Embed Size (px)
DESCRIPTION
Apostila de SQL Server 2005
Citation preview

Apostila de MS SQL Server Pág.: 1 / 86
Conceitos
O que é um Banco de Dados?Em termos simples, um banco de dados é uma coleção de dados, onde os dados são armazenados em tabelas. Alguns gostam de pensar em um banco de dados como um mecanismo organizado que tem a capacidade de armazenar informações, pela qual um usuário pode recuperar as informações armazenadas de uma amaneira eficaz e eficiente.
Um banco de dados relacional é um banco de dados dividido em unidades lógicas chamadas tabelas, em que as tabelas são relacionadas entre si dentro do banco de dados. Um banco de dados relacional permite dividir os dados em unidades lógicas menores, mais gerenciáveis, oferecendo melhor e mais fácil manutenção e desempenho ótimo do banco de dados de acordo com o nível de organização.
O Que é SQL?SQL (Structured Query Language) é a linguagem padrão utilizado para comunicar-se com um banco de dados relacional. O protótipo original foi desenvolvido pela IBM utilizando o artigo do Dr. E. F. Codd (“A Relational Modelo of Data for Large Shared Data Banks”) Modelo Relacional de Informações de Dados para Grandes Bancos de Dados Compartilhados.
Visão geral do Transact-SQLTransact-SQL é a linguagem do SQL Server para definição, consulta e manipulação de dados. Essa linguagem é baseada no padrão ANSI SQL-92, também suportado por outros bancos de dados, e acrescenta extensões ao padrão ANSI, exclusivas do SQL Server. SQL é a sigla de estruture Query Language, embora ela faça bem mais do que consulta.
Os comandos Transact-SQL podem ser divididos nas seguintes categorias (note que isso não abrange todos os comandos, só os comuns que serão utilizados nesse curso):
DLL, DML, Comandos Select e DCL
ANSI SQLSignifica American National Standards Institute, uma organização que é responsável por planejar padrões para vários produtos e conceitos. No caso do SQL, isso fornece um esqueleto básico de fundamentos básicos necessários, que como um resultado final, permite consistência entre várias implementações. Com a linguagem SQL podemos nos comunicar com qualquer banco de dados que trabalhe com o sistema (RDBMS), afinal, se tivéssemos uma linguagem para cada banco de dados, ficaria difícil a comunicação e até mesmo a migração desses dados entre bancos de dados.
Exemplo, imagine que cada país fosse um banco de dados, logo, cada país tem uma língua nativa, dificultando então a comunicação entre eles, com isso, teríamos que aprender cada língua desses países. Assim como o inglês que é uma língua de comunicação universal, o SQL é a língua universal de comunicação entre banco de dados relacional, tornando mais fácil a comunicação entre os usuários e aplicativos com o banco de dados. Sessões de SQL

Pág.: 2 / 86 Apostila de MS SQL Server
É uma ocorrência de um usuário que interage com um banco de dados relacional por meio da utilização de comandos de SQL. Comandos válidos de uma sessão SQL podem ser inseridos para consultar o banco de dados, manipular dados e definir estruturas do banco de dados, como tabelas.
Quando um usuário conecta-se a um banco de dados, a sessão de SQL é inicializada.
Sistemas Gerenciadores de Banco de Dados
O acesso a informações em sistemas em sistemas de processamentos de dados que não utiliza Sistemas Gerenciadores de Bancos de Dados (SGBDs), é feito pelo acesso seqüencial a um ou mais arquivos. Cabe ao desenvolvedor criar mecanismo de recuperação da informação. Com a utilização de um SGBD, porém, o acesso fica diferente: pede-se as informações ao gerenciador de banco de dados e elas são devolvidas pelo mesmo.
O processo pode ser comparado a uma compra em uma loja de departamento e uma compra em uma loja de autopeças, no primeiro caso o cliente dirige-se a loja e procura por todas as seções, encontra o produto desejado e efetua a compra. Já na segunda o cliente pede o ao balconista o item desejado e este entrega-o.No caso da compra em loja de departamentos o trabalho é toda do cliente, sendo este responsável inclusive pelas especificações necessárias (fazer a escolha certa). Já na loja de auto peças, o balconista assume toda a responsabilidade pela entrega da mercadoria desejada.
Arquitetura Cliente-ServidorO SQL Server é um banco de dados relacional, destinado a ser compatível com aplicações que apresentam arquitetura Cliente/Servidor, no qual o banco de dados fica residente em um computador central chamado Servidor e cujas informações são compartilhados por diversos usuários que executam as aplicações em seus computadores locais ou clientes.
A arquitetura Cliente/Servidor reduz consideravelmente o tráfego de rede, pois retorna ao usuário apenas os dados solicitados.

Apostila de MS SQL Server Pág.: 3 / 86
Arquitetura do SQL Server
O Banco de dados SQL Server é dividido em diversos componentes lógicos, como tabelas, índices, visões e outros componentes visíveis para o usuário.
Um servidor SQL Server pode conter vários bancos de dados pertencentes a diversos usuários.
Cada instância de um SQL Server 2005 possui quatro bancos de dados de sistema (System Databases) chamados master, model, tempdb e msdb. Cada um desses bancos de dados é exigido pelo SQL Server e não pode ser renomeado e nem removido sem antes desativar o SQL Server. Os dois outros bancos de dados que são criados o pubs e northwind, são bancos de dados de usuário e são bancos de dados de exemplo e podem ser removidos sem afetar as operações do SQL Server.
Embora ambos os tipos de bancos de dados (Sistema e Usuário) armazenem dados, o SQL Server utiliza os bancos de Sistema para operar e gerenciar o sistema.
Master É o banco de dados principal de configuração do SQL Server. Ele contém informações em todos os bancos de dados que existe no servidor, incluindo os arquivos de banco de dados físico e suas localizações, também contém as definições de configuração e contas de login do SQL Server. Informações contidas no Banco de Dados Master:
• Registro de servidor e logins remotos,• Bancos de dados e arquivos de banco de dados locais,• Contas de logins,• Processos e trancaduras,• Definição de configurações de servidor.
Com estas informações, é valido dizer que um backup atual do banco de dados master é crucial para qualquer recuperação do servidor.
R

Pág.: 4 / 86 Apostila de MS SQL Server
O processo de instalação cria o banco de dados master (master.mdf) e o arquivo de log do banco de dados master (masterlog.ldf) no diretório do C:\Arquivos de programas\Microsoft SQL Server\MSSQL\Data. No caso de um banco de dados master ser corrompido ou destruído e não puder ser restaurado do backup, você poderá reconstruir o banco de dados master no seu estado padrão, a Microsoft fornece um utilitário chamado rebuildm.exe, que esta localizada no subdiretório C: \Arquivos de programas\Microsoft SQL Server\80\Tools\Binn.
Após reconstruir o banco de dados master, você terá que fazer manualmente qualquer alteração de configuração e registro de banco de dados e servidor, além de recriar os logins para restaurar o servidor no seu estado anterior.
Tempdb
O Banco de dados Tempdb é usado para o armazenamento de tabelas temporárias e stored procedures temporários.
O banco de dados Tempdb é recriado toda vez que o SQLServer for iniciado, então o Tempdb não poderia ser usado para o armazenamento de dados persistente. As tabelas e as procedures temporárias que são geradas pelo SQL Server são soltas automaticamente quando as conexões são fechadas. Por isso se não houver atividade de conexão, o Tempdb fica vazio, todos os bancos de dados e processos no SQL Server compartilham o Tempdb para gravação de trabalhos. O arquivo de banco de dados Tempdb (tempdb.mdf) e os arquivos de log (templog.ldf) estão no diretório C:\Arquivos de programas\Microsoft SQL Server\MSSQL\Data.
Msdb
É um banco de dados do sistema que é utilizado por vários componentes do SQL Server, como o serviço do SQL Server Agent. Além da configuração do SQL Server Agent e das informações sobre a tarefa, a replicação, o envio de log e os dados de plano de manutenção são armazenados no banco de dados Msdb.
Informações contidas no banco de dados Msdb:
• Informações sobre o plano de manutenção do banco de dados, como função e histórico do plano de manutenção.• Informações sobre os publicadores e os distribuidores de replicação.• Informação sobre a configuração do envio de log e monitoramento.
O arquivo de banco de dados msdb (msdb.mdf) e os arquivos de log do Msdb (msdb.ldf) estão localizados no diretório C:\Arquivos de programas\Microsoft SQL Server\MSSQL\Data. Devido à quantidade de informações sobre configuração armazenadas no Msdb, o backup do banco de dados é recomendado rotineiramente. Se o banco de dados Msdb for corrompido, você poderá reconstruir um Msdb padrão usando um script de construção do SQL Server instalado no processo de instalação. O filename do script de instalação do Msdb é instmsdb.sql e esta localizado no diretório C:\Arquivos de programas\Microsoft SQL Server\MSSQL\Install.
Se o banco de dados Msdb não existir, o script o criará primeiro e, em seguida construirá todos os objetos de banco de dados necessários, depois você poderá ter que reconfigurar todas as funções de programação, planos de manutenção, envio de log e configuração de replicação.

Apostila de MS SQL Server Pág.: 5 / 86
Model
É um banco de dados template que o SQL Server usa para criar novos bancos de dados. Cada vez que você cria um banco de dados novo no SQL Server, o conteúdo do banco de dados Model é copiado para dentro do novo banco de dados para estabelecer seus objetos padrões, incluindo tabelas, stored procedures e outros objetos de banco de dados. O banco de dados é necessário mesmo que você não pretenda criar nenhum banco de dados de usuário. Cada vez que o SQL Server é iniciado, o banco de dados Tempdb é recriado usando o Banco de dados Model como seu template. Por padrão o banco de dados encontra-se vazio ao ser criado. O arquivo de banco de dados Model (model.mdf) e os arquivos de log do banco de dados Model (modellog.ldf) são criados no diretório C:\Arquivos de programas\Microsoft SQL Server\MSSQL\Data, durante o processo de instalação.
Localização dos Bancos de dadosOs bancos de dados ficam armazenados em arquivos físicos que recebem o nome de DEVICE. Um device ocupa sempre a quantidade de disco que for a ele destinada, independente da existência ou não de banco de dados em seu interior e independente da taxa de ocupação destes databases.
Arquitetura de Armazenamento FísicoOs Bancos de dados SQL Server são armazenados em grupos de arquivos que contem dados individuais e arquivos de log, cada banco de dados é feito de arquivos de dados principal e, opcionalmente, de secundários, assim como arquivos de log. Estes arquivos são identificados por suas extensões padrão de arquivos, arquivo de dados principal (*,mdf) e arquivo de log (*.ldf). O arquivo de log e de dados podem ser armazenados em qualquer unidade não comprimida FAT e NTFS.
Com exceção dos arquivos de log, os dados no arquivos do SQL Server são gravados em unidades chamadas paginas. Cada Pagina armazena 8k de dados permitindo um Maximo de 8060 bytes em cada pagina (96bytes são usados para cada cabeçalho de pagina).
Devido ao limite de dados de pagina de 8060 bytes, o tamanho Maximo de registro também é de 8060 bytes, que inclui todos os tipos de dados, exceto ntext, text e dados de imagem. Text, ntext e dados de imagem são gravados em uma coleção de páginas separadas que permitem até 2GB de informações por item de dados. Um ponteiro para estas paginas de dados é gravado com o registro fonte.

