Embed Size (px)
Citation preview

IBM TRIRIGA Application PlatformVersão 3 Release 5.2
Construção de aplicativos para oIBM TRIRIGA Application Platform:Estrutura de desempenho
IBM

NotaAntes de usar estas informações e o produto suportado por elas, leia as informações em “Avisos” na página 77.
Esta edição se aplica à versão 3, liberação 5, modificação 2 do IBM TRIRIGA Application Platform e a todas asliberações e modificações subsequentes até que seja indicado de outra forma em novas edições.
© Copyright IBM Corporation 2011, 2016.

Índice
Capítulo 1. Estrutura de desempenho . . 1
Capítulo 2. Estruturas de dados . . . . 3Visão geral da arquitetura . . . . . . . . . . 3Tabelas de fatos . . . . . . . . . . . . . 4
Exemplo de tabela de fatos e dimensõesassociadas . . . . . . . . . . . . . . 7
Estrutura de métricas . . . . . . . . . . . 8Integração ETL . . . . . . . . . . . . . 10
Arquitetura de integração do ETL . . . . . . 10Processo de integração ETL . . . . . . . . 12Configuração de pré-requisito para integraçãoETL . . . . . . . . . . . . . . . . 15Definindo e mantendo conversões ETL . . . . 16
Usando ETLs com Pentaho Spoon . . . . . 16Usando ETLs com o Editor de Configuraçãodo IBM Tivoli Directory Integrator. . . . . 33
Executando conversões ETL . . . . . . . . 56Itens da tarefa ETL, grupos de tarefas eprogramadores de tarefa . . . . . . . . 57Criando ou modificando itens da tarefa ETL 57Incluindo ou modificando grupos de tarefas 59Criando ou modificando programadores detarefa . . . . . . . . . . . . . . 60
Customizando objetos de conversão . . . . . 62Definindo objetos de negócios, formulários efluxos de trabalho de conversão . . . . . 62Salvando o XML de conversão no ContentManager . . . . . . . . . . . . . 62Configurando o tempo de execução do fluxode trabalho . . . . . . . . . . . . 63
Executando uma especificação de tarefa defluxo de trabalho customizado ETL . . . . 63
Capítulo 3. Métricas . . . . . . . . . 65Relatórios de métricas . . . . . . . . . . . 65Key Metrics . . . . . . . . . . . . . . 66Métricas de formulário . . . . . . . . . . 66
Filtragem de dados . . . . . . . . . . . 67Sub-relatórios. . . . . . . . . . . . . 67
Capítulo 4. Compressor de hierarquia 69Hierarquias simples . . . . . . . . . . . 69
Exemplos de hierarquias simples . . . . . . 70Gerenciador de estrutura de hierarquia . . . . . 71
Acessando estruturas de hierarquia . . . . . 71Criando uma hierarquia de dados . . . . . . 71Criando uma hierarquia de formulário . . . . 72
Capítulo 5. Tabelas de fatos. . . . . . 73Lista de tabelas de fatos e as métricas suportadas . 73Fatos que requerem tabelas de migração de dados eETLs especiais . . . . . . . . . . . . . 73ETLs dependentes . . . . . . . . . . . . 74
Avisos . . . . . . . . . . . . . . . 77Marcas comerciais . . . . . . . . . . . . 79Termos e Condições para a Documentação doProduto . . . . . . . . . . . . . . . 79Declaração de privacidade online da IBM . . . . 80
© Copyright IBM Corp. 2011, 2016 iii

iv © Copyright IBM Corp. 2011, 2016

Capítulo 1. Estrutura de desempenho
O IBM® TRIRIGA Workplace Performance Management e o IBM TRIRIGA RealEstate Environmental Sustainability fornecem soluções viáveis para ajudar ascorporações a planejar, gerenciar, avaliar e melhorar estrategicamente os processosque estão relacionados a instalações e imóveis.
A estrutura de desempenho do IBM TRIRIGA é gerenciada no TRIRIGA WorkplacePerformance Management e TRIRIGA Real Estate Environmental Sustainability, queincluem os componentes a seguir:v Serviços de conversão de dados e carregamento da tabela de fatosv Um construtor de métrica que usa o modelador de dadosv Um mecanismo de consulta de métricav Gerenciador de relatório aprimorado para construir relatórios de métricasv Recursos avançados de portal para renderizar pontuações de métricav Uma série de métricas, relatórios e alertas pré-construídos que melhoram
significativamente a produtividade das muitas funções suportadas no TRIRIGA
© Copyright IBM Corp. 2011, 2016 1

2 © Copyright IBM Corp. 2011, 2016

Capítulo 2. Estruturas de dados
O TRIRIGA usa o ambiente de desenvolvimento extrair, transformar e carregar(ETL) como o mecanismo para mover dados de tabelas de objetos de negócios paratabelas de fatos. Para apresentar métricas, relatórios, pontuações e outras medidasde desempenho, os dados devem estar em um formato de tabelas de fatos e tabelasde hierarquias simples que as ferramentas de relatórios podem processar.
Visão geral da arquiteturaOs dados de origem do TRIRIGA Workplace Performance Management sãoprovenientes do banco de dados de aplicativos do TRIRIGA, dados de resumofinanceiro que são importados de um sistema financeiro externo e dados domedidor de construção que são importados de sistemas de gerenciamento deconstrução externa.
Usando a tecnologia ETL, os dados de origem são carregados nas tabelas de fatos.As tabelas de fatos e as tabelas de dimensões estão no mesmo repositório de bancode dados dos aplicativos TRIRIGA. As tabelas de fatos armazenam os dadosnuméricos, referidos como fatos, que são utilizados para calcular os valores demétrica do TRIRIGA Workplace Performance Management. Cada linha em umatabela de fatos faz referência a um ou mais objetos de negócios relacionados,classificações ou listas que agrupam e filtram os fatos. Essas linhas são chamadasde dimensões.
O mecanismo de consulta de métrica executa consultas nas tabelas de fatos edimensões. As consultas de métricas rapidamente recalculam valores de métricasconforme o usuário move para cima e para baixo uma dimensão hierárquica.
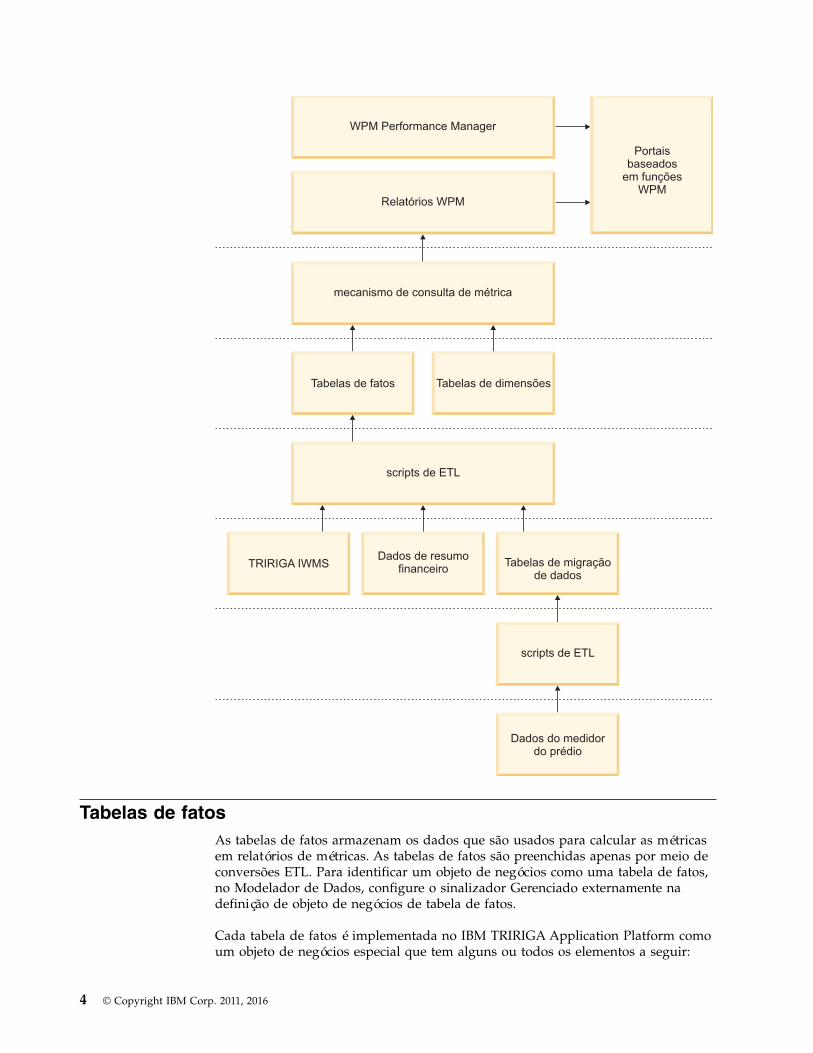
O diagrama a seguir mostra as camadas distintas que compõem essa arquitetura eo fluxo de dados entre essas camadas:
© Copyright IBM Corp. 2011, 2016 3
Relatórios WPM
Tabelas de fatos Tabelas de dimensões
WPM Performance Manager
mecanismo de consulta de métrica
scripts de ETL
Portaisbaseados
em funçõesWPM
TRIRIGA IWMSDados de resumo
financeiroTabelas de migração
de dados
scripts de ETL
Dados do medidordo prédio
Tabelas de fatosAs tabelas de fatos armazenam os dados que são usados para calcular as métricasem relatórios de métricas. As tabelas de fatos são preenchidas apenas por meio deconversões ETL. Para identificar um objeto de negócios como uma tabela de fatos,no Modelador de Dados, configure o sinalizador Gerenciado externamente nadefinição de objeto de negócios de tabela de fatos.
Cada tabela de fatos é implementada no IBM TRIRIGA Application Platform comoum objeto de negócios especial que tem alguns ou todos os elementos a seguir:
4 © Copyright IBM Corp. 2011, 2016
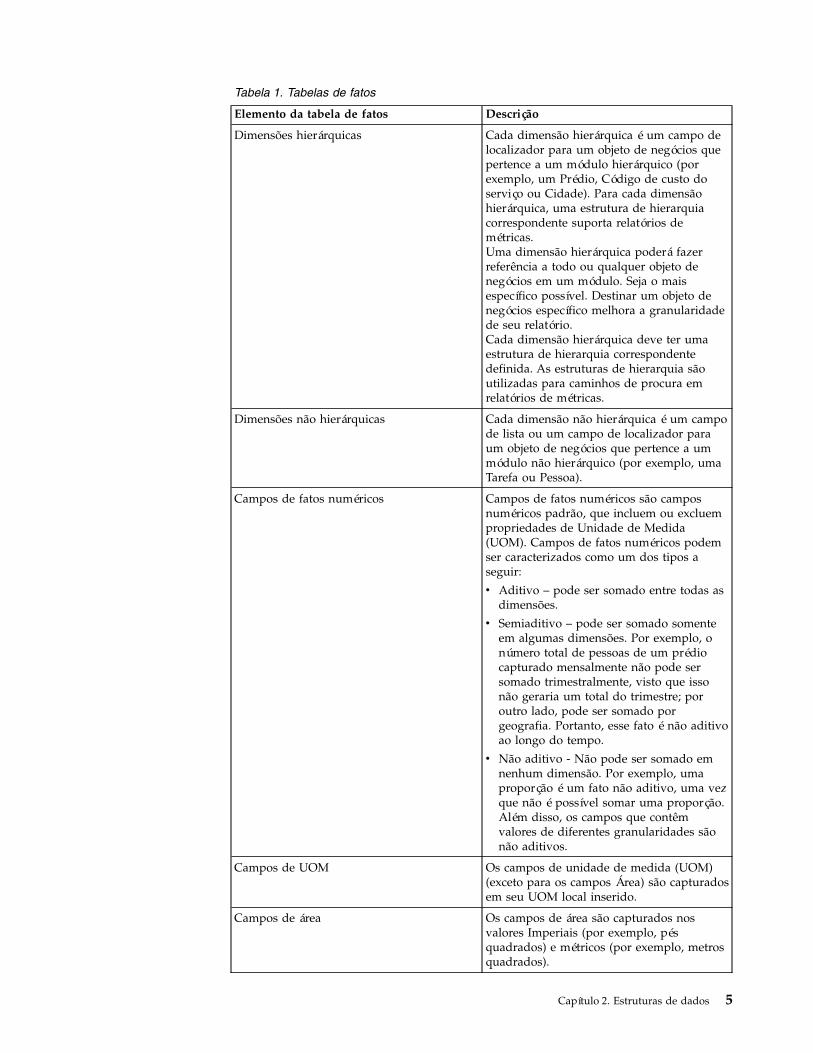
Tabela 1. Tabelas de fatos
Elemento da tabela de fatos Descrição
Dimensões hierárquicas Cada dimensão hierárquica é um campo delocalizador para um objeto de negócios quepertence a um módulo hierárquico (porexemplo, um Prédio, Código de custo doserviço ou Cidade). Para cada dimensãohierárquica, uma estrutura de hierarquiacorrespondente suporta relatórios demétricas.Uma dimensão hierárquica poderá fazerreferência a todo ou qualquer objeto denegócios em um módulo. Seja o maisespecífico possível. Destinar um objeto denegócios específico melhora a granularidadede seu relatório.Cada dimensão hierárquica deve ter umaestrutura de hierarquia correspondentedefinida. As estruturas de hierarquia sãoutilizadas para caminhos de procura emrelatórios de métricas.
Dimensões não hierárquicas Cada dimensão não hierárquica é um campode lista ou um campo de localizador paraum objeto de negócios que pertence a ummódulo não hierárquico (por exemplo, umaTarefa ou Pessoa).
Campos de fatos numéricos Campos de fatos numéricos são camposnuméricos padrão, que incluem ou excluempropriedades de Unidade de Medida(UOM). Campos de fatos numéricos podemser caracterizados como um dos tipos aseguir:
v Aditivo – pode ser somado entre todas asdimensões.
v Semiaditivo – pode ser somado somenteem algumas dimensões. Por exemplo, onúmero total de pessoas de um prédiocapturado mensalmente não pode sersomado trimestralmente, visto que issonão geraria um total do trimestre; poroutro lado, pode ser somado porgeografia. Portanto, esse fato é não aditivoao longo do tempo.
v Não aditivo - Não pode ser somado emnenhum dimensão. Por exemplo, umaproporção é um fato não aditivo, uma vezque não é possível somar uma proporção.Além disso, os campos que contêmvalores de diferentes granularidades sãonão aditivos.
Campos de UOM Os campos de unidade de medida (UOM)(exceto para os campos Área) são capturadosem seu UOM local inserido.
Campos de área Os campos de área são capturados nosvalores Imperiais (por exemplo, pésquadrados) e métricos (por exemplo, metrosquadrados).
Capítulo 2. Estruturas de dados 5
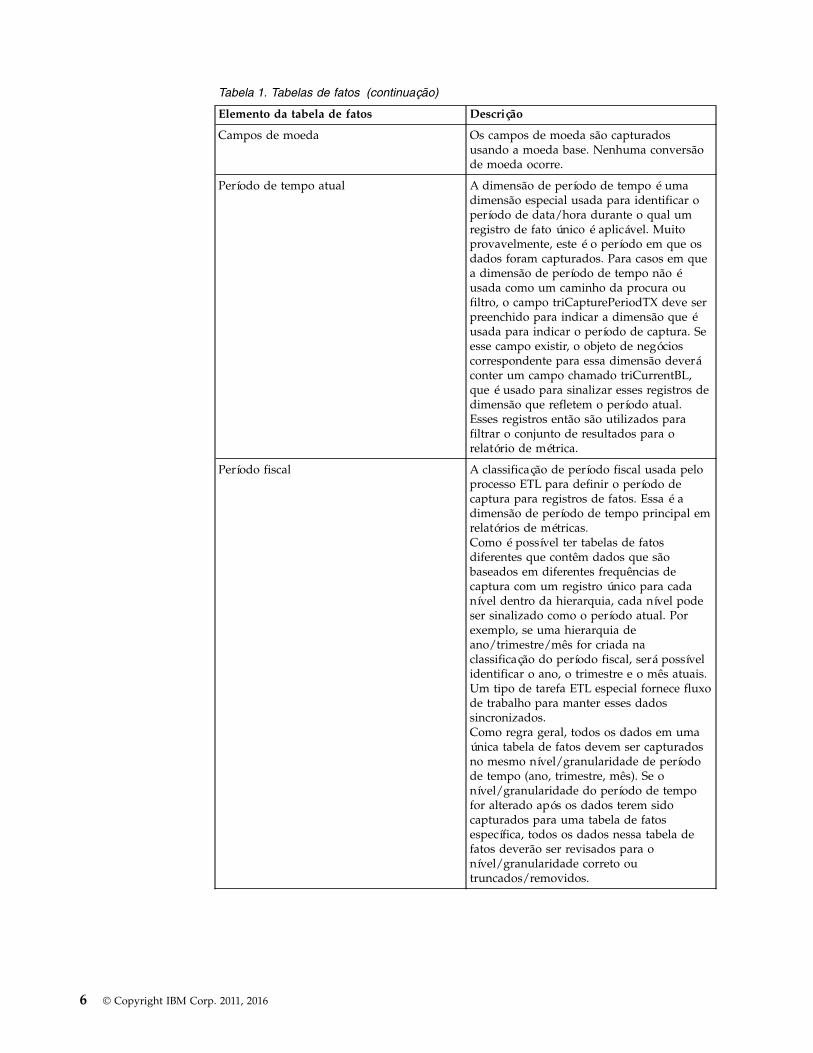
Tabela 1. Tabelas de fatos (continuação)
Elemento da tabela de fatos Descrição
Campos de moeda Os campos de moeda são capturadosusando a moeda base. Nenhuma conversãode moeda ocorre.
Período de tempo atual A dimensão de período de tempo é umadimensão especial usada para identificar operíodo de data/hora durante o qual umregistro de fato único é aplicável. Muitoprovavelmente, este é o período em que osdados foram capturados. Para casos em quea dimensão de período de tempo não éusada como um caminho da procura oufiltro, o campo triCapturePeriodTX deve serpreenchido para indicar a dimensão que éusada para indicar o período de captura. Seesse campo existir, o objeto de negócioscorrespondente para essa dimensão deveráconter um campo chamado triCurrentBL,que é usado para sinalizar esses registros dedimensão que refletem o período atual.Esses registros então são utilizados parafiltrar o conjunto de resultados para orelatório de métrica.
Período fiscal A classificação de período fiscal usada peloprocesso ETL para definir o período decaptura para registros de fatos. Essa é adimensão de período de tempo principal emrelatórios de métricas.Como é possível ter tabelas de fatosdiferentes que contêm dados que sãobaseados em diferentes frequências decaptura com um registro único para cadanível dentro da hierarquia, cada nível podeser sinalizado como o período atual. Porexemplo, se uma hierarquia deano/trimestre/mês for criada naclassificação do período fiscal, será possívelidentificar o ano, o trimestre e o mês atuais.Um tipo de tarefa ETL especial fornece fluxode trabalho para manter esses dadossincronizados.Como regra geral, todos os dados em umaúnica tabela de fatos devem ser capturadosno mesmo nível/granularidade de períodode tempo (ano, trimestre, mês). Se onível/granularidade do período de tempofor alterado após os dados terem sidocapturados para uma tabela de fatosespecífica, todos os dados nessa tabela defatos deverão ser revisados para onível/granularidade correto outruncados/removidos.
6 © Copyright IBM Corp. 2011, 2016

Tabela 1. Tabelas de fatos (continuação)
Elemento da tabela de fatos Descrição
Objeto de negócios de tabela de fatos Para identificar um objeto de negócios comoum que terá as tabelas de fatos que osuportem, selecione o botão de opçõesGerenciado externamente nas propriedadesdo objeto de negócios ao criar o objeto denegócios.
Dica: Não exclua ou altere qualquer um dos objetos de negócios de fatos, tabelasde fatos ou scripts ETL que são entregues com o software padrão TRIRIGA. Emvez disso, para alterar um existente, copie-o, renomeie a cópia e customize a cópiapara suas necessidades.
Exemplo de tabela de fatos e dimensões associadasAs tabelas de fato e dimensão são construídas usando o método de esquema emestrela do design de armazém de dados. Elas são armazenadas no mesmorepositório de banco de dados que os aplicativos do TRIRIGA.
O diagrama a seguir mostra um exemplo de uma das tabelas de fatospré-configuradas no TRIRIGA Workplace Performance Management:
Objeto de negócios do espaço
Campos de tabela de fatos
Capacidade de espaço
Número total de pessoas
Capacidade restante
Área do espaço
Área alocada
ID do espaço
ID do prédio
ID da localização
ID da geografia
ID da classe de espaço
ID da classe do prédio
ID de aforamento do prédio
Tabelas de dimensões
Objeto de negócios do prédio
Hierarquia de locais
Hierarquia da geografia
Hierarquia de classes de espaço
Hierarquia de classes do prédio
Hierarquia de aforamento do prédio
O diagrama mostra o fato do espaço com cinco fatos, incluindo a capacidade deespaço, número total de pessoas, capacidade restante, área de espaço e áreaalocada. O fato do espaço também referencia sete dimensões, incluindo espaço,prédio, localização, geografia, classe de espaço, classe de prédio e título de
Capítulo 2. Estruturas de dados 7
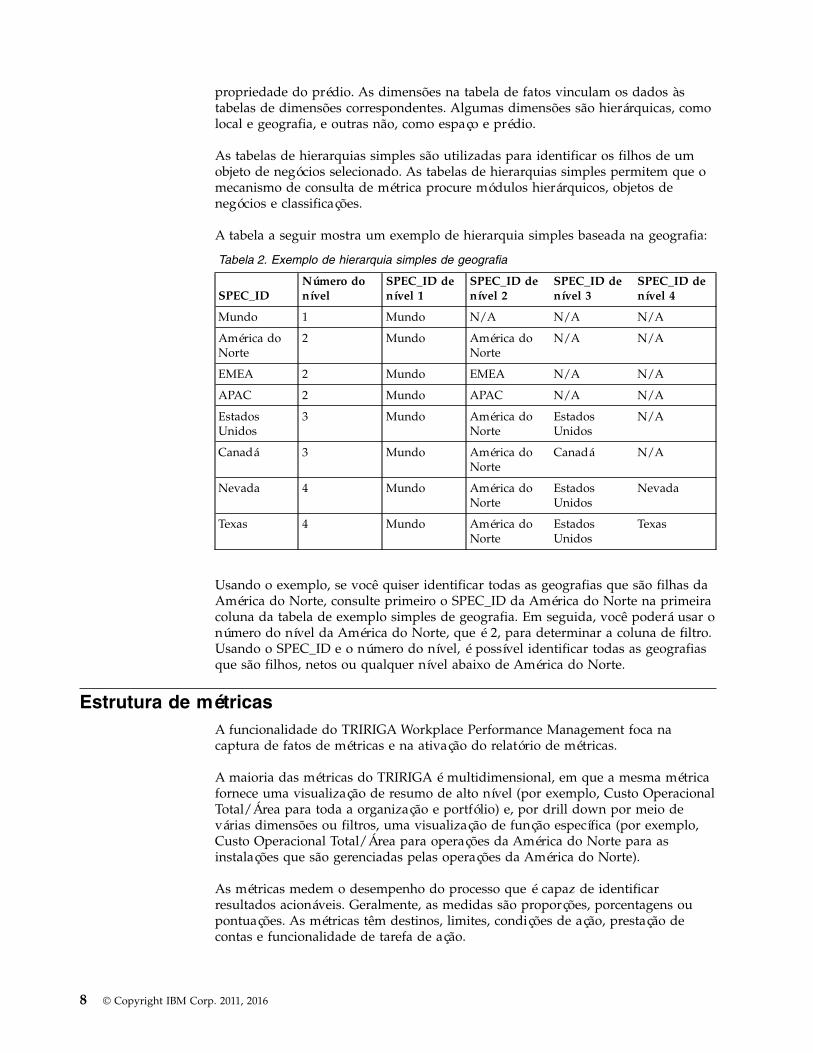
propriedade do prédio. As dimensões na tabela de fatos vinculam os dados àstabelas de dimensões correspondentes. Algumas dimensões são hierárquicas, comolocal e geografia, e outras não, como espaço e prédio.
As tabelas de hierarquias simples são utilizadas para identificar os filhos de umobjeto de negócios selecionado. As tabelas de hierarquias simples permitem que omecanismo de consulta de métrica procure módulos hierárquicos, objetos denegócios e classificações.
A tabela a seguir mostra um exemplo de hierarquia simples baseada na geografia:
Tabela 2. Exemplo de hierarquia simples de geografia
SPEC_IDNúmero donível
SPEC_ID denível 1
SPEC_ID denível 2
SPEC_ID denível 3
SPEC_ID denível 4
Mundo 1 Mundo N/A N/A N/A
América doNorte
2 Mundo América doNorte
N/A N/A
EMEA 2 Mundo EMEA N/A N/A
APAC 2 Mundo APAC N/A N/A
EstadosUnidos
3 Mundo América doNorte
EstadosUnidos
N/A
Canadá 3 Mundo América doNorte
Canadá N/A
Nevada 4 Mundo América doNorte
EstadosUnidos
Nevada
Texas 4 Mundo América doNorte
EstadosUnidos
Texas
Usando o exemplo, se você quiser identificar todas as geografias que são filhas daAmérica do Norte, consulte primeiro o SPEC_ID da América do Norte na primeiracoluna da tabela de exemplo simples de geografia. Em seguida, você poderá usar onúmero do nível da América do Norte, que é 2, para determinar a coluna de filtro.Usando o SPEC_ID e o número do nível, é possível identificar todas as geografiasque são filhos, netos ou qualquer nível abaixo de América do Norte.
Estrutura de métricasA funcionalidade do TRIRIGA Workplace Performance Management foca nacaptura de fatos de métricas e na ativação do relatório de métricas.
A maioria das métricas do TRIRIGA é multidimensional, em que a mesma métricafornece uma visualização de resumo de alto nível (por exemplo, Custo OperacionalTotal/Área para toda a organização e portfólio) e, por drill down por meio devárias dimensões ou filtros, uma visualização de função específica (por exemplo,Custo Operacional Total/Área para operações da América do Norte para asinstalações que são gerenciadas pelas operações da América do Norte).
As métricas medem o desempenho do processo que é capaz de identificarresultados acionáveis. Geralmente, as medidas são proporções, porcentagens oupontuações. As métricas têm destinos, limites, condições de ação, prestação decontas e funcionalidade de tarefa de ação.
8 © Copyright IBM Corp. 2011, 2016

