Embed Size (px)
Citation preview

1. ANÁLISE DESCRITIVA DE VARIÁVEIS QUANTIOTATIVAS
1.1. CONCEITOS:
População: é formada pelo conjunto de indivíduos (ou itens) que queremos abranger em nosso estudo e para os quais desejamos que as conclusões da pesquisa (inferências) sejam válidas.
Em alguns estudos (especialmente os experimentais) a população não pode ser
representada por um “ente físico”. Nesses a população é definida pelo
conjunto de todos os valores possíveis de serem observados.
Também será denotada por população objetivo, que é sobre a qual
desejamos obter informações e/ou fazer inferências.
Pode, ainda, ser chamada de Universo.
Será denotada por: Nu,,u,u,uU 321
iu unidades elementares, i = 1, 2, . . . , N.
N = no de elementos, ou tamanho, da população.
Amostra: é um subconjunto, necessariamente finito, de uma população.
é selecionada de forma que todos os elementos da população tenham a mesma chance de serem escolhidos.
A população pode ser infinita, mas a amostra é sempre finita.
Parâmetro Populacional: normalmente denotado por , é uma característica populacional de interesse, que pode ser expressa através de uma quantidade
numérica. Normalmente é desconhecido e fixo.
Estatística: é uma medida numérica, que descreve uma característica da amostra.
Uma Estatística é uma função da amostra: S = f(X1, X2, . . . , Xn)
X1, X2, . . . , Xn representa as n observações da amostra

Exemplos
n
XX
n
ii
1 (média amostral)
1
1
2
2
n
XX
s
n
ii
(variância amostral)
min = valor mínimo da amostra denotado por X(1)
max = valor máximo da amostra denotado por X(n)
PARÂMETROS E ESTATÍSTICAS
Nome ESTATÍSTICA (Amostra) PARÂMETRO (População)
Média X
Variância s2
2
Correlação rX,Y X,Y
Proporção p̂ p
Variável uma variável é uma característica desconhecida, que pode variar de
um indivíduo para outro da população e que, ao ser observada ou mensurada, deve gerar uma única resposta.
Tipos de variáveis:
a) Variáveis qualitativas: variáveis cujos possíveis resultados são atributos ou qualidades. São NÃO NUMÉRICAS.
Podem ser classificadas em: i) ORDINAIS, quando obedecem a uma ordem natural ou ii) NOMINAIS, quando não obedecem nenhuma ordem.
b) Variáveis quantitativas: variáveis cujos possíveis resultados são valores numéricos resultantes de uma mensuração ou contagem.
Podem ser classificadas em: i) DISCRETAS, quando assumem valores inteiros, ou ii) CONTÍNUAS, quando assumem valores reais.
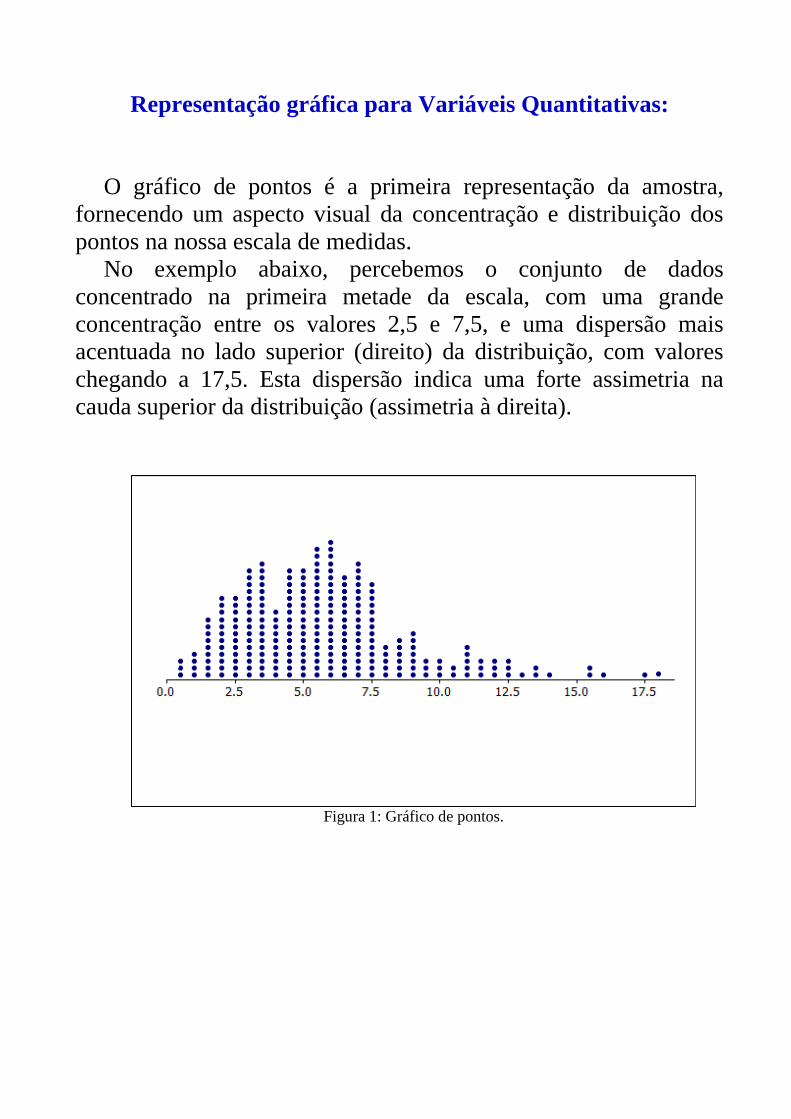
Representação gráfica para Variáveis Quantitativas:
O gráfico de pontos é a primeira representação da amostra,
fornecendo um aspecto visual da concentração e distribuição dos
pontos na nossa escala de medidas.
No exemplo abaixo, percebemos o conjunto de dados
concentrado na primeira metade da escala, com uma grande
concentração entre os valores 2,5 e 7,5, e uma dispersão mais
acentuada no lado superior (direito) da distribuição, com valores
chegando a 17,5. Esta dispersão indica uma forte assimetria na
cauda superior da distribuição (assimetria à direita).
Figura 1: Gráfico de pontos.
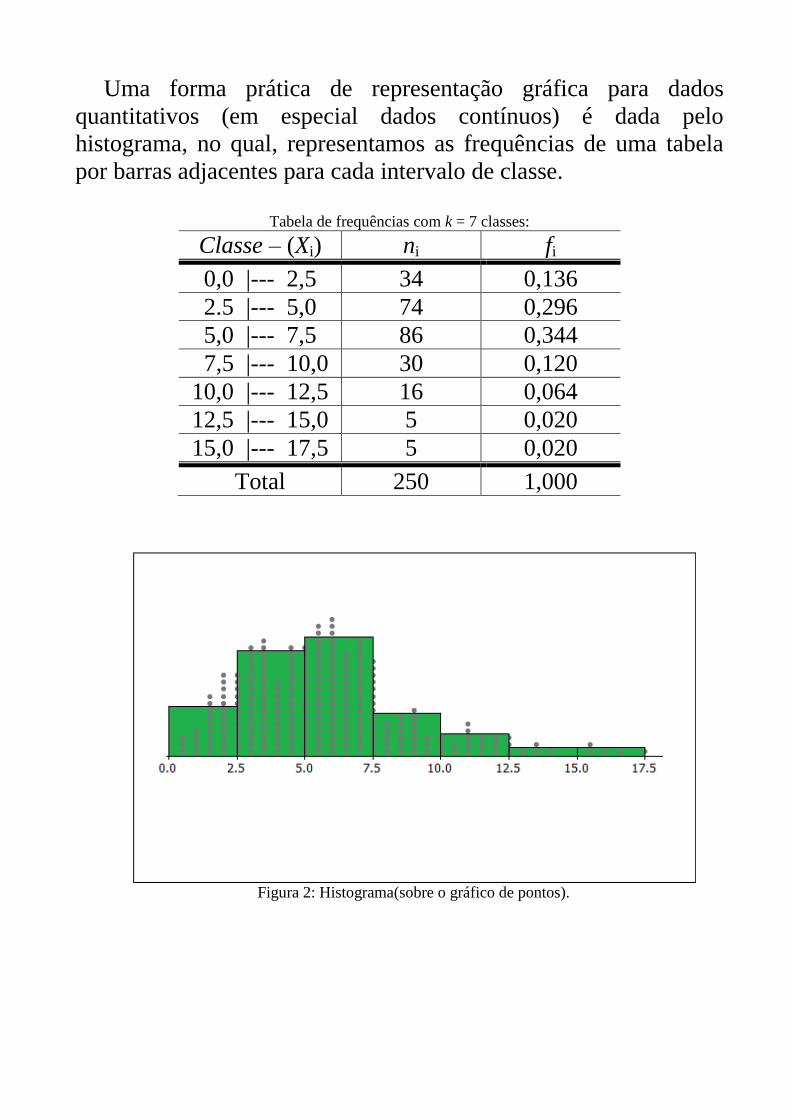
Uma forma prática de representação gráfica para dados
quantitativos (em especial dados contínuos) é dada pelo
histograma, no qual, representamos as frequências de uma tabela
por barras adjacentes para cada intervalo de classe.
Tabela de frequências com k = 7 classes:
Classe – (Xi) ni fi
0,0 |--- 2,5 34 0,136
2.5 |--- 5,0 74 0,296
5,0 |--- 7,5 86 0,344
7,5 |--- 10,0 30 0,120
10,0 |--- 12,5 16 0,064
12,5 |--- 15,0 5 0,020
15,0 |--- 17,5 5 0,020
Total 250 1,000
Figura 2: Histograma(sobre o gráfico de pontos).
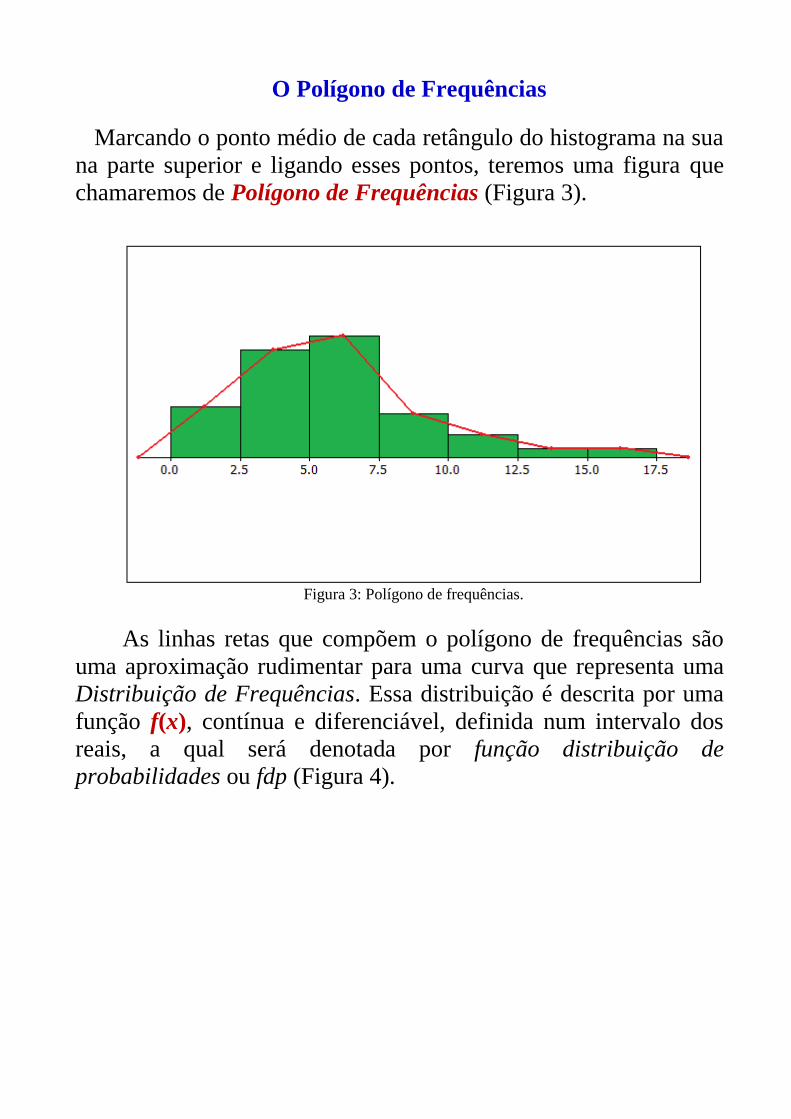
O Polígono de Frequências
Marcando o ponto médio de cada retângulo do histograma na sua
na parte superior e ligando esses pontos, teremos uma figura que
chamaremos de Polígono de Frequências (Figura 3).
