Embed Size (px)
Citation preview

RELATÓRIO DO PROJETO DE ENSINO
ESTUDO E ANÁLISE DE TÉCNICAS E FERRAMENTAS DEMINERAÇÃO DE DADOS
MARIA MADALENA DIAS
RESUMO
Apesar da existência de técnicas e ferramentas de mineração de dados, muitas
organizações ainda desconhecem o quanto o computador pode dar suporte à tomada de
decisão. A pouca utilização dessas técnicas e ferramentas podem estar relacionadas à
dificuldade na escolha da técnica e/ou ferramenta de mineração de dados mais adequada
ao tipo de aplicação. Este relatório sugere alguns parâmetros a serem considerados na
escolha da técnica e da ferramenta de mineração de dados.

2
SUMÁRIO
RESUMO ....................................................................................................................................................1
1 INTRODUÇÃO .......................................................................................................................................4
2 MINERAÇÃO DE DADOS ....................................................................................................................5
2.1 TAREFAS DESEMPENHADAS POR TÉCNICAS DE MINERAÇÃO DE DADOS..............................................62.2 TÉCNICAS DE MINERAÇÃO DE DADOS .................................................................................................72.3 ÁREAS DE APLICAÇÃO DE TÉCNICAS DE MINERAÇÃO DE DADOS ........................................................7
3 O PROCESSO DE DESCOBERTA DE CONHECIMENTO.............................................................9
4 COMO ESCOLHER A TÉCNICA DE MINERAÇÃO DE DADOS MAIS ADEQUADA ............10
5 FERRAMENTAS DE MINERAÇÃO DE DADOS............................................................................12
6 METODOLOGIA PARA AVALIAÇÃO E SELEÇÃO DE SOFTWARE DE MINERAÇÃO DEDADOS......................................................................................................................................................14
6.1 APLICAÇÃO METÓDICA DA ESTRUTURA ..............................................................................17
7 EXEMPLOS DE FERRAMENTAS DE MINERAÇÃO DE DADOS ..............................................18
8 ESTUDO DE CASO..............................................................................................................................19
8.1 PRÉ-PROCESSAMENTO ......................................................................................................................198.2 MINERAÇÃO DE DADOS.....................................................................................................................25
8.2.1 Descoberta de Regras de Associação........................................................................................268.2.2 Árvore de Decisão .....................................................................................................................31
8.3 PÓS-PROCESSAMENTO ......................................................................................................................32
9 PARÂMETROS NA ESCOLHA DE TÉCNICAS DE MINERAÇÃO DE DADOS .......................33
10 PARÂMETROS NA ESCOLHA DE FERRAMENTA DE MINERAÇÃO DE DADOS .............34
11 CONSIDERAÇÕES FINAIS..............................................................................................................35
12 REFERÊNCIAS BIBLIOGRÁFICAS ..............................................................................................36

3
LISTA DE FIGURAS
FIGURA 1: A MINERAÇÃO DE DADOS COMO UM CAMPO MULTIDISCIPLINAR ...............................................5FIGURA 2: PROCESSO DE DESCOBERTA DE CONHECIMENTO .........................................................................9FIGURA 3: FASES DA METODOLOGIA PARA SELEÇÃO DE FERRAMENTAS DE MINERAÇÃO DE DADOS.........17
LISTA DE TABELAS
TABELA 1: TAREFAS REALIZADAS POR TÉCNICAS DE MINERAÇÃO DE DADOS .............................................6TABELA 2: TÉCNICAS DE MINERAÇÃO DE DADOS.........................................................................................7TABELA 3: CARACTERÍSTICAS DE DADOS ...................................................................................................11TABELA 4: CARACTERÍSTICAS GERAIS DA FERRAMENTA ...........................................................................13TABELA 5: CONECTIVIDADE DE BANCOS DE DADOS DA FERRAMENTA.......................................................13TABELA 6: CARACTERÍSTICAS DE MINERAÇÃO DE DADOS DA FERRAMENTA .............................................14TABELA 7: CRITÉRIOS DE DESEMPENHO COMPUTACIONAL ........................................................................15TABELA 8: CRITÉRIOS DE FUNCIONALIDADE ..............................................................................................15TABELA 9: CRITÉRIOS DE USABILIDADE .....................................................................................................16TABELA 10: CRITÉRIOS DE SUPORTE DE ATIVIDADES PRINCIPAIS DE UMA ORGANIZAÇÃO OU SISTEMA ....16TABELA 11: FERRAMENTAS DE MINERAÇÃO DE DADOS .............................................................................18TABELA 12: ATRIBUTOS SELECIONADOS DAS TABELAS DOS BANCOS DE DADOS DA CAPES ....................20TABELA 13: DISCRETIZAÇÃO DOS DADOS DAS TABELAS DO DATASET ......................................................24TABELA 14: RELAÇÃO DAS TABELAS DO DATASET E SEUS ATRIBUTOS......................................................25TABELA 15: REGRAS GERADAS PARA O PRIMEIRO OBJETIVO - APRIORI.....................................................26TABELA 16: REGRAS GERADAS PARA O SEGUNDO OBJETIVO - APRIORI.....................................................28TABELA 17: REGRAS GERADAS PARA O TERCEIRO OBJETIVO - APRIORI ....................................................29TABELA 18: REGRAS GERADAS PARA O PRIMEIRO OBJETIVO – C4.5 E J48.................................................31

4
1 INTRODUÇÃO
Durante várias décadas, desde a invenção do primeiro computador, o principal
objetivo da utilização do computador é solucionar problemas operacionais da
organização. A grande maioria das organizações ainda não possui meios de utilização
dos recursos computacionais na tomada de decisão. Apesar da existência de grandes
bancos de dados com muitas informações sobre o negócio da empresa, ainda são
encontradas dificuldades na descoberta de conhecimento baseada nessas informações.
Essas dificuldades podem estar relacionadas a um dos seguintes fatores: falta de
conhecimento da existência de técnicas de mineração de dados; complexidade na
implementação e aplicação de uma técnica de mineração de dados; falta de ferramentas
adequadas; alto custo das ferramentas de mineração de dados disponíveis no mercado;
falta de parâmetros de referência na escolha da técnica e da ferramenta mais adequadas
a cada problema a ser solucionado.
As técnicas de mineração de dados são aplicadas em sistemas de descoberta de
conhecimento em banco de dados com o objetivo de extrair informações estratégicas
escondidas em grandes bancos de dados, através da pesquisa dessas informações e da
determinação de padrões, classificações e associações entre elas (Goebel e Gruenwald,
1999).
A seguir, na próxima seção, são apresentados alguns conceitos de mineração de
dados e descritas, sucintamente, tarefas e técnicas de mineração de dados. Na seção 3
são mostrados os passos básicos do processo de descoberta de conhecimento. Na seção
4 são discutidas algumas sugestões de como escolher a técnicas de mineração de dados
mais adequada ao tipo de aplicação. Na seção 5 são relacionadas características
importantes na escolha de uma ferramenta de mineração de dados. Na seção 6 é descrita
uma metodologia para avaliação e seleção de software de mineração de dados. Na seção
7 são relacionadas algumas ferramentas de mineração de dados. Na seção 8 é mostrada
a realização de um estudo de caso onde são aplicadas duas técnicas de mineração de
dados sobre dados de cursos de pós-graduação do Brasil. Nas seções 9 e 10 são
relacionados parâmetros a serem considerados na escolha de uma técnica e de uma
ferramenta de mineração de dados, respectivamente. Finalmente, na seção 11, é
apresentada a conclusão deste trabalho.

5
2 MINERAÇÃO DE DADOS
A mineração de dados pode ser considerada como uma parte do processo de
Descoberta de Conhecimento em Banco de Dados (KDD – Knowledge Discovery in
Databases). Segundo Goebel e Gruenwald (1999), o termo KDD é usado para
representar o processo de tornar dados de baixo nível em conhecimento de alto nível,
enquanto mineração de dados pode ser definida como a extração de padrões ou modelos
de dados observados.
A mineração de dados combina métodos e ferramentas das seguintes áreas:
aprendizagem de máquina, estatística, banco de dados, sistemas especialistas e
visualização de dados, conforme Figura 1 (Cratochvil, 1999).
Figura 1: A Mineração de Dados como um Campo Multidisciplinar
“Mineração de dados é a exploração e a análise, por meio automático ou semi-
automático, de grandes quantidades de dados, a fim de descobrir padrões e regras
significativos” (Berry e Linoff, 1997, p.5). Os principais objetivos da mineração de
dados são descobrir relacionamentos entre dados e fornecer subsídios para que possa ser
feita uma previsão de tendências futuras baseada no passado.
Os resultados obtidos com a mineração de dados podem ser usados no
gerenciamento de informação, processamento de pedidos de informação, tomada de
decisão, controle de processo e muitas outras aplicações.
A mineração de dados pode ser aplicada de duas formas: como um processo de
verificação e como um processo de descoberta (Groth, 1998). No processo de
verificação, o usuário sugere uma hipótese acerca da relação entre os dados e tenta
SistemasEspecialistas
Banco deDados
Aprendizagemde Máquina
Estatística
Visualização
KDD

6
prová-la aplicando técnicas como análises estatística e multidimensional sobre um
banco de dados contendo informações passadas. No processo de descoberta não é feita
nenhuma suposição antecipada. Esse processo usa técnicas, tais como descoberta de
regras de associação, árvores de decisão, algoritmos genéticos e redes neurais.
2.1 Tarefas Desempenhadas por Técnicas de Mineração de dados
As técnicas de mineração de dados podem ser aplicadas a tarefas1 como
classificação, estimativa, associação, segmentação e sumarização. Essas tarefas são
apresentadas de forma resumida na Tabela 1 (Dias, 2001).
Tabela 1: Tarefas Realizadas por Técnicas de Mineração de Dados
TAREFA DESCRIÇÃO EXEMPLOSClassificação Constrói um modelo de algum tipo
que possa ser aplicado a dados nãoclassificados a fim de categorizá-losem classes, o objetivo é descobrir umrelacionamento entre um atributo meta(cujo valor será previsto) e umconjunto de atributos de previsão
• Classificar pedidos de crédito• Esclarecer pedidos de seguros
fraudulentos• Identificar a melhor forma de
tratamento de um paciente
Estimativa(ou Regressão)
Usada para definir um valor paraalguma variável contínuadesconhecida
• Estimar o número de filhos ou a rendatotal de uma família
• Estimar o valor em tempo de vida de umcliente
• Estimar a probabilidade de que umpaciente morrerá baseando-se nosresultados de diagnósticos médicos
• Prever a demanda de um consumidorpara um novo produto
Associação Usada para determinar quais itenstendem a serem adquiridos juntos emuma mesma transação
• Determinar que produtos costumam sercolocados juntos em um carrinho desupermercado
Segmentação(ou Clustering)
Processo de partição de umapopulação heterogênea em váriossubgrupos ou grupos maishomogêneos
• Agrupar clientes por região do país• Agrupar clientes com comportamento
de compra similar• Agrupar seções de usuários Web para
prever comportamento futuro de usuárioSumarização Envolve métodos para encontrar uma
descrição compacta para umsubconjunto de dados
• Tabular o significado e desvios padrãopara todos os itens de dados
• Derivar regras de síntese
1 Neste contexto, tarefa é um tipo de problema de descoberta de conhecimento a ser solucionado.

