Embed Size (px)
Citation preview

UNIVERSIDADE DE LISBOAFaculdade de Ciencias
Departamento de Informatica
SUBSTRATO DE ARMAZENAMENTO PARASISTEMAS DE FICHEIROS SEGUROS PARA
CLOUDS-OF-CLOUDS
Tiago Moreno Oliveira
DISSERTACAO
MESTRADO EM ENGENHARIA INFORMATICAEspecializacao em Arquitectura, Sistemas e Redes de Computadores
2012


UNIVERSIDADE DE LISBOAFaculdade de Ciencias
Departamento de Informatica
SUBSTRATO DE ARMAZENAMENTO PARASISTEMAS DE FICHEIROS SEGUROS PARA
CLOUDS-OF-CLOUDS
Tiago Moreno Oliveira
DISSERTACAO
Dissertacao orientada pelo Prof. Doutor Alysson Neves Bessanie co-orientada pelo Prof. Doutor Marcelo Pasin
MESTRADO EM ENGENHARIA INFORMATICAEspecializacao em Arquitectura, Sistemas e Redes de Computadores
2012


Agradecimentos
Em primeiro lugar quero agradecer a toda a minha famılia. Em especial aos meus paispor toda a educacao, dedicacao, valores e amor que me deram durante toda a minha vida.Sem o vosso apoio nao tinha chegado onde cheguei. Sao os melhores pais do mundo.Aos meus maninhos mais novos, que eu sei que me adoram. Dava tudo por eles e sei queeles davam tudo por mim. Tenho muito orgulho em voces. Ao meu tio Luıs, um muitoobrigado pelas palavras e apoio que sempre me deste. A minha avo Quim, por todas asoracoes que eu sei que ela rezou e reza por mim. Quero tambem agradecer a duas pessoasmuito especiais que nunca deixaram e nunca deixarao de estar presentes na minha vida, aminha avo Ana e ao meu tio Dimas. Obrigado famılia.
Em segundo lugar quero agradecer a minha namorada, Patrıcia. A sua compreensao,motivacao, amor e amizade foram muito importantes para mim. Em todos os momentos,bons ou menos bons, tu sempre me deste coragem. Obrigado por estares sempre presentee por seres quem es.
Quero tambem deixar uma palavra de agradecimento a todos os meus amigos. Emespecial a todos os meus companheiros de casa, com quem eu partilhei momentos derisada total, o Zabibu, o Fernandinho, o Veiga, e em especial o Toze. Ao pessoal deFicalho, que quando nos encontramos e para a desgraca, o Rato, o Manel, a Filipa, o ZeGato, o Mikel, a Ines, o Varela, o Alacrau ,o Ze Francisco e a Monica. Ao pessoal que meacompanhou na minha vida academica, o Ricardo, o Guns, o Marcos, o Jonny, o Reis, oDiogo, o Teixeira, o Gordo, o Panka, e o Chico. Com eles passei os momentos mais durose mais alucinantes que a faculdade nos proporcionou. Um obrigado especial ao Ricardo,que foi a pessoa com quem mais horas passei nestes ultimos 5 anos, por toda a ajuda ecompanheirismo. Sei que posso contar com todos voces para qualquer coisa. Obrigadopor toda a forca e amizade.
Deixo tambem um obrigado muito especial para o meu orientador, Professor AlyssonBessani, e co-orientador, Professor Marcelo Pasin, pela orientacao e ajuda que me deramneste projecto. O “a vontade” com que me deixaram, a forma aberta como trocamosideias, e todo o bom ambiente que me foi concedido foram fundamentais para o meuempenho, motivacao e boa disposicao. Com voces aprendi muito. Muito obrigado.
Um sincero obrigado a todos aqueles que influenciaram, de uma forma ou de outra, omeu crescimento como pessoa e como profissional.
iii


As boas memorias.


Resumo
O armazenamento de dados em provedores de clouds tem vindo a tornar-se bastantecomum entre empresas, programadores e utilizadores. Porem existem ainda algumas di-ficuldades de acessos aos mesmos. Estas dificuldades tem vindo a ser mitigadas pelo usode sistemas de ficheiros que armazenam os dados, de uma forma transparente, nas clouds.Contudo, nestes sistemas, a disponibilidade dos dados e comprometida, pois estes depen-dem da disponibilidade do provedor de armazenamento em uso. O DepSky e um servicode armazenamento tolerante a faltas bizantinas que melhorar a disponibilidade dos da-dos armazenados nas clouds atraves da replicacao dos dados por um conjunto destas, aomesmo tempo que garante a integridade e confidencialidade dos mesmos. Ao conceito dearmazenar os dados em varias clouds foi dado o nome cloud-of-clouds.
Assim nasce o C2FS, um sistema de ficheiros seguro e fiavel para cloud-of-clouds,que vem cobrir estas limitacoes pois, ao mesmo tempo que fornece uma interface do estiloPOSIX, armazena os dados em multiplas clouds atraves do DepSky. Este projecto apre-senta o servico de armazenamento construıdo para o C2FS que visa melhorar a utilizacaodo Depsky atraves do uso intensivo de dois nıveis de cache, o de memoria e o de disco.Este servico suporta tambem dois modelos de envio de dados para as clouds, podendo esteser sıncrono ou assıncrono. O nıvel de consistencia fornecido pelo C2FS e influenciadopelo cliente aquando da configuracao do nıvel de cache e do modelo de envio de dados.
Neste projecto e tambem apresentada uma avaliacao experimental que mostra o de-sempenho do servico de armazenamento de dados com diferentes configuracoes. Os re-sultados obtidos mostram que, ao mesmo tempo que as diversas limitacoes mencionadassao ultrapassadas, e fornecido um desempenho muito satisfatorio.
Palavras-chave: sistemas de ficheiros, armazenamento em clouds, computacao emclouds, tolerancia a faltas, cache
vii


Abstract
Storing data in the cloud is becoming quite common today. However, there are stillsome difficulties related with how to access and manage this data. These difficulties arebeen mitigated by the use of cloud-backed file systems that store data, in a transparentmanner, in the cloud. Nevertheless, with these systems, data availability is directly tiedwith the availability of the storage provider being used. Recently, the problem of cloudunavailability was addressed through the use multiple cloud providers (cloud-of-clouds).DepSky is a Byzantine fault-tolerant storage service, which has improved the availabilityof data stored in clouds through replication of data by a set of clouds, while ensuring theintegrity and confidentiality.
The project described in this thesis contributes to C2FS, a secure and dependablecloud-backed file system that addresses the mentioned limitations by providing a familiarfile system interface and, at the same time, storing the data in cloud-of-clouds using Dep-Sky. More specifically, it presents the C2FS storage service that aims improve the use osDepSky through intensive use of two cache levels: memory and disk. This service alsosupports two cloud data transfer models, which can be synchronous or asynchronous. Thelevel of consistency provided by this service is controlled by the level of cache and datasending model parameters, as configured by the user.
This thesis also presents an experimental evaluation that shows the performance of thestorage service with different settings. The results show that, while the various mentionedlimitations are overcomed, the system provides a very satisfactory performance.
Keywords: file systems, cloud storage, clouds computing, Byzantine fault tolerance,cache
ix


Conteudo
Lista de Figuras xiii
Lista de Tabelas xv
1 Introducao 11.1 Motivacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Objectivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Contribuicoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Publicacoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.5 Planeamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.6 Estrutura do documento . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Trabalho relacionado 72.1 Servicos de Armazenamento . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Petal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.1.2 OceanStore . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.3 Ursa Minor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.1.4 DepSky . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.1.5 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Sistemas de Ficheiros Distribuıdos . . . . . . . . . . . . . . . . . . . . . 122.2.1 Andrew File System . . . . . . . . . . . . . . . . . . . . . . . . 122.2.2 Ceph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.3 CODA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.4 Frangipani . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2.5 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Sistemas de Ficheiros para Clouds . . . . . . . . . . . . . . . . . . . . . 182.3.1 S3FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3.2 S3QL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.3 BlueSky . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.4 Frugal cloud File System . . . . . . . . . . . . . . . . . . . . . . 212.3.5 Cumulus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
xi

