Embed Size (px)
DESCRIPTION
Resumo em português da apostila do curso TADM51 ORACLE da Academia SAP BASIS
Citation preview

TADM51
Unit 1 - Database Overview Database Architecture
Terminologia: Oracle é composto: Processes, Memory (SGA) e Database. Database: Coleção de dados manipulados logicamente como uma unidade (Tablespaces). Fisicamente armazenados em um ou mais data files em discos (Data Files). Tablespaces são compostas de um ou mais Datafiles. Instance: Oracle (background) processes + memória (buffers). Cada execução de um Oracle Database é associado com uma Instance. Obs: Utilizando RAC (Real Application Clusters), um Database pode servir para dois ou mais Instances. SGA: Quando uma Instance é iniciada uma SGA (system global área) é alocada. Cada Instancia tem sua própria SGA. Processes: Quando uma Instance é iniciada, Oracle BackGround Processes são também iniciados, e também finalizados quando a Instance for encerrada. system identifier (DBSID): Cada Database possue uma identificação (DBSID). Para o SAP (SAPSID). Compostos com 3 caracteres sendo o primeiro maiúsculo.

Quando uma Instance é iniciada o processo Listener abre e estabiliza comunicação entre os clientes e a Instance Oracle. O Listener não faz parte da Instance, ele é parte do processo de rede (networking).
Quando um Work Process faz um pedido, o Listener cria processo dedicado e estabelece uma ligação adequada.
Oracle background processes executa várias tarefas requeridas pelo Database para um funcionamento correto.
Para acelerar o leitura e gravação dos dados, eles são armazenados no database buffer cache na SGA.
O Oracle Database mantém os executáveis na Shared SQL Area (também chamada de Shared Cursor Cache), qua faz parte da Shared Pool alocada na SGA. Outra parte da Shared Pool chamada de Row Cache armazena informações do dicionário Oracle.
Os dados são armazenados nos Data Files, mas quando for necessário realizar alguma atualização, eles são copiados para o Database Buffer Cache da SGA caso não estiverem lá.
A menor unidade lógica do Oracle para copiar dados entre Datafiles e o Buffer Cache é o Data Block. Definido durante a criação do database. O SAP é sempre 8kb. Por questões de performance os discos também devem ser formatados com 8kb.
Writing of Modified Data Alterações em dados Oracle são sempre feitos no Buffer Cache. Entretanto o Oracle Shadow Process nunca copia dados modificados (dirty blocks) do Buffer Cache para o disco. Esta tarefa é feita pelo processo database writer (DBW0). O DBW0 grava dirty blocks nas situações:
Quando precisar de espaço no DataBase Buffer Cache; Cada vez que ocorrer um checkpoint process (CKPT);
DBW0: Grava dados alterados do DATA BUFFER CACHE nos DATA FILES. Embora um Database Write Process (DBW0) seja suficiente para maioria dos sistemas, um novo DBW1 (e assim por diante) pode ser configurado em casos especiais. Logging of Modifications LGWR: Grava os dados registrados no REDO LOG BUFFER nos REDO LOG FILES.

Redo Entries (ou after images) contém os dados dos “novos” valores modificados. Também utilizados para reconstruir (roll) ou gravar os dados no database após um commit. O Oracle Shadow Process grava estas entradas no Redo Log Buffer (uncommitted and committed). O Oracle Background Process (LGWR) grava todas informações do Redo Log Buffer para os Redo Log File no disco. Estas informações são gravadas quando:
Uma transação é gravada (commit) A cada três segundos Quando o Redo Log Buffer está um terço completo
Quando o DBW0 escrever dirty blocks no disco, mas esses ainda não foram para o online redo log.
Quando um User (Work Process) grava uma transação, ela é “marcada” com um SNC (system change number). O oracle grava o SNC junto com a entrada de transação no Redo Log.
Para garantir consistência nos dados e na leitura, Oracle mantém redo entries para executar comandos e undo entries para roll back, em caso de crashes. Undo Entries (ou before images) contém os dados dos “velhos” valores necessários para que um RollBack possa ser realizado com os dados alterados por uma declaração SQL sem que tenha sido gravada (commit). Grava as imagens anteriores
para opção rollback. Contém informações para undo ou roll back, e suas entradas são chamadas before images. Essas entradas estão separadas do redo log, em undo tablespaces ou rollback segments. Log Switch Os Redo Logs Files não crescem dinamicamente, portanto quando o arquivo (online) estiver “cheio” o processo Log Writer(LGWR) fecha este arquivo e inicia a gravação no próximo arquivo. Isto é chamado de Log Switch. Os Redo Logs são definidos normalmente por 4 arquivos (sistemas SAP 50mb) e esta gravação é cíclica. Em cada Log Switch o Oracle incrementa o LSN Log Sequence Number e através do LSN o Oracle cria automaticamente uma seqüência numerando os Redo Logs. Control Files

Control Files Cada database possui um control file, que contém entradas que especificam a estrutura física e o estado da base, como tablespaces, nomes e localizações dos data files e redo logs, ou o LSN. Control file é apenas alterada pelo Oracle, deve estar disponível para escrita quando o banco é ativado e no SAP ele é espelhado em 3 lugares diferentes por segurança. Checkpoints O termo checkpoint tem dois significados:
É o ponto no qual o DBW0 grava todas alterações do buffer no buffer cache nos Data Files.
DBW0: O checkpoint process (CKPT) sinaliza o DBW0 copiar todos os dirty blocs para o disco.
O CKPT ainda atualiza os headers dos data files gravando os detalhes do checkpoint e escreve a posição do checkpoint no online redo log. Checkpoint ocorre a cada log switch e quando especificado em parâmetros do Oracle (no SAP esses parâmetros não são usados, e o checkpoint apenas no log switch).
Database recovery O recorvery na inicialização da base consiste de duas etapas:
inicia a partir do checkpoint, refazendo atividades do redo log, incluindo mudanças na undo space;
atividades que sofreram roll back explicitamente antes do crash são reprocessadas e o undo é garantido porque o Oracle não apaga entradas de transações abertas na undo space.
Durante o restart de uma instance ou no momento de abrir o database Oracle, especialmente após um “crash” ou quando uma instance não foi finalizada (shut down) corretamente, nesta situação o Oracle inicia automaticamente uma recuperação chamada de Database Recovery (ou Instance Recover).
Redo Log Mirroring Os redo logs devem ser espelhados, em duas ou mais cópias, e cada redo log deve estar em discos separados. O Oracle trás essa característica e é usada na instalação do SAP como default. Desta forma, não é necessário utilizar soluções externas. Como o online redo log é limitado em tamanho e não pode crescer automaticamente, Oracle deve sobrescrever redo logs antigos por novas entradas.

Archiving Para retornar uma situação antes do crash, normalmente é necessário além do backup aplicar os online redo logs posteriores. Para evitar perda de dados, os online redo log devem ser gravados em um local seguro, tarefa do archiver (ARC0). Archiving deve ser explicitamente ativado, via parâmetro LOG_ARCHIVE_START to TRUE. Em ambientes produtivos este parâmetro deve ser ativado, e os offline redo log devem ser guardados em discos espelhados (RAID).
Other Background Process (pg 18) SMON (System Monitor):
executa o recovery quando a instância é inicializada (se necessário); escreve log de alertas se outro processo da instância falha; limpa segmentos temporários que não estão em uso.
PMON (Process Monitor):
monitora os shadow processes; no caso de crash, faz roll back dos dados não comitados, para os shadow
process e libera recursos que os processos estavam usando.

Estrutura de diretórios Oracle no SAP
No UNIX na <release>, sub-diretório abaixo do “/oracle/<DBSID>” também contem informações da versão do Oracle (se usa 32 ou 64 bits). Ex.: “/oracle/<DBSID>/920_64” para Oracle versão 9.20 e 64 bits.

dbs (on UNIX) or database (on Windows): Os arquivos (profiles) init<DBSID>.ora or spfile<DBSID>.ora guardam os parâmetros de configuração do Oracle Instance; O arquivo init<DBSID>.sap guarda parâmetros de configuração da ferramenta de administração BR*Tools. sapdata<n>: Contém os Data Files das Tablespaces origlogA/B, mirrlogA/B: Os Online Redo Log Files são arquivados nos diretórios “origlog” e “mirrlog”. oraarch: Os Offline redo log files são gravados no diretório “oraarch”. saptrace: Utilizado para armazenar informações dos “dump” Oracle; O arquivo de alerta do Oracle alert_<DBSID>.log é gravado em saptrace/background; Os arquivos de Trace do Oracle shadow processes são gravados em saptrace/usertrace. saparch: Armazena os logs da ferramenta SAP BRARCHIVE. sapbackup: Armazena os logs da ferramenta SAP BRBACKUP, BRRESTORE, and BRRECOVER. sapreorg: Usado pelo BRSPACE para armazenar logs de diferentes ações. sapcheck: Usado pelo BRCONNECT para armazenar logs de diferentes ações. Oracle Directories and Environment Variables (pg 21) No database server as variáveis de ambiente ORACLE_SID, ORACLE_HOME e SAPDATA_HOME devem sempre ser configuradas para o user <sapsid>adm, bem como para o user ora<dbsid> no UNIX. ORACLE_SID: system ID para a instância; ORACLE_HOME: diretório home do Oracle, que contém o Bin, DBS e network; SAPDATA_HOME: contém arquivos do banco de dados; Others variables:
o no caso do Windows, se diretórios diferentes do SAPDATA_HOME são usados, SAPARCH, SAPBACKUP, SAPCHECK, SAPREORG.
o no UNIX, as variáveis ORA_NLS10 são também configuradas para o user ora<dbsid>. O valor padrão para ORA_NLS10 é $ORACLE_HOME/nls/data.
Connecting to the Database (pg 29) Para proteger o SAP, é necessário controlar usuários em três níveis:
Sistema Operacional; Banco de Dados; SAP.

Operating System and Database Users
Oracle System Privileges System Pivileges controla operações realizadas por um usuário em uma instância ou database. Object privileges controla operações em objetos, como select, update, etc. Special system privileges SYSDBA e SYSOPER são oferecidos durante as conexões. Em um sistema SAP no SO é usado autenticação para conexão no Oracle com privilégios SYSDBA e SYSOPER.

Operation System Users and Groups Usuários do sistema operacional membros do grupo dba ou ORA_DBA (ou ORA_<SID>_DBA) podem conectar no banco com o privilégio SYSDBA. Membros do grupo oper (UNIX) ou ORA_<SID>_OPER (windows) como SYSOPER.
Oracle Database Users Cada DB Oracle contém duas contas administrativa de usuários , SYS e SYSTEM, criados automaticamente durante a instalação e associados a role DBA. SYS é o usuário mais poderoso no Oracle:
todas as tabelas e views do data dictionary são guardadas no schema sys. Essas tabelas são críticas para o Oracle, não podem ser alteradas ou novas tabelas criadas nesse schema;
SYS garante adicionais privilégios que a role DBA, e pode alterar qualquer dado no banco.
OBS: SCHEMA é uma coleção de objetos de dados pertencentes a um usuário como OWNER. Um SCHEMA sempre possue o mesmo nome que o OWNER. SYSTEM é usado pelo Oracle para criar tabelas internas e views adicionais para exibir informações administrativas. Não possui permissão para alterar tabelas do dicionário de dados. ** No SAP:
SYSTEM recebe função SAPDBA para que o BR*Tools possam acessar certas tabelas no schema SYS;
SYSTEM é o usuário default quando se usa SAP tools para administração do Oracle.
**

Durante a instalação do SAP, é criado no banco um usuário SAP<SCHEMA-ID> (ou SAPR3 até Basis 4.6D). Todas as tabelas do SAP são guardadas neste schema, porém o usuário não possui direitos administrativos no database (não associado a role DBA ou SAPDBA). Outros usuários criados no Oracle fazem uso do operating system authentication. Se o usuário chamado OPS$<USERNAME> é definido como identificador externo no nível do DB, ele não tem senha e o user <USERNAME> do SO pode conectar no DB sem autenticação, assumindo que os parâmetros do Oracle são configurados como:
REMOTE_OS_AUTHENT=TRUE; OS_AUTHENT_PREFIX=OPS$;
OPS$, autentica user do SO como user DB. Se conectar com JJ no SO, pode-se conectar com OPS$JJ no DB. Oracle Database Role Role DBA contém todos os privilégios necessários para administração do DB, entretanto algumas tarefas não são disponíveis como start/shut down que precisam dos privilégios de sistema SYSDBA ou SYSOPER. Na instalação do SAP, duas roles são criadas: SAPDBA: permite acesso a tabelas usadas pelas SAP tools para administração do DB SAPCONN: é associada para o user OPS$ na instalação.

