mining and sentiment analysis. In: FLAIRS conference. [S.l.: s.n.], 2012. p.202–207. Citado 2 vezes nas páginas 11 e 33.
CAMBRIA, E.; HUSSAIN, A. Sentic computing. [S.l.]: Springer, 2012. Citado 2 vezes naspáginas 11 e 32.
CAMBRIA, E. et al. Towards Crowd Validation of the UK National Health Service. In: ACMWeb Science Conference (WebSci). [S.l.: s.n.], 2010. Citado na página 32.
CAMBRIA, E. et al. Senticnet: A publicly available semantic resource for opinion mining. In:AAAI fall symposium: commonsense knowledge. [S.l.: s.n.], 2010. v. 10, p. 02. Citado3 vezes nas páginas 11, 13 e 32.
CAVALCANTI, D. C. et al. Análise de sentimento em citações científicas para definição defatores de impacto positivo. In: International Workshop on Web and Text Intelligence,WTI: Curitiba. [S.l.: s.n.], 2012. Citado 2 vezes nas páginas 17 e 28.
CHOWDHURY, G. G. Natural language processing. Annual Review of Information Sci-ence and Technology, Wiley Subscription Services, Inc., A Wiley Company, v. 37, n. 1, p.
51–89, 2003. ISSN 1550-8382. Disponível em: <http://dx.doi.org/10.1002/aris.1440370103>.Citado na página 16.
DANIEL, J.; JAMES, H. Speech and language processing: An introduction to natural lan-guage processing. Computational Linguistics and Speech Recognition. Prentice Hall,NJ, USA, 2000. Citado na página 16.
DAVE, K.; LAWRENCE, S.; PENNOCK, D. M. Mining the peanut gallery: Opinion extractionand semantic classification of product reviews. In: ACM. Proceedings of the 12th inter-national conference on World Wide Web. [S.l.], 2003. p. 519–528. Citado 4 vezes naspáginas 4, 20, 23 e 40.
DAVE, K.; LAWRENCE, S.; PENNOCK, D. M. Mining the peanut gallery: Opinion extractionand semantic classification of product reviews. p. 519–528, 2003. Citado na página 11.
DIAS, P. Hipertexto, hipermédia e media do conhecimento: representação distribuída eaprendizagens flexíveis e colaborativas na web. 2000. Citado na página 1.
DODDS, P. S.; DANFORTH, C. M. Measuring the happiness of large-scale written expression:songs, blogs, and presidents. Journal of Happiness Studies, v. 11, n. 4, p. 441–456, 2009.Citado 2 vezes nas páginas 13 e 36.
ESULI, A.; SEBASTIANI, F.; MORUZZI, V. G. SENTIWORDNET: A Publicly Available Le-xical Resource for Opinion Mining. Proceedings of LREC 2006, p. 417–422, 2006. ISSN09255273. Citado 2 vezes nas páginas 13 e 36.
52

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 67/71
EVANGELISTA, T. R.; PADILHA, T. P. P. Monitoramento de Posts Sobre Empresas de E-Commerce em Redes Sociais Utilizando Análise de Sentimentos. 2013. Citado na página28.
FAMA, E. F. The behavior of stock-market prices. Journal of business, JSTOR, p. 34–105,1965. Citado na página 11.
FAMA, E. F. et al. The adjustment of stock prices to new information. International econo-mic review, JSTOR, v. 10, n. 1, p. 1–21, 1969. Citado na página 11.
FELDMAN, R. Techniques and applications for sentiment analysis. Communications ofthe ACM, ACM, v. 56, n. 4, p. 82–89, 2013. Citado na página 17.
FERSINI, E.; MESSINA, E.; POZZI, F. Sentiment analysis: Bayesian ensemble learning.Decision Support Systems, Elsevier, v. 68, p. 26–38, 2014. Citado 2 vezes nas páginas12 e 13.
FILHO, P. P. B.; PARDO, T. A.; ALUISIO, S. M. An evaluation of the brazilian portugueseliwc dictionary for sentiment analysis. In: In 9th Brazilian Symposium in Information andHuman Language Technology, Fortaleza, Ceara. [S.l.: s.n.], 2013. Citado na página 10.
GOMIDE, J. et al. Dengue surveillance based on a computational model of spatio-temporal lo-cality of twitter. In: ACM. Proceedings of the 3rd International Web Science Conference.[S.l.], 2011. p. 3. Citado 3 vezes nas páginas 4, 11 e 13.