2.3.6 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . 232.4 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3 Armazenamento de Dados do C2FS 253.1 C2FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.1 Arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.1.2 Modelo do Sistema . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 FUSE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.3 DepSky . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.4 Servico de Armazenamento . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.1 Visao Geral da Gestao do Armazenamento . . . . . . . . . . . . 323.4.2 Algoritmos de Gestao de Armazenamento . . . . . . . . . . . . . 343.4.3 Modelo de Envio de Dados . . . . . . . . . . . . . . . . . . . . . 433.4.4 Durabilidade dos Dados . . . . . . . . . . . . . . . . . . . . . . 443.4.5 Colector de Lixo . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.5 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4 Concretizacao do Servico de Armazenamento 494.1 Diagrama de Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.2 Diagramas de Sequencia . . . . . . . . . . . . . . . . . . . . . . . . . . 504.3 Agente C2FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.4 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5 Avaliacao 595.1 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.2 Latencia das Escritas e Leituras de Dados . . . . . . . . . . . . . . . . . 605.3 Desempenho do Servico de Armazenamento do C2FS . . . . . . . . . . . 615.4 Comparacao do C2FS com outros Sistemas de Ficheiros para Cloud . . . 635.5 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6 Conclusao 676.1 Trabalho Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Bibliografia 72
xii

Lista de Figuras
2.1 Arquitectura do Petal [29]. . . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Arquitectura do Ursa Minor [18]. . . . . . . . . . . . . . . . . . . . . . . 102.3 Arquitectura do DepSky [19]. . . . . . . . . . . . . . . . . . . . . . . . . 112.4 Arquitectura do Andrew File System. . . . . . . . . . . . . . . . . . . . 132.5 Arquitectura do Ceph [47]. . . . . . . . . . . . . . . . . . . . . . . . . . 142.6 Arquitectura do Frangipani [43]. . . . . . . . . . . . . . . . . . . . . . . 172.7 Arquitectura de Sistemas de Ficheiros para clouds. . . . . . . . . . . . . 19
3.1 Arquitectura do C2FS. . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.2 Caminho percorrido por cada chamada ao sistema. . . . . . . . . . . . . 283.3 Fluxo dos dados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.4 Desencadeamento das chamadas ao sistema no servico de armazenamento. 43
4.1 Modelo de classes do sistema. . . . . . . . . . . . . . . . . . . . . . . . 514.2 Operacao de leitura das clouds. . . . . . . . . . . . . . . . . . . . . . . . 544.3 Operacao de escrita em cache. . . . . . . . . . . . . . . . . . . . . . . . 554.4 Operacao de escrita para as clouds. . . . . . . . . . . . . . . . . . . . . . 56
5.1 Latencia das escritas e leituras (em segundos) para a cloud-of-clouds . . . 615.2 Tempo de execucao (em segundos) do IOzone e PostMark para escritas
sıncronas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 625.3 Tempo de execucao (em segundos) do IOzone e PostMark para escritas
assıncronas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 625.4 Latencia e throughput das operacoes de escrita e leitura nao sequenciais.
Valores medidos atraves da execucao do workload randomrw do Filebench 63
xiii


Lista de Tabelas
3.1 Operacoes FUSE-J. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.2 Durabilidade dos dados. . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.1 Linhas de codigo das classes do servico de armazenamento . . . . . . . . 52
5.1 Comparacao dos tempos de execucao (em segundos) com o S3FS. . . . . 645.2 Comparacao dos tempos de execucao (em segundos) com o S3QL. . . . . 65
xv


Capıtulo 1
Introducao
Nos dias de hoje, os utilizadores normais de computadores e internet, os programadoresou ate mesmo empresas tem vindo a fazer cada vez mais uso dos diversos provedoresde armazenamento baseados nas clouds (cloud storage), para armazenar os seus dados.A crescente popularizacao destes servicos deve-se a necessidade e/ou vontade que osutilizadores tem em exteriorizar os seus dados tanto para fins de backup e facilidade deacesso aos mesmos, como para a partilha de ficheiros. Alguns exemplos destes servicossao o iCloud [5], a Amazon S3 [4] e o Google Storage [9].
Com este aumento de utilizacao das clouds para armazenar dados, nasce a necessidadede estudar as abstraccoes necessarias para que os programadores possam fazer as suasaplicacoes acederem as clouds. O modelo mais utilizado hoje em dia para tal finalidadee a disponibilizacao de web services por parte das clouds que podem ser acedidos viaREST, SOAP ou XML-RPC. Este modelo nao e nada mais que uma instancia do modeloclassico de chamada remota a procedimentos (RPC) que, apesar de ser muito bom para atroca directa de mensagens, e muito mais orientado para controlo que para os dados.
Um modelo de acesso bem mais atraente aos olhos dos utilizadores e a gestao deficheiros na cloud atraves de um sistema de ficheiros. Esta abstraccao fornece aos uti-lizadores uma forma muito mais simples e familiar para a gestao de dados nos provedoresde armazenamento. Esta ideia ja tem sido suportada por alguns sistemas de ficheiros quearmazenam os dados em clouds como o S3FS [16] e o BlueSky[45]. Porem, todos estessistemas mostram algumas limitacoes devido ao facto de armazenarem os dados num soprovedor de armazenamento, dependendo assim da disponibilidade, da polıtica de acessoe dos custos oferecidos por este.
A equipa de investigacao Navigators tem estado a trabalhar num projecto financiadopela Comissao Europeia chamado TClouds [14] que tem como principal objectivo elimi-nar essas limitacoes. Este objectivo e alcancado atraves do uso de varios provedores emnuvem ao inves de um so. Este colectivo de clouds e denominado de cloud-of-clouds.
Neste contexto, nasce a ideia de concretizar um sistema de ficheiros que, ao mesmotempo que fornece uma semantica bem conhecida aos utilizadores, semantica essa sim-
1

Capıtulo 1. Introducao 2
ilar a definida pelo padrao POSIX (concretizado pelos sistemas Unix) [13], elimina aslimitacoes que os sistemas existentes apresentam. Um dos principais objectivos e tornara gestao de dados na cloud-of-clouds tao simples quanto a gestao de dados num sistemade ficheiros local. A este sistema de ficheiros foi dado o nome de C2FS (Cloud-of-CloudsFile System).
Com esta finalidade, surge este Projecto de Engenharia Informatica (PEI) que se focaassim no desenho do substracto de armazenamento para este sistema de ficheiros e temcomo objectivos fundamentais a construcao da abstraccao de discos virtuais onde os blo-cos de dados serao armazenados e a sua integracao numa interface de sistema de ficheirosdo estilo POSIX.
1.1 Motivacao
Como ja mencionado, existem alguns sistemas de ficheiros exploraram a ideia de ar-mazenar os seus dados em servicos de armazenamento como as clouds. O uso destesservicos para armazenar dados apresenta algumas vantagens como a facilidade de acessoque os utilizadores tem para aceder aos dados, o seu baixo custo e o seu modelo de paga-mento conforme o uso, que nao necessita investimento inicial. Contudo, o uso de umaso cloud por estes sistemas de ficheiros para o armazenamento dos dados acarreta al-gumas desvantagens que podem ser bastante problematicas em condicoes adversas. Aprimeira desvantagem prende-se no facto da disponibilidade dos dados ser directamenteafectada pela disponibilidade do provedor utilizado, isto e, se o provedor sofrer qualquertipo de problema ou se a ligacao ate ele mostrar alguma deficiencia os dados tornam-seinacessıveis. Outra desvantagem prende-se com o acesso nao controlado do provedoraos dados por ele armazenados, o que levanta algumas preocupacoes quando se quer ar-mazenar informacao crıtica. Outro possıvel perigo esta relacionado com o facto de oprovedor poder corromper os dados devido a faltas (maliciosas ou nao) na sua infraestru-tura. A ultima limitacao a apontar diz respeito ao possıvel aumento do preco por parte doprovedor de armazenamento, que pode impedir os utilizadores de remover de la os seusdados. Este acontecimento e conhecido por vendor lock-in [23].
Recentemente, foi provado pelo servico de armazenamento DepSky [19] que estaslimitacoes podem ser ultrapassadas se aliarmos o uso de provedores independentes atecnicas de tolerancia a faltas e a criptografia. Este sistema armazena os blocos de dadosnuma cloud-of-clouds para que estes se mantenham confidenciais e disponıveis mesmoque uma fraccao dos provedores sejam faltosos, tolerando assim faltas bizantinas (isto e,quando apresentam um comportamento arbitrario fora da sua especificacao). Contudo,a interface disponibilizada pelo DepSky e de baixo nıvel pois assemelha-se a um discovirtual onde os blocos de dados sao armazenados. O uso deste tipo de interface e bastantecomplicado para programadores que tem intencao de construir aplicacoes que armazenam

