Embed Size (px)
Citation preview

FUNDAÇÃO EDSON QUEIROZ UNIVERSIDADE DE FORTALEZA MESTRADO EM INFORMÁTICA APLICADA
Juliana de Oliveira Carvalho
ABSTRAÇÃO DE PROVAS PARA EXPLICAÇÃO NA WEB
Fortaleza 2008

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

ii
FUNDAÇÃO EDSON QUEIROZ UNIVERSIDADE DE FORTALEZA MESTRADO EM INFORMÁTICA APLICADA
Juliana de Oliveira Carvalho
ABSTRAÇÃO DE PROVAS PARA EXPLICAÇÃO NA WEB
Dissertação apresentada ao Curso de Mestrado em Informática Aplicada da Universidade de Fortaleza como requisito parcial para a obtenção do Título de Mestre em Informática.
Orientador: Prof. Dr. João José Vasco Peixoto Furtado
Fortaleza 2008

iii
C331a Carvalho, Juliana de Oliveira.
Abstração de provas para explicações na web / Juliana de Oliveira
Carvalho. - 2008.
101 f.
Cópia de computador.
Dissertação (mestrado) – Universidade de Fortaleza, 2008.
“Orientação: Prof. Dr. João José Vasco Peixoto Furtado.”
1. Web semântica. 2. Representação de conhecimento. 3. Internet.
4. Inteligência artificial. I. Título.
CDU 681.3:004.822

iv
Juliana de Oliveira Carvalho
ABSTRAÇÃO DE PROVAS PARA EXPLICAÇÃO NA WEB Data de Aprovação: __/__/____
Banca Examinadora:
_______________________________________________ Prof. João José Vasco Peixoto Furtado, D.Sc.
(Prof. Orientador – Universidade de Fortaleza - UNIFOR)
________________________________________________ Prof. Pedro Porfírio Muniz Farias, D. Sc.
(Membro – Universidade de Fortaleza - UNIFOR)
_______________________________________________ Prof. Paulo Pinheiro da Silva, Ph.D.
(Membro – University of Texas - UTEP)

v
Aos meus pais, Tarcísio e Júlia, pelo amor e apoio incondicional.

vi
Agradecimentos Gostaria de deixar meus sinceros agradecimentos a todos que de alguma forma contribuíram para a realização deste trabalho, e em especial: A Deus, pela luz, pela força, coragem e perseverança ao longo de todo este período; Aos meus pais e irmãs, pela minha educação, por todo o apoio e incentivo durante todos esses anos e por compreenderem minha ausência em muitas reuniões familiares. Obrigada por tudo! Este trabalho é dedicado a vocês! Ao meu noivo Gustavo, que mesmo sendo também um mestrando e tendo mil coisas pra fazer, sempre encontrava tempo e paciência pra me ajudar. Obrigada pelo companheirismo e pelo apoio em todos os sentidos. Amo você! Ao meu orientador, Prof. Vasco Furtado, que durante todos esses anos me ensinou muito mais do que o que posso colocar em artigos e neste trabalho. Obrigada por sempre cobrar de mim e de todos os seus alunos o trabalho com compromisso, responsabilidade e senso de urgência. Obrigada também pelos conselhos e pelos muitos “Vamos em frente!” nos momentos de desmotivação. Aos pesquisadores do laboratório KSL da Universidade de Stanford, da Universidade do Texas UTEP e de Google Inc., em especial a Paulo Pinheiro, Deborah McGuinness, Cynthia Chang, Priyendra Deshwal e Dhyanesh Narayanan, pela parceria no desenvolvimento deste trabalho, e por responderem meus muitos emails sempre com presteza e atenção. Aos professores Paulo Pinheiro e Pedro Porfírio, por aceitarem fazer parte dessa banca; Aos amigos Adriano, Daniel e Leonardo, por acompanharem diariamente essa minha caminhada enquanto seguiam também atarefados com suas dissertações. O incentivo e amizade de vocês foram fundamentais para a realização deste trabalho. Ao amigo Tiago Cordeiro, por sempre se mostrar disponível para me ajudar quando eu estava enrolada na programação ou em qualquer outra coisa. Obrigada por tudo! Aos amigos Vládia, Eurico, e todos os outros participantes da célula Engenharia do Conhecimento, pelas dicas e conselhos ao longo desta etapa e pelos muitos “Boa Sorte!”. Obrigada a todos! A FUNCAP, pelo suporte financeiro durante boa parte do meu mestrado; Por fim, a todos os meus familiares e amigos, especialmente a D. Rita, Sr. Anderson, Carol, Virgínia, André, Mabel, Lia, Heitor, Bia, Elaine, Rachel, Andrezza e Diana, pela torcida e pelas palavras de incentivo sempre.

vii
Resumo da Dissertação apresentada ao Corpo Docente do Curso de Mestrado em Informática Aplicada da Universidade de Fortaleza como parte dos requisitos necessários para a obtenção do título de Mestre em Informática (M.Sc.)
ABSTRAÇÃO DE PROVAS PARA EXPLICAÇÃO NA WEB
Juliana de Oliveira Carvalho Julho / 2008
Orientador: João José Vasco Peixoto Furtado, D.Sc. A fim de responderem as consultas realizadas pelas pessoas na web, agentes inteligentes utilizam um mecanismo de raciocínio para processar as informações e acessar os serviços disponíveis na web. Todos os passos desse raciocínio formam uma prova e as informações dessas provas auxiliam nas explicações dos resultados aos usuários. Entretanto, essas provas, geradas por raciocinadores automáticos, não estão prontas para serem exibidas a pessoas e precisam ser transformadas e simplificadas em explicações mais próximas da linguagem das pessoas. Nesta dissertação, apresentamos uma arquitetura de abstração de provas para torná-las apropriadas para explicações para pessoas. Essa arquitetura utiliza padrões de abstração, que são fragmentos de provas que podem ser substituídos por regras com um significado maior para as pessoas. A nossa abordagem de abstração consiste em uma extensão do algoritmo IWAbstractor, desenvolvido por pesquisadores da universidade de Stanford, que juntamente com um conjunto de estratégias é utilizado para abstrair provas utilizando os padrões de abstração. Dessa forma, as provas geradas por raciocinadores automáticos tornam-se mais simples e compreensíveis para pessoas. Palavras-chave: Inteligência Artificial, Web Semântica, Representação de Conhecimento, Abstração, Explicação.

viii
Abstract of the dissertation presented to the board of faculties of the
Master Program in Applied Informatics at the University of Fortaleza, as partial fulfillment of the requirements for the degree of Master of Computer Science (M.Sc.)
ABSTRACTING PROOFS FOR WEB EXPLANATIONS
Juliana de Oliveira Carvalho July / 2008
Advisor: João José Vasco Peixoto Furtado, D.Sc. In order to answer queries to human users on the web, intelligent agents use a reasoning mechanism to process information and access services available on the web. Every step of this reasoning process form a proof and the information presented in these proofs facilitate generating explanations from proofs on the web. However, these automatic generated proofs are not ready to be presented to human users and they need to be transformed and simplified into explanations closer to human language. In this dissertation, we present an architecture for abstracting proofs in order to make them more appropriate for human explanation. This architecture uses abstraction patterns, which are proof fragments that can be replaced by rules that are more meaningful for people. Our abstraction approach consists of using the IWAbstractor algorithm, which has been developed by researchers of Stanford University, along with a set of strategies to abstract automatic generated proofs using abstraction patterns. This way, proofs become simpler and more comprehensible for people. Keywords: Artificial Intelligence, Semantic Web, Knowledge Representation, Abstraction, Explanation.

ix
Sumário
1. Introdução ........................................................................................ 15
1.1 Motivação e Problema ..................................................................... 15
1.2 Proposta .......................................................................................... 17
1.3 Organização ................................................................................. 19
2. Estado da Arte ...................................................................................... 21
2.1 Explicações na Web ........................................................................ 21
2.1.1 PML (Proof Markup Language) ................................................. 22
2.1.2 O Framework InferenceWeb (IW) ............................................. 23
2.2 Raciocinadores Automáticos ........................................................... 27
2.2.1 Thousands of Problems for Theorem Provers (TPTP) .............. 29
2.3 Trabalhos Relacionados .................................................................. 30
2.4 Problemática e Motivação ............................................................... 33
3. A Proposta ............................................................................................ 36
3.1 Abstração ........................................................................................ 36
3.2 Arquitetura da Proposta .................................................................. 38

x
3.3 Padrões de Abstração (PAs) ........................................................... 40
3.3.1 Criando Padrões de Abstração .................................................... 41
3.3.2 Exemplificando a criação de PAs .............................................. 42
3.4 Categorização de Padrões de Abstração ........................................ 47
3.5 O algoritmo IWAbstractor ................................................................ 49
3.5.1 Heurística do Código Hash ....................................................... 53
3.6 Repositório de Padrões de Abstração (PAs) ................................... 56
4. Usando Padrões de Abstração ............................................................. 59
4.1 Utilização de Padrão de Abstração sem categorização .................. 59
4.1.1 Exemplo de solução da biblioteca TPTP................................... 59
4.1.2 Exemplo do projeto KANI(Knowledge Associates for Novel
Intelligence) ........................................................................................................ 63
4.2 Utilização de Padrão de Abstração do tipo Recursivo ..................... 66
4.3 Utilização de Padrão de Abstração do tipo Paralelo ....................... 69
4.4 Utilização de padrão de Abstração do tipo Seqüencial ................... 72
5.Avaliação da Proposta ........................................................................... 75
5.1 Avaliação Comparativa ................................................................... 75
5.1.1 Metodologia .............................................................................. 75
5.1.2 Cenário ..................................................................................... 76
5.2 Análise dos Resultados ................................................................... 82
6. Conclusão............................................................................................. 85
6.1 Considerações Finais ...................................................................... 85

xi
6.2 Trabalhos Futuros ........................................................................... 87
Referências .............................................................................................. 88
Apêndice................................................................................................... 93
Apêndice I - Interfaces para Parsers ........................................................ 94
Apêndice II – Documentos utilizados na avaliação................................... 99

xii
Lista de Figuras
FIGURA 1 TRECHO DE PROVA EM PML ..............................................................................................................23
FIGURA 2 ARQUITETURA DO INFERENCE WEB – FONTE: FIGURA ADAPTADA DE (MCGUINNESS E PINHEIRO DA
SILVA, INFRASTRUCTURE FOR WEB EXPLANATIONS 2003)........................................................................25
FIGURA 3 EXEMPLO DE SEGMENTO DE PROVA VISUALIZADA NO IWBROWSER ....................................................26
FIGURA 4 ARQUITETURA DE ABSTRAÇÃO DE PROVAS ........................................................................................40
FIGURA 5 PROVA ORIGINAL DO DOMÍNIO DE SEAFOOD. ..................................................................................43
FIGURA 6 PADRÃO DE ABSTRAÇÃO CLASSTRANSITIVITY ...................................................................................45
FIGURA 7 PROVA ABSTRATA DO DOMÍNIO SEAFOOD .......................................................................................46
FIGURA 8 TRECHO DE ARQUIVO PML DE PADRÃO DE ABSTRAÇÃO DO TIPO RECURSIVO ......................................47
FIGURA 9 TRECHO DE PROVA ILUSTRANDO A HEURÍSTICA DO CÓDIGO HASH. ......................................................54
FIGURA 10 TRECHO DE PROVA EM PML ILUSTRANDO A HEURÍSTICA DO CÓDIGO HASH. ......................................55
FIGURA 11 ABSTRAÇÃO DA RELAÇÃO INSTÂNCIA-CLASSE ..................................................................................57
FIGURA 12 PA REPRESENTANDO PROPRIEDADE TRANSITIVA EM PROVA N3 .........................................................58
FIGURA 13 SOLUÇÃO PARA PROBLEMA GEO003-1 DA BASE DE PROBLEMAS TPTP. ............................................61
FIGURA 14 ESTRUTURA DA SOLUÇÃO GEO002-1 DE TPTP E DETALHE DO PA IDENTIFICADO NA PROVA .............62
FIGURA 15 – TRECHO DA PROVA DE GEO002-1 DE TPTP APÓS ABSTRAÇÃO .......................................................63

xiii
FIGURA 16 EXEMPLO DE UTILIZAÇÃO DE PADRÃO DE ABSTRAÇÃO ESPECÍFICO DE UM DOMÍNIO. (PROJETO KANI)
..............................................................................................................................................................65
FIGURA 17 REPRESENTAÇÃO EM ESTILO DISCURSIVO PARA UMA PROVA ABSTRATA ............................................65
FIGURA 18 EXEMPLO DE PA RECURSIVO ...........................................................................................................67
FIGURA 19 EXEMPLO DE PROVA COM PROCEDIMENTO RECURSIVO ......................................................................68
FIGURA 20 ABSTRAÇÃO DE PA RECURSIVO .......................................................................................................69
FIGURA 21 TRECHO DE PROVA COM PROCESSOS PARALELOS ..............................................................................71
FIGURA 22 DETALHE DA ABSTRAÇÃO DE PROCESSOS PARALELOS .....................................................................72
FIGURA 23 TRECHO DE PROVA COM PA DO TIPO SEQUENCIAL ............................................................................74
FIGURA 24 MELHOR OPÇÃO DE COMPRA DO LIVRO ............................................................................................78
FIGURA 25 SERVIÇOS EXECUTADOS PARA BUSCA DO LIVRO ...............................................................................78
FIGURA 26 EXPLICAÇÃO DO SERVIÇO BUSCAR LOJAS ........................................................................................79
FIGURA 27 EXPLICAÇÃO DO SERVIÇO PROCURAR MELHOR FRETE ......................................................................79
FIGURA 28 EXPLICAÇÃO DO SERVIÇO SELECIONAR MELHOR PREÇO ..................................................................80
FIGURA 29 EXPLICAÇÃO DO SERVIÇO DE FRETE NA PROVA COMPLETA. ..............................................................81
FIGURA 30 EXPLICAÇÃO DO SERVIÇO DE FRETE NA PROVA ABSTRAÍDA. ..............................................................82

xiv
Lista de Quadros
QUADRO 1 ALGORITMO IWABSTRACTOR ....................................................................... 50

1. Introdução
1.1 Motivação e Problema
Usuários humanos farão cada vez consultas mais complexas na web
com o uso de agentes inteligentes para responderem perguntas que requerem
o uso de raciocínio automático. Tais agentes deverão utilizar um mecanismo de
raciocínio para responderem as perguntas dos usuários e assim poderão
fornecer um “rastro” de todos os passos executados até a obtenção do
resultado.
Para obter o resultado de uma consulta feita pelo usuário, pode ser
necessário que o agente utilize serviços de outros agentes inteligentes. Um
rastro ou prova para obter o resultado final do agente pode ser visto como um
registro histórico, descrevendo os passos de manipulação de informação
usados pelos serviços para derivar o resultado final. Geralmente, a prova do
resultado final é gerada por raciocinadores ou provadores automáticos e,
portanto, seu formato é em geral de difícil entendimento para os usuários.
Analisar uma prova gerada por um agente inteligente pode não ser suficiente
para que o usuário compreenda como o resultado final foi alcançado e o
usuário pode requerer uma explicação em nível mais detalhado.
Quando uma pessoa requisita uma explicação do que foi feito por
um agente ou quais serviços foram invocados, o agente pode interagindo com
a pessoa usar um componente de explicação para analisar o rastro executado

16
até a obtenção do resultado e gerar uma explicação para o usuário. Entretanto,
essas explicações das provas para as respostas geradas pelos agentes podem
ser bastante extensas e conter muitos detalhes de execução dos passos que
não são interessantes para o usuário.
A habilidade de agentes inteligentes de apresentarem e justificarem
seu raciocínio para usuários humanos tem sido estudada no contexto de
sistemas baseados em conhecimento desde 1970. As explicações nesses
sistemas basicamente forneciam alguma abstração (compreensível) do rastro
de raciocínio do agente (Buchanan e Shortliffe 1984), (Clancey 1986).
Outra geração de sistemas de explicações foi introduzida com o
Explainable Expert System (Swartout, Paris e Moore 1991). Esses sistemas,
entretanto, basicamente têm fortes suposições: dados e regras são confiáveis;
e o modelo de domínio conceitual é gerado por um engenheiro do
conhecimento juntamente com um especialista do domínio.
Outra área foco para pesquisa de explicações é a que explana
respostas geradas por sistemas provadores de teoremas. Reconhecendo que
provas geradas por provadores e raciocinadores automáticos são difíceis de
serem lidas por pessoas, pesquisadores nesse contexto tentam transformar
automaticamente essas provas em provas de dedução natural (Oliveira, de
Souza e Haeusler 1999), ou em provas em nível de assertivas (Huang 1994).
A abordagem de assertivas permite que passos (macro) em
linguagem de alto nível sejam explicados pela aplicação de teoremas, lemas ou
definições, que são chamados de assertivas, e que devem estar no mesmo
nível de abstração de uma prova que seja gerada por uma pessoa. Entretanto,
as simplificações produzidas por essas abordagens não são abstratas o
suficiente para serem usadas como explicações, porque mesmo com as regras
reescrevendo a semântica por trás das formulações fica difícil para as pessoas
compreenderem essas explicações.
A natureza distribuída e evolucionária e a diversidade da web têm
quebrado suposições adjacentes a essas abordagens anteriores. Por exemplo,
técnicas de extração de informação usadas em um processo de derivação de