Connecting to Oracle (pg 37)
Um user SO pode somente executar com sucesso um: “connect /” se o correspondente user OPS$ existir no DB; “connect / {AS SYSDBA | AS SYSOPER}” se o user for membro do grupo do SO (dba ou oper no UNIX, ORA_DBA, ORA_<SID>_DBA, ORA_<SID>_OPER no Windows); Conexões AS SYSDBA e AS SYSOPER substituem o CONNECT INTERNAL em versões Oralce acima de 8.x. Work Process Connect to Oracle
** Quando um SAP WP inicia e tenta conectar com o DB, as seguintes ações acontecem:
1. WP loga no DB com seu user OPS$ correspondente com autenticação do SO; 2. WP realiza um SELECT na tabela SAPUSER e lê a senha do SAP<SCHEMA-ID>;
3. WP disconecta do Oracle; 4. WP conecta com o username SAP<SCHEMA-ID> e a senha lida da tabela
SAPUSER. A senha do user SAP<SCHEMA-ID> somente pode ser alterada com BRCONNECT **

Net Services Na rede, a comunicação é via TCP/IP e no topo, no software layer, o OracleNet (Oracle Network Services). Na mesma máquina o SAP usa o interprocess communication (IPC) protocol Named Pipes. OracleNet existe tanto no cliente quanto no servidor, e é responsável por estabelecer e manter a conexão entre os dois, bem como controlar as mensagens entre eles, usando protocolos padrões, como o TCP/IP. Um processo chamado listener (OracleNet Listener) se encarrega de ouvir novas conexões e ligá-las ao servidor. Após a conexão ser estabelecida, a comunicação passa ser diretamente entre cliente e servidor. Três arquivos são usados para essa configuração:
listener.ora: configura o listener e é usado apenas no servidor. Contém todas entradas dos sistemas Oracle que deverão aceitar conexões;
tnsnames.ora: contem a lista de services names que podem ser acessados via rede;
sqlnet.ora: pode conter informações do cliente, como domínio, traces, etc. Oracel Listener O utilitário lsnrctl é usado para parar e ativar o listener, bem como ver seu status. No Unix o processo tnslsnr. No Windows serviço Oracle<DBSID><Release>TNSListener. Se várias instâncias são usadas em um único host, geralmente há apenas um listener com todas entradas. O listener pode ser pingado via utilitário tnsping <DBSID>. ** Comando lsnrctl status, mostra informações como versão do OracleNet , tempo de start, e localização de parâmetros e log files do listener. Database server listener tracing pode ser configurado pelo arquivo listener.ora. Opções do listener tracing: NO SET: No tracing (default); USER: Limitado nível de informações de tracing ADMIN: trace detalhada ** TNSPING <DBSID> O resultado indica se: A conexão pode ser estabelecida; <DBSID> não pode ser resolvido no tnsnames.ora O Listener não esta configurado para comunicar com <DBSID> através do listener.ora; O Listener não está executando no database server; Database Administration Tools (pg 50) Administração do banco de dados Oracle pode ser feito via SAP administration tools, chamados de BR*Tools. Estão no diretório /usr/sap/<SID>/SYS/exe/run e podem ser usados em qualquer versão do SAP, a partir do Oracle 9i. BRTOOLS é disponibilizado como uma interface baseada em caracteres, para os programas BRBACKUP, BRARCHIVE, BRRESTORE, BRRECOVER, BRSPACE e BRCONNECT. Além do BRTOOLS, existe o BRGUI, baseado em Java, que usa as funções via BRTOOLS. Oracle TOOLS SQL*Plus
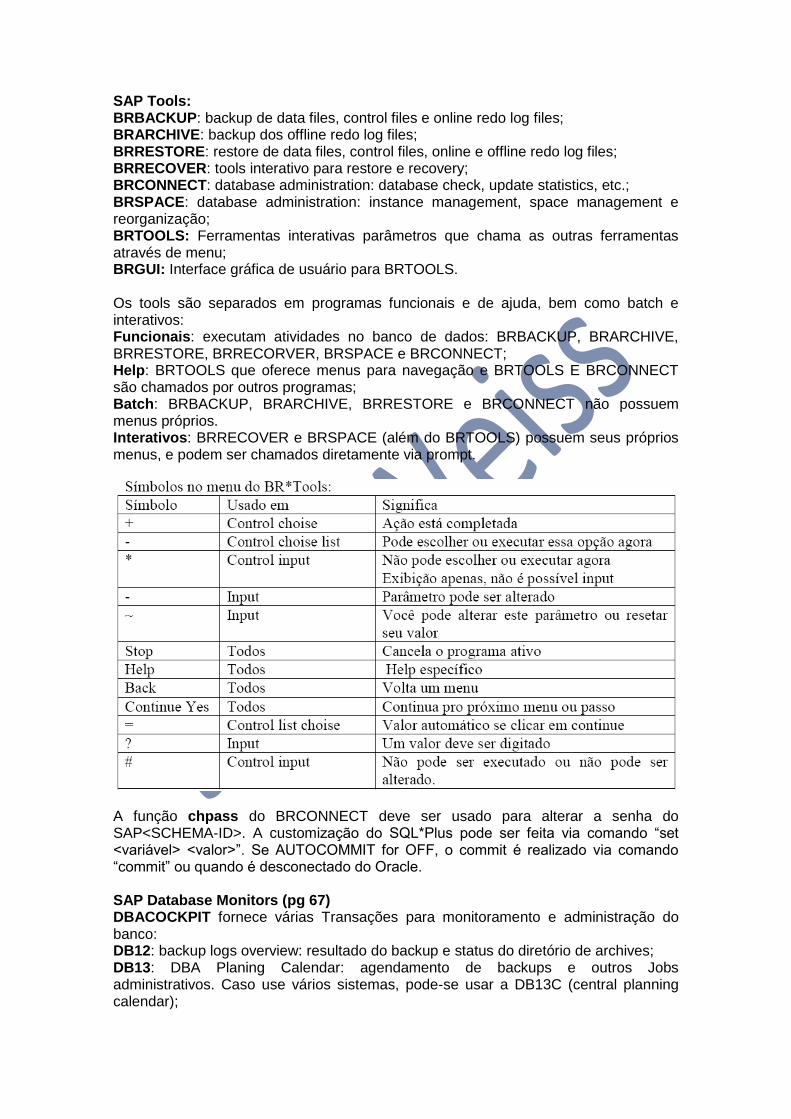
SAP Tools: BRBACKUP: backup de data files, control files e online redo log files; BRARCHIVE: backup dos offline redo log files; BRRESTORE: restore de data files, control files, online e offline redo log files; BRRECOVER: tools interativo para restore e recovery; BRCONNECT: database administration: database check, update statistics, etc.; BRSPACE: database administration: instance management, space management e reorganização; BRTOOLS: Ferramentas interativas parâmetros que chama as outras ferramentas através de menu; BRGUI: Interface gráfica de usuário para BRTOOLS. Os tools são separados em programas funcionais e de ajuda, bem como batch e interativos: Funcionais: executam atividades no banco de dados: BRBACKUP, BRARCHIVE, BRRESTORE, BRRECORVER, BRSPACE e BRCONNECT; Help: BRTOOLS que oferece menus para navegação e BRTOOLS E BRCONNECT são chamados por outros programas; Batch: BRBACKUP, BRARCHIVE, BRRESTORE e BRCONNECT não possuem menus próprios. Interativos: BRRECOVER e BRSPACE (além do BRTOOLS) possuem seus próprios menus, e podem ser chamados diretamente via prompt.
A função chpass do BRCONNECT deve ser usado para alterar a senha do SAP<SCHEMA-ID>. A customização do SQL*Plus pode ser feita via comando “set <variável> <valor>”. Se AUTOCOMMIT for OFF, o commit é realizado via comando “commit” ou quando é desconectado do Oracle. SAP Database Monitors (pg 67) DBACOCKPIT fornece várias Transações para monitoramento e administração do banco: DB12: backup logs overview: resultado do backup e status do diretório de archives; DB13: DBA Planing Calendar: agendamento de backups e outros Jobs administrativos. Caso use vários sistemas, pode-se usar a DB13C (central planning calendar);

DB14: DBA Operations Monitor: logs de backup, update statistics, database checks; DB16: overview of database checks; DB17: manter os valores usados durante um database system check; DB20: manter estatísticas; DB21: parâmetros de geração de estatísticas; DB26: parâmetros do banco de dados; DB02: table and indexes Monitor: monitora o tamanho do BD, e o status dos objetos do banco; ST04: Database Performance Monitor: mostra os indicadores mais importantes (buffers, acessos de usuários, etc.) e a parametrização atual; RZ20: database alert monitor. A DB13 é usada para agendar Jobs administrativos, como database check, backup, adapting next extents e update statistics. São executados os Jobs DBA:*, com base na tabela SDBAC. A DB14 é usada para monitoramento diário, clicar em “all activities”. Para limitar por data: Edit > Selection Options. DBACOCKPIT Fornece uma área de navegação no qual é visível através da árvore de menu com os pontos: Performance (ST04); Space (DB02); Jobs (DB13, DB12, DB14, DB13C); Diagnostics; Um dos recursos da DBACOCKPIT é monitorar e administrar DB externos incluindo sistemas ABAP e não ABAP. Quando adicionar um DB externo na configuração do DBA CockPit, criar sua própria entrada na tabela DBCON. Administration of Oracle Instances (pg 79) Durante o startup do banco, passa-se por três fases: NOMOUNT: o arquivo de parâmetros é lido, a instância é iniciada e os recursos alocados no sistema operacional. Usado para criar a database e recriar control files perdidos; MOUNT: os control files são abertos, informações da estrutura física são lidas, parte do data dictionay é carregado. Usado para recovery, alteração do ARCHIVELOG, renomear data files, adicionar, remover ou renomear online redo log files; OPEN: todos arquivos restantes são abertos, instance recovery é realizada (se necessário). Para inicializar via BRTOOLS: Instance Management > Start up database, ou brspace –c force –f dbstart –s <state>. Para parar: Instance Management > Shut down database, ou brspace –c force –f dbshut –m <mode>.

Estados de uma Instance: NOMOUNT: é necessário para criar um database e para recriar control files perdidos; MOUNT: necessário para media recover, para alterar o modo do ARCHIVELOG, renomear (mover) data files, e para adicionar, dropar, ou renomear online redo log files. Tipos de shutdown: NORMAL: não aceita novas conexões, mas aguarda todos os usuários fazerem logout. Padrão do Oracle; TRANSACTIONAL: não aceita novas conexões, aguarda transações atuais terminarem, mas não executa novas transações; IMMEDIATE: não aceita novas conexões, não executa novas transações e faz roll back das transações atuais. Padrão do BRSPACE; ABORT: não aceita novas conexões, não exeuta novas transações e cancela as transações atuais, sem roll back. Requer recovery (automaticamente executado) no próximo startup. OBS: Somente na opção ABORT o DB fica “inconsistent state”, nos demais “consistent state”. Initialization Parameters (pg 82) O arquivo de parâmetros de inicialização tradicionalmente era em formato texto, com nome init<DBSID>.ora. A partir da versão 9i, pode-se manter em formato binário (SPFILE), com nome spfile<DBSID>.ora, ou spfile.ora. SPFILE é totalmente suportado a partir do BR*Tools 6.40 e a SAP recomenda usar SPFILE no upgrade para Oracle 9i. Quando um parâmetro é alterado no SPFILE, um init<DBSID>.ora é gerado automaticamente, permanecendo uma consistência entre eles. É recomendado criar e guardar o SPFILE no local default do Oracle (ORACLE_HOME/dbs ou ORACLE_HOME\database). Quando uma instância é iniciada sem especificação de uma profile em particular, a ordem de pesquisa é:
1. spfile<DBSID>.ora 2. spfile.ora 3. init<DBSID>.ora A inicialização com um spfile não padrão só é recomendado em casos emergenciais. Para modificar parâmetros do Oracle, via BRTOOLS acesse: Instance Management > Alter database parameters. Digite diretamente o parâmetro que quer alterar, ou “c” para continuar (pesquisa). Maintenance of Oracel Parameters

** Mensagens de informação, warnings ou erros são gravados em dump files. Os locais são definidos nos parâmetros: BACKGROUND_DUMP_DEST (padrão: $SAPDATA_HOME/saptrace/background):
log de alerta (alert_<dbsid>.log), que loga eventos e mensagens de atividades;
traces em caso de erros; USER_DUMP_DEST (padrão: /saptrace/usertrace): traces escridos pelos shadow processes, quando ocorre problema com a conexão do cliente. **