Figura 3: Polígono de frequências.
As linhas retas que compõem o polígono de frequências são
uma aproximação rudimentar para uma curva que representa uma
Distribuição de Frequências. Essa distribuição é descrita por uma
função f(x), contínua e diferenciável, definida num intervalo dos
reais, a qual será denotada por função distribuição de
probabilidades ou fdp (Figura 4).
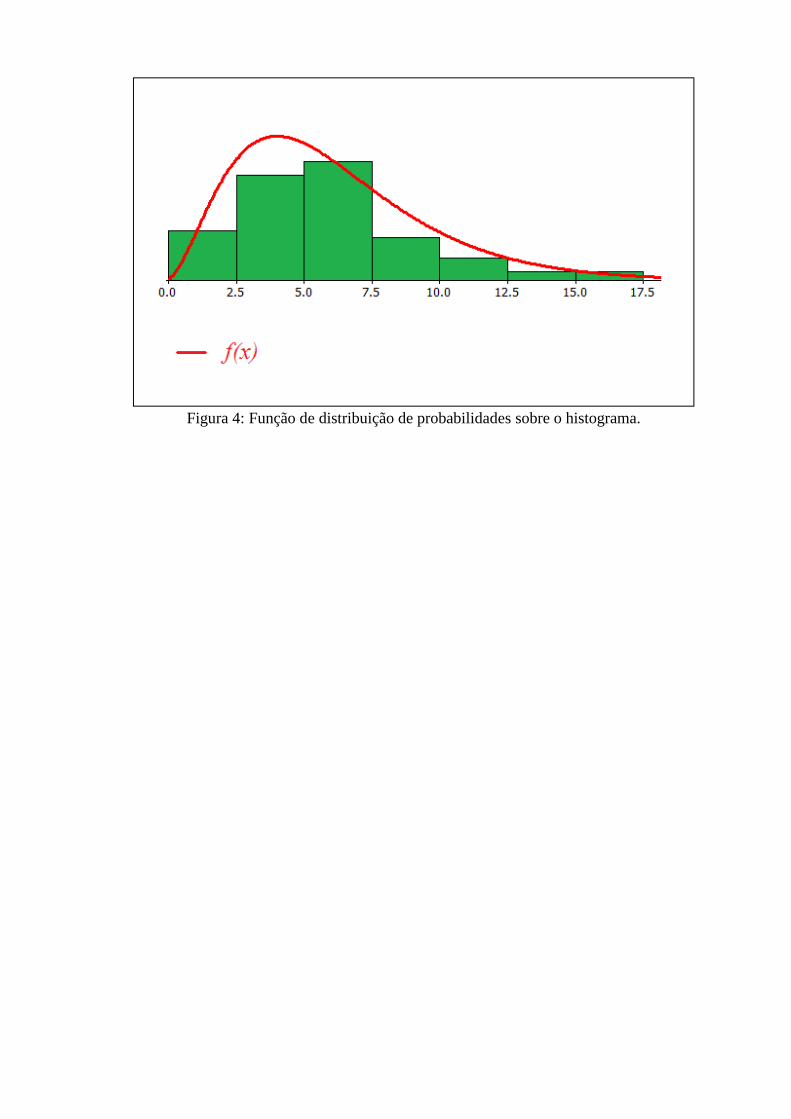
Figura 4: Função de distribuição de probabilidades sobre o histograma.
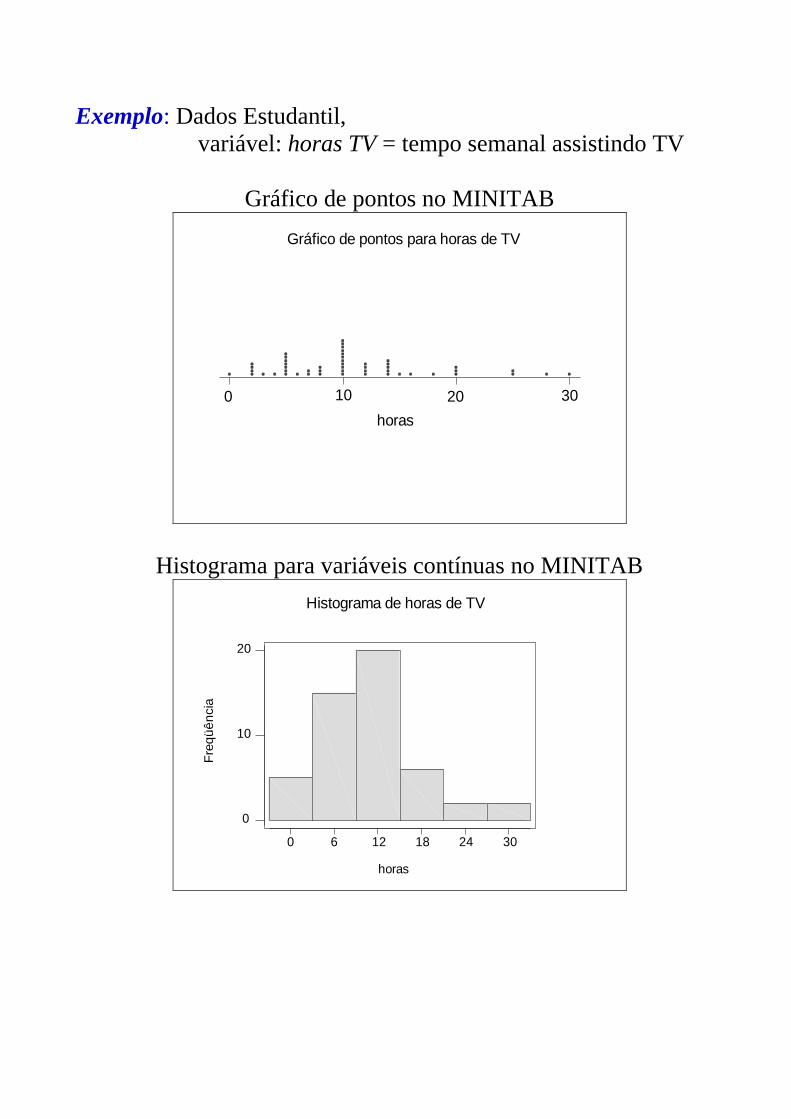
Exemplo: Dados Estudantil,
variável: horas TV = tempo semanal assistindo TV
Gráfico de pontos no MINITAB
3020100
horas
Gráfico de pontos para horas de TV
Histograma para variáveis contínuas no MINITAB
0 6 12 18 24 30
0
10
20
horas
Fre
qü
ên
cia
Histograma de horas de TV
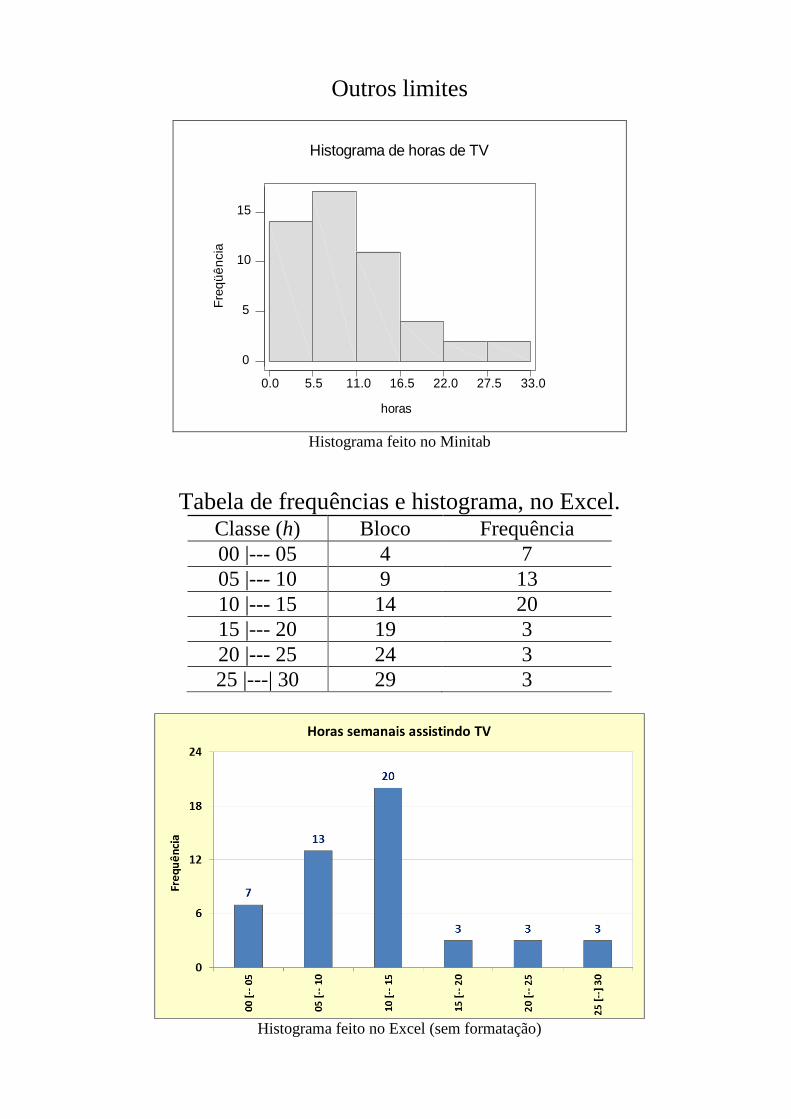
Outros limites
0.0 5.5 11.0 16.5 22.0 27.5 33.0
0
5
10
15
horas
Fre
qü
ên
cia
Histograma de horas de TV
Histograma feito no Minitab
Tabela de frequências e histograma, no Excel. Classe (h) Bloco Frequência
00 |--- 05 4 7
05 |--- 10 9 13
10 |--- 15 14 20
15 |--- 20 19 3
20 |--- 25 24 3
25 |---| 30 29 3
Histograma feito no Excel (sem formatação)

A) Dados Contínuos:
Exemplo 1: Altura (em metros) dos alunos da turma B de
Bioestatística no primeiro semestre de 2015.
X = altura dos alunos (em metros).
