Embed Size (px)
Citation preview


Topicos em Gerenciamento deDados e Informacoes 2014
1a Edicao
EditoraSociedade Brasileira de Computacao – SBC
OrganizadoresBernadette Farias Loscio, Carmem S. Hara e Vidal Martins
ISBN 978-85-7669-290-4

T674 Simpósio Brasileiro de Banco de Dados (29. : 2014 out. 6-9 : Curitiba, PR). Tópicos em Gerenciamento de Dados e Informações 2014 [recurso eletrônico] / [Organização: Departamento de Informática da UFPR e Escola Politécnica da PUC-PR ; editado por Bernardette Farias Lóscio... et al.]. – Curitiba: UFPR; PUC-PR, 2014. 1 pendrive.
Disponível também no site do SBBD 2014: http://www.inf.ufpr.br/sbbd-sbsc2014/sbbd. ISBN 978-85-7669-290-4.
1. Bancos de dados - Encontros. 2. Gerência de Informações. 3. SBBD. I. Universidade Federal do Paraná. Departamento de Informática (Org.). II.Pontifícia Universidade Católica do Paraná. Escola Politécnica (Org.). III. Lóscio, Bernardette Farias (Ed.). IV. Título.
CDD: 005.74

Editorial
Os minicursos do SBBD sao cursos de curta duracao que abordam temas relevantesda area de Banco de Dados e tem como objetivo promover discussoes sobre os fun-damentos, tendencias e desafios relacionados ao tema abordado. Os minicursos, comtres horas de duracao cada, constituem uma excelente oportunidade de atualizacaopara academicos e profissionais da area.
Nesta edicao, foram selecionadas tres propostas para serem apresentadas durante oSBBD 2014. A selecao das propostas foi realizada por um Comite de Avaliacao for-mado por cinco avaliadores. Durante o processo de selecao, as propostas submetidasforam avaliadas por todos os membros do comite. Os textos dos minicursos selecio-nados, que correspondem aos capıtulos desse livro, foram revisados por membros docomite para garantir a qualidade final dos mesmos.
Os minicursos do SBBD 2014 abordam temais atuais e relevantes relacionados aBig Data e Cloud Computing. O primeiro minicurso, “Big Social Data: Princıpiossobre Coleta, Tratamento e Analise de Dados Sociais”, apresenta uma abordagem deanalise de Big Data em redes sociais online (Big Social Data), incluindo a coleta etratamento de grande volume de dados sociais, mineracao e princıpios de analise deinteracoes sociais. O segundo minicurso, “Estrategias para Protecao da Privacidadede Dados Armazenados na Nuvem”, apresenta e discute os principais conceitos,metodos e tecnicas relacionados a seguranca e a privacidade dos dados armazenadosou processados na nuvem. O terceiro minicurso, “Otimizacao de Desempenho emProcessamento de Consultas MapReduce”, tem como tema central as solucoes detuning para processadores de consulta baseados em MapReduce com foco principalnuma solucao baseada em Hadoop, Hive e AutoConf.
Gostaria de agradecer aos autores, pela submissao das propostas e geracao dos textosfinais, e ao Comite de Avaliacao, pela dedicacao e eficiencia em todo o processo deselecao dos minicursos.
Bernadette Farias Loscio, UFPECoordenadora de Minicursos do SBBD 2014
Carmem S. Hara, UFPRVidal Martins, PUC-PR
Coordenadores Locais do SBBD 2014

XXIX Simposio Brasileiro de Banco de Dados
6 a 9 de Outubro 2014Curitiba – PR – Brasil
MINICURSOS
Promocao
Sociedade Brasileira de Computacao – SBCComissao Especial de Banco de Dados da SBC
Organizacao
Universidade Federal do Parana – UFPRPontifıcia Universidade Catolica do Parana – PUC-PR
Comite Diretivo do SBBD
Ana Carolina Salgado, UFPECristina Ciferri, ICMC-USP (coord.)Jose Palazzo Moreira de Oliveira, UFRGSMarco A. Casanova, PUC-RioMirella M. Moro, UFMGVanessa Braganholo, UFF

Coordenadores do SBBD 2014
Coordenadora do Comite DiretivoCristina Ciferri, ICMC-USP
Coordenadores LocaisCarmem Hara, UFPR and Vidal Martins, PUC-PR
Coordenadoras do Comite de ProgramaMirella M. Moro, UFMG and Renata Galante, UFRGS
Coordenadores da Sessao de Demos e AplicacoesJose Antonio Macedo, UFC and Flavio Sousa, UFC
Coordenadores do Workshop de Teses e Dissertacoes em Banco de DadosJoao Eduardo Ferreira, IME-USP and Fabio Porto, LNCC
Coordenadora de MinicursosBernadette Farias Loscio, UFPE
Coordenadora de TutoriaisVanessa Braganholo, UFF
Comite de Organizacao Local
Carmem Satie Hara, UFPR (coord.)Cristina Vercosa Perez Barrios de Souza, PUC-PRDaniel S. Kaster, UEL (proceedings)Marcos A. Carrero, UFPRNadia Puchalski Kozievitch, UTFPRVidal Martins, PUC-PR (coord.)
Comite de Avaliacao de Minicursos
Angelo Brayner, UNIFORDamires Souza, IFPBEdleno Silva de Moura, UFAMRicardo Rodrigues Ciferri, UFSCARRonaldo Mello, UFSC

Sumario
Capıtulo 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Big Social Data: Princıpios sobre Coleta, Tratamento e Analise de Dados Sociais
Tiago Cruz Franca, Fabrıcio Firmino de Faria, Fabio Medeiros Rangel, ClaudioMiceli de Farias, Jonice Oliveira
Capıtulo 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
Estrategias para Protecao da Privacidade de Dados Armazenados na Nuvem
Eliseu Castelo Branco Junior, Javam Machado, Jose Maria da Silva Monteiro Filho
Capıtulo 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Otimizacao de Desempenho em Processamento de Consultas MapReduce
Ivan Luiz Picoli, Leandro Batista de Almeida, Eduardo Cunha de Almeida

Capítulo
1
Big Social Data: Princípios sobre Coleta,
Tratamento e Análise de Dados Sociais
Tiago Cruz França, Fabrício Firmino de Faria, Fabio Medeiros Rangel,
Claudio Miceli de Farias e Jonice Oliveira
Abstract
Online social networks have become a popular mean of sharing and disseminating data.
From these data one can extract information about patterns of interpersonal interactions
and opinions, aiding in the understanding of a phenomenon, an event prediction or
decision making. Nowadays, the studies and techniques for social network analysis need
to work with the increase of variety and volume of data besides quickly processing them.
Therefore, new approaches are required to be employed in those analyzes. Data that have
such characteristics (volume, variety and velocity) are called Big Data. This short course
aims to present an approach for analyzing Big Data in online social networks (Social Big
Data), including the collection and processing of large volumes of social data mining and
analysis principles of social interactions.
Resumo
Os dados das redes sociais online podem ser usados para extrair informações sobre
padrões de interações interpessoais e opiniões. Esses dados podem auxiliar no
entendimento de fenômenos, na previsão de um evento ou na tomada de decisões. Com a
ampla adoção dessas redes, esses dados aumentaram em volume, variedade e precisam
de processamento rápido, exigindo, por esse motivo, que novas abordagens no
tratamento sejam empregadas. Aos dados que possuem tais características (volume,
variedade e necessidade de velocidade em seu tratamento), chamamo-los de Big Data.
Este minicurso visa apresentar uma abordagem de análise de Big Data em redes sociais
online (Big Social Data), incluindo a coleta e tratamento de grande volume de dados
sociais, mineração e princípios de análise de interações sociais.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
cap:1
8

1.1. Introdução
A ‘redescoberta’ da importância da análise de redes sociais se deu pelo uso intensivo das
mídias sociais. Nesta seção entenderemos os conceitos básicos de redes sociais,
aplicações da análise de redes sociais e como a coleta e tratamento de dados das redes
sociais online (ou mídias sociais) podem ser caracterizados como um problema de Big
Data.
1.1.1 Conceitos de Redes Sociais e a Aplicabilidade da Análise de Redes
Sociais
Por definição, uma rede social é um conjunto de atores que pode possuir relacionamentos
uns com os outros [Wasserman 1994].
Redes Sociais são como um organismo vivo, onde cada célula é uma pessoa.
Como em todo organismo, vemos toda a sorte de células: as que permanecem nele por
alguns dias, outras por alguns meses e aquelas que perduram por anos. Porém,
invariavelmente, essas células acabam por deixar de existir, dando lugar a células novas
ou muitas vezes nem isso. Se sairmos do campo metafórico e buscarmos algo mais
concreto, do nosso dia-a-dia, podemos observar o mesmo padrão: pessoas que ficam
desempregadas, se aposentam, são promovidas, empresas que se fundem, falecimentos,
novas amizades, namoros e muito mais.
Em nosso dia-a-dia não faltam exemplos práticos de redes sociais: nossa família,
nossos amigos de faculdade, de academia, de trabalho ou até mesmo encontros casuais,
imprevistos. Eles podem ser vistos e caracterizados como a criação de um relacionamento
entre dois indivíduos (nós), ligando assim as redes já existentes de ambos. Tal
relacionamento pode nunca mais ser nutrido ou, como em alguns casos, vir a se tornar
algo mais forte do que todos os relacionamentos já existentes. A estrutura que advém
dessas inúmeras relações, normalmente, se mostra complexa.
A análise das redes sociais é feita do todo para a parte; da estrutura para a relação
do indivíduo; do comportamento para a atitude. Para isto é estudada a rede como um todo,
usando uma visão sociocêntrica (com todos os elos contendo relações específicas em uma
população definida) ou como redes pessoais, em uma visão egocêntrica (com os elos que
pessoas específicas possuem, bem como suas comunidades pessoais) [Hanneman 2005].
Podemos citar alguns cenários onde é aplicada a análise de redes sociais. No caso
de uma empresa, por exemplo, é importante saber como os seus funcionários se
organizam, pois assim é possível evitar problemas característicos que dificultam a
disseminação de conhecimento [Wasserman 1994]. No campo da Ciência, as redes sociais
podem auxiliar no estudo de propagações de endemias ou mesmo de epidemias [Pastor-
Satorras 2001; Mikolajczyk 2008], bem como serem utilizadas para entender
[Albuquerque 2014; Stroele 2011] ou melhorar a formação de grupos [Souza et al. 2011;
Monclar et al. 2012; Melo e Oliveira 2014; Zudio et al. 2014]. Como tática de propaganda
e ‘marketing’ podemos usá-las como uma ferramenta para ajudar a propagar uma
determinada marca ou conceito, podendo servir, também, para o estudo de um público-
alvo relacionado, verificando em quais nós aquelas informações morrem e em quais elas
seguem em frente [Kempe 2003; Santos e Oliveira 2014]. Além disso, podemos
aproveitar uma das grandes questões do início do século XXI desde os eventos de 11 de
setembro de 2001, os atentados, para pensar na detecção e identificação de terroristas.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
9

Pode-se realizar uma verificação de pessoas com as quais os terroristas costumam se
relacionar, traçando um padrão de redes que auxilie futuras investigações [Svenson
2006]. Outra aplicação advém do levantamento de relacionamentos entre ‘Weblogs’1 que
realizam propaganda de ideais terroristas, montando a respectiva rede social representada
por eles, como visto em [Yang 2007].
A tendência de pessoas se unirem e formarem grupos é uma característica de
qualquer sociedade [Castells 2000]. Esse comportamento é retratado, nos dias atuais,
através do avanço das mídias sociais e comunidades online que evidenciam o poder de
unir usuários ao redor do mundo. Conteúdos gerados por seus usuários atingiram alto
grau de alcance através de seus comentários, relatos de acontecimentos quase em tempo
real, experiências, opiniões, críticas e recomendações que são lidos, compartilhados e
discutidos, de forma quase instantânea, em diversas plataformas disponíveis na Web.
1.1.2 Redes Sociais no Mundo Digital: Redes Sociais Online
O crescimento de usuários de telefones celulares e tablets com acesso à rede permite que
as pessoas permaneçam conectadas ao longo do dia, aumentando a quantidade de
informações disponibilizadas na Internet. De acordo com o relatório do instituto de
pesquisa tecnológica Cozza et al. [2011], 428 milhões de dispositivos móveis, incluindo
celulares, smartphones e tablets foram vendidos ao redor do mundo no primeiro semestre
do ano de 2011 com 19% por cento de crescimento em relação ao ano anterior. Grande
parte do acesso e disponibilização do conteúdo se deve à popularização das mídias
sociais.
Mídias Sociais é um tipo de mídia online que permite que usuários ao redor do
mundo se conectem, troquem experiências e compartilhem conteúdo de forma instantânea
através da Internet. Elas são fruto do processo de socialização da informação nos últimos
anos representado pela extensão do diálogo e do modo como as informações passaram a
ser organizadas através da Web.
As mídias sociais e consequentemente o crescimento do seu uso pela população
implicaram numa mudança de paradigma em relação à disseminação da informação. As
grandes mídias como jornais, revistas e portais passaram a não ser os mais importantes
provedores de informações para a população, ou seja, o modelo de disseminação “um
para muitos” foi sendo substituído pelo modelo “muito para muitos” [Stempel 2000]. As
mídias sociais deram espaço para que usuários gerassem e compartilhassem conteúdo de
forma expressiva, deixando de lado o comportamento passivo de absorção da informação
que possuíam, caracterizando uma forma de democratização na geração de conteúdo.
Segundo Solis (2007), o termo mídia social descreve tecnologias e práticas online
que pessoas usam para compartilhar opiniões, experiências e perspectivas, podendo se
manifestar em diferentes formatos incluindo texto, imagens, áudio e vídeo. A expansão
dessas mídias tornou mais simples encontrar amigos, compartilhar ideias e opiniões e
obter informações, ou seja, uma democratização do conteúdo em que todos participam na
construção de uma comunidade virtual.
Existem diversos tipos de mídias sociais com os mais diferentes focos. As
categorias mais conhecidas são:
1 ‘Weblogs’ são páginas pessoais, ou sites sem fim lucrativos, dedicados a trazer informações sobre um determinado tema [Blood 2002].
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
10

• Colaboração: está relacionada às redes sociais colaborativas, ou seja, sites em
que é importante a interação de diferentes usuários compartilhando informações a fim de
atingir um objetivo comum. Como exemplo destacam-se a Wikipedia, Yelp e Digg.
• Comunicação: está relacionada ao fenômeno da conversação entre pessoas e o
modo como essa conversa é percebida por seus participantes, que podem participar de
forma direta, através da realização de comentários e produção de conteúdo, ou indireta,
compartilhando e divulgando conteúdo e, consequentemente, ajudando a promover
discussões. Podem-se citar, neste contexto, os blogs e microblogs, as redes sociais online
(RSO) e os fóruns. Como exemplo, é possível mencionar WordPress2, Twitter3,
Facebook4 e GoogleGroups5, respectivamente.
• Multimídia: refere-se aos componentes audiovisuais que ficam além do texto
puro e simples como fotos, vídeos, podcasts e músicas. Alguns exemplos dessas mídias,
respectivamente, são Flickr6, YouTube7, JustinTV8 e Lastfm9.
• Entretenimento: diz respeito aos conteúdos que geram um mundo virtual
favorecendo o desenvolvimento da “gamificação”, ou seja, ambientes focados em games
online ou ainda atividades que podem ser transformadas em algum tipo de competição,
nos quais seus usuários se juntam com o objetivo de jogarem juntos ou compartilharem
informações a respeito do tema. Como exemplo podem ser citados o Second Life10 e
TvTag11.
A popularidade dessas plataformas pode ser evidenciada através da capacidade
que possuem de produzir enormes volumes de conteúdo. Conforme as estatísticas do
Facebook [Statistics Facebook 2011], este possui mais de 800 milhões de usuários ativos
e 50% destes usuários acessam o site todo dia. De acordo com o Compete12, o Twitter
possuía em Setembro de 2012 cerca de 42 milhões de usuários únicos registrados
representando o vigésimo primeiro site da Internet em número de visitantes únicos e
segundo Dale [2007], o YouTube concentra 20% de todo o tráfego de dados da Internet.
A monitoração destas mídias sociais tornou-se um problema de Big Data, onde
precisamos tratar um volume grande de dados, variedade (já que tais mídias apresentam
características distintas no que se relaciona à estrutura, dinâmica, uso e modelagem) e
necessidade de velocidade em seu tratamento para que diferentes análises sejam viáveis.
1.2 Redes Sociais Online: Coleta de dados e Técnicas de Análise
Nesta seção, apresentamos os princípios da coleta dos dados e a análise das redes sociais
extraídas a partir destes dados.
2 https://wordpress.com 3 http://www.twitter.com 4 https://www.facebook.com 5 https://groups.google.com 6 https://www.flickr.com/ 7 https://www.youtube.com/ 8 http://www.justin.tv/ 9 http://www.lastfm.com.br/ 10 http://secondlife.com/ 11 http://tvtag.com/ 12 http://www.compete.com
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
11

1.2.1 A informação dos dados coletados na Web
A Web é composta por uma grande quantidade de dados que não possuem uma estrutura
definida ou que não possuem uma semântica explícita. Por exemplo, uma página HTML
possui uma estrutura, mas esta estrutura pouco atribui informações sobre os dados
presentes na página. Sendo assim, ao encontrar uma tag “<img>” em um determinado
ponto do arquivo HTML é possível afirmar que se trata de uma imagem, porém pouco se
pode afirmar sobre o conteúdo desta imagem. Ainda que a tag “<img>” possua um
atributo que seja um texto relativo a essa imagem, textos são dados não estruturados e é
necessário aplicar técnicas em mineração de dados para extrair informações do texto.
Segundo Chen (2001), estima-se que 80% de todo conteúdo mundial online são
textos. Considerando que dados não estruturados englobam textos, imagens, vídeos e
músicas, pode-se perceber que realmente grande parte da Web é composta de dados não
estruturados.
Devido à necessidade de aperfeiçoar os mecanismos de busca e utilizar a Web
como plataforma de integração, por meio de serviços, há uma busca crescente em
estruturar os dados. Essa estruturação, entretanto, deve ter uma flexibilidade dado a
própria natureza da Web em que há uma vasta variedade de dados. Com base nesse
problema, alguns padrões foram criados. Entre eles, os padrões XML e JSON são os mais
utilizados. Entretanto, nada impede de que outros padrões sejam criados ou aplicados.
Essa diversidade cria um problema no processamento dos dados, pois é necessário criar
uma aplicação para cada padrão de representação. Além disso, um mesmo padrão de
representação pode estruturar o mesmo conjunto de dados de diferentes formas, como
ilustrado na Figura 1.1.
1.2.2 Coleta de Dados: Crawler de páginas e APIs de RSO
Atualmente, as principais redes sociais online (RSO) provêem interfaces ou serviços para
a captura parcial ou total de seus dados. Nesta seção, comentaremos os principais desafios
e recursos para se trabalhar com as principais (RSO) existentes atualmente.
1.2.2.1 Coletando Dados de Páginas Estáticas e Dinâmicas da Web:
Ferramentas e Desafios
Considera-se dinâmica uma página cuja atualização dependa de uma aplicação Web,
enquanto páginas estáticas costumam não ter seu conteúdo modificado. Quando se faz
necessário coletar dados de páginas, sejam estáticas ou dinâmicas, é necessário entender
a estrutura dos dados contidos nessa página a fim de desenvolver um crawler capaz de
buscar e armazenar esses dados. Quando a página não possui API de consumo ou a API
possui limites indesejados, é possível utilizar ferramentas para capturar as páginas e
extrair os dados sem a utilização de APIs. Um exemplo dessas ferramentas é o Node.js.
O Node.js é uma plataforma construída na máquina virtual Javascript do Google para a
fácil construção de aplicações de rede rápidas e escaláveis [Node 2014].
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
12

Figura 1.1. Exemplos de conjuntos de dados em diferentes representações.
1.2.2.2 Coletando Dados do Twitter, Facebook, YouTube e Foursquare
Normalmente, há duas formas diferentes de coleta de dados das redes sociais online. A
primeira forma consiste em determinar termos e coletar por citações destes termos no
passado. Desta forma, existe a possibilidade de restrições na obtenção de dados antigos,
pois normalmente há um período de tempo viável para a coleta dos dados. A segunda se
baseia em um conceito de streaming, onde a aplicação criada funciona como um
“ouvinte” da rede e captura os dados à medida que estes surgem.
O Twitter é uma rede social online que possui duas APIs diferentes para a captura dos
seus dados: REST API e Streaming API. Para a utilização de ambas APIs é necessário
inicialmente que o usuário tenha uma conta no Twitter. Acessando a página
https://dev.twitter.com, é possível autenticar-se com a conta do Twitter e cadastrar uma
aplicação. Após o cadastro da aplicação é necessário gerar o Access Token da mesma.
Importante destacar que, tanto o API Secret como o Access Token Secret da sua aplicação
não devem ser divulgados por questões de segurança. Essas chaves serão utilizadas na
autenticação da sua aplicação de captura de dados.
O Twitter trabalha com o padrão de arquivo JSON. Todos os dados são recebidos
nesse formato. Um exemplo da utilização do Streaming API pode ser visto na Figura 1.2.
Os programas usados como exemplo de crawlers para o Twitter foram codificados
em Python 2.7. No primeiro exemplo (Figura 1.3), foram utilizadas as bibliotecas
“Auth1Session” e “json”. A Auth1Session é responsável pelo estabelecimento da
conexão com o Twitter e a biblioteca JSON é responsável por transformar o texto
recebido em um objeto Python cuja estrutura é no formato JSON. Assim, é possível
manipular o arquivo JSON. Um exemplo utilizando a REST API do Twitter pode ser visto
na Figura 1.3.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
13

import json
from requests_oauthlib import OAuth1Session
key = "{sua API key}"
secret = "{sua API secret}"
token = "{seu Acess Token}"
token_secret = "{seu Acess Token Secret}"
requests = OAuth1Session(key, secret, token, token_secret)
r = requests.post('https://stream.twitter.com/1/statuses/filter.json',
data={'track': 'bom dia'},
stream=True)
for line in r.iter_lines():
if line:
print json.loads(line) # tweet retornado
Figura 1.2. Exemplo usando a Streaming API.
import oauth2 as oauth
import json
import time
CONSUMER_KEY = "{sua API key}"
CONSUMER_SECRET = "{sua API secret}"
ACCESS_KEY = "{seu Acess Token}"
ACCESS_SECRET = "{seu Acess Token Secret}"
consumer = oauth.Consumer(key=CONSUMER_KEY, secret=CONSUMER_SECRET)
access_token = oauth.Token(key=ACCESS_KEY, secret=ACCESS_SECRET)
client = oauth.Client(consumer, access_token)
q = 'israel' #termo a ser buscado
url = "https://api.twitter.com/1.1/search/tweets.json?q="+str(q)+"&count=100"+"&lang=pt"
response, data = client.request(URL, "GET")
tweets = json.loads(data)
for tweet in tweets['statuses']:
print str(tweet)
Figura 1.3. Exemplo usando a REST API.
No código apresentado na Figura 1.3, a variável “q” representa a consulta buscada
no Twitter. Neste caso, buscou-se pelo termo “israel”. A API retorna os 100 tweets mais
recentes que possuem esse termo, que foi passado como parâmetro na URL de requisição
através do parâmetro “count” igual a 100. Ainda sobre a consulta, a API retorna tweets
com todos os termos presentes na string “q” separados por espaços. Ou seja, se “q” possui
“israel guerra”, todos os tweets retornados possuirão as duas palavras. Exemplo: “Há
guerra em Israel” seria um possível texto do tweet retornado.
Utilizando a REST API, existem algumas restrições impostas pelo Twitter. Ao
que se sabe, o Twitter não permite que a API busque por tweets mais antigos do que 7
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
14

dias e ainda bloqueia a aplicação caso ultrapasse o número de requisições permitidas,
sendo necessário um intervalo de 15 minutos para que a aplicação seja desbloqueada.
Uma das APIs de consumo disponibilizadas pelo Facebook se chama Graph API. Existe
outra API chamada Public Feed API, porém esta possui acesso restrito a um conjunto de
editores de mídia e seu uso requer aprovação prévia do Facebook [Facebook 2014].
import httplib
app_id = "{sua app id}"
app_secret = "{seu app secret}"
client_credentials = "{label para de identificação do cliente}"
url =
"/oauth/access_token?client_id="+app_id+"&client_secret="+app_secret+"&grant_type=client_credentials"
conn = httplib.HTTPSConnection("graph.facebook.com")
conn.request("GET", str(url))
response = conn.getresponse()
print response.read() #access token
Figura 1.4. Exemplo usando a Graph API.
Primeiramente, para utilizar a Graph API é necessário criar uma aplicação. Essa
aplicação pode ser criada no site https://developers.facebook.com/ e será vinculada a uma
conta no Facebook. A segunda etapa consiste em gerar um access token para aquela
sessão. Um exemplo, utlizando Python 2.7, de como adquirir o access token pode ser
visto na Figura 1.4. Neste exemplo, utilizou-se a biblioteca httplib para executar a
requisição.
É importante destacar que algumas requisições necessitam de um app access
token e outros necessitam do user access token. Este último deve ser criado no próprio
site do Facebook através do endereço https://developers.facebook.com/tools
/accesstoken/.
Com o Graph API é possível buscar no Facebook por certos objetos que possuam
um determinado termo. Esses objetos podem ser usuário, páginas, eventos, grupos e
lugares. Porém, uma limitação da API é que não é possível procurar por posts públicos
onde um determinado termo aparece. Entretanto, a busca por páginas e lugares requer um
app access token, enquanto buscas pelos outros objetos utilizam o user access token.
A Figura 1.5 mostra a utilização do Graph API na busca por usuários com o termo
“Fabio”, codificado utilizando Python 2.7.
As requisições ao Facebook do tipo search retornam objetos no formato JSON.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
15

import httplib
user_access_token = "{seu user access token}"
q = "Fabio"
url_consulta = "/search?q="+str(q)+"&type=user&access_token="+str(user_access_token)
conn = httplib.HTTPSConnection("graph.facebook.com")
conn.request("GET", str(url_consulta))
response = conn.getresponse()
print response.read()
Figura 1.5. Segundo exemplo usando a Graph API.
Youtube
A API do Youtube atual é a versão 3.0. Nesta versão, é possível buscar por informações
de vídeos e canais com base nos seus ids. Entretanto, não é possível buscar por usuários
que comentaram em um determinado vídeo ou mesmo por comentários de um vídeo. Isso
pode ser uma grande limitação quando se pensa em análises utilizando o Youtube. Mesmo
assim, dado um id de um determinado vídeo e requisições feitas em determinados
intervalos de tempo, é possível conhecer a progressão de visualizações de um vídeo e
acompanhar sua divulgação em outra rede social, correlacionando esses dados e
estudando a interatividade entre as redes.
Para utilizar a API do youtube, é necessário a criação de uma aplicação na Google, no
site https://console.developers.google.com/. Após a criação, é necessário a ativação da
API do Youtube v3.0. Para a consulta de dados de vídeos ou vídeos de um determinado
canal, utiliza-se o protocolo HTTPS. Uma uri exemplo para uma consulta é:
https://www.googleapis.com/youtube/v3/videos?part=statistics&id=ZKugnwXU5_s&ke
y={Key da sua aplicação}.
Nesse caso, serão retornadas as estatísticas do vídeo cujo id foi passado como
parâmetro, no formato JSON. Mais informações e exemplos de requisições estão
disponíveis em https://developers.google.com/youtube/v3/docs/.
Foursquare
O Foursquare pode ser definido como uma rede geossocial, onde seus usuários podem
indicar onde se encontram ou procurar por outros usuários que estejam próximos
geograficamente. A API de consumo do Foursquare permite buscas por uma determinada
latitude e longitude a fim de retornar locais de interesse público daquela região. No
retorno das requisições é possível verificar a quantidade de check-in desses locais, além
da quantidade de pessoas que recentemente efetuaram um check-in naquele local. Além
desta busca, a API permite outra busca por tips (dicas), que tem como retorno dicas dos
usuários sobre locais em uma determinada região. A API pode ser acessada no site
https://developer.foursquare.com e o usuário precisa criar uma aplicação no site para
começar a utilizar. Um exemplo de requisição da API do Foursquare, codificada em
Python 2.7, pode ser visto na Figura 1.6.
Dentre os parâmetros da requisição HTTP, “v” é um apenas um controle de versão,
onde o desenvolvedor da aplicação pode informar ao foursquare se está utilizando uma versão
anterior da API. No caso, este parâmetro recebe uma data no formato YYYYMMDD.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
16

import urllib2
client_id = "{seu client id}"
client_secret = "{seu client secret}"
par_v = "20141107"
location = "40.7,-74"
query = "sushi"
response = urllib2.urlopen("https://api.foursquare.com/v2/tips/search"+
"?client_id="+client_id+
"&client_secret="+client_secret+
"&v="+par_v+
"&ll="+location+
"&query="+query)
html = response.read()
print str(html)
Figura 1.6. Exemplo usando a API do Foursquare.
1.2.3 Princípios de Análises de Redes Sociais
Após a leitura, desambiguação13 dos nós e montagem do sociograma (grafo de
relacionamentos), chegou a hora de analisarmos a rede social.
Em um sociograma, podemos representar os relacionamentos como arestas, as
quais podem ser direcionadas (João envia um e-mail para Maria) ou não (João e Maria
participaram de uma reunião). Nesta seção, apresentamos apenas métricas de grafos não
direcionados. Vale lembrar que para todas as métricas apresentadas neste capítulo existem
suas respectivas versões para grafos direcionados. Maiores detalhes sobre tais métricas
podem ser encontradas em [Newman 2010]. Casos e exemplos de uso podem ser obtidos
em [Easley e Kleinberg 2010].
1.2.3.1 Principais Métricas de Análise de Redes Sociais
A seguir, resumidamente foram descritas algumas métricas divididas naquelas que são
referentes aos nós de modo individual e aquelas que medem o comportamento da rede
como um todo.
13 Quando estamos lidando com mídias sociais, normalmente temos diferentes usuários associados à uma única entidade. Por exemplo, imagine o João da Silva (entidade) que possui várias contas. No Twitter pode ser reconhecido como JS_RJ. No Facebook ele possui duas contas, uma de caráter profissional (Prof. João da Silva) e outra pessoal (João Carioca). O processo de desambiguação dos nós significa identificar as diferentes contas de uma mesma entidade e associá-las. Neste exemplo, identificaríamos que “JS_RJ”, “Prof. João da Silva” e “João Carioca” são diferentes contas de uma mesma pessoa.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
17