Unit 2 – Backup, Restore & Recovery (pg 103) Backup Strategy A estratégia de backup deve ser adequada com as necessidades da empresa. Ela deve ser testada antes do GO Live e sempre após mudanças na mesma. O SAP oferece ferramentas para diferentes tipos de backup, como full online, incremental com RMAN, split-mirror. Importance of Redo Log Files Para executar um complete recover e recuperar os dados ata o momento do crash, são necessários todos offline e online redo log files. Devem-se manter pelo menos duas cópias dos offline redo logs em discos ou fitas. Ao se fazer point-in-time recovery, é necessário voltar toda a base, para manter consistência entre as tabelas. Desta forma, os dados entre o point-in-time e o momento em que a base foi desativada serão pedidos. Desta forma, point-in-time não deve ser a opção padrão para erros lógicos em produção. Pode-se ativar outra base com o backup e copiar os dados manualmente.
Disaster Recovery

Verification of Data O backup deve incluir verificação dos dados a sofrerem backup, bem como os dados nas fitas. Para verificar consistência no banco, um logical data check deve ser executado para descobrir data blocks corrompidos:
o Corrupt Oracle blocks (erro ORA-1578) podem aparecer no banco devido erros de sistema operacional ou hardware;
o Sem o check, os corrupt data blocks serão encontrados apenas no acesso aos mesmos;
o Base com corrupt data blocks sofre backup, porém o mesmo não pode ser usado;
O check é recomendado uma vez por semana;
Para verificar as fitas usadas pelo backup, executa-se o physical data check. Durante este check, as fitas são lidas e se a conexão com os dados é possível;
No Offline backup, pode-se fazer um check para ver se os binários da fita são iguais aos do banco. Isto requer que a base fique desativada enquanto isso;
No backup online, apenas verifica-se se os arquivos nas fitas podem ser lidos; Backup Cycle Um cliclo de backup é o tempo em que o backup fica em fita. SAP recomenda o ciclo de backup de quatro semanas. O ciclo de backup do banco e dos offline redo logs deve ser o mesmo:
o backup completo online todo dia útil (work day); o backup completo offline uma vez no ciclo; o backup dos offline redo logs todo dia útil, bem como após backups online e
offline. Gravar os offline redo logs em duas fitas diferentes antes de apagar do disco;
o fazer um logical check antes ou após o backup e pelo menos um physical check no ciclo (recomendado uma vez por semana);
o retirar a fita do último backup offline do ciclo e guardar. Substituí-la por uma nova.
A freqüência de backups completos se dá ao ponto de ter vários backups deste tipo disponível. Desta forma, evita-se perda de dados caso o último backup não esteja disponível. Executar backups adicionais após reorgs e upgrades, e guardar esses backups em long-term storage. Backup Types (pg 112) Dois métodos principais de backups em um DB Oracle: User-managed backups: Backup manual no SO (Sistema operacional) Server-managed backup: Usando o Oracle Recovery Manager. Oracle usa shadow process do Oracle Server. Tipos de backup:
Offline: o banco é parado antes do backup e os data files são copiados. Desta forma, não é necessário restaurar offline redo logs;
Online: o banco continua aberto durante o backup, então modificações podem ocorrer e é necessário aplicar offline redo logs após o mesmo.
Backup completo: o full (via RMAN): salva toda a base e o catálogo são salvos no control
file, permitindo posterior backup incremental; o whole: toda base, porém não salva informações do catálogo.

Incremental Backup: backup somente dos data blocks modificados após último full. Todos os data blocks são lidos, então o tempo pode não ser reduzido:
o só pode ser executado após um full; o controlado via RMAN (utiliza control file para isto); o via SAP tools, apenas acumulativo é suportado (é feito com base no
último full); o via SAP tools, apenas o backup de todo banco é possível, não dá para
selecionar apenas alguns data files; o Oracle lê todos blocos de todos data files para checar qual possue
alteração.
Backup parcial: backup de apenas algumas partes do banco. OBS: A performance do sistema é comprometida durante um backup on-line, de modo online backups devem ser agendados em períodos de baixa atividade. Backup Strategy (pg 115) A estratégia de backups pode conter backups incrementais ao invés de completos, economizando tempo de backup. Para recovery da base, é necessário o último full, restore do último parcial e os redo logs.
Backup Tools (pg 120)
O BRBACKUP faz backup dos data files, control file e online redo log, se necessário. É usado para backup do diretório do banco e do SAP.
O BRARCHIVE faz o backup dos offline redo logs;
O BRRESTORE pode restaurar todos os arquivos do banco de dados: data files e offline redo log.
O programa interativo BRRECOVERY verifica se arquivos do banco estão faltando, chama o BRRESTORE para restauração, executa o recovery e abre o banco.
O BRBACKUP e o BRARCHIVE gravam as ações em arquivos de logs, que são analisados pelo BRRESTORE para restauração de arquivos inexistentes.

Customizing SAP Backup and Restore Tools O arquivo de configuração init<DBSID>.sap contém parâmetros para os BR*Tools. Pode ser editada com um editor de textos. Itens mais importantes: backup_mode: escopo do backup (all, full, incr...); backup_type: offline ou online; backup_dev_type: mídia do backup (tape, disk); tape_copy_cmd: comando de cópia (cpio, dd > recomendado, mais rápido que cpio); disk_copy_cmd: comando de cópia para discos locais; expir_period e tape_use_count: data de expiração da fita e quantidade de vezes que ela pode ser sobrescrita; volume_backup e volume_archive: nome dos volumes para backup e archives; tape_adress: endereço do drive de fitas. Integration of Oracle Recovery Manager (RMAN) into SAP Tools (pg 124) O Oracle Recovery Manager (RMAN) é o programa padrão para backup e restore. O BRBACKUP suporta o RMAN para backup de duas diferentes formas:
classificar um backup como completo (level 0) que servirá como base para um incremental (level 1);
dados podem ser escritos em fitas via RMAN, ao invés de comandos CPIO e DD.
Se o backup é levado para fita via RMAN, este deve ser usado para restore e recovery, fato q é detectado pelo BRRECOVER. Caso este encontre algum problema, é necessário fazer o restore manualmente. Para copiar para a fita via BRBACKUP, escolha tape_copy_cmd como CPIO ou DD. Para deixar o controle com o RMAN, colocar valor rman. No caso do RMAN, na última etapa, o backup_mode é setado para full, RMAN escreve informações no control file e o CPIO copia o control file para a fita. O RMAN copia diretamente para disco, mas não para fita. Nete caso, ele necessita de uma biblioteca System Backup to tape (SBT), provida pela Oracle e que cada fabricante de fitas deve prover uma biblioteca. Antes de usar backup com RMAN, a biblioteca deve ser instalada:
caso não a tenha, o SAP instala automaticamente em /SYS/exe/run;
para usar um utilitário de backup externo, deve ser instalada a biblioteca SBT do mesmo. Oracle trás uma versão limitada single-server do Legato Networker. Para usar setar backup_dev_type para rman_disk ou rman_util.
** Vantagens de usar o RMAN:
todos blocks são verificados, procurando blocos corrompidos. Neste caso, o backup é consistente e futuros checks não são necessários;
apenas blocos usados são gravados (mesmo vazios, se já foram usados);
durante backups online, a tablespace é configurada para modo de backup, para evitar inconsistência.
** Obs: A partir do Web AS 6.10, RMAN também pode ser usado no BRARCHIVE, o que garante verificação interna de consistência nos offline redo logs.

Quando se usa o RMAN, a biblioteca de backup SAP provê uma forma de otimizar o uso de fast tape drives, combinando vários data files em save sets. Neste caso, vários data files são lidos ao mesmo tempo, maximizando o fluxo de dados no modo streaming. Cada save set contém um header, um trailer e os blocos de pelo menos um data file. O parâmetro saveset_members, dentro do init<SAPSID>.sap permite os valores:
1,2,3,4: número de files que podem ser agrupados (default: 1);
tsp: um save set por table space (contém todos data files da table space)
all: um save set com todos data files do DB.
Usar save sets grandes ajuda a acelerar o backup, porém tem a desvantagem do restore/recovery se tornar mais lento. Todo o save set deve ser lido da fita. Backups para disco via RMAN (backup_dev_type = disk e disk_copy_cmd = rman), nenhum save set é formado. Data files são copiados diretamente para disco, como no uso dos comandos CP ou DD. Em outras palavras, uso de save sets só é possível quando uma SBT library é usada para backups incrementais. Preparation Run (SAP SBT Library)
Se um backup via RMAN criará save sets com mais de um membro (saveset_members <> 1) ou se usa tape stations com compressão e se quer levar em consideração a compressão para calcular o tamanho do save set, deve-se executar uma preparação para determinar a distribuição otimizada de tape sets. Esta preparação é executada via DB13 > Prepare for RMAN Backup. Neste caso, o BRBACKUP inicializa o RMAN para backup dos data files. Nenhum backup é feito nesta etapa, o BRBACKUP apenas comprime os arquivos para estimar a taxa de compressão. O BRBACKUP determina quais data files são alocados nos save sets para cada valor possível do saveset_members, e calcula a taxa de compressão de cada save set. As informações de compressão e composição do save set são gravados no banco, para futuras utilizações. Essas informações não podem ser alteradas manualmente, apenas via uma nova preparação. Se durante um backup o RMAN identifica um data file não incluído na última preparação de execução, um novo save set é criado. É recomendado executar a preparação uma vez por ciclo, e após grandes modificações no banco.

Incremental Backup (SAP SBT Library) (pg 133)
Um backup incremental é sempre um backup de todo o banco de dados, não de um individual data file. Ferramentas de sistema operacional não podem ser usados para cópia para fita, os parâmetros tape_copy_cmd ou disk_copy_cmd são ignorados e implicitamente alterados para RMAN. Após, completado o backup incremental, o control file é copiado para fita via CPIO. Apenas um save set (.INCR) é criado, uma vez que o parâmetro saveset_members é internamente setado para all. Desta forma, o backup pode ser feito em apenas uma fita. Se um data file foi criado entre o backup full e o incremental, um backup nível 0 é executado antes do início do backup nível 1. Todos novos data files são gravados em um novo file set (.FULL). A volta de backup neste caso se dá em três passos:
volta os data files do backup nível 0;
os blocos alterados do backup de nível 1 podem ser importados no data file;
finalmente um recovery deve ser executado, do horário em que o backup nível 1 foi feito.
External Backup Tools (pg 137) Os tools BRBACKUP, BRARCHIVE, BRRECOVER e BRRESTORE podem utilizar uma interface chamada BACKINT para acessar programas externos de backup. Vantagens:
Pode-se usar mídias de backup específicas de um fabricante, como robôs e magnet-optical media;
pode-se fazer um backup consistente de file systems e banco de dados;
client/Server backup configuration permite uso de backup Server. De qualquer forma, o backup deve ser inicializado via SAP tools, para manter logs atualizados, monitoramento via CCMS e permitir restore/recover via BRRECOVER. Para configurar uma interface BACKINT, atribua ao parâmetro backup_dev_type para util_file ou util_file_online (coloca tablespace em backup mode) no init<DBSID>.sap e altere o parâmetro util_par_file para o arquivo de configuração do utilitário de backup. Para usar com RMAN, colocar backup_dev_type como rman_util, rman_disk ou rman_stage.

