Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
INSTITUTO DE MATEMÁTICA
DEPARTAMENTO DE MÉTODOS ESTATÍSTICOS
Análise Bayesiana de Processos de Difusão
Multivariados com Observações Discretas
Vinicius Pinheiro Israel
Orientador: Prof. Dr. Hélio S. Migon
Rio de Janeiro - RJ
2011

ANÁLISE BAYESIANA DE PROCESSOS DE DIFUSÃOMULTIVARIADOS COM OBSERVAÇÕES DISCRETAS
Vinicius Pinheiro Israel
Tese de Doutorado submetida ao Programa de Pós-
graduação em Estatística do Instituto de Matemática
da Universidade Federal do Rio de Janeiro como parte
dos requisitos necessários para obtenção do grau de
Doutor em Ciências Estatísticas.
Orientador: Hélio dos Santos Migon
Rio de Janeiro, fevereiro de 2011.

ANÁLISE BAYESIANA DE PROCESSOS DEDIFUSÃO MULTIVARIADOS COM OBSERVAÇÕES
DISCRETAS
Vinicius Pinheiro Israel
Orientador: Hélio dos Santos Migon
Tese de Doutorado submetida ao Programa de Pós-graduação em Estatística do Insti-
tuto de Matemática da Universidade Federal do Rio de Janeiro como parte dos requisitos
necessários para obtenção do grau de Doutor em Ciências Estatísticas.
Aprovada por:
Prof. Hélio dos Santos Migon
IM-UFRJ - Orientador
Prof. Leandro P. R. Pimentel
IM-UFRJ
Profa. Chang Chung Yu Dorea
UnB
Prof. Dani Gamerman
IM-UFRJ
Prof. Bernardo Nunes Borges de Lima
UFMG
Rio de Janeiro, fevereiro de 2011.

FICHA CATALOGRÁFICA
Israel, Vinicius Pinheiro.
Análise Bayesiana de Processos de Difusão Multivariados com
Observações Discretas / Vinicius Pinheiro Israel. - Rio de Janeiro:
UFRJ, IM, Programa de Pós-graduação em Estatística, 2011.
xi, 189 f.: il..; 31 cm.
Orientador: Hélio dos Santos Migon
Tese (Doutorado) - UFRJ, IM, Programa de Pós-graduação em
Estatística, 2011.
Referências bibliográfica: f.182-189.
1. Processos estocásticos. 2. Inferência bayesiana. 3. Estatística
Espacial. - Tese. I. Migon, Hélio dos Santos. II. UFRJ / IM /
Programa de Pós-graduação em Estatística. III. Título.

À minha família e em memória de
meus avós Daniel e América Israel
e da amiga Jacinay de Ávila.

“Sonha e serás livre de espírito...
luta e serás livre na vida.”
Che Guevara.

Agradecimentos
Esta é uma das partes mais importantes da tese. Os nomes que aparecem a seguir
foram fundamentais para o início, desenvolvimento e conclusão deste trabalho.
Agradeço ao meu orientador Hélio Migon por me dar a oportunidade de entrar no
doutorado e por aceitar o desafio de percorrer comigo essa jornada.
Agradeço ao meu orientador de mestrado, Mauro Rincon, que além de convidar o
Migon como avaliador da minha dissertação de mestrado me deu apoio incondicional em
minha mudança de área.
O suporte da minha família foi decisivo para enfrentar as barreiras que apareceram no
caminho. Então agradeço a meu pai José Paulo, minha mãe Angela, minha avó Isaura,
minhas irmãs Karina e Isabela e a Maria de Lourdes, que acompanha a minha família há
mais de 50 anos.
Algumas pessoas me ensinaram o significado de fazer uma pós-graduação mostrando
o que isto implica como transformação e aprofundamento profissional/intelectual. Muito
obrigado à Jacinay de Ávila e à Gisely Pereira. Na verdade se fosse agradecer a Gisely
por tudo que ela me ajudou essa seção viraria um capítulo, talvez um volume. Estendo
esse muito obrigado a minha irmã emprestada Jocasta.
Muitas pessoas entraram e saíram da pós-graduação no período que estive no douto-
rado. Gostaria de agradecer a todos os amigos que fiz neste período. Como são muitos
e corro o risco de ser indelicado esquecendo alguém, cito aqueles que entraram junto
comigo. Obrigado, Josi Baldo, Luzia Tonon, Joaquim Neto, Flavio Bambirra, Vinicius
Mayrink, Fidel Castro, Valmária Rocha, Leonardo da Costa, Alexandre Silva e Fernando
Nascimento. Em especial agradeço a Priscilla Silva que me ensinou que existem coisas na
vida de que não se deve abrir mão. E agradeço à Nathania Altman por sempre ter um
sorriso incentivador e um olhar doce para as horas mais assustadoras e por me mostrar
um caminho.

Agradeço ao amigo Carlos Abanto Valle pela ajuda sempre pronta em exercícios de
probabilidade e inferência. Exercícios que para mim pareciam impossíveis ele os tratava
como triviais. Obrigado pelas boas conversar na hora do cafezinho e pelos conselhos e
ensinamentos que guardo com cuidado. Estendo esse agradecimento à Magda e ao Andrès,
esposa e filho do Abanto, amigos que ganhei por tabela.
Ao término do doutorado, me dei conta como um único centro de ensino pode formar
pesquisadores desde o inicio da vida profissional, até o doutorado. Por isso sou pro-
fundamente grato à UNIVERSIDADE FEDERAL DO RIO DE JANEIRO, minha casa
desde 1998 quando entrei para estudar matemática, no auge dos meus 17 anos. Primeiro
agradeço a todos os funcionários, em especial, Tia Deise, Davi, Cristiano e Eduardo (se-
cretários) e Samantha e Leila (bibliotecárias). Nas minhas estimativas, durante todo meu
período de formação tive aula com mais de 40 professores do Instituto de Matemática,
fazendo mais de 53 cursos (sem contar os seminários e cursos como ouvinte). Agradeço a
todos os professores em especial aos do programa de Pós-Graduação em Estatística.
Agradeço ao Departamento da Ciência da Computação (DCC-UFRJ). Foi lá que
aprendi a lecionar quando fui professor substituto o que me permitiu arcar financeira-
mente com o primeiro ano de doutorado.
Esta tese só foi possível pelo financiamento concedido pelo CNPq.

Resumo
Processos de difusão vêm ganhando cada vez mais espaço na literatura estatística
recente. Impulsionados por problemas em finanças e em virtude de seu vasto campo
de aplicação (como Engenharia, Física, Meio Ambiente, entre outros) esses processos
configuram campo interessante de estudo teórico e de aplicação estatística. Inicialmente
este trabalho faz uma revisão na literatura sobre estimação de parâmetros de processos
de difusão e aumento de dados. Em seguida, propõe-se uma extensão multivariada do
processo de Cox et al. (1985) e desenvolve-se formas de inferência de seus parâmetros.
Uma aplicação é feita para o problema de estimar a taxa de emissão de um gás poluente
proveniente de áreas alagadas por reservatórios de hidrelétricas. Modelos são apresentados
em duas direções: partindo da solução de uma equação diferencial ordinária (EDO) e
baseados em uma equação diferencial estocástica (EDE) fazendo uso de algum esquema
de discretização. Coloca-se uma estrutura hierárquica para representar a relação entre as
posições espaciais das observações com a dinâmica do gás no tempo. Modelos hierárquicos
aplicados à emissão de gases de efeito estufa, fazendo uso de inferência bayesiana, são
novos na literatura e contribuem para estimar a quantidade de poluição deste tipo que é
lançada na atmosfera pelo Brasil. Os modelos propostos são aplicados a dados reais e os
resultados são apresentados.
Ao final, formula-se um processo de difusão multivariado espaço-temporal. A esti-
mação dos parâmetros, na prática, parte de observações em períodos de tempo discreto
enquanto o modelo é contínuo. A contribuição original está em desenvolver processos
de difusão espaciais e fornecer técnicas de estimação para seus parâmetros. A estrutura
espacial será colocada na função de volatilidade. Aplicações com dados simulados são
apresentadas. A inferência segue o enfoque bayesiano partindo de técnicas de MCMC
tanto para estimação dos parâmetros quanto para o aumento de dados.
Palavras-chaves: equações diferenciais estocásticas, modelos espaço-temporais contí-
nuos e discretos, modelos hierárquicos, processos estocásticos, estimação bayesiana, au-
mento de dados.

Abstract
Diffusion processes have become a standard tool in recent statistical literature.
Motivated by problems in finance and by virtue of its broad scope (such as Engineering,
Physics, Environment, among others), these processes make up an interesting field of
theoretical study and statistical application. First this thesis reviews the literature on
parameter estimation of diffusion processes and data augmentation. Then, we propose a
multivariate extension of the Cox et al. (1985) process and we develop ways to infer its
parameters.
An application is made for the problem of estimating the emission rate of a polluting
gas from areas flooded by an hydroelectric reservoir. Models are presented in two directi-
ons: from the solution of an ordinary differential equation (ODE) and from a discretization
scheme applied on a stochastic differential equation (SDE). We place a hierarchical struc-
ture to represent the relationship between the spatial positions of the observations with
the gas dynamics in time. Hierarchical models applied to emission of greenhouse gases,
using Bayesian inference, are new in the literature and contribute to estimate the amount
of pollution of this type that is released into the atmosphere by Brazil. The proposed
models are applied to real data and results are presented.
At the end, we make up a multivariate space-time diffusion process. The estimation of
parameters in practice, comes from observations in discrete time periods while the model
is continuous. The contribution is to develop spatial diffusion processes and techniques
for estimating its parameters overcoming discretization bias. Spatial structure will be
placed on the volatility function. Applications using simulated examples are presented.
The inference follows the Bayesian approach using MCMC techniques for both parameters
and data augmented estimations.
Keywords: stochastic differential equations, continuous and discrete space-time mo-
dels, hierarchical models, stochastic processes, Bayesian estimation, data augmentation.

Sumário
1 Introdução 1
1.1 Breve histórico sobre processos de difusão . . . . . . . . . . . . . . . . . . 1
1.2 Contribuições e organização do trabalho . . . . . . . . . . . . . . . . . . . 4
1.3 Notação empregada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Preliminares 8
2.1 Definições básicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Equações diferenciais estocásticas - EDEs . . . . . . . . . . . . . . . . . . . 11
2.3 Esquemas de discretização . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 Esquema de Euler-Maruyama . . . . . . . . . . . . . . . . . . . . . 15
2.3.2 Esquemas de Milstein e ordem superior . . . . . . . . . . . . . . . . 15
2.4 Verossimilhança do processo de difusão . . . . . . . . . . . . . . . . . . . . 16
2.4.1 Pela Fórmula de Girsanov . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.2 Por densidades de transição . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Aumento de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.6 Principais processos de difusão . . . . . . . . . . . . . . . . . . . . . . . . . 21
3 Processo CIR 23
3.1 CIR univariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.1 Esquema de Euler-Maruyama . . . . . . . . . . . . . . . . . . . . . 24
3.1.2 Inferência bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . 24
i

3.1.3 Exemplo simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 CIR multivariado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.1 Notas sobre a existência e unicidade de soluções . . . . . . . . . . . 33
3.2.2 Esquema de Euler-Maruyama . . . . . . . . . . . . . . . . . . . . . 34
3.2.3 Transformação dos dados . . . . . . . . . . . . . . . . . . . . . . . . 34
3.2.4 Inferência bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.5 Exemplo simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4 Aumento de Dados 46
4.1 Movimentos simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.1.1 Exemplo simulado - CIR univariado . . . . . . . . . . . . . . . . . . 49
4.1.2 Exemplo simulado - CIR multivariado . . . . . . . . . . . . . . . . 58
4.2 Fórmula de Girsanov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.2.1 Fatoração da medida dominante . . . . . . . . . . . . . . . . . . . . 64
4.2.2 Inferência dos parâmetros e dos dados aumentados . . . . . . . . . 67
4.2.3 Exemplo simulado - CIR univariado . . . . . . . . . . . . . . . . . . 68
4.3 Discussões e trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . . . . 74
5 Modelos para Difusão de Gases em Reservatórios de Hidrelétricas 75
5.1 Definição do problema e descrição dos dados . . . . . . . . . . . . . . . . . 76
5.2 Modelos hierárquicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2.1 Modelo sem estrutura espacial (M1) . . . . . . . . . . . . . . . . . . 80
5.2.2 Modelo com estrutura espacial (M2) . . . . . . . . . . . . . . . . . 86
5.3 Modelos de difusões multivariadas para expansão de gases . . . . . . . . . 92
5.3.1 Modelo CIR multivariado . . . . . . . . . . . . . . . . . . . . . . . 92
5.3.2 CIR hierárquico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.4 Comparação entre modelos . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
5.5 Regressão total . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5.6 Cálculo da emissão total do reservatório . . . . . . . . . . . . . . . . . . . 109
ii

5.6.1 Cálculo da emissão total pela taxa conjunta . . . . . . . . . . . . . 110
5.6.2 Cálculo da emissão total por sub-regiões . . . . . . . . . . . . . . . 113
5.6.3 Cálculo da emissão total pelo acréscimo de um nível de hierarquia
relacionado a regiões de influência . . . . . . . . . . . . . . . . . . . 114
6 Processo de Difusão com Estrutura Espacial 116
6.1 Modelos com estrutura espacial . . . . . . . . . . . . . . . . . . . . . . . . 118
6.1.1 Estrutura espacial sobre a função de volatilidade - PDEEv . . . . . 119
6.1.2 Estrutura espacial hierárquica - PDEEh . . . . . . . . . . . . . . . 120
6.2 Função de covariância e de correlação . . . . . . . . . . . . . . . . . . . . . 120
6.2.1 Família exponencial de potência . . . . . . . . . . . . . . . . . . . . 121
6.2.2 Família Matérn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.2.3 Família esférica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.3 CIR multivariado com estrutura espacial . . . . . . . . . . . . . . . . . . . 122
6.3.1 Estrutura espacial na volatilidade . . . . . . . . . . . . . . . . . . . 123
6.3.2 Estrutura espacial hierárquica . . . . . . . . . . . . . . . . . . . . . 123
6.4 Inferência . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.4.1 Inferência dos parâmetros espaciais e do vetor direção . . . . . . . . 126
6.5 Exemplo simulado 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
6.6 Exemplo simulado 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
7 Conclusões e Trabalhos Futuros 143
A Análise dos dados de Corumbá 146
A.1 Modelo hierárquico sem estrutura espacial - M1 . . . . . . . . . . . . . . . 146
A.2 Modelo hierárquico com estrutura espacial - M2 . . . . . . . . . . . . . . . 154
A.3 Modelo CIR hierárquico . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
B Programa CIR multivariado com estrutura espacial 170
iii

Referências Bibliográficas 182
iv

Lista de Tabelas
2.1 Processos de difusão. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1 Estatísticas do procedimento de inferência: médias a posteriori e desvios-
padrão (em parênteses). A primeira linha exibe os parâmetros e a segunda
linha seus valores verdadeiros. A terceira linha refere-se ao exemplo com
todos os dados observados como feito na Seção 3.1, a quarta linha considera
somente observados os dados de 10 em 10 unidades de tempo e a última
linha corresponde ao exemplo em questão. . . . . . . . . . . . . . . . . . . 56
4.2 Sumário das amostras a posteriori de α, β e σ2. . . . . . . . . . . . . . . . 72
5.1 Estatísticas (média, desvio padrão e quartis) sobre a amostra a posteriori
dos principais parâmetros do modelo M1 para as campanhas 1, 2 e 3 do
reservatório de Corumbá. . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.2 Estatísticas (média, desvio padrão e quartis) sobre a amostra a posteriori
dos principais parâmetros do modelo CIR hierárquico para as campanhas
1, 2 e 3 do reservatório de Corumbá. . . . . . . . . . . . . . . . . . . . . . 99
5.3 Comparação entre os modelos por DIC e funções escore. . . . . . . . . . . 104
5.4 Modelos para regressão total. . . . . . . . . . . . . . . . . . . . . . . . . . 106
5.5 Sumário das estatísticas (média, desvio padrão e quartis) das amostras a
posteriori dos fluxos pelos modelos M1T e M2T para as campanhas 1, 2 e
3 do reservatório de Corumbá. . . . . . . . . . . . . . . . . . . . . . . . . 106
5.6 Critérios de comparação de modelos da regressão total . . . . . . . . . . . 109
v

5.7 Estatísticas da emissão total do reservatório de Corumbá considerando as
três campanhas e os métodos M1 e CIR hierárquico (MH) em tonelada
CH4/dia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
6.1 Raiz do erro quadrado médio√EQM . . . . . . . . . . . . . . . . . . . . . 141
1.1 Estatísticas das taxas de emissão no instante inicial para as campanhas 1,
2 e 3 do reservatório de Corumbá - M1. . . . . . . . . . . . . . . . . . . . 147
1.2 Estatísticas das taxas de emissão no instante inicial para as campanhas 1,
2 e 3 do reservatório de Corumbá - M2. . . . . . . . . . . . . . . . . . . . 155
1.3 Estatísticas das taxas de emissão no instante inicial para as campanhas 1,
2 e 3 do reservatório de Corumbá - CIR hierárquico. . . . . . . . . . . . . 163
vi

Lista de Figuras
2.1 Aumento de dados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1 Dados simulados e dados transformados. . . . . . . . . . . . . . . . . . . . 28
3.2 Resultado do Amostrador de Gibbs. Traço (coluna 1), função de auto-
correlação (coluna 2) e histograma (coluna 3), para os parâmetros α, β e
σ2. As retas horizontais e verticais que aparecem nos traços e histogramas,
respectivamente, representam os valores verdadeiros. . . . . . . . . . . . . . 29
3.3 Comparação entre as amostras a posteriori dos parâmetros do processo CIR
univariado para ∆ = 1 (linha contínua) e ∆ = 10 (linha tracejada). As
linhas pontilhadas indicam os valores verdadeiros dos parâmetros. . . . . . 31
3.4 Dados simulados e dados transformados. . . . . . . . . . . . . . . . . . . . 38
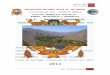
3.5 Saída do MCMC para o parâmetro ϕ. . . . . . . . . . . . . . . . . . . . . . 39
3.6 Histogramas da amostra a posteriori de ϕ. . . . . . . . . . . . . . . . . . . 40
3.7 Saída do MCMC para Σ. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.8 Histogramas da amostra a posteriori de Σ. . . . . . . . . . . . . . . . . . . 42
3.9 Comparação dos ϕs a posteriori para ∆ = 1 (linha contínua) e ∆ = 10
(linha tracejada). As retas verticais pontilhadas representam os valores
verdadeiros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.10 Comparação dos Σs a posteriori para ∆ = 1 (linha contínua) e ∆ = 10
(linha tracejada). As retas verticais pontilhadas representam os valores
verdadeiros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
vii

4.1 Dados simulados e pontes lineares (gráfico da esquerda) e média a posteriori
das pontes com IC95% (gráfico da direita). . . . . . . . . . . . . . . . . . . 50
4.2 Saída do MCMC. Traços (coluna 1), funções de autocorrelação (coluna 2)
e histogramas (coluna 3) para os parâmetros α, β e σ2. As retas horizontais
(nos traços) e verticais (nos histogramas) assinalam os valores verdadeiros
dos parâmetros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.3 Média a posteriori das pontes (linhas), IC95% (arcos), dados verdadeiros
(pontos em círculos) e raiz do EQM para cada uma das variáveis latentes
(retas verticais). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.4 Saída do MCMC para o procedimento em Eraker (2001). Traços (coluna
1), funções de autocorrelação (coluna 2) e histogramas (coluna 3) para os
parâmetros α, β e σ2. As retas horizontais (nos traços) e verticais (nos
histogramas) assinalam os valores verdadeiros dos parâmetros. . . . . . . . 55
4.5 Comparação entre as densidades a posteriori. Observados 201 dados (linha
contínua), 21 observados, sem dados aumentados (linha tracejada) e 21
observados com dados aumentados e MCMC como em Eraker (2001) (linha
pontilhada). As retas tracejadas verticais indicam os valores verdadeiros. . 57
4.6 Densidade a posteriori para ϕ. Considerando todos os dadosN = 201 (linha
contínua), N = 21 sem aumento (linha tracejada) e N = 21 com aumento
(linha pontilhada). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.7 Densidade a posteriori para Σ. Considerando todos os dados N = 201
(linha contínua), N = 21 sem aumento (linha tracejada) e N = 21 com
aumento (linha pontilhada). . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.8 Média a posteriori dos dados não observados (linhas), IC 95%, pontes ver-
dadeiras (pontos) e raiz do EQM (barras verticais). . . . . . . . . . . . . . 71
4.9 Taxa de aceitação para cada ponte. . . . . . . . . . . . . . . . . . . . . . . 71
viii

4.10 Saída do MCMC. Traços (coluna 1), funções de autocorrelação (coluna 2)
e histogramas (coluna 3) para os parâmetros α, β e σ2. As retas horizontais
(nos traços) e verticais (nos histogramas) assinalam os valores verdadeiros
dos parâmetros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.1 Coleta dos dados em um reservatório e câmaras de difusão utilizadas (fo-
tos superiores). Procedimento de cromatografia gasosa para obtenção das
concentrações dos gases nas câmaras (foto inferior). . . . . . . . . . . . . . 77
5.2 Saída do MCMC dos parâmetros µη, σ2η, µκ e σ2
η referente a segunda cam-
panha de Corumbá. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.3 Histogramas das amostras a posteriori. . . . . . . . . . . . . . . . . . . . . 83
5.4 Taxas de emissão inicial dos sítios 1 ao 20 e a taxa de emissão inicial coletiva. 84
5.5 Taxa de emissão inicial coletiva para segunda campanha de Corumbá. . . . 85
5.6 Concentrações do metano (CH4) nos tempos 0, 3, 6 e 12 minutos. As letras
representam as localizações. . . . . . . . . . . . . . . . . . . . . . . . . . . 89
5.7 Taxas locais ri e coletiva rc para segunda campanha de Corumbá. . . . . . 90
5.8 Saída do MCMC (esquerda) e histograma (direita) dos parâmetros ψ e σ2W
(superior e inferior, respectivamente). . . . . . . . . . . . . . . . . . . . . . 91
5.9 Traços das amostras a posteriori dos parâmetros µα, σ2α, µβ e σ2
β pelo modelo
CIR hierárquico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.10 Histogramas das amostras a posteriori dos parâmetros µα, σ2α, µβ e σ2
β pelo
modelo CIR hierárquico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.11 Taxas de emissão inicial para a segunda campanha de Corumbá. Localiza-
ções 1 a 20 e taxa coletiva. . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
5.12 Taxa de emissão inicial coletiva para segunda campanha de Corumbá. . . . 98
5.13 Comparação entre taxas de emissão inicial coletivas por dois métodos. . . . 100
5.14 Amostras a posteriori das taxas de emissão inicial por: CIR hierárquico
(histogramas), modelo M1 (linhas contínuas) e mínimos quadrados (linhas
tracejadas verticais) para segunda campanha de Corumbá, locais 1 ao 12. 102
ix

5.15 Amostras a posteriori das taxas de emissão inicial por: CIR hierárquico
(histogramas), modelo M1 (linhas contínuas) e mínimos quadrados (linhas
tracejadas verticais) para segunda campanha de Corumbá, locais 13 ao 20. 103
5.16 Ajustes dos modelos (primeira linha), traços dos fluxos (segunda linha) e
histogramas dos fluxos (terceira linha) para os modelos M1T e M2T para
segunda campanha de Corumbá. . . . . . . . . . . . . . . . . . . . . . . . . 107
5.17 Reservatório de Corumbá com os locais de amostragem da segunda campanha.111
5.18 Emissão do reservatório de Corumbá para cada uma das campanhas pelos
métodos: M1 e CIR hieráquico - MH. . . . . . . . . . . . . . . . . . . . . . 112
6.1 Processo de difusão multivariado espacial. . . . . . . . . . . . . . . . . . . 118
6.2 Localização das observações (esquerda) e séries simuladas (direita). . . . . 131
6.3 Traços e histogramas do parâmetro α do vetor direção do CIR multidimen-
sional com estrutura espacial. As retas indicam os valores verdadeiros da
simulação. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.4 Traços e histogramas do parâmetro β do vetor direção do CIR multidimen-
sional com estrutura espacial. As retas indicam os valores verdadeiros da
simulação. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
6.5 Traços e histogramas dos parâmetros da estrutura espacial. As retas indi-
cam os valores verdadeiros da simulação. . . . . . . . . . . . . . . . . . . . 134
6.6 Locais da geração (superior esquerdo), valores iniciais das séries (superior
direito), séries no tempo (inferior esquerdo) e fluxos verdadeiros (inferior
direito). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
6.7 Locais observados (superior esquerdo), valores iniciais das séries (superior
direito), séries no tempo (inferior esquerdo) e fluxos verdadeiro (inferior
direito). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
1.1 Convergência das taxas para a campanha 1 de Corumbá. . . . . . . . . . . 148
1.2 Convergência das taxas para a campanha 2 de Corumbá. . . . . . . . . . . 149
x

1.3 Convergência das taxas para a campanha 3 de Corumbá. . . . . . . . . . . 150
1.4 Histogramas das taxas de emissão inicial - Corumbá - campanha 1. . . . . 151
1.5 Histogramas das taxas de emissão inicial - Corumbá - campanha 2. . . . . 152
1.6 Histogramas das taxas de emissão inicial - Corumbá - campanha 3. . . . . 153
1.7 Traços das taxas para a campanha 1 de Corumbá. . . . . . . . . . . . . . . 156
1.8 Traços das taxas para a campanha 2 de Corumbá. . . . . . . . . . . . . . . 157
1.9 Traços das taxas para a campanha 3 de Corumbá. . . . . . . . . . . . . . . 158
1.10 Histogramas das taxas de emissão inicial - Corumbá - campanha 1. . . . . 159
1.11 Histogramas das taxas de emissão inicial - Corumbá - campanha 2. . . . . 160
1.12 Histogramas das taxas de emissão inicial - Corumbá - campanha 3. . . . . 161
1.13 Convergência das taxas para a campanha 1 de Corumbá. . . . . . . . . . . 164
1.14 Convergência das taxas para a campanha 2 de Corumbá. . . . . . . . . . . 165
1.15 Convergência das taxas para a campanha 3 de Corumbá. . . . . . . . . . . 166
1.16 Histogramas das taxas para a campanha 1 de Corumbá. . . . . . . . . . . . 167
1.17 Histograma das taxas para a campanha 2 de Corumbá. . . . . . . . . . . . 168
1.18 Histograma das taxas para a campanha 3 de Corumbá. . . . . . . . . . . . 169
xi

Capítulo 1
Introdução
Processos de difusão são ferramentas úteis para modelar uma grande variedade de
fenômenos que evoluem continuamente no tempo. As aplicações aparecem em diferentes
campos do conhecimento podendo-se citar: finanças, biologia, física, engenharia, dentre
outros. Esta introdução tem por objetivo apresentar ao leitor a importância destes pro-
cessos na ciência, fornecer uma visão geral da organização deste trabalho e delinear os
caminhos da tese.
1.1 Breve histórico sobre processos de difusão
Um dos tópicos centrais que envolve processos de difusão e equações diferenciais esto-
cásticas (EDEs) é o movimento browniano. Em 1828, o botânico escocês Robert Brown
observou que grãos de polén submersos em líquido comportam-se realizando movimentos
irregulares, aparentemente aleatórios. Intrigado, observou que o mesmo fenômeno ocorria
em partículas de pó, o que lhe permitiu concluir que os movimentos não eram devidos a
mecanismos biológicos associados ao pólen. Apesar de não ter conseguido encontrar uma
explicação concisa para o fenômeno observado, ele passou a designar-se por movimento
browniano, em honra do seu descobridor.
O primeiro a descrever matematicamente o movimento browniano foi Thorvald N. Thi-
1

ele em um artigo de 1880 baseado no método de mínimos quadrados. Independentemente,
Luis Bachelier foi o pioneiro no uso de movimento browniano em finanças. Foi no dia 29
de março de 1900 na “Faculté des Sciences” de Paris que Bachelier, sob orientação do
célebre matemático Henri Poincaré, defendeu tese de doutorado intitulada “Théorie de la
Spéculation”. Para muitos pesquisadores este evento marca o início do estudo moderno de
finanças, pois, em sua tese, Bachelier assumiu que o preço de um ativo financeiro segue um
movimento browniano com direção zero; iniciando assim o casamento entre modelagem de
preços de ativos e cálculo estocástico. Somente em 1905, Albert Einstein, em um de seus
artigos daquele ano, forneceu uma explicação física concisa do fenômeno do movimento
das partículas imersas em líquido.
Mais de uma década depois, Nobert Wiener combinou teoria da medida e séries de
Fourier para, em 1923, construir sua versão do movimento browniano. Neste período,
Wiener e outros pesquisadores mostraram que os caminhos do movimento browniano têm
variação quadrática não nula igual a (t−s) no intervalo (s, t) e, além disso, os caminhos do
movimento browniano têm variação infinita num intervalo compacto, quase certamente.
Em reconhecimento ao trabalho de Wiener, essa construção do movimento browniano
ficou conhecida por processo de Wiener.
Nas décadas seguintes o desenvolvimento da teoria de probabilidade, em especial a
teoria sobre processos de Markov, e o início dos trabalhos sobre integração estocástica
somaram-se ao conhecimento sobre processos de Wiener para formar a estrutura base
do cálculo estocástico e, posteriormente, de sua utilização em finanças. Em 1931, A.
N. Kolmogorov escreve sobre a construção de Bachelier acerca do movimento browni-
ano. Kolmogorov mostra que processos de Markov contínuos dependem essencialmente
de um parâmetro de velocidade na função de direção e um parâmetro para o tamanho da
componente puramente aleatória (componente difusiva).
Na década de 1950, Kiyosi Itô construiu uma equação diferencial estocástica da forma
dXt = µ(Xt)dt + σ(Xt)dWt, sendo que Wt representa o processo de Wiener padrão. Em
sua busca para dar sentido matemático preciso ao termo σ(Xt) e conectar a difusão Xt
2

ao trabalho de Kolmogorov sobre processos de Markov, Itô fornece a base da integração
estocástica. Em seu trabalho de 1951, ele cria uma das principais ferramentas do cálculo
estocástico que ficou conhecida por Fórmula de Itô.
Itô ficou conhecido como o criador da teoria moderna de análise estocástica por conta
da contribuição científica de seus trabalhos. Por exemplo, sua fórmula básica é ampla-
mente conhecida e vastamente utilizada em campos da ciência dos mais diversos como
Física e Economia.
A segunda metade do século XX foi frutífera no desenvolvimento da teoria sobre
processos de difusão e cálculo estocástico. Dentre os autores que contribuíram para a
evolução deste campo de pesquisa pode-se citar: J. L. Doob, P. A. Meyer e os trabalhos
relacionados a transformações de difusões derivados dos trabalhos de Girsanov.
O desenvolvimento de técnicas de estimação de parâmetros de processos de difusão foi
intenso nas últimas duas décadas. Uma das principais razões desse desenvolvimento deve-
se à diversidade de áreas de aplicação de processos de difusão e principalmente seu vasto
uso em finanças para modelar séries de preços. Como a observação da ocorrência completa
de um processo de difusão é impossível, as formas paramétricas de estimação partem
da aproximação da função de verossimilhança. O trabalho de Kloeden e Platen (1992)
trata com rigor matemático soluções numéricas para equações diferenciais estocásticas,
tornando-se um livro de referência sobre o assunto.
O ponto central da inferência sobre difusões é modelar fenômenos contínuos contando
com observações discretas. Os trabalhos de Bibby e Sørensen (1995) e Pedersen (1995)
são boas referências sobre o assunto. Eles fornecem estratégias de aproximação da função
de verossimilhança por funções de transição e discutem ainda aumento de dados para
refinar essa tarefa.
A estatística bayesiana vem ocupando posição central para estimar parâmetros e sele-
cionar modelos partindo de difusões. A partir da década de 1990, com o desenvolvimento
de Métodos de Monte Carlo via Cadeia de Markov (MCMC) e acesso a computadores mais
rápidos, a inferência bayesiana teve um crescimento acelerado. Polson e Roberts (1994)
3

desenvolveram métodos de seleção de modelos partindo de processos cuja solução exata
da equação diferencial estocástica era avaliada, Roberts e Stramer (2001) escreveram um
importante trabalho para aproximar a função de verossimilhança pela discretização da
fórmula de Girsanov. O presente texto está repleto de referências sobre inferência baye-
siana e vão aparecendo conforme os tópicos forem apresentados. Vale no entanto ainda
citar os trabalhos de Jones (1998), Johannes e Polson (2003), Kalogeropoulos (2006), Ka-
logeropoulos (2007), Eraker (2001), Elerian et al. (2001), referências importantes sobre o
assunto.
A história dos processos de difusão e do cálculo estocástico podem ser obtidas em
diversas fontes. Os livros de cálculo estocástico que têm o cuidado de fazer uma conexão
entre teoria e embasamento histórico são boas referências (por exemplo ver Øksendal
(1995) e Steele (2001)). Páginas da internet também trazem informações valiosa desde
biografias dos principais nomes aqui citados até trabalhos na íntegra. O texto de Jarrow
e Protter (2003) faz um belo relato sobre a história da integração estocástica e finanças
matemática e traz ainda uma farta lista de referências bibliográficas (mais de 80 trabalhos)
que fizeram esta história.
1.2 Contribuições e organização do trabalho
O presente trabalho apresenta contribuições em algumas direções. A primeira delas
refere-se a uma caracterização multivariada do processo de Cox et al. (1985) no qual,
através de um esquema de discretização, torna-se possível a estimação dos parâmetros
com auxílio da teoria de modelos de regressão multivariado. A inferência é feita sob o
enfoque bayesiano através de Métodos de Monte Carlo via Cadeia de Markov (MCMC).
Uma aplicação é realizada para o problema de estimação da taxa de emissão de gases
poluentes provenientes de reservatórios de hidrelétricas. A contribuição está em desenvol-
ver modelos para o problema da emissão de gases e realizar inferência sobre o conjunto de
dados. São aplicadas técnicas de estimação sobre modelos hierárquicos, modelos hierár-
4

quicos com estrutura espacial e modelos partindo de difusões. Essa aplicação configura
uma contribuição original na análise de dados desse tipo no Brasil.
Uma das novidades centrais deste trabalho está na formulação de processos de difusão
multivariados com estrutura espacial e hierárquico. Isto é, assume-se que vários processos
de difusão univariados estão dispostos geograficamente no plano e sua estrutura de cor-
relação é função da sua posição. Esta formulação é apresentada juntamente com técnicas
de estimação dos parâmetros.
Por fim, no decorrer de todo o texto apresenta-se o que há de mais recente na literatura
estatística sobre: técnicas de discretização, aumento de dados e inferência sobre processos
de difusão com dados discretamente observados.
A estrutura do trabalho está organizada da seguinte forma:
• O Capítulo 2 apresenta os principais conceitos e resultados que são base para tese.
Nele definem-se movimento browniano, equação diferencial estocástica, Fórmula de
Itô, dentre outros. Apresentam-se, ainda, formas para a verossimilhança de um
processo de difusão e uma breve introdução sobre inferência e aumento de dados.
Ao final do capítulo, os principais processos de difusão recorrentes na literatura são
listados;
• No Capítulo 3, caracteriza-se o processo CIR multivariado e se faz a inferência ba-
seada na aproximação da função de verossimilhança pelo produtório das densidades
de transição, que são obtidas do esquema de discretização de Euler-Maruyama. Os
dados são transformados para trabalhar com modelos de regressão multivariado sob
o enfoque bayesiano;
• Uma das principais questões em utilizar modelos contínuos com dados discretamente
observados está na presença do erro ou viés de discretização. Técnicas de aumento
de dados são utilizadas para reduzir este efeito sendo que dados não observados
podem ser adicionados ao procedimento de inferência sob a forma de parâmetros.
Técnicas de aumento de dados são apresentadas e discutidas no Capítulo 4;
5

• Partindo do que foi visto nos capítulos anteriores, no Capítulo 5 são apresentados
alguns modelos correntes na literatura e alguns modelos partindo de difusões com o
objetivo de estimar taxa de emissão de gases poluentes. Apesar das técnicas já serem
conhecidas, a aplicação delas na estimação da taxa de emissão de gases poluentes
provenientes de reservatórios de hidrelétricas constitui uma novidade na literatura;
• No Capítulo 6, define-se o processo de difusão com estrutura espacial. A função
de covariância é apresentada e desenvolvida no contexto de processos de difusão
multivariados. Desenvolve-se o processo CIR multivariado com estrutura espacial e
por fim, desenvolve-se técnicas de estimação;
• O Capítulo 7 apresenta as conclusões e as direções para trabalhos futuros.
1.3 Notação empregada
O texto do presente trabalho segue as novas regras estabelecidas no acordo ortográfico
que devem ser implantadas nos países de língua portuguesa a partir de 2009. Este pode
ser visto no manual de Bechara (2008). As regras para numeração seguem o padrão
americano com ponto separando a parte decimal da parte fracionária. Esta abordagem
facilita usar os resultados em publicações e torna a programação compatível com a maioria
dos softwares e pacotes existentes.
O processo de difusão é denotado por Xt ou X(t) na versão univariada e em negrito,
X t ou X(t), no caso multivariado. O mesmo vale para o movimento browniano Bt e Bt,
casos uni e multivariado, respectivamente.
Tratando de equações diferenciais estocásticas, a função de direção será denotada por
bt, e no caso vetorial por bt. A função de volatilidade será denotado por σt e no caso
matricial por σt. Está é uma forma abreviada, pois essas funções podem depender ainda
dos parâmetros e do próprio processo. Em geral o vetor de parâmetros é denotado por θ
e o espaço paramétrico por Θ.
6

Quando se tratar de observações discretas de um processo de difusão univariado refere-
se ao conjunto
Y = Yk = Xtk , k = 0, 1, . . . , N,
sendo t0 < t1 < . . . < tN os tempos de observações. O negrito, em Y , será utilizado para
denotar observações discretas de um processo de difusão multivariado sendo que é uma
matriz n (dimensão do caso multivariado) por N + 1 observações.
O símbolo′
(linha) será utilizado para representar o transposto de uma matriz ou
vetor.
As notações aqui apresentadas são as mais importantes, outras aparecerão no decorrer
do texto, em especial no próximo capítulo.
7

Capítulo 2
Preliminares
Neste capítulo são apresentados os principais resultados teóricos, as definições funda-
mentais e as notações que serão utilizados no decorrer do trabalho. O capítulo não tem
a pretensão de esgotar matematicamente os tópicos aqui descritos. Para uma abordagem
extra dos principais conceitos e resultados que tangem Teoria da Probabilidade sugere-se
a leitura de Karatzas e Shreve (1991), Øksendal (1995), Steele (2001) e Klebaner (2005).
E para uma abordagem detalhada do tratamento numérico de equações diferenciais esto-
cásticas ver Kloeden e Platen (1992).
2.1 Definições básicas
Definição 2.1.1. Um processo estocástico é uma coleção de variáveis aleatórias X(t)no qual para cada t fixo, com t = 0, . . . , T, (caso discreto) ou t ∈ IR+, (caso contínuo) X(t)
é uma variável aleatória em (Ω,F), onde Ω é um espaço amostral e F uma σ−álgebra de
eventos.
Definição 2.1.2. Uma filtração IF é uma coleção de σ−álgebras tal que
IF = Ft, t ∈ I,
sendo Ft ⊂ Ft+1, com I = IN (caso discreto) ou Ft ⊂ Fs, ∀t < s e I = IR+ (caso
8

contínuo).
A filtração IF é usada para modelar um fluxo de informação em t, isto é, conforme o
tempo passa obtém-se mais informação tornando mais refinadas as partições de um espaço
amostral Ω.
Definição 2.1.3. Um processo estocástico é dito adaptado à filtração IF se para todo
t ∈ I, X(t) é uma variável aleatória em Ft, isto é, se X(t) é Ft-mensurável.
Observação: comumente na literatura o processo estocástico X(t) é denotado por Xt.
Definição 2.1.4. Um movimento browniano B(t) é um processo estocástico com as
seguintes propriedades:
(i) Incrementos independentes: B(t) − B(s), para t > s, é independente do passado,
isto é, independe de Bu, 0 ≤ u ≤ s ou de Fs = σ(Bu, u ≤ s).
(ii) Incrementos normais: B(t)− B(s) ∼ N(0, |t− s|).
(iii) Continuidade dos caminhos: B(t), t ≥ 0 é uma função contínua de t, quase certa-
mente.
Definição 2.1.5. Um movimento browniano d−dimensional é um vetor aleatório
B(t) = (B(1)(t), . . . , B(d)(t)) no qual as coordenadas B(i)(t), com i = 1, . . . , d, são movi-
mentos brownianos unidimensionais independentes.
O movimento browniano B(t) é conhecido também por processo de Wiener e B(t) por
processo de Wiener d−dimensional.
As definições a seguir são fundamentais no tratamento de equações diferenciais es-
tocásticas (EDE) caracterizadas por movimentos brownianos. Primeiro será definida a
Integral de Itô com respeito ao movimento browniano. Esta integral determina o tipo
de cálculo estocástico que será considerado nesta tese. A Integral de Itô é definida para
processos simples adaptados. Esta definição pode ser estendida para processos adaptados
9

vistos como limites em probabilidade de sequências de processos simples (ver Øksendal
(1995, cap. 3) ou Steele (2001, cap. 6)). Em seguida enuncia-se um dos resultados mais
importantes do cálculo estocástico conhecido como Fórmula de Itô. Ele estabelece que
certas funções aplicadas a processos estocásticos especiais (processos de Itô) ainda são
processos de Itô com forma conhecida.
Definição 2.1.6. Um processo de Itô é da forma
X(t) = X(0) +
∫ t
0
b(u)du+
∫ t
0
σ(u)dB(u), 0 ≤ t ≤ T, (2.1)
sendo que X(0) é F0-mensurável e os processos b(t) e σ(t) são Ft-adaptados com∫ T
0
|b(t)|dt <∞ e
∫ T
0
σ2(t)dt <∞.
A forma integral do processo de Itô, presente na equação (2.1), pode ser substituída
pela forma diferencial como aparece enunciado no teorema a seguir. Vale ressaltar que a
forma diferencial dB(t) só faz sentido em termos de notação uma vez que a derivada de
um movimento browniano não existe em nenhum ponto quase certamente.
Teorema 2.1. (Fórmula de Itô) Seja X como em (2.1) e f(x, t) ∈ C2,1(IR × [0, T ])
(i.e. duas vezes diferenciável em relação a x e uma vez em relação a t) então a equação
diferencial estocástica do processo Y (s) = f(Xs, s) existe e é um processo de Itô dado por
df(Xt, t) =∂f(Xt, t)
∂sdt+
∂f(Xt, t)
∂xdXt +
1
2
∂2f(Xt, t)
∂x2d[X,X ](t),
sendo d[X,X ](t) = (dXt)2 e pelas regras do cálculo estocástico: dBtdt = 0, (dt)2 = 0 e
(dBt)2 = d[B,B](t) = dt; resulta que
df(Xt, t) =
[
∂f(Xt, t)
∂s+∂f(Xt, t)
∂xb(t) +
1
2
∂2f(Xt, t)
∂x2σ2(t)
]
dt+∂f(Xt, t)
∂xσ(t)dBt.
Um processo de Itô n-dimensional pode ser definido como extensão do caso univari-
ado substituindo: b(u) por uma função vetorial em IRn, σ2(u) por uma função matricial
IRn×d e Bu por um movimento browniano d−dimensional. Isto sob a condição de que as
coordenadas bi(u) e σ2ij(u) satisfaçam os critérios da definição 2.1.6.
A versão multidimensional da Fórmula de Itô é dada pelo teorema a seguir.
10

