Embed Size (px)
Citation preview

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO
MAR CURSO DE CIÊNCIA DA COMPUTAÇÃO
APLICAÇÃO DE MAPAS DE KOHONEN PARA MINERAÇÃO DE DADOS NA REDE SOCIAL FACEBOOK
Jorge Gustavo Sandoval Simão
São José, novembro / 2014
Orientadora: Anita Maria da Rocha Fernandes, Doutora Área de Concentração: Inteligência Artificial
Linha de Pesquisa: Redes Neurais Palavras-chave: Redes Neurais, Mineração de Dados, Redes Sociais.
Número de páginas: 93

RESUMO
Com o desenvolvimento da tecnologia e a sua aplicação em diversos setores, a geração de dados por parte dos sistemas de informação tornou-se maior. Um dos adventos do avanço tecnológico foi a virtualização do conceito de redes sociais através de sites, incentivando usuários a constantemente criarem novas informações dos mais diferentes tipos, tais como texto, imagens, vídeo e áudio. O volume de dados gerado por essas redes sociais resultou em uma quantidade massiva de informações, de onde a extração de dados úteis tornou-se mais complexa. Uma das aplicações possíveis com a mineração de informações é a descoberta de compatibilidade entre perfis das redes sociais associados ao usuário, para determinar as melhores localizações a serem visitadas pelo o usuário do aplicativo. Visando realizar essa descoberta utilizando uma combinação dos conceitos de redes neurais, mineração de dados, big data e Mapas de Kohonen foi desenvolvido um aplicativo para dispositivos móveis (mais especificamente, o iPhone) que permitiu que um usuário em viagem consiga, ao chegar em um determinado local, analisar quem são os contatos que ele possui naquela cidade e filtrar quais possuem gostos em comum (através dos dados fornecidos pelo Facebook Graph API, que permite que dados específicos sejam recuperados de usuários) podendo, assim, identificar os lugares que eles tem frequentado, criando um demonstrativo do padrão de onde encontrá-los e quais os lugares que poderiam ser mais compatíveis com os dados apresentados pelo usuário no seu perfil. Os testes do aplicativo indicaram que ele obteve sucesso em buscar as informações e mapear o padrão de dados que mais se assemelha aos parâmetros de entrada definidos pelo usuário, permitindo assim o descobrimento das localidades desejadas de acordo com o perfil de quem realiza a pesquisa.

ABSTRACT
With the development of technology and its application in various sectors, generation of data by the information systems become larger. One of the advent of technological advancement was the virtualization of the social networking concept through sites, encouraging users to constantly create new information from different types, such as text, images, video and audio. The volume of data generated by these social networks has resulted in a massive amount of information, where the extraction of useful data has become more complex. One possible application with data mining is the discovery of compatibility between profiles of the social networks associated with the user, to determine the best locations to be visited by the user application. Aiming to accomplish this discovery, using a combination of the concepts of neural networks, data mining, big data and Kohonen maps was developed an application for mobile devices (more specifically the iPhone) that allow an user to be able to travel, arrive at a given location, analyze who are the contacts he has in that city and filter which have tastes in common (using data provided by the Facebook Graph API, which allows data to be retrieved from specific users) can thus identify the places they have attended, creating a statement of the standard of where to find them and the places where they could be more compatible with the data presented in their user profile. The tests indicated that the application succeeded in seeking information and map the data pattern that more closely resembles the input parameters defined by the user, thereby allowing the discovery of desired locations according to the profile of who conducts the survey.

LISTA DE TABELAS Tabela 1. Análise comparativa dos trabalhos acadêmicos ................................................................. 51 Tabela 2. Análise comparativa dos trabalhos comerciais .................................................................. 52 Tabela 3. Parâmetros de treinamento ................................................................................................. 63 Tabela 4. Parâmetros de entrada para o treinamento ......................................................................... 63 Tabela 5. Parâmetros da Recuperação de Informações ..................................................................... 66 Tabela 6. Variáveis de entrada ........................................................................................................... 78 Tabela 7. Retorno dos dez primeiros registros da rede treinada ........................................................ 79

LISTA DE FIGURAS
Figura 1. Ilustração simbólica do modelo McCullock-Pitts .............................................................. 36 Figura 2. Função Linear de Threshold ............................................................................................... 37 Figura 3. Exemplo do funcionamento de uma Rede Neural Artificial .............................................. 38 Figura 4. Exemplo do funcionamento de uma Rede Neural Artificial feedfoward ........................... 39 Figura 5. Exemplo do funcionamento de uma Rede Neural Artificial feedback ............................... 39 Figura 6. Exemplo de funcionamento de um Mapa de Kohonen ....................................................... 44 Figura 7. Vizinhança dos neurônios de um Mapa de Kohonen no padrão retangular ....................... 45 Figura 8. Vizinhança dos neurônios de um Mapa de Kohonen no padrão hexagonal ....................... 45 Figura 9. Visão Geral do Sistema ...................................................................................................... 53 Figura 10. Diagrama de Caso de Uso ................................................................................................ 58 Figura 11. Modelo Físico do Banco de Dados .................................................................................. 60 Figura 12. Modelo Lógico do Banco de Dados ................................................................................. 60 Figura 13. Neurônio Padrão do Sistema ............................................................................................ 63 Figura 14. Interface gráfica do sistema em funcionamento ............................................................... 77

LISTA DE QUADROS
Quadro 1. Inicialização da geolocalização ........................................................................................ 64 Quadro 2. Geocoder e Geocoder reverso .......................................................................................... 65 Quadro 3. Correção da função loginViewFetchedUserInfo ............................................................... 65 Quadro 4. Código da fase de Recuperação de Informações .............................................................. 66 Quadro 5. Criação das tabelas "LUGARES" e "LUGARES_TREINADOS" ................................... 67 Quadro 6. Tratamento das informações retornadas ........................................................................... 68 Quadro 7. Inserção da linha processada na tabela LUGARES .......................................................... 68 Quadro 8. Transmissão de dados da tabela LUGARES para a matriz .............................................. 71 Quadro 9. Conversão implícita de tipos ............................................................................................ 71 Quadro 10. Criação de matrizes em Objective-C .............................................................................. 71 Quadro 11. Criação de matriz no Objective-C utilizando o formato da linguagem C ...................... 71 Quadro 12. Obtenção do primeiro parâmetro de entrada (e1_) ......................................................... 72 Quadro 13. Obtenção do segundo parâmetro de entrada (e2_) ......................................................... 73 Quadro 14. Cálculo da função euclidiana para a Entrada 1 ............................................................... 74 Quadro 15. Atualização dos pesos do neurônio vencedor ................................................................. 74 Quadro 16. Atualização da taxa de aprendizagem ............................................................................ 75 Quadro 17. Retorno dos dados e ordenação pela distância euclidiana .............................................. 75

LISTA DE ABREVIATURAS E SIGLAS
ADVISE Analysis, Dissemination, Visualization, Insight, Semantic Enhancement API Application Programming Interface BCM Bienenstock Cooper Munro CAPPS Computer Assisted Passenger Prescreening System CEO Chief Executive Officer CMOS Complementary Metal-Oxide Semicondutor CRISP-DM Cross Industry Standard Process for Data Mining DBCS Department of Brain and Cognitive Science DCEE Department of Civil and Environment Engineering DHS Department of Homeland Security DNA Desoxiribunucleic Acid DMG Data Mining Group GIS Geographic Information Systems GNU GNU’s Not Unix GPL General Public License HTTP Hyper Text Transfer Protocol IEEE Institute of Electrical and Electronics Engineers IOS InterNetwork Operational System JDM Java Data Mining KDD Knowlege Database Discovery MIR Music Information Retrieval MIT Massachusetts Institute of Technology MGI McKinsey Global Institute MVC Modelo-Visão-Controlador PDP Programmed Data Processor PMML Predictive Model Markup Language SOM Self-Organizing Maps TCC Trabalho de Conclusão de Curso TIA Total Information Awareness UNIVALI Universidade do Vale do Itajaí WHO World Health Organization XML Extensible Markup Language

SUMÁRIO
1 INTRODUÇÃO ...................................................................................... 7 1.1 PROBLEMA DE PESQUISA ........................................................................... 9 1.1.1 Solução Proposta ............................................................................................. 10 1.1.2 Delimitação de Escopo .................................................................................... 11 1.1.3 Justificativa ..................................................................................................... 11 1.2 OBJETIVOS ...................................................................................................... 12 1.2.1 Objetivo Geral ................................................................................................. 12 1.2.2 Objetivos Específicos ...................................................................................... 12 1.3 METODOLOGIA ............................................................................................. 13 1.3.1 Metodologia da Pesquisa ................................................................................ 13 1.3.2 Procedimentos Metodológicos ....................................................................... 14 2 FUNDAMENTAÇÃO TEÓRICA ..................................................... 17 2.1 REDES SOCIAIS ............................................................................................. 17 2.1.1 História das Redes Sociais ............................................................................. 17 2.1.2 A Rede Social Móvel ....................................................................................... 19 2.2 MINERAÇÃO DE DADOS .............................................................................. 20 2.2.1 História da Mineração de Dados ................................................................... 21 2.2.2 Tarefas da Mineração de Dados .................................................................... 22 2.2.3 Aplicações da Mineração de Dados ............................................................... 23 2.3 BIG DATA ........................................................................................................ 28 2.3.1 Os 3V’s do Big Data ........................................................................................ 29 2.3.2 Etapas do Big Data ......................................................................................... 31 2.3.3 Aplicações do Big Data ................................................................................... 31 2.4 REDES NEURAIS ARTIFICIAIS .................................................................. 33 2.4.1 História das Redes Neurais Artificiais .......................................................... 33 2.4.2 Evolução das Redes Neurais Artificiais ........................................................ 35 2.4.3 Características das Redes Neurais Artificiais .............................................. 36 2.4.4 Aplicações das Redes Neurais Artificiais ...................................................... 40 2.5 MAPAS AUTO-ORGANIZÁVEIS ................................................................. 41 2.5.1 Estruturas Neurais ......................................................................................... 42 2.5.2 Arquitetura do Mapa de Kohonen ................................................................ 43 3 TRABALHOS RELACIONADOS ..................................................... 47 3.1 TRABALHOS ACADÊMICOS ....................................................................... 47 3.1.1 Análise de Desempenho de Aprendizagem Não-Supervisionada para Previsão de Velocidade de uma Rede Rodoviária .................................................. 47 3.1.2 Redes Neurais e sua Aplicação para o Auto-Diagnóstico Estrutural ........ 47 3.1.3 Entendendo os Padrões de Mobilidade Humana Através dos Registros Telefônicos ................................................................................................................. 48

8
3.2 TRABALHOS COMERCIAIS ........................................................................ 49 3.2.1 Advizor ............................................................................................................ 49 3.2.2 Augify ............................................................................................................... 49 3.2.3 Centrifuge Visual Network Analytics ........................................................... 49 3.2.4 Hawrkore ......................................................................................................... 50 3.2.5 Paper Boy Online ............................................................................................ 50 3.2.6 Plotly ................................................................................................................ 50 3.3 ANÁLISE COMPARATIVA ........................................................................... 51 3.3.1 Análise dos Trabalhos Acadêmicos ............................................................... 51 3.3.2 Análise dos Trabalhos Comerciais ................................................................ 51 4 DESENVOLVIMENTO ..................................................................... 53 4.1 VISÃO GERAL DO SISTEMA ....................................................................... 53 4.2 ANÁLISE DE REQUISITOS ........................................................................... 54 4.2.1 Requisitos Funcionais ..................................................................................... 54 4.2.2 Requisitos Não Funcionais ............................................................................. 57 4.2.3 Regras de Negócio ........................................................................................... 57 4.3 MODELAGEM DO SISTEMA ....................................................................... 58 4.3.1 Diagramas de Casos de Uso ........................................................................... 58 4.3.2 Diagramas de Bancos de Dados ..................................................................... 59 4.3.3 Pré-Processamento ......................................................................................... 62 4.3.4 Mapas de Kohonen ........................................................................................ 62 4.4 DETALHAMENTO DO DESENVOLVIMENTO ........................................ 64 4.4.1 Geolocalização ................................................................................................. 64 4.4.2 Recuperação de Informações ......................................................................... 66 4.4.3 Pré-Processamento ......................................................................................... 70 4.4.4 Treinamento .................................................................................................... 72 4.4.5 Interface Gráfica ............................................................................................. 76 4.5 DESCRIÇÃO DOS EXPERIMENTOS .......................................................... 77 4.6 RESULTADOS .................................................................................................. 78 5 CONCLUSÕES .................................................................................... 80 5.1 TRABALHOS FUTUROS ................................................................................ 83 REFERÊNCIAS BIBLIOGRÁFICAS ................................................... 85

7
1 INTRODUÇÃO
Com o desenvolvimento da tecnologia e a sua aplicação em diversos setores, a geração de
dados por parte dos sistemas de informação está se tornando cada vez maior. Um dos adventos do
avanço tecnológico foi a virtualização do conceito de redes sociais através de sites (Facebook,
Twitter, Orkut, MySpace, Cyworld, Bebo entre outros), incentivando usuários a constantemente
criarem novas informações dos mais diferentes tipos, tais como texto, imagens, vídeo e áudio.
Entretanto, essas redes sociais alcançaram grandes volumes de armazenamento de informação, o
que levou à criação do conceito de “Big Data” para definir suas características (SATHI, 2013).
O conceito “Big Data” acabou se tornando cada vez mais comum, conforme a interação
entre usuários e tecnologia de informação (mais especificamente as redes sociais) ia se
popularizando. Com isso, o volume de informação ampliou exponencialmente, principalmente com
a expansão da computação móvel nos últimos anos. Para poder desfrutar das vantagens de possuir
sistemas de bancos de dados com esse volume de informações em tempo hábil, foram aplicadas
diversas técnicas de mineração de dados para os mais variados fins (RUSSEL, 2013).
Agora a sociedade está entrando em uma nova era da computação, na qual a tecnologia
móvel e as redes sociais tem se combinado nas redes sociais móveis – um meio das pessoas se
socializarem e se encontrarem através de seus dispositivos móveis (CHIN; ZHANG, 2013).
Através da análise dos sistemas de armazenamento das redes sociais é possível explorar os
dados e responder às seguintes perguntas:
• Quem são as pessoas mais influentes/populares em uma rede social ?
• Sobre o que as pessoas estão conversando (e é valioso) ?
• Quem está interessado em virtualizar sua vida social e porquê ?
As respostas para essas perguntas trazem informações valiosas e oportunidades lucrativas
para os empresários, cientistas e outros estudiosos que estão tentando compreender o
comportamento social (RUSSEL, 2013). A inteligência artificial, dentro desse escopo, é utilizada
justamente com esse fim: coletar as informações significativas para a utilização corporativa. Uma
das técnicas empregadas para a análise de informação é a de redes neurais, cuja premissa básica é
modelar o padrão de aprendizado não-linear do cérebro humano.
Essa técnica provê um método de processamento de dados adaptativo, tolerante a falhas, e
com soluções para processamento de dados distribuídos e paralelos. Uma rede neural é uma caixa

8
preta que diretamente aprende as relações internas de um sistema desconhecido, sem adivinhar
funções para descrever as relações de causa e efeito. Esse modelo pode ser utilizado para
aproximação de funções, classificação, mapeamento não-linear, memória associativa, quantificação
de vetores, otimização, extração e recursos, processamento distribuído e inferência por
aproximação. As redes neurais possuem aplicações em quase todas as áreas da ciência e engenharia
(KOHONEN, 2001)
Utilizando-se de uma combinação dos conceitos de redes neurais, mineração de dados, big
data e Mapas de Kohonen foi desenvolvido um aplicativo para dispositivos móveis (mais
especificamente, o iPhone) que permite que um usuário em viagem consiga, ao chegar em um
determinado local, analisar quem são os contatos que ele possui naquela cidade e filtrar quais
possuem gostos em comum (através dos dados fornecidos pelo Facebook Graph API, que permite
que dados específicos sejam recuperados de usuários), podendo assim identificar os lugares que
eles tem frequentado, criando assim um demonstrativo do padrão de onde encontrá-los e quais os
lugares que poderiam ser mais compatíveis com os dados apresentados pelo usuário no seu perfil.
Diferentemente de aplicativos específicos de redes sociais tais como o FourSquare, que
apenas registra as informações da presença de pessoas em um determinado local (baseado no
registro que o próprio usuário faz no sistema) e o do Facebook, que armazena informações do
usuário, o aplicativo desenvolvido nesta pesquisa trabalha com reconhecimento de padrões entre os
dados da rede social Facebook e da localização geográfica no momento da busca.
Este aplicativo utiliza parte desses registros (que também são compartilhados nas redes
sociais) para sugerir ao usuário lugares que ele gostaria ou poderia frequentar, baseado nas
informações recuperadas pelo Facebook Graph API e analisadas através de mapas auto-
organizáveis.
Optou-se pelo desenvolvimento dessa pesquisa utilizando como base a computação móvel
pois ela representa atualmente grande parte dos dispositivos pelos quais os usuários mantém-se
conectados diariamente. Em 2014, 58% da população adulta (acima de vinte anos) possuía um
smartphone e 34% do usuários acessavam a internet somente utilizando esses aparelhos
(PEWRESEARCH INTERNET PROJECT, 2014).
A rede social utilizada para análise foi o Facebook, sendo que a coleta dos dados é realizada
através da API (Application Programming Interface - Interface de Programação de Aplicações)
disponibilizada para Xcode. As informações foram analisadas através de mapas auto-organizáveis

9
(mapas de Kohonen), com o objetivo de distribuir dimensionalmente os dados complexos em
grupos, de acordo com suas relações.
Segundo Teuvo Kohonen (2001), os mapas auto-organizáveis de Kohonen (ou apenas mapas
auto-organizáveis), são um tipo de rede neural assim denominado pois nenhuma supervisão é
requerida. Eles aprendem à medida que mapeiam a informação inserida. Outra propriedade
intrínseca dessa rede neural é a quantização vetorial. Os mapas auto-organizáveis de Kohonen
provêm uma maneira de representar informação multi-dimensional em um espaço dimensional
muito inferior (tipicamente uma ou duas dimensões). Isso ajuda no quesito visualização, pois
humanos são mais proficientes em entender uma informação em poucas dimensões do que em
muitas. Isso torna esses mapas ferramentas essenciais para lidar com uma vasta quantidade de
informações e transformá-las para serem mais compreensíveis pelo cérebro humano.
1.1 PROBLEMA DE PESQUISA
Com a popularização dos dispositivos móveis, a integração entre pessoas tornou-se uma das
aplicações bastante comuns à esse gênero tecnológico. Milhares de pessoas ao redor do mundo
estão eventualmente, ao longo do dia, utilizando-se de diversos aplicativos (Twitter, Facebook,
Tinder, Skype, entre milhares de outros) para comunicar-se com as outras pelos mais variados
motivos, desde lazer até trabalho. Com a popularização das redes sociais computacionais e da cada
vez mais frequente adesão de usuários, o volume de informação expandiu-se de forma muito rápida,
alcançando volumes muito grandes. Com isso, a manipulação desses volumes (que podem ir de
texto até mídia) tornou-se uma tarefa para algoritmos específicos de manipulação de grandes
quantidades de dados.
O problema de pesquisa aqui apresentado é o reconhecimento de padrões entre usuários da
rede social utilizando dispositivos móveis. No desenvolvimento da pesquisa devem ser respondidas
as seguintes perguntas:
• É possível reconhecer padrões entre os usuários das redes sociais utilizando o
dispositivo móvel especificado na pesquisa?
• As informações recuperadas da rede social proposta permitem essa análise sem a
adição de outros dados?

10
• Os padrões reconhecidos possuem relacionamento com as especificações do usuário
que solicitou a análise?
• Há a necessidade de um agente externo para o pré-processamento dessa informação?
Essas questões foram respondidas durante o desenvolvimento da pesquisa, conforme os
objetivos alcançados.
1.1.1 Solução Proposta
Como solução proposta ao problema apresentado, o objetivo da pesquisa é o
desenvolvimento de uma aplicação para dispositivos móveis que permita ao usuário, ao chegar à
uma localidade, mapear os dados dos seus contatos na rede social, encontrando assim as
combinações em comum com os mesmos e os melhores lugares para frequentar, baseado na
combinação de semelhanças entre o seu perfil e o perfil analisado.
A hipótese é que através dos mapas auto-organizáveis de Kohonen consiga-se analisar as
informações recuperadas pelo Facebook Graph API e combiná-las de maneira que sejam
encontrados os padrões de comportamento entre os usuários relacionados. Essas informações são
disponibilizadas para o uso em aplicativos através de APIs que essa rede social disponibiliza para
diversas linguagens, permitindo assim a integração de diversos recursos e dispositivos ao Facebook.
A Graph API é utilizada para inserir e recuperar informações dos relacionamentos do Facebook. Ela
é uma biblioteca que torna essa operação transparente aos usuários (baseada em HTTP – Hyper
Text Transfer Protocol), que o aplicativo pode utilizar para recuperar informações, criar novas
postagens, enviar novas fotos e uma variedade de outras tarefas que um sistema precisa fazer
(FACEBOOK DEVELOPERS, 2014).
O desenvolvimento desse sistema criou uma maior possibilidade de facilitar aos usuários o
acesso ao lazer em um ambiente que não lhes é conhecido (por exemplo, uma outra cidade),
permitindo que o usuário consiga analisar as preferências de outro (o que pode trazer resultados
positivos em uma relação de negócios ou interpessoal) e também que ele as combine com as suas
próprias para, assim, analisar o nível de compatibilidade com o indivíduo-alvo, de acordo com as
suas informações nas redes sociais.

11
1.1.2 Delimitação de Escopo
O aplicativo desenvolvido no escopo desse trabalho é uma aplicação para dispositivos
móveis e o equipamento utilizado para desenvolvimento foi um iPhone 4S. Enquanto a versão final
pode dar suporte a outros modelos de smartphone da mesma linha, esse foi o escolhido para testes
por uma questão de disponibilidade.
A linguagem de implementação foi o Objective-C. A escolha foi feita baseada no fato de que
essa linguagem é nativa para o sistema operacional Mac OS desde o princípio da implementação do
mesmo, assim como para o seu antecessor, o NeXTSTEP da NeXT Computer. Essa herança
estendeu-se para os dispositivos móveis da Apple, quando optaram por uma versão simplificada do
Mac OS (também conhecida como iOS – Internetwork Operational System), e mantiveram a
linguagem base de implementação.
A opção de rede social para coleta de informações foi o Facebook, devido à amplitude de
informações que ela apresenta sobre os seus usuários, e por manter uma integração eficiente com o
XCode. Enquanto é tecnicamente possível ampliar o escopo e estender a coleta de dados à outras
redes sociais, tais como Twitter e Foursquare (entre muitas outras), essa versão manterá seu escopo
no Facebook, visando focar com eficiência nas estruturas de dados de Kohonen.
Os mapas de Kohonen foram escolhidos como ferramenta de análise pois são um recurso de
inteligência artificial que permite, com a entrada correta de dados, detectar e aprender padrões,
permitindo assim a análise de uma quantidade considerável de informações em dimensões aonde o
cérebro humano consegue acompanhar com clareza (unidimensional ou bidimensional). Apesar de
outras técnicas poderem possivelmente analisar essas informações com níveis de desempenhos
diferentes, os mapas auto-organizáveis foram escolhidos como uma ferramenta que permitirá,
dentro da proposta de Inteligência Artificial, analisar os dados conforme o escopo desse trabalho.
1.1.3 Justificativa
O estudo abordado por este TCC buscou a integração entre redes neurais (mais
especificamente mapas de Kohonen) e dispositivos móveis com o intuito de minerar dados e
padrões dentro de um escopo aonde essas tecnologias não são vistas comumente atuando em
conjunto.

