Embed Size (px)
Citation preview

USO DE UM PROCESSO ETL EM UM MODELO DATAWAREHOUSE PARA A GERAÇÃO DE DASHBOARDS DE
INDICADORES DE REDES DE TELEFONIA CELULAR
Antonio Luiz Bonna de Lyra
Projeto de Graduação apresentado ao CorpoDocente do Departamento de EngenhariaEletrônica e de Computação da EscolaPolitécnica da Universidade Federal do Rio deJaneiro, como parte dos requisitos necessáriosà obtenção do título de Engenheiro Eletrônicoe de Computação.
Orientador: Flávio Luis de Mello
Rio de JaneiroAgosto de 2016

USO DE UM PROCESSO ETL EM UM MODELO DATAWAREHOUSE PARA A GERAÇÃO DE DASHBOARDS DE
INDICADORES DE REDES DE TELEFONIA CELULAR
Antonio Luiz Bonna de Lyra
PROJETO DE GRADUAÇÃO SUBMETIDO AO CORPO DOCENTE DODEPARTAMENTO DE ENGENHARIA ELETRÔNICA E DE COMPUTAÇÃODA ESCOLA POLITÉCNICA DA UNIVERSIDADE FEDERAL DO RIODE JANEIRO COMO PARTE DOS REQUISITOS NECESSÁRIOS PARAA OBTENÇÃO DO GRAU DE ENGENHEIRO ELETRÔNICO E DECOMPUTAÇÃO.
Autor:
Antonio Luiz Bonna de Lyra
Orientador:
Prof. Flávio Luis de Mello, D.Sc.
Examinador:
Prof. Heraldo Luís Silveira de Almeida, D.Sc.
Examinador:
Prof. Ricardo Rhomberg Martins, D.Sc.
RIO DE JANEIRO, RJ – BRASILAGOSTO DE 2016

Bonna de Lyra, Antonio LuizUso de um Processo ETL em um Modelo Data
Warehouse para a Geração de Dashboards de Indicadoresde Redes de Telefonia Celular / Antonio Luiz Bonna deLyra. – Rio de Janeiro: UFRJ/Escola Politécnica, 2016.
XVI, 90 p.: il.; 29, 7cm.Orientador: Flávio Luis de MelloProjeto de Graduação – UFRJ/Escola Politécnica/
Departamento de Engenharia Eletrônica e de Computação,2016.
Referências Bibliográficas: p. 62 – 66.1. ETL. 2. Banco de Dados. 3. Data Warehouse.
4. Redes de Telefonia. 5. KPI. 6. Dashboard. I.Luis de Mello, Flávio. II. Universidade Federal do Rio deJaneiro, Escola Politécnica, Departamento de EngenhariaEletrônica e de Computação. III. Uso de um ProcessoETL em um Modelo Data Warehouse para a Geração deDashboards de Indicadores de Redes de Telefonia Celular.
iii

UNIVERSIDADE FEDERAL DO RIO DE JANEIROEscola Politécnica - Departamento de Eletrônica e de ComputaçãoCentro de Tecnologia, bloco H, sala H-212, Cidade UniversitáriaRio de Janeiro - RJ CEP 21949-900
Este exemplar é de propriedade da Universidade Federal do Rio de Janeiro, quepoderá incluí-lo em base de dados, armazenar em computador, microfilmar ou adotarqualquer forma de arquivamento.
É permitida a menção, reprodução parcial ou integral e a transmissão entre bibli-otecas deste trabalho, sem modificação de seu texto, em qualquer meio que estejaou venha a ser fixado, para pesquisa acadêmica, comentários e citações, desde quesem finalidade comercial e que seja feita a referência bibliográfica completa.
Os conceitos expressos neste trabalho são de responsabilidade do(s) autor(es).
iv

A todos os professores efuncionários da UFRJ.
v

AGRADECIMENTOS
Agradeço a equipe da Huawei NPM, principalmente aos engenheiros Carlos Edu-ardo Covas Costa e Eduardo Martins Montenegro, pela ajuda, ensinamentos e ami-zade durante todo o período em que fiz meu estágio na empresa, onde tive a opor-tunidade de desenvolver a ferramenta que apresento neste trabalho; aos meus chefesEng. Bruno Leonardo Barbosa de Oliveira e Eng. Henrique Amaral Omena, quecoordenaram o desenvolvimento da ferramenta na Huawei.
Agradeço a todos os professores do curso de Engenharia Eletrônica e de Com-putação da UFRJ que contribuíram para minha formação acadêmica, em especialao meu orientador acadêmico e coordenador de curso Carlos José Ribas D’Avila, eaos professores Heraldo Luís Silveira de Almeida e Ricardo Rhomberg Martins queaceitaram o convite de participação na banca de defesa deste projeto de graduação.E, finalmente, ao professor Flávio Mello que aceitou me orientar nesse trabalho.
vi

Resumo do Projeto de Graduação apresentado à Escola Politécnica/UFRJ comoparte dos requisitos necessários para a obtenção do grau de Engenheiro Eletrônicoe de Computação
USO DE UM PROCESSO ETL EM UM MODELO DATA WAREHOUSE PARAA GERAÇÃO DE DASHBOARDS DE INDICADORES DE REDES DE
TELEFONIA CELULAR
Antonio Luiz Bonna de Lyra
Agosto/2016
Orientador: Flávio Luis de Mello
Departamento: Engenharia Eletrônica e de Computação
RESUMO
Este trabalho destina-se em desenvolver uma ferramenta capaz coletar dados dasredes de telefonia 3G e 4G e gerar relatórios com os indicadores de performanceda rede com menor atraso de tempo possível. A intenção foi desenvolver umprocesso ETL (Extract, Transform, Load) capaz de extrair dados dos servidoresda operadora, transformá-los e carregá-los em um Data Warehouse. Inicialmenteforam feitos testes para escolher quais tecnologias a serem utilizadas. Essestestes foram de suma importância para garantir que o processo ocorra de formarápida, com poucos erros e com menos atraso. Neste sentido, foram escolhi-das diferentes ferramentas para cada etapa do processo. A partir de então, osdados já carregados no Data Warehouse foram processados para cálculos dosprincipais indicadores das redes de telefonia, e depois agrupados em maioresníveis de granularidade. Por fim, foi utilizada uma aplicação web para extrairesses dados do Date Warehouse para gerar dashboards em uma interface web, demodo que o usuário possa analisar esses dados através de diversos tipos de consultas.
Palavras-Chave: ETL, Banco de Dados, Data Warehouse, KPI, 3G, 4G, dashboard.
vii

Abstract of Graduation Project teste presented to POLI/UFRJ as a partialfulfillment of the requirements for the degree of Electronic and Computer Engineer
AN ETL PROCESS IN DATA WAREHOUSE TO GENERATE KPIDASHBOARDS FOR MOBILE NETWORKS
Antonio Luiz Bonna de Lyra
August/2016
Advisor: Flávio Luis de Mello
Department: Electronic and Computer Engineering
ABSTRACT
This work aims to develop a tool that can collect data from 3G and 4G mobilenetworks and generate reports with the network performance indicators withless delay as long as possible. The intention was to develop an ETL (Extract,Transform, Load) process capable of extracting data from the enterprise servers,transform and load it in a Data Warehouse. Initially tests were made to choosewhich technologies to be used. These tests were of very importance to guaranteethat the process occurs as fast as possible, with fewer errors and less delay. Inthis sense, they were chosen different tools for each step of the process. With thedata already loaded in the Data Warehouse, KPIs (Key Performance Indicator) ofthe mobile networks are calculated and grouped into higher levels of granularity.Finally, a web application extract data from the Data Warehouse to generatedashboards on a web interface, then the user can analyze the data from differentkinds of views.
Key-words : ETL, Database, Data Warehouse, KPI, 3G, 4G, dashboard.
viii

Sumário
Lista de Figuras xi
Lista de Tabelas xiii
Lista de Abreviaturas e Siglas xiv
1 Introdução 11.1 Tema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Delimitação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Justificativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.4 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.5 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.6 Descrição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Fundamentação Teórica 52.1 Tecnologias de telefonia móvel . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Breve histórico sobre a telefonia móvel . . . . . . . . . . . . . 52.1.2 Cenário atual . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.3 Características do UMTS . . . . . . . . . . . . . . . . . . . . . 82.1.4 Características do LTE . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Conceitos de KPI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.3 Conceitos de BI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.1 ETL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3.2 Data Warehouse . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.3 Data Marts . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.3.4 Dashboard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 Solução implementada 233.1 Arquitetura do Sistema . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1.1 Servidores Externos . . . . . . . . . . . . . . . . . . . . . . . . 243.1.2 Implementação do ETL . . . . . . . . . . . . . . . . . . . . . 273.1.3 Aplicação MVC . . . . . . . . . . . . . . . . . . . . . . . . . . 37
ix

3.2 Materiais e Métodos . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2.1 Infra-estrutura . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2.2 Ferramentas utilizadas . . . . . . . . . . . . . . . . . . . . . . 393.2.3 Funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4 Resultados e Discussões 504.1 KPIs básicos para tecnologia UMTS . . . . . . . . . . . . . . . . . . . 534.2 Principais ofensores por RNC . . . . . . . . . . . . . . . . . . . . . . 554.3 KPIs personalizados para tecnologia UMTS . . . . . . . . . . . . . . 564.4 KPIs básicos para tecnologia LTE . . . . . . . . . . . . . . . . . . . . 574.5 Discussões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5 Conclusões e Trabalhos Futuros 595.1 Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.2 Trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Referências Bibliográficas 62
A Códigos Fonte - ETL 67A.1 Extração . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
A.1.1 Ftp.py . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68A.1.2 Auto-get-performance.sh . . . . . . . . . . . . . . . . . . . . . 70
A.2 Conversão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71A.2.1 pm-convert.sh . . . . . . . . . . . . . . . . . . . . . . . . . . . 71A.2.2 auto-convert.sh . . . . . . . . . . . . . . . . . . . . . . . . . . 73A.2.3 parser.py . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74A.2.4 auto-parse.sh . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
A.3 Carga . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78A.3.1 staging.sh . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78A.3.2 auto-staging.sh . . . . . . . . . . . . . . . . . . . . . . . . . . 82
B Códigos Fonte - Processamento 83B.1 Cálculo dos KPIs de Acessibilidade . . . . . . . . . . . . . . . . . . . 84
B.1.1 View vw_acessibility.sql . . . . . . . . . . . . . . . . . . . . . 84B.1.2 Função PL/SQL inserir_kpi_accessibility.sql . . . . . . . . . . 85B.1.3 inserir_kpi_accessibility.sh . . . . . . . . . . . . . . . . . . . 86
B.2 Cálculo dos ofensores por RNC dos KPIs de Acessibilidade . . . . . . 87B.2.1 Função PL/SQL inserir_worst_cells_rnc_accessibility.sql . . 87B.2.2 inserir_worst_cells_rnc_accessibility.sh . . . . . . . . . . . . 89
x

Lista de Figuras
2.1 Evolução dos padrões de telefonia móvel 3GPP. Fonte: 5G Americas [1]. . 62.2 Números de celulares no mundo ano a ano, em bilhões. Fonte: Teleco [2]. . 72.3 Projeção do números de assinantes globais em cada tecnologia, em milhões.
Fonte: 5G Americas [3]. . . . . . . . . . . . . . . . . . . . . . . . . . . 72.4 Projeção para os acessos móveis no Brasil. Fonte: 5G Americas [4]. . . . . 82.5 Divisão lógica da rede móvel em rede de acesso e núcleo de rede. . . . . . 92.6 Topologia UMTS. Fonte: Qualcomm Wireless Academy [5]. . . . . . . . . 102.7 UTRAN - UMTS Terrestrial Radio Access Network. Fonte: Qualcomm
Wireless Academy [5]. . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.8 Core Network Fonte: Qualcomm Wireless Academy [5]. . . . . . . . . . . 112.9 Arquitetura E-UTRAN . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.10 Valores típicos de RTWP. Fonte: telecomHall [6] . . . . . . . . . . . . . . 152.11 Softer Handover. Fonte: Teleco [7] . . . . . . . . . . . . . . . . . . . . . 152.12 Soft Handover. Fonte: Teleco [7] . . . . . . . . . . . . . . . . . . . . . . 162.13 Hard Handover. Fonte: Teleco [7] . . . . . . . . . . . . . . . . . . . . . 162.14 Inter-RAT Hard Handover. Fonte: Teleco [7] . . . . . . . . . . . . . . . . 172.15 Arquitetura tecnológica de um BI. [8] . . . . . . . . . . . . . . . . . . . 192.16 Estrutura do ETL. [9] . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1 Arquitetura do Sistema. . . . . . . . . . . . . . . . . . . . . . . . . . . 243.2 Estrutura do EMS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.3 Diagrama de Fluxos do Processo de ETL. . . . . . . . . . . . . . . . . . 283.4 Exemplo de um arquivo XML contendo uma família com contadores de RRC. 303.5 Objeto de um arquivo XML contendo o nome do RNC, e o nome e identi-
ficador de uma célula. . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.6 Objeto de um arquivo XML da rede LTE contendo o nome e identificador
de um eNode-B, e o nome e identificador de uma célula. . . . . . . . . . . 313.7 Tempo de carga em uma base de dados vazia, em segundos. . . . . . . . . 323.8 Tempo de carga em uma base de dados já populada, em segundos. . . . . 323.9 Arquivo do exemplo anterior após a conversão para uma planilha em CSV. 323.10 Arquivo do exemplo anterior após o parser. . . . . . . . . . . . . . . . . 33
xi

3.11 Volume de dados por arquivo (MB). . . . . . . . . . . . . . . . . . . . . 353.12 Diagrama de Fluxos do Processamento dos Dados. . . . . . . . . . . . . . 363.13 Arquitetua MVC. Fonte: CodeIgniter Brasil [10]. . . . . . . . . . . . . . 383.14 Diagrama de um processador XSLT. . . . . . . . . . . . . . . . . . . . . 413.15 Arquivo DTD usado para validar um arquivo XML. . . . . . . . . . . . . 423.16 Tempo de carga de 4 GB de dados, em segundos. Fonte: página oficial do
pg_bulkload [11]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.17 Tempo de carga de 1 GB de dados para diferentes métodos de inserção, em
minutos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.18 Monitoramento do ETL . . . . . . . . . . . . . . . . . . . . . . . . . . 483.19 Monitoramento dos KPIs . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.1 Organização do Banco de Dados. . . . . . . . . . . . . . . . . . . . . . . 514.2 Página inicial da ferramenta. . . . . . . . . . . . . . . . . . . . . . . . . 514.3 Menu com os indicadores de performance. . . . . . . . . . . . . . . . . . 524.4 Tecnologias disponíveis. . . . . . . . . . . . . . . . . . . . . . . . . . . 524.5 Agregações de KPIs disponíveis. . . . . . . . . . . . . . . . . . . . . . . 524.6 KPIs básicos de Accessibility e Retainability. . . . . . . . . . . . . . . . . 534.7 KPIs básicos de Traffic. . . . . . . . . . . . . . . . . . . . . . . . . . . 534.8 KPIs básicos de Service Integrity e Retention. . . . . . . . . . . . . . . . 544.9 KPIs básicos de Mobility. . . . . . . . . . . . . . . . . . . . . . . . . . . 544.10 KPIs básicos de Availability e Coverage. . . . . . . . . . . . . . . . . . . 544.11 Ranqueamento das piores células de um RNC. . . . . . . . . . . . . . . . 554.12 KPI de uma célula ao longo de um dia. . . . . . . . . . . . . . . . . . . 554.13 KPIs personalizados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.14 Piores células para o KPI QDA PS . . . . . . . . . . . . . . . . . . . . . 564.15 KPIs básicos da rede LTE. . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.1 Modelo Multidimensional proposto. [8] . . . . . . . . . . . . . . . . . . . 60
xii

Lista de Tabelas
2.1 Principais mercados de celular no mundo, em milhões. Fonte: Teleco [2]. . 8
3.1 RNCs disponíveis em cada um dos servidores do EMS . . . . . . . . . . . 263.2 Exemplo de uma tabela de uma família de contadores por RNC. . . . . . . 333.3 Exemplo de uma família com contadores por Node-B . . . . . . . . . . . 343.4 Exemplo de uma família de contadores do LTE . . . . . . . . . . . . . . 34
xiii

Lista de Abreviaturas e Siglas
1G 1st Generation, p. 5
2G 2nd Generation, p. 5, 8
3GPP 3rd Generation Partnership Project, p. 5
3G 3rd Generation, p. 1, 2, 4, 5, 8, 9, 23
4G Fourth Generation, p. 1, 2, 4, 6, 8, 23
API Application Programming Interface, p. 48
BI Business Intelligence, p. 4, 18, 39
CRUD Create, Read, Update, Delete, p. 38
CSV Comma-separated values, p. 31, 34, 41, 42, 45, 59
CS Circuit Switched, p. 9–14, 17
CTL Control Temporal Logic, p. 45
DTD Document Type Definition, p. 42
E-UTRAN Evolved Universal Terrestrial Radio Access, p. 11
EDGE Enhanced Data rates for GSM Evolution, p. 5
EMS Element Management System, p. 25, 29, 49
EPC Evolved Packet Core, p. 11
ETL Extract, Transform, Load, p. 1, 3, 4, 18–20, 23, 27, 31, 39, 45,48, 49, 58, 59
FTP File Transfer Protocol, p. 27, 40, 49
GERAN GSM EDGE Radio Access Network, p. 9
GGSN Gateway GPRS Support Node, p. 11
xiv

GMSC Gateway Mobile Switching Center, p. 11
GPRS General Packet Radio Services, p. 5
GSM Global System for Mobile Communications, p. 5, 7, 9, 15–17,59
GUI Graphical User Interface, p. 44
HSDPA High Speed Downlink Packet Access, p. 6, 14, 18
HSPA High Speed Packet Access, p. 6, 9
HSUPA High Speed Uplink Packet Access, p. 6
IP Internet Protocol, p. 27
ISDN Integrated Service Digital Network, p. 11
JSON JavaScript Object Notation, p. 3
KPI Key Performance Indicator, p. 1–4, 12, 13, 18, 23, 27, 29, 35,37, 39, 40, 43, 45, 46, 48–58, 83
LTE Long Term Evolution, p. 6–8, 11, 17, 25, 29, 31, 34, 35, 37, 50,57
MSC Mobile Switching Center, p. 11
MVC Model, View, Controler, p. 3, 37, 39, 46, 59
OFDM Orthogonal Frequency Division Multiple Access, p. 11
OLAP Online Analytical Processing, p. 60
PL/SQL Procedural Language/Structured Query Language, p. 39, 43,44, 46
PSTN Public Switched Telephone Network, p. 11
PS Packet Switched, p. 9–11, 13, 14, 17
RAB Radio Access Bearer, p. 13, 14, 27
RAN Radio Access Network, p. 9
RF Radio Frequência, p. 1, 10
xv

RNC Radio Network Controller, p. 10, 12, 14, 15, 25–27, 30, 33, 37,50, 52, 55, 60
RRC Radio Resource Control, p. 13, 27, 29
RTWP Received Total Wideband Power, p. 14
SGSN Serving GPRS Support Node, p. 11
SMS Short Message Service, p. 5
SQL Structured Query Language, p. 2, 43, 44, 49
SSH Secure Shell, p. 47
UF Unidade da Federação, p. 27, 57
UMTS Universal Mobile Telecommunication System, p. 5, 6, 8, 9, 11,15–17, 25, 29, 30, 35, 37, 50, 53, 57
USIN Universal Subscriber Identity Module, p. 9
UTRAN UMTS Terrestrial Radio Access Network, p. 9, 10, 12, 17
VBA Visual Basic for Applications, p. 2
VPN Virtual Private Network, p. 49
VoIP Voice over Internet Protocol, p. 14
WCDMA Wideband Code Division Multiple Access, p. 8
XML eXtensible Markup Language, p. 27, 31, 41, 42, 59
XSLT eXtensible Stylesheet Language for Transformation, p. 41
xvi