Teorema 2.2. (Fórmula de Itô multidimensional) Sejam X um processo de Itô n −dimensional e f(x, t) = (f1(x, t), . . . , fn(x, t)) ∈ C2,1(IRn × [0, T ]) (i.e. duas vezes
diferenciável em relação a x e uma vez em relação a t) uma aplicação em IRp. Então a
equação diferencial estocástica do processo Y (s) = f(Xs, s) existe e é um processo de Itô
cujas componentes são dadas por
dY(k)t =
∂fk(X t, t)
∂sdt+
∑
i
∂fk(Xt, t)
∂xkdX
(i)t +
1
2
∑
i,j
∂2fk(X t, t)
∂xixjdX
(i)t dX
(j)t ,
sendo dB(i)t dB
(j)t = 0, se i 6= j, dB
(i)t dB
(j)t = dt, se i = j e dB
(i)t dt = dt dB
(j)t =
dt dt = 0.
Na seção a seguir será apresentada a definição de equações diferenciais estocásticas
(EDE’s) e os seus principais resultados.
2.2 Equações diferenciais estocásticas - EDEs
Sejam B(t), t ≥ 0, um movimento browniano d-dimensional e θ um vetor de parâme-
tros, que pode apresentar dinâmica no tempo, pertencente ao espaço dos parâmetros Θ.
Chama-se aqui de equação diferencial estocástica (EDE) governada pelo movimento
browniano B(t) a equação da forma
dX(t) = b(X(t), t; θ)dt+ σ(X(t), t; θ)dB(t), (2.2)
sendo que
(a) b : IRn × IR+ ×Θ → IRn é uma função vetorial conhecida como função direção;
(b) σ : IRn × IR+ × Θ → IRn×d é uma função matricial denominada por função de
volatilidade e cuja forma a := σ′σ é chamada de matriz de difusão e
(c) X(t) é uma difusão n-dimensional descrita pela EDE.
11

A equação (2.2) pode ser escrita sob a forma de coordenadas por
dX(i)(t) = bi(X(t), t; θ)dt+d∑
j=1
σij(X(t), t; θ)dB(j)(t), i = 1, . . . , n.
E também pode ser escrita na notação completa por integrais para todo t > 0 e i = 1, . . . , n
por
X(i)(t) = X(i)(0) +
∫ t
0
bi(X(u), u; θ)du+
d∑
j=1
∫ t
0
σij(X(u), u; θ)dB(j)(u), (2.3)
sendo a última integral a integral de Itô.
A seguir são descritas algumas propriedades importantes sobre os termos das EDEs
que permitem avaliar a existência e unicidade de soluções. Em seguida definem-se soluções
forte e fraca de uma EDE e enunciam-se os principais resultados sobre o tema.
(C1) Condição de Lipschitz - Os coeficientes b e σ são localmente lipschitzianos em x
com uma constante K independente de t se para todo N > 0, existe K = K(T,N)
constante tal que para todo |x1|, |x2| ≤ N e para todo t ∈ [0, T ] tem-se
|b(x1, t)− b(x2, t)|+ |σ(x1, t)− σ(x2, t)| < K|x1 − x2|,
sendo |b| e |x| a norma euclidiana do IRn e |σ| = traço(σσ′).
(C2) Condição de crescimento - A condição de crescimento linear para os coeficientes
b e σ é satisfeita se para todo N > 0 existir constante K = K(T,N) tal que para
todo |x| ≤ N e para todo t ∈ [0, T ] tem-se
|b(x, t)|+ |σ(x, t)| ≤ K(1 + |x|).
Definição 2.2.1. Um processo X(t) é chamado de solução forte de uma EDE se para
todo t > 0 as integrais
∫ t
0
bi(X(u), u; θ)du e
d∑
j=1
∫ t
0
σij(X(u), u; θ)dB(j)(u)
existem para i = 1, . . . , n e X(t) satisfaz (2.3).
12

A solução forte de uma EDE deve ser interpretada como um funcional F (t, (Bs, s ≤ t)) do
movimento browniano B(t) dado. Além disto, quando σt = 0 (no caso unidimensional)
a EDE torna-se uma equação diferencial ordinária (EDO) em que a solução perde seu
caráter estocástico.
Teorema 2.3. Se as condições (C1) e (C2) são atendidas, X(0) é independente de
(B(t), 0 ≤ t ≤ T ) e E[|X(0)|2] < ∞ então existe uma única solução forte X(t) da
EDE (2.2) e além disto, no caso de X unidimensional,
E
(
sup0≤t≤T
X2(t)
)
< C[1 + E(X2(0))],
sendo C constante em relação a X.
Prova: ver Øksendal (1995, p. 66) ou Steele (2001, p. 142).
Uma propriedade importante da solução forte X(t) é que ela possui a propriedade
markoviana, i.e., dada Ft a σ−álgebra gerada pelo processo até o tempo t, para qualquer
0 ≤ s ≤ t, tem-se
P (X(t) ∈ A|Fs) = P (X(t) ∈ A|X(s)) quase certamente.
Isto significa que dado o processo X no estado presente o futuro é independente do
passado.
Teorema 2.4. Se para cada t > 0 as funções b(x, t) e σ(x, t) forem contínuas e limitadas
com relação as variáveis x e t, então a EDE em (2.2) tem ao menos uma solução fraca,
começando em x1 e terminando em x2, para todo x1 e x2 pertencentes a IRd.
O conceito de solução fraca é importante, pois permite dar sentido a uma EDE quando
a solução forte não existe. Soluções fracas são soluções em distribuição, podem ser defi-
nidas em outros espaços de probabilidade e existem sob condições menos exigentes com
relação aos coeficientes da EDE.
A construção de soluções fracas, assim como extensões e variações deste teorema, podem
ser vistas em Klebaner (2005, p. 138).
13

A ponte browniana é uma transformação do movimento browniano sob a condição
de possuir valores fixos nas fronteiras do intervalo [0, T ], i.e., X(0) = a e X(T ) = b.
A notação B(0, a;T, b) representa a ponte browniana cujo valor no tempo zero é a e no
tempo T é b. Esse conceito será importante mais a frente como opção para técnicas de
aumento de dados sendo definido a seguir.
Definição 2.2.2. Chama-se de ponte browniana a solução da EDE
dXt =b−Xt
T − tdt+ dBt, para 0 ≤ t < T, X0 = a,
sendo Bt um movimento browniano.
A ponte browniana pode ser caracterizada, ainda, como um processo da forma
Xt = a
(
1− t
T
)
+ bt
T+ (T − t)
∫ t
0
dBt
T − s,
com 0 ≤ t < T e sendo a última integral a integral de Itô.
2.3 Esquemas de discretização
Uma das principais questões colocadas ao utilizar processos de difusão para modelar
fenômenos da natureza está no fato das observações da difusão serem finitas enquanto a
EDE que modela a difusão é contínua. Alguns resultados de convergência para esque-
mas de discretização justificam o uso de processos discretizados. Para uma leitura mais
profunda sobre métodos numéricos em EDEs sugere-se Kloeden e Platen (1992).
A ideia central dos esquemas apresentados a seguir é assumir que é conhecida uma
quantidade de pontos da difusão X t, para 0 ≤ t ≤ T . E dada a discretização em [0, T ]
da forma 0 = t0 ≤ t1 ≤ . . . ≤ tN = T é possível escrever uma equação de evolução para
Y tk (pontos discretamente observados) com k = 0, . . . , N, que substitua o incremento
infinitesimal do movimento browniano dBt. Esta aproximação só faz sentido se limδ→0
Y tk =
X t, sendo δ = maxk=0,...,N−1
|tk+1 − tk|.
14

2.3.1 Esquema de Euler-Maruyama
Este é certamente o método numérico mais utilizado para fazer uma discretização de
uma EDE. Define-se a versão discretizada Y = Y k := Y tk = X tk , 0 = t0 < . . . < tN =
T de X t, 0 ≤ t ≤ T e, então, a EDE em (2.2) é escrita sob o esquema de Euler-Maruyama
da forma
Y k+1 = Y k + b(Y k, tk; θ)∆+k + σ(Y k, tk; θ)∆Bk, com k = 0, . . . , N − 1, (2.4)
sendo ∆+k = tk+1 − tk e ∆Bk = Btk+1
−Btk ∼ Nn(0n,∆+k In), com 0n o vetor de zeros de
dimensão n e In a matriz identidade de ordem n. Por simplicidade de notação toma-se
∆k = ∆+k para representar a diferença adiantada.
Convergência:
Para o caso de difusões unidimensionais (i.e. n = 1) pode-se mostrar que Y converge
fortemente para X em ordem 1/2 pois existem constantes C > 0 e δ0 > 0 tais que
E(|XT − YtN |) ≤ Cδ1/2, com δ = mink=0,...,N−1
|tk+1 − tk| ∈ (0, δ0).
Diz-se ainda que Y converge fracamente para X em ordem 1 se existem constante C > 0
e δ0 > 0 tais que para toda função polinomial g tem-se
|E[g(XT )]− E[g(YtN )]| ≤ Cδ, com δ = mink=0,...,N−1
|tk+1 − tk| ∈ (0, δ0).
2.3.2 Esquemas de Milstein e ordem superior
A forma de discretização de Milstein é resultado da aplicação da expansão de Taylor
e fórmula de Itô em EDE. Uma abordagem detalhada encontra-se nos Capítulos 5 e 10
de Kloeden e Platen (1992). O esquema para difusões unidimensionais é dado por
Yk+1 = Yk + b(Yk, tk; θ)∆k + σ(Yk, tk; θ)∆Bk+
+1
2σ(Yk, tk; θ)
∂σ(Yk, tk; θ)
∂Yk(∆Bk)
2 −∆k, com k = 0, . . . , N − 1,
(2.5)
no qual ∂σ(Yk, tk; θ)/∂Yk é a derivada parcial de σ( . , t; θ) com relação à Yk, ∆k = tk+1−tke ∆Bk = Btk+1
− Btk ∼ N(0,∆+k ).
15

Kloeden e Platen (1992) mostram que Y converge fortemente para X em ordem 1 o
que indica que o esquema de Milstein é superior ao esquema de Euler-Maruyama. Ou
seja, para discretizações idênticas em ambos os esquemas o processo estocástico Y obtido
por Milstein tem valor esperado mais próximo de X em T do que o de Euler-Maruyama.
Observe que caso σ(Xt, t; θ) não dependa de Xt então ∂σ(Xk, tk; θ)/∂Xk = 0 e, portanto,
os dois esquemas coincidem.
A ordem de convergência dos processos discretizados pode ser aumentada considerando
esquemas de discretização que envolvam expansões de Itô-Taylor conforme sugerido por
Kloeden e Platen (1992, seção 5.5). Apesar destes esquemas não serem comuns na li-
teratura pode-se citar os esquemas de Taylor de ordem de convergência 1.5 e de ordem
2.0.
2.4 Verossimilhança do processo de difusão
Jones (1998) coloca que “uma dificuldade inicial em estimar os parâmetros de um pro-
cesso de difusão está na intratabilidade das densidades de transição e, consequentemente,
da função de verossimilhança”. Uma forma de obter a função de verossimilhança de modo
analítico, sem usar densidades de transição, é pelo Teorema de Girsanov. Esta aborda-
gem aparece em Roberts e Stramer (2001) e, num contexto de seleção de modelos, em
Polson e Roberts (1994) e Dellaportas et al. (2006). Apesar de ser possível obter uma
forma analítica para verossimilhança, esta em geral é escrita por integrais estocásticas
que não podem ser calculadas. Isto implica na necessidade de alguma aproximação para
resolvê-las. Esta abordagem será discutida a seguir. Outra maneira é obter a função de
verossimilhança aproximadamente a partir do produtório das densidades de transição que
são obtidas através de esquemas de discretização. Esta abordagem aparece em uma série
de trabalhos dentre os quais vale mencionar os manuais de Johannes e Polson (2003) e
Jones (1998) e os artigos de Jones (2003), Elerian et al. (2001) e Eraker (2001).
Em ambos os casos faz-se necessário usar aproximações, seja para calcular integrais
16

estocásticas, seja para obter as densidades de transição do processo de difusão discretizado.
Técnicas de aumento de dados são discutidas com o propósito de melhorar as aproximações
e consequentemente refinar a inferência sobre os parâmetros.
2.4.1 Pela Fórmula de Girsanov
Uma maneira intuitiva de explicar a obtenção da função de verossimilhança de um
processo de difusão pelo Teorema de Girsanov encontra-se em Kalogeropoulos (2006).
Nele, considera-se uma ocorrência completa, até o tempo T, de um processo de difusão X t,
como em (2.2). Denotando este caminho por Xω = Xt(ω) : t ∈ [0, T ], a probabilidade
do caminho estar em A é dada por
Pθ(Xω ∈ A) =
∫
A
L(x; θ)dx,
no qual L(x; θ) representa a verossimilhança para o parâmetro θ e a integração é feita
com respeito a medida de Lebesgue que neste caso é chamada medida de referência ou
medida dominante.
Como a medida de Lebesgue não é a única opção para a medida de referência pode-se
supor que para uma função positiva h(x) defina-se a medida
H(A) =
∫
A
h(x)dx
e, portanto, usa-se
Pθ(Xω ∈ A) =
∫
A
L(x; θ)
h(x)h(x)dx =
∫
A
L∗(x; θ)dH(x),
sendo L∗(x; θ) =L(x; θ)
h(x)a nova função de verossimilhança.
Observe que ambas as verossimilhanças L(x; θ) e L∗(x; θ) são equivalentes para esti-
mação, uma fez que são proporcionais em relação a θ.
Outra forma de ver as verossimilhanças L∗ e L é pela derivada de Radon-Nikodym
entre as medidas IPθ e H escrevendo
dIPθdH
= L∗(x, θ) edIPθ
dLeb(x)= L(x, θ).
17

Uma questão crucial é que a medida H precisa ser independente de θ. É esta restrição
que permite usar L∗ no lugar de L para realizar a inferência. Contudo, esta restrição sobre
H significa que a função de volatilidade σ(X t, t; θ) não pode depender de θ. Só assim é
possível escrever a verossimilhança a partir da Fórmula de Girsanov. Esta restrição pode
ser contornada através de transformações do processos.
Steele (2001, cap. 13) faz uma explanação detalhada acerca do que ele chama de “Teo-
ria de Girsanov”. Ele ressalta que “a coleção de teoremas que nos diz como fazer a função
de direção desaparecer é comumente chamada de Teoria de Girsanov, contudo a contri-
buição de I.V. Girsanov não foi a primeira nem tão pouco a última nesta nobre linha”.
O teorema que será enunciado a seguir é um dos resultados desta Teoria. O resultado
a seguir aparece em Roberts e Stramer (2001) no caso univariado e em Kalogeropoulos
(2007) e Kalogeropoulos et al. (2007) no caso multivariado. O conjunto de resultados da
Teoria de Girsanov é bem mais extenso do que está aqui descrito e envolve: mudança de
medida, retirada da função de direção do processo e obtenção de martingais.
Teorema 2.5. Sejam o processo de difusão X definido pela EDE (2.2) e a ocorrência
Xω = Xt(ω) : 0 ≤ t ≤ T. Denota-se a lei de X por IP e a lei do martingal local
dX t = σ(X t, t; θ)dBt por W. Como as medidas são absolutamente contínuas uma com
respeito a outra, a derivada de Radon-Nikodym da lei de X com respeito a lei do martingal
local é
dIP
dW= G(Xω, b,σ; θ) =
= exp
∫ T
0
(Σ−1b(X t, t; θ))′
dX t −1
2
∫ T
0
b(X t, t; θ)′
Σ−1b(X t, t; θ)dt,
(2.6)
sendo [σ(X t, t; θ)σ(X t, t; θ)′]−1 = Σ−1. A função G(Xω, b,σ; θ) é a verossimilhança do
processo XT e a equação (2.6) será chamada no presente texto de Fórmula de Girsanov.
Prova: Para a forma da função G ver Steele (2001, cap. 13) e para interpretação de G
como verossimilhança do processo ver Roberts e Stramer (2001).
Como foi visto no início desta seção, a Fórmula de Girsanov só representa a verossi-
milhança de Xω caso a medida W não dependa de θ. Em geral isto não acontece e então
18

sugerem-se duas formas para contornar este problema. A primeira é obter um estimador
para a função de volatilidade e utilizá-lo, sendo o mais comum trabalhar com o processo
de variação quadrática. Malliavin e Mancino (2002) sugerem alternativas aos esquemas de
estimação por variação quadrática através de métodos de estimação da função de volatili-
dade utilizando séries de Fourier. Uma vantagem, segundo eles, é aproximar o integrando
da variação quadrática (que é o quadrado da função de volatilidade) sem utilizar derivadas
aproximadas.
A outra maneira é realizar uma mudança de variável no processo de difusão transformando-
o em um processo com função de volatilidade constante igual a 1, no caso unidimensional,
ou função de volatilidade matricial igual a identidade, no caso multidimensional (ver Ka-
logeropoulos et al. (2007)). Estas duas abordagens (estimação da variação quadrática e
transformação do processo) serão discutidas mais adiante.
Note que a primeira integral da equação (2.6) é uma integral estocástica, que na maio-
ria dos casos não tem forma analítica conhecida. O procedimento mais usado é aproximar
numericamente a integral, sendo as fórmulas de quadratura as que mais aparecem na
literatura. Além disto, estas aproximações são naturais, dado que raramente se observa
uma ocorrência completa do processo Xω; o que se observa é um conjunto de pontos em
tempos de observação tk, com k = 0, . . . , N.
2.4.2 Por densidades de transição
Aqui será ilustrada a obtenção da verossimilhança através do produto de densidades
de transição. Dado o processo observado no conjunto Y = Y k = X tk : k = 0, . . . , N a
partir dos procedimentos de discretização de difusões, tratados na Seção 2.3, obtém-se as
densidades de transição p(Y k+1|Y k, θ). Assim a verossimilhança do processo de difusão é
aproximada por
L(Y ; θ) = p(Y 0)
N−1∏
i=0
p(Y k+1|Y k, θ).
19

Pode-se mostrar que quando a distância máxima da partição vai para zero a verossi-
milhança aproximada converge para a verossimilhança verdadeira (ver Pedersen (1995,
teorema 3)). Aplicando-se o esquema de Euler-Maruyama a densidade de transição
p(Y k+1|Y k, θ) tem a forma de uma distribuição normal, com isso o produtório fica fácil
de ser obtido.
2.5 Aumento de dados
Claro que aproximar modelos contínuos por modelos discretos gera um viés de discre-
tização relacionado à amplitude da discretização. No entanto, foi dito acima que quando
os intervalos de discretização vão a zero o processo discretizado converge para o processo
de difusão. Neste contexto, uma alternativa para obter uma função de verossimilhança
aproximada com viés de discretização reduzido é realizar um procedimento de aumento
de dados. Este procedimento consiste em acrescentar entre cada par de dados observados
uma quantidade de variáveis latentes ou não observadas. Este procedimento é discutido
sob o ponto de vista bayesiano em Jones (1998), Eraker (2001) e Elerian et al. (2001),
entre outros. Estes artigos discutem modos de proceder o aumento de dados enfatizando
prós e contras. Técnicas de aumento de dados e inferência neste contexto são discutidas
no Capítulo 4 dando ênfase ao processo CIR.
Dada a EDE em (2.2) considera-se o conjunto de observações do processo X t dado por
Y . Chama-se de Y o = (Y 0,Y 1, . . . ,Y N )′o vetor dos dados observados. Assume-se que
entre cada par de pontos observados (tk−1,Y k−1) e (tk,Y k) sejam gerados mk−1 dados
não observados, isto é, simula-se (tk−1,j,Y k−1,j), com k = 1, . . . , N e j = 1, . . . , mk−1 de
forma que
tk−1 < tk−1,1 < tk−1,2 < . . . < tk−1,mk−1≤ tk.
A Figura 2.1 mostra o esquema de aumento de dados
20

t0
.y0
t01
.y01
. . .
. . .
t0m0
.y0m1
t1
.y1
t11
.y11
. . .
. . .
t1m1
.y1m1
t2
.y2
. . .
. . .
tN
.ytN
Figura 2.1: Aumento de dados.
O conjunto de dados não observados é denotado por
Y no = Y kj, k = 0, . . . , N − 1, j = 1, . . . , mk.
Vale ressaltar que a quantidade de elementos não observados mk, entre cada k−ésimo
par de observados, não precisa ser a mesma, tampouco o espaçamento entre os dados
observados ou não observados precisa ser igual.
O procedimento de inferência é feito via MCMC e consiste em amostrar alternadamente
de
p(θ|Y o,Y no) e p(Y no|θ,Y o)
de modo que p(θ,Y no|Y o) convirja a uma distribuição invariante cujo objeto de interesse
é a distribuição marginal p(θ|Y o). Para uma visão ampla e detalhada dos métodos MCMC
sugere-se a leitura de Gamerman e Lopes (2006).
No Capítulo 4 o procedimento de inferência com aumento de dados é detalhado e,
nele, são discutidas maneiras eficientes de gerar o vetor Y no.
2.6 Principais processos de difusão
Processos de difusão foram apresentados na Seção 2.2 como soluções de EDE’s (2.2).
Pelos resultados de existência e unicidade de soluções de EDE’s, no caso de existência
de solução forte, a difusão X(t) é unicamente determinada pela função de direção b e
21

pela função de volatilidade σ. Na tabela 2.1 são apresentados os principais processos de
difusão unidimensionais.
Modelos b(X(t), t; θ) σ(X(t), t; θ)
(1) Merton µ γ
(2) Dothan µXt γ
(3) Ornstein-Uhlenbeck κ(µ−Xt) γ
(4) Mov. brown. geométrico µXt γXt
(5) Vasicek α + βXt γ
(6) Cox-Ingerson-Ross (CIR) α + βXt γX1/2t
(7) Hull-White α + βXt γXψt
(8) CIR afim α0 + α1Xt β0 + β1Xt1/2
(9) Paramétrico geral α0 + α1Xt + α2X2t + α3/Xt β0 + β1Xt + β2X
β3t .
Tabela 2.1: Processos de difusão.
Nos exemplos γ deve ser positivo. O modelo (9) foi estudado em Aït-Sahalia (1996b),
onde são encontradas as condições sobre os parâmetros e as propriedades do processo.
Muitos outros processos de difusão aparecem na literatura. Outras listas encontram-se na
tese de doutorado de Elerian (1999) e, num contexto de processos de taxa de juros, em
Klebaner (2005, p. 327) e Aït-Sahalia (1996a).
Modelos multivariados também são comuns na literatura. O caráter multivariado pode
aparecer relacionado a modelos de volatilidade estocástica como em Golightly e Wilkinson
(2006) e Eraker (2001), nos quais uma dimensão do processo modela a evolução do ativo e
outra dimensão representa a evolução da volatilidade. Abordagens mais gerais de proces-
sos multivariados encontram-se em Sanford e Martin (2006a), com difusões centradas em
modelos para taxa de juros, e em Kalogeropoulos (2007) e Kalogeropoulos et al. (2007),
para processo cuja verossimilhança é obtida pela Fórmula de Girsanov multivariada.
No Capítulo 3 será proposta uma extensão multivariada do processo CIR. Nele, a
modelagem e a parte inferencial são tratadas e apresenta-se um exemplo simulado.
22

Capítulo 3
Processo CIR
Este capítulo versa sobre um dos principais processos de difusão recorrentes na litera-
tura. O nome CIR deve-se ao cuidadoso trabalho de Cox, Ingersoll e Ross (1985) acerca
deste processo, mas ele também aparece na literatura de finanças com o nome de processo
de taxa de juros. Neste capítulo são, primeiramente, discutidas técnicas bayesianas para
estimação dos parâmetros do processo CIR univariado. Apesar do tratamento estatístico
do processo CIR para o caso univariado ser recorrente na literatura (ver Elerian et al.
(2001), Eraker (2001), Jones (1998), Johannes e Polson (2003), entre outros) o trata-
mento dado aqui tem por objetivo motivar e orientar a generalização multivariada. Este
será o tópico da primeira seção. Na seção seguinte, é apresentada uma extensão multiva-
riada para o processo CIR. Para o caso multivariado são desenvolvidas alternativas para
estimação Bayesiana dos parâmetros. O enfoque principal está na estimação a partir da
discretização da difusão do processo usando o esquema de Euler sem considerar aumento
de dados. Isto é, assume-se que a discretização é refinada o suficiente para que a estima-
ção dos parâmetros do processo discretizado não seja significativamente influenciada pelo
esquema de Euler. No capítulo seguinte considera-se aumentar o conjunto de dados, cri-
ando variáveis latentes, com o objetivo de melhorar a aproximação do processo observado
(discreto) para o processo de difusão (contínuo).
23

3.1 CIR univariado
Seja a equação diferencial estocástica (EDE) apresentada no Capítulo 2 com n = 1
e d = 1 e determinada pelo vetor de parâmetros θ = (α, β, σ2)′, pela função de média
b(Xt, t; θ) = α + βXt e função de volatilidade σ(Xt, t; θ) =√σ2Xt. Então a difusão X
evolui no tempo de acordo com o processo CIR univariado da forma
dXt = (α + βXt)dt+√
σ2XtdBt. (3.1)
No artigo de 1985 de Cox, Ingersoll e Ross mostra-se que a EDE descrita por (3.1)
tem solução analítica forte determinada por uma qui-quadrada não central se o vetor
paramétrico θ for conhecido. Em problemas reais, no entanto, toma-se uma amostra,
finita, dos dados (i.e. a difusão é discretamente observada) e deseja-se obter informações
acerca dos parâmetros à luz dos dados coletados. Isto motiva o uso de esquema de
discretização de dados como descrito na próxima subseção.
3.1.1 Esquema de Euler-Maruyama
Suponha que são observados N + 1 ocorrências da difusão X nos tempos 0 = t0 ≤t1 ≤ . . . ≤ tN = T. Assume-se a aproximação Yk ≈ Xtk , k = 0, . . . , N de maneira que
a observação no instante tk é dada por Yk = yk . Pelo Esquema de Euler a EDE (3.1) é
discretizada por
Yk+1 = Yk + (α + βYk)∆k +√
∆kσ2Yk εk, com k = 0, . . . , N − 1, (3.2)
sendo ∆k = tk+1− tk e εk ∼ N(0, 1) independentes para todo k. Lembre-se, pelo Esquema
de Euler descrito na Subseção 2.3.1, o termo εk aparece, pois√∆kεk = Btk+1
− Btk ∼N(0,∆k), onde B é um movimento browniano padrão.
3.1.2 Inferência bayesiana
O objetivo é obter a distribuição a posteriori do vetor de parâmetros θ′= (α, β, σ2).
Dado um conjunto de dados y = y0, . . . , yN e assumindo uma distribuição a priori p(θ)
24

para o vetor θ resulta da Fórmula de Bayes que
p(θ|y) = p(y|θ)p(θ)p(y)
.
A função p(y|θ) é a função de verossimilhança obtida por
p(y|θ) = p(y0)
N−1∏
k=0
p(yk+1|θ, yk),
sendo que p(yk+1|θ, yk) é a densidade de transição do processo discretizado.
Uma vez que calcular a preditiva p(y) é muito complicado isto faz com que, em
geral, não seja possível obter analiticamente uma expressão para p(θ|y). Para resolver
este problema utiliza-se Métodos de Monte Carlo via Cadeia de Markov (MCMC) para
gerar uma amostra aleatória θ(g)Gg=1 da distribuição a posteriori de θ.
Há na literatura uma variedade de métodos para realizar a inferência bayesiana no
contexto de processos CIR. Alguns artigos não partem de esquemas de discretização ob-
tendo a função de verossimilhança a partir do Teorema de Girsanov (ver, por exemplo,
Johannes e Polson (2003) ou Roberts e Stramer (2001)).
Quando se utiliza a discretização de Euler, uma abordagem bastante seguida é realizar
uma mudança de variáveis para obter uma equação sob a forma de um modelo de regressão
linear. Esta abordagem é desenvolvida a seguir e pode ser seguida também em Jones
(1998). Seja a transformação da equação (3.2) da forma
Zk :=Yk+1 − Yk√
∆kYk= (αY
−1/2k + βY
1/2k )
√
∆k + σεk, (3.3)
com k = 0, . . . , N − 1 e εk ∼ N(0, 1).
Assumindo o vetor das observações transformadas z = (z0, . . . , zN−1)′a equação (3.3)
é escrita por
z =Mϕ + σε, (3.4)
25

sendo ϕ := (α, β)′, ε ∼ NN (0, IN) e M é a matriz em IRN×2 de regressores definida por
M =
√
∆0
y0
√
∆0y0√
∆1
y1
√
∆1y1
......
√
∆N−1
yN−1
√
∆N−1yN−1
N×2
.
A literatura estatística sobre modelos de regressão linear é extensa. Uma visão geral
dela, seguindo uma abordagem não bayesiana, pode ser encontrada no trabalho clássico
de McCullagh e Nelder (1999). Seguindo uma abordagem bayesiana mais ampla sugere-se
Zellner (1971) e para uma discussão mais detalhada sobre a elicitação de prioris e técnicas
MCMC ver Marin e Robert (2007).
A função de verossimilhança para z é dada por
p(z|θ) = p(z|ϕ, σ2) = (2πσ2)−N/2 exp
− 1
2σ2‖ z −Mϕ ‖2
,
tal que ‖ . ‖ é a norma euclidiana.
Considera-se uma distribuição a priori não informativa para θ dada por p(θ) ∝ 1/σ2.
Em seguida, calcula-se as condicionais completas para ϕ′= (α, β) e σ2 como segue.
1.) Obtenha a forma da posteriori para θ:
p(θ|z) ∝ p(z|θ)p(θ) = (2πσ2)−N/2 exp
− 1
2σ2‖ z −Mϕ ‖2
1
σ2
∝ (σ2)−N2−1 exp
− 1
2σ2‖ z −Mϕ ‖2
.
2.) Calcule as condicionais completas para ϕ e σ2 colocando os termos que não dependem
dos parâmetros em questão na relação de proporcionalidade.
(a) Condicional completa para ϕ:
p(ϕ|z, σ2) ∝ exp
− 1
2σ2‖ z −Mϕ ‖2
,
26

somando e subtraindo Mϕ dentro da norma, com ϕ = (M′M)−1M
′z, expandindo-a e
observando que (z −Mϕ)′(Mϕ−Mϕ) = 0 tem-se
p(ϕ|z, σ2) ∝ exp
− 1
2σ2(ϕ− ϕ)
′
(M′
M)(ϕ− ϕ)
. (3.5)
(b) Condicional completa para σ2:
p(σ2|z, ϕ) ∝ (σ2)−N2−1 exp
− 1
2σ2‖ z −Mϕ ‖2
. (3.6)
As distribuições condicionais completas têm forma conhecida. Na equação (3.5) observa-
se o núcleo de uma normal multivariada com vetor de média ϕ e matriz de covariância
σ2(M′M)−1. Na equação (3.6) a condicional completa tem a forma de uma distribuição
Gama para 1/σ2 com parâmetros N/2 + 2 e ‖ z −Mϕ ‖2 /2.Portanto, gera-se uma amostra a posteriori θ(g)Gg=1 de tamanho G usando o algo-
ritmo amostrador de Gibbs. Isto é feito amostrando-se alternadamente das seguintes
distribuições:
ϕ|z, σ2 ∼ N2(ϕ, σ2(M
′M)−1) e
1/σ2|z, ϕ ∼ Gama
(
N
2+ 2,
‖ z −Mϕ ‖22
)
.
O procedimento de inferência descrito nessa seção usa técnicas de MCMC para motivar
o procedimento do caso multivariado. Contudo, para escolhas adequadas das prioris não
é necessário fazer aproximações por Monte Carlo, pois a distribuição a posteriori (ϕ, σ2)
tem forma analítica na família normal-gama.
3.1.3 Exemplo simulado
Neste exemplo pretende-se mostrar o procedimento de estimação dos parâmetros do
processo CIR univariado e destacar o efeito da discretização sobre a estimação. Para isto
é gerada uma amostra do processo discretizado para parâmetros α, β e σ2 conhecidos.
Resultados para diferentes tamanhos de malha são comparados.
Gera-se 201 observações do processo discretizado (3.2) do tempo inicial zero com
valor inicial yt0 = 0.3 conhecido, ao tempo final 200, com espaçamento entre os tempos de
27

observações de ∆ = 1. A Figura 3.1 mostra os dados gerados para os parâmetros α = 0.04,
β = −0.02 e σ2 = 0.005 e a transformação dos dados como feito em (3.3).
0 50 100 150 200
0.5
1.0
1.5
2.0
Dados simulados
tempo
y t
0 50 100 150 200−
0.1
0.0
0.1
0.2
Dados Transformados
tempo
z
Figura 3.1: Dados simulados e dados transformados.
O procedimento de inferência segue o que foi sugerido na Subseção 3.1.2. O algoritmo
de Gibbs foi utilizado sendo realizadas 11000 iterações. Delas foram descartadas as pri-
meiras 1000 (aquecimento ou burn in) e só consideradas as amostras tomadas de 10 em
10 totalizando 1000 amostras da posteriori. A Figura 3.2 mostra os gráficos da saída do
MCMC (ou traço dos parâmetros), na primeira coluna, a função de autocorrelação, na
segunda, e o histograma com a linha de densidade, na última coluna. Isto para cada um
dos parâmetros: α linha 1, β linha 2 e σ2 na linha 3.
28

0 200 600 1000
−0.
010.
03Saída do MCMC
iteração
α
0 5 15 25
0.0
0.4
0.8
Lag
fac
α Histograma
α
freq
üênc
ia
0.00 0.04
010
30
0 200 600 1000
−0.
040.
00
Saída do MCMC
iteração
β
0 5 15 25
0.0
0.4
0.8
Lag
fac
β Histograma
β
freq
üênc
ia
−0.05 −0.02 0.01
020
40
0 200 600 1000
0.00
300.
0050
Saída do MCMC
iteração
σ2
0 5 15 25
0.0
0.4
0.8
Lag
fac
σ2 Histograma
σ2
freq
üênc
ia
0.0030 0.0045 0.0060
040
080
0
Figura 3.2: Resultado do Amostrador de Gibbs. Traço (coluna 1), função de autocorrela-
ção (coluna 2) e histograma (coluna 3), para os parâmetros α, β e σ2. As retas horizontais e
verticais que aparecem nos traços e histogramas, respectivamente, representam os valores
verdadeiros.
O procedimento foi repetido, sobre o mesmo conjunto de dados, considerando agora
∆ = 10. Isto é, tem-se como observações Y0, Y10, Y20, . . . , Y200. O fato de passar de 201
observações para 21 gera maior imprecisão nos resultados e o viés gerado por este proce-
29

dimento é mostrado na Figura 3.3. Nela percebe-se que o aumento da distância entre as
observações e, consequentemente, a redução das observações gera amostras a posteriori
deslocadas dos valores verdadeiros.
Nesta seção foi realizado o procedimento de inferência bayesiana considerando prioris
não informativas. Esta escolha teve por objetivo motivar o que será feito a seguir no caso
multivariado. Vale ressaltar que para prioris ϕ | σ2 ∼ N(µϕ, σ2Σϕ), com hiperparâmetros
µϕ ∈ IR2 e Σϕ matriz de ordem 2 positiva definida, e σ2 ∼ IG(a/2, b/2), a, b > 0, as
posterioris têm forma fechada com ϕ | y uma distribuição t-Student bivariada e σ2|y com
distribuição Gama Invertida (ver Marin e Robert (2007, p. 54)).
30

0.00 0.02 0.04 0.06 0.08
020
40
α
dens
idad
e
0.00 0.02 0.04 0.06 0.08
020
40
−0.06 −0.04 −0.02 0.00 0.02
020
40
β
dens
idad
e
−0.06 −0.04 −0.02 0.00 0.02
020
40
0.001 0.002 0.003 0.004 0.005 0.006 0.007
040
080
0
σ2
dens
idad
e
0.001 0.002 0.003 0.004 0.005 0.006 0.007
040
080
0
Figura 3.3: Comparação entre as amostras a posteriori dos parâmetros do processo CIR
univariado para ∆ = 1 (linha contínua) e ∆ = 10 (linha tracejada). As linhas pontilhadas
indicam os valores verdadeiros dos parâmetros.
3.2 CIR multivariado
Nesta seção apresenta-se uma versão multivariada para o processo CIR de acordo com
a notação geral definida na Seção 2.2. Processos de difusão multivariados são vistos sob
31

diversos pontos de vista a partir da forma geral. Por exemplo, modelos de volatilidade
estocástica podem ser escritos como difusões bivariadas como aparece em Kalogeropoulos
(2007) ou Eraker (2001). Ou ainda, EDEs multivariadas são comuns em modelos de
estrutura a termo da taxa de juros ou modelos afins. Elas podem ser encontradas em
Sanford e Martin (2006b), Jones (2003) e Geyer e Pichler (1999). Duffie (2001, capítulo 7)
apresenta vários modelos de estrutura a termo e Duffie e Kan (2001) discutem a existência
e unicidade de soluções de EDEs desta natureza, para os casos uni e multivariados.
Nesta seção propõe-se uma generalização multivariada do processo CIR considerando
múltiplas difusões univariadas correlacionadas. Trabalhos nesta direção aparecem em
Sanford e Martin (2006a), Duffie e Kan (2001) e em Elerian (1999, capítulo 11).
Seja o movimento browniano d−dimensional B(t) = Bt = (B(1)t , . . . , B
(d)t )
′e um vetor
de parâmetros θ, diz-se que a difusão X de dimensão n evolui no tempo de acordo com
a EDE dada por
dX(t) = b(X(t), t; θ)dt+ σ(X(t), t; θ)dB(t), (3.7)
tal que as funções b e σ são como em (2.2) e X(t) = X t = (X(1)t , . . . , X
(n)t ). Para simpli-
ficar a notação a função de direção será chamada de bt. Uma generalização multivariada
imediata do processo CIR em (3.1) é obtida considerando
bt := b(X(t), t; θ) =
α1 + β1X(1)t
...
αn + βnX(n)t
n×1
= Ft ϕ,
sendo que tomando ϕi = (αi, βi)′e F (i)
t = (1 X(i)t ), com i = 1, . . . , n, tem-se
Ft =
F(1)t 0 . . . 0
0 F(2)t . . . 0
.... . .
0 0 . . . F(n)t
n×2n
e ϕ =
ϕ1
ϕ2
...
ϕn
2n×1
.
Desta forma, a função de direção bt do processo CIR multivariado, como aqui caracteri-
zado, pode ser escrita pelo produto entre uma matriz Ft de dimensão n× 2n e um vetor
32

2n−dimensional ϕ.
E, além disto, a função de volatilidade, que por uma questão de simplificação de
notação denota-se por σt, é expressa da forma
σt := σ(X(t), t; θ) = DXtDσP,
sendo DXt:= diag
(
X(1)t
1/2, . . . , X
(n)t
1/2)
n×n, Dσ := diag
(
σ(1), . . . , σ(n))
n×ne P é uma
matriz n× d.
Note que DXté uma matriz que depende da difusão multivariada X t enquanto a
matriz Dσ não depende nem do tempo nem da difusão. Assume-se que os movimentos
brownianos B(j), com j = 1, . . . , d, são independentes e, portanto, toda estrutura de
covariância entre as componentes do processo está presente na matriz P . Assim, o caso
em que d = n e a matriz P for a identidade resulta em n processos de difusão CIR
univariados independentes com as componentes não nulas da matriz Dσ representando as
volatilidades de cada um dos processos univariados independentes.
3.2.1 Notas sobre a existência e unicidade de soluções
É fácil verificar que o processo CIR multivariado possui solução fraca. De fato, como
as funções bt e σt são contínuas e limitadas, o Teorema 2.3 garante a existência de pelo
menos uma solução fraca. Isto é suficiente para o uso da equação (3.7) nos capítulos
subsequentes e para o procedimento de inferência apresentado mais adiante.
O que não é possível é garantir existência de solução forte da EDE (3.7). Pode-se
mostrar que elas atendem à condição de crescimento linear e que
∫ t
0
b(i)(X(s), s; θ)ds en∑
j=1
∫ t
0
σij(X(s), s; θ)dB(i)(s)
existem para i = 1, . . . , n. Contudo, a condição de Lipschitz não é atendida para X t
próximo da origem. O problema está na raiz quadrada dentro da função σt.
Duffie e Kan (2001) estabeleceram condições sobre as funções de direção e volatilidade
para que os modelos de taxa de juros (modelos afim) atendam a condição de Lipschitz
33

e X t não tenha coordenada negativa para todo t. Isto só é possível sobre restrições
na função de direção de modo que ela seja positiva com força suficiente. No entanto,
as condições apresentadas por Duffie e Kan (2001) são demasiadamente restritivas, não
garantindo solução forte para a maioria das configurações da matriz P, componente da
função de volatilidade σt.
3.2.2 Esquema de Euler-Maruyama
Estendendo o que foi desenvolvido no caso univariado, suponha que são observadas
N+1 ocorrências do vetor de difusão X t nos tempos 0 = t0 < t1 < . . . < tN = T. Assume-
se a aproximação Y k ≈ X(tk), k = 0, . . . , N de maneira que a observação no instante
tk é dada por Y k = yk. Novamente, para enxugar a notação, adota-se simplesmente o
índice k para representar o tempo tk. Pelo Esquema de Euler a EDE (3.7) é discretizada
por
Y k+1 = Y k + bk∆k + σk
√
∆k εk, com k = 0, . . . , N − 1, (3.8)
tal que ∆k = tk+1 − tk e εk ∼ Nd(0, Id) é a normal padrão multivariada independentes
para todo k.
3.2.3 Transformação dos dados
O procedimento para inferência é realizado considerando um modelo de regressão linear
multivariado. Para isto, primeiramente, são feitas algumas transformações na equação
(3.8) nos mesmos moldes que as realizadas no caso unidimensional. Em seguida, o vetor
de observações é reorganizado considerando as decomposições da função de volatilidade.
Desta forma, seja a transformação dos dados feita por
Zk :=1
∆1/2k
D−1Y k
(Y k+1 − Y k) =Mkϕ+ Aεk, (3.9)
tal que Z′
k = (Z(1)k , Z
(2)k , . . . , Z
(n)k ), DY k
:= diag(
Y(1)k
1/2, . . . , Y
(n)t
1/2)
, Mk =√
∆kD−1Y kFk
e A = DσP com k = 0, . . . , N − 1 e εk ∼ Nd(0, Id).
34