Métricas Individuais
A importância de um vértice pode ser identificada através do cálculo de centralidade.
Uma destas centralidades é o grau do vértice (também conhecida como grau de
centralidade ou ainda centralidade local por Wasserman e Faust (1994)), ou seja, o
número de arestas conectadas diretamente a ele. A centralidade global de um vértice,
também conhecida como closeness ou grau de proximidade é a soma do menor caminho
entre um vértice e os demais vértices da rede. Um vértice que tenha a menor soma das
menores distâncias está mais perto dos demais. Ou seja, quanto maior a centralidade
global, maior será a distância de um membro para com os demais. Isto significa que o
trajeto de um dado, informação ou conhecimento para chegar a um destes membros
isolados é maior, e consequentemente, pode demorar mais, como também podem chegar
deturpados e com ruído.
Outra medida de centralidade muito utilizada é o betweenness ou grau de
intermediação, que está relacionado ao número de caminhos mínimos aos quais um
vértice pertence. O grau de intermediação revela o quanto um vértice está no caminho
entre os outros vértices numa rede. Quanto maior for o valor deste grau, significa que este
vértice é uma “passagem obrigatória”, muitas vezes conectando diferentes grupos.
Seja xi a quantidade de todos os caminhos mínimos entre s e t (caso exista mais de
um) cujo vértice i está incluído, então, sendo nsti um destes caminhos mínimos entre os
vértices s e t, nsti =1, se o vértice i pertence a este caminho mínimo e nst
i =0 caso contrário
[5], como está representado na equação (3.2):
st
i
sti n=x
Seja gst o número total de caminhos mínimos entre s e t, então o grau de
intermediação do vértice i será Xi calculado através da equação (3.3):
st
ii
g
x=X
Outra métrica, conhecida como coeficiente de agrupamento, pode informar para
cada vértice e para a rede como um todo, como uma rede se apresenta em termos de
grupos. Desta análise vem a definição de coeficiente de agrupamento: a probabilidade de
que dois vizinhos de um vértice serão vizinhos entre si. Para calcular o coeficiente de
agrupamento Ci, são contados todos os pares de vértice que são vizinhos de i e sejam
conectados entre si, então, divide-se este valor pelo número total de vizinhos de i, ou ki,
que é o grau de i:
hoDeiresdeVizinNúmerodePa
osãoConectadhosDeiQueSresDeVizinNúmeroDePa=Ci
Outras centralidades igualmente importantes são o PageRank e o cálculo de Hubs,
que podem ser encontrados em [Newman 2010].
Métricas da Rede
Watts e Strogatz (1998) propuseram o cálculo do coeficiente de agrupamento médio, Cm,
para a rede através da média do coeficiente de agrupamento local para cada vértice. Ou
seja, Cm é o somatório dos coeficientes de agrupamento de cada vértice do grafo,
normalizado pelo número total de vértices.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
18

n
im Cn=C1
/1
Outra medida é o diâmetro da rede, que é a distância máxima entre dois vértices, é
o maior caminho mínimo (geodésico) entre dois vértices da rede, simbolizando o nível de
ligação entre os vértices da rede. Newman (2010) define a densidade de uma rede
utilizando o grau médio da rede em questão. Primeiramente calculando o valor de M, o
número máximo possível de arestas numa rede de n vértices.
1n2
1
2
n=
nM
Sendo G o grau médio já calculado para esta rede com m arestas, a densidade é
obtida fazendo-se:
11
2m
2
n
G=
nn=
n
m=ρ
Se a densidade de uma rede varia no intervalo [0,1], quanto mais próximo de zero,
menos conectada é a rede. O contrário é válido, quanto mais próximo de um, a rede é
mais densa. A vantagem do uso desta medida está na simplicidade de seu cálculo, no
entanto, para redes com extenso número de nós, torna-se custoso realizar tal cálculo.
1.2.3.2 Principais Ferramentas
Existem diversas ferramentas (muitas delas gratuitas!) que automatizam a análise, possuindo
as principais métricas implementadas e ferramentas de visualização e extração de relatórios.
Várias delas lêem e exportam para diferentes formatos. Em [Huisman e Van Duijn 2005]
vocês têm uma análise comparativa destas principais ferramentas. Os autores mantêm o site
http://www.gmw.rug.nl/~huisman/sna/software.html atualizado com novos programas
destinados à análise de redes sociais.
Neste curso a ferramenta Gephi14 será utilizada. Essa ferramenta se apresentou como
uma boa opção quando se analisa redes não muito grandes.
1.2.4 Princípios de Mineração de Informação
Mineração de dados é o processo de explorar dados à procura de padrões consistentes. Na
análise de redes sociais, esses padrões descrevem como os indivíduos interagem ou as
características (regras) que dão origem às redes sociais. Identificar fatores e as tendências-
chave dos dados que a rede produz também são aplicações possíveis de mineração de
dados em redes sociais.
Grafos representam estruturas de dados genéricas que descrevem componentes e
suas interações, sendo assim são adotados para representar as redes sociais. Como
consequência, os métodos de mineração de dados apresentados a seguir terão como foco
a mineração em grafos. Segundo a taxonomia apresentada por Getoor e Diehl [Getoor e
Diehl 2005], a mineração para grafos pode ser dividia em três grandes grupos: mineração
orientados a objetos; mineração orientada a links; e mineração orientada a grafos. Os
grupos e os métodos de cada grupo são: (i) Tarefas relacionadas a objetos; (ii) Tarefas
14 https://gephi.github.io/
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
19

relacionadas a ligações e (iii) Tarefas relacionadas a grafos. Por sua vez Tarefas
relacionadas a objetos se dividem em: (i) Ranking baseado em ligação de objetos (RBLO);
(ii) Classificação baseada em ligação de objeto (CBLO); (iii) Agrupamento de objetos e
(iv) Identificação de objetos. As tarefas relacionadas a ligações resumem-se à predição
de ligações. Por fim, as tarefas relacionadas a grafos se dividem em: (i) Descoberta de
subgrafos e (ii) Classificação de grafos. Nas próximas subseções será feito o
detalhamento de cada método. Essa taxonomia de tarefas de mineração em grafos foi
retirada de [Getoor e Diehl 2005].
1.2.4.1 Ranking baseado em link de objetos
Uma das tarefas mais comuns na mineração de dados em grafos, o ranking baseado em
link de objetos explora a estrutura dos links de um grafo para ordenar e priorizar o
conjunto de vértices. Dentre os métodos para RBLO, os algoritmos HITS [Kleinberg
1999] e PageRank [Ranking e Order 1998] são os mais conhecidos.
O PageRank funciona contando o número de ligações entre os vértices de um
grafo orientado para estimar a importância desse vértice. Ligações de vértices importantes
(onde a importância é definida pelo valor de PageRank desse vértice) para um vértice,
fazem com que esse último melhore seu ranking. As ligações que um vértice faz com
outros, ponderado pela importância desse vértice, faz com que o primeiro diminua sua
importância. O balanço entre quais vértices apontam e são apontados determinam o grau
de importância de um nó.
O algoritmo HITS é um processo mais complexo se comparado com o PageRank,
modelando o grafo com dois tipos de vértices: hubs e entidades. Hubs são vértices que
ligam muitas entidades e por consequência, entidades são ligadas por hubs. Cada vértice
do grafo nesse método recebe um grau de hub e de entidade. Esses valores são calculados
por um processo iterativo que atualiza os valores de hub e entidade de cada vértice do
grafo baseado na ligação entre os vértices. O algoritmo de HITS tem relação com o
algoritmo de PageRank com dois loops separados: um para os hubs e outro para as
entidades, correspondendo a um grafo bi-partido.
1.2.4.2 Classificação baseada em ligação de objetos
A classificação baseada em ligação de objetos (CBLO) tem como função rotular um
conjunto de vértices baseado nas suas características, diferindo dessa forma das técnicas
de classificação tradicionais de mineração de dados por trabalhar com estruturas não
homogêneas. Apesar da sua importância, é uma área de mineração não consolidada,
apresentando como desafio o desenvolvimento de algoritmos para classificação coletiva
que explorem as correlações de objetos associados [Getoor e Diehl 2005].
Dentre as propostas da CBLO, destacam-se os trabalhos de Lafferty et al (2001),
que é uma extensão do modelos de máxima entropia em casos restritos onde os grafos
são cadeias de dados. Taskar et al. (2002) estenderam o modelo Lafferty et al (2001) para
o caso em que os dados formam um grafo arbitrário. Lu e Getoor (2003) estenderam um
classificador simples, introduzindo novas características que medem a distribuição de
classes de rótulos em uma cadeia de Markov.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
20

1.2.4.3 Agrupamento de objetos
O objetivo do Agrupamento de Objetos é o agrupamento de vértices de um grafo por
meio de características comuns. Várias técnicas foram apresentadas em várias
comunidades para essa finalidade. Entretanto, o desenvolvimento de métodos escaláveis
adequados para exploração de grafos complexos em tempo hábil ainda é um desafio.
Para grafos com arestas e vértices de um único tipo e sem atributos, pode-se
utilizar técnicas de agrupamento aglomerativo ou divisivos. A tarefa de agrupamento
envolve o particionamento de redes sociais em conjuntos de indivíduos que possuam um
conjunto similar de links entre si. Uma medida de similaridade entre o conjunto de arestas
e o agrupamento aglomerativo é definida e usada para identificar as posições. Métodos
de separação espectral do grafo resolvem o problema de detecção de grupo, identificando
um conjunto mínimo aproximado de arestas que devem ser removidas do grafo para
atingir um determinado número de grupos.
Outras abordagens para detecção de grupo fazem uso das medidas de betweenness
dos vértices. Um exemplo é o método Girva-Newman (2002), o qual detecta uma
comunidade removendo progressivamente arestas do grafo original. Esses autores
consideram que se dois vértices possuem uma aresta ligando-os e se esses nós apresentam
um valor de betweenness alto, provavelmente a aresta que os liga é uma ponte. Se a ponte
for removida, os agrupamentos tornam-se visíveis.
1.2.4.4 Identificação de Entidades
Denominada também de resolução de objetos, a identificação de entidades tem como
objetivo determinar quais dados que fazem referência a entidades do mundo real.
Tradicionalmente, a resolução de entidades é vista como um problema de semelhança
entre atributos de objetos. Recentemente, houve significante interesse em usar links para
aperfeiçoar a resolução de entidades com o uso de ligações entre vértices [Getoor e Diehl
2005].
A ideia central é considerar, em adição aos atributos dos vértices de um grafo que
representa uma rede social, os atributos dos outros vértices que estão ligados com ele.
Essas ligações podem ser, por exemplo, coautorias em uma publicação científica, onde
os atributos dos indivíduos (nome, área de pesquisa) seriam utilizados em conjunto com
os atributos dos coautores que trabalham com ele [Alonso et al. 2013].
1.2.4.5 Predição de Ligações
A predição de links trata do problema de predizer a existência de ligações entre dois
vértices baseado em seus atributos e nos vértices existentes. Exemplos incluem predizer
ligações entre atores de uma rede social, como amizade, participação dos atores em
eventos, o envio de email entre atores, chamadas de telefone, etc. Na maior parte dos
casos, são observados alguns links para tentar predizer os links não observados ou se
existe algum aspecto temporal.
O problema pode ser visto como uma simples classificação binária: dado dois
vértices v1 e v2, preveja quando um vértice entre v1 e v2 será 1 ou 0. Uma abordagem é
fazer a predição ser inteiramente baseada em propriedades estruturais da rede. Liben-
Nowell e Kleinberg (2007) apresentaram um survey sobre predição de links baseado em
diferentes medidas de proximidade. Outra abordagem fazendo uso de informações dos
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
21

atributos é a de Popescul et al (2003), que propõe um modelo de regressão logística
estrutural que faz uso das relações para predizer a existência de novas ligações.
O’Madadhain et al (2005) propõe a construção de um modelo local de probabilidades
condicionais, baseado nos atributos e na estrutura. A respeito de predição de ligações,
podemos ainda referenciar o minicurso de Appel e Hruschka (2011), ministrado no
próprio SBBD.
1.2.4.6 Descoberta de subgrafos
A determinação de subgrafoss frequentes é um importante instrumento para a análise de
redes sociais, pois permite caracterizar e discretizar conjuntos de grafos, criar
mecanismos de classificação e agrupamento, criar índices de busca, etc. Por exemplo, em
um conjunto de grafos que representam uma rede colaborativa de coautoria em trabalhos
científicos, os subgrafos frequentes podem identificar os grupos de pesquisas ou grupos
de um mesmo laboratório.
Um grafo g’ é definido como subgrafo de um grafo g se existir um padrão
isomórfico entre g’ e g, ou seja, o conjunto de vértices e arestas de g’ são subconjuntos
dos conjuntos de vértices e arestas de g respectivamente. Dentre os métodos de mineração
de subgrafoss frequentes, duas abordagens são as mais empregadas: a abordagem baseada
no método apriori e a abordagem baseada em padrões de crescimento. Ambas possuem
em comum buscar estrutura frequentes nas bases de grafos. A frequência mínima que um
subgrafo deve ocorrer na base D para que seja considerado frequente recebe o nome de
suporte.
A busca por grafos frequentes, utilizando o método apriori, começa por subgrafos
de menor “tamanho” e procede de modo bottom-up gerando candidatos que possuam um
vértice, aresta ou caminho extra que possuam um valor de suporte maior do que um valor
pré-definido (min_sup). Para determinar se um grafo de tamanho k+1 é frequente, é
necessário checar todos os subgrafos correspondentes de tamanho k para obter o limite
superior de frequência (busca em largura).
A abordagem baseada em padrões de crescimento é mais flexível se comparada
com as abordagens baseadas no método apriori, pois é possível tanto fazer buscas em
largura quanto busca em profundidade. Essa abordagem permite um menor consumo de
memória, de acordo com o método de busca empregado, pois não é preciso gerar todo o
conjunto de grafos candidatos de mesmo tamanho antes de expandir um grafo. Entretanto,
a abordagem apresenta como limitação ser menos eficiente já que um mesmo grafo pode
ser gerado mais de uma vez durante o processo de busca. O método inicia com um
conjunto de subgrafos iniciais que são expandidos por meio da adição de arestas válidas.
Grafos frequentes, com suporte igual ou maior que um valor pré-definido, são
selecionados para dar origem à próxima geração de grafos frequentes. A busca continua
até que seja gerado um grafo com suporte inferior ao mínimo definido, o último grafo
gerado é armazenado para ser apresentado no conjunto de respostas. A busca prossegue
com os outros candidatos.
1.2.4.7 Classificação de Grafos
Classificação de grafos é um processo supervisionado de aprendizagem. O objetivo é
caracterizar um grafo como todo como uma instância de um conceito. A classificação de
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
22

grafos não exige inferência coletiva - como é necessário para classificar vértices e arestas
- devido ao grafo ser geralmente gerado de forma independentemente.
Existem basicamente três abordagens que foram exploradas pelas comunidades
de mineração de dados: Programação de Lógica Indutiva (PLI); Mineração de
Características (MC); e definição de Kernel do Grafo (DK). A MC está relacionada com
as técnicas de descoberta de grafo. A MC é usualmente feita encontrando as subestruturas
informativas do grafo. Essas subestruturas são usadas para transformar os dados do grafo
em uma tabela de dados e então aplicar classificadores tradicionais. A PLI usa relações
como vértice (grafo_id, vértice_id, vértice_label, vértice_atributos) e aresta (grafo_id,
vértice_id_1,vértice_id_3,aresta_label) para então aplicar em um sistema de PLI para
encontrar um hipótese no espaço.
Encontrar todas as subestruturas frequentes em um grafo pode ser um processo
computacionalmente proibitivo. Uma abordagem alternativa faz uso dos métodos de
kernel. Gartner [2002] e Kashima e Inokuchi [2002] proporam métodos baseado em
medidas de caminhos no grafo para obter o kernel. Gartner [2002] conta caminhos com
rótulos iguais no inicio e no fim, enquanto Kashima e Inokuchi [2002] faz uso da
probabilidade de caminhar aleatoriamente em uma sequência de rótulos identicos.
1.3 Redes Sociais Online e Big Data: Métodos de Tratamento de Grande
Volume de Dados
Redes Sociais Online (RSOs) como Facebook, YouTube e Twitter estão conectando
pessoas que estão produzindo exabytes de dados em suas interações [Tan et al. 2013]. O
volume, a velocidade de geração e processamento dos dados de diferentes fontes criam
grandes desafios isolados ou combinados a serem superados, tais como: armazenamento,
processamento, visualização e, principalmente análise dos dados.
A quantidade de dados produzidas na rede aumenta a cada dia e novas unidades
de medida surgem para tão grande volume de dados. Para ilustrar este fato, previu-se que
o valor chegue próximo a uma dezena de zettabytes em 2015 [Oliveira et al. 2013].
Tamanho crescimento faz com que muitas das soluções existentes para manipulação de
dados (armazenamento, visualização e transmissão) não sejam úteis nesse cenário.
Somadas as RSOs, outras fontes de dados também contribuem para o aumento do volume
de dados: sensores, medidores elétricos inteligentes, dados convencionais de aplicações
da Internet, dentre outros.
O grande volume de dados heterogêneos produzidos por diferentes fontes
autônomas, distribuídas e descentralizadas que geram rapidamente dados com relações
complexas e em evolução é chamado Big Data [Silva et al. 2013]. O termo Big Data é
frequentemente associado a 3Vs: i) Volume, relacionado a um grande conjunto de dados;
ii) Velocidade, relacionado a necessidade de processo rápido dos dados; e iii) Variedade
por provir de fontes diversas de dados [Kwon 2013 apud Oliveira 2013].
A grande quantidade de usuários das RSOs tem atraído a atenção de analistas e
pesquisadores que desejam extrair ou inferir informações, podendo estar relacionadas a
diversas áreas como predição de comportamento, marketing, comércio eletrônico, entre
outras interações [Tan et al. 2013]. As análises devem ser eficientes, realizadas quase em
tempo real e capazes de lidar com grafos com milhões de nós e arestas. Além disso,
existem outros problemas, como falhas e redundâncias.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
23

Esta seção aborda algumas das principais questões relacionadas ao tratamento de
grandes massas de dados produzidas nas RSOs mais utilizadas no Brasil e no mundo. São
apresentadas discussões sobre termos relacionados à Big Data, tecnologias utilizadas e
características particulares das RSOs.
1.3.1 Armazenamento e Gerência de Grandes Volumes de Dados de RSO
Quando se fala da gerência dos dados, o volume varia de acordo com a capacidade das
ferramentas utilizadas em cada área de aplicação. Por exemplo, as informações de um
grafo com milhões de nós e bilhões de arestas podem ser armazenadas em um arquivo de
alguns gigabytes. O tamanho desse arquivo pode não ser grande do ponto de vista de
armazenamento, porém o processamento desse grafo (a aplicação de técnicas de análises)
pode exceder a capacidade das ferramentas utilizada com tal finalidade. Percebe-se que,
apesar do tamanho ser a parte mais evidente do problema, a definição de Big Data deve
observar outras características, as quais podem não estar diretamente associados ao
tamanho absoluto dos dados [Costa et al. 2012].
Além de observar a capacidade das ferramentas utilizadas, segundo [Costa et al.
2012] há outros pontos a serem observados no cenário de Big Data, tais como: a
velocidade de geração e de processamento dos dados, além da quantidade de fontes de
geração desses dados. Sob este ponto de vista, pode-se citar como exemplo o Twitter com
milhões de usuários ao redor do mundo. O Twitter recebe mensagens enviadas em uma
frequência muito alta. Apesar de uma mensagem individual ser pequena, a quantidade de
mensagens enviadas por diferentes usuários (fontes) gera um grande volume de dados.
Cada dado precisa ser armazenado, disponibilizado e publicado para outros usuários dessa
mídia. Ou seja, o dado precisa ser armazenado, processado, relacionado a outras
informações (que usuários seguem?, quem publicou o dado?) e transmitido. O mesmo
pode ser observado em outras RSOs como Facebook ou YouTube.
Outro aspecto a ser observado é a estrutura (ou a sua ausência) dos dados das
RSOs, os quais possuem formatos diferentes. O Twitter armazena mensagens textuais
pequenas (de 140 caracteres, no máximo), além de outras informações como identificação
da mensagem, data da postagem, armazena uma cópia das hashtags em um campo
específico, posição geográfica do usuário ao enviar a mensagem (quando disponível),
entre outros. A própria mídia trata com dados heterogêneos. O Facebook por, outro lado,
armazena mensagens textuais, imagens, etc. O YouTube, além dos vídeos, mantém os
comentários dos usuários relacionados ao conteúdo de multimídia. Além, dessas
informações, essas mídias armazenam dados sobre os usuários, sobre suas interações na
rede (seus amigos, curtidas, favoritismo, comentários, citações, dentre outros) e páginas
ou canais mais acessados (no caso do Facebook e YouTube, respectivamente). Do ponto
de vista da estrutura, percebe-se que as informações dessas redes podem ser armazenadas,
parcialmente, em estruturas/formatos e tipos pré-definidos, enquanto outra parte não tem
um tipo pré-estabelecido (não são estruturados). Do ponto de vista do relacionamento de
dados de diferentes fontes, observa-se que as dificuldades são aumentadas. Um exemplo
seria identificar, relacionar e analisar conteúdo dos perfis dos usuários do Twitter e do
Facebook.
A observação sobre o conteúdo de mídias sociais permite que se perceba que os
dados gerados são diversificados, estão relacionados (ex: um vídeo no YouTube está
relacionado aos comentários, curtidas, etc.) e fazem parte de um repositório comum de
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
24

cada mídia. Ou seja, o YouTube possui a sua base, o Twitter a sua e assim por diante.
Antes da correlação dos dados, é necessário extrair os dados das fontes heterogêneas,
cada uma com suas particularidades.
Três exemplos de RSOs cujos dados são utilizados em muitos estudos são o
Facebook, o YouTube e o Twitter. Segundo o serviço Alexa15, no ranking dos sites mais
acessados no mundo, essas três mídias estão entre as 10 mais: O Facebook é o segundo
site mais acessado no mundo atualmente, o YouTube é o terceiro e o Twitter ocupa o
sétimo lugar. No Brasil, o Facebook é o segundo mais acessado, o YouTube o quarto e o
Twitter o décimo segundo, segundo o ranking do Alexa Brasil16. Além dessas mídias
digitais, existem outras redes bastante utilizadas no Brasil como LinkedIn17, Google+18 e
o Foursquare19.
Os dados das RSOs são abundantes. Para se ter uma ideia, o Facebook é acessado
por mais 1 bilhão de usuários a cada mês [Zuckerberg 2012; Facebook Data Center 2013]
e registrou uma média de 829 milhões de usuários ativos por dia no mês de junho de 2014
(624 milhões em dispositivos móveis), chegando a passar de 1,32 bilhões no dia 30 de
junho [Facebook NewsRoom 2014]. A média de likes (curtidas) registrada por dia passa
de 2,7 bilhões e quantidade total de itens (texto ou conteúdo multimídia como fotos e
vídeos) compartilhados entre amigos é superior a 2,4 bilhões. Em 2011, o espaço ocupado
pelas fotos compartilhadas no Facebook já ultrapassava 1,5 petabyte de espaço, sendo
mais de 60 bilhões de fotos. Em 2013, o Instagram (aplicativo de compartilhamento de
fotos e vídeos curtos, pertencente ao Facebook) registrou uma média de 100 milhões de
usuários por mês. Diferentes tipos de relacionamentos acontecem entre os usuários do
Facebook formando redes. Por exemplo, rede amizades, citações em mensagens ou
marcações em imagens [Facebook NewsRoom 2014].
Outro exemplo que pode ser citado é o YouTube, o qual possui uma taxa de
upload de vídeo superior a 100 horas de vídeo por minuto, sendo acessado por milhões
de usuários mensalmente [ComScore 2014; YouTube Statistics 2014]. O conteúdo de 60
dias do YouTube equivale a 60 de vídeos televisionado pela emissoras norte-americanas
NBC, CBS e ABS juntas [Benevenuto et al. 2011]. Dados mais recentes sobre essa mídia
informam que mais de 1 bilhão de usuários visitam o YouTube mensalmente, e mais de
6 bilhões de horas de vídeo são assistidas a cada mês. A identificação de mais de 400 anos
de vídeo são verificados diariamente devido as buscas por conteúdo e milhões de novas
assinaturas feitas todos os meses [YouTube Statistics 2014].
O Twitter, por sua vez, possui mais de 600 milhões de usuários, recebe mais de
500 milhões de mensagens por dia e tem uma média de 271 milhões de usuários ativos
por mês. Em julho, o total de atividades registradas era de 646 milhões e 2,1 bilhões de
consultas foram realizadas em média. No Twitter, as redes podem ser formadas
observando quem segue quem, quem mencionou quem ou quem fez um retweet
(republicou a mensagem de) quem [Twitter Statistics 2014; About Twitter 2014].
As grandes empresas como Facebook, Google (proprietária do YouTube) e
Twitter possuem centros de dados espalhados pelo mundo. Alguns desses centros de
15 http://www.alexa.com/topsites 16 http://www.alexa.com/topsites/countries/BR 17 https://linkedin.com/ 18 https://plus.google.com 19 https://foursquare.com/
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
25

dados ocupam grandes áreas e custam milhões para serem implantados e mantidos. Por
exemplo, o centro de dados do Facebook em Iowa (o quarto da empresa) foi construído
após o centro de dados da empresa na Carolina do Norte nos Estados Unidos, o qual
custou aproximadamente 450 milhões [Online Tech 2011]. Empresas como as
mencionadas acima possuem políticas próprias de gerência dos dados e definem as
tecnologias a serem utilizadas. Além disso, elas também impõem uma série de restrições
para acesso aos dados da sua base. Por esse motivo, os interessados em realizar análises
precisam coletar (geralmente em períodos próximos à publicação), armazenar e gerenciar
os dados do seu interesse [Costa et al. 2013]. Um exemplo são os dados publicados pelo
Facebook sobre as publicações relacionadas à Copa do Mundo de Futebol de 2014.
Segundo dados do próprio Facebook, mais de 1 bilhão de interações (publicações,
comentários e curtidas) ocorreram durante este evento [Facebook World Cup 2014].
Aqueles que conseguiram coletar dados sobre esse evento nessa mídia precisam
armazenar e gerenciar esses dados (um desafio à parte).
Costa et al. (2012) apresentam uma discussão sobre o ciclo de vida dos dados por
meio da comparação com o ciclo de vida biológico. Os autores observaram as seguintes
fases: geração (nascimento), agregação (crescimento com a agregação de valores ao
dado), análise (reprodução, quando a combinação de novos dados traz significado sobre
os dados iniciais) e apagamento (morte). O apagamento pode não ser uma tarefa tão
simples, pois não é simples definir quando um conjunto de dados não possui mais valor
para ser analisado. Esse valor pode ser finalizado em um contexto, mas sob outros pontos
de vista os dados podem possuir valor em novas análises. Por esse motivo, definir quanto
tempo os dados devem permanecer armazenados (ou pelo menos parte dele) não é trivial,
um dado pode ficar armazenado mais do que o seu valor consumindo recursos valiosos.
Porém, descartar um dado valioso por causa das restrições de infraestrutura pode ser
lamentável. Finalmente, não é possível definir valores fixos (prazos ou períodos exatos)
de validade dos dados. Cabe aquele que gerencia o dado tomar a decisão de descartá-lo
ou não. É um consenso que sempre que possível os dados devem ser mantidos (ou seja, a
sua remoção deve ser evitada).
Somadas aos desafios de armazenar esses volumes de dados, também existe o
desafio de recuperar e analisar os dados dessas mídias digitais. Os problemas relacionados
ao armazenamento, recuperação e análise são agravados por novas variações dos dados
decorrente das alterações nas mídias digitais ocasionadas por novas tendências, pelo
surgimento de novas mídias digitais com características novas e por comportamentos
diferentes por parte dos usuários. Vale ressaltar que outras características desses dados
são: redundâncias, inconsistências, dados com algum tipo de falha, etc. Todavia, apesar
de todas essas dificuldades, as grandes massas de dados impulsionam a necessidade de
extrair sentido dos mesmos. Correlacioná-los para compreendê-los apesar das constantes
alterações dos dados podem trazer a tona informações preciosas, podendo se tornar
essencial no futuro.
Observamos que as tecnologias de bancos de dados utilizados nas RSOs devem
ser capazes de atender os requisitos de armazenamento e processamento de Big Data,
como alta velocidade e a capacidade de lidar com dados não relacionais, executando
consultas em paralelo [Oliveira et al. 2013a]. Pesquisadores ou qualquer interessado em
analisar esses dados também precisam de tecnologias adequadas. Do ponto de vista do
armazenamento, os Sistemas de Gerenciamento de Banco de Dados (SGBDs)
convencionais disponíveis comercialmente não são capazes de lidar com volumes de
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
26

dados na ordem de petabytes [Madden 2012]. Ao observar a velocidade e variedade os
sistemas de banco de dados também podem não ter um bom desempenho, sobretudo
quando são feitas recuperações textuais, de imagens ou vídeos. A análise de grandes
volumes de dados requer SGBDs especializados capazes de processar dados estruturados
e não estruturados distribuindo dados a fim de escalar grandes tamanhos [Begoli 2012
apud Oliveira et al. 2013a]. Dados como grafos, documentos hierárquicos e dados geo-
espaciais são dados úteis para diversos tipos de análise no contexto das RSOs, mas não
podem ser modelados em bancos de dados relacionais. Para esses dados existem
ferramentas especializadas como: PostGIS 20e GeoTools21 para dados geo-espaciais;
HBase22 ou Cassandra23 para organização hierárquica de dados no formato chave-valor;
e um exemplo de ferramenta para analisar grafos é o Neo4j24.
Porém, mesmos essas tecnologias ainda não são suficientes para suprir todos os
desafios citados até aqui. Faz-se necessário explorar devidamente e de forma plena as
informações disponíveis nas RSOs. Várias tecnologias estão sendo desenvolvidas e
adaptadas para manipular, analisar e visualizar Big Data. As seções 1.3.2 e 1.3.3
apresentam uma discussão sobre técnicas e tecnologias apropriadas para se trabalhar com
grandes volumes de dados.
Neste trabalho, abordaremos em maiores detalhes o Hadoop (uma implementação
do MapReduce) no domínio do armazenamento e análise de dados. O Hadoop permite
que aplicações escaláveis sejam desenvolvidas provendo um meio de processar os dados
de forma distribuída e paralela [White 2012; Shim 2012 apud Oliveira et al. 2013a].
1.3.2 Tratamento de Grande Volume de Dados: Quando Processar se
Torna Difícil?
Uma série de desafios vem à tona quando o volume de dados excede os tamanhos
convencionais, quando esses dados são variados (diferentes fontes, formatos e estruturas)
e são recebidos em uma velocidade maior do que a capacidade de processamento. Por
exemplo, ao extrair uma rede de retweets do Twitter e formar uma rede a partir desses
retweets de um grande volume de dados, pode-se obter um grafo que excede a capacidade
de tratamento em ferramentas convencionais de análise de redes sociais (como Gephi, por
exemplo). Ou quando se deseja realizar processamento de linguagem natural de um texto
muito grande a fim de realizar análises estatísticas do texto, o processamento e memória
necessários excede a capacidade de computadores pessoais convencionais. Ou seja, os
recursos de hardware (como a memória RAM, por exemplo) não comportam o volume
dos dados [Jacobs 2009].
Jacobs (2009) apresentou um exemplo de difícil tratamento de um grande volume
de dados usando um banco de dados relacional com 6,75 bilhões de linhas, com sistema
de banco de dados PostgreSQL25 em uma estação com 20 megabytes de memória RAM
e 2 terabytes de disco rígido. O autor apresentou que obteve vários problemas de falhas e
um alto tempo de processamento para as consultas realizadas.
20 http://postgis.net/ 21 http://www.geotools.org/ 22 http://hbase.apache.org/ 23 http://cassandra.apache.org/ 24 http://www.neo4j.org/ 25 http://www.postgresql.org/
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
27

