
Nível de Micro ArquiteturaMelhorando o Desempenho
Referências:
• Structured Computer Organization, A.S. Tanenbaum, (c) 2006 Pearson Education Inc
• Computer Organization and Architecture, W. Stallings, Prentice Hall
Orlando Loquesoutubro 2006
parte 3

� Melhoria na implementação– Não muda a arquitetura; mantém a compatibilidade reversa;
– eg: usar clock mais rápido– Analisar gargalos e tentar reduzi-los
� Melhoria na Arquitetura– Radical: CISC → RISC– Incremental: adicionar novas instruções ou registros
(mantém a compatibilidade reversa)
� Exemplo de Técnicas– Memória cache– Previsão de desvios– Execução fora-de-ordem– Execução especulativa
Melhorando o Desempenho

Cache Memory
A system with three levels of cache.
� Em geral, os conteúdos são unificados L1 ⊂ L2 ⊂ L3� L1 ~ 16KB/64KB� L2 ~ 512KB / 1MB� L3 ~ alguns MB

Direct-Mapped Caches (1)(a) A direct-mapped cache(b) A 32-bit virtual address
Line

Direct-Mapped Caches (2)
� Tag – corresponde aos bits de Tag nas linhasda tabela
� Line – indica que linha da tabela que conterá o dado correspondente, se ele for presente
� Word – informa qual a palavra é requerida nalinha referenciada
� Byte – endereça o byte na palavra, só é usadoquando o acesso por bytes for necessário
endereço virtual de 32-bits

Direct-Mapped Caches (3)
� Valid - indica se a Linha correspondente contém dados válidos – existem2048 (211) linhas
� Tag (16 bits – 64K) - identifica a linha de memória de onde veio o dado� Data – contém a cópia do dado na memória – a linha contém 32 bytes / 8
palavras de 32 bits� Esta cache tem capacidade de 64KBytes (2048 linhas x 25)� Note que regiões com a mesma linha, porém com tags diferentes,
podem provocar superposições na cache
direct-mapped cache
Line
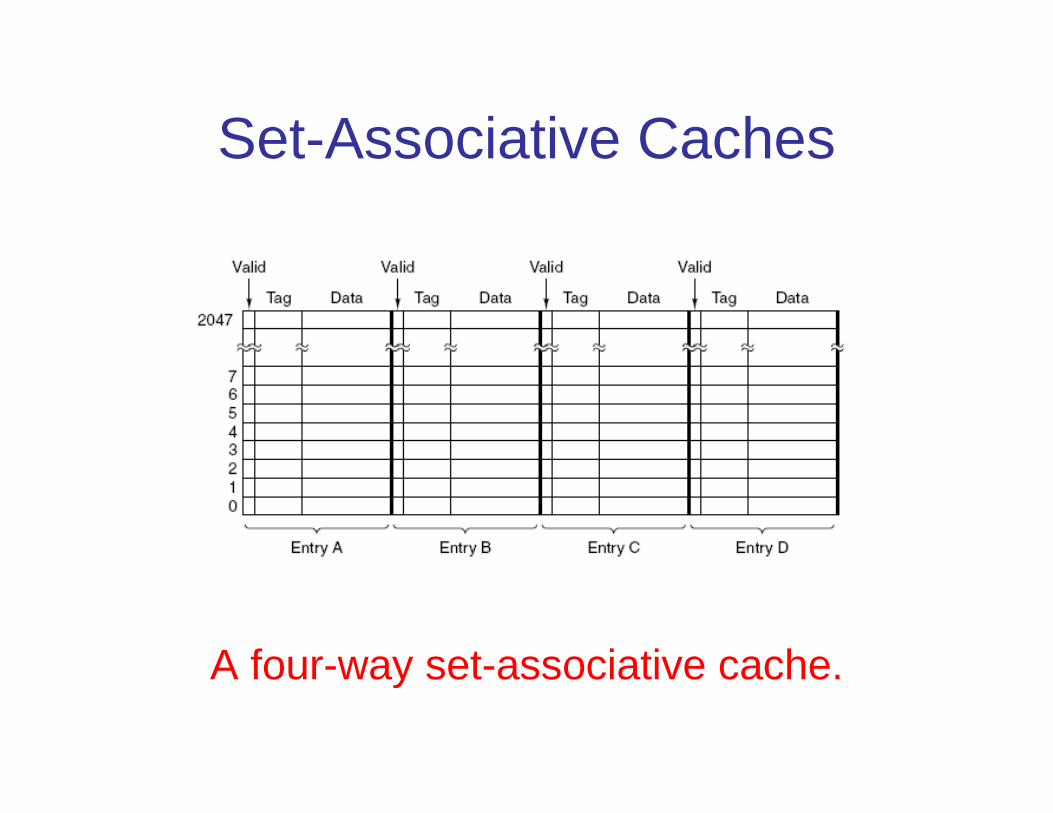
Set-Associative Caches
A four-way set-associative cache.

