
PROYECTO DE GRADO
Presentado ante la ilustre UNIVERSIDAD DE LOS ANDES como requisito final para obtener el Título de INGENIERO DE SISTEMAS
Desarrollo de un Sistema de Información Web para la gestión de incidentes de falla en la plataforma tecnológica de PDVSA AIT
Servicios Comunes Centro
Por
Br. Carlos Germán Medina Albornoz
Tutor: Prof. Judith Barrios
Asesor Industrial: Ing. José Casanova
Febrero 2009
©2009 Universidad de Los Andes Mérida, Venezuela

Desarrollo de un sistema de Información Web para la Gestión de Incidentes de Falla en
la plataforma tecnológica de PDVSA AIT SCC.
Br. Carlos Germán Medina Albornoz
Proyecto de Grado – Sistemas Computacionales, 170 páginas
Resumen: En el presente proyecto se desarrolla un sistema de información web como herramienta
de apoyo a los procesos de negocio llevados a cabo por la Gerencia de Mantenimiento de la
Plataforma (MAP), unidad adscrita a la Gerencia de Automatización, Informática y
Telecomunicaciones de Petróleos de Venezuela S.A., en el área denominada Servicios Comunes
Centro. El proyecto surge por la iniciativa de la Coordinación de Confiabilidad, unidad que se encarga
de aplicar técnicas de ingeniería de confiabilidad para apoyar a la Gerencia MAP en la planificación del
mantenimiento y en el mejoramiento de la confiabilidad de la plataforma.
Las necesidades de información son un factor crítico para los encargados de la toma de
decisiones dentro de la Gerencia MAP. Existe además una dependencia de la información generada
por otras unidades en la organización. Es por ello que se ha implementado un sistema de información
que, basado en tecnología web y disponible a los miembros de la Empresa a través de la intranet,
automatiza el proceso de llenado de los reportes de las fallas ocurridas en la plataforma durante las
guardias de los grupos encargados de su mantenimiento, y a partir de estos reportes obtiene
indicadores de confiabilidad y disponibilidad, que a su vez son complementados con datos registrados
por el sistema Nagios, encargado de monitorear el estado de la plataforma. De este modo se obtiene
un histórico de fallas y una base de conocimientos del mantenimiento realizado para cada equipo y
aplicación de la plataforma. El proceso de desarrollo del sistema fue guiado por el método Watch para
el desarrollo de aplicaciones empresariales, obteniéndose dos versiones funcionales del sistema.
Debido al proceso de soberanía tecnológica que se está llevando a cabo dentro de PDVSA, el sistema
fue desarrollado utilizando software libre.
Palabras clave: Sistema de Información Web, Ingeniería de Confiabilidad, mantenimiento,
disponibilidad.

ii
Dedicatoria
A mi madre, a mi padre y a mi hermano, las tres personas más importantes en mi vida. Sin su
apoyo no lo hubiera logrado, gracias.

iii
Índice
DEDICATORIA................................................................................................................................................. II
ÍNDICE .............................................................................................................................................................III
ÍNDICE DE FIGURAS ...................................................................................................................................... VI
ÍNDICE DE TABLAS ..........................................................................................................................................X
AGRADECIMIENTO........................................................................................................................................ XI
CAPÍTULO 1 ...................................................................................................................................................... 1
INTRODUCCIÓN .............................................................................................................................................. 1
1.1 DESCRIPCIÓN DE LA EMPRESA .................................................................................................................... 21.1.1 PDVSA AIT...................................................................................................................................... 3
1.3 ANTECEDENTES.......................................................................................................................................... 71.4 PLANTEAMIENTO DEL PROBLEMA ............................................................................................................... 81.5 JUSTIFICACIÓN........................................................................................................................................ 101.5 OBJETIVOS .............................................................................................................................................. 11
1.5.1 Objetivo General............................................................................................................................ 111.5.2 Objetivos Específicos ...................................................................................................................... 11
1.6 METODOLOGÍA ....................................................................................................................................... 121.7 ESTRUCTURA DEL DOCUMENTO ................................................................................................................ 13
CAPÍTULO 2 .................................................................................................................................................... 15
MARCO TEÓRICO Y HERRAMIENTAS DE SOPORTE ................................................................................. 15
2.1 SISTEMAS DE INFORMACIÓN..................................................................................................................... 152.1.1 Actividades que realiza un sistema de información ........................................................................ 162.1.2 Tipos de sistemas de información ................................................................................................... 172.1.3 Sistemas de Información Web ........................................................................................................ 18
2.2 INGENIERÍA DE CONFIABILIDAD ............................................................................................................... 192.2.1 Conceptos Básicos........................................................................................................................... 192.2.2 Definición ...................................................................................................................................... 202.2.3 Estimación de la confiabilidad ....................................................................................................... 212.2.4 Análisis de confiabilidad basado en historiales de falla ................................................................. 212.2.5 Indicadores de confiabilidad .......................................................................................................... 222.2.6 Tipos de Mantenimiento................................................................................................................. 23
2.3 BASES DE DATOS ...................................................................................................................................... 232.3.1 Bases de datos relacionales ............................................................................................................ 242.3.2 Lenguaje Estructurado de Consulta (SQL) ..................................................................................... 242.3.3 El sistema de gestión de bases de datos PostgreSQL ....................................................................... 25
2.4 ARQUITECTURA ORIENTADA A SERVICIOS (SOA) ..................................................................................... 262.5 PROTOCOLO SOAP ................................................................................................................................. 28
2.5.1 NuSOAP ........................................................................................................................................ 292.6 LENGUAJE DE MODELADO UNIFICADO (UML) ......................................................................................... 30

iv
2.6.1 Diagramas de clases ...................................................................................................................... 312.6.2 Diagramas de componentes............................................................................................................ 312.6.3 Diagramas de objetos .................................................................................................................... 312.6.4 Diagramas de despliegue............................................................................................................... 322.6.5 Diagramas de paquetes ................................................................................................................. 322.6.6 Diagramas de actividades.............................................................................................................. 322.6.7 Diagramas de casos de uso............................................................................................................. 322.6.8 Diagramas de secuencia................................................................................................................. 33
2.7 EL LENGUAJE DE PROGRAMACIÓN PHP..................................................................................................... 332.8 CONCLUSIONES DEL CAPÍTULO.................................................................................................................. 34
CAPÍTULO 3 .................................................................................................................................................... 35
DESARROLLO DE LA PRIMERA VERSIÓN DEL SISTEMA ........................................................................... 35
3.1 PLANIFICACIÓN DEL PROYECTO ................................................................................................................ 353.2 MODELADO DE NEGOCIOS ....................................................................................................................... 36
3.2.1 Delimitación del sistema de negocios.............................................................................................. 373.2.2 Diagrama de Procesos del negocio.................................................................................................. 383.2.3 Estructura de la Gerencia MAP...................................................................................................... 383.2.4 Cadena de Valor de la Gerencia MAP............................................................................................. 393.2.5 Diagrama de flujo entre procesos para la gestión de incidentes de falla ......................................... 453.2.6 Identificación de las reglas de negocio............................................................................................ 483.2.7 Modelado de los actores de negocio ................................................................................................. 513.2.8 Identificación de los objetos de negocio........................................................................................... 52
3.3 INGENIERÍA DE REQUISITOS ..................................................................................................................... 543.3.1 Definición de los requisitos de software.......................................................................................... 553.3.2 Definición de requisitos según actores............................................................................................ 563.3.3 Clasificación de los requisitos y definición de prioridades ............................................................... 593.3.4 Definición de casos de uso .............................................................................................................. 613.3.5 Matriz Casos de Uso vs. Requisitos................................................................................................. 68
3.4 DISEÑO DEL SISTEMA ............................................................................................................................... 693.4.1 Metas de diseño.............................................................................................................................. 693.4.2 Definición del estilo arquitectónico y justificación.......................................................................... 703.4.3 Identificación de subsistemas ......................................................................................................... 713.4.4 Diseño de componentes .................................................................................................................. 723.4.5 Diagrama de clases del sistema...................................................................................................... 773.4.6 Diagrama de despliegue del sistema .............................................................................................. 783.4.7 Diseño de la base de datos ............................................................................................................. 803.4.8 Diseño de la interfaz del usuario ................................................................................................... 82
3.5 FASE DE IMPLEMENTACIÓN Y PRUEBAS ..................................................................................................... 843.5.1 Implementación del sistema ........................................................................................................... 853.5.2 Pruebas del sistema ....................................................................................................................... 89
3.6 CONCLUSIONES DEL CAPÍTULO.................................................................................................................. 95
CAPÍTULO 4 .................................................................................................................................................... 97
DESARROLLO DE LA SEGUNDA VERSIÓN DEL SISTEMA........................................................................... 97
4.1 REVISIÓN DEL MODELO DE NEGOCIOS ......................................................................................................... 974.1.1 Modelado de las reglas de negocio.................................................................................................... 98

v
4.1.2 Modelado de objetos de Negocio ..................................................................................................... 994.2 REQUISITOS DE LA SEGUNDA VERSIÓN .......................................................................................................100
4.2.1 Redefinición de los perfiles de usuario ............................................................................................1014.2.2 Definición de requisitos según actores...........................................................................................1024.2.3 Clasificación y negociación de requisitos .........................................................................................1034.2.4 Elaboración de casos de uso...........................................................................................................1064.2.5 Matriz Caso de Uso vs. Requisitos .................................................................................................111
4.3 DISEÑO DE LA SEGUNDA VERSIÓN.............................................................................................................1124.3.1 Metas de diseño.............................................................................................................................1124.3.2 Identificación de subsistemas ........................................................................................................1124.3.3 Diseño de componentes .................................................................................................................1134.3.4 Diagrama de clases del sistema.....................................................................................................1194.3.5 Diagrama de despliegue del sistema .............................................................................................1204.3.6 Diseño de la base de datos ............................................................................................................1224.3.7 Diseño de la interfaz del sistema ..................................................................................................123
4.4 FASE DE IMPLEMENTACIÓN Y PRUEBAS .....................................................................................................1254.4.1 Implementación de componentes ...................................................................................................1254.4.2 Fase de pruebas del sistema ..........................................................................................................128
4.5 ENTREGA FINAL DEL SISTEMA ....................................................................................................................1324.6 CONCLUSIONES DEL CAPÍTULO ...........................................................................................................133
CAPÍTULO 5 ...................................................................................................................................................134
CONCLUSIONES Y RECOMENDACIONES....................................................................................................134
5.1 CONCLUSIONES ......................................................................................................................................1345.2 APORTES A LA EMPRESA ..........................................................................................................................1355.3 APORTES A LA UNIVERSIDAD ...................................................................................................................1365.4 APORTES AL TESISTA ...............................................................................................................................1365.5 RECOMENDACIONES ...............................................................................................................................137
REFERENCIAS BIBLIOGRÁFICAS .................................................................................................................140
ANEXO A ........................................................................................................................................................142
PLANIFICACIÓN DEL PROYECTO................................................................................................................142
ANEXO B.........................................................................................................................................................144
INTERFACES USUARIO/SISTEMA VERSIÓN 1 ............................................................................................144
ANEXO C.........................................................................................................................................................151
INTERFACES USUARIO/SISTEMA VERSIÓN 2 ............................................................................................151

vi
Índice de figuras
Figura 1.1 Cadena de valor de PDVSA …………………………………………………….4
Figura 1.2 Estructura organizativa de PDVSA AIT ……………………………………….5
Figura 1.2 AIT Servicios Comunes ………………………………………………………...6
Figura 1.3 Estructura de PDVSA AIT Servicios Comunes Centro ………………………..6
Figura 2.1 Arquitectura orientada a servicios …………………………………………...28
Figura 3.1 Delimitación del sistema de Negocios ………………………………………..37
Figura 3.2 Diagrama de procesos del Mantenimiento de la Plataforma ………………..38
Figura 3.3 Estructura Organizativa Gerencia MAP …...…………………………………39
Figura 3.4 Cadena de Valor de la Gerencia MAP ………………………………………...40
Figura 3.5 Diagrama del proceso “Registrar mantenimiento ejecutado” ……………...43
Figura 3.6 Diagrama del proceso “Aplicar Ingeniería de Confiabilidad” ……………...44
Figura 3.7 Diagrama del proceso “Monitorear la plataforma” …………………………44
Figura 3.8 Diagrama de flujo entre procesos para la gestión de incidentes de falla …..46
Figura 3.9 Flujo de actividades a obtener luego de automatizar el proceso …………...47
Figura 3.10 Modelado de objetos de negocio . …………………………………………..54
Figura 3.11 Perfiles de usuario del sistema ………………………..……………………..62
Figura 3.12 Diagrama de casos de uso para usuario general ……………………………63
Figura 3.13 Diagrama de casos de uso para usuario intermedio ………………………..64
Figura 3.14 Diagrama de caso de uso para usuario avanzado …………………………..65
Figura 3.15 Diagrama de caso de uso para administrador ………………………..……..66
Figura 3.16 Identificación de subsistemas ………………………..……………………...71
Figura 3.17 Subsistema de control de usuarios …………………………………………..74
Figura 3.18 Subsistema de gestión de incidentes y soluciones ………………………….75
Figura 3.19 Subsistema de gestión de reportes de monitoreo …………………………..76
Figura 3.21 Diagrama de clases del sistema ……………………………………………...78
Figura 3.22 Diagrama de despliegue del sistema ………………………………………...79

vii
Figura 3.23 Modelo de la base de datos del sistema ……………………………………..80
Figura 3.24 Pantalla de inicio del sistema ………………………………………………..83
Figura 3.25 Pantalla general de usuarios …………………..…………………..…………83
Figura 3.26 Diagrama de flujo de pantallas …………………..………………………….84
Figura 3.27 Formulario de ingreso de incidentes de falla …………………..…………..87
Figura 3.28 Prueba de ingreso de usuario …………………..……………………………90
Figura 3.29 Mensaje obtenido al ingresar usuario inválido …………………………….91
Figura 3.30 Mensaje obtenido al tratar de ingresar un incidente con campos faltantes 91
Figura 3.31 Resultado obtenido al consultar incidentes por período de tiempo ……...92
Figura 3.32 Incidentes reportados por el Grupo Z-Series entre el 01-01-2008 y el 01-01-
2009 ……………………………………………………………..…………………..……...93
Figura 3.33 Cálculo de indicadores para el grupo Z-Series ……………………………..94
Figura 3.34 Resultado obtenido luego de corregir el error de los indicadores .……….94
Figura 4.1 Diagrama de objetos de la segunda versión del SINCFA …………………...100
Figura 4.2 Diagrama de casos de uso para usuario general ……………………………107
Figura 4.3 Diagrama de casos de uso para usuario MAP ……………………………….108
Figura 4.4 Diagrama de casos de uso para usuario GDS ………………………………..109
Figura 4.5 Diagrama de casos de uso para usuario de confiabilidad ………………….110
Figura 4.6 Identificación de subsistemas para la segunda versión del SINCFA ………113
Figura 4.7 Componentes agregados y modificados en el subsistema de control de
usuarios …………………..…………………..…………………..………………………115
Figura 4.8 Componentes agregados y modificados en el subsistema de gestión de
incidentes y soluciones …………………..…………………..………………………….116
Figura 4.9 Componentes agregados y modificados en el subsistema de gestión de
reportes de monitoreo …………………..…………………..…………………………..117
Figura 4.10 Componentes agregados y modificados en el subsistema de inventario de
componentes AIT …………………..…………………..…………………..……………118
Figura 4.11 Componentes del subsistema de auditoria del SINCFA …………………..119
Figura 4.12 Diagrama de clases para la segunda versión del sistema ………………….120
Figura 4.13 Diagrama de despliegue para la segunda versión del sistema ……………121

viii
Figura 4.14 Modelo de la base de datos del sistema …………………..………………..122
Figura 4.15 Pantalla de inicio del sistema …………………..…………………………..123
Figura 4.16 Estructura general de las pantallas del sistema …………………..………..124
Figura 4.17 Diagrama de flujo de pantallas …………………..………………………...124
Figura 4.18 Componente de calendario en JavaScript …………………..……………..125
Figura 4.19 Pantalla de modificación de componentes ………………………………..126
Figura 4.20 Pantalla de modificación de incidentes ……………………………………126
Figura 4.21 Asignación de fecha de minuta directamente por el sistema …………….127
Figura 4.22 Mensaje de aviso al usuario ………………………………………………...127
Figura 4.23 Prueba de acceso de usuario ya conectado …………………..……………129
Figura 4.24 Prueba de cierre de reporte abierto …………………..…………………...129
Figura 4.25 Prueba de consulta de reporte conjunto …………………..………………130
Figura 4.26 Prueba de longitud de campos en ingreso de incidente ………………….131
Figura 4.27 Mensaje obtenido al tratar de ingresar el incidente ……………………...131
Figura A.1 Planificación inicial del proyecto …………………..………………………142
Figura A.2 Revisión de la planificación del proyecto …………………..……………...143
Figura B.1 Pantalla de ingreso de incidentes …………………..……………………….144
Figura B.2 Pantalla de Verificación de ingreso del incidente …………………………145
Figura B.3 Consulta de incidentes reportados por período de tiempo ……………….145
Figura B.4 Reporte de incidentes por período de tiempo ….…………………..……..146
Figura B.5 Reporte exportado a una hoja de cálculo ………………………………….146
Figura B.6 Cálculo de indicadores operativos de la plataforma ………………………147
Figura B.7 Consulta de incidentes por grupo operativo ………………………………147
Figura B.8 Consulta de incidentes por componente …………………..……………….148
Figura B.9 Consulta de incidentes y soluciones …………………..……………………148
Figura B.10 Pantalla de eliminación de incidente …………………..………………….149
Figura B.11 Reporte conjunto de incidentes de falla …………………..……………...149
Figura B.12 Ingreso de componentes al inventario AIT …………………..…………...150
Figura B.13 Consulta de componentes de inventario AIT ……………………………..150
Figura C.1 Pantalla de ingreso de incidentes …………………..……………………….151

ix
Figura C.2 Pantalla de Verificación de ingreso del incidente …………………………152
Figura C.3 Consulta de incidentes reportados por período de tiempo ……………….152
Figura C.4 Reporte de incidentes por período de tiempo …………………..………...153
Figura C.5 Reporte de incidentes por grupo operativo …………………..…………...153
Figura C.6 Cálculo de indicadores para un grupo operativo ………………………….154
Figura C.7 Consulta de incidentes por fecha de minuta …………………..…………...154
Figura C.8 Imprimir minuta …………………..…………………..…………………….155
Figura C.9 Reporte de incidentes y soluciones …………………..…………………….155
Figura C.10 Pantalla de eliminación de incidente …………………..………………….156
Figura C.11 Consulta de reportes abiertos …………………..………………………….156
Figura C.12 Consulta en conjunto de minutas y Nagios …………………..…………...157
Figura C.13 Consulta de alertas de Nagios por equipo o aplicación …………………..157
Figura C.14 Pantalla de definición de servicio asociado a una aplicación ……………158
Figura C.15 Auditoria del sistema …………………..…………………..………………158

x
Índice de tablas Tabla 3.1 Modelado de actores del negocio…………………………………………….. 52
Tabla 3.2 Clasificación de los requisitos …………………………………………………59
Tabla 3.3 Casos de uso del sistema ………………………………………………………..67
Tabla 3.4 Matriz de Casos de Uso vs. Requisito …………………………………………69
Tabla 3.5 Pruebas de Caja Negra ………………………………………………………….90
Tabla 4.1 Clasificación y Negociación de requisitos …………………………………...104
Tabla 4.2 Descripción de los nuevos casos de uso incorporados a la versión 2 del
SINCFA …..……………………………………………………………………………….111
Tabla 4.3 Matriz de Casos de Uso vs. Requisitos para la segunda versión ……...…….112
Tabla 4.4 Pruebas de caja negra del sistema …………………………………………....128

xi
Agradecimiento
Este documento no hubiera podido realizarse sin el aporte de todas las personas e instituciones que
intervinieron en algún momento sobre el proyecto, y que gracias a su experiencia, interés,
dedicación, apoyo y confianza hicieron posible su realización. Por ello tengo que agradecer:
A la ilustre Universidad de Los Andes, particularmente a la Escuela de Ingeniería de Sistemas, por
contribuir en mi formación profesional.
A la profesora Judith Barrios, por ser una excelente guía y un gran apoyo desde el comienzo hasta
el final del proyecto.
Al ingeniero José Casanova por ser un buen mentor, guía y apoyo dentro de la Empresa.
A todos los miembros de la Coordinación de Confiabilidad, por el apoyo y confianza
suministrados.
A los miembros de las Gerencias MAP y GDS de PDVSA AIT Servicios Comunes Centro que
contribuyeron en el desarrollo del proyecto.
A mi amigo y compañero de clases Manuel Gómez, quien desarrolló su proyecto de grado en la
misma unidad, gracias por ser un excelente apoyo dentro y fuera de la Empresa.
A todos aquellos amigos y compañeros, que de alguna forma intervinieron en la realización de
este trabajo.

1 Introducción
Capítulo 1
Introducción
En un mundo cada vez más dominado por las tecnologías, las empresas se esmeran por obtener un
mejor conocimiento de sus procesos productivos y por lograr una mayor explotación de la
información que estos generan. Dicha información les permite coordinar sus actividades de una
manera eficiente, rápida y con una mejor administración de los recursos. Sin embargo, para que la
información fluya de manera eficiente y oportuna dentro de las diferentes unidades que se pueden
aprovechar de ella para la toma de decisiones, es necesario que la empresa proporcione un conjunto
de instrumentos y canales que, además de servir de soporte para la comunicación entre las unidades
que la integran, posea la flexibilidad suficiente como para adaptarse a los cambios que pueda
experimentar al pasar el tiempo. Es por ello que las grandes empresas dan cada vez más importancia a
las tecnologías que apoyan el flujo de datos y la transmisión de información entre sus miembros.
Petróleos de Venezuela S.A. (PDVSA) no es la excepción a ésta regla. A lo largo de los años se ha
caracterizado por mantenerse a la vanguardia en lo que respecta a la incorporación de tecnologías en
sus procesos, convirtiéndose así en una empresa de alto nivel y dominio tecnológico. La plataforma
tecnológica de la Empresa constituye un activo esencial para el correcto desenvolvimiento de todos
los procesos productivos y por ello resulta vital poder garantizar la mejor disponibilidad posible en los
servicios brindados.
La Gerencia de Automatización, Informática y Telecomunicaciones (AIT) es la encargada de
regir, proveer y mantener los servicios y soluciones integrales de tecnologías de automatización,
información y comunicaciones de la corporación; contribuyendo al mantenimiento de la continuidad
operativa y la ejecución de planes de actualización e innovación. El mantenimiento de la plataforma
tecnológica es una labor a la cual dedican gran cantidad de esfuerzo varias unidades dentro de ésta
gerencia, entre las que destaca la Gerencia de Mantenimiento de la Plataforma (MAP).

2 Introducción
Como toda labor dentro de la empresa, el poder garantizar una alta disponibilidad de los equipos
y sistemas que conforman la plataforma tecnológica involucra toma de decisiones por parte de
miembros a distintos niveles en la organización. Para poder tomar decisiones es necesario conocer a
profundidad la situación actual del problema y el impacto de cada una de las alternativas entre las
cuales se puede elegir. Dicho conocimiento demanda cierta cantidad de información, que no sólo se
requiere que sea veraz, sino también oportuna. Es decir, que esté disponible en el formato adecuado y
en el momento deseado.
La necesidad de información veraz y oportuna ha sido una de las mayores razones para que las
empresas se preocupen más por la organización y procesamiento de dicha información. De allí, el
auge que han tenido los Sistemas de Información Empresariales. El presente proyecto comprende el
desarrollo de un Sistema de Información Web de apoyo a algunas de las actividades de gestión del
mantenimiento de la plataforma tecnológica de PDVSA, particularmente dentro de PDVSA AIT
Servicios Comunes Centro. El sistema automatiza un proceso que era llevado a cabo manualmente y
que comprende el registro y consulta de los reportes de las fallas ocurridas en la plataforma.
1.1 Descripción de la Empresa
Petróleos de Venezuela S.A. (PDVSA) es la corporación estatal venezolana que se encarga de la
exploración, producción, manufactura, transporte y mercadeo de los hidrocarburos del país. Por
mandato de la Constitución de la República Bolivariana de Venezuela, la totalidad de las acciones de
PDVSA pertenecen al Estado Venezolano y se encuentra adscrita al Ministerio del Poder Popular para
la Energía y Petróleo. Es una de las mayores empresas petroleras a nivel mundial y ha sido catalogada
como una de las empresas más grandes del mundo. Actualmente, es la petrolera con mayores reservas
petrolíferas del planeta, alcanzando una suma total de 3,1 billones de barriles. Sus instalaciones se
encuentran distribuidas a lo largo de todo el territorio nacional y posee varias filiales nacionales e
internacionales [1].
PDVSA cumple con todas las actividades propias del negocio petrolero, constituyéndose en una
corporación que abarca todos los procesos, desde la explotación hasta la comercialización de los

3 Introducción
hidrocarburos gaseosos y no gaseosos, y sus derivados. De su cadena de valor (véase Figura 1.1) se
divide en las siguientes cuatro unidades de trabajo:
� Exploración y Producción: Área encargada de la evaluación, exploración, certificación y
perforación de yacimientos petroleros. Es el primer eslabón de la cadena, cubre además la
perforación y construcción de los pozos petrolíferos.
� Refinación: Área encargada de la separación, mejoramiento y obtención de productos o
derivados del petróleo a través de plantas de procesamiento y refinerías.
� Distribución y comercialización: Área encargada de colocar los productos obtenidos (Crudo y
derivados) en los diferentes mercados internacionales.
� Gas: Área encargada de la explotación y comercialización de los hidrocarburos gaseosos. Con
unas reservas probadas por 147 billones de pies cúbicos, Venezuela es una de las potencias
mundiales del sector de hidrocarburos gaseosos.
1.1.1 PDVSA AIT
Para dar apoyo a sus procesos de negocio y ejecutar estos de la manera más eficiente, PDVSA requiere
de una infraestructura tecnológica de vanguardia. Es por ello que existe una gerencia dentro de su
organigrama dedicada exclusivamente a proveer, suministrar y coordinar los servicios y las soluciones
integrales en toda el área que abarca las tecnologías de automatización, información y comunicación;
esta gerencia es la Gerencia AIT de PDVSA (Gerencia de Automatización, Información y
Comunicación). PDVSA AIT no sólo se encarga de contribuir a mantener la continuidad operativa de
la plataforma tecnológica de la empresa, sino que también coordina y ejecuta planes para mantener
dicha plataforma actualizada, todo ello buscando propiciar un ecosistema tecnológico que estimule los
poderes creadores del pueblo, el conocimiento libre, el desarrollo endógeno sustentable y la
economía social productiva con el fin de alcanzar la soberanía tecnológica [2].