A velocidade do processamento, armazenamento, leitura e transferência de dados
nos barramentos frequentemente fazem com que apenas extratos (amostras) dos dados
sejam analisados o que não permite que todos os detalhes daquele conjunto de dados
sejam observados [DiFranzo et al. 2013]. O desejo dos analistas é estudar as bases de
dados por completo, não apenas uma amostra, ou ao menos aumentar as amostras o
máximo possível. A necessidade de novas técnicas e ferramentas é reforçada pelo atual
interesse em se empregar técnicas de análises que excedam as técnicas tradicionais de
business intelligence. Extrair conhecimento a partir de grandes massas de dados é de fato
desafiador como discutido até aqui, pois além de serem heterogêneos em sua
representação, os dados das RSOs são de conteúdo multidisciplinar [Lieberman 2014].
As técnicas convencionais são utilizas em dados estruturados com formatos
padronizados. As soluções de Big Data tratam com dados brutos, heterogêneos com e
sem estrutura e sem padrão. Entender como tratar os desafios de Big Data é mais difícil
do que entender o que significa o termo e quando empregá-lo. Apesar dos bancos de dados
convencionais apresentam bons desempenhos no tratamento de dados estruturados e
semiestruturados, as análises no contexto de Big Data requerem um modelo iterativo (de
consultas recursivas) para análise de redes sociais e emprego de técnicas de clusterização
como K-Mean ou PageRank [Silva et al. 2013]. O desafio do processamento dos grandes
volumes de dados está relacionado a três aspectos: armazenamento dos dados na memória
principal, a grande quantidade de iterações sobre os dados e as frequentes falhas (diferente
dos bancos de dados convencionais onde as falhas são tratadas como exceções, no
contexto de Big Data, as falhas são regras) [Silva et al. 2013].
O processamento intensivo e iterativo dos dados excede a capacidade individual
de uma máquina convencional. Nesse contexto, clusters (arquiteturas de aglomeração)
computacionais possibilitam a distribuição das tarefas e processamento paralelo dos
dados. Em alguns cenários, não será possível processar e armazenar todos os dados. Nesse
caso, é possível utilizar técnicas de mineração de dados para manipular os dados,
sumarizando-os, extraindo conhecimento e fazendo predições sem intervenção humana,
visto que o volume dos dados, seus tipos e estruturas não permitem tal intervenção.
Muitas empresas têm apresentado requisitos de gerenciar e analisar grande
quantidade de dados com alto desempenho. Esses requisitos estão se tornando cada vez
mais comuns aos trabalhos de análise de redes sociais [DiFranzo et al. 2013]. Diferentes
soluções têm surgido como proposta para esses problemas. Dentre as propostas, destaca-
se o paradigma MapReduce implementado pelo Hadoop, o qual permite o processamento
distribuído de grandes conjuntos de dados em clusters de computadores [White 2012]. O
Hadoop é uma poderosa ferramenta para a construção de aplicações paralelas que fornece
uma abstração da aplicação do paradigma do MapReduce para processar dados
estruturados e não estruturados em larga escala, sendo essa sua grande vantagem [Silva
et al. 2013].
Muitos algoritmos de mineração de dados utilizados na descoberta automática de
modelos e padrões utilizam técnicas como classificação, associação, regressão e análise
de agrupamento podem ser paralelizados com MapReduce [Shim 2012 apud Oliveira et
al. 2013]. Segundo Silva et al. (2013), os projetos de mineração de dados no contexto de
Big Data precisam de três componentes principais. O primeiro é um cenário de aplicação
que permita que a demanda por descoberta de conhecimento seja identificada. O segundo
é um modelo que realize a análise desejada. O terceiro é uma implementação adequada
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
28

capaz de gerenciar um grande volume de dados. Além desses componentes fatores como
a complexidade do dado, o tamanho da massa de dados, a dificuldade de transporte dos
dados e a possibilidade de paralelização dos algoritmos empregados no processamento
devem ser observados.
O processamento do volume de dados variados em tempo hábil exige tecnologias
de software e hardware adequados. O Hadoop pode ser utilizado para distribuir e
paralelizar dados em diferentes estações de trabalhos comuns, aumentando a capacidade
de hardware por meio da clusterização de máquinas comuns. Devido a essas
características e as demais utilizadas, o Hadoop tem sido adotado em muitos trabalhos.
1.3.2.1 Capacidade de Processamento de Hardware vs Volume de Dados
Como apresentado, o volume de dados na Internet cresce vertiginosamente. Não
diferente, as RSOs acompanham esse crescimento à medida que novas mídias surgem e
novos usuários começam a participar de RSOs possuindo contas em diferentes redes. As
empresas que gerenciam as grandes RSOs possuem centros de dados gigantescos,
distribuídos e gerenciam os seus dados contando com equipes especializadas. O sucesso
dessas mídias permite que elas alcancem grandes ganhos financeiros, possibilitando-lhes
a manutenção dessa estrutura.
Empresas como a IBM, EMC, entre outras, são fornecedores de hardware e
tecnologias para tratar grandes volumes de dados. Apesar de tratarem com volumes de
dados na ordem de petabytes ou até exabytes, as grandes mídias sociais possuem
condições para adquirir, criar e manter tecnologias para armazenar e gerenciar essas
grandes massas de dados.
Os analistas que coletam dados nas RSOs para analisá-los, como discutido nas
seções anteriores, desejam armazenar, gerenciar e analisar esses dados. Todavia quando
o volume dos dados ultrapassa a medida de gigabytes e passa a ser medida em terabytes
ou dezenas de terabytes, muitos grupos já se veem na necessidade de excluir partes dos
dados ou armazenar parte dos seus dados em tecnologias de mais baixo custo que
normalmente tornam o acesso a esses dados mais difíceis. Sob o ponto de vista da análise,
outros fatores se somam ao volume, como o tipo de análise que é realizada: grafos com
milhões de nós e de centenas de milhões ou bilhões de áreas, processamento de linguagem
natural de textos diferentes que exigem grande quantidade de processamento, entre outros
exemplos. Nesses casos a dificuldade é saber qual (ou quais) plataforma(s) de hardware
se deve utilizar para lidar com grandes massas de dados, os quais superam a capacidade
de tratamento possibilitada pelos sistemas tradicionais.
Para serem mais abrangentes (analisar maiores amostras de dados), as análises de
redes sociais precisam tratar com amostras que podem ser consideradas Big Data sob a
ótica apresentada neste trabalho. Essas análises exigem mais capacidade de hardware do
que um computador pessoal comum pode oferecer. Por esse motivo, a capacidade do
hardware utilizado nas análises, assim como os softwares utilizados, é um aspecto que
não pode ser ignorado.
O simples uso de servidores convencionais, antes empregados para abrigarem
banco de dados relacionais, servidores Web, sistemas de intranet, entre outros, não são
adequados para as tarefas de tratamento de enormes quantidades de dados. Estes
servidores, ainda que possuam hardware superior aos computadores pessoais
convencionais, podem ainda não ter a capacidade de hardware suficiente para algumas
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
29

análises, não fornecendo um rendimento adequado. Aumentar a capacidade desses
servidores pode significar sua substituição. Quando adquirir equipamentos e softwares
específicos para tratar grandes massas dados não são viáveis para os analistas por causa
dos custos associados ou por causa da mão de obra para trabalhar com essas soluções,
possíveis opções são: usar infraestruturas de nuvens privadas ou por contratação de
provedores de serviços por meio do pagamento sob demanda de uso ou contratando
pacotes de serviços específicos. Outra opção é distribuir e paralelizar o processamento e
armazenamento dos dados que desejam manipular em cluster usando soluções como o
Hadoop. A verdade é que qualquer solução exige conhecimento e investimento, porém o
que deve ser considerado é o menor esforço e o menor custo de cada possível solução.
As soluções de nuvem exigem, no caso da nuvem privada, esforços por parte dos
analistas para criar e manter suas nuvens de dados, além de custos relacionados à compra
de ferramentas específicas (quando proprietárias) ou de hardware. Quando se contrata
um serviço de nuvem de terceiros, além dos custos para pagar esses serviços, existem
desafios relacionados à movimentação dos dados (download ou upload) quando, por
exemplo, é necessário manipular dados com ferramentas específicas não fornecidas pelo
provedor contratado. No caso de uma solução de cluster como o Hadoop, a infraestrutura
já existente pode ser aproveitada, fazendo com que a capacidade de hardware subutilizada
seja direcionada para o processamento e armazenamento de dados. Faz-se necessário
elaborar algoritmos adequados de MapReduce, tolerar ruídos e falhas existentes no
mundo real. O Hadoop o primeiro passo para a análise dos dados [Silva et al. 2013;
Oliveira et al. 2013 a].
1.3.2.2 Processamento Paralelo e Distribuído: Técnicas e Ferramentas
Essa seção visa apresentar algumas técnicas e ferramentas para o processamento
distribuído de dados de RSO. Entre elas podemos citar o uso de clusters, sensoriamento
participativo, computação em nuvem e técnicas de fusão de dados.
Entre as técnicas de processamento distribuído, o sensoriamento participativo
ganha destaque. Os telefones celulares, cada vez mais se tornando dispositivos multi-
sensores, acumulando grandes volumes de dados relacionados com a nossa vida diária.
Ao mesmo tempo, os telefones celulares também estão servindo como um importante
canal para gravar as atividades das pessoas em serviços de redes sociais na Internet. Estas
tendências, obviamente, aumentam o potencial de colaboração, mesclando dados de
sensores e dados sociais em uma nuvem móvel de computação de onde os aplicativos em
execução na nuvem são acessados a partir de thin clients móveis. Tal arquitetura oferece
poder de processamento praticamente ilimitado. Os dois tipos de dados populares, dados
sociais e de sensores, são de fato mutuamente compensatórios em vários tipos de
processamento e análise de dados. O Sensoriamento Participativo, por exemplo, permite
a coleta de dados pessoais via serviços de rede sociais (por exemplo, Twitter) sobre as
áreas onde os sensores físicos não estão disponíveis. Simultaneamente, os dados do sensor
são capazes de oferecer informações de contexto preciso, levando a análise eficaz dos
dados social. Obviamente, o potencial de combinar dados sociais e de sensores é alta. No
entanto, eles são normalmente processados separadamente em aplicações em nuvem
móvel e o potencial não tem sido investigado suficientemente. Um trabalho que explora
essa capacidade é o Citizen Sensing [Nagarjaran et al. 2011]. O estudo introduz o
paradigma da Citizen Sensing, ativada pelo sensor do celular e pelos seres humanos nos
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
30

computadores - os seres humanos agindo como cidadãos na Internet onipresente, que
atuam como sensores e compartilham suas observações e visão através de Web 2.0.
Outra técnica promissora é o uso de Sistemas de fusão de dados escaláveis. Muitos
trabalhos buscam o uso de técnicas de fusão de dados distribuídas para o processamento
de dados de RSOs. Os autores em [Lovett et al. 2010] apresentam métodos heurísticos e
probabilísticos para a fusão de dados que combinam calendário pessoal do usuário com
mensagens das RSOs, a fim de produzir uma interpretação em tempo real dos
acontecimentos do mundo real. O estudo mostra que o calendário pode ser
significativamente melhorado como um sensor e indexador de eventos do mundo real
através de fusão de dados.
Outra tendência é o uso da Nuvem (Cloud) que está começando a se expandir a
partir da aplicação das TIC (Tecnologias da Informação e Comunicação) aos processos
de negócios para a inovação, que se destina a aumentar as vendas e otimizar sistemas,
identificando informações valiosas através de análise de dados das RSO agregados em
nuvens. A inovação torna-se significativamente útil quando é aplicada diretamente no
cotidiano das pessoas, auxiliando os usuários a tomarem decisões (por exemplo, que
caminho tomar em um dia de engarrafamento [Lauand 2013; Sobral 2013]), e isso torna-
se gradualmente claro enquanto os grandes dados coletados são analisados de diversas
maneiras. Por essa razão, a análise dos dados deve ser repetida muitas vezes a partir de
diferentes perspectivas e é necessária alta velocidade e processamento de baixo custo em
todas as fases de desenvolvimento e operação. Os benefícios oferecidos pela nuvem,
como a disponibilidade temporária de grandes recursos de computação e de redução de
custos através da partilha de recursos têm o potencial de atender a essa necessidade.
Apesar dos clusters HPC tradicionais (High Performance Computing) serem mais
adequados para os cálculos de alta precisão, um cluster HPC orientado a lotes ordenados
oferece um potencial máximo de desempenho por aplicativos, mas limita a eficiência dos
recursos e flexibilidade do usuário. Uma nuvem HPC pode hospedar vários clusters HPC
virtuais, dando flexibilidade sem precedentes para o processamento de dados das RSO.
Neste contexto, existem três novos desafios. O primeiro é o das despesas gerais de
virtualização. A segunda é a complexidade administrativa para gerenciar os clusters
virtuais. O terceiro é o modelo de programação. Os modelos de programação HPC
existentes foram projetados para processadores paralelos homogêneos dedicados. A
nuvem de HPC é tipicamente heterogênea e compartilhada. Um exemplo de um cluster
HPC típico é o projeto Beowulf (2014).
1.3.3 Exemplo Prático: Analisando Dados de RSP Usando Processamento
Paralelo e Distribuído com Hadoop
Hadoop é uma plataforma de software escrita em Java para computação distribuída. Essa
plataforma é voltada para armazenar e processar grandes volumes de dados, tem como
base o processamento com MapReduce [Dean e Ghemawat 2004] e um sistema de
arquivos distribuído denominado Hadoop File System (HFS), baseado no GoogleFS
(GFS) [Ghemawat et al. 2003]. Para a análise de redes sociais, o Hadoop apresenta como
benefício: i) capacidade de armazenar grandes volumes de dados utilizando commodity
hardware (no contexto de TI, é um dispositivo ou componente que e relativamente barato
e disponível); ii) armazenar dados com formatos variados; iii) além de trazer um modelo
de alto nível para processar dados paralelamente.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
31

A arquitetura básica de um cluster Hadoop está apresentada na Figura 1.7. Nessa
figura, cada retângulo representa um computador em um cluster fictício. No primeiro
computador, da esquerda para direita, recebe a notação de NameNode, enquanto os
demais recebem a denominação de DataNode. O NameNode é responsavel por gerenciar
o espaço de nomes do sistema de arquivos e por regular o acesso de arquivos pelos
clientes. O DataNode compõe a unidade de armazenamento do cluster, onde os arquivos
estão distribuídos e replicados. Na imagem também estão apresentados os serviços de
JobTracker, que gerencia as tarefas de MapReduce, coordenando sua execução e o
TaskTracker que é o serviço de execução de tarefas do MapReduce.
Figura 1.7: Arquitetura básica de um cluster Hadoop, adaptado de [Menon 2013].
O MapReduce é um modelo de programação para processar grandes volumes de
dados de forma paralela. Um programa MapReduce é construído seguindo princípios de
programaçao funcional para processar lista de dados. Nesse modelo, deve existir uma
função de Mapeamento que processa partes de uma lista de dados paralelamente, ou seja,
a função de mapeamento é executada por vários nós do cluster, processando partes
independentes dos dados e uma função de Redução, que recebe os dados dos nós do
cluster que estão executando a função de mapeamento, combinando-as. Por exemplo,
considere um corpus textual onde se deseja obter as freqüências das palavras. Um
programa em pseudocódigo, descrevendo a função de mapeamento e de redução, pode
ser visto na Figura 1.8.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
32

function map(String document):
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += ParseInt(pc)
emit (word, sum)
Figura 1.8: Exemplo Hadoop
1.3.3.1 Ecossistema Hadoop
Além da capacidade de armazenar grande volume de dados de forma distribuída, permitir
que esses dados apresentem diferentes formatos e prover mecanismos para processamento
desses dados por meio de programas MapReduce, o Hadoop apresenta um ecossistema
de ferramentas e bibliotecas que auxiliam em tarefas administrativas para o cluster, no
processamento e análise de dados e no próprio armazenamento de dados. A Figura 1.9
apresenta algumas ferramentas que compõem esse ecossistema.
As ferramentas apresentadas são:
D3: é uma biblioteca JavaScript para visualização de dados [http://d3js.org/]
.
Tableau: plataforma de visualizaçao e análise de dados proprietária,
entretanto, possui versões gratuitas para estudantes e para universidades.
[http://www.tableausoftware.com/pt-br]
Mahout: é um projeto da Apache Software Foundation para produzir
implementações livres de algoritmos de aprendizado de máquina escaláveis,
focados principalmente nas áreas de filtragem colaborativa, clustering e
classificação [https://mahout.apache.org/].
R: ambiente para análise estatísticas [http://www.r-project.org/]
Java/Python/...: Java é a linguagem oficial para criar programas em um
cluster Hadoop, entretanto, é possível utilizar outras linguagens como Python
e Ruby.
Pig: é uma plataforma para análise de dados que consiste de uma linguagem
de alto nível para expressar uma análise de dados e a infraestrutura para
executar essa linguagem. [http://pig.apache.org/]
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
33

Figura 1.9: Ecossistema Hadoop, adaptado de [Bidoop Layes 2014]
Hive: fornece um mecanismo para projetar, estruturar e consultar os dados
usando uma linguagem baseada em SQL, chamado HiveQL
[http://hive.apache.org/]
HDFS: Não é uma ferramenta nem uma biblioteca, mas é o cerne da
plataforma Hadoop. HDFS é um sistema de arquivos distribuído projetado
para ser executado em commodity hardware
HBASE: é um banco de dados orientado a colunas e foi construído para
fornecer pedidos com baixa latência sob Hadoop HDFS.
[http://hbase.apache.org/]
MongoDB: banco de dados orientado a documentos no formato JSON.
[http://www.mongodb.org/]
Kettle: ferramenta de ETL que permite tratamento de dados construindo
workflows gráficos. [http://community.pentaho.com/projects/data-
integration/]
Flume: ferramenta de coleta e agregação eficiente de streams de dados.
[http://flume.apache.org/]
Sqoop: ferramenta que permite a transferência de dados entre bancos
relacionais e a plataforma Hadoop. [http://sqoop.apache.org/]
Chukwa: sistema de coleta de dados para monitoramento de sistemas
[https://chukwa.apache.org/]
Oozie: é um sistema gerenciador de workflows para gerenciar tarefas no
Hadoop. [http://oozie.apache.org/]
Nagios: ferramenta para monitorar aplicativos e redes
[http://www.nagios.org/]
Zoo Keeper: é um serviço centralizador para manter informações de
configuração. [http://zookeeper.apache.org/]
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
34

1.3.3.2 Exemplo de Análise de Redes Sociais
Como exemplo será apresentado um algoritmo baseado em MapReduce para contagem
de frequência em grafos. Algoritmos como APRIORI necessitam contar a frequência de
cada subgrafo em uma base de grafos. Como esse processo é computacionalmente custoso
e deve ser executado em cada etapa do APRIORI, abaixo está apresentado um exemplo
simplificado para contagem de frequência. Considere uma base de Grafos D e a sua
representação como uma lista de vértices e arestas como exemplificado na Figura 1.10.
1 a,b,c,d,e,f,g | ab,de,gf,dc
2 h,i,c,d,e,f,n | hc,dc,ef, en
…
N a,g,h,j,n,r,h | ag,ah,aj,rh
Figura 1.10: Base de grafos D, contendo N grafos. O formato da base é id do grafo, vértices, arestas.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
35

#MAP
import sys
sub_graf = #representação do subgrafo aqui
for ling in sys.stdin:
is_subgraph = True
lista_vertices, lista_arestas = parser_grafo(line) # transformando o arquivo do grafo em uma lista de vértices e
outra lista de arestas
#checando se todos os vértices de sub_graf_input são vértices em graf
for v in sub_graf.vertices:
if v not in lista_vertices:
is_subgraph = False
break
#checando se todas arestas de sub_graf_input são arestas em graf
if is_subgraph:
for a in sub_graf.arestas:
if a not in lista_arestas:
is_subgraph = False
if is_subgraph:
print "%d\t%d"%(sub_graf.id, 1)
else:
print "%d\t%d"%(sub_graf.id, 0)
Figura 1.11: Algoritmo de mapeamento.
O primeiro passo é criar o algoritmo para mapeamento. Ele deve processar um
conjunto de subgrafos, com representação idêntica da Figura 1.11, comparando cada um
com um dos subgrafos representados na variável sub_graf. Esses subgrafos poderiam ser
provenientes de arquivos ou outras estruturas de armazenamento, mas foram postos
diretamente no código apenas para simplicar o exemplo. Para definir se um grafo é
subgrafo de outro está sendo feito a comparação dos vértices e das arestas. Quando todos
vértices e arestas estão contidos no grafo, o algoritmo de mapamento retorna o id do
subgrafo e o valor 1. Quando existe uma ou mais arestas ou vértices que não fazem parte
do grafo, o algoritmo retorna o id do sub_grafo e valor 0.
O algoritmo de redução agrega os resultados das tarefas de mapeamento,
retornando o somatório dos valores para cada id do subgrafo (Figura 1.12).
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
36

#Reducer
import sys
current_graph = None
current_count = 0
subgraph_id = None
for line in sys.stdin:
# removendo espaços em branco
line = line.strip()
# parseando o resultado produzido pelo mapper
subgraph_id, count = line.split('\t')
#convertento o contador para um inteiro
count = int(count)
#conta enquanto existirem valores para serem reduzidos
if current_graph == subgraph_id:
current_count += count
else:
#imprime o resultado caso outro id de sub_grafo esteja sendo processado
if current_graph:
print '%s\t%s' % (current_graph, current_count)
current_count = count #zerando o contador
current_graph = subgraph_id #atribuindo o novo id de sub_grafo
#necessário para imprimir o ultimo resultado
if current_graph == subgraph_id:
print '%s\t%s' % (current_graph, current_count)
Figura 1.12: Reducer.
1.4 Principais Desafios e oportunidades de pesquisa
Analisar grandes volumes de dados extraídos das redes sociais online permite que novas
informações sejam obtidas, as quais não eram possíveis de serem verificadas devido às
amostras desses tipos de dados ser menor. Porém, o aumento dos dados a serem
analisados somam novos desafios aos já existentes na área de análise de redes sociais.
Agora esses desafios são tanto do ponto de vista da análise de redes sociais quanto do
ponto de vista do avanço das tecnologias de Big Data. O aumento das massas de dados
das redes sociais está fazendo com que as técnicas, metodologias e ferramentas de
mineração de dados e análise de grafos sejam adaptadas, melhoradas ou soluções novas
sejam criadas.
Alguns dos principais desafios (que trazem novas oportunidades de pesquisa) são:
Algoritmos adequados e escaláveis para milhões ou até bilhões de elementos a
serem analisados;
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
37

Algoritmos que possam ser distribuídos, paralelizados e capazes de tratar de
ruídos e falhas;
Algoritmos que permitam análises rápidas de grandes massas de dados, sendo a
análise quase em tempo real;
Segurança dos dados, no contexto das RSOs, principalmente privacidade;
Diminuir o consumo de recursos necessário para armazenar, gerenciar,
processar e enviar grandes massas de dados;
Segurança e confiabilidade da informação (publicação de informações íntimas
por usuários leigos, geração e propagação de boatos nas RSOs, etc.);
Desafios relacionados à multidisciplinaridade dos dados das RSOs que exigem
conhecimentos de diferentes áreas do conhecimento sendo, quase sempre,
necessário que profissionais de diferentes áreas consigam interagir e colaborar
nessas análises;
Analisar mensagens não estruturadas como análises de linguagem natural, de
imagens e de vídeos; e
Estruturas físicas para armazenar dados fornecendo acesso rápido aos mesmos.
1.5 Conclusão
A quantidade de dados produzidos na Internet aumenta diariamente. Novas aplicações
usadas na rede, aliadas às aplicações existentes e ao aumento do uso de sensores e
dispositivos eletrônicos (medidores elétricos, por exemplo) aumentam cada vez mais a
quantidade de dados produzidos. As redes sociais online seguem essa tendência. À
medida que novas mídias digitais surgem e se popularizam, novas funcionalidades são
adicionadas as mídias e novos usuários participam dessas redes, levando ao aumento da
quantidade de dados oriundos de interações sociais. As informações das RSOs são
multidisciplinares, em grandes quantidades, produzidos rapidamente e em diferentes
fontes.
Esses dados, produzidos em grande volume, velocidade e de fontes variadas
precisam ser armazenados, gerenciados e possivelmente analisados sob diferentes óticas
para geração de novos conhecimentos. Big data é o termo empregado para esse grande
volume de dados oriundos de fontes heterogêneas, produzidos, transmitidos e processados
em altas velocidades.
O volume de conteúdo produzido e compartilhado nas redes sociais online,
associado ao grande número de usuários (cidadãos de diferentes localidades), é fonte de
diversas informações que se propagam e agregam novos valores às informações de
diversas áreas. Atualmente, analisar essa grande massa de dados é um desafio, visto que
as ferramentas utilizadas para mineração de dados, estudos de grafos, entre outras, podem
não ser adequadas para tratar com grandes volumes de dados.
Este trabalho apresentou uma discussão sobre tecnologias e abordagens para
análises de redes sociais online, contextualizou o problema de análise de grandes volumes
de dados, abordou as principais abordagens existentes para se trabalhar com esses dados
e apresentou um exemplo prático de análise de grandes volumes de dados extraídos de
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
38

redes sociais online. Trabalhar com amostras maiores de dados possibilita que
informações antes ocultas sejam aproveitadas e tragam novas e melhores informações.
Ainda existem muitos desafios a serem enfrentados, porém a possibilidade de
trabalhar com amostras maiores de dados das redes sociais online permite que novas
informações sejam extraídas e que informações antes obtidas sejam mais consistentes,
visto que a amostra analisada será maior. Além do desafio técnico de analisar grandes
quantidades de dados, novos desafios surgem a partir dessa nova oportunidade de análise,
visto que novas informações que antes não eram consideradas devido às limitações
técnicas e humanas podem e devem ser agora consideradas. Tratar essas novas
informações adequadamente extrapola as áreas técnicas da computação (e até da área das
ciências exatas) visto que conhecimentos de áreas de humanas (como antropologia,
sociologia, psicologia, entre outros) são necessários. Este trabalho introduziu o tema de
Big Data e análise de redes sociais, permitindo que pesquisadores e analistas de redes
sociais que desejam trabalhar com grande volume de dados conheçam as principais
abordagens e desafios que existem atualmente. Ao mesmo tempo, este trabalho também
pode ser utilizado por profissionais que estão trabalhando com Big Data e desejam agora
analisar dados de redes sociais.
Referências
About Twitter (2014) “Our mission: To give everyone the power to create and share ideas
and information instantly, without barriers”, Disponível em:
https://about.twitter.com/company, Acessado em: 19 de julho de 2014.
Albuquerque, R. P., Oliveira, J., Faria, F. F., Studart, R. M., Souza, J. M.(2014),
“Studying Group Dynamics through Social Networks Analysis in a Medical
Community”, Social Networking, v. 03, p. 134-141.
Alonso, O., Ke, Q., Khandelwal, K., Vadrevu S. (2013), “Exploiting Entities In Social
Media”, Proceedings of the sixth international workshop on Exploiting semantic
annotations in information retrieval (ESAIR ), ACM, p. 9-12.
Appel, A. P., Hruschka, E.(2011), “Por dentro das redes complexas: detectando grupos e
prevendo ligações”, Anais do XXVI Simpósio Brasileiro de Banco de Dados, SBC.
Bidoop Layer (2014), “Soluções em Big Data Baseadas em Hadoop”, Disponível em:
http://www.bidoop.es/bidoop_layer, Acessado em: 10 de maio de 2014.
Benevenuto, F., Almeida, J., Silva, A. S. (2011), “Explorando Redes Sociais Online: Da
Coleta e Análise de Grandes Bases de Dados as Aplicacões”, Minicurso do XXVI
Simpósio Brasileiro de Redes de Computadores, SBC.
Beowulf (2014), “The Beowulf Archives”, Disponível em: http://www.beowulf.org/,
Acessado em: 14 de fevereiro de 2014.
Castells, M. (1996), “Rise of the Network Society: The Information Age: Economy,
Society and Culture”, Vol. 1, John Wiley & Sons.
Chen, H. (2001), “Knowledge management systems: a text mining perspective”,
Arizona: Knowledge Computing Corporation.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
39