Capítulo 1
Introdução
1.1 Tema
O tema do trabalho é o desenvolvimento de uma ferramenta que utiliza o pro-cesso de ETL (Extract, Transform, Load - Extração, Transformação, Carga) voltadopara arquitetura de um Data Warehouse (Armazém de Dados) [12] com a finalidadede gerar dashboards (painel de indicadores) contendo os principais indicadores deperformance de redes de telefonia celular que utilizam as tecnologias 3G (3rd Ge-neration - Terceira Geração) e 4G (Fourth Generation - Quarta Geração). Nestesentido, pretende-se estudar os seguintes problemas: (1) como extrair dados de fon-tes diversas de uma empresa de telecomunicações (que fornece serviços para umaoperadora de telefonia celular) e transformá-los de modo a serem carregados em umBanco de Dados; (2) como esses dados podem ser processados para cálculos dosKPIs (Key Performance Indicator - Indicador-chave de Desempenho) da rede; (3)como esses indicadores podem ser apresentados em dashboards por uma interfaceweb, com menor atraso de tempo possível.
1.2 Delimitação
O desenvolvimento da ferramenta é voltado para o mercado de telecomunicações,onde os engenheiros de RF (rádio frequência) usam arquivos de performance extraí-dos dos servidores das empresas para monitoramento ou confecção de relatórios.
O objeto de estudo do trabalho é limitado ao desenvolvimento de uma soluçãoETL para um modelo Data Warehouse e geração de dashboards de indicadores emuma interface web. Não faz parte do escopo do trabalho a análise desses indicadores.Tampouco o design da interface web, mas sim o modelo da aplicação web que realizaconsultas a um Banco de Dados.
1

1.3 Justificativa
No ramo das telecomunicações atualmente é muito exigido pelas empresas con-tratantes a elaboração de relatórios técnicos por engenheiros, contendo os diversosindicadores de performance sobre as redes de telefonia. Além da elaboração dos re-latórios, outra tarefa dos engenheiros é o monitoramento da rede e a realização dasotimizações necessárias a fim de melhorar os indicadores. Isso acaba tomando boaparte do seu tempo, pois primeiro eles têm que extrair manualmente os dados darede em forma de planilhas, depois fazer gráficos no Excel, para só depois analisar oestado da rede, elaborar relatórios e fazer as otimizações. Outra dificuldade é a faltade padronização dos relatórios, podendo cada engenheiro realizá-los de uma formabem diferente.
Com o aumento da quantidade de dispositivos móveis, chegando, inclusive, a maisde 7,7 bilhões de dispositivos móveis espalhados pelo mundo [13], surgiu a necessi-dade de expansão de toda rede de telefonia. Com isso, a demanda de engenheiros daárea de telecomunicações é crescente, e a tendência do mercado é juntar os conhe-cimentos técnicos de engenharia e de Banco de Dados, pois o números de dados aserem analisados é cada vez maior, ficando cada vez mais inviável o uso de planilhase a criação de macros em VBA (Visual Basic for Applications) no Excel.
É seguindo essa tendência que surgiu a ideia desenvolvida na ferramenta destetrabalho, com a criação de um Banco de Dados contendo, de forma centralizada, asinformações necessárias de uma rede de telefonia celular, para consultas simplificadasvia SQL (Structured Query Language - Linguagem de Consulta Estruturada). Alémdo Banco de Dados, uma interface Web poderá gerar relatórios de forma rápida,dinâmica e customizável através de consultas ao banco. Através dos dashboards dainterface web, o monitoramento da rede pode ser feito de forma constante.
1.4 Objetivos
O objetivo geral do trabalho é desenvolver de uma ferramentaOpenSource (CódigoAberto) capaz de gerar dashboards com os KPIs de redes de telefonia 3G e 4Gatravés de uma consulta a um Data Warehouse. Desta forma, tem-se como objetivosespecíficos:
• Extrair dados dos servidores externos de uma empresa de telecomunicações,contendo os arquivos necessários para análise das redes 3G e 4G
• Realizar as transformações nos arquivos para carregá-los em um Banco deDados
2

• Calcular os KPIs da rede de telefonia
• Fazer agregações dos KPIs por datas (dia e semana) e por outros parâmetrosde acordo com a tecnologia da rede em questão, como por RNC, Node-B,eNodeb, cidade, etc para obter um nível maior de granularidade dos dados, ecalcular os principais ofensores de cada KPI para cada granularidade
• Gerar tabelas e gráficos em uma interface web com os indicadores calculados
1.5 Metodologia
Para o desenvolvimento do trabalho, foi consultada a documentação oficial daempresa de telecomunicações [14] que fornece os serviços a uma operadora de redes detelefonia, com o objetivo de saber quais os principais KPIs usados, quais as fórmulasassociadas para o cálculo de cada KPI e quais contadores específicos precisam serextraídos dos servidores da empresa para realizar os cálculos.
O passo seguinte foi a criação de um Banco de Dados em um servidor próprio,com tabelas e campos no mesmo formato dos arquivos de performance e configura-ção presentes nos servidores da empresa. As tabelas foram divididas em schemas(esquemas), sendo indexadas nos campos onde são realizadas a maior parte das con-sultas e adicionadas constraints (restrições) para persistência dos dados, seguindo amodelagem relacional. [12]
Outro servidor de arquivos foi usado para o primeiro passo do ETL, onde arquivosde performance e configuração são extraídos dos servidores externos e armazenadosem disco, e onde esses arquivos são transformados para o mesmo formato das tabelascorrespondentes no Banco de Dados. A última etapa do ETL foi realizada no servi-dor do Banco de Dados, ocorrendo a carga dos dados e processamento para cálculosdos KPIs, agregação dos dados para obter maior nível de granularidade e cálculodos principais ofensores da rede. Todas essas etapas do ETL foram agendadas paraserem executadas variando de um minuto a duas horas.
O último passo foi o desenvolvimento de uma aplicação web em um servidorutilizando a arquitetura MVC (Model, View, Controler - Modelo, Visão, Controle)[15]. Assim foi possível separar a camada de acesso aos dados do Data Warehouse(Model) da interface (View). Alguns arquivos no formato JSON (JavaScript ObjectNotation) também foram gerados para diminuir os acessos ao Banco de Dados.
3

Com isso, o presente trabalho reúne conceitos de telecomunicações, onde serãoestudados como são estruturadas as redes de telefonia móvel que usam as tecnologiasUMTS (3G) e LTE (4G) e quais seus principais indicadores utilizados para análise deperformance da rede e satisfação do usuário. Reúne também conceitos de Banco deDados e ETL, onde um grande volume de dados será armazenado e processado. Porfim reúne o conceito de aplicação web, onde uma interface web irá gerar dashboardsatravés de consultas ao Banco de Dados.
1.6 Descrição
No capítulo 2 será feita a fundamentação teórica do trabalho, começando comum breve histórico sobre a telefonia celular e descrevendo as características dasUMTS e LTE. Após serão apresentados os conceitos básicos de KPI, ressaltando osprincipais indicadores utilizados para análise de redes de telecomunicações. Por fimserão apresentados os principais conceitos de BI (Business Intelligence - Inteligênciade Negócios) para o entendimento do tema abordado no trabalho.
O capítulo 3 apresenta a solução proposta e implementada. Será detalhada cadaetapa do trabalho dando alguns exemplos práticos do uso do processo ETL. Neste ca-pítulo também serão apresentadas as ferramentas e tecnologias utilizadas e o porquêde cada uma dessas escolhas.
Os resultados são apresentados no capítulo 4. Nele será apresentada a interfaceweb do trabalho, o menu com as opções disponíveis e alguns exemplos de gráficos etabelas que podem ser gerados com a ferramenta desenvolvida.
As conclusões e sugestões para trabalhos futuros se encontram no capítulo 5.
4

Capítulo 2
Fundamentação Teórica
2.1 Tecnologias de telefonia móvel
2.1.1 Breve histórico sobre a telefonia móvel
Os telefones móveis analógicos começaram a ser utilizados na década de 80, e sãoclassificados como de primeira geração, 1G (1st Generation). Gradativamente essesforam substituídos pelos de segunda geração, 2G (2nd Generation), que utilizama tecnologia GSM (Global System for Mobile Communications - Sistema Globalpara Comunicações Móveis) e técnicas digitais. Estes sistemas foram desenvolvidospara suportar comunicações de voz, porém, é possível também enviar pequenasmensagens de texto (SMS - Short Message Service - Serviço de mensagens curtas)entre os dispositivos da rede. [16, 17]
Os sistemas 2G evoluíram para permitir que os usuários acessassem a Internet apartir de seus aparelhos. Estes sistemas ficaram conhecidos como sistemas de se-gunda geração e meia (2,5G). Dentre os sistemas 2,5G, destacam-se o GPRS (GeneralPacket Radio Services - Serviços Gerais de Pacote por Rádio) e o EDGE (EnhancedData rates for GSM Evolution - Taxas de Dados Ampliadas para a Evolução doGSM), ambos são evoluções do GSM. No GPRS, um usuário alcança uma taxa depico, para transmissão de dados, de 140 Kbps, enquanto no EDGE esta taxa chegaa 384 Kbps. [16]
Entretanto, as taxas atingidas por esses sistemas não eram suficientes para atenderas novas demandas de comunicação. Em dezembro de 1998, foi criada a 3GPP (3rdGeneration Partnership Project), uma organização global de comunicações sem fioque trabalha em colaboração para desenvolver normas e especificações para tecno-logias de rádio e arquiteturas de serviço. Como evolução das redes GPRS e EDGE,o UMTS (Universal Mobile Telecommunication System - Sistema Universal de Tele-
5

comunicações Móveis) foi proposto e apresentado na Release-99 (R99) da 3GPP noano de 2000, para ser uma solução integrada para aspectos de transmissão de voz edados na telefonia 3G.
Com o rápido avanço do UMTS, uma nova tecnologia foi incorporada na Release-2005 (R5), oferecendo maiores taxas de download. Desta forma, o sistema tambémrecebeu o nome de High Speed Downlink Packet Access (HSDPA). Por conseguinte,foi incorporada na Release-2006 (R6) a tecnologia HSUPA , que permitiu maiorestaxas de upload. Quando as tecnologias HSDPA e HSUPA são implementadas juntasem uma rede, são comumente referidos como HSPA (High Speed Packet Access). [1]
A evolução do HSPA veio na Release 7, chamado de HSPA+. Foi na Realease 8 quefoi introduzida a quarta geração de tecnologia móvel (4G), a tecnologia LTE (LongTerm Evolution), com o objetivo de oferecer velocidades maiores na transmissão dedados. A Figura 2.1 mostra o gráfico da evolução das tecnologias 3GPP duranteos anos, incluindo o LTE-Advance, proposto na Release 10 e que propôs melhoriastecnológicas para o LTE.
Figura 2.1: Evolução dos padrões de telefonia móvel 3GPP. Fonte: 5G Americas [1].
2.1.2 Cenário atual
A maior parte dos habitantes do mundo já possui acesso à telefonia móvel. Con-forme dito na seção 1.3, o número de dispositivos móveis já ultrapassou a marca de7 bilhões desde 2015, conforme ilustra a Figura 2.2. Além disso, deve-se conside-rar que o número de usuários com dois ou mais dispositivos (podendo ser celulares,tablets, notebooks, etc) está se tornando cada vez mais comum. Isto sugere que onúmero de dispositivos móveis irá ultrapassar o número de habitantes no mundo.1
1Atualmente (agosto de 2016), o número de habitantes no mundo passou a marca de 7,4 bilhõesde pessoas.[18]
6

Figura 2.2: Números de dispositivos móveis no mundo ano a ano, em bilhões. Fonte:Teleco [2].
Os recursos de comunicações móveis são, na grande maioria, destinados a serviçosde envio de mensagens de texto (SMS), chamadas de voz e acesso básico a redede dados (Internet). Neste cenário das comunicações móveis, o LTE vem sendoadotado como o próximo padrão de telefonia móvel pela maior parte das operadorasde telefonia celular. A Figura 2.3 mostra que, apesar de atualmente a maioria dosusuários de dispositivos móveis no mundo serem assinantes da tecnologia GSM, atendência é que até 2020 a maioria utilize a tecnologia LTE.
Figura 2.3: Projeção do números de assinantes globais em cada tecnologia, em milhões.Fonte: 5G Americas [3].
7

No Brasil, também é visível o crescimento acelerado das comunicações móveis. Atecnologia LTE vem surgindo para suprir a demanda dos usuários por serviços móveissempre com taxas de transmissão de dados cada vez maiores, pois as tecnologias2,5G e 3G utilizadas pelas operadoras brasileiras não conseguem oferecer serviçosde qualidade aos clientes em função das limitações de taxa de transferência de dados.
Atualmente o Brasil é o quinto maior mercado do mundo em telefonia celular,conforme indicado na tabela 2.1. Até 2014, cerca de 40% dos dispositivos aindautilizavam a tecnologia 2G, enquanto apenas 2% destes usavam a tecnologia 4G.Seguindo a tendência mundial, a projeção é que até 2019 a porcentagem de acessos4G suba para 47,5% e a de acessos 2G caia para 11%, como mostra os gráficos daFigura 2.4.
Tabela 2.1: Principais mercados de celular no mundo, em milhões. Fonte: Teleco [2].
Ranking País 2008 2009 2010 2011 2012 2013 2014 MAno1 China 641 747 859 986 1.112 1.229 1.286 4,6%2 Índia 347 525 752 894 865 886 944 6,5%3 EUA 270 286 296 316 326 336 355 5,8%4 Indonésia 141 159 220 237 281 304 319 4,9%5 Brasil 152 174 203 242 262 271 281 3,6%6 Rússia 188 208 215 228 231 243 221 -9,1%7 Japão 110 115 121 130 138 146 153 4,6%
Figura 2.4: Projeção para os acessos móveis no Brasil. Fonte: 5G Americas [4].
2.1.3 Características do UMTS
O UMTS usa a técnica de múltiplo acesso WCDMA (Wideband Code DivisionMultiple Access) como interface de rádio, pois necessita de uma banda larga comalta capacidade. Ela utiliza um canal de rádio portador de 5 Mhz, e aperfeiçoa a
8

utilização dessa banda, apresentando menor custo por bit transmitido. Isso o tornamelhor adaptado para a realização múltiplos serviços como internet móvel, e-mail,transferência de dados em alta velocidade, vídeo-chamada, multimídia, vídeo sobredemanda e streaming de áudio. Estes serviços de dados necessitam maior veloci-dade e menor tempo de atraso na transmissão de dados. Com as novas tecnologiasHSPA, é possível atingir taxas de download e upload de 14,4 Mbits/s e 5,76 Mbits/srespectivamente.
No WCDMA existe uma divisão lógica entre a rede de acesso de rádio, RAN(Radio Access Network - Rede de Acesso), que garante acesso sem fio do usuário emum ambiente móvel, e o de núcleo de rede, Core Network (Núcleo da Rede), queprocessa as chamadas de voz e conexão de dados, garantindo a conexão do usuáriocom outras redes de telecomunicações. Essa divisão é ilustrada na Figura 2.5.
Figura 2.5: Divisão lógica da rede móvel em rede de acesso (RAN) e núcleo de rede(Core Network.)
A Figura 2.6 mostra a topologia de uma rede UMTS. O primeiro bloco refere-seao dispositivo do usuário, como um aparelho celular que possuiu seu próprio SimCard (USIM - Universal Subscriber Identity Module). O segundo bloco refere-sea rede de acesso, onde a fim de garantir o investimento das operadoras, existe acompatibilidade do dispositivo e entre as redes 2G e 3G. Para o primeiro caso, arede de acesso chama-se GERAN (GSM EDGE Radio Access Network), que servepara as tecnologias GSM, GPRS e EDGE. No segundo caso, a rede se chamadaUTRAN (UMTS Terrestrial Radio Access Network), que garante o acesso para astecnologias UMTS e HSPA. Por fim a rede se comunica com a Core Network, quepossui o domínio PS (Packet Switched - Comutação por Circuitos) e o domínioCS (Circuit Switched - Comutação por Pacotes), sendo o primeiro responsável peloacesso à internet e o segundo responsável por chamadas de voz.
9

Figura 2.6: Topologia UMTS. Fonte: Qualcomm Wireless Academy [5].
A Figura 2.7 detalha o funcionamento da UTRAN, que faz a interface entre odispositivo móvel e a Core Network. Ela é composta de dois equipamentos prin-cipais, o Node-B e o RNC (Radio Network Controller). O Node-B, ou estaçãomóvel, desempenha funções de amplificação de sinal RF, modulação e codificação, emultiplexação/demultiplexação das informações dos usuários. É o equipamento daUTRAN que implementa a interface de comunicação sem fio com as unidades mó-veis. Cada Node-B tipicamente possuiu três setores de cobertura, a qual chamamosde célula. O RNC é um elemento que gerencia vários Node-Bs sendo responsávelprincipalmente pelos procedimentos ligados à alocação de canais na interface aéreae a garantia da qualidade dos enlaces de RF.[5, 16, 19]
Figura 2.7: UTRAN - UMTS Terrestrial Radio Access Network. Fonte: QualcommWireless Academy [5].
A Figura 2.8 mostra o núcleo de uma Core Network. Pode-se observar que osdomínios PS e CS ocorrem em paralelo na rede. A interface de um RNC com a Core
10

Network CS é chamada de Iu-CS, enquanto a interface de um RNC com a CoreNetwork se chama de Iu-PS.
No domínio PS existem dois elementos, SGSN (Serving GPRS Support Node)e GGSN (Gateway GPRS Support Node), que servem para prover serviços de da-dos comutados por pacotes à rede de telefonia móvel. O SGSN tem a função deroteamento e transferência de pacotes, conexão e desconexão de estações móveis,autenticações e gerenciamento lógico das conexões. O GGSN serve como interfacepara outra rede baseada em comutação de pacotes, como a internet. [5, 16, 17]
No domínio CS destaca-se a MSC (Mobile Switching Center), que tem tem asfunções de comutação das chamadas de voz, gerência de mobilidade dos usuários,sinalização de conexão, entre outras. A MSC pode se conectar a uma rede detelefonia pública comutada (PSTN – Public Switched Telephone Network), ou a umarede digital com integração de serviços (ISDN – Integrated Service Digital Network)por meio de uma ponte de rede, denominado GMSC (Gateway Mobile SwitchingCenter). Assim é possível realizar ligações entre telefonias fixas e móveis. [5, 16]
Figura 2.8: Core Network. Fonte: Qualcomm Wireless Academy [5].
2.1.4 Características do LTE
A tecnologia LTE possui transmissão de dados de 100 Mbps para o downlink e de50 Mbps para o uplink em uma banda de 20 MHz. Utiliza a técnica de transmissãoOFDM (Orthogonal Frequency Division Multiple Access).
A arquitetura do LTE é considerada mais simples que a da UMTS, como pode-seser visto na Figura 2.9. A rede de acesso agora é chamada de E-UTRAN (EvolvedUniversal Terrestrial Radio Access) e o núcleo de rede de EPC (Evolved PacketCore). A E-UTRAN é caracterizada, basicamente, por dois requisitos:
11

