Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Angelo Carvalho, Partner Solutions Architect
Em Tempo Real - Ingestão,
Processamento e Análise de Dados

Agenda
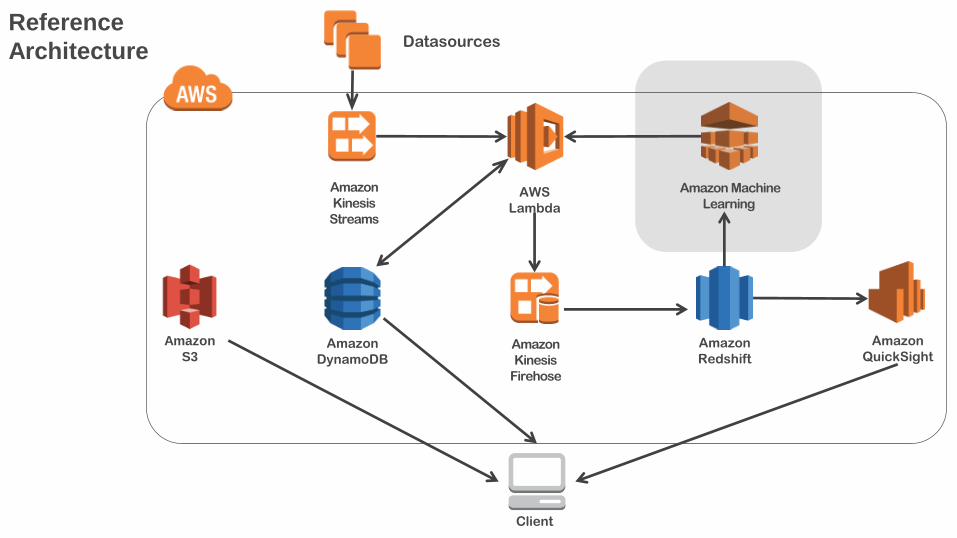
1. Reference Architecture
2. AWS Services
3. Reference Architecture: Demo

Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing
Big Data Pattern for Batch processing

Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing
What About Real-Time?

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

• Real Time Analytics:• ATC: Detect Collisions!
• Air Defense: Find suspicious aircrafts!

Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing

Ingesting Data:
Amazon Kinesis Platform

Amazon Kinesis: Streaming Data Done the AWS WayMakes it easy to capture, deliver, and process real-time data streams
Pay as you go, no up-front costs
Elastically scalable
Right services for your specific use cases
Real-time latencies
Easy to provision, deploy, and manage

Amazon Kinesis: Streaming data made easyServices make it easy to capture, deliver and process streams on AWS
Kinesis Streams
For Technical Developers
Kinesis Firehose
For all developers, data
scientists
Kinesis Analytics
For all developers, data
scientists
Build your own custom
applications that process
or analyze streaming data
Easily load massive
volumes of streaming
data into S3 and Redshift
Easily analyze data
streams using standard
SQL queries

Amazon Kinesis Streams

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

Amazon Kinesis StreamsBuild your own data streaming applications
Easy administration: Simply create a new stream, and set the desired level of
capacity with shards. Scale to match your data throughput rate and volume.
Build real-time applications: Perform continual processing on streaming big data
using Kinesis Client Library (KCL), Apache Spark/Storm, AWS Lambda, and more.
Low cost: Cost-efficient for workloads of any scale.

Amazon Web Services
AZ AZ AZ
Durable, highly consistent storage replicates dataacross three data centers (availability zones)
Aggregate andarchive to S3
Millions ofsources producing100s of terabytes
per hour
FrontEnd
AuthenticationAuthorization
Ordered streamof events supportsmultiple readers
Real-timedashboardsand alarms
Machine learningalgorithms or
sliding windowanalytics
Aggregate analysisin Hadoop or adata warehouse
Inexpensive: $0.028 per million puts
Real-Time Streaming Data Ingestion
Custom-built
Streaming
Applications
(KCL)
Inexpensive: $0.014 per 1,000,000 PUT Payload Units
Amazon Kinesis Streams - GA 2013Fully managed service for real-time processing of streaming data