Como os εk’s são variáveis aleatórias normais multivariadas, com matriz de covariância
identidade e independentes para todo k, pode-se organizar os vetores Zk’s obtendo o vetor
Z da forma
Z =
Z(1)
Z(2)
...
Z(n)
=
(z(1)0 , z
(1)1 , . . . , z
(1)N−1)
′
(z(2)0 , z
(2)1 , . . . , z
(2)N−1)
′
...
(z(n)0 , z
(n)1 , . . . , z
(n)N−1)
′
=
M (1) 0 . . . 0
0 M (2) . . . 0...
.... . .
...
0 0 . . . M (n)
ϕ1
ϕ2
...
ϕn
+ε,
(3.10)
tal que, para i = 1, . . . , n, define-se
M (i) :=
M(i)0
...
M(i)N−1
=
√
∆0
y(i)0
√
∆0y(i)0
......
√
∆N−1
y(i)N−1
√
∆N−1y(i)N−1
e ε ∼ N(0,Σ ⊗ IN) sendo que a matriz Σ é resultado do produto matricial AA′=
DσPP′Dσ. As componentes da matriz Σ são denotadas por (Σ)ij = sij e o símbolo ⊗
refere-se ao produto de Kronecker que é dado por
Σ⊗ IN =
s11IN s12IN . . . s1nIN
s21IN s22IN . . . s2nIN
......
. . .
sn1IN sn2IN . . . snnIN
Nn×Nn
.
3.2.4 Inferência bayesiana
O procedimento da seção anterior é aplicado ao conjunto de dados obtido pelo vetor
das observações y = y0,y1, . . . ,yN. A transformação da equação (3.9) é realizada
resultando em
Z = Mϕ+ ε, (3.11)
35

sendo M = diag M (1), . . . ,M (n), ϕ′= (ϕ
′
1, . . . , ϕ′
n) e ε ∼ NNn(0,Σ⊗ IN).
O tratamento de modelos como o da equação (3.11) pode ser visto em Zellner (1971)
(seção 8.5).
Os parâmetros de interesse são ϕ e Σ. A verossimilhança do processo é escrita por
l(Z; ϕ,Σ) ∝ |Σ−1|N/2 exp
−1
2(Z −Mϕ)
′
Σ−1 ⊗ IN(Z −Mϕ)
∝ |Σ−1|N/2 exp
−1
2tr(HΣ−1)
,
tal que
H =
(Z(1) −M (1)ϕ1)′(Z(1) −M (1)ϕ1) . . . (Z(1) −M (1)ϕ1)
′(Z(n) −M (n)ϕn)
.... . .
...
(Z(n) −M (n)ϕn)′(Z(1) −M (1)ϕ1) . . . (Z(n) −M (n)ϕn)
′(Z(n) −M (n)ϕn)
.
Assume-se uma distribuição a priori conjunta não informativa dada por
p(ϕ,Σ−1) = p(ϕ)p(Σ−1) ∝ |Σ−1|−(n+1)/2. (3.12)
E, portanto, a posteriori conjunta para os parâmetros ϕ e Σ−1 é dada por
p(ϕ,Σ−1|Z) ∝ |Σ−1|N−(n+1)/2 exp
−1
2(Z −Mϕ)
′
[Σ−1 ⊗ IN ](Z −Mϕ)
∝ |Σ−1|N−(n+1)/2 exp
−1
2tr(HΣ−1)
.
Para obter uma amostra da posteriori do vetor ϕ e da matriz Σ utiliza-se o algoritmo
amostrador de Gibbs. Para isto amostra-se de uma distribuição condicional completa
normal Nn− dimensional para ϕ dada por
ϕ|Σ−1,Z ∼ NNn(m,C), (3.13)
tal que
m = [M′
(Σ−1 ⊗ IN)M ]−1M′
(Σ−1 ⊗ IN)Z e C = [M′
(Σ−1 ⊗ IN )M ]−1.
e em seguida amostra-se de uma distribuição Wishart para Σ−1 da forma
Σ−1|ϕ,Z ∼W (H,N, n), (3.14)
36

cuja função de densidade é
p(Σ−1|ϕ,Z) ∝ |Σ−1|N−(n+1)/2 exp
−1
2tr(HΣ−1)
.
Vale destacar que a transformação da equação (3.9), que leva ao modelo (3.11), não é
única. Reorganizando de maneira adequada a expressão (3.9) é possível obter um modelo
de regressão cuja inferência bayesiana possui conjugação. Isto é, para escolhas adequadas
das prioris, as posterioris têm forma fechada no modelo normal-gama. Esta proposição é
uma proposta para trabalho futuro.
3.2.5 Exemplo simulado
O procedimento de estimação desenvolvido nessa seção é apresentado para um con-
junto de dados simulados. A motivação está nos problemas reais que aparecerão nos
capítulos finais desse texto sobre emissão de gases e estimação de parâmetros em proces-
sos de difusão multivariados com estruturas espaciais. No exemplo mostra-se o efeito de
aumentar o espaçamento das observações sobre a distribuição a posteriori dos parâmetros.
Foram simuladas 201 observações y = y0,y1, . . . ,yN considerando um processo de
três dimensões, n = 3, em um intervalo de tempo t ∈ [0, 200]. Assumindo que o tempo
entre as observações é constante e igual a 1 e y′
0 = (0.4, 0.8, 1.2) os dados foram gerados
a partir da equação (3.8) pelos parâmetros
ϕ =
ϕ1
ϕ2
ϕ3
=
(α1, β1)′
(α2, β2)′
(α3, β3)′
=
(0.6,−0.25)′
(0.4,−0.15)′
(0.2,−0.05)′
e a matriz
Σ = AA′
=
0.05 0.0375 −0.025
0.0375 0.05 −0.0125
−0.025 −0.0125 0.05
.
A Figura 3.4 exibe os dados simulados e a transformação deles.
37

0 50 100 150 200
12
34
56
Simulação
tempo
série
s
0 50 100 150 200
12
34
56
Simulação
tempo
série
s
0 50 100 150 200
12
34
56
Simulação
tempo
série
s
0 50 100 150 200
−0.
50.
00.
5
Transformação
tempo
série
s
0 50 100 150 200
−0.
50.
00.
5
Transformação
tempo
série
s
0 50 100 150 200
−0.
50.
00.
5
Transformação
tempo
série
s
Figura 3.4: Dados simulados e dados transformados.
O algoritmo amostrador de Gibbs é utilizado para inferência das variáveis de interesse
ϕ e Σ de acordo com a teoria desenvolvida na Subseção 3.2.4. A priori conjunta para
(ϕ,Σ) é dada pela equação (3.12) com valores iniciais Σ(1) = I3, a matriz identidade de
ordem 3, e ϕ(1) = 0 vetor nulo.
A cada iteração o algoritmo evolui amostrando-se de ϕ|Σ−1,Z, uma normal multi-
variada, como em (3.13), e de uma Wishart para Σ−1|ϕ,Z, como em (3.14). Com isto
obtém-se uma amostra de (ϕ(g),Σ(g))Gg=1, os parâmetros de interesse, com G = 11000.
Para os gráficos só são consideradas as amostras de 1001 até 11000 (i.e. burn in de 1000)
tomando-as de 10 em 10. Disto resulta em uma amostra a posteriori de 1000 valores dos
parâmetros.
Fazendo uma análise gráfica dos resultados do amostrador de Gibbs têm-se na Figura
3.5 o traço e na Figura 3.6 o histograma do parâmetro ϕi, com i = 1, . . . , 3. As retas
horizontais representam os valores verdadeiros usados na geração dos dados.
38
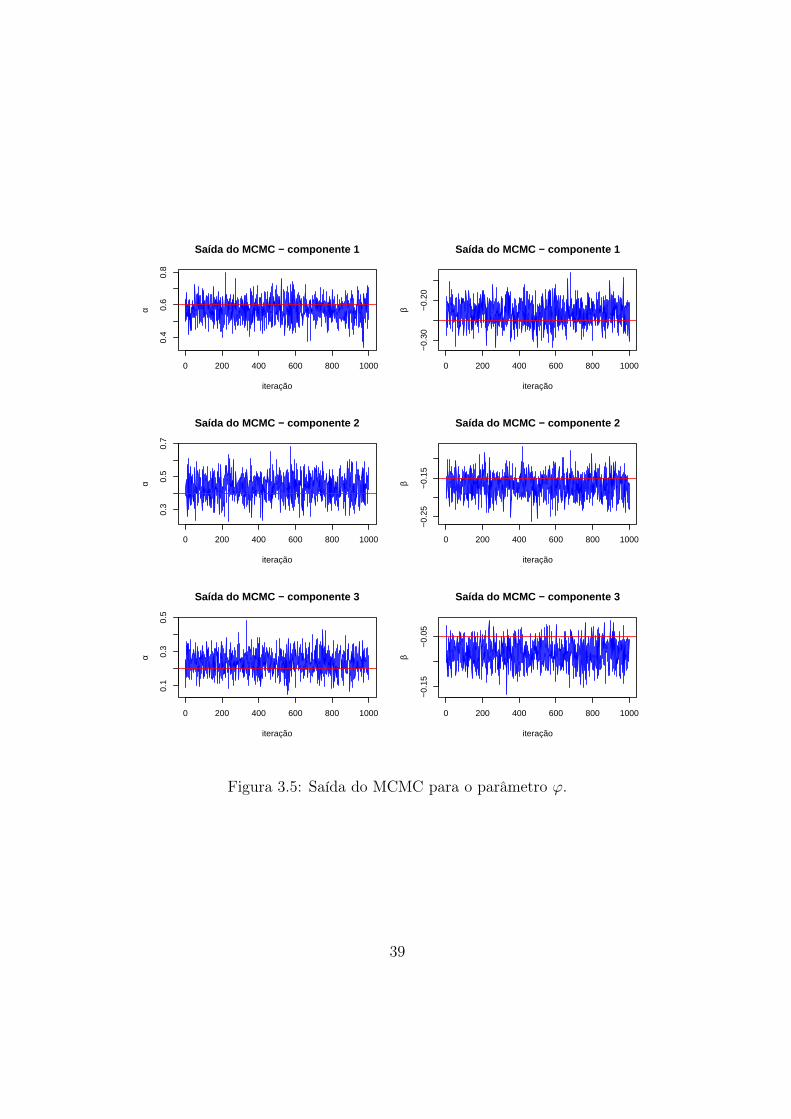
0 200 400 600 800 1000
0.4
0.6
0.8
Saída do MCMC − componente 1
iteração
α
0 200 400 600 800 1000
−0.
30−
0.20
Saída do MCMC − componente 1
iteração
β
0 200 400 600 800 1000
0.3
0.5
0.7
Saída do MCMC − componente 2
iteração
α
0 200 400 600 800 1000
−0.
25−
0.15
Saída do MCMC − componente 2
iteração
β
0 200 400 600 800 1000
0.1
0.3
0.5
Saída do MCMC − componente 3
iteração
α
0 200 400 600 800 1000
−0.
15−
0.05
Saída do MCMC − componente 3
iteração
β
Figura 3.5: Saída do MCMC para o parâmetro ϕ.
39

Histograma − componente 1
α
freq
üênc
ia
0.4 0.5 0.6 0.7 0.8
01
23
45
6
Histograma − componente 1
β
freq
üênc
ia
−0.30 −0.25 −0.20 −0.15
04
812
Histograma − componente 2
α
freq
üênc
ia
0.3 0.4 0.5 0.6 0.7
01
23
45
6
Histograma − componente 2
β
freq
üênc
ia
−0.25 −0.20 −0.15 −0.100
48
12
Histograma − componente 3
α
freq
üênc
ia
0.1 0.2 0.3 0.4 0.5
02
46
Histograma − componente 3
β
freq
üênc
ia
−0.15 −0.10 −0.05
05
1015
Figura 3.6: Histogramas da amostra a posteriori de ϕ.
40

Na Figura 3.7 têm-se os traços dos elementos da matriz Σ e na Figura 3.8 os histo-
gramas. Como a matriz Σ(g) é simétrica para todas as iterações do amostrador de Gibbs
(g = 1, . . . , G) os traços e histogramas também são simétricos, só precisando exibir os ele-
mentos s11, s12, s13, s22, s23 e s33. Novamente as retas horizontais representam os valores
verdadeiros.
0 200 400 600 800 1000
0.04
00.
055
0.07
0
Saída do MCMC
iteração
s 1
1
0 200 400 600 800 1000
0.03
00.
045
0.06
0
Saída do MCMC
iteraçãos
1 2
0 200 400 600 800 1000
−0.
040
−0.
025
Saída do MCMC
iteração
s 1
3
0 200 400 600 800 1000
0.04
50.
060
0.07
5
Saída do MCMC
iteração
s 2
2
0 200 400 600 800 1000
−0.
030
−0.
015
Saída do MCMC
iteração
s 2
3
0 200 400 600 800 1000
0.04
0.06
Saída do MCMC
iteração
s 3
3
Figura 3.7: Saída do MCMC para Σ.
41

Histograma
s 1 1
freq
üênc
ia
0.04 0.05 0.06 0.07
020
4060
Histograma
s 1 2
freq
üênc
ia
0.030 0.040 0.050 0.060
020
60
Histograma
s 1 3
freq
üênc
ia
−0.040 −0.030 −0.020
040
80
Histograma
s 2 2
freq
üênc
ia
0.045 0.055 0.065 0.0750
2040
60
Histograma
s 2 3
freq
üênc
ia
−0.030 −0.020 −0.010
040
80
Histograma
s 3 3
freq
üênc
ia
0.04 0.05 0.06 0.07
020
4060
80
Figura 3.8: Histogramas da amostra a posteriori de Σ.
42

Nas Figuras 3.5, 3.6, 3.7 e 3.8 percebe-se que os valores verdadeiros são bem estimados.
Em especial, o procedimento desenvolvido consegue identificar as correlações entre os 3
processos discretizados. Em aplicações reais, como análise de séries financeiras e séries de
concentração de gases poluentes, é importante estimar bem a matriz de correlação Σ. Isto
ajuda a determinar a estrutura de influência entre as coordenadas do processo indicando
as características do fenômeno.
Assim como foi feito para o caso univariado é de interesse saber o efeito de aumentar
o espaçamento entre as observações. Assumem-se observados apenas y0,y10, . . . ,y200. As
Figuras 3.9 e 3.10 mostram o deslocamento das densidades a posteriori dos parâmetros ϕ
e Σ quando se assume uma malha menos refinada.
É intuitivo que trabalhar com uma maior quantidade de dados melhora a estimação
e, isto fica evidente na comparação exibida nos gráficos. Contudo, existe um erro de
discretização intrínseco ao se aproximar processos de difusão contínuos por formas dis-
cretas. Este erro, conhecido por viés de discretização, cresce a medida que aumenta-se
o espaçamento ∆. No capítulo a seguir são discutidas técnicas para reduzir problemas
relacionados à discretização.
43
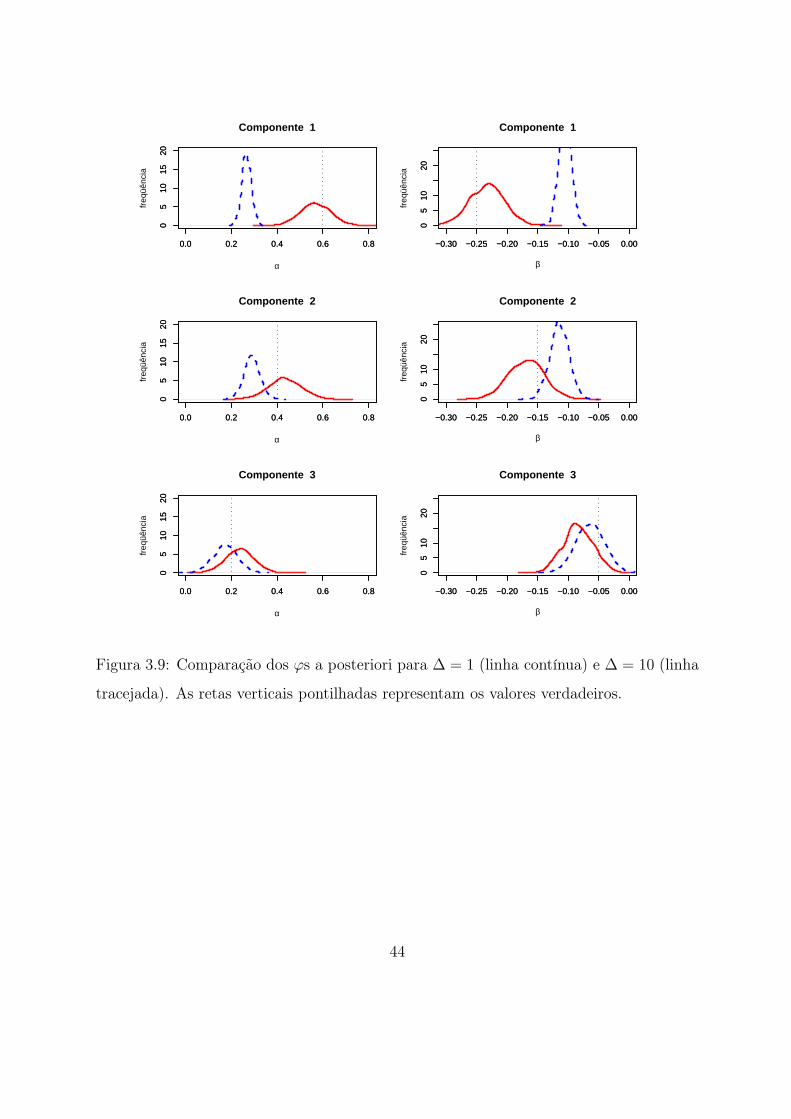
0.0 0.2 0.4 0.6 0.8
05
1015
20
Componente 1
α
freq
üênc
ia
0.0 0.2 0.4 0.6 0.8
05
1015
20
−0.30 −0.25 −0.20 −0.15 −0.10 −0.05 0.00
05
1020
Componente 1
β
freq
üênc
ia
−0.30 −0.25 −0.20 −0.15 −0.10 −0.05 0.00
05
1020
0.0 0.2 0.4 0.6 0.8
05
1015
20
Componente 2
α
freq
üênc
ia
0.0 0.2 0.4 0.6 0.8
05
1015
20
−0.30 −0.25 −0.20 −0.15 −0.10 −0.05 0.000
510
20
Componente 2
β
freq
üênc
ia
−0.30 −0.25 −0.20 −0.15 −0.10 −0.05 0.000
510
20
0.0 0.2 0.4 0.6 0.8
05
1015
20
Componente 3
α
freq
üênc
ia
0.0 0.2 0.4 0.6 0.8
05
1015
20
−0.30 −0.25 −0.20 −0.15 −0.10 −0.05 0.00
05
1020
Componente 3
β
freq
üênc
ia
−0.30 −0.25 −0.20 −0.15 −0.10 −0.05 0.00
05
1020
Figura 3.9: Comparação dos ϕs a posteriori para ∆ = 1 (linha contínua) e ∆ = 10 (linha
tracejada). As retas verticais pontilhadas representam os valores verdadeiros.
44

0.00 0.02 0.04 0.06 0.08 0.10
020
4060
Densidades
s 1 1
freq
üênc
ia
−0.06 −0.04 −0.02 0.00 0.02 0.04 0.06
020
4060
80
Densidades
s 1 2
freq
üênc
ia
−0.06 −0.04 −0.02 0.00 0.02 0.04 0.06
020
6010
0
Densidades
s 1 3
freq
üênc
ia
0.00 0.02 0.04 0.06 0.08 0.100
2040
60
Densidades
s 2 2
freq
üênc
ia
−0.06 −0.04 −0.02 0.00 0.02 0.04 0.06
020
6010
0
Densidades
s 2 3
freq
üênc
ia
0.00 0.02 0.04 0.06 0.08 0.10
020
4060
80
Densidades
s 3 3
freq
üênc
ia
Figura 3.10: Comparação dos Σs a posteriori para ∆ = 1 (linha contínua) e ∆ = 10 (linha
tracejada). As retas verticais pontilhadas representam os valores verdadeiros.
45

Capítulo 4
Aumento de Dados
O procedimento de aumento de dados consiste em assumir uma quantidade latente
de dados não observados entre cada par de dados observados. Essa quantidade latente é
tratada como parâmetro a ser estimada seguindo algum critério de inferência. A motivação
por trás do aumento de dados é que algumas distribuições a posteriori são mais facilmente
obtidas se uma quantidade maior de observações estiver presente. Além disso, quando
deseja-se estimar os parâmetros de um processo de difusão com dados discretamente
observados é necessário que a frequência dos dados seja refinada o suficiente para evitar
viés de discretização.
Seguindo a notação da Seção 2.5 considera-se um conjunto de dados observados yo e
um conjunto de não observados yno de modo que
yo = yk : k = 0, . . . , N e yno = ykj : k = 0, . . . , N − 1 e j = 1, . . . , mk.
Note que o índice k representa uma abreviação do tempo tk e a dupla de índices (k, j)
representa o tempo da j−ésima observação latente entre os tempos tk e tk+1.
O objetivo é obter a distribuição de θ|yo e isto é feito pelo algoritmo amostrador de
Gibbs que consiste em amostrar alternadamente de
p(θ|yo,yno) e p(yno|θ,yo). (4.1)
46

A seguir descreve-se o procedimento para amostrar das distribuições em (4.1). Seja
y = yo ∪ yno o conjunto total de dados. O primeiro termo é obtido da Fórmula de Bayes
por
p(θ|y) = p(y|θ)p(θ)p(y)
∝ p(y|θ)p(θ),
sendo que, no caso em que a função de transição é obtida pelo esquema de discretização de
Euler-Maruyama, obtém-se uma aproximação da função de verossimilhança do processo
de difusão dada por
p(y|θ) ∝ p(yo0 | θ)
N−1∏
k=0
p(yno(k) 1|yok, θ)[
mk−1∏
j=1
p(yno(k) j+1|yno(k) j , θ)]
p(yok+1|ynokmk, θ)
. (4.2)
Uma simplificação da equação (4.2) é obtida considerando uma redução na notação. Seja
o conjunto dos tempos em que os dados foram observados, T o, e o conjunto dos tempos
dos dados não observados, T no, ambos os conjuntos com os tempos ordenados. Define-se
T = T o ∪ T no,
que representa o conjunto de todos os tempos dos dados (observados ou não) ordenados.
Assim, τk ∈ T indica o tempo de ocorrência de um dado, com τk < τk+1 e k = 0, . . . , K :=
N +∑N−1
k=0 mk. A equação (4.2) pode ser rescrita por
p(y|θ) ∝ p(yτ0 | θ)
K−1∏
k=0
p(yτk+1|yτk , θ)
. (4.3)
Dada uma distribuição a priori para o vetor paramétrico θ é possível calcular p(θ|y).O passo seguinte é obter p(yno|θ,yo). O procedimento de inferência, alternando a geração
das distribuições em (4.1), resulta em amostras yno(g), θ(g)Gg=1 de uma cadeia de Markov.
Nas seções a seguir são apresentadas formas de determinar a distribuição condicional dos
dados não observados.
Vale ressaltar que os dados não observados são obtidos do modelo considerado. O que
será discutido nas seções a seguir são formas de sorteá-los e aceitá-los dentro dos passos
do MCMC.
47

4.1 Movimentos simples
O primeiro procedimento para obtenção do estado da cadeia de Markov yno(g) é aquele
que obtém cada yτk por vez, com τk ∈ T no. O algoritmo de Metropolis-Hastings é utilizado
para obter amostras de yτk |yτ\k , θ, sendo τ\k todos os tempos do conjunto T exceto o
k−ésimo tempo. Esta abordagem pode ser vista em Jones (1998) e para uma discussão
mais detalhada de métodos MCMC sugere-se Gamerman e Lopes (2006).
Usando a propriedade de Markov e realizando algumas contas tem-se
p(yτk |yτ\k , θ) = p(yτk |yτk+1,yτk−1
, θ) =p(yτk ,yτk+1
,yτk−1|θ)
p(yτk+1,yτk−1
|θ) =
= p(yτk+1|yτk ,yτk−1
, θ)p(yτk |yτk−1, θ)
p(yτk−1|θ)
p(yτk+1,yτk−1
|θ) .(4.4)
Considerando novamente a propriedade de Markov no primeiro termo da última igualdade
de (4.4) e observando que a última fração é uma função que não depende de yτk obtém-se
p(yτk |yτ\k , θ) ∝ p(yτk+1|yτk , θ)p(yτk |yτk−1
, θ). (4.5)
Em geral não é possível determinar de forma fechada qual é a distribuição em (4.5). O
algoritmo de Metropolis-Hastings é utilizado para obter uma amostra de yτk |yτ\k , θ. O
procedimento é como segue:
(1) Propõe-se um valor inicial y(0)τk para a cadeia.
(2) Gera-se um valor proposto y(∗)τk , na iteração g, de uma distribuição proposta q. Nesse
caso assume-se q( . ) ∼ p( . |y(g−1)τk−1 , θ
(g−1)).
(3) Aceita-se o valor proposto y(∗)τk com probabilidade igual a
min
1,p(y
(g−1)τk+1 |y(∗)
τk , θ(g−1))
p(y(g−1)τk+1 |y(g−1)
τk , θ(g−1))
,
caso contrário y(g)τk = y
(g−1)τk .
A seguir são apresentados exemplos desta abordagem no contexto do processo CIR
como desenvolvido no Capítulo 3.
48

4.1.1 Exemplo simulado - CIR univariado
Considere o exemplo simulado da Seção 3.1. Assume-se observado o conjunto de dados
yo = y0, y10, . . . , y200. No exemplo a frequência de dados é aumentada de 21 (∆ = 10)
para 201 (∆ = 1) resultando no conjunto total dos dados y = y0, y1, y2, . . . , y200. O
conjunto dos dados observados é o mesmo do exemplo simulado da Seção 3.1 que é exibido
na Figura 3.1 considerando somente as observações de 10 em 10 unidades de tempo.
A inferência do vetor de parâmetros θ′= (α, β, σ2) é feita pelo algoritmo amostrador
de Gibbs para p(θ|y) do mesmo modo que feito na Seção 3.1. A estimação das variáveis
latentes entre cada par de dados observados (também chamados de pontes ou dados não
observados) segue os procedimentos que serão descritos nesta seção.
Note que os dados não observados não podem ser negativos uma vez que o processo
discretizado tem um termo raiz quadrada sobre yτk como segue
yτk+1= yτk + (α + βyτk)∆τk +
√
σ2yτk∆τkετk , ετk ∼ N(0, 1),
sendo ∆τk = τk+1 − τk, k = 0, . . . , K.
Assim, para evitar que os dados aumentados sejam gerados nos negativos, propõe-se
uma mudança de variável sobre o processo de difusão dXt = (α + βXt)dt +√
σ2XtdBt
dada por Ut = lnXt. Aplicando a Fórmula de Itô univariada tem-se
dUt =
(
αe−Ut + β − σ2 e−Ut
2
)
dt+ σe−Ut/2dBt. (4.6)
Considerando os dados transformados uτk = ln yτk e discretizando a equação (4.6) obtém-
se
uτk+1|uτk , θ ∼ N
uτk +
(
αe−uτk + β − σ2 e−uτk
2
)
∆τk, σ2e−uτk∆τk
. (4.7)
Assim é possível obter uma amostra de
p(uτk |uτ\k , θ) ∝ p(uτk+1|uτk , θ)p(uτk |uτk−1
, θ)
pelo algoritmo de Metropolis-Hastings. Após obtidas todas as pontes da g−ésima iteração
do amostrador de Gibbs faz-se yτk = euτk , com k = 0, . . . , K, e atualiza-se o vetor de
parâmetros θ.
49

No procedimento de inferência foram consideradas 11000 iterações da cadeia de Mar-
kov, sendo os valores iniciais para yno(0) obtidos por interpolação linear entra cada par de
pontos observados e, para os parâmetros, os valores iniciais foram α(0) = 3, β(0) = −0.5 e
(σ2)(0) = 0.05. Do total de iterações foram tomadas as 10000 últimas (i.e. burn in de 1000)
e guardadas de 10 em 10. Disso resultou uma amostra a posteriori de 1000 elementos para
cada uma das quantidades de interesse.
A Figura 4.1 mostra o gráfico do conjunto de dados iniciais sendo que a reta representa
a construção linear das pontes yno(g), para g = 0 (gráfico da esquerda). Na mesma Figura,
o gráfico da direita mostra a média a posteriori dos dados não observados e o intervalo de
credibilidade de 95% (IC95%).
0 50 100 150 200
0.5
1.0
1.5
2.0
tempo (min)
y t
0 50 100 150 200
0.5
1.0
1.5
2.0
0 50 100 150 200
0.5
1.0
1.5
2.0
Pontes a posteriori
tempo (min)
y t
Figura 4.1: Dados simulados e pontes lineares (gráfico da esquerda) e média a posteriori
das pontes com IC95% (gráfico da direita).
A Figura 4.2 exibe a saída do MCMC para os parâmetros α, β e σ2. Note que os
parâmetros verdadeiros, representados pelas linhas horizontais nos traços e linhas verticais
nos histogramas, foram bem estimados. Chama-se atenção para o aumento da correlação
entre as iterações do MCMC se comparado com o caso sem aumento de dados na Figura
3.1. Esse fenômeno ocorre em todos os parâmetros, mas é mais evidente em relação ao
50

gráfico da função de autocorrelação de σ2. Segundo mostra Roberts e Stramer (2001) e
Elerian et al. (2001) o aumento de dados gera problemas nos algoritmos MCMC. Conforme
a quantidade de dados aumentados vai para infinito o processo discretizado converge para
o processo exato, contudo o MCMC não converge. Uma forma de melhorar a convergência
do método é escolher técnicas mais adequadas para obtenção dos dados aumentados.
Eraker (2001) propõe mudanças na construção das pontes tornando o MCMC mais
eficiente. Primeiro ele assume que a densidade proposta é dada por
q( . |uτk−1, uτk+1
, θ) ∼ N(mk,Σk)
tal que o vetor de média e a matriz de covariância são dados, respectivamente, por
mk =1
2(uτk−1
+ uτk+1) e Σk =
1
2σ(uτk−1
)σ(uτk−1)′
∆τk.
No caso univariado Σk é a variância da densidade proposta. E a densidade objetivo é
proporcional ao produtório das densidades de transição dadas em (4.7). Em seguida, ele
propõe, ao invés de usar somente Metropolis-Hastings para obter uma amostra a posteriori
das pontes, usar um algoritmo híbrido de Metropolis-Hastings e Aceitação-Rejeição (MH-
AR). Para uma visão detalhada desses algoritmos ver Chib e Greenberg (1995), Smith e
Gelfand (2001) e Gamerman e Lopes (2006, cap. 6).
O procedimento de MH-AR consiste em tomar a proposta para o estado da cadeia
de Markov vindo do algoritmo de Aceitação e Rejeição, sendo que não é garantido que
p(x) < c q(x), ∀x ∈ IR. Isto é, a função c q(x) não domina a densidade objetivo e por isto é
chamada de proposta pseudo-dominante. Em seguida, a proposta é aceita ou não usando
o algoritmo de Metropolis-Hastings levando-se em consideração as regiões de transição da
cadeia de Markov. O algoritmo MH-AR, como desenvolvido em Eraker (2001) e detalhado
em Chib e Greenberg (1995), é o seguinte:
(1) Gerar u(∗)τk ∼ q até que seja aceito com probabilidade
α1 = min
1,p(u
(∗)τk |u(g)τk−1, u
(g−1)τk+1 , θ)
c q(u(∗)τk )
, sendo c =p(mk|u(g)τk−1, u
(g−1)τk+1 , θ)
q(mk|u(g)τk−1 , u(g−1)τk+1 , θ)
.
51

0 200 400 600 800
0.00
0.04
0.08
Saída do MCMC
iteração
α
0 5 10 15 20 25 300.
00.
40.
8
Lag
fac
α Histograma
α
freq
üênc
ia
0.00 0.04 0.08
05
1525
0 200 400 600 800
−0.
08−
0.04
0.00
Saída do MCMC
iteração
β
0 5 10 15 20 25 30
0.0
0.4
0.8
Lag
fac
β Histograma
β
freq
üênc
ia
−0.08 −0.04 0.000
1020
30
0 200 400 600 800
0.00
50.
015
Saída do MCMC
iteração
σ2
0 5 10 15 20 25 30
0.0
0.4
0.8
Lag
fac
σ2 Histograma
σ2
freq
üênc
ia
0.005 0.015
050
150
Figura 4.2: Saída do MCMC. Traços (coluna 1), funções de autocorrelação (coluna 2) e
histogramas (coluna 3) para os parâmetros α, β e σ2. As retas horizontais (nos traços) e
verticais (nos histogramas) assinalam os valores verdadeiros dos parâmetros.
52

(2) Escreve-se u(g)τk = u(∗)τk com probabilidade igual a
α2 =
1, se p(u(g−1)τk
|u(g)τk−1, u(g−1)
τk+1, θ) < c q(u(g−1)
τk)
c q(u(g−1)τk )
p(u(g−1)τk |u(g)τk−1, u
(g−1)τk+1 , θ)
, sep(u(g−1)
τk|u(g)τk−1
, u(g−1)τk+1
, θ) > c q(u(g−1)τk
) e
p(u(∗)τk |u(g)τk−1
, u(g−1)τk+1
, θ) < c q(u(∗)τk )
min
1,p(u
(∗)τk |u(g)τk−1, u
(g−1)τk+1 , θ)q(u
(g−1)τk )
p(u(g−1)τk |u(g)τk−1, u
(g−1)τk+1 , θ)q(u
(∗)τk )
, caso contrário.
Caso contrário faça u(g)τk = u(g−1)τk .
Segundo Eraker (2001), apesar do algoritmo de Metropolis-Hastings funcionar bem
para modelos com um fator, o algoritmo híbrido MH-AR aparenta convergir mais ra-
pidamente. Se o procedimento de construção das pontes realizado em Jones (1998) for
comparado com o desenvolvido por Eraker (2001) (híbrido ou não) o último é muito mais
estável e a cadeia de Markov é menos autocorrelacionada.
A Figura 4.3 exibe as pontes a posteriori. As linhas entre cada par de pontos observa-
dos é a média a posteriori das variáveis latentes e os arcos são os intervalos de credibilidade
de 95%. Neste gráfico encontram-se todos os dados que geraram a série, apesar de serem
considerados apenas 21 na inferência. E por fim, cada barra vertical, na base do gráfico,
representa a raíz quadrada do erro quadrático médio (EQM) entre os valores verdadeiros
da série (que não foram utilizados na inferência) e cada uma das variáveis latentes obtidas
nas iterações do MCMC. Essa medida é dada pela raiz quadrada da fórmula
EQM(yτk) =1
G
G∑
g=1
(
y(g)τk− y(v)τk
)2, (4.8)
sendo G a quantidade de iterações do algoritmo MCMC e y(v)τk o valor verdadeiro do dado
no instante τk.
A Figura 4.4 mostra a saída do MCMC para o procedimento sugerido por Eraker
(2001). As funções de autocorrelação evidenciam que o algoritmo com MH-AR obtém
amostras a posteriori menos correlacionadas.
A Figura 4.5 compara as densidades a posteriori dos parâmetros para três casos dis-
tintos. O primeiro, que será chamado de completo, foi obtido no exemplo da Seção 3.1 e
53

0 50 100 150 200
0.0
0.5
1.0
1.5
2.0
tempo (min)
y t
0 50 100 150 200
0.0
0.5
1.0
1.5
2.0
Figura 4.3: Média a posteriori das pontes (linhas), IC95% (arcos), dados verdadeiros
(pontos em círculos) e raiz do EQM para cada uma das variáveis latentes (retas verticais).
54

0 400 800
0.00
0.06
Saída do MCMC
iteração
α
0 10 20 30
0.0
0.6
Lagfa
c
α Histograma
α
freq
üênc
ia
0.00 0.04
020
0 400 800
−0.
06−
0.01
Saída do MCMC
iteração
β
0 10 20 30
0.0
0.6
Lag
fac
β Histograma
βfr
eqüê
ncia
−0.06 −0.02
020
40
0 400 800
0.00
20.
012
Saída do MCMC
iteração
σ2
0 10 20 30
0.0
0.6
Lag
fac
σ2 Histograma
σ2
freq
üênc
ia
0.002 0.008 0.014
015
0
Figura 4.4: Saída do MCMC para o procedimento em Eraker (2001). Traços (coluna 1),
funções de autocorrelação (coluna 2) e histogramas (coluna 3) para os parâmetros α, β
e σ2. As retas horizontais (nos traços) e verticais (nos histogramas) assinalam os valores
verdadeiros dos parâmetros.
55

considera que todos os dados são observados (201 observações). Ele é representado pelas
linhas contínuas nos gráficos. O caso sem aumento, representado pelas curvas trace-
jadas, é referente a retirada de dados do exemplo da Seção 3.1 de modo a ficar com 21
observações e sem considerar aumento de dados. E, por fim, com aumento é o procedi-
mento de aumento de dados descrito na presente seção e representado nos gráficos pelas
linhas pontilhadas. Note como o aumento de dados melhora a posição das densidades a
posteriori com relação aos valores verdadeiros (linhas tracejadas verticais) se comparado
com o esquema que não considera aumento de dados. Obviamente o melhor resultado é
aquele que considera todos os dados.
A Tabela 4.1 resume as médias e os desvios-padrão a posteriori dos procedimentos
completo, sem aumento e com aumento. Como o procedimento descrito por Jones
(1998) é mais simples e menos eficiente, como já descrito na literatura, ele não será
comparado.
Parâmetro α β σ2
Verdadeiro 0.04 −0.02 0.005
Completo (N = 201) 0.0303 (0.0326) −0.0180 (0.0338) 0.0045 (0.0005)
Sem aumento (N = 21) 0.0252 (0.0321) −0.0142 (0.0332) 0.0037 (0.0012)
Com aumento (N = 21) 0.0309 (0.0133) −0.0203 (0.0113) 0.0050 (0.0024)
Tabela 4.1: Estatísticas do procedimento de inferência: médias a posteriori e desvios-
padrão (em parênteses). A primeira linha exibe os parâmetros e a segunda linha seus
valores verdadeiros. A terceira linha refere-se ao exemplo com todos os dados observados
como feito na Seção 3.1, a quarta linha considera somente observados os dados de 10 em
10 unidades de tempo e a última linha corresponde ao exemplo em questão.
56
−0.02 0.00 0.02 0.04 0.06
010
3050
α
dens
idad
es
−0.06 −0.04 −0.02 0.00 0.02
020
4060
β
dens
idad
es
0.002 0.004 0.006 0.008 0.010
040
080
0
σ2
dens
idad
es
Figura 4.5: Comparação entre as densidades a posteriori. Observados 201 dados (linha
contínua), 21 observados, sem dados aumentados (linha tracejada) e 21 observados com
dados aumentados e MCMC como em Eraker (2001) (linha pontilhada). As retas trace-
jadas verticais indicam os valores verdadeiros.
57

4.1.2 Exemplo simulado - CIR multivariado
Considere os dados gerados no exemplo simulado para o processo CIR multivariado da
Seção 3.2. Nele foram consideradas 201 observações (N = 200) de três séries temporais
(n = 3). Os tempos de observação foram de minuto em minuto e os parâmetros foram os
mesmos descritos no exemplo multivariado de 3.2, gerados pela equação (3.8).
Inferência dos parâmetros
A inferência dos parâmetros foi realizada sobre o modelo de regressão multivariado em
3.2.4 (ver Zellner (1971)) considerando o modelo CIR multivariado descrito na Seção 3.2.
O procedimento de aumento de dados utilizou passos simples. Dessa forma, tem-se
Verossimilhança:
p(Z|ϕ,Σ−1) ∝ |Σ−1|N/2 exp
−1
2tr(HΣ−1)
,
sendo (H)ij = (Zi −Riϕi)′(Zj − Rjϕj), com i, j = 1, . . . , n.
Distribuição a priori:
p(ϕ,Σ−1) = p(ϕ)p(Σ−1) ∝∣
∣Σ−1∣
∣
(n+1)/2.
Distribuição a posteriori:
p(ϕ,Σ−1|Z) ∝ |Σ−1|N−(n+1)/2 exp
−1
2tr(HΣ−1)
.
Algoritmo amostrador de Gibbs:
ϕ|Σ−1,Z ∼ N2n(m,C),
Σ−1|ϕ,Z ∼W (H,N, n),
(4.9)
com
m = [R′
(Σ−1 ⊗ IN )R]−1R
′
(Σ−1 ⊗ IN)Z, C = [R′
(Σ−1 ⊗ IN )R]−1 e
p(Σ−1|ϕ,Z) ∝ |Σ−1|N−(n+1)/2 exp
−1
2tr(HΣ−1)
.
58

Inferência dos dados aumentados
O procedimento de aumento de dados é da seguinte forma:
• Para cada tempo τk gera-se o estado corrente de um dado não observado ynok por
passos de Metropolis.
• Para que, ao realizar a atualização das pontes, evite-se a geração de coordenadas ne-
gativas para yk trabalha-se com a mudança de variável U (i)t = lnX
(i)t , i = 1, . . . , n.
Para essa transformação utiliza-se a Fórmula de Itô multivariada, como pode ser
visto no Teorema 2.2, e a sua aplicação resulta em
dU t = mtdt+MtdBt,
sendo
mt =
e−U(1)t 0
. . .
0 e−U(n)t
bt −(
1
2e−2U
(1)t , . . . ,
1
2e−2U
(n)t
)
diag(σtσ′
t)
e
MtM′
t =
e−U(1)t 0
. . .
0 e−U(n)t
σtσ′
t
e−U(1)t 0
. . .
0 e−U(n)t
,
sendo que bt e σt são, respectivamente, o vetor de direção e a matriz de volatilidade,
do processo X t definidos na Seção 3.2. A matriz diag(σtσ′
t) é a matriz diagonal
cujos elementos são as componentes (σtσ′
t)ii.
• Do esquema de Euler multivariado sobre U t tem-se
U k+1|U k, ϕ,Σ ∼ Nn[U k +mk∆k, MkM′
k∆k ].
• Para o procedimento de MCMC por passos de Metropolis assume-se como densi-
dade proposta
u(∗)k ∼ q( . ) = Nn[0.5(uk−1 + uk+1), 0.5Mk−1M
′
k−1∆k−1].
59