17
respostas podem não ser conhecidas antecipadamente e o conhecimento do
domínio deve ser adquirido de diferentes fontes, cada fonte representando
conhecimento em diferentes níveis de granularidade. As provas geradas para
respostas nessas configurações podem ser complexas e podem conter uma
grande quantidade de passos de inferência que são inapropriados para serem
exibidos a pessoas, tanto porque são passos óbvios ou porque podem estar
em um nível de granularidade muito detalhado.
1.2 Proposta
Uma forma de atender as dificuldades de explicação a partir de
registros de histórico de raciocinadores é realizando abstrações. Nesta
dissertação, apresentaremos uma arquitetura de abstração de provas geradas
por raciocinadores automáticos e que representam um rastro de raciocínio de
um agente. Almejamos assim tornar as provas mais compreensíveis para
pessoas através de um melhor suporte a processos de geração de explicação.
Nossa abordagem de abstração considera tanto as questões de
compreensão de explicações por pessoas quanto a questão da natureza
distribuída da web. Acreditamos que explicações podem ser melhoradas
através da escolha, pelos próprios usuários da web, de níveis de abstração
apropriados para apresentação de provas, incluindo a remoção de detalhes
irrelevantes. Analisando diferentes provas, pessoas podem identificar
características particulares de cada prova e com esse conhecimento da prova
auxiliar no processo de abstração. Além disso, pessoas familiarizadas com
agentes inteligentes específicos podem ter noção da granularidade de
abstração e podem distinguir entre detalhes relevantes e irrelevantes para a
explicação do resultado.
Fornecemos suporte para descrição de como explicações
representadas em provas em baixo nível (geradas por raciocinadores

18
automáticos) podem ser abstraídas para provas em alto nível (linguagem
humana) usualmente chamadas de explicações.
O método de abstração tenta ser genérico e modular usando
templates de fragmentos de provas chamados de padrões de abstração (PAs)
que podem ser usados em provas diferentes. O método de abstração é
baseado nesses PAs que são fragmentos possíveis de serem encontrados em
provas completas. Diferentes tipos de provas requerem métodos de abstração
apropriados, o que nos levou a categorizar PAs dentro de nossa arquitetura de
abstração. Esses PAs podem ser reusados e até mesmo combinados em
diferentes situações. Usando os padrões definidos por pessoas, o método de
abstração apropriado é selecionado e usado para reescrever a prova original,
eliminando axiomas e introduzindo uma nova regra de inferência em nível mais
alto codificada em um PA, com o objetivo de dar explicações em alto nível.
Criaremos também um repositório de PAs que podem ser tanto
genéricos quanto específicos a um domínio, permitindo aos usuários gerarem
explicações customizadas. Um algoritmo é usado para tentar encontrar os PAs
na prova original, numa operação chamada de matching.
O algoritmo utilizado é uma extensão do algoritmo IWAbstractor
desenvolvido em colaboração com a Universidade de Stanford. A fim de usar o
repositório de PAs em contextos distribuídos e diversos na web,
desenvolveremos nossa abordagem no framework InferenceWeb (IW)
(McGuinness e Pinheiro da Silva 2004). Neste framework, provas são
codificadas em Proof Markup Language (PML) (Pinheiro da Silva, McGuinness
e Fikes 2004) que trabalha como uma interlíngua para explicações de
respostas de agentes na web. A especificação das provas em PML permite que
os nós das provas sejam associados com suas fontes de informações. Dessa
forma, as informações utilizadas para a explicação do usuário tornam-se mais
confiáveis.
Nesse trabalho, o framework IW é estendido para que técnicas de
abstração de provas sejam incluídas. A arquitetura de abstração proposta é
projetada para permitir fácil extensão e integração de provas em diferentes

19
linguagens e formatos. Em nossa abordagem, utilizaremos também algumas
soluções da biblioteca de problemas TPTP (Sutcliffe e Suttner 2008) que foram
traduzidas para PML para que possam ser abstraídas utilizando o
IWAbstractor.
Além da definição da arquitetura de abstração de provas, podemos
contabilizar como contribuições deste trabalho, melhorias no IWAbstractor, a
categorização de padrões de abstração que identifica características dos
padrões que são essenciais para o processo de abstração e a definição de
heurísticas que devem ser utilizadas juntamente com os padrões para tornar o
processo de abstração de cada tipo de padrão mais eficiente. Além disso, as
categorias de PAs identificadas podem ser estendidas para que novas
categorias sejam incluídas e novas estratégias de abstração sejam
implementadas. Outra contribuição é a definição de uma interface que deve ser
implementada para que provas em diferentes linguagens e formatos possam
ser explicadas e abstraídas pelo IWAbstractor por meio do framework Inference
Web. Para este trabalho, implementamos algumas dessas interfaces para
abstrairmos provas em diferentes linguagens.
1.3 Organização
No Capítulo 2, serão apresentados os conceitos básicos deste
trabalho que serão úteis para o entendimento da proposta. Primeiramente,
descreveremos os conceitos relevantes para Explicações na Web: a linguagem
PML utilizada para a manipulação das provas formais; e o framework Inference
Web com suas diversas ferramentas para manipulação, apresentação e
explicação de provas. Em seguida, apresentaremos conceitos relacionados à
raciocinadores automáticos para fornecerem subsídio para o entendimento de
nossa proposta. Mostraremos também os trabalhos propostos nas áreas de
transformação, apresentação, explicação e abstração de provas formais e

20
como eles estão relacionados com nossa proposta. Por fim, identificaremos a
problemática que motivou o desenvolvimento deste trabalho.
No Capítulo 3, descreveremos o objetivo principal de nosso trabalho:
propor uma arquitetura de abstração de provas capaz de torná-las mais
compreensíveis para uma pessoa. Para isso, apresentaremos o algoritmo
IWAbstractor juntamente com técnicas utilizadas para a abstração dessas
provas formais.
No Capítulo 4, apresentaremos diferentes exemplos de uso da
ferramenta de abstração de provas por meio da aplicação de padrões de
abstração de variados tipos. Analisaremos as características específicas de
cada prova exemplo e justificaremos o uso de uma técnica de abstração
apropriada para cada uma.
No Capítulo 5, apresentaremos as considerações finais deste
trabalho e alguns trabalhos que vislumbramos para aprimorar as técnicas de
abstração, e dessa forma melhorar a explicação de provas para o usuário final.

2. Estado da Arte
Neste capítulo, apresentamos o estado da arte com relação ao
trabalho apresentado nesta dissertação. A Seção 2.1 apresentará os conceitos
de Explicações na Web, por meio da apresentação da linguagem PML,
utilizada para a representação de provas, e do framework Inference Web,
utilizado para a implementação deste trabalho. A Seção 2.2 apresentará os
conceitos relacionados à raciocinadores automáticos, necessários para o
entendimento deste trabalho. Esta seção introduzirá também a biblioteca TPTP
que funciona como repositório de problemas para auxiliar nos testes dos
sistemas provadores automáticos de teoremas. Na Seção 2.3, alguns trabalhos
relacionados da área de explicações e transformação de provas serão
apresentados de forma a prover subsídios para o problema de abstrair provas
em explicações que possam ser entendidas por pessoas. Por fim, a Seção 2.4
descreverá a problemática deste trabalho.
2.1 Explicações na Web
Quando realizam consultas na web, os usuários podem estar
utilizando agentes raciocinadores que por sua vez podem acessar os serviços
disponíveis para tentar responder as consultas requisitadas. Todo o raciocínio

22
executado por um agente para a obtenção do resultado das consultas constitui
uma prova. A partir de uma prova, componentes de explicação de provas
podem ser utilizados a fim de gerar uma explicação ao usuário sobre como um
resultado foi obtido. Os componentes de explicação precisam ser capazes de
interpretar as provas geradas, para que possam montar uma explicação para o
usuário. Nesta seção apresentaremos a linguagem PML para representação de
provas e o framework InferenceWeb para geração da explicação ao usuário.
2.1.1 PML (Proof Markup Language)
Devido à necessidade de um formato unificado para manipulação de
provas geradas potencialmente por múltiplos agentes, foi desenvolvida uma
interlíngua para representação de provas chamada PML- Proof Markup
Language (Pinheiro da Silva, McGuinness e Fikes 2004) (McGuinness, Ding, et
al. 2007). Descritas em PML, as provas podem ser compartilhadas por diversos
tipos de aplicações distribuídas. PML é usada para representação de provas de
diferentes tipos: derivações de dedução natural, provas produzidas por
provadores de teoremas, provas resultantes da execução de serviços web,
processamento de tarefas, explicações, etc.
PML é construída em cima da Linguagem de Ontologia da Web
(OWL) (McGuinness e Harmelen 2004). InferenceStep (Passo de Inferência) e
NodeSet (Nó) são os dois principais blocos de construção da linguagem. O
InferenceStep traz informações que justificam a conclusão de um NodeSet, tais
como a regra que foi utilizada para a produzir a conclusão, o conjunto de nós
antecedentes do NodeSet em questão, a máquina de inferência que produziu
esse passo. O NodeSet representa um nó ou passo da prova. O NodeSet
contém informações sobre um passo da prova, tais como a conclusão do passo
da prova, e a linguagem em que a conclusão está representada. Cada NodeSet
é unicamente identificado na Web por um URI. InferenceSteps precisam ser
definidos no contexto de um NodeSet. A Figura 1 mostra um trecho de uma

23
prova descrita em PML. A figura exibe as informações de um NodeSet, como
por exemplo: sua conclusão (linha 2), sua linguagem (linha 3) e seu passo de
inferência (linhas 5 a 12).
Figura 1 Trecho de prova em PML
2.1.2 O Framework InferenceWeb (IW)
InferenceWeb (IW) é um framework para explicação de resultados
gerados por agentes de software, quando este agente é inteligente ou não.
Resultados são explicados por meio de armazenamento, troca, combinação,
abstração, anotação, comparação e renderização de provas e fragmentos de
provas obtidos através de aplicações de respostas a perguntas incluindo
agentes web. Através de InferenceWeb, explicações para essas aplicações
podem ser geradas de forma portável e distribuída, o que possibilita sua
disponibilização na web. (McGuinness e Pinheiro da Silva 2003).
As ferramentas IW tratam de alguns requisitos para dar maior
credibilidade à informação manipulada em suas provas:
1<iw:NodeSet rdf:about="http://mia.unifor.br/owlsparalelo/proof1.owl#branch1">
2 <iw:hasConclusion>Executing(FindCheaperBook).</iw:hasConclusion>
3 <iw:hasLanguage rdf:resource="http://inferenceweb.stanford.edu/registry/LG/English.owl#English"/>
4 <iw:isConsequentOf>
5 <iw:InferenceStep>
6 <iw:hasInferenceEngine rdf:resource="http://inferenceweb.stanford.edu/registry/IE/sds.owl#sds"
7 rdf:type="http://inferenceweb.stanford.edu/2004/07/iw.owl#InferenceEngine"/>
8 <iw:hasRule
9 rdf:resource="http://inferenceweb.stanford.edu/registry/DPR/executing.owl#executing"/>
10 <iw:hasAntecedent
11 rdf:resource"http://mia.unifor.br/owlsparalelo/proof1.owl#branch1_1"/> 12 </iw:InferenceStep>
13 </iw:isConsequentOf>
14</iw:NodeSet>

24
Proveniência da informação: disponibiliza aos usuários dados
sobre a fonte de informações apresentadas (nome da fonte,
autor, data de atualização, etc.);
Informação sobre o raciocínio: fornece informações sobre o
raciocinador, método de raciocínio, regras de inferência,
suposições e outras informações utilizadas para derivar
informações;
Geração da Explicação: provê explicações e abstrações de
provas para facilitar o entendimento dos usuários;
Distribuição de Provas: gera provas que são portáveis e
facilmente disponibilizadas na web;
Apresentação de Provas/Explicações: fornece ferramentas
para suporte à navegação e apresentação de provas e suas
explicações (IWBrowser).
Em resumo, ferramentas IW fornecem suporte a provas portáveis e
distribuídas, apresentação de provas e geração de explicação. Os dados
manipulados pelas ferramentas IW incluem provas e explicações publicadas
localmente ou na web e representadas em PML (McGuinness e Pinheiro da
Silva 2004).
Em PML, uma prova é definida como uma árvore de conjuntos de
nós (NodeSets) conectados por passos de inferência (InferenceSteps),
explicando o processo de derivação de respostas. Cada nó possui uma
conclusão obtida até aquele ponto para a prova e o passo de inferência que foi
aplicado para que esta conclusão fosse derivada. Um passo de inferência é a
aplicação de uma regra de inferência sobre os antecedentes dos passos de
inferência ou uma assertiva. Regras de inferência são usadas para derivar
conclusões dos nós a partir de conclusões de outros nós (antecedentes). Um
passo de inferência contém ponteiros para os nós representando os
antecedentes, a regra de inferência usada e a informação de mapeamentos
entre variáveis e termos usados pela regra de inferência. Um NodeSet
representa um nó folha (ou axioma) em uma prova se seu passo de inferência
não tem antecedentes. Geralmente, um passo de inferência de nós folha é o

25
resultado da aplicação das regras Direct Assertion ou Assumption, que indicam
que esses nós foram afirmados ou assumidos como verdade e por isso não
possuem antecedentes na prova. Uma prova pode ser vista como um conjunto
de NodeSets conectados por regras de inferência.
A Figura 2 apresenta a arquitetura básica do InferenceWeb. Nela
podemos observar que as máquinas de inferência geram provas PML na web.
As informações referentes a essas provas são armazenadas no repositório
Registry através dos agentes web Registrars. Os agentes IWBrowsers são
responsáveis pela exibição dessas provas ao usuário.
Figura 2 Arquitetura do Inference Web – Fonte: Figura adaptada de (McGuinness e Pinheiro da Silva, Infrastructure for Web Explanations 2003).
Na Figura 3, podemos visualizar um segmento de prova PML exibida
no IWBrowser. Essa prova é um exemplo derivado do trabalho de (Oliveira, de
Souza e Haeusler 1999). O trecho abaixo é gerado como resposta a pergunta:
In Paranagua ?x, ou seja, Onde fica Paranaguá? Nesse exemplo, a prova é
apresentada em linguagem KIF (Knowledge Interchange Format) (Genesereth

26
e Fikes 1992). A resposta apresentada para essa pergunta foi (in Paranagua
SouthRegion), ou seja, Paranaguá fica na Região Sul. Esse NodeSet foi
derivado de outros dois pela aplicação da regra de inferência Generalized
Modus Ponens:
(and (in Paranagua Parana) (in Parana SouthRegion)), ou
seja, Paranagua fica em Parana e Parana fica na Região Sul;
(<= (in Paranagua SouthRegion) (and (in Paranagua Parana)
(in Parana SouthRegion))), ou seja, Se Paranaguá fica em
Paraná e Paraná fica na Região Sul, então Paranaguá fica na
Região Sul.
Figura 3 Exemplo de segmento de prova visualizada no IWBrowser

27
2.2 Raciocinadores Automáticos
Raciocinar é a habilidade de realizar inferências. Programas de
computadores que automatizam processos de inferência são chamados de
raciocinadores automáticos (Portoraro 2007).
Raciocinadores automáticos têm como objetivo automatizar
diferentes tipos de inferências e são freqüentemente utilizados para realização
de provas de teoremas. Um raciocinador é implementado a partir da descrição
de um formalismo para que possa provar teoremas nesse formalismo de forma
eficiente.
Provadores de teoremas devem definir qual a classe de problemas
eles irão tentar resolver, qual linguagem irão utilizar para representar o
conhecimento que irão manipular e quais regras de inferências irão utilizar para
resolver os problemas. Um problema a ser resolvido por um raciocinador
consiste de uma conclusão, que representa a pergunta que deve ser
respondida pelo raciocinador, e de um conjunto de assertivas, que representam
o conhecimento disponível para o raciocinador. Para resolver um problema, um
raciocinador deve tentar provar a conclusão desse problema utilizando as
assertivas do problema através da aplicação de regras de inferência do
raciocinador.
A classe de problemas que um programa raciocinador deve tentar
resolver é chamada de Domínio do Problema. O domínio dos problemas pode
ser genérico ou específico. Um domínio bastante utilizado por provadores
automáticos de teoremas é o da lógica de primeira ordem. Além de considerar
como os problemas em seu domínio devem ser representados, os
raciocinadores também devem considerar como esses problemas serão
representados internamente e como a solução desses problemas será
apresentada ao usuário. O formalismo mais utilizado para a representação
desses problemas é a Lógica de Primeira Ordem.
A lógica de primeira ordem (LPO) é um sistema de representação de
conhecimento. A LPO trabalha com objetos e relações entre objetos,

28
permitindo expressar fatos sobre alguns desses objetos ou sobre todos os
objetos de um universo de discurso. Os elementos básicos da LPO utilizados
para representar objetos, relações e funções são chamados de símbolos
(Russel e Norvig 2004). A representação do conhecimento em LPO ocorre com
a utilização desses símbolos (constantes, funções e predicados) juntamente
com variáveis, conectivos e quantificadores da linguagem. Seguem alguns
exemplos de sentenças representadas em LPO:
Toda criança gosta de brigadeiro.
(∀𝑥) 𝑐𝑟𝑖𝑎𝑛ç𝑎 𝑥 → 𝑔𝑜𝑠𝑡𝑎𝑟(𝑥, 𝑏𝑟𝑖𝑔𝑎𝑑𝑒𝑖𝑟𝑜)
Maria não é alta.
┐𝑎𝑙𝑡𝑎 (𝑀𝑎𝑟𝑖𝑎)
João possui pelo menos um cachorro.
∃𝑥 𝑐𝑎𝑐ℎ𝑜𝑟𝑟𝑜 𝑥 ⋀ possui (João, x)
Raciocinadores podem utilizar inferências dedutivas. Um sistema
dedutivo é formado por um conjunto de axiomas lógicos e regras de dedução
que são utilizados para a derivação de novas fórmulas a partir das já
existentes. Uma regra de dedução bastante utilizada é a Resolução. Regras
dedutivas como a Resolução fazem uso de mecanismos de unificação de
sentenças dos problemas para encontrar soluções. O mecanismo de nificação
é considerado um dos mais importantes para a implementação de
raciocinadores automáticos.
Unificar duas sentenças diferentes consiste em encontrar valores
para as variáveis dessas duas sentenças a fim de torná-las idênticas. Os
algoritmos de unificação realizam as substituições necessárias para tornar os
termos que recebem como entrada em termos equivalentes. Eles recebem
duas sentenças e encontram um unificador para elas, se houver um (Russel e
Norvig 2004).
Considere-se que um algoritmo de unificação receba as seguintes
sentenças para unificar:
Irmão (João, x), Irmão (y, Maria).