12
As redes sociais possuem um alto volume de dados, que são constantemente atualizados
pelos seus usuários. Este TCC permitiu a exploração e o reconhecimento de padrões entre esses
dados para fins comerciais ou de pesquisa.
O resultado da mineração de dados e análise de padrões proposto por este TCC possibilita ao
usuário do dispositivo móvel uma maior chance de encontrar lugares que tenham maior afinidade
com seus gostos pessoais, permitindo assim uma maior economia de tempo ao escolher um lazer em
uma área urbana que o mesmo desconhece.
O tema proposto por este trabalho também cria a possibilidade de que essa integração de
tecnologias possa ser utilizada por outras áreas de interesse que precisem identificar padrões em
meio a Big Data tais como ciência, engenharia e saúde.
1.2 OBJETIVOS
1.2.1 Objetivo Geral
Desenvolver um aplicativo para iOS que consiga pré-processar dados do Facebook e aplicar
mapas de Kohonen para minerá-los, visando demonstrar ao usuário quais as melhores opções de
lugares a frequentar quando ele chega a uma nova localidade.
1.2.2 Objetivos Específicos
1. Realizar a pesquisa bibliográfica;
2. Realizar modelagem do sistema;
3. Criar a interface do XCode;
4. Implementar sistema de geolocalização no iOS;
5. Implementar biblioteca do Facebook para XCode;
6. Analisar informações que serão recuperadas para os mapas de Kohonen;
7. Analisar comportamento dos mapas de Kohonen em diversos volumes de dados;
8. Implementar os mapas de Kohonen com a informação do Facebook API;
9. Especificar as informações de retorno para o usuário; e
10. Testar e validar o funcionamento do sistema.

13
1.3 METODOLOGIA
1.3.1 Metodologia da Pesquisa
A realização das pesquisas aplicadas a esse trabalho segue o princípio metodológico dos
trabalhos científicos. O conhecimento científico não é constituído de informações lapidadas
(prontas e finalizadas), e isso permite que o mesmo seja analisado de diferentes formas por
diferentes pessoas.
Com vários questionamentos, é possível propor uma ou mais soluções para um referido
problema. Métodos científicos são as formas mais seguras inventadas pelo homem para controlar o
movimento das coisas que cerceiam um fato de montar formas de compreensão adequadas de
fenômenos (BUNGE, 1974).
Segundo Wazlawick (2008) a proposta do método de pesquisa destina-se a apresentar uma
sequência de passos de tal forma que, obedecidos, resultem no objetivo proposto. Portanto, para
atingir o objetivo geral e os objetivos especifícos desse projeto, inicialmente foi feito o
levantamento bibliográfico, aonde foram estudados os conceitos de Big Data, Mineração de Dados,
Redes Sociais e Redes Neurais.
A elaboração de um modelo que utilize redes neurais e mineração de dados para promover a
coleta e análise de informações através da aplicação de técnicas de Big Data e mapas de Kohonen
no qual os resultados são obtidos por uma cadeia de raciocínio baseado nas informações
recuperadas, leva esse trabalho a classificar-se como método dedutivo.
Sob o ponto de vista de sua natureza, o trabalho proposto tem a intenção de gerar
conhecimentos para uma aplicação prática com foco na solução de um problema específico,
portanto, pode ser classificado como uma pesquisa aplicada.
Do ponto de vista de seus objetivos a pesquisa é exploratória, sendo que envolveu um
levantamento bibliográfico, análise de diferentes métodos e algoritmos e a manipulação de
diferentes tipos de informação para a obtenção do resultado esperado.

14
1.3.2 Procedimentos Metodológicos
A seguir tem-se a metodologia para o desenvolvimento deste Trabalho de Conclusão de
Curso:
1. Pesquisa bibliográfica: esta etapa atendeu o Objetivo Específico 1 do TCC e compreende
a execução das seguintes atividades:
a. Definição de critérios: definição dos critérios a serem utilizados para seleção de
trabalhos relacionados;
b. Pesquisa bibliográfica: busca e seleção de artigos em bases de dados;
c. Análise dos trabalhos: leitura e análise dos artigos selecionados;
2. Modelagem do sistema: esta etapa atendeu o Objetivo Específico 2 do TCC e
compreende a execução das seguintes atividades:
a. Criação dos casos de uso: criação dos casos de uso do sistema
b. Modelagem de Banco de Dados: criação do modelo entidade-relacionamento
para o sistema.
c. Modelagem do Mapa de Kohonen: criação, treinamento e validação do Mapa de
Kohonen.
3. Criação da interface no Xcode: esta etapa atendeu o Objetivo Específico 3 do TCC e
compreende a execução das seguintes atividades:
a. Modelagem da interface gráfica: modelagem da interface gráfica do sistema;
b. Teste de interface gráfica: teste do modelo da interface gráfica do sistema;
c. Implementação da interface gráfica: implementação da interface gráfica no
Xcode;
4. Implementação do sistema de geolocalização no iOS: esta etapa atendeu o Objetivo
Específico 4 do TCC e compreende a execução das seguintes atividades:
a. Análise da documentação da API: análise da documentação do sistema de
geolocalização do iOS, focando nos recursos principais a serem utilizados pela
pesquisa;

15
b. Implementação do código teste: implementação do código para testar conceitos
analisados no passo anterior;
c. Implementação do sistema de geolocalização: implementação (no aplicativo da
pesquisa) do sistema de geolocalização.
5. Implementação da biblioteca do Facebook para o Xcode: esta etapa atendeu o Objetivo
Específico 5 do TCC e compreende a execução das seguintes atividades:
a. Análise da documentação da API: análise da documentação do sistema de
recuperação de informações do Facebook para iOS, focando nos recursos
principais a serem utilizados pela pesquisa;
b. Implementação do código teste: implementação do código para teste dos
conceitos analisados no passo anterior;
c. Implementação da Facebook Graph API: implementação (no aplicativo da
pesquisa) do sistema de coleta de informações do Facebook.
6. Análise das informações que serão recuperadas para os mapas de Kohonen: esta etapa
atendeu o Objetivo Específico 6 do TCC e compreende a execução das seguintes
atividades:
a. Implementação do algoritmo em sistema adjacente: implementação do algoritmo
dos mapas de Kohonen em um sistema à parte para testes;
b. Teste do algoritmo dos mapas auto-organizáveis: teste do algoritmo dos mapas
auto-organizáveis com banco de dados de informações de testes;
c. Implementação do algoritmo dos mapas auto-organizáveis: implementação do
algoritmo dos mapas auto-organizáveis de Kohonen na aplicação da pesquisa.
7. Análise do comportamento dos mapas de Kohonen em diversos volumes de informação:
esta etapa atendeu o Objetivo Específico 7 do TCC e compreende a execução das
seguintes atividades:
a. Criação do banco de dados para testes: criação do banco de dados com volume
de informações grande para teste;
b. Implementação do banco de dados em algoritmo de Kohonen: implementação do
banco de dados de teste no algoritmo do passo 5c;

16
c. Análise do comportamento do algoritmo: análise do comportamento do algoritmo
em grandes volumes de informação, com o objetivo de testar sua viabilidade.
8. Implementação dos mapas de Kohonen com a informação do Facebook API: esta etapa
atendeu o Objetivo Específico 8 do TCC e compreende a execução das seguintes
atividades:
a. Coleta de informações com o Facebook Graph: coleta de informações válidas
através do Facebook Graph;
b. Processamento das informações em mapas auto-organizáveis: processamento das
informações coletadas através dos mapas auto-organizáveis;
9. Especificação das informações de retorno para o usuário: esta etapa atendeu o Objetivo
Específico 9 do TCC e compreende a execução das seguintes atividades:
a. Análise da viabilidade das informações: anaálise das informações comparando-as
com a solicitação do usuário;
b. Retorno de informações: retorno das informações de maneira que o usuário as
compreenda com facilidade, dentro do padrão de exibição determinado pela
interface gráfica;
10. Teste e validação do funcionamento do sistema: esta etapa atendeu o Objetivo
Específico 10 do TCC e compreende a execução das seguintes atividades:
a. Validação do aplicativo: validação do funcionamento do aplicativo, se todas as
informações integradas estão de acordo com as necessidades do usuário;
b. Teste de desempenho: teste do retorno de dados para o usuário, e analisar se o
mesmo está sendo realizado em um tempo de resposta válido;

17
2 FUNDAMENTAÇÃO TEÓRICA
Este capítulo aborda os conceitos que envolvem o contexto dessa pesquisa (Redes Sociais,
Big Data, Mineração de Dados e Redes Neurais), fazendo uma revisão bibliográfica sobre o tema
para que após a aquisição do conhecimento, possa ser proposto um sistema aplicando tais
fundamentos.
2.1 REDES SOCIAIS
Segundo Wasserman e Faust (1999) é caracterizada como rede social uma estrutura formada
de indivíduos (ou organizações), também chamadas de “nodos”, que estão conectados por um ou
mais tipos de interdependências tais como amizade, coleguismo, interesse comum, relações
financeiras, gostos, contatos sexuais, relacionamentos, credos, conhecimento ou prestígio.
É um mapa de laços específico entre os nodos. Esses nodos são também chamados de
“contatos sociais” desse indíviduo, e o seu relacionamento pode ser utilizado para medir o capital
social de uma pessoa específica (o valor que aquele indivíduo possui na rede social). Existem
conceitos que são essenciais quando trata-se de análises de redes sociais. Esses conceitos são: ator
(ou nodo), relacionamento, grupo, subgrupo, laços relacionais e rede de contatos. Utilizando-se dos
mesmos é possível discutir qualquer camada da mesma, ao se analisar uma rede social
(WASSERMAN; FAUST, 1999).
2.1.1 História das Redes Sociais
Nos meados de 1800, Émile Durkhein e Ferdinand Tönnies vislumbraram o conceito de
redes sociais nas suas teorias e pesquisas por grupos sociais. Tönnies afirmava que grupos sociais
podem existir a partir de conexões de indivíduos que compartilham os mesmos valores e crenças
(TÖNNIES, 2001). Segundo Durkheim (1887, apud FUHRT, 2010), o fenômeno social surge
quando a interação entre indivíduos constitui uma realidade que não pode mais ser contabilizada em
termos de propriedades ou atores individuais.
Os desenvolvimentos a respeito do conceito de redes sociais continuaram, principalmente a
partir de 1930 por diversos grupos em psicologia, antropologia e matemática que trabalhavam
independentemente (SCOTT, 2000). Na década de 70, um grupo crescente de estudiosos trabalhou

18
para combinar as diferentes linhas de pesquisa desenvolvidas. Um grupo constituído do sociologista
Harrison White e os seus estudantes do Harvard Department of Social Relations, que dentre esses,
agindo de forma independente estava Charles Tilly, que focou o conceito de redes em sociologia
política e movimentos sociais e também Stanley Milgram, que desenvolveu a tese dos seis graus de
separação. Mark Granovetter e Barry Wellman também estavam entre os alunos de White que
elaboraram e constituíram o conceito de análise de redes sociais (WELLMAN, 1988).
A evolução da rede social móvel iniciou-se em 1999 com serviços de conversas básicos e
serviços de texto. Com o desenvolvimento da tecnologia de dispositivos móveis, as redes sociais
têm alcançado um novo nível a cada quatro gerações (LUGANO, 2008). A primeira geração, entre
1999 e 2000, utilizava tecnologias baseadas em aplicações pré-instaladas nos equipamentos, (tais
como aplicativos de comunicação via texto) no modelo de chat. Pessoas envolvidas nesse serviço
eram anônimas, e a maioria dos serviços dessa geração era pago pelo uso ou através de
mensalidades.
A segunda geração deu-se entre 2004 e 2006, com a introdução da tecnologia 3G e telefones
com câmeras. Essa nova tecnologia permitiu que recursos como armazenamento de fotos online,
busca por pessoas através do perfil ou contato, flertes anônimos, entre outros. A distribuição
regional desses recursos incluía Japão, Coréia, Autrália, Leste Europeu e Estados Unidos, com
aplicações mais voltadas, na maioria das vezes, para relacionamentos ou encontros. Assim como na
primeira geração, a maioria dos serviços era pago pelo uso ou mensalidade.
Os experimentos para a terceira geração iniciaram-se em 2006, tendo extendido-se até
2008/2009. Essa geração trouxe modificações significativas e tornou as redes sociais como parte da
vida cotidiana. Os recursos incluem uma experiência de usuário mais rica, publicações automáticas
para perfis web e atualizações de status, busca por grupo ou interesses, alertas, serviços de
localização e compartilhamento de conteúdo (especialmente música), suporte a WAP 2.0, Java no
servidor, MMS (Multimedia Messaging Service), captura de voz, entre outros. Os aplicativos dessa
geração eram focados em interesses gerais ou em um conteúdo de distribuição específico, e o
suporte à propaganda começou a se tornar mais importante. Enquanto os serviços de pagamento por
uso se mantiveram, a maioria dos serviços de mensalidade tornaram-se plataformas de distribuição
de conteúdo.

19
A quarta geração iniciou-se em 2008 e seguiu até 2010, tendo como principal característica
um avanço dos recursos da terceira geração, habilidade de mascarar a sua presença nos dispositivos
móveis, jogos online de múltiplos jogadores, entre outros. O modelo de negócio da geração anterior
se estendeu, juntamente com o conceito de propriedade virtual - a compra e venda de bens ou itens
virtuais (POWERS, 2010).
2.1.2 A Rede Social Móvel
Uma rede social móvel é uma rede social em que indivíduos com interesses similares
comunicam-se e conectam-se mutuamente através de um dispositivo móvel (normalmente um
smartphone ou tablet). Tais como as redes sociais baseadas em ambiente web, os usuários de redes
sociais móveis organizam-se em comunidades virtuais.
Sites de redes sociais tais como o Facebook criaram aplicativos que permitem ao seus
usuários acessar o seu conteúdo em tempo real através de smartphones e tablets, porém, existem
redes sociais nativas aos dispositivos móveis (tais como Foursquare, Instagram e Path) que são
construídas visando essa estrutura (LAI, 2007). Inicialmente, haviam apenas dois tipos básicos de
redes sociais móveis. O primeiro eram as companhias que realizavam parcerias com operadoras de
telefone wireless ara distribuir suas comunidades através das páginas iniciais dos navegadores dos
dispositivos móveis, como por exemplo, a JuiceCaster. O segundo tipo eram as companhias que não
possuíam essas parcerias e utilizavam-se de outros métodos para atrair usuários (POWERS, 2010).
Segundo Raento e Antti (2008) existem seis modelos mais comuns de redes sociais, pois a
grande maioria deles oferece serviços que são muito semelhantes entre si. Muitos possuem recursos
únicos, porém a função principal da rede social em si é exatamente como à de outros serviços da
mesma categoria. São esses os modelos:
• Group Texter: esse tipo de rede social foca na habilidade de enviar pequenas mensagens de
texto para um número grande de pessoas de uma vez. O objetivo dessas redes sociais é
entregar as mensagens às pessoas certas da maneira mais simples e rápida possível. Ex:
GroupMe, Zemble.
• Location Aware: essa categoria de rede social foca em saber a sua localização e a
localização dos seus amigos. Elas tiram vantagem do interesse crescente em serviços

20
baseados em localização, traçando com frequência aonde os seus contatos estão. Muitos
sistemas que se enquadram nessa classificação permitem saber se alguém está próximo à
uma rua ou localização em particular, próximo ao usuário ou à uma geolocalização
específica. Eles compartilham essa informação marcando as posições dos indivíduos em
mapas acessíveis à todos os usuários. Ex: Foursquare, Whrll.
• Social Gaming: essa categoria foca em conectar pessoas através de jogos multijogador, ou
competições em jogos para um jogador. Os smartphones mais novos com processadores
mais potentes se tornaram uma plataforma formidável para jogos, fazendo com que essa
categoria crescesse exponencialmente. Ex: Playstation Network, Xbox Live.
• Dating Services: esses serviços são muito semelhantes àqueles sites de encontro. Os usuários
criam um perfil e combinam esse perfil com outros perfis cadastrados. Essa categoria
usualmente também possui um nível de segurança alto, dada a quantidade de informações
que ele possui sobre os indivíduos cadastrados, para que as mesmas não sejam
disponibilizadas sem permissão dos mesmos. Ex: Parperfeito, Tinder.
• Social Networker: esse padrão procura modelar o conceito de rede social da forma mais
perfeita possível. Eles oferecem uma grande gama de funções, incluindo posts multimídia,
salas de chat, compartilhamento de imagens, mensagens instantâneas e páginas
customizáveis. Alguns sistemas adeptos à esse padrão oferem inclusive chamadas
internacionais e SMS à um custo barato. Ex: Facebook, Orkut.
• Media Sharer: essa categoria é a versão de áudio e vídeo do Group Texter. O objetivo é
compartilhar arquivos de forma mais eficiente e simples possível com os contatos e grupos.
Muitos deles armazenam o conteúdo dos dispositivos online, para evitar abarrotar os
smartphones ou tablets dos usuários. Outra função inerente à categoria é a aceitação de
conteúdo de streaming e a sua distribuição automática para a lista de contatos. Ex:
Whatsapp, Viber.
2.2 MINERAÇÃO DE DADOS
Mineração de dados é o nome dado ao processo computacional de descobrir padrões em
quantidades grandes de informação envolvendo métodos de inteligência artificial, estatísticas e

21
bancos de dados (CLIFTON, 2010). O objetivo do processo de mineração de dados é extrair
informações de uma estrutura de dados e transformá-la em uma estrutura compreensível para uso
futuro (HASTIE; TIBSHIRANI; FRIEDMAN, 2009).
A mineração de dados pode ser automática ou semi-automática e pode detectar padrões tais
como grupos de registros específicos (análise de cluster), registros incomuns (detecção de
anomalias) e dependências (mineração por regras e associação). Isso normalmente envolve utilizar
técnicas tais como índices e bancos de dados espaciais. Esses padrões podem ser considerados
como um sumário para o conjunto de dados, e pode ser utilizado em análises posteriores ou ainda
para aprendizado de máquina ou análise preditiva.
2.2.1 História da Mineração de Dados
A extração manual de padrões de informação ocorre há séculos. Métodos antigos de
identificação de padrões de informação incluem o teorema de Bayes e análise de regressão, ambos
datados do século XVI e XVII, respectivamente. O avanço tecnológico e de poder de
processamento permitiu um aumento exponencial da habilidade de guardar, coletar e manipular
informações. Os grupos de informações aumentaram em complexidade e tamanho e a manipulação
dos dados foi aumentada com processamento de dados indireto e automatizado, tais auxiliado por
outras descobertas em ciência da computação, tais como redes neurais, análise de clusters,
algoritmos genéticos e árvores de decisão. A mineração de dados aplicou essas técnicas com a
intenção de descobrir padrões escondidos em quantidades de dados massivas (KANTARDZIC,
2003).
Nos meados dos anos 60, estatísticos utilizavam termos como “Data Fishing” ou “Data
Dredging” para referir-se ao que eles consideravam uma prática pouco eficiente de analisar
informação sem nenhum tipo de parâmetro. O termo “Mineração de Dados” surgiu perto dos anos
90 nas comunidades de bancos de dados. No início, o termo era “Mineração de Bancos de Dados”,
porém havia uma marca semelhante registrada por uma companhia em San Diego, relativo à um
sistema de mineração de informações (MENA, 2011). Pesquisadores, por consequência, mudaram
o termo para “Mineração de Dados”. Outros termos tais como “Arqueologia de Dados”, “Colheita
de Informações”, “Pesquisa de Informações” e “Extração de Conhecimento” também são utilizados.
Gregory Piatetsky-Shapiro criou o termo “Descoberta de Conhecimento em Bancos de Dados” para
o primeiro workshop no mesmo tópico (1989) e esse termo tornou-se mais popular na comunidade

22
de inteligência artificial (PIATETSKY-SHAPIRO; PARKER, 2011). Atualmente, “Mineração de
Dados” e “Descoberta de Conhecimento” são os termos mais utilizados.
2.2.2 Tarefas da Mineração de Dados
O processo de mineração de dados, para Groth (1998, apud FERNANDES, 2005), é aquele
responsável pela descoberta automática de informações. Segundo Fayyad, Piatetsky-Shapiro e
Smyth (1996) a mineração de dados possui seis tipos comuns de tarefas:
• Detecção de Anomalias – A identificação de registros não-usuais, que podem ser
interessantes ou erros de informação que requerem algum tipo de investigação.
• Aprendizado por associação (Modelo de Dependência) – Procura por relacionamentos entre
variáveis, como por exemplo um supermercado que pode coletar informações sobre os
hábitos de compra de um cliente. Utilizando essa tarefa, o supermercado pode determinar
quais produtos são frequentemente comprados juntos e usar essa informação para propósitos
de propaganda.
• Clusterização – A tarefa de descobrir os grupos e estruturas do grupo de informações alvo
que são de uma forma ou outra similares, sem utilizar as estruturas conhecidas desse grupo
de informações.
• Classificação – A tarefa de catalogar a informação em categorias conhecidas, tal como um
gerenciador de email que cataloga os novos e-mails como legítimos ou spams.
• Regressão – Tenta encontrar uma função que modela a informação baseado no que se
aprendeu com o último erro.
• Sumarização – Provê uma representação mais compacta do grupo de informações, incluindo
visualização e geração de relatórios.
Houveram esforços para estabelecer um padrão para os processos de mineração de dados,
como por exemplo o CRISP-DM 1.0 e o JDM 1.0. O desenvolvimento de sucessores desses
processos (CRISP-DM 2.0 e JDM 2.0) foi iniciado em 2006, mas estancou desde então. O JDM 2.0

23
acabou sendo descartado sem ao menos chegar a um rascunho final (GÜNNERMAN; KREMER;
SEIDL, 2011).
Para trabalhar com a mineração de informações, em particular a análise preditiva, o padrão
adotado acabou sendo o PMML (Predictive Model Markup Language), que é uma linguagem
baseada em XML (Extensible Markup Language) desenvolvido pelo Data Mining Group (DMG) e
suportado como formato de troca de dados entre diversas aplicações de mineração de dados. Como
o nome sugere, ele cobre apenas modelos preditivos, uma tarefa de mineração de dados de grande
importância para os modelos de negócios. Entretanto, extensões para cobrir outros processos (como
a clusterização, por exemplo) foram propostos independentemente do DMG (GÜNNERMAN;
KREMER; SEIDL, 2011).
2.2.3 Aplicações da Mineração de Dados
A seguir apresenta-se algumas aplicações da mineração de dados na área de jogos, negócios,
ciência e engenharia, direitos humanos, mineração de dados espacial, sensores, música, vigilância e
mineração de padrões.
2.2.3.1 Jogos
Desde os meados dos anos 60, com a disponibilidade de certos “oracles” (máquina abstrata
utilizada para estudar problemas de decisão) para análise combinatória, principalmente em jogos de
xadrez, uma nova área para aplicação de mineração de dados havia surgido.
Visando extrair as estratégias utilizadas pelos humanos que jogavam contra as máquinas em
jogos de xadrez, foram utilizados diversos experimentos com tablebase (sistema que possui uma
análise pré-calculada da posição das peças em um tabuleiro de xadrez) que combinado com um
estudo intensivo da informação adquirida, gerou uma sequência de padrões preditivos. Berlekamp e
John Nunn são exemplos notáveis de pesquisadores nessa área (O’BRIEN; MARAKAS, 2011).
2.2.3.2 Negócios
A mineração de dados é utilizada para analisar o histórico de transações comerciais,
armazenadas como informações estáticas em data warehouses para revelar padrões e tendências
escondidas. Programas de mineração de dados utilizam algoritmos de reconhecimento de padrões

24
em grandes quantidades de informação para auxiliar no descobrimento de informações de negócios
estratégicas (O’BRIEN; MARAKAS, 2011). São alguns exemplos deste tipo de aplicação:
• Com a tecnologia atual, a informação é coletada pelas companhias em uma
proporção gigantesca. Por exemplo o Walmart processa 20 milhões de transações
comerciais por dia. Essa informação é armazenada em um banco de dados
centralizado, e seria inútil sem algum tipo de programa de mineração de dados para
analisá-lo. Ao aplicar a técnica de mineração de dados sobre esse conjunto de
informações, o Walmart consegue determinar tendências de vendas, desenvolver
campanhas de marketing, e prever mais precisamente as ações a serem tomadas para
conseguir a fidelidade do consumidor (ALEXANDER, 2014).
• Toda vez que um cartão de crédito ou um cartão de fidelidade é utilizado, é coletada
informação sobre o comportamento das transações do usuário. Apesar de muitas
pessoas acreditarem que essas informações armazenadas por companhias tais como
Google, Facebook e Amazon possam ser utilizadas de forma a quebrar a privacidade
do usuário, empresas como a Ford e a Audi esperam um dia ter coletado informações
suficientes sobre os hábitos de direção dos usuários a ponto de sugerir rotas mais
seguras e alertar usuários sobre condições da estrada perigosas (GOSS, 2013).
• Mineração de dados é útil em departamento de recursos humanos, identificando as
características dos funcionários de maior sucesso. A informação obtida – tal como as
universidades frequentadas por esses funcionários – auxilia o departamento a
direcionar os esforços de recrutamento adequadamente (MONK; WAGNER, 2006).
• Mineração de dados é uma ferramenta muito efetiva para catalogar informações na
indústria da propaganda. Essa indústria possui um rico banco de dados de históricos
transacionais de milhões de consumidores em períodos de anos. Ferramentas de
mineração de dados podem identificar padrões entre consumidores e ajudar a
identificar clientes mais aptos a responder propagandas por email (BATTITI;
BRUNATO, 2011).

