Embed Size (px)
Citation preview

Renato Celso Santos Rodrigues
DETECÇÃO DE REFRÃO USANDO CORRELAÇÃO SOBRE A
ENVOLTÓRIA DO SOM
Dissertação de Mestrado
Universidade Federal de [email protected]
www.cin.ufpe.br/~posgraduacao
RECIFE
2016

Renato Celso Santos Rodrigues
DETECÇÃO DE REFRÃO USANDO CORRELAÇÃO SOBRE A
ENVOLTÓRIA DO SOM
Trabalho apresentado ao Programa de Pós-graduação em
Ciência da Computação do Centro de Informática da Univer-
sidade Federal de Pernambuco como requisito parcial para
obtenção do grau de Mestre em Ciência da Computação.
Orientador: Geber Lisboa Ramalho
Co-Orientador: Giordano Ribeiro Eulálio Cabral
RECIFE
2016

Catalogação na fonteBibliotecário Jefferson Luiz Alves Nazareno CRB 4-1758
R696d Rodrigues, Renato Celso Santos. Detecção de refrão usando correlação sobre a envoltória do som /
Renato Celso Santos Rodrigues – 2016. 95f.: fig., tab.
Orientador: Geber Lisboa Ramalho. Dissertação (Mestrado) – Universidade Federal de Pernambuco. CIn.
Ciência da Computação, Recife, 2016. Inclui referências e apêndices.
1. Computação musical. 2. Recuperação de informação musical. 3. Detecção de refrão. I. Ramalho, Geber Lisboa. (Orientador). II. Titulo.
006.5 CDD (22. ed.) UFPE-MEI 2016-171

Renato Celso Santos Rodrigues
Detecção de Refrão usando Correlação sobre a Envoltória do Som
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Ciência da
Computação da Universidade Federal de
Pernambuco, como requisito parcial para a
obtenção do título de Mestre em Ciência da
Computação
Aprovado em: 14/09/2016.
___________________________________________ Orientador: Prof. Dr. Geber Lisboa Ramalho
BANCA EXAMINADORA
__________________________________________
Profa. Dra. Veronica Teichrieb
Centro de Informática / UFPE
__________________________________________
Prof. Dr. Tiago Alessandro Espinola Ferreira
Departamento de Estatística e Informática / UFRPE
__________________________________________
Prof. Dr. Giordano Ribeiro Eulalio Cabral
Centro de Informática / UFPE (Co-rientador)

Ao meu Deus, por sua providência e amor.

Agradecimentos
Agradeço à professora Liliane Salgado que, ainda na graduação, me incentivou a tentar
o mestrado. Agradeço aos meus colegas de trabalho da Fast Soluções Tecnológicas, que
também me incentivaram, inclusive Rafael Barreira e Elvio Gomes, que vivenciaram comigo
uma parte desta jornada.
Agradeço ao Centro de Informática da UFPE, no qual acredito e sinto orgulho de ter
feito parte, por me proporcionar um ambiente de nível internacional. Agradeço à professora
Edna Natividade, por suas orientações e paciência desde o início da graduação até o fim do
mestrado.
Agradeço aos meus orientadores, Geber Ramalho e Giordano Cabral, por sempre terem
acreditado no meu trabalho, mesmo quando eu sumia por tempo indeterminado. Agradeço
ao grupo MusTIC por me mostrar que eu não era o único maluco no mundo querendo juntar
computação e música. Agradeço aos professores Verônica Teichrieb e Tiago Ferreira por terem
aceitado participar da banca de defesa, mesmo aos 45 minutos do segundo tempo.
Agradeço aos meus pais, José Celso e Rejane Maria, pela provisão e apoio incessante,
mesmo nos momentos em que eu não demonstrava tanto progresso. Agradeço aos meus
filhos Emanuele Ágatha, Clara Évelin e Davi Celso, por sempre torcerem pelo papai mesmo
sem saberem direito o que ele estava fazendo, e por terem me compreendido quando não
pude estar presente.
Agradeço à minha esposa Bianca Fabrízzia, pelo amor e pela parceria que desenvolve-
mos juntos, pela paciência, companheirismo e lealdade que sempre teve para comigo, e por
estar ao meu lado nos momentos mais difíceis, quando mais precisei de ajuda.
Agradeço ao meu Deus pela vida, saúde, energia, ânimo, forças, providência e amor
que sempre me deu desde o início desta etapa, sem os quais jamais haveria chegado à sua
conclusão.

“You don’t get harmony when everyone sings the same note”.
Doug Floyd

Resumo
Em aplicações de Preview de serviços de streaming de música, onde uma rápida impressão
de um álbum desconhecido é proporcionada pela navegação de suas músicas, a inclusão do
refrão no trecho de trinta segundos fornecido para cada música torna a aplicação muito mais
precisa e eficaz. O refrão pode também funcionar como uma “miniatura” representativa da
música, melhorando o desempenho e a precisão das consultas, se realizadas somente
procurando pelos refrãos em vez de se procurar por músicas inteiras. Diante da importância
de obter o trecho mais representativo de uma canção, o objetivo de um sistema de detecção
de refrão é identificar este segmento ou, mais precisamente, os seus instantes inicial e final.
Métodos do Estado da Arte buscam extrair features associadas a notas musicais e timbre
como vetores Chroma e MFCC, e a partir destas identificar as repetições entre os segmentos
da música, inclusive o refrão. Este tipo de abordagem torna o método pouco robusto no
processamento de músicas onde notas musicais e variedade de timbres não são tão presentes,
como em estilos musicais mais percussivos. Este trabalho propõe uma mudança de paradigma
para a detecção de refrão, baseada na exploração do domínio do tempo em lugar do
domínio da frequência, com o objetivo de obter um método mais competitivo no processa-
mento de músicas percussivas. O método proposto elimina a etapa de segmentação, substitui
as features harmônicas e timbrais pela envoltória do sinal e utiliza a função de correlação
entre as envoltórias das partes da música como métrica de similaridade, tornando o método
menos dependente de notas musicais e timbres. Os testes mediram o grau de degeneração
das taxas de acertos do método proposto e de uma versão modificada usando vetores de
Chroma sobre uma base harmônica e uma base percussiva. Os resultados indicam que a
abordagem proposta sofre uma degeneração duas vezes menor que a versão modificada,
comprovando a hipótese de que um método de detecção de refrão que explore o domínio
do tempo é mais competitivo, ao processar músicas percussivas, que um método limitado à
exploração do domínio da frequência. Palavras-chave: Detecção de Refrão. Recuperação
de Informação de Música. Computação Musical.

Abstract
In Preview applications of music streaming services, where a fast printing from an unknown
album is provided by the navigation of your songs, including the chorus in thirty seconds excerpt
provided for each song makes the application much more accurate and effective. The chorus
can also function as a “miniature” representative of music, enhancing the performance and
accuracy of search, if carried out only by looking choruses instead of searching for entire
songs. Given the importance of getting the most representative excerpt of a song, the goal of a
chorus detection system is to identify this segment, or more precisely, its beginning and its
end. State of the art methods seek to extract features associated with musical notes and timbre,
like Chroma and MFCC vectors and identify from these repetitions between segments of music,
including the chorus. This approach type makes method little robust in music where musical
notes and variety of timbres are not as present, as in percussive music for example. This paper
proposes a paradigm shift for the chorus detection, based on the exploitation of the time domain
instead of the frequency domain, in order to obtain a more competitive method in the processing
of percussive music. The proposed method eliminates the segmentation, replaces the harmonic
and timbral features with the envelope of the signal, and uses the correlation function between
the envelope of the music segments as a metric of similarity, to make it less dependent on
musical notes and timbre. The tests measured the degree of degeneration of hit rates of the
proposed method and of a modified version using Chroma vectors on a harmonic basis and a
percussive basis. The results indicate that the proposed approach have a degeneration two
times lower than the modified version, proving the hypothesis that a chorus detection method
that exploits the time domain is more competitive when processing percussive songs than a
method limited to the frequency domain exploitation. Keywords: Chorus Detection. Music
Information Retrieval. Music Computing.

Lista de Figuras
1.1 Receitas da indústria fonográfica por segmento de vendas de 2005 a 2015. . . 14
1.2 Receitas em música por segmento de vendas em 2015. . . . . . . . . . . . . . 15
1.3 Receitas de Streaming de 2011 a 2015 segundo o IFPI, incluindo percentual de
crescimento de cada ano. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.4 Número de assinantes pagos de serviços de Streaming de 2012 a 2015. . . . . 16
2.1 Interface do Touch Preview do Spotify. . . . . . . . . . . . . . . . . . . . . . . 20
4.1 Fluxograma de um detector de refrão baseado em repetitividade. . . . . . . . . 28
4.2 Ilustração do processo de construção do Chroma vector. . . . . . . . . . . . . 30
4.3 SDM construída com vetores Chroma. . . . . . . . . . . . . . . . . . . . . . . 32
4.4 SDM construída com vetores MFCC. . . . . . . . . . . . . . . . . . . . . . . . 33
4.5 Triângulo Time-lag usado por Goto, construído com vetores Chroma. . . . . . . 34
5.1 Representação gráfica do modelo ADSR de variação de intensidade do som. . 41
5.2 Forma de onda de uma nota tocada por um violão. . . . . . . . . . . . . . . . . 41
5.3 Forma de onda de uma melodia de 15 notas tocadas por um violão. . . . . . . 42
5.4 Modelo ADSR típico de sons de instrumentos cordofones. . . . . . . . . . . . . 42
5.5 Modelo ADSR típico de sons de instrumentos aerofones. . . . . . . . . . . . . 42
5.6 Modelo ADSR típico de sons de instrumentos membranofones. . . . . . . . . . 43
5.7 Gráficos de sons de três instrumentos diferentes no domínio do tempo: (1) tabla;
(2) trompa; (3) flauta. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.8 Correlação: Sinal de entrada, sinal alvo, e sinal de correlação cruzada. . . . . . 46
5.9 Máquina de Correlação. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
6.1 Fluxograma das etapas do método proposto para detecção de refrão. . . . . . 51
6.2 Fluxograma com os processos da etapa de Extração de Envoltória do método
proposto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6.3 Gráfico de uma nota Lá tocada por um violão com cordas de nylon. . . . . . . . 54
6.4 Gráfico da envoltória do sinal da Figura 6.3 para uma janela de 20ms. . . . . . 55
6.5 Gráfico da envoltória do sinal da Figura 6.3 para uma janela de 50ms. . . . . . 55
6.6 Gráfico da envoltória do sinal da Figura 6.3 para uma janela de 200ms. . . . . . 55
6.7 Fluxograma com processos da etapa de Construção da Matriz de Similaridade. 57
6.8 SSM construída com correlação sobre envoltória para a música Yesterday. . . . 57
6.9 Fluxograma com os processos da etapa de Extração de Repetições do método
proposto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.10 SSM da Figura 6.8, após processo de filtragem de nitidez. . . . . . . . . . . . . 59

6.11 SSM da Figura 6.10, após processo de remoção das diagonais de baixa similari-
dade. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.12 SSM da Figura 6.11, após processo de limiarização dinâmica. . . . . . . . . . 61
6.13 SSM da Figura 6.12, após remoção de gaps nulos e não nulos. . . . . . . . . . 63
6.14 SSM da Figura 6.13, com diagonal selecionada pela Similaridade Média destacada. 65
7.1 Deslocamento (ms) x Tempo de resposta (s) na Extração de Envoltória. . . . . 70
7.2 Taxa média de acertos (%) de cada deslocamento da janela, na Extração de
Envoltória. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
7.3 Deslocamento (s) x tempo de resposta (s/4min) na Construção da Matriz de
Similaridade. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
7.4 Taxa média de acertos (%) de cada deslocamento e tamanho da janela, na
Construção da Matriz de Similaridade. . . . . . . . . . . . . . . . . . . . . . . 72
7.5 Percentual do tempo de resposta de cada etapa do método usando limiarização
com percentual de corte fixo. . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
7.6 Percentual do tempo de resposta de cada etapa do método usando limiarização
dinâmica. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
7.7 Taxa média de acertos (%) por percentual de corte fixo (%), na Extração de
Repetições. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
7.8 Taxa média de acertos (%) por percentual de área sob a curva (%), na Extração
de Repetições. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
7.9 Taxa média de acertos (%) por heurística avaliada e tipo de limiarização. . . . . 77
7.10 Taxa média de acertos (%) por álbum da base TUT e por tipo de limiarização. . 77
7.11 Taxa de acertos (%) da abordagem com limiar dinâmico para as bases de dados
TUT e percussiva. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
7.12 Taxa de acertos (%) da abordagem com limiar dinâmico para as bases de dados
TUT e percussiva para o método modificado (com FFT). . . . . . . . . . . . . . 80
7.13 Degeneração na taxa de acertos (%) para o método proposto, com correlação
de envoltória (CE), e para o método modificado, que usa FFT (FFT). . . . . . . 81

Lista de Tabelas
3.1 Métodos de análise de estrutura musical por tipo de abordagem. . . . . . . . . 25
7.1 Tempo de resposta (s) por tipo de limiarização e tamanho da música (s). . . . . 73
7.2 Taxa de acertos (%) por heurística e tipo de limiarização, para a base TUT
completa. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
7.3 Taxa de acertos (%) por heurística para as bases de dados TUT e percussiva, e
degeneração (%) por ausência de elementos harmônicos e melódicos para o
método proposto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
7.4 Taxa de acertos (%) por heurística para as bases de dados TUT e percussiva, e
degeneração (%) por ausência de elementos harmônicos e melódicos para o
método modificado (com FFT). . . . . . . . . . . . . . . . . . . . . . . . . . . 80
1 Taxa de acertos (%) por heurística e deslocamento da janela, na Extração de
Envoltória, para o álbum Revolver, dos Beatles (base TUT). . . . . . . . . . . . 90
2 Taxa de acertos (%) por heurística, deslocamento e tamanho da janela, na
Construção da Matriz de Similaridade, para o álbum Revolver, dos Beatles (base
TUT). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
3 Taxa de acertos (%) por heurística e percentual de corte fixo, na Extração de
Repetições. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4 Taxa de acertos (%) por heurística e percentual de área sob a curva, na Extração
de Repetições. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
5 Taxa de acertos (%) por heurística e por álbum da base TUT, para abordagem
com percentual de corte fixo. . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6 Taxa de acertos (%) por heurística e por álbum da base TUT, para abordagem
com limiar dinâmico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95

Lista de Acrônimos
ADSR Attack, Decay, Sustain and Release
CDM Centre for Digital Music
FFT Fast Fourier Transform
GPU Graphics Processing Unit
IFPI International Federation of the Phonographic Industry
MFCC Mel-Frequency Cepstral Coefficients
MIR Music Information Retrieval
MIREX Music Information Retrieval Evaluation eXchange
MPEG Moving Picture Experts Group
RWC Real World Computing
SALAMI Structural Analysis of Large Amounts of Music Information
SDM Self-Distance Matrix
STFT Short-Time Fourier Transform
TUT Tampere University of Technology
UPF Universitat Pompeu Fabra

Sumário
1 Introdução 14
2 A Detecção de Refrão 19
3 O Estado da Arte 22
4 Métodos Harmônicos e Timbrais 27
4.1 A Segmentação do Sinal de Áudio . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 A Extração de Características Acústicas . . . . . . . . . . . . . . . . . . . . . 29
4.3 A Medição e Armazenamento da Similaridade . . . . . . . . . . . . . . . . . . 31
4.4 A Rotina de Identificação das Repetições . . . . . . . . . . . . . . . . . . . . . 34
4.5 A Rotina de Seleção de Refrão . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.6 Os Resultados Obtidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5 Correlação de Envoltória 39
5.1 A Envoltória do Sinal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2 A Função de Correlação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6 O Método Proposto 50
6.1 A Extração da Envoltória do Sinal . . . . . . . . . . . . . . . . . . . . . . . . . 51
6.2 A Construção da Matriz de Similaridade . . . . . . . . . . . . . . . . . . . . . 56
6.3 A Extração das Repetições . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.4 A Seleção do Segmento Refrão . . . . . . . . . . . . . . . . . . . . . . . . . . 62
7 Experimentos e Resultados 66
7.1 As Bases de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7.2 A Metodologia dos Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.3 Os Resultados Obtidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
7.4 A Avaliação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
8 Conclusão 83
Referências 85
Apêndice 89

141414
1Introdução
Segundo relatório da International Federation of the Phonographic Industry (2016),
divulgado em Abril de 2016, as receitas do mercado global de música gravada tiveram em
2015 um crescimento de 3,2% em relação ao ano anterior, atingindo US$ 15,0 Bilhões, depois
de mais de uma década de declínio. Além disso, as receitas de música em formato digital
cresceram 10,2%, chegando a US$6,7 bilhões, e superaram as receitas de música em mídia
física, que caíram 4,5%, conforme ilustrado no gráfico da Figura 1.1.
Figura 1.1: Receitas da indústria fonográfica por segmento de vendas de 2005 a 2015.
Receitas de música em formato digital representaram em 2015 45% do total de receitas
do mercado global de música gravada, comparados aos 39% do formato físico, segundo mostra
o gráfico da Figura 1.2.

15
Figura 1.2: Receitas em música por segmento de vendas em 2015.
Este aumento, tanto nas receitas do mercado global como nas de música em formato
digital, foi impulsionado principalmente pelo aumento nas receitas de Streaming, que mais
do que compensou o declínio nas receitas de downloads e de mídia física. As receitas de
streaming cresceram 45,2%, respondendo agora por 43% do total de receitas digitais, quase
ultrapassando as receitas por downloads (45%). Downloads atualmente são 20% do total de
receitas global, mas caíram 10,5% em relação a 2014, enquanto as receitas de Streaming
são as que crescem mais rápido, 4 vezes nos últimos 5 anos conforme o gráfico da Figura
1.3, representando 19% do total de receitas do mercado global atualmente. Este crescimento
do streaming, segundo o IFPI, é impulsionado pela propagação dos smartphones, e pelo
crescimento da disponibilidade dos serviços de assinatura de alta qualidade.
O total de subscritores “Premium” de streaming cresceu 65,8% em 2015, somando 68
milhões de assinantes em todo o mundo. A Figura 1.4 traz um gráfico contendo o número de
assinantes pagos dos anos 2012 a 2015.
Como se pode observar, os serviços de Streaming têm provocado uma mudança de

16
comportamento no consumidor e uma consequente transformação na indústria fonográfica
para se adaptar e atender a esta nova demanda. São exemplos de serviços de Streaming:
Spotify, Pandora, TuneIn, Deezer, Amazon Music, Apple Music, Google Play Music, Rdio,
Tidal, Groove Music, Napster, SoundCloud.
O estímulo à liberdade de escolha do ouvinte é um grande diferencial dos serviços de
Streaming. Desde o início da indústria fonográfica, quando a tecnologia permitiu a gravação
de áudio, a liberdade de escolha do ouvinte era limitada ao que as gravadoras estavam
interessadas em oferecer, enquanto músicos iniciantes tinham grande dificuldade para divulgar
sua música.
Figura 1.3: Receitas de Streaming de 2011 a 2015 segundo o IFPI, incluindopercentual de crescimento de cada ano.
Figura 1.4: Número de assinantes pagos de serviços de Streaming de 2012 a 2015.
Mesmo com o avanço das tecnologias de gravação (mídias digitais e mais baratas) e de
compartilhamento (aplicações P2P), que facilitaram o acesso à música, a liberdade de escolha
ainda era limitada, pois a capacidade de busca em programas P2P era pequena, limitada
ao nome de artistas, faixas ou álbuns que o usuário precisava conhecer antecipadamente,
e músicas novas não tinham grande sucesso na divulgação, pois as pessoas não sabiam

17
como encontrá-las. Com o surgimento dos serviços de streaming, esta liberdade de escolha
aumentou significativamente, sobretudo no que se refere ao descobrimento de novas canções
e de novos artistas.
O serviço de Preview das aplicações de Streaming é um ambiente onde o usuário pode
obter uma rápida impressão de uma lista de reprodução ao navegar as músicas de um álbum
desconhecido, recebendo um trecho de cada música que deve representá-la como um todo.
Suportado por plataformas de inteligência musical como a The Echo Nest Company (2005), o
Preview proporciona identificação, navegação, recuperação, e recomendação de música aos
usuários, a partir da análise de produtores e consumidores de música, tornando muito mais
acessível ao usuário não só as músicas que ele conhece e quer ouvir, mas aquelas que ele
ainda não conhece, e possivelmente vai gostar.
Desta maneira, por conta do Preview, o usuário é muito mais assistido em sua liberdade
de escolha, e as tarefas de busca e recuperação de música constituem parte essencial deste
serviço. Entretanto, é importante que o trecho da música fornecido ao ouvinte seja o mais
representativo da música, senão ela não terá sido bem apresentada, e o ouvinte poderá não
se interessar.
Segundo GOTO (2006), o coro (chorus) ou refrão (refrain) na música popular é a seção
mais representativa, elevada (ou intensa) e proeminente da estrutura musical de uma canção,
e ouvintes humanos podem facilmente entender quais são as secções de coro porque estas
são as partes mais repetidas e memoráveis de uma canção. Por isso, o refrão é o trecho
mais indicado para representar a música inteira, sempre que se deseja obter uma rápida
referência ou visualização desta música. A inclusão do refrão no trecho da música que o
Preview disponibiliza o torna mais eficaz na apresentação de cada música de um álbum.
Na tarefa de recuperação de música, por sua vez, o refrão funcionaria como uma
“miniatura” representativa da música, que poderia ser útil para melhorar o desempenho e
a precisão das consultas, uma vez que estas consultas poderiam ser realizadas somente
procurando pelos coros, em vez de se procurar por músicas inteiras.
Assim, a detecção automática de coro se torna essencial em aplicações de navegação
e recuperação de música. Diante da necessidade de obter o trecho mais representativo de
uma canção, o objetivo de um sistema de detecção de refrão é a identificação deste segmento
ou, mais precisamente, de seus extremos no eixo temporal ao longo da música, que são o
instante no qual ele começa e o instante no qual ele termina.
Na literatura existem soluções desenvolvidas para o problema da detecção de refrão,
todas baseadas em features extraídas a partir de elementos harmônicos ou timbrais da
música. Estas soluções funcionam, mas, pelo princípio de formação de suas features, ao
processarem músicas onde estes elementos harmônicos ou timbrais são menos presentes,
tendem a sofrer uma alta degeneração de sua taxa de acertos. Músicas percussivas, como
a Batucada, a Embolada, o Coco ou o Afoxé, por exemplo, caracterizam-se pela ausência
de acompanhamento harmônico, sendo a presença de notas musicais limitada ao canto,

18
normalmente solo, e a presença de timbres limitada aos instrumentos de percussão e à voz,
que praticamente não mudam ao longo de toda a música. Para estas músicas, subentende-se
que os métodos desenvolvidos, por serem dependentes da presença de notas musicais e
timbres, não devem apresentar um bom desempenho, o que configura uma baixa robustez.
Desta forma, pode-se concluir que ainda há espaço para a exploração de soluções
alternativas ou melhoramentos sobre as soluções já existentes, seja para obter redução na
taxa de erros ou no custo da solução, para descobrir formas mais simples de realizar a mesma
tarefa com custo e taxas de erro na mesma ordem de grandeza, ou para a obtenção de
soluções mais robustas, que apresentem boas taxas de acertos ao se variar o tipo de música.
O objetivo deste trabalho é propor uma mudança de paradigma para soluções em
detecção de refrão, apresentando uma abordagem alternativa às harmônicas e timbrais, mais
competitiva no contexto do processamento de músicas percussivas. A abordagem apresentada
é construída a partir da correlação entre as envoltórias dos trechos da música, features
obtidas explorando-se o domínio do tempo em lugar do domínio da frequência. Assim, a
hipótese a ser testada é: Um método de detecção de refrão que explore o domínio do tempo é
mais competitivo, ao processar músicas percussivas, que um método limitado ao domínio da
frequência.
Este trabalho está dividido em 8 capítulos. No próximo capítulo é apresentado o
problema específico da detecção de refrão e as dificuldades encontradas ao se desenvolver
uma solução para este problema. No capítulo 3 discute-se o Estado da Arte no contexto da
detecção de refrão, discutindo os conceitos de MIR, MIREX, Análise de Estrutural Musical e
os tipos de abordagens existentes nesta área de pesquisa. O capítulo 4 apresenta as últimas
soluções desenvolvidas para este problema, enquanto identifica padrões e analisa vantagens e
desvantagens destas técnicas. O capítulo 5 apresenta os conceitos de Envoltória e Correlação,
que constituem respectivamente a feature e a métrica de similaridade do método proposto. A
abordagem proposta é então apresentada no capítulo 6, destacando diferenças em relação às
técnicas apresentadas no capítulo 4. Posteriormente, o capítulo 7 apresenta o experimento
realizado, descrevendo as bases de dados escolhidas e relatando desde os testes e ajustes de
parâmetros de cada etapa da solução ao teste da hipótese, resultados obtidos e uma breve
discussão destes resultados. Finalmente, o capítulo 8 traz a conclusão do trabalho, destacando
suas contribuições e também algumas possibilidades futuras de evolução da pesquisa.