4 Introducción
Figura 1.1 Cadena de valor de PDVSA (Fuente: [1])
i) Organización
PDVSA AIT se encuentra dividida en unidades dedicadas a dar apoyo a cada uno de los procesos del
negocio petrolero y a las filiales más importantes de la corporación. Adicionalmente, existen unidades
de apoyo y coordinación de recursos para la ejecución de proyectos de mayor alcance en la empresa.
La organización de las unidades dentro de PDVSA AIT se puede observar en el organigrama de la
Figura 1.2.
ii) AIT Servicios Comunes Centro
Dentro de la gerencia AIT, la línea de servicios comunes es la responsable de coordinar los recursos
necesarios para garantizar la continuidad operativa de los servicios AIT que apoyan los negocios de
PDVSA que conviven en una región determinada (ver Figura 1.3). Existen tres unidades AIT de
Servicios Comunes: Oriente, Occidente y Centro.
AIT Servicios Comunes Centro comprende los servicios de PDVSA AIT en las regiones
metropolitana, centro y sur. Entre los servicios que abarca se pueden mencionar: el mantenimiento
de la plataforma, la gestión del servicio a los usuarios, la implantación de nuevas soluciones, la gestión

5 Introducción
de necesidades y oportunidades en el negocio, entre otras. La Figura 1.3 muestra la estructura
organizativa de PDVSA AIT Servicios Comunes Centro.
El presente proyecto fue desarrollado dentro de la Gerencia de Mantenimiento de la Plataforma
(MAP) de PDVSA AIT Servicios Comunes Centro, en las instalaciones de Intevep ubicadas en Los
Teques, estado Miranda.
Figura 1.2 Estructura organizativa de PDVSA AIT (Fuente: [2])

6 Introducción
Figura 1.2 AIT Servicios Comunes
Figura 1.3 Estructura de PDVSA AIT Servicios Comunes Centro

7 Introducción
1.3 Antecedentes
El mantenimiento de un activo tiene como objetivo primordial garantizar su disponibilidad durante el
mayor tiempo posible, alargando así sus ciclos de vida útil. Las prácticas tradicionales se orientan a la
ejecución de mantenimientos correctivos (actividades de mantenimiento que buscan corregir fallas en
la operación del activo) complementados con mantenimientos preventivos (actividades de
mantenimiento que buscan prevenir fallas en la operación del activo). Sin embargo, el paradigma está
cambiando, la criticidad de los activos hace necesario que las empresas busquen mejorar la
planificación de sus mantenimientos preventivos para garantizar una mayor disponibilidad y disminuir
así los costos asociados. Esto ubica al mantenimiento preventivo prácticamente al mismo nivel, o
incluso un nivel mayor, de importancia respecto al mantenimiento correctivo.
Actualmente, con el objetivo de optimizar sus procesos de gestión del mantenimiento, dentro de
PDVSA se están implantando nuevas prácticas. Entre estas, la Ingeniería de Confiabilidad constituye
una de las principales y más efectivas herramientas, ya que permite optimizar considerablemente el
mantenimiento de los activos basándose en técnicas de análisis estadístico.
La Ingeniería de Confiabilidad (o de fiabilidad) es el estudio de la vida y el fallo de los equipos o
sistemas. El análisis de la confiabilidad de un equipo o sistema busca determinar, entre otras cosas, la
probabilidad de que este ejecute su funcionalidad prevista durante un período de tiempo, operando
bajo un conjunto de condiciones establecidas y para las cuales ha sido diseñado. El concepto de
ingeniería de confiabilidad involucra una amplia gama de metodologías, como por ejemplo:
Mantenimiento Centrado en Confiabilidad (MCC), Análisis Causa Raíz (ACR), Análisis de Datos de
Vida, Modelado y Simulación de Sistemas, Análisis de Criticidad, Inspección Basada en Riesgo (IBR),
entre otras. [3]
A pesar de que las técnicas de la ingeniería en confiabilidad parecieran estar dirigidas
exclusivamente al mantenimiento de equipos y sistemas mecánicos, es posible aplicar dichas técnicas
en cualquier ambiente donde la alta disponibilidad y confiabilidad de los sistemas y equipos sea un
elemento crítico para el negocio [4]. Por ello el enfoque ha sido adaptado a la gestión de
mantenimiento de la plataforma tecnológica de cualquier empresa. En la actualidad, dicha adaptación
está siendo llevada a cabo dentro de PDVSA AIT por la Coordinación de Confiabilidad.

8 Introducción
La Coordinación de Confiabilidad dentro de PDVSA AIT Servicios Comunes Centro (SCC), es
una unidad adscrita a la Gerencia de Mantenimiento Operacional de la Plataforma AIT (MAP) y se
encarga de aplicar prácticas de ingeniería de confiabilidad a la plataforma tecnológica de la empresa, la
cual comprende un conjunto amplio de equipos y aplicaciones, entre las que se pueden mencionar:
servicios de telecomunicaciones, servidores, sistemas de automatización, equipos de infraestructura,
equipos de videoconferencia, redes de alcance local, redes de amplio alcance, sistemas operativos,
herramientas de ofimática, herramientas de gestión de proyectos, soluciones ERP, sistemas de
autogestión, sistemas desarrollados dentro de la empresa, entre otros.
El objetivo principal de la Coordinación de Confiabilidad es supervisar que se cumplan las dos
condiciones mencionadas anteriormente para todas estas tecnologías; es decir, garantizar la
confiabilidad y la disponibilidad de todos los sistemas y equipos que conforman la plataforma
tecnológica de PDVSA AIT Servicios Comunes Centro.
Para el apoyo de su gestión, la Coordinación de Confiabilidad ha definido un conjunto de
estándares y prácticas que le permiten alcanzar los objetivos de su gestión y han implementado varias
metodologías propias de la ingeniería de confiabilidad. Sin embargo, como en toda técnica estadística,
la calidad y precisión de los datos es esencial para que la ingeniería de confiabilidad arroje buenos
resultados. En base a esto, la coordinación obtiene información acerca de las fallas ocurridas y el
mantenimiento realizado para corregirlas a partir de los reportes de falla hechos por los grupos
operativos responsables, también adscritos a la Gerencia MAP.
Por otro lado, el Centro Integral de Monitoreo de PDVSA AIT SCC supervisa continuamente el
estado de los componentes que integran la plataforma y cuyo desempeño resulta crítico para el
negocio. Para el monitoreo de los equipos se utilizan varias aplicaciones, entre las que resalta el
programa Nagios. Este programa, basado en software libre, registra constantemente el estado de los
componentes de la plataforma y de los servicios que ellos prestan, generando notificaciones a los
grupos responsables de su mantenimiento en caso de presentarse alguna anomalía o caída del servicio.
1.4 Planteamiento del Problema
La Coordinación de Confiabilidad de PDVSA AIT SCC se encarga de la evaluación del desempeño de
la plataforma tecnológica de la empresa, manteniendo un registro de las ocurrencias de fallas y

9 Introducción
elaborando, en base a ese registro, análisis que permiten planificar el mantenimiento de la plataforma
y estimar el impacto de las fallas ocurridas, a fin de sugerir prácticas para disminuir su ocurrencia. El
análisis de confiabilidad realizado se centra en la determinación de indicadores de la probabilidad de
que los equipos y sistemas que conforman la plataforma operen sin fallas por un determinado período
de tiempo bajo ciertas condiciones de operación establecidas.
Actualmente se efectúa una “Reunión de Incidentes Diarios”, en la cual los analistas que están de
guardia por cada una de las especialidades que componen la plataforma AIT reportan los incidentes y
novedades que se presentaron durante su guardia. Con los reportes emitidos en esta reunión se genera
una “Minuta de Incidentes Diarios” que contiene la información sobre las novedades reportadas y en la
que se precisan los detalles de los incidentes ocurridos en la plataforma. Una vez armada, la minuta se
pone a disposición del personal que la requiera a través de la intranet de la empresa. Los analistas de
confiabilidad cargan manualmente la información contenida en la minuta en una hoja de cálculo, y
obtienen indicadores determinísticos, como por ejemplo: Tiempo Promedio entre Fallas (TPEF),
Duración de la falla (expresada en horas) y Tiempo Promedio de Solución (TPS). Estos indicadores
sirven como parte del insumo para realizar estudios de criticidad, simulación de sistemas y otros
análisis.
La Coordinación de Confiabilidad desea implementar un Sistema de Información Web, basado en
los estándares de software libre, que apoye sus actividades y que suministre la información que los
analistas requieren para estudiar la confiabilidad de los componentes que conforman la plataforma
tecnológica de la empresa. El sistema a desarrollar debe integrar los reportes de los analistas de
guardia en las reuniones de incidentes diarios y a partir de estos reportes calcular los indicadores ya
mencionados, también debe permitir tener una base de conocimientos acerca de la naturaleza de las
fallas que se presentan en la plataforma y el mantenimiento realizado para corregirlas; adicionalmente,
debe capturar datos del sistema Nagios, utilizado por el Centro Integral de Monitoreo, sobre las
alertas significativas que se detectaron durante la jornada, complementando así los datos suministrados
por los analistas y los indicadores calculados. Se requiere que el sistema esté disponible a través de la
intranet de la empresa para que de ese modo sea accesible a todo el personal involucrado desde
cualquier punto de la red PDVSA.

10 Introducción
1.5 Justificación
Al momento de ocurrir alguna falla en la plataforma, los datos acerca del mantenimiento ejecutado
resultan casi tan importantes como la solución del incidente y la continuidad operativa del servicio
afectado. La información contenida en los reportes elaborados por los analistas debe ser lo más precisa
y completa posible, pues constituye una base de conocimiento de altísimo valor para la organización y
de la cual se pueden obtener muchos productos, como por ejemplo, los indicadores de confiabilidad
de la plataforma.
La generación y el análisis de los indicadores de confiabilidad, permite a los analistas estimar la
vida útil y la criticidad de todos los equipos y sistemas que conforman la plataforma tecnológica de
PDVSA. Mediante estos indicadores es posible realizar simulaciones para estimar, entre otras cosas, el
impacto y la frecuencia de posibles fallas en los sistemas y equipos, haciendo también posible una
adecuada planificación del mantenimiento. Por tratarse de un proceso de carácter vital para la gestión
del mantenimiento y estando basado en técnicas estadísticas, el análisis de confiabilidad requiere de
datos con la mayor exactitud posible.
El proceso mediante el cual se gestionan actualmente las fallas y se analiza la confiabilidad de la
plataforma podría mejorar su eficiencia y precisión, en el sentido de que el cálculo de los indicadores
requiere una dedicación considerable de tiempo por parte de los miembros de la unidad. Además, la
precisión de los valores calculados viene determinada por la veracidad de los datos suministrados por
los analistas en sus reportes, particularmente en cuanto al momento exacto en que se produjo la falla y
la duración de ésta. Otro de los problemas asociados es la falta de estandarización al momento de
generar el reporte, ya que muchas veces se omiten campos importantes acerca de la naturaleza de la
falla.
Además de lo anterior, es conveniente complementar los datos de los reportes de incidentes con
las alertas emitidas por el sistema Nagios, ya que, si bien estas se concentran en la disponibilidad de los
componentes en la red y pueden estar sujetas a alteraciones debido a problemas en la comunicación,
muchas veces aportan datos más precisos en cuanto al instante en que se produjo la falla y el instante
de su finalización, lo que se refleja en los indicadores.
Los problemas de información que poseen actualmente las unidades involucradas pudieran ser
solventados mediante la implementación de un SI que agilice la gestión de los reportes emitidos por

11 Introducción
los analistas, su recuperación y almacenamiento, facilitando así la toma de decisiones y convirtiéndose
en un recurso muy valioso para proporcionar, administrar e interpretar la información por él
generada; además, brindaría un insumo de carácter vital para la gestión del mantenimiento de la
plataforma: un repositorio histórico de incidentes de falla.
Uno de los principales requerimientos que tienen los miembros de la Empresa respecto al sistema
es la posibilidad de que todos los actores involucrados en el proceso puedan utilizarlo de manera
oportuna. Es por ello que se hace necesario que el sistema de información desarrollado esté disponible
a través de la intranet de la Empresa para todos los usuarios involucrados, tratándose entonces de un
tipo particular de SI, conocido como Sistema de Información Web (en inglés Web Information System,
de ahora en adelante SIW).
Enmarcado en el nuevo proyecto que busca la migración de los sistemas dentro de PDVSA hacia
tecnologías libres, para dar así cumplimiento al decreto 3.390, uno de los principales requerimientos
de la Empresa con respecto al SIW es que esté basado en software libre.
1.5 Objetivos
1.5.1 Objetivo General
Desarrollar un Sistema de Información Web basado en software libre que automatice el proceso de
gestión de las fallas ocurridas en la plataforma tecnológica de PDVSA AIT SCC.
1.5.2 Objetivos Específicos
� Realizar un estudio detallado del dominio de aplicación en que se enmarca el sistema
(modelado de negocios).
� Analizar los requisitos de los actores involucrados.
� Realizar un diseño detallado de la estructura y distribución del sistema.
� Desarrollar tablas de datos que almacenen de manera efectiva y organizada las variables de los
procesos involucrados.

12 Introducción
� Diseñar la interfaz web de manera que esté adaptada a los estándares que se manejan dentro
de la empresa y que sea amigable, eficaz y sencilla, para la consulta e interpretación de los
datos.
� Desarrollar los componentes de software que resulten necesarios.
� Realizar pruebas al producto de software para verificar su correcto funcionamiento.
� Refinar iterativamente el Sistema mediante el versionado sucesivo.
� Entregar el sistema listo para su puesta en producción a los miembros de la Coordinación de
Confiabilidad, junto con su documentación y manual de usuarios.
1.6 Metodología
El método a utilizar para el desarrollo del Sistema fue el método Watch para el desarrollo de
aplicaciones empresariales en su versión 2004 [5]. Éste método tiene ventajas en el desarrollo de
aplicaciones, entre las que se pueden mencionar:
� Agrega visibilidad al proyecto de desarrollo, permitiendo que los usuarios del sistema y el
grupo de desarrollo conozcan el estado del proyecto en cualquier momento.
� Facilita al líder del proyecto la planificación y el control del mismo.
� Establece un marco metodológico único que estandariza el proceso de desarrollo y unifica la
información que se produce a lo largo del proyecto.
� Se fundamenta en la ingeniería basada en componentes de software y emplea las mejores
prácticas, técnicas y notaciones utilizadas actualmente en la industria de software.
El método consta de los siguientes tres componentes:
Modelo del producto: que describe el producto que se va a desarrollar, estableciendo las
características arquitectónicas generales de la aplicación.
Modelo del proceso: Mediante el cual se describe de manera estructurada el conjunto de
actividades que el grupo de desarrollo debe seguir para producir la aplicación.

13 Introducción
Modelo del grupo de desarrollo: Que describe los roles que tendrán cada uno de los miembros
del grupo de desarrollo y su organización1.
Dentro del modelo de procesos establecido en el método Watch se establece un marco
metodológico cíclico, iterativo y controlado, mediante el cual en cada iteración se desarrolla una
nueva versión del sistema o un nuevo subsistema. Para el desarrollo del SIW se realizaron dos
iteraciones completas y en cada una de ellas se obtuvo una versión operativa del mismo.
Para el modelado del SIW se utilizó el Lenguaje Unificado de Modelado UML en su versión 2.0.
Este lenguaje permite representar los diferentes aspectos de un sistema de software de una manera
clara y versátil, de modo que cualquier persona lo pueda entender, y que se puedan expresar de
manera explícita y clara las diferentes características del sistema en la etapa previa a su construcción,
obteniendo a la vez una documentación que permite la evolución y revisión del mismo [6]. El
modelado del sistema se hizo utilizando la herramienta CASE Enterprise Architect de Sparx Systems en su
versión 6.1.
Para el desarrollo del sistema se utilizó el lenguaje de programación PHP en su versión 5.2.0-8 y
el manejador de bases de datos PostgreSQL en su versión 8.1.9-0. Se incorporaron funcionalidades en
Javascript para algunos componentes. Para la integración de servicios web se utilizó la librería nuSOAP
en su versión 0.7.3.
1.7 Estructura del documento
El presente documento se estructura de la siguiente manera:
El Capítulo 1 expone los antecedentes del problema de manera introductoria, habla sobre la
Empresa en la que se desarrollo el proyecto y plantea el problema a resolver, justificando su
importancia. Se mencionan los objetivos del proyecto y se habla de la metodología a utilizar.
1 Para efectos del proyecto realizado, el grupo de desarrollo estuvo conformado por el tesista (quien desempeñó varios de los roles dentro de un grupo de desarrollo), el asesor industrial, el tutor académico y ciertos usuarios clave.

14 Introducción
En el Capítulo 2 se hace una breve reseña de las herramientas y conceptos que fueron necesarios
manejar para el desarrollo del proyecto. Se habla acerca de los sistemas de información y su
clasificación, se hace mención del lenguaje de modelado unificado UML, se desarrollan ciertos
conceptos acerca de las bases de datos relacionales y se hace una breve descripción de las herramientas
técnicas más representativas que se utilizaron en el proyecto: el lenguaje de programación PHP, el
manejador de Bases de datos PostgreSQL, la arquitectura orientada a servicios (SOA), entre otros.
En el Capítulo 3 se desarrolla la primera versión del sistema enmarcada en el modelo de procesos
Watch; se comienza con la fase de modelado de negocios en la que se analiza el dominio de la
aplicación y se modelan los principales procesos a automatizar. Se habla acerca de los requisitos de la
aplicación y luego se detalla el diseño del sistema, se mencionan algunos aspectos resaltantes de la
implementación y se habla sobre la fase de pruebas del mismo, se culmina con una breve revisión de
los resultados más importantes obtenidos con la entrega de la primera versión del sistema.
El Capítulo 4 contiene todos los detalles de la implementación de la segunda versión del sistema.
Se hace una breve descripción de los nuevos requisitos incorporados, se resaltan los nuevos
componentes del sistema y se habla acerca de la fase final de pruebas y los resultados obtenidos con la
entrega final del sistema.
El Capitulo 5 abarca las conclusiones y recomendaciones finales del proyecto.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 15
Capítulo 2
Marco Teórico y Herramientas de Soporte
Para el desarrollo del proyecto se hace necesario dominar un conjunto de conceptos y herramientas.
El presente capítulo hace una breve mención de los conceptos íntimamente vinculados con el
proyecto. Se comienza desarrollando el concepto de sistema de información, su clasificación y se habla
del tipo de sistema de información que comprende el proyecto: el sistema de información web, se
exponen algunos conceptos relacionados con la ingeniería de confiabilidad, se mencionan brevemente
los aspectos mas resaltantes de las bases de datos relacionales y del manejador de bases de datos
PostgreSQL, se habla acerca de la arquitectura orientada a servicios (SOA), se explica brevemente el
protocolo SOAP (Simple Access Object Protocol) y se comenta sobre la librería nuSOAP utilizada en el
proyecto. En cuanto a otras herramientas utilizadas, se habla un poco acerca del lenguaje de modelado
unificado (UML) y se explica la estructura y utilidad de los diagramas utilizados en el proyecto;
también se habla del lenguaje de programación PHP.
2.1 Sistemas de Información
Un Sistema de Información es un conjunto de componentes interrelacionados que operan de manera
sistemática para capturar, procesar, almacenar y distribuir información que sirva de apoyo a la toma
de decisiones, la coordinación, el control y el análisis dentro de una organización [7].
En ese sentido, algunas de las características que resultan necesarias para cualquier Sistema de
Información son las siguientes [8]:
� Disponibilidad de información cuando sea necesario y por los medios adecuados.
� Suministro de información de manera selectiva.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 16
� Variedad en la forma de presentación de la información.
� Cierto grado de autonomía para la toma de decisiones
� Tiempo de respuesta adecuado a las necesidades del usuario.
� Exactitud en la información suministrada.
� Generalidad, como las funciones para atender a las diferentes necesidades.
� Flexibilidad, capacidad de adaptación.
� Fiabilidad, para que el sistema opere correctamente.
� Seguridad, protección contra pérdidas.
� Amigabilidad, para el usuario.
2.1.1 Actividades que realiza un sistema de información
Se distinguen cuatro actividades básicas que realiza cualquier sistema de información, las cuales son: la
captura, el procesamiento, el almacenamiento y la salida o distribución de la información [7].
Captura de la Información: Mediante este proceso, el sistema toma los datos que requiere para
procesar la información. La forma como se introducen los datos puede ser manual o automática.
La entrada manual de los datos requiere que estos sean introducidos directamente por el usuario,
mientras que la automática se produce cuando el sistema captura los datos de entrada de otro
sistema o módulo.
Procesamiento de la Información: Es el proceso mediante el cual el sistema de información
realiza transformaciones y cálculos sobre los datos basado en una secuencia de operaciones
preestablecida. Las operaciones pueden ser realizadas sobre los datos recientemente capturados o
sobre aquellos ya almacenados. Mediante la transformación de los datos es posible la toma de
decisiones por parte de los encargados de interpretar la información generada por el sistema.
Almacenamiento de la información: Permite que la información generada en el proceso anterior
pueda ser guardada para ser recuperada más adelante. Por lo general, la información es
almacenada utilizando archivos y bases de datos que utilizan como medio de almacenamiento los
discos magnéticos o discos duros, los discos compactos, los dvds, entre otros.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 17
Salida de la información: Es la capacidad que tiene un sistema de información para mostrar la
información procesada al exterior. La salida de un sistema puede ser la entrada de otro sistema de
información o modulo o puede ser mostrada directamente al usuario en el formato que éste
desee.
2.1.2 Tipos de sistemas de información
En [9] se clasifican los sistemas de información basándose en tres criterios: el grado de cobertura de
las actividades organizacionales, el grado de apoyo a la ejecución de las actividades en la organización y
las tecnologías en las que se basa su desarrollo2. A continuación se describen cada una de estas
clasificaciones.
De acuerdo al grado de cobertura de las actividades organizacionales, un sistema de información
puede clasificarse en:
Sistemas independientes (Sind): Surgen como resultado de requisitos individuales de los
miembros de una organización, apoyando las actividades del usuario en forma completa y sujetos
a las necesidades de éstos.
Sistemas integrados (SII): Están conformados por la conjunción y colaboración de los sistemas de
información ya existentes en la organización.
Sistemas organizacionales (SIO): Proporcionan un grado de cobertura e integración total de las
actividades y procesos organizacionales, aportando así un grado de apoyo máximo a la toma de
decisiones.
De acuerdo al apoyo brindado a la ejecución de las actividades organizacionales los sistemas de
información pueden ser:
Sistemas operacionales (SIOp): Son sistemas de bajo nivel que apoyan la automatización de tareas
y operaciones básicas dentro de una organización, como por ejemplo las actividades
administrativas y de producción.
2 Esta clasificación no es exclusiva, pues los criterios permiten caracterizar a un SI como perteneciente a más de una clasificación

Capítulo 2. Marco Teórico y –Herramientas de Soporte 18
Sistemas gerenciales (SIGe): Están orientados a brindar apoyo a las actividades de nivel gerencial y
de coordinación dentro de la organización.
Sistemas de Apoyo a la Toma de Decisiones (SATD): Son sistemas que contribuyen de forma
directa y explícita al proceso de toma de decisiones dentro de una organización, permitiendo
visualizar el panorama organizacional desde el punto de vista de los resultados y/o consecuencias
de tomar alguna acción en un momento dado.
De acuerdo a las tecnologías en las que se basan, los sistemas de información pueden ser:
� Sistemas cliente/servidor.
� Sistemas basados en tecnologías web.
� Sistemas basados en agentes.
� Sistemas basados orientados a servicios.
Existe una cuarta clasificación de los sistemas de información en base al apoyo de actividades
organizacionales muy especializadas. Dentro de este grupo se encuentran los ya mencionados SATD,
los Sistemas Expertos (SE), que incorporan la automatización de “experticia humana” en la realización
de determinada actividad y Sistemas de Información Geográfica (SIG) que están relacionados con el
manejo de información geográfica o referenciada espacialmente.
2.1.3 Sistemas de Información Web
En [10] se define un Sistema de Información Web (SIW) como: “Un sistema de información que utiliza
una arquitectura web para proporcionar información (datos) y funcionalidad (servicios) a usuarios finales a través
de una interfaz de usuario basada en presentación e interacción sobre dispositivos con capacidad de trabajar en la
web. Los SIW varían ampliamente en su ámbito, desde sistemas de información hasta sistemas de transacciones e-
business, incluso sistemas de servicios web distribuidos”. Se clasifican los sistemas de información web como
sigue:

Capítulo 2. Marco Teórico y –Herramientas de Soporte 19
� Las intranets, que dan apoyo al trabajo interno dentro de la Empresa.
� Los sitios de presencia en la web, los cuales son herramientas utilizadas para alcanzar
consumidores fuera de la empresa.
� Los sistemas de Comercio electrónico que dan apoyo a la interacción con el consumidor.
� Las extranets que son un conjunto de sistemas internos y externos que apoyan las
comunicaciones entre la empresa y otras empresas.
Por lo general, los SIW manejan una gran cantidad de datos, que se encuentra en fuentes
heterogéneas, se maneja en distintos formatos, y un conjunto de componentes que están por lo
general codificados en diferentes lenguajes de programación y están distribuidos en diferentes
plataformas. Al igual que los SI tradicionales, más allá que una infraestructura para la entrega de
información (en tiempo de ejecución), los SIW deben proporcionar una infraestructura de desarrollo
y mantenimiento que permita manejar e interpretar los datos y que proporcione funcionalidades a los
usuarios finales para capturar, almacenar, procesar y mostrar la información, dando solución a sus
necesidades.
Los SIW son diseñados, desarrollados y mantenidos con el propósito de alcanzar objetivos
específicos de los usuarios finales. Éstos objetivos, deben constituir la base del proyecto de desarrollo
de todo SIW.
2.2 Ingeniería de Confiabilidad
Previo a la definición de las técnicas propias de la ingeniería de confiabilidad, se desarrollará un
conjunto de términos que se encuentran íntimamente vinculados con el análisis de confiabilidad. Los
siguientes conceptos fueron tomados de [10].
2.2.1 Conceptos Básicos
Confiabilidad: Se define la confiabilidad como:”la propiedad de un sistema o equipo de cumplir las
funciones para él previstas, manteniendo su capacidad de trabajo bajo los regímenes y condiciones

Capítulo 2. Marco Teórico y –Herramientas de Soporte 20
prescritos y durante el intervalo de tiempo requerido. Dicho de otra forma, la confiabilidad es la
propiedad del sistema de mantenerse sin experimentar un suceso de falla durante el tiempo y las
condiciones de explotación establecidos”. En éste sentido también define falla como sigue:
Falla: “Suceso después del cual un sistema tecnológico deja de cumplir (total o parcialmente) sus funciones. La
falla es la alteración de la capacidad de trabajo del componente o sistema”.
Mantenibilidad: “Es la probabilidad de que un sistema, subsistema o equipo que ha fallado pueda ser
reparado dentro de un período de tiempo determinado”.
Disponibilidad. “Es la probabilidad que un sistema, subsistema o equipo esté disponible para su uso durante
un tiempo dado”.
2.2.2 Definición
La Ingeniería de Confiabilidad se define como la disciplina técnica que estima, controla y gerencia la
probabilidad de fallas en dispositivos, equipos o sistemas, con el propósito de garantizar una alta
disponibilidad y confiabilidad [10].
De la definición anterior, la cuantificación de la confiabilidad (en términos de probabilidades)
resulta esencial. El conocimiento de los parámetros de confiabilidad y mantenibilidad son
determinantes en el cálculo de la disponibilidad de cualquier dispositivo, sistema o equipo. Mediante
éstos parámetros se proporcionan los datos fundamentales para el análisis del mantenimiento,
generando de ése modo gran cantidad de información técnica que resulta vital para la toma de
decisiones.
La gran cantidad de información técnica generada requiere de evaluación permanente y de la
ayuda de sistemas computarizados que permitan un adecuado análisis, interpretación y obtención de
los datos de manera oportuna. Los resultados del esfuerzo en el conocimiento de los indicadores se
traducen en un aumento de la efectividad del proceso productivo, asociado a menores costos de
penalización y mantenimiento; para tales propósitos se desprende la necesidad de un monitoreo
constante mediante un sistema de información que, basado en modelos estadísticos y matemáticos,
sirva de apoyo técnico para la planificación y programación del mantenimiento.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 21
2.2.3 Estimación de la confiabilidad
Para la estimación de la confiabilidad o la probabilidad de fallas, existen dos métodos que dependen
del tipo de data disponible; estos son:
Estimación Basada en Datos de Condición: Altamente recomendable para equipos estáticos,
que presentan patrones de “baja frecuencia de fallas” y por ende no se tiene un “historial de
fallas” que permita algún tipo de análisis estadístico.
Estimación Basada en el Historial de Fallas: Recomendable para equipos dinámicos, los cuales
por su alta frecuencia de fallas, normalmente permiten el almacenamiento de un historial de
fallas que hace posible el análisis estadístico.
Debido a las características de los equipos y sistemas que conforman la plataforma tecnológica de
PDVSA AIT se desarrollarán los conceptos asociados a la estimación del historial de fallas.
2.2.4 Análisis de confiabilidad basado en historiales de falla
Para una adecuada toma de decisiones es necesario tener datos exactos acerca de la ocurrencia de las
fallas. Por lo general, dentro de las industrias existen registros históricos de las fallas de los equipos,
los cuales se encuentran almacenados en grandes bases de datos. La adquisición de los datos se reduce
a la consulta en esas bases de datos.
Sin embargo, la recuperación oportuna de los datos para la realización de mejoras en la
confiabilidad resulta un factor crítico en muchas circunstancias. Muchas veces se considera más
relevante la realización de mejoras inmediatas en los equipos y la corrección de las fallas, que el
registro histórico acerca de las acciones tomadas. La educación de los encargados de tomar las
decisiones y de los recolectores de los datos acerca del valor de la información de los bancos de datos
resulta vital para la mejora de los índices de confiabilidad, ya que se traduce en un incremento en la
veracidad de los datos recolectados [11].