• Pela propriedade de Markov a densidade objetivo pode ser escrita sob a forma
proporcional por
p(uk|u\k, ϕ,Σ) ∝ p(uk+1|uk, ϕ,Σ)p(uk|uk−1, ϕ,Σ)
Os passos de Metropolis podem ser feitos considerando outras propostas como o pro-
cedimento híbrido de Metropolis com Aceitação e Rejeição. No presente exemplo aceita-se
o estado corrente u(∗)k com probabilidade
min
1,p(u
(g−1)k+1 |u(∗)
k , ϕ,Σ)p(u(∗)k |u(g)
k−1, ϕ,Σ)q(u(g)k )
p(u(g−1)k+1 |u(g−1)
k , ϕ,Σ)p(u(g−1)k |u(g)
k−1, ϕ,Σ)q(u(∗)k )
.
Resultados da simulação
O exemplo simulado foi realizado considerando:
• Para controle foi feita a inferência utilizando todos os 201 dados observados (completo).
Isto está representado nas Figuras 4.6 e 4.7 pelos gráficos com linhas contínuas.
• Para testar o procedimento de aumento de dados tomaram-se as observações de 10
em 10 fazendo: 21 observados sem dados aumentados (gráficos com linhas tracejadas
- sem aumento) e 21 observados com 4 aumentados entre cada par de dados
(gráficos pontilhados - com aumento).
• Os valores iniciais do MCMC foram Σ(1) = I3 e ϕ(1) = 0.
• A cada iteração o amostrador de Gibbs obtém alternadamente ϕ|Σ−1,Z de uma
normal multivariada e Σ−1|ϕ de uma Wishart como em (4.9).
• Obtém-se uma amostra dos parâmetros de interesse (ϕ(g),Σ(g))Gg=1 com G = 11000.
Descartando os primeiros 1000 (i.e. burn in de 1000) e considerando as iterações de
10 em 10 tem-se como resultado uma amostra com 1000 elementos da distribuição
a posteriori dos parâmetros.
60

Note nos gráficos das Figuras 4.6 e 4.7 que o procedimento de estimação com dados
aumentados foi melhor para quase todas as componentes de ϕ e melhor para algumas
componentes de Σ. Observe que o aumento de dados reduz a variância dos parâmetros a
posteriori.
Este exercício simulado, por considerar espaçamentos da ordem de uma unidade de
tempo numa amplitude de 200 minutos, gerou estimações não muito boas, mesmo con-
siderando o caso completo N = 201. Para espaçamentos mais refinados as estimativas
melhoram significativamente em todos os casos. Contudo, não é possível destacar, pelo
menos graficamente, a diferença entre os procedimentos. O mais interessante desse exercí-
cio é mostrar que, mesmo para poucos pontos (N = 21), o método de estimação consegue
recuperar os parâmetros dentro de um intervalo de credibilidade aceitável e quando con-
sidera o aumento de dados obtém-se maior acurácia nas estimativas.
Outra observação importante é que o número de parâmetros cresce significativamente
com o aumento da dimensão n. O número total de parâmetros a ser estimado é 2n para a
função de direção mais n(n + 1)/2 para a matriz de volatilidade, considerando o modelo
CIR multivariado. No Capítulo 6 serão discutidas técnicas de redução da quantidade
desses parâmetros ao acrescentar estrutura espacial ao modelo.
61

0.51.0
1.5
0.0 0.5 1.0 1.5 2.0 2.5
α1
densidade
0.51.0
1.5
0.0 0.5 1.0 1.5 2.0 2.5
densidade
0.51.0
1.5
0.0 0.5 1.0 1.5 2.0 2.5
densidade
−0.8
−0.6
−0.4
−0.2
0.0
0 1 2 3 4
β1
densidade
−0.8
−0.6
−0.4
−0.2
0.0
0 1 2 3 4
densidade
−0.8
−0.6
−0.4
−0.2
0.0
0 1 2 3 4
densidade
0.00.5
1.01.5
2.0
0.0 0.5 1.0 1.5
α2
densidade
0.00.5
1.01.5
2.0
0.0 0.5 1.0 1.5
densidade
0.00.5
1.01.5
2.0
0.0 0.5 1.0 1.5
densidade
−0.8
−0.6
−0.4
−0.2
0.00.2
0.0 0.5 1.0 1.5 2.0 2.5 3.0
β2
densidade
−0.8
−0.6
−0.4
−0.2
0.00.2
0.0 0.5 1.0 1.5 2.0 2.5 3.0
densidade
−0.8
−0.6
−0.4
−0.2
0.00.2
0.0 0.5 1.0 1.5 2.0 2.5 3.0
densidade
−0.5
0.00.5
1.01.5
0.0 0.5 1.0 1.5
α3
densidade
−0.5
0.00.5
1.01.5
0.0 0.5 1.0 1.5
densidade
−0.5
0.00.5
1.01.5
0.0 0.5 1.0 1.5
densidade
−2.0
−1.5
−1.0
−0.5
0.00.5
0.0 0.5 1.0 1.5
β3
densidade
−2.0
−1.5
−1.0
−0.5
0.00.5
0.0 0.5 1.0 1.5
densidade
−2.0
−1.5
−1.0
−0.5
0.00.5
0.0 0.5 1.0 1.5
densidade
Figura
4.6:D
ensidadea
posteriori
paraϕ.
Considerando
todosos
dadosN
=201
(li-
nhacontínua),
N=
21sem
aumento
(linhatracejada)
eN
=21
comaum
ento(linha
pontilhada).
62

0.02 0.04 0.06 0.08 0.10
020
4060
80
s 1 1
dens
idad
e
0.02 0.04 0.06 0.08 0.10
020
4060
80
s 1 1
0.02 0.04 0.06 0.08 0.10
020
4060
80
s 1 1
0.02 0.04 0.06 0.08
020
4060
8010
0
s 1 2
dens
idad
e
0.02 0.04 0.06 0.08
020
4060
8010
0
s 1 2
0.02 0.04 0.06 0.08
020
4060
8010
0
s 1 2
−0.06 −0.04 −0.02 0.00 0.02
020
4060
8010
0
s 1 3
dens
idad
e
−0.06 −0.04 −0.02 0.00 0.02
020
4060
8010
0
s 1 3
−0.06 −0.04 −0.02 0.00 0.02
020
4060
8010
0
s 1 3
0.02 0.04 0.06 0.08 0.10 0.12 0.14
020
4060
80
s 2 2
dens
idad
e
0.02 0.04 0.06 0.08 0.10 0.12 0.14
020
4060
80
s 2 2
0.02 0.04 0.06 0.08 0.10 0.12 0.14
020
4060
80
s 2 2
−0.05 −0.04 −0.03 −0.02 −0.01 0.00 0.01 0.020
2040
6080
100
s 2 3
dens
idad
e
−0.05 −0.04 −0.03 −0.02 −0.01 0.00 0.01 0.020
2040
6080
100
s 2 3
−0.05 −0.04 −0.03 −0.02 −0.01 0.00 0.01 0.020
2040
6080
100
s 2 3
0.02 0.04 0.06 0.08 0.10
020
4060
80
s 3 3
dens
idad
e
0.02 0.04 0.06 0.08 0.10
020
4060
80
s 3 3
0.02 0.04 0.06 0.08 0.10
020
4060
80
s 3 3
Figura 4.7: Densidade a posteriori para Σ. Considerando todos os dados N = 201 (li-
nha contínua), N = 21 sem aumento (linha tracejada) e N = 21 com aumento (linha
pontilhada).
63

4.2 Fórmula de Girsanov
Uma alternativa para estimar os parâmetros do processo de difusão é trabalhar com
a verossimilhança obtida pela Fórmula de Girsanov como descrito na Seção 2.4. Os pri-
meiros trabalhos sobre esse tópico, para poder usar a Fórmula de Girsanov, estimavam
a função de volatilidade usando variação quadrática ou algum método não paramétrico.
Isto resolvia os problemas das medidas dependerem do vetor de parâmetros θ. Roberts
e Stramer (2001) propuseram uma transformação do processo de difusão de tal maneira
que fosse possível fatorar a medida dominante e, com isso, trabalhar com medidas inde-
pendentes dos parâmetros da função de volatilidade.
4.2.1 Fatoração da medida dominante
Seja o processo de difusão dado por dXt = b(Xt, t; θ)dt+ σ(Xt, t; θ)dBt e suponha que
todo caminho do processo Xt, denotado por Xω = Xt(ω) : 0 ≤ t ≤ T, seja conhecido.
A lei de X é dada por IPσ e Wσ denota a lei do martingal local dW = σ(Xt, t; θ)dBt.
Então, como visto na Subseção 2.4.1, a verossimilhança do processo é dada por
dIPσdWσ
= G(Xω, b, σ; θ) = exp
∫ T
0
b(Xt, t; θ)
σ2(Xt, t; θ)dXt −
1
2
∫ T
0
b2(Xt, t; θ)
σ2(Xt, t; θ)dt
.
Propõe-se uma fatoração da medida dominante Wσ como descrita em Roberts e Stramer
(2001) e Kalogeropoulos (2006). Considera-se um movimento browniano em [tk, tk+1]
condicionado a Xtk = ytk e Xtk+1= ytk+1
e define-se IBσ(tk, ytk ; tk+1, ytk+1) a lei da ponte
browniana. A fatoração da medida de Wiener e, consequentemente, de IPσ, é dada por
Wσ = ⊗N−1k=0 IBσ(tk, ytk ; tk+1, ytk+1
)⊗ LebN (yo)× f(t,yo; σ),
sendo que yo é a ocorrência discreta do caminho, f denota a densidade conjunta dos dados
observados com respeito a medida de Lebesgue sob a medida de Wiener Wσ,
f(t,yo; σ) =
(
1
2πσ2
)N/2
exp
−N−1∑
k=0
(ytk+1− ytk)
2
2∆tkσ2
64

e LebN denota a medida de Lebesgue N−dimensional. Considerando a densidade de
Lebesgue N−dimensional sob IPσ, denotando-a por gb(t,yo; σ), e que são observados yo
nos tempos tk, com k = 0, . . . , N, escreve-se a densidade condicional dos caminhos não
observados, ynokj , entre os tempos tk e tk+1, com respeito a medida da ponte browniana
pordIPσ
dIBσ(tk, ytk ; tk+1, ytk+1)(ynok |yo) = G(y, b, σ)
f(t,yo, σ)
gb(t,yo; σ)∝ G(y, b, σ),
sendo y os dados observados e não observados.
Para que este procedimento seja realizado é preciso que IBσ(tk, ytk ; tk+1, ytk+1) não
dependa dos parâmetros em θ. Contudo, IBσ é uma medida relacionada com σ, no caso
de σ escalar, ou da função σ(Xt, t; θ) que depende dos parâmetros. Para contornar esse
problema pode-se obter a verossimilhança e fazer a fatoração substituindo σ2 por uma
forma conhecida. Uma maneira é utilizar o estimador de variação quadrática, [yo,yo] =∑N−1
k=0 (yotk+1
− yotk)2∆k, que se baseia no resultado do cálculo estocástico
plimN→∞
N−1∑
k=0
(Xtk+1−Xtk)
2∆tk =
∫ T
0
σ2t dt.
Formas não paramétricas para obter estimativas da função σ(Xt, t; θ) são recorrentes na
literatura. Em Zhang et al. (2005) são discutidos e comparados vários estimadores da
integral de σ2t e, ainda, propõe-se estimadores ótimos quando processos contínuos são
discretamente observados apresentando erros de microestrutura. Malliavin e Mancino
(2002) propõem utilizar aproximações por séries de Fourier para estimar a função σ2t .
Conhecer bem a função σt é fundamental para saber o comportamento do processo de
difusão.
Estimativas ruins da função de volatilidade levam a problemas para estimar outras
quantidade de interesse e tornam inviável o uso da Fórmula de Girsanov. Mais ainda,
dependendo do modelo, faz-se necessário conhecer os parâmetros que compõem σt(Xt, t; θ)
de tal modo que métodos baseados em variação quadrática são impraticáveis.
Uma solução é fazer uma transformação do processo, da forma Xt = hθ(Xt), de modo
que o resultado seja um processo transformado que possua função de volatilidade unitária.
65

Para tal assume-se
hθ(x) =
∫ x
0
1
σ(s, t; θ)ds,
sob a condição de hθ ∈ C2,1(IR × [0, T ]). As derivadas parciais são dadas por
∂
∂thθ(Xt) = 0,
∂
∂xhθ(Xt) =
1
σ(Xt, t; θ)e
∂2
∂x2hθ(Xt) = − 1
σ2(Xt, t; θ)
∂
∂xσ(Xt, t; θ).
Aplicando a Fórmula de Itô tem-se
dhθ(Xt) =∂
∂thθ(Xt)dt+
∂
∂xhθ(Xt)dXt +
1
2
∂2
∂x2hθ(Xt)(dXt)
2
que resulta em
dXt =1
σ(h−1θ (Xt), t; θ)
b(h−1θ (Xt), t; θ)dt+ σ(h−1
θ (Xt), t; θ)dBt
− 1
2σ2(h−1θ (Xt), t; θ)
(
∂
∂xσ(h−1
θ (Xt), t; θ)
)
σ2(h−1θ (Xt), t; θ)dt,
sendo Xt = h−1θ (Xt) a função inversa de hθ. Rearrumando os termos obtém-se
dXt = µ(h−1θ (Xt), t; θ)dt+ dBt, (4.10)
com
µ(h−1θ (Xt), t; θ) =
b(h−1θ (Xt), t; θ)
σ(h−1θ (Xt), t; θ)
− ∂
∂xσ(h−1
θ (Xt), t; θ).
A verossimilhança do processo observado transformado, Xt = hθ(Xt), em [0, T ] é
obtida pela Fórmula de Girsanov por
G(X, µ, 1; θ) = exp
∫ T
0
µ(h−1θ (Xs), s; θ)dXs −
1
2
∫ T
0
µ2(h−1θ (Xs), s; θ)ds
,
sendo que a notação G(X, µ, 1; θ) significa a verossimilhança pela Fórmula de Girsanov
do processo X, com função de direção µ, função de volatilidade unitária e com vetor de
parâmetros θ. Por simplicidade de notação pode-se suprimir θ.
66

4.2.2 Inferência dos parâmetros e dos dados aumentados
O procedimento de inferência é feito, como anteriormente, baseado no enfoque baye-
siano. Assume-se prioris para os parâmetros de θ e para as quantidades não observadas
yno. Utilizando as transformações da subseção anterior obtém-se a verossimilhança do
processo que será utilizada na Fórmula de Bayes.
As observações são dadas pelas duplas (tk, ytk), com k = 0, . . . , N. Entre cada k−ésimo
par de dados observados são obtidos mk dados não observados que serão tratados como
parâmetros a serem estimados. O algoritmo amostrador de Gibbs é utilizado cuja saída
são amostras a posteriori yno(g)Gg=1 das variáveis latentes e θ(g)Gg=1 dos parâmetros.
Isto é feito simulando alternadamente de
p(θ(g)|yno(g−1),yo) ∝ G(y, µ, 1; θ(g))p(θ(g)) e
p(yno(g−1)|θ(g),yo) ∝ G(y, µ, 1; θ(g))p(yno(g)).
Em geral estas distribuições não têm forma fechada e portanto passos de Metropolis são
necessários.
As propostas para ynok , que são as pontes entre os tempos tk e tk+1, são dadas pelas
pontes brownianas da seguinte forma:
(1) Gera-se pontes brownianas padrão discretas Y (∗) ∼ IB(tk, 0; tk+1, 0). Esta será a ponte
proposta no passo de Metropolis.
(2) Sobre o processo transformado Y toma-se a k−ésima ponte, com k = 1, . . . , N − 1,
Y (g)s = Ys − δsytk + (1− δs)ytk+1
,
sendo δs =tk+1 − s
∆tke s = tkj, com k = 0, . . . , N − 1 e j = 1, . . . , mk.
Define-se a transformação inversa
ηk(Y ) = Y + δsytk + (1− δs)ytk+1.
A distribuição dos dados faltantes é dada por
dIPσdIBt
(Y no|Y ) ∝ Gηk(Y ), µ, 1; θ
67

(2) Aceita-se a ponte, ηk(Y (∗)), entre os tempos tk e tk+1, com probabilidade
min
1,Gηk(Y (∗)), µ, 1; θGηk(Y (g)), µ, 1; θ
,
caso contrário o estado corrente ηk(Y (g)) permanece.
Existem outras formas de propor as variáveis latentes. Pode-se utilizar, por exemplo,
o processo de Ornstein-Uhlenbeck para gerar as pontes ou outro processo adequado ao
problema considerando funções ηk( . ) adequadas.
A geração das pontes nesse caso é feita em blocos, ou seja, entre cada par de pontos
observados são construídas todas as quantidades não observados de uma só vez de acordo
com o algoritmo de Metropolis-Hastings. Isso difere do que vinha sendo feito neste capí-
tulo onde cada dado num tempo não observado era construído um por vez (movimento
simples). O procedimento de gerar pontes por blocos quando a verossimilhança é ob-
tida por funções de transição não se mostrou eficiente, havendo divergência na cadeia de
Markov dos dados não observados na maioria das vezes.
4.2.3 Exemplo simulado - CIR univariado
O mesmo exemplo da Subseção 4.1.1 é reproduzido considerando o que foi desenvolvido
nesta seção. Desta forma, para o processo CIR univariado, dXt = (α+βXt)dt+σXψt dBt,
assumindo ψ = 1/2, fixo, e vetor paramétrico θ′= (α, β, σ2), a transformação que retira
a função de volatilidade é dada por
x = hθ(x) =
∫ x
0
1
σuψdu =
x1−ψ
σ(1− ψ)cuja inversa é x = h−1
θ (x) = σ(1− ψ)x(1−ψ)−1
.
Pela equação (4.10) o processo transformado Xt = hθ(Xt) é dado por
dXt = µh−1θ (Xt), t; θdt+ dBt,
sendo µh−1θ (Xt), t; θ = (α+ βh−1
θ (X))h−1
θ (X)−ψσ
− σψ
2h−1
θ (X)ψ−1.
Assumem-se o conjunto de dados observados yo = y0, y10, . . . , y200, os mesmos da
Subseção 4.1.1, e o conjunto de dados não observados yno = ykj : k = 0, . . . , N−1 e j =
68

1, . . . , mk. O conjunto de todos os dados ordenados (observados ou não) é y = yo ∪ yno
nos tempos τk, k = 0, . . . , K e K = N +∑N−1
k=0 mk.
O logaritmo da verossimilhança deste processo é aproximado por
logG =K−1∑
k=0
µh−1θ (Yτk), τk; θ(Yτk+1
− Yτk)−1
2µ2(h−1
θ (Yτk), τk; θ)(τk+1 − τk).
As observações transformadas são dadas por yτk = hθ(yτk). Representando os tempos
τk’s apenas pelos índices k’s, abrindo a função µ e chamando ∆yk = yk+1 − yk, ∆τk =
(τk+1 − τk) e yk = h−1θ (yk) obtém-se logG igual a
K−1∑
k=0
(
(α+ βyk)y−ψkσ
− ψσyψ−1k
2
)
∆yi −1
2
(
(α + βyk)y−ψkσ
− ψσyψ−1k
2
)2
∆τk
. (4.11)
Por (4.11) pode-se escrever logG como função de α da forma
− 1
2σ2
K−1∑
k=0
α2y−2ψk ∆τk − 2α
[
σy−ψk ∆yk +σ2ψy−1
k
2∆tk − βy1−2ψ
k ∆τk
]
+ C1, (4.12)
sendo C1 um termo constante em relação a α. Ou ainda, escrevendo logG como função
de β tem-se
− 1
2σ2
K−1∑
k=0
β2y2(1−ψ)k ∆τk − 2β
[
σy1−ψk ∆yi +σ2ψ
2∆τk − αy1−2ψ
k ∆τk
]
+ C2, (4.13)
cujo termo C2 é constante em relação a β.
Tomando a mesma priori, p(θ) = 1/σ2, utilizada na Subseção 4.1.1, as distribuições
condicionais completas são obtidas pela Fórmula de Bayes por
p(α|y, β, σ2) ∝(
K−1∏
k=0
Gηk(y);µ, 1)
, p(β|y, α, σ2) ∝(
K−1∏
k=0
Gηk(y);µ, 1)
e p(σ2|y, α, β) ∝(
K−1∏
k=0
Gηk(y);µ, 1)
f(t, y, 1)(σ2)−N−1.
Pela forma em (4.12) a condicional completa para α é conhecida e, pelo algoritmo amos-
trador de Gibbs, são obtidas amostras a posteriori de α gerando-se de
α|y, β, σ2 ∼ NB−1A,B−1σ2,
69

com
B =
K−1∑
k=0
y−2ψk ∆τk e A =
K−1∑
k=0
(
σy−ψk ∆yk +σ2ψy−1
k
2∆τk − βy1−2ψ
k ∆τk
)
.
Analogamente, por (4.13), gera-se de
β|y, α, σ2 ∼ ND−1C,D−1σ2,
com
D =K−1∑
k=0
y2(1−ψ)k ∆τk e C =
K−1∑
k=0
(
σy1−ψk ∆yk +σ2ψ
2∆τk − αy1−2ψ
k ∆τk
)
.
A amostra a posteriori do parâmetro σ2 é obtida por passos de Metropolis uma vez que
a condicional completa σ2|y, β, α não tem forma fechada. Propõe-se um valor σ2(∗) da
distribuição q( . ) para a g−ésima iteração do algoritmo, sendo
q(x) =φ(x,m, d)
Φ(S,m, d)− Φ(s,m, d),
onde φ e Φ são as funções de densidade e distribuição acumulada da normal padrão,
respectivamente, m é a média e d o desvio-padrão da normal e S e s são os limites superior
e inferior de truncamento, respectivamente. Assume-se que a distribuição proposta seja
uma normal truncada, de zero a infinito, com média σ2(g−1) e variância 0.001. Este valor
de variância foi escolhido de tal forma que a taxa de aceitação fique em torno de 40%.
O valor σ2(∗) é aceito para o estado σ2(g) da cadeia de Markov com probabilidade
min
1,p(σ2(∗)|α(g), β(g),yno(g−1),yo)q(σ2(g))
p(σ2(g)|α(g), β(g),yno(g−1),yo)q(σ2(∗))
,
caso contrário assume-se o estado corrente σ2(g−1).
A Figura 4.8 exibe a média a posteriori dos dados não observados (linhas), os intervalos
de credibilidade de 95% (semi-círculos), as pontes verdadeiras, que foram descartadas na
estimação, e a raiz quadrada do erro quadrático médio (EQM). Em seguida, na Figura
4.9, tem-se a taxa de aceitação dos passos de Metropolis para cada uma das pontes.
Comparando a Figura 4.3 com a Figura 4.8 nota-se que os procedimentos de estimação
das pontes, aproximando a função de verossimilhança por funções de transição ou pela
70

0 50 100 150 200
0.0
0.5
1.0
1.5
2.0
tempo (min)
y t
0 50 100 150 200
0.0
0.5
1.0
1.5
2.0
Figura 4.8: Média a posteriori dos dados não observados (linhas), IC 95%, pontes verda-
deiras (pontos) e raiz do EQM (barras verticais).
5 10 15 20
0.86
0.88
0.90
0.92
0.94
0.96
0.98
Ponte
Taxa
de ace
itação
Figura 4.9: Taxa de aceitação para cada ponte.
71

Fórmula de Girsanov, geraram resultados bem parecidos. O EQM e os intervalos de
credibilidade obtidos na Subseção 4.1.1 são praticamente os mesmos que os obtidos no
exemplo. Vale frisar que os valores iniciais das cadeias de Markov foram os mesmos, seja
para as pontes ou para os parâmetros. Mais ainda, a quantidade de amostras a posteriori,
o período de aquecimento das cadeias (burn in) e os intervalos que foram salvos as saídas
dos MCMCs também foram iguais.
Quanto à estimação do vetor de parâmetros θ, observa-se na Figura 4.10 que α, β
e σ2 foram bem estimados e tiveram funções de autocorrelação menores que as exibidas
na Figura 4.4. Inclusive para o parâmetro σ2 que teve taxa de aceitação dos passos de
Metropolis na casa de 42%. Este é um fator importante, o aumento de dados prejudica
o MCMC na medida que aumenta a autocorrelação da série e isto fica mais evidente no
parâmetro de volatilidade (ver Roberts e Stramer (2001)).
Em termos das estatísticas sobre as amostras a posteriori dos parâmetros os resultados
do exemplo não diferiram acentuadamente dos obtidos na Subseção 4.1.1. Esse fato pode
ser visto comparando os resultados da Tabela 4.2 com os apresentados na Tabela 4.1.
De certo modo, este fenômeno já era esperado uma vez que as verossimilhanças, seja por
densidade de transição, seja pela Fórmula de Girsanov, representam a mesma função de
verossimilhança escrita sob diferentes enfoques. Em termos de velocidade de convergência,
o procedimento descrito neste exemplo leva certa vantagem em relação ao apresentado na
Subseção 4.1.1.
Parâmetro α β σ2
Verdadeiro 0.04 −0.02 0.005
Média 0.0311 −0.0204 0.00524
Desvio-padrão 0.0127 0.0115 0.0021
IC 95% (0.0103, 0.0518) (−0.0397, −0.0020) (0.0028, 0.0094)
Tabela 4.2: Sumário das amostras a posteriori de α, β e σ2.
72

0 200 400 600 800 1000
−0.
020.
04
Saída do MCMC
iteração
α
0 5 10 15 20 25 30
0.0
0.4
0.8
Lag
fac
α Histograma
α
freq
üênc
ia
−0.02 0.00 0.02 0.04 0.06
010
2030
0 200 400 600 800 1000
−0.
060.
00
Saída do MCMC
iteração
β
0 5 10 15 20 25 30
0.0
0.4
0.8
Lag
fac
β Histograma
β
freq
üênc
ia−0.06 −0.02 0.02
010
30
0 200 400 600 800 1000
0.00
50.
015
Saída do MCMC
iteração
σ2
0 5 10 15 20 25 30
0.0
0.4
0.8
Lag
fac
σ2 Histograma
σ2
freq
üênc
ia
0.005 0.010 0.015
010
020
0
Figura 4.10: Saída do MCMC. Traços (coluna 1), funções de autocorrelação (coluna 2) e
histogramas (coluna 3) para os parâmetros α, β e σ2. As retas horizontais (nos traços) e
verticais (nos histogramas) assinalam os valores verdadeiros dos parâmetros.
73

4.3 Discussões e trabalhos futuros
Um caminho a ser seguido consiste em realizar o procedimento de aumento de da-
dos considerando a quantidade de dados não observados aleatória. Elerian et al. (2001)
desenvolveu este tópico para o caso em que a verossimilhança do processo é obtida por
densidades de transição. Outra alternativa para construção das pontes é usar a Fórmula
de Girsanov como em Roberts e Stramer (2001) adaptando ao esquema de construção de
pontes “exatas” propostas em Beskos et al. (2006).
Na literatura são comuns modelos para processos de difusão multivariados tratados
como problemas de filtragem (Øksendal (1995, capítulo 6)). Problemas desse tipo apa-
recem também como modelos de volatilidade estocástica e de espaço de estado contínuos
como podem ser vistos, por exemplo, em Kalogeropoulos (2006), Golightly e Wilkinson
(2006) e Eraker (2001). Uma vertente interessante é trabalhar com múltiplos processos de
difusão correlacionados. A partir de escolhas adequadas da função de direção vetorial e
da função de volatilidade matricial é possível construir processos de difusão multivariados
e desenvolver técnicas de inferência nesse contexto.
No Capítulo 5 são discutidos modelos para difusão de gases poluentes. Apesar de
muitas das técnicas estatísticas serem conhecidas e a programação ser simples, o capítulo
motiva a modelagem de processos de difusão multivariados acrescentando-se estruturas
espaciais. A novidade está na análise bayesiana como alternativa aos métodos determinís-
ticos, baseados em soluções de equações diferenciais, ou métodos de mínimos quadrados.
É interessante notar que processos de difusão que são utilizados para modelar um
fenômeno real (seja físico ou financeiro, por exemplo) podem estar correlacionados através
de uma medida de distância que podem ser geográfica ou através de algum índice que
indique proximidade ou distância. Essa influência, dita geográfica, pode ser modelada
através da função de volatilidade ou através de alguma estrutura hierárquica. Esse é o
tema central do Capítulo 6 e constitui uma das principais contribuição dessa tese.
74

Capítulo 5
Modelos para Difusão de Gases em
Reservatórios de Hidrelétricas
As mudanças climáticas que vem ocorrendo no planeta nas últimas décadas têm mo-
tivado uma série de estudos sobre a emissão de poluentes que contribuem para esse fenô-
meno. Vários gases poluentes são lançados na atmosfera contribuindo para o aquecimento
global e a aceleração das mudanças climáticas. Dentre eles, pode-se citar o metano (CH4),
o dióxido de carbono (CO2) e o óxido nitroso (N2O). Eles são os principais responsáveis
pela destruição da camada de ozônio e o efeito estufa.
No contexto de um país com dimensões continentais como o Brasil, cuja energia hi-
drelétrica constitui sua principal fonte energética, faz-se necessário um estudo sobre a
quantidade de poluição emitida em reservatórios de usinas hidrelétricas. Nessas áreas
grande quantidade de biomassa é alagada e a consequente decomposição desta resulta na
emissão de diversos gases.
Neste capítulo é feito um estudo acerca de modelos para estimação da taxa de emissão
destes gases. Primeiramente são discutidos modelos hierárquicos, pois eles permitem
representar a dinâmica da emissão de um gás no tempo e levam em consideração as
diferentes regiões de coleta de dados. Mais ainda, modelos hierárquicos permitem que
a informação proveniente de locais diferentes de um reservatório sejam compartilhadas.
75

Isto é de fundamental importância quando a quantidade de observações em cada local é
pequena. Em seguida é feita uma análise dos dados considerando todos os dados agregados
em seus respectivos tempos. Esse procedimento será chamado de regressão total. Os
modelos serão comparados usando critérios de seleção recentes na literatura.
Na década de 1980, modelos determinísticos baseados na solução de equações diferen-
ciais ordinárias (EDOs) eram bastante utilizados. Estes modelos não percebiam o caráter
aleatório dos dados não incorporando as características estocásticas do problema. Uma
direção possível, que inclui as componentes aleatórias, é usar técnicas que partem de um
processo de difusão para modelar a taxa de emissão de um gás. Este tópico será discu-
tido mais adiante. Modelos que utilizam equações diferenciais estocásticas (EDEs) são
extensões naturais dos modelos determinísticos baseados em EDOs e vem ganhado cada
vez mais espaço na literatura estatística recente. A inferência segue o enfoque bayesi-
ano utilizando-se métodos de Monte Carlo via Cadeia de Markov (MCMC). Os modelos
propostos são aplicados a um conjunto de dados reais.
No final do capítulo são apresentadas propostas para estimar a emissão de um gás
poluente para o reservatório como um todo.
5.1 Definição do problema e descrição dos dados
O objetivo deste capítulo é obter a taxa de emissão de um gás poluente em áreas
alagadas por reservatórios de hidrelétricas. A coleta de dados é feita em duas etapas:
a primeira utiliza câmaras de difusão para obter amostras da concentração dos gases
e a outra é feita em laboratório para cálculo da concentração deles num procedimento
conhecido por cromatografia gasosa. A Figura 5.1 mostra as câmeras de difusão utilizadas
para coleta de dados e o processo laboratorial de obtenção das concentrações dos gases
nas câmaras.
As amostras foram coletadas em vários locais dentro de diferentes reservatórios. Por
limitações tecnológicas e financeiras, em cada local de amostragem, foram feitas somente
76

Figura 5.1: Coleta dos dados em um reservatório e câmaras de difusão utilizadas (fotos
superiores). Procedimento de cromatografia gasosa para obtenção das concentrações dos
gases nas câmaras (foto inferior).
quatro medições nos tempos: 0 (medida inicial), 3, 6 e 12 minutos.
Os dados foram fornecidos pelo Programa de Planejamento Energético da COPPE-
UFRJ e os procedimentos de amostragem estão especificados no relatório de Rosa et al.
(2002). As medições foram feitas em diversos reservatórios de hidrelétricas podendo-se
citar: Corumbá, Furnas, Funil, Luiz Carlos Barreto de Carvalho, Manso e Itumbiara.
Os resultados que serão apresentados são provenientes das três campanhas realizadas no
reservatório de Corumbá. Por campanha entende-se uma incursão ao reservatório para
coleta de dados. A primeira foi em novembro de 2004, a segunda em março de 2005 e
a terceira campanha em agosto de 2005. Os dados referem-se à concentração de metano
(CH4) dentro das câmaras de difusão, nos quatro tempos, nas localizações, para as três
campanhas.
A modelagem do problema é apresentada como segue. Seja Yt a concentração de um
gás obtida num tempo t e seja Y0 a concentração inicial do gás no tempo t = 0. O
parâmetro de interesse é a taxa inicial de emissão dada por r0 = dYt(0)/dt.
A taxa de emissão inicial refere-se a quantidade de gás (em partes por milhão - ppm)
77

que é emitida por unidade de área (em metros quadrados) e por unidade de tempo (em
dias). Essa é a medida de interesse e indica o fluxo de gás poluente no local de medição.
Métodos determinísticos estimam a taxa de emissão a partir da solução da EDO
dYt/dt = (ADp/V d)(η − Yt), (5.1)
sendo que A e V denotam a área e o volume de cobertura, respectivamente, Dp é o
coeficiente de difusão gasosa do gás no meio e η sua concentração a uma profundidade d
da superfície. Assumindo κ = [(A/V )(Dp/d)] o modelo pode ser escrito na forma
dYtdt
= κ(η − Yt)
cuja solução é dada por
Yt = η + (Y0 − η)e−κt.
A taxa de emissão inicial é calculada pela derivada de Yt no instante zero sendo expressa
por r0 = −κ(Y0 − η). É mais interessante trabalhar com a solução da EDO (5.1) do que
com modelos exponencial gerais do tipo Yt = a + be−ct. Isto porque o primeiro utiliza
somente dois parâmetros, η e κ, os quais tem interpretação física direta proveniente da
formulação da EDO.
Os métodos empregados estimam os parâmetros η e κ e, consequentemente, fornecem a
taxa de emissão no tempo t = 0. Um dos primeiros métodos determinísticos desenvolvidos
para estimação da taxa de emissão foi proposto por Hutchinson e Mosier (1981). Ele é bas-
tante rudimentar e por condições de existência é obrigado a descartar grande quantidade
de dados. Nele é assumida a realização de três medições, Y0, Y1 e Y2, em tempos equidis-
tantes, t = 0, t = ∆ e t = 2∆. Se as condições de positividade são atendidas obtém-se
κ =1
∆log
(
Y1 − Y0Y2 − Y1
)
, η =Y 21 − Y0Y2
2Y1 − Y0 − Y2e r0 =
(Y1 − Y0)2
∆(2Y1 − Y0 − Y2)log
(
Y1 − Y0Y2 − Y1
)
.
Apesar dos diversos problemas desse método e de seu desuso decorrente de avanços na
direção de métodos que suportam séries mais longas e que não descartem dados, ele pode
ser utilizado para inicializar os parâmetros em métodos iterativos de estimação. Essa
estratégia não foi utilizada nos programas de estimação apresentados nesse capítulo, mas
constitui uma alternativa viável.
78

Outra família de métodos determinísticos bastante usada são os métodos de mínimos
quadrados que aparecem bastante em engenharia e cálculo numérico. Eles têm o pro-
blema de não trazerem informações importantes sobre a variabilidade das estimativas e
frequentemente não fornecem boas estimativas quando poucos dados são avaliados.
Para contornar estes problemas, Pedersen (2000) e Pedersen et al. (2001) propõem um
método que permita o uso de séries longas (com mais medidas de concentração). Esse
método é baseado em aproximações das funções de transição para obter a verossimilhança
aproximada (ver Pedersen (1995)). Uma classe de funções que é usada para esse objetivo,
pode ser vista em Bibby e Sørensen (1995), tem por base polinômios martingales. Con-
siderando Yimi=0, concentrações obtidas em tempos t ∈ T = t = k∆ | k = 0, . . . , m,são calculados
S1 =
m∑
i=1
Yi, S2 =
m∑
i=1
Yi−1, S3 =
m∑
i=1
Yi/Yi−1 e S4 =
m∑
i=1
Y 2i /Yi−1.
E então as estimativas são obtidas por
κ =1
∆log
(
S1S4 −m2
S1S4 −mS3
)
e η =S2S3 −mS1
m(S3 −m)− S4(S1 − S2).
O método de Pedersen (2000) e Pedersen et al. (2001) é vulnerável para poucas medi-
ções, é muito influenciado por amostras mal condicionadas e não compartilha informações
entre locais diferentes.
Note que por restrições técnicas e financeiras foram obtidas apenas quatro medidas
de concentração em cada local de amostragem. E, apesar disso, para estimar a taxa de
emissão de um gás num sítio qualquer é preciso conhecer dois parâmetros, η e κ. Esse
problema pode ser contornado considerando modelos que compartilhem as informações
vindas dos diversos locais. Modelos hierárquicos conseguem fazer isso e serão discutidos
na próxima seção com aplicação ao conjunto de dados.
O problema de obter a taxa de emissão de um determinado gás será tratado a seguir de
duas maneiras. A primeira é baseada na função que é solução da EDO (5.1) acrescida de
um fator de erro. Esse caminho é o mais simples e recorrente na literatura. A outra forma
79

consiste em trabalhar com a equação diferencial estocástica que é resultado do acréscimo
de um termo de pertubação na equação (5.1). A forma diferencial da perturbação é repre-
sentada pelo movimento browniano. É interessante notar que se a função de volatilidade
for σ(Xt, t, θ) =√σ2Xt, como proposto por Pedersen (2000) e Pedersen et al. (2001) para
o problema de emissão de gases, então a EDE obtida é um processo CIR da forma
dXt = (α + βXt)dt+√
σ2XtdBt,
com α = κη e β = −κ como apresentado no Capítulo 3. O arcabouço teórico desenvolvido
nas seções anteriores, que versam sobre tratamento estatístico de EDEs, será utilizado
neste contexto. Nesse caso Xt representa o processo de difusão da concentração do gás.
5.2 Modelos hierárquicos
Modelos deste tipo consideram que os parâmetros estão relacionados de acordo com
uma determinada estrutura hierárquica. Para uma primeira leitura sobre esses modelos
sugere-se Migon et al. (2008) e para a extensão deles como modelos dinâmicos hierárquicos
ver Gamerman e Migon (1993).
No contexto do problema de emissão de gases considera-se que a emissão em cada
sítio do reservatório está relacionada com a emissão do reservatório como um todo. Nesse
sentido, apesar de serem poucas medições em cada localização, as informações das demais
regiões são consideradas e compartilhadas. Os modelos apresentados nesta seção seguem
esta ótica e o procedimento de inferência é feito sob o enfoque bayesiano. Assim, métodos
MCMC são aplicados e obtém-se amostras das distribuições a posteriori dos parâmetros
de interesse dos modelos.
5.2.1 Modelo sem estrutura espacial (M1)
Neste modelo é assumido que a concentração de um gás, yt, em uma dada região,
comporta-se de acordo com yt = η + (y0 − η)e−κt mais um fator de erro e os parâmetros
80

seguem uma estrutura hierárquica. O modelo é representado por
y(i)k = µ
(i)k + v
(i)k , v
(i)k ∼ N(0, σ2),
µ(i)k = ηi + (y
(i)0 − ηi)e
−κiτk ,
ηi ∼ N(µη, σ2η) e κi ∼ N(µκ, σ
2κ),
(5.2)
com i = 1, . . . , n, sendo que n é a quantidade de sítios amostrados (podendo haver re-
plicações) e k = 1, . . . , N − 1, com N sendo a quantidade de amostras em um mesmo
sítio. Observe que os parâmetros µη e σ2η referem-se a média e variância do parâmetro
η para todos os sítios do reservatório. O mesmo vale para os parâmetros µκ e σ2κ com
relação ao parâmetro κ. Portanto, o caráter hierárquico do modelo está na relação entre
emissões locais e a emissão conjunta do reservatório. Os erros v(i)k são independentes entre
os diferente i′s e independentes de ηi e κi; e τk = 0, 3, 6, 12 é o vetor dos tempos de
coleta das amostras.
A estratégia para a escolha das distribuições a priori foi considerá-las não informativas,
embora possam ser elicitadas por especialistas porque os parâmetros têm interpretação
física clara (ver O’Hagan (1998)). As prioris utilizadas foram
µη ∼ N(0.0, 105), σ2η ∼ IG(0.001, 0.001),
µκ ∼ N(0.0, 105), σ2κ ∼ IG(0.001, 0.001)
e σ2 ∼ IG(0.001, 0.001).
O modelo foi implementado no programa WinBUGS (versão 1.4.2) em conjunto com o
R (versão 2.7.1) para os dados obtidos nas campanhas de Corumbá. Os locais de coleta não
foram os mesmos, nem a quantidade de sítios amostrados, de uma campanha para outra.
No algoritmo de MCMC foram executadas 30000 iterações tomando-se elementos de 10
em 10 com período de aquecimento (burn in) de 10000. Deste procedimento resulta na
amostra da distribuição a posteriori com 2000 elementos amostrados para cada parâmetro.
As cadeias de Markov convergiram para todos os parâmetros considerados: ηi, κi, com
i = 1, . . . , n, µη, σ2η, µκ, σ
2κ e σ2. A Figura 5.2 exibe os traços das amostras a posteriori
81

dos parâmetros µη, σ2η, µκ e σ2
η para a segunda campanha de Corumbá. A Figura refere-
se a duas cadeias inicializadas em pontos diferentes para cada um dos parâmetros. O
comportamento apresentado na figura foi bem parecido nas demais campanhas ao utilizar
esse modelo. A Figura 5.3 apresenta os histogramas onde pode-se perceber o ganho de
informação dos parâmetros à luz dos dados.
0 500 1500
510
1520
iteração
µ η
0 500 15000
200
400
iteração
σ η2
0 500 1500
0.00
0.02
0.04
iteração
µ κ
0 500 1500
0.00
020.
0012
iteração
σ κ2
Figura 5.2: Saída do MCMC dos parâmetros µη, σ2η, µκ e σ2
η referente a segunda campanha
de Corumbá.
A taxa de emissão no instante zero é dada pela derivada de y(i)k no primeiro instante
t = 0 para cada um dos i-ésimos sítios. Assim, para cada um dos sítios, a taxa de emissão
é dada por
ri = −(y(i)0 − ηi)κi, com i = 1, . . . , n. (5.3)
Com o intuito de obter uma distribuição para a taxa inicial de emissão que leve em
82

