Embed Size (px)
Citation preview

THE R* - TREE : AN EFFICIENTAND ROBUST ACCESS METHOD
FOR POINTS AND RECTANGLES+
São Carlos, 01 de outubro 2010

É uma variante da R-tree utilizada paraindexação de informação espacial;
Estruturada hierarquicamente na forma deuma árvore balanceada;
Suporte a dados espaciais;
Conceito R* -tree

Tem um custo ligeiramente superior ao deoutras R-tree na inserção de dados;
Foi proposta por Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider e Bernhard Seeger em 1990.
Conceito R* -tree

A minimização da área, a margem, e asobreposição é crucial para o desempenhodas árvores;
Em uma consulta ou inserção de dados,mais de um galho da árvore deve serexpandido (devido à redundância dearmazenamento);
Diferença entre R-tree and R*-tree

Baseada na observação de que asestruturas R-tree são altamentesuscetíveis a ordem em que as suasentradas estão inseridas, a exclusão ereinserção de entradas permite"encontrar" um lugar na árvore que podeser mais apropriada do que a sualocalização original.
Diferença entre R-tree and R*-tree

R1
R2
R3
R5
R4
Exemplo
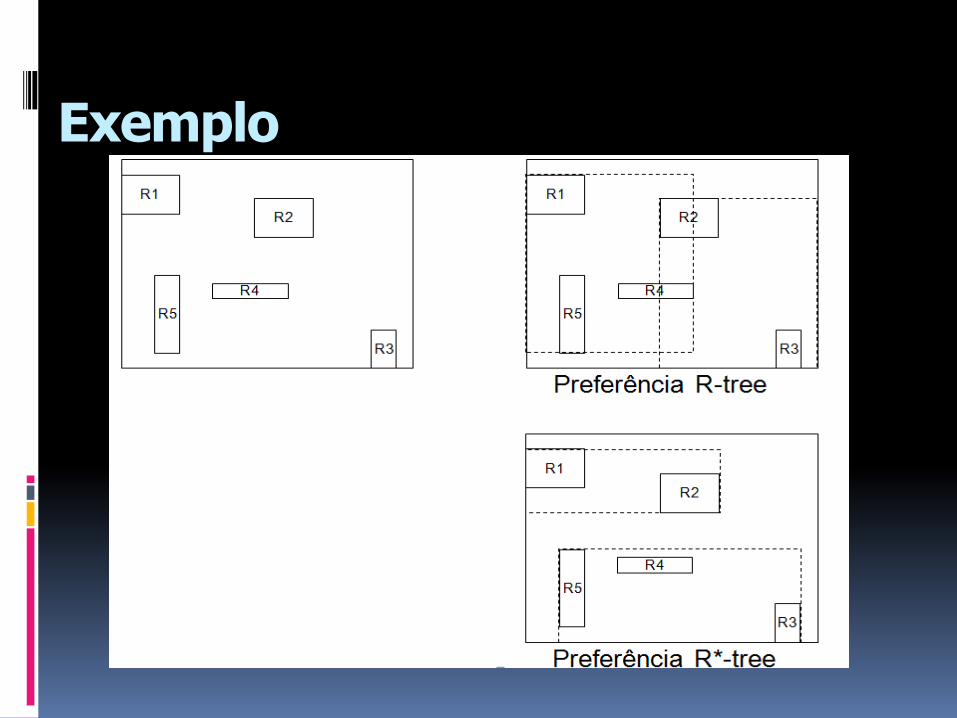
Exemplo
R1
R2
R3
R5
R4

Melhora significativa sobre prováveisvariantes outra árvore R, mas não hásobrecarga devido ao método dereinserção.
Suporta eficientemente dados de ponto eespacial ao mesmo tempo
Desempenho

A árvore R*-tree usa o mesmo algoritmoque a R-tree para consulta e exclusão;
A principal diferença é o algoritmo deinserção, especificamente, como eleescolhe qual ramo para inserir o novo nóe a metodologia para a divisão de um nóque está cheio.
Algoritmo

