Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE TECNOLOGIA PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA E COMPUTAÇÃO
Novas estratégias para conserto de soluções degeneradas no algoritmo k-means
Nielsen Castelo Damasceno
Orientador: Prof. Dr. Daniel Aloise
Número de ordem do PPgEEC: D183 Natal – RN, outubro de 2016.

Universidade Federal do Rio Grande do Norte - UFRN Sistema de Bibliotecas - SISBI
Catalogação de Publicação na Fonte. UFRN - Biblioteca Central Zila Mamede
Damasceno, Nielsen Castelo. Novas estratégias para conserto de soluções degeneradas no algoritmo k-means / Nielsen Castelo Damasceno. - 2016. 64 f.: il. Universidade Federal do Rio Grande do Norte, Centro de Tecnologia, Programa de Pós-Graduação em Engenharia Elétrica e Computação. Natal, RN, 2016. Orientador: Prof. Dr. Daniel Aloise. 1. Algoritmos - Tese. 2. Heuristica - Linguagem de programação - Tese. 3. Rede de computadores - Tese. 4. Agrupamento - Tese. 5. K-means - Tese. I. Aloise, Daniel. II. Título. RN/UF/BCZM CDU 004.421

Novas estratégias para conserto de soluções degeneradas no algoritmo k-means
Nielsen Castelo Damasceno
Tese de Doutorado aprovada em 05 de outubro de 2016 pela banca
examinadora formada pelos seguintes membros:
Natal – RN, outubro de 2016.

Agradecimentos
Primeiramente, agradecer a Deus por ter me dado sabedoria e amparo
para chegar aonde estou.
Ao meu orientador, Professor Dr. Daniel Aloise, por fazer do aprendizado
um bom trabalho. Obrigado pelos puxões de orelha (“no bom sentido”), pois sem
eles não poderia chegar até aqui. E principalmente pela paciência multiplicada
por setenta vezes sete na doação sem limite e sem restrições. Muito obrigado!
Ao professor Nenad Mladenovi , pela sua valiosa contribuição em nossa
pesquisa. Ao admirável Professor Dr. Allan de Medeiros Martins. E aos colegas
Daniel Pinheiro e Tales Wilson pelo suporte nos algoritmos.
Aos meus pais, pelo amor incondicional, permitindo-me chegar bem mais
longe do que um dia acreditei. Aos meus irmãos, familiares e à família Dantas
pelo apoio moral e espiritual. Muito Obrigado!
E, finalmente, um agradecimento especial à minha esposa, visto que
desde o primeiro instante me apoiou e caminhou ao meu lado, com sua paciência
ao ouvir explicar os detalhes da pesquisa e por permitir compartilhar meu
entusiasmo por aquilo que faço.

Resumo
O k-means é um algoritmo benchmark bastante utilizado na análise de cluster.
Ele pertence a grande categoria de heurísticas com base em etapas de
localização-alocação que, alternadamente, localiza centros de cluster e atribui
registros de dados até que nenhuma melhoria seja possível. Tais heurísticas são
conhecidas por sofrer um fenômeno chamado de degeneração, na qual alguns
dos clusters estão vazios e, portanto, em desuso. Nesta tese são propostas
várias comparações e uma série de estratégias para consertar soluções
degeneradas durante a execução do algoritmo k-means. Os experimentos
computacionais demonstram que essas estratégias são eficientemente levadas
a melhores soluções na clusterização, na grande maioria dos casos, em que a
degeneração aparece no algoritmo k- means.
Palavras-chave: k-means, minimização da soma dos quadrados, Degeneração,
Agrupamentos, Heuristicas.

Abstract
The k-means is a benchmark algorithm used in cluster analysis. It belongs to the
large category of heuristics based on location-allocation steps that alternately
locate cluster centers and allocate data points to them until no further
improvement is possible. Such heuristics are known to su er from a phenomenon
called degeneracy in which some of the clusters are empty, and hence, out of
use. In this thesis, we compare and propose a series of strategies to circumvent
degenerate solutions during a k-means execution. Our computational
experiments demonstrate that these strategies are e cient leading to better
clustering solutions in the vast majority of the cases in which degeneracy appears
in k-means. Keywords: k-means, Minimum Sum-of-Squares, Degeneracy, Clustering,
Heuristics.

Sumário
Sumário ........................................................................................................ 7
Lista de Figuras ............................................................................................ 9
Lista de Tabelas ........................................................................................... 10
Lista de Abreviaturas .................................................................................... 11
Lista de Símbolos ......................................................................................... 12
Lista de Algoritmos ....................................................................................... 13
Capítulo 1 – Introdução ................................................................................ 14
1.1 Objetivos ......................................................................................... 22
1.2 Organização do trabalho ................................................................. 22
Capítulo 2 – Revisão da Literatura ............................................................... 23
2.1 Definições básicas ........................................................................... 23
2.2 Algoritmos Hierárquicos de agrupamento ....................................... 24
2.2.1 Ligação Simples .............................................................................. 26
2.2.2 Ligação Completa............................................................................ 27
2.2.3 Ligação Média ................................................................................. 28
2.2.4 Ward ................................................................................................ 29
2.3 Algoritmos Particionais .................................................................... 30
2.3.1 k-medoids ........................................................................................ 32
2.3.2 Variações do k-means ..................................................................... 32
2.4 Métodos de inicialização dos centros .............................................. 33
2.4.1 Forgy ............................................................................................... 33
2.4.2 k-means++ ...................................................................................... 33
2.4.3 R-Ward ............................................................................................ 35
2.4.4 Algoritmo m_k-means ...................................................................... 35
Capítulo 3 – Estratégias para remover a degeneração ................................ 37
3.1 Random ........................................................................................... 38
3.2 Greedy ............................................................................................. 39
3.3 -Random ........................................................................................ 40
3.4 -Greedy .......................................................................................... 41
3.5 Mixed ............................................................................................... 43
3.6 Discrete Bipartition (DB) .................................................................. 44
Capítulo 4 – Experimentos Computacionais ................................................. 47
Capítulo 5 – Considerações Finais ............................................................... 58
Referências Bibliográficas ............................................................................ 60

Lista de Figuras
Figura 1.1 – Scatter representando o conjunto de registros dos peixes ....... 16
Figura 1.2 – Exemplo de degeneração na base sintética ............................. 18
Figura 2.1 – Agrupamento hierárquico aglomerativo e divisivo .................... 25
Figura 2.2 – Dendograma formado com um conjunto de cinco registros ..... 26
Figura 2.3 – Exemplo de mecanismo de inicialização do k-means++, para
= 3 ....................................................................................... 34
Figura 3.1 – Ilustra o método Random ......................................................... 39
Figura 3.2 – Ilustra o método Greedy ........................................................... 40
Figura 3.3 – Ilustra o método -Random com = 3 ..................................... 42
Figura 3.4 – Ilustra o método -Greedy ........................................................ 43
Figura 3.5 – Ilustra o método Mixed ............................................................. 44
Figura 3.6 – Ilustra o método DB .................................................................. 46

Lista de Tabelas
Tabela 1.1 – Coordenadas da base de dados sintética................................ 18
Tabela 1.2 – Número de soluções degeneradas encontradas em 100
execuções do k-means ........................................................... 20
Tabela 1.3 – Distribuição do grau de degeneração obtida com 100 execuções
do k-means aplicado ao problema de 50 registros ................. 21
Tabela 4.1 – Instâncias utilizadas para os experimentos ............................. 47
Tabela 4.2 – Resultado benchmark do k-means .......................................... 48
Tabela 4.3 – Comparação entre os seis métodos para remover a degeneração
.............................................................................................. 49
Tabela 4.4 – Score entre os 84 experimentos .............................................. 55
Tabela 4.5 – Resumo dos melhores resultados obtidos pelos métodos de
remoção de degeneração, o k-means++, R-Ward e m_k-means
.............................................................................................. 57

Lista de Abreviaturas
CPU Central Processing Unit
Custo MSSC
DB Discrete Bipartition
MSSC Minimum Sum-of-Square Clustering

Lista de Símbolos
, Clusters
í-ésimo centros
Grau de degeneração
Distância
Grau máximo de degeneração
Quantidade de registros
Amostras ou complexidade
Número de cluster ou centro
Proporção de partições
, í-ésimo ou j-ésimo registros
O registro mais distante em relação a y
Atributos ou entidade
Número de Stirling
Dimensão das amostras
, Pertubação
j-ésimo registros desconhecidos
Coordenada do novo centro
y Centro do cluster com maior MSSC
Conjunto de solução
Média do centro
Variável de decisão binária
Solução ótima
Um registro
Norma euclidiana

Lista de Algoritmos
Algoritmo 1.1 – k-means............................................................................... 16
Algoritmo 2.1 – Single Linkage ..................................................................... 26
Algoritmo 2.2 – Complete Linkage ............................................................... 28
Algoritmo 2.3 – Average Linkage ................................................................. 29
Algoritmo 2.4 – Ward .................................................................................... 29
Algoritmo 2.5 – k-means++ .......................................................................... 33
Algoritmo 2.6 – R-Ward ................................................................................ 35
Algoritmo 2.7 – m_k-means .......................................................................... 36
Algoritmo 3.1 – First Improving ..................................................................... 37
Algoritmo 3.2 – Last Improving ..................................................................... 38
Algoritmo 3.4 – DB ....................................................................................... 45

14
Capítulo 1 – Introdução
A computação e a comunicação têm produzido uma sociedade que se
alimenta de informação. A maioria das informações é representada por dados,
que são caracterizados como fatos registrados. A informação é um conjunto de
padrões, ou expectativas, que fundamenta os dados (COSTA et al., 2014). Logo,
há uma enorme quantidade de dados que são trocados em banco de dados de
informações potencialmente importantes para a sociedade. No entanto, algumas
dessas informações não foram descobertas ou analisadas.
A mineração de dados é a competência da área de ciências que busca
métodos apropriados para filtrarem dados de forma automática em busca de um
padrão nas informações ou uma regularidade. Caso esses padrões sejam
encontrados provavelmente generalizarão previsões precisas sobre eles.
Na busca por informação, são requeridos métodos e ferramentas
eficientes para a análise e a organização dos dados. A classificação é uma das
técnicas de mineração de dados mais utilizadas (HANSEN et al., 2012), haja
vista ser uma das mais realizadas tarefas humanas no auxilio à compreensão do
ambiente em que se vive. O ser humano está sempre classificando, criando
classes de relações humanas e dando a cada classe uma forma diferente de
tratamento.
Os algoritmos de classificação são divididos basicamente em
supervisionados e não supervisionados. Nos métodos supervisionados têm-se a
informação sobre que classe pertence cada registro do conjunto de dados. Em
seguida, os métodos realizam um treinamento para que o classificador possa
funcionar adequadamente, classificando de forma correta o conjunto de registros
que não estejam no conjunto inicial de treinamento.
Na literatura, os métodos paramétricos são classificados como algoritmos
supervisionados (DUDA; HART, 1998). Os classificadores que utilizam estes
métodos possuem funções discriminantes parametrizadas ( , ) para
classificar um vetor de atributos em uma classe , representada pelo vetor de
parâmetros . O objetivo é encontrar que parâmetros de melhor descrevem as
amostras dos registros. Outros métodos supervisionados utilizam apenas as

15
informações das amostras para classificar um registro, chamados na literatura
como não-paramétricos (DUDA; HART, 1998).
No tocante aos métodos não supervisionados, exemplificamos as técnicas
de agrupamento de dados, comumente chamadas na literatura de clustering
(HANSEN; JAUMARD, 1997), cujo objetivo principal é classificar registros de
acordo com algum critério. Outros métodos não supervisionados utilizam a
estimação da máxima verossimilhança (EVERITT, 1993), em que parâmetros de
uma função discriminante são estimados sem a presença da informação das
classes das amostras. Para um maior aprofundamento sobre esses assuntos,
sugerimos livros que foram escritos na década de 80, os quais incluem Spath
(1980), Jain e Dubes (1988), Massart e Kaufman (1983) e Titterigton et al. (1985).
Este último é dedicado aos métodos de mistura de densidade de probabilidade.
Um exemplo tradicional de agrupamentos de dados é apresentado por
Duda e Hart (1998) na clusterização de duas espécies de peixes. O objetivo é
identificar cada um dos peixes presentes no conjunto de registros como
pertencentes a uma das duas espécies, tendo como únicas informações
disponíveis as medidas de largura e comprimento.
Uma forma de visualizar o exemplo da classificação de peixes é através
de uma matriz ou tabela. Cada peixe do conjunto a ser classificado pode ser
representado por uma linha, e a coluna por uma dimensão física do peixe. O
gráfico pode ser outra forma de representar esse conjunto de dados. A Figura
1.1 apresenta-os em forma de registros, denominado na literatura como Scatter.
Nela, cada registro representa dois atributos - comprimento (ordenada) e largura
(abscissa) - no exemplo dos peixes. Esse tipo de diagrama funciona
devidamente apenas para 2 ou até 3 dimensões.
No exemplo dos peixes, o conjunto de registros para treinamento é a
tabela com os atributos das amostras (largura e comprimento) e a classe das
amostras (salmão e sardinha). Já nas classificações não supervisionadas são
dados apenas os atributos dos peixes. Os métodos de agrupamento podem ser
utilizados quando nada ou pouco se sabe sobre os dados. Outro problema é a
alta dimensão de dados. Alguns autores fizeram um estudo acerca dessa
complexidade (BISHOP, 2002), cuja solução seria reduzir a dimensão de dados
a serem classificados e posteriormente a utilização de uma técnica mais simples
(JOLLIFFE, 1986), (FRALEY; RAFTERY, 2002).

