Embed Size (px)
Citation preview

Unidade 1 Fundamentos sobre incidente de segurança
Objetivos de Aprendizagem
• Conhecer o que são incidentes de segurança da informação e quais os seus tipos.
• Compreender a importância do tratamento de incidentes de segurança da informação.
• Entender com que termos da área de T.I., normalmente, os incidentes de segurança da informação estão vinculados.
Introdução
Esta unidade descreve os princípios que se relacionam com os
incidentes de segurança da Informação. Tais princípios abrangem uma vasta
gama de assuntos, os quais podem ser sistematizados por processos,
modelagens, normas, experiências práticas, análises de riscos e impactos
sobre os negócios. Envolvem também esses incidentes em si, os quais podem
ser simples, como uma tentativa de invasão mal sucedida ou um vírus
detectado a tempo pelos sistemas de defesa da organização, ou podem ser
extremamente complexos, como os desastres que assustam a população em
geral e não apenas aos responsáveis pela proteção do patrimônio mais difícil
de ser recuperado em uma empresa, os seus ativos de informação. Tais
desastres podem ser naturais (Furacões, vendavais, tempestades, tsunamis,
terremotos, inundações, deslizamentos de terra) ou podem ter natureza
criminosa ou acidental, como incêndios, roubos, panes elétricas. Embora os
termos Incidente”, Desastre”e Cyber Crime”possam aparecer em conjunto na
literatura, existem normas e planos específicos para cada tipo destes eventos.
Leitura 1

Título da leitura: Necessidade e componentes gerais da segurança da informação
Sinopse: Nessa Leitura veremos que erros e omissões em relação ao uso de
informações numa organização são considerados incidentes de segurança da
informação. Quando eles são mais graves que ataques diretos aos ativos de uma
organização? Essa Leitura buscará responder a isso.
Também apresentará que os componentes gerais dessa segurança são: as
ferramentas, os processos e as pessoas ligados aos ativos a serem protegidos.
Por que são esses os componentes gerais? Leia esse texto para compreender.
<Fim de sinopse>
Numa sociedade centrada em tecnologia, afinal estamos na era da
informação e do conhecimento, ainda poucas empresas podem assegurar
que estão livres de incidentes, mesmo as que investem o suficiente na
proteção dos seus ativos de informação, os quais podem ser representados
por documentos, livros e arquivos em papel ou Informação armazenada
eletronicamente (Electronically Stored Information -‐ ESI).
A proteção para minimizar os riscos de incidentes envolve
elevados recursos financeiros, humanos e computacionais, os quais
justificam-‐se na medida em que possíveis perdas desses ativos de
informação possam inviabilizar a continuidade do negócio da empresa a que
pertencem.
A habilidade de detectar os problemas quando da ocorrência dos
incidentes de segurança e de responder de maneira efetiva a isso é
necessária, inclusive sob os aspectos regulatórios. Por exemplo, o roubo ou
abuso no uso de informações financeiras ou de prontuários médicos – para
citar somente alguns casos -‐ podem ter consequências legais mais graves do
que a simples perda dessas informação.
Outros fatores como perdas devido a utilização incorreta ou ilícita
de ativos pelos próprios funcionários da organização têm gerado prejuízos
estimados em milhões de dólares anuais.

Além disso, erros e omissões na utilização de informações são
responsáveis diretos por prejuízos significativos, e de uma forma mais
danosa que os ataques intencionais aos ativos de informação. Esses
fatos, os quais atuam como fontes geradoras de incidentes de segurança, são
mais difíceis de detectar, uma vez que a origem do problema pode estar
bastante difusa em um elevado número de eventos e procedimentos.
Portanto, o domínio de métodos, normas e técnicas de tratamento
dos incidentes de segurança torna-‐se cada vez mais necessário nos
ambientes empresariais atuais, altamente informatizados e dependentes de
seus ativos de informação.
O usuário da informação é um aspecto complexo da segurança da
mesma, pois existe uma relação inversa entre segurança e a satisfação do
usuário:
Obviamente, quanto mais controles, políticas e permissões de acesso
você insere em uma rede, menos confortável ficará a utilização dos recursos por
seus usuários. Uma questão central é: Quanto de conforto o usuário abre mão
para sentir-‐se seguro nas questões de rede? Regras draconianas motivam
boicotes às políticas. Exemplo desse tipo de regra: “nenhum uso dos recursos
de rede pode ser pessoal” pode ter consequencias adversas. Mas, você precisa
dos usuários atuantes nas políticas de segurança.
Aspectos gerais da segurança da informação (DG, TÍTULO 2) Qualquer componente ou fase de um programa de segurança da
informação não envolve somente tecnologia. Uma abordagem correta para a
implementação dessa segurança inicia sempre pelas pessoas.
1
satisfação Segurança =

O diagrama a seguir mostra o inter-‐relacionamento entre os
componentes envolvidos nos diversos aspectos dos planejamentos
relacionados com segurança da informação
Figura 1-‐Abordagem correta para Segurança da Informação.
Fonte: Marcio Zapater & Rodrigo Suzuki Promon Business & Technology Review -‐ Segurança da Informação Um diferencial determinante na competitividade das
corporações (2009) Acompanhemos, pontualmente, cada um desses componentes desse diagrama.
Pessoas (dg, título 3)
As pessoas são o elemento mais importante na gestão da segurança, pois em
essência são elas que executam e suportam os processos de uma organização.
Uma abordagem correta dos componentes responsáveis pela segurança da
informação trata com as pessoas os assuntos relacionados a essa área.
Estabelece com elas seus papéis e responsabilidades na organização. O que, por
sua vez, abrange desde a capacitação dos profissionais responsáveis pela
segurança até o treinamento dos colaboradores, passando pela criação de uma
cultura e conscientização da organização e de seus parceiros (fornecedores,
clientes, terceirizados) em relação à necessidade de se estabelecer a segurança
da informação.
<Abrir destaque> Importante

Os usuários devem entender os propósitos básicos do programa de segurança da
Informação e a sua implementação antes que ganhem acesso a recursos de TI.
<Fim de destaque>
No mínimo, os usuários devem entender os seguintes componentes de segurança
de TI:
• Confidencialidade. • Segurança das Senhas: Logging Off; Multiplos Sign-‐Ons. • Comportamentos adequados para segurança dos sistemas de TI. • Software malicioso. • Armadilhas dos emails . • Back-‐ups. • Uso da Internet. • Licenciamento de Software. • Etiqueta para uso de Email. • Expectativas de privacidade. • Como reportar incidentes. • Segurança nos sistemas de telecomunicações • Resumo do funcionamento da rede. • Login Remoto. • Segurança física. • Disponibilidade de informação sensível ou sigilosa. • Consequência do mau uso dos recursos dos sistemas de TI. Processos (dg, título 3)
Esse elemento da abordagem da segurança da informação é o principal eixo de
sua gestão nas tarefas diárias de uma organização. Compreende desde a visão da
corporação -‐ o modelo de negócios, os objetivos, a definição dos ativos de
informação que se quer proteger, a estratégia de segurança para protegê-‐los, a
definição das políticas para a implementação dessa segurança -‐ até os processos
que colocam em prática tais políticas -‐ os procedimentos, a documentação de
controle e os padrões de conformidade dessa mesma segurança.
Através de processos bem definidos, uma organização torna a segurança da
informação uma responsabilidade de todos e não apenas da equipe de
segurança.
Essa gestão, portanto, determina, por meio de diretrizes, as maneiras corretas de
se agir nos processos da organização para comprometer o mínimo possível a

segurança.
Ferramentas (dg, título 3)
Elas são as soluções de segurança empregadas para suportar os processos
delineados na organização. Portanto, devem facilitar a devida aplicação das
políticas de segurança da informação e seu monitoramento. Incluem diversas
funcionalidades, desde a identificação dos usuários, criptografia de dados, defesa
contra ameaças, até a gestão da segurança.
Referências
1. Stacey, T. R. (2007): Contingency Planning Best Practices and Program Maturity in: Information Security Management Handbook (2007)
2. Swanson, M.; Wohl, A.; Pope, L.; Grance, T.; Hash, J. & Thomas, R. (2002): Contingency Planning Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology
3. Tipton, H. & Krause, M.(2007): Information Security Management
Handbook - 6th Ed – Auerbach Publications 4. Zapater, M. & Suzuki, R. (2009): Segurança da Informação Um
diferencial determinante na competitividade das corporações. Promon Business & Technology Review
5. Stallings, W. (2007): Network Security Essentials, 4th. ed – Pearson
Education
Leitura 2 Título da Leitura: O “ecossistema” em que se figura a segurança da informação Sinopse: Nessa Leitura você pode verificar os relacionamentos presentes entre
os principais elementos que compõe a segurança da informação no que tange aos
processos de negócios das organizações.
E qual a relevância da “computação em nuvem” para essa segurança? E por que
os datas centers voltaram a ser centralizados em virtude dessa segurança? Ao
final dessa Leitura você deve conseguir responder essas perguntas.

Também verá nessa Leitura o Ciclo de Maturidade da segurança da Informação.
Você sabe responder como analisar em que fase desse ciclo uma empresa está? .
<Fim de Sinopse>
Você já estudou o conceito de segurança da informação antes, mas para
contextualizar o tratamento de incidentes precisamos revisar alguns tópicos que
fazem parte de todo o “ecossistema” em que se figura essa segurança. Tal sistema
está representado no diagrama presente a seguir.
Diagrama 1 -‐ relacionamentos entre os componentes de segurança da informação. Fonte: Adaptado de Roberto Amaral,2003.
Dentro deste contexto complexo de relacionamentos (causas e efeitos),
segurança da informação pode ser definida como “um conjunto de
procedimentos cuja finalidade é a salva-‐guarda dos ativos de informação contra
o seu uso ou exposição não autorizados”. Pode ser também o resultado de
qualquer sistema de políticas e procedimentos administrativos utilizados para

identificar, controlar e proteger as informações contra o uso não autorizado, em
ações determinadas por ordens executivas ou estatutárias” (Tipton & Krause
2007).
Empresas digitais
Estamos entrando em uma era onde os negócios emergentes são
classificados como “Empresas digitais”. Nessas quase todas as relações
significativas de negócios com os clientes, fornecedores e funcionários são
disponibilizadas digitalmente, e todos os ativos chaves da corporação são
gerenciados por meios digitais.
Neste cenário, os ativos de informação precisam ser protegidos
segundo as normas de segurança mais rígidas possíveis, de forma a evitar a
ocorrência de incidentes que possam interromper a continuidade dos negócios.
Data Centers Os data centers podem ser considerados como uma usina de
processamento das informações organizacionais e, por isso, são a joia da
coroa a ser protegida.
Os paradigmas tecnológicos e as funcionalidades dos data centers
sofreram mudanças significativas desde o início da “era da informação”.
Figura 2 -‐ Mudanças de paradigmas e funcionalidades dos data centers Fonte: Adaptado de Error! Reference source not found.
Cloud Computing
VDI

Os sistemas centralizados em mainframes na década de 1960 migraram em
grande escala para sistemas distribuídos a partir dos anos 1990. Com esse
movimento, as questões relativas à segurança em datacenters ficaram mais
difíceis de gerenciar, uma vez que os alvos possíveis não se encontravam em
um único ponto.
Com a difusão dos virtualizadores a partir da metade da primeira década do
século XXI, iniciou-‐se um movimento de retorno aos sistemas centralizados.
Vários servidores virtuais passaram a executar tarefas diversas dentro de
um único hospedeiro físico. Essa arquitetura tornou-‐se muito parecida com
aquela proposta pelos antigos mainframes. Tais mainframes também
evoluíram, e sua proposta hoje é a de consolidar os datacenters usando para
isso centenas de servidores virtuais em uma máquina extremamente potente
em termos de recursos computacionais.
Refere-‐se também a redução de custos com atualizações constantes de
hardware, gerenciamento facilitado, redução do espaço nos datacenters,
redução da refrigeração e do consumo de energia das próprias máquinas
A Computação em Nuvem
Cloud Computing, ou “Computação em Nuvem”, utiliza a rede para
conectar usuários a recursos baseados em “nuvem”, ao contrário de recursos
efetivamente em sua posse (como o poder computacional do equipamento
utilizado para realizar esta conexão). A “nuvem” pode ser acessada através
de uma rede corporativa, da Internet, ou de ambos estes.
O provedor dos serviços em nuvem pode requisitar o poder
computacional de múltiplos computadores remotos na “nuvem” para
completar uma tarefa, desde tarefas pouco intensas como o processamento
de texto ou tarefas mais intensas como o backup de um grande volume de
dados.
Características-‐chave da Computação em Nuvem:
• Agilidade – Menos tempo gasto suprindo necessidades em infraestrutura;

• Custo reduzido – Despesas com bens de capital são substituídas por
despesas operacionais;
• Escalabilidade – Provisionamento dinâmico dos recursos adaptando os
sistemas para picos de uso;
• Independência de local e equipamento – Sistemas acessados por browser
em diferentes plataformas (PC, tablet, smartphone, …) e em qualquer
lugar através da Internet;
• Desempenho monitorado.
• Manutenção facilitada – Aplicações não precisam ser instaladas nos
computadores de cada usuário. Maior facilidade de suporte e
implementação de melhorias. <Abrir destaque> Importante Do ponto de vista da segurança da informação, a Computação em Nuvem apresenta características avançadas:
• Maior confiabilidade – Com o uso de servidores redundantes se o serviço fica indisponível em um nó da grade de processamento, outros cobrem a demanda.
• Backups automatizados testados e confiáveis.
• Recuperação de incidentes e desastres com downtime mínimo.
• Resiliência. <Fim de destaque> Infra-‐estrutura de Desktops Virtuais
Atualmente uma nova onda de centralização. ainda maior que a da
primeira década dos anos 2000, começa a ganhar o cenário dentro das
estratégias dos CIOs: trata-‐se da VDI, ou Virtual Desktop Infraestructure
(Infra-‐estrutura de Desktops Virtuais). A técnica consiste em hospedar um
sistema operacional de desktop em uma máquina virtual rodando em um
servidor central.
Conceitualmente, a VDI separa o ambiente de computação pessoal
em desktop de uma máquina física e armazena a totalidade de programas,
aplicações, processos e dados em um servidor central. Alguns modelos de

máquinas de grande porte, como a linha System z Enterprise, da IBM
conseguem virtualizar até 1.000 desktops usando uma única CPU física.
De imediato essa abordagem apresenta vantagens em vários
aspectos:
• Permite aos usuários acessarem seus ambientes virtualizados a partir
de qualquer dispositivo com um browser web.
• O provisionamento é simples e rápido.
• O tempo de parada (down time) é menor.
• Reduz o custo de licenciamentos.
• Aumenta o ciclo de atualizações de hardware.
• Reduz o custo do hardware necessário. <Abrir destaque> Importante
Do ponto de vista da segurança da informação, a gerência centralizada de todos os ambientes dos usuários permite um controle muito mais efetivo em relação a invasões, instalações indevidas, ataques de vírus e outros incidentes. <Fim de destaque>
De acordo com um relatório do Gartner Group, o mercado de VDI irá atingir 49
milhões de unidades de desktops em 2013, podendo com isso abranger 40% do
mercado mundial de computadores de PCs de uso profissional.
Ciclo de Maturidade da segurança da Informação
Pode-‐se afirmar que em um cenário ideal, a continuidade dos
negócios nunca seria interrompida (zero down time). Mas para se chegar em
um estágio destes, várias fases devem ser vencidas em uma escalada das
corporações rumo a maturidade da segurança da informação.
Arbitrariamente, podemos classificar esses graus de maturidade em 5 fases,
as quais sucedem-‐se entre si e encontram na sequência:
Maturidade zero -‐ Fase do Descaso: A empresa não possui qualquer tipo de
proteção para seus ativos de informação. Provavelmente tais ativos são
desconsiderados, ou considerados não críticos.