O TRIRIGA Workplace Performance Management inclui os seguintes tipos demétricas, que são as categorias de Pontuação na seção do portal Key Metrics:
Métricas do clienteMedir a satisfação do cliente
Métricas FinanceirasMedir o desempenho financeiro
Métricas de PortfólioMedir a utilização operacional e o funcionamento do ciclo de vida do ativo
Métricas de processoMedir a eficiência e a efetividade do processo
Métricas de relatório e análiseAnalisar uma métrica de desempenho específica
Além disso, o TRIRIGA Real Estate Environmental Sustainability inclui os tipos demétricas a seguir:
AmbientalMedir o desempenho de iniciativas ambientais
Medidores de prédioMedir as características de um prédio como relatada pelos medidores esensores
O diagrama de processo de alto nível a seguir descreve como as métricas sãodefinidas, capturadas e apresentados ao usuário:
Mecanismo de processamento de métrica(ferramenta de analítica/relatório)
Dadosexternos TRIRIGA
Fato Dimensão
Portal de aplicativos TRIRIGA
Preparação
O banco de dados do TRIRIGA é a origem primária de dados para reunir dadosoperacionais a serem carregados nas tabelas de fatos. Como opção, você podeextrair dados de outras origens para serem carregados nas tabelas de fatos.
Capítulo 2. Estruturas de dados 9

Cada tabela de fatos contém o nível mais baixo de dados agregados (como nível deconstrução) para cada categoria de métrica. Por motivos de eficiência, uma tabelade fatos é uma tabela não normalizada (comprimida) que contém os elementos dedados de várias tabelas do TRIRIGA.
A tabela de dimensões contém dimensões para cada métrica. As dimensões sãoarmazenadas em uma tabela separada para fins de eficiência. A tabela de fatoscontém uma chave (ID de especificação) para cada dimensão. A tabela dedimensões pode ser uma tabela de hierarquia simples ou uma tabela de objetos denegócios do TRIRIGA.
O Mecanismo de processamento de métrica (Ferramenta de analítica/relatório)gera métricas usando dados armazenados em tabelas de fatos com dados deconfiguração de métrica e dados de dimensão.
Dados de métrica, com notificações, ações e alertas, são apresentados aos usuáriosem um portal baseado em função em vários formatos (incluindo relatórios,consultas e gráficos) conforme definido na tabela de configuração de métrica. Umusuário pode realizar drill down em um objeto ou caminho de procura específicopara analisar melhor os dados de métrica apresentados a ele.
O relatório de métrica é dependente de tabelas de fatos de métricas. Essas tabelasde fatos são implementadas utilizando o modelador de dados, mas sãoidentificados com um tipo de objeto exclusivo que significa que é um objeto demétrica. Os objetos de métrica são preenchidos utilizando um ambiente dedesenvolvimento ETL, que é diferente de todos os outros tipos de objetos que sãoatualizadas por meio da camada de metadados. O planejamento do processo ETL écontrolado no sistema TRIRIGA usando o planejador de tarefa.
Integração ETLO TRIRIGA usa o editor de configuração do ambiente de desenvolvimento ETL doTivoli Directory Integrator ou o Spoon do ambiente de desenvolvimento ETL doPentaho. Essas conversões, quando executadas por meio da API, movem dados dastabelas de origem para destino.
Arquitetura de integração do ETLO TRIRIGA usa dois ambientes ETL para criar os scripts ETL que preenchem astabelas de fatos. Os dois ambientes de desenvolvimento ETL são o editor deconfiguração do Tivoli Directory Integrator e a ferramenta Spoon do Pentaho DataIntegration. Os ambientes de desenvolvimento ETL permitem a criação deconsultas SQL que lêem dados das tabelas de objeto de negócios do TRIRIGA, bemcomo mapeiam e transformam os resultados para as colunas de dimensão e fato databela.
O diagrama a seguir mostra o fluxo de dados entre os dados de origem, oambiente de desenvolvimento ETL e as camadas de modelo de dados do TRIRIGAWorkplace Performance Management:
10 © Copyright IBM Corp. 2011, 2016

Instalações
TRIRIGA IWMS
Imóvel
Operações
Projetos
Dados de resumofinanceiro
Tabelas de dimensões
Tabelas de fatos
Editor de configuraçãoou Spoon
Dados de origem Ambiente dedesenvolvimento ETL
Modelo de dados WPM
Dados do medidordo prédio
Tabelas de migraçãode dados
Itens de tarefas ETL são os objetos de negócios que fazem referência aos scriptsETL usados para preencher as tabelas de fatos.
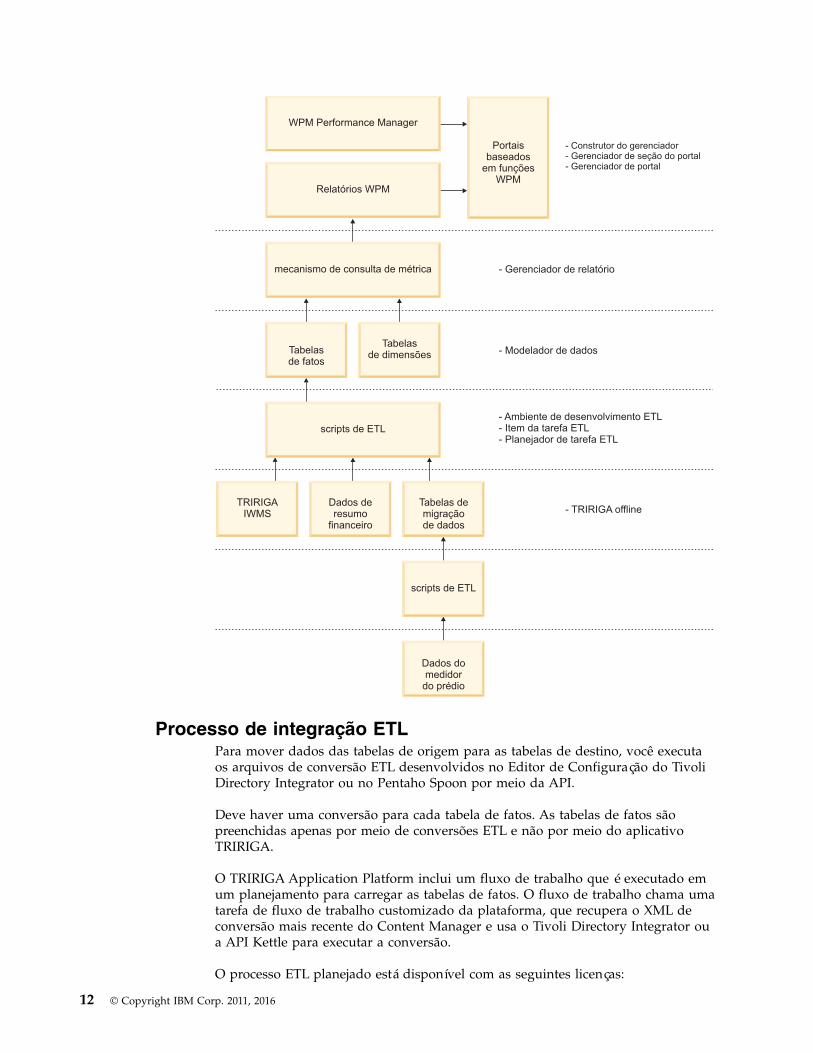
O TRIRIGA Workplace Performance Management usa as ferramentas padrão doTRIRIGA Application Platform.
O diagrama a seguir mostra as ferramentas da plataforma do aplicativo:
Capítulo 2. Estruturas de dados 11
- Construtor do gerenciador- Gerenciador de seção do portal- Gerenciador de portal
- Gerenciador de relatório
- Modelador de dados
- Ambiente de desenvolvimento ETL- Item da tarefa ETL- Planejador de tarefa ETL
- TRIRIGA offline
scripts de ETL
Portaisbaseados
em funçõesWPM
Dados deresumo
financeiro
TRIRIGAIWMS
Tabelas demigraçãode dados
scripts de ETL
Dados domedidor
do prédio
Tabelasde dimensõesTabelas
de fatos
mecanismo de consulta de métrica
Relatórios WPM
WPM Performance Manager
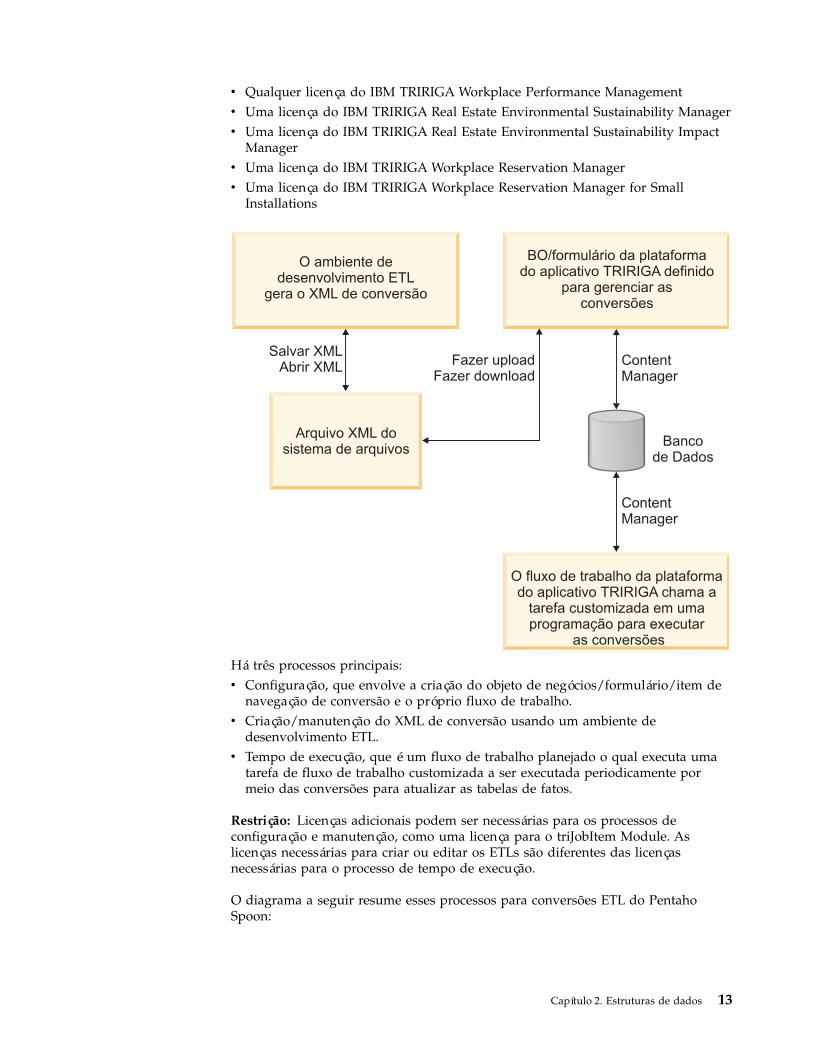
Processo de integração ETLPara mover dados das tabelas de origem para as tabelas de destino, você executaos arquivos de conversão ETL desenvolvidos no Editor de Configuração do TivoliDirectory Integrator ou no Pentaho Spoon por meio da API.
Deve haver uma conversão para cada tabela de fatos. As tabelas de fatos sãopreenchidas apenas por meio de conversões ETL e não por meio do aplicativoTRIRIGA.
O TRIRIGA Application Platform inclui um fluxo de trabalho que é executado emum planejamento para carregar as tabelas de fatos. O fluxo de trabalho chama umatarefa de fluxo de trabalho customizado da plataforma, que recupera o XML deconversão mais recente do Content Manager e usa o Tivoli Directory Integrator oua API Kettle para executar a conversão.
O processo ETL planejado está disponível com as seguintes licenças:
12 © Copyright IBM Corp. 2011, 2016
v Qualquer licença do IBM TRIRIGA Workplace Performance Managementv Uma licença do IBM TRIRIGA Real Estate Environmental Sustainability Managerv Uma licença do IBM TRIRIGA Real Estate Environmental Sustainability Impact
Managerv Uma licença do IBM TRIRIGA Workplace Reservation Managerv Uma licença do IBM TRIRIGA Workplace Reservation Manager for Small
Installations
Bancode Dados
Arquivo XML dosistema de arquivos
O ambiente dedesenvolvimento ETL
gera o XML de conversão
Salvar XMLAbrir XML
BO/formulário da plataformado aplicativo TRIRIGA definido
para gerenciar asconversões
Fazer uploadFazer download
ContentManager
O fluxo de trabalho da plataformado aplicativo TRIRIGA chama a
tarefa customizada em umaprogramação para executar
as conversões
ContentManager
Há três processos principais:v Configuração, que envolve a criação do objeto de negócios/formulário/item de
navegação de conversão e o próprio fluxo de trabalho.v Criação/manutenção do XML de conversão usando um ambiente de
desenvolvimento ETL.v Tempo de execução, que é um fluxo de trabalho planejado o qual executa uma
tarefa de fluxo de trabalho customizada a ser executada periodicamente pormeio das conversões para atualizar as tabelas de fatos.
Restrição: Licenças adicionais podem ser necessárias para os processos deconfiguração e manutenção, como uma licença para o triJobItem Module. Aslicenças necessárias para criar ou editar os ETLs são diferentes das licençasnecessárias para o processo de tempo de execução.
O diagrama a seguir resume esses processos para conversões ETL do PentahoSpoon:
Capítulo 2. Estruturas de dados 13

Agente 2Editor de telas
Na plataforma do aplicativo TRIRIGA- Criar BO do fato- Determinar mapeamento entre fatoe metadados
Criar
No Spoon- Criar XML de conversão- Salvar no arquivo do sistema de arquivos
Na plataforma do aplicativo TRIRIGA- Fazer upload do arquivo XML comformulário de conversão
Agente 3Serviços profissionais
Na plataforma do aplicativo TRIRIGA- Fazer download do arquivo XML comformuláriode conversão
Editar
No Spoon- Editar XML de conversão- Salvar no arquivo do sistema dearquivos
Na plataforma do aplicativo TRIRIGA- Fazer upload do arquivo XML comformulário de conversão
Mantendo conversões - para cada fato
Agente 1Editor de telas
Na plataforma do aplicativo TRIRIGA- Criar BO/formulário de conversão- Criar fluxo de trabalho para chamar tarefa customizada
Configuração - executada uma vez
Sistema
Na plataforma do aplicativo TRIRIGA- Fluxo de trabalho acionará a tarefa customizada para cada conversão- Reunir variáveis- Fazer download do XML para um arquivo temporário- Configurar JNDI para servidor de aplicativos- Chamar API Kettle para executar a conversão
Tempo de execução - em um planejamento
O diagrama a seguir resume esses processos para conversões ETL do Editor deConfiguração do Tivoli Directory Integrator:
14 © Copyright IBM Corp. 2011, 2016

Agente 2Editor de telas
Na plataforma do aplicativo TRIRIGA- Criar BO do fato- Determinar mapeamentos entre fatoe metadados
Criar
No Editor de Configuração- Criar XML de conversão- Salvar no arquivo do sistema de arquivos
Na plataforma do aplicativo TRIRIGA- Fazer upload do arquivo XML comformulário de conversão
Agente 3Serviços profissionais
Na plataforma do aplicativo TRIRIGA- Fazer download do arquivo XML comformulário de conversão
Editar
No Editor de Configuração- Editar XML de conversão- Salvar no arquivo do sistema de arquivos
Na plataforma do aplicativo TRIRIGA- Fazer upload do arquivo XML comformulário de conversão
Mantendo conversões - para cada fato
Agente 1Editor de telas
Na plataforma do aplicativo TRIRIGA- Criar BO/formulário de conversão- Criar fluxo de trabalho para chamar tarefa customizada- Definir configurações de conexão JDBC
Configuração - executada uma vez
Sistema
Na plataforma do aplicativo TRIRIGA- Fluxo de trabalho acionará a tarefa customizada para cada conversão- Reunir variáveis- Obter as configurações de conexão JDBC- Enviar XML ao servidor TDI para executar conversão
Tempo de execução - em um planejamento
Os dados são extraídos por scripts ETL de objetos de negócios, incluindo o objetode negócios Resumo Financeiro, no qual os registros de resumo financeiro sãoimportados de planilhas ou por interfaces projetadas pelo cliente com um sistemafinanceiro.
Configuração de pré-requisito para integração ETLNo TRIRIGA Application Platform, um objeto de negócios e um formuláriogerenciam as conversões. As tabelas de fatos de origem e destino devem serdefinidas e os mapeamentos entendidos para criar a transformação.
Há um registro para cada tabela de fatos carregada por meio de uma conversão.Um campo binário no objeto de negócios de Conversão extrai o arquivo XML de
Capítulo 2. Estruturas de dados 15

conversão no Content Manager. O formulário fornece uma maneira de fazerupload/download do arquivo XML para que o XML de conversão possa serfacilmente mantido. O TRIRIGA vem pré-configurado com um Item da Tarefa ETLcomo a implementação deste objeto de negócios ou formulário.
No TRIRIGA Application Platform, um fluxo de trabalho é executado em umplanejamento e chama uma tarefa de fluxo de trabalho customizado para cadatabela de fatos que precisa ser carregado ou atualizado. O planejador de tarefafornece um mecanismo que automaticamente chama a tarefa de fluxo de trabalhocustomizado para itens de tarefa ETL.
O TRIRIGA envia todos os objetos de negócios, formulários e fluxos de trabalhonecessários para suportar os produtos TRIRIGA Workplace PerformanceManagement e TRIRIGA Real Estate Environmental Sustainability como entregues.
Definindo e mantendo conversões ETLUse um ambiente de desenvolvimento ETL para criar uma transformação paramover dados. Durante a conversão, é possível fazer cálculos e usar variáveis doTRIRIGA Application Platform e do sistema.
Usando ETLs com Pentaho SpoonÉ possível usar o Pentaho Spoon como um ambiente de desenvolvimento ETL.
Visão geral do uso do Pentaho Spoon:
Devem-se primeiro criar as tabelas de origem e de destino e estabelecer osmapeamentos correspondentes. Em seguida, devem-se identificar as variáveis queprecisam ser passadas para a conversão e incluir essas variáveis no objeto denegócios ou formulário de conversão. Em seguida, é possível usar o Pentaho Spoone as etapas a seguir para definir e manter as conversões.
Dica: Pode não ser necessário executar todas as etapas a seguir. As etapas que sãonecessárias dependem se você estiver definindo ou mantendo uma conversão.v Execute o arquivo spoon.bat ou kettle.exe abrindo o Spoon. Selecione Nenhum
repositório, já que você não precisa usar um.v Abra um arquivo XML existente, que foi transferido por download para o
sistema de arquivos usando o Formulário de transformação ou use Arquivo >Novo > Transformação para criar uma nova transformação.
v Defina as configurações de JNDI para o banco de dados local. Use o TRIRIGAcomo o nome da conexão. Configure a conexão com o banco de dados naferramenta usando Visualizar > Conexões com o banco de dados > Novo.Quando a conversão é executada pelo fluxo de trabalho, a conexão é sobrescritapelas informações de conexão do servidor de aplicativos.
v Use o menu Design para criar o layout da conversão:– Extraia linhas das tabelas usando Design > Entrada > Entrada de tabela.– Certifique-se de que todos os campos de linha tenham valores quando usados
em um cálculo com Design > Conversão > Mapeador de valor.– Use Design > Conversão > Calculadora para cálculos.– Forneça o sequenciamento para as linhas de destino com Design > Consulta
> Chamar procedimento do BD usando o procedimento armazenado debanco de dados NEXTVAL.
– Use Script > Valor JavaScript modificado e outras etapas para transformardados conforme necessário.
16 © Copyright IBM Corp. 2011, 2016

– Identifique a tabela à qual as linhas são saída com Design > Saída > Saída databela
– Mapeie os campos pelos Mapeamentos Gerados com relação à Etapa deDestino.
v Vincule as etapas usando Visualizar > Hops e crie o layout da conversão, passoa passo.
v Teste cuidadosamente usando execute e outros utilitários disponíveis. O testeassegura que o processo esteja exato e as linhas esperadas sejam retornadas etransformadas de maneira apropriada.
v Salve a conversão usando Arquivo > Salvar. Não salve no repositório. Em vezdisso, configure o tipo de arquivo como XML e salve com a extensão de arquivo.ktr. Se você não configurar o tipo de arquivo, o padrão será a conversão Kettle,que salva um arquivo XML com a extensão de arquivo .ktr.
Instalando o Pentaho Spoon:
É possível instalar o Pentaho Spoon como um ambiente de desenvolvimento ETL.Use a versão 3.1, que é a versão com a qual o TRIRIGA se integra.
Procedimento
1. Localize o Pentaho Spoon versão 3.1 em http://sourceforge.net/projects/pentaho/files/Data%20Integration/3.1.0-stable/pdi-open-3.1.0-826.zip.
2. Extraia os arquivos do arquivo .zip e mantenha as estruturas de diretóriosintactas.
3. Revise a versão mais recente do Pentaho Spoon e a documentação detalhada deacompanhamento em http://kettle.pentaho.org/.
Configurando uma JNDI local:
Você deve definir as configurações da JNDI local para seu banco de dadosatualizando o arquivo de propriedades.
Procedimento
1. No diretório pdi-open-3.1.0-826/simple-jndi, edite o arquivo jdbc.propertiese inclua as propriedades a seguir:v LocalJNDI/type=javax.sql.DataSource
v LocalJNDI/driver=oracle.jdbc.driver.OracleDriver
v LocalJNDI/url=jdbc:oracle:thin:@localhost:1521:orcl
v LocalJNDI/user=tridata2
v LocalJNDI/password=tridata2
2. Atualize as informações conforme apropriado, incluindo o driver se vocêestiver usando o DB2 ou SQL Server.
3. Salve e feche o arquivo.
Criando conversões e conexões com o banco de dados:
É possível criar conversões e conexões com o banco de dados para uso entrePentaho Spoon e TRIRIGA
Procedimento
1. Execute o arquivo spoon.bat no diretório pdi-open-3.1.0-826 abrindo aferramenta Spoon. Escolha a execução sem um repositório.
Capítulo 2. Estruturas de dados 17

2. Para criar uma nova conversão, clique com o botão direito em Transformaçõese selecione Novo.
3. No modo de Visualização, crie a conexão com o banco de dados. Clique com obotão direito nas conexões com o banco de dados em Transformações eselecione Novo.
4. A tarefa de fluxo de trabalho customizado substitui a conexão do TRIRIGApelas configurações da JNDI do servidor de aplicativos. Configure a conexãocom o banco de dados da seguinte forma:v Nome de conexão: TRIRIGA
v Tipo de conexão: Oracle
v Acesso :JNDI
v Configurações: Nome JNDI: Local JNDI
5. Selecione Teste para certificar-se de que a conexão esteja configuradacorretamente.
6. Salve os detalhes da conexão com o banco de dados.7. Certifique-se de salvar a conversão como um arquivo XML não no repositório.
A extensão para a transformação Kettle é .ktr. O padrão para a transformaçãoKettle salva o arquivo como .ktr.
Executando uma conversão do Pentaho Spoon:
Você pode executar uma conversão que esteja concluída ou esteja no processo deser concluída.
Procedimento
1. Salve a conversão e selecione Executar.2. Configure variáveis, se necessário.3. Selecione Visualização para exibir as mudanças no fluxo de entrada conforme
cada etapa é executada.
Selecionando etapas do Spoon:
Você pode usar o Modo de Design para selecionar os vários tipos de etapas doSpoon e incluí-los em uma conversão.
Procedimento
1. Para incluir uma etapa em uma conversão, selecione Tipo de etapa e arraste aetapa na navegação esquerda para a paleta.
2. Para vincular duas etapas, selecione Visualizar na navegação esquerda e cliqueduas vezes em Saltos.
3. Coloque nas etapas De e Para e selecione OK.4. Como alternativa, você pode selecionar Ctrl+clique em duas etapas, clicar com
o botão direito em uma das etapas e selecionar Novo salto.5. Para incluir uma nota na conversão, clique com o botão direito na paleta e
selecione Nova nota.
Exemplo de conversão do Spoon:
É possível fazer download de uma cópia de qualquer um dos scripts .ktr existentesque estão contidos em um item de tarefa ETL existente para seguir adiante nasdescrições de etapa. Segue um exemplo de conversão do Spoon.
18 © Copyright IBM Corp. 2011, 2016