Sending & Reading Data from Kinesis Streams
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client Library
+
Connector Library
Apache
Storm
Amazon Elastic
MapReduce
Sending Consuming
AWS Mobile
SDK
Kinesis
Producer
Library
AWS Lambda
Apache
Spark

• Streams are made of Shards
• Each Shard ingests data up to 1MB/sec,
and up to 1000 TPS
• Each Shard emits up to 2 MB/sec
• All data is stored for 24 hours – 7 days
• Scale Kinesis streams by splitting or
merging Shards
• Replay data inside of 24Hr -7days
Window
Amazon Kinesis StreamManaged Ability to capture and store Data

Simple Put Interface to put Data in Amazon
Kinesis Producers use a PUT call to store data in a
Stream. Each record <= 1 MB
PutRecord {Data,StreamName,PartitionKey}
PutRecords {Records{Data,PartitionKey}, StreamName}
A Partition Key is supplied by producer and used to
distribute (MD5 hash) the PUTs across (hash key range)
of Shards
A unique Sequence # is returned to the Producer upon
a successful PUT call
Putting Data in Amazon Kinesis

Latency
> 200 ms

Amazon Kinesis Firehose

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture
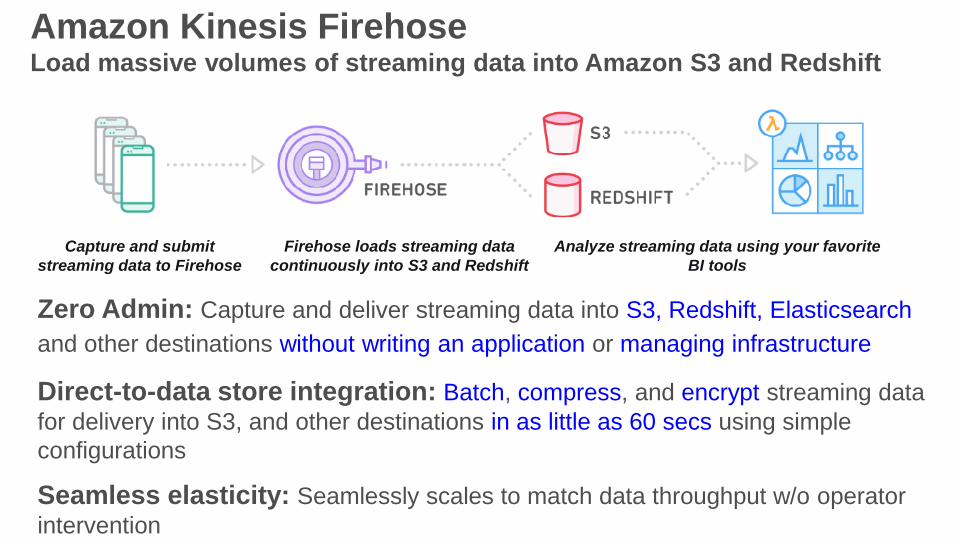
Amazon Kinesis FirehoseLoad massive volumes of streaming data into Amazon S3 and Redshift
Zero Admin: Capture and deliver streaming data into S3, Redshift, Elasticsearch
and other destinations without writing an application or managing infrastructure
Direct-to-data store integration: Batch, compress, and encrypt streaming data
for delivery into S3, and other destinations in as little as 60 secs using simple
configurations
Seamless elasticity: Seamlessly scales to match data throughput w/o operator
intervention
Capture and submit
streaming data to Firehose
Firehose loads streaming data
continuously into S3 and Redshift
Analyze streaming data using your favorite
BI tools

AWS Platform SDKs Mobile SDKs Kinesis Agent AWS IoT
Amazon S3 Amazon Redshift
• Send data from IT infra, mobile devices, sensors
• Integrated with AWS SDK, Agents, and AWS IoT
• Fully-managed service to capture streaming
data
• Elastic w/o resource provisioning
• Pay-as-you-go: 3.5 cents/ GB transferred
• Batch, compress, and encrypt data before loads
• Loads data into Redshift tables base on COPY
command
Amazon Kinesis Firehose
Capture IT & App Logs, Device & Sensor Data, and more Enable near-real time analytics using existing tools
Amazon Elasticsearch

