Embed Size (px)
Citation preview

7
CAPÍTULO 1
CONCEITOS E MÉTODOS ESTATÍSTICOS
Marcelo Silva de OliveiraDaniel Furtado Ferreira
Júlio Sílvio de Souza BuenoPaulo César Lima
Renato Ribeiro de LimaRuben Delly Veiga
Marcelo de Carvalho Alves
1.1 APRESENTAÇÃO
Este capítulo apresenta a fundamentação estatística, conceitual e metodológica, utilizada neste zoneamento. Sendo a Estatística a ciência fundamental para o tratamento correto de dados que envolvem incerteza, como é o caso do zoneamento, uma correta abordagem estatística faz-se necessária para que o produto final, informação, ganhe toda a segurança possível de lhe ser conferida. Quatro seções serão tratadas aqui, exatamente sobre os temas diretamente pertinentes aos usos praticados na construção do Zoneamento Ecológico-Econômico do Estado de Minas Gerais (ZEE-MG), a saber: uma seção sobre o Sistema de Mensuração e de Informação, uma sobre Geoestatística, outra sobre Análise de Componentes Principais e, finalmente, a última sobre Regressão.
1.2 SISTEMAS DE MENSURAÇÃO E DE INFORMAÇÃO
O Projeto ZEE-MG concretizou-se tendo como produtos finais os seguintes artefatos:
- Um banco de dados digitalizado em SIG (Sistema de Informações Geográficas), contendo todos os indicadores obtidos a partir dos dados analisados, com georreferenciamento.- Mapas temáticos digitais e em papel com informações textuais que adicionam compreensão aos usuários em relação aos mapas.- Análise de casos de usos dos dois artefatos anteriores.
Obviamente, além destes produtos tangíveis, obteve-se também o aumento do conhecimento e experiência das instituições e pesquisadores envolvidos. Tanto os três artefatos tangíveis, quanto o ganho científico dos pesquisadores e instituições, descansam sobre mensurações ou medições, as quais foram desenvolvidas num contexto sistêmico, com o fim de dar informações para o gestor ou pesquisador. Por causa desta importância basilar, é descrito a seguir o discernimento conceitual sobre o sistema de medição que balizou o trabalho desenvolvido por todos os pesquisadores. Uma seção final introduzirá o conceito de sistema de informações (geográficas), que será posteriormente estendido em outro capítulo.
1.2.1 Definição do sistema de mensuração Um sistema é um conjunto de partes (ou componentes) interrelacionados, interdependentes, e interinteligíveis, que cooperam articuladamente para cumprir um propósito pré-estabelecido. Um sistema de mensuração (ou de medição) é um sistema de conceitos e métodos metrológicos. O particular modelo deste sistema de medição adotado neste zoneamento é explicitado nas linhas a seguir.
1.2.1.1 Medição Diferentes tipos de variáveis (ou atributos) foram utilizadas. Numa classificação mais geral, uma variável pode ser classificada em um de dois tipos fundamentais: quantitativas ou qualitativas.
8
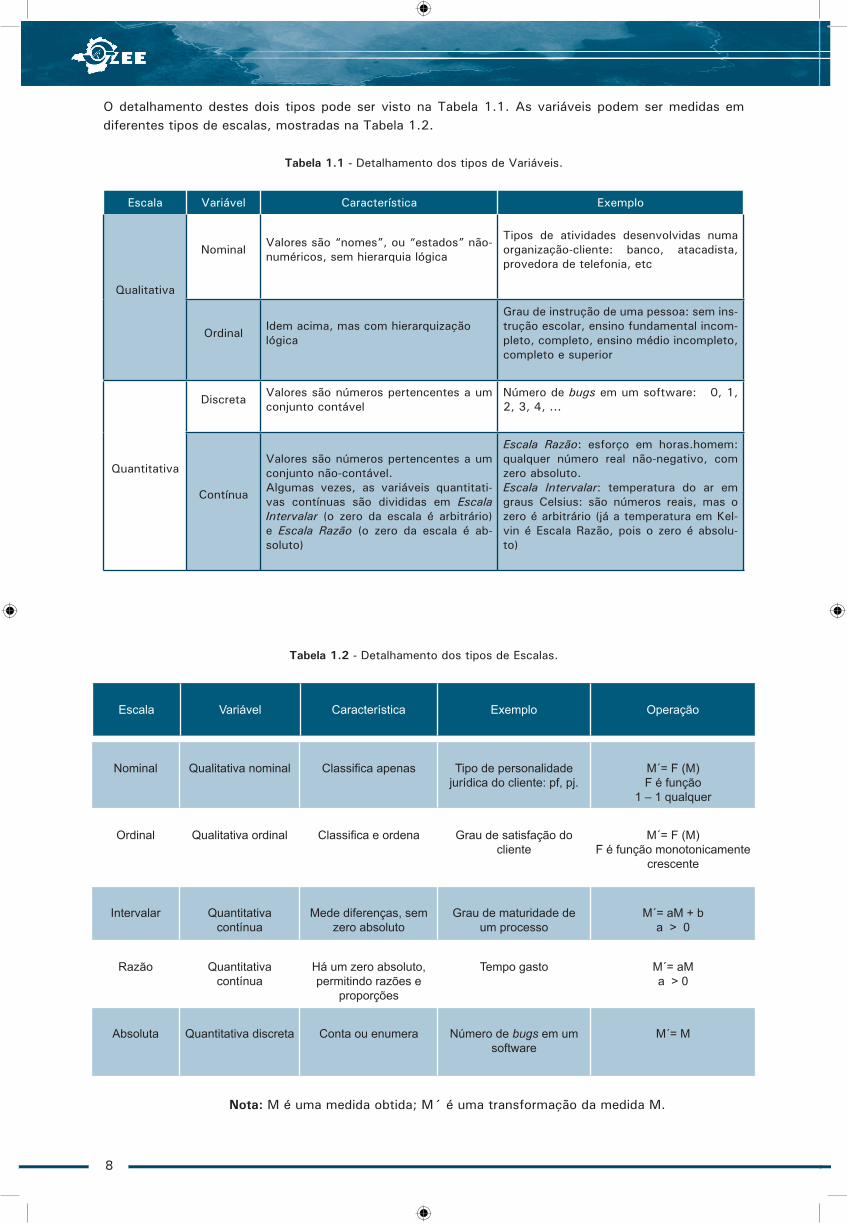
O detalhamento destes dois tipos pode ser visto na Tabela 1.1. As variáveis podem ser medidas em diferentes tipos de escalas, mostradas na Tabela 1.2.
Tabela 1.1 - Detalhamento dos tipos de Variáveis.
Escala Variável Característica Exemplo
Qualitativa
Nominal Valores são “nomes”, ou “estados” não-numéricos, sem hierarquia lógica
Tipos de atividades desenvolvidas numa organização-cliente: banco, atacadista, provedora de telefonia, etc
Ordinal Idem acima, mas com hierarquizaçãológica
Grau de instrução de uma pessoa: sem ins-trução escolar, ensino fundamental incom-pleto, completo, ensino médio incompleto, completo e superior
Quantitativa
Discreta Valores são números pertencentes a um conjunto contável
Número de bugs em um software: 0, 1, 2, 3, 4, ...
Contínua
Valores são números pertencentes a um conjunto não-contável. Algumas vezes, as variáveis quantitati-vas contínuas são divididas em Escala Intervalar (o zero da escala é arbitrário) e Escala Razão (o zero da escala é ab-soluto)
Escala Razão: esforço em horas.homem: qualquer número real não-negativo, com zero absoluto.Escala Intervalar: temperatura do ar em graus Celsius: são números reais, mas o zero é arbitrário (já a temperatura em Kel-vin é Escala Razão, pois o zero é absolu-to)
Tabela 1.2 - Detalhamento dos tipos de Escalas.
Escala Variável Característica Exemplo Operação
Nominal Qualitativa nominal Classifica apenas Tipo de personalidade jurídica do cliente: pf, pj.
M´= F (M)F é função
1 – 1 qualquer
Ordinal Qualitativa ordinal Classifica e ordena Grau de satisfação do cliente
M´= F (M)F é função monotonicamente
crescente
Intervalar Quantitativacontínua
Mede diferenças, sem zero absoluto
Grau de maturidade de um processo
M´= aM + ba > 0
Razão Quantitativacontínua
Há um zero absoluto, permitindo razões e
proporções
Tempo gasto M´= aM a > 0
Absoluta Quantitativa discreta Conta ou enumera Número de bugs em um software
M´= M
Nota: M é uma medida obtida; M´ é uma transformação da medida M.

9
A partir desta conceituação básica sobre medição, cabe agora estabelecer um framework para proceder ao desenvolvimento do sistema de medição. Para tanto, foi utilizada a norma ISO/IEC 15939 (referência internacional para orientação no processo de construção de indicadores de performance de sistemas). Um sistema de medição, segundo a norma ISO/IEC 159391, compreende essencialmente dois componentes: - O modelo de medição. - O processo de medição.
É apresentado, a seguir, um detalhamento desses dois componentes.
1.2.1.2 Modelo de medição
Um modelo de medição compreende, segundo a norma ISO/IEC 15939, os elementos citados na Figura 1.1. Em primeiro lugar, uma necessidade de informação define uma entidade que será medida. Esta entidade é aquilo que se entende possuir a informação necessária para satisfazer a necessidade de informação. Quase sempre é um ente físico tangível. Um conceito mensurável é uma idéia sobre como uma necessidade de informação pode ser satisfeita a partir de entidades. Em outras palavras, é a idéia que liga mensurativamente uma necessidade de informação a uma entidade. Um conceito mensurável pode ser implementado por diferentes construções mensuráveis. Um detalhamento de como uma construção mensurável é feita é mostrado na Figura 1.2. Como se pode ver, uma construção mensurável define um produto de informação, que satisfará as necessidades de informação. Este produto de informação é produzido a partir de atributos, os quais representam as entidades. Uma construção mensurável é composta, essencialmente, por medidas básicas, medidas derivadas e indicadores, relacionados entre si e com atributos e produto de informação através de conectores lógicos (método de medição, função de medição, modelo de análise, critério de decisão). Uma medida básica inclui um atributo mensurável de uma entidade, através de um método de medição para quantificação do atributo e um valor resultante da aplicação do método. A seqüência fundamental para um modelo de medição encontra-se na Figura 1.3. Relacionados a uma medida básica, têm-se os conceitos de escala de medição (já definido), unidade de medição, observação (como o ato de designar um valor) e unidade de observação. Deve-se salientar que uma medida derivada incorpora informações sobre dois ou mais atributos ou várias observações de um mesmo atributo. Uma medida derivada inclui dois ou mais valores de medidas básicas e/ou medidas derivadas, uma função matemática combinando os valores (função de medição), e um valor resultante da aplicação da função. Um indicador é uma medida que fornece uma estimativa ou avaliação de atributos especificados em relação a uma necessidade de informação. Um indicador demanda:
- Um ou mais valores de medidas básicas e/ou derivadas;- Um modelo de análise combinando os valores resultantes;- Um valor resultante da aplicação do modelo;- Um critério de decisão utilizado para avaliar o valor resultante do indicador.
Freqüentemente, visando a simplificação, os conceitos de atributos, medidas básicas, medidas derivadas, e indicadores, são enfeixados genericamente sob o rótulo de variáveis.
1 International Organization for Standardization (ISO). ISO/IEC 15939: Software Engineering – Software Measurement Process. (s.1.), Genebra,
Suiça. 2001.