7
2.2 Técnicas de Mineração de dados
Harrison (1998) afirma que não há uma técnica que resolva todos os problemas
de mineração de dados. Diferentes métodos servem para diferentes propósitos, cada
método oferece suas vantagens e suas desvantagens. A familiaridade com as técnicas é
necessária para facilitar a escolha de uma delas de acordo com os problemas
apresentados. A Tabela 2 apresenta um resumo das técnicas de mineração de dados
normalmente usadas.
Tabela 2: Técnicas de Mineração de Dados
TÉCNICA DESCRIÇÃO TAREFAS EXEMPLOSDescoberta deRegras deAssociação
Estabelece uma correlaçãoestatística entre atributos dedados e conjuntos de dados
• Associação Apriori, AprioriTid, AprioriHybrid,AIS, SETM (Agrawal e Srikant,1994) e DHP (Chen et al, 1996).
Árvores deDecisão
Hierarquização dos dados,baseada em estágios dedecisão (nós) e naseparação de classes esubconjuntos
• Classificação• Regressão
CART, CHAID, C5.0, Quest (TwoCrows, 1999);ID-3 (Chen et al, 1996); SLIQ(Metha et al, 1996); SPRINT (Shaferet al, 1996).
RaciocínioBaseado emCasos ou MBR
Baseado no método dovizinho mais próximo,combina e comparaatributos para estabelecerhierarquia de semelhança
• Classificação• Segmentação
BIRCH (Zhang et al, 1996);CLARANS (Chen et al, 1996);CLIQUE (Agrawal et al, 1998).
AlgoritmosGenéticos
Métodos gerais de busca eotimização, inspirados naTeoria da Evolução, onde acada nova geração, soluçõesmelhores têm mais chancede ter “descendentes”
• Classificação• Segmentação
Algoritmo Genético Simples(Goldberg, 1989); Genitor, CHC(Whitley, 1993);Algoritmo de Hillis (Hillis, 1997);GA-Nuggets (Freitas, 1999); GA-PVMINER (Araújo et al, 1999).
Redes NeuraisArtificiais
Modelos inspirados nafisiologia do cérebro, ondeo conhecimento é fruto domapa das conexõesneuronais e dos pesosdessas conexões
• Classificação• Segmentação
Perceptron, Rede MLP, Redes deKohonen, Rede Hopfield, RedeBAM, Redes ART, Rede IAC, RedeLVQ, Rede Counterpropagation,Rede RBF, Rede PNN, Rede TimeDelay, Neocognitron, Rede BSB(Azevedo, 2000), (Braga, 2000),(Haykin, 2001)
2.3 Áreas de Aplicação de Técnicas de Mineração de dados
A seguir, são relacionadas as principais áreas de interesse na utilização de
mineração de dados (Cratochvil, 1999), (Mannila, 1996), (Viveros et al, 1996):
• Marketing. Técnicas de mineração de dados são aplicadas para descobrir
preferências do consumidor e padrões de compra, com o objetivo de realizar
marketing direto de produtos e ofertas promocionais, de acordo com o perfil do
consumidor.

8
• Detecção de fraudes. Muitas fraudes óbvias (tais como, a compensação de cheque
por pessoas falecidas) podem ser encontradas sem mineração de dados, mas padrões
mais sutis de fraude podem ser difíceis de serem detectados, por exemplo, o
desenvolvimento de modelos que predizem quem será um bom cliente ou aquele que
poderá se tornar inadimplente em seus pagamentos.
• Medicina: caracterizar comportamento de paciente para prever visitas, identificar
terapias médicas de sucesso para diferentes doenças, buscar por padrões de novas
doenças.
• Instituições governamentais: descoberta de padrões para melhorar as coletas de
taxas ou descobrir fraudes.
• Ciência: técnicas de mineração de dados podem ajudar cientistas em suas pesquisas,
por exemplo, encontrar padrões em estruturas moleculares, dados genéticos,
mudanças globais de clima, oferecendo conclusões valiosas rapidamente.
• Controle de processos e controle de qualidade: auxiliar no planejamento
estratégico de linhas de produção e buscar por padrões de condições físicas na
embalagem e armazenamento de produtos.
• Banco: detectar padrões de uso de cartão de crédito fraudulento, identificar clientes
“leais”, determinar gastos com cartão de crédito por grupos de clientes, encontrar
correlações escondidas entre diferentes indicadores financeiros.
• Apólice de seguro: análise de reivindicações – determinar quais procedimentos
médicos são reivindicados juntos, prever quais clientes comprarão novas apólices,
identificar padrões de comportamento de clientes perigosos, identificar
comportamento fraudulento.
• Transporte: determinar as escalas de distribuição entre distribuidores, analisar
padrões de carga.
• C & T (Ciência e Tecnologia): avaliar grupos de pesquisa do país (Gonçalves,
2000), (Romão, 1999), (Dias, 2001).
• Web: existem muitas pesquisas direcionadas à aplicação de mineração de dados na
Web, tais como: (Loh et al, 2000), (Kosala e Blockeel, 2000), (Ma et al, 2000),
(Mobasher et al, 2000), (Sarawagi e Nagaralu, 2000), (Spiliopoulou, 2000).

9
3 O Processo de Descoberta de Conhecimento
O processo de descoberta de conhecimento é um método semi-automático
complexo e iterativo (Mannila, 1996). De acordo com Groth (1998), ele pode ser
dividido em cinco passos básicos: preparação de dados, definição de um estudo,
construção de um modelo, entendimento do modelo e predição.
Para Lans (1997), existe um passo que antecede a preparação de dados, trata-se
da definição de objetivos.
A Figura 2 representa o processo de descoberta de conhecimento (Dias,2001).
Figura 2: : Processo de Descoberta de Conhecimento
Definição deObjetivos
Acesso ePreparação de
Dados
Definiçãode um Estudo
Construção deum Modelo
Análise doModelo
Predição
Planejamento de ação Planejamento deavaliação de resultados
Seleção e transformação dos dados Registro no Metadados Registro do DW, DM ou DS
Articular um alvo Escolher uma variável dependente Especificar os campos de dadosusados no estudo
Aplicação de uma técnicade mineração de dados
Análise baseada no tipode técnica de mineraçãode dados aplicada
Escolha do melhorresultado possível

10
4 Como Escolher a Técnica de Mineração de dados mais Adequada
A escolha de uma técnica de mineração de dados a ser aplicada não é uma tarefa
fácil. Segundo Harrison (1998), a escolha das técnicas de mineração de dados dependerá
da tarefa específica a ser executada e dos dados disponíveis para análise. Berry e Linoff
(1997) sugerem que a seleção das técnicas de mineração de dados deve ser dividida em
dois passos:
1) Traduzir o problema de negócio a ser resolvido em séries de tarefas de mineração de
dados;
2) Compreender a natureza dos dados disponíveis em termos de conteúdo e tipos de
campos de dados e estrutura das relações entre os registros.
O primeiro passo na seleção da técnica de mineração de dados é, portanto,
estabelecer uma meta comercial como, por exemplo, ‘manter os clientes’ e transformá-
la em uma ou mais das tarefas de mineração de dados apresentadas anteriormente. Neste
exemplo, a estratégia é identificar assinantes que tenham a intenção de desistir do
serviço, descobrir suas razões para isso e fazer algum tipo de oferta especial que os
agrade. Para o sucesso da estratégia, é preciso não somente identificar os assinantes que
podem cancelar, mas dividi-los em grupos de acordo com seus motivos presumíveis
para a desistência. A primeira tarefa é, obviamente, a classificação. Usando um conjunto
de dados de treinamento com exemplos de clientes que cancelaram o serviço juntamente
com exemplos daqueles que permaneceram, é possível construir um modelo capaz de
rotular cada cliente como ‘fiel’ ou ‘instável’.
O segundo passo, determinar as características dos dados em análise, tem como
meta selecionar a técnica de mineração de dados que minimiza o número e dificuldades
de transformação de dados para, a partir destes, obter bons resultados. A Tabela 3
mostra uma lista de características de dados, baseada em (Berry e Linoff, 1997), que
ajudará na escolha de uma abordagem de mineração de dados.

11
Tabela 3: Características de Dados
Característica Descrição Técnicas de Mineraçãode Dados
Variáveis de categorias São campos que apresentam valores de umconjunto de possibilidades limitado epredeterminado
• Descoberta de regras deassociação
• Árvores de decisãoVariáveis numéricas São aquelas que podem ser somadas e ordenadas • Raciocínio baseado em
casos (MBR)• Árvores de Decisão
Muitos campos porregistro
Este pode ser um fator de decisão da técnicacorreta para uma aplicação específica, uma vezque os métodos de mineração de dados variam nacapacidade de processar grandes números decampos de entrada
• Árvores de decisão
Variáveis dependentesmúltiplas
Caso em que é desejado prever várias variáveisdiferentes baseadas nos mesmos dados deentrada
• Redes neurais
Registro de comprimentovariável
Apresentam dificuldades na maioria das técnicasde mineração de dados, mas existem situaçõesem que a transformação para registros decomprimento fixo não é desejada
• Descoberta de regras deassociação
Dados ordenadoscronologicamente
Apresentam dificuldades para todas as técnicas e,geralmente, requerem aumento dos dados deteste com marcas ou avisos, variáveis dediferença etc.
• Rede neural intervalar(time-delay)
• Descoberta de regras deassociação
Texto sem formatação A maioria das técnicas de mineração de dados éincapaz de manipular texto sem formação
• Raciocínio baseado emcasos (MBR)
“Diferentes esquemas de classificação podem ser usados para categorizar
métodos de mineração de dados sobre os tipos de bancos de dados a serem estudados, os
tipos de conhecimento a serem descobertos e os tipos de técnicas a serem utilizadas”
(Chen et al,1996, p.4), como pode ser visto a seguir:
• Com que tipos de bancos de dados trabalhar:
Um sistema de descoberta de conhecimento pode ser classificado de acordo com os
tipos de bancos de dados sobre os quais técnicas de mineração de dados são
aplicadas, tais como: bancos de dados relacionais, bancos de dados de transação,
orientados a objetos, dedutivos, espaciais, temporais, de multimídia, heterogêneos,
ativos, de herança, banco de informação de Internet e bases textuais.
• Qual o tipo de conhecimento a ser explorado:
Vários tipos de conhecimento podem ser descobertos por extração de dados,
incluindo regras de associação, regras características, regras de classificação, regras
discriminantes, grupamento, evolução e análise de desvio.