GONÇALVES, P. et al. Comparing and combining sentiment analysis methods. In: Proce-edings of the 1st ACM Conference on Online Social Networks (COSN’13) . [S.l.: s.n.],
2013. Citado 6 vezes nas páginas 2, 3, 9, 13, 19 e 45.
GONCALVES, P.; BENEVENUTO, F. O Que Tweets Contendo Emoticons Podem RevelarSobre Sentimentos Coletivos? In: II Brazilian Workshop on Social Network Analysis andMining (BraSNAM). [S.l.: s.n.], 2013. Citado 2 vezes nas páginas 37 e 38.
HALL, M. et al. The weka data mining software: an update. ACM SIGKDD explorationsnewsletter, ACM, v. 11, n. 1, p. 10–18, 2009. Citado na página 40.
HONG, L.; CONVERTINO, G.; CHI, E. H. Language Matters in Twitter: A Large Scale Study.In: Proceedings of the Fifth International AAAI Conference on Weblogs and Social
Media. [S.l.: s.n.], 2011. p. 518–521. Citado na página 2.HU, M.; LIU, B. Mining and summarizing customer reviews. In: ACM. Proceedings ofthe tenth ACM SIGKDD international conference on Knowledge discovery and datamining. [S.l.], 2004. p. 168–177. Citado na página 19.
INDURKHYA, N.; DAMERAU, F. J. Handbook of natural language processing. [S.l.]: CRCPress, 2010. v. 2. Citado 3 vezes nas páginas 16, 17 e 18.
JAVA, A. et al. Why we twitter: understanding microblogging usage and communities. In:ACM. Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 workshop on Webmining and social network analysis. [S.l.], 2007. p. 56–65. Citado na página 16.
KELLER, E.; BERRY, J. One American in ten tells the other nine how to vote, where to eat,and what to buy. They are The Influentials, New York, v. 25, n. 5, p. 1–8, 2003. Disponívelem: <http://www.johnbesaw.com/The_Influentials.pdf>. Citado 2 vezes nas páginas 2 e 16.
53

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 68/71
KHAN, F. H.; QAMAR, U.; JAVED, M. Y. Sentiview: A visual sentiment analysis framework. In:IEEE. Information Society (i-Society), 2014 International Conference on. [S.l.], 2014. p.291–296. Citado na página 28.
KOULOUMPIS, E.; WILSON, T.; MOORE, J. Twitter sentiment analysis: The good the badand the omg! Icwsm, v. 11, p. 538–541, 2011. Citado na página 8.
LEITE, A.; BENEVENUTO, F.; MORO, M. TripTag: Ferramenta de planejamento de viagensbaseada em experiências de usuários de redes sociais. 28th Brazilian symposium ondatabases, 2013. Disponível em: <http://sbbd2013.cin.ufpe.br/Proceedings/artigos/pdfs/ sbbd\_dem\_07.pdf>. Citado na página 11.
LERTSUKSAKDA, R. Thai sentiment terms construction using the Hourglass of Emotions.Knowledge and Smart Technology (KST), 2014 6th International Conference on, p. 46–50, 2014. Disponível em: <http://ieeexplore.ieee.org/xpls/abs\_all.jsp?arnumber=6775392>.
Citado 2 vezes nas páginas 9 e 11.LIU, B. Opinion mining and sentiment analysis. In: Web Data Mining. [S.l.]: Springer, 2011.p. 459–526. Citado 3 vezes nas páginas 4, 7 e 8.
LIU, B. Sentiment analysis and opinion mining. Synthesis Lectures on Human LanguageTechnologies, Morgan & Claypool Publishers, v. 5, n. 1, p. 1–167, 2012. Citado na página17.
LIU, B. et al. Text classification by labeling words. In: AAAI. [S.l.: s.n.], 2004. v. 4, p. 425–430.Citado na página 3.
MALHEIROS, Y.; LIMA, G. Uma Ferramenta para Análise de Sentimentos em Redes SociaisUtilizando o SenticNet. Simpósio Brasileiro de Sistemas de Informação, IX, p. 517–522,2013. Disponível em: <http://www.lbd.dcc.ufmg.br/colecoes/sbsi/2013/0047.pdf>. Citadona página 2.
MCCALLUM, A.; NIGAM, K. A comparison of event models for naive bayes text classification.In: AAAI-98 Workshop on ’Learning for Text Categorization’. [S.l.: s.n.], 1998. Citado 2vezes nas páginas 20 e 23.
MILLER, G. A. WordNet: a lexical database for English. Communications of the ACM,v. 38, n. 11, p. 39–41, 1995. Citado 2 vezes nas páginas 11 e 36.
OHANA, B.; TIERNEY, B. Sentiment classification of reviews using sentiwordnet. In: 9th. IT& T Conference. [S.l.: s.n.], 2009. p. 13. Citado 2 vezes nas páginas 11 e 19.