Capıtulo 1. Introducao 3
os dados nas clouds, e ainda mais complicado para utilizadores que apenas desejam ar-mazenar os seus ficheiros na cloud-of-clouds e que nao tem nenhum conhecimento eexperiencia sobre como usar este tipo de interface.
Como referido na seccao anterior, uma abstraccao muito mais familiar aos utilizadorese/ou programadores sao os sistemas de ficheiros. Constitui assim um desafio interessanteimplementar um sistema de ficheiros que armazene os seus dados numa cloud-of-cloudsatraves do DepSky. A concretizacao deste sistema de ficheiros consegue assim unir todasas garantias fornecidas pelo DepSky a uma interface bem conhecida.
1.2 Objectivos
Para a construcao do C2FS e necessario a integracao de uma serie de servicos distin-tos: o DepSpace, o DepSky e o FUSE. O DepSpace [20] e um sistema de coordenacaotolerantes a faltas bizantinas. A utilizacao deste servico no C2FS tem como principais ob-jectivos fornecer o servico de directorias para a gestao dos metadados e o servico de lockspara coordenar escritas concorrentes sobre o mesmo ficheiro. O desenvolvimento destesdois servicos e a sua integracao no C2FS foi efectuado em outro Projecto de EngenhariaInformatica [32]. Este PEI foca-se no uso do FUSE [7] e do DepSky para contrucao deum servico de armazenamento para o C2FS. Assim, os objectivos especıficos deste PEIsao:
• Estudar os servicos de armazenamento e sistemas de ficheiros existentes, principal-mente os que armazenam dados nas clouds.
• Estudar e implementar uma interface de sistemas de ficheiros.
• Estudar e modificar a implementacao do DepSky de modo a este responder o melhorpossıvel as necessidades do C2FS.
• Concretizar um servico de armazenamento cliente do DepSky e integra-lo na inter-face de sistemas de ficheiros disponibilizada pelo FUSE.
• Avaliar este servico para mostrar que ao mesmo tempo que fornece mais garantias,tem um desempenho similar aos dos sistemas existentes que armazenam dados nasclouds.
1.3 Contribuicoes
Este projecto contribuiu com alguns pontos essenciais para o desenho do C2FS. Umadas contribuicoes foi a disponibilizacao da interface de sistemas de ficheiros para o C2FSatraves do modulo FUSE. Este e um servico que nos permite implementar sistemas de

Capıtulo 1. Introducao 4
ficheiros a nıvel do utilizador, nao sendo assim necessario quaisquer alteracoes a nıveldo kernel. Outra contribuicao foi a introducao de novas tecnicas do DepSky. Outracontribuicao importante foi a concretizacao do servico de armazenamento de dados queusa os discos virtuais do DepSky para armazenar os dados na cloud-of-clouds. Esteservico fornece dois nıveis diferentes de cache (cache em disco e cache em memoria) eduas formas distintas de enviar os dados para as clouds sendo elas sıncrona e assıncrona.Os utilizadores podem escolher qual o nıvel de cache pretendido e qual a forma de envio autilizar de modo a preencher as suas necessidades. Por fim, foi concretizado um colectorde lixo para eliminar todos os dados dispensaveis ainda armazenados na cloud-of-clouds.
1.4 Publicacoes
O trabalho descrito nesta dissertacao foi contribuiu para a publicacao de um artigocientıfico no INForum 2012, na track “Computacao Paralela, Distribuıda e de Larga Es-cala” [33].
1.5 Planeamento
No inıcio o plano de trabalho para este PEI consistia em:
• Tarefa 1 (Setembro e Outubro 2011): Revisao bibliografica e estudo das tecnologiasenvolvidas (acesso aos provedores de armazenamento em cloud e construcao desistemas de ficheiro em espaco de utilizador).
• Tarefa 2 (Novembro 2011): Desenho da abstraccao de disco virtual e sua integracaono sistema de ficheiros como um todo (tarefa a ser realizada em conjunto com outrosmembros do Navigators que estejam a trabalhar no sistema de ficheiro).
• Tarefa 3 (Dezembro 2011): Evolucao do DepSky visando robustez e facilidade deutilizacao.
• Tarefa 4 (Janeiro e Fevereiro 2012): Concretizacao de um cliente FUSE para odisco virtual baseado no DepSky.
• Tarefa 5 (Marco 2012): Integracao do trabalho realizado com os outros mecanis-mos do sistema de ficheiro (nomeadamente a coordenacao e servico de nomes edirectorias).
• Tarefa 6 (Abril 2012): Avaliacao do sistema atraves de benchmarks de sistemas deficheiros utilizados na industria.
• Tarefa 7 (Maio 2012): Escrita da tese e, idealmente, de um artigo cientifico paraworkshop ou conferencia de medio porte.

Capıtulo 1. Introducao 5
A ordem de trabalho que foi desenvolvida neste projecto seguiu este planeamento atea tarefa 4. A tarefa 5, 6 e 7 sofreram alguns atrasos devido a optimizacoes que foramefectuadas no servico de armazenamento.
1.6 Estrutura do documento
Esta dissertacao esta organizada da seguinte forma:
• Capıtulo 2 - Este capıtulo apresenta o estudo realizado sobre o trabalho relacionadocom o sistema de ficheiros que se pretendia desenvolver. Aqui sao descritas ascaracterısticas dos servicos de armazenamento, de alguns sistemas de ficheiros dis-tribuıdos, e dos sistemas de ficheiros para clouds existentes.
• Capıtulo 3 - Neste capıtulo e primeiramente apresentada a arquitectura do C2FS.Posteriormente e apresentada a interface de sistemas de ficheiros implementada esao explicadas as modificacoes mais relevantes efectuadas a nıvel do Depsky. Porultimo e descrito em pormenor o servico de armazenamento concretizado.
• Capıtulo 4 - Aqui sao apresentados alguns detalhes de concretizacao do servico dearmazenamento.
• Capıtulo 5 - Este capıtulo apresenta uma avaliacao preliminar do C2FS, efectuadaessencialmente sobre as operacoes de escrita e leitura de dados, focando-nos as-sim mais no desempenho do servico de armazenamento concretizado. E tambemefectuada uma comparacao entre o C2FS e outros dois sistemas de ficheiros paraclouds, sendo eles o S3FS [16] e o S3QL [17].
• Capıtulo 6 - Este ultimo capıtulo descreve as conclusoes a retirar do trabalho de-senvolvido e sao introduzidas abordagens a seguir no futuro de forma a aumentar odesempenho do C2FS.

Capıtulo 1. Introducao 6

Capıtulo 2
Trabalho relacionado
Nesta capıtulo sao primeiro apresentados, na seccao 2.1, alguns dos servico de ar-mazenamento representativos. Posteriormente, na seccao 2.2, sao apresentados alguns sis-temas ficheiros distribuıdos tradicionais que foram concretizados sobre o modelo cliente-servidor. Por fim, na seccao 2.3, sao descritos os sistemas de ficheiros que utilizam cloudspara armazenar os dados.
2.1 Servicos de Armazenamento
Nesta seccao sao introduzidos alguns servicos de armazenamento estudados. Estesservicos diferem da abstraccao de sistemas de ficheiros por duas principais razoes: primeironao permitem a criacao de directorias e da estrutura em arvore que os sistemas de ficheirosusualmente tem; em segundo nao implementam uma interface de sistemas de ficheiros,fornecendo so uma pequena lista de operacoes para a leitura e escrita de dados. Contudo,alguns dos sistemas de ficheiros existentes utilizam estes tipos de servicos para armazenaros seus dados.
2.1.1 Petal
Petal [29] e um sistema de armazenamento distribuıdo facil de gerir, que forneceaos seus clientes (sistemas de ficheiros e bases de dados) uma total abstraccao da suavisualizacao fısica, mostrando-lhes uma coleccao de discos virtuais que podem ser ace-didos atraves de uma interface de chamada remota de procedimentos (RPC). Cada discovirtual fornece um espaco de 264 bytes para armazenamento, onde cada leitura ou escritae feita em blocos de tamanho variavel. A sua arquitectura fısica baseia-se num con-junto de servidores de armazenamento distribuıdos que cooperam entre si como mostra afigura 2.1.
O sistema replica cada bloco de dados por cada par de servidores vizinhos, isto sig-nifica, que sao mantidas para cada bloco de dados duas replicas. Assim mesmo que umservidor falhe, os pedidos que a este sao efectuados podem ser respondidos pelo servidor
7