1,62 1,60 1,60 1,65 1,60 1,73 1,78 1,72 1,62 1,58 1,65
1,81 1,62 1,63 1,67 1,65 1,80 1,75 1,80 1,70 1,65 1,80
1,76 1,60 1,57 1,65 1,70 1,73 1,75 1,65 1,70 1,66 1,74
1,51 1,63 1,55 1,58 1,56 1,80 1,75 1,67 1,58 1,77
Dados ordenados 1,51 1,55 1,56 1,57 1,58 1,58 1,58 1,60 1,60 1,60 1,60
1,62 1,62 1,62 1,63 1,63 1,65 1,65 1,65 1,65 1,65 1,65
1,66 1,67 1,67 1,70 1,70 1,70 1,72 1,73 1,73 1,74 1,75
1,75 1,75 1,76 1,77 1,78 1,80 1,80 1,80 1,80 1,81
Construindo a tabela de frequências:
a) Número de classes (fórmula de Sturges):
k = 1 + 3,32log10(n)
k = 1 + 3,32log10(43) = 6,43 = 7 classes (6 ou 7)
b) Amplitude da classe:
A = 1,51 – 1,81 = 0,30 0428,07
30,0h
Podemos arredondar h para 0,043 ou para um valor mais
apropriado, no caso 0,05.
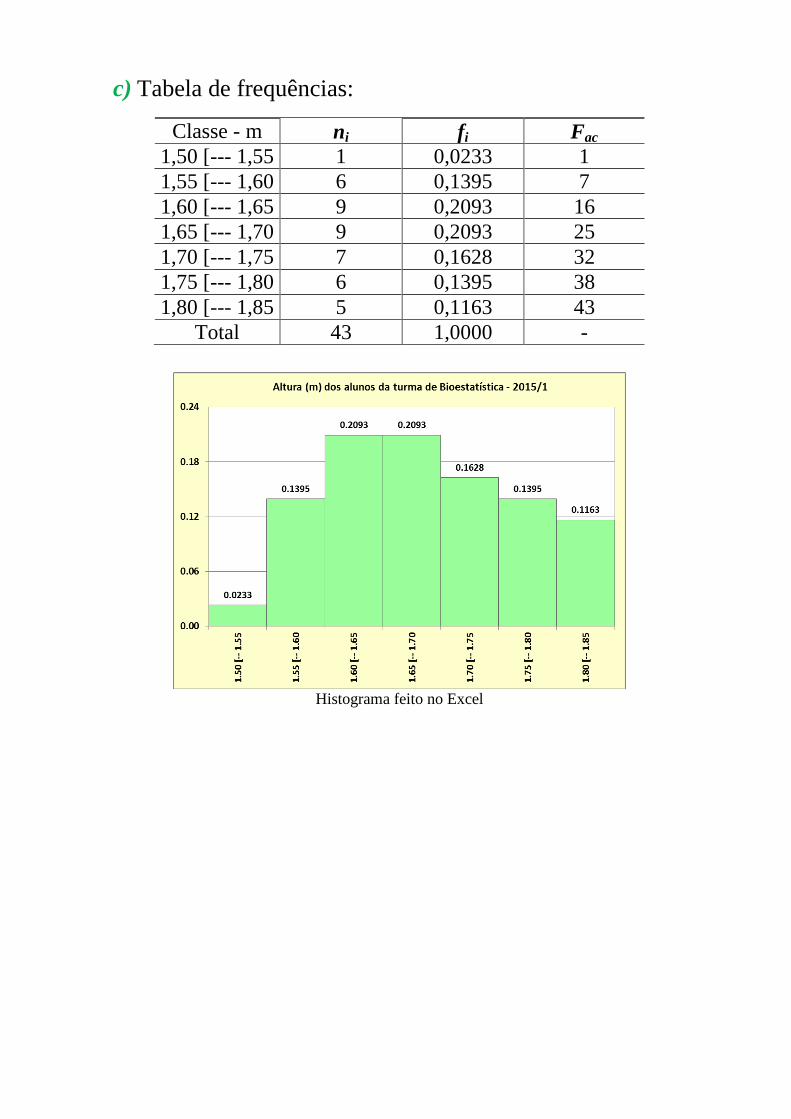
c) Tabela de frequências:
Classe - m ni fi Fac
1,50 [--- 1,55 1 0,0233 1
1,55 [--- 1,60 6 0,1395 7
1,60 [--- 1,65 9 0,2093 16
1,65 [--- 1,70 9 0,2093 25
1,70 [--- 1,75 7 0,1628 32
1,75 [--- 1,80 6 0,1395 38
1,80 [--- 1,85 5 0,1163 43
Total 43 1,0000 -
Histograma feito no Excel
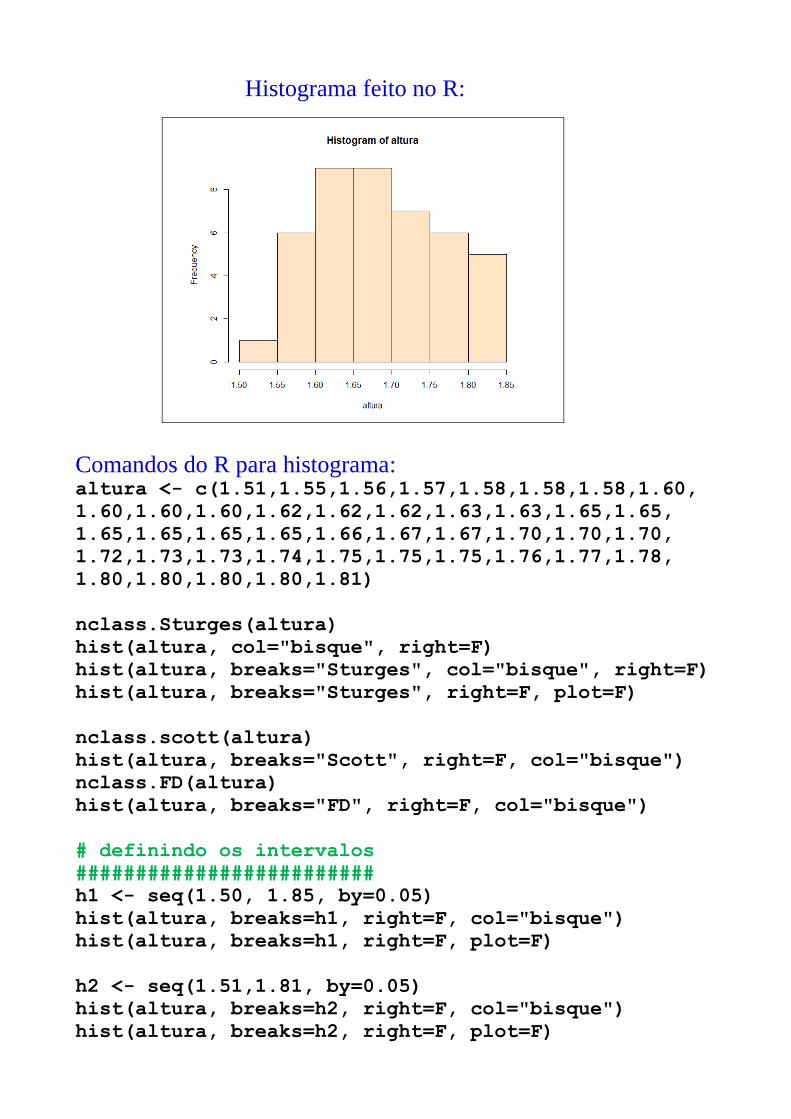
Histograma feito no R:
Comandos do R para histograma: altura <- c(1.51,1.55,1.56,1.57,1.58,1.58,1.58,1.60,
1.60,1.60,1.60,1.62,1.62,1.62,1.63,1.63,1.65,1.65,
1.65,1.65,1.65,1.65,1.66,1.67,1.67,1.70,1.70,1.70,
1.72,1.73,1.73,1.74,1.75,1.75,1.75,1.76,1.77,1.78,
1.80,1.80,1.80,1.80,1.81)
nclass.Sturges(altura)
hist(altura, col="bisque", right=F)
hist(altura, breaks="Sturges", col="bisque", right=F)
hist(altura, breaks="Sturges", right=F, plot=F)
nclass.scott(altura)
hist(altura, breaks="Scott", right=F, col="bisque")
nclass.FD(altura)
hist(altura, breaks="FD", right=F, col="bisque")
# definindo os intervalos
#########################
h1 <- seq(1.50, 1.85, by=0.05)
hist(altura, breaks=h1, right=F, col="bisque")
hist(altura, breaks=h1, right=F, plot=F)
h2 <- seq(1.51,1.81, by=0.05)
hist(altura, breaks=h2, right=F, col="bisque")
hist(altura, breaks=h2, right=F, plot=F)

Exemplo 2: Medidas do pH em precipitação pluviométrica durante
o período de 20/12/1973 a 23/05/1974 no nordeste dos Estados
Unidos.
X = medida do pH em amostras de chuva.
Dados ordenados 4,12 4,12 4,26 4,26 4,29 4,30 4,31 4,39 4,39
4,40 4,41 4,45 4,52 4,56 4,57 4,60 4,63 4,64
4,73 4,82 5,08 5,29 5,51 5,62 5,67 5,78
a) Número de classes (fórmula de Sturges):
k = 1 + 3,322log10(26) = 5,70 = 6 classes (5 ou 6)
b) Amplitude da classe:
A = 5,78 – 4,12 = 1,66 28,06
66,1h
c) Tabela de frequências:
Classe - pH ni fi Fac
4,12 [--- 4,40 9 0,346 0,346
4,40 [--- 4,68 9 0,346 0,692
4,68 [--- 4,96 2 0,077 0,769
4,96 [--- 5,24 1 0,038 0,807
5,24 [--- 5,52 2 0,077 0,884
5,52 [--- 5,80 3 0,115 0,999
Total 26 0,999 * -
* o valor 0.999 ocorreu devido ao arredondamento na precisão considerada (3 casas).