Maturidade 1 -‐ Fase da Proteção: A empresa já considera seus ativos de
informação como um patrimônio importante, e investe em tecnologia e
equipamentos para protegê-‐los. Normalmente os recursos humanos ainda não
possuem cultura de segurança da informação, e poucas políticas de proteção são
adotadas formalmente.
Maturidade 2 -‐ Fase da capacidade de recuperação: A empresa não só
protege seus ativos de informação, como está preparada para a recuperação
desses ativos em caso de algum incidente ou desastre. Existe uma cultura forte
em relação às questões de proteção e ações para evitar riscos. As políticas são
mandatórias, claras e bem documentadas. Sistemas de backup são executados
regularmente. O tempo de recuperação é relativamente longo, pela ausência de
um plano eficiente e bem testado. Os prejuízos podem ser elevados, com risco de
comprometer a continuidade dos negócios.
Maturidade 3 -‐ Fase da capacidade de continuidade: A empresa está
preparada para, depois de recuperar-‐se de um incidente ou desastre em relação
a proteção dos seus ativos, dar continuidade nos seus negócios em um tempo
relativamente curto, sendo afetada de forma não disruptiva com o período de
down time. Data centers redundantes com sistemas de backup síncronos são
utilizados.
Maturidade 4 -‐ Fase da resilência: A empresa não interrompe seu negócio,
mesmo durante a ocorrência do incidente ou desastre. Considera-‐se que é um
negócio Resiliente. Resiliência é a propriedade intrínseca de um sistema o qual
continua funcionando mesmo em condições teoricamente muito adversas ou
desfavoráveis.
Todas essas fases e a ordem de sequência entre elas estão expressos na figura a
seguir.

Investimentos
Figura 3 -‐ Fases de maturidade da segurança da informação nas corporações
Fonte: Um exemplo da falta de uma segurança da informação adequada é expresso na charge presente na sequência.
“Nossa política de resposta automática para a perda de grandes volumes de dados de grandes empresas é NOTIFICAR A GERÊNCIA, FAZER UMA CÓPIA DOS DADOS QUE SOBRARAM E VENDER 90% DAS NOSSAS AÇÕES DA EMPRESA AFETADA.”
(A 5A. Onda, Rich Tennant [Error! Reference source not found.]).
Os planos de contingência, recuperação de desastres e de incidentes se relacionam, em maior ou menor grau, com outros planos voltados a segurança de TI nas organizações. A
Tabela 1 abaixo mostra os escopos e propósitos de cada um desses
planos, segundo a norma NIST 800-‐34:
Tabela 1 -‐ Propósito e escopo dos planos de emergência de segurança em TI Plano Propósito Escopo
Descaso
proteção
recuperação
con/nuidade resiliência
Agilidade na recuperação

Plano de continuidade do negócio - Business Continuity Plan (BCP)
Descrever procedimentos para manter as operações essenciais enquanto se recupera de uma ruptura significativa nos processos.
Endereçado aos processos do negócio; TI envolvida somente como base no suporte para os processos de negócio.
Plano de recuperaçao do negócio - Business Recovery (or Resumption) Plan (BRP)
Descreve os procedimentos para recuperar as operações do negócio imediatamente após um desastre
Direcionado aos processos do negócio; Não tem foco em TI, a qual apenas deve suportar os processos de negócio.
Plano de continuidade de das operações - Continuity of Operations Plan (COOP)
Provê procedimentos e capacidades para manter as funções essenciais e estratégicas de uma organização em um site alternative por pelo menos 30 dias.
Dirigido a um subconjunto de uma organização o qual é responsável pelas missões mais críticas; Usualmente escrito para funcionar no nível das sedes das empresas; Não tem foco em TI.
Plano de Continuidade de suporte/Plano de contingencia de TI - Continuity of Support Plan/IT Contingency Plan
Provê procedimentos e capacidades para recuperar as aplicações mais importantes ou um sistema genérico de suporte
Igual ao plano de contingência de TI. Dirigido a rupturas no sistema de TI; Não é focado em processos de negócio.
Plano de comunicação de crises - Crisis Communications Plan
Provê procedimentos para disseminação de relatórios e boletins sobre o estado das operações para o público interno e externo.
Dirigido para comunicação somente. Não tem foco em TI.
Plano de resposta para Incidentes Cibernéticos - Cyber Incident Response Plan
Provê estratégias para detectarm responder a e limitar as consequencias de um incidente cibernético maliciso
Dirigido para a equipe de resposta a incidentes de segurança os quais afetem os sistemas e/ou as redes
Plano de Recuperação de desastres - Disaster Recovery Plan (DRP)
Provê procedimentos detalhados para facilitar a recuperação das capacidades de operações em um site alternativo
Muitas vezes focado em TI; Limitado a rupturas maiores com efeitos de longo prazo.
Plano de ocupação de Emergencia - Occupant Emergency Plan (OEP)
Provê procedimentos coordenados para minimizar perdas humanas e danos materiais, em resposta a uma ameaça física.
Focado nas pessoas e nos bens materiais; não é procedimento de negócio ou funcionalidades de sistemas de TI
Fonte:
A interrelação entre os diversos planos voltados a segurança pode ser
melhor visualizada na figura a seguir.

Figura 4 -‐ Interrelação entre os planos emergenciais de segurança de TI
1. Fonte: [Error! Reference source not found.]\ Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.
Referências
1. Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.
2. Stallings, W. (2007): Network Security Essentials, 4th. ed – Pearson Education
3. Wallace, M. & Webber, L. (2004): THE DISASTER RECOVERY
HANDBOOK A Step-by-Step Plan to Ensure Business Continuity and Protect Vital Operations, Facilities, and Assets -AMACOM- American Management Association
4. Jackson , C. B. (2007): The Role of Continuity Planning in the
Enterprise Risk Management Structure in: Information Security Management Handbook pag 1591
5. Doughty, K. (2007): Selecting the Right Business Continuity Strategy - in Information Security Management Handbook pag 1551

Leitura 3
Título da Leitura: Os Incidentes de segurança mais comuns e suas
relações com o RTO e o RPO
Sinopse: Nessa Leitura, entenderemos o que é incidente de segurança a ponto de
entendermos que podemos dividir a segurança de sistemas de informações em três
partes: segurança do computador; segurança da comunicação; segurança de sistemas
de informação.
Considerando essas áreas suscetíveis aos referidos incidentes veremos a análise e
gerência de risco dos mesmos, as quais devem contar com o que chamamos por RTO
e RPO.
Atente para todos esses itens cujas definições e imortânci para segurança da
informação seguem nessa Leitura. <Fim de Sinopse>
Incidente de segurança
Os incidentes de segurança são potencializados pelas ameaças e
pelos riscos que comprometem a tríade de atributos que compõe a segurança da
Informação: Confidencialidade, Integridade e Disponibilidade. Podem ser
definidos como: “Qualquer ato ou circunstância que envolva a ruptura de algum
requisito das normas oficiais de segurança adotadas por uma organização ou
governo” [Tipton, H. & Krause, M.(2007)].
Por exemplo, com relação a informação, tais atos ou circunstâncias
podem levar ao seu comprometimento, ou possível comprometimento, exposição
inadvertida ou não autorizada, desvios ou alterações, perdas, bloqueios ou
outros fatos causadores de sua indisponibilidade.
Segundo a norma NIST 800-‐61 [19], um Incidente é um Evento
Adverso.
Um evento pode ser considerado qualquer ocorrência observável em
um sistema ou rede. Eventos na área da informação digital incluem um usuário
conectando em um sistema de compartilhamento de arquivos, um servidor
recebendo uma requisição de páginas web através do HTTP, ou um usuário

enviando e recebendo emails, e um firewall bloqueando pacotes que estejam
tentando uma conexão.
Eventos Adversos são aqueles com consequências negativas, como
uma pane em um sistema, inundação de pacotes na rede (packets flood) acesso
não autorizado a sistemas privilegiados ou dados sensíveis bem como a execução
de código malicioso que pode levar a perda de dados.
Um incidente de segurança computacional é uma violação ou
ameaça de violação eminente das políticas de segurança, do uso aceitável dessas
políticas ou das práticas padrões de segurança da informação computaci
Exemplo de incidente pode ser o DDOS (ataque distribuído de
negação de serviço).
Segurança de Sistemas
Existem três partes distintas na segurança de sistemas[Error!
Reference source not found.]: segurança do computador; segurança da
comunicação; segurança de sistemas de informação.
• Segurança do computador -‐ Computer security (COMPUSEC): É
composta por medidas e controles que protegem um sistema de
informações automatizado -‐ automated information system (AIS) contra
negação de service, exposição não autorizada, modificação, destruição do
AIS e dos dados/informação.
• Segurança da comunicação-‐ Communications security (COMSEC): são
medidas e controles tomados para negar pessoas não autorizadas o
acesso a informações oriundas de sistemas de telecomunicações.
• Segurança de sistemas de informação -‐ Information systems security
(INFOSEC): São controles e medidas tomadas para proteger os sistemas
de telecomunicações (telefones, radios) e sistemas de informação
automatizados (AIS), bem como a informação a qual eles processam,

transmitem ou armazenam.
Análise e gerência de Risco
Uma análise e gestão dos recursos de informação existentes na
organização, seus controles e a partir desses dados, o que permanence como
vulnerabilidade nos sistemas computacionais e na organização como um
conjunto. Combina o potencial de perdas de cada recurso, ou conjunto de
recursos, com uma taxa estimada de ocorrências para estabelecer o nível de
danos, em moeda ou outro tipo de ativo. Os planos de contingência e recuperação
podem dessa forma ser analisados sob a perspectiva da análise e gerência de
riscos . A figura a seguir busca representar esses panos.
Figura 5 Plano de contingência como um elemento da implementação da gerencia de risco.
Fonte: [11] Tradução: Contingency Planning: Plano de contingência Risk Management: Gerencia de Risco Security Control Implementation: Implementacao de controle de segurançaa Emergency event: Evento de emergência Contingency plan execution: Execuçao do plano de contingencia
A análise e gerência de riscos é muito importante no contexto da
segurança da informação. Para uma boa gerência nessa área, deve-‐se estabelecer
um “Programa de Gerência de Riscos”, que busca identificar e quantificar todos
os riscos, ameaças, e vulnerabilidades dos sistemas de informação da empresa e
dos dados.

Gráfico 6-‐Conveniência de uso com impacto direto nos riscos
1. Fonte: Stacey, T. R. (2007): Contingency Planning Best Practices and Program Maturity in: Information Security Management Handbook (2007)
A gerência de riscos deve balancear as ameaças com a usabilidade dos
recursos, conforme o gráfico apresentado a pouco mostra.
As estratégias de recuperação podem ser associadas aos grupos
determinados pela gerência dos riscos. Os riscos podem ser classificados
segundo a metodologia descrita na Tabela 2, disponível a seguir.
Uma matriz de avaliação dos riscos pode ser aplicada para verificação
das probabilidades de ocorrência de incidente de segurança da informação e
pode ser elaborado um escore para a classificação desses riscos em tipos. Cada
estratégia de recuperação é tabulada em função do escore do risco, associa-‐se a
estratégia ao grau de risco. A estratégia de recuperação que oferecer o menor
risco na execução será implementada.
Tabela 2 -‐ Metodologia de gerencia de riscos

Fonte: [21]
Traduçao: Drescriptor: Descrição Meaning: Significado
Recuperação
É a restauração do serviço de processamento da informação ou
outros ativos relacionados a informação, após algum incidente, dano ou
destruição física. Exige ações pré-‐determinadas para ser efetiva. Essas ações
estão descritas nos planos de recuperação (sejam de incidentes, desastres ou de
contingencia).
Esses planos precisam considerar o RPO e o RTO, os quais veremos na
sequência.

Objetivo do ponto de recuperação – RPO É a medida do ponto anterior a uma interrupção, a partir do qual os
dados devem ser recuperados. Pode ser tratado como a idade dos arquivos os
quais devem ser recuperados da mídia de armazenamento de backups,
objetivando o retorno ao normal das operações de um computador, sistema ou
rede após um evento danoso.
O RPO é expresso em unidades de tempo passado desde o momento
da falha, podendo ser especificado em segundos, minutos, horas ou dias. <ABRIR DESTAQUE> Importante
Ele é uma consideração muito importante nos planos de contingência
(CP), recuperação de incidentes (IRP) ou recuperação de desastres (DRP). <Fim
de destaque>
Uma vez que o Objetivo do Ponto de Recuperação de um dado
computador, sistema ou rede tenha sido definido, ele determina a frequência
minima na qual os backups deve ser processados.
O Objetivo do Tempo de Recuperação (RTO) auxilia na escolha das
tecnologias que devem ser empregadas para o desempenho esperado na
recuperação do evento. Por exemplo, se o RPO é de 1 hora, os backups devem ser
executados no mínimo a cada hora. Nesse caso, discos externos redundantes
podem solucionar o problema. Se o RPO for de 5 dias, (120 horas), os backups
devem ser executados em períodos de 120 horas ou menos. Nessa situação, os
backups em fita podem ser usados.

Objetivo do tempo de recuperação (RTO) O Recovery time objective, conhecido como “RTO” é o montante de
tempo permitido até a recuperação de uma função do negócio ou um recurso
após a ocorrência de um evento (incidente ou desastre).
Nos processos de planejamento de recuperação de incidentes, todas
as funcionalidades críticas para os negócios devem ser analisadas para
determinar-‐se os requisitos de tempo de restauração dos serviços. Os objetivos
de tempo de restauração são determinados para cada funcionalidade ou sistema,
e irão direcionar a seleção de procedimentos. A Tabela 3, presente a seguir,
mostra uma matriz genérica usada para classificar as necessidades de
recuperação em termos temporais para funcionalidades ou sistemas necessários
aos negócios da organização.
Tabela 3 – Classificação dos Objetivos de Tempo de Recuperação
AAA Necessita recuperação imediata. Nenhum tempo de parada é permitido AA Necessta recuperação total das funcionalidades em no maximo 4. A Recuperação necessária no mesmo dia útil B Aceitável parade de até 24 horas. C Aceitável parade de 24 a 72 horas. D Paradas superiores a 72 horas são aceitáveis
Fonte: [11]
O RTO e o RPO e suas relações com os custos para minimizar os
tempos de recuperação de incidentes, bem como as técnicas mais usadas em
cada momento após o evento estão iliustrados na Figura 7 a seguir.