29
Nesse caso, o algoritmo retornaria que x= Maria e y= João, ou seja,
João é irmão de Maria. Considerando agora outras duas sentenças para
unificação:
Irmão (João, x), Irmão (x, José).
Nesse segundo caso, ocorreria uma falha na unificação, pois o
algoritmo não poderia atribuir dois valores diferentes para x e não conseguiria
unificar as sentenças.
Atualmente, muitos problemas para serem utilizados por
raciocinadores automáticos ou provadores de teoremas estão disponíveis na
web. Com o uso desses problemas, a capacidade dos raciocinadores pode ser
testada e podemos comparar o desempenho de um raciocinador com relação
aos outros. Na seção seguinte apresentaremos um exemplo de uma biblioteca
de problemas para esses raciocinadores.
2.2.1 Thousands of Problems for Theorem Provers (TPTP)
TPTP (Sutcliffe e Suttner 2008) é uma biblioteca de problemas para
provadores automáticos de teoremas. Em TPTP, os problemas estão
separados em domínios específicos e para cada problema estão disponíveis
algumas soluções geradas por diversos sistemas provadores automáticos de
teoremas (ATP).
A principal característica de TPTP é servir de suporte para testes de
sistemas ATP. Pela utilização desse repositório comum de problemas, os
sistemas ATP podem ser avaliados de forma significativa e podem fazer
comparações de seus resultados obtidos com os dos outros sistemas ATP. O
repositório TPTP facilita também a repetição e reprodução de testes realizados
por sistemas ATP e, por fim, produz resultados estatisticamente significativos.
TPTP também provê a funcionalidade de converter os problemas em seu

30
formato próprio para formatos de outros sistemas ATP existentes, como por
exemplo, formato KIF.
O arquivo de cada um dos problemas da biblioteca TPTP apresenta
informações sobre a descrição do problema, um conjunto de referências para o
problema e outras informações relevantes para sua utilização.
2.3 Trabalhos Relacionados
Alguns trabalhos compartilham o objetivo de abstrair e transformar
provas a fim de simplificá-las.
Huang (Huang 1996) estudou provas de resolução (lógica
matemática) em termos de operações significativas empregadas por
matemáticos. Huang argumenta que as provas geradas por provadores
automáticos de teoremas (ATP) são de difícil leitura e que a transformação
dessas provas para um formato de dedução natural (DN) bem estruturado
auxiliaria a compreensão delas pelos matemáticos. A abordagem de Huang
tenta estabelecer uma relação entre os termos e operações matemáticas em
provas de resolução, e estruturas de provas em dedução natural, que podem
ser mais facilmente entendidas por matemáticos. Para isso, heurísticas devem
ser aplicadas às provas, mas tais heurísticas são adequadas para apenas
alguns tipos específicos de provas. Neste contexto, provas em dedução natural
não são simples o suficiente para prover um entendimento do processo de
raciocínio.
Em (Huang 1994), Huang define que alguns segmentos de provas
em DN podem ser explicados simplesmente como a aplicação de uma
definição matemática ou teorema. A aplicação de uma definição ou teorema é
chamada de assertiva em nível de compreensão humana. Dessa forma, provas
em DN podem ser simplificadas e reduzidas em nível de assertivas. A fim de

31
determinar a forma de apresentação de cada uma das provas em DN, Huang
analisa os padrões de regras de inferências presentes nas provas.
Buscando facilitar o entendimento de provas formais por usuários
humanos, Dahn e Wolf (Dahn e Wolf 1994) (Dahn e Wolf 1996) propõem uma
variação de dedução natural chamada de Block Calculus (BC) que pode ocultar
subprovas formais que não são interessantes para os usuários. BC propõe uma
estrutura de blocos na qual provas em diferentes formatos podem ser
traduzidas, gerando assim um formato unificado para que essas provas
possam ser simplificadas e explicadas. Essa estrutura permite que provas de
diferentes formatos sejam apresentadas em um formato unificado, um conjunto
de fatos em linguagem PROLOG (Wielemaker 2008).
A apresentação das provas é independente da sintaxe de cada
prova e exige apenas que as provas estejam na estrutura de BC. Entretanto,
depois de transformadas, as provas em estrutura de blocos podem conter
detalhes supérfluos e muitos passos óbvios, tornando a prova complexa. As
provas podem ser simplificadas com o uso de várias técnicas de transformação
dos blocos de provas, como eliminação de linhas desnecessárias, fórmulas
duplicadas ou triviais.
A técnica de BC também faz uso de regras de inferência para
simplificar as provas. Essa abordagem fornece ferramentas de manipulação e
reestruturação das provas. O usuário pode editar a prova simplificada na
ferramenta BC no formato de uma seqüência de linhas de uma prova similar ao
texto em um editor de textos.
Oliveira et al. (1999) mostram que provas em dedução natural
possuem informações irrelevantes para explicações para usuários humanos.
Sabendo que apenas dedução natural não é suficiente para gerar uma
explicação de qualidade para usuários humanos, esta abordagem utiliza uma
variação de dedução natural que gera as provas em sua forma normal,
fornecendo a fórmula mínima de cada ramo da prova.
Os citados autores argumentam que informações desnecessárias
presentes em uma prova devem ser eliminadas, pois podem ser mal

32
interpretadas pelo usuário que pode entender que elas são necessárias para a
conclusão da prova. Os autores definem também várias estratégias para
simplificação e redução de tamanho dessas provas, como por exemplo:
omissão de regras que possuem apenas uma premissa, junção de instâncias
sucessivas de uma mesma regra, etc. As provas simplificadas são
apresentadas em forma de hipertextos, onde maiores detalhes de explicação
são apresentados sob demanda do usuário.
Fiedler e Horacek (2001) também consideraram que provas de
dedução natural são muito grandes e possuem detalhes irrelevantes que
diminuem a compreensão humana, e apresentaram técnicas de representação
de provas geradas por provadores ou raciocinadores automáticos em um nível
mais adequado para usuários humanos. Eles propuseram um método interativo
que permite aumento ou diminuição de detalhes das provas dependendo da
audiência.
Os referidos autores argumentam que para tornar explicações mais
compreensíveis, alguns trechos de provas devem ser omitidos, tornando os
textos mais concisos. Eles assumem, por exemplo, que os usuários são
capazes de inferir algumas definições e executar alguns passos de inferência
mentalmente, permitindo assim que esses passos sejam retirados das provas.
Axiomas simples, assumidos de serem conhecidos pela audiência, são
ocultados das provas. Por outro lado, eles sugerem que outros passos das
provas devem ser expandidos, pois requerem mais detalhes, para que sejam
melhor compreendidos. De acordo com essa técnica, a aplicação de axiomas
como o da transitividade, por exemplo, em provas formais, torna-se mais
explícita quando toda a instanciação do teorema aparece exposta na prova em
passos separados, ou seja, quando todos os detalhes da aplicação do axioma
estão presentes na prova apresentada ao usuário. A abordagem de Fiedler e
Horacek tem sido utilizada no contexto de provadores automáticos de teoremas
e também em sistemas tutoriais inteligentes em que é possível categorizar um
usuário humano, como por exemplo, um aluno.
Buscando simplificar provas distribuídas, Denzinger e Schulz (1996)
apresentam um método baseado em várias heurísticas, como structural

33
features, que determina quão isolada uma subprova é. Essa abordagem impõe
uma estrutura hierárquica na prova para facilitar sua apresentação. Para criar
essa estrutura hierárquica, a prova é quebrada em partes menores, os axiomas
e subprovas, isoladas do resto da prova, que são separados. Depois de
estruturada, a prova torna-se uma listagem de passos de inferência menores e
mais simples para o entendimento humano. Entretanto, outras heurísticas
devem ainda ser aplicadas para que conjuntos de passos de inferência, como
cadeias de equações, sejam reescritos e substituídos por descrições mais
amigáveis, eliminando passos intermediários das equações.
Visando produzir textos inteligentes a partir de provas formais,
Coscoy et al. (1995) propõem um método para transcrever objetos das provas
em uma linguagem que chama de pseudo dedução natural. Essa abordagem
utiliza textos para explicar a estrutura lógica da prova, substituindo expressões,
funções, símbolos, argumentos e outras construções da prova por uma
descrição textual. Dessa forma, eles conseguem fazer com que uma prova
formal torne-se mais clara para a compreensão humana, apesar de mais longa
do que a prova original. Eles fazem uso de técnicas para tentar diminuir o
tamanho da prova, como por exemplo: introdução de símbolos para representar
teoremas, omissão de axiomas ou teoremas considerados usuais e de
aplicação implícita pelos usuários. Esta técnica mostrou-se adequada apenas
para provas de tamanho pequeno a moderado.
2.4 Problemática e Motivação
A partir dos trabalhos analisados na seção anterior, podemos
identificar que as abordagens presentes atualmente apresentam algumas
limitações no que diz respeito à transformação de provas e geração de
explicação apropriada para pessoas.
A abordagem de Huang (1996) (1994), por exemplo, mostrou-se
adequada para ser utilizada apenas por especialistas no domínio das

34
aplicações, e definiu formas de apresentações de provas variadas dependendo
do tipo de prova.
Outros trabalhos, como os de (Dahn e Wolf 1996), (Oliveira, de
Souza e Haeusler 1999) e (Fieldler e Horacek 2001) mostraram-se
inadequados para ambientes heterogêneos e distribuídos como a web.
Em (Dahn e Wolf 1996), a abordagem requer a edição por parte do
usuário para cada prova, a fim de simplificá-la.
Em (Oliveira, de Souza e Haeusler 1999), a abordagem proposta
restringe-se a alguns tipos de provas, e algumas estratégias de simplificação
só podem ser aplicadas em provas normalizadas para garantir que fragmentos
de fórmula mínima sejam obtidos.
A suposição do conhecimento de características das provas é
impraticável no contexto de sistemas distribuídos complexos. Em (Fieldler e
Horacek 2001), axiomas mais complexos, não podem ser simplificados pela
eliminação de informações. Ao contrário disso, eles defendem que axiomas
complexos necessitam de mais informações detalhadas nas provas a fim de se
tornarem compreensíveis.
O trabalho de (Coscoy, Kahn e Théry 1995) mostrou-se inadequado
para ser aplicado em provas de tamanho grande e, dessa forma, torna-se
também inadequado para ser aplicado a provas geradas por agentes web que
podem ser bastante extensas.
Com base nas limitações identificadas, surgiu a necessidade de
criação de uma abordagem para suprir tais limitações.
Propomos uma técnica de abstração que contempla as seguintes
características:
É projetada para ser usada tanto por especialistas quanto
por usuários finais;
Define uma forma unificada de apresentação das provas,
independente do tipo da prova ou do provador utilizado;

35
É apropriada para ambientes universais e distribuídos
como a web;
Utiliza padrões de abstração que podem ser projetados por
especialistas. Esses padrões podem ser configurados para
serem genéricos e aplicáveis na simplificação de várias provas;
Permite a criação de padrões para axiomas complexos,
permitindo que a semântica inserida pelo projetista do padrão
para esses axiomas possa tornar as provas onde eles aparecem
mais compreensíveis para pessoas.
Utiliza heurísticas pré-definidas juntamente com padrões
construídos por especialistas para simplificação das provas;
Pode ser aplicada a provas de qualquer tamanho, e os
padrões de abstração definidos pelo especialista podem ser
utilizados diversas vezes para uma mesma prova.
A definição da proposta de abstração de provas com essas
características é descrita no próximo capítulo.

3. A Proposta
Neste capítulo, apresentaremos uma proposta de abstração de
provas que tem por objetivo torná-las mais compreensíveis por usuários
humanos. Para cumprir esse objetivo, introduziremos primeiramente o conceito
de Abstração que serve como base para o entendimento de nossa proposta.
Na Seção 3.2 apresentamos nossa proposta de arquitetura de abstração de
provas formais. Na Seção 3.3 apresentaremos o conceito de Padrões de
Abstração, que são utilizados para a abstração das provas, e como esses
padrões são criados. A Seção 3.4 descreverá como esses padrões podem ser
classificados em categorias para otimizar a técnica de abstração das provas
onde são encontrados. A Seção 3.5 detalhará o algoritmo IWAbstractor
utilizado nesse trabalho como método de abstração de provas. No decorrer da
Seção 3.5, discutiremos também outros aspectos do algoritmo com sua
complexidade e heurísticas utilizadas para realizar a abstração de provas. Por
fim, a Seção 3.6 descreverá o repositório de padrões de abstração que são
utilizados para simplificar as provas.
3.1 Abstração
Em (Giunchiglia e Walsh 1992), o conceito de abstração foi definido
como um processo onde uma nova representação para um problema é criada.

37
Essa nova representação consiste de uma forma breve da representação
original. A representação de um problema, chamada de representação original
ou concreta, é mapeada para uma nova representação chamada de
representação abstrata. Esse mapeamento auxilia no tratamento do problema
original, tornando-o mais simples, preservando características e propriedades
desejáveis e eliminando detalhes irrelevantes.
As abstrações devem preservar a consistência da prova original que
deve ser semelhante à prova abstrata. Cada axioma, fórmula ou regra de
inferência da prova abstrata pode ser substituído por um axioma, fórmula ou
regra de inferência da prova original. O processo de abstração é visto como
um processo que ocorre naturalmente com o raciocínio humano, em que as
pessoas sempre consideram o que é relevante e desconsideram o que é
irrelevante, seja o que for que estejam fazendo.
Segundo Giunchiglia e Walsh, abstrações são comumente usadas
em áreas como: resolução de problemas, provas de teoremas, procedimentos
de decisões, aprendizado, raciocínio de senso comum, explicações, raciocínio
baseado em modelos, raciocínio quantitativo, analogia, verificação de hardware
e software, e várias outras sub-áreas da inteligência artificial.
Uma formalização da semântica de abstração é proposta em
(Ghidini e Giunchiglia 2004). Eles definem abstração como um par de
linguagens de sistema formal juntamente com um mapeamento entre essas
linguagens. Abstração é uma forma de representar as coisas de maneira
simplificada, capturando o que é relevante, apresentando um mesmo fenômeno
em diferentes níveis de detalhes. Eles argumentam também que abstração é
uma forma dos humanos lidarem com a complexidade de seu mundo,
construindo uma versão simplificada dele.
Em sua abordagem, os referidos autores acreditam que as
representações concreta e abstrata dos problemas são modeladas em lógica
de primeira ordem e, assim desenvolveram um relação de compatibilidade para
assegurar que as duas representações são semelhantes. Uma prova formal
abstrata é uma versão simplificada de uma prova formal original ou concreta.

38
Os passos de inferência da prova concreta em que ocorrem a manipulação e o
tratamento dos detalhes considerados irrelevantes são abstraídos da prova
abstrata. Eles apresentam abstração como um conceito muito importante para
a representação do conhecimento e seu raciocínio.
Tendo definido o conceito de abstração, apresentaremos uma
arquitetura para abstração de provas formais capaz de simplificar a
compreensão dessas provas pelas pessoas.
3.2 Arquitetura da Proposta
A Figura 4 apresenta a arquitetura de abstração proposta para este
trabalho. Ela foi projetada para permitir fácil extensão e integração de provas
em diferentes linguagens e formatos como KIF, PROLOG, TPTP e N3. As
provas originais representam a entrada de dados para a arquitetura. Para
abstrair essas provas em várias linguagens, elas têm que estar codificadas em
PML.
A tarefa de abstração de provas inclui um projetista que é
responsável por analisar as provas originais e a partir delas identificar
fragmentos de provas que possam ser simplificados. Esses fragmentos são
chamados de padrões de abstração (PAs) e cabe ao projetista interpretar e dar
semântica aos mesmos. É papel do projetista também identificar características
específicas das provas, e informá-las ao algoritmo de abstração para que ele
consiga fazer a melhor abstração possível da prova original. No momento da
criação de um PA, o projetista fornece informações sobre características e
semântica do PA. Os PAs identificados nas provas são adicionados a um
repositório de padrões que serão utilizados por um algoritmo para realizar a
abstração das provas. A semântica inserida pelo projetista em um PA é
apresentada a um usuário na forma de uma regra de inferência na explicação
de uma prova onde tal PA é encontrado.

39
O algoritmo utilizado para abstrair as provas é chamado de
IWAbstractor, que foi desenvolvido em colaboração com pesquisadores da
Universidade de Stanford e foi estendido para este trabalho. Um parser da
linguagem da prova deve estar integrado com o algoritmo IWAbstractor. O
parser da linguagem é necessário a fim de fazer o algoritmo reconhecer e fazer
a associação entre pares de sentenças das provas e nós dos PAs, em uma
operação chamada de matching. Diferentes parsers de linguagens devem ser
integrados a arquitetura de abstração por meio da implementação de uma
interface que faz a conversão das sentenças no formato de uma linguagem
especifica para o formato de sentenças reconhecido pela infra-estrutura de
explicação do IW. (verificar Apêndice I para ver alguns exemplos de
implementações dessa interface). As sentenças dos nós das provas são
representadas em formato LPO (Lógica de Primeira Ordem) para que o
algoritmo possa unificar as sentenças das provas e PAs. Uma vez que padrões
tenham sido reconhecidos nas provas, ou seja, uma vez que o matching tenha
sido realizado, o algoritmo executa o processo de abstração da prova e
apresenta ao usuário a prova abstraída (PAr), codificada em PML e com os nós
de suas sentenças descritos na linguagem original da prova.