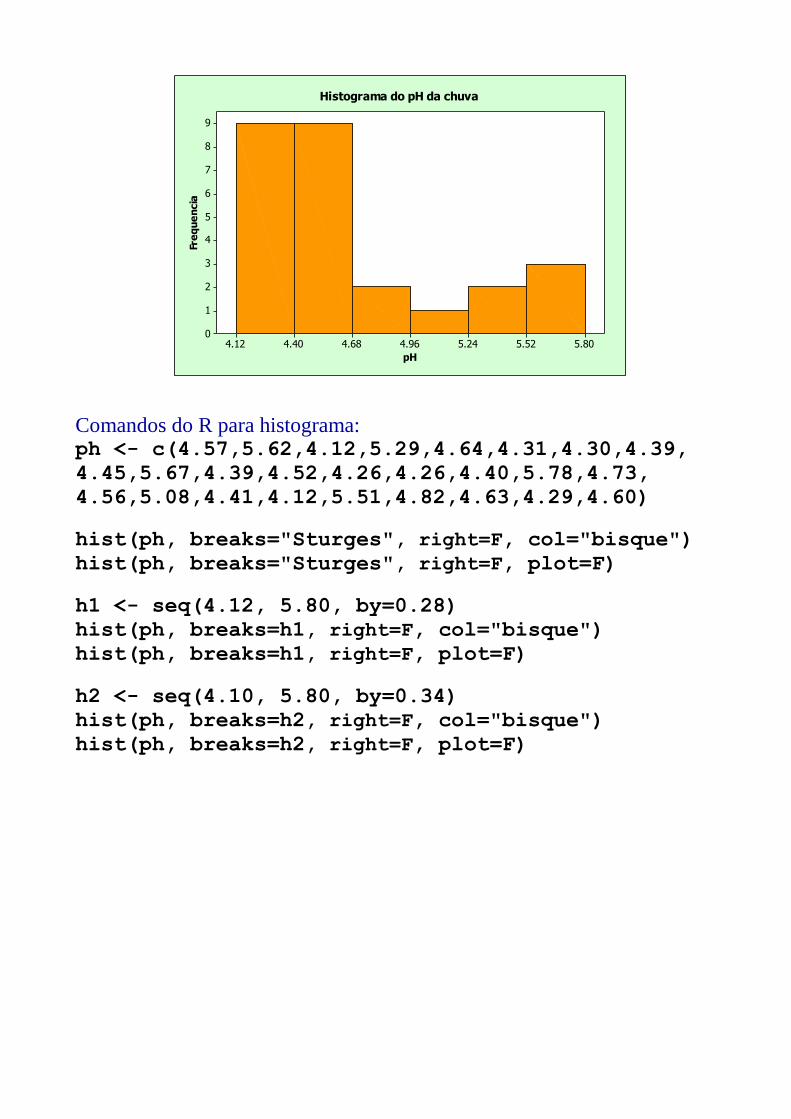
5.805.525.244.964.684.404.12
9
8
7
6
5
4
3
2
1
0
pH
Fre
qu
en
cia
Histograma do pH da chuva
Comandos do R para histograma: ph <- c(4.57,5.62,4.12,5.29,4.64,4.31,4.30,4.39,
4.45,5.67,4.39,4.52,4.26,4.26,4.40,5.78,4.73,
4.56,5.08,4.41,4.12,5.51,4.82,4.63,4.29,4.60)
hist(ph, breaks="Sturges", right=F, col="bisque")
hist(ph, breaks="Sturges", right=F, plot=F)
h1 <- seq(4.12, 5.80, by=0.28)
hist(ph, breaks=h1, right=F, col="bisque")
hist(ph, breaks=h1, right=F, plot=F)
h2 <- seq(4.10, 5.80, by=0.34)
hist(ph, breaks=h2, right=F, col="bisque")
hist(ph, breaks=h2, right=F, plot=F)
Exemplo 3: Notas de teste verbal aplicado em 87 alunos da rede
pública americana.
X = nota do aluno
2,5 2,8 2,8 3,2 3,5 3,6 3,7 3,8 3,9 4,0
4,1 4,1 4,1 4,1 4,2 4,5 4,6 4,7 4,7 4,7
4,7 4,8 4,8 4,9 4,9 5,0 5,0 5,1 5,1 5,1
5,2 5,2 5,2 5,2 5,2 5,3 5,3 5,3 5,3 5,4
5,4 5,4 5,4 5,5 5,5 5,5 5,6 5,7 5,7 5,8
5,9 5,9 5,9 5,9 6,0 6,1 6,1 6,1 6,1 6,2
6,2 6,2 6,3 6,4 6,4 6,4 6,4 6,5 6,5 6,5
6,5 6,5 6,6 6,6 6,7 6,7 6,7 6,7 6,8 6,9
6,9 7,0 7,0 7,1 7,2 7,3 7,5
k = 1 + 3,322log1087 = 7,44 = 8 classes (7 ou 8)
A = 7,5 – 2,5 = 5 h = 5/7 = 0,714 0,72
Distribuição de frequências com k = 8 classes:
Xi (nota) ni fi Fac
2,50 |--- 3,15 3 0,034 0,034
3,15 |--- 3,80 4 0,046 0,080
3,80 |--- 4,45 8 0,092 0,172
4,45 |--- 5,10 12 0,138 0,310
5,10 |--- 5,75 22 0,253 0,563
5,75 |--- 6,40 14 0,161 0,724
6,40 |--- 7,05 20 0,230 0,954
7,05 |--- 7,70 4 0,046 1,000
Total 87 1,000 -
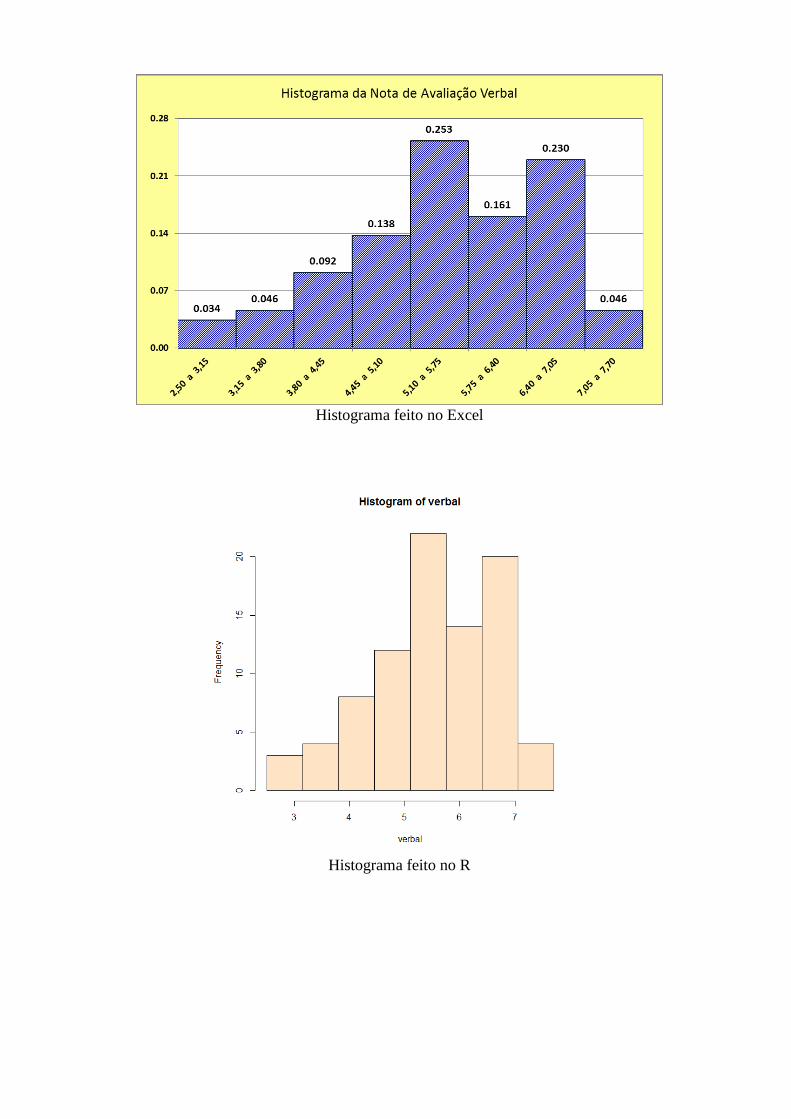
Histograma feito no Excel
Histograma feito no R
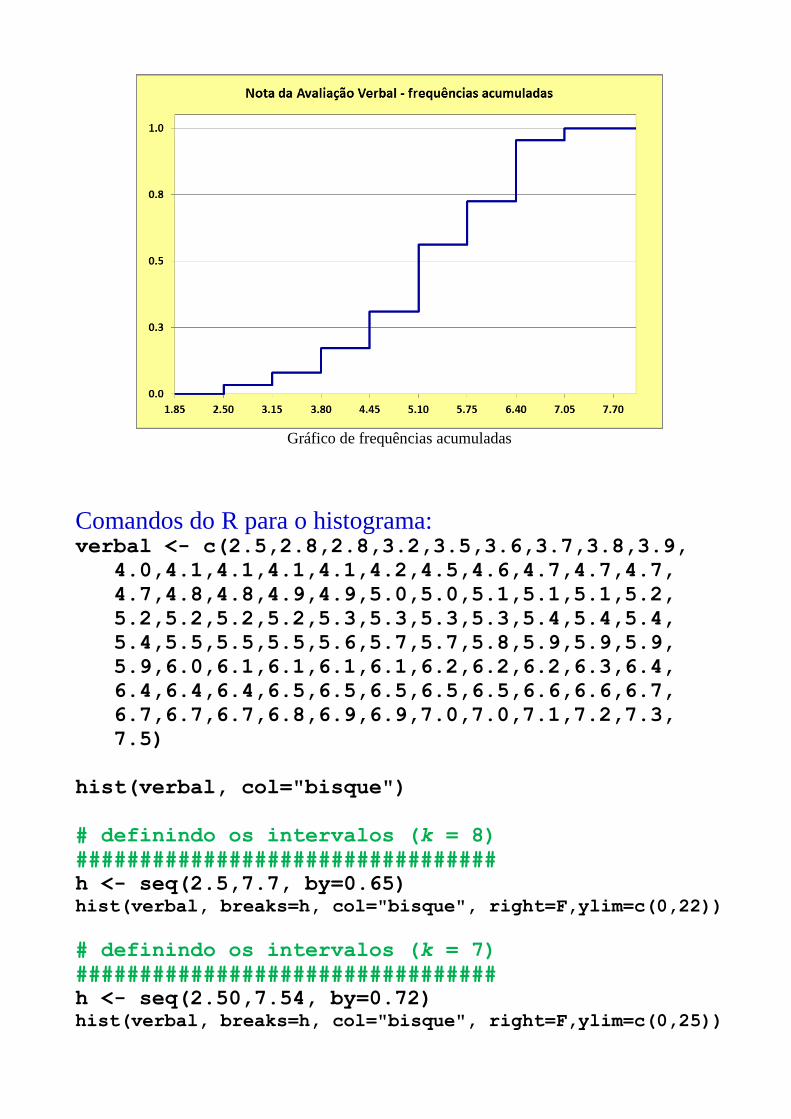
Gráfico de frequências acumuladas
Comandos do R para o histograma: verbal <- c(2.5,2.8,2.8,3.2,3.5,3.6,3.7,3.8,3.9,
4.0,4.1,4.1,4.1,4.1,4.2,4.5,4.6,4.7,4.7,4.7,
4.7,4.8,4.8,4.9,4.9,5.0,5.0,5.1,5.1,5.1,5.2,
5.2,5.2,5.2,5.2,5.3,5.3,5.3,5.3,5.4,5.4,5.4,
5.4,5.5,5.5,5.5,5.6,5.7,5.7,5.8,5.9,5.9,5.9,