Algoritmo ChooseSubtree
Escolha retângulo em N que necessita de um mínimo de sobreposição de alargamento para incluir novos dados;
Resolve os laços, pelo menos com alargamento da área;
Aumenta o custo de CPU;
Reduz o número de acessos ao disco.
R*-tree

Algorithm ChooseSubtree
CS1 Conjunto de N a ser o nó raizCS2 Se N é uma folha,
return Nsenão
Se o childpointers no ponto N para as folhas[Determinar o mínimo de sobreposição]escolher a entrada em N, cujo retângulo precisa de pelo alargamento a sobreposição do retângulo de novos dados. Resolve laços escolhendo a entrada cujo retângulo necessita do alargamento da área, pelo menos,
then a entrada com o retângulo de menor área
Se o childpointers em N não apontam para folhas[Determinar o custo mínimo da área]
escolher a entrada em N, cujo retângulo necessita do alargamento da área, pelo menos para incluir o retângulo de novos dados. Resolve laços escolhendo a entrada com o retângulo de área menor
fimCS3 Conjunto N ser o childNode apontado pelo childpointer da
entrada escolhida. Repita a partir do CS2
Algoritmo ChooseSubtree
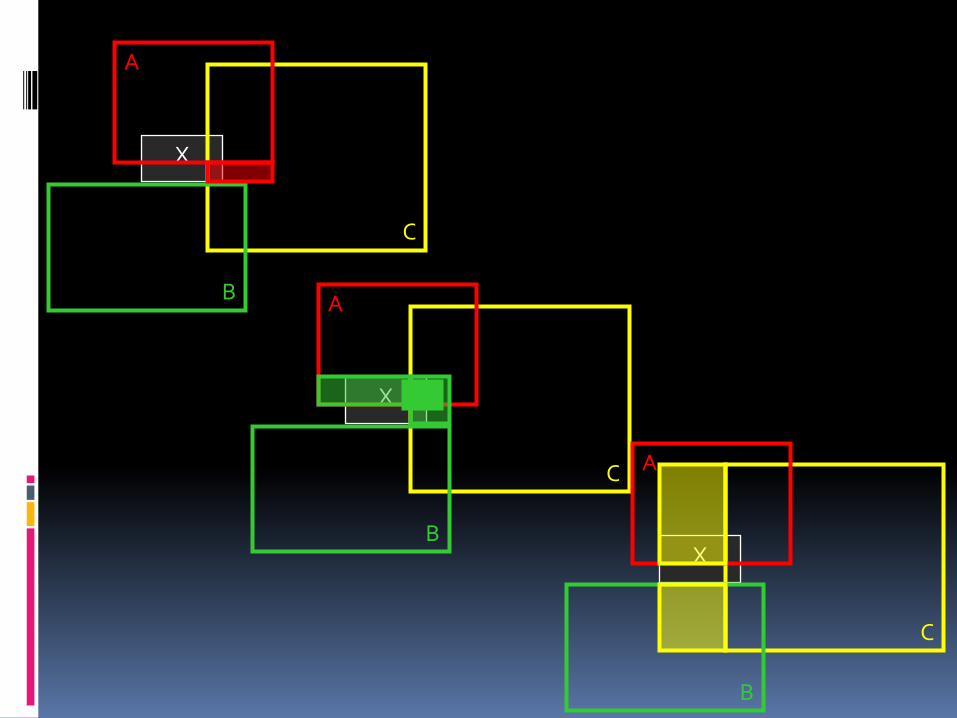
X
C
A
B
X
C
A
BX
C
A
B

Classificar as entradas em ordem crescente em cada eixo;
Ordenar por valores superiores a seus retângulos;
M-2m+2 distribuição de M+1 entradas em 2 grupos;
Para cada distribuição calcular valores de goodness, estes valores determinam a distribuição final.
Splitting