16
Figura 1.1 – Scatter representando o conjunto de registros dos peixes.
Fonte: Própria.
O algoritmo k-means (MACQUEEN, 1967) é um dos mais conhecidos na
literatura para agrupamento de dados, representando cada cluster pelo seu
centro. Em linhas gerais, ele consiste em inicializar os centros (usando alguma
heurística) e separar os registros de acordo com esses centros para, em seguida,
calcular novos centros a partir das classes atualmente calculadas. Esse
processo é repetido até que não haja mais nenhuma variação dos clusters. O
algoritmo clássico do k-means é descrito a seguir.
Algoritmo 1.1: k-means
Entradas: conjunto de registros x, número de clusters k
é o i-ésimo cluster.
1. ( , , … , ) = partição inicial de x;
2. Repete:
a. Calcule a distância entre os centros e os registros;
b. Atribua cada registro ao seu respectivo centro;
c. Atualize os novos centros.
3. Enquanto não houver variação dos clusters.
O algoritmo k-means é sensível à seleção de partição inicial e pode
convergir para um mínimo local (CELEBI; KINGRAVI; VELA, 2013). Esse é um

17
ponto bastante relevante neste estudo, no qual veremos que uma indevida
inicialização pode apresentar clusters degenerados.
São basicamente dois tipos de possíveis soluções degeneradas na
otimização do MSSC (Minimum sum-of-squares clustering) que surgem durante
a execução do k-means (BRIMBERG; MLADENOVI , 1999): 1) Existir um ou
mais centros de clusters que não têm registros (atribuídos) e; 2) Dois ou mais
centros de clusters são idênticos. Dizemos que a solução degenerada tem grau
se o número de cluster vazio na solução for igual a (BRIMBERG;
MLADENOVI , 1999).
A Figura 1.2 ilustra a ocorrência da degeneração do tipo 1. No exemplo,
utilizou-se a base de dados sintética, que possui 20 registros com 2 dimensões,
apresentada na Tabela 1.1. O algoritmo k-means foi inicializado com 4 centros
( = 4), sendo as coordenadas desses centros , , e (ver Tabela 1.1).
A Figura 1.2a apresenta os centros iniciais marcados com o símbolo ‘x’
em vermelho e cada registro atribuído ao seu centro mais próximo. Em seguida,
eles são atualizados (Figura 1.2b). A Figura 1.2c apresenta a segunda etapa de
alocação de registros. Nela há um centro isolado, ou seja, nenhum registro é
atribuído a esse centro. Na 2ª iteração do k-means a degeneração (Figura 1.2d)
resulta em apenas 3 clusters.
Embora a Figura 1.2 apresente um exemplo em que uma solução
degenerada de tipo 1 é encontrada, o k-means pode, eventualmente, reduzir a
degeneração do tipo 1 automaticamente, atribuindo registros para os centros
vazios nas iterações subsequentes.

18
Figura 1.2 – Exemplo de degeneração na base sintética.
a) Inicialização dos centros (em vermelho), = 4. b) Atualização dos centros (1ª iteração).
c) Atribuição dos registros aos centros. d) 2ª iteração com apenas 3 clusters.
Fonte: Própria.
Tabela 1.1 – Coordenadas da base de dados sintética.
24,6360 22,0049
20,0285 32,3832
21,2632 20,9310
24,8459 28,2252
29,9418 18,4504
20,6629 27,0567

19
22,6288 22,4438
26,1121 30,9956
34,3566 25,4818
25,5500 22,7709
26,4791 34,9847
25,8400 28,4848
24,1023 18,1681
22,8944 26,8152
16,6116 22,1648
30,2208 29,4319
21,5143 34,2010
22,5799 33,1410
25,9688 30,8689
26,8905 27,0771
Fonte: Própria.
A base de dados sintética descrita na Tabela 1.1 será útil para melhor
apresentar os métodos propostos nesta tese (discutido no Capítulo 3), uma vez
que ela representa boa visualização da dispersão de dados contendo apenas 20
registros em 2 dimensões.
A busca exaustiva pela partição ótima é proibitiva para um número
relativamente pequeno de registros. O número de diferentes partições de n
registros em k clusters não vazios é dado pelo número de Stirling do segundo
tipo (ANDERBERG, 1973):
( , ) =1
! 1) ( ) . (1.1)
em que representa a combinação de k tomados t a t. Sabe-se que ( , )
primeiramente aumenta para em seguida diminuir, isso no tocante a k. O número
de partições de n registros em k clusters ou menos é dado por
= ( , ). (1.2)
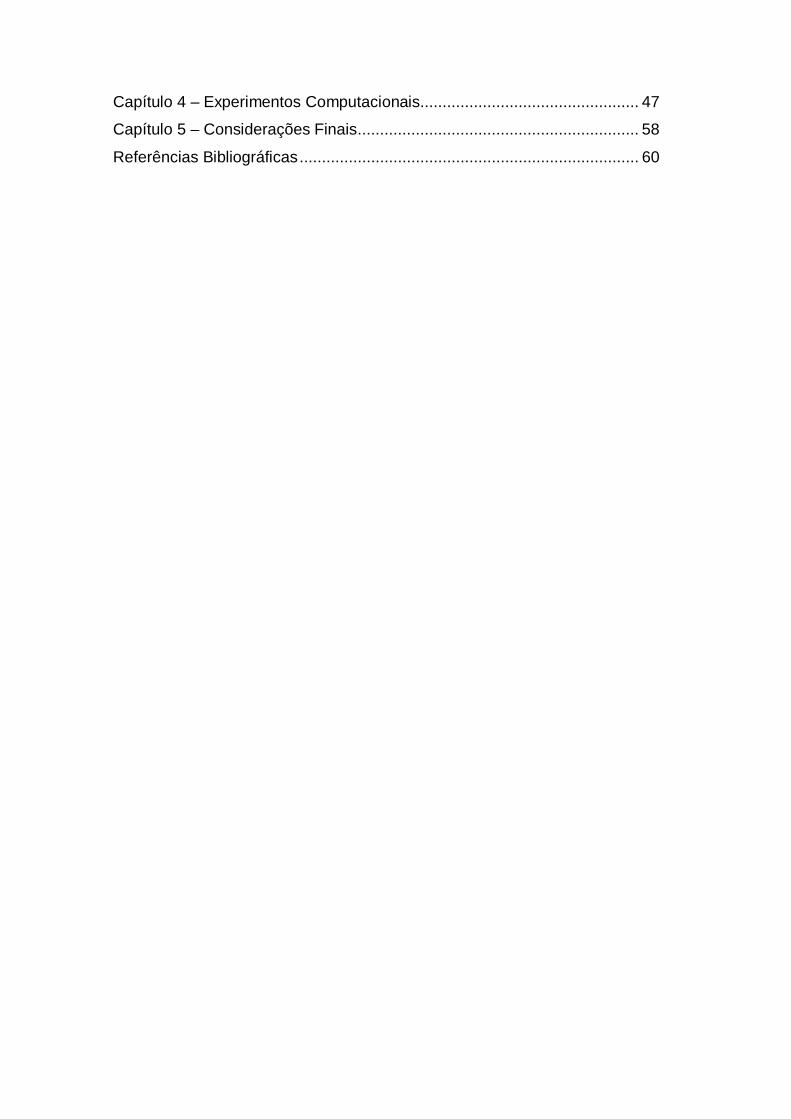
20
Assim, a proporção de partições não degeneradas de n registros em k
clusters é igual a
( , ) =( , )
. (1.3)
A proporção de partições não degeneradas ( , ) é relativamente alta
para k pequenos, diminuindo rapidamente com maiores valores de k para
aproximadamente 0%.
A Tabela 1.2 mostra diferentes instâncias para o número de vezes que
foram encontradas soluções degeneradas em 100 execuções distintas do
algoritmo k-means. A última coluna apresenta os casos nos quais o algoritmo foi
capaz de remover a degeneração automaticamente. As soluções iniciais foram
obtidas a partir de partições aleatórias de n registros entre os k clusters.
Tabela 1.2: Número de soluções degeneradas encontradas em 100 execuções
do k-means.
Instâncias Degeneração na solução
Resolvido pelo k-means
Eilon
(EILON, 1971) 50 5
10 15
17 90 100
17 83 2
Ruspini
(RUSPINI, 1970) 75 5
10 20
67 100 100
66 3 0
Iris
(BACHE; LICHMAN, 2013) 150 5
10 20
60 99 100
60 34 0
Wine
(BACHE; LICHMAN, 2013) 178
5 10 20
11 46 96
11 46 16
B-Câncer
(BACHE; LICHMAN, 2013) 699 5
10 20
0 73 98
0 73 98
Image Segmentation
(BACHE; LICHMAN, 2013) 2312 5
10 20
2 48 99
2 48 99
Fonte: Própria.
Na Tabela 1.2 as soluções iniciais aleatórias levam, muitas vezes, à
solução degenerada, especialmente quando a relação / é pequena. A última

21
coluna mostra que o algoritmo tem mais dificuldade para remover a degeneração
automaticamente na medida em que relação / diminui.
Como suposto pelas Equações 1.1, 1.2 e 1.3, observa-se na Tabela 1.3
que no conjunto de dados (usando a base de dados EILON) a distribuição de d
para diferentes valores de k tende a ter forma de uma senóide, semelhante à
distribuição normal. Cada linha representa o número de vezes que os valores
individuais de degeneração foram obtidos com 100 execuções do k-means.
Tabela 1.3: Distribuição do grau de degeneração obtida com 100 execuções do
k-means aplicado ao problema de 50 registros (EILON, 1971). Grau da degeneração ( )
k 0 1 2 3 4 5 6 7 8 9 4 100
8 100
12 69 25 6
16 12 34 34 18 2
20 2 7 22 35 26 7 1
24 5 23 24 22 14 6 5 1
28 4 17 20 24 20 12 3
32 3 14 16 26 22 12 6 1
36 1 3 12 22 34 18 9 1
40 6 13 16 36 20 8 1
44 1 1 12 32 47 7
48 18 82
Fonte: Própria.
Existem duas motivações relevantes para a realização desta pesquisa: 1ª)
Vários trabalhos utilizam métodos alternativos de clusterização como, por
exemplos, na logística (COOPER, 1964), na indústria de óleo (HAVERLY, 1978),
na neurociência (MAIRAL; BACH; PONCE, 2012) (MAK; WOLPAW, 2009) e no
marketing (BLANCHARD; ALOISE, 2012), sendo conhecidos por compartilhar a
lacuna de degeneração (BRIMBERG; MLADENOVI , 1999); 2ª) A questão da
degeneração poder ser considerada insignificante usando bons métodos de
inicialização (veja o artigo (CELEBI; KINGRAVI; VELA, 2013) para uma pesquisa
recente ou executar o k-means várias vezes. Muito dos melhores algoritmos

22
encontrados na literatura para o clustering usa o k-means como uma sub-rotina,
que é parte de uma estrutura maior de otimização (HANSEN; MLADENOVI ,
2001) (PACHECO; VALENCIA, 2003). Desse modo, ele pode ser iniciado com
todos os tipos de soluções, incluindo as degeneradas. Nesse cenário, as
soluções degeneradas podem levar a mínimos locais ruins ou até mesmo
comportamento anômalo.
1.1 Objetivos
Diante do exposto, novos métodos são propostos para remover a
degeneração na solução durante ou ao final da execução do algoritmo k-means.
Propomos uma nova estratégia chamada de First Improving e quatro novos
métodos com a finalidade de realizar uma extensa comparação das estratégias
para eliminar a degeneração e comparar os quatro novos métodos com três
métodos da literatura.
1.2 Organização do trabalho
Esta tese dividi-se em 5 Capítulos. O Capítulo 2 descreve a revisão da
literatura. O Capítulo 3 apresenta uma série de estratégias para remover a
degeneração no k-means, incluindo as quatro novas propostas. O Capítulo 4
apresenta os resultados experimentais que comparam as estratégias com
relação a sua eficiência e eficácia. E o Capítulo 5 finaliza a tese apresentando
as considerações finais acerca do desenvolvimento.

23
Capítulo 2 – Revisão da Literatura
2.1 Definições básicas As técnicas de agrupamento são usualmente classificadas em particional
e hierárquica (JAIN et al, 1999). Antes de apresentá-las vamos definir alguns
termos que serão usados posteriormente.
Na literatura de agrupamento de dados palavras diferentes podem ser
usadas para expressar sentidos semelhantes. Por exemplo, dado um banco de
dados que contém muitos registros o termo ponto de dados, observação, objeto,
item e entidade são todos utilizados para designar um único item. Nesta tese,
usaremos o termo registro. Para um registro com alta dimensão, o termo atributo
será usado para denotar um componente escalar individual (JAIN et al, 1999).
Matematicamente, um determinado conjunto de registros não rotulados é
dado por = { , , }, em que cada registro , = 1, é descrito por
(atributos ou características).
Na literatura, medidas de similaridade, medidas de dissimilaridade ou
distâncias são usadas para descrever quantitativamente a similaridade ou
dissimilaridade de dois registros. Considere dois registros de dados =
( , , … , ) e = ( , , … , ) , por exemplo. A distância Euclidiana ao
quadrado entre x e y é calculada como:
( , ) = ( ) .
Cada algoritmo de agrupamento é baseado no índice de similaridade ou
diissimilaridade entre os registros de dados (JAIN et al, 1999).
A similaridade é geralmente simétrica, ou seja, ( , ) = ( , ).
Medidas de similaridade assimétricas também foram discutidas em
(CONSTANTINE; GOWER, 1978).
Uma métrica de distância é uma função de distância definida em um
conjunto que satisfaz as seguintes propriedades (ANDERBERG; 1973):
1. Não negatividade: ( , 0;

24
2. Reflexividade: ( , ) = 0 = ;
3. Comutatividade: ( , ) = ( , );
4. Desigualdade triangular: ( , ) ( , ) + ( , ), em que , e são
registros arbitrários.
Geralmente, existem muitas outras estruturas de similaridade e de
dissimilaridade. Hartigan (1967) enumera 12 tipos de estruturas.
2.2 Algoritmos Hierárquicos de agrupamento
Desenvolvida inicialmente no campo da biologia (SOKAL; SNEAD, 1973),
essas técnicas ganharam popularidade devido sua versatilidade, simplicidade e
noção intuitiva de que graus relativos de semelhança entre os registros poderiam
ser visualizados em uma espécie de representação em árvore ou hierarquias.
Esses métodos hierárquicos produzem uma sucessão de partições, cada
qual correspondendo a uma diferente quantidade de clusters, sendo divididos
em técnicas aglomerativas e divisórias. A Figura 2.1 ilustra a forma como esses
dois métodos, o aglomerativo como um método de bottom/up e divisivos como
top/bottom, podem ser vistos.
Essas técnicas, por qualquer método de aglomeração ou de divisão,
produzem um dendrograma representado por um diagrama bidimensional que
ilustra as fusões ou divisões realizadas em cada nível. A Figura 2.2a mostra um
dendrograma formado a partir de um conjunto de dados com cinco registros com
duas dimensões (Figura 2.2b), e o eixo da ordenada representa a distância entre
os registros.
As técnicas aglomerativas operam, geralmente, sobre uma matriz de
similaridades ou dissimilaridades produzindo uma sequência de partições. O que
basicamente diferenciam os métodos é a escolha da métrica utilizada para a
fusão de agrupamentos a ser adotada ou o critério de união entre os
agrupamentos durante as sucessivas fusões, assim como são recalculadas as
distâncias entre um agrupamento formado a todos os outros restantes. O
procedimento geral pode ser descrito em poucos passos:
1. Cada cluster , , … , contém um único objeto;

25
2. Determine o par de cluster distinto , com maior (menor) grau
de similaridade (dissimilaridade);
3. Forma-se um novo cluster pela união dos clusters e , ou seja,
.
4. Calcula-se as novas medidas de similaridade (dissimilaridade) entre o
novo cluster e todos os outros restantes. Diminui-se o número total de
cluster em 1.
5. Os passos 2, 3 e 4 são executados 1) vezes até que todos os
registros estejam em um único cluster.
Figura 2.1: Agrupamento hierárquico aglomerativo e divisivo.
Fonte: Própria.
, , , ,
, ,
,
,
Agl
omer
ativ
o
Div
isiv
o

26
Figura 2.2: Dendrograma formado com um conjunto de cinco registros.
a) Dendrograma. b) conjunto de dados.
Fonte: Própria.
2.2.1 Ligação Simples
Conhecido como o método dos vizinhos mais próximos, ele é o mais
simples dentre os algoritmos aglomerativos, sendo caracterizado por considerar
a dissimilaridade entre dois clusters como a menor dissimilaridade entre cada
par de registros formado por um registro pertencente a e outro pertencente a
(FLOREK et al., 1951). Considere , e serem três clusters em um
conjunto de dados. A distância entre e pode ser obtida a partir da
fórmula de Lance Williams dada a seguir:
( , ) = min { ( , ), ( , )},
em que (. , . ) é a distância entre dois clusters. O algoritmo Single-Linkage é
descrito a seguir.
Algoritmo 2.1: Single-Linkage
Os agrupamentos são representados por número de sequências 0,1,2, ..., (
1).
( ) é o nível de agrupamento de ordem .
Um cluster com o número de sequência m é denotado ( ).
1. Comece com diferentes agrupamentos com o nível (0) = 0 e o número
de sequência = 0;
2. Encontre o par de registros mais próximo na matriz de distância.