5.9,6.0,6.1,6.1,6.1,6.1,6.2,6.2,6.2,6.3,6.4,
6.4,6.4,6.4,6.5,6.5,6.5,6.5,6.5,6.6,6.6,6.7,
6.7,6.7,6.7,6.8,6.9,6.9,7.0,7.0,7.1,7.2,7.3,
7.5)
hist(verbal, col="bisque")
# definindo os intervalos (k = 8)
#################################
h <- seq(2.5,7.7, by=0.65) hist(verbal, breaks=h, col="bisque", right=F,ylim=c(0,22))
# definindo os intervalos (k = 7)
#################################
h <- seq(2.50,7.54, by=0.72) hist(verbal, breaks=h, col="bisque", right=F,ylim=c(0,25))
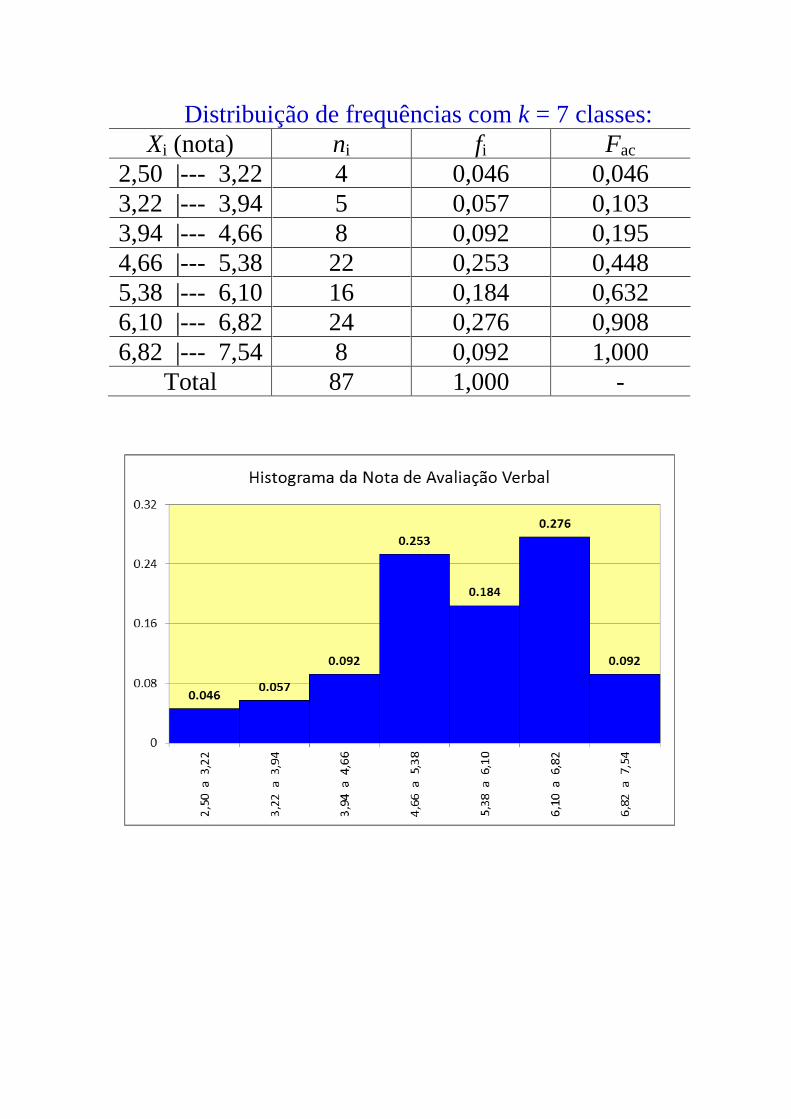
Distribuição de frequências com k = 7 classes:
Xi (nota) ni fi Fac
2,50 |--- 3,22 4 0,046 0,046
3,22 |--- 3,94 5 0,057 0,103
3,94 |--- 4,66 8 0,092 0,195
4,66 |--- 5,38 22 0,253 0,448
5,38 |--- 6,10 16 0,184 0,632
6,10 |--- 6,82 24 0,276 0,908
6,82 |--- 7,54 8 0,092 1,000
Total 87 1,000 -
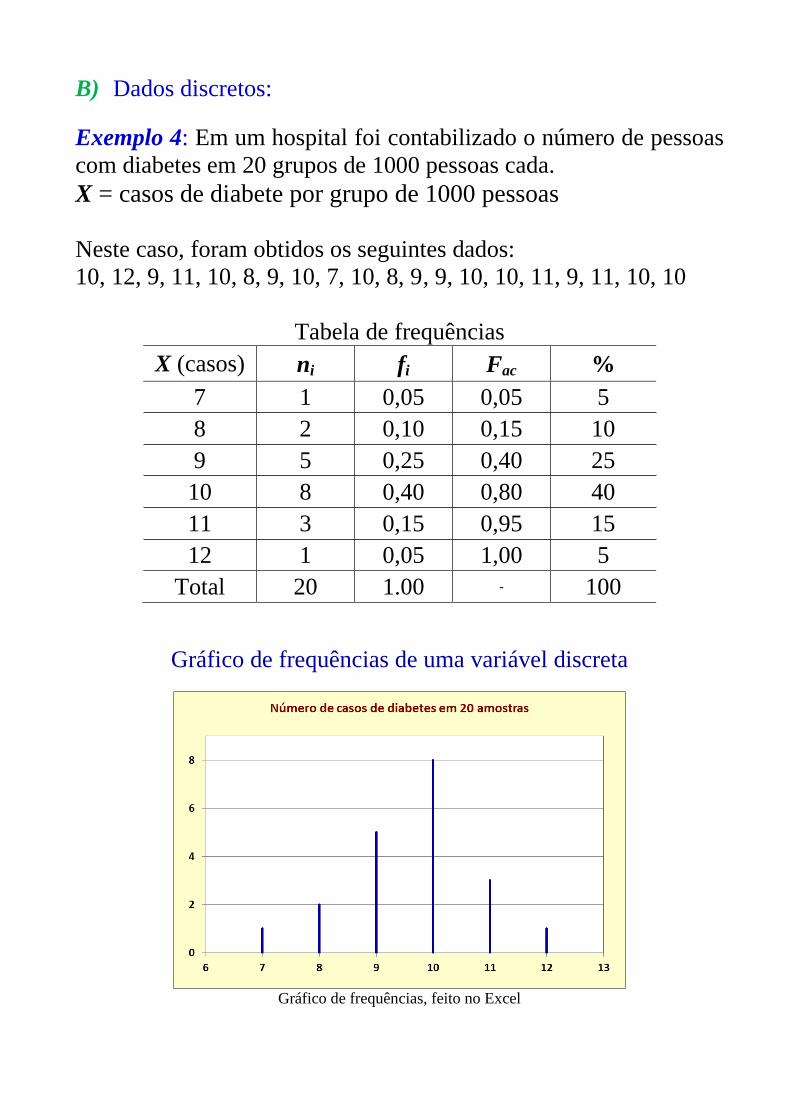
B) Dados discretos:
Exemplo 4: Em um hospital foi contabilizado o número de pessoas
com diabetes em 20 grupos de 1000 pessoas cada.
X = casos de diabete por grupo de 1000 pessoas
Neste caso, foram obtidos os seguintes dados:
10, 12, 9, 11, 10, 8, 9, 10, 7, 10, 8, 9, 9, 10, 10, 11, 9, 11, 10, 10
Tabela de frequências
X (casos) ni fi Fac %
7 1 0,05 0,05 5
8 2 0,10 0,15 10
9 5 0,25 0,40 25
10 8 0,40 0,80 40
11 3 0,15 0,95 15
12 1 0,05 1,00 5
Total 20 1.00 - 100
Gráfico de frequências de uma variável discreta
Gráfico de frequências, feito no Excel
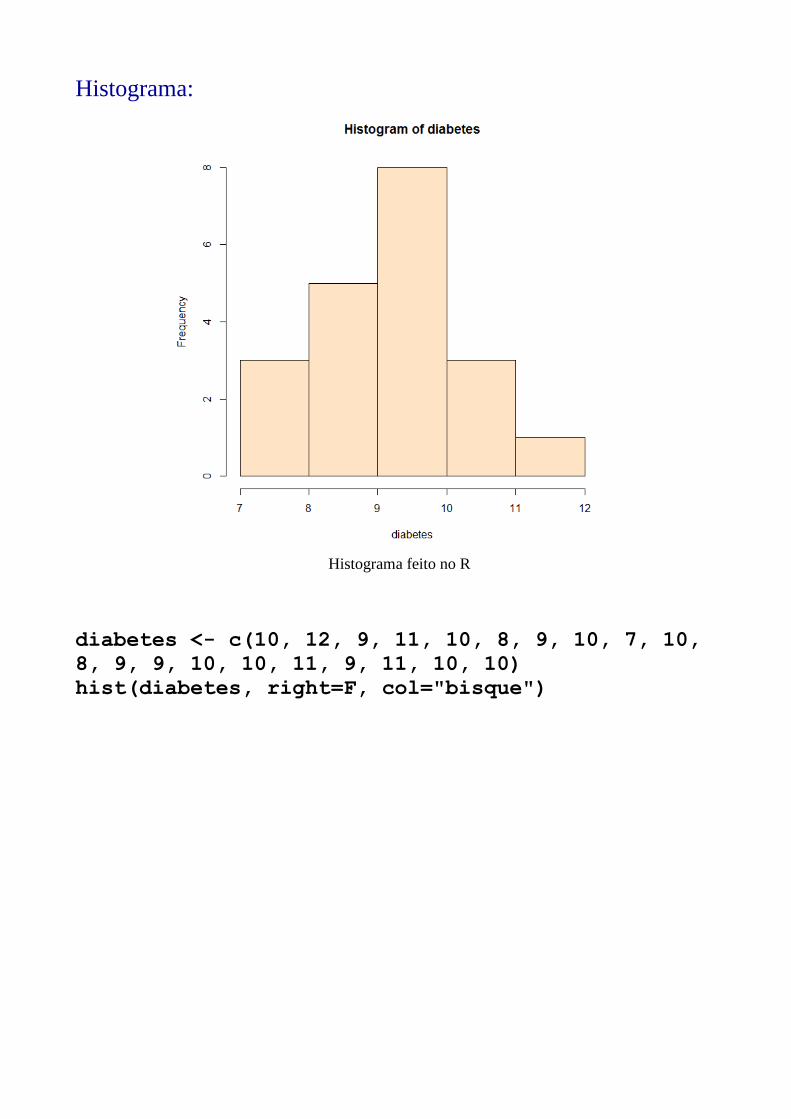
Histograma:
Histograma feito no R
diabetes <- c(10, 12, 9, 11, 10, 8, 9, 10, 7, 10,
8, 9, 9, 10, 10, 11, 9, 11, 10, 10)
hist(diabetes, right=F, col="bisque")

B.1) Dados discretizados:
Exemplo 5: Uma grande companhia está preocupada com o tempo
que seus e ficam em manutenção na assistência técnica. Sendo
assim, fez um levantamento do tempo de manutenção (dias) de 50
equipamentos para um estudo mais detalhado.
X = dias em manutenção de equipamentos.