25
2.2.3.3 Ciência e Engenharia
Nos últimos anos, a mineração de dados tem sido amplamente utilizada em áreas como
ciência e engenharia, tal como bioinformática, genética, medicina, educação e engenharia elétrica.
Seguem exemplos de aplicações:
• No estudo da genética humana, a mineração das sequências ajuda a mapear a relação
entre as variações individuais na sequência do DNA humano em caso de variações
ou suscetabilidade à doenças. A mineração de dados demonstra como as
modificações na sequência de DNA afetam os riscos de desenvolver doenças comuns
como o câncer, o que é de grande importância para o melhoramento dos métodos de
diagnóstico, prevenção e tratamento dessas doenças. Um dos métodos utilizados para
realizar essa tarefa é conhecido como Redutor de Dimensionalidade Multifator
(ZHU; DAVIDSON, 2007).
• Na área da engenharia elétrica, as técnicas de mineração de dados têm sido
amplamente utilizadas para monitoração de condições de equipamentos elétricos de
alta voltagem. O propósito do monitoramento de condições é obter informações
valiosas sobre, por exemplo, a situação do sistema de isolamento elétrico (ou outros
parâmetros de segurança relacionados). Técnicas de clusterização de dados (assim
como os mapas auto-organizáveis) são aplicadas para detectar condições anormais e
gerar hipóteses sobre a natureza das anomalias (MCGRAIL et al, 2011).
• Na pesquisa educacional, aonde a mineração de dados é utilizada para estudar os
fatores que levam os estudantes a comportamentos que estão reduzindo sua taxa de
aprendizado e para estudar fatores que influenciam a retenção de estudantes na
universidade (AGUIRRE; VANDAMME; MESKENS, 2006).
• Na vigilância de reações adversas à medicamentos, o Uppsala Monitoring Center
tem, desde 1988, usado métodos de mineração de dados para detectar padrões
indicativos de problemas de segurança com medicamentos emergentes no banco de
dados global da WHO (que possui 4.6 milhões de acidentes suspeitos de reação
adversa) (BATE et al, 1998). Uma metodologia semelhante foi desenvolvida para
minerar grandes coleções de registros de saúde associando a prescrição de
medicamentos com diagnósticos médicos (NORÉN et al, 2008).

26
2.2.3.4 Direitos Humanos
Mineração de dados em registros governamentais – particularmente registros do
departamento de justiça – permite o descobrimento de um padrão de violação de direitos humanos,
em conexão com a geração e publicação de registros inválidos ou fraudulentos por várias agências
governamentais (ZERNIK, 2010).
2.2.3.5 Mineração de Dados Espacial
Esse método consiste na aplicação de mineração de dados em dados espaciais. O objetivo
final da mineração de dados espaciais é encontrar padrões na informação a respeito da geografia. Há
algum tempo, a mineração de dados e o GIS (Geographic Information Systems) existiam como duas
tecnologias separadas, cada uma com os seus métodos, tradições e maneira próprias de lidar com a
visualização e análise de informação. O aumento nas informações sobre referências geográficas
ocasionadas pelo desenvolvimento em tecnologia da informação, mapeamento digital,
sensoriamento remoto e a difusão global do GIS enfatizaram a importância do desenvolvimento de
sistemas de informação indutivos para análise e modelagem geográficos (MAGUIRE;
GOODCHILD; RHIND, 1991).
A mineração de dados oferece grandes benefícios potenciais para uma aplicação de tomada
de decisões baseada em GIS. A tarefa de integrar essas duas tecnologias tornou-se de importância
crítica, especialmente com várias organizações de setores públicos e privados possuindo imensos
bancos de dados com referências geográficas, tais como:
• Escritórios que possuem análise ou referências à informações geoestatísticas;
• Serviços de saúde públicos com informações sobre doenças em áreas geográficas;
• Agência do meio-ambiente com análises do impacto na modificação do clima de
acordo com o uso do terreno;
• Companhias de geo-marketing fazendo segmentação dos clientes baseado na
localização espacial (MAGUIRE; GOODCHILD; RHIND, 1991).

27
2.2.3.6 Sensores
Sensores de redes wireless podem ser usados para facilitar a coleta de informações para
mineração de dados espaciais em uma variedade de aplicações, como por exemplo monitoramento
de poluição do ar (MA et al, 2008). Uma característica dessas redes é a proximidade desses
sensores registram tipicamente os mesmos valores. Esse tipo de redundância de informação, mais a
correlação espacial entre as observações dos sensores pede o uso de técnicas de agregação e
mineração de dados. Medindo a correlação espacial entre diferentes sensores, uma classe especial
de algoritmos podem ser desenvolvidas visando uma mineração de dados mais eficiente (MA et al,
2011).
2.2.3.7 Música
Técnicas de mineração de dados, em particular análises de co-ocorrência são utilizadas para
descobrir similaridades relevantes na indústria fonográfica com o propósito de classificar a música
em gêneros de uma maneira mais objetiva (PACHET; WESTERMANN; LAIGRE, 2001).
2.2.3.8 Vigilância
Mineração de dados foi utilizada pelo governo dos Estados Unidos em programas como
TIA, CAPPS, ADVISE (GOVERNMENT ACCOUNTABILITY OFFICE, 2014), e o MATRIX
(SECURITY ON NBCNEWS, 2014). Esses programas foram descontinuados devido à controvérsia
sobre eles violarem a quarta emenda à constituição dos Estados Unidos, embora muitos programas
que se formaram tendo os citados anteriormente como base continuam a ser financiados por
diversas organizações ou sob nomes diferentes (ELETRONIC FRONTIER FOUNDATION, 2014).
2.2.3.9 Mineração de Padrões
“Mineração de Padrões” é uma técnica de mineração de dados que envolve a descoberta de
padrões em um determinado volume de dados. Nesse contexto, entende-se como padrões regras de
associação entre os registros. Apesar do motivo original da pesquisa sobre a mineração de padrões
ser o uso em transações comerciais, seu estudo tornou-se voltado à identificação de atividades
terroristas. O National Research Council define a mineração de padrões como uma ferramenta para
identificar padrões anômalos que possam ser associados à atividades terroristas.

28
Esses padrões podem ser identificados como pequenos sinais em um oceano de ruídos
(NATIONAL RESEARCH COUNCIL, 2008). A mineração de padrões também inclui novas áreas
tais como a MIR, em que os padrões temporais e atemporais são importados para serem utilizados
com os métodos clássicos de descoberta de conhecimento.
2.3 BIG DATA
O termo “Big Data” tornou-se um dos mais utilizados na tecnologia da informação em todo
o mundo, porém as implicações e os principais benefícios para as empresas que investem nessa
tecnologia ainda estão ainda a ser realizado nos próximos anos. De acordo com a IBM (2014) todos
os dias são criados 2,5 quintilhões (1018) bytes de dados e quase noventa por cento dos dados
atualmente foram criados nos últimos dois anos.
A explosão de dados global é altamente impulsionada por tecnologias tais como vídeo
digital, música, smartphones e a internet (ORACLE, 2014). Esses dados têm suas origens em uma
variedade de fontes, incluindo pesquisas na web, sensores, transações comerciais, as interações de
mídia social, uploads de áudio e vídeo, e os sinais de telefone celular GPS (IBM, 2014).
Segundo o site DOMOSPHERE (2014) a cada minuto usuários de email enviem mais de
204 milhões de mensagens, o Google receba mais de 2.000.000 de consultas de pesquisa, os
usuários do Facebook compartilhem mais de 684 mil dados de conteúdo, os consumidores gastem
mais 270.000 dólares em compras na web, os usuários do Twitter enviem mais de 100.000 tweets,
mais de 570 novos sites são criados, e os usuários do Instagram compartilham 3.600 novas fotos.
Dessa forma, todas essas fontes de informação contribuirão para atingir 35 zettabytes de dados
armazenados em 2020 (EATON et al, 2012).
Estes conjuntos de dados cada vez mais diversos se complementam e permitem às empresas
descobrir padrões escondidos e explorar novas idéias. Desvendar esses padrões melhora as
operações, as tomadas de decisão e dá elementos para melhorar os processos de negócios
(GARTNER RESEARCH, 2014).
A quantidade e variedade de fontes de informação criaram desafios de armazenamento,
processamento e análise significativo de organizações em todo o mundo. No entanto, a tremenda
tamanho e da complexidade do "Big Data" são apenas um lado da questão. O outro aspecto da

29
grande questão dos dados é a demanda por custo formas eficazes de coleta, armazenamento, análise
e visualização. Em seu ciclo de vida, a informação tem diferentes requisitos de qualidade,
segurança e acesso, e essas diferenças formam a maior parte dos aspectos de grande complexidade
(GARTNER RESEARCH, 2014).
2.3.1 Os 3V’s do Big Data
O gerenciamento de dados evoluiu principalmente em torno de dois problemas
fundamentais: volume e capacidade de processamento. No entanto, os desafios mudaram e não é
mais uma questão de armazenamento ou mesmo capacidade de processamento, mas como os dados
se tornaram mais complexos e com uma variedade de fontes novas, eles são recolhidos em
velocidade recorde; isso cria uma árvore de dimensões que segundo a Gartner Research (2014), é
descrita conforme segue: “Big Data é um conjunto de informações de alto volume, velocidade e
variedade que demandam formas inovadoras de processamento de informações para aprimorar as
idéias e tomadas de decisões econômicas”.
2.3.1.1 Volume dos Dados
Segundo Steve Lohr (2014) do New York Times destacou em seu artigo "The Age of Big
Data", tendências em tecnologia estão abrindo as portas trazendo uma nova abordagem para
compreensão do mundo e modificando as maneiras de tomar decisões. Hoje há muito mais dados do
que podemos processar, e esse volume continua crescendo a 50% ao ano, ou mais do que dobrando
a cada dois anos.
De acordo com a Gartner Research (2014), um volume de informações que caracterize Big
Data pode ser definido conforme segue: “O volume de informações é considerado Big Data quando
a capacidade de processamento das tecnologias de captura nativas e seus processos são insuficientes
para entregar resultados para os casos de uso subsequentes. Ele também pode ocorrer quando a
tecnologia existente foi especificamente desenhada para lidar com esses volumes – uma solução de
sucesso para o Big Data”.

30
2.3.1.2 Velocidade dos Dados
Os dados evoluíram para um fluxo contínuo. A velocidade com que as organizações estão
coletando dados está em constante crescimento com a chegada de tecnologias de streaming e com o
aumento constante das fontes de informação. O que no passado costumavam ser análises de
informações negócios em um determinado período de tempo evoluíram para análises de
informações em tempo real (GARTNER RESEARCH, 2014).
No entanto, o problema não é apenas um fluxo maior de dados, e sim informações
inteiramente novas. Por exemplo, já existem inúmeros sensores digitais em telefones, automóveis,
utilitários e equipamentos industriais, para medir e comunicar localização, movimento, vibração,
temperatura e umidade, entre muitas outras variáveis (GARTNER RESEARCH, 2014).
De acordo com a Gartner Research (2014), a velocidade dos dados é definida da seguinte
forma: “É considerada alta velocidade quando há uma alta taxa de chegada e/ou consumo de dados,
mas com foco na velocidade variável de um grupo de dados ou nas taxas de troca entre dois ou mais
grupos de dados”.
2.3.1.3 Variedade dos Dados
O maior desafio no conceito de “Big Data” não é sobre o tamanho ou a velocidade dos
dados coletados, mas como essa informação pode ser utilizada para tratar os objetivos de negócios
específicos e como as organizações acabarão por adaptar os seus processos para obter vantagens
dessa oportunidade concedidas pelos dados.
O maior benefício da variedade de dados nesse conceito é a capacidade de responder
questões de alta complexidade, coletar dados relevantes e usar as tecnologias certas para traduzir e
processar essas informações em análise que levam às mais diferentes idéias, permitindo a tomada de
decisões em tempo real.
De acordo com a Gartner Research (2014), a variedade de dados é definida da seguinte
forma: “Ativos de informação altamente variáveis que incluem uma mistura de formas, tipos e
estruturas múltiplas e dados subutilizados habilitados para novas formas de processamento
representam variabilidade.”

31
2.3.2 Etapas do Big Data
Segundo a Microsoft Developer Network (2014), a mineração de dados usa análise
matemática para derivar padrões e tendências que existem nos dados. Esses padrões não podem ser
descobertos com a exploração de dados tradicional pelo fato de as relações serem muito complexas
ou haverem muitos dados.
Segundo Jiawei Han e Micheline Kamber (2001) processo de KDD (Knowledge Discovery
in Database – Busca de Conhecimento em Banco de Dados) consiste de uma sequência iterativa
dos seguintes passos:
• Limpeza de dados: remove dados inconsistentes e fora do padrão (noise data);
• Integração de dados: possibilita a integração de várias fontes de dados, mantendo a
consistência e a coerência dos dados integrados;
• Seleção dos dados: seleciona os dados relevantes para a aplicação das técnicas de
mineração de dados;
• Transformação de dados: possibilita a transformação ou consolidação dos dados no
formato apropriado para o processo de mineração, através de operações do tipo
sumarizaçãoo ou agregação, entre outras técnicas;
• Mineração dos dados: processo essencial, onde técnicas são aplicadas para análise e
extração dos padrões dos dados.
• Avaliação dos padrões: identifica os padrões verdadeiramente interessantes entre os
diversos apresentados pelo processo de mineração de dados, baseados em algumas medidas
de interesse.
2.3.3 Aplicações do Big Data
Segundo o McKinsey Global Institute (2014), há cinco maneiras aplicáveis de processar
grandes quantidades de dados que ofereçam um potencial de transformação para criação de valores
e têm implicações na forma como as organizações irão processá-los, organizá-los e gerenciá-los, a
saber:

32
• Criando transparência: ao fazer o “Big Data” mais acessível às partes interessadas
em tempo hábil.
• Permitindo experimentos, expondo variabilidades e aumentando o desempenho: as
organizações coletam mais informações detalhadas (em tempo real) em várias
dimensões (inventários de produtos, lista de dados de funcionários, etc). Esse
processo consiste em criar experimentos controlados com esses dados. Usar esse
método também permite análises da variabilidade em desempenho e entender as suas
causas, com o objetivo de permitir reajuste no desempenho para níveis mais
elevados.
• Segmentando populações para personalizar ações: Esse processo permite que mais
organizações criem segmentos altamente específicos e adaptem produtos para
atender à essa segmentação. Essa abordagem é altamente conhecida em propaganda e
gerenciamento de riscos, e mesmo companhias que têm usado segmentação de
clientes há anos começaram a aplicar técnicas de Big Data, tal como segmentação
em tempo real de consumidores para direcionar promoções e anúncios.
• Substituindo/ajudando tomadas de decisões humanas com algoritmos automáticos:
Análises sofisticadas podem melhorar substancialmente tomadas de decisões,
minimizar riscos e revelar informações valiosas. Tais análises têm aplicações para
organizações de avaliação de risco de crédito em instituições financeiras com o preço
de ajuste fino automático no varejo. Em alguns casos, as decisões não serão
necessariamente automatizadas, mas aumentadas por meio da análise de enormes
conjuntos de dados e tecnologias. Muitas organizações já estão fazendo as melhores
decisões através da análise de conjuntos de dados inteiros de clientes, funcionários,
ou até mesmo sensores incorporados nos produtos.
• Inovando modelos de negócios, produtos e serviços: Grandes quantidades de dados
podem permitir às empresas criar novos produtos e serviços para melhorar os já
existentes ou mesmo inventar modelos de negócios inteiramente novos. Os
fabricantes estão utilizando dados obtidos a partir da utilização de produtos reais
para melhorar o desenvolvimento da próxima geração de produtos e criar ofertas de
pós-vendas. O surgimento dessa análise de dados em tempo real criou todo um novo

33
grupo de serviços baseados em localização, que são considerados nos preços dos
seguros contra acidentes com base em onde e como as pessoas dirigem seus carros,
por exemplo.
2.4 REDES NEURAIS ARTIFICIAIS
As Redes Neurais artificiais são definidas por Kohonen (1982 apud FERNANDES, 2005)
como redes massivamente paralelas e interconectadas, de elementos simples, com organização
hierárquica e que interagem com objetivos do mundo real da mesma maneira que o sistema nervoso
biológico.
Redes Neurais Artificiais (RNAs) são modelos computacionais inspirados no sistema
nervoso central (especificamente o cérebro) que é capaz de realizar aprendizado e reconhecimento
de padrões. Elas são normalmente apresentadas como “neurônios” interconectados que podem
calcular os valores das entradas (HAYKIN, 1999).
As redes neurais artificiais são capazes de aprender os relacionamentos entre um conjunto de
entradas e uma saída específica quando sua dependência é desconhecida. Ela consiste de várias
unidades computacionais (neurônios) que processam os dados de entrada de modo a produzir o
resultado desejado. Os neurônios são dispostos em camadas, sendo as entradas de cada camada
sendo definidas pelas saídas das camadas anteriores. Dessa maneira as entradas da primeira camada
são as entradas da rede, e as saídas da última camada são as respostas para a rede (HAYKIN, 1999).
Em um exemplo, uma rede neural para o reconhecimento da escrita manual é definida por
um conjunto de neurônios que podem ser ativados pelos pixels de uma imagem de entrada. As
ativações desses neurônios são então processadas, medidas e transformadas em uma função definida
pelo engenheiro dessa rede, para outros neurônios. Esse processo é repetido até que finalmente o
neurônio de saída é ativada. Isso determina que o caractere foi lido (HAYKIN, 1999).
2.4.1 História das Redes Neurais Artificiais
Warren McCulloch e Walter Pitts, em 1943, criaram um modelo computacional para redes
neurais baseado em matemática e algoritmos. Eles chamaram esse modelo de “Threshold Logic”. O
modelo abriu caminho para a pesquisa de redes neurais dividirem-se em duas abordagens distintas:
uma focada em processos biológicos do cérebro e a outra focada na aplicação das redes neurais para

34
inteligência artificial (MCCULLOC; PITTS, 1943 apud CONSORTIUM ON COGNITIVE
SCIENCE INSTRUCTION, 2014).
Nos meados dos anos 40 o psicólogo Donald Hebb criou uma hipótese de aprendizagem
com base no mecanismo de plasticidade neural que agora é conhecido como aprendizagem
Hebbiana. A aprendizagem Hebbiana é considerada uma regra de aprendizagem “típica” sem
supervisão, e suas variantes posteriores foram os primeiros modelos de potenciação a longo prazo.
Essas idéias começaram a ser aplicadas à modelos computacionais em 1948 com máquinas do tipo
B de Turing (HEBB, 1949 apud HAYKIN, 1999).
Segundo Farley e Clark (1954 apud SAFFELL; MOODY, 2001) inicialmente foram
utilizadas máquinas computacionais (calculadoras) para simular uma rede Hebbiana no MIT. Outras
máquinas foram simulando redes neurais foram criadas por Rochester, Holland, Haibt e Duda em
1956 (ROCHESTER et al,1956 apud JACOB et al, 2012).
Segundo Rosenblatt (1958, apud JACKSON, 2014), sua pesquisa originou o Perceptron, um
algoritmo para reconhecimento de padrões baseado em uma rede de computadores de aprendizagem
de duas camadas usando simples adição e subtração. Com notação matemática, Rosenblatt também
criou outro circuito mais avançado, cuja computação não pôde ser processada até a criação do
algoritmo de retropropagação de Paul Werbos, em 1975 (WERBOS, 1975 apud XIAO, 2014).
Segundo Minsky e Papert (1969, apud JACKSON, 2014) a pesquisa em redes neurais
estagnou depois da sua publicação do estudo de aprendizado de máquina. Eles descobriram duas
questões fundamentais com os sistemas computacionais que processavam redes neurais. A primeira
questão foi que redes neurais de camada única eram incapazes de processar o circuito “ou”
exclusivo. A segunda foi que os computadores não eram sofisticados o suficiente para gerir
eficazmente o tempo de longo prazo de processamento exigido por grandes redes neurais e com
isso, as pesquisas em redes neurais desaceleraram até haver poder de processamento suficiente. A
criação do algoritmo de retropropagação também foi um salto para resolver o problema de “ou”
exclusivo. (WERBOS, 1975 apud XIAO, 2014).
O processamento distribuído paralelo, em meados dos anos 80, permitiram um maior
processamento das redes que simulavam processos neurais (RUMELHART; MCCLELLAND, 1986
apud HSIEH, 2014). Na década de 90, as redes neurais foram ultrapassadas em popularidade pela

35
aprendizagem de máquina e outros métodos, muito mais simples, classificados como “lineares”. O
interesse renovado em redes neurais foi desencadeado no ano 2000, com o advento do conceito de
aprendizagem profunda (RUSSEL, 2014).
2.4.2 Evolução das Redes Neurais Artificiais
Modelos biofísicos, como a teoria BCM (Bienenstock Cooper Munro), têm sido importantes
para a compreensão dos mecanismos de plasticidade sináptica, e tiveram aplicações tanto em
ciência da computação como em neurociência. A pesquisa focou na compreensão dos algoritmos
computacionais utilizados no cérebro, com alguma evidência biológica recente para redes de base
radial e retropropagação neural, assim como mecanismos de processamento de dados.
Dispositivos computacionais foram criados em CMOS (Complementary Metal-Oxide
Semicondutor), tanto para simulação biofísica quanto para a computação neuromórfica. Esforços
mais recentes mostram a possibilidade de criação de nanodispositivos. Se bem sucedidos, esses
esforços poderiam inaugurar uma nova era de computação neural que é um passo além da
computação digital, por depender de aprendizagem ao invés da programação e porque é
fundamentalmente analógico ao invés de digital, mesmo que as primeiras instâncias possam, de
fato, estar com dispositivos digitais CMOS (YANG et al, 2008).
Entre 2009 e 2012, as redes neurais recorrentes e de busca profunda desenvolvidas pelo
grupo de pesquisa Jürgen Schmidhuber no Swiss AI Lab IDSIA ganharam oito competições
internacionais de reconhecimento de padrões e aprendizagem de máquina (KURZWEIL, 2012). A
rede neural LSTM ganhou três competições em reconhecimento de escrita à mão na ICDAR sem
qualquer conhecimento prévio das três diferentes linguagens a serem aprendidas (GRAVES;
SCHMIDHUBER, 2012).
Variantes do algoritmo de retropropagação assim como métodos de Geoff Hinton e seus
colegas na Universidade de Toronto (HINTON; OSINDERO; TEH, 2006) podem ser utilizados
para treinar arquiteturas profundas e altamente não-lineares similares ao Neocognitron de Kunihiko
Fukushima (FUKUSHIMA, 1980) e a “Arquitetura Padrão de Visão” inspirado pelas pesquisas nas
células simples e complexas identificadas por David H. Hubel e Torsten Wiesel no córtex visual
primário (RISENHUBER; POGGIO, 1999).