PAIVA, V. de; RADEMAKER, A.; MELO, G. de. Openwordnet-pt: An open Brazilian Wordnetfor reasoning. In: Proceedings of COLING 2012: Demonstration Papers. Mumbai, India:The COLING 2012 Organizing Committee, 2012. p. 353–360. Published also as Techre-port http://hdl.handle.net/10438/10274. Disponível em: <http://www.aclweb.org/anthology/ C12-3044>. Citado 2 vezes nas páginas 11 e 37.
PAK, A.; PAROUBEK, P. Twitter as a corpus for sentiment analysis and opinion mining. In:
CHAIR), N. C. C. et al. (Ed.). International Conference on Language Resources andEvaluation (LREC’10). Valletta, Malta: European Language Resources Association (ELRA),2010. ISBN 2-9517408-6-7. Citado na página 2.
54

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 69/71
PALTOGLOU, G.; THELWALL, M. Twitter, myspace, digg: Unsupervised sentiment analysis insocial media. ACM Transactions on Intelligent Systems and Technology (TIST), ACM,v. 3, n. 4, p. 66, 2012. Citado na página 2.
PANG, B.; LEE, L. Opinion Mining and Sentiment Analysis. Foundations and Trends inInformation Retrieval 2, v. 1-2, n. 1, 2008. Citado 2 vezes nas páginas 1 e 18.
PANG, B.; LEE, L.; VAITHYANATHAN, S. Thumbs up?: sentiment classification usingmachine learning techniques. In: ASSOCIATION FOR COMPUTATIONAL LINGUISTICS.Proceedings of the ACL-02 conference on Empirical methods in natural languageprocessing-Volume 10. [S.l.], 2002. p. 79–86. Citado 2 vezes nas páginas 7 e 8.
PRABOWO, R.; THELWALL, M. Sentiment analysis: A combined approach. Journal ofInformetrics, v. 3, n. 2, p. 143–157, 2009. Citado 4 vezes nas páginas 9, 12, 13 e 18.
READ, J. Using emoticons to reduce dependency in machine learning techniques for senti-
ment classification. In: ASSOCIATION FOR COMPUTATIONAL LINGUISTICS. Proceedingsof the ACL Student Research Workshop. [S.l.], 2005. p. 43–48. Citado 2 vezes nas pági-nas 37 e 43.
REIS, J. et al. Breaking the news: First impressions matter on online news. arXiv preprintarXiv:1503.07921, 2015. Citado na página 12.
RESEARCH, S. C. for B. I. Protege open source ontology editor and knowledge-baseframework [online]. In: . [s.n.], 2013. Disponível em: <http://protege.stanford.edu/>. Citadona página 11.
RIGO, S.; ALVES, I.; GAZOLA, O. Abordagem linguística para identificação da dimensãoafetiva expressa em textos de Ambientes Virtuais de Aprendizagem?um Léxico da Emoção.Anais do Simpósio Brasileiro de Informática na Educação, n. Cbie, p. 738–747, 2013.Disponível em: <http://br-ie.org/pub/index.php/sbie/article/view/2552>. Citado na página 9.
SAKAKI, T.; OKAZAKI, M.; MATSUO, Y. Earthquake shakes twitter users: real-time eventdetection by social sensors. In: ACM. Proceedings of the 19th international conferenceon World wide web. [S.l.], 2010. p. 851–860. Citado 2 vezes nas páginas 4 e 11.
SCARTON, C. VerbNet. Br: construção semiautomática de um léxico computacional deverbos para o português do Brasil. 8th Brazilian Symposium in Information and Hu-
man Language Technology, p. 20–29, 2011. Disponível em: <http://nilc.icmc.sc.usp.br/til/ stil2011\_English/stil/artigos/Long/STIL2011\_P3.pdf>. Citado na página 18.
SCHWARTZ, H. A. et al. Towards assessing changes in degree of depression throughfacebook. In: Proceedings of the Workshop on Computational Linguistics and ClinicalPsychology: From Linguistic Signal to Clinical Reality. [S.l.: s.n.], 2014. p. 118–125.Citado na página 4.
SEBASTIANI, F. Machine learning in automated text categorization. ACM computing sur-veys (CSUR), ACM, v. 34, n. 1, p. 1–47, 2002. Citado na página 28.
SILVA, M.; TEAM, R. Notas sobre a Realização e Qualidade do Twitómetro. [S.l.], 2011.Citado 3 vezes nas páginas 10, 11 e 12.