(1) Suporte apenas para comutação de pacote (não existindo mais o domínio CS)(2) Baixa latência
Para atingir esses requisitos foi necessário diminuir os elementos de rede, poisassim o processamento com relação aos protocolos de rede é menor, assim como émenor o custo com testes e interfaces. Com isso a rede de acesso contém apenasos eNode-Bs (Evolved Nodeb-B), que incorpora as funções que RNC e Node-B ti-nham na rede UTRAN. Pode-se notar ainda que um eNode-B também se comunicadiretamente com outros eNode-Bs. [16]
Figura 2.9: Arquitetura E-UTRAN.
2.2 Conceitos de KPI
KPI é um indicador chave, utilizado para medir o desempenho dos processos deuma iniciativa, estratégia ou negócio de uma empresa e, com essas informações,colaborar para que alcance seus objetivos. Esse indicador deve ser quantificávelpor meio de um índice (normalmente representado por um número) que retrate oandamento do processo como um todo ou em parte.
KPIs não são exclusividade de telecomunicações ou da área tecnológica, podendoexistir KPIs financeiros ou econômicos. Nesses casos é de suma importância definire escolher qual indicador usar para que esteja ligado ao objetivo do processo. Nestetrabalho usaremos os KPIs mais utilizados e já definidos na documentação oficial daempresa de comunicações [14], que são comumente usados para monitorar e avaliaro funcionamento da uma rede de telefonia celular, além de monitorar o tráfego derede, monitorar a distribuição de recursos e facilitar a expansão da rede e otimização.
Na grande maioria dos casos esses KPIs estão diretamente ligados à qualidade darede, no entanto alguns KPIs são criados com a finalidade de retratar, ou melhor,tentar retratar a experiência do usuário ou qualidade do serviço.
12

KPIs são, geralmente, computados por fórmulas e não dados brutos. As fórmulasnormalmente não são iguais para operadoras de telefonia diferentes. Como exemplotemos uma fórmula para o KPI Acessibilidade RRC :
100×
RRC.SuccConnEstab.OrgConvCall +RRC.SuccConnEstab.OrgStrCall+RRC.SuccConnEstab.OrgInterCall +RRC.SuccConnEstab.OrgBkgCall+RRC.SuccConnEstab.OrgSubCall +RRC.SuccConnEstab.TmConvCall
+RRC.SuccConnEstab.TmStrCall +RRC.SuccConnEstab.TmItrCallRRC.AttConnEstab.OrgConvCall +RRC.AttConnEstab.OrgStrCall
+RRC.AttConnEstab.OrgInterCall +RRC.AttConnEstab.OrgBkgCall+RRC.AttConnEstab.OrgSubCall +RRC.AttConnEstab.TmConvCall
+RRC.AttConnEstab.TmStrCall +RRC.AttConnEstab.TmItrCall
Onde:
OrgConvCall = Originating Conversational Call
OrgStrCall = Originating Streaming Call
OrgInterCall = Originating Interactive Call
OrgBkgCall = Originating Background Call
OrgSubCall = Originating Subscribed traffic Call
TmConvCall = Terminating Conversational Call
TmStrCall = Terminating Streaming Call
TmItrCall = Terminating Interactive Call
Os elementos que fazem parte da fórmula são os contadores, ou dados dedesempenho, retirados dos servidores da empresa. Pode-se observar que a fór-mula usa o conceito Sucessos/Tentativas. Também é possível usar o conceito[(Tentativas− Falhas)/Tentativas] que exprime a mesma realidade.
Os KPIs escolhidos para o desenvolvimento do trabalho são divididos em grupos,conforme a documentação oficial da empresa [14]. São estes:
• Acessibilidade (do inglês, Accessibility): Capacidade do usuário para obter oserviço de chamada, seja de voz (domínio CS) ou dados (domínio PS). Podemosdividir uma chamada em duas partes simples: a sinalização (ou controle) e osdados (ou informação). Já adiantando um dos principais conceitos, podemosentender o RRC (Radio Resource Control) como responsável pela parte decontrole, e o RAB (Radio Access Bearer) como responsável pela parte dainformação. [20]
13

– RRC Setup Succcess Ratio: Mede a taxa de sucessos (em %) de conexõesRRC para chamadas de voz, streaming, chamadas de emergência, chama-das de espera, etc. Note que uma conexão RRC apenas não é suficientepara estabelecimento desses serviços de chamada.
– CS RAB Setup Success Ratio (apenas para tecnologia UMTS): Medea taxa de sucessos (em %) de conexões RAB para chamadas de voz estreaming no domínio CS da Core Network. Só é possível estabeleceruma conexão RAB após o estabelecimento de uma conexão RRC.
– PS RAB Setup Success Ratio (apenas para tecnologia UMTS): Mede ataxa de sucessos (em %) de conexões RAB para chamadas de voz e stre-aming no domínio PS da Core Network.
– E-RAB Setup Success Rate (apenas para tecnologia LTE): Mede a taxade sucessos (em %) de conexões E-RAB (Evolved Radio Access Bearer)para todos os serviços de rádio ou VoIP (Voice over Internet Protocol).Só é possível estabelecer uma conexão E-RAB após o estabelecimento deuma conexão RRC.
– HSDPA RAB Setup Success Ratio (apenas para tecnologia UMTS): Medea taxa de sucessos (em %) de conexões RAB para serviços que utilizama tecnologia HSDPA, no domínio PS.
• Disponibilidade (do inglês, Availability): Indica a disponibilidade dos servi-ços da rede.
– Cell Unavailability duration: Mede a duração total do tempo (em segun-dos) que uma célula ficou indisponível na rede por causa de alguma falhano sistema.
• Cobertura (do inglês, Coverage): Monitora as interferências das células e ouso de Soft Handovers em um RNC.
– RTWP (Received Total Wideband Power): Representa a medida do níveltotal de ruído (em dB) dentro da banda de frequência de uma célula. Estárelacionada com a interferência de uplink, e a sua monitoração ajuda nocontrole de queda de chamadas - principalmente no domínio CS. (apenaspara tecnologia UMTS). Em redes não congestionadas, o valor médioaceitável de RTWP é de -104.5 a -105.5 dBm. Valores muito abaixoindicam interferência de uplink na rede, conforme indica a Figura 2.10.
– Soft Handover Overhead (apenas para tecnologia UMTS): Verifica o con-sumo da rede devido à Soft Handovers.
14

Figura 2.10: Valores típicos de RTWP. Fonte: telecomHall [6]
• Mobilidade (do inglês,Mobility): Monitora as taxas de sucesso de vários tiposde handover. O conceito de sucesso de handover é manter a integridade de umachamada em movimento, sem que haja interrupções. Isto é necessário porqueo usuário pode mover-se (talvez com alta velocidade) e seria inconveniente sea chamada caísse quando o usuário mudasse de uma célula para outra. Emmuitos casos, um usuário pode até entrar em uma área onde há cobertura darede UMTS e terminar a mesma chamada sem interrupções em uma rede GSM/ GPRS.
– Softer Handover Success Ratio (apenas para tecnologia UMTS): Mede ataxa de sucesso (em %) de Softer Handover em um RNC, que consistena transferência de chamada de uma célula para outra célula do mesmoNode-B.
Figura 2.11: Softer Handover. Fonte: Teleco [7]
– Soft Handover Success Ratio (apenas para tecnologia UMTS): Mede ataxa de sucesso (em %) de Soft Handover em um RNC, que consiste na
15

transferência de chamada de um Node-B para outro Node-B.
Figura 2.12: Soft Handover. Fonte: Teleco [7]
– Intra-frequency Hard Handover Success Ratio: Mede a taxa de sucesso(em %) do Intra-frequency Hard Handover Success, que ocorre quando aconexão com o Node-B atual é interrompida antes de ser conectada comum novo Node-B de mesma frequência.
– Inter-frequency Hard Handover Success Ratio: Mede a taxa de sucessodo Intra-frequency Hard Handover Success, que ocorre quando a conexãocom o Node-B atual é interrompida antes de ser conectar com um novoNode-B de outra frequência.
Figura 2.13: Hard Handover. Fonte: Teleco [7]
– W2G Inter-RAT Hard Handover Success Ratio: Mede a taxa de sucesso(em %) da transferência de chamada de um sistema UMTS para GSMou vice-versa. A finalidades básica é manter a continuidade da chamadaem sistema de borda de cobertura UMTS, transferindo assim a chamadasem interrupções para um sistema GSM ou de um GSM para um UMTS.
16

Figura 2.14: Inter-RAT Hard Handover. Fonte: Teleco [7]
– L2W Inter-RAT Handover Out Success Rate: Mede a taxa de sucesso(em %) da transferência de chamada de um sistema LTE para UMTS ouvice-versa.
– L2G Inter-RAT Handover Out Success Rate: Mede a taxa de sucesso(em %) da transferência de chamada de um sistema LTE para GSM ouvice-versa.
• Capacidade de Retenção (do inglês, Retainability): Mede a capacidade dousuário de manter uma conexão estabelecida sem que esta seja finalizada deforma anormal. Comumente medimos a porcentagem de quedas nos serviçosprovidos aos usuários, mas também é possível medi-la nos canais de sinalização.
– CS Service Drop Ratio: Taxa de quedas de serviços CS na rede UTRAN.
– PS Call Drop Ratio: Taxa de quedas de chamadas PS na rede UTRAN.
• Integridade de Serviço (do inglês, Service Integrity): Indica principalmentea capacidade da taxa de transferência em cada célula e qualidade de serviçona rede.
– HSDPA Throughput : Indica a média de downlink throughput (taxa detransferência, em kbit/s) em uma célula.
– HSUPA Throughput : Indica a média de uplink throughput (taxa de trans-ferência, em kbit/s) em uma célula.
• Tráfego (do inglês, Traffic): Mede o tráfego da rede, quantidade de dados ede usuários.
17

– HSDPA RLC Traffic Volume: Fornece o total em bytes de downlink detodos os tipos de serviços em uma célula.
– HSUPA RLC Traffic Volume: Fornece o total em bytes de uplink de todosos tipos de serviços em uma célula.
– Number of HSDPA Users : Fornece a quantidade total e a quantidademédia de usuários usando a tecnologia HSDPA.
– Number of HSUPA Users : Fornece a quantidade total e a quantidademédia de usuários usando a tecnologia HSUPA.
Os contadores e fórmulas usadas para cálculo desses KPIs podem ser encontradosna documentação oficial da empresa. Os KPIs apresentados no trabalho são geral-mente os padrões que as empresas utilizam para análise de uma rede de telefonia,mas é possível também definir um KPI personalizado para uma operadora, sabendoque contadores usar e qual a metodologia para o seu cálculo.
2.3 Conceitos de BI
O termo Business Intelligence (BI), inteligência de negócios, refere-se ao processode coleta, organização, análise, compartilhamento e monitoramento de informaçõesque oferecem suporte à gestão de negócios. É o conjunto de teorias, metodolo-gias, processos, estruturas e tecnologias que transformam uma grande quantidadede dados brutos em informação útil para tomadas de decisões estratégicas. [21]
Pode-se resumir da definição anterior que BI é um sistema capaz de transformaruma quantidade de informação em informações realmente úteis para uma rápida vi-sualização dos objetivos propostos. Esse conceito será utilizado no trabalho, quandodados provenientes de fontes dispersas serão transformados com o objetivo de gerarKPIs das redes de telecomunicações. A Figura 2.15 mostra a arquitetura tecnoló-gica de um BI, onde é possível verificar a existência de fontes externas ou internascontendo os dados desejados, podendo essas fontes serem arquivos em diversos for-matos ou outros bancos de dados. Pode-se observar também a existência de umprocesso ETL para carga dos dados em uma Data Warehouse. Por fim, informaçõespresentes em Data Marts serão analisadas pelos usuários de um sistema BI atravésde aplicações Front-End. No caso deste trabalho, através de dashboards.
18

Figura 2.15: Arquitetura tecnológica de um BI. [8]
Cada um dos conceitos usados em BI será melhor explicado a seguir:
2.3.1 ETL
A sigla ETL significa Extração, Transformação e Carga (em inglês Extract, Trans-form and Load) e visa trabalhar com toda a parte de extração de dados de fontesexternas, transformação para atender às necessidades de negócios e carga dos dadosdentro do Data Warehouse.[22] ETL é uma das etapas mais importantes do projeto,sendo necessária bastante atenção na integridade dos dados a serem carregados emum Data Warehouse. Existem estudos que indicam que o ETL e as ferramentas delimpeza de dados consomem cerca de 70% dos recursos de desenvolvimento e ma-nutenção de um projeto de Data Warehouse.[12] A Figura 2.16 apresenta cada umadas etapas do ETL que serão descritas a seguir:
Figura 2.16: Estrutura do ETL. [9]
19

Extração
É a coleta de dados dos sistemas de origem, que podem ser outras bases dedados relacionais ou arquivos, extraindo-os e transferindo-os para a staging area(área de transição ou área temporária), onde o processo de ETL pode operar deforma independente.
Transformação
É nesta etapa que são realizados os devidos ajustes dos dados extraídos, apli-cando uma série de regras ou funções para assim melhorar a qualidade dos dados econsolidar dados de duas ou mais fontes. Algumas fontes de dados necessitarão demuito pouca manipulação de dados. Em outros casos, diversos tipos de transforma-ções são feitas para atender as regras do negócio. [9, 22]
Carga
Consiste em carregar os dados para dentro do Data Warehouse. Dependendodas necessidades da organização, o tempo de execução deste processo pode variarbastante, podendo ter dados atualizados semanalmente ou a cada meia hora.
2.3.2 Data Warehouse
É um depósito de dados é utilizado para armazenar, de forma consolidada, in-formações relativas às atividades de uma organização em bancos de dados. Nessecontexto, o Data Warehouse possibilita a confecção de relatórios, a análise de gran-des volumes de dados históricos, permitindo uma melhor análise de eventos passados,oferecendo suporte às tomadas de decisões estratégicas que podem facilitar a tomadade decisão.
Por definição, os dados em um Data Warehouse não são voláteis, ou seja, eles nãomudam, salvo quando é necessário fazer correções de dados previamente carregados.Fora de um caso específico os dados estão disponíveis somente para leitura e nãopodem ser alterados.
Os Data Warehouse surgiram como conceito acadêmico na década de 1980. Como amadurecimento dos sistemas de informação empresariais, as necessidades de aná-lise dos dados cresceram paralelamente. Nesse contexto, a implementação do DataWarehouse passou a se tornar realidade nas grandes corporações. O mercado deferramentas de Data Warehouse, que faz parte do mercado de Business Intelligence,cresceu então, e ferramentas melhores e mais sofisticadas foram desenvolvidas paraapoiar a estrutura do Data Warehouse e sua utilização.
20

Como principais requisitos para um Data Warehouse bem elaborado, pode-sedestacar: [22]
• Tornar a informação facilmente acessível. O Conteúdo do Data Warehousedeve ser intuitivo e de fácil entendimento para o usuário (não apenas para odesenvolvedor).
• Apresentar informações consistentes. Informação consistente significa infor-mação de alta-qualidade. Significa que todos os dados são relevantes, precisose completos. Os dados apresentados devem ser confiáveis e íntegros.
• Adaptável e flexível à mudanças. As necessidades dos usuários, os dados e ascondições do negócio vão mudar com o passar do tempo, então é preciso queo Data Warehouse esteja apto a endereçar novas questões, novas necessidadessem que se perca todo o trabalho realizado.
• Auxiliar no processo de tomada de decisão e ser aceito pela comunidade denegócios. De nada adianta um Data Warehouse com milhões de dados quenão tragam os indicadores necessários para a tomada de decisão da empresa.
Um dos maiores problemas no desenvolvimento do Data Warehouse é a compre-ensão dos dados, onde as dimensões devem ser definidas conforme a necessidadede visualização do usuário. Pode-se armazenar grandes quantidades de informação,sendo o modelo mais utilizado conhecido como modelagem multidimensional. Ape-sar de bastante utilizado, não existe um padrão na indústria de software para oarmazenamento de dados. Existem, na verdade, algumas controvérsias sobre quala melhor maneira para estruturar os dados em um Data Warehouse.[23, 24] Nestetrabalho não será usada a modelagem multidimensional, pois acredita-se que issoatrasaria a carga dos dados e aumentaria tempo de latência. Porém a modelagemmultidimensional não está descartada em trabalhos futuros.
2.3.3 Data Marts
O Data Warehouse é normalmente acedido através de Data Marts, que é umaestrutura similar ao do Data Warehouse, porém com uma proporção menor de in-formações. Trata-se de um subconjunto de informações do Data Warehouse quepodem ser identificadas por assuntos ou departamentos específicos. Por exemplo:um Data Mart financeiro poderia armazenar informações consolidadas dia-a-dia paraum usuário gerencial e em periodicidades maiores (semana, mês, ano) para um usuá-rio no nível da diretoria. Um Data Mart pode ser composto por um ou mais cubosde dados. [9, 23]
21

2.3.4 Dashboard
Na tradução simples um dashboard é um painel de indicadores, com seus principaisindicadores e gráficos compilados em um único painel de fácil acesso, manuseio evisualização.
O dashboard organizará e apresentará melhor os conteúdos informativos, dando aeles um design mais profissional e interativo. Todo resultado apresentado será maisfacilmente analisado possibilitando uma melhor tomada de decisões. [25]
22

Capítulo 3
Solução implementada
O escopo da ferramenta desenvolvida no trabalho, conforme descrito na seção 1.4,é criar dashboards com os principais KPIs de redes de telefonia que utilizam astecnologias 3G e 4G. Ela possui somente a interface de usuário, que irá interagirapenas com a interface web.
Este capítulo descreve a arquitetura do trabalho e suas funcionalidades na se-ção 3.1. Na seção 3.2 serão apresentadas as ferramentas e tecnologias utilizadas notrabalho e alguns dos motivos de suas escolhas.
3.1 Arquitetura do Sistema
A Figura 3.1 apresenta a arquitetura geral do sistema, mostrando como se en-contram divididas as principais etapas do trabalho. Pode-se observar a presençade servidores externos onde arquivos contendo os dados necessários serão extraídos,transformados e carregados em um Data Warehouse (que na arquitetura do sistema,fica dentro do Servidor de Dados), que é justamente o processo de ETL descrito naseção 2.3.1 da fundamentação teórica. A seguir será realizada uma descrição de cadauma dessas etapas.
23

Figura 3.1: Arquitetura do Sistema.
3.1.1 Servidores Externos
São elementos que fazem parte da rede de móvel que irão prover os dados ne-cessários ao sistema. O trabalho foi desenvolvido usando os servidores externos daempresa Huawei, mas poderiam ser usados os de qualquer outra empresa de teleco-municações que possua os dados de performance e configuração de redes de telefoniacelular.
24

A solução da Huawei para gerenciar redes móveis se chama EMS (Element Ma-nagement System), uma plataforma de gerenciamento para suportar operadoras detelecomunicações com uma única interface para as diversas tecnologias existentes,os modelos disponíveis são conhecidos como M2000 e U2000. O sistema opera deuma forma cliente-servidor e a estrutura do hardware geralmente é composta porservidores, clientes, alarm-boxes dedicados e outros dispositivos dedicados de redecomo arrays de discos, roteadores, etc. A Figura 3.2 mostra como se organiza aestrutura do EMS.
Figura 3.2: Estrutura do EMS.
O trabalho utiliza três servidores do EMS para a rede UMTS, chamados de ATAE,15 e 40. Já para a rede LTE utiliza apenas um servidor, chamado de 10. Cadaservidor da rede UMTS possui um conjunto de RNCs, conforme indica a tabela 3.1,em um total de 43 RNCs.
25