Figura 7 -‐ RPO & RTO
Fonte: [13]
Referência 1. Tipton, H. & Krause, M.(2007): Information Security Management
Handbook - 6th Ed – Auerbach Publications
2. Cisco Systems(2006): Data Centers Disaster Recovery - DC 2602 – Cisco Networkers 2006
3. Stoneburner, G.; Goguen, A. & Feringa, A. (2002): Risk Management Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology – NIST Special Publication 800-30
4. Jackson , C. B. (2007): The Role of Continuity Planning in the Enterprise Risk Management Structure in: Information Security Management Handbook pag 1591
5. Doughty, K. (2007): Selecting the Right Business Continuity Strategy - in Information Security Management Handbook pag 1551
6. Shaurette, K. M (2008): Technology Convergence and Security: A Simplified Risk Management Model

Atividades de Autoaprendizagem
Professor, providenciar essa atividade.
1-RESUMA em 5 linhas as diferenças entre RPO e RTO
2-Crie uma tabela com base na tabela 3, onde estejam especificados
os Objetivos de tempo de recuperação para um cenário empresarial
que tenha um plano de recuperação de incidentes envolvendo os
seguintes ativos de informação: Banco de dados corporativo
Servidor WEB; servidor de email; servidor de impressão; link de
Internet.
Atividade Colaborativa
Síntese
Nessa unidade você pode verificar o que são incidentes de segurança da informação e
a importância de proteger os ativos de informação desses incidentes. Compreendeu,
portanto, que os negócios de uma organização podem ser comprometidos a cada vez
que ela é acometida por um tal incidente.
Vimos que deve-se fazer o máximo possível para evitar esses incidentes, mas que não
há como garantir que não se será cometido por eles. Daí a necessidade de se ter um
plano de recuperação desses incidentes. No entanto, o máximo que se conseguir evitá-
los é mais conveniente para as organizações que a recuperação deles.
Você acompanhou que para evitá-los precisa-se contar com políticas de segurança da
informação, afinal o aliado indispensável nessa prevenção são as pessoas que lidam
com os ativos de informações. Aqui seguiu, então, um importante apontamento que
sempre está incluso quando se fala em segurança da informação: é preciso
conscientizar as pessoas que lidam com os ativos de informação da necessidade de
segurança da informação e poder contar com as mesmas para a obtenção dessa
segurança.
Acompanhamos que a “Computação em Nuvem” é uma importante aliada na
segurança da informação. Você já pensou em trabalhar com essa nova proposta?
As infra-estruturas de desktops virtuais, chamados VDI, restabeleceram uma condição
que existia no início da computação, a centralização de vários desktop em uma única

CPU. Conforme acompanhamos nessa unidade, conceitualmente, a VDI separa o
ambiente de computação pessoal em desktop de uma máquina física e armazena a
totalidade de programas, aplicações, processos e dados em um servidor central.
Necessário que você tenha claro porque isso é benéfico em relação a incidentes de
segurança da informação.
Como em qualquer outro processo de gestão, a gestão de risco em relação a essa
segurança também conta com a necessidade de construção de cenários diante das
dificuldades que possam lhe assolar, os eventos adversos – incidentes de segurança da
informação. Por isso, estratégias de ação devem estar prontas para serem usadas por
essa gestão diante desses eventos, devem fazer parte do cenário de ação da
organização. Que estratégia de ação, cenário de ação, usar depende do tipo de
incidente de que se quer recuperar a organização e que ferramentas e conhecimentos
que ela possui disponível para tal. Aí entra a necessidade das organizações de
conhecerem os incidentes mais comuns para se prepararem caso esses lhe venham
acometer.
As estratégias de recuperação de incidentes de segurança devem ter claro o que
esperam do RTO E ROP. Você tem claro o que significam esses termos? Se não tiver,
reveja o conteúdo dessa unidade para ter claro esses importantes elementos da
segurança da informação.
Information Security Policy Papers URL : http://www.sans.org/rr/policy DESC : Sans Institute Security Policy Papers URL : http://www.secinf.net/policy_and_standards/ DESC : Secinf's Policies Directory URL : http://packetstormsecurity.org/docs/infosec/policies/ DESC : Packetstorm's Security Policies Directory URL : http://www.ietf.org/rfc/rfc2196.txt?Number=2196 DESC : Site Security Handbook URL : http://www.utoronto.ca/security/policies.html DESC : University of Toronto

Unidade 2
Título da unidade Estratégia para organizar o processo de tratamento de incidente de segurança xxxxxxxxxx
Objetivos de Aprendizagem
Conhecer como preparar um ambiente de informações para este ser seguro -‐ Entender como funcionam as ferramentas proteção e de detecção de falhas/intrusões nesse ambiente -‐ Aprender a projetar e manter um sistema de defesa para evitar e erradicar incidentes de segurança -‐ Conhecer os tipos de incidentes principais e as estratégias para executar ações após esses incidentes para possibilitar a continuidade dos negócios da organização
Introdução

Nessa unidade você conhecerá as ferramentas de proteção e detecção e de
intrusão, os tipos de incidentes de segurança da informação mais comuns. Verá,
então, quais sãos os golpes atualmente mais comuns sendo praticados na área
da informação.
Acompanhará que esses golpistas contam com a ingenuidade dos usuários da
informação para atingi-‐lo e também com a alta navegabilidade desses.
Acompanhará que as redes WIi-‐fi são excelentes locais para os golpistas da área
da informação atuarem.
Esperamos que diante de cada um dos ataques a informações apresentados
nessa unidade, você saiba o que fazer para proteger seus sistema de informações
deles.
Leitura 1 Título da Leitura: Tipos de incidente de segurança da informação (DG, Título 2) Sinopse: Quais são os tipos de incidentes de segurança da informação mais comuns? Os vírus? Como esses incidentes conseguem atingir suas vítimas? Buscaremos apresentar respostas a essas perguntas nessa Leitura. Acompanhe! <Fim de Sinopse>
As ameaças colocam em risco os ativos de informação. Em geral, essas
ameaças seguem determinados padrões de comportamento ou método de
exploração das vulnerabilidades desses ativos.
Os vírus surgiram há 27 anos e agora possuem variantes (worms,
zumbis, spywares e outros tipos de código que se convencionou chamar de
“malware” ou “Código Maliciosos”).
Provavelmente a desinformação dos usuários e a alta taxa de
“conectividade”, seja através do computador convencional ou de unidades
móveis, usando sinais de radio (Wi-‐Fi, Bluetooth, celulares, tablets), são os
maiores responsáveis pela multiplicação dos incidentes de segurança. O gráfico

seguinte mostra o número de ocorrências reportadas no Brasil nos últimos 10
anos.
Figura 8 -‐ Total de incidentes reportados no Brasil
Fonte: http://www.cert.br/stats/incidentes/
Já o diagrama presente na sequência mostra os principais formatos de
utilização ilícita da Informação:
• Interrupção do fluxo.
• Interceptação.
• Modificação.
• Fabricação da informação.

Figura 9 -‐ Formas de uso ilícito da informação
Fonte: Stallings, W. (2007): NETWORK SECURITY ESSENTIALS, FOURTH EDITION – Pearson Education
1. FERRAMENTAS de protecao, prevençao e detecçao de intrusão
Neste tópico apresentamos os firewalls e os sistemas de prevencao e detecção de intrusao (IPS e IDS) Os firewalls são uma parte muito importante na segurança das redes. Podemos
dividir a técnica em dois grupos:
1º. Os filtros de pacotes e
2º. os filtros de conteúdo.
No primeiro grupo, encontramos os dispositivos que analisam as PDUs, sem
abrir os conteúdos. São mais antigos, mas ainda, sem dúvida, são os mecanismos
mais utilizados para proteção das redes.
Nos filtros de conteúdo, no segundo grupo, temos os proxies, dispositivos que
servem como intérpretes na comunicação entre a Internet e uma rede local.
Os firewalls podem executar ainda uma terceira tarefa fundamental para a
segurança das redes que é a conversão de endereços de redes (NAT – Network
Address Translator), que também é chamada de mascaramento IP.

Para executar essas três tarefas, o firewall deve ficar entre a Internet e a rede
local (Figura 10.12). Todo o tráfego que chega ou sai da rede deve passar pelo
firewal, datagrama por datagrama. Os pacotes (datagramas, na linguagem
correta das PDUs) são analisados e comparados com as regras de acesso (ACLs,
ou Access Control Lists). Caso exista uma regra permitindo a passagem, o
datagrama poderá passar. Caso não exista regra permitindo, é negada a
passagem do datagrama.
Figura 10.12 -‐ Posicionamento do firewall na topologia da rede
Fonte: Building Internet Firewalls, Second Edition Elizabeth D. Zwicky,
Simon Cooper, D. Brent Chapman Second Edition 2000.
Tradução: Internal Network: rede interna
O que um firewall pode e o que ele não pode fazer Um firewall é um mecanismo muito efetivo no controle dos datagramas, mas ele
não é a proteção total da rede. Você não pode pensar que está seguro só porque
implantou corretamente um desses dispositivos.
Um firewal pode:

a) Tornar-‐se o centro das decisões de segurança. Como todos os
pacotes, supostamente, passam através do firewall, ele pode
concentrar as decisões sobre o que pode entrar ou sair da rede.
b) Forçar as políticas de segurança. A maior parte dos serviços
solicitados na Internet é inseguro. Você pode pensar no firewall
como o policial no portão de entrada. Só permite o uso dos
serviços aprovados pela política de segurança da coorporação.
c) Registrar as atividades de Internet com eficiência. Uma vêz
que todo trafego passa pelo firewall, ele pode ser registrado em
arquivos de log (registro).
d) Limitar a exposição da rede interna. Esse ponto é,
particularmente, relevante quando o firewall está posicionado
entre duas ou mais redes dentro da corporação. Nesse caso, ele
pode evitar que uma rede invadida comprometa as demais.
Um firewall não pode:
a) Proteger contra usuários internos. Sabe-‐se que estes são
responsáveis pela maioria dos ataques e, realmente, o firewall não
pode fazer nada contra esses indivíduos.
b) Proteger contra conexões que não passem através dele. Como
o firewall necessita examinar os cabeçalhos dos datagramas, não
têm nenhuma ação nos datagramas que cegam ou saem da rede
através de outras conexões, como linhas discadas, acessos ADSL ou
outro tipo de enlace que o usuário possa estar utilizando.
c) Proteger contra riscos novos. Um firewall, mesmo bem
configurado, pode não ter ação alguma contra novos tipos de
ataques. Por isso, o administrador deve sempre estar atento às
novidades e atualizar os sistemas e as regras.

d) Proteger completamente contra vírus. Mesmo que alguns
firewalls possam praticar varreduras contra vírus, ele não oferece
proteção plena. Outros softwares auxiliares precisam ser instalados
em conjunto para garantir proteção contra a entrada dos bichinhos.
e) Configurar-‐se e ativar-‐se por conta própria. Todos os firewall
exigem um certo volume de configuração, uma vez que cada rede
possui suas particularidades.Você não pode simplesmente acinar o
firewall e pensar que agora, tudo está seguro.
Classificação dos firewalls Além da divisão simples entre filtros de pacotes e de aplicações (conteúdos),
podemos ter os filtros de pacotes divididos em estáticos e dinâmicos (ou com
estados, do inglês statefull) – Figura 10.13.
Figura 10.13 -‐ Tipos de Firewalls
Fonte: adaptado de Building Internet Firewalls, Second Edition Elizabeth
D. Zwicky, Simon Cooper, D. Brent Chapman Second Edition 2000.
a) Filtros de pacotes (datagramas) do tipo estático Os filtros de pacote estáticos (também denominados sem estado ou stateless)
avaliam os pacotes baseados na informação do cabeçalho do IP e nas portas do
Pacotes Conteúdos

nível 4. Essa é uma forma rápida de regular o tráfego, mas peca pela
simplicidade.
Figura -‐ Firewall estático
Building Internet Firewalls, Second Edition Elizabeth D. Zwicky,
Simon Cooper, D. Brent Chapman Second Edition 2000.
Tradução:
Data: ignored-‐ dados ignorados
Other header info: ignored – outras informações do cabeçalho: ignoradas
Tcp Header: src and dest. Ports – cabeçalho do TCP: portas de origem e destino
IP header: src and dest IP addresses – cabeçalho IP: endereços IP de origem e
destino
Packet is send: pacote é enviado
Packet is passed if allowed, dropped if denied: pacote passa se for permitido, e é
descartado se for negado
É um filtro simples porque ignora outras informações dos cabeçalhos, como o
estado da conexão do TCP (início, finalização, estágios do 3-‐way handshake).
Tampouco, avalia os conteúdos. Exemplo de firewall estático é o IPChains,
utilizado a algum tempo, mas já superado pelos filtros dinâmicos.
b) Filtros de pacotes do tipo dinâmicos (ou de estados -‐ statefull) Esse tipo de filtro é o mais usado atualmente, pois podemos permitir a entrada
de pacotes externos se foram solicitados por aplicações válidas de dentro da rede
interna (Figura 10.15).

O termo dinâmico ou de estado se refere ao acompanhamento das conexões TCP
começando com o "three-‐way handshake" (SYN, SYN/ACK, ACK), que ocorre no
início de cada transação TCP e termina com o último pacote de cada sessão ( FIN
or RST).
Exemplos desses firewalls são o IPTables, PIX firewall (Cisco), NetScreen
(Juniper), SonicWall e muitos outros.
Tradução: source ip/ port – porta e IP de origem
Dest ip/ port-‐porta e ip de destino
State: estado
Seconds until expired – segundos até a expiração
No replied-‐to -‐ não respondido
Established: estabelecido
Figura 10.15 – Firewall Dinâmico ou statefull
Building Internet Firewalls, Second Edition Elizabeth D. Zwicky,
Simon Cooper, D. Brent Chapman Second Edition 2000.
Tradução:
Data: ignored-‐ dados ignorados

Other header info: ignored – outras informações do cabeçalho: ignoradas
Tcp Header: src and dest. Ports – cabeçalho do TCP: portas de origem e destino
IP header: src and dest IP addresses – cabeçalho IP: endereços IP de origem e
destino
Packet is send: pacote é enviado
Packet is passed if allowed, dropped if denied: pacote passa se for permitido, e é
descartado se for negado
c) Filtros do tipo proxy (filtros de conteúdo ou da camada de
apicação)
Um proxying firewall atua como intermediário em todas as transações que
passam através dele, ao contrário dos filtros stateless e dos statefull packet-‐
filters, os quais inspecionam, mas não alteram os pacotes (exceto em alguns
casos para re-‐endereçamento ou redirecionamento).
Perceba que nesse tipo de dispositivo, o cliente nunca troca informações
diretamente com o servidor, como acontecia com os filtros anteriores (Figura
10.16). O firewall recebe um pacote, examina o conteúdo e se o pacote passa
pelas regras, envia outro pacote (2) ao destinatário interno. Ao receber a
resposta do servidor interno (pacote 3), o proxy examina novamente, e se as
regras permitirem, envia um novo pacote com a resposta (pacote 4).
Figura 10.16 -‐ Proxy firewall (filtro de conteúdos)
Building Internet Firewalls, Second Edition Elizabeth D. Zwicky,
Simon Cooper, D. Brent Chapman Second Edition 2000.
Tradução:

actual –atual
reply: resposta
proxied: intermediada
request: requisição
client: cliente
server: servidor
firewall: firewall
Ferramentas de detecção e prevenção de intrusão Para conter as ameaças estudadas neste capítulo vários fabricantes projetaram
produtos comerciais para o Mercado, como os firewall vistos acima, sistemas de
criptografia, autenticações, assinaturas digitais e controles de acessoEstes produtos,
embora provendo seguranca em uma certa medida, possuem limitações as quais
permitem que um intruso possa burlar as técnicas. Ameaças complexas a sistemas
de segurança requerem contramedidas complexas. Assim, existe uma necessidade
clara de uma tecnologia de segurança complementar, a qual possa:
• Monitorar de forma inteligente a rede para ocorrencias de intrusao em temo real.
• Ser reconfigurada rapidamente e dinamcamente, em resposta a eventos de
intrusao.
• Responder a intrusoes através de uma variedade de customizações pelo próprio
usuário.
Essa tecnologia é o Sistema de detecção de Intrusao (IDS) e Sistema de Prevenção de
Intrusão(IPS)
Enquanto a detecção de intrusao baseia-‐se em análise de dados que já representam
um evento intrusive, os IPS buscam evitar que a intrusao de fato ocorra.