15 13 21 9 5 5 10 6 2 2
9 10 3 4 2 13 12 16 7 6
4 11 8 6 6 10 17 13 9 5
2 5 9 14 15 3 6 18 3 4
5 7 8 3 10 5 5 4 5 2
Dados Ordenados:
2 2 2 2 2 3 3 3 3 4
4 4 4 5 5 5 5 5 5 5
5 6 6 6 6 6 7 7 8 8
9 9 9 9 10 10 10 10 11 12
13 13 13 14 15 15 16 17 18 21
Tabela de frequências:
k = 1 + 3,322log1050 = 6,64 = 7 classes (6 ou 7)
A = 21 – 2 = 19 h = 19/6 = 3,16 3,2
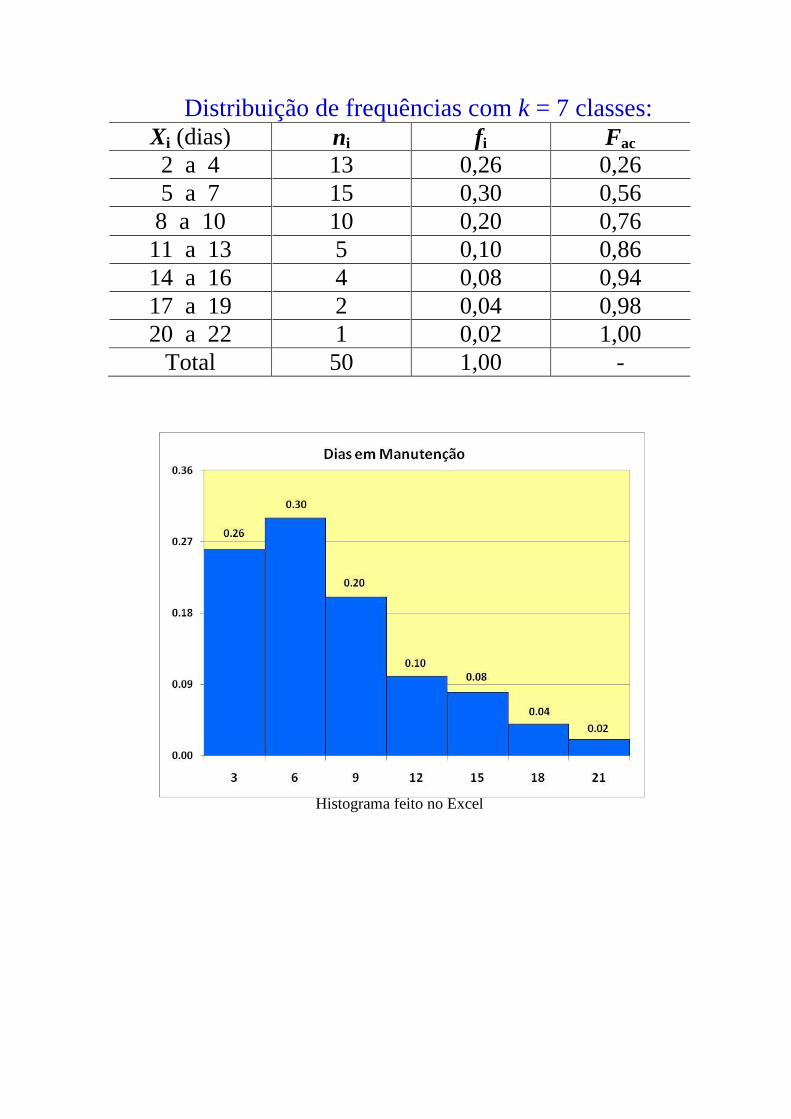
Distribuição de frequências com k = 7 classes: Xi (dias) ni fi Fac
2 a 4 13 0,26 0,26
5 a 7 15 0,30 0,56
8 a 10 10 0,20 0,76
11 a 13 5 0,10 0,86
14 a 16 4 0,08 0,94
17 a 19 2 0,04 0,98
20 a 22 1 0,02 1,00
Total 50 1,00 -
Histograma feito no Excel
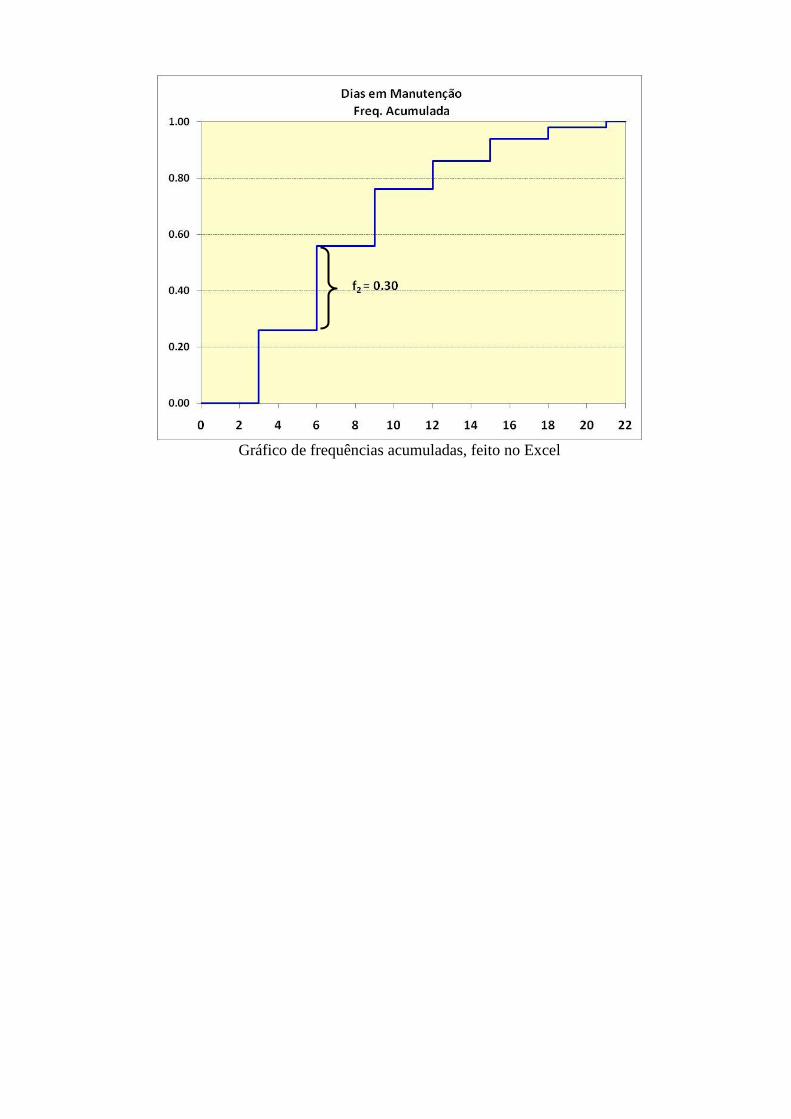
Gráfico de frequências acumuladas, feito no Excel
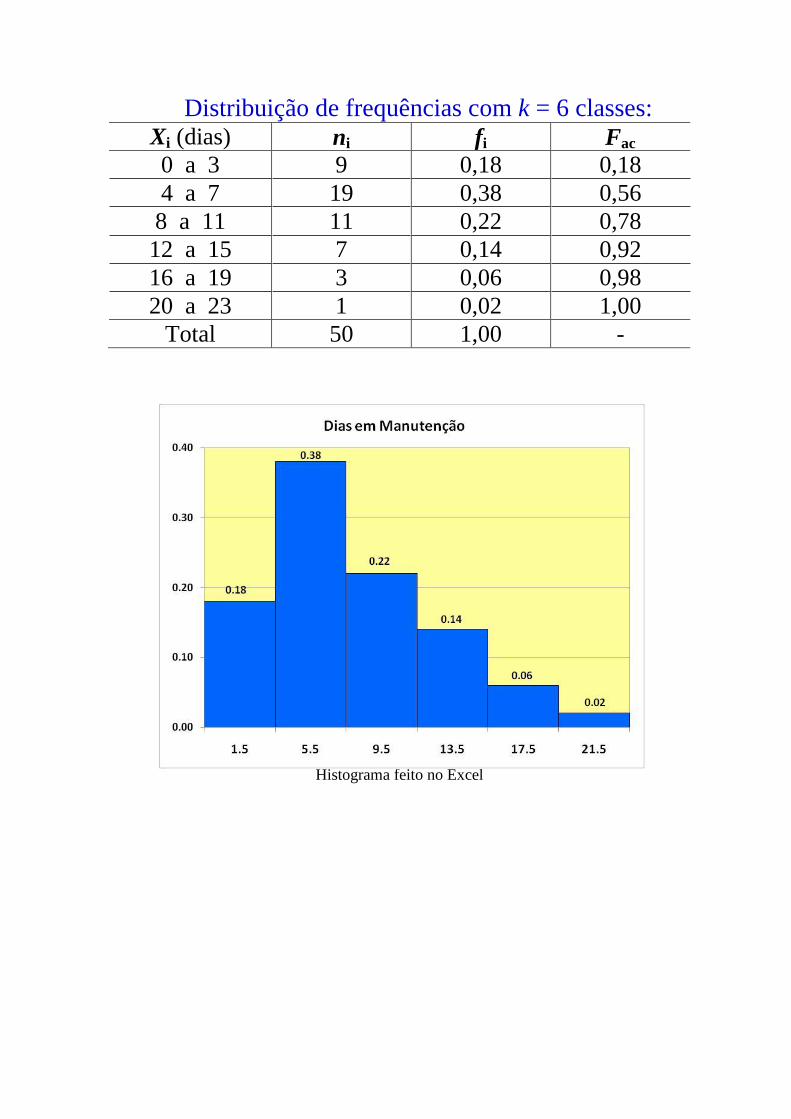
Distribuição de frequências com k = 6 classes: Xi (dias) ni fi Fac
0 a 3 9 0,18 0,18
4 a 7 19 0,38 0,56
8 a 11 11 0,22 0,78
12 a 15 7 0,14 0,92
16 a 19 3 0,06 0,98
20 a 23 1 0,02 1,00
Total 50 1,00 -
Histograma feito no Excel

Comandos do R para o histograma: manuten <-c(15,13,21, 9, 5, 5,10, 6, 2, 2, 9,10,
3, 4, 2,13,12,16, 7, 6, 4,11, 8, 6, 6,10,17,13,
9, 5, 2, 5, 9,14,15, 3, 6,18, 3, 4, 5, 7, 8, 3,
10, 5, 5, 4, 5, 2)
nclass.Sturges(manuten)
hist(manuten, col="bisque")
hist(manuten, breaks="Sturges", col="bisque")
nclass.scott(manuten)
hist(manuten, breaks="Scott", col="bisque")
nclass.FD(manuten)
hist(manuten, breaks="FD", col="bisque")
hist(manuten, breaks=7, col="bisque")
hist(manuten, breaks=8, col="bisque")
# definindo os intervalos
#########################
h1 <- c(0.5,4.5,8.5,12.5,16.5,20.5,24.5)
hist(manuten, breaks=h1, col="bisque")
h2 <- c(1.5,4.5,7.5,10.5,13.5,16.5,18.5,22.5)
hist(manuten, breaks=h2, col="bisque")

Mais exemplos
A- Representação gráfica para Variáveis Qualitativas
Exemplo1: Pesquisa PNAD 2004 – Moradores por domicílio Brasil.
a) Tabela de uma entrada: número de domicílios por região
Região domicílios %
SE 23 157 114 44,8
NE 13 090 124 25,3
S 8 198 266 15,8
CO 3 745 500 7,2
NE 3 561 524 6,9
51 752 528 100,0
Gráfico de setores (pizza) do número de domicílios por região.
Proporções (freq. Relativas) e ângulo do número de domicílios/região.
Região Domicílios Proporção Ângulo
SE 23 157 114 0,447 161 o
NE 13 090 124 0,253 91 o
S 8 198 266 0,158 57 o
CO 3 745 500 0,072 26 o
NE 3 561 524 0,069 25 o
51 752 528 1,000 360 o
- Para achar o ângulo, deve-se usar a relação: 100% = 360o.
- Portanto, se uma categoria tem proporção de 0,447, então, basta
multiplicar 0,447 por 360o para encontrar o ângulo correspondente
(regra de três).