Três valores para goodness area-value area[bb(first group)] +
area[bb(second group)]
margin-value margin[bb(first group)] +
margin[bb(second group)]
overlap-value area[bb(first group)
bb(second group)]
Dependendo desses valores, a distribuição final das entradas é determinada.
bb: caixa delimitadora de um conjunto de retângulos
Splitting - distribuição

Algorithm Split
S1 Invoca ChooseSplitAxis para determinar o eixo,
perpendicular ao que a separação é realizada
S2 Invoca ChooseSplitIndex para determinar a melhor distribuição em dois
grupos ao longo desse eixo
S3 Distribuir as entradas em dois grupos
Algorithm ChooseSplitAxis
CSA1 Para cada eixo
Classificar as entradas pela então o valor mais baixo por cima de seus retângulos e determinar todas as distribuições, como descrito acima. Calcule S, a soma de toda a margem de valores de diferentes distribuições final
CSA2 Escolha o eixo com o mínimo de S como eixo dividido
Algorithm ChooseSplitIndex
CSI1 Ao longo do eixo dividido escolhido, escolher a distribuição com o mínimo de sobreposição de valor. Resolve laços escolhendo a distribuição com área mínima de valor
Algoritmos

Distribuição #1 Distribuição #2 Distribuição #3
Area-value = 1.00 Area-value = 1.11
M=9, m=4

Split de R*-tree
Testes com m = 20%, 40% e 45% de M
Melhor desempenho m = 40%
M=9, m=4
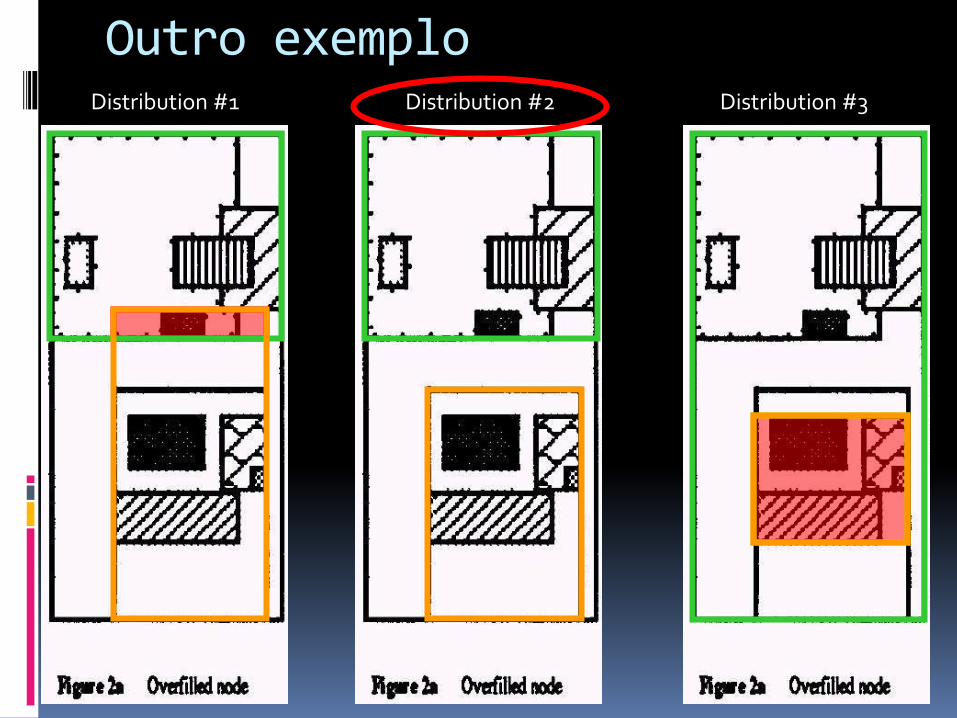
Distribution #1 Distribution #2 Distribution #3
Outro exemplo


forma não determinista atribuição das entradas;
Força reinsert durante as rotinas de inserção
Inserções de mudança forçada de entradas entre vizinhos
utilização do armazenamento é melhorada
Ocorre menos splits;
Diretório retângulos são mais quadrática
Forced Reinsert