27
3. Incremente = + 1. Junte os clusters e para formar o próximo
cluster . Defina o nível deste cluster para ( ) = ( , ).
4. Atualize a matriz de distância apagando as linhas e as colunas
correspondentes aos clusters e e adicione uma nova linha e coluna
correspondentes ao cluster recém formado. A distância entre o novo
cluster, denotado por , e o velho , é definido como ( , ) =
min { ( , ), ( , )}.
5. Caso todos os registros estejam atribuídos a um cluster pare. Do
contrário, volte para o passo 2.
O Algoritmo 2.1 cria o primeiro grupo unindo os dois registros mais
próximos. Na próxima fase, duas situações podem acontecer: ou um terceiro
registro se unirá ao cluster já formado ou outros dois registros que agora estão
mais próximos se unirão para formar o segundo cluster. Essa decisão é dita pelo
critério de distância mínima entre os registros dos clusters. O processo se repete
até que todos os registros pertençam a um só cluster.
2.2.2 Ligação Completa
O Complete Linkage segue a mesma forma do Single-Linkage, havendo
uma única diferença: a escolha da distância.
No algoritmo de Ligação Completa, a menor dissimilaridade entre dois
registros quaisquer de dois clusters determina a dissimilaridade entre esses
grupos.
Considere , e serem três clusters em um conjunto de dados. A
distância entre e pode ser obtida a partir da fórmula de Lance Williams
dada a seguir:
( , ) = max { ( , ), ( , )},
O algoritmo Complete Linkage é descrito a seguir.

28
Algoritmo 2.2: Complete Linkage
Os agrupamentos são representados por número de sequências 0,1,2, ..., (
1).
( ) é o nível de agrupamento de ordem .
Um cluster com o número de sequência m é denotado ( ).
1. Comece com diferentes agrupamentos com o nível (0) = 0 e o número
de sequência = 0;
2. Encontre o par de registros mais próximo na matriz de distância.
3. Incremente = + 1. Junte os clusters e para formar o próximo
cluster . Defina o nível deste cluster para ( ) = ( , ).
4. Atualize a matriz de distância apagando as linhas e colunas
correspondentes aos clusters e e adicione uma nova linha e coluna
correspondentes ao cluster recém formado. A distância entre o novo
cluster, denotado por , e o velho , é definido como ( , ) =
max { ( , ), ( , )}.
5. Caso todos os registros estejam atribuídos a um cluster pare. Do
contrário, volte para o passo 2.
2.2.3 Ligação Média
Também conhecido como Average Linkage, este algoritmo segue a
mesma forma de união dos métodos descritos anteriormente. Na Ligação Média,
a similaridade entre dois grupos é dada pela similaridade média entre todos os
registros dos dois grupos. Considere , e serem três grupos em um
conjunto de dados. A distância entre e pode ser obtida a partir da
fórmula de Lance Williams dada a seguir:
( , ) =| |
| | +( , ) +
| | +( , ),
em que (. , . ) é a distância entre dois clusters. O algoritmo Average Linkage é
uma variação do Single e Complete Linkage e será descrito a seguir.

29
Algoritmo 2.3: Average Linkage
Os agrupamentos são representados por número de sequências 0,1,2, ..., (
1).
( ) é o nível de agrupamento de ordem .
Um cluster com o número de sequência m é denotado ( ).
1. Comece com diferentes agrupamentos com o nível (0) = 0 e o número
de sequência = 0;
2. Encontre o par de registros mais próximo na matriz de distância.
3. Incremente = + 1. Junte o cluster e para formar o próximo
cluster . Defina o nível deste cluster para ( ) = ( , ).
4. Atualize a matriz de distância apagando as linhas e colunas
correspondentes aos clusters e e adicione uma nova linha e coluna
correspondentes ao cluster recém formado. A distância entre o novo
cluster, denotado por , e o velho , é definido como
( , ) = | || |
( , ) +| |
( , ).
5. Caso todos os registros estejam atribuídos a um cluster pare. Do
contrário, volte para o passo 2.
2.2.4 Ward
O método Ward propõe que os agrupamentos sejam formados com o
objetivo de minimizar (WARD, 1963) a variância (perda da informação) ou a
soma dos quadrados dos desvios (ou distâncias) em relação a média dentro dos
grupos.
Normalmente, a perda da informação é qualificada em termos da soma
dos quadrados dos erros (SQE). O algoritmo Ward é dado a seguir.
Algoritmo 2.4: Ward
1. Atribui-se cada registro como um cluster;
2. Repita os seguintes passos até que a quantidade desejada de clusters
seja obtida:

30
a. Junte os dois clusters mais próximos respeitando-se a
variância;
b. Calcule a distância deste novo cluster para todos os outros
clusters seguindo a fórmula ( , ) = ( , ) +
( , ( , ), em que e são os dois
clusters que acabaram de serem unidos, é o número de
elementos do cluster , e ( , ) a distância entre os clusters
e .
2.3 Algoritmos Particionais
Esses métodos produzem uma partição de registros em vários
agrupamentos. Em muitas situações, esses registros podem ser considerados
como registros no espaço euclidiano.
Muitos são os critérios usados na literatura para expressar
homogeneidade e/ou separação dos clusters procurados (HANSEN; BRIGITTE,
1997). Entre eles, um dos mais utilizados é a soma mínima das distâncias
euclidianas quadráticas de cada registro para o centro do cluster ao qual
pertence, também conhecido como Minimum sum-of-squares clustering (MSSC).
Uma formulação matemática do MSSC é dada a seguir:
min,
(2.1)
sujeito a,
= 1, = 1,2, … , (2.2)
{0,1}, = 1,2, … , ; = 1,2, … , .
Os dados numéricos com registros são representados por registros =
( , = 1, … , ) em para = 1, … , ; centros de cluster devem estar
localizados em registros desconhecidos , para = 1,2, … , . A norma
indica a distância euclidiana ao quadrado entre os dois registros em seu
argumento considerando um espaço euclidiano com -dimensão. As variáveis

31
de decisão binárias expressam a atribuição do registro ao cluster , cujo
conjunto de restrições (2.2) garante que cada registro , = 1, … , seja atribuído
a exatamente um cluster.
Em dimensões gerais, o MSSC é NP-hard, mesmo para = 2 (ALOISE
et al., 2009), e conhecido como o problema enfrentado pelo clássico k-means
(MACQUEEN, 1967).
A heuristica k-means faz uso do MSSC aproveitando as seguintes
propriedades:
i. Se é fixo, a condição {0,1} pode ser modificada por
[0,1], uma vez que em uma solução ideal para o problema
resultante cada registro pertence ao cluster com o centro mais
próximo;
ii. Para um fixo, as condições de primeira ordem sobre o gradiente
da função objetivo requerem que em uma solução ótima os
centros de cluster correspondam sempre aos centros dos clusters
dados por:
= 0, , , ,
= , . (2.3)
A partir de uma partição inicial, o k-means procede através da readmissão
de registros ao seu centro mais próximo e atualiza suas posições até que a
estabilidade seja alcançada, ou seja, alternadamente o algoritmo aplica as
propriedades (i) e (ii) até que um mínimo local seja atingido.
O k-means faz parte dessa classe de técnicas e busca minimizar o erro
quadrático de registros em relação aos centros de seus grupos, conforme
exposto no Capítulo 1. Outro representante é o k-medoid (PARK; JUN, 2009),
que utiliza a mediana dos elementos em um grupo como ponto de referência,
denominado medóide. Esta estretégia será apresentada na próxima seção.

32
2.3.1 k-medoids
Esta estratégia utiliza o conceito de medóide descrevendo-o da seguinte
maneira: dado um conjunto de registros com atributos e fixando um número
de clusters deve-se selecionar, dentre os registros, registros denominados
medóides. Os demais registros serão alocados ao medóide correspondente mais
próximo, segundo uma medida de distância. Dessa forma, busca-se a
determinação dos medóides de forma que a soma das distâncias dos demais
registros ao seu respectivo medóide seja a menor possível. Na pesquisa
operacional, este problema é conhecido como p-mediana (REESE, 2006).
Alguns autores propuseram estratégias para selecionar os medóides.
Kaufman e Rousseeuw (1989) proporam o algoritmo PAM (Partitioning Around
Medoids). Em linhas gerais, esta heurística efetua a construção de
agrupamentos mediante a aplicação de dois procedimentos determinísticos,
quais sejam: Build e Swap. O primeiro é responsável pela construção de uma
solução viável. E o segundo tem caráter similar ao de uma busca local que atua
sobre a solução produzida pelo procedimento Build. Em Park e Jun (2009), foi
apresentado um algoritmo para o k-medoids que utiliza algumas ideias do
algoritmo k-means.
2.3.2 Variações do k-means
Muitos dos algoritmos de agrupamento originários do algoritmo k-means
são apresentados em (FABER, 1994), (BRADLEY; FAYYAD, 1998), (ALSABTI
et al., 1998), e (BOTTOU; BENGIO, 1995). Estes algoritmos foram desenvolvidos
para melhorar o desempenho do clássico algoritmo k-means.
Faber (1994) propôs o contínuo k-means, que tem os seguintes aspectos:
primeiramente, os registros de referência são escolhidos como uma amostra
aleatória de toda a base de dados; em segundo lugar, os registros dos dados
são tratados de forma diferente. Durante cada iteração, o contínuo k-means
examina apenas uma amostra de registros dos dados, enquanto que o k-means
padrão analisa todos.

33
O algoritmo sort-means foi proposto por Phillips (2004). Nele, as médias
são ordenadas por ordem de aumento da distância a partir de cada média a fim
de obter um aumento de velocidade.
Anteriormente, apresentamos alguns métodos objetivando melhorar o
desempenho do algoritmo k-means. Além dos supramencionados, várias outras
extensões do k-means padrão são propostas com o intuito de melhorar a
velocidade e a qualidade do algoritmo. Na próxima seção, será apresentado
outros métodos baseados na inicialização dos centros.
2.4 Métodos de inicialização dos centros
O algoritmo k-means apresenta alguns inconvenientes. Em particular, seu
desempenho depende da inicialização dos centros. Como resultado, alguns
métodos para a seleção de bons centros iniciais são propostos, conforme
descritos a seguir.
2.4.1 Forgy
O método de Forgy (1965) atribui aleatoriamente cada registro para um
dos clusters. Os centros são dados pelos centróides destes grupos iniciais.
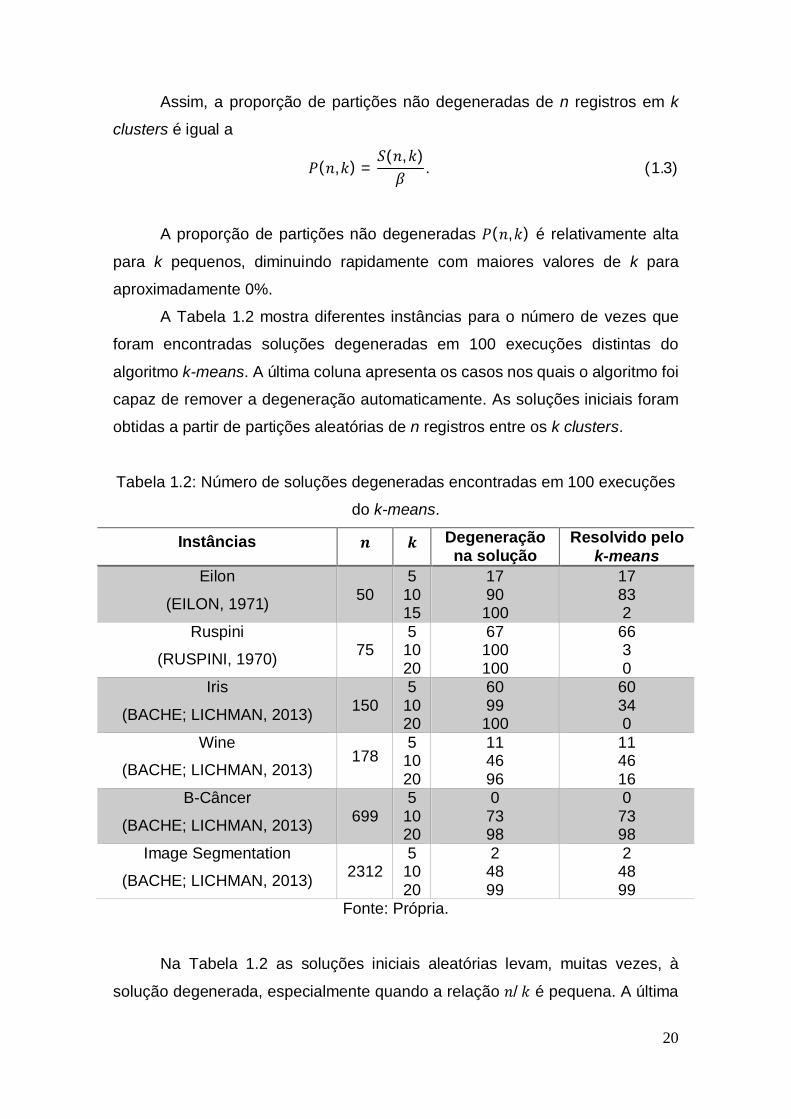
2.4.2 k-means++
O algoritmo foi desenvolvido por Arthur e Vassilvitsskii (2007), tendo como
ideia principal a implementação do método de inicialização dos centros, que é
encontrar os melhores centros antes de aplicar o k-means tradicional. O método
faz o seguinte procedimento:
Algoritmo 2.5: k-means++
1. Pega-se o primeiro centro, , escolhido aleatoriamente do conjunto de
registros ;
2. Pega-se um novo centro , escolhendo com probabilidade ( )
( ), no qual ( ) é a distância mais próxima do registro para
os centros previamente selecionados;
34
3. Volta-se para 2 até que se tenha encontrado todos os centros;
4. Executa-se o k-means normalmente.
A Figura 2.3 ilustra o funcionamento do método de inicialização dos
centros no k-means++. Nesse exemplo, considera-se apenas 9 registros, no qual
o algoritmo tem que encontrar os três melhores centros ( = 3). O primeiro
centro, , escolhido aleatoriamente, é o registro com coordenada (3,6). Em
seguida, calcula-se a distância dos 8 registros restantes em relação ao primeiro
centro. O registro mais distante de provavelmente será aquele com
coordenada (5,1), escolhido e chamado de . O terceiro centro a ser escolhido
será selecionado de modo que os itens dos dados com valores das distâncias
ao quadrado tenham baixa probabilidade de seleção e os registros de dados com
grandes valores de distância ao quadrado tenham elevada probabilidade de
serem selecionados. Portanto, provavelmente o será o novo centro com a
coordenada (8,4).
Figura 2.3: Exemplo de mecanismo de inicialização do k-means++ para = 3.
Fonte: Própria.
Provável centro