Capítulo 2. Marco Teórico y –Herramientas de Soporte 22
2.2.5 Indicadores de confiabilidad
Los datos históricos del desempeño de los equipos o sistemas pueden ser convertidos en indicadores
de comportamiento fáciles de analizar. Un simple concepto aritmético resulta muy útil en la
estimación de la confiabilidad.
La confiabilidad se observa cuando el tiempo medio de fallas, para dispositivos no reparables o el
tiempo medio entre fallas para aquellos dispositivos reparables es largo comparado con el tiempo de
servicio efectivo. Del mismo modo, cuando los valores de los índices de tiempo medio son pequeños
comparados con el tiempo de servicio efectivo, son indicadores de falta de confiabilidad.
Los recíprocos de los indicadores de tiempo medio proporcionan las tasas de fallas que por lo
general también proporcionan información útil y muchas veces considerada mejor para realizar
cálculos.
Algunos de los indicadores más utilizados son [10]:
Tiempo de disponibilidad (tiempo de trabajo sin fallas): Número de horas de trabajo de un
componente sin fallas.
Tiempo promedio de solución o tiempo promedio para reparar: Es el tiempo medio, en
horas, de duración de la reparación de un elemento después de experimentar una falla.
Intensidad de fallas o rata de fallas: Es el número de fallas ocurridas en un período de tiempo.
Tiempo Promedio entre fallas: Proporciona una medida del tiempo promedio transcurrido entre
las caídas de algún componente.
Probabilidad de trabajo sin fallas o probabilidad de supervivencia: Es la probabilidad de
que en un intervalo de tiempo prefijado (o en los límites de las horas de trabajo dadas) con
regímenes y condiciones de trabajo establecidos, no se produzca ninguna falla, es decir, la
probabilidad de que el dispositivo dado conserve sus parámetros en los límites prefijados
durante un intervalo de tiempo determinado y para condiciones de explotación dadas. Se
denota como Ps(t).
Probabilidad de falla: es la probabilidad de que en un intervalo de tiempo prefijado se produzca al
menos una primera falla. Se denota como Pf(t).

Capítulo 2. Marco Teórico y –Herramientas de Soporte 23
Por lo general, la precisión en los índices mejora entre mayor cantidad de registros históricos
se posea.
2.2.6 Tipos de Mantenimiento
El mantenimiento puede ser clasificado en las siguientes cinco categorías [10]:
Mantenimiento a condición: actividades preventivas y/o correctivas que surgen de la condición
de los equipos, generalmente detectada por sus operadores a través de los dispositivos de
control y monitoreo (scadas, salas de control, panel de instrumentación).
Mantenimiento de rutina y preventivo: incluye el mantenimiento periódico, como la ejecución
de tareas previamente programadas, inspecciones y trabajos menores repetitivos.
Mantenimiento correctivo: es el proceso de efectuar reparaciones tan pronto como sea posible
después del reporte de una falla.
Mantenimiento a frecuencia fija: son los basados en estrategias (horas de operación, tiempo,
volumen de operaciones, entre otras) que generan un plan de mantenimiento.
Mantenimiento para optimizar: implica determinar las causas de descomposturas repetidas y
eliminar la causa mediante la modificación del diseño. Generalmente se ejecutan actividades
como la ingeniería de confiabilidad (principalmente metodologías basadas en el análisis causa
raíz) para optimizar el diseño.
2.3 Bases de datos
Una base de datos es una colección de datos relacionados, es decir un conjunto de hechos que pueden
registrarse y que tienen un significado implícito. Por lo general, las bases de datos representan
aspectos del mundo real y son diseñadas, construidas y pobladas con datos que tienen un propósito
específico, se caracterizan por la coherencia de los datos que la integran. [12]. Hay cinco modelos
principales de bases de datos: el modelo jerárquico, el modelo en red, el modelo relacional, el
modelo de bases de datos deductivas y el modelo de bases de datos orientado a objetos. Para el
desarrollo del proyecto fue necesario manejar el concepto de bases de datos relacionales.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 24
2.3.1 Bases de datos relacionales
Constituye el modelo más utilizado en la actualidad para el modelado de problemas reales y la
administración de datos dinámicamente. Almacena la información en varias tablas (filas y columnas de
datos) o ficheros independientes y realiza búsquedas que permiten relacionar datos que han sido
almacenados en más de una tabla. Se basa en el uso de relaciones, donde cada relación es una tabla
compuesta por registros (las filas de una tabla) y campos (las columnas de una tabla). En el modelo
relacional, cada fila representa un hecho que normalmente se corresponde con un vínculo o una
entidad del mundo real. El nombre de la tabla y de las columnas ayuda a interpretar el significado de
los valores que están en cada fila. En el modelo relacional una fila se denomina tupla, una cabecera de
columnas se denomina atributo y la tabla se denomina relación.
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia. Esto tiene
la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la
base de datos. La información puede ser recuperada o almacenada mediante “consultas” que ofrecen
una amplia flexibilidad y poder para administrar la información [12].
2.3.2 Lenguaje Estructurado de Consulta (SQL)
Es un lenguaje de base de datos normalizado, utilizado por los diferentes motores de bases de datos
para realizar determinadas operaciones sobre los datos o sobre la estructura de los mismos. Está
diseñado como un lenguaje amplio que incluye instrucciones para definir, consultar y actualizar la base
de datos.
Las funcionalidades que proporciona el SQL van más allá de la simple consulta (o recuperación)
de datos. Permite definir los tipos de datos y manipular los datos. Además, permite la concesión y
denegación de permisos, la implementación de restricciones de integridad y controles de transacción,
y la alteración de esquemas.
El lenguaje SQL está compuesto por comandos, cláusulas, operadores y funciones agregadas.
Estos elementos se combinan en las instrucciones para crear, actualizar y manipular las bases de datos
[12].

Capítulo 2. Marco Teórico y –Herramientas de Soporte 25
2.3.3 El sistema de gestión de bases de datos PostgreSQL
PostgreSQL es un gestor de bases de datos muy conocido y usado en entornos de software libre por el
conjunto de funcionalidades avanzadas que soporta, lo que lo sitúa al mismo o a un mejor nivel que
muchos otros sistemas gestores comerciales.
El origen de PostgreSQL se sitúa en el gestor de bases de datos “POSTGRES” desarrollado en la
Universidad de Berkeley y que se abandonó en favor de PostgreSQL a partir de 1994. Ya entonces,
contaba con prestaciones que lo hacían único en el mercado y que otros gestores de bases de datos
comerciales han ido añadiendo durante este tiempo.
PostgreSQL se distribuye bajo licencia BSD, que permite su uso, redistribución, modificación con
la única restricción de mantener el copyright del software a sus autores, en concreto el PostgreSQL
Global Development Group y la Universidad de California.
PostgreSQL destaca por su amplísima lista de prestaciones que lo hacen capaz de competir con
cualquier SGBD comercial [13]:
� Está desarrollado en el lenguaje de programación C.
� Posee interfaces compatibles con C, C++, Java, Perl, PHP y TCL, entre otros.
� Cuenta con un rico conjunto de tipos de datos que permiten, además, su extensión mediante
tipos y operadores definidos y programados por el usuario.
� Su administración se basa en usuarios y privilegios.
� Sus opciones de conectividad abarcan TCP/IP, sockets Unix y sockets NT, además de soportar
completamente ODBC.
� Los mensajes de error pueden estar en español y hacer ordenaciones correctas con palabras
acentuadas o con la letra ‘ñ’.
� Es altamente confiable en cuanto a estabilidad se refiere.
� Puede extenderse con librerías externas para soportar encriptación, búsquedas por similitud
fonética (soundex), etc.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 26
� Control de concurrencia multi-versión, lo que mejora sensiblemente las operaciones de
bloqueo y transacciones en sistemas multi-usuario.
� Posee soporte para vistas, claves foráneas, integridad referencial, disparadores,
procedimientos almacenados, subconsultas y casi todos los tipos y operadores soportados en
SQL92 y SQL99.
� Implementación de algunas extensiones de orientación a objetos. En PostgreSQL es posible
definir un nuevo tipo de tabla a partir de otra previamente definida.
2.4 Arquitectura Orientada a Servicios (SOA)
Vista como un marco para el desarrollo de productos de software, la arquitectura orientada a servicios
es un paradigma para utilizar y organizar servicios distribuidos que pueden encontrarse bajo varios
dominios y estar implementados utilizando diferentes tecnologías. Se basa en los conceptos de
escalabilidad y reutilización del software. Por lo general, las organizaciones desarrollan funciones y
aplicaciones que son útiles para automatizar ciertas tareas dentro de los procesos de negocio. Sin
embargo, muchas veces una solución puede ser útil a nivel intermedio para varios procesos o unidades
dentro de la organización con fines diferentes. El concepto de arquitectura orientada a servicios
implica que los desarrolladores creen un conjunto de funciones independientes entre si (llamadas
servicios) que aceptan llamadas y generan respuestas mediante interfaces bien definidas y que son
puestos a disposición de los clientes como utilidades que pueden ser reutilizadas por diversas
aplicaciones dentro de la organización. La implementación de los servicios es transparente para los
usuarios ya que a estos no le interesa conocer sino el tipo y formato de las entradas admitidas y de las
salidas generadas por el servicio [14].
En un ambiente SOA, los nodos de la red hacen disponibles sus recursos a otros participantes en
la red como servicios independientes a los que tienen acceso de un modo estandarizado. La mayoría
de las definiciones de SOA identifican la utilización de Servicios Web (empleando SOAP y WSDL) en
su implementación, no obstante se puede implementar SOA utilizando cualquier tecnología basada en
servicios [15].

Capítulo 2. Marco Teórico y –Herramientas de Soporte 27
Las arquitecturas orientadas a servicios difieren de las arquitecturas orientadas a objetos en que se
encuentran formadas por servicios débilmente acoplados y altamente interoperables. Estos servicios
definen una estructura para comunicarse entre si que es independiente del lenguaje en que se
encuentran implementados y el lenguaje de programación, todo ello buscando maximizar la
reutilización de los componentes desarrollados [15].
La arquitectura SOA es muy utilizada por las grandes organizaciones en la actualidad, entre tantas
cosas por el hecho de permitir la creación o cambios en los procesos de negocio automatizados de
forma ágil, a través de una composición de nuevos procesos utilizando las funcionalidades del negocio
contenidas en las aplicaciones actuales o futuras consumidas por medio de servicios web. Una
arquitectura de este tipo es la que se muestra en la figura 2.1. De la figura se observa como los
componentes se distribuyen en tres capas:
� La capa de presentación, en la que, a través de las interfaces de usuario generadas, se establece
una relación entre el usuario y el sistema, logrando de esta forma el uso de la aplicación por
parte del usuario. Se le da el formato a los datos recibidos desde el bus de integración con el
fin de que el usuario visualice la información en una página web.
� El bus de integración, en el que se encuentran los servicios web del negocio, así como los
objetos manipulados por esos servicios, y todos los servicios comunes para todas las funciones
de negocio. Esta capa implementa la lógica de negocios de la aplicación.
� La capa de datos que mantiene la implementación de las estructuras que almacenan los datos
de la aplicación (bases de datos).

Capítulo 2. Marco Teórico y –Herramientas de Soporte 28
Figura 2.1 Arquitectura orientada a servicios (Fuente: [16])
Para la implementación del proyecto se utilizó un protocolo basado en servicios web, mejor conocido
como Protocolo de Acceso a Objetos Simples (SOAP, por sus siglas en inglés).
2.5 Protocolo SOAP
SOAP es un protocolo de comunicación definido para el intercambio de datos mediante el paso de
mensajes en formato XML. Define los estándares para la comunicación entre dos objetos de diferentes
procesos a través de una conexión de Internet. Es utilizado para el acceso a servicios web. Permite la
llamada de procedimientos remotos mediante http entre aplicaciones distribuidas en distintos
servidores. Existen varios protocolos parecidos, como por ejemplo RMI de Java y ORPC de CORBA.
Sin embargo, SOAP es uno de los más utilizados y aceptados por las grandes compañías del mundo.
Las principales razones de su éxito son [17]:

Capítulo 2. Marco Teórico y –Herramientas de Soporte 29
� No esta asociado con ningún lenguaje: SOAP no especifica una API, por lo que la
implementación de la API se deja al lenguaje de programación y la plataforma.
� No se encuentra fuertemente asociado a ningún protocolo de transporte: Un
mensaje de SOAP no es más que un documento XML, por lo que puede transportarse
utilizando cualquier protocolo capaz de transmitir texto.
� No está atado a ninguna infraestructura de objeto distribuido: La mayoría de los
sistemas de objetos distribuidos se pueden extender, y muchos de ellos ya lo están para que
admitan SOAP.
� Aprovecha los estándares existentes en la industria: Por ejemplo, SOAP aprovecha
XML para la codificación de los mensajes, en lugar de utilizar su propio sistema de tipo que ya
están definidas en la especificación esquema de XML. Y como ya se ha mencionado, SOAP no
define un medio de trasporte para los mensajes; los mensajes de SOAP se pueden asociar a los
protocolos de transporte existentes como http y SMTP.
� Permite la interoperabilidad entre múltiples entornos: SOAP se desarrolló sobre los
estándares existentes de la industria, por lo que las aplicaciones que se ejecuten en
plataformas con dichos estándares pueden comunicarse mediante mensaje SOAP con
aplicaciones que se ejecuten en otras plataformas.
Existen varias implementaciones de SOAP que proporcionan la estructura para definir servicios
web bajo un lenguaje particular, entre estas implementaciones, para el proyecto se utilizó la librería
NuSOAP elaborada para PHP.
2.5.1 NuSOAP
NuSOAP es un kit de herramientas (ToolKit) para desarrollar servicios web bajo el lenguaje PHP. Está
compuesto por una serie de clases que facilitan el desarrollo de servicios web. Provee soporte para el
desarrollo de clientes (aquellos que consumen los servicios) y de servidores (aquellos que los
proveen). Incorpora métodos que generan los mensajes XML a partir de unas pocas líneas de código
por parte del desarrollador. Además, permite agregar datos nuevos creados por el usuario,

Capítulo 2. Marco Teórico y –Herramientas de Soporte 30
incrementando su flexibilidad. NuSOAP está basado en SOAP 1.1, WSDL 1.1 y http 1.0/1.1. Existen
otras herramientas de soporte para el desarrollo de servicios web bajo PHP, sin embargo NuSOAP es
uno de los que se encuentra en la fase de desarrollo más avanzada, a pesar de que aun se encuentra en
su fase experimental [18].
2.6 Lenguaje de Modelado Unificado (UML)
UML (Unified Modelling Language) es un lenguaje gráfico para el modelado de sistemas de software que
permite representar gráficamente la estructura de un sistema, haciendo posible que cualquier persona,
ajena o no al proceso de diseño, lo pueda entender. Mediante UML se pueden especificar, visualizar y
documentar de manera explícita las características de un sistema de software antes y durante su
construcción. UML es sólo un lenguaje para el modelado, por lo que su utilización es independiente
del proceso de desarrollo, aunque para su uso óptimo debe aplicarse en un proceso centrado en
arquitectura, dirigido a casos de uso, iterativo e incremental [19].
Es lo suficientemente expresivo como para modelar pruebas del sistema, sistemas de hardware,
sistemas de negocios, el flujo de trabajo en una empresa, diseño de estructura de una organización,
actividades de planificación de proyectos y otros sistemas no informáticos.
El UML se deriva de la unificación de tres metodologías de análisis y diseño orientada a objeto, la
metodología de Grady Booch para la descripción de conjuntos de objetos y sus relaciones, la técnica
de modelado orientada a objetos de James Rumbaugh (OMT: Object-Modeling Technique) y la
aproximación de Ivar Jacobson (OOSE: Object Oriented Software Engineering) mediante la metodología de
casos de uso. De estas tres metodologías, las de Rumbaugh y Booch se pueden clasificar como
metodologías directamente orientadas a objetos, mientras que la metodología de Jacobson está
orientada al usuario, ya que todo en su método se deriva de los escenarios de uso del sistema.
Su desarrollo comenzó a finales de 1994 cuando Grady Booch y Jim Rumbaugh de Racional
Software Corporation comenzaron a unificar sus métodos. A finales de 1995, Ivar Jacobson y su
compañía Objectory se incorporaron, aportando el método OOSE. Los anteproyectos de UML
empezaron a circular en la industria de software y las reacciones resultantes trajeron modificaciones
considerables. Conforme diversos corporativos vieron que el UML era útil a sus propósitos se fueron
agregando nuevos aportes. En 1997 se produjo la versión 1.0 del UML y se puso a consideración del

Capítulo 2. Marco Teórico y –Herramientas de Soporte 31
OMG (Object Management Group), propuesto como un lenguaje de modelado estándar. Desde entonces,
UML ha atravesado una serie de revisiones y refinamientos hasta llegar a su versión actual: UML 2.0
[20].
El UML está compuesto por diversos elementos gráficos que se combinan para conformar
diagramas. Como se trata de un lenguaje, UML aporta las reglas para combinar tales elementos. Los
diagramas permiten representar diversas perspectivas de un sistema, indicando lo que supuestamente
hará, pero no la forma como se implementará. En la versión 2.0 del Uml, se define un total de 13
diagramas para representar la estructura y dinámica del sistema. Sin embargo, para efectos del
proyecto solo se utilizaron ciertos diagramas. Los diagramas utilizados en el proyecto se describen a
continuación.
2.6.1 Diagramas de clases
Son utilizados durante el proceso de análisis y diseño conceptual de la información manejada por el
sistema. Son estructuras estáticas que dan una visión general del conjunto de clases existentes en el
sistema modelado y las relaciones existentes entre casa una de ellas. Se trata de diagramas estáticos
pues muestran las relaciones entre las clases pero no especifica su interacción dinámicamente.
2.6.2 Diagramas de componentes
Son utilizados para modelar la estructura del software y las dependencias entre sus componentes.
Modelan y agrupan los componentes del sistema en forma de paquetes, muestra las interfaces de los
componentes, sus dependencias, relaciones e interacciones.
2.6.3 Diagramas de objetos
Son parte de la vista estática del sistema. Permiten modelar las instancias de las clases que fueron
representadas en el diagrama de clases. Muestran los objetos y sus relaciones pero en un momento
concreto del sistema. Pueden incorporar clases para mostrar la clase a la que pertenece un objeto
representado.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 32
2.6.4 Diagramas de despliegue
Muestran la distribución física de los distintos nodos que componen el sistema, la comunicación entre
los nodos y la disposición de los componentes sobre ellos. Un nodo es un recurso de ejecución tal
como un computador, un dispositivo o memoria. Los estereotipos permiten precisar la naturaleza del
equipo. Los elementos utilizados en la representación gráfica de estos diagramas son los mismos que
son utilizados en los diagramas de componentes.
2.6.5 Diagramas de paquetes
Permiten visualizar la distribución de los componentes del sistema en paquetes y las dependencias
entre ellos.
2.6.6 Diagramas de actividades
Son utilizados para modelar el flujo de control de las actividades que tienen lugar a lo largo del tiempo
junto a las tareas concurrentes que pueden realizarse a la vez. Muestra las interacciones entre las clases
mediante el flujo de control de actividades ordenadas cronológicamente con el fin de lograr la
ejecución de un proceso más complejo.
2.6.7 Diagramas de casos de uso
Representan la forma como un usuario opera con el sistema en desarrollo y la forma, tipo y orden en
la que interactúan sus elementos. Los elementos implicados en un diagrama de casos de uso son:
Actores: Son entidades con un comportamiento definido y que realizan alguna interacción con el
sistema. Pueden representar usuarios, organizaciones u otros sistemas informáticos.
Casos de uso: Son descripciones de las secuencias de acciones que se producen de la interacción
entre un actor y el sistema.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 33
Relaciones entre casos de uso: Las relaciones entre los casos de uso son de inclusión y extensión.
Un caso de uso puede incluir a otro caso de uso como parte de su procesamiento. Generalmente
se asume que los casos de uso incluidos se llamarán cada vez que se ejecute el camino base. Un
Caso de Uso puede ser incluido por uno o más casos de uso, ayudando así a reducir la duplicación
de funcionalidad al factorizar el comportamiento común en los casos de uso que se reutilizan. Un
caso de uso puede extender el comportamiento de otro caso de uso típicamente cuando ocurren
situaciones excepcionales o cuando depende de ciertos criterios, entonces se realiza una
interacción adicional. El caso de uso que extiende describe un comportamiento opcional del
sistema a diferencia de la relación incluye que se da siempre que se realiza la interacción descrita.
2.6.8 Diagramas de secuencia
Representan la interacción ordenada entre los objetos de un sistema de acuerdo a una secuencia
temporal de eventos. En particular muestran los objetos que participan en la interacción y los
mensajes que intercambian en orden temporal.
2.7 El lenguaje de programación PHP
PHP es un lenguaje de programación del lado del servidor diseñado originalmente para la generación
de páginas dinámicas. Es un lenguaje de programación interpretado o de script que permite insertar
fragmentos de código dentro de la página HTML y realizar determinadas acciones de una forma fácil y
eficaz sin tener que generar programas en un lenguaje distinto al HTML. Por otra parte, PHP ofrece
un sinfín de funciones para la explotación de bases de datos de una manera llana y sin complicaciones.
Generalmente se ejecuta en un servidor web, tomando el código en PHP como su entrada y creando
páginas web como salida. Puede ser desplegado en la mayoría de los servidores web y en casi todos los
sistemas operativos y plataformas sin costo alguno. PHP se encuentra instalado en más de 20 millones
de sitios web y en un millón de servidores [21].
Una de sus mayores ventajas es el parecido que posee con otros lenguajes de programación
estructurada como Perl y C que permite a la mayoría de los programadores crear aplicaciones
complejas de manera muy sencilla, pues no se requiere mucho tiempo para su aprendizaje.

Capítulo 2. Marco Teórico y –Herramientas de Soporte 34
Cuando el cliente hace una petición al servidor para que le envíe una página web, el servidor
ejecuta el intérprete de PHP. Éste procesa el script solicitado y genera de manera dinámica el
contenido. El resultado es enviado por el intérprete al servidor, quien a su vez le envía la página
HTML al cliente. Mediante extensiones es también posible la generación de archivos PDF, Flash, así
como imágenes en diferentes formatos. PHP puede ser ejecutado bajo casi cualquier plataforma
(UNIX, Windows, Mac OS) [21].
Si bien no es un lenguaje completamente orientado a objetos, en su última versión (versión 5.0)
se incorporan varios onstructor de programación orientada a objetos. Su creación y desarrollo se da
en el ámbito de los sistemas libres, bajo la licencia GNU. Existen muchos editores y entornos
integrados de desarrollo disponibles en el mercado para desarrollar aplicaciones en PHP. Para el
desarrollo del sistema se utilizó el editor OpenKomodo de ActiveState en su versión 5.0.
2.8 Conclusiones del capítulo
La importancia de los temas desarrollados en este capítulo radica en que para lograr satisfacer las
necesidades del cliente con respecto al sistema, es necesario tener un conocimiento a profundidad de
los conceptos vinculados y de las herramientas que agilizan el proceso de desarrollo. Este
conocimiento permite abordar el problema de manera eficaz y así obtener un producto de calidad con
el menor esfuerzo posible.