12
• Qual tipo de técnica a ser utilizada:
A extração de dados pode ser categorizada de acordo com as técnicas de mineração
de dados subordinadas. Por exemplo, extração dirigida a dados, extração dirigida a
questionamento e extração de dados interativa. Pode ser categorizada, também, de
acordo com a abordagem de mineração de dados subordinada, tal como: extração
de dados baseada em generalização, baseada em padrões, baseada em teorias
estatísticas ou matemáticas, abordagens integradas, etc.
Atualmente, a descoberta de regras de associação parece ser uma das técnicas de
mineração de dados mais utilizada, sendo encontrada em diversas pesquisas (Agrawal e
Srikant, 1994), (Chen et al, 1996), (Hipp et al, 2000), (Holsheimer et al, 1996),
(Mannila, 1997), (Viveros et al, 1996).
5 Ferramentas de Mineração de dados
De acordo com Goebel e Gruenwald (1999), muitas ferramentas atualmente
disponíveis são ferramentas genéricas da Inteligência Artificial ou da comunidade de
estatística. Tais ferramentas geralmente operam separadamente da fonte de dados,
requerendo uma quantidade significativa de tempo gasto com exportação e importação
de dados, pré- e pós-processamento e transformação de dados. Entretanto, segundo os
autores, a conexão rígida entre a ferramenta de descoberta de conhecimento e a base de
dados analisada, utilizando o suporte do SGBD (Sistema de Gerenciamento de Banco de
Dados) existente, é claramente desejável. Para Goebel e Gruenwald (1999), as
características a serem consideradas na escolha de uma ferramenta de descoberta de
conhecimento devem ser as seguintes:
• A habilidade de acesso a uma variedade de fontes de dados, de forma on-line e off-
line;
• A capacidade de incluir modelos de dados orientados a objetos ou modelos não
padronizados (tal como multimídia, espacial ou temporal);
• A capacidade de processamento com relação ao número máximo de
tabelas/tuplas/atributos;
• A capacidade de processamento com relação ao tamanho do banco de dados;

13
• Variedade de tipos de atributos que a ferramenta pode manipular; e
• Tipo de linguagem de consulta.
Goebel e Gruenwald (1999) propõem, também, um esquema de classificação de
características que pode ser usado para estudar ferramentas de descoberta de
conhecimento e de mineração de dados. Neste esquema, as características das
ferramentas são classificadas em três grupos chamados características gerais,
conectividade de banco de dados e características de mineração de dados. As Tabelas 4,
5 e 6 mostram como as características das ferramentas são classificadas de acordo com
esses grupos.
Tabela 4: Características Gerais da Ferramenta
Característica ClassificaçãoProduto Nome e vendedor do produto de softwareStatus da Produção P=Comercial, A=Alfa, B=Beta, R=Protótipo de PesquisaStatus Legal PD=Domínio Público, F=Freeware, S=SharewareLicença Acadêmica Se existe licença acadêmica livre disponível ou redução de custoDemo D=Versão Demo disponível para download na internet, R=Demo disponível
através de requisição, U=Não conhecidoArquitetura S=Standalone, C/S=Cliente/Servidor, P=Processamento ParaleloSistemasOperacionais
Lista de sistemas operacionais para os quais a versão atual do software podeser obtida.
Tabela 5: Conectividade de Bancos de Dados da Ferramenta
Característica ClassificaçãoFontes de Dados T=Arquivos texto Ascii, D=Arquivos Dbase, P=Arquivos Paradox,
F=Arquivos Foxpro, Ix=Informix, O=Oracle, Sy=Sybase, Ig=Ingres, A=MSAccess, OC=Conexão aberta de banco de dados (ODBC), SS=Servidor MSSQL, Ex=MS Excel, L=Lótus 1-2-3.
Conexão a BD Onl=Online, Offl=OfflineTamanho S=Pequeno (até 10.000 registros), M=Mediano (10.000 a 1.000.000 registros),
L=Grande (mais de 1.000.000)Modelo R=Relacional, O=Orientado a Objetos, 1= Uma TabelaAtributos Co=Contínuo, Ca=Categórico (valores numéricos discretos), S=SimbólicoConsulta S=Linguagem de consulta estruturada (SQL ou derivada), Sp=Uma linguagem
de consulta específica, G=Interface gráfica de usuário, N=Não aplicável,U=Não conhecido

14
Tabela 6: Características de Mineração de Dados da Ferramenta
Característica ClassificaçãoTarefas Descobertas Pré=Processamento de Dados (Amostragem, Filtragem), P=Predição,
Regr=Regressão, Clã=Classificação, Clu=Agrupamento, A=Associação,Vis=Visualização do Modelo, EDA=Análise de Dados Exploratória
Metodologia deDescoberta
NN=Redes Neurais, GA=Algoritmos Genéticos, FS=Conjuntos Fuzzy,RS=Conjuntos Irregulares (Rough), St=Métodos Estatísticos, DT=Árvores deDecisão, RI=Indução de Regras, BN=Redes Bayseanas, CBR= RaciocínioBaseado em Casos
Interação Humana A=Autônoma, G=Processo de descoberta guiado ao homem, H=Altamenteinterativo.
6 Metodologia para Avaliação e Seleção de Software de Mineração de Dados
Collier et al (1999) apresentam uma estrutura para avaliar ferramentas de
mineração de dados e descrevem uma metodologia para aplicação desta estrutura.
Quatro categorias de critérios para avaliar ferramentas de mineração de dados
podem ser sugeridas: desempenho, funcionalidade, usabilidade e suporte de atividades
principais de uma organização ou sistema (Collier et al, 1999). A seguir, estas
categorias são descritas.
• Desempenho
Desempenho é a habilidade de manipular uma variedade de fontes de dados de
maneira eficiente. A Tabela 7 relaciona critérios de desempenho computacional.
• Funcionalidade
Funcionalidade é a inclusão de uma variedade de capacidades, técnicas e
metodologias para mineração de dados. Ajuda avaliar o quanto a ferramenta adaptar-se-
á a diferentes domínios de problema de mineração de dados. A Tabela 8 mostra critérios
de funcionalidade.
• Usabilidade
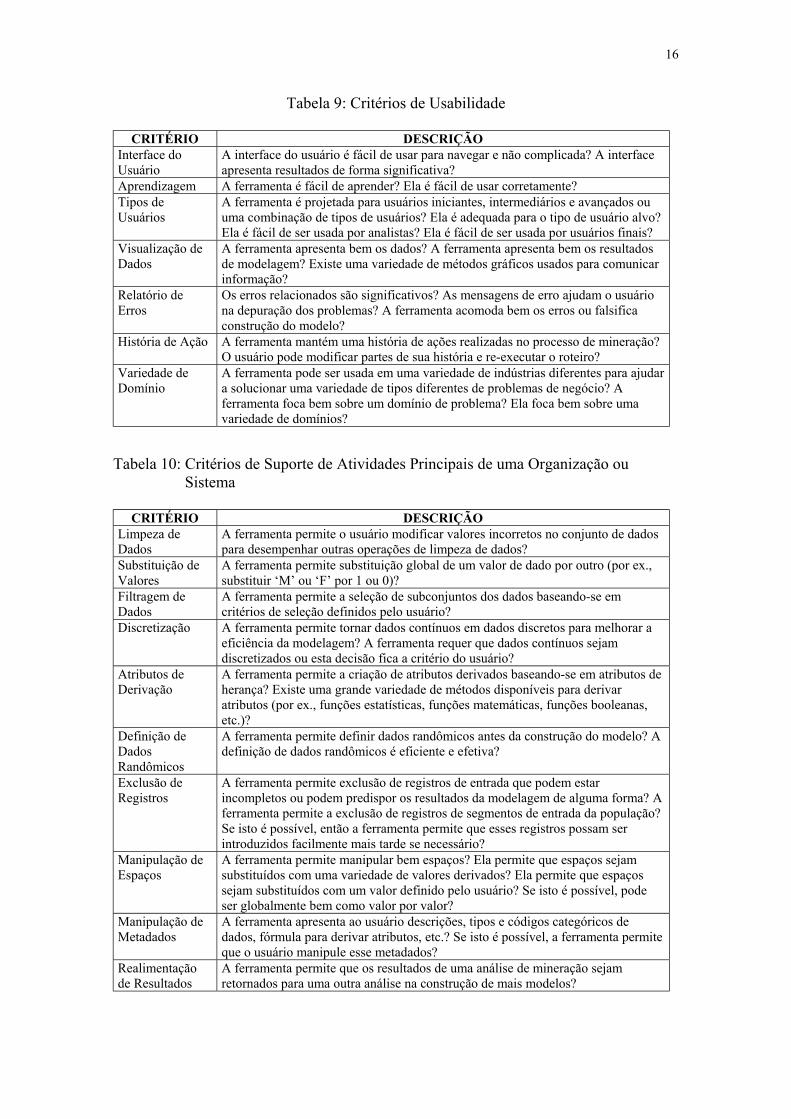
Usabilidade é a acomodação de diferentes níveis e tipos de usuários sem perda
de funcionalidade ou utilidade. Uma boa ferramenta deve fornecer parâmetros
significativos para ajudar a depurar problemas e melhorar a saída. A Tabela 9 relaciona
critérios de usabilidade.