ComScore (2014), “comScore Releases March U.S. Online Video Rankings”. Disponível
em: https://www.comscore.com/por/Insights/Press-Releases/2014/4/comScore-
Releases-March-2014-US-Online-Video-Rankings, Acessado em 19 de julho de 2014.
Costa, L. H. M. K., Amorim, M. D., Campista, M. E. M., Rubinstein, M. G., Florissi, P.,
Duarte, O. C. M. B. (2012), “Grandes Massas de Dados na Nuvem: Desafios e
Técnicas para Inovação”, Minicurso do XXX Simpósio Brasileiro de Redes de
Computadores e Sistemas Distribuídos, SBC, p. 58.
Cozza, R., Milanesi, C., Gupta, A., Nguyen, T. H., Lu, C. K., Zimmermann, A., & De La
Vernge, H. J. (2011), “Market Share Analysis: Mobile Devices”, Gartner Report,
Disponível em: http://www.gartner.com/newsroom/id/1689814, Acessado em 20 de
julho de 2014.
Dale, C., Cheng, X., Liu. J. (2007), “Understanding the Characteristics of Internet Short
Video Sharing : YouTube as a Case Study”, Technical Report arXiv:0707.3670v1,
Cornell University.
Dean, J., Ghemawat, S. (2008). “MapReduce: simplified data processing on large
clusters”. Communications of the ACM, v. 51, n. 1, p. 107-113.
DiFranzo, D., Zhang, Q., Gloria, K., Hendler, J. (2013). “Large Scale Social Network
Analysis Using Semantic Web Technologies”, AAAI Fall Symposium Series.
Easley, D., Kleinberg, J. (2010). “Networks, crowds, and markets: Reasoning about a
highly connected world”, Cambridge University Press.
Facebook (2014), “Public Feed API”, Disponível em:
https://developers.facebook.com/docs/public_feed, Acessado em 21 de janeiro de
2014.
Facebook Data Center (2014), “A New Data Center for Iowa”, Disponível em:
https://newsroom.fb.com/news/2013/04/a-new-data-center-for-iowa/, Acessado em
20 de julho de 2014.
Facebook NewsRoom (2014), “NewsRoom”, Disponível em:
http://newsroom.fb.com/company-info/, Acessado em 20 de julho de 2014.
Facebook World Cup (2014), “World Cup 2014: Facebook Tops A Billion Interactions”,
Disponível em: https://newsroom.fb.com/news/2014/06/world-cup-2014-facebook-
tops-a-billion-interactions/, Acessado em: 20 de julho de 2014.
Gärtner, T. (2002), “Exponential and geometric kernels for graphs”, NIPS Workshop on
Unreal Data: Principles of Modeling Nonvectorial Data, Vol. 5, pp. 49-58.
Getoor, L., Diehl, C. P. (2005), “Link mining: A survey”, ACM SIGKDD Explorations
Newsletter, v. 7, n. 2, p. 3–12.
Ghemawat, S., Gobioff, H., Leung, S. T. (2003), “The Google file system”, ACM
SIGOPS Operating Systems Review, ACM , v. 37, n. 5, p. 29-43.
Girvan, M., Newman, M. (2002), “Community structure in social and biological
networks”, Proceedings of the National Academy of Sciences, v. 99, n. 12, p. 7821-
7826.
Gomide, J., Veloso, A., Meira Jr, W., Almeida, V., Benevenuto, F., Ferraz, F., Teixeira,
M. (2011), “Dengue surveillance based on a computational model of spatio-temporal
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
40

locality of Twitter”, Proceedings of the 3rd International Web Science Conference,
ACM, p. 3-11.
Hanneman, R. A., Riddle, M., “Introduction to social network methods”, Disponível em:
http://faculty.ucr.edu/~hanneman/, Acessado em 20 de julho de 2014.
Huisman, M., Van Duijn, M. A. J. (2005), “Software for Social Network Analysis”. In
Carrington, P .J., Scott, J., ,Wasserman, S. (Editors), “Models and Methods in Social
Network Analysis”, New York: Cambridge University Press, p. 270-316.
Jacobs, A. (2009) . “The pathologies of Big Data”. Magazine Communications of the
ACM - A Blind Person's Interaction with Technology, New York, NY, USA. v. 52, n.
8, p. 36-44.
Junior, E. A. S., Oliveira, J. (2013), “Hermes: Identificação de Menores Rotas em
Dispositivos Móveis”. Anais do XXVIII Simpósio Brasileiro de Banco de Dados -
Demos e Aplicações, Pernambuco, SBC.
Kashima, H., Inokuchi, A. (2002), “Kernels for graph classification”. Proceedings of
ICDM Workshop on Active Mining.
Kempe, D., Kleinberg, J., Tardos, E. (2003), “Maximizing the Spread of Influence
through a Social Network”, Proceedings of the ninth ACM SIGKDD international
conference on Knowledge discovery and data mining, ACM, pp. 137-146.
Kleinberg, J. M. (1999), “Authoritative sources in a hyperlinked environment”, Journal
of the ACM, v. 46, n. 5, p. 604-632.
Krauss, J., Nann, S., Simon, D., Gloor, P. A., Fischbach, K. (2008), “Predicting movie
success and academy awards through sentiment and social network analysis”,
Proceedings of European Coferance on Information Systems, p 2026–2037.
Lafferty, J., McCallum, A., Pereira, F. C. N. (2001), “Conditional random fields:
Probabilistic models for segmenting and labeling sequence data”, Proceedings of
XVIII International Conference on Machine Learning, Morgan Kaufmann Publishers,
p. 282-289.
Lam, C. (2010), “Hadoop in action”, Manning Publications Co.
Lauand, B.; Oliveira, J. (2013), “TweeTraffic: ferramenta de análise das condições de
trânsito baseado nas informações do Twitter”. Anais do II Brazilian Workshop on
Social Network Analysis and Mining (BraSNAM), SBC.
Liben-Nowell, D., Kleinberg, J. (2007), “The link-prediction problem for social
networks”, Journal of the American Society for Information Science and Technology,
v. 58, n. 7, p. 1019–1031.
Lieberman, M., “Visualizing Big Data: Social network analysis”, Disponível em:
http://mvsolution.com/wp-content/uploads/Visualizing-Big-Data-Scial-Network-
Analysis-Paper-by-Michael-Lieberman.pdf, Acessado em 20 de julho de 2014.
Lu, Q., Getoor, L. (2003), Link-based Classification, Proceedings of XX International
Conference on Machine Learning, v. 20, n. 2, p. 1–42.
Nagarajan, M., Sheth, A., Velmurugan, S. (2011), “Citizen sensor data minning, social
media analytics and development centric Web applications”. Proceedings of the 20th
international conference companion on World Wide Web, ACM, pp. 289-290.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
41

Manovich, L. (2011), “Trending: the promises and the challenges of big social data”,
Minneapolis, MN: University of Minnesota Press.
Melo, H., Oliveira, J. (2014), “Ambiente Analítico Web para Análise da Colaboração
Científica no Cenário Médico”, Anais do X Simpósio Brasileiro de Sistemas de
Informação, SBC, p.387-398 .
Menon, R. (2013), “Introducing Hadoop – Part II”, Disponível em:
http://rohitmenon.com/index.php/introducing-hadoop-part-ii/, Acessado em: 10 de
dezembro de 2013.
Mikolajczyk, R. T., Kretzschmar, M. (2008), “Collecting social contact data in the context
of disease transmission: Prospective and retrospective study designs”, Social
Networks, Elsevier, v. 30, n. 2, p. 127-135.
Monclar, R.S., Oliveira, J., Faria, F.F., Ventura, L.V.F., Souza, J. M., Campos, M.L.M.
(2012), “The Analysis and Balancing of Scientific Social Networks in Cancer
Control”, Handbook of Research on Business Social Networking: Organizational,
Managerial and Technological Dimensions, IGI Global, p. 915-941.
Nakamura, E. F., Loureiro, A. A. F., Frery, A. C. (2007), “Information fusion for wireless
sensor networks: Methods, models, and classifications”, Computing Surveys, ACM,
v. 39, n. 3, p. 9-64.
Neto, B.; Oliveira, J.; Souza, J. M. (2010). “Collaboration in Innovation Networks:
Competitors can become partners”, Proceedings of International Conference on
Information Society, IEEE, p. 455-461.
Newman, M. E. J. (2010), “Networks: An Introduction”, Oxford: Oxford University
Press.
Nodejs (2014), “Node.js”, Disponível em: http://nodejs.org, Acessado em: 20 de junho
de 2014.
O’Madadhain, J., Hutchins, J., Smyth, P. (2005), “Prediction and ranking algorithms for
event-based network data”, ACM SIGKDD Explorations Newsletter, 7(2), 23-30.
Oliveira, A. C., Salas, P. R., Roseto S., Boscarioli C., Barbosa W., Viterbo A. (2013a),
“Big Data: Desafios e Técnicas para a Análise Eficiente de Grandes Volumes e
Variedades de Dados”, Minicurso do IX Simpósio Brasileiro de Sistemas de
Informação, SBC.
Oliveira, J., Santos, R. P. (2013b), “Análise e Aplicações de Redes Sociais em
Ecossistema de Software”, Minicurso do IX Simpósio Brasileiro de Sistema de
Informação.
Online Tech (2014), “Cloud computing prompts 2012 data center expansion plans”,
Disponível em: http://resource.onlinetech.com/cloud-computing-prompts- 2012-data-
center-expansion-plans/, Acessado em: 19 de julho de 2014.
Pastor-Satorras, R., Vespignani, A. (2001), “Epidemic spreading in scale-free networks”,
Physical Review Letters, v. 86, n. 14, p. 3200-3203.
Popescul, A; Ungar, L. H. (2003), “Statistical Relational Learning for Link Prediction”,
Proceedings of IJCAI workshop on learning statistical models from relational data.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
42

Ranking, T. P. C., Order, B. (1998), “The PageRank Citation Ranking: Bringing Order
to the Web”. Technical Report, Stanford University, Disponível em
http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf , Acessado em: 23 de setembro de
2014.
Santos, F. B., Oliveira, J. (2014), “More than Just a Game: The Power of Social Media
on Super Bowl XLVI”, Social Networking, Scientific Research, v. 03, p. 142-145.
Silva, I. S., Gomide, J., Barbosa, G. A. R., Santos, W., Veloso A., Meira, W. Jr., Ferreira,
R. (2011). “Observatório da Dengue: Surveillance based on Twitter Sentiment Stream
Analysis”. XXVI Simpósio Brasileiro de Banco de Dados-Sessão de Demos.
Silva, T. L. C., Araújo, A. C. N., Sousa, F. R. C., Macêdo, J. A. F., Machado, J. C. (2013),
“Análise em Big Data e um Estudo de Caso utilizando Ambientes de Computação em
Nuvem”. Minicurso do XXVII Simpósio Brasileiro de Banco de Dados.
Solis, B. (2007), “Manifesto, The Social Media”, Disponível em:
http://www.briansolis.com/2007/06/future-of-communications-manifesto-for/ ,
Acessado em: 20 de junho 2014.
Souza, J. M., Neto, B., Oliveira, J. (2011), “Innovation Networks as a Proposal to
Overcome Problems and Improve Innovation Projects”. International Journal for
Infonomics, Infonomics Society, v. 4, p. 623-632.
Statistics | Facebook (2014), Disponível em:
http://www.facebook.com/press/info.php?statistics, Acessado em: 20 de junho de
2014.
Stempel, G. H., Hargrove, T., Bernt, J. P. (2000), “Relation of Growth of Use of the
Internet to Changes in Media Use from 1995 to 1999”, Journalism & Mass
Communication Quarterly, SAGE Journals, v. 77, n. 1, p. 71-79.
Stroele, V., Silva, R., Souza, M.F., Mello, C. E., Souza, J. M., Zimbrao, G., Oliveira, J.
(2011), “Identifying Workgroups in Brazilian Scientific Social Networks”, Journal of
Universal Computer Science, v. 17, p. 1951-1970.
Studart, R. M.; Oliveira, J.; Faria, F.F.; Ventura, L.V.F.; Souza, J. M.; Campos, M.L.M.
(2011), “Using social networks analysis for collaboration and team formation
identification”, Proceedings of XV International Conference on Computer Supported
Cooperative Work in Design, IEEE, p. 562-569.
Svenson, P., Svensson, P., Tullberg, H. (2006), “Social Network Analysis And
Information Fusion For Anti-Terrorism”, Proceedings of Conference on Civil and
Military Readiness, Paper S3.1.
Lovett, T., O’Neill, E., Irwin, J., Pollington, D. (2010). “The calendar as a sensor: analysis
and improvement using data fusion with social networks and location” Proceedings of
XXII International Conference on Ubiquitous Computing, ACM, p. 3–12.
Tan, W., Blake, M. B., Saleh, I., Dustdar, S. (2013), “Social-Network-Sourced Big Data
Analytics”. Internet Computing. IEEE Computer Society, v. 17, n. 5, p. 62-69.
Taskar, B., Abbeel, P., Koller, D. (2002), “Discriminative probabilistic models for
relational data”, Proceedings of the Eighteenth conference on Uncertainty in artificial
intelligence, p. 485-492
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
43

Twitter Statistics (2014), “Twitter Statistics Verification”, Disponível em:
<http://www.statisticbrain.com/twitter-statistics/>, Acessado em: 19 de julho de 2014.
Wasserman, S., Faust, K. (1994), “Social Network Analysis: Methods and Applications”,
Cambridge University Press.
Watts, D. J.; Strogatz, S. H. (1998), “Collective dynamics of small-world networks”,
Nature, v. 393, n. 6684, p. 440-442.
White, T. (2009), “Hadoop: The Definitive Guide”, O’Reilly Media.
Yang, C.C., Ng, T.D. (2007), “Terrorism and Crime Related Weblog Social Network:
Link,Content Analysis and Information Visualization”, Intelligence and Security
Informatics, IEEE. p. 55-58.
YouTube Statistics (2014), Disponível em:
https://www.youtube.com/yt/press/statistics.html, Acessado em: 19 de julho de 2014.
Zikopoulos, P., Eaton, C. (2011), “Understanding Big Data: Analytics for enterprise class
Hadoop and streaming data”, McGraw-Hill Osborne Media.
Zuckerberg, M. (2014), “One Billion People on Facebook”, Disponível em:
https://newsroom.fb.com/news/2012/10/one-billion-people-on-facebook/, Acessado
em: 20 de julho de 2014.
Zudio, P., Mendonca, L., Oliveira, J. (2014), “Um método para recomendação de
relacionamentos em redes sociais científicas heterogêneas” , Anais do XI Simpósio
Brasileiro de Sistemas Colaborativos, SBC.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
44

Sobre os Autores
Tiago Cruz França é professor assistente da Universidade Federal Rural do Rio de Janeiro
(UFRRJ) e aluno de doutorado no Programa de Pós-Graduação em Informática, onde desenvolve
pesquisas nas áreas de análise de redes sociais e big data. Tem interesse em tecnologias Web,
Engenharia de Software e Análise de Redes Sociais. Nos últimos anos, Tiago tem atuado nos
seguintes temas: Serviços Web, Mashups Web, Web das Coisas, Análise de Sentimentos, Fusão
de Dados Web e dados oriundos de dispositivos inteligentes.
Fabrício Firmino de Faria é professor substituto da Universidade Federal do Rio de Janeiro
(UFRJ), possui mestrado em Informática pela Universidade Federal do Rio de Janeiro, durante o
qual realizou intercâmbio no Digital Enterprise Research Institute (DERI, Irlanda). Atualmente
atua em pesquisas com Web Semântica, Data Warehousing, Análises de Redes Sociais e Big
Data. Nos últimos anos trabalhou com processamento de linguagem natural para análise de dados
textuais e com o desenvolvimento de plataformas para captura e armazenamento de dados
produzidos por sensores.
Fabio Medeiros Rangel é graduando da Universidade Federal do Rio de Janeiro, possui
experiência em Análise de Redes Sociais, com foco em visualização de dados e desenvolvimento
de algoritmos para cálculo de métricas em ambientes distribuídos. Possui interesse nas áreas de
Data Mining e Big Data.
Claudio Miceli de Farias possui graduação em Ciência da Computação pela Universidade
Federal do Rio de Janeiro (2008), mestrado (2010) e doutorado (2014) em Informática pela
Universidade Federal do Rio de Janeiro. Atuou como professor substituto no Departamento de
Ciência da Computação da UFRJ durante o período de 2012 a 2014. Atualmente é professor do
Colégio Pedro II e professor visitante no laboratório de Redes e Multimídia do iNCE-UFRJ. Atua
como revisor no SBSEG e SBRC. É também membro do comitê de programa das conferências
Wireless Days e IDCS. As principais áreas de atuação são: Redes de Sensores sem Fio, Redes de
Sensores Compartilhadas, Fusão de Dados, Escalonamento de tarefas, Smart Grid, Análise de
Dados e Segurança.
Jonice Oliveira obteve o seu doutorado em 2007 em Engenharia de Sistemas e Computação,
ênfase em Banco de Dados, pela COPPE/UFRJ. Durante o seu doutorado recebeu o prêmio IBM
Ph.D. Fellowship Award. Na mesma instituição realizou o seu Pós-Doutorado, concluindo-o em
2008. Atualmente é professora adjunta do Departamento de Ciência da Computação da UFRJ,
coordenadora do curso de Análise de Suporte à Decisão (habilitação do Bacharelado em Ciências
da Matemática e da Terra) e atua no Programa de Pós-Graduação em Informática (PPGI-UFRJ).
Em 2013, tornou-se Jovem Cientista do Nosso Estado pela FAPERJ. Coordena o Laboratório
CORES (Laboratório de Computação Social e Análise de Redes Sociais), que conduz pesquisas
multidisciplinares para o entendimento, simulação e fomento às interações sociais. É
coordenadora de Disseminação e Parcerias do Centro de Referência em Big Data, da UFRJ. Suas
principais áreas de pesquisa são Gestão do Conhecimento, Análise de Redes Sociais, Big Data e
Computação Móvel.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
45

Capítulo
2Estratégias para Proteção da Privacidade deDados Armazenados na Nuvem
Eliseu C. Branco Jr., Javam C. Machado e Jose Maria Monteiro
Abstract
This short course describes the problem of data privacy in cloud computing. Besides,a short review of the main concepts about security and privacy in cloud environmentsis presented and discussed. In addition, it presents methods and techniques concerningprivacy preserving of data stored or processed in the cloud. Finally, an original solutionto ensure data privacy in cloud computing environments is discussed.
Resumo
Este minicurso discute o problema da privacidade de dados na computação em nuvem.Além disto, uma revisão dos principais conceitos relacionados à segurança e à privaci-dade em computação em nuvem é apresentada e discutida. Adicionalmente, os principaismétodos e técnicas atualmente existentes para a proteção da privacidade dos dados ar-mazenados ou processados na nuvem são apresentados. Por fim, uma solução originalpara assegurar a privacidade de dados em ambientes de computação em nuvem é discu-tida.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
cap:2
46

2.1. IntroduçãoA computação em nuvem é uma tecnologia que tem como objetivo proporcionar serviçosde Tecnologia da Informação (TI) sob demanda com pagamento baseado no uso. A nuvemcomputacional é um modelo de computação em que dados, arquivos e aplicações residemem servidores físicos ou virtuais, acessíveis por meio de uma rede em qualquer dispositivocompatível (fixo ou móvel), e que podem ser acessados a qualquer hora, de qualquer lugar,sem a necessidade de instalação ou configuração de programas específicos.
Contudo, para que todo o potencial da computação em nuvem possa ser exploradopelas organizações, é de fundamental importância garantir a segurança e a privacidade dosdados armazenados na nuvem. O relatório Top Threats to Cloud Computing, 2013, produ-zido pela Cloud Security Alliance-CSA 1, lista as 10 maiores ameaças para a computaçãoem nuvem. Em primeiro lugar no ranking desta pesquisa ficou o "roubo de dados"e emsegundo lugar a "perda de dados". Portanto, não será possível atingir todo o potencial dacomputação em nuvem sem o desenvolvimento de estratégias que assegurem a proteçãoda privacidade dos dados de seus usuários.
2.1.1. O que é Privacidade?
Os trabalhos de pesquisa sobre privacidade abrangem disciplinas da filosofia à ciênciapolítica, teoria política e legal, ciência da informação e, de forma crescente, engenha-ria e ciência da computação. Um aspecto comum entre os pesquisadores do tema é queprivacidade é um assunto complexo. Privacidade é um conceito relacionado a pessoas.Trata-se de um direito humano, como liberdade, justiça ou igualdade perante a lei. Pri-vacidade está relacionada ao interesse em que as pessoas têm em manterem um espaçopessoal, sem interferências de outras pessoas ou organizações. Segundo [Jr et al. 2010],existem basicamente três elementos na privacidade: o sigilo, o anonimato e o isolamento(ou solidão, o direito de ficar sozinho).
Inicialmente, é importante fazer uma distinção entre dados e informação. O pa-drão RFC-2828 define informação como "fatos e ideias que podem ser representados(codificados) sob vários formatos de dados"e dados como "informações em uma repre-sentação física específica, normalmente uma sequência de símbolos que possuem um sig-nificado; especialmente uma representação da informação que pode ser processada ouproduzida por um computador."
[Jr et al. 2010] definem 3 dimensões para a privacidade:
a) Privacidade Territorial: proteção da região próxima a um indivíduo.
b) Privacidade do Indivíduo: proteção contra danos morais e interferências indesejadas.
c) Privacidade da Informação: proteção para dados pessoais coletados, armazenados,processados e propagados para terceiros.
A privacidade, em relação aos dados disponibilizados na nuvem, pode ser vistacomo uma questão de controle de acesso, em que é assegurado que os dados armazenados
1https://downloads.cloudsecurityalliance.org/initiatives/top_threats/The_Notorious_Nine_Cloud_Computing_Top_Threats_in_2013.pdf, acessado em março de 2014.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
47

estarão acessíveis apenas para pessoas, máquinas e processos autorizados. A privacidadeassegura que os indivíduos controlam ou influenciam quais informações relacionadas aeles podem ser coletadas e armazenadas por alguém e com quem elas podem ser compar-tilhadas [Stallings 2007].
Adicionalmente, privacidade em computação em nuvem é a habilidade de umusuário ou organização controlar que informações eles revelam sobre si próprios na nu-vem, ou seja, controlar quem pode acessar qual informação e de que forma isto podeocorrer. Neste contexto, a proteção de dados está relacionada ao gerenciamento de infor-mações pessoais. De modo geral, informações pessoais descrevem fatos, comunicaçõesou opiniões relacionadas ao indivíduo, as quais ele desejaria manter em segredo, contro-lando sua coleta, uso ou compartilhamento. Informações pessoais podem ser associadasa um indivíduo específico tais como nome, cpf, número do cartão de crédito, número daidentidade. Algumas informações pessoais são consideradas mais sensíveis do que outras.Por exemplo, informações sobre saúde (registros médicos) são consideradas sensíveis emtodas as circunstâncias. Também são exemplos de informações sensíveis: aquelas rela-cionadas à biometria de um indivíduo e os resultados de uma avaliação de desempenhorealizada com os funcionários de uma determinada empresa. Este tipo de informaçãonecessita de proteção adicional em relação à privacidade e segurança.
Para que seja possível discutir em detalhes os principais aspectos relacionados àprivacidade dos dados armazenados na nuvem, necessitamos definir precisamente o que écomputação em nuvem. Existem várias definições para computação em nuvem. Contudo,neste trabalho, será utilizada a definição apresentada em [Hon et al. 2011]:
a) A computação em nuvem fornece acesso flexível, independente de localização, pararecursos de computação que são rapidamente alocados ou liberados em resposta àdemanda.
b) Serviços (especialmente infraestrutura) são abstraídos e virtualizados, geralmente sendoalocados como um pool de recursos compartilhados com diversos clientes.
c) Tarifas, quando cobradas, geralmente, são calculadas com base no acesso, de formaproporcional, aos recursos utilizados.
À medida em que grandes volumes de informações pessoais são transferidas paraa nuvem, cresce a preocupação de pessoas e organizações sobre como estes dados serãoarmazenados e processados. O fato dos dados estarem armazenados em múltiplos locais,muitas vezes de forma transparente em relação à sua localização, provoca insegurançaquando ao grau de privacidade a que estão expostos.
Segundo [Pearson 2013], a terminologia para tratar questões de privacidade dedados na nuvem inclui a noção de controlador do dado, processador do dado e sujeitoproprietário do dado. Estes conceitos serão descritos a seguir:
a) Controlador de Dado: Uma entidade (pessoa física ou jurídica, autoridade pública,agência ou organização) que sozinha ou em conjunto com outros, determina a maneirae o propósito pela qual as informações pessoais são processadas.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
48

b) Processador de Dado: Uma entidade (pessoa física ou jurídica, autoridade pública,agência ou organização) que processa as informações pessoais de acordo com as ins-truções do Controlador de Dado.
c) Sujeito do Dado: Um indivíduo identificado ou identificável ao qual a informaçãopessoal se refere, seja por identificação direta ou indireta (por exemplo por referênciaa um número de identificação ou por um ou mais fatores físicos, psicológicos, mentais,econômicos, culturais ou sociais).
2.2. Conceitos FundamentaisNesta seção, iremos apresentar os principais conceitos relacionados à segurança e à pri-vacidade em computação em nuvem.
2.2.1. Privacidade de Dados na Nuvem
Diversos estudos têm sido realizados para investigar os problemas relacionados à pri-vacidade e segurança em ambientes de computação em nuvem. [Liu et al. 2012] es-tudou o assunto nas áreas de saúde e energia elétrica. Já o trabalho apresentado por[Gruschka and Jensen 2010] sugeriu modelar o ecosistema de segurança baseado em trêsparticipantes do ambiente de nuvem: o usuário do serviço, a instância do serviço e oprovedor do serviço. Os ataques podem ser classificados em 6 categorias, conforme des-crição na Tabela 2.1. Em cada categoria representa-se a origem e o destino dos ataques.Por exemplo, “usuário -> provedor” indica ataques de usuários a provedores de nuvem.
Tabela 2.1. Tipos de Ataques na Nuvem
Usuário doServiço
Instância doServiço
Provedor deNuvem
Usuário doServiço
usuário→serviço
usuário →provedor
Instância doServiço
serviço →usuário
serviço →provedor
Provedor deNuvem
provedor →usuário
provedor →serviço
[Spiekermann and Cranor 2009] classificou 3 domínios técnicos para o armazena-mento de dados na nuvem: esfera do usuário, esfera da organização e esfera dos provedo-res de serviços. O autor relacionou áreas de atividades que causam grande preocupaçãoem relação à privacidade de dados com as 3 esferas de privacidade, conforme ilustrado naTabela 2.2, a seguir.
O National Institute of Standards and Technology (NIST) propõe uma ter-minologia para a classificação de problemas relacionados à privacidade e a se-gurança em ambientes de computação em nuvem. A terminologia proposta con-tém 9 áreas: governança, conformidade, confiança, arquitetura, gerenciamento deacesso e identidade, isolamento de software, proteção de dados, disponibili-dade e resposta a incidentes [Jansen and Grance 2011]. Em relação à proteção de da-dos, o NIST recomenda que sejam avaliadas a adequação de soluções de gerenciamento
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
49