Performing Backups (pg 163)
O backup deve incluir todos os objetos, como sistema operacional, arquivos do SAP e do
software do Oracle. Geralmente sofrem backup via sistema operacional, uma vez por ciclo.
** Phases of a Database Backup
**

Creating database backups (pg 168) Ttransação DBACOCKPIT ou DB13 pode agendar vários tipos de jobs BRBACKUP e BRARCHIVE. Este método é recomendado para agendamento de estratégias de backup. Os jobs são criados em background (BRBACKUP e BRARCHIVE são chamados a nível de SO). Podem ser monitorados via SM37. Para executar um backup do DB com BRTOOLS ou BRGUI, selecionar: Backup and database copy > Database backup. As seguintes opções são exibidas:
Backup Device Type (device): Especifica o device que o backup deve ser executado;
Tape volumes for backup (volume): Se o Backup Device Type é tape, tape_auto ou tape_box o volume pode ser informado;
Backup Type (type): tipo backup online ou offline;
Back up disk backup (backup): BRBACKUP fully suporta duas fases de estratégias de backup: a primeira executada para device DISK e o segundo passo para uma TAPE;
Files for backup (mode): Modo do backup (all, full, incr); Creating backups of archived redo log files (pg 173) Após um Log Switch, o processo ARC0 copia os online redo log file que tem o corrente redo log file antes do Log Switch para o diretório oraarch como um offline redo log file. BRARCHIVE copia estes arquivos para um backup médio. Durante um backup para TAPE, um offline redo log file tem o status ARCHIVE. Ele é salvo (status SAVED), em seguida copiado (COPIED) e após deletado (DELETED). Durante um backup para DISK, um offline redo log file tem o status DISK. Uma segunda cópia não é suportada. Primeira vez salvo no disco (DISKSAV) e deletado após cópia (DISKDEL). OBS: SAP recomenda usar a opção -cds (copy_delete_save), que é a opção default quando iniciado o BRARCHIVE da DBA Cockpit ou DB13. Para verificar os DB archive log files pode-se utilizar BR*Tools 7.00 com o RMAN. O RMAN VALIDATE é chamado internamente. Pode ser ativado usando o seguinte comando: BRARCHIVE: -w | -verify use_rmv | firts_rmv | only_rmv Consistent Online Backups (pg 177) Um backup consistente é um backup no modo online que contém logicamente dados consistentes. Neste caso, os offline redo log files gerados durante o backup são salvos para o mesmo volume que os databases files que são backed com o BRBACKUP. Checar regularmente o resultado de todos Backups.
DB14 é a principal ferramenta para checar;
DBA Cockpit (DB13) nos calendários é possível ver as ações com cores de warnings e errors;
DB12 visualiza somente os logs de backup;

Restore and Recovery Oracle cria sincronização usando timestamps. Timestamps são inteiros incrementados por certos eventos, como logwriter e checkpoint. Ex.: log sequence number (LSN) a cada log switch e system change number (SCN) a cada commit e checkpoint. Para analisar problemas no banco, verificar o alert log e trace files no diretório $ORACLE_HOME/saptrace/background.
Se ocorrer um problema no database, analisar e criar uma estratégia para resolve-lo. Faça um backup completo offline do banco corrompido antes de restaurar o backup. Isto é recomendado principalmente em point-in-time recovery ou database reset, que envolve perdas de dados. Da mesma forma, fazer um backup dos offline redo logs. Para testar a realidade da estratégia de backup, execute o Recovery report na transação DB12. Ele contém informações que podem ser usadas em caso de recovery. O report informa o último backup com sucesso, incluindo o tipo de backup e o nome da fita, qual backup deve ser usado para recovery e quais redo log files estão disponívels. O report também ajuda a detectar gaps nos backups:
redo log files que estão faltando;
se a lista de redo logs está grande, o tempo de recovery pode se tornar muito longo.

Concepts: Complete Database Recovery (pg 188)
Usado para restaurar data files que estão faltando, e para restaurar a base até o status imediatamente anterior ao erro ocorrido. Para sincronização, o Oracle utiliza informações salvas nos cabeçalhos dos arquivos. O banco requer todos os offline redo log files desde o último database file. Com o complete database recovery, todas as alterações são feitas novamente, desde que todos os arquivos tenham o mesmo SCN. Este procedimento é chamado de media recovery. Para realizar um Complete Database Recovery com o Brtools, acesse: Restore and recovery > complete database recovery. Fases: 1. Check the status of database files: verifica o status de todos os arquivos do banco,
com ajuda das views V$, e escreve os logs no diretório sapbackup; 2. Select database backup: BRRECOVER determina os backups utilizáveis (código
de retorno 0 ou 1) via log back<DBSID>.log. Data files ausentes podem ser recuperados de vários backups. Um backup incremental pode ser escolhido antes de aplicar os offline redo log files. Neste caso, o BRRECOVER escolhe o backup full correspondente.
3. Restore data files: BRRECOVER chama o BRRESTORE para restaurar os arquivos para o local de origem (o diretório sapdata não é criado automaticamente, mas os sub-diretórios sim);
4. Restore and apply incremental backup: se existir backup incremental, é aplicado nesse ponto;
5. Restore and apply archive logs: com base no arch<DBSID>.log, a lista de offline redo log files é montada. BRRECOVER chama BRRESTORE para restaurar os archivos da fita para o diretório oraarch. Finalmente o BRRECOVER chama o SQL*Plus para aplicar os offline redo log files. Eles são aplicados em grupos de 100.
6. Open database: BRRECOVER ativa a base e verifica o status dos arquivos e tabespaces.

Concepts: Point-in-time Recovery:
Usado para restaurar a base a em certo horário, com a ajuda de um backup completo. Point-in-time recovery sempre resulta em perda de dados. Quando a base é ativada, é usado o comando ALTER DATABASE OPEN RESETLOGS, o que reinicia os contadores de LSN. Desta forma, deve-se fazer um backup full antes de liberar para uso. O point-in-time pode ser usado para toda base ou só para umas tablespaces específicas (ex.: usando MCOD). Para executar via BRTOOLS, acessar: Restore and recovery > Database point-in-time recovery. Fases: 1. Set point-in-time for recovery: LSN, SCN ou horário específico; 2. Select database backup: BRRECOVER determina os backups utilizáveis (código
de retorno 0 ou 1) via log back<DBSID>.log. Data files ausentes podem ser recuperados de vários backups. Um backup incremental pode ser escolhido antes de aplicar os offline redo log files. Neste caso, o BRRECOVER escolhe o backup full correspondente.
3. Check the status of database file: BRRECOVER verifica status de todos os arquivos e determina quais serão sobrescritos;
4. Restore control file: se necessário; 5. Restore data files; 6. Restore and apply incremental backup: se selecionado anteriormente; 7. Restore and apply archivelog files: BRRECOVER verifica no arch<DBSID>.log os
offline redo log files necessário, chama o BRRESTORE para copiar da fita para o oraarch e chama o SQL*Plus para importar no banco.

Concepts: Whole Database Reset
Usado para restaurar a base para o momento imediatamente após o backup completo. Como o point-in-time recovery, database reset resulta em perda de dados. Para executar via BRTOOLS, acessar: Restore and recovery > Whole database reset. Passos: 1. Select consistent database backup: BRRECOVER determina backups que podem
ser usados, com base no back<DBSID>.log. Se escolher um backup incremental, o backup full correspondente é escolhido para restaurar todos data files;
2. Restore control files and redolog files: sempre restaurados se um backup online é escolhido;
3. Restore data files; 4. Apply incremental backup: se escolhido; 5. Apply archivelog files: se escolhido online backup; 6. Open database: ativa o banco (se necessário com RESETLOGS), cria arquivos
temporários que possam estar faltando, verifica o status dos data files e tablespaces, deleta aquivos desnecessários .
Disaster Recovery (pg 199) Usado quando não houver arquivos de controle e profiles de configuração. Disaster Recover é somente um passo anterior de preparação para um database recovery com database point-in-time ou whole database reset. Pré requisitos: SAP e Oracle corretamente instalados; File system com os diretórios sapdata existentes e configurados como antes do “disaster”. Para realizar o disaster database recovery, via BRTOOLS: Restore and recovery > Disaster recovery.

Para executar um Disaster Recovery, BRRECOVER primeiro verifica de onde os arquivos serão restaurados, lendo estas informações do init<DBSID>.sap. Após restaurar o init<DBSID>.sap, o backup summary log back<DBSID>.log é restaurado e o sistema conhece através de quais backups fará o restore. Outros profiles e logs podem ser restaurados através de uma lista. Na maioria dos casos, não é necessário mudar a seleção default, uma vez que o BRRECOVERY já determina quais arquivos devem ser restaurados. Na próxima seleção, Restore of BRBACKUP detail logs, a lista de backup detail logs é exibida para restore. Outras funções do BRRECOVER, não tratadas aqui são: Restore of individual backup files: restaurar um arquivo de backup para restauração manual; Restore and application of archivelog files: para recovery manual. Advanced Backup Techniques (pg 209) Algumas técnicas podem melhorar a estratégia de backup, mas em compensação exige esforços como: - Hardware; - Treinamento dos administradores; - Aumento na administração do ambiente. Methods for accelerating the backup and restore process
Hardware: (tape drives, disks, system e I/O)
Parallel Backup: vários tape drives;
Using DD: com BRBACKUP usar o DD para copia de Data Files (não CPIO);
Using the BACKINT interface: conexão com ferramentas de backup externas;
Optimizing BEGIN BACKUP runtimes:
Incremental Backup;
Partial Backup;
Two Phase Backup: 1 step tape, 2 step disk;
Split Mirror Backup;
Snapshots;
Standby database;
Split-mirror Disk Backup (pg211) Pode significar redução de tempo de backup. O backup é executado conforme segue: Online: tablespaces em backup mode Break up (quebra) do mirror (espelhamento) Produção sai do modo backup Backup online no mirror Resincronização do mirror. Offline: shutdown do banco Break up (quebra) do mirror (espelhamento) inicialização da base de produção Backup offline no mirror Resincronização do mirror.
Algumas alterações são necessárias no init<DBSID>.sap e o BRBACKUP do servidor mirror deve enchergar o servidor de produção.

SAP Tools and the Oracle Standby Database Um Oracle standby database consiste de dois database servers. O banco de dados de produção fica aberto, porém o standby em status “mount” e frequentemente recebe os offline redo log files do de produção. No caso de falha do Server, este pode ser usado como produção. O backup é feito na base standby via BRBACKUP, backup_type = offline_standby, com ações registradas nas tabelas SDBAH e SDBAD do servidor de produção, além do diretório sapbackup (devem estar acessíveis do standby Server). O BRARCHIVE roda nos dois servidores, sendo no Server colocando os archives em disco, e no standby lendo do oraarch e jogando em fita. Os redo são aplicados com a opção “ -m | -modify <delay>”, onde delay é o tempo para atualização. Structure Retaining Database Copy Usado para criar uma base com outro DBSID no mesmo servidor, ou outra base com mesmo ou diferente DBSID em outro Server.
Unit 3- Monitors and Tools Introduction to Oracle Data Management Segment contém dados de uma tablespace. Existem 4 tipos de segmentos: - Data: Um data segment contém dados em linhas na tabela; - Index: usado para acelerar o acesso e forçar unique constraint; - Temporary: usado para sorts e criação de índices; - rollback/undo: prover consistência, roll back ou undo e para recovery. Qualquer seguimento é guardado em uma tablespace, mas pode estar em vários data files. Para atender a demanda de bancos grandes, as tabelas e índices podem ser particionados, o que permite que dados possam ser quebrados em pedaços menores e mais maleáveis. Cada partição é guardada em seu próprio segmento, e gerenciada manualmente. SAP recomenda utilizar a mesma tablespace original. No SAP, um segmento possui:
todos os dados de uma tabela particionada; ou
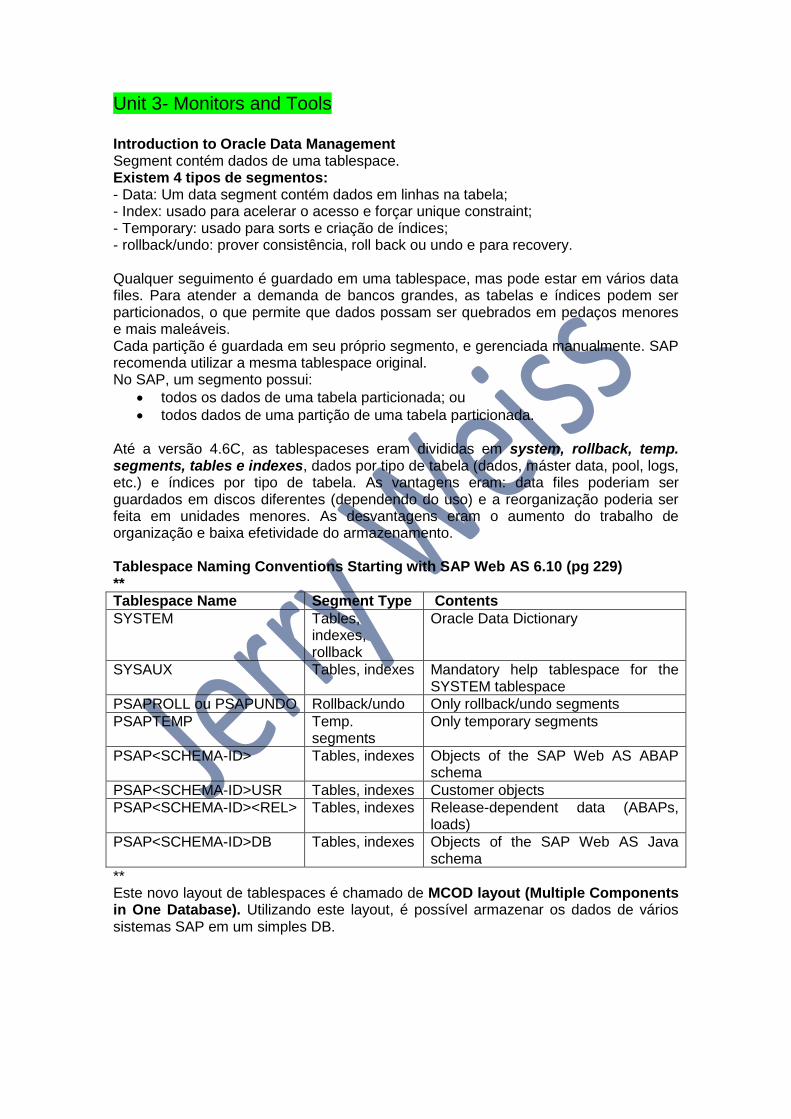
todos dados de uma partição de uma tabela particionada. Até a versão 4.6C, as tablespaceses eram divididas em system, rollback, temp. segments, tables e indexes, dados por tipo de tabela (dados, máster data, pool, logs, etc.) e índices por tipo de tabela. As vantagens eram: data files poderiam ser guardados em discos diferentes (dependendo do uso) e a reorganização poderia ser feita em unidades menores. As desvantagens eram o aumento do trabalho de organização e baixa efetividade do armazenamento. Tablespace Naming Conventions Starting with SAP Web AS 6.10 (pg 229) **
Tablespace Name Segment Type Contents
SYSTEM Tables, indexes, rollback
Oracle Data Dictionary
SYSAUX Tables, indexes Mandatory help tablespace for the SYSTEM tablespace
PSAPROLL ou PSAPUNDO Rollback/undo Only rollback/undo segments
PSAPTEMP Temp. segments
Only temporary segments
PSAP<SCHEMA-ID> Tables, indexes Objects of the SAP Web AS ABAP schema
PSAP<SCHEMA-ID>USR Tables, indexes Customer objects
PSAP<SCHEMA-ID><REL> Tables, indexes Release-dependent data (ABAPs, loads)
PSAP<SCHEMA-ID>DB Tables, indexes Objects of the SAP Web AS Java schema
** Este novo layout de tablespaces é chamado de MCOD layout (Multiple Components in One Database). Utilizando este layout, é possível armazenar os dados de vários sistemas SAP em um simples DB.