15
• Suporte de atividades principais de uma organização ou sistema
Esta categoria permite ao usuário desempenhar limpeza, manipulação,
transformação, visualização de dados e outras tarefas para suporte à mineração de
dados. A Tabela 10 mostra critérios para a categoria de suporte de atividades principais
de uma organização ou sistema.
Tabela 7: Critérios de Desempenho Computacional
CRITÉRIO DESCRIÇÃOVariedade dePlataforma
O software executa sobre uma grande variedade de plataformas computacionais?Ele executa sobre plataformas de usuário típicas de negócio?
Arquitetura deSoftware
O software usa arquitetura cliente-servidor ou arquitetura stand-alone? O usuáriotem uma escolha de arquiteturas?
Acesso a DadosHeterogêneos
O software tem interface com uma variedade de fontes de dados (RDBMS,ODBC, CORBA etc)? Ele requer qualquer software auxiliar para fazer isto?
Tamanho dosDados
O software escala para grandes conjuntos de dados? O desempenho é linear ouexponencial?
Eficiência O software produz resultados em uma quantidade razoável de tempo relativo aotamanho dos dados, as limitações do algoritmo e outras variáveis?
Interoperabilidade A ferramenta facilita a interface com outras ferramentas de suporte KDD? Ela usauma arquitetura padrão tal como CORBA ou alguma outra API proprietária?
Robustez A ferramenta executa consistentemente sem parar? Se a ferramenta não realizauma análise de mineração de dados, ela falha quando a análise parece estar quasecompleta?
Tabela 8: Critérios de Funcionalidade
CRITÉRIO DESCRIÇÃOVariedadeAlgorítmica
O software fornece uma variedade adequada de técnicas e algoritmos de mineraçãoincluindo redes neurais, indução de regas, árvores de decisão, agrupamento, etc?
MetodologiaPrescrita
O software ajuda o usuário a apresentar um estilo, metodologia de mineraçãopasso a passo para ajudar a evitar resultados incorretos?
Validação doModelo
A ferramenta suporta validação do modelo além da sua criação? A ferramentaencoraja validação como parte da metodologia?
Flexibilidade deTipo de Dado
A implementação dos algoritmos manipula uma grande variedade de tipos dedados, dados contínuos sem amarração, etc?
Facilidade deModificação dosAlgoritmos
O usuário tem a habilidade para modificar e sintonizar bem os algoritmos demodelagem?
Amostragem deDados
A ferramenta permite amostragem randômica de dados para modelagem depredição?
Reportagem Os resultados de uma análise de mineração resultam em uma variedade decaminhos? A ferramenta fornece resultados resumidos e resultados detalhados? Aferramenta seleciona registros de dados precisos que capacitam um perfil meta?
Exportação deModelo
Após um modelo ser validado, a ferramenta fornece uma variedade de caminhospara ser exportada para uso em outro ambiente (por ex., programa C, SQL, etc.)?
16
Tabela 9: Critérios de Usabilidade
CRITÉRIO DESCRIÇÃOInterface doUsuário
A interface do usuário é fácil de usar para navegar e não complicada? A interfaceapresenta resultados de forma significativa?
Aprendizagem A ferramenta é fácil de aprender? Ela é fácil de usar corretamente?Tipos deUsuários
A ferramenta é projetada para usuários iniciantes, intermediários e avançados ouuma combinação de tipos de usuários? Ela é adequada para o tipo de usuário alvo?Ela é fácil de ser usada por analistas? Ela é fácil de ser usada por usuários finais?
Visualização deDados
A ferramenta apresenta bem os dados? A ferramenta apresenta bem os resultadosde modelagem? Existe uma variedade de métodos gráficos usados para comunicarinformação?
Relatório deErros
Os erros relacionados são significativos? As mensagens de erro ajudam o usuáriona depuração dos problemas? A ferramenta acomoda bem os erros ou falsificaconstrução do modelo?
História de Ação A ferramenta mantém uma história de ações realizadas no processo de mineração?O usuário pode modificar partes de sua história e re-executar o roteiro?
Variedade deDomínio
A ferramenta pode ser usada em uma variedade de indústrias diferentes para ajudara solucionar uma variedade de tipos diferentes de problemas de negócio? Aferramenta foca bem sobre um domínio de problema? Ela foca bem sobre umavariedade de domínios?
Tabela 10: Critérios de Suporte de Atividades Principais de uma Organização ouSistema
CRITÉRIO DESCRIÇÃOLimpeza deDados
A ferramenta permite o usuário modificar valores incorretos no conjunto de dadospara desempenhar outras operações de limpeza de dados?
Substituição deValores
A ferramenta permite substituição global de um valor de dado por outro (por ex.,substituir ‘M’ ou ‘F’ por 1 ou 0)?
Filtragem deDados
A ferramenta permite a seleção de subconjuntos dos dados baseando-se emcritérios de seleção definidos pelo usuário?
Discretização A ferramenta permite tornar dados contínuos em dados discretos para melhorar aeficiência da modelagem? A ferramenta requer que dados contínuos sejamdiscretizados ou esta decisão fica a critério do usuário?
Atributos deDerivação
A ferramenta permite a criação de atributos derivados baseando-se em atributos deherança? Existe uma grande variedade de métodos disponíveis para derivaratributos (por ex., funções estatísticas, funções matemáticas, funções booleanas,etc.)?
Definição deDadosRandômicos
A ferramenta permite definir dados randômicos antes da construção do modelo? Adefinição de dados randômicos é eficiente e efetiva?
Exclusão deRegistros
A ferramenta permite exclusão de registros de entrada que podem estarincompletos ou podem predispor os resultados da modelagem de alguma forma? Aferramenta permite a exclusão de registros de segmentos de entrada da população?Se isto é possível, então a ferramenta permite que esses registros possam serintroduzidos facilmente mais tarde se necessário?
Manipulação deEspaços
A ferramenta permite manipular bem espaços? Ela permite que espaços sejamsubstituídos com uma variedade de valores derivados? Ela permite que espaçossejam substituídos com um valor definido pelo usuário? Se isto é possível, podeser globalmente bem como valor por valor?
Manipulação deMetadados
A ferramenta apresenta ao usuário descrições, tipos e códigos categóricos dedados, fórmula para derivar atributos, etc.? Se isto é possível, a ferramenta permiteque o usuário manipule esse metadados?
Realimentaçãode Resultados
A ferramenta permite que os resultados de uma análise de mineração sejamretornados para uma outra análise na construção de mais modelos?

17
6.1 Aplicação Metódica da Estrutura
A metodologia proposta por Collier et al (1999) para seleção entre ferramentas
de mineração de dados comercialmente disponíveis fornece um meio de evitar a seleção
de uma ferramenta inadequada. Ela é dividida em seis fases. A Figura 3 representa estas
fases.
Figura 3: Fases da Metodologia para Seleção de Ferramentas de Mineração de Dados
Pré-seleção daFerramenta
Identificação deCritérios de
Seleção
Atribuição dePesos aosCritérios
Registro dosPontos da
Ferramenta
Avaliação dosPontos
Seleção daFerramenta
Reduzir o conjunto de ferramentas Eliminar ferramentas que não serão selecionadasdevido a restrições rígidas da organização ou dovendedor
Identificar quaisquer critérios adicionais que sãoespecíficos a uma organização particular Considerar custo do software, restrições deplataforma, habilidades do usuário final, projetosde mineração de dados específicos, etc.
Assinalar pesos para cada critério dentro de cadacategoria, de tal forma que o total de pesos emcada categoria seja 1.00 ou 100%.
Escolher uma ferramenta de referência e atribuir 3pontos para cada critério. Registrar pontos a cada critério de seleção para asoutras ferramentas, usando uma escala de taxasdiscretas e baseando-se na ferramenta de referência Atribuir peso para cada categoria de critérios, pordefault pode ser 0.20, mas os pesos podem serajustados para enfatizar ou não particularidades decategorias de critérios.
Rever os pesos assinalados para os critérios deseleção e ajustá-los se necessário.
Escolher a ferramenta com maior peso médio

18
7 EXEMPLOS DE FERRAMENTAS DE MINERAÇÃO DE DADOS
Existem ferramentas que implementam uma ou mais técnicas de mineração de
dados. A Tabela 11 relaciona algumas dessas ferramentas, fornecendo informações tais
como: a empresa fornecedora, as técnicas implementadas de mineração de dados e
exemplos de aplicações.
Tabela 11: Ferramentas de Mineração de Dados
Ferramenta/Empresa Fornecedora
Técnicas deMineração de Dados
Aplicações
AIRA/Hycones IT (1998)
Regras de associação Gerenciamento de relacionamento de cliente,marketing, detecção de fraude, controle deprocesso e controle de qualidade.
Alice 5.1/Isoft AS. (1998)
Árvore de decisãoRaciocínio baseadoem casos
Política de crédito, marketing, saúde, controlede qualidade, recursos humanos.
Clementine/Integral Solutions Limited(ISL, 1996)
Indução de regrasÁrvores de decisãoRedes neurais
Marketing direto, identificação deoportunidades de venda cruzada, retenção decliente, previsão de lucro do cliente,detecção de fraude, segmentação e lucro docliente.
DataMind /DataMind Technology Center(1998), (Groth, 1998)
(abordagem própria) Não identificadas.
Decision Series/Neovista Solutions Inc.(1998)
Árvore de decisãoMétodos estatísticosIndução de regrasRedes neurais
Marketing direcionado, detecção de fraude,retenção de cliente, análise de risco,segmentação de cliente, análise de promoção.
Intelligent Miner/IBM (1997)
Árvores de decisãoRedes neurais
Segmentação de cliente, análise de conjuntode itens, detecção de fraude.
KnowledgeSEEKER/Angoss IL (Groth, 1998)
Árvores de decisãoIndução de regras
Lucro e segmentação de cliente para detecçãode fraude e análise de risco, controle deprocesso, marketing direto.
MineSet/Silicon Graphics ComputerSystems (2000)
Métodos estatísticosÁrvores de decisãoIndução de regras
Áreas da saúde, farmacêutica, biotecnologia equímica.
NeuralWorks Predict/NeuralWare (Groth, 1998)
Rede neural Indústria.
PolyAnalyst/Megaputer Intelligence Ltd.(1998)
Algoritmo genéticoMétodos estatísticosIndução de regras
Marketing direto, pesquisa médica, análise deconjunto de itens.
WEKA Regras de associaçãoÁrvore de decisãoIndução de regras
Marketing direto, detecção de fraude, etc.