A maioria dos ETLs como entregues tem o mesmo fluxo que o exemplo, mas asparticularidades são diferentes, por exemplo, as tabelas de banco de dados a partirdas quais os dados são extraídos e como os dados são transformados.
O exemplo de conversão inclui os itens a seguir:v Puxa linhas de entrada e campos da organização
T_TRIORGANIZATIONALLOCATION e do espaço T_TRISPACE, em queorg.TRILOCATIONLOOKUPTXOBJID = space.SPEC_ID.
v Usa IBS_SPEC.UPDATED_DATE para limitar as linhas que são selecionadas,usando o intervalo de data que é passado do objeto de negócios de conversão.
v Use o Mapeador de valor para certificar-se de que haja um valor em todas aslinhas para space.TRIHEADCOUNTNU, space.TRIHEADCOUNTOTHERNU eorg.TRIALLOCPERCENTNU, se não, configure-o para 0.
v Usa a Calculadora para configurar TRIFACTTOTALWORKERSASS para(space.TRIHEADCOUNTNU + space.TRIHEADCOUNTOTHERNU) *org.TRIALLOCPERCENTNU.
v Obtém TRICREATEDBYTX e TRIRUNDA, passados do BO de Conversão pormeio da etapa Obter variáveis.
v Usa Incluir constante para configurar o nome e o incremento da sequência, demodo que esteja disponível no fluxo de entrada para a etapa de sequenciamento.
v Usa o Procedimento de BD NEXTVAL para configurar o SPEC_ID, configure estaetapa para usar cinco encadeamentos para desempenho aprimorado.
v Usa uma etapa de script JavaScript para determinar se o projeto estava no prazoou não e para calcular a duração do projeto. Configure esta etapa para usar trêsencadeamentos para melhor desempenho.
v Mapeia os campos para T_TRISPACEALLOCFACTOID.
As coisas importantes a considerar à medida que você construir uma conversãoincluem os itens a seguir:v Testa conforme você inclui cada etapa para certificar-se de que a conversão esteja
fazendo o que se deseja.v Conversões precisam ser desenvolvidas de forma defensiva. Por exemplo, se
você estiver fazendo cálculos baseados em campos específicos, todas as linhasdeverão ter um valor nesses campos, e nenhum vazio. Se não, a conversão seráparalisada. Use o Mapeador de valor para certificar-se de que todos os camposusados em um cálculo tenham um valor.
v As datas são difíceis de manipular porque os bancos de dados suportados peloTRIRIGA mantêm DATE e TIME no campo de data. As soluções de datamostram como manipular os intervalos de data em SQL.
v Certifique-se de usar as configurações da JNDI e de que o banco de dados deconversão seja independente, especialmente se sua solução precisar executarvárias plataformas de banco de dados (DB2, Oracle e Microsoft SQL Server).
v Quaisquer atributos no objeto de negócios de Conversão são enviados para aconversão como uma variável. Existem algumas exceções. Atributos do tipoHora ou Variável do sistema são ignorados. É possível usar as variáveis em seuSQL ou puxá-las para o fluxo de entrada usando Obter variáveis com a sintaxe aseguir: ${VariableName}, em que VariableName é o nome do atributo.
v Certifique-se de testar completamente e configurar a conversão antes de usarvariáveis na entrada da tabela. É um desafio testar JavaScript, Visualização deentrada da tabela e Mapeamento de tabela. É possível configurar variáveis na
Capítulo 2. Estruturas de dados 19

conversão com Editar > Configurar variáveis de ambiente ou na páginaExecutar, seção Variáveis. Usando variáveis, mais das funções de teste no Spoonsão disponibilizadas.
v Teste a conexão antes de usar a JNDI, antes de executar uma procura ou antesde executar uma conversão do Spoon. A conexão JNDI deve ser testada paraevitar que o Spoon tenha qualquer possível problema de desempenho.
v Considere incluir um índice. Ele pode ser a chave para o desempenho, pois osETLs puxam dados das tabelas T de um modo diferente do aplicativo regular.
Os itens anteriores detalham a conversão à medida que você configura as etapasdo Spoon utilizadas. O itens se concentram nas etapas principais que são utilizadaspelas conversões entregues com o TRIRIGA. O Spoon fornece outros tipos de etapaque você pode usar para manipular seus dados; use as etapas conforme necessário,dependendo de suas necessidades de conversão.
Configurando etapas de entrada do Spoon:
É possível usar etapas de entrada para trazer os dados para a conversão.
Sobre Esta Tarefa
Entrada de tabela é a origem da maioria dos dados. Usando a conexão com obanco de dados especificada, você pode configurar o SQL para extrair dados dastabelas.
Procedimento
1. Clique duas vezes duplo em uma etapa de entrada da tabela para abrir asinformações da etapa.
2. Configure a conexão como TRIRIGA ou o banco de dados de origem.3. Insira o SQL na tabela de SQL.4. Selecione OK para salvar a entrada da tabela.5. Selecione Visualizar para visualizar os dados que a entrada da tabela inclui. Se
você estiver usando variáveis em SQL, as variáveis deverão ser configuradaspara que Visualizar funcione. Você deve codificar permanentemente os valoresdas variáveis durante o teste ou selecionar Editar > Configurar variáveis deambiente para configurar os valores das variáveis. As variáveis em SQL são$(triActiveStartDA_MinDATE} e ${triActiveEndDA_MaxDATE}.
Resultados
O SQL fornecido extrai linhas de entrada da organizaçãoT_TRIORGANIZATIONALLOCATION e do espaço T_TRISPACE, em queorg.TRILOCATIONLOOKUPTXOBJID = space.SPEC_ID. Ele usa as datas do objetode negócios de conversão para limitar os dados incluídos.
Configurando etapas de conversão do Spoon:
É possível usar etapas de conversão para alterar dados de entrada ou incluirinformações no fluxo de entrada.
Sobre Esta Tarefa
Na conversão de exemplo do Spoon, as etapas Calculadora, Incluir constantes eMapeador de valor são usadas. É possível incluir uma seqüência por meio do
20 © Copyright IBM Corp. 2011, 2016

Spoon, mas não é independente do banco e não funciona no SQL Server. Em vezdisso, é possível usar o Procedimento do BD fornecido.
Procedimento
1. Use a etapa Mapeador de valor para assegurar que os campos possuam valoresou para configurar valores diferentes dos campos. É possível configurar valorespara um campo de destino com base nos valores de um campo de origem. Se ocampo de destino não for especificado, o campo de origem será configurado nolugar do campo de destino. Devem-se assegurar que todos os campos em umcálculo tenham um valor. Se um valor nulo for encontrado durante um cálculo,a conversão falhará.
2. Clicar duas vezes no Mapeador de valor abre o diálogo para inserir asinformações necessárias. Na conversão de exemplo do Spoon, ele é usado paraconfigurar um campo para 0, se não tiver um valor.
3. Use a etapa Incluir constantes para incluir constantes no fluxo de entrada epara configurar os valores que são necessários para o Procedimento do BDNEXTVAL.
4. Deve-se ter essa etapa em todos as conversões que usam o Procedimento doBD NEXTVAL. Configure SEQ_NAME para SEQ_FACTSOID e INCR para 1.
5. Use a etapa Calculadora para tomar os campos e executar um conjuntolimitado de cálculos. Ela fornece um conjunto de funções que são usadas nosvalores dos campos. A etapa Calculadora executa melhor do que usar as etapasde script JavaScript.
6. Os cálculos integrados são limitados. Selecione a coluna Cálculo para mostrar alista de funções disponíveis.
Configurando as etapas de consulta Spoon:
É possível usar as etapas de consulta para extrair dados extras do banco de dadosno fluxo de dados.
Sobre Esta Tarefa
O procedimento Chamar BD permite que a conversão chame um procedimento debanco de dados. As informações fluem através do procedimento e de volta para aconversão. É possível criar sequências para as entradas da tabela de fatos.
Procedimento
1. Configure a chamada de procedimento do BD para uso de NEXTVAL, envio noSEQ_NAME e INCR e saída utilizando CURR_VALUE.
2. Determine quantas instâncias dessa etapa de consulta executar. Quando estivertestando a conversão, executar esta etapa com cinco instâncias ajuda muito nodesempenho. Por exemplo, para 30.000 registros, o tempo de desempenho éreduzido de 90 segundos para 30 segundos.
3. Altere o número de encadeamentos que executam uma etapa clicando com obotão direito na etapa e selecionando Alterar número de cópias a sereminiciadas.
4. Ajuste o número de encadeamentos que estão executando a etapa deProcedimento do BD.
Capítulo 2. Estruturas de dados 21

Configurando etapas de tarefas do Spoon:
Mesmo que você não esteja criando as tarefas de que precisa para obter variáveis ecampos Kettle no fluxo de entrada, será necessário assegurar que você possaconfigurar um campo de saída como uma variável.
Sobre Esta Tarefa
Na conversão Spoon de exemplo, as variáveis triCreatedByTX e triRunDA sãotrazidas para o fluxo de entrada. Você também obtém as variáveis a serem puxadasnas variáveis ONTIME e DURATION para que seja possível configurá-las duranteas etapas do script JavaScript.
Procedimento
É importante, no caso de haver uma falha durante uma conversão, registrar a datae hora da execução da conversão. O exemplo faz isso usando a variável triRunDAe isso fornece um meio para recuperação, embora o processo não tenha etapasexplícitas para ele. Quando você estiver configurando campos como valores naconversão, eles deverão ser do mesmo tipo; caso contrário, a transformação falhará.
Configurando etapas de script Spoon:
É possível usar etapas de script para implementar recursos do JavaScript.
Sobre Esta Tarefa
É possível utilizá-lo para manipulações de dados específicas no fluxo de entradaque não pode ser feito com a calculadora. É possível calcular a duração ouconfigurar os valores no fluxo, que é baseado em outros valores com uma cláusulaif/then/else. Você pode configurar valores no fluxo de conversão que sãoconstantes ou são de uma variável.
Procedimento
1. Use script JavaScript se precisar de lógica para configurar os valores.2. No exemplo de conversão Spoon, a duração é calculada subtraindo duas datas
uma da outra. A duração então determina se um plano estava no prazo.3. Com os recursos de script JavaScript, se você desejar informações fora das
linhas de Entrada da Tabela, deverá iterar para localizar o campo desejado. Nãoé possível acessar o campo diretamente, a menos que crie o alias do campo naetapa de entrada da tabela.
Exemplo
O exemplo de script JavaScript detalha como obter e configurar as variáveis.var actualEnd;var actualStart;var plannedEnd;var plannedStart;var duration;var valueDuration;var valueOnTime;
// loop through the input stream row and get the fields// we want to play withfor (var i=0;i<row.size();i++) {
var value=row.getValue(i);
22 © Copyright IBM Corp. 2011, 2016

// get the value of the field as a numberif (value.getName().equals("TRIACTUALENDDA")) {actualEnd = value.getNumber();
}if (value.getName().equals("TRIACTUALSTARTDA")) {actualStart = value.getNumber();
}if (value.getName().equals("TRIPLANNEDENDDA")) {plannedEnd = value.getNumber();
}if (value.getName().equals("TRIPLANNEDSTARTDA")) {plannedStart = value.getNumber();
}
// these are the ’variables’ in the stream that we want// to update with the duration and ontime setting// so we want the actual Value class not the value// of the variableif (value.getName().equals("DURATION")) {valueDuration = value;
}if (value.getName().equals("ONTIME")) {valueOnTime = value;
}}
// calculate the duration in daysduration = Math.round((actualEnd - actualStart) / (60*60*24*1000));// calculate the duration in hours// duration = (actualEnd - actualStart) / (60*60*1000);
// set the duration into the ’variable’ in the rowvalueDuration.setValue(duration);
// determine ontime and set the value into the// ’variable’ in the row streamif ((actualEnd == null) || (plannedEnd == null))
valueOnTime.setValue("");else if (actualEnd > plannedEnd)
valueOnTime.setValue("no");else
valueOnTime.setValue("yes");
Selecione Script de teste para certificar-se de que o JavaScript seja compilado. Asetapas Script de teste e Visualização na entrada da tabela não podem manipularvariáveis, a menos que sejam configuradas. É possível configurar variáveis naconversão usando Editar > Configurar variáveis de ambiente. Isso faz mais doque testar a função no Pentaho Spoon.
Por exemplo, é possível usar Editar > Configurar variáveis de ambiente econfigurar triActiveStartDA_MinDATE como to_date(‘20061201’, ‘YYYYmmdd’).
Se você estiver usando aliases de coluna quando estiver definindo sua consulta,use o mesmo alias quando estiver consultando a coluna com getName.
O exemplo a seguir, na etapa de entrada da tabela, mostra a opção de seleção:SELECT mainProject.triProjectCalcEndDA ActualEndDate,
mainProject.triProjectActualStartDA ActualStartDate
Se você estiver consultando o valor para ActualEndDate, use o alias e não o nomeda coluna do banco de dados, conforme ilustrado:
Capítulo 2. Estruturas de dados 23

if (value.getName().equals("ActualEndDate")) {actualEnd = value.getNumber();
}
Configurando etapas de saída do Spoon:
É possível usar etapas de saída para gravar dados novamente no banco de dados.
Sobre Esta Tarefa
O mapeamento do resultado da tabela armazena informações em um banco dedados. Essas informações então são utilizadas nas tabelas de fatos. Quando vocêtiver todas as informações para salvar uma conversão, poderá incluir as etapas dasaída no final da conversão e conectá-las à última etapa.
Procedimento
1. Clique duas vezes e inclua as informações de conexão e a tabela de fatos quevocê deseja usar como tabela de saída.
2. Quando configurada e as etapas conectadas, clique com o botão direito naetapa de saída da tabela.
3. Selecione Gerar mapeamento com relação a esta etapa de destino.4. Mapeie os campos de origem para os campos de destino no banco de dados de
destino e selecione OK. Os campos de origem incluem campos adicionaisincluídos no fluxo de entrada. Assegure-se de configurar o mapeamento detabela antes de usar variáveis na etapa de entrada da tabela.
5. Para concluir a conversão, arraste a etapa de mapeamento entre as duasúltimas etapas.
6. Se necessário, você pode modificar e incluir mais campos na etapa demapeamento.
Testando a conversão:
É possível testar a conversão depois que você incluir cada etapa do Spoon, ou notérmino quando todas as etapas do Spoon estiverem concluídas. O teste após cadaetapa torna a depuração mais fácil. Antes de poder testar a conversão, deve-seprimeiro salvar a conversão.
Sobre Esta Tarefa
A seção de variáveis detalha as variáveis que são usadas na conversão. Quandovocê testa a conversão usando Spoon, é possível configurar valores para essasvariáveis. Quando a conversão é executada a partir de dentro do TRIRIGA, asvariáveis fazem parte do objeto de negócios de conversão. Configure e salve osvalores que são usados no objeto inteligente antes de a tarefa de fluxo de trabalhocustomizado ser chamada.
Procedimento
1. Configure a variável triRunDA para a data e hora da execução do fluxo detrabalho. Não precisa ser um atributo no objeto de negócios de conversão. É arepresentação de Número de data e hora da execução. triRunDA não possuiseis formatos da data, pois é gerada dinamicamente pela tarefa de fluxo detrabalho customizado. triRunDA é necessária para configurar a data de criaçãoda linha de fato.
2. triCreatedByTX é um atributo no objeto de negócios de conversão.
24 © Copyright IBM Corp. 2011, 2016

3. triActiveStartDA_MinDATE e triActiveEndDA_MaxDATE são as representaçõesagrupadas de triActiveStartDA e triActiveEndDA. Durante o teste do Spoon, sevocê estiver testando no Oracle ou DB2, devem-se agrupá-las com to_date (‘adata desejada’, ‘o formato’).
4. Clique em Ativar para executar a conversão. Se uma etapa tiver um erro, aetapa aparecerá em vermelho e o erro será salvo no arquivo de log. É possívelacessar o arquivo de log por meio da página de log.
Solução de data:
Diversas variáveis de data requerem cálculo e comparação quando usadas peloPentaho Spoon. A solução de data fornece esses cálculos e comparações.
Há três instâncias em que solução de data é necessária:1. Comparar duas datas. Essa comparação é usada para determinar se um projeto
está dentro do prazo.2. Calcular a duração entre duas datas em dias. Em alguns casos, esse cálculo é
usado para calcular a duração em horas.3. Comparar uma data, como uma data de modificação ou data de
processamento, com um intervalo de datas, como o primeiro dia do mês eúltimo dia do mês.
A primeira e segunda instâncias são resolvidas usando as etapas de scriptJavaScript.
A terceira instância é resolvida usando um intervalo de data na tabela de entrada.
Há dois tipos de datas. Datas que são armazenadas como um Data no banco dedados e datas que são armazenadas como um Número no banco de dados.
Dica: Todos os objetos do TRIRIGA armazenam os campos Data e Data e horacomo números de campos no banco de dados. Selecione um campo como umnúmero para interagir com tabelas de objetos de negócios. Selecione um campocomo uma data interagir com campos da tabela de plataformas do sistemadefinidos como data.
Selecionar campo como data:
É possível interagir com campos de tabelas da plataforma do sistema definidoscomo data selecionando um campo como uma data.
O código de exemplo a seguir usa IBS_SPEC.UPDATED_DATE como o campo de datapara determinar se uma linha é necessária. triActiveStartDA e triActiveEndDA sãoo intervalo de data. Essas datas são provenientes dos campos triActiveStartDA etriActiveEndDA no objeto de negócios de conversão.
A tabela IBS_SPEC não é um objeto do TRIRIGA. É uma tabela da plataforma dosistema usada para controlar objetos no TRIRIGA. Ela inclui um campo que mudatoda vez que um objeto no TRIRIGA é atualizado. O campo é o campoUPDATED_DATE e, no banco de dados, ele é um campo de data, não um campode número.
Capítulo 2. Estruturas de dados 25

No código de exemplo a seguir, ${triActiveStartDA_MinDATE} e${triActiveEndDA_MaxDATE} são usados. Esses campos de datas agrupadasprocuram todos os registros de 0h na data de início até 23h59 na data deencerramento.SELECT org.SPEC_ID ORG_SPEC_ID, org.TRIORGANIZATIONLOOKUOBJID,space.CLASSIFIEDBYSPACESYSKEY, org.TRIALLOCPERCENTNU, org.TRIALLOCAREANU,space.TRIHEADCOUNTNU, space.TRIHEADCOUNTOTHERNU, spec.UPDATED_DATEFROM T_TRIORGANIZATIONALLOCATION org, T_TRISPACE space, IBS_SPEC specWHERE org.TRILOCATIONLOOKUPTXOBJID = space.SPEC_IDand space.SPEC_ID = spec.SPEC_IDand spec.UPDATED_DATE >= ${triActiveStartDA_MinDATE}and spec.UPDATED_DATE <= ${triActiveEndDA_MaxDATE} order by UPDATED_DATE
No Oracle ou DB2, ${triActiveStartDA_MinDATE} é exibido como to_date(‘20070701 00:00:00’, ‘YYYYmmdd hh24:mi:ss’) e ${triActiveEndDA_MaxDATE} éexibido como to_date (‘20070731 23:59:59’, ‘YYYYmmdd hh24:mi:ss’).
No SQL Server, essas datas serão um pouco diferentes devido às particularidadesdo banco de dados, mas são configuradas para capturar todas as linhas entre asduas datas.
Selecionar campo como número:
É possível interagir com tabelas de objetos de negócios selecionando um campocomo um número.
Em vez de usar IBS_SPEC.UPDATED_DATE como o campo de determinação de datapara a data do TRIRIGA, este método compara o campo de determinaçãodiretamente com triActiveStartDA e triActiveEndDA, uma vez que todos eles sãonúmeros no banco de dados.
No código de exemplo a seguir, triCaptureDA é um campo em T_TRISPACE.SELECT org.SPEC_ID ORG_SPEC_ID, org.TRIORGANIZATIONLOOKUOBJID,space.CLASSIFIEDBYSPACESYSKEY, org.TRIALLOCPERCENTNU, org.TRIALLOCAREANU,space.TRIHEADCOUNTNU, space.TRIHEADCOUNTOTHERNU, space.TRICAPTUREDAFROM T_TRIORGANIZATIONALLOCATION org, T_TRISPACE space, IBS_SPEC specWHERE org.TRILOCATIONLOOKUPTXOBJID = space.SPEC_IDand space.TRICAPTUREDA >= ${triActiveStartDA_Min}and space.TRICAPTUREDA <= ${triActiveEndDA_Max} order by space.TRICAPTUREDA
Semelhante ao campos de data, use as variáveis Min e Max para assegurar que oinício seja 0h e o término seja 23h59min59s. Por exemplo, use essas variáveis parafazer sua procura escolher um registro em 31 de dezembro às 13h54 da tarde.
Variáveis de data:
Para cada atributo de data e data e hora no objeto de negócios de Conversão defato, o sistema cria seis variáveis Kettle.
A tabela a seguir resume estas variáveis Kettle:
Tabela 3. Variáveis Kettle
Variável Kettle Descrição
${triActiveStartDA} Nenhum sufixo = é o valor emmilissegundos desde 1º de janeiro de 2014,sem mudanças no horário. Essa variável épara campos que são representados comoum número.
26 © Copyright IBM Corp. 2011, 2016

Tabela 3. Variáveis Kettle (continuação)
Variável Kettle Descrição
${triActiveStartDA_Min} Min = é o valor em milissegundos desde 1ºde janeiro de 2014, com o valor de horárioconfigurado para 00:00:00 para a dataespecificada. Essa variável é para camposque são representados como um número.
${triActiveStartDA_Max} Max = é o valor em milissegundos desde 1ºde janeiro de 2014, com o valor de horárioconfigurado para 23:59:59 para a dataespecificada. Essa variável é para camposque são representados como um número.
${triActiveStartDA_DATE} DATE = é o valor agrupado no formato dedata, sem mudanças no horário. Essavariável é para campos que sãorepresentados como data no banco de dados.Para Oracle ou DB2, ele é agrupado eexibido como: to_date (‘2007061522:45:10’,’YYYYmmdd h24:mi:ss’)Para SQL Server, ele é exibido como:‘20070615 22:45:10’
${triActiveStartDA_MinDATE} MinDATE = é o valor agrupado no formatode data, com o valor de horário configuradopara 00:00:00. Essa variável é para camposque são representados como data no bancode dados.
${triActiveStartDA_MaxDATE} MaxDATE = é o valor agrupado no formatode data, com o valor de horário configuradopara 23:59:59. Essa variável é para camposque são representados como data no bancode dados.
Ao especificar as variáveis ${triActiveStartDA_Min} e ${triActiveStartDA_Max}para ver um período de tempo entre as duas datas, é necessário capturar todas aslinhas dentro do período de tempo. É necessário iniciar à meia-noite e parar em 1segundo antes da meia-noite. Se você usar somente o valor de data, pode nãoobter todas as linhas desejadas, dependendo do tempo na variável. Devem-seespecificar os minutos e segundos porque ambos os bancos de dados TRIRIGAarmazenam as datas em um campo de data e hora ou número.
As variáveis ${triActiveStartDA_MinDATE} e ${triActiveStartDA_MaxDATE} ajudamcom as comparações de data.
Por exemplo, para triActiveStartDA cujo valor é 20070615 22:45:10,triActiveStartDA_MinDATE =(Oracle) to_date('20070615 00:00:00','YYYYmmdd h24:mi:ss')(SQL Server) '20070615 00:00:00'triActiveStartDA_MaxDATE =(Oracle) to_date('20070615 23:59:59','YYYYmmdd h24:mi:ss')(SQL Server) '20070615 23:59:59'
Movendo scripts ETL para o TRIRIGA a partir do Kettle:
Depois que a conversão é concluída e testada, ela deve ser transferida por uploadpara o item da tarefa ETL do TRIRIGA.
Capítulo 2. Estruturas de dados 27