** NOTA: Oracle DB 10g tem uma nova tablespace, a SYSAUX. É uma tablespace de help obrigatória para a tablepace SYSTEM e se dispõe de uma localização central para meta dados fora da SYSTEM. Por um lado ela reduz a leitura na tablespace SYSTEM e simplifica a administração. A SYSAUX é sempre criada com uma nova instalação ou upgrade do DB. ** Enquanto no layout antigo o SAP SID e o ORACLE SID eram iguais, no novo layout os dois SIDs podem ser diferentes. Definições: SAP SID: identificador do SAP System (DEV, QAS, PRD); Database SID: identificador do banco de dados, pode ser diferente do SAPSID; Schema ID: usado como identificador de parte de tablespace e do user SAP (owner SAPDEV, SAPQAS,..); Todos IDs podem ser diferentes, mas não precisam ser. Se MCOD não é usado, todos IDs devem ser iguais. Se é usado, o segundo SAP System deve ter um SCHEMA-ID diferente do DBSID. O MCOD pode ser usado a partir do 4.6C SR2, e o BR*Tools pode ser usado em
qualquer tipo de layout de tablespace (e sempre suportará).
Data files (pg 232) Convensões para os data files:
criado no diretório sapdata<n>, onde <n> é número da divisão da tablespace; possui o nome da tablespace, sem PSAP e com final .data<n>.
Se uma tablespace está cheia, três saídas podem ser adotadas:
criar um novo datafile; data file pode ser aumentado; o data file pode ser alterado para autoextensible. Ele crescerá até o tamanho
máximo (MAXBYTES) em intervalos de INCREMENT_BY. Como o tamanho da base não é importante (salvo sistemas 32 bits), o número de data files deve ser em torno de 100, quando a base está no tamanho esperado. Neste caso, será múltiplos de 2Gb, sendo tamanho máximo/100:
Tamanho de Database esperado Tamanho do Arquivo (data file)
Até 200 GB 2GB
200 até 400 GB 4GB
400 até 800 GB 8 GB
Maior que 800 GB 16 GB
RAW devices (pg 233) são somente suportados em UNIX, e nesse caso o Oracle vai gerenciar o uso do disco. No uso de RAC (Real Application Cluster), deve-se usar um cluster file system ou um RAW device, uma vez que existem várias instâncias acessando o mesmo datafile. Vantagens de usar RAW: I/O mais rápido; um pouco menos de espaço requerido recovery mais rápido. Desvantagens do RAW: deve ser bem documentado, apenas um data file por raw device, backup somente via RMAN ou dd (ambos suportados pelo BR*Tools).

Dictionary-Managed Tablespaces (pg 234) Eram usados no formato antigo de tablespaces, mas a SAP recomenta usar Locally Managed Tablespaces (possível via reorganization).
Cada segmento é formado por um ou mais extents (coleção de blocos alocados sequencialmente). O Oracle verifica e atualiza o dicionário de dados sempre que precisar alocar um novo extent. O tamanho do extent e outros parâmetros são chamados de storage parameters, e são guardados do dicionário de dados. Esses parâmetros são configurados na criação da tablespace, e podem ser sobrepostos na criação de uma tabela ou alterado via BR*Tools para as tabelas existentes. Os parâmetros principais são:
MINEXTENTS: mínimo nro de extents alocados na criação da tabela;
INITIAL: tamanho do extent inicial que é alocado quando a tabela é criada;
NEXT: tamanho dos extents criados quando os anteriores estão cheios;
PCTINCREASE: não usado no SAP. Porcentagem maior do anterior a ser criado;
MAXEXTENTS: quantidade máxima de extents que podem ser criados. Desvantagens deste tipo de alocação de espaço:
deve haver área livre contínua maior que o NEXT. Pequenas áreas livres não são usadas neste caso;
quando um segmento é dropado, ele pode ser usado. Porém áreas livres subseqüentes não são aproveitadas como uma área grande livre, até execução do coalesce;
o administrador deve verificar se está perto de MAXEXTENTS. Para evitar erro (ORA-01553 maxextents reached), aumentar o tamanho de NEXT;
o parâmetro NEXT deve ser verificado freqüêntemente para evitar que cresça mais que o necessário para o período. O BRCONNECT pode ser usado para adaptar o NEXT extents.
O BRSPACE pode ser usado para coalesce manual, e o brconnect –f ceck para coalesce de forma automática.

Locally Managed Tablespaces Todas tablespace criadas pelo SAP são usadas no novo layout MCOD. Cada data file tem um bitmap listando blocos usados e livres. O Oracle procura em cada data file se há espaço contínuo para alocar um novo extent. O tamanho do extent não é mais definido por parâmetro. Ele pode ser idêntico para todos extents (UNIFORM) ou escolhido de acordo com o tamanho do segmento (AUTOALLOCATE), escolhidos na criação da tablespace e não mais alterado posteriormente. SAP usa locally managed tablespace, com automatic extent allocation, exceto:
PSAPTEMP: é criada LM (locally Managed) mas com extent size UNIFORM; PSAPROLL: dictionary-managed (substituída pela PSAPUNDO: UNIFORM); Em sistemas SAP BW, tablespaces que contém tabelas fact ou aggregats,
devem ser criadas com uniform extent size de 1Mb. Vantagens
adaptação de NETX ou MAXEXTENTS não é mais necessário; devido ao tamanho máximo do extent ser 64Mb, menos fragmentação é
causado e o espaço no data file é melhor gerenciado; melhor performance em dropps ou criação de tabelas em paralelo, uma vez
que não é necessário atualizar o dicionário de dados. Desvantagem
a busca por blocos usados e livres consome recurso. Rollback tablespace O gerenciamento de extents é similar ao da dictionary-managed tablespace, porém com a adição do parâmetro OPTIMAL. Quando uma transação sofre commit, o extent é marcado para sobreescrito. Em certos casos, o Oracle redimensiona a tablespace para seu tamanho OPTIMAL. Desvantagens:
parâmetros devem ser experimentados até chegar a um bom valor, pois depende do tamanho e uso do sistema;
como o Oracle pode escolher qualquer segmento de rollback, os parâmetros devem ser alterados para todos os segmentos de rollback;
em caso de grande movimentação de dados, a SAP recomenda criar outra tablespace de rollback.
Undo Tablespace (pg 241)
A partir da versão 9i a Oracle introduziu o automatic undo management (AUM). Vantagens:
gerenciados automaticamente; uma transação pode usar mais de um undo segment; o tempo em que um segmento pode ser sobreposto não é mais o commit, e
sim o tempo definido em undo_retention, evitando o erro ORA-01555; alterar para undo tablespaces grandes, para grande movimentação de dados, é
mais fácil. Parâmetros adicionados: undo_management: MANUAL ou AUTO (para ativar); undo_tablespace: comando CREATE UNDO TABLESPACE “PSAPUNDO”; undo retention: tempo de retenção em segundos, antes que o dado possa ser sobreposto; undo_supress_errors: suprime os erros ao tentar mudar manualmente.

** OBS: SAP recomenda que faça switch da tablespace Rollback para tablespace UNDO no Oracle 9.20. Passos para alterar de rollback para undo: 1) Criar tablespace PSAPUNDO; 2) Alterar ou inserir os 4 parâmetros; 3) Drop em todos os segmentos de rollback (exceto no SYSTEM); 4) Remover ou comentar o parâmetro rollback_segments; 5) Remover a tablespace de rollback Pricipais Erros Oracle
Erro Descrição
ORA-1578 Corrupt Oracle Blocks
ORA-1553 Maxetents reached
ORA-1653 Tablespace Overflow - Tables
ORA-1654 Tablespace Overflow - Index
ORA-1555 Snapshot to old
ORA-272
***
Database System Check (pg 248) O BRCONNECT é usado para verificar o banco de dados, adaptar NEXT extents, criar estatísticas e apagar DBA logs. Transação DB13 (DBACOCKPIT) : Check the database Checking the Database A ferramenta brconnect -f check deve ser agendada diariamente. Para fazer o check do banco de dados, o BRCONNECT verifica as condições na tabela DBCHECKORA. O log é criado /sapcheck/c<encoded_timestamp>.chk, e pode ser visto via editor de textos, BRTOOLS ou DB14. Erros e warnings podem ser vistos ainda na DB16 e CCMS. Pode ser executado via BRTOOLS > Check and verification > Database system check ou comando brconnect –f check. Para atualizar os parâmetros, acessar DB17:
adicionar novas condições DBO, ORA ou PROF;
excluir condições do check;
especificar valores padrão;
criar condições para serem excluídas do check;
criar condições para definir valores padrões;
especificar ações de correção;
manter descrições das condições. Tipos de verificação na tabela DBCHECKORA:
Database administration (DBAs): operações de administração, como configuração, gerenciamento de espaço. Não podem ser adicionados. Para excluir, usar parâmetro check_exclude do init<DBSID>.sap;
Database operation (DBO): verificações de operação, como backup e falhas; - Oracle messages: o arquivo e log é verificado em busca de erros.
Oracle profile parameters (PROF): verificação de parâmetros do profile.