Set-Associative Caches� Diferentes linhas da memória principal competem pelas fatias da
cache– Por exemplo, se um programa usa intensivamente palavras com
endereços 0 e 65536 conflitos serão frequentes; potencialmente, cada referência pode provocar o despejo da outra da cache
� Uma solução é associar n (duas ou mais) linhas de memória a cadaentrada da cache
� Maior complexidade: a entrada na tabela é selecionadaautomaticamente (Line), mas as (n) tags tem que ser examinadaspara validar o acesso
� Experimentos comprovam que duas ou quatro entradas por linhapermitem eficiência capaz de justificar a complexidade
� Quando uma nova entrada deve ser cacheada, qual a entradapresente a ser descartada?
– Bola de cristal? – LRU (least recently used) – ordena os acessos e descarta o mais
antigo

Set-Associative Caches
� Caso extremo: todas as (2048) entradas de linhas são associativas (line=0)
� O lookup requer comparação de todas as tags (espaço de endereçamento menos campo de WORD e Byte) na cache
� Em caso de substituição qualquer entrada pode ser candidata, tornando LRU inpraticável (a lista tem que ser atualizada em todo acesso)
� Surprendentemente, caches de alta associatividade não melhoram significativamente o rendimento, sendo em alguns casos até pioram. Assim, caches com mais que quatro associações são raras

Cache: Write Issues� Um write requer a atualização da palavra ou sua reti rada da cache
� Quase todo design realiza o update na cache. Contudo , existem diferentes opções para o update da memória principal:
– Update imediato, chamado de write through; é mais con fiável (multiprocessador) e simples de implementar, facilita a recuperação do e stado da memória em caso de erros, mas impõe mais tráfego na barra
– Adiar até que seja necessário a substituição (pela LRU), chamado de write deferredou write back, mais complexo (especialmente no caso de multiprocessador)
� Write em locação não cacheada: o dado deve ser cache ado ou somente escrito na memória principal?
– Write deferred designs tendem a trazer o dado para a c ache, técnica conhecida como write allocation
– Write through designs tendem a não cachear para não co mplicar o projeto basicamente simples
– Write allocation é vantajoso se existirem writes repet idos de palavras dentro de uma mesma linha na cache

Previsão de Desvio - Branch Prediction
(b) tradução em assembler
� Duas das cinco instruções sã desvios, sendo um condicional (BNE)
� A maior seqüência linear tem duas instruções� Em geral, 15 a 20% das instruções podem ser de desvio
– A eficiência do pipeline pode ser altamente prejudicada
(a) programa

Previsão de Desvio - Branch Prediction
� Computadores usam intensivamente pipelines; alguns com mais que 10 estágios
� Pipeline funciona bem com código linear, buscando palavras consecutivas namemória e enviando-as para a unidade de decodificação
� Programas reais contém instruções de desvio, que mesmo sendoincondicionais complicam a situação
� Com pipeline, a busca vem antes da decodificação; assim, somente no próximo ciclo sabe-se que a instrução é de desvio. Contudo, normalmente, a busca da instrução seguinte já foi feita
� A maioria dos computadores executa a instrução seguinte a de desviocondicional (posicionada no chamado delay slot). Compiladores podem tentartornar útil essa instrução ou usar uma NOP
– O Pentium II supera essa questão a custa de circuitos enormementecomplexos