Lembre-se: Salve a conversão com o tipo de arquivo como XML e extensão .ktr.
O gráfico a seguir descreve o fluxo entre o ambiente ETL e o TRIRIGA.
Bancode Dados
Arquivo XML dosistema de arquivos
O ambiente dedesenvolvimento ETL
gera o XML de conversão
Salvar XMLAbrir XML
BO/formulário da plataformado aplicativo TRIRIGA definido
para gerenciar asconversões
Fazer uploadFazer download
ContentManager
O fluxo de trabalho da plataformado aplicativo TRIRIGA chama a
tarefa customizada em umaprogramação para executar
as conversões
ContentManager
Variáveis passadas para o Kettle:
Todas as variáveis passadas para o Kettle são do tipo Sequência. As variáveis denúmero são convertidas pela tarefa de fluxo de trabalho customizado para o tipoSequência. Os tipos de campos do TRIRIGA que são suportados no Kettle sãoTexto, Booleano, Data, Data e hora, Localizadores e Números.
Tabela 4. A seguir estão os campos de exemplo no Item da Tarefa ETL:
Nome do campo Rótulo do campo Tipo de campo
triActiveEndDA Data de Encerramento Ativa Data
triActiveStartDA Data de Início Ativa Data
triBONamesTX Nomes de BOs Texto
triControlNumberCN Número de controle Número de controle
triCreatedByTX Criado por Texto
triLocator triLocator Texto
triModuleNamesTX Nomes de módulo Texto
triNameTX Nome Texto
triTransformBI Arquivo de Conversão Binário
28 © Copyright IBM Corp. 2011, 2016
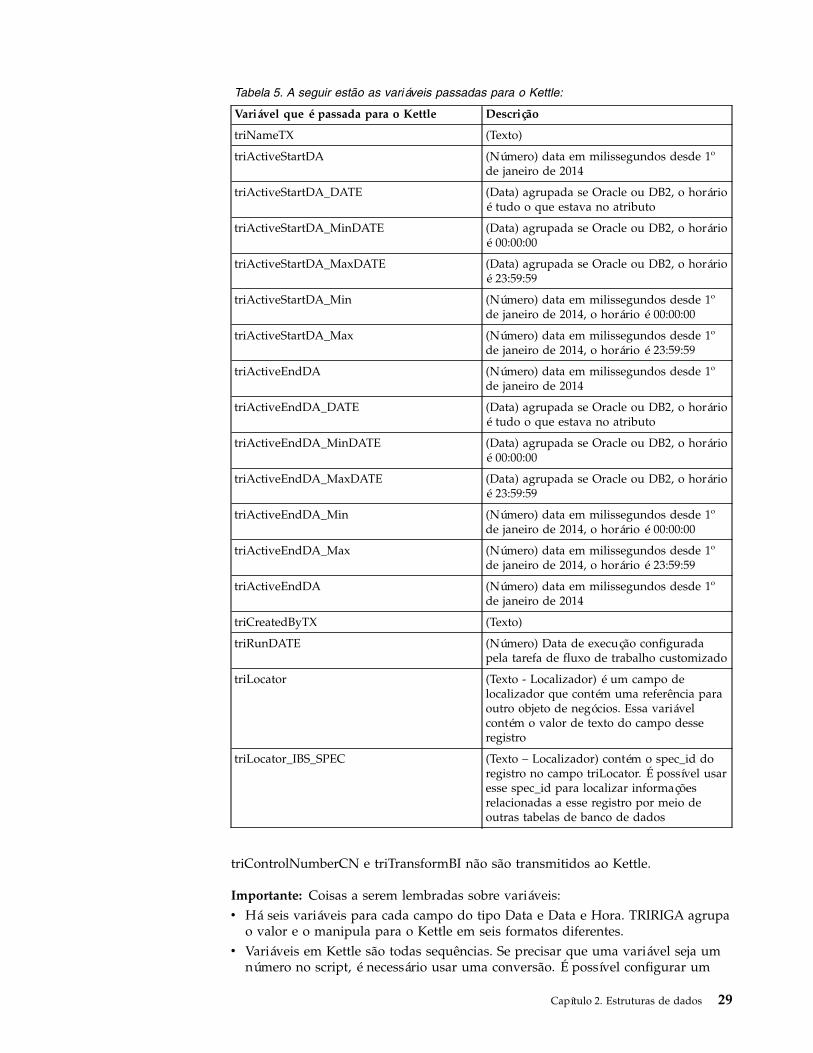
Tabela 5. A seguir estão as variáveis passadas para o Kettle:
Variável que é passada para o Kettle Descrição
triNameTX (Texto)
triActiveStartDA (Número) data em milissegundos desde 1ºde janeiro de 2014
triActiveStartDA_DATE (Data) agrupada se Oracle ou DB2, o horárioé tudo o que estava no atributo
triActiveStartDA_MinDATE (Data) agrupada se Oracle ou DB2, o horárioé 00:00:00
triActiveStartDA_MaxDATE (Data) agrupada se Oracle ou DB2, o horárioé 23:59:59
triActiveStartDA_Min (Número) data em milissegundos desde 1ºde janeiro de 2014, o horário é 00:00:00
triActiveStartDA_Max (Número) data em milissegundos desde 1ºde janeiro de 2014, o horário é 23:59:59
triActiveEndDA (Número) data em milissegundos desde 1ºde janeiro de 2014
triActiveEndDA_DATE (Data) agrupada se Oracle ou DB2, o horárioé tudo o que estava no atributo
triActiveEndDA_MinDATE (Data) agrupada se Oracle ou DB2, o horárioé 00:00:00
triActiveEndDA_MaxDATE (Data) agrupada se Oracle ou DB2, o horárioé 23:59:59
triActiveEndDA_Min (Número) data em milissegundos desde 1ºde janeiro de 2014, o horário é 00:00:00
triActiveEndDA_Max (Número) data em milissegundos desde 1ºde janeiro de 2014, o horário é 23:59:59
triActiveEndDA (Número) data em milissegundos desde 1ºde janeiro de 2014
triCreatedByTX (Texto)
triRunDATE (Número) Data de execução configuradapela tarefa de fluxo de trabalho customizado
triLocator (Texto - Localizador) é um campo delocalizador que contém uma referência paraoutro objeto de negócios. Essa variávelcontém o valor de texto do campo desseregistro
triLocator_IBS_SPEC (Texto – Localizador) contém o spec_id doregistro no campo triLocator. É possível usaresse spec_id para localizar informaçõesrelacionadas a esse registro por meio deoutras tabelas de banco de dados
triControlNumberCN e triTransformBI não são transmitidos ao Kettle.
Importante: Coisas a serem lembradas sobre variáveis:v Há seis variáveis para cada campo do tipo Data e Data e Hora. TRIRIGA agrupa
o valor e o manipula para o Kettle em seis formatos diferentes.v Variáveis em Kettle são todas sequências. Se precisar que uma variável seja um
número no script, é necessário usar uma conversão. É possível configurar um
Capítulo 2. Estruturas de dados 29

campo de número como, por exemplo, TRICREATEDDA, com uma variávelcomo, por exemplo, triRunDATE. O Kettle executa algumas conversõesimplícitas, mas se você desejar executar quaisquer cálculos com uma variável,deve-se primeiro converter a variável em um número.
v Para datas, deve-se usar a representação correta. Por exemplo, não é possívelincluir spec.UPDATED_DATE >= ${triCreatedDA} em sua seleção.spec.UPDATED_DATE é uma data, enquanto triCreatedDA é um número. Osresultados são inexatos ou o SQL falha.
v Os tipos de atributos suportados a serem transmitidos ao Kettle são limitados aTexto, Booleano, Data, Data e Hora e Números. Todos os outros tipos de dadosdo TRIRIGA são ignorados (exceto Localizadores).
v Para campos Localizador, duas variáveis são criadas, uma para o texto doLocalizador e outra para o SPEC_ID do registro vinculado. É possível usar oSPEC_ID para localizar informações que estão relacionadas a esse registro pormeio de outras tabelas de banco de dados.
Depurando scripts ETL no aplicativo:
Para depurar scripts ETL no aplicativo, você deve primeiro configurar a criação delog e depois acionar a tarefa de fluxo de trabalho customizado RunETL paravisualizar as informações de log.
Configurando a criação de log:
O TRIRIGA fornece recursos de depuração quando scripts ETL são executados noaplicativo TRIRIGA.
Procedimento
1. No console do administrador, selecione o objeto gerenciado Criação de log daplataforma. Em seguida, selecione a opção para ativar a criação de log ETL.
2. Selecione Categoria ETL > Conversões > Executar conversão para ativar acriação de log de depuração no código da plataforma do TRIRIGA que processaitens da tarefa ETL. As mensagens de log são impressas no server.log.
3. Selecione Categoria ETL > Conversões > Kettle para ativar a criação de log dedepuração nas conversões Kettle. As mensagens de log são impressas noserver.log.
4. Aplique as mudanças. Agora, quando um script ETL for executado, asinformações relacionadas a ETL serão colocadas no log do servidor.
Importante: Devido ao grande volume de informações que você podeencontrar em um log, configure a criação de log do Pentaho Spoon paradepurar somente uma execução do item da tarefa ETL.
Depurando usando tarefas ETL:
Depois de ter configurado a criação de log, você precisará de uma maneira paraacionar a tarefa de fluxo de trabalho customizado RunETL para ver todas asinformações nos logs.
Sobre Esta Tarefa
Se você estiver usando o item da tarefa ETL, será possível simplesmente clicar naação Executar processo nesse formulário.
30 © Copyright IBM Corp. 2011, 2016

Procedimento
Não se esqueça de preencher os valores dos campos no formulário que o scriptETL esperaria. Somente use a ação Executar processo para propósitos dedepuração. Para produção, use o Planejador de tarefa em seu lugar. Observe queExecutar processo atualizará as tabelas no banco de dados; por isso, não use essaação em um ambiente de produção.
Exemplo
Veja a seguir uma saída de log de amostra:2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triCalendarPeriodTX_SPEC_ID} = 3103902
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triCalendarPeriodTX} = \Classifications\Calendar Period\2010\Q4 - 2010\October - 2010
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) *** objectfield found = BoFieldImpl[name=triEndDA,id=1044,Section=BoSectionImpl[name=General,id=BoSectionId[categoryId=1,subCategoryId=1],Business Object=BoImpl[name=triETLJobItem,id=10011948,module=ModuleImpl[name=triJobItem,id=22322]]]]
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triEndDA_MinDATE} = to_date(’20101031 00:00:00’,’YYYYmmdd hh24:mi:ss’)
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triEndDA_MaxDATE} = to_date(’20101031 23:59:59’,’YYYYmmdd hh24:mi:ss’)
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triEndDA_DATE} = to_date(’20101031 00:00:00’,’YYYYmmdd h24:mi:ss’)
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triEndDA} = 1288508400000
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triEndDA_Min} = 1288508400000
2011-01-21 14:01:27,125 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) Kettlevariable set - ${triEndDA_Max} = 1288594799000
2011-01-21 14:02:10,595 INFO [SpaceFact](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) SpaceFact - Process Remove Nulls (LEGALINTEREST_SPEC_ID)’.0ended successfully, processed 3282 lines. ( 76 lines/s)
2011-01-21 14:02:10,595 INFO [SpaceFact](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) SpaceFact - Process Remove Nulls ( REALPROPERTYUSE_SPEC_ID)’.0 ended successfully, processed 3282 lines. ( 76 lines/s)
2011-01-21 14:02:10,595 INFO [SpaceFact](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) SpaceFact - Process Remove Nulls ( REALPROPERTYTYPE_SPEC_ID)’.0 ended successfully, processed 3282 lines. ( 76 lines/s)
Capítulo 2. Estruturas de dados 31

2011-01-21 14:02:10,595 INFO [SpaceFact](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) SpaceFact - Process Filter rows’.0 ended successfully,processed 3307 lines. ( 76 lines/s)
2011-01-21 14:02:10,595 INFO [SpaceFact](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) SpaceFact - Process Dummy (do nothing)’.0 ended successfully,processed 25 lines. ( 0 lines/s)
2011-01-21 14:02:10,595 INFO [SpaceFact](WFA:11325389 - 3070255 triProcessManual:38447392 IE=38447392) SpaceFact - Process Query for Space’.0 ended successfully,processed 0 lines. ( 0 lines/s)
Dicas de ajuste de desempenho:
Use as dicas a seguir para melhorar o desempenho de ETLs com o Spoon.
Resumo
1. Quando você tiver concluído de preparar o ETL para fazer o que deseja que elefaça, tome uma medida de desempenho de linha de base.
2. Usando o Spoon, execute o ETL com relação a um banco de dados no qual vocêpossua milhares de linhas incluídas na tabela de fatos.
3. Certifique-se de que você esteja usando uma conexão JNDI e executando oSpoon na rede em que o banco de dados reside de forma que não tenhalatência de rede. Não o execute por meio de uma VPN.
4. Obtenha uma lista concluída de sua execução. Por exemplo, a partir de umaexecução do ETL triSpacePeopleFact.
Análise
1. As etapas JavaScript e Procedimento do BD (Obter próximo ID deespecificação) possuem várias cópias. Clique com o botão direito na etapa ealtere o número de cópias a serem iniciadas.v Para o ETL triSpacePeopleFact na execução do exemplo anterior, alterando as
etapas JavaScript e Procedimento do BD (Obter próximo ID de especificação)para três cópias de cada:
v Inalterado: 12.9, 12.7, 12.5, 12.6v Três cópias de cada: 11.4, 11.6, 12.3, 12.2
2. Altere o tamanho do conjunto de linhas padrão de 1000 para 10000. As novastransformações possuem isso configurado automaticamente. Clique com obotão direito no ETL e abra as propriedades da conversão.
3. Analise a execução. Há um gargalo? Há uma etapa mais lenta que outras?Possivelmente, outras etapas podem ter várias cópias para melhor rendimento.
4. A etapa de Entrada de Dados é um gargalo? Um índice para o banco de dadosajudará? Se sim, inclua um índice e execute novamente. O desempenho estámelhor? Talvez use uma etapa de Filtro em vez de usar o banco de dados parafiltrar o conjunto de resultados.
5. A análise é um processo iterativo. Sempre tenha várias cópias das etapasJavaScript e Procedimento do BD (Obter próximo ID de especificação).
6. Uma ETL executado com 300 a 800 linhas por segundo está executando bem edefinitivamente no intervalo de desempenho aceitável.
Para o ETL triSpacePeopleFact, após o desenvolvimento inicial, melhoriassubstanciais foram obtidas apenas executando as etapas 1 e 2.
Considerando que, para o ETL triSpaceFact, melhorias substanciais foram obtidasexecutando as etapas 1, 2 e 4.
32 © Copyright IBM Corp. 2011, 2016

Veja a seguir o ETL triSpacePeopleFact executado com as etapas 1 e 2:Query for Space People: Time = 11.6 sec; Speed (r/s) = 743.6
Veja a seguir o ETL triSpaceFact executado com as etapas 1 e 2:Query for Space: Time = 313.9 sec; Speed (r/s) = 24.0
Observe que está claro que a etapa Consulta de espaço, que é a etapa de Entradade dados, é um gargalo em 24 linhas por segundo.
Observe que a Consulta de pessoas do espaço não é um gargalo como a etapa deConsulta de espaço. O ETL triSpaceFact também é executado sem qualquermodificação, além das etapas 1 e 2, ficando acima de 700 linhas por segundo.
Para a etapa 4 no ETL triSpaceFact, examine a SQL para a tarefa de Consulta deespaço. Observe na SQL que existem SUMs. SUMs são dispendiosos, especialmenteporque há dois deles e nenhum dos campos são indexados.
Inclua um índice emT_TRIORGANIZATIONALLOCATION.TRILOCATIONLOOKUPTXOBJID. Só énecessário incluir um índice para TRILOCATIONLOOKUPTXOBJID, mesmo que oTRISTATUSCL esteja em SELECT SUM WHERE. TRISTATUSCL é um campo de1000 caracteres e torna o índice lento e ainda inviável no SQL Server.CREATE INDEX IDX01_TRIORGALLOC ON T_TRIORGANIZATIONALLOCATION(TRILOCATIONLOOKUPTXOBJID) NOPARALLEL;
Execute novamente o ETL.
Veja a seguir o ETL triSpaceFact executado com as etapas 1, 2 e 4.Query for Space: Time = 3.2 sec; Speed (r/s) = 2378.3
Observe que a mudança nas linhas por segundo (2378,3) da etapa Entrada dedados e quanto tempo o ETL levou para ser executado (3,2 seconds para 7544linhas).
Importante: Coisas a serem lembradas enquanto você estiver desenvolvendo seuETLs:v Evite SQL complexo e funções agregadas como COUNT, MIN, MAX e SUM. Se
for necessário usar essas funções, veja se um índice ajuda na etapa Entrada dedados. Não crie um índice em um campo que é varchar grande; o SQL Serverpode manipular somente índices < 900 bytes.
v Evite OR e NOT e o uso de visualizações (M_TableName nos bancos de dadosdo TRIRIGA ), se possível.
v Use a etapa Calculadora em vez de JavaScript se isso for possível. A etapaJavaScript pode ser dispendiosa.
v Tenha somente uma etapa de script JavaScript.
Usando ETLs com o Editor de Configuração do IBM TivoliDirectory IntegratorO Editor de Configuração do Tivoli Directory Integrator é o ambiente dedesenvolvimento ETL que é incluído no Tivoli Directory Integrator. O Editor deConfiguração permite criar, manter, testar e depurar conversões ETL, que o TivoliDirectory Integrator chama de arquivos de configuração; ele é construído sobre aplataforma Eclipse para fornecer um ambiente de desenvolvimento que éabrangente e extensível.
Capítulo 2. Estruturas de dados 33

Antes de Iniciar
Os desenvolvedores de sistema que são responsáveis pela definição ou manutençãode conversões usando o Editor de Configuração devem ter acesso e experiência detrabalhar com bancos de dados do TRIRIGA.
Antes de poder definir e manter as conversões ETL usando o Editor deConfiguração do Tivoli Directory Integrator, devem-se concluir as tarefas a seguir:v Criar as tabelas de origem e destinov Estabelecer os mapeamentos correspondentesv Identificar as variáveis que precisam ser passadas para a conversãov Incluir as variáveis no objeto de negócios ou formulário de conversão
Instalando o editor de configuração do Tivoli Directory Integrator:
Embora o servidor de runtime do Tivoli Directory Integrator seja instaladoautomaticamente com o TRIRIGA, para criar ou modificar AssemblyLines do TivoliDirectory Integrator, devem-se instalar o Editor de Configuração na estação detrabalho que você usará para desenvolvimento de ETL.
Procedimento
1. Faça download e instale o pacote de instalação apropriado do Tivoli DirectoryIntegrator a partir do Passport Advantage em http://www.ibm.com/software/howtobuy/passportadvantage/pao_customers.htm.
Opção Descrição
TDI711_TAP340_Install_Wind.zip Instalador do IBM Tivoli DirectoryIntegrator V7.1.1 para o IBM TRIRIGAApplication Platform V3.4.0 no WindowsMultilíngue
TDI711_TAP340_Install_Linux.tar Instalador do IBM Tivoli DirectoryIntegrator V7.1.1 para o IBM TRIRIGAApplication Platform V3.4.0 no LinuxMultilíngue
TDI711_TAP340_Install_SOLIntl.tar Instalador do IBM Tivoli DirectoryIntegrator V7.1.1 para o IBM TRIRIGAApplication Platform V3.4.0 no Solaris IntelMultilíngue
TDI711_TAP340_Install_SOLSprc.tar Instalador do IBM Tivoli DirectoryIntegrator V7.1.1 para o IBM TRIRIGAApplication Platform V3.4.0 no Solaris SparcMultilíngue
TDI711_TAP340_Install_AIX.tar Instalador do IBM Tivoli DirectoryIntegrator V7.1.1 para o IBM TRIRIGAApplication Platform V3.4.0 no AIXMultilíngue
2. Atualize para o IBM Tivoli Directory Integrator V7.1.1 Fixpack 3, que estádisponível em http://www.ibm.com/support/docview.wss?uid=swg27010509.
3. Aplique o 7.1.1-TIV-TDI-LA0014, que está disponível entrando em contato como suporte IBM.
4. No diretório de instalação do TRIRIGA, copie o driver JDBC para o tipo debanco de dados ao qual os AssemblyLines irão se conectar no diretório TDIInstall Directory/jars do Tivoli Directory Integrator.
34 © Copyright IBM Corp. 2011, 2016

v Para SQL Server, copie jtds-1.2.8.jarv Para Oracle, copie ojdbc6.jarv Para DB2, copie db2jcc4.jar
Alterando as portas que são usadas pelo Tivoli Directory Integrator:
Você especifica as portas que são usadas pelo Tivoli Directory Integrator durante ainstalação do TRIRIGA. Em raros casos, pode ser necessário alterar essasconfigurações de porta.
Sobre Esta Tarefa
Para alterar a porta na qual o TRIRIGA envia as conversões ETL para o TivoliDirectory Integrator para serem executadas, altere TDI_HTTP_SERVER_PORT emTRIRIGAWEB.properties.v
Para alterar a porta que é usada pelo Tivoli Directory Integrator Agent paragerenciar o servidor Tivoli Directory Integrator, conclua as tarefas a seguir:v Altere TDI_SERVER_PORT em TRIRIGAWEB.propertiesv Altere api.remote.naming.port em TRIRIGA_Install_Directory/TDI_IE/
TDISolDir/solution.properties
Introdução ao editor de configuração do Tivoli Directory Integrator:
Para preparar-se para definir e manter os ETLs com o Editor de Configuração,deve-se primeiro aprender as tarefas básicas, tais como abrir o Editor deConfiguração, entender as visualizações e criar um projeto, AssemblyLine, gancho,script ou conector, e importar um arquivo de configuração.
O Editor de Configuração é iniciado usando o script wrapper ibmditk. Esse scriptestá no diretório de instalação do Tivoli Directory Integrator. Escolha uma pasta daárea de trabalho para armazenar seus projetos e arquivos.
A janela da área de trabalho do editor de configuração exibe as visualizações aseguir:v O navegador (parte superior esquerda) contém todos os projetos e arquivos de
origem para configurações do servidor e soluções Tivoli Directory Integrator. Onavegador pode conter também outros arquivos e projetos, como arquivos detexto. O Editor de Configuração trata os projetos do Tivoli Directory Integratorespecificamente, de modo que outros arquivos e projetos não são afetados peloEditor de Configuração.
v A visualização servidores (parte inferior esquerda) mostra o status de cada umdos servidores que estão definidos no projeto Servidores TDI. É possível definirum número ilimitado de servidores. A visualização do servidor fornece váriasfunções para operar em servidores e suas configurações. O botão Atualizaratualiza o status de todos os servidores na visualização.
v A área do editor (superior direita) é onde você abre um documento, como umaconfiguração de AssemblyLine, para editar. Essa área é dividida verticalmentecom uma área que contém diversas visualizações para fornecer outrasinformações relevantes. Entre as mais importantes estão a visualizaçãoProblemas que mostra potenciais problemas com um componente do TivoliDirectory Integrator, o Log de erro que mostra erros que ocorrem enquanto vocêestá desenvolvendo soluções e a visualização Console que mostra o log do
Capítulo 2. Estruturas de dados 35

console para executar servidores Tivoli Directory Integrator, por exemplo,aqueles que são iniciados pelo Editor de Configuração.
As atividades comuns incluem as tarefas básicas a seguir:v Para criar um projeto, clique com o botão direito em Arquivo > Novo > Projeto.v Para criar um AssemblyLine, selecione um projeto a partir do navegador e
clique em Arquivo > Novo > AssemblyLine. Um AssemblyLine é um conjuntode componentes que são enfileirados juntos para mover e transformar dados.Um AssemblyLine descreve a rota ao longo da qual os dados serão passados. Osdados que são manipulados por meio desse trajeto são representados como umobjeto de Entrada. O AssemblyLine funciona com uma única entrada por vez emcada ciclo do AssemblyLine. Ele é a unidade de trabalho no Tivoli DirectoryIntegrator e geralmente representa um fluxo de informações de uma ou maisorigens de dados para um ou mais destinos. Deve-se inserir o nome dado aonovo AssemblyLine ao criar o item da tarefa ETL que executa esse AssemblyLinea partir do TRIRIGA.
v Para incluir um gancho de AssemblyLine, na área do editor, clique em Opções >Ganchos de AssemblyLine. Ative a caixa de seleção ao lado de um dos ganchose clique em Fechar. Depois que o gancho foi incluído, é possível selecioná-lo eincluir código JavaScript.
v Para incluir um script, na área do editor, selecione a pasta Feed ou Data Flow.Clique com o botão direito e selecione Incluir componente. Selecione o filtro descripts, em seguida, selecione um componente e clique em Concluir. Selecione oscript que foi incluído em seu AssemblyLine e incluir um bloco definido pelousuário de código JavaScript.
v Para incluir um conector, na área do editor, selecione a pasta Feed ou Data Flow.Clique com o botão direito e selecione Incluir componente. Selecione o filtro deconectores; em seguida, selecione um componente e clique em Concluir.Selecione o conector que foi incluído em seu AssemblyLine e especifique osdados de configuração necessários.
v Para importar um arquivo de configuração, clique em Arquivo > Importar, emseguida, selecione IBM Tivoli Directory Integrator e Configuração. Clique emAvançar, especifique um arquivo de configuração e, em seguida, clique emConcluir. Quando for solicitado o nome do projeto, insira um nome e clique emConcluir.
Para obter mais informações sobre o uso do Tivoli Directory Integrator, consulte ocentro de informações do IBM Tivoli Directory Integrator Versão 7.1.1 emhttp://publib.boulder.ibm.com/infocenter/tivihelp/v2r1/topic/com.ibm.IBMDI.doc_7.1.1/welcome.htm.
Tivoli Directory Integrator Agent:
O Tivoli Directory Integrator Agent fornece a interface para iniciar e parar oservidor de runtime do Tivoli Directory Integrator a partir do TRIRIGA.
O processo ETL planejado está disponível com as seguintes licenças:v Qualquer licença do IBM TRIRIGA Workplace Performance Managementv Uma licença do IBM TRIRIGA Real Estate Environmental Sustainability Managerv Uma licença do IBM TRIRIGA Real Estate Environmental Sustainability Impact
Managerv Uma licença do IBM TRIRIGA Workplace Reservation Manager
36 © Copyright IBM Corp. 2011, 2016

v Uma licença do IBM TRIRIGA Workplace Reservation Manager for SmallInstallations
O servidor Tivoli Directory Integrator deve estar em execução para que os itens datarefa ETL do Tivoli Directory Integrator sejam executados com êxito. Os itens datarefa ETL falharão se o servidor Tivoli Directory Integrator não estiver emexecução e um erro será impresso no log do servidor TRIRIGA.
Para iniciar ou parar o servidor Tivoli Directory Integrator, acesse o painel doAgent Manager no Console do Administrador e inicie ou pare o Tivoli DirectoryIntegrator Agent. Depois de iniciado, esse agente é executado em umaprogramação e monitora o servidor Tivoli Directory Integrator. Se ele descobrir queo servidor Tivoli Directory Integrator não está em execução, tentará reiniciá-lo.
Para obter mais informações no painel do Agent Manager, consulte o Guia doUsuário do IBM TRIRIGA Application Platform 3 Administrator Console.
Configuração do Tivoli Directory Integrator Agent:
É possível configurar propriedades para verificar se o servidor Tivoli DirectoryIntegrator está em execução.
A propriedade TDI_AGENT_SLEEPTIME para o servidor de aplicativos que executa oTivoli Directory Integrator Agent controla com que frequência o agente verifica seo servidor Tivoli Directory Integrator está em execução e tenta reiniciá-lo.
A propriedade TDI_SERVER_TIMEOUT para o servidor de aplicativos que executa oTivoli Directory Integrator Agent controla quanto tempo esperar até que umcomando de início ou de parada do servidor Tivoli Directory Integrator sejaconcluído, antes de levantar uma falha.
Essas propriedades são definidas no arquivo TRIRIGAWEB.properties.
Criação de Log do Tivoli Directory Integrator Agent:
Problemas com o Tivoli Directory Integrator Agent são registrados no server.log.Para obter informações adicionais, ative a criação de log de depuração no TivoliDirectory Integrator Agent alterando as configurações de criação de log daplataforma no Console Administrativo no servidor no qual o agente está emexecução.
A configuração de criação de log adicional pode ser feita alterando asconfigurações de log4j no servidor no qual o agente está em execução.
Por exemplo, é possível monitorar problemas com o servidor Tivoli DirectoryIntegrator seguindo as convenções padrão de log4j. Se o Tivoli Directory IntegratorAgent não conseguir iniciar o servidor Tivoli Directory Integrator, ele gravará umerro na categoria do log4j a seguir:"com.tririga.platform.tdi.agent.TDIAgent.TDISTARTFAILED". Por padrão, os errosgravados nessa categoria vão para o log do servidor TRIRIGA. É possívelconfigurar um comportamento diferente, como enviar uma notificação demensagem, configurando esse categoria para gravar em um anexador do log4jdiferente.
Capítulo 2. Estruturas de dados 37