191919
2A Detecção de Refrão
Dentre as aplicações que mais necessitam de uma solução de detecção de refrão, a
mais representativa é certamente a aplicação de Preview, uma ferramenta capaz de conceder
a um possível comprador de uma lista de reprodução de mídia musical (como um CD de uma
banda específica, por exemplo) uma pré-visualização desta lista, onde normalmente um trecho
de cerca de trinta segundos de cada música é fornecido ao ouvinte, para que possa avaliar
cada música desta lista. Trata-se de um problema de miniaturização, onde este trecho de trinta
segundos deverá representar a música inteira. Por isso, é essencial que este trecho fornecido
seja o mais representativo possível, pois poderá exercer direta influência sobre o número de
unidades vendidas de um determinado álbum, porque se as canções deste álbum não forem
bem representadas na pré-visualização, os consumidores poderão não demonstrar interesse
pelo produto, quando certamente se agradariam das músicas se tivessem ouvido o seu trecho
mais representativo. A Figura 2.1 mostra a interface do Touch Preview, o serviço de Preview
do Spotify.
Diante do problema da pré-visualização de uma lista de reprodução de mídia musical a
detecção de refrão tem grande importância, pois o refrão normalmente é este segmento mais
representativo, proeminente e memorizável de uma canção, melhor parte para representar a
música como um todo.
Vale salientar, entretanto, que o problema da detecção de refrão possui alto grau de
dificuldade. Um refrão pode ser definido de maneira mais simples como o trecho da música
que mais se repete, e esta é a principal característica que o torna o trecho mais facilmente
assimilado por um ouvinte nesta música. Mas, na prática, entretanto, definir o refrão é bem
mais complicado, sobretudo para um computador.
Muito embora intuitivamente um ouvinte possa facilmente identificar um refrão em
uma música, nem mesmo ele consegue muitas vezes definir precisamente onde o mesmo
começa e onde termina. Uma função de detecção de refrão normalmente retorna dois
instantes no tempo da música, o início e o fim do refrão, e a definição exata dos extremos
do refrão exerce influência direta sobre o percentual de acertos de seu algoritmo, porque as
métricas de sucesso normalmente utilizadas nos trabalhos em detecção de refrão consideram,

20
no cálculo do percentual de acertos, a interseção entre o trecho de refrão detectado pela
solução e o trecho de refrão anotado no processo de criação da base de dados utilizada nos
testes. Ou seja, para um computador qualquer imprecisão na marcação dos extremos do
refrão pode causar uma diminuição da taxa de acertos, o que exige um cuidado especial no
processo de desenvolvimento das bases de dados disponibilizadas para testes de soluções
em segmentação estrutural de música, incluindo a detecção de refrão. Os trabalhos de criação
da base SALAMI, de SMITH et al. (2011) e o da base RWC, de GOTO et al. (2002, 2004),
são exemplos de processos de desenvolvimento de bases de dados construídas com esta
finalidade.
Figura 2.1: Interface do Touch Preview do Spotify.
Outra dificuldade está ligada ao fato de que soluções de detecção de refrão são
normalmente baseadas na extração de similaridade, seja para detectar repetitividade, novidade,
ou homogeneidade, mas uma ocorrência do refrão pode apresentar diferenças em relação
às demais. Dependendo das características acústicas usadas no processo de medição da
similaridade, aspectos como a presença ou ausência de um ou mais instrumentos específicos,
ou a inclusão de arranjos musicais em alguns refrãos, mas não em todos, podem reduzir o
grau de similaridade entre um par de ocorrências do refrão na música, confundindo a solução
de detecção de refrão ao serem geradas lacunas (ou lags) de baixa similaridade em trechos
de alta similaridade.
Outro aspecto que pode interferir na medida da similaridade são as alterações na
intensidade (ou proeminência) dos refrãos, como é muito comum em músicas diversas, onde
os refrãos são executados com diferentes intensidades ao longo da canção, conferindo mais
emoção à música. Considerando 3 ocorrências de refrão, aquela que for executada com menor
intensidade apresentará menor similaridade em relação às demais entre si, dependendo da

21
forma usada para medir similaridade, podendo este fato exercer algum tipo de influência no
processamento da solução de detecção de refrão.
Outra questão que pode dificultar é que a definição mais precisa de refrão na verdade
incluiria aspectos mais semânticos relacionados à letra da música, bem como a relação
destes com o significado semântico de todas as outras partes da música, e o tratamento destes
aspectos talvez fuja um pouco do escopo da computação musical no momento. Nas marcações
das bases de dados desenvolvidas para testes, feitas por humanos, muito provavelmente estes
aspectos foram considerados ao serem atribuídos os rótulos (como introdução, verso e refrão)
aos segmentos das músicas. Entretanto, para simplificar, as aplicações desenvolvidas tanto
neste trabalho como nos últimos desenvolvidos no Estado da Arte estão mais limitadas ao
tratamento de aspectos do escopo da computação musical, como a presença de notas musicais,
variação de intensidade ou a detecção de repetitividade, novidade e homogeneidade.
O comportamento mínimo esperado de uma solução para o problema da detecção
de refrão pode ser definido. Primeiramente, espera-se uma taxa de erros pequena, segundo
alguma métrica particular para esta taxa. Espera-se também que a solução apresente baixo
custo, traduzido por baixo tempo de resposta. Normalmente o tempo de resposta é uma função
somente do tamanho da entrada, mas nem sempre isso acontece.
Outro comportamento esperado para uma solução de detecção de refrão é a robustez,
que significa ter um desempenho que varie pouco em função das características peculiares ao
estilo musical das canções, como o ritmo, por exemplo. Em outras palavras, a solução deve
apresentar uma taxa de acertos e um tempo de resposta que variem minimamente em função
das diferenças de estilo musical, independente de se estar processando canções de forró, pop,
rock, gospel, dance, ou qualquer outro estilo musical. Desta forma, ser capaz de identificar o
refrão em músicas pertinentes a uma ampla variedade de estilos ou ritmos é claramente uma
vantagem para a solução de detecção de refrão.
No capítulo a seguir será descrito o Estado da Arte no contexto das soluções desenvol-
vidas para o problema da detecção de refrão em arquivos de áudio, com base em pesquisa
bibliográfica realizada.

222222
3O Estado da Arte
Recuperação de Informação Musical, ou Music Information Retrieval (MIR), é um
Campo de pesquisa multidisciplinar que se baseia nas tradições, metodologias e técnicas
de uma ampla gama de disciplinas. Uma lista incompleta destas disciplinas inclui acústica,
psicoacústica, processamento de sinal, informática, musicologia, biblioteconomia, informática
e aprendizagem de máquina. O objetivo principal da pesquisa MIR, independentemente do
paradigma disciplinar em que é realizado, é fornecer um nível de acesso ao vasto acervo
do mundo da música igual ou superior ao que está sendo oferecido pelos motores de busca
baseados em texto (DOWNIE, 2008). MIR é uma área de pesquisa que tem crescido a partir
da necessidade de gerir florescentes coleções de música em formato digital (FUTRELLE;
DOWNIE, 2003).
O grande desafio da pesquisa em MIR é o desenvolvimento de sistemas de recu-
peração que lidam com a música através dos fenômenos acústicos, rítmicos, harmônicos,
estruturais e culturais que a compõem. Os pesquisadores em MIR buscam construir sistemas
de recuperação em que a música em si é o principal mecanismo de interação do usuário
com o sistema, quer esteja no formato auditivo (e.g. MP3, WAV), simbólico (e.g. MIDI, par-
titura) ou ambos. Em outras palavras, as pesquisas em MIR querem desenvolver sistemas
que possibilitem aos usuários pesquisar conteúdo de música a partir de consultas que são
formuladas musicalmente, como a consulta por canto (query-by-singing), a consulta por um
exemplo (query-by-example, onde uma música em MP3 é fornecida em busca de músicas
similares), ou a consulta por notação (e.g. consultar por notas escritas em uma pauta musical).
O Music Information Retrieval Evaluation eXchange (MIREX) é um framework baseado
na comunidade MIR para a avaliação formal de algoritmos e sistemas de MIR (DOWNIE,
2008). É um conjunto de avaliações formais definidas pela comunidade MIR através das
quais os sistemas, algoritmos e técnicas do Estado da Arte são avaliados sob condições
controladas. Desde que começou em 2005, MIREX tem promovido anualmente grandes
avanços não apenas em áreas específicas de MIR, mas também na compreensão geral de
como os sistemas e algoritmos de MIR devem ser avaliados (DOWNIE et al., 2010).
Cada evento anual do MIREX tem um conjunto de Tarefas de Avaliação, ou catego-

23
rias nas quais trabalhos em MIR podem ser submetidos para serem avaliados conforme as
condições estabelecidas pela comunidade MIR. Uma destas tarefas é a Análise de Estrutura
Musical, ou Structural Segmentation (MIREX, 2016), relevante na área de MIR e no campo da
Computação Musical. Seu principal objetivo é segmentar automaticamente uma música em
suas diferentes seções (segmentação), e agrupá-los com base em sua similaridade acústica
(rotulagem), para que se obtenham as seções A, B, C, ou verso, ponte, refrão (MARL, 2016).
A estrutura musical surge de determinadas relações entre os elementos da música
(notas, acordes, e assim por diante) que compõem a música. Os princípios utilizados para criar
tais relacionamentos incluem ordem temporal, contraste, variação, homogeneidade e repetição
(PAULUS; MÜLLER; KLAPURI, 2010). A ordem temporal de eventos, conforme enfatizado
por CASEY; SLANEY (2006), é de importância crucial para a construção de entidades musi-
calmente e perceptivelmente significativas, como progressões melódicas ou harmônicas. O
princípio do contraste é introduzido por ter duas partes musicais sucessivas com características
diferentes como, por exemplo, uma passagem tranquila pode ser contrastada com uma alta,
uma seção lenta com uma rápida, ou uma parte orquestral com um solo. Outro princípio é o da
variação, onde as partes da música são apanhadas novamente em uma forma modificada ou
transformada (LERDAHL; JACKENDOFF, 1999). Um segmento é muitas vezes caracterizado
por alguns tipos de homogeneidade inerente, por exemplo, a instrumentação, o ritmo, ou o
material harmônico sendo semelhante dentro do segmento, o que exemplifica o princípio da
homogeneidade.
Finalmente, o princípio da repetição é central para a música, como HORNER; SWISS
(1999) afirma: “Tem sido frequentemente observado que a repetição desempenha um papel
particularmente importante na música - em praticamente qualquer tipo de música que se pode
pensar, na realidade. [. . . ] Na música popular, os processos de repetição são especialmente
fortes“. Padrões recorrentes, que podem ser de natureza rítmica, harmônica, ou melódica,
provocam no ouvinte a sensação de familiaridade e compreensão da música.
Tendo em vista os vários princípios que influenciam decisivamente a estrutura musical,
diferentes abordagens para a análise da estrutura musical têm sido desenvolvidas. Segundo
estudo realizado por PAULUS; MÜLLER; KLAPURI (2010) é possível distinguir três diferentes
classes de métodos de análise estrutural de música baseada em processamento de áudio: (1)
baseados em repetitividade, que buscam identificar padrões recorrentes; (2) baseados em
novidade que buscam detectar transições entre partes contrastantes; (3) baseados em homo-
geneidade, que buscam passagens que são consistentes em relação a alguma propriedade
musical.
A partir de um ponto de vista técnico, a abordagem baseada em homogeneidade
é muitas vezes referida como “abordagem de estado” enquanto os métodos baseados em
repetitividade são também chamados de “abordagens de sequência”. As abordagens baseadas
em novidade e as baseadas em homogeneidade são dois lados da mesma moeda: detecção de
novidade é baseada na observação de algum evento surpresa ou alteração após a ocorrência

24
de um segmento mais homogêneo.
O princípio do contraste ou mudança introduz diversidade na música, atraindo a atenção
de um ouvinte. O objetivo de procedimentos baseados em novidade é automaticamente
localizar os pontos onde ocorrem essas mudanças. São exemplos de métodos baseados em
novidade os trabalhos de FOOTE (2000), JENSEN (2006) e TURNBULL et al. (2007).
Uma continuação direta do processo baseado em novidade é a analisar o conteúdo
dos segmentos criados e classificá-los, construindo grupos mais homogêneos. Os trabalhos de
LOGAN; CHU (2000), COOPER; FOOTE (2003), PEETERS (2004), AUCOUTURIER; PACHET;
SANDLER (2005), JEHAN (2005), XU; MADDAGE; KANKANHALLI (2006), LEVY; SANDLER
(2008) e BARRINGTON; CHAN; LANCKRIET (2010) são exemplos de métodos baseados em
homogeneidade.
A repetição de entidades musicais é um elemento importante na imposição da estrutura
sobre uma sequência de sons musicais, e a ordem temporal em que os eventos da música
ocorrem é crucial para se conceber musicalmente entidades importantes como as melodias
ou as progressões de acordes. Por conseguinte, a tarefa de extrair a repetitividade de um
sinal de áudio de uma música resume-se em primeiro processar o áudio extraindo dele uma
sequência adequada de características acústicas e, em seguida, encontrar as subsequências
repetidas nesta sequência. São exemplos de métodos baseados em repetitividade as soluções
desenvolvidas por DANNENBERG; HU (2002), WELLHAUSEN; HÖYNCK (2003)LU; WANG;
ZHANG (2004), BARTSCH; WAKEFIELD (2005), SHIU; JEONG; KUO (2005), GOTO (2006),
MAROLT (2006), ONG (2006), PAULUS; KLAPURI (2006), ERONEN; TAMPERE (2007)MÜL-
LER; KURTH (2006), PEETERS (2007), RHODES; CASEY et al. (2007), RHODES; CASEY
et al. (2007) e MAUCH; NOLAND; DIXON (2009).
Existem ainda métodos híbridos, que reúnem características de mais de um tipo de
abordagem de Análise de Estrutura Musical, como o método de PAULUS; KLAPURI (2009).
Estes métodos, além de classificados quanto ao tipo de abordagem (novidade, homo-
geneidade e repetitividade), são diferentes entre si também quanto à tarefa realizada, onde uns
buscam a estrutura completa da música, outros buscam miniaturização, outros buscam detectar
o refrão, outros buscam achar repetições. Também são diferentes quanto à característica
acústica usada, onde uns usam Chroma, outros MFCC, outros MPEG-7 timbre descriptor, ou
combinações de features.
A Tabela 3.1 traz uma lista contendo exemplos de vários métodos classificados pelo tipo
de abordagem, mostrando também a tarefa realizada pelo método e a feature usada. Apesar
de usarem features diferentes, observa-se na Tabela 3.1 que os métodos em geral usam
features que são baseadas em elementos da música harmônicos ou timbrais, construídas a
partir de transformadas (e.g. Fast Fourier Transform).

25
Tabela 3.1: Métodos de análise de estrutura musical por tipo de abordagem.
Approach Year Author Task Acoustic features
novelty 2000 Foote segmentation MFCC
2007 Jensen segmentation MFCC + chroma + rhythmogram
2007 Turnbull et al. segmentation Various
homogeneity 2000 Logan & Chu key phrase MFCC
2003 Cooper & Foote summarisation magnitude spectrum
2004 Peeters full structure dynamic features
2005Aucouturier et
al.full structure spectral envelope
2005 Jehan pattern learning MFCC + chroma + loudness
2006 Maddage full structure Chroma
2008 Levy & Sandler full structure MPEG-7 timbre descriptor
2010 Barrington et al. full structure MFCC / chroma
repetition 2002Dannenberg &
Hurepetitions Chroma
2003Wellhausen &
Höynckthumbnailing MPEG-7 timbre descriptor
2004 Lu et al. thumbnailing constant-Q spectrum
2005Bartsch &
Wakefieldthumbnailing Chroma
2005 Chai full structure Chroma
2005 Shiu et al. full structure Chroma
2006 Goto chorus detection MFCC + chroma
2006 Marolt thumbnailing Chroma
2006 Ong full structure Multiple
2006 Paulus & Klapuri repeated parts MFCC + chroma
2007 Eronen chorus detection MFCC + chroma
2007 Müller & Kurthmultiple
repetitionschroma statistics
2007 Peeters repeated partsMFCC + chroma + spec. contrast
repetition
2007Rhodes &
Casey
hierarchical
structuretimbral features
2009 Mauch et al. full structure Chroma
combined 2009 Paulus & Klapuri full description MFCC + chroma + rhythmogram
Dentre os trabalhos citados, os métodos de GOTO (2006) e ERONEN; TAMPERE
(2007), ambos baseados em repetitividade, foram desenvolvidos especificamente para a tarefa

26
de detecção de refrão, sendo por isso descritos mais detalhadamente no capítulo 4 como
exemplos típicos de métodos harmônicos e timbrais.
Uma abordagem comum na tarefa de encontrar repetições em uma sequência de
características acústicas é construir uma matriz de distância (SDM) e procurar listras diagonais
de altos valores paralelas à diagonal principal. Embora seja muitas vezes fácil para seres
humanos reconhecer estas listras, a extração automatizada de tais listras constitui um problema
difícil para um computador devido a significativas distorções que são causadas por variações
em parâmetros como dinâmica, timbre, execução de arranjos, modulação, articulação, ou
progressão rítmica. Entretanto, para as tarefas de detecção de refrão e de miniaturização de
áudio, selecionar um segmento que tem sido repetido na maioria das vezes em uma música
tem provado ser uma abordagem eficaz (PAULUS; MÜLLER; KLAPURI, 2010).

272727
4Métodos Harmônicos e Timbrais
Neste capítulo serão abordadas as características mais gerais, comuns aos métodos de
detecção de refrão baseados em harmonia ou timbre, através da descrição das duas soluções
mais recentes encontradas no Estado da Arte para o problema da detecção de refrão em sinais
de áudio, que são os trabalhos desenvolvidos por GOTO (2006), e ERONEN; TAMPERE (2007),
ambos baseados em características acústicas extraídas a partir de elementos harmônicos ou
de elementos timbrais da música. Dentre as duas abordagens, a proposta por Eronen, por
possuir um grau de semelhança maior em relação à abordagem proposta neste trabalho, será
descrita com mais ênfase do que a abordagem de Goto. Do ponto de vista da classificação dos
métodos de análise de estrutura musical, tanto a abordagem de Eronen quanto a abordagem
de Goto são baseadas em repetitividade.
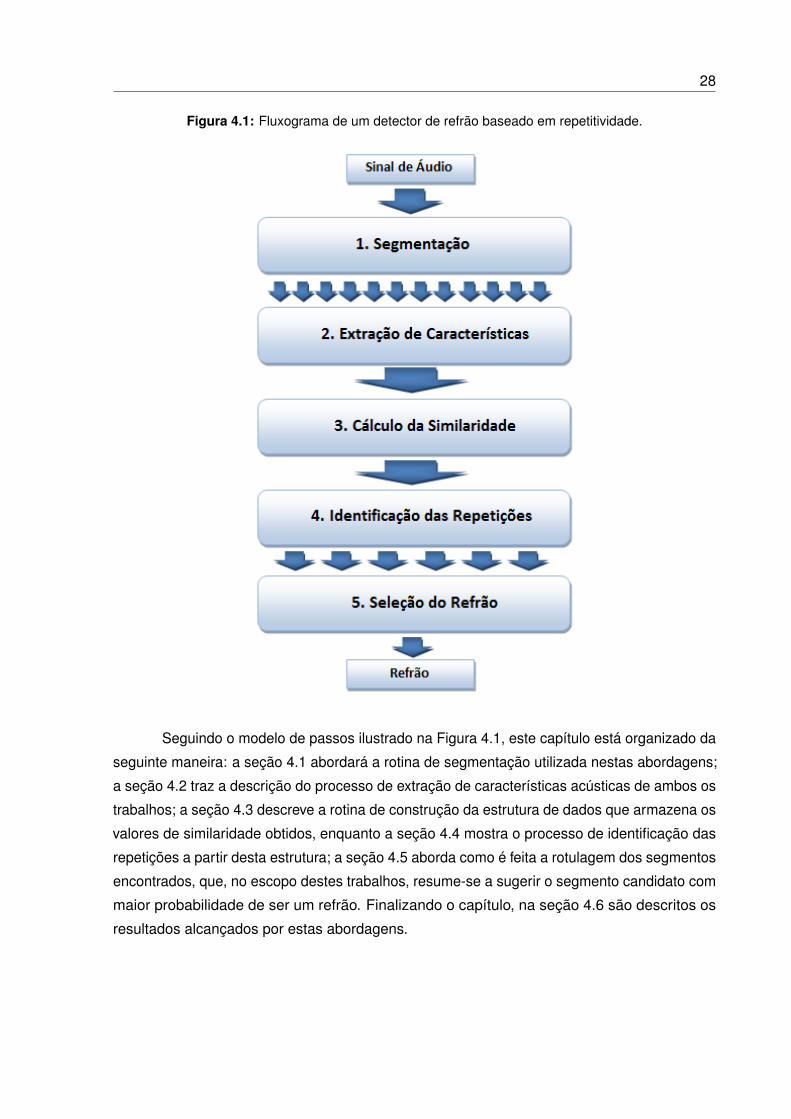
Uma solução baseada em repetitividade tem seus passos de execução bem definidos:
(1) A Segmentação do Sinal, que divide o sinal em pequeninos fragmentos que possam ser
comparados entre si; (2) A Extração de Características (ou Features), onde uma ou mais
características acústicas são construídas a partir de cada fragmento do sinal, registrando-as
em uma estrutura de dados sequencial; (3) Cálculo da Similaridade, que mede a similaridade
(ou distância) entre cada par de fragmentos do sinal a partir de suas features, armazenando-a
em outra estrutura de dados sequencial; (4) A Identificação das Repetições, que procura
identificar, dentro desta última estrutura sequencial, as subsequências de valores de alta
similaridade, que representam as repetições ou correspondências entre dois trechos do sinal,
identificando estes dois trechos do sinal pelos seus extremos (início e final); (5) A Seleção do
Refrão, onde estes segmentos são rotulados (ou agrupados) conforme a probabilidade de ser
um refrão. A Figura 4.1 traz um fluxograma deste processo.
É importante distinguir os intervalos obtidos no passo de segmentação do sinal, que
são fragmentos menores compreendidos entre duas batidas do sinal, dos intervalos obtidos na
etapa de identificação de repetições, estes maiores, e que compreendem uma subsequência
daqueles fragmentos menores, que apresentou alta similaridade com outra subsequência
destes fragmentos menores, localizada em outra parte do sinal de áudio.
28
Figura 4.1: Fluxograma de um detector de refrão baseado em repetitividade.
Seguindo o modelo de passos ilustrado na Figura 4.1, este capítulo está organizado da
seguinte maneira: a seção 4.1 abordará a rotina de segmentação utilizada nestas abordagens;
a seção 4.2 traz a descrição do processo de extração de características acústicas de ambos os
trabalhos; a seção 4.3 descreve a rotina de construção da estrutura de dados que armazena os
valores de similaridade obtidos, enquanto a seção 4.4 mostra o processo de identificação das
repetições a partir desta estrutura; a seção 4.5 aborda como é feita a rotulagem dos segmentos
encontrados, que, no escopo destes trabalhos, resume-se a sugerir o segmento candidato com
maior probabilidade de ser um refrão. Finalizando o capítulo, na seção 4.6 são descritos os
resultados alcançados por estas abordagens.

4.1. A SEGMENTAÇÃO DO SINAL DE ÁUDIO 29
4.1 A Segmentação do Sinal de Áudio
A abordagem de Eronen adota como rotina de segmentação a fragmentação do sinal
sincronizada às batidas da música, onde a detecção destas batidas é a mesma desenvolvida no
trabalho de SEPPÄNEN; ERONEN; HIIPAKKA (2006). Esta rotina divide o sinal em pequenos
fragmentos, onde cada fragmento compreende aproximadamente o trecho do sinal situado
entre duas batidas consecutivas detectadas.
Esta técnica permite a obtenção da menor fragmentação possível do sinal de áudio
que garanta razoavelmente a preservação da similaridade entre as características acústicas
harmônicas, o que sugere um bom compromisso entre a preservação da similaridade e a
redução de custos de processamento nas etapas seguintes, pela diminuição do número de
fragmentos obtidos. Uma fragmentação ainda menor que a segmentação sincronizada às
batidas teria fragmentos maiores que o intervalo entre duas batidas, o que certamente levaria
à inclusão de mais de um acorde em um mesmo fragmento, podendo confundir a extração de
características acústicas na etapa seguinte da solução, pois é intimamente ligada à disposição
dos acordes da música, como será visto mais adiante, na próxima seção deste capítulo.
Entretanto, subentende-se que músicas mais aceleradas, por possuírem maior frequên-
cia de batidas da música, terão uma maior quantidade de fragmentos obtidos neste processo
de segmentação, que consequentemente implicará em um maior custo de processamento para
as etapas seguintes, porque mais batidas existirão para uma mesma quantidade de tempo da
música.
A abordagem de Goto utiliza uma janela de Hanning deslizante de 256ms, com desloca-
mento de 80ms conforme descrito em seu trabalho, não utilizando, portanto, uma segmentação
explícita, como a sincronizada às batidas.
4.2 A Extração de Características Acústicas
Após o processo de segmentação do sinal de áudio, é realizada, para cada segmento,
a extração de características acústicas (features) que serão utilizadas para medir a similaridade
entre cada par de segmentos. Tanto na abordagem de Goto quanto na de Eronen, nesta
etapa, para cada fragmento do sinal deverá ser associado uma feature, o Chroma Vector, vetor
que traz a informação das notas musicais presentes ao longo deste fragmento. Este vetor é
construído com doze posições que representam cada uma as doze notas musicais de uma
oitava, segundo a escala temperada padrão da música ocidental.
A escala temperada é um conjunto de valores tabelados das frequências fn das notas
musicais, construído a partir de uma progressão geométrica de razão q = 12√
2 e termo inicial
fi = 440Hz, onde:
fn = 440(2n−112 ), n inteiro (1)

4.2. A EXTRAÇÃO DE CARACTERÍSTICAS ACÚSTICAS 30
O valor fi = 440Hz é um valor de frequência padrão, atribuído à nota Lá2 (nota Lá
da 2ª oitava de um piano), a partir do qual todos os valores de frequência das demais notas
musicais podem ser definidos segundo a equação 1. A razão q = 12√
2 originou-se da ideia
de interpolar 12 meios geométricos, um para cada nota musical (C, C#, D, D#, E, F, F#, G, G#,
A, A#, B), entre a frequência de uma nota musical e a frequência desta mesma nota na oitava
imediatamente seguinte. Desta maneira, se a nota Lá2 tem uma frequência de 440 Hz, a nota
Lá3 tem uma frequência de 880 Hz, e as notas intermediárias possuem como frequências
fundamentais os 12 meios geométricos interpolados entre estas duas frequências, conforme a
equação 1. Estes valores tabelados são utilizados na construção do vetor de Chroma, como
explicado a seguir.
Figura 4.2: Ilustração do processo de construção do Chroma vector.
Primeiramente, ao longo de cada segmento uma janela deslizante é processada para
coleta de espectros de frequência por STFT (Short Time Fourier Transform), e a média destes
espectros obtidos ao longo de um mesmo segmento é considerada para o próximo passo. A
seguir cria-se o vetor propriamente dito, que se trata de um histograma que armazena em
cada uma das doze posições a soma das amplitudes relativas às frequências de cada uma
das notas musicais no espectro obtido, para todas as oitavas consideradas no processamento.
Somente foram consideradas no histograma as notas musicais de seis oitavas, da nota C3 à
nota B8, cobrindo a faixa de frequência de 130 Hz a 8 kHz, ou seja, das frequências obtidas
pela equação 1 para n =−21,−20, ...,59,60. A Figura 4.2, obtida do trabalho de Goto,
ilustra o processo de construção do Chroma vector.
Por exemplo, no processo de construção do vetor de Chroma, a posição do vetor
relativa à nota Lá (A) armazena a soma dos valores das magnitudes das frequências 220 Hz,

4.3. A MEDIÇÃO E ARMAZENAMENTO DA SIMILARIDADE 31
440 Hz, 880 Hz, 1760 Hz, 3520 Hz e 7040 Hz no espectro médio obtido por STFT para o
segmento processado.
Na literatura, diz-se que cada uma das posições do Chroma Vector está associada a
uma Pitch Class, que pode ser compreendida como sendo a classe formada por todas as notas
musicais com frequências obtidas por uma progressão geométrica de termo inicial fi = f0 e
razão q = 2 , onde:
fn = fi(2n−1), n inteiro. (2)
Isto significa, por exemplo, que todas as notas Dó presentes no piano pertencem a
uma Pitch Class, e estão associadas a uma posição no Chroma vector.
Na abordagem de Eronen, além do Chroma Vector, outra feature também é extraída de
cada fragmento do sinal: o vetor MFCC (Mel-Frequency Cepstral Coefficients) que, de modo
similar ao Chroma vector, traz a informação do timbre dos instrumentos presentes no intervalo
de tempo considerado.
4.3 A Medição e Armazenamento da Similaridade
Obtidas para cada pequeno fragmento do sinal as suas respectivas características
acústicas, pode-se medir a similaridade (ou distância) existente entre cada par de fragmentos
do sinal em relação a estas características. A forma de se medir a similaridade que foi utilizada
em ambas as abordagens de Goto e Eronen foi a Distância Euclidiana entre os vetores dos dois
fragmentos do sinal (Chroma ou MFCC), que apresenta, na realidade, o inverso da similaridade.
Em outras palavras, quanto menor for o valor obtido no cálculo da distância euclidiana, mais
similares são os dois respectivos fragmentos de sinal quanto à presença de notas musicais (ou
quanto ao timbre dos instrumentos presentes).
Um processamento fundamental e obrigatório a ambas as soluções apresentadas nesta
seção ocorre neste ponto: o tratamento de modulações. Como as abordagens desenvolvidas
por Goto e Eronen extraem como característica musical básica para processamento o Chroma,
característica essencialmente ligada às notas musicais, sempre que ocorrer uma modulação
na música, se não tiver uma lógica de tratamento da modulação, o sistema não identificará por
distância euclidiana a similaridade existente entre dois trechos da música que são similares,
mas executados em diferentes tonalidades. Para contornar este problema as abordagens
precisam considerar aqui o cálculo de distância euclidiana entre dois vetores de características
x e y, calculando a distância entre x e doze versões de y, uma sem deslocamentos e as outras
onze versões com deslocamento de uma a onze vezes para a direita ou para a esquerda. Desta
forma, se houve, por exemplo, uma modulação de dois tons em um dado instante localizado
entre o final de um e o início de outro, haverá uma baixa distância euclidiana entre o vetor
de característica x e o vetor y deslocado quatro vezes (ou oito vezes para o lado oposto).