10
Produto de Informação
Necessidade de Informação
Construção Mensurável
Atributo Entidade
Conceito mensurável
Figura 1.1. Visão geral do Modelo de Medição segundo a norma ISO/IEC 15939.
Atributo
Medida Básica
Função de Medição
Medida Derivada
Modelo de Análise
Critério de Decisão
Indicador
Produto de Informação Necessidades de Informação
Método de Medição
Entidades
Medida Derivada
Medida Básica
Atributo
Figura 1.2 - Detalhamento de uma construção mensurável segundo a norma ISO/IEC 15939.

11
Entidade
s Atributo Medida Básica
Medida Derivada Indicador
Necessidades de Informação
Figura 1.3 - Seqüência fundamental de um modelo de medição.
1.2.1.3 Processo de medição O processo de medição envolve as seguintes atividades:
- Estabelecer e sustentar comprometimento para medição;- Planejar o processo de medição;- Realizar o processo de medição;- Avaliar a medição.
As Figuras 1.4 e 1.5 mostram exemplos ilustrativos da aplicação do modelo de medição.
Atributo Existência de aeroporto
Função de Medição Média aritmética
Medida Derivada Distância média
Modelo de Análise Exame direto da média
Critério de Decisão Se média < 10 km
então condições aeroportuárias são adequadas.
Indicador A própria média aritmética
Produto de Informação Necessidades de Informação
Quais as condições aeroportuárias do município X ?
Método de Medição Registro das coordenadas espaciais de todos os aeroportos de classe Y
no Estado
Entidades Municípios
Medida Básica Distâncias de cada ponto do município aos 4 aeroportos
de classe Y mais próximos em cada quadrante
Figura 1.4 - Criação hipotética ilustrativa de um indicador para satisfazer a necessidade de informação sobre infra-
estrutura aeroportuária.

12
Atributo Malha rodoviária asfaltada
Medida Básica Comprimento total asfaltado Função de Medição
Função identidade
Medida Derivada Comprimento total asfaltado
Modelo de Análise Composição das duas
Critério de Decisão Se IMRQ > 50% e IMRE > 80 km, então condições
rodoviárias são adequadas para atividade Y
Indicador Comprimento asfaltado/Comprimento total = IMRQ
(Índice de Qualidade de Malha Rodoviária)
Produto de Informação Necessidades de Informação Quais as condições rodoviárias do município X
para o desenvolvimento da atividade Y ?
Método de Medição Medição física em mapas ou
tabelas
Entidades Municípios
Medida Derivada Comprimento total não-asfaltado
Medida Básica Comprimento total não-asfaltado
Atributo Malha rodoviária não-asfaltada
Indicador Comprimento asfaltado = IMRE
(Índice de Extensão de Malha Rodoviária)
Figura 1.5 - Criação hipotética ilustrativa de um indicador para satisfazer a necessidade de informação sobre
infraestrutura rodoviária.
1.2.2. Estrutura de dados para análise estatística
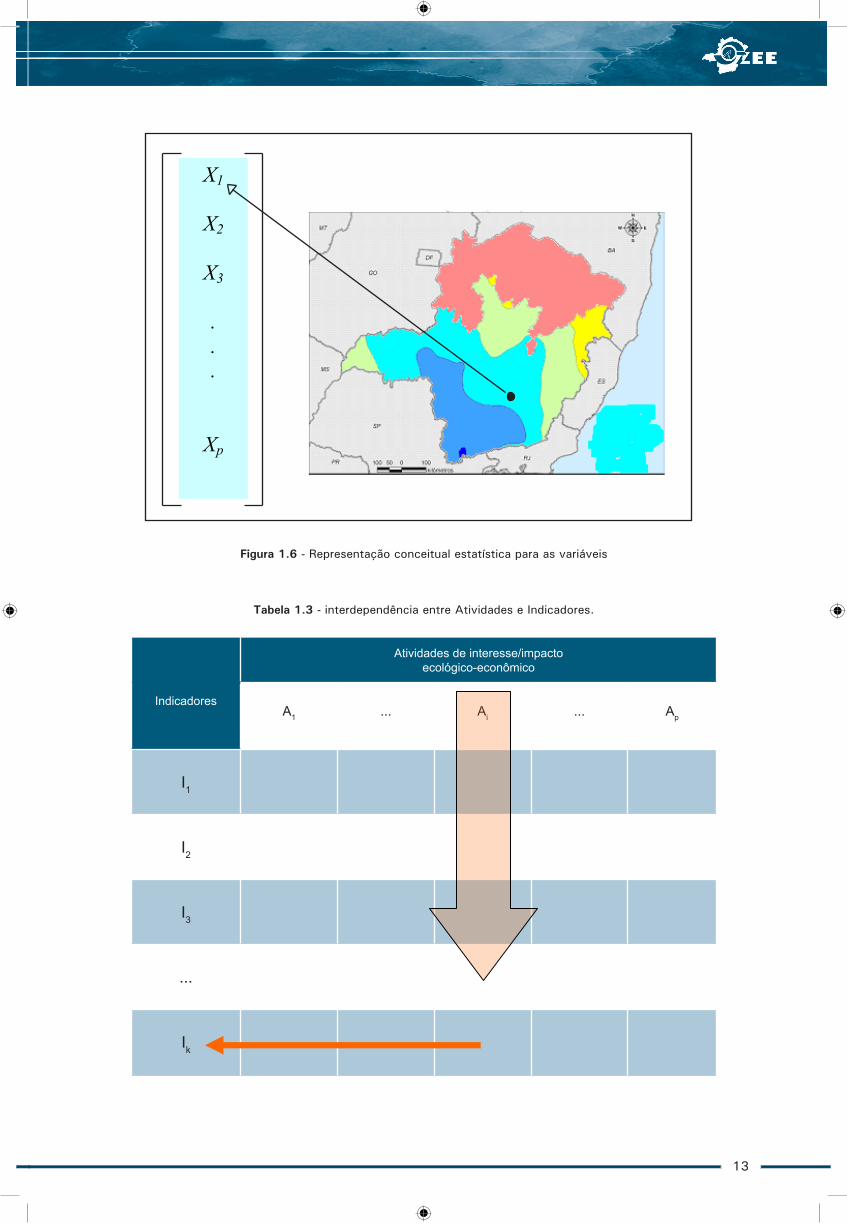
As informações georreferenciadas obedecem a uma estrutura apropriada ditada pelo banco de dados subsidiário ao SIG, porém, para a análise estatística entende-se a estrutura de dados como sendo essencialmente um conjunto de vetores-coluna indexados espacialmente (pelas coordenadas espaciais, isto é, georreferenciadas), cujos componentes serão as variáveis medidas em cada ponto espacial do Estado. A Figura 1.6 procura ilustrar esta idéia. As variáveis X1 e X2 são forçosamente as coordenadas espaciais. As demais (X3, X4, ..., Xp) são os atributos, medidas básicas, medidas derivadas, ou indicadores construídos. Eventualmente as variáveis X3 em diante poderão receber nova denominação, tal como Y, para declará-las diferentes de coordenadas espaciais. Estes vetores podem ser combinados em matrizes para análise estatística, se esta combinação melhorar ou facilitar alguma análise em especial.
1.2.3 Atividades de impacto ecológico e econômico.
As determinações de atributos, medidas básicas e derivadas, e indicadores, dependem da definição das atividades que causam impacto ecológico e econômico a população do Estado. Em graus variados, a recíproca também é verdadeira. Essencialmente, esta interdependência entre atividades e variáveis pode ser vista segundo a matriz mostrada na Tabela 1.3. O número k de Indicadores e a própria definição dos indicadores dependem do número p de atividades e da definição destas. Por exemplo, uma atividade Ai qualquer, pode exigir que o conjunto de indicadores contemple até o indicador Ik, para ser bem gerenciada. Portanto, existem três caminhos de análise:
13
X1
X2
X3 . . .
Xp
Figura 1.6 - Representação conceitual estatística para as variáveis
Tabela 1.3 - interdependência entre Atividades e Indicadores.
Indicadores
Atividades de interesse/impacto ecológico-econômico
A1 ... Ai ... Ap
I1
I2
I3
...
Ik

14
- Procura-se definir as atividades Ai, e, a partir daí, os indicadores Ij;- Procura-se definir os indicadores Ij, e, a partir deles, as atividades Ai;- Procura-se definir os dois conceitos concomitantemente.
Quanto às atividades elencadas, há dois grupos fundamentais:- Atividades Naturais: aquelas que podem ocorrer sem a intervenção antrópica. Pertencem aos escopos lito, hidro, atmos, flora, e fauna;- Atividades Antrópicas: aquelas que somente ocorrem sob intervenção humana. Pertencem aos escopos agro-silvo-pastoril (agropecuária), industrial, urbano, de gestão ambiental geral, energético, entre outros.
Este framework portou-se como um pano-de-fundo para todo o trabalho de transformação de dados em informação, buscando-se atender às expectativas dos usuários destas informações segundo padrões de qualidade com aprovação consensual contemporânea. 1.2.4 Sistema de informação
Os Sistemas de Informações Geográficas (SIGs) podem ser considerados como uma subárea da tecnologia da informação, passíveis de serem integrados com outras tecnologias, tais como a inteligência artificial, com diferentes propósitos e aplicações2. Os SIGs apresentam inúmeras aplicações e podem ser utilizados para fornecer informações sobre gerenciamento do espaço geográfico (urbano e rural), rotas, estudos de impactos ambientais, gestão e qualidade de água, definição de impostos e taxas, monitoramento e gerenciamento agrícola, modelagem e predição de clima e doenças, suporte à decisão na aplicação de produtos fitossanitários e fertilizantes em taxa variável, manejo, planejamento e otimização da extração e replantio de florestas, entre muitos outros.
Assim, a modificação rápida do uso do meio físico, particularmente em áreas de expansão de fronteiras agrícolas e urbanização das cidades, impõe a adoção de técnicas de avaliação e de diagnóstico da dinâmica espaço-temporal do uso das terras e de seu potencial ecológico-econômico.
Considerando-se que metodologias de Geociências apresentam enorme potencial de utilização em um país de dimensões continentais como o Brasil, onde existe carência de informações para auxiliar o processo de tomada de decisão acerca de questões relacionadas com variáveis ecológico-econômicas, objetivou-se nesta seção abordar uma introdução aos princípios conceituais dos SIGs.
PrincípiosA natureza complexa, dinâmica e não-linear dos ecossistemas requer soluções baseadas no
avanço da Tecnologia da Informação (TI) para melhor compreender e solucionar questões ligadas à alimentação, meio-ambiente, produção de matéria-prima, habitação, e recursos energéticos. Dessa forma, à medida que os custos das ferramentas tecnológicas diminuem, catalisa-se um maior número de trabalhos utilizando aplicações de Geociências.
Nos Sistemas de Informações Geográficas (SIGs), os fenômenos relacionados ao mundo real podem ser descritos de três maneiras: espacial, temporal e temática. Espacial, quando a variação muda de lugar para lugar; temporal, quando a variação muda com o tempo e temática, quando as variações são detectadas por meio de mudanças de características. Essas três maneiras de observar os fenômenos que ocorrem na superfície da terra compõem, coletivamente, as informações denominadas de dados espaciais.
Pode-se identificar os seguintes componentes relacionados de forma hierárquica num SIG (Figura 1.7):
- Interface com usuário;- Entrada e integração de dados;- Consulta, análise espacial e processamento de imagens;- Visualização e plotagem; - Armazenamento e recuperação de dados (organizados sob a forma de um banco de dados geográficos).
2 Burrough, P.A.; Mc Donnell, R.A.. Principles of Geographical Information Systems. New York: Oxford University Press, 1998, 331p..