35
2.4.3 R-Ward
Este método consiste nos seguites passos:
Algoritmo 2.6: R-Ward
1. Defina cada registro como um cluster;
2. Repita os seguintes passos até que a quantidade desejada de clusters
seja obtida:
a. Junte os dois clusters mais próximos;
b. Calcule a distância deste novo cluster para todo os outros clusters
seguindo a fórmula: , = ( , ) +
, , , em que e são os dois
clusters que acabaram de serem unidos, é o número de
elementos do cluster e ( , ) é a distância entre os clusters
e .
Em (HELSEN; GREEN, 1991), os autores tomam uma amostra aleatória
do conjunto de dados e aplicam o algoritmo R-Ward nesta amostra (por exemplo,
10%, 20% e 30% do total de registros). Eles fazem isso várias vezes com
diferentes amostras objetivando obter diferentes resultados ao final do k-means.
Dependendo da inicialização, o k-means pode levar a grupos vazios. Em outras
palavras, uma melhor solução na próxima iteração do algoritmo pode ser
encontrada, mas com um menor número de clusters.
Essas soluções podem ser facilmente melhoradas pela adição de um
novo centro na posição de qualquer registro existente, desde que não seja o
centro de outro cluster. O próximo capítulo apresenta as nossas estratégias para
a remoção da degeneração.
2.4.4 Algoritmo m_k-means
Esse algoritmo foi proposto por Pakhira (2009) e elimina clusters vazios.
O algoritmo m_k-means utiliza a seguinte expressão para atualizar os centros:

36
( ) =1+ 1 ( + ( )) , (2.4)
em que é o número de registros do cluster . A equação 2.4 indica que cada
cluster deve conter sempre pelo menos um registro. As etapas de execução do
algoritmo são descritas a seguir.
Algoritmo 2.7: m_k-means
Entradas: conjunto de registros , número de clusters k.
1. Escolher aleatoriamente k registros .
2. Repete:
a. Calcule a distância entre os centros e os registros;
b. Calcule os novos centros usando a equação 2.4;
c. Atribua cada registro ao seu respectivo centro;
d. Calcule os novos centros dos clusters.
3. Enquanto não houver variação dos clusters.

37
Capítulo 3 – Estratégias para remover a degeneração Neste capítulo são apresentados seis métodos para remover a
degeneração na execução do algoritmo k-means. As duas primeiras são
utilizadas na literatura e as demais propostas nesta tese.
Duas estratégias são usadas para executar os métodos que removem a
degeneração na execução do k-means, quais sejam: First Improving e Last
Improving. A nova estratégia First Improving executa o método para remover a
degeneração sempre que surgir clusters vazios, ou seja, a cada iteração um
método é chamado para corrigi-la. Na estratégia Last Improving (BRIMBERG;
MLADENOVI , 1999), o k-means é executado até o fim. Caso exista um cluster
vazio, o método é chamado para corrigir e em seguida o algoritmo é novamente
executado. Essas duas estratégias são descritas em detalhes no Algoritmo 3.1
e 3.2, respectivamente.
Na linha 3.d do Algoritmo 3.1, a função Grau() verifica se houve alguma
degeneração e retorna zero caso não encontre nenhuma. Do contrário, ela volta
e em seguida chama o método para removê-lo (linha 3.e.i), e o procedimento é
repetido.
Algoritmo 3.1: First Improving
1. Os centros são escolhidos aleatoriamente;
2. w = true;
3. Enquanto w faça:
a. Calcule a distância entre os centros e os registros;
b. Atribua cada registro ao seu respectivo centro;
c. Calcule os novos centros;
d. gr = Grau();
e. if (gr != 0);
i. Chama o método para remover a degeneração de grau d;
f. if (os grupos se estabilizaram);
i. w = false.
4. Fim Enquanto.

38
No Algoritmo 3.2, o k-means é executado normalmente até o final.
Havendo degeneração ele é consertado, novamente executado e resumido em
duas estruturas de repetição. Na linha f.i um Flag é utilizado para verificar se
houve degeneração. A função Grau() (linha f) retorna o zero se não houver
degeneração, caso contrário retorna o grau e modifica o Flag e, em seguida, um
método é chamado para remover a degeneração.
Algoritmo 3.2: Last Improving
1. Os centros são escolhidos aleatoriamente;
2. Flag = true;
3. Enquanto Flag faça:
a. Flag = false;
b. w = true;
c. Enquanto w faça:
i. Calcule a distância entre os centros e os dados;
ii. Atribua cada registro ao seu respectivo centro;
iii. Calcule os novos centros;
iv. if (os grupos se estabilizaram).
1. w = false.
d. Fim Enquanto;
e. gr = Grau();
f. if (gr != 0);
i. Flag = true;
ii. Chama o método para remover a degeneração de grau d.
4. Fim Enquanto.
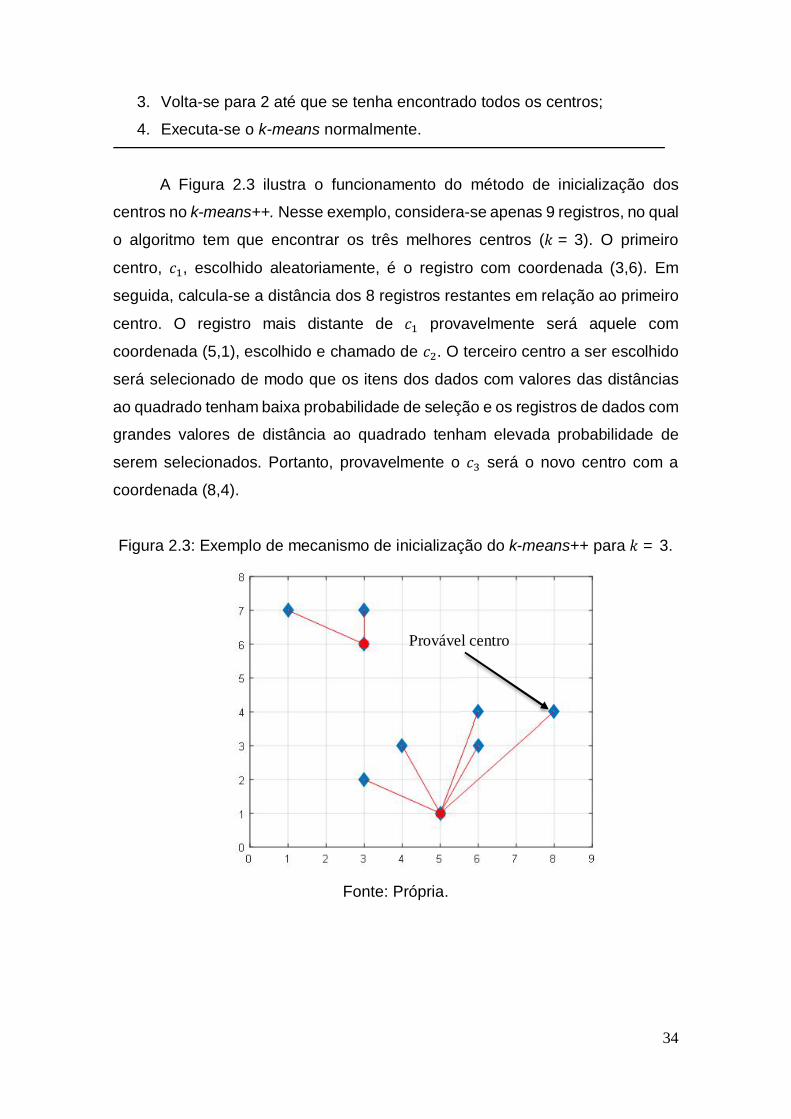
3.1 Random Esse método consiste em selecionar novos centros aleatoriamente a
partir dos registros e foi proposto por (BRIMBERG; MLADENOVI , 1999) para o
problema multi-source Web.
A Figura 3.1 mostra a iteração do k-means depois que o método Random
é aplicado. O centro (símbolo ‘x’ de cor ciano) foi escolhido casualmente (Figura
3.1b), e em seguida os registros atribuídos aos centros e atualizados (Figura 3.1c
39
e 3.1d, respectivamente). Todos os exemplos ilustrados neste Capítulo são
apresentados utilizando a base de dados sintética (Tabela 1.2), e os centros
iniciais são os registros , , e .
Figura 3.1: Ilustra o método Random.
a) Inicialização dos centros. b) O centro escolhido aleatoriamente.
c) Os registros são atribuídos aos centros. d) Os centros são atualizados.
Fonte: Própria.
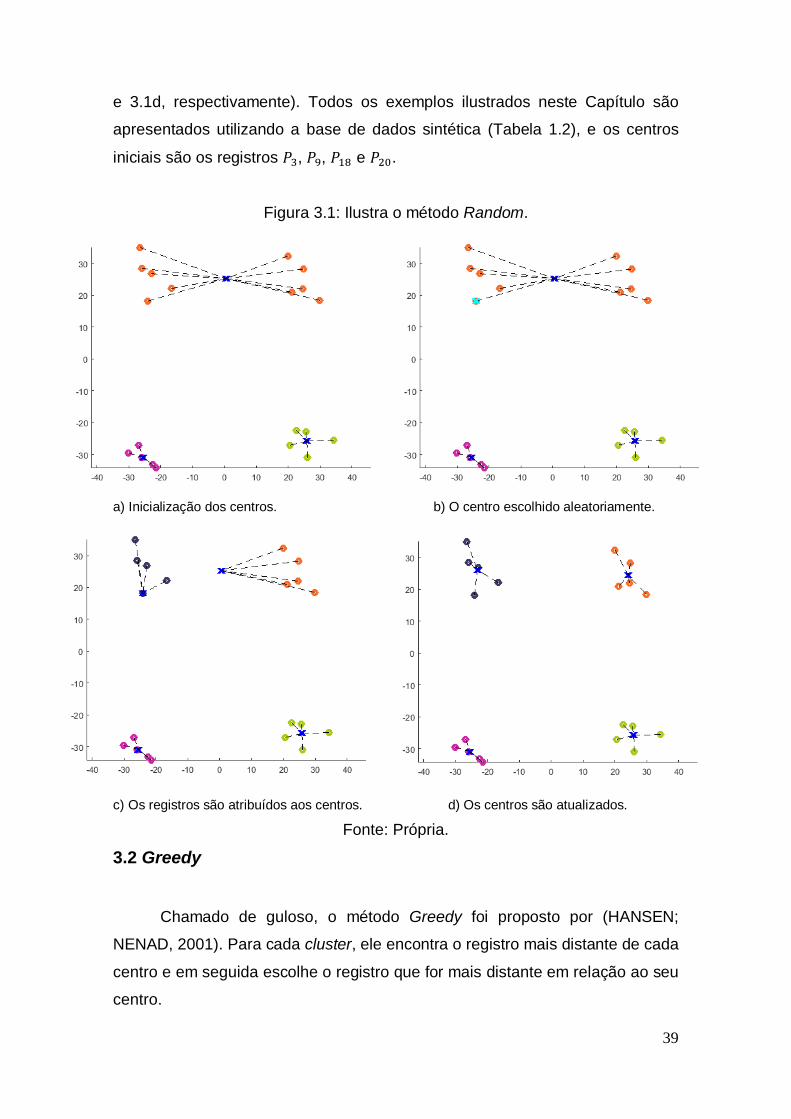
3.2 Greedy Chamado de guloso, o método Greedy foi proposto por (HANSEN;
NENAD, 2001). Para cada cluster, ele encontra o registro mais distante de cada
centro e em seguida escolhe o registro que for mais distante em relação ao seu
centro.