Detecção de intrusão é um conjunto de técnicas e métodos que são usados para
detectar atividades suspeitas. Tais atividades podem ser nos hosts ou nas redes. A
abordagem para cada uma gera dois tipos de IDS: NIDS e HIDS.
Os IDS podem ser classificados ainda segundo o método usado para detectar as
atividades:
Por assinatura e por anomalias.
Invasores possuem assinaturas da mesma forma que um virus, as quais podem ser
detectadas utilizando-‐se ferramentas de detecção. Voce tenta encontrar, com essas
ferramentas, pacotes de dados os quais contém qualquer assinatura relacionada a
uma intrusão ou anomalias relacionadas com os protocolos de Internet. Baseado
nesse conjunto de assinaturas e outro conjunto de regras, o sistema é capaz de
encontrar e registrar atividade suspeita, podendo entaão gerar alertas ou disparar
rotinas de prevenção ou bloqueio da atividade, reagindo automaticamente.
Os sistemas baseados em anomalias normalmente dependem de anormalidades
presentes nos cabeçalhos dos pacotes dos protocolos de rede
Traducao: Packet decoder: Decodificador de pacotes Preprocessors=pré-‐processadores Detection Engine= Mecanismo de detecção Packet s dropped= pacote é descartado

Logging and alerting system= sistema de alerta e registros Output modules: Modulos de saída Output alert=alerta de saída Log to file=registro em um arquivo Figura xxx-‐ Componentes de um sistema de detecção de Intrusão Fonte: Stephen Northcutt e outros Snort 2.1 Intrusion Detection, Second Edition 2004 by Syngress Publishing,
Figura xxx-‐ Posição dos sistemas de prevenção e detecçãoo de intrusão na topologia das redes Fonte: Network Intrusion Detection: An Analyst's Handbook Stephen Northcutt (2005) Publisher: New Riders Publishing
TIPOS DE ATAQUES Na sequência, são apresentados os incidentes que atualmente são os mais comuns.
Phishing (Dg, título 3)
São os golpes aplicados via e-‐mail. Existe uma alta probabilidade do
usuário em acreditar nas mensagens, seus links e arquivos anexados. Os
e-‐mails falsos chegam cada vez mais próximos dos verdadeiros. São bem

construídos, abordando temas atuais, e explorando as fraquezas naturais
do ser humano.
Roubo de Identidade (Dg, título 3)
Com o aumento das interfaces de comunicação e das redes sociais online
(Twitter, Orkut, Facebook, Myspace, Flickcr), e a
necessidade/ingenuidade do usuário em expor detalhes de sua vida
privada possibilitam o ataque conhecido como “roubo de identidade”,
com a obtenção não autorizada ou a simples adivinhação de senhas de
acesso e chaves de identificação.
Vírus em PCs, Smatphones, PADs e Tablets (Dg, título 3) Os códigos maliciosos (Error! Reference source not found.presente
logo na sequência) crescem e tornam-‐se cada vez mais especializados. A
exploração de vulnerabilidades se dá com auxílio dos próprios usuários.
Os dispositivos móveis também começam a ser alvo de ataques, tanto de
negação de serviço quanto de destruição de dados.
Figura 10 -‐ Classificação dos códigos maliciosos
Fonte: [5]
A elaboração de uma política para uso de anti-‐vírus é uma medida
necessária para minimizar os riscos de incidentes dessa natureza. Tal política

pode ser idealizada de diferentes maneiras, a começar pela abordagem: Você vai
utilizar um sistema de proteção com filtros na rede ou os sistemas serão
individuais, instalados em cada dispositivo que venha a conectar-‐se a rede?
As políticas serão escritas em forma de normas de conduta, similar a
uma “lei interna” ou com um viés de “melhores práticas”. Se a empresa opta por
políticas mais brandas e a estratégia é proteção individual, uma declaração
adequada poderia ser:
“Todos os recursos computacionais de usuários
devem ter software de proteção anti-virus instalados antes de
acessar os recursos da rede corporativa. Os usuários devem
atuar na manutenção e atualização dessa proteção. Os usuários
não devem desabilitar as funcionalidades. Se o software de
anti-vírus for desabilitado por alguma razão, como por
exemplo, a instalação de uma nova aplicação, o usuário deve
se responsabilizar pela execução de uma varredura completa
do sistema antes de iniciar o uso de recursos do sistema
novamente.
DOS e DDOS (Dg, título 3)
Denial of Service – DOS – Negação de serviço (DG, TÍTULO 4)
Um ataque de negação de serviço é caracterizado por uma tentativa explícita
de interromper os serviços que algum usuário legítimo esteja tentando
utilizar. Exemplos:
• Tentativa de inundação de rede, impedindo o tráfego legítimo.
• Tentativa de interromper a conectividade entre duas máquinas,
impedindo o acesso ao serviço.
• Tentativa de romper o service especificamente de um sistema, por
exemplo, o servidor Web.

Ataques distribuídos de negação de Serviço (DDOS) (DG, TÍTULO 4)
Os ataques distribuídos de negação de serviço (DDOS ou Distributed
Denial of Service) são poderosos e bastante estudados. Veja mais sobre
esses assunto em <http://staff.washington.edu/dittrich/misc/ddos/>.
Nessa situação os atacantes invadem várias máquinas e a partir delas
executam o ataque a uma rede ou serviço específico, aumentando em
muito o poder de destruição.
Os atacantes iniciam criando uma rede de computadores zumbis, que
irão funcionar como seu ‘exército’ de ataque.
<Abrir conceito> Conceito
Um zumbi é um computador que foi invadido sem que a vítima tenha
suspeita do fato. A maquina passa a ser utilizada para atividades ilegais.
<Fim de destaque>
Essa rede de zumbis é acionada para conectar computadores
“inocentes” denominados refletores (Error! Reference source not
found.a seguir). Quando os refletores recebem as solicitações, percebem
que elas partiram não dos zumbis, mas do sistema alvo. Quase sempre o
desempenho da vítima cai drasticamente ou mesmo interrompe toda
comunicação, sendo inundado por múltiplas respostas não solicitadas, de
forma simultânea.

Figura 11 -‐ Ataque Distribuído de Negação de Serviço
Fonte: http://www.hackersbay.in/2011/01/what-‐is-‐ddos-‐attack-‐and-‐how-‐does-‐it.html
Do ponto de vista da vítima, quem realizou o ataque foram os
refletores. Do ponto de vista dos refletores, a vítima é que requisitou os pacotes.
Os zumbis permanecem escondidos.
Sites famosos já foram vitimas desse tipo de ataque: Microsoft ,
Amazon, CNN, Yahoo e eBay.
<Abrir hiperlink> Veja o caso do ataque a computadores da Coréia do
Sul e dos EUA no seguinte endereço: http://blog.bkis.com/en/korea-‐and-‐us-‐
ddos-‐attacks-‐the-‐attacking-‐source-‐located-‐in-‐united-‐kingdom/ <Fim de
hiperlink>
Alguns nomes para os ataques DDoS:

• Mailbomb – Zumbis enviam quantidades massivas de email, interrompendo
os servidores de email
• Smurf Attack – Zumbis enviam pacotes Internet Control Message Protocol
(ICMP) para os refletores.
• Teardrop – zumbis enviam pedaços de pacotes ilegítimos. A vítima tenta
combiner as peças em um pacote válido e acaba ‘travando’.
SPAM (Dg, título 3) SPAM são correspondências eletrônicas não autorizadas. Continuam
crescendo, consomem tempo, link de Internet, o poder de processamento
dos computadores, espaços em discos e caixas de email. Os spams estão
sempre testando os mecanismos de filtragem, e podem ser associados a
phishing e vírus.
Ataques pelos dispositivos móveis (celular, PADs, agendas, tablets) (Dg, título 3)
Alguns destes dispositivos podem ser usados para autenticações e realização de
pagamentos. As invasões podem ter objetivos de desvio de recursos, roubo de
identidade ou perda de informações. Mensagens estranhas solicitando comandos
e ações podem ser consideradas como SPAM de SMS.
Ataques Wi-‐Fi e Bluetooth (Dg, título 3)
As redes sem fio Wi-‐Fi e Bluetooth com acesso à Internet se popularizaram em
2007 e podem ser encontradas em toda parte, muitas vezes, sem a proteção
mínima. O alto nível de conectividade oferecido pelos dispositivos móveis,
principalmente em locais públicos, podem funcionar como um play ground para
golpistas que procuram equipamentos desprotegidos, simplesmente para
infiltrar um vírus ou ainda procurar dados sigilosos e senhas que trafegam neste
ambiente. Além disso, mensagens indesejadas, simples propagandas ou a
transferência não autorizada de dados podem ocorrer.

CAVALOS DE TRÓIA -‐Keylogger Trojans(Dg, título 3)
Os cavalos de Tróia são códigos maliciosos que quando executados
possuem um comportamento inesperado, como a instalação de softwares
que podem causar danos ou gerar logs de atividades, especialmente com
capacidade de registrar sem autorização e silenciosamente tudo que é
digitado no teclado.
Com o aumento dos links de comunicação e a popularização dos
pacotes domésticos de broadband (“banda larga”), as potenciais vítimas
tornam-‐se disponíveis por mais tempo ao longo do dia, dando assim ainda
mais tempo para os golpistas estudarem o alvo, penetrar e monitorar.
Rootkits (Dg, título 3)
Os rootkits são softwares de fácil utilização e com poder de destruição
relativamente alto. Essas ferramentas são disponibilizadas livremente em
sites e grupos de discussão na Internet e enviados aos computadores das
vítimas.
Chegam, portanto, vindo de múltiplas origens, seja uma simples
atualização automática de rotina do sistema operacional, seja um e-‐mail
com arquivo anexado ou ainda um pacote de atualização de um dos
inúmeros softwares instalados. Fica, portanto, difícil distinguir o que é
legítimo, levando o usuário a autorizar o download, a instalação e até
mesmo a liberação do pacote através da alteração na regra do firewall.
Referências 6. Wallace, M. & Webber, L. (2004): THE DISASTER RECOVERY
HANDBOOK A Step-by-Step Plan to Ensure Business Continuity and Protect Vital Operations, Facilities, and Assets -AMACOM- American Management Association
7. Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security
Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.

8. Jackson , C. B. (2007): The Role of Continuity Planning in the Enterprise Risk Management Structure in: Information Security Management Handbook pag 1591
9. Zapater, M. & Suzuki, R. (2009): Segurança da Informação Um diferencial determinante na competitividade das corporações. Promon Business & Technology Review
10. Stallings, W. (2007): Network Security Essentials, 4th. ed – Pearson
Education
Saiba mais:
Ø www.cert.br -‐ o CERT edita uma excelente cartilha de segurança (já está
na terceira edição, que pode ser encontrada pelo endereço
<http://cartilha.cert.br>).
Ø www.netfilter.org – para obter informações sobre firewalls.
Ø www.sans.org –Informações sobre segurança de computadores,
treinamentos, certificações e pesquisas
Ø http://www.ietf.org/rfc/rfc2196.txt -‐ RFC 2196 (Site Security Handbook)
para receber algumas sugestões:
Ø Consulte a página do Computer Emergency Response Team (CERT) em
www.cert.org. Existe também um repositotório de documentos e notícias
sobre segurança no servidor de arquivos do CERT: ftp://cert.org/pub
Practical Unix and Internet Security -‐Simson Garfinkel & Gene Spafford; 148-‐
8, 1004 pages. Ed. O’Reilly.
Building Internet Firewalls, Second Edition Elizabeth D. Zwicky,
Simon Cooper, D. Brent Chapman Second Edition 2000.
Leitura 2
Título da Leitura: Os usuários desatentos e a necessidade de segurança da informação Sinopse: O poder de decisão para ser vítima ou não de um incidente de segurança da informação é sempre do usuário da informação. Logo, necessário
que ele não só fique atento às ameaças, mas também se previna delas. Ações de

prevenção muito simples podem ser realizadas, nas empresas elas compõem a
capacidade de resosta desta diante desses incidentes. <Fim de sinopse>
Os usuários continuam sendo uma das principais ameaças à segurança da
informação. Seja pela falta de uma cultura de uso, pela complexidade tecnológica,
pela especialização dos golpes ou simplesmente ansiedade para avaliar cada
situação. Continua nas mãos do usuário a decisão de ir em frente, clicar,
autorizar, aceitar, executar ou simplesmente ignorar os arquivos recebidos.
Afinal, entre os arquivos recebidos e que pode estar um arquivo que causrá um
incidente de segurança da informação.
O gráfico abaixo demonstra os incidentes classificados, que ocorreram no 1º. Semestre de 2011 e foram reportados ao CERT.br.
Figura 12 -‐ Tipos de incidentes reportados no Brasil
Fonte: http://www.cert.br/stats/incidentes/2011-‐apr-‐jun/tipos-‐ataque-‐acumulado.html
Este gráfico não inclui os dados referentes a worms.
Legenda:

• dos (DoS -- Denial of Service): notificações de ataques de negação de
serviço, onde o atacante utiliza um computador ou um conjunto de
computadores para tirar de operação um serviço, computador ou rede.
• invasão: um ataque bem sucedido que resulte no acesso não
autorizado a um computador ou rede.
• web: um caso particular de ataque visando especificamente o
comprometimento de servidores Web ou desfigurações de páginas na
Internet.
• scan: notificações de varreduras em redes de computadores, com o
intuito de identificar quais computadores estão ativos e quais serviços
estão sendo disponibilizados por eles. É amplamente utilizado por
atacantes para identificar potenciais alvos, pois permite associar
possíveis vulnerabilidades aos serviços habilitados em um
computador.
• fraude: segundo Houaiss, é "qualquer ato ardiloso, enganoso, de má-
fé, com intuito de lesar ou ludibriar outrem, ou de não cumprir
determinado dever; logro". Esta categoria engloba as notificações de
tentativas de fraudes, ou seja, de incidentes em que ocorre uma
tentativa de obter vantagem.
• outros: notificações de incidentes que não se enquadram nas
categorias anteriores.

Capacidade de resposta
A capacidade de resposta a incidentes possui dois componentes primários:
1. A criação de sistemas capazes de identificar anomalias e processos ilícitos
nos servidores e nas redes. Esse serviço deve estar apto a monitorar
constantemente e ter clareza das notificações necessárias,
2. Criação de uma equipe de resposta a incidentes (Incident Response Team -‐
IRT) para as seguintes tarefas:
§ Analise de notificações de eventos .
§ Resposta a incidentes que a análise assim exigir.
§ Definir os procedimentos para escalar os problemas.