Pág.: 6 / 86 Apostila de MS SQL Server
Trabalhando com Grupos de ArquivosCom grupos de arquivos é permitido explicitamente a colocação de objetos de banco de dados sobre um conjunto específico de arquivos de banco de dados. Isso pode ser útil para administração assim como para o desempenho, você pode colocar o grupo de arquivos sobre unidades físicas de disco separadas e depois colocar os objetos do banco de dados sobre os arquivos que são membros desse grupo de arquivos. Isso pode melhorar o desempenho por que leituras e gravações no banco de dados executam em unidades físicas de disco separadas ao mesmo tempo. Uma vantagem administrativa é que pode ser feito o backup e restaurar arquivos individuais em um grupo de arquivos.
Os grupos de arquivos são criados quando se altera o banco de dados e adiciona-se arquivos a um grupo de arquivos específico.
Criando Banco de Dados ( Primeiro Projeto )
CREATE DATABASE Praticando_SQL ON PRIMARY(
NAME = 'Praticando_SQL', FILENAME = 'D:\Laerte\BD\Praticando_SQL.mdf' , SIZE = 10MB , MAXSIZE = 100MB , FILEGROWTH = 5MBKB
)
LOG ON (
NAME = 'Praticando SQL_log', FILENAME = 'D:\Laerte\BD\Praticando SQL_log.ldf' , SIZE = 5MB , MAXSIZE = 50MB , FILEGROWTH = 5MB
)
Alterando Banco de DadosPara alterar o banco de dados usamos o comando ALTER DATABASE, podemos modificar o nome do banco de dados Praticando_SQL para Praticando_SQL_Server.
ALTER DATABASE Praticando_SQLMODIFY NAME = Praticando_SQL_Server
Adicionando FileGroup ao Banco de Dados
ALTER DATABASE Praticando_SQL_Server ADD FILEGROUP SECUNDARY
Adicionando mais Arquivos de Dados ao Banco de Dados

Apostila de MS SQL Server Pág.: 7 / 86
ALTER DATABASE Praticando_SQL_Server ADD FILE
(NAME = Praticando_SQL_Server2,FILENAME = 'D:\Alunos\Laerte\BD2\Praticando_SQL_Server.ndf',SIZE = 5MB,MAXSIZE = 50MB,FILEGROWTH = 5MB)
TO FILEGROUP SECUNDARY
Excluindo Arquivos de Dados ao Banco de Dados
ALTER DATABASE Praticando_SQL_Server REMOVE FILE Praticando_SQL_Server2
Excluindo FileGroup do Banco de Dados
ALTER DATABASE Praticando_SQL_Server REMOVE FILEGROUP SECUNDARY
Excluindo o Banco de DadosDROP DATABASE Praticando_SQL_Server

Pág.: 8 / 86 Apostila de MS SQL Server
Criando o Banco de Dados com Wizard (Segundo Projeto)
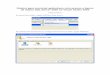
O caminho mais rápido para Se criar um novo branco do banco de dados Utilizando Microsoft SQL Server Management Studio Express é fazer um clique direito sobre o Databases e em seguida escolher a opção “New Database...” , como mostrado na imagem abaixo.
Surgira então a Caixa de Dialgo New Database, que veremos logo a seguir.

Apostila de MS SQL Server Pág.: 9 / 86
O primeiro passo do assistente apresenta o quadro a baixo figura - .
figura - Caixa de Dialgo New Database
Tabela de Definições para Caixa de Dialgo New DatabasePropriedade DefiniçãoLogical Name Nome da base de dados. Referenciado em conexões.File Type Tipo de dados armazenado. Dados ou Log de operações.File Group Grupo a que pertence o arquivo, identificado por um endereço físico.Initial Size Tamanho inicial do arquivo de dados. Apartir de MB.
AutogrowthConforme demosntrado na caixa de dialogo “Change Autogrowth for Banco_Curso”, define parâmetros que determinarão a forma em que os arquivos de dados irão se expandir.
Path Endereço (diretório) onde são armazenados os arquivos de dados.
File Name Nome do arquivo de dados, com sufixo .MDF para arquivo de dados e .LGF para arquivo de log.

Pág.: 10 / 86 Apostila de MS SQL Server
Caixa de Dialgo Change Autogrowth
Propriedade DefiniçãoEnabled Autogrowth Habilita ou não crescimento automático, baseado em parâmetros.File Growth Define crescimento em percentual ou Megabytes.
Maximum File Size Restinge crescimento da área em Megabytes ou permite crescimento indeterminado.
Tabela de Definições para Caixa de Dialgo Change Autogrowth
Vamos Preencher com os valore inseridos conforme a figura – e quando pronto clicar no botão “OK”, ai estara criado o nosso “BD_(Nome do Aluno)_SQL”.

Apostila de MS SQL Server Pág.: 11 / 86
Criando Group File’s com Wizard
Criando um FileGroup’s 1/2
Criando um FileGroup’s 2/2

Pág.: 12 / 86 Apostila de MS SQL Server
Adicionando Arquivos (File) de Dados ao Banco de Dados com Wizard

Apostila de MS SQL Server Pág.: 13 / 86
Estrutura da Linguagem SQL
A linguagem SQL é dividida em subconjuntos de acordo com as operações que queremos efetuar sobre um banco de dados. Neste curso aprenderemos apenas sobre os dois primeiros subconjuntos, mas é importante que o estudante tenha uma noção geral dos subconjuntos básicos.
Tipos de Comandos de SQL
Linguagem de definição de dados (DDL, Data Definition Language)
É um conjunto de comandos dentro da SQL usada para a definição das estruturas de dados, fornecendo as instruções que permitem a criação, modificação e remoção das tabelas, assim como criação de índices. Estas instruções SQL permitem definir a estrutura de uma base de dados, incluindo as linhas, colunas, tabelas, índices, e outros metadados.
Entre os principais comandos DDL estão CREATE (Criar), DROP (deletar) e ALTER (alterar).
Linguagem de manipulação de dados (DML, Data Manipulation Language)
é o grupo de comandos dentro da linguagem SQL utilizado para manipular dados dentro de objetos de um banco de dados relacional: recuperação, inclusão, remoção e modificação de informações em bancos de dados.
Os principais comandos DML são SELECT (Seleção de Dados), INSERT (Inserção de Dados), UPDATE (Atualização de Dados) e DELETE (Exclusão de Dados).
Linguagem de controle de dados (DCL, Data Control Language)
é o grupo de comandos que permitem ao administrador de banco de dados controlar o acesso aos dados deste banco. Alguns exemplos de comandos DCL são:
• GRANT: Permite dar permissões a um ou mais usuários e determinar as regras para tarefas determinadas;
• REVOKE: Revoga permissões dadas por um GRANT.
As tarefas básicas que podemos conceder ou barrar permissões são:
• CONNECT
• SELECT
• INSERT
• UPDATE
• DELETE
• USAGE

Pág.: 14 / 86 Apostila de MS SQL Server
Comandos de Administração de DadosPermitem ao usuário realizar auditorias e realizar análises em operações dentro do banco de dados, são dois comandos gerais de administração de dados:
START AUDITSTOP AUDIT
Comandos de Controle TransacionalPermitem ao usuário gerenciar transações dentro de banco de dados.
Comando DefiniçãoCommit Salvar transações dentro do banco de dados.RollBack Desfaz transações dentro do banco de dados.
SavePoint Cria pontos dentro de grupos de transações até que eles desfaçam as transações com rollback ou salvar com commit.
Set Transaction Atribui um nome em uma transação.

Apostila de MS SQL Server Pág.: 15 / 86
Procedimentos Armazenados do SistemaUm procedimento armazenado [stored procedure] é uma seqüência de comandos da linguagem Transact-SQL, compilados e armazenados num banco de dados. Os procedimentos armazenados do sistema [system stored procedures] são fornecidos pelo SQL Server, armazenados no banco de dados Máster e automatizam várias tarefas comuns de gerenciamento.Por Exemplo, o procedimento sp_databases mostra quais os nomes de bancos de dados existentes.
Exemplos de estored procedures armazenados:
• sp_databases – mostra quais os nomes de bancos de dados existente.• sp_helpdb aula – mostra informações sobre o banco de dados aula.
Note que todos os procedimentos armazenados do sistema têm nomes que começam com ‘sp_’ (abreviatura de System Procedures). Ao executar um procedimento que inicie com ‘sp_’ o procedimento sera procurado no banco de dados atual, se não for encontrado ele será procurado no banco de dados Máster.
Quando um procedimento inicia com ‘xp_’ ele é um procedimento estendido, quer dizer que não foi escrito em SQL, mas foi compilado como parte de uma DLL.
Exemplo: xp_cmdshell ‘calc.exe’

Pág.: 16 / 86 Apostila de MS SQL Server
Tabelas
Entidades, Relacionamentos e Atributos
Quanto mais organizadas estiverem as informações no Banco de dados, mais forte será a “Conversa” com o Gerenciador de Banco de Dados. Para Isso criou-se um modelo chamado de Modelo de Entidade e Relacionamentos, do qual fazem parte três elementos:
Entidades: Uma entidade é um objeto de interesse do qual podem ser colecionadas informações. Ex: Tabelas de clientes, Tabela de pedidos de clientes.
Relacionamentos: As entidades podem ser relacionadas entre si pelos relacionamentos.Ex: Entidade de Clientes e Entidade de Pedidos (“clientes fazem pedidos”).
Atributos: São as características das entidades. São representadas pelas colunas das tabelas. Ex: nome, endereço, telefone e etc.
Componentes de uma Tabela
O armazenamento e a manutenção de dados valiosos é a razão para a existência de qualquer banco de dados. Lembre-se de que uma tabela é a forma mais simples de armazenamento de dados em um banco de dados relacional.A seguir os componentes de uma tabela:
Campo: É uma coluna em uma tabela que é projetada para manter informações específicas sobre cada registro na tabela. Ex:
ID_CLIENTE NOME ENDEREÇO TELEFONE
Registro ou Linha de dados: É cada entrada individual que existe em uma tabela. Ex:
ID_CLIENTE NOME ENDEREÇO TELEFONE20003 João da Silva R. Conde Pameira 3333-323520004 Marcos Pereira R. Paula Frontes 2522-8589
Coluna: É uma entidade vertical em uma tabela que contém todas as informações associadas com um campo específico em uma tabela. Ex:
ID_CLIENTE200032000420005

Apostila de MS SQL Server Pág.: 17 / 86
Criando Tabelas Uma tabela [table] é um objeto do banco de dados, composto de zero ou mais linhas [rows], contendo os dados, organizados em uma ou mais colunas [columns]. Para criar a tabela você pode usar o Enterprise Manager ou utilizando comandos SQL DDL (Data Definition Language ) no SQL Query Analyzer. Antes de criar suas tabelas, é importante levar em conta um bom projeto do banco de dados, que determina quais as informações a serem guardadas.
Tipos de DadosCada coluna tem um tipo de dados [data type], que determina que tipo de informações (caracteres, números, datas/horas) podem ser colocadas nas colunas e quais as características desses dados. O tipo de dados é determinado quando a tabela é criada e não pode ser alterado posteriormente. Você pode usar tipo de dados do sistema, predefinidos, ou criar novos tipos de dados, chamados tipo de dados do usuário baseados nos tipos de dados existentes.
Os tipos de dados existentes são:
Tipo Definição Tamanho
Char(n), Caracteres Alpha Numéricos – Posição Fixa Até 4.000Varchar(n) Caracteres Alpha Numéricos – Posição Não Fixa Até 4.000
Decimal(p,e) Caracteres Numéricos com definiçao de precisão e escala Até (38,38)
numeric(p,e) Caracteres Numéricos com definiçao de precisão e escala Até (38,38)
BigInt Caracteres Numéricos Inteiros de 8 bytes –2^63 a 2^63-1Int Caracteres Numéricos Inteiros de 4 bytes –2^17 a 2^17-1SmallInt Caracteres Numéricos Inteiros de 2 bytes –2^14 a 2^14 -1TinyInt Caracteres Numéricos Inteiros de 1 byte –2^7 a 2^7 -1
Real Caracteres Numéricos de Ponto Flutuante de 8 bytes 15 digitos
Money Caracteres Numéricos de 4 Casas Decimais de 8 bytes –2^63 a 2^63-1
Smallmoney Caracteres Numéricos de 4 Casas Decimais de 4 bytes –2^17 a 2^17-1
Datetime Caracteres de Data e Hora de 4 bytes January 1, 1753-December 31, 9999
Smalldatetime Caracteres de Data e Hora de 2 bytes January 1, 1900, through June 6, 2079
Binary(n) Tipos de Dados Binários de tamanho Fixo de bytes de n. n deve ser um valor de 1 a 8000
Bytes n+4
varbinary(n) Tipos de Dados Binários de tamanho variável de bytes de n. n deve ser um valor de 1 a 8000
Comprimento real dos dados + 4 bytes, não bytes de n
Imagem Tipos de Dados Binários de tamanho variável 2^31-1Text, Caracteres Alpha Numéricos de tamanho variável 2^30-1Bit Caracteres Numéricos de 1 bit 0-1

Pág.: 18 / 86 Apostila de MS SQL Server
Criando Tabelas do Projeto de Aula
Tabela de ClientesCREATE TABLE Clientes(
ID_Cliente Bigint NOT NULL,Nome varchar (50) NOT NULL,Cnpj char (25) NOT NULL,Tipo char (1) NOT NULL,Status Bigint NOT NULL,Data datetime NOT NULL,Credito money NULL
)
Criando a Tabela de Produtos
CREATE TABLE Produtos(
ID_Produto Bigint NOT NULL ,Descricao varchar (25) NOT NULL ,PrecoCompra money NOT NULL ,Saldo Bigint NOT NULL
)
Criando a Tabela de Pedidos no Filegropes Secundary
CREATE TABLE Pedidos(
ID_Pedido Bigint NOT NULL ,ID_Cliente Bigint NOT NULL ,DataPed datetime NOT NULL
) On SECUNDARY