15
Figura 1.7 - Arquitetura de um sistema de informações geográficas.
A informação geográfica pode ser analisada por diferentes metodologias e técnicas baseadas em estatísticas clássicas (média, variância, desvio-padrão, etc.), ou por metodologias de Estatística Espacial (Geoestatística, Padrão de Pontos, etc). Quaisquer que sejam as técnicas e métodos utilizados, a integridade, consistência, e acessibilidade do banco de dados são fundamentais para a consecução das operações. Devido à complexidade das informações geográficas, a melhor maneira de gerenciá-las é através de um SIG. Este pode tanto fornecer dados numa estrutura adequada a uma metodologia de análise quanto a outras, sejam estatísticas ou analíticas de qualquer outra espécie (econômicas, sociais, ecológicas, etc). Essa versatilidade confiável é a grande virtude eleitora dos SIGs como framework padrão hoje para o tratamento de dados oriundos de variáveis espacialmente distribuídas.
1.3 GEOESTATÍSTICA
Diferentes áreas do conhecimento estudam processos de variação espacial e/ou temporal, como:
- A distribuição espacial do teor de estanho, expresso em lb/ton, em uma jazida; - A distribuição espacial da quantidade de chuva, em mm, que cai em uma certa região, num determinado período de tempo; - O estudo da distribuição espaço-temporal da poluição atmosférica, por exemplo, chuva ácida, em uma determinada região geográfica; - A variabilidade espacial da taxa de infiltração da água no solo, medida no campo;- A variabilidade espacial da produção de uma cultura agrícola, sob Agricultura de Precisão;- A distribuição espacial de oferta de recursos econômicos numa dada região do estado;
Nestes estudos, principalmente dois elementos podem ser discernidos:(i) A necessidade de considerar explicitamente ab initio as relações de dependência entre os valores de uma variável em pontos vizinhos;(ii) A construção de preditores (ou estimadores) utilizando a dependência acima e a informação fornecida por dados amostrais.

16
O elemento (i) acima às vezes é referido como “uma das principais leis da Geografia”, e, por extensão, um elemento que não pode ser desprezado em qualquer estudo sobre superfícies e volumes na Terra. Os registros históricos mais antigos sobre estudos da variabilidade espacial ocorreram em ciência do solo para uso agrícola, a saber, os ensaios de uniformidade de Mercer e Hall em 1911, realizados na estação experimental de Rothamsted, na Inglaterra. Desde então, pesquisadores na área agrícola buscaram modelar a variação espacial de diferentes formas, até que, na década de 1950, D. G. Krige, estudando a estimação de teores de minério de ouro em minas da África do Sul, propôs uma metodologia que seria a semente utilizada por G. Matheron, no início da década de 1960 na França, para formalizar sua Teoria das Variáveis Regionalizadas, que passou a ser denominada Geoestatística. Esta teoria incorpora os elementos (i) e (ii), acima, e as boas idéias oriundas das pesquisas agrícolas anteriores. Inicialmente, a Geoestatística voltava-se para a solução de problemas de variação espacial na mineração, mas hoje a teoria é aplicada em vários outros campos da ciência, como por exemplo, às distribuições das variáveis espaciais e temporais mencionadas acima. Porém, neste zoneamento, serão consideradas somente variáveis espaciais, e não temporais. É também conveniente salientar que a Geoestatística não é hoje, como seu nome poderia sugerir, o conjunto de todas as técnicas estatísticas aplicáveis em ciência da terra, nem tampouco restringe sua aplicação somente à ciência geológica. Será adotada uma linguagem matemática precisa, para contemplar a expectativa buscada pelo usuário que deseja conhecer rigorosamente a base estatística.
1.3.1 Modelo estatístico Os modelos estatísticos fundamentais para a Geoestatística3 podem ser expressos todos eles na forma de processos estocásticos (ou funções aleatórias). Serão considerados aqui três tipos de modelos, exatamente aqueles que foram utilizados neste zoneamento: processos pontuais, processos de média espacial e processos correlacionados.
1.3.1.1 Processos pontuais
Um processo estocástico (real) pontual é uma coleção { }( ) : pY x x R∈ ⊂ de variáveis
aleatórias reais, definidas sobre um mesmo espaço de probabilidade, indexadas em um subconjunto R do espaço vetorial p-dimensional
p . Este último é chamado espaço de índices do processo estocástico. Nesta seção, o subconjunto R será denominado região e necessitará de outras considerações sobre sua geometria. Em particular, um processo estocástico é dito ser de 2a ordem se a esperança matemática
2[ ( )]E Y x é finita, ∀ ∈x R . O espaço de índices p é definido de tal maneira que seja possível
representar variações aleatórias em espaços de qualquer dimensão, por exemplo, p = 1 para variações no tempo (como as estudadas nas séries de tempo), p = 2 para variações em superfícies, p = 3 para variações no espaço tridimensional e p = 4 para variação no espaço-tempo. Obviamente, pode-se trabalhar em espaços com dimensão p >4, porém, neste zoneamento, a dimensão utilizada será p=2, para variabilidade espacial em superfícies (na superfície do Estado de Minas Gerais).
A Geoestatística baseia-se no suposto de que a distribuição espacial e/ou temporal de uma
variável realizada y em uma região R é uma realização { }( ) : py x x R∈ ⊂ do processo estocástico
{ }( ) : pY x x R∈ ⊂ . Esta realização será também chamada nesta seção de população de valores
da variável estudada na região R. Neste trabalho dotar-se-á o processo estocástico básico com algumas
características que o tornam tratável estatisticamente, explicitadas a seguir.
Seja uma população { }2( ) :y X x R∈ ⊂ , realização do processo estocástico de 2a ordem
{ }2( ) :Y X x R∈ ⊂ , que satisfaz o seguinte suposto de estacionaridade, chamada tradicionalmente
de hipótese intrínseca:
3 Cressie, N.. Statistics for Spatial Data, revised ed. New York: John Wiley, 1993, 614 p..

17
(i) , onde é uma constante real desconhecida.
(ii) , onde é
uma função real não-negativa.
A função é chamada variograma e é chamada semivariograma. O valor é
chamado semivariância entre dois pontos separados pelo vetor h = x y− . Se a função semivariograma
só depende da distância entre os pontos x e y (isto é, se só depende da norma
| |x y− ), o semivariograma é dito ser isotrópico. Se depende não só da distância, mas também
da direção da reta que passa pelos pontos x e y, o semivariograma é dito ser anisotrópico.
As seguintes propriedades para a função decorrem de sua própria definição:
(i)
1,..., mx x∀ ∈ , 1,..., ma a∀ ∈ tal que 1
0m
ii
a=
=∑ , m∀ ∈ .
O sentido físico do semivariograma pode ser percebido quando se analisa sua definição: ele mede a variabilidade das diferenças entre as realizações da variável aleatória de interesse, de tal maneira que quanto menor a semivariância, menor a variação dessas diferenças. A compreensão deste fato pode ser melhorada quando se considera um conjunto de processos estocásticos que satisfazem à hipótese intrínseca: o conjunto dos processos estacionários de 2a ordem ou estacionários com respeito à covariância. Estes são processos de 2a ordem que satisfazem
(a)
(b)
onde são denominadas função de covariância.
Nesse caso, pode-se mostrar que . Essa relação permite ver
que, enquanto cresce (os pontos ficam mais correlacionados espacialmente), a semivariância
decresce. Alguns modelos para a função têm sido propostos, todos eles satisfazendo as exigências (i), (ii) e (iii) acima. Estes modelos são denominados na literatura da área como modelos autorizados, por atenderem às três exigências mencionadas. Alguns destes modelos autorizados são os modelos linear, esférico, exponencial, gaussiano e os da classe Matérn. Alguns fenômenos exigem uma descontinuidade na origem do semivariograma, chamada efeito pepita, que expressa limitação na estimação do semivariograma em pequenos espaçamentos. Sua ocorrência pode estar associada ao aumento acentuado na dependência espacial entre pares de pontos próximos, como quando há grãos ou palhetas de metal nativo, em mineração, particularmente de ouro (“pepitas”), vindo daí seu nome. De fato, um semivariograma pode ser modelado completamente pelo efeito pepita, isto é, para,
. Isto é um caso extremo e estaria associado a um processo onde toda a variação seria aleatória, isto é, há uma correlação zero entre os pontos da região. O mais comum é o efeito pepita estar combinado aos modelos usuais, por exemplo, com o linear: .
1.3.1.2 Processos de médias espaciais O processo estocástico visto acima é pontual, pois refere-se à realização da variável espacial em pontos x da área geográfica. Porém, o interesse pode ser em médias espaciais sobre uma sub-região geográfica. Suponha que para x∈ é considerada a sub-região ( )R x de forma e dimensão fixas,

18
contendo o ponto x (Figura 1.8). Assuma ainda que a sub-região ( )R x esteja contida numa região R maior (no caso deste zoneamento, esta região R é o Estado de Minas Gerais), e que a função seja tal que a integral
é finita, e que ( )R x não impossibilite a existência da variável aleatória
definida como a média espacial da variável y na sub-região ( )R x ( ( )R x é o volume de ( )R x ).
Uma realização ( )s x de ( )S x é a média aritmética da subpopulação { }( ) : ( )y t t R x R∈ ⊂ . Nessas
condições, pode ser demonstrado que o processo { }2( ) : ( )S x R x R⊂ ⊂ é de 2a ordem e que satisfaz a hipótese intrínseca, isto é:
[ ]( )E S x(i)
é constante e coincide com Yµ , ( )R x R∀ ⊂ .
(ii)
Figura 1.8 - Duas formas diferentes para as subregiões R(x) distribuídas na região R: (a) regular (b) forma arbitrária.