Resolução e relatórios para as partes adequadas.
Na Figura 13abaixo, diagrama que demonstra as fases para gerência dos incidentes, iniciando com as prevenções e terminando com as análises forenses.
Security event Handling Steps =passos para tratamento de eventos de segurança CERT Advisory: Comite de alertas do CERT Manual Response: Resposta manual, nao automatica Automated response=resposta automática Security Response Team=Equipe de resposta de segurança Security event incident=evento de incidente de seguranca Forensics: relato do incidente e dos resultados das Análises das provas para efeitos legais e regulatorios Analyze damage and preserve evidence=analizar os danos e preservar as provas Incident Handling Steps= passos de tratamento de incidentes Prevention=prevencao Detection=detecção Response/decision=resposta/decisao Deterrence/Containment=Detençao/contencao Damage assessment=levantamento dos danos Prosecution=proseguimento dos processos legais inerentes ao incidente (se for o caso)
Figura 13 -‐ Passos para gerencia e controle de incidentes
Fonte: (WWW.cert.org 2011)
Como a figura acima demonstra, Auditoria forense é o último passo no tratamento do incidente e emgloba as análises abaixo:
– das operações;
– dos processos;

– dos sistemas;
– das responsabilidades;
Seu objetivo é o de verificar a conformidade do uso da informação com
normas, regras, políticas ou padrões;
• Auditoria tem três fases:
– planejamento;
– execução;
– relatório;
Referências
1. Swanson, M.; Wohl, A.; Pope, L.; Grance, T.; Hash, J. & Thomas, R. (2002): Contingency Planning Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology
2. Tipton, H. & Krause, M.(2007): Information Security Management
Handbook - 6th Ed – Auerbach Publications
11. Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.
Atividade Colaborativa
Analise as principais ferramentas comerciais de auxílio a prevenção
de incidentes: Firewalls e IDS/IPS. Faça um levantamento de preços
dos principais fabricantes. Descubra quais são as funcionalidades
que mais influenciam no preço
Atividade de Autoaprendiagem
Estude um caso de negação de serviço distribuído (DDOS) e suas
consequências, desde os danos causados até penalização imputada
aos culpados. Tente descrever um cenário onde o caso pudesse ter
sido evitado.

Síntese Nessa unidade você pode acompanhar ferramentas de auxílio ao combate de
incidentes (filtros e detectores de intrusão. Estudou ainda os mais importantes ataques
de golpistas a sistemas de informações. Por isso, você acompanhou a apresentação de
vírus, desde aqueles que simplesmente buscam travar o sistema de informações até
aqueles que buscam causar maiores danos, como roubo de senhas e obtenção de
informações de suas vítimas.
O ideal da prevenção a esses ataques conta, conforme você também acompnahou
nessa unidade, com esclarecimentos das possíveis vítimas sobre os mesmos e como se
proteger deles. Em organizações, essa proteção precisa contar com ajuda
especializada. Ajuda especializada que culmina com análise forense dos incidentes de
segurança da informação.
Esperamos que você tenha compreendido a estrutura geral em que se figuram os
passos para gerenciar e controlar os incidentes .
Saiba mais Professor, apresentar aqui referências bibliográficas onde o aluno pode pesquisar para
aprofundar os conteúdos estudados nessa unidade. Se quiser comentar essas
referências, não mais que um comentário de 8 linhas para cada, fique à vontade
U.S. Government Accountability Office. 2004. Government Accountability Office
report on responsibilities, reporting relationships, tenure and challenges of
agency chief information officers.
U.S. Government Accountability Office, July 21,
http://www.gao.gov/new.items/d04823. pdf
(accessed October 27, 2006).
Tucci, L. 2005. CIO Plays the Apprentice. http://www.searchcio.com
National Institute of Standards and Technology 1996. An Introduction to
Computer Security: The
NIST Handbook, Special Publication 800-‐12, National Institute of Standards and

Technology.
United States General Accounting Office 1999. Federal Information System
Controls Audit Manual.
United States General Accounting Office.
Fitzgerald, T. 2005. Building management commitment through security councils.
Information
Systems Security, 14(2), 27–36 (May/June 2005).

Unidade 3
Estratégia para organizar o processo de tratamento de incidente de segurança Objetivos de Aprendizagem -‐ Conhecer como preparar um ambiente de informações para este ser seguro.
-‐ Aprender a projetar e manter um plano de recuperação de incidentes para
tentar evitar e erradicar sistematicamente incidentes de segurança.
-‐ Conhecer estratégias para executar ações após esses incidentes para
possibilitar a a retro-‐alimentacao do plano e melhorar sua efetividade.
Introdução
Essa unidade descreve os processos de desenvolvimento e
manutenção de um plano efetivo de contingência para a Tecnologia da
Informação. O conteúdo segue as determinações das normas NIST 800-‐34 [11] e
NIST 800-‐61 revisao 1 [19].
Nos processos de planejamento de recuperação de incidentes, todas as
funcionalidades críticas para os negócios devem ser analisadas para determinar-se os
requisitos de tempo de restauração dos serviços. Os objetivos de tempo de restauração
são determinados para cada funcionalidade ou sistema, e irão direcionar a seleção de
procedimentos.
Como determinar os itens para se poder determinar o tempo dessas
restaurações será foco de estudo dessa unidade.
Leitura 1
Título da Leitura: Os planos de recuperação de incidentes e suas relações
com a CSIRC

Sinopse: Nessa Leitura você acompanhará a organização de uma capacidade de
resposta a incidentes de segurança computacional, o que contará com a estipulação do
que deve cuidar a equipe que trata dos incidentes de segurança da informação, a IRT.
Quais sãos as perguntas gerais que uma tal equipe deve conseguir responder para
demonstrar que ela está preparada em relação a esses incidentes? Essa Leitura
apresentará essas perguntas. Também apresentará como uma organização pode avaliar
seus custos de recuperação desses incidentes e quais deles priorizar o tratamento.
<Fim de sinopse>
A cultura atual das organizações em relação aos incidentes de
segurança da informação
As organizações normalmente destinam orçamentos consideráveis em
recursos para segurança da informação, focando basicamente a prevenção de ataques
dirigidos aos sistemas computacionais. Os métodos de autenticação são fortes e
valorizados, com uso de biometria, tokens, senhas difíceis de quebrar, as quais são
trocadas com frequência e usam-se certificações digitais. Além disso, os componentes
de rede são mantidos em áreas controladas e protegidas, usando-se para isso os
sistemas mais atualizados do mercado. Existem várias camada de software protegendo
os ativos de informação contra códigos maliciosos. Vários serviços são bloqueados,
os sistemas operacionais são reforçados e os privilégios das contas são mantidos em
níveis mínimos. Os sistemas são auditados regularmente, testes de vulnerabilidade e
de penetração são avaliados. Somando-se todo esse “arsenal” de defesas, o montante
dos investimentos em tempo e dinheiro são bastante elevados para essa segurança.
Os diretores e gerentes investem na defesa dos ativos de informação sem
prestar atenção a uma questão muito clara e simples: No mundo real é impossível
bloquear com sucesso todos os ataques efetuados contra os sistemas computacionais.
Em um determinado momento, quase todas as organizações deverão responder a
algum incidente severo na segurança dos sistemas computacionais. Devido a esse
fato, um plano de resposta a incidentes de segurança muito bem detalhado torna-se
vital para garantir a continuidade do negócio.

Da mesma forma que a recuperação de um desastre, a resposta aos incidentes de
segurança devem ser desenvolvido com muito critério e nível de profundidade, e
também colocado em prática com a mesma severidade, embora se queira que ele
nunca precise ser executado.
Organização da capacidade de reposta a incidentes de segurança computacional -‐ CSIRC
A organização de uma Capacidade de Resposta a Incidentes de segurança
computacional (Computer Security Incident Response Capability) -‐ CSIRC -‐ efetiva
envolve uma série de decisões e ações importantes. A primeira decisão a ser
tomada pela instituição a qual está organizando uma CSIRC deve ser a criação de
uma definição específica para o uso do termo “Incidente” dentro da instituição,
de forma a deixar claro qual é o escopo do termo.
Incidentes e desastres podem significar qualquer evento, desde a
perda de um recurso computacional até um evento natural extremo. Qualquer
ocorrência que cause uma ruptura nos processos ou operações normais do
negócio podem ser considerada incidentes. Sem um planejamento criterioso e
detalhado, a maior parte das organizações tende a não sobreviver a uma
interrupção importante nos negócios.
A organização deve:
A. Decidir quais os serviços que a equipe de resposta a incidentes (IRT)
deve prover;
B. Considerar quais as ferramentas, estruturas de equipe e modelos
podem prover esses serviço;
C. Selecionar e implementar uma ou mais equipes (IRTs);
D. Escrever políticas específicas para a CSIRC;
E. Escrever detalhadamente o plano de resposta a incidentes (IRP), o qual
deve ser totalmente aderente as políticas. O plano deve ter
procedimentos detalhados;
F. Manter, revisar, testar e atualizar as ações anteriores.

Se os procedimentos presentes nesse quadro forem seguidos com a
devida importância, a resposta aos incidentes será conduzida efetiva, eficiente e
consistentemente. Esses procedimentos devem refletir as interações da equipe
(IRT) com as demais equipes da instituição e também com os parceiros e
organizações externas, como fornecedores, a mídia, órgãos reguladores e
jurídicos (NIST SP 800-86)1. Organizações responsáveis pelas respostas a incidentes
(por exemplo, o CERT ou CERT.br) também devem interagir com a IRT de uma
organização.
Necessidade de uma resposta a incidentes
A resposta aos incidentes torna-‐se necessária (e em um grau
ascendente) porque os ataques têm sido cada vez mais frequentes. Os diversos
tipos de incidentes têm interrompido ou danificado milhões de sistemas e redes
no mundo inteiro. As ameaças e os riscos que elas representam têm causado
ampla aceitação e aderência dos Planos de Resposta a Incidentes nas esferas
governamentais, privadas e acadêmicas.
A CSIRC pode trazer os benefícios listados a seguir:
• Resposta sistemática aos incidentes, de forma a executar os
procedimentos corretos.
• Ajuda às pessoas a recuperarem seus sistemas, minimizando as
perdas ou roubos de informações ou interrupções nos serviços;
• Usando-‐se a informação obtida durante o enfrentamento do incidente
pode-‐se melhorar as ações futuras e prover uma proteção mais forte.
• Pode-‐se adequar melhor as questões legais as quais podem surgir
durante os incidentes.
A rede da associação Trans Europeia de pesquisa e educação (The
Trans-‐European Research and Education Networking Association -‐ TERENA)
desenvolveu a RFC 3067, TERENA's Incident Object Description and Exchange
Format Requirements <Abrir hiperlink>Você Pode ver mais sobre isso em:
<http://www.ietf.org/rfc/rfc3067.txt> <Fim de hiperlink>.
1 NIST SP 800-86, Guide to Integrating Forensic Techniques Into Incident Response, prove informações detalhadas sobre o estabelecimento de habilidades e capacidades forenses, incluindo o desenvolvimento de políticas e procedimentos para tal .

A RFC trata-‐se de um documento, o qual prove recomendações sobre
qual informação deve ser coletada em cada incidente. O Grupo de trabalho da
Força Tarefa de Engenharia da Internet, criou uma RFC que expande o trabalho
da TERENA. A RFC é a 5070, denominada Incident Object Description Exchange
Format.
Intercomunicação entre as partes
Os planos de recuperação de incidentes - ou desastres - (DR) relacionam-
se com a preparação para a ocorrência e a resposta caso o incidente ocorra. O
objetivo do plano é a sobrevivência de uma organização. Devido à extensão do
assunto, precisamos focar somente na recuperação dos elementos vinculados de
alguma forma a Tecnologia de Informação, inclusive os usuários de processos críticos
para o negócio.
Figura 14 -‐ Comunicações dos incidentes relacionadas a parceiros externos
Fonte: [19] TRADUCAO: SOFTWARE VENDORS=FABRICANTES DE SOFTWARE TELE-‐COMMUNICATIONS PRIVIDERS=OPERADORAS DE TELECOMUNICACOES AFFECTED EXTERNAL PARTY=PARCEIRO EXTERNO AFETADO OTHER INCIDENT RESPONSE TEAMS= OUTRAS EQUIPES DE RESPOSTA A INCIDENTES OWNERS OF ATTACKING ADDRESS= PROPRIETÁRIOS DO ENTEREÇO DO ATACANTE LAW ENFORCEMENT AGENCIES=AGENCIAS DE APLICAÇÃO DAS LEIS INCIDENT REPORTING ORGANIZATIONS=ORGANIZAÇÕES DE RELELATOS DE INCIDENTES

MEDIA=MEIOS DE COMUNICACAO ORGANIZATION’S ISP=PROVEDOR DE INTERNET DA ORGANIZACAO.
Em um mundo ideal, os incidentes nunca ocorreriam, ou pelo menos eles
ocorreriam somente após a existencia do plano de recuperacao de incidentes (IRP-
Incident recovery Plan). O plano define as equipes de resposta a incidentes (IRT –
Incident Response Team) e os passos a serem tomados durante uma ocorrencia, e
deve tentar cobrir todos os cenários considerados razoáveis. Obviamente, é
impossivel se prever todas as possibilidades.
A resposta da organização a um incidente depende das capacitacoes
técnicas das equipes e da cultura organizacional com respeito as políticas. Se as
políticas para os eventos cotidianos são aplicadas, aceitas e comprendidas pelos
colaboradores, as chances de uma recuperação de um incidente são maiores.
Quando a cultura das pessoas não é aderente as políticas de segurança, a
tendencia é de que mesmo um bom plano de recuperação venha a não ser tão
efetivo quanto o esperado, e de que algumas perdas ocorram, em maior ou
menor grau.
Check-‐list – Você e sua equipe estão preparados?
Incidentes ocorrem com uma frequência muito maior do que
imaginamos. Os grandes eventos e catástrofes das manchetes diárias das mídias
sobre isso não são corriqueiros, mas existe uma infinidade de pequenos eventos
que podem causar danos de mesma proporção (falhas nos computadores, no
fornecimento de energia, etc). A questão não é sobre se algum incidente vai
acontecer e sim quando ele irá ocorrer. A menos que você possa responder sim a
todas as questões abaixo, você precisa rever seu IRP (ou começar a construí-‐lo
imediatamente):
• Você sabe quanto tempo seu sistema de no-‐breaks (UPS-‐ Uninterruptible
Power Supply) irá suportar o suprimento de energia do qual seus
equipamentos necessitam em caso de interrupção do fornecimento pela

concessionária de energia?
• Você sabe qual o primeiro equipamento que deve ser desligado caso esse
tipo de evento aconteça?
• Você sabe onde encontrar suprimentos críticos caso seu fornecedor
primário tenha problemas (HDs, placas, componentes, links de internet,
etc)?
• Você sabe localizar todas as suas licenças de software?
• Você tem certeza de que seus clientes não migrarão para os concorrentes
imediatamente após saberem que você sofreu um incidente?
• Você testa com frequência seus backups para saber se os dados podem
realmente ser recuperados?
• Você usa aplicações customizadas? Caso positivo, a restauração do
backup dessas aplicações está funcionando corretamente?
• seu time sabe quem deve ser chamado e/ou avisado em caso de incêndio
nas suas instalações?
• Você sabe o que fazer se algum acidente romper seus cabos de
telecomunicações ou dados?
• Sua ferramenta de antivírus está atualizada?
• Você sabe localizar as chaves de registro, os códigos e as informações de
garantia para todos os seus softwares e hardwares?
• Você possui uma alternativa para repor seus equipamentos de produção
enquanto você tenta recuperar os originais ou adquirir outros?
<Abrir destaque> Importante
Embora os planos de recuperação não evitem os incidentes, eles são
fundamentais para manutenção do negócio. Várias pesquisas mostram que cerca de
metade das empresas que sofrem algum tipo de desastre e não possuem planos de
recuperação, não conseguem retornar ao Mercado. <Fim de destaque>
A Equipe de Resposta a Incidentes

