Embed Size (px)
Citation preview

Universidade de São Paulo
Escola de Engenharia de São Carlos
TRABALHO DE CONCLUSÃO DE CURSO
Rafael Taniwaki
Aplicação do descritor LMP para o reconhecimento facial
ENGENHARIA ELÉTRICA – ÊNFASE EM ELETRÔNICA
Orientador: Prof. Dr. Adilson Gonzaga
São Carlos, 2016


Universidade de São Paulo
Escola de Engenharia de São Carlos
TRABALHO DE CONCLUSÃO DE CURSO
Rafael Taniwaki
Aplicação do descritor LMP para o reconhecimento facial
Trabalho de Conclusão de Curso – apresentado como parte dos pré-requisitos para a obtenção do título de Engenheiro Eletricista/Eletrônico, à Universidade de São Paulo – USP “Escola de Engenharia de São Carlos – EESC”
Orientador: Prof. Dr. Adilson Gonzaga
São Carlos, 2016


FOLHA DE APROVAÇÃO
Nome: Rafael Taniwaki
Título: "Aplicação do descritor LMP para o reconhecimento facial"
Trabalho de Conclusão de Curso defendido e aprovado emlái.J_JLJ <0. (z
1, pela Comissão Julgadora:
Prof. Associado Adilson Gonzaga - Orientador - SEUEESCIUSP
Profa. Dra. Maria Stela Veludo de Paiva - SEUEESCIUSP
Mestre Raissa Tavares Vieira - Doutoranda-SEUEESCIUSP
Coordenador da CoC-Engenharia Elétrica - EESCIUSP: Prof. Associado José Carlos de Melo Vieira Júnior


DEDICATÓRIA
Dedico este trabalho aos que com palavras de incentivo e/ou renúncia de
momentos de convívio me ajudaram a concluí-lo, de forma especial a minha
família.
AGRADECIMENTOS
Agradeço ao Prof Dr Adilson Gonzaga, por ter compartilhado seu
conhecimento, por suas preciosas orientações e talento como mestre.
À minha família pela solidariedade e aos colegas de classe pelo
companheirismo durante os anos de faculdade,
À Raissa Tavares Vieira pela contribuição com informações relevantes
para a realização deste trabalho.
A Deus, Orientador Maior.


RESUMO
Com os recorrentes casos de furtos de aparelhos eletrônicos, cartões de banco e documentos pessoais (CPF, RG, CNH...) muitas vezes esses objetos são utilizados pelos infratores na tentativa de se obter alguma informação. Tendo esse problema em vista surgiu a ideia de se criar um sistema biométrico baseado no reconhecimento facial, o que possibilitaria, através de um banco de dados, identificar a pessoa e vinculá-la com os seus pertences ou até mesmo verificar se possui alguma pendência com o Estado. Alguns aparelhos móveis já possuem um sistema de desbloqueio via reconhecimento facial, porém muitos deles necessitam de vários registros devido a mudança da iluminação fazendo com que seja necessária a apresentação de uma segunda forma de desbloqueio. Será estudada a possibilidade de se utilizar o descritor LMP (Local Mapped Pattern), desenvolvido no LAVI (Laboratório de Visão Computacional) em programação MatLab (Matrix Laboratory), no reconhecimento facial. Neste trabalho será descrita a metodologia utilizada para obter as imagens utilizadas para testar o método de Viola-Jones, responsável pela segmentação da região da face, e para obter as imagens utilizadas nos testes para o descritor de textura LMP. Também será feita a análise dos resultados obtidos através do método Qui-quadrado para validar a utilização do código LMP como uma “senha” para identificar cada pessoa, mesmo com variações no ambiente e na fisionomia.
Palavras-chave: Reconhecimento facial, Local Mapped Pattern, Viola-Jones


Sumário 1. Introdução .................................................................................................... 1
1.1. Motivação .............................................................................................. 2
1.2. Objetivos ............................................................................................... 2
1.3. Estrutura do Trabalho ............................................................................ 2
2. Fundamentação Teórica .............................................................................. 3
2.2. Viola-Jones ........................................................................................... 3
2.2.1. Imagem Integral ................................................................................. 4
2.2.2. AdaBoost ........................................................................................... 5
2.2.3. Método em Cascata ........................................................................... 7
2.3. LMP (Local Mapped Pattern) ................................................................ 7
2.4. Qui-Quadrado (X²)................................................................................. 8
3. Metodologia ................................................................................................. 9
3.1. Software/Equipamento .......................................................................... 9
3.2. Imagens ................................................................................................ 9
3.3. Algoritmo de Viola-Jones .................................................................... 11
3.4. Algoritmo do LMP ................................................................................ 13
3.5. Algoritmo do Qui-Quadrado (X²) ......................................................... 14
3.6. Programa Principal .............................................................................. 14
4. Resultados ................................................................................................. 15
4.1. Teste do Algoritmo de Viola-Jones ..................................................... 15
4.2. Teste de Identificação ......................................................................... 20
5. Conclusão e continuidade do trabalho ....................................................... 25
5.1. Sugestão de Continuidade do Trabalho .............................................. 28
Referências ...................................................................................................... 29
Apêndice .......................................................................................................... 31
Amostra do banco de imagens utilizado ....................................................... 33
Apêndice A – Códigos em MATLAB (Viola-Jones) ........................................... 35
Apêndice B – Códigos em MATLAB (LMP) ...................................................... 37
Apêndice C – Códigos em MATLAB (Qui-Quadrado) ...................................... 39
Apêndice D – Códigos em MATLAB (Main for) ................................................ 41
Apêndice E – Códigos em MATLAB (Main)...................................................... 43
Função - Leitura das Imagens Base ............................................................. 43
Função - Leitura das Imagens Teste............................................................. 43


Lista de Figuras
Figura 1: Diagrama de etapas. ........................................................................... 1 Figura 2: Resultado da integral de imagem para uma coordenada [1]. .............. 4 Figura 3: Representação gráfica da equação (5) [2]. ......................................... 5 Figura 4: Exemplos de características retangulares definidas para o algorítmo de Viola-Jones. As figuras (A) e (B) representam as características de dois retângulos. A figura (C) mostra a característica de três retângulos, e a figura (D) é a de quatro retângulos [1]................................................................................ 5 Figura 5: Características selecionadas pelo AdaBoost [1]. ................................ 6
Figura 6: ilustração do processo em cascata. .................................................... 7 Figura 7: Diferença de níveis de cinza em uma vizinhança 3x3 [4]. ................... 7
Figura 8: Banco de imagens tiradas pelo celular. ............................................. 10
Figura 9: Imagens retiradas do banco de imagens Faces in the Wild. ............. 10 Figura 10: Ilustração das quatro características estudadas. ............................ 11 Figura 11: Resultado da detecção da face através do algoritmo de Viola-Jones. ......................................................................................................................... 12
Figura 12: Recorte do segmento da imagem correspondente a face detectada pelo algoritmo de Viola-Jones. ......................................................................... 12
Figura 13: Conversão do recorte para níveis de cinza. .................................... 13 Figura 14: Histograma LMP resultante para a face apresentada. .................... 13 Figura 15: Demonstração do cálculo do LMP [4]. ............................................. 14
Figura 16: Resultado da detecção facial utilizando o algoritmo de Viola-Jones [1]. .................................................................................................................... 15
Figura 17: Gráfico com os resultados percentual das detecções nas imagens testes. ............................................................................................................... 16
Figura 18: Caricaturas 3x4 (de Geraldo R. da Silva). ....................................... 18 Figura 19: Gráfico da porcentagem de detecções corretas. ............................. 19
Figura 20: Ocorrência de falso negativo. .......................................................... 19 Figura 21: Número de acertos para cada modificação. .................................... 24
Figura 22: Detecção em condições adversar. .................................................. 25 Figura 23: Gráfico da análise separada por acertos em cada pessoa teste. .... 27 Figura 24: Gráfico da análise separada por números de acertos. .................... 27


Lista de Tabelas Tabela 1: Diretrizes para o treinamento da cascata de detecção [11]. ............. 17 Tabela 2: Resultado para P1 e P2 e suas variações. ....................................... 20 Tabela 3: Resultado para P3 e P4 e suas variações. ....................................... 21 Tabela 4: Resultado para P5 e P6 e suas variações. ....................................... 21 Tabela 5: Resultado para P9 e P10 e suas variações. ..................................... 22
Tabela 6: Resultado para P9 e P10 e suas variações. ..................................... 22 Tabela 7:Resultado para P11 e suas variações. .............................................. 23 Tabela 8: Exemplo de mudança no resultado com a alteração do valor de Beta de 1 para 0,1. ................................................................................................... 26