19
8 ESTUDO DE CASO
No estudo de caso apresentado a seguir, foram utilizados dados da CAPES do
ano de 1998. A CAPES é uma agência de fomento à Pós-Graduação do Brasil que
mantém um sistema de avaliação de cursos, reconhecido e utilizado por outras
instituições nacionais (CAPES, 2001).
A CAPES possui bancos de dados contendo informações sobre os Programas de
Pós-Graduação do Brasil, tais como: nível do curso, pesquisadores vinculados ao
Programa, produção científica, teses/dissertações defendidas, identificação do
orientador de cada tese/dissertação, etc.
Como pode ser notado, a CAPES é responsável pela avaliação e credenciamento
da pós-graduação strito-senso do país. Para tal, seus instrumentos de captura de
informações, utilizados por cerca de 1400 Programas, procuram mapear as atividades
realizadas anualmente no âmbito de cada Programa. O resultado é a construção de
ampla base de dados que permite inspecionar diversos aspectos da pós-graduação
brasileira.
Para a realização deste estudo de caso, a descoberta de conhecimento foi
realizada seguindo, basicamente, três etapas, são elas: Pré-processamento, Mineração de
Dados e Pós-processamento. A seguir essas etapas são descritas.
8.1 Pré-Processamento
Na etapa de pré-processamento, as principais atividades são (ver Figura 2):
definição de objetivos, acesso e preparação de dados (seleção e transformação de dados)
e definição de um estudo.
Neste estudo, o principal objetivo é mostrar a aplicação de técnicas de mineração
de dados na solução de problemas de associação e de classificação. As técnicas
aplicadas são: Descoberta de Regras de Associação e Árvore de Decisão. Para tal, foram
inspecionados os seguintes objetivos de investigação:
1) Estudo da relação Fomento x Nível de Formação do Quadro Funcional do
Programa: verificar se existe alguma relação entre quantidade de bolsas fornecidas
ao Programa, sua produtividade e a titulação de seus docentes, pesquisadores, e
discentes autores;

20
2) Estudo da relação entre a carga de orientação e tempo de titulação dos orientandos:
verificar se existe alguma relação entre o tempo de formação do aluno e o total de
orientandos do seu orientador;
3) Estudo da relação entre o tempo de titulação com a disponibilidade do Fomento
(bolsas) no Programa ou com a participação discente em projetos: verificar se existe
alguma relação entre o tempo de formação do aluno com o fato do mesmo possuir
ou não bolsa e com a vinculação de sua dissertação a projetos.
O conhecimento descoberto poderá ser aplicado pela CAPES visando:
• A inspeção sobre os dados para verificar se indicadores de qualidade da pós-
graduação apresentam coerência, quando relacionados;
• A verificação de hipóteses de “senso comum” comentadas na comunidade científica
(ex: mais orientandos maior tempo médio de titulação).
Após os objetivos da mineração de dados serem definidos, deve-se selecionar os
atributos necessários para as investigações a serem realizadas. A Tabela 12 relaciona os
atributos selecionados de cada tabela de banco de dados utilizada como base para o
estudo de caso. A seleção de alguns atributos de identificação é necessária, neste
momento, para possibilitar a junção das tabelas na fase de transformação dos dados.
Tabela 12: Atributos Selecionados das Tabelas dos Bancos de Dados da CAPES
Nome da Tabela de Entrada Atributos
COL_PROGRAMAS AnoBase, Codigo, IdIESPais, RdnNivel, Nome, IdAreaBasicaCOL_TESES AnoBase, IdPrograma, Sequencial, IdPessoal, MatriculaAutor,
DefesaTese, Nivel, IdProjetoPesquisaCOL_R_TESES_AGENCIAS AnoBase, IdPrograma, IdTese, NumeroMesesCOL_R_TESES_ORIENTADORES AnoBase, IdPrograma, IdTese, IdPessoalOrientador, TipoCOL_DISCENTES_AUTORES AnoBase, IdPrograma, IdPessoal, NivelTitulacaoCOL_DOCENTES AnoBase, IdPrograma, IdPessoal, NumeroOrientandosMestrado,
NumeroOrientandosDoutorado, TitulacaoAtualCOL_PESQUISADORES AnoBase, IdPrograma, IdPessoal, TitulacaoAtualCOL_PRODUCAO AnoBase, IdPrograma, AreaProdução, VinculoTese,
IdTipoProducao, IdOrientadorTeseG_IES_PAÍS Codigo, Nome, SiglaG_AREA_SUBAREA Código, IdGrandeArea, IdArea
O terceiro passo na etapa de pré-processamento é definir as transformações
necessárias sobre os atributos selecionados. Neste caso, alguns resumos devem ser
obtidos.

21
A seguir, para cada objetivo, são relacionadas tabelas usadas como fonte de
entrada na obtenção de cada tabela de saída, que são as tabelas de dataset2 usadas como
entrada para o algoritmo de mineração de dados. Os resumos são descritos nos atributos
das tabelas de saída.
1) Estudo da relação Fomento x Nível de Formação do Quadro Funcional do Programa
Tabelas de entrada:- COL_TESES
- COL_R_TESES_AGENCIAS
- COL_PRODUCAO
- COL_DOCENTES
- COL_PESQUISADORES
- COL_DISCENTES_AUTORES
- COL_PROGRAMAS
- G_IES_PAIS
- G_AREA_SUBAREA
Tabela de saída:DS_BOLSAS_PRODUTIVIDADE
- IdGrArea;
- Área: descrição da área básica;
- GrandeArea: descrição da grande área;
- BolsaAluno: média do número de meses do financiamento por Programa
(BolsaAluno = ∑ sNumeroMese / ∑Alunos );
- TotalProducao: somatória das produções por Programa.
- Produtividade: média de produção por docente/pesquisador/discente autor
(Produtividade = ∑ oducaoPr / (∑Docentes + quisadoresPes∑ +
∑ utoresDiscentesA ));
- TotalGraduados: total de docentes, pesquisadores e discentes autores com
titulação atual de graduação;
- TotalMestres: total de docentes, pesquisadores e discentes autores com
titulação atual de mestrado;
- TotalDoutores: total de docentes, pesquisadores e discentes autores com
titulação atual de doutorado;
2 Dataset pode ser definido como um “banco de dados” (em um sentido fraco do termo) contendo apenaso conjunto de dados específico para um tipo de investigação a ser realizada.

22
2) Estudo da relação entre a carga de orientação e tempo de titulação dos orientandos
Tabelas de entrada:- COL_R_TESES_ORIENTADORES
- COL_TESES
- COL_DOCENTES
- COL_PROGRAMAS
- G_IES_PAIS
Tabela de saída:DS_ORIENTANDOS_FORMACAO
- IdGrArea;
- Área: descrição a área básica;
- GrandeArea: descrição da grande área;
- TotalOrientandos: número orientandos mestrado + número orientandos
doutorado por orientador;
- MediaMeses: média de meses de formação dos alunos por orientador;
3) Estudo da relação entre o tempo de titulação com a disponibilidade do Fomento
(bolsas) no Programa ou com a participação discente em projetos
Tabelas de entrada:
- COL_TESES
- COL_R_TESES_AGENCIAS
- COL_PRODUCAO
- COL_PROGRAMAS
- G_IES_PAIS
- G_AREA_SUBAREA
Tabela de saída:DS_FORMACAO_BOLSA_VINCULO
- IdGrArea;
- Área: descrição a área básica;
- GrandeArea: descrição da grande área;
- MesesFormação: total de meses para formação do aluno;
- Bolsa: 1 – com bolsa, 0 – sem bolsa;
- Vínculo: 1 – com vínculo a projeto, 0 – sem vínculo a projeto;
Os dados de cada tabela do DataSet foram discretizados, ou seja, transformados
em variáveis de categorias, para diminuir a quantidade de regras geradas por algoritmos

23
de mineração de dados e, principalmente, facilitar o entendimento dos resultados
obtidos. A discretização foi realizada de acordo com as especificações apresentadas na
Tabela 13. Cada variável de entrada é dividida em faixas de valores. As faixas foram
manualmente definidas após uma análise realizada sobre os valores dos dados dos
cursos de pós-graduação da Universidade Federal de Santa Catarina.
A Tabela 14 mostra a relação das tabelas do DataSet, com a unidade de análise
para cada uma das tabelas.
O número de tuplas obtidas em cada tabela do DataSet foi:
• DS_BOLSAS_PRODUTIVIDADE: 474;
• DS_ORIENTANDOS_FORMACAO: 4981;
• DS_FORMACAO_BOLSA_VINCULO: 8398.
Os dados utilizados foram dos cursos de pós-graduação das seguintes
instituições de ensino do Brasil, por região do país3:
• Região Sul: UFSC, UFRGS, UFPR, CEFET/PR, PUC/PR, PUC/RS, UEL, UFPEL,
FURG, UNISINOS, FFFCMPA, UPF.
• Região Sudeste: UFRJ, UFU, UFMG, UFSCAR, UNICAMP, USP, USP/CENA,
USP/RP, UMESP, UNESP, UNESP/ARAR, UNESP/ASS, UNESP/BOT,
UNESP/GUAR, UNESP/JAB, UNESP/MAR, UNESP/RC, UNESP/SJC,
UNESP/SJRP, UNI-RIO, UNIMEP, UGF, UNIFESP.
• Região Nordeste: UFBA, UFPB/CG, UFPB/JP, UFPE, UFRN, UFC, UFPA.
• Região Centro-Oeste: UFG, UFMT, UNB.
3 Não foi possível utilizar os bancos de dados operacionais de todos os cursos de pós-graduação do Brasil
porque houve problema na descompressão de alguns deles.

24
Tabela 13: Discretização dos Dados das Tabelas do DataSet
Variável Faixas ValoresIdGrandeArea Ciências Exatas e da Terra
Ciências BiológicasEngenhariasCiências da SaúdeCiências AgráriasCiências Sociais AplicadasCiências HumanasLingüística, Letras e ArtesGrande Área não InformadaOutros
10000003200000063000000940000001500000046000000770000000800000029000000090000005
BolsaAluno BolsaAluno0_12BolsaAluno13_18BolsaAluno19_24BolsaAluno25_30BolsaAluno31_
maior ou igual a 0 e menor ou igual a 12maior ou igual a 13 e menor ou igual a 18maior ou igual a 19 e menor ou igual a 24maior ou igual a 25 e menor ou igual a 30maior ou igual a 31
Produtividade(Quantitativa)
Produtiv0_1Produtiv2_3Produtiv4_6Produtiv7_10Produtiv11_
maior ou igual a 0 e menor ou igual a 1maior ou igual a 2 e menor ou igual a 3maior ou igual a 4 e menor ou igual a 6maior ou igual a 7 e menor ou igual a 10maior ou igual a 11
TotalProducao TotProd0_50TotProd50_100TotProd101_200TotProd201_300TotProd301_400TotProd401_
maior ou igual a 0 e menor ou igual a 50maior ou igual a 51 e menor ou igual a 100maior ou igual a 101 e menor ou igual a 200maior ou igual a 201 e menor ou igual a 300maior ou igual a 301 e menor ou igual a 400maior ou igual a 401
TotalGraduados TotalGrad0_5TotalGrad6_20TotalGrad21_40TotalGrad41_70TotalGrad71_100TotalGrad101_
maior ou igual a 0 e menor ou igual a 5maior ou igual a 6 e menor ou igual a 20maior ou igual a 21 e menor ou igual a 40maior ou igual a 41 e menor ou igual a 70maior ou igual a 71 e menor ou igual a 100maior ou igual a 101
TotalMestres TotalMest0_20TotalMest21_40TotalMest41_20TotalMest71_20TotalMest101_200TotalMest201_
maior ou igual a 0 e menor ou igual a 20maior ou igual a 21 e menor ou igual a 40maior ou igual a 41 e menor ou igual a 70maior ou igual a 71 e menor ou igual a 100maior ou igual a 101 e menor ou igual a 200maior ou igual a 201
TotalDoutores TotalDout0_20TotalDout21_40TotalDout41_60TotalDout61_80TotalDout81_100TotalDout101_
maior ou igual a 0 e menor ou igual a 20maior ou igual a 21 e menor ou igual a 40maior ou igual a 41 e menor ou igual a 60maior ou igual a 61 e menor ou igual a 80maior ou igual a 81 e menor ou igual a 100maior ou igual a 101
NumeroOrientandos NumOrient_1NumOrient_2NumOrient_3NumOrient4_7NumOrient8_
igual a 1igual a 2igual a 3maior ou igual a 4 e menor ou igual a 7maior ou igual a 8
MesesFormacao MesesForm0_12MesesForm13_18MesesForm19_24MesesForm25_30MesesForm31_36MesesForm36_
maior ou igual a 0 e menor ou igual a 12maior ou igual a 13 e menor ou igual a 18maior ou igual a 19 e menor ou igual a 24maior ou igual a 25 e menor ou igual a 30maior ou igual a 31 e menor ou igual a 36maior ou igual a 36