Equipe de resposta a incidente (Incident Response Team) - IRT - é o
centro da organização para resposta a incidentes. Ela deve exercer a liderança e a
autoridade para executar todas as ações necessárias para corrigir o problema e obter as
metas desejadas pelas políticas e pelo plano de recuperação, durante o incidente. Isso
significa que o time deve ser composto pelas pessoas corretas nas funções mais
adequadas as sas atividades no cotidiano dos processos da organização.
Naturalmente, essas pessoas devem ter o perfil de líderes e devem estar
imbuídas com poderes para exercer a sua autoridade durante o evento. A equipe deve
estar preparada e para isso são necessários treinamentos periódicos.
Tabela 4 -‐ Papel dos componentes da Equipe de Resposta a Incidentes (IRT)
Fonte: [24] Composição da equipe de recuperação de incidentes -‐ IRT
A composição da equipe de resposta a incidentes é uma questão a
ser definida caso a caso, em função dos objetivos, modelos e processos do
negócio. A Figura 15seguinte mostra uma estrutura básica para composição
de uma IRT.
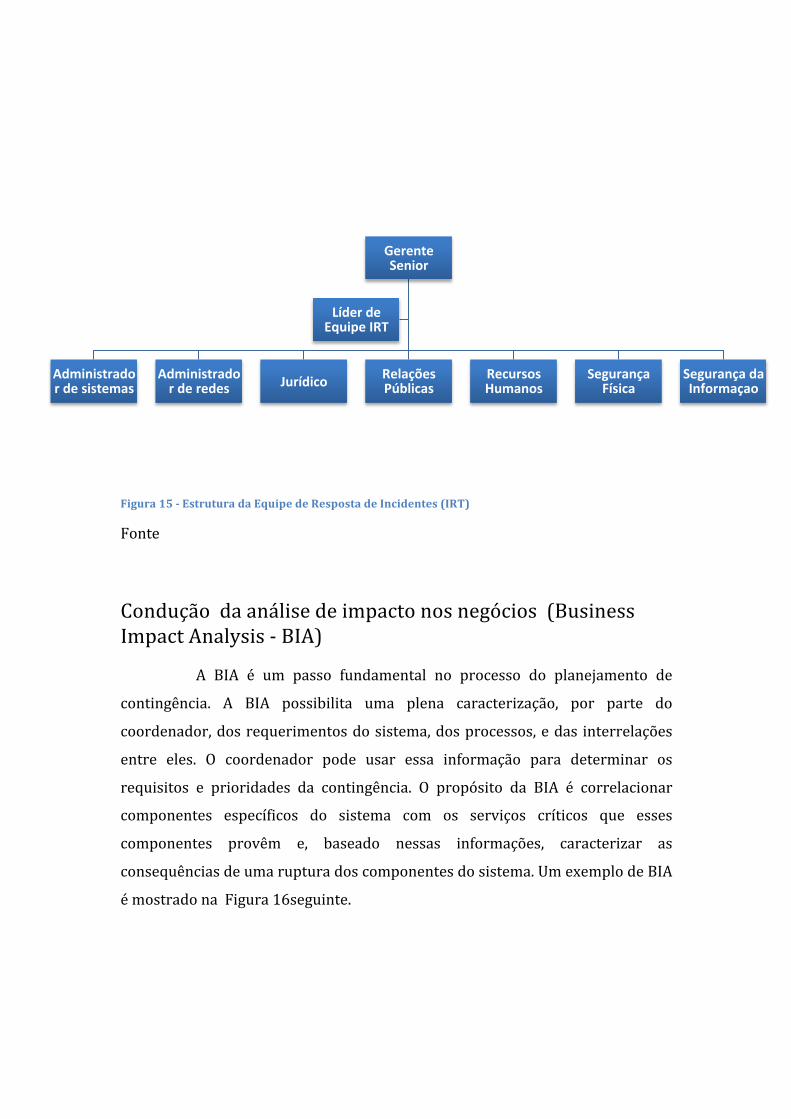
Figura 15 -‐ Estrutura da Equipe de Resposta de Incidentes (IRT)
Fonte
Condução da análise de impacto nos negócios (Business Impact Analysis -‐ BIA)
A BIA é um passo fundamental no processo do planejamento de
contingência. A BIA possibilita uma plena caracterização, por parte do
coordenador, dos requerimentos do sistema, dos processos, e das interrelações
entre eles. O coordenador pode usar essa informação para determinar os
requisitos e prioridades da contingência. O propósito da BIA é correlacionar
componentes específicos do sistema com os serviços críticos que esses
componentes provêm e, baseado nessas informações, caracterizar as
consequências de uma ruptura dos componentes do sistema. Um exemplo de BIA
é mostrado na Figura 16seguinte.
Gerente Senior
Administrador de sistemas
Administrador de redes Jurídico Relações
Públicas Recursos Humanos
Segurança Física
Segurança da Informaçao
Líder de Equipe IRT

Figura 16 BUSINESS IMPACT ANALYSIS (BIA)
Fonte: Avaliação do custo de recuperação
O coordenador do plano de contingência deve determinar o ponto
ótimo para recuperação dos sistemas de TI pelo balanceamento entre os custos
de inoperabilidade do sistema contra os custos dos recursos necessários para
restaurar o sistema. Esse balanço pode ser ilustrado pelo gráfico presente na
sequência. O ponto de cruzamento das linhas desse gráfico definirá quanto
tempo a organização pode suportar até que seu sistema seja recuperado.
Figura 17 -‐ Balanço do custo de recuperação em função do tempo
Traaducao: Cost=cuto Disruption=ruptura Recover=recuperação Time: tempo Fonte: [19] Priorização do Incidente

Priorizar o atendimento ao incidente talvez seja a parte mais crítica do plano de
tratamento do incidente. Os incidentes não podem ser tratados como uma fila
FIFO normal (First In, First Out ou “primeiro que chega é o primeiro que sai”). O
tratamento dos incidentes deve ser priorizado com base em 2 fatores: Efeitos Técnicos atuais e potenciais de danos futuros relativos ao incidente.
A equipe de tratamento de incidentes não pode considerar
somente os efeitos técnicos negativos presentes do incidente (como, por
exemplo, acesso não autorizado), mas também a probabilidade de um efeito
futuro efeito se o incidente não for imediatamente contido. Por exemplo, a
propagação de um Worm pelas estações de trabalho pode não ter um efeito
inicial tão desastroso. Porém, em poucas horas ela poderá derrubar a rede
devido ao volume de tráfego gerado.
Criticidade dos recursos afetados
Os recursos afetados no incidente podem ser os mais variados, e cada
um possui graus de criticidade diferentes. Por exemplo, os roteadores e os
enlaces de Internet podem ser mais ou menos críticos para uma ou outra
organização dependendo do tipo de negócio no qual ela se enquadra. Um
escritório de contabilidade pode se ressentir mais de incidentes que afetem as
estações de trabalho que estão sendo usadas para digitar os lançamentos
contábeis do que pela queda do enlace de internet, por exemplo. Já a queda da
conectividade pode ser gravíssima para provedores de service de Internet (ISPs)
ou para empresas baseadas em e-‐commerce.
A criticidade de um recurso está baseada primariamente nos seus
dados ou serviços, usuários, relações de confiança e interdependências com
outros recursos. A visibilidade também pode influenciar. Um servidor web
externo ou interno, por exemplo. Técnicas de determinação da criticidade devem
ser fundamentadas ou nos esforços necessários planejados para a continuidade
do negócio (BCP, business continuity plan) ou nos acordos de níveis de serviço
(Service LevelAgreements) -‐SLA, os quais determinam o tempo máximo
permitido para a restauração da de cada recurso critico.

A IRT, através da combinação da criticidade dos recursos afetados e
dos efeitos técnicos atuais e potenciais gerados pelo incidente, pode determinar
o impacto do incidente nos negócios (BIA).
<Abrir destaque> Importante
A equipe deve priorizar a resposta a cada incidente baseada na
estimativa do BIA. Por exemplo, o uso inadequado de um determinado recurso é
um incidente que não necessita tratamento tão imediato quanto possíveis outros
tipos de incidentes (roubo de uma senha, por exemplo), porque seu impacto nos
negócios é relativamente pequeno. <Fim de destaque>
A determinação dos efeitos e potenciais efeitos de incidentes podem
ser melhor quantificados pela própria organização que está planejando seus
processos de resposta, devido ao seu conhecimento das situações e das
criticidades dos diversos recursos. Os órgãos de regulação devem ser avisados
desses incidentes (no Brasil, ao Cert.br).
Para determinação do grau de severidade de um incidente, deve-‐se primeiramente determinar a classificação dos efeitos, o que pode-‐se realizar com base na Tabela 6seguinte. A determinação do grau de severidade geral de um incidente, deve-se utilizar a formula a seguir:
Severidade geral/Grau do efeito = ((Grau do efeito
atual * 2.5) + (Grau do efeito projetado * 2.5) + (grau de
criticidade do sistema * 5))
O valor resultante pode ser aplicado para se determinar o grau geral de impacto do
incidente, usando-se como base uma nova
Tabela 8, a seguinte:
Tabela 5 -‐ Grau de IMPACTO do Incidente
Impact Rating Score Rating 00.00 – 00.99 Nenhum
01.00 – 02.49 Minimo
02.50 – 03.74 Baixo
03.75 – 04.99 Medio
05.00 – 07.49 Alto
07.50 – 10.00 Critico

Fonte: [18],
Duas classificações são necessárias para cada incidente: O efeito
corrente (atual) e o efeito potencial (projetado).
Tabela 6 -‐ Definições do grau de efeitos dos incidentes
Value Rating Definition 0.00 Nenhum Sem efeito em um único site, departamento ou em múltiplos sites,
departamentos ou na infraestrutura crítica.
0.10 Minimo Efeitos negligíveis em um único site.
0.25 Baixo Efeitos moderados2 em um único site.
0.50 Medio Efeitos severos3 em um único site ou negligíveis em múltiplos sites, departamentos ou infraestrutura crítica
0.75 Alto Efeito moderado em múltiplos sites, departamentos ou infraestrutura crítica.
1.00 Critico Efeito severo em múltiplos sites, departamentos ou na infraestrutura crítica.
Fonte: [19], baseado em www.cert.org 2011
Depois de estabelecer os graus de efeitos (Tabela 6x) as instituições
devem utilizar a Tabela 7presente na sequência para designar o grau de
criticidade dos sistemas envolvidos no incidente.
Tabela 7 -‐ Definição do grau de criticidade dos recursos computacionais
Value Rating Definition 0.10 Minimo Non-critical system (e.g., employee workstations), systems, or
infrastructure
0.25 Baixo System or systems that support a single agency’s mission (e.g., DNS servers, domain controllers), but are not mission critical
0.50 Medio System or systems that are mission critical (e.g., payroll system) to a single agency
0.75 Alto System or systems that support multiple agencies or sectors of the critical infrastructure (e.g., root DNS servers)
1.00 Critico System or systems that are mission critical to multiple agencies or critical infrastructure
Fonte: [19], baseado em www.cert.org 2011
<Abrir destaque> Importante
A determinação do grau de severidade geral de um incidente, deve-se utilizar a 2 Para efeitos desta tabela, MODERADO é definido como “com limites razoáveis ou médios; não sério, nem com desabilitações ou incapacidades permanentes. 3 Para os efeitos desta tabela SEVERO é definido como “sério; muito perigoso ou destrutivo”.

formula (1) a seguir:
Severidade geral/Grau do efeito = ((Grau do efeito
atual * 2.5) + (Grau do efeito projetado * 2.5) + (grau de
criticidade do sistema * 5))
O valor resultante pode ser aplicado para se determinar o grau geral de impacto do
incidente, usando-se como base uma nova
Tabela 8, a seguinte:
Tabela 8 -‐ Grau de IMPACTO do Incidente
Impact Rating Score Rating 00.00 – 00.99 Nenhum
01.00 – 02.49 Minimo
02.50 – 03.74 Baixo
03.75 – 04.99 Medio
05.00 – 07.49 Alto
07.50 – 10.00 Critico
Fonte: [18],
Em um documento complementar, deve-‐se formatar uma matriz com
um guia de prioridades, segundo o exemplo da Tabela 9xxx. Nessa tabela, o
cabeçalho das colunas listam a criticidade do recurso computacional envolvido, e
as linhas listam as categorias de impactos técnicos. Cada valor da matriz
especifica o tempo máximo que a IRT possui para iniciar a resposta ao
incidente. Esse tempo pode ser definido como um SLA para a resposta ao
incidente.
Geralmente, o SLA não especifica o tempo máximo para resolver o
incidente, pois este fator é extremamente variável e pode fugir do controle da
IRT. As organizações devem customizar sua matriz de acordo com suas
necessidades próprias e pelo grau com o qual os recursos são considerados
críticos. A partir desse escore se pode dirigir a resposta ao incidente para a IRT
ou para a equipe de suporte unicamente.
É desejável que se tenha duas versões dessa matriz: A primeira
versão para ser utilizada em horário comercial de dias úteis e a segunda para

momentos sem expediente.
Tabela 9 -‐ Matriz de criticidade do recurso impactado ou com probabilidade de ser impactado por
incidentes e SLA de resposta
Current Impact or Likely Future Impact of the Incident
High (e.g., Internet Connectivity, Public
Web Servers, Firewalls, Customer Data)
Medium (e.g., System Administrator
Workstations, File and Print Servers, XYZ Application Data)
Low (e.g., User Workstations)
Root-level access 15 minutos 30 minutes 1 hour
Modificacao de dados nao autorizada 15 minutos 30 minutes 2 hours
Acesso nao autorizado a dados sensíveis
15 minutos 1 hour 1 hour
Acesso nao autorizado no nivel de usuário
30 minutos 2 hours 4 hours
Serviço indisponível 30 minutos 2 hours 4 hours
Brincadeiras4 30 minutes Equipe local de TI Local IT staff
Fonte=[18]
Pode ser aplicada mais de uma entrada na matriz em um incidente se
tal incidente afetar múltiplos recursos (por exemplo, sistemas, aplicações,
dados). A equipe de tratamento deve identificar o mais urgente.
A abordagem do tratamento de incidentes através da criação dessas
matrizes propicia uma reação criteriosa por parte da IRT. As matrizes
economizam tempo no tratamento dos incidentes. Durante um incidente, os
membros da IRT trabalham sob grande carga de stress, e a tomada de decisões
pode ser um desafio considerável. A IRT deve, portanto, tomar cuidado para
não decidir por conta própria, principalmente em situações não
corriqueiras.
As organizações devem estabelecer um processo de escalada no
organograma quando a IRT não responder ao incidente dentro dos prazos
previstos. O processo de escalada deve estabelecer o tempo máximo de espera
pela resposta e qual pessoa deve ser ativada caso o responsável falhe. Referências 4 Essa categoria de impactos refere-‐se a incidentes sem maiores consequências, apena podendo irritar os usuários, como por exemplo o aparecimento de frases na tela provocado por algum código malicioso (malware).