36
2.4.3 Características das Redes Neurais Artificiais
Uma rede neural artificial é composta por várias unidades de processamento, cujo
funcionamento é bastante simples. Essas unidades, geralmente são conectadas por canais de
comunicação que estão associados a determinado peso. As unidades fazer operações apenas sobre
os seus dados locais, que são entradas recebidas pelas suas conexões (FERNANDES, 2005).
Segundo Filho (1996, apud FERNANDES, 2005), a operação de uma unidade de
processamento pode ser resumida da seguinte maneira:
• Sinais são apresentados à entrada;
• Cada sinal é multiplicado por um número, ou peso, que indica sua influência na saída
da unidade;
• É feita a soma ponderada dos sinais que produz um nível de atividade;
• Se este nível de atividade exceder um certo limite (threshold) a unidade produz uma
determinada resposta de saída.
Figura 1. Ilustração simbólica do modelo McCullock-Pitts. Fonte: Kawagushi (2014).

37
Figura 2. Função Linear de Threshold Fonte: Kawagushi (2014).
Segundo Fernandes (2005) considerando os sinais de entrada I1, I2,..., IN, os pesos W1, W2,...,
WN, a função f representada na Figura 2 e o limitador T; com sinais assumindo valores booleanos (0
ou 1) e pesos e valores reais, o nível de atividade é dado por:
f = W1I1 + W2I2 +... + WnXn
A saída y é dada por:
Y = 1, se f >= t ou y = 0, se f < t
A maioria dos modelos de redes neurais possui alguma regra de treinamento, onde os pesos
de suas conexões são ajustados de acordo com os padrões apresentados.
Segundo Kawagushi (2014) as arquiteturas de redes neurais artificiais são compostas por
camadas interconectadas que podem ser classificadas em três grupos:
• Camada de Entrada: Nessa camada os valores iniciais são apresentados à rede
• Camadas Intermediárias: aonde o processamento dos dados é realizado, visando
definir as características
• Camada de Saída: Aonde o resultado final é concluído e apresentado.
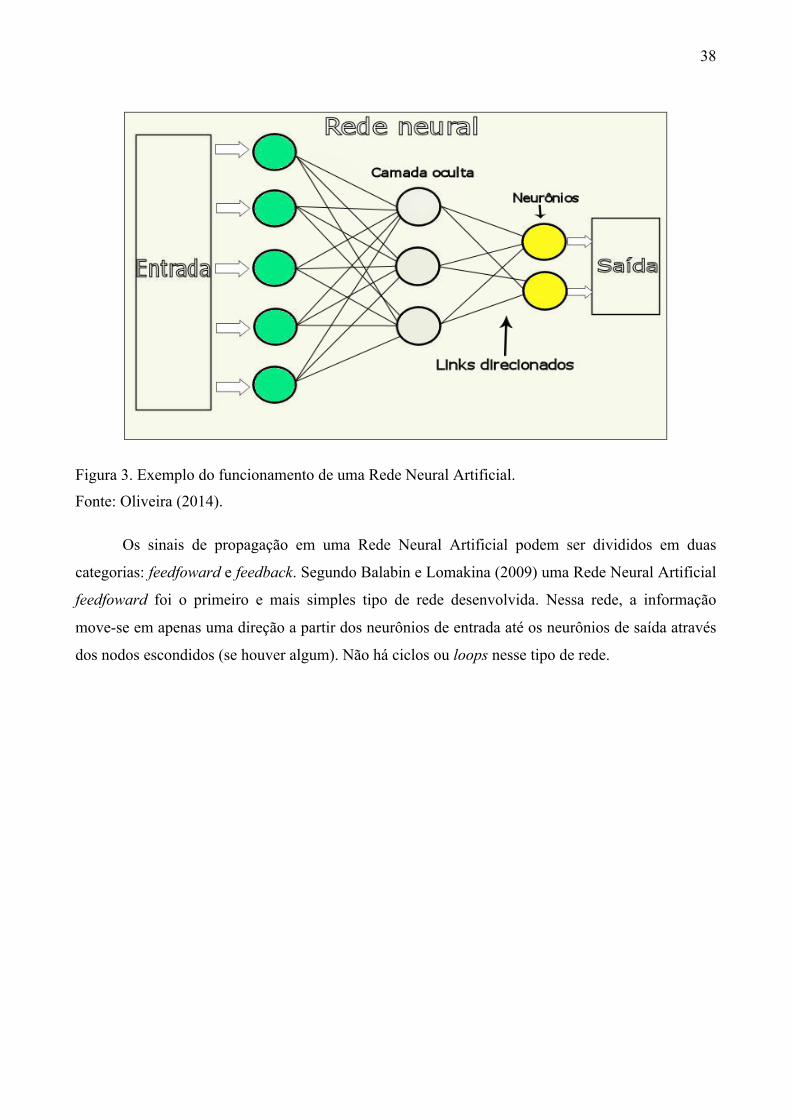
38
Figura 3. Exemplo do funcionamento de uma Rede Neural Artificial.
Fonte: Oliveira (2014).
Os sinais de propagação em uma Rede Neural Artificial podem ser divididos em duas
categorias: feedfoward e feedback. Segundo Balabin e Lomakina (2009) uma Rede Neural Artificial
feedfoward foi o primeiro e mais simples tipo de rede desenvolvida. Nessa rede, a informação
move-se em apenas uma direção a partir dos neurônios de entrada até os neurônios de saída através
dos nodos escondidos (se houver algum). Não há ciclos ou loops nesse tipo de rede.
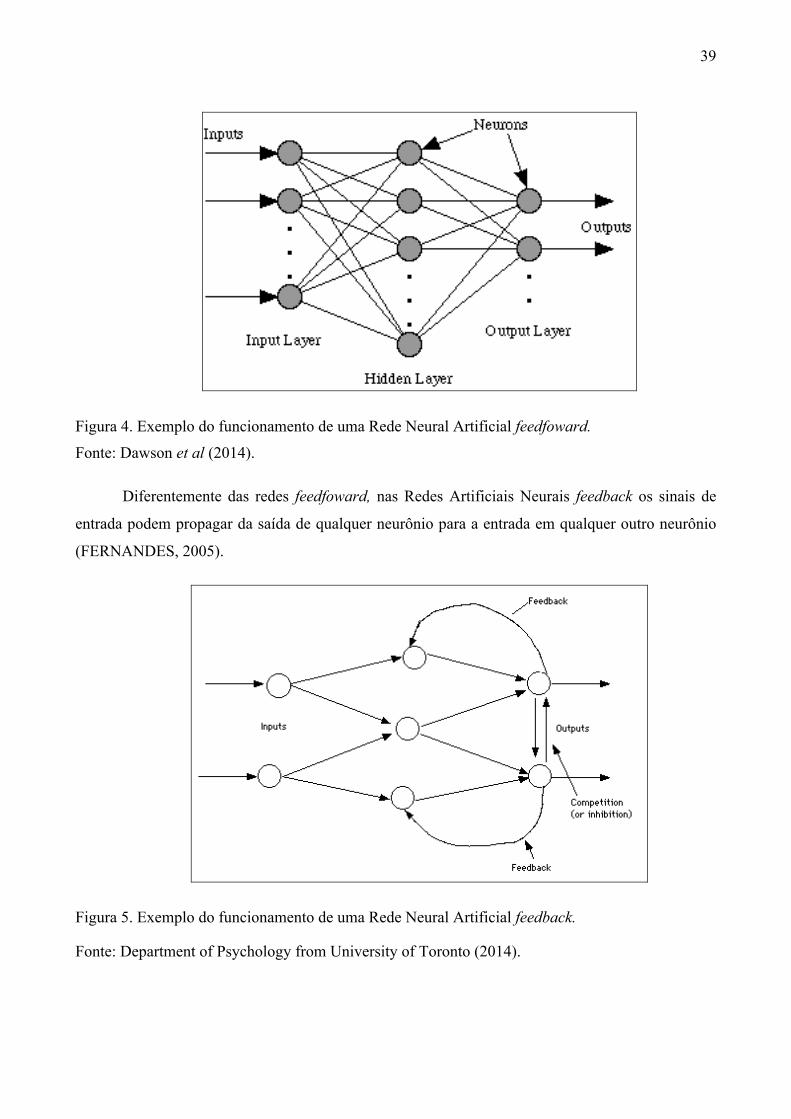
39
Figura 4. Exemplo do funcionamento de uma Rede Neural Artificial feedfoward.
Fonte: Dawson et al (2014).
Diferentemente das redes feedfoward, nas Redes Artificiais Neurais feedback os sinais de
entrada podem propagar da saída de qualquer neurônio para a entrada em qualquer outro neurônio
(FERNANDES, 2005).
Figura 5. Exemplo do funcionamento de uma Rede Neural Artificial feedback.
Fonte: Department of Psychology from University of Toronto (2014).

40
Segundo Fernandes (2005), outro fator importante é a maneira pela qual uma rede neural se
relaciona com o ambiente. Nesse contexto, existem os seguintes paradigmas de aprendizado:
• Aprendizado Supervisionado: quando é utilizado um agente externo que indica à rede a
resposta desejada para o padrão de entrada;
• Aprendizado Não-Supervisionado: quando não existe um agente externo indicando a
resposta desejada para os padrões de entrada;
• Reforço: quando um crítico externo avalia a resposta fornecida pela rede.
O tipo de rede neural utilizada pelo aplicativo deste TCC é a dos Mapas de Auto-
Organização de Kohonen, classificada como uma rede feedfoward de treinamento não-
supervisionado.
2.4.4 Aplicações das Redes Neurais Artificiais
Segundo Balabin e Lomakina (2009) a utilidade dos modelos de redes neurais artificiais
estão no fato de que eles podem ser utilizados para deduzir uma função a partir de observações. Isto
é particularmente útil em aplicações em que a complexidade dos dados ou tarefa torna a criação de
uma tal função à mão impraticável. As tarefas nas quais as redes neurais artificiais são aplicadas
tendem a se encaixar nas seguintes categorias:
• Função de aproximação, ou análise de regressão, incluindo predição de séries de
tempo e modelagem.
• Classificação, incluindo reconhecimento de padrões e sequências e tomada de
decisões sequenciais.
• Processamento de dados, incluindo clusterização, filtragem e compressão.
• Robótica, incluindo manipuladores diretos, tais como próteses.
• Controles.
As áreas de aplicação incluem a identificação de sistemas e controle (controle de veículos,
controle de processos, gestão de recursos naturais), química quântica, jogos e tomadas de decisões

41
(gamão, xadrez, pôquer), reconhecimento de padrões (sistemas de radar, reconhecimento facial e
etc), o reconhecimento de seqüências (gestos, falas, reconhecimento de texto escrito à mão),
diagnósticos médicos, aplicações financeiras (por exemplo, sistemas de negociação automatizados),
mineração de dados (KDD) e filtragem de spams de email (BALABIN; LOMAKINA, 2009).
Segundo Gurney (1997 apud FERNANDES, 2005), as etapas de desenvolvimento de aplicações de
redes neurais são:
1. Coleta de Dados e Separação em Conjuntos;
2. Configuração da Rede;
3. Treinamento;
4. Teste; e
5. Integração.
As redes neurais artificiais também têm sido utilizadas para diagnosticar diversos tipos de
câncer. Um sistema híbrido de detecção de câncer de pulmão baseado em redes neurais chamado
HLND melhora a precisão do diagnóstico e a velocidade da radiologia do câncer de pulmão
(GANESAN, 2012). Essas redes também têm sido utilizadas para diagnosticar câncer de próstata.
Os diagnósticos podem ser utilizados para fazer modelos específicos baseados em um grande grupo
de pacientes. O câncer colorretal também pode ser previsto com a utilização de redes neurais com
mais precisão que os métodos clínicos atuais (BOTTACI, 1997).
2.5 MAPAS AUTO-ORGANIZÁVEIS
Os mapas auto-organizáveis (SOM – Self Organizing Maps) são uma estrutura de dados
computacional originalmente proposto por Tuevo Kohonen em 1982. A estrutura de dados e os seus
algoritmos associados procuram imitar, ao menos em comportamento, a natureza básica de
organização dos neurônios, tal como descrito anteriormente. Os mapas auto-organizáveis procuram
identificar padrões em informações inseridas, se reorganizando de acordo com o treinamento dado
pelos ciclos de dados repetidos (KOHONEN, 2001).

42
Em sua forma mais básica, os mapas auto-organizáveis são um plano de células distribuído
em uma topologia simples (muitas vezes apenas uma grade). Cada célula representa parte dos
dados, geralmente um vetor de valores numéricos. Vetores de entrada do mesmo formulário são
apresentados então aos mapas auto-organizáveis durante sua fase de treinamento. Cada entrada é
usada para modificar ligeiramente o mapa de modo que uma parte do plano de células torne-se
"mais como" o vetor de entrada. Após ciclos repetidos de inserções, os conjuntos desenvolvem uma
similaridade e as formações tornam-se evidentes em um plano de duas dimensões, facilitando a
visualização dos padrões (KOHONEN, 2001).
Mapas auto-organizáveis são consideradas ferramentas poderosas de aprendizagem
estatísticos pois funcionam sem supervisão permitem uma visualização simples, e podem ser usado
como um algoritmo para o desenvolvimento do cluster. Por causa da flexibilidade do paradigma dos
mapas auto-organizáveis, eles têm sido utilizados para uma variedade de aplicações, desde o
processamento acústico até análise da bolsa (OJA, KASKI, 1999).
2.5.1 Estruturas Neurais
Embora ainda existam controvérsias sobre como exatamente o cérebro processa e armazena
informações, a idéia da estrutura auto-organizável dentro do panorama neural é aceita, apesar dos
debates constantes sobre aprendizado, evolução e genética a respeito desse tópico. Muitos estudos
têm demonstrado que as conexões neurais e mesmo arranjo espacial das funções neurais no cérebro
se desenvolvem em resposta aos padrões do mundo em que o indivíduo está exposto. Por exemplo,
demonstrou-se que, dentro do córtex auditivo do cérebro existe um mapa dos neurônios (conhecido
como o mapa tonotópico). Os neurônios que compõem esse mapa são ordenados espacialmente de
acordo com o tom e freqüência dos tons percebidos (KOHONEN, 2001).
Esse fenômeno não é específico ao córtex, mas pode ser encontrada em outras áreas do
cérebro. O estudo de estruturas neurais de ratos demonstraram que os mapas do seu ambiente
geográfico desenvolvem-se dentro do hipocampo. Nesse caso, a posição de um rato em um quarto
ou labirinto corresponde a uma seção específica do mapa hipocampal (KOHONEN, 2001).
Embora a exata natureza do processamento cerebral não seja clara, há evidências biológicas
que podem descrever a percepção neural da seguinte forma: quando os órgão sensoriais percebem
as entradas, esses valores são passados para certas partes do cérebro e estimulam as células neurais.

43
As células estimuladas, por sua vez, passam a resposta ao longo dos seus vizinhos até que algum
fator de decaimento interrompa a propagação dos sinais. Dependendo do valor de entrada, uma
parte do cérebro é acionada. Uma vez expostos a vários estímulos semelhantes, podem-se
desenvolver clusters de padrões. Um aspecto interessante desse processo é que ele pode ser
executado em paralelo em muitas partes do cérebro. Por exemplo, a percepção de um carro
vermelho dirigindo por uma rua pode ativar vários grupos de neurônios. Um cluster pode tornar-se
animado por causa da cor do carro (um cluster correspondente a entrada visual vermelho, talvez),
outro pode tornar-se animado devido ao ruído dissonante voz alta, e ainda um outro por causa de
uma pessoa que andando ao mesmo tempo. A ativação dos vários grupos ao mesmo tempo faz com
que os clusters criem associações entre si. Dentro desse contexto, se um determinado indivíduo é
repetidamente exposto a esta cena, ele pode aprender (via associação) que um ruído dissonante alto
é geralmente associado com a cor vermelha (SETH, 2014).
A descrição acima é uma interpretação simplificada do processo de aprendizagem e
processamento neural, porém é o suficiente para o desenvolvimento de modelos computacionais
baseados no cérebro. O desenvolvimento de clusters dentro de mapas neurais com base nos padrões
do espaço de entrada tem inspirado muitas das técnicas que se enquadram na categoria mais ampla
de redes neurais.
2.5.2 Arquitetura do Mapa de Kohonen
Segundo Fernandes(2005, apud LOESH, 1996) a rede de Kohonen é dividida em duas
camadas: a camada de entrega (Xi) e a camada competitiva de neurônios (Yj). Cada neurônio da
camada competitiva está conectado à camada de vetores por pesos sinápticos (Wij) que são
ajustados por um processo de aprendizado não-supervisionado.
Os pesos sinápticos são utilizados para associar um padrão de entrada à um neurônio da
camada competitiva, e é selecionado como vencedor aquele que mais se assemelha ao vetor de
entrada (menor distância euclidiana em relação à esse vetor). A distância euclidiana é calculada
através da seguinte equação:
dj = SS (Wij (t) – Xi (t));

44
Figura 6. Exemplo de funcionamento de um Mapa de Kohonen.
Fonte: Clark (2014).
Aos valores iniciais são atribuídos números de pontos flutuantes que formam o padrão de
entrada para a rede. Uma rede de Kohonen exige que essas entradas sejam normalizadas para o
intervalo entre -1 e 1. Apresentando um padrão de entrada para a rede irá causar uma reação dos
neurônios de saída (HEATON, 2013).
Dentro da equação apresentada, Xi (t) é o elemento do vetor de entrada no instante t, e Wij (t)
é o valor dos pesos no vetor de pesos no instante t. Quando o processo de seleção é finalizado, os
pesos do neurônio vencedor e dos seus vizinhos são ajustados, o que provê a auto-organização da
rede neural (FERNANDES, 2005).
A camada competitiva de um Mapa de Kohonen é representada em uma matriz
bidimensional onde a vizinhança de um neurônio pode estar representada de algumas formas
(TAFNER 1995 apud FERNANDES, 2005).

45
Figura 7. Vizinhança dos neurônios de um Mapa de Kohonen no padrão retangular
Fonte: Mnemosyne Studio (2014).
A Figura 7 representa a vizinhança de um Mapa de Kohonen no padrão retangular, porém
esse é apenas um dos padrões que pode ser assumido, como demonstra a Figura 8.
Figura 8. Vizinhança dos neurônios de um Mapa de Kohonen no padrão hexagonal.
Fonte: Mnemosyne Studio (2014).
O neurônio vencedor e seus vizinhos são chamados de regiões, que fazem o reconhecimento
dos padrões de entrada, tendo seu raio reduzido no decorrer do treinamento. Em um momento final,
a vizinhança tende a resumir-se em um único neurônio vencedor, tendo somente seus pesos
ajustados.
Segundo Staker (1995 apud FERNANDES, 2005) o ajuste dos pesos dos neurônios da
camada competitiva pode ser expressado pela seguinte equação:

46
Wij(t+1) = Wij(t) + aa(t)[Xi(t) – Wij(t)]
Onde:
Wij(t): valor dos pesos do vetor de pesos no instante t;
aa(t): taxa de aprendizagem no instante t; e
Xi(t): elemento do vetor de entrada no instante t.
O decréscimo da taxa de aprendizagem pode ser expresso pela equação:
aa (t) = aa (t) [1 – t / T]
Onde:
t: iteração atual;
T: número total de iterações no processo de aprendizagem.
A taxa de aprendizagem decresce a cada iteração, e o número total de iterações no processo
de aprendizagem é um parâmetro que deve ser fixado antes do treinamento da rede. A medida
adotada é de pelo menos 500 vezes o número de neurônios da camada de saída (FERNANDES,
2005).
O processo de treinamento para os mapas de Kohonen é competitivo. Para cada treinamento
um neurônio irá “vencer”. Esse neurônio vencedor tem os seus pesos ajustados, o que faz com que
ele reaja ainda mais fortemente à entrada na próxima iteração. Como diferentes neurônios “vencem”
para diferentes padrões, sua habilidade de reconhecer aquele padrão em particular será aumentada
(HEATON, 2013).

47
3 TRABALHOS RELACIONADOS
Existem diversos softwares que utilizam conceitos de redes neurais e Big Data. Porém,
dentro do foco de dispositivos móveis, encontram-se apenas aplicativos que utilizam esses
conceitos independentemente ou, no máximo, dois conceitos dentro de um mesmo trabalho. Sendo
assim, existem determinados trabalhos que especificamente se assemelham à pesquisa proposta,
conforme itens a seguir.
3.1 TRABALHOS ACADÊMICOS
Nessa seção são apontados os trabalhos acadêmicos que utilizam conceitos similares ao da
pesquisa.
3.1.1 Análise de Desempenho de Aprendizagem Não-Supervisionada para Previsão de Velocidade de uma Rede Rodoviária
Muitas aplicações de sistemas de transporte inteligente requerem previsões específicas de
parâmetros de tráfego. Métodos de aprendizado de máquina direcionados à dados, tal como
regressão de suporte vetorial podem efetivamente efetuar essa tarefa com precisão. Entretanto, esses
métodos sempre foram testados em pequenos segmentos de estrada. Essa pesquisa propôs um
método escalável utizando regressão de suporte vetorial para lidar com o problema de previsão de
velocidade em uma rede de estradas grande e heterogênea. Ela utilizou técnicas de aprendizagem
sem supervisão, através de mapas auto-organizáveis e clusterização (IEEEXPLORE DIGITAL
LIBRARY, 2014). Essa pesquisa realizou mineração de dados através de Mapas de Kohonen, que é
o método escolhido para a mineração de informações neste TCC.
3.1.2 Redes Neurais e sua Aplicação para o Auto-Diagnóstico Estrutural
Segundo Hsieh (2014), o objetivo desse estudo foi a concepção de uma rede neural em
JAVA para estimar a localização e o tamanho de fissuras em uma viga. Esse estudo também
explorou o potencial das redes neurais artificiais para o auto-diagnóstico estrutural. Foi formulada
uma arquitetura de rede neural para auto-diagnóstico estrutural visando atingir esse objetivo.
Existem três componentes dessa arquitetura: o modelo do sistema físico, as unidades de pré-
processamento de dados e as redes neurais que são treinadas para prever a localização e a

48
magnitude do dano. Pontos importantes do projeto incluem as variáveis a serem observadas, a
arquitetura das redes neurais, e o algoritmo de aprendizado. Inicialmente, um modelo de diagnóstico
de dano estrutural é desenvolvido e testado. O mesmo então estende-se para lidar com dois pontos
de danos, e assim sucessivamente. Os resultados deste trabalho podem ser usados para a inspeção
de elementos estruturais, principalmente vigas. O método proposto resolve eficazmente o problema
inverso de estimar o tamanho e localização de danos a partir da informação de deslocamento do
feixe para este cenário restrito. A rede neural também possui um desempenho adequado para dados
contaminados por erros de medição. Tal trabalho utilizou a mineração de dados via redes neurais
sobre um mapa de dados, assim como este TCC, para identificar padrões diversos na estrutura dos
dados analisados.
3.1.3 Entendendo os Padrões de Mobilidade Humana Através dos Registros Telefônicos
Segundo Yan (2014) nesta tese é apresentado um estudo cultural sobre a distribuição
humana e como ela pode ser influenciada por fatores sócio-econômicos regionais, como a densidade
populacional, a renda e a taxa de desemprego. Registros de telefonia móvel contém informações de
chamadas detalhadas da localização espaço-temporal de centenas de milhares de usuários, que
podem ser utilizadas para representar o deslocamento humano. Os comportamentos de usuários de
24 regiões autônomas (5 em São Francisco, 3 na República Dominicana e 16 em um país europeu)
são estudadas através dessa massa de dados de telefonia móvel. Nessa pesquisa é relatado que as
pessoas em diferentes regiões tem padrões muito heterogêneos de deslocamento, que podem ser
agrupados em quatro famílias distintas. Os dados obtidos como resultado demonstram que a
distribuição dos deslocamentos em relação ao comprimento da viagem possuem um certo grau de
correlação com a densidade populacional e sua renda. Esse trabalho se utiliza de Mapas de
Kohonen, mineração de dados em Big Data com dispositivos móveis para reconhecimento de
padrõs de comportamento humano, em uma proposta relacionada à pesquisa.