25
Tabela 14: Relação das Tabelas do DataSet e seus Atributos
Nome da tabela Atributos Unidade Básicade Análise
DS_BOLSAS_PRODUTIVIDADE IdGrArea, Área, GrandeArea,BolsaAluno, TotalProducao,Produtividade, TotalGraduados,TotalMestres, TotalDoutores
Programa dePós-Graduação
DS_ORIENTANDOS_FORMACAO IdGrArea, Área, GrandeArea,TotalOrientandos, MediaMeses
Orientador
DS_FORMACAO_BOLSA_VINCULO IdGrArea, Área, GrandeArea,MesesFormacao, Bolsa, Vinculo
Orientando
8.2 Mineração de Dados
Na etapa de mineração de dados foram identificadas duas tarefas a serem
solucionadas, associação e classificação. Considerando que os dados são classificados
como variáveis de categorias, por terem sido discretizados, Descoberta de Regras de
Associação e Árvore de Decisão são as técnicas mais indicadas para a solução das
tarefas identificadas, de acordo com as Tabelas 2 e 3.
As técnicas de mineração de dados foram aplicadas sobre os dados da CAPES
com a utilização de três algoritmos. O primeiro foi o “apriori”, que implementa a
técnica de Descoberta de Regras de Associação, realizando assim a tarefa de associação.
Este algoritmo foi implementado por Gonçalves (2000) e aplicado através do protótipo
do ambiente ADesC (Dias, 2001).
O segundo algoritmo foi o C4.5 (Quinlan, 1993), que implementa a técnica de
Árvore de Decisão e realiza a tarefa de classificação. Este algoritmo foi estudado e
aplicado no Trabalho de Final de Curso de Igarashi (2002), utilizando o programa C4.5
Decision Tree Generator (C4.5DTG – Versão 1.00), obtido através do endereço
www.sff.sdf.br.
O terceiro algoritmo aplicado foi o J48.PART, que também implementa a
técnica de Árvore de Decisão e realiza a tarefa de classificação. Este algoritmo foi
estudado e aplicado no Trabalho de Graduação de Centeio (2002), utilizando o Weka 3,
que é um software de aprendizagem de máquina em Java, obtido através do endereço
www.cs.waikato.ac.nz/ml/weka/index.html.
A seguir são apresentados os resultados obtidos com a aplicação das técnicas de
Descoberta de Regras de Associação e de Árvore de Decisão.

26
8.2.1 Descoberta de Regras de Associação
A técnica de Descoberta de Regras de Associação foi aplicada neste trabalho
através do algoritmo “apriori”, tendo como parâmetros de entrada os dados dos
Programas de Pós-Graduação do Brasil, já preparados e armazenados no dataset, o
suporte mínimo e o grau de confiança. Os dois últimos parâmetros podem ser escolhidos
e ajustados na busca de resultados que levem aos objetivos relacionados na etapa de
análise do sistema. Os valores mínimos de suporte e confiança utilizados nos
experimentos foram 8% e 40%, respectivamente.
A análise dos resultados baseou-se na abordagem objetiva, ou seja, procurou-se
selecionar as regras de associação de maior interesse conforme os valores de suporte e
confiança e em consistência com os dados. De acordo com os objetivos de investigação
definidos anteriormente, tem-se (Dias, 2001):
1) Estudo da relação Fomento x Nível de Formação do Quadro Funcional do Programa
A Tabela 15 relaciona as regras geradas para este estudo.
Tabela 15: Regras Geradas para o Primeiro Objetivo - Apriori
Regra Suporte ConfiançaSe o Programa possui de 21 a 40 mestres, então ele produz de2 a 3 publicações em média por pesquisador por ano
21,73% 45,18%
Se o Programa possui de 19 a 24 meses de financiamento poraluno concluído, então ele produz de 2 a 3 publicações emmédia por pesquisador
19,62% 53,76%
Se o Programa possui de 25 a 30 meses de financiamento poraluno concluído, então ele produz de 2 a 3 publicações porpesquisador
16,88% 48,19%
Se o Programa possui de 25 a 30 meses de financiamento poraluno concluído, então ele possui de 21 a 40 Mestres
15,19% 43,37%
Interpretação das Regras:
• 21 a 40 mestres implica em Produtividade 2 a 3
21,73% dos Programas de pós-graduação do Brasil possuem de 21 a 40
mestres no corpo docente e discente e produzem de 2 a 3 publicações em
média por pesquisador4.
45,18% dos Programas de pós-graduação do Brasil que possuem de 21 a 40
mestres produzem de 2 a 3 publicações em média por pesquisador.

27
• Bolsa x Aluno 19 a 24 meses implica em Produtividade 2 a 3
19,62% dos Programas possuem em média 19 a 24 meses de financiamento
por aluno concluído e produzem de 2 a 3 publicações em média por
pesquisador.
53,76% dos Programas que possuem em média 19 a 24 meses de
financiamento por aluno concluído produzem de 2 a 3 publicações em média
por pesquisador.
• Bolsa x Aluno 25 a 30 meses implica em Produtividade 2 a 3
16,88% dos Programas possuem em média 25 a 30 meses de financiamento
por aluno e produzem de 2 a 3 publicações por pesquisador.
48,19% dos Programas que possuem em média 25 a 30 meses de
financiamento por aluno concluído produzem de 2 a 3 publicações por
pesquisador.
• Bolsa x Aluno 25 a 30 meses implica em 21 a 40 Mestres
15,19% dos Programas possuem em média 25 a 30 meses de financiamento
por aluno concluído e possuem de 21 a 40 mestres.
43,37% dos Programas que possuem em média 25 a 30 meses de
financiamento por aluno concluído possuem 21 a 40 mestres.
Pode-se observar que o aumento relativo na quantidade de bolsas de um
Programa implica em aumento na Produção, mas há um nível de saturação para esta
regra (quando a média de bolsa por aluno está entre 25 e 30 meses). É interessante
observar que esta constatação vai de encontro à política de redução do tempo máximo
de bolsa adotada pela CAPES.
As regras referentes à Titulação do corpo Docente e Discente não permitem o
mesmo tipo de análise, dado que apresentaram relações absolutas e independentes.
2) Estudo da relação entre a carga de orientação e tempo de titulação dos orientandos:
A Tabela 16 relaciona as regras geradas para este estudo.
4 Pesquisador neste contexto inclui, também, docente e discente-autor.

28
Tabela 16: Regras Geradas para o Segundo Objetivo - Apriori
Regra Suporte ConfiançaSe o orientador possui de 4 a 7 orientandos, então a média detempo de formação de seus orientandos de mestrado é maiorque 36 meses
16,92% 49,21%
Se o orientador possui 1 orientando, então o tempo deformação de seu orientando de mestrado é maior que 36meses
8,43% 41,71%
Interpretação das Regras:
• Número Orientandos 4 a 7 implica em Meses Formação > 36
16,92% dos orientadores têm de 4 a 7 orientandos e o tempo médio de
formação de seus orientandos é maior que 36 meses.
49,21% dos orientadores que têm de 4 a 7 orientandos, o tempo médio de
formação de seus orientandos é maior que 36 meses.
• Número Orientandos 1 implica em Meses Formação > 36
8,43% dos orientadores têm 1 orientando e o tempo de formação de seu
orientando é maior que 36 meses.
41,71% dos orientadores que têm 1 orientando, o tempo de formação de seu
orientando é maior que 36 meses.
O estudo mostra que há um equilíbrio nos valores de confiança entre o número
de orientandos de um orientador e o tempo médio de formação de seus orientandos. Isto
indica que não há suporte para a afirmação que alunos de um professor com mais
orientandos tenham maior tempo médio de titulação.
3) Estudo da relação entre o tempo de titulação com a disponibilidade do Fomento
(bolsas) no Programa ou com a participação discente em projetos:
A Tabela 17 relaciona as regras geradas para este estudo.

29
Tabela 17: Regras Geradas para o Terceiro Objetivo - Apriori
Regra Suporte ConfiançaSe o aluno possui bolsa, então sua dissertação está vinculadaa projeto de pesquisa
36,88% 53,27%
Se o aluno possui bolsa, então seu tempo de formação émaior que 36 meses
28,34% 40,94%
Se a dissertação está vinculada a projeto, então o tempo deformação do aluno é maior que 36 meses
21,30% 42,72%
Se o aluno possui bolsa e sua dissertação está vinculada aprojeto, então seu tempo de formação é maior que 36 meses
14,11% 38,26%
Se a área é Ciências Exatas e da Terra, então o aluno possuibolsa
10,16% 82,66%
Se a área é Ciências Humanas, então o aluno possui bolsa 13,06% 72,70%
Se a área é Engenharia, então o aluno possui bolsa 11,44% 65,78%
Se a área é Engenharia, então a dissertação possui vínculocom projeto
10,04% 57,70%
Interpretação das Regras:
• Bolsa implica em Vínculo com projeto
36,88% dos alunos possuem bolsa e sua dissertação tem vínculo com
projeto.
53,27% dos alunos que possuem bolsa, sua dissertação tem vínculo com
projeto.
• Bolsa implica em meses de formação maior que 36
28,34% dos alunos possuem bolsa e seu tempo de formação é maior que 36
meses.
40,94% dos alunos que possuem bolsa, seu tempo de formação é maior que
36 meses.
• Vínculo com projeto implica em meses de formação maior que 36
21,30% das dissertações têm vínculo com projeto e o tempo de formação do
aluno é maior que 36 meses.
42,72% das dissertações que têm vínculo com projeto, o tempo de formação
do aluno é maior que 36 meses.
• Bolsa e vínculo com projeto implicam em meses de formação maior que
36
14,11% dos alunos de mestrado possuem bolsa e vínculo com projeto e o
tempo de formação do aluno é maior que 36 meses.