4.3. A MEDIÇÃO E ARMAZENAMENTO DA SIMILARIDADE 32
Esta lógica de tratamento de modulação não é difícil de ser realizada e funciona bem, mas
acrescenta à solução um pouco mais de complexidade e custo.
Conforme os valores de similaridade vão sendo calculados, precisam ser armazenados
em uma estrutura de dados para que possam estar disponíveis ao processamento das etapas
posteriores da solução. Na abordagem de Eronen, a estrutura usada é a matriz de distância
(SDM ou Self-Distance Matrix na literatura), que é uma matriz que armazena em cada posição
a distância entre cada dois vetores de características obtidos anteriormente, onde a posição
ai j armazena a distância calculada entre o vetor do i-ésimo fragmento e o vetor do j-ésimo
fragmento do sinal. É notável que a diagonal principal desta matriz deverá conter valores
máximos de similaridade (ou valores nulos de distância), por se tratar da medida de similaridade
de um segmento com ele mesmo. Outro fato notável sobre a matriz de similaridade é que ela é
simétrica em relação à sua diagonal principal. A Figura 4.3 traz um exemplo de SDM construída
a partir da distância euclidiana entre vetores de Chroma, enquanto a Figura 4.4 mostra uma
matriz construída por distância euclidiana entre vetores MFCC.
Figura 4.3: SDM construída com vetores Chroma.
A abordagem de Goto, por sua vez, utiliza uma alternativa diferente, mas similar, à
matriz de distância: um triângulo de similaridade no qual, em cada linha horizontal de alta
similaridade, para um dado lag h indicado pela altura desta linha (valor no eixo vertical), registra
a similaridade entre dois segmentos da música, ambos medindo o mesmo comprimento desta
linha, distantes entre si o valor deste lag. Esta linha de alta similaridade e altura h, iniciando
no índice i do eixo horizontal e terminando no índice j deste eixo indica que há uma alta

4.3. A MEDIÇÃO E ARMAZENAMENTO DA SIMILARIDADE 33
similaridade entre dois segmentos da música, onde o primeiro inicia em i e termina em j, e o
segundo inicia em (i+ j) e termina em ( j+h).
Figura 4.4: SDM construída com vetores MFCC.
A Figura 4.5 mostra uma representação desta estrutura. Neste exemplo, o trecho C da
música que está sendo processada representa o seu refrão, que se repete 6 vezes ao longo da
música. As duas metades deste refrão são também similares entre si, o que gera os pequenos
traços horizontais menores, de cor acinzentada na ilustração, abaixo de cada linha horizontal
de cor preta que representa uma ocorrência de C. A linha horizontal mais comprida no gráfico
corresponde à repetição da ocorrência da sequência ABCC de 4 segmentos consecutivos na
música, onde A e B possivelmente são dois versos diferentes, seguidos de duas ocorrências
do refrão C, que implica na necessidade de uma rotina de tratamento que, comparando esta
linha maior com outras encontradas no gráfico, identifique que esta sequência não é uma parte
isolada da música, mas uma sequência de partes consecutivas que se repete.
Uma das vantagens de se utilizar a Matriz de distância (ou de similaridade) é que esta
estrutura permite a aplicação de filtros de processamento de imagem para refinamento de
seus valores. Após a construção da matriz na solução de Eronen, esta é processada por filtros
para a eliminação de valores espúrios na matriz de similaridade, como um filtro que realça as
diagonais de maior similaridade em relação aos valores de menor similaridade, ou ainda um
filtro para a remoção de quadrados na SDM construída a partir de Chromas, relacionados aos
acordes que persistem por mais de uma batida da música.

4.4. A ROTINA DE IDENTIFICAÇÃO DAS REPETIÇÕES 34
Figura 4.5: Triângulo Time-lag usado por Goto, construído com vetores Chroma.
O filtro que realça a nitidez das diagonais de alta similaridade utiliza um kernel de vinte
e cinco posições (5x5), o qual varre toda a matriz e verifica a localização do valor máximo
de similaridade no kernel. Se o valor máximo de similaridade estiver localizado na diagonal
principal do kernel, então este valor máximo é somado ao valor da posição central, e se o
máximo estiver localizado fora da matriz principal do kernel, então o valor mínimo do kernel é
somado ao valor da posição central do kernel. Espera-se que, ao final deste processamento,
as diagonais de repetições entre segmentos estejam mais evidentes em relação às demais
posições na matriz de similaridade. Filtros de processamento de imagem similares a estes são
utilizados na abordagem de Goto nesta etapa da execução.
Na abordagem de Eronen, neste ponto da execução realiza-se a soma das duas
matrizes de distância, a que foi preenchida por valores de distância entre vetores MFCC e a
preenchida por distâncias entre vetores de Chroma.
4.4 A Rotina de Identificação das Repetições
Uma vez construída a matriz de distâncias, vários cortes são realizados na matriz
através da anulação dos valores de algumas de suas posições, para que sejam retirados os
valores de similaridade que não interessam para as etapas seguintes da solução. O primeiro
corte consiste em preservar as diagonais de mais alta similaridade média, anulando-se todos

4.5. A ROTINA DE SELEÇÃO DE REFRÃO 35
os valores das demais diagonais da matriz de similaridade. A quantidade de diagonais a
serem preservadas foi escolhida segundo o método de dicotomização de Otsu para sinal
unidimensional (OTSU, 1979), processado sobre um sinal contendo as médias de distância de
cada diagonal da SDM.
Após o corte das diagonais de menor similaridade média é realizado um processo de
binarização (ou dicotomização) dos valores ainda não nulos da matriz, que é o estabelecimento
de um limiar e a categorização de todas as posições em duas classes: acima do limiar e
abaixo do limiar. Com o limiar calculado, toda posição cujo valor estiver acima do limiar (baixa
similaridade) é anulada, enquanto toda posição abaixo do limiar (alta similaridade) tem seu
valor substituído por um. A escolha deste limiar no trabalho de Goto é também realizada
conforme descrito no trabalho de Otsu, enquanto no trabalho de Eronen, a escolha foi do
valor de 20% fixo, sobre as diagonais com valores suavizados. Com o valor percentual do
limiar calculado, as diagonais não nulas são concatenadas em uma sequência, que é então
ordenada, e o valor contido na i-ésima posição, correspondente ao percentual do limiar de
corte calculado, é adotado como o valor de similaridade do limiar de corte.
Como resultado destes dois cortes espera-se que somente os trechos de mais alta
similaridade dentre as diagonais de mais alta similaridade da matriz estejam com valor não
nulo, enquanto as demais posições da matriz estejam com valor zero.
Após este processo de anulação de valores, um processamento sobre as diagonais
que ainda tem valores não nulos é realizado para remoção de pequenos intervalos nulos entre
dois trechos não nulos (gaps), provenientes possivelmente de curtas diferenças de similaridade
entre os segmentos de alta similaridade entre si, tais como pequenos arranjos diferentes
realizados por um músico ou algumas notas musicais tocadas por um instrumento distinto,
presentes em um dos segmentos da repetição e ausentes no outro. O processamento consiste
em somente verificar se entre dois trechos das diagonais existe um intervalo nulo relativamente
pequeno, e caso seja encontrado, seus valores são alterados para um, unindo os dois trechos
não nulos em um só.
A abordagem de Goto apresenta para a extração das linhas de repetições uma abor-
dagem análoga, adaptada para o triângulo de correspondências. Entretanto, sua abordagem
não foi abordada em detalhes por ser mais distante da abordagem da rotina de Extração de
Repetições do método proposto neste trabalho.
4.5 A Rotina de Seleção de Refrão
Aplicações de segmentação estrutural de música não necessitam retornar um segmento
apenas, pois retornam todos os segmentos encontrados, agrupados ou rotulados conforme
aparecem ao longo do tempo na música. No contexto das soluções de detecção de refrão,
entretanto, após o processo de rotulagem ou mesmo substituindo-o, a etapa de selecionar um
e apenas um dentre os segmentos listados é necessária, pois é esperado como retorno da

4.5. A ROTINA DE SELEÇÃO DE REFRÃO 36
solução apenas um trecho da música que possa ser apresentado como o refrão.
Desta forma, nas abordagens apresentadas nesta seção, logo após terem sido encon-
tradas todas as repetições (pares de segmentos da música que apresentaram alta similaridade
entre si), para cada repetição, os seus dois segmentos, o do eixo horizontal e o do eixo vertical
da matriz, são adicionados em uma lista de segmentos através do registro de seus extremos
(instante inicial e instante final do segmento). Esta lista então deverá ser varrida posteriormente
por um classificador que atribuirá a cada segmento um score que representa a probabilidade
deste segmento de ser um refrão, segundo o critério adotado pelo classificador. Após classifi-
cados todos os segmentos, aquele que apresentar maior valor para o score de classificação
será o segmento retornado pelo detector de refrão, segundo o critério do classificador que foi
utilizado.
Como as aplicações de detecção de refrão devem retornar apenas um segmento como
resposta, a etapa de seleção de um dentre os segmentos listados possui grande impacto na
taxa de erros da aplicação. Este grande impacto se deve ao fato de que não há serventia
alguma o refrão ser precisamente definido por um dentre os segmentos listados nas etapas
anteriores, se este segmento não for o escolhido na etapa de seleção. Não se pode esquecer
que as repetições também trazem outras partes da música que se repetem e não são refrãos,
e um bom classificador deve adotar critérios de seleção que possam distinguir o refrão das
demais partes da música.
Nas abordagens do Estado da Arte citadas neste trabalho, este processo de seleção é
realizado através de diversas heurísticas que escolhem um e exatamente um dos segmentos
listados como saída única da solução de detecção de refrão, usando critérios de seleção
baseados em observações dos próprios autores a respeito de aspectos comuns a refrãos de
diversas músicas populares.
Eronen testou quatro heurísticas para classificação dos segmentos candidatos a refrão,
baseadas em observações realizadas sobre a base de dados utilizada em seu trabalho: (1) a
localização do segmento de alta similaridade, assumindo que a localidade mais provável de um
refrão no tempo da música é próxima a um quarto ou três quartos do tempo da música; (2) a
similaridade média do segmento, onde é assumido que uma repetição com similaridade média
mais alta mais provavelmente contém um par de refrãos; (3) a amplitude média do segmento,
onde um segmento com mais alta amplitude média tem maior probabilidade de conter um refrão,
por serem os refrãos tocados normalmente com mais intensidade que as demais partes da
música; (4) a existência de uma estrutura peculiar de compartilhamento de segmentos repetidos
com outras duas diagonais na matriz, onde uma diagonal a que compartilha razoavelmente
um trecho do sinal de áudio no eixo horizontal da matriz de similaridade com uma diagonal b
e, da mesma forma, também compartilha o outro trecho repetido, no eixo vertical, com uma
diagonal c, provavelmente contem um par de refrãos, ou em outras palavras, uma repetição
que tem cada um de seus segmentos presentes em outras repetições, ainda que parcialmente,
provavelmente tem um par de refrãos.

4.6. OS RESULTADOS OBTIDOS 37
A abordagem de Goto, por sua vez, testou três heurísticas para classificação de cada
segmento candidato forte a refrão: (1) o range de tamanho do refrão, onde se estabelecem
limites de tamanho para um refrão, e uma diagonal com segmentos fora do range de 7,7 segun-
dos a 40 segundos é descartada; (2) a inclusão de um segmento menor, aceito pela heurística
anterior, no final de outro maior e que esteja fora do range, onde a este segmento menor é
atribuída maior probabilidade de ser um refrão, por se considerar que o segmento maior é uma
repetição que inclui um verso ou ponte que se repete seguido de um refrão que se repete,
muito comum em músicas pop; (3) a existência de um segmento maior, aceito pela primeira
heurística, e que contém dois outros segmentos menores, inclusos em suas metades, onde a
este segmento que contém dois outros é atribuída maior probabilidade de conter um refrão,
por se observar que comumente um refrão contém duas seções que se repetem.
4.6 Os Resultados Obtidos
Nos procedimentos experimentais realizados, cada autor utilizou uma base de dados
diferente. Goto utilizou a “RWC Music Database: Popular Music”, uma parte da base de dados
RWC, construída com a participação do próprio Goto (GOTO et al., 2004), constituída por
100 músicas populares, sendo 20 músicas americanas populares nos anos 80, e 80 músicas
japonesas populares nos anos 90. Eronen, por sua vez, utilizou uma base composta por 206
canções de música popular e rock, cujas anotações foram feitas manualmente por ele mesmo,
usando uma ferramenta dedicada que disponibilizava uma SDM sincronizada a batidas para
facilitar o processo de anotação, conforme relatado em seu trabalho. Segundo Eronen, a
maior parte destas canções possuía uma estrutura verso-refrão bem clara, embora existissem
algumas instâncias com uma estrutura menos óbvia.
A métrica de sucesso utilizada nos experimentos de ambos os trabalhos de Goto e Ero-
nen é a F-Measure, definida como a média harmônica entre a taxa de Recall (R) e a Precisão
(P). Seja a o refrão anotado manualmente e b o refrão retornado pela solução. Primeiro se
mede a interseção entre estes dois intervalos Intersect(a,b), e depois é calculado o valor
de R, razão entre Intersect(a,b) e o tamanho de a (Equação 3), e o valor de P, razão entre
Intersect(a,b) e o tamanho de b (Equação 4). Depois se calcula a média harmônica de Re P, razão entre o produto de R e P e a soma de R e P (Equação 5), que é a taxa de acerto
para o retorno da solução que está sendo avaliado.
R =Intersect(a,b)
length(a) (3)
P =Intersect(a,b)
length(b) (4)
Fmeasure =2RPR+P (5)

4.6. OS RESULTADOS OBTIDOS 38
Desta forma, a F-Measure retorna um valor entre zero e um que representa a cor-
respondência no tempo entre a e b, onde zero significa correspondência nula (interseção
inexistente) e um indica correspondência máxima, caso onde a possui exatamente os mesmos
extremos (início e fim) que b. Em função da forma como a taxa de acertos é calculada pela
F-Measure, o processo de desenvolvimento das anotações das bases de dados torna-se ainda
mais delicado, requerendo uma atenção maior e critérios bem definidos na marcação dos
extremos do refrão anotado, pois mesmo um erro na marcação de poucos décimos de segundo,
para mais ou para menos, altera o resultado do cálculo da F-Measure e, consequentemente, a
taxa de acertos final.
Goto em seu trabalho definiu como correta uma detecção de refrão com F-Measure
acima de 75%. Por este critério, sua abordagem acertou 80 das 100 músicas da base de
dados que utilizou, ou seja, 80 das 100 músicas alcançaram uma taxa de acertos acima de
75%. Eronen, conforme relatado em seu trabalho, para a base de dados que utilizou, alcançou
uma taxa de acertos medida por F-Measure média de 86%.
Já com relação ao custo da solução, as duas soluções operam em uma ordem de
grandeza de aproximadamente 10 segundos para uma música de aproximadamente 3 a 4
minutos de duração, para um computador de configuração mediana, acessível no mercado a
um usuário comum.

393939
5Correlação de Envoltória
Métodos de detecção de refrão com features baseadas em elementos harmônicos ou
timbrais da música, pelo princípio de construção destas features, tendem a sofrer uma alta
degeneração de sua taxa de acertos ao processarem músicas com menor presença de notas
musicais e de variedade de timbres. No propósito de se reduzir esta degeneração na taxa de
acertos, uma abordagem alternativa que inclui o processamento de uma feature diferente pode
ser proposta, a qual pode ser adicionada aos sistemas de detecção já existentes, melhorando
sua robustez. Mas é necessário que esta solução seja razoavelmente simples para que, neste
contexto, não venha a adicionar grande complexidade ou custo de processamento às soluções
já existentes.
Desta forma, o objetivo deste trabalho é propor uma abordagem alternativa de se
extrair features e similaridade para métodos de detecção de refrão ou ainda para métodos
de segmentação de música baseados em repetitividade, novidade ou homogeneidade, que
apresente maior robustez que os métodos harmônicos e timbrais no contexto do processamento
de músicas percussivas, as quais tipicamente têm menor presença de notas musicais e de
variedade de timbres. No intuito de se atingir este objetivo, o método proposto extrai uma
feature alternativa para cada fragmento do sinal, a Envoltória do Sinal (Curva de Intensidade),
e adota a Função de Correlação como forma de extrair informação de similaridade de cada par
de fragmentos a partir desta feature.
A Envoltória do sinal foi escolhida como feature para conceder à solução mais robustez,
pois por não depender da presença de notas musicais o uso desta feature pode minimizar
a degeneração da taxa de acertos do método em músicas percussivas. A Correlação, por
sua vez, foi escolhida como métrica de similaridade entre curvas de intensidade do sinal por
ser uma função muito utilizada para medir o grau de semelhança entre dois sinais e que,
limitando-se o tamanho destes sinais, não acrescenta muito custo à solução.
A seção 5.1 traz uma discussão sobre a envoltória de sinais de áudio e como esta
é capaz de preservar a similaridade entre as partes da música que se repetem ao longo do
tempo no sinal, enquanto a seção 5.2 apresenta a função de correlação, sua utilidade como
métrica de similaridade entre sinais, e discute o seu custo computacional.

5.1. A ENVOLTÓRIA DO SINAL 40
5.1 A Envoltória do Sinal
Nesta seção será apresentada a feature usada no trabalho proposto, e será discutida
como esta feature preserva a similaridade entre fragmentos de sinais no sinal de envoltória,
mesmo que não estejam mais presentes as frequências acima de 20Hz, que serviram de base
para a construção dos vetores Chroma e MFCC das abordagens descritas no capítulo 4.
A envoltória do sinal pode ser definida como sendo a variação da intensidade do sinal
ao longo do tempo, descrevendo também a sua variação de energia. O sinal de áudio tem
sua envoltória modulada por ondas na faixa de frequência audível pelo ouvido humano, com
frequências entre 20 Hz e 20 KHz, de ondas resultantes da soma das frequências dos sons
que estão sendo executados em cada intervalo da música.
A envoltória tem participação direta na definição do timbre. O timbre é uma caracte-
rística subjetiva do som que nos permite diferenciar sons de altura e intensidade iguais, mas
executados por diferentes instrumentos. O timbre de um instrumento, ou a “cor” de seu som,
pode ser definido pelo produto de duas componentes: (1) uma forma de onda composta por
uma combinação linear de uma onda que oscila numa frequência fundamental com outras
ondas oscilando nas frequências harmônicas desta frequência fundamental (múltiplas), e com
amplitudes relativas bem definidas no instante zero da onda; (2) Um sinal de contorno de
amplitude associado a frequências menores que 20Hz (fora da faixa audível), que define a
variação da amplitude da primeira componente no seu tempo de duração.
A primeira componente do timbre é composta pelas frequências de modulação da
envoltória. As frequências fundamentais estão associadas às notas musicais presentes na
música, segundo valores de frequências tabelados pelo sistema de temperamento musical, de
onde se extrai o Chroma Vector, enquanto as frequências harmônicas estão mais relacionadas
à construção de vetores MFCC.
A segunda componente, objeto de estudo desta seção, é a envoltória do som, tão
importante quanto a primeira na definição do timbre do instrumento, de modo que duas notas
musicais criadas em um sintetizador com a mesma forma de onda, mas com envelopes
diferentes, soarão distintas uma da outra, produzindo diferentes percepções auditivas.
Para uma melhor compreensão de como a envoltória participa na definição do timbre,
é interessante observar a curva de intensidade do som a partir de um modelo teórico, como,
por exemplo, o modelo ADSR (Attack, Decay, Sustain e Release), muito usado no estudo dos
envelopes sonoros, que divide a variação da intensidade de um som em quatro fases distintas -
Ataque, Decaimento, Sustentação e Relaxamento – conforme mostrado na Figura 5.1. A Figura
5.2 descreve graficamente este padrão, para uma nota musical tocada por um violão, enquanto
a Figura 5.3 mostra uma forma de onda gerada por uma melodia de 15 notas consecutivas
tocadas pelo mesmo violão.

5.1. A ENVOLTÓRIA DO SINAL 41
Figura 5.1: Representação gráfica do modelo ADSR de variação de intensidade dosom.
Figura 5.2: Forma de onda de uma nota tocada por um violão.
A Combinação das intensidades e dos tempos de duração de cada fase do modelo
ADSR está diretamente ligada à cor do som do instrumento, e pode variar de acordo com
o tipo do instrumento executado e com a forma como o instrumentista está tocando a nota
musical. As Figuras 5.4, 5.5 e 5.6 trazem uma representação do modelo ADSR de envoltória
típico de sons de instrumentos cordofones (cordas), aerofones (sopro) e membranofones
(percussão), respectivamente. A Figura 5.7 traz três gráficos de notas musicais tocadas por
três instrumentos diferentes: (1) uma tabla (tambor indiano); (2) uma trompa e (3) uma flauta.

5.1. A ENVOLTÓRIA DO SINAL 42
Figura 5.3: Forma de onda de uma melodia de 15 notas tocadas por um violão.
Figura 5.4: Modelo ADSR típico de sons de instrumentos cordofones.
Figura 5.5: Modelo ADSR típico de sons de instrumentos aerofones.