Amazon Kinesis Streams is a service for workloads that requires
custom processing, per incoming record, with sub-1 second
processing latency, and a choice of stream processing frameworks.
Amazon Kinesis Firehose is a service for workloads that require
zero administration, ability to use existing analytics tools based
on S3, Redshift or Elasticsearch, and a data latency of 60
seconds or higher.

Latency
>= 1 min

Amazon Kinesis Analytics

Amazon Kinesis AnalyticsAnalyze data streams continuously with standard SQL
Apply SQL on streams: Easily connect to data streams and apply existing SQL skills.
Build real-time streaming applications: Perform continual processing on streaming
big data with processing latencies in seconds
Easy and interactive experience: Complete most stream processing use cases in
minutes, and easily progress toward sophisticated scenarios
Connect to streaming data
sourcesRun standard SQL queries
against data streams
Send SQL results to downstream
destinations

Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing

Processing Data:
Lambda

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

AWS Lambda
A compute service where you
don’t have to think about:
• Servers
• Being over/under capacity
• Deployments
• Scaling and fault tolerance
• OS or language updates
• Metrics and logging
…but where you can easily
• Bring your own code…
even native libraries
• Run code in parallel
• Create backends, event
handlers, and data
processing systems
• Never pay for idle!

AWS Lambda – Benefits
EVENT-DRIVEN SCALESERVERLESS SUBSECOND BILLING

AWS Lambda – How It Works
DEPLOYMENT
AUTHORING
MONITORING & LOGGING
STATELESS

AWS Services Integrated with AWS Lambda
Amazon
S3
Amazon
DynamoDB
Amazon
Kinesis
AWS
CloudTrail
Amazon
CloudWatch
Logs
AWS
CloudFormation
Amazon
SNS
Amazon
SWF
Amazon
SES
Amazon
API Gateway
Amazon
Cognito

Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing

Storing Data:
Amazon DynamoDB

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

Why NoSQL?
Horizontal scalability
Simplicity of design (Unstructured Data)
Finer control of availability
Less/No limitation in database size
Administrative burden of sharding RDBMS

What is DynamoDB?
Non-Relational Managed NoSQL Database Service• Schema less data model
• Consistent low latency performance (single digit ms)
• Predictable provisioned throughput
• Seamless Scalability
• No storage limits
• High durability and availability (replication between 3 facilities)
• Easy Administration – We scale for you!
• Low Cost
• Cost modelling on throughput and size
DynamoDB

Scalability
No limit in terms of throughput (reads/writes per second)
No limit in terms of storage
DynamoDB automatically partitions data by the hash key
Auto-Partitioning occurs when:
• Data set growth
• Provisioned capacity increasepartitions
1 .. N
table

Durability
WRITES3-way replication
Quorum acknowledgment
Persisted to disk (custom SSD)
READSStrongly or eventually consistent
No trade-off in latency

Easy Administration – It’s a service!
Making life easier for developers…
Developers are freed from:• Performance tuning (latency)
• Automatic 3-way multi-AZ replication
• Scalability (and scaling operations)
• Security inspections, patches, upgrades
• Software upgrades, patches
• Automatic hardware failover
• Improving the underlying hardware
…and lots of other stuff

Customer References

Latency
Single digit miliseconds latency
Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing

Analyzing Data:
Amazon Redshift

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

Fast, simple, petabyte-scale data warehousing for less than $1,000/TB/Year
Amazon Redshift

Relational data warehouse
Massively parallel; Petabyte scale
Fully managed
HDD and SSD Platforms
$1,000/TB/Year; starts at $0.25/hour
Amazon
Redshift
a lot faster
a lot simpler
a lot cheaper