49
3.2 TRABALHOS COMERCIAIS
Nessa seção são apontados os trabalhos comerciais que utilizam conceitos similares ao deste
TCC, tais como:
3.2.1 Advizor
Segundo a Advizor Solutions (2014), o Advisor é um sistema de Business Intelligence
baseado em análise preditiva e gerenciamento de dados em memória, o que permite um retorno
rápido dos dados analisados para o usuário. Ele é baseado em uma tecnologia de 15 anos dos
laboratórios Bell, cuja pesquisa era focada em como os humanos percebem e reagem à informação
recebida. Essa análise de padrões humanos é o que o relaciona com o trabalho de pesquisa, que
também minera dados dos perfis utilizando redes neurais.
3.2.2 Augify
O Augify é um sistema em nuvem que permite depurar aplicações de Big Data na nuvem.
Segundo o Augify (2014) ele consegue coletar dados de diferentes fontes (tais como notícias, blogs,
fórum e mídia social), prever comportamentos e eventos e utilizar a rede neural mais adequada para
as suas necessidades. Assim como este TCC, ele se utiliza de fontes de informações de redes sociais
(e afins, no caso do Augify) para minerar dados sobre os usuários das mesmas.
3.2.3 Centrifuge Visual Network Analytics
O Centrifuge Visual Network Analytics é uma tecnologia de descoberta de conhecimento
em Big Data que provê a capacidade de conectar-se, visualizar e analisar dados combinando análise
de informações, visualizações interativas e recursos de colaboração para simplificar o
reconhecimento de padrões e de conexões entre nodos. Segundo a Centrifuge Systems (2014), o
sistema combina integração de dados com mapeamento de relacionamento dinâmico e análise visual
para resolver fraudes e investimentos de risco em serviçoes financeiros, farmacêuticos e
governamentais. Assim como este TCC, o Centrifuge faz mapeamento de dados em Big Data com
Mapas de Kohonen, visando descobrir padrões implícitos.

50
3.2.4 Hawrkore
Esse aplicativo permite o reconhecimento de escrita utilizando-se mapas de Kohonen. O
usuário escreve na tela do dispositivo móvel com o toque e o algoritmo interpreta o caractere ou
frase e faz o seu reconhecimento, permitindo assim copiá-lo para memória para ser colado em
outros aplicativos de notas (ITUNES APP STORE, 2014). O Hawrkore é um aplicativo para
dispositivos móveis em Objective-C, assim como a proposta da pesquisa, e utiliza também a mesma
técnica de redes neurais para realizar a sua análise.
3.2.5 Paper Boy Online
Segundo a iTunes App Store (2014) esse aplicativo refere-se a uma rede neural de notícias.
Um bot lê feeds RSS e determina se os artigos possuem algo em comum. O Paper Boy classifica os
artigos de três formas diferentes: eventos, eventos relacionados e palavras dos eventos.
Se os artigos possuem características comuns, o algoritmo irá colocá-los no mesmo evento.
Se os eventos parecem relacionados, então serão classificados em uma seção de “eventos
relacionados”. Cada evento é derivado de palavras encontradas na descrição e título dos artigos.
Essas palavras podem ser escolhidos para ver se outros artigos compartilham as mesmas palavras.
O aplicativo faz uso de redes neurais para classificar e relacionar as informações de forma
organizada para o usuário.
Assim como na pesquisa, o aplicativo faz uso de redes neurais para a mineração de dados e
o relacionamento de informações, visando buscar um padrão solicitado pelo usuário. Ele também
utiliza a mesma tecnologia e linguagem de programação.
3.2.6 Plotly
O Plotly é um sistema online de análise e visualização de dados. Ele permite a criação de
gráficos online, análises, um terminal para utilização de Python bem como bibliotecas gráficas para
Python, R, MATLAB, Perl, Julia, Arduino e REST. Segundo o Plotly (2014), ele permite a análise
de informações no formato de planilhas de Excel, CSV, TSV, arquivos de MATLAB, Microsoft
Access ou Texto. Assim como este TCC, o Plotly faz mineração de dados em Big Data.
51
3.3 ANÁLISE COMPARATIVA
Após a pesquisa bibliográfica das tecnologias existentes, foi realizada uma análise
comparativa dos aplicativos existentes que as usavam para determinar a relevância de cada um deles
para o trabalho. Durante a análise foram verificados quais dos requisitos eram atendidos por eles e
de que forma. Os trabalhos acadêmicos foram consultados na base de artigos do MIT (Massachusets
Institute of Technology), mais especificamente do IEEE (Institute of Electrical and Electronics
Engineers), DCEE (Department of Civil and Environmental Engineering) e DBCS (Department of
Brain and Cognitive Sciences).
Os trabalhos comerciais são ferramentas online ou aplicativos que possuem similaridades
com o trabalho a ser desenvolvido pela pesquisa.
3.3.1 Análise dos Trabalhos Acadêmicos
Nessa seção são apontadas as comparações entre os trabalhos acadêmicos e a proposta do
TCC, conforme a Tabela 1.
Tabela 1. Análise comparativa dos trabalhos acadêmicos Índice Dispositivos
Móveis Rede Neural Big Data Mineração de
Dados Linguagem Tecnologia
3.1.1 Não Mapas de Kohonen Não Sim JAVA Cliente-Servidor
3.1.2 Não Perceptron Não Sim JAVA Cliente-Servidor
3.1.3 Sim Mapas de Kohonen Sim Sim JAVA Cliente-Servidor
Pesquisa Sim Mapas de Kohonen Sim Sim Objective-C Aplicativo Mobile
3.3.2 Análise dos Trabalhos Comerciais
Nessa seção são apontadas as comparações entre os trabalhos comerciais e a proposta do
TCC, conforme a Tabela 2.
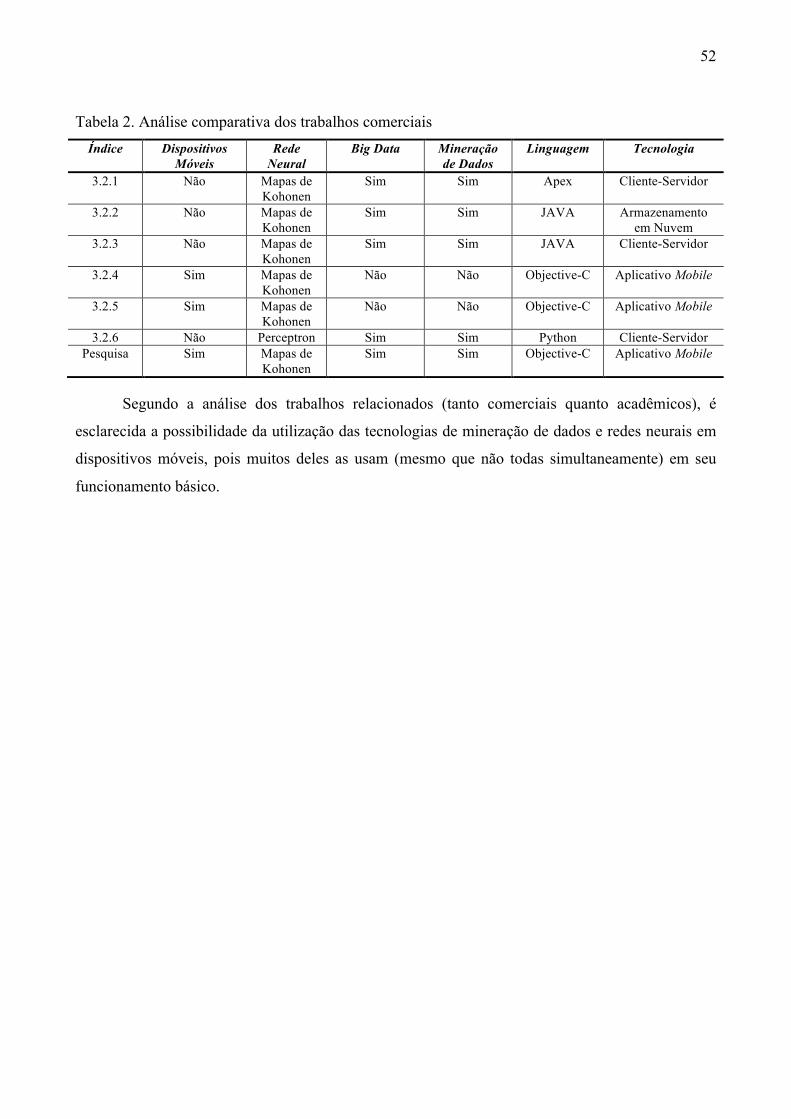
52
Tabela 2. Análise comparativa dos trabalhos comerciais Índice Dispositivos
Móveis Rede
Neural Big Data Mineração
de Dados Linguagem Tecnologia
3.2.1 Não Mapas de Kohonen
Sim Sim Apex Cliente-Servidor
3.2.2 Não Mapas de Kohonen
Sim Sim JAVA Armazenamento em Nuvem
3.2.3 Não Mapas de Kohonen
Sim Sim JAVA Cliente-Servidor
3.2.4 Sim Mapas de Kohonen
Não Não Objective-C Aplicativo Mobile
3.2.5 Sim Mapas de Kohonen
Não Não Objective-C Aplicativo Mobile
3.2.6 Não Perceptron Sim Sim Python Cliente-Servidor Pesquisa Sim Mapas de
Kohonen Sim Sim Objective-C Aplicativo Mobile
Segundo a análise dos trabalhos relacionados (tanto comerciais quanto acadêmicos), é
esclarecida a possibilidade da utilização das tecnologias de mineração de dados e redes neurais em
dispositivos móveis, pois muitos deles as usam (mesmo que não todas simultaneamente) em seu
funcionamento básico.

53
4 DESENVOLVIMENTO
Este capítulo possui a descrição dos processos que culminaram na criação do aplicativo
desta pesquisa. É descrita a visão geral do sistema, a análise de requisitos, a modelagem do sistema,
o detalhamento do desenvolvimento, a descrição dos experimentos e os resultados obtidos.
4.1 VISÃO GERAL DO SISTEMA
O aplicativo coleta informações do Facebook através do Facebook Graph API (uma
biblioteca criada para tal fim). Uma vez que os dados tenham sido recuperados, eles são pré-
processados e armazenados em um banco de dados local, conforme a Figura 9. O aplicativo
desenvolvido foi escrito em Objective-C e C para iOS 7.0 utilizando XCode 6.0 com banco de
dados SQLite.
Figura 9. Visão Geral do Sistema
Durante o pré-processamento, o módulo de geolocalização calcula a posição do usuário e a
compara com os dados obtidos do sistema de mapas da Apple (o mesmo usado no Apple Maps),
visando encontrar a cidade aonde o usuário se encontra. Após organizados os dados, os mapas de
Kohonen analisam a informação do banco de dados local demonstrando assim os resultados ao
usuário. Enquanto a visão geral do sistema parece simples, cada um dos processos envolve um
grupo de passos específicos para alcançar os resultados esperados.

54
4.2 ANÁLISE DE REQUISITOS
Para esclarecer o modo como o sistema funciona, os próximos tópicos demonstram os
requisitos funcionais, não funcionais e as regras de negócios que o delimitam, de acordo com os
conceitos de engenharia de software citados por Sommervile (2011).
4.2.1 Requisitos Funcionais
No contexto do sistema desenvolvido, há quatro módulos categorizados dentro do conceito
de Modelo-Visão-Controlador:
• Geolocalização: Fase responsável pela descoberta da latitude e longitude do usuário
no momento do carregamento do aplicativo, com uma precisão de seis dígitos.
• Recuperação de Informações: Ainda durante o carregamento, logo após a
descoberta da geolocalização, o aplicativo baixa do banco de dados do Facebook
informações específicas das localidades em um raio de mil metros de acordo com a
categoria estabelecida e as insere no banco de dados SQLite. Essas informações são
as variáveis a serem tratadas no treinamento dos mapas, sendo elas: latitude,
longitude, número de checkins, número de likes e o número de likes de perfis
associados.
• Pré-Processamento: Os dados baixados através da fase de Recuperação de
Informações são convertidos em um formato passível de cálculo (double) e tem sua
precisão ajustada, enquanto são inseridos em uma matriz de x por y, onde x é igual ao
número de dendritos e y é igual ao número de localidades recuperadas pela fase
anterior, representando os neurônios.
• Treinamento: Durante essa fase (a única híbrida de C e Objective-C, visando
aumentar a velocidade do processamento descartando a orientação a objetos e
realizando conversões implícitas) são realizados os cálculos de distância euclidiana,
ajustes de peso e ajuste de taxa de aprendizagem para todos os neurônios em um
determinado número de variáveis, visando obter os resultados especificados na
proposta do aplicativo. É treinada uma matriz bidimensional com neurônios de cinco
dendritos, cada um contendo um aspecto relevante da pesquisa (latitude, longitude,

55
checkins, número de likes e número de likes de amigos). A escolha desse grupo de
dados deu-se visando um maior nível de detalhamento no resultado final.
Geolocalização
RF01: O sistema deverá checar a conexão com a internet;
RF02: O sistema deverá calcular a latitude e longitude do usuário (geocoder);
RF03: O sistema deverá comparar as informações de posição com as APIs de mapas da
Apple (geocoder reverso);
RF04: O sistema deverá descobrir o nome da cidade baseada nos dados obtidos; e
RF05: O sistema deverá armazenar o nome da cidade e os dados de latitude e longitude no
banco de dados local.
Recuperação de Informações
RF01: O sistema faz a chamada à API;
RF02: Utilizando a latitude e longitude do usuário na fase de pré-processamento, o sistema
recupera os dados de longitude, latitude, número de checkins, número de likes, de todas as
localidades no cadastradas como páginas públicas no Facebook dentro de um raio de mil metros e
categorizadas como "Restaurant". Esta categoria, nesta versão do sistema desenvolvida para a
pesquisa, é especificada no código e imutável. Ela foi escolhida pois é a que mais apresentou um
retorno de dados adequado para testes;
RF03: O sistema grava as informações na tabela LUGARES.
Pré-Processamento
RF01: O sistema recupera as informações do banco de dados;
RF02: O sistema aplica uma conversão de tipos (double) sobre as informações numéricas a
serem calculadas;

56
RF03: O sistema realiza um ajuste de precisão (de 2 a 6 casas), dependendo do dado
processado; e
RF04: O sistema insere os dados pré-processados em uma matriz de x por y, aonde x é o
número de dendritos do neurônio (5 para esta pesquisa) e y é o número de localidades descobertas
na fase de Recuperação de Informações.
Treinamento
RF01: O sistema deve selecionar os dados de entrada para treinamento, buscando os dados
da linha do maior e do menor número de likes e armazenando-os em variáves;
RF02: O sistema deve submeter todos os neurônios da matriz à função de distância
euclidiana utilizando como parâmetro a primeira entrada;
RF03: O sistema deve encontrar o neurônio vencedor do resultado da primeira entrada;
RF04: O sistema deve ajustar os pesos do neurônio vencedor do resultado da primeira
entrada;
RF05: O sistema deve submeter todos os neurônios da matriz à função de distância
euclidiana utilizando como parâmetro a segunda entrada;
RF06: O sistema deve encontrar o neurônio vencedor do resultado da segunda entrada;
RF07: O sistema deve ajustar os pesos do neurônio vencedor do resultado da segunda
entrada;
RF08: O sistema deve ajustar a taxa de aprendizagem
RF09: O sistema deve submeter todos os neurônios da matriz à função de distância
euclidiana utilizando como parâmetro a entrada de dados do usuário;
RF10: O sistema deve armazenar todas os dados processados na tabela
LUGARES_TREINADOS; e
RF11: O sistema deve alimentar a tabela da interface gráfica, com os dados ordenados da
menor para a maior distância euclidiana.

57
4.2.2 Requisitos Não Funcionais
RNF01: O sistema deve ser desenvolvido na plataforma iOS 7.x;
RNF02: O sistema deve ser desenvolvido nas linguagens Objective-C e C;
RNF03: O sistema deve utilizar banco de dados SQLite;
RNF05: O sistema deve possuir acesso à internet;
RNF06: O sistema deve solicitar acesso do usuário ao Facebook;
RNF07: O sistema deve mostrar uma foto do usuário quando a conexão com o Facebook for
realizada com sucesso;
RNF08: O sistema deve mostrar a cidade e estado aonde o usuário se encontra;
RNF09: O sistema deve possuir dois botões (Logout e Pesquisar) para ativação das suas
funcionalidades; e
RN10: O sistema deve exibir os resultados em uma tabela, em ordem de prioridade do
resultado mais adequado ao menos adequado à pesquisa.
4.2.3 Regras de Negócio
RN01: O sistema selecionará os dados a serem analisados de acordo com os perfis
associados ao usuário;
RN02: O sistema deverá demonstrar aos usuários as localizações apropriadas para visitas;
RN03: As análises deverão ser feitas através de um Mapa de Kohonen;
RN04: O sistema deve armazenar os dados após processamento juntamente com sua
distância euclidiana;
RN05: O sistema deverá utilizar a Facebook API para realizar o seu login inicial;
RN06: O sistema deverá avisar ao usuário enquanto estiver pré-processando dados; e

58
RN07: O sistema deverá avisar ao usuário enquanto estiver minerando dados com Mapas de
Kohonen.
4.3 MODELAGEM DO SISTEMA
Nesta seção é apresentada a modelagem do sistema subdividida em itens conforme segue.
4.3.1 Diagramas de Casos de Uso
Os diagramas de caso de uso são os modelos para a representaçãoo das funcionalidades
observáveis do sistema e dos elementos externos a ele. O diagrama de casos de uso mostra como a
análise de requisitos molda o sistema (BEZERRA, 2002). O modelo de desenvolvimento para
dispositivos móveis (dentro do escopo do iOS) segue o padrão Modelo-Visão-Controlador (MVC)
(APPLE DEVELOPER, 2014), e os casos de uso são apresentados nesse padrão conforme mostra a
Figura 10.
Figura 10. Diagrama de Caso de Uso

59
• Login (API): Os dados para a comparação só podem ser retornados se o usuário
efetuar login na rede social (no caso, no Facebook);
• Solicitar Análise: O usuário solicita a análise dos perfis dos usuários associados ao
dele;
• Requisitar Localização: O sistema de geolocalização captura a localização atual do
usuário;
• Validar Usuário: Paralelamente aos casos “Solicitar Análise” e “Requisitar
Localização”, a senha do usuário é validada;
• Requisitar Dados: São requisitados os dados dos perfis associados ao usuário;
• Comparar Resultados: O Mapa de Kohonen analisa os resultados e cria padrões; e
• Mostrar Análise: A análise das melhores localizações a serem frequentadas são
retornadas ao usuário.
Com esses passos, será possível ao usuário recuperar as informações e efetuar a análise
solicitada baseada nos perfils dos usuários associados.
4.3.2 Diagramas de Bancos de Dados
O banco de dados do sistema desenvolvido nesta pesquisa é composto de duas tabelas
(LUGARES e LUGARES_TREINADOS). A tabela LUGARES tem a função de armazenar os
dados trazidos através da fase de Recuperação de Informações, enquanto a tabela
LUGARES_TREINADOS armazena os dados já processados pela fase de Treinamento. Os
modelos físico e lógico são demonstrados na Figuras 11 e Figura 12, respectivamente.

60
Figura 11. Modelo Físico do Banco de Dados
Figura 12. Modelo Lógico do Banco de Dados
Os campos das tabelas demonstradas na Figura 11 e na Figura 12 possuem as
funcionalidades descritas conforme segue:
• Código do Lugar (CD_LUGAR): Armazena o código único criado para gerar uma
distinção entre os registros, e também é a chave primária, não permitindo a inserção
de valores repetidos nesse campo;
• Código do Facebook (CD_FACEBOOK): Armazena o código dos locais públicos
no Facebook. Cada um dos lugares trazidos pela fase de Recuperação de
Informações possui um identificador único atribuído a ele pelo sistema do Facebook.
Essa é utilizada para buscar qualquer referência ao local dentro dos dados dessa rede
social;

61
• Nome do Lugar (NM_LUGAR): Armazena o nome da localidade de acordo com o
seu cadastro no Facebook;
• Nome da Categoria (NM_CATEGORIA): Armazena a categoria do local de
acordo com sua classificação no Facebook. O Facebook possui diversas categorias,
escolhidas durante a criação da página pública. A definida para o escopo desta
pesquisa é a categoria "Restaurant" (Restaurante), pois é a que mais apresentou um
grupo de retornos adequados para testes;
• Número de Checkins (NU_CHECKINS): Armazena o número total de checkins
recebido por aquele local no Facebook. Esse campo armazena o número total de
checkins recebidos por aquela página pública até o momento da pesquisa;
• Número de Likes (NU_LIKES): Armazena o número total de likes recebidos por
aquele local no Facebook. Esse campo armazena o número total de likes recebido por
aquela página até o momento da pesquisa;
• Número de Likes de Amigos (NU_LIKESFRIENDS): Armazena o número total
de likes de perfis relacionados ao usuário que executou a pesquisa recebidos por
aquele local no Facebook. Esse campo armazena o número total de likes de perfils
relacionados recebido por aquela página até o momento da pesquisa;
• Número da Latitude (NU_LATITUDE): Armazena o valor da latitude do local,
segundo cadastro no Facebook;
• Número da Longitude (NU_LONGITUDE): Armazena o valor da longitude do
local, segundo cadastro no Facebook;
• Valor da Distância Euclidiana (VL_DIST_EUCLI): Possuído apenas pela tabela
"LUGARES_TREINADOS", esse campo armazena o valor da distância euclidiana
após o processamento dos dados de entrada do usuário (após o treinamento da rede),
para que a informação possa ser classificada de acordo com sua prioridade e
mostrada ao usuário.