Apostila de MS SQL Server Pág.: 19 / 86
Criando a Tabela de Itens no Filegropes Secundary utilizando Wizard
Acione com o botão direito do mouse na caixa de dialogo Object Explore, clicando em New Table. Logo em seguida pode ser definido aspectos como nome da tabela, local de armazenamento e a qual esquema pertence. Para tanto, observe a caixa de dialogo Properties.
CREATE TABLE Itens(
ID_Pedido Bigint NOT NULL,ID_Produto Bigint NOT NULL,Quantidade Bigint NOT NULL,PrecoVenda money NOT NULL
) On SECUNDARY
Área de Trabalho – Create Table
Nota 01:Observe a tabela de tipos pagina 17, anteriormente exibida nessa apostila visando conhecer os vários tipos possíveis para cada coluna da tabela.
Nota 02:Ao final, ainda não sendo definido o nome da tabela, será solicitado conforme caixa de dialogo

Pág.: 20 / 86 Apostila de MS SQL Server
Choose Name.
Nota 03:Nessa etapa podemo definir a Chave-Primária da tabela, bastando somente definir (selecionar usando a tecla shift) as colunas que irão compor essa chave, e com o botão direito do mouse optar por Set Primary Key.
Caixa de Dialogo Choose Name

Apostila de MS SQL Server Pág.: 21 / 86
Constraints
Chave Primária [Primary Key]
A chave primaria [primary key] de uma tabela é uma coluna ou seqüência de colunas que identificam unicamente uma linha dentro da tabela, ou seja, seu valor não pode ser repetido para outras linhas. Ao definir uma chave primária, automaticamente é criado um índice na tabela. Só pode haver uma chave primária na tabela.Na criação da tabela, essa restrição pode ser definida da seguinte forma (quando a chave primária é composta de uma só coluna):
Definindo Primary Key (Chave Primária) na criação da tabela
CREATE TABLE Clientes2 (
ID_CLIENTE bigint not null identity (1,1) primary key,NOME varchar (50) not null,CNPJ char (18) not null,TIPO char (1) not null,STATUS bit not null,DATA_CADASTRO datetime not null,HISTORICO Text,CREDITO money,
)
Obs.: Uma chave primária pode ser acrescentada à tabela depois que ela foi criada com o comando ALTER TABLE. Por exemplo, vamos criar chaves primárias à tabela clientes de duas maneiras distintas:
1ª Maneira:ALTER TABLE Clientes add primary key (id_cliente)
2ª Maneira:ALTER TABLE Clientes add constraint PK_Clientes primary key (id_cliente)
Utilizando o Wizard para definir “Primary Key”.
No Enterprise Manager, podemos facilmente definir a Primary Key, clicando com o botão direito sobre a

Pág.: 22 / 86 Apostila de MS SQL Server
tabela e na caixa de dialogo escolher a opção “Desing”, em ai selecionando as linhas (que representam coluna), clicando em seguida com o botão direito do mouse e escolhendo no menu de contexto a opção “Set Primary Key”.
Pronto esta setado a coluna “ID_Cliente” como Primary Key!

Apostila de MS SQL Server Pág.: 23 / 86
Criando Chave Primária para as Tabelas do Projeto
ALTER TABLE Produtos add constraint PK_Produtos primary key (id_produto)ALTER TABLE Pedidos add constraint PK_Pedidos primary key (id_pedido)ALTER TABLE Itens_Pedidos add constraint PK_Itens primary key (Id_Pedido , Id_Produto)
Unicidade [Unique]
Uma restrição unique em uma coluna ou grupo colunas determina que seu valor deva ser único na tabela. Esse tipo de restrição é usado para chaves alternadas, ou seja, valores que se repetem na tabela além da chave primária. Pode haver várias restrições UNIQUE na tabela e as colunas de uma restrição UNIQUE permitem valores nulos. Repare na sintaxe:
ALTER TABLE Clientes ADD UNIQUE (CNPJ)
Chave Estrangeira [Foreign Key]
Uma forma importante de integridade no banco de dados é a integridade referencial, que é a verificação de integridade feita entre duas tabelas. Por exemplo, a tabela ‘dbo.itens’ será usada para relacionar dados de produtos e pedidos. Ela contém as colunas ID_PRODUTO e ID_PEDIDO. Uma chave estrangeira é uma restrição de integridade referencial. Ela consiste de uma coluna ou grupo de colunas cujo valor deve coincidir com valores de outra tabela. No nosso caso, vamos adicionar duas chaves estrangeiras na tabela ‘dbo.itens’: ID_PEDIDO faz referencia a coluna ID_PEDIDO da tabela dbo.pedidos e ID_PRODUTO que faz referência à coluna ID_PRODUTO da tabela dbo.produtos e uma chave estrangeira na tabela ‘dbo.pedidos’: ID_CLIENTE que faz referencia a coluna ID_CLIENTE da tabela ‘dbo.clientes’, como seguem abaixo:
ALTER TABLE pedidos ADD CONSTRAINT fk_pedidos_clientes FOREIGN KEY (id_cliente) References clientes (id_cliente)
ALTER TABLE Itens ADD CONSTRAINT fk_itens_pedidosFOREIGN KEY (id_pedido) References pedidos (id_pedido)
ALTER TABLE Itens ADD CONSTRAINT fk_itens_produtosFOREIGN KEY (id_produto) References produtos (id_produto)
Para excluir uma restrição, é preciso saber o seu nome. Se você não informou o nome na criação, terá que descobri-lo, o que pode ser feito usando-se:
sp_help 'dbo.clientes2'
Esse comando mostra informações sobre a tabela, inclusive os nomes de cada restrição. Para excluir, usa-se ALTER TABLE, com a opção DROP (independente do tipo de restrição).

Pág.: 24 / 86 Apostila de MS SQL Server
ALTER TABLE clientes DROP CONSTRAINT nome_da_restrição
Uma restrição também pode ser desabilitada temporariamente e depois reabilitada com o comando ALTER TABLE, usando as opções NOCHECK (para desabilitar) e CHECK (para habilitar). Isso não funciona com primary key, unique ou default, apenas com as outras restrições.
ALTER TABLE itens NOCHECK CONSTRAINT nome_da_restrição
Diagrama entidade relacionamento
Diagrama entidade relacionamento é um modelo diagramático que descreve o modelo de dados de um sistema com alto nível de abstração. Ele é a principal representação do Modelo de Entidades e Relacionamentos. É usado para representar o modelo conceitual do negócio. Não confundir com modelo relacional, que representam as tabelas, atributos e relações materializadas no banco de dados.MER: Conjunto de conceitos e elementos de modelagem que o projetista de banco de dados precisa conhecer. O Modelo é de Alto Nível.DER: Resultado do processo de modelagem executado pelo projetista de dados que conhece o MER.[editar]Tipos de relações
Os tipos de relações que são utilizadas neste diagrama:
Relação 1..1 (lê-se relação um para um) - indica que as tabelas têm relação unívoca entre si. Você escolhe qual tabela vai receber a chave estrangeira;
Relação 1..n (lê-se um para muitos) - a chave primária da tabela que tem o lado 1 vai para a tabela do lado N. No lado N ela é chamada de chave estrangeira;
Relação n..n (lê-se muitos para muitos) - quando tabelas têm entre si relação n..n, é necessário criar uma nova tabela com as chaves primárias das tabelas envolvidas, ficando assim uma chave composta, ou seja, formada por diversos campos-chave de outras tabelas. A relação então se reduz para uma relação 1..n, sendo que o lado n ficará com a nova tabela criada.

Apostila de MS SQL Server Pág.: 25 / 86
Diagrama
Diagrama de Entidade e Relacionamento (DER).
Através deste diagrama poderemos representar, de forma sucinta e bem estruturada, todos os elementos essenciais abstraídos no processo de análise de sistemas. Denominamos entidade (retângulo) estes elementos. Atribuímos a cada entidade definida atributos pertinentes ao sistema. Desta forma, podemos definir conceitualmente que representaremos como entidades aqueles elementos no qual gostaríamos de armazenar dados – que por sua vez, são representadospelos atributos. Através do relacionamento (losango) representaremos o tipo de relação existente entre as entidades.

Pág.: 26 / 86 Apostila de MS SQL Server
Criando Chave Estrangeira com Wizard
Basta selecionar a coluna desejável, clicando com o botão direito do mouse na opção RelationsShips, clicando em seguida no botão Add. Imediatamente a caixa de dialogo Foreign Key RelationsShips passa apresentar as propriedades conforme ilustrado.
Caixa de Dialogo Foreign Key RelationsShips
Propriedade Definição
Check Existing Data on Create
Quando assinaldo Yes, verifica a existência de dados que possam impedir a criação da chave, devido a existência de valores na coluna não válidos. Não válidos aqui refere-se a valores não encontrados previamente na coluna de referência na tabela de referência.
Tables and Columns Especification
Exibe uma Caixa de Dialogo onde é solicitado:
Escolha das colunas que irão compor a chave estrangeira.Escolha da tabela de referência (Foreign Table) e a coluna nessa tabela onde será verificado a existência prévia de valor correspondente quando da inclusão ou auteração de registros.
Name Nome da chave estrangeira, normalmente no padrão FK_NomeTabelaOrigem_NomeTabelaDestino
Tabela de Definições para Caixa de Dialogo Foreign Key RelationsShips

Apostila de MS SQL Server Pág.: 27 / 86
Índices
Porque Índices?
Índice é um mecanismo que acelera bastante o acesso aos dados. Consiste de uma estrutura de dados que contém ponteiros ordenados para os dados. O SQL Server usa [Indexes ou Índices] automaticamente em varias situações para acelerar a pesquisa e atualização de dados. Por exemplo:
• Se uma coluna esta na cláusula WHERE em um comando SELECT, UPDATE ou DELETE, o SQL Server verifica as condições mais rapidamente se houver um índice, caso contrário ele faz uma varredura seqüencial da tabela [table scan].
• Se uma coluna é muito usada para ordenar valores (com ORDER BY), essa ordenação é mais eficiente se ela tiver um índice.
• Se uma coluna é usada para fazer junção de duas tabelas, essas junções podem ser feitas mais eficientes se ela estiver indexada.
No entanto, índices levam tempo para serem criados e ocupam espaço em disco. Cada atualização na tabela também atualiza dinamicamente todos os índices definidos. Portanto se você criar muitos índices inúteis numa tabela, pode estar atrapalhando o desempenho da atualização de dados sem agilizar muito o tempo de resposta nas consultas.Para criar um Índice usamos o comando CREATE INDEX.
Alguns Exemplos do comando “CREATE INDEX”:
CREATE INDEX Idx_Clientes_Nome ON Clientes(Nome)
CREATE INDEX Idx_ProdutoS_Descricao ON Produtos(Descricao) On SECUNDARY
CREATE INDEX Idx_Pedidos_DataPed ON Pedidos(DataPed) On SECUNDARY

Pág.: 28 / 86 Apostila de MS SQL Server
Criando Índices com Wizard
Antes de mas nada vamos excluir o index na Tabela Produtos. Ai sim Clicando sobre o nó Table, em seguida procedendo da mesma maneira com o nó que representa a tabela onde criaremos o índice, selecione e clique em seguida com o botão direito do mouse sobre o nó Index. A caixa de dialogo New Index combinada com a caixa de dialogo Select collumns proverá todo o processo. Ainda, observe nas tabelas de referência dessas ciaxas de dialogos as definições para cada propriedade envolvida.
Caixa de dialogo New Index – Aba General

Apostila de MS SQL Server Pág.: 29 / 86
Propriedade Definição
Index Name Naturalmente o nome do objeto Index, no padrão desejável Idx_NomeTabela_NomeCampos
Index Type
NonClusterd ou Clustered. Nesse caso não, uma vez que somente um índice clusterizado pode existir em uma tabela.Um índice clusterizado ordena fisicamnente uma tabela pela coluna ou colunas indicadas, aasim, como naturalmente a criação da chave primária (indicando a locuna ID_PRODUTO) gerou um índice clusterizado, não há mais possibilidade.Um índice clusterizado é desejável por não necessitar de uma tabela extra para o índice, economizando espaço em mídia e pelo fato de ser mais rápido já que os daados serão ordenados ficamente na tabela.
Index Key Columns
A partir do botão Add, podemos escolher as colunas que irão compor o Índice.
Caixa de dialogo Selct Colummns

Pág.: 30 / 86 Apostila de MS SQL Server
Aspectos Importantes na Criação de Índices
Base de dados para serém eficientes, necessitam de índices e sobretudo, de bons índices. Algumas características observadas na caixa de dialgo New Index, especificamente na Aba Options concorrem para isso. Veja na tabela sobre definições algumas dessas características.
Caixa de Dialogo New Index – Aba Options
Propriedade DefiniçãoAutomatically recompute statistics
Mantém estatísiticas úteis na execução de futuros Seclects. Desejável, mas com o inconviniente de gerar dados extas na base.
Use row locks when accessing the index
Não provocar lock de registros quando sendo utilizado index para obtenção de daods. A prática de uso de lock é raro nos modelos de negócios atuais (uso de banco de dados) pois impacta a concorrência de dados, sobretudo nos modelos que atemdem a web.
Stored intermediate sort result in tempdb
Armazena resultados na base temporária para recuperação mais rápida imediatamente após sua execução. Isso pode ajuda na performance de uma seleção subsequente.
Set fill factor
Define o percentual de uso das páginas de índices. O aconselhável é 80%, determinando uma sobra de 20% em cada página de índice.Essa sobra de espaço, prove solução para quando da entrada de um novo registro, que provocaria a divisão da página de índice em duas, acomodando esse valor, que devido ao critério de indexação deveria estar nessa página. Isso retarda mas não evita em definitivo a fragmentação pela divisão de páginas de índices cheias.