Detalhes no Log do Database System Check Tablespaces and Data Files: lista todos tablespaces e seus data files (status, size); Redo Log Files: todos Redo log files (size); Control files: controls files (size); Database disk volumes: lista os volumes dos discos contendo dados do DB; Tablespaces fragmentation: estatísticas de nro data files, tables, index, extents, usage e free space das tablespaces; Check conditions for Database Administration: lista todas condições de check do DBCHECKORA; Adapting the NEXT Extent Size Brconnect –f next deve ser executado regularmente para adaptar o parâmetro NEXT de todas as tablespaces gerenciadas por dicionário para evitar: ter vários pequenos segmentos (degrada performance, perto do limite de
MAXEXTENTS); ter segmentos muito grandes (perda de espaço em disco, fragmentação,
tablespace overflow). Objetos em tablespaces localmente gerenciadas são automaticamente excluídos. Comando normalmente utilizado: brconnect –u / -c –f next –t all
O algorítimo utilizado para determinar o valor otimizado para NEXT garante que NEXT é: não é valor menor que o valor atual e como especificado no SAP data dictionary
para este tipo de tabela ou índice; em torno de 10% do tamanho total da tabela ou índice, se o tamanho é maior que
o esperado; menor que a maior área livre contínua da tablespace, se esta não é auto-
extensível. O log é guardado em /sapcheck, com extensão .nxt e pode ser visto da mesma forma que o log da database system check.
Checking and Updating Database Statistics (pg 260) Oracle usa otimizador baseado em custo para encontrar o melhor caminho quando selecionando tabelas. No SAP, o parâmetro optimizer_mode é configurado para CHOOSE, o que indica que o Oracle usará o otimizador baseado em custo quando estatísticas estão disponíveis. Isto porque algumas tabelas sofrem alterações de dados frequentemente, e não devem ter estatísticas geradas. Para fazer o update statistics, executar brconnect –f stats, que verificará se as estatísticas estão desatualizadas e atualizará as necessárias. SAP recomenda a execução de brconnect –u / -c –f stats –t all semanalmente. Pode ser agendada via DB13. Para atualizar apenas as tabelas que não possuem estatísticas (ex.: recém criadas): brconnect –f stats –t missing, ou DB20 > Global statistics > Create missing. O log é gerado em sapcheck, com a extensão .sta, e pode ser visualizado como no database system check. Cleaning Up Old Logs and Traces (pg 262) Para limpar logs e arquivos intermediários (como backups), execute brconnect –f cleanup, que limpará: Logs detalhados do BR*Tools; Backups em disco; Export dumps e scripts criados pelo BRSPACE; log records e check results nas tabelas SDBAH, SDBAD, DBA*, e DBMSGORA; Oracle trace e audit files.

Comando normalmente executado: brconnect –u / -c –f cleanup Por padrão, arquivos anteriores a 30 dias e database log records anteriores a 100 dias são removidos. Esses valores podem ser alterados via parâmetros específicos no init<DBSID>.sap. Checking Database Growth (pg 263) Os dados estatísticos sobre o crescimento do banco podem ser visualizados via DB02. A tela de entrada mostra um sumário das informações do tamanho do banco de dados e espaço livre. Overview das funções na memória space analysis na DBA Cockpit:
Space Overview: size DB e free space; Database: estatísticas da memória de todo DB; Users: informações sobre usuários e objetos associados a ele, (status user
acount, user bolcked); Tablespaces: current size, free espace, status (on/offline)... Segments: size e nro segments, extents alocados; Aditional Functions: job que coleta dados, BW;
Para mais detalhes, selecionar os botões:
Space statistics: estatísticas do espaço de toda a base; Current sizes: tamanho e status de tablespaces e tabelas; Space statistics: estatísticas de espaço por tablespace; Freespace Statistics: informações detalhadas do espaço livre nas
tablespaces, incluindo fragmentação; Space critical obects: todos os segmentos que o next extent é maior que a
maior área livre. Para coletar estatísticas do banco de dados, SO e SAP, e guardar os dados em tabelas, o job COLLECTOR_FOR_PERFORMANCE_MONITOR deve estar agendado em freqüência horária, executando o ABAP report RSCOLL00. O report RSCOLL00 lê a tabela TCOLL para ver o que será verificado e em que horário. O report coleta as informações e guarda nas tabelas MONI (dados estatísticos) e PAHI (parâmetros). CCMS Alert Monitor (PG 274) O CCMS pode ser usado para monitorar e verificar as seguintes funções: Space Management: tablespaces e segments; Performance: otimizador de estatísticas, buffers, logs e checkpoints; Backup or restore; Consistency: entre objetos ABAP e dicionários do Oracle; Health: system checks do BRCONNECT. O principal coletor de informações sobre o banco é o BRCONNECT, que escreve os resultados na DBMSGORA, lida pelo CCMS. Os MTEs (Monitoring Tree Element) na RZ20 podem ser removidos, após alteração de parâmetros na DB17. Após remoção, executar programa RSDBMON0 para recriá-los, com as novas configurações. Para evitar acessos excessivos à view DBA_SEGMENTS, é necessário executar o brconnect –f check uma vez por dia. Caso os dados sejam mais antigos que um dia na DBMSGORA, os dados serão exibidos da DBA_SEGMENTS.

Unit 4 – Storage Management Tablespace Administration Principais atividades na administração das Tablespaces: Criar, Deletar, Extender (para adicionar um data file ou tempfile), Mover. Em operação “normal”, a criação de uma nova tablespace ou a remoção de uma existente não é necessária. Este é o caso de upgrade e preparação de uma reorganização online. Para criar uma nova tablespace, acessar BRTOOLS > Space management > Create tablespace. Opções: tablespace: nome da tablespace, seguindo padrão SAP (PSAP<SCHEMA-ID><unique name>; contents: data (dados + índices), temp ou undo; space: auto (gerenciamento de espaços de segmento automático) ou manual. Sempre é criado locally managed tablespaces; class: opção para table data type quando criar uma tabela (all, old_tsp, old_tsp_list) owner: só em casos de MCOD; data: table, índex ou both (recomendado para facilitar administração); joint: se escolheu table ou índex acima, especificar a tablespace de índice ou tabelas correspondente. Após o continue, um novo menu é apresentado: file: o nome do novo data file para a tablespace; rawlink: Soft link para um raw disk ou diretório externo; size: em MB; autoextend: Yes (cresce automaticamente) ou no; maxsize: para autoextensible data files (tamanho MAX em MB); incrsize: para autoextensible data files (increased automatic); Antes e a pós a criação, um backup do control file é criado em /sapreorg, além de log da operação em /sapreorg/struc<DBSID>.log. Para remover, BRTOOLS > Space management >Drop tablespace. Por padrão, uma tablespace não é apaga se não estiver vazia. O parâmetro force = Yes altera isso. Quando dropar um tablespace, BRSPACE vai:
criar um backup do control file antes de após a remoção; verificar se a tablespace está vazia; torná-la offline; removê-la, inclusive seus data files; remover todos os subdiretórios; criar uma entrada no log struc<DBSID>.log.
** Enlarging Tablespace Para aumentar uma tablespace, três opções são possíveis:
adicionar novo data file; as propriedades do data file pode ser mudada para “autoextensible”; um data file pode ser aumentado.
**

Add new datafile: BRTOOLS > Space managment > Extend tablespace. O menu é similar ao de criar uma tablespace nova (ou BRSPACE -f tsextend > enter).
Resize datafile: BRTOOLS > Space Management > Alter data file > Resize data
file. (ou BRSPACE -f dfalter > Resize data file). Turn on and maintain autoextend: BRTOOLS > Space Management > Alter data
file > Turn on and mantainance autoextend (ou BRSPACE -f df alter > Turn on and mantainance autoextend;
Turn off autoextend: BRTOOLS > Space management > Alter data file > Turn off
autoextend; Rename data file: BRSPACE > Alter data file > Rename data file; Drop empty data file: BRSPACE > Alter data file > Drop empty data file; Moving ou rename data file, o BRSPACE o faz somente com padrão de
nomenclatura SAP. BRTOOLS > Space management > Move data file; Informações de uma tablespace: BRTOOLS > Space management > Additional
space functions. ** Para alterar uma tablespace: BRTOOLS > Space management > Alter tablespace Possibilidades: Set tablespaces offline ou online; Todas tablespaces devem ser online Set ou reset the backup status: quando o BRBACKUP apresenta erro, uma ou
mais tablespaces podem ficar em status backup mode. Neste caso, um shutdown não funciona e se for um shutdown abort, é necessário recovery manual.
Coalesce free extents: Rename Tablespaces: ** Reorganization of Tables(pg 306) Reorganização é normalmente utilizada para retirar a fragmentação de objetos do banco. Executando ela, melhora-se a performance e recupera-se espaços fragmentados. O modelo clássico é:
export das tabelas; drop das tabelas (e tablespace); recriação da tablespace (se foi removida); import das tabelas.
Nas versões de Oracle 8 e 9i, junto com a evolução de discos e RAID, novas características foram introduzidas, diminuindo a necessidade de reorganizações:
locally managed tablespaces possuem alocações mais eficientes; usando automatic segment space allocation, a fragmentação de blocos é
significadamente reduzida e a performance de queries em paralelo melhorada; discos grandes com RAID e buffers maiores e mais seguros diminuem o I/O.

Usando as facilidades de redefinição online do Oracle, a reorganização (online table redefinition) ocorre de forma mais fácil. Vantagens e características:
pode ser feita online; pode ser paralelizado; pode ser usado para mover tabelas para outras tablespaces; pode ser usado para recriar uma tabela, reduzindo fragmentação; diminui o risco, onde verificações são feitas antes do processo e a remoção do
objeto apenas após a criação do mesmo. Razões para desfragmentação no Oracle 9i:
tabelas fragmentadas e índices fragmentados ou degenerados; transformar dictionary-managed em locally managed tablespaces; mover tabelas para novas tablespaces.
BRSPACE suporta online table redefinition e métodos tradicionais de reorganização. BRTOOLS > Segment Management. Métodos de Reorganização: Reorganize Tables: redefinição online, usado para diminuir fragmentação, transformar dictionary-managed tablespaces em locally managed, transformar tablespaces do layout tradicional em layout do MCOD, mover tabelas grandes para uma tablespace separada. Rebuild indexes: recriar índices; Export e Import tables: método tradicional de reorganização. Usado em Oracle 9i em tabelas com campos LONG; Alter tables e indexes: algumas funções de performance, como “switch on table monitoring”, onde o Oracle controlará se a tabela foi alterada (acelerando consulta para update statistics) e “set parallel degree”, para prover performance em INSERTs (com o aval da SAP, não usado em produção). Steps for online table redefinition (pg 312)
BRSPACE usa o PL/SQL DBMS_REDEFINITION; tabelas são verificadas se podem ser redefinidas online; cria uma tabela temporária, com nome <ORIGINAL>#$; copia os dados para a temporária, pode ser paralelizado; cria índices, contraints, triggers, etc.; termina o processo com o pacote DBMS_REDEFINITION; objetos criados são renomeados; - BRSPACE apaga a tabela temporária.
Em caso de erros, a tabela original permanece intacta, e o BRSPACE apaga a tabela temporária. Antes de iniciar a reorganização usando online table redefinition, verifique:
se vai mover para nova tablespace, ela existe? tablespace é locally managed? há espaço na tablespace/disco?
Para reorganização, BRTOOLS > Segment management > Reorganize tables. Pode-se usar caracteres para tabelas ([<owner>].<prefix>* ou *), especificar a tablespace (todas tabelas sem LONG sofrerão reorg) ou deixar em branco (serão apresentadas as tabelas). O parâmetro reorg_table no init<DBSID>.sap pode ser usado para informar quais tabelas sofrerão reorg. Os parâmetros para reorganização são: newts: nova tablespace ou vazio para atual; indts: tablespace de índice (se diferente da de tabelas); parallel: paralelismo; degree: paralelismo de cópia para as tabelas temporárias;

ddl: NO (comando DDL gerado apenas internamente, não recomendado), YES (gera ddl.sql em /sapreorg), FIRST (gera o ddl.sql e aguarda confirmação antes de executar). Initial: Categoria do INITIAL extend size; Sortind: acesso seqüencial parcial; Mode: default DBMS_REDEFINITION (online). Rebuild Indexes Para recriar índices, acessar BRTOOLS > Segment management > Rebuild indexes. As opções são similares à de reorganização, porém não é Criado DDL (é usado o comando ALTER INDEX REBUILD ONLINE), especificando a tabela, todos índices dela serão recriados e uma nova tablespace para os índices pode ser informada. O BRSPACE suporta o método tradicional EXP/IMP, porém só é recomendado para tabelas que não podem sofrer redefinição online. Além do utilitário, vários passos devem ser feitos manualmente. Transformation of Dictionary-Managed into Locally Managed Tablespaces (p 319) Para transformar uma tablespace gerenciada pelo dicionário de dados em localmente gerenciada, faz-se a online reorganization em uma nova tablespace, com os passos adicionais: 1. Criar uma tablespace localmente gerenciada, que conterá dados e índices.
Recomenda-se que seja auto-extensível; 2. BRTOOLS > Segment management > Reorganize tables, escolha a tablespace e
coloque “*” para as tabelas; 3. Continue e confirm; 4. Em “Options for reorganization of tables, defina o nome da nova tablespace. Tabelas que não podem ser reorganizadas online permanecerão na tablespace antiga. Neste caso: - utilizar export / import após a reorganização; Assim que possível, usar o BRSPACE para converter LONG em LOB antes da reorganização. Segment Shirinking (pg 320) Oferece uma alternativa para a desfragmentação de uma reorganização por segmento ganhando assim mais espaço livre. Alguns pré-requisitos devem ser atendidos:
Deve ocorrer em uma tablespace ASSM; Não permitido para Tabelas com campos LONG e LONG RAW, Tabelas
mapeadas e overflow segments de IOTs e Tabelas compactadas; ROW MOVEMENT deve estar ativo;
Housekeeping and Troubleshooting (pg 327) Revisão das atividades: Database System check deve rodar diariamente, agendada via DB13. DB14 deve
ser verificada para warnings/erros. Warnings e erros devem ser solucionados; Check and adapt NEXT extents: executar semanalmente, agendada via DB13.
Verificar logs na DB14; Update optimizer statistics: deve rodar semanalmente, agendada via DB13.
Verificar logs na DB14; Clean up old logs and traces: deve rodar semanalmente, agendada via DB13.
Verificar logs na DB14; Database backup deve rodar diariamente, agendada via DB13 (DBA Cockpit)