40
Figura 4 Arquitetura de Abstração de Provas
3.3 Padrões de Abstração (PAs)
O algoritmo IWAbstractor tem como objetivo construir mapeamentos
entre provas de alto e baixo nível, ambas representadas em PML, mas
baseadas em diferentes regras de inferência e axiomas. Cada nó em uma
prova representa um conjunto de fórmulas bem formadas (wffs) com pelo
menos um passo de inferência associado.
Dadas duas linguagens 𝐿𝑔 e 𝐿𝑝, 𝑎𝑏𝑠 ∶ 𝐿𝑔 → 𝐿𝑝 é uma abstração.
𝐿𝑔 é a prova original ou concreta, enquanto 𝐿𝑝 é a prova abstrata e 𝑎𝑏𝑠 é a
função de mapeamento. Um padrão de abstração (PA) é definido por um
especialista humano e associado com a linguagem original para produzir a
abstração. Um PA é uma meta-prova também codificada em PML onde os
nodesets geralmente representam sentenças, incluindo meta-variáveis que

41
serão unificadas durante o processo de matching. IWAbstractor é
especificamente interessado em usar padrões que resultem em provas mais
simples e mais compreensíveis. O algoritmo IWAbstractor usa padrões para
abstrair detalhes que inibam a compreensão da prova e podem ser usados
para seu melhor entendimento. A aplicação de padrões de abstração em uma
prova original irá produzir provas abstraídas ou abstratas (PAr). A prova
abstrata contém uma porção da prova original, incluindo menos detalhes,
juntamente com a nova regra de inferência, identificando o padrão de
abstração aplicado. Os PAs podem ter características específicas e serem
classificados em grupos ou categorias de acordo com essas características. De
acordo com a categoria do PA aplicado na prova original, há uma estratégia
diferente associada para produzir a PAr.
3.3.1 Criando Padrões de Abstração
O framework InferenceWeb disponibiliza uma ferramenta para
auxiliar o especialista na criação de um padrão de abstração. Essa ferramenta,
editor de padrões de abstração, permite que o especialista construa um padrão
a partir de uma prova formal original. O processo de criação de um PA é
bastante subjetivo e o especialista dispõe de funcionalidades para excluir
nodesets da prova, alterar, renomear e atualizar termos e variáveis, excluir
ramos inteiros de uma prova e excluir também regras de inferência dos
nodesets. Os passos gerais abaixo descrevem os objetivos de se criar padrões
de abstração:
Ocultar regras de inferência em linguagem de máquina, por
exemplo, resoluções e eliminação do quantificador universal;
Ocultar axiomas complexos que são implicitamente
identificados no nome das regras nas PArs;
Ocultar partes de uma prova que possam ser irrelevantes (ou
muito óbvias) para certos tipos de explicações;

42
Remover resultados intermediários que são desnecessários
para o entendimento humano da explicação.
Por exemplo, Transitividade é uma propriedade da relação
subclasse-de assim como da relação parte-de. Muitos raciocinadores usam
axiomas descrevendo tal propriedade durante os processos de derivação de
resposta. Fazendo isto, provas tornam-se grandes e cheias de passos
detalhados que podem não ser apropriados para o consumo de explicações
pelas pessoas. Logo, nesse contexto, um PA tem o objetivo de abstrair passos
usados pelo raciocinador para concluir a resposta a alguma consulta baseada
em transitividade.
3.3.2 Exemplificando a criação de PAs
Uma das formas de se construir PAs é modificando provas
concretas. Um editor de PA foi desenvolvido para auxiliar na criação de PAs
sintaticamente corretos a partir de provas existentes. A Figura 5 mostra um
exemplo de como esse processo de edição pode ser feito utilizando a
propriedade da transitividade. O exemplo é do KSL Wine Agent (McGuinness,
Hsu, et al. 2003) que utiliza raciocínio dedutivo para associar comidas a vinhos.
Neste caso, um vinho está sendo associado à especialidade de Tony. Após
aprender que a comida deve ser combinada com um vinho branco, alguém
perguntou pelo tipo da comida que estava sendo combinada. A prova
resultante gerada pelo raciocinador JTP (Frank, Jenkins e Fikes 2002) é
mostrada pelo IWBrowser na Figura 5.

43
Figura 5 Prova original do Domínio de SEAFOOD.
Nesta prova, descobrimos que a especialidade de Tony é CRAB.
Entretanto, para derivar que CRAB é um tipo de SEAFOOD, o raciocinador JTP
utilizou vários passos. O fragmento de prova que demonstra que CRAB é um
tipo de SEAFOOD está destacado no lado esquerdo da Figura 5. Este
fragmento é um possível candidato a tornar-se um PA. Alguns nós foram
numerados para facilitar a explicação. O nó de número 3 representa a
conclusão do PA e deve permanecer na PAr. Analisando o PA, o projetista
decide que apenas as informações dos nós de número 1 e 2 devem
permanecer na PAr. Por decisão do projetista, todo o ramo com os
antecedentes do lado esquerdo do nó (subClassOf CRAB SEAFOOD) deve ser
eliminado após a abstração e poderão ser compreendidos pela utilização da
regra de Transitividade de Classe ( Class Transitivity). Dessa forma, o ramo do
lado esquerdo da prova original será bastante simplificado.

44
Usando o editor de PA, o projetista do PA decide reusar este
fragmento da prova a partir do nó que define (subClassof CRAB SEAFOOD),
ou seja, CRAB é uma subclasse de SEAFOOD. A partir desse fragmento de
prova, o projetista define como será feita a abstração do PA, quais nós devem
permanecer e quais nós devem ser excluídos após a abstração. Ele elimina os
nós do lado direito da árvore de prova original, assim como aqueles que estão
duplicados porque eles não são utilizados na abstração.
A fim de criar sua especificação final, o projetista precisa substituir
os identificadores no fragmento da prova original por variáveis. O editor de PA
oferece suporte para esta tarefa na forma de um mecanismo global
Localizar/Substituir. Por exemplo, substituindo subClassOf CRAB SHELLFISH
por ?subClassOf ?c ?b. O template final do PA é apresentado na Figura 6. A
idéia básica por trás de tal processo de edição é que a fim de explicar que uma
conclusão foi obtida por transitividade apenas os predicados destacados são
necessários para o ponto de vista de um usuário final humano. Então, no
processo de abstração quando tal padrão é encontrado, todos os outros nós
podem ser abstraídos.
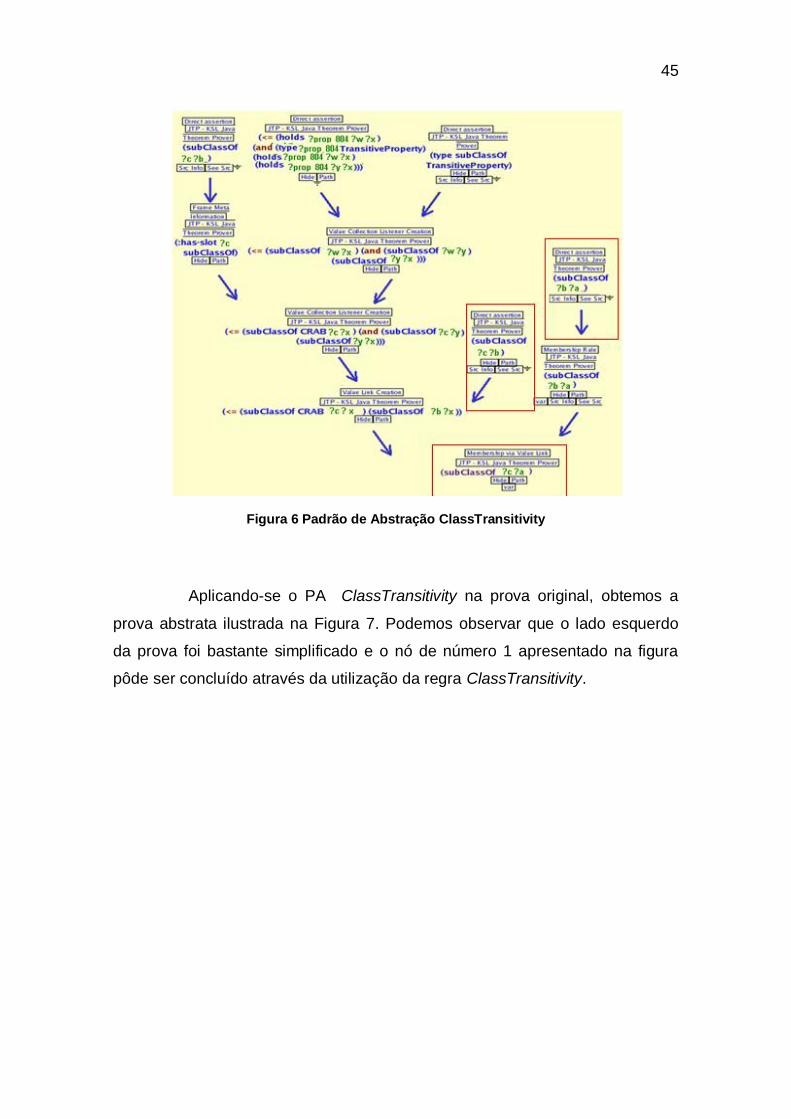
45
Figura 6 Padrão de Abstração ClassTransitivity
Aplicando-se o PA ClassTransitivity na prova original, obtemos a
prova abstrata ilustrada na Figura 7. Podemos observar que o lado esquerdo
da prova foi bastante simplificado e o nó de número 1 apresentado na figura
pôde ser concluído através da utilização da regra ClassTransitivity.

46
Figura 7 Prova Abstrata do domínio SEAFOOD
Algumas provas apresentam características especiais e precisam de
abordagens especificas para conseguirem uma melhor abstração da prova. Por
meio do editor de PAs, o projetista pode informar tais características para que o
algoritmo possa identificar qual estratégia de abstração usar para gerar a PAr.
Por exemplo, se criarmos um padrão e dissermos que ele é Recursivo, o
algoritmo saberá que tem que abstrair todos os nós nos vários níveis de
recursão e então introduzir uma nova regra de inferência, explicando o conceito
por trás da recursão. Essa estratégia de abstração está associada ao PA
Recursivo no algoritmo IWAbstractor.
A Figura 8 exibe um trecho do arquivo PML gerado pela criação de
um padrão de abstração do tipo Recursivo. Nela podemos verificar que o
projetista definiu o padrão como sendo Recursivo através da utilização da
marcação <iw:isRecursive> destacada em vermelho. Para esse tipo de padrão,
o projetista também precisa definir qual o conceito representado pela estrutura
recursiva. Esse conceito será utilizado como informação para a nova regra de
inferência criada quando o padrão for aplicado em uma prova. A informação do
conceito é a explicação da estrutura recursiva que foi abstraída e é

47
apresentada no arquivo do padrão através da marcação <iw:concept>
destacada em vermelho na figura abaixo.
Figura 8 Trecho de arquivo PML de Padrão de Abstração do tipo Recursivo
3.4 Categorização de Padrões de Abstração
O processo de abstração pode ser adaptado para se comportar de
forma diferente de acordo com as características identificadas pelo projetista
para o padrão de uma prova. Na criação de um PA, o projetista pode indicar a
que categoria ele pertence.
PAs podem ser distribuídos em diferentes categorias de acordo com
suas características. Por exemplo, alguns conjuntos de nós (nodesets) podem
aparecer repetidamente em uma prova porque representam uma função
recursiva que faz a chamada a ela mesma por várias vezes até que uma
<iw:NodeSet rdf:about="http://mia.unifor.br/registry/DR/oddFactor/proof1.owl#proof1">
<iw:hasLanguage
rdf:resource="http://inferenceweb.stanford.edu/registry/LG/ENGLISH.owl#ENGLISH"/>
<iw:hasConclusion rdf:datatype="http://www.w3.org/2001/XMLSchema#string"
>\+has_factor(X, Y).</iw:hasConclusion>
<iw:isConsequentOf>
<iw:InferenceStep>
<iw:hasIndex rdf:datatype="http://www.w3.org/2001/XMLSchema#int" >0</iw:hasIndex> <iw:hasRule
rdf:resource="http://inferenceweb.stanford.edu/registry/DPR/Hyp-Resolution.owl#Hyp-Resolution"/>
<iw:hasAntecedent rdf:parseType="Collection">
<rdf:Description rdf:about="http://mia.unifor.br/registry/DR/oddFactor/proof1_1.owl#proof1_1"/>
<rdf:Description rdf:about="http://mia.unifor.br/registry/DR/oddFactor/proof1_2.owl#proof1_2"/>
</iw:hasAntecedent>
</iw:InferenceStep>
</iw:isConsequentOf>
<iw:isRecursive
rdf:datatype="http://www.w3.org/2001/XMLSchema#string">true</iw:isRecursive>
<iw:variables>X</iw:variables>
<iw:concept rdf:datatype="http://www.w3.org/2001/XMLSchema#string">
Verifies the existence of oddNumber that divides {X}</iw:concept>
</iw:NodeSet>

48
condição de parada seja alcançada. Neste caso, podemos identificar que essa
estrutura recursiva pode ser transformada em um PA que pode ser
caracterizado com um PA Recursivo.
Outras estruturas (conjuntos de nós) podem ser encontradas
repetidamente em uma prova, representando um laço dentro de um fluxo de
processo, por exemplo. Nesse caso, também poderíamos categorizar essas
estruturas como PAs e eles seriam do tipo Repetitivo. Esta categoria de PAs
Repetitivos pode ser dividida em PAs Seqüenciais ou Paralelos. PAs
Seqüenciais representam um laço de processos onde os processos são
executados um após o outro, enquanto nos PAs Paralelos os processos são
executados ao mesmo tempo.
Identificamos e implementamos estratégias para o processo de
abstração para essas três categorias de PAs: Recursivo, Seqüencial e
Paralelo.
A estratégia do PA Recursivo é baseada na idéia de que para
explicar a execução de uma prova com chamadas recursivas não é necessário
explicar cada uma dessas chamadas, mas somente o conceito representado
pelo método recursivo e o resultado de sua execução. Os detalhes e os
parâmetros usados pelo método durante suas iterações são irrelevantes para o
usuário final que deseja apenas entender o que o método está fazendo. Esta
estratégia consiste em abstrair todos os nós presentes em todas as iterações
da recursão na árvore de prova e introduzir uma nova regra de inferência com
uma declaração ou texto explicando a recursão.
PAs do tipo Seqüencial e Paralelo são padrões que aparecem
repetidamente em uma prova. PAs Seqüenciais aparecem repetidamente em
vários níveis de uma árvore de prova, um acima do outro, enquanto PAs
Paralelos aparecem em um mesmo nível de uma árvore de prova. Para abstrair
PAs Seqüenciais, o algoritmo tem que identificar quantas vezes o padrão é
repetido na prova e abstrair todos os nós do padrão. Uma nova regra de
inferência é introduzida com uma indicação do nome do PA aplicado e quantas
vezes ele foi encontrado na prova. PAs Paralelos são similares aos

49
Seqüenciais e são abstraídos da mesma forma. Entretanto, o algoritmo tem
que seguir uma estratégia diferente quando encontrar um PA Paralelo porque
ele tem que identificar o padrão, repetidas vezes, em um mesmo nível da
árvore de prova.
A abstração de PAs com características diferentes não pode ser feita
sempre da mesma forma, pois utilizando essas diferentes estratégias de
abstração, o algoritmo IWAbstractor tenta deixar a prova abstrata mais clara
para a compreensão humana.
3.5 O algoritmo IWAbstractor
O IWAbstractor, desenvolvido por uma equipe de pesquisadores da
universidade de Stanford, é uma ferramenta disponível na forma de serviço
web que utiliza um repositório de PA‟s para transformar provas. Ele consiste
em duas fases: matching do PA e abstração da prova original. O usuário pode
selecionar quais PA‟s do repositório o algoritmo deve usar para tentar fazer o
matching em uma prova. Não há limitação quanto à quantidade de PA‟s a
serem procurados em uma prova, o usuário pode selecionar todos os padrões
do repositório e o algoritmo tentará fazer o matching de todos eles para a
prova. Para cada PA selecionado no repositório, o IWAbstractor tenta
inicialmente fazer o matching da sua conclusão e então dos nós folhas com
aqueles da prova. Após um padrão ser encontrado, ele é aplicado para abstrair
a prova original pela eliminação dos axiomas originais que são excluídos no
padrão de abstração e pela substituição do nome da regra de inferência como
explicação para a conclusão do nó. O nome da regra de inferência recebe o
nome do PA utilizado para abstrair a prova. Os axiomas eliminados são
aqueles nós intermediários, que fazem parte do PA, ou aqueles nós folha que
foram explicitamente marcados para serem excluídos da prova uma vez tendo
sido encontrado o PA. O algoritmo IWAbstractor é descrito no Quadro 1.

50
n0: nó de conclusão da prova a ser abstraída abstractProof(n0): para cada padrão de abstração p, se(match(n0, p)<>[]) abstractNodeset(match(n0, p), n0, p); senão próximo p; se verificou todos os p's , para todos os antecedentes n de n0, abstractProof(n); abstractNodeset(L, n, p): //Verifica se a abstração pode ser feita checando se existirão nós isolados após a abstração Se (IsThereIsolatedNodes(L,n) == falso) Criar novo nó n' n'.conclusão = n.conclusão adicionar passo de inferência com padrão p a n' adicionar nós folha de L, que estejam marcados para permanecer na prova, como antecedentes imediatos de n' eliminar nós folha de L que estejam marcados para serem eliminados da prova eliminar todos os nós compreendidos por L até n.conclusão chamar abstractProof para os nós antecedentes de n' match(n, p) : // retorna os nós de n que foram matched n: nó a ser matched p: padrao a ser matched Percorrer a árvore de prova do padrão p para pegar uma lista L1 de nós folha + conclusão Percorrer a árvore de prova a partir do nó n para pegar uma lista L2 de conclusão + antecedentes //tentar fazer matching da conclusão do padrão com todos os nós intermediários da prova Para todos os elementos i de L2 exceto nós folha{ se (unifiable(r.conclusão, i )) { int unifiedNodes = matchLeafNodes(i); se (L1.tamanho == unifiedNodes); retornar L2 }senão{ retornar []; } matchLeafNodes(i): //matching continua para os nós folha de L1 //retornar a quantidade de nós unificados Percorrer a arvore para nó i para pegar uma lista L3 de antecedentes int unifiedNodes; para todos os elementos q de L3{ para todos os elementos p de L1 { //tentar match todos os nós folha da regra com todos os nós da prova //isto é independente de ordem if(unifiable(p, q)) unifiedNodes++; } }
Quadro 1 Algoritmo IWAbstractor

51
O método abstractProof(n0) representa o fluxo principal do
algoritmo, onde para cada padrão de abstração tenta-se fazer o matching a
partir do nó atual (n0). Caso consiga-se fazer o matching, chama-se o método
abstractNodeset(L, n, p) passando-se como parâmetros o conjunto de nós da
prova (L), o nó atual (n) e qual o padrão (p), a partir do qual foi feito o
matching.
Para tentar fazer o matching de um padrão em uma prova, o
algoritmo utiliza o método match(n, p). Primeiramente, esse método tenta
unificar a conclusão do padrão de abstração p com um dos nós intermediários
da prova, percorrendo a lista L2 formada por todos os nós da prova a partir do
nó n recebido como parâmetro pelo método match(n,p) até o penúltimo nível da
prova. Não há necessidade de se percorrer o último nível da prova, pois não
faz sentido ter os nós folhas da prova como conclusão de um padrão de
abstração. Caso o método consiga unificar algum nó da prova com a conclusão
do padrão, as variáveis do padrão e valores do nó que foram unificados são
guardados em uma lista.
Em seguida, o método percorre o resto da prova tentando fazer o
matching dos demais nós do padrão com os nós da prova acima do nó que fez
o matching com a conclusão. O método caminha pela prova recursivamente,
tentando fazer o matching dos nós folha do padrão. Para isso, primeiramente o
método verifica se o nó que está sendo analisado é um axioma para saber se
já chegou ao fim de um ramo da árvore e não há mais nós para serem
percorridos em busca dos nós folha do padrão de abstração. O método verifica
também se a quantidade nós da lista L1, formada pelo nós folha e conclusão
do padrão de abstração, é igual a quantidade de nós unificados. Os valores
dos nós da prova são unificados com as variáveis do padrão de abstração e
são verificados para garantir que os valores sejam os mesmos já inseridos na
lista de valores dos nós. Cada novo valor encontrado é também inserido nessa
lista de valores dos nós.