Capıtulo 2. Trabalho relacionado 8
Figura 2.1: Arquitectura do Petal [29].
vizinho que mantenha a outra replica. Devido a este mecanismo de replicacao, o Petalfaz tambem balanceamento de carga pelos diferentes servidores. Algoritmos distribuıdosasseguram que todos os servidores tem a mesma carga e obtem informacao acerca dequalquer falha existente no sistema.
Um dos servicos prestado pelo Petal e a possibilidade de efectuar snapshots. Estassnapshots sao imagens consistentes dos discos fısicos que permitem aos clientes fazerembackup do sistema. Para a criacao destas snapshots e necessario uma pausa do sistemapor um perıodo de tempo, o que pode prejudicar a disponibilidade do mesmo. Outraimportante funcionalidade e o facto de os servidores poderem recuperar depois de umaeventual falha devido a manutencao de um log com os seus blocos de dados.
O sistema permite a adicao e remocao de discos fısicos com uma simples operacao dereconfiguracao.
2.1.2 OceanStore
O OceanStore [28] e uma arquitectura para um sistema de armazenamento persistentea escala global. Ele consiste num conjunto de servidores altamente conectados espalhadospelo mundo, a que os clientes se podem conectar (podem estar conectados a mais que umservidor e estao ligados aos servidores geograficamente mais perto). Este sistema permiteuma adaptacao transparente e automatica aquando da adicao ou remocao de servidores.
Os seus principais objectivos e permitir dados nomadas (dados que podem ser guarda-dos em qualquer lugar a qualquer instante) e construir um sistema que corra sobre servi-dores nao confiaveis suportando faltas bizantinas. Como os dados podem fluir pela inter-net de um servidor para outro, sao necessarios algoritmos que encontrem onde os dadosestao guardados a um qualquer instante. Para tal sao usados dois algoritmos distintos.Primeiro e executado uma algoritmo probabilıstico baseando-se no facto de os dadospoderem estar no servidor vizinho (i.e., mais proximo) da localizacao do cliente. Este

Capıtulo 2. Trabalho relacionado 9
algoritmo e bastante rapido, mas so se os dados estiverem na vizinhanca do cliente. Casoeste falhe, e executado um algoritmo global que e mais lento, mas mais confiavel. Estelocaliza os dados que nao podem ser encontrados localmente atraves de uma estrutura dedados hierarquica de larga escala ao estilo ds difinida por Plaxton et al [35].
Cada objecto do sistema e identificado por um identificador unico que e um resumocriptografico (criado com a tecnica SHA-1) gerado sobre a chave privada do cliente jun-tamente com informacao introduzida por este. Para fornecer disponibilidade, os objectossao replicados e guardados em multiplos servidores geograficamente distribuıdos. Exis-tem duas camadas de replicas para fazer actualizacoes (mudanca nos dados guardados)sem ocorrer conflitos: a primaria e a secundaria. A camada primaria decide se umaactualizacao pode ser efectuada ou deve ser abortada atraves do protocolo de acordobizantino [21]. Quando a camada primaria toma uma decisao, faz multicast do resultadopara as replicas da camada secundaria para estas procederem a actualizacao. Os objec-tos sao representados em duas formas: activa e arquivada. Todas as actualizacoes saoefectuadas sobre objectos na forma activa enquanto que objectos arquivados representamuma versao permanente so de leitura. Os objectos sao armazenados utilizando codigos deapagamento. Para assegurar a integridade de cada fragmento produzido pelos codigos deapagamento aquando da sua recuperacao e utilizado um metodo de resumo criptograficohierarquico para verifica-los.
2.1.3 Ursa Minor
Ursa Minor [18] e um sistema de armazenamento versatil baseado em clusters quefornece aos seus clientes a oportunidade de escolher o modo de armazenamento (codigosde apagamento ou replicacao), o tamanho dos blocos, a localizacao dos dados, o modelode falha dos servidores de armazenamento (paragem ou bizantino), numero de falhas atolerar e o modelo de tempo (assıncrono ou sıncrono). Este sistema permite tambem areconfiguracao de alguns destes parametros (e.g., modelo de tempo e tamanho dos blo-cos) para dados on-line. Parametros como o modelo de tempo e modelo de falha para osclientes e servidores compromete a performance, a disponibilidade e fiabilidade dos da-dos. Este sistema assume armazenamento baseado em objectos. O armazenamento destesobjectos e feito seguindo o padrao de OSDs (object store devices) [24]. Cada objectono Ursa Minor, alem de ter os dados associados, guarda tambem informacao acerca dotamanho dos blocos, ACLs e outros parametros.
A figura 2.2 mostra a arquitectura do sistema. Os clientes para acederem aos objectosarmazenado nos servidores de armazenamento acedem primeiro ao Object manager paraobterem os metadados, isto e, a localizacao do objecto e a autorizacao para acede-lo.
Como mencionado, existem duas formas de armazenar os dados nos nos de armazena-mento: com replicacao ou usando codigos de apagamento. O uso de codigos de apaga-mento melhora a performance do sistema. Para tal e utilizado um esquema de codigos

Capıtulo 2. Trabalho relacionado 10
Figura 2.2: Arquitectura do Ursa Minor [18].
de apagamento [34] em que primeiro, o bloco de dados e dividido em m fragmentos(stripe-fragments), e em segundo, estes fragmentos sao utilizados para criar c (c e igual nmenos m, em que n e numero de servidores para replicar os objecto) fragmentos codifica-dos (code-fragments) que fornecem a redundancia necessaria. Quaisquer m fragmentospodem reconstruir o bloco de dados original. Note-se que se m for igual a 1 e usadoreplicacao. Para assegurar a integridade dos dados armazenados nos nos de armazena-mento e computado um resumo criptografico para cada fragmento seguindo o conceito dechecksums cruzados [38] onde cada checksum cruzado e concatenado a cada fragmento.
Aquando de uma operacao de escrita, antes do envio dos dados para cada no de ar-mazenamento, cada fragmento e marcado com um timestamp unico. Assim, na operacaode leitura, os clientes tem que obter os blocos de dados dos servidores de armazenamentocom o mesmo timestamp para obter os fragmentos do mesmo bloco de dados. E mantidoum colector de lixo pois cada escrita cria uma versao nova dos fragmentos.
Os nos de armazenamento usam uma cache write-back para evitar acessos ao discoaumentando assim a performance. Esta cache so mantem fragmentos com o ultimo times-tamp.
2.1.4 DepSky
O DepSky [19] e um servico de armazenamento fiavel e seguro que armazena osdados em multiplas cloud formando assim uma cloud-of-clouds. Este conceito e intro-duzido na imagem 2.3 onde sao utilizadas quatro diferentes clouds. Este servico fornecealta disponibilidade, integridade e confidencialidade dos dados armazenados replicando-os, codificando-os e encriptando-os. Existem dois protocolos disponıveis para usar estesistema: DepSky-A e DepSky-CA. DepSky-A fornece disponibilidade e integridade dosdados enquanto que o DepSky-CA assegura estas duas garantias acrescentado a confiden-

Capıtulo 2. Trabalho relacionado 11
cialidade dos mesmos.
Figura 2.3: Arquitectura do DepSky [19].
Para suportar falhas bizantinas o DepSky utiliza um protocolo de quoruns (sao necessarios3f + 1 servidores para suportar f falhas), efectuando cada operacao (escrita ou leitura)em n−f clouds, onde n e o numero total de clouds utilizadas. O DepSky implementa umregisto onde sao permitidos a cada instante um escritor e multiplos leitores, pois os nosde armazenamento sao incapazes de executar codigo que elimine conflitos entre escritasconcorrentes.
Os programadores acedem aos seus dados atraves de uma interface de armazenamentode objectos. Cada operacao (e.g., leitura e escrita) e efectuada usando um objecto denom-inado data unit. Basicamente, cada data unit corresponde a um contentor em cada cloud.Cada contentor armazena todas as versoes dos dados, pois cada operacao de escrita criauma nova versao. E tambem mantido em cada contentor um ficheiro de metadados quecontem o numero da versao mais actual armazenada e um resumo criptografico para as-segurar a integridade desta versao. Numa operacao de escrita sao primeiro escritos osdados e so depois os metadados. Esta sequencia assegura que so irao ser lidos metadadosde dados previamente armazenados no sistema. As versoes antigas dos dados podem sereliminados utilizando um protocolo para colectar lixo. Este modelo de dados abstrai paraos cliente a heterogeneidade de armazenar dados em diferentes clouds.
Como foi mencionado acima, o DepSky fornece dois protocolos para a manutencaodos dados na cloud-of-clouds. O DepSky-A garante disponibilidade replicando os da-dos na cloud-of-clouds usando tecnicas de quoruns, e integridade computando um re-sumo criptografico como descrito em cima. Apesar de assegurar estas duas garantias, oDepSky-A mostra-se inutil quando os programados precisam armazenar dados crıticos