Tabela 3.1: RNCs disponíveis em cada um dos servidores do EMS
Servidor RNC
15
RNCMG01RNCMG02RNCMG03RNCMG04RNCMG05RNCMG06RNCMG07RNCMS01RNCMS02RNCMS03RNCMT02RNCRO01RNCTO01
40
RNCAL01RNCBA01RNCBA02RNCBA03RNCBA04RNCBA05RNCCE01RNCCE02RNCPB01RNCPE01RNCPE02RNCPE04RNCPI01RNCPI02RNCRN01
ATAE
RNCAC01RNCDF02RNCDF03RNCDF04RNCES01RNCGO01RNCGO04RNCGO05RNCPR01RNCPR02RNCPR03RNCPR04RNCPR05RNCSC01RNCSC02
26

Através da tabela 3.1 pode-se perceber que a nomenclatura de cada RNC segue opadrão {RNC}{UF}{Numeração com dois algarismo}, sendo possível determinar oestado do Brasil onde se encontra um RNC através do UF (Unidade da Federação).Cada um dos três servidores possui seu endereço IP (Internet Protocol - Protocolode Internet) onde é possível conectar-se através de uma interface FTP (File TransferProtocol - Protocolo de Transferência de Arquivos) e extrair os arquivos de confi-guração (contendo diversas informações como a quantidade de Node-Bs e célulasque um RNC possui, em qual frequência cada célula se encontra, em qual bairroou cidade uma célula está localizada, etc.) e de performance nos formatos XML(eXtensible Markup Language - Linguagem de Marcadores Extensível).
Os arquivos de performance contém contadores em amostras de 15, 30 ou 60minutos de diversos tipos de famílias, como as famílias com contadores de conexõesRRC e RAB, as de medidas dos diversos tipos de handover, as de medidas de tráfego,etc. Esses contadores são usados para cálculos dos KPIs, conforme dito na seção 2.2.
3.1.2 Implementação do ETL
O conceito de ETL introduzido na seção 2.3.1 foi implementado no trabalho con-forme o Diagrama de Fluxos da Figura 3.3. É importante ressaltar que antes de seiniciar o processo é necessário atender os seguintes pré-requisitos:
• Tabelas de todas as famílias de contadores tenham sido criadas no Banco deDados
• Uma tabela de log de todos os arquivos baixados tenha sido criada no Bancode Dados
Em seguida será detalhada cada etapa do processo ETL, dando exemplos práticospara o seu melhor entendimento.
27
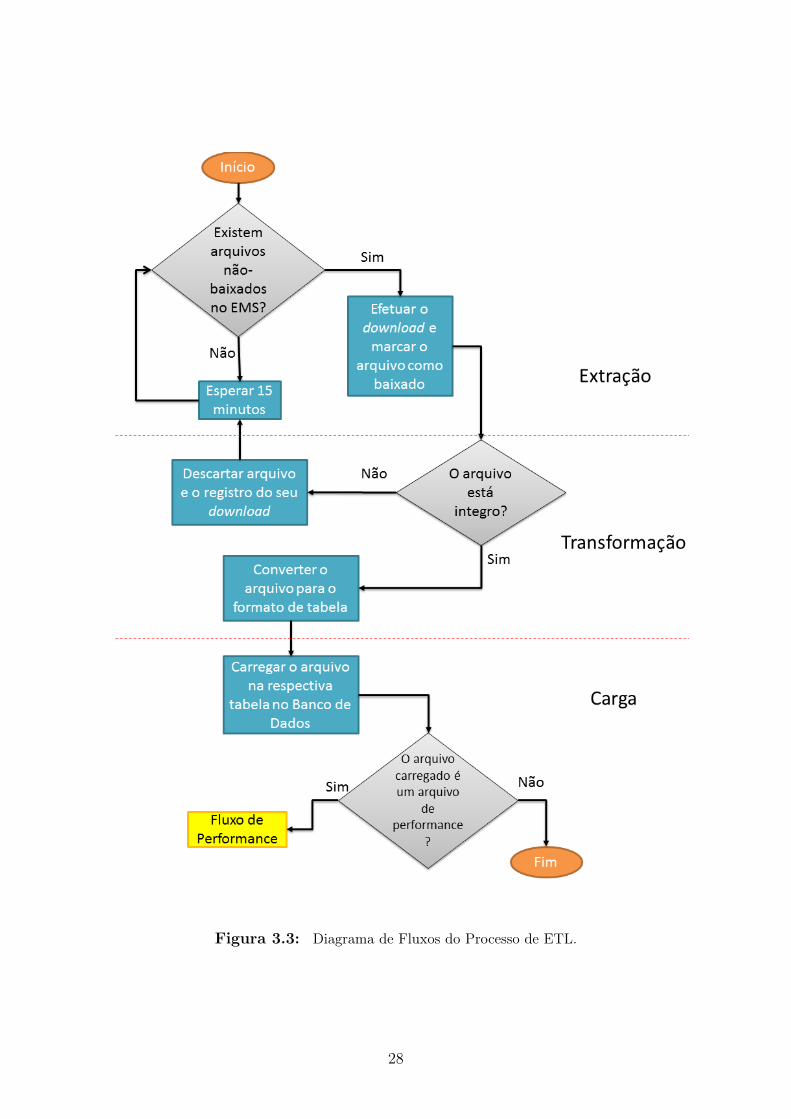
Figura 3.3: Diagrama de Fluxos do Processo de ETL.
28

Extração
Arquivos de desempenho e configuração são baixados dos servidores EMS, ondeapenas os arquivos de performance contendo as famílias dos contadores usados notrabalho para os cálculos dos KPIs serão extraídos. Para a rede UMTS isso significaum total de 29 famílias, enquanto para a tecnologia LTE são extraídos arquivospara 11 famílias de contadores. Das 29 famílias de contadores da rede UMTS, 27são disponíveis em amostras de 30 minutos e duas em amostras de 60 minutos.Para a rede LTE, todas as famílias baixadas são de contadores com amostras de 60minutos. A informação de cada arquivo baixado é armazenada em uma tabela delog no Banco de Dados para que durante esta etapa seja feita uma verificação dequais arquivos já foram baixados, a fim de evitar downloads desnecessários.
Os arquivos baixados estão todos no formato XML. O XML é uma linguagem deprogramação de marcadores como a HTML e foi desenhada para descrever dados,com a grande vantagem de que é extensível , ou seja, pode-se criar as suas própriastags, assim sendo ela é uma linguagem auto definível. O XML possui estruturaem árvore, contendo elementos da raiz (pai), elementos filhos e assim por diante.Usando a estrutura de árvore, pode-se conhecer todos os ramos que partem da raiz.[12, 26]
XML é muito usado para a transferência de dados. A desvantagem do formatoXML é que com uma grande quantidade de dados em uma mesma estrutura, pode-se gerar um arquivo extremamente complexo e ineficiente para ser carregado emuma base de dados. A Figura 3.4 mostra um exemplo de um arquivo XML usadono trabalho para uma família com contadores de RRC da rede UMTS, aberto emum editor de texto. O objeto <cbt> destacado na quarta linha contem a data daamostra com os valores do ano, mês, dia e hora. O objeto <gp> destacado na nonalinha contem o intervalo da mostra em minutos, no caso de 30 minutos. Os demaisobjetos a partir da décima linha possuem os nomes dos contadores.
29

Figura 3.4: Exemplo de um arquivo XML contendo uma família com contadores deRRC.
A linha 156 do mesmo arquivo possui o objeto <moid>, contendo as informaçõesdo nome e identificador de uma célula, e qual seu RNC, conforme destacado naFigura 3.5. Abaixo do objeto estão os valores que os contadores dessa célula recebem.Toda a rede UMTS possui aproximadamente 46 mil células.
Figura 3.5: Objeto de um arquivo XML contendo o nome de um RNC, e o nome eidentificador de uma célula.
30

A Figura 3.6 mostra agora um exemplo do objeto <moid> para a rede LTE,contendo então o nome e identificador de um eNode-B, e o nome e identificador deuma célula. A rede LTE possui aproximadamente 8.500 células.
Figura 3.6: Objeto de um arquivo XML da rede LTE contendo o nome e identificadorde um eNode-B, e o nome e identificador de uma célula.
Transformação
Como dito anteriormente, arquivos XML muito grandes acabam se tornando ine-ficientes para serem carregados em um Data Warehouse. Pensando nisso, a segundaetapa do processo ETL é dividida em duas partes, sendo a primeira a conversão doarquivo do formato XML para CSV (Comma-separated values) e a segunda a trans-formação desse arquivo para o mesmo formato da sua respectiva tabela no Bancode Dados, comumente chamada de parser.
Antes da primeira conversão é necessário validar o arquivo XML para garantir suaintegridade, evitando erros de arquivos danificados ou mal-baixados. A conversãodo arquivo XML para planilhas no formato CSV faz com que o arquivo fique maisleve e fácil de ser manipulado, além de ser muito mais inteligível para o usuário. Emmédia, um arquivo convertido para CSV fica 70% menor que o original em XML.1
Com isso, a carga de um arquivo no formato CSV no Banco de Dados é muito maisrápida do que de um arquivo XML.
Para se ter uma ideia mais precisa da vantagem de um arquivo CSV, foram tes-tados dois cenários: o primeiro comparando o tempo de carga de um arquivo XMLcom o tempo das etapas de transformação, parser e carga de um arquivo CSV emuma base de dados vazia; o segundo faz a mesma comparação, mas para uma basede dados já povoada. A Figura 3.7 mostra que, para o primeiro cenário, a cargado arquivo XML de 26 MB demorou aproximadamente 13 segundos, enquanto to-das as etapas para o arquivo CSV demoraram aproximadamente 11 segundos. Osegundo cenário é apresentado na Figura 3.8, onde o mesmo arquivo XML demo-rou aproximadamente 37 segundos e as etapas com o arquivo CSV próximo dos 14segundos.
1O arquivo XML do exemplo anterior tinha 26 MB, ficando com 8 MB após a conversão paraCSV.
31

Figura 3.7: Tempo de carga em uma base de dados vazia, em segundos.
Figura 3.8: Tempo de carga em uma base de dados já populada, em segundos.
O arquivo do exemplo anterior após a conversão é mostrado na Figura 3.9, abertono Excel. Em vez de tags e objetos, a nova estrutura é formada por linhas e colunasem que os cabeçalhos são CBT, GP, MOID e os contadores daquela família.
Figura 3.9: Arquivo do exemplo anterior após a conversão para uma planilha em CSV.
32

A segunda etapa da conversão consiste em ajustar os campos da coluna CBT paradata no formato padrão do Banco de Dados (ano-mês-dia hora:minuto), quebrar oscampos da coluna CBT em várias colunas e ordenar todas as colunas para o mesmoformato da sua tabela correspondente no Banco de Dados.
Essa etapa também elimina cabeçalhos e os dados de contadores que não estãosendo utilizados, diminuindo o tamanho do arquivo e fazendo com que a carga paradentro do Data Warehouse se torne mais rápida. O formato das tabelas no Bancode Dados para as famílias de contadores por RNC segue o padrão da tabela 3.2,contendo sempre as mesmas cinco primeira colunas no cabeçalho (RNC, Cellname,CellID, Datetime e GP) e os contadores nas colunas restantes.
Tabela 3.2: Exemplo de uma tabela de uma família de contadores por RNC.
RNC Cellname Cellid Datetime GP ...RNCAC01 UACABL01A 63096 2016-06-01 00:00 30 ...
... ... ... ... ... ...RNCSC02 USCTIO02G 64843 2016-06-01 23:30 30 ...
Continuando com os exemplos anteriores, a Figura 3.10 mostra o arquivo anteriorapós o parser, aberto no Excel. Foi tirado o cabeçalho e agora existem colunasnovas e reordenadas seguindo o modelo da tabela 3.2. Notam-se também colunascom todos os campos em branco, indicando que essa família possui contadores quenão estão sendo utilizados no trabalho.
Figura 3.10: Arquivo do exemplo anterior após o parser.
33

Para famílias com contadores por Nodeb-B, o padrão seguido é o da tabela 3.3.Neste trabalho existem duas famílias desse tipo, ambas com amostragem de umahora (exatamente por isso a coluna GP possui valor igual a 60).
Tabela 3.3: Exemplo de uma família com contadores por Node-B
Nodeb Locell Datetime GP ...CBA0036S 0 2016-06-01 00:00 60 ...
... ... ... ... ...WTOTAQ08 2 2016-06-01 23:30 60 ...
A tabela 3.4 mostra um exemplo para uma família do LTE, possuindo sem-pre as mesmas cinco primeiras colunas (eNodebID, eNodeb, Locall Cell, Cell-name,Datetime e GP) com contadores em amostras de uma hora.
Tabela 3.4: Exemplo de uma família de contadores do LTE
eNodebid eNodeb LoCellid Cellname Datetime GP ...270016 EESCAR01 0 EESCAR01A 2016-06-01 00:00 60 ...
... ... ... ... ... ... ...880216 ECESOL12 2 ECESOL12C 2016-06-01 23:30 60 ...
Carga dos Dados
Após os arquivos passarem pelo processo de transformação, já é possível ser feitaa carga destes no Data Warehouse. Quando os dados são carregados no Bancode Dados acabam ocupando um maior volume do que quando estavam no formatode arquivo CSV, conforme mostra a Figura 3.11. Porém é importante ressaltar queexistem grandes vantagens de utilizar uma base de dados, das quais pode-se destacara resposta mais rápida a consultas e manipulação dos dados.
34

Figura 3.11: Volume de dados por arquivo (MB).
Dados de configuração ficam armazenados no Banco de Dados para consultas,sendo atualizados diariamente. Os dados de performance por sua vez precisam pas-sar por mais uma etapa, onde ocorrerá o processamento dos dados para os cálculosdos KPIs das redes UMTS e LTE.
Processamento dos Dados
A Figura 3.12 apresenta o diagrama de fluxos do processamento dos dados da fer-ramenta. É feita sempre uma verificação periódica se todos arquivos de performanceque foram carregados para alguma meia hora.
35

Figura 3.12: Diagrama de Fluxos do Processamento dos Dados.
36

Com meias horas completas, já é possível começar a calcular os indicadores de30 minutos por célula e RNC mencionados na seção 2.2. Os dados dos indicadorescalculados são armazenados em tabelas no Banco de Dados. Ao final de um diaespera-se que todos os KPIs das 48 meia horas do dia já tenham sido calculadospara rede UMTS, assim como os KPIs das 24 horas do dia para rede LTE. Entãosão calculados outros indicadores diários, tais como:
• Cálculos dos indicadores diários por célula, agregando também por região, porRNC e por cidade. Cada cálculo é armazenado em sua tabela correspondenteno Banco de Dados.
• Cálculos dos ofensores diários. Neste caso são ranquedas as piores célulasdiárias (em geral, as com maior quantidades de falhas) por RNC, cidade eregional, e é feita a previsão de quanto cada KPI irá melhorar quando corrigidasessas falha.
• Cálculo de outros KPIS customizáveis, não presentes na seção 2.2, asism comoseus ofensores.
Ao término de uma semana, as mesmas agregações dos indicadores diários tambémsão feitas para semana que passou.
3.1.3 Aplicação MVC
MVC (Model, View, Controller) é a modelagem padrão usada para comunicaçãoentre a interface web e o Banco de Dados. Essa arquitetura é muito utilizada emEngenharia de Sofware, onde é possível dividir tarefas, garantindo que cada camadada aplicação tenha seu próprio escopo e definição e que a comunicação entre todaselas se dê de maneira eficiente e controlada.
Em aplicações que enviam um conjunto de dados para o usuário, o desenvolvedor,frequentemente, separa os dados (Model) da interface (View). Desta forma, alte-rações feitas na interface não afetam a manipulação dos dados, e estes podem serreorganizados sem alterar a interface do usuário. O Model-View-Controller resolveeste problema através da separação das tarefas de acesso aos dados e lógica do negó-cio da apresentação e interação com o usuário, introduzindo um componente entreos dois: o Controller. [10, 27]
A arquitetura MVC é apresentada na Figura 3.13, onde é possível visualizar adivisão de cada uma das camadas descritas a seguir:
37

Figura 3.13: Arquitetura MVC. Fonte: CodeIgniter Brasil [10].
Descrição da camada de Visão (do inglês, View)
Nesta camada estão as telas do sistema que fazem as interfaces com o usuário.É a apresentação, é o que aparece, é o que é visualizado por quem usa o sistema.É no View que as informações, sejam elas quais forem e de qual lugar tenha vindo,serão exibidas para a pessoa. No caso do trabalho, essas informações são exibidasatravés de dashboards.
Essa camada possui além da definição da interface, controladores para a corretamanipulação da tela em questão. Tratam corretamente tanto o envio quanto aapresentação de dados.
Descrição da camada de Modelo (do inglês, Model)
Esta camada representa os dados da aplicação e as regras do negócio que gover-nam o acesso e a modificação dos dados. É esta camada que manipula as estruturasde dados e realiza a conexão com o Banco de Dados. É somente no Model que asoperações de CRUD (Create, Read, Update, Delete) devem acontecer.
Descrição da camada de Controle (do inglês, Controller)
Como sugere o nome, camada de controle é responsável por controlar todo ofluxo do programa, a ligação da camada Model com a camada View. É o “cérebro”
38

e o “coração” do aplicativo, quem define o comportamento da aplicação, é ela queinterpreta as ações do usuário e as mapeia para chamadas do modelo. No controlleré definido desde o que deve ser consultado no Banco de Dados à tela que vai serexibida para quem usa o programa.
3.2 Materiais e Métodos
3.2.1 Infra-estrutura
Para o ambiente de desenvolvimento foram utilizados dois computadores comsistema operacional Linux, distribuição Debian 8.1. O primeiro deles foi usado para oservidor de arquivos conforme indicado na Figura 3.1, com um processador Intel Corei7, com 8 GB de memória RAM e disco rígido com capacidade de armazenamentode 500 GB. O segundo foi usado para o servidor de dados, com um processador IntelCore i5, com 8 GB de memória RAM e disco rígido de 1,5 TB.
3.2.2 Ferramentas utilizadas
Segundo Kimball [12], para o uso de um processo de ETL pode-se utilizar fer-ramentas pagas existentes no mercado ou desenvolver todo o código do programaatravés de uma ou mais linguagens de programação. Para o autor, uma das vanta-gens da ferramenta paga é a sua rapidez (não é preciso perder tempo desenvolvendotodo o código), robustez (um programa já bastante testado e consolidado no mer-cado tende a ter menos erros) e facilidade no uso (geralmente acompanha um manualpara o usuário, não sendo necessário que o mesmo tenha um amplo conhecimentoem programação). Já o segundo método permite uma maior flexibilidade do pro-cesso, afinal utilizando linguagens de programação pode-se desenvolver programascom inúmeras possibilidades e menos custosos computacionalmente (desde que sejamescritos códigos que façam somente o estritamente necessário para o projeto).
Inicialmente no projeto foi utilizado o Pentaho para o processo de ETL, umsofware de BI desenvolvido em Java. [28] Depois foram desenvolvidos programasescritos nas linguagens Python e Shell Script para realizarem o processo, havendoum ganho considerável de desempenho, o que se encontra de acordo com a teoriade Kimball. Para gerenciar o Banco de Dados, foi usado o software PostgreSQL.É também no PostgreSQL que foram desenvolvidas funções na linguagem PL/SQL(Procedural Language/Structured Query Language) para cálculos dos KPIs. Já paraa aplicação MVC, foi utilizado o framework PHP CodeIgniter. O servidor webutilizado é baseado em tecnologia Apache e opera sob o sistema operacional Linux.
39