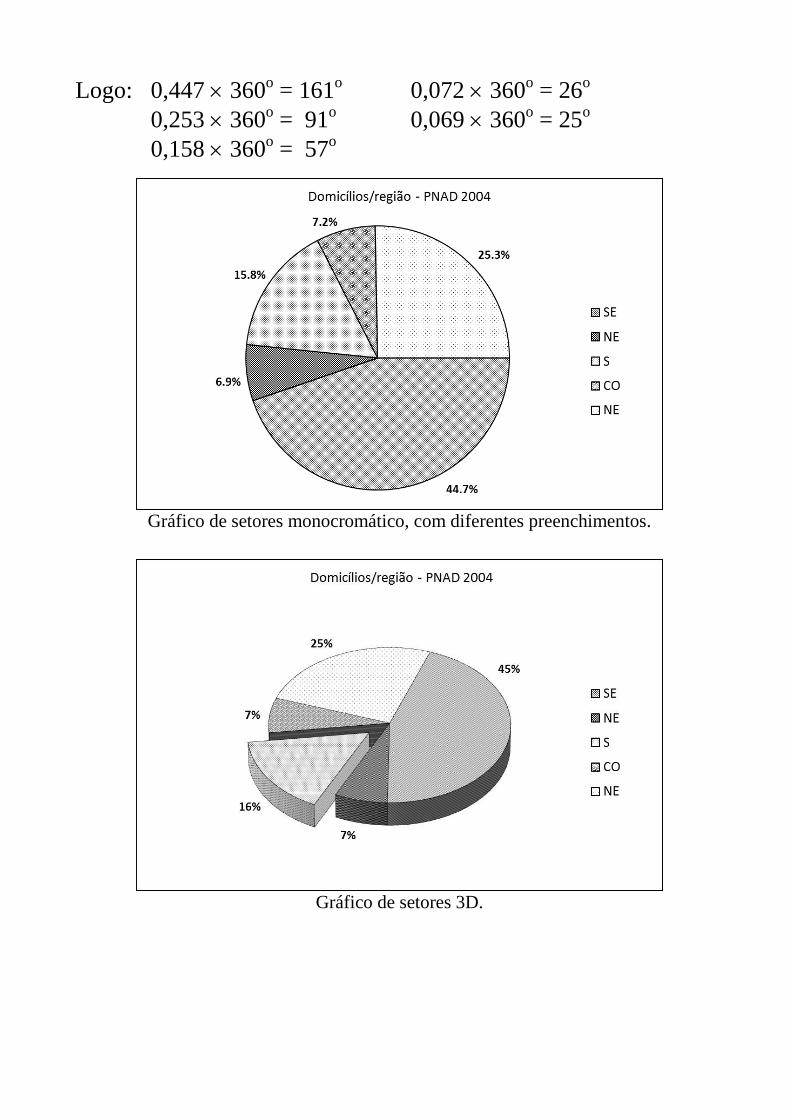
Logo: 0,447 360o = 161o 0,072 360o = 26o
0,253 360o = 91o 0,069 360o = 25o
0,158 360o = 57o
Gráfico de setores monocromático, com diferentes preenchimentos.
Gráfico de setores 3D.
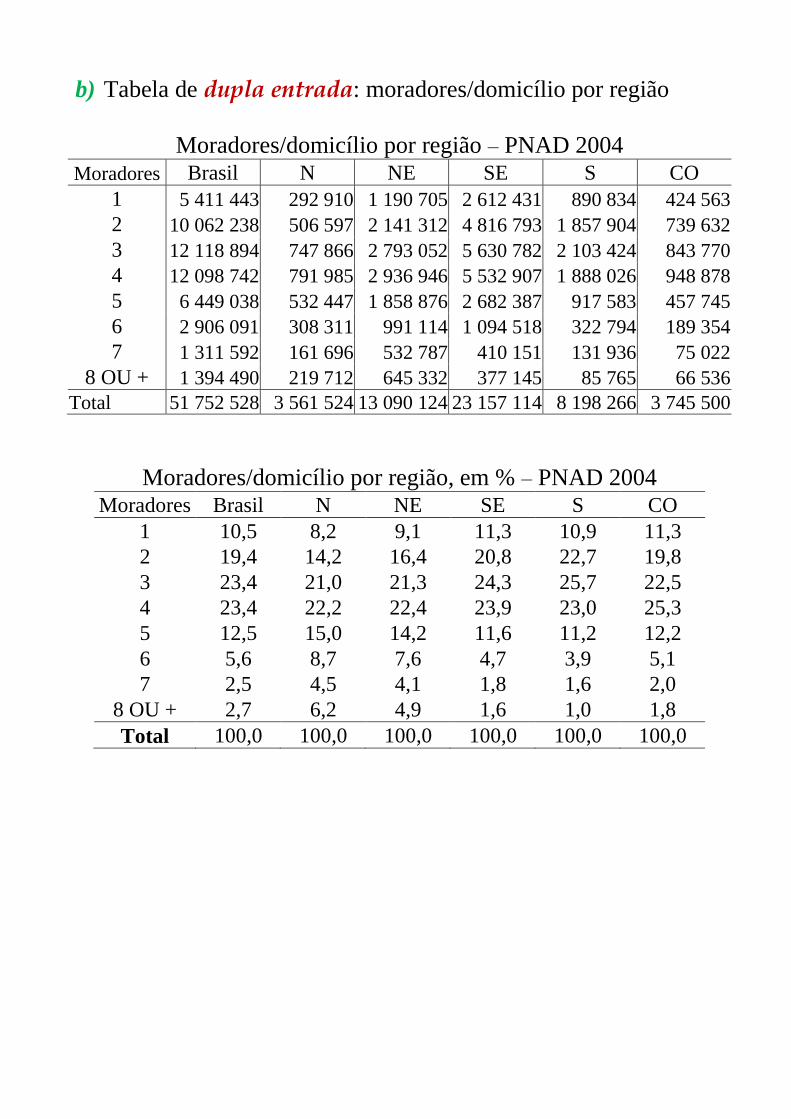
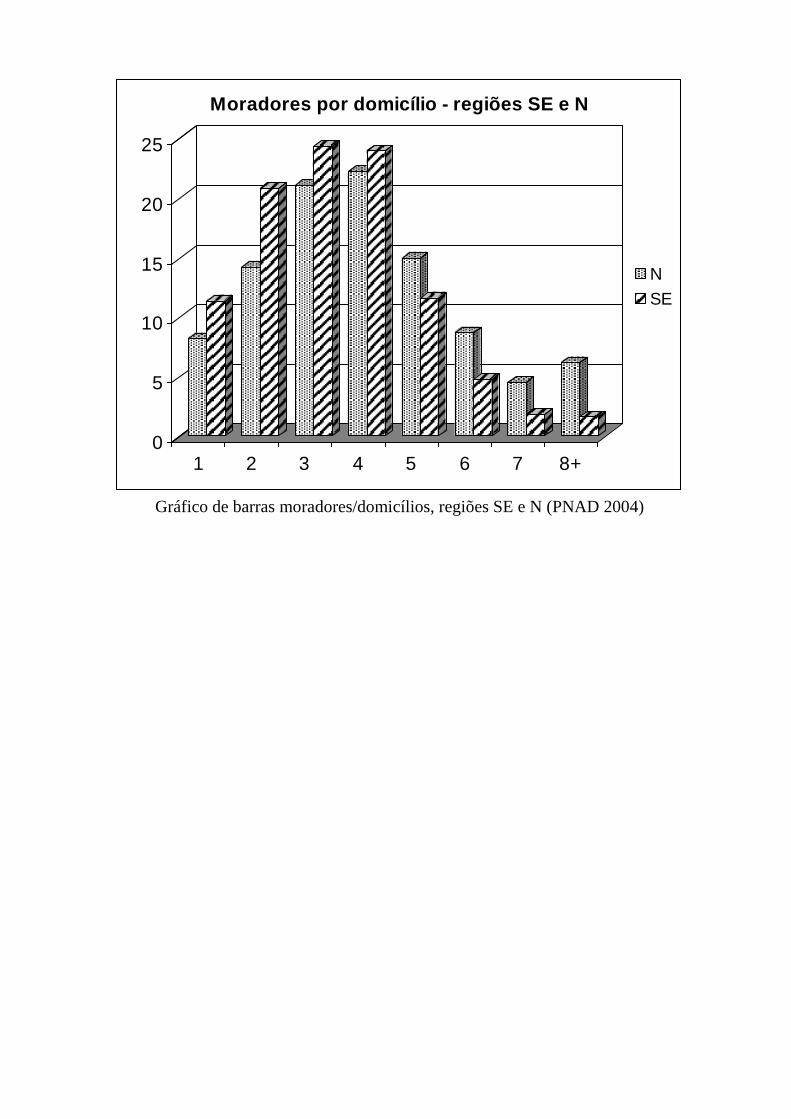
b) Tabela de dupla entrada: moradores/domicílio por região
Moradores/domicílio por região – PNAD 2004 Moradores Brasil N NE SE S CO
1 5 411 443 292 910 1 190 705 2 612 431 890 834 424 563
2 10 062 238 506 597 2 141 312 4 816 793 1 857 904 739 632
3 12 118 894 747 866 2 793 052 5 630 782 2 103 424 843 770
4 12 098 742 791 985 2 936 946 5 532 907 1 888 026 948 878
5 6 449 038 532 447 1 858 876 2 682 387 917 583 457 745
6 2 906 091 308 311 991 114 1 094 518 322 794 189 354
7 1 311 592 161 696 532 787 410 151 131 936 75 022
8 OU + 1 394 490 219 712 645 332 377 145 85 765 66 536
Total 51 752 528 3 561 524 13 090 124 23 157 114 8 198 266 3 745 500
Moradores/domicílio por região, em % – PNAD 2004 Moradores Brasil N NE SE S CO
1 10,5 8,2 9,1 11,3 10,9 11,3
2 19,4 14,2 16,4 20,8 22,7 19,8
3 23,4 21,0 21,3 24,3 25,7 22,5
4 23,4 22,2 22,4 23,9 23,0 25,3
5 12,5 15,0 14,2 11,6 11,2 12,2
6 5,6 8,7 7,6 4,7 3,9 5,1
7 2,5 4,5 4,1 1,8 1,6 2,0
8 OU + 2,7 6,2 4,9 1,6 1,0 1,8
Total 100,0 100,0 100,0 100,0 100,0 100,0
0
5
10
15
20
25
1 2 3 4 5 6 7 8+
Moradores por domicílio - regiões SE e N
N
SE
Gráfico de barras moradores/domicílios, regiões SE e N (PNAD 2004)
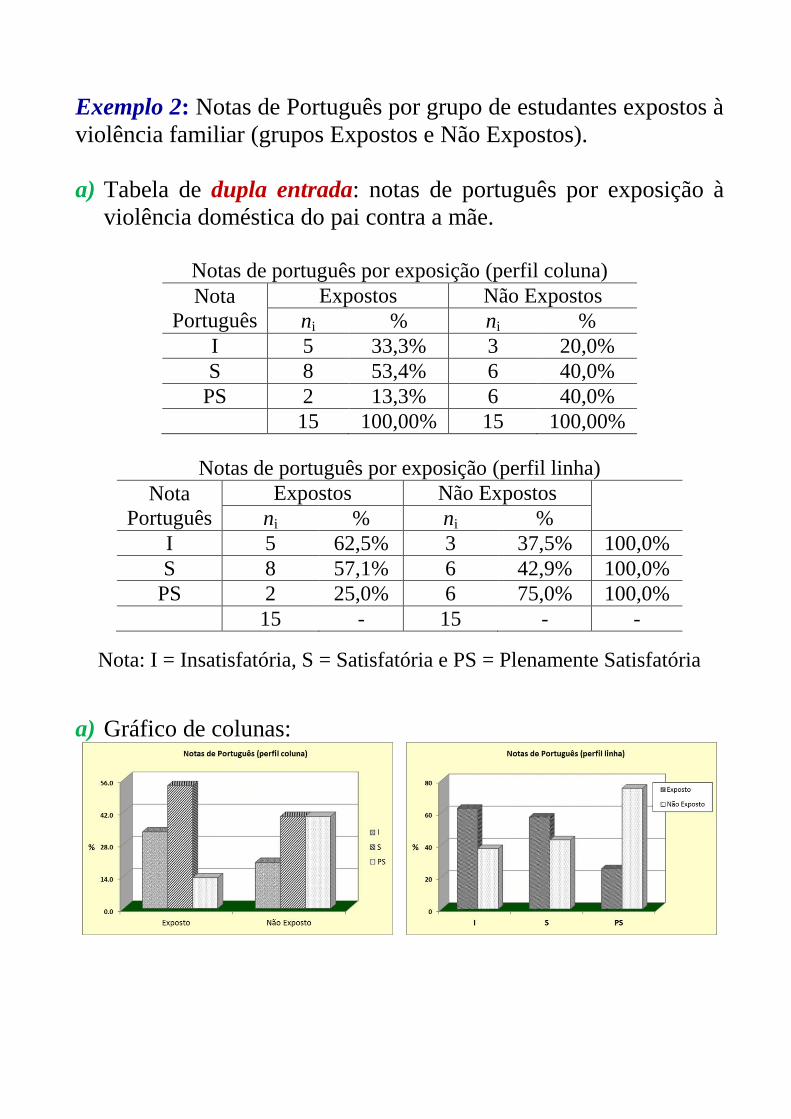
Exemplo 2: Notas de Português por grupo de estudantes expostos à
violência familiar (grupos Expostos e Não Expostos).