Capıtulo 2. Trabalho relacionado 12
e confidenciais, pois os dados sao replicados na forma de texto em claro. O protocoloDepSky-CA cobre esta limitacao encriptando os dados com uma chave simetrica. Nesteprotocolo, sao criados key shares atraves de um esquema de partilha de segredos e sao uti-lizados codigos de apagamento para codificar os dados encriptados. Assim, e armazenadoem cada cloud um fragmento codificado concatenado um key share (como sao usadas 4clouds, sao gerados 4 key shares e 4 fragmentos codificados).
2.1.5 Consideracoes Finais
Dos servicos de armazenamento descritos nestas seccoes, podemos verificar que so oPetal oferece uma interface para o armazenamento de blocos, enquanto que os restantesoferecem uma interface para o armazenamento de objecto. Ao inves do armazenamentobaseado em blocos, o armazenamento baseado em objectos facilita o agrupamento dediferentes informacoes para cada bloco de dados armazenado, como tambem permite ar-mazenar objectos de tamanho variavel. Outra vantagem inerente ao uso de servicos dearmazenamento de objectos refere-se ao facto de nao ser necessario manter estruturasque nos indiquem onde cada bloco esta armazenado, bastando utilizar o identificador doobjecto para efectuar operacoes de escrita ou leitura.
2.2 Sistemas de Ficheiros Distribuıdos
Nesta seccao sao descritos alguns dos sistemas de ficheiros distribuıdos que mais in-fluenciaram alguns dos sistemas de ficheiros de hoje em dia. Um sistema de ficheiros dis-tribuıdo e um sistema que permite aos programadores ou utilizadores armazenar os seusdados remotamente, ou seja, numa outra localizacao atraves da internet, exactamente damesma forma que o fazem nos sistemas de ficheiros locais, sendo assim a transparenciauma das principais propriedades destes [22]. Estes foram desenhados seguindo o con-hecido modelo cliente-servidor de sistemas distribuıdos.
2.2.1 Andrew File System
O Andrew File System (AFS) [40] e um sistema de ficheiros antigo que foi desen-volvido para um ambiente de mais ou menos 5000 clientes. A sua arquitectura e designinfluenciaram muitos dos sistemas de ficheiros dos dias de hoje. Apesar de a cache sero ponto chave do seu design, e dada uma grande atencao a seguranca, a transparencia dalocalizacao dos dados, a escalabilidade, a mobilidade do utilizador, a heterogeneidade ea partilha de dados. Existem duas principais entidades na sua arquitectura como mostra afigura 2.4: Vice e Virtue. A entidade Vice e o conjunto de servidores responsaveis de ar-mazenar os dados que as varias estacoes de trabalho Virtue querem guardar. E importantereferir que e assumido que o Vice e seguro. Cada estacao Virtue foi concretizada em duas

Capıtulo 2. Trabalho relacionado 13
distintas partes: algumas modificacoes necessarias a nıvel do kernel para ser possıvel in-terceptar as chamadas ao sistema referentes a ficheiros pertencentes ao AFS, e a entidadeque realmente comunica com o Vice e que gere a cache local denominada Venus.
Figura 2.4: Arquitectura do Andrew File System.
Para obter uma boa performance, mobilidade e escalabilidade, o AFS utiliza umacache no lado do cliente e transfere os ficheiros completos para os servidores. A cache,alem de manter os dados actualizados, guarda tambem informacao sobre o seu estado esobre a sua custodia. Este sistema de ficheiros so executa operacoes (escrita e leitura) emficheiros que estejam em cache. Se um ficheiro nao estiver em cache, entao Venus comu-nica com o servidor Vice que mantem o ficheiro armazenado (os dados sao so guardadosnum servidor) e transfere-o para a sua cache local. Para garantir que os ficheiros emcache tem uma vista coerente em diferentes estacoes de trabalho, o AFS usa um sistemade validacao da cache que necessita alguma computacao nos servidores pertencentes aoVice. Basicamente, a Virtue notifica o Vice quando um ficheiro em cache e fechado eo Vice notifica as outras estacoes de trabalho que partilham o mesmo ficheiro de que oficheiro foi modificado. Note-se que sao armazenados ficheiros inteiros ao inves de blocose que os ficheiros so sao armazenados depois do seu fecho. Esta abordagem simplifica arecuperacao de falhas das estacoes de trabalho. Para melhorar a disponibilidade dos dadosguardados, o Vice replica versoes so de leitura de ficheiros que sao raramente modificadose frequentemente acedidos para leitura.
Como e suposto que toda a rede e nao confiavel, todas as comunicacoes entre aVirtue e o Vice iniciam com um protocolo de autenticacao que gera uma chave unicapara encriptar toda a informacao trocada em cada conexao. Esta chave e obtida atravesde uma informacao especıfica do utilizador (password). E tambem na autenticacao que e

Capıtulo 2. Trabalho relacionado 14
fornecido o controlo de acesso usando listas de acesso (ACLs).
2.2.2 Ceph
O Ceph [47] e um sistema de ficheiros distribuıdo desenhado para ser fiavel, disponıvel,e com um alto desempenho ao mesmo tempo que e altamente escalavel. Estas pro-priedades sao alcancadas atraves das caracterısticas de desenho presentes na sua arqui-tectura onde a principal ideia e separar a gestao dos metadados e dos dados.
O sistema e assim composto por tres diferentes componentes como mostra a figura 2.5:o cluster de OSDs (object store devices) que e responsavel por armazenar os dados eos metadados; o cluster de servidores de metadados (MDS) que concretiza o espaco denomes e que coordena a seguranca, a consistencia e a coerencia do sistema; e o clienteque executa operacoes de metadados nos MDSs e armazena os dados comunicando direc-tamente com os OSDs.
Figura 2.5: Arquitectura do Ceph [47].
Os OSDs oferecem grande escalabilidade pois disponibilizam uma interface para ar-mazenamento de objectos. Esta permite a escrita e a leitura de intervalos muito maiores,e com tamanho variaveis, de bytes, do que a tradicional interface ao nıvel do bloco. Estesutilizam um sistema de ficheiros local especial para armazenar os dados no disco. O clus-ter de MDSs baseia-se numa estrategia de particao dinamica de sub-arvores que distribuihierarquicamente os metadados pelo diferentes nos MDS, permitindo adaptar-se aos difer-entes tipos de carga de trabalho que esta presentes nos sistemas de ficheiros. Embora estesservidores respondam aos clientes maioritariamente usando os metadados em cache, ar-mazenam os seus nos de metadados nos OSDs. Estes servidores sao tambem responsaveispor efectuar controlo de acesso aos ficheiros. Os clientes efectuam operacoes de escrita eleitura no cluster de OSDs e tanto o podem efectuar comunicando directamente com os