Essas e as demais ferramentas utilizadas no trabalho serão descritas a seguir:
Python
Python [29] é uma linguagem de programação de altíssimo nível, de sintaxemoderna, interpretada, orientada a objetos, com tipagem forte (não há conversõesautomáticas) e dinâmica (não há declaração de variáveis e elas podem conter di-ferentes objetos) e multiplataforma. Sua primeira versão foi lançada em 1991, e aversão mais recente (3.4.1) foi lançada em maio de 2014. Atualmente possui ummodelo de desenvolvimento comunitário e aberto. [30]
A linguagem foi projetada com a filosofia de enfatizar a importância do esforço doprogramador sobre o esforço computacional. Prioriza a legibilidade do código sobre avelocidade ou expressividade. Combina uma sintaxe concisa e clara com os recursospoderosos de sua biblioteca padrão e por módulos e frameworks desenvolvidos porterceiros.
A grande motivação para o uso do Python no trabalho foi o fato da linguagem sermultiplataforma e ser atualmente a quarta linguagem mais usada no mundo [31],fazendo com que haja muito material disponível na internet para realizar consultase tirar dúvidas. A etapa do processo ETL do trabalho que executa a extração dosdados foi desenvolvida em Python usando a biblioteca ftplib [32], que implementaum servidor FTP. A etapa que faz o parser dos arquivos também foi desenvolvidaem Python, utilizando a biblioteca csv [33]. Para a conexão com o PostgreSQL, foiusada a biblioteca psycopg [34].
Shell Script
O Shell Script é uma linguagem simples e que não precisa ser compilada paraexecutar as tarefas, ou seja, ela é interpretada diretamente pelo shell. É usada emvários sistemas operacionais, com diferentes dialetos, dependendo do interpretadorde comandos utilizado. O interpretador de comandos usado no trabalho é o bash[35], disponível na grande maioria das distribuições GNU/Linux.
Diversos scripts em Shell foram desenvolvidos no trabalho, para todas as etapasdo ETL e também para os cálculos dos KPIs. Inclusive os programas em Pythondescritos anteriormente são executados por scripts em Shell, que antes verificam seo programa já está em execução através do comando pgrep e também possibilitamque vários scripts rodem em paralelo através da ferramenta GNU Parallel, a próximaa ser descrita.
40

GNU Parallel
GNU Parallel [36] é uma ferramenta de código aberto que possibilita a execuçãode vários processos em paralelo, tanto no mesmo computador, quanto em computa-dores diferentes.
Ela foi utilizada no trabalho para rodar em paralelo scripts em Shell e em Python.A execução é feita usando o comando parallel, podendo opcionalmente ser pas-sado como parâmetro a quantidade de processos que deseja-se serem executados emparalelo. Por padrão, o número de processos executados em paralelo é o mesmo daquantidade de núcleos do processador.
Saxon
Saxon [37] é um processador XSLT (eXtensible Stylesheet Language for Transfor-mation) OpenSource(Código Aberto) desenvolvido na linguagem Java pela empresaSaxonica. Com ele é possível transformar arquivos no formato XML para os forma-tos CSV, texto ou HTML. O Saxon é executado por linha de comando, devendo terum ambiente Java habilitado para o seu funcionamento.
O Saxon realiza a transformação de um arquivo XML para o formato CSV con-forme o diagrama da Figura 3.14:
Figura 3.14: Diagrama de um processador XSLT.
Para o Saxon executar a transformação é preciso de um arquivo externo XSLcontendo um código na linguagem XSLT. A linguagem XSLT serve justamente paratransformar arquivos XML em qualquer outro formato, contendo uma sintaxe sim-ples para quem já está familiarizado com a estrutura de um XML. No trabalho foiutilizado o programa Stylus Studio [38] para criar o template contendo o códigoXSLT necessário para a transformação.
41

Abaixo um exemplo do uso do Saxon para transformar uma fonte XML em umarquivo CSV:
java -cp saxon9he.jar net.sf.saxon.Transform -t -s:fonte.xml \
-xsl:estilo.xls -o:arquivo.csv
LibXML
Antes de ser feita conversão do arquivo XML é necessário validá-lo para garantirsua integridade, conforme já havia sido indicado no diagrama de fluxos da Figura 3.3.Para que um documento XML seja validado é preciso usar a Definição do Tipo doDocumento ou, originalmente, DTD (Document Type Definition).
O propósito do DTD é definir uma construção de blocos válida para um docu-mento XML, e ela define a estrutura do documento usando uma lista de elementosválidos. O DTD pode ser declarado dentro de um documento XML ou em umarquivo externo. [26]
O DTD permite descrever cada marca e fornecer regras para interpretar cada in-formação usada em um arquivo XML. Para o trabalho foi usado um arquivo externo,apresentado na Figura 3.15:
Figura 3.15: Arquivo DTD usado para validar um arquivo XML.
Para fazer a validação do XML foi usada a libXML [39], uma ferramenta gratuitaescrita na linguagem C que faz diversas análises de arquivos no formato XML. É
42

preciso colocar o arquivo DTD no diretório indicado no arquivo XML, e executar ocomando xmllint, seguido da opção valid e do nome do arquivo:
xmllint --valid arquivo.xml
PostgreSQL
PostgreSQL [40] é um sistema gerenciador de Banco de Dados relacional e orien-tado a objetos. Um de seus atrativos é ser otimizado para aplicações complexas, istoé, que envolvem grandes volumes de dados ou que tratam de informações críticas.Além disso, trata-se de um Banco de Dados versátil, seguro, com suporte a grandeparte do padrão SQL, gratuito e de código aberto. [41]
Entre suas características e funcionalidades, tem-se:
• Compatibilidade multi-plataforma, ou seja, executa em vários sistema opera-cionais
• Consultas complexas em SQL
• Chaves estrangeiras
• Integridade transacional
• Gatilhos
• Visões
• Funções
• Tipos de Dados
• Operadores
• Funções de agregação
• Métodos de índice
• Linguagens procedurais (PL/SQL, PL/Python, PL/Java, PL/Perl)
A escolha do PostgreSQL como o gerenciador de Banco de Dados do trabalho foidevido ao fato de ser bastante otimizado para trabalhar com um grande volume dedados, tendo também bastante flexibilidade nas suas configurações de desempenho.Foram criadas diversas funções na linguagem PL/SQL para os cálculos dos KPIs edos principais ofensores, que depois de armazenados podem ser chamados por linhade comando, passando opcionalmente parâmetros como data, cidade, RNC, etc.
43

A linguagem PL/SQL pode ser entendida como uma extensão da linguagem SQL,adicionada de funcionalidades que a tornam uma linguagem de programação com-pleta: controle de fluxo, tratamento de exceções, orientação a objetos, entre outras.Com a PL/SQL podemos escrever programas inteiros, desde os mais simples até osmais sofisticados. [42]
Para auxiliar no uso do PostgreSQL foi utilizada a GUI (Graphical User Interface)pgAdmin [43], que é uma plataforma grátis desenvolvida em C++ e a mais popularpara o PostgreSQL. O pgAdmin está disponível para os sistemas operacionais Linux,FreeBSD, Solaris, Mac OSX e Windows, com isso foi possível acessar remotamente oBanco de Dados para realizar consultas em SQL ou desenvolver funções em PL/SQLmesmo de uma máquina com Windows.
Pg_bulkload
O pg_bulkload [11] é uma ferramenta para o PostgreSQL desenvolvida parafazer a carga de uma grande quantidade de dados em um Banco de Dados. É umaalternativa mais rápida para o comando COPY [44] do PostgreSQL, além de possuiroutras funcionalidades como substituir linhas duplicadas e ignorar eventuais errosde parser.
A Figura 3.16 apresenta o tempo de carga para 4 GB de dados em tabelas vaziasindexadas e não-indexadas, usando o comando COPY e usando o pg_bulkload. Nota-se que tabelas com índices demoram mais tempo para carregar os dados, mas é umaboa prática indexar algumas colunas da tabela para otimizar as consultas via SQL.Existem dois métodos de escrita para o pg_bulkload, direct e parallel, sendo oparallel o mais rápido e que pode durar menos de 50% do tempo do COPY.
44

Figura 3.16: Tempo de carga de 4 GB de dados, em segundos. Fonte: página oficialdo pg_bulkload [11].
Para a última etapa do processo ETL foi utilizado o pg_bulkload para carregaros dados dos arquivos CSV nas respectivas tabelas do Banco de Dados através docomando:
pg_bulkload -i arquivo.csv -O tabela_do_bd arquivo_controle.ctl
O arquivo de controle no formato CTL (Control Temporal Logic) contém as opçõesutilizadas para o pg_bulkload, como o método de escrita (parallel), tipo de arquivo(CSV), além de outras opções como ignorar erros e substituir linhas duplicadas porlinhas novas.
O pg_bulkload também foi usado no trabalho para carregar os KPIs calculadosnas tabelas de KPIs do Banco de Dados. Para isso foram testados cinco métodosdiferentes:
1. Utilizando a instrução SQL INSERT [45]
2. Utilizando o comando COPY do PostgreSQL
3. Utilizando o comando COPY binário do PostgreSQL
4. Com o pg_bulkload para um arquivo CSV
5. Com o pg_bulkload para uma função
45

Para os métodos 2, 3 e 4 é preciso antes criar um arquivo intermediário (CSVou binário) usando o comando COPY antes de carregá-lo no Banco de Dados. Osmétodos 1 e 5 possuem a vantagem de não precisar de arquivos intermediários. AFigura 3.17 apresenta os tempo necessários para carregar 1 GB de dados em tabelasvazias e em tabelas já com 4 GB de dados para cada um dos métodos citados:
Figura 3.17: Tempo de carga de 1 GB de dados para diferentes métodos de inserção,em minutos.
O método de inserção usando o pg_bulkload com uma função como tipo de en-trada foi o mais rápido nos testes tanto para tabelas vazias quanto para tabelas jápopuladas. Essa foi a solução utilizada no trabalho, sendo necessário então criar asfunções em PL/SQL com as fórmulas necessárias para o cálculo dos KPIs e executaro seguinte comando para inserir os dados com KPIs calculados nas tabelas de KPIs:
pg_bulkload -i nome_funcao() -O tabela_kpi arquivo_controle.ctl
CodeIgniter
O CodeIgniter [46] é um framework de desenvolvimento gratuito de aplicaçõesem PHP. Seu objetivo é disponibilizar um framework de máxima performance ecapacidade, que seja flexível e o mais leve possível. A primeira versão pública doCodeIgniter foi lançada em 28 de fevereiro de 2006.
O CodeIgniter permite que se mantenha o foco em um projeto, minimizando aquantidade de código necessário para uma dada tarefa. CodeIgniter foi desenvolvidosob o paradigma da programação Orientada a Objetos sob o padrão de arquiteturade software MVC.
A aplicação MVC do trabalho descrita na seção 3.1.3 foi construída utilizando oCodeIgniter devido à ampla biblioteca de classes disponíveis neste framework, que
46

possuem uma estrutura de atributos e métodos que facilitam a implementação detarefas comuns ao desenvolvimento de qualquer uma das aplicações necessárias, taiscomo, conexão com o Banco de Dados, tratamento e consultas de dados retornados,construção de formulários e outros conteúdos HTML para a criação da interfacevisual da aplicação, entre várias outras. Além disso, possui um conjunto de helpers,que pode ser compreendido como bibliotecas de funções, agrupadas de acordo comsuas finalidades.
As URL’s geradas pelo CodeIngniter são limpas e amigáveis. Está entre os fra-meworks PHP mais utilizados em 2016 [47].
Apache
O servidor Apache [48] é o mais bem sucedido servidor web livre. Foi criadoem 1995 por Rob McCool. Em uma pesquisa realizada em novembro de 2015 [49],foi constatado que a utilização do Apache representava cerca de 50% dos servidoresativos no mundo.
Assim como qualquer servidor do tipo, o Apache é responsável por disponibilizarpáginas e todos os recursos que podem ser acessados por um internauta. Envio dee-mails, mensagens, compras online e diversas outras funções podem ser executadasgraças a servidores como o Apache. O que vale destacar no Apache é que, apesar detudo, ele é distribuído sob a licença GNU, ou seja, é gratuito e pode ser estudadoe modificado através de seu código fonte por qualquer pessoa. É graças a essacaracterística que o software foi (e continua sendo) melhorado com o passar dos anos.Graças ao trabalho muitas vezes voluntário de vários desenvolvedores, o Apachecontinua sendo o servidor Web mais usado no mundo.
MobaXterm
OMobaXterm [50] é um terminal de simulação OpenSource para Windows, usadoprincipalmente para estabelecer conexões seguras de acesso remoto a servidores viaSSH (Secure Shell). Permite abrir múltiplas abas para executar simultaneamentevárias operações diferentes. Eles rodam com o servidor gratuito Xorg, para expor-tar o display Unix/Linux e vários dos novos comandos GNU Unix. Foi utilizadono trabalho para poder acessar os servidores Linux via SSH através de máquinasWindows.
47

Telepot
Com o intuito de monitorar cada etapa em todos os processos do trabalho, foiutilizado o Telepot [51], um framework em Python que funciona como um bot utili-zando a API (Application Programming Interface) do Telegram [52], um aplicativode mensagens para celular.
Foram desenvolvidos scripts em Python para o envio automático de mensagenspara um canal no Telegram usando a biblioteca do Telepot. A Figura 3.18 mostraum exemplo de mensagem indicando o andamento de cada parte do processo ETL,e a Figura 3.19 apresenta um exemplo de mensagem indicando para quais horas osKPIs já foram calculados.
Figura 3.18: Monitoramento do ETL Figura 3.19: Monitoramento dos KPIs
3.2.3 Funcionamento
Antes de começar o processo ETL, é necessário criar todas as tabelas necessáriasno PostgreSQL, que são: as tabelas de todas as famílias de contadores de perfor-mance, as tabelas para todos os grupos de KPIs, as tabelas que irão armazenar osdados de configuração e as tabelas de controle que irão armazenar o log de arquivosbaixados, convertidos e carregados no Banco de Dados.
48

Após todas as tabelas terem sido criadas, os scripts desenvolvidos para o processoETL são agendados na cron [53] do Linux. Para extrair os arquivos dos quatroservidores do EMS, é preciso que uma VPN (Virtual Private Network) da empresaesteja conectada. Os scripts que fazem o FTP são agendados para serem executadosa cada 10 minutos no servidor de arquivos.
Os outros scripts do processo ETL que fazem a conversão e o parser no servidor dearquivos são agendados para serem executados a cada minuto. Os arquivos prontospara serem carregados no Data Warehouse são enviados para o servidor de dadosonde os scripts de carga são agendados para serem executados a cada dois minutos.Também neste servidor é feito o processamento dos dados, já descritos anteriormenteconforme a Figura 3.12, agendados para serem executados a cada 30 minutos. Comoo processo de carga e de cálculos dos KPIs são muito pesados e devido à limitação dosprocessadores usado no trabalho, foi feito um controle simples para que os mesmosnão sejam executados ao mesmo tempo: enquanto os cálculos dos KPIs ocorrem écriado um arquivo temporário em um diretório específico impedindo que carga dosdados seja inicializada.
Logo após qualquer etapa do processamento dos dados, são executados os coman-dos SQL Vacuum e Analyze, para limpeza dos registros e atualização das estatísticasdos cálculos, a fim de sempre otimizar o desempenho do Banco de Dados.
49

Capítulo 4
Resultados e Discussões
A ferramenta desenvolvida no trabalho apresentou resultados satisfatórios, in-cluindo os seguintes recursos:
• Interface gráfica contendo os KPIs básicos para as tecnologias UMTS e LTE.
• Os mesmos KPIs podem ser acessados quando agrupados por célula, região,RNC, cidade, meias-horas, dia e semana.
• Ranqueamento das piores células, mostrando os maiores ofensores por RNC(UMTS) e região (LTE) para um determinado KPI, e quanto este KPI irámelhorar quando corrigidas suas falhas.
• KPIs personalizados, agregados por dia e semana e mostrando também seuspiores ofensores por RNC.
A Figura 4.1 mostra a interface do pgAdmin, destacando como foi feita a orga-nização do Banco de Dados no PostgreSQL. Divisão em esquemas por tecnologia(UMTS e LTE) e por KPI, control, counter, configuration etc serviram para organi-zar e facilitar o acesso aos dados do banco.
50

Figura 4.1: Organização do Banco de Dados.
A Figura 4.2 exibe a página inicial da interface web da ferramenta. Por padrão éexibida uma tabela com os KPIs básicos da última semana calculada, por região. Nomenu superior é possível selecionar se deseja exibir os indicadores de performanceagrupados por dia ou semana, ou se deseja exibir outros indicadores personalizados,como mostra a Figura 4.3.
Figura 4.2: Página inicial da ferramenta.
51

Figura 4.3: Menu com os indicadores de performance.
No menu superior à direita é possível selecionar a tecnologia (Figura 4.4) e asagregações desejadas dos KPIs, por região, RNC ou cidade (Figura 4.5).
Figura 4.4: Tecnologias disponíveis.
Figura 4.5: Agregações de KPIs disponíveis.
52

Nas seções seguintes serão destacados alguns dos principais dashboards geradosno trabalho.
4.1 KPIs básicos para tecnologia UMTS
A seguir, serão apresentados exemplos de relatórios semanais contendo os gráfi-cos de KPIs básicos, sendo eles de Accessibility e Retainability (Figura 4.6); Traffic(Figura 4.7); Service Integrity e Retention (Figura 4.8); Mobility (Figura 4.9); Avai-lability e Coverage (Figura 4.10). Nesses exemplos aparecem as variações dos KPIsdiários para toda a rede UMTS.
Figura 4.6: KPIs básicos de Accessibility e Retainability.
Figura 4.7: KPIs básicos de Traffic.
53

Figura 4.8: KPIs básicos de Service Integrity e Retention.
Figura 4.9: KPIs básicos de Mobility.
Figura 4.10: KPIs básicos de Availability e Coverage.
54

4.2 Principais ofensores por RNC
Uma das funcionalidades desenvolvidas no trabalho foi a possibilidade fazer drill-down em cada um dos KPIs de um determinado RNC e descobrir quais foramsuas piores células durante um dia específico. Em geral, a pior célula é aquela queapresenta mais falhas. É feito o ranqueamento dessas células e qual o peso que todasas falhas de cada célula tiveram no KPI do RNC, e o quanto o KPI do RNC irámelhorar quando as falhas forem corrigidas. Como exemplo, a Figura 4.11 mostraas piores células para o RNC RNCMG01 do KPI Acessibilidade RRC.
Figura 4.11: Ranqueamento das piores células de um RNC.
É possível também fazer drill-down em uma célula específica e descobrir qual foi avariação no KPI daquela célula durante as horas do dia, como mostra a Figura 4.12.
Figura 4.12: KPI de uma célula ao longo de um dia.
55

4.3 KPIs personalizados para tecnologia UMTS
Os KPIs básicos apresentados anteriormente servem, em teoria, para medir odesempenho da rede de telefonia. Portanto bons níveis do KPI deveriam tambémgarantir a satisfação dos usuários destas redes. Porém esse conceito não é um con-senso em todas as empresas, por conta disso algumas delas criaram KPIs própriospara chegar a um indicador que se aproxime mais do nível de satisfação do usuário.
Alguns desses KPIs personalizados foram feitos para o trabalho, chamados deAMX NQI. Encontram-se na Figura 4.13, e os ofensores do KPI QDA PS com oranqueamento das piores células do RNC RNCMG01 pode ser visto na Figura 4.14.
Figura 4.13: KPIs personalizados.
Figura 4.14: Piores células para o KPI QDA PS.
56