40
A Figura 3.2a apresenta apenas três clusters. Na Figura 3.2b o cluster
laranja apresenta o registro (símbolo ‘x’ de cor ciano) mais distante em relação
ao centro. Em seguida, são atribuídos os registros em relação aos seus
respectivos centros (Figura 3.2c) e atualizados.
Figura 3.2: Ilustra o método Greedy.
centros (Figura 4.2d).
a) Degeneração com três clusters. b) Registro mais distante do cluster. c) Os registros são atribuídos aos centros. d) Os centros são atualizados.
Fonte: Própria.
3.3 -Random Este método é semelhante ao Random. No entanto, ele utiliza uma
perturbação dada por , cujo procedimento executa dois passos:
Escolhe aleatoriamente um centróide a partir da solução;

41
Em seguida a nova coordenada do centróide é perturbada de a partir
de .
Com esse procedimento, o + ou – tem 50% de probabilidade. No exemplo
apresentado nesta seção (Figura 3.3), utilizou-se um = 3 apenas para fins
ilustrativos. A Figura 3.3a apresenta apenas três clusters. Em seguida, o cluster
verde claro foi escolhido aleatoriamente e o novo centro selecionado (o centro
marcado com um símbolo ‘x’ de cor amarelo).
3.4 - Greedy Neste método, os novos centros são obtidos a partir dos centros dos
grupos, tendo os maiores valores de MSSC. Com esse procedimento é realizada
a divisão de grandes clusters que talvez sejam menos homogêneos. Além disso,
a perturbação com o para gerar os novos centros não é feita aleatoriamente,
mas na direção do registro mais distante em relação ao centro selecionado.
Denota-se como o centro do cluster com maior MSSC e como o
registro mais distante em relação a . As coordenadas do novo centro são
dadas por
= + ( ) (3.1)
Na prática, é um número muito pequeno. A Figura 3.4 ilustra a aplicação
do método para = 0.2 (apenas para fins de esclarecimentos). O cluster laranja
é escolhido por ter o maior MSSC (Figura 3.4b). Em seguida é gerado novo
registro e deslocado com (registro com símbolo ‘x’ de cor ciano). Na Figura
3.4c os registros são atribuídos e na Figura 3.4d os centros são atualizados.

42
Figura 3.3: Ilustra o método -Random com = 3.
a) Cluster degenerado. b) Cluster escolhido aleatoriamente com épsilon
c) Atribuição dos registros. d) Atualização dos centros com quatro clusters.
Fonte: Própria.

43
Figura 3.4: Ilustra o método Greedy.
a) Um centro foi degenerado. b) Maior custo e deslocado com o épsilon.
c) Atribuição dos registros aos centros. d) Atualização dos centróides.
3.5 Mixed Este método mescla os dois métodos anteriores. Primeiramente é feita
uma decisão gulosa sobre a seleção do cluster com maior MSSC, como
apresentado pelo método Greedy. Em seguida, aplicada uma perturbação
aleatória de ± , como descrito no método . Na Figura 3.5b, o centro
do cluster (símbolo ‘x’ de cor amarelo) é deslocado (o símbolo ‘x’ de cor ciano)
com = 3.
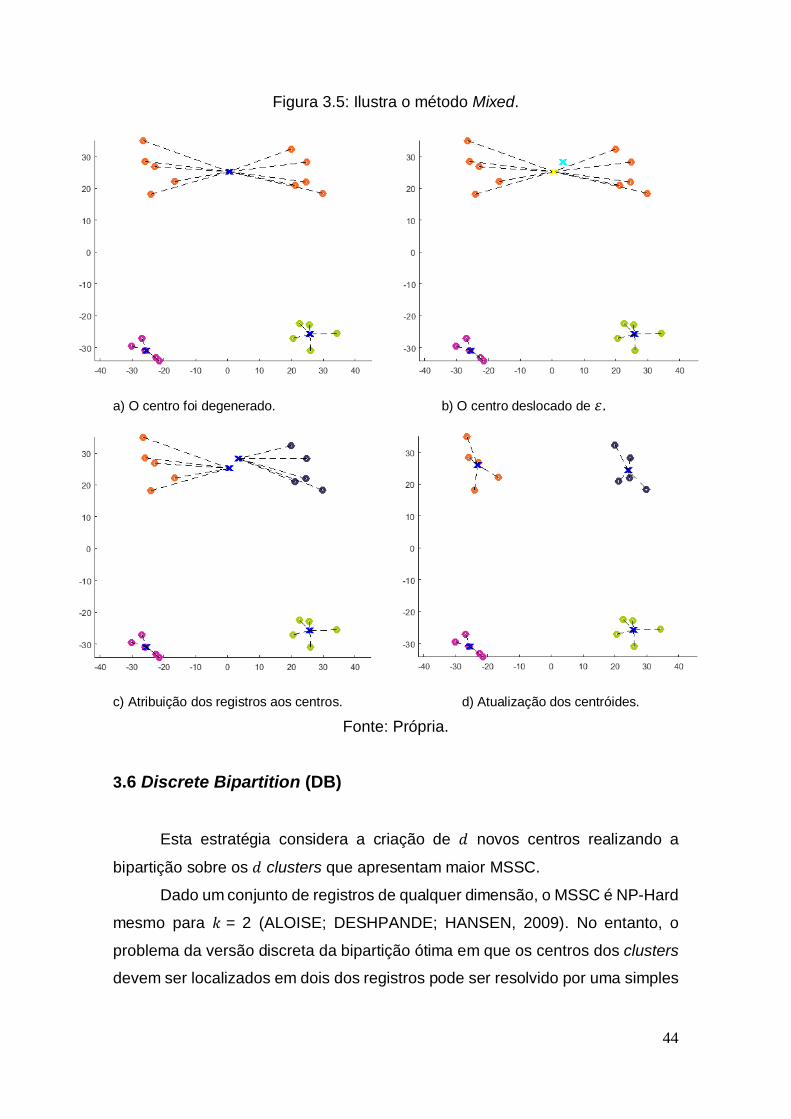
44
Figura 3.5: Ilustra o método Mixed.
a) O centro foi degenerado. b) O centro deslocado de .
c) Atribuição dos registros aos centros. d) Atualização dos centróides.
Fonte: Própria.
3.6 Discrete Bipartition (DB)
Esta estratégia considera a criação de novos centros realizando a
bipartição sobre os clusters que apresentam maior MSSC.
Dado um conjunto de registros de qualquer dimensão, o MSSC é NP-Hard
mesmo para = 2 (ALOISE; DESHPANDE; HANSEN, 2009). No entanto, o
problema da versão discreta da bipartição ótima em que os centros dos clusters
devem ser localizados em dois dos registros pode ser resolvido por uma simples

45
enumeração. Uma implementação simples em tempo ( ) com distâncias pré-
calculadas entre cada par de registros é dada pelo Algoritmo 3.3.
Algoritmo 3.3: Discrete Bipartition (DB)
Entrada: cluster composto por = { , , … , | |}.
Define-se ( , ) o custo MSSC de partição com os centros dos grupos
localizados em e .
Define-se o custo MSSC das melhores bipartições encontrado até
o momento.
1 2 Para = 1, … , | | 1 faça 3 Para = + 1, … , | | faça 4 Para = 1, … , | | faça 5 Se então 6 Atribua para o centro do grupo ; 7 Se não 8 Atribua para o centro do grupo ; 9 Fim Para 10 Se ( ( , ) < ) então 11 ( , ); 12 ; ; 13 Fim Se 14 Fim Para 15 Fim Para 16 Execute a bipartição associada a e .
A Figura 3.6 mostra a iteração do k-means depois que surge uma solução
degenerada. Em seguida, o método DB é aplicado. Observa-se que os dois
centros encontrados estão marcados com símbolo ‘x’ de cor ciano (Figura 3.6b).
Na Figura 3.6c todos os registros são atribuídos aos seus centros. E na Figura
3.6d os centros são atualizados.

46
Figura 3.6: Ilustra o método DB.
a) Centro degenerado. b) Os dois registros são selecionados.
c) Atribuição dos registros aos centros. d) Atualização dos centróides.
Fonte: Própria.

47
Capítulo 4 – Experimentos Computacionais Neste capítulo será apresentado uma série de experimentos que utilizam
diversos métodos descritos nas seções anteriores. As instâncias utilizadas são
apresentadas na Tabela 4.1 e foram escolhidas por ser umas das mais utilizadas
em análise de clustering (Iris, Wine, B-Câncer e Image Segmentation). Além
disso, os artigos de estado da arte sobre o estudo da degeneração utilizam as
instâncias Eilon e Ruspini.
Tabela 4.1: Instâncias utilizadas para os experimentos.
Instâncias Dimensão
Eilon (EILON, 1971) 50 2
Ruspini (RUSPINI, 1970) 75 2
Iris (BACHE; LICHMAN, 2013) 150 4
Wine (BACHE; LICHMAN, 2013) 178 14
B-Câncer (BACHE; LICHMAN, 2013) 699 10
Image Segmentation (BACHE; LICHMAN, 2013)
2312 19
Fonte: Própria.
Nos próximos experimentos são considerados 20 diferentes execuções
do k-means de soluções iniciais conhecidas por levar a solução degenerada.
Elas são movidas a partir de partições aleatórias de registros disponíveis em
clusters. Os códigos foram implementados em ambiente Matlab e disponíveis
para download no endereço eletrônico: http://ncdd.com.br. E os testes realizados
em um computador com processador Xeon (R) CPU X5650 2.67GHz e 62GB de
memória RAM.
A Tabela 4.2 reporta os resultados quanto a aplicação do algoritmo k-
means. Ela serve como referência para os resultados apresentados nas
próximas tabelas. Em relação às 20 execuções, a coluna avg. sol. relata a média
das soluções obtida em cada caso, ao passo que a coluna iter apresenta o
número médio de iterações do k-means; a coluna time é o tempo médio em
segundos e; a coluna faz referência ao grau máximo de degeneração
observado em 20 execuções diferentes do algoritmo acima citado.
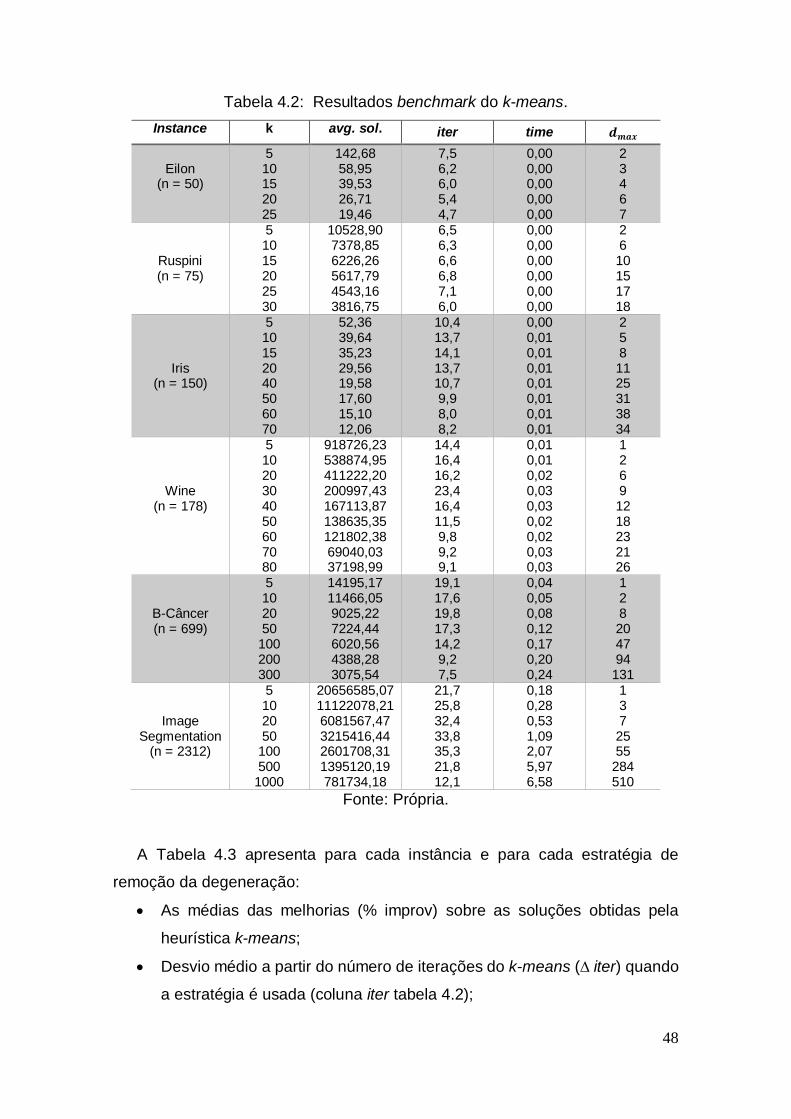
48
Tabela 4.2: Resultados benchmark do k-means. Instance k avg. sol. iter time
Eilon
(n = 50)
5 10 15 20 25
142,68 58,95 39,53 26,71 19,46
7,5 6,2 6,0 5,4 4,7
0,00 0,00 0,00 0,00 0,00
2 3 4 6 7
Ruspini (n = 75)
5 10 15 20 25 30
10528,90 7378,85 6226,26 5617,79 4543,16 3816,75
6,5 6,3 6,6 6,8 7,1 6,0
0,00 0,00 0,00 0,00 0,00 0,00
2 6 10 15 17 18
Iris (n = 150)
5 10 15 20 40 50 60 70
52,36 39,64 35,23 29,56 19,58 17,60 15,10 12,06
10,4 13,7 14,1 13,7 10,7 9,9 8,0 8,2
0,00 0,01 0,01 0,01 0,01 0,01 0,01 0,01
2 5 8 11 25 31 38 34
Wine (n = 178)
5 10 20 30 40 50 60 70 80
918726,23 538874,95 411222,20 200997,43 167113,87 138635,35 121802,38 69040,03 37198,99
14,4 16,4 16,2 23,4 16,4 11,5 9,8 9,2 9,1
0,01 0,01 0,02 0,03 0,03 0,02 0,02 0,03 0,03
1 2 6 9 12 18 23 21 26
B-Câncer (n = 699)
5 10 20 50
100 200 300
14195,17 11466,05 9025,22 7224,44 6020,56 4388,28 3075,54
19,1 17,6 19,8 17,3 14,2 9,2 7,5
0,04 0,05 0,08 0,12 0,17 0,20 0,24
1 2 8 20 47 94
131
Image Segmentation
(n = 2312)
5 10 20 50
100 500
1000
20656585,07 11122078,21 6081567,47 3215416,44 2601708,31 1395120,19 781734,18
21,7 25,8 32,4 33,8 35,3 21,8 12,1
0,18 0,28 0,53 1,09 2,07 5,97 6,58
1 3 7 25 55
284 510
Fonte: Própria.
A Tabela 4.3 apresenta para cada instância e para cada estratégia de
remoção da degeneração:
As médias das melhorias (% improv) sobre as soluções obtidas pela
heurística k-means;
Desvio médio a partir do número de iterações do k-means ( iter) quando
a estratégia é usada (coluna iter tabela 4.2);