Executando conversões a partir do Editor de Configuração do Tivoli DirectoryIntegrator:
Para executar uma conversão que esteja no processo de desenvolvimento ouconcluída, salve a conversão e, em seguida, clique em Executar na barra deferramentas.
Sobre Esta Tarefa
Uma nova janela ou guia é aberta na área do editor com o mesmo nome que oAssemblyLine. Essa janela mostrará os resultados da execução do AssemblyLine.Também é possível usar o botão Depurador para ver as mudanças no fluxo deentrada conforme cada etapa é executada.
Conversão de exemplo do Editor de Configuração do Tivoli DirectoryIntegrator:
As informações a seguir fornecem um exemplo de algumas das etapas envolvidasem uma conversão do Tivoli Directory Integrator.
É possível fazer o download de uma cópia do arquivo de configuração ‘LoadMeter Item Staging Table’ .xml que está contido em um item de tarefa ETLexistente para seguir nas descrições da etapa. Muitos dos ETLs conforme entreguesseguem o mesmo fluxo, exceto que as especificações são diferentes; por exemplo,as tabelas de banco de dados das quais os dados são extraídos e como os dadossão transformados.
Esta conversão de exemplo faz o seguinte:v Especifica os parâmetros de criação de log que são usados por este
AssemblyLine, incluindo o Tipo de criador de logs, Caminho do arquivo,Anexar, Padrão de data, Padrão de layout, Nível de log e Log ativado.
v Estabelece uma conexão com o banco de dados usando os parâmetros deconexão do AssemblyLine, conforme configurado para DB-TRIRIGA.
v Recupera o parâmetro Tempo de atraso do log de energia a partir da tabelaConfigurações do aplicativo
v Usa um conector JDBC para recuperar registros da tabela Fatos por hora doativo
v Usa um Mapa de atributos de entrada para mapear as colunas de banco dedados para atributos da entrada de trabalho interno do Tivoli DirectoryIntegrator
v Usa ganchos e scripts do Tivoli Directory Integrator para executar conversões dedados.
v Usa um conector JDBC para inserir ou atualizar registros na tabela de migraçãode dados Item de medidor ambiental
v Usa um Mapa de atributos de saída para mapear variáveis de trabalho internopara as colunas de banco de dados na tabela que está configurada no Conectorde saída JDBC
v Usa o gancho No sucesso para concluir as tarefas a seguir:– Registrar estatísticas de processamento para a execução– Configurar errCount e errMsg
v Usa o gancho Na falha do Tivoli Directory Integrator para concluir as tarefas aseguir:– Registrar mensagens de erro
38 © Copyright IBM Corp. 2011, 2016

– Configurar errCount e errMsg
As seções a seguir fornecem mais detalhes sobre os componentes principais daconversão do Tivoli Directory Integrator. A discussão se concentra noscomponentes principais que são usados pela conversão entregue pelo TRIRIGA. OTivoli Directory Integrator fornece muitos outros componentes que podem serusados para manipular seus dados dependendo de suas necessidades deconversão.
Considere as dicas a seguir à medida que você construir uma conversão:v Use os recursos de teste que estão disponíveis à medida que construir seu
AssemblyLine para certificar-se de que a conversão esteja fazendo o que vocêdeseja.
v Conversões precisam ser desenvolvidas de forma defensiva. Por exemplo, sevocê estiver fazendo cálculos que usam campos específicos, todas as linhasdeverão ter um valor nesses campos e nenhum vazio. Se não, a conversão seráparalisada. Inclua a lógica de verificação para assegurar que todos os camposusados em um cálculo tenham um valor.
v Verifique se há variáveis nulas ou indefinidas e erros de retorno se as variáveisnulas ou indefinidas forem necessárias para que o AssemblyLine obtenhasucesso. Por exemplo, se seu AssemblyLine depende das variáveis DB-OTHER(por exemplo, jdbcOthUrl, jdbcOthDriver) a fim de fazer uma conexão com umbanco de dados externo, ele deve verificar se essas variáveis estão definidas emanipular o caso de erro adequadamente.
v As datas são difíceis porque todos os bancos de dados suportados pelo TRIRIGAmantêm DATE e TIME no campo de data.
v Certifique-se de usar as Conexões do AssemblyLine e tornar seu banco de dadosde conversão independente, especialmente se sua solução precisar executarvárias plataformas de banco de dados (DB2, Oracle e Microsoft SQL Server).
v Teste suas Conexões do AssemblyLine antes de executar a conversão do TivoliDirectory Integrator. Caso contrário, sua conversão poderá terminar com umerro de conexão com o banco de dados.
Configurando criadores de logs:
Configure os criadores de logs do AssemblyLine e especifique os parâmetros decriação de log que serão usados por este conjunto, como Tipo de criador de logs,Caminho da arquivo, Anexar, Padrão de data, Padrão de layout, Nível de log eLog ativado.
Sobre Esta Tarefa
Nota: Obedeça às convenções de configurações de log a seguir para que oTRIRIGA manipule sua criação de log ETL corretamente quando a conversão forexecutada a partir do TRIRIGA:v Quando você configurar o caminho do arquivo, especifique o caminho relativo
../../log/TDI/log name, em que log name é o nome do AssemblyLine. Porexemplo, Caminho do arquivo = ../log/TDI/triLoadMeterData.log. Issoassegura que o triLoadMeterData.log possa ser visualizado a partir do consolede administração do TRIRIGA com o restante dos logs do TRIRIGA.
v Configure o Tipo de criador de logs para DailyRollingFileAppender para ficarconsistente com outros logs do TRIRIGA.
Essas configurações de log se aplicam aos logs que são criados quando a conversãoé executada a partir do Editor de Configuração. Alguns dos valores serão
Capítulo 2. Estruturas de dados 39

substituídos quando a conversão for chamada a partir de um Item da Tarefa ETLTRIRIGA. Nível de log, Padrão de data e Padrão de layout serão substituídos porvalores especificados nos arquivo .xml do log4j do TRIRIGA para tornar os logs doTivoli Directory Integrator consistentes com os logs do TRIRIGA e configuráveis damesma maneira que os logs do TRIRIGA.
Procedimento
Na área do editor, clique em Opções > Configurações de log para configurar oscriadores de logs do AssemblyLine e especifique os parâmetros de criação de logque serão usados por esse conjunto.
Exemplo
No exemplo, configuramos um log DailyRollingFileAppender com o caminho doarquivo configurado para ../../log/TDI/triLoadMeterData.log. Os ganchos deAssemblyLine podem gravar dados nesse log, chamando um comando semelhanteao seguinte:var methodName = "triLoadMeterData - LookupMeterItemDTO ";task.logmsg("DEBUG", methodName + "Entry");
Inicializando AssemblyLines:
Durante a inicialização do AssemblyLine, o mecanismo de script é iniciado e osGanchos de Prólogo do AssemblyLine são chamados.
Procedimento
1. Na área do editor, crie um Gancho de AssemblyLine clicando em Opções >Ganchos de AssemblyLine e ative a caixa de seleção Prólogo - Antes dainicialização.
2. Inclua o código JavaScript a seguir no script para estabelecer uma conexão como banco de dados e recuperar os parâmetros de Configuração do Aplicativo:var methodName = "triLoadMeterData - Prolog - Before Init - ";
// By default, this AL is setup to run from TRIRIGA.To run this AL from TDI CE,// the runStandAlone flag should be set to 1 and the database connection// parameters should be specified below.var runStandAlone = 1;
// Retrieve database connection parameters passed into this AL from TRIRIGAif (runStandAlone == 0){task.logmsg("DEBUG", methodName + "Set TRIRIGA db connection parameters");var op = task.getOpEntry();var jdbcTriURL = op.getString("jdbcTriURL");var jdbcTriDriver = op.getString("jdbcTriDriver");var jdbcTriUser = op.getString("jdbcTriUser");var jdbcTriPassword = op.getString("jdbcTriPassword");
}else// Modify these database connection parameters if running directly from TDI{task.logmsg("DEBUG", methodName + "StandAlone: Set default TRIRIGA db
connection parameters");var jdbcTriURL = "jdbc:oracle:thin:@1.1.1.1:1521:test";var jdbcTriDriver = "oracle.jdbc.driver.OracleDriver";var jdbcTriUser = "userid";var jdbcTriPassword = "password";
40 © Copyright IBM Corp. 2011, 2016

}
try{
triConn.initialize(new Packages.com.ibm.di.server.ConnectorMode("Iterator"));}catch (err){
task.logmsg("ERROR", methodName + "TRIRIGA Connection Failed");task.logmsg("DEBUG", methodName + "Exception:" + err);dbConnectionFailed = true;errCount=1;system.abortAssemblyLine("TRIRIGA DB Connection Failed");return;
}triConn.setCommitMode("After every database operation (Including Select)");var conn2 = triConn.getConnection();conn2.setAutoCommit(true);task.logmsg("DEBUG", methodName + "TRIRIGA connection success");
...
// Get application settingstask.logmsg("DEBUG", methodName + "Get triALEnergyLogLagTimeNU fromApplication Settings");
var selectStmt1 = conn1.createStatement();var query = "select TRIALENERGYLOGLAGTIMEN from T_TRIAPPLICATIONSETTINGS";task.logmsg("DEBUG", methodName + "query:" + query);var rs1 = selectStmt1.executeQuery(query);var result = rs1.next();while (result){
try{
energyLogLagTime = rs1.getString("TRIALENERGYLOGLAGTIMEN");if (energyLogLagTime == null) energyLogLagTime=5
}catch (err){task.logmsg("INFO", methodName + "Setting Default Values for
Application Settings");energyLogLagTime=5}
task.logmsg("INFO", methodName + "energyLogLagTime:" + energyLogLagTime);result = rs1.next();
}rs1.close();selectStmt1.close();
3. Salve o gancho de AssemblyLine.
Exemplo
Em nosso exemplo, as tarefas a seguir são concluídas no gancho Prólogo - Antesda inicialização:v Recuperar variáveis de transformação do Tivoli Directory Integrator passadas
para o AssemblyLine. Isso só ocorre quando o AssemblyLine é executado apartir de um item da tarefa ETL. Quando o AssemblyLine é chamado a partir doEditor de Configuração, os parâmetros de conexão JDBC precisam serconfigurados no Prólogo.
v Estabelecer conexões com o banco de dados.
Capítulo 2. Estruturas de dados 41

v Recuperar configurações específicas do AssemblyLine a partir do registro deConfigurações do aplicativo.
Recuperação de dados:
Os dados entram no AssemblyLine a partir de sistemas conectados usandoConectores e algum tipo de modo de entrada.
Em nosso exemplo, usamos um conector JDBC e um mapa de atributos paraalimentar dados em nosso AssemblyLine.
Conector
Entrada de tabela é a origem da maioria dos dados. Este é o local no qual vocêconfigura um conector para puxar dados de tabelas usando os parâmetros deconexão com o banco de dados passados ao AssemblyLine durante a inicialização.
Em nosso exemplo, o conector nomeado JDBCConnectorToHourlyFact recuperalinhas de entrada da tabela Fatos por jora. Esse componente é incluído na seção defeed do AssemblyLine.
A guia Conexão permite que você configure parâmetros de conexão JDBC. Noexemplo, usamos Avançado (Javascript) para recuperar os parâmetros de conexãopassados ao AssemblyLine durante a inicialização. Além disso, a consulta SQL aseguir é especificada sob a seção Avançado no campo SQL Select para limitar oescopo dos dados recuperados da tabela de banco de dados.select * from T_TRIASSETENERGYUSEHFACT where TRIMAINMETERBL in (’TRUE’) andTRI-MAINMETERPROCESSEDN = 0 order by TRIWRITETIMETX.
Dica: Para ativar a criação de log de instruções SQL para um conector, ative acaixa de seleção Log detalhado na guia Conexão dos conectores.
Mapa de atributos
Use um Mapa de Atributos do Conector para assegurar que determinados campostenham um valor ou para configurar um campo para um valor diferente. No Mapade Atributos, é possível configurar valores para um campo de destino com basenos valores de um campo de origem. Se o campo de destino não for especificado, ocampo poderá ser configurado para um valor padrão em vez do campo de destino.
Clique no conector JDBCConnectorToHourlyFact, em seguida, clique na guia Mapade entrada para exibir o Mapa de Atributos. No exemplo, usamos o mapa paraconfigurar valores padrão para alguns dos campos.
Depois que o primeiro Conector fez o seu trabalho, o depósito de informações (a"entrada de trabalho", denominada adequadamente de "trabalho") é passadajuntamente com o AssemblyLine para o próximo Componente.
Script:
Os scripts podem ser incluídos para implementar um bloco definido pelo usuáriode código JavaScript.
No exemplo, script é usado para incluir processamento customizado noAssemblyLine. As seções a seguir descrevem algumas das diferentes maneiras decomo o script foi usado.
42 © Copyright IBM Corp. 2011, 2016

Validação
Em nosso exemplo, executamos a validação do campo em nossos dados de entradaconforme mostrado no script a seguir:var methodName = "triLoadMeterData - JDBCConnectorToHourlyFact -GetNext Successful ";
task.logmsg("DEBUG", methodName + "Entry");
rowsProcessed = parseInt(rowsProcessed) + 1;
var SPEC_ID = work.SPEC_ID.getValue();task.logmsg("DEBUG", methodName + "SPEC_ID: " + SPEC_ID);
// Verify Required Fields and do not process record is anyvalues are missingvalidData = true;if (work.TRICAPTUREDDT.getValue() == null){task.logmsg("ERROR", methodName + "TRICOSTNU is null.");validData=false;}if (work.TRICOSTNU.getValue() == null){task.logmsg("ERROR", methodName + "TRICOSTNU is null.");validData=false;}if (work.TRICOSTNU_UOM.getValue() == null){task.logmsg("ERROR", methodName + "TRICOSTNU_UOM is null.");validData=false;}if (work.TRIDIMASSETTX.getValue() == null){task.logmsg("ERROR", methodName + "TRIDIMASSETTX is null.");validData=false;}if (work.TRIENERGYTYPECL.getValue() == null){task.logmsg("ERROR", methodName + "TRIENERGYTYPECL is null.");validData=false;}if (work.TRIENERGYTYPECLOBJID.getValue() == null){task.logmsg("ERROR", methodName + "TRIENERGYTYPECLOBJID is null.");validData=false;}if (work.TRIMETERIDTX.getValue() == null){task.logmsg("ERROR", methodName + "TRIMETERIDTX is null.");validData=false;}if (work.TRIRATENU.getValue() == null){task.logmsg("ERROR", methodName + "TRIRATENU is null.");validData=false;}if (work.TRIRATENU_UOM.getValue() == null){task.logmsg("ERROR", methodName + "TRIRATENU_UOM is null.");validData=false;}if (work.TRIWRITETIMETX.getValue() == null){task.logmsg("ERROR", methodName + "TRIWRITETIMETX is null.");validData=false;
Capítulo 2. Estruturas de dados 43

}
if (!validData){rowsNotValid = rowsNotValid + 1;task.logmsg("ERROR", methodName + "Record will NOT be processed.");var selectStmt1 = conn1.createStatement();
var query = "update " + tableName + " set TRIMAINMETERPROCESSEDN =3 where SPEC_ID = \’" + SPEC_ID + "\’";
task.logmsg("DEBUG", methodName + "query:" + query);var count = selectStmt1.executeUpdate(query);task.logmsg("DEBUG", methodName + "Update count:" + count);selectStmt1.close();system.exitBranch();
}
Filtragem de dados
Em nosso exemplo, há um script que determina se um registro deve serprocessado. O script a seguir inclui uma instrução condicional para comparar doiscampos de data. Se a condição for verdadeira, o método system.exitBrankch()será chamado, fazendo com que o registro atual seja ignorado.// Should we process this record?if (capturedDT < earliestDateUTC){
task.logmsg("DEBUG", methodName + "Skip!");rowsSkipped = rowsSkipped + 1;
// Set triMainMeterProcessedNU=2 flag in T_TRIASSETENERYUSEHFACT table// indicating that we will not process this recordvar selectStmt1 = conn1.createStatement();var query = "update " + tableName + " set TRIMAINMETERPROCESSEDN =
2 where SPEC_ID = \’" + SPEC_ID + "\’";task.logmsg("DEBUG", methodName + "query:" + query);var count = selectStmt1.executeUpdate(query);task.logmsg("DEBUG", methodName + "Update count:" + count);selectStmt1.close();system.exitBranch();
}
Chamar procedimento do BD
Os procedimentos armazenados podem ser chamados a partir do JavaScript. Asinformações podem fluir para fora do procedimento e podem fluir de volta para aconversão.
Nosso exemplo não implementa uma chamada de procedimento armazenado, masum exemplo foi fornecido abaixo. Aqui está um exemplo de como criar sequênciaspara as entradas de tabela de fatos. Ele chama um Procedimento do BD no DB2,SQL Server ou Oracle chamado NEXTVAL. A seguir está um exemplo doprocedimento armazenado NEXTVAL:// Stored procedure calltask.logmsg("DEBUG", methodName + "Call Stored Procedure")var command = "{call NEXTVAL(?,?,?)}";try{
cstmt = conn2.prepareCall(command);cstmt.setString(1, "SEQ_FACTSOID");cstmt.setInt(2, 1);cstmt.registerOutParameter(3, java.sql.Types.INTEGER);cstmt.execute();result = cstmt.getInt(3);task.logmsg("DEBUG", methodName + "Result:" + result);
44 © Copyright IBM Corp. 2011, 2016

work.setAttribute("SPECID", result)cstmt.close();
}catch (e){
task.logmsg("DEBUG", "Stored Procedure call failed with exception:" + e);}
Associando dados de diferentes origens de dados usando um conector de consulta:
É possível executar uma consulta que permite associar dados de diferentes origensde dados. Essa ação pode ser implementada usando um script customizado ouusando um conector de consulta.
Sobre Esta Tarefa
Em nosso exemplo, usamos um script para executar uma consulta ao banco dedados e puxar dados adicionais para o fluxo de dados.
Procedimento
1. Na área do editor, clique em Fluxo de dados para criar um script.2. Clique em Incluir componente, selecione o componente Script vazio e clique
em Concluir.3. Inclua o código JavaScript a seguir no script para executar uma consulta em
um registro na tabela DTO do item de medidor.var methodName = "triLoadMeterData - LookupMeterItemDTO ";
task.logmsg("DEBUG", methodName + "Entry");
// Lookup Meter Item DTO recordvar recordFound = false;var selectStmt1 = conn1.createStatement();var rs1 = selectStmt1.executeQuery("select DC_SEQUENCE_ID,TRICOSTPERUNITNU, TRIQUANTITYNU from S_TRIENVMETERITEMDTO1where TRIMETERIDTX = \’" + work.TRIMETERIDTX.getValue() + "\’and TRITODATEDA = " + TRITODATEDA );var result = rs1.next();while (result){...}rs1.close();selectStmt1.close();
Saída de entradas para uma origem de dados:
Durante a saída, os dados transformados são passados juntamente com oAssemblyLine para outro conector JDBC em algum modo de saída, que envia osdados para o sistema conectado. Como o sistema conectado é orientado porregistro, os vários atributos no trabalho são mapeados para as colunas no registrousando um Mapa de atributos de saída.
Conector
A saída da tabela é o destino da maioria de seus dados. Este é o local onde vocêconfigura um conector JDBC para inserir ou atualizar dados em tabelas usando osparâmetros de conexão com o banco de dados passados para a linha de montagemdurante a inicialização.
Capítulo 2. Estruturas de dados 45

Em nosso exemplo, o conector nomeado JDBCConnectoToMeterItemDTO é usadopara armazenar informações na tabela de migração de dados do Log de MedidorAmbiental do TRIRIGA. Esse componente é incluído no término de seuAssemblyLine depois de ter todas as informações geradas para salvamento.
A guia Critérios de link no conector é usada para especificar os critérios a seguirusados para gerar uma instrução SQL para atualizar a tabela de saída. Em nossoexemplo, os critérios incluem as entradas a seguir:v TRIMETERIDTX equals $TRIMETERIDTXv TRITODATEDA equals $TRITODATEDA
Dica: O $ é usado para indicar que o nome da variável que se segue deve sersubstituído pelo valor da entrada de trabalho interno.
Mapa de atributos
O conector possui um Mapa de atributos de saída que é usado para especificar omapeamento entre as variáveis de trabalho interno e os nomes das colunas natabela de saída.
Selecione o componente ‘JDBCConnectorToMeterItemDTO’, em seguida, clique naguia Mapa de saída. A página Mapa de saída é aberta. Use esta página paramapear os campos de origem para os campos de destino no banco de dados dedestino. Observe que os campos de origem incluem os campos adicionais incluídosno fluxo de entrada.
Propagando o status para itens da tarefa ETL:
Todos os scripts devem conter ambos os ganchos, No sucesso ou Na falha, quepreenchem os atributos de trabalho errCount e errMsg para relatar o status devolta para o TRIRIGA quando a conversão é executada a partir de um item datarefa ETL.
Sobre Esta Tarefa
O atributo de trabalho errCount é o número de erros encontrados quando oarquivo do AssemblyLine foi executado. O atributo de trabalho errMsg é amensagem de erro gravada no log do TRIRIGA.
Procedimento
1. Para incluir ganchos de AssemblyLine, na área do editor, clique em Opções >Ganchos de AssemblyLine.
2. Selecione as caixas de seleção ao lado dos ganchos No sucesso e Na falha eclique em Fechar.
3. Modifique o gancho No sucesso para configurar os atributos de trabalhoerrCount e errMsg usando o código a seguir.// Set errCount and errMessage for ALif (task.getResult() == null) {
var result = system.newEntry();result.errCount = errCount;result.errMsg=’Assembly line completed successfully.’;task.setWork(result);
}else
46 © Copyright IBM Corp. 2011, 2016

{work.errCount = errCount;work.errMsg=’Assembly line completed successfully.’;
}
4. Modifique o gancho Na falha para configurar os atributos de trabalho errCounte errMsg usando o código a seguir.// Set errCount and errMessage for triDispatcher ALif (task.getResult() == null) {
var result = system.newEntry();result.errCount = 1;result.errMsg=’Assembly line failed.’;task.setWork(result);
}else{
work.errCount = 1;work.errMsg=’Assembly line failed.’;
}
Teste de conversão no Tivoli Directory Integrator:
O teste após cada etapa torna a depuração mais fácil.
É necessário salvar antes de executar uma conversão; caso contrário, o TivoliDirectory Integrator chamará o AssemblyLine sem as mudanças que foram feitasdesde o último salvamento.
À medida que você desenvolve o AssemblyLine, é possível testá-lo executando atéa conclusão ou por etapas por meio dos componentes, um a um. Há dois botõespara executar o AssemblyLine. A ação Executar no console inicia o AssemblyLine emostra a saída em uma visualização de console. A ação Depurador executa oAssemblyLine com o depurador.
O processo de iniciar um AssemblyLine passa pelas etapas a seguir:1. Se o AssemblyLine contiver erros, como mapas de saída ausentes, será
solicitado que você confirme a execução do AssemblyLine com a mensagem aseguir: Este AssemblyLine possui um ou mais erros. Continuar com aexecução?
2. A próxima verificação é se o servidor Tivoli Directory Integrator estádisponível. Se o servidor estiver inacessível, você verá esta mensagem: Aconexão com o Default.tdiserver não pode ser obtida.
3. Por último, o Editor de Configuração transfere a configuração de tempo deexecução para o servidor e aguarda o AssemblyLine ser iniciado. Nesta etapa,você verá uma barra de progresso na parte superior da janela. O botão da barrade ferramentas para parar o AssemblyLine também estará esmaecido, uma vezque ele não foi iniciado ainda. Depois que o AssemblyLine estiver em execução,a barra de progresso ficará girando e você deverá ver as mensagens na janelade log. Agora é possível parar o AssemblyLine clicando na ação Parar na barrade ferramentas.
Movendo scripts ETL para o TRIRIGA a partir do Tivoli Directory Integrator:
Depois que a conversão é concluída e testada, ela deve ser transferida por uploadpara o item da tarefa ETL do TRIRIGA.
O gráfico a seguir descreve o fluxo entre o ambiente ETL e o TRIRIGA.
Capítulo 2. Estruturas de dados 47