62
4.3.3 Pré-Processamento
Segundo Fernandes (2005) antes da aplicação nas redes de Kohonen, os dados precisam ser
pré-processados através de normalizações, escalonamentos e conversões de formato para torná-los
mais apropriados a sua utilização na rede. O pré-processamento será dividido nas seguintes etapas,
visando obter um conjunto de dados que garanta o funcionamento correto do Mapa de Kohonen:
1. Seleção de dados utilizáveis: Logo após a fase de Recuperação de Informações,
apenas os dados especificados nos parâmetros da string de busca disponibilizada
pelo Facebook Graph API são inseridos no banco de dados, para não haver o retorno
de informações desnecessárias.
2. Conversão de tipos (double): Os dados provenientes do banco de dados são
inseridos na matriz na forma de NSString, e precisam ser convertidos para poderem
ser úteis para os cálculos. Os dados de latitude, longitude, número de checkins,
número de likes e número de likes de perfis associados são convertidos para double
através de uma conversão implícita.
3. Ajuste de precisão: Quando são convertidos para o padrão numérico, alguns dados
(tais como latitude e longitude) são convertidos para seis casas de precisão, visando
uma melhor especificação da localização do usuário.
4.3.4 Mapas de Kohonen
De todos os dados armazenados durante a fase de Recuperação de Informações, o neurônio
padrão do sistema desenvolvido nesta pesquisa usa cinco deles para realizar o treinamento do mapa.
Conforme demonstrado na Figura 13, os cinco dendritos são compostos dos dados de Checkins,
Latitude, Longitude, Likes e Likes de perfis associados. O número de neurônios é variável,
dependendo da posição do usuário e do número de localidades à volta dele compatíveis com os
dados de busca em um determinado raio.

63
Figura 13. Neurônio Padrão do Sistema
Os neurônios (N={C, LA, LO, L, L(A)}) são armazenados em uma matriz x por y, aonde x é
igual ao número de dendritos e y é igual ao número de localidades recuperadas. Segundo Fernandes
(2005) o número de iterações necessárias utilizada como padrão é de 500 multiplicado pelo número
de neurônios. Para esta pesquisa, utilizou-se inicialmente esta quantidade de iterações (o que
proporcionou um tempo de treinamento de mais de sessenta segundos), então outros valores foram
testados visando-se manter o resultado original, descobrindo-se finalmente o parâmetro registrado
na Tabela 3 no item "Número de iterações" (número de neurônios multiplicado por 10).
Tabela 3. Parâmetros de treinamento Parâmetros Valores
Número de dendritos (x) 5 Número de neurônios (y) Variável de acordo com a localidade
Taxa de Aprendizagem (aa) 0.9 Número de iterações y multiplicado por 10
Os parâmetros de entrada para o treinamento são extraídos do próprio volume retornado na
fase de Recuperação de Informações. São utilizados como dados para fim as extremidades do
parâmetro likes, ou seja, todos os dados do maior número de likes e todos os dados do menor
número de likes, visando assim gerar uma granularização e uma maior amplitude do
reconhecimento de padrões da rede neural artificial.
Tabela 4. Parâmetros de entrada para o treinamento Parâmetros Valores
Latitude Latitude (menor/maior likes) Longitude Longitude (menor/maior likes)
Número de Checkins Checkins (menor/maior likes) Número de Likes Mínimo/Máximo dos dados recuperados
Número de Likes de Perfis Associados Likes Perfis Associados (menor/maior likes)

64
A Tabela 4 define os dados dos dois parâmetros de entrada (E={C, LA, LO, L, L(A)}),
sendo estes os neurônios com menor e maior número de likes.
4.4 DETALHAMENTO DO DESENVOLVIMENTO
O desenvolvimento do aplicativo desta pesquisa foi realizado de acordo com os módulos
(dividos em fases) pré-estabelecidos, e testados individualmente. Foi criado um aplicativo para cada
fase (com exceção da fase de Treinamento), e posteriomente o código foi unificado para a
concepção do sistema.
4.4.1 Geolocalização
Para a criação do funcionamento da geolocalização, houve a necessidade de consulta com o
Apple Maps. Esse recurso permitiu a localização do dispositivo e a tradução desses dados em
latitude, longitude e da cidade aonde o usuário se encontra (através das funções de geocoder e
geocoder reverso). Durante a inicialização do aplicativo (função viewDidLoad) o localizador é
alocado, e os parâmetros são setados para haver uma atualização a cada 100 metros, conforme o
Quadro 1.
localizador = [[CLLocationManager alloc] init]; localizador.distanceFilter = kCLDistanceFilterNone; localizador.desiredAccuracy = kCLLocationAccuracyHundredMeters; [localizador startUpdatingLocation];
Quadro 1. Inicialização da geolocalização. Mesmo tendo sido a geolocalização inicializada, o aplicativo ainda não consultou a latitude
e longitude do usuário. Esses processos são realizados quando o usuário efetua o login, na função
loginViewFetchedUserInfo. Assim que esses dados são obtidos, o aplicativo inicializa a
geolocalização reversa, para descobrir em qual cidade e estado o usuário se encontra.
latitude=localizador.location.coordinate.latitude; longitude=localizador.location.coordinate.longitude; CLGeocoder *geocoder = [[CLGeocoder alloc] init]; CLLocation *location = [[CLLocation alloc]initWithLatitude:latitude longitude:longitude]; [geocoder reverseGeocodeLocation:location completionHandler:^(NSArray *placemarks, NSError *error) { if (error) { NSLog(@"Geocode falhou com o erro: %@", error); return; }

65
CLPlacemark *myPlacemark = [placemarks objectAtIndex:0]; NSString *countryState = myPlacemark.administrativeArea; NSString *countryCity = myPlacemark.locality; lblCidadeEstado.text = [NSString stringWithFormat:@"%@%@%@",countryCity,@" - ",countryState]; }];
Quadro 2. Geocoder e Geocoder reverso
Conforme demonstrado no Quadro 2, a geolocalização se efetua após o login do usuário no
Facebook, e o descobrimento do nome da cidade se dá com base na latitude e longitude encontradas
anteriormente, que são utilizadas para alimentar o objeto location, que é utilizado como parâmetro
para a geolocalização reversa (retorna o nome da cidade e estado, que são mostradas na interface
gráfica).
Ao realizar o processo de geolocalização, um erro foi encontrado durante essa fase do
desenvolvimento. A função loginViewFetchedUserInfo executava as operações do Quadro 2 duas
ou três vezes, atrasando e eventualmente comprometendo o processo de geolocalização. Esse
comportamento da função é um defeito específico da Facebook API (replicação da execução do
código de duas a três vezes, aleatoriamente), e não da maneira como a mesma estava sendo utilizada
(primeira hipótese erguida durante esta pesquisa).
Para que a execução ocorresse apenas uma vez e as informações de geolocalização fossem
recuperadas de forma correta, foi adicionada uma variável booleana chamada FacebookCounter,
que controla o número de execuções. Ela é iniciada como false e tem o seu valor modificado para
true quando as operações são executadas.
-(void)loginViewFetchedUserInfo:(FBLoginView *)loginView user:(id<FBGraphUser>)user{ if (facebookCounter == false) { ... }; }
Quadro 3. Correção da função loginViewFetchedUserInfo A medida adotada no Quadro 3 corrigiu o funcionamento do módulo de geolocalização, e
permitiu que as informações fossem retornadas e a geolocalização reversa calculada uma única vez.
Os procedimentos descritos nos Quadros 1 e 2 ocorrem todos dentro da condição lógica apresentada
no Quadro 3. Uma vez que esses dados tenham sido descobertos, é caracterizado o fim da fase 1.

66
4.4.2 Recuperação de Informações Após a descoberta da geolocalização, o aplicativo a utiliza como parâmetro para retornar do
banco de dados do Facebook informações específicas das localidades em um raio de mil metros.
Tanto a categoria da localidade como o raio de busca são parâmetros previamente definidos na
consulta, conforme demonstrado no Quadro 4.
NSString *caminhoBusca = [NSString stringWithFormat: @"/search?q=restaurant&type=place¢er=%@,%@&distance=1000",latitude,longitude]; [FBRequestConnection startWithGraphPath:caminhoBusca parameters:nil HTTPMethod:@"GET" completionHandler:^( FBRequestConnection *connection, id result, NSError *error ) { ... }
Quadro 4. Código da fase de Recuperação de Informações.
Os parâmetros de entrada (distance e q) da string de busca são variáveis, definidas pelo
desenvolvedor e inseridos no código, aonde o primeiro é o valor da distância em metros, e o
segundo é o valor da categoria (definida pelo Facebook). Os parâmetros de entrada para a string de
busca estão especificados na Tabela 5.
Tabela 5. Parâmetros da Recuperação de Informações Parâmetros Valores
Latitude Latitude no momento da inicialização Longitude Longitude no momento da inicialização Categoria Restaurant Raio (m) 1000
Os dados são tratados durante a recuperação das informações, linha a linha. Como cada
linha representa um neurônio, as informações de relevância são tratadas em inseridas no banco de
dados SQLite. A criação das tabelas utilizada nas quatro fases são realizadas na inicialização do
sistema, conforme o Quadro 5.
Durante a função viewDidLoad (função que realiza ações durante a inicialização de um
aplicativo em Objective C) é verificada a existência de um banco de dados chamado "kohonen.db".
Caso ele exista, para fins de teste da aplicação, ele é removido e o seu caminho é atribuído à
variável "dbCaminho".

67
Uma vez que a variável "dbCaminho" possua as informações da localização do banco de
dados, o aplicativo cria um novo arquivo kohonen.db e as tabelas associadas a esse arquivo
(LUGARES e LUGARES_TREINADOS), conforme a estrutura descrita no item 4.3.2 (Diagrama
de Bancos de Dados). Essas tabelas irão comportas os dados originais (LUGARES) e os dados da
rede treinada (LUGARES_TREINADOS).
A criação dessas tabelas tem relevância apenas a partir da segunda fase (Recuperação de
Informações), já que a primeira fase não faz utilização de banco de dados no seu processamento.
Caso as tabelas não consigam ser criadas, um aviso é enviado no log do compilador para fins de
debug. Nenhum feedback é enviado para o usuário nesta versão da aplicação desenvolvida para esta
pesquisa, porém posteriormente os erros podem ser reportados através do sistema de notificações do
iOS.
if ([filemgr fileExistsAtPath: dbCaminho ] == NO) { const char *dbpath = [dbCaminho UTF8String]; if (sqlite3_open(dbpath, &kohonenDB) == SQLITE_OK) { char *errMsg; const char *sql_stmt = "CREATE TABLE IF NOT EXISTS LUGARES (CD_LUGAR INTEGER PRIMARY KEY AUTOINCREMENT, CD_FACEBOOK TEXT, NM_LUGAR TEXT, NM_CATEGORIA TEXT, NU_CHECKINS REAL, NU_LIKES REAL, NU_LATITUDE REAL, NU_LONGITUDE REAL, NU_LIKESFRIENDS REAL)"; if (sqlite3_exec(kohonenDB, sql_stmt, NULL, NULL, &errMsg) != SQLITE_OK) { NSLog(@"Falhou ao criar tabela LUGARES"); } sql_stmt = "CREATE TABLE IF NOT EXISTS LUGARES_TREINADOS (CD_LUGAR INTEGER PRIMARY KEY, CD_FACEBOOK TEXT, NM_LUGAR TEXT, NM_CATEGORIA TEXT, NU_CHECKINS REAL, NU_LIKES REAL, NU_LATITUDE REAL, NU_LONGITUDE REAL, NU_LIKESFRIENDS REAL, VL_DIST_EUCLI REAL)"; if (sqlite3_exec(kohonenDB, sql_stmt, NULL, NULL, &errMsg) != SQLITE_OK) { NSLog(@"Falhou ao criar tabela LUGARES_TREINADOS"); } sqlite3_close(kohonenDB); } else { NSLog(@"Falhou ao abrir/criar banco de dados"); } }
Quadro 5. Criação das tabelas "LUGARES" e "LUGARES_TREINADOS"

68
A Facebook Graph API retorna os dados no formato JSON. Esses dados são recuperados da
API atribuindo a informação vinda nas chaves à variáveis locais para tratamento, conforme o
Quadro 6. Quando a instrução objectForKey possui mais de um parâmetro, significa que está
retornando dados de estruturas que estão dentro de outras estruturas.
No caso da variável "likesfriends", por exemplo, o sistema está tratando o número total de
perfis associados que deram like, parâmetro esse que está dentro do parâmetro "summary", que por
sua vez está dentro do "friends_who_like" que está dentro do "context".
id checkins = [result objectForKey:@"checkins"]; id likes = [result objectForKey:@"likes"]; id latitude = [result objectForKey:@"location"][@"latitude"]; id longitude = [result objectForKey:@"location"][@"longitude"]; id likesfriends = [result objectForKey:@"context"][@"friends_who_like"][@"summary"][@"total_count"];
Quadro 6. Tratamento das informações retornadas.
Uma vez que esses dados são recuperados e atribuídos às suas respectivas variáveis,
conforme demonstrado no Quadro 6, eles são inseridos na tabela LUGARES de acordo com o
Quadro 7.
sqlite3_stmt *statement; const char *dbpath = [dbCaminho UTF8String]; if (sqlite3_open(dbpath, &kohonenDB) == SQLITE_OK) { NSString *insertSQL = [NSString stringWithFormat:@"INSERT INTO LUGARES (CD_FACEBOOK, NM_LUGAR, NM_CATEGORIA, NU_CHECKINS, NU_LIKES, NU_LATITUDE, NU_LONGITUDE, NU_LIKESFRIENDS) VALUES (\"%@\", \"%@\", \"%@\", \"%@\", \"%@\", \"%@\", \"%@\", \"%@\")",codigo, nome, categoria, checkins, likes, latitude, longitude, likesfriends]; const char *insert_stmt = [insertSQL UTF8String]; sqlite3_prepare_v2(kohonenDB, insert_stmt,-1, &statement, NULL); if (sqlite3_step(statement) == SQLITE_DONE) { NSLog(@"Inserido => %s", insert_stmt); contadorLinhas++; } else { NSLog(@"Falhou => %s", insert_stmt); NSLog(@"Erro: %s", sqlite3_errmsg(kohonenDB)); } sqlite3_finalize(statement); sqlite3_close(kohonenDB); }
Quadro 7. Inserção da linha processada na tabela LUGARES. Os códigos apresentados nos Quadros 5, 6 e 7 ocorrem até que todas as localidades
recuperadas pelo processo de busca (Quadro 4) tenham sido inseridas nos bancos de dados. Cada

69
uma dessas localidades é um neurônio a ser utilizado pela fase de treinamento. Os trechos definidos
como "NSLog" são informações sobre o andamento do processamento das fases, retornadas ao
terminal do compilador para fins de debug. Uma vez que a última linha tenha sido inserida, é
caracterizado o fim da fase 2 (Recuperação de Informações) e o aplicativo aguarda a interação com
o usuário (clique no botão "Pesquisar"), para dar início às fases 3 e 4 (Pré-Processamento e
Treinamento).
Um dos empecilhos mais complexos ao desenvolvimento foi encontrado nesta fase. Sua
complexidade pode ser considerada alta pois sua resolução dependia puramente de fatores externos
(que por sua vez, não ocorreram), criando assim uma demanda de modificações no projeto para
garantir o seu funcionamento.
Durante o projeto do sistema desta pesquisa, entendia-se como "Friend" ou "Amigo",
qualquer perfil que fosse associado ao perfil do usuário que realiza a pesquisa. No escopo inicial,
esse seria o parâmetro utilizado (de forma escalar) para retornar os dados necessários para o
treinamento do Mapa de Kohonen, tais como checkins e likes que esses "Friends" criassem.
Porém, segundo o Facebook Developers (2014), em abril as políticas de segurança da
empresa em relação à distribuição de dados dos usuários mudaram, assim como algumas
expressões. Para o Facebook Graph API, o "Friend" ou "Amigo", que antes referia-se ao perfil
associado ao do usuário da pesquisa, passou a ser utilizado para definir qualquer usuário que além
de estar associado, deveria também ter instalado o aplicativo utilizado pelo usuário que realizava a
pesquisa (inviabilizando a recuperação de informações por esse método, já que o aplicativo estava
em desenvolvimento e em uso apenas pelo pesquisador).
Dentro do novo conceito de "Friend" também foram criados duas novas expressões:
invitable_friends e taggable_friends. A expressão invitable_friends permitia que os perfis
associados fossem avisados da existência do seu aplicativo (operação que usualmente utilizava o
identificador do usuário, necessário para o cumprimento desta demanda de Recuperação de
Informações), porém essa nova expressão gerava um novo identificador substituto, que pela sua
característica temporária, inviabilizava seu uso para os fins requeridos pelo aplicativo da pesquisa.
A expressão taggable_friends permitia que fosse referenciados quaisquer perfis associados que
tivessem sido marcados em fotos, o que também divergia da necessidade da demanda de
Recuperação de Informações.

70
A fase de Recuperação de Informações conseguiu ser realizada com um ajuste conceitual do
projeto. Ao invés de traçar as localidades através dos perfis associados, foi feito o caminho
contrário, traçando-se as localidades em um raio de mil metros e depois verificando-se quais perfis
associados fizeram referência a ela, permitindo assim que fossem encontradas todas as localizações
próximas juntamente com seus relacionamentos aos perfis associados ao do usuário que efetuou a
pesquisa.
4.4.3 Pré-Processamento
A fase de pré-processamento é a terceira fase, e consiste na fase de ajuste dos dados a serem
utilizados pelos mapas de Kohonen, e é iniciada assim que há uma interação do usuário com a
interface do software (botão "Pesquisar" é pressionado). No caso do aplicativo desta pesquisa, para
que o treinamento dos mapas auto-organizáveis possa ser efetuado com o máximo de acerto
possível na identificação dos padrões, as informações utilizadas por ele devem possuir formatos e
precisões similares.
NSString *querySQL = [NSString stringWithFormat:@"SELECT CD_LUGAR, CD_FACEBOOK, NM_LUGAR, NM_CATEGORIA, NU_CHECKINS, NU_LIKES, ROUND(NU_LATITUDE,4), ROUND(NU_LONGITUDE,4), NU_LIKESFRIENDS FROM LUGARES"]; const char *query_stmt = [querySQL UTF8String]; if (sqlite3_prepare_v2(kohonenDB, query_stmt, -1, &statement, NULL) == SQLITE_OK) { while (sqlite3_step(statement) == SQLITE_ROW) { mapaLugares[0][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 0)]; mapaLugares[1][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 1)]; mapaLugares[2][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 2)]; mapaLugares[3][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 3)]; mapaLugares[4][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 4)]; mapaLugares[5][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 5)]; mapaLugares[6][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 6)]; mapaLugares[7][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 7)]; mapaLugares[8][mapaContador] = [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 8)]; mapaContador++; } sqlite3_finalize(statement); }

71
Quadro 8. Transmissão de dados da tabela LUGARES para a matriz
Para realizar a tarefa de pré-processamento, inicialmente o aplicativo copia os dados da
tabela LUGARES para uma matriz NSString de x por y (conforme o Quadro 8), onde x é o número
de dendritos e y o número total de registro no banco de dados (que corresponde ao total de
localidades encontradas), visando realizar a operação diretamente na memória do dispositivo móvel.
Uma vez que os dados estejam todos alocados na matriz (e consequentemente, na memória),
os dados provenientes de x = {4, 5, 6, 7, 8} (que são respectivamente os checkins, likes, latitude,
longitude e likes de amigos) para todos os neurônios são convertidos para o tipo double e atribuídos
à variáveis conforme o Quadro 9.
m_nuCheckins = [mapaLugares[4][mapaContador] doubleValue]; m_nuLikes = [mapaLugares[5][mapaContador] doubleValue]; m_latitude = [mapaLugares[6][mapaContador] doubleValue]; m_longitude = [mapaLugares[7][mapaContador] doubleValue]; m_nuLikesFriends = [mapaLugares[8][mapaContador] doubleValue];
Quadro 9. Conversão de tipos
Alguns dos problemas apresentados na fase de pré-processamento foi a dificuldade de
criação de matrizes e manipulação de objetos em Objective-C. Enquanto no Objective-C a própria
sintaxe tornava a criação e manipulação de matrizes de objetos mais difícil que a criação e
manipulação de matrizes de valores inerente à linguagem C, o cálculo utilizando-se de valores
diretos mostrou um desempenho superior ao cálculo utilizando valores dentro de objetos.
NSMutableArray *dataArray = [[NSMutableArray alloc] initWithCapacity: 3]; [dataArray insertObject:[NSMutableArray arrayWithObjects:@"0",@"0",@"0",nil] atIndex:0]; [dataArray insertObject:[NSMutableArray arrayWithObjects:@"0",@"0",@"0",nil] atIndex:1]; [dataArray insertObject:[NSMutableArray arrayWithObjects:@"0",@"0",@"0",nil] atIndex:2];
Quadro 10. Criação de matrizes em Objective-C O Quadro 10 mostra a criação de matrizes de objetos, que alocam dentro de si apenas outros
objetos. A utilização desse tipo de matriz faria com que os valores acessados necessitassem de um
tempo de processamento maior.
NSString *mapaLugares[9][nuRegistros];
Quadro 11. Criação de matriz no Objective-C utilizando o formato da linguagem C
O Quadro 11 mostra a criação de matrizes conforme foi realizada no aplicativo. Apesar de
fazer utilização do tipo NSString, o padrão de criação similar ao da linguagem C faz com que essa

72
matriz aceite apenas valores NSString diretamente, tornando seu processamento mais efetivo em
termos de tempo.
4.4.4 Treinamento
Caracterizada como a quarta fase do aplicativo desta pesquisa, a fase do treinamento aplica
diversas funções matemáticas sobre as variáveis obtidas nas fases anteriores, visando obter um
reconhecimento de padrões que permita encontrar similaridades entre os dados treinados e os dados
apresentados após o treinamento.
A fase de treinamento possui duas entradas, que caracterizam os extremos do mapa. A
primeira entrada são os dados da localidade com o maior número de likes. A segunda localidade são
os dados da localidade com o menor número de likes. Esses parâmetros foram escolhidos visando
aumentar a possibilidade do mapa de encontrar padrões entre esses valores, e gerar uma
granularização do mesmo, conforme o Quadro 12.
querySQL = [NSString stringWithFormat:@"SELECT NU_CHECKINS, NU_LIKES, NU_LIKESFRIENDS, ROUND(NU_LATITUDE,4), ROUND(NU_LONGITUDE,4) FROM LUGARES WHERE NU_LIKES = (SELECT MAX(NU_LIKES) FROM LUGARES) LIMIT 1"]; query_stmt = [querySQL UTF8String]; if (sqlite3_prepare_v2(kohonenDB, query_stmt, -1, &statement, NULL) == SQLITE_OK) { if (sqlite3_step(statement) == SQLITE_ROW) { e1_nuCheckins = sqlite3_column_double(statement, 0); e1_nuLikes = sqlite3_column_double(statement, 1); e1_nuLikesFriends = sqlite3_column_double(statement, 2); e1_latitude = sqlite3_column_double(statement, 3); e1_longitude = sqlite3_column_double(statement, 4); } sqlite3_finalize(statement); }
Quadro 12. Obtenção do primeiro parâmetro de entrada (e1_)
Toda variável que possui o prefixo "e1_" armazena os dados relativos à primeira entrada,
para serem utilizados nos cálculos. A Entrada 1, representada no Quadro 12, refere-se aos dados
com maior número de likes, caracterizando assim a extremidade "superior" de entrada.
Os dados da Entrada 2 (a extremidade "inferior") é coletada através de um SQL similar, mas
que utiliza o parâmetro "MIN" ao invés do parâmetro "MAX", obtendo os resultados inversamente
proporcionais ao do SQL da Entrada 1.