Apostila de MS SQL Server Pág.: 31 / 86
Linguagem SQL
Inserindo Dados ( DML )
Em um banco de dados, inserir dados em uma tabela, significa preencher uma linha de determinada tabela com dados correspondentes aos tipos determinados naquela tabela. Esta inserção de dados deve seguir as regras de integridade da tabela, assim como respeitar as regras de chave primária estabelecidas na tabela.
O comando “INSERT” insere linhas em uma tabela. A forma mais simples do comando insert somente uma linha de dados. Nesse caso, são informados os valores de todas as colunas da tabela, na ordem em que elas foram definidas na tabela. Mas é possível inserir dados parciais de apenas algumas colunas, desde que a mesma não estejam definidas como “NOT NULL” .
Na linguagem SQL, para inserirmos dados em uma tabela, utilizamos o seguinte comando:
INSERT INTO Nome_Tabela VALUES (valor 1, valor2, valor3,...)
Obs.: Os valores valor1 , valor2, etc..., seguem a ordem dos campos da tabela, sendo utilizado valor vazio (' ') para campos que não necessitem de preenchimento. Dados de tipo numérico podem ser escritos sem a necessidade de aspas simples. Dados do tipo carácter (como char e varchar), devem ser escritos entre aspas simples.
Exemplo:
INSERT INTO Clientes VALUES ( 1 , 'MADEIRAS SAMAN' , '0002002/0001' , 'J' , 1 , 2003/6/25 , 1505.00 )
Tabela de Clientes
ID_Cliente Nome CNPJ Tipo Status Data Crédito
1 MADEIRAS SAMAN 0002002/0001 J 1 25/06/2003 1.505
2 CAR VEICULOS 10025600/0001 J 1 12/04/2005 1.112
3 CARLOS PEDREIRA 052116852-85 F 1 12/04/2004 500.00
9 FERNADA FERRAZ 011452369-85 F 1 11/02/2002 250.00
10 DANIEL SILVA 014548987-20 F 1 16/03/2001 150.00
11 FRAN ADESIVOS 2005006/0001 J 0 05/04/2005 50.00
12 SAPATOS E CIA. 10060085/0001 J 1 05/05/2003 900.50
13 CALÇADOS VARTA 2002550/0001 J 0 12/07/2001 874.60
21 SALE ADVOGADOS 00010003/0001 J 1 04/06/2004 20.00
22 PAULA MEDEIROS 003254896-84 F 0 01/06/2002 10.00

Pág.: 32 / 86 Apostila de MS SQL Server
Tabela de Pedidos
INSERT INTO Pedidos VALUES (1 , 1 , 10-05-2010)
ID_PEDIDO ID_CLIENTE DATAPED
1 1 10/05/2007
2 2 10/05/2007
3 1 25/05/2007
4 3 01/06/2007
5 9 04/06/2007
6 9 27/06/2007
7 10 10/07/2007
8 2 13/07/2007
9 10 15/07/2007
Tabela de Produtos
INSERT INTO Nome_Tabela VALUES ( valor 1 , valor2 , valor3 , valor4 )
ID_PRODUTO DESCRIÇÃO PRECO_CPOMPRA SALDO1 CANETA 0.19 202 LAPIS 0.10 1123 BORRACHA 0.05 425 PAPEL LISO 5.60 237 PAPEL A4 5.80 2210 COLA 1.19 311 GRAMPO 1.52 5212 COPO PLASTICO 1.06 1421 CADERNO 2.26 1622 FICHAS 2.42 120

Apostila de MS SQL Server Pág.: 33 / 86
Tabela de Itens
INSERT INTO Nome_Tabela VALUES ( valor 1 , valor2 , valor3 , valor4 )
ID_PEDIDO ID_PRODUTO QUANTIDADE PRECO_VENDA01 1 2 2,5001 2 16 1,7502 2 10 1,7503 3 11 4,0003 7 8 0,2503 1 45 2,5004 2 14 1,7504 7 9 0,2504 1 10 2,5005 3 18 4,00

Pág.: 34 / 86 Apostila de MS SQL Server
Atualizando Dados
Os dados em uma tabela pode ser modificada utilizando o comando UPDATE. O comando update não adiciona novos registros a uma tabela, e nem remove os registros, simplesmente atualiza os dados existentes. A forma mais simples da instrução update é a sua utilização para atualizar uma única coluna em uma tabela. Tanto uma única linha de dados como numerosos registros podem ser atualizados ao atualizar uma única coluna em uma tabela.
Synopsis
UPDATE [ ONLY ] tabela SET coluna = expressão [, ...] [ FROM lista_de ] [ WHERE condição ]
UPDATE clientes Set tipo = ‘F’WHERE id_cliente = 1
Excluindo Dados
O comando delete é utilizado para remover linhas inteiras de dados de uma tabela. O comando delete não é utilizado para remover valores de colunas especificas, um registro completo, incluindo todas as colunas é removido. A instrução delete deve ser usada com cautela, ela funciona muito bem. Para excluir um único registro ou registro selecionados de uma tabela, a instrução delete deve ser utilizada com a seguinte sintaxe:
Synopsis
DELETE FROM [ ONLY ] tabela [ WHERE condição ]
DELETE FROM clientesWhere ID_CLIENTE = 22

Apostila de MS SQL Server Pág.: 35 / 86
A Sintaxe SELECT
O comando SELECT recupera dados de uma ou mais tabelas, é a instrução utilizada para construir consultas no banco de dados. A cláusula FROM é a cláusula obrigatória e sempre deve ser utilizada em conjunção com a instrução SELECT.Há quatro cláusulas, que são partes valiosas de uma instrução SELECT, A sintaxe mais simples para recuperar dados dentro de um banco de dados:
• Consulta a dados de uma tabela
SELECT listas_de_colunasFROM listas_de_tabelasWHERE condições
A lista_de_colunas especifica quais colunas serão retornadas como resultado, separadas por vírgula ou um asterisco (*) que indica todas as colunas da tabela.A cláusula FROM, com uma lista_de_tabelas, especifica quais tabelas serão consultadas.A cláusula WHERE especifica condições que devem ser satisfeitas pelas linhas das tabelas.
O comando SELECT pode ser utilizado para mostrar o conteúdo de variáveis, valores literais, etc... Exemplo, execute o comando:
SELECT @@version
Comandos Select
SELECT, o camando que representa a Data Query Language (DQL) em que SQL, é a instrução utilizada para construir consultas no banco de dados. A cláusula FROM é a cláusula obrigatória e sempre deve ser utilizada em conjunção com a instrução SELECT.Há quatro cláusulas, que são partes valiosas de uma instrução SELECT:
SELECTFROMWHEREORDER BY

Pág.: 36 / 86 Apostila de MS SQL Server
Exemplo 01:
SELECT * FROM clientes
Exemplo 02:
SELECT id_cliente, nome, cnpj, status, tipoFROM clientes
Agora adicione uma condição à mesma consulta.
SELECT id_cliente, nome, cnpj, status, tipo, dataFROM clientesWHERE id_cliente in (2, 3, 9)
Operadores Aritméticos Permitidos
Os operadores aritméticos desempenham operações matemáticas em duas expressões de um ou mais dos tipos de dados da categoria de tipo de dados numéricos.
Operador Significado
(Adicionar) Adição- (Subtrair) Subtração* (Multiplicar) Multiplicação/ (Dividir) Divisão
% (Modulo) Retorna o resto de inteiro de uma divisão. Por exemplo, 12% 5 = 2 porque o resto de 12 dividido por 5 é 2.

Apostila de MS SQL Server Pág.: 37 / 86
Funções de agregação
Realizam cálculos em um conjunto de valores e retornam um único valor. Com exceção da função COUNT, as funções de agregação ignoram valores nulos.
COUNTA função COUNT é utilizada para contar linhas ou valores de uma coluna que não tem valor null. A função COUNT quando utilizada com uma consulta retorna valor numérico.
SELECT COUNT (*) FROM CLIENTES
SUMÉ utilizada para retornar um total nos valores de uma coluna para um grupo de linhas.
SELECT SUM (CREDITO) FROM CLIENTES
MAXA função MAX é utilizada para retornar o valor máximo para valores de uma coluna em um grupo de linhas.
SELECT MAX (CREDITO) FROM CLIENTES
MINA função MIN retorna o valor mínimo de uma coluna para um grupo de linhas.
SELECT MIN (CREDITO) FROM CLIENTES
AVGA função AVG retorna o valor médio não ponderado de uma coluna para um grupo de linhas.
SELECT AVG (CREDITO) FROM CLIENTES

Pág.: 38 / 86 Apostila de MS SQL Server
Duas Formas Possíveis de Select
Com ALIAS (Significa segundo nome, ou apelido.)
SELECT Cl.nome,Cl.credito,Pe.DataPed,
Sum(It.Quantidade * It.Preco_Venda) As Total
FROM Clientes Cl, Pedidos Pe, Itens It
WHERE Cl.id_cliente = Pe.id_cliente AND Pe.id_pedido = It.id_pedido
GROUP BY Cl.nome, Cl.credito, Pe.DataPed
Ou Sem ALIAS
SELECT Clientes.nome, Clientes.credito,Pedidos.DataPed,
Sum(Itens.Quantidade * Itens.Preco_Venda) As Total
FROM Clientes, Pedidos, Itens
WHERE Clientes.id_cliente = Pedidos.id_cliente AND Pedidos.id_pedido = Itens.id_pedido
GROUP BY Clientes.nome, Clientes.credito, Pedidos.DataPed

Apostila de MS SQL Server Pág.: 39 / 86
Operadores LógicosSão aqueles operadores que utilizam palavras-chave de SQL para fazer comparações em vez de símbolos. Os operadores lógicos abordados são:
IS NULL
Utilizado para comparar um valor com um valor null. No exemplo, o campo crédito não tem valor.
SELECT * FROM CLIENTES WHERE CREDITO IS NULL
BETWEEN
É utilizado para procurar valores que estão dentro de um conjunto de valores, dado o valor mínimo e o valor máximo. No exemplo, o campo valor deve estar entre 20 e 50.
SELECT * FROM CLIENTES WHERE credito BETWEEN 20 AND 50
IN
É utilizado para comparar um valor com uma lista de valores literais que foi especificada. No exemplo, o campo crédito deveria ser um dos valores da lista.
SELECT * FROM CLIENTES WHERE CREDITO IN (20, 30, 50)
LIKE
É utilizado para comparar um valor com valores semelhantes utilizando operadores curinga (%) porcentagem ou (_) sublinhado.
-Exemplolo: Localiza quaisquer valores que comecem com PAB
SELECT * FROM CLIENTES WHERE nome LIKE 'PAB%'
-Exemplo: Localiza quaisquer valores que contenham ABL a partir da segunda casa e terminem com quaisquer valores.
SELECT * FROM CLIENTES WHERE nome LIKE 'ABL%'
EXISTS
É utilizado para procurar a presença de uma linha em uma tabela específica que atenda a certos