Capítulo 3 Desarrollo de la primera versión del sistema 35
Capítulo 3
Desarrollo de la primera versión del sistema
El presente capítulo describe las fases de desarrollo de la primera versión del Sistema de Gestión de
Incidentes de Falla (SINCFA). Como se mencionó en el Capítulo 1, para el desarrollo del sistema se
utiliza el Método Watch en su versión 2004 [5]. A continuación se describe cada una de las fases
contempladas en el método y que son aplicadas para obtener la primera versión del sistema. Se
comienza hablando de la planificación estimada de recursos y tiempo para la primera fase del
proyecto, se describe el modelado de negocios realizado para la unidad organizativa en estudio (la
Gerencia MAP, específicamente la Coordinación de Confiabilidad), se comenta acerca de los
requisitos de la aplicación y de los casos de uso modelados, se describe el diseño de la arquitectura y la
implementación de los componentes, para finalmente mencionar los resultados obtenidos en las
pruebas de esta primera versión. Se culmina el capítulo con una breve revisión de los requisitos y una
discusión acerca de las ocurrencias de mayor impacto durante el desarrollo.
3.1 Planificación del proyecto
La planificación y estimación de los recursos necesarios para el desarrollo del producto resulta esencial
dentro de cualquier proyecto de desarrollo de software. Durante las primeras conversaciones con los
usuarios y el cliente, se tenía previsto desarrollar el sistema mediante tres iteraciones del método
Watch: la primera iteración se iba a concentrar en el modelado de negocios y la especificación de
requisitos, la segunda iba a enfocarse en el diseño detallado de la arquitectura del sistema y la
implementación de los primeros componentes, mientras que en la tercera iteración se iba a obtener la
implementación definitiva del sistema y las pruebas finales. La planificación se basaba en el supuesto

Capítulo 3 Desarrollo de la primera versión del sistema 36
de que el sistema solamente se encargaría de la generación de indicadores de disponibilidad y fallas en
la plataforma a partir de un conjunto de datos suministrados por los usuarios.
Luego de conversaciones posteriores, durante la fase de análisis del problema, se observa como
los requisitos y expectativas del cliente, respecto al sistema, abarcan un alcance mucho mayor:
automatizar el vaciado de las minutas de reuniones de incidentes diarios, integrando los datos
reportados en estas minutas con los datos manejados por el Centro Integral de Monitoreo, todo ello
con miras a automatizar el proceso de gestión de incidentes de falla en la plataforma desde el
momento en que los grupos solucionadores reportan el incidente, hasta cuando los analistas de
confiabilidad extraen los indicadores. La cantidad de tiempo y recursos necesarios para desarrollar el
sistema se incrementan considerablemente. Es entonces necesario reducir el número de iteraciones
del método Watch a dos e incrementar el tiempo estimado para el desarrollo del proyecto (Ver Anexo
A). En cada iteración se obtiene una versión operativa del sistema, siendo la segunda una versión
“mejorada” de la primera. La primera iteración se concentra en el modelado de los procesos de
negocio, la satisfacción de los principales requisitos del cliente y el desarrollo de los componentes base
del sistema, En la segunda iteración los esfuerzos se concentran en incorporar nuevos requisitos,
desarrollar los componentes necesarios, integrar dichos componentes con los componentes ya
desarrollados en la primera iteración y realizar las pruebas finales al sistema.
3.2 Modelado de Negocios
Esta fase resulta vital dentro del proceso de desarrollo del producto de software, pues permite
obtener un conocimiento a fondo del sistema de negocios u organización bajo la cual se enmarca el
proyecto. Un conocimiento a profundidad del dominio de la aplicación resulta esencial para
determinar de la mejor manera posible sus requisitos [22].
En el contexto de las aplicaciones empresariales, el dominio de aplicación se refiere a la
organización o sistema de negocios que será apoyada por la aplicación o SI, obteniendo como
producto final el modelo de negocios de la organización. Un modelo de negocios es una
representación que captura la estructura y dinámica de la organización objetivo bajo la cual se
incorporará el SI. Mediante el modelo de negocios es posible obtener un conocimiento a profundidad

Capítulo 3 Desarrollo de la primera versión del sistema 37
de la organización, sus problemas de información y los requisitos funcionales que deben ser satisfechos
por el SI [5].
3.2.1 Delimitación del sistema de negocios
Dentro de PDVSA AIT Servicios Comunes Centro, la Gerencia de Mantenimiento de la Plataforma
(MAP) coordina los recursos necesarios para la ejecución del mantenimiento de los equipos y
servicios que integran la plataforma tecnológica. La ejecución del mantenimiento de la plataforma
tiene como objetivo maximizar la disponibilidad de los equipos y sistemas a un mínimo costo. A pesar
de que en el proceso intervienen casi todas las subgerencias de PDVSA AIT SCC, dentro de los
subprocesos que serían apoyados por el SIW sólo interviene directamente la Gerencia MAP, mientras
que la Gerencia de Gestión del Servicio (GDS) actúa indirectamente brindando apoyo en el control de
las reuniones de incidentes diarios. Ambas gerencias aparecen resaltadas dentro del organigrama de la
Figura 3.1.
Figura 3.1 Delimitación del sistema de Negocios

Capítulo 3 Desarrollo de la primera versión del sistema 38
3.2.2 Diagrama de Procesos del negocio Mediante el modelado de los procesos del negocio es posible la descripción de la organización en
términos de las actividades que están diseñadas, organizadas y que se llevan a cabo para que ésta logre
alcanzar sus objetivos [22].
El proceso fundamental que realiza la Gerencia MAP de PDVSA AIT SCC es la ejecución del
Mantenimiento de la Plataforma. Dicho proceso aparece resumido en el diagrama de la Figura 3.2. En
él se establece el conjunto de eventos que originan la realización del proceso, los actores que generan
dichos eventos, los lineamientos que rigen el proceso, el objetivo principal del mantenimiento, los
productos e información que se generan, la información requerida por el proceso y el conjunto de
actores encargados de llevarlo a cabo.
Figura 3.2 Diagrama de procesos del Mantenimiento de la Plataforma 3.2.3 Estructura de la Gerencia MAP
La Gerencia MAP se encuentra organizada en seis unidades operativas y tres unidades de apoyo. Las
unidades operativas coordinan a su vez un conjunto de grupos operativos solucionadores, encargados
de realizar mantenimiento a las especialidades dentro de la plataforma. Las unidades de apoyo

Capítulo 3 Desarrollo de la primera versión del sistema 39
coordinan y controlan los recursos para la ejecución del mantenimiento. La figura 3.3 muestra la
estructura de la Gerencia MAP.
Figura 3.3 Estructura Organizativa Gerencia MAP
3.2.4 Cadena de Valor de la Gerencia MAP
La cadena de valor es una representación del conjunto de procesos que se llevan a cabo dentro de la
organización para el logro de sus objetivos. El concepto de cadena de valor fue popularizado por
Michael Porter en 1985 [23]. De acuerdo con Porter, toda compañía puede entenderse como una
organización humana que ejecuta un conjunto de actividades mediante las cuales se crea valor para el
cliente. La cadena de valor divide estas actividades en dos categorías: actividades primarias, que
abarcan todos los procesos fundamentales mediante los cuales la organización genera valor, y
actividades de apoyo, que no forman parte del proceso productivo como tal, pero brindan soporte
para la ejecución de las actividades primarias. Analizando cada actividad dentro de una organización en
términos de su cadena de valor, una empresa puede aislar las fuentes potenciales de su ventaja
competitiva. A pesar de que el concepto de cadena de valor está basado en empresas de producción,
puede ser ampliado para apoyar la planificación estratégica dentro de cualquier unidad de negocio con
fines claramente establecidos [24].
Gerencia MAP
Infraestructura Transmisión Redes
Planificación y Programación del Mantenimiento
Dispositivos de Campo
Centro Integral de Monitoreo
Confiabilidad de la Plataforma
Plataforma TI Aplicaciones, ATC y Bases de Datos

Capítulo 3 Desarrollo de la primera versión del sistema 40
En el caso de la Gerencia MAP, la cadena de valor es un equivalente a su mapa de procesos y
especifica los procesos fundamentales llevados a cabo por la unidad para el logro de sus objetivos junto
con los procesos que no intervienen de manera directa sobre sus actividades pero que permiten la
planificación y optimización del mantenimiento. Dentro del diagrama de la Figura 3.4 se muestra la
cadena de valor de la Gerencia MAP y se resaltan los procesos que serían apoyados por la
implementación del SIW. Estos procesos serán descritos con mayor detalle.
Figura 3.4 Cadena de Valor de la Gerencia MAP
Vale la pena resaltar que la forma como se representan los procesos fundamentales y de apoyo
dentro del diagrama no implican ningún tipo de secuencia. Si bien existe dependencia entre los
resultados de algunos procesos y las entradas de otros, estos se pueden ejecutar simultáneamente o sin
seguir un orden específico.
La clasificación del mantenimiento determina la secuencia de actividades que se llevarán a cabo
durante su ejecución, éste puede ser a condición, a frecuencia fija, preventivo, de optimización y

Capítulo 3 Desarrollo de la primera versión del sistema 41
correctivo. Dependiendo de la naturaleza del mantenimiento, la generación de las órdenes puede ser
una actividad planificada o una reacción ante algún incidente. La ejecución del mantenimiento puede
realizarse remotamente o en sitio. El registro de la actividad de mantenimiento es casi tan importante
como la actividad en si, pues garantiza la existencia de datos históricos acerca de la ocurrencia de fallas
en los equipos y sistemas de la plataforma. La planificación y programación del mantenimiento
comprende la estimación de recursos necesarios para las actividades a ejecutar, la definición de
estrategias a aplicar con el fin de optimizar el desempeño de la plataforma y muchas veces, la
generación de órdenes de mantenimiento preventivos o de optimización. La planificación del
mantenimiento muchas veces se apoya en los análisis realizados aplicando ingeniería de confiabilidad.
La aplicación de ingeniería de confiabilidad utiliza los datos estadísticos generados en el proceso de
registro de las actividades de mantenimiento para emitir análisis y recomendaciones útiles para
optimizar el desempeño de las actividades de mantenimiento. El proceso de ingeniería de
confiabilidad involucra también la supervisión y control del estado de la plataforma. El monitoreo de
la plataforma detecta actividades de mantenimiento a condición y genera las órdenes
correspondientes. A continuación se explican detalladamente los procesos resaltados en la Figura 3.4.
i) PF 4 Registrar mantenimiento ejecutado
La existencia de una orden de mantenimiento conlleva a que los analistas dentro de las especialidades
de la Gerencia MAP ejecuten actividades de mantenimiento de manera remota o en el sitio donde
corresponda. Una vez ejecutado el conjunto de actividades, se elabora un registro ordenado y
detallado del mantenimiento realizado. Esto permite reunir datos históricos sobre los incidentes y
problemas ocurridos en sistemas y equipos, los modos en que se pueden producir las fallas, los
tiempos de operación entre las fallas de la plataforma, el impacto de los incidentes sobre el negocio, la
cantidad de recursos (tiempo, dinero, recursos auxiliares) utilizados en el mantenimiento, y las
actividades necesarias para finalizar el incidente. El registro del mantenimiento es de suma
importancia porque cierra el ciclo de la actividad, reflejando la realidad de la ejecución de la misma.
Es importante resaltar que no todas las actividades de mantenimiento son generadas por fallas en la
plataforma, como es el caso de los mantenimientos preventivos y a frecuencia fija. Sin embargo, para
efectos del presente proyecto, las actividades de mantenimiento correctivo fueron el centro de

Capítulo 3 Desarrollo de la primera versión del sistema 42
atención. En la Figura 3.5 se muestra el diagrama del proceso PF 4 señalando, entre otras cosas, sus
entradas, salidas y productos.
ii) PA 2 Aplicar Ingeniería de Confiabilidad
La aplicación de ingeniería de confiabilidad busca lograr la optimización de la plataforma mediante las
actividades de diagnóstico y control de los equipos y sistemas que la integran. El diagnóstico de la
plataforma permite identificar las áreas en las que resulta oportuno realizar mejoras al negocio y
ejecutar acciones correctivas para reducir los costos asociados al mantenimiento, representando una
mejora en la seguridad y confiabilidad de los activos. Mediante las actividades realizadas en el
diagnóstico de la plataforma es posible establecer una ruta crítica a seguir para aplicar acciones
óptimas. El control de la plataforma se realiza mediante las herramientas propias de la ingeniería de
confiabilidad (Mantenimiento Centrado en Confiabilidad (MCC) y Análisis Causa Raíz (ACR)) que
contribuyen a controlar los parámetros que definen el funcionamiento adecuado de la plataforma y
permiten garantizar que los activos que la conforman se comporten adecuadamente dentro de un
contexto operativo establecido y durante un determinado período de tiempo.
De la mano con las actividades de control de la plataforma, se encuentran las actividades de
optimización. La optimización de la plataforma consiste en el modelado y análisis de los distintos
escenarios que se pueden presentar para así determinar el momento oportuno en el que se pueda
realizar una actividad (mantenimiento mayor, inspección, etc.), permitiendo conocer la viabilidad
económica del mantenimiento y determinar la cantidad óptima de recursos. Ante alguna necesidad de
optimizar el mantenimiento de la plataforma para prolongar su vida útil, se toma la solicitud emitida
por la etapa de control o diagnóstico, se evalúan las diferentes estrategias a optimizar y las vías de
canalización, se ponen en práctica las consideraciones, adecuaciones o mejoras pertinentes y se emiten
las recomendaciones que permiten ajustar el plan de mantenimiento, obteniéndose también insumos
que generan los indicadores operativos de la plataforma. El diagrama general del proceso de aplicación
de ingeniería de confiabilidad se muestra en la Figura 3.6.

Capítulo 3 Desarrollo de la primera versión del sistema 43
iii) PA 3 Monitorear la plataforma
Mediante esta actividad se identifican los mantenimientos a condición en la plataforma, cuya necesidad
pudo generarse de forma preactiva (visualizada en los planes de mantenimiento) o de manera
reactiva(a partir de problemas provenientes de GDS o detectados mediante las herramientas propias
de monitoreo). Dependiendo de la naturaleza de la tarea de mantenimiento identificada, se procede a
generar una orden o se realiza un monitoreo continuo de las variables seleccionadas hasta detectar un
incidente (que genere pérdida total o parcial de la función), el cual genera una orden o tiene una
solución inmediata remotamente. El diagrama de la Figura 3.7 muestra el proceso de forma general.
Figura 3.5 Diagrama del proceso “Registrar mantenimiento ejecutado”

Capítulo 3 Desarrollo de la primera versión del sistema 44
Figura 3.6 Diagrama del proceso “Aplicar Ingeniería de Confiabilidad”
Figura 3.7 Diagrama del proceso “Monitorear la plataforma”

Capítulo 3 Desarrollo de la primera versión del sistema 45
3.2.5 Diagrama de flujo entre procesos para la gestión de incidentes de
falla
Con un mayor conocimiento de los procesos llevados a cabo por la Gerencia MAP, se empieza a
analizar el conjunto de actividades que son automatizadas mediante el SIW. Uno de los tipos de
mantenimientos que se llevan a cabo en la plataforma es el mantenimiento correctivo. La ejecución de
mantenimientos correctivos es generada a partir de incidentes de falla ocurridos durante las guardias
de los analistas de los grupos operativos solucionadores. El flujo de actividades que se describe a
continuación vincula cada uno de los procesos que ya fueron descritos en la parte anterior e incorpora
sin mayor detalle el proceso PF3 Ejecutar Mantenimiento y el proceso llevado a cabo por la Gerencia
de Gestión de Servicio. Vale la pena destacar que estos dos procesos no fueron descritos con mucho
detalle en la parte anterior pues no se considera que se encuentren vinculados esencialmente con el
dominio de la aplicación. El diagrama de la Figura 3.8 muestra el flujo de las actividades llevadas a
cabo para gestionar los reportes de incidentes de falla durante el período de tiempo en que se realiza
el estudio.
La implementación de un SIW para automatizar el proceso permitiría agilizar la consulta y el
cálculo de los indicadores operativos de la plataforma. El papel jugado por la Gerencia GDS se
desplegaría del flujo de actividades principal y pasaría a ser un agregado dentro del proceso de gestión
de incidentes de falla. Armar la minuta dejaría de ser su responsabilidad, pues ésta podría ser obtenida
directamente de la consulta al sistema, evitando así que la Coordinación de Confiabilidad dependiera
de dicho documento para realizar sus análisis. Adicionalmente los indicadores serían complementados
con los datos manejados por el Centro Integral de Monitoreo acerca de las notificaciones emitidas. El
diagrama de actividades propuesto luego de la implementación del SIW se muestra en la Figura 3.9
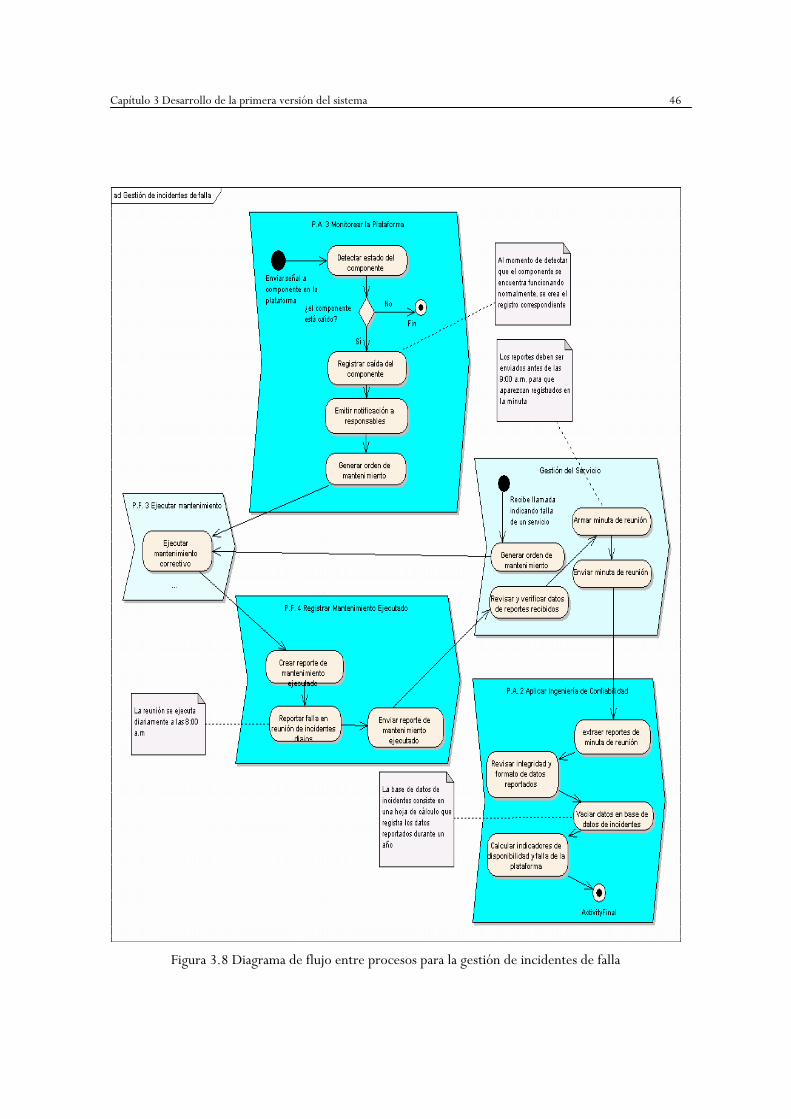
Capítulo 3 Desarrollo de la primera versión del sistema 46
Figura 3.8 Diagrama de flujo entre procesos para la gestión de incidentes de falla

Capítulo 3 Desarrollo de la primera versión del sistema 47
Figura 3.9 Flujo de actividades a obtener luego de automatizar el proceso

Capítulo 3 Desarrollo de la primera versión del sistema 48
3.2.6 Identificación de las reglas de negocio
Las reglas de negocio describen, controlan y restringen la estructura y las operaciones de la
organización, en nuestro caso de la Gerencia MAP. Para los procesos descritos en la parte anterior se
encontraron las siguientes reglas de negocio:
1. Normas de Seguridad Higiene y Ambiente de PDVSA.
2. Lineamientos del Sistema de Gerencia Integral de Riesgos.
3. Normas de Protección de Activos de Información.
4. Normas de Protección de Activos e Información.
5. Normas Técnicas de PDVSA.
6. Norma SAE JA1011 para definir tipos de mantenimiento.
7. Norma ISO 9000-2000.
8. Normas internacionales de instrumentación y Sistemas (ISA)
9. Normas OSA de administración de seguridad y salud ocupacional.
10. Diariamente los Grupos Operativos Solucionadores (GOS) se encuentran atentos ante cualquier
incidente que surja respecto al desempeño de los servicios que brinda la plataforma AIT y están
preparados para resolver tales incidentes. Las guardias que ejecutan los GOS tienen una duración
de una semana y existe un grupo operativo por cada una de las siguientes especialidades:
� Centro integral de Monitoreo.
� Servidores Windows.
� Servidores AS/400.
� Servidores UNIX.
� Redes WAN.
� Redes LAN.
� Conmutación
� Redes de Transmisión.
� Bases de Datos.
� Respaldo y Almacenamiento.

Capítulo 3 Desarrollo de la primera versión del sistema 49
� SAP.
� SAND.
� STARS-PAWS-RD-RDOJD.
� SICOPROSA-SIGPLAN – Aplicaciones Web-AIT.
� FILIP / SIMAF / SIRET RESET, GADET, SIPREFID, NAF, FUP.
� ATC.
� Servidores Z-Series.
� Soporte Integral.
� Plataformas de Escritorio.
� Dispositivos de campo.
� Control de activos.
� Infraestructura.
� Nómina.
� Seguridad AIT.
� Video Conferencia.
� Instalaciones.
� Soporte a Usuarios Críticos.
11. Simultáneamente a los GOS, el Centro Integral de Monitoreo supervisa el estado y
funcionamiento de la mayoría de los dispositivos físicos y de algunas aplicaciones. Para ello se
apoya en el uso de sistemas especializados en el monitoreo de los recursos. Uno de los más
importantes es el sistema Nagios.
12. El sistema Nagios envía señales a través de la red esperando respuesta por parte de los equipos
(Hosts), en caso de recibir una respuesta, se registra que el equipo está funcionando correctamente
y no se ejecuta ninguna acción. En caso contrario se continúan enviando señales en intervalos de
tiempo cada vez menores, de no detectarse respuesta por parte del equipo se generan
notificaciones vía SMS a los analistas responsables de su mantenimiento, generándose así una
orden de mantenimiento correctivo. El sistema sigue enviando señales al equipo esperando

Capítulo 3 Desarrollo de la primera versión del sistema 50
obtener una respuesta y, al momento de recibirla, registra que el equipo se encuentra
funcionando normalmente.
13. De producirse alguna falla en alguno de los servicios de la plataforma a cualquier nivel dentro de
la organización, la persona que detecta la falla la puede reportar por teléfono a la Gerencia GDS a
través del Centro de Atención al Usuario. El Centro de Atención al Usuario se encarga de
identificar el grupo solucionador correspondiente y generar la orden de mantenimiento.
14. Es responsabilidad del Centro de Atención al Usuario garantizar la disponibilidad de todos los
servicios brindados por AIT SCC. Por ello se encarga de rastrear las órdenes de mantenimiento
emitidas utilizando sistemas especializados en el control y seguimiento de los casos generados por
los usuarios.
15. Al ser notificado con el incidente de falla, el analista de guardia verifica que la falla sea de alguno
de los servicios bajo su supervisión. De ser así procede a determinar la solución del problema, en
caso contrario remite a la persona encargada de reportar la falla (CIM o Centro de Atención al
Usuario) para que reporte al grupo adecuado.
16. Una vez solucionado el incidente, el GOS comunica a quien la notificó que ya ha finalizado el
problema. También le corresponde generar un reporte del mantenimiento ejecutado.
17. Diariamente a las 8:00 a.m. se realiza una reunión de incidentes diarios en la que cada uno de los
analistas de guardia informa acerca de las eventualidades que se produjeron durante la jornada del
día anterior. El analista debe enviar al personal de GDS un reporte escrito indicando los datos del
incidente. La información proporcionada contiene datos acerca del analista de guardia, el tiempo
de inicio y de fin de la falla, el impacto sobre el negocio, el diagnóstico de la causa de la falla, la
acción ejecutada para resolverla y el estado actual del servicio correspondiente (puede ocurrir que
al momento de la reunión no se haya solucionado del todo la falla).
18. Una vez realizada la reunión, el personal de GDS se encarga de integrar todos los reportes, armar
en un documento la minuta de la reunión de incidentes diarios y de ponerlo a disposición de todos
los involucrados.
19. El personal de la Coordinación de Confiabilidad se encarga de revisar la minuta de la reunión
diaria de incidentes y transferir los datos de dicha minuta a una Base de Datos, el proceso de

Capítulo 3 Desarrollo de la primera versión del sistema 51
llenado de la base de datos implica la revisión manual y la depuración del documento de la
minuta.
20. De la base de datos de incidentes se extraen indicadores como tiempo promedio de solución de
fallas (TPSF), el cual viene dado por la ecuación:
NumFallas
FallaHoraInicioónFallaHoraSolucioFallaFechaIniciiónFallaFechaSolucTPSF
NumFallas
iiiii�
�
���� 1
24*)(24*)(
21. Otro de los indicadores calculados a partir de la base de datos de incidentes es el Tiempo
Promedio Entre Fallas (TPEF) el cual viene dado por:
NumFallasFallaHoraInicioFallaHoraIniciooFallaFechaInicioFallaFechaInici
TPEFNumFallas
i iiii�� �� ���� 2 11 24*)(24*)(
22. De la base de datos de incidentes se extrae el número de fallas por especialidad, que viene
representado por el conteo de incidentes reportado por cada GOS.
De las reglas descritas en la parte anterior, las reglas 10, 12, 15, 16, 17, 19, 20, 21 y 22 son
implementadas como parte de la lógica de negocios del SINCFA.
3.2.7 Modelado de los actores de negocio
Un actor puede ser una persona o una máquina capaz de ejecutar un conjunto de tareas definidas. Los
actores interactúan con el sistema de negocios para satisfacer sus necesidades o proveer recursos. La
identificación y el modelado de los actores que intervienen en el proceso de negocios permiten lograr
un mayor entendimiento de las necesidades de información que motivan el desarrollo del sistema.
Para el desarrollo del SINCFA se identifican cuatro actores principales cuyos objetivos dentro del
dominio de la aplicación se mencionan en la Tabla 3.1.

Capítulo 3 Desarrollo de la primera versión del sistema 52
Actor Objetivos.
Analista de Confiabilidad.
1. Llenar la Base de datos de incidentes a partir de las minutas
de las reuniones de incidentes diarios.
2. Obtener reportes de falla y disponibilidad por especialidad
para un período de tiempo determinado.
3. Obtener reportes de grupos operativos con mayor cantidad
de incidentes.
4. Generar recomendaciones acerca de la criticidad y
confiabilidad de la plataforma
Analistas del Centro Integral de
Monitoreo
1. Monitorear el estado de la plataforma AIT.
2. Reportar incidentes de fallas a los GOS correspondientes.
3. Generar Reportes de incidentes detectados durante una
jornada
Analistas de Grupos Operativos
Solucionadores
1. Atender incidentes ocurridos para los activos de su
especialidad.
2. Proporcionar reportes de incidentes diarios.
3. Reportar solución de incidente de falla.
4. Determinar impacto de la falla sobre la plataforma.
Centro de Atención al Usuario
(GDS)
1. Reunir los reportes enviados por los analistas en las minutas
de incidentes diarios.
2. Suministrar minuta de incidentes diarios a todos los
interesados.
Tabla 3.1 Modelado de actores del negocio
3.2.8 Identificación de los objetos de negocio
En esta actividad se determinan los diferentes tipos de objetos que intervienen en los procesos de
negocio y se definen las relaciones entre estos. La identificación de los objetos del negocio constituye

Capítulo 3 Desarrollo de la primera versión del sistema 53
la primera aproximación a los tipos de datos que serán implementados a través del SIW. En el caso del
SINCFA y sus procesos asociados, se han identificado las siguientes entidades:
Incidente: Al producirse una interrupción o falla en alguno de los componentes de la plataforma se
dice que se ha producido un incidente de falla. Un incidente de falla tiene un único reporte
asociado.
Componente: Un componente de la plataforma es un equipo o sistema que es responsabilidad de un
grupo operativo. Un componente se distingue por un nombre único dentro de la plataforma y una
ubicación.
Minuta: Los incidentes reportados por los analistas durante una reunión de guardia se incluyen en la
minuta de la reunión de incidentes diarios.
AlertaNagios: Cuando el sistema Nagios detecta que un componente no se encuentra funcionando
correctamente se registra una alerta de caída del componente. Cuando sistema detecta que el
componente vuelve a funcionar normalmente se registra el fin de la alerta. Una alerta puede estar
asociada con un único componente.
Notificación: Al momento de detectarse la falla en el componente, el sistema Nagios genera una
notificación a los analistas responsables del mantenimiento. Del mismo modo se generan
notificaciones al momento de finalizar la alerta.
Una vez identificados los objetos que intervienen en los procesos descritos, se procede a modelar
las relaciones entre esos objetos. El diagrama de la Figura 3.10 muestra el modelado de los objetos
principales identificados.