19
Uma amostra de tamanho n da população { }( ) : Yy x x R∈ ⊂ é um subconjunto finito { }1( ),..., ( )ny x y x da mesma.
1.3.1.3 Processos correlacionados Este tipo de processo ocorre quando o interesse é estudar conjuntamente duas ou mais variáveis espaciais que se realizam cada nos mesmos pontos do espaço, simultaneamente. Um processo estocástico (real) correlacionado é uma coleção { }1 2( ( ), ( ),..., ( )) : ∈ ⊂ p
mY x Y x Y x x R de vetores aleatórios reais, tais que as m variáveis que compõem as coordenadas dos vetores são variáveis aleatórias que se realizam concomitantemente no espaço considerado. Por exemplo, podemos ter Y1 sendo a precipitação pluviométrica, Y2 a altitude no ponto, Y3 a latitude e Y4 a longitude. Nesse tipo de processo ocorrem, além dos autosemivariogramas, os semivariogramas cruzados. Definidos os supostos teóricos adotados, serão abordados, a seguir, com os tipos usuais de inferências.
1.3.2 Inferências As inferências no modelo estatístico definido na subseção anterior podem agora ser discutidas. Para desenvolvê-las é necessário realizar determinações de três tipos:
Estimação da função semivariograma (i) , usada para descrever a dependência espacial no processo sob estudo;Predição (ii) da variável ( )y x , x R∈ . Predizer ( )Y x baseado numa amostra
{ }1( ),..., ( )ny x y x é construir uma função real mensurável 0 ( ,..., )g ⋅ ⋅ tal que o
número 0 1ˆ( ) ( ( ),..., ( ))ny x g y x y x= opere como substituto do valor desconhecido
de ( )y x ; o valor ˆ( )y x é chamado predição de ( )y x . A variável aleatória
{ }0 1ˆ( ) ( ),..., ( )nY x g Y x Y x= é dita ser um preditor de ( )Y x . Como a predição é feita
para a realização da variável aleatória em um ponto x R∈ , tal predição é dita pontual;
Predição da variável (iii) ( )s x para ( )R x R⊂ usando a amostra { }1( ),..., ( )ny x y x . A
variável aleatória ( )S x é predita pelo preditor ˆ( )S x .
O conhecimento do semivariograma é fundamental para desenvolver as predições. A função é estimada usando uma amostra, não necessariamente a mesma que será usada nas predições:
sua estimação poderá se basear numa pré-amostragem. Neste zoneamento todos os semivariogramas foram estimados utilizando-se os dados completos de cada variável. Estimadores e procedimentos para estimação de semivariogramas são tratados resumidamente abaixo. Apresentações mais detalhadas podem ser encontradas na literatura de Geoestatística4.
A estimação do semivariograma é feita pelo semivariograma experimental :
(2)
em que, = Semivariância estimada;
N(h) = Número de pares de observações (y(xi), y(xi + h)), separados pela distância h.
A análise completa do semivariograma compreende os seguintes passos:- Levantamento do semivariograma experimental;- Ajuste a uma família de modelos de semivariogramas teóricos;- Validação do modelo a ser utilizado nos procedimentos da krigagem.
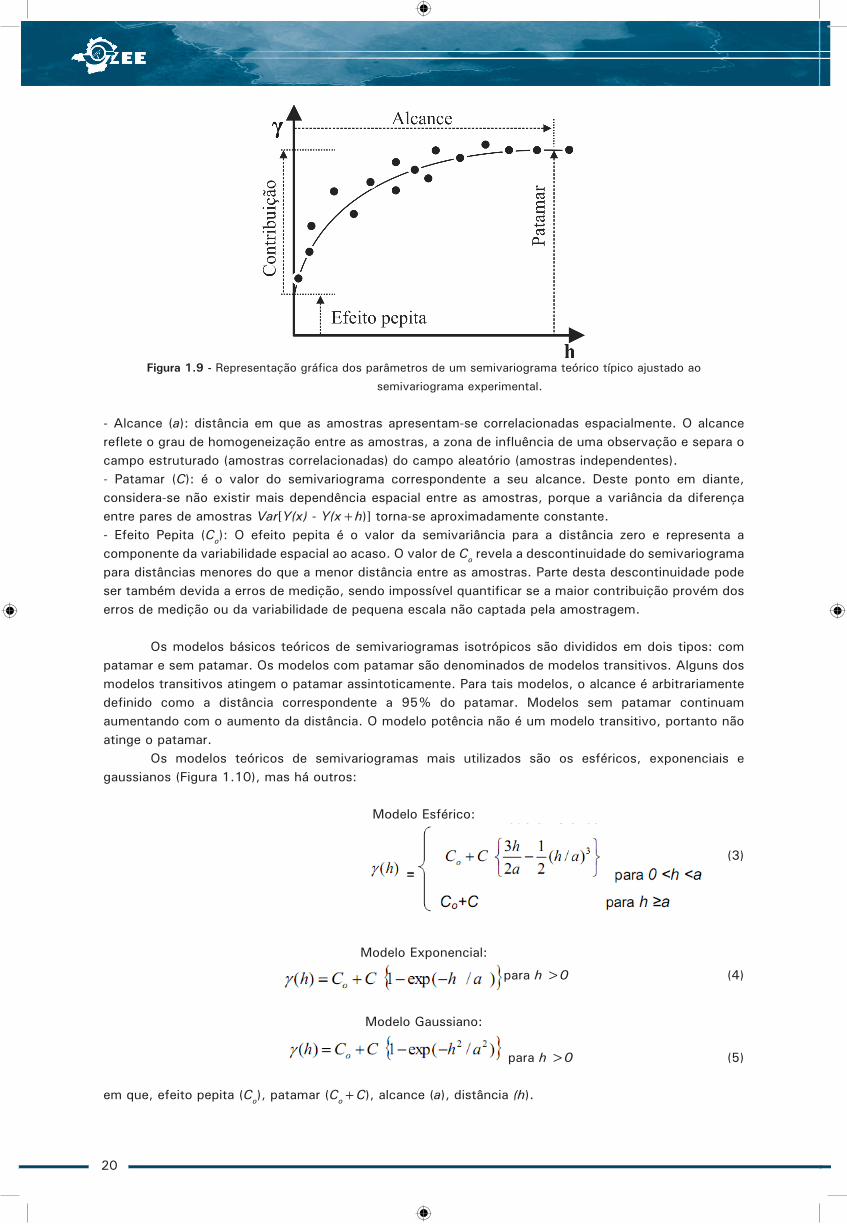
Ao semivariograma experimental pode-se ajustar uma família de modelos de semivariogramas teóricos, caracterizados geralmente por três parâmetros: efeito pepita ( = Co), patamar (Co + C), alcance (a), onde (Figura 1.9):
4 Journel, A.G.; Huijbregts, C.J.. Mining Geoestatistics. London: Academic Press. 1978, 600p..
20
Figura 1.9 - Representação gráfica dos parâmetros de um semivariograma teórico típico ajustado ao
semivariograma experimental.
- Alcance (a): distância em que as amostras apresentam-se correlacionadas espacialmente. O alcance reflete o grau de homogeneização entre as amostras, a zona de influência de uma observação e separa o campo estruturado (amostras correlacionadas) do campo aleatório (amostras independentes).- Patamar (C): é o valor do semivariograma correspondente a seu alcance. Deste ponto em diante, considera-se não existir mais dependência espacial entre as amostras, porque a variância da diferença entre pares de amostras Var[Y(x) - Y(x+h)] torna-se aproximadamente constante.- Efeito Pepita (Co): O efeito pepita é o valor da semivariância para a distância zero e representa a componente da variabilidade espacial ao acaso. O valor de Co revela a descontinuidade do semivariograma para distâncias menores do que a menor distância entre as amostras. Parte desta descontinuidade pode ser também devida a erros de medição, sendo impossível quantificar se a maior contribuição provém dos erros de medição ou da variabilidade de pequena escala não captada pela amostragem.
Os modelos básicos teóricos de semivariogramas isotrópicos são divididos em dois tipos: com patamar e sem patamar. Os modelos com patamar são denominados de modelos transitivos. Alguns dos modelos transitivos atingem o patamar assintoticamente. Para tais modelos, o alcance é arbitrariamente definido como a distância correspondente a 95% do patamar. Modelos sem patamar continuam aumentando com o aumento da distância. O modelo potência não é um modelo transitivo, portanto não atinge o patamar.
Os modelos teóricos de semivariogramas mais utilizados são os esféricos, exponenciais e gaussianos (Figura 1.10), mas há outros:
Modelo Esférico:
(3)
Modelo Exponencial:
para h >0 (4)
Modelo Gaussiano:
para h >0 (5)
em que, efeito pepita (Co), patamar (Co+C), alcance (a), distância (h).

21
Modelo K-Bessel:
para todo h, (6)
em que, θs ≤0, θr ≥0, Ωθk corresponde a um valor numérico de forma que γ(θr)=0,95 θs para qualquer θk, Г(θk) é a função gama,
∞ −Γ = −∫ t 1
0( t ) x exp( x )dx (7)
e Kθs é a função bessel modificada de segunda ordem θk .
Figura 1.10 - Representação gráfica dos modelos teóricos de semivariogramas esféricos, exponenciais gaussianos.
O procedimento de ajuste dos modelos teóricos de semivariograma não é direto e automático, como no caso de uma regressão, mas interativo, pois nesse processo o intérprete faz um primeiro ajuste e verifica a adequação do modelo teórico. Dependendo do ajuste obtido, pode-se redefinir ou não o modelo, até conseguir um que seja mais satisfatório.
No caso de ajuste de semivariogramas a uma variável que apresenta o mesmo comportamento para diferentes direções, há isotropia no fenômeno estudado; caso contrário, há anisotropia. O estudo da isotropia considera que o fenômeno apresenta comportamento semelhante para todas as direções, porém, na anisotropia, há direções específicas que condicionam a gênese do fenômeno sob estudo (Figura 1.11).
Figura 1.11 - Convenções direcionais da geoestatística representando isotropia (a) e anisotropia (b).
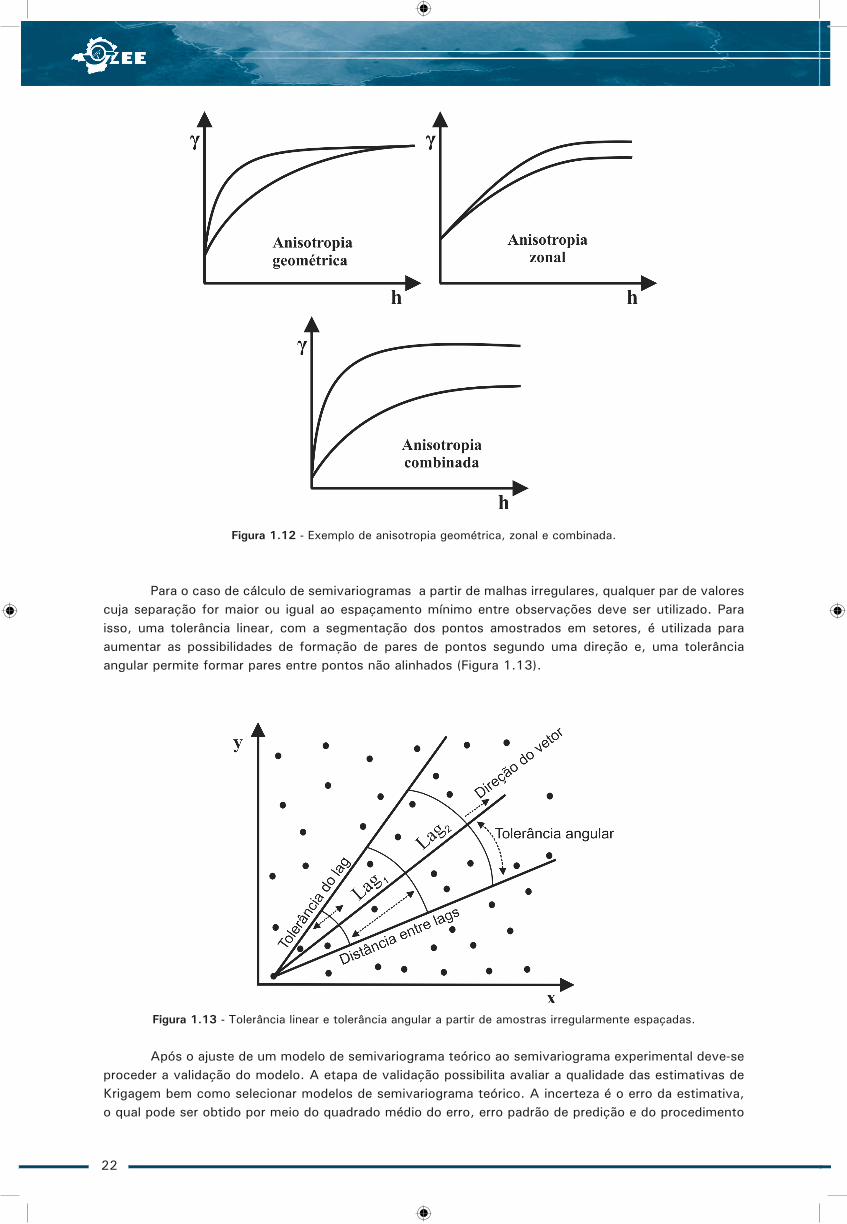
Se a anisotropia é observada para diferentes direções, com o mesmo patamar e diferentes alcances, é denominada geométrica, quando apresenta os mesmos alcances e diferentes patamares é denominada zonal. A combinação da anisotropia zonal e geométrica é denominada de anisotropia combinada (Figura 1.12).
22
Figura 1.12 - Exemplo de anisotropia geométrica, zonal e combinada.
Para o caso de cálculo de semivariogramas a partir de malhas irregulares, qualquer par de valores cuja separação for maior ou igual ao espaçamento mínimo entre observações deve ser utilizado. Para isso, uma tolerância linear, com a segmentação dos pontos amostrados em setores, é utilizada para aumentar as possibilidades de formação de pares de pontos segundo uma direção e, uma tolerância angular permite formar pares entre pontos não alinhados (Figura 1.13).
Figura 1.13 - Tolerância linear e tolerância angular a partir de amostras irregularmente espaçadas.
Após o ajuste de um modelo de semivariograma teórico ao semivariograma experimental deve-se proceder a validação do modelo. A etapa de validação possibilita avaliar a qualidade das estimativas de Krigagem bem como selecionar modelos de semivariograma teórico. A incerteza é o erro da estimativa, o qual pode ser obtido por meio do quadrado médio do erro, erro padrão de predição e do procedimento