30
38,26% dos alunos de mestrado que possuem bolsa e vínculo com projeto, o
tempo de formação do aluno é maior que 36 meses.
• Ciências Exatas e da Terra implica em bolsa
10,16% dos alunos de mestrado são da área de Ciências Exatas e da Terra e
possuem bolsa.
82,66% dos alunos de mestrado da área de Ciências Exatas e da Terra
possuem bolsa.
• Ciências Humanas implica em bolsa
13,06% dos alunos de mestrado são da área de Ciências Humanas e possuem
bolsa.
72,70% dos alunos de mestrado da área de Ciências Humanas possuem
bolsa.
• Engenharia implica em bolsa
11,44% dos alunos de mestrado são da área de Engenharia e possuem bolsa;
65,78% dos alunos de mestrado da área de Engenharia possuem bolsa.
• Engenharia implica em vínculo com projeto
10,04% dos alunos de mestrado são da área de Engenharia e possuem
vínculo com projeto.
57,70% dos alunos de mestrado da área de Engenharia possuem vínculo com
projeto.
O estudo permitiu constatar que há um aumento no tempo médio de titulação
quando o aluno possui bolsa ou quando sua dissertação está relacionada a projeto de
pesquisa.
O estudo também comparou a implicação de participação de bolsistas em
projetos. A regra permite afirmar que o impacto da concessão de bolsa na vinculação
com projeto é maior do que no tempo médio de titulação.
Constatou-se ainda que os Programas das áreas de Ciências Exatas e da Terra,
Ciências Humanas e Engenharia são aqueles que possuem o maior número de bolsas e,
também, que mais da metade das dissertações da área de Engenharia possui vínculo com
projeto.

31
8.2.2 Árvore de Decisão
A técnica de Árvore de Decisão foi aplicada através dos algoritmos C4.5 e
J48.PART do Weka, tendo como parâmetros de entrada os dados dos Programas de Pós-
Graduação do Brasil, os mesmos utilizados no algoritmo “apriori”.
A análise dos resultados também foi baseada na abordagem objetiva e é
apresentada a seguir de acordo com os objetivos de investigação definidos
anteriormente:
1) Estudo da relação Fomento x Nível de Formação do Quadro Funcional do
Programa:
Neste estudo, o atributo meta definido foi “média de produção anual por
pesquisador”.
A Tabela 18 relaciona as regras geradas para este estudo.
Tabela 18: Regras Geradas para o Primeiro Objetivo – C4.5 e J48
Regra ConfiançaSe a grande área for Ciências Exatas e da Terra, então aprodutividade do Programa é de 2 a 3 publicações em médiapor pesquisador
81,5%
Se a grande área for Engenharias, então a produtividade doPrograma é de 2 a 3 publicações em média por pesquisador
76,1%
Se a grande área for Ciências Biológicas, então aprodutividade do Programa é de 2 a 3 publicações em médiapor pesquisador
74,2%
Se a grande área for Ciências Agrárias, então a produtividadedo Programa é de 2 a 3 publicações em média porpesquisador
72,6%
Se a grande área for Ciências Sociais Aplicadas, então aprodutividade do Programa é de 2 a 3 publicações em médiapor pesquisador
67,7%
Se a grande área for Ciências Humanas e o total de mestresfor de 41 a 70, então a produtividade do Programa é de 2 a 3publicações em média por pesquisador
64%
Se a grande área for Lingüística, Letras e Artes, então aprodutividade do Programa é de 4 a 6 publicações em médiapor pesquisador
74,1%
Se a grande área for Ciências Humanas, então aprodutividade do Programa é de 4 a 6 publicações em médiapor pesquisador
56,5%
A produtividade do Programa é de 2 a 3 publicações emmédia por pesquisador, independente da área e da formaçãodos pesquisadores
67,3%

32
O estudo mostra que quase 70% dos pesquisadores produzem em média de 2 a 3
publicações por ano, independente de sua formação e de sua área de atuação. Sendo que
para as áreas de Ciências Exatas e da Terra, Engenharias, Ciências Biológicas e
Ciências Agrárias, este percentual é um pouco maior. As regras geradas mostram
também que a produção anual média por pesquisador é maior nas áreas de Lingüística,
Letras e Artes e Ciências Humanas.
A partir das regras geradas, podemos concluir que o atributo “grau de formação
dos pesquisadores” não pode ser considerado como atributo de previsão do atributo
meta. Outro atributo que foi sugerido como um possível atributo previsor, “média de
meses de bolsa por aluno”, nem sequer foi incluído nas regras geradas pelo algoritmo de
classificação.
2) Estudo da relação entre a carga de orientação e tempo de titulação dos orientandos:
Neste estudo, o atributo meta definido foi “tempo de formação do aluno de
mestrado”.
O resultado obtido foi que o aluno de mestrado demora 31 meses ou mais para se
formar, independente do número de orientandos que seu orientador possui e da área do
curso, com 66,7% de confiança.
4) Estudo da relação entre o tempo de titulação com a disponibilidade do Fomento
(bolsas) no Programa ou com a participação discente em projetos:
Neste estudo, o atributo meta definido também foi “tempo de formação do aluno
de mestrado”.
O resultado obtido foi que o aluno de mestrado demora 31 meses ou mais para se
formar, independente da área do curso, dele possuir ou não bolsa e de sua dissertação
estar ou não vinculada a projeto, com 64,7% de confiança. Portanto, os atributos
selecionados nesta investigação e na anterior não influenciam no tempo de formação do
aluno de mestrado, não sendo encontrado, assim, nenhum atributo previsor para este
atributo meta.
8.3 Pós-Processamento
Para a primeira investigação realizada, os resultados obtidos com a aplicação dos
algoritmos de associação e classificação mostram que um pesquisador produz em média

33
2 a 3 publicações por ano, independente de sua formação e da média de meses de bolsa
por aluno de mestrado do programa. Os resultados dos algoritmos de classificação
mostram ainda que a área de atuação do pesquisador pode ser considerada como um
atributo previsor da média de publicação por pesquisador por ano.
Os resultados da segunda investigação realizada, obtidos pelos algoritmos de
associação e de classificação, mostram que o número de orientandos de um orientador
não influencia no tempo de formação do aluno de mestrado.
Na terceira investigação realizada, os resultados obtidos com a aplicação do
algoritmo “apriori” mostram que os fatos de o aluno possuir bolsa e de sua dissertação
estar vinculada a um projeto podem influenciar no tempo de formação do aluno de
mestrado e que mais da metade dos alunos que possuem bolsa sua dissertação está
vinculada a projeto. Também mostrou que determinadas áreas possuem maior número
de bolsas por aluno.
Os resultados obtidos com a aplicação dos algoritmos de classificação para a
terceira investigação mostram que não existe nenhum atributo previsor para o atributo
meta analisado, que foi o tempo de formação do aluno.
Na análise dos resultados deve ser considerado, também, que os dados de
treinamento não abrangem todos os programas de pós-graduação do Brasil e são
restritos ao ano de 1998. Neste ano, o prazo máximo para a conclusão do mestrado
ainda era de 36 meses. Portanto, o fato do aluno de mestrado demorar mais de 31 meses
para se formar era comum.
Através dos resultados obtidos com os algoritmos de associação e de
classificação, pode-se concluir que, para o tipo de aplicação estudado, Ciência &
Tecnologia, as técnicas Descoberta de Regras de Associação e Árvore de Decisão
podem ser utilizadas com sucesso.
A tarefa de classificação deve ser usada quando o objetivo é descobrir atributo(s)
previsor(es) para um ou poucos atributos meta. A vantagem da tarefa de associação é a
correlação que é feita entre todos os atributos, podendo resultar na descoberta de
atributos previsores para mais de um atributo meta.
9 PARÂMETROS NA ESCOLHA DE TÉCNICAS DE MINERAÇÃO DE DADOS
Basicamente, os principais parâmetros a serem considerados na escolha de uma
técnica de mineração de dados são:

34
• Tipo de problema de descoberta de conhecimento a ser solucionado: este parâmetro
é obtido com a definição da tarefa de mineração de dados, que deve estar de acordo
com os objetivos definidos para a descoberta de conhecimento em questão.
• Características dos dados: a adequação da técnica de mineração de dados às
características dos dados (ver Tabela 3) visa, principalmente, minimizar as
dificuldades geralmente encontradas na transformação de dados.
• Forma de aplicação da mineração de dados: a mineração de dados pode ser aplicada
como um processo de verificação, onde o usuário tenta provar uma hipótese acerca
da relação entre os dados, ou como um processo de descoberta, onde não é feita
nenhuma suposição antecipada. Existem técnicas mais propícias para o processo de
verificação (análises estatística e multidimensional) e outras para o processo de
descoberta (regras de associação, árvores de decisão, algoritmos genéticos e redes
neurais). No entanto, pesquisas atuais mostram a aplicação de algoritmo genético no
processo de verificação (Romão, 2002).
• Disponibilidade de ferramenta de mineração de dados: um problema de descoberta
de conhecimento pode ser solucionado, em determinados casos, com a aplicação de
mais de um tipo de técnica de mineração de dados. Assim, pode ser escolhida uma
técnica ou outra dependendo da ferramenta disponível.
10 PARÂMETROS NA ESCOLHA DE FERRAMENTA DE MINERAÇÃO DE
DADOS
Nas seções 5 e 6 deste relatório, foram descritos parâmetros para a escolha de
ferramenta de mineração de dados, sugeridos por (Goebel e Gruenwald, 1999) e (Collier
et al, 1999). Todos os parâmetros sugeridos são bastante relevantes, no entanto, deve-se
considerar a real necessidade da organização e feita uma análise cuidadosa de custo e
benefício na aquisição e utilização de uma ferramenta desse tipo.
Outro parâmetro muito importante a ser considerado é o suporte técnico da
empresa fornecedora. Geralmente, uma ferramenta de mineração de dados, por mais
amigável que seja a sua interface, apresenta dificuldades em sua utilização, inerentes ao
tipo de aplicação. O usuário de uma ferramenta de mineração de dados precisa ter um
bom conhecimento sobre a área de negócio da organização, sobre as técnicas de
mineração de dados implementadas pela ferramenta e de todo o processo de descoberta