Capítulo 3 Desarrollo de la primera versión del sistema 54
Figura 3.10 Modelado de objetos de negocio
3.3 Ingeniería de Requisitos
Dentro del método Watch, la fase de ingeniería de requisitos comprende dos fases primordiales: una
de ellas es la definición y la otra es la especificación del conjunto de requisitos funcionales y no
funcionales del producto de software. En la fase de definición se clasifican los requisitos y se les asigna
prioridades de acuerdo con las necesidades del cliente. También se lleva a cabo la negociación de los
requisitos, siendo posible que el equipo encargado del desarrollo proponga nuevos requisitos y
modifique algunos de los previamente establecidos a fin de que exista compatibilidad entre los
mismos. La fase de especificación de requisitos deriva un conjunto de modelos en los que se obtiene la
primera visión de lo que será la arquitectura del sistema.
Para la ingeniería de requisitos del SINCFA se comienza realizando una descripción en lenguaje
natural de los necesidades expresadas por el cliente durante las reuniones, a partir de esta descripción

Capítulo 3 Desarrollo de la primera versión del sistema 55
se realiza una clasificación de los requisitos en funcionales y no funcionales y a partir de los funcionales
se generan los casos de uso del sistema.
3.3.1 Definición de los requisitos de software
Para definir los requisitos se deben tomar en consideración los actores del proceso. Dentro de la fase
de modelado de negocio se obtuvo un primer panorama del conjunto de actores dentro de la empresa
que intervenían en los procesos a ser apoyados por el SIW. Sin embargo, en esta fase sólo se
determinaron los objetivos de los actores en el contexto del sistema de negocios y no se fue
totalmente explícito en la definición de los roles de dichos actores en su interacción con el SIW. A
continuación se enuncian los principales actores dentro del proceso de Desarrollo:
Cliente: Es quien tiene el problema y desea que sea solucionado, Éste solicita el desarrollo de un
determinado sistema de software de acuerdo a sus problemas y necesidades, debe aportar sus
ideas al proceso de diseño. En el caso del SIW a implementar, el cliente es la Gerencia MAP de
PDVSA AIT SCC, particularmente la Coordinación de Confiabilidad, la cual está representada
por el líder de la unidad Ing. Máximo Silveira.
Desarrolladores/Analistas: Los miembros del equipo de desarrolladores ejecutan diferentes roles
como por ejemplo: coordinador, analista de sistemas, promotor de software y consejero o guía
informático. Para satisfacer las necesidades del cliente, los desarrolladores intentan cumplir con
sus peticiones en características específicas de calidad. El grupo de desarrolladores y analistas en
este caso viene representado por el tesista Carlos Germán Medina Albornoz, el tutor académico
Prof. Judith Barrios y el tutor industrial ing. José Casanova.
Usuarios del sistema final: La experiencia y aportes brindados por las personas a las cuales está
dirigido el SIW son esenciales para el proceso de desarrollo. En este caso, el grupo de usuarios
finales del SIW, hasta los momentos, está constituido por los miembros de la Coordinación de
Confiabilidad. Sin embargo, se deben permitir diferentes niveles de acceso a los usuarios del
sistema, con miras a que éste pueda ser utilizado por miembros de otras unidades o gerencias. Es
decir, el sistema debe reconocer por lo menos los siguientes perfiles de usuario:

Capítulo 3 Desarrollo de la primera versión del sistema 56
� Administrador: El administrador debe ser capaz de acceder al sistema para la
corrección de fallas, la incorporación de nuevos servicios en el inventario de la
plataforma, el ingreso de datos, la consulta sobre la base de datos de incidentes y la
base de datos de Nagios, la modificación de datos de incidentes ya ingresados y la
eliminación de registros erróneos o que carezcan de interés para el sistema de
negocios.
� Usuario Avanzado: El perfil de usuario avanzado debe permitir tanto el ingreso de
datos, la consulta sobre la base de datos de incidentes y la base de datos de monitoreo
y su comparación, la modificación de datos ya ingresados y la eliminación de registros
erróneos o que carezcan de interés para el sistema de negocios.
� Usuario Intermedio: El usuario intermedio podrá realizar la inserción de datos de
incidentes de falla y realizar consultas sobre la base de datos de incidentes.
� Usuarios Generales: El usuario general podrá consultar sobre la base de datos de
incidentes.
3.3.2 Definición de requisitos según actores
i) Requisitos del Cliente.
1. Los estilos del diseño utilizado en el desarrollo de las páginas web deben cumplir con los
estándares de la gerencia AIT, así como también, los nombres de las páginas, funciones,
variables, procedimientos almacenados, vistas y tablas de datos del sistema.
2. El acceso al sistema solo puede realizarse a través de la intranet de la empresa.
3. Que tenga interfaz gráfica agradable y de fácil entendimiento.
4. Todas las respuestas a las consultas al servidor de base de datos deben ser lo más rápidas y
eficientes posible, es por esto, que se ha definido el tiempo máximo a 60 seg., solo se podrá
exceder este tiempo con una clara justificación del tiempo requerido.
5. El sistema debe validar el perfil del usuario al momento de iniciar sesión contra el directorio
activo de PDVSA.
6. Presentar mensajes de error que sean de fácil comprensión.

Capítulo 3 Desarrollo de la primera versión del sistema 57
7. El sistema debe estar implementado utilizando una arquitectura de tres capas distribuidas en
tres nodos.
ii) Requisitos de los usuarios.
1. Debe permitir la introducción individual de los incidentes de fallas. Los datos introducidos
acerca de cada incidente de falla deben incluir la siguiente información:
a. Fecha de la minuta.
b. Grupo Operativo que reporta.
c. Localidad en la que se produce el incidente.
d. Componente en que se produce el incidente.
e. Resumen de incidente.
f. Fecha de inicio del incidente.
g. Hora de inicio del incidente.
h. Fecha de fin del incidente.
i. Hora de fin del incidente.
j. Causa del incidente.
k. Acciones tomadas para resolver el incidente.
l. Impacto del incidente.
m. Comentarios sobre el incidente.
n. Nombre del analista que reporta.
2. El sistema debe calcular los siguientes indicadores para cada registro de incidente de falla:
a. Tiempo entre falla actual y falla anterior dentro del grupo.
b. Tiempo entre falla actual y falla anterior del componente.
c. Duración de la falla.
3. Generar reportes de las fallas totales ocurridas en la plataforma, es decir, debe ser posible la
generación de reportes que indiquen el número de ocurrencias de fallas en los dispositivos
durante un periodo determinado de tiempo fijado por el usuario. Los reportes de fallas totales
ocurridas deben incluir los indicadores de TPEF, TPSF y Número de fallas para el grupo.
4. Se debe permitir al usuario filtrar los reportes de Falla por Grupo Operativo.

Capítulo 3 Desarrollo de la primera versión del sistema 58
5. Al momento de reportar un incidente, la selección del componente en que se produjo la falla
debe ser dinámica, pues se debe permitir al usuario escoger la ubicación y el grupo operativo
para poder seleccionar luego sólo los componentes dentro de esos dos parámetros.
6. Generar reportes de fallas por componente durante un período de tiempo determinado. Los
reportes de fallas totales ocurridas deben incluir los indicadores de TPEF, TPSF y Número de
fallas para el componente.
7. Generar reportes de soluciones de fallas en los que para cada incidente de falla ocurrido para
un determinado componente, se indiquen las causas, soluciones y acciones tomadas.
8. Permitir realizar reportes conjuntos entre los datos obtenidos de las minutas y los obtenidos a
partir de Nagios.
9. Generar los reportes en formatos fácilmente exportables a alguna hoja de cálculo, de modo
que puedan ser utilizados para el apoyo de informes dirigidos a la alta gerencia.
10. El sistema debe permitir cerrar sesión al usuario actual.
11. El sistema debe permitir al usuario verificar información del reporte del incidente antes de
ingresarla al sistema.
12. El sistema debe incorporar un módulo de ayuda en línea al usuario.
13. Permitir manejar un inventario sencillo de los componentes que integran la plataforma
tecnológica de PDVSA AIT SCC. Este inventario debe incluir el nombre del componente, el
grupo responsable y su ubicación.
iii) Requisitos del desarrollador.
1. El software se debe implantar con el lenguaje de programación PHP en el lado del servidor y
contenidos en HTML y Javascript en el lado del cliente.
2. El sistema gestor de bases de datos debe ser PostgreSQL.
3. El equipo donde se ejecute el sistema debe tener las siguientes características:
a. Memoria principal de al menos 128 megas
b. Procesador mayor a 1.0 Ghz.
c. Un monitor.
d. Un ratón

Capítulo 3 Desarrollo de la primera versión del sistema 59
e. Un Teclado.
f. Una tarjeta de video de 32 MB.
g. Una tarjeta de red con capacidad de conexión a la intranet de la Empresa.
h. El sistema operativo Windows XP o Linux.
i. Navegador Mozilla Firefox 3.0.
3.3.3 Clasificación de los requisitos y definición de prioridades
Los requisitos pueden clasificarse en dos tipos:
Requisitos funcionales: describen las funciones y servicios que el sistema debe hacer.
Requisitos no funcionales: describen las diferentes respuestas que debe dar el sistema ante los
distintos tipos de errores, los cuales imponen restricciones y atributos.
Además de clasificarse, los requisitos son priorizados dependiendo de su importancia para el
desarrollo del producto y el resultado que se desea obtener. Es por esto que los requisitos se clasifican
con números del 1 al 5, siendo el 1 la prioridad más baja (requisito casi prescindible) y el 5 la
prioridad más alta (requisito obligatorio). La Tabla 3.2 muestra la clasificación de los requisitos.
N° de requsito
Nombre del requisito
Clasificación. Prioridad. Tipo de requisito.
R1 El sistema debe cumplir con los estándares de la gerencia AIT.
No Funcional. 4 Restricción.
R2 El acceso al sistema sólo puede realizarse a través de la intranet de la empresa.
No Funcional. 5 Restricción.
R3 El sistema debe incorporar interfaz gráfica agradable y de fácil entendimiento.
No Funcional. 4 Aseguramiento de la calidad.
R4 Las respuestas a las consultas al servidor de base de datos deben ser lo más rápidas y eficientes posible
No Funcional. 4 Aseguramiento de la calidad.

Capítulo 3 Desarrollo de la primera versión del sistema 60
N° de requsito
Nombre del requisito
Clasificación. Prioridad. Tipo de requisito.
R5 Validar el perfil del usuario al iniciar sesión contra el directorio activo.
Funcional. 4 Seguridad.
R6 El sistema debe presentar mensajes de error que sean de fácil comprensión.
No funcional. 3 Aseguramiento de la calidad.
R7 La arquitectura debe ser implementada en 3 capas distribuidas en 3 nodos
No funcional 5 Restricción
R8 Permitir introducir los incidentes de falla.
Funcional. 5 Funcionalidad
R9 Calcular indicadores para cada registro de incidente de falla.
Funcional. 5 Funcionalidad
R10 Generar reportes de las fallas totales ocurridas en la plataforma por período de tiempo.
Funcional. 5 Funcionalidad
R11 Filtrar los reportes de Falla por Grupo Operativo.
Funcional. 5 Funcionalidad
R12 Ingresar componente en que se produjo la falla dinámicamente seleccionando localidad y grupo
Funcional 5 Funcionalidad
R13 Generar reportes de fallas por componente durante un período de tiempo determinado.
Funcional. 4 Funcionalidad
R14 Generar reportes de soluciones de fallas.
Funcional. 5 Funcionalidad
R15 Realizar consultas sobre las alertas registradas por el sistema Nagios comparándolas con los incidentes registrados en las minutas.
Funcional. 3 Funcionalidad
R16 El sistema debe generar los reportes en formatos fácilmente exportables a una hoja de cálculo.
No Funcional. 2 Aseguramiento de la calidad.

Capítulo 3 Desarrollo de la primera versión del sistema 61
N° de requsito
Nombre del requisito
Clasificación. Prioridad. Tipo de requisito.
R17 Permitir cerrar sesión. Funcional. 5 Funcionalidad. R18 El sistema debe permitir al
usuario verificar la información del reporte antes de ingresarla
No Funcional. 4 Uso y factores humanos.
R19 Manejar un inventario de los componentes que integran la plataforma de PDVSA AIT SCC.
Funcional 5 Funcionalidad
R20 El sistema debe incorporar ayuda al usuario.
No funcional. 2 Aseguramiento de la calidad.
R21 El software se debe implantará con el lenguaje de programación PHP en el lado del servidor y contenidos en HTML y Javascript en el lado del cliente.
No Funcional. 5 Restricción.
R22 El sistema gestor de bases de datos debe ser PostgreSQL.
No Funcional. 5 Restricción.
R23 El equipo donde se ejecute el sistema debe tener ciertas características.
No Funcional. 4 Restricción.
Tabla 3.2 Clasificación de los requisitos
Vale la pena resaltar que, a pesar de que el producto aquí mostrado es resultado de un proceso de
refinamiento y validación junto al cliente, en la medida que se sigue avanzando en la primera versión
los requisitos de los actores involucrados y sus expectativas respecto al sistema cambian
constantemente. Por ello se trata de mantener la recolección inicial de requisitos, negociando con el
cliente que aquellos que surgieran sobre la marcha serán considerados para el desarrollo de la segunda
versión. De ese modo se trata de abarcar todos los requisitos enunciados.
3.3.4 Definición de casos de uso
La elaboración de los casos de uso se realiza clasificando las funciones del sistema de acuerdo al actor
al que van dirigidas. La jerarquía de actores definida se muestra en la Figura 3.11.

Capítulo 3 Desarrollo de la primera versión del sistema 62
Figura 3.11 Perfiles de usuario del sistema
La Figura 3.12 indica el modelado de los casos de uso para la interacción del usuario general con
el sistema. La Figura 3.13 muestra los casos de uso para el usuario intermedio, mientras que las
Figuras 3.14 y 3.15 muestran los diagramas de casos de uso para los usuarios avanzado y
administrador respectivamente. En cada diagrama, los casos de uso que se incorporan respecto al
diagrama anterior son resaltados en un color más oscuro.

Capítulo 3 Desarrollo de la primera versión del sistema 63
Figura 3.12 Diagrama de casos de uso para usuario general

Capítulo 3 Desarrollo de la primera versión del sistema 64
Figura 3.13 Diagrama de casos de uso para usuario intermedio

Capítulo 3 Desarrollo de la primera versión del sistema 65
Figura 3.14 Diagrama de caso de uso para usuario avanzado

Capítulo 3 Desarrollo de la primera versión del sistema 66
Figura 3.15 Diagrama de caso de uso para administrador

Capítulo 3 Desarrollo de la primera versión del sistema 67
i) Descripción textual de los casos de uso.
Para una mayor comprensión de la secuencia de tareas asociadas a los casos de uso, se hace una breve
descripción de cada uno de ellos en la Tabla 3.3.
Caso de Uso
Nombre del Caso de Uso
Descripción
CU1 Acceder al sistema El usuario introduce su indicador (nombre de usuario en la red PDVSA) y su clave en la ventana de inicio del sistema.
CU2 Validar perfil de usuario.
El sistema verifica el nombre del usuario y la clave, dándole acceso a un conjunto de funciones de acuerdo a su perfil.
CU3 Consultar incidentes por grupo operativo.
El usuario introduce el nombre de un grupo operativo. El sistema genera un reporte de todas las fallas registradas para los componentes o servicios dentro de ese grupo operativo. Se calcula la duración y tiempo entre fallas para cada incidente.
CU4 Consultar indicadores operativos de la plataforma.
El usuario introduce un período de tiempo para consultar los indicadores de la plataforma. El sistema genera una lista con los grupos operativos y sus indicadores. Los indicadores calculados son el TPEF, el TPSF y el número total de incidentes.
CU5 Consultar incidentes por componente
El usuario introduce el nombre de un componente dentro de la plataforma AIT. El sistema genera un reporte con todos los incidentes de falla registrados para ese componente y sus indicadores. Se calcula la duración y tiempo entre fallas para cada incidente.
CU6 Consultar incidentes por período de tiempo.
El usuario introduce una fecha de inicio y una fecha de fin para consultar los incidentes de falla que se produjeron durante ese período. El sistema genera un reporte de los incidentes registrados entre esas fechas. Se calcula la duración y tiempo entre fallas para cada incidente.
CU7 Consultar alertas de Nagios por período de tiempo.
El usuario introduce el período de tiempo en el que desea consultar las alertas detectadas por Nagios. El sistema genera un reporte con todas las alertas detectadas para ese período de tiempo. También se incluyen los incidentes de falla reportados para ese período.
CU8 Procesar log de Nagios El sistema procesa el archivo de log del sistema Nagios, almacenando las alertas relacionadas con la caída y recuperación de los componentes de la plataforma.
CU9 Consultar reportes de solución de incidentes.
El usuario introduce el nombre de un componente a consultar. El sistema genera un reporte de las fallas registradas para ese componente, los diagnósticos y las soluciones dadas.
Capítulo 3 Desarrollo de la primera versión del sistema 68
Caso de Uso
Nombre del Caso de Uso
Descripción
CU10 Cerrar sesión. El usuario cierra su sesión en el sistema.
CU11 Ingresar datos de incidente de falla
El usuario introduce en un formulario los datos de un incidente de falla. Luego de que el usuario confirme la inserción, el sistema almacena los datos.
CU12 Eliminar incidente. El usuario elimina los datos de un incidente de falla del sistema, para ello introduce la fecha del incidente y el nombre del componente en que se produjo.
CU13 Modificar incidente El usuario actualiza o modifica los datos de algún incidente de falla almacenado, para ello introduce la fecha del incidente y el nombre del componente en que se produjo. El sistema carga luego un formulario para que el usuario edite los datos que considere necesarios.
CU14 Ingresar componente El usuario ingresa un nuevo componente al inventario de componentes de la plataforma AIT. Luego de que el usuario confirme la inserción, el sistema almacena los datos del componente.
CU15 Eliminar componente El usuario elimina un componente del inventario de componentes de la plataforma AIT, para ello introduce el nombre del componente.
CU16 Modificar componente El usuario modifica los datos de un componente dentro del inventario de componentes de la plataforma AIT, para ello introduce el nombre del componente. El sistema luego permite la edición de los datos del componente.
CU17 Consultar inventario de componentes AIT.
El usuario consulta el inventario de componentes de la plataforma AIT. El sistema genera una lista con todos los componentes que integran la plataforma.
Tabla 3.3 Casos de uso del sistema
3.3.5 Matriz Casos de Uso vs. Requisitos
Parte esencial del proceso de ingeniería de requisitos es la validación y verificación de los requisitos
del sistema. Mediante la matriz de Casos de Uso vs. Requisitos es posible determinar si los requisitos
del cliente fueron satisfechos con los casos de uso especificados. En la matriz de la tabla 3.4 se
observa como cada requisito se ve incluido en por lo menos un caso de uso, por lo que se han cubierto
todos los requisitos funcionales del sistema.

Capítulo 3 Desarrollo de la primera versión del sistema 69
Caso de uso Requisito
CU 1
CU 2
CU 3
CU 4
CU 5
CU 6
CU 7
CU 8
CU 9
CU 10
CU 11
CU 12
CU 13
CU 14
CU 15
CU 16
CU 17
R5 � �
R8 � � �
R9 � � � �
R10 � � �
R11 �
R12 �
R13 �
R14 �
R15 � �
R17 �
R19 � � � � �
Tabla 3.4 Matriz de Casos de Uso vs. Requisito
3.4 Diseño del sistema
Una vez especificados y definidos los requisitos, se procede a diseñar el sistema. La fase de diseño
pretende determinar la estructura de la aplicación a fin de satisfacer los requisitos obtenidos en el paso
anterior, estableciendo la interconexión de los distintos subsistemas que la conforman, junto con los
parámetros que regulan que el sistema apoye los procesos de la organización y cumpla con los
objetivos fijados. Dentro de esta fase se establece el conjunto de metas con las que debe cumplir el
diseño, se determina cuáles de los requerimientos se encuentran relacionados con la arquitectura del
sistema, se describen la arquitectura utilizando distintos enfoques, se diseña la interfaz
usuario/sistema y se diseña la base de datos.
3.4.1 Metas de diseño
Con el fin de que la aplicación realmente satisfaga las necesidades expresadas por los actores,
junto con los estándares de rendimiento que se espera que ésta cumpla, es necesario fijar un conjunto

Capítulo 3 Desarrollo de la primera versión del sistema 70
de objetivos o metas para la fase de diseño del sistema. Las metas de diseño se enuncian a
continuación:
� La arquitectura del sistema estará basada en el uso de servicios web que estarán claramente
especificados y que podrán ser reutilizados por cualquier componente que los necesite.
� Los componentes diseñados van a buscar cumplir los requisitos de los actores involucrados de la
manera más eficiente posible.
� La arquitectura estará basada en la utilización de componentes modulares bien estructurados y
con entradas y salidas claramente definidas.
� El diseño será fácil de entender y modificar, permitiendo probar y detectar fallas rápidamente.
� El diseño se caracterizará por una alta cohesión de los componentes dentro de cada subsistema y
un bajo acoplamiento, es decir, poca dependencia de componentes de otros subsistemas.
3.4.2 Definición del estilo arquitectónico y justificación
Para el desarrollo del SIW se sigue un patrón de diseño basado en una arquitectura de 3 capas. En este
enfoque, la lógica de negocios de la aplicación se instala y ejecuta en una localidad distinta a la parte
del programa encargada del manejo de los datos y diferente también a la utilizada para manejar la
interfaz Usuario/Sistema.
La principal ventaja de la utilización de éste patrón está en la capacidad de lograr un sistema
altamente flexible, pues al separar al máximo los tres grupos de componentes dentro de la aplicación,
se puede modificar alguno de los componentes de una capa sin que ello implique hacer modificaciones
sobre los componentes de las otras capas. Al mismo tiempo se obtiene un código más limpio y
entendible, garantizando la mantenibilidad y facilidad de prueba.
La distribución física del sistema es otra de las razones que motivan el uso de éste patrón
arquitectónico, pues el SIW se encuentra alojado en 3 servidores distintos: un servidor web, en el
cual se puede alojar todos los componentes relacionados con la presentación visual del sistema y su
interacción con los usuarios (éste servidor no posee acceso a la base de datos), un servidor de
aplicaciones, en el cual se puede ejecutar toda la lógica de negocios de la aplicación y todo lo

Capítulo 3 Desarrollo de la primera versión del sistema 71
relacionado al acceso a las bases de datos, y finalmente, un servidor de bases de datos, en el que se
alojan los elementos persistentes del sistema.
Debido a la naturaleza de los servidores, toda la lógica asociada con la manipulación de los datos
obtenidos mediante consultas con la base de datos es implementada en el servidor de aplicaciones,
mientras que toda la validación de los datos de entrada y la presentación a los usuarios es manejada
por el servidor web. La comunicación entre el servidor de aplicaciones y el servidor web está basada
en la implementación de servicios web.
3.4.3 Identificación de subsistemas
Luego de analizar las actividades apoyadas por el sistema, se determina que el mejor criterio para la
subdivisión del SIW es la utilización de módulos o subprogramas.
Se realiza la división del sistema en base a los casos de uso, clasificando estos por funcionalidades
similares y dividiendo los subsistemas en funciones más pequeñas que conformarán módulos más
simples. De este modo se obtiene una primera división del sistema en cuatro subsistemas, tal y como
se muestra en la Figura 3.16.
Figura 3.16 Identificación de subsistemas

Capítulo 3 Desarrollo de la primera versión del sistema 72
El subsistema de control de usuarios se encarga de la validación del ingreso de usuarios al sistema,
el subsistema de gestión de incidentes y soluciones contiene los componentes relacionados con el
manejo de los datos de incidentes de falla y los reportes obtenidos, el subsistema de gestión de
reportes de monitoreo se encarga de capturar los datos del sistema Nagios y generar los reportes
correspondientes. El subsistema de inventario de componentes AIT maneja la información referente a
los componentes que integran la plataforma.
3.4.4 Diseño de componentes
Una de las características de un buen diseño es que está formado por componentes o módulos cuyas
entradas y salidas están bien definidas y sus propósitos están claramente establecidos. Un componente
de software representa una pieza de software que libera un conjunto de servicios utilizados a través de
interfaces bien definidas [24].
En base a estos principios, se diseña la arquitectura del sistema especificando el conjunto de
componentes que integran cada uno de sus subsistemas. Debido a que se utiliza un enfoque
arquitectónico de 3 capas, se han resaltado los diagramas con colores distintos para indicar que
pertenecen a capas distintas. De este modo, en los siguientes diagramas se muestran los componentes
de la capa de lógica resaltados en color crema, los componentes de la capa de presentación en color
azul y los componentes de la capa de datos en color verde.
El estilo utilizado en el diseño de los componentes de cada subsistema sigue un mismo patrón que
se caracteriza por:
� En la capa de presentación se incluyen componentes de captura y presentación de datos. Los
componentes de captura de datos por lo general son formularios y se les ha colocado el
estereotipo <<form>> y los componentes de presentación de datos comienzan con la palabra
“Vista”. Existen componentes de presentación que consumen servicios web y se denotan con
el estereotipo <<ws_client>>.
� Los componentes de negocio están representados por el conjunto de servicios web que
implementan la lógica de la aplicación. Estos componentes se especifican con el estereotipo
<<web_sevicet>>.

Capítulo 3 Desarrollo de la primera versión del sistema 73
� En la capa de datos los componentes especificados se refieren a cada una de las tablas de la
base de datos.
Otra característica a resaltar del diseño de los componentes es que se logra un mínimo acoplamiento y
una alta cohesión en cada subsistema.
i) Subsistema de control de usuarios
El subsistema de control de usuarios maneja los datos relacionados con los perfiles del usuario,
abarcando los casos de uso CU1, CU4 y CU18. Los componentes que integran el subsistema se
muestran en la figura 3.17. Se observa que se hace referencia a un componente externo que es el
directorio activo de PDVSA. El directorio activo se encuentra alojado en un servidor externo a la
aplicación y es accedido para validar los perfiles de los usuarios dentro de la red PDVSA.
ii) Subsistema de gestión de incidentes y soluciones
El subsistema de gestión de incidentes y soluciones puede ser visto como el corazón del sistema, pues
maneja los datos relacionados con los incidentes reportados por los analistas que es el objetivo esencial
del sistema dentro de la organización. Comprende los casos de uso CU2, CU3, CU5, CU6, CU7,
CU8, CU9, CU11, CU12, CU14 y CU15. Los componentes que integran el subsistema se muestran
en la Figura 3.18. Se especifican entre paréntesis los componentes que pertenecen a otros
subsistemas.
iii) Subsistema de gestión de reportes de monitoreo
Este subsistema se encarga de procesar los datos capturados del sistema Nagios y permitir la consulta
en conjunto entre los reportes realizados por los analistas y las notificaciones generadas por dicho
sistema. Para ello se vale de un archivo de texto plano (Nagios.log) que registra todas las
notificaciones emitidas por el sistema, el cual procesa y captura los datos que corresponden a las

Capítulo 3 Desarrollo de la primera versión del sistema 74
caídas y recuperaciones de los componentes. Abarca los casos de uso CU10 y CU13. La estructura
del subsistema se muestra en la Figura 3.19.
iv) Subsistema de inventario de componentes AIT.
Este subsistema maneja la información de los componentes (equipos y aplicaciones) que integran la
plataforma tecnológica de PDVSA AIT. Los componentes en él especificados abarcan los casos de uso
CU16, CU18, CU19, CU20 y CU21. Los componentes que integran este subsistema se muestran en
la Figura 3.20.
Figura 3.17 Subsistema de control de usuarios

Capítulo 3 Desarrollo de la primera versión del sistema 75
Figura 3.18 Subsistema de gestión de incidentes y soluciones

Capítulo 3 Desarrollo de la primera versión del sistema 76
Figura 3.19 Subsistema de gestión de reportes de monitoreo

Capítulo 3 Desarrollo de la primera versión del sistema 77
Figura 3.20 Subsistema de inventario de componentes AIT
3.4.5 Diagrama de clases del sistema
A partir del modelo de objetos de negocio obtenido en la primera fase se construye el diagrama de
clases del sistema (Ver Figura 3.21). En él se observa que se han eliminado algunas clases que
aparecían en el diagrama de objetos pero que para efectos de implementación resultan redundantes,
como es el caso de la clase Reporte. También se observa que algunos de los elementos modelados
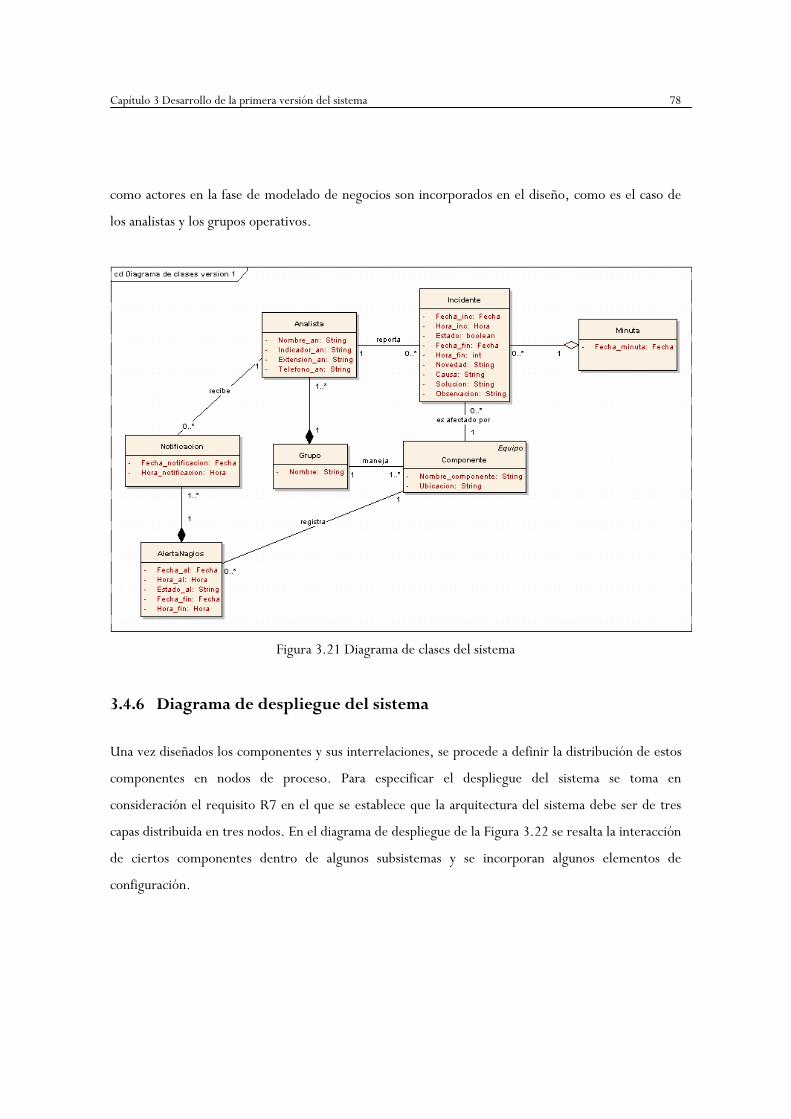
Capítulo 3 Desarrollo de la primera versión del sistema 78
como actores en la fase de modelado de negocios son incorporados en el diseño, como es el caso de
los analistas y los grupos operativos.
Figura 3.21 Diagrama de clases del sistema
3.4.6 Diagrama de despliegue del sistema
Una vez diseñados los componentes y sus interrelaciones, se procede a definir la distribución de estos
componentes en nodos de proceso. Para especificar el despliegue del sistema se toma en
consideración el requisito R7 en el que se establece que la arquitectura del sistema debe ser de tres
capas distribuida en tres nodos. En el diagrama de despliegue de la Figura 3.22 se resalta la interacción
de ciertos componentes dentro de algunos subsistemas y se incorporan algunos elementos de
configuración.