Bancode Dados
Arquivo XML dosistema de arquivos
O ambiente dedesenvolvimento ETL
gera o XML de conversão
Salvar XMLAbrir XML
BO/formulário da plataformado aplicativo TRIRIGA definido
para gerenciar asconversões
Fazer uploadFazer download
ContentManager
O fluxo de trabalho da plataformado aplicativo TRIRIGA chama a
tarefa customizada em umaprogramação para executar
as conversões
ContentManager
Configurando as conexões de AssemblyLine do banco de dados do TRIRIGA:
Antes de fazer upload do arquivo de configuração do runtime para um registro deitem da tarefa ETL do TRIRIGA, deve-se configurar as conexões de AssemblyLinedo banco de dados do TRIRIGA com os parâmetros a serem passados para oconjunto do Tivoli Directory Integrator durante a inicialização.
Procedimento
1. Clique em Ferramentas > Configuração do sistema > Geral > Configuraçõesdo aplicativo.
2. Na guia Configurações ambientais, na seção Configurações de AssemblyLine,configure as conexões de AssemblyLine do banco de dados.a. Necessário: Configure o DB-TRIRIGA como a conexão para seu banco de
dados TRIRIGA. Se essa conexão não estiver configurada, os itens da tarefaETL do Tivoli Directory Integrator não serão executados.
b. Opcional: Configure DB-OTHER se os AssemblyLines do Tivoli DirectoryIntegrator devem se conectar a um banco de dados externo. ComoDB-OTHER é opcional, o TRIRIGA não verifica se ele está configurado.Portanto, o AssemblyLine deve verificar se essa conexão está configuradaantes de usá-la.
3. Clique em Testar conexão com BD para verificar se os dados de conexão estãocorretos.
48 © Copyright IBM Corp. 2011, 2016

Recuperando os parâmetros do AssemblyLine:
Depois que as conexões de AssemblyLine do banco de dados do TRIRIGA tiveremsido configuradas, modifique o AssemblyLine para recuperar os parâmetros.
Procedimento
1. Abra o script Prólogo que inicializa o AssemblyLine.2. Inclua as instruções a seguir para recuperar os parâmetros de conexão do
TRIRIGA-DB.var op = task.getOpEntry();var jdbcTriURL = op.getString("jdbcTriURL");var jdbcTriDriver = op.getString("jdbcTriDriver");var jdbcTriUser = op.getString("jdbcTriUser");var jdbcTriPassword = op.getString("jdbcTriPassword");
3. Inclua as instruções a seguir para recuperar os parâmetros de conexãoOTHER-DB.var op = task.getOpEntry();var jdbcOthURL = op.getString("jdbcOthURL");var jdbcOthDriver = op.getString("jdbcOthDriver");var jdbcOthUser = op.getString("jdbcOthUser");var jdbcOthPassword = op.getString("jdbcOthPassword");
4. Salve as mudanças.
Movendo scripts ETL para o TRIRIGA:
Depois de ter desenvolvido um script ETL no Editor de Configuração do TivoliDirectory Integrator, deve-se movê-lo para o TRIRIGA.
Sobre Esta Tarefa
O Editor de Configuração do Tivoli Directory Integrator armazenaautomaticamente o arquivo de configuração do runtime no local a seguir:Workspace/ProjectName/Runtime-ProjectName/ProjectName.xml.
Procedimento
1. Crie um registro de item da tarefa ETL com o campo Tipo de item da tarefaconfigurado para Transformação do Tivoli Directory Integrator.
2. Configure o campo Nome do AssemblyLine para o nome da AssemblyLineque você deseja iniciar após o carregamento do arquivo de configuração.
3. Configure o campo Arquivo de conversão fazendo upload do arquivo deconfiguração do runtime que você criou no Editor de Configuração.
4. Opcional: Se a conversão ETL requerer quaisquer arquivos como entrada,associe esses arquivos ao item da tarefa ETL como arquivos de recursos. Porexemplo, se a conversão ETL deve processar dados de um arquivo de planilha,deve-se associar esse arquivo como um arquivo de recursos.a. Na seção Arquivo de recursos, clique em Incluir.b. Configure o Nome do recurso para um nome que é usado para identificar o
arquivo de recursos. Esse nome será parte do nome do arquivo de recursostemporário que o TRIRIGA envia para a conversão ETL. Isso é útil se vocêassociar mais de um Arquivo de Recursos a um item da tarefa ETL porquepermite que a conversão ETL identifique os diversos arquivos que sãoenviados a ele por nome.
Capítulo 2. Estruturas de dados 49

c. Para configurar o campo Arquivo de recursos, clique no ícone Fazer uploaddo arquivo de recursos ao lado do campo, especifique o local do arquivo eclique em OK para fazer upload desse arquivo para o campo Arquivo derecursos.
Variáveis passadas para o Tivoli Directory Integrator:
O TRIRIGA passa diversas variáveis de entrada para os ETLs do Tivoli DirectoryIntegrator.
Para usar qualquer uma dessas variáveis em um AssemblyLine, acesse-as por meioda interface getOpEntry() do Tivoli Directory Integrator. Por exemplo, var op =task.getOpEntry(); var jdbcTriURL = op.getString("jdbcTriURL");
O TRIRIGA extrai os valores dos campos do registro de item da tarefa ETL e ospassa como parâmetros de entrada. Os tipos de campos que são suportadas sãoTexto, Booleano, Data, Data e hora, Localizadores e Números. Qualquer campo deitem da tarefa ETL desse tipo é passado como variáveis.
Se um item da tarefa ETL tiver os campos a seguir, as variáveis na segunda tabelaserão passadas para o Tivoli Directory Integrator:
Tabela 6. Campos de itens da tarefa ETL
Nome do campo Rótulo do campo Tipo de campo
triActiveEndDA Data de Encerramento Ativa Data
triActiveStartDA Data de Início Ativa Data
triControlNumberCN Número de controle Número de controle
triCreatedByTX Criado por Texto
triLocator triLocator Texto
triNameTX Nome Texto
triTransformBI Arquivo de Conversão Binário
As variáveis que são passadas para o Tivoli Directory Integrator são as seguintes:
Tabela 7. Variáveis passadas para o Tivoli Directory Integrator
Variável passada para o Tivoli DirectoryIntegrator Descrição
triNameTX (Texto)
triActiveStartDA (Número) data em milissegundos desde 1 dejaneiro de 1970
triActiveStartDA_DATE (Data) agrupada se Oracle ou DB2, o horárioé tudo o que estava no atributo
triActiveStartDA_MinDATE (Data) agrupada se Oracle ou DB2, o horárioé 00:00:00
triActiveStartDA_MaxDATE (Data) agrupada se Oracle ou DB2, o horárioé 23:59:59
triActiveStartDA_Min (Número) data em milissegundos desde 1 dejaneiro de 1970, a hora é 00:00:00
triActiveStartDA_Max (Número) data em milissegundos desde 1 dejaneiro de 1970, a hora é 23:59:59
50 © Copyright IBM Corp. 2011, 2016

Tabela 7. Variáveis passadas para o Tivoli Directory Integrator (continuação)
Variável passada para o Tivoli DirectoryIntegrator Descrição
triActiveEndDA (Número) data em milissegundos desde 1 dejaneiro de 1970
triActiveEndDA_DATE (Data) agrupada se Oracle ou DB2, o horárioé tudo o que estava no atributo
triActiveEndDA_MinDATE (Data) agrupada se Oracle ou DB2, o horárioé 00:00:00
triActiveEndDA_MaxDATE (Data) agrupada se Oracle ou DB2, o horárioé 23:59:59
triActiveEndDA_Min (Número) data em milissegundos desde 1 dejaneiro de 1970, a hora é 00:00:00
triActiveEndDA_Max (Número) data em milissegundos desde 1 dejaneiro de 1970, a hora é 23:59:59
triCreatedByTX (Texto)
triRunDATE (Número) Data de execução configuradapela tarefa de fluxo de trabalho customizado
triLocator (Texto - Localizador) é um campo delocalizador que contém uma referência paraoutro objeto de negócios. Essa variávelcontém o valor de texto do campo desseregistro
triLocator_IBS_SPEC (Texto – Localizador) contém o spec_id doregistro no campo triLocator. É possível usaresse spec_id para localizar informaçõesrelacionadas a esse registro por meio deoutras tabelas de banco de dados
triAssemblyLineNameTX O nome do AssemblyLine principal naconversão ETL que você deseja executar
O TRIRIGA também passa variáveis do Arquivo de Recursos. Um Arquivo deRecursos é um arquivo que uma conversão ETL requer como entrada. Porexemplo, se uma conversão ETL deve processar dados de um arquivo CommaSeparated Value (.csv), ela precisa saber onde e como referenciar esse arquivoquando ele é executado.
Se um item da tarefa ETL tiver dois registros do Arquivo de Recursos associados,cada um incluirá os campos a seguir:
Tabela 8. Campos associados a registros do Arquivo de Recursos
Nome do campo Rótulo do campo Tipo de campo
triResourceNameTX Nome que é usado paraidentificar o arquivo derecursos
Texto
triResourceFileBI Conteúdo do arquivo derecursos
Binário
As variáveis que são passadas para o Tivoli Directory Integrator para essesregistros do Arquivo de Recursos são as seguintes:
Capítulo 2. Estruturas de dados 51

Tabela 9. Variáveis passadas para o Tivoli Directory Integrator
Variável passada para o Tivoli DirectoryIntegrator Descrição
RESOURCE_1 Nome completo do arquivo de recursos. Onome do arquivo contém o valor do campotriResourceNameTX para ajudar a conversãoETL a identificá-lo
RESOURCE_2 Nome completo do arquivo do outroarquivo de recursos. O nome do arquivocontém o valor do campotriResourceNameTX para ajudar a conversãoETL a identificá-lo
Tabela 10. O TRIRIGA também passa variáveis de entrada JDBC que estão definidas nasConfigurações do Aplicativo.
Variável passada para o Tivoli DirectoryIntegrator Descrição
jdbcTriURL URL do driver de banco de dados doTRIRIGA
jdbcTriDriver Nome do driver de banco de dados doTRIRIGA
jdbcTriUser Nome de usuário do banco de dados doTRIRIGA
jdbcTriPassword Senha do banco de dados do TRIRIGA
jdbcOthURL Outra URL do driver de banco de dados
jdbcOthDriver Outro nome do driver de banco de dados
jdbcOthUser Outro nome de usuário do banco de dados
jdbcOthPassword Outros dados
Depurando scripts ETL no aplicativo:
Para depurar scripts ETL no aplicativo, você deve primeiro configurar a criação delog e depois acionar a tarefa de fluxo de trabalho customizado RunETL paravisualizar as informações de log.
Configurando a criação de log:
O TRIRIGA fornece recursos de depuração quando scripts ETL são executados noaplicativo TRIRIGA.
Procedimento
1. No console do administrador, selecione o objeto gerenciado Criação de log daplataforma. Em seguida, selecione a opção para ativar a criação de log ETL.
2. Selecione Categoria ETL > Conversões > Executar conversão para ativar acriação de log de depuração no código da plataforma do TRIRIGA que processaitens da tarefa ETL. As mensagens de log são impressas no server.log.
3. Selecione Categoria ETL > Conversões > Tivoli Directory Integrator paraativar a criação de log de depuração nos AssemblyLines do Tivoli DirectoryIntegrator. As mensagens de log são impressas para o log do AssemblyLine.Cada AssemblyLine possui seu próprio arquivo de log.
52 © Copyright IBM Corp. 2011, 2016

4. Aplique as mudanças. Agora, quando um script ETL for executado, asinformações relacionadas ao ETL serão colocadas no log do servidor ou log doAssemblyLine.
Importante: Devido ao grande volume de informações que você podeencontrar em um log, configure a criação de log do Tivoli Directory Integratorpara depurar somente uma execução do item da tarefa ETL.
Depurando usando tarefas ETL:
Depois de ter configurado a criação de log, será necessário acionar a tarefa defluxo de trabalho customizado RunETL para ver quaisquer informações nos logs.
Procedimento
Se você estiver usando o Item da Tarefa ETL, é possível simplesmente clicar emExecutar processo nesse formulário. Não se esqueça de preencher os valores doscampos no formulário que o script ETL esperaria.
Nota: Somente use a ação Executar processo para propósitos de depuração. Paraprodução, use o Planejador de tarefa em seu lugar. Observe que Executar processoatualizará as tabelas no banco de dados, portanto, não use essa ação em umambiente de produção.
Exemplo
A seguir é mostrada uma saída de log do servidor de amostra:2014-03-27 13:18:10,427 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: getETLVarsFromFields...2014-03-27 13:18:10,431 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: getETLVarsFromFields2014-03-27 13:18:10,431 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: getETLVarsFromResourceFiles2014-03-27 13:18:10,432 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: getETLVarsFromResourceFiles2014-03-27 13:18:10,432 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Processing Job Item with Type = Tivoli Directory Integrator Transformation2014-03-27 13:18:10,432 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: transformRecordTDI2014-03-27 13:18:10,474 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.TDIRequest](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: init2014-03-27 13:18:10,474 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.TDIRequest](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: init2014-03-27 13:18:10,483 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL]
Capítulo 2. Estruturas de dados 53

(WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189) ***ETL Variable = triIdTX : triLoadMeterData2014-03-27 13:18:10,483 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189) ***ETL Variable = triAssemblyLineNameTX : triLoadMeterData...2014-03-27 13:18:10,483 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)*** ETL Variable = triNameTX :Carregar Tabela de Migração de Dados do Item de Medidor2014-03-27 13:18:10,488 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.DataSourceConnectionInfoImpl] (WFA:221931 - 15290804triProcessManual:305676189 IE=305676189)Entry: init2014-03-27 13:18:10,495 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.DataSourceConnectionInfoImpl](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: init2014-03-27 13:18:10,495 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.DataSourceConnectionInfoImpl](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: init2014-03-27 13:18:10,496 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.DataSourceConnectionInfoImpl](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: init2014-03-27 13:18:10,497 INFO [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Setting TDI log level to Debug.2014-03-27 13:18:10,503 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.LogSettingsServiceImpl](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: getLogSettings2014-03-27 13:18:10,503 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.LogSettingsServiceImpl](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Found DailyRollingFileAppender.2014-03-27 13:18:10,503 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.LogSettingsServiceImpl](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: getLogSettings2014-03-27 13:18:10,503 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.TDIRequest](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Entry: send2014-03-27 13:18:14,396 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.TDIRequest](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: send2014-03-27 13:18:14,396 INFO [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)RunETL request returned fromTDI server version: 7.1.1.3 - 2013-12-06 running on host: i3650x3cr22014-03-27 13:18:14,396 INFO [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)
54 © Copyright IBM Corp. 2011, 2016
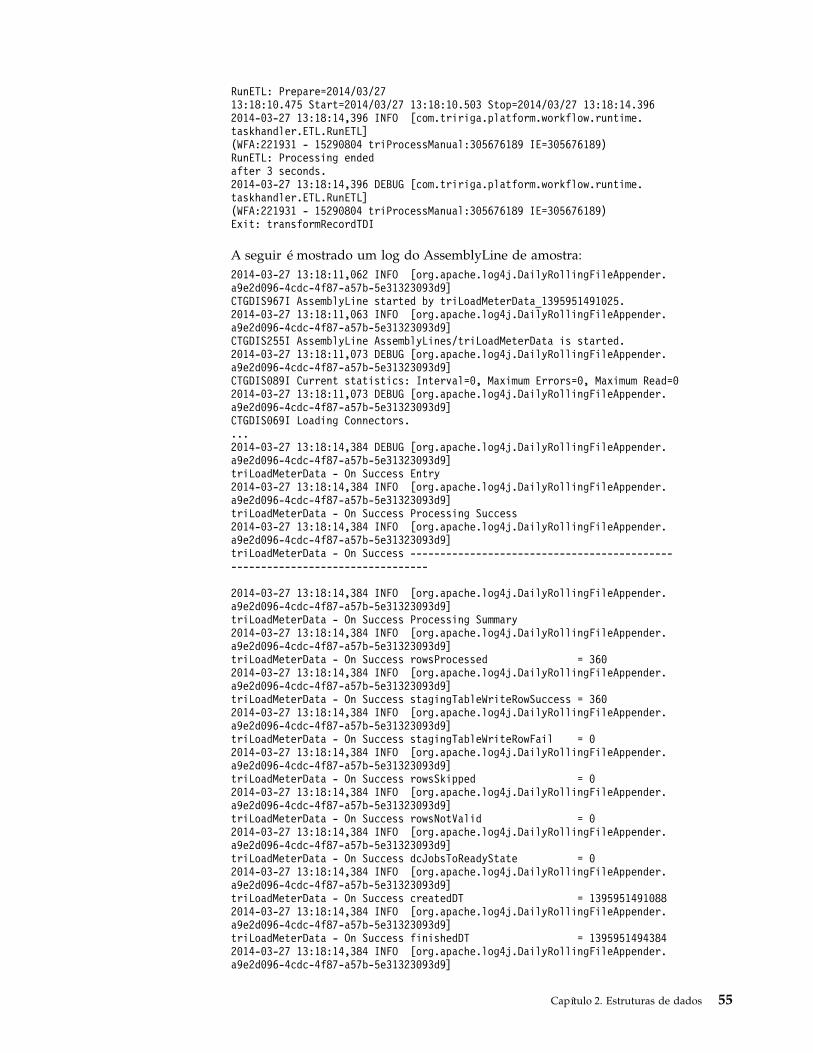
RunETL: Prepare=2014/03/2713:18:10.475 Start=2014/03/27 13:18:10.503 Stop=2014/03/27 13:18:14.3962014-03-27 13:18:14,396 INFO [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)RunETL: Processing endedafter 3 seconds.2014-03-27 13:18:14,396 DEBUG [com.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL](WFA:221931 - 15290804 triProcessManual:305676189 IE=305676189)Exit: transformRecordTDI
A seguir é mostrado um log do AssemblyLine de amostra:2014-03-27 13:18:11,062 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]CTGDIS967I AssemblyLine started by triLoadMeterData_1395951491025.2014-03-27 13:18:11,063 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]CTGDIS255I AssemblyLine AssemblyLines/triLoadMeterData is started.2014-03-27 13:18:11,073 DEBUG [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]CTGDIS089I Current statistics: Interval=0, Maximum Errors=0, Maximum Read=02014-03-27 13:18:11,073 DEBUG [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]CTGDIS069I Loading Connectors....2014-03-27 13:18:14,384 DEBUG [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success Entry2014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success Processing Success2014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success -----------------------------------------------------------------------------
2014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success Processing Summary2014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success rowsProcessed = 3602014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success stagingTableWriteRowSuccess = 3602014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success stagingTableWriteRowFail = 02014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success rowsSkipped = 02014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success rowsNotValid = 02014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success dcJobsToReadyState = 02014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success createdDT = 13959514910882014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success finishedDT = 13959514943842014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]
Capítulo 2. Estruturas de dados 55

triLoadMeterData - On Success seconds = 32014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success secondsPerRecord = 0.012014-03-27 13:18:14,384 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success -----------------------------------------------------------------------------2014-03-27 13:18:14,386 DEBUG [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]triLoadMeterData - On Success Exit2014-03-27 13:18:14,386 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]CTGDIS116I Scripting hook of type onsuccess finished.2014-03-27 13:18:14,386 INFO [org.apache.log4j.DailyRollingFileAppender.a9e2d096-4cdc-4f87-a57b-5e31323093d9]CTGDIS080I Terminated successfully (0 errors).
Dicas de ajuste de desempenho:
Use as informações a seguir para melhorar o desempenho.
Quando você tiver terminado de preparar o ETL para fazer o que deseja que elefaça, tome uma medida de desempenho de linha de base.1. Usando o Editor de Configuração do Tivoli Directory Integrator, execute o ETL
com relação a um banco de dados no qual você terá milhares de linhasincluídas na tabela de fatos.
2. Certifique-se de que você esteja usando uma conexão com o banco de dados eexecutando a transformação do Tivoli Directory Integrator na rede em que obanco de dados reside para que não tenha latência de rede. Não o execute pormeio de uma VPN.
3. Revise as informações registradas para sua execução. Por exemplo, a partir deuma execução do ETL triLoadMeterData, revise o arquivotriLoadMeterData.log.
Análise da execução:1. Analise a execução. Há uma etapa mais lenta que outras?2. A etapa de entrada de dados é lenta? Deve ser incluído um índice no banco de
dados? Se sim, inclua um índice e execute novamente. O desempenho estámelhor? Talvez uma etapa de filtro deveria ser usada em vez de usar o bancode dados para filtrar o conjunto de resultados.
Dicas para desenvolver ETLs:v Evite SQL complexo e funções agregadas como COUNT, MIN, MAX e SUM. Se
precisar utilizá-los, veja se um índice ajudará na etapa de Entrada de dados. Nãocrie um índice em um campo que é varchar grande; o SQL Server só podemanipular índices < 900 bytes.
v Evite OR e NOT e o uso de visualizações (M_TableName nos bancos de dadosdo IBM TRIRIGA), se possível.
Executando conversões ETLUse o Programador de Tarefa do TRIRIGA para executar os itens da tarefa ETL eos grupos de tarefas que são usados para mover dados para as tabelas de fatos outabelas de hierarquias comprimidas do TRIRIGA.
56 © Copyright IBM Corp. 2011, 2016