4.4 KPIs básicos para tecnologia LTE
A Figura 4.15 mostra KPIs básicos gerados para rede LTE.
Figura 4.15: KPIs básicos da rede LTE.
Seguindo o mesmo padrão da rede UMTS, a ferramenta também gerou relatóriosdos KPIs da rede LTE agrupados por região, cidade e UF, além de tabelas com aspiores células de cada região.
4.5 Discussões
A ferramenta desenvolvida neste trabalho cumpriu seu objetivo de gerar dash-boards com indicadores de performance rede de telefonia celular para as tecnologiasUMTS e LTE, através de uma interface web. O atraso apresentado para os cálculosKPIs foi de no mínimo duas horas (diferença entre a hora atual e a hora do últimoKPI calculado). Apesar dessa limitação, os resultados foram bastante satisfatórios,sendo possível consultar não só os KPIs do dia atual como os dos dias retroativos,além de diversas outras agregações e funcionalidades, tais como KPIs das cidades,RNCs e regiões, seus principais ofensores, consulta aos parâmetros e configuraçõesda rede, etc.
57

O trabalho inicial de extração, transformação e carga em um modelo Data Wa-rehouse. Desde o início teve-se a dúvida se seria melhor usar uma ferramenta pagapara fazer o processo de ETL ou se criava-se todos os códigos para cada etapa doprocesso. O segundo método foi escolhido porque observou-se que o processo ficavamais rápido e consumia menos recursos visto as limitações de processamento doscomputadores utilizados. Um processo mais rápido é fundamental para garantir queos KPIs sejam calculados com o menor atraso possível no trabalho.
58

Capítulo 5
Conclusões e Trabalhos Futuros
5.1 Conclusões
Todas as ferramentas escolhidas para o processo ETL e para aplicação MVC semostraram úteis e funcionais. Porém uma das dificuldades para desenvolver todoo processo com várias ferramentas diferentes foi a falta de controle externo paragerenciar todas as etapas do processo, algo presente nas ferramentas pagas. Aforma escolhida para contornar esse problema foi através de envio automático demensagens pelo Telegram para monitorar cada etapa.
O trabalho todo foi feito usando dados de performance e de configuração presentesnos servidores externos da empresa Huawei, mas pode ser estendido para qualquerempresa de telecomunicações que forneça esses arquivos nos formatos XML ou CSV.
5.2 Trabalhos futuros
Mesmo com boa parte dos objetivos iniciais cumpridos, é importante ressaltarque muitas outras funcionalidades podem ser incorporadas na ferramenta, comocálculo dos ofensores para outros tipos de agregações (cidade, semana, mês, etc),indicadores de capacidade das redes de telefonia, georreferenciamento de antenas,adição de outras tecnologias como GSM, etc.
Outra das principais e possíveis mudanças no trabalho é adotar a modelagem mul-tidimensional. A modelagem multidimensional é a técnica de projeto mais freqüen-temente utilizada para a construção de um Data Warehouse. O objetivo é buscarum padrão de apresentação de dados que seja facilmente visualizado pelo usuáriofinal e que possua um bom desempenho para consultas.
59

O modelo dimensional é formado por uma tabela central (tabela de fatos) e vá-rias outras a ela interligadas (tabelas de dimensão), sempre por meio de chavesespeciais, que associam o fato a uma dimensão do cubo. O conceito de dimensãopode ser entendido como a organização dos dados, determinando possíveis consul-tas/cruzamentos. Para o trabalho, por exemplo, poderiam ser RNC, Node-B, data,hora e cidade. Cada dimensão pode ainda ter seus elementos, chamados membros,organizados em diferentes níveis hierárquicos. As tabelas de dimensão geralmentesão tabelas simples em relação ao número de linhas, mas podem conter um númeromuito grande de colunas. [8, 54]
A tabela de fatos é a principal tabela de um modelo dimensional, onde as me-dições numéricas de interesse da empresa ficam armazenadas. A palavra “fato” éusada para representar uma medição de negócio da empresa, ou seja, cada linhada tabela representa uma medição. A tabela de fatos registra os fatos que serãoanalisados e os dados a serem agrupados. A Figura 5.1 mostra uma futura propostade modelo multidimensional para o trabalho, utilizando o chamado Modelo Estrela(Star Schema).
Figura 5.1: Modelo Multidimensional proposto. [8]
Como consulta a banco de dados multidimensionais temos um conjunto de aplica-ções que se denominam ferramentas OLAP (Online Analytical Processing - Proces-samento Analítico Online). OLAP é a denominação que se dá a uma ferramenta quetem a capacidade de manipular e analisar um grande volume de dados sob múltiplasperspectivas, chamada de cubo. O principal benefício do uso de uma ferramenta
60

OLAP é a disponibilidade de métodos para acessar, visualizar e analisar dados commuita flexibilidade e velocidade.
61

Referências Bibliográficas
[1] AMERICAS, G. “Evolução Tecnológica da 3GPP”. 2016. Dispo-nível em: <http://www.4gamericas.org/pt-br/resources/technology-education/3gpp-technology-evolution/>. (Acessoem 12 de maio de 2016).
[2] TELECO. “Estatísiticas de Celular no Mundo”. 2016. Disponível em: <http://www.teleco.com.br/pais/celular.asp>. (Acesso em 08 de maio de2016).
[3] AMERICAS, G. “Mobile Technology Statistics - Global”. 2016. Dispo-nível em: <http://www.4gamericas.org/en/resources/statistics/statistics-global/>. (Acesso em 13 de maio de 2016).
[4] AMERICAS, G. “Mercado móvel Brasil 2014 - 2019”. 2015. Disponívelem: <http://www.4gamericas.org/pt-br/resources/infographics/mercado-movel-argentina-2014-20191/>. (Acesso em 09 de maio de2016).
[5] PERINI, P. UMTS/HSDPA Protocols, Procedures and Operations. Relatóriotécnico, Qualcomm Wireless Academy, Washington, D.C., May 2003.
[6] TELECOMHALL. “O que é RRC e RAB?” 2011. Disponível em: <http://www.telecomhall.com/BR/o-que-e-rtwp.aspx>. (Acesso em 18 demaio de 2016).
[7] TELECO. “Redes 3G: Tipos de Handover”. 2016. Disponível em: <http://www.teleco.com.br/tutoriais/tutorial3ghandover/pagina_2.asp>.(Acesso em 18 de maio de 2016).
[8] DOS SANTOS, V. V. “Data Warehouse: Análise da Performance de Ferramentasde ETL”. 2013. Disponível em: <http://www.uniedu.sed.sc.gov.br/wp-content/uploads/2013/10/Valdinei-Valmir-dos-Santos.pdf>.(Acesso em 20 de maio de 2016).
62

[9] ELIAS, D. “Entendendo o processo de ETL”. 2015. Disponível em: <http://corporate.canaltech.com.br/noticia/business-intelligence/
entendendo-o-processo-de-etl-22850/>. (Acesso em 22 de maio de2016).
[10] ZEMEL, T. “MVC (Model – View – Controller)”. 2009. Dis-ponível em: <http://codeigniterbrasil.com/passos-iniciais/mvc-model-view-controller/>. (Acesso em 20 de junho de 2016).
[11] “pg_bulkload: Project Home Page”. Disponível em: <http://ossc-db.github.io/pg_bulkload/index.html>. (Acesso em 03 de julho de2016).
[12] KIMBALL, R., CASERTA, J. The Data Warehouse ETL Toolkit. USA, Wiley,2004.
[13] INTELLIGENCE, G. “Definitive data and analysis for the mobile indus-try”. 2016. Disponível em: <https://www.gsmaintelligence.com/>.(Acesso em 07 de maio de 2016).
[14] BSC6900 UMTS Product Documentation, v900r015c00 ed. Huawei, April 2015.
[15] GABARDO, A. C. PHP e MVC com CodeIgniter. Brasil, NOVATEC, 2012.
[16] AQUINO, G. P. “Curso Tecnologia Celular 4G-LTE”. 2013. Inatel.
[17] GUSSEN, C. M. G. “Estudo e Simulação da Camada Física do 3G–LTE naConexão Downlink ”. 2009. Disponível em: <http://monografias.poli.ufrj.br/monografias/monopoli10002720.pdf>.
[18] WORLDOMETERS. “Current World Population”. Disponível em: <http://www.worldometers.info/world-population/>. (Acesso em 02 de julhode 2016).
[19] D’ÁVILA, D. C. K. “UTRAN - UMTS Terrestrial Radio Access Network |3G Wireless | O que é”. 2009. Disponível em: <http://www.cedet.com.br/index.php?/O-que-e/3G-Wireless/utran.html>. (Acesso em 16 demarço de 2016).
[20] TELECOMHALL. “O que é RRC e RAB?” 2013. Disponível em: <http://www.telecomhall.com/br/o-que-e-rrc-e-rab.aspx>. (Acesso em18 de maio de 2016).
63

[21] DA NET, O. “O que é Business Intelligence?” 2014. Dis-ponível em: <https://www.oficinadanet.com.br/post/13153-o-que-e-business-intelligence>. (Acesso em 20 de maio de2016).
[22] RIBEIRO, V. “O que é ETL?” 2011. Disponível em: <https://vivianeribeiro1.wordpress.com/2011/06/28/o-que-e-etl-2/>.(Acesso em 10 de março de 2016).
[23] OLIVEIRA, M., 2008. Disponível em: <http://www.datawarehouse.inf.br/Academicos/A%20PUBLICAR_DATA_WAREHOUSE_MARCELL_OLIVEIRA.
pdf>. (Acesso em 23 de maio de 2016).
[24] WIKIPÉDIA, A. E. L. “Armazém de dados”. Disponível em: <https://pt.wikipedia.org/wiki/Armaz%C3%A9m_de_dados>. (Acesso em 23de maio de 2016).
[25] BORGES, L. “Dicas importantes para elaborar um dashboard útile profissional”. Disponível em: <http://blog.luz.vc/excel/dicas-importantes-para-elaborar-um-dashboard-util-e-profissional/>.(Acesso em 30 de maio de 2016).
[26] MACORATTI.NET. “XML – Introdução e conceitos básicos”. Disponível em:<http://www.macoratti.net/xml.htm>. (Acesso em 31 de maio de2016).
[27] DA SILVA ANTUNES, D. L. “Sistema de Gerenciamento e Automatizaçãode Cálculo de Indicadores (SGACI)”. 2009. Disponível em: <http://monografias.poli.ufrj.br/monografias/monopoli10002083.pdf>.
[28] “Pentaho | Data Integration, Business Analytics and Big Data Leaders”. Dis-ponível em: <http://www.pentaho.com/>. (Acesso em 1° de julho de2016).
[29] “Python Programming Language”. . Disponível em: <https://www.python.org/>. (Acesso em 1° de julho de 2016).
[30] BRASIL, P. “PerguntasFrequentes/SobrePython”. Disponível em: <http://wiki.python.org.br/PerguntasFrequentes/SobrePython>. (Acessoem 1° de julho de 2016).
[31] CASS, S. “The 2015 Top Ten Programming Languages”. 2015.Disponível em: <http://spectrum.ieee.org/computing/software/
64

the-2015-top-ten-programming-languages>. (Acesso em 1° de julhode 2016).
[32] “ftplib - FTP protocol client - Python documentation”. Disponível em: <https://docs.python.org/2.7/library/ftplib.html>. (Acesso em 02 de ju-lho de 2016).
[33] “csv - CSV File Reading and Writing - Python documentation”. . Disponívelem: <https://docs.python.org/2/library/csv.html>. (Acesso em02 de julho de 2016).
[34] “PostgreSQL + Python | Psycopg”. Disponível em: <http://initd.org/psycopg/>. (Acesso em 02 de julho de 2016).
[35] “Bash - GNU Project - Free Software Foundation”. Disponível em: <https://www.gnu.org/software/bash/>. (Acesso em 1° de julho de 2016).
[36] “GNU Parallel - GNU Project - Free Software Foundation”. Disponível em:<https://www.gnu.org/software/parallel/>. (Acesso em 02 de julhode 2016).
[37] “Saxonica - XSLT and Xquery Processing”. Disponível em: <http://www.saxonica.com/>. (Acesso em 02 de julho de 2016).
[38] “XML Editor, XML Tools, and XQuery - Stylus Studio”. Disponível em: <http://www.stylusstudio.com/>. (Acesso em 02 de julho de 2016).
[39] “libXML - The XML C parser and toolkit of Gnome”. Disponível em: <http://xmlsoft.org/>. (Acesso em 02 de julho de 2016).
[40] “PostgreSQL: The world’s most advanced open source database”. Disponível em:<https://www.postgresql.org/>. (Acesso em 1° de julho de 2016).
[41] ALECRIM, E. “Banco de dados MySQL e PostgreSQL”. 2008. Disponível em:<http://www.infowester.com/postgremysql.php>. (Acesso em 03 dejulho de 2016).
[42] CORRÊA, E. “Conhecendo o PL/SQL”. Disponível em: <http://www.devmedia.com.br/conhecendo-o-pl-sql/24763>. (Acesso em 03 de ju-lho de 2016).
[43] “pgAdmin: PostgreSQL administration and management tools”. Disponível em:<https://www.pgadmin.org/>. (Acesso em 03 de julho de 2016).
65

[44] “PostgreSQL: Documentation: 9.5: COPY”. Disponível em: <https://www.postgresql.org/docs/current/static/sql-copy.html>. (Acesso em10 de julho de 2016).
[45] “PostgreSQL: Documentation: 9.5: INSERT”. Disponível em: <https://www.postgresql.org/docs/current/static/sql-insert.html>. (Acessoem 10 de julho de 2016).
[46] “CodeIgniter Web Framework”. Disponível em: <https://www.codeigniter.com/>. (Acesso em 1° de julho de 2016).
[47] REVISIONS, W. “Best PHP Framework for 2016”. 2016.Disponível em: <http://webrevisions.com/tutorials/php-framework-the-best-php-framework-for-2013/>. (Acessoem 11 de julho de 2016).
[48] “The Apache HTTP Server Project”. Disponível em: <https://httpd.apache.org/>. (Acesso em 11 de julho de 2016).
[49] NETCRAFT. “November 2015 Web Server Survey”. 2015. Dis-ponível em: <http://news.netcraft.com/archives/2015/11/16/november-2015-web-server-survey.html>. (Acesso em 11 de julho de2016).
[50] “MobaXterm free Xserver and tabbed SSH client for Windows”. Disponível em:<http://mobaxterm.mobatek.net/>. (Acesso em 11 de julho de 2016).
[51] “Python framework for Telegram Bot API”. . Disponível em: <https://github.com/nickoala/telepot>. (Acesso em 11 de julho de 2016).
[52] “Telegram Messenger”. . Disponível em: <https://telegram.org/>. (Acessoem 11 de julho de 2016).
[53] “Agendando Tarefas com cron e atd”. Disponível em: <https://www.debian.org/doc/manuals/debian-handbook/sect.
task-scheduling-cron-atd.pt-br.html>. (Acesso em 12 de ju-lho de 2016).
[54] ROHDEN, R. B. “Banco de Dados: Relacional X Multidimensio-nal”. Disponível em: <https://pt.scribd.com/doc/22742853/Artigo-Banco-de-Dados-Relacional-vs-Multidimensional>.(Acesso em 14 de julho de 2016).
66

Apêndice A
Códigos Fonte - ETL
Neste apêndice se encontram os códigos fonte do processo ETL, contendo aspartes de extração, conversão e carga. Além desses códigos fonte, também estádisponível o script em Shell que faz a execução de cada uma dessas partes.
67

A.1 Extração
A.1.1 Ftp.py
1 ### imports n e c e s s á r i o s ###2 from f t p l i b import FTP3 import psycopg24 import time5 import datet ime6 import os7 import s h u t i l8 import re9
10 de f getpm( ip , user , password , pmfolder , p r e f i x ) : # função que f a z o FTP11 ### de f i n i ç õ e s dos arqu ivos e d i r e t ó r i o s ###12 l o c a l d i r = ' / e t l /umts/performance /temp/ f tp / '13 f i n a l d i r = ' / e t l /umts/performance /raw/ '14 conve r t edd i r = ' / e t l /umts/performance / converted / '15 backupdir = ' / e t l /backup/umts/performance / '16 l o g f i l e = ' /home/ e t l u s e r / log / f tp . l og '17
18 t ry :19 conn = psycopg2 . connect ( "dbname=' pos tg r e s ' user=' pos tg r e s ' host=
host_ip password=password_db" ) # conecta no Banco de Dados20 except :21 pr in t ( 'db e r r o r ' )22 sq l l oaded = "SELECT CONCAT( oss , '_ ' , f i l e ) FROM umts_control . l og_et l
WHERE datet ime >= ( current_date − i n t e r v a l '4 day ' ) AND oss = '%s 'ORDER BY f i l e ; " % s e rv e r
23 s q l s e l e c t e d = "SELECT DISTINCT(CONCAT( funct ionsubset_id , '_ ' , gp ) ) FROMumts_control . counte r_re f e rence WHERE counter_enable = 'TRUE ' ; "
24 cur so r = conn . cur so r ( )25 cur so r . execute ( sq l l oaded )26 time . s l e e p ( 0 . 5 )27 s q l l o a d e d f i l e s = [ item [ 0 ] f o r item in cur so r . f e t c h a l l ( ) ]28 cur so r . execute ( s q l s e l e c t e d )29 time . s l e e p ( 0 . 5 )30 s q l s e l e c t e d s u b s e t = [ item [ 0 ] f o r item in cur so r . f e t c h a l l ( ) ]31 f t p = FTP( ip , user , password )32 f t p . l o g i n ( )33 f t p . cwd( pmfolder )34 d i r l i s t = f tp . n l s t ( )35
36 f o r dirname in d i r l i s t :37 matchdir = re . match ( ' .∗ pmexport_ .∗ ' , dirname )38 i f matchdir :
68