Lista de Siglas
CPF Cadastro de Pessoa Física
CHN Carteira Nacional de Habilitação
EMV Europay, Mastercard e Visa
LAVI Laboratório de Visão Computacional
LMP Local Mapped Pattern
MATLAB Matrix Laboratory
NFC Near Field Communication
PSO Particle Swarm Optimization
RG Registro Geral
SCM Sample Classification Modifier
X² Qui-Quadrado


1
1. Introdução
Com o desenvolvimento da computação e das tecnologias de captura de imagens, a área de visão computacional vem ganhando espaço gradativamente devido às inúmeras possibilidades de aplicação de seu conceito teórico. Desenvolver e construir sistemas artificiais capazes de retirar informações através da análise de uma imagem ou quaisquer dados multidimensionais é o principal foco de estudo de muitas empresas interessadas no campo da visão computacional. Tão abrangente é a sua aplicação que é possível encontrar exemplos de sua aplicação em diversos setores. A aplicação estudada neste trabalho é voltada para o campo da biometria facial através da utilização do descritor LMP como código gerador das características que irão distinguir uma face da outra. O diagrama da figura 1 mostra cada etapa, desde a obtenção das imagens até o resultado final.
Figura 1: Diagrama de etapas.
A obtenção das imagens será feita de duas formas. Por meio do uso de aparelho celular e pelo uso do banco de imagens Faces in the Wild. Todas as imagens serão utilizadas para testar o método de detecção da face humana de Viola-Jones, porém apenas as imagens obtidas pelo celular serão utilizadas na validação do descritor de textura LMP como um reconhecedor de pessoas. Através das características geradas pelo LMP, o método Qui-quadrado irá avaliar a viabilidade do uso do descritor LMP como um método válido para o reconhecimento facial.
Obtenção das Imagens
Celular
Viola-Jones
LMP
Qui-quadrado
Viabilidade
Comparação
Teste
Banco de imagens Faces in the Wild
Viola-Jones
Viabilidade
Comparação
Teste
método

2
1.1. Motivação Através do convívio na vida profissional com meios de pagamento que
utilizam cartões de plástico EMV (Europay, Mastercard e Visa), mais conhecidos como cartões de chip, foi percebido que com o avanço tecnológico os cartões passaram da utilização da tarja magnética para a utilização dos chips e posteriormente vem sendo utilizados chips com tecnologia sem contato e pagamentos via NFC (Near Field Communication) devido a sua rapidez. Uma característica que não mudou foi a necessidade de possuir um cartão e junto dele lembrar de várias senhas para assegurar a autenticidade do adquirente e para que o mesmo não sofra furtos e/ou fraudes em sua conta pessoal.
Uma alternativa seria a utilização de um sistema biométrico facial que pudesse identificar e validar os serviços sem a necessidade do adquirente precisar decorar diversas senhas, podendo fazer a validação da portabilidade de forma rápida e segura, já que não é necessário que o portador entre em contato com os equipamentos. Além da rapidez, a biometria facial é um método barato quando comparado com as demais formas de biometria. Com apenas uma webcam e um computador a biometria facial pode sem implementada, diferente dos outros métodos que necessitam de equipamentos próprios para a sua aplicação.
1.2. Objetivos
O objetivo deste trabalho é investigar a utilização do descritor de textura
LMP (Local Mapped Pattern) como um extrator de características de um segmento obtido pelo método de Viola-Jones e analisar se essas características obtidas possuem alguma singularidade que permita a sua utilização na identificação pessoal.
Como padrão, será utilizado o método de detecção facial de Viola-Jones para obter o segmento correspondente a face humana, para posteriormente aplicar o descritor de textura LMP.
1.3. Estrutura do Trabalho
Este trabalho de conclusão de curso está dividido da seguinte forma: Capítulo 2 Explanação dos fundamentos teóricos utilizados em cada etapa da
criação da programação responsável pela análise da viabilidade da utilização do descritor de textura LMP como descritor facial.
Capítulo 3 Explanação geral da metodologia e dos algoritmos, divididos em partes. Capítulo 4 Discussão dos resultados. Capítulo 5 Conclusão e sugestões de continuidade.

3
2. Fundamentação Teórica
Neste capítulo serão apresentados os fundamentos teóricos que irão dar base ao trabalho durante todas as etapas da pesquisa. A revisão bibliográfica aqui tem por objetivo dar noção do que será analisado a respeito da aplicação do descritor de textura LMP como método para descrever uma face humana.
Assim será feito primeiramente uma breve contextualização dos métodos utilizados na obtenção dos resultados para viabilizar o LMP como descritor de faces.
2.1. Detecção Facial O primeiro passo no reconhecimento facial é a sua detecção. Em
primeira instância a ideia de reconhecer uma face humana parece ser simples, uma atividade cotidiana para as pessoas. Porém essa função se torna desafiadora para sistemas computacionais devido às diversas variáveis: posição da face, iluminação, características fisiológicas, interferência visual, uso de acessórios, entre outras.
Nesse trabalho será utilizado o método de Viola-Jones para identificar e segmentar a região correspondente a face humana. Como padrão, serão utilizadas fotos em formato 3x4, com variações na iluminação, utilização de acessórios, mudança da expressão facial, obstrução e angulação. As duas últimas alterações serão utilizadas apenas para análise do algoritmo de Viola-Jones.
O segundo passo corresponde a etapa de processamento. O processamento será feito utilizando o descritor de textura LMP, em que o código LMP resultante servirá de base para comparação com as variações testadas (outra face, presença de sorriso, iluminação de flash e uso de acessórios).
O terceiro passo é o método de análise. A análise será feita através da aplicação da distribuição qui-quadrado para comparar o código LMP gerado para cada face base com as faces de teste.
2.2. Viola-Jones
Paul Viola e Michael Jones divulgaram em 2001 o seu detector de objetos que apresentava uma nova forma de representar uma imagem. Chamado de imagem integral (integral image), ele permitia uma análise rápida das características de um objeto [1].
Com base na função de Haar, Viola e Jones desenvolveram um algoritmo que realiza a comparação entre a soma dos pixels de uma área retangular com a soma dos pixels da área retangular vizinha. Através dessas comparações é feito o treinamento das características utilizando o método de aprendizagem AdaBoost e posteriormente é feita a classificação através do método de cascata, que aumenta drasticamente a velocidade de detecção do objeto alvo. Cada passo será descrito nas secções seguintes.

4
2.2.1. Imagem Integral
A imagem integral permite calcular a área retangular definida por uma ou mais coordenadas de uma imagem [1,2]. Usando a equação (1) é possível calcular a imagem integral para uma determinada coordenada.
𝑖𝑖(𝑥, 𝑦) = ∑ 𝑖(𝑥′, 𝑦′)𝑥′<𝑥,𝑦′<𝑦 (1)
em que, ii(x,y) é a imagem integral e i(x,y) é a imagem original. A equação (1) permite calcular a soma dos pixels da coordenada (x,y) até a origem do plano cartesiano. Lembrando que para imagens a origem do plano cartesiano fica localizada no ponto superior esquerdo (figura 2).
Através do par de equações (2) e (3), em que, s(x,y) é a soma cumulativa
da linha, a resultante será a equação (4) que possibilita calcular qualquer segmento tomado no interior da imagem analisada. As funções com coordenadas negativas são consideradas de valor nulo, pois em imagens todas as coordenadas possuem valores superiores positivos.
{𝑠(𝑥, 𝑦) = 𝑠(𝑥, 𝑦 − 1) + 𝑖(𝑥, 𝑦) (2)
𝑖𝑖(𝑥, 𝑦) = 𝑖𝑖(𝑥 − 1, 𝑦) + 𝑠(𝑥, 𝑦) (3)
𝑖𝑖(𝑥, 𝑦) = 𝑖(𝑥, 𝑦) + 𝑖𝑖(𝑥 − 1, 𝑦) + 𝑖𝑖(𝑥, 𝑦 − 1) − 𝑖𝑖(𝑥 − 1, 𝑦 − 1) (4)
Tomando a figura 3 como exemplo, a área do retângulo ABCD é definida
pela equação (5), que nada mais é do que a relação entre as equações (1) e (4).
𝑖𝑖𝐴𝐵𝐶𝐷(𝑥, 𝑦) = 𝑖𝑖𝐷(𝑥′, 𝑦′) + 𝑖𝑖𝐴(𝑥′, 𝑦′) − 𝑖𝑖𝐵(𝑥′, 𝑦′) − 𝑖𝑖𝐶(𝑥′, 𝑦′) (5)
Figura 2: Resultado da integral de imagem para uma coordenada [1].

5
A partir da integral de imagem em conjunto com as características de Haar, Viola e Jones criam um detector que compara a diferença de luminosidade entre duas áreas adjacentes, mostrando ser mais rápida do que a comparação baseada em pixels. A figura 4 mostra quatro possíveis tipos de características-base que são calculadas subtraindo a soma dos valores dos pixels da(s) região(ões) branca(s) com a soma dos valores dos pixels da(s) região(ões) preta(s).
Figura 4: Exemplos de características retangulares definidas para o algorítmo de Viola-Jones. As figuras (A) e (B) representam as características de dois retângulos. A figura (C) mostra a característica de três
retângulos, e a figura (D) é a de quatro retângulos [1].
2.2.2. AdaBoost AdaBoost (Adaptive Boosting) é um algoritmo de aprendizagem, criado
por Yoav Freund e Robert Schapire [3], que pode ser usado para a classificação ou regressão. Embora AdaBoost seja mais resistente à overfitting do que outros algoritmos de aprendizagem de máquina, ele ainda é sensível a dados ruidosos e de valores discrepantes.
AdaBoost é chamado de adaptativo pois ele usa de múltiplas iterações para gerar um único classificador forte. Isso é feito criando vários classificadores fracos iterativamente durante cada ciclo de formação, onde um vetor de ponderação faz com que os classificadores mais fracos sejam combinados para formar um melhor classificador. A margem de precisão dos classificadores fracos
Figura 3: Representação gráfica da equação (5) [2].

6
para o valor esperado é de 51%. AdaBoost é um procedimento eficaz para a busca de um número pequeno de boas características que, no entanto, tem grande variedade. O desafio está em associar o maior peso para os bons classificadores e um peso menor para os classificadores mais fracos. Um método prático é restringir os classificadores fracos em um conjunto de classificação que se restringe a uma única característica. Para essa característica, o classificador fraco determina a melhor função classificadora do limiar (threshold), fazendo com que ocorra um menor número de classificações erradas.
Um classificador fraco, definido pela equação (7), é expresso pela função de característica (f), pelo limiar (θ) e pela polaridade (p). Onde x é uma região da imagem de 24x24 pixels.
ℎ(𝑥) = {1, 𝑠𝑒 𝑝𝑓(𝑥) < 𝑝𝜃0, 𝑐. 𝑐.
(7)
Um classificador forte, definido pela equação (8), é expresso pelo peso
de cada classificador (α).
𝐻(𝑥) = {1, 𝑓(𝑥) ≥
1
2∑ 𝛼
0, 𝑐. 𝑐. (8)
A figura 5 ilustra duas características escolhidas pelo AdaBoost para
reconhecer uma face humana. A característica (A) mede a diferença de intensidade entre a região do olho com a região da bochecha. O algoritmo percebe que a região do olho é mais escura do que a região da bochecha, o mesmo ocorre para a característica (B) onde são comparadas as diferenças de intensidade entre a região dos olhos, região mais escura, com a linha divisória, região mais clara.
Figura 5: Características selecionadas pelo AdaBoost [1].

7
2.2.3. Método em Cascata
Para evitar a perda de tempo computacional, o método em cascata é
aplicado em conjunto com o AdaBoost. As características fortes são postas em sequência para serem aplicadas de forma crescente, filtrando as janelas que não apresentam corretamente as características esperadas. A cada característica, menor será o processamento necessário devido a rejeição dos falsos fragmentos e dos falsos positivos, que reduz o número de análises a serem executadas. A figura 6 ilustra o processo citado.
Figura 6: ilustração do processo em cascata.
2.3. LMP (Local Mapped Pattern)
O descritor LMP [4] [5] assume que cada conjunto de níveis de cinza
distribuídos em uma vizinhança é um padrão. Esse padrão pode ser representado pela diferença dos níveis de cinza das bordas em relação ao valor central. A figura 7 demonstra uma vizinhança de tamanho 3x3 e sua representação em 3D.
Figura 7: Diferença de níveis de cinza em uma vizinhança 3x3 [4].
Cada padrão definido por uma vizinhança WxW pode ser calculado pela
equação (8).
ℎ𝑏 = 𝑟𝑜𝑢𝑛𝑑 (∑ ∑ (𝑓𝑔(𝑖,𝑗)𝑃(𝑘,𝑙))𝑊
𝑙=1𝑊𝑘=1
∑ ∑ 𝑃(𝑘,𝑙)𝑊𝑙=1
𝑊𝑘=1
(𝐵 − 1)) (8)
em que fg(i,j) é a função de mapeamento, P(k,l) é a matriz de peso com valores predefinidos para cada pixel e B é o número de bins do histograma.

8
A equação 8 calcula a soma ponderada da diferença entre cada valor dos pixels da vizinhança com o valor do pixel central, o resultado final é arredondado para o valor inteiro que corresponda a algum valor de bin.
Para análise de texturas, é utilizado como função de mapeamento uma equação comum de uma curva sigmoide definida pela equação (9). Em que, β define a inclinação da curva, A(k,l) é o nível de cinza do pixel da borda da vizinhança e g(i,j) é o nível de cinza do pixel central da vizinhança. A matriz de peso padrão utilizada é uma matriz de 1 de tamanho 3x3.
𝑓𝑔(𝑖, 𝑗) =1
1+𝑒−[𝐴(𝑘,𝑙)−𝑔(𝑖,𝑗)]
𝛽
(9)
2.4. Qui-Quadrado (X²)
Qui-quadrado [6] é uma distribuição utilizada em estatística inferencial, é um teste de hipóteses utilizado para encontrar valores da dispersão para duas variáveis categóricas nominais, avaliando a associação existente entre variáveis qualitativas.
É um teste não paramétrico, ou seja, não depende de parâmetros populacionais como média e variância.
A equação utilizada para o cálculo do X² é a equação (10), que representa a distância Chi-quadrado [7]. A equação de X² tem como parâmetros Pi e Qi, onde Pi é a frequência dos níveis de cinza do LMP da amostra base e Qi é a frequência dos níveis de cinza do LMP da amostra avaliada.
𝑋2(𝑃𝑖𝑄𝑖) =1
2∑
(𝑃𝑖−𝑄𝑖)²
(𝑃𝑖+𝑄𝑖)
255𝑖=0 (10)

9
3. Metodologia
Nas próximas seções serão descritos o equipamento/software e os algoritmos utilizados para obter os dados de análise da viabilidade do uso do LMP para extração de características no processo de reconhecimento facial.
3.1. Software/Equipamento
O software utilizado foi o MatLab (Matrix Laboratory) por ser um software
de ótima qualidade e que possui diversas funcionalidades, além de uma linguagem de programação muito intuitiva para qualquer pessoa que já tenha tido contato com alguma linguagem de programação. Possui compatibilidade com os mais conhecidos sistemas operacionais existentes (Windows, OS, Linux), além de possuir compatibilidade com sistemas móveis como Android e IOS.
Um dos principais motivos da utilização do MatLab no lugar de outros softwares foi a vasta biblioteca de funções matemáticas e algoritmos numéricos, e a presença de Toolbox específicos para processamento de imagens [11] como Computer Vison System Toolbox, Image Processing Toolbox e Image Acquisition Toolbox. A utilização das Toolbox e das funções facilita e melhora o processamento/rendimento da programação, tornando a escrita mais limpa e menos suscetível a erros, pois o programador irá apenas inserir os dados e fazer modificações pontuais. Mesmo inserindo dados errados, o próprio programa irá avisar onde está ocorrendo o erro, seja de escrita ou de valores negados.
As fotos utilizadas foram tiradas de aparelhos móveis de diferentes modelos, alguns deles são: Iphone 6 (câmera traseira 12MP), Sony Xperia SP (câmera traseira 8MP). Alguns pré-processamentos são executados pelo aparelho móvel automaticamente para melhorar o ajuste de luminosidade e de cores (contraste, brilho), e o foco da imagem. Apesar desse pré-processamento ser visualmente agradável aos olhos humanos, essas alterações podem acarretar em mudanças positivas ou negativas na análise final deste trabalho.
3.2. Imagens
Este trabalho avalia dois bancos de imagens: as imagens obtidas através
do uso da câmera de aparelhos móveis (figura 8) e do banco de imagens Faces in the Wild, disponibilizado abertamente pela Universidade de [15].

10
Figura 8: Banco de imagens tiradas pelo celular.
Nos dois bancos as imagens estão no formato 3x4, e apresentam
variações na iluminação, no uso de acessórios, mudança na fisionomia, angulação e obstrução parcial da face. As duas últimas alterações ocorrem apenas no banco de imagens Faces in the Wild. A figura 9 mostra alguns exemplos das faces deste banco.
Figura 9: Imagens retiradas do banco de imagens Faces in the Wild.

11
Neste trabalho foram utilizadas 10 pessoas diferentes com 4 fotos para cada uma delas. Cada pessoa recebeu uma identificação numérica e uma letra inicial que identifica a característica modificada em relação a foto principal (foto base). A figura 10 mostra o que foi modificado para cada foto da 6° pessoa a ser analisada. Pn representa a foto base (padrão 3x4 com fundo branco), Pni representa a utilização de iluminação, Pnm é a representação da foto com uso de algum acessório que possa causar alteração na análise e Pns é a representação da foto com fisionomia alegre (sorriso).
Figura 10: Ilustração das quatro características estudadas.
3.3. Algoritmo de Viola-Jones
O Algoritmo de detecção de faces utilizado (apêndice A) faz uso da
função cascadeObjectDetector(), presente na biblioteca Computer Vision System Toolbox, que realiza a detecção de objetos usando o algoritmo de Viola-Jones [11]. No caso, como a detecção é voltada para faces humanas, o algoritmo procura pelas características de uma face humana vista frontalmente (nariz, olhos, boca). Após encontrar as possíveis faces na imagem analisada (figura 11). O algoritmo recorta, reserva e redimensiona o recorte para posteriormente ser aplicado no descritor LMP (figura 12).
Neste trabalho serão utilizados como parâmetros iniciais do LMP uma vizinhança de 3x3, matriz de peso 3x3 de valores 1, 256 bins, imagem de 125x125 pixels e um β fixo em 1. Os valores de bin e de β foram escolhidos aleatoriamente. Devido ao fato do LMP ser paramétrico, para futuros aprimoramentos, o valor de β e de B devem ser calculados para cada caso de forma a maximizar os resultados obtidos anteriormente com os valores fixos.

12
Figura 11: Resultado da detecção da face através do algoritmo de Viola-Jones.
Figura 12: Recorte do segmento da imagem correspondente a face detectada pelo algoritmo de Viola-
Jones.
É importante lembrar que uma das configurações possíveis de
treinamento de detecção de faces para a função cascadeObjectDetector() é composta pelo descritor LBP (Local Binary Pattern) [11], sendo assim um forte indício favorável a aplicação do LMP como detector de faces, já que o mesmo é uma derivação do LBP. Neste trabalho o LMP será usado apenas para a etapa de classificação da face, deixando a tarefa de identificar o segmento em uma imagem para o algoritmo de Viola-Jones.

13
3.4. Algoritmo do LMP
Uma vez que o processamento feito pelo LMP (apêndice B) é executado em imagens de níveis de cinza, o primeiro processo é a conversão do recorte da face feito pelo algoritmo de Viola-Jones em uma imagem de níveis de cinza através da função rgb2gray() (figura 13).
Figura 13: Conversão do recorte para níveis de cinza.
Após a conversão, é feita uma breve verificação do tamanho da imagem
para que ela não seja processada caso a imagem seja menor do que as dimensões da vizinhança. Neste trabalho a matriz de vizinhança possui tamanho 3x3, sendo assim, 3x3 o tamanho mínimo para a imagem ser processada. Feita a verificação de tamanho, é feito o processamento para o cálculo da equação (8) e da equação (9) para obter o código LMP. O resultado é convertido para o formato uint8 que pode ser representado na forma de histograma, como demonstra a figura 14.
Figura 14: Histograma LMP resultante para a face apresentada.

14
A figura 15 [4] exemplifica como são calculados os códigos LMP no decorrer da imagem analizada.
Figura 15: Demonstração do cálculo do LMP [4].
3.5. Algoritmo do Qui-Quadrado (X²)
No algoritmo destinado ao qui-quadrado é feita a aplicação da equação
(10) para obter a comparação entre as faces a serem examinadas com as faces base (apêndice C).
O cálculo do X² é feito através do uso da função Sample Cassification Modifier que tem como parâmetros de entrada: o número de bins do histograma (B), o número de imagens do conjunto alvo (NI), o número de imagens do conjunto de busca (NI2), os vetores de características do conjunto alvo (IHL) e os vetores de características do conjunto de busca (IHL2).
Em poucas linhas de programação é possível realizar extensos cálculos entre matrizes, com dimensões da casa das centenas, de forma mais prática do que a utilização de comandos como o “for” encadeado (apêndice D). Essa facilidade se dá graças a possibilidade de criar um vetor de células, ou seja, um vetor que pode armazenar vetores/matrizes dentro de cada segmento.
3.6. Programa Principal
O programa principal “Main.m” (apêndice E) faz a chamada das funções
IMG_TESTE e IMG_BASE, que são responsáveis pela leitura das imagens a serem testadas e das imagens base, respectivamente. Seguido pela chamada do algoritmo de Viola-Jones, o programa realiza o processamento para a obtenção do código LMP e realiza a contagem das frequências de ocorrência de cada código LMP da imagem analisada através do comando histcounts().
Após a obtenção das frequências de cada código LMP, é feita a chamada da função sampleClassificationModified para realizar os cálculos do qui-quadrado de cada imagem de teste com cada imagem base, formando uma matriz resultante 10x4. Da matriz de resultados do cálculo do qui-quadrado são retirados quarenta resultados referentes a análise de dez imagens base com quatro variações cada uma, que são analisadas a cada ciclo completo do programa totalizando 400 resultados.

15
4. Resultados A seguir serão apresentados os resultados dos algoritmos relacionados
à detecção e a identificação facial.
4.1. Teste do Algoritmo de Viola-Jones
O algoritmo utilizado foi bem-sucedido na detecção de faces do que o utilizado por Braga [1] em seu trabalho. Realizando os testes de detecção com a mesma imagem utilizada por Braga, onde foram detectados casos de falsos negativos e falsos positivos. O algoritmo de Viola-Jones obteve total êxito em encontrar todas as faces e não detectou os casos de erros presentes no algoritmo de Braga. A figura 16 mostra o resultado de Braga (contorno branco) paralelamente com o resultado atual obtido (contorno amarelo).
Figura 16: Resultado da detecção facial utilizando o algoritmo de Viola-Jones [1].
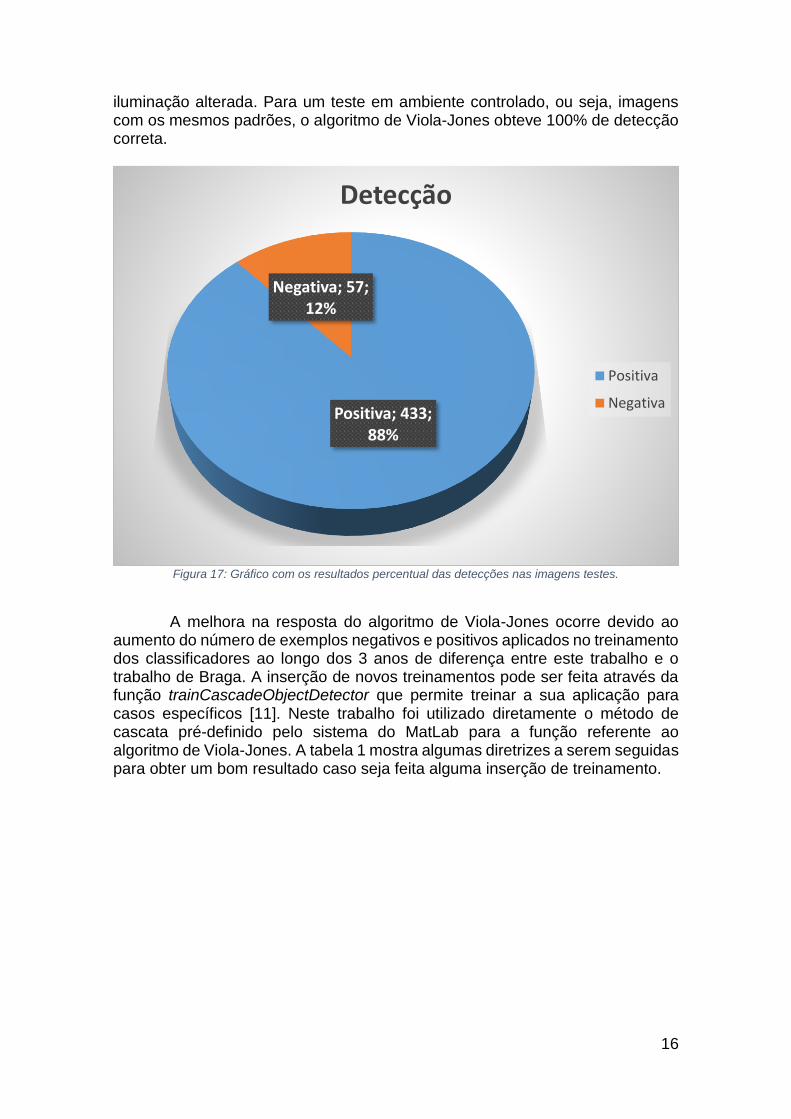
Cerca de 3000 faces retiradas do banco de imagens Faces in the Wild
(Labeled Faces in the Wild, University of Massachusetts – Amherst 1863) [15], foram utilizadas neste trabalho para testar a eficiência do algoritmo de Viola-Jones. A figura 17 mostra o gráfico referente a taxa de detecções de faces. Foi obtido uma taxa de 88% de acerto para uma análise quantitativa, onde foram testados 5 conjuntos de 90 faces mais as 40 faces utilizadas para a análise qui-quadrada, totalizando 490 faces testadas. É importante citar que na análise quantitativa, foram utilizadas imagens de diferentes configurações, entre elas estão: a utilização de acessórios, angulação do rosto, obstrução visual e
16
iluminação alterada. Para um teste em ambiente controlado, ou seja, imagens com os mesmos padrões, o algoritmo de Viola-Jones obteve 100% de detecção correta.
Figura 17: Gráfico com os resultados percentual das detecções nas imagens testes.
A melhora na resposta do algoritmo de Viola-Jones ocorre devido ao
aumento do número de exemplos negativos e positivos aplicados no treinamento dos classificadores ao longo dos 3 anos de diferença entre este trabalho e o trabalho de Braga. A inserção de novos treinamentos pode ser feita através da função trainCascadeObjectDetector que permite treinar a sua aplicação para casos específicos [11]. Neste trabalho foi utilizado diretamente o método de cascata pré-definido pelo sistema do MatLab para a função referente ao algoritmo de Viola-Jones. A tabela 1 mostra algumas diretrizes a serem seguidas para obter um bom resultado caso seja feita alguma inserção de treinamento.
Positiva; 433; 88%
Negativa; 57; 12%
Detecção
Positiva
Negativa

17
Tabela 1: Diretrizes para o treinamento da cascata de detecção [11].
Condição Consideração
Grande número de treinamentos. Aumenta o número de estágios e causa um aumento na ocorrência de falsos positivos para cada estágio da cascata.
Baixo número de treinamentos. Diminui o número de estágios e causa diminuição na ocorrência de falsos positivos para cada estágio da cascata.
Para diminuir a probabilidade de não detecção.
Aumentar o número de casos positivos. Entretanto, uma alta taxa de casos positivos pode eliminar a taxa desejada de falsos positivos em cada nível da cascata, tornando o detector mais susceptível a detecção de falsos negativos.
Para diminuir o número de falsas detecções.
Aumentar o número de estágios ou diminuir a taxa de falsas detecções por estágio.
A figura 18 mostra um conjunto de caricaturas onde algumas delas foram
detectadas pelo detector facial de Viola-Jones. A detecção de faces desenhadas se faz útil para casos de reconhecimento de suspeitos/perdidos onde se possui apenas o seu retrato falado, que certamente não é um método 100% confiável já que a descrição detalhada baseada apenas na memória de uma pessoa não é muito confiável, porém serve como um meio de filtrar os casos a serem analisados.

18
Figura 18: Caricaturas 3x4 (de Geraldo R. da Silva).
A figura 19 mostra o gráfico das detecções corretas. O gráfico mostra que foi detectado 1 caso de falso positivo e 6 casos de detecções mútuas do total de 433 detecções, esse resultado nos dá uma taxa de 99,8% de acerto, já que detecções mútuas correspondem a detecções corretas. Apesar da taxa de 0,20% de erro na detecção, deve-se verificar o resultado da detecção visualmente antes de passar para a análise do código LMP para evitar uma falsa análise.

19
Figura 19: Gráfico da porcentagem de detecções corretas.
A figura 20 mostra a detecção de falso negativos.
Figura 20: Ocorrência de falso negativo.
Comparativamente, Braga testou 200 imagens e obteve 130 detecções,
das 130 detecções foi relatado 1 caso de falso positivo, que corresponde a 0,7%. Ao final, é obtido o resultado de 65% de detecção de fragmentos que possivelmente correspondam a faces humanas e uma taxa de 99,3% de acerto.
Positivo; 426; 98%
Falso Positivo; 1; 0%
Detecção Mútua; 6; 2%
Casos Positivos
Positivo
Falso Positivo
Detecção Mútua

20
4.2. Teste de Identificação
Para o teste de identificação foram utilizadas apenas as imagens tiradas pelo celular, tendo assim maior controle e definição das modificações analisadas.
Os resultados das comparações entre os valores de X² para a classificação das imagens foram tabelados para facilitar a visualização. Em vermelho estão marcados os campos que deveriam ter o menor valor de qui-quadrado e em azul os casos com valores menores do que o apresentado em vermelho. A variação é calculada através da diferença entre o valor obtido para a face correspondente e o menor valor obtido na mesma coluna. A variação total é calculada pela diferença entre o maior valor e o menor valor. A porcentagem de variação para cada teste é calculada a partir da variação total com a variação. A análise da tabela é feita comparando os valores de cada coluna separadamente, sendo independente o valor de uma coluna com o valor da coluna vizinha.
A tabela 2 mostra os resultados da comparação entre as imagens de teste P1 e P2 e as imagens base, identificadas na primeira linha superior e na primeira coluna à esquerda, respectivamente.
Tabela 2: Resultado para P1 e P2 e suas variações.
P1 P1i P1m P1s P2 P2i P2m P2s
P1 0 22,4 103,3 9 473,4 337,8 103,5 274,5
P2 473,4 368,2 758,2 506,3 0 67 357,9 102,5
P3 110,1 93,1 229,5 108,9 206,8 102,4 36,3 47,6
P4 4,8 19,6 112,5 6,8 487,2 338 114,5 285
P5 698,4 555.9 1054,8 743,4 65,1 158 606,3 237,7
P6 43,8 87,1 47,2 30,1 536,4 335,1 82,4 280
P7 134,6 251,6 14,5 103,9 851,8 612,6 142,8 468,2
P8 334,5 509,2 134,3 303,1 1194,9 959,3 330,8 737,3
P9 65,2 154,9 23,1 48 729,9 523,9 115,1 400,6
P10 577,3 393,2 1124,6 657,7 377,8 495,6 797,4 578,1
Variação 0 2,8 88,8 2,2 0 0 321,6 54,9
Variação total
698,4 536,3 1110,1 736,6 1194,9 892,3 761,1 689,7
Variação (%)
0 0,5 8 0,3 0 0 42,2 8
A tabela 3 mostra os resultados da comparação entre as imagens de
teste P3 e P4 e as imagens base, identificadas na primeira linha superior e na primeira coluna à esquerda, respectivamente.
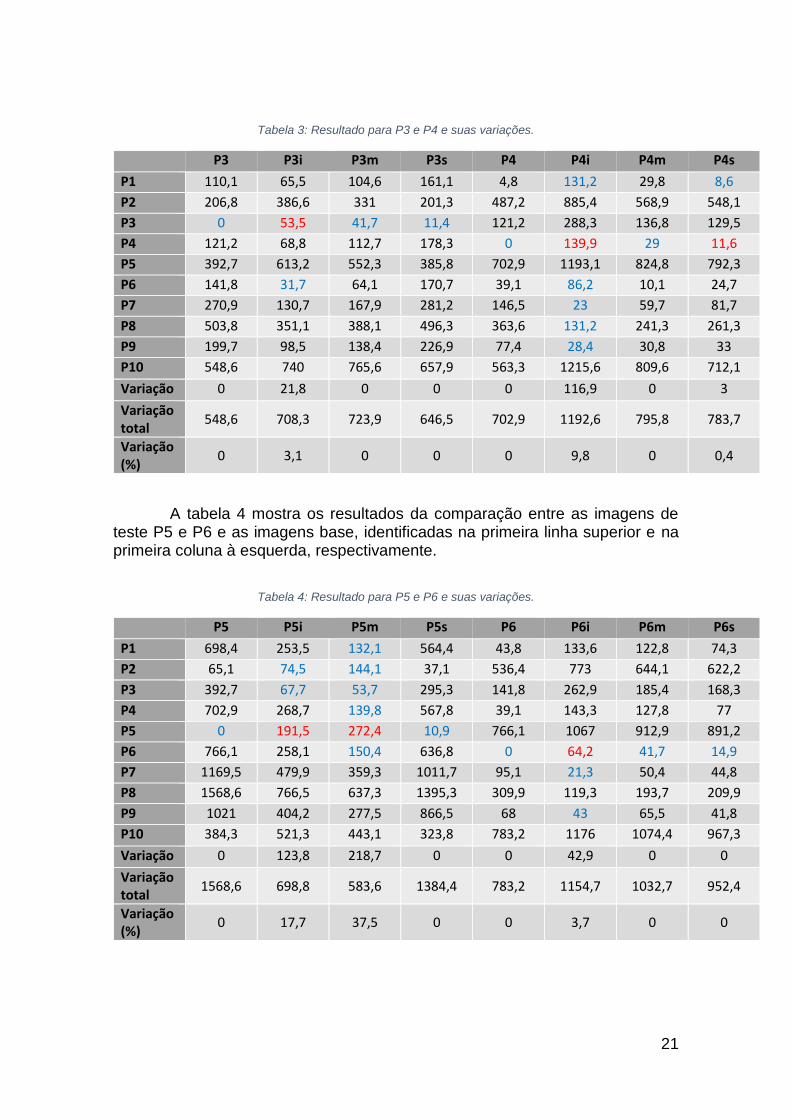
21
Tabela 3: Resultado para P3 e P4 e suas variações.
P3 P3i P3m P3s P4 P4i P4m P4s
P1 110,1 65,5 104,6 161,1 4,8 131,2 29,8 8,6
P2 206,8 386,6 331 201,3 487,2 885,4 568,9 548,1
P3 0 53,5 41,7 11,4 121,2 288,3 136,8 129,5
P4 121,2 68,8 112,7 178,3 0 139,9 29 11,6
P5 392,7 613,2 552,3 385,8 702,9 1193,1 824,8 792,3
P6 141,8 31,7 64,1 170,7 39,1 86,2 10,1 24,7
P7 270,9 130,7 167,9 281,2 146,5 23 59,7 81,7
P8 503,8 351,1 388,1 496,3 363,6 131,2 241,3 261,3
P9 199,7 98,5 138,4 226,9 77,4 28,4 30,8 33
P10 548,6 740 765,6 657,9 563,3 1215,6 809,6 712,1
Variação 0 21,8 0 0 0 116,9 0 3
Variação total
548,6 708,3 723,9 646,5 702,9 1192,6 795,8 783,7
Variação (%)
0 3,1 0 0 0 9,8 0 0,4
A tabela 4 mostra os resultados da comparação entre as imagens de teste P5 e P6 e as imagens base, identificadas na primeira linha superior e na primeira coluna à esquerda, respectivamente.
Tabela 4: Resultado para P5 e P6 e suas variações.
P5 P5i P5m P5s P6 P6i P6m P6s
P1 698,4 253,5 132,1 564,4 43,8 133,6 122,8 74,3
P2 65,1 74,5 144,1 37,1 536,4 773 644,1 622,2
P3 392,7 67,7 53,7 295,3 141,8 262,9 185,4 168,3
P4 702,9 268,7 139,8 567,8 39,1 143,3 127,8 77
P5 0 191,5 272,4 10,9 766,1 1067 912,9 891,2
P6 766,1 258,1 150,4 636,8 0 64,2 41,7 14,9
P7 1169,5 479,9 359,3 1011,7 95,1 21,3 50,4 44,8
P8 1568,6 766,5 637,3 1395,3 309,9 119,3 193,7 209,9
P9 1021 404,2 277,5 866,5 68 43 65,5 41,8
P10 384,3 521,3 443,1 323,8 783,2 1176 1074,4 967,3
Variação 0 123,8 218,7 0 0 42,9 0 0
Variação total
1568,6 698,8 583,6 1384,4 783,2 1154,7 1032,7 952,4
Variação (%)
0 17,7 37,5 0 0 3,7 0 0

22
A tabela 5 mostra os resultados da comparação entre as imagens de teste P7 e P8 e as imagens base, identificadas na primeira linha superior e na primeira coluna à esquerda, respectivamente.
Tabela 5: Resultado para P9 e P10 e suas variações.
P7 P7i P7m P7s P8 P8i P8m P8s
P1 134,6 75,1 327,9 183,3 334,5 151,8 355,1 401,3
P2 851,8 767,3 1145,6 895,4 1194,9 916,6 1205,8 1313,9
P3 270,9 228,5 473,1 307 503,9 316,1 507,2 576,2
P4 146,5 83,7 343,6 198,7 363,6 165,4 380,9 428,3
P5 1169,5 1051,4 1502,9 1225,1 1568,6 1233,8 1577,6 1703,6
P6 95,1 54,9 218,1 116,7 309,9 113 297,6 348,7
P7 0 14 48 7,8 67,2 3,6 61,5 84,9
P8 67,2 120,7 62,7 63,5 0 56,8 9,9 8,7
P9 16,6 6 117,6 41,7 116 22,5 122,1 151,7
P10 1224 1045,6 1694,7 1351,7 1646,6 1278,5 1726,8 1813,3
Variação 0 8 0 0 0 53,2 0 0
Variação total
1224 1045,4 1646,7 1343,9 1646,6 1274,9 1716,9 1804,6
Variação (%)
0 0,8 0 0 0 4,2 0 0
A tabela 6 mostra os resultados da comparação entre as imagens de teste P9 e P10 e as imagens base, identificadas na primeira linha superior e na primeira coluna à esquerda, respectivamente.
Tabela 6: Resultado para P9 e P10 e suas variações.
P9 P9i P9m P9s P10 P10i P10m P10s
P1 65,2 15,7 227 158,2 577,3 402 753,2 557,5
P2 729 470,7 1006,7 909,6 377,8 120,9 358,4 368,9
P3 199,7 104,3 375,2 304,3 548,6 276,6 637,5 522
P4 77,4 13,4 249,6 177 563,3 395,2 744,8 545,3
P5 1021 696,8 1345 1244 384,3 156 356,2 381,3
P6 68 14,6 192,2 136,3 783,2 527,7 972,6 766,3
P7 16,6 106,4 22,9 5,9 1224 915,9 1419 189,4
P8 116 309,1 16 41,3 1646,6 1313,9 1828,6 1601,7
P9 0 61,7 58,5 23,3 1000,2 742,4 1196,2 968,4
P10 1000,2 654,1 1428,2 1277,5 0 85,8 48,1 5,1
Variação 0 48,3 42,5 17,4 0 0 0 0
Variação total
1021 683,4 1412,2 1271,6 1646,6 1228,1 1780,5 1596,6
Variação (%)
0 7,1 3 1,4 0 0 0 0

23
A tabela 7 mostra os resultados da comparação entre as imagens de teste P11 e as imagens base, identificadas na primeira linha superior e na primeira coluna à esquerda, respectivamente.
Tabela 7:Resultado para P11 e suas variações.
P11 P11i P11m P11s
P1 0,37 10³ 1 10³ 0,5 10³ 0,2 10³
P2 0,3 10³ 0,4 10³ 0,2 10³ 0,3 10³
P3 0,39 10³ 0,8 10³ 0,4 10³ 0,3 10³
P4 0,35 10³ 0,9 10³ 0,5 10³ 0,2 10³
P5 0,35 10³ 0,36 10³ 0,17 10³ 0,4 10³
P6 0,5 10³ 1,16 10³ 0,65 10³ 0,3 10³
P7 0,9 10³ 1,7 10³ 1,1 10³ 0,67 10³
P8 1,35 10³ 2,2 10³ 1,57 10³ 1,06 10³
P9 0,7 10³ 1,5 10³ 0,9 10³ 0,5 10³
P10 0,07 10³ 0,09 10³ 0,1 10³ 0,15 10³
P11 0 0,19 10³ 0,05 10³ 0,03 10³
Variação 0 0,1 10³ 0 0
Variação total 1,35 10³ 1,31 10³ 1,52 10³ 1,03 10³
Variação (%)
0 7,6 0 0
Como esperado, a utilização de acessórios é o maior causador de
variações nas comparações das características obtidas, uma vez que é inserido
um corpo estranho que dificulta a análise da face.
No total foi obtido 61% de acerto e 39% de erro para um Beta fixo no
valor β=1. A média da porcentagem da variação fica em 3,7%, mostrando que o
não sucesso na classificação ocorre por uma diferença muita pequena.
Feita a investigação da possibilidade de viabilizar o descritor de textura
LMP no reconhecimento facial e através da análise dos resultados obtidos (figura
21), conclui-se que a variação na iluminação causa a maior taxa de erro na
seleção correta do indivíduo.

24
Figura 21: Número de acertos para cada modificação.
0
2
4
6
8
10
12
Alteração de condições
Número de acertos
Iluminação Uso de acessórios fisionomia padrão

25
5. Conclusão e continuidade do trabalho
O sistema avaliado neste trabalho é constituído de um algoritmo de
detecção facial, um de extração de características e, por fim, um de análise. O algoritmo de detecção utilizado foi baseado no método de Viola-Jones e apresentou resultado de 88% de detecção correta do total de 490 imagens analisadas em 5 conjuntos de 90 imagens, mais as 44 imagens em padrão 3x4. Analisando os 437 casos de detecção, temos: 430 faces corretas, 1 falso negativo e 6 detecções mútuas. Essa taxa pode chegar perto dos 100% de acerto caso sejam usadas apenas imagens no padrão 3x4, com iluminação controlada e com visão frontal da face. Seguindo este padrão, mesmo com a utilização de acessórios, e com a mudança da fisionomia, o algoritmo é capaz de identificar a face humana, alguns exemplos são exibidos na figura 22.
Figura 22: Detecção em condições adversar.
O algoritmo de extração de características, baseado no descritor de
textura LMP, não teve problemas devido à pré-verificação do tamanho da imagem, que deve ser de tamanho maior do que o tamanho da matriz de vizinhança utilizada, e do redimensionamento feito anteriormente a obtenção do código LMP. O seu resultado é juntamente analisado com o resultado final obtido do algoritmo de análise. O algoritmo de análise, baseado no qui-quadrado, mostrou que o resultado favorável de 60% faz necessária a otimização dos parâmetros Beta e Bin no processo de obtenção do código LMP de cada imagem para eliminar/reduzir a variação de 3,7% do valor esperado e aumentar as chances de sucesso na discriminação do indivíduo. Esse processo irá afetar

26
diretamente no cálculo do código LMP e no vetor de características, favorecendo uma análise otimizada para se obter o valor qui-quadrado.
A tabela 8 mostra um exemplo de como a alteração do Beta pode afetar a análise, melhorando o seu desempenho.
Tabela 8: Exemplo de mudança no resultado com a alteração do valor de Beta de 1 para 0,1.
P1i P1i
P1 22,4 4,2
P2 368,2 276,1
P3 93,1 46,3
P4 19,6 6
P5 555,9 450,7
P6 87,1 23,7
P7 251,6 35,6
P8 509,2 120,9
P9 154,9 25,9
P10 393,2 58,6
Variação 2,8 0
Variação total
536,3 446,5
Variação (%)
0,5 0
BETA 1 0,1
A taxa de 60% de acerto irá aumentar para uma análise com maior
número de faces testes e com otimização dos parâmetros Beta e Bin, como mostra a tabela 8. Os gráficos representados nas figuras 23 e 24, mostram a análise da distribuição da taxa de acertos para cada conjunto de imagem e a frequência de ocorrência de acertos. Apesar do gráfico mostrar um empate entre os conjuntos que tiveram de 25% a 50% de acerto e entre os conjuntos que tiveram de 51% a 100% de acerto, a média ponderada fica em 2,4 acertos por conjunto e tenderá a aumentar com a aplicação dos critérios citados anteriormente.
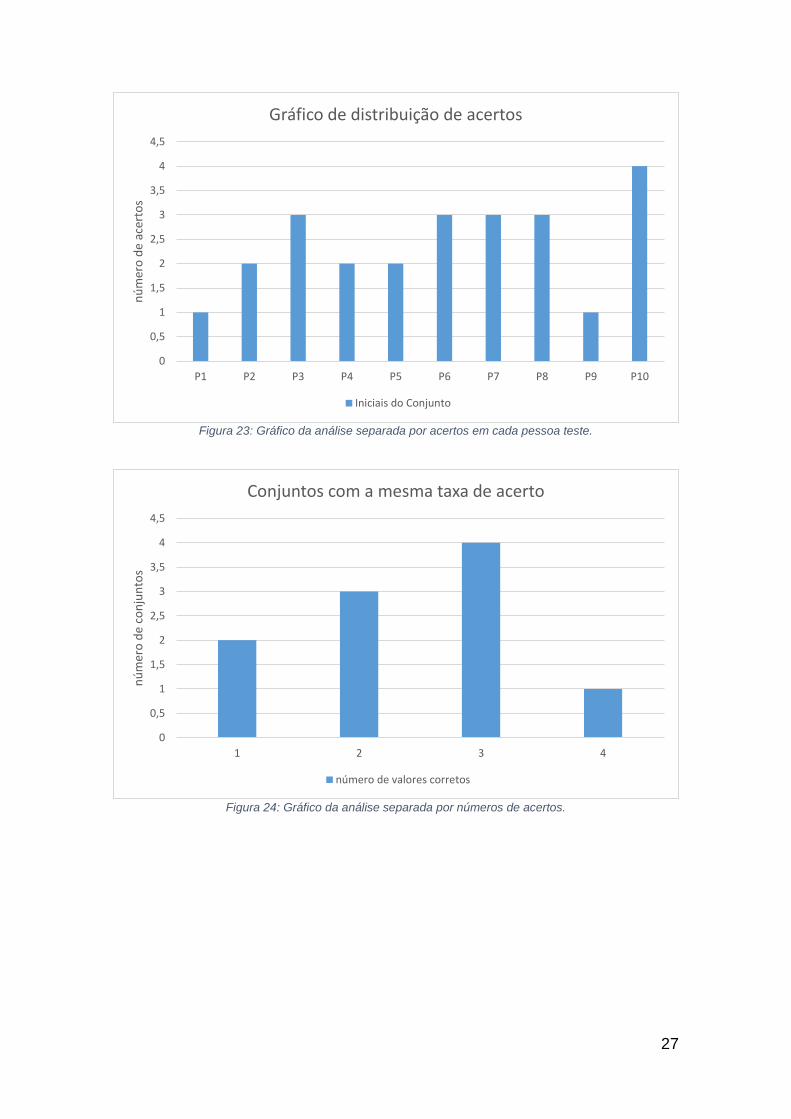
27
Figura 23: Gráfico da análise separada por acertos em cada pessoa teste.
Figura 24: Gráfico da análise separada por números de acertos.
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
P1 P2 P3 P4 P5 P6 P7 P8 P9 P10
nú
mer
o d
e ac
erto
s
Gráfico de distribuição de acertos
Iniciais do Conjunto
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
1 2 3 4
nú
mer
o d
e co
nju
nto
s
Conjuntos com a mesma taxa de acerto
número de valores corretos

28
5.1. Sugestão de Continuidade do Trabalho
Para a continuidade desse trabalho pode ser feita a otimização do detector facial de Viola-Jones melhorando o método de cascata realizando o treinamento do “boosting”, melhorando a detecção para imagens fora do padrão 3x4 definido neste trabalho. Recomenda-se a realização de mais testes para aumentar a base de testes para firmar a viabilidade do uso do LMP como reconhecimento facial.
Pode-se também fazer a aplicação do algoritmo de otimização PSO (Particle Swarm Optimization), desenvolvido por James Kennedy e Russel Eberthart em 1995, para otimizar os valores de Beta e Bin para cada fragmento analisado.

29
Referências [1] Paul Viola, M. J. (13 de Julho de 2001). Robust Real-time Object Detection.
Vancouver, Canadá. [2] Braga, L. F. (2013). Sistemas de Reconhecimento Facial. São Carlos, São
Paulo, Brasil. [3] Yoav Freund, R. E. (20 de Setembro de 1995). A Decision-Theoretic
Generalization of on-Line Learning and an Application to Boosting. Murray Hill, NJ, USA.
[4] Vieira, R. T. (2015). Otimização do descritor paramétrico LMP para a classificação de texturas com variação de rotação. São Carlos, SP, Brasil.
[5] Carolina Toledo Ferraz, O. P. (2014). Feature description based on Mean Local Mapped. São Carlos, SP, Brasil.
[6] PELE, O. &. (2010). The Quadratic-Chi Histogram Distance Family. In: Proceedings of the 11th European Conference on Computer Vision.
[7] Conti, F. (s.d.). Biometria Qui-Quadrado. PA, Brasil. [8]. (s.d.). http://www.mathworks.com/help/?s_tid=hp_ff_l_doc. [9]..(s.d.)https://www.mathworks.com/help/vision/ref/vision.cascadeobject
detector-class.html. [10] Ojala Timo, P. M. (2002). Multiresolution Gray-Scale and Rotation Invariant
Texture Classification with Local Binary Patterns. [11]. (s.d.). Train a Cascade Object Detector,
https://www.mathworks.com/help/vision/ug/train-a-cascade-object-detector.html.
[12] Daniel Maturana, D. M. (s.d.). Face Recognition with Local Binary Patterns, Spatial Pyramid Histograms and Naive Bayes Nearest Neighbor classification. Santiago, Chile.
[13] João Paulo Brognoni Casati, E. L. (2013). Método para segmentação de pele humana em imagens faciais baseado em informações de cor e textura. São Carlos, SP, Brasil.
[14] Kwok-Wai Wong, K.-M. L.-C. (25 de Agosto de 2000). An efficient algorithm for human face detection and facial feature extraction under different conditions. Hung Hom, Hong Kong, China.
[15]. (s.d.). http://vis-www.cs.umass.edu/lfw/#download.

30

31
Apêndice

32

33
Amostra do banco de imagens utilizado

34

35
Apêndice A – Códigos em MATLAB (Viola-Jones) function [result] = Viola_Jones_img( Img ) %Viola_Jones_img( Img ) % Img - input image % Example how to call function:
Viola_Jones_img(imread('name_of_the_picture.jpg'))
faceDetector = vision.CascadeObjectDetector; bboxes = step(faceDetector, Img); figure, imshow(Img), title('Detected faces');hold for i=1:size(bboxes,1) rectangle('Position',bboxes(i,:),'LineWidth',1,'EdgeColor','y'); end num = 1; for i=1:size(bboxes,1) %% Recorte das faces img = imcrop(Img,bboxes(i,:)); %recorta a face
%% Chamando a função LMP img = imresize(img, [125 125]); %mesmo tamanho para todas as
imagens neighborSize = 3; %não mudar!!! bin = 256; %se possível será otimizado beta = 1; %se possível será otimizado result = LMP(img, neighborSize, bin, beta); %tira o histograma
LMP de cada rosto
end end

36

37
Apêndice B – Códigos em MATLAB (LMP) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % LMP - Local Mapped Pattern % % Input arguments: % img - Gray scale image. % neighborSize - number of sample point in an square window. % beta - sigmoid function parameter. % bin - number of histogram bins % function result = LMP(img, neighborSize, bin, beta)
% Argumentos de inicialização figure, subplot(1,2,1), imshow(img); img = rgb2gray(img); imshow(img)
%Programa LPM if neighborSize < 3 || floor(neighborSize/2) == 0 error('A vizinhança deve ser um número ímpar maior ou igual a
3!'); end;
img = double(img); img = img(:,:,1);
% Tamanho da imagem original [ysize xsize] = size(img);
if(xsize < neighborSize || ysize < neighborSize) error('Imagem muito pequena. Deve ter pelo menos o tamanho da
janela.'); end
weightMatrix = [1 1 1; 1 1 1; 1 1 1]; % weightMatrix = [1 1 1; 1 0 1; 1 1 1];
border = fix(neighborSize/2); dataMatrix = img(2*border : ysize - border, 2*border : xsize -
border);
[matrixSizeY matrixSizeX] = size(dataMatrix); pertinenceSum = zeros(matrixSizeY, matrixSizeX); weightSum = 0;
for i = 1 : neighborSize for j = 1 : neighborSize weight = weightMatrix(i, j);
windowData = img(i : (i+matrixSizeY) - 1, j : (j+matrixSizeX)
- 1);
expData = windowData - dataMatrix; map = 1./(1 + exp(-expData/beta));

38
mapSum = pertinenceSum + (map * weight); weightSum = weightSum + weight; end end
result = round(mapSum / weightSum * bin); result = uint8(result); subplot(1,2,2), imhist(result);hold end

39
Apêndice C – Códigos em MATLAB (Qui-Quadrado) function MCS = sampleClassificationModified(B,NI,NI2,IHL,IHL2)
% B = bins dos histograma, % NI = número de imagens do conjunto alvo % NI2 = número de imagens do conjunto busca % IHL = vetores de caracteríticas do conjunto alvo % IHL2 = vetores de características do conjunto busca
HistComp = zeros(1, B); HistRef = zeros(1, B); ChiSquare = zeros(1, NI); MatrixChiSquare = zeros(length(NI), NI);
for r = 1 : NI2 HistRef = IHL2{r};
% Comparação da Sample de referência com as demais Samples da base
de dados for p = 1 : NI HistComp = IHL{p};
subMatrix = HistComp - HistRef; subMatrix2 = subMatrix .^2; addMatrix = HistComp + HistRef;
idxZero = find(addMatrix == 0); addMatrix(idxZero) = 1;
DistMat = subMatrix2./addMatrix; DV = sum(DistMat,2);
ChiSquare(p) = DV; %armazena os valores chi-quadrado end
MCS(r, :) = ChiSquare'; end end

40

41
Apêndice D – Códigos em MATLAB (Main for) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Rafael Taniwaki 2016 % % Escola de Engenharia de São Carlos - EESC USP % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% clear all clc
Img = imread('p1.jpg'); [result] = Viola_Jones_img(Img); N1 = histcounts(result);
Img = imread('p1.jpg'); [result] = Viola_Jones_img(Img); N2 = histcounts(result);
Img = imread('p2.jpg'); [result] = Viola_Jones_img(Img); N3 = histcounts(result);
Img = imread('p3.jpg'); [result] = Viola_Jones_img(Img); N4 = histcounts(result);
Img = imread('p4.jpg'); [result] = Viola_Jones_img(Img); N5 = histcounts(result);
[m n] = size(N1); N12 = 0; N13 = 0; N14 = 0; N15 = 0; for a = 1:1:m for b = 1:1:n if N1(a,b) ~= 0 & N2(a,b) ~= 0 N12=N12+((N2(a,b)-N1(a,b))^2)/(N1(a,b)+N2(a,b)); end if N1(a,b) ~= 0 & N3(a,b) ~= 0 N13=N13+((N3(a,b)-N1(a,b))^2)/(N1(a,b)+N3(a,b)); end if N1(a,b) ~= 0 & N4(a,b) ~= 0 N14=N14+((N4(a,b)-N1(a,b))^2)/(N1(a,b)+N4(a,b)); end if N1(a,b) ~= 0 & N5(a,b) ~= 0 N15=N15+((N5(a,b)-N1(a,b))^2)/(N1(a,b)+N5(a,b)); end end end N12 = N12/2 N13 = N13/2 N14 = N14/2 N15 = N15/2

42

43
Apêndice E – Códigos em MATLAB (Main) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % Rafael Taniwaki 2016 % % Escola de Engenharia de São Carlos - EESC USP % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% clear all clc %% Parâmetros para o SCM B = 256; NI = 4; NI2 = 10;
%% Número do conjunto de imagens a serem analisadas (pn, pni, pnm,
pns) n = 1;
%% Chamada das funções destinadas a leitura das imagens de teste e de
base [IHL] = IMG_TESTE(n); [IHL2] = IMG_BASE(NI2);
%% Chamada do SCM para cálculo do X² MCS = sampleClassificationModified(B,NI,NI2,IHL,IHL2); MCS = MCS/2
Função - Leitura das Imagens Base function [IHL2] = IMG_BASE(NI2)
for i = 1:1:NI2 nome{i} = ['p',num2str(i),'.jpg']; Img = imread(nome{i}); [result] = Viola_Jones_img(Img); IHL2{i} = histcounts(result); end end
Função - Leitura das Imagens Teste function [IHL] = IMG_TESTE(n)
nome{1} = ['p',num2str(n),'.jpg']; nome{2} = ['p',num2str(n),'i.jpg']; nome{3} = ['p',num2str(n),'m.jpg']; nome{4} = ['p',num2str(n),'s.jpg']; for i = 1:1:4 Img = imread(nome{i}); [result] = Viola_Jones_img(Img); IHL{i} = histcounts(result); end end




