5.1. A ENVOLTÓRIA DO SINAL 43
Figura 5.6: Modelo ADSR típico de sons de instrumentos membranofones.
O ataque de uma nota é a fase de elevação inicial da intensidade do som, que vai do
limiar de silêncio até o pico de sua intensidade. Quando o instrumentista bate em um tambor,
inicia uma arcada em um violino ou sopra um clarinete ele inicia o ataque. O instante exato
onde o ataque tem início é chamado de Onset.
O tempo de duração que o som leva para ir do silêncio até a sua intensidade máxima
varia. Instrumentos de sopro, por exemplo, podem produzir ataques muito suaves, com notas
ligadas umas às outras (legato) ou notas de início muito brusco e separadas umas das outras
(staccato). Instrumentos de corda com arco, como o violino, podem ter ataques muito suaves,
levando uma mesma nota a crescer do silêncio até uma intensidade elevada ao longo de vários
segundos, se o instrumentista assim o desejar. A Figura 5.7 mostra diferenças no ataque
de três instrumentos distintos, e também diferenças entre as próprias notas de um mesmo
instrumento, provocadas pela forma como o instrumentista tocou o instrumento em cada nota.
Figura 5.7: Gráficos de sons de três instrumentos diferentes no domínio do tempo: (1)tabla; (2) trompa; (3) flauta.
Terminado o ataque, a intensidade do som sofre um decaimento antes de atingir um
nível de estabilidade. Em um instrumento de sopro, por exemplo, ao cessar o esforço inicial

5.1. A ENVOLTÓRIA DO SINAL 44
necessário para colocar a palheta em vibração, é necessário um esforço relativamente menor
para manter esta nota em um nível de intensidade estável, o que explica o leve decaimento
até a intensidade desejada. O decaimento costuma ser muito rápido, durando algumas vezes
pouco menos que um décimo de segundo. Nos exemplos da Figura 5.7, o decaimento é
claramente perceptível nas notas da tabla. Decaimentos normalmente são mais perceptíveis
em instrumentos de percussão, como a conga e o atabaque, ou em instrumentos de cordas,
como o piano e o violão.
A sustentação é a fase do som onde a sua intensidade atingiu um nível de razoável
estabilidade, permanecendo assim por um tempo. Na maioria dos instrumentos, este tempo
pode ser controlado pelo instrumentista, como é o caso das notas da trompa e da flauta nos
gráficos 1 e 2 da Figura 5.7. Alguns instrumentos, entretanto, não permitem controlar a duração
deste tempo, (e.g. instrumentos de percussão), havendo ainda os instrumentos onde a fase de
sustentação é praticamente inexistente, de forma que o decaimento da intensidade do som é
imediatamente seguido pelo seu relaxamento.
Finalizando a envoltória do som no modelo ADSR, segue-se a fase de relaxamento,
quando a intensidade sonora diminui até ser anulada. Pode ser brusco, como em um ins-
trumento de sopro quando o instrumentista corta repentinamente o fluxo de ar, ou como em
um tambor, quando a pele é silenciada com a mão. Também pode ser muito lento, como em
um gongo ou um piano com o pedal de sustentação acionado. Nestes casos a nota pode
permanecer soando por vários segundos antes de atingir o silêncio. O instante exato onde o
som se extingue é chamado de Offset do som.
No terceiro gráfico da Figura 5.7, a nota da flauta tem um final suave devido à reverbe-
ração da sala onde a música foi executada, que levou o som a permanecer ainda por um tempo
mesmo após o término do sopro, o que mostra que as condições do ambiente de gravação do
som também podem exercer algum tipo de influência na envoltória do sinal digital de áudio que
foi gravado.
Diante deste conceito do modelo ADSR, e partindo da compreensão de que melodia,
harmonia e ritmo de uma música significam, respectivamente, a sequência, simultaneidade
e disposição dos sons de uma música ao longo do tempo, infere-se que a envoltória do som
é, na realidade, a soma de vários destes padrões ADSR de variação de intensidade (ataque,
decaimento, sustentação e relaxamento) em sequência, simultaneidade, e disposição ao longo
do tempo, um para cada som específico executado por um instrumento ao longo da música.
Vale salientar que a voz é também um instrumento, e que uma configuração específica destas
variações de intensidade de cada som produzido pela fala humana é específica a um fonema,
como as vogais ou as consoantes, da língua que está sendo falada (ou cantada, no caso de
uma música), independente da frequência de modulação deste som.
Assim, sendo um trecho da música composto por sons simultâneos ou sequenciais
dispostos ao longo do tempo, pode-se concluir que para cada parte que se repete ao longo
da música ocorrerá não apenas a repetição das frequências fundamentais e harmônicas das

5.2. A FUNÇÃO DE CORRELAÇÃO 45
notas musicais presentes, mas ocorrerá também a repetição destes padrões ADSR de variação
de intensidade somados em um só sinal, visto que são também partes intrínsecas do som
destas notas musicais. Desta forma, uma abordagem que explora somente a envoltória do
sinal de áudio é também capaz de extrair informação de repetitividade do sinal, uma vez que os
padrões ADSR dos sons, presentes na envoltória do sinal, também guardam esta informação
de repetitividade.
Importante observar que, como a envoltória do som independe das frequências das
notas musicais tocadas, uma solução que use a envoltória do sinal como feature teoricamente
também pode ser utilizada para a identificação de trechos que se repetem em uma gravação
de poesia, prosa, locução de rádio, narração, sons puramente percussivos, ou qualquer outro
tipo de gravação de áudio, seja de fala, cantada, instrumental, ou ambos.
5.2 A Função de Correlação
Uma vez que a feature proposta apresentada na seção anterior é um sinal em vez de
um vetor, a distância euclidiana não pode mais ser usada como métrica de similaridade entre
dois pares de fragmentos do sinal. Desta forma, a Função de Correlação é proposta para se
medir a similaridade a partir da feature, sendo apresentada nesta seção.
A correlação é uma operação matemática utilizada em diversas áreas de conhecimento
que mostra o grau de similaridade entre duas variáveis, sendo assim também muito utilizada
para detectar um sinal conhecido dentro de outro sinal desconhecido. No processamento
digital de sinais, o calculo da correlação recebe dois sinais de entrada discretos no tempo e
gera um sinal de saída a partir deles, chamado de correlação cruzada, que nos mostra o grau
de similaridade entre estes dois sinais de entrada, levando em conta deslocamentos aplicados
a um destes sinais. Se um sinal é correlacionado com ele mesmo, o sinal resultante é chamado
de auto-correlação.
A Figura 5.8 apresenta um exemplo do funcionamento da correlação, com dois sinais
de entrada, o sinal desconhecido e o sinal alvo (conhecido), e como saída temos um terceiro
sinal, que é o sinal de correlação cruzada entre estes dois sinais de entrada.
A amplitude de cada amostra do sinal de correlação cruzada é uma medida de quanto
o sinal alvo está relacionado com o sinal desconhecido para aquele deslocamento aplicado ao
sinal alvo. Cada pico que surgir no sinal da correlação cruzada indica que o sinal alvo tem sua
forma de onda presente no sinal desconhecido para o deslocamento indicado pela abcissa
deste pico. No exemplo ilustrado na Figura 5.8, os dois picos no sinal de saída representam
as duas ocorrências do sinal alvo no sinal desconhecido. O valor da correlação cruzada é
maximizado quando o sinal alvo está alinhado com o intervalo do sinal desconhecido que
lembra as suas características.
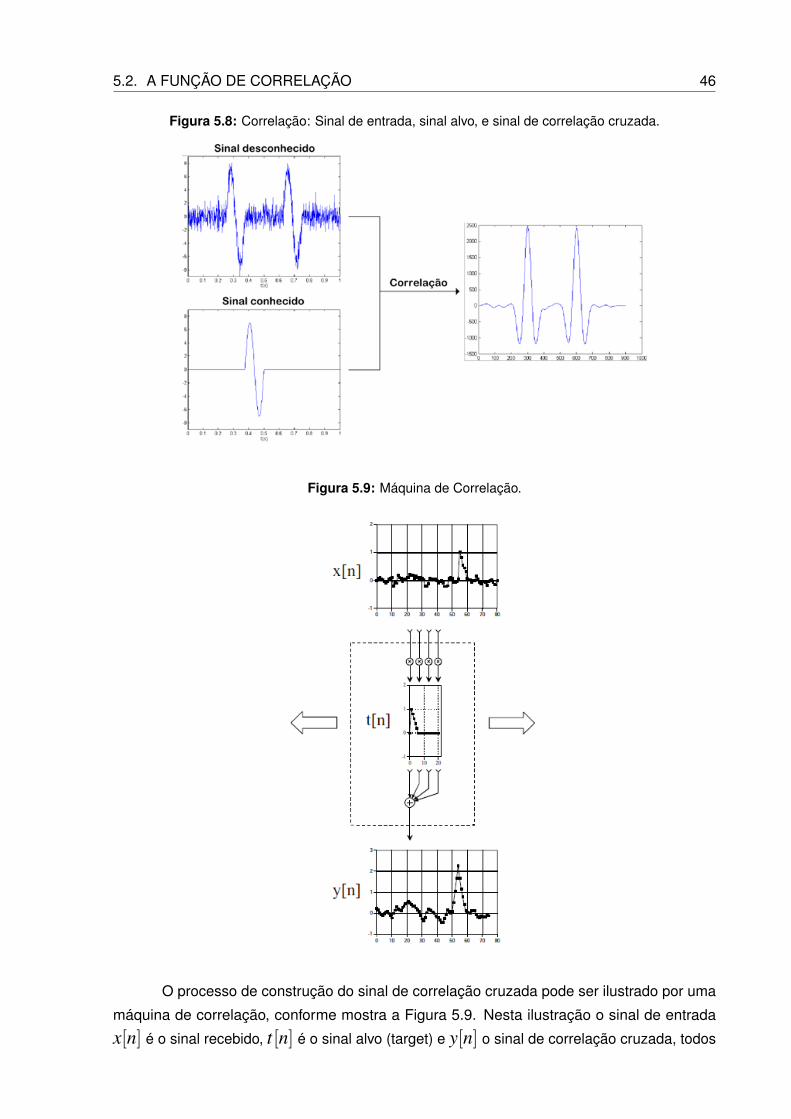
5.2. A FUNÇÃO DE CORRELAÇÃO 46
Figura 5.8: Correlação: Sinal de entrada, sinal alvo, e sinal de correlação cruzada.
Figura 5.9: Máquina de Correlação.
O processo de construção do sinal de correlação cruzada pode ser ilustrado por uma
máquina de correlação, conforme mostra a Figura 5.9. Nesta ilustração o sinal de entrada
x[n] é o sinal recebido, t[n] é o sinal alvo (target) e y[n] o sinal de correlação cruzada, todos

5.2. A FUNÇÃO DE CORRELAÇÃO 47
discretos. Na i-ésima iteração da construção do sinal, a i-ésima amostra y[i]do sinal de
correlação cruzada é calculada movendo a máquina de correlação da esquerda para a direita,
emparelhando-se um intervalo do sinal de entrada com um intervalo do sinal alvo. Cada par de
amostras emparelhadas tem seus valores multiplicados, e a soma de todos estes produtos é o
valor armazenado na amostra y[i].A amplitude de cada amostra de y[n] é a medida de quanto o sinal recebido se
assemelha ao sinal alvo para aquela localidade (ou deslocamento). Isto significa que um pico
vai ocorrer no sinal de correlação cruzada para cada sinal alvo que for apresentado no sinal
recebido. Em outras palavras, o valor da correlação cruzada é maximizado quando o sinal alvo
é alinhado com um trecho do sinal recebido.
Se o sinal alvo e o sinal desconhecido tiverem amostras negativas, o pico referente
ao alinhamento destes dois padrões será também positivo. Se a máquina de correlação
está posicionada de modo que o sinal alvo está perfeitamente alinhado com um trecho do
sinal recebido, as amostras do sinal alvo são multiplicadas com suas respectivas amostras
alinhadas no sinal recebido. Negligenciando o ruído, uma amostra positiva será multiplicada
por ela mesma resultando em valor positivo, e uma amostra negativa será multiplicada por ela
mesma, resultando também em uma amostra positiva em y[n]. Ainda que o sinal alvo seja
completamente negativo, o pico no sinal de correlação cruzada relativo a um alinhamento será
positivo.
Se há ruído no sinal recebido, também haverá ruído no sinal de correlação cruzada.
Mesmo assim, a correlação cruzada ainda pode ser usada para se encontrar um sinal alvo
somado a um ruído. Os picos gerados no sinal de correlação cruzada referentes a um sinal
alvo em um ruído (sobretudo ruído branco) são geralmente maiores do que os picos produzidos
por qualquer outro sistema linear. Além disso, os picos gerados na correlação cruzada, exceto
para os ruídos randômicos, são simétricos ao se deslocar para a esquerda ou para a direita.
A Equação 6 (ou a equação 7) apresenta a função de correlação para sinais analógicos,
enquanto a Equação 8 (ou a equação 9) apresenta a função de correlação para sinais discretos.
CA(τ) =∫ t ′+T
t ′ x(t + τ)y(t)dt , t ’ constante (6)
CA(τ) =∫ t ′+T
t ′ x(t)y(t− τ)dt , t ’ constante (7)
CD(τ) = ∑t ′+Tt=t ′ x[t + τ]y[t], t ’ constante (8)
CD(τ) = ∑t ′+Tt=t ′ x[t]y[t− τ], t ’ constante (9)
Como no contexto deste trabalho os sinais de entradas e o de saída são digitais e,
portanto, discretos, a equação 8 (ou a equação 9) é a que deve ser considerada nesta análise.
Desta forma, considerando a equação 8, cada amostra CD[τ = i] do sinal de correlação é um
somatório de parcelas do tipo x[t + τ]y[t], para cada valor de lag τ específico, onde t varia

5.2. A FUNÇÃO DE CORRELAÇÃO 48
de zero até o limite T da janela de observação (parâmetro fornecido na chamada da função
de correlação) e τ varia de zero até o tamanho do sinal x. O limite máximo para a janela de
observação é o tamanho do sinal y.
O valor deste somatório de parcelas x[t + τ]y[t] para um τ específico será maior
quanto menos parcelas negativas existirem, e também quanto maior for o valor absoluto destas
parcelas x[t + τ]y[t], supondo que são positivas. Sempre que um padrão em x alinha-se
com um padrão em y para um dado lag τ o somatório da Equação 8 obtém mais parcelas de
alto valor, pois valores positivos de x serão multiplicados com valores positivos em y e valores
negativos em x serão multiplicados com valores negativos, gerando parcelas positivas em
ambos os casos. Além disso, o valor das parcelas positivas x[t + τ]y[t] é maximizado em
trechos de maior magnitude de x alinhados com trechos de maior magnitude em y, pois o valor
absoluto destas parcelas é maximizado.
Desta forma, um máximo local em τ = a implica em forte casamento de padrões (ou
similaridade) entre x e y para um lag de valor a e, implicitamente, grooo valor deste pico traz
também a informação de quão grande é a amplitude destes sinais x e y para este lag a, se
comparado a outros possíveis alinhamentos de padrões entre x e y, se existirem, com τa.
Assim, além da similaridade, a intensidade do sinal também é considerada no valor de cada
amostra do sinal de correlação cruzada resultante.
Assim, como se pode observar a partir da equação 8, o processo de construção do sinal
de correlação cruzada é simples de entender e de implementar, resumindo-se a um somatório
do produto entre os pares de amostras dos dois sinais de entrada, para cada amostra do sinal
de saída, dispensando o uso de operações mais complicadas, como as transformadas.
Importante ressaltar que a função de correlação poderia ser usada para medir a
similaridade entre fragmentos do próprio sinal de áudio, mas esta escolha é inviável por conta
do custo computacional associado. Considerando n o tamanho dos sinais x e y, tem-se τ
variando de zero a n e t variando de zero a τ . Assim, para cada valor de τ durante a construção
do sinal de correlação, (n− τ) produtos do tipo x[t + τ]y[t] precisam ser computados, e
tem-se desta forma um total de
[n+(n−1)+(n+2)+ ...+2+1] = n(n+1)/2 (10)
produtos computados, o que significa que a função de correlação tem complexidade da
ordem de O(n2), ou seja, um crescimento exponencial em função do tamanho das entradas xe y. Por isso, mesmo a função de correlação sendo uma referência na métrica de similaridade
entre sinais, para que seja realmente vantajoso utilizá-la para detectar similaridade entre sinais,
as entradas não podem ser muito grandes, caso contrário o custo computacional do cálculo da
função será muito elevado.
Se x e y na equação 8 forem sinais digitais de áudio comuns, para que seja coberta a
maior frequência audível pelo ouvido humano (20kHz) devem possuir uma taxa de amostragem
de 44100Hz (chegando a ter o dobro deste valor quando é estéreo). Um sinal deste tipo com

5.2. A FUNÇÃO DE CORRELAÇÃO 49
quatro minutos de música (uma música de tamanho médio) possuem cerca de 10 milhões
amostras, o que constitui um valor muito alto de amostras para que venha a ser processado
por uma função de correlação, tornando inviável o uso desta função para a estimativa de
similaridade entre sinais de áudio.
Entretanto, para o caso em que o sinal de áudio é processado de tal forma que
tenha seu tamanho reduzido em algumas ordens de grandeza preservando a informação de
similaridade entre suas partes, o uso da função de correlação torna-se viável para a detecção
de padrões repetidos, como no caso de uma solução para o problema da detecção de refrão
em sinais de áudio baseada em repetitividade. Esta redução é alcançada pela Extração da
Envoltória do Sinal, conforme será visto na seção 6.1.

505050
6O Método Proposto
As soluções para o problema da detecção de refrão disponíveis no Estado geralmente
utilizam características acústicas relacionadas às notas musicais presentes no sinal ou aos
timbres dos instrumentos que as executam, explorando desta forma o domínio da frequência,
através de transformadas de Fourier.
A solução apresentada neste capítulo se propõe a utilizar a envoltória (curva de
intensidade) e a correlação, que podem ser tratadas explorando-se somente o domínio do
tempo, com o objetivo de se obter mais robustez em relação à detecção de refrão em músicas
mais percussivas e menos harmônicas ou timbrais.
Desta forma, a principal mudança no método proposto em relação às abordagens
de Goto e Eronen é a substituição da extração das características acústicas Chroma Vector
e vetor MFCC pela extração da envoltória dos fragmentos do sinal. Esta mudança torna o
método independente das frequências das notas musicais do sinal, dispensando também
a necessidade de um tratamento de modulações. Para a métrica de similaridade entre os
fragmentos do sinal substituiu-se a distância euclidiana, que obtinha seus valores a partir dos
vetores de Chroma e MFCC, pelo máximo da função de correlação, que é obtido a partir de
sinais, que neste caso são as envoltórias dos fragmentos do sinal de áudio.
Outra mudança proposta é a substituição da etapa de segmentação pela janela desli-
zante, que simplifica o método, remove o custo empregado na detecção de batidas, torna o
seu tempo de resposta independente da frequência destas batidas, e possibilita uma maior
precisão no corte dos extremos do refrão, que não estarão mais limitados às batidas do sinal.
A Figura 6.1 traz o fluxograma contendo as etapas do método proposto neste trabalho
para solução do problema de detecção de refrão: (1) Extração da envoltória do sinal de áudio,
onde o sinal de envoltória é construído; (2) Construção da Matriz de Similaridade, onde é
registrado o grau de similaridade dos fragmentos da música entre si dois a dois; (3) Extração
das Repetições, onde são listados em pares os segmentos da música que apresentaram
alta similaridade entre si; (4) Seleção do Segmento Refrão, onde um e apenas um dos
segmentos listados será escolhido como o retorno da solução, segundo critérios específicos
preestabelecidos. Cada seção deste capítulo apresenta um destes quatro passos aqui listados,

6.1. A EXTRAÇÃO DA ENVOLTÓRIA DO SINAL 51
na exata ordem de execução, destacando as diferenças e as semelhanças em relação às
abordagens mais recentes encontradas na literatura para detecção de refrão, que foram
descritas no capítulo 4.
Figura 6.1: Fluxograma das etapas do método proposto para detecção de refrão.
6.1 A Extração da Envoltória do Sinal
Existem várias formas de se encontrar a envoltória do sinal como, por exemplo: filtros
passa-baixa, como descrito por BELLO et al. (2005), que traz a mesma ideia da demodulação
clássica de sinais modulados em amplitude, com o devido ajuste na frequência de corte para
eliminar as frequências do pitch das notas minimizando a perda da informação da envoltória;
valor quadrático médio da energia do sinal (Root Mean Square), conforme abordado por HAJDA
(1996), que usa uma janela deslizante para rastrear a variação da potência média do sinal como
uma estimativa da envoltória; predição linear do domínio da frequência (FDLP), como descrito
no trabalho de ATHINEOS; ELLIS (2003), desenvolvido para aplicações em processamento de
fala; aplicar o cepstrum sobre um sinal no domínio do tempo, pré-processado para aparentar a
magnitude de um espectro, conforme CAETANO; BURRED; RODET (2010). Cada uma das
formas de estimar a envoltória do sinal possui suas vantagens e desvantagens, normalmente
sendo umas mais simples, imprecisas e de menor custo, enquanto outras são mais complexas

6.1. A EXTRAÇÃO DA ENVOLTÓRIA DO SINAL 52
e custosas, porém mais precisas.
Numa solução de detecção de refrão, para a finalidade de encontrar repetitividade
em relação à presença de notas musicais, é teoricamente suficiente uma precisão capaz de
encontrar a localidade exata dos sons no tempo e a duração e intensidade das quatro fases do
modelo ADSR de cada som encontrado, não sendo necessário identificar quaisquer detalhes
ou minúcias menores que estas. Isto porque, com a localidade de cada nota identificada, as
melodias de duas partes da música poderão ser comparadas entre si, através do alinhamento
do início exato e da duração exata de cada nota musical encontrada em ambas as partes.
Da mesma maneira, com os modelos ADSR das notas musicais identificados na envoltória, é
possível avaliar se dois sons alinhados foram produzidos por um mesmo instrumento, através
da componente de mais baixa frequência do timbre.
Diante disso, a forma escolhida neste trabalho para se estimar a envoltória do sinal
de áudio foi detectar o máximo de uma janela deslizante ao longo deste sinal no domínio do
tempo. Antes do processo de extração dos máximos da janela deslizante, o sinal de áudio é
pré-processado obtendo-se outro sinal que contem os valores absolutos do sinal original, sendo
facilmente construído através da inversão de cada valor negativo que for encontrado ao longo
do sinal. Depois, a sequência destes valores máximos obtidos pela janela deslizante no sinal
de valores absolutos é armazenada em outro sinal que, com o devido ajuste de parâmetros,
deve reproduzir a variação da intensidade do sinal ao longo do tempo, com uma precisão que
permita identificar a localidade exata das notas musicais presentes no sinal e a duração das
fases do modelo ADSR da envoltória de cada nota encontrada, atuando de maneira similar
a um filtro passa-baixa. Esta solução é simples, funcional, e tem baixo custo computacional.
A Figura 6.2 mostra um fluxograma contendo os processamentos da etapa de Extração de
Envoltória do método proposto.
A Extração de envoltória por janela deslizante possui dois parâmetros importantes:
o tamanho da janela e o valor do deslocamento, ambos medidos em unidades de tempo.
O tamanho da janela exerce influência sobre o custo computacional da própria etapa de
construção do sinal de envoltória, enquanto o valor do deslocamento adotado, por sua vez,
pode regular o tamanho do sinal de envoltória construído, exercendo direta influência sobre o
custo computacional das etapas posteriores da solução, que serão realizadas a partir deste
sinal.
O sinal de envoltória resultante construído desta maneira é menor que o sinal original,
conforme será visto mais adiante, com uma redução do número de amostras de algumas ordens
de grandeza, que pode ser parametrizada pela escolha do tamanho da janela e principalmente
do valor do deslocamento da janela. Esta redução pode ser medida pela razão entre o tamanho
do sinal original de áudio pelo tamanho do deslocamento da janela escolhido.
A redução no tamanho do sinal de envoltória em relação ao tamanho do sinal de áudio
original é muito importante por possibilitar o uso da correlação como métrica de similaridade
entre as partes do sinal, além de proporcionar uma grande redução no custo da solução
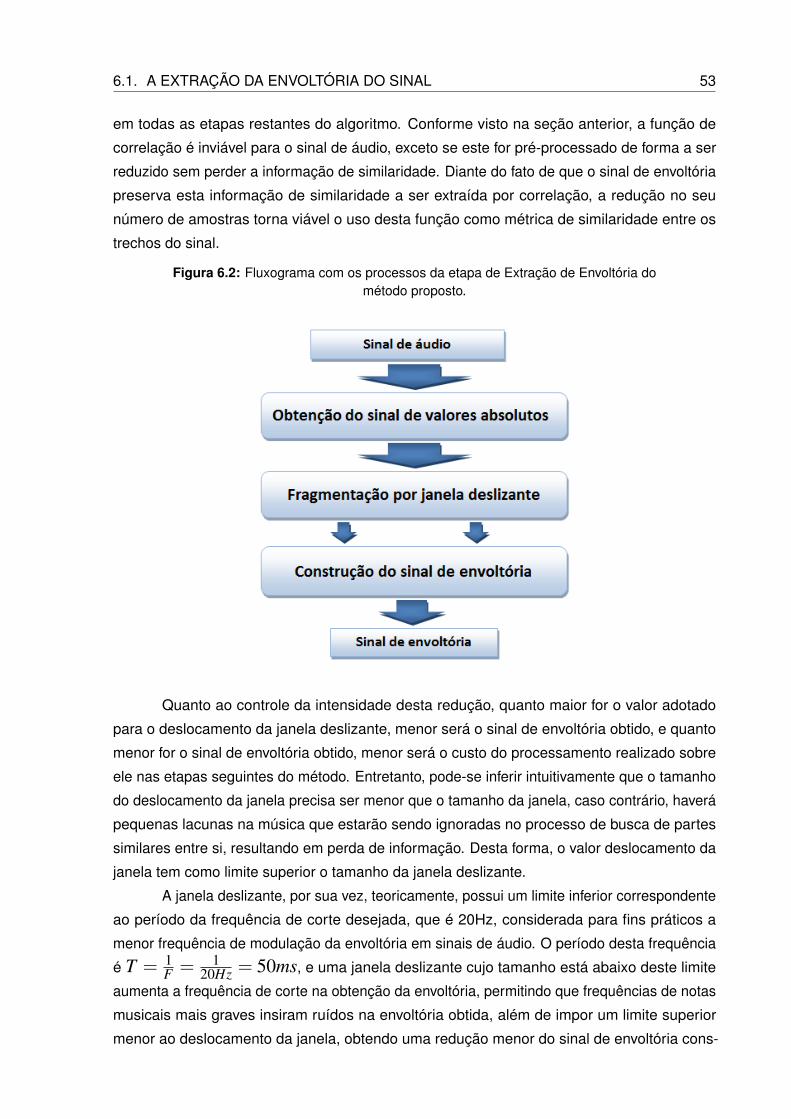
6.1. A EXTRAÇÃO DA ENVOLTÓRIA DO SINAL 53
em todas as etapas restantes do algoritmo. Conforme visto na seção anterior, a função de
correlação é inviável para o sinal de áudio, exceto se este for pré-processado de forma a ser
reduzido sem perder a informação de similaridade. Diante do fato de que o sinal de envoltória
preserva esta informação de similaridade a ser extraída por correlação, a redução no seu
número de amostras torna viável o uso desta função como métrica de similaridade entre os
trechos do sinal.
Figura 6.2: Fluxograma com os processos da etapa de Extração de Envoltória dométodo proposto.
Quanto ao controle da intensidade desta redução, quanto maior for o valor adotado
para o deslocamento da janela deslizante, menor será o sinal de envoltória obtido, e quanto
menor for o sinal de envoltória obtido, menor será o custo do processamento realizado sobre
ele nas etapas seguintes do método. Entretanto, pode-se inferir intuitivamente que o tamanho
do deslocamento da janela precisa ser menor que o tamanho da janela, caso contrário, haverá
pequenas lacunas na música que estarão sendo ignoradas no processo de busca de partes
similares entre si, resultando em perda de informação. Desta forma, o valor deslocamento da
janela tem como limite superior o tamanho da janela deslizante.
A janela deslizante, por sua vez, teoricamente, possui um limite inferior correspondente
ao período da frequência de corte desejada, que é 20Hz, considerada para fins práticos a
menor frequência de modulação da envoltória em sinais de áudio. O período desta frequência
é T = 1F = 1
20Hz = 50ms, e uma janela deslizante cujo tamanho está abaixo deste limite
aumenta a frequência de corte na obtenção da envoltória, permitindo que frequências de notas
musicais mais graves insiram ruídos na envoltória obtida, além de impor um limite superior
menor ao deslocamento da janela, obtendo uma redução menor do sinal de envoltória cons-

6.1. A EXTRAÇÃO DA ENVOLTÓRIA DO SINAL 54
truído, aumentando o custo de processamento nas etapas seguintes da solução. Entretanto,
na prática, raramente uma música tem notas musicais tão graves, e o custo de processamento
acrescentado à solução pode não ser tão grande dependendo do valor da janela e do desloca-
mento, tendo sido admitido nos testes valores abaixo deste limite no intuito de verificar nos
resultados as suas relações de custo-benefício para a solução.
Se a janela for muito grande, por outro lado, perde-se precisão, podendo ser incluídas
num mesmo frame muitas variações de intensidade que caracterizariam mais precisamente as
diferentes fases do padrão ADSR, ou até mesmo pode-se incluir mais de uma nota musical
nesta janela, para o caso de uma melodia de um instrumentista muito ágil, com notas de
duração muito curta, o que causaria muita perda de informação de similaridade. Além disso,
quanto maior o tamanho da janela, maior o custo do processo de construção do sinal de
envoltória realizado nesta etapa da solução, porque uma janela maior vai requerer um número
maior de comparações de valores escalares na função de detecção do valor máximo da janela.
Desta forma, é necessário escolher valores para a janela e para o deslocamento da
janela que tenham um bom compromisso entre redução do sinal e redução da perda de
informação da envoltória. Mais de um valor para estes parâmetros foi testado, cujos resultados
serão discutidos no capítulo 5.
A Figura 6.3 traz a representação gráfica um sinal de áudio no domínio do tempo da
nota musical Lá tocada por um violão com cordas de nylon. As figuras 6.4, 6.5 e 6.6 trazem as
envoltórias desta nota musical para uma janela e deslocamento de, respectivamente, 20ms,
50ms e 200ms.
Figura 6.3: Gráfico de uma nota Lá tocada por um violão com cordas de nylon.
Observando o eixo horizontal dos gráficos das Figuras 6.3 a 6.6 nota-se a redução no
tamanho do sinal de duas a três ordens de grandeza, dependendo do tamanho do desloca-
mento adotado, o que permite uma significativa redução de custos nas etapas seguintes deste
método. É fácil de notar também que quanto mais se aumenta o valor do deslocamento mais
reduzido é o sinal gerado e maior é a perda na precisão da informação da envoltória.