Archiver stuck Ocorre quando não é possível copiar o online redo log e o LGWR necessita sobrepor este arquivo. Isto normalmente ocorre quando o disco do diretório de archive está cheio. Para evitar, recomenda-se: ter bastante espaço no diretório de archives, pelo menos 3x o tamanho diário
esperado; criar um arquivo dummy 10x maior que um archive. Assim ele pode ser apagado, o
sistema volta a funcionar e rotinas como backup de offline redo log files podem ser executadas;
usar o diretório de archive em uma unidade diferente de onde o BRARCHIVE guarda os logs.
Online Backup Crashed Quando ocorre erro durante o backup online, algumas tablespaces podem ficar em estado de backup. Para verificar, executar brspace –c force –f dbshow –t tslist. Neste caso: Verificar no sistema operacional se o BRBACKUP está em execução; Iniciar BRTOOLS > Space management > alter tablespace > Reset backup status; coloque 0 para selecionar todas tablespaces; remover arquivo /sapbackup/.lock.brb; executar um teste de backup para ver se está OK. Caso o banco tenha caído durante o backup, o erro ORA – 01113: file N needs media recovery. Um recovery pode ser necessário: brrecover –c force –t complete; ou via SQL*Plus: ALTER DATABASE END BACKUP, em que o recovery não é
executado (somente se um data file não precisou ser restaurado).

Unit 5 – Introduction to Oracle cache management Oracle System Global Area Em sistemas SAP, o único usuário que deve acessar o banco é o administrador do banco. Terminologia: database: coleção de dados, logicalmente formam uma unidade, fisicamente um ou mais datafiles. Um objeto do banco de dados (ex.: tabela) está em uma tablespace (unidade lógica), que pode ter um ou mais datafile. Instance = memory + processes: memory: shared memory = system global area (SGA). Cada instância possui sua
própria SGA, que não é compartilhada com outras instances. processes: processos background. No Unix se vê processo a processo, no NT
apenas um “Oracle” (usa threads). DBSID: identificador do banco de dados, nome único, no caso da SAP com 3 caracteres (upercase, sendo primeiro obrigatóriamente letra, os outros 2, letras ou número)
Listerner não faz parte da instância, faz parte de processos de rede. Cada work process se comunica com um shadow process. O work process se conecta automaticamente após queda/startup do banco. O gerenciamento de memória separa área de memória que pode ser usada por todos os processos (SGA) ou para cada processo individualmente (PGA) – parâmetros em bytes:

SGA (System Global Area ou shared memory): Buffer Pool (Data Buffer ou Buffer Cache): buffer para data blocks
(DB_BLOCK_BUFFERS em blocos ou DB_CACHE_SIZE usando dynamic SGA); Shared Pool: buffer para comandos SQL (Shared SQL Area, Shared Cursor
Cache ou Library Cache) e informações do dicionário de dados (Dictionary Cache ou Row cache). Parâmetro SHARED_POOL_SIZE;
Java Pool: cache para java (JAVA_POOL_SIZE); Large Pool: buffer para dados especiais (multi-thread, RMAN com vários I/O,
PL/SQL, etc.). Parâmetro LARGE_POOL_SIZE; Redo Buffer: buffer para redo log (LOG_BUFFER). PGA (Program Global Area ou process-local memory): Buffer para sorting, hash joing e outras atividades temporárias (PGA_AGGREGATE_TARGET quando usa automatic PGA administration). Parametrização do SAP:
Buffer pool: grande o suficiente para a qualidade ser maior que 95%; Shared pool: pelo menos 400Mb; Java Pool: se não usado, valor 0; Large Pool: não necessita configuração, pois usa pouca memória; Redo buffer: bom valor: 1Mb, não deve ser excedido; PGA: valor máximo que conseguir.
Dynamic SGA(pg 354) Até oracle 8.1.7.* as áreas de memórias não eram mudadas dinamicamente. A partir da versão 9, com a opção Dynamic SGA, o boot não é requerido. Multiple Block Sizes para tablespaces não são recomentadas pela SAP. Parâmetros para Dynamic SGA: SGA_MAX_SIZE: tamanho máximo em que a SGA pode crescer automaticamente (soma dos parâmetros das subáreas da SGA); DB_CACHE_SIZE: tamanho do buffer cache, e que ativa o Dynamic SGA. Não usar junto com DB_BLOCK_BUFFERS (Oracle 8i e menores); Parâmetros que podem ser alterados dinamicamente quando ativo o Dynamic SGA:
DB_CACHE_SIZE: buffer cache; SHARED_POOL_SIZE: shared pool; LARGE_POOL_SIZE: large pool.
Parâmetros não alterados dinamicamente: SGA_MAX_SIZE: tamanho máximo da SGA; LOG_BUFFER: tamanho do redo log; JAVA_POOL_SIZE: java pool.
Oracle Program Global Área - PGA (pg 366) Program Global Area conhewcido como Process Global Area ou Work Area. Optimun: comando feito sort na PGA. Ideal > 90% (OLTP); One-pass: acessa tabela temporária para fazer 1 nível de sort (separa em “blocos” de sort e depois junta tudo no banco). Ideal < 10% (OLTP); Multi-pass: necessita criar vários níveis de sort até chegar no resultado esperado. Não deve ocorrer. No Oracle 8i: SORT_AREA_SIZE HASH_AREA_SIZE BITMAP_MERGE_AREA_SIZE BITMAP_CREATE_AREA_SIZE

Parâmetros estáticos. No Oracle 9i: WORKAREA_SIZE_POLICY = AUTO PGA_AGGREGATE_TARGET = 100MB Define-se o tamanho total da PGA da instância, e o Oracle gerencia de forma automática como deve ser. O parâmetro é dinâmico, ou seja, pode ser alterado em runtime. O Oracle avalia toda a memória disponível na PGA, a quantidade que o comando precisa e aloca a memória necessária. O Oracle calcula, em regra geral (9i):
máximo 5% para Shadow Process; máximo 30% para processo paralelos da Shadow Process; máximo 200Mb para Shadow Process.
Cálculo estimado para a PGA: PGA_AGGREGATE_TARGET = <memória física > * 20% (OLTP); PGA_AGGREGATE_TARGET = <memória física > * 40% (OLAP); PGA_AGGREGATE_TARGET = (SORT_AREA_SIZE + HASH_AREA_SIZE + ...) * (#Shadow process / 10).

Unit 6 – Monitoring of the database instance A nova transação ST04N pode ser usada para monitoramento do Oracle, seja ele single ou RAC. Ela substitui a antiga ST04 e busca informações das views V$, GV$ (existe apenas no RAC) e DBA. A nova transação é apenas para Oracle 9i+. The Performance Overview Monitor Nova transação DBACOCKPIT fornece estrutura e dados eficiêncientes nos itens: General informations, Data Buffer, Shared Pool, Log buffer, Calls, Time statistics, Redo logging, Table scans and fetches, Sorts e Instance efficiency. ** Muitos números dependem uns dos outros. Abaixo algumas “figuras-chave” do desempenho do DB: Data buffer quality: proporção das leituras físicas em relação ao total de leituras.
Deve estar acima de 94% em um total de 15 milhões de leituras; ratio of user and recursive calls: uma boa performance indica proporção maior
que 2; number of reads per user call: se exceder de 30, pode indicar expensive SQL; Time/User Call: valores acima de 15 ms indicam necessidade de otimização; -
Busy wait tine X CPU time: valores em torno de 60:40 indicam um sistema estável. Valores muito acima indicam necessidades de melhoria;
DD-cache quality: deve estar acima de 80%. ** As novas funcionalidades do Oracle 9i suportadas pela SAP são:
uso do SPFILE; Automatic Undo Management (AUM); Automatic segment space management (ASSM), que provê um uso melhor de
espaço, reduzindo buffer busy waits; Dynamic System Global Area: permite alterar parâmetros de buffers online; Automatic Program Global Area memory management; Online reorganization of tables: também possível no 8i; Defaul temporary tablespace: a partir do AS 6.40, tablespace PSAPTEMP é a
tablespace temporária padrão, não usando a SYSTEM para isso; Locally managed SYSTEM tablespace; Suporte ao RAC; Snapshots = dados históricos; Dados históricos do SAP são guardados na tabela MONI; Dados históricos do banco são gravados em tabelas GVD*, atualizadas via
report RSORAHCL (ou RSORAHIST); UNIT 7 - monitoring of the database instance (não deve cair na prova)

Unit 8 - Analysing Application Design Consequences of Expensive SQL Statements (Conseqüências de instruções SQL caras) Expensive statements são definidos como todas as instruções SQL que fazem com que o banco de dados possa ler muitos blocos (do disco ou buffer). Expensive SQL statements poderia ter consequencias negativas na performance do sistema SAP: O DB é ocupado lendo muitos blocos. Todas as tarefas podem ser lentas; Muitos blocos poderiam ser deslocados do DB buffer; pode ter impacto negativo
nas próximas requisições; O WP é bloqueado (aguardando resposta do DB) e não disponível para outras
requisições; ** Perguntas e Respostas no sistema SAP
Pergunta Onde posso encontrar a resposta
Quais reports/transações contem Expensive selects? SM50/SM66 - atual ST03, STAD - passado
Qual tabela é acessada expensively? SM50/SM66, ST04/DBACOCKPIT
Qual índice é usado para o acesso? ST04/ DBACOCKPIT, ST05
Qual clausula WHERE esta sendo usada? ST04/DBACOCKPIT, ST05, SM50
Qual statement é melhor parâmetros atunning? ST03, ST04/DBACOCKPIT
** Using SM50/SM66 to Find Expensive SQL Statements (PG 459) SM50 - Local WP SM66 - Global WP Como identificar: Identificar atividades longas relacionadas ao banco (ex.: sequential read, insert, update); Anotar o nome do report e da transação (SM66) para análise detalhada; Anotar o nome da tabela em que a ação é executada; Anotar o nome do usuário para possíveis futuras assistências; Na SM50, é possível ver o SQL atual.
Using ST03N/STAD to Find Expensive SQL Statements Usando a ST03N, é possível identificar transações que usam uma parte significativa do tempo total de resposta, bem como transações com tempo de banco de dados grande. Escolha “Standard Transaction Profile” na transação ST03 e restrinja por Dialog. Como usar a transaction profile: Ordene por Total Database Time: acima de 5% do tempo todal deve ser avaliada; Ordene por Average Database Time per dialog step para encontrar transações
com a maior média de load database; Acessar a STAD e escolher: um período de tempo; Task Type D; Valor relevante do DB Request Time.

Using ST04N to Find Expensive SQL Statements A ST04N oferece uma visão diretamente nos processos atuais do banco de dados. Isto é útil para identificar queries em execução e prover maiores detalhes do quê está acontecendo. Como usar o Oracle Session Monitor:
1. ST04 > Performance > Wait Event Analysis > Session Monitor; 2. Identificar o work process ID (proveniente da SM50/SM66); 3. Verificar a ação em SQL text; 4. Analizar o explain plan da query.
** Logical Reads: Número de Oracle buffers blocks para ler a declaração a partir dos data buffers; Buffer Gets: Número de Oracle buffers blocks para ler a declaração a partir dos data buffers; identico no sentido lógico para leituras; Physical reads/disk reads: Número de Oracle blocks lidos para as instruções do hard disk; ** Obtendo expensives SQL statements usando o shared cursor cache: 1. Chamar ST04 > Performance > SQL Statement Analysis. Shared Cursor Cache:
Analysis of Shared Cursor Cache; 2. Selecionar em buffer gets, um numero igual a 5% dos logical reads da ST04N; 3. Verificar as SQLs que causam esse consumo; 4. Analisar o explain plan (com link para o call point no programa ABAP); Using the SQL Trace to Find Expensive SQL Statements (pg 480) ST05 é uma ferramenta para analisar acessos ao banco de dados. Grava tempos de acessos em diferentes passos executados no banco. Também faz trace de enqueue, RFC e buffer. O tamanho máximo é definido pelo parâmetro rsrt/Max_filesize_MB, que normalmente é 16MB no ECC. Exlusive Lockwaits (pg 488) Os locks podem ser divididos em “Database Locks”/”Database enqueues” e “SAP Enqueues”. Tipos de lock Oracle: User enqueues:
TX (Tansaction enqueue); TM (DML Enqueue): quando o objeto todo está em lock (ex.: rebuild,
VALIDATE STRUCTURE); System enqueues:
ST (space transaction): em tablespaces dictionary-managed em alocação ou liberação de extents;
CI (Cross Instance Invocation enqueue call): em truncates, drops, etc. O monitoramento de database locks pode ser feito via análise do wait event “enqueue”, via V$LOCK ou ST04N. A duração pode ser acompanhada na V$ENQUEUE_STAT ou ST04N > Detailed Analyses > Exceptional Conditions > Enqueue Monitor.