a) Tabela de dupla entrada: notas de português por exposição à
violência doméstica do pai contra a mãe.
Notas de português por exposição (perfil coluna)
Nota
Português
Expostos Não Expostos
ni % ni %
I 5 33,3% 3 20,0%
S 8 53,4% 6 40,0%
PS 2 13,3% 6 40,0%
15 100,00% 15 100,00%
Notas de português por exposição (perfil linha)
Nota
Português
Expostos Não Expostos
ni % ni %
I 5 62,5% 3 37,5% 100,0%
S 8 57,1% 6 42,9% 100,0%
PS 2 25,0% 6 75,0% 100,0%
15 - 15 - -
Nota: I = Insatisfatória, S = Satisfatória e PS = Plenamente Satisfatória
a) Gráfico de colunas:
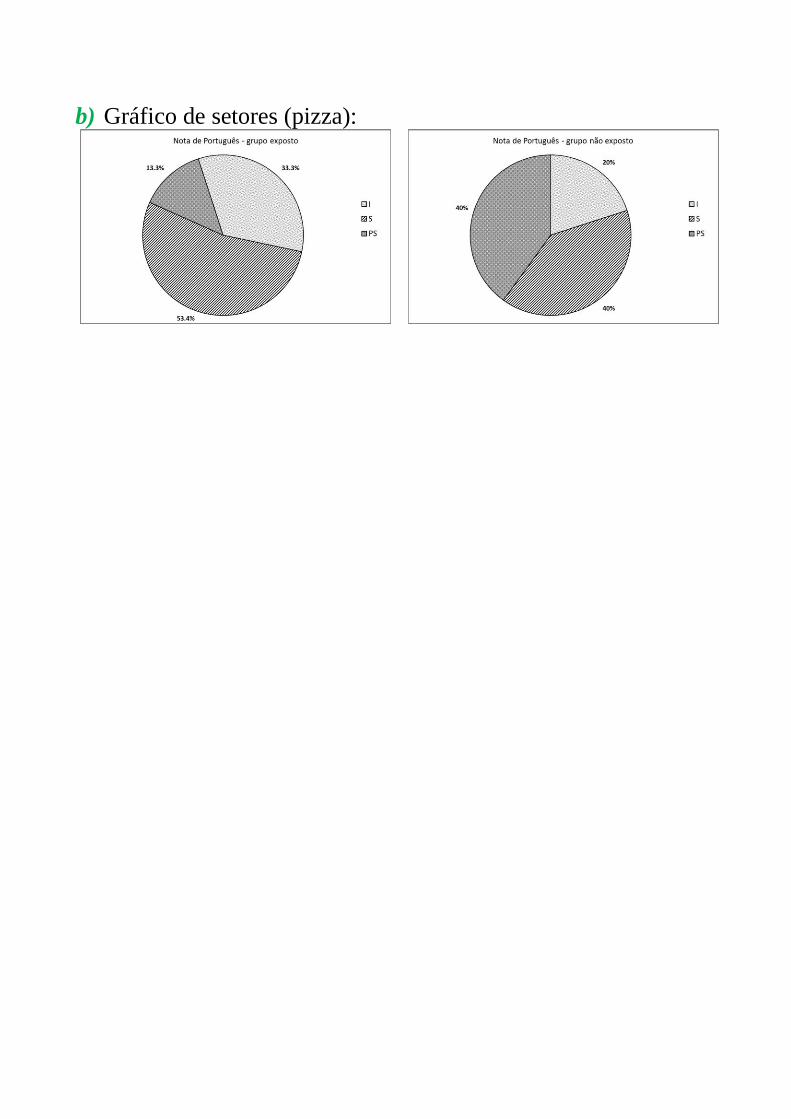
b) Gráfico de setores (pizza):

Exemplos A) Dados DISCRETOS não agrupados:
X = variável representando o número de vezes que um sistema
travou, por período de execução, na sua carga máxima de
processamento.
4 4 1 6 3 2 3 3 4 3 4 2 4 5 2 5 1 2 5 4 6 3 1 2 3
Medidas de tendência central mais comuns, no Excel:
a) Média aritmérica ...... =MÉDIA(A1:A25)
b) Mediana ................... =MED(A1:A25)
c) Moda ........................ =MODO(A1:A25)
d) Média geométrica .... = MÉDIA.GEOMÉTRICA(A1:A25)
e) Média harmônica ..... = MÉDIA.HARMÔNICA(A1:A25)
Para construir Tabelas de Frequências no Excel i) marcar os dados
ii) selecionar > Inserir > Tabela Dinâmica
iii) arrastar X para a margem esquerda e centro da tabela
iv) clicar com o botão direito sobre a coluna Total, selecionar >
Resumir Dados por e marcar a opção Contagem;
v) inserir as colunas e concluir a tabela, atentando para que os
cálculos sejam feitos corretamente.
Tabela de Frequências:
X ni fi Fac
1 3 0,12 0,12
2 5 0,20 0,32
3 6 0,24 0,56
4 6 0,24 0,80
5 3 0,12 0,92
6 2 0,08 1,00
Total 25 1,00
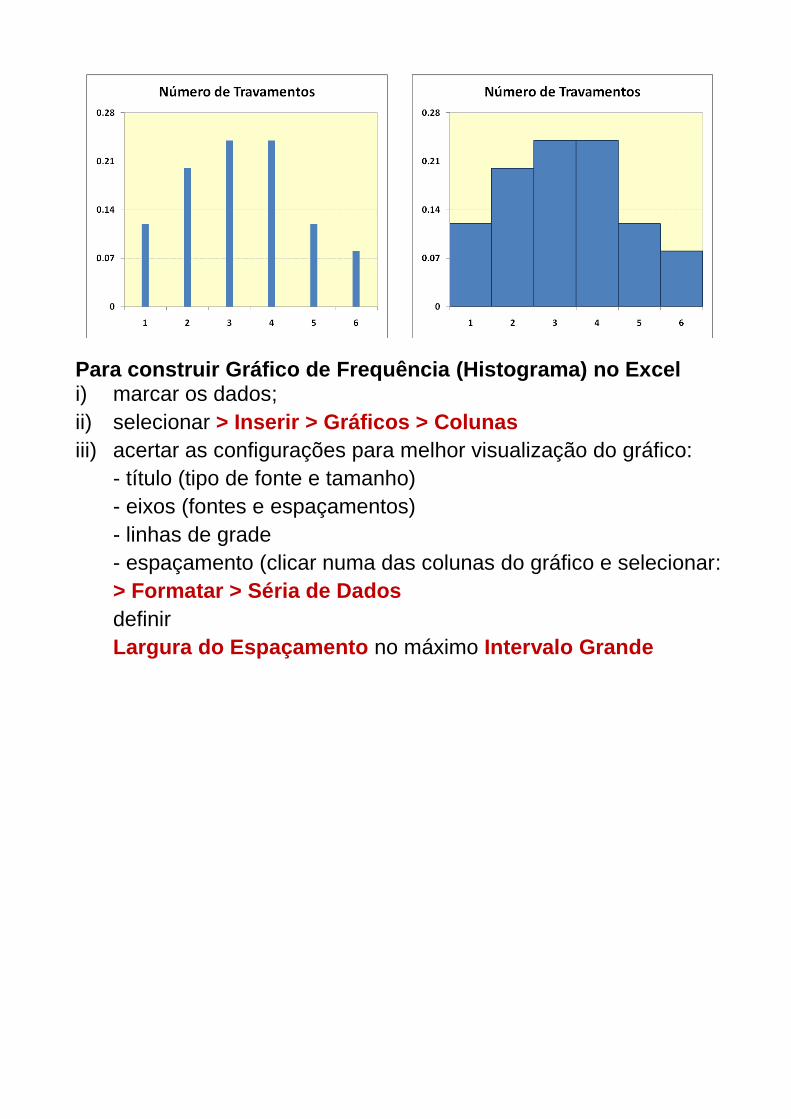
Para construir Gráfico de Frequência (Histograma) no Excel i) marcar os dados;
ii) selecionar > Inserir > Gráficos > Colunas
iii) acertar as configurações para melhor visualização do gráfico:
- título (tipo de fonte e tamanho)
- eixos (fontes e espaçamentos)
- linhas de grade
- espaçamento (clicar numa das colunas do gráfico e selecionar:
> Formatar > Séria de Dados
definir
Largura do Espaçamento no máximo Intervalo Grande

Construindo a Tabela de Frequência e o Histograma no Excel i) > Dados > Análise de Dados > Histograma > OK
ii) Marcar as opções:
- Intervalo de entrada => conjunto de dados para a tabela
- Intervalo do bloco => coluna com os limites das classes da
tabela
- Intervalo de saída => local onde a tabela será colocada
- marcar Porcentagem cumulativa para obter a freqüência
acumulada Fac
- marcar Resultado do gráfico para obter o Histograma
iii) Escolher a opção Estatística Descritiva

B) Dados CONTÍNUOS:
Exemplo: Em 1798 o cientista Henry Cavendish mediu a densidade
do glogo terrestre em 29 ensaios. Os dados foram obtidos do
Annals os Statistics, 1977.
X = densidade do globo terrestre (g/cm3).
5,50 5,61 4,88 5,07 5,26 5,55 5,36 5,29 5,58 5,65 5,57 5,53 5,62 5,29 5,44 5,34 5,79 5,10 5,27 5,39 5,42 5,47 5,63 5,34 5,46 5,30 5,75 5,68 5,85
Dados ordenados
4,88 5,07 5,10 5,26 5,27 5,29 5,29 5,30 5,34 5,34 5,36 5,39 5,42 5,44 5,46 5,47 5,50 5,53 5,55 5,57 5,58 5,61 5,62 5,63 5,65 5,68 5,75 5,79 5,85
99,157x
09,8622x





