Professor, apresentar referências bibliográficas dessa Leitura.
1. Stoneburner, G.; Goguen, A. & Feringa, A. (2002): Risk Management Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology – NIST Special Publication 800-30
2. Swanson, M.; Wohl, A.; Pope, L.; Grace, T.; Hash, J. & Thomas, R. (2002) : Contingency Planning Guide for Information Technology Systems - Recommendations of the National Institute of Standards and Technology – NIST Special Publication 800-34
3. Wallace, M. & Webber, L. (2004): THE DISASTER RECOVERY HANDBOOK A Step-by-Step Plan to Ensure Business Continuity and Protect Vital Operations, Facilities, and Assets -AMACOM- American Management Association
4. Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security
Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.
Leitura 2
Título da Leitura: Componentes do plano de resposta a incidentes de segurança da informação (IRP) <Sinopse> Essa Leitura é extremamente importante para essa disciplina, já
que nela são apresentadas as fases que compõe o plano de resposta a
incidentes de segurança da informação (IRP). Atente para o conteúdo de cada
ma delas, a sequência entre as mesmas e se existem fases concomitantes, Boa
leitura! <Fim de sinopse>
É importante a formalização do plano de resposta a incidentes (IRP).
Isso auxilia na manutenção do foco, na coordenação das atividades e na
efetividade das ações. Para que uma organização possua de fato uma capacidade
de resposta, é necessária a elaboração desse plano.

Tal plano provê uma escala temporal para a implementação da
capacidade de resposta aos incidentes. Ele deve possuir uma abordagem de alto
nível, para envolver toda a organização e capacitá-‐la integralmente para
responder aos incidentes.
<Abrir destaque> Importante
Cada empresa ou instituição deve elaborar um plano de acordo com
suas necessidades específicas, as quais se relacionam a sua missão, tamanho,
estrutura, funções e procedimentos. <Fim de destaque>
O pano deve mostrar claramente os recursos e suporte que serão
necessários para manter e aprimorar a capacidade de resposta a esses
incidentes. Os elementos chaves que devem ser contemplados no plano devem
ser os seguintes:
• Missão.
• Estratégia e objetivos.
• Aprovação da alta gerência.
• Abordagem organizacional para resposta a incidentes.
• Como será a comunicação entre a IRT e o restante da organização.
• Métricas para medir a capacidade de resposta.
• Planejamento para maturação da capacidade de resposta.
• Pontos de interface e integração do plano com toda a organização.
A missão, objetivos e estratégias organizacionais para a resposta a incidentes
devem auxiliar na determinação da estrutura necessária para a capacidade de
resposta requerida. A estrutura do programa de resposta deve estar inclusa no
plano.
Fases do Plano de Resposta a Incidentes
A maior parte dos autores aceita como sendo seis o número de fases
de um plano de resposta a incidentes (ver a figura seguinte). O ciclo formado
por essas fases inicia logo após a ocorrência do evento adverso à segurança da
informação. Em alguns desses eventos, incidentes, algumas fases ocorrem

concorrentemente. Particularmente, a Erradicação e a Recuperação são fases
normalmente paralelas.
“Bem,
quem quer que seja que roubou minha senha, certamente, possui uma mente brilhante. Especialmente pelo fato de que nenhum dos meus lembretes desapareceu.”

Figura 18 -‐ Fases do plano de Resposta a Incidentes (IRP)
Fonte:Baseado em [24]
As responsabilidades dos grupos de especialistas que devem compor
a equipe de resposta a incidentes (IRT) estão descritas resumidamente na Tabela
10 presente a seguir.
Tabela 10 -‐ Responsabilidades da equipe de resposta a incidentes (IRT)
Preparação
Detecção
Contenção
Erradicação
Recuperação
Prosseguimentos
Incidente

Fonte: [24] Os objetivos de cada fase do plano de resposta a incidentes estão resumidos nessa outra tabela: Tabela 11 -‐ Metas de cada fase do plano de resposta a incidentes (IRP)
Fonte: [24] Agora sigamos para a apresentação de cada uma dessas fases.

Fase de preparação
Certamente é a fase mais importante do plano. Assim como devemos
dedicar 70% do tempo projetando e 30% executando o projeto, a fase de
preparação deve ser minuciosamente estudada e detalhada. O melhor momento
para iniciarmos esta fase é certamente antes da ocorrência do primeiro
incidente. Lembre-‐se: Não é uma questão de se ele vai ocorrer e sim de quando
isso vai acontecer.
<Abrir destaque> Importante
Essa fase é o momento de comprometer toda a organização, em todos
os níveis gerenciais, com a capacidade de resposta a ser consolidada através do
plano. <Fim de destaque>
Nessa fase, os controles de prevenção e detecção, bem como o
desenvolvimento das capacidades são planejados. O gerente responsável pelo
IRP deve:
o Nomear os indivíduos e substitutos do IRT.
o Preencher todas as áreas funcionais (Tabela 10xxx-‐
Responsabilidades da equipe de resposta a incidentes (IRT))
com especialistas com poder de decisão e autoridade para
coordenar as atividades.
o Assegurar a existência de um mecanismo para contactar os
componentes da IRT. É possível se usar os mesmos
mecanismos dos outros planos voltados à segurança
(Recuperação de desastres, contingenciamento, etc).
o Incluir instruções para decisão do momento de convocação da
IRT. Uma política crucial a ser considerada é a resposta para a
pergunta: “Qual é o critério para se declarar a ocorrência de um
incidente?
o Especificar a prioridade relativa das ações, em função da matriz
de impactos.
o Priorizar a vida e a segurança dos seres humanos, antes de
aplicar a matriz de impactos.
o Planejar e executar sessões de treinamentos para a aplicação

do plano, simulando incidentes.
o Decidir a filosofia a seguir em resposta a uma intrusão. Por
exemplo, um atacante deve ser neutralizado imediatamente
(proteger e prosseguir) ou a organização deve seguir seus
passos para coletar provas e evidências (perseguir e executar
judicialmente)?
o Assegurar que exista uma expectativa respoável de que o IRT
consiga desempenhar suas tarefas com a competência
necessária em todas as áreas.
o Ajustar o plano baseado nos exercícios de treinamento e nas
respostas já realizadas.
o Revisar as práticas de segurança para assegurar que:
Ø Sistemas de IDS e IPS estejam funcionando a contento
Ø O sistema de logs esteja ativo
Ø O sistema de backups está correspondendo ao RTO e RPO,
e que seja functional
Ø Identificar as vulnerabilidades (testes de intrusão) e
corrigi-‐las.
Fase de detecção
O objetivo dessa fase é determinar o momento da ocorrência do
incidente. Existem muitos sintomas que podem caracterizar a ocorrência de um
incidente. Alguns dos mais comuns podem ser:
• Novas contas de usuários criadas por pessoas sem autorização.
• Atividade nao usual em uma conta (usuário em férias ou em horário
não comercial)
• Alteração inesperada nos timestamps dos arquivos do sistema
operacional. <Abrir hiperlink> Data e hora da última alteração dos
arquivos <Fim de hiperlink>
• Atividade não usual em servidores, tráfego de rede ou degradação de
performance de sistemas.
• Múltiplas tentativas de logar-‐se no sistema.
• Uso de ferramentas (IDS, IPS, Honey nets, flow controls, sniffers, data

integrity checkers…)
Fase de Contenção
A meta da fase de contenção é evitar que o incidente espalhe-‐se pelos
diversos dispositivos ou recursos computacionais. Neste momento, as ações
devem voltar-‐se para limitar os danos. Se o incidente tartar-‐se de um código
malicioso, por exemplo, os servidores, estações e outros dispositivos de usuários
os quais se encontram atingidos, devem ser desconectados da rede. Se houver
um intruso na rede, o segmento invadido deve ser isolado e as contas de
privilégios mais elevados devem se desabilitadas. Quando se tratar de uma
negação de serviço, as origens dos ataques devem ser identificadas e seu acesso
a rede deve ser bloqueado. Caso algum host tenha sido comprometido, ele deve
ser isolado da rede.
Algumas técnicas, se aplicadas em uma fase anterior ao incidente,
podem facilitar bastante a fase de contenção. Isolar os servidores de missão
crítica em uma subrede especial, por exemplo, permite que ações rápidas surtam
efeito imediato, como nesse caso: o isolamento do tráfego de e para essa subrede.
O plano de resposta a incidentes deve prever, por exemplo, em que
momento o serviço de emails deve ser interrompido caso ocorra um evento de
worm sendo espalhado pela rede de usuários do serviço.
Essa fase é a fase na qual os serviços de comunicação aos usuários
devem ser disparados. As mensagens devem ser escritas por especialistas,
principalmente no caso de comunicados externos (parceiros, fornecedores,
prestadores de serviço, clientes, etc.).
Fase de erradicação
Conceitualmente, essa fase é simples. Os métodos e ferramentas
usados para erradicaão dos incidentes irão depender da natureza e da extensão
do problema. Essa é a fase na qual o problema deve ser eliminado.
<Abrir destaque> Exemplos
Ataque de vírus: As assinaturas devem ser atualizadas ou

desenvolvidas e então aplicadas. Os HDs e sistemas de emails devem ser varridos
(scaneados) antes que os sistemas afetados possam ser acessados novamente,
para que o problema não retorne.
Intrusão: Os sistemas no qual o intruso executou login devem ser
identificados e as sessões ativas do intruso devem ser encerradas. Deve ser
possível separar os sistemas lógica e fisicamente do restante da rede. Se o ataque
se originou de uma rede externa, as conexões com o restante da Internet devem
ser desabilitadas. <Fim de exemplos>
Adicionalmente aos efeitos imediatos de um incidente, outras
alterações não autorizadas podem ter sido programadas para ocorrerem
posteriormente. A fase de erradicação deve contemplar o exame dos
componentes de rede que podem ter sido comprometidos por alterações nos
arquivos de configuração. O aparecimento de cavalos de tróia ou backdoors, os
quais podem facilitar invasões futuras, devem ser identificados. Novas contas
que tenham sido criadas também devem ser bloqueadas.
Fase de Recuperação
Durante a fase de recuperação, os sistemas devem retornar ao seu
estado normal de operações. Nessa fase, os administradores determinam a
extensão dos danos causados pelo incidente e utilizam as ferramentas adequadas
para a recuperação das funcionalidades. É uma tarefa primariamente técnica,
e a natureza do evento é que determina os passos necessários para a volta do
cenário de normalidade.
Para códigos maliciosos, o mecanismo de recuperação mais comum
são os softwares de antivírus. Ataques de negação de serviço podem até nem
possuir essa fase de recuperação. Um incidente envolvendo o uso não autorizado
de contas administrativas deve provocar nessa fase uma revisão dos arquivos de
configuração , definicoes de usuários, permissões de acesso ao file system em
todos os servidores ou domínio onde o intruso se logou. Adicionalmente, a
integridade de todos os bancos de dados deve ser verificada.
Essa fase do plano pode ser marcada pela tomada de decisões
radicais, como a de se restaurar backups anteriores ao incidente em caso de
suspeita de uma violação mais contundente, com a implantação de cavalos de

tróia, backdoors ou bombas relógio. Pode-‐se inclusive ter que decidir pela
reinstalação de todo sistema a partir do nível zero, com a reformatação física dos
HDs. Tais procedimentos são demorados, especialmente em datacenters de
grande porte, com centenas de servidores físicos e muitos outros servidores
virtuais, onde muitos deles possam ter sido comprometidos.
Se a decisão tomada é a de não recuperar os backups ou reinstalar os
sistemas, existe o risco de que o problema não seja erradicado totalmente. A fase
de preparação é que deve contemplar a análise dos riscos decorrentes
dessa decisão.
Fase de continuidade
Mesmo depois da fase de recuperação existe muito trabalho a ser
executado pela IRT. Na fase de continuidade da resposta ao incidente, existe a
obrigatoriedade de uma revisão de todas as atividades das fases anteriores.
Ações específicas dessa fase incluem:
• Consolidação de toda documentação gerada durante o incidente.
• Cálculo dos custos: custos diretos da perda de dados, perdas
monetárias devido a indisponibilidade de alguma parte da rede, custos
legais, custos de restauração, custos com as equipes envolvidas, custos
com a inatividade dos funcionários que tiveram seus recursos
computacionais indisponíveis.
• Exame de todo incidente, analisando a efetividade das atividades de
preparação, detecção, contenção, erradicação e recuperação.
• Fazer os ajustes necessários ao plano de resposta a incidentes.
• Consolidação da documentação, a qual deve ser arquivada
metodicamente.
• Cuidados e check-‐list das questões legais, as quais podem se extender
por prazos longos (vários anos, dependendo da legislação envolvida).
Uma lista de questionamentos pode ser encontrada no exemplo mostrado na Tabela 12 abaixo. O Check list do exemplo serve para evitarmos complicações legais no futuro, bem como para uma revisão interna de que todos os cuidados foram realmente tomados no tratamento do incidente.

Tabela 12 -‐ Questões de revisão posteriores a fase de restauração
Fonte: [24]
Como não existe plano perfeito, a fase de revisão posterior ao
incidente serve para aprendizado e melhoria de possíveis falhas ou omissões. A
revisão pode mostrar que são necessárias alterações em muitos aspectos, desde
o próprio plano de resposta a incidentes, sistemas de controle e detecção,
monitoramento, técnicas forenses, experiência e nível técnico da IRT, ou mesmo
o envolvimento de equipes não relacionadas com TI.
Referências Professor, apresentar as referências bibliográficas dessa Leitura.
1. Jackson, C. B. (2007): The Role of Continuity Planning in the Enterprise Risk Management Structure in: Information Security Management Handbook (2007) pag 1591

2. Gregory, P. (2008): IT Disaster Recovery Planning For Dummies Publ. Wiley Publishing, Inc. 111 River Street Hoboken, NJ 070305774
3. Stacey, T. R. (2007): Contingency Planning Best Practices and Program Maturity in: Information Security Management Handbook (2007)
4. Swanson, M.; Wohl, A.; Pope, L.; Grance, T.; Hash, J. & Thomas, R. (2002): Contingency Planning Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology
5. Tipton, H. & Krause, M.(2007): Information Security Management
Handbook - 6th Ed – Auerbach Publications
12. Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.
Leitura 3
Título da Leitura: Planejamento de contingência e a continuidade dos negócios Sinopse: O processo de contingência descrito nessa Leitura é comum para todos os sistemas de
TI. Existem várias abordagens para esses procedimentos, e iremos analisar a
metodologia para sua implantação, a qual divide os procedimentos em sete etapas.
Nessa Leitura você encontrará, entre outras coisas, a definição dessas etapas para a
implementação do plano contigência. <Fim de sinopse>
Planos de contingência ocorrem regularmente no nosso cotidiano.
Eles são baseados em ações diárias e tão frequentes que, muitas vezes, não
percebemos sua ocorrência, nem porque agimos daquela forma. Tais ações
podem ser classificadas em três grupos:
• Mitigação: Algo que fazemos para reduzir as chances de uma
ocorrência ou o total de danos que possam ser causados por um
evento inevitável.