Algorithm InsertData
ID1 Invoke Insert a partir do nível folha como parâmetro, para inserir um retângulo de novos dados
Algorithm Insert
I1 Invoke ChooseSubtree, com o nível como um parâmetro, para encontrar um adequado nó N, em que para colocar o E a entrada de novos
I2 Se N tem menos de entradas M, acomodar E em N. Se N tem entradas M, invocar OverflowTreatment com o nível de N como parâmetro [para a reinserção ou dividir]
I3 Se OverflowTreatment foi chamado e uma divisão foi realizada, propagar para cima OverflowTreatment se necessárioSe OverflowTreatment causou uma divisão da raiz, criar uma nova raiz
I4 Ajuste todos os retângulos que cobrem o caminho de inserção de tal forma que eles estão colocando em seguida MBRs retângulos filhos
Forced Reinsert

Algorithm OverflowTreatment
OT1 Se o nível não é o nível da raiz e esta é a primeira chamada de OverflowTreatment em determinado nível durante a inserção de um retângulo de dados, então
invoca Reinsert
senão
invoca Split
fim
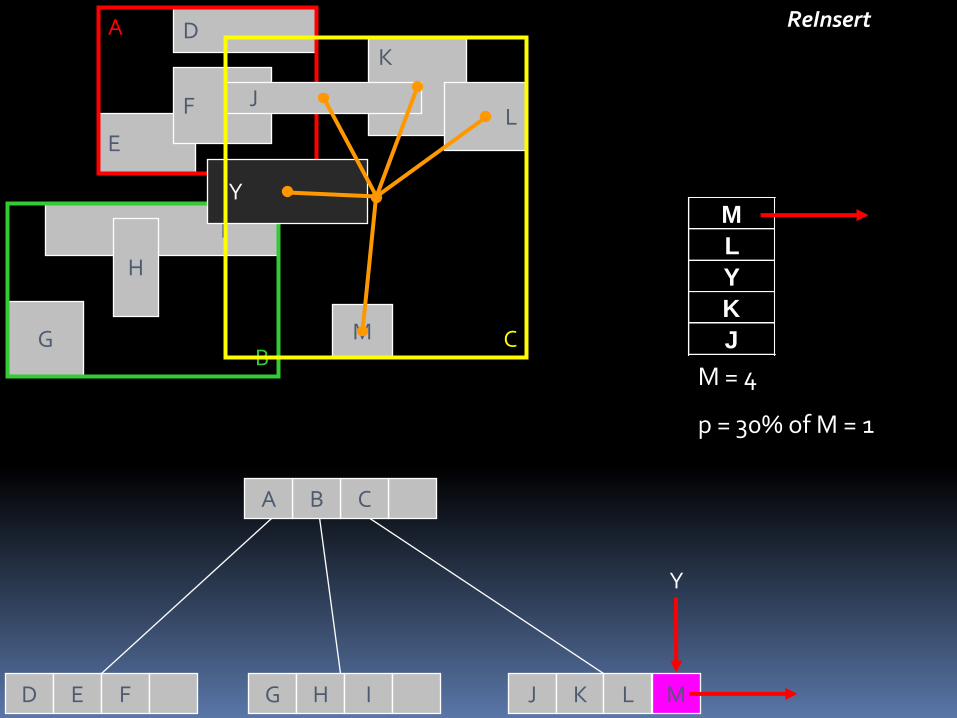
Algorithm Reinsert
RI1 Para todos os M + 1 entradas de um nó N, calcular a distância entre os centros das retângulos e no centro do retângulo delimitador de N
RI2 Classificar as entradas em ordem decrescente de suas distâncias computadas em RI1