Previsão de Desvio - Branch Prediction
� Desvios condicionais são mais complicados
� Além do delay slot, a unidade de busca só pode conhecer a próximainstrução a ser lida muito mais tarde, depois da decisão
� As máquinas antigas atolavam (stalled, por 3 ou 4 ciclos) até que a decisão fosse conhecida. O estrago podia ser grande, considerando que15 a 20% das instruções podem ser de desvio condicional
� Técnicas de previsão
– Bola de Cristal– Assumir que desvios para tráz serão efetivados e para frente não. Lógica:
muitos desvios são colocados no fim de loops que são executados muitasvezes
– Desvios para frente são mais dificeís de serem aproveitados; eg, ocorrem devido a erros (arquivo inexistente) que são raros. Ou seja, a regra é melhor que nada!

Previsão de Desvio - Branch Prediction
� Execução com previsão correta ou errada:
– Correta: a execução simplesmente continua
– Errada:
1. as instruções são executadas com o uso de registros de rascunho que no final são copiados para registros reais
2. escrever o conteúdo do registro a ser modificado numregistro de rascunho e fazer um roolback se necessário
– As soluções são complexas --- imagine que um segundodesvio possa ocorrer!

Dynamic Branch Prediction (1)
(a) A 1-bit branch history (b) A 2-bit branch history(c) A mapping between branch instruction address and target address.

Dynamic Branch Prediction (2)
� A history table registra os desvios condicionaisconforme eles ocorrem
� A tabela (esquema a) contém endereços de cada instrução de desvio e um bit representando a decisão tomada na execuçãoanterior
� A aposta é que a nova decisão será a mesmada anterior; se a decisão for diferente o bit é alterado
� A tabela é limitada; instruções de desviopodem se sobrepor. Soluções tipo cache associativa podem ser adotadas

Dynamic Branch Prediction (3)
� Problema com o esquema (a): a previsão falhano fim de um loop, provocando nova falha se ele for re-executado; isso pode acontecerfrequentemente em casos comuns: loops aninhados
� O esquema (b) permite uma segunda chance, alterando a tabela somente se a previsãofalhar duas vezes consecutivas
� O esquema (c) contempla instruções quecalculam o desvio através de operaçõesaritméticas – armazena também o resultado do cálculo

Dynamic Branch Prediction (4)
A 2–bit finite–state machine for branch prediction

Static Branch Predictionfor (i=0; i < 100000; i++) { ... }
→ o compilador pode passar para o hardware a informação sobre o desvio
� O UltraSPARC II tem um um segundo conjunto de instruções de desvio (para compatibilidade reversa) que incluem um bit que pode ser setado pelo compilador, de acordo com a previsão de desvio
� A técnica de profiling (execução do programa num simulador visando capturar seu comportamento) também pode ser usada para alimentar o compilador, que então usa as instruções especiais de desvio

Pipeline: Speedup X N_instructions X N_estágios

Arquiteturas Super-escalares
� Implementar a CPU de maneira que mais que uma instrução possa ser executada (completada) em cada momento
� Envolve a replicação de algumas ou de todas as partes da UCPU
� Exemplos:
– Busca várias instruções ao mesmo tempo– Decodifica varias instruções …– Executa adição e multiplicação …– Realiza load/stores em paralelelo com operações na ALU
� O ganho de desempenho (speedup) aumenta aumenta com o paralelismo na execução de instruções

Arquiteturas Superscalares (i)
• Pipeline duplo de cinco estágios, com uma unidade de busca comum
• Conflitos sobre o uso de recursos (eg: registros) e interdependência dos resultados têm que ser evitados: compilação ou durante a execução (com hardware extra)

Arquiteturas Superscalares (ii)
Processador super-escalar com cinco unidades funcionais