49
O grau máximo de degeneração ( ) encontrado como resultado de 20
execuções do k-means com inicialização aleatória;
Tempo de processamento médio ( time - em segundos) gasto pelo k-
means quando a estratégia é aplicada (coluna time da tabela 4.2).
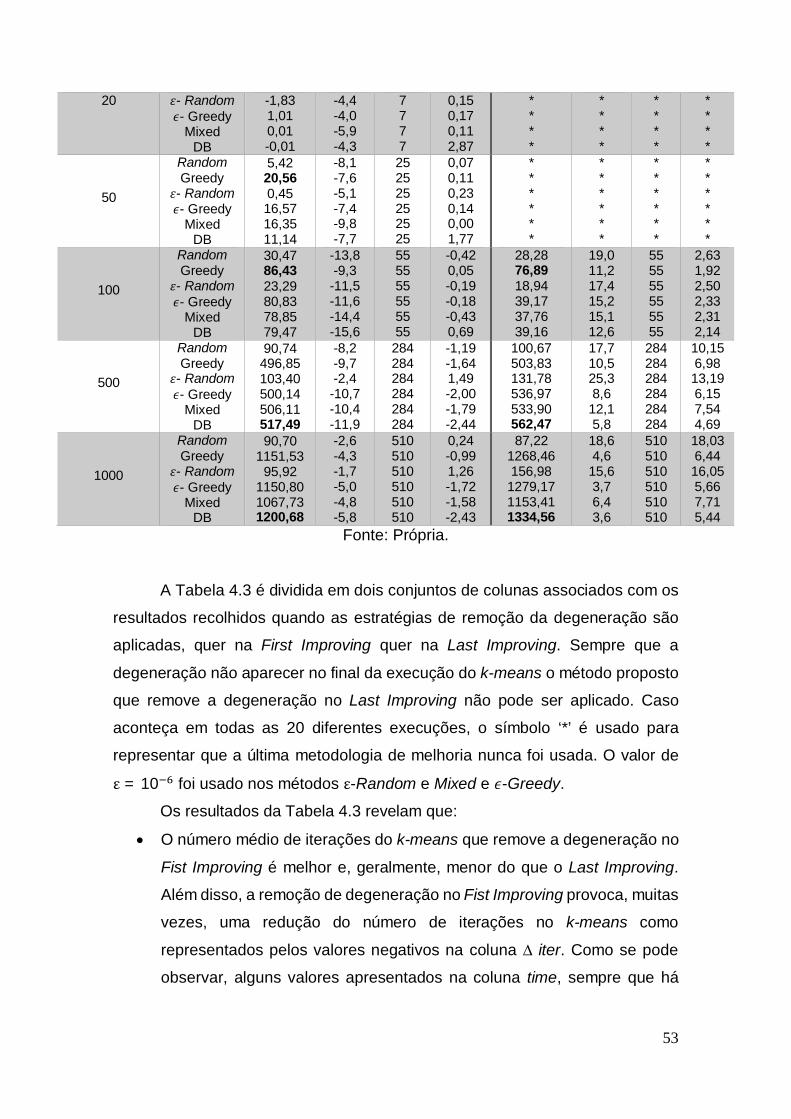
Tabela 4.3: Comparação entre os seis métodos para remover a degeneração. First Improving Last Improving
k strategy %improv Iter time %improv. Iter
time (a) Eilon
5
Random Greedy
- Random - Greedy Mixed
DB
0,24 3,89 -1,34 6,67 4,94 6,31
-0,5 -0,0 -0,8 -1,3 -1,5 -1,5
2 2 2 2 2 2
0,00 0,00 0,00 0,00 0,00 0,00
* * * * * *
* * * * * *
* * * * * *
* * * * * *
10
Random Greedy
- Random - Greedy Mixed
DB
0,83 3,11 0,36 4,57 3,39 3,97
0,8 -0,4 0,1 -0,5 -0,4 -0,7
3 3 3 3 3 3
0,00 0,00 0,00 0,00 0,00 0,00
2,28 2,73 0,52 2,26 2,26 2,26
0,7 0,3 0,2 0,2 0,2 0,2
3 3 3 3 3 3
0,00 0,00 0,00 0,00 0,00 0,00
15
Random Greedy
- Random - Greedy Mixed
DB
17,46 18,70 16,20 23,16 22,47 26,02
0,2 -0,2 -0,2 -0,7 -0,5 -0,7
4 4 4 4 4 4
0,00 0,00 0,00 0,00 0,00 0,00
14,00 20,89 9,04 29,86 27,84 31,94
2,4 1,7 1,6 1,6 1,6 1,7
4 4 4 4 4 4
0,00 0,00 0,00 0,00 0,00 0,00
20
Random Greedy
- Random - Greedy Mixed
DB
32,84 34,07 25,09 47,55 51,39 50,55
-0,1 -0,8 -0,1 -0,9 -0,8 -1,0
6 6 6 6 6 6
0,00 0,00 0,00 0,00 0,00 0,00
25,36 58,97 16,52 65,03 65,19 64,49
2,7 2,0 1,9 1,9 2,0 1,9
6 6 6 6 6 6
0,00 0,00 0,00 0,00 0,00 0,00
25
Random Greedy
- Random - Greedy Mixed
DB
50,32 110,09 31,71
100,81 106,04 105,80
0,7 -0,7 -0,4 -0,5 -0,4 -0,7
7 7 7 7 7 7
0,00 0,00 0,00 0,00 0,00 0,00
39,94 137,12 32,82
119,54 112,39 118,85
3,5 2,0 2,0 2,0 2,0 2,0
7 7 7 7 7 7
0,00 0,00 0,00 0,00 0,00 0,00
(b) Ruspini
5
Random Greedy
- Random - Greedy Mixed
DB
-30,48 -3,79 -48,18 -5,69 -5,62 -4,20
-0,3 -0,8 -0,5 -1,2 -1,2 -1,2
2 2 2 2 2 2
0,00 0,00 0,00 0,00 0,00 0,00
* * * * * *
* * * * * *
* * * * * *
* * * * * *
10
Random Greedy
- Random - Greedy Mixed
DB
21,36 35,44 17,53 42,78 43,03 43,35
1,0 0,0 1,1 -0,2 0,0 -1,0
6 6 6 6 6 6
0,00 0,00 0,00 0,00 0,00 0,00
28,36 41,32 29,18 47,18 49,27 49,41
4,0 3,0 3,8 2,6 2,3 2,0
6 6 6 6 6 6
0,00 0,00 0,00 0,00 0,00 0,00
Random Greedy
67,09 94,15
1,0 -0,8
10 10
0,00 0,00
73,07 121,85
4,9 3,1
10 10
0,00 0,00

50
15
- Random - Greedy Mixed
DB
39,11 107,08 104,62 113,50
0,2 -1,5 -0,4 -1,8
10 10 10 10
0,00 0,00 0,00 0,00
63,67 114,04 112,27 117,52
4,0 2,1 2,3 2,0
10 10 10 10
0,00 0,00 0,00 0,00
20
Random Greedy
- Random - Greedy Mixed
DB
125,81 176,79 100,08 172,55 156,27 172,16
-0,1 -1,5 -0,1 -2,1 -1,3 -2,5
15 15 15 15 15 15
0,00 0,00 0,00 0,00 0,00 0,00
121,81 182,78 87,93
175,64 161,46 176,75
6,1 2,6 4,2 2,5 3,4 2,1
15 15 15 15 15 15
0,01 0,00 0,01 0,00 0,01 0,00
25
Random Greedy
- Random - Greedy Mixed
DB
159,11 219,13 101,99 214,08 202,36 223,72
-0,3 -1,9 -0,6 -2,0 -1,7 -2,8
17 17 17 17 17 17
0,00 0,00 0,00 0,00 0,00 0,00
138,06 239,06 125,01 217,77 200,38 232,33
6,2 3,0 4,8 2,6 3,3 2,1
17 17 17 17 17 17
0,01 0,01 0,01 0,01 0,01 0,00
30
Random Greedy
- Random - Greedy Mixed
DB
182,47 297,37 115,42 260,45 257,00 285,63
0,7 -1,2 -0,1 -1,3 -0,8 -1,6
18 18 18 18 18 18
0,00 0,00 0,00 0,00 0,00 0,00
173,18 311,88 139,44 270,44 265,27 305,08
6,1 2,9 5,1 2,5 3,0 2,1
18 18 18 18 18 18
0,01 0,01 0,01 0,01 0,01 0,00
(c) Iris
5
Random Greedy
- Random - Greedy Mixed
DB
1,21 1,53 1,98 0,75 2,58 -0,36
0,1 -1,9 0,4 -2,8 -0,4 -3,7
2 2 2 2 2 2
0,00 0,00 0,00 0,00 0,00 0,00
* * * * * *
* * * * * *
* * * * * *
* * * * * *
10
Random Greedy
- Random - Greedy Mixed
DB
24,21 37,81 11,94 35,44 33,25 32,95
-3,1 -2,9 -2,2 -3,8 -3,1 -2,7
5 5 5 5 5 5
0,00 0,00 0,00 0,00 0,00 0,01
13,86 17,00 6,22 17,02 17,05 17,04
4,2 3,9 2,8 2,5 3,6 2,1
5 5 5 5 5 5
0,01 0,01 0,01 0,01 0,01 0,01
15
Random Greedy
- Random - Greedy Mixed
DB
51,68 65,98 35,05 55,32 57,99 52,41
-4,7 -3,3 -2,4 -5,7 -4,9 -6,9
8 8 8 8 8 8
0,00 0,00 0,00 0,00 0,00 0,00
47,65 61,75 23,78 57,78 58,09 58,85
6,3 7,8 6,5 3,8 5,6 2,3
8 8 8 8 8 8
0,01 0,02 0,01 0,01 0,01 0,01
20
Random Greedy
- Random - Greedy Mixed
DB
55,98 67,63 35,53 53,93 60,25 57,38
-4,5 -3,3 -4,1 -5,8 -5,0 -6,8
11 11 11 11 11 11
0,00 0,00 0,01 0,00 0,00 0,00
53,17 67,18 22,94 59,63 62,31 65,07
6,0 7,0 4,7 3,7 4,5 3,3
11 11 11 11 11 11
0,01 0,02 0,01 0,01 0,01 0,01
40
Random Greedy
- Random - Greedy Mixed
DB
76,66 122,44 43,59
115,74 119,20 126,08
-2,5 -3,5 -1,6 -4,3 -3,7 -4,3
25 25 25 25 25 25
0,00 0,00 0,01 0,00 0,00 0,00
78,95 129,81 56,56
127,24 121,44 139,20
8,3 3,4 5,7 3,2 4,0 3,1
25 25 25 25 25 25
0,02 0,02 0,02 0,02 0,02 0,02
50
Random Greedy
- Random - Greedy Mixed
DB
115,89 181,31 64,44
157,51 160,92 177,66
-2,1 -3,3 -1,8 -3,7 -3,6 -4,0
31 31 31 31 31 31
0,00 0,00 0,01 0,00 0,00 0,00
102,29 192,19 83,75
178,96 170,96 199,20
8,6 3,2 6,1 3,2 3,8 2,7
31 31 31 31 31 31
0,03 0,02 0,02 0,02 0,02 0,02
60 Random Greedy
117,06 218,23
-1,0 -2,0
38 38
0,01 0,01
116,94 246,66
8,1 3,0
38 38
0,03 0,02

51
- Random - Greedy Mixed
DB
69,36 200,99 187,87 208,06
-0,8 -2,6 -2,2 -3,0
38 38 38 38
0,01 0,00 0,01 0,00
78,13 210,50 195,26 232,61
7,2 2,9 4,1 2,2
38 38 38 38
0,03 0,02 0,02 0,02
70
Random Greedy
- Random - Greedy Mixed
DB
100,06 236,08 56,59
199,98 197,76 221,45
-0,9 -2,6 -1,2 -3,2 -2,5 -3,4
34 34 34 34 34 34
0,01 0,00 0,01 0,00 0,01 0,00
102,05 258,55 70,86
231,44 199,39 241,94
8,7 2,3 6,7 2,4 3,2 2,0
34 34 34 34 34 34
0,03 0,02 0,03 0,02 0,02 0,02
(d) Wine
5
Random Greedy
- Random - Greedy Mixed
DB
-4,96 -2,45 -1,74 0,25 0,25 0,25
-2,8 -6,2 -3,2 -6,9 -6,8 -7,1
1 1 1 1 1 1
0,00 0,00 0,00 0,00 0,00 0,00
* * * * * *
* * * * * *
* * * * * *
* * * * * *
10
Random Greedy
- Random - Greedy Mixed
DB
2,56 91,77 1,39 -0,74 -0,74 -0,74
-2,5 0,8 -0,3 -2,2 -2,2 -2,1
2 2 2 2 2 2
0,01 0,02 0,01 0,01 0,01 0,01
* * * * * *
* * * * * *
* * * * * *
* * * * * *
20
Random Greedy
- Random - Greedy Mixed
DB
18,62 133,70 0,93 69,60 71,06 74,34
-2,7 -4,2 -0,8 -3,3 -3,5 -3,4
6 6 6 6 6 6
0,00 0,00 0,01 0,00 0,00 0,01
35,01 124,46 24,10
129,78 129,83 129,79
4,4 2,9 4,0 2,0 2,1 2,2
6 6 6 6 6 6
0,02 0,02 0,02 0,01 0,01 0,01
30
Random Greedy
- Random - Greedy Mixed
DB
23,73 103,68 13,25 64,97 71,69 67,46
-7,4 -13,3 -0,8
-16,0 -15,5 -15,5
9 9 9 9 9 9
0,00 -0,01 0,02 -0,02 -0,02 -0,01
50,51 92,83 23,16 86,52 87,43 86,61
6,6 4,6 4,0 2,7 2,8 2,2
9 9 9 9 9 9
0,03 0,03 0,03 0,02 0,02 0,02
40
Random Greedy
- Random - Greedy Mixed
DB
81,01 208,07 16,89
175,52 173,21 178,23
-4,3 -8,3 -2,3 -9,6 -9,7 -9,9
12 12 12 12 12 12
0,00 -0,01 0,01 -0,01 -0,01 -0,01
85,07 202,13 46,37
176,31 176,09 182,54
7,8 4,4 4,8 3,2 3,7 2,5
12 12 12 12 12 12
0,04 0,03 0,03 0,02 0,03 0,02
50
Random Greedy
- Random - Greedy Mixed
DB
105,68 344,38 28,41
299,81 293,06 320,14
-3,3 -5,7 -0,5 -5,3 -5,0 -5,1
18 18 18 18 18 18
0,00 -0,01 0,01 0,00 0,00 0,00
109,51 338,85 73,17
300,66 291,00 321,77
7,6 6,2 5,4 3,4 4,2 4,1
18 18 18 18 18 18
0,04 0,04 0,03 0,03 0,03 0,03
60
Random Greedy
- Random - Greedy Mixed
DB
133,25 584,66 51,66
524,00 505,43 552,00
-1,2 -3,5 1,0 -4,2 -2,9 -4,4
23 23 23 23 23 23
0,01 0,00 0,02 0,00 0,00 0,00
150,84 544,24 63,02
520,42 503,70 561,90
7,8 5,3 5,2 2,4 3,4 3,2
23 23 23 23 23 23
0,04 0,03 0,03 0,02 0,03 0,03
70
Random Greedy
- Random - Greedy Mixed
DB
87,62 471,88 53,70
416,84 406,39 432,48
-1,1 -3,2 0,8 -4,0 -3,7 -4,0
21 21 21 21 21 21
0,01 0,00 0,02 0,00 0,00 0,00
115,36 479,00 53,57
462,69 435,25 450,28
8,6 2,8 3,9 2,8 3,4 2,7
21 21 21 21 21 21
0,05 0,03 0,03 0,03 0,03 0,03
80 Random Greedy
110,21 370,37
-1,4 -3,6
26 26
0,01 0,00
61,18 400,32
7,7 2,1
26 26
0,06 0,03