Pág.: 40 / 86 Apostila de MS SQL Server
critérios. Veja como pesquisar para ver se id_cliente 982 está na tabela clientes.
SELECT * FROM CLIENTES WHERE EXISTS ( Select id_cliente From clientes Where id_cliente = 982)
NOT EXISTS
É utilizado para procurar a não ocorrência de uma linha em uma tabela específica que atenda a certos critérios. Veja como pesquisar para ver se existe clientes que não compraram. Logo não ocorrem na tabela pedidos.
SELECT * FROM CLIENTES WHERE NOT EXISTS ( Select id_cliente From PedidosWHERE Pedidos.id_cliente = Clientes.id_Cliente )

Apostila de MS SQL Server Pág.: 41 / 86
Conceitos bá sico s de junçõesUsando junções, é possível recuperar dados de duas ou mais tabelas com base em relações lógicas entre as tabelas. Junções indicam como Microsoft SQL Server deveriam usar dados de uma tabela para selecionar as linhas em outra tabela.Uma condição de junção define o modo como duas tabelas são relacionadas em uma consulta por:
• Especificando a coluna de cada tabela a ser usada para a junção. Uma condição de junção típica especifica uma chave estrangeira de uma tabela e sua chave associada na outra tabela.
• Especificando um operador lógico (por exemplo, = ou <>) a ser usado na comparação de valores das colunas.
Para esse exemplo vamos adicionar uma nova tabela em nosso banco:
CREATE TABLE Cidades(
ID_Cidade int NOT NULL PRIMARY KEY,CidadeNome varchar (50) NOT NULL,Estado char (2) NOT NULL
)
ALTER TABLE CLIENTES Add Id_Cidade char (2) NOT NULL
INNER JOINSUm INNER JOIN conecta duas ou mais tabelas segundo uma condição de junção. O INNER JOIN retorna os registros que forem encontrados nas tabelas e respeitarem as condições de busca.
SELECT Clientes.Nome, Cidades.CidadeNome, Cidades.EstadoFROM Clientes INNER JOIN Cidades ON Clientes.ID_Cidade = Cidades.ID_Cidade
OUTER JOINS
Como podemos reparar no INNER JOIN, somente as linhas que possuem dados nas duas colunas do relacionamento são retornadas. Caso uma das colunas não possua valor (tenha null), este registro não participará da junção do SELECT.
Isto pode não uma determinada pergunta. Você pode estar querendo saber, por exemplo, quais os clientes que você tem cadastrado, e, se houver a informação, o nome da cidade destes.
LEFT OUTER JOINS
Neste caso, você precisa de um OUTER JOIN. Um OUTER JOIN traz todas as linhas de uma determinada tabela, tendo ou não relacionamento completo, e as linhas da segunda tabela que satisfizerem o relacionamento. Vamos construir o exemplo dito antes:
SELECT Clientes.Nome, Cidades.CidadeNome, Cidades.EstadoFROM Clientes LEFT OUTER JOIN Cidades ON Clientes.ID_Cidade = Cidades.ID_Cidade;

Pág.: 42 / 86 Apostila de MS SQL Server
Nome CidadeNome EstadoCliente1 Rio de Janeiro RJCliente2 São Paulo SPCliente3 NULL NULLCliente4 São Paulo MG
RIGHT OUTER JOINS
Se quiséssemos trazer todas as cidades, e os clientes que existirem nelas, faríamos:
SELECT Clientes.Nome, Cidades.CidadeNome, Cidades.EstadoFROM Clientes RIGHT OUTER JOIN Cidades ON Clientes.ID_Cidade = Cidades.ID_Cidade
Nome CidadeNome EstadoCliente1 Rio de Janeiro RJCliente2 São Paulo SPCliente4 São Paulo MGNULL Vitória ES
Que esteja bem claro que a palavra LEFT ou RIGHT refere-se apenas à ordem escrita das tabelas, vamos ver um outro exemplo de trazer todos os clientes e as cidades destes:
SELECT Clientes.Nome, Cidades.CidadeNome, Cidades.EstadoFROM Cidades RIGHT OUTER JOIN Clientes ON Clientes.ID_Cidade = Cidades.ID_Cidade
Nome CidadeNome EstadoCliente1 Rio de Janeiro RJCliente2 São Paulo SPCliente3 NULL NULLCliente4 São Paulo MG
FULL OUTER JOINS
E podemos, ainda, juntar os dois modos: ou seja, fazer um LEFT e RIGHT OUTER JOIN ao mesmo tempo. Isto, na, verdade, se chama FULL OUTER JOIN. E o exemplo está a seguir:
SELECT Clientes.Nome, Cidades.CidadeNome, Cidades.EstadoFROM Cidades FULL OUTER JOIN ClientesON Clientes.ID_Cidade = Cidades.ID_Cidade;
Nome CidadeNome EstadoCliente1 Rio de Janeiro RJCliente2 São Paulo SPCliente4 São Paulo MGNULL Vitória ESCliente3 NULL NULL

Apostila de MS SQL Server Pág.: 43 / 86
ViewsUma visão (View) é uma forma alternativa de olhar os dados contidos em uma ou mais tabelas. Para definir uma visão, usa-se um comando SELECT que faz uma consulta sobre as tabelas. A visão aparece depois como se fosse uma tabela.Visões têm as seguintes vantagens:
• Uma visão pode restringir quais as colunas da tabela podem ser acessadas (para leitura ou modificação), o que é útil no caso de controle de acesso,
• Uma consulta SELECT que é usado muito frequentemente pode ser criada como visão. Com isso, a cada vez que ela é necessária, basta selecionar dados da visão,
• Visões podem conter valores calculados ou valores de resumo, o que simplifica a operação,
• Uma visão pode usada para exportar dados para outras aplicações.
Criando uma visão Vamos criar uma visão no banco de dados Aluno, usando a tabela Clientes. Essa visão vai mostrar o código, nome e histórico de clientes de pessoas jurídicas.Para criar uma visão use o comando CREATE VIEW.
CREATE VIEW VIEWClientesAS
SELECT Clientes.ID_Cliente,Clientes.Nome,Clientes.Historico
FROM Clientes
WHERE (Tipo = 'J')
CREATE VIEW VIEWcase AS
SELECT Clientes.Nome,Clientes.Credito,'Avaliação'=
CaseWhen Credito Between 0 and 100 then 'Regular'When Credito Between 101 and 200 then 'Bom'Else 'Ótimo'
End
FROM Clientes

Pág.: 44 / 86 Apostila de MS SQL Server
CREATE VIEW VIEWCube AS
SELECT Produtos.Descricao,Pedidos.Dataped,
SUM (Itens.Quantidade) as Quantidade
FROM Pedidos INNER JOIN ITENS ON Pedidos.ID_Pedido = Itens.ID_PedidoINNER JOIN PRODUTOS ON Itens.ID_Produto =
Produtos.ID_Produto
GROUP BY Produtos.Descricao,Pedidos.Dataped
WITH Cube
Obs:O operador CUBE é utilizado junto com a cláusula Group By para produzir linhas adicionais de resumo. Ele produzirá linhas superagregadas utilizando cada possível combinação das colunas na cláusula Group By, produzirá médias parciais e somas parciais mas também colunas de referência cruzada para retornar linhas adicionais de resumo.
CREATE VIEW VIEWROLLUP AS
SELECT Produtos.Descricao,Pedidos.Dataped,
SUM (Itens.Quantidade) as Quantidade
FROM Pedidos INNER JOIN ITENS ON Pedidos.ID_Pedido = Itens.ID_PedidoINNER JOIN PRODUTOS ON Itens.ID_Produto =
Produtos.ID_Produto
GROUP BY Produtos.Descricao,Pedidos.Dataped
WITH ROLLUP
Obs:Assim como o operador Cube, o RollUp funciona em conjunto com a cláusula Group By, geralmente utilizado para produzir médias em execução ou somas em execução aplicando a função agregada para cada coluna que consta na cláusula Group By.

Apostila de MS SQL Server Pág.: 45 / 86
Stored Procedure
Um procedimento armazenado [stored procedure] é um conjunto de comandos SQL que são compilados e armazenados no servidor. Ele pode ser chamado a partir de um comando SQL qualquer. A vantagem de usar procedimentos armazenados é que eles podem encapsular rotinas de uso freqüente no próprio servidor, e estarão disponíveis para todas as aplicações. Parte da lógica do sistema pode ser armazenada no próprio banco de dados, em vez de ser codificada várias vezes em cada aplicação. Eles também aumentam o desempenho de várias operações, pois são executados no servidor e pré-compilados, ao contrário de comandos SQL que devem ser interpretados no momento da execução.Para criar um procedimento, use o comando CREATE PROCEDURE. Exemplo o procedimento abaixo recebe um parâmetro (@nome) e mostra todos os clientes cujo nome contenha o nome informado:
CREATE PROCEDURE ProcIncCliente (
@ID_Cliente Int,@Nome Varchar(50),@Cnpj Char(14),@Tipo Char(1),@Status Bit,@Data DateTime,@Historico Text,@Foto Image,@Credito Money) AS
BEGIN
INSERT IntoClientes(ID_Cliente , Nome, Cnpj, Tipo, Status, Data, Historico,
Foto, Credito)Values(@ID_Cliente, @Nome, @Cnpj, @Tipo, @Status, @Data, @Historico, @Foto ,@Credito)
)
END

Pág.: 46 / 86 Apostila de MS SQL Server
CREATE PROCEDURE ProcIAltCliente(
@ID_Cliente Int,@Nome Varchar(50),@Cnpj Char(14),@Tipo Char(1),@Status Bit,@Data DateTime,@Historico Text,@Foto Image,@Credito Money
)
AS
BEGIN
Begin Transaction
Update Clientes Set Clientes.Nome = @Nome,Clientes.Cnpj = @Cnpj,
Clientes.Tipo = @Tipo,Clientes.Status = @Status,Clientes.Data = @Data,Clientes.Historico = @Historico,Clientes.Foto = @Foto,Clientes.Credito = @Credito
Where Clientes.ID_Cliente = @ID_Cliente
If @@Error = 0Begin
Commit Transaction Return (0)
EndElse
BeginRollback Transaction Return (1)
EndEND

Apostila de MS SQL Server Pág.: 47 / 86
CREATE PROCEDURE ProcExcCliente(@ID_Cliente Bigint)As
Declare @Msg Varchar (255),@Erro Bigint
BEGIN
Delete From ClientesWhere Clientes.ID_Cliente = @ID_Cliente
set @Erro = @@Error
If @Erro <> 0
BEGIN
Select @Msg = 'Operação Não Realizada devido ao seguinte erro: ' + Convert (Varchar (255), @Erro)
Raiserror (@Msg, 10, 1)
END
END
CREATE PROCEDURE ProcVendaProduto(
@DataIni DateTime,@DataFim DateTime,@Valor Money) As
BEGIN
Select Produtos.Descricao,Sum(Itens.Quantidade * Itens.Precovenda) As Total
From Produtos INNER JOIN ItensOn Produtos.ID_Produto = Itens.ID_ProdutoINNER JOIN PedidosOn Pedidos.ID_Pedido = Itens.ID_Pedido
Where Pedidos.DataPed BetWeen @DataIni And @DataFimGroup By Produtos.DescricaoHaving Sum(Itens.Quantidade * Itens.Precovenda) > @ValorOrder By Produtos.Descricao
END

Pág.: 48 / 86 Apostila de MS SQL Server
CREATE PROCEDURE ProcVendasMesAno (@DataIni DateTime,@DataFim DateTime ) AS
BEGINSelect Convert(Varchar(15), Datepart(mm,Pedidos.Dataped)) + '-' + Convert(Varchar(15),Datepart(yy,Pedidos.Dataped))AS 'Ano_Mes', Sum(Itens.Quantidade * Itens.Precovenda) AS Total
From Itens INNER JOIN Pedidos On Itens.ID_Pedido = Pedidos.ID_PedidoWhere Pedidos.Dataped Between @Dataini And @DataFimGroup By Convert(Varchar(15),Datepart(Mm,Pedidos.Dataped))+ '-' +
Convert(Varchar(15),Datepart(Yy,Pedidos.Dataped)) Order By Convert(Varchar(15),Datepart(Mm,Pedidos.Dataped))+ '-' + Convert(Varchar(15),Datepart(Yy,Pedidos.Dataped))END
CREATE PROCEDURE ProcCursor ASDeclare cursorX Cursor for Select Produtos.* From ProdutosDeclare @ID_Produto Bigint,
@descricao varchar(25),@precocompra money,@saldo Bigint
BEGINopen cursorx
Create Table #tempProduto( ID_Produto Bigint,
Descricao varchar(25),PrecoCompra money,Saldo Bigint
)fetch cursorx into @ID_Produto, @descricao, @precocompra, @saldowhile (@@fetch_status = 0)
beginif @saldo > 1
beginInsert Into #tempProduto
values( @ID_Produto,@descricao,@precocompra,@saldo)
endfetch cursorx into @ID_Produto, @descricao, @precocom-
pra, @saldoend
close cursorx
Deallocate cursorx
select * from #tempProdutoend