Tabela 2.2. Esferas de Influência Associadas às Preocupações com Privacidadede Dados. Adaptado de [Spiekermann and Cranor 2009].
Esfera de Influência Preocupação com a Privacidade de DadosEsfera do usuário • Coleção e armazenamento de dados não autorizados
• Acesso não autorizado a dados• Exposição de dados• Entrada indesejada de dados
Esfera da organização • Exposição de dados•Mau julgamento a partir de dados parciais ou incorretos• Acesso não autorizado a dados pessoais• Uso não autorizado de dados por terceiros envolvidos na co-leta dos dados ou por outras organizações com as quais os dadosforam compartilhados
Esfera dos provedores deserviços de nuvem
•Uso não autorizado de dados por terceiros envolvidos na coletados dados• Uso não autorizado por outras organizações com as quais osdados foram compartilhados• Acesso não autorizado de dados pessoais• Erros acidentais ou deliberados em dados pessoais•Mau julgamento a partir de dados parciais ou incorretos• Combinação de dados pessoais, a partir de banco de dadosdiferentes para recriar o perfil de um sujeito
de dados do provedor de nuvem para os dados organizacionais envolvidos e a capacidadede controlar o acesso aos dados, para proteção dos dados em repouso, em movimento eem uso, incluindo o descarte dos dados.
2.2.2. Segurança de Dados na Nuvem
O NIST Computer Security Handbook define segurança computacional como sendo "aproteção conferida a um sistema de informação automatizado, a fim de atingir os objetivospropostos de preservação da integridade, disponibilidade e confidencialidade dos recursosdo sistema de informação (incluindo hardware, software, firmware, informações/dados etelecomunicações)"[Guttman and Roback 1995]. Esta definição contém 3 conceitos cha-ves para segurança computacional: confidencialidade, disponibilidade e integridade.
Além dos riscos e ameaças inerentes aos ambientes tradicionais de TI, o ambi-ente de computação em nuvem possui seu próprio conjunto de problemas de segurança,classificados por [Krutz and Vines 2010] em sete categorias: segurança de rede, interfa-ces, segurança de dados, virtualização, governança, conformidade e questões legais. Osprincípios fundamentais da segurança da informação: confidencialidade, integridade edisponibilidade, definem a postura de segurança de uma organização e influenciam oscontroles e processos de segurança que podem ser adotados para minimizar os riscos.Estes princípios se aplicam também aos processos executados na nuvem.
O processo de desenvolvimento e implantação de aplicações para a plataforma decomputação em nuvem, que seguem o modelo software como um serviço (Software as aService - SaaS), deve considerar os seguintes aspectos de segurança em relação aos dadosarmazenados na nuvem [Subashini and Kavitha 2011]:
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
50

a) Segurança dos dados: no modelo SaaS, os dados são armazenados fora dos limitesda infraestrutura de tecnologia da organização, por isso o provedor de nuvem deveprover mecanismos que garantam a segurança dos dados. Por exemplo, isso podeser feito utilizando técnicas de criptografia forte e mecanismos de ajuste preciso paraautorização e controle de acesso.
b) Segurança da rede: os dados do cliente são processados pelas aplicações SaaS e ar-mazenados nos servidores da nuvem. A transferência dos dados da organização paraa nuvem deve ser protegida para evitar perda de informação sensível. Por exemplo,pelo uso de técnicas de encriptação do tráfego de rede, tais como Secure Socket Layer(SSL) e Transport Layer Security (TLS).
c) Localização dos dados: no modelo SaaS, o cliente utiliza as aplicações SaaS paraprocessar seus dados, mas não sabe onde os dados serão armazenados. Isto pode serum problema, devido à legislação sobre privacidade em alguns países proibir que osdados sejam armazenados fora de seus limites geográficos. O que ocorre, por exemplo,em relação ao armazenamento de dados médicos na nuvem, em alguns países da UniãoEuropéia.
d) Integridade dos dados: o modelo SaaS é composto por aplicações multi-inquilino hos-pedadas na nuvem. Estas aplicações utilizam interfaces baseadas em API-ApplicationProgram Interfaces XML para expor suas funcionalidades sob a forma de serviços Web(web services). Embora existam padrões para gerenciar a integridade das transaçõescom web services, tais como WS-Transaction e WS-Reliability, estes padrões não sãoamplamente utilizados pelos desenvolvedores de aplicações SaaS.
e) Segregação dos dados: os dados de vários clientes podem estar armazenados no mesmoservidor ou banco de dados no modelo SaaS. A aplicação SaaS deve garantir a segre-gação, no nível físico e na camada de aplicação, dos dados dos clientes.
f) Acesso aos dados: o ambiente muilti-inquilino da nuvem pode gerar problemas relaci-onados à falta de flexibilidade de aplicações SaaS para incorportar políticas específicasde acesso a dados pelos usuários de organizações clientes do serviço SaaS.
2.2.3. Vulnerabilidades da Nuvem
[Zhifeng and Yang 2013] relaciona características da nuvem que causam vulnerabilidadesde segurança e privacidade, as quais são descritas a seguir:
a) Máquinas virtuais de diferentes clientes compartilhando os mesmos recursos físicos(hardware) possibilitam ataque de canal lateral (side-channel attack), situação em queo atacante pode ler informações do cache da máquina e descobrir o conteúdo de chavescriptográficas de outros clientes.
b) Perda de controle físico da máquina pelo cliente, que não pode se proteger contraataques e acidentes. Por exemplo: alteração ou perda de dados.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
51

c) Sub-provisionamento da largura de banda da rede, o que provocou o surgimento de umnovo tipo de ataque de negação de serviço (DOS- Denial of Service) que se aproveitado fato da capacidade de rede do provedor de nuvem ser menor do que a quantidadede máquinas alocadas na mesma sub-rede [Liu 2010].
2.3. Modelos de Preservação da PrivacidadeAs soluções propostas para preservação da privacidade de dados armazenados ou pro-cessados na nuvem, que são discutidas neste documento, são classificadas em quatro ca-tegorias. A primeira categoria trata da proteção da privacidade de dados privados quedevem ser disponibilizados na nuvem de forma pública. Neste contexto, pode-se aplicaros modelos de anonimização apresentados na Seção 2.4. A segunda categoria se refere asituações nas quais deseja-se realizar consultas sobre dados criptografados disponibiliza-dos na nuvem, sem revelar o conteúdo destes dados, nem o conteúdo da consulta para oprovedor de nuvem. Para este cenário, a técnica de Busca Criptográfica, apresentada naSeção 2.5, pode ser aplicada. A terceira categoria engloba os cenários nos quais é neces-sário assegurar a privacidade do acesso na recuperação de dados armazenados na nuvem.Neste contexto, pode-se aplicar a a técnica de proteção PIR-Private Information Retrie-val, discutida na Seção 2.6. A quarta categoria, trata do problema de manter a privacidadeem transações distribuidas na nuvem. Neste contexto, a técnica SMC-Secure MultipartyComputation, apresentada na Seção 2.7, pode ser utilizada. Por fim, a Seção 2.8 apresentauma proposta de uma nova técnica para assegurar a privacidade de dados armazenados nanuvem, utilizando decomposição e fragmentação de dados.
2.4. Anonimização de Dados na NuvemOrganizações públicas e privadas têm, cada vez mais, sido cobradas para publicar seus da-dos "brutos"em formato eletrônico, em vez de disponibilizarem apenas dados estatísticosou tabulados. Esses dados "brutos"são denominados microdados (microdata). Neste caso,antes de sua publicação, os dados devem ser “sanitizados”, com a remoção de identifica-dores explícitos, tais como nomes, endereços e números de telefone. Para isso, pode-seutilizar técnicas de anonimização.
O termo anonimato, que vem do adjetivo "anônimo", representa o fato do sujeitonão ser unicamente caracterizado dentro de um conjunto de sujeitos. Neste caso, afirma-se que o conjunto está anonimizado. O conceito de sujeito refere-se a uma entidade ativa,como uma pessoa ou um computador. Conjunto de sujeitos pode ser um grupo de pessoasou uma rede de computadores [Pfitzmann and Köhntopp 2005]. Um registro ou transaçãoé considerada anônima quando seus dados, individualmente ou combinados com outrosdados, não podem ser associados a um sujeito particular [Clarke 1999].
Os dados sensíveis armazenados em sistemas de banco de dados relacionais so-frem riscos de divulgação não autorizada. Por este motivo, tais dados precisam ser pro-tegidos. Os dados são normalmente armazenados em uma única relação r, definida porum esquema relacional R(a1,a2,a3,...,an), onde ai é um atributo no domínio Di, com i =1,..,n. Na perspectiva da divulgação de dados de indivíduos, os atributos em R podem serclassificados da seguinte forma [Camenisch et al. 2011]:
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
52

a) Identificadores: atributos que identificam unicamente os indivíduos (ex.: CPF, Nome,Número da Identidade).
b) Semi-identificadores (SI): atributos que podem ser combinados com informações ex-ternas para expor alguns ou todos os indivíduos, ou ainda reduzir a incerteza sobresuas identidades (ex.: data do nascimento, CEP, cargo, função, tipo sanguíneo).
c) Atributos sensíveis: atributos que contêm informações sensíveis sobre os indivíduos(ex.: salário, exames médicos, lançamentos do cartão de crédito).
2.4.1. Operações de Anonimização
[Clarke 1999] conceitua privacidade da informação como sendo “o interesse que um in-divíduo tem em controlar, ou, ao menos, influenciar significativamente, o conjunto dedados a seu respeito”. Com o crescimento da oferta de serviços de armazenamento dedados e programas em nuvem, preocupações com segurança e privacidade dos dados temrequerido, dos provedores destes serviços, a implementação de estratégias para mitigarriscos e aumentar a confiança dos usuários. Existe a preocupação de que dados privativoscoletados e armazenados em bancos de dados na nuvem estejam protegidos e não sejamvisualizados por pessoas não autorizadas, citados na literatura como “bisbilhoteiros dedados”, “espião de dados”, intruso ou atacante [Duncan et al. 2001].
As técnicas atualmente existentes para a proteção de dados, (generalização, su-pressão, embaralhamento e perturbação), propostas pela comunidade acadêmica, podemser utilizadas e/ou combinadas com o objetivo de anonimizar os dados. Essas técnicas sãoapresentadas a seguir:
a) Generalização: para tornar o dado anônimo, esta técnica substitui os valores de atri-butos semi-identificadores por valores menos específicos, mas semanticamente con-sistentes, que os representam. A técnica categoriza os atributos, criando uma taxo-nomia de valores com níveis de abstração indo do nível particular para o genérico.Como exemplo, podemos citar a generalização do atributo Código de EndereçamentoPostal (CEP), o qual pode ser generalizado de acordo com os seguintes níveis: CEP(60.148.221) -> Rua -> Bairro -> Cidade -> Estado -> País.
b) Supressão: esta técnica exclui alguns valores de atributos identificadores e/ou semi-identificadores da tabela anonimizada. Ela é utilizada no contexto de bancos de dadosestatísticos, onde são disponibilizados apenas resumos estatísticos dos dados da tabela,ao invés dos microdados [Samarati 2001].
c) Encriptação: esta técnica utiliza esquemas criptográficos normalmente baseados emchave pública ou chave simétrica para substituir dados sensíveis (identificadores, semi-identificadores e atributos sensíveis) por dados encriptados.
d) Perturbação (Mascaramento): esta técnica é utilizada para preservação de privacidadeem data mining ou para substituição de valores dos dados reais por dados fictícios paramascaramento de bancos de dados de testes ou treinamento. A idéia geral é alterarrandomicamente os dados para disfarçar informações sensíveis enquanto preserva as
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
53

características dos dados que são críticos para o modelo de dados. Duas abordagenscomuns desta técnica são a randomização (Random Data Perturbation - RDP) e acondensação dos dados [Chen and Liu ].
• Condensação de Dados: técnica proposta por [Aggarwal and Philip 2004], con-densa os dados em múltiplos grupos de tamanhos predefinidos. Informaçõesestatísticas sobre média e correlações entre diferentes dimensões de cada gruposão preservadas. Dentro de um grupo não é possível distinguir diferenças entreos registros. Cada grupo tem um tamanho mínimo k, que é o nível de privacidadeobtido com esta técnica.• Random Data Perturbation (RDP): esta técnica adiciona ruídos, de forma randô-
mica, aos dados numéricos sensíveis. Desta forma, mesmo que um bisbilhoteiroconsiga identificar um valor individual de um atributo confidencial, o valor ver-dadeiro não será revelado. A maioria dos métodos utilizados para adicionar ruídorandômico são casos especiais de mascaramento de matriz. Por exemplo, seja oconjunto de dados X , o conjunto Z dos dados randomizados é computado comoZ = AXB+C, onde A é uma máscara de transformação de registro, B é um más-cara de transformação de atributo e C é um mascara de deslocamento (ruído)[Domingo-Ferrer 2008, Muralidhar and Sarathy 1999].
O mascaramento de dados é utilizado para disponibilizar bases de dados para testeou treinamento de usuários, com informações que pareçam reais, mas não revelem in-formações sobre ninguém. Isto protege a privacidade dos dados pessoais presentes nobanco de dados, bem como outras informações sensíveis que não possam ser colocadasa disposição para a equipe de testes ou usuários em treinamento. Algumas técnicas demascaramento de dados são descritas a seguir [Lane 2012]:
a) Substituição: substuição randômica de conteúdo por informações similares, mas semnenhuma relação com o dado real. Como exemplo, podemos citar a substituição desobrenome de família por outro proveniente de uma grande lista randômica de sobre-nomes.
b) Embaralhamento (Shuffling): substituição randômica semelhante ao item anterior, coma diferença de que o dado é derivado da própria coluna da tabela. Assim, o valor doatributo A em uma determinada tupla c1 é substituído pelo valor do atributo A em umaoutra tupla cn, selecionada randomicamente, onde n 6= 1.
c) Blurring: esta técnica é aplicada a dados numéricos e datas. A técnica altera o valordo dado por alguma percentagem randômica do seu valor real. Logo, pode-se alteraruma determinada data somando-se ou diminuindo-se um determinado número de dias,determinado randomicamente, 120 dias, por exemplo; valores de salários podem sersubstituídos por um valor calculado a partir do valor original, aplicando-se, para maisou para menos, uma percentagem do valor original, selecionada randomicamente, porexemplo, 10% do valor inicial.
d) Anulação/Truncagem (Redaction/Nulling ): esta técnica substitui os dados sensíveispor valores nulos (NULL). A técnica é utilizada quando os dados existentes na tabelanão são requeridos para teste ou treinamento.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
54

2.4.2. Tipos de Ataque à Privacidade dos Dados
O controle de inferência em banco de dados, também conhecido como Statistical Disclo-sure Control (SDC), trata da proteção de dados que podem ser publicados sem revelarinformações confidenciais que possam ser relacionadas a pessoas específicas aos quais osdados publicados correspondem. A proteção que as técnicas de SDC proporcionam, pro-vocam, em algum grau, modificação nos dados publicados, dentro dos limites de nenhumamodificação (máxima utilidade para os usuários e nenhuma proteção dos dados) e encrip-tação de dados (máxima proteção e nenhuma utilidade para o usuário sem a chave cripto-gráfica). O desafio para SDC é prover a proteção necessária e suficiente para as informa-ções divulgadas com o mínimo de perda de informação possível [Domingo-Ferrer 2008].Existem dois tipos de divulgação de informações que podem ocorrer em dados anonimi-zados: divulgação de identidade, que ocorre quando a identidade de um indivíduo podeser reconstruída e associada com um registro em uma tabela; e divulgação de atributo,que ocorre quando o valor de um atributo pode ser associado a um indivíduo (sem neces-sariamente poder ser associado a um registro específico). Modelos de privacidade paraproteção da divulgação de informações propostos por [Fung et al. 2010] são classificadosem duas categorias, com base nos tipos de ataques possíveis:
a) A primeira categoria considera que a ameaça à privacidade dos dados ocorre quandoum adversário consegue ligar um proprietário de dados a um registro da tabela, ou aum atributo sensível da tabela ou ainda à tabela inteira. Estes tipos de ataques sãodenominados de: ataque de ligação ao registro, ataque de ligação ao atributo e ataquede ligação à tabela.
b) A segunda categoria considera a variação no conhecimento do adversário antes e de-pois de acessar os dados anonimizados. Caso esta variação seja significativa, estasituação configura o ataque probabilístico.
A remoção ou encriptação de atributos do tipo Identificadores é o primeiro passopara anominização. A tabela resultante desta alteração é chamada tabela anonimizada.Para ilustrar os ataques e os modelos de anominização, considere a Tabela 2.3, que apre-senta dados fictícios de infrações de trânsito. A Tabela 2.3 é anonimizada, utilizando-se astécnicas de generalização e supressão, sendo os atributos classificados da seguinte forma:atributos identificadores: Motorista, Número da Placa e CPF. Esses atributos serão su-primidos da tabela anonimizada; atributos semi-identificadores: data nascimento e datainfração. Esses atributos serão generalizados; atributos sensíveis: tipo de infração e valorda multa.
A Tabela 2.4 ilustra o resultado do processo de anonimização aplicado sobre aTabela 2.3. Os modelos de ataque (de ligação ao atributo, ao registro e à tabela) contra atabela com dados anonimizados (Tabela 2.4) são apresentados a seguir.
2.4.2.1. Ataque de Ligação ao Atributo
Neste tipo de ataque, valores de atributos sensíveis são inferidos a partir dos dados anoni-mizados publicados. Caso o atacante saiba que o Sr. José Sá nasceu em 05/1978 e recebeu
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
55

Tabela 2.3. Dados Privados sobre Infrações de Trânsito
NúmeroPlaca
Motorista CPF Data Nasci-mento
DataInfração
TipoInfra-ção
ValorMulta
HXR-1542 José Pereira 258.568.856 14/03/1977 03/01/2013 1 170,00HTS-5864 Jorge Cury 566.548.584 04/03/1977 03/01/2013 2 250,00HUI-5846 Paula Maria 384.987.687 24/05/1977 03/01/2013 1 170,00HTR-5874 Joatan Lima 054.864.576 20/04/1978 04/01/2013 1 170,00HOI-6845 José Sá 244.684.876 22/05/1978 04/01/2013 2 250,00HQO-5846 Kilvia Mota 276.684.159 13/05/1978 05/01/2013 2 250,00HUY-8545 José Pereira 538.687.045 15/05/1978 05/01/2013 1 170,00
Tabela 2.4. Dados Públicos Anonimizados sobre Infrações de Trânsito
NúmeroPlaca
Motorista CPF Data Nasci-mento
DataInfração
Tipo In-fração
ValorMulta
* * * 03/1977 01/2013 1 170,00* * * 03/1977 01/2013 2 250,00* * * 05/1977 01/2013 1 170,00* * * 04/1978 01/2013 1 170,00* * * 05/1978 01/2013 2 250,00* * * 05/1978 01/2013 2 250,00* * * 05/1978 01/2013 1 170,00
uma multa de trânsito em 01/2013, por exemplo, analisando a Tabela 2.4, ele pode infe-rir com 2/3 de confiança que o valor da multa paga pelo Sr. José Sá foi de R$ 250,00,conforme descrito na Tabela 2.5. Para evitar este ataque, a estratégia geral é diminuir acorrelação entre os atributos sensíveis e os atributos semi-identificadores.
Tabela 2.5. Ataque de Ligação ao Atributo
Data_Nascimento Data_Infração Tipo_Infração Valor_Multa03/1977 01/2013 1 170,0003/1977 01/2013 2 250,0005/1977 01/2013 1 170,0004/1978 01/2013 1 170,0005/1978 01/2013 2 250,0005/1978 01/2013 2 250,0005/1978 01/2013 1 170,00
2.4.2.2. Ataque de Ligação ao Registro
Neste tipo de ataque, registros com os mesmos valores para um determinado conjuntode atributos semi-identidicadores formam um grupo. Se os valores dos atributos semi-identificadores estiverem vulneráveis e puderem ser ligados a um pequeno número deregistros no grupo, o adversário poderá identificar que um determinado registro refere-sea um indivíduo (vítima) particular.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
56

Por exemplo, considere a Tabela 2.6, a qual contém dados de infrações de trân-sito. Suponha que a Secretaria da Fazenda do Ceará - SEFAZ publicou uma relação dosproprietários de veículos de Fortaleza (Tabela 2.7). Supondo que cada pessoa com umregistro na Tabela 2.6 tenha um registro na Tabela 2.7. O conjunto de registros dos atribu-tos semi-identificadores (data nascimento e data infração) do grupo {05/1977,01/2013}possui apenas um registro. Neste caso é possível ligar este registro com o registro da Sra.Paula Maria na Tabela 2.7.
Tabela 2.6. Ataque de Ligação ao Registro na Tabela de Multas
Data Nasci-mento
Data Infra-ção
Tipo In-fração
ValorMulta
03/1977 01/2013 1 170,0003/1977 01/2013 2 250,0005/1977 01/2013 1 170,0004/1978 01/2013 1 170,0005/1978 01/2013 2 250,0005/1978 01/2013 2 250,0003/1985 01/2013 1 170,00
Tabela 2.7. Tabela dos Proprietários de Veículos (Dados Externos)
Número daPlaca
Motorista CPF Data Nasci-mento
HXR-1542 José Pereira 258.568.856 14/06/1977HTS-5864 Jorge Cury 566.548.584 04/06/1977HUI-5846 Paula Maria 384.987.687 24/05/1977HTR-5874 Joatan Lima 054.864.576 20/05/1978HOI-6845 Leonardo Sá 244.684.876 22/05/1978HQO-5846 Kilvia Mota 276.684.159 13/06/1977HUY-8545 José Pereira 538.687.045 15/06/1977
2.4.2.3. Ataque de Ligação à Tabela
O ataque de ligação à tabela acontece quando o adversário consegue inferir a ausência oua presença de um registro da vítima na tabela anonimizada. No caso de registros médicosou financeiros, a simples identificação da presença do registro da vítima na tabela já podecausar prejuizo a ela.
Um exemplo deste tipo de ataque ocorre quando uma tabela anonimizada T (Ta-bela 2.8) é disponibilizada e o adversário tem acesso a uma tabela pública P (Tabela 2.7)em que T ⊆ P. A probabilidade da Sra. Kilvia Mota Maria estar presente na Tabela 2.8é de 3/4 = 0,75, uma vez que há 3 registros na Tabela 2.8 contendo a data de nascimento"06/1977"e 4 registros na Tabela 2.7 com data de nascimento "06/1977"
2.4.3. Modelos de Anonimização
Com a finalidade de evitar os ataques discutidos anteriormente, vários modelos de anoni-mização foram propostos por [Wong et al. 2010], [Tassa et al. 2012], [Last et al. 2014] e
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
57

Tabela 2.8. Ataque de Ligação à Tabela
DataNascimento
DataInfração
TipoInfração
Valor daMulta
06/1977 01/2013 1 170,0006/1977 01/2013 2 250,0006/1977 01/2013 1 170,0004/1978 01/2013 1 170,0005/1978 01/2013 2 250,0005/1978 01/2013 2 250,0003/1978 01/2013 1 170,00
[Gionis et al. 2008]. A seguir, são apresentados os principais modelos de anonimizaçãoencontrados na literatura: k-anonymity, l-diversity, LKC-Privacy, t-closeness e b-likeness.
2.4.3.1. k-anonymity
O modelo k−anonymity requer que qualquer combinação de atributos semi-identificado-res (grupo SI) seja compartilhada por pelo menos k registros em um banco de dados ano-nimizado [Samarati 2001], onde k é um valor inteiro positivo definido pelo proprietáriodos dados, possivelmente como resultado de negociações com outras partes interessadas.Um valor alto de k indica que o banco anonimizado tem baixo risco de divulgação, porquea probabilidade de re-identificar um registro é de 1/k, mas isto não protege o banco contradivulgação de atributos. Mesmo que o atacante não tenha capacidade de re-identificar oregistro, ele pode descobrir atributos sensíveis no banco anonimizado.
[Samarati and Sweeney 1998] apresentam dois esquemas de transformação dosdados por generalização e supressão. O primeiro esquema substitui os valores de atribu-tos semi-identificadores por valores menos específicos, mas semanticamente consisten-tes, que os representam. Como exemplo, pode-se trocar datas (dd/mm/aaaa) por mês/ano(mm/aaaa). A supressão é um caso extremo de generalização, o qual anula alguns va-lores de atributos semi-identificadores ou até mesmo exclui registros da tabela. A su-pressão deve ser utilizada como uma forma de moderação para a técnica de generaliza-ção, quando sua utilização provocar um grande aumento de generalização dos atributossemi-identificadores em um conjunto pequeno de registros com menos de k ocorrências.[Fung et al. 2007] propõe discretizar os atributos SI que apresentem valores contínuos,substituindo-os por um intervalo que contenha estes valores. Como exemplo, pode-sesubstituir o preço de produtos de supermercado por uma faixa de valores [1 a 3], [3 a 7],etc.
O esquema de generalização para o grupo SI (data nascimento, data infração) faz omapeamento destes valores para um nível hierárquico mais genérico, conforme ilustradona Tabela 2.9, em que vários valores diferentes de um domínio inicial são mapeados paraum valor único em um domínio final.
Utilizando o modelo k-anonymity na Tabela 2.10 com o valor de k = 2 para ogrupo SI = {data nascimento, data infração}, os registros 3 e 4 foram excluídos porque a
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
58
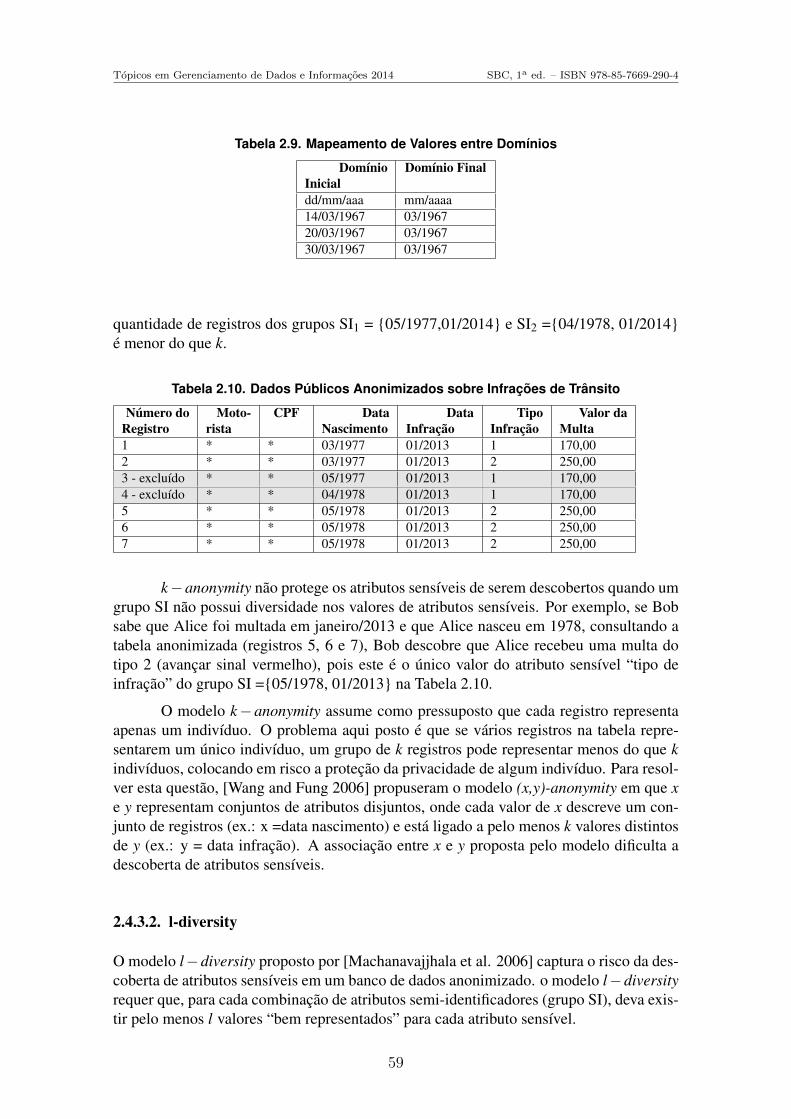
Tabela 2.9. Mapeamento de Valores entre Domínios
DomínioInicial
Domínio Final
dd/mm/aaa mm/aaaa14/03/1967 03/196720/03/1967 03/196730/03/1967 03/1967
quantidade de registros dos grupos SI1 = {05/1977,01/2014} e SI2 ={04/1978, 01/2014}é menor do que k.
Tabela 2.10. Dados Públicos Anonimizados sobre Infrações de Trânsito
Número doRegistro
Moto-rista
CPF DataNascimento
DataInfração
TipoInfração
Valor daMulta
1 * * 03/1977 01/2013 1 170,002 * * 03/1977 01/2013 2 250,003 - excluído * * 05/1977 01/2013 1 170,004 - excluído * * 04/1978 01/2013 1 170,005 * * 05/1978 01/2013 2 250,006 * * 05/1978 01/2013 2 250,007 * * 05/1978 01/2013 2 250,00
k−anonymity não protege os atributos sensíveis de serem descobertos quando umgrupo SI não possui diversidade nos valores de atributos sensíveis. Por exemplo, se Bobsabe que Alice foi multada em janeiro/2013 e que Alice nasceu em 1978, consultando atabela anonimizada (registros 5, 6 e 7), Bob descobre que Alice recebeu uma multa dotipo 2 (avançar sinal vermelho), pois este é o único valor do atributo sensível “tipo deinfração” do grupo SI ={05/1978, 01/2013} na Tabela 2.10.
O modelo k−anonymity assume como pressuposto que cada registro representaapenas um indivíduo. O problema aqui posto é que se vários registros na tabela repre-sentarem um único indivíduo, um grupo de k registros pode representar menos do que kindivíduos, colocando em risco a proteção da privacidade de algum indivíduo. Para resol-ver esta questão, [Wang and Fung 2006] propuseram o modelo (x,y)-anonymity em que xe y representam conjuntos de atributos disjuntos, onde cada valor de x descreve um con-junto de registros (ex.: x =data nascimento) e está ligado a pelo menos k valores distintosde y (ex.: y = data infração). A associação entre x e y proposta pelo modelo dificulta adescoberta de atributos sensíveis.
2.4.3.2. l-diversity
O modelo l−diversity proposto por [Machanavajjhala et al. 2006] captura o risco da des-coberta de atributos sensíveis em um banco de dados anonimizado. o modelo l−diversityrequer que, para cada combinação de atributos semi-identificadores (grupo SI), deva exis-tir pelo menos l valores “bem representados” para cada atributo sensível.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
59