Capıtulo 2. Trabalho relacionado 15
OSDs ou atraves de um sistema de ficheiros implementado a nıvel do utilizador atravesdo FUSE [7].
Os clientes mantem uma cache local para aumentar a performance das operacoes deescrita e leitura. Esta cache e invalidade pelos MDSs na existencia de multiplos escritoresou de um conjunto de escritores e leitores para o mesmo ficheiro. Neste cenario, o clienteque adquirir o lock do ficheiro e obrigado a efectuar escritas sıncronas para os OSDs.Contudo, os cliente podem tambem efectuar escritas assıncronas se utilizarem um servicode locks que os OSDs disponibilizam onde os clientes podem aceder exclusivamente a umdeterminado OSD.
O Ceph, para mapear os objectos pelo diferentes OSDs disponıveis, recorre a umafuncao de dados distribuıda, chamada CRUSH [46], que elimina a preocupacao com listasdistribuıdas que mantenham a localizacao (OSD) dos dados. Os objectos armazenadospelos diferentes OSDs chamam-se placement groups (PGs), onde cada um e composto pordiferentes blocos de diferentes ficheiros. Estes diferentes blocos de diferentes ficheirossao mapeados para dentro de cada PGs atraves uma funcao de hash.
Para manter os dados sempre disponıveis, o sistema replica os PGs por uma lista den OSDs. A replicacao e feita da seguinte forma: os pedidos de escrita sao efectuadosao primeiro OSD disponıvel da lista (chamado primary); este actualiza a versao do PGque recebe o novo bloco a escrever, e envia a escrita aos restantes OSDs (replicas) quemantem este PG. Os clientes recebem um ack quando os dados atingem o buffer de todasas replicas (quando fica visıvel aos outros clientes) e da mesmo forma, um commit quandoa escrita e armazenada em memoria estavel por todas as replicas. Na ocorrencia do acko sistema tolera a falha de um unico OSD presente na lista, enquanto que no commit ocliente tem a garantia que mesmo que todos os OSDs da lista falhem, os dados podem serrecuperados.
O Ceph mantem tambem um sistema de deteccao de falhas de OSDs que permiteperceber se as listas de OSDs para cada PG esta disponıvel. Quando algum OSD e dadocomo nao disponıvel, outro e adicionado a lista para permitir o mesmo nıvel de replicacao.
2.2.3 CODA
O Coda [41] e um sistema de ficheiros cujo objectivo e manter a disponibilidademesmo com clientes moveis, isto e, com conexao intermitente. A sua construcao foibaseada no Andrew File System onde as caracterısticas que mantem deste sao: o mod-elo, onde servidores confiaveis armazenam dados provenientes de estacao de trabalhoUnix nao confiaveis; os clientes continuam a fazer cache de ficheiros inteiros e a guardarinformacao sobre onde os seus dados estao armazenados; usa tambem callbacks (promessado envio de uma notificacao aquando de uma alteracao a qualquer ficheiro) para assegurara coerencia da cache nas diferentes estacoes, mas de uma forma mais complexa; utilizareplicas so de leitura; e para assegurar seguranca utiliza um protocolo de autenticacao

Capıtulo 2. Trabalho relacionado 16
baseado em tokens e cifra todas as mensagens trocadas.Este sistema fornece uma disponibilidade mais alta que o AFS porque lida com falhas
quer dos servidores, como da rede. Para tal sao usadas duas estrategias complementares.A primeira e o facto de replicar os dados por diferentes servidores. A segunda prende-sena possibilidade que os clientes tem em fazer operacoes desconectados, ou seja, mesmosem acesso a rede, estes podem continuar a operar na cache local. Para tal ser possıvel,o Coda lida com falhas na rede usando uma estrategia optimista que assegura que depoisde ocorrer uma particao, todos os conflitos irao ser detectados e resolvidos.
A coleccao de servidores que armazenam os dados (a unidade de replicacao e chamadavolume e representa um conjuntos de ficheiros e/ou directorias) e denominada de volumestompe group (VSG). Cada cliente mantem um subconjunto do VSG denominado ac-cessible volume stompe group (AVSG) que sao os membros do VSG disponıveis, isto e,acessıveis, no momento. Para replicar os dados e utlizado uma variante da abordagemread-one, write-all1. A leitura e efectuada de um servidor previamente marcado comoservidor preferido, contudo, e necessario contactar tambem os outros servidores do AVSGpara assegurar que o servidor preferido tem a versao mais actual dos dados. Quandoe encontrado um servidor com uma versao mais actual que o servidor preferido, este emarcado como novo servidor preferido e e estabelecida uma callback com ele. Ja naoperacao de escrita, depois do ficheiro ser fechado, ele e replicado por todos servidorespertencentes ao AVSG em paralelo. Para manter a coerencia da cache, as estacoes detrabalho que executam o sistema de ficheiros tem que detectar 3 tipos de acontecimentosno maximo t segundos depois de terem ocorrido. Assim, e necessario estar alerta para:
• O aumento do AVSG (quando um servidor inacessıvel se torna acessıvel) tentandocontactar os servidores que se encontram inacessıveis, a cada t segundos. Quandoeste acontecimento se verifica, os clientes descartam as callbalcks dos objectos emcache, pois eles podem ja nao ser a versao mais actualizada;
• A diminuicao do AVSG (quando um servidor acessıvel se torna inacessıvel) tes-tando a cada t segundos se todos os membros do AVGS se mantem acessıveis. Se oservidor preferido se tornar inacessıvel, as callbacks desse servidor sao descartadas;
• A perda de callbacks simplesmente esperando callbacks dos servidores.
As operacoes desconectadas comecam assim que todos os membros do VSG se tor-nam inacessıveis. A troca do modo de operacao normal (replicacao) para o modo deoperacao desconectado e o contrario e completamente transparente para o cliente ex-cepto quando algum ficheiro em cache e perdido (o que acontece raramente). Obvia-mente, durante este modo, os clientes armazenam os dados na sua cache local. Quando os
1Cada operacao de escrita e efectuada em todos os servidores e a operacao de leitura obtem os dados sode um.

Capıtulo 2. Trabalho relacionado 17
clientes conseguem aceder novamente a alguns membros do VSG e iniciado um processode reintegracao onde sao executados um conjunto de actualizacoes a todos os membrosdo AVSG de forma a todas as replicas ficarem iguais a cache local.
2.2.4 Frangipani
O Frangipani [43] e um sistema de ficheiros distribuıdos que fornece quase as mesmasgarantias semanticas que os sistemas de ficheiros Unix. A figura 2.6 apresenta a arqui-tectura do Frangipani. Como podemos ver a sua estrutura e dividida em duas camadas.A camada de baixo contem dois servicos: o Petal (servico de armazenamento descritoanteriormente) e um servico de lock distribuıdo. O Petal ajuda o Frangipani a forneceruma facil administracao, escalabilidade e tolerancia a faltas. Estes dois servicos (Petale lock) nao necessitam estar na mesma maquina, ate porque nao trocam qualquer tipode informacao entre si. Na camada de cima encontram-se os clientes e os servidores deficheiros Frangipani. Os clientes (programas do utilizador) acedem ao Frangipani atravesde uma interface padrao de chamadas ao sistema.
Figura 2.6: Arquitectura do Frangipani [43].
Os servidores de ficheiros Frangipani comunicam com o Petal e com o servico delock. Para comunicar com o Petal, os servidores usam uma driver de dispositivo. Estadriver ve o Petal como um disco virtual com 264 bytes de espaco e esconde a real naturezadistribuıda presente na sua arquitectura fısica. Neste disco virtual e definido previamenteespaco para logs, para inodes, para blocos pequenos e para blocos grandes.

Capıtulo 2. Trabalho relacionado 18
O sistema permite a adicao e remocao de servidores recorrendo a poucas tarefas deadministracao (o sistema adapta-se ao novo numero de servidores automaticamente). Paraa recuperacao apos uma falha de um servidor (fail recovery) e usado write-ahead loggingde metadados no Petal. Como nao e feito log dos blocos de dados, os clientes nao temgarantias de consistencia depois de uma recuperacao.
Para manter sincronizacao quando diferentes clientes requisitam o mesmo bloco dedados, o Frangipani utiliza o modelo de lock multi-reader/single-writer. Os locks saoefectuados a ficheiros inteiros ou directorias ao contrario de blocos individuais. A cachefoi implementada seguindo a ideia da cache do AFS, mas neste caso cada servidor Frangi-pani envia uma notificacao aos outros servidores para actualizarem a sua cache. Numaoperacao de escrita, so e garantido que os blocos de dados alcancem memoria nao volatilquando duas chamadas especıficas ao sistema sao executadas - fsync ou sync.
Como o Petal, o Frangipani permite tambem tirar snapshots ao sistema para a manutencaode backups. Estas snapshots sao crash-consistent, o que significa que sao uma imagemcoerente do sistema.
2.2.5 Consideracoes Finais
Desta seccao podemos retirar muitas ideias para aplicar na construcao do C2FS. Comopodemos verificar, a utilizacao de cache no lado do cliente e essencial para o bom desem-penho de um sistema de ficheiros. Outra interessante estrategia introduzida pelo AFS[40] e a transferencia de ficheiros completos para os servidores de armazenamento. Istopermite alcancar um bom desempenho do sistema pois elimina a necessidade lidar comlatencias inerentes a transferencia de blocos de dados individualmente. Por sua vez, oCeph [47] utiliza a ideia da separacao do tratamento de metadados com o armazenamentodos dados para o aumento do desempenho e da escalabilidade. Esta ideia e tambem bas-tante interessante pois uma vez que os sistema de ficheiros efectuam muito mais operacoesnos metadados do que nos dados, e as operacoes de dados por norma sao mais lentas queas de metadados, a distribuicao da carga de trabalho e bem conseguida. Por fim e impor-tante dar enfase as garantias de consistencia de cache expostas pelo AFS e pelo Frangipanionde so e garantido que os dados sejam devidamente armazenados em memoria estavelapos o seu fecho ou aquando das operacoes fsync ou sync.
Contudo, e importante referir que todas as propostas de validacao de cache apresen-tadas por estes necessitam computacao nos servidores de armazenamento, o que nao severifica no C2FS.
2.3 Sistemas de Ficheiros para Clouds
Nesta seccao sao apresentados alguns dos sistemas de ficheiros que armazenam os seusdados nos diferentes provedores de armazenamento. A figura 2.7 demonstra a arquitectura