Apostila de MS SQL Server Pág.: 49 / 86
CREATE PROCEDURE ProcCursorTabTemp AS Declare cursorX Cursor forSelect Clientes.Nome,Sum(Itens.Quantidade * Itens.PrecoVenda) as TotalFrom Clientes INNER JOIN Pedidos
On Pedidos.ID_Cliente = Clientes.ID_ClienteINNER JOIN ItensOn Itens.ID_Pedido = Pedidos.ID_Pedido
Group By Clientes.Nome
Declare @nome varchar(35), @total Money
BEGIN
open cursorx
Create Table #tempPedidosCliente(Nome varchar(35), Totalmoney)
fetch cursorx into @nome, @total
While (@@fetch_status = 0)beginif @total > 1
beginInsert Into #tempPedidosCliente Val-
ues(@nome, @total)end
fetch cursorx into @nome, @totalend
close cursorxDeallocate cursorxSelect * From #tempPedidosCliente
END

Pág.: 50 / 86 Apostila de MS SQL Server
TriggersUm gatilho [trigger] é um tipo de procedimento armazenado, que é executado automaticamente quando ocorre algum tipo de alteração numa tabela. Gatilhos “disparam” quando ocorre uma operação INSERT, UPDATE e DELETE numa tabela.
Geralmente gatilhos são utilizados para reforçar restrições de integridade que não podem ser tratadas pelos recursos mais simples, como regras, restrições, a opção NOT NULL etc.
Um gatilho também pode ser usado para calcular e armazenar valores automaticamente em outra tabela.
Vamos criar um gatilho, chamado ValidaCredito, que será ativado por uma operação INSERT na tabela dbo.clientes.
CREATE TRIGGER ValidaCredito ON Clientes FOR Insert ASDeclare @ValorCredito money, @IDCliente int
BEGINSelect @ValorCredito = Inserted.Credito, @IDCliente = Inserted.ID_ClienteFrom InsertedIf @ValorCredito > 10000Update Clientes set Clientes.Credito = 10000 Where Clientes.ID_Cliente = @IDCliente
END
CREATE TRIGGER AtualizaSaldoInc ON Itens FOR INSERT ASDECLARE @QTD INT,
@COD INT,@SALDO INT,@NRO INT,@Descricao varchar(255),@msg varchar(255)
BEGIN SELECT @QTD = INSERTED.QUANTIDADE, @COD = INSERTED.ID_PRODUTO,
@NRO = INSERTED.ID_PEDIDOFROM INSERTEDSELECT @SALDO = PRODUTOS.SALDO, @DESCRICAO = PRODUTOS.DESCRICAOFROM PRODUTOS WHERE PRODUTOS.ID_PRODUTO = @COD
IF @SALDO >= @QTDUPDATE PRODUTOS SET PRODUTOS.SALDO = PRODUTOS.SALDO - @QTDWHERE PRODUTOS.ID_PRODUTO = @COD ELSE
BEGINSELECT @MSG = 'INI Não aceito, pois saldo do produto '
+ @descricao+ ' é: ' + Convert (Varchar(255), @saldo) + ' não atendendo a necessidade. FIM'
Raiserror (@msg, 14, 1)Rollback
END END

Apostila de MS SQL Server Pág.: 51 / 86
CREATE TRIGGER AtualizaSaldoExc ON Itens FOR DELETE ASDECLARE @Qtd INT, @Cod INT
BEGINSELECT @Qtd = Deleted.Quantidade, @Cod = Deleted.ID_ProdutoFROM DELETEDUPDATE Produtos SET Saldo = Saldo + @QtdWHERE ID_PRODUTO = @Cod
END
CREATE TRIGGER AtualizaSaldoAlt ON ITENS FOR UPDATE ASDECLARE @QTDNovo INT,
@CODNovo INT,@QTDAnterior INT,@CODAnterior INT,@SALDO INT,@Descricao varchar(25),@Msg varchar(255)
BEGINSELECT @QTDNovo = INSERTED.QUANTIDADE,
@CODNovo = INSERTED.ID_PRODUTO FROM INSERTED
SELECT @QTDAnterior = DELETED.QUANTIDADE,@CODAnterior = DELETED.ID_PRODUTO
FROM DELETED
UPDATE PRODUTOS SET PRODUTOS.SALDO = PRODUTOS.SALDO + @QTDAnterior
WHERE PRODUTOS.ID_PRODUTO = @CODAnterior
SELECT @SALDO = PRODUTOS.SALDO,@DESCRICAO=PRODUTOS.DESCRICAO
FROM PRODUTOSWHERE PRODUTOS.ID_PRODUTO = @CODNovo
IF @SALDO >= @QTDNovo UPDATE PRODUTOS SET
PRODUTOS.SALDO = PRODUTOS.SALDO - @QTDNovoWHERE PRODUTOS.ID_PRODUTO = @CODNovoELSE BEGIN
SELECT @MSG = 'INI Não aceito, pois saldo do produto '+ @Descricao+ ' é: ' + Convert (Varchar(255), @saldo) + ' não atendendo a necessidade. FIM'
Raiserror (@Msg, 14, 1)Rollback
END END

Pág.: 52 / 86 Apostila de MS SQL Server
Controle de Transação
Controlando Transação Simples
Begin Begin Transaction
Insert Into Produtos(Id_produto, Descricao, Saldo, PrecoCompra)
Values(Id_produto 'Novo Produto', 1200, 12.78)Insert Into Produtos(Id_produto, Descricao, Saldo,
PrecoCompra)Values(Id_produto 'Novo Produto', 400, 23.78)If @@Error = 0
BeginPrint 'Registro inserido com sucesso.'Commit Transaction
EndElse
BeginPrint 'Registro não incluído.'Rollback Transaction
EndEnd
Controlando Transações com Savepoints (Circunstancial)
Begin Begin Tran
Save Tran Trans1Insert Into Produtos(Id_produto, Descricao, Saldo,
PrecoCompra)Values(Id_produto 'Novo Produto', 1200, 12.78)If @@Error <> 0
BeginPrint 'Produto não incluído.'Rollback Tran Trans1
EndSave Tran Trans2
Insert Into Produtos(Id_produto, Descricao, Saldo, PrecoCompra)
Values(Id_produto 'Novo Produto', 1200, 12.78)If @@Error <> 0
BeginPrint 'Produto não incluído.'
Rollback Tran Trans2End
Commit TranEnd Outros Objetos

Apostila de MS SQL Server Pág.: 53 / 86
CREATE DEFAULT (Transact-SQL)
Cria um objeto chamado padrão. Quando associado a uma coluna ou um tipo de dados de alias, um padrão especifica um valor a ser inserido na coluna á qual o objeto está associado (ou em todas as colunas, no caso de um tipo de dados de alias), quando nenhum valor é fornecido explicitamente durante uma inserção.
ImportanteEsse recurso será removido em uma versão futura do Microsoft SQL Server. Evite usar esse recurso em desenvolvimentos novos e planeje modificar os aplicativos que atualmente o utilizam. Em vez dela, use definições padrão criadas com a palavra-chave DEFAULT de ALTER TABLE ou CREATE TABLE.
CREATE DEFAULT DefautGetData as GetData()CREATE DEFAULT DefautISigla as 'RJ'
CREATE Rule (Transact-SQL)
Cria um objeto chamado regra. Quando associada a uma coluna ou a um tipo de dados de alias, a regra especifica os valores aceitáveis que podem ser inseridos naquela coluna.
CREATE RULE Sigla as @Valor = 'RJ' / 'ES' / 'MG' CREATE RULE Sigla2 as @Valor in ('RJ', 'ES', 'MG' )CREATE RULE Faixa as @Valor >= 1 and @Valor <= 1000
ImportanteEsse recurso será removido em uma versão futura do Microsoft SQL Server. Evite usar esse recurso em desenvolvimentos novos e planeje modificar os aplicativos que atualmente o utilizam. Recomenda-se o uso de restrições de verificação. As restrições de verificação são criadas pelo uso da palavra-chave CHECK de CREATE TABLE ou ALTER TABLE.

Pág.: 54 / 86 Apostila de MS SQL Server
Criando Login
No SQL SERVER Login é um conjunto de caracteres composto de LoginName, password database default, default language e UserName solicitado para os usuários que por algum motivo necessitam acessar algum sistema de banco de dados. Geralmente os sistemas computacionais solicitam um login e uma senha para a liberação do acesso.
Para adicionar um usuário ao banco de dados do SQL Server você tem que seguir três passos:
Primeiro: você deve criar um login, que é um "cara" que tem permisssão de se logar no SQL Sever
CREATE LOGIN ALUNO_NOME WITH PASSWORD = '123';
Segundo: você deve criar um usuário para o banco de dados que deseja mapeando esse usuário para o login criado, assim seu usuário conseguirá se logar no SQL Server e entrar no banco de dados desejado.
CREATE USER ALUNO_NOME FROM LOGIN ALUNO_NOME;
Terceiro: você deve dar ou remover permissões ao usuário porque até o segundo passo o usuário criado só tem direito a entrar no banco de dados, dando as permissões o usuário já pode operar no banco de dados. Se o usuário for comum você pode adicioná-lo apenas as roles de db_reader e db_writer, que permitirá que o usuário faça select, insert, delete e update em todas as tabelas do referido banco de dados.
EXEC SP_ADDROLEMEMBER 'DB_DATAREADER', 'ALUNO_NOME'
EXEC SP_ADDROLEMEMBER 'DB_DATAWRITER', 'ALUNO_NOME'
Obs.: Se quiser ver melhor isso na parte gráfica, pode consultar dentro do "Object Explorer" a guia "Security", dentro dela clique em "Login", botão direito em "sa", "Properties", escolha a guia "User Mapping". Aqui você verá as roles do SQL Server pra cada usuário. Caso queira saber o que dá direito a cada role procure no SQL Server Books Online.

Apostila de MS SQL Server Pág.: 55 / 86
Usando comandos DDL
CREATE LOGIN Digidata_LoginWITH PASSWORD = '123',DEFAULT_DATABASE = digidata,DEFAULT_LANGUAGE = Português
Usando system procedure
SP_AddLogin 'Digidata_Login',' 123','digidata'
Como criar um logon do SQL ServerSQL Server 2008 R2 Outras versões SQL Server 2008 A maioria os usuários do Windows precisa de um logon SQL Server para se conectar a SQL Server. Este tópico mostra como criar um logon do SQL Server.
Para criar um logon do SQL Server que usa Autenticação do SQL Server (SQL Server Management Studio)
1.No SQL Server Management Studio, abra o Pesquisador de Objetos e expanda a pasta da instância de servidor onde criar o novo logon.
2.Clique com o botão direito na pasta “Security” (Segurança), aponte para “New” (Novo) e clique em “Login” (Logon).
3.Na página “Geral”, insira o nome de um usuário do Windows na caixa Nome de logon .
4.Selecione “SQL Server authentication”, Obs.: determine o Banco a onde será criado e a Linguagem.
5.Insira uma senha para o logon.
6.Selecione as opções de diretiva de senha que devem ser aplicadas ao novo logon. Em geral, a diretiva de imposição de senha é a opção mais segura.
7.Clique em “OK”.

Pág.: 56 / 86 Apostila de MS SQL Server
Criando Login com Wizard
Escolha do nome de Login, senha, banco de dados padrão e linguagem

Apostila de MS SQL Server Pág.: 57 / 86
Escolha do BD default, UserName e Papeis de Sistema
Criando Usuário Usando comandos DDL
CREATE USER Digidata_User FOR LOGIN Digidata_Login
Usando system procedure
SP_AddUser ' Digidata_Login',' Digidata_User'

Pág.: 58 / 86 Apostila de MS SQL Server
Como criar um usuário de banco de dados SQL Server
Este tópico mostra como criar um usuário de banco de dados mapeado para um logon do SQL Server. Assume-se que já exista um logon correspondente do SQL Server.
Criar um usuário de banco de dados usando o SQL Server Management Studio
1.No SQL Server Management Studio, abra o Pesquisador de Objetos e expanda a pasta Bancos de Dados.
2.Expanda o banco de dados no qual o novo usuário de banco de dados será criado.
3.Clique com o botão direito do mouse na pasta “ Security” Segurança, aponte para “new” Novo e clique em “User” Usuário.
4.Na página Geral, insira um nome para o novo usuário na caixa Nome de Usuário.
5.Na caixa Nome de Logon, digite o nome de um logon do SQL Server para mapear para o usuário de banco de dados.
6.Clique em OK.
Obs.: Para Criar um usuário de banco de dados certifique que esteja conectado ao mesmo.