SILVA, M. J. et al. Automatic expansion of a social judgment lexicon for sentiment analysis.2010. Citado na página 10.
55

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 70/71
SOKOLOVA, M.; LAPALME, G. A systematic analysis of performance measures for classi-fication tasks. Information Processing & Management, Elsevier, v. 45, n. 4, p. 427–437,2009. Citado na página 27.
SOUZA, M.; VIEIRA, R. Sentiment analysis on twitter data for portuguese language. In:Computational Processing of the Portuguese Language. [S.l.]: Springer, 2012. p. 241–247. Citado na página 10.
SOUZA, M. et al. Construction of a portuguese opinion lexicon from multiple resources.STIL, 2011. Citado na página 10.
SOUZA, M. V. d. S. Mineração de opiniões aplicada a mídias sociais. Pontifícia UniversidadeCatólica do Rio Grande do Sul, 2012. Citado na página 17.
SPENCER, J.; UCHYIGIT, G. Sentimentor: Sentiment analysis of twitter data. In: CEURWorkshop Proceedings. [S.l.: s.n.], 2012. v. 917, p. 56–66. ISBN 9781932432961. ISSN16130073. Citado na página 28.
SUMMERS, D. Longman Dictionary Of Contemporary English(F/C):. [S.l.: s.n.], 1995.(Longman Corpus network). Citado na página 34.
THELWALL, M. Heart and soul: Sentiment strength detection in the social web with sen-tistrength. Proceedings of the CyberEmotions, Citeseer, p. 1–14, 2013. Citado 4 vezesnas páginas 11, 13, 19 e 35.
THELWALL, M. SentiStrength 2.0. 2015. Disponível em: <http://sentistrength.wlv.ac.uk/>.Citado na página 35.
TUMASJAN, A. et al. Predicting elections with twitter: What 140 characters reveal aboutpolitical sentiment. ICWSM, v. 10, p. 178–185, 2010. Citado 2 vezes nas páginas 4 e 11.
TURNEY, P.; LITTMAN, M. L. Unsupervised learning of semantic orientation from a hundred-billion-word corpus. 2002. Citado na página 20.
TURNEY, P. D. Thumbs up or thumbs down?: semantic orientation applied to unsupervisedclassification of reviews. In: ASSOCIATION FOR COMPUTATIONAL LINGUISTICS. Proce-edings of the 40th annual meeting on association for computational linguistics. [S.l.],2002. p. 417–424. Citado 7 vezes nas páginas 7, 8, 17, 19, 20, 23 e 40.
WAN, X. Using Bilingual Knowledge and Ensemble Techniques for Unsupervised ChineseSentiment Analysis. In: Proceedings of the Conference on Empirical Methods. [S.l.: s.n.],2008. p. 553–561. Citado na página 12.
WANG, G. et al. Sentiment classification: The contribution of ensemble learning. Decisionsupport systems, Elsevier, v. 57, p. 77–93, 2014. Citado 4 vezes nas páginas 12, 13, 19e 28.
WANG, H. et al. A system for real-time twitter sentiment analysis of 2012 us presidentialelection cycle. In: ASSOCIATION FOR COMPUTATIONAL LINGUISTICS. Proceedings of
the ACL 2012 System Demonstrations. [S.l.], 2012. p. 115–120. Citado na página 13.WIEBE, J. Learning subjective adjectives from corpora. In: AAAI. [S.l.: s.n.], 2000. p. 735–740. Citado na página 20.
56

8/18/2019 TÉCNICAS PARA ANÁLISE DE SENTIMENTOS DE APLICAÇÕES DA WEB EM LÍNGUA PORTUGUESA
http://slidepdf.com/reader/full/tecnicas-para-analise-de-sentimentos-de-aplicacoes-da-web-em-lingua-portuguesa 71/71
WILSON, T.; WIEBE, J.; HOFFMANN, P. Recognizing contextual polarity in phrase-levelsentiment analysis. In: ASSOCIATION FOR COMPUTATIONAL LINGUISTICS. Proceedingsof the conference on human language technology and empirical methods in naturallanguage processing. [S.l.], 2005. p. 347–354. Citado 2 vezes nas páginas 9 e 10.
YIN, R. K. Applications of case study research. [S.l.]: Sage, 2011. Citado na página 30.
ZHANG, Z. Weighing stars: Aggregating online product reviews for intelligent e-commerceapplications. Intelligent Systems, IEEE, 2008. Disponível em: <http://ieeexplore.ieee.org/ xpls/abs\_all.jsp?arnumber=4629725>. Citado 2 vezes nas páginas 4 e 11.





