Quando um processo aguarda um lock para utilizar um recurso, é chamado Exclusive Lockwaits. Lockwaits podem ser enfileirados de forma que ocupem todos os WP disponíveis, sendo necessária a eliminação do processo via sistema operacional. O Oracle Lock Montor pode ser acessado via DB01 ou ST04N > Detailed Analysis > Exceptional Conditions > Lock monitor, que indica o causador do lock, os bloqueados e a chave bloqueada. Para evitar exclusive lockwaits, o lock deve ser requisitado pelo programa o mais tarde prossível.

Unit 9 – Index Management and Optimization (pg 503) Index utilization (pg 504) Index serve apenas para acelerar o acesso ao dado, apontando diretamente para onde ele está. A criação de índices não necessita alteração de códigos SQL. Um índice é composto de um ou mais campos de tabelas. Cada linha de uma tabela é identificada por um ROWID, que é o datafile number + data block + row number. No índice, as colunas são ordenadas para facilitar o acesso. Quanto menos campos em um índice, a reusabilidade aumenta e a decisão do otimizador melhora. Index scheme: B-Tree: um bloco “root”, com pointers para outros blocos; Bitmap: bom para vários valores repetidos, aponta para uma range de valores na
tabela. Tipos de índices: primário: define normalmente o unique da tabela; secundário: para acelerar pesquisas sem ser pelos campos chaves; unique secondary: índice secundário, com unique constraint. Acesso a índices: Fast Full Index: campos requeridos estão no índice. Index Unique Scan: quando a cláusula where tem os mesmos campos que no
índice; Index Range Scan: quando a cláusula where tem menos campos que o índice.
Nesse caso, a ordem é importante para acelerar o processo; Unselective Index Range Scan: quando um campo da cláusula where está no
índice, o outro não. Todos os dados são lidos do índice, onde é feito um sort do outro campo. Muita carga é gerada, e pode ser interessante o full table scan neste caso;
Index Skip Scan: até Oracle 8i, só podia usar índices compostos (mais de um campo) caso o where contivesse todos os campos necessários. A partir do Oracle 9i, caso apenas dois campos estejam na query, um índice com 3 campos não na mesma sequência pode ser usado. As vantagens são: aceleração de algumas queries e obtenção de uma boa performance com menos índices (ocupa menos espaço, acelera manutenções e DMLs).
Full Table Scan: são verificados todos os blocos da tabela, sem índice. Pode ser eficiente se vários dados são requisitados.
Creating an Index (pg 521) Antes de sair criando indices: se o SQL for original, procurar por notas ou abrir chamados; se o SQL for customizado, tentar usar técnicas como “matched tables” e “SAP
business índex tables”, reescrever o código para usar índices já existentes ou adaptar um índice já existente.
Índices secundários crescem junto com a tabela, o que torna a pesquisa cada vez mais lenta.

Regras gerais: colocar apenas campos selecionáveis na query; usar poucos campos como possível (máximo de 4); posição dos campos no índice: campos geralmente não utilizados colocar no final; índices devem ser disjunct: não se parecer com outros índices; usar poucos índices em uma tabela: geralmente até 5, exceto quando tabelas que
sofrem muita leitura, como máster data; não alterar índices originais da SAP. Antes de criar um índice, deve-se ver quão seletivo ele será. Para isso, acessar a DB05, ou via SQL*Plus (having count(*) > 100, para ver se retornará mais de 100 linhas diferentes). Na DB05, se adicionado um campo para o índice e o número de valores únicos não aumentar, este campo não deve entrar no índice. Os índices são criados e mantidos no ABAP Dictionary, via SE11. Para verificar índices criados no ABAP, mas que faltam no banco, acessar DB02 >Missing Indexes. Caso um índice primário esteja faltando: SE11 >nome da tabela >Utilities Database Utility >selecionar o índice e clicar em “Choose” >Create Database Index. Caso um índice secundário: DB02 >missing indexes >selecionar o índice >Create in DB.

Unit 10 – Cost Based Optimizer Update Statistics O otimizador baseado em custo procura o caminho (access path) com menor custo esperado de I/O. Casos em que estatísticas não são necessárias: quando se usa Rule Based Optimizer (RBO) ou usando o comando RULE; tabelas de pools e clusters; exceções de acordo com a DBSTATC; Oracle DDIC Objects; para comandos Insert. Tipos de estatísticas: table statistics: informações como número de linhas, número de blocos usados,
exatidão (sample_size) e data das últimas estatísticas; índex statistics: tamanho da árvore do índice, número de chaves diferentes, etc; column statistics: número de valores diferentes, o menor e o maior valor, exatidão
e data da última criação de estatísticas. Para atualizar: SQL ANALYSE TALE: deve cair em desuso; Oracle DBMS_STATS package: forma mais recente. Para mudar de tipo de
estatísticas, deve-se deletar a anterior; BR*TOOLS ou BRCONNECT: método recomendado e deve ser agendado via
DB13. Utiliza o ANALYSE TABLE, mas pode ser alterado para DBMS_STATs no init<sid>.sap;
DB20: para tabelas especificadas manualmente; Report RSANAORA: pode gerar novas estatísticas para tabelas ou índices. A partir do BRCONNECT 6.10, uma opção chamada table-monitoring pode ser ativada e é recomendado pela SAP. Esse monitor acelera a fase de check das estatísticas, pois se baseia em mudanças na tabela. Cost Evaluation Parâmetros que influenciam: OPTIMIZER_MODE: deve ser “CHOOSE”, para ativar o CBO; OPTIMIZER_INDEX_COST_ADJ: fator de multiplicação do custo de acesso por
índice. Ex.: valor 10 significa 10% do custo; OPTIMIZER_INDEX_CACHING: porcentagem de blocos do índice que irão para
cachê. DB_FILE_MULTBLOCK_READ_COUNT: quantidade de blocos lidos por vez. HASH_AREA_SIZE / PGA_AGGREGATE_TARGET: quanto maior, menor o custo
de hash join; SORT_AREA_SIZE / PGA_AGGREGATE_TARGET: usada para sort. Quanto
maior, menor custo. O custo de um full table scan pode ser estimado pelo número de blocos lidos, além do parâmetro DB_FILE_MULTIBLOCK_READ_COUNT. Para bases SAP R/3, o acesso deve ser feito via índice, então este parâmetro deve estar configurado para evitar o full table scan. A experiência mostra que o valor deve ser 8. “Oracle hints” são comandos para forçar o CBO a ir a uma direção estabelecida. Além de manual hints, também existem generated hints, que podem ser controlados via parâmetro dbs/ora/use_hints. Valor padrão é -1 (ativado).

Unit 11 - Analyzing Physical and Logical Layout (pg 581) Se uma query está consumindo recursos e o uso do índice está apropriado e o código ABAP está otimizado, pode ser problema de índice fragmentado. Para desfragmentá-lo, é necessário reorganizá-lo. Um índice fragmentado consiste de blocos vazios ou páginas vazias ou com poucos registros, sendo necessária a leitura de vários blocos para poucas informações. Um exemplo de índices que precisam de reorganização são índices de tabelas de RFC. Índices se tornam fragmentados: após archive de dados; após várias records serem removidas; tabelas dinâmicas. Identifying a Fragment Index (pg 584) Existem treis formas de se medir a fragmentação de índices: índex storage quality, que compara espaço livre e usado; deleted Leaf rows: compara número de leaf rows removidas com todas leaf rows. Comparing the index size and the table size, se um índice é maior que uma
tabela, quer dizer que o índice esta fragmentado. Índex storage quality compara o espaço disponível com o espaço usado, onde os dados são levantados como: - espaço disponível: número de blocos de índices usados multiplicados pelo tamanho do bloco, menos cabeçalho dos blocos; - espaço usado: número de entradas no índice multiplicadas pela média de tamanho de uma entrada mais 6 bytes para o ROWID e o cabeçalho para os blocos root e branch. Devido à imprecisão da análise dos dois métodos, eles são apenas indicadores do nível de fragmentação do índice, mas não podem dizer o quanto influencia na performance. Para estimar a qualidade de storage, o report RSORATAD pode ser executado diretamente na SE38 ou a funcionalidade pode ser acessada via DB02. A percentagem exibida não é precisa, mas em índices abaixo de 70% a desfragmentação é recomendada. Para índices pequenos, a percentagem pode ser baixa mesmo quando o índice foi reorganizado. Para índices abaixo de 10 blocos, outro método é recomendado. Vantagens: lock não é necessário; mostra informação exata sobre a fragmentação do índice; Desvantagens: um índice por vez; execução demorada; aumenta a carga do sistema. Estimar a proporção de leaf rows e deleted leaf rows pode ser feita via ANALYZE INDEX VALIDATE STRUCTURE diretamente no Oracle ou via DB02. A relação entre deleted/entries deve ser menor que 25%. No Oracle 9, a adição de “online” permite a diminuição do lock, porém estatísticas não são criadas.

Vantagens: diretamente no Oracle, todos índices podem ser analizados (via script); fornece informações exatas sobre fragmentação do índice. Desvantagens: a tabela é bloqueada para comandos DML; execução demorada; aumenta carga no sistema. Nos logs de execução de estatísticas do BRCONNECT, entradas informando que o índice “is unbalanced” indicam que o índice está fragmentado. Razões para esta entrada no log podem ser: - índice não balanceado; - parâmetro STATS_CHANGE_THRESHOLD no init<DBSID>.sap está com valor baixo (padrão: 50%); - a precisão do cálculo do índice está baixa, devido aos valores definidos na DBSTATC. Vantagens: - não é necessário lock; - não é necessário aumento de carga no sistema; Desvantagens: - não há garantia que todos índices fragmentados sejam reconhecidos. Para desfragmentar, 3 formas são possíveis: Drop and create view; Rebuild:
vantagens: pode-se mudar de tablespace, cria nova árvore do índice, possível mudar parâmetros sem necessidade de remover o índice, lock na tabela pode ser evitado via parâmetro “online”.
desvantagens: requer espaço em disco ou em memória. Pode ser feito via BRSPACE, report RSANAORA e via DB02 (tables and indexes monitor).
Coalesce índex: para liberar espaço livre interno. Pode ser feito online. vantagens: não requer espaço adicional, solução rápida, libera blocos para uso
futuro, não causa lock; desvantagens: não pode mudar de tablespace, não resolve todos problemas de
storage quality baixa. I/O contention (pg 602) Contenção em I/O refere-se à altos tempos de I/O, por processos acessando o banco de dados. Quando vários shadow proesses e o DBWR acessam o mesmo disco ao mesmo tempo, contenção de I/O pode ocorrer. Contenção de I/O pode ocorrer: design de aplicação não é eficiente; I/O não distribuído em vários discos; acessos pesados a tabelas ou índices não distribuídos em vários discos; configuração incorreta de hardware, file system e sistema operacional. Contenção de I/O normalmente é causado por problemas de design da aplicação, então este item deve ser verificado primeiro. Para identificar, usar o submonitor “Filesystem requests” na ST04N, que exibe informações baseadas na V$FILESTAT: I/O per File (data file); Total per devices; I/O per Path. Verificar se a média de escritas e leituras está alta, acima de 20ms. Verificar existência de eventos como “write complete waits”, “free buffer waits” e “log file switch” (checkpoint not complete).

Para resolver problemas de contenção de disco: distribuir o I/O nos discos disponívels; distribuir o I/O em mais discos; usar discos mais rápidos; mover tabelas ou índices muito acessados para discos próprios. Unit 12 – Analysing Memory Configuration (pg 609) - (não deve cair na prova)


















![[Oracle plsql] programando em oracle](https://img.document.onl/doc/110x75/55962c6d1a28ab59448b4641/oracle-plsql-programando-em-oracle.jpg)