73
querySQL = [NSString stringWithFormat:@"SELECT NU_CHECKINS, NU_LIKES, NU_LIKESFRIENDS, ROUND(NU_LATITUDE,4), ROUND(NU_LONGITUDE,4) FROM LUGARES WHERE NU_LIKES = (SELECT MIN(NU_LIKES) FROM LUGARES) LIMIT 1"]; query_stmt = [querySQL UTF8String]; if (sqlite3_prepare_v2(kohonenDB, query_stmt, -1, &statement, NULL) == SQLITE_OK) { if (sqlite3_step(statement) == SQLITE_ROW) { e2_nuCheckins = sqlite3_column_double(statement, 0); e2_nuLikes = sqlite3_column_double(statement, 1); e2_nuLikesFriends = sqlite3_column_double(statement, 2); e2_latitude = sqlite3_column_double(statement, 3); e2_longitude = sqlite3_column_double(statement, 4); } sqlite3_finalize(statement); }
Quadro 13. Obtenção do segundo parâmetro de entrada (e2_). Toda variável que possui o prefixo "e2_" armazena os dados relativos à segunda entrada,
para serem utilizados nos cálculos. A Entrada 2, representada no Quadro 13 refere-se aos dados
com menor número de likes, caracterizando assim a extremidade "inferior" de entrada.
Uma vez que os parâmetros de entrada (Entrada 1 e Entrada 2) foram obtidos e atribuídos às
variáveis, é inicializado o treinamento do mapa. O mesmo é feito através do cálculo de distância
euclidiana para todos os neurônios e ajuste dos pesos do neurônio vencedor (para ambas as
entradas), seguido posteriormente do ajuste da taxa de aprendizagem.
O Quadro 14 demonstra como é efetuado no sistema desta pesquisa o cálculo da distância
euclidiana. O neurônio vencedor é encontrado através de uma condição lógica que é executada ao
fim de cada instrução for. Para cada uma das entradas, a primeira vez que o for é executado, o
sistema armazena aquele valor para referência (mapaContador igual a zero) e através do if ele
realiza comparação com todos os valores posteriores, armazenando o resultado do menor cálculo de

74
distância euclidiana (padrão utilizado para indicar qual é o neurônio vencedor) até o encerramento
do loop, permitindo assim que os dados do neurônio vencedor sejam enviados à fase de ajuste de
pesos.
for (mapaContador = 0; mapaContador < nuRegistros; mapaContador++) { m_nuCheckins = [mapaLugares[4][mapaContador] doubleValue]; m_nuLikes = [mapaLugares[5][mapaContador] doubleValue]; m_latitude = [mapaLugares[6][mapaContador] doubleValue]; m_longitude = [mapaLugares[7][mapaContador] doubleValue]; m_nuLikesFriends = [mapaLugares[8][mapaContador] doubleValue]; //-- Aplica função euclidiana (d = ∑(x-w)2) r_funcaoEuclidiana = pow((e1_nuCheckins-m_nuCheckins),2) + pow((e1_nuLikes-m_nuLikes),2) + pow((e1_latitude-m_latitude),2) + pow((e1_longitude-m_longitude),2) + pow((e1_nuLikesFriends-m_nuLikesFriends),2); if (mapaContador == 0 || r_funcaoEuclidiana < r_Vencedor){ r_Vencedor = r_funcaoEuclidiana; posNeuronioVencedor = mapaContador; } }
Quadro 14. Cálculo da função euclidiana para a Entrada 1. Quando o neurônio vencedor é encontrado, seus pesos são calculados e atualizados de
acordo com os parâmetros daquela entrada (esse processo ocorre para as Entradas 1 e 2) e atribuídos
às variáveis, conforme o Quadro 15.
n_nuCheckins = [mapaLugares[4][posNeuronioVencedor] doubleValue] + (e_taxaAprendizagem*(e1_nuCheckins-[mapaLugares[4][posNeuronioVencedor] doubleValue])); n_nuLikes = [mapaLugares[5][posNeuronioVencedor] doubleValue] + (e_taxaAprendizagem*(e1_nuLikes-[mapaLugares[5][posNeuronioVencedor] doubleValue])); n_latitude = [mapaLugares[6][posNeuronioVencedor] doubleValue] + (e_taxaAprendizagem*(e1_latitude-[mapaLugares[6][posNeuronioVencedor] doubleValue])); n_longitude =[mapaLugares[7][posNeuronioVencedor] doubleValue] + (e_taxaAprendizagem*(e1_longitude-[mapaLugares[7][posNeuronioVencedor] doubleValue])); n_nuLikesFriends = [mapaLugares[8][posNeuronioVencedor] doubleValue] + (e_taxaAprendizagem*(e1_nuLikesFriends-[mapaLugares[8][posNeuronioVencedor] doubleValue]));
Quadro 15. Atualização dos pesos do neurônio vencedor

75
Uma vez que a atualização dos pesos da Entrada 1 ocorre, o processo de cálculo da distância
euclidiana e atualização de pesos ocorre também para a Entrada 2. Uma vez que esses processos
tenham ocorrido para as duas entradas, a taxa de aprendizagem é atualizada, de acordo com o
Quadro 16. Essas operações ocorrem em uma taxa de dez vezes o número de neurônios encontrados
durante a fase de Recuperação de Informações (y multiplicado por 10).
e_taxaAprendizagem = e_taxaAprendizagem * (1-((double)contadorIteracoes/ nuIteracoes));
Quadro 16. Atualização da taxa de aprendizagem Uma vez que o processamento das iterações termine, os parâmetros de entrada do usuário
(alocados no código) são utilizados na rede recém-treinada, visando obter-se um resultado ordenado
pela menor distância euclidiana. Quando esses resultados são obtidos, eles são armazenados na
tabela LUGARES_TREINADOS, que diferencia-se da tabela LUGARES apenas pela inserção do
campo VL_DIST_EUCLI, que guarda os dados da distância euclidiana da última consulta.
if (sqlite3_open(dbpath, &kohonenDB) == SQLITE_OK) { NSString *querySQL = [NSString stringWithFormat:@"SELECT CD_LUGAR, CD_FACEBOOK, NM_LUGAR, NM_CATEGORIA, NU_CHECKINS, NU_LIKES,ROUND(NU_LATITUDE,4), ROUND(NU_LONGITUDE,4), NU_LIKESFRIENDS, VL_DIST_EUCLI FROM LUGARES_TREINADOS ORDER BY VL_DIST_EUCLI"]; const char *query_stmt = [querySQL UTF8String]; if (sqlite3_prepare_v2(kohonenDB, query_stmt, -1, &statement, NULL) == SQLITE_OK) { while (sqlite3_step(statement) == SQLITE_ROW) { [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 2)], [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 4)], [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 5)], [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 8)], [[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 9)]); [nomesLugares addObject:[[NSString alloc] initWithUTF8String:(const char *) sqlite3_column_text(statement, 2)]]; mapaContador++; } sqlite3_finalize(statement); } sqlite3_close(kohonenDB); } [self.tbeResultados reloadData];
Quadro 17. Retorno dos dados e ordenação pela distância euclidiana.

76
Por último, conforme o Quadro 17, os dados são recuperados da tabela
LUGARES_TREINADOS e replicados na interface gráfica, ordenados pela menor distância
euclidiana de acordo com os dados de entrada do usuário na rede treinada, finalizando assim as
quatro fases descritas que constituem o funcionamento básico do aplicativo desta pesquisa.
Durante a construção do aplicativo, a necessidade do treinamento do mapa de Kohonen
poderia ser solucionada através de três métodos: a primeira, com a utilização de um framework
externo para o treinamento do mapa, a segunda através do treinamento em um servidor e a terceira
através do treinamento dos dados no próprio dispositivo móvel. Enquanto a primeira e segunda
opções demonstravam vantagens óbvias (diminuição do tempo de processamento e implementação
mais fácil), a terceira opção permitia uma maior versatilidade do treinamento (já que as localidades
mudam de acordo com o raio de latitude e longitude), e uma menor dependência de internet, já que
a transmissão de dados é realizada apenas na fase de Recuperação de Informações. A opção pelo
terceiro método também permitiu testar a possibilidade de um dispositivo móvel processar o
volume de dados proposto na pesquisa.
Durante o desenvolvimento desta pesquisa, uma vez escolhida a realização da quarta fase no
próprio aplicativo, houve uma certa dificuldade de encontrar material específico para realizar os
cálculos propostos por Teuvo Kohonen. A grande maioria dos artigos e trabalhos consultados
sempre faziam uso de um framework externo, o que tornava a compreensão de como o processo era
realizado bastante dificultada. Essa demanda foi solucionada consultando a segunda edição do livro
"Inteligência Artificial: Noções Gerais" que demonstrava as equações passo-a-passo.
4.4.5 Interface Gráfica
A interface gráfica do aplicativo é composta de quatro itens, distribuídos de maneira a
fornecer ao usuário o melhor feedback possível. A parte superior aloca a foto e a cidade aonde o
usuário se encontra (descoberta na fase um, pelo processo de geolocalização reversa), a parte central
possui uma lista para exibição de dados cadenciados e a parte inferior possui os dois únicos
elementos de interação com o usuário, o botão "Logout" e o botão "Pesquisar".
A foto do usuário indica que a conexão com o perfil da rede social (Facebook) foi realizado
com sucesso, enquanto a descrição da cidade serve como um indicador de que o sistema de
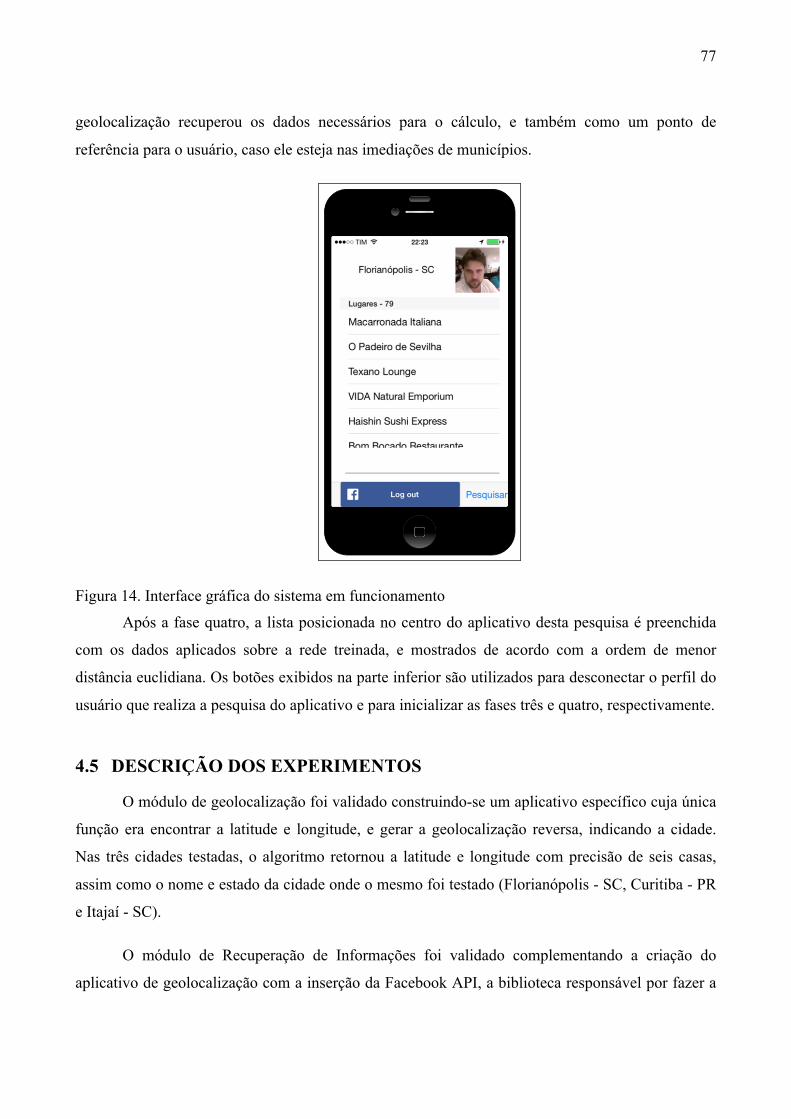
77
geolocalização recuperou os dados necessários para o cálculo, e também como um ponto de
referência para o usuário, caso ele esteja nas imediações de municípios.
Figura 14. Interface gráfica do sistema em funcionamento
Após a fase quatro, a lista posicionada no centro do aplicativo desta pesquisa é preenchida
com os dados aplicados sobre a rede treinada, e mostrados de acordo com a ordem de menor
distância euclidiana. Os botões exibidos na parte inferior são utilizados para desconectar o perfil do
usuário que realiza a pesquisa do aplicativo e para inicializar as fases três e quatro, respectivamente.
4.5 DESCRIÇÃO DOS EXPERIMENTOS
O módulo de geolocalização foi validado construindo-se um aplicativo específico cuja única
função era encontrar a latitude e longitude, e gerar a geolocalização reversa, indicando a cidade.
Nas três cidades testadas, o algoritmo retornou a latitude e longitude com precisão de seis casas,
assim como o nome e estado da cidade onde o mesmo foi testado (Florianópolis - SC, Curitiba - PR
e Itajaí - SC).
O módulo de Recuperação de Informações foi validado complementando a criação do
aplicativo de geolocalização com a inserção da Facebook API, a biblioteca responsável por fazer a

78
transmissão dos dados. Os dados recuperados do Facebook foram comparados com as páginas
públicas aos quais essas informações pertencem, e em todos os casos elas foram validadas em todas
as cidades pesquisadas.
Os testes do Pré-processamento foram validados de acordo com a utilização dos dados pelo
mapa de Kohonen. Quando um dado pré-processado era recusado por algum motivo (precisão ou
conversão incompatíveis), ele era corrigido até que todos os dados fossem aceitos para treinamento
nos diversos pontos testados (sendo sua grande maioria no centro de Florianópolis e Curitiba).
O treinamento do mapa de Kohonen foi feito utilizando-se como padrão de entrada os
registros com maior e menor número de likes, o que provou-se válido para criar uma granularização
e um reconhecimento de padrões entre os registros envolvidos no processo. As iterações utilizadas
começaram com 500 multiplicado pelo número de neurônios, porém esse parâmetro fazia com que
o treinamento demorasse muito a ser efetuado.
4.6 RESULTADOS
Os testes para o aplicativo foram realizados no centro de Florianópolis (latitude: -27.591194,
longitude: -48.558224), obtendo um total de 79 localizações de acordo com os parâmetros de
recuperação de informações da Tabela 1. As entradas para os testes após o treinamento estão de
acordo com a Tabela 6.
Tabela 6. Variáveis de entrada Variáveis: Rede Neural Artificial Valores
Latitude -27.591194 Longitude -48.558224
Número de Checkins 1300 Número de Likes 7000
O número total de iterações realizadas pelo treinamento foi de 790 (79 neurônios
multiplicado pelo parâmetro de iterações, que é igual a 10), processado em 12.71 segundos em um
iPhone 4S (Processador Apple A5 dual-core de 1GHz, 512 MB de RAM).
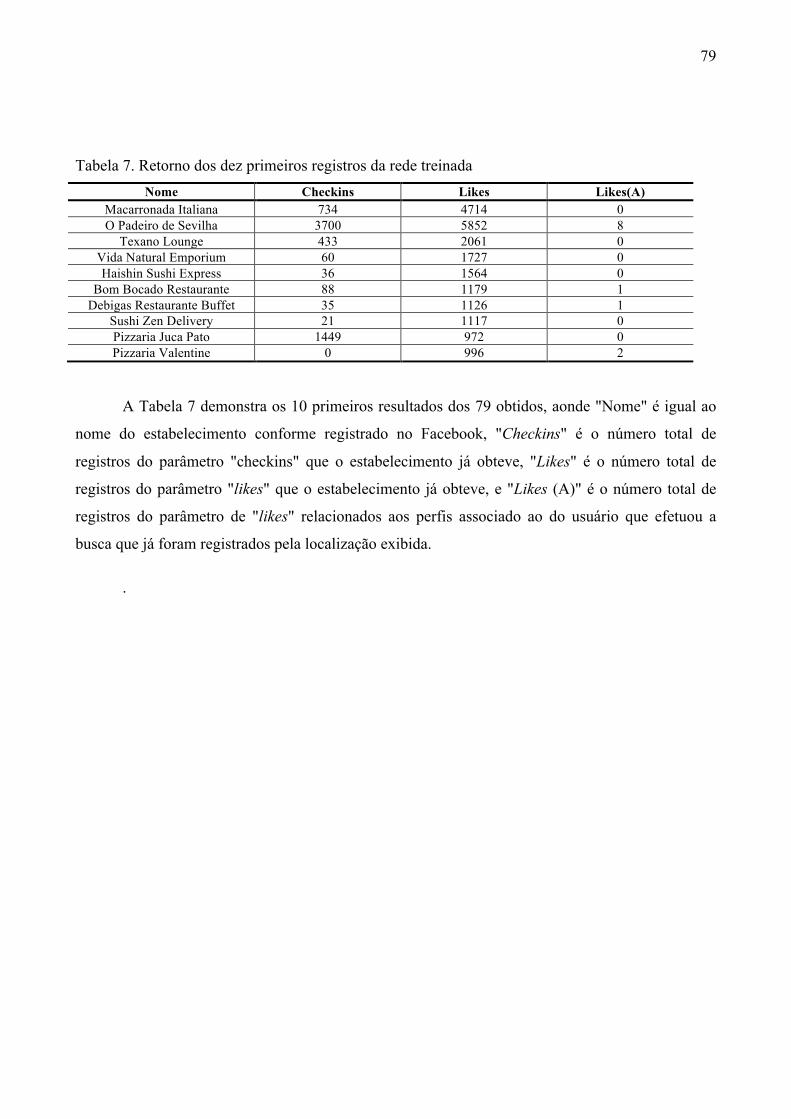
79
Tabela 7. Retorno dos dez primeiros registros da rede treinada Nome Checkins Likes Likes(A)
Macarronada Italiana 734 4714 0 O Padeiro de Sevilha 3700 5852 8
Texano Lounge 433 2061 0 Vida Natural Emporium 60 1727 0 Haishin Sushi Express 36 1564 0
Bom Bocado Restaurante 88 1179 1 Debigas Restaurante Buffet 35 1126 1
Sushi Zen Delivery 21 1117 0 Pizzaria Juca Pato 1449 972 0 Pizzaria Valentine 0 996 2
A Tabela 7 demonstra os 10 primeiros resultados dos 79 obtidos, aonde "Nome" é igual ao
nome do estabelecimento conforme registrado no Facebook, "Checkins" é o número total de
registros do parâmetro "checkins" que o estabelecimento já obteve, "Likes" é o número total de
registros do parâmetro "likes" que o estabelecimento já obteve, e "Likes (A)" é o número total de
registros do parâmetro de "likes" relacionados aos perfis associado ao do usuário que efetuou a
busca que já foram registrados pela localização exibida.
.

80
5 CONCLUSÕES
A arquitetura proposta por esse trabalho reconheceu, com um número baixo de iterações
(790) as variáveis mais aproximadas de acordo com os parâmetros de entrada, durante um tempo de
processamento alto (12,57 segundos) para um aplicativo comercial (contanto que haja o feedback
adequado para o usuário).
Durante o desenvolvimento houveram modificações na política de compartilhamento de
dados do Facebook (implementadas em abril de 2014) que comprometeram o andamento do
software, tais como a modificação do conceito de perfil associado (criando uma identificação
temporária para o mesmo, ao invés de retornar a identificação padrão) e a limitação ao acesso dos
checkins por usuário, permitindo apenas que os mesmos fossem feitos através do acesso aos perfis
públicos que possuíssem esse atributo. Esses obstáculos foram resolvidos através da utilização do
perfil público dos lugares visitados ao invés do perfil dos usuários associados durante a fase de
Recuperação de Informações.
A fase de Geolocalização ocorre durante a inicialização e após o login. A Facebook API
possui um erro de programação que faz com que as instruções pós-login sejam replicadas de duas a
três vezes (aleatoriamente), aumentando o tempo de processamento e dificultando a obtenção das
informações necessárias para o início da segunda fase. Através de uma variável booleana foi
possível solucionar esse problema, permitindo que o processo ocorresse apenas uma vez.
Para obter acesso aos dados do Facebook, o aplicativo precisou conter determinados
parâmetros (parte da política de segurança dessa rede social), sem os quais o funcionamento do
aplicativo seria inviabilizado, sendo esses public_profile (permite acesso aos dados de perfis
públicos), email (permite acesso aos emails do usuários), user_likes (permite acesso ao parâmetro
likes dos usuários), user_friends (permite acesso aos relacionamentos entre perfis) e manage_pages
(permite a recuperação de informações de páginas públicas). Caso o aplicativo fosse publicado
comercialmente, graças aos parâmetros envolvidos, haveria a necessidade de aprovação do sistema
pelo Facebook. Qualquer projeto de aplicativo que utilizar o Facebook como rede social para
mineração de dados deverá considerar em seu estudo as regras das novas políticas de segurança
como ponto de partida para o desenvolvimento de funções para o sistema. Dependendo da natureza
do aplicativo, essas políticas poderão limitar severamente ou mesmo inviabilizar a concepção do

81
software.
O SQLite, apesar de eficiente em sua funcionalidade, não apresentou (em conjunção com o
XCode) um retorno apropriado dos erros ocorridos no banco de dados, dependendo assim da
implementação de um sistema de logs do aplicativo desta pesquisa para cada parte do processo que
envolvesse interação com o SQLite. Com isso, supriu-se a demanda da identificação dos erros que
ocorriam em meio às quatro fases.
O treinamento da rede (durante a terceira fase) também mostrou-se muito lento com os
dados especificados nesta pesquisa, quando se fazia essa operação diretamente trazendo
informações do SQLite (cerca de 50 a 60 segundos por treinamento) e das instruções nativas do
Objective-C. Para solucionar essa demanda, os dados foram transferidos para matrizes durante essa
fase (para realizar toda operação em memória), e tanto a matriz quando os cálculos são realizados
utilizando-se de instruções em C ANSII. Existem determinadas operações em Objective-C que
tornam-se mais viáveis (pelo quesito velocidade de processamento) se são processadas sem a
orientação a objetos. Considerando que os smartphones possuem uma capacidade inferior à dos
computadores convencionais, determinados cálculos (tais como o treinamento dos mapas de
Kohonen) possuem um desempenho melhor se feitos em memória com a passagem de valores
diretamente para as variáveis. Como o número de neurônios varia de acordo com a entrada, o tempo
de resposta do treinamento dos mapas pode vir a ser diferente dependendo do número de
localidades descobertas em um raio de mil metros. Em grandes centros, possivelmente esse tempo
de processamento pode vir a aumentar exponencialmente (e diminuir em cidades menores).
Os parâmetros de entrada possuíam uma proporção de 18% entre as variáveis de checkins e
likes. Uma proporção de 15% a 21% foi mantida em todos os resultados cujo parâmetro Likes (A) é
igual a zero (pois a interferência dessa variável é desconsiderada nas conclusões nesses casos),
indicando assim um reconhecimento de padrão por parte da Rede Neural Artificial proposta no
sistema desenvolvido.
Com base nos resultados obtidos, conclui-se então que é possível realizar a mineração de
dados da rede social Facebook utilizando um dispositivo móvel (apesar do código utilizado para o
treinamento do mapa de Kohonen precisar de ajustes para minimizar o tempo de processamento) e
que das perguntas do problemas de pesquisa, todas conseguiram ser respondidas, já que mostrou-se
possível utilizar o smartphone especificado neste trabalho, não houve a necessidade de um agente

82
externo, a análise foi feita sem a necessidade de adição de outros dados (apenas com informações
recuperadas do Facebook) e foi reconhecido um padrão de frequência entre as localidades sugeridas
pelos perfis da rede social e o usuário da aplicação, mostrando então que é possível o
desenvolvimento de software que utilizam mapas de Kohonen para reconhecimento de padrões em
dispositivos móveis.