A definição de l−diversity proposta por [Machanavajjhala et al. 2006] é a se-guinte: um grupo SI é l-diverso se contiver pelo menos l valores bem representados paraos atributos sensíveis. Uma tabela é l-diversa se cada grupo SI for l-diverso. Proporcionaprivacidade, mesmo quando não são conhecidas quais informações o atacante possui, poisgarante a existência de pelo menos l valores de atributos sensíveis em cada grupo SI.
Dado um grupo SI = {data nascimento, data infração}, considere uma tabela aser anonimizada onde existem registros de motoristas com datas de nascimento de 1960a 1980, totalizando 240 meses e datas de infração do ano de 2013 (12 meses). Nestatabela, podem existir no máximo 240 x 12 = 2.880 grupos SI distintos. Se for definidoum limite k = 5 para a k-anonimização destes dados, cada grupo SI deverá ter pelo menos5 registros com valores identicos para os atributos semi-identificadores. Por exemplo,utilizando-se o modelo l−diversity, os atributos sensíveis (tipo de infração e valor damulta) deverão ter l valores distintos em cada grupo SI. A Tabela 2.11 ilustra um exemplodos registros do grupo SI = {03/1977,01/2013}. Se for definido o valor de l = 3, estegrupo deverá ser excluído pois a diversidade dos atributos sensíveis tem apenas 2 valoresdistintos ({1,2},{170,250}) neste grupo.
Tabela 2.11. Grupo SI = 03/1977,01/2013
DataNascimento
DataInfração
TipoInfração
Valor daMulta
03/1977 01/2013 1 170,0003/1977 01/2013 2 250,0003/1977 01/2013 1 170,0003/1977 01/2013 1 170,0003/1977 01/2013 2 250,0003/1977 01/2013 2 250,0003/1977 01/2013 2 250,00
A interpretação do princípio de valores “bem representados” para os atri-butos de cada grupo SI pela métrica l-diversity originou 3 variações desta mé-trica: [Ninghui et al. 2007]
a) l−diversity com valores distintos: neste caso existem l valores distintos para cadagrupo SI. Um grupo SI pode ter um valor que apareça mais frequentemente que outrosvalores, possibilitando ao atacante re-identificar este valor ao sujeito que está presenteno grupo SI. Este ataque é denominado ataque de probabilidade de inferência.
b) l−diversity com entropia: neste caso, a entropia da tabela inteira deve ser pelo menoslog(l) e a entropia de cada grupo SI deve ser maior ou igual a log(l). Esta definição émais forte do que a definição anterior e pode ser muito restritiva se existirem poucosvalores com alta frequência de ocorrência na tabela. A entropia de cada grupo SI édefinida pelo indíce de diversidade de Shannon:
Entropia(SI) = −∑s∈SI f (s)log( f (s)) onde f (s) é a fração de registros do grupo SIque contem atributo sensível com valor igual a s.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
60

c) (c,l)-diversity recursivo: Considere um grupo SI em que existem diversos valores parao atributo S, dado pelo conjunto {s1,...,sm}. Considere o conjunto de contagem destesvalores (Ex.: ’r1 = count(*) where S=s1’), ordenados em ordem decrescente {r1,...rm},neste caso, dada uma constante c, cada grupo SI satisfaz recursivamente (c,l)-diversityse r1 < c(rl + rl+1 +...+ rm). Este procedimento assegura que valores muito frequentesnão apareçam tão frequentemente e que valores mais raros não apareçam tão raramentenos grupos SI. Um grupo SI satisfaz (c,l)-diversity recursivo se for possível eliminarum valor sensível e mesmo assim o grupo SI continuar (c,l-1)-diverso.
[Ninghui et al. 2007] apresenta alguns problemas do modelo l−diversity:
a) O modelo é limitado na pressuposição do conhecimento do adversário sobre os atibu-tos sensíveis. Por exemplo, não considera a possibilidade do adversário obter informa-ções sobre um atributo sensível a partir da informação da frequência da distribuiçãoglobal deste atributo na tabela.
b) O modelo assume que todos os atributos sensíveis são categorizados, desconsiderandoatributos numéricos, nos quais, apenas pode ser suficiente a descoberta de valoresaproximados.
Segundo [Ninghui et al. 2007], l−diversity é vulnerável a dois tipos de ataques:ataque de assimetria (Skewness attack) e ataque de similaridade (Similiarity attack). Essesataques são discutidos a seguir:
a) Ataque de assimetria: ocorre quando existe grande assimetria na distribuição dos va-lores dos atributos sensíveis. Por exemplo, um atributo com 2 valores em que existe99% de ocorrencia de um valor e 1% de ocorrência do outro valor.
b) Ataque de similaridade: ocorre quando os valores em um grupo SI são distintos massemanticamente equivalentes. Por exemplo, o atributo salário poderia ser discretizadopor faixa de valores, mas as faixas de valores mais altas indicariam que os indivíduosocupavam funções de chefia, enquanto faixas de valores mais baixas poderiam indicarpessoas recém-contratadas que ocupavam funções operacionais.
2.4.3.3. LKC-Privacy
Uma das maneiras de evitar o ataque de ligação de atributo consiste em utilizar a técnicade generalização de dados em grupos SI, de forma que cada grupo contenha k regis-tros com os mesmos valores de semi-identificadores e diversificação dos atributos sensí-veis para desorientar inferências do atacante sobre atributos da vítima conhecidos por ele[Fung et al. 2010]. O problema de aplicar esta técnica quando a quantidade de atributossemi-identificadores é muito grande é que a maior parte dos atributos tem que ser supri-mida para se obter k-anonimização, o que diminue a qualidade dos dados anominizados.Este problema foi identificado por [Aggarwal 2005] e é conhecido como problema da altadimensionalidade dos dados em k-anonimização.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
61

[Mohammed et al. 2009] criaram o modelo LKC−Privacy como uma propostade solução para o problema da alta dimensionalidade dos dados. Este modelo partedo pressuposto de que o atacante não possui todas as informações dos atributos semi-identificadores do seu alvo. Neste caso, é razoável supor que o atacante possui conheci-mento de pelo menos "L"valores de atributos semi-identificadores.
O modelo LKC−Privacy assegura que cada combinação de valores de atributosSI em SI j ⊆ SI com tamanho máximo L em uma tabela T seja compartilhada por pelomenos K registros, e a confiança da inferência de qualquer valor sensível em S não sejamaior do que C, onde L, K e C são limites e S é um conjunto de valores de atributos semi-identificadores. O modelo limita a probabilidade de sucesso na identificação do registroda vítima a ser menor ou igual a 1/K e a probabilidade de sucesso no ataque de ligação deatributo a ser menor ou igual a C, considerando que o conhecimento prévio do adversárionão excede o valor de L.
[Fung et al. 2010] apresenta propriedades do modelo LKC−Privacy que são ade-quadas para anominização de dados com alta dimensionalidade:
a) Requer que apenas um subconjunto de atributos semi-identificadores seja comparti-lhado por k registros. Este relaxamento da restrição tradicional de k-anonimizaçãobaseia-se na premissa de que o adversário tem limitado conhecimento dos atributossensíveis da vítima.
b) Generaliza vários modelos tradicionais de k-anonimização. Por exemplo: k-anonymityé um caso especial de LKC−Privacy onde L = Conjunto de Todos os Atributos semi-identificadores, K = k e C = 100%; l−diversity é um caso especial de LKC−Privacyonde L= conjunto de todos os atributos semi-identificadores, K = 1 e C = 1/l.
c) É flexível para ajustar o dilema entre privacidade de dados e utilidade de dados. Au-mentando L e K ou diminuindo C pode-se aumentar a privacidade, embora isso reduzaa utilidade dos dados
d) É um modelo de privacidade geral que evita ataques de ligação de registro e ligaçãode atributos. É aplicável para anonimização de dados com ou sem atributos sensíveis.
A seguir, na Tabela 2.14, é apresentado um exemplo de anonimização utilizandoo modelo LKC−Privacy que satisfaz (2,2,50%)-privacidade pela generalização de todosos valores dos atributos SI da Tabela 2.12, de acordo com a taxonomia proposta na Tabela2.13.
Cada possível valor de SI j (SI1 = {Sexo, Idade}, SI2 = {Sexo, Data Infração}, SI3= {Idade, Data Infração}) com tamanho máximo igual a 2 na Tabela 2.14 é compartilhadopor pelo menos 2 registros. Neste caso, a confiança do atacante inferir o valor sensível detipo de infração = 1 não é maior do que 50%.
2.4.3.4. t-closeness
Este modelo propõe-se a corrigir algumas limitações de l−diversity no que diz respeitoà proteção contra divulgação de atributo. O objetivo é limitar o risco de descoberta a
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
62
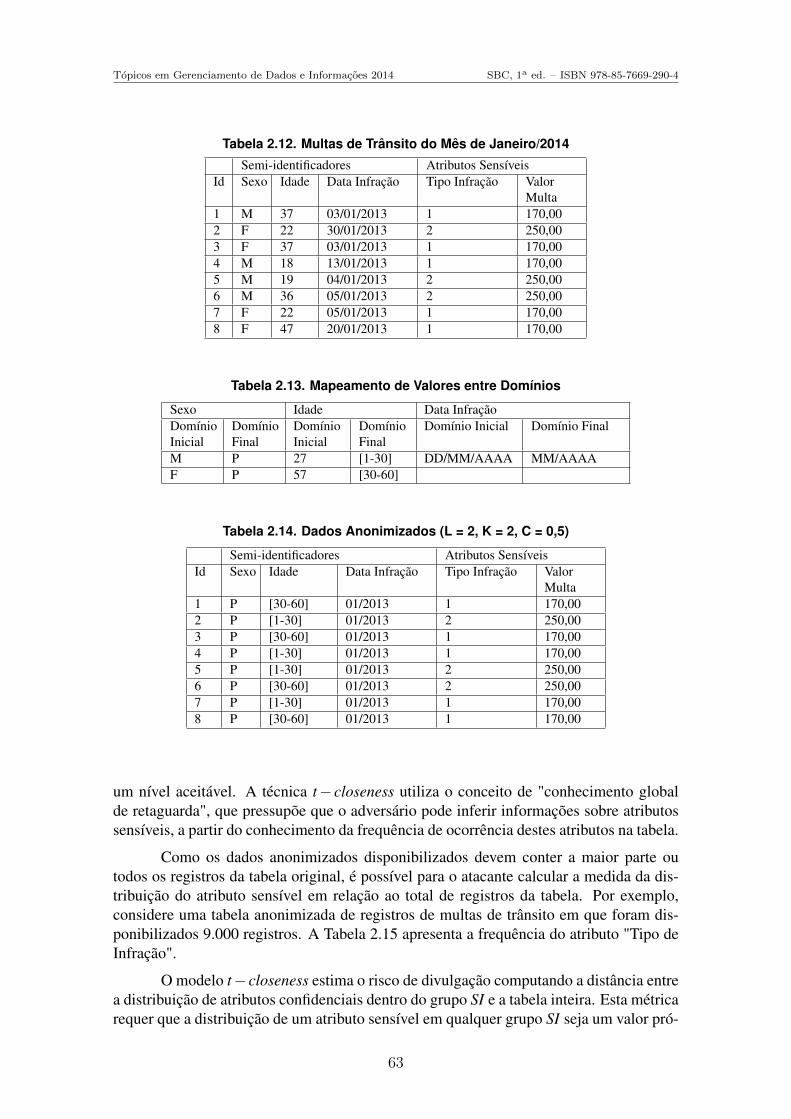
Tabela 2.12. Multas de Trânsito do Mês de Janeiro/2014
Semi-identificadores Atributos SensíveisId Sexo Idade Data Infração Tipo Infração Valor
Multa1 M 37 03/01/2013 1 170,002 F 22 30/01/2013 2 250,003 F 37 03/01/2013 1 170,004 M 18 13/01/2013 1 170,005 M 19 04/01/2013 2 250,006 M 36 05/01/2013 2 250,007 F 22 05/01/2013 1 170,008 F 47 20/01/2013 1 170,00
Tabela 2.13. Mapeamento de Valores entre Domínios
Sexo Idade Data InfraçãoDomínioInicial
DomínioFinal
DomínioInicial
DomínioFinal
Domínio Inicial Domínio Final
M P 27 [1-30] DD/MM/AAAA MM/AAAAF P 57 [30-60]
Tabela 2.14. Dados Anonimizados (L = 2, K = 2, C = 0,5)
Semi-identificadores Atributos SensíveisId Sexo Idade Data Infração Tipo Infração Valor
Multa1 P [30-60] 01/2013 1 170,002 P [1-30] 01/2013 2 250,003 P [30-60] 01/2013 1 170,004 P [1-30] 01/2013 1 170,005 P [1-30] 01/2013 2 250,006 P [30-60] 01/2013 2 250,007 P [1-30] 01/2013 1 170,008 P [30-60] 01/2013 1 170,00
um nível aceitável. A técnica t− closeness utiliza o conceito de "conhecimento globalde retaguarda", que pressupõe que o adversário pode inferir informações sobre atributossensíveis, a partir do conhecimento da frequência de ocorrência destes atributos na tabela.
Como os dados anonimizados disponibilizados devem conter a maior parte outodos os registros da tabela original, é possível para o atacante calcular a medida da dis-tribuição do atributo sensível em relação ao total de registros da tabela. Por exemplo,considere uma tabela anonimizada de registros de multas de trânsito em que foram dis-ponibilizados 9.000 registros. A Tabela 2.15 apresenta a frequência do atributo "Tipo deInfração".
O modelo t− closeness estima o risco de divulgação computando a distância entrea distribuição de atributos confidenciais dentro do grupo SI e a tabela inteira. Esta métricarequer que a distribuição de um atributo sensível em qualquer grupo SI seja um valor pró-
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
63

Tabela 2.15. Frequência do Atributo "Tipo de Infração"
Tipo deInfração
Quant. Re-gistros
Frequência
1 1000 11%2 1000 11%3 4000 44%4 3000 33%Total 9000 100%
ximo do valor da distribuição do atributo em relação à tabela inteira [Ninghui et al. 2007].Sendo Q a medida da distribuição do atributo sensível em toda a tabela e P a medida dadistribuição do atributo sensível em um grupo SI, quanto mais próximas estas medidasestiverem, menor será o conhecimento que o atacante poderá ter sobre indivíduos es-pecíficos e maior será o grau de privacidade dos grupos SI. A distância entre as duasdistribuições não pode ser maior que um limite t.
t− closeness limita as possibilidades de um adversário obter informações so-bre atributos sensíveis pela análise da distribuição de valores globais destes atri-butos. [Ninghui et al. 2007] sugere o uso da fórmula da distância variacional para cal-cular a distância entre P = {p1,p2,p3,...,pm} e Q ={q1,q2,q3,...,qm}, definida pela me-dida Earth-Mover Distance (EMD), que mede a quantidade mínima de esforço neces-sário para mover uma distribuição de massa entre pontos de um espaço probabilístico[Liang and Yuan 2013]. O valor de EMD entre duas distribuições em um espaço nor-malizado é um número entre 0 e 1. A fórmula EMD é apresentada a seguir: D[P,Q] =
∑mi=1
12 |pi−qi|.
Por exemplo, considere o grupo SI = {03/1977,01/2013} da Tabela 2.16 que con-tém apenas infrações do tipo 1 e 2. A distribuição de frequência do atributo "tipo deinfração"no grupo SI é P = {50%,50%,0%,0%}. A distribuição do atributo "tipo de infra-ção"na tabela toda, de acordo com a tabela 2.16 é Q = 11%,11%,44%,33%. Calculando adistância entre P e Q utilizando EMD, obtem-se o valor de 0,775 (77,5%). Quanto maiorfor a distância entre P e Q, maior a probabilidade da descoberta de atributos sensíveis.
Tabela 2.16. Grupo SI = (03/1977,01/2013)
DataNascimento
DataInfração
TipoInfração
Valor daMulta
03/1977 01/2013 1 170,0003/1977 01/2013 2 250,0003/1977 01/2013 1 170,0003/1977 01/2013 1 170,0003/1977 01/2013 2 250,0003/1977 01/2013 2 250,00
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
64

2.4.3.5. b-likeness
O modelo b− likeness, proposto por [Cao and Karras 2012], assegura que a confiançade um atacante no valor de um atributo sensível não aumenta em termos relativos, maisque um limite b pré-estabelecido, depois que o atacante tem conhecimento dos dadospublicados.
A definição básica de b− likeness, formulada por [Cao and Karras 2012], é deque dada uma tabela T que contem atributos sensíveis (sensitive attributes-SA), seja V ={v1,v2,v3,...,vm} o domínio de SA e P = {p1,p2,p3,...,pm} a distribuição global de SA em T .Uma classe de equivalência G com distribuição de atributos sensíveis Q = {q1,q2,q3,...,qm}satisfaz um limite básico b− likeness, se e somente se max{D(pi,qi)|pi ∈ P, pi < qi} ≤ bonde b > 0 é um limite e D é uma função de distância entre pi e qi. A distância D deve sergrande o suficiente para proteger os dados de ataques de assimetria (Skewness attack) e desimilaridade (Similiarity attack). Esta técnica difere das anteriores em relação ao uso dafunção de distância D para estabelecer o limite de distância máximo, ao invés da distânciacumulativa entre os atributos sensíveis. É utilizada uma medida relativa, ao invés dasmedidas absolutas utilizadas pelas funções cumulativas de diferenças de frequências dosoutros modelos anteriores. D é calculado pela fórmula D(pi,qi) =
pi,qipi
O modelo b− likeness apresenta-se como uma solução ao problema da exposi-ção de privacidade de valores de atributos sensíveis que ocorrem com menor frequência.Em geral, modelos de privacidade, como o t-closeness, que utilizam funções cumulativasde diferenças de frequências entre as distribuições não conseguem fornecer uma relaçãocompreensível entre o limite t e a privacidade proporcionada pelo modelo. Tais modelosnão dão atenção aos valores de atributos sensíveis que são menos frequentes e que sãomais vulneráveis a exposição de privacidade.
A restrição imposta à função D(pi,qi) de ser menor ou igual ao limite b, temcomo consequência, a criação de um limite superior para a frequência de vi ∈ V em qual-quer classe de equivalência G, conforme descrito na expressão (qi− pi)/pi ≤ b⇒ qi ≤pi× (1+b). Esta função representa um limite de proteção de privacidade compreensívelapenas se pi× (1+b)< 1, neste caso, valores de pi < 1/(1+b) devem ser monitorados,pois pode ocorrer de tais valores assumirem valor igual a 1 na classe de equivalência,tornando possível ao atacante, que saiba que o registro da vítima está presente na classede equivalência, a inferência do valor atributo sensível com 100% de confiança.
2.5. Busca CriptográficaBusca Criptográfica (Searchable Encryption) é uma técnica que provê funcionalidades depesquisa em dados encriptados sem requerer a chave de encriptação. Esta técnica utilizaduas partes: um cliente e um servidor que armazena um banco de dados D encriptado,onde o cliente possui uma chave de acesso Q e a utiliza para obter o resultado da consultaQ(D) sem revelar o texto e o resultado da consulta para o servidor. Uma chave de acesso éum conjunto de palavras codificadas que estão relacionadas a palavras-chaves associadasaos registros da tabela pesquisada no banco de dados. A consulta retornará os registrosem que houver coincidência entre as palavras da chave de acesso Q e as palavras dosregistros da tabela.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
65

Como exemplo de um cenário de uso de busca encriptada, suponha que um de-terminado cliente deseja armazenar seus dados médicos criptografados em um banco dedados na nuvem, de forma que possa recuperar os registros seletivamente. O cliente as-socia um conjunto de palavras-chaves para cada registro da tabela, por exemplo tipo dadoença. Para usar a busca criptográfica, o cliente criptografa o conjunto de palavras cha-ves que estão associadas aos registros da tabela. Os registros dos dados médicos tambémsão criptografados usando algum esquema de criptografia padrão. As palavras-chaves eos dados médicos são armazenados em uma tabela no banco de dados. Para consultarregistros que estejam associados com a palavra "diabetes", o cliente cria uma chave deconsulta Q usando a palavra "diabetes"e envia a consulta para o servidor, que verificarcada palavra-chave da tabela e seleciona os registros onde existe correspondência entrea chave de consulta e a palavra-chace "diabetes", retornando estes registros para o cli-ente, caso existam. Neste caso, o servidor obtém a informação de quais registros foramretornados, mas não aprende nada sobre o conteúdo destes registros.
Esquemas de busca criptográfica podem utilizar esquemas criptográficos basea-dos em chave simétrica ou chave pública. Esquemas de chave pública são adequados paraatributos multi-usuário, em que qualquer cliente pode encriptar os dados utilizando parâ-metros públicos, mas somente um usuário pode realizar consultas aos dados. No esquemade chave simétrica, apenas o proprietário da chave secreta pode criar as palavras-chaves.A Tabela 2.17 mostra uma comparação entre os esquemas de criptografia de chave públicae chave simétrica.
Tabela 2.17. Comparação entre Esquemas de Busca Criptográfica. Fonte:[Sedghi 2012]
Busca criptográfica comchave simétrica
Busca criptográfica com chave pú-blica
Construção dotexto cifradopesquisável
Criado por uma chave se-creta
Criado por parâmetros públicos
Gerenciamentoda chave
Atributos de usuário único Atributos de multiusuário
Funcionalidade Busca por um palavra chave Busca por uma palavra chave e de-criptação parcial dos dados
Desempenho Mais eficiente Menos eficiente
2.6. Private Information RetrievalSegundo [Yang et al. 2011a], para proteger a privacidade do padrão de acesso a dados, aintenção de cada operação de acesso a dados deve ficar escondida de forma que quem esti-ver observando a transação, não obtenha nenhuma informação significativa. PIR - PrivateInformation Retrieval é uma técnica de consulta em bancos de dados públicos não cripto-grafados com proteção à violação de privacidade de acesso dos usuários. Uma violaçãode privacidade de acesso ocorre quando, além de aprender as propriedades dos dados es-tatísticos agregados, o provedor de nuvem pode, com alta probabilidade de acerto, saberdeterminada informação privada do usuário a partir de dados criptografados armazenados.Protocolos PIR permitem que clientes recuperem informações de bancos de dados públi-cos ou privados sem revelarem para os servidores de banco de dados quais registros são
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
66

recuperados. [Olumofin and Goldberg 2012] argumentam que, pela proteção do conteúdodas consultas, PIR pode proteger importantes domínios de aplicações, tais como banco dedados de patentes, banco de dados farmaceuticos, censo online, serviços baseados emlocalização e análise de comportamento online para propaganda pela rede.
Um esquema PIR modela o banco de dados como uma string binária x = x1,x2,x3,...,xn de tamanho n. Cópias idênticas desta string são armazenadas em k servidores, sendok ≥ 2. Os usuários possuem um índice i (um inteiro entre 1 e n) e estão interessados emobter o valor do bit xi fazem consultas aleatórias aos servidores e obtém respostas com asquais podem computar o bit xi. As consultas realizadas aos servidores são distribuidas in-dependentemente do valor de i para que os servidores não obtenham nenhuma informaçãosobre i. As consultas não recuperam necessariamente um bit em particular ou conjuntosde bits. Elas podem definir funções computadas pelos servidores, como por exemplo,uma consulta pode especificar um conjunto de índices entre 1 e n e a resposta do servidorpode ser o XOR dos bits que possuem estes índices.
O parâmetro de maior relevância nos esquemas PIR é a complexidade da comu-nicação entre o usuário e os servidores. Os protocolos mais eficientes para comunicaçaocom 2 servidores têm complexidade de comunicação de O(n
13 ) [Chor et al. 1998]. De-
vido ao fato dos esquemas PIR utilizarem dados não criptografados, [Yang et al. 2011b]argumenta que eles não são adequados para uso em ambientes de nuvens não confiáveis.
2.7. SMC-Secure Multiparty ComputationSMC (Secure Multiparty Computation) é técnica de processamento distribuido de dados,com garantia de privacidade. No SMC, um conjunto de partes interessadas deseja avaliaralguma função de interesse comum ao grupo e para tal processa dados individuais priva-dos sem revelar estes dados uns aos outros. Apenas a saída da função é disponibilizadapara todas as partes. O processamento de dados de forma colaborativa é muitas vezesnecessário em ambiente de nuvem. No processamento distribuído, as partes podem seradversários passivos que tentam obter informação "extra"sobre os dados de outras partes.Neste método, cada cliente Ci possui uma entrada privada xi, e todos os clientes compu-tam uma função pública f (x1,x2,x3,...,xn) sem revelar xi para os outros, exceto o que podeser derivado da entrada ou saída da função.
2.8. Anonimização por DecomposiçãoA criptografia é uma ferramenta útil para proteção da confidencialidade de dados sensí-veis. Entretanto, quando os dados são encriptados, a realização de consultas se torna umdesafio. Assim, embora a encriptação dos dados proporcione confidencialidade, os dadosencriptados são muito menos convenientes para uso do que os dados descriptografados.Quando utilizada com bancos de dados relacionais, a criptografia cria dois grandes pro-blemas. O primeiro problema é que os bancos relacionais requerem que os tipos de dadossejam definidos antes do seu armazenamento. O segundo problema é que consultas oufunções não podem ser executadas sobre dados criptografados. Não é possível avaliarfaixas de datas ou fazer comparações de valores em dados criptografados. As estruturasde índice também não podem ser utilizadas.
Adicionalmente, os métodos baseados em criptografia precisam incluir estraté-
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
67

gias de geração e distribuição de chaves [Tian and Zhang 2012]. Porém, existem váriasdesvantagens relacionadas com a gestão de chaves criptográficas, tais como:
a) A necessidade de guardar as chaves pelo mesmo tempo em que os dados permanece-rem criptografados.
b) A atribuição ou a revogação de chaves para o acesso aos dados por parte dos usuários.
c) A necessidade de manter múltiplas cópias encriptadas do mesmo arquivo, para acessomulti-usuário utilizando chave-pública.
Neste sentido, novas técnicas para assegurar a privacidade dos dados armazenadosna nuvem, que não sejam baseadas em criptografia, tornam-se necessárias em diversoscenários de aplicação. Desta forma, esta seção apresenta uma estratégia para preservar aprivacidade dos dados armazenados na nuvem, denominada "decomposição", que utilizadecomposição e dispersão de arquivos para separar dados em partes irreconhecíveis earmazená-las em servidores distribuídos na nuvem. Além disso, a abordagem propostanão criptografa os dados a serem armazenados e processados na nuvem.
A técnica de "decomposição"extrai informações dos arquivos de dados sobre quan-tidade, qualidade e medida. Os arquivos de dados são considerados objetos. Cada objeto,segundo Hegel, na doutrina do SER [HEGEL 1988], possui três características que o de-terminam: a qualidade, a quantidade e a medida. Em um arquivo de dados, a qualidade érepresentada pelas 256 combinações possíveis dos 8 bits que formam os bytes que com-põem o arquivo. A quantidade é o número de vezes que cada byte é encontrado no arquivoe a medida é a ordem em que os bytes estão dispostos no arquivo. Por exemplo, em um ar-quivo de 256 bytes onde ocorrem apenas os bytes que representam as letras "A","B","C"e"D"em igual proporção, por exemplo:
Arquivo: "ABCDABCDABCDABCDABCDABCDABCD...ABCD"(256 bytes)Quantidade: 64(A), 64(B), 64(C) ,64(D)Qualidade: A,B,C,DMedida: A (1o,5o,9o,13o...253o), B (2o,6o,10o,14o...,254o), C (3o,7o,11o,15o...,255o), D(4o,8o,12o,16o,256o)
A seguir, apresentamos as etapas que compõem a técnica de "decomposição":
1) O algoritmo de decomposição lê sequências de 256 bytes do arquivo de dados. Iremosnos referir de agora em diante a este conjunto de bytes como I-Objeto.
2) O algoritmo extrai as informações de qualidade, quantidade e medida do I-Objeto, ar-mazenando estas informações em dois arrays com tamanho de 256 elementos cadaum: o array de inteiros Quantidade-Qualidade[256] e o array de caracteres Me-dida[256]. Iremos nos referir a estes arrays como vetores daqui por diante.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
68

3) O vetor Quantidade-Qualidade[256] irá armazenar, para cada um dos diferentes bytesexistentes no I-Objeto, o número de vezes que este byte é encontrado no I-Objeto. Porexemplo, se o byte 000011112 = 1510 estiver presente 20 vezes no I-Objeto, o itemQuantidade-Qualidade[15] será igual a 20. Caso o byte 1510 não estiver presente, ovalor do item Quantidade-Qualidade[15] será igual a zero.
4) Para cada item do vetor Quantidade-Qualidade, o algoritmo de decomposição, con-verte o valor do item em uma sequência de bits ’1’, caso o elemento do vetor sejamaior que zero. Exemplo: Quantidade-Qualidade[25]=3 ⇒ VetorBits[25] = ’111’.Caso o elemento do vetor Quantidade-Qualidade seja igual a zero, o VetorBits não iráarmazenar nenhum valor.
5) Os itens do VetorBits são concatenados da seguinte forma: VetorBits[0]+’0’+ Vetor-Bits[1]+’0’+,...+’0’+VetorBits[255], produzindo um vetor de 512 elementos, que éusado como entrada em uma função que lê o vetor em sequências de 8 itens e convertepara a representação ASCII correspondente, criando uma sequência de 64 bytes, queé gravada no arquivo quantidade-qualidade.dec. Ex: ’01000001’ é convertido para aletra ’A’
6) O vetor de caracteres Medida[256] irá armazenar, para cada elemento do vetor Quan-tidade-Qualidade[256] > 0, a ordem em que os bytes aparecem no I-Objeto. A posiçãodos bytes irá variar de 0 a 255, representando do 1o ao 256o byte contido no bloco dedados. O vetor usará o valor decimal do byte para representar os valores das posiçõesdos bytes do I-Objeto. A Tabela 2.18 mostra um exemplo em que o byte-1 ocorre 3vezes e o byte-3 ocorre 1 vez no I-Objeto e não há ocorrência dos bytes 0, 2 e 255. Ovetor Medida[256] é gravado no arquivo medida.dec.
Tabela 2.18. Exemplo de Preenchimento de Vetores de Qualidade-Quantidade e Medida
Itens Vetor Quanti-dade_Qualidade[256]
Itens Vetor Medida[256]
Quantidade_Qualidade[0]=0Quantidade_Qualidade[1]=3 Medida[1] = 510 = 0000 01012
Medida[2] = 2710=0001 10112Medida[3] = 4310 =0010 10112
Quantidade_Qualidade[2]=0Quantidade_Qualidade[3]=1 Medida[4] = 5410 =0011 01102...Quantidade_Qualidade[255]=0
Os arquivos medida.dec e quantidade-qualidade.dec são armazenados em prove-dores de nuvem diferentes. Neste caso, cada um dos arquivos é insuficiente para recons-truir o arquivo original. Por exemplo, supondo que o provedor que possua o arquivoquantidade-qualidade.dec tentasse reconstruir um bloco de 256 bytes do arquivo original.Utilizando o método de força-bruta para tentar reconstruir a sequência de 256 bytes deum I-Objeto, a probabilidade do provedor descobrir a sequência correta dos bytes, conhe-cendo a quantidade e a qualidade é uma permutação repetida P de 256 elementos: Prob =
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
69

1/P256n1,n2,n3... , onde n1,n2,n3... são os itens de quantidade e qualidade conhecidos. Para
um I-Objeto com apenas 1 byte de qualidade ou quantidade, a probabilidade é de 1/256.Para um I-Objeto com 2 bytes diferentes, a probabilidade é de aproximadamente 1/1076.A medida que a quantidade de itens de quantidade ou qualidade aumenta, a probabilidadede descoberta da ordem dos bytes tende a zero. Com 10 bytes diferentes no I-Objeto,a probabilidade já chega a 1/10256. Para o provedor de nuvem que armazena o arquivomedida.dec, ou seja, a ordem em que os bytes estão dispostos no bloco, a probabilidadede recomposição do I-Objeto, utilizando força-bruta é 1/256!, ou seja, aproximadamente1/10506. Quanto maior for o arquivo, maior será a dificuldade do atacante para reconstrui-lo.
As vantagens desta técnica sobre as técnicas convencionais que utilizam cripto-grafia para garantir confidencialidade dos dados armazenados na nuvem são as seguintes:
a) Não utilização de chaves criptográficas.
b) Aplicabilidade da técnica para soluções SaaS, PaaS e IaaS sem que haja nenhumaalteração nas interfaces dos aplicativos do usuário.
c) A técnica pode ser aplicada a qualquer formato de dado armazenado (dados e progra-mas).
d) Não há limitação máxima para o tamanho do arquivo a ser anonimizado.
e) A solução suporta expurgo de dados da nuvem, pois os arquivos disponibilizados emprovedores distintos não revelam informações sobre os dados originais. Caso o usuáriodeixe a nuvem, os dados podem ser considerados automaticamente expurgados.
A recomposição do arquivo original é feita pela recuperação dos arquivos quanti-dade-qualidade.dec e medida.dec que estão armazenados em 2 provedores distintos nanuvem, que são utilizados como entrada para o algoritmo de remontagem do arquivooriginal. A complexidade computacional do algoritmo de recomposição é de O(n). Acomplexidade de comunicação é de O(5×n
4 ), devido a soma do tamanho dos arquivosquantidade-qualidade.dec e medida.dec ser 25% maior do que o tamanho do arquivo ori-ginal.
2.9. Considerações FinaisPara que todo o potencial da computação em nuvem possa ser explorado pelas organiza-ções, é de fundamental importância garantir a segurança e a privacidade dos dados arma-zenados na nuvem. Nos últimos anos, vários mecanismos para assegurar privacidade dosdados armazenados na nuvem têm sido propostos [Stefanov and Shi 2013, Li et al. 2013,Yang et al. 2013, Jung et al. 2013, Yeh 2013, Nimgaonkar et al. 2012]. Este minicursodiscutiu o problema da privacidade dos dados armazenados e processados nos ambientesde computação em nuvem, bem como as principais abordagens atualmente existentes parasolucionar este importante problema. Por fim, uma nova técnica para assegurar a privaci-dade dos dados processados e armazenados nos ambientes de computação em nuvem foiapresentada.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
70