23
chamado autovalidação, validação cruzada ou ́ jackknifing`. Resumidamente, o processo de autovalidação envolve a re-estimação dos valores conhecidos por meio do modelo de semivariograma ajustado aos dados, sendo que cada valor observado é sucessivamente retirado e predito com base no restante dos dados. O método consiste no cálculo de uma regressão linear entre os pares de valores medidos (xi) e estimados Y(xi) de cada valor amostral (Figura 1.14):
= +i iY * ( x ) a bY( x ) (6)
Em que, a é a interseção, b é o coeficiente angular da reta e r é o coeficiente de correlação entre Y* (xi) e Y(xi).
Figura 1.14 - Autovalidação do semivariograma e da interpolação por krigagem.
No caso de baixa qualidade de ajuste do semivariograma, todos os cálculos posteriores são comprometidos, de forma a influenciar na exatidão e na precisão das estimativas de krigagem. Na predição pontual, uma atitude usual é considerar preditores que são uma combinação linear
dos elementos da amostra. Dentre estes, procura-se um preditor ótimo, no sentido
de que seja não-tendencioso e que possua o menor erro quadrático médio de predição dentre todos os preditores lineares não-tendenciosos. Assim, o preditor procurado ˆ( )Y x deve satisfazer às condições:
(i)
(ii)
onde o mínimo é obtido entre todos os preditores *( )Y x que satisfazem (i).
Numa linguagem estatística mais universal, procura-se um BLUP (Best Linear Unbiased Predictor) no contexto do modelo definido acima. A condição de não-tendenciosidade para todo implica
em . Para obter os valores de , que minimizam ,
basta resolver a equação matricial

24
onde α é um multiplicador de Lagrange associado à restrição , é uma matriz n x n cujo
elemento na posição (i,j) é , 1é o vetor n x 1 com todos os elementos iguais à 1 e é um
vetor n x 1 cujo i-ésimo elemento é . O preditor ótimo assim obtido recebe o nome de preditor
de krigagem linear ordinária ou resumidamente preditor de krigagem, ou ainda apenas krigagem. Definindo
1( ( ),..., ( ))nY Y x Y x′ = pode-se anotá-lo como
Seu erro quadrático médio de predição é chamado variância de krigagem. Ela é dada pela fórmula
onde ( )diag K é a diagonal principal da matriz K com o elemento (i,j) dado por ( , )Y i jx xk . Por causa do desconhecimento da função de covariância ( , )Yk ⋅ ⋅ , usa-se outra expressão equivalente, a saber
Os números são chamados pesos de krigagem. Note que a variância de krigagem
não depende da realização { }1( ),..., ( )ny x y x , pois apenas as semivariâncias e os pesos de krigagem
(que por si também só dependem das semivariâncias) são requeridos para calculá-la. Porém, ela é função da configuração da amostra, pois depende das distâncias e da posição relativa dos pontos amostrados entre si. Deve-se informar que, se a variável Y em estudo for em especial uma variável indicadora de algum evento de interesse, a krigagem recebe o nome especial de krigagem indicadora ou krigagem indicatriz. Um preditor para a média espacial ( )S x (com ( )R x R⊂ ), pode ser construído de modo análogo.
A combinação linear 1
ˆ( ) ( )n
i ii
S x Y xu=
=∑ fornece o preditor não tendencioso de mínimo erro quadrático médio
dentre todos os preditores lineares não-tendenciosos, se os pesos de krigagem forem a solução da equação matricial
onde é um multiplicador de Lagrange associado à restrição é um vetor n x 1 cujo
i-ésimo elemento é . Preditor de krigagem de bloco ou
apenas krigagem de bloco é sua denominação usual. A krigagem de bloco pode ser utilizada, além do cálculo de médias espaciais, também para suavizar a modelagem da variabilidade espacial de variáveis muito caóticas. Seu erro quadrático médio de predição é chamado variância de krigagem de bloco. Em linguagem matricial:
onde . Pelo fato das covariâncias serem desconhecidas, usa-se a expressão equivalente
onde

25
Outra vez pode-se notar que a variância de krigagem (de bloco) é função apenas da estrutura de dependência espacial do processo sob estudo, da forma e dimensão da sub-região ( )R x e da posição relativa dos pontos amostrados entre si e entre pontos amostrados e a sub-região. Assim, os valores da amostra não influem no risco, sendo este função apenas da configuração e tamanho amostrais. Observe, por fim, que a Geoestatística incorpora na sua teoria a estrutura de dependência espacial, através do semivariograma, e fornece um preditor espacial ótimo, a krigagem (tanto pontual quanto de blocos), com uma medida calculável para sua qualidade, a variância de krigagem. Isto é uma vantagem definida sobre outros métodos de interpolação (estimação ou predição) propostos na literatura, tais como o método do inverso da potência da distância e, em problemas onde é razoável supor a validade da hipótese intrínseca, pode fornecer um argumento conclusivo para a escolha do preditor. Para este zoneamento, a Geoestatística atendeu tal razoabilidade para muitas variáveis, sendo, portanto, o método estatístico utilizado para a espacialização destas variáveis com estrutura de dependência espacial para as quais modelos objetivos podem ser explicitados.
1.3.3 Resultados do ZEE-MG
A Geoestatística foi utilizada no Zoneamento Ecológico-Econômico de Minas Gerais para caracterizar a magnitude e a estrutura de dependência espacial, e mapear os índices resultantes das potencialidades dos índices sócio-econômicos (Índice Geral), das componentes institucional, produtiva, humana e natural, bem como do índice de umidade de Thornthwaite (Iu), para regiões do Estado de Minas Gerais (regionalização do COPAM) utilizando-se altitude, latitude e longitude como covariáveis.
No caso do estudo com os índices econômicos, foi utilizada a localização das Sedes Municipais como o ponto de referência para realizar a análise de krigagem ordinária (Figura 1.15). Cabe ressaltar que os índices Geral, Humano e Natural foram calculados a partir da análise de Componentes Principais, de forma a gerar um índice para representar a maior extensão da variabilidade de um conjunto de variáveis indicadoras referentes a cada índice.
Figura 1.15 - Localização das 853 sedes municipais utilizadas para calcular os índices de potencialidade social, e
componentes produtivo, institucional, humano e natural.
26
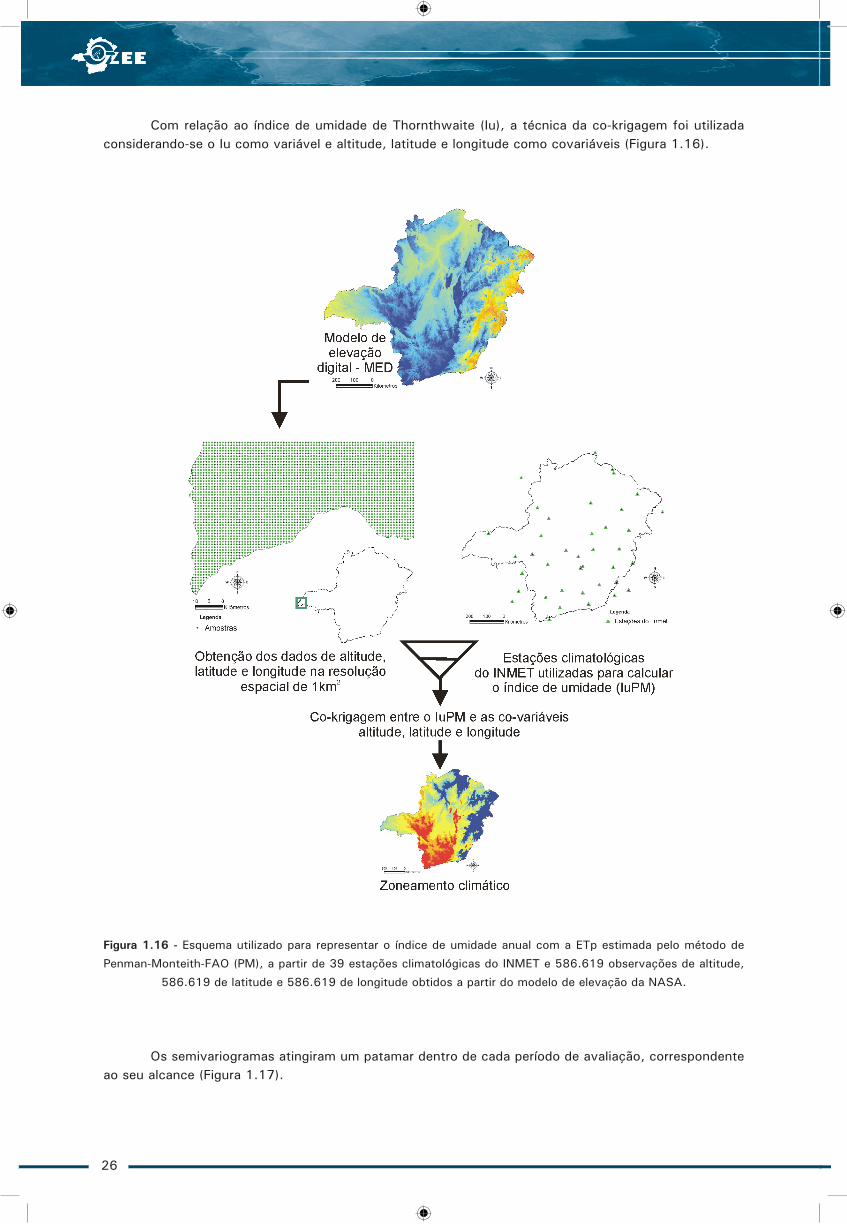
Com relação ao índice de umidade de Thornthwaite (Iu), a técnica da co-krigagem foi utilizada considerando-se o Iu como variável e altitude, latitude e longitude como covariáveis (Figura 1.16).
Figura 1.16 - Esquema utilizado para representar o índice de umidade anual com a ETp estimada pelo método de
Penman-Monteith-FAO (PM), a partir de 39 estações climatológicas do INMET e 586.619 observações de altitude,
586.619 de latitude e 586.619 de longitude obtidos a partir do modelo de elevação da NASA.
Os semivariogramas atingiram um patamar dentro de cada período de avaliação, correspondente ao seu alcance (Figura 1.17).

27
Figura 1.17 - Semivariogramas ajustados ao componente institucional do índice de potencialidade sócio-econômica
(a), potencial humano (b), potencial natural (c), e semivariograma cruzado do índice de umidade de Thornthwaite
com as covariáveis altitude, latitude e longitude (d), para o Estado de Minas Gerais.
Com o uso da krigagem, foi possível constatar nos mapas dos diferentes temas estudados, padrões correspondentes entre os índices (Figura 1.18), levantando-se a hipótese de que a predominância climática de uma região pode influenciar na variabilidade espacial das potencialidades sócio-econômicas de Minas Gerais.