µη
freq
uênc
ia
5 10 15 20 25 30
0.00
0.06
0.12
ση2
freq
uênc
ia
0 100 3000.00
00.
015
µκ
freq
uênc
ia
0.00 0.02 0.04 0.06
020
4060
σκ2
freq
uênc
ia
0.0000 0.0008
020
00
Figura 5.3: Histogramas das amostras a posteriori.
consideração todas as localizações define-se a taxa de emissão conjunta rc por
rc = −µκ(y0 − µη), (5.4)
sendo y0 = n−1∑n
i=1 y(i)0 a média das concentrações iniciais dos locais.
Em cada uma das localizações é possível obter o estimador pontual do parâmetro, por
exemplo, pela média a posteriori fazendo
ri =1
G
G∑
g=1
r(g)i = − 1
G
G∑
g=1
(y(i)0 − η
(g)i )κ
(g)i ,
tal que G = 2000 é a quantidade de amostras da posteriori e i = 1, . . . , n. O procedimento
bayesiano, com o uso do MCMC, fornece uma amostra da distribuição a posteriori dos
parâmetros. Em particular pode-se medir a acurácia pela variância a posteriori. Estas
estatísticas encontram-se no Apêndice A.
83

Na Figura 5.4 mostram-se os gráficos de boxplotes das taxas de emissão inicial de
cada sítio ri e a conjunta rc também da segunda campanha de Corumbá. Nela é possível
comparar o efeito de cada localização sobre o coletivo e vice versa. Observa-se que a taxa
de emissão coletiva rc aparenta estar no centro se vista verticalmente. Note ainda que ela
é deslocada para cima por influência das taxas das posições 14 e 15.
locais
taxa
s (
ppm
/(m
in m
2 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 rc
0.0
0.2
0.4
0.6
0.8
Figura 5.4: Taxas de emissão inicial dos sítios 1 ao 20 e a taxa de emissão inicial coletiva.
84

A Figura 5.5 exibe o traço e o histograma da taxa de emissão inicial coletiva rc para
a segunda campanha de Corumbá. O fluxo coletivo rc é importante, pois é uma medida
representativa da emissão do reservatório como um todo. A Tabela 5.1 fecha essa seção
fornecendo um resumo das estatísticas comparativas das três campanhas para os principais
parâmetros. Observa-se que as estimativas pontuais variam muito de uma campanha para
outra.
0 500 1000 1500 2000
0.0
0.2
0.4
Saída do MCMC
iteração
r c
0 500 1000 1500 2000
0.0
0.2
0.4
Histograma
rc
freq
uênc
ia
0.0 0.1 0.2 0.3 0.4
02
46
8
Figura 5.5: Taxa de emissão inicial coletiva para segunda campanha de Corumbá.
Os resultados da análise estatística sobre o modelo (M1), concentrando-se nas taxas
de emissão inicial, para as campanhas de Corumbá encontram-se no Apêndice A.
85
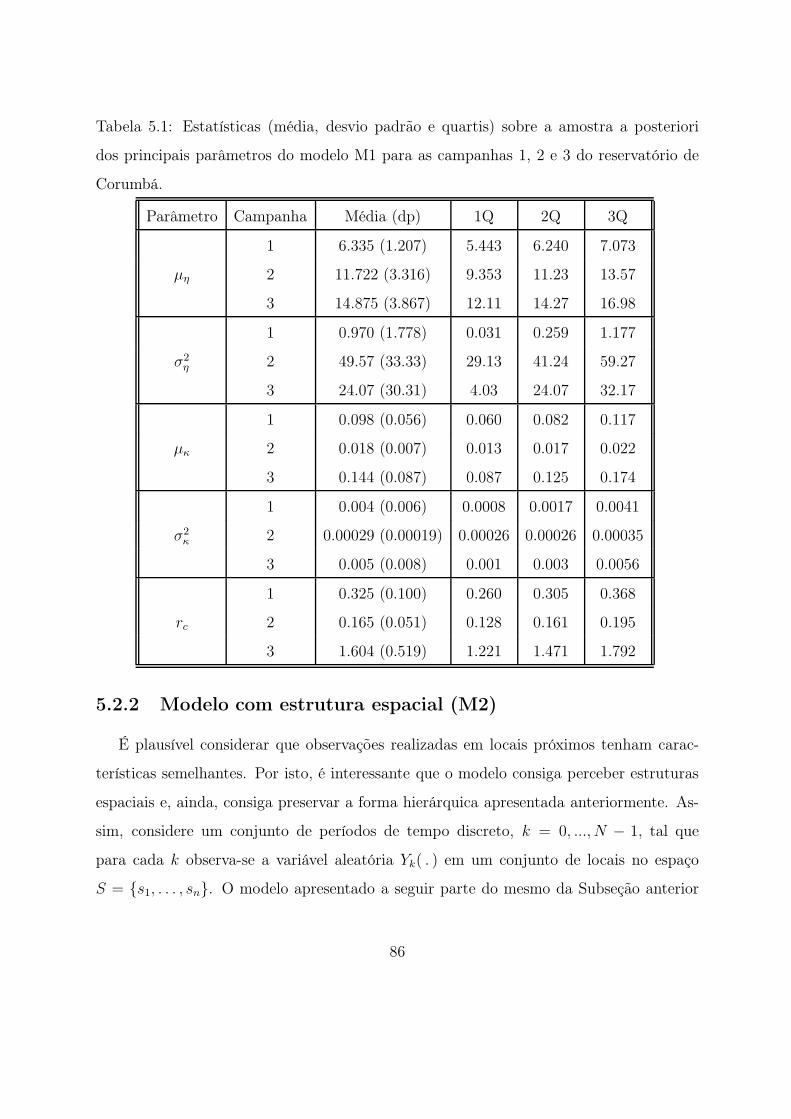
Tabela 5.1: Estatísticas (média, desvio padrão e quartis) sobre a amostra a posteriori
dos principais parâmetros do modelo M1 para as campanhas 1, 2 e 3 do reservatório de
Corumbá.
Parâmetro Campanha Média (dp) 1Q 2Q 3Q
1 6.335 (1.207) 5.443 6.240 7.073
µη 2 11.722 (3.316) 9.353 11.23 13.57
3 14.875 (3.867) 12.11 14.27 16.98
1 0.970 (1.778) 0.031 0.259 1.177
σ2η 2 49.57 (33.33) 29.13 41.24 59.27
3 24.07 (30.31) 4.03 24.07 32.17
1 0.098 (0.056) 0.060 0.082 0.117
µκ 2 0.018 (0.007) 0.013 0.017 0.022
3 0.144 (0.087) 0.087 0.125 0.174
1 0.004 (0.006) 0.0008 0.0017 0.0041
σ2κ 2 0.00029 (0.00019) 0.00026 0.00026 0.00035
3 0.005 (0.008) 0.001 0.003 0.0056
1 0.325 (0.100) 0.260 0.305 0.368
rc 2 0.165 (0.051) 0.128 0.161 0.195
3 1.604 (0.519) 1.221 1.471 1.792
5.2.2 Modelo com estrutura espacial (M2)
É plausível considerar que observações realizadas em locais próximos tenham carac-
terísticas semelhantes. Por isto, é interessante que o modelo consiga perceber estruturas
espaciais e, ainda, consiga preservar a forma hierárquica apresentada anteriormente. As-
sim, considere um conjunto de períodos de tempo discreto, k = 0, ..., N − 1, tal que
para cada k observa-se a variável aleatória Yk( . ) em um conjunto de locais no espaço
S = s1, . . . , sn. O modelo apresentado a seguir parte do mesmo da Subseção anterior
86

com o acréscimo de uma estrutura espacial na média. Dado um conjunto de observações
dos yk(s)′s o modelo é dado por
yk(s) = µk(s) + vk(s), vk(s)ind.∼ N(0, σ2),
µk(s) = η(s) + y0(s)− η(s)e−κ(s)τk +W (s),
η(s)ind.∼ N(µη, σ
2η), κ(s)
ind.∼ N(µκ, σ2κ),
e W ∼ Nn(0, σ2WΣ),
(5.5)
sendo σ2W um parâmetro escalar, Σ a matriz de covariância de ordem n, com (Σ)ij =
f(dij; Φ), e 0 o vetor de zeros.
A matriz Σ é dada pela função f(dij,Φ) que depende da distância entre as observações,
dij, e de parâmetros Φ. Existe na literatura uma variedade de formas para a função f,
para uma visão geral sobre elas sugere-se ver Paez e Gamerman (2005) ou Schmidt e
Sansó (2006). A função utilizada é a exponencial potência dada por
f(dij; Φ) = exp[−(ψdij)φ], com ψ > 0 e φ ∈ (0, 2],
sendo que Φ′= (ψ, φ) é o vetor dos parâmetros da parte espacial e dij é a distância
euclidiana entre os pontos si e sj. O parâmetro φ está relacionado com a suavidade da
f enquanto o parâmetro ψ controla a taxa de decaimento da correlação. De modo que
quando ψ cresce o decaimento é mais rápido e quando ψ decresce o decaimento é mais
lento. Em geral os parâmetros do vetor Φ são difíceis de estimar e quando o conjunto
de dados é pequeno, como é o caso, fica ainda mais complicado. Para amenizar esta
dificuldade sugere-se assumir φ = 1, fixo, e distribuição a priori informativa para ψ. A
estratégia para a escolha das distribuições a prioris é a mesma do modelo anterior com o
acréscimo de
σ2W ∼ IG(0.001, 0.001) e ψ ∼ Uniforme[0.0005, 0.3],
sendo que a amplitude da distribuição uniforme está relacionada com a distância máxima
entre os locais de observação.
87

Os dados são os mesmos da seção anterior, dados das três campanhas de Corumbá, que
consistem nas concentrações do metano (CH4) em partes por milhão (ppm). Os tempos
de coleta são 0, 3, 6, e 12 minutos realizados nos sítios amostrais de cada campanha, só
que agora indexados com componentes espaciais latitude e longitude.
As concentrações que tiveram replicações nas localizações foram agregadas pela média.
Isto se justifica, pois as concentrações em locais repetidos tiveram valores bem próximos.
Assim, n é o número de locais não repetidos indicados por si, com i = 1, . . . , n. Outra
forma de trabalhar com as replicações é considerar o modelo com um índice a mais da
forma yijk, com j = 1, . . . , ni representando a quantidade de repetições no local i. Isto
torna a programação um pouco mais difícil e não foi ainda desenvolvido. A Figura 5.6
exibe o conjunto de dados para a segunda campanha de Corumbá.
O mesmo procedimento de MCMC da subseção anterior usando o WinBUGS (versão
1.4.2) em conjunto com o R (versão 2.7.1) foi realizado. Pelos resultados há indícios que
o modelo não consegue capturar a estrutura espacial. Seja pela pouca informação, prove-
niente do reduzido número de dados, seja pela própria ausência desta estrutura. As séries
não convergiram para todos os parâmetros. Os problemas mais evidentes apareceram
para µκ, σκ, µη e ση e os parâmetros relacionados à região 12 da segunda campanha de
Corumbá. Em todas as campanhas o algoritmo não convergiu para o parâmetro κi na
maioria das localizações i. A análise estatística para as taxas de emissão encontra-se no
Apêndice A.
88

tempo = 0 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95
0 2
4 6
810
48.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
latitude
long
itude
conc
entr
ação
(pp
m)
b
cjmanode
k h gf
il
tempo = 0 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95
0 2
4 6
810
48.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
tempo = 3 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95 0
2 4
6 8
1048.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
latitude
long
itude
conc
entr
ação
(pp
m)
b
c
jmanode
kh
gf
i
l
tempo = 3 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95 0
2 4
6 8
1048.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
tempo = 6 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95
0 2
4 6
810
48.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
latitude
long
itude
conc
entr
ação
(pp
m)
b
cjma
node
k h
gf
i
l
tempo = 6 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95
0 2
4 6
810
48.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
tempo = 12 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95
0 2
4 6
810
48.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
latitude
long
itude
conc
entr
ação
(pp
m)
b
cj
ma
no
d
e
k
h
gf
i
l
tempo = 12 min
17.60 17.65 17.70 17.75 17.80 17.85 17.90 17.95
0 2
4 6
810
48.45
48.50
48.55
48.60
48.65
48.70
48.75
48.80
Figura 5.6: Concentrações do metano (CH4) nos tempos 0, 3, 6 e 12 minutos. As letras
representam as localizações.
89

Na segunda campanha, quando as regiões com duplicação são agregadas, o número
de sítios amostrais é reduzido para 15. A Figura 5.7 apresenta os boxplotes das taxas
ri de cada uma das regiões amostradas e o boxplot da taxa conjunta rc para a segunda
campanha de Corumbá. A influência da duplicação das regiões 14 e 15 do modelo anterior
(M1) se faz presente na região agregada 12 deste modelo (M2).
locais
taxa
s (
ppm
/(m
in m
2 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 rc
0.0
0.2
0.4
0.6
0.8
Figura 5.7: Taxas locais ri e coletiva rc para segunda campanha de Corumbá.
90

Na Figura 5.8 são exibidas as amostras a posteriori de ψ e σ2W . A análise da distribuição
desses parâmetros não indicou que a localização das observações seja relevante. Isto pode
ter ocorrido pela pouca quantidade de observações em cada localização impedido que se
perceba tal estrutura ou pela própria falta dela no fenômeno. Além disso, a não captura
das componentes espaciais pode ter influenciado na instabilidade da inferência refletindo
nos demais parâmetros. Foram assumidos outros parâmetros para distribuição uniforme a
priori de ψ e o quadro não se alterou. No capítulo a seguir é feito um estudo simulado com
modelos espaço-temporais partindo de processos de difusão e os parâmetros da estrutura
espacial são bem estimados.
0 500 1000 1500 2000
0.00
0.10
0.20
0.30
Saída do MCMC
índice
ψ
Histograma
ψ
freq
uênc
ia
0.00 0.10 0.20 0.30
01
23
4
0 500 1000 1500 2000
0.0
0.4
0.8
Saída do MCMC
índice
σ W2
Histograma
σW2
freq
uênc
ia
0 2 4 6
01
23
45
Figura 5.8: Saída do MCMC (esquerda) e histograma (direita) dos parâmetros ψ e σ2W
(superior e inferior, respectivamente).
91

5.3 Modelos de difusões multivariadas para expansão
de gases
Nesta seção considera-se o arcabouço teórico sobre processos de difusão desenvolvido
nos capítulos anteriores aplicado ao problema em questão. Supõe-se que a emissão de
um gás no reservatório se comporta como um processo estocástico multivariado no qual
a emissão em cada localização do reservatório responde por uma das coordenadas do
processo.
5.3.1 Modelo CIR multivariado
Seja o modelo CIR multivariado desenvolvido na Seção 3.2 e assuma que a evolução
da concentração de um gás em uma câmara de difusão num determinado reservatório siga
a EDE
dX(t) = b(X(t), t; θ)dt+ σ(X(t), t; θ)dB(t),
cujas função vetorial de direção, bt, e a função matricial de volatilidade, σt, sejam as
definidas na Seção 3.2.
O procedimento de inferência para os parâmetros ϕ e Σ foi desenvolvido usando apro-
ximação da verossimilhança por funções de transição e pela fórmula de Girsanov. No
Capítulo 4 foi desenvolvida a técnica de aumento de dados para reduzir o viés de discre-
tização. Essa modelagem serve para motivar o uso de processos de difusão multivariados
em problemas desse tipo. Na prática utilizar técnicas de estimação, seguindo esse modelo,
para o conjunto de dados apresentado é inviável por uma questão de dimensionalidade.
Como a quantidade de observações é menor que a quantidade de locais não é possível
realizar a inferência. Contudo, a razão principal de apresentar essa estrutura é motivar
técnicas para redução da dimensão do vetor de parâmetros (que será vista no capítulo a
seguir), e com isso possibilitar o procedimento de inferência.
A relação entre os parâmetros α e β com os parâmetros κ e η é descrita por κ = −β e
92

η = −α/β. Daí, a taxa de emissão inicial dada pela equação (5.3) pode ser reescrita por
ri = αi + y(i)0 βi, com i = 1, . . . , n. (5.6)
E o estimador para a taxa de emissão inicial no local i, com i = 1, . . . , n, é dado pela
média a posteriori de ri que é aproximado via MCMC por
ri =1
G
G∑
g=1
(
α(g)i + y
(i)0 β
(g)i
)
,
sendo G a quantidade de elementos da amostra a posteriori.
O total de parâmetros é dado por
ϕ =
α1
β1...
αn
βn
e Σ =
s11 s12 . . . s1n
s21 s22 . . . s2n...
. . .
sn1 sn2 . . . snn
,
o que resulta na quantidade de 2n parâmetros para ϕ e, como Σ é simétrica, a quantidade
de parâmetros não repetidos é n(n + 1)/2.
O número de parâmetros é grande, pois os locais de coleta dos dados foram muitos
em cada campanha: n = 19 para primeira campanha, n = 20 para segunda e n = 12
para a terceira. No entanto, para cada uma das localizações, tem-se poucas medições
(somente quatro). O procedimento de aumento de dados não contorna o problema. Os
dados artificiais não podem ser usados para corrigir problemas de dimensionalidade e
quando são usados o procedimento de inferência resulta em amostras a posteriori com
grande variância e deslocadas dos valores se comparado com outros métodos.
No modelo CIR multivariado não existem parâmetros que sejam coletivos. Pode-se, no
entanto, obter uma medida da emissão para todo o reservatório de várias formas diferentes.
Uma delas é interpolar as taxas para obter a superfície de emissão inicial do reservatório.
A partir disso é possível calcular a emissão do reservatório como um todo ao aproximar a
integral sobre a superfície da taxa de emissão por somas de Riemann. Este procedimento
93

pode ser melhorado fazendo previsões sobre regiões não amostradas e considerando-as na
interpolação.
O revés óbvio do modelo aqui exposto é o grande número de parâmetros. Se por
um lado Σ trás informações importantes sobre a correlação das múltiplas dimensões do
processo ele incha o modelo de parâmetros. No próximo capítulo desenvolvem-se métodos
para trabalhar de forma mais eficiente com a matriz de variância e covariância tornando
o modelo mais parcimonioso sem perder o poder explicativo.
Um outro modelo possível, partindo de difusões multivariadas, é construído através da
introdução de hierarquias sobre os parâmetros do processo após sua discretização. Essa
ideia será introduzida na seção a seguir e no próximo capítulo serão desenvolvidas formas
parsimoniosas de representar a matriz de covariância do processo.
5.3.2 CIR hierárquico
Vários modelos podem ser formulados partindo tanto da solução da EDO quanto da
discretização da EDE. O último modelo proposto nesse capítulo parte do processo CIR
unidimensional, em cada localização, com a adição de estruturas hierárquicas. Esse tópico
é apresentado no próximo capítulo.
O modelo CIR hierárquico considera que os parâmetros αi e βi, em cada localização
i, estejam relacionados com parâmetros coletivos. A formulação do modelo é como segue
zk =y(i)k+1 − y
(i)k
y(i)k
1/2∆
1/2k
=(
αi y(i)k
−1/2+ βi y
(i)k
1/2)
∆1/2k + σε
(i)k ,
αi ∼ N(µα, σ2α) e βi ∼ N(µβ, σ
2β),
(5.7)
com i = 1, . . . , n e k = 0, . . . , N − 1, sendo os ε(i)k normais padrão independentes. Como
cada equação é vista de forma univariada relacionada ao local, o WinBugs trabalha bem
com a versão y(i)k+1 = y(i)k + (αi + βi y
(i)k )∆k +∆
1/2k y
(i)k
1/2σε
(i)k .
O modelo foi programado no WinBugs (versão 1.4.1) sendo assumidas as distribuições
94

a prioris
σ2 ∼ IG(0.001, 0.001),
µα ∼ N(0, 1000), σ2α ∼ IG(0.001, 0.001),
µβ ∼ N(0, 1000) e σ2β ∼ IG(0.001, 0.001).
As cadeias de Markov foram inicializadas com valores diferentes e convergiram para
o mesmo lugar, indicando convergência do algoritmo. Foram realizadas 30000 iterações
do MCMC tomando-se elementos de 10 em 10 com aquecimento de 10000. A saída do
algoritmo é apresentada na Figura 5.9 para os parâmetros µα, σ2α, µβ e σ2
β considerando
a segunda campanha. A Figura 5.10 exibe os histogramas para a mesma campanha.
0 500 1000 1500 2000
0.1
0.3
0.5
iteração
µ α
0 500 1000 1500 2000
0.00
0.04
0.08
iteração
σ α2
0 500 1000 1500 2000
−0.
20−
0.10
0.00
iteração
µ β
0 500 1000 1500 20000.00
00.
006
0.01
2
iteração
σ β2
Figura 5.9: Traços das amostras a posteriori dos parâmetros µα, σ2α, µβ e σ2
β pelo modelo
CIR hierárquico.
95

µα
freq
uênc
ia
0.1 0.2 0.3 0.4 0.5 0.6
01
23
45
σα2
freq
uênc
ia
0.00 0.04 0.08
010
2030
µβ
freq
uênc
ia
−0.20 −0.10 0.00
02
46
812
σβ2
freq
uênc
ia
0.000 0.004 0.008 0.012
010
020
030
0
Figura 5.10: Histogramas das amostras a posteriori dos parâmetros µα, σ2α, µβ e σ2
β pelo
modelo CIR hierárquico.
A taxa de emissão é calculada segundo a equação (5.6) e a taxa de emissão coletiva é
obtida pela fórmula
rc = µα + y0µβ, sendo y0 =1
n
n∑
i=1
y(i)0 . (5.8)
96

A Figura 5.11 exibe os boxplotes das distribuições a posteriori das taxas de emissão
inicial em cada localização da segunda campanha de Corumbá e o último boxplot é a taxa
coletiva para mesma campanha e reservatório. Observa-se que o boxplot da taxa coletiva,
rc, encontra-se verticalmente no centro, sendo deslocado para cima por influência das
taxas dos locais 14 e 15. O mesmo comportamento foi destacado no modelo M1.
locais
taxa
s (
ppm
/(m
in m
2 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 rc
0.0
0.2
0.4
0.6
0.8
Figura 5.11: Taxas de emissão inicial para a segunda campanha de Corumbá. Localizações
1 a 20 e taxa coletiva.
97

A Figura 5.12 exibe o traço e o histograma da taxa de emissão inicial coletiva rc para
a segunda campanha de Corumbá. Na Tabela 5.2 são apresentadas as estatísticas resumo
dos principais parâmetros do modelo considerando as três campanhas. Observa-se que,
assim como no modelo M1, as estimativas pontuais variam muito de uma campanha para
outra.
0 500 1000 1500 2000
−0.
050.
100.
25
Saída do MCMC
iteração
r c
Histograma
rc
freq
uênc
ia
0.0 0.1 0.2 0.3
02
46
810
Figura 5.12: Taxa de emissão inicial coletiva para segunda campanha de Corumbá.
No Apêndice A encontra-se uma tabela com o resumo das principais estatística e
gráficos da convergências das taxas de emissão para cada local em cada campanha de
98
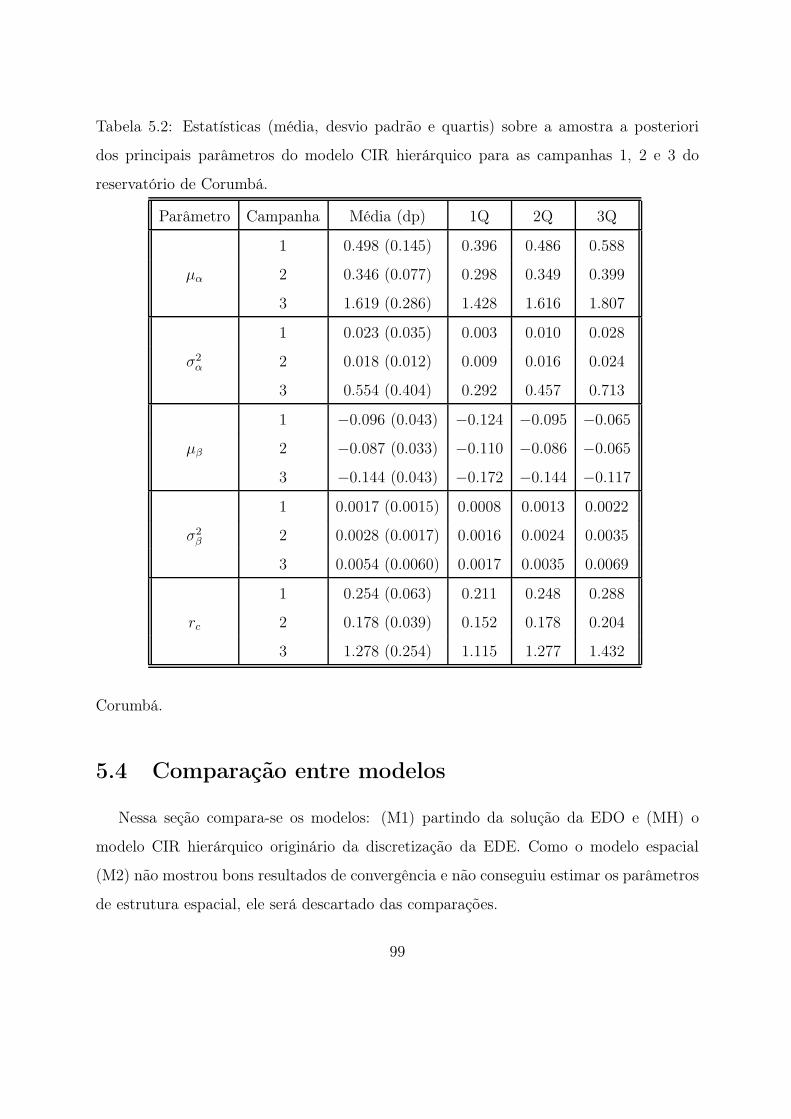
Tabela 5.2: Estatísticas (média, desvio padrão e quartis) sobre a amostra a posteriori
dos principais parâmetros do modelo CIR hierárquico para as campanhas 1, 2 e 3 do
reservatório de Corumbá.
Parâmetro Campanha Média (dp) 1Q 2Q 3Q
1 0.498 (0.145) 0.396 0.486 0.588
µα 2 0.346 (0.077) 0.298 0.349 0.399
3 1.619 (0.286) 1.428 1.616 1.807
1 0.023 (0.035) 0.003 0.010 0.028
σ2α 2 0.018 (0.012) 0.009 0.016 0.024
3 0.554 (0.404) 0.292 0.457 0.713
1 −0.096 (0.043) −0.124 −0.095 −0.065
µβ 2 −0.087 (0.033) −0.110 −0.086 −0.065
3 −0.144 (0.043) −0.172 −0.144 −0.117
1 0.0017 (0.0015) 0.0008 0.0013 0.0022
σ2β 2 0.0028 (0.0017) 0.0016 0.0024 0.0035
3 0.0054 (0.0060) 0.0017 0.0035 0.0069
1 0.254 (0.063) 0.211 0.248 0.288
rc 2 0.178 (0.039) 0.152 0.178 0.204
3 1.278 (0.254) 1.115 1.277 1.432
Corumbá.
5.4 Comparação entre modelos
Nessa seção compara-se os modelos: (M1) partindo da solução da EDO e (MH) o
modelo CIR hierárquico originário da discretização da EDE. Como o modelo espacial
(M2) não mostrou bons resultados de convergência e não conseguiu estimar os parâmetros
de estrutura espacial, ele será descartado das comparações.
99

Primeiramente faz-se uma comparação gráfica entre as taxas, obtidas a posteriori, para
M1 e MH. Na Figura 5.13 são comparados os boxplotes da taxa de emissão inicial coletiva
pelo modelo hierárquico partindo da solução da EDO (M1) e pelo CIR hierárquico (MH).
A conclusão da figura é que tanto por um modelo quanto pelo outro os resultados foram
bem próximos. Isso ocorreu também nas demais companhas, o que aumenta a confiança
sobre os resultados.
taxa
s (
ppm
/(m
in m
2 ))
M1 CIR hierárquico
0.0
0.1
0.2
0.3
0.4
Figura 5.13: Comparação entre taxas de emissão inicial coletivas por dois métodos.
Nas Figuras 5.14 e 5.15 comparam-se as distribuições a posteriori das taxas por mé-
todos diferentes. Elas referem-se as taxas de emissão inicial da campanha 2 de Corumbá.
Os métodos são: CIR hierárquico - MH (histogramas), modelo hierárquico partindo da
solução da EDO - M1 (curva de densidade) e método de mínimos quadrado (reta vertical
100

pontilhada). Note que o modelo M1 apresenta menor variância nas estimativas das taxas.
Esse modelo é homoscedástico o que justifica a menor variância em comparação com o
CIR hierárquico.
Fazendo uma análise das Figuras 5.13, 5.14 e 5.15 destaca-se como os modelos hierár-
quicos conseguem contornar o problema de poucas observações através do compartilha-
mento da informação. Além disso, ambos os modelos, modelo (M1) e o CIR hierárquico
(MH), tiveram resultados parecidos nas taxas de emissão, seja para cada localização ou
coletiva.
Existem várias medidas de comparação de modelos. Na Tabela 5.3 são exibidos a
“deviance bayesiana”, o pd, o DIC (ver Spiegelhalter et al. (2002)) e as medidas escore (ver
Gneiting e Raftery (2004)). As três primeiras colunas com valores são obtidas diretamente
da saída do WinBugs. O deviance, D, é calculado por
D =1
G
G∑
g=1
−2 logL(θ(g)),
sendo que G é a quantidade de amostras a posteriori do vetor paramétrico θ, e L(θ)
é a verossimilhança do modelo. A medida pd é obtida pela diferença D − D, sendo
D = −2 logL(θ) e θ a média a posteriori dos parâmetros. Segundo Spiegelhalter et al.
(2002), D pode ser visto como uma medida de adequação do modelo enquanto pd é a
proposta do número efetivo de parâmetros. O DIC (“deviance information criterion”) é
usado para seleção de modelos, é dado por
DIC = D + pd,
que é a soma entre a medida de adequação D penalizado pela medida de número de
parâmetros pd.
Outra forma de comparar os modelos é usar regras de escore estritamente próprias
como descrito em Gneiting e Raftery (2004). Eles consideram regras escore para obter
bondades de ajuste que num contexto bayesiano estão relacionadas com utilidades. O
101

Histograma 1
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 2
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 3
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 4
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 5
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 6
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 7
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 8
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 9
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 10
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 11
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 12
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Figura 5.14: Amostras a posteriori das taxas de emissão inicial por: CIR hierárquico
(histogramas), modelo M1 (linhas contínuas) e mínimos quadrados (linhas tracejadas
verticais) para segunda campanha de Corumbá, locais 1 ao 12.
102

Histograma 13
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 14
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 15
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 16
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 17
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 18
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 19
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Histograma 20
Taxa
dens
idad
e
0.0 0.2 0.4 0.6 0.8
05
1015
2025
30
Figura 5.15: Amostras a posteriori das taxas de emissão inicial por: CIR hierárquico
(histogramas), modelo M1 (linhas contínuas) e mínimos quadrados (linhas tracejadas
verticais) para segunda campanha de Corumbá, locais 13 ao 20.
escore médio é definido por
S(θ) =1
n(N − 1)
n∑
i=1
N−1∑
k=1
S(Pθ; y(i)k ),
sendo Pθ = p(y|θ) o modelo paramétrico e S( . ) uma regra escore própria.
No contexto bayesiano, as regras escore são utilizadas como medidas de comparação de
modelos baseadas nas distribuições preditivas a posteriori. Na presente análise utiliza-se
103

os escores logarítmicos (LS) e probabilísticos (CRPS). Eles são dados, respectivamente,
por
LS(Pθ, y(i)k ) = log p(yrep = y
(i)k |y) e
CRPS(Pθ, y(i)k ) =
1
2E|y(i)rep,k − y
(i)rep,k| − E|y(i)rep,k − y
(i)k |,
sendo y(i)rep,k e y(i)rep,k réplicas independentes da distribuição preditiva a posteriori p( . |y).Gschlößl e Czado (2005) propõem formas simples de obter os escores fazendo uso das
saídas do MCMC. As funções escore LS e CPRS são obtidas pelas fórmulas
ˆlog p(yrep = y(i)k |y) = 1
G
G∑
g=1
log p(y(i)k |θ(g)),
E|y(i)rep,k − y(i)rep,k| =
1
G
G∑
g=1
|y(i)(g)rep,k − y(i)(g)rep,k | e
E|y(i)rep,k − y(i)k | = 1
G
G∑
g=1
|y(i)(g)rep,k − y(i)k |,
no qual θ(g) é a g−ésima saída do MCMC para o vetor paramétrico θ(g) e sendo y(i)(g)rep,k e
y(i)(g)rep,k amostras de p(y(i)k |θ(g)).
Ao contrário do DIC, o modelo que deve ser escolhido é aquele com maior escore, não
importando se esse valor é negativo.
Tabela 5.3: Comparação entre os modelos por DIC e funções escore.
Campanha Modelo Deviance pd DIC LS CPRS
1M1 203.813 4.851 208.665 −1.783 −0.718
MH 157.041 14.445 171.485 −1.383 −0.575
2M1 −28.036 −138.950 −166.986 0.238 −0.105
MH 11.985 23.805 35.790 −0.099 −0.155
3M1 171.125 −0.202 170.923 −2.371 −1.428
MH 153.191 15.656 168.847 −2.128 −1.286
A leitura da Tabela 5.3 deve ser feita aos pares de linhas. Como a quantidade de
parâmetros é diferente de uma campanha para outra, só faz sentido comparar M1 com
104

MH na mesma campanha. Nas campanhas 1 e 3 as “deviances” e os DICs foram menores
para o modelo MH e os escores foram maiores para as mesmas campanhas e modelo.
Isto indica que o modelo MH é melhor considerando os dados da primeira e terceira
campanhas. Nas campanhas 2 e 3 o pd foi negativo para M1. Segundo Spiegelhalter et al.
(2002), quando isto acontece “é um indicativo que há conflito entre a priori e os dados
ou que a média a posteriori dos parâmetros é um estimador pobre (como em distribuições
simétricas bimodais)”. As funções escore só não indicaram o modelo MH para os dados
da segunda campanha. Pode-se interpretar que as funções escore estão acompanhando a
anomalia do pd e DIC negativos e, portanto, dando preferencia para M1 na campanha 2.
Outras formas de comparação de modelos podem ser utilizadas como BIC ou AIC.
Pode-se ainda utilizar critérios baseados na verossimilhança marginal, proposto em Chib
e Jeliazkov (2001). Essas outras propostas não foram implementadas nesse trabalho.
5.5 Regressão total
O objetivo desta seção é calcular a emissão total do reservatório considerando as
observações (concentrações) agregadas em seus respectivos tempos. A análise dos dados
é feita sem considerar estruturas hierárquicas tanto para o modelo que parte da solução
da EDO, que será denominado M1T, quanto para o modelo que parte da discretização
da EDE, referenciado por M2T. Em ambos utiliza-se uma regressão única para todas as
observações.
A Tabela 5.4 apresenta os modelos considerados nesta seção. A programação foi feita
em WinBugs 1.4.1 com auxílio do R versão 2.7.1. A estratégia das distribuições a priori
foi considerá-las não informativas como feito nas seções anteriores.
O procedimento de MCMC consistiu em gerar uma amostra de tamanho 300000, com
aquecimento (burn in) de 100000. Os elementos da cadeia foram tomados de 100 em
100 para garantir independência entre eles, o que de fato se constatou pelos gráficos de
autocorrelação (não exibidos aqui). O resultado foi uma amostra de 2000 elementos da
105

M1T - EDO M2T - EDE
y(i)k = µ
(i)k + v
(i)k , v
(i)k ∼ N(0, σ2),
µ(i)k = η + (y
(i)0 − η)e−κτk .
zk =y(i)k+1 − y
(i)k
y(i)k
1/2∆
1/2k
=
=(
α y(i)k
−1/2+ β y
(i)k
1/2)
∆1/2k + σε
(i)k ,
com ε(i)k ∼ N(0, 1).
Tabela 5.4: Modelos para regressão total.
distribuição a posteriori dos parâmetros e a partir deles as taxas de emissão inicial foram
obtidas. As taxas foram calculadas pela derivada da função de evolução das concentrações
no instante zero, de acordo com os modelos da Tabela 5.4, e obtidas, respectivamente,
por r = κ(η − y0) e r = α + βy0, sendo y0 = n−1∑n
i=1 y(i)0 . Os parâmetros convergiram
para as três campanhas.
A Tabela 5.5 apresenta o resumo das estatísticas dos fluxos pelo procedimento de
regressão total para as três campanhas de Corumbá.
Tabela 5.5: Sumário das estatísticas (média, desvio padrão e quartis) das amostras a
posteriori dos fluxos pelos modelos M1T e M2T para as campanhas 1, 2 e 3 do reservatório
de Corumbá.
Campanha Modelo Média (dp) 1Q 2Q 3Q
1M1T 0.120 (0.017) 0.109 0.121 0.132
M2T 0.215 (0.039) 0.188 0.215 0.243
2M1T 0.104 (0.012) 0.096 0.104 0.112
M2T 0.088 (0.021) 0.074 0.088 0.102
3M1T 0.315 (0.031) 0.293 0.315 0.336
M2T 1.085 (0.174) 0.974 1.081 1.203
A Figura 5.16 exibe os ajustes dos modelos (na primeira linha), os traços das taxas de
emissão inicial (segunda linha) e os histogramas das taxas (terceira linha) somente para a
segunda campanha de Corumbá. Os gráficos do lado esquerdo referem-se ao modelo M1T
106

e do lado direito ao M2T.
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
Regressão Total
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
24
68
10
0 500 1000 1500 2000
0.06
0.08
0.10
0.12
0.14
iteração
r
0 500 1000 1500 2000
0.05
0.10
0.15
iteração
r
r
dens
idad
e
0.06 0.08 0.10 0.12 0.14
05
1015
2025
30
r
dens
idad
e
0.05 0.10 0.15
05
1015
20
Figura 5.16: Ajustes dos modelos (primeira linha), traços dos fluxos (segunda linha)
e histogramas dos fluxos (terceira linha) para os modelos M1T e M2T para segunda
campanha de Corumbá.
107

Comparação entre os modelos
Existem três formas principais para analisar os dados de concentração de gases consi-
derando que eles são obtidos em locais diferentes. A primeira consiste em analisar cada
local independentemente e obter os fluxos para cada sítio sem olhar para os vizinhos. Essa
abordagem não foi desenvolvida aqui porque estimar 3 parâmetros contendo 4 observa-
ções nos leva a um alto grau de incerteza. Isto deve ser somado a incerteza inerente às
limitações técnica para obtenção dos dados.
Outra forma é assumir uma estrutura hierárquica para compartilhar as informações
entre os locais e com isso reduzir os problemas de mau condicionamento das amostras e
poucas observações em cada local. Por fim, pode-se analisar as concentrações agregando
todas as informações no procedimento que aqui denominou-se regressão total. Os dois
últimos casos tiveram seus modelos baseados ou na solução da EDO ou na discretização da
EDE. Ambos modelam a evolução, no tempo, da concentração do gás dentro das câmaras
de difusão.
A comparação é feita utilizando os critérios de seleção de modelos para os modelos
da regressão total, M1T e M2T. A Tabela 5.6 traz a medidas pd, DIC, e funções escore
logarítmico (LS) e probabilístico (CPSR). Lembrando que os melhores modelos são aqueles
com menor DIC e maior escore. A conclusão da tabela é que o modelo M2T foi melhor
que o M1T para todos os critérios considerando todas as campanhas de Corumbá.
A última coluna da Tabela 5.6 mostra a correlação entre as cadeias a posteriori η e
κ de M1T e α e β de M2T. Em ambos os casos a correlação foi negativa, sendo esta
característica mais acentuada entre os parâmetros de M2T.
A distribuição dos dados na regressão total, como exibida nos ajustes na Figura 5.16,
indicam que as variâncias das concentrações aumentam com o tempo. O modelo M2T
leva isto em consideração, pois a raiz quadrada da concentração aparece multiplicando o
termo estocástico (diferencial do movimento browniano). Esta pode ser a razão pela qual
o modelo M2T supera o modelo M1T segundo os critérios de seleção.
Comparando agora a regressão total com os modelos hierárquicos, segundo as tabelas
108

Campanha Modelo pd DIC LS CPSR Correlação
1M1T 2.21 223.71 −1.94 −0.88 −0.38
M2T 3.09 173.43 −1.49 −0.65 −0.91
2M1T 2.05 200.39 −1.65 −0.62 −0.75
M2T 3.05 93.33 −0.80 −0.28 −0.97
3M1T 2.12 215.30 −2.96 −2.60 −0.58
M2T 3.13 190.26 −2.60 −1.88 −0.84
Tabela 5.6: Critérios de comparação de modelos da regressão total
5.6 e 5.3, os critérios de escolha de modelos indicam que os modelos hierárquicos superam
os modelos de regressão total em todas as campanhas de Corumbá.
Os modelos baseados na regressão total têm o problema de não informar características
particulares de uma região, pois colocam todos os dados empilhados em seus respectivos
tempos. Além disso, os modelos M1T e M2T só têm parâmetros para o todo não forne-
cendo parâmetros locais.
Na seção a seguir são propostas formas de estimar a emissão para o reservatório como
um todo.
5.6 Cálculo da emissão total do reservatório
Nesta seção são apresentadas três propostas para estimação da emissão do metano
(CH4) para todo o reservatório de Corumbá. Estimar a emissão total de um gás poluente
em um reservatório é de grande importância para formular políticas energéticas mais
limpas. Os modelos apresentados neste capitulo e as técnicas de estimação da emissão total
do reservatório constituem um trabalho pioneiro no Brasil e de importância estratégica.
Hoje não só o custo da geração de energia deve ser considerado, mas também o quanto a
geração dela prejudica o meio ambiente e contribui para o aquecimento global.
Teoricamente o cálculo da emissão total do reservatório é feito pela integral da curva da
109

taxa de emissão inicial com respeito à área do reservatório da forma R =∫
Ards, se o fluxo
contínuo para toda superfície do reservatório fosse conhecido. Na prática, são conhecidas
as taxas de emissão em alguns locais e a taxa de emissão coletiva. As propostas partem
de aproximações da integral usando essas quantidades de interesse.
A Figura 5.17 mostra o reservatório de Corumbá e os locais de coleta das concentrações
dos gases da segunda campanha. A análise de dados realizada nesse capítulo só considerou
as amostras obtidas por câmaras de difusão sobre o espelho d’água. Os códigos na figura
referem-se as denominações dos locais de amostragem. Mais detalhes sobre o procedimento
de amostragem e sobre as características do reservatório estão presentes nos relatórios:
dos Santos et al. (2005a,b, 2006), para cada uma das campanhas, respectivamente.
As campanhas estão relacionadas com períodos climáticos: seco, chuvoso ou interme-
diário. Por isso as características do reservatório variam de acordo com as campanhas o
que envolve área de cobertura, temperatura, etc. O reservatório de Corumbá está locali-
zado no sudeste do estado de Goiás possuindo as características climáticas e de vegetação
dessa região.
5.6.1 Cálculo da emissão total pela taxa conjunta
Assume-se que a emissão do reservatório todo está bem representada pela taxa de
emissão coletiva rc. Observe que não está sendo considerada a média das concentrações
nos locais e sim a taxa coletiva resultado do compartilhamento de informações pelo modelo
hierárquico.
Dessa proposta, segue que a emissão para o reservatório, na campanha l, com l =
1, 2, 3, é dada por
Rl = Al r(l)c , (5.9)
sendo que Rl é a taxa de emissão inicial do reservatório, Al é a área do espelho d’água do
reservatório e r(l)c é a taxa de emissão inicial coletiva do reservatório, todos considerando a
campanha l. A taxa é transformada de ppm/(minm2) para tonelada CH4/(diam2) usando
fatores físicos de conversão, que dependem: da pressão atmosférica, da temperatura, do
110