Paralelismo: Limitações� Paralelismo de máquina: mede a capacidade do processador aproveitar o
paralelismo a nível de instrução para aumentar o desempenho
– Limitado pelo número de instruções que podem ser buscadas e executadas ao mesmotempo (número de pipelines paralelos) e pelo desempenho e sofistificação dos mecanismos usados para identificar instruções independentes
– O desempenho depende da natureza do programa; contudo, a limitação de paralelismolimita o desempenho de qualquer programa
– O uso de instruções de tamanho fixo (como em RISCs) facilita obter o paralelismo de execução de instrução
� Importante: de qualquer maneira, os resultados da compu tação tem que seros mesmos que seriam obtidos numa execução estritamente seq uencial
– Dependência de dados: duas instruções não podem ser executadas em paralelo se o dado produzido por uma serve como entrada da outra ou se ambas escrevem a mesmalocação de saída
� Tratamento de interrupção de “Instruções” pode ser complicado

Tipos de dependência� Dependência de dados real: duas instruções não podem ser executadas em
paralelo se o dado produzido por uma serve como entrada da outra ou se ambasescrevem a mesma locação de saída
� Consideraqndo:
S1: A = B + C S2: D = A + 1 S3: B = E + FS4: A = E + 3
� Dependência (competição) sobre recursos: na sequência acima, a soma é muito usada; o paralelismo é limitado pelo número de ALUS
� Dependência procedural: as instruções que vêm após o desvio possuem umadependência procedural em relação ao desvio, só podendo ser executadas`após o mesmo
� Outras: veremos adiante!

Ordem de emissão e execução de instruções
� In–order issue, in–order completion–Simples, mas limita o desempenho–Ordenação estrita das instruções: dependencias
de dados e procedimentos retardam todas as instruções subsequentes
–Execução “lenta” de algumas instruções retardamtodas as instruções subsequentes
– Por exemplo, instruções que buscamoperandos na memória

� In-order issue, out-of-order completion– Um certo número de instruções pode ser executado ao mesmo tempo– A emissão de instruções ainda é limitada por conflitos sobre uso de recursos ou
dependências de dados ou procedimentos– Dependências de saida (write-write dependency) resultantes de execuções fora
de ordem têm que ser resolvidas
I1: R3 ← R3 + R5I2: R4 ← R3 + 1 -- I1 depende de I2I3: R3 ← R5 + 1 -- I1 depende de I3 ?I4: R7 ← R3 + R4 -- I4 depende de I3
–
– Tratamento de Interrupção de “Instruções” também pode ser complicado
Ordem de emissão e execução de instruções
I3 tem que completar após I1 (e I2), para garantir a va lidade de R4 e I4; o resultado de I3 pode ser destruído por I1

Ordem de emissão e execução de instruções
� Out-of-order issue, out-of-order completion– Os estágios de decodificação e execução são desacoplados através de um
buffer janela (“window”) de instrução– As instruções decodificadas são armazenadas na janela esperando a hora
da execução– As unidades funcionais retiram as instruções da janela, procurando se
manter ocupadas– Isso pode resultar em execução “out-of-order”
– Dependências tipo “anti-dependência ” (read-write dependency) tambémtêm que ser consideradas
I1: R3 ← R3 + R5I2: R4 ← R3 + 1I3: R3 ← R5 + 1I4: R7 ← R3 + R4
– I3 escreve R3 que é também usado por I2, assim I3 não pode ser executadoantes de I2 (é o contrário da dependência real, onde a segunda instruçãousa o resultado da primeira)

Superscalar Instruction Issue and Completion Policies
I1 – requer 2 ciclos de execuçãoI3 e I4 – competem pela mesma unidade funcionalI5 – depende do valor produzido por I4I5 e I6 – competem por uma unidade funcional

Dependências
� Dependência Real: a segunda instrução usaum resultado da primeira
� Dependência de saída (output or write-write dependency): o resultado da segundainstrução pode ser destruído pelo da primeira
� Anti–dependência (read-write dependency): a segunda instrução destrói um valor que a primeira usa (é o contrário da dependênciareal)