83
5.1 TRABALHOS FUTUROS
O aplicativo apresentado nesta pesquisa realiza uma sequência de fases para chegar ao
resultado final, que é o reconhecimento de padrões baseado na mineração de dados das redes
sociais. Porém, existem melhorias e novas utilidades que podem ser trabalhadas no software desta
pesquisa, tais como:
• Diminuição da interação do SQLite: uma menor utilização da interação do banco
de dados SQLite durante o processo de treinamento poderia aumentar a velocidade
de processamento;
• Diminuição do número de dendritos: com os devidos testes executados, uma
diminuição do número de dendritos (utilizar apenas número de likes, checkins e
número de likes de amigos por exemplo) poderia ser utilizado na tentativa de
diminuir o tempo de processamento (mantendo o reconhecimento de padrões
similar).
• Melhorias na interface gráfica: a interface gráfica poderia ser melhorada,
permitindo que o usuário modificasse os padrões de entrada ou mesmo outras
categorias fossem escolhidas (o que mudaria os parâmetros de fases como
Geolocalização e Treinamento), ampliando assim a versatilidade do aplicativo;
• Otimização do código: determinados pontos do código (tal como as ações do
SQLite ou a fase de Treinamento) poderiam ser transformados em classes específicas
para realizar essas funções, permitindo o reaproveitamento e tornando o código mais
fácil de ser mantido;
• Otimização do banco de dados: o projeto do banco de dados apresentado nesta
pesquisa não considera a criação de índices (usando apenas uma chave primária) ou
triggers, entre outras funções disponíveis. A utilização dessas funções ou mesmo
uma melhor normalização poderia facilitar a manutenção de aumentar a velocidade
de acesso aos dados;
• Avisos de erros: algumas fases do aplicativo desta pesquisa poderiam ter um retorno
mais adequado para o usuário aos erros apresentados durante o processamento das

84
quatro fases (Ex: Erro de conexão com o Facebook, Geolocalização não encontrada,
problemas ao realizar o treinamento da rede e etc).
• Treinamento dos mapas em um servidor: o treinamento dos mapas de Kohonen é
realizado dentro do smartphone, de acordo com esta pesquisa. Como existe uma
obrigatoriedade de conexão com a internet, o treinamento dos mapas poderia ser
realizado em um servidor adequado para tal fim, aumentando assim a velocidade de
resposta e permitindo uma análise de padrões sobre as pesquisas feitas pelo usuário,
possibilitando o relacionamento entre elas.
• Reconhecimento de caracteres: se a entrada não for a partir da mineração de dados
de redes sociais, e sim uma entrada de dados a partir de uma interação do usuário, o
processamento dos mapas de Kohonen podem ser utilizados para reconhecer um ou
mais caracteres usados como parâmetro de entrada.
• Reconhecimento de padrões em jogos: em jogos que precisem realizar
determinadas associações baseados na análise de entradas do jogador, o treinamento
do mapa de Kohonen do aplicativo desta pesquisa permite a modificação do mesmo
para este tipo de funcionalidade.
• Reconhecimento de padrões em outras redes sociais: ao se utilizar outra API
(Twitter ou Instagram, por exemplo) e ajustando-se o treinamento do mapa de
Kohonen, é possível usar o mesmo tipo de reconhecimento de dados para outras
redes sociais, sendo que o Instagram exigiria uma alteração para o reconhecimento
de dados através do processamento digital de imagens
• Reconhecimento de padrões em imagens: modificando-se os parâmetros de entrada
para imagens e não texto, o mapa pode ser utilizado para reconhecer padrões de
imagens utilizando os mapas de Kohonen.
Diversos ajustes podem ser realizados no aplicativo da pesquisa visando sua melhoria e/ou
modificação. A mineração em banco de dados Big Data e o treinamento de redes de Kohonen
podem ser realizados por um smartphone contanto que hajam um pré-processamento e uma
implementação adequados dos treinamentos dos mapas de Kohonen.

85
REFERÊNCIAS BIBLIOGRÁFICAS
ADVIZOR SOLUTIONS. Advizor Solutions Overview. Disponível em: <http://www.advizorsolutions.com>. Acesso em: 12 de jun. de 2014. AGUIRRE, Juan Francisco; VANDAMME, Jean-Phillipe; MESKENS, Nadine. Determinations of Factors Influencing the Achievement of the First-Year University Students Using Data Mining Methods. Disponível em: <http://www.educationaldatamining.org/ITS2006EDM/superby.pdf>. Acesso em: 11 de maio de 2014. AGRAWAL, Rakesh; MANILLA, Heikki; SRIKANT; Ramakrishnan; TOIVONEN, Hannu; VERKAMO, Inkeri. Advances in Knowledge Discovery and Data Mining. Cambridge: MIT Press, 1996.
ALEXANDER, Doug. Data Mining. Disponível em: <http://www.laits.utexas.edu/~anorman/BUS.FOR/course.mat/Alex/>. Acesso em: 08 de maio de 2014.
APPLE DEVELOPER. Concepts in Objective-C Programming. Disponível em: <https://developer.apple.com/library/ios/documentation/general/conceptual/CocoaEncyclopedia/Model-View-Controller/Model-View-Controller.html>. Acesso em: 05 de jun. de 2014.
APPLE PRESS INFO. Apple Launches iPhone 4S, iOS5 & iCloud. Disponível em: <http://www.apple.com/pr/library/2011/10/04Apple-Launches-iPhone-4S-iOS-5-iCloud.html>.Acesso em: 28 de maio de 2014. AUGIFY. Data Science and Visualization Cloud. Disponível em: < http://www.augify.com>. Acesso em: 12 de jun de 2014. BALABIN, Roman; LOMAKINA, Ekaterina. Neural Networks Approach to Quantum-Chemistry Data: Accurate prediction of density functional theory energies. Journal of Chemical Physics. Vol. 131, n. 7, ago 2009. BATE, Andrew; LINDQUIST, Marie; EDWARDS, Ralph; OLSSON, Sten; ORRE, Roland; LANSNER, Anders; FREITAS, Rogerio Melhado. A Bayesian Neural Network Method for Adverse Drug Reaction Signal Generation. European Journal of Clinical Pharmacology. Vol. 54, n. 4, Jun 1998.
BATTITI, Roberto; BRUNATO, Mauro. Reative Business Intelligence. From Data to Models to Insight. Reactive Search Srl, 2011.
BEZERRA, Eduardo. Princípios de Análise e Projeto de Sistemas com UML. Rio de Janeiro: Campus, 2002.

86
BOTTACI, Leonardo. Artificial Neural Networks Applied to Outcome Prediction of Colorectal Cancer Patients in Separate Institutions. Disponível em: <http://www.lcc.uma.es/~jja/recidiva/042.pdf >. Acesso em: 02 de jun. de 2014.
BUNGE, Mário. Teoria e Realidade. São Paulo: Perspectiva, 1974. CENTRIFUGE SYSTEMS. Centrifuge. Disponível em: < http://centrifugesystems.com>. Acesso em: 12 de jun. de 2014. CHIN, Alvin; ZHANG, Daqing. Mobile Social Networking: An Innovative Approach (Computional Social Sciences). Springer, 2013. CONSORTIUM ON COGNITIVE SCIENCE INSTRUCTION. McCulloch Pits Neurons. Disponível em: <http://www.mind.ilstu.edu/curriculum/mcp_neurons/mcp_neuron_1.php>. Acesso em: 11 de jun. de 2014. CLARK, Richard M. Machine Vision Systems (MVS) and Object Recognition. Disponível em: <http://homepage.ntlworld.com/richard.clark/rs_kohonen.html>. Acesso em: 18 de jul. de 2014. CLIFTON, Christopher. Encyclopedia Britannica: Definition of Data Mining. Disponível em: <http://global.britannica.com/EBchecked/topic/1056150/data-mining>. Acesso em: 09 de maio de 2014. DAWSON, Christian; WILBY, Robert L.; BROWN, Martin R.; HARPHAM, Colin; DARBY, Edmund J.; CRANSTON, Elspeth. Modelling Ranunculus Presence in the Rivers Test and Itchen Using Artificial Neural Networks. Disponível em: <http://www.geocomputation.org/2000/GC016/Gc016.htm>. Acesso em: 17 de jul. de 2014. DEEROS, Dirk; EATON, Chris; LAPIS, George; ZIKOPOULOS, Paul; DEUTSCH, Tom. Harness The Power Of Big Data: The IBM Big Data Plataform. New York: McGrall Hill, 2012. DEPARTMENT OF PSYCHOLOGY FROM UNIVERSITY OF TORONTO. Artificial Neural Networks Technology. Disponível em: < http://www.psych.utoronto.ca/users/reingold/courses/ai/cache/neural2.html >. Acesso em: 18 de jul. de 2014. DOMOSPHERE. How Much Data Is Created Every Minute? Disponível em: <http://www.domo.com/blog/2012/06/how-much-data-is-created-every-minute/ >. Acesso em: 15 de maio de 2014. EATON, Chris; DEEROS, Dirk; LAPIS, George; ZIKOPOULOS, Paul; DEUTSCH, Tom. Understanding Big Data. Analytics for Enterprise Class Hadoop and Streaming Data. Disponível em: <http://public.dhe.ibm.com/common/ssi/ecm/en/iml14296usen/IML14296USEN.PDF>. Acesso em: 11 de jun. de 2014.

87
ELECTRONIC FRONTIER FOUNDATION. Total/Terrorism Information Awareness (TIA). Is It Truly Dead? Disponível em: < http://w2.eff.org/Privacy/TIA/20031003_comments.php>. Acesso em: 11 de maio de 2014. ENGADGET. iPhone 4S Review. Disponível em: < http://www.engadget.com/2011/10/14/iphone-4s-review/>. Acesso em: 28 de maio de 2014. FACEBOOK DEVELOPERS. Using the Graph API. Disponível em: <https://developers.facebook.com/docs/graph-api/using-graph-api/>. Acesso em: 07 de mar. de 2014 FAYYAD, Usama; PIATETSKY-SHAPIRO; Gregory; SMYTH, Padhraic. From Data Mining to Knowledge Discovery in Databases. AI Magazine, Vol. 17, n. 37-54, out. 1996. FERNANDES, Anita Maria da Rocha. Inteligência Artificial: Noções Gerais. 2a ed. Florianópolis: Visual Books, 2005.
FUHRT, Borko. Handbook of Social Network Technologies and Applications. Springer, 2010. FUKUSHIMA, Kunihiko. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biological Cybernetics. Vol. 36, n 4, ago 1980. GANESAN, Narayan. Application of Neural Networks in Diagnostic Cancer Using Demographic Data. International Journal of Computer Applications. Vol. 1, n 26, jul 2010. GARTNER RESEARCH. The Importance of Big Data: A Definition. Disponível em: <https://www.gartner.com/doc/2057415/importance-big-data-definition>. Acesso em: 19 de maio de 2014. GOSS, Sherri. Data Mining and Our Personal Privacy. Disponível em: <http://www.macon.com/2013/04/10/2429775/data-mining-and-our-personal-privacy.html>. Acesso em: 08 de maio de 2014. GOVERNMENT ACCOUNTABILITY OFFICE. Data Mining: Early Attention To Privacy in Developing a Key DHS Program Could Reduce Risks. Disponível em: <http://www.gao.gov/products/GAO-07-293> Acesso em: 11 de maio de 2014. GRAVES, Alex; SCHMIDHUBER, Jürgen. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. Disponível em: <http://www.idsia.ch/~juergen/nips2009.pdf>. Acesso em: 11 de jun. de 2014 GÜNNEMANN, Stephan; KREMER, Hardy; SEIDL, Thomas. An Extension of the PMML Standard to Subspace Clustering Models. Workshop on Predictive Markup Language Modeling. Vol. 11, n. 48, ago 2011. HASTIE, Trevor; TIBSHIRANI, Robert; FRIEDMAN, Jerome. The Elements of Statistical Learning: Data Mining, Inference and Prediction. 2a ed. Springer, 2009.

88
HAYKIN, Simon. Neural Networks: A Comprehensive Foundation. Prentice Hall, 1999. HEATON, Jeff. Introduction to Neural Networks with Java. Heaton Research, 2013. HINTON, Geoffrey; OSINDERO, Simon; TEH, Yee-Whye. A Fast Learning Algorithm For Deep Belief Nets. Neural Computation. Vol. 18, n. 7, out 2006. HSIEH, Tung-Ju. Neural Networks and Their Application for Structural Self-Diagnosis. Disponível em: < http://dspace.mit.edu/handle/1721.1/84217>. Acesso em: 11 de jun. de 2014. IBM. What Is Big Data. Disponível em: <http://www-01.ibm.com/software/data/bigdata/what-is-big-data.html>. Acesso em: 12 de maio de 2014.
IEEEXPLORE DIGITAL LIBRARY. Unsupervised Learning Based Performance Analysis of n-Support Vector Regression for Speed Prediction of a Large Road Network. Disponível em: < http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6338917>. Acesso em: 11 de jun. de 2014.
ITUNES APP STORE. Paper Boy Online App. Disponível em: <https://itunes.apple.com/gb/app/paper-boy-online-app/id412548455?mt=8>. Acesso em: 27 de maio de 2014. ITUNES APP STORE. Hawrkore. Disponível em: <https://itunes.apple.com/en/app/hawrkore/id388014361?mt=8>. Acesso em: 27 de maio de 2014. JIAWEI, Han; KAMBER, Micheline. Data Mining – Concepts and Techniques. Morgan Kaufmann Publishers, 2001. JACKSON, Jonathan Lee. Extensible Neural Network Software: Applications in Gene Expression Analysis. Disponível em: <https://dspace.mit.edu/bitstream/handle/1721.1/33285/62277185.pdf?sequence=1 > Acesso em: 12 de jun. de 2014. JACOB, Joseph Biju; CHEW, Yeow Eng; TAN, Javan; QUEK, Chai. Self-Organizing TSK Fuzzy Inference System with BCM Theory of Meta-Plasticity. Neural Networks, The 2012 International Joint Conference On, 2012. KANTARDZIC, Mehmed. Data Mining: Concepts, Models, Methods and Algorithms. 2a ed. New Jersey: John Wiley & Sons, 2003. KAWAGUSHI, Kiyoshi. A Multithreaded Software Model for Backpropagation Neural Network Applications. Disponível em: < http://wwwold.ece.utep.edu/research/webfuzzy/docs/kk-thesis/kk-thesis-html/>. Acesso em: 17 de jul. de 2014. KOHONEN, Teuvo. Self Organizing Maps. Springer, 2001.

89
KURZWEIL. How Bio-Inspired Deep Learning Keeps Winning Competitions. Disponível em: <http://www.kurzweilai.net/how-bio-inspired-deep-learning-keeps-winning-competitions>. Acesso em: 02 de jun. de 2014. LAI, Chi-Hui. Understanding The Design of Mobile Social Networks. M/C Journal, Vol. 10, n. 1, mar. 2007. LOHR, Steve. The Age of Big Data. Disponível em: <http://www.nytimes.com/2012/02/12/sunday-review/big-datas-impact-in-the-world.html?pagewanted=all&_r=0 >. Acesso em: 16 de jul. de 2014. LUGANO, Giuseppe. Mobile Social Networking in Theory and Practice. FirstMonday, Vol. 13, n. 11, nov. 2008. MA, Yajie; RICHARDS, Mark; GHANEM, Moustafa; GUO, Yike; HASSARD, John. Air Pollution Monitoring and Mining Based on Sensor Grid in London. Sensors. Vol. 8, n. 6, mai. 2008. MA, Yajie; YIKE, Guo; XIANGCHUAN, Tian; GHANEM, Moustafa. Distributed Clustering-Based Aggregation Algorithm for Spatial Correlated Sensor Networks. IEEE Sensors Journal. Vol. 11, n. 3, Set 2010. MAC APP STORE. Xcode. Disponível em: < https://itunes.apple.com/us/app/xcode/id497799835>. Acesso em: 27 de maio de 2014. MAC DEV CENTER. Developing for OS X Mavericks. Disponível em: <https://developer.apple.com/devcenter/mac/index.action>. Acesso em: 27 de maio de 2014. MAGUIRE, David; GOODCHILD, Michael; RHIND, David. Geographic Information Systems: Principles and Applications. Londres: Longman, 1991. MENA, Jesús. Machine Learning Forensics for Law Enforcement, Security and Intelligence. Boca Raton: CRC Press, 2011. MCGRAIL, Anthony; GULSKI, Edward; ALLAN, David; BIRTWHISTLE, David; BLACKBURN; Trevor; GROOT, Edwin. Data Mining Techniques to Assess the Condition of High Voltage Electrical Plant. CIGRE, Vol. 1, n. 39, ago. 2002. MCKINSEY GLOBAL INSTITUTE. Big Data: The Next Frontier For Innovation, Competition And Productivity. Disponível em: <http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation>. Acesso em: 22 de maio de 2014. MICROSOFT DEVELOPER NETWORK. Conceitos de Mineração de Dados. Disponível em < http://msdn.microsoft.com/pt-br/library/ms174949.aspx>. Acesso em: 08 de jun. de 2014. MONK, Ellen; WAGNER, Bret. Concepts in Enterprise Resource Planning. 2a ed. Boston: Thomson Course Technology. 2006.

90
MNEMOSINE STUDIO. Kohonen Self-Organizing Maps. Disponível em: <http://mnemstudio.org/neural-networks-kohonen-self-organizing-maps.htm>. Acesso em: 18 de jul. de 2014. NÓREN, Niklas; BATE, Andrew; HOPSTADIUS, Johan; STAR, Kristina; EDWARDS, Ralph. Temporal Pattern Discovery for Trends and Transient Effects: Its Application to Patient Records. Fourteenth International Conference on Knowledge Discovery and Data Mining. Vol. 1, n. 963, out 2008. O’BRIEN, James; MARAKAS, George. Management Information Systems. New York: McGraw-Hill/Irwin, 2011. OJA, Erkii; KASKI, Samuel. Kohonen Maps. Amsterdam: Elsevier, 1999. OLIVEIRA, Jeymisson. Redes Neurais Artificiais. Disponível em: <http://www.dsc.ufcg.edu.br/~pet/jornal/setembro2011/materias/informatica.html>. Acesso em: 17 de jul. de 2014. ORACLE. Meeting The Challenge of Big Data. Disponível em: <http://www.oracle.com/us/technologies/big-data/big-data-ebook-1866219.pdf >. Acesso em: 29 de maio de 2014. PACHET, François; WESTERMANN, Gert; LAIGRE, Damien. Musical Data Mining for Eletronic Music Distribution. First WedelMusic Conference. Vol. 1, n. 101, dez 2001. PEWRESEARCH INTERNET PROJECT. Mobile Technology Fact Sheet. Disponível em: <http://www.pewinternet.org/fact-sheets/mobile-technology-fact-sheet/>. Acesso em: 07 de jun. de 2014. PIATETSKY-SHAPIRO, Gregory; PARKER, Gary. Lesson: Data Mining, and Knowledge Discovery: An Introduction. Disponível em: <http://www.kdnuggets.com/data_mining_course/x1-intro-to-data-mining-notes.html>. Acesso em: 09 de maio de 2014. PLOTLY. Analyze and Visualize Data, Together. Disponível em: < https://plot.ly>. Acesso em: 12 de jun. de 2014. POWERS, William. Hamlet’s Blackberry: A Pratical Philosophy for Building a Good Life in the Digital Age. New York: Harper, 2010. RAENTO, Mika; ANTTI Oulasvirta. Designing for Privacy and Self-presentation in Social Awareness. Personal Ubiquituous Comput, Vol. 12, n. 7, out 2008. RIESENHUBER, Maximilian; POGGIO, Tomaso. Hierarchical Models of Object Recognition in Cortex. Nature Neuroscience. Vol. 2, n. 1019, ago 1999. RUSSEL, Ingrid. Neural Networks Module. Disponível em: <http://uhaweb.hartford.edu/compsci/neural-networks-definition.html>. Acesso em: 02 de jun. de 2014.

91
RUSSEL, Matthew. Mining the Social Web: Data Mining Facebook, Twitter, Linkedin, Google+, GitHub and More. O’Reilly Media, 2013. SAFFELL, Matthew; MOODY, John. Learning to Trade Via Direct Reinforcement. Neural Networks, IEEE Transactions On. Vol. 12, n. 4, Jul 2001. SATHI, Arvind. Big Data Analytics: Disruptive Technologies for Changing the Game. MC Press, 2013. SCHMIDHUBER, Jürgen; GRAVES, Alex. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. Disponível em: <http://www.idsia.ch/~juergen/nips2009.pdf>. Acesso em 02 de jun. de 2014. SCOTT, John P. Social Network Analysis: A Handbook. 2a ed. Thousand Oaks: Sage Publications, 2000. SECURITY ON NBCNEWS. DHS Halts Anti-Terror DataMining Program. Disponível em: <http://www.nbcnews.com/id/20604775/#.U3KB7V4k_Ew>.Acesso em: 10 de maio de 2014. SETH, Ronald Tardiff. Self Organizing Event Maps. Disponível em: <http://dspace.mit.edu/bitstream/handle/1721.1/17982/57189321.pdf?sequence=1>. Acesso em: 12 de jun. de 2014. SOMMERVILE, IAN. Engenharia de Software. 9a ed. São Paulo: Pearson, 2011. SMYTH, Neil. Objective-C 2.0 Essentials. 3a ed. Payload Media, 2013. TÖNNIES, Ferdinand. Community and Civil Society. Cambridge: Cambridge University Press, 2001. WASSERMAN, Stanley; FAUST Katherine. Social Network Analysis: Methods and Applications. 5 ed. Cambridge: Cambridge University Press, 1999. WELMANN, Barry. Social Structures: A Network Approach. Cambridge: Cambridge University Press, 1988. WAZLAWICK, Raul Sidney. Metodologia de Pesquisa para Ciência da Computação. Rio de Janeiro: Elsevier, 2008.
XIAO, Nancy. Using The Modified Back-Propagation Algorithm to Perform Automated Downlink Analysis. Disponível em: < http://dspace.mit.edu/handle/1721.1/40206 >. Acesso em: 12 de jun. de 2014.
YAN, Ji. Understanding Human Mobility Patterns Through Mobile Phone Records: a Cross-Cultural Study. Disponível em: < http://dspace.mit.edu/handle/1721.1/66867>. Acesso em: 11 de jun. de 2014.

92
YANG, Joshua; PICKETT, Matthew; LI, Xuema; OHLBERG, Douglas; STEWART, Duncan; WILLIANS, Stanley. Memristive Switching Mechanism for Metal/Oxide/Metal Nanodevices. Nature Nanotechnology. Vol 3, n. 429, jun 2008. ZERNIK, Joseph. Data Mining as a Civic Duty – Online Public Prisoners Registration Systems. International Journal on Social Media: Monitoring, Measurement, Mining. Vol. 1, n. 69, ago 2010. ZHU, Xingquan; DAVIDSON, Ian. Knowledge Discovery and Data Mining: Challenges and Realities. New York: Hershey, 2007.

93





