28
Figura 1.18 - Cartas de krigagem ordinária do componente institucional do índice de potencialidade sócio-econômica
(a), humana (b), natural (c) e de cokrigagem do índice de umidade de Thornthwaite (Iu) (d), para regiões do Estado de
Minas Gerais (regionalização do COPAM) utilizando-se, em (d), da altitude, latitude e longitude como covariáveis.
Os índices estudados apresentaram estrutura de dependência espacial constado a partir da modelagem variográfica. Com o uso de metodologias de análise Geoestatística foi possível explorar e compreender a variabilidade espacial de variáveis ecológico-econômicas de forma a auxiliar à tomada de decisão sobre questões associadas ao clima e os potenciais de desenvolvimento Sócio-econômico, Humano e Natural no Estado de Minas Gerais. A modelagem da estrutura de dependência espacial para as variáveis sócio-econômicas e ecológicas do ZEE-MG, e sua conseqüente incorporação nos artefatos do zoneamento, é mais um diferencial de qualidade científica que distingue este zoneamento de outros.
1.4 ANÁLISE DE COMPONENTES PRINCIPAIS
A Análise de Componentes Principais é uma das metodologias propostas dentro do escopo maior da Análise Multivariada5 e está relacionada com a explicação da estrutura de covariância ou de correlação entre variáveis por meio de poucas combinações lineares destas variáveis em estudo. Estas combinações lineares formam um conjunto de novas variáveis, conhecidas por variáveis latentes. Esta transformação irá conduzir a tantas variáveis latentes quanto há no grupo original, porém com a característica fundamental de não apresentarem correlações entre si. Estas variáveis latentes são conhecidas como componentes principais e possuem objetivos específicos, quais sejam: a) redução da dimensão original; e b) facilitação da interpretação das análises realizadas. Em geral, a explicação de toda a variabilidade do sistema determinado por p variáveis só pode ser efetuada por p componentes principais, como já mencionado anteriormente. Felizmente, uma grande parte dessa variabilidade pode ser explicada por um pequeno número r de componentes, r ≤ p. Os componentes principais são considerados uma técnica de análise intermediária e, portanto, não se constituem em 5 Johnson, R.A.; Wichern, D.W. Applied multivariate statistical analysis. 4th ed. New Jersey: Prentice Hall, 1998. 816p.

29
um método final e conclusivo. Esse tipo de análise dos dados se presta fundamentalmente como um passo intermediário em grandes investigações científicas. No zoneamento ecológico e econômico de Minas Gerais esta técnica foi utilizada para a obtenção de índices que mantivessem a maior parte da variabilidade de um conjunto de variáveis para as quais se pretendia gerar mapas de potencialidades e vulnerabilidades. Existem muitas aplicações relatadas na literatura para a obtenção dos componentes principais, como: (a) na análise de regressão múltipla, principalmente, nos casos de colinearidade ou de multicolinearidade; (b) na análise de agrupamento e (c) para estimar fatores nas técnicas multivariadas denominadas de análises fatoriais. A aplicação da técnica e a obtenção dos componentes principais se resumem basicamente ao cálculo de autovalores e autovetores de uma matriz positiva semidefinida. Assim, a técnica fica completamente definida a partir da decomposição espectral ou diagonalização desta matriz de covariâncias ou de correlações. Pode-se modelar tanto a matriz de covariância ou de regressão populacional quanto amostral. No zoneamento ecológico serão tratados os dados de todos os Municípios e, portanto, se for considerado estaticamente o tempo, pode-se considerar a modelagem como sendo populacional. Ademais, não havia a intenção da aplicação de técnicas inferenciais, mas apenas descritivas.
1.4.1 Componentes principais populacionais.
Algebricamente, os componentes principais representam combinações lineares de p variáveis aleatórias X1, X2, …, Xp e geometricamente, representam a seleção de novos eixos coordenados, que são obtidos por rotações do sistema de eixos original X1, X2, …, Xp. Estes novos eixos representam as direções de máxima variabilidade. Assim, pode-se demonstrar que os componentes principais dependem somente da matriz de covariância (ou da matriz de correlação ρ ) e de X1, X2, …, Xp. A obtenção dos componentes principais não faz restrição alguma a respeito da distribuição destas variáveis, como, por exemplo, exigência de normalidade multivariada ou a respeito da escala das variáveis. A princípio, será dada ênfase na definição de componentes principais populacionais. Seja o vetor aleatório de uma distribuição p-variada qualquer com covariância , cujos autovalores são λ1 ≥ λ2 ≥ … ≥ λp ≥ 0, então, os componentes principais (Y1, Y2,…,Yp) são as combinações lineares dadas:
Pode-se verificar que:
Dessa forma, pode-se definir o i-ésimo componente principal (Yi), assumindo que o vetor X
possui covariância , com pares de autovalores e autovetores ( ), , 1, 2, ...,i ie i pλ =
, em que λ1 ≥ λ2 ≥ …
≥ λp ≥ 0, por:
Os componentes principais podem se derivados formalmente a partir da maximização de formas quadráticas. Esta maximização tem solução dada pelo conjunto de todos os pares de autovalores e autovetores da matriz núcleo da forma quadrática considerada. Os autovetores devem ser submetidos à restrição de comprimento unitário, para que haja uma solução única. Assim, considere a forma quadrática dada por , cujo máximo é obtido tomando sua derivada com respeito ao vetor e
e igualando-se
o sistema de equações formado a zero. Portanto, o seu máximo é obtido pela resolução do sistema de equações homogêneas dado por:

30
Pode-se perceber que da equação acima surge a seguinte óbvia relação, obtida no ponto de máximo, dada por: . Portanto, a variância e a covariância de Yi, especificadas anteriormente, são dadas por:
Utilizando algumas propriedades matriciais, pode-se demonstrar que:
Desta relação, pode-se concluir que variação total existente nas variáveis Xi, i=1, 2,...,p é igual à variação existente nos p componentes principais. Para demonstrar isso, seja Σ a matriz de covariância entre as p variáveis X, cujos pares de autovalores e autovetores são dados por (λi, ie
). O componente
principal Yi é definido por ti iY e X=
e possui variância igual a λi.
Da decomposição espectral de Σ = PΛPt, em que P é uma matriz ortogonal de autovetores e Λ é uma matriz diagonal dos autovalores e sabendo que PPt = PtP = I, verifica-se que:
Utilizando a propriedade do traço dada por tr(AB ) = tr(BA) e fazendo A = P e B = ΛPt, então, obtém-se
ficando demonstrada a relação entre as variâncias das variáveis originais e latentes. Portanto, a porcentagem da variação total explicada pelo k-ésimo componente principal é dada por:
Em muitas situações em que se aplicam os componentes principais, se uma porcentagem de 70% ou mais for atribuída aos primeiros r componentes principais, então, esses podem substituir as p variáveis originais sem perda demasiada de informação. A determinação dessa porcentagem da variação explicada pelos primeiros r componentes deve ser feita pelo pesquisador interessado e que possui maior conhecimento da área estudada. A determinação do número r de componentes, para que uma determinada porcentagem fixada da informação seja contemplada por eles, é um dos problemas dessa metodologia. Os componentes do autovetor 1 2
ti i i ipe e e e =
podem informar sobre a importância das variáveis para o i-ésimo componente principal, por meio de suas magnitudes. No entanto, esses componentes são influenciados pela escala das variáveis. Para contornar tal problema, os pesquisadores podem utilizar uma importante medida de associação, a qual não depende da magnitude das mensurações (escala) das variáveis originais, que é o coeficiente de correlação entre Yi e Xk. Esse coeficiente de correlação é apresentado por:
Demonstração: Para demonstrar a expressão acima é utilizada a definição do coeficiente de correlação. Para isso, cada termo dessa expressão foi avaliado individualmente. Seja a correlação entre as variáveis Yi e Xk expressa por:

31
Assim, ( ) ( ) ( ), , ,t t ti k i k iCov Y X Cov e X X Cov e X X= =
com, , vetor composto de valores 0 e com 1 na k-ésima posição. Logo,
( ) ( ), ,t t t ti k i i iCov Y X Cov e X X e e= = Σ = Σ
Como , então,
Da mesma forma, as variâncias de Yi e Xk são:
e
Assim, obtém-se:
concluindo a prova.
Os componentes principais podem ser obtidos pela padronização das variáveis originais por:
Em notação matricial, tem-se:
em que V -1/2 é uma matriz diagonal com os elementos da diagonal dados . É fácil verificar que:
Então, os componentes principais de Z
são dados pelos autovalores e autovetores de ρ, matriz de correlação de X
. Entretanto, os autovalores e autovetores de Σ são, em geral, diferentes daqueles
derivados de ρ. Sejam as variáveis padronizadas Z1, Z2, ...., Zp disposta no vetor Z
com , então,
os componentes principais são dados por:
Da mesma forma, se verifica que:
Também se verifica que:

32
Sendo que em todos esses casos (λi , ie
) são os autovalores e autovetores de ρ, com λ1 ≥ λ2
≥ ... ≥ λp. As demonstrações podem ser realizadas da mesma forma que as demonstrações anteriores, substituindo Σ por ρ. Para algumas matrizes de covariância, com estruturas especiais, existem simples formas de se expressar os componentes principais. Serão tratados alguns desses casos, conforme apresentado na literatura especializada. Para uma matriz Σ diagonal,
Os autovalores e autovetores são dados por com 1 na i-ésima posição e 0 nas demais. A demonstração disso pode ser facilmente realizada, uma vez que das equações de maximização de formas quadráticas verifica-se que: . Assumindo-se as definições anteriores para os autovalores e autovetores verifica-se que:
Dessa forma, pode-se concluir que (σii, ie
), com ie
definido anteriormente, são os pares de autovalores e autovetores de Σ. Desde que os componentes principais são dados pelas combinações lineares t
ie X
= Xi, então, os componentes principais são as próprias variáveis originais não correlacionadas, cujos autovalores são as próprias variâncias originais das respectivas variáveis aleatórias. Do ponto de vista de extração de componentes principais não há ganhos, uma vez que os eixos originais já estão no sentido de maior variabilidade. Dessa forma não há necessidade para fazer rotação dos eixos originais. A estandardização não altera a situação, uma vez que ρ = I, e o par autovalor e componente principal é dado por (1, Zi), em que Zi é a i-ésima variável padronizada. Existe sempre a questão importante do número de componentes a ser retido no modelo. Não existe uma resposta definitiva para essa questão. Os aspectos que devem ser considerados incluem a quantidade da variação explicada, o tamanho relativo dos autovalores e a interpretação subjetiva dos componentes. Uma ferramenta visual importante para auxiliar a determinação do número necessário de componentes a ser retido é o scree plot. O termo scree refere-se ao acúmulo de rochas nas bases de um penhasco, portanto os scree plots são considerados “gráficos de cotovelos”. Na Figura 1.19 é ilustrada uma situação para exemplificar e pode-se observar que um cotovelo é formado aproximadamente na posição i = 4. Isso significa que os componentes além do terceiro possuem aproximadamente a mesma magnitude e são relativamente pequenos. Isso indica que os três primeiros, talvez os quatros primeiros componentes, são suficientes para resumir a variação total.