Capítulo 3 Desarrollo de la primera versión del sistema 79
Figura 3.22 Diagrama de despliegue del sistema

Capítulo 3 Desarrollo de la primera versión del sistema 80
3.4.7 Diseño de la base de datos
Del modelo de clases obtenido en la parte anterior, se realiza un análisis de las clases y entidades que
se identificaron junto con sus atributos y relaciones, armando así el modelo relacional. En la Figura
3.23 se muestra el modelo relacional del sistema. Las claves primarias son precedidas por las letras
PK.
Figura 3.23 Modelo de la base de datos del sistema

Capítulo 3 Desarrollo de la primera versión del sistema 81
i) Dependencias funcionales y esquema normalizado
Sean a y b atributos de una misma tabla o relación T. Se dice que b es funcionalmente dependiente de
a y se denota a -> b, si todo posible valor de a tiene asociado un único valor de b, o lo que es lo
mismo, en todas las tuplas de T en las que el atributo a toma el mismo valor v1, el atributo b toma
también un mismo valor v2. Claramente a -> b no implica b -> a.
De este modo, por ejemplo, para la tabla tr003_componente se observa como nombre_comp ->
ubicación pues conociendo el nombre del componente podemos conocer su ubicación y
nombre_comp -> grupo_op, ya que en la definición del problema el componente solo posee un
grupo responsable de su mantenimiento.
La normalización consiste pues en descomponer los esquemas relacionales (tablas) en otros
equivalentes (puede obtenerse el original a partir de los otros) de manera que se verifiquen unas
determinadas reglas de normalización. Evidentemente las reglas de normalización imponen una serie
de restricciones en lo relativo a la existencia de determinados esquemas relacionales. Según se avance
en el cumplimiento de reglas y restricciones se alcanzará una mayor forma normal.
ii) Primera forma normal
Una tabla está en Primera Forma Normal (1FN) sólo si:
� Todos los atributos son atómicos.
� La tabla contiene una clave primaria
� La tabla no contiene atributos nulos
� La tabla no posee ciclos repetitivos.
Básicamente la regla de la primera forma normal establece que las columnas repetidas deben
eliminarse y colocarse en tablas separadas [12]. El modelo relacional del sistema se encuentra en 1FN,
pues todas las tablas poseen elementos claves primarios, todos los atributos son atómicos y no se
producen columnas con valores repetidos.

Capítulo 3 Desarrollo de la primera versión del sistema 82
iii) Segunda Forma Normal
Una relación está en 2FN si está en 1FN y si los atributos que no forman parte de ninguna clave
dependen de forma completa de la clave principal. Es decir, que no existen dependencias parciales
[12].
En la base de datos se observa cómo para todas las tablas, los atributos dependen exclusivamente y
de forma completa de los valores de la clave principal. Por lo tanto, el esquema se encuentra en
segunda forma normal.
iv) Tercera Forma Normal
Una base de datos se encuentra en Tercera Forma Normal si está en Segunda Forma Normal y cada
atributo que no forma parte de ninguna clave, depende directamente y no transitivamente de la clave
primaria.
Todas las tablas se encuentran en tercera forma normal, pues no existen dependencias de
atributos que no son claves.
3.4.8 Diseño de la interfaz del usuario
Para todos los usuarios, al acceder al sistema a través de la intranet de la empresa, se carga la misma
pantalla de acceso en la que se pide al usuario que ingrese su indicador y clave de red. La pantalla
inicial del sistema se muestra en la Figura 3.24.
Una vez dentro del sistema, la estructura de la interfaz sigue los estándares de presentación de
PDVSA para las aplicaciones disponibles a través de la intranet. En ella se distingue un menú lateral en
el que se señalan las opciones disponibles para el usuario de acuerdo a su perfil, el área de encabezado
en la que se indica el nombre de la aplicación y la fecha, y el área de trabajo en la que se cargan los
contenidos a mostrar (formularios, resultados de consultas a la base de datos, mensajes de error, entre
otros). La Figura 3.25 muestra la estructura general de las pantallas.
El flujo entre las pantallas del sistema se muestra en la Figura 3.26, en él se incluyen las
principales pantallas de los módulos del sistema.

Capítulo 3 Desarrollo de la primera versión del sistema 83
Figura 3.24 Pantalla de inicio del sistema
Figura 3.25 Pantalla general de usuarios
Menú de usuario
Encabezado
Área de trabajo

Capítulo 3 Desarrollo de la primera versión del sistema 84
Figura 3.26 Diagrama de flujo de pantallas
3.5 Fase de Implementación y Pruebas
Esta fase comprende la implementación de las tres capas de la arquitectura que fueron diseñadas en la
parte anterior. Se construyen e integran los componentes de la capa de presentación, los componentes
de la capa de lógica de negocios y los componentes de la capa de datos. Estos componentes son
probados individualmente durante su implementación y, una vez integrados, se realiza un conjunto de

Capítulo 3 Desarrollo de la primera versión del sistema 85
pruebas que permiten determinar si la aplicación cumple con los requisitos funcionales y no
funcionales. El producto final que se obtiene es la primera versión del sistema probada y corregida.
3.5.1 Implementación del sistema
El sistema es implementado en tres servidores (tal y como se tenía previsto durante la fase de diseño).
La capa de presentación es implementada en un servidor web, el cual sólo debe ejecutar las funciones
de captura de datos por parte del usuario y generación de páginas web ya que sólo se puede comunicar
con el servidor de aplicaciones y con el cliente. Los componentes de la capa de lógica de negocios se
implementan en un servidor de aplicaciones que se encarga de la captura y procesamiento de los datos
del servidor de bases de datos, en el que se encuentra implementada la capa de datos del sistema. Los
servidores utilizados para la implementación del sistema son servidores de desarrollo que tienen las
mismas configuraciones que los servidores de producción, de modo que no haya que hacer muchas
configuraciones para ubicar el sistema en su ambiente final de operación.
Se busca garantizar la mantenibilidad del sistema, para ello, se trata de separar al máximo el
código escrito en PHP con el código HTML, se le da particular importancia a la documentación de los
componentes, y se hace énfasis en lograr un sistema altamente modular. Para la nomenclatura de las
funciones y las variables, así como para documentar los componentes, se sigue un conjunto de
lineamientos establecidos por la Gerencia de Desarrollo e Implementación de Soluciones de PDVSA
AIT [16]. Entre los principales estándares seguidos para la nomenclatura se pueden mencionar:
� Se utilizan letras mayúsculas para el inicio de cada palabra de un método y se evita el uso
de guiones en la nomenclatura de métodos.
� Se utiliza el carácter de guión bajo (‘_’) como separador de palabras para los elementos
de los arreglos.
� Se utilizan letras mayúsculas para las variables globales.
� Los comentarios siguen una estructura en la que se indica el autor del código, la versión del componente, la fecha de última modificación, la descripción de las funciones, de los parámetros que reciben y de los valores retornados.

Capítulo 3 Desarrollo de la primera versión del sistema 86
� La nomenclatura de las tablas de la base de datos sigue el formato “tr_num_Nombre_Tabla” donde la r denota que es una tabla regular, num indica el número de la tabla y el nombre de la tabla es separado por caracteres de guión bajo (‘_’).
i) Implementación de la capa de presentación
Durante el desarrollo de la primera versión del sistema se comienza ensamblando los componentes de
la capa de presentación. La interfaz U/S comprende la codificación e integración de componentes del
lado del servidor web y componentes del lado del cliente:
� El código del lado del cliente, contiene los elementos visuales (HTML, controles de servidor
y texto estático) y el código que se debe ejecutar en el navegador del cliente, en la forma de
funciones JavaScript.
� El código del lado del servidor web, contiene la lógica de programación de las páginas y es
implementado mediante segmentos de código PHP embebidos dentro de las páginas HTML y
mediante funciones contenidas en scripts externos a las páginas.
Para la implementación de esta capa se desarrollan cada una de las páginas web identificadas en el
diseño del sistema. El formato de las páginas (color y tamaño del texto, tablas, imágenes, menús de
usuario y formularios) es tomado de la hoja de estilos CSS que utilizan las aplicaciones disponibles a
través de la intranet de PDVSA.
Una de las páginas mas complejas en su desarrollo es la de ingreso de incidentes de falla. Los
requisitos asociados a los reportes de los analistas de guardia, hacen que esta página incorpore varios
aspectos dinámicos. Por ejemplo, para el ingreso del componente en que se produce la falla, el
requisito R12 establece que la selección de este debe ser dinámica, realizándose un filtro previo de
acuerdo al grupo operativo que reporta la falla y la ubicación del componente. Si el componente o la
ubicación son nuevos, o no aparecen en la lista, se permite que el usuario ingrese los datos
correspondientes activándose ciertos campos del formulario. Otros campos que se activan
dependiendo del estado del incidente, son los correspondientes a su solución. Parte de la estructura

Capítulo 3 Desarrollo de la primera versión del sistema 87
del formulario, junto con algunos de los estilos utilizados se muestran en la Figura 3.27. Algunas de
las pantallas de la primera versión del sistema pueden ser apreciadas en el Anexo B.
Figura 3.27 Formulario de ingreso de incidentes de falla
Se desarrolla un repositorio de funciones comunes utilizadas por todos los componentes de la capa
de presentación. Entre las funcionalidades se pueden mencionar: métodos que generan la estructura
de las páginas y del menú dinámicamente de acuerdo al perfil del usuario, funciones de validación,
funciones que llaman servicios web, entre otras.
ii) Implementación de la capa de lógica de negocios
En la capa de lógica de negocios obtenida en esta iteración se implementan las operaciones
encargadas de obtener la información de los incidentes de falla de la plataforma, calcular los
indicadores de disponibilidad y falla, manejar el inventario de componentes y procesar las alertas del

Capítulo 3 Desarrollo de la primera versión del sistema 88
sistema Nagios. En esta capa se encuentran los componentes encargados de la inserción, edición y
modificación de los datos antes mencionados.
La implementación de la lógica de negocios se hace mediante servicios web utilizando la librería
NuSOAP escrita en PHP. Esta librería se encarga de generar dinámicamente el código WSDL, es decir, el
formato XML mediante el cual se describen los datos transferidos entre el servidor de aplicaciones y el
servidor web. Se desarrollan scripts para agrupar servicios que manipulen las mismas tablas en la base de
datos y el acceso a estos servicios desde el servidor web es implementado en scripts externos a las páginas,
de modo que para los componentes de la capa de presentación, la llamada a los servicios web resulta
transparente.
Uno de los componentes más complejos de la capa de lógica de negocios es el encargado de
procesar el log de Nagios. Diariamente se obtiene un archivo de texto que contiene el registro (log) de
las alertas detectadas y las notificaciones emitidas por el sistema durante la jornada. Se desarrolló un
método que procesa dicho archivo y captura el momento en que el sistema detecta la caída de un
componente, almacenando el evento en la base de datos (en la tabla tr005_nagios_alert) como una
caída que no ha finalizado, luego sigue procesando el archivo detectando nuevas caídas y en caso de
capturar una alerta que corresponda a la recuperación de un componente, actualiza el registro
correspondiente en la base de datos. La transferencia del log entre los dos servidores (el servidor de
aplicaciones del SINCFA y el servidor donde se aloja Nagios) y la ejecución del script que lo procesa
son configuradas para llevarse a cabo todos los días a una misma hora como tareas programadas del
sistema operativo.
iii) Implementación de la capa de datos
La implementación de la base de datos del sistema no difiere del diseño que se hizo en el apartado
anterior. La naturaleza de las transacciones y la sencillez de las relaciones hacen que no sea necesario
definir vistas ni restricciones complejas para la recuperación de los datos. Para la administración de la
base de datos se utiliza la herramienta pgAdmin, que facilita la ejecución de las consultas antes de ser
implementadas en la lógica de negocios y hace posible al desarrollador visualizar y manipular
directamente el contenido de la base de datos.

Capítulo 3 Desarrollo de la primera versión del sistema 89
3.5.2 Pruebas del sistema
Las pruebas del sistema buscan lograr detectar y corregir el mayor número de errores posibles y con
una cantidad razonable de tiempo y esfuerzo. En el caso del SINCFA, las pruebas permiten verificar
que la aplicación funciona correctamente en condiciones típicas de operación y que se satisface los
requisitos funcionales y no funcionales determinados previamente. Para el desarrollo de las pruebas se
sigue la siguiente estrategia:
� Se comienza probando individualmente cada uno de los componentes utilizando pruebas
caja negra. En este tipo de prueba se toman datos de entrada considerados sin tomar en
cuenta el funcionamiento interno del componente, utilizando valores ubicados justo en los
límites permitidos y fuera de ellos, donde probablemente ocurran excepciones.
� En caso de detectarse un resultado inesperado durante la ejecución de las pruebas de caja
negra, se realizan pruebas de caja blanca, en las que se rastrea el comportamiento interno
del componente, verificando la ejecución de cada una de las instrucciones involucradas en el
caso de prueba, esto con el fin de detectar y corregir la instrucción en la que se produce el
error.
� La integración de los componentes es probada utilizando pruebas funcionales orientadas
a caso de uso. En estas pruebas se verifica que los componentes que intervienen en cada
caso de uso funcionan correctamente, cumpliendo así con los requisitos funcionales.
� Finalmente se hace una verificación y validación de los requisitos de los actores.
Esto con el fin de detectar el grado de cobertura de los requisitos en la primera versión del
sistema y determinar las metas a cumplir en el desarrollo de la segunda versión.
i) Pruebas de caja negra del sistema
El enfoque funcional o de caja negra consiste en estudiar la especificación de las funciones, la entrada y
la salida con el fin de verificar que los componentes se comportan de la manera esperada. Aquí, la
prueba ideal del software consistiría en probar todas las posibles entradas y salidas del programa. Sin
embargo, se puede generalizar un conjunto de valores que abarque el mayor número de casos de

Capítulo 3 Desarrollo de la primera versión del sistema 90
entrada posibles y de ese modo cubrir varios escenarios a la vez. En el caso del SINCFA se realizan
pruebas de caja negra a los sesenta y ocho (68) componentes del sistema. La Tabla 3.5 muestra
algunas de las pruebas de caja negra realizadas.
Módulo Parámetros de Entrada
Salida Resultado
Acceso de usuarios (UsuarioValido.php)
Clave incorrecta Mensaje indicando que el usuario no es válido.
Satisfactorio, pero se observa un mensaje de advertencia no esperado y que luego es corregido. (Ver Figura 3.28 y Figura 3.29).
Ingreso de incidentes. (IngresoIncidente.php)
Campo obligatorio Faltante.
Mensaje indicando que se deben completar todos los campos del formulario.
Satisfactorio (Ver Figura 3.30).
Reporte de incidentes por período de tiempo. (VistaReporteFecha.php)
Período de tiempo válido.
Lista de los incidentes reportados entre las dos fechas.
Satisfactorio (Ver Figura 3.31).
Tabla 3.5 Pruebas de Caja Negra
Figura 3.28 Prueba de ingreso de usuario

Capítulo 3 Desarrollo de la primera versión del sistema 91
Figura 3.29 Mensaje obtenido al ingresar usuario inválido
Figura 3.30 Mensaje obtenido al tratar de ingresar un incidente con campos faltantes

Capítulo 3 Desarrollo de la primera versión del sistema 92
Figura 3.31 Resultado obtenido al consultar incidentes por período de tiempo
ii) Pruebas de caja blanca
El enfoque estructural o de caja blanca consiste en centrarse en la estructura interna (implementación)
del programa para elegir los casos de prueba. En este caso, la prueba ideal del software consistiría en
probar todos los posibles caminos de ejecución, a través de las instrucciones del código, que puedan
trazarse. Las pruebas de caja blanca son más exhaustivas que las pruebas de caja negra, por lo que son
realizadas solo en aquellos casos de prueba en los que los resultados obtenidos difieren de los
resultados esperados. Esto con el fin de poder rastrear y corregir los errores. El dominio que se tiene
del conjunto de instrucciones asociadas a cada módulo hace que no sea necesario revisar
exhaustivamente el código ni recurrir a análisis de complejidad ciclomática para el diseño de las
pruebas.
Uno de los casos de prueba en los que resulta necesario verificar el funcionamiento interno del
componente fue para el módulo de cálculo de indicadores por grupo operativo. En la prueba realizada
se consultan los indicadores de los grupos operativos entre el 01-01-2008 y el 01-01-2009 y para

Capítulo 3 Desarrollo de la primera versión del sistema 93
probar que el cálculo de los indicadores resulta correcto se toma como prueba el grupo “Z-Series” (los
incidentes reportados por el grupo se muestran en la Figura 3.32).
Figura 3.32 Incidentes reportados por el Grupo Z-Series entre el 01-01-2008 y el 01-01-2009
De acuerdo a la fórmula tomada para el cálculo de los indicadores, se espera que el valor de TPS
sea de (15+22+170)/3 = 69 horas, el TPEF debería valer (268+4988)/2 = 2628 horas y el número
de incidentes reportados por el grupo debe ser 3. Sin embargo en la Figura 3.33 se observa que los
indicadores calculados para el grupo no son los esperados.

Capítulo 3 Desarrollo de la primera versión del sistema 94
Figura 3.33 Cálculo de indicadores para el grupo Z-Series
Luego de revisar el funcionamiento interno del algoritmo encargado de calcular los indicadores,
se observa que el error se produce porque el algoritmo recibe correctamente el parámetro de número
de incidentes, lo que ocasiona que se omita siempre el último incidente de cada grupo en el cálculo de
los indicadores. Se corrige el error y se obtiene el resultado de la Figura 3.34.
Figura 3.34 Resultado obtenido luego de corregir el error de los indicadores
Durante la ejecución de pruebas al sistema se realizan pruebas de caja blanca a ocho (8) módulos del
sistema de un total de sesenta y ocho (68) componentes desarrollados.
iii) Pruebas Funcionales
Para verificar que el sistema satisface los requisitos funcionales recolectados en la fase de ingeniería de
requisitos, se desarrolla un conjunto de pruebas en las que los componentes que intervienen en cada
caso de uso son probados de manera general, en condiciones que simulan las condiciones normales de
operación del sistema. En estas pruebas también se revisa que los componentes se integran de manera
adecuada, cumpliendo con las especificaciones hechas en la fase de diseño. Las pruebas realizadas se

Capítulo 3 Desarrollo de la primera versión del sistema 95
incluyen en un documento de pruebas que es entregado junto con la primera versión del sistema.
Dicho documento contiene un total de diecisiete (17) casos de prueba, varios de los cuales incluyen
algunos escenarios, se realizan un total de veintiocho (28) pruebas funcionales.
iv) Verificación y validación de los requisitos
En esta actividad, se determina que el sistema cumple con los requisitos establecidos en el análisis y
que estos satisfacen las necesidades de los usuarios. La verificación consiste en comprobar que el
sistema cumple con la especificación de requisitos; parte de este proceso fue llevada a cabo durante la
ejecución de las pruebas funcionales orientadas a caso de uso y se encontró que todos los casos de uso
incluidos en el análisis fueron construidos en el sistema.
La validación determina si el sistema satisface las necesidades de los usuarios. Para la entrega final
de la primera versión se hace una presentación al cliente y a los usuarios principales, en la que se
ejecutan los procesos apoyados por el sistema y se comprueba que el comportamiento en condiciones
típicas de operación es el esperado, midiéndose el grado de aceptación y de satisfacción de las
necesidades de información de los usuarios finales. En estas pruebas el cliente sugiere correcciones
que se le deben hacer al sistema para que apoye de manera más efectiva sus funciones. Estas
correcciones son tomadas en cuenta para el desarrollo de la segunda versión.
Vale la pena resaltar que durante todo el proceso de desarrollo, la participación del cliente y los
usuarios fue activa y se realizaron correcciones al sistema en base a las observaciones que iban
surgiendo. Sin embargo, estas últimas pruebas permitieron la validación final de todos los requisitos.
3.6 Conclusiones del capítulo
La primera iteración del método Watch fue la más compleja, ya que se empezó capturando las ideas
difusas que tenía el cliente acerca de lo que deseaba que hiciera el sistema, y en base a estas ideas se
fue construyendo un producto esperando satisfacer sus necesidades. La mayor complicación surgió
debido a que en la medida que el cliente iba madurando sus ideas y participaba en el proceso de
desarrollo, sus expectativas respecto al sistema aumentaban, esto hacía que sus requisitos cambiaran y
que hubiera que incorporar nuevos detalles al diseño sobre la marcha. Sin embargo, una vez hechas las

Capítulo 3 Desarrollo de la primera versión del sistema 96
mejoras necesarias, los actores quedaron satisfechos con el producto obtenido y se establecieron las
bases para el desarrollo de una segunda versión.
Se observó que una de las principales ventajas de utilizar un diseño arquitectónico de tres capas
orientado a servicios fue la facilidad para separar las funciones de cada componente, lo que permitió
detectar y corregir errores rápidamente.

Capítulo 4 Desarrollo de la segunda versión del sistema 97
Capítulo 4
Desarrollo de la segunda versión del sistema
En el presente capítulo se habla del desarrollo de la segunda versión del sistema SINCFA. Para esta
segunda versión se cuenta con un mayor conocimiento de los procesos de negocio y de las necesidades
de información de los usuarios. Este conocimiento, junto con un mayor dominio de las herramientas
utilizadas, permite mejorar los productos obtenidos en la primera versión y alcanzar resultados de
manera más rápida. Se comienza revisando brevemente algunos de los aspectos del modelo de
negocios, se incorporan los nuevos requisitos y se desarrollan los casos de uso correspondientes, se
diseñan los nuevos componentes y se habla sobre la fase de implementación y pruebas de la versión
final. El principal producto de esta fase es el sistema listo para su puesta en producción.
4.1 Revisión del modelo de negocios
En esta iteración los cambios que surgen en el dominio de la aplicación son muy pocos, ya que el
alcance del sistema y los procesos de negocio siguen siendo básicamente los mismos. Sin embargo, se
incorporan nuevas reglas, principalmente relacionadas con el manejo de servicios por parte del
sistema Nagios y con la automatización del proceso de obtención de la minuta de incidentes (que
aparece especificado en la regla 18 del apartado 3.1.6 y que no fue tomado en cuenta para la primera
versión). La incorporación de nuevas reglas hace que se incorporen algunos objetos al modelo de
negocios; no obstante, siguen interviniendo los mismos actores con los mismos objetivos.

Capítulo 4 Desarrollo de la segunda versión del sistema 98
4.1.1 Modelado de las reglas de negocio
Con un mejor conocimiento de los procesos de negocio, se incorporan nuevas reglas que no fueron
tomadas en cuenta durante el desarrollo de la primera versión o que surgieron en la medida que se
conocía mejor el dominio de la aplicación. Las reglas incluidas son las siguientes:
23. Documento de lineamientos y controles de seguridad para las aplicaciones disponibles en la
intranet PDVSA.
24. El sistema Nagios también detecta el estado de servicios dentro de los Hosts. Para Nagios un
servicio es una propiedad de un Host que puede ser monitoreada a través de la red y que tiene
cierto estado en un momento dado, por ejemplo, el espacio en disco o el uso de memoria en
un servidor. El estado de un servicio puede ser normal (internamente se maneja el término
OK), de advertencia (WARNING) o crítico (CRITICAL). El monitoreo de los servicios hace
posible que Nagios supervise el estado de aplicaciones cuyo desempeño resulta crítico para el
negocio. En este sentido, una aplicación puede abarcar varios servicios dentro de varios Hosts
de la plataforma.
25. Para el monitoreo de los servicios la lógica es básicamente la misma, el sistema envía señales
esperando respuesta por parte del servicio dentro del Host, al momento de detectar que el
estado de un servicio es crítico se emiten notificaciones a los grupos responsables y se
registran las notificaciones emitidas, del mismo modo se notifica y registra cuando el estado
del servicio vuelve a la normalidad.
26. Para que un incidente aparezca reportado en la minuta de una reunión, es necesario que el
analista envíe su reporte a GDS antes de las 9:00 a.m., ya que a esa hora es que se pone a
disposición la minuta a los grupos operativos, gerentes y demás interesados. de lo contrario el
reporte aparece registrado en la minuta de la próxima reunión.
27. Es posible calcular la disponibilidad de una aplicación o un componente para un período de
tiempo dado. El porcentaje de disponibilidad viene dado por la razón entre el número de
horas que opera el componente sin fallas y el número total de horas del período consultado

Capítulo 4 Desarrollo de la segunda versión del sistema 99
Estas cuatro reglas fueron tomadas en cuenta durante la implementación del sistema,
adicionalmente se toma en cuenta la regla 18, que tiene que ver con la estructura de la minuta de
incidentes diarios. Esta regla fue incluida en el modelado de reglas y objetos de negocio del capítulo
anterior pero no fue incorporada al diseño ni modelada como un caso de uso.
4.1.2 Modelado de objetos de Negocio
Para el modelado de objetos de negocios en la segunda iteración, se hace distinción entre dos tipos de
componentes: las aplicaciones y los equipos. Durante la primera iteración se tomaba en cuenta un solo
tipo de notificaciones asociadas con componentes físicos de la plataforma. De este modo, los términos
Equipo y AlertaNagiosHost sustituyen a los términos Componente y AlertaNagios de la
primera versión. Los objetos que se incorporan son los siguientes:
Reporte: Los analistas arman un reporte con los datos del incidente de falla. El reporte reúne los
datos de la falla ocurrida y las acciones llevadas a cabo para solventarla. Esta información es
integrada en una minuta de incidentes diarios dependiendo de la hora y la fecha en que se haga el
reporte.
Aplicación: Las aplicaciones críticas en la plataforma son un tipo especial de componentes que están
asociadas a un conjunto de servicios monitoreados por la aplicación Nagios.
Servicio: Tal y como se mencionó anteriormente, un servicio es una propiedad de un Host que puede
ser monitoreada por Nagios a través de la red y que tiene cierto estado en un momento dado.
AlertaNagiosService: Cuando Nagios detecta que un servicio se encuentra en estado crítico, se
registra internamente dicho evento. Cuando sistema detecta que el servicio se encuentra
funcionando normalmente se registra el fin de la alerta. Una alerta puede estar asociada con un
único servicio.
El diagrama de objetos de la segunda versión del sistema se muestra en la Figura 4.1, en ella se
resaltan con un color más oscuro las nuevas entidades incorporadas al modelo.