39 f t p . cwd( pmfolder+dirname )40 f i l enames = f tp . n l s t ( )41 f i l enames = sor t ed ( f i l enames , key=lambda x : x . s p l i t ( "_" ) [ 3 ] )42 f o r f i l ename in f i l enames :43 OutputFilename = p r e f i x + f i l ename44 i f OutputFilename not in s q l l o a d e d f i l e s :45 f o r s e l e c t i o n in s q l s e l e c t e d s u b s e t :46 match f i l e = re . match ( ' .∗ '+s t r ( s e l e c t i o n )+ ' .∗ ' , f i l ename )47 i f mat ch f i l e :48 i f ( os . path . e x i s t s ( f i n a l d i r+OutputFilename ) or os . path .
e x i s t s ( conve r t edd i r+OutputFilename+ ' . csv ' ) ) :49 pr in t ( '%s Ex i s t s ' % OutputFilename )50 e l s e :51 pr in t ( 'Opening l o c a l f i l e ' + OutputFilename )52 f i l e = open ( l o c a l d i r +OutputFilename , 'wb ' )53 pr in t ( ' Getting ' + OutputFilename )54 t ry :55 f t p . r e t r b i na ry ( 'RETR %s ' % fi lename , f i l e . wr i t e )56 cur so r . execute ( 'INSERT INTO umts_control . l og_et l ( oss
, f i l e , f s s , datetime , f tp ) VALUES (%s , %s , %s , %s , %s ) ' , ( p r e f i x . s p l i t ('_ ' ) [ 0 ] , f i l ename , f i l ename . s p l i t ( '_ ' ) [ 1 ] , f i l ename . s p l i t ( '_ ' ) [ 3 ] [ 0 : 4 ]+ '− ' + f i l ename . s p l i t ( '_ ' ) [ 3 ] [ 4 : 6 ] + '− ' + f i l ename . s p l i t ( '_ ' )[ 3 ] [ 6 : 8 ] + ' ' + f i l ename . s p l i t ( '_ ' ) [ 3 ] [ 8 : 1 0 ] + ' : ' + f i l ename .s p l i t ( '_ ' ) [ 3 ] [ 1 0 : 1 2 ] + ' : 00 ' , s t r ( datet ime . datet ime . now( ) ) [ 0 : 1 9 ] ) )
57 conn . commit ( )58 time . s l e e p ( 0 . 5 )59 f i l e . c l o s e ( )60 os . rename ( l o c a l d i r+OutputFilename , f i n a l d i r+
OutputFilename )61 s h u t i l . c o p y f i l e ( f i n a l d i r+OutputFilename , backupdir+
OutputFilename )62 time . s l e e p ( 0 . 5 )63 l og = open ( l o g f i l e , "a" )64 l og . wr i t e ( datet ime . datet ime . now( ) . s t r f t ime ( '%d/%m/%Y
− %H:%M:%S ' )+" : arquivo "+OutputFilename+" baixado\n" )65 l og . c l o s e ( )66 except :67 pr in t ( "Error " )68 pr in t ( ' Clos ing f i l e ' + f i l ename )69 f i l e . c l o s e ( )70 f t p . qu i t ( )71 cur so r . c l o s e ( )72
73 getpm( server_ip , server_user , server_password , server_path , s e r v e r + '_ ' )
69

A.1.2 Auto-get-performance.sh
1 #!/ bin /bash2
3 LOG="/home/ e t l u s e r / l og /auto−get−performance . l og "4 FTPLOG="/home/ e t l u s e r / l og / f tp . l og "5
6 ### de f i n i ç õ e s ###7 hora r i o ( ) # função que pega a data atua l8 {9 date +%d/%m/%Y" − "%H:%M:%S
10 }11
12 pgrep −f f t p . py # v e r i f i c a se o s c r i p t de FTP já e s tá sendo executado13
14 i f [ $? −ne 0 ] ; then15 echo "$ ( ho ra r i o ) : FTP executado . ">>$LOG16 echo −e "−\n$ ( ho ra r i o ) : I n i c i o da execucao . ">>$FTPLOG17 python / e t l / s c r i p t s / f tp . py # executa o s c r i p t de FTP18 echo "$ ( ho ra r i o ) : Fim da execucao . ">>$FTPLOG19 e x i t 020 f i21
22 echo "$ ( ho ra r i o ) : Processo ja em execucao . ">>$LOG23
24 e x i t 0
70

A.2 Conversão
A.2.1 pm-convert.sh
1 #!/ bin /bash2
3 #de f i n i ç õ e s4
5 TEMP_DIR="/ e t l /umts/performance /temp/ x s l t /"6 OUT_DIR="/ e t l /umts/performance / converted /"7 IMP_DIR="/ e t l /umts/performance /raw/"8 XSLT="/ e t l / s c r i p t s /pmResult . x s l "9 SAXON="/usr / share /maven−repo /net / s f / saxon/Saxon−HE/debian /Saxon−HE−
debian . j a r "10 LOG="/home/ e t l u s e r / l og /ConvertXml2Csv . l og "11 TREADS=412 Tes t In t e rva l=113
14 export TEMP_DIR OUT_DIR IMP_DIR XSLT SAXON LOG TREADS Tes t In t e rva l15
16 #mata a execução se o d i r e t o r i o não f o r encontrado17 [ −d $IMP_DIR ] | | e x i t 118
19 #funcao que pega hora atua l20 hora r i o ( )21 {22 date +%d/%m/%Y" − "%H:%M:%S23 }24 #exporta a função para s h e l l s f i l h o s25 export −f ho ra r i o26
27 #função que f a z a conversao28 Convert2Csv ( ) {29
30 FileName=$131 [ −r $FileName ] && xml l in t −−noout −−va l i d ${IMP_DIR}/${FileName}32
33 i f [ $? −eq 0 ] ; then34 time java −cp ${SAXON} net . s f . saxon . Transform −t −s : ${FileName
} −x s l : ${XSLT} −o : ${TEMP_DIR}/${FileName } . csv \35 && psq l −d pos tg r e s −h $HOST_IP −U pos tg r e s −c "UPDATE
umts_control . l og_et l SET x s l t ='$ ( date +"%Y−%m−%d %T" ) ' WHERE oss='${FileName%%_∗} ' AND f i l e ='${FileName#∗_} ' ; " \
36 && rm ${FileName} \37 && mv ${TEMP_DIR}/${FileName } . csv ${OUT_DIR}38
71

39 echo "$ ( ho ra r i o ) : Arquivo $FileName conver t ido ">>$LOG40 e l s e41 psq l −d pos tg r e s −h $HOST_IP −U pos tg r e s −c "DELETE FROM
umts_control . l og_et l WHERE oss='${FileName%%_∗} ' AND f i l e ='${FileName#∗_} ' ; "
42 rm −f ${FileName}43 f i44
45 }46 #exporta a função para s h e l l s f i l h o s47 export −f Convert2Csv48
49 Tota lF i l e s=$ ( l s ${IMP_DIR}∗ . xml | wc − l )50 cd ${IMP_DIR}51 echo −e "−\n$ ( ho ra r i o ) : I n i c i o da execucao ">>$LOG52
53 p a r a l l e l −j$TREADS −u Convert2Csv {}\ ; ' echo −e "\ nProgress : {#}/ '$Tota lF i l e s ' F i l e s converted \n" '\ ; s l e e p $Tes t In t e rva l : : : $ ( l s ∗ .xml | s o r t −t "_" −k 5)
54
55 echo "$ ( ho ra r i o ) : Fim da execucao ">>$LOG56 echo −e "\n"57 e x i t 0
72

A.2.2 auto-convert.sh
1 #!/ bin /bash2
3 IMP_FILES="/ e t l /umts/performance /raw/"4 LOG="/home/ e t l u s e r / l og /auto_convert . l og "5
6 hora r i o ( )7 {8 date +%d/%m/%Y" − "%H:%M:%S # função que pega a data atua l9 }
10
11 i f [ [ ! $ ( l s −A $IMP_FILES/∗ . xml ) ] ] ; then12 echo "$ ( ho ra r i o ) : Nao ha arqu ivos a serem carregados . ">>$LOG13 e x i t 114 e l s e15 pgrep −f pm−convert . sh # v e r i f i c a se o s c r i p t de conversão já e s tá
sendo executado16 i f [ $? −ne 0 ] ; then17 echo "$ ( ho ra r i o ) : Converted executado . ">>$LOG18 / e t l / s c r i p t s /pm−convert . sh19 e x i t 020 f i21 f i22
23 echo "$ ( ho ra r i o ) : Processo ja em execucao . ">>$LOG24 e x i t 0
73

A.2.3 parser.py
1 import os2 import csv3 import time4 import psycopg25 import time6 import datet ime7 import re8 import sys9 import f t p l i b
10
11 #####SET DIR12 conve r t edd i r = ' / e t l /umts/performance / converted / '13 tempdir = ' / e t l /umts/performance /temp/ par s e r / '14 outd i r = ' /performance /umts/ '15 l o g f i l e = ' /home/ e t l u s e r / log /parsePM . log '16
17 #####Get F i l e18 f i l e = sys . argv [ 1 ]19
20 #####Connect to the database21 db_conn = psycopg2 . connect ( "dbname=' pos tg r e s ' user=' pos tg r e s ' host='
host_ip ' password='password_db ' " ) # conecta no Banco de Dados22 cur so r = db_conn . cur so r ( )23
24 t ry :25 pr in t ( ' Converting f i l e '+f i l e )26 i f i l e = open ( conve r t edd i r+f i l e , " r " )27 reader = csv . r eader ( i f i l e , d e l im i t e r= ' ; ' )28 o f i l e = open ( tempdir+f i l e , "w" , newl ine="\n" , encoding="utf−8" )29 wr i t e r = csv . wr i t e r ( o f i l e , d e l im i t e r= ' ; ' , quot ing=csv .QUOTE_MINIMAL
)30
31 ###parse header32 f o r row in reader33 row . i n s e r t (0 , " datet ime " )34 row . i n s e r t (0 , " c e l l i d " )35 row . i n s e r t (0 , " ce l lname " )36 row . i n s e r t (0 , " rnc " )37 row = [ r . r ep l a c e ( " . " , "_" ) f o r r in row ]38 row = [ r . lower ( ) f o r r in row ]39 wr i t e r . writerow ( row )40 break41
42 ###parse body43 f o r row in reader :
74

44 row = [ r . r ep l a c e ( "NULL" , "" ) f o r r in row ]45 row . i n s e r t ( 0 , ( row [ 0 ] [ 0 : 4 ] + '− ' + row [ 0 ] [ 4 : 6 ] + '− ' + row [ 0 ] [ 6 : 8 ]
+ ' ' + row [ 0 ] [ 8 : 1 0 ] + ' : ' + row [ 0 ] [ 1 0 : 1 2 ] ) )#datet ime46 row . i n s e r t (0 , row [ 3 ] . s p l i t ( ' , ' ) [ 1 ] [ 8 : ] )##c e l l i d47 row . i n s e r t (0 , row [ 4 ] . s p l i t ( ' , ' ) [ 0 ] . s p l i t ( '= ' ) [ 1 ] )##cel lname48 row . i n s e r t (0 , row [ 5 ] . s p l i t ( ' / ' ) [ 0 ] )##rnc49 wr i t e r . writerow ( row )50 i f i l e . c l o s e ( )51 o f i l e . c l o s e ( )52
53 ###Query s e l e c t e d columns54 f s s = s t r ( f i l e . s p l i t ( '_ ' ) [ 2 ] )55 query = "SELECT counter_name FROM umts_control . counte r_re f e rence
WHERE counter_enable = 'TRUE ' and funct ionsubse t_id = ' "+f s s+" ' ; "56 cur so r . execute ( query )57 enabled_columns = [ item [ 0 ] f o r item in cur so r . f e t c h a l l ( ) ]58 se lected_columns = [ ' rnc ' , ' ce l lname ' , ' c e l l i d ' , ' datet ime ' , ' gp ' ] #
s e l e c t header59 se lected_columns . extend ( enabled_columns )60
61 ###Query columns order62 t ab l e = ' f ss_ '+s t r ( f i l e . s p l i t ( '_ ' ) [ 2 ] )63 query = "SELECT column_name FROM INFORMATION_SCHEMA.COLUMNS WHERE
table_schema = ' umts_counter ' and table_name = ' "+tab l e+" ' order byo rd ina l_pos i t i on ; "
64 cur so r . execute ( query )65 columns = [ item [ 0 ] f o r item in cur so r . f e t c h a l l ( ) ]66
67 ###Read and wr i t e columns in bulk load format68 i f i l e = open ( tempdir+f i l e , " r " )69 reader = csv . DictReader ( i f i l e , d e l im i t e r= ' ; ' )70 o f i l e = open ( tempdir+f i l e+ ' . tx t ' , "w" , newl ine="\n" , encoding="utf
−8" )71 wr i t e r = csv . DictWriter ( o f i l e , f i e ldnames=columns , r e s t v a l= ' ' ,
e x t r a s a c t i on= ' i gno r e ' , d e l im i t e r= ' \ t ' )72
73 #wr i t e r . wr i t eheader ( )74 f o r row in reader :75 newrow = {k : v f o r k , v in row . items ( ) i f k in se lected_columns }76 wr i t e r . writerow (newrow)77 i f i l e . c l o s e ( )78 o f i l e . c l o s e ( )79
80 except IndexError :81 pr in t ( 'Couldnt convert ' )82 i f i l e . c l o s e ( )83 o f i l e . c l o s e ( )
75

84 os . remove ( tempdir+f i l e )85
86 e l s e :87 pr in t ( 'Could Convert ' )88 s e s s i o n = f t p l i b .FTP( ' host_ip ' , ' pos tg r e s ' , 'password_db ' )89 up l o a d f i l e = open ( tempdir+f i l e+ ' . tx t ' , ' rb ' )90 s e s s i o n . s t o rb ina ry ( 'STOR '+outd i r+f i l e+ ' . tx t ' , u p l o a d f i l e ) #
envia o arquivo para o s e rv ido de dados91 up l o a d f i l e . c l o s e ( )92 s e s s i o n . qu i t ( )93 query = "UPDATE umts_control . l og_et l SET f i l t e r ='"+s t r ( datet ime .
datet ime . now( ) ) [ 0 : 19 ]+ " ' WHERE oss='"+s t r ( f i l e . s p l i t ( '_ ' ) [ 0 ] )+" 'AND f i l e ='"+s t r ( ( f i l e . r p a r t i t i o n ( f i l e . s p l i t ( '_ ' ) [0 ]+ '_ ' ) [ 2 ] ) [ : −4 ] )+" ' "
94 cur so r . execute ( query )95 db_conn . commit ( )96 l og = open ( l o g f i l e , "a" )97 l og . wr i t e ( datet ime . datet ime . now( ) . s t r f t ime ( '%d/%m/%Y − %H:%M:%S ' )+"
: arquivo "+f i l e+" parseado \n" )98 l og . c l o s e ( )99 os . remove ( conve r t edd i r+f i l e )
100 os . remove ( tempdir+f i l e )101 os . remove ( tempdir+f i l e+ ' . tx t ' )102
103 cur so r . c l o s e ( )
76

A.2.4 auto-parse.sh
1 #!/ bin /bash2
3 IMP_FILES="/ e t l /umts/performance / converted /"4 LOG="/home/ e t l u s e r / l og /auto_parse . l og "5 PARSELOG="/home/ e t l u s e r / log /parsePM . log "6 TREADS=47 Tes t In t e rva l=08
9 export IMP_FILES LOG PARSELOG TREADS Tes t In t e rva l10
11 hora r i o ( ) # função que pega a data atua l12 {13 date +%d/%m/%Y" − "%H:%M:%S14 }15 export −f ho ra r i o16
17 i f [ [ ! $ ( l s −A $IMP_FILES) ] ] ; then18 echo "$ ( ho ra r i o ) : Nao ha arqu ivos a serem carregados . ">>$LOG19 e x i t 120 e l s e21
22 pgrep −f pa r s e r . py # v e r i f i c a se o s c r i p t de par s e r j á e s tá sendoexecutado
23 i f [ $? −ne 0 ] ; then24 echo "$ ( ho ra r i o ) : Parse executado . ">>$LOG25 echo −e "−\n$ ( ho ra r i o ) : I n i c i o da execucao . ">>$PARSELOG26 cd $IMP_FILES27 Tota lF i l e s=$ ( l s ∗ . csv | wc − l )28 p a r a l l e l −j$TREADS −u python3 . 4 / e t l / s c r i p t s / par s e r . py {}\ ; ' echo −e
"\ nProgress : {#}/ ' $Tota lF i l e s ' F i l e s parsed \n" '\ ; s l e e p$Tes t In t e rva l : : : $ ( l s ∗ . csv | s o r t −t "_" −k 5)
29 echo "$ ( ho ra r i o ) : Fim da execucao . ">>$PARSELOG30 e x i t 031 f i32 f i33
34 echo "$ ( ho ra r i o ) : Processo ja em execucao . ">>$LOG35
36 e x i t 0
77

A.3 Carga
A.3.1 staging.sh
1 #!/ bin /bash2
3 #d e f i n i e s4 PSQL=" psq l "5 IOSTAT="/usr /bin / i o s t a t "6 #Var iave i s t r o ca r conforme nec e s s i ad e7 Tes t In t e rva l=18 TAB_Pref="umts"9 IMP_DIR="/home/ pos tg r e s /$TAB_Pref/ performance /"
10 LOG="/home/ pos tg r e s / l og / s tag ing /"11 CONTROLE="/home/ pos tg r e s / s c r i p t s / stag ing_bulk load . c l t "12 #con t r o l e de p ro c e s s o s13 MAXCPULOAD=3.2 #sys l oad 1min14 MINMEMFREE=100000 #kB15 MAXkBreads=50000 #kB_read/ s i n s t a l l s y s s t a t16 MAXkBwrtns=100000 #kB_wrtn/ s17 MAXTreads=118 MAXHDUsage=90 # % de d i sk para parar19 BLOCK_DIR="/home/ pos tg r e s / block_process "20
21 #exporta todas as v a r i a v e i s para poder usar com os s h e l l s f i l h o s22 export PSQL IOSTAT Tes t In t e rva l TAB_Pref IMP_DIR MAXCPULOAD MINMEMFREE
MAXkBreads MAXkBwrtns MAXTreads MAXHDUsage LOG CONTROLE BLOCK_DIR23
24 #mata a execuo se o d i r e t o r i o no f o r encontrado25 [ −d $IMP_DIR ] | | e x i t 126
27 #python $STATUS_MESSAGE ' Staging . sh r e s t a r t ed '28
29 CatchErrors ( ) {30 i f [ $? −eq 1 ] | | [ $? −eq 2 ] ; then31 echo −e "\ nScr ip t aborted , because o f e r r o r s . \ n"32 k i l l $$33 e x i t 134 f i35 }36 export −f CatchErrors37 #funo para r e a l i z a r o import propiamente d i t o38 RunPSQL( ) {39
40 FileName=$141 TAB_Name=$ ( echo $1 | cut −d"_" −f 3 )
78

42 echo −ne "\n\npg_bulkload − i $FileName −O umts_counter . fss_$TAB_Name\n"
43 [ −r $FileName ] && time pg_bulkload − i $FileName −O umts_counter .fss_$TAB_Name −P ${LOG}parseLog$TAB_Name . txt −u ${LOG}duplicadosLog$TAB_Name . txt $CONTROLE
44 CatchErrors45 DATE=$ ( date +"%Y−%m−%d %T" )46 CutFi le=${FileName##∗/}47 OSS=$ ( echo $CutFi le | cut −d"_" −f 1 )48 FILE=$ ( echo ${CutFi le%%.csv . txt } | cut −d"_" −f2−6)49 psq l −c "UPDATE umts_control . l og_et l SET bulk load = '$DATE'
WHERE oss = '$OSS ' AND f i l e = '$FILE ' ; "50 rm −f "$FileName" && echo "removed $CutFi le "51
52 }53 #exporta a funo para s h e l l s f i l h o s54 export −f RunPSQL55 ControlLoad ( ) {56
57 #ro t i n a s de t e s t e58 CPULOAD=$ ( cat /proc / loadavg | cut −d" " −f 1 | t r " , " " . " )59 MEMFREE=$ ( cat /proc /meminfo | grep "MemFree" | t r −s " " | cut −d" "
−f 2 | t r " , " " . " ) # pode sem com o MemAvailable60 IOrwvet=($ ($IOSTAT | grep " sda" | t r −s " " | cut −d" " −f3 , 4 | t r " ,
" " . " ) )61 NTreads=$ ( jobs | grep −c "RunPSQL" )62 HDUsage=$ ( df 2> /dev/ nu l l | grep "/var / l i b / po s t g r e s q l " | t r −s " " |
cut −d" " −f 5 | t r −d "%" ) # t ro ca r o argumento do grep pe lod i r e t o r i o de montagem como aparece no df 2> /dev/ nu l l
63
64 [ $ ( echo " $CPULOAD >= $MAXCPULOAD " | bc ) −eq 1 ] && blkCPU=1 | |blkCPU=0
65 [ $ ( echo " $MEMFREE <= $MINMEMFREE " | bc ) −eq 1 ] && blkMEM=1 | |blkMEM=0
66 [ $ ( echo " ${IOrwvet [ 0 ] } > $MAXkBreads | | ${ IOrwvet [ 1 ] } > $MAXkBwrtns" | bc ) −eq 1 ] && blkIO=1 | | blkIO=0
67 [ $ ( echo " $NTreads >= $MAXTreads " | bc ) −eq 1 ] && blkTread=1 | |blkTread=0
68 [ [ $ ( echo " $HDUsage >= $MAXHDUsage " | bc ) −eq 1 ] ] && blkHDFull=1| | blkHDFull=0
69 [ [ ` l s −A "$BLOCK_DIR"` ] ] && BLOCK_PROCESS=1 | | BLOCK_PROCESS=070
71 # echo " $CPULOAD >= $MAXCPULOAD "72 # echo " $MEMFREE <= $MINMEMFREE "73 # echo " ${IOrwvet [ 0 ] } > $MAXkBreads | | ${ IOrwvet [ 1 ] } > $MAXkBwrtns "74 BLOQUEADO=$ ( echo " $blkCPU + $blkMEM + $blkIO + $blkTread +
$BLOCK_PROCESS " | bc )
79