33
1 2 3 4 5 6
0
2
4
6
8
10λi
componente principal
Figura 1.19 - Scree plot de um exemplo com p = 6 componentes principais para ilustrar o processo de determinação
de o número apropriado de componentes a ser retido.
Os gráficos provenientes dos componentes principais podem ser reveladores de diversos aspectos presentes nos dados de interesse do pesquisador. Em muitas áreas os pesquisadores utilizam os primeiros e mais importantes componentes para agrupar objetos e itens de acordo com a representação em duas ou no máximo três dimensões. As realizações dos componentes principais obtidos a partir dos dados originais são chamadas de escores. A definição do escore do k-ésimo componente principal para a j-ésima realização da variável aleatória multidimensional é dada por:
De uma forma geral, os escores dos p componentes principais, representados pelo vetor
1 2 ...tj j j jpY Y Y Y =
para a j-ésima realização da variável aleatória multidimensional 1 2 ...tj j j jpX X X X =
,
são dados por:
1
2
t
tt
j j j
tp
ee
Y P X X
e
= =
.
Para o agrupamento de objetos obtêm-se gráficos dos primeiros componentes retidos em um diagrama contendo pares de componentes. Para a verificação de observações suspeitas, os gráficos dos últimos componentes principais tomados dois a dois são utilizados. Da equação acima, e relembrando que P é uma matriz ortogonal (pois t tPP P P I= = , ou ainda, que ( ) 1tP P
−= ), pode-se demonstrar que:
1 2
1 1 2 2 .
j j p j
j j j jp p
X PY e e e Y
X Y e Y e Y e
= =
= + + +
Essa é uma importante equação que mostra que a observação multivariada jX
pode ser recuperada dos escores dos componentes principais correspondentes. Constitui-se, portanto, em uma proeminente forma de identificar com elevada precisão as observações suspeitas.

34
1.5 REGRESSÃO LINEAR MÚLTIPLA E SELEÇÃO DE VARIÁVEIS. A proposição de modelos que embasem uma gestão segura e lúcida dos processos e temas de interesse humano freqüentemente passa pela busca do ajuste de modelos estatísticos adequados, os quais serão usados para a explicação do fenômeno de interesse e para a realização de inferências a respeito do comportamento funcional entre duas ou mais variáveis. Utiliza-se, em geral, modelos lineares, pela sua simplicidade e facilidade de ajuste6. Os modelos lineares entre uma variável Y resposta (dependente) e variáveis regressoras Xk (k = 1, 2, ..., m) são representados, de forma geral, por:
em que os m β´s são parâmetros do modelo e os resíduos do modelo. O índice i indica repetições das observações, isto é, admite-se que será utilizada uma amostra de n observações para a análise de regressão:
Uma questão que deve ser elucidada, refere-se à necessidade da diferenciação entre os modelos lineares e os modelos não-lineares. Diz-se, em geral, que os modelos são lineares ou não-lineares, baseando essa classificação nos parâmetros, em função da definição utlizada para diferenciá-los. Ilustra-se um modelo não-linear nos parâmetros por:
,
em que a e b são parâmetros deste modelo estatístico. Para que os dois modelos sejam diferenciados em linear e não-linear, utiliza-se a seguinte definição: um modelo é considerado linear se as derivadas parciais da variável dependente em relação a cada parâmetro não forem funções dos parâmetros deste modelo. Caso contrário, o modelo será considerado não-linear. Não pode haver confusão entre a relação funcional que as variáveis estabelecem e a classificação do modelo em linear e não-linear de acordo com esta definição. Considere o primeiro modelo acima: tomando-se as derivadas parciais da variável resposta em relação aos parâmetros, vê-se que elas são funções apenas da constante 1 (para β0) ou de Xk (para βk). Assim, este modelo é classificado como linear. Para o segundo caso, as derivadas parciais são dadas por:
Estas derivadas parciais são funções dos parâmetros a e b, o que classifica o modelo em não-linear. Uma vez especificado o modelo estatístico, o pesquisador precisa estimar os seus parâmetros a partir de uma amostra aleatória retirada da população de interesse. Para isso, em geral, é utilizado algum tipo de critério de otimização. Os estatísticos utilizam o critério de minimizar as somas de quadrados dos resíduos (método dos quadrados mínimos). No caso da inferência, suposições adicionais devem ser admitidas para o resíduo do modelo. Em geral se pressupõe que a distribuição dos erros é normal e que o erro de uma observação é independentemente distribuído em relação ao erro de outra unidade amostral, além de os resíduos serem homocedásticos, isto é, possuírem variância uniforme.6 Draper, N.R.; Smith, H. Applied regression analysis, 3rd ed. New York: John Wiley, 1998, 706 p.

35
1.5.1 Ajuste do modelo e análise de variância
Para o ajuste do modelo e, portanto, estimação de seus parâmetros, utiliza-se o método dos quadrados mínimos. Neste método, a soma de quadrados dos resíduos é minimizada. Expressando o modelo linear anterior em notação matricial temos:
em que Y é o vetor de variáveis resposta de dimensão n × 1; X a matriz do modelo ou das derivadas parciais de dimensão n × (m+1); β o vetor de parâmetros de dimensão (m+1) × 1; e ε o vetor de resíduos de dimensão n × 1 suposto normal multivariado com vetor de médias 0 e matriz de covariâncias σ2I. A soma de quadrados dos resíduos εTε deve ser minimizada, o que resulta nas equações normais (EN), dadas matricialmente por:
Assim, uma solução do sistema de equações normais é dada por:
O vetor é igual à , isto é,
Os valores escalares das estimativas dos parâmetros β0 , β1 , β2 , ... ,βm são, obviamente, obtidos através das coordenadas do vetor . Obtida a solução de quadrados mínimos da equação acima, deve-se determinar as somas de quadrados para viabilizar a realização de inferências. Para isso, deve-se obter as somas de quadrados do modelo e resíduo. A soma de quadrados do modelo é obtida simplesmente por:
e a do resíduo por:
em que refere-se a notação de redução e significa a redução que ocorre na soma de
quadrados devido ao ajuste de um modelo com parâmetros . Deve-se ainda determinar as somas de quadrados devidas a cada parâmetro individualmente. Para isso existem duas formas bem definidas na literatura baseadas em diferentes fundamentações. A primeira refere-se a somas de quadrados do tipo I (seqüencial) e a segunda a somas de quadrados do tipo II (parcial). As somas de quadrados seqüenciais referem-se a ajustes de modelos que diferem apenas pela exclusão de um dos parâmetros por vez. Em cada modelo encaixado é obtida a redução correspondente na soma de quadrados. A soma de quadrado de um determinado parâmetro é obtida tomando-se a diferença entre dois modelos, sendo que um deles contém o efeito em questão e o outro contém todos os outros parâmetros do primeiro, exceto este para o qual pretende-se obter a soma de quadrados do tipo I. No caso das somas de quadrados parciais, ajusta-se o modelo completo e retira-se uma variável por vez do mesmo. Por meio da diferença das reduções obtidas no modelo completo e reduzido, pode-se obter as somas de quadrados do tipo II para cada parâmetro.

36
Para ilustrar o uso da notação de redução (notação R) considera-se um modelo com duas variáveis dado por:
Seja também o modelo de duas variáveis, eliminando-se a terceira, dado por:
Então a redução devida a β3 é obtida por:
R(β3/β0,β1,β2)=SQmodelo(A) – SQmodelo(B).
Conhecendo-se a lógica por trás da notação R, pode-se apresentar agora os dois tipos de somas de quadrados para todas as variáveis deste modelo (Tabela 1.4). A soma de quadrados do tipo I (seqüencial) refere-se a reduções consecutivas do modelo e a tipo II refere-se a reduções de um parâmetro por vez a partir do modelo completo.
Tabela 1.4 - Somas de quadrados tipo I e tipo II associadas a cada variável do modelo com três variáveis.
Variáveis Tipo I (seqüencial) Tipo II (parcial)
X1 R(β1/β0) R(β1/β0,β2,β3)X2 R(β2/β0,β1) R(β2/β0,β1,β3)X3 R(β3/β0,β1,β2) R(β3/β0,β1,β2)
As somas de quadrados do tipo I são dependentes da ordem de entrada das variáveis no modelo, uma vez que deve-se retirar cada variável do modelo em cada etapa na ordem inversa de sua entrada no modelo. As somas de quadrados do tipo II, por sua vez, são invariantes em relação a ordem de entrada de variáveis no modelo. Nos procedimentos de seleção de modelos, os testes de hipóteses são realizados tomando-se por base as somas de quadrados do tipo II, indiretamente, no cálculo de suas estatísticas. Filosoficamente, a soma de quadrados do tipo I está relacionada à importância de uma variável ignorando as que a sucedem, mas ajustando seu efeito para aquelas que a antecedem. A soma de quadrados do tipo II considera a importância de uma variável ajustando seu efeito para todas as outras do modelo. Assim, uma variável que apresentar não significância em um teste que utiliza a soma de quadrados do tipo II, não necessariamente pode ser considerada desprezível para explicar a variação na variável resposta. Deve-se sim, interpretar que possivelmente esta variável tenha informação redundante com outras variáveis regressoras devido à estrutura de correlação entre elas e por isso pode ser descartada do modelo. A sua informação está indiretamente sendo explicada por outras variáveis do modelo. Uma medida da qualidade do modelo ajustado é o R2, que se refere à quantidade da variação total da variável resposta Y que é explicada pelo modelo de regressão. No entanto, esta medida pode não ser adequada para comparar o desempenho dos ajustes de modelos com diferentes números de variáveis. Isso ocorre porque na medida em que o número de variáveis aumenta, o R2 tende a aumentar na direção de 1 de uma forma muito rápida, sem que a real contribuição da variável adicional tenha sido de fato proporcional a esse aumento. Assim, muitos autores recomendam utilizar o 2
ajR ajustado para estes casos, que é definido por:
22 1 11
1aj( R )( n )R
n m− −
= −− −
em que n é o número de observações da amostra; e m é o número de parâmetros, com exceção do intercepto. Este valor deve ser preferido, pelo fato de que com o 2
ajR não ocorre como ocorre com o R2 , quando este último, com o simples incremento de variáveis no modelo, faz com que haja um crescimento em direção a 1, mesmo que o benefício provocado por elas seja pequeno. Uma vez que se tenha obtido o melhor ajuste para o modelo de regressão, para que seja atendido o objetivo de realizar predições do valor da variável resposta Y, basta utilizar a equação encontrada. Portanto, com base no modelo ajustado pode-se fazer predições pontuais por:

37
Por exemplo, para predizer o valor da observação n + 1 (ainda não observada ou medida), basta fazer
O segundo passo após a determinação do valor predito ^Y para a variável Y seria a determinação
do erro embutido naquela estimativa, isto é
− =^Y Y e
Obviamente este erro não pode ser calculado observação a observação, já que a predição de Y por ^Y
pressupõe exatamente o não conhecimento de Y. Porém, por questões de confiabilidade da informação obtida, permanece o interesse de determinar os erros associados a essas predições. Como em regressão a predição é uma média, a solução para a determinação dos erros de predição é também a determinação de erros médios, os quais podem ser compostos em intervalos (de confiança, de predição, e de tolerâncias).
Dois intervalos especialmente utilizados seriam os intervalos de 100(1-α)% de confiança, para a média ^Y e para uma predição futura 1+
^nY . Para o primeiro caso, o erro padrão da predição da média é:
1^
S(Y ) ( z ( X X ) z )QME−= ′ ′
onde, z é o vetor de coeficientes da linha da matriz X associada a predição que pretendemos fazer, e
2
1== = −∑
n
ii
ˆQME SQR e s / v ( y y ) / v
(v é o número de graus de liberdade do resíduo).
O intervalo de confiança para média da população específica é dado, portanto, por:
2
^ ^
/Y t S(Y )a±
em que 2/ta representa o quantil superior da distribuição t de Student com v graus de liberdade, igual ao do resíduo do modelo ajustado. Para o segundo caso, o intervalo de confiança para uma observação futura é dado por:
1 2+ ± −^ ^ ^
n /Y t V(Y Y )a
em que o estimador da variância do estimador da predição futura é dado por:
11 1 −+− = + ′ ′
^ ^
nV(Y Y ) ( z ( X X ) z )QME
1.5.2 Seleção de modelo de equações de regressão
Muitas vezes as somas de quadrados do modelo de regressão apresentam teste F altamente significativo. No entanto, algumas, ou até mesmo todas as variáveis, apresentam F parcial não significativo. A primeira vista, isto parece uma incoerência ou até mesmo uma inconsistência do método, mas ao se analisar com maior profundidade, percebe-se que não se trata de nenhum paradigma. Este fato ocorre simplesmente porque algumas variáveis possuem informações redundantes da variação que ocorre na variável dependente Y. Dessa forma, a variação adicional explicada por essa variável, na presença de outra ou outras, não é suficientemente importante para ser detectada naquele nível de precisão, devendo esta ser descartada do modelo. Para esta finalidade alguns métodos existem, sendo os mais comuns Stepwise, Backward e Forward.
α
α
α