52
- Random - Greedy Mixed
DB
47,27 311,48 303,42 320,97
-0,8 -4,1 -3,6 -4,2
26 26 26 26
0,01 -0,01 0,00 -0,01
52,20 343,01 328,25 357,99
3,7 2,2 3,1 2,1
26 26 26 26
0,03 0,03 0,03 0,03
(e) B-Câncer
5
Random Greedy
- Random - Greedy Mixed
DB
-0,13 -0,68 0,14 -0,62 -0,30 0,02
0,4 -1,7 -1,4 -2,2 -2,8 -2,3
1 1 1 1 1 1
0,03 0,02 0,02 0,02 0,02 0,09
* * * * * *
* * * * * *
* * * * * *
* * * * * *
10
Random Greedy
- Random - Greedy Mixed
DB
-0,50 0,99 -0,92 0,83 1,06 0,66
-0,2 -2,4 0,1 0,2 -0,9 0,4
2 2 2 2 2 2
0,03 0,02 0,03 0,03 0,03 0,26
* * * * * *
* * * * * *
* * * * * *
* * * * * *
20
Random Greedy
- Random - Greedy Mixed
DB
-2,63 2,48 -0,91 1,67 -0,18 0,67
-2,2 -1,4 -3,4 -0,3 -1,7 1,0
8 8 8 8 8 8
0,03 0,04 0,02 0,04 0,03 0,44
* * * * * *
* * * * * *
* * * * * *
* * * * * *
50
Random Greedy
- Random - Greedy Mixed
DB
9,12 19,74 6,65 15,91 16,05 14,73
-3,2 -4,5 -3,1 -4,9 -5,6 -6,7
20 20 20 20 20 20
0,03 0,02 0,03 0,02 0,01 0,18
7,30 13,66 6,44 14,83 14,59 14,94
8,0 5,9 6,3 5,1 6,8 5,1
20 20 20 20 20 20
0,15 0,13 0,13 0,12 0,14 0,16
100
Random Greedy
- Random - Greedy Mixed
DB
21,60 55,12 20,60 43,77 44,19 46,21
-3,3 -4,3 -2,8 -5,9 -5,2 -5,6
47 47 47 47 47 47
0,02 0,02 0,04 -0,02 0,00 0,02
22,26 50,86 24,19 46,34 43,07 48,96
8,8 4,4 8,6 5,5 5,8 4,5
47 47 47 47 47 47
0,27 0,18 0,27 0,21 0,21 0,20
200
Random Greedy
- Random - Greedy Mixed
DB
47,55 135,86 46,36
106,24 97,33
117,15
-0,7 -2,0 -0,4 -3,0 -2,3 -3,0
94 94 94 94 94 94
0,08 0,04 0,10 0,00 0,03 0,01
44,61 146,67 43,51
127,47 103,35 133,90
14,0 2,5 9,8 2,8 4,5 2,7
94 94 94 94 94 94
0,66 0,21 0,50 0,23 0,30 0,22
300
Random Greedy
- Random - Greedy Mixed
DB
86,44 454,92 100,87 338,24 288,13 352,54
4,6 -1,5 0,3 -2,5 -1,8 -2,6
131 131 131 131 131 131
0,39 0,05 0,15 -0,01 0,03 -0,02
81,55 414,09 88,91
336,26 281,04 351,25
22,9 2,0
10,8 2,2 4,4 2,1
131 131 131 131 131 131
1,46 0,25 0,76 0,26 0,39 0,25
(f) Image Segmentation
5
Random Greedy
- Random - Greedy Mixed
DB
-2,08 18,43 -4,33 11,85 -1,74 -2,92
0,5 -3,1 -1,7 -2,9 2,1 -0,5
1 1 1 1 1 1
0,11 0,06 0,08 0,07 0,13 4,09
* * * * * *
* * * * * *
* * * * * *
* * * * * *
10
Random Greedy
- Random - Greedy Mixed
DB
-0,10 5,73 0,64 1,64 1,30 0,37
-2,8 5,4 0,2 -0,6 -2,4 0,4
3 3 3 3 3 3
0,10 0,26 0,16 0,15 0,12 3,12
* * * * * *
* * * * * *
* * * * * *
* * * * * *
Random Greedy
-0,83 6,69
-4,3 -7,0
7 7
0,14 0,08
* *
* *
* *
* *
53
20
- Random - Greedy Mixed
DB
-1,83 1,01 0,01 -0,01
-4,4 -4,0 -5,9 -4,3
7 7 7 7
0,15 0,17 0,11 2,87
* * * *
* * * *
* * * *
* * * *
50
Random Greedy
- Random - Greedy Mixed
DB
5,42 20,56 0,45 16,57 16,35 11,14
-8,1 -7,6 -5,1 -7,4 -9,8 -7,7
25 25 25 25 25 25
0,07 0,11 0,23 0,14 0,00 1,77
* * * * * *
* * * * * *
* * * * * *
* * * * * *
100
Random Greedy
- Random - Greedy Mixed
DB
30,47 86,43 23,29 80,83 78,85 79,47
-13,8 -9,3
-11,5 -11,6 -14,4 -15,6
55 55 55 55 55 55
-0,42 0,05 -0,19 -0,18 -0,43 0,69
28,28 76,89 18,94 39,17 37,76 39,16
19,0 11,2 17,4 15,2 15,1 12,6
55 55 55 55 55 55
2,63 1,92 2,50 2,33 2,31 2,14
500
Random Greedy
- Random - Greedy Mixed
DB
90,74 496,85 103,40 500,14 506,11 517,49
-8,2 -9,7 -2,4
-10,7 -10,4 -11,9
284 284 284 284 284 284
-1,19 -1,64 1,49 -2,00 -1,79 -2,44
100,67 503,83 131,78 536,97 533,90 562,47
17,7 10,5 25,3 8,6
12,1 5,8
284 284 284 284 284 284
10,15 6,98 13,19 6,15 7,54 4,69
1000
Random Greedy
- Random - Greedy Mixed
DB
90,70 1151,53
95,92 1150,80 1067,73 1200,68
-2,6 -4,3 -1,7 -5,0 -4,8 -5,8
510 510 510 510 510 510
0,24 -0,99 1,26 -1,72 -1,58 -2,43
87,22 1268,46 156,98
1279,17 1153,41 1334,56
18,6 4,6
15,6 3,7 6,4 3,6
510 510 510 510 510 510
18,03 6,44 16,05 5,66 7,71 5,44
Fonte: Própria.
A Tabela 4.3 é dividida em dois conjuntos de colunas associados com os
resultados recolhidos quando as estratégias de remoção da degeneração são
aplicadas, quer na First Improving quer na Last Improving. Sempre que a
degeneração não aparecer no final da execução do k-means o método proposto
que remove a degeneração no Last Improving não pode ser aplicado. Caso
aconteça em todas as 20 diferentes execuções, o símbolo ‘*’ é usado para
representar que a última metodologia de melhoria nunca foi usada. O valor de
= 10 foi usado nos métodos -Random e Mixed e -Greedy.
Os resultados da Tabela 4.3 revelam que:
O número médio de iterações do k-means que remove a degeneração no
Fist Improving é melhor e, geralmente, menor do que o Last Improving.
Além disso, a remoção de degeneração no Fist Improving provoca, muitas
vezes, uma redução do número de iterações no k-means como
representados pelos valores negativos na coluna iter. Como se pode
observar, alguns valores apresentados na coluna time, sempre que há

54
redução, é grande o tempo total de CPU do k-means com Fist Improving
e menor do que o tempo de CPU gasto pelo clássico k-means;
Uma vez que o k-means modificado remove a degeneração no Last
Improving ele apresenta um maior número de iterações do que a versão
clássica e mais tempo de computação é necessário para a convergência.
Por exemplo, para um conjunto de dados image segmentation com k =
1000, o tempo médio adicional em uma execução de k-means utilizando
a estratégia Random é de aproximadamente 18 segundos. Essa
complexidade computacional do k-means é uma função não-decrescente
em n e k, cujos tempos adicionais resultantes da aplicacao das estrategias
de reparacao da degeneracao também aumentam com estes dois
parâmetros;
O grau máximo de degeneração (coluna ) é o mesmo, independente
da estratégia utilizada. Isto ocorre porque os maiores graus são
encontrados logo após a etapa da inicialização, no qual é aleatoriamente
alocado os registros de dados nos clusters;
A estratégia de remoção da degeneração leva a soluções melhores do
que os obtidos pelo algoritmo k-means, na maioria dos casos testados
(aproximadamente 88%) para First Improving e 100 % dos casos para
Last Improving. Além disso, as melhorias produzidas a partir de
estratégias de remoção da degeneração podem ser significativas (mais
do que 1000%) como, por exemplo, nas instâncias image segmentation
com k = 1000. Observa-se que quanto maior for o grau de degeneração
para cada conjunto de dados maiores serão as médias das melhorias
geradas pelas diferentes estratégias propostas nesta tese;
O k-means está mais propenso a remover a degeneração sozinho quando
o valor de k é pequeno. Para 12 dos 42 casos, o k-means foi capaz de
remover a degeneração automaticamente em todas as 20 execuções
avaliadas. Mesmo nestes casos, a estratégia Fist Improving leva a
soluções em média 1,79% melhor do que obtido pelo k-means. Além
disso, as estratégias propostas são, muitas vezes, mais rápidas do que o
k-means;

55
Nos t-testes estatísticos para os pares de observações (JAIN, 2008) foi
possível concluir que para todas as estratégias propostas, fixando a
degeneração através da estratégia Last Improving, é melhor do que
fixando a degeneração assim que ocorre. Os níveis de confiança que
suportam esta afirmação são de 90%, com exceção do método Random.
Isso estabelece uma tradeoff entre First Improving e Last Improving para
remover a degeneração, uma vez que o primeiro é mais
computacionalmente eficiente (o que pode permitir mais execuções do k-
means);
Estratégias baseadas em decisões gulosas levam a melhorias maiores do
que aquelas tomadas de forma aleatória. O método Greedy, por exemplo,
é melhor do que a Random, com exceção de um único caso do conjunto
de dados B-Câncer com = 5 usando a estratégia First Improving. O
método -Greedy é melhor do que -Random em aproximadamente 94%
dos casos testados. Em relação a abordagem Mixed é quase sempre
melhor do que -Random (ou seja, em 97,6% dos casos de teste), ao
mesmo tempo que é superado por -Greedy em aproximadamente 70%
dos casos;
Em cada instância, as seis estratégias são comparadas, totalizando 84
casos de teste. Os registros foram dados com base nas regras de
pontuação da Fórmula 1 utilizadas entre 1991 e 2002. Isso significa que
os seis ranks receberam um número decrescente de pontos (10, 6, 4, 3,
2, 1). A Tabela 4.4 apresenta o total de score somado em todos os casos
testados, indicando a superioridade das estratégias Greedy e DB.
Tabela 4.4: Score entre os 84 experimentos.
Estratégias Score
Ramdom 146
Greedy 565
- Random 102
-Greedy 325
Mixed 312
DB 438

56
Apesar de não ter sido apresentado nas tabelas, observou-se que a
degeneração do tipo-2 acontece raramente no k-means. Na verdade, o tipo-2 de
degeneração aconteceu nos testes apenas na inicialização para conjunto de
dados que continham registros repetidos.
A Tabela 4.5 resume os melhores resultados relatados na Tabela 4.3 e os
compara com o algoritmo k-means++, R-Ward e o m_k-means. O algoritmo R-
Ward foi executado 20 vezes para em seguida utilizar 50% dos registros. E o
algoritmo m_k-means também executado 20 vezes.
Observa-se na Tabela 4.5 que o método Greedy é superior às outras na
maior parte dos casos testados. O segundo melhor método foi o DB, que pode
ser certamente complicado para k-means, especialmente para os clusters que
contêm grande número de registros. No entanto, quando são pequenos
aglomerados (que é provavelmente o caso quando k é grande), o método DB
aplicado na estratégia First Improving foi capaz de até mesmo diminuir o tempo
total do k-means (ver os resultados para k = 500 e k = 1000 para a instância
image segmentation).
Por outro lado, os métodos de remoção da degeneração produziram os
melhores resultados em 16 dos 42 casos testados (38% dos casos). O método
Greedy produziu o melhor resultado, com 28 dos 42 casos testados (66,67% dos
casos), e o método DB apresentou o resultado com 19% dos casos testados.
Estes números são expressivos, podendo, também, serem usados dentro dos
métodos de agrupamento baseados em memória (por exemplo: (CARRIZOSA;
ALGUWAIZANI; HANSEN, 2014) e (LU, 2011)) com o fim de reiniciar a busca a
partir de uma nova solução completa obtida por meio do k-means++ ou qualquer
outro método de inicialização.
O algoritmo m_k-means não apresentou melhorias significativas quanto
aos métodos apresentados nesta tese. Os resultados mostram que o algoritmo
m_k-means resolveu o problema dos clusters vazios, no entanto não melhorou
as soluções como, por exemplo o caso dos resultados usando a instância Iris.