6.1. A EXTRAÇÃO DA ENVOLTÓRIA DO SINAL 55
Figura 6.4: Gráfico da envoltória do sinal da Figura 6.3 para uma janela de 20ms.
Figura 6.5: Gráfico da envoltória do sinal da Figura 6.3 para uma janela de 50ms.
Figura 6.6: Gráfico da envoltória do sinal da Figura 6.3 para uma janela de 200ms.

6.2. A CONSTRUÇÃO DA MATRIZ DE SIMILARIDADE 56
Conforme visto no capítulo 4, na abordagem de Eronen se utiliza a segmentação
sincronizada a batidas no intuito de reduzir um custo futuro. Embora não haja uma segmentação
explícita no processo descrito nesta seção, o propósito da redução de custos de processamento
posteriores também é alcançado utilizando-se esta técnica, por causa desta redução no
tamanho do sinal.
A seção seguinte descreve o cálculo de similaridade entre segmentos da música, bem
como a construção da matriz de similaridade.
6.2 A Construção da Matriz de Similaridade
Nesta etapa da solução será descrita a etapa da solução proposta neste trabalho que
calcula os valores de similaridade entre os fragmentos do sinal, constrói uma estrutura de
dados que armazenará estes valores. A estrutura usada é a Matriz de Similaridade (SSM ou
Self Similarity Matrix na literatura), análoga à matriz de distância utilizada na abordagem de
Eronen, mas com a diferença de que cada posição ai j terá a similaridade entre o i-ésimo e o
j-ésimo fragmento do sinal em vez da distância entre eles.
Da mesma maneira que a matriz de distância, a matriz de similaridade possui simetria
em relação à sua diagonal principal, e a sua diagonal principal terá valores máximos de
similaridade, pois são medidas de similaridade de cada segmento com ele mesmo.
Para reduzir o custo do método nesta etapa é preenchido apenas do triângulo inferior
da matriz de similaridade. Uma vez que ela é simétrica, apenas um dos triângulos é necessário
e suficiente para os processamentos posteriores, que somente utilizarão esta metade da
matriz.
Quanto aos fragmentos do sinal cujos pares dois a dois correspondem a cada posição
da matriz de similaridade, em vez do processo de segmentação utilizado no método de Eronen,
estes são obtidos por duas janelas deslizantes, que devem se deslocar sobre o sinal de
envoltória obtido no processamento da seção anterior. Esta escolha teoricamente permite um
pouco mais de precisão, uma vez que os extremos dos intervalos não mais estarão limitados
às batidas do sinal.
Desta forma, em cada posição da matriz de similaridade é armazenado, como métrica
de similaridade, o máximo do sinal de correlação obtido tendo como entrada estas duas janelas
deslizantes, que se deslocam ao longo do sinal de envoltória.
Os fragmentos i-ésimo e j-ésimo do sinal são fornecidos como entrada da função de
correlação, que produzirá um terceiro sinal contendo a correlação entre os dois fragmentos do
sinal para cada deslocamento aplicado sobre o segundo sinal, conforme o cálculo descrito na
seção 5.2. Entretanto, é necessário um valor escalar que possa representar a similaridade
entre estes dois fragmentos do sinal. Desta forma, varre-se este sinal de correlação cruzada
resultante em busca do seu valor máximo, sendo então este valor armazenado na posição ai j
da matriz de similaridade. Este pico encontrado indica que, para um dado deslocamento no

6.2. A CONSTRUÇÃO DA MATRIZ DE SIMILARIDADE 57
tempo entre os fragmentos de sinal, a envoltória do primeiro fragmento do sinal alinhou-se com
a envoltória do segundo, por terem alta similaridade.
Figura 6.7: Fluxograma com processos da etapa de Construção da Matriz deSimilaridade.
Figura 6.8: SSM construída com correlação sobre envoltória para a música Yesterday.
A Figura 6.7 traz um Fluxograma que representa os processos realizados nesta etapa
da solução, enquanto a Figura 6.8 traz um exemplo de matriz de similaridade construída desta
maneira, pela execução desta etapa sobre um sinal de áudio wav contendo a música Yesterday
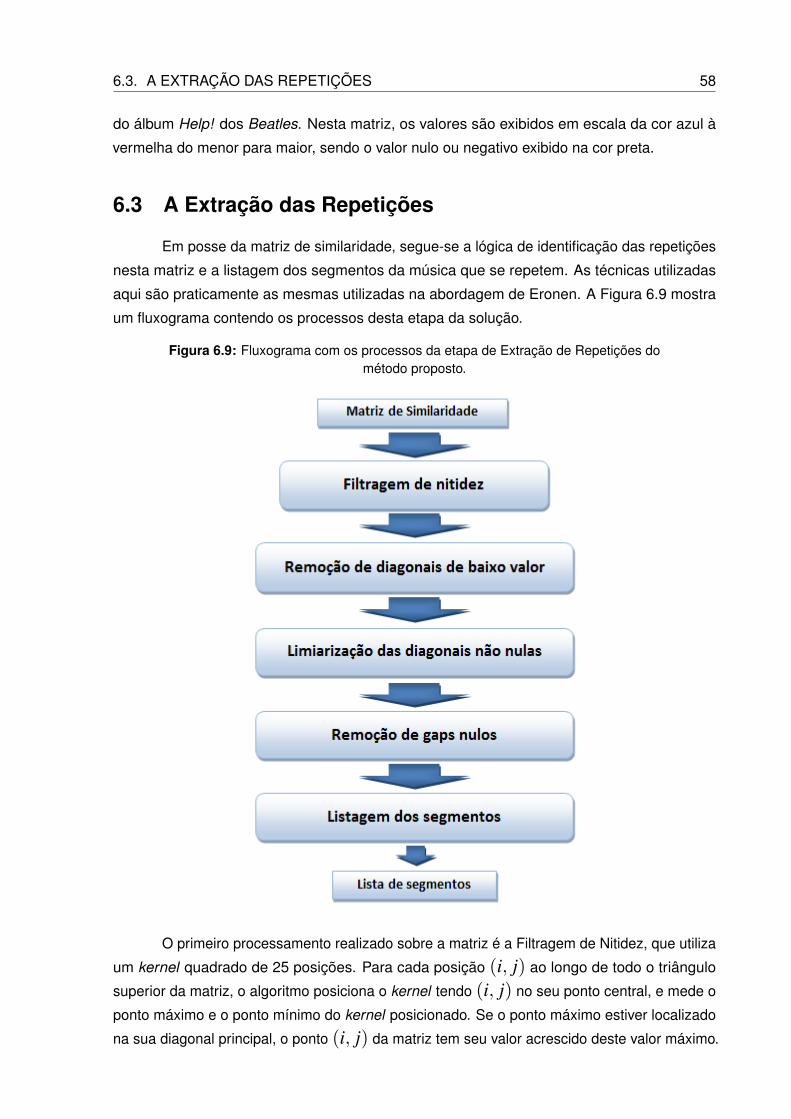
6.3. A EXTRAÇÃO DAS REPETIÇÕES 58
do álbum Help! dos Beatles. Nesta matriz, os valores são exibidos em escala da cor azul à
vermelha do menor para maior, sendo o valor nulo ou negativo exibido na cor preta.
6.3 A Extração das Repetições
Em posse da matriz de similaridade, segue-se a lógica de identificação das repetições
nesta matriz e a listagem dos segmentos da música que se repetem. As técnicas utilizadas
aqui são praticamente as mesmas utilizadas na abordagem de Eronen. A Figura 6.9 mostra
um fluxograma contendo os processos desta etapa da solução.
Figura 6.9: Fluxograma com os processos da etapa de Extração de Repetições dométodo proposto.
O primeiro processamento realizado sobre a matriz é a Filtragem de Nitidez, que utiliza
um kernel quadrado de 25 posições. Para cada posição (i, j) ao longo de todo o triângulo
superior da matriz, o algoritmo posiciona o kernel tendo (i, j) no seu ponto central, e mede o
ponto máximo e o ponto mínimo do kernel posicionado. Se o ponto máximo estiver localizado
na sua diagonal principal, o ponto (i, j) da matriz tem seu valor acrescido deste valor máximo.

6.3. A EXTRAÇÃO DAS REPETIÇÕES 59
Se o ponto máximo não estiver na diagonal principal, então o ponto (i, j) tem seu valor
acrescido do valor mínimo do kernel. Ao fim deste processo, espera-se que as diagonais de
mais alta similaridade estejam mais nítidas em relação aos demais valores da matriz. A Figura
6.10 mostra a matriz resultante deste processo de filtragem de nitidez sobre a matriz da Figura
6.8.
Figura 6.10: SSM da Figura 6.8, após processo de filtragem de nitidez.
O próximo processamento é a eliminação dos valores irrelevantes, que são os de
baixa similaridade. Este processo se dá em dois passos: (1) Remoção das diagonais de
baixa similaridade; (2) Limiarização das diagonais não nulas restantes (chamado também de
dicotomização ou binarização).
No primeiro passo, calcula-se a similaridade média de cada diagonal do triângulo
superior da matriz, e estes valores são armazenados em um array. Em seguida, as 10
diagonais de maior média são selecionadas, e as demais são cortadas da matriz pela anulação
de todos os seus valores. A Figura 6.11 mostra a matriz da Figura 6.10 após este processo de
remoção das diagonais de menor similaridade.
No segundo passo da eliminação dos valores irrelevantes é estabelecido um limiar
de similaridade, de modo que todo valor abaixo deste limiar é considerado irrelevante sendo
assim anulado. Para este processo de limiarização duas abordagens foram testadas: (1)
Percentual de corte fixo sobre a quantidade de valores não nulos, que determina qual o
percentual de valores não nulos que devem permanecer; (2) Percentual de corte variável,

6.3. A EXTRAÇÃO DAS REPETIÇÕES 60
calculado dinamicamente, em função de características inerentes à distribuição destes valores
não nulos restantes.
Figura 6.11: SSM da Figura 6.10, após processo de remoção das diagonais de baixasimilaridade.
O limiar pelo percentual de corte fixo é a mesma forma utilizada por Eronen, que
estabeleceu 20%, obtido empiricamente em seu trabalho, como o percentual fixo de valores
que devem permanecer após a anulação. O valor de similaridade exato deste limiar é obtido em
3 passos: (1) Concatenação das 10 diagonais não nulas em uma só sequência de valores; (2)
Ordenação (sort) decrescente desta sequência; (3) Seleção do valor de similaridade da posição
que divida a sequência ordenada em duas partes, onde a primeira deve conter exatamente 20%
do comprimento da sequência. Este valor de similaridade selecionado é o limiar, e todo valor
abaixo dele na matriz deverá ser anulado. Para o método proposto, mais valores percentuais
além de 20% foram testados, cujos resultados serão discutidos mais adiante.
O percentual obtido dinamicamente segue os mesmos passos que o fixo, com a
diferença de que no terceiro passo o percentual não estabelece a quantidade de valores que
deve permanecer, mas estabelece o percentual da área sob a curva gerada pela sequência
construída nos passos (1) e (2) para os valores que devem permanecer, em relação à área sob
a curva total. Para obter este valor calcula-se a área sob a curva total, e depois é subtraído
um a um, do maior para o menor, o valor de cada amostra da sequência ordenada, até que
a área subtraída corresponda ao percentual estabelecido, como 20%, por exemplo. O valor
de similaridade subtraído na última amostra corresponde ao limiar de corte. Assim como no

6.3. A EXTRAÇÃO DAS REPETIÇÕES 61
limiar de percentual fixo, para o método também foram testados diversos valores, conforme
será discutido no próximo capítulo.
Ao fim deste processo espera-se que somente os trechos de mais alta similaridade nas
diagonais de maior similaridade média estejam não nulos na matriz. A matriz da Figura 6.12 é
resultante deste processo de corte aplicado sobre a matriz da Figura 30, com o percentual de
corte da matriz obtido dinamicamente, permanecendo os maiores valores que correspondem,
neste exemplo, a 30% da área sob a curva obtida nos passos (1) e (2).
Figura 6.12: SSM da Figura 6.11, após processo de limiarização dinâmica.
O último processamento sobre a matriz de similaridade é a remoção de gaps nulos
entre diagonais não nulas, provenientes de curtas diferenças existentes entre os refrãos. São
removidos os gaps inseridos em um intervalo não nulo de pelo menos 12 segundos, e que
não ultrapassem o limite máximo de 4 segundos. Estes valores foram obtidos a partir dos
valores sugeridos no trabalho de Eronen, originalmente medidos em batidas da música, sendo
ajustados empiricamente em testes.
Todas as técnicas usadas nesta etapa são similares às desenvolvidas por Eronen em
sua abordagem. Apenas a remoção de quadrados não foi utilizada, porque foi desnecessária a
sua utilização. Isto porque a presença de quadrados se deve ao fato de que acordes (notas
musicais tocadas simultaneamente) acabavam gerando pequenas sequências de vetores de
Chroma praticamente idênticos, o que provocava a formação destes quadrados na matriz
de similaridade. Uma vez que a similaridade medida através de correlação de envoltórias

6.4. A SELEÇÃO DO SEGMENTO REFRÃO 62
desconsidera a presença das notas musicais que estão sendo tocadas, não existe esta
sensibilidade aos acordes, e não há formação de quadrados.
No final do processo descrito nesta seção espera-se ter as repetições bem definidas
na matriz de similaridade, cada uma contendo a correspondência entre dois trechos da música
similares entre si. É necessário então extrair os pares segmentos de cada repetição encontrada
e armazená-los em uma lista, registrando seus extremos (instante inicial e instante final). Para
isso, varre-se cada diagonal da matriz de similaridade que, ao final de todo o processo realizado
nesta seção sobre a matriz, ainda contenha algum valor não nulo. Para cada diagonal verificada,
para cada trecho não nulo nesta diagonal onde ai j é sua posição inicial e bkl é a sua posição
final, serão registrados os intervalos [i,k] e [ j, l] como dois segmentos candidatos a refrão.
Observa-se que os valores i, j, k e l estão medidos em amostras do sinal de envoltória, mas
seus valores devem ser convertidos em segundos, unidade padrão das marcações das bases
de dados públicas na área de MIR, para que seja possível realizar comparações com estas
marcações durante os testes.
6.4 A Seleção do Segmento Refrão
Neste passo, cada par de segmentos das repetições encontradas na matriz de similari-
dade na etapa anterior estão listados pelo armazenamento de seus extremos (instante inicial e
instante final). Dentre estas repetições, que podem incluir tanto um refrão como outra parte da
música que também é repetida, somente uma deve ser retornada pelo método como refrão
obtido. Tal como nas soluções de Goto e Eronen, este processo de seleção é realizado por
heurísticas.
A primeira heurística adotada nesta solução é a do range de tamanho de refrãos. O
range adotado com base em observações exaustivas sobre músicas de diversos estilos musi-
cais é o intervalo de 5% a 25% da música, onde segmentos fora deste range são descartados.
O descarte de segmentos com tamanho fora do range é realizado porque segmentos maiores
que 25% do comprimento do sinal provavelmente possuem muitos trechos que não fazem
parte do refrão, e segmentos menores que 5% do tamanho da música provavelmente não
têm comprimento suficiente para conter um refrão. Esta heurística é a mesma adotada por
Goto, conforme descrito na seção 3.5, que adotou um range de 7,7s a 40s, fixos independente
do tamanho da música. Para o método proposto, preferiu-se a adoção de um range variável
conforme o tamanho da música, partindo-se do pressuposto de que músicas maiores tendem
a ter refrãos maiores.
O descarte dos segmentos menores que 5% do tamanho da música é realizado
removendo-se as diagonais muito curtas da matriz. A matriz da Figura 6.13 é resultante
deste processo de descarte por range de refrãos sobre a matriz da Figura 6.12, juntamente
com o processo de remoção de gaps nulos descrito na etapa anterior do método. Dentre as
heurísticas utilizadas na solução proposta neste trabalho, esta heurística é a única que exclui

6.4. A SELEÇÃO DO SEGMENTO REFRÃO 63
segmentos dentre os candidatos a refrão.
Figura 6.13: SSM da Figura 6.12, após remoção de gaps nulos e não nulos.
As demais heurísticas, descritas a seguir, foram implementadas na forma de classifica-
dores que retornam um score normalizado (entre zero e um) para cada segmento classificado,
que pode ser interpretado como a probabilidade deste segmento de ser um refrão segundo os
critérios de avaliação desta heurística.
A segunda heurística adotada foi construída como um classificador que atribui como
score o somatório (normalizado) do grau de correspondência do segmento com os outros
segmentos listados, onde o segmento que tiver maior soma do grau de correspondência
com todos os demais segmentos é um forte candidato a refrão. A correspondência entre
dois segmentos é calculada usando F-measure, cujo cálculo foi descrito na seção 4.6. Este
cálculo retorna um valor entre zero e um, para dois intervalos a e b, o qual mede o grau de
correspondência entre ambos, onde grau zero indica correspondência nula, quando não há
interseção entre os intervalos em questão, enquanto grau um indica correspondência máxima,
quando os intervalos são exatamente iguais, possuindo os mesmos pontos extremos (instante
inicial e instante final).
Uma matriz de correspondência é criada, equivalente à matriz de similaridade, e cada
posição armazenará a correspondência de cada par de segmentos entre si, com cada segmento
correspondendo a uma linha e uma coluna segundo a sequência a qual foram extraídos da
matriz de similaridade na etapa anterior da solução. Assim, a medida desta heurística, para
cada segmento, é a soma dos valores contidos na linha com os valores contidos na coluna

6.4. A SELEÇÃO DO SEGMENTO REFRÃO 64
deste segmento nesta matriz de correspondência. Este valor, no fim, é normalizado, para que
seja retornado um valor entre zero a um, o score do classificador desta heurística para cada
segmento classificado. Esta heurística considera o número de repetições de um trecho do sinal
ao longo da música, porque um segmento que foi listado por um número maior de repetições
tem maior chance de ser um refrão, pela própria definição de refrão como parte que mais se
repete.
A terceira heurística é a Similaridade Média, construída como um classificador que
atribui maior score a um segmento de uma repetição cuja diagonal na matriz possui similaridade
média mais alta. Desta forma, as similaridades médias de cada diagonal são calculadas e
depois os valores são também normalizados.
Nesta heurística, implicitamente é considerada também a heurística da amplitude média
usada por Eronen, pois a correlação apresenta maiores valores para sinais alinhados que
tenham maiores amplitudes. Ou seja, para duas repetições distintas, aquela cujos segmentos
apresentam maior intensidade (maiores valores de envoltória), terá os seus segmentos classi-
ficados com um score maior em relação a outras, segundo o critério de classificação desta
heurística.
A quarta heurística considerada é a do último segmento. Observando diversas músicas
de diversos estilos musicais, observa-se que é muito comum a música terminar com o refrão,
ou com uma sequência de dois ou três refrãos consecutivos, ou ter um refrão como penúltimo
segmento da música anterior a um segmento que não se repete, e que por isso não estaria
entre os segmentos listados pelas repetições. Desta forma, o classificador desenvolvido
para esta heurística atribuirá um score maior ao segmento localizado mais próximo à região
final da música. Mais especificamente, a probabilidade do segmento de conter um refrão é
inversamente proporcional à distância entre seu ponto médio e o final da música.
A quinta heurística considerada é a da localização da diagonal da repetição na matriz
de similaridade, onde o classificador atribui score mais alto aos segmentos da repetição que
seja uma combinação do trecho mais próximo a um quarto combinado com o trecho mais
próximo a três quartos do sinal de música. A probabilidade aqui é calculada de maneira similar
à quarta heurística, mas a distância considerada aqui é a do ponto médio do segmento até
o ponto equivalente a 1/4 e 3/4 da música no eixo do tempo. Esta hipótese foi levantada
por Eronen, tendo sido adotada neste trabalho para que pudesse ser testada também com a
métrica de similaridade proposta neste trabalho.
A Figura 6.14 mostra a matriz de similaridade da Figura 6.13 com a diagonal cujo
segmento foi selecionado pela heurística Similaridade Média destacada com as cores vermelha
e azul alternadas. O método proposto, com a configuração contendo janela e deslocamento
de 32ms na Extração de Envoltória, janela de 2s e deslocamento de 1s na Construção da
Matriz de Similaridade, e uma Extração de Repetições com limiar dinâmico e percentual de
30% da área sob a curva, com a heurística da Similaridade Média, atingiu uma taxa de acerto
de 97,37% para a canção Yesterday ao selecionar este segmento da música.

6.4. A SELEÇÃO DO SEGMENTO REFRÃO 65
Figura 6.14: SSM da Figura 6.13, com diagonal selecionada pela Similaridade Médiadestacada.
Nos testes realizados, combinações destas heurísticas foram também testadas. O
próximo capítulo descreve o procedimento de testes, bem como os resultados alcançados e
uma discussão sobre estes resultados.