Itens da tarefa ETL, grupos de tarefas e programadores de tarefaOs itens da tarefa ETL definem um script de transformação ETL ou processo dereconstrução de hierarquia que é usado para capturar informações do banco dedados TRIRIGA, transformá-las e carregá-las ems tabelas de fatos. Os grupos detarefas ETL são simplesmente coleções de itens da tarefa ETL. Os programadoresde tarefas definem quando os itens da tarefa ETL e os grupos de tarefas devem serexecutados. Uma programação de tarefas deve ser ativada para executar as tarefasque estão associadas a ela.
A ferramenta de analítica/relatório do TRIRIGA Workplace PerformanceManagement calcula as métricas que são usadas para gerar relatórios e gráficosusando consultas com relação a tabelas de fatos agrupadas pelos dados nas tabelasde hierarquias simples. Os itens da tarefa ETL são usados pelo Programador deTarefa para acionar os fluxos de trabalho que extraem dados de tabelas de origem,como tabelas de objetos de negócios do TRIRIGA, e os carrega nas tabelas de fatos.Os itens da tarefa ETL também podem ser usados para atualizar hierarquiassimples.
Há três tipos de itens da tarefas ETL no TRIRIGA Workplace PerformanceManagement:
Conversão KettleExtrai dados de tabelas de objetos de negócios do TRIRIGA e carrega osdados em tabelas de fatos do TRIRIGA Workplace PerformanceManagement.
Transformação do Tivoli Directory IntegratorExtrai dados de tabelas de objetos de negócios do TRIRIGA ou tabelas deorigens externas e carrega os dados nas tabelas de fatos do TRIRIGAWorkplace Performance Management.
Hierarquia de ReconstruçãoExtrai dados de tabelas de objetos de negócios do TRIRIGA e carrega osdados em tabelas de hierarquias simples do TRIRIGA WorkplacePerformance Management.
Criando ou modificando itens da tarefa ETLOs itens da tarefa ETL definem os scripts que capturam informações do banco dedados do TRIRIGA, transformam e carregam-as em tabelas de fatos ou tabelas dehierarquias simples.
Procedimento1. Clique em Ferramentas > Configuração do sistema > Programação de tarefas
> Item da tarefa ETL.2. Selecione um item da tarefa existente ou clique em Incluir.3. Na seção Geral, insira um ID para o item da tarefa ETL. Inclua o nome da
tabela de fatos no campo ID. O status é fornecido pelo sistema TRIRIGAquando o item da tarefa ETL é criado.
4. Insira um nome e uma descrição para o item da tarefa ETL. Na seçãoDetalhes, o campo Classe de item de tarefa é configurado como ETL pelosistema TRIRIGA.
5. Selecione o Tipo de item de tarefa.6. Se o tipo de item de tarefa for Reconstruir hierarquia, conclua as etapas a
seguir.
Capítulo 2. Estruturas de dados 57

a. Insira o nome do módulo de hierarquia. Se especificado, ele deve ser ummódulo com uma hierarquia definida no TRIRIGA, como Local. Quandoesse item da tarefa ETL é executado, todas as hierarquias simples para essemódulo são reconstruídas.
b. Insira o nome da hierarquia. Quando esse item da tarefa ETL é executado,a hierarquia simples para esse objeto de negócios é reconstruída. Seespecificado, o nome da hierarquia terá precedência sobre o nome domódulo de hierarquia.
c. O sistema TRIRIGA ignora as informações inseridas no período decalendário, período fiscal e outras datas na seção Detalhes.
d. Para reconstruir todas as hierarquias simples de um módulo específico,especifique o nome do módulo de hierarquia e deixe o nome da hierarquiaem branco.
e. Para reconstruir uma única hierarquia simples, especifique o nome domódulo de hierarquia e o nome da hierarquia.
f. Se o nome do módulo de hierarquia e o nome da hierarquia estiverem embranco ou contiverem Todos, todas as hierarquias simples serãoreconstruídas.
7. Se o tipo de item de tarefa for Conversão Kettle ou Conversão TDI, concluaas etapas a seguir.a. Especifique o arquivo de conversão navegando para o arquivo e
selecionando-o. O sistema TRIRIGA espera que o arquivo de conversãoKettle esteja no formato .ktl ou .xml e o arquivo de conversão do TivoliDirectory Integrator esteja no formato .xml.
b. Opcional: Depois de fazer upload do arquivo de conversão, ele pode servisualizado clicando em Visualizar conteúdo.
8. Quando o tipo de item de tarefa for Conversão TDI, insira um nome de linhade montagem.
9. Quando o tipo de item de tarefa for Conversão Kettle,a. Insira os nomes dos módulos. Se mais de um nome for especificado, eles
deverão ser delimitados com uma vírgula.v Cada nome de módulo é convertido em uma variável para o arquivo de
conversão no formato ${Module.<moduleName>.ViewName} em que<moduleName> é o nome do módulo.
v O valor de cada variável que é passado para o ETL é o nome daVisualização para esse módulo. Este valor dessa variável poderá serusado se o ETL precisar saber o nome da visualização de um móduloespecífico.
b. Insira os nomes de objetos de negócios. Se você especificar mais de umnome de objeto de negócios, os nomes deverão ser delimitados por umavírgula.v Cada nome de objeto de negócios é convertido em uma variável para o
arquivo de conversão no formato ${BO.<boName>.TableName}, em que<boName> é o nome do objeto de negócios.
v Não é garantido que um objeto de negócios seja exclusivo em todo obanco de dados, a menos que o nome do módulo seja incluído. Se vocêusar um objeto de negócios que não seja nomeado exclusivamente,inclua o nome do módulo na lista separada por vírgula. Use a sintaxe aseguir: <moduleName>::<boName>, em que <moduleName> é o nome domódulo e <boName> é o nome do objeto de negócios.
v Uma variável é fornecida ao arquivo de conversão como${BO.<moduleName>::<boName>.TableName}. O valor de cada variável é o
58 © Copyright IBM Corp. 2011, 2016

nome da tabela para esse objeto de negócios. O valor dessa variávelpoderá ser usado se o ETL precisar saber o nome da tabela de umObjeto de Negócios específico.
10. Se o tipo de item de tarefa for Conversão Kettle ou Conversão TDI, concluaas etapas a seguir.a. Geralmente, os itens da tarefa ETL são executados sob o controle de uma
ou mais programações de tarefas.b. Para teste de unidade do item da tarefa ETL, configure os parâmetros de
data na seção Detalhes.c. Os parâmetros de data a seguir dependem do ETL, alguns ETLs usam as
informações, alguns ETLs não. Os parâmetros de data são sobrescritosquando um item da tarefa ETL é executado pelo Programador de Tarefa.v Selecione o Período de calendário para passar uma variável que contém
o período de calendário da tarefa.v Selecione o Período fiscal para passar uma variável que contém o
período fiscal da tarefa. O período fiscal é usado pelo campo Período decaptura nas tabelas de fatos do TRIRIGA Workplace PerformanceManagement.
v Selecione a Data para passar uma variável que contém o registro de datada tarefa. O registro de data é usado para registrar o campo Dimensãode data nas tabelas de fatos do TRIRIGA Workplace PerformanceManagement.
v Selecione a Data para passar uma variável que contém a data da tarefa.Insira uma data ou clique no ícone Calendário e selecione uma data.
v Selecione a Data de início para especificar a data da primeira captura dedados e para passar uma variável que contém a data de início da tarefa.Insira uma data ou clique no ícone Calendário e selecione uma data.
v Selecione a Data de encerramento para especificar a data da últimacaptura de dados e para passar uma variável que contém a data deencerramento da tarefa. Insira uma data ou clique no ícone Calendário eselecione uma data.
11. A seção Métricas resume os dados de criação de log para esse item da tarefaETL. O Duração média é calculada com base no Duração total e no Nº deexecuções (Duração total / Nº de execuções).
12. A seção Logs mostra o horário e o status de cada vez que o item da tarefaETL é executado. Esses dados são resumidos na seção Métricas.
13. Clique em Criar rascunho.14. Clique em Ativar.
Resultados
O registro de item da tarefa ETL é criado e está pronto para ser incluído em umgrupo de tarefas, uma programação de tarefas, ou ambos.
O que Fazer Depois
Para teste de unidade, clique em Executar processo para acionar a conversão Kettleou Tivoli Directory Integrator ou o processo Reconstruir hierarquia que estáespecificado no item da tarefa ETL.
Incluindo ou modificando grupos de tarefasPara simplificar o planejamento de tarefas, use os grupos de tarefas para fazer comque as coleções de itens da tarefa ETL sejam executadas na mesma programação.
Capítulo 2. Estruturas de dados 59

Procedimento1. Clique em Ferramentas > Configuração do sistema > Programação de tarefas >
Grupo de tarefas.2. Selecione um grupo de tarefas existente ou clique em Incluir.3. No formulário Grupo de tarefas, insira um nome e uma descrição para o grupo
de tarefas.4. Inclua ou remova itens da tarefa ETL do grupo de tarefas na seção Itens da
tarefa usando as ações Localizar ou Remover.5. Opcional: Ajuste a sequência dos itens da tarefa.6. Clique em Criar.
Resultados
O registro de grupo de tarefas está disponível para ser incluído em umaprogramação de tarefas.
Criando ou modificando programadores de tarefaUse programadores de tarefa para planejar quando o TRIRIGA executará itens datarefa ETL e grupos de tarefas. É possível planejar tarefas para serem executadasem uma base por hora, diária, semanal ou mensal.
Antes de Iniciar
Embora o TRIRIGA inclua programadores de tarefa predefinida, nenhuma tarefaserá planejada até que você revise os programadores de tarefa predefinida ou crieum novo programador de tarefa com uma data de início e data de encerramento eclique em Ativar.
Procedimento1. Clique em Ferramentas > Configuração do sistema > Programação de tarefas >
Programador de tarefa.2. Selecione um programador de tarefa existente ou clique em Incluir.3. Insira um nome e uma descrição para o planejador de tarefa.4. Na seção Planejamento, selecione a frequência Tipo de planejamento na lista
apresentada.v Se você selecionar a árvore de planejamento Diário, os campos Por hora e A
cada serão exibidos. Clique na caixa de seleção Por hora para planejar astarefas para serem executadas por hora, em seguida, clique no campo A cadapara especificar o número de horas entre cada tarefa planejada.
v Se você selecionar o tipo de programação Avançado, o campo Padrão derecorrência será exibido na seção Programação. Clique em Padrão derecorrência para abrir o formulário Evento de tarefa, que fornece opçõesflexíveis para planejar tarefas.
5. Opcional: Na seção Planejamento, marque a caixa de seleção Executar capturashistóricas? para indicar que dados históricos são incluídos nas métricascalculadas a partir dos resultados das atividades nesse planejamento de tarefa.Quando essa programação de tarefas está ativada, essa opção instrui oprogramador de tarefa a gerar e executar tarefas em que a data planejada éanterior a hoje. Os parâmetros, como data de início, data de encerramento eperíodo fiscal, para o intervalo de tempo ou período são passados para cadaitem da tarefa para simular uma captura histórica. No entanto, visto que oprocesso está sendo executado agora, o sucesso é totalmente dependente de
60 © Copyright IBM Corp. 2011, 2016

como os scripts ETL usam esses parâmetros. A execução de capturas históricasé uma opção avançada que requer um entendimento completo de como cadascript funciona.
6. Selecione a data de início para a primeira captura, a data de encerramento paraa última captura e o atraso de captura da data de encerramento de cadacaptura, que é a quantia de tempo que o sistema aguarda para iniciar os fluxosde trabalho que processam a tarefa. Cada período de captura de dados écalculado usando a data de início e o tipo de planejamento. O sistema acionaum fluxo de trabalho para executar os itens de tarefas ETL imediatamente apóso atraso de captura a partir do final de cada período de captura. Por exemplo,se a data de início for 01/01/2014, o tipo de programação for mensal e o atrasode captura for um dia, os eventos a seguir serão planejados:
Tabela 11. Execuções de tarefa planejadas a partir do início do mês
Execuções de tarefa - Logoapós a meia-noite em
Data de início dos dadoscapturados
Data de encerramento dosdados capturados
01/02/2014 01/01/2014 31/01/2014
01/03/2014 01/02/2014 28/02/2014
01/04/2014 01/03/2014 31/03/2014
A Data de encerramento determina o último evento a ser capturado. Usando oexemplo anterior, se 15/03/2014 fosse a data de encerramento, o último eventoseria planejado conforme a seguir:
Tabela 12. As execuções de tarefa planejadas a partir do meio do mês
Execuções de tarefa - Logoapós a meia-noite em
Data de início dos dadoscapturados
Data de encerramento dosdados capturados
16/03/2014 01/03/2014 15/03/2014
v Quando a caixa de seleção Reconfigurar período de captura? estáselecionada, ela força o sistema a assegurar que o período de captura sejamantido atual toda vez que uma tarefa é executada.
v Por exemplo, se um planejador de tarefa ativado estiver configurado com otipo de planejamento mensal, o sistema será ativado a cada mês e executaráos itens de tarefas no registro. Durante a ativação, se o período de captura dereconfiguração do planejador de tarefa estiver selecionado, o sistemaassegurará que o período de captura seja configurado corretamente com basena data de ativação.
v Ao especificar itens de tarefas e/ou grupos de tarefas e ativar esse registrode planejamento de tarefa, a lista de eventos planejados para essePlanejamento de tarefa é mostrada na seção Tarefas planejadas.
7. Na seção Itens da tarefa, use as ações Localizar ou Remover para selecionar ositens da tarefa ETL e grupos de tarefas a serem incluídos na programação eclique em OK. O itens da tarefa são executados na ordem especificada nacoluna Sequência.v Quando esse planejamento de tarefa está ativado, a seção Métricas resume os
dados de criação de log para este planejamento de tarefa.v A Duração média é calculada com base na Duração total e no Número de
execuções (Duração total / Número de execuções).v Quando esse planejamento de tarefa está ativado, a seção Logs mostra o
horário e o status cada vez que esse planejamento de tarefa é executado.8. Opcional: Ajuste a sequência dos itens da tarefa.9. Clique em Criar rascunho e, em seguida, clique em Ativar.
Capítulo 2. Estruturas de dados 61

Resultados
O sistema TRIRIGA cria um conjunto de tarefas planejadas baseadas no tipo deplanejamento e nas datas de início e encerramento. Estas podem ser vistas na seçãode tarefas planejadas do planejamento de tarefa.
Customizando objetos de conversãoO TRIRIGA fornece itens da tarefa ETL e objetos de conversão. Em vez de definirum novo objeto de conversão, é possível customizar um objeto de conversão deitem da tarefa ETL existente. Se você usar um objeto de conversão existente,deve-se definir ou manter a conversão. No entanto, não é necessário definir oumanter os objetos de negócios, formulários ou tarefas de fluxo de trabalho, poiseles já estão definidos.
Definindo objetos de negócios, formulários e fluxos de trabalhode conversãoÉ possível usar o item da tarefa ETL existente do TRIRIGA como um exemplo aodefinir um novo objeto de conversão. Definir um novo objeto de conversão própriotambém requer que você defina e mantenha os objetos de negócios, formulários efluxos de trabalho.
Antes de Iniciar
Crie as tabelas de origem e destino (objetos de negócios) e estabeleça osmapeamentos correspondentes.
Procedimento1. Crie o objeto de negócios de conversão.
a. Identifique as variáveis a serem passadas para a conversão e inclua-as noobjeto de negócios de conversão. Por exemplo, período de tempo.
b. Assegure-se de que exista um campo binário para o XML de transformação.2. Crie o formulário de conversão e forneça um item de navegação, ou outro
método, para mostrar o formulário de conversão.3. Crie o fluxo de trabalho que chama a tarefa de fluxo de trabalho customizado
de conversão ETL.a. Configure o fluxo de trabalho para ser executado em uma programação.b. Itere por meio de todos os registros de objetos de negócios de conversão
que devem ser executados, chamando a tarefa de fluxo trabalhocustomizada para cada um.
Salvando o XML de conversão no Content ManagerDepois de definir o XML de conversão, é possível salvá-lo no sistema de arquivose fazer upload dele para o TRIRIGA Content Manager. O XML de conversão podeentão ser testado usando um ambiente de desenvolvimento ETL.
Procedimento1. Abra o item de navegação para o objeto de negócios de conversão. Edite um
objeto de negócios de conversão existente ou inclua um novo.2. Use o campo binário para fazer upload do XML de conversão no TRIRIGA
Content Manager.3. Atualize outros campos, se necessário.4. Salve o registro de conversão.
62 © Copyright IBM Corp. 2011, 2016

Configurando o tempo de execução do fluxo de trabalhoDepois de fazer upload do XML de conversão para o TRIRIGA Content Manager, épossível configurar o fluxo de trabalho para ser executado em uma programação.O fluxo de trabalho itera por meio de todos os registros de objeto de negócios deconversão e chama a tarefa de fluxo de trabalho customizado para cada registro.
Procedimento1. O fluxo de trabalho obtém os registros para o objeto de negócios de conversão.2. O fluxo de trabalho determina os registros a serem enviados para a tarefa de
fluxo de trabalho customizado.3. O fluxo de trabalho itera por meio da chamada da tarefa de fluxo de trabalho
customizado para cada registro. O nome da classe deve sercom.tririga.platform.workflow.runtime.taskhandler.ETL.RunETL.
4. A tarefa de fluxo de trabalho customizado:a. Carrega o XML de conversão do Content Manager em um arquivo
temporário.b. Reúne todos os campos no objeto de negócios e cria uma variável para
entregar para a ferramenta ETL. Uma manipulação especial é necessáriapara os formatos de data/data e hora.
c. Cria o ambiente ETL.d. Configura a conexão do TRIRIGA com o JNDI do servidor de aplicativos
local.e. Executa a conversão usando a API do ETL.f. Retorna false se ocorrer um erro durante o processamento, caso contrário,
retorna true para o fluxo de trabalho.
Executando uma especificação de tarefa de fluxo de trabalhocustomizado ETLO fluxo de trabalho itera por meio de todos os registros de objeto de negócios deconversão e chama a tarefa de fluxo de trabalho customizado para cada registro. Atarefa de fluxo de trabalho customizado inclui uma especificação definida.
Quando a tarefa de fluxo de trabalho customizado é chamada para cada objeto denegócios de conversão, os campos contidos nela são processados como a seguir:1. O campo triTransformBI é obrigatório e contém a referência ao arquivo XML
de transformação que você deseja executar.2. O campo triBONamesTX, se presente, é analisado como uma lista separada por
vírgula de nomes de objetos de negócios. A tarefa de fluxo de trabalhocustomizado cria variáveis do formulário ${BO.<boName>.TableName}. Porexemplo, se o campo contiver triBuilding, haverá uma variável${BO.triBuilding.TableName} disponível no script ETL. Essa variável contém onome da tabela de banco de dados real que armazena registros triBuilding.Como os nomes de objetos de negócios podem não ser exclusivos, você tem aopção de especificar o módulo usando o formulário <moduleName>::<boName>,que resulta em uma variável ${BO.<moduleName>::<boName>.TableName}correspondente. Por exemplo, Locations::triBuilding está disponível como avariável ${BO.Location::triBuilding.TableName} no script ETL.
3. O campo triModuleNamesTX, se presente, é analisado como uma lista separadapor vírgula de nomes de módulos. A tarefa de fluxo de trabalho customizadocria variáveis do formulário ${Module.<moduleName>.ViewName}.
Capítulo 2. Estruturas de dados 63

64 © Copyright IBM Corp. 2011, 2016

Capítulo 3. Métricas
Uma métrica é um objetivo operacional que você deseja medir. Todas as métricasdo TRIRIGA usam a mesma tecnologia métrica e dados, mas métricas diferentessão destinadas a propósitos diferentes.
As métricas podem ser divididas nos dois propósitos a seguir:
Métricas de desempenhoMétricas que medem o desempenho do processo para identificar ações quepodem ser tomadas para melhoria. Geralmente, as medidas sãoproporções, porcentagens ou pontuações. As métricas de desempenho têmdestinos, limites, condições de ação, prestação de contas e funções de tarefade ação.
Análise e métricas de relatórioMétricas que são as informações para o relatório geral ou análise adicionalde uma métrica de desempenho relacionada. Essas informações são úteispara análise dimensional e navegação, portanto, elas usam os recursos demétrica do aplicativo de gerenciamento de desempenho. A análise e asmétricas de relatório não têm destinos, limites, condições de ação,prestação de contas e tarefas de ação. Os valores das métricas de chavepara os campos Resultados, Destino e Status estão em branco para essetipo de métrica.
Para obter mais informações, consulte o Guia do Usuário do IBM TRIRIGA 10Workplace Performance Management.
Relatórios de métricasOs relatórios de métricas usam as dimensões e os campos de fatos que sãodefinidos nas tabelas de fatos para representar um cálculo de métrica específico. Osrelatórios de métricas mostram os valores agregados para uma única métrica.
As coleções de relatórios de métricas para a função de cada usuário aparecem naPágina inicial do portal e no Gerenciador de Desempenho.
Não edite ou modifique os relatórios de métricas como entregues à medida quevocê customizar o software TRIRIGA para o ambiente de sua empresa. Em vezdisso, crie um relatório de métricas derivado, copiando um relatório de métricasexistente, renomeando e editando-o ou criando um relatório de métricas totalmentenovo. Visualize os relatórios de métricas em Meus relatórios > Relatórios dosistema com o filtro Módulo configurado para triMetricFact, o filtro Tipo deexibição configurado para Métrica e o filtro Nome configurado para Métrica. Paravisualizar os relatórios tabulares de métricas que estão relacionados aos relatóriosgráficos de métrica, configure o filtro Nome para Relatórios relacionados.
Cada relatório de métricas consiste nos elementos a seguir:
Caminhos de procuraUm recurso de relatório especial que aproveita a vantagem de dimensõeshierárquicas, fornecendo aos usuários do relatório a capacidade paramover-se para cima e para baixo em uma hierarquia.
© Copyright IBM Corp. 2011, 2016 65

Filtros Forneça aos usuários do relatório a capacidade de alterar ou filtrar osdados que são apresentados em um relatório.
Cálculo de métricaA métrica, que é o foco principal do relatório.
Relatórios relacionadosExiba mais dados, possivelmente não de métrica, para um relatório demétricas.
Para obter mais informações, consulte o Guia do Usuário do IBM TRIRIGAApplication Platform 3 Reporting.
Key MetricsO portal Pontuação inclui seções Key Metrics que coletam diversas métricas emuma única visualização.
Não edite ou modifique as métricas de chave como entregues à medida que vocêcustomizar o TRIRIGA para sua organização. Em vez disso, crie métricas de chavederivadas copiando um métrica de chave como entregue, renomeando eeditando-a. Também é possível criar uma seção do portal de métricas de chavetotalmente nova.
O processo de usar o Builder de pontuação, Builder de portal e Builder denavegação para configurar um portal é documentado no Guia do Usuário do IBMTRIRIGA Application Platform 3 User Experience.
Dicas:
v Na guia Consultas do formulário Pontuação, inclua todas as consultas quedevem aparecer nessa seção do portal Key Metrics na seção Consultasselecionadas.
v Quando você colocar a Pontuação em um item de navegação, especifique oRelatório padrão.
v O tempo de resposta que os usuários experienciam enquanto se movem em seuportal Página inicial e seu Gerenciador de Desempenho pode variar. O tempo deresposta está diretamente relacionado ao número de métricas que são incluídasna Pontuação e a quantia de dados por trás de cada métrica. Quando maispreciso os filtros, mais o desempenho melhora.
Métricas de formulárioUm método alternativo para exibir métricas é usando uma visualização deformulário.
A exibição de métricas em um formulário é realizada definindo uma seção deconsulta em um formulário, em que a consulta referenciada é uma consulta demétrica. Os dados que a consulta de métrica seleciona podem ser filtrados paraexibição com base no registro pai no qual o formulário é exibido. A comutaçãorelacionada de relatórios permite a troca de consultas que são baseadas em açõesdo usuário.
No tempo de design, defina uma consulta de métrica com um filtro $$RECORDID$$ e$$PARENT::[Section]:: [Field]$$. No tempo de execução, o registro pai no qual oformulário é exibido filtra implicitamente os dados que o Mecanismo de Consultade Métrica seleciona para exibição.
66 © Copyright IBM Corp. 2011, 2016

É possível definir outras consultas de métrica como relatórios relacionados. Notempo de execução, quando a consulta de métrica é exibida dentro de um relatóriorelacionado ao formulário, alternar o controle permite que o usuário troque aconsulta exibida.
Filtragem de dadosAntes de as métricas serem exibidas em um formulário, os dados são filtrados.
No tempo de execução, antes que a consulta seja executada,v O filtro $$RECORDID$$ é substituído pelo ID de registro do registro pai dentro do
qual o formulário está sendo exibido.v Um filtro $$PARENT::[Section]::[Field]$$ é resolvido para o valor do campo
de registro pai definido.v Se uma consulta de métrica for exibida fora de um registro pai, quaisquer filtros
sensíveis ao pai, como $$RECORDID$$ e $$PARENT::[Section]::[Field]$$, serãoignorados.
Defina os filtros $$RECORDID$$ e $$PARENT::[Section]::[Field]$$ com relação aoscampos que são definidos como um caminho de procura na tabela de fatos. Amétrica que é filtrada para um programa ou uma classificação, e que usa essesfiltros, age semelhante a selecionar a partir da lista do caminho da procura. Elatambém filtra para o registro especificado e inclui todos os filhos desse registro.
Quando um valor de filtro $$PARENT::[Section]::[Field]$$ é especificado em umfiltro hierárquico, um campo pai nulo é o equivalente a escolher o nó raiz docaminho da procura. Ele também inclui todos os registros que correspondem aovalor raiz. Um filtro não hierárquico se comporta de forma muito semelhante a umfiltro de consulta de objeto de negócios e filtra para registros com um valor nuloquando o valor do campo pai é nulo.
Os filtros $$RECORDID$$ e $$PARENT::[Section]::[Field]$$ se comportam como sefossem filtros de execução, exceto que seu valor é passado a partir do registro pai.
Se uma consulta de métrica tiver os filtros $$RUNTIME$$ e$$PARENT::[Section]::[Field]$$ que são definidos com relação ao mesmo campo,quando a consulta for exibida dentro de um formulário, o controle de filtro$$RUNTIME$$ não será usado. Em vez disso, o valor do$$PARENT::[Section]::[Field]$$ é usado como o valor de filtro.
Sub-relatóriosAs métricas de formulário podem incluir sub-relatórios tabulares e gráficos.
Um sub-relatório tabular define o relatório relacionado de um Gerenciador deDesempenho. Um sub-relatório não tabular representa um gráfico de métricas quepode ser alternado no formulário.
Os relatórios tabulares e gráficos podem ser incluídos na seção Sub-relatórios deuma métrica de consulta. No tempo de execução, um Gerenciador de Desempenhoexibe somnte relatórios tabulares como Relatórios Relacionados e uma Métrica emuma seção de consulta de formulário possui somente relatórios gráficos comoopções nos controle de troca da seção Sub-relatório.
Capítulo 3. Métricas 67

O tipo do sub-relatório (por exemplo, métrica, consulta ou relatório) é exibido naseção Sub-relatórios do Construtor de Relatório. Para consultas de métrica, osinalizador Saída tabular está disponível.
Uma consulta de métrica pode exibir outras consultas de métrica comosub-relatórios.
68 © Copyright IBM Corp. 2011, 2016