52
Caso o método consiga fazer o matching dos demais nós do padrão
na prova, o resultado desse método é uma lista com os nós que foram
encontrados. Caso não seja possível fazer o matching dos demais nós do
padrão, o método continua a percorrer todos os antecedentes do nó que estava
sendo analisado, tentando unificá-los com os nós do padrão. Esse processo de
tentativa de unificação é repetido para todos os nós antecedentes do nó atual
que existirem.
O método abstractNodeset(L, n, p) monta a prova abstraída. O
parâmetro L representa a lista de nós da prova que correspondem aos nós do
padrão de abstração. O parâmetro n representa o nó a partir do qual a
abstração deve ser feita e p representa o padrão de abstração usado para
abstrair a prova. Esse método verifica também se a abstração de um segmento
da prova não resultará em nós isolados na prova. Após essa verificação, um
novo nó n' é criado e sua conclusão é setada com a conclusão do nó que fez o
matching. O passo de inferência do novo nó é setado com o padrão de
abstração que fez o matching. Em seguida, esse método pega os nós que
foram unificados com a regra e seta-os como novos antecedentes do novo nó
com a conclusão, eliminando assim os nós compreendidos entre a conclusão e
os nós folha.
Em relação aos nós folha, esse método verifica quais nós devem
permanecer ou não na prova. Isso é feito verificando os nós que possuam uma
regra de inferência, ou seja, nós que não foram marcados no padrão de
abstração para serem excluídos após o matching. No momento da criação de
um padrão de abstração, o usuário pode excluir a regra de inferência de um nó,
indicando assim que esse nó deve ser procurado na prova, mas não deverá
fazer parte dela uma vez que seja feita sua abstração.
IWAbstractor utiliza um algoritmo de unificação baseado em
(Paterson e Wegman 1976), com complexidade linear de tempo. Entretanto, a
complexidade geral do algoritmo IWAbstractor é exponencial, pois a
manutenção da independência de ordem dos axiomas requer permutação dos
nós folha dos padrões de abstração para cada unificação. Geralmente, o

53
número de nós folha de um PA é pequeno (variando de 3 a 7), e por isso, a
abstração na prática permanece viável.
Além disso, computamos um código hash que é usado com um
índice para guiar a fase de matching de padrões do algoritmo. O código é
construído baseado no predicado do nó e suas variáveis. Cada nó mantém
uma lista de códigos hash de seus antecedentes. Quando o algoritmo tenta
fazer o match de um nó do PA com um nó da prova, o código hash é gerado.
Com este código, o algoritmo verifica a lista de códigos hash dos nós da prova
e descobre se o código do template que ele está procurando faz parte da
prova. Por exemplo, se o algoritmo está procurando por um match para o nó
com o template “p x1 x2”, onde p é o predicado e x1 e x2 são as variáveis, ele
gera o código hash para este template e então verifica se este código hash
está presente na lista de códigos hash dos nós da prova. Esta técnica evita que
o algoritmo percorra a prova inteira procurando por um nó cujo template não
faz parte da prova. Essa heurística do código hash é descrita na próxima
seção.
3.5.1 Heurística do Código Hash
A Figura 9 ilustra o funcionamento da heurística de código hash. Os
nós desse trecho de prova estão numerados para facilitar a explicação. No
canto superior esquerdo da figura, uma tabela exemplifica os templates e os
respectivos códigos hash dos nós de 1 a 12. Por exemplo, para o nó 1 cujo
conteúdo na prova é „occurs Paranagua frost’, o template correspondente é
„occurs x1 x2‟, onde o predicado occurs permanece inalterado e os valores
Paranagua e frost tornam-se variáveis x1 e x2, respectivamente. Cada nó da
prova possui um template associado e cada template possui um código hash
correspondente. Um mesmo template pode representar vários nós em uma
prova. Na Figura 9, podemos verificar que os nós de número 5, 7 e 11, por
exemplo, apresentam o mesmo código hash, ou seja, apresentam também o
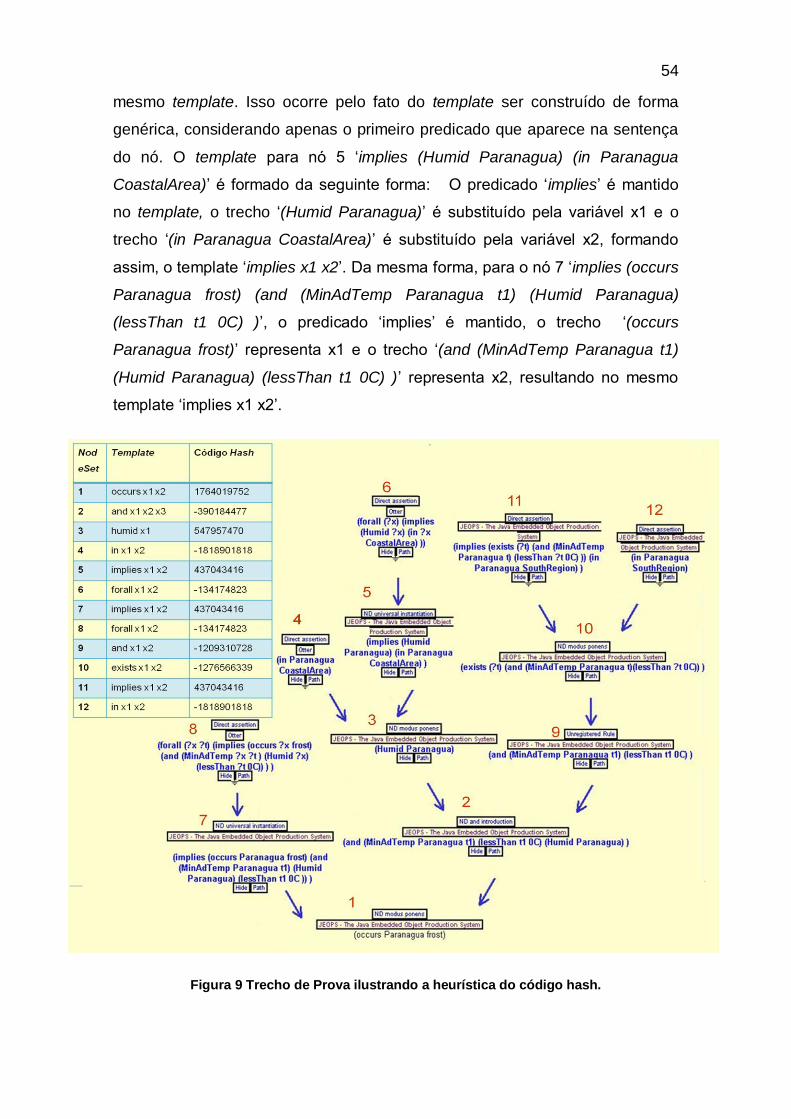
54
mesmo template. Isso ocorre pelo fato do template ser construído de forma
genérica, considerando apenas o primeiro predicado que aparece na sentença
do nó. O template para nó 5 „implies (Humid Paranagua) (in Paranagua
CoastalArea)‟ é formado da seguinte forma: O predicado „implies‟ é mantido
no template, o trecho „(Humid Paranagua)‟ é substituído pela variável x1 e o
trecho „(in Paranagua CoastalArea)‟ é substituído pela variável x2, formando
assim, o template „implies x1 x2‟. Da mesma forma, para o nó 7 „implies (occurs
Paranagua frost) (and (MinAdTemp Paranagua t1) (Humid Paranagua)
(lessThan t1 0C) )‟, o predicado „implies‟ é mantido, o trecho „(occurs
Paranagua frost)‟ representa x1 e o trecho „(and (MinAdTemp Paranagua t1)
(Humid Paranagua) (lessThan t1 0C) )‟ representa x2, resultando no mesmo
template „implies x1 x2‟.
Figura 9 Trecho de Prova ilustrando a heurística do código hash.

55
Além disso, cada nó armazena uma lista com seu código hash, os
dos seus antecedentes diretos e os dos antecedentes de seus antecedentes,
sem repetições. A Figura 10 apresenta um trecho da prova PML do exemplo da
Figura 9 representando as informações do nó de número 3. Podemos observar
que esse nó possui uma lista com quatro códigos hash: o código do próprio nó
3 e os códigos dos nós 4, 5 e 6. Os nós de número 4, 5 e 6 representam os
nós que antecedem o nó 3 na prova.
Figura 10 Trecho de Prova em PML ilustrando a heurística do código Hash.
Durante a etapa de matching, o algoritmo calcula o template e
código hash do nó do padrão de abstração que ele está tentando localizar na
prova e verifica se esse código está presente no nó de conclusão da prova.
Dessa forma, se um nó não estiver presente em uma prova, essa heurística
permite que isso seja percebido logo na primeira verificação.
O algoritmo IWAbstractor percorre as árvores de provas em
profundidade e, por isso, o uso da heurística do código hash evita que o
algoritmo percorra vários ramos profundos de uma árvore de prova até que
descubra que um dado nó não se encontra na prova.
<iw:NodeSet rdf:about="http://mia.unifor.br/hash/lastproof1.owl#lastproof1_3">
<iw:hasConclusion>(Humid Paranagua)</iw:hasConclusion> <iw:hasLanguage rdf:resource="http://inferenceweb.stanford.edu/registry/LG/KIF.owl#KIF"/>
<iw:isConsequentOf>
<iw:InferenceStep>
<iw:hasInferenceEngine rdf:resource="http://inferenceweb.stanford.edu/registry/IE/JTP.owl#JTP"/>
<iw:hasRule rdf:resource="http://inferenceweb.stanford.edu/registry/DPR/Hyp-Resolution.owl#Hyp-
Resolution"/>
<iw:hasAntecedent rdf:resource="http://mia.unifor.br/hash/lastproof1.owl#lastproof1_4"/>
<iw:hasAntecedent rdf:resource="http://mia.unifor.br/hash/lastproof1.owl#lastproof1_5"/>
</iw:InferenceStep>
</iw:isConsequentOf>
<iw:hashCode>547957470,-1818901818, 437043416, -134174823 </iw:hashCode> </iw:NodeSet>

56
A utilização da heurística do código hash contribui para diminuir a
complexidade do algoritmo, já que pode diminuir a quantidade de nós que
devem ser percorridos durante o processo de unificação.
3.6 Repositório de Padrões de Abstração (PAs)
O sucesso dessa abordagem de abstração depende do tamanho do
repositório de PAs, pois quanto maior a quantidade de PAs disponíveis, maior a
chance de se abstrair provas de diversos domínios utilizando esses PAs. Os
padrões ideais são aqueles que são genéricos e independentes de domínio,
mas padrões de domínio específico também podem ser construídos e são
muitas vezes bastante úteis para simplificação de provas específicas. Nesta
seção, descrevemos alguns padrões que estão disponíveis em nosso
repositório de PA e seu uso em contextos diferentes.
A definição de Transitividade pode ser definida na forma de um
padrão de abstração genérico. Várias relações possuem tal propriedade e um
PA para essa propriedade pode ser útil para muitas provas.
A relação classe-subclasse, por exemplo, declara que se X é uma
subclasse de Y, e Y é uma subclasse de Z, então X é uma subclasse de Z. Da
mesma forma, a relação de transitividade do tipo instância-classe declara que
se X é uma subclasse de Y, e x é uma instância de X, então x é também uma
instância de Y.
A Figura 11 ilustra as informações que o projetista julgou serem
necessárias para o entendimento da relação instância-classe. O PA projetado
para representar essa relação define que todas as outras informações sobre
como essa propriedade transitiva foi derivada são irrelevantes para o usuário.
O nodeset que representa a conclusão dessa relação (tipo ?instancia ?classe)

57
é derivado dos nós (tipo ?instancia ?subclasse) e (subClasseDe ?subClasse
?classe) através da aplicação da regra “Instância de Subclasse é Instância da
Classe”.
Figura 11 Abstração da relação instância-classe
Ainda sobre a propriedade de transitividade, podemos observar na
Figura 12 um PA identificado para a relação parte-de em uma prova em
linguagem N3 (Berners-Lee 2005) pertencente ao domínio do projeto TAMI
(W3C e KSL 2006). Os nodesets destacados na figura, além da conclusão,
representam as informações relevantes para o entendimento da Transitividade.
Os outros dois nodesets podem ser eliminados quando ocorrer matching desse
PA em uma prova.

58
Figura 12 PA representando propriedade transitiva em prova N3
Além de relações genéricas como essa, as específicas do domínio
também podem ser criadas com o auxílio da ferramenta.
Neste trabalho, utilizamos a biblioteca de problemas TPTP como
uma fonte para a criação de padrões de abstração específicos de domínio.
TPTP apresenta seus problemas e soluções divididos em 35 domínios
diferentes. Identificamos que PAs projetados especificamente para um prova
ou solução de um determinado domínio, muitas vezes, podem ser reusados e
aplicados para outras soluções dentro daquele mesmo domínio. Para isso,
utilizamos as soluções TPTP traduzidas para a linguagem PML (McGuinness,
Chang e Pinheiro da Silva 2008). Analisando o domínio de problemas de
Álgebra Booleana (BOO), por exemplo, podemos criar PAs a partir de soluções
bem específicas como BOO003-1 que define que a operação de multiplicação
é idempotente ou BOO008-1 que define que a propriedade de adição é
associativa. Apesar de serem PAs criados especificamente para um domínio,
álgebra booleana, esses PAs são bastante úteis e podem ser aplicados a
várias soluções dentro desse domínio que apresenta 139 soluções de
problemas.

4. Usando Padrões de Abstração
Neste capítulo, mostraremos alguns exemplos de utilização da
técnica de abstração proposta com o uso de padrões de abstração em provas.
Primeiramente, na seção 4.1, apresentaremos exemplos da utilização de
padrões sem categorização para abstração de provas. Em seguida, nas seções
4.2, 4.3 e 4.4, apresentaremos exemplos da utilização de padrões
categorizados como Recursivo, Paralelo e Seqüencial, respectivamente.
Através desses exemplos de provas, utilizando diferentes linguagens,
buscaremos validar a infra-estrutura de abstração proposta nesse trabalho,
bem como a técnica de abstração específica utilizada em cada caso.
4.1 Utilização de Padrão de Abstração sem
categorização
4.1.1 Exemplo de solução da biblioteca TPTP

60
Para o primeiro exemplo, utilizamos uma prova gerada a partir da
solução de um problema da biblioteca TPTP (Sutcliffe & Suttner, 2008) da
versão v3.4.2 que utiliza linguagem TPTP. Analisamos o domínio de problemas
de geometria chamado de GEO. Esse domínio contém 489 problemas.
Considerando uma solução para o problema GEO003-1, produzida pelo
provador de teoremas EP 0.999 (Schulz 2002), podemos observar que a prova
gerada pode ser considerada um padrão de abstração por se tratar de um
problema de geometria bem específico e passível de reuso.
A Figura 13 ilustra uma solução para o problema GEO003-1. Essa
solução consiste em provar que para dois pontos X e Y, Y está entre X e Y. Um
padrão de abstração foi criado a partir desse segmento de prova e foi chamado
de “Para qualquer ponto entre X e Y, Y está entre X e Y”. Para a criação do
padrão de abstração, os termos X1, X2, X3 e X4 foram transformados nas
variáveis ?X1, ?X2, ?X3 e ?X4, respectivamente. Os nós da prova foram
enumerados para facilitar a explicação. Os nós de número 1, 2 e 3 representam
os nós folha da solução. O nó 5 representa a conclusão da prova e o nó 4 é um
nó intermediário da solução.
Ao fazer o matching da conclusão e dos nós folha de um PA em uma
prova, o algoritmo IWAbstractor se encarrega de eliminar os nós intermediários
desse segmento na prova e verifica dentre os nós folha quais foram marcados
pelo projetista do PA para serem também eliminados na PAr. Logo, para o
padrão “Para qualquer ponto entre X e Y, Y está entre X e Y”, o nó de número
3 é eliminado, pois foi marcado pelo projetista do PA e o nó 4, por sua vez,
também será eliminado da prova após a abstração por ser um nó intermediário.

61
Figura 13 Solução para problema GEO003-1 da base de problemas TPTP.
A Figura 14 ilustra um esboço da estrutura da solução GEO002-1 da
base TPTP produzida pelo raciocinador EP 0.999. O problema GEO002-1
também trata sobre o assunto de intervalo de pontos em geometria. Dessa
forma, verificamos que o padrão identificado em GEO003-1 pode ser aplicado
para essa prova também. A Figura 14 mostra que para a prova GEO002-1, o
padrão da “Para qualquer ponto entre X e Y, Y está entre X e Y” pode ser
encontrada quatro vezes, conforme aparece destacado na figura.