38
O fundamento básico destes modelos é a utilização da importância relativa de uma variável na presença e na ausência de outras para determinar a sua entrada/permanência no modelo. As principais idéias de cada um dos métodos destacados anteriormente são sumarizadas a seguir.
O Backward é um método em que o pesquisador especifica todas as variáveis que ele julga ser adequadas para pertencer ao modelo. É feito um teste de hipótese do tipo parcial utilizando as somas de quadrados do tipo II e a variável que tiver o menor valor de F parcial que for não-significativo em um nível de significância de permanência especificado pelo pesquisador a priori, deve ser eliminada do modelo. Um novo ajuste é realizado e o mesmo procedimento é aplicado eliminando a próxima variável que menos e de forma não-significativa explicar a variação da variável resposta Y. Este processo é repetido até que se obtenha um modelo com todas as variáveis presentes com F parcial significativo no nível pré-fixado de significância ou um modelo que contenha apenas o intercepto. No Forward é realizada uma análise separada para cada variável candidata a entrar no modelo. A primeira variável a entrar no modelo será aquela entre as que atingiram um nível de significância de entrada estabelecido a priori que apresentar maior valor de F parcial. Novos ajustes são feitos considerando um modelo com a variável que entrou no modelo no passo 1, adicionado de cada uma das candidatas a entrar, uma por vez. A segunda variável a entrar no modelo será aquela entre as candidatas que atingiram o nível de significância de entrada que apresentar maior valor de F parcial. O processo é repetido novamente formando um modelo com as duas variáveis que entraram nos passos anteriores e uma das candidatas. O processo pára se em algum passo nenhuma das variáveis atingir o nível de significância de entrada, ou se não houver mais variáveis candidatas a entrar no modelo. O Stepwise é um procedimento muito parecido com o Forward. A diferença básica ocorre por que no Stepwise, após cada passo de entrada ocorre um procedimento de Backward no modelo recém-formado. As variáveis, se ocorrerem, que forem eliminadas no passo de Backward não são candidatas a entrar mais no modelo. Se não houver mais variáveis a serem eliminadas nos passos de Backward, é realizado o passo seguinte de Forward. Essencialmente, na entrada de uma variável durante um processo de Forward, pode ocorrer que alguma ou algumas das variáveis que já estavam no modelo, inclusas em passos anteriores, deixem de apresentar contribuição significativa para a variação da variável Y. No Stepwise estas variáveis são eliminadas. Assim, um nível de significância de entrada e outro de saída das variáveis precisam ser especificados a priori neste método.
1.5.3 Análise de resíduo e diagnose na análise de regressão
Vamos considerar o modelo de regressão:
em que, β é o vetor de parâmetros, X a matriz de incidência, e ε o vetor de erros experimentais não observáveis, com E(ε)=0 e V(ε)=E(ε’ε)=Iσ2. O estimador (preditor) do erro experimental é dado por:
e=Y-Xb
em que b= é o estimador do vetor de parâmetros. Podemos reescrever
e=Y-X(X’X)-1X’Y e definir
R= X(X’X)-1X’ Assim, tem-se
e=Y-RY=(I-R)Ysendo,

39
e-E(e)=(I-R)Y-E[(I-R)Y)]=(I-R)Y-(I-R)Xβ=(I-R) [Y-Xβ]=(I-R)ε
logo,
V(e)=E{[e-E(e)] [e-E(e)]’}=E{(I-R) ε [(I-R) ε]’}= E{(I-R) εε’ (I-R)}= (I-R) E(εε’) (I-R)= (I-R) Iσ2 (I-R)
=(I-R-R+RR) σ2=(I-R-R+R)σ2=(I-R)σ2
V(e)= (I-R)σ2
Portanto, para obter os erros padrão de uma estimativa do resíduo basta então calcular para cada observação:
QMExXXxeS ]')(1[)( 1−′−=
Assim, pode-se definir os resíduos estudentizados internamente por:
)(*
eSee i
i =
O objetivo dessas técnicas é verificar e mensurar a influência de cada observação nas estimativas dos parâmetros, matriz de covariâncias predições e erros das predições. Para isso, sejam b(i) o estimador do parâmetro β após a eliminação da i-ésima observação; s2(i) a estimativa da variância; X(i) a matriz X sem a i-ésima observação; Y(i) o valor predito sem a i-ésima observação; iii YYr ˆ−= o i-ésimo resíduo; e seja hi a i-ésima diagonal da matriz de projeção no espaço preditor, então define-se
iii xXXxh 1)'( −=
em que ix é a i-ésima observação. Assim, pode-se determinar as seguintes quantidades na análise de influência e de resíduos:
Resíduo a) estudentizado externamente
)1()()(
i
i
hiSriRStudent−
=
É conveniente salientar que a diferença desses resíduos para o resíduo estudentizado anterior é que S(i) é usado no lugar de S.
CovRatiob) : Mede a troca no determinante da matriz de covariância das estimativas pela deleção da observação i.
DFFITSc) : Medida escalar da troca dos valores preditos pela deleção da i-ésima observação. Grandes valores indicam elevada influência da observação.
)(
)(
)(
ˆˆ)(
i
ii
hiSYY
iDFFITS−
=
em que, )(1
)()( )'( iii xXXxh −= .
DFBETASd) : mede a troca nas estimativas dos parâmetros pela deleção da i-ésima observação
pjXXiS
ibbiDFBETAS
jj
jj ...,,1,0)'()(
)()( =
−=
em que, jjXX )'( refere-se ao (j, j)-ésimo elemento de (X’X)-1.

40
1.6 GLOSSÁRIO
Acurácia – refere-se a quão próximo do valor real está uma estimativa de acordo com algum padrão conhecido. O significado estatístico da acurácia refere-se ao grau de proximidade de uma estimativa média ao verdadeiro valor da média.Análise de Componentes Principais – método de análise multivariada de dados utilizado para representar sua variação com relação a um número mínimo de componentes principais ou combinações lineares das variáveis originais parcialmente correlacionadas. Amostragem – técnica de obtenção de uma séria de observações que possibilitem representar de forma satisfatória o fenômeno estudado.Alcance – é a diferença aritmética entre o maior e o menor valor em um conjunto em análise geoestatística é a distância na qual o semivariograma estabiliza após o aumento dos valores de semivariância. Algoritmo – conjunto de regras para resolver um problema. Anisotrópico – adjetivo para descrever a variabilidade espacial de um fenômeno com estruturas diferentes e direções específicas.Cartografia – ciência e arte de representar cartas e mapas.Cenário – é o resultado de um modelo de simulação numérica em que algumas entradas de dados devem ser fornecidas para se obter resultados de situações ainda não observadas.Cokrigagem – técnica de estimativa de uma variável regionalizada por meio de observações suplementares de uma ou mais covariáveis na mesma área geográfica, de forma a proporcionar redução da variância estimada no caso de haver menor densidade amostral da variável original.Dado geográfico – localidade no espaço com um valor relativo a um fenômeno.Digital – representação de dados de forma discreta em unidades ou dígitos.Evapotranspiração – transferência de água do sistema solo-planta para a atmosfera por evaporação direta da água e transpiração das plantas.Efeito Pepita – na krigagem e variografia, a parte da variância de uma variável regionalizada sem representação espacial (erro experimental e de densidade de amostragem).Evapotranspiração potencial (ETp) – evapotranspiração em extensa área com vegetação densa, rasteira, de crescimento ativo, cobrindo toda a superfície (grama batatais) e sob condições de solo sem restrição hídrica. Conceito introduzido por Thornthwaite em 1948, sendo mais apropriado para estudos climatológicos.Evapotranspiração de referência (ETo) – conceito introduzido por Doorenbos e Pruitt (1977) e adotado pela FAO - Food and Agriculture Organization, sendo a grama substituída por uma cultura hipotética (Allen et AL, 1998). Conceito apropriado para manejo de irrigação.Escala – é a relação entre o tamanho de um objeto em um mapa e seu tamanho real.GPS – (Global Positioning System) – conjunto de satélites em órbita geoestacionária da Terra, organizados de forma a constituir uma rede de apoio para determinar a localização na superfície terrestre por meio de receptores eletrônicos.Normais Climatológicas – média de série de 30 anos de elementos meteorológicos diários, sendo as últimas normais correspondente ao período de 1961-1990.Krigagem em blocos – estimativas de atributos em blocos quadrados de área por métodos de interpolação geoestatística.Krigagem indicatriz – método de interpolação de krigagem não-linear caracterizado por transformar os dados originais em escala binária e mapear sua probabilidade de ocorrência espacial a partir de um limiar.Krigagem ordinária – método de interpolação de dados com a teoria das variáveis regionalizadas, em que os pesos das estimativas são obtidos do semivariograma ajustado aos dados.Krigagem simples – técnica de interpolação utilizada para estimar valores com base em regressão linear generalizada, sob pressuposição da estacionariedade de segunda ordem e média conhecida.Malha – conjunto de pontos amostrais arranjados de forma regular no espaço.Modelo – é a representação de atributos ou feições da superfície da terra em uma base digital; um conjunto de algoritmos codificados em computador para descrever a variabilidade espacial de um processo físico ou fenômeno natural da superfície terrestre; uma função ajustada a dados para representar observações.Modelo de dados geográficos – esquema formal de representação de dados com localização e características.

41
Modelo de elevação digital – uma malha de dados de elevação obtidos por imagem de radar orbital.Precisão – refere-se ao grau de exatidão ou de refinamento de uma medida; grau de acurácia de uma representação numérica; número de dígitos significativos; grau de variação de uma observação com relação a sua média.Programa – conjunto de informações codificadas em computador e organizadas para realizar determinada tarefa.Pixel – elemento de imagem digital; menor unidade de informação em uma imagem digital.Resolução – é a menor distância entre dois elementos processados ou o menor tamanho de feições passíveis de serem mapeadas ou amostradas.Sensoriamento Remoto – informação de unidade amostral ou alvo obtidos por meio de aparelhos remotos, os quais não entram em contato direto com o alvo amostrado.Sistema de Informação Geográfica (SIG) – Conjunto de ferramentas computacionais para capturar, armazenar, recuperar, transformar e projetar dados espaciais.Semivariograma – gráfico da semivariância versus a distância; constítui uma série de funções matemáticas que possibilitam ajustar pontos a modelos esféricos, exponenciais, gaussianos, lineares, etc.Unidade amostral – menor unidade de avaliação experimental.Validação cruzada – método de validação no qual as estimativas estatísticas são utilizadas para verificação da qualidade do ajuste de um modelo.Variável regionalizada – função aleatória definida a partir de uma medida de um fenômeno natural no espaço de acordo com conjunto de coordenadas em escala que possibilite sua representação analítica.

42





