35
de conhecimento. Além disso tudo, o usuário precisa saber analisar os resultados
obtidos pela ferramenta e onde e como utilizá-los.
Os parâmetros, sugeridos pelos autores citados e neste projeto, podem ser
resumidos como segue:
• Habilidade de acesso a uma variedade de fontes de dados, de forma on-line e off-
line;
• Capacidade de incluir modelos de dados orientados a objetos ou modelos não
padronizados;
• Capacidade de processamento com relação ao tamanho do banco de dados e ao
número máximo de tabelas/tuplas/atributos;
• Variedade de tipos de atributos que a ferramenta pode manipular;
• Tipo de linguagem de consulta;
• Capacidade de acomodação de diferentes níveis e tipos de usuários sem perda de
funcionalidade ou utilidade;
• Capacidade de adaptar-se a diferentes domínios de problema de mineração de
dados;
• Capacidade de desempenhar limpeza, manipulação, transformação, visualização de
dados e outras tarefas para suporte à mineração de dados;
• Custo x benefício;
• Suporte técnico da empresa fornecedora.
11 CONSIDERAÇÕES FINAIS
A mineração de dados surgiu com o objetivo principal de dar suporte à tomada
de decisões na empresa. Portanto, a aplicação de técnicas de mineração de dados em
sistemas de descoberta de conhecimento em banco de dados busca a descoberta de
regras e padrões em dados que trarão o conhecimento suficiente e adequado para
aquelas pessoas responsáveis pela tomada de decisões na empresa.
O usuário de um sistema de descoberta de conhecimento em banco de dados
precisa ter um sólido entendimento do negócio da empresa para ser capaz de selecionar
corretamente os subconjuntos de dados e as classes de padrões mais interessantes.
Os resultados de mineração de dados obtidos no estudo de casos, apesar da
confiança não chegar a 50% em muitas regras, permitiram levantar hipóteses da

36
justificativa para políticas organizacionais (redução no tempo máximo das bolsas de
pós-graduação pode ser justificável como instrumento de diminuição do tempo médio
de titulação) e elucidar características relevantes de discussão no âmbito da comunidade
científica e de avaliação de cursos de pós-graduação (por exemplo, o fato de não
necessariamente o aumento no total de orientandos implicar em maior tempo de
titulação dos orientados e do acréscimo no tempo médio de bolsas de um programa não
implicar em maior adesão a projetos por parte do corpo discente).
Quando são poucos os atributos analisados no sistema de descoberta de
conhecimento, não faz muita diferença utilizar a técnica de Descoberta de Regras de
Associação ou a técnica Árvore de Decisão, porque os resultados obtidos quase não se
diferem.
Este relatório de projeto de ensino apresentou uma visão geral das áreas de
mineração de dados e descoberta de conhecimento, mostrou os resultados da aplicação
de algoritmos de associação e classificação e relacionou alguns parâmetros a serem
considerados na escolha de técnicas e de ferramentas de mineração de dados, baseados
em sugestões de diversos autores.
12 REFERÊNCIAS BIBLIOGRÁFICAS
AGRAWAL, R., SRIKANT, R. Fast algorithms for mining association rules. 1994.
AGRAWAL, R. et al. Automatic subspace clustering of high dimensional data for data
mining applications. In: SIGMOD Conference, 1998: 94-105.
ARAÚJO, D.L.A.; LOPES, H.S.; FREITAS, A.A. A parallel genetic algorithm for rule
Discovery in large databases. In: IEEE Systems, Man and Cybernetics Conf., v. III,
940-945. Tokyo, Oct. 1999.
AZEVEDO, F.M.; BRASIL, L.M.; OLIVEIRA, R.C.L. Redes neurais com aplicações
em controle e em sistemas especialistas. Visual Books, 2000.
BERRY, M.J.A.; LINOFF, G. Data mining techniques. John Wiley & Sons, Inc. 1997.
BRAGA, A.P.; LUDERMIR, T.B.; CARVALHO, A.C.P.L.F. Redes neurais artificiais:
teoria e aplicações, Livros Técnicos e Científicos Editora S.A., 2000.
CAPES. Coordenação de Aperfeiçoamento de Pessoal de Nível Superior.
URL:http://www.capes.gov.br, 2001.

37
CENTEIO, S. J. D. M. Mineração de dados usando WEKA. Monografia de final do
curso de Bacharelado em Ciência da Computação da Universidade Estadual de
Maringá, 2002.
CHEN, M.-S.; HAN, J.; YU, P.S. Data mining: an overview from database perspective.
TKDE 8(6): 866-883, 1996.
COLLIER, K.; CAREY, B.; SAUTTER, D.; MARJANIEMI, C. A methodology for
evaluating and selecting data mining software. In: 32nd Hawaii International
Conference on System Sciences, 1999.
CRATOCHVIL, A. Data mining techniques in supporting decision making. Master
thesis, Universiteit Leiden, 1999.
DataMind Technology Center. Agent network technology.
URL:http://datamindcorp.com/paper_agetnetwork.html, 1998.
DIAS, M.M. Um modelo de formalização do processo de desenvolvimento de sistemas
de descoberta de conhecimento em banco de dados. Tese de Doutorado do Curso
de Pós-Graduação em Engenharia de Produção da Universidade Federal de Santa
Catarina, 2001.
FREITAS, A.A. A genetic algorithm for generalized rule induction. In: R. Roy et al.
Advances in Soft Computing – Engineering Design and Manufaturing, 340-353.
(Proc. WSC3, 3rd On-Line World Conference on Soft Computing, hosted on the
Internet, July 1998.) Springer-Verlag, 1999.
GOEBEL, M.; GRUENWALD, L. A survey of data mining and knowledge discovery
software tools. In: SIGKDD Explorations, June 1999.
GOLDBERG, D.A. Genetic algorithms in search, otimization, and machine learning.
Addison-Wesley, Reading, MA, 1989.
GONÇALVES, A.L. Utilização de técnicas de mineração de dados na análise dos
grupos de pesquisa no Brasil. Dissertação de Mestrado do Curso de Pós-Graduação
em Engenharia de Produção da Universidade Federal de Santa Catarina, 2000.
GROTH, R. Data mining. Prentice Hall, Inc. 1998.
HARRISON, T.H. Intranet data warehouse. Editora Berkeley, 1998.
HAYKIN, S. Redes neurais: princípios e prática. Bookman, 2001.

38
HILLIS, D.B. Using a genetic algorithm for multi-hypothesis tracking. In: 9th
International Conference on Tools with Artificial Intelligence (ICTAI’97), 1997.
HIPP, J.; GÜNTZER, U.; NAKHAEIZADEH, G. Algorithms for association rule
mining – a general survey and comparison. In: ACM SIGKDD, July/2000, Vol. 2,
No. 1, p. 58-64.
HOLSHEIMER, M.; KERSTEN, M.; MANNILA, H.; TOIVONEN, H. A perspective
on databases and data mining. In: First International Conference on Knowledge
Discovery and Data Mining, pages 447-467, AAAI Press, Menlo Park, CA. 1996.
HSU, W.; LEE, M.L.; LIU, B.; LING, T.W. Exploration Mining in Diabetic Patients
Databases: Findings and Conclusions. In: KDD 2000, Boston MA USA, 430-436,
2000.
Hycones Information Technology. AIRA – Data mining tool.
URL:http://www.hycones.com.br/portuguese.aira.htm, 1998.
IBM. Intelligent Miner.URL:http://scanner-
group.mit.edu/DATAMINING/Datamining/ibm.html,1997.
IGARASHI, W. Análise e Aplicação de uma Técnica de Mineração de Dados.
Monografia de final do curso de Bacharelado em Informática da Universidade
Estadual de Maringá, 2002.
ISL Decision Systems Inc. Clementine – visual tools.
URL:http://www.isl.co.uk/toolkit.html, 1996.
ISOFT SA. Alice 5.1. URL: http://www.alice-soft.com, 1998.
KOSALA, R.; BLOCKEEL, H. Web mining research: a survey. In: ACM SIGKDD,
July/2000, Vol. 2, No. 1, p. 1-15.
LANS, R.V. O que é data mining e uma análise do mercado de produtos. In: 8o
Congresso Nacional de Novas Tecnologias e Aplicações em Banco de Dados.
1997.
LOH, S.; WIVES, L.K.; OLIVEIRA, J.P.M. Concept-based knowledge Discovery in
texts extracted from the web. In: ACM SIGKDD, July/2000, Vol. 2, No. 1, p. 29-39.

39
MA, Y.; LIU, B.; WONG, C.K. Web for data mining: organizing and interpreting the
discovered rules using the web. In: ACM SIGKDD, July/2000, Vol. 1, No. 1, p.16-
23.
MANNILA, H. Methods and problems in data mining. In: International Conference on
Database Theory, Delphi, Greece, January 1997.
Megaputer Intelligence Ltd. PolyAnalyst 3.5. http://www.megaputer.com, 1998.
MEHTA, M. et al. SLIQ: a fast scalable classifier for data mining. EDBT, 1996: 18-32.
MOBASHER, B.; COOLEY, R.; SRIVASTAVA, Automatic personalization based on
web usage mining. In: Communications of the ACM, Vol. 43, No. 8, 2000, p. 142-
151.
NeoVista Solutions Inc. Decision Series 3.0. http://www.neovista.com, 1998.
QUINLAN, Ross. C4.5: Programs for Machine Learning. San Francisco, CA: Morgan
Kaufmann, 1993.
ROMÃO, W. et al. Extração de regras de associação em C & T: o algoritmo Apriori. In:
XIX Encontro Nacional em Engenharia de Produçao, V ICIE - International
Congress of Industrial Engineering. Rio de Janeiro, 1999.
ROMÃO, W. Descoberta de Conhecimento Relevante em Banco de Dados sobre
Ciência e Tecnologia. Tese de Doutorado do Curso de Pós-Graduação em
Engenharia de Produção da Universidade Federal de Santa Catarina, 2001.
SARAWAGI, A.; NAGARALU, S.H. Data mining models as services on the internet.
In: ACM SIGKDD, July/2000, Vol 2, No. 1, p. 24-28.
SHAFER, J.C. et al. SPRINT: a scalable parallel classifier for data mining . VLDB,
1996: 544-555.
Silicon Graphics Computer Systems. MineSet.
http://www.sgi.com/chembio/apps/datamine.html, 2000.
SPILIOPOULOU, M. Web usage mining for web site evaluation. In: Communications
of the ACM, Vol. 43, No. 8, 2000, p.127-134.
Two Crows Corporation. Introduction to data mining and knowledge discovery. Third
Edition, 1999.

40
VIVEROS, M.S.; NEARHOS, J.P.; ROTHMAN, M.J. Applying data mining techniques
to a health insurance information system. In: 22nd VLDB Conference, Mumbai
(Bombay), India, 1996.
WEKA. Waikato Environment for Knowledge Analysis) (2001 URL:
http://www.cs.waikato.ac.nz/ml/weka).
WHITLEY, D. A Genetic algorithm tutorial. Technical Report, 1993.
ZHANG, T. et al. BIRCH: an efficient data clustering method for very large database.
SIGMOD, 1996, p. 103-114.





