62
Figura 14 Estrutura da Solução GEO002-1 de TPTP e detalhe do PA identificado na prova
Utilizando o algoritmo IWAbstractor, pode-se abstrair a prova
transformando os quatro segmentos destacados na figura em uma estrutura
mais simples, conforme ilustrado na Figura 15. No destaque da figura podemos
verificar que os nós de número 3 e 4 foram abstraídos pela utilização do padrão
“Para qualquer ponto entre X e Y, Y está entre X e Y”, que aparece agora como
regra de inferência na prova abstrata.

63
Figura 15 – Trecho da prova de GEO002-1 de TPTP após abstração
Além de ser utilizado na Solução GEO002-1, verificamos que o
padrão de abstração criado a partir da solução GEO003-1 também pode ser
utilizado para abstrair várias outras soluções para esse mesmo domínio GEO
da base TPTP, como por exemplo: GEO001-1, GEO006-1, GEO006-2,
GEO007-1, GEO008-1, GEO009-1, GEO010-1. Os problemas citados tratam
de pontos da geometria sobre intervalos entre 3, 4 e 5 pontos, conectividade de
intervalos e colinearidade de pontos; e todos eles apresentam as informações
da solução GEO003-1 para a qual foi definido o padrão de abstração de “Regra
de Intervalo entre 2 Pontos”.
4.1.2 Exemplo do projeto KANI(Knowledge Associates for
Novel Intelligence)
O próximo exemplo que iremos descrever mostra como a
abordagem de abstração foi usada no projeto Knowledge Associates for Novel
Intelligence (KANI) (Fikes, Ferrucci e Thurman 2005). KANI dá suporte à tarefa

64
de análise de inteligência (Murdock, et al. 2006) (Dahn e Wolf 1996) ajudando
analistas a identificarem, estruturarem, agregarem, analisarem e visualizarem
informações relevantes para a tarefa. Esse projeto também auxilia na
construção de modelos explícitos de hipóteses alternativas (cenários,
relacionamentos, etc.).
Como parte desse esforço, um componente de Resposta e
Explicação de Consultas foi desenvolvido para permitir a analistas fazerem
perguntas ao sistema. Respostas são apresentadas juntamente com
informações adicionais sobre fontes, suposições, resumos de explicação e
explicação interativa. No contexto de KANI, nem todas as fontes são confiáveis
e atuais. Além disso, algumas técnicas de manipulação de informação (por
exemplo, extratores de informações) podem não ser conhecidas previamente.
Nesse exemplo em particular, conceitos de pessoa, escritório, dono e
organização estão envolvidos no processo de raciocínio que tem por objetivo
concluir o relacionamento entre donos de uma organização e seus escritórios.
A prova para esse exemplo utiliza a linguagem KIF (Genesereth e Fikes 1992).
A Figura 16 mostra um exemplo de abstração onde um PA
específico de domínio chamado de “Dono de uma Organização geralmente tem
um escritório na Organização”, pode abstrair detalhes da prova. A Figura
destaca o segmento de prova original e a derivação feita para generalizar a
prova. Os axiomas originais que o projetista do PA deseja manter foram
especificados na regra de inferência (nesse caso na forma de uma assertiva
direta) que o produz. O template abstrato destacado na parte superior da
Figura 16 descreve a forma pela qual um PA foi gerado a partir de uma prova
original gerada por JTP (Frank, Jenkins e Fikes 2002). Basicamente, há duas
aplicações da regra de inferência de modus ponens a partir de assertivas
diretas e implicações que estão simplesmente dizendo que “um dono de uma
organização geralmente tem um escritório em sua organização”. A prova
abstrata está destacada no canto superior direito da figura.

65
Figura 16 Exemplo de utilização de Padrão de Abstração específico de um domínio. (Projeto KANI)
Uma possível explicação para a conclusão “JosephGradgrind tinha
um escritório em GradgrinFoods em 1 de abril de 2003 ” foi derivada a partir da
prova abstrata e pode ser apresentada em estilo discursivo, conforme mostra a
Figura 17.
Figura 17 Representação em estilo discursivo para uma prova abstrata

66
4.2 Utilização de Padrão de Abstração do tipo
Recursivo
Em provas onde ocorre recursão, podemos identificar um padrão de
abstração para o procedimento recursivo. Os nós que formam o padrão
representam o procedimento recursivo da prova e serão encontrados na prova
quantas vezes for chamada a recursão. Uma chamada recursiva é uma
tentativa de se obter um resultado através da execução de um mesmo método
por diversas iterações, onde a chamada do método é feita por ele mesmo, até
que se encontre uma condição de parada. Para explicarmos a execução de
uma prova que possui chamadas recursivas, não é necessário que
expliquemos cada uma das chamadas repetidamente e sim o conceito
representado pelo método recursivo e o resultado de sua execução. Os
detalhes e os parâmetros utilizados pelo método recursivo, durante suas
iterações, são irrelevantes para o usuário final que deseja apenas entender o
que o método está tentando fazer.
Padrões de Abstração do tipo recursivo são criados no
InferenceWeb com uma identificação de que são recursivos e com uma
definição do conceito que o método recursivo representa. O IWAbstractor ao
identificar em uma prova um padrão definido como recursivo, simplifica a prova
substituindo todos os nós correspondentes ao padrão de abstração por uma
descrição do conceito representado pelo padrão.
No próximo exemplo, apresentaremos uma prova em linguagem
PROLOG (Wielemaker 2008) que demonstra que a soma dos elementos de
uma lista é um número par. Para isso, faz-se necessário primeiro somar os
elementos de uma lista para só então verificar se essa soma é um número par.
Nesse exemplo, a soma dos elementos da lista é feita através de um método
recursivo chamado addup(). Um padrão de abstração para esse exemplo é
formado pelo método addup() e outras assertivas necessárias para a soma dos
elementos.
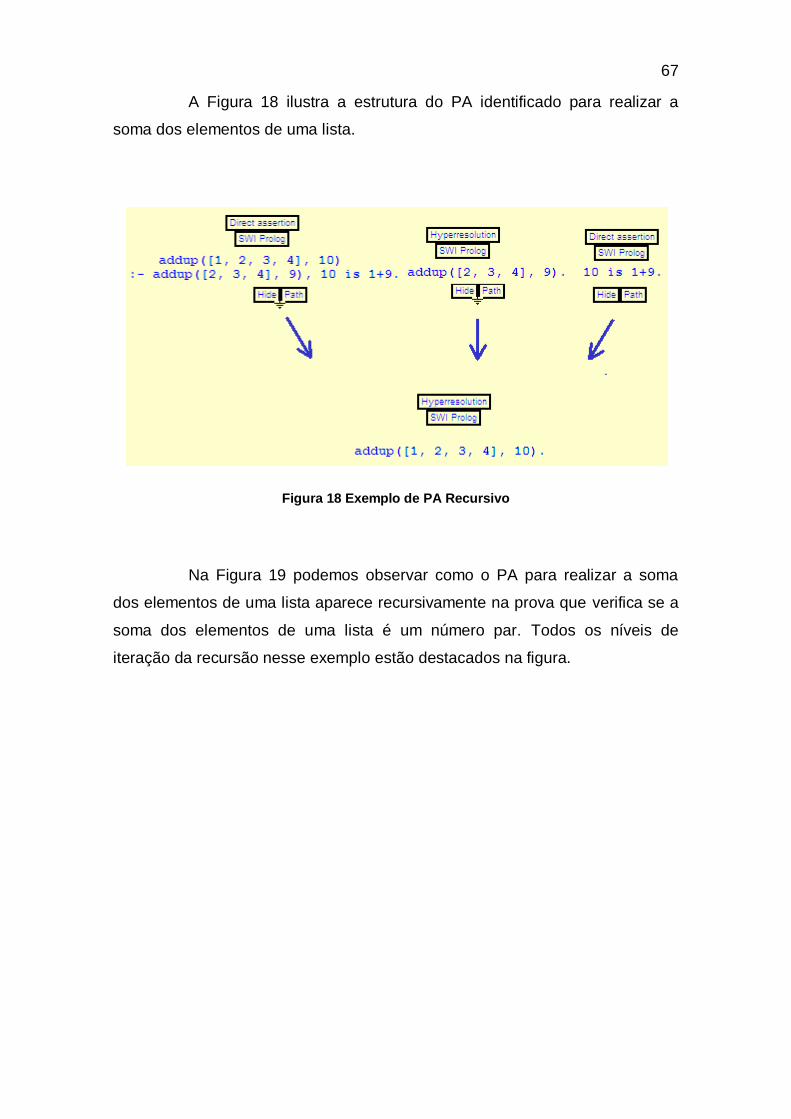
67
A Figura 18 ilustra a estrutura do PA identificado para realizar a
soma dos elementos de uma lista.
Figura 18 Exemplo de PA Recursivo
Na Figura 19 podemos observar como o PA para realizar a soma
dos elementos de uma lista aparece recursivamente na prova que verifica se a
soma dos elementos de uma lista é um número par. Todos os níveis de
iteração da recursão nesse exemplo estão destacados na figura.

68
Figura 19 Exemplo de prova com procedimento recursivo
A Figura 20 exibe a prova após a abstração do procedimento
recursivo. Na prova abstraída, todos os passos do procedimento recursivo

69
foram excluídos e uma descrição que explica o conceito recursivo foi
adicionada como regra de inferência para o nó que é derivado pelo
procedimento recursivo. A nova regra de inferência explica que o procedimento
recursivo addup() adiciona os elementos de uma lista.
Figura 20 Abstração de PA recursivo
4.3 Utilização de Padrão de Abstração do tipo Paralelo
Podemos observar que algumas provas apresentam métodos que
são executados várias vezes em paralelo. Em provas onde ocorre paralelismo,
podemos identificar um padrão de abstração para o procedimento que é
repetido na prova. Tal procedimento é identificado várias vezes em um mesmo
nível da árvore da prova. Os nós que formam o padrão serão identificados na
prova quantas vezes o procedimento for repetido. Em provas com padrões do
tipo Paralelo, as várias repetições do procedimento são executadas
simultaneamente. Para explicarmos a execução de uma prova que possui
chamadas repetidas, não é necessário que expliquemos cada uma das
chamadas repetidamente e sim o conceito representado pela repetição e um

70
resumo de sua execução. Os detalhes e os parâmetros utilizados pelo método
repetido durante suas iterações são irrelevantes para o usuário final que deseja
apenas entender qual o objetivo de se executar tal método repetidas vezes.
Padrões de Abstração do tipo Paralelo são criados no InferenceWeb
com uma identificação de que são Paralelos. Dessa forma, ao encontrar um
padrão paralelo, o IWAbstractor irá identificar quantas vezes esse padrão é
executado e qual o resultado de sua execução. O IWAbstractor ao identificar
em uma prova um padrão definido como Paralelo, simplifica a prova
substituindo todos os nós correspondentes ao padrão de abstração por uma
indicação da quantidade de vezes que tal método foi executado.
Analisando logs de fluxos de processos na web, podemos verificar
que esses fluxos apresentam estruturas de regras bem definidas. No próximo
exemplo analisaremos um trecho de um fluxo de execução de um processo de
compra de livro. As regras que estruturam a execução de um processo
apresentam passos como, por exemplo: verificação de precondições para
execução do processo, verificação das condições de finalização do processo e
verificação dos objetivos do processo. Fluxos como essas características são
comuns em provas quer representam o fluxo de processos na web. Se
considerarmos, por exemplo, o fluxo de execução de serviços web que
realizem buscas de produtos, podemos verificar que esses serviços podem
disparar a execução de vários outros serviços em paralelo ou em seqüência,
pois serviços como esse realizam buscas de produtos em vários
estabelecimentos disponíveis na web (Fernandes, et al. 2008).
A Figura 21 exibe um trecho de uma prova que representa o fluxo do
processo de compra de um livro. O fluxo do processo de compra de um livro é
bastante extenso e para facilitar a explicação exibimos apenas parte da prova
gerada. No trecho exibido na figura, verificamos o fluxo da execução do
processo de busca de um serviço de transporte para o livro. Na busca de um
serviço de transporte para o livro, foram encontrados três serviços de
transportadora e um processo de busca do melhor transporte foi executado
paralelamente para cada um deles. Dessa forma, podemos identificar que o
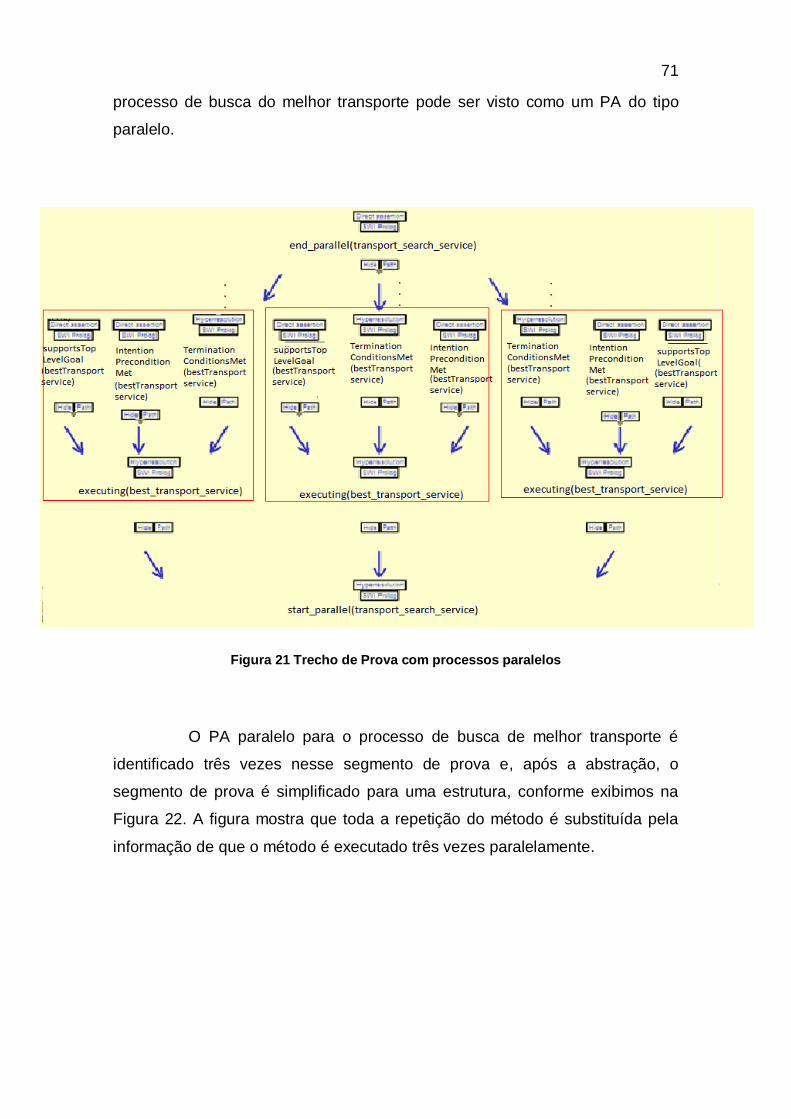
71
processo de busca do melhor transporte pode ser visto como um PA do tipo
paralelo.
Figura 21 Trecho de Prova com processos paralelos
O PA paralelo para o processo de busca de melhor transporte é
identificado três vezes nesse segmento de prova e, após a abstração, o
segmento de prova é simplificado para uma estrutura, conforme exibimos na
Figura 22. A figura mostra que toda a repetição do método é substituída pela
informação de que o método é executado três vezes paralelamente.

72
Figura 22 Detalhe da Abstração de Processos Paralelos
4.4 Utilização de padrão de Abstração do tipo
Seqüencial
Algumas provas apresentam métodos que se repetem
seqüencialmente. Em provas onde ocorre essa repetição seqüencial, podemos
identificar um padrão de abstração para o procedimento que é repetido
seqüencialmente na prova. Os nós que formam o padrão serão identificados na
prova quantas vezes o procedimento for repetido. Diferentemente das provas
com padrões do tipo Paralelo, em provas com padrões do tipo Seqüencial, as
várias repetições do procedimento são executadas seqüencialmente e não
simultaneamente. Para explicarmos a execução de uma prova que possui
chamadas repetidas não é necessário que expliquemos cada uma das
chamadas repetidamente e sim o conceito representado pela repetição e um
resumo de sua execução. Os detalhes e os parâmetros utilizados pelo método
repetido durante suas iterações são irrelevantes para o usuário final que deseja
apenas entender qual o objetivo de se executar tal método repetidas vezes.