� Dependências de saída (output dependency) e anti-dependências são eliminadas usando registros extras (alocados de um “pool” de registros)
– Para cada instrução que escreve num registro X, um “novo” registro X é alocado
– Multiplos “registros Xs” podem co-existir
� Considerando:
S1: R3 = R3 + R5S2: R4 = R3 + 1S3: R3 = R5 + 1S4: R7 = R3 + R4
� Renomeação:
S1: R3b = R3a + R5aS2: R4b = R3b + 1S3: R3c = R5a + 1S4: R7b = R3c + R4b
Register renaming – Renomeação de Registros
Anti-dependência (read-write dependency): a segunda instrução destrói um valor que a primeira usa (é o contrário da dependênciareal)
Dependência de saída (write-write dependency): o resultado da segunda instrução pode ser destruídopelo da primeira
Registros extras evitam as dependências; No final, os conteúdos têm que ser compatibilizados

Impactos: Out-of-order issue, out-of-order completion
� Adicionar unidades funcionais sem suportar renomeação de registros pode ser ineficaz em termos de custo-benefício
–O desempenho será limitado pelas dependências de dados
� O uso de janelas grandes de buffers é benéfico
–Facilita as unidades funcionais acharem instruções prontas para serem executadas

Execução Especulativa (i)
Programa Blocos correspondentes
→ as instruções de soma (lentas, porque evensum e oddsum estãoem memória) podem ser posicionadas acima do if, e executadasem paralelo; só um dos resultados será aproveitado

Execução Especulativa (ii)
� Requer cooperação entre o hardware e o software. O hardware não vê blocos explicitamente: o compilador tem que mover as instruções explicitamente
� Essa movimentação não pode causar efeitos irrevogáveis: usar re-nomeação de registros
� Exceções causadas por instruções especulativas? eg, LOAD, com falta de cacheou de memória virtual!
– Instrução especial (SPECULATIVE_LOAD) que pode ser abortada; quando os resultados forem realmemtenecessários a instrução é então executada

Execução Especulativa (iii)
� Considere: if (x>0) z=y/x
–Adiantando a execução de z=y/x, pode causarum erro se x=0
� A especulação causou um erro num programacorreto!
� Solução: registro com “poison bit”; marcam queo resultado é provisório, indicando que o errosó vai ser considerado se o registro for usado

Overview of the NetBurst Microarchitecture

Pentium 4 NetBurstPipeline
A simplified view of the data path

The Microarchitecture of the 8051 CPU



Recommended

![Martim Apresentação.pptx [Só de leitura] › ... › 2018 › ...Apresentacao.pdf · Microsoft PowerPoint - Martim_Apresentação.pptx [Só de leitura] Author: mcosta](https://img.document.onl/doc/110x75/5f0f21a97e708231d442a503/martim-apresentaffopptx-sf-de-leitura-a-a-2018-a-apresentacaopdf.jpg)


![1ª Sà RIE - LITERATURA BRASILEIRA - ARCADISMO - …...Title: Microsoft PowerPoint - 1ª Sà RIE - LITERATURA BRASILEIRA - ARCADISMO - continua - ROMERO - OK [Modo de Compatibilidade]](https://img.document.onl/doc/110x75/601c4480bd3db4031a4c500a/1-sf-rie-literatura-brasileira-arcadismo-title-microsoft-powerpoint.jpg)
![2ª Sà RIE - BIOLOGIA - REINO PLANTAE - …...Microsoft PowerPoint - 2ª Sà RIE - BIOLOGIA - REINO PLANTAE - THARCIO - OK [Modo de Compatibilidade] Author Estudio Created Date](https://img.document.onl/doc/110x75/5f0f13517e708231d4425e47/2-sf-rie-biologia-reino-plantae-microsoft-powerpoint-2-sf.jpg)




![Zonas costeiras e zonas de vertente [Só de leitura].pdf](https://img.document.onl/doc/110x75/55cf91a4550346f57b8f3131/zonas-costeiras-e-zonas-de-vertente-sa-de-leiturapdf.jpg)