666666
7Experimentos e Resultados
Neste capítulo será detalhado o procedimento experimental adotado, tanto para a
avaliação da taxa de acertos e do custo computacional do método desenvolvido neste trabalho,
como para medição da degeneração das taxas de acertos em base percussiva em relação
a uma abordagem que explora o domínio da frequência. A hipótese testada é a de que
uma solução em detecção de refrão que explore o domínio do tempo é mais competitiva em
relação a métodos limitados ao domínio da frequência quando é testada em bases percussivas,
apresentando menor degeneração da taxa de acertos.
A seção 7.1 descreve as bases de músicas que foram utilizadas nos testes. A seção
7.2 mostra os procedimentos de testes realizados, bem como os resultados alcançados pelas
diversas heurísticas que foram descritas no capítulo anterior. Na seção 7.3 são discutidos os
resultados obtidos.
7.1 As Bases de Dados
Foram utilizadas duas bases de dados nos testes. A primeira é a base editada pela
Universidade de Tecnologia de Tampere (TUT) e referenciada por Jouni Paulus em sua web-
page sobre Análise de Estrutura Musical (Tampere University of Technology, 2016). Esta base,
dentre outras bases relevantes, é referenciada também no site do MIREX, na seção Structural
Segmentation (The International Music Information Retrieval Systems Evaluation Laboratory,
2016). Constituída pela discografia dos Beatles, compreende 175 músicas distribuídas nos
12 álbuns lançados pela banda ao longo de oito anos de carreira, sendo citada pelo próprio
MIREX como uma “base relevante” para as pesquisas em Segmentação Estrutural de Música,
que incluem também a Detecção de Refrão. É uma base pública, estando assim disponível
para pesquisas posteriores.
Entre 1989 e 2000, o musicólogo Allan Pollack analisou todas as músicas na discografia
dos Beatles. Suas análises foram abrangentes, e incluíram a discussão de cada estilo musical,
forma, melodia, harmonia e arranjo, e toda a sua pesquisa foi lançada gratuitamente na Internet,
estando disponível desde então (POLLACK, 2016). Posteriormente, um conjunto de anotações

7.1. AS BASES DE DADOS 67
para este corpus foi criado na Universitat Pompeu Fabra (UPF), adicionando às análises de
Pollack informações de tempo. Estas anotações foram então editadas por pesquisadores
da Universidade de Tecnologia de Tampere (TUT), recebendo algumas melhorias. As duas
versões incluem anotações de 175 músicas dos Beatles, tendo sido liberadas livremente na
Internet sob uma licença Creative Commons, embora seja necessário adquirir os álbuns dos
Beatles por conta própria caso se pretenda usar o corpus em algum trabalho. As anotações
TUT estão disponíveis na webpage de Jouni Paulus (Tampere University of Technology, 2016),
e as anotações originais, da UPF, também estão disponíveis na internet (Universitat Pompeu
Fabra, 2016).
Um conjunto paralelo de anotações sobre a discografia dos Beatles, também disponível
gratuitamente on-line, foi criado no Centro de Música Digital (CDM) da Queen Mary University
of London. Estas anotações também são baseadas nas pesquisas de Pollack, mas foram
criadas independentemente das anotações da UPF e da TUT, e incluem todas as 180 canções
dos álbuns de estúdio dos Beatles. Isso inclui cinco canções que foram omitidas nas versões
UPF e TUT, presumivelmente porque a estrutura formal destas músicas foi considerada muito
idiossincrática ou ambígua, como, por exemplo, ”Happiness is a warm gun“, com uma estrutura
tipo ABCD, e ”Revolution 9” (Queen Mary University of London, 2016).
No contexto da detecção de refrão abordada neste trabalho, algumas dificuldades
inerentes à discografia dos Beatles precisaram ser resolvidas para que a base de dados
pudesse ser devidamente utilizada na avaliação do método proposto. Observando-se as
anotações da base TUT, verificou-se que a maior parte das músicas dos Beatles não possui
um refrão propriamente dito. Isto se deve ao fato de que a definição mais precisa de refrão
inclui aspectos semânticos relacionados à letra da música, não sendo puramente definido
como uma parte que se repete, inclusive por aqueles que participaram do desenvolvimento das
anotações da base. Assim, muitas músicas não têm uma parte rotulada com refrão, embora
tenham partes que se repetem, outras têm refrão, mas este não é a parte que mais se repete,
e existem ainda aquelas que, com refrão ou sem refrão, não possuem repetições, tornando
inviável a detecção de refrão de uma solução baseada em repetitividade.
Ao ser realizada uma filtragem das músicas que têm refrão e que tem repetições,
verificou-se que apenas 31 músicas, num conjunto de 175 anotações, possuíam partes
rotuladas como refrão que eram as mais repetidas na música. Desta forma, para as músicas
que não têm partes rotuladas como refrão, o retorno de partes que se repetem foi considerado
um acerto, e estas músicas foram inclusas na base utilizadas nos testes. As músicas que
não possuem partes repetidas, por sua vez, não foram consideradas na análise. Desta forma,
foram utilizadas nos testes, ao todo, 152 músicas da base. Nas bases de dados utilizadas por
Goto e Eronen em seus testes, ficou claro em seus trabalhos que as músicas possuíam uma
clara estrutura verso-refrão, e que suas bases estavam apropriadas para os testes de uma
solução para detecção de refrão baseada em repetitividade.
A segunda base de dados é constituída por músicas p33ercussivas do ritmo Coco,

7.2. A METODOLOGIA DOS EXPERIMENTOS 68
típico da Região Nordeste do Brasil. Foram reunidas nesta base músicas das obras de Selma
do Coco, Coco Raízes de Arcoverde e Caju e Castanha, referências do ritmo na região. A
base conta ao todo com 20 músicas, cujos refrãos foram anotados manualmente. As músicas
desta base contém uma estrutura que têm partes que se repetem e podem ser consideradas
como sendo o refrão da música para a finalidade dos testes, tendo sido ignorados os aspectos
semânticos das partes da música. Esta base também encontra-se disponível para pesquisas
posteriores(RODRIGUES, 2016).
7.2 A Metodologia dos Experimentos
Para cada música da base foi calculada a F-Measure entre o refrão anotado e o refrão
retornado pelo método, conforme o cálculo descrito na seção 4.6, para cada heurística ou
combinação de heurísticas. Ao fim do processamento, foi calculada a F-Measure média de
cada heurística ou combinação de heurísticas. No caso da combinação de heurísticas, o score
retornado pelo classificador é a soma dos scores retornados pelas heurísticas combinadas,
todas com peso 1, sendo o score final normalizado em relação aos demais segmentos
classificados, para que também seja um valor entre 0 e 1.
Para uma melhor compreensão da qualidade dos classificadores de cada heurística,
as taxas de acerto obtidas por cada heurística foram comparadas com os resultados obtidos
pelo caso ótimo e com os obtidos pelo caso randômico. O caso ótimo foi implementado
como uma rotina que recebe informação a posteriori das marcações da base de dados para
simular uma heurística que sempre acerta o segmento ótimo, aquele que maximiza o valor
da F-Measure para uma música. Já o caso randômico foi implementado como uma função
de escolha aleatória, representando assim o pior caso, que é a escolha sem critérios de um
segmento qualquer dentre os extraídos da matriz de similaridade na etapa de Extração das
Repetições, descrita na seção 6.3.
Os primeiros testes contemplaram a avaliação do tempo de resposta e da taxa de
acertos para várias configurações da solução, onde foram testadas diversas combinações
de valores dos parâmetros que regulam cada etapa do método, tendo sido identificadas as
combinações que mais se destacaram na base de dados TUT. Os parâmetros da primeira,
segunda e terceira etapas do método (seções 6.1, 6.2 e 6.3) foram variados em testes
individuais, sendo observada a variação do percentual de acertos e do tempo de resposta
em função desta variação de parâmetros. Em cada teste, os parâmetros de uma etapa eram
variados enquanto os valores dos parâmetros nas demais etapas permaneciam com valor fixo.
Após os testes de ajustes de parâmetros, a configuração da solução que obteve melhor
relação entre a taxa de acertos e o tempo de resposta foi escolhida para o teste da hipótese,
que consistiu em avaliar o método proposto na base pública TUT e, posteriormente, na base
percussiva, medindo-se a degeneração da taxa de acertos em função da mudança do tipo de
música processado.

7.3. OS RESULTADOS OBTIDOS 69
Com a finalidade de realizar uma comparação com os métodos que exploram o domínio
da frequência testes paralelos foram realizados, onde o método proposto foi modificado
substituindo-se a sua feature (Envoltória) por Chroma Vector, construído como nos trabalhos
de Goto e Eronen, a partir do espectro obtido por FFT (seção 4.2). A métrica de similaridade do
método proposto (Correlação), usada na construção da Matriz de Similaridade, foi substituída
por Distância Euclidiana, conforme usada nos métodos de Goto e Eronen para construir a
Matriz ou Triângulo de Distâncias (seção 4.3). Assim como nos testes do método proposto, esta
versão modificada usando FFT também passou por testes de combinações dos parâmetros das
3 primeiras etapas em busca da melhor configuração, e por testes de medição da degeneração
da taxa de acertos em função da mudança do processamento da base TUT para a base
percussiva.
7.3 Os Resultados Obtidos
Esta seção mostra os resultados dos experimentos realizados. Nas tabelas mostradas
nesta seção, as heurísticas avaliadas são identificadas por letras, onde R é a Randômica, O é o
Caso Ótimo, H1 é Grau de Correspondência, H2 é Similaridade Média, H3 é Último Segmento
e H4 é Localização da Repetição, conforme definidas na seção 6.4. As combinações de
heurísticas são representadas pela letra H seguida dos números referentes a cada heurística,
onde H123, por exemplo, significa a combinação das heurísticas: Grau de Correspondência,
Similaridade Média e Último Segmento.
Para os testes de tempo de resposta realizados, vale ressaltar que os resultados
obtidos são os mesmos que seriam obtidos em qualquer outra base de dados, pois o tempo de
resposta no método é função apenas do tamanho do sinal de áudio e de alguns dos parâmetros
escolhidos nas etapas de Extração de Envoltória, Construção da Matriz de Similaridade e
Extração de Repetições, conforme será visto mais adiante.
Nos testes da primeira etapa da abordagem deste trabalho, a Extração de Envoltória,
descrita na seção 6.1, o tamanho da janela deslizante e deslocamento da janela foram sempre
mantidos com valores iguais, pois um deslocamento menor que a janela poderia levar à
repetição de um mesmo valor máximo em duas ou mais amostras consecutivas no sinal de
envoltória construído, e um deslocamento maior que a janela levaria ao descarte de pequenos
fragmentos do sinal na extração da envoltória.
Na avaliação do tempo de resposta, os valores do deslocamento foram variados de
1ms a 100ms na execução de uma música de 4 minutos, onde foi verificado que o tempo
de resposta cai exponencialmente com o aumento do deslocamento, convergindo para 6s e
atingindo uma estabilidade razoável a partir de 30ms aproximadamente. Os resultados para
o tempo de resposta são apresentados no gráfico da Figura 7.1, onde o eixo horizontal tem
o valor do deslocamento da janela (e do tamanho da janela também) e o eixo vertical traz o
tempo de resposta do método.
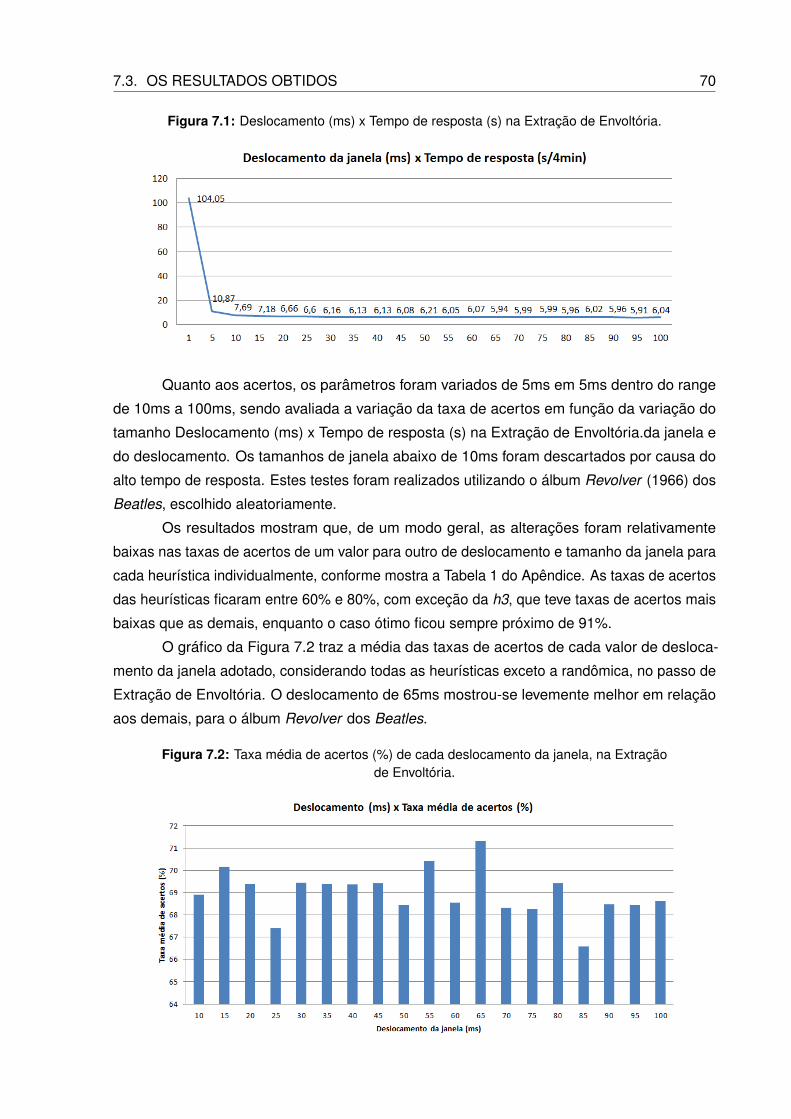
7.3. OS RESULTADOS OBTIDOS 70
Figura 7.1: Deslocamento (ms) x Tempo de resposta (s) na Extração de Envoltória.
Quanto aos acertos, os parâmetros foram variados de 5ms em 5ms dentro do range
de 10ms a 100ms, sendo avaliada a variação da taxa de acertos em função da variação do
tamanho Deslocamento (ms) x Tempo de resposta (s) na Extração de Envoltória.da janela e
do deslocamento. Os tamanhos de janela abaixo de 10ms foram descartados por causa do
alto tempo de resposta. Estes testes foram realizados utilizando o álbum Revolver (1966) dos
Beatles, escolhido aleatoriamente.
Os resultados mostram que, de um modo geral, as alterações foram relativamente
baixas nas taxas de acertos de um valor para outro de deslocamento e tamanho da janela para
cada heurística individualmente, conforme mostra a Tabela 1 do Apêndice. As taxas de acertos
das heurísticas ficaram entre 60% e 80%, com exceção da h3, que teve taxas de acertos mais
baixas que as demais, enquanto o caso ótimo ficou sempre próximo de 91%.
O gráfico da Figura 7.2 traz a média das taxas de acertos de cada valor de desloca-
mento da janela adotado, considerando todas as heurísticas exceto a randômica, no passo de
Extração de Envoltória. O deslocamento de 65ms mostrou-se levemente melhor em relação
aos demais, para o álbum Revolver dos Beatles.
Figura 7.2: Taxa média de acertos (%) de cada deslocamento da janela, na Extraçãode Envoltória.

7.3. OS RESULTADOS OBTIDOS 71
Nos testes com variação de parâmetros da etapa de Construção da Matriz de Similari-
dade, o deslocamento da janela deslizante, que exerce forte influência no custo das etapas
restantes do método, foi variado entre 0,1s e 1,3s, para análise do tempo de resposta da
solução em função de sua variação, enquanto o tamanho da janela neste teste foi sempre o
dobro do tamanho do deslocamento.
Assim como nos testes de tempo de resposta da etapa anterior da solução, verifica-se
que o custo da solução cai exponencialmente com o aumento do valor do deslocamento da
janela, conforme apresentado na Figura 7.3.
Comparando com o tempo de resposta médio dos métodos descritos no capítulo 4, que
é de aproximadamente 10 segundos para uma música de 3 a 4 minutos, apenas os valores de
deslocamento de janela acima de 0,7s são viáveis.
Figura 7.3: Deslocamento (s) x tempo de resposta (s/4min) na Construção da Matriz deSimilaridade.
Para a análise da variação da taxa de acertos, o deslocamento da janela foi testado
para os valores 0,25s, 0,5s, 0,75s, 1s e 1,25s, enquanto o tamanho da janela assumiu os
valores de uma, duas e quatro vezes o tamanho do deslocamento em cada teste. Estes
testes também foram realizados utilizando o álbum Revolver dos Beatles, e seus resultados
encontram-se na Tabela 2 do Apêndice.
Observando o gráfico da Figura 7.4 que traz a taxa média de acertos por tamanho de
janela e valor de deslocamento, verifica-se que usar um deslocamento de 0,25s não alcança
uma taxa média de acertos boa em relação aos demais valores de deslocamento.

7.3. OS RESULTADOS OBTIDOS 72
Figura 7.4: Taxa média de acertos (%) de cada deslocamento e tamanho da janela, naConstrução da Matriz de Similaridade.
Além disso, observando a Figura 7.3, verifica-se que um deslocamento de 0,25s leva a
solução a ter um tempo de resposta de quase 100s para uma música de 4 minutos, cerca de
10 vezes maior que o tempo de resposta médio declarado pelos trabalhos descritos no capítulo
4, sendo assim inviável.
O deslocamento de 0,5s atinge taxas acima de 70% para um deslocamento de 1s ou
de 2s, mas seu custo ainda é alto, pois é aproximadamente o dobro do custo declarado no
Estado da Arte, conforme visto na Figura 7.3. O deslocamento de 1,25s obteve as taxas de
acertos mais baixas, que não justificariam o seu baixo custo. Os deslocamentos de 0,75s
e 1s têm aproximadamente as mesmas taxas de acertos, sendo assim preferível adotar um
deslocamento de 1s, pois a resposta do método é quase duas vezes menor. Apesar do
deslocamento de 1s com a janela de 4s ter obtido resultados melhores para o álbum usado
nestes testes, foi verificado que, para a base completa, a configuração com 1s de deslocamento
e janela deslizante de 2s obteve melhores taxas de acertos.
Na etapa de Extração das Repetições, dois experimentos foram realizados, um com a
limiarização com percentual fixo, variando o percentual nos testes, e outro com a limiarização
com percentual dinâmico, variando o percentual da área sob a curva.
Verificou-se em testes que a variação dos valores do percentual do limiar, tanto o da
limiarização com percentual de corte fixo como o da área sob a curva na limiarização dinâmica,
exerce influência desprezível sobre o tempo de resposta do método.
Entretanto, os tempos de resposta do método usando limiarização com percentual fixo
em relação ao outro tipo de limiarização foi levemente superior nos casos de teste. A Tabela
7.1 mostra os resultados de tempo de resposta das duas abordagens para músicas de 25, 50,
120, 180, 240 e 500 segundos de comprimento aproximadamente, e o tempo de resposta que
cada abordagem obteve.

7.3. OS RESULTADOS OBTIDOS 73
Tabela 7.1: Tempo de resposta (s) por tipo de limiarização e tamanho da música (s).
25s 50s 120s 180s 240s 500s
Limiarização com percentual fixo 0,23s 0,49s 2,07s 4,18s 6,23s 24,97s
Limiarização dinâmica 0,20s 0,47s 2,04s 3,96s 6,07s 24,76s
A abordagem com percentual fixo apresentou um tempo de resposta levemente maior,
tendo sido observado em testes também que a etapa seguinte, a de Seleção do Segmento
Refrão, tem um leve custo adicional quando se usa este tipo de limiarização. Este custo
adicional faz com que a etapa de Seleção de Refrão, que praticamente não acrescentava
tempo de resposta ao método, passe a ter alguma contribuição significativa. A distribuição do
tempo de resposta nas etapas do método pode ser observada nos gráficos das Figuras 7.5 e
7.6, para as abordagens com limiar de percentual fixo e limiar dinâmico, respectivamente.
Figura 7.5: Percentual do tempo de resposta de cada etapa do método usandolimiarização com percentual de corte fixo.
Para os testes de taxa de acertos da etapa de Extração das Repetições, para cada
forma de limiarização foi realizado um experimento separado, onde na abordagem com
percentual de corte fixo foi variado o valor do percentual de corte de 20% a 50%, cujos
resultados estão na Tabela 3 do Apêndice, e na outra abordagem foi variado o percentual
de área sob a curva também de 20% a 50%, cujos resultados encontram-se na Tabela 4 do
Apêndice.
A Figura 7.7 traz a taxa média de acertos para cada valor do limiar para a abordagem
de limiarização com percentual de corte fixo. Nota-se que, com exceção do percentual de 20%,
que apresentou valor mais baixo, os demais valores apresentaram uma taxa de acertos média
superior a 67%. A variação de percentuais de 25% a 50%, curiosamente, pouco alterou a taxa
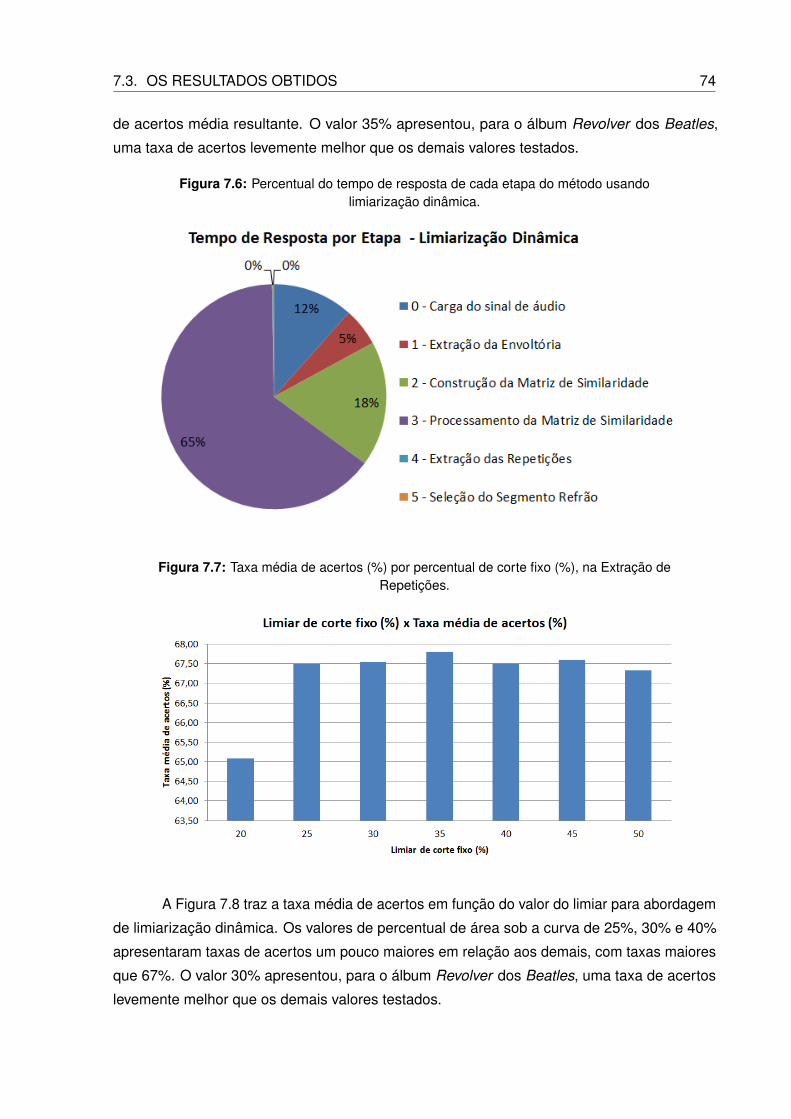
7.3. OS RESULTADOS OBTIDOS 74
de acertos média resultante. O valor 35% apresentou, para o álbum Revolver dos Beatles,
uma taxa de acertos levemente melhor que os demais valores testados.
Figura 7.6: Percentual do tempo de resposta de cada etapa do método usandolimiarização dinâmica.
Figura 7.7: Taxa média de acertos (%) por percentual de corte fixo (%), na Extração deRepetições.
A Figura 7.8 traz a taxa média de acertos em função do valor do limiar para abordagem
de limiarização dinâmica. Os valores de percentual de área sob a curva de 25%, 30% e 40%
apresentaram taxas de acertos um pouco maiores em relação aos demais, com taxas maiores
que 67%. O valor 30% apresentou, para o álbum Revolver dos Beatles, uma taxa de acertos
levemente melhor que os demais valores testados.

7.3. OS RESULTADOS OBTIDOS 75
Figura 7.8: Taxa média de acertos (%) por percentual de área sob a curva (%), naExtração de Repetições.
A partir da observação dos testes de variação de parâmetros acima, duas configurações
foram testadas em toda a base TUT, uma com limiar dinâmico e outra com percentual de
corte fixo, a saber: (1) Tamanho de janela e deslocamento de 32ms para a Extração da
Envoltória, Janela deslizante de 2s de comprimento e deslocamento de 1s para a Construção
da Matriz de Similaridade e limiarização com percentual de corte fixado em 45% na Extração
das Repetições; (2) Tamanho de janela e deslocamento de 32ms para a Extração da Envoltória,
janela deslizante de 2s de comprimento e deslocamento de 1s para a Construção da Matriz de
Similaridade e limiarização dinâmica com um percentual 30% de área abaixo da curva dos
valores não nulos da matriz, na Extração das Repetições.
Quanto aos testes de tempo de resposta, uma vez que o custo computacional deste
método é uma função apenas do tamanho da entrada, foi bastante escolher uma só música de
quatro minutos para testar o tempo de resposta da aplicação, para que seja comparável com o
resultado obtido no Estado da Arte, de aproximadamente dez segundos para músicas de três a
quatro minutos. O tempo de resposta obtido foi de 6,23 segundos para a primeira configuração,
com limiarização de percentual fixo, e de 6,07 segundos para a segunda configuração, com
limiarização dinâmica, para a música Yer Blues, do álbum The Beatles (1968), que possui
exatamente quatro minutos, uma música de tamanho médio, conforme a literatura.
Para cada uma das duas configurações, um teste de taxas de acertos foi separada-
mente realizado utilizando toda a base de dados TUT, cujas taxas médias de acertos por álbum
são apresentadas nas Tabelas 5 e 6 do Apêndice. Os álbuns da base TUT estão listados
nestas tabelas em ordem cronológica de lançamento, onde o 1º é o Please Please Me (1963)
e o 13º é o último, Let It Be (1970). O 10º álbum da banda, The Beatles (1968), lançado como
disco duplo em 1968, foi tratado nos testes como sendo dois álbuns diferentes, o 10º e o 11º.
A Tabela 7.2, por sua vez, mostra as taxas médias de acertos de cada heurística para
toda a base TUT, para os dois tipos de limiarização.