73
Padrões de Abstração do tipo Seqüencial são criados no
InferenceWeb com uma identificação de que são repetitivos. Dessa forma, ao
encontrar um padrão Seqüencial, o IWAbstractor irá identificar quantas vezes
esse padrão é executado e qual o resultado de sua execução. O IWAbstractor
ao identificar em uma prova um padrão definido como Seqüencial, simplifica a
prova substituindo todos os nós correspondentes ao padrão de abstração por
uma indicação da quantidade de vezes que tal método foi executado.
A Figura 23 apresenta um segmento de uma prova onde ocorre um
procedimento Seqüencial. Para esse exemplo, utilizaremos o mesmo processo
de compra de livro descrito na seção anterior. Entretanto, o processo de busca
do melhor transporte é agora executado duas vezes e de forma seqüencial.
O processo repetitivo está destacado na figura. O PA que representa
esse processo deve ser categorizado como sendo do tipo Seqüencial e a
aplicação desse PA na prova resulta em um segmento simplificado, conforme
ilustrado no lado direito da figura. Após a abstração da prova, uma regra de
inferência indicando que o processo de busca do melhor transporte foi
executado duas vezes seqüencialmente é inserida.
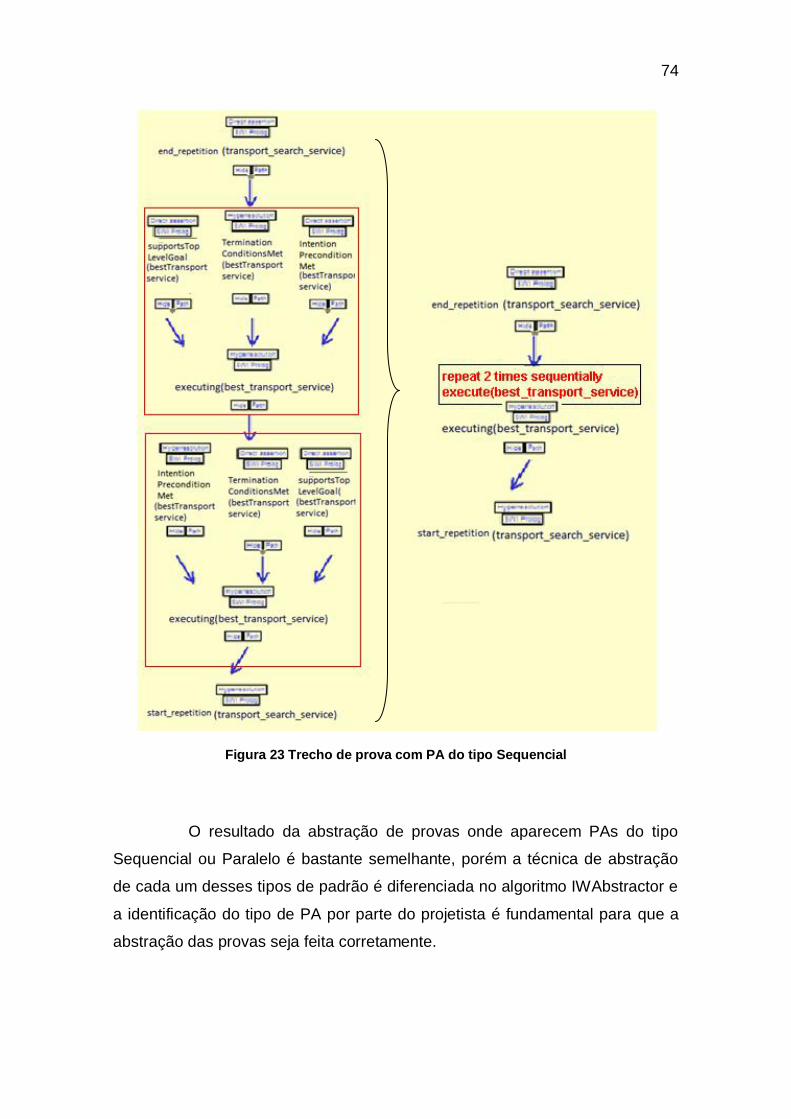
74
Figura 23 Trecho de prova com PA do tipo Sequencial
O resultado da abstração de provas onde aparecem PAs do tipo
Sequencial ou Paralelo é bastante semelhante, porém a técnica de abstração
de cada um desses tipos de padrão é diferenciada no algoritmo IWAbstractor e
a identificação do tipo de PA por parte do projetista é fundamental para que a
abstração das provas seja feita corretamente.

5.Avaliação da Proposta
Neste capítulo, iremos avaliar nossa proposta de abstração de
provas na web. Realizamos uma avaliação comparativa através de testes de
manipulação de provas/explicações realizados com usuários, a fim de observar
a interação dos usuários com as explicações apresentadas. Apresentamos aos
usuários explicações de provas com e sem o uso das técnicas de abstração.
Esses testes foram realizados a fim de verificarmos o êxito em alcançar os
objetivos propostos neste trabalho.
5.1 Avaliação Comparativa
5.1.1 Metodologia
Buscamos explorar a visão dos usuários sobre as explicações
apresentadas. As provas ou explicações serão apresentadas aos usuários
através da ferramenta XPlainS (Fernandes 2008). Utilizaremos técnicas de
observação e registro do uso do sistema seguido de entrevista composta por
perguntas abertas e fechadas. Realizamos os testes com 20 participantes com
perfil de usuários que freqüentemente pesquisam produtos e realizam compras
pela internet.

76
Os perfis dos participantes selecionados foram 12 homens e 08
mulheres com idade variando entre 23 e 41 anos. Os participantes atuam na
área de sistemas de informação e apresentam nível de escolaridade entre nível
superior e pós-graduação.
Inicialmente, os participantes receberam dois documentos (vide
Apêndice II – Documentos utilizados na avaliação): um termo de
consentimento, onde o participante autorizava a utilização das informações
coletadas durante os testes; e um documento que apresentava o experimento e
o cenário a ser seguido durante o teste.
A aplicação de todos os testes foi acompanhada pela pesquisadora
e com o uso da ferramenta XPlainS, todos os passos executados pelos
usuários durante a realização dos testes foram registrados para análise
posterior. Após cada interação, os participantes receberam um questionário
com perguntas que buscavam avaliar o entendimento do resultado encontrado
pela pesquisa de um produto para compra na internet.
O objetivo dessa primeira avaliação é tentar validar a seguinte
hipótese sobre as provas abstraídas:
Hipótese 1: A explicação gerada a partir de uma prova abstraída é
suficiente para um usuário que deseja entender como o
resultado foi obtido.
5.1.2 Cenário
Todos os participantes receberam um texto que apresentava o
seguinte cenário:

77
Você precisa comprar um livro. Para isso, você acessa a página
http://localhost:8080/xplainsweb/simuladorloja que é o endereço de
uma loja virtual onde você pode comprar tal produto. Para efetuar
a compra, você informa o produto, as características deste produto
e os dados para entrega. Esta loja busca na Internet onde o
produto encontra-se mais barato e a transportadora que realiza
pelo menor preço o transporte do produto. Ao final da compra,
você deve justificar a compra como sendo a melhor opção
encontrada. Para isso, você deverá usar as informações oferecidas
pelo sistema XPlainS.
Ao término da leitura, o usuário acessaria o endereço do site da loja
onde iria realizar a compra. Utilizamos uma aplicação que simula esse
processo de compra de livro para ser utilizada neste teste. Essa aplicação
armazena os passos executados pelo usuário para que possam ser analisados
posteriormente. Para realizar o teste, o usuário deve preencher os dados da
compra que lhe foram fornecidos juntamente com o cenário do teste, e em
seguida, solicitar a pesquisa do produto. A ferramenta apresenta o resultado da
pesquisa ao usuário.
O processo de busca de livro consiste de uma composição de
serviços web. XPlainS provê explicações da execução de serviços na Web,
através da geração de informações acerca de sua execução.
Para este cenário de busca de livro, o usuário obtém a seguinte
resposta como melhor opção de compra:
“Loja: Amazon; Preço do Livro: R$ 201,13; Transportadora: Tam
Cargas e Correios; Preço do Frete: R$ 68,13.”
O preço do livro na loja Amazon juntamente com o valor do frete que
deve ser realizado por duas empresas configurou-se como melhor opção de
compra do produto. A Figura 24 apresenta o resultado encontrado como melhor
opção de compra do livro.

78
Figura 24 Melhor opção de compra do livro
O site apresenta também informações sobre outras quatro lojas
onde o livro pesquisado pode ser comprado. Para produzir este resultado, a
loja executou três serviços: Buscar Lojas, Procurar Melhor Frete e Selecionar
Melhor Preço, conforme exibido na Figura 25.
Figura 25 Serviços executados para busca do livro
O serviço Buscar Lojas procura as lojas onde o livro pode ser
encontrado. Para esse exemplo, o serviço encontrou quatro lojas, mas uma
delas estava indisponível e não pode ser consultada. Essa informação pode ser
visualizada na Figura 26.

79
Figura 26 Explicação do Serviço Buscar Lojas
O serviço Procurar Melhor Frete buscava para cada uma das lojas,
empresas que realizassem o frete da loja até o endereço do comprador com
menor preço pro usuário. Para esse cenário, encontrou 3 lojas que realizam
frete para o endereço desejado, conforme aparece na Figura 27.
Figura 27 Explicação do serviço Procurar Melhor Frete
O serviço Selecionar Melhor Preço compara os preços de todas as
lojas consultadas e seleciona a loja que apresenta melhor preço de produto
adicionado de frete de entrega. A explicação desse processo é feita conforme a
Figura 28.

80
Figura 28 Explicação do Serviço Selecionar Melhor Preço
Dez participantes realizaram os testes visualizando as provas
completas e os outros dez realizaram os testes visualizando as provas
simplificadas ou abstraídas. A escolha dos participantes que receberam cada
tipo de explicação ou prova foi feita aleatoriamente. Todos os usuários
puderam fazer uso do sistema livremente para tentar entender como o
resultado apresentado foi produzido e o que fez com que uma das opções
fosse sugerida para compra.
A Figura 29 exibe a seqüência de explicações apresentadas para o
trecho da prova referente ao serviço de busca de frete para a livraria Cultura. A
Figura 30, por sua vez, apresenta a explicação simplificada para o mesmo
trecho na prova abstraída.

81
Figura 29 Explicação do serviço de Frete na prova completa.

82
Figura 30 Explicação do serviço de frete na prova abstraída.
5.2 Análise dos Resultados
Ao final dos testes, analisamos os questionários respondidos pelos
participantes e as informações registradas através da interação do usuário com
o XPlainS. Dessa forma, buscamos verificar se a hipótese que defendíamos
antes da realização dos testes havia sido confirmada ou refutada.
Nossa hipótese afirma que a explicação gerada a partir de uma
prova abstraída apresenta informações suficientes para que o usuário consiga
entender como o processo foi realizado e como o resultado foi obtido. Para
verificarmos a validade dessa hipótese, buscamos identificar alguns pontos
através dos questionários e do histórico de navegação dos participantes na
ferramenta:
Verificar se o usuário consegue explicar como o processo ocorreu
com as informações fornecidas pela prova completa e abstraída;
Verificar se o usuário consegue buscar informações que
expliquem trechos do processo navegando pelas explicações;
Verificar se o usuário sente dificuldade em explicar algum trecho
da prova por falta de informações.
Para analisarmos o primeiro ponto, solicitamos a todas as pessoas
que explicassem/descrevessem como o resultado foi obtido a partir das
explicações apresentadas pelas provas completas e abstraídas. Apenas duas
das vinte pessoas não conseguiram descrever completamente como o
resultado foi obtido, pois não mencionaram a questão do frete do produto que
foi realizado por duas empresas. Dessas duas pessoas, uma recebeu a prova

83
completa e a outra recebeu a prova abstraída para realizar o teste. Trata-se de
uma forte indicação de que o fato de uma das provas apresentar as
informações simplificadas e com menos detalhes não impediu os usuários de
conseguirem entender e explicar o processo de compra do livro. As duas
pessoas citadas anteriormente compreenderam apenas uma parte do
processo, pois não conseguiram descrever com detalhes como o frete do livro
foi realizado. Esse entendimento parcial da explicação apresentada
demonstrado pelas respostas dessas duas pessoas não pode ser atribuído à
abstração da explicação.
Além de verificar se o usuário entendeu como a primeira opção de
compra foi encontrada, as perguntas do questionário também buscaram
verificar o entendimento do processo de busca do livro como um todo. A fim de
analisarmos o segundo ponto, os usuários foram perguntados sobre a segunda
melhor opção de compra para fazer com que eles navegassem nas explicações
apresentadas a fim de encontrarem a resposta. Monitoramos também a
navegação dos usuários durante a busca dessa resposta.
Observamos que o número de cliques de interação dos participantes
nas provas foi em média catorze considerando os testes das pessoas que
receberam as provas completas e dez para as provas abstraídas. Apesar da
quantidade de cliques nas provas completas ser superior a das provas
abstraídas, observamos que apenas três das dez pessoas que receberam a
prova completa para o teste buscaram informações detalhadas sobre partes do
processo de compra, acessando assim informações que não poderiam ser
encontradas nas provas simplificadas. Todos os participantes dos testes
conseguiram responder corretamente a pergunta sobre a segunda melhor
opção de compra.
Quando indagados se tiveram dificuldade em entender o processo
de compra por falta de informações detalhadas na prova, apenas uma das dez
pessoas que realizaram os testes com as provas simplificadas reportou ter
sentido dificuldade em entender como o resultado final tinha sido obtido.

84
Verificamos também que essa pessoa foi uma das que também não conseguiu
descrever corretamente como a melhor opção de compra foi obtida.
De um modo geral, podemos concluir que as informações
apresentadas pela prova simplificada dão suporte ao usuário para responder
perguntas sobre o processo executado. O entendimento do usuário
demonstrado pela avaliação dos questionários serviu de base para confirmar
nossa hipótese.

6. Conclusão
6.1 Considerações Finais
Neste trabalho, descrevemos uma abordagem genérica para abstrair
provas geradas por diferentes raciocinadores ou provadores automáticos de
teoremas na web e codificadas em PML para explicações em alto nível.
Utilizamos estruturas chamadas de Padrões de Abstração para tentar
identificar trechos das provas que podem ser simplificados pela eliminação de
informações desnecessárias para o entendimento da prova. A principal
contribuição deste trabalho consiste na definição de uma arquitetura de
abstração de provas, em que o projetista de um padrão de abstração consegue
inserir semântica na definição de um padrão, para que ele possa ser utilizado
na simplificação de provas.
Os padrões de abstração usados nesse processo são manualmente
definidos por projetistas com a ajuda de um conjunto de ferramentas para
manipulação de provas em PML. Através da definição de um padrão de
abstração, um projetista consegue introduzir semântica a um conjunto de
assertivas, derivações e aplicações de regras de inferências presentes nas
provas. Ao fazer isso, um projetista consegue definir o conceito por trás do
conjunto de nós que formam um padrão, melhor do que qualquer método
sintático poderia fazer. Outra contribuição que identificamos está na

86
categorização dos padrões, pois fazendo isso o projetista fornece informações
sobre as características de um padrão que serão relevantes para o método de
abstração.
O algoritmo IWAbstractor percorre a árvore da prova buscando os
padrões de abstração e abstraindo axiomas irrelevantes e, dessa forma,
produzindo explicações simplificadas para responder às consultas do usuário.
Neste trabalho, podemos identificar outra contribuição na extensão
do algoritmo IWAbstractor que foi acrescido de estratégias de abstração
especificas para determinado tipo de padrão e de uma estratégia que utiliza
código hash para diminuir a complexidade do processo de busca dos padrões
nas provas. Essas estratégias são utilizadas juntamente com os padrões
categorizados para realizar a simplificação de provas de maneira mais
eficiente.
Além disso, contribuímos também com a implementação de
interfaces reusáveis para linguagens como PROLOG, TPTP e N3, para que
provas nesses formatos possam ser explicadas e abstraídas utilizando o
framework InferenceWeb.
Nossa abordagem tem a limitação de exigir um projetista com
habilidades para criação dos padrões de abstração. Além de conhecer a
ferramenta para criação de um padrão de abstração, o projetista deve também
conhecer e entender um pouco da prova gerada, pois o padrão deverá ser
criado a partir da análise dos passos de inferência e regras presentes na prova.
A tarefa de projetar um PA é de alguma forma subjetiva e a explicação final
para certa conclusão irá depender fortemente da qualidade desses padrões.
Entretanto, acreditamos que ferramentas para criações de padrões podem
auxiliar nesse processo, oferecendo um conjunto de dicas e opções para que o
projetista consiga definir os PAs de forma mais eficiente.

87
6.2 Trabalhos Futuros
Estamos estudando maneiras de automaticamente eliminar axiomas
em uma prova inteira. Nossa idéia é propagar a eliminação de axiomas pela
aplicação de estratégias de simplificação em certos axiomas afetados por
regras de inferência específicas. A inclusão do „ou‟ em sistemas de dedução
natural é um exemplo de uma regra de inferência que produz axiomas
irrelevantes que podem ser eliminados da prova inteira. Geralmente, esses
axiomas são inseridos na prova com o objetivo de dar suporte à resolução do
problema, apesar de não agregarem novas informações para propósitos de
explicação.
Vislumbramos, também, a geração automática de padrões de
abstração que sejam genéricos e reutilizáveis em diversas provas. Estamos
estudando a biblioteca de problemas TPTP como opção de fonte para geração
desses padrões. Acreditamos que as soluções para problemas bem específicos
de um domínio podem configurar um padrão de abstração genérico que pode
ser utilizado para outras soluções do seu mesmo domínio. Estamos estudando
estratégias para identificar como transformar essas soluções em padrões e
como identificar nesses padrões quais as informações que deveriam
permanecer ou não nas provas abstraídas.
Além disso, estamos também identificando e aplicando padrões de
abstração em casos reais de fluxos de serviços web. Vislumbramos definir
regras de rescritas e realizar avaliações de compreensibilidade das provas
abstraídas geradas.

Referências
Berners-Lee, T. Notation 3 Logic . 2005.
http://www.w3.org/DesignIssues/N3Logic (acesso em 2008).
Buchanan, B, e E Shortliffe. “Rule based expert systems: The
MYCIN experiments of the Stanford Heuristic Programming Project.” (Addison-
Wesley, Reading) 1984.
Clancey, W. “From GUIDON to NEOMYCIN and HERACLES in
Twenty Short Lessons: ORN Final Report 1979-1985.” AI Magazine, 1986: 7(3),
pp. 40-60.
Coscoy, Y, G Kahn, e L Théry. “Extracting text from proofs.” Edição:
G., Felty, A., Herbelin, H., Huet, G., Murthy, C., Parent, C., Paulin-Mohring, C.,
& Werner, B. (1993). Dowek. In Typed Lambda Calculus and its Applications,
volume 902 of Lecture Notes in Computer Science. (Springer-Verlag), 1995:
109--123.
Dahn, B, e A Wolf. “A Calculus Supporting Structured Proofs.”
Journal of Information Processing and Cybernetics (5-6), 1994: 262-276.
Dahn, B, e A Wolf. “Natural language presentation and Combination
of Automatically Generated Proofs.” Frontiers of Combining Systems, 1996:
175-192.