The legacy view of data warehousing ...
Global 2,000 companies
Sell to central IT
Multi-year commitment
Multi-year deployments
Multi-million dollar deals

… Leads to dark data
This is a narrow view
Small companies also have big data
(mobile, social, gaming, adtech, IoT)
Long cycles, high costs, administrative
complexity all stifle innovation
0
200
400
600
800
1000
1200
Enterprise Data Data in Warehouse
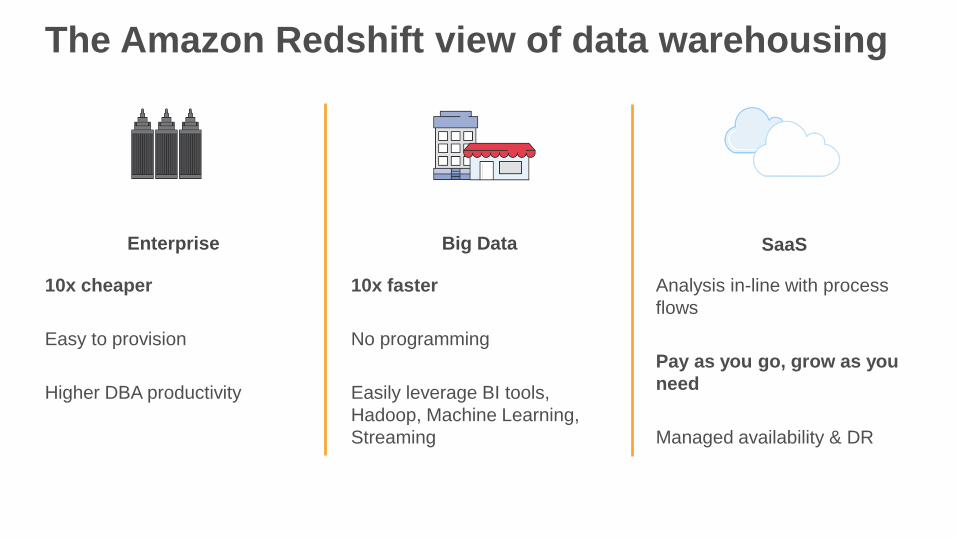
The Amazon Redshift view of data warehousing
10x cheaper
Easy to provision
Higher DBA productivity
10x faster
No programming
Easily leverage BI tools,
Hadoop, Machine Learning,
Streaming
Analysis in-line with process
flows
Pay as you go, grow as you
need
Managed availability & DR
Enterprise Big Data SaaS

Selected Amazon Redshift customers
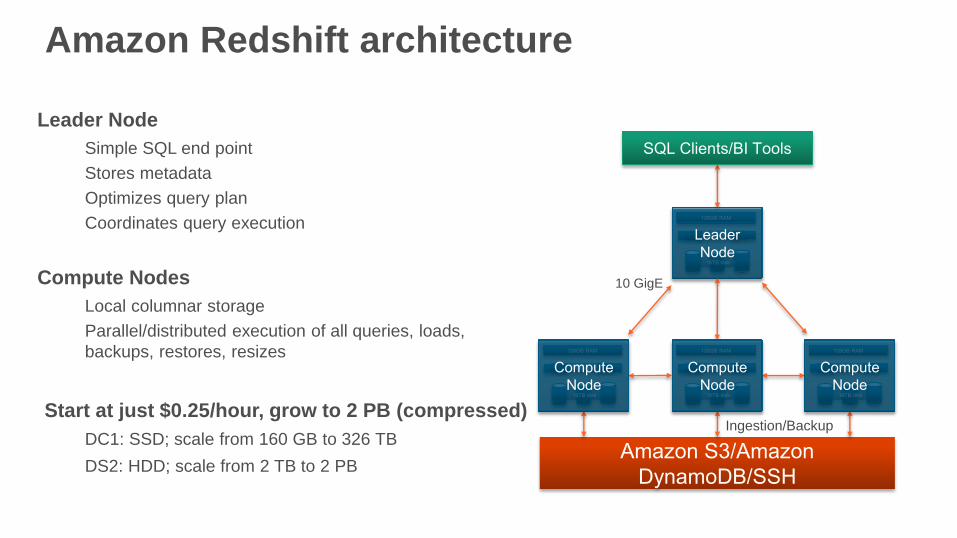
Amazon Redshift architecture
Leader Node
Simple SQL end point
Stores metadata
Optimizes query plan
Coordinates query execution
Compute Nodes
Local columnar storage
Parallel/distributed execution of all queries, loads,
backups, restores, resizes
Start at just $0.25/hour, grow to 2 PB (compressed)
DC1: SSD; scale from 160 GB to 326 TB
DS2: HDD; scale from 2 TB to 2 PB
Ingestion/Backup
Backup
Restore
JDBC/ODBC
10 GigE
(HPC)