Figura 5.17: Reservatório de Corumbá com os locais de amostragem da segunda campa-
nha.
volume molar do gás, do volume da câmara e da área de abertura da câmara. Esses fatores
de conversão foram fornecidos pelo Programa de Planejamento Energético da COPPE-
UFRJ.
A Figura 5.18 exibe os boxplotes das emissões de todo o reservatório de Corumbá,
pela equação (5.9), para as três campanhas pelos métodos (M1) e CIR hierárquico (MH).
A área do reservatório de Corumbá foi considerada a mesma nas três campanhas sendo
111
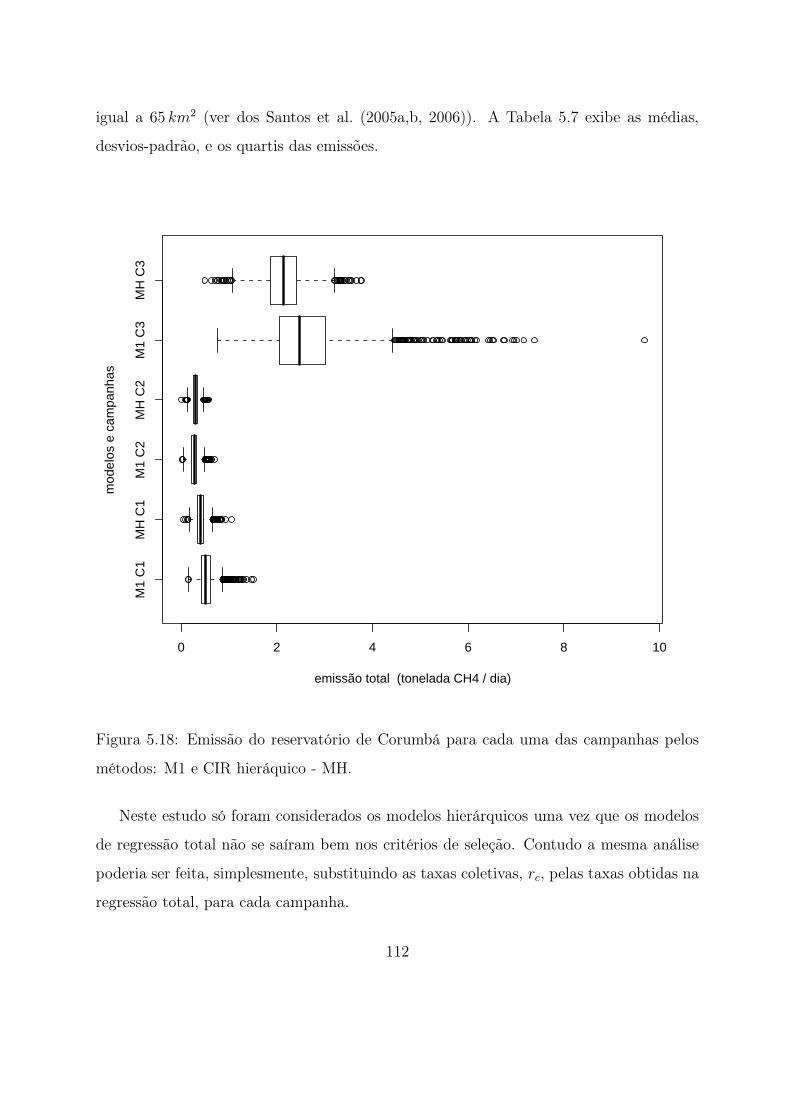
igual a 65 km2 (ver dos Santos et al. (2005a,b, 2006)). A Tabela 5.7 exibe as médias,
desvios-padrão, e os quartis das emissões.
emissão total (tonelada CH4 / dia)
mod
elos
e c
ampa
nhas
M1
C1
MH
C1
M1
C2
MH
C2
M1
C3
MH
C3
0 2 4 6 8 10
Figura 5.18: Emissão do reservatório de Corumbá para cada uma das campanhas pelos
métodos: M1 e CIR hieráquico - MH.
Neste estudo só foram considerados os modelos hierárquicos uma vez que os modelos
de regressão total não se saíram bem nos critérios de seleção. Contudo a mesma análise
poderia ser feita, simplesmente, substituindo as taxas coletivas, rc, pelas taxas obtidas na
regressão total, para cada campanha.
112

Tabela 5.7: Estatísticas da emissão total do reservatório de Corumbá considerando as três
campanhas e os métodos M1 e CIR hierárquico (MH) em tonelada CH4/dia.
Campanha Modelo Média (dp) 1Q Mediana 3Q
Campanha 1M1 0.5341 (0.1652) 0.4286 0.5020 0.6059
MH 0.4171 (0.1029) 0.3472 0.4067 0.4725
Campanha 2M1 0.2772 (0.0867) 0.2157 0.2714 0.3283
MH 0.2991 (0.0658) 0.2561 0.2988 0.3425
Campanha 3M1 2.6100 (0.8717) 2.0495 2.4689 3.0083
MH 2.145 (0.4271) 1.8720 2.1402 2.403
A estimação da emissão do reservatório como um todo pode ser refinada de diversas
maneiras. A seguir são apresentadas propostas que visam considerar sub-regiões do re-
servatório. As propostas a seguir não podem fazer uso da regressão total, pois precisam
de informações dos fluxos nos locais que não são fornecidos pelo método.
5.6.2 Cálculo da emissão total por sub-regiões
Considera-se que cada taxa de emissão local r(l)i , com i = 1, . . . , n, esteja relacionada
com uma área do reservatório A(l)i , na campanha l = 1, 2, 3. Assumindo que
∑
iA(l)i = A(l)
a emissão total do reservatório, na campanha l, pode ser calculada por
Rl =
n∑
i=1
A(l)i r
(l)i . (5.10)
Esta proposta parte da divisão da área do reservatório em sub-áreas. Uma forma
refinada de proceder é construir uma malha para o reservatório (e.g. por quadrículas) e
para cada tempo estimar, usando o modelo, as concentrações dos locais não observados.
Isto é feito pelo cálculo de
p(yno|yo) =∫
Θ
p(yno|θ)p(θ|yo)dθ, (5.11)
113

sendo yno as concentrações no tempo e espaço, não observadas, e θ os parâmetros do
modelo pertencentes ao espaço paramétrico Θ. Em geral a integral da equação 5.11
não possui forma analítica conhecida e por isso métodos MCMC são aplicados. Esse
procedimento deve ser levado em consideração no planejamento amostral para se obter
observações espalhadas da melhor maneira.
O primeiro problema desta abordagem está na geografia do reservatório que segue o
formato do rio. Ou seja, em geral a área de interesse é comprida e estreita (veja Figura
5.17) e isso dificulta construir boas malhas. Outro revés é que por limitações tecnológicas
e financeiras não é possível cobrir boa parte do reservatório. Dependendo do formato dele
isso gera grande quantidade de locais sem observações. Ao estimar as concentrações dos
locais a variância dos parâmetros (locais não observados) fica muito grande o que significa
que a incerteza associada a este procedimento é muito elevada.
5.6.3 Cálculo da emissão total pelo acréscimo de um nível de
hierarquia relacionado a regiões de influência
Uma proposta viável é considerar características de sub-regiões do reservatório. Por
exemplo, pode-se dividi-lo em montante, vazante e jusante. Espera-se que observações
nas mesmas regiões tenham comportamento semelhante.
Esta abordagem implica na formulação de modelos com mais um nível de hierarquia.
Os parâmetros que antes estavam relacionados com médias e variâncias coletivas teriam
uma relação intermediária com as sub-regiões. Isso resultaria no cálculo para taxas locais,
r(l)ji
, taxas por sub-regiões r(l)j e a taxa coletiva r(l)c , para cada campanha l. A emissão do
reservatório é calculada, para a campanha l, por
Rl =J∑
j=1
A(l)j r
(l)j , (5.12)
sendo que J é a quantidade de sub-regiões amostrais.
A aplicação dessas últimas propostas depende de um planejamento amostral bem
feito que considere: (1) locais representativos do reservatório para amostragem, (2) espa-
114

çamento entre as observações visando cobrir boa parte do reservatório e (3) quantidade
de observações nas sub-regiões que consigam representá-las.
Após estimar a emissão do reservatório para cada campanha é preciso desenvolver
formas de estimar a emissão anual do reservatório. Esse é um tópico ainda a ser desenvol-
vido, mas que certamente deve considerar as características climáticas de cada campanha
(chuvoso, seco e intermediário) e o período de influência desses durante o ano.
No próximo capítulo será desenvolvida a ideia de processos de difusão multivariados
com estrutura espacial. No decorrer dele pode-se perceber que modelar de forma mais
adequada a função matricial de volatilidade em processos de difusão melhora a inferência
e torna a análise estatística mais eficiente. A grande novidade é observar os processos
de difusão multivariados como processos espaço-temporais. Uma das vantagens é que,
através de técnicas de discretização, é possível recair em modelos espaço-temporais já
conhecidos na literatura.
115

Capítulo 6
Processo de Difusão com Estrutura
Espacial
O procedimento de inferência sobre os parâmetros de vários processos de difusão univa-
riados e correlacionados pode ser tratado como o problema de estimação dos parâmetros
de um processo de difusão multivariado. Uma dificuldade em trabalhar com processos
multivariados está em determinar os parâmetros da função de volatilidade. Isto porque a
quantidade de parâmetros cresce consideravelmente com a dimensão do processo. Se fosse
possível assumir conhecidas algumas das características das componentes da difusão seria
possível reduzir a dimensão dos parâmetros da função de volatilidade. Procedimentos
dessa natureza aparecem, por exemplo, na literatura sobre grafos em séries temporais.
Em alguns casos, que envolvem o processo de difusão X t =(
X(1)t , X
(2)t , . . . , X
(n)t
)
, as
componentes X(i)t estão relacionadas com suas posições espaciais. A influência da posição
espacial das componentes do processo X t pode agir sobre a função de volatilidade de modo
a aumentar a correlação das componentes que estão próximas e reduzir das distantes.
Trabalhar com funções de volatilidade que usem funções especiais de distância diminui
sensivelmente a dimensão do espaço dos parâmetros e ainda pode melhorar o ajuste do
modelo.
No Capítulo 3 foram apresentadas técnicas para estimação dos parâmetros do processo
116

CIR multivariado usando o esquema de discretização de Euler-Maruyama e aplicando
inferência bayesiana sobre um modelo de regressão multivariado. Em Kalogeropoulos
et al. (2007) a inferência também é feita sob o ponto de vista bayesiano só que aproxi-
mando a função de verossimilhança pela Fórmula de Girsanov e decompondo-a através da
transformação do processo em um cuja matriz de volatilidade é matriz identidade. Essa
abordagem é uma extensão de Roberts e Stramer (2001) e aparece descrito na versão
multivariada em Kalogeropoulos (2007).
A contribuição principal deste capítulo é desenvolver processos de difusão espaciais e
fornecer técnicas de estimação para os parâmetros destes processos. Na primeira seção
apresenta-se o processo de difusão multivariado com estrutura espacial por duas formula-
ções:
(i) Uma com estrutura espacial sobre a função de volatilidade na qual as componentes
espaciais estarão presentes somente na função de volatilidade, isto é, a função de
direção não é influenciada pela posição das componentes do processo e
(ii) A outra é uma formulação espacial hierárquica construída de tal maneira que as
estruturas espacial e hierárquica incidam sobre a função de direção.
Na segunda seção apresenta-se formalmente a função de covariância e suas principais
propriedades. Na terceira seção caracteriza-se o processo CIR multivariado com estrutura
espacial, como extensão do que foi visto na Seção 3.2. O procedimento de inferência
é descrito na Seção 6.4 e nas seções 6.5 e 6.6 são apresentadas aplicações com dados
simulados.
Pela dificuldade em encontrar dados espaço-temporais, em geral, e em particular dados
de emissão de gases em reservatórios com séries mais longas não foi feita uma aplicação
com dados reais. Nas próximas campanhas de coleta de dados o avanço tecnológico das
técnicas de amostragem já permite obter por volta de 60 observações no tempo (antes
eram apenas 4) em vários locais dos reservatórios.
117

6.1 Modelos com estrutura espacial
Seja X t(s) =(
X(1)t (s1), X
(2)t (s2), . . . , X
(n)t (sn)
)
um processo de difusão n-dimensional
cujas componentes estão relacionadas com s ∈ D ⊂ IRp, sendo s = (s1, s2, . . . , sn) o
conjunto das localizações na região D contida no espaço euclidiano p−dimensional. Nesse
trabalho assume-se p = 2, ou seja, si = (xi, yi) são as coordenadas no plano.
A Figura 6.1 mostra a representação gráfica de um processo de difusão multivariado
na região D.
Figura 6.1: Processo de difusão multivariado espacial.
A seguir serão apresentadas duas formulações para processos de difusão acrescentando-
se estruturas espaciais. Na primeira a componente espacial será introduzida na função
de volatilidade através da função de covariância. Essa função leva em consideração a
118

distância euclidiana entre os locais funcionando como pesos sobre a volatilidade do pro-
cesso. Essa composição reduz sensivelmente a dimensão dos parâmetros na função de
volatilidade. A segunda estrutura espacial resulta do acréscimo de um nível hierárquico
onde os parâmetros da função vetorial de direção assumem um processo gaussiano (PG).
Neste caso, a relação de dependência entre as n componentes do processo n−dimensional
está descrito na função de covariância do PG e a função matricial de volatilidade será
diagonal.
6.1.1 Estrutura espacial sobre a função de volatilidade - PDEEv
Um processo de difusão com estrutura espacial na função de volatilidade (PDEEv)
pode ser escrito por
dX t(s) = b(X t(s), t; θ1)dt+ σ(X t(s), t; θ2)dBt, (6.1)
sendo que θi ∈ Θi, (i = 1, 2), com Θ1 ∪Θ2 = Θ e Θ1 ∩Θ2 = ∅. A função de volatilidade
é construída com o auxílio da função de covariância f(dij; θ2), com dij = ‖si − sj‖ , a
distância euclidiana entre as localizações si e sj.
A função matricial de volatilidade, que será denotada por σt, pode ser decomposta da
forma
σtσ′
t = DXtΣD
′
Xt,
sendo (Σ)ij = f(dij; θ2) a matriz obtida pela função de covariância e DXtuma matriz que
só depende de X t.
Existe uma variedade de funções de covariância como por exemplo
f(dij; θ2) = γ exp−dij/φ, γ > 0 e φ > 0,
no qual os parâmetros de estrutura espacial são θ2 = (γ, φ). Na próxima seção as funções
de covariância serão abordadas. Para uma visão geral de funções desse tipo ver Diggle e
Ribeiro (2007); Schmidt e Sansó (2006); Paez e Gamerman (2005).
119

6.1.2 Estrutura espacial hierárquica - PDEEh
Um processo de difusão com estrutura espacial hierárquica (PDEEh) é escrito por
dX t(s) = b(X t(s), t; θ1)dt+ σ(X t(s), t; θ1)dBt,
θ1 ∼ PG(m(θ2), Σ),
(6.2)
sendo m( . ) a função de média, (Σ)ij = f(dij; θ2) a função de covariância, com dij =
‖si − sj‖ , de um processo gaussiano PG( . , . ) e
(σtσ′
t)ij =
(σ(i)t )2G(X t), se i = j
0, se i 6= j,
com θi ∈ Θi, (i = 1, 2), Θ1 ∪ Θ2 = Θ e Θ1 ∩ Θ2 = ∅ e G uma função que só depende do
processo X t.
Ao aplicar esquemas de discretização sobre PDEEh recai-se sobre modelos espaço-
temporais já conhecidos na literatura. Por esta razão a inferência e os exercícios de
simulação não serão desenvolvidos sobre esse processo. O interessante é notar a conver-
gência das teorias em tempo contínuo, no que tange os processos de difusão, e os processos
espaço-temporais discretos.
6.2 Função de covariância e de correlação
A função de covariância pode ser escrita por
f(dij; θ) =√vivj ρ(dij; θ),
no qual ρij := ρ(dij; θ) é chamada função de correlação e vi e vj são parâmetros de
variabilidade associados aos locais si e sj , respectivamente.
A função de covariância deve ter propriedades desejáveis para que as formulações
PDEEv e PDEEh tenham sentido matemático. Isto é, a função de correlação precisa
atender certas condições para permitir a existência de um processo de difusão que seja
120

solução da EDE e, além disso, ela deve modelar a estrutura espacial do processo. Paez e
Gamerman (2005) listam algumas propriedades desejáveis dessa função:
1. ρ(dij; θ) é monótona não crescente em dij, ou seja, a correlação entre dois processos
decresce com o aumento da distância entre as localizações;
2. ρ(dij; θ) → 0 quando dij → ∞, isto é, a correlação entre processos distantes no
espaço tendem a zero;
3. Pelo menos um parâmetro do modelo controla a taxa com que ρ( . , θ) decai para
zero, visto que essa taxa geralmente não é conhecida. O decaimento pode ser,
portanto, mais ou menos lento, dependendo deste(s) parâmetro(s) e
4. A matriz Σ, cujas componentes são f(dij; θ), e dependem de ρij , deve ser positiva
definida.
A última propriedade permite tomar a função de volatilidade como a decomposição (de
Cholesky) da Σ na equação (6.1). E a função de covariância do PG em (6.2) fica correta-
mente especificada.
Existem famílias de funções que compartilham das propriedades acima enumeradas.
As principais são sumarizadas a seguir e podem ser encontrados com mais detalhes em
Diggle e Ribeiro (2007), Schmidt et al. (2003), Schmidt e Sansó (2006) e na dissertação
de Paez (2000).
6.2.1 Família exponencial de potência
A definição desta classe de funções (ver Oliveira et al. (1997)) é dada por
ρ(dij;ψ, φ) = exp
[
−(
dijψ
)φ]
, com ψ > 0 e 0 < φ ≤ 2.
Essa família tem parâmetros de escala ψ e parâmetro de forma φ. Quando φ = 1 a função
ρ(dij;ψ, φ) é chamada função de correlação exponencial. Quando φ = 2 tem-se a função
gaussiana.
121

6.2.2 Família Matérn
Essa família de funções de correlação (ver Matérn (1986)) é definida por
ρ(dij;ψ, φ) =(dij/ψ)
φKφ(dij/ψ)
2φ−1Σ(φ), com ψ > 0 e φ > 0,
sendo Kφ( . ) a função de Bessel modificada do tipo três de ordem φ.
Essa família têm um parâmetro de forma φ e um de escala ψ, assim como a família
exponencial de potência, sendo que a primeira família é mais flexível que a segunda.
Quando φ = 0.5 a função Matérn equivale a função de covariância exponencial e quando
φ→ ∞ obtém-se a função de correlação gaussiana.
6.2.3 Família esférica
Essa família de funções de correlação (ver Wackernagel (1995)) é definida por
ρ(dij;φ) =
1− 3
2(dij/φ) +
1
2(dij/φ)
3, se 0 ≤ dij ≤ φ
0, se dij > φ.
Essa função pode ser interpretada geometricamente como o volume da interseção entre
duas esferas tridimensionais de diâmetro φ, cujos centros estão distanciados de dij. Assim,
qualquer par de localidades com distância entre si maior que φ tem correlação nula.
6.3 CIR multivariado com estrutura espacial
Nesta seção caracteriza-se o processo CIR multivariado acrescentando uma estrutura
espacial: sobre a função de volatilidade (PDEEv) ou pelo acréscimo de estrutura hie-
rárquica (PDEEh). O procedimento é uma extensão da caracterização do processo CIR
multivariado que foi desenvolvido na Seção 3.2 e também aparece, de forma mais com-
pacta, em Kalogeropoulos et al. (2007).
Sejam o movimento browniano d−dimensional B(t) = Bt = (B(1)t , . . . , B
(d)t )
′e um
vetor de parâmetros θ ∈ Θ1 ∪ Θ2 = Θ. A difusão X t, solução da EDE (3.7), pode ser
122

escrita como (6.1) ou (6.2) com função vetorial de direção
bt := b(X(t), t; θ) = Ft ϕ,
sendo ϕi = (αi, βi)′, F
(i)t = (1 X
(i)t ), com i = 1, . . . , n, e
Ft =
F(1)t 0 . . . 0
0 F(2)t . . . 0
.... . .
0 0 . . . F(n)t
n×2n
e ϕ =
ϕ1
ϕ2
...
ϕn
2n×1
e função matricial de volatilidade
σt := σ(X(t), t; θ) = DXtDσP,
sendo DXt:= diag
(
X(1)t
1/2, . . . , X
(n)t
1/2)
n×n, Dσ := diag
(
σ(1), . . . , σ(n))
n×ne P é uma
matriz n× d.
6.3.1 Estrutura espacial na volatilidade
A estrutura espacial é acrescentada na função de volatilidade do processo CIR multiva-
riado substituindo DσP pela decomposição de Cholesky da matriz (Σ), isto é, DσPP′Dσ =
Σ. Assim, tem-se
σtσ′
t = DXtΣDXt
,
sendo Σ a matriz de covariância cujas componentes dependem da função de correlação
ρij .
6.3.2 Estrutura espacial hierárquica
A estrutura espacial é introduzida ao colocar um nível hierárquico no modelo da forma
ϕ ∼ PG(ϕ0,Σ⊗ I2),
123

com (Σ)ij = f(dij; θ2), dim(ϕ) = dim(ϕ0) e sendo Σ ⊗ I2 o produto de Kronecker da
matriz de covariância com a matriz identidade de ordem 2.
A função matricial de volatilidade é diagonal dada por
σtσ′
t = DXtDσInDσDXt
.
6.4 Inferência
O procedimento de inferência é feito sob o ponto de vista da estatística bayesiana. Em
geral não é possível obter a verossimilhança para uma ocorrência completa do processo de
difusão multivariado, pois o processo é contínuo enquanto suas observações são discretas.
As observações são Y = Y k(s) = X tk(s), com k = 0, . . . , N, isto é, as observações
são feitas nos tempos t0 < t1 < . . . < tN e indexadas ao conjunto de localizações s =
s1, . . . , sn ∈ D. O que pode ser feito é obter uma aproximação para verossimilhança de
duas maneiras: a primeira partindo de um esquema de discretização a outra utilizando a
Fórmula de Girsanov.
No primeiro caso o processo de difusão escrito em (6.1) ou (6.2) pode ser discretizado
pelo esquema de Euler-Maruyama obtendo-se
Y k+1(s) = Y k(s) + bk∆k + σk∆kBk, com k = 0, . . . , N − 1,
sendo bk a função vetorial de direção, σk a função matricial de volatilidade, ambas na
notação reduzida, pois dependem de Y k(s), tk e dos parâmetros; ∆k = tk+1− tk e ∆Bk =
Bk+1 −Bk ∼ Nn(0,∆k In).
A função de verossimilhança aproximada é obtida pela produtório das densidades de
transição que são resultado da discretização. Isso é garantido pela propriedade markoviana
resultando em
p(Y (s)|θ) = p(Y 0(s))
N−1∏
i=0
p(Y k+1(s)|Y k(s), θ),
sendo
Y k+1(s)|Y k(s), θ ∼ N [Y k(s) + bk∆k, σkσ′
k∆k].
124

Essa forma da verossimilhança é equivalente à obtida por transformações sobre o processo
discretizado como feito na Subseção 3.2.3. Pela simplicidade da forma e pela facilidade
em realizar os passo do MCMC será utilizada a verossimilhança sobre o processo trans-
formado.
Outra forma de obter uma aproximação para a função de verossimilhança é através
da Fórmula de Girsanov.
Denotando-se por IP a lei de X e por W a lei do martingal local dX t(s) = σtdBt,
como as medidas são absolutamente contínuas, a derivada de Radon-Nikodym da lei de
X com respeito a lei do martingal local é
dIP
dW= G(X(s); θ) = exp
∫ T
0
Ψ−1btdX t −1
2
∫ T
0
b′
tΨ−1btdt
,
sendo Ψ−1 := [σkσ′
k]−1 e G(X; θ) é a verossimilhança do processo. Em muitos casos não
é possível calcular analiticamente as integrais envolvidas em G sendo necessário aproximá-
las. Uma forma simples é definir a verossimilhança de maneira aproximada por
G(Y (s); θ) = exp
N−1∑
k=0
Ψ−1k bk[Y k+1(s)− Y k(s)]−
1
2
N−1∑
k=0
b′
kΨ−1bk∆k
.
Existe uma vasta literatura sobre estimação de parâmetros no contexto não paramé-
trico. Dentre elas pode-se citar Aït-Sahalia (1996a) e Aït-Sahalia (1996b).
A quantidade de dados observados e o espaçamento entre as observações influenciam
na qualidade da inferência. Isto porque o modelo é contínuo enquanto as observações são
discretas. Isto gera um viés relacionado a discretização.
A introdução de dados não observados (dados aumentados) tem a finalidade de reduzir
o erro de discretização e estabilizar o modelo quando tem-se poucas observações. O
objetivo é utilizar esse recurso para obter a distribuição a posteriori do vetor de parâmetros
θ com menos influência do erro de discretização. Isto é feito facilmente ao utilizar métodos
de Monte Carlo via Cadeia de Markov (MCMC) amostrando-se alternadamente de
p(θ|Y o(s),Y no(s)) e p(Y no(s)|Y o(s), θ),
125

sendo Y o(s) o conjunto dos dados observados (i.e., Y o(s) := Y (s)) e Y no(s) o conjunto
dos não observados que são tratados como parâmetro pelo MCMC. Tanto os observados
quanto os não observados estão indexados por suas posições no espaço.
A geração dos não observados pode ser feita de várias formas diferentes e os esquemas
de MCMC podem assumir propostas variadas. Dentre as formas diferentes pode-se citar
a geração dos dados a cada tempo, com a quantidade de não observados fixa (ver Jones
(2003) e Eraker (2001)) ou aleatória (ver Elerian et al. (2001)). Ou ainda, pode-se obter
os não observados em blocos como em Eraker (2001) ou por pontes brownianas como em
Roberts e Stramer (2001), para o caso unidimensional, e Kalogeropoulos et al. (2007),
para o multidimensional, ou de forma exata como em Beskos et al. (2006).
Em geral a obtenção dos dados aumentados e dos parâmetros é feita da seguinte forma:
(1) Inicialize os dados não observados. Pode-se fazer isso, por exemplo, por interpolação,
por métodos spline ou simplesmente traçando retas entre os observados.
(2) Amostre dos parâmetros pela condicional
p(θ|Y o(s),Y no(s)) ∝ p(Y o(s),Y no(s)|θ)p(θ),
sendo o primeiro termo do lado direito da relação de proporcionalidade uma das
formas da verossimilhança e o segundo termo a priori para θ.
(3) Amostre os não observador por
p(Y no(s)|Y o(s), θ) ∝ p(Y o(s), θ|Y no(s))p(Y no(s)).
(4) Repetir os passos (2) e (3) até obter convergência dos parâmetros e dos não obser-
vados.
6.4.1 Inferência dos parâmetros espaciais e do vetor direção
Os parâmetros que envolvem a estrutura espacial serão estimados sob o enfoque baye-
sianos através de métodos MCMC. Em muitos casos a distribuição a posteriori dos parâ-
metros não é conhecida e as distribuições condicionais completas não têm forma fechada.
126

Para esses casos utiliza-se passos de Metropolis para obter amostras da posteriori. Se por
outro lado houver conhecimento da forma da condicional completa gera-se da distribuição
conhecida.
Considerando o caso em que a função de covariância pertença à família exponencial
de potência os parâmetros a serem estimados são σ2, ψ e φ. Em geral o parâmetro φ é
difícil de estimar e será considerado fixo igual a 1.
Para o modelo CIR, assumindo que a estrutura espacial esteja presente na função de
volatilidade, a verossimilhança obtida da transformação, da equação (3.11), dada por
Z = Mϕ+ ε, ε ∼ NNn(0,Σ⊗ IN)
é da forma
p(Z|ϕ,Σ) ∝ |Σ−1|N/2 exp
−1
2tr(HΣ−1)
,
tal que
H =
(Z(1) −M (1)ϕ1)′(Z(1) −M (1)ϕ1) . . . (Z(1) −M (1)ϕ1)
′(Z(n) −M (n)ϕn)
.... . .
...
(Z(n) −M (n)ϕn)′(Z(1) −M (1)ϕ1) . . . (Z(n) −M (n)ϕn)
′(Z(n) −M (n)ϕn)
.
Distribuições a priori:
Na família exponencial de potência tem-se
(Σ−1) = (1/σ2)Σ−1ψ ,
com (Σψ)ij = e−dij/ψ e dij as distâncias entre as localizações si e sj .
A priori dos parâmetros espaciais pode ser escrita, supondo independência, por
p(Σ−1) = p(σ2, ψ) = p(σ2)p(ψ)
sendo σ2 ∼ IG(a, b), inversa gama, e ψ ∼ Gama(c, d) cujas densidades são, respectiva-
mente,
p(σ2) ∝(
1
σ2
)a+1
exp
−(
1
σ2
)
b
e p(ψ) ∝ ψc−1 exp −ψd .
127

A priori para ϕ é não informativa
p(ϕ) ∝ 1.
Distribuições a posteriori:
p(ϕ,Σ|Z) ∝ p(Z|ϕ,Σ)p(ϕ,Σ) ∝ p(Z|ϕ,Σ) p(ϕ, Σ) p(Σ)∝ p(Z|ϕ,Σ)p(ϕ)p(σ2)p(ψ).
Logo, a distribuição a posteriori conjunta para os parâmetros é dada por
p(ϕ, σ2, ψ|Z) ∝
∝ |Σ−1|N/2 exp
−1
2tr(HΣ−1)
(
1
σ2
)a+1
exp
− 1
σ2b
ψc−1 exp −ψd
∝(
1
σ2
)nN/2+a+1
|Σ−1ψ |N/2 ψc−1 exp
−(
1
σ2
)
[tr(H Σ−1ψ )/2 + b]− ψd
,
pois
|Σ−1|N/2 = |(1/σ2)Σ−1ψ |N/2 = (1/σ2)nN/2 |Σ−1
ψ |N/2 e
tr(HΣ−1) = tr((1/σ2)HΣ−1ψ ) = (1/σ2)tr(HΣ−1
ψ ).
Condicionais Completas:
Para ϕ :
p(ϕ|Z,Σ) ∝ exp
−1
2(Z −Mϕ)
′
(Σ−1 ⊗ IN)(Z −Mϕ)
.
Para obter uma amostra da posteriori do vetor ϕ utiliza-se o algoritmo amostrador de
Gibbs gerando-se da distribuição condicional completa normal Nn− dimensional dada
por
ϕ|Σ−1,Z ∼ NNn(m,C),
sendo
m = [M′
(Σ−1 ⊗ IN)M ]−1M′
(Σ−1 ⊗ IN)Z e C = [M′
(Σ−1 ⊗ IN )M ]−1.
Para σ2 :
p(σ2|Z, ϕ,Σψ) ∝(
1
σ2
)nN/2+a+1
exp
−(
1
σ2
)
[tr(H Σ−1ψ )/2 + b]
.
128

A condicional completa para σ2 tem forma conhecida dada por
σ2|Z,Σψ, ϕ ∼ GI
(
nN
2+ a,
1
2tr(HΣ−1
ψ ) + b
)
.
Para ψ :
p(ψ|Z, ϕ, σ2) ∝ |Σ−1ψ |N/2 ψc−1 exp
−(
1
σ2
)
[tr(H Σ−1ψ )/2 + b]− ψd
.
Define-se p(ψ) como o lado direito da relação de proporcionalidade da condicional com-
pleta de ψ. Como a condicional completa não tem forma conhecida, a amostra de ψ é
obtida por passos de Metropolis da seguinte forma:
(1) Amostra-se da densidade proposta
ψ(p) ∼ LogN(µψ, σ2ψ),
isto é, ψ(p) = eX , com X ∼ N(µψ, σ2ψ).
A densidade é dada por
q(ψ) ∝ ψ−1 exp
− 1
2σ2ψ
(lnψ − µψ)2
.
(2) Aceita-se o valor proposto ψ(p) em lugar do valor corrente ψ(c) com probabilidade
min
p(ψ(p)) q(ψ(c))
p(ψ(c)) q(ψ(p)), 1
.
6.5 Exemplo simulado 1
O objetivo desta simulação é mostrar a formulação do CIR multivariado com estrutura
espacial na função de volatilidade (PDEEv), desenvolvido na Seção 6.3, e proceder a
inferência como discutido na Seção 6.4. O uso de dados simulados é útil para testar
os algoritmos e o procedimento de inferência. Foi feito um exercício simulado no qual
geraram-se 201 dados observados (N = 200) em n = 10 localizações, ou seja,
Y o = Y (i)k , k = 0, . . . , N, e i = 1, . . . , n.
129

As observações foram feitas no conjunto de tempo
t0 + k∆k, k = 0, . . . , N
com, t0 = 0, ∆k = 0.05 minutos e, portanto, tN = 10 minutos.
Os parâmetros utilizados para simulação foram
α1 = 0.674, α2 = 1.242, α3 = 0.594, α4 = 1.722, α5 = −0.077,
α6 = 0.098, α7 = 0.728, α8 = 0.710, α9 = 0.789, α10 = 0.723,
β1 = −0.008, β2 = −0.111, β3 = −0.001, β4 = −0.207, β5 = −0.176,
β6 = −0.090, β7 = −0.333, β8 = −0.058, β9 = −0.212, β10 = −0.147.
As localizações foram geradas no programa R usando o pacote geoR para a família
exponencial de potência pelo comando
grf(n, cov.pars = c(sig2, psi))
com parâmetros (sig2 =)σ2 = 0.005 e (psi =)ψ = 0.25.
Daí, obteve-se a matriz (Σ)ij = σ2e−dij/ψ, com dij a distância entre as posições si e
sj. A Figura 6.2 apresenta as localizações das observações (figura da esquerda) e as séries
simuladas (figura da direita).
As distribuições a priori para os parâmetros foram escolhidas de modo que a média a
priori seja igual ao valor verdadeiro e a variância igual a 10. Isto é,
σ2 ∼ IG(2, 0.05) e ψ ∼ G(0.0625, 0.025).
Para os parâmetros da função de direção foi escolhida uma priori não informativa impró-
pria.
A inferência foi feita considerando todos os dados gerados e considerando somente as
observações de 10 em 10, isto é, os dados para inferência foram somente com ∆t = 0.5.
Os resultados foram bem parecidos para ∆t = (0.25, 0.1, 0.05) e sem aumento ∆t = 0.5.
Comparando a inferência com descarte dos dados gerados e a inferência sem descartar
130

dados, as amostras a posteriori para os parâmetros do vetor direção foram bem próximos
para ambos os casos enquanto, da matriz de volatilidade, obteve-se maior variância a
posteriori ao descartar dados.
As Figuras 6.3 e 6.4 apresentam os traços e os histogramas das amostras a posteriori dos
parâmetros considerando o aumento de dados. As figuras referem-se ao melhor resultado
que foi obtido ao acrescentar uma observação entre cada par de observados (∆t = 0.25).
a
b
c
de
f
g
h
i
j
0.2 0.4 0.6 0.8
0.0
0.2
0.4
0.6
0.8
Região D
coordenada x
coor
dena
da y
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
0 2 4 6 8 10
02
46
810
Simulação
tempo
série
s
a
b
cd
e
f
g
h
i
j
Figura 6.2: Localização das observações (esquerda) e séries simuladas (direita).
131
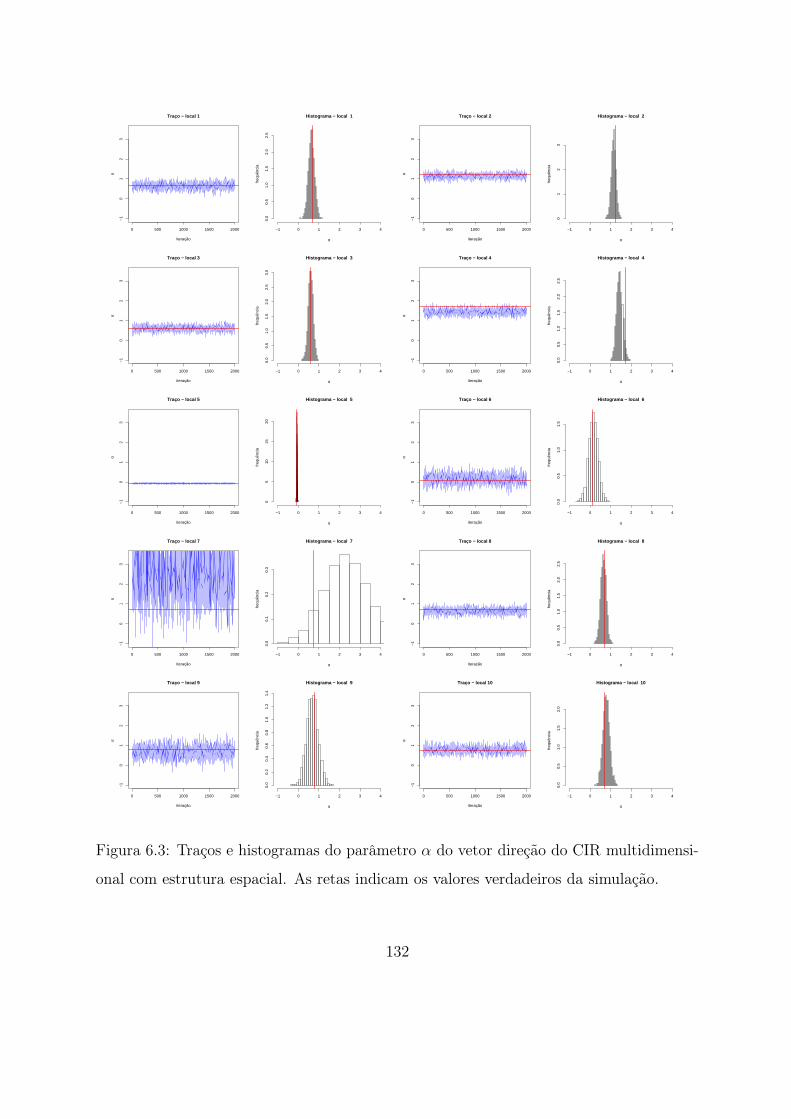
0 500 1000 1500 2000
−1
01
23
Traço − local 1
iteração
αHistograma − local 1
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
2.5
0 500 1000 1500 2000
−1
01
23
Traço − local 2
iteração
α
Histograma − local 2
α
freq
uênc
ia
−1 0 1 2 3 4
01
23
0 500 1000 1500 2000
−1
01
23
Traço − local 3
iteração
α
Histograma − local 3
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
2.5
3.0
0 500 1000 1500 2000
−1
01
23
Traço − local 4
iteração
α
Histograma − local 4
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
2.5
0 500 1000 1500 2000
−1
01
23
Traço − local 5
iteração
α
Histograma − local 5
α
freq
uênc
ia
−1 0 1 2 3 4
05
1015
20
0 500 1000 1500 2000
−1
01
23
Traço − local 6
iteração
αHistograma − local 6
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.5
1.0
1.5
0 500 1000 1500 2000
−1
01
23
Traço − local 7
iteração
α
Histograma − local 7
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.1
0.2
0.3
0 500 1000 1500 2000
−1
01
23
Traço − local 8
iteração
α
Histograma − local 8
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
2.5
0 500 1000 1500 2000
−1
01
23
Traço − local 9
iteração
α
Histograma − local 9
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
0 500 1000 1500 2000
−1
01
23
Traço − local 10
iteração
α
Histograma − local 10
α
freq
uênc
ia
−1 0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
Figura 6.3: Traços e histogramas do parâmetro α do vetor direção do CIR multidimensi-
onal com estrutura espacial. As retas indicam os valores verdadeiros da simulação.
132
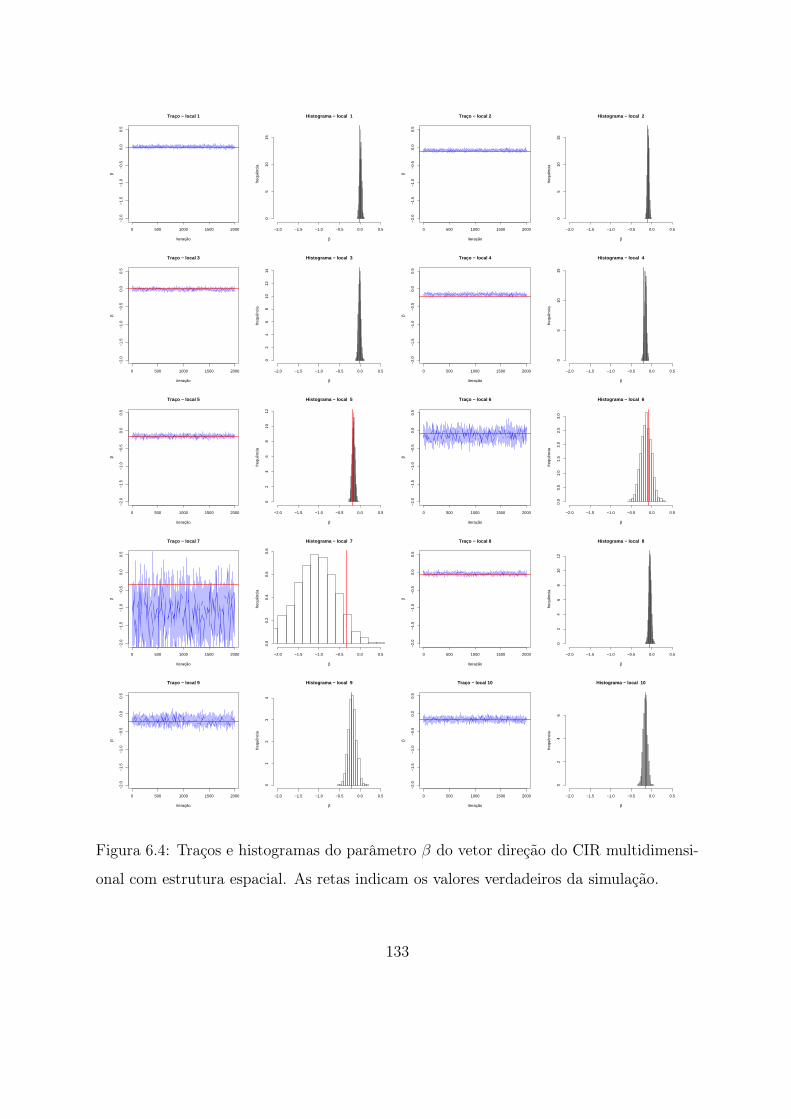
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 1
iteração
βHistograma − local 1
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
05
1015
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 2
iteração
β
Histograma − local 2
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
05
1015
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 3
iteração
β
Histograma − local 3
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
02
46
810
1214
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 4
iteração
β
Histograma − local 4
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
05
1015
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 5
iteração
β
Histograma − local 5
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
02
46
810
12
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 6
iteração
βHistograma − local 6
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 7
iteração
β
Histograma − local 7
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
0.0
0.2
0.4
0.6
0.8
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 8
iteração
β
Histograma − local 8
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
02
46
810
12
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 9
iteração
β
Histograma − local 9
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
01
23
4
0 500 1000 1500 2000
−2.
0−
1.5
−1.
0−
0.5
0.0
0.5
Traço − local 10
iteração
β
Histograma − local 10
β
freq
uênc
ia
−2.0 −1.5 −1.0 −0.5 0.0 0.5
02
46
Figura 6.4: Traços e histogramas do parâmetro β do vetor direção do CIR multidimensi-
onal com estrutura espacial. As retas indicam os valores verdadeiros da simulação.
133