Capıtulo 2. Trabalho relacionado 19
que estes sistemas de ficheiros adoptam. Alguns destes sistema utilizam uma proxy a queos clientes se conectam, e esta por sua vez e que contacta a cloud. Note-se que nestecaso, a proxy e um ponto unico de falha. Outros sao executados directamente na maquinado cliente, conectando-se assim directamente a cloud. A comunicacao existente entre osclientes e as clouds e efectuado via APIs fornecidas por estas. A utilizacao de cloudspara armazenar os dados, ao contrario dos sistemas de ficheiros descritos anteriormente,tem a vantagem de fornecer um espaco de armazenamento quase ilimitado (ou mesmoilimitado) enquanto que o custo nao e muito elevado.
Figura 2.7: Arquitectura de Sistemas de Ficheiros para clouds.
2.3.1 S3FS
O S3FS [16] e um sistema de ficheiros para sistemas Unix que permite montar umbucket da Amazon S3 [4] como um sistema de ficheiros local atraves do FUSE [7]. Estesistema permite o uso de uma cache local efectuada em disco de forma a aumentar odesempenho do sistema. Note-se que esta cache so e utilizada se o cliente o indicar.Quando um ficheiro e aberto, e feita a transferencia do ficheiro completo para a cache,e quando e fechado, e enviado para a cloud, efectuando assim todas as operacoes deescrita e leitura localmente. Quando uma transferencia para a cloud nao e efectuada comsucesso, o sistema volta a tentar mais 2 vezes antes de abortar a mesma. De forma aminimizar as transferencia de dados da Amazon S3, sao usados resumos criptograficos(computados atraves da tecnica MD5) para validar a cache. Esta cache pode crescerinfinitamente, podendo assim ocupar todo o espaco em disco. Se tal acontecer, e daresponsabilidade do cliente eliminar os ficheiros de forma ao espaco do disco nao ficartodo preenchido. E mantida tambem uma cache em memoria (por omissao 4MB) paraarmazenar os metadados dos ficheiros.

Capıtulo 2. Trabalho relacionado 20
2.3.2 S3QL
O S3QL [17] e um sistema de ficheiro para sistemas operativos tipo Unix que ar-mazena os seus dados em provedores de armazenamento como Google Storage [9], eAmazon S3 [4]. Este sistema utiliza uma base de dados local que serve de cache tantopara dados como para metadados. Todas as operacoes, como a criacao de uma directo-ria, a renomeacao de um ficheiro, a alteracao de permissoes, sao efectuadas nesta cache.Estas alteracoes sao enviadas assincronamente para a cloud. Os ficheiros presentes no sis-tema de ficheiros sao divididos e armazenados em blocos pequenos. Esta opcao permiteoptimizar o desempenho e o custo associado a transferencia dos dados para a cloud poisso os blocos requisitados/modificados necessitam ser obtidos ou enviados tanto da/para acache, como da/para a cloud. Antes da transferencia dos dados para a cloud, este passamprimeiro por um mecanismo de compressao (como LZMA ou bzip2) e posteriormentesao cifrados atraves da tecnica AES com um chave de 256 bits. Para manter a integridadedos dados armazenados nas clouds o servico armazena tambem um resumo criptografico(usado SHA256 HMAC) para cada bloco de dados transferido.
Uma outra caracterıstica interessante do S3QL e que ele a geracao snapshots de di-rectorias servindo estas para backup.
2.3.3 BlueSky
O BlueSky [45] e um sistema de ficheiros que foi principalmente desenhado paraser utilizado por clientes dentro de empresas. Para tal, o sistema adopta um arquitecturabaseada no conceito de proxy. Os clientes comunicam assim com a proxy, que por sua vezinterage directamente com a cloud para armazenar os dados. A comunicacao feita entreos clientes e a proxy pode ser efectuada atraves de dois diferentes protocolos de sistemasde ficheiros do modelo cliente-servidor: o NFS (versao 3) e o CIFS.
A proxy concretiza uma cache write-back usando o seu disco local, computando assimquase todos os pedidos localmente. Devido a isto, deve ser instalada na rede dos clientespara minimizar a latencia inerentes aos pedidos. Os pedidos sao assim todos satisfeitosna cache (pedidos de leitura e escrita) com a excepcao da eventualidade de um pedidode leitura ser efectuado sobre um ficheiro que nao esta em cache. Neste caso o ficheiroe obtido da cloud e armazenado na cache. Quando a cache esta cheia (visto a cloudter mais capacidade que o disco local) os ficheiros sao substituıdos atraves de polıticasLRU (Least Recently Used). Os ficheiros sao mantidos em cache divididos em blocossequencialmente numerados onde cada bloco tem o tamanho de poucos megabytes. Istopermite melhorar a performance do sistema, pois so sao lidos do disco os blocos referentesao offset requisitado.
Todas as escritas para as clouds sao efectuadas assincronamente. Inerente a estaopcao, existe o problema da possibilidade da falha do disco local. Se tal acontecer,

Capıtulo 2. Trabalho relacionado 21
poderao haver dados que serao perdidos, e consequentemente nunca propagados paraa cloud. Para minimizar este risco, o BlueSky envia dados para as clouds a cada cincosegundos. Note-se que se um envio demorar mais que cinco segundos, o envio posteriorso iniciara quando este terminar.
O sistema adopta uma estrutura baseada em log, sendo este log a unidade de armazena-mento utilizada. Cada log armazenado na cloud e composto por varios segmentos de log,e cada um deste segmentos de log agrega multiplos objectos. Os logs sao construıdos deforma a terem um tamanho de aproximadamente 4MB (para esconder a latencia inerentea efectuar escritas para a cloud com um tamanho pequeno). Note-se o sistema permiteefectuar leituras parciais nestes logs armazenados na cloud.
O sistema armazena quatro tipos diferentes de objectos nos logs. Estes objectos rep-resentam tando os dados como os metadados e podem ser blocos de dados, inodes, mapasde inodes e checkpoints. Os blocos de dados representam os proprios dados e cada umtem o tamanho fixo de 32KB (excepto o ultimo bloco de um ficheiro que pode ser maispequeno). Os inodes representam os metadados dos ficheiros contento informacoes sobreo dono do ficheiro, listas de controlo de acesso, timestamp e os apontadores para cadabloco de dados. Os mapas de inodes sao utilizados para localizar as versoes mais recentesde cada inode dentro do segmento. Por fim, os checkpoints contem os apontadores paraa localizacao do mapas de inodes em uso. Os checkpoints sao tambem utilizados paramanter a integridade do sistema apos uma falha da proxy e para fornecer backups porversao.
Para manter a confidencialidade dos dados, cada objecto e cifrado individualmenteantes do seu envio para a cloud (atraves da tecnica AES) e protegidos com codigos deautenticacao de mensagens (com HMAC-SHA-256).
Para limpar os dados nao mais necessarios presentes na estrutura em log armazenadana cloud, o BlueSky implementa um colector de lixo. Este colector de lixo tanto pode serexecutado na proxy como numa instancia de computacao nas clouds (Amazon EC2 porexemplo), sendo neste ultimo caso mais eficiente em relacao aos custo e a performance.
2.3.4 Frugal cloud File System
O Frugal cloud File System (FCFS) [36] e um sistema de ficheiros que foi concretizadotendo em conta o objectivo de reduzir ao maximo os custos monetarios impostos por estesservico relativos ao armazenamento e acesso aos dados.
Para efectuar esta melhoria nos custos necessarios para manter os dados nas clouds, oFCFS baseia-se nas diferentes opcoes de armazenamento que as algumas clouds fornecemque diferem nao so nos custos, mas tambem no tempo de resposta aos pedidos. A Ama-zon por exemplo, fornece tres diferentes opcoes de armazenamento: a Amazon S3 [4],a Amazon EBS [1] e a Amazon Elasticache [3]. A Amazon S3 fornece baixo custo dearmazenamento, contudo, tem a desvantagem de cada pedido ter um preco associado (es-