Referências[Aggarwal 2005] Aggarwal, C. C. (2005). On k-anonymity and the curse of dimensionality. In
Proceedings of the 31st international conference on Very large data bases, pages 901–909.VLDB Endowment.
[Aggarwal and Philip 2004] Aggarwal, C. C. and Philip, S. Y. (2004). A condensation approachto privacy preserving data mining, pages 183–199. Springer.
[Camenisch et al. 2011] Camenisch, J., Fischer-Hübner, S., and Rannenberg, K. (2011). Privacyand identity management for life. Springer.
[Cao and Karras 2012] Cao, J. and Karras, P. (2012). Publishing microdata with a robust privacyguarantee. Proc. VLDB Endow., 5(11):1388–1399.
[Chen and Liu ] Chen, K. and Liu, L. Privacy preserving data classification with rotation per-turbation. In Proceedings of the Fifth IEEE International Conference on Data Mining, pages589–592. IEEE Computer Society.
[Chor et al. 1998] Chor, B., Kushilevitz, E., Goldreich, O., and Sudan, M. (1998). Private infor-mation retrieval. Journal of the ACM (JACM), 45(6):965–981.
[Clarke 1999] Clarke, R. (1999). Introduction to dataveillance and information privacy, and defi-nition of terms.
[Domingo-Ferrer 2008] Domingo-Ferrer, J. (2008). A survey of inference control methods forprivacy-preserving data mining, pages 53–80. Springer.
[Duncan et al. 2001] Duncan, G. T., Keller-McNulty, S. A., and Stokes, S. L. (2001). Disclosurerisk vs. data utility: The ru confidentiality map. In Chance. Citeseer.
[Fung et al. 2010] Fung, B. C., Wang, K., Fu, A. W.-C., and Yu, P. S. (2010). Introduction toPrivacy-Preserving Data Publishing: Concepts and Techniques. Chapman-Hall.
[Fung et al. 2007] Fung, B. C. M., Ke, W., and Yu, P. S. (2007). Anonymizing classification datafor privacy preservation. Knowledge and Data Engineering, IEEE Transactions on, 19(5):711–725.
[Gionis et al. 2008] Gionis, A., Mazza, A., and Tassa, T. (2008). k-anonymization revisited. InData Engineering, 2008. ICDE 2008. IEEE 24th International Conference on, pages 744–753.IEEE.
[Gruschka and Jensen 2010] Gruschka, N. and Jensen, M. (2010). Attack surfaces: A taxonomyfor attacks on cloud services. In Cloud Computing (CLOUD), 2010 IEEE 3rd InternationalConference on, pages 276–279.
[Guttman and Roback 1995] Guttman, B. and Roback, E. A. (1995). An introduction to computersecurity: the NIST handbook. DIANE Publishing.
[HEGEL 1988] HEGEL, G. (1988). Enciclopédia das ciências filosóficas em epítome. 3 vols.lisboa.
[Hon et al. 2011] Hon, W. K., Millard, C., and Walden, I. (2011). The problem of ‘personaldata’in cloud computing: what information is regulated?—the cloud of unknowing. Internati-onal Data Privacy Law, 1(4):211–228.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
71

[Jansen and Grance 2011] Jansen, W. and Grance, T. (2011). Guidelines on security and privacyin public cloud computing. NIST Special Publication, pages 800–144.
[Jr et al. 2010] Jr, A. M., Laureano, M., Santin, A., and Maziero, C. (2010). Aspectos de segu-rança e privacidade em ambientes de computação em nuvem.
[Jung et al. 2013] Jung, T., Li, X.-y., Wan, Z., and Wan, M. (2013). Privacy preserving cloud dataaccess with multi-authorities. In INFOCOM, 2013 Proceedings IEEE, pages 2625–2633.
[Krutz and Vines 2010] Krutz, R. L. and Vines, R. D. (2010). Cloud security: A comprehensiveguide to secure cloud computing. Wiley. com.
[Lane 2012] Lane, A. (2012). Understanding and selecting data masking solutions: Creatingsecure and useful data.
[Last et al. 2014] Last, M., Tassa, T., Zhmudyak, A., and Shmueli, E. (2014). Improving accuracyof classification models induced from anonymized datasets. Information Sciences, 256:138–161.
[Li et al. 2013] Li, M., Yu, S., Ren, K., Lou, W., and Hou, Y. T. (2013). Toward privacy-assuredand searchable cloud data storage services. Network, IEEE, 27(4):56–62.
[Liang and Yuan 2013] Liang, H. and Yuan, H. (2013). On the complexity of t-closeness anony-mization and related problems. In Database Systems for Advanced Applications, pages 331–345. Springer.
[Liu 2010] Liu, H. (2010). A new form of dos attack in a cloud and its avoidance mechanism. InProceedings of the 2010 ACM workshop on Cloud computing security workshop, pages 65–76.ACM.
[Liu et al. 2012] Liu, J., Xiao, Y., Li, S., Liang, W., and Chen, C. L. P. (2012). Cyber security andprivacy issues in smart grids. Communications Surveys & Tutorials, IEEE, 14(4):981–997.
[Machanavajjhala et al. 2006] Machanavajjhala, A., Gehrke, J., Kifer, D., and Venkitasubrama-niam, M. (2006). L-diversity: privacy beyond k-anonymity. In Data Engineering, 2006. ICDE’06. Proceedings of the 22nd International Conference on, pages 24–24.
[Mohammed et al. 2009] Mohammed, N., Fung, B. C., Hung, P. C., and Lee, C.-k. (2009).Anonymizing healthcare data: A case study on the blood transfusion service. In Proceedings ofthe 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,KDD ’09, pages 1285–1294, New York, NY, USA. ACM.
[Muralidhar and Sarathy 1999] Muralidhar, K. and Sarathy, R. (1999). Security of random dataperturbation methods. ACM Transactions on Database Systems (TODS), 24(4):487–493.
[Nimgaonkar et al. 2012] Nimgaonkar, S., Kotikela, S., and Gomathisankaran, M. (2012). Ctrust:A framework for secure and trustworthy application execution in cloud computing. In CyberSecurity (CyberSecurity), 2012 International Conference on, pages 24–31.
[Ninghui et al. 2007] Ninghui, L., Tiancheng, L., and Venkatasubramanian, S. (2007). t-closeness: Privacy beyond k-anonymity and l-diversity. In Data Engineering, 2007. ICDE2007. IEEE 23rd International Conference on, pages 106–115.
[Olumofin and Goldberg 2012] Olumofin, F. and Goldberg, I. (2012). Revisiting the computatio-nal practicality of private information retrieval, pages 158–172. Springer.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
72

[Pearson 2013] Pearson, S. (2013). Privacy, Security and Trust in Cloud Computing, pages 3–42.Springer.
[Pfitzmann and Köhntopp 2005] Pfitzmann, A. and Köhntopp, M. (2005). Anonymity, unobser-vability, and pseudonymity—a proposal for terminology. In Designing privacy enhancing te-chnologies, pages 1–9. Springer.
[Samarati 2001] Samarati, P. (2001). Protecting respondents identities in microdata release. Kno-wledge and Data Engineering, IEEE Transactions on, 13(6):1010–1027.
[Samarati and Sweeney 1998] Samarati, P. and Sweeney, L. (1998). Protecting privacy when dis-closing information: k-anonymity and its enforcement through generalization and suppression.Technical report, Technical report, SRI International.
[Sedghi 2012] Sedghi, S. (2012). Towards provably secure efficiently searchable encryption. Uni-versity of Twente.
[Spiekermann and Cranor 2009] Spiekermann, S. and Cranor, L. F. (2009). Engineering privacy.Software Engineering, IEEE Transactions on, 35(1):67–82.
[Stallings 2007] Stallings, W. (2007). Network security essentials: applications and standards.Pearson Education India.
[Stefanov and Shi 2013] Stefanov, E. and Shi, E. (2013). Oblivistore: High performance oblivi-ous cloud storage. In Security and Privacy (SP), 2013 IEEE Symposium on, pages 253–267.
[Subashini and Kavitha 2011] Subashini, S. and Kavitha, V. (2011). Review: A survey on securityissues in service delivery models of cloud computing. J. Netw. Comput. Appl., 34(1):1–11.
[Tassa et al. 2012] Tassa, T., Mazza, A., and Gionis, A. (2012). k-concealment: An alternativemodel of k-type anonymity. Transactions on Data Privacy, 5(1):189–222.
[Tian and Zhang 2012] Tian, M. and Zhang, Y. (2012). Analysis of cloud computing and itssecurity. In International Symposium on Information Technology in Medicine and Education(ITME), TIME ’12.
[Wang and Fung 2006] Wang, K. and Fung, B. C. M. (2006). Anonymizing sequential releases.In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discoveryand Data Mining, KDD ’06, pages 414–423, New York, NY, USA. ACM.
[Wong et al. 2010] Wong, W. K., Mamoulis, N., and Cheung, D. W. L. (2010). Non-homogeneousgeneralization in privacy preserving data publishing. In Proceedings of the 2010 ACM SIGMODInternational Conference on Management of data, pages 747–758. ACM.
[Yang et al. 2013] Yang, K., Jia, X., Ren, K., Zhang, B., and Xie, R. (2013). Dac-macs: Effectivedata access control for multiauthority cloud storage systems. IEEE Transactions on InformationForensics and Security, 8(11):1790–1801.
[Yang et al. 2011a] Yang, K., Zhang, J., Zhang, W., and Qiao, D. (2011a). A light-weight solutionto preservation of access pattern privacy in un-trusted clouds. In Proceedings of the 16th Eu-ropean Conference on Research in Computer Security, ESORICS’11, pages 528–547, Berlin,Heidelberg. Springer-Verlag.
[Yang et al. 2011b] Yang, K., Zhang, J., Zhang, W., and Qiao, D. (2011b). A light-weight solutionto preservation of access pattern privacy in un-trusted clouds, pages 528–547. Springer.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
73

[Yeh 2013] Yeh, C.-H. (2013). A secure shared group model of cloud storage. In Proceedings ofthe 2013 27th International Conference on Advanced Information Networking and ApplicationsWorkshops, WAINA ’13, pages 663–667, Washington, DC, USA. IEEE Computer Society.
[Zhifeng and Yang 2013] Zhifeng, X. and Yang, X. (2013). Security and privacy in cloud com-puting. Communications Surveys & Tutorials, IEEE, 15(2):843–859.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
74

Sobre os AutoresEliseu Castelo Branco Júnior é aluno do Curso de Doutorado em Ciências da Computação doMDCC-Mestrado e Doutorado em Ciências da Computação da UFC-Universidade Federal do Ce-ará e Professor do Centro Universitário Estácio do Ceará desde 2000. Possui graduação em Ba-charelado em Filosofia pela Universidade Estadual do Ceará (1992),Especialização em Redes deComputadores(1994) e Mestrado em Informática Aplicada pela UNIFOR-Universidade de Forta-leza(2001). Possui e Especialização em Ciências da Computação(1995) pela UFC. Atualmenteé Coordenador de Curso de Pos-graduação em Gestão de Projetos do Centro Universitário Está-cio do Ceará. Possui experiência na área de Ciência da Computação, com ênfase em Sistemasde Informação, atuando nos seguintes temas: computação em nuvem, segurança da informação,privacidade de dados, gerência de projetos, multicritério, avaliação de qualidade e processos desoftware. Prof. Eliseu Castelo Branco Jr. é autor de artigos publicados em periódicos e conferên-cias internacionais e nacionais.
Javam de Castro Machado possui graduação em Processamento de Dados pela UniversidadeFederal do Ceará (1987), mestrado em Ciências da Computação pela Universidade Federal doRio Grande do Sul (1990), Diplome dEtudes Approfondies (Dea) em Informática - Universite deGrenoble I (1992) e doutorado em Informática também pela Universite de Grenoble I (1995). Foidiretor da Secretaria de Tecnologia de Informação da UFC por 8 anos. Atualmente é professorassociado do Departamento de Computação da Universidade Federal do Ceará, Vice-diretor doCentro de Ciências da mesma Universidade e coordenador do Laboratório de Sistemas e Bancode Dados (LSBD). É também coordenador de vários projetos de pesquisa e desenvolvimento emComputação, além de atuar como pesquisador do Programa de Mestrado e Doutorado em Ciênciada Computação da UFC. Prof Javam tem vários artigos publicados em veículos nacionais e inter-nacionais e participa de projetos de cooperação internacional com universidades européias. Nomomento suas áreas de interesse são sistemas de banco de dados e computação em nuvens, alémde sistemas distribuídos
José Maria da Silva Monteiro Filho é professor Adjunto do Departamento de Computação daUniversidade Federal do Ceará, onde leciona nos cursos de graduação, mestrado e doutorado emCiência da Computação. Possui graduação em Bacharelado em Computação pela UniversidadeFederal do Ceará (1998), mestrado em Ciência da Computação pela Universidade Federal doCeará (2001) e doutorado em Informática pela Pontifícia Universidade Católica do Rio de Janeiro- PUC-Rio (2008). Tem mais de 15 anos de experiência na área de Ciência da Computação,com ênfase em Banco de Dados e Engenharia de Software, atuando principalmente nos seguintestemas: sintonia automática de bancos de dados, bancos de dados em nuvem, big data, data sciencee qualidade de software. Prof. José Maria Monteiro é autor de mais de 30 artigos publicados emperiódicos e conferências internacionais e nacionais.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
75

Capítulo 3
Otimização de Desempenho em Processamento de
Consultas MapReduce
Ivan Luiz Picoli, Leandro Batista de Almeida, Eduardo Cunha de Almeida
Abstract
Performance tuning in MapReduce query processing systems is a current hot topic in
database research. Solutions like Starfish and AutoConf provide mechanisms to tune
MapReduce queries by changing the values of the configuration parameters for the entire
query plan. In this course, it will be presented some performance tuning solutions for
query processors based on MapReduce focused on a solution using Hadoop, Hive and
AutoConf. Furthermore, it will be presented how the unsupervised learning can be used
as a powerful tool for the parameter tuning.
Resumo
Otimização de desempenho em processamento de consulta MapReduce é um tópico de
pesquisa bastante investigado atualmente. Soluções como o Starfish e AutoConf fornecem
mecanismos para ajustar a execução de consultas MapReduce através da alteração de
parâmetros de configuração. Neste minicurso serão apresentadas soluções de tuning
para processadores de consulta baseados em MapReduce com foco principal numa
solução baseada em Hadoop, Hive e AutoConf. Além disso, iremos discutir como um
sistema de aprendizado de máquina não supervisionado pode ser utilizado como uma
poderosa ferramenta na tarefa de configuração de parâmetros do sistema.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
cap:3
76

3.1 Introdução
Na última década, houve um crescimento exponencial na quantidade de dados a serem
armazenados na rede mundial. A Internet se tornou o meio de comunicação mais utilizado
do planeta e devido à facilidade que essa tecnologia proporciona cada vez mais pessoas
se juntam às redes sociais e utilizam sistemas em nuvem para armazenar arquivos e
assistir vídeos em alta resolução. Além disso, ligações utilizando voz sobre IP também
crescem a cada ano, auxiliando no aumento do tráfego de dados. Segundo a empresa
Cisco, em 2015 o tráfego de dados mundial anual atingirá 1.0 ZB, o que equivale a 87,125
PB por mês [Cisco 2012]. Aliado a isso, sistemas de business intelligence começam a
utilizar uma massa de dados cada vez maior, para gerar relatórios e estratégias de negócio.
Fatores como: crescente massa de dados, a exaustão de recursos dos sistemas
centralizados e seu custo mais alto para aumento de capacidade exige escalabilidade dos
sistemas, obrigando a utilização de sistemas distribuídos. A escalabilidade gera grandes
esforços de hardware e software para o armazenamento, processamento e transferência
de informações, e processos que levavam algumas horas passam a levar dias para
concluírem. Da mesma forma, podemos analisar os esforços no desenvolvimento de
novos sistemas de banco de dados e data warehouse distribuídos, de acordo com a
necessidade de processamento.
Com o crescimento da demanda de processamento analítico, outro esforço no
desenvolvimento de novos data warehouses baseados em sistemas escaláveis é atender
as propriedades MAD (Magnetic, Agile e Deep) [Cohen 2009] criadas em 2009 que
determinam uma arquitetura para padronização e realização de business inteligence em
data warehouses. Essas características exigem que o sistema de data warehouse seja
capaz de processar em tempo hábil toda a demanda requisitada. No cenário de hoje,
reduzir o tempo em processamento de consultas pode gerar benefícios como economia
no uso de recursos de hardware [Babu e Herodotou 2011]. O presente minicurso aborda
os esforços atuais e formas de otimização do desempenho de data warehouses baseados
em MapReduce. Também apresentaremos uma solução de otimização de consultas
baseada em uma abordagem de aprendizado não supervisionada de máquinas.
3.2. BigData
O conceito de Big Data é amplo, mas pode ser resumidamente definido como o
processamento (eficiente e escalável) analítico de grandes volumes de dados complexos,
produzidos por possivelmente várias aplicações [Labrinidis e Jagadish 2012]. É uma
estratégia que se adequa a cenários onde se faz necessário analisar dados semiestruturados
e não estruturados, de uma variedade de fontes, além dos dados estruturados
convencionalmente tratados. Também se mostra interessante quando o conjunto completo
de informações de uma determinada fonte deve ser analisada e processada, isso torna o
processamento lento, permitindo análises interativas e exploratórias.
Esses conceitos se apoiam nos chamados “V”s de BigData: Variedade, Volume e
Velocidade, além de Veracidade e Valor [Troester 2012]. De maneira simplista, a
Variedade mostra que os dados podem vir de fontes das mais diversas, com estrutura ou
não, em formatos também diversificados. O Volume acrescenta a complexidade de se
tratar espaços de dados da ordem de Pb ou Zb, e a Velocidade exige que esse
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
77

processamento ocorra ainda em tempo suficientemente pequeno para que as análises
possam ser de utilidade. O Valor e Veracidade se referenciam a confiabilidade, correlação
e validação das informações. Analisado pela ótica dos “V”s, o panorama de BigData se
mostra complexo e com tarefas que fogem ao que geralmente é encontrado em
processamento de dados.
Sendo assim, novas técnicas de processamento distribuído vêm sendo
pesquisadas, desenvolvidas e aprimoradas. Uma das tecnologias existentes é o
MapReduce [Dean e Ghemawat 2004]. Desenvolvido para simplificar o processamento
distribuído, o MapReduce torna os problemas de escalabilidade transparentes,
possibilitando que um programa do usuário seja executado de forma distribuída sem a
preocupação com os diversos fatores que dificultam esse tipo de programação. Exemplos
de dificuldades são as falhas de rede e a comunicação entre os nodos de armazenamento
espalhados pela rede.
3.3. MapReduce
O MapReduce, desenvolvido em 2004 pela Google Inc. [Dean e Ghemawat 2004]
foi projetado para simplificar as tarefas de processamento distribuído que necessitavam
de escalabilidade linear. Esse tipo de tarefa e plataformas baseadas em nuvem podem ser
reduzidas às aplicações MapReduce, juntamente com o ecossistema de aplicações
envolvidas a partir dessa tecnologia emergente [Labrinidis e Jagadish 2012] .
As principais características do MapReduce são a transparência quanto à programação
distribuída. Dentre elas se encontram o gerenciamento automático de falhas, de
redundância dos dados e de transferência de informações; balanceamento de carga; e a
escalabilidade. O MapReduce é baseado na estrutura de dados em formato de chave/valor.
Gerenciar uma grande quantidade de dados requer processamento distribuído, e o uso de
sistemas de armazenamento e busca utilizando pares de chave/valor tornou-se comum
para esse tipo de tarefa, pois oferecem escalabilidade linear.
O Hadoop [Apache 2014] é uma implementação de código aberto do MapReduce,
hoje gerenciado e repassado a comunidade de desenvolvedores através da Fundação
Apache. Existem outras implementações baseadas em MapReduce, como por exemplo o
Disco [Papadimitriou e Sum 2008], Spark [UC Berkeley 2012], Hadapt [Abouzeid 2011]
e Impala [Cloudera 2014].
3.3.1. Arquitetura do MapReduce
Uma tarefa ou Job é um programa MapReduce sendo executado em um cluster de
máquinas. Os programas são desenvolvidos utilizando as diretivas Map e Reduce, que em
linguagem de programação são métodos definidos pelo programador. Abaixo é detalhado
o modelo de cada primitiva.
Map: Processa cada registro da entrada, gerando uma lista intermediária de pares
chave/valor;
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
78

Reduce: A partir da lista intermediária, combina os pares que contenham a mesma
chave, agrupando os valores;
Para exemplificar o modelo MapReduce utilizaremos um programa que realiza a
contagem da frequência de palavras em um arquivo texto. A Figura 3.1 ilustra um
programa MapReduce.
A função map recebe por parâmetro uma chave (nome do documento) e um valor
(conteúdo do documento) e para cada palavra emite um par intermediário onde a chave é
a palavra e o valor é o inteiro 1. A função reduce recebe como parâmetro uma chave (a
palavra) e o valor (no caso, uma lista de inteiros 1 emitidos por map), em seguida a
variável result recebe a soma dos valores contidos na lista values, e por fim a função
emite o valor total de ocorrências da palavra contida em key.
Figura 3.1. Primitivas Map e Reduce contando a frequência de palavras em um texto [Dean e Ghemawat 2004]
3.3.2. Hadoop
O Hadoop é um framework de código aberto desenvolvido na linguagem Java, C
e Bash. O framework disponibiliza bibliotecas em Java (.jar) para desenvolvimento de
aplicações MapReduce, onde o programador poderá criar suas próprias funções Map e
Reduce.
3.3.2.1. Entrada e Saída de Dados
O Hadoop possui o HDFS (Hadoop Distributed File System) [Shvachko 2010]
como sistema de arquivos, sendo responsável pela persistência e consistência dos dados
distribuídos. Ele também possui transparência em falhas de rede e replicação dos dados.
Para que o Hadoop processe informações, essas devem estar contidas em um diretório do
HDFS. Os dados de entrada são arquivos de texto, que serão interpretados pelo Hadoop
como pares de chave/valor de acordo com o programa definido pelo desenvolvedor
MapReduce. Após o processamento da tarefa, a saída é exportada em um ou vários
arquivos de texto armazenados no HDFS e escritos no formato chave/valor.
3.3.2.2. Arquitetura do Hadoop
O software é dividido em dois módulos, o sistema de arquivos global denominado
HDFS e o módulo de processamento. Como arquitetura do sistema distribuído temos uma
máquina que coordena as demais denominada master, e as outras máquinas de
processamento e armazenamento denominadas slaves ou workers.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
79

DataNode: cliente do HDFS que gerencia o armazenamento local de dados e
controla pedidos de leitura e escrita em disco;
NameNode: servidor mestre do HDFS que gerencia a distribuição dos arquivos
na rede e controla o acesso aos arquivos;
JobTracker: servidor mestre do motor de processamento do Hadoop; é
responsável por coordenar a distribuição das funções Map e Reduce para cada
nodo.
TaskTracker: cliente do motor de processamento do Hadoop; é responsável por
executar as funções Map e Reduce recebidas do JobTracker sobre os dados locais
do próprio nodo;
O motor de processamento MapReduce é formado pelo servidor JobTracker e
vários clientes TaskTracer. Usualmente, mas não necessariamente, executa-se um
DataNode e um TaskTracker por nodo, enquanto que executa-se apenas um
JobTracker e um NameNode em toda a cluster/rede.
A Figura 3.2 mostra a arquitetura do Hadoop e seus módulos.
Figura 3.2. Arquitetura do Hadoop e seus módulos
Algumas tarefas importantes executadas pelo servidor mestre (master node) são
as descritas abaixo.
Controla as estruturas de dados necessárias para a gerência do cluster, como o
endereço das máquinas de processamento, a lista de tarefas em execução e o
estado das mesmas;
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
80

Armazena o estado de tarefas Map e Reduce, como: idle (em espera), in-progress
(sendo processada) ou completed (completa);
Armazena as regiões e tamanhos dos arquivos onde estão localizados os pares
intermediários de chave/valor;
Controla todos os “workers” (máquinas que executam Datanode e Tasktracker),
verificando se estão ativos através de estímulos por “ping”.
A Figura 3.3 mostra o fluxo de informações citadas nesta seção, usando como
exemplo a contagem de palavras. O processamento inicia-se a partir de arquivos
armazenados no HDFS. Esses arquivos são divididos em partes de acordo com o tamanho
definido nos parâmetros de configuração. Uma das máquinas é definida para executar o
servidor mestre, responsável por atribuir tarefas de Map e Reduce às demais denominadas
workers. Os workers lêem sua partição de entrada, produzindo as chaves e valores que
serão passadas para a função Map definida pelo usuário. Pares intermediários de chave e
valor são armazenados em buffer na memória e periodicamente salvos em disco em
regiões de memória que são enviadas ao servidor mestre.
Figura 3.3. Fluxo de informações durante um programa MapReduce para contar palavras
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
81

O fluxo de informações pode ser dividido nas fases a seguir:
SPLIT - Fase em que a entrada é dividida entre os workers disponíveis;
MAP - Execução das funções Map;
SHUFFLE - Fase em que pode ocorrer o agrupamento das saídas dos Maps pela
chave, facilitando os trabalhos de Reduce;
REDUCE - Execução das funções Reduce;
OUTPUT - Criação dos dados de saída contendo o resultado do Job.
3.4. Frameworks construídos sobre sistemas baseados em MapReduce
O uso do MapReduce e do Hadoop em ambientes de produção cresceu na última
década devido a grande massa de dados denominada BigData. Pode-se destacar o uso
dessas tecnologias principalmente nas grandes empresas de tecnologia da informação.
Para cada situação do cotidiano da empresa novos programas MapReduce eram gerados,
porém, com o tempo o número de programas cresceu e tornou-se inviável a reescrita de
programas todos os dias conforme a necessidade da empresa. Tendo em vista o desafio
de gerar programas MapReduce mais eficazes e rapidamente, a empresa Facebook
desenvolveu o Data Warehouse Apache Hive [Thusoo 2009] que hoje é gerenciado pela
Fundação Apache e possui código aberto.
O Hive é um exemplo de framework desenvolvido sobre o Hadoop. Ele possui
uma linguagem declarativa chamada HiveQL para geração de consultas. O principal
objetivo desse framework é a geração automática de programas MapReduce através da
análise da consulta HiveQL para manipulação do data warehouse. A linguagem HiveQL
não possibilita alteração e deleção de registros, mas possibilita a criação de tabelas e
importação de dados de arquivos. Possibilita também criar partições nos dados para
melhorar o desempenho do sistema. Quando uma partição é criada, a tabela é dividida em
subtabelas internamente, tornando possível selecionar os dados apenas de uma partição
se assim desejar. Isso auxilia na redução de leitura em disco. A Figura 3.4 mostra um
script HiveQL gerado pela empresa Facebook.
Figura 3.4. Exemplo de script HiveQL [Thusoo 2009]
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
82