7.3. OS RESULTADOS OBTIDOS 76
Tabela 7.2: Taxa de acertos (%) por heurística e tipo de limiarização, para a base TUTcompleta.
fixo dinâmico
R 61,07 62,92
O 91,78 91,59
H1 69,44 69,98
H2 66,34 67,47
H3 45,00 48,60
H4 69,23 70,50
H12 70,30 70,69
H13 66,60 66,68
H14 72,28 70,22
H23 58,35 61,11
H24 68,88 71,37
H34 64,25 64,56
H123 67,23 66,95
H124 68,70 68,90
H134 67,04 66,96
H234 66,10 66,22
H1234 67,73 69,81
A Figura 7.9 traz em um gráfico os dados da Tabela 7.2. A configuração do método
com limiar dinâmico obteve taxas superiores à configuração com limiar fixo em 13 das 17
heurísticas, incluindo a randômica e o caso ótimo. O caso ótimo alcançou taxas de acerto
acima de 91% para os dois tipos de limiarização, o que significa que, normalmente, dentre os
segmentos listados na etapa de Extração de Repetições, ao menos um deles traz o refrão com
precisão acima de 91%.
Abaixo do caso ótimo, a heurística que mais se destacou foi a H14, combinação das
heurísticas H1 (Grau de Correspondência) e H4 (Localização da Repetição), alcançando
uma taxa de acertos superior a 70% para ambas as abordagens de limiarização. Sete das
heurísticas avaliadas ficaram bem próximas de 70%, e o restante permaneceu entre 60% e
70%, com exceção de h13, que alcançou aproximadamente 60%, e de h3, que ficou abaixo de
50%, que demonstrou ser uma heurística muito ruim, ficando abaixo do randômico.
A Figura 7.10 traz a taxa média de acertos em função da heurística avaliada e do
tipo de limiarização. A abordagem com limiarização dinâmica obteve taxas superiores em 8
heurísticas dos 13 álbuns da base TUT em relação ao método usando limiar com percentual
fixo.
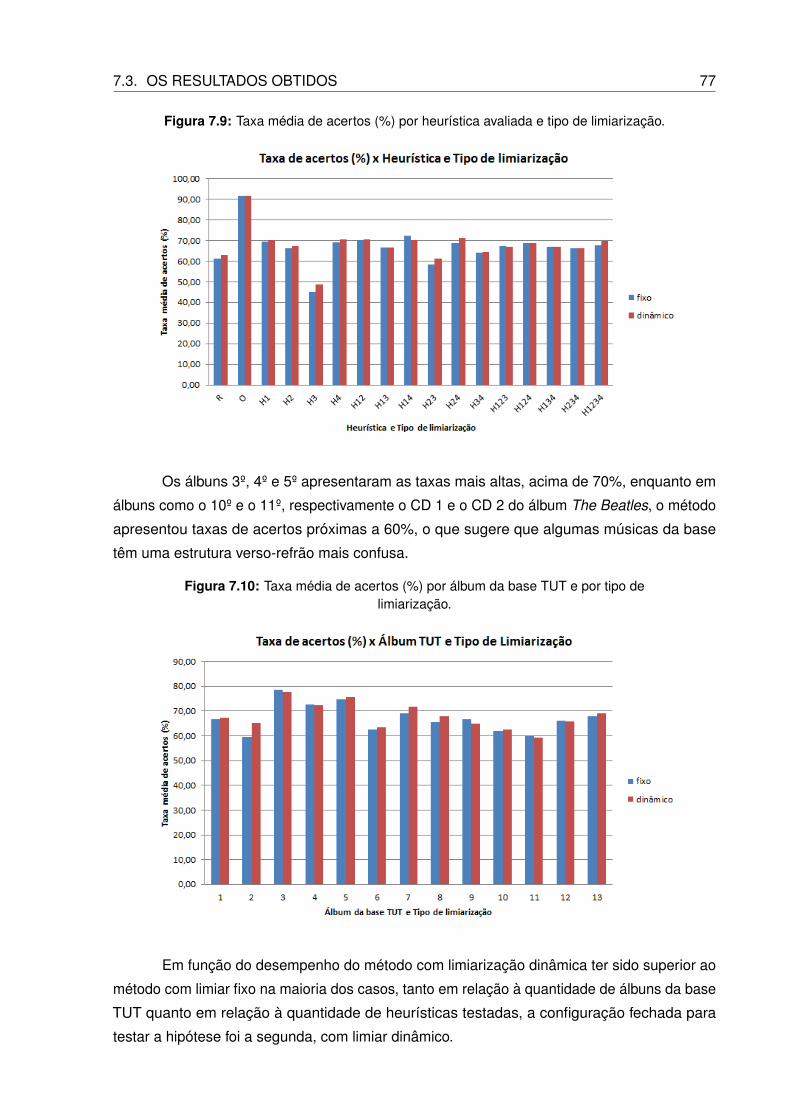
7.3. OS RESULTADOS OBTIDOS 77
Figura 7.9: Taxa média de acertos (%) por heurística avaliada e tipo de limiarização.
Os álbuns 3º, 4º e 5º apresentaram as taxas mais altas, acima de 70%, enquanto em
álbuns como o 10º e o 11º, respectivamente o CD 1 e o CD 2 do álbum The Beatles, o método
apresentou taxas de acertos próximas a 60%, o que sugere que algumas músicas da base
têm uma estrutura verso-refrão mais confusa.
Figura 7.10: Taxa média de acertos (%) por álbum da base TUT e por tipo delimiarização.
Em função do desempenho do método com limiarização dinâmica ter sido superior ao
método com limiar fixo na maioria dos casos, tanto em relação à quantidade de álbuns da base
TUT quanto em relação à quantidade de heurísticas testadas, a configuração fechada para
testar a hipótese foi a segunda, com limiar dinâmico.
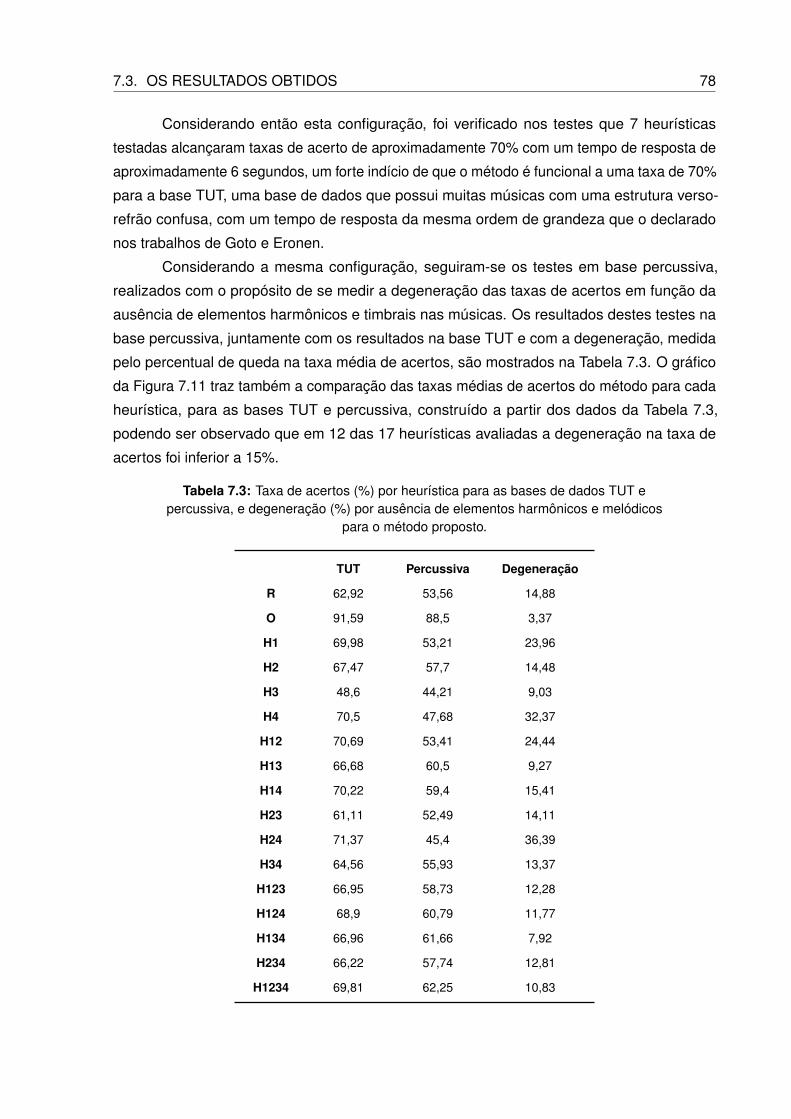
7.3. OS RESULTADOS OBTIDOS 78
Considerando então esta configuração, foi verificado nos testes que 7 heurísticas
testadas alcançaram taxas de acerto de aproximadamente 70% com um tempo de resposta de
aproximadamente 6 segundos, um forte indício de que o método é funcional a uma taxa de 70%
para a base TUT, uma base de dados que possui muitas músicas com uma estrutura verso-
refrão confusa, com um tempo de resposta da mesma ordem de grandeza que o declarado
nos trabalhos de Goto e Eronen.
Considerando a mesma configuração, seguiram-se os testes em base percussiva,
realizados com o propósito de se medir a degeneração das taxas de acertos em função da
ausência de elementos harmônicos e timbrais nas músicas. Os resultados destes testes na
base percussiva, juntamente com os resultados na base TUT e com a degeneração, medida
pelo percentual de queda na taxa média de acertos, são mostrados na Tabela 7.3. O gráfico
da Figura 7.11 traz também a comparação das taxas médias de acertos do método para cada
heurística, para as bases TUT e percussiva, construído a partir dos dados da Tabela 7.3,
podendo ser observado que em 12 das 17 heurísticas avaliadas a degeneração na taxa de
acertos foi inferior a 15%.
Tabela 7.3: Taxa de acertos (%) por heurística para as bases de dados TUT epercussiva, e degeneração (%) por ausência de elementos harmônicos e melódicos
para o método proposto.
TUT Percussiva Degeneração
R 62,92 53,56 14,88
O 91,59 88,5 3,37
H1 69,98 53,21 23,96
H2 67,47 57,7 14,48
H3 48,6 44,21 9,03
H4 70,5 47,68 32,37
H12 70,69 53,41 24,44
H13 66,68 60,5 9,27
H14 70,22 59,4 15,41
H23 61,11 52,49 14,11
H24 71,37 45,4 36,39
H34 64,56 55,93 13,37
H123 66,95 58,73 12,28
H124 68,9 60,79 11,77
H134 66,96 61,66 7,92
H234 66,22 57,74 12,81
H1234 69,81 62,25 10,83

7.3. OS RESULTADOS OBTIDOS 79
Figura 7.11: Taxa de acertos (%) da abordagem com limiar dinâmico para as bases dedados TUT e percussiva.
Continuando o teste da hipótese, tomando a configuração do método com limiarização
dinâmica, a feature (envoltória) foi substituída por Chroma Vector, construído a partir do
espectro obtido por FFT, como nos trabalhos de Goto e Eronen (seção 4.2), e a similaridade
do método foi calculada a partir da Distância Euclidiana entre os vetores, no processo de
construção da Matriz de Similaridade. A partir desta etapa, o método seguiu da mesma
maneira que foi descrita no capítulo 6.
Esta versão do método, que explora o domínio da frequência em lugar do domínio do
tempo, foi então testada da mesma maneira que a versão original, primeiramente variando os
parâmetros de cada etapa do método em busca da melhor configuração, e posteriormente
executada na base TUT e na base percussiva medindo-se o percentual de degeneração da
taxa média de acertos. A configuração para a versão do método com FFT foi: tamanho de
janela e deslocamento de 32ms para a Extração da Envoltória, Janela deslizante de 2s de
comprimento e deslocamento de 1s para a Construção da Matriz de Similaridade e limiarização
dinâmica com um percentual 60% de área abaixo da curva dos valores não nulos da matriz, na
Extração das Repetições. Os valores de taxas de acertos obtidos para cada heurística testada
na versão do método com FFT estão descritos na Tabela 7.4 e na Figura 7.12.
Observa-se que os resultados para a versão do método com FFT foram menores que
os resultados obtidos para a versão original do metodo proposto. Além disso, a heurística h3,
tal como na abordagem original, apresentou as taxas de acertos mais baixas, e as demais
heurísticas que combinam a classificação de h3 com quaisquer outras apresentaram taxas de
acertos igualmente baixas, além da h124.

7.3. OS RESULTADOS OBTIDOS 80
Tabela 7.4: Taxa de acertos (%) por heurística para as bases de dados TUT epercussiva, e degeneração (%) por ausência de elementos harmônicos e melódicos
para o método modificado (com FFT).
TUT Percussiva Degeneração
R 39,95 21,21 46,91
O 82,93 72,09 13,07
H1 44,19 22,10 49,99
H2 48,44 23,96 50,54
H3 0,00 0,00 0,00
H4 56,41 34,33 39,14
H12 43,36 22,60 47,88
H13 6,95 4,98 28,35
H14 44,29 30,05 32,15
H23 0,00 0,00 0,00
H24 57,10 34,33 39,88
H34 0,00 0,00 0,00
H123 4,07 4,20 -3,19
H124 3,03 3,18 -4,95
H134 2,55 2,03 20,39
H234 0,00 0,00 0,00
H1234 3,86 1,76 54,40
Figura 7.12: Taxa de acertos (%) da abordagem com limiar dinâmico para as bases dedados TUT e percussiva para o método modificado (com FFT).
Em posse dos percentuais de degeneração em função da mudança do tipo de música
executada para ambos os métodos, com Correlação de Envoltórias (CE) e com Distância

7.4. A AVALIAÇÃO 81
Euclidiana entre Vetores de Chroma construídos com FFT (FFT), estes percentuais foram
comparados entre si para cada heurística conforme mostra Figura 7.13, sendo entretanto
desconsideradas nesta comparação as heurísticas h3, h13, h23, h34, h123, h124, h134, h234
e h1234, porquanto apresentaram taxas de acertos inferiores a 5% para a versão do método
com FFT.
Figura 7.13: Degeneração na taxa de acertos (%) para o método proposto, comcorrelação de envoltória (CE), e para o método modificado, que usa FFT (FFT).
Dentre as heurísticas consideradas, a degeneração média para o método com FFT
foi de 39,95%, aproximadamente duas vezes maior que a degeneração média para o método
proposto, que foi de 20,66%.
7.4 A Avaliação
O custo computacional do método proposto é função apenas do tamanho da entrada,
pois a razão entre o tamanho da música e o tempo de resposta é sempre mantida, o que
torna suficiente o teste de tempo de resposta em apenas uma música. No teste de custo da
solução o método proposto obteve um tempo de resposta de aproximadamente 6 segundos
para uma música de 4 minutos. Apesar do tempo de resposta ter sido aproximadamente
metade do tempo declarado nos trabalhos do Estado da Arte, pode-se inferir que o custo
computacional obtido é da mesma ordem de grandeza, porque espera-se que um computador
com configuração média na data da publicação deste trabalho seja naturalmente mais rápido
que os computadores comuns no ano da publicação dos métodos descritos no capítulo 4.
Algumas heurísticas ou combinação de heurísticas para o método proposto atingiram
uma taxa de acertos acima de 80% para alguns álbuns da base, outras alcançaram taxas de

7.4. A AVALIAÇÃO 82
acertos entre 70% e 80%, e outras entre 60% e 70%, e poucas tiveram ocasionalmente taxas
abaixo de 60%, para a base de dados pública TUT. O Caso Ótimo atingiu taxas de acertos
de aproximadamente 91% na maioria dos casos, enquanto o Randômico ficou normalmente
bem próximo de 62%. Embora estas taxas de acertos sejam menores que as taxas de acertos
declaradas nos trabalhos do Estado da Arte descritos no capítulo 4 nas bases que utilizaram,
é importante ressaltar que a base de dados TUT possui muitas músicas que não têm uma
estrutura verso-refrão bem definida, o que naturalmente pode causar esta redução em relação
aos percentuais de acertos declarados nas soluções do Estado da Arte, diferente da base de
dados utilizada por Eronen, por exemplo, que declarou em seu trabalho ser constituída por
músicas que tinham uma estrutura verso-refrão bem definida.
Da mesma maneira, apesar das taxas de acertos da versão do método proposto
usando FFT terem sido menores que as do método proposto usando Correlação de Envoltórias,
deve-se ressaltar que esta versão com FFT não é totalmente fiel a uma dentre as descritas
no capítulo 4, uma vez que o propósito deste trabalho não foi o de comparar as abordagens
harmônica e não harmônica entre si, mas o de observar a mudança de comportamento de
uma mesma abordagem em base harmônica e em base percussiva quando utiliza uma feature
obtida explorando-se o domínio do tempo e quando utiliza uma feature explorando-se o
domínio da frequência. Uma comparação mais precisa do desempenho deste método em
relação aos métodos do Estado da Arte exige o teste destas soluções na mesma base pública
(TUT) ou então o teste deste método nas mesmas bases utilizadas nos trabalhos do Estado da
Arte.
Ao processar a base de dados percussiva, o método proposto apresentou uma degene-
ração média de 20,66% em relação a oprocessamento da base TUT para as heurísticas consi-
deradas, enquanto o método com FFT apresentou uma degeneração média de 39,95% para
estas mesma heurísticas, indicando que o método com Correlação de Envoltória sofre uma
degeneração duas vezes menor que sua versão com FFT quando os elementos harmônicos
ou timbrais são menos presentes na música.

838383
8Conclusão
A hipótese testada nos experimentos foi a de que um método de detecção de refrão
que explore o domínio do tempo é mais competitivo, ao processar músicas percussivas, que
um método limitado ao domínio da frequência. Os resultados obtidos nos testes realizados
comprovaram esta hipótese, uma vez que, no procesamento da base de dados percussiva em
relação ao processamento da base de dados não percussiva, o método com Correlação de
Envoltória, feature obtida na exploração do domínio do tempo, sofre uma degeneração duas
vezes menor que sua versão com FFT, limitada a explorar o domínio da frequência.
Uma vantagem da solução proposta neste trabalho é uma maior independência da
presença de notas musicais, uma vez que soluções limitadas à exploração do domínio da
frequência, além de sujeitas a dificuldades como a modulação, que exigem uma lógica de
tratamento adicional, têm maior degeneração na taxa de acertos do que as soluções que
exploram o domínio do tempo ao processarem músicas que não têm notas musicais tão
presentes, como os estilos musicais mais percussivos.
A partir do que foi observado nos resultados deste trabalho, infere-se que a existência
de vários tipos de música gera a necessidade de diversos tipos de abordagens nos processa-
mentos em MIR, com a finalidade de se atingir a meta de se obter um nível de acesso à música
semelhante ao que já existe para buscas baseadas em texto, pois abordagens diferentes
possuem vantagens e desvantagens diferentes que poderão ser mais adequadas a cada tipo
particular de música. Desta maneira, para que se obtenha mais robustez, uma solução ideal
para detecção de refrão deve conter mais de um tipo de abordagem, incluindo ao menos uma
baseada na exploração do domínio da frequência, com características acústicas harmônicas e
timbrais, e ao menos uma baseada na exploração do domínio do tempo, diretamente ligada a
características acústicas rítmicas, por exemplo, tal como o método proposto neste trabalho,
garantindo uma melhor qualidade a funções de Preview em serviços de Streaming de música.
Trabalhos futuros envolvem o desenvolvimento de soluções usando correlação de
envoltórias para resolução de problemas de outras áreas de MIR, como Segmentação Estrutural
no MIREX, por exemplo, no intuito de tornar mais ampla a avaliação da envoltória do som
como uma característica acústica (feature), e da correlação de envoltórias como uma métrica

84
de similaridade em música.
Ainda no contexto da detecção de refrão, considerando uma possível melhoria no tempo
de resposta do método, trabalhos futuros podem incluir paralelismo na abordagem através da
utilização de uma GPU (Unidade de Processamento Gráfico) na etapa de processamento da
matriz de similaridade, que é a etapa mais lenta em todo o método, ocupando mais de 60% do
total do tempo de resposta.
Considerando a taxa de acertos do método proposto, uma possibilidade de trabalhos
futuros é a exploração mais profunda das heurísticas empregadas na etapa de seleção de
refrão, refinando as que já existem ou encontrando novas formas de se eleger uma repetição
candidata, pois ainda há espaço para a redução da diferença entre as taxas de acertos das
heurísticas e do caso ótimo.
Entretanto, uma vez consolidada uma técnica de Segmentação Estrutural de música
usando uma matriz construída com correlação de envoltória, esta técnica poderia efetivamente
substituir as etapas de Extração de Repetições e Seleção de Refrão do método proposto neste
trabalho, dispensando o uso de heurísticas o que, possivelmente, eliminaria grande parte da
defasagem existente entre as taxas de acertos do caso ótimo e das heurísticas. Isto porque,
uma vez segmentada a música e rotulada as suas partes, bastaria retornar como refrão um
dos segmentos do conjunto cujo rótulo foi atribuído ao maior número de segmentos.

858585
Referências
ATHINEOS, M.; ELLIS, D. P. Frequency-domain linear prediction for temporal features. In:AUTOMATIC SPEECH RECOGNITION AND UNDERSTANDING, 2003. ASRU’03. 2003 IEEEWORKSHOP ON. Anais. . . [S.l.: s.n.], 2003. p.261 – 266.
AUCOUTURIER, J.; PACHET, F.; SANDLER, M. “ The way it Sounds”: timbre models foranalysis and retrieval of music signals. IEEE Transactions on Multimedia, [S.l.], v.7, n.6,p.1028 – 1035, 2005.
BARRINGTON, L.; CHAN, A. B.; LANCKRIET, G. Modeling music as a dynamic texture. IEEETransactions on Audio, Speech, and Language Processing, [S.l.], v.18, n.3, p.602 – 612,2010.
BARTSCH, M. A.; WAKEFIELD, G. H. Audio thumbnailing of popular music usingchroma-based representations. IEEE Transactions on multimedia, [S.l.], v.7, n.1, p.96 – 104,2005.
BELLO, J. P. et al. A tutorial on onset detection in music signals. IEEE Transactions onspeech and audio processing, [S.l.], v.13, n.5, p.1035 – 1047, 2005.
CAETANO, M. F.; BURRED, J. J.; RODET, X. Automatic segmentation of the temporal evolutionof isolated acoustic musical instrument sounds using spectro-temporal cues. In:INTERNATIONAL CONFERENCE ON DIGITAL AUDIO EFFECTS (DAFX-10). Anais. . .[S.l.: s.n.], 2010. p.11 – 21.
CASEY, M.; SLANEY, M. The importance of sequences in musical similarity. In: IEEEINTERNATIONAL CONFERENCE ON ACOUSTICS SPEECH AND SIGNAL PROCESSINGPROCEEDINGS, 2006. Anais. . . [S.l.: s.n.], 2006. v.5, p.5 – 8.
COOPER, M.; FOOTE, J. Summarizing popular music via structural similarity analysis. In:APPLICATIONS OF SIGNAL PROCESSING TO AUDIO AND ACOUSTICS, 2003 IEEEWORKSHOP ON. Anais. . . [S.l.: s.n.], 2003. p.127 – 130.
DANNENBERG, R. B.; HU, N. Pattern discovery techniques for music audio. In: IN PROC.INTERNATIONAL CONFERENCE ON MUSIC INFORMATION RETRIEVAL. Anais. . .[S.l.: s.n.], 2002. p.63 – 70.
DOWNIE, J. S. The music information retrieval evaluation exchange (2005-2007): a windowinto music information retrieval research. Acoustical Science and Technology, [S.l.], v.29,n.4, p.247 – 255, 2008.
DOWNIE, J. S. et al. The music information retrieval evaluation exchange: some observationsand insights. In: Advances in music information retrieval. [S.l.: s.n.], 2010. p.93 – 115.
ERONEN, A.; TAMPERE, F. Chorus detection with combined use of MFCC and chromafeatures and image processing filters. In: INTERNATIONAL CONFERENCE ON DIGITALAUDIO EFFECTS, 10. Proceedings. . . [S.l.: s.n.], 2007. p.229 – 236.

REFERÊNCIAS 86
FOOTE, J. Automatic audio segmentation using a measure of audio novelty. In: MULTIMEDIAAND EXPO, 2000. ICME 2000. 2000 IEEE INTERNATIONAL CONFERENCE ON. Anais. . .[S.l.: s.n.], 2000. v.1, p.452 – 455.
FUTRELLE, J.; DOWNIE, J. S. Interdisciplinary research issues in music information retrieval:ismir 2000–2002. Journal of New Music Research, [S.l.], v.32, n.2, p.121 – 131, 2003.
GOTO, M. A chorus section detection method for musical audio signals and its application to amusic listening station. IEEE Transactions on Audio, Speech, and Language Processing,[S.l.], v.14, n.5, p.1783 – 1794, 2006.
GOTO, M. et al. RWC Music Database: popular, classical and jazz music databases. In: ISMIR.Anais. . . [S.l.: s.n.], 2002. v.2, p.287 – 288.
GOTO, M. et al. Development of the RWC music database. In: INTERNATIONAL CONGRESSON ACOUSTICS (ICA 2004), 18. Proceedings. . . [S.l.: s.n.], 2004. v.1, p.553 – 556.
HAJDA, J. A new model for segmenting the envelope of musical signals: the relative salience ofsteady state versus attack, revisited. In: AUDIO ENGINEERING SOCIETY CONVENTION 101.Anais. . . [S.l.: s.n.], 1996.
HORNER, B.; SWISS, T. Key terms in popular music and culture. [S.l.: s.n.], 1999. 141 –155p.
International Federation of the Phonographic Industry. Global Music Report 2016 ofInternational Federation of the Phonographic Industry. Disponível em:<http://www.ifpi.org/downloads/GMR2016.pdf>. Acesso em: 26/11/2016.
JEHAN, T. Creating music by listening. 2005. Tese (Doutorado em Ciência da Computação)— .
JENSEN, K. Multiple scale music segmentation using rhythm, timbre, and harmony. EURASIPJournal on Advances in Signal Processing, [S.l.], v.2007, n.1, p.1 – 11, 2006.
LERDAHL, F.; JACKENDOFF, R. S. A Generative Theory of Tonal Music. , [S.l.], 1999.
LEVY, M.; SANDLER, M. Structural segmentation of musical audio by constrained clustering.IEEE Transactions on Audio, Speech, and Language Processing, [S.l.], v.16, n.2, p.318 –326, 2008.
LOGAN, B.; CHU, S. Music summarization using key phrases. In: ACOUSTICS, SPEECH,AND SIGNAL PROCESSING, 2000. ICASSP’00. PROCEEDINGS. 2000 IEEEINTERNATIONAL CONFERENCE ON. Anais. . . [S.l.: s.n.], 2000. v.2, p.II749 – II752.
LU, L.; WANG, M.; ZHANG, H. Repeating pattern discovery and structure analysis fromacoustic music data. In: ACM SIGMM INTERNATIONAL WORKSHOP ON MULTIMEDIAINFORMATION RETRIEVAL, 6. Proceedings. . . [S.l.: s.n.], 2004. p.275 – 282.
MARL. Music Structure Analysis definition, Music Audio Research Laboratory.Disponível em: <http://steinhardt.nyu.edu/marl/research/music_structure_analysis>. Acessoem: 26/11/2016.
MAROLT, M. A Mid-level Melody-based Representation for Calculating Audio Similarity. In:ISMIR. Anais. . . [S.l.: s.n.], 2006. p.280 – 285.