Capítulo 4 Desarrollo de la segunda versión del sistema 100
Figura 4.1 Diagrama de objetos de la segunda versión del SINCFA
4.2 Requisitos de la segunda versión
Para la segunda versión se incorporan nuevos requisitos, muchos de los cuales fueron surgiendo en la
medida en que se avanzaba en el desarrollo de la primera versión. En esta etapa, los requisitos se
concentran en incorporar las nuevas reglas de negocio y en incrementar los controles de seguridad en
el sistema. Los actores que intervienen en el proceso de ingeniería de requisitos siguen siendo los
mismos, sin embrago, se redefinen los perfiles de los usuarios de la aplicación.

Capítulo 4 Desarrollo de la segunda versión del sistema 101
4.2.1 Redefinición de los perfiles de usuario
Para la primera versión del SINCFA se identificaron cuatro niveles de acceso de los usuarios a las
funciones del sistema. Sin embargo, los perfiles definidos no estaban vinculados con ninguna unidad
específica dentro de la organización. Para la segunda versión se asocia cada uno de los perfiles a un
grupo de usuarios dentro de PDVSA AIT SCC y se obtienen los siguientes tipos de usuario:
Usuario de Confiabilidad: La Coordinación de Confiabilidad es la unidad responsable del sistema,
y sus miembros son los encargados de administrar el SINCFA. Entre sus privilegios se puede
mencionar: auditar el sistema cuando sea necesario, manejar el inventario de equipos y
aplicaciones de PDVSA AIT SCC, modificar los datos de los reportes de incidentes hechos por los
analistas de guardia y consultar todos los reportes generados por el sistema.
Usuario de GDS: Las funciones de los miembros de la Gerencia de Gestión del Servicio están
relacionadas con la consulta y generación de la minuta de incidentes diarios y la supervisión de
que los analistas completen los reportes pendientes por solución, también pueden acceder a
ciertos reportes generados por el sistema.
Usuario de MAP: Son los usuarios que pertenecen a los grupos operativos solucionadores,
responsables de cada una de las especialidades de la plataforma AIT SCC. Sus privilegios se
concentran en la creación de reportes de incidentes de falla y solo pueden modificar los reportes
que hayan quedado pendientes por solución. Además de eso, pueden consultar algunos reportes
generados por el sistema.
Usuario General: Este perfil se mantiene respecto a la primera versión, está representado por los
usuarios dentro de otras unidades de PDVSA AIT SCC y sólo puede hacer ciertas consultas sobre
la base de datos de incidentes.

Capítulo 4 Desarrollo de la segunda versión del sistema 102
4.2.2 Definición de requisitos según actores
i) Requisitos del cliente
1. La jerarquía de roles del sistema debe estar estructurada en el Directorio Activo. Es
responsabilidad del administrador del sistema solicitar a la gerencia responsable de dicho
directorio la creación de los grupos de usuarios correspondientes y las autorizaciones para
cada usuario.
2. Hacer uso de archivos de registros de eventos (Logs) para auditar el sistema y permitir
reconstruir en un momento dado la sesión de algún usuario.
3. Incorporar módulo para la auditoria del sistema.
4. Bloquear la sesión del usuario después de cierto tiempo de inactividad.
5. Minimizar a uno (1) el número de sesiones simultáneas de un usuario en el sistema, evitando
así los accesos no autorizados.
6. La autenticación de los usuarios en la aplicación debe hacerse con la utilización de un canal
seguro, pudiéndose utilizar SSL para obtener HTTPS. Este tipo de canal debe ser utilizado
para las transferencias de datos que se consideren confidenciales o cuando se requiera el
llenado de formularios con datos sensibles. Luego de haberse realizado la autenticación o
transferencia del dato sensible puede proceder a utilizar el protocolo http.
7. Evitar el ingreso a cualquier página de la aplicación, a través de la manipulación del URL o
enlace ubicado en “Favoritos”, sin haber realizado el proceso de autenticación.
8. Evitar arrojar mensajes de advertencia y errores de la aplicación en el navegador de Internet.
En estos casos se debe presentar al usuario un mensaje general sobre lo ocurrido (diseñar una
página estándar para cualquier tipo de error; sin especificar el tipo de error).
9. El módulo de control de inventario de equipos y aplicaciones de la plataforma AIT sólo debe
ser manipulado por cierto tipo de usuarios con privilegios especiales dentro del sistema.
10. Incorporar un módulo para obtener la minuta directamente del sistema, en base a los reportes
ingresados por los analistas.
11. Incorporar un módulo para capturar las alertas emitidas por Nagios para las aplicaciones de la
plataforma.

Capítulo 4 Desarrollo de la segunda versión del sistema 103
ii) Requisitos de los usuarios
2. Se deben hacer más explícitos los mensajes mostrados en la interfaz, permitiendo que el
usuario pueda ubicar fácilmente las funciones dentro del sistema.
3. Incorporar un módulo para que los analistas cierren los reportes pendientes por solución y
para hacer un seguimiento de estos reportes.
4. Se debe incorporar un módulo que lleve control de las guardias de los analistas.
5. Al momento de consultar los incidentes reportados para un equipo o aplicación, se debe
incorporar un indicador de disponibilidad respecto al período de tiempo consultado.
6. Se debe incorporar un módulo para graficar los indicadores.
7. Distinguir entre los analistas que no hayan reportado novedad y aquellos que hayan estado
ausentes en la reunión de guardia.
8. Incorporar un módulo de control de datos de los analistas de los Grupos Operativos
Solucionadores.
9. Incluir un módulo de reportes que permita consultar las alertas emitidas por Nagios y filtrar
dichas alertas por período de tiempo, grupo operativo o por equipo o sistema. Los reportes
deben incorporar el cálculo de los indicadores correspondientes y solamente serán manejados
por la Coordinación de Confiabilidad.
10. Incorporar un módulo de ayuda en línea.
iii) Requisitos del desarrollador
1. La segunda versión debe incorporar controles que agilicen el llenado de la minuta por parte
de los analistas.
2. Se deben realizar mejoras a la interfaz y documentación del sistema.
4.2.3 Clasificación y negociación de requisitos
Luego de analizar la cantidad de esfuerzo asociada con cada requisito se realizan negociaciones con el
cliente a fin de fijar prioridades a estos y enfocar el desarrollo de la segunda versión del sistema

Capítulo 4 Desarrollo de la segunda versión del sistema 104
solamente en aquellos íntimamente vinculados con la gestión de incidentes de falla. La clasificación y
las prioridades de los requisitos se muestran en la Tabla 4.1.
N° de requsito
Nombre del requisito
Clasificación Prioridad Tipo de requisito
R1 La jerarquía de roles del sistema debe estar estructurada en el Directorio Activo.
No Funcional 4 Restricción de seguridad
R2 Hacer uso de archivos de registros de eventos (Logs) para auditar el sistema
No Funcional 3 Aseguramiento de la calidad
R3 Incorporar módulo para la auditoria del sistema.
Funcional 3 Aseguramiento de la calidad
R4 El sistema debe bloquear la sesión del usuario después de cierto tiempo de inactividad.
No Funcional 3 Restricción de seguridad
R5 Se debe minimizar a uno (1) el número de sesiones simultáneas de un usuario en el sistema
No Funcional 4 Restricción de seguridad
R6 La autenticación de los usuarios en la aplicación debe hacerse con la utilización de un canal seguro, pudiéndose utilizar SSL para obtener HTTPS.
No Funcional 3 Restricción de seguridad
R7 Se debe evitar el ingreso a cualquier página de la aplicación sin haberse autenticado primero
No Funcional 2 Restricción de seguridad
R8 Se deben presentar al usuario mensajes generales cuando ocurran errores o excepciones en el sistema.
No Funcional 2 Restricción de seguridad
R9 El módulo de control de inventario de equipos y aplicaciones de la plataforma AIT sólo debe ser manipulado por cierto tipo de usuarios
No Funcional 4 Restricción

Capítulo 4 Desarrollo de la segunda versión del sistema 105
N° de requsito
Nombre del requisito
Clasificación. Prioridad. Tipo de requisito.
R10 Incorporar un módulo para obtener la minuta directamente del sistema
Funcional 5 Funcionalidad
R11 Incorporar un módulo para capturar las alertas emitidas por Nagios para las aplicaciones de la plataforma.
Funcional 5 Funcionalidad
R12 Se deben hacer más explícitos los mensajes mostrados en la interfaz, permitiendo que el usuario pueda ubicar fácilmente las funciones dentro del sistema
No Funcional 2 Uso y factores humanos.
R13 Incorporar un módulo para que los analistas cierren los reportes pendientes por solución y para hacer un seguimiento de estos reportes
Funcional 4 Funcionalidad
R14 Incorporar un módulo que lleve control de las guardias de los analistas
Funcional Descartado en
negociación
Funcionalidad
R15 Los reportes deben incorporar un indicador de disponibilidad respecto al período de tiempo consultado
No Funcional 5 Restricción
R16 Incorporar un módulo para graficar los indicadores.
Funcional Descartado en
negociación
Funcionalidad
R17 Distinguir entre los analistas que no hayan reportado novedad y aquellos que hayan estado ausentes en la reunión.
Funcional Descartado en
negociación
Funcionalidad
R18 Incorporar un módulo de control de datos de los analistas.
Funcional Descartado en
negociación
Funcionalidad

Capítulo 4 Desarrollo de la segunda versión del sistema 106
N° de requsito
Nombre del requisito
Clasificación. Prioridad. Tipo de requisito.
R19 Incluir un módulo de reportes que permita consultar las alertas emitidas por Nagios y filtrar dichas alertas por grupo y por equipo o aplicación.
Funcional 3 Funcionalidad
R20 Incluir un módulo de ayuda en línea.
Funcional 3 Aseguramiento de la calidad
R21 La segunda versión debe incorporar controles que agilicen el llenado de la minuta por parte de los analistas.
No Funcional 2 Uso y factores humanos
R22 Se deben realizar mejoras a la interfaz y documentación del sistema
No Funcional 2 Aseguramiento de la calidad
Tabla 4.1 Clasificación y Negociación de requisitos
4.2.4 Elaboración de casos de uso
Para la segunda versión se refina el modelo de casos de uso y se consideran los nuevos perfiles de
usuario. Los diagramas se muestran en las Figuras 4.2, 4.3, 4.4 y 4.5. Obsérvese como los casos de
uso agregados para la segunda versión son resaltados en color crema.
La descripción textual de los nuevos casos de uso aparece en la Tabla 4.2. En ella se observa que
las principales mejoras al sistema ocurren en la incorporación de nuevos reportes a partir del sistema
Nagios y en la definición de servicios asociados a aplicaciones. Adicionalmente, se incorpora un caso
de uso para que los usuarios de GDS puedan consultar los reportes que están pendientes por solución
y de ese modo hacer seguimiento a los analistas. Un usuario de MAP sólo puede consultar y modificar
los reportes que hayan sido creados por él. Se incorpora el caso de uso “Auditar sistema” y abarca la
consulta de los logs del sistema para reconstruir las sesiones de los usuarios.

Capítulo 4 Desarrollo de la segunda versión del sistema 107
Figura 4.2 Diagrama de casos de uso para usuario general

Capítulo 4 Desarrollo de la segunda versión del sistema 108
Figura 4.3 Diagrama de casos de uso para usuario MAP

Capítulo 4 Desarrollo de la segunda versión del sistema 109
Figura 4.4 Diagrama de casos de uso para usuario GDS

Capítulo 4 Desarrollo de la segunda versión del sistema 110
Figura 4.5 Diagrama de casos de uso para usuario de confiabilidad

Capítulo 4 Desarrollo de la segunda versión del sistema 111
Caso de Uso
Nombre del Caso de Uso
Descripción
CU18 Consultar ayuda. El usuario consulta el manual de ayuda en línea.
CU19 Consultar incidentes reportados en minuta.
El usuario introduce la fecha de la minuta que desea consultar y el sistema carga una lista con los incidentes reportados en la reunión de esa fecha.
CU20 Consultar incidentes pendientes por solución.
El usuario consulta los incidentes que haya reportado con anterioridad y hayan quedado pendientes por datos acerca de la solución y finalización.
CU21 Cerrar reporte abierto.
El usuario agrega datos acerca de la finalización y solución del incidente reportado.
CU22 Imprimir minuta. El usuario de GDS genera la minuta de la reunión de incidentes diarios automáticamente desde el sistema.
CU23 Consultar analistas con reportes abiertos
El usuario consulta los analistas que tengan reportes pendientes por solución. El sistema genera una lista con los datos de los reportes y de los analistas responsables.
CU24 Definir servicio El usuario define un servicio asociado a una aplicación particular y monitoreada por el sistema Nagios.
CU25 Eliminar servicio El usuario elimina los datos de un servicio.
CU26 Consultar alertas de Nagios por grupo operativo
El usuario consulta las alertas detectadas por el sistema Nagios para los equipos y aplicaciones de un grupo operativo en particular.
CU27 Consultar alertas de Nagios por equipo o aplicación.
El usuario consulta las alertas detectadas por el sistema Nagios para un equipo o aplicación en particular. En caso de una aplicación se muestran todas las alertas de servicios asociados.
CU28 Auditar sistema El usuario consulta el archivo de registro de eventos para reconstruir las sesiones de otros usuarios y las modificaciones hechas por estos sobre la base de datos.
Tabla 4.2 Descripción de los nuevos casos de uso incorporados a la versión 2 del SINCFA
4.2.5 Matriz Caso de Uso vs. Requisitos
La incorporación de nuevos requisitos y la definición de nuevos casos de uso hacen que para el
desarrollo de la segunda versión sea necesaria una nueva verificación de los requisitos cubiertos. La
matriz de Casos de uso vs. Requisitos se muestra en la tabla 4.3. En ella aparecen solamente los
nuevos requisitos funcionales contra los nuevos casos de uso.

Capítulo 4 Desarrollo de la segunda versión del sistema 112
Caso de uso Requisito
CU 18
CU 19
CU 20
CU 21
CU 22
CU 23
CU 24
CU 25
CU 26
CU 27
CU 28
R3 �
R10 � �
R11 � � � �
R13 � � �
R19 � �
R20 �
Tabla 4.3 Matriz de Casos de Uso vs. Requisitos para la segunda versión
4.3 Diseño de la segunda versión
Los componentes diseñados durante la primera iteración del método Watch sirven de base para la
extensión del sistema. La arquitectura de la versión anterior fue diseñada de tal forma que facilita la
incorporación de nuevos componentes sin necesidad de hacer muchos cambios a los ya existentes. De
modo que la mayoría de los cambios que surgen sobre el diseño son debidos a los nuevos requisitos. El
enfoque y los estilos utilizados en el diseño de la arquitectura siguen siendo los mismos.
4.3.1 Metas de diseño
Los objetivos planteados para la fase de diseño del sistema siguen se conservan. Solo se incorpora una
meta al diseño de la nueva versión: El diseño incorporará mecanismos que mejoren los niveles de
seguridad del sistema ante fraudes computarizados y lo hagan robusto ante errores por parte del
usuario.
4.3.2 Identificación de subsistemas
Se incorpora un nuevo subsistema encargado de la auditoria del SINCFA. Este subsistema abarca el
registro de los accesos de usuarios al sistema y de las modificaciones que estos hagan sobre las bases de
datos. Todos esos eventos son registrados en los archivos de registro de eventos (Logs) del SINCFA.

Capítulo 4 Desarrollo de la segunda versión del sistema 113
De este modo, es posible que el administrador de la aplicación construya la sesión del usuario a partir
de una simple consulta al log correspondiente. El diagrama de la figura 4.6 muestra la división del
sistema en subsistemas.
Figura 4.6 Identificación de subsistemas para la segunda versión del SINCFA
4.3.3 Diseño de componentes
Dentro de cada uno de los subsistemas que son identificados para la segunda versión del SINCFA se
incorporan nuevos componentes, siguiendo los mismos estilos que se definieron en el diseño de la
primera versión.
i) Subsistema de control de usuarios
A pesar de que ninguno de los casos de uso definidos en la parte anterior está directamente
relacionado con el control de acceso de los usuarios, algunos de los requisitos no funcionales
recolectados sugieren la incorporación de modificaciones sobre ese subsistema. Tal es el caso de los
requisitos R4, R5, R6 y R7 que tienen que ver con la seguridad del sistema. Estos requisitos motivan
la incorporación de nuevos elementos al diseño y la modificación de otros componentes. La Figura
4.7 muestra los componentes que fueron incorporados al subsistema de control de usuarios y aquellos
que fueron modificados en el desarrollo de la segunda versión.

Capítulo 4 Desarrollo de la segunda versión del sistema 114
ii) Subsistema de gestión de incidentes y soluciones
En este subsistema se incorporan componentes para la generación de la minuta y el cierre de reportes
abiertos, tal y como está especificado en los casos de uso CU19, CU21, CU22 y CU23. El diagrama
de la Figura 4.8 muestra los componentes diseñados y modificados en el subsistema.
iii) Subsistema de gestión de reportes de monitoreo
Los casos de uso que se incorporan en este subsistema son CU26 y CU27. También se hacen
modificaciones considerables al componente que procesa el log de Nagios para que incluya las
aplicaciones. El diagrama de la Figura 4.9 muestra los componentes que se modificaron y los que se
diseñan para este subsistema.
iv) Subsistema de inventario de aplicaciones AIT
Las modificaciones de este subsistema están relacionadas con los casos de uso CU24 y CU25, es decir,
con la definición de servicios por parte de los usuarios. El diagrama de la Figura 4.10 muestra los
componentes diseñados y modificados en el subsistema.
v) Subsistema de auditoria del SINCFA
El caso de uso CU28 hace que sea agregado el subsistema de auditoria para revisar las transacciones
hechas por los usuarios del sistema. La estructura del subsistema se muestra en la Figura 4.11.
Vale la pena resaltar que el caso de uso CU18 no fue especificado como un subsistema por su
sencillez, ya que el manual de ayuda del sistema consiste en un documento cargado directamente en
línea cuando el usuario lo desea.

Capítulo 4 Desarrollo de la segunda versión del sistema 115
Figura 4.7 Componentes agregados y modificados en el subsistema de control de usuarios

Capítulo 4 Desarrollo de la segunda versión del sistema 116
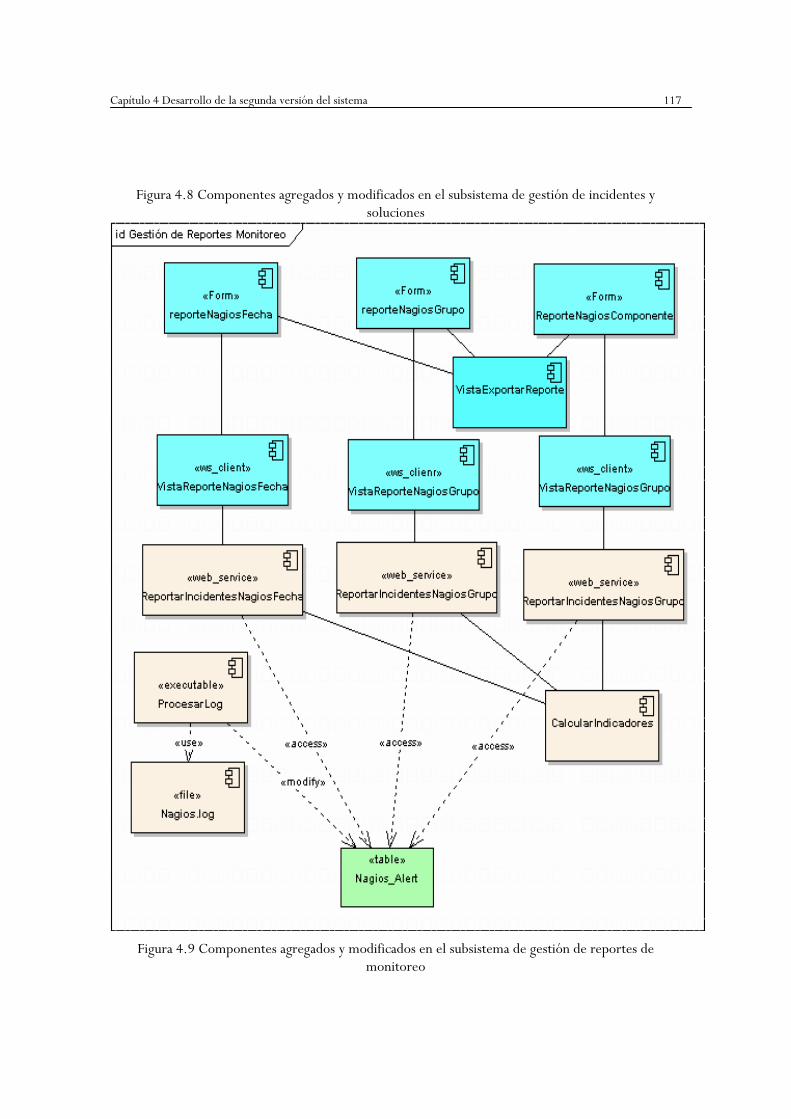
Capítulo 4 Desarrollo de la segunda versión del sistema 117
Figura 4.8 Componentes agregados y modificados en el subsistema de gestión de incidentes y soluciones
Figura 4.9 Componentes agregados y modificados en el subsistema de gestión de reportes de monitoreo

Capítulo 4 Desarrollo de la segunda versión del sistema 118
Figura 4.10 Componentes agregados y modificados en el subsistema de inventario de componentes AIT

Capítulo 4 Desarrollo de la segunda versión del sistema 119
Figura 4.11 Componentes del subsistema de auditoria del SINCFA
4.3.4 Diagrama de clases del sistema
En el diagrama de clases desarrollado para la segunda versión se observa que aparecen nuevas clases,
de las cuales la mayoría no incorpora atributos nuevos, convirtiéndose en especializaciones de las
clases base. El diagrama de la Figura 4.12 muestra el nuevo diagrama de clases, se observa que las
clases nuevas son resaltadas con color azul.

Capítulo 4 Desarrollo de la segunda versión del sistema 120
Figura 4.12 Diagrama de clases para la segunda versión del sistema
4.3.5 Diagrama de despliegue del sistema
La distribución del sistema sigue siendo básicamente la misma, se incorporan los componentes
asociados con los nuevos subsistemas y dentro de cada uno de los paquetes presentados se incluyen los
componentes que ya fueron diseñados. Las modificaciones a nivel de despliegue son muy pocas, pues
la estructura del sistema sigue no cambia de manera significativa. El diagrama de despliegue de la
Figura 4.13 muestra la distribución de la segunda versión del sistema en nodos. Los cambios
agregados son resaltados en gris.

Capítulo 4 Desarrollo de la segunda versión del sistema 121
Figura 4.13 Diagrama de despliegue para la segunda versión del sistema

Capítulo 4 Desarrollo de la segunda versión del sistema 122
4.3.6 Diseño de la base de datos
Luego de refinar el modelo de clases del sistema se obtiene el modelo conceptual de la base de datos
del SINCFA. A pesar de que teóricamente el modelo orientado a objetos deriva en modelo relacional
con las mismas entidades, muchas veces es necesario hacer refinamientos al momento de la
implementación para optimizar el espacio utilizado [12]. Luego de estos refinamientos se observa que
el nuevo modelo incorpora solamente dos tablas nuevas, una de las cuales corresponde a los datos de
los usuarios conectados al sistema en conformidad con el requisito R5 y la otra comprende los
servicios asociados a las aplicaciones críticas. El esquema conceptual de la base de datos se muestra en
la figura 4.14, en él se resaltan las nuevas tablas en color azul. Al igual que en la primera versión el
esquema se encuentra en Tercera Forma Normal (3FN).
Figura 4.14 Modelo de la base de datos del sistema

Capítulo 4 Desarrollo de la segunda versión del sistema 123
4.3.7 Diseño de la interfaz del sistema
Los nuevos componentes especificados en el diseño de la capa de presentación hacen necesario
incorporar pantallas para las nuevas funcionalidades del sistema. Al redefinir el flujo de pantallas se
mantiene el formato y los estilos utilizados en la interfaz de la primera versión, haciéndose ligeras
modificaciones principalmente en los mensajes mostrados. En la figura 4.15 se muestra la nueva
pantalla de inicio y se observa como se han hecho mejoras estéticas de acuerdo a recomendaciones del
cliente. La Figura 4.16 muestra la nueva estructura general de las pantallas del sistema, como se
puede apreciar, no se agregan muchos cambios, pero resalta la incorporación de un mensaje de
bienvenida personalizado y de nuevas opciones en el menú. El nuevo diagrama de flujo de pantallas se
muestra en la Figura 4.17, en él solamente aparecen las nuevas pantallas agregadas al diseño.
Figura 4.15 Pantalla de inicio del sistema

Capítulo 4 Desarrollo de la segunda versión del sistema 124
Figura 4.16 Estructura general de las pantallas del sistema
Figura 4.17 Diagrama de flujo de pantallas

Capítulo 4 Desarrollo de la segunda versión del sistema 125
4.4 Fase de implementación y pruebas
El dominio que se tiene sobre las herramientas utilizadas reduce considerablemente la cantidad de
tiempo para implementar los nuevos componentes. Además de codificar los nuevos elementos
diseñados, los esfuerzos se concentran en refinar el código de todos los componentes, eliminando
segmentos redundantes y mejorando la documentación. La fase de pruebas es más exhaustiva, pues en
esta iteración se busca corregir todos los detalles y así entregar al cliente el sistema listo para su puesta
en operación.
4.4.1 Implementación de componentes
Las modificaciones hechas abarcan la incorporación de nuevos componentes y la modificación de
algunos de los módulos de la primera versión. De los componentes agregados al sistema resalta un
conjunto de controles para agilizar las operaciones de los usuarios. Entre estos controles se incorpora
un botón de calendario para el ingreso de fechas dentro de los formularios3 (Figura 4.18). Otras
modificaciones sobre componentes de la primera versión que se pueden mencionar son: filtros de
búsqueda para el módulo de inventario AIT (Figura 4.19), cambios en la pantalla principal del módulo
de modificación de incidentes para seleccionar el incidente lista (Figura 4.20), ajustes en el módulo de
ingreso de incidentes para asignar la fecha de minuta automáticamente en conformidad con la regla 26
del modelo de negocios (Figura 4.21), mejoras de los mensajes mostrados al usuario (Figura 4.22),
entre otros. Algunas de las pantallas de la segunda versión del sistema pueden ser apreciadas en el
Anexo 3.
Figura 4.18 Componente de calendario en JavaScript
3 El componente es reutilizado a partir de una versión disponible en la web [26]

Capítulo 4 Desarrollo de la segunda versión del sistema 126
Figura 4.19 Pantalla de modificación de componentes del módulo de inventario AIT
Figura 4.20 Pantalla de modificación de incidentes

Capítulo 4 Desarrollo de la segunda versión del sistema 127
Figura 4.21 Asignación de fecha de minuta directamente por el sistema
Figura 4.22 Mensaje de aviso al usuario