Capıtulo 2. Trabalho relacionado 22
crita ou leitura, e no caso das leituras existe tambem um preco associado a quantidade deGB lidos) e as respostas a esses pedidos sofrerem de uma latencia maior. Ja a AmazonEBS fornece um custo para escritas e leituras mais baixo, mas o preco de armazenamentoe mais elevado em relacao a Amazon S3. A ultima opcao referida, a Amazon Elasticache,e a que fornece o melhor tempo de resposta (mantem os dados em memoria) nao cobrandonada pelos pedidos nem pela quantidade de GB lidos, contudo o preco de armazenar osdados e muito mais elevado do que nas outras duas opcoes. Basicamente, quanto maiorfor o preco do armazenamento dos dados, menores serao os precos associados aos pedi-dos e quantidades de bytes transferidos, e menor a latencia nos pedidos. Note-se que aElasticache e a EBS nao podem ser acedidos de foram da Amazon, o que implica que oFCFS so possa ser executado nas VMs (virtual machines) da Amazon EC2 [2].
O FCFS utiliza assim a Amazon S3 como disco do sistema (onde o armazenamentodos dados e mais barato) e a Amazon EBS ou Amazon Elasticache como cache (ondeobter os dados e mais barato). Os ficheiros sao armazenados em blocos de dados de 4MB. Estes blocos de dados podem ser obtidos directamente do disco ou da cache. Nesteultimo caso os blocos de dados tem de ter sido previamente transferidos do disco. Estatransferencia (do disco para a cache) tem um preco associado se as suas bases de dados(S3 e EBS/Elasticache) estiverem em servidores diferentes. Note-se que quando os blocosde dados sao carregados para a cache nao sao eliminados do disco devido a motivos dedisponibilidade. Por omissao, os dados sao armazenado no disco pelo simples motivodo preco de armazenamento ser mais baixo. Os blocos de dados, quando armazenadosna cache, sao mantidos dentro de volumes de armazenamento que podem ser ajustaveisa qualquer instante, de modo a terem exactamente a capacidade de armazenar os blocosque, para esse instante, sao precisos manter em cache. A troca de ficheiros em cache eefectuada atraves de polıticas de substituicao de cache do tipo LRU e ARC [31].
2.3.5 Cumulus
O Cumulus [44] e um sistema que permite aos utilizador fazerem backup dos seussistemas de ficheiros atraves de snapshots. Apesar de este sistema nao ser um sistemade ficheiros, esta inserido nesta seccao porque os backups que este permite efectuar so-bre os sistemas de ficheiros sao armazenados na cloud. A interface fornecida para osclientes comunicarem com o servidor consiste em somente 4 operacoes: get, put, list edelete. Estas operacoes operam em ficheiros inteiros. Como os sistemas de ficheirostem muitos ficheiros pequenos, e armazena-los individualmente nas clouds tras algunsproblemas como maiores tempos de latencia e custos monetarios mais elevados devidoaos modelos de custos apresentados pelas clouds, o Cumulus agrupa varios ficheiros pe-quenos e coloca-os dentro de uma unidade denominada segmentos. Estas unidades saoarmazenadas da mesma forma que os ficheiros possuindo tambem um identificador unico.

Capıtulo 2. Trabalho relacionado 23
Cada snapshot inclui um log de metadados e os proprios dados. O log de metadadoscontem entradas para cada ficheiro, onde sao guardadas informacoes sobre as permissoese custodia do ficheiros, um resumo criptografico para garantir a integridade dos dados, e osapontadores para a localizacao dos dados. Cada snapshot e transformada num segmento,comprimida e encriptada antes de ser enviada para a cloud.
Os clientes podem fazer uma recuperacao completa extraindo todos os ficheiros ouuma recuperacao parcial recuperando so parte deles.
2.3.6 Consideracoes Finais
Apos o estudo destes sistemas de ficheiros para cloud, e importante dar relevanciaa tres importantes limitacoes que estes apresentam. A primeira limitacao refere-se aocaso dos sistema que adoptam uma arquitectura baseada em proxy, pois esta e um pontounico de falha. A segunda relata com o facto de nenhum deles permitir a partilha deficheiros controlada por diferentes utilizadores em diferentes localizacoes (note-se que nocaso de uma arquitectura com proxy e permitida a partilhar de ficheiros entre os clientesque a estejam conectados a mesma proxy). Por ultimo, estes so confiam unicamente numprovedor de armazenamento dependendo assim deste, nao efectuando assim nenhumareplicacao de dados.
Apesar destas limitacoes, e de notar o mecanismo de validacao de cache que algunsdescrevem, em que sao comparados resumos criptograficos efectuados para cada versao.
2.4 Consideracoes Finais
Neste capıtulo foram introduzidos e descritos alguns dos servico de armazenamento,sistemas de ficheiros distribuıdos e sistemas de ficheiros para clouds estudados que nosajudaram a desenhar e concretizar o C2FS. No proximo capıtulo e introduzida a arquitec-tura e modelo de sistema do C2FS, e e descrito em pormenor o servico de armazenamentoconcretizado para este.

Capıtulo 2. Trabalho relacionado 24

Capıtulo 3
Armazenamento de Dados do C2FS
3.1 C2FS
Conforme ja mencionado, o trabalho desenvolvido neste PEI enquadra-se num pro-jecto maior que e um sistema de ficheiros que armazena os seus dados na cloud-of-cloudschamado C2FS (cloud-of-clouds file system). Assim nesta seccao e introduzida a arquitec-tura e o modelo de sistema do C2FS para melhor se perceber a descricao dos componentesrealizados por este projecto nas seccoes seguintes.
3.1.1 Arquitectura
A figura 3.1 apresenta a arquitectura do C2FS. Na base na arquitectura esta o FUSE-J[8]. Este e o componente responsavel por interceptar as chamadas de sistema para recur-sos pertencentes ao C2FS. E tambem devido ao uso deste modulo que o C2FS fornece aosseus clientes uma interface do estilo POSIX [13]. As chamadas de sistemas interceptadassao passadas ao agente C2FS pois este implementa uma interface fornecida pelo FUSE-J. O agente C2FS concretiza assim uma lista de operacoes de sistemas de ficheiros (i.e.,open, write, etc) onde integra os outros componentes do sistema: o servico de directorias,o servico de locks e o servico de armazenamento. Note-se que a interaccao com estessistemas depende da operacao recebida pelo agente C2FS, tendo cada operacao um com-portamento especıfico. Alem desta integracao, o agente C2FS e tambem responsavel porgerar a chave de encriptacao para cada ficheiro. Na seccao 3.2 e explicado em pormenoro funcionamento do FUSE-J e as operacoes de sistemas de ficheiros que este permiteimplementar.
O servico de directorias [32] e o componente responsavel por armazenar os metadadosdos recursos do C2FS. Juntamente com os metadados, e tambem armazenada a chave deencriptacao. Este mecanismo faz tambem controlo de acesso a ficheiros partilhados. Estasfuncoes sao concretizadas tendo por base um servico de coordenacao distribuıdo chamadoDepSpace [20] que e executado em diferentes provedores de computacao, fazendo uso doconceito cloud-of-clouds, assim como o DepSky. Este componente faz uso de um sistema
25

Capıtulo 3. Armazenamento de Dados do C2FS 26
de cache para diminuir o numero de chamadas ao DepSpace, diminuindo assim tambemos custos associados a estas chamadas, e aumentando a performance do sistema.
O servico de locks [32] tem a tarefa de manter a consistencia dos ficheiros controlandoo acesso em simultaneo aos mesmos. Assim, o C2FS garante que enquanto um utilizadoresta a escrever num determinado ficheiro, mais nenhum outro pode efectuar esta mesmaoperacao. Como o servico de directorias, este servico tambem e cliente do DepSpace.
O servico de armazenamento tem o objectivo de gerir os dados na cloud-of-cloudsatraves do DepSky. Este componente fornece dois nıveis distintos de cache. No primeiroos dados sao mantidos no disco local para evitar chamadas as clouds, enquanto que nosegundo, os dados sao mantidos em memoria de forma a diminuir o tempo de resposta,aumentando assim o desempenho do sistema. Este servico permite tambem duas formasdistintas de escrever os dados nas clouds. No primeiro as escritas sao efectuadas de formasıncrona enquanto que no segundo sao efectuadas de forma assıncrona. Neste caso emantida uma fila de tarefas a correr em background para gerir estas mesmas escritas. Osdados sao encriptados antes do envio para as clouds, ou seja, os dados em cache estao emclaro. Este servico e descrito em detalhe na seccao 3.4.
Figura 3