REFERÊNCIAS 87
MAUCH, M.; NOLAND, K.; DIXON, S. Using Musical Structure to Enhance Automatic ChordTranscription. In: ISMIR. Anais. . . [S.l.: s.n.], 2009. p.231 – 236.
MIREX. Structural Segmentation Task of Music Information Retrieval EvaluationeXchange (MIREX). Disponível em:<http://www.music-ir.org/mirex/wiki/2016:Structural_Segmentation>. Acesso em: 26/11/2016.
MÜLLER, M.; KURTH, F. Towards structural analysis of audio recordings in the presence ofmusical variations. EURASIP Journal on Advances in Signal Processing, [S.l.], v.2007, n.1,p.1 – 18, 2006.
ONG, B. S. Structural analysis and segmentation of music signals. 2006. Tese(Doutorado em Ciência da Computação) — .
OTSU, N. A threshold selection method from gray-level histograms. , [S.l.], v.9, p.62 – 66, 1979.
PAULUS, J.; KLAPURI, A. Music structure analysis by finding repeated parts. In: ACMWORKSHOP ON AUDIO AND MUSIC COMPUTING MULTIMEDIA, 1. Proceedings. . .[S.l.: s.n.], 2006. p.59 – 68.
PAULUS, J.; KLAPURI, A. Music structure analysis using a probabilistic fitness measure and agreedy search algorithm. IEEE Transactions on Audio, Speech, and LanguageProcessing, [S.l.], v.17, n.6, p.1159 – 1170, 2009.
PAULUS, J.; MÜLLER, M.; KLAPURI, A. Audio-Based Music Structure Analysis. In: ISMIR.Anais. . . [S.l.: s.n.], 2010. p.625 – 636.
PEETERS, G. Deriving Musical Structures from Signal Analysis for Music Audio SummaryGeneration:“sequence” and “state” approach. Computer Music Modeling and Retrieval,[S.l.], p.143 – 166, 2004.
PEETERS, G. Sequence Representation of Music Structure Using Higher-Order SimilarityMatrix and Maximum-Likelihood Approach. In: ISMIR. Anais. . . [S.l.: s.n.], 2007. p.35 – 40.
POLLACK, A. W. Allan W. Pollack works: notes on. . . series. Disponível em:<http://www.icce.rug.nl/∼soundscapes/DATABASES/AWP/awp-notes_on.shtml>. Acesso em:26/11/2016.
Queen Mary University of London. The Beatles Annotations dataset, Queen MaryUniversity of London. Disponível em:<http://www.isophonics.net/content/reference-annotations-beatles>. Acesso em: 26/11/2016.
RHODES, C.; CASEY, M. A. et al. Algorithms for determining and labelling approximatehierarchical self-similarity. , [S.l.], 2007.
RODRIGUES, R. C. S. Base percussiva Coco (Nordeste Brasileiro). Disponível em:<http://www.cin.ufpe.br/∼rcsr/base_percussiva>. Acesso em: 26/11/2016.
SEPPÄNEN, J.; ERONEN, A.; HIIPAKKA, J. Joint Beat & Tatum Tracking from Music Signals. ,[S.l.], 2006.
SHIU, Y.; JEONG, H.; KUO, C. J. Musical structure analysis using similarity matrix and dynamicprogramming. In: IN PROC. OF SPIE VOL. 6015 - MULTIMEDIA SYSTEMS ANDAPPLICATIONS VIII. Anais. . . [S.l.: s.n.], 2005. v.6015, p.398 – 409.

REFERÊNCIAS 88
SMITH, J. B. L. et al. Design and creation of a large-scale database of structural annotations.In: ISMIR. Anais. . . [S.l.: s.n.], 2011. v.11, p.555 – 560.
Tampere University of Technology. Beatles Sections TUT dataset. Disponível em:<http://www.cs.tut.fi/sgn/arg/paulus/structure.html>. Acesso em: 26/11/2016.
The Echo Nest Company. The Echo Nest Music Intelligence Company. Disponível em:<http://the.echonest.com>. Acesso em: 26/11/2016.
The International Music Information Retrieval Systems Evaluation Laboratory. RelevantCollections, in Structural Segmentation at MIREX webpage. Disponível em:<http://www.music-ir.org/mirex/wiki/2016:Structural_Segmentation#Relevant_Development_Collections>.Acesso em: 26/11/2016.
TURNBULL, D. et al. A Supervised Approach for Detecting Boundaries in Music UsingDifference Features and Boosting. In: ISMIR. Anais. . . [S.l.: s.n.], 2007. p.51 – 54.
Universitat Pompeu Fabra. Structure Beatles dataset. Disponível em:<http://www.dtic.upf.edu/∼perfe/annotations/sections/license.html>. Acesso em: 26/11/2016.
WELLHAUSEN, J.; HÖYNCK, M. Audio thumbnailing using MPEG-7 low-level audiodescriptors. In: ITCOM 2003. Anais. . . [S.l.: s.n.], 2003. p.65 – 73.
XU, C.; MADDAGE, N. C.; KANKANHALLI, M. S. Automatic structure detection for popularmusic. Ieee Multimedia, [S.l.], v.13, n.1, p.65 – 77, 2006.

Apêndice

90
Tabe
la1:
Taxa
deac
erto
s(%
)por
heur
ístic
ae
desl
ocam
ento
daja
nela
,na
Ext
raçã
ode
Env
oltó
ria,p
ara
oál
bum
Rev
olve
r,do
sB
eatle
s(b
ase
TUT)
.
ms
RO
H1
H2
H3
H4
H12
H13
H14
H23
H24
H34
H12
3H
124
H13
4H
234
H12
34
1056
,692
,072
,673
,052
,278
,172
,664
,472
,761
,572
,975
,263
,270
,566
,963
,163
,9
1567
,892
,270
,973
,751
,277
,971
,567
,771
,759
,675
,273
,968
,469
,270
,064
,067
,7
2070
,791
,272
,772
,551
,577
,170
,566
,272
,657
,877
,268
,764
,367
,866
,765
,466
,7
2565
,293
,667
,373
,853
,671
,366
,970
,268
,361
,074
,368
,164
,864
,564
,258
,660
,1
3072
,792
,772
,971
,444
,876
,272
,169
,773
,160
,474
,266
,569
,572
,062
,963
,665
,8
3564
,592
,271
,569
,053
,275
,972
,870
,170
,956
,873
,871
,470
,066
,470
,361
,269
,8
4073
,990
,468
,975
,054
,175
,866
,369
,770
,960
,475
,563
,065
,769
,469
,761
,569
,4
4566
,991
,369
,275
,654
,572
,669
,672
,067
,064
,275
,763
,067
,666
,070
,365
,269
,5
5066
,591
,069
,268
,455
,172
,465
,466
,965
,163
,475
,470
,766
,667
,767
,764
,567
,7
5572
,991
,272
,265
,256
,274
,674
,470
,068
,365
,271
,272
,865
,471
,167
,470
,269
,0
6062
,990
,367
,872
,441
,374
,069
,069
,670
,059
,176
,872
,069
,467
,165
,471
,566
,6
6564
,089
,474
,169
,949
,879
,177
,874
,476
,564
,678
,966
,974
,770
,966
,265
,269
,8
7070
,390
,471
,475
,945
,274
,868
,271
,170
,560
,574
,269
,663
,564
,465
,062
,264
,4
7563
,991
,072
,268
,745
,674
,864
,967
,568
,660
,380
,065
,766
,767
,767
,167
,368
,7
8074
,190
,568
,171
,452
,070
,069
,868
,069
,361
,671
,869
,069
,172
,768
,966
,067
,9
8567
,889
,267
,869
,539
,573
,468
,368
,668
,654
,777
,867
,256
,768
,863
,267
,063
,8
9055
,090
,569
,768
,753
,371
,770
,573
,664
,557
,376
,371
,267
,374
,068
,265
,866
,4
9571
,691
,268
,173
,453
,869
,768
,559
,067
,161
,377
,064
,069
,469
,268
,563
,568
,7
100
75,7
91,0
68,0
64,8
53,7
74,5
72,6
66,8
68,3
52,9
75,7
68,0
67,5
66,1
68,3
66,6
66,0

91
Tabe
la2:
Taxa
deac
erto
s(%
)por
heur
ístic
a,de
sloc
amen
toe
tam
anho
daja
nela
,na
Con
stru
ção
daM
atriz
deS
imila
ridad
e,pa
rao
álbu
mR
evol
ver,
dos
Bea
tles
(bas
eTU
T).
desl
=0,
25s
desl
=0,
5sde
sl=
0,75
sde
sl=
1sde
sl=
1,25
s
0,25
s0,
5s1s
0,5s
1s2s
0,75
s1,
5s3s
1s2s
4s1,
25s
2,5s
5s
R56
,557
,171
,258
,871
,768
,260
,367
,071
,772
,674
,075
,562
,656
,37
51,8
7
O64
,574
,085
,388
,290
,490
,687
,489
,091
,292
,392
,391
,590
,986
,81
88,1
9
H1
59,7
63,3
71,4
70,3
71,1
71,6
67,3
70,4
73,9
62,8
70,7
72,0
69,0
65,1
057
,23
H2
56,2
66,2
76,1
69,8
77,3
75,3
70,1
71,5
77,1
71,1
72,9
73,0
58,3
45,9
263
,15
H3
43,9
55,3
66,0
53,9
61,3
66,0
70,0
51,7
54,7
55,2
58,8
49,8
32,6
31,9
843
,3
H4
56,9
68,6
72,2
72,5
72,0
78,2
70,1
70,9
71,9
68,3
73,1
73,3
54,3
65,6
057
,78
H12
59,1
61,4
70,1
68,3
72,2
72,8
63,6
72,5
73,9
66,8
70,7
74,1
71,5
67,2
252
,57
H13
54,9
60,8
68,4
64,0
75,2
69,5
66,8
65,8
69,7
65,1
73,5
75,3
60,8
58,6
856
,05
H14
57,0
62,8
68,2
66,9
70,3
71,8
71,4
67,7
70,6
71,1
69,0
73,5
71,4
62,2
756
,88
H23
44,7
56,6
68,5
57,2
71,8
70,7
71,4
53,9
65,5
53,9
63,3
70,5
46,2
42,9
651
,64
H24
57,1
67,2
71,5
72,6
71,8
74,7
72,0
66,7
74,9
69,2
74,9
75,1
56,1
57,7
257
,27
H34
48,5
58,0
67,0
62,6
68,7
70,8
77,4
67,9
69,5
67,5
76,8
66,9
65,5
53,4
053
,34
H12
346
,460
,167
,171
,172
,268
,969
,167
,167
,564
,670
,575
,770
,851
,40
57,5
6
H12
453
,257
,564
,363
,770
,970
,172
,071
,670
,866
,570
,474
,162
,862
,17
56,9
9
H13
454
,157
,865
,059
,474
,971
,374
,673
,066
,763
,769
,373
,268
,162
,20
53,3
2
H23
448
,558
,066
,266
,873
,473
,978
,571
,569
,462
,468
,568
,857
,251
,93
62,4
4
H12
3454
,161
,567
,663
,672
,972
,769
,771
,968
,468
,170
,276
,863
,659
,41
60,0
5
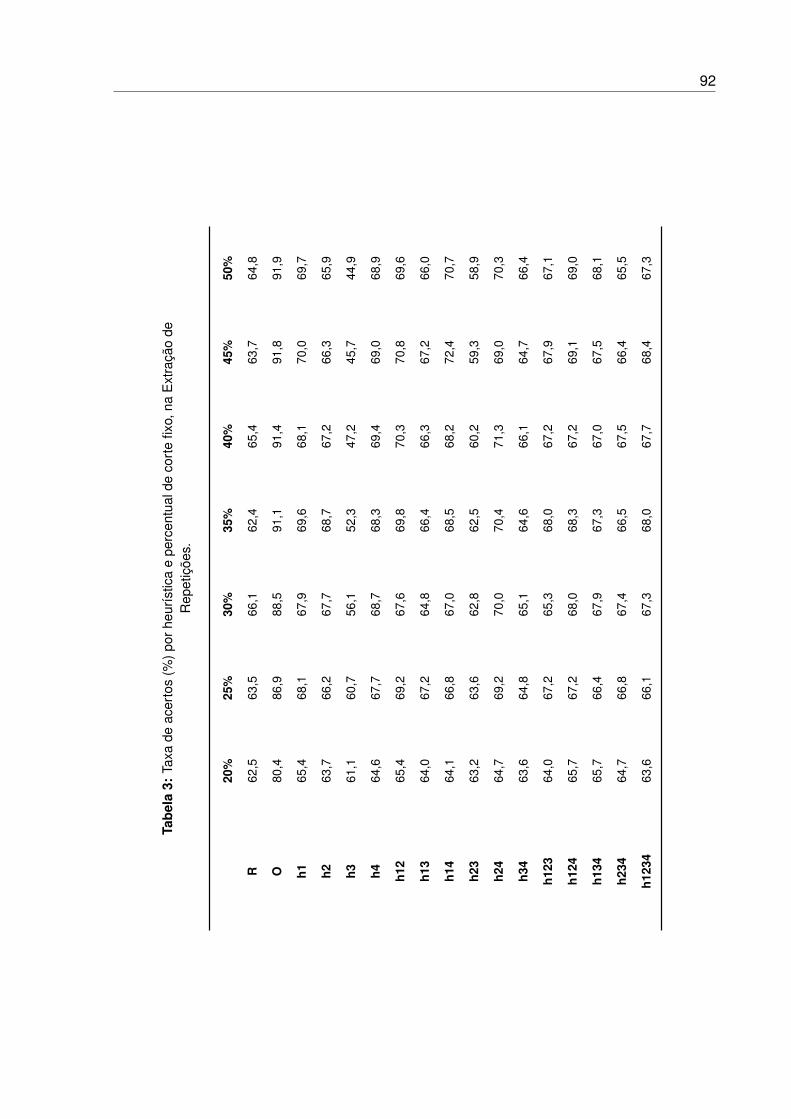
92
Tabe
la3:
Taxa
deac
erto
s(%
)por
heur
ístic
ae
perc
entu
alde
cort
efix
o,na
Ext
raçã
ode
Rep
etiç
ões.
20%
25%
30%
35%
40%
45%
50%
R62
,563
,566
,162
,465
,463
,764
,8
O80
,486
,988
,591
,191
,491
,891
,9
h165
,468
,167
,969
,668
,170
,069
,7
h263
,766
,267
,768
,767
,266
,365
,9
h361
,160
,756
,152
,347
,245
,744
,9
h464
,667
,768
,768
,369
,469
,068
,9
h12
65,4
69,2
67,6
69,8
70,3
70,8
69,6
h13
64,0
67,2
64,8
66,4
66,3
67,2
66,0
h14
64,1
66,8
67,0
68,5
68,2
72,4
70,7
h23
63,2
63,6
62,8
62,5
60,2
59,3
58,9
h24
64,7
69,2
70,0
70,4
71,3
69,0
70,3
h34
63,6
64,8
65,1
64,6
66,1
64,7
66,4
h123
64,0
67,2
65,3
68,0
67,2
67,9
67,1
h124
65,7
67,2
68,0
68,3
67,2
69,1
69,0
h134
65,7
66,4
67,9
67,3
67,0
67,5
68,1
h234
64,7
66,8
67,4
66,5
67,5
66,4
65,5
h123
463
,666
,167
,368
,067
,768
,467
,3
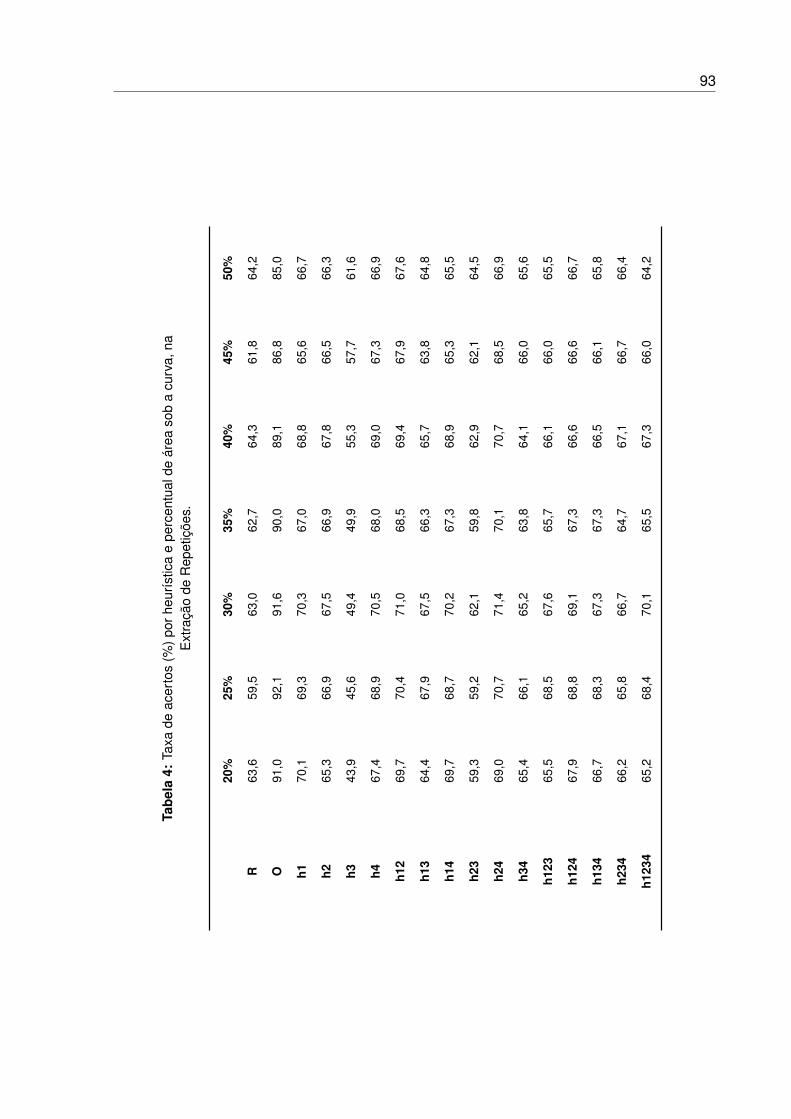
93
Tabe
la4:
Taxa
deac
erto
s(%
)por
heur
ístic
ae
perc
entu
alde
área
sob
acu
rva,
naE
xtra
ção
deR
epet
içõe
s.
20%
25%
30%
35%
40%
45%
50%
R63
,659
,563
,062
,764
,361
,864
,2
O91
,092
,191
,690
,089
,186
,885
,0
h170
,169
,370
,367
,068
,865
,666
,7
h265
,366
,967
,566
,967
,866
,566
,3
h343
,945
,649
,449
,955
,357
,761
,6
h467
,468
,970
,568
,069
,067
,366
,9
h12
69,7
70,4
71,0
68,5
69,4
67,9
67,6
h13
64,4
67,9
67,5
66,3
65,7
63,8
64,8
h14
69,7
68,7
70,2
67,3
68,9
65,3
65,5
h23
59,3
59,2
62,1
59,8
62,9
62,1
64,5
h24
69,0
70,7
71,4
70,1
70,7
68,5
66,9
h34
65,4
66,1
65,2
63,8
64,1
66,0
65,6
h123
65,5
68,5
67,6
65,7
66,1
66,0
65,5
h124
67,9
68,8
69,1
67,3
66,6
66,6
66,7
h134
66,7
68,3
67,3
67,3
66,5
66,1
65,8
h234
66,2
65,8
66,7
64,7
67,1
66,7
66,4
h123
465
,268
,470
,165
,567
,366
,064
,2

94
Tabe
la5:
Taxa
deac
erto
s(%
)por
heur
ístic
ae
porá
lbum
daba
seTU
T,pa
raab
orda
gem
com
perc
entu
alde
cort
efix
o.
1º2º
3º4º
5º6º
7º8º
9º10
º11
º12
º13
º
R52
,90
48,6
463
,54
72,0
063
,47
70,4
667
,96
55,2
863
,05
59,0
353
,69
56,0
667
,86
O91
,07
91,2
892
,38
90,7
894
,23
92,9
092
,53
92,0
892
,51
91,6
291
,48
90,1
290
,19
H1
77,4
957
,06
81,7
870
,45
79,7
172
,86
70,6
765
,75
67,6
363
,21
62,2
565
,48
68,3
9
H2
65,7
867
,46
79,4
864
,24
66,3
673
,14
68,3
263
,47
76,5
652
,53
58,2
365
,35
61,5
0
H3
35,2
130
,07
70,1
569
,51
53,6
143
,75
54,9
442
,00
28,6
239
,31
38,4
232
,00
47,4
0
H4
67,1
478
,64
77,5
066
,53
69,0
763
,68
70,9
167
,75
77,7
161
,92
64,1
166
,86
68,1
3
H12
70,6
457
,94
81,5
570
,43
84,8
669
,36
72,8
368
,62
71,4
268
,44
63,2
966
,95
67,5
2
H13
69,0
052
,44
79,7
970
,99
74,8
054
,85
71,9
565
,10
59,3
461
,74
66,6
770
,98
68,1
9
H14
71,9
272
,54
80,2
569
,56
80,0
975
,18
70,8
775
,00
68,3
967
,85
70,2
567
,95
69,8
1
H23
58,1
634
,45
81,6
275
,71
70,7
754
,30
59,0
853
,37
44,5
953
,05
52,5
958
,14
62,7
8
H24
73,3
976
,43
80,0
066
,57
70,7
957
,35
69,4
871
,74
72,0
759
,71
58,8
872
,02
67,0
5
H34
57,7
364
,97
73,5
473
,02
75,0
553
,53
67,7
464
,59
56,0
563
,83
49,5
362
,79
72,9
1
H12
367
,88
49,9
081
,39
74,8
776
,95
52,9
873
,26
68,5
874
,03
61,2
357
,13
68,7
567
,04
H12
471
,70
59,3
273
,85
75,5
878
,83
65,6
665
,76
70,4
275
,09
61,8
356
,58
65,0
573
,47
H13
468
,04
56,3
678
,10
71,3
977
,08
57,0
766
,78
66,8
468
,39
70,4
358
,74
68,5
263
,78
H23
467
,46
66,6
176
,71
77,8
974
,28
54,2
963
,26
54,5
366
,67
53,7
858
,35
72,8
072
,73
H12
3468
,10
50,7
481
,75
75,0
380
,14
53,8
566
,50
68,3
472
,49
63,9
158
,73
73,8
767
,10

95
Tabe
la6:
Taxa
deac
erto
s(%
)por
heur
ístic
ae
porá
lbum
daba
seTU
T,pa
raab
orda
gem
com
limia
rdin
âmic
o.
1º2º
3º4º
5º6º
7º8º
9º10
º11
º12
º13
º
R56
,99
57,6
975
,52
73,2
269
,45
70,9
976
,38
49,5
655
,03
52,4
655
,81
61,6
963
,15
O91
,82
91,5
292
,62
90,2
093
,60
92,1
392
,29
92,6
392
,88
90,3
192
,22
88,3
590
,04
H1
68,9
967
,02
77,7
570
,34
77,0
872
,37
70,6
870
,08
65,2
369
,20
61,2
971
,63
68,1
3
H2
68,4
671
,90
71,9
865
,66
70,0
273
,54
72,9
161
,81
74,2
253
,73
61,7
165
,31
65,9
2
H3
52,3
739
,49
69,4
463
,93
54,0
147
,73
58,7
651
,04
30,7
241
,12
44,5
633
,55
45,1
1
H4
68,0
977
,58
81,4
970
,48
72,9
863
,43
73,1
275
,31
74,6
861
,50
59,3
367
,89
70,5
9
H12
67,1
766
,28
78,0
375
,83
81,4
870
,68
70,7
268
,98
71,5
165
,90
60,6
471
,78
69,9
7
H13
77,4
557
,25
74,9
571
,37
78,4
953
,82
73,5
064
,20
61,6
257
,74
62,2
262
,18
72,0
2
H14
62,9
877
,35
77,5
074
,83
76,7
773
,67
69,0
069
,61
66,6
968
,24
59,1
065
,90
71,2
4
H23
62,2
243
,94
77,4
578
,43
74,2
653
,77
63,3
260
,20
40,4
258
,67
52,8
062
,03
66,9
7
H24
70,8
477
,53
79,3
968
,19
69,6
565
,07
74,9
177
,72
75,0
364
,01
58,1
572
,53
74,8
3
H34
62,0
664
,12
76,2
267
,00
76,7
355
,60
76,7
669
,29
52,3
663
,47
48,5
557
,06
70,0
2
H12
370
,76
56,5
876
,23
72,2
183
,03
52,3
870
,47
64,6
376
,10
59,8
954
,32
68,4
665
,26
H12
466
,88
67,8
974
,52
71,4
574
,74
64,3
170
,39
69,9
869
,41
66,3
460
,20
72,1
367
,48
H13
465
,93
61,0
277
,18
71,7
874
,70
54,5
869
,29
70,1
362
,16
69,5
365
,65
60,1
168
,39
H23
465
,59
65,5
680
,48
69,7
678
,07
58,8
168
,45
71,9
158
,26
58,2
549
,86
66,8
768
,96
H12
3465
,05
67,4
280
,65
73,3
281
,82
54,2
870
,18
67,1
975
,94
63,1
162
,02
72,9
373
,60





![COMO SE CADASTRAR E SE ATIVAR NA LIFE ESSENCE BRASIL · 2015. 11. 30. · L_E] painel.lifeessencebrasil.com.br/p/celso CELSO celso Celso Silva Login Senha LifeEsse Pais X - L' aça](https://img.document.onl/doc/110x75/60351e1e2bf6f4726f5b8c10/como-se-cadastrar-e-se-ativar-na-life-essence-brasil-2015-11-30-le-painellifeessencebrasilcombrpcelso.jpg)