RI3 Remova as entradas p primeiro a partir de N e ajustar o retângulo delimitador de N
RI4 Na classificação, definida em RI2, começando com a distância máxima (= muito reinserir) ou distância mínima (= fechar reinserir), invocar Inserir para reinserir as entradas
Forced Reinsert
I
D
E
F
G M
A
B
H
K
LJ
D E F G H I J K L M
CBA
M
L
Y
K
J
M = 4
p = 30% of M = 1
ReInsert
Y
C
Y
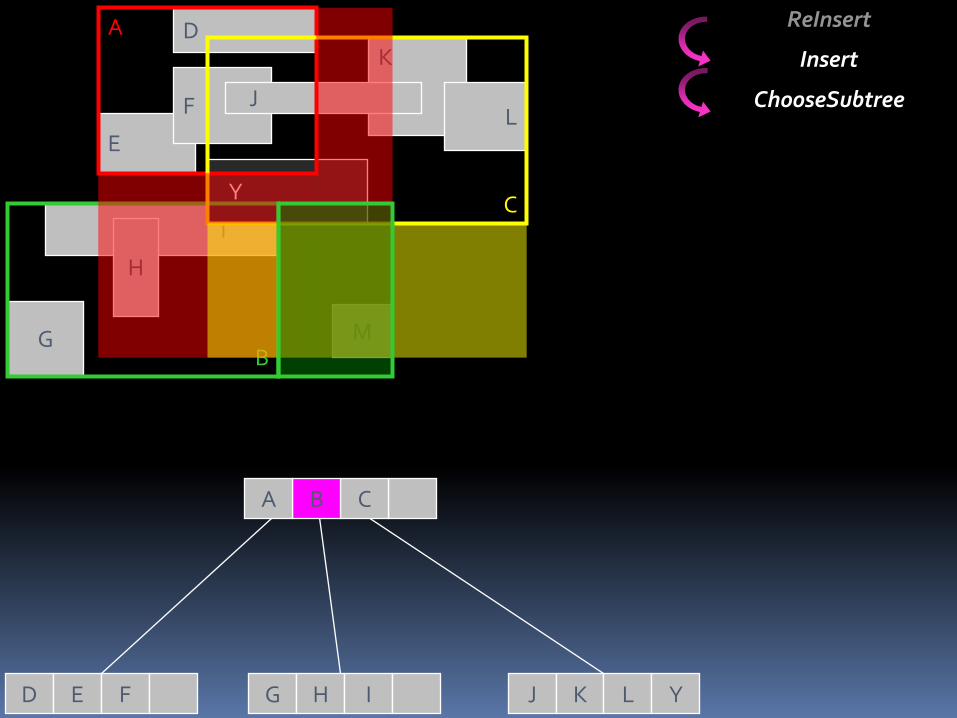
D E F G H I J K L Y
CBA
Insert
ReInsert
ChooseSubtree
I
D
E
F
G M
H
K
J
Y
A
B
L
C

D E F G H I M J K L Y
CBA
Insert
ReInsert
ChooseSubtree
I
D
E
F
G M
H
K
J
Y
A
B
L
C

• As R*-tree precisam de menos acesso a disco e sempreganham em performance;
• Maior ganho com R*-tree para consultas retângulomenor;
• As R*-tree são 400% melhor do que o linear, 200%melhor do que Greene (R-tree), e 180% melhor do quea Quadrática;
• Elas tem um melhor aproveitamento;
• Reinsert forçado mais reduzido do que as outras R-tree;
• Desempenho médio com maior ganho para R*-treeo quad (147%), Greene (171%), linear (261%) maisacessos
Resultados

Conclusão
R*- tree pode ser usada eficientemente como um método de acesso e organização em sistemas de banco de dados multidimensional e de dados espaciais.
R*- tree proporciona um melhor desempenho na manipulação de objetos espaciais de dimensão não zero quando comparado a R-tree.





