89
Denzinger, J, e S Schulz. “Recording and Analyzing Knowledge-
based Distributed Deduction Process.” Journal of Symbolic Computation, (11),
1996.
Fernandes, C, V Furtado, A Glass, e D McGuinness. “Towards the
generation of explanations for semantic web services in OWL-S.” SAC - ACM
Symposium on Applied Computing, 2008: 2350-2351.
Fernandes, Carlos Gustavo. “XPLAINS: Uma Abordagem para
Geração de Explicações de Fluxos de Serviços Web Semânticos.” Dissertação
de Mestrado apresentada no Mestrado de Informática Aplicada da Unifor.
Fortaleza, 07 de Julho de 2008.
Fieldler, A, e H Horacek. “Argumentation in Explanations to Logical
Problems.” Proceedings of ICCS, LNCS 2073 (Springer Verlag), 2001.
Fikes, R, D Ferrucci, e D Thurman. “Knowledge Associates for Novel
Intelligence (KANI).” Proceedings of the 2005 International Conference on
Intelligence Analysis (McLean, VA) , 2005.
Frank, G, J Jenkins, e R Fikes. KSL Java Theorem Prover. 2002.
http://www.ksl.stanford.edu/software/jtp/ (acesso em Junho de 2008).
Furtado, V, et al. “Abstracting Web Agent Proofs into Human-Level
Justifications.” In the Proceedings of the Twentieth International FLAIRS
Conference, 2007.
Genesereth, M, e R Fikes. Knowledge Interchange Format Version 3
Reference Manual, Logic-92-1, Stanford University Logic Group. 1992.
http://logic.stanford.edu/kif/kif.html.
Ghidini, C, e F Giunchiglia. “A Semantics for Abstraction.” European
Conference on AI,, 2004.
Giunchiglia, F, e T Walsh. “A theory of abstraction.” Artificial
Intelligence 57 (Elsevier Science Publishers B. V), 1992: 323 – 389.

90
Huang, X. “Human Oriented Proof Presentation: A Reconstructive
Approach.” Ph. D Dissertation, DISKI 112, 1996.
Huang, X. “Planning Argumentative Texts.” In Proceedings of
COLING94, 1994.
Huang, X. “Reconstructing proofs at the assertion level.” Edição: In
Alan Bundy. Proc. Of 12th International Conference on Automated Deduction,
LNAI-814 (Springer), 1994: 738-752.
McGuinness, D, C Chang, e P Pinheiro da Silva. TPTP-PML
Translation Research Project. 2008. http://browser.inference-
web.org/tptppml/ListProof?scope=domain (acesso em 2008).
McGuinness, D, e F Harmelen. OWL Web Ontology Language
Overview. 10 de Fevereiro de 2004. http://www.w3.org/TR/2004/REC-owl-
features-20040210/ (acesso em Junho de 2008).
McGuinness, D, e P Pinheiro da Silva. “Explaining Answers from the
Semantic Web: The Inference Web Approach.” Journal of Web Semantics.(1),
n.4, 2004: pp: 397-413.
McGuinness, D, e P Pinheiro da Silva. “Infrastructure for Web
Explanations.” Edição: K. Sycara and J. Mylopoulos (Eds.), LNCS 2870,
Sanibel Is. D. Fensel. In Proceedings of 2nd International Semantic Web
Conference (ISWC2003) (Springer,), 2003: pp: 113-129, 200.
McGuinness, D, et al. K S L W i n e A g e n t. 2003.
http://ksl.stanford.edu/people/dlm/webont/wineAgent/ (acesso em Junho de
2008).
McGuinness, D, L Ding, P Pinheiro da Silva, e C Chang. “PML 2: A
Modular Explanation Interlingua.” Proceedings of the 2007 Workshop on
Explanation-aware Computing (ExaCt-2007), July 22-23 de 2007.

91
Meier, A. “System Description: TRAMP: Transformation of Machine-
Found Proofs into Natural Deduction Proofs at the Assertion Level.” Volume
1831 of Lecture notes in computer science ( Springer), 2000: 460--464.
Murdock, J, D McGuinness, P Pinheiro da Silva, C Welty, e D
Ferrucci. “Explaining Conclusions from Diverse Knowledge Sources.” Proc. of
the 5th International Semantic Web Conference, 2006: pp:861-872.
Oliveira, D, C de Souza, e E Haeusler. “Structured Argument
Generation in a Logic-Based KB-System.” In Logic, Language and
Computation, L. Moss, J. Ginzburg, M. de Rijke (eds) (CSLI Publication) v. 2.
(1999).
Paterson, M, e M Wegman. “Linear Unification.” ACM Symposium of
Theory of Computing, 1976: 181-186.
Pinheiro da Silva, P, D McGuinness, e R Fikes. “A Proof Markup
Language for Semantic Web.” Technical Report KSL Tech Report KSL-04-01,
2004.
Pinheiro, V, V Furtado, P Pinheiro da Silva, e D McGuinness.
“WebExplain: A UPML Extension to Support the Development of Explanations
in the Web for Knowledge-Based Systems.” Proc. Software Engineering and
Knowledge Engineering Conference, 2006.
Portoraro, F. Automated Reasoning. The Stanford Encyclopedia of
Philosophy. Edição: E Zalta. Spring. 2007.
http://plato.stanford.edu/archives/spr2007/entries/reasoning-automated/
(acesso em Junho de 2008).
Russel, S, e P Norvig. Inteligência Artificial. Rio de Janeiro : Elsevier,
2004.
Schulz, S. “E: A Brainiac Theorem Prover.” AI Communications 15(2-
3), 2002: 111-126.
Sutcliffe, G, e C Suttner. 2008. http://www.cs.miami.edu/~tptp/.

92
Swartout, W, C Paris, e J Moore. “Explanations in Knowledge
Systems: Design for Explainable Expert Systems.” IEEE Expert: Intelligent
Systems and Their Applications, (6) n. 3 (1991): pp. 58-64.
W3C, e KSL. Integrating Cwm with Inference Web - TAMI PROJECT.
2006. http://iw.stanford.edu/2006/tami/ e http://people.csail.mit.edu/lkagal/tami/
(acesso em 2008).
Wielemaker, J. SWI-Prolog's Home. 2008. http://www.swi-prolog.org/
(acesso em 2008).

93
Apêndice

94
Apêndice I - Interfaces para
Parsers
Essas classes representam a implementação de uma interface de
integração dos parsers de diversas linguagens para o formato de sentenças
utilizado pelo framework InferenceWeb (IW). A interface possui um método
chamado translate() que recebe como parâmetro uma sentença do tipo String
no formato da Linguagem que desejam ser integrada com o IW. Esse método
retorna a sentença no formato iw.infml.fol.FOLSentNode que é o formato
utilizado pelo framework IW para manipular suas sentenças. Seguem alguns
exemplos de implementação para essa interface de integração.
1) Classe para linguagem Prolog
package br.unifor.prolog;
import gnu.prolog.io.OperatorSet;
import gnu.prolog.io.ReadOptions;
import gnu.prolog.io.TermReader;
import gnu.prolog.term.AtomTerm;
import gnu.prolog.term.CompoundTerm;
import gnu.prolog.term.FloatTerm;
import gnu.prolog.term.IntegerTerm;
import gnu.prolog.term.Term;
import gnu.prolog.term.VariableTerm;
import iw.infml.fol.FOLNode;
import iw.infml.fol.FOLSentNode;
import iw.infml.fol.FOLTermNode;
import java.util.ArrayList;
import java.util.List;
public class PrologTranslator {
private FOLNode toFolSent(Term t) {
String str = "";
switch (t.getTermType()) {
case Term.COMPOUND:
CompoundTerm cpdTerm = (CompoundTerm)t;
ArrayList list = new ArrayList(3);
FOLNode pred = new
FOLTermNode(FOLTermNode.CONSTANT_TERM, cpdTerm.tag.functor.value,
null);;
FOLNode arg1 = toFolSent(cpdTerm.args[0]);
list.add(pred);

95
list.add(arg1);
if (cpdTerm.args.length > 1) {
FOLNode arg2 =
toFolSent(cpdTerm.args[1]);
list.add(arg2);
}
int bollOp = FOLSentNode.NO_OP;
if (",".equals(pred)) {
bollOp = FOLSentNode.AND;
list.remove(0);
} else if (":-".equals(pred)) {
bollOp = FOLSentNode.IMPLIES;
list.remove(0);
}
return new FOLSentNode(FOLSentNode.NO_QUANT,
null, bollOp, list);
case Term.INTEGER:
IntegerTerm intTerm = (IntegerTerm)t;
return new
FOLTermNode(FOLTermNode.CONSTANT_TERM,
"\""+Integer.toString(intTerm.value)+"\"", null);
case Term.ATOM:
AtomTerm atomTerm = (AtomTerm)t;
return new
FOLTermNode(FOLTermNode.CONSTANT_TERM, "\""+atomTerm.value+"\"",
null);
case Term.FLOAT:
FloatTerm floatTerm = (FloatTerm)t;
return new
FOLTermNode(FOLTermNode.CONSTANT_TERM,
"\""+Double.toString(floatTerm.value)+"\"", null);
case Term.VARIABLE:
VariableTerm varTerm = (VariableTerm)t;
return new
FOLTermNode(FOLTermNode.VARIABLE_TERM, varTerm.toString(), null);
}
//System.out.println(t.getClass().getName());
return null;
}
public FOLSentNode translate(String prologString) throws
Exception {
ReadOptions rd_ops = new ReadOptions();
rd_ops.operatorSet = new OperatorSet();
Term t = TermReader.stringToTerm(rd_ops, prologString);
return (FOLSentNode)toFolSent(t);
}
}

96
2) Classe para linguagem TPTP
package tptp;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.Iterator;
import tptp.SimpleTptpParserOutput.Literal;
import tptp.SimpleTptpParserOutput.Symbol;
import tptp.SimpleTptpParserOutput.Term;
import tptp.TptpParserOutput.TptpInput.Kind;
import antlr.RecognitionException;
import antlr.TokenStreamException;
import gnu.prolog.term.VariableTerm;
import iw.infml.fol.FOLNode;
import iw.infml.fol.FOLSentNode;
import iw.infml.fol.FOLTermNode;
public class TPTPTranslator {
public FOLSentNode translate(String tptpString) {
SimpleTptpParserOutput outputManager = new
SimpleTptpParserOutput();
TptpLexer lexer = new TptpLexer(new
StringReader(tptpString));
TptpParser parser = new TptpParser(lexer);
try {
SimpleTptpParserOutput.TopLevelItem item =
(SimpleTptpParserOutput.TopLevelItem)parser.topLevelItem(outputM
anager);
Kind k = item.getKind();
if (k.equals(Kind.Clause)) {
SimpleTptpParserOutput.AnnotatedClause clause =
(SimpleTptpParserOutput.AnnotatedClause)item;
Iterator<Literal> itr =
clause.getClause().getLiterals().iterator();
if (itr.hasNext()) {
Literal literal = itr.next();
FOLNode node = this.toFolSent(literal);
return (FOLSentNode)node;
}
}
} catch (RecognitionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TokenStreamException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
private FOLNode toFolSent(Literal literal) {

97
ArrayList list = new ArrayList(5);
FOLNode pred = new FOLTermNode(FOLTermNode.CONSTANT_TERM,
literal.getAtom().getPredicate(), null);
list.add(pred);
Iterable<Term> term_list =
literal.getAtom().getArguments();
for (Term term : term_list) {
list.add(toFolSent(term));
}
int bollOp = FOLSentNode.NO_OP;
// if (",".equals(pred)) {
// bollOp = FOLSentNode.AND;
// list.remove(0);
// } else if (":-".equals(pred)) {
// bollOp = FOLSentNode.IMPLIES;
// list.remove(0);
// }
return new FOLSentNode(FOLSentNode.NO_QUANT, null, bollOp,
list);
}
private FOLNode toFolSent(Term term) {
Symbol symbol = term.getTopSymbol();
if (symbol.isVariable()) {
return new FOLTermNode(FOLTermNode.VARIABLE_TERM,
symbol.getText(), null);
}
else if (term.getArguments() == null) {
return new FOLTermNode(FOLTermNode.CONSTANT_TERM,
"\""+symbol.getText()+"\"", null);
}
else {
ArrayList list = new ArrayList(5);
FOLNode pred = new
FOLTermNode(FOLTermNode.CONSTANT_TERM, symbol.getText(), null);
list.add(pred);
Iterable<Term> term_list = term.getArguments();
for (Term term2 : term_list) {
list.add(toFolSent(term2));
}
int bollOp = FOLSentNode.NO_OP;
return new FOLSentNode(FOLSentNode.NO_QUANT, null,
bollOp, list);
}
}
}
3) Classe para linguagem N3
package iw.abstractor;
import java.io.StringReader;
import java.util.HashMap;

98
import antlr.RecognitionException;
import iw.infml.fol.FOL;
import iw.infml.fol.FOLSentNode;
import iw.infml.fol.ParseException;
import iw.n3.N3Parser;
public class N3Translator {
// N3Parser parser;
public static FOLSentNode translate(String n3String) throws
Exception {
n3String = n3String.replaceAll("@forAll", "this
log:forAll");
n3String = n3String.replaceAll("@forSome", "this
log:forSome");
N3EventHandler handler = new N3EventHandler(System.out);
N3Parser parser = new N3Parser(new StringReader(n3String),
handler);
parser.parse();
return handler.getSent();
}
public static void main(String[] args) {
try {
String t = "(=> (eq ?start-int ?end-int) (eq ?s
(value ?func ?start-int)))";
FOL parser1 = new FOL(new StringReader(t));
// FOL parser1 = new FOL(new
StringReader(RemoveSpecialCharacters(_s1)));
FOLSentNode sent1 = parser1.Sent();
System.out.println(sent1);
String s = "@prefix :
<http://dig.csail.mit.edu/TAMI/lkagal/abstractions/trans-prop.n3#>
.\n"
+"@prefix foo: <file:/Users/lkagal1/Research/dig-
repos/TAMI/lkagal/abstractions/trans-prop.proof#> .\n"
+"@prefix log:
<http://www.w3.org/2000/10/swap/log#> .\n"
+"@prefix owl: <http://www.w3.org/2002/07/owl#>
.\n"
+"@forAll :O, :P, :S .\n"
+"{\n"
+"@forSome foo:_g3 .\n"
+"foo:_g3 :P :O .\n"
+":P a owl:TransitiveProperty .\n"
+":S :P foo:_g3 .\n"
+"} log:implies {:S :P :O .\n"
+"} .";
sent1 = N3Translator.translate(s);
System.out.println(sent1);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}}

99
Apêndice II – Documentos
utilizados na avaliação
Célula de Pesquisa em
Engenharia do Conhecimento
Centro de Ciências Tecnológicas, UNIFOR
Rua Washington Soares, 1321 Edson Queiroz – Fortaleza – CE –
60811-90
Tel. (85) 3477-3287
Termo de Consentimento
Termo de consentimento para realização de experimentos com pessoas na área de informática.
O objetivo desse experimento é avaliar a proposta apresentada no trabalho de mestrado intitulado: ABSTRAÇÃO DE PROVAS PARA EXPLICAÇÃO NA WEB, proposto pela aluna do mestrado em Informática Aplicada da UNIFOR, Juliana de Oliveira Carvalho.
Por estas razões, solicitamos seu consentimento para observarmos sua interação (uso) com o protótipo do sistema durante a realização de algumas atividades pré-programadas por este experimento, para a realização de entrevista, bem como a gravação da interação e da entrevista. Para tanto, é importante que você tenha algumas informações adicionais:
a) Os dados coletados durante a observação e a entrevista destinam-se estritamente a atividades de pesquisa e desenvolvimento.
b) A divulgação destes resultados pauta-se no respeito à sua privacidade e o anonimato dos mesmos é preservado em quaisquer documentos que elaboramos.
c) O consentimento para as atividades supracitadas é uma escolha livre, feita mediante a prestação de todos os esclarecimentos necessários sobre a pesquisa.
d) Você tem toda liberdade para interromper esta observação e/ou a entrevista no momento em que desejar.
e) Nossa equipe encontra-se disponível para contato através do telefone 3477-3287, ou pelo email pessoal do pesquisador responsável Juliana de Oliveira Carvalho.
De posse das informações acima, gostaríamos que você se pronunciasse acerca da observação e da entrevista.
( ) Dou meu consentimento para sua realização.
( ) Não autorizo sua realização.
Fortaleza, ___________________________________________
Participante Pesquisador
Nome: ____________________________________________
Assinatura:________________________________________
Nome: ___________________________________________
Assinatura:________________________________________

100
Este experimento
Neste experimento você vai fazer uso da ferramenta XPlainS, que provê explicações de
serviços na web, com base no cenário descrito a seguir. Após o experimento prático, será
apresentado um questionário que nos auxiliará a avaliar a proposta.
Cenário:
Você precisa comprar um livro. Para isso, você acessa a página
http://localhost:8080/xplainsweb/simuladorloja que é o endereço de uma loja virtual onde você
pode comprar tal produto. Para efetuar a compra, você informa o produto, as características
deste produto e os dados para entrega. Esta loja busca na Internet onde o produto encontra-se
mais barato e a transportadora que realiza pelo menor preço o transporte do produto.
Ao final da compra, você deve justificar a compra como sendo a melhor opção
encontrada. Para isso, você deverá usar as informações oferecidas pelo sistema XPlainS.
Para efetuar a compra, siga TODAS as instruções abaixo.
Instruções para a compra do produto:
1. Informar que deseja comprar um livro e confirmar.
2. Informar as características do livro que deseja comprar, que nesse caso será:
a. Título: Algoritmos:Teoria e Prática;
b. Autor: Cormen;
c. Editora: Campus;
d. Ano: 2002.
3. Confirmar as informações.
4. Preencher os dados para entrega:
a. Endereço: seu endereço
b. Cidade: Fortaleza;
c. País: Brasil.
5. Confirmar as informações e esperar o resultado. Para qualquer outra opção, não
existirá produto disponível.
6. O resultado é apresentado na tela.
7. Como você justificaria o resultado?

101
Questionário
Dados do participante:
Idade: Sexo:
Escolaridade: Profissão:
Sobre sua experiência com a internet:
1) Você usa sites de busca/pesquisa (marque apenas uma das opções):
Mensalmente Semanalmente Diariamente Várias vezes ao dia
2) Você confia nos resultados apresentados por estes sites de busca/pesquisa e se utiliza destes resultados para suas compras?
Sobre a interação (teste)
3) Porque o livro selecionado foi sugerido como melhor opção de compra?
4) O resultado apresentado é realmente o melhor dentre os pesquisados pelo site? Explique como esse resultado foi obtido?
5) Qual seria sua segunda melhor opção de compra? Por quê?
6) As informações (explicações) apresentadas pelo sistema são suficientes para que você entenda como o resultado foi encontrado? Em caso negativo, quais partes precisariam ser mais detalhadas?
Comentários:

Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas
Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo





