• Evitabilidade: Algo que fazemos para não participar de um
evento.
• Transferência: Passar para outra pessoa nosso risco de um
evento incontrolável.
O processo de contingência descrito é comum para todos os sistemas
de TI. Existem várias abordagens para esses procedimentos, e iremos analisar a
metodologia recomendada em [10], a qual divide os procedimentos em sete
etapas, listadas a seguir:
Desenvolver as políticas do plano de contingência -‐ Uma agência ou
departamento formais para desenvolvimento das políticas provê a autoridade,
status e o formato necessários para o desenvolvimento de um plano de
contingência efetivo.
Conduzir a análise de impacto nos negócios (BIA-‐business impact
analysis)-‐ Essa análise ajuda a identificar e a priorizar os sistemas e
componentes de TI os quais são críticos para o negócio.
Identificar os controles preventivos -‐ Medidas tomadas para reduzir os efeitos
das rupturas no sistema podem aumentar a disponibilidade e reduzir os custos
do ciclo de vida do contingenciamento.
Desenvolver as estratégias de recuperação -‐ Essa técnica assegura que o
sistema posa ser recuperado rápida e efetivamente após uma ruptura.
Desenvolver o plano de contingência de TI -‐ O plano de contingencia deve
ser um guia detalhado, com procedimentos claros para restaurar um sistema
danificado.
Testar o plano, treiná-‐lo e exercitá-‐lo -‐ A aplicação de testes auxilia a
identificação de falhas ou omissões, enquanto os treinamentos preparam a
equipe de recuperação (IRT) para a ativação do plano. As duas atividades
melhoram a efetividade do plano e a preparação geral da organização para um
evento.

Efetuar manutenções periódicas no plano -‐ Os planejamentos relativos a
segurança da informação devem ser documentos “vivos”, os quais sofrem
atualizações periódicas, acompanhando o ciclo de vida dos sistemas.
Estes passos representam fatores chave na capacidade de um
planejamento de contingência compreensível. Deve haver um coordenador(a)
para o desenvolvimento do plano de contingência, que normalmente gerencia o
desenvolvimento e a execução do plano.
Todas as aplicações significativas e sistemas de suporte devem
possuir planos de contingência. A Figura 21presente a seguir ilustra o processo de
planejamento de contingência.
Desenvolver p
olí/ca do
plano de
con
/ngencia (P
C)
Iden/ficar requerimentos de estatuto e de legislacao para planos de con/ngência Desenvolver as polí/cas aderentes a TI Obter aprovacao das poli/cas Publicar as polí/cas
Cond
uzir análise
de im
pacto
nos n
egócios Iden/ficar recursos
cri/cos de TI Iden/ficar impactos de down/me e tempos permi/dos para down/me iden/ficar prioridades de recuperacao Id
en/fi
car o
s con
troles
preven
/vos
Implementar os controles Dar manutençao aos controles
Desenvolver e
stratégias de
recupe
ração Iden/ficar métodos
Integrar com arquitetura dos sistemas
Desenvolver p
lano
de
con/
ngen
cia documentar a
estratégia de recuperação
Teste, treinamen
to e
exercios
Desenvolver os obje/vos dos testes determinar critérios de sucesso documentar o aprendizado incorporar ao plano treinar as equipes
Manuten
ção do
plano
Rever e atualizar coordenar com estruturas internas e externas Documentar as alteracoes Distribuir novos documentos

Figura 19 -‐ Processos de planejamento para contingência
1. A norma NIST Special Publication 800-‐34 [11] Swanson, M.; Wohl, A.; Pope, L.; Grance, T.; Hash, J. & Thomas, R. (2002): Contingency Planning Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology
dá suporte e recomendações para planos de contingência para 7 tipos de
plataformas de Tecnologia da Informação, conforme listado a seguir:
• Desktops e sistemas portáteis.
• Servidores.
• Web sites.
• Redes Locais (LANs ou Local area networks).
• Redes de longa distância (WANs ou Wide area networks).
• Sistemas distribuídos.
• Sistemas de Mainframes.
Essa Norma provê estratégias e técnicas comuns a todos os sistemas.
Assim como na NIST 800-‐34, consideramos neste livro “Plataformas de TI” e
“Sistemas de TI” como sendo um sistema genérico de suporte ou aplicações de
propósito geral, e os termos serão usados de forma intercambiável.
Os planos de contingência, além das diferentes fases, quando vistos
sob o aspecto puramente de projeto, devem ser desenhados em um processo
normal (análise, desenho, implementação, teste e manutenção), conforme
descrito por Stacey, 2007[25]

Figura 20 -‐ Projeto do plano de contingencia
Fonte: [25]
Componentes do plano de contingência
O plano de contingência pode ser separado em 6 fases principais. As
informações de suporte e os apêndices do plano provêm informações essenciais
para assegurar um plano compreensível. As fases de Notificação/Ativação ,
Recuperação e Reconstituição focam em ações específicas que a organização
deve tomar após uma ruptura de sistema ou uma emergência.
• Figura 21 -‐ Fases de um plano de contingência
Desenvolvimento do plano: Incorporação do BIA Estratégia de reuperação da Documentação
Informações de suporte: Introdução Conceitos operacionais
Fase de a/vação e no/ficação: Processo de no/ficacao Contabilizacao dos danos A/vação
Fase de Recuperação:
Procedimentos de recuperação
Fase de recons/tuição: Restauração do site Teste dos sistemas Final das operacaoes
Apêndices do Plano: Listas dos testes de conceitos requesitos dos sistemas Registros vitais

Estratégia de notificação
A estratégia de notificação deve definir procedimentos a serem
seguidos caso a pessoa determinada não seja contatada. Essa estratégia deve
ser claramente documentada no plano de contingência. Um método
comumente usado para isso é uma árvore de notificações. Esta técnica envolve a
designação de canais de notificação para indivíduos específicos, os quais, por sua
vez, são responsáveis pela notificação de outra pessoa. A árvore deve fornecer
métodos de contato primários e alternativas, e deve apontar para os
procedimentos que devem ser seguidos caso um indivíduo não possa ser
contatado. A Figura 22 mostra um exemplo de árvore de notificações.
Figura 22-‐ Exemplo de uma árvore de notificação
1. Fonte: Swanson, M.; Wohl, A.; Pope, L.; Grace, T.; Hash, J. &
Coordenador IRT
Lider do /me de Redes
Admin de redes
Tec. de suporte ao desenvolv.
Tec. de suporte a desktops
Téc. de Help Desk
Lider Dnaco de dados
Administrador SGBD
Admin de SQL
Analista de Bancos
Lider Telecom
Engenheiro de WAN
Eng. de sistemas
Técnico de telecom
Líder do /me de Servidores
Administrador de emails
Administrador de aplicacoes
Técnico de suporte
Corrdenador IRT alterna/vo

Thomas, R. (2002) : Contingency Planning Guide for Information Technology Systems - Recommendations of the National Institute of Standards and Technology – NIST Special Publication 800-34
Atividade Colaborativa Com base na figura 18 escreva as fases para recuperação de um incidente de infestação por um novo tipo de vírus, nao detectado no sistema antivírus de uma empresa que mantém uma rede de jogos online, como foi o caso da Sony com a rede doPlaystation. Atividade de Autoaprendizagem Elabore uma arvore de notificação para incidentes de segurança com base no organograma da empresa onde você trabalha (ou trabalhou). Insira ou retire elementos do exemplo apresentado na figura 22 Síntese Nesta unidade você aprendeu várias técnicas que auxiliam na elaboração de um plano de resposta a incidentes de segurançaa. Utilizando índices de severidade e outros fatores, você aprendeu a calcular o grau de impacto do incidente, bem como o tempo previsto para que os processos voltem a normalidade. Aprendeu também a organizar uma equipe de resposta aos incidentes, e todas as fases que devem ser percorridas até a completa resolução do problema. Aprendeu também a importância de uma árvore de notificações dos incidentes e observou um exemplo de elaboração de dessa arvore de notificações. SAIBA MAIS A RFC é a 5070, denominada Incident Object Description Exchange Format., a qual está disponível, atualmente, (http://www.ietf.org/rfc/rfc5070.txt). A rede da associação Trans Europeia de pesquisa e educação (The Trans-‐
European Research and Education Networking Association -‐ TERENA)
desenvolveu a RFC 3067, TERENA's Incident Object Description and Exchange
Format Requirements <Abrir hiperlink>Você Pode ver mais sobre isso em:
<http://www.ietf.org/rfc/rfc3067.txt> <Fim de hiperlink>.


Bibliografia
2. Jackson, C. B. (2007): Developing Realistic Continuity Planning Process Metrics , in Information Security Management Handbook (2007) pag 1517
3. Jackson, C. B. (2007): The Role of Continuity Planning in the Enterprise Risk Management Structure in: Information Security Management Handbook (2007) pag 1591
4. Doughty, K. (2007): Selecting the Right Business Continuity Strategy – in: Information Security Management Handbook (2007) pag 1551
5. Gregory, P. (2008): IT Disaster Recovery Planning For Dummies Publ. Wiley Publishing, Inc. 111 River Street Hoboken, NJ 070305774
6. Stacey, T. R. (2007): Contingency Planning Best Practices and Program Maturity in: Information Security Management Handbook (2007)
7. Stacey, T. R. (2007): Contingency Planning Best Practices and Program Maturity in: Information Security Management Handbook (2007)
Amaral, R.
8. Wallace, M. & Webber, L. (2004): THE DISASTER RECOVERY HANDBOOK A Step-by-Step Plan to Ensure Business Continuity and Protect Vital Operations, Facilities, and Assets American Management Association (AMACOM) 2004
9. Snedaker, S. (2007): Business Continuity and Disaster Recovery
Planning for IT Professionals Copyright © 2007 by Elsevier, Inc
10. Maiwald, E. & Sieglein, W. (2002): Security Planning & Disaster Recovery-McGraw-Hill/Osborne
11. Swanson, M.; Wohl, A.; Pope, L.; Grance, T.; Hash, J. & Thomas, R. (2002): Contingency Planning Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology
12. Tipton, H. & Krause, M.(2007): Information Security Management
Handbook - 6th Ed – Auerbach Publications

13. Cisco Systems(2006): Data Centers Disaster Recovery - DC 2602 –
Cisco Networkers 2006
14. Stoneburner, G.; Goguen, A. & Feringa, A. (2002): Risk
Management Guide for Information Technology Systems Recommendations of the National Institute of Standards and Technology – NIST Special Publication 800-30
15. Swanson, M.; Wohl, A.; Pope, L.; Grace, T.; Hash, J. & Thomas, R. (2002) : Contingency Planning Guide for Information Technology Systems - Recommendations of the National Institute of Standards and Technology – NIST Special Publication 800-34
16. Zapater, M. & Suzuki, R. (2009): Segurança da Informação Um
diferencial determinante na competitividade das corporações. Promon Business & Technology Review
17. Stallings, W. (2007): Network Security Essentials, 4th. ed – Pearson
Education
18. Wallace, M. & Webber, L. (2004): THE DISASTER RECOVERY HANDBOOK A Step-by-Step Plan to Ensure Business Continuity and Protect Vital Operations, Facilities, and Assets -AMACOM- American Management Association
19. Scarfone, K.; Grance, T. & Masone, K. (2008): Computer Security
Incident Handling Guide Special Publication 800-61 Revision 1 - National Institute of Standards and Technology.
20. Jackson , C. B. (2007): The Role of Continuity Planning in the Enterprise Risk Management Structure in: Information Security Management Handbook pag 1591 6th Ed – Auerbach Publications
21. Doughty, K. (2007): Selecting the Right Business Continuity Strategy - in Information Security Management Handbook pag 1551 6th Ed – Auerbach Publications
22. Shaurette, K. M (2008): Technology Convergence and Security: A Simplified Risk Management Model
23. Akin, T. (2007): Cyber-Crime: Response, Investigation, and
Prosecution in Information Security Management Handbook pag 3048 6th Ed – Auerbach Publications
24. Vangelos, M. (2007): Managing the Response to a Computer Security
Incident in Information Security Management Handbook pag 2990 6th Ed –

Auerbach Publications
25. Stacey, T. R. (2007): Contingency Planning Best Practices and Program Maturity in Information Security Management Handbook 6th Ed – Auerbach Publications
Recursos Information Security Policy Papers URL : http://www.sans.org/rr/policy DESC : Sans Institute Security Policy Papers URL : http://www.secinf.net/policy_and_standards/ DESC : Secinf's Policies Directory URL : http://packetstormsecurity.org/docs/infosec/policies/ DESC : Packetstorm's Security Policies Directory URL : http://directory.google.com/Top/Computers/Security/Policy/ DESC : Google's Security Policies Directory WindowSecurity.com -‐ Windows Security resource for IT admins. 25 Copyright © 2003 Internet Software Marketing Ltd. All rights reserved. URL : http://www.ietf.org/rfc/rfc2196.txt?Number=2196 DESC : Site Security Handbook URL : http://www.utoronto.ca/security/policies.html DESC : University of Toronto URL : http://irm.cit.nih.gov/security/sec_policy.html DESC : Security Policies URL : http://www.ruskwig.com/security_policies.htm DESC : Security Policies URL : http://www.iwar.org.uk/comsec/resources/canada-ia/infosecawareness.htm DESC : A comprehensive paper on the building processes of a Security Policy URL : http://www.sun.com/software/white-papers/wp-security-devsecpolicy/ DESC : How to build a Security Policy URL : http://www.boran.com/security/detail_toc.html DESC : IT Security Cookbook URL : http://eleccomm.ieee.org/email-policy.shtml DESC : E-mail Security Policy URL : http://www.giac.org/practical/Kerry_McConnell_GSEC.doc DESC : How to develop Security Policies URL : http://www.giac.org/practical/Caroline_Reyes_GSEC.doc DESC : What makes a good Security Policy URL : http://www.giac.org/practical/jack_albright_gsec.doc DESC : The basics of an IT Security Policy ISO Web Sites http://security.vt.edu/ http://security.isu.edu/ http://www.itso.iu.edu/ http://www.ox.ac.uk/it/compsecurity/ http://www.columbia.edu/acis/security/ https://www.certisign.com.br/companhia/icp-‐brasil/video-‐icp Como limpar os spywares do Windows http://www.codinghorror.com/blog/archives/000888.html Index do yahoo para segurança da informação:

http://dir.yahoo.com/Computers_and_Internet/Security_and_Encryption/ Legislação: http://www.out-‐law.com/page-‐0 Estatísticas sobre incidentes de segurança (até 2008) http://www.cert.org/stats/cert_stats.html
Professor, existiam tabelas aqui, não entendi o que significavam, já que não estavam atreladas a textos nenhum. Atividade Colaborativa Atividades de Autoaprendizagem Saiba mais Síntese





