Capítulo 4 Desarrollo de la segunda versión del sistema 128
4.4.2 Fase de pruebas del sistema
Se utiliza la misma estrategia de pruebas que la establecida para el desarrollo de la primera versión: Se
realizan pruebas de caja negra sobre los componentes nuevos y sobre los modificados, en caso de
detectarse un comportamiento inesperado se hacen pruebas de caja blanca y para verificar la
integración, exactitud y consistencia se siguen realizando pruebas de integración funcionales
orientadas a caso de uso.
i) Pruebas de caja negra del sistema
Durante el desarrollo de la segunda versión solamente se prueban los componentes agregados y
aquellos cuya estructura cambió considerablemente. Se realizan un total de cincuenta y dos (52)
pruebas de caja negra de las cuales treinta y cinco (35) corresponden a los componentes nuevos y
diecisiete (17) a los componentes modificados. Algunos ejemplos de las pruebas realizadas se
muestran en la Tabla 4.4.
Módulo Parámetros de Entrada
Salida Resultado
Acceso de usuarios (ValidarSesion.php).
Usuario ya conectado.
Mensaje indicando que la sesión no se puede crear.
Satisfactorio (Ver Figura 4.23).
Consulta de reportes abiertos (ListarReportesAb.php)
Analista con reportes Abiertos
Lista de los reportes abiertos para el analista.
Satisfactorio (Ver Figura 4.24).
Reporte de incidentes en minutas y nagios (ReporteMonitoreo.php)
Período de tiempo válido.
Lista de los incidentes reportados y las alertas detectadas entre las dos fechas.
Satisfactorio (Ver Figura 4.25).
Tabla 4.4 Pruebas de caja negra del sistema
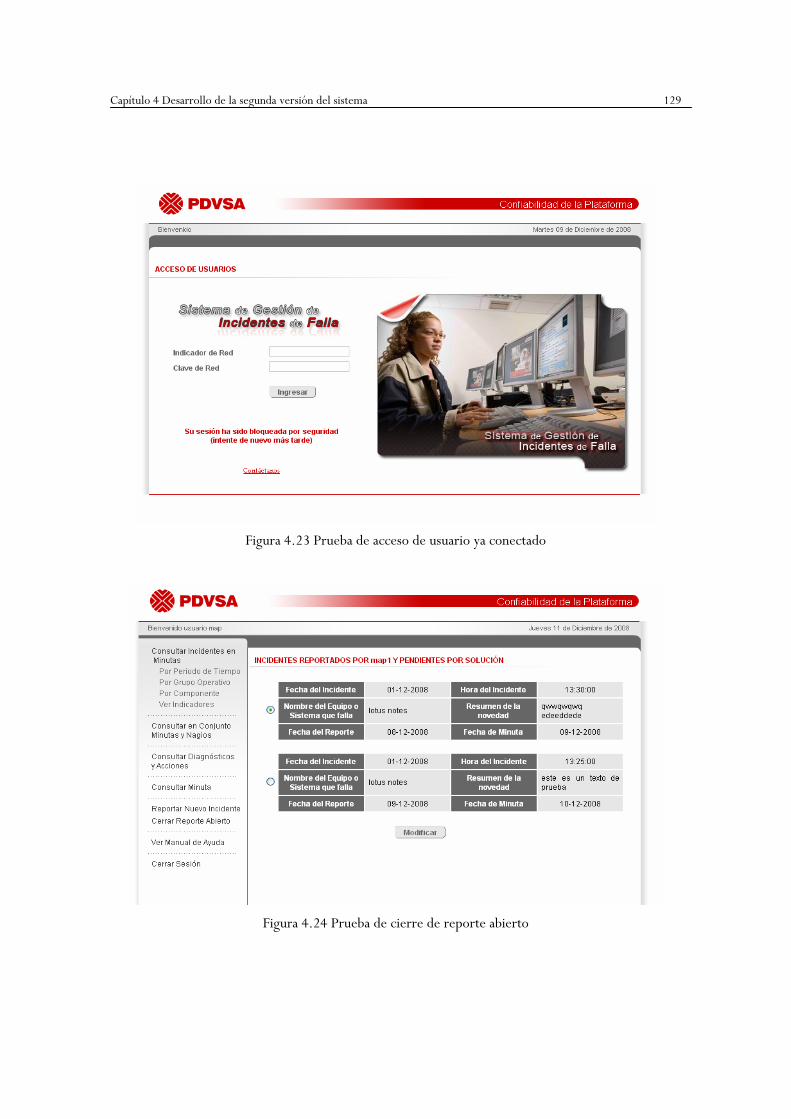
Capítulo 4 Desarrollo de la segunda versión del sistema 129
Figura 4.23 Prueba de acceso de usuario ya conectado
Figura 4.24 Prueba de cierre de reporte abierto

Capítulo 4 Desarrollo de la segunda versión del sistema 130
Figura 4.25 Prueba de consulta de reporte conjunto
ii) Pruebas de caja blanca del sistema
Para la segunda versión es necesaria la realización de once (11) pruebas de caja blanca para detectar los
resultados inesperados de las pruebas de caja negra realizadas. Por ejemplo, uno de los componentes
probados (Validar.js) se encarga de la validación de caracteres en los formularios y valida la longitud
de los campos abiertos para que no excedan el tamaño definido en la base de datos. En la prueba
realizada al módulo de ingreso de incidentes se detectan errores en el componente, pues a pesar de
que genera un mensaje indicando que el usuario se ha excedido de la longitud de caracteres permitida
(Ver Figura 4.26) se permite el ingreso del incidente, generando un error al momento de ingresar en
la base de datos. El mensaje indicando el error se muestra en la Figura 4.27.
Luego de revisar el componente se determina que la secuencia de instrucciones no retorna el
resultado de la validación al formulario, lo que hace que el usuario pueda saltar el mensaje de
advertencia. Luego de corregir el error no se permite el ingreso de los datos cuando excedan la
longitud permitida.

Capítulo 4 Desarrollo de la segunda versión del sistema 131
Figura 4.26 Prueba de longitud de campos en ingreso de incidente
Figura 4.27 Mensaje obtenido al tratar de ingresar el incidente

Capítulo 4 Desarrollo de la segunda versión del sistema 132
iii) Pruebas Funcionales
Parte de la entrega final del sistema comprende un documento en el que se muestran los resultados de
todas las pruebas funcionales realizadas. Las pruebas están orientadas a cada uno de los casos de uso,
debido a que ocurren cambios en varios componentes de la primera versión y se desea probar la
integración de los componentes. Se realiza un total de cuarenta y nueve (49) pruebas sobre los
veintiocho (28) casos de uso.
4.5 Entrega final del sistema
Para que el SINCFA entre en operación es necesario que todas las gerencias encargadas de validar la
calidad, mantenibilidad y seguridad de los sistemas de la corporación realicen un conjunto de pruebas
para determinar que se ha cumplido con sus lineamientos. Los trámites relacionados con estas pruebas
son principalmente administrativos y el tiempo requerido para su realización supera el tiempo
estimado para el proyecto, por lo que la entrega final del sistema comprende la fase previa a su puesta
en producción. Sin embargo, todas las restricciones y controles establecidos fueron cumplidos
durante las fases del desarrollo y las condiciones del ambiente en el que fue implementado el sistema
simulan completamente a las del ambiente de operación definitivo, lo que hace que la puesta en
producción del sistema no presente mayores complicaciones.
La documentación entregada al cliente junto con el sistema comprende: manuales de usuario para
los perfiles definidos, manual de mantenimiento para el administrador del sistema, diccionario de
datos, diagrama de despliegue y documento de pruebas realizadas. Además, se hizo una presentación
orientada a los usuarios en la que se mostraron las funcionalidades del sistema y se dio un
adiestramiento a las personas responsables de su mantenimiento.
Durante la entrega final del sistema se verifica que todos los requisitos de los actores son
satisfechos. Sin embargo, surgen observaciones y recomendaciones acerca de aspectos que se pueden
incorporar para mejorar las funcionalidades del sistema. Estas sugerencias hacen posible pensar en el
desarrollo de una tercera versión más adelante.

Capítulo 4 Desarrollo de la segunda versión del sistema 133
4.6 Conclusiones del capítulo
El desarrollo de la segunda versión no requirió de una dedicación considerable de tiempo ni de
recursos, pues la mayor ventaja del enfoque utilizado para el diseño de la primera versión fue la
facilidad para incorporar nuevos componentes sin hacer muchas modificaciones a los ya existentes. En
muy pocos casos fue necesario hacer ajustes sobre los componentes para lograr la compatibilidad con
los nuevos elementos del sistema. Adicionalmente, el probar de forma exhaustiva la primera versión
como si se tratara de la entrega final del sistema permitió concentrar los esfuerzos de prueba de la
segunda versión solamente sobre los nuevos componentes.
Una de las mayores dificultades enfrentadas durante la segunda iteración del método Watch fue la
negociación de los requisitos con el cliente, algunos requisitos fueron descartados. Esto debido a que
era necesario hacer un balance entre las necesidades de los actores y la cantidad de recursos
(principalmente tiempo) disponibles. También hubo que considerar que muchos de los nuevos
requisitos surgieron de procesos que se escapaban del dominio de la aplicación, tal fue el caso del
requisito R18 en el que se establecía la necesidad de un módulo para llevar el registro de los datos de
los analistas de guardia. Este requisito no fue tomado en cuenta por escaparse del alcance definido
para el sistema. Sin embargo, la participación activa del cliente durante todo el proceso de desarrollo
fue provechosa, pues permitió refinar constantemente los productos obtenidos hasta alcanzar
resultados plenamente satisfactorios en las áreas impactadas.

Capítulo 5 Conclusiones y Recomendaciones
134
Capítulo 5
Conclusiones y recomendaciones
5.1 Conclusiones
Luego de revisar y verificar los objetivos planteados al comienzo del proyecto, se llega a la conclusión
de que todos esos objetivos fueron alcanzados con éxito. Sin embargo, gran parte de ese logro vino
determinado por la metodología utilizada. El desarrollo de software es un proceso complejo que
requiere la aplicación de metodologías bien estructuradas para obtener productos de alta calidad a un
costo mínimo. Las metodologías imponen un proceso disciplinado sobre el desarrollo de software con
el propósito de hacerlo más predecible y eficiente. En el caso del Sistema de Gestión de Incidentes de
Falla, la aplicación del método Watch fue determinante para poder cumplir con los objetivos
planteados. Este método permitió la aplicación estructurada de un conjunto de actividades en las que
fue posible para el cliente conocer en todo momento el grado de avance del proyecto y participar de
manera activa sobre el proceso de desarrollo, colaborando en el refinamiento de los productos
intermedios que se iban obteniendo en cada fase.
Una de las mayores ventajas del método Watch es su flexibilidad, pues a pesar de que su modelo
de procesos establece un conjunto de actividades y productos a obtener, en muchos casos se pueden
hacer adaptaciones al contexto de la aplicación particular, permitiendo al equipo de desarrollo escoger
el nivel de detalle a alcanzar en el diseño. Para el caso del sistema desarrollado, se consideró un nivel
de detalle adecuado a su naturaleza y complejidad, buscando agilizar las fases del proceso de
desarrollo. De este modo, todos los productos obtenidos en las fases y descritos en este documento
resultaban necesarios para expresar algún aspecto del sistema.
De todas las fases del método, la ingeniería de requisitos es una de las más complejas debido a las
variaciones en los requisitos del cliente. Para lidiar con los requisitos cambiantes, la estrategia seguida
consistente en refinar iterativamente los productos de cada fase y generar versiones funcionales

Capítulo 5 Conclusiones y Recomendaciones
135
sucesivas del sistema fue satisfactoria y permitió realizar correcciones en conjunto con el cliente a
intervalos frecuentes de tiempo, redirigiendo el curso del proyecto en alineación con sus necesidades.
El impacto que puede tener la implementación de un Sistema de Información en una organización
viene dado por la capacidad del sistema para alinearse con el modo de trabajo dentro de ésta y sólo
sugerir aquellos cambios que sean necesarios para mejorar su desempeño. El apoyo de todos los
niveles dentro de la organización resulta vital para el éxito de cualquier proyecto de este tipo, pues de
lo contrario el efecto del sistema no será beneficioso sino perjudicial. En el presente proyecto se logró
integrar procesos involucrados con diferentes unidades dentro de la Gerencia MAP, organizando su
flujo de actividades sin alterar significativamente su modo de trabajo.
La información generada por los procesos de mantenimiento resulta vital para optimizar el
desempeño de los equipos y alargar su vida útil, pues permite orientar las prácticas no solo a
garantizar una disponibilidad sobre la marcha, sino a planificar y controlar las actividades de
mantenimiento, buscando disminuir a futuro la ocurrencia de errores y caídas de servicios. En base a
ello, el sistema desarrollado proporciona a la Gerencia MAP una herramienta valiosa para tener un
conocimiento global del desempeño de los activos bajo su responsabilidad y tomar decisiones para
optimizar su gestión.
5.2 Aportes a la empresa
El Sistema de Gestión de Incidentes de Falla (SINCFA) permite automatizar un proceso manual
que deja información de fallas dispersa, inconcisa y difusa, y que no se puede aprovechar al máximo.
En este sentido se pueden mencionar algunos de sus beneficios puntuales para la gestión de la
Gerencia MAP:
• Incorpora un repositorio histórico de fallas detallado por equipos y sistemas. Esta información
antes del desarrollo del sistema era manejada de forma difusa, dispersa y muchas veces
incompleta.
• Facilita la obtención de estadísticas de confiabilidad y disponibilidad de la plataforma,
calculados con una mayor precisión que en el proceso manual, pues se cuenta con un

Capítulo 5 Conclusiones y Recomendaciones
136
repositorio bien estructurado de datos que puede ser incluso utilizado por la Coordinación de
Confiabilidad para simular el comportamiento de la plataforma.
• Hace posible realizar proyecciones y planes de desincorporación o sustitución de equipos por
cumplimiento del ciclo de vida útil o por fallas recurrentes.
• Apoya el proceso de programación de los planes de mantenimiento de los equipos y sistemas
de la plataforma, mediante las estadísticas de fallas.
• Permite la visualización de los incidentes y estadísticas de falla en la plataforma, no sólo desde
la perspectiva de los grupos operativos, sino también desde el punto de vista de los equipos y
sistemas que la integran. Antes de la implementación del sistema, la forma como se manejaba
el repositorio de incidentes dificultaba la obtención de una perspectiva centrada en
componentes.
• Integra la información manejada por el Centro Integral de Monitoreo con los datos
reportados por los Analistas de los Grupos Operativos Solucionadores.
• Proporciona las bases para tener un inventario básico de las aplicaciones y equipos que
integran la plataforma.
• Proporciona una base de conocimiento referente a la obtención de históricos de causas de
fallas y resolución de problemas por cada equipo o sistema.
• Hace posible la obtención de información oportuna y útil para la toma de decisiones, pues
está disponible para todos los usuarios involucrados a través de la intranet de la empresa.
5.3 Aportes a la universidad
Proyectos como el desarrollado permiten crear vínculos estratégicos entre la Universidad de Los
Andes, particularmente, la Escuela de Ingeniería de Sistemas (EISULA) y la industria. Brindando
prestigio a la institución como formadora de profesionales de alto nivel y permitiendo a la comunidad
estudiantil mejorar su formación profesional mediante primeros contactos con el campo laboral.
5.4 Aportes al tesista

Capítulo 5 Conclusiones y Recomendaciones
137
La experiencia adquirida mediante el presente proyecto brinda al tesista una primera idea del trabajo
llevado a cabo dentro de una gran organización como lo es PDVSA, permitiéndole familiarizarse con
sus procesos, lineamientos y con las herramientas que son manejadas en la industria, brindándole a su
vez una idea de la manera como se aplican los conceptos aprendidos durante la carrera a la resolución
de problemas con la presión, exigencias y restricciones del mundo real. El trabajo desarrollado viene
aportando al tesista una experiencia integral que debe permitir su crecimiento profesional,
capacitándolo para abordar los problemas complejos que se le presenten más adelante.
5.5 Recomendaciones
En base a las conclusiones y los resultados obtenidos, es conveniente resaltar algunas recomendaciones
que pudieran extender los resultados del proyecto, o que podrían ser consideradas por los futuros
trabajos que se realicen en el área. En este sentido se recomienda:
� Integrar el Sistema de Gestión de Incidentes de Falla con otros sistemas utilizados por la
Gerencia GDS y la Gerencia MAP: El SINCFA aborda el problema de las fallas en la
plataforma desde el punto de vista de los reportes realizados por los analistas. Una extensión
que se pudiera incorporar al sistema es la integración con el subproceso de mantenimiento
visto desde la perspectiva del usuario que tiene el problema. La Gerencia de Gestión de
Servicio se encarga de llevar control sobre las solicitudes de los usuarios dentro de PDVSA y
actualmente maneja varios sistemas para el apoyo de sus procesos. Estos sistemas han sido
desarrollados dentro de la organización y generan órdenes de mantenimiento para la mayoría
de las solicitudes hechas por los usuarios. Una integración del SINCFA con esos sistemas
impactaría positivamente la gestión de ambas gerencias, pues permitiría integrar la
información manejada por ambas unidades, incorporando aspectos para medir y mejorar la
calidad y continuidad de los servicios de la plataforma.
� Incorporar mecanismos que creen los reportes de falla en el sistema directamente de las
alertas detectadas por Nagios: Se pudieran diseñar procedimientos para que las alertas
detectadas por Nagios creen directamente reportes de incidentes abiertos en el sistema y sus
datos quedarían pendientes por ser completados por parte del analista responsable. Esto

Capítulo 5 Conclusiones y Recomendaciones
138
permitiría que la integración entre la información reunida en los reportes de los analistas de
guardia y la manejada por el sistema Nagios pueda ser aprovechada en una razón aun mayor.
Sin embargo, para lograr este objetivo es necesario terminar de adaptar el sistema Nagios a la
plataforma, haciendo que las alertas que genere sean más precisas y confiables.
� Incorporar módulos al sistema para supervisar el desempeño de los analistas dentro de las
diferentes especialidades de la Gerencia MA: Una primera idea de los mecanismos requeridos
fue incorporada en la fase de ingeniería de requisitos de la segunda versión, los requisitos
fueron descartados por salirse de la delimitación del problema. El control sobre las guardias
de los analistas y sobre su asistencia a las reuniones de incidentes permitiría medir la
efectividad de los grupos y generar indicadores de gestión, tanto para cada uno de ellos, como
para toda la gerencia MAP. Además haría posible diseñar estrategias para medir la
confiabilidad del factor humano.
� Divulgar la importancia y utilidad del sistema entre las diferentes unidades que se pueden
beneficiar de él: La Coordinación de Confiabilidad de la Plataforma fue la unidad principal
dentro de MAP en la que se desarrolló el proyecto. Muchas de las funcionalidades del
SINCFA buscan apoyar y mejorar considerablemente su gestión, permitiendo la integración
de sus actividades con las de las otras coordinaciones y el intercambio de información entre
ellas. Sin embargo, una de las mayores dificultades que podrían enfrentar durante la
transición del sistema sería lograr que los analistas se sientan identificados con él lo
suficientemente como para integrarlo completamente a sus actividades, esto debido a que
muchos de los beneficios que aportará el sistema serán apreciables a largo plazo, cuando se
cuente con un historial de fallas considerable. Es entonces responsabilidad de la Coordinación
de Confiabilidad resaltar los beneficios que incorporará el sistema, de modo que se cuente
con el apoyo y colaboración de las otras unidades.
� Incorporar un catálogo de modos de fallas al sistema: La naturaleza de los equipos y sistemas
que integran la plataforma repercute sobre las diferentes formas en las que pueden ocurrir las
fallas. Muchas veces un componente o grupo de componentes presenta un conjunto reducido
de formas en las que pueden fallar, o puede ocurrir también que varias de las fallas tengan un
mismo diagnóstico o una misma acción a ejecutar. La definición de categorías para los modos

Capítulo 5 Conclusiones y Recomendaciones
139
de falla haría que, al momento de reportar un incidente, el analista escoja la novedad, el
diagnóstico y la acción ejecutada a partir de una lista. Esto agilizaría el llenado de los reportes,
además de optimizar el uso de la base de datos y eliminar la existencia de datos ambiguos,
redundantes y confusos que se presentan con mucha frecuencia cuando se manejan campos de
texto abiertos. Sin embargo, la categorización de los modos de falla de la plataforma implica
un estudio detallado de las características de los equipos que la integran, que se debe lograr en
conjunto con cada uno de los grupos responsables y debe buscar mantenerse vigente ante
cambios que se incorporen en la plataforma.
� Estudiar la factibilidad de modificaciones al método Watch para hacerlo más ligero: A pesar de
que los resultados alcanzados no hubieran sido los mismos sin la aplicación del método,
pudieran realizarse modificaciones a este para hacer que sus resultados se enfoquen más en la
obtención del producto final que en la documentación del mismo, de modo que para
complementar esta última, se puede hacer la participación del cliente en el proceso de
desarrollo más activa. Estas modificaciones harían del Watch un método más adaptable a
cambios en los requisitos del cliente que predictivo en cuanto al tiempo y recursos a utilizar
para cumplir dichos requisitos, ajustando sus actividades a la naturaleza humana de los actores
involucrados y concentrando dichas actividades en la obtención del producto más que en el
proceso necesario para obtenerlo.

Referencias Bibliográficas
140
Referencias Bibliográficas
[1] Sitio Web de PDVSA, http://www.pdvsa.com
[2] Intranet de PDVSA, http://intranet.pdvsa.com
[3] Nachias, J. (1995). Fiabilidad. ISDEFE.
[4] Perez, C. y Moubray, J. (2003). Mantenimiento centrado en confiabilidad: Aplicación e impacto. Actas del Primer Congreso Mexicano de Confiabilidad y Mantenimiento, León, México.
[5] Montilva, J. (2004). Desarrollo de aplicaciones empresariales: El método Watch. Universidad de Los Andes, Mérida, Venezuela.
[6] Object Management Group – UML Resource Page, http://www.uml.org/ [7] Schmal, R. y Cisternas, E. (2000). Sistemas de Información: Una metodología para su
estructuración. Actas de la XXVI Conferencia Latinoamericana de Informática, México. Instituto Tecnológico y de Estudios Superiores de Monterrey.
[8] Muñoz, A. (2003). Sistemas de información en las empresas, http://www.hipertext.net/web/pag251.htm.
[9] Barrios, J (2000), Sistemas de Información, Universidad de Los Andes, Mérida, Venezuela. [10] Mosquera, G. (2000). Estimación de parámetros de confiabilidad y mantenibilidad de sistemas
industriales. Centro de altos estudios gerenciales ISID. [11] Barringer, P. (1996). An overview of reliability engineering principles. Penn Well
Conferences, Houston, TX. [12] Elmasri, R. y Navathe S. (2002). Fundamentos de bases de datos. Tercera Edición. Pearson
Educación, Madrid. [13] Pérez, O. (2005). Bases de datos. Universitat Oberta de Catalunya,
http://republicajoven.org.ve/archivos/software_libre/UOC/Basededatos.pdf [14] Nickul D. (2007). Service Oriented Architecture (SOA) and Specialized Messaging Patterns.
Adobe Systems Incorporated, http://www.adobe.com/enterprise/pdfs/Services_Oriented_Architecture.pdf
[15] Arquitectura Orientada a Servicios (SOA) – Wikipedia, la enciclopedia libre, http://es.wikipedia.org/wiki/Arquitectura_orientada_a_servicios
[16] Modelo de referencia técnico: Lineamientos para la construcción de aplicaciones (2008). PDVSA, Gerencia de Desarrollo e Implementación de Soluciones.
[17] Simple Acces Object Protocol (SOAP) – DesarrolloWeb, http://www.desarrolloweb.com/articulos/1557.php
[18] Comenzando a utilizar NuSOAP – DesarrolloWeb, http://www.desarrolloweb.com/articulos/1884.php
[19] Object Managing Group. Introduction to UML, http://www.omg.org/UML/

Referencias Bibliográficas
141
[20] Lenguaje Unificado de Modelado (UML) – Wikipedia, la enciclopedia libre, http://es.wikipedia.org/wiki/Lenguaje_Unificado_de_Modelado
[21] PHP - Wikipedia, la enciclopedia libre, http://es.wikipedia.org/wiki/.php [22] Montilva, J. y Barrios, J (2004). BMM: A Business Modelling Method for Information Systems
Development. CLEI Electronic Journal, Vol 7, Nº 2, Paper 3 [23] Porter, M.E.: Competitive Advantage. The Free Press. New York (1985) [24] Cadena de Valor – Wikipedia, la enciclopedia libre,
http://es.wikipedia.org/wiki/Cadena_de_valor [25] Barrios, J. (2007). Diseño de Software: Programas y Componentes. Apuntes de ingeniería del
software [26] Garret, A. (2006). Simple calendar Widget,
http://www.garrett.nildram.co.uk/calendar/scw.htm

Anexo A Planificación del proyecto
142
Anexo A
Planificación del proyecto
Figura A.1 Planificación inicial del proyecto

Anexo A Planificación del proyecto
143
Figura A.2 Revisión de la planificación del proyecto

Anexo B interfaces Usuario/Sistema Versión 1
144
Anexo B
Interfaces Usuario/Sistema Versión 1
Figura B.1 Pantalla de ingreso de incidentes

Anexo B interfaces Usuario/Sistema Versión 1
145
Figura B.2 Pantalla de Verificación de ingreso del incidente
Figura B.3 Consulta de incidentes reportados por período de tiempo

Anexo B interfaces Usuario/Sistema Versión 1
146
Figura B.4 Reporte de incidentes por período de tiempo
Figura B.5 Reporte exportado a una hoja de cálculo

Anexo B interfaces Usuario/Sistema Versión 1
147
Figura B.6 Cálculo de indicadores operativos de la plataforma
Figura B.7 Consulta de incidentes por grupo operativo

Anexo B interfaces Usuario/Sistema Versión 1
148
Figura B.8 Consulta de incidentes por componente
Figura B.9 Consulta de incidentes y soluciones

Anexo B interfaces Usuario/Sistema Versión 1
149
Figura B.10 Pantalla de eliminación de incidente
Figura B.11 Reporte conjunto de incidentes de falla

Anexo B interfaces Usuario/Sistema Versión 1
150
Figura B.12 Ingreso de componentes al inventario AIT
Figura B.13 Consulta de componentes de inventario AIT

Anexo C interfaces Usuario/Sistema Versión 2
151
Anexo C
Interfaces Usuario/Sistema Versión 2
Figura C.1 Pantalla de ingreso de incidentes

Anexo C interfaces Usuario/Sistema Versión 2
152
Figura C.2 Pantalla de Verificación de ingreso del incidente
Figura C.3 Consulta de incidentes reportados por período de tiempo

Anexo C interfaces Usuario/Sistema Versión 2
153
Figura C.4 Reporte de incidentes por período de tiempo
Figura C.5 Reporte de incidentes por grupo operativo

Anexo C interfaces Usuario/Sistema Versión 2
154
Figura C.6 Cálculo de indicadores para un grupo operativo
Figura C.7 Consulta de incidentes por fecha de minuta

Anexo C interfaces Usuario/Sistema Versión 2
155
Figura C.8 Imprimir minuta
Figura C.9 Reporte de incidentes y soluciones

Anexo C interfaces Usuario/Sistema Versión 2
156
Figura C.10 Pantalla de eliminación de incidente
Figura C.11 Consulta de reportes abiertos

Anexo C interfaces Usuario/Sistema Versión 2
157
Figura C.12 Consulta en conjunto de minutas y Nagios
Figura C.13 Consulta de alertas de Nagios por equipo o aplicación

Anexo C interfaces Usuario/Sistema Versión 2
158
Figura C.14 Pantalla de definición de servicio para monitorear aplicación
Figura C.15 Auditoria del sistema
Recommended

