Apostila de MS SQL Server Pág.: 59 / 86
Criando Usuário com Wizard
Escolha do Login, Nome do Usuário

Pág.: 60 / 86 Apostila de MS SQL Server
Escolha dos Objetos de BD e permissões
Concedendo Permissões aos Usuários
Para conceder ou revogar permissões a um usuário, é mais fácil usar:
GRANT ALL TO Digidata_UserREVOKE ALL FROM Digidata_User
GRANT create table TO Digidata_UserREVOKE create table FROM Digidata_User
GRANT select ON clientes TO Digidata_UserREVOKE select ON clientes TO Digidata_User

Apostila de MS SQL Server Pág.: 61 / 86
Criando Role (Funções)
As funções são protegíveis no nível de banco de dados. Depois de criar uma função, configure as permissões no nível de banco de dados da função usando GRANT, DENY e REVOKE. Para adicionar membros a uma função de banco de dados, use o procedimento armazenado sp_addrolemember.
Usando comandos DDL
CREATE ROLE Digidata_Role AUTHORIZATION Digidata_User
Usando system procedure
SP_Addrole Digidata_Role
Adicionando o User a Role
EXEC SP_Addrolemember Digidata_Role, Digidata_User
Adicionando privilégios a Role
GRANT SELECT ON Clientes TO Digidata_Role GRANT CREATE TABLE TO Digidata_Role DENY CREATE TABLE TO Digidata_Role

Pág.: 62 / 86 Apostila de MS SQL Server
Criando Role com Wizard
Escolha do RoleName,
Selecionando os objetos e permissões 1/3

Apostila de MS SQL Server Pág.: 63 / 86
Selecionando os objetos e permissões 2/3
Selecionando os objetos e permissões 3/3

Pág.: 64 / 86 Apostila de MS SQL Server

Apostila de MS SQL Server Pág.: 65 / 86
Criando BackUp e Restore
Fazer um backup consiste em copiar o banco de dados para um local seguro.
Uma cópia de backup deve ser feita na medida do possível em outra máquina da rede, para uma fita magnética ou outro meio magnético. O backup copia tudo o que esta dentro do banco de dados, incluindo o log de transação.
O log de transação é um registro serial de todas as modificações feitas no banco de dados. Esse log é usado no processo de restauração para fazer todas as alterações que ocorrem no banco de dados desde o ultimo backup.
A restauração do banco de dados, quando bem sucedida, retorna o banco ao estado em que estava no momento da execução do backup. Se durante a execução de backup alguam transação não tiver sido concluída,ela será desfeita para garantir a consistência da base de dados.
O SQL Server 2005 permite a confecção de dois tipos de backup: o backup completo e o diferencial. O backup completo, como o nome diz, é uma fotografia exata de todo o banco de dados. O backup diferencial é uma cópia das alterações feitas no banco de dados, desde a realização do ultimo backup completo.

Pág.: 66 / 86 Apostila de MS SQL Server
Criando backup completo
Criando backup diferencial

Apostila de MS SQL Server Pág.: 67 / 86
Efetuando o Restore full e diferencial
Efetuando um Restore pontual

Pág.: 68 / 86 Apostila de MS SQL Server
Anexo - 1
Registrar Servidores
Arquitetura Distribuída do SQL ServerO SQL Server utiliza uma arquitetura na qual vários servidores distribuídos podem ser acessados a partir de um único servidor. Para que isto seja possível, estes servidores devem ser configurados como Linked Servers.
Para executarmos esta atividade, você deve criar na sua máquina um linked server apontando para o a máquina de um colega (sugestão: caso queira executar a atividade em uma mesma máquina, faça uma segunda instalação do SQL Server, dando à nova instância que será criada um nome diferente do padrão 'SQLEXPRESS'). A configuração de um Linked Server pode ser feita usando a stored procedure sp_addlinkedserver ou através do SQL Server Management Studio Express, selecionando a opção de menu 'New Linked Server':

Apostila de MS SQL Server Pág.: 69 / 86
A janela de diálogo 'New Linked Server' será exibida. Na página 'General' defina o nome e o tipo do servidor. Na página 'Security' defina mapeamentos de usuários entre os servidores local e remoto, caso necessário; e defina como proceder para logins que não foram mapeados (sugestão: use a opção 'Be made using the login´s current security context').

Pág.: 70 / 86 Apostila de MS SQL Server
Para acessar dados no servidor remoto, devemos referenciar o nome do servidor, o banco de dados, o esquema e o nome da tabela. Uma seleção na relação 'Rel' do banco de dados 'BD' do servidor 'SERVER\SQLEXPRESS' teria a seguinte sintaxe em SQL:
select * from [NomeServidor\SQLEXPRESS].NomeBanco.Esquema.NomeTabela
-Como exemplo poderíamos considerar:
select * from [Servidor01\SQLEXPRESS].BancoCurso.dbo.Clientes

Apostila de MS SQL Server Pág.: 71 / 86
Anexo – 2
Conhecendo o SQL Server 2005 Express EditionAntes de mais nada, vamos esclarecer uma coisa. O SQL Server 2005 Express Edition (SQL Server Express) não é o SQL Server 2005 propriamente dito. O SQL Server Express é uma plataforma de banco de dados baseada nas tecnologias do SQL Server 2005 e chega para substituir o MSDE 2000. Ele é um produto gratuito e possui características de rede e segurança que o diferenciam das demais edições do SQL Server 2005.
Neste artigo pretendo fazer uma introdução básica sobre o SQL Server Express 2005, falando sobre suas principais características e fazendo uma comparação com o atual MSDE 2000.
Esta edição do SQL Server Express tem como grande promessa uma superior facilidade de utilização com um processo de instalação simples e robusto e com uma ferramenta gráfica (SQL Express Manager), que permitirá realizar a adminsitração do servidor de uma forma simples e prática. Esta ferramenta gráfica ainda esta em desenvolvimento e será disponibilizada como um download gratuíto no site da Microsoft.
O SQL Server Express foi desenvolvido tendo em mente duas utilizações básicas: A primeira, como um servidor de produtos, especialmente como um Web Server ou Database Server. O segundo, como um cliente stand-alone, onde a aplicação não precise depender de uma rede para obter acesso aos dados.
O Engine (Motor)O SQL Server Express usa o mesmo engine que as demais edições do SQL Server 2005, mas por ser uma edição digamos, light, possui algumas limitações. O engine suporta 1CPU, 1GB RAM e banco de dados com até 4GB. Uma mudança significativa em relação ao MSDE 2000 é que o engine do SQL Express não possui a limitação de usuários concorrentes, conhecida como “Concurrent Workload Governor” onde a performance do MSDE 2000 é extremamente prejudicada na medida em que as conexões concorrentes de usuários aumentam. Para saber mais sobre esta limitação do MSDE 2000, clique aqui.
O SQL Server Express até pode ser instalado em máquinas multiprocessadas mas somente 1 CPU será reconhecida pelo engine. Como consequência, características como execução de consultas em paralelo não é suportado pelo SQL Server Express.
O limite de 1GB RAM é apenas para o buffer pool. O buffer pool é usado para o armazenamento de páginas de dados e outras informações. A memória necessária para o gerenciamento de conexões, locks e outros não estão incluídos neste limite de 1GB. Sendo assim, o SQL Express pode ser instalado normalmente em máquinas com mais de 1GB, mas ele nunca usará mais que 1GB para o buffer pool. AWE ou /3GB não é suportado.
O limite de 4GB para o banco de dados é aplicado apenas para o arquivo de dados. Entretanto, não existe limite para o número de banco de dados que você pode colocar no servidor.
O SQL Server Express suporta instalação side-by-side com outras versões do SQL Server, podendo coexistir na mesma máquina junto com instalações do SQL Server 2000, SQL Server 2005 ou MSDE 2000. Suporta um número máximo de 50 instâncias na mesma máquina desde que cada instância seja unicamente identifica, ou seja, você pode realizar até 50 instalações do SQL Express desde que cada instância tenha um nome diferente. Por padrão o SQL Server Express é instalado com uma named instance chamada SQLEXPRESS.

Pág.: 72 / 86 Apostila de MS SQL Server
FerramentasDiferente do MSDE 2000 que não possui ferramenta gráfica, o SQL Server Express possuirá uma ferramenta gráfica chamada SQL Server Management Studio Express (SSMSE). Esta, ainda em fase de desenvolvimento, mas já disponível para download público, será uma versão ligth do atual SQL Server Management Studio disponível nas demais edições do SQL Server 2005 e permitirá uma fácil administração dos bancos de dados.
O SSMSE suportará conexões para SQL Server Express e outras edições do SQL Server 2005, SQL Server 2000 e MSDE 2000. Uma janela de conexão guiará o usuário através da seleção de uma instância e o método de autenticação a ser utilizado, suportando conexões locais ou remotas. Diversas funcionalidades de gerenciamento de banco de dados estarão disponíveis através do menu de contexto (botão direito) e wizards. Entre elas podemos citar, criar e modificar banco de dados, tabelas, usuários e logins. O Query Editor do SSMSE também permitirá o desenvolvimento e execução de instruções T-SQL e scripts.

Apostila de MS SQL Server Pág.: 73 / 86
Funcionalidades
O SQL Server Express suporta a maioria das funcionalidades do SQL Server 2005. A tabela abaixo mostra algumas características e componentes suportados:
Stored ProceduresSQL Computer ManagerViewsReplication (as a subscriber only)TriggersAdvanced Query OptimizerCursorsSMO / RMOSqlcmd and osql utilitiesIntegration with Visual Studio 2005Snapshot Isolation LevelsService Broker (as a client only)Native XML support, including XQuery and XML SchemasSQL CLRT-SQL language supportMultiple Active Result Sets (MARS)
Tabela 01
A tabela abaixo destaca os principais componentes do SQL Server 2005 que não são suportados nesta versão do SQL Express Edition:
- Reporting Services - Notification Services - Analysis Services - SQL Agent - Full text search - DTS - OLAP Services / Data Mining - English Query

Pág.: 74 / 86 Apostila de MS SQL Server
SQL Server Management Studio Express (SSMSE).
O Microsoft SQL Server 2008 Management Studio Express (SSMSE) é um ambiente de desenvolvimento integrado gratuito para acessar, configurar, gerenciar e desenvolver todos os componentes do SQL Server. O SQL Server 2008 Management Studio Express combina um amplo grupo de ferramentas gráficas com editores de scripts sofisticados que fornecem acesso ao SQL Server a desenvolvedores e administradores de todos os níveis de experiência. Desenvolvedores terão uma experiência familiar e os administradores de banco de dados terão um único utilitário abrangente que combina ferramentas gráficas fáceis de usar com sofisticadas capacidades de script.
Figura 01

Apostila de MS SQL Server Pág.: 75 / 86
Anexo - 3Suporte a Rede Embora o usuário possa habilitar o suporte a protocolos como TCP/IP e Named Pipes , por padrão o SQL Server Express é instalado apenas com suporte a shared memory. Isto faz com que por default o SQL Server Express funcione apenas localmente na máquina onde foi instalado e não suporte conexões de clientes em uma rede. Para suportar conexões de clientes remotos, é necessário habilitar o suporte a rede no SQL Server Express. Para habilitar o suporte a rede, você tem as seguintes opções: -Usar o SQL Server Configuration Manager para habilitar os protocolos necessários (normalmente TCP/IP) e iniciar o serviço SQL Server Browser. A figura abaixo mostra o uso do SQL Server Configuration Manager para habilitar protocolos de rede.
Você pode acessar a funcionalidade descrita acima, clicando em Iniciar / Programas / Microsoft SQL Server 2005 / Configuration Tools / SQL Server Configuration Manager no menu suspenso do seu Windows.
Figura 02
O SQL Browser é um novo serviço do SQL Server 2005 que identifica as portas que as named instances estão usando. Este serviço vem desativado por default e deve ser ativado para que a comunicação entre um cliente remoto e um servidor SQL Server Express funcione corretamente.
Complementando a configuração necessária, observe a Figura 03, onde a propriedade Enabled é habilitada (Yes). Observe ainda a Figura 04 onde as propriedades Active e Enabled também devem estar habilitadas (Yes).