Latency (using firehose)
Latency >= 1 min

Generation Collection &
Storage
Analytics &
Computation
Collaboration &
Sharing

Analyzing Data:
Amazon Machine Learning
Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

Data is part of the fabric of the applications
Front-end and UX Mobile Back-end
and operations
Data and
analytics

Three types of data-driven development
Retrospective
analysis and
reporting
Amazon Redshift
Amazon RDS
Amazon S3
Amazon EMR

Three types of data-driven development
Retrospective
analysis and
reporting
Here-and-now
real-time processing
and dashboards
Amazon Kinesis
Amazon EC2
AWS Lambda
Amazon Redshift,
Amazon RDS
Amazon S3
Amazon EMR

Three types of data-driven development
Retrospective
analysis and
reporting
Here-and-now
real-time processing
and dashboards
Predictions
to enable smart
applications
Amazon Kinesis
Amazon EC2
AWS Lambda
Amazon Redshift,
Amazon RDS
Amazon S3
Amazon EMR

Machine learning and smart applications
Machine learning is the technology that
automatically finds patterns in your data and
uses them to make predictions for new data
points as they become available

Machine learning and smart applications
Machine learning is the technology that
automatically finds patterns in your data and
uses them to make predictions for new data
points as they become available
Your data + machine learning = smart applications

Smart applications by example
Based on what you
know about the user:
Will they use your
product?

Smart applications by example
Based on what you
know about the user:
Will they use your
product?
Based on what you
know about an order:
Is this order
fraudulent?

Smart applications by example
Based on what you
know about the user:
Will they use your
product?
Based on what you
know about an order:
Is this order
fraudulent?
Based on what you know
about a news article:
What other articles are
interesting?

And a few more examples…
Fraud detection Detecting fraudulent transactions, filtering spam emails,
flagging suspicious reviews, …
Personalization Recommending content, predictive content loading,
improving user experience, …
Targeted marketing Matching customers and offers, choosing marketing
campaigns, cross-selling and up-selling, …
Content classification Categorizing documents, matching hiring managers and
resumes, …
Churn prediction Finding customers who are likely to stop using the
service, free-tier upgrade targeting, …
Customer support Predictive routing of customer emails, social media
listening, …

Latency (for RT predictions)
Mostly within 100 MS

Latencies and Parallelism

Latencies and Parallelism
• Kinesis Streams: Latency > 200 ms
• Set IdleTimeBetweenReadsInMillis
• Kinesis Firehose: Latency >= 1 min
• Set S3 buffer interval
• DynamoDB: Single digit miliseconds latency
• Don’t set anything

Latencies and Parallelism
• Lambda: Process kinesis stream in parallel:
• Create many shards in your stream
• Make you lambda call other lambdas
• Use many threads
• ML: Use real time predictions
• Mostly within 100 ms

Amazon
Kinesis
Firehose
AWS
Lambda
Amazon
Kinesis
Streams
Amazon
DynamoDB
Amazon
Redshift
Amazon Machine
Learning
Amazon
QuickSight
Datasources
Client
Amazon
S3
Reference
Architecture

Demo Time!
• Real Time Analytics:• ATC: Detect Collisions!
• Air Defense: Find suspicious aircrafts!

Remember to complete
your evaluations!
AWS Summit App






