0 500 1000 1500 2000
0.00
40.
006
0.00
8σ2
iteração
σ2
0.004 0.006 0.008
020
040
060
0
0 500 1000 1500 2000
0.1
0.2
0.3
0.4
ψ
iteração
ψ
0.1 0.2 0.3 0.4
02
46
810
Figura 6.5: Traços e histogramas dos parâmetros da estrutura espacial. As retas indicam
os valores verdadeiros da simulação.
No trabalho de Duan et al. (2009) desenvolve-se uma modelagem espaço-temporal de
equações diferenciais estocásticas. Eles propõem que as observações para cada tempo e
local discretizado seguem uma distribuição normal cuja média evolui segundo uma equa-
ção diferencial ordinária (EDO conhecida por equação logística). A taxa de crescimento
da EDO segue uma equação diferencial estocástica (EDE) e nela está descrita a depen-
134

dência espacial. A modelagem parte de estruturas hierárquicas para relacionar: equação
de observações, EDO e EDE. A inferência é feita sob o enfoque bayesiano partindo de
esquemas de discretização de primeira ordem e usando algoritmos MCMC.
As principais diferenças entre o trabalho de Duan et al. (2009) e essa tese são: (a)
nesse trabalho as observações são feitas diretamente do processo de difusão, (b) a estrutura
espacial aparece no termo que acompanha o movimento browniano ou aparece de forma
hierárquica modelada como um processo gaussiano e (c) não utiliza-se nessa tese estrutura
determinística (EDO) para modelar a evolução no tempo do fenômeno, toda evolução
temporal está presente na EDE.
6.6 Exemplo simulado 2
O objetivo desta simulação é verificar a influência: do número de tempos, quantidade
de locais de observação, do aumento de dados e da variação dos parâmetros espaciais,
sobre a inferência do processo CIR multivariado com estrutura espacial na função de
volatilidade.
A motivação desse exemplo é o problema da emissão de gases poluentes. Numa região
do plano (quadrado unitário) é gerado um processo CIR multivariado onde cada coorde-
nada espacial do processo está uniformemente distribuída na região do quadrado unitário.
O fluxo ou taxa de emissão verdadeiro é conhecido em cada localização.
A medida de comparação utilizada é o erro quadrático médio (EQM) entre os fluxos
verdadeiros e a mediana a posteriori dos fluxos estimados, somente nos locais sorteados.
A medida (EQM) é dada por
EQM =1
no
no∑
i=1
(
r(i)v − r(i))2,
sendo r(i)v o fluxo verdadeiro e r(i) a mediana a posteriori do fluxo, com i = 1, . . . , no, o
índice do local sorteado.
O exercício de simulação é feito da seguinte forma:
135

1. Gera-se um processo CIR multivariado com n = 100 coordenadas espaciais e 121
tempos discretizados (N = 120) no intervalo [0, 12] minutos. A geração é feita como
na seção anterior.
2. Dos N + 1 tempos discretizados gerados (N = 120) serão considerados como obser-
vados No+ 1 tempos (No = 24 / No = 12).
3. Dos 100 locais do processo multivariado sorteiam-se no = 10 e no = 15 locais, sendo
no o número de locais observados.
4. O procedimento de inferência é feito conforme descrito neste capítulo. Os parâme-
tros são estimados e com isso obtém-se os fluxos para cada um dos locais sorteados.
5. Os parâmetros considerados da função exponencial de potência foram
σ2 = 0.005, 0.05, 0.5 e ψ = 0.1, 0.5, 0.9.
6. O efeito do aumento de dados foi estudado para 0, 4 e 9 não observados entre cada
par de observados.
7. Os parâmetros da função de direção foram diferentes para cada simulação gerados
a partir de normais com médias comuns.
O número de exercícios é dado por
2 (#tempos)× 2 (#locais)× 3 (#σ2)× 3 (#ψ)× 3 (#aumento de dados),
totalizando 108 simulações.
Os comandos para geração dos dados em C++ e o programa completo para inferência
estão no Apêndice B. O procedimento é análogo ao da seção anterior, com geração de αi
e βi e variando os parâmetros espaciais em cada simulação.
A Figura 6.6 exibe uma ocorrência do processo CIR multivariado com n = 100 localiza-
ções uniformemente distribuídas no quadrado unitário e 121 tempos observados (N = 120)
igualmente espaçados no intervalo [0, 12] minutos. Os parâmetros espaciais de geração
136

foram σ2 = 0.005 e ψ = 0.1. Na figura do canto superior esquerdo observa-se os 100 locais,
na figura do canto superior direito têm-se os valores iniciais das gerações, Y 0, o gráfico
inferior esquerdo apresenta as 100 séries no tempo e no canto inferior direito tem-se o
gráfico dos valores dos fluxos iniciais verdadeiros.
3
4
5
6
7
8
9
:
;
<
=
>
?
@
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
[
\
]
^
_
‘
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
|
~
...
,
f
"
.
...
...
^
...
S
<
O
Z
ı
’
’
"
"
.
−
0.2 0.4 0.6 0.8
0.2
0.4
0.6
0.8
Região D
coordenada x
coor
dena
da y
Concentração inicial
0.0 0.2 0.4 0.6 0.8 1.0
1.4
1.6
1.8
2.0
2.2
2.4
2.6
0.0
0.2
0.4
0.6
0.8
1.0
coordenada x
coor
dena
da yY0
−
O,
x
n
d
Z
P
F
<
.
<
wm
cY
O
E;"
S
...
v
l
b
X
ND
:"
...
uk
a
W
MC
9
’
^
~
t
j‘
V
L
B
8
’...
s
i
_U
K
A
7ı
...
|
rh
^
T
J@
6
.
qg]
SI
?
5
Z"
zp
f
\RH
>
4 fy
o
e
[
Q
G
=
3
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
0 2 4 6 8 10 12
12
34
56
7
Séries
tempo
conc
entr
ação
Fluxos
0.0 0.2 0.4 0.6 0.8 1.0
0.20
0.25
0.30
0.35
0.40
0.0
0.2
0.4
0.6
0.8
1.0
coordenada x
coor
dena
da y
fluxo
−
O
,
x
n
dZP
F
<
.
<
w
m
c
Y
O
E
;
"S
...
v
l
b
X
N
D
:"
...
u
k
a
W
MC
9
’
^~t
j
‘
VL
B
8’...
si
_
U
K
A
7ı
...|
rh
^
T
J@
6
.q
g]
S
I
?
5
Z"
z
p
f\
RH
>4
f
y
o
e
[Q
G
=
3
Figura 6.6: Locais da geração (superior esquerdo), valores iniciais das séries (superior
direito), séries no tempo (inferior esquerdo) e fluxos verdadeiros (inferior direito).
137

A Figura 6.7 exibe os locais sorteados e os tempos observados do processo CIR multi-
variado gerado pela Figura 6.6, sendo no = 10 locais e 13 tempos observados (No = 12).
Na figura do canto superior esquerdo observa-se os 10 locais, na figura do canto superior
direito têm-se os valores iniciais das gerações, Y 0, no canto inferior esquerdo apresentam-
se as 10 séries no tempo e no canto inferior direito está o gráfico dos valores dos fluxos
iniciais verdadeiros.
O procedimento de MCMC considerou 5500 iterações, com período de aquecimento
de 500, e guardando os valores de 5 em 5. O uso de séries com poucos elementos se
deve ao elevado tempo computacional, que mesmo em máquinas razoavelmente rápidas
(processador Intel 2.60 GHz) e usando a linguagem C++, levava de alguns minutos (no =
10, No = 12 e sem aumento de dados) até aproximadamente uma semana (no = 15,
No = 24 e aumento de 9 não observados entre cada par de observados). Dentre as
estratégia para contornar esse problema está otimizar a programação e usar computação
paralela.
A análise dos resultados constatou que a raiz do EQM foi inferior a 1 para praticamente
todos as simulações que convergiram. E o aumento de dados não traz vantagem na maioria
dos casos estudados e gera maiores EQM quando aumenta-se 9 elementos entre cada par
de observados, para No = 24. Para No = 12 o aumento de dados trás problemas na
convergência. Por conta do tempo computacional não foi possível testar mais valores de
aumento de dados, como 1, 2, 3 elementos entre cada para de observados. Isto fica como
proposta futura, mas é um exercício interessante para saber em que ponto o aumento de
dados se torna desvantajoso.
Conforme os valores dos parâmetros espaciais (σ2 e ψ) aumentam também aumenta o
EQM. No caso em que σ2 = 0.5 e ψ = 0.1, 0.5, 0.9 o processo gerado é muito volátil e
em vários casos não obteve-se convergência das cadeias geradas pelo MCMC. Os melhores
casos se deram quando σ2 = 0.005, 0.05.O aumento do número de locais observados no = 10 para no = 15 não significa redução
no EQM. Neste modelo o número de locais está relacionado ao número de parâmetros de
138

acordo com a fórmula 2no (parâmetros do vetor de direção) + 2 (parâmetros da função de
volatilidade). Poderia-se reduzir os 2no parâmetros do vetor de direção assumindo alguma
estrutura hierárquica. Esse procedimento não foi feito aqui, pois para essa simulação,
seguindo o fenômeno da emissão de gases, optou-se por trabalhar com o modelo mais
0.2 0.4 0.6 0.8
0.2
0.4
0.6
0.8
Região D
coordenada x
coor
dena
da y
0.0 0.2 0.4 0.6 0.8 1.0
1.6
1.8
2.0
2.2
2.4
2.6
0.0
0.2
0.4
0.6
0.8
1.0
coordenada x
coor
dena
da y
y 0
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0 2 4 6 8 10 12
23
45
6
locais
tempo (min)
conc
entr
ação
(pp
m)
0.0 0.2 0.4 0.6 0.8 1.0
0.26
0.28
0.30
0.32
0.34
0.36
0.38
0.0
0.2
0.4
0.6
0.8
1.0
coordenada x
coor
dena
da y
fluxo
Figura 6.7: Locais observados (superior esquerdo), valores iniciais das séries (superior
direito), séries no tempo (inferior esquerdo) e fluxos verdadeiro (inferior direito).
139

geral, com menos suposições a priori.
A Tabela 6.1 apresenta as raízes dos EQM. SemA e Aum4 significam, respectivamente,
sem aumento e com aumento de 4 não observados entre cada par de observados. O caso
de aumento com 9 não observados não foi exposto, ele é muito caro computacionalmente
e não atinge convergência para poucas iterações do MCMC. As células preenchidas com
X referem-se a simulações que não convergiram. Observa-se que os exercícios em que
σ2 e ψ são maiores e com aumento de dados apresentou-se os maiores problemas de
convergência. Nos demais casos constatou-se boa convergência e a raiz do EQM pequena
indica qualidade na estimação dos fluxos verdadeiros.
140

Tabela 6.1: Raiz do erro quadrado médio√EQM .
SemA Aum4 SemA Aum4 SemA Aum4
No = 24
σ2 = 0.005 ψ = 0.1 σ2 = 0.05 ψ = 0.1 σ2 = 0.5 ψ = 0.1
no = 10 0.1696 0.3104 0.2467 0.4563 1.0062 X
no = 15 0.2051 0.4001 0,3677 0.3062 0.9500 X
σ2 = 0.005 ψ = 0.5 σ2 = 0.05 ψ = 0.5 σ2 = 0.5 ψ = 0.5
no = 10 0.1169 0.2235 0.1605 0.4390 0.3536 X
no = 15 0.1931 0.2927 0.1688 0.7255 0.4030 0.9490
σ2 = 0.005 ψ = 0.9 σ2 = 0.05 ψ = 0.9 σ2 = 0.5 ψ = 0.9
no = 10 0.0866 0.2003 0.5340 0.3085 0.4860 X
no = 15 0.2852 0.2167 0.2636 0.5415 0.4684 X
No = 12
σ2 = 0.005 ψ = 0.1 σ2 = 0.05 ψ = 0.1 σ2 = 0.5 ψ = 0.1
no = 10 0.1409 0.7472 0.1717 1.4026 0.7768 X
no = 15 0.1773 1.0297 0.3281 2.5002 0.9040 X
σ2 = 0.005 ψ = 0.5 σ2 = 0.05 ψ = 0.5 σ2 = 0.5 ψ = 0.5
no = 10 0.0884 0.3897 0.3686 1.8661 0.8649 X
no = 15 0.2002 0.6270 0.4642 1.0896 1.5185 X
σ2 = 0.005 ψ = 0.9 σ2 = 0.05 ψ = 0.9 σ2 = 0.5 ψ = 0.9
no = 10 0.0419 0.2844 0.7219 1.9376 1.0065 X
no = 15 0.1354 0.8349 0.3035 3.3236 0.3967 X
141

Este exercício de simulação teve por objetivo analisar o efeito da mudança dos parâ-
metros e da quantidade de dados espaço-tempo na inferência. Mais ainda, essa simulação
prepara o uso das técnicas de estimação para aplicação em dados reais, assim que eles
estiverem disponíveis. Na maioria das simulações os parâmetros espaciais foram recupe-
rados e o objetivo principal, que era estimar os fluxos em cada local, foi atingido. Um
desafio imediato é reduzir o tempo computacional e otimizar a programação.
O que se desenvolveu aqui não fica restrito ao problemas de emissão de gases em
reservatório de hidrelétricas. Na área de meio ambiente existe outros fenômenos que se
comportam como processos de difusão com estrutura espacial. Outra área de interesse
é o mercado financeiro. Em finanças é possível relacionar múltiplas séries de preços ou
índices com distâncias econométricas. Como trabalho futuro pode-se comparar as técnicas
e resultados aqui obtidos com outros trabalhos que modelam fenômenos espaço-temporais
em tempo discreto.
142

Capítulo 7
Conclusões e Trabalhos Futuros
A motivação inicial desse trabalho era estimar parâmetros de um processo de difusão
quando os dados são discretamente observados. Essa tarefa foi abordada partindo de téc-
nicas de discretização, fazendo uso de aumento de dados e seguindo o enfoque bayesiano.
Existe uma grande quantidade de artigos, bayesianos ou não, que se propõem a reali-
zar essa tarefa. Os artigos sobre o tema concentram-se principalmente em desenvolver
técnicas de aumento de dados e propostas eficientes de algoritmos MCMC.
Os primeiros capítulos da tese destinam-se em fazer uma revisão concisa da literatura
sobre estimação de parâmetros em processos de difusão e fornecem uma base teórica
probabilística sobre o assunto. Nesse campo ainda há espaço para novas propostas de
construção de pontes (dados não observados) e aproximações melhores para a função de
verossimilhança.
No capítulo sobre o processo CIR, propõe-se uma generalização multivariada desse
processo e discutiu-se a existência e unicidade dele.
A motivação principal do trabalho foi o problema de estimar a taxa de emissão de gases
de efeito estufa proveniente de reservatórios de hidrelétricas. Esse problema apareceu
sugerido pelo Programa de Planejamento Energético da COPPE-UFRJ e é um dos temas
mais relevantes dessa virada de século, pois está relacionado com a redução da emissão de
gases poluentes e controle/redução do aquecimento global. Em termos técnicos, deseja-
143

se conhecer os parâmetros da equação que modela a evolução da concentração de gases
poluentes em câmeras de difusão e, a partir disso, estimar a taxa de emissão inicial em
locais do reservatório. O objetivo é extrapolar a estimação das taxas de emissão nos locais
para todo o reservatório e daí para toda rede de hidrelétricas do Brasil. Essa extensão
está em desenvolvimento e ainda depende de novas campanhas de coleta de dados.
O Capítulo 5 concentrou-se em apresentar o problema de emissão de gases e propor
modelos para representar a evolução da concentração. A modelagem seguiu duas verten-
tes: na primeira a concentração do gás poluente é modelada por uma EDO e a inferência
dos parâmetros é feita sobre a solução dessa equação e na segunda os modelos partem de
uma EDE. Em ambos os casos acrescenta-se estruturas hierárquicas para os parâmetros.
A comparação entre os modelos é feita de forma visual e usando os critérios de comparação
de modelos DIC e funções escore (logarítmica e probabilística).
Com respeito a estimação de parâmetros em processos de difusão sugere-se como tra-
balhos futuros:
• Comparar algoritmos MCMC com técnicas de filtragem e métodos não paramétricos.
• Assumir que os modelos apresentam dinâmica temporal nos parâmetros dos pro-
cessos de difusão, o que implica em fazer uma junção entre a teoria de modelos
dinâmicos e processos em tempo contínuo.
• Trabalhar com equações diferenciais parciais estocásticas considerando aleatoriedade
no espaço.
Apesar da motivação no campo da Biologia, outras áreas podem fazer uso do arcabouço
teórico aqui desenvolvido. Na área de Finanças, por exemplo, pode-se modelar a evolução
de preços ou taxas de juros usando estruturas semelhantes.
No Capítulo 6 propõe-se acrescentar estrutura espacial em EDE’s multivariadas, sendo
que esse tema é pouco abordado na literatura estatística. Nesse trabalho sugere-se uma
formulação inédita do processo CIR multivariado ao adicionar estrutura espacial, seja
sobre a função de volatilidade ou sobre a função de direção com estrutura hierárquica. A
144

inferência sobre a segunda forma não foi desenvolvida aqui, pois a partir de esquemas de
discretização essa abordagem recaí em trabalhos já conhecidos na literatura de Estatística
Espacial.
Esse trabalho abre a possibilidade de discutir em tempo contínuo outras formas de
processos de difusão multivariado onde as funções de direção e de volatilidade sejam
escritas de modo mais adequado e com isso aproveitem as características do fenômeno ao
qual o processo modela.
Ainda como trabalho futuro, aplicar os procedimentos de modelagem e inferência do
CIR multivariado com estrutura espacial em dados reais como, por exemplo, dados na
área de Meio Ambiente e/ou Finanças.
145

Apêndice A
Análise dos dados de Corumbá
Este apêndice trás as principais estatísticas e resultados da análise das medidas de
concentração de metano (CH4) no reservatório de Corumbá considerando as três cam-
panhas realizadas. Cada seção refere-se a um modelo específico estudado: M1 - modelo
hierárquico sem estrutura espacial, M2 - modelo hierárquico com estrutura espacial e o
terceiro é o CIRhierárquico - modelo CIR com estrutura hierárquica.
A.1 Modelo hierárquico sem estrutura espacial - M1
A Tabela 1.1 exibe as taxas de emissão inicial ri para cada localização e coletiva rc
considerando as três campanhas no reservatório de Corumbá. A unidade de medida das
taxas é ppm /(min m2). As medições em cada campanha não foram realizadas nos mesmos
locais e nem na mesma quantidade de sítios.
A análise de convergência é feita graficamente. Duas séries com valores iniciais di-
ferentes foram rodadas para cada umas das taxas ri em cada uma das campanhas. As
Figuras 1.1, 1.2 e 1.3 mostram as convergências das séries das taxas de emissão ri obtidas
por (5.3) em cada uma das campanhas, respectivamente. Os gráficos indicam que as séries
convergiram. As Figuras 1.4, 1.5 e 1.6 exibem os histogramas das amostras a posteriori
das taxas de emissão inicial para cada uma das campanhas de Corumbá, respectivamente.
146

Tabela 1.1: Estatísticas das taxas de emissão no instante inicial para as campanhas 1, 2
e 3 do reservatório de Corumbá - M1.
Campanha 1 Campanha 2 Campanha 3
taxas média dp taxas média dp taxas média dp
r1 0.2123 0.2252 r1 0.0985 0.0164 r1 0.8816 0.4034
r2 0.3530 0.2439 r2 0.0800 0.0133 r2 0.4972 0.2983
r3 0.1542 0.1994 r3 0.1476 0.0155 r3 1.5417 0.4666
r4 0.4942 0.3147 r4 0.0455 0.0135 r4 1.4853 0.4914
r5 0.3837 0.2727 r5 0.0523 0.0129 r5 2.6950 0.9564
r6 0.4451 0.2782 r6 0.1837 0.0146 r6 1.9655 0.4692
r7 0.2006 0.2040 r7 0.1931 0.0184 r7 0.8771 0.4259
r8 0.2557 0.2458 r8 0.2326 0.0186 r8 0.6858 0.3247
r9 0.1319 0.2057 r9 0.1558 0.0133 r9 2.1041 0.8403
r10 0.2815 0.2306 r10 0.1778 0.0164 r10 0.8195 0.4065
r11 0.6601 0.3922 r11 0.1033 0.0136 r11 1.9384 0.4535
r12 0.5531 0.3148 r12 0.1005 0.0141 r12 2.7880 0.5708
r13 0.3741 0.5124 r13 0.1022 0.0132
r14 0.3784 0.3057 r14 0.7415 0.0272
r15 0.7325 0.5571 r15 0.6070 0.0297
r16 0.2529 0.2367 r16 0.0907 0.0132
r17 0.0518 0.1769 r17 0.0408 0.0125
r18 0.3676 0.2422 r18 0.0045 0.0112
r19 0.3902 0.2523 r19 0.0962 0.0137
r20 0.0159 0.0123
rc 0.3526 0.1283 rc 0.1650 0.0528 rc 1.6035 0.5126
147
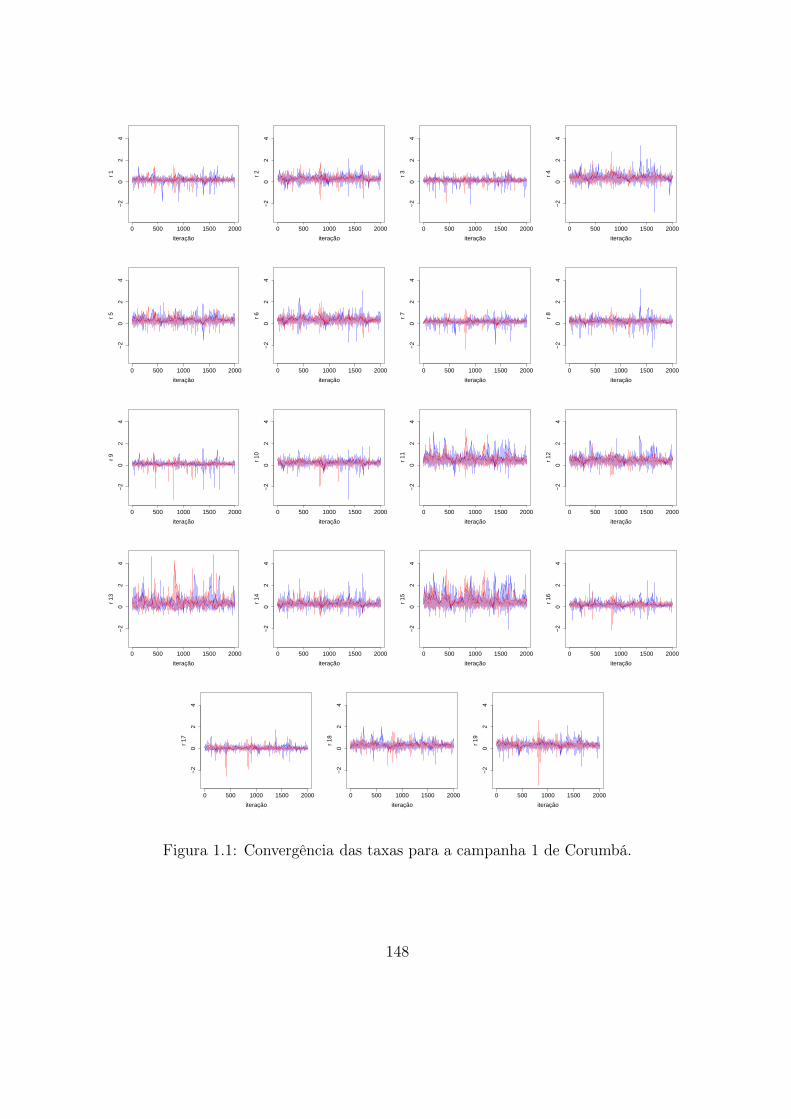
0 500 1000 1500 2000
−2
02
4
iteração
r 1
0 500 1000 1500 2000
−2
02
4
iteração
r 2
0 500 1000 1500 2000
−2
02
4
iteração
r 3
0 500 1000 1500 2000
−2
02
4
iteração
r 4
0 500 1000 1500 2000
−2
02
4
iteração
r 5
0 500 1000 1500 2000
−2
02
4
iteração
r 6
0 500 1000 1500 2000
−2
02
4
iteração
r 7
0 500 1000 1500 2000
−2
02
4
iteração
r 8
0 500 1000 1500 2000
−2
02
4
iteração
r 9
0 500 1000 1500 2000
−2
02
4
iteração
r 10
0 500 1000 1500 2000
−2
02
4
iteração
r 11
0 500 1000 1500 2000
−2
02
4
iteração
r 12
0 500 1000 1500 2000
−2
02
4
iteração
r 13
0 500 1000 1500 2000
−2
02
4
iteração
r 14
0 500 1000 1500 2000
−2
02
4
iteração
r 15
0 500 1000 1500 2000
−2
02
4
iteração
r 16
0 500 1000 1500 2000
−2
02
4
iteração
r 17
0 500 1000 1500 2000
−2
02
4
iteração
r 18
0 500 1000 1500 2000
−2
02
4
iteração
r 19
Figura 1.1: Convergência das taxas para a campanha 1 de Corumbá.
148

0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 1
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 2
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 3
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 4
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 5
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 6
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 7
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 8
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 9
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 10
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 11
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 12
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 13
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 14
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 15
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 16
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 17
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 18
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 19
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 20
Figura 1.2: Convergência das taxas para a campanha 2 de Corumbá.
149

0 500 1000 1500 2000
05
1015
iteração
r 1
0 500 1000 1500 2000
05
1015
iteração
r 2
0 500 1000 1500 2000
05
1015
iteração
r 3
0 500 1000 1500 2000
05
1015
iteração
r 4
0 500 1000 1500 2000
05
1015
iteração
r 5
0 500 1000 1500 2000
05
1015
iteração
r 6
0 500 1000 1500 2000
05
1015
iteração
r 7
0 500 1000 1500 2000
05
1015
iteração
r 8
0 500 1000 1500 2000
05
1015
iteração
r 9
0 500 1000 1500 2000
05
1015
iteração
r 10
0 500 1000 1500 2000
05
1015
iteração
r 11
0 500 1000 1500 2000
05
1015
iteração
r 12
Figura 1.3: Convergência das taxas para a campanha 3 de Corumbá.
150

r 1
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 2
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 3
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 4
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 5
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 6
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 7
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 8
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 9
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 10
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 11
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 12
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 13
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 14
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 15
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 16
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 17
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 18
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 19
frequência
−2
02
4
0.0 0.5 1.0 1.5 2.0 2.5 3.0
Figura
1.4:H
istogramas
dastaxas
deem
issãoinicial
-C
orumbá
-cam
panha1.
151

r 1
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 2
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 3
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 4
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 5
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 6
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 7
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 8
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 9
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 10
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 11
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 12
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 13
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 14
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 15
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 16
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 17
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 18
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 19
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
r 20
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
010
2030
40
Figura 1.5: Histogramas das taxas de emissão inicial - Corumbá - campanha 2.
152
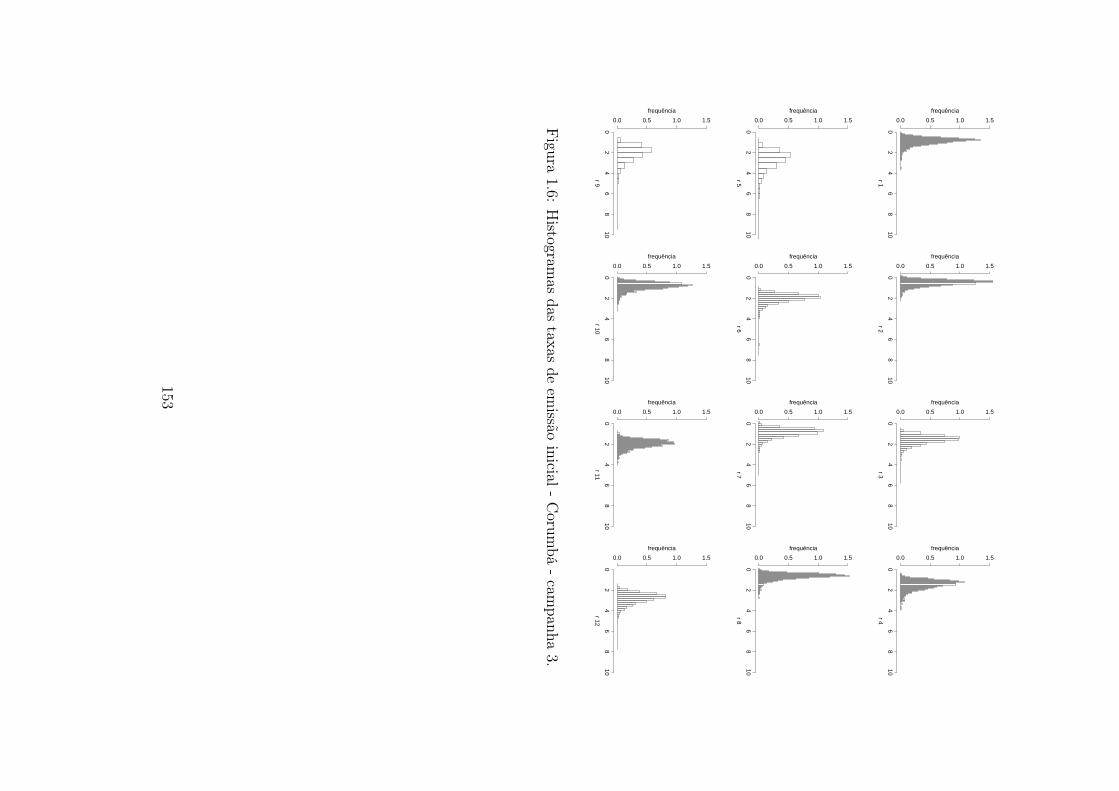
r 1
frequência
02
46
810
0.0 0.5 1.0 1.5
r 2
frequência
02
46
810
0.0 0.5 1.0 1.5
r 3
frequência
02
46
810
0.0 0.5 1.0 1.5
r 4
frequência
02
46
810
0.0 0.5 1.0 1.5
r 5
frequência
02
46
810
0.0 0.5 1.0 1.5
r 6
frequência
02
46
810
0.0 0.5 1.0 1.5
r 7
frequência
02
46
810
0.0 0.5 1.0 1.5
r 8
frequência
02
46
810
0.0 0.5 1.0 1.5
r 9
frequência
02
46
810
0.0 0.5 1.0 1.5
r 10
frequência
02
46
810
0.0 0.5 1.0 1.5
r 11
frequência
02
46
810
0.0 0.5 1.0 1.5
r 12
frequência
02
46
810
0.0 0.5 1.0 1.5
Figura
1.6:H
istogramas
dastaxas
deem
issãoinicial
-C
orumbá
-cam
panha3.
153

A.2 Modelo hierárquico com estrutura espacial - M2
A Tabela 1.2 exibe a média e desvio padrão das taxas de emissão inicial ri, para cada
localização, e coletiva rc considerando as três campanhas no reservatório de Corumbá para
o modelo M2. A unidade de medida das taxas é ppm /(min m2). As medições em cada
campanha não foram realizadas nos mesmos locais e nem na mesma quantidade de sítios.
Observe que o modelo espacial agrega (pela média) as concentrações em cada sítio e, com
isso, a quantidade de locais considerados é menor. Os locais aqui são considerados pelas
coordenadas (latitude e longitude) sem repetição.
As Figuras 1.7, 1.8 e 1.9 mostram a saída do MCMC das taxas de emissão ri obtidas
por (5.3) em cada uma das campanhas, respectivamente. O procedimento de inferência
foi realizado para duas série com valores iniciais diferentes. A Figura 1.7 mostra uma
perturbação nas cadeias indicando não convergência. As demais figuras mostraram cadeias
com alguns problemas por exemplo na posição 12 da Figura 1.7, as demais mostraram-se
mais estáveis indicando convergência.
As Figuras 1.10, 1.11 e 1.12 exibem os histogramas das amostras a posteriori das taxas
de emissão inicial para cada uma das campanhas de Corumbá, respectivamente.
154

Tabela 1.2: Estatísticas das taxas de emissão no instante inicial para as campanhas 1, 2
e 3 do reservatório de Corumbá - M2.
Campanha 1 Campanha 2 Campanha 3
taxas média dp taxas média dp taxas média dp
r1 0.9669 1.3557 r1 0.0966 0.0160 r1 0.6766 0.3555
r2 1.2986 1.4378 r2 0.0779 0.0139 r2 1.4619 0.3896
r3 0.8335 1.4052 r3 0.1451 0.0180 r3 2.4388 1.0028
r4 1.6423 1.6084 r4 0.1159 0.0157 r4 3.6978 1.2624
r5 1.6812 1.7785 r5 0.1820 0.0169 r5 1.6812 0.3299
r6 0.9765 1.4653 r6 0.1921 0.0198 r6 0.8151 0.3805
r7 1.1075 1.4831 r7 0.2301 0.0225 r7 0.6014 0.2391
r8 0.6956 1.4169 r8 0.1549 0.0155 r8 0.0328 0.1876
r9 1.1531 1.4555 r9 0.1737 0.0193 r9 2.0178 0.4537
r10 2.2494 2.0588 r10 0.1002 0.0147
r11 2.6026 2.4299 r11 0.1008 0.0129
r12 2.8191 2.3872 r12 0.6894 0.0333
r13 1.2243 1.4865 r13 0.0874 0.0134
r14 0.5915 1.3895 r14 0.0206 0.0124
r15 1.4451 1.5646 r15 0.0151 0.0126
rc 1.4074 0.9335 rc 0.1678 0.0595 rc 2.2438 1.8597
155

0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 1
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 2
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 3
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 4
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 5
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 6
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 7
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 8
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 9
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 10
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 11
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 12
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 13
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 14
0 500 1000 1500 2000
−10
−5
05
1015
iteração
r 15
Figura 1.7: Traços das taxas para a campanha 1 de Corumbá.
156

0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 1
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 2
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 3
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 4
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 5
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 6
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 7
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 8
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 9
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 10
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 11
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 12
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 13
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 14
0 500 1000 1500 2000
0.0
0.2
0.4
0.6
0.8
iteração
r 15
Figura 1.8: Traços das taxas para a campanha 2 de Corumbá.
157

0 500 1000 1500 2000
05
1015
iteração
r 1
0 500 1000 1500 2000
05
1015
iteração
r 2
0 500 1000 1500 2000
05
1015
iteração
r 3
0 500 1000 1500 2000
05
1015
iteração
r 4
0 500 1000 1500 2000
05
1015
iteração
r 5
0 500 1000 1500 2000
05
1015
iteração
r 6
0 500 1000 1500 2000
05
1015
iteração
r 7
0 500 1000 1500 2000
05
1015
iteração
r 8
0 500 1000 1500 2000
05
1015
iteração
r 9
Figura 1.9: Traços das taxas para a campanha 3 de Corumbá.
158

r 1
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 2
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 3
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 4
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 5
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 6
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 7
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 8
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 9
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 10
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 11
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 12
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 13
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 14
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
r 15
frequência
−10
−5
05
1015
0.0 0.1 0.2 0.3 0.4 0.5
Figura
1.10:H
istogramas
dastaxas
deem
issãoinicial
-C
orumbá
-cam
panha1.
159

r 1
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 2
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 3
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 4
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 5
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 6
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 7
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 8
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 9
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 10
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 11
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 12
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 13
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 14
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
r 15
frequência
0.00.2
0.40.6
0.8
0 5 10 15 20 25 30 35
Figura
1.11:H
istogramas
dastaxas
deem
issãoinicial
-C
orumbá
-cam
panha2.
160

r 1
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 2
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 3
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 4
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 5
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 6
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 7
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 8
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
r 9
frequência
02
46
810
0.0 0.5 1.0 1.5 2.0 2.5 3.0
Figura
1.12:H
istogramas
dastaxas
deem
issãoinicial
-C
orumbá
-cam
panha3.
161

A.3 Modelo CIR hierárquico
A Tabela 1.3 exibe as taxas de emissão inicial ri para cada localização e coletiva rc
considerando as três campanhas no reservatório de Corumbá pelo modelo CIR hierárquico.
A unidade de medida das taxas é ppm /(min m2). As medições em cada campanha não
foram realizadas nos mesmos locais e nem na mesma quantidade de sítios.
A análise de convergência é feita graficamente. Duas séries com valores iniciais diferen-
tes foram rodadas para cada umas das taxas ri em cada uma das campanhas. As Figuras
1.13, 1.14 e 1.15 mostram a convergência das séries das taxas de emissão ri obtidas por
(5.6) em cada uma das campanhas, respectivamente. Os gráficos indicam que as séries
convergiram.
Os histogramas das amostras a posteriori das taxas de emissão inicial são apresentados
nas Figuras 1.16, 1.17 e 1.18 para as três campanhas de Corumbá, respectivamente.
162

Tabela 1.3: Estatísticas das taxas de emissão no instante inicial para as campanhas 1, 2
e 3 do reservatório de Corumbá - CIR hierárquico.
Campanha 1 Campanha 2 Campanha 3
taxas média dp taxas média dp taxas média dp
r1 0.2574 0.0900 r1 0.1126 0.0419 r1 0.8903 0.2793
r2 0.3134 0.1028 r2 0.1079 0.0372 r2 0.5618 0.2623
r3 0.1988 0.0940 r3 0.1895 0.0423 r3 1.2661 0.2938
r4 0.3802 0.1243 r4 0.0707 0.0375 r4 1.3279 0.3108
r5 0.3032 0.1071 r5 0.0753 0.0383 r5 2.3614 0.4329
r6 0.3605 0.1123 r6 0.2193 0.0424 r6 1.3371 0.3186
r7 0.2242 0.0957 r7 0.2192 0.0438 r7 0.7286 0.2947
r8 0.2736 0.0941 r8 0.2748 0.0461 r8 0.6799 0.2546
r9 0.1755 0.0967 r9 0.1904 0.0383 r9 2.0229 0.7668
r10 0.2738 0.0971 r10 0.2127 0.0434 r10 0.8654 0.2880
r11 0.3465 0.1350 r11 0.1310 0.0404 r11 1.3927 0.3127
r12 0.3658 0.1263 r12 0.1295 0.0387 r12 2.0758 0.3630
r13 0.0809 0.1846 r13 0.1334 0.0391
r14 0.1943 0.1148 r14 0.6001 0.0676
r15 0.3690 0.2417 r15 0.5501 0.0664
r16 0.1973 0.1014 r16 0.1212 0.0385
r17 0.0287 0.1284 r17 0.0689 0.0376
r18 0.3164 0.1015 r18 0.0147 0.0370
r19 0.3240 0.1073 r19 0.1277 0.0389
r20 0.0308 0.0391
rc 0.2538 0.0626 rc 0.1780 0.0391 rc 1.2778 0.2544
163
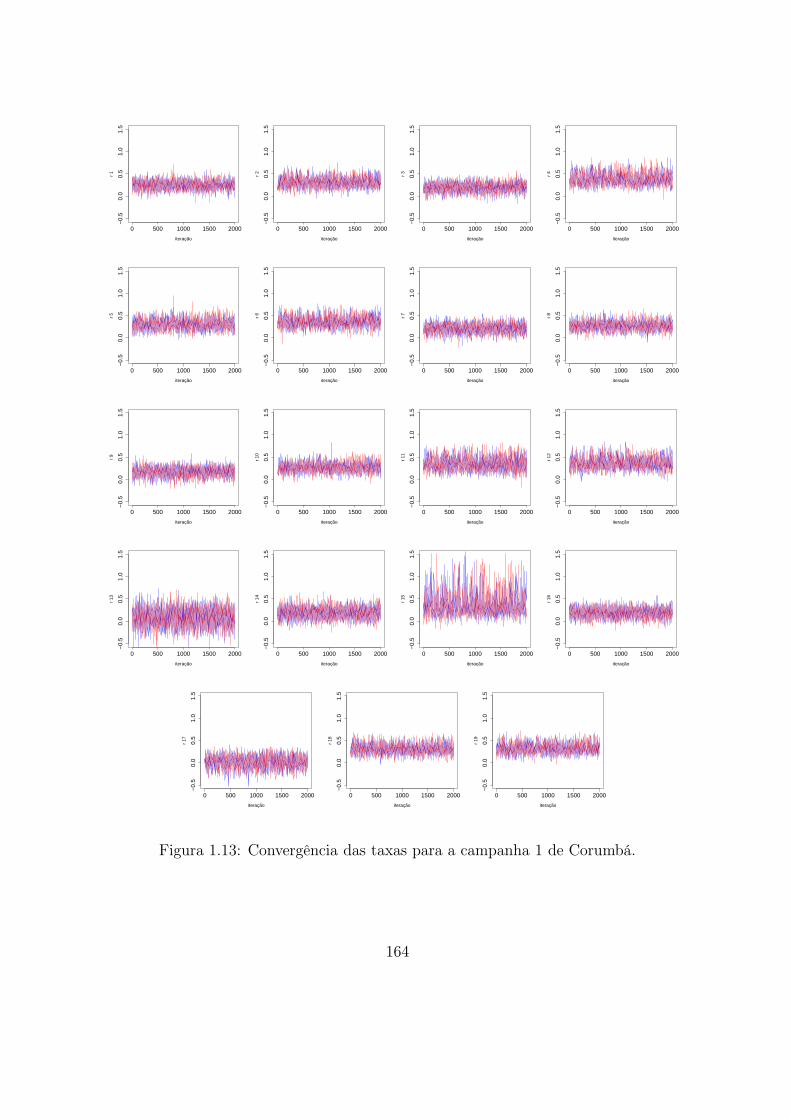
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 1
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 2
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 3
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 4
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 5
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 6
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 7
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 8
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 9
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 10
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 11
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 12
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 13
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 14
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 15
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 16
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 17
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 18
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 19
Figura 1.13: Convergência das taxas para a campanha 1 de Corumbá.
164