Pág.: 76 / 86 Apostila de MS SQL Server
Figura 03
Figura 04

Apostila de MS SQL Server Pág.: 77 / 86
Anexo – 4Acessando o utilitário Microsoft SQL Server Management Studio Express
Por último, acessando o utilitário Microsoft SQL Server Management Studio Express, clique no nó Logins escolhendo em seguida o login SA (naturalmente com o botão direito do mouse) acessando Propriedades no menu suspenso. A Figura abaixo será exibida, devendo ser observado em Login name a opção SQL Server Authentication. Defina um valor para password e pronto.
Figura 05

Pág.: 78 / 86 Apostila de MS SQL Server
Anexo – 5Exercícios Extras
Variações do Comando Select
Subqueries (Exists, Not Exists, In e Not In)
Select Clientes.Nome From Clientes Where Exists(Select * From Pedidos Where Clientes.ID_Cliente = Pedidos.ID_Cliente)
Select Clientes.Nome From Clientes Where Not Exists(Select * From Pedidos Where Clientes.ID_Cliente = Pedidos.ID_Cliente)
Select Produtos.Descricao From Produtos Where Produtos.ID_Produto In(Select Itens.ID_Produto From Itens Where Itens.Quantidade > 100 )
Select Produtos.Descricao From Produtos Where Produtos.ID_Produto Not In(Select Itens.ID_Produto From Itens Where Itens.Quantidade > 100 )
Obtendo Dados pela União de Tabelas ou Views (Union)Select Clientes.Nome, Clientes.Cnpj From Clientes
UnionSelect Fornecedores.Nome, Fornecedores.Cnpj From Fornecedores
Obtendo Melhor Performance com o Operador LikeSelect Clientes.Nome From Clientes Where Clientes.Nome Like 'Mar%'Pode alcançar melhor performance se substituida por:Select Clientes.Nome From Clientes WhereClientes.Nome >= 'Mar' And Clientes.Nome Like 'Mar%'

Apostila de MS SQL Server Pág.: 79 / 86
Criar as seguintes tabelas e Índices
AssociadoCreate Table Associado(Id Int Not Null,Nome Varchar(50) Not Null,Cidade Varchar(25) Not Null,Estado Char(2) Not Null,Data DateTime)
EspecialidadeCreate Table Especialidade(Id Int Not Null,Descricao Varchar(25) Not Null)
Associado_EspecialidadeCreate Table Associado_Especialidade(Id Int Not Null,AssociadoID Int Not Null,EspecialidadeID Int Not Null)
Nota 1:Entidades Associado e Especialidade referem-se as tabelas que identificam os agentes do projeto. Já Associado_Especialidade, armazena os relacionamentos possíveis entre associados e especialidades.
Nota 2:Quanto a chave primária, para Associado e Especialidade, os respectivos campos iniciados com Id compõem a chave primária; e para a tabela Associado_Especialidade, que numa visão clássica, as duas colunas, a saber, AssociadoID e EspecialidadeID iriam compor a chave primária. Mas numa visão mais atualizada, cada entidade deve ter um atributo que defina sua chave primária, logo o campo ID é inserido neste contexto para servir de chave primária para esta entidade.
Nota 3:Finalizando a estrutura, observa-se que as colunas AssociadoID e EspecialidadeID da tabela Associado_ Especialidade, são individualmente chave estrangeira, respectivamente com referência as tabelas Associado e Especialidade.
Nota 4:Adicionar 4 registros a tabela Associado, 4 registros a tabela Especialidade e pelo menos 8 registros na tabela Associado_Especialidade.
Nota 5:Criar índices para os campos nome, cidade e estado da tabela Associado e índice para o campo descricao da tabela Especialidade.

Pág.: 80 / 86 Apostila de MS SQL Server
Obs.: Usar a seguinte nomenclatura: Idx_campo_tabela
CREATE INDEX idx_Nome_Associado ON Associado(Nome)
CREATE INDEX idx_Cidade_Associado ON Associado(Cidade)
CREATE INDEX[idx_Estado_Associado ON Associado(Estado)
CREATE INDEX idx_Descricao_Especialidade ON Especialidade(Descricao)
Criar as Seguintes Views
-View que retorne a quantidade de cadastros de Associados por mês
Select Convert(Varchar(15), Datepart(mm,A.Data)) + '-' + Convert(Varchar(15), Datepart(yy,A.Data)) AS 'Mes-Ano',
Count(A.nome) As QtdFrom Associado AGroup by Convert(Varchar(15), Datepart(mm,A.Data)) + '-' +
Convert(Varchar(15), Datepart(yy,A.Data))
-View que retorne quantas especialidades tem cada associado, com mais de uma especialidade.Select A.Nome,
Count(AESP.Id_Associado) As QtdFrom Associado A INNER JOIN Associado_Especialidade AESPOn A.Id_Associado = AESP.AssociadoIDGroup by A.NomeHaving Count(AESP.AssociadoID) > 1

Apostila de MS SQL Server Pág.: 81 / 86
Criar as Seguintes Procedures
-Criar uma procedure para a inclusão de associados, possibilitando alteração e exclusão. Também implementar tratamento de erros (exception) e controle de Transação.
Create procedure Proc_Manut_Associados(@Id Int, @nome Varchar(50),@cidade Varchar(25), @estado Char(2),@data DateTime, @operacao Char(1)
) As
Declare @Msg Varchar(255), @Erro int
BEGIN If @operacao = 'I'
BeginInsert Into Associado(Id, nome, cidade, estado, data)Values(@Id, @nome, @cidade, @estado, @data)
set @Erro = @@ErrorIf @Erro <> 0 Begin
Select @Msg = 'Operação não realizada devido ao seguinte erro: '+ Convert(Varchar(255),@Erro)
Raiserror(@Msg,10,1) End
End Else If @operacao = 'A'
BeginUpdate Associado Set
Associado.Nome = @nome, Associados.Cidade = @cidade,Associado.Estado = @estado, Associados.Data = @data,
Where Associado.Id = @id
set @Erro = @@ErrorIf @erro <> 0
BeginSelect @Msg = 'Operação não realizada devido ao seguinte erro: '
+ Convert(Varchar(255),@Erro)Raiserror(@Msg,10,1)
EndEnd
ElseBegin
Delete AssociadoWhere Associado.Id = @id
set @Erro = @@ErrorIf @erro <> 0 Begin
Select @Msg = 'Operação não realizada devido ao seguinte erro: '+ Convert(Varchar(255),@Erro)
Raiserror(@Msg,10,1) End
EndEnd

Pág.: 82 / 86 Apostila de MS SQL Server
-Criar uma Procedure que retorna a quantidade de associados que tenham especialidades por estado. Esta Procedure deverá prover um parâmetro para escolha do estado.
CREATE Procedure Proc_QtdeAssociados_Estado(@estado char(2)) AsBegin
Select Count(Associado.Id)From Associado INNER JOIN Associado_EspecialidadeOn Associado.Id = Associado_Especialidade.AssociadoIDWhere Associado.estado = @estado
End

Apostila de MS SQL Server Pág.: 83 / 86
Criar as Seguintes Triggers
-Criar Trigger que dispare uma exceção, quando da inclusão ou alteração na tabela especialidades, provocar um conteúdo para o campo descrição com menos de três caracteres.
CREATE TRIGGER Trig_Valida_Descricao ON Especialidade FOR INSERT, UPDATE AS Declare @Tam intBegin Select @Tam = Convert(int , DataLength ( Inserted.Descricao))
From Inserted If @Tam < 3 Begin
Raiserror ('Erro' ,10,1)Rollback
EndEnd
-Criar uma Trigger que limite o total de especialistas de uma especialidade(Descricao) em no máximo 4 (quatro), por Estado.
Create Trigger Trig_Controla_Limite_Especialistas on Associado_EspecialidadeFor Insert, Update AS
Declare @total Numeric, @estado Char(2)
BeginSelect @estado = Associado.EstadoFrom Associados , InsertedWhere Associado.Id = Inserted.Id
Select @total = Count(Associado.Estado)From AssociadoINNER JOIN Associado_EspecialidadeOn Associados.Id = Associado_Especialidade.AssociadoID INNER JOIN InsertedOn Associado_Especialidade. EspecialidadeID = Inserted.EspecialidadeIDWhere Associado.Estado = @estado
If @total > 4Begin
Raiserror('Minha Mensagem.....',10,1)End
End

Pág.: 84 / 86 Apostila de MS SQL Server
Anexo – 6 Tabelas Particionadas
Tabela Particionada? O que é isso?A maneira mais simples de entender este conceito é através de um exemplo. Imagine que você tenha que armazenar em uma tabela todas as notas fiscais emitidas por uma cadeia nacional de “fast food” em suas centenas de lojas pelo Brasil. A tabela deve ficar grande, não? Agora imagine o trabalho que as operações do dia-a-dia realizam nesta tabela. Não só Inserções, Consultas e Alterações, mas também operações de Backup, Ordenação, Desfragmentação…
Agora pense na seguinte solução: Armazenar as notas fiscais referentes a cada mês em uma partição desta tabela. Algo como ter um caderninho para controle de cada mês. Não fica bem mais fácil? Na maior parte do tempo, você só manipulará os dados do mês atual. Você pode até manter a partição do mês atual como “read-write” e as outras como “read-only”. Talvez você não precise de backups diários das partições relativas a meses anteriores, o que reduzirá drasticamente a janela de backup!
Ilustração de Tabela Particionada
Aumentando o Desempenho com múltiplos discos
Agora uma afirmação que pode causar espanto. Pode ser intuitivo pensar que é vantajoso, do ponto de vista de desempenho, colocar cada partição em um disco físico separado, não é mesmo?.A princípio, temos a impressão que estaremos utilizando todos os discos ao mesmo tempo, o que melhora o desempenho.
Pois não é bem assim... Apesar dos ganhos de desempenho serem claros nas operações que acabamos de discutir em tabelas particionadas, o SQL Server executa operações de ordenação em uma partição de cada vez. Em outras palavras: somente um disco seria utilizado por vez, o que reduziria o desempenho...
A maneira mais eficiente de utilizar múltiplos discos é configurando volumes distribuídos em vários discos, em estruturas RAID. Desta forma, mesmo quando uma operação de ordenação é realizada numa única partição, todos os discos da estrutura RAID são utilizados em paralelo. Interessante, não? :)
Próximos Passos…
Obs.: No SQLEXPRESS, Não permite criação de particionamento.

Apostila de MS SQL Server Pág.: 85 / 86
1. Criar a seguinte Tabela:
CREATE TABLE LANCAMENTO_CONTABIL (
ID_LANCAMENTO_CONTABIL BIGINT NOT NULL,DATA_LANCAMENTO DATETIME,DATA_FATO DATETIME,ID_CONTA_CONTABIL INT,VALOR MONEY
)
2. Criar a função de particionamento com DataType DATETIME como parâmetro
CREATE PARTITION FUNCTION PF_Tabela_Lancamento_Contabil(DATETIME)
AS RANGE RIGHTFOR VALUES (
'2006-07-01','2006-10-01','2007-01-01','2007-04-01')
Obs.: Surgirar a seguinte Msg:
”Msg 7736, Level 16, State 1, Line 3Partition function can only be created in Enterprise edition of SQL Server. Only Enterprise edition of SQL Server supports partitioning.”
3. Adicionar 10 FILEGROUPS ao Banco de Dados
ALTER DATABASE DBA ADD FILEGROUP FG_TAB_LancContab_QBASEALTER DATABASE DBA ADD FILEGROUP FG_TABLancContab _Q1ALTER DATABASE DBA ADD FILEGROUP FG_TABLancContab _Q2ALTER DATABASE DBA ADD FILEGROUP FG_TABLancContab _Q3

Pág.: 86 / 86 Apostila de MS SQL Server
4. Implementar a Partition Scheme PS_Tabela_Lancamento_Contabil, com a Partition Function PF_Tabela_Lancamento_Contabil como parâmetro
CREATE PARTITION SCHEME PS_TabelaXPTOQuarterly AS PARTITION PFTabelaXPTOQuarterly TO(
FG_TAB_LancContab_QBASEFG_TABLancContab _Q1,FG_TABLancContab _Q2,FG_TABLancContab _Q3 )
• Nesta situação, o primeiro FG tem todos os dados desde Abril 2006 até Julho 2006.• Os seguintes FG’s tem a data que correspondente ao valor de cada partition.• O último FG tem todos os dados com data superior a Abril 2008.