57
Tabela 4.5: Resumo dos melhores resultados obtidos pelos métodos de
remoção da degeneração, o k-means++, R-Ward e o m_k-means.
Fonte: Própria.
k-means++ R-Ward m_k-means First Improving (best) Last Improving (best)
Instance k %
improv. time % improv. time %
improv.
time %
Improv. time method %
Improv. time method
Eilon (n = 50)
5 10 15 20 25
5,92 11,21 40,37 58,12 98,92
0,00 0,00 0,00 0,00 0,00
7,32 20,35 49,59 50,22 43,44
0,00 0,00 0,00 0,00 0,00
-2,25 -0,67 -5,81 -4,54 -2,73
0,00 0,00 -0,00 0,00 0,00
6,67 4,57 26,02 51,39 110,09
0,00 0,00 0,00 0,00 0,00
-Greedy -Greedy
DB Mixed
Greedy
* 2,73 31,94 65,19 137,12
* 0,00 0,00 0,00 0,00
* Greedy
DB Mixed
Greedy
Ruspini (n = 75)
5 10 15 20 25 30
-3,76 30,28 94,31 154,53 206,43 256,59
0,00 0,00 0,00 0,00 0,00 0,00
-2,35 42,76 114,31 164,75 190,48 230,04
0,00 0,00 0,00 0,00 0,00 0,00
0,97 -3,53 -4,74 -3,20 -2,27 -2,67
-0,00 0,00 0,00 0,00 -0,00 0,00
-3,79 43,35 113,50 176,79 223,72 297,37
0,00 0,00 0,00 0,00 0,00 0,00
Greedy DB DB
Greedy DB
Greedy
* 49,41 121,85 182,78 239,06 311,88
* 0,00 0,00 0,00 0,01 0,01
* DB
Greedy Greedy Greedy Greedy
Iris (n = 150)
5 10 15 20 40 50 60 70
5,83 42,34 67,77 81,86 132,37 183,68 209,12 236,08
0,00 0,00 0,00 0,00 0,00 0,01 0,01 0,01
8,98 47,67 77,03 92,04 133,89 175,15 184,72 169,83
0,01 0,01 0,00 0,00 0,00 0,00 0,00 0,00
-0,25 -2,95 -2,68 -1,47 -1,25 -0,80 -1,38 -0,80
0,00 -0,00 -0,00 0,00 0,00 0,00 0,00 0,00
2,58 37,81 65,98 67,63 126,08 181,31 218,23 236,08
0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
Mixed Greedy Greedy Greedy
DB Greedy Greedy Greedy
* 17,05 61,75 67,18 139,20 199,20 246,66 258,55
* 0,01 0,02 0,02 0,02 0,02 0,02 0,02
* Mixed
Greedy Greedy
DB DB
Greedy Greedy
Wine (n = 178)
5 10 20 30 40 50 60 70 80
-7,06 111,64 368,15 313,10 460,04 604,74 790,26 585,82 391,50
0,00 0,00 -0,01 -0,02 -0,01 0,00 0,01 0,01 0,01
-4,51 128,03 392,37 279,64 362,79 417,92 477,70 317,57 114,16
0,01 0,01 0,00 -0,02 -0,01 0,00 0,00 0,00 0,00
0,25 2,04 -0,25 -5,17 4,65 -0,09 -1,60 -0,62 -0,29
-0,00 0,00 0,00 -0,00 0,00 0,00 0,00 0,00 0,01
0,25 91,77 133,70 103,68 208,07 344,38 584,66 471,88 370,37
0,00 0,02 0,00 -0,01 -0,01 -0,01 0,00 0,00 0,00
-Gr/Mixed/DB Greedy Greedy Greedy Greedy Greedy Greedy Greedy Greedy
* *
129,83 92,83 202,13 338,85 561,90 479,00 400,32
* *
0,01 0,03 0,03 0,04 0,03 0,03 0,03
* *
Mixed Greedy Greedy Greedy
DB Greedy Greedy
B-Câncer (n = 699)
5 10 20 50 100 200 300
-0,41 3,60 6,88 29,51 69,48 199,93 536,39
0,00 0,01 0,00 0,01 0,05 0,18 0,27
-0,40 7,09 10,27 35,22 79,27 125,09 66,14
0,19 0,19 0,16 0,12 0,09 0,06 0,06
-0,25 -1,18 0,03 -1,84 -2,34 -0,63 -0,11
-0,00 0,00 0,00 0,01 0,01 0,06 0,05
0,14 1,06 2,48 19,74 55,12 135,86 454,92
0,02 0,03 0,04 0,02 0,02 0,04 0,05
-Random Mixed
Greedy Greedy Greedy Greedy Greedy
* * *
14,94 50,86 146,67 414,09
* * *
0,16 0,18 0,21 0,25
* * *
DB Greedy Greedy Greedy
Image Segmentation
(n = 2310)
5 10 20 50 100 500 1000
12,42 4,06 7,79 31,17 103,31 551,28 1149,68
-0,03 0,00 -0,11 -0,17 -0,62 -1,63 0,49
19,10 10,54 14,18 30,14 83,07 138,74 66,35
5,32 5,23 4,93 4,44 3,33 -1,46 -1,70
-0,00 -0,11 -0,97 -2,07 -2,84 0,89 -2,52
0,00 0,01 -0,05 0,23 0,17 0,61 1,34
18,43 5,73 6,69 20,56 86,43 517,49 1200,68
0,06 0,26 0,08 0,11 0,05 -2,44 -2,43
Greedy Greedy Greedy Greedy Greedy
DB DB
* * * *
76,89 562,47 1334,56
* * * *
1,92 4,69 5,44
* * * *
Greedy DB DB

58
Capítulo 5 – Considerações Finais
O algoritmo k-means é amplamente utilizado em vários domínios. Um
possível evento em uma execução do algoritmo é o aparecimento de soluções
degeneradas em que um ou mais clusters estão vazios. Nesta tese, analisou-se
em detalhe a importância de enfrentar soluções degeneradas que aparecem
durante a execução de k-means, tanto em termos de desempenho quanto a
qualidade das soluções obtidas. Foi realizada uma extensa comparação dos
métodos para eliminar degeneração, sendo quatro delas novas para a literatura
- Random, -Greedy, Mixed e DB).
Foi proposto, também, uma nova estratégia chamada de First Improving.
Na maioria dos casos, as estratégias foram capazes de melhorar a qualidade
das soluções obtidas pelo algoritmo k-means na presença da degeneração,
chegando a atingir 1000% em um dos casos testados. Em particular, as
melhorias conseguidas executando o k-means foram maiores na presença de
soluções com grandes graus de degeneração.
Além disso, observou-se que no momento em que a degeneração foi
tratada também influenciou o desempenho global do k-means. Em geral, o
tratamento da degeneração usando a estratégia First Impriving teve um impacto
muito menor sobre o tempo de CPU gasto na execução do k-means.
Outra importante contribuição desta tese foram que os métodos de
remoção da degeneração são fáceis de executar e podem ser incorporados em
qualquer implementação do algoritmo k-means, sendo uma alternativa flexível
para reinicializações em método de agrupamentos baseados em memória como,
por exemplo: VNS, Algoritmo Genéticos, Bat-Algorithm, entre outros. Nesses
algoritmos, se considerarmos que um shake (VNS), uma mutação (Algoritmo
Genético) ou Random walk (Bat Algorithm) venha ser realizado sobre uma
solução ótima é muito provável que depois da execução desses procedimentos
possam surgir clusters vazios. Logo, os métodos propostos nesta tese são
capazes de consertar a degeneração sem “prejudicar” as soluções.
Como futuro trabalho, pretende-se realizar um estudo de algoritmos
utilizando outros tipos de medida de distância ao invés da Euclidiana, bem como
a aplicação de estratégias com outros algoritmos de inteligência computacional.

59
E finalmente, uma análise da dependência do parâmetro épsilon usado no
método -Random e -Greedy.

60
Referências Bibliográficas
ALOISE, Daniel; DESHPANDE, A.; HANSEN, P.; POPAT, P. NP-hardness of Euclidean sum-of-squares clustering. Machine Learning, 75:245–249, 2009. ALOISE, Daniel; HANSEN, P.; LIBERTI, L. An improved column generation algorithm for minimum sum-of-squares clustering. Mathematical Programming, 131(1-2):195–220, 2012. ALSABTI, K.; RANKA, S.; SINGH, V. An ef cient k-means clustering algorithm. In Proceedings of IPPS/SPDP Workshop on high performance data mining, pág. 881–892, Orlando, Florida: IEEE Computer Society, 1998. ANDERBERG, M. R. Cluster analysis for application. Nova York, USA: Academic Press, 1973. ARTHUR, David; VASSILVITSKII, Sergei. k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics, pág. 1027–1035, 2007. BACHE, K.; LICHMAN, M. UCI machine learning repository, 2013. BISHOP, Christopher M. Neural Networks for pattern recognition. Oxford, 2002. BOTTOU, L.; BENGIO, Y. Convergence properties of the k-means algorithms. In Tesauro, G., Touretzky, D., and Leen, T., editors, Advances in Neural Information Processing Systems, volume 7, pág. 585–592. Cambridge, MA: The MIT Press, 1995. BRADLEY, P.; FAYYAD, U. Re ning initial points for k-means clustering. In Proceedings of the fteenth international conference on machine learning, pág. 91–99. San Francisco: Morgan Kaufmann, 1998. BRIMBERG, J.; MLADENOVI , N. Degeneracy in the multi-source Weber problem’, Mathematical Programming 85, no. 1, 213–220. 53, 58, 63. 1999. BLANCHARD, S. J.; ALOISE, Daniel; DESARBO, W. S. The heterogeneous p-median problem for categorization based clustering. Psychometrika, 77(4):741–762, 2012. CARRIZOSA, E.; ALGUWAIZANI, A.; HANSEN, P.; MLADENOVI , N. New heuristic for harmonic means clustering. Journal of Global Optimization, pág. 1–17, 2014. CELEBI, M. E.; KINGRAVI, H. A.; VELA, P. A. A comparative study of e cient initialization methods for the k-means clustering algorithm. Expert Systems with Applications, 40(1):200–210, 2013.

61
COOPER, L. Heuristic methods for location-allocation problems. Siam Review, 6(1):37–53, 1964. CONSTANTINE, A.; GOWER, J. Graphical representation of asymmetric matrices. Applied Statistics, 27: pág. 297–304, 1978. COSTA, J. A.; FERANDES, A. P.; MATTOZO, T. C.; SILVA, G. S.; Uma introdução à mineração de dados: conceitos e aplicações, Ed.: EdUFERSA, 2014. DUDA, R. O.; HART, P.E. Pattern Classification. John Wiley & sons, 1998. EILON, S.; WATSON-GANDY, C.; CHRISTO DES, N. Distributed management. Hafner, New York, 1971. EVERITT, B. S. Cluster analysis. 3. Ed. New York: Wiley, 1993. FABER, V. Clustering and the continuous k -means algorithm. Los Alamos Science, 22: pág. 138–144, 1994. FORGY, E.; Cluster Analysis of Multivariate Data: E ciency vs. Interpretability of Classi cation, Biometrics 21, pág. 768, 1965. FLOREK, K.; LUCKASZEWIEZ, J.; PERKAL, J.; STEINHAUS, H.; ZUBRZCHI, S. Sur la liason et la division des ponts d’un ensample fini. Colloquium Methematicum, v. 2, pág.: 282-285, 1951. FRALEY, C.; RAFTERY, A. Model-based clustering, discriminant analysis and density estimation. Journal of American Statistical Association, 97, pág. 611–631, 2002. HELSEN, K.; GREEN, P. E. A Computational Study of Replicated Clustering with an Application to Market Segmentation, Journal of the decision sciences intitute, vol.22, pág. 1124-1141, 1991. HANSEN, P.; JAUMARD, B. Cluster analysis and mathematical programming Mathematical Programming, vol. 79, pág. 191–215, 1997. HANSEN, P.; RUIZ, M., ALOISE, D. A Variable Neighborhood Search Heuristic for Normalized Cut Clustering, Journal Pattern Recognition archive Volume 45 Issue 12, December, Elsevier Science Inc. New York, NY, USA, pág. 4337-4345, 2012. HANSEN, P.; MLADENOVI , N. J-means: a new local search heuristic for minimum sum of squares clustering. Pattern Recognition, 34:405–413, 2001. HANSEN, P.; BRIGITTE, Jaumard. Cluster analysis and mathematical programming. Mathematical Programming, 79:191–215, 1997.

62
HARTIGAN, J. Representation of similarity matrices by trees. Journal of the American Statistical Association, 62(320), pág. 1140–1158, 1967. HAVERLY, C. A. Studies of the behavior of recursion for the pooling problem. ACM SIGMAP Bulletin, (25):19–28, 1978. JAIN, A. K; DUBES, R. C. Algorithms for clustering data. Englewood, USA: Prentice Hall, 1998. JAIN, A. K.; MURTY, M.; FLYNN, P. Data clustering: A review. ACM Computing Surveys, 31(3): pág. 264–323, 1999. JAIN, A. K. The art of computer systems performance analysis. John Wiley & Sons, 2008. JOLLIFFE, Ian T. Principal Component Analisys. Springer Verlag, 1986. LANCE, G. N.; WILLIAMS, W. T. A General Theory of Classi catory Sorting Strategies. 1. Hierarchical Systems, The Computer Journal 9, pág. 373–380, 1967. MAIRAL, J.; BACH, F.; PONCE, J. Sparse modeling for image and vision processing. Foundations and Trends in Computer Graphics and Vision, 8(2-3):85–283, 2012. MACQUEEN, J. Some methods for classi cation and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematics, Statistics and Probability, Vol. 1, Chicago, USA, pág. 281–296, 1967. MASSART, D. L.; KAUFMAN, L. The interpretation of analytical chemical data by the use of cluster analysis. New York, USA: John Wiley & Sons, 1993. MAK, J. N.; WOLPAW, J. R. Clinical applications of brain-computer interfaces: current state and future prospects. Biomedical Engineering, IEEE Reviews, 2:187–199, 2009. PAKHIRA, K. M. A modified k-means algorithm to avoide empty clusters. International Jornal of Recent Trends in Engineering, Vol 1, No. 1, May, pág. 220-226, 2009. PARK, H-S; JUN, C-H. A simple and fast algorithm for K-medoids clustering. Expert Systems with Applications. 36, 3336-3341, 2009. KAUFMAN, L.; ROUSSEEUW, P.J. Finding Groups in Data – An Introduction to Cluster Analysis. Wiley-Interscience Publication, 1989. REESE, J. Solution Methods for the p-Median Problem: An Annotated Bibliography, 2006.

63
RUSPINI, E.H. Numerical method for fuzzy clustering. Information Sciences, 2:319–350, 1970. SOKAL, R. R; SNEATH, P. H. A. Numerical taxonomy. San Francisco, USA: W. H. Freeman, 1973. SPÄTH, H. Cluster analysis algorithms: for data reduction and classification of objects. West Sussex, GBR: Ellis Horwood; Chichester, 1980. TITTERINGTON, D. M.; SMITH, A. F. M.; MAKOV, U. E. Statistical analysis of finite mixture distributions. New York, USA: John Wiley & Sons, 1985. WARD, J. H. Hierarchical grouping to optimize an objective function. Jornal of the American Statistical Association, v. 58, pág.: 236-244, 1963.





