Podemos observar na Figura 3.4 a manipulação de duas tabelas e a execução de
um join. Após, é populada a tabela gender_summary que conterá o resultado do
agrupamento pelo atributo gender. E por fim, é populada a tabela school_summary
contendo o resultado do agrupamento pela escola.
Existem diversos frameworks desenvolvidos sobre sistemas baseados em
MapReduce, outro exemplo de framework sobre o Hadoop é o Pig [Olston 2008] e sua
linguagem declarativa PigLatin. Outro exemplo de framework é o Shark sobre o Spark
[UC Berkeley 2012]. Além de sistemas de data warehouse, existem frameworks para
otimização das tarefas executadas. Existem várias formas de otimizar a execução de uma
tarefa, uma delas é ajustar os valores dos parâmetros de configuração do sistema
MapReduce. O Hadoop, por exemplo, possui mais de 200 parâmetros de configuração.
Um exemplo de framework construído sobre o Hadoop para otimização é o Starfish
[Herodotou 2011], sendo responsável por sugerir uma melhor configuração de parâmetros
ao administrador do sistema para cada tarefa MapReduce executada.
3.5. Otimização de Consultas em MapReduce
Nesta seção apresentamos de forma geral como funciona a otimização de
desempenho do processamento de consultas MapReduce. O desempenho de aplicações
MapReduce é afetado por diversos fatores, como por exemplo a leitura e escrita em disco
que torna-se custoso devido ao sistema de arquivos estar fragmentado na rede. Tarefas
com diferentes usos de recursos requerem configurações diferentes em seus parâmetros
para que haja diminuição no tempo de resposta da aplicação. Um software auto ajustável,
o qual ajusta seus parâmetros de acordo com a carga de trabalho submetida é uma solução
para a diminuição do tempo de processamento dos dados.
O ajuste de parâmetros para otimização pode ser feito de duas formas, pelo
administrador do cluster ou automaticamente por uma ferramenta de auto ajuste. A
segunda alternativa é mais complexa, pois é necessário que as tarefas sejam classificadas
e os parâmetros sejam ajustados antes que a tarefa seja executada. Os parâmetros
geralmente já estão predefinidos no sistema de otimização, como no Starfish, mas sua
arquitetura apenas gera um perfil da tarefa que foi executada e não aplica o ajuste em
tempo de execução. O administrador deverá ajustar esses parâmetros manualmente para
que nas próximas tarefas o sistema esteja otimizado.
O desempenho das aplicações MapReduce está ligado diretamente aos parâmetros
de configuração, e o correto ajuste desses parâmetros faz com que as aplicações aloquem
recursos computacionais distribuídos de maneira mais eficiente. Para que um software de
auto ajuste de parâmetros seja capaz de identificar os valores corretos, vê-se necessário a
implementação de regras que classificam as tarefas de MapReduce. Alguns softwares de
otimização preveem o possível uso de recurso computacional antes mesmo da execução
propriamente dita. Porém, essa classificação não mostra o real uso de recursos que a tarefa
irá utilizar e sim uma projeção através de regras impostas, este é o caso do Starfish e
AutoConf. A sessão 3.5.1 mostra uma visão sobre como classificar uma tarefa
MapReduce através de um perfil e como é possível utilizar arquivos de log para classificá-
las. A sessão 3.5.2 apresenta o AutoConf, uma ferramenta que auxilia um data warehouse
baseado em MapReduce a otimizar suas consultas a partir da análise dos operadores da
consulta. A sessão 3.5.3 mostra uma abordagem que utiliza a análise de log em conjunto
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
83

com uma ferramenta de otimização baseada em regras, com o objetivo de obter uma
otimização mais eficaz.
3.5.1. Geração de Perfis e Análise de Log
A geração de perfis consiste em coletar informações sobre a execução de uma
tarefa e criar o que chamamos de perfil, contendo todas as informações coletadas. Essa
técnica é importante, pois através de buscas e análises nas informações coletadas é
possível ajustar os parâmetros de sistemas MapReduce.
A análise de log irá auxiliar na geração de um perfil mais preciso para as tarefas, pois os
arquivos de log contêm informações de tarefas já executadas e qual foi o comportamento
das mesmas, em termos de uso de recursos computacionais. Sendo assim, tarefas
similares podem receber ajustes de parâmetros de acordo com o comportamento já
conhecido.
Sistemas como o Mochi [Tan 2009] e o Rumen [Apache 2013] analisam os logs
do Hadoop com a finalidade de mostrar ao administrador informações relevantes sobre o
ambiente, como tempo total de execução, volume de dados processados e tarefas falhas.
O uso de logs para descoberta de padrões de comportamento é uma opção que auxilia na
otimização. O Hadoop, por exemplo, possui um módulo que gerencia o histórico de
execução de suas tarefas chamado JobHistory, onde no decorrer da execução de uma
tarefa esse módulo cria logs que são constituídos por dois arquivos, um arquivo de
configuração (xml) e outro contendo o histórico de execução detalhado. É a partir desses
logs que se torna possível o uso de um mecanismo de classificação para encontrar um
comportamento comum de uso de recursos computacionais.
No caso do Hadoop, as informações mais relevantes a serem extraídas se
encontram armazenadas nos contadores gerados durante a execução da tarefa. Como por
exemplo, a quantidade bytes lidos do HDFS. A Figura 3.5 mostra alguns exemplos de
parâmetros de configuração utilizados por uma tarefa Hadoop, e a Figura 3.6 mostra o
histórico de um Map contendo um contador. Ambas as figuras foram extraídas de arquivos
de log do Hadoop.
Na Figura 3.5 podemos observar nas linhas 15, 16 e 17 parâmetros contendo
valores inteiros, porém, a partir da linha 18 observamos um parâmetro contendo uma
consulta, esse parâmetro é o nome da tarefa.
Na Figura 3.6, podemos observar na linha 9 o identificador do Job e seu estado.
Na linha 10 observamos uma subtarefa de Map, seu identificador e horário de início em
milissegundos. Nas linhas 11 e 12 observamos as fases de execução do Map e seu
histórico, contendo os contadores e as informações a serem extraídas para classificação.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
84

Figura 3.5. Exemplos de parâmetros de configuração armazenados em arquivo de log do Hadoop
Figura 3.6. Histórico de execução de um Map extraído de arquivo de log do Hadoop
3.5.2. AutoConf
AutoConf [Lucas Filho 2013] é uma ferramenta desenvolvida para otimização de
consultas do sistema de Data Warehouse Apache Hive. O Hive analisa a consulta e a
divide em estágios, onde cada estágio é um Job no Hadoop. O AutoConf realiza a análise
dos operadores utilizados em cada estágio da consulta e extrai uma assinatura de código
para esses estágios, por exemplo, se uma consulta possui um operador TableScan e um
GroupBy então é atribuído a assinatura de código referente a essa estrutura. Cada
assinatura possui uma configuração de parâmetros associada, a qual é aplicada em tempo
de execução no Hadoop antes da tarefa ser executada. Ou seja, as tarefas MapReduce ou
estágios da consulta serão executados após o autoajuste dos parâmetros, e cada estágio
poderá receber valores de parâmetros diferentes de acordo com os operadores da consulta.
Os grupos de tarefas classificadas a partir das assinaturas de código recebem o nome de
grupos de intenção. A Figura 3.7 mostra a arquitetura do AutoConf e sua integração com
o ecossistema do Hadoop.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
85

O processo de otimização do AutoConf na Figura 3.7 é descrito a seguir.
Em (1) as Interfaces de Usuário submetem uma consulta HiveQL;
Após o Hive gerar e otimizar o plano de consulta, em (2) os estágios da consulta
(Jobs) são enviados ao Hadoop;
O JobTracker antes de ordenar a execução em (3) envia a consulta ao AutoConf;
Após a extração da assinatura de código e a associação com a configuração
correta, em (4) o AutoConf envia ao JobTracker os valores de parâmetros a serem
ajustados;
Por fim o JobTracker ajusta os parâmetros e ordena a execução da tarefa que agora
possui as configurações ajustadas.
Figura 3.7. AutoConf em meio ao ecossistema do Hive e Hadoop [Lucas Filho 2013]
3.5.3. Uma Abordagem de Otimização de Consultas por Análise de Log
O AutoConf, como vimos, classifica os estágios da consulta (tarefas MapReduce)
antes da execução, analisando o script HiveQL e extraindo os operadores. Essa forma de
otimização prevê o uso de recursos computacionais para classificar as tarefas. A junção
da análise da consulta, no caso HiveQL, e a análise do histórico de logs é uma forma de
classificar mais corretamente as tarefas oriundas da consulta. Essa hipótese existe devido
aos seguintes tópicos.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
86

Os arquivos de log dos sistemas MapReduce contêm dados que não se encontram
antes da execução da tarefa, como por exemplo a quantidade total de bytes lidos
e escritos em disco;
O uso de regras para classificação gera predições de uso de recursos
computacionais, predições são menos representativas do que os dados
armazenados em arquivos de log;
Os clusters e perfis criados antes da execução da tarefa são pouco representativos
em termos do comportamento real das tarefas, pois utilizam regras;
A melhoria citada é recriar e ajustar os grupos gerados pelos otimizadores que
abordam as tarefas antes de sua execução. Por exemplo, as assinaturas de código do
AutoConf substituindo por grupos mais consistentes que representam o consumo real de
recursos das máquinas. As informações serão extraídas dos arquivos de log, sendo
possível encontrar padrões com mais precisão e voltados para os recursos computacionais
definidos pelo administrador do sistema.
Para analisar os arquivos de log, utilizaremos algoritmos de classificação não
supervisionados, responsáveis por classificar os logs em grupos, onde os logs integrantes
de cada grupo possuirão comportamento similar. Sendo assim, tarefas oriundas de novas
consultas poderão ser comparadas aos clusters gerados pelo algoritmo. O AutoConf
classifica as tarefas de acordo com a assinatura de código recebida, então denominaremos
os grupos de distintas assinaturas de código como “grupos de intenção”. O aprendizado
não supervisionado classifica os logs das tarefas através do comportamento encontrado
pelo algoritmo, então, denominaremos esses grupos como “grupos de comportamento”.
É possível utilizar diversos algoritmos de aprendizagem não supervisionada durante a
otimização, um deles é o K-Means [Jain 2008].
O estudo sugere o uso de logs de tarefas MapReduce, sendo assim, é possível
utilizar qualquer sistema baseado em MapReduce que gere algum tipo de arquivo de log.
3.6. Aprendizado de Máquina
A classificação é uma técnica de mineração de dados [Rezende 2005]. Sua função
é classificar os dados de forma a determinar grupos de dados com características comuns.
Abordaremos o algoritmo de aprendizagem não supervisionada K-Means para geração
dos grupos de comportamento.
3.6.1. K-Means
O algoritmo K-Means é capaz de classificar as informações de acordo com os
próprios dados de entrada. Esta classificação é baseada na análise e na comparação entre
as distâncias dos registros em valores numéricos a partir dos centroides dos clusters. Por
exemplo, se desejamos seis grupos, o registro será classificado para o grupo onde a
distância do centroide é mais próxima. Desta maneira, o algoritmo automaticamente
fornecerá uma classificação sem nenhum conhecimento preexistente dos dados. Nesta
sessão veremos como são calculados os valores dos centroides dos grupos e as distâncias
entre os registros.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
87

O usuário deve fornecer ao algoritmo a quantidade de classes desejadas. Para geração
dessas classes e classificação dos registros o algoritmo faz uma comparação entre cada
valor de cada linha por meio da distância, onde geralmente é utilizada a distância
euclidiana [Qian, 2004] para calcular o quão distante uma ocorrência está da outra. Após
o cálculo das distâncias o algoritmo calcula centroides para cada uma das classes.
Considere os pontos P e Q em (1).
(1)
A equação abaixo (2) representa o cálculo da distância euclidiana entre os pontos P e Q
em um espaço n-dimensional.
(2)
Uso com logs: No caso de logs, suponhamos que estamos trabalhando com apenas duas
dimensões (total de bytes lidos e total de bytes escritos). Essas são as dimensões contidas
no vetor P e Q da equação descrita. Suponhamos que P seja o ponto do centroide de uma
das classes no espaço bidimensional e Q seja o ponto para um determinado log no espaço
bidimensional. Os valores das dimensões do centroide são iguais às médias das dimensões
de todos os logs classificados na classe de tal centroide, logo, a fórmula nos trará a
distância do log em relação à média de todos da mesma classe.
Cada tipo de informação que um log possui é uma dimensão para o algoritmo, se os
logs possuem, por exemplo, três tipos de informação pode-se dizer que o K-Means
trabalhará com três dimensões. O K-Means pode ser descrito em cinco passos, descritos
pelo Algoritmo 3.1.
No Algoritmo 3.1, os vetores C e LC armazenam o resultado final da classificação.
C contém as classes que representam o uso dos recursos computacionais, onde os recursos
são representados pelas dimensões dim_x. LC contém a referência para os logs e a qual
classe eles pertencem após a classificação.
A Figura 3.8 contém um exemplo de execução do K-Means com duas dimensões
(bytes lidos e escritos). Podemos observar na Figura 3.8 a mudança da posição dos
centroides no decorrer dos 6 estágios e a redistribuição dos registros (logs) nas classes de
acordo com suas distâncias euclidianas.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
88
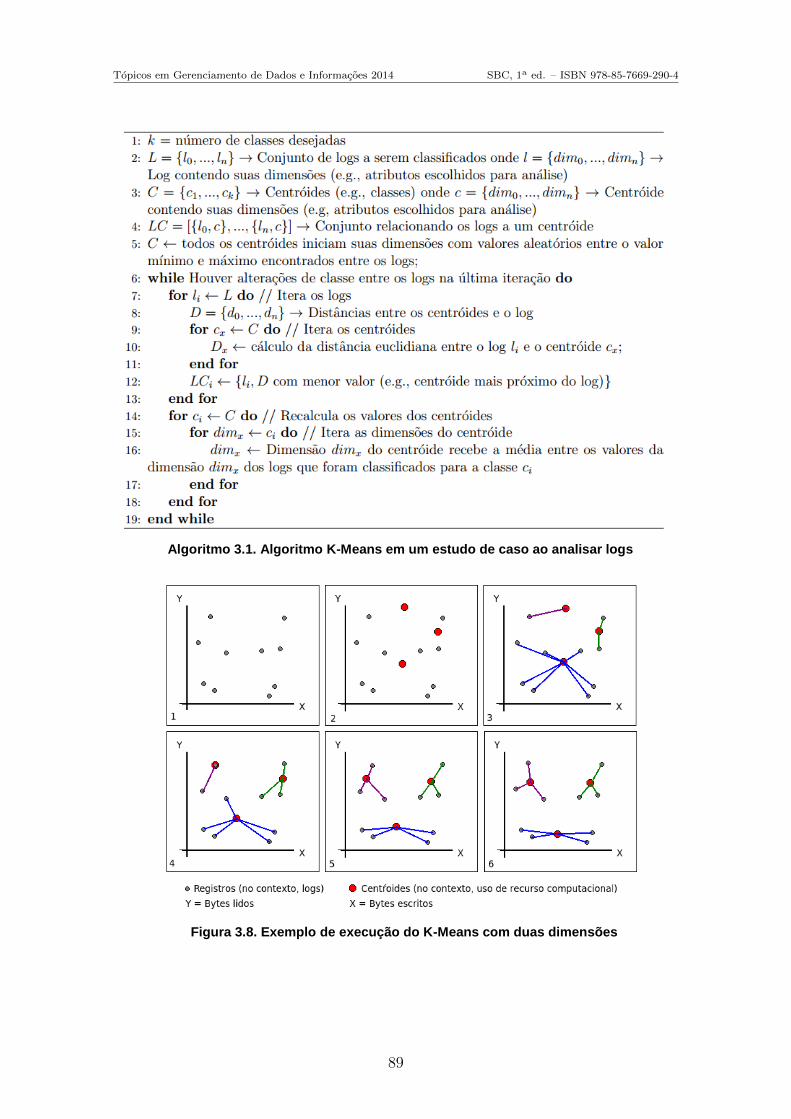
Algoritmo 3.1. Algoritmo K-Means em um estudo de caso ao analisar logs
Figura 3.8. Exemplo de execução do K-Means com duas dimensões
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
89

3.7. Chameleon: Otimização de Consultas por Análise de Log
Chameleon é a uma ferramenta de auto ajuste de desempenho que utiliza o
algoritmo K-Means sobre os logs de execução do Hadoop. O Chameleon complementa o
AutoConf auxiliando na otimização de consultas do Hive, através da atribuição de um
grupo de comportamento às tarefas da consulta. A Figura 3.9 mostra a arquitetura do
Chameleon e onde se enquadra no ecossistema do Hadoop.
Como extensão da Figura 3.7, a Figura 3.9 adiciona a Análise de Log ao
ecossistema, onde dois módulos distintos trabalham separadamente. O Hadoop Log
Parser é a implementação dos dados de entrada, nesse caso especificamente para o
Hadoop, mas também seria possível ser implementado para outros frameworks
MapReduce. O outro módulo é o algoritmo K-Means implementado. O Workload
Database é um dos pontos de interação entre as arquiteturas, O Hadoop Log Parser usa-o
para armazenar os logs que encontra, e por sua vez o K-Means busca os logs e salva seus
resultados na mesma base de dados.
Figura 3.9. Chameleon e o ecossistema do Hadoop
3.7.1. Workload Database
O Workload Database é uma base de dados relacional contendo os logs do Hadoop
estruturados de forma que outros módulos possam acessá-los mais facilmente. A base de
dados contém informações sobre a execução da tarefa e também quais foram os
parâmetros utilizados no momento da execução. A Figura 3.10 mostra o modelo entidade-
relacionamento da base de dados.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
90

Figura 3.10. Modelo Entidade-Relacionamento da base de dados do Workload DW
Na Figura 3.10 a tabela job é a tabela principal, que armazena as informações
únicas de cada log das tarefas executadas, e as tabelas iniciadas com conf_ armazenam as
configurações de parâmetros de diferentes tipos que foram utilizadas na execução das
tarefas. As tabelas task e task_attempt armazenam o histórico de execução, nelas se pode
encontrar os contadores que são utilizados pelo algoritmo de classificação. Após a
execução do algoritmo K-Means, os valores dos clusters de comportamento são
armazenados na tabela clusters e por fim, cada log é classificado a um cluster de
comportamento através da tabela job_cluster.
3.7.2. Hadoop Log Parser
Hadoop Log Parser é a implementação da entrada de logs para o Chameleon, tem
a função de coletar os logs do Hadoop, criar a estrutura de tabelas e popular o Workload
Database com os logs. Esse módulo pode ser executado no modo loop, proporcionando a
verificação de novos logs conforme o Hadoop processa novos Jobs. Algumas
características fazem com que o LogParser torne-se um módulo inteligente na coleta e
estruturação dos logs, pois além do modo loop é possível determinar se os logs serão
coletados do histórico do Hadoop ou a partir de uma pasta determinada pelo
administrador. Outras características são a verificação de logs já existentes evitando a
duplicação; e a exclusão de logs corrompidos ou incompletos, possibilitando uma maior
consistência do Workload Database.
3.7.3. Classificação
A Figura 3.9 demonstra o módulo responsável por gerar os chamados grupos de
comportamento, que determinam quais os recursos computacionais usados pelo Hadoop
em determinadas tarefas. No caso do Chameleon são os recursos usados pelas consultas
do Hive. O módulo de classificação possui diversas configurações que podem ser
alteradas pelo administrador. A Figura 3.11 mostra o arquivo de configuração do módulo.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
91

Figura 3.11. Arquivo com algumas configurações do módulo de classificação
refresh-time: tempo de espera da Classificação para realizar uma classificação
dos logs.
number-of-classes: valor de k do algoritmo de classificação ou a quantidade de
clusters de comportamento que deseja que os logs sejam agrupados.
clustering-execs: número de execuções do algoritmo para uma mesma
classificação, quanto maior valor, mais precisa é a média dos valores encontrados
pelo algoritmo.
Outra característica importante é a possibilidade de escolha das dimensões que
deseja utilizar para a classificação. Uma dimensão é cada tipo de informação selecionada
dos logs para processamento do algoritmo. Foram encontrados 63 tipos de informações
possíveis de se extrair dos logs do Hadoop, e o módulo de classificação possui um arquivo
de configuração que determina quais delas serão utilizadas. Então, o administrador pode
configurar o Chameleon de acordo com as necessidades de hardware de seu sistema. O
número de informações escolhidas é o número de dimensões que o algoritmo de
classificação irá trabalhar.
3.7.4. Viewer
Para visualização dos clusters gerados pela classificação foi desenvolvido o
módulo Viewer, que se trata de uma interface web onde é possível a visualização dos
clusters de comportamento gerados pelo K-Means e o histórico do uso de recursos. A
Figura 3.12 mostra um exemplo de clusters de comportamento gerados pelo Chameleon.
A Figura 3.13 mostra um exemplo de dimensões utilizadas com o uso de recurso
computacional encontrado pelo algoritmo e a Figura 3.14 mostra o histórico do uso de
um recurso no decorrer do tempo. Todas as figuras foram extraídas do Viewer.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
92

Figura 3.12. Clusters de comportamento gerados pelo Chameleon
Podemos observar na Figura 3.12 a predominância de um cluster, onde a 65% dos
logs possuem comportamento similar.
Na Figura 3.13 podemos observar seis dimensões utilizadas no agrupamento de
logs pelo algoritmo K-Means. Cada dimensão possui um valor diferente em cada cluster
de comportamento, esse valor é a média de todos os logs, ou seja, o valor do centroide da
dimensão.
Figura 3.13. Clusters de comportamento com as dimensões utilizadas
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
93

Figura 3.14. Histórico de bytes lidos durante 10 minutos de execução do Chameleon
Na Figura 3.14 podemos observar o histórico dos valores dos clusters de
comportamento por dimensão, no caso, hdfs_byte_read durante um período de execução
de dez minutos. Neste período, novas consultas chegaram e foram executadas pelo
Chameleon, cada tarefa gerou um novo arquivo de log, esses arquivos foram adicionados
à nova classificação do K-Means, o que resultou na mudança dos valores dos clusters e
na quantidade de logs em cada cluster. O gráfico de linhas da Figura 3.14 demonstra essa
mudança.
3.7.5. Integração do K-Means e AutoConf
Tendo como base o funcionamento dos módulos e o objetivo do Chameleon na
otimização das consultas do Hive, viu-se necessário a criação de uma integração entre o
AutoConf e a Classificação. A conexão foi realizada após a identificação da assinatura de
código e antes da aplicação da nova configuração. Nesse instante o AutoConf realiza uma
chamada remota a um método da Classificação, o qual é responsável por determinar qual
será a configuração que deverá ser aplicada a partir dos grupos de comportamento. O
método pode ser visualizado no Algoritmo 3.2, que mostra o processo de ajuste utilizando
os grupos de comportamento.
Algoritmo 3.2. Algoritmo para aplicação da configuração a partir dos clusters de comportamento
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
94

No Algoritmo 3.2, ao chamar o método remoto o AutoConf envia ao método um
histórico de tarefas (I) que utilizaram a mesma configuração da tarefa a ser ajustada, ou
seja, que possuam a mesma assinatura de código. Como essas tarefas de histórico já foram
completados elas possuem logs que estarão armazenados no Workload DB, então a
Classificação gera uma lista chave/valor (C) onde a chave é o identificador do grupo de
comportamento e o valor é a quantidade de logs que foram enviados pelo AutoConf e que
estão relacionados ao grupo. Esses dados são adquiridos ao analisar as duas tabelas
citadas e podemos visualizar a geração da lista no laço entre as linhas 4 e 7 do Algoritmo
3.2.
O retorno do método remoto é o identificador do grupo de comportamento o qual
a tarefa a ser ajustada se enquadra, ou seja, o grupo que mais obteve ocorrências de tarefas
vindas do grupo de intenção (linha 8 e 9 do Algoritmo 3.2). Em seguida, o AutoConf
aplica a configuração relacionada ao grupo de comportamento encontrado.
3.7.6. Visão Geral sobre o Autoajuste do Chameleon
O autoajuste possui duas fases, na primeira é a extração dos operados da consulta
do Hive e a partir da assinatura de código é gerado o grupo de intenção. Na segunda fase,
através da classificação pelo K-Means são gerados os grupos de comportamento que
determinam os recursos reais utilizados pelas tarefas. Através da comparação entre o
grupo de intenção da tarefa a ser ajustada e os grupos de comportamento é determinada
um configuração de parâmetros à tarefa. É importante saber que cada grupo de
comportamento possui uma configuração de parâmetros predeterminada, que pode ser
modificada pelo administrador do sistema. Então, quando uma nova tarefa chega, os
parâmetros são ajustados de acordo com o arquivo de configuração atrelado ao grupo de
comportamento da tarefa.
3.8. Conclusão
Neste minicurso apresentamos uma visão geral do processamento de consultas
MapReduce e exemplificamos este processamento através de uma solução que engloba
os sistemas Hive e AutoConf. Além de processamento de consultas sobre MapReduce,
esta solução tem como objetivo encontrar os melhores parâmetros de configuração de
desempenho. A modificação dos valores de parâmetros em diferentes tipos de tarefas
influencia diretamente no uso de recursos, economizando processamento, disco e rede.
Esse fato transforma essa abordagem de otimização em uma área ampla de pesquisas,
abrindo oportunidades para diversos novos estudos. Aliando os parâmetros com análise
dos operadores da consulta, arquivos de log e algoritmos de aprendizagem de máquina,
ampliamos ainda mais as possibilidades de inovações na área.
Novos sistemas baseados em MapReduce são criados de forma a aperfeiçoar as
tecnologias já existentes. Portanto, abordagens de otimização que são capazes de abranger
as inovações da área de BigData e MapReduce conforme sua evolução, de forma ampla
para vários sistemas, serão de extremo valor no avanço das pesquisas na área. Dessa
forma, esperamos incentivar pesquisadores a unir seus esforços na pesquisa sobre
otimização de consultas MapReduce.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
95

Referências
Abouzeid, A. e Pawlikowski, K. B. e Abadi, D. J. e Silberschatz, A. e Paulson , E. Efficient
processing of data warehousing queries in a split execution environment. Very Large
Data Base Endowment Inc. (VLDB), 2011.
Apache. Apache Hadoop Documentation, 2014. Disponível em < http://hadoop.apache.org/>.
Apache. The Apache Software Fundation. Rumen: a tool to extract job characterization
data from job tracker logs, 2013. Disponível em < http://hadoop.apache.org/docs/r1.2.1/rumen.html>.
Babu, Shivnath e Herodotou, Herodotos. Profiling, What-if Analysis, and Cost-based
Optimization of MapReduce Programs. Very Large Databases (VLDB), 2011.
Cisco Visual Networking Index (VNI). Cisco visual networking index: Forecast and
methodology, 2012 a 2017. Relatório técnico, Cisco, 2012.
Cloudera. Impala: Real-time Query for Hadoop, 2014. Disponível em <http://
www.cloudera.com/content/cloudera/en/products-and-services/cdh/impala.html>
Cohen, Jeffrey e Dolan, Brian e Dunlap, Mark e Hellerstein, Joseph M. e Welton, Caleb.
MAD Skills: New Analysis Practices for Big Data. Very Large Databases (VLDB).
2009.
Dean, J. e Ghemawat, S. MapReduce: Simplied data processing on large clusters. 6th
Symposium on Operating System Design and Implementation (OSDI), 2004.
Herodotou, H. e Lim, H. e Luo, Gang e Borisov, N. e Dong, Liang e Cetin, F. B. e Babu,
S. Starfish: A self-tuning system for big data analytics. 5a Biennal Conference on
Innovative Data Systems Research (CIDR), 2011.
Jain, Anil K. Data clustering: 50 years beyound k-means. International Conference on
Pattern Recognition (ICPR). 19a International Conference on Pattern Recognition
(ICPR), 2008.
Labrinidis, A. e Jagadish, H. V. Challenges and opportunities with big data. Very Large
Data Base Endowment Inc. (VLDB), 2012.
Lucas Filho, Edson Ramiro. HiveQL self-tuning – Curitiba, 2013. 44f. : il. color. ; 30 cm.
Dissertation (master) – UFPR, Pos-graduate Program in Informatics, 2013.
Olston, C. e Reed, B. e Srivastava, U. e Kumar, R. e Tomkins, A. Pig latin: A not-so-
foreign language for data processing. Special Interest Group on Management of Data
(SIGMOD), 2008.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
96

Papadimitriou, Spiros e Sum, Jimeng. Disco: Distributed co-clustering with MapRe-
duce. IEEE International Conference on Data Mining (ICDM), 2008.
Qian, Gang e Sural, Shamik e Gu, Yuelong e Pramanik, Sakti. Similarity between
Euclidian and cosine angle distance for nearest neighbor queries. Symposium on
Applied Computing (SAC), 2004.
Rezende, Solange Oliveira. Mineração de dados. XXV Congresso da Sociedade Brasileira
de Computação (SBC), UNISINOS, 2005.
Shvachko, K. e Kuang, H. e Radia, S. e Chansler R. The Hadoop Distributed File Sys-
tem. IEEE Computer Society. Mass Storage Systems and Technologies (MSST), 2010.
Troester, Mark. Big Data Meets Big Data Analytics: Three Key Technologies for
Extracting Real-Time Business Value from the Big Data That Threatens to Overwhelm
Traditional Computing Architectures. SAS Institute Inc. White Paper. 2012.
Tan, Jiaqi e Pan, Xinghao e Kavulya, Soila e Gandhi, Rajeev e Narasimhan, Priya. Mochi:
visual log-analysis based tools for debugging hadoop. Workshop in Hot Topics in
Cloud Computing (USENIX), 2009.
Thusoo, A. e Sarma, J. S. e Jain, N. e Shao, Z. e Chakka, P. e Anthony, S. e Liu, Hao e
Wyckoff, P. e Murthy, R. Hive - a warehousing solution over a mapreduce framework.
Very Large Data Base Endowment Inc. (VLDB), 2009.
UC Berkeley. Spark and Shark - High-Speed In-Memory Analytics over Hadoop and
Hive Data, 2012. Disponível em <https://spark.apache.org/>.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
97

Sobre os Autores
Eduardo Cunha de Almeida é Professor Adjunto III na Universidade Federal do Paraná
(UFPR). Seus principais interesses de pesquisa são em sistemas de bancos de dados e data
warehousing, com atenção especial na automatização e testes de sistemas de
processamento distribuído de consultas. Recebeu seu doutorado em Ciência da
Computação, com grandes honras (félicitations du jury), da Universidade de Nantes,
França, em 2009. Sua tese de doutorado foi em testes de tabelas hash distribuídas (DHT).
De 1998 a 2005, trabalhou como engenheiro de tecnologia de data warehouse no Banco
HSBC, na GVT Telecom e na Fundação UFPR. De 2010 a 2012, serviu como Vice-
Coordenador do Programa de Pós-Graduação em Ciência da Computação da UFPR.
Leandro Batista de Almeida é professor de Ciência da Computação na Universidade
Tecnológica Federal do Paraná (UTFPR) desde 1994, onde ministra disciplinas sobre
sistemas de bancos de dados, computação móvel e linguagens de programação. Recebeu
seu grau de mestre em 2000, em telemática, e seus principais interesses de pesquisa são
em análise de redes sociais e BigData.
Ivan Luiz Picoli nasceu em 1990, é atualmente estudante de mestrado na Universidade
Federal do Paraná (UFPR) com uma bolsa de tempo integral da Capes. Seus principais
interesses em pesquisa são sistemas de bancos de dados baseados em MapReduce e data
warehousing. Sua dissertação de mestrado trata de otimização de consultas em sistemas
baseados em MapReduce usando aprendizado não-supervisionado e análises de logs. Ele
obteve sua graduação em Análise e Desenvolvimento de Sistemas da Universidade
Tecnológica Federal do Paraná (UTFPR) em 2012. De 2012 a 2013, trabalhou como
desenvolvedor Java no Instituto Nacional de Colonização e Reforma Agrária (INCRA)
em Brasília.
Topicos em Gerenciamento de Dados e Informacoes 2014 SBC, 1a ed. – ISBN 978-85-7669-290-4
98






