75 whi le [ $BLOQUEADO −ne 0 ] ; do76 #rot i na de t e s t e77 CPULOAD=$ ( cat /proc / loadavg | cut −d" " −f 1 | t r " , " " . " )78 MEMFREE=$ ( cat /proc /meminfo | grep "MemFree" | t r −s " " | cut −d"
" −f 2 | t r " , " " . " ) # pode sem com o MemAvailable79 IOrwvet=($ ($IOSTAT | grep " sda" | t r −s " " | cut −d" " −f3 , 4 | t r
" , " " . " ) )80 NTreads=$ ( jobs | grep −c "RunPSQL" )81 HDUsage=$ ( df 2> /dev/ nu l l | grep "/var / l i b / pgsq l " | t r −s " " | cut
−d" " −f 5 | t r −d "%" ) # t ro ca r o argumento do grep pe lo d i r e t o r i ode montagem como aparece no df 2> /dev/ nu l l
82 [ $ ( echo " $CPULOAD >= $MAXCPULOAD " | bc ) −eq 1 ] && blkCPU=1 | |blkCPU=0
83 [ $ ( echo " $MEMFREE <= $MINMEMFREE " | bc ) −eq 1 ] && blkMEM=1 | |blkMEM=0
84 [ $ ( echo " ${IOrwvet [ 0 ] } > $MAXkBreads | | ${ IOrwvet [ 1 ] } >$MAXkBwrtns " | bc ) −eq 1 ] && blkIO=1 | | blkIO=0
85 [ $ ( echo " $NTreads >= $MAXTreads " | bc ) −eq 1 ] && blkTread=1 | |blkTread=0
86 [ [ $ ( echo " $HDUsage >= $MAXHDUsage " | bc ) −eq 1 ] ] && blkHDFull=1 | | blkHDFull=0
87 [ [ ` l s −A "$BLOCK_DIR"` ] ] && BLOCK_PROCESS=1 | | BLOCK_PROCESS=088
89 BLOQUEADO=$ ( echo " $blkCPU + $blkMEM + $blkIO + $blkTread +$blkHDFull + $BLOCK_PROCESS" | bc )
90
91 echo "Blk s t a tu s ($BLOQUEADO) ; CPU: $CPULOAD >= $MAXCPULOAD($blkCPU)/ MEM: $MEMFREE <= $MINMEMFREE($blkMEM) / IO : ${IOrwvet [ 0 ] } >
$MAXkBreads | | ${ IOrwvet [ 1 ] } > $MAXkBwrtns( $blkIO ) / NTreads :$NTreads >= $MAXTreads( $blkTread ) / HD: $HDUsage >= $MAXHDUsage ($blkHDFull ) | | FLAG BLOCK: $BLOCK_PROCESS"
92 s l e e p $Tes t In t e rva l93 done94 #chama a funo de import em background95 RunPSQL $196 }97 #exporta a funo para s h e l l s f i l h o s98 export −f ControlLoad99
100 #l i s t a os arqu ivos ordenando por data e r e v e r t e a sequenc ia chamando afuno a cada l i nha
101 Tota lF i l e s=$ ( l s $IMP_DIR | wc − l )102 count=1103 f o r t imes in $ ( l s $IMP_DIR | cut −d"_" −f 5 | s o r t | uniq ) ; do104 # echo −ne "\ r \ t \ t \ t t imes : $t imes "105 f o r FILE in $ ( l s $IMP_DIR/∗${ t imes }_∗) ; do106 echo −ne "\ nProgress : $count/ $Tota lF i l e s F i l e s load . "
80

107 ( ( count++))108 #echo $FILE109 ControlLoad $FILE110 #s l e ep $Tes t In t e rva l111 done112 done113 echo −e "\n"
81

A.3.2 auto-staging.sh
1 #!/ bin /bash2
3 BLOCK_DIR="/home/ pos tg r e s / block_process "4 IMP_FILES="/home/ pos tg r e s / performance /umts"5 PROCESS=" s tag ing . sh"6 LOG="/home/ pos tg r e s / l og / s tag ing . txt "7 Error l og="/home/ pos tg r e s / l og /auto_stag . txt "8
9 hora r i o ( ) # função que pega a data atua l10 {11 date +%d/%m/%Y" − "%H:%M:%S12 }13
14 [ [ ` l s −A $BLOCK_DIR` ] ] && echo "$ ( ho ra r i o ) : Stag ing bloqueado . ">>$Error log && ex i t 1
15
16 i f [ [ ! ` l s −A $IMP_FILES` ] ] ; then17 echo "$ ( ho ra r i o ) : Nao ha arqu ivos a serem carregados . ">>$Error log18 e x i t 119 e l s e20 pgrep −f $PROCESS # v e r i f i c a se o s c r i p t de s tag ing já e s tá sendo
executado21 i f [ $? −ne 0 ] ; then22 echo "$ ( ho ra r i o ) : Stag ing executado . ">>$Error log23 /home/ pos tg r e s / s c r i p t s /$PROCESS24 e x i t 025 f i26 f i27
28 echo "$ ( ho ra r i o ) : Processo ja em execucao . ">>$Error log29 e x i t 0
82

Apêndice B
Códigos Fonte - Processamento
Neste apêndice estão alguns dos códigos fonte do processamento proposto nestetrabalho. Para não ficar muito extenso, está disponível apenas o cálculo dos KPIsde Acessibilidade e o cálculo dos ofensores por RNC destes KPIs.
83

B.1 Cálculo dos KPIs de Acessibilidade
B.1.1 View vw_acessibility.sql
1 CREATE OR REPLACE VIEW umts_kpi . vw_acc e s s i b i l i t y AS2 SELECT fss_67109365 . rnc ,3 fss_67109365 . cel lname ,4 fss_67109365 . c e l l i d ,5 fss_67109365 . datetime ,6 fss_67109365 . gp ,7 r r c_succconnes tab_org in t e r ca l l + rrc_succconnestab_orgbkgca l l +
rrc_succconnestab_orgsubca l l + rrc_succconnestab_tmitrca l l +rrc_succconnestab_tmbkgcal l AS acc_rrc_num ,
8 r r c_at t conne s tab_org in t e r ca l l + rrc_attconnestab_orgbkgca l l +rrc_attconnestab_orgsubca l l + rrc_attconnes tab_tminterca l l +rrc_attconnestab_tmbkgcal l AS acc_rrc_den ,
9 vs_rab_succestabcs_amr + vs_rab_succestabcs_amrwb AS acc_cs_rab_num,
10 vs_rab_attestab_amr + vs_rab_attestabcs_amrwb AS acc_cs_rab_den ,11 vs_rab_succestabps_conv + vs_rab_succestabps_str +
vs_rab_succestabps_int + vs_rab_succestabps_bkg AS acc_ps_rab_num ,12 vs_rab_attestabps_conv + vs_rab_attestabps_str +
vs_rab_attestabps_int + vs_rab_attestabps_bkg AS acc_ps_rab_den ,13 vs_hsdpa_rab_succestab AS acc_hs_num ,14 vs_hsdpa_rab_attestab AS acc_hs_den ,15 vs_attrec fg_f2h_datatranst r ig + vs_attrec fg_p2h_datatranstr ig AS
acc_hs_f2h_num ,16 vs_succrec fg_f2h_datatranstr ig + vs_succrec fg_p2h_datatranstr ig AS
acc_hs_f2h_den17 FROM umts_counter . fss_6710936518 JOIN umts_counter . fss_67109368 ON fss_67109365 . rnc = fss_67109368 .
rnc AND fss_67109365 . datet ime = fss_67109368 . datet ime ANDfss_67109365 . c e l l i d = fss_67109368 . c e l l i d
19 JOIN umts_counter . fss_67109372 ON fss_67109365 . rnc = fss_67109372 .rnc AND fss_67109365 . datet ime = fss_67109372 . datet ime ANDfss_67109365 . c e l l i d = fss_67109372 . c e l l i d
20 JOIN umts_counter . fss_67109390 ON fss_67109365 . rnc = fss_67109390 .rnc AND fss_67109365 . datet ime = fss_67109390 . datet ime ANDfss_67109365 . c e l l i d = fss_67109390 . c e l l i d
21 LEFT JOIN umts_counter . fss_82864131 ON fss_67109365 . rnc =fss_82864131 . rnc AND fss_67109365 . datet ime = fss_82864131 . datet imeAND fss_67109365 . c e l l i d = fss_82864131 . c e l l i d ;
84

B.1.2 Função PL/SQL inserir_kpi_accessibility.sql
1 CREATE OR REPLACE FUNCTION umts_kpi . i n s e r i r_kp i_a c c e s s i b i l i t y (2 data timestamp without time zone )3 RETURNS SETOF umts_kpi . a c c e s s i b i l i t y AS4 $BODY$5
6 BEGIN7
8 re turn query execute format ( ' s e l e c t vw_acc e s s i b i l i t y . rnc ,vw_acc e s s i b i l i t y . cel lname , vw_acc e s s i b i l i t y . c e l l i d ,vw_acc e s s i b i l i t y . datetime , vw_acc e s s i b i l i t y . gp ,
9 vw_acce s s i b i l i t y . acc_rrc_num , vw_acce s s i b i l i t y . acc_rrc_den ,vw_acc e s s i b i l i t y . acc_cs_rab_num , vw_acce s s i b i l i t y . acc_cs_rab_den ,
10 vw_acce s s i b i l i t y . acc_ps_rab_num , vw_acce s s i b i l i t y . acc_ps_rab_den ,vw_acc e s s i b i l i t y . acc_hs_num , vw_acce s s i b i l i t y . acc_hs_den ,
11 vw_acce s s i b i l i t y . acc_hs_f2h_num , vw_acce s s i b i l i t y . acc_hs_f2h_den12
13 from umts_kpi . vw_acc e s s i b i l i t y WHERE datet ime = ' '%I ' ' %s ' ,data ) ;
14 END;15 $BODY$16 LANGUAGE p lpg sq l
85

B.1.3 inserir_kpi_accessibility.sh
1 #!/ bin /bash2
3 l og="/home/ pos tg r e s / l og / i n s e r i rKPIAc e s s i b i l i d ad e . txt "4 l ogErro r="/home/ pos tg r e s / l og / e r r o r I n s e r i rKP IAc e s s i b i l i d ad e . txt "5 CONTROLE="/home/ pos tg r e s / s c r i p t s / bulk load_contro l_funct ion . c l t "6 BLOCK_DIR="/home/ pos tg r e s / block_process /"7
8 catch_errors ( ) {9 i f [ $? −eq 1 ] | | [ $? −eq 2 ] ; then
10 echo −e "\n$ ( ho ra r i o ) : S c r i p t f i n a l i z a d o devido a e r r o s . \ n"11 echo "$ ( ho ra r i o ) : S c r i p t f i n a l i z a d o devido a e r r o s . ">>$log12 k i l l $$13 e x i t 114 f i15 }16
17 hora r i o ( )18 {19 date +%d/%m/%Y" − "%H:%M:%S20 }21 DATA=$1 # recebe a data por l i nha de comando22
23 echo "−">>$log24 echo "$ ( ho ra r i o ) : I n i c i o da execucao . ">>$log25 echo −e "\n$ ( ho ra r i o ) : I n i c i o da execucao para c a l c u l o de KPIs
Ac e s s i b i l i d ad e para a data $DATA"26
27 time ( echo −e "\n"28 pg_bulkload − i "umts_kpi . i n s e r i r_kp i_a c c e s s i b i l i t y ( '$DATAS' ) " −O
umts_kpi . a c c e s s i b i l i t y −P $logError $CONTROLE29 catch_errors30 echo "$ ( ho ra r i o ) : KPI a c e s s i b i l i d a d e ca l cu l ado para a data $DATA">>
$log31 echo −e "\n$ ( ho ra r i o ) : KPI a c e s s i b i l i d a d e ca l cu l ado para a data $DATA
" )32
33 echo "$ ( ho ra r i o ) : Fim da execucao . ">>$log34 echo −e "\n$ ( ho ra r i o ) : Fim da execucao para c a l c u l o s do KPI
a c c e s s i b i l i d a d e para a data $DATA"35
36 e x i t 0
86

B.2 Cálculo dos ofensores por RNC dos KPIs de
Acessibilidade
B.2.1 Função PL/SQL inserir_worst_cells_rnc_accessibi-
lity.sql
1 CREATE OR REPLACE FUNCTION umts_kpi .i n s e r i r_wo r s t_c e l l s_ rn c_ac c e s s i b i l i t y (
2 kpi text ,3 data date )4 RETURNS SETOF umts_kpi . wo r s t_ce l l s_rnc_acc e s s i b i l i t y AS5 $BODY$6 de c l a r e7 cur_row2 text ;8 cur_row record ;9 r wor s t c e l l s_rnctype ;
10 rank i n t e g e r ;11
12 begin13 f o r cur_row2 in execute format ( 'SELECT d i s t i n c t rnc FROM umts_kpi .
a c c e s s i b i l i t y_ rn c WHERE datet ime : : date = ' '%s ' ' ORDER BY rnc ' , data)
14 loop15 r . new_rnc_kpi := 2 ;16 r . rank := 0 ;17 f o r cur_row in execute format ( 'SELECT A. rnc , A. c e l l i d , A. date , %
s_num as cell_kpi_num , %1$s_den as cell_kpi_den , (%1$s_den − %1$s_num) as c e l l _ f a i l s , rnc_kpi_num , rnc_kpi_den ,
18 ( rnc_kpi_den − rnc_kpi_num) as r n c_ f a i l s FROM umts_kpi .a c c e s s i b i l i t y_d a i l y A JOIN
19 (SELECT rnc , date , SUM(%1$s_num) as rnc_kpi_num , SUM(%1$s_den ) asrnc_kpi_den FROM umts_kpi . a c c e s s i b i l i t y_d a i l y WHERE rnc = ' '%s ' 'AND date = ' '%s ' ' GROUP BY rnc , date ) B
20 ON A. rnc = B. rnc AND A. date = B. date21 WHERE A. rnc = ' '%2$s ' ' AND A. date = ' '%3$s ' ' ORDER BY c e l l _ f a i l s
DESC ' , kpi , cur_row2 , data )22
23 loop24
25 i f ( r . new_rnc_kpi = 2) then26 r . new_rnc_kpi := COALESCE( cur_row . rnc_kpi_num / NULLIF ( cur_row
. rnc_kpi_den , 0) , 1) ;27 end i f ;28
29 r . rnc := cur_row . rnc ;
87

30 r . c e l l i d := cur_row . c e l l i d ;31 r . date := cur_row . date ;32 r . kpi := format ( '%s ' , kpi ) ;33 r . cell_kpi_num := cur_row . cell_kpi_num ;34 r . cel l_kpi_den := cur_row . cel l_kpi_den ;35 r . c e l l _ f a i l s := cur_row . c e l l _ f a i l s ;36 r . rnc_kpi_num := cur_row . rnc_kpi_num ;37 r . rnc_kpi_den := cur_row . rnc_kpi_den ;38 r . impact := COALESCE( cur_row . c e l l _ f a i l s / NULLIF ( cur_row .
rnc_fa i l s , 0) , 0) ;39 r . rnc_kpi := COALESCE( cur_row . rnc_kpi_num / NULLIF ( cur_row .
rnc_kpi_den , 0) , 1) ;40 r . new_rnc_kpi := r . new_rnc_kpi + COALESCE( cur_row . c e l l _ f a i l s /
NULLIF ( cur_row . rnc_kpi_den , 0) , 0) ;41 r . rank := r . rank + 1 ;42
43 re turn next r ;44 end loop ;45 end loop ;46
47 end ;48 $BODY$49 LANGUAGE p lpg sq l
88

B.2.2 inserir_worst_cells_rnc_accessibility.sh
1 #!/ bin /bash2
3 l og="/home/ pos tg r e s / l og / in s e r i rWor s tCe l l sRNCAcce s s ib i l i t y . txt "4 l ogErro r="/home/ pos tg r e s / l og / e r r o r In s e r i rWor s tCe l l sRNCAcce s s i b i l i t y . txt
"5 CONTROLE="/home/ pos tg r e s / s c r i p t s / bulk load_contro l_funct ion . c l t "6
7 catch_errors ( ) {8 i f [ $? −eq 1 ] | | [ $? −eq 2 ] ; then9 echo −e "\n$ ( ho ra r i o ) : S c r i p t f i n a l i z a d o devido a e r r o s . \ n"
10 echo "$ ( ho ra r i o ) : S c r i p t f i n a l i z a d o devido a e r r o s . ">>$log11 k i l l $$12 e x i t 113 f i14 }15
16 hora r i o ( )17 {18 date +%d/%m/%Y" − "%H:%M:%S19 }20 DIA=$1 #recebe o dia por l i nha de comando21
22 echo "−">>$log23 echo "$ ( ho ra r i o ) : I n i c i o da execucao . ">>$log24 echo −e "\n$ ( ho ra r i o ) : I n i c i o da execucao para c a l c u l o s das p i o r e s
c e l u l a s para o dia $DIA"25
26 l i s taDeKPIs=" rrc_e fc27 cs_rab_acc28 ps_rab_acc29 hs_acc30 hs_acc_f2h"31
32 f o r KPI in $l i staDeKPIs ; do33 time ( echo −e "\n"34 pg_bulkload − i "umts_kpi . i n s e r i r_wo r s t_c e l l s_ rn c_ac c e s s i b i l i t y ( '$KPI
' , ' $DIA ' ) " −O umts_kpi . wo r s t_ce l l s_rnc_acc e s s i b i l i t y −P $logError$CONTROLE
35 catch_errors36 echo "$ ( ho ra r i o ) : Worst Ce l l s RNC Ac c e s s i b i l i t y do KPI $KPI
car regados para o dia $DIA">>$log37 echo −e "\n$ ( ho ra r i o ) : Worst Ce l l s RNC Ac c e s s i b i l i t y do KPI $KPI
car regados para o dia $DIA" )38 done39
89

40 echo "$ ( ho ra r i o ) : Fim da execucao . ">>$log41 echo −e "\n$ ( ho ra r i o ) : Fim da execucao para c a l c u l o s das p i o r e s c e l u l a s
para o dia $DIA"42 psq l −c "VACUUM ANALYZE umts_kpi . wo r s t_ce l l s_rnc_acc e s s i b i l i t y ; "43
44 e x i t 0
90





