Capítulo 4. Compressor de hierarquia
A definição de uma hierarquia no TRIRIGA Application Platform forneceflexibilidade para implementações com diversas permutações de hierarquias dedados, por exemplo, as organizações. No entanto, as ferramentas de relatóriopreferem um resumo de dados mais estruturado para simplificar o relatório emaximizar o desempenho.
O propósito da ferramenta compressora de hierarquia é para um administradordefinir um conjunto de estruturas nomeadas que são usadas pelo mecanismo deRelatório de Métrica do TRIRIGA para processar rapidamente os dadoshierárquicos no sistema. A estrutura resultante é referida como uma hierarquiasimples e essas estruturas são usadas em um relatório de métricas.
Os administradores usam o programador de tarefa, com a ajuda de itens da tarefaETL, para executar o processo compressor de hierarquia. Os desenvolvedores desistema acionam o processo usando uma tarefa de fluxo de trabalho customizado.Neste caso, o nome de classe que é usado para executar o processo compressor dehierarquia écom.tririga.platform.workflow.runtime.taskhandler.flathierarchy.RebuildFlatHierarchies
O acionamento do processo usando uma tarefa de fluxo de trabalho customizado édiscutido em Application Building para o IBM TRIRIGA Application Platform 3.
Importante: Sempre que uma hierarquia no TRIRIGA é alterada, a árvore dehierarquia é imediatamente atualizada. Por exemplo, suponha que você inclua umnovo triBuilding, então, a hierarquia Locais será atualizada. No entanto, ahierarquia simples correspondente para triBuilding não é atualizada até que você areconstrua com um Item de Tarefa Reconstruir Hierarquia. Portanto, é importanteplanejar itens da tarefa reconstruir hierarquia ao mesmo tempo que quando vocêplaneja a captura de dados do TRIRIGA Workplace Performance Management pormeio de tabelas de fatos. Os itens da tarefa Reconstruir hierarquia asseguram quevocê mantenha as informações atuais.
Hierarquias simplesAs definições de estrutura de hierarquia dependem de em que o nivelamento estábaseado. A hierarquia simples pode ser baseada nos relacionamentos pai-filhopadrão para a hierarquia de um módulo especificado. A hierarquia simplestambém pode ser baseada em níveis específicos da hierarquia do módulo e seusrespectivos objetos de negócios.
Cada definição de estrutura de hierarquia contém um registro de cabeçalho únicoque identifica o nome da hierarquia, módulo e tipo de hierarquia. O nome dahierarquia descreve a hierarquia e o módulo é o módulo que a hierarquiarepresenta. O tipo de hierarquia é usado pelo processo de compressão paraentender como comprimir os dados. Existem dois tipos de hierarquia, Dados eFormulário.
Uma hierarquia de dados é usada para comprimir o caminho de dados com basenos relacionamentos pai-filho padrão para a hierarquia do módulo especificado.Esse tipo de hierarquia não possui níveis nomeados porque os aplicativos do
© Copyright IBM Corp. 2011, 2016 69

TRIRIGA Application Platform permitem que diferentes tipos de dados sejamrepresentados no mesmo nível físico na hierarquia de um módulo. Por exemplo,uma hierarquia de locais pode ter dados para propriedade, prédio e piso e paraprédio e piso. Assim, o primeiro nível da hierarquia conteria uma combinação depropriedades e prédios e o segundo nível conteria uma combinação de prédios episos.
Uma hierarquia de formulário é usada para comprimir o caminho de dados combase nos relacionamentos pai-filho para a hierarquia do módulo especificado e osobjetos de negócios que representam os níveis. Somente um objeto de negóciospode representar cada nível.
Cada hierarquia de formulário deve especificar níveis explícitos que contêm onúmero do nível, o objeto de negócios que o nível representa e o tipo. O tipo éusado pelo processo de compressão para entender como localizar os dados para onível. O tipo tem três opções: Localizar, Ignorar e Efetuar recursão.v Quando o valor de tipo é Localizar, o sistema procura por meio dos subníveis
dos dados da instância para um encadeamento específico até que um registroseja localizado para o formulário especificado. Se não forem localizadosregistros, os níveis restantes na definição de hierarquia serão ignorados enenhum outro dado simples será criado para esse encadeamento. Se um registrofor localizado, o sistema criará um registro de dados simples para esse nó econtinuará com o próximo nível na definição. Esse modo fornece o recurso parareduzir uma árvore para alinhar melhor seus dados de negócios.
v Quando o valor de tipo é Ignorar, o sistema procura o formulário especificado,um nível abaixo do último pai. Se um registro não for localizado, o sistemacriará uma diferença para esse nível e continuará com o próximo nível nadefinição. Se um registro for localizado, o sistema criará um registro de dadossimples para esse nó e continuará com o próximo nível na definição. Esse modofornece o recurso para expandir uma árvore para alinhar melhor seus dados denegócios. Para facilitar o processo de relatório, as diferenças devem receber umnome ou rótulo. Use o valor de Intervalo de diferença no Gerenciador deEstrutura de Hierarquia para esse propósito.
v Quando o valor de tipo é Efetuar recursão, o sistema procura por meio dossubníveis dos dados de instância um encadeamento específico até que umregistro seja localizado para o formulário especificado. Se não forem localizadosregistros, os níveis restantes na definição de hierarquia serão ignorados enenhum outro dado simples será criado para esse encadeamento. Para cadaregistro localizado, o sistema cria um registro de dados simples para esse nóantes de continuar com o próximo nível na definição.
Exemplos de hierarquias simplesÉ possível referenciar exemplos de hierarquia simples para entender melhor aestrutura de uma definição de hierarquia simples.
Registros de cabeçalho de hierarquia simples de amostra
A tabela a seguir mostra exemplos de hierarquias simples que são baseados emmódulos dentro de hierarquias:
Tabela 13. Registros de cabeçalho de amostra
Nome da hierarquia Módulo Tipo de hierarquia
Hierarquia de espaço Local GUI
Hierarquia de terreno Local GUI
70 © Copyright IBM Corp. 2011, 2016

Tabela 13. Registros de cabeçalho de amostra (continuação)
Nome da hierarquia Módulo Tipo de hierarquia
Hierarquia de cidade Geografia GUI
Hierarquia integral de locais Local Dados
Hierarquia integral daorganização
Organização Dados
Hierarquia interna daorganização
Organização GUI
Hierarquia externa naorganização
Organização GUI
Registros de nível de hierarquia simples de amostra
A tabela a seguir mostra exemplos de hierarquias simples que são baseados emníveis dentro de hierarquias:
Tabela 14. Registros de nível de hierarquia simples de amostra
Nome da hierarquia Número de nível Formulário Localizar módulo
Hierarquia de espaço 1 Propriedade Ignorar
Hierarquia de espaço 2 Prédio Localizar
Hierarquia de espaço 3 Piso Localizar
Hierarquia de espaço 4 Espaço Efetuar recursão
Hierarquia interna daorganização
1 Empresa Localizar
Hierarquia interna daorganização
2 Divisão Ignorar
Hierarquia interna daorganização
3 Departamento Efetuar recursão
Gerenciador de estrutura de hierarquiaÉ possível definir hierarquias e informações de nível usando o Gerenciador deestrutura de hierarquia. O Gerenciador de estrutura de hierarquia fornece umainterface única para criar, atualizar e excluir hierarquias simples.
Acessando estruturas de hierarquiaPara incluir, modificar ou excluir hierarquias, acesse a funcionalidade de estruturasde hierarquia.
Procedimento1. Clique em Ferramentas > Ferramentas do Builder > Modelador de dados.2. Clique em Utilitários.3. Clique em Estruturas de hierarquia.
Criando uma hierarquia de dadosUma hierarquia de dados é usada para comprimir o caminho de dados com basenos relacionamentos pai-filho padrão para a hierarquia do módulo especificado.
Capítulo 4. Compressor de hierarquia 71

Quando você cria uma hierarquia de dados, os níveis nomeados não sãonecessários porque diferentes tipos de dados podem ser representados no mesmonível físico na hierarquia de um módulo.
Procedimento1. Clique em Criar hierarquia.2. No campo Nome, insira um nome para descrever o que a hierarquia
representa.3. Na lista Módulo, selecione o módulo relevante para a hierarquia de dados.4. Na lista Tipo de hierarquia, selecione Dados.5. Clique em Criar.6. Clique em Salvar e, em seguida, clique em Fechar.
Criando uma hierarquia de formulárioUma hierarquia de formulário é usada para comprimir o caminho de dados combase nos relacionamentos pai-filho para a hierarquia do módulo especificado e osobjetos de negócios que representam os níveis. Quando você cria uma hierarquiade formulário, somente um objeto de negócios pode representar cada nível.
Procedimento1. Clique em Criar hierarquia.2. No campo Nome, insira um nome para descrever o que a hierarquia
representa.3. Na lista Módulo, selecione o módulo relevante para a hierarquia de
formulário.4. Na lista Tipo de hierarquia, selecione Formulário.5. Clique em Criar. A seção Níveis é exibida. Insira informações para o
formulário de nível 1.6. Na lista Objeto de negócios, selecione o objeto de negócios relevante.7. Na lista Formulário, selecione o formulário relevante.8. Na lista Tipo, selecione Localizar. O Rótulo de diferença é o rótulo
especificado quando Ignorar está selecionado na lista Tipo e um registro não élocalizado.
9. Clique em Salvar.10. Continue a inserir e salvar as informações até que todos os níveis estejam
definidos.11. Clique em Salvar e, em seguida, clique em Fechar.
72 © Copyright IBM Corp. 2011, 2016

Capítulo 5. Tabelas de fatos
As tabelas de fatos consistem nas medidas, métricas ou fatos de um processo denegócios. As tabelas de fatos armazenam os dados que são usados para calcular asmétricas em relatórios de métricas.
As informações da tabela de fatos são baseadas nos produtos TRIRIGA WorkplacePerformance Management e TRIRIGA Real Estate Environmental Sustainabilitycomo entregues. A implementação em sua empresa pode ser diferente.
Cada tabela de fatos tem um ETL para carregar dados e outro para limpar dados.Os nomes dos ETLs que limpam dados terminam com - Limpar, por exemplo Fatode custo do prrédio - Limpar. Para visualizar os ETLs, clique em Ferramentas >Configuração do sistema > Itens da tarefas ETL.
Lista de tabelas de fatos e as métricas suportadasÉ possível referenciar a lista de tabelas de fatos e métricas que são suportadas naimplementação do TRIRIGA em sua empresa.
Acessando as tabelas de fatos
Clique em Ferramentas > Ferramentas do Builder > Modelador de dados.
Localize triMetricFact e selecione-o para exibir a lista de objetos de negócios detabela de fatos.
Acessando as métricas
Clique em Ferramentas > Ferramentas do Builder > Gerenciador de relatório >Relatórios do sistema.
Filtre por Objeto de negócios e Módulo para classificar as informações de métricase obter a lista de relatórios relevantes.
Dica: #FM# significa que uma métrica também é uma métrica de formulário nosistema.
Fatos que requerem tabelas de migração de dados e ETLs especiaisPara a maioria das tabelas de fatos, o processo para carregar os dadosarmazenados para calcular métricas é simples. No entanto, algumas tabelas defatos requerem tabelas de migração de dados especiais e ETLs para ajudar com oprocesso de carregamento.
A tabela a seguir mostra os fatos que requerem tabelas de migração de dados eETLs especiais:
Tabela 15. Fatos que requerem tabelas de migração de dados e ETLs especiais
Nome da tabela de fatos Objeto de negócios de tabela de fatos
Resumo Financeiro triFinancialSummary
Horas Padrão triStandardHours
© Copyright IBM Corp. 2011, 2016 73

Tabela 15. Fatos que requerem tabelas de migração de dados e ETLsespeciais (continuação)
Nome da tabela de fatos Objeto de negócios de tabela de fatos
Detalhes de Horas Padrão triStandardHoursDetails
Fato por hora de analítica de ativo triAssetAnalyticHFact
Fato diário de uso de energia de ativo triAssetEnergyUseDFact
Fato por hora de uso de energia de ativo triAssetEnergyUseHFact
Fato mensal de uso de energia de ativo triAssetEnergyUseMFact
ETLs dependentesAlguns ETLs dependem de outros ETLs para ajudar com o processo decarregamento.
A tabela a seguir mostra os ETLs que dependem de outros ETLs:
Tabela 16. ETLs dependentes
Nome da tabela de fatos Objeto de negócios de tabela de fatos
ETL carregamento de fato de custo deconstrução
Esse ETL depende da disponibilidade dosdados na tabela Resumo financeiro. A tabelaResumo financeiro pode ser carregada porintegração de backend com seu sistemafinanceiro ou usando o processo ExcelResumo financeiro offline. Para facilitar oprocesso Excel Resumo financeiro offline, háum ETL especial para enviar por push osdados do processo Excel/Offline para atabela Resumo financeiro. No TRIRIGAWorkplace Performance Management comoentregue, os ETLs especiais são nomeadosCarregar resumo financeiro de offlinetemporário e Limpar resumo financeiro deoffline temporário. Se você estiverimportando dados de resumo financeiro como processo Excel Resumo financeiro offline,deve-se primeiro executar o ETL Carregarresumo financeiro de offline temporário.Deve-se então executar o ETL Carregamentode fato de custo de construção.
74 © Copyright IBM Corp. 2011, 2016
Tabela 16. ETLs dependentes (continuação)
Nome da tabela de fatos Objeto de negócios de tabela de fatos
ETL Carregamento de fato de construção Esse ETL depende da disponibilidade dosdados na tabela Resumo financeiro. A tabelaResumo financeiro pode ser carregada porintegração de backend com seu sistemafinanceiro ou usando o processo ExcelResumo financeiro offline. Para facilitar oprocesso Excel Resumo financeiro offline, háum ETL especial para enviar por push osdados do processo Excel/Offline para atabela Resumo financeiro. No TRIRIGAWorkplace Performance Management comoentregue, os ETLs especiais são nomeadosCarregar resumo financeiro de offlinetemporário e Limpar resumo financeiro deoffline temporário. Se você estiverimportando dados de resumo financeiro como processo Excel Resumo financeiro offline,deve-se primeiro executar o ETL Carregarresumo financeiro de offline temporário.Deve-se então executar o ETL Carregamentode fato de construção.
ETL Carregamento de fato de recurso Dependente do ETP Carregamento de horaspadrão.
ETL Carregamento de horas padrão Dependente do ETL Carregamento dedetalhes de horas padrão.
ETL Fato diário do ativo
ETL Fato por hora do ativo
ETL Fato mensal do ativo
Esses ETLs dependem da disponibilidadedos dados em uma tabela de migração dedados. Os tipos de tabela de migração dedados devem ser genéricos. A tabela demigração de dados deve incluir camposespecíficos. A tabela de migração de dadospode ser carregada por integração debackend com o sistema de gerenciamento deconstrução. A tabela de migração de dadostambém pode ser carregada usando um ETLpara trazer os dados a partir de um bancode dados externo.Consulte o Integrated Service ManagementLibrary para obter mais detalhes, incluindoas tabelas de migração de dados de amostrae os ETLs de amostra.
Capítulo 5. Tabelas de fatos 75

76 © Copyright IBM Corp. 2011, 2016

Avisos
Estas informações foram desenvolvidas para produtos e serviços oferecidos nosEUA. Este material pode estar disponível na IBM em outros idiomas. No entanto,pode ser necessário possuir uma cópia do produto ou da versão de produto nomesmo idioma para acessá-lo.
É possível que a IBM não ofereça os produtos, serviços ou recursos discutidosnesta publicação em outros países. Consulte um representante IBM local para obterinformações sobre produtos e serviços disponíveis atualmente em sua área.Qualquer referência a produtos, programas ou serviços IBM não significa queapenas produtos, programas ou serviços IBM possam ser utilizados. Qualquerproduto, programa ou serviço funcionalmente equivalente, que não infrinjanenhum direito de propriedade intelectual da IBM poderá ser utilizado emsubstituição a este produto, programa ou serviço. Entretanto, a avaliação everificação da operação de qualquer produto, programa ou serviço não IBM são deresponsabilidade do Cliente.
A IBM pode ter patentes ou solicitações de patentes pendentes relativas a assuntostratados nesta publicação. O fornecimento desta publicação não lhe garante direitoalgum sobre tais patentes. Pedidos de licença devem ser enviados, por escrito,para:
Gerência de Relações Comerciais e Industriais da IBM BrasilGerência de Relações Comerciais e Industriais da IBM BrasilAv. Pauster 138-146Rio de Janeiro, RJCEP 22290-240
Para pedidos de licença relacionados a informações de DBCS (Conjunto deCaracteres de Byte Duplo), entre em contato com o Departamento de PropriedadeIntelectual da IBM em seu país ou envie pedidos de licença, por escrito, para:
Intellectual Property LicensingLegal and Intellectual Property LawIBM Japan Ltd.19-21, Nihonbashi-Hakozakicho, Chuo-kuTokyo 103-8510, Japan
A INTERNATIONAL BUSINESS MACHINES CORPORATION FORNECE ESTAPUBLICAÇÃO "NO ESTADO EM QUE SE ENCONTRA", SEM GARANTIA DENENHUM TIPO, SEJA EXPRESSA OU IMPLÍCITA, INCLUINDO, MAS A ELASNÃO SE LIMITANDO, AS GARANTIAS IMPLÍCITAS DE NÃO INFRAÇÃO,COMERCIALIZAÇÃO OU ADEQUAÇÃO A UM DETERMINADO PROPÓSITO.Algumas jurisdições não permitem a renúncia de garantias explícitas ou implícitasem determinadas transações, portanto, esta declaração pode não se aplicar aoCliente.
Essas informações podem conter imprecisões técnicas ou erros tipográficos. Sãofeitas alterações periódicas nas informações aqui contidas; tais alterações serãoincorporadas em futuras edições desta publicação. A IBM pode, a qualquermomento, aperfeiçoar e/ou alterar os produtos e/ou programas descritos nestapublicação, sem aviso prévio.
© Copyright IBM Corp. 2011, 2016 77

Referências nestas informações a websites não IBM são fornecidas apenas porconveniência e não representam de forma alguma um endosso a esses websites. Osmateriais contidos nesses websites não fazem parte dos materiais desse produtoIBM e a utilização desses websites é de inteira responsabilidade do Cliente.
A IBM pode utilizar ou distribuir as informações fornecidas da forma que julgarapropriada sem incorrer em qualquer obrigação para com o Cliente.
Os licenciados deste programa que desejarem obter informações sobre este assuntocom o propósito de permitir: (i) a troca de informações entre programas criadosindependentemente e outros programas (incluindo este) e (ii) o uso mútuo dasinformações trocadas, deverão entrar em contato com:
Gerência de Relações Comerciais e Industriais da IBM BrasilGerência de Relações Comerciais e Industriais da IBM BrasilAv. Pauster 138-146Rio de Janeiro, RJCEP 22290-240
Tais informações podem estar disponíveis, sujeitas a termos e condiçõesapropriadas, incluindo em alguns casos o pagamento de uma taxa.
O programa licenciado descrito nesta publicação e todo o material licenciadodisponível são fornecidos pela IBM sob os termos do Contrato com o Cliente IBM,do Contrato Internacional de Licença do Programa IBM ou de qualquer outrocontrato equivalente.
Os exemplos de dados de desempenho e de clientes citados são apresentadosapenas para propósitos ilustrativos. Resultados de desempenho reais podem variardependendo das configurações específicas e das condições operacionais.
As informações relativas a produtos não IBM foram obtidas junto aos fornecedoresdos respectivos produtos, de seus anúncios publicados ou de outras fontesdisponíveis publicamente. A IBM não testou estes produtos e não pode confirmar aprecisão de seu desempenho, compatibilidade nem qualquer outra reivindicaçãorelacionada a produtos não-IBM. Dúvidas sobre os recursos de produtos não IBMdevem ser encaminhadas diretamente a seus fornecedores.
As declarações relacionadas aos objetivos e intenções futuras da IBM estão sujeitasa alterações ou cancelamento sem aviso prévio e representam apenas metas eobjetivos.
Estas informações contêm exemplos de dados e relatórios utilizados nas operaçõesdiárias de negócios. Para ilustrá-los da forma mais completa possível, os exemplosincluem nomes de indivíduos, empresas, marcas e produtos. Todos estes nomes sãofictícios e qualquer semelhança com pessoas ou empresas reais é meracoincidência.
LICENÇA DE COPYRIGHT:
Estas informações contêm programas de aplicativos de amostra na linguagemfonte, ilustrando as técnicas de programação em diversas plataformas operacionais.O Cliente pode copiar, modificar e distribuir estes programas de amostra dequalquer forma sem a necessidade de pagar à IBM, com objetivos dedesenvolvimento, utilização, marketing ou distribuição de programas deaplicativos em conformidade coma interface de programação de aplicativo da
78 © Copyright IBM Corp. 2011, 2016

plataforma operacional para a qual os programas de amostra são criados. Essesexemplos não foram testados completamente em todas as condições. Portanto, aIBM não pode garantir ou implicar a confiabilidade, manutenção ou função destesprogramas. Os programas de amostra são fornecidos "NO ESTADO EM QUE SEENCONTRAM", sem garantia de nenhum tipo. A IBM não é responsável pornenhum dano decorrente do uso dos programas de amostra.
Cada cópia ou parte destes programas de amostra ou qualquertrabalho derivado deve incluir um aviso de copyright com os dizeres:© (nome da empresa) (ano).Partes deste código são derivadas dos Programas de Amostra da IBM.© Copyright IBM Corp. _digite o ano ou anos_.
Marcas comerciaisIBM, o logotipo IBM e ibm.com são marcas comerciais ou marcas registradas daInternational Business Machines Corp., registradas em vários países no mundotodo. Outros nomes de produtos e serviços podem ser marcas comerciais da IBMou de outras empresas. Uma lista atual de marcas comerciais da IBM estádisponível na web em "Copyright and trademark information" emwww.ibm.com/legal/copytrade.shtml.
Java™ e todas as marcas comerciais e logotipos baseados em Java são marcascomerciais ou marcas registradas da Oracle e/ou de suas afiliadas.
Linux é uma marca comercial de Linus Torvalds nos Estados Unidos e/ou emoutros países.
Microsoft, Windows, Windows NT e o logotipo Windows são marcas comerciais daMicrosoft Corporation nos Estados Unidos e/ou em outros países.
UNIX é uma marca registrada do The Open Group nos Estados Unidos e emoutros países.
Outros nomes de produtos e serviços podem ser marcas comerciais da IBM ou deoutras empresas.
Termos e Condições para a Documentação do ProdutoPermissões para o uso destas publicações são concedidas sujeitas aos termos econdições a seguir.
Aplicabilidade
Estes termos e condições são complementos dos termos de uso do website da IBM.
Uso pessoal
É possível reproduzir essas publicações para seu uso pessoal e não comercial desdeque todos os avisos do proprietário sejam preservados. Você não pode distribuir,exibir ou criar trabalho derivativo destas publicações, ou de qualquer parte delas,sem o consentimento expresso da IBM.
Avisos 79

Uso comercial
É possível reproduzir, distribuir e exibir estas publicações exclusivamente dentrode sua empresa desde que todos os avisos do proprietário sejam preservados. Vocênão pode criar trabalhos derivativos destas publicações, ou reproduzir, distribuirou exibir estas publicações, ou qualquer parte delas fora de sua empresa, sem oconsentimento expresso da IBM.
Direitos
Exceto como expressamente concedido nesta permissão, nenhuma outra permissão,licença ou direito é concedido, seja expresso ou implícito, para as Publicações oupara quaisquer informações, dados, software ou outra propriedade intelectual nelascontidos.
A IBM reserva-se o direito de retirar as permissões aqui concedidas sempre que, aseu critério, o uso das publicações for prejudicial aos seus interesses ou, conformedeterminado pela IBM, as instruções acima não estiverem sendo seguidascorretamente. corretamente.
Você não deve fazer download destas informações, exportá-las ou reexportá-las,exceto em conformidade total com todas as leis e regulamentos aplicáveis,incluindo todas as leis e regulamentos de exportação dos Estados Unidos.
A IBM NÃO FORNECE GARANTIA QUANTO AO CONTEÚDO DESTASPUBLICAÇÕES. AS PUBLICAÇÕES SÃO FORNECIDAS "NO ESTADO EM QUESE ENCONTRAM" E SEM GARANTIA DE QUALQUER TIPO, SEJA EXPRESSAOU IMPLÍCITA, INCLUINDO, MAS A ELAS NÃO SE LIMITANDO ÀSGARANTIAS IMPLÍCITAS DE COMERCIALIZAÇÃO E DE ADEQUAÇÃO PARAUM PROPÓSITO ESPECÍFICO.
Declaração de privacidade online da IBMOs produtos de Software IBM, incluindo o software como soluções de serviços,(“Ofertas de Software”) podem usar cookies ou outras tecnologias para coletarinformações sobre o uso do produto, para ajudar a melhorar a experiência dousuário final, para customizar interações com o usuário final ou para outrospropósitos. Em muitos casos, as Ofertas de Software não coletam nenhum tipo deinformações de identificação pessoal. Algumas de nossas Ofertas de Softwarepodem ajudar a coletar informações de identificação pessoal. Se as Ofertas deSoftware usarem cookies para coletar informações de identificação pessoal,especifique a informações sobre o uso desta oferta de cookies definidas abaixo.
Esta Oferta de Software não usa cookies ou outras tecnologias para coletarinformações de identificação pessoal.
Se as configurações implementadas para esta Oferta de Software fornecerem avocê, como cliente, a capacidade de coletar informações de identificação pessoaldos usuários finais por meio de cookies e outras tecnologias, deve-se consultar oseu próprio conselho jurídico a respeito de quaisquer leis aplicáveisà coleta dedados, incluindo quaisquer requisitos de aviso e consentimento.
Para obter informações adicionais sobre o uso de diversas tecnologias, incluindocookies, para esses propósitos, consulte a Política de Privacidade da IBM emhttp://www.ibm.com/privacy e a Declaração de Privacidade On-line da IBM emhttp://www.ibm.com/privacy/details na seção intitulada Cookies, Web Beacons e
80 © Copyright IBM Corp. 2011, 2016

Outras Tecnologias e a "Declaração de Privacidade de Software como Serviço e deProdutos de Software IBM" emhttp://www.ibm.com/software/info/product-privacy/.
Avisos 81

82 © Copyright IBM Corp. 2011, 2016


IBM®
Impresso no Brasil