0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 1
0 500 1000 1500 2000−
0.5
0.0
0.5
1.0
1.5
iteração
r 2
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 3
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 4
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 5
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 6
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5iteração
r 7
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 8
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 9
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 10
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 11
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5iteração
r 12
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 13
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 14
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 15
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 16
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 17
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 18
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 19
0 500 1000 1500 2000
−0.
50.
00.
51.
01.
5
iteração
r 20
Figura 1.14: Convergência das taxas para a campanha 2 de Corumbá.
165

0 500 1000 1500 2000
01
23
4
iteração
r 1
0 500 1000 1500 2000
01
23
4
iteração
r 2
0 500 1000 1500 2000
01
23
4iteração
r 3
0 500 1000 1500 2000
01
23
4
iteração
r 4
0 500 1000 1500 2000
01
23
4
iteração
r 5
0 500 1000 1500 2000
01
23
4
iteração
r 6
0 500 1000 1500 2000
01
23
4
iteração
r 7
0 500 1000 1500 2000
01
23
4iteração
r 8
0 500 1000 1500 2000
01
23
4
iteração
r 9
0 500 1000 1500 2000
01
23
4
iteração
r 10
0 500 1000 1500 2000
01
23
4
iteração
r 11
0 500 1000 1500 2000
01
23
4
iteração
r 12
Figura 1.15: Convergência das taxas para a campanha 3 de Corumbá.
166

Histograma
r 1
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 2
freq
uênc
ia0.0 0.5 1.0 1.5
01
23
45
Histograma
r 3
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 4
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 5
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 6
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 7
freq
uênc
ia0.0 0.5 1.0 1.5
01
23
45
Histograma
r 8
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 9
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 10
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 11
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 12fr
equê
ncia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 13
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 14
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 15
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 16
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 17
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 18
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Histograma
r 19
freq
uênc
ia
0.0 0.5 1.0 1.5
01
23
45
Figura 1.16: Histogramas das taxas para a campanha 1 de Corumbá.
167

Histograma
r 1
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 2
freq
uênc
ia0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 3
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 4
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 5
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 6
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 7
freq
uênc
ia0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 8
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 9
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 10
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 11
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 12fr
equê
ncia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 13
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 14
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 15
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 16
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 17
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 18
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 19
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Histograma
r 20
freq
uênc
ia
0.0 0.2 0.4 0.6 0.8
02
46
810
12
Figura 1.17: Histograma das taxas para a campanha 2 de Corumbá.
168

Histogram
r 1
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 2
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 3frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 4
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 5
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 6
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 7
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 8frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 9
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 10
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 11
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Histogram
r 12
frequency
01
23
4
0.0 0.5 1.0 1.5 2.0
Figura
1.18:H
istograma
dastaxas
paraa
campanha
3de
Corum
bá.
169

Apêndice B
Programa CIR multivariado com
estrutura espacial
// Livrarias
#include <iostream> #include <scythestat/rng/mersenne.h>
#include <scythestat/distributions.h> #include <scythestat/ide.h>
#include <scythestat/la.h> #include <scythestat/matrix.h>
#include <scythestat/rng.h> #include <scythestat/smath.h>
#include <scythestat/stat.h> #include <scythestat/optimize.h>
#include <cstdlib> #include <cmath>
#include <ctime> #include <cstdio>
#include <fstream> #include <stdio.h>
#include <math.h> #include <stdlib.h>
#include <fstream> #include <ctime>
#include "CIRmultAUM.h"
// Site
using namespace scythe;
using namespace std;
// Declaração de variáveis globais
const int n = 100; // 100, 91, 64, 49 // Num de series (localizações)
const int N = 120; // Num de observações (no tempo) N = 120
const float ti = 0.0, tf = 12.0; // Tempos inicial e final (minutos)
double h = (tf-ti)/float((N+1)-1); // Delta t (fixo)
Matrix<double> tempos(N+1,1); // Tempos de observação
// Parâmetros - estrutura espacial - família exponencial de potência:
double sig2; // 0.005, 0.05, 0.5
double phi; // 0.1, 0.5, 0.9
170

Matrix<double> Y = ones(N+1,n), U(N+1,n); // Matriz N+1 x n(tempos por locais)
Matrix<double> Dist(n,n), S(n,n); // Matriz de distâncias e expon.pot.
Matrix<double> xy(n,2); // Coordenadas (x, y)
// PRINCIPAL -------------------------------------------------------------------
int main(int argc, char *argv[])
int i, j, k;
// Semente
srand((unsigned)time(NULL));
unsigned long ss0=rand();
myrng.initialize(ss0+100000);
// Parâmetros - alpha e beta
Matrix<double> alpha=0.0, beta=0.0; // Parâmetros da função de direção
alpha = myrng.rnorm(n, 1, 0.5, 0.02);
beta = myrng.rnorm(n, 1, -0.1, 0.01);
// Tempos e coordenadas
for(k=0; k<N+1; ++k) tempos(k) = double(k)*h;
for(i=0; i<sqrt(n); ++i)
for(j=0; j<sqrt(n); ++j)
xy(i*(int (sqrt(n))) + j, 0) = i*(1.0/sqrt(n))+(1.0/(2*sqrt(n)));
xy(i*(int (sqrt(n))) + j, 1) = j*(1.0/sqrt(n))+(1.0/(2*sqrt(n)));
// Matriz de covariância da exponencial potência
cout<< "Família exponencial pot.: rho(sig2,phi)=sig2*exp(-d_ij/phi)\n";
cout<< "Escolha os valores dos parâmetros espaciais da simulação:\n";
cout<< "Sig2 = 0.005, 0.05 ou 0.5?\n";
cin>> sig2;
cout<< "phi = 0.1, 0.5, 0.9?\n";
cin>> phi;
for(i=0; i<n; ++i) for(j=0; j<n; ++j)
Dist(i,j) = sqrt((xy(i,0)-xy(j,0))*(xy(i,0)-xy(j,0))+(xy(i,1)-xy(j,1))*(xy(i,1)-xy(j,1)));
S(i,j) = sig2*exp(-Dist(i,j)/phi);
// Salva parâmetros verdadeiros
ofstream myfile("ParVerd.txt"), param("Sig2Phi.txt");
if (myfile.is_open() && param.is_open())
myfile << "’local’ ’alpha’ ’beta’\n";
for(i=0;i<n;++i) myfile << i+1 <<" "<< alpha(i,0)<<" "<< beta(i,0)<< endl;
myfile << "Parâmetros da estrutura espacial.\n";
myfile << "Sig2 = "<< sig2<< endl;
myfile << "Phi = " << phi << endl;
myfile.close();
param << sig2 <<" "<< phi << endl;
171

param.close();
else cout << "Algum dos arquivos não abriu!\n";
// Concentrações (dados) - valores verdadeiros
Matrix<double> mU(n,1), SU(n,n), SS(n,n), dg1(n,n), dg2(n,n), dg3(n,n);
bool tt=0;
do
// Valores de tempo inicial: Y_0^(i)
Y(0,_) = 2*Y(0,_) + t(cholesky(S)*myrng.rnorm(n, 1, 0.0, 1.0));
U(0,_) = log(Y(0,_));
for (k=0; k<N; ++k)
cout<< k << endl;
for(i=0;i<n;++i)
dg1(i,i) = exp(.5*U(k,i));
dg2(i,i) = exp(-U(k,i));
dg3(i,i) = exp(-2*U(k,i));
SS = dg1*S*dg1;
mU = dg2*( alpha + beta\%t(exp(U(k,_))) ) - 0.5*dg3*diag(SS);
SU = dg2*SS*dg2;
U(k+1,_) = U(k,_)+t(mU)*h+t(cholesky(SU*h)*myrng.rnorm(n,1,0.0,1.0));
if ( max( exp( U(k+1,_) ) <= 0*ones(1,n) ) )
cout<< "Problemas na geracao" << endl;
tt=0;
break;
else tt=1;
Y = exp(U);
while(!tt);
// Salva dados, tempos, coordenadas e parâmetros.
Y.save("Y.txt",’o’, false);
tempos.save("tempos.txt",’o’, false);
xy.save("xy.txt",’o’, false);
alpha.save("alpha.txt",’o’, false);
beta.save("beta.txt",’o’, false);
// Valores observados para estimação ----------------------------------------
int No; // 24 ou 12 (+1) tempos observados
cout<< "Quantos tempos deseja considerar? 24 ou 12?" <<endl;
cin>> No;
int no; // 15 ou 10 locais observados
cout<< "Quantos locais deseja considerar? 10 ou 15?" <<endl;
cin>> no;
Matrix<double> yo(No+1,no); // Concentrações observadas
Matrix<double> to(No+1,1); // Tempos observados
172

Matrix<double> xyo(no,2); // Coordenadas observadas
Matrix<int> tp(No+1,1); // Índice dos tempos
Matrix<int> locais(no,1); // Índice dos locais
bool teste[no];
// Sorteio dos locais
if(n == no)
for(i=1;i<no;++i) locais(i,0) = i;
else
locais(0,0) = int((n+1)*myrng());
teste[locais(0,0)] = 1;
for(i=1;i<no;++i)
locais(i,0) = int( (n+1)*myrng.runif() );
while(teste[locais(i,0)]) locais(i,0) = int((n+1)*myrng());
teste[locais(i,0)] = 1;
locais = sort(locais);
cout<<"Locais sorteados:\n" << locais <<endl;
// Tempos e locais observados
for(k=0; k<No+1; ++k)
tp(k,0) = 0 + k*N/No;
to(k,0) = tempos(tp(k,0),0);
for(i=0;i<no;++i) yo(k,i) = Y(tp(k,0), locais(i,0));
// Coordenadas observadas
for(i=0; i<no; ++i)
xyo(i,_)= xy(locais(i,0),_);
// Dados, tempos e coordenadas observadas e índices do locais observados.
yo.save("yo.txt",’o’, false);
to.save("to.txt",’o’, false);
xyo.save("xyo.txt",’o’, false);
locais.save("locais.txt",’o’, false);
// Estimação dos Parâmetros -------------------------------------------------
// Aumento de dados no tempo - Sem aumento, 4 aumentados e 9 aumentados
// (1*No, 5*No e 10*No)
cout<< "Quantos dados deseja aumentar entre cada par de observados? 0, 4 ou 9?" <<endl;
int Na;
cin>> Na; Na = (Na+1)*No;
Matrix<double> ta(Na+1,1); // Tempos de observações aumentados
h = (max(to)-min(to))/((Na+1)-1); // Delta t aumentado (fixo)
for(k=0; k<Na+1; ++k) ta(k,0)=double(k)*h;
CIRma(yo,to,ta,xyo); // CIR MULTIVARIADO COM DADOS AUMENTADOS
173

system("pause");
return EXIT_SUCCESS;
/* FUNÇÃO fZ -------------------------------------------------------------------
Entrada: y - matriz ( N+1 (tempos) por n (locais) )
delta - tempos entre observações
Saída: Z - matriz ( N por n )
Z = (\Delta_k)^-.5 D_\bfX_k^-1 (\bfY_k+1 - \bfY_k)
------------------------------------------------------------------------------*/
Matrix<double> fZ(Matrix<double>y, Matrix<double>delta)
int N = y.rows()-1; // Número de tempos de observação
int n = y.cols(); // Número de processos (locais)
Matrix<double> Zes(N, n), dg(n,n);
for(int k=0;k<N;++k)
for(int i=0; i<n; ++i) dg(i,i) = 1.0/sqrt(y(k,i));
Zes(k,_) = (1.0/sqrt(delta(k,0)))*( y(k+1,_) - y(k,_) )*dg;
Matrix<double> Z(N*n,1);
for(int i=0;i<n;++i) for (int k=0;k<N;++k) Z(i*N+k,0) = Zes(k,i);
return (Z);
/* FUNÇÃO fR -------------------------------------------------------------------
Entrada: y - matriz ( N (tempos) por n (locais) )
delta - tempos entre observações
Saída: R - matriz ( N*n por 2*n )
------------------------------------------------------------------------------*/
Matrix<double> fR(Matrix<double>y, Matrix<double>delta)
int N = y.rows()-1; // Número de tempos de observação
int n = y.cols(); // Número de processos (locais)
Matrix<double> Rp(N, 2), R(N*n,2*n);
for(int i=0;i<n;++i)
for (int k=0;k<N;++k)
Rp(k,0) = sqrt( delta(k,0)/y(k,i) );
Rp(k,1) = sqrt( delta(k,0)*y(k,i) );
for(int l=0; l<N; ++l) for(int m=0; m<2; ++m)
R(i*N+l,2*i+m) = Rp(l,m);
return (R);
/* FUNÇÃO fH -------------------------------------------------------------------
Entrada: N e n (Num de tempos e num de locais)
Z - matriz ( N (tempos) por n (locais) )
174

R - matriz ( N*n por 2*n )
varphi - vetor ( 2*n por 1 )
Saída: H - matriz ( n por n )
------------------------------------------------------------------------------*/
Matrix<double> fH(int N, int n, Matrix<double>Z, Matrix<double>R, Matrix<double>varphi)
Matrix<double> Ax(N,1), Bx(N,1), Rp(N,2), vp(2,1), Sa(N,1), Sb(N,1), H(n,n);
for (int i=0; i<n; ++i)
for(int s=0;s<N;++s) Ax(s,0) = Z(i*N+s,0);
for(int l=0;l<N;++l) for(int m=0;m<2;++m) Rp(l,m) = R(i*N+l,2*i+m);
for(int m=0;m<2;++m) vp(m,0) = varphi(2*i+m,0);
Sa = Ax - Rp*vp;
for (int j=0; j<n; ++j)
for(int s=0;s<N;++s) Bx(s,0) = Z(j*N+s,0);
for(int l=0;l<N;++l) for(int m=0;m<2;++m) Rp(l,m) = R(j*N+l,2*j+m);
for(int m=0;m<2;++m) vp(m,0) = varphi(2*j+m,0);
Sb = Bx - Rp*vp;
for(int l=0;l<N;++l) H(i,j) += Sa(l,0)*Sb(l,0);
return (H);
/* FUNÇÃO fMHphi ---------------------------------------------------------------
Entrada: Sigmaphi, Dist, H - matriz ( n (locais) por n (locais) )
tr, sig2 e phi - double ( traço, sig2 e estado corrente )
c, d, N, tx - int ( tx de aceit, hiperparâmetros e Num tempos )
Saída: phic - ( novo phi corrente )
------------------------------------------------------------------------------*/
double fMHphi(Matrix<double>Sigmaphi, Matrix<double>Dist, Matrix<double>H,
double tr, double sig2, double phi, double c, double d, int N,
int& tx, bool U)
int n = Sigmaphi.rows();
Matrix<double> Sigmaphip(n,n);
double A, B, pclog, mc, varp, qclog, phip, pplog, qplog, p_ac;
A = (N/2.0)*log(det(invpd(Sigmaphi))) + (c-1)*log(phi);
B = -(1.0/(2.0*sig2))*tr - phi*d;
pclog = A + B; // Densidade objetivo corrente
if (U)
varp = 0.5; // Variância da proposta (log-normal)
mc = log(phi) - varp/2.0; // Média da proposta (log-normal)
// Densidade proposta corrente
qclog = - log(phi) - (0.5/varp)*(log(phi)-mc)*(log(phi)-mc);
phip = exp(sum(myrng.rnorm(1, 1, mc, sqrt(varp))));
175

// Densidade proposta na proposta
qplog = - log(phip) - (0.5/varp)*(log(phip)-mc)*(log(phip)-mc);
else
phip = min(Dist) + (max(Dist)-min(Dist))*myrng.runif();
qplog = qclog = 0; // Densidade proposta na proposta e na corrente
for(int i=0;i<n;++i)for(int j=0;j<n;++j) Sigmaphip(i,j)=exp(-Dist(i,j)/phip);
tr = sum(diag(H*invpd(Sigmaphip)));
A = (N/2.0)*log(det(invpd(Sigmaphip))) + (c-1)*log(phip);
B = -(1.0/(2.0*sig2))*tr - phip*d;
pplog = A + B; // Densidade objetivo proposta
p_ac = exp(pplog + qclog - (pclog + qplog));
if(min(p_ac, 1.0) > myrng.runif())
phi = phip;
tx++;
return (phi);
/* -----------------------------------------------------------------------------
FUNÇÃO CIR Multivariado com Dados Aumentados:
Entrada: yo - matriz dos observados (N+1 tempos) x (no coordenadas),
to - vetor dos tempos de observação,
ta - vetor dos tempos totais observados e não observados e
xyo- coordenadas das observações no plano.
Saída: varphi e sigma (vetor e matriz dos parâmetros).
------------------------------------------------------------------------------*/
Matrix<double> CIRma(Matrix<double>yo, Matrix<double>to, Matrix<double>ta, Matrix<double>xyo)
int No = yo.rows()-1; // Número de tempos de observação
int no = yo.cols(); // Número de processos (locais)
int Na = ta.rows()-1; // Número de observações aumentadas
Matrix<double> ya(Na+1,no); // Dados aumentados
double h = (max(ta)-min(ta))/((Na+1)-1); // Delta t aumentado (fixo)
time_t init, fim; // Contador do tempo de execução
double dif;
int i, j, k;
init = fim = time(NULL);
time (&init); time (&fim);
dif = difftime (fim,init);
cout<< "Tempo de execucao \t(CIRma 01) \t\t= " << dif << endl;;
// Pontes iniciais (lineares)
Matrix<double> txp(Na,1); // taxa de aceitação do MH pra phi
if (Na == No) ya = yo;
176

else
j = 0;
ya(j,_) = yo(0,_);
for(i=0; i<No; ++i)
j++;
while(ta(j,0) < to(i+1,0))
ya(j,_) =((yo(i+1,_)-yo(i,_))/(to(i+1,0)-to(i,0)))*(ta(j,0)-to(i,0))
+ yo(i,_);
j++;
ya(j,_) = yo(i+1,_);
ya.save("ya.txt",’o’, false);
ta.save("ta.txt",’o’, false);
time (&fim); dif = difftime (fim,init);
cout<< "Tempo de execucao \t(CIRma 02) \t\t= " << dif << endl;
Matrix<double> delta(Na,1); // Delta ta
for (k=0; k<Na;++k) delta(k,0)= ta(k+1,0)-ta(k,0);
Matrix<bool> iobs(Na+1,1); // indicadora de dado observado
for(i=0;i<Na+1;++i) for(j=0;j<No+1;++j)
if(abs(ta(i,0)-to(j,0))<h/100.0) iobs(i,0) = 1;
// MCMC ---------------------------------------------------------------------
int na = 5500; // Número total de iterações
int bi = 500; // Burn in (aquecimento)
int la = 5; // Lag
// Prioris -> p(vaphi, Sigma) propto p(vaphi | Sigma) p(Sigma)
double sig2= 0.5; // Variância da estrutura espacial - valor inicial
double phi = 0.1; // Parâmetro de forma da estrutura espacial -valor inicial
Matrix<double> Sigmas(2,(na-bi)/la);
// sig2 ~ InvGamma(shape = a, rate = b)
double a = (sig2*sig2)/5.0 + 2.0;
double b = (sig2*sig2*sig2)/5.0 + sig2;
// phi ~ Gamma(shape = c, rate = d)
int txphi = 0; // taxa de aceitação do MH pra phi
double c = phi*phi/5.0;
double d = phi/5.0;
// varphi | Sigma ~ vaphi | Sigma ~ N (vaphi0, Sigma kronecker I_N )
Matrix<double> varphi(2*no,1);
Matrix<double> varphis(2*no, (na-bi)/la);
Matrix<double> Dist(no,no), Sigma(no,no);
for(i=0; i<no; ++i) for(j=0; j<no; ++j)
Dist(i,j) = sqrt( (xyo(i,0)-xyo(j,0))*(xyo(i,0)-xyo(j,0))+
177

(xyo(i,1)-xyo(j,1))*(xyo(i,1)-xyo(j,1)) );
Sigma(i,j) = sig2*exp(-Dist(i,j)/phi);
// Iterações do MCMC --------------------------------------------------------
Matrix<double> Z(Na*no,1), R(Na*no,2*no), Ddelta(Na,Na);
Matrix<double> K0(2*no,2*no), IN=eye(Na), Kr(Na*no,Na*no);
Matrix<double> m(2*no,1), C(no*Na,no*Na), H(no,no), Sigmaphi(no,no);
double tr, A, B;
cout<< "MCMC" << endl << "Num de locais observados: no = " << no << endl;
cout<< "Num de tempos observados e aumentados: " << "No = "<< No <<" Na = " << Na << endl;
for(int g=0;g<na;++g)
cout<< g << endl;
time (&fim); dif = difftime (fim,init);
cout<< "Tempo de execucao \t(CIRma MCMC) \t\t= " << dif << endl;;
// Z = R \varphi + \varepsilon, \varepsilon~N(0, Sigma kronecker I_N)
Z = fZ(ya, delta);
R = fR(ya, delta);
for(k=0;k<Na;++k) Ddelta(k,k) = delta(k,0);
// Atualiza parâmetros - Algoritmo amostrador de Gibbs -------------------
// K0 = sig2*B0;
Kr = kronecker(invpd(Sigma), IN);
// varphi - amostrador de Gibbs
m = invpd(t(R)*Kr*R)*(t(R)*Kr*Z);
C = invpd(t(R)*Kr*R);
varphi = m + cholesky(C)*myrng.rnorm(2*no, 1, 0.0, 1.0);
time (&fim); dif = difftime (fim,init);
cout<< "\t\t\t(CIRma varphi) \t\t= " << dif << endl;;
// sig2 - amostrador de Gibbs
H = fH(Na, no, Z, R, varphi);
for(i=0;i<no;++i) for(j=0;j<no;++j) Sigmaphi(i,j) = exp(-Dist(i,j)/phi);
tr = sum(diag(H*invpd(Sigmaphi)));
A = (Na/2.0)*no + a;
B = tr/2.0 + b;
sig2 = myrng.rigamma(A, B);
time (&fim); dif = difftime (fim,init);
cout<< "\t\t\t(CIRma Sigma sig2) \t= " << dif << endl;
// phi - passos de Metropolis
phi = fMHphi(Sigmaphi, Dist, H, tr, sig2, phi, c, d, Na, txphi, 0);
for(i=0; i<no; ++i)
for(j=0; j<no; ++j) Sigma(i,j) = sig2*exp(-Dist(i,j)/phi);
time (&fim); dif = difftime (fim,init);
cout<< "\t\t\t(CIRma Sigma phi) \t= " << dif << endl;
// Pontes brownianas - passos de metropolis
178

ya = fMHAR(ya, iobs, delta, varphi, Sigma, txp);
time (&fim); dif = difftime (fim,init);
cout<< "\t\t\t(CIRma Pontes) \t\t= " << dif << endl;
// Salvando saída --------------------------------------------------------
if ((g-(bi-1))%la==0 && g>=bi)
varphis(_,(g-bi)/la) = varphi(_,0);
Sigmas(0,(g-bi)/la) = sig2;
Sigmas(1,(g-bi)/la) = phi;
ya.save("ya.txt",’o’, false);
cout<< "(g-bi)/la = " << (g-bi)/la << endl;
cout<< "varphis = \n" << varphis(_,(g-bi)/la) << endl;
cout<< "Sigmas = \n" << Sigmas(_,(g-bi)/la) << endl;
cout<< "Tx Aceit phi = \n" << (float) txphi / ((float) g+1.0) << endl << endl;
if (Na != No) cout<< "Tx Aceit pontes = \n" << txp / ((float) g+1.0)
<< endl << endl;
varphis.save("varphis.txt",’o’, false);
Sigmas.save("Sigmas.txt", ’o’, false);
return EXIT_SUCCESS;
/* FUNÇÃO fMHAR - Pontes Brownianas (Aceitação e Rejeição com P. de Metropolis)
Entrada: ya - matriz ( N+1 (tempos) por n (locais) )
No - Número de observados
delta - tempos entre observações
varphi e Sigma - parâmetros
Saída: Y^g - matriz ( N+1 por n )
------------------------------------------------------------------------------*/
Matrix<double> fMHAR(Matrix<double>y, Matrix<double>iobs, Matrix<double>delta,
Matrix<double>varphi, Matrix<double>Sigma, Matrix<double>& tx)
int N = y.rows()-1; // Número de tempos de observação
int n = y.cols(); // Número de processos (locais)
Matrix<double> u = t(log(y)); // Fórmula de Itô - multidimensional
Matrix<double> Fk(n, 2*n), S(n,n);
Matrix<double> dg1(n,n), dg2(n,n), dg3(n,n), ma(n,1), mb(1,n);
Matrix<double> m1(1,n), m2(1,n), mp(1,n), M1(n,n), M2(n,n), Mp(n,n);
Matrix<double> m3(1,n), M3(n,n), m4(1,n), M4(n,n), up(1,n);
double razao, pupa, pupb, pup, puq, pmpa, pmpb, pmp, puta, putb, put, qut;
double qup, qmp, co, p_ac;
for (int k=1;k<N-1;++k)
if(iobs(k,0)==0)
179

razao = 0.0;
while(razao < myrng.runif()) // Proposta por Aceitação-Rejeição
// p( . | u_k-1) -------------------------------------------------
for(int i=0;i<n;++i)
dg1(i,i) = exp( 0.5*u(i,k-1));
dg2(i,i) = exp( - u(i,k-1));
dg3(i,i) = exp(-2.0*u(i,k-1));
S = dg1*Sigma*dg1;
for(int a=0;a<n;++a)
Fk(a,2*a) = 1.0;
Fk(a,2*a+1)= exp(u(a,k-1));
ma = u(_,k-1) + dg2*(Fk*varphi)*delta(k-1,0);
mb = -0.5*dg3*diag(S)*delta(k-1,0);
m1 = ma + mb;
M1 = dg2*S*dg2*delta(k-1,0);
// gerando da proposta => up ~ q(.) ~ N(m, M) ----------------------
mp = 0.5*(u(_,k-1)+ u(_,k+1));
Mp = 0.5*M1;
up = mp + cholesky(Mp)*myrng.rnorm(n, 1, 0.0, 1.0);// Valor Proposto
// p( . | up) ------------------------------------------------------
for(int i=0;i<n;++i)
dg1(i,i) = exp( 0.5*up(i,0));
dg2(i,i) = exp( - up(i,0));
dg3(i,i) = exp(-2.0*up(i,0));
S = dg1*Sigma*dg1;
for(int a=0;a<n;++a)
Fk(a,2*a) = 1.0;
Fk(a,2*a+1)= exp(up(a,0));
ma = up + dg2*(Fk*varphi)*delta(k,0);
mb = -0.5*dg3*diag(S)*delta(k,0);
m2 = ma + mb;
M2 = dg2*S*dg2*delta(k,0);
// p( . | mp) ------------------------------------------------------
for(int i=0;i<n;++i)
dg1(i,i) = exp( 0.5*mp(i,0));
dg2(i,i) = exp( - mp(i,0));
dg3(i,i) = exp(-2.0*mp(i,0));
S = dg1*Sigma*dg1;
180

for(int a=0;a<n;++a)
Fk(a,2*a) = 1.0;
Fk(a,2*a+1)= exp(mp(a,0));
ma = mp + dg2*(Fk*varphi)*delta(k,0);
mb = -0.5*dg3*diag(S)*delta(k,0);
m3 = ma + mb;
M3 = dg2*S*dg2*delta(k,0);
// densidade objetivo: pup = p(u_k+1 | up) p(up | u_k-1)
// p(u_k+1 | up)
pupa = sum(-0.5*log(det(M2))-0.5*t(u(_,k+1)-m2)*invpd(M2)*(u(_,k+1)-m2));
// p(up | u_k-1)
pupb = sum(-0.5*t(up - m1)*invpd(M1)*(up - m1));
// densidade:
pup = pupa + pupb;
qup = sum(-0.5*t(up - mp)*invpd(Mp)*(up - mp));
// Constante c -----------------------------------------------------
// pmp = p(u_k+1 | mp) p(mp | u_k-1)
// p(u_k+1 | mp)
pmpa=sum(-0.5*log(det(M3))-0.5*t(u(_,k+1)-m3)*invpd(M3)*(u(_,k+1)-m3));
// p(mp | u_k-1)
pmpb = sum(-0.5*t(mp-m1)*invpd(M1)*(mp-m1));
// densidade:
pmp = pmpa + pmpb;
qmp = 0.0;
co = pmp - qmp;
razao = exp(pup - (qup + co));
// p( . | u_t) --------------------------------------------------------
for(int i=0;i<n;++i)
dg1(i,i) = exp( 0.5*u(i,k));
dg2(i,i) = exp( - u(i,k));
dg3(i,i) = exp(-2.0*u(i,k));
S = dg1*Sigma*dg1;
for(int a=0;a<n;++a)
Fk(a,2*a) = 1.0;
Fk(a,2*a+1)= exp(u(a,k));
ma = u(_,k) + dg2*(Fk*varphi)*delta(k,0);
mb = -0.5*dg3*diag(S)*delta(k,0);
m4 = ma + mb;
M4 = dg2*S*dg2*delta(k,0);
181

// put = p(u_k+1 | u_k) p(u_k | u_k-1)
// p(u_k+1 | u_k)
puta = sum(-0.5*log(det(M4)) -.5*t(u(_,k+1)-m4)*invpd(M4)*(u(_,k+1)-m4));
// p(u_t | u_k-1)
putb = sum(-0.5*t(u(_,k)-m1)*invpd(M1)*(u(_,k)-m1));
// densidade:
put = puta + putb;
qut = sum(-.5*t(u(_,k) - mp)*invpd(Mp)*(u(_,k) - mp));
p_ac=(put<co+qut)?1.0:(pup < co+qup)?exp((co+qut)-put):min(1.0,exp((pup+qut)-(put+qup)));
if (p_ac > myrng.runif())
u(_,k) = up;
y(k,_) = t(exp(up));
tx(k,0)++;
return y;
182

Referências Bibliográficas
Aït-Sahalia, Y. (1996a) Nonparametric pricing of interest rate derivative securities. Eco-
nometrica, 64, 527–560.
— (1996b) Testing continuous-time models of the spot interest rate. The Review of
Financial Studies, 9, 385–426.
Bechara, E. (2008) O que muda com o novo acordo ortográfico. Editora Nova Fronteira,
Rio de Janeiro - RJ.
Beskos, A., Papaspiliopoulos, O., Roberts, G. O. e Fearnhead, P. (2006) Exact and compu-
tational efficiente likelihood-based estimation for discretely observed diffusion process.
J. R. Statist. Soc. B, 68, 333–382.
Bibby, B. M. e Sørensen, M. (1995) Martingale estimation functions for discretely observed
diffusion processes. Bernoulli, 1, 17–39.
Chib, S. e Greenberg, E. (1995) Understanding the metropolis-hastings algorithm. The
American Statistician, 49, 327–335.
Chib, S. e Jeliazkov, I. (2001) Marginal likelihood from the metropolis-hastings output.
JASA, 96, 270–281.
Cox, J. C., Ingersoll, J. E. e Ross, S. A. (1985) A theory of the term structure of interest
rates. Econometrica, 53, 385–407.
183

Dellaportas, P., Friel, N. e Roberts, G. O. (2006) Bayesian model selection for partially
observed diffusion models. Biometrika, 93, 809–825.
Diggle, P. J. e Ribeiro, P. J. (2007) Model-based Geostatistics. Nova Iorque: Springer.
Duan, J. A., Gelfand, A. E. e Sirmans, C. F. (2009) Modeling space-time data using
stochastic differential equation. Bayesian Analysis, 4, 733–758.
Duffie, D. (2001) Dynamic Asset Pricing Theory. Nova Jersey: Princeton University
Press, terceira ed.
Duffie, D. e Kan, R. (2001) A yield-factor model of interest rates. Mathematical Finance,
6, 379–406.
Elerian, O. (1999) Simulation Estimation of Continuous-Time Models with Application to
Finance. Tese de Doutorado, Nuffield College, University of Oxford.
Elerian, O., Chib, S. e Sheppard, N. (2001) Likelihood inference for discretely observed
nonlinear diffusions. Econometrica, 69, 959–993.
Eraker, B. (2001) MCMC analysis of diffusion models with application to finance. Journal
of Business & Economic Statistics, 19, 177–191.
Gamerman, D. e Lopes, H. F. (2006) Markov Chain Monte Carlo: stochastic simulation
for Bayesian Inference. Boca Raton - Londres - Nova Iorque: Chapman & Hall / CRC,
segunda ed.
Gamerman, D. e Migon, H. S. (1993) Dynamic hierarchical models. J. R. Statist. Soc. B,
3, 629–642.
Geyer, A. L. J. e Pichler, S. (1999) A state-space approach to estimate and test multifactor
cox-ingersoll-ross models of the term structure. The Journal of Financial Research, 1,
107–130.
184

Gneiting, T. e Raftery, A. E. (2004) Strictly proper scoring rules, prediction, and estima-
tion. Relatório técnico, Department of Statistics, University of Washington.
Golightly, A. e Wilkinson, D. J. (2006) Bayesian sequential inference for nonlinear multi-
variate diffusion. Statistics and Computing, 16, 323–338.
Gschlößl, S. e Czado, C. (2005) Spatial modelling of claim frequency and claim size in
insurance. Relatório técnico, Universidade de Tecnologia de Munique.
Hutchinson, G. L. e Mosier, A. R. (1981) Improved soil cover method for field measurement
of nitrous oxide fluxes. Soil Sci. Soc. Am. J., 311–316.
Jarrow, R. e Protter, P. (2003) A short history of stochastic integration and mathematical
finance - the early years, 1880 - 1970. Relatório técnico, Cornell University.
Johannes, M. e Polson, N. (2003) MCMC Methods for Continuous-Time Financial Eco-
nometrics. Graduate School of Business, Columbia University, 3022 Broadway, Nova
Iorque, Nova Iorque.
Jones, C. S. (1998) Bayesian Estimation of Continuous-Time Finance Models. Simon
School of Business, Rochester, Nova Iorque, 14627.
— (2003) Nonlinear mean reversion in the short-term interest rate. The Review of Finan-
cial Studies, 28, 793–843.
Kalogeropoulos, K. P. (2006) Bayesian Inference for Multidimensional Diffusion Process.
Tese de Doutorado, Athens University of Economics and Business.
— (2007) Likelihood-based inference for a class of multivariate diffusions with unobserved
paths. Journal of Statistical Planning and Inference, 137, 3092–3102.
Kalogeropoulos, K. P., Dellaportas, P. e Roberts, G. O. (2007) Likelihood-based inference
for correlated diffusions. Submetido ao Munich Personal RePEc Archive - MPRA. URL:
http://mpra.ub.uni-muenchen.de/5696/.
185

Karatzas, I. e Shreve, S. E. (1991) Brownian Motion and Stochastic Calculus. Nova Iorque:
Springer-Verlag.
Klebaner, F. C. (2005) Introduction to stochastic calculus with applications. Londres:
Imperial college Press, segunda ed.
Kloeden, P. E. e Platen, E. (1992) Numerical Solution of Stochastic Differential Equations.
Springer-Verlag.
Øksendal, B. (1995) Stochastic Differential Equations: an introduction with applications.
Berlim: Springer-Verlag.
Malliavin, P. e Mancino, M. E. (2002) Fourier series method for measurement of multiva-
riate volatilities. Finance Stochastic, 6, 49–61.
Marin, J.-M. e Robert, C. P. (2007) Bayesian Core: A Practical Approach to Computati-
onal Bayesian Statistic. Nova Iorque: Springer.
Matérn, B. (1986) Spatial Variation. Berlim: Springer-Verlag, segunda ed.
McCullagh, P. e Nelder, J. A. (1999) Generalized Linear Models. Chapman & Hall / CRC,
segunda ed.
Migon, H. S., Souza, A. D. P. e Schmidt, A. M. (2008) Modelos hierárquicos e aplicações.
Minicurso 18o. Sinape, Estância de São Pedro - SP.
O’Hagan, A. (1998) Eliciting experts beliefs in substantial practical application. The
statistician, 47, 21–35.
Oliveira, V. D., Kedem, B. e Short, D. A. (1997) Bayesian prediction of transformed
gaussian random fields. Journal of the American Statistical Association, 92, 1422–
1433.
Paez, M. S. (2000) Estudo das concentrações de partículas inaláveis na região metropoli-
tana do Rio de Janeiro. Tese de Doutorado, DME-IM-UFRJ.
186

Paez, M. S. e Gamerman, D. (2005) Modelagem de processos espaço-temporais. Minicurso
11a Escola de Séries Temporais e Econometria, Vila Velha - ES.
Pedersen, A. R. (1995) A new approach to maximum likelihood estimation for stochastic
differential equations based on discrete observations. Scandinavian Journal of Statistics,
22, 55–71.
— (2000) Estimating the nitrous oxide emission rate from the soil surface by means of a
diffusion model. Scandinavian Journal of Statistics, 27, 385–403.
Pedersen, A. R., Petersen, S. O. e Vinther, F. P. (2001) Stochastic diffusion model for
estimating trace gas emissions with static chamber. Sci. Soc. Am. J., 65, 49–58.
Polson, N. G. e Roberts, G. O. (1994) Bayes factors for discrete observations from diffusion
processes. Biometrika, 81, 11–26.
Roberts, G. O. e Stramer, O. (2001) On inference for partially observed nonlinear diffusion
models using the metropolis-hastings algorithm. Biometrika, 88, 603–621.
Rosa, L. P., Sikar, B. M., dos Santos, M. A., Monteiro, J. L., Sikar, E. M., Silva, M. B.,
dos Santos, E. O. e Junior, A. P. (2002) Emissão de gases de efeito estufa derivados de
reservatórios hidrelétricos. Relatório Técnico Projeto BRA/00/029, Agência Nacional
de Energia Elétrica - ANEEL. Capacitação do setor elétrico brasileiro em relação à
mudança global do clima.
Sanford, A. D. e Martin, G. M. (2006a) Bayesian comparison of several continuous time
models of the australian short rate. Accounting and Finance, 46, 309–326.
— (2006b) Simulation-based bayesian estimation of an affine term structure model. Com-
putational Statistics & Data Analysis, 49, 527–554.
dos Santos, M. A., Rosa, L. P., Sikar, B. M., Monteiro, J. L., Xavier, A. E., Patchinee-
lam, S. R., Silva, M. B., dos Santos, E. O., Rocha, C. H. E. D., Junior, A. M. P. B.,
187

Sikar, E. M. e Costa, R. S. (2005a) O balanço de carbono em reservatórios de FURNAS
CENTRAIS ELÉTRICAS S.A - estimativa de fluxo de CO2, CH4 e N2O na interface
água-atmosfera e coluna d’água e determinação de aporte e das taxas de sedimentação
de carbono. Relatório Técnico Projeto Balanço de Carbono de Furnas Centrais Elé-
tricas S.A., IVIG/COPPE/UFRJ. Relatório 5 - Primeira Campanha de Medições nos
Reservatórios Hidrelétricos de Corumbá e Itumbiara.
dos Santos, M. A., Rosa, L. P., Sikar, B. M., Xavier, A. E., Patchineelam, S. R., Silva,
M. B., dos Santos, E. O., Rocha, C. H. E. D., Junior, A. M. P. B., Sikar, E. M.
e Costa, R. S. (2005b) O balanço de carbono em reservatórios de FURNAS CEN-
TRAIS ELÉTRICAS S.A - estimativa de fluxo de CO2, CH4 e N2O na interface água-
atmosfera e coluna d’água e determinação de aporte e das taxas de sedimentação de
carbono. Relatório Técnico Projeto Balanço de Carbono de Furnas Centrais Elétri-
cas S.A., IVIG/COPPE/UFRJ. Relatório 6 - Segunda Campanha de Medições nos
Reservatórios Hidrelétricos de Corumbá e Itumbiara.
— (2006) O balanço de carbono em reservatórios de FURNAS CENTRAIS ELÉTRI-
CAS S.A - estimativa de fluxo de CO2, CH4 e N2O na interface água-atmosfera e
coluna d’água e determinação de aporte e das taxas de sedimentação de carbono.
Relatório Técnico Projeto Balanço de Carbono de Furnas Centrais Elétricas S.A.,
IVIG/COPPE/UFRJ. Relatório 7 - Terceira Campanha de Medições nos Reservatórios
Hidrelétricos de Corumbá e Itumbiara.
Schmidt, A. M., Nobre, A. A. e Ferreira, G. S. (2003) Alguns aspectos da modelagem de
dados espacialmente referenciados. Relatório técnico, Universidade Federal do Rio de
Janeiro. URL: http://www.dme.ufrj.br/alex/rbe.pdf.
Schmidt, A. M. e Sansó, B. (2006) Modelagem Bayesiana da Estrutura de Covariância de
Processos Espaciais e Espaço-Temporais. Minicurso 17o. Sinape, Caxambú - MG.
188

Smith, A. F. M. e Gelfand, A. E. (2001) Bayesian statistics without tears: a sampling-
resampling perspective. The American Statistician, 46, 84–88.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P. e van der Linde, A. (2002) Bayesian
measures of model complexity and fit. J. R. Statist. Soc. B, 64, 1–34.
Steele, J. M. (2001) Stochastic calculus and financial applications. Nova Iorque: Springer.
Wackernagel, H. (1995) Multivariate Geostatistics. Springer-Verlag: Berlim.
Zellner, A. (1971) An Introduction to Bayesian Inference in Econometrics. John Wiley &
Sons.
Zhang, L., Mykland, P. A. e Aït-Sahalia, Y. (2005) A tale of two time scales: determining
integrated volatility with noisy high-frequency data. Journal of American Statistical
Association, 100, 1394–1411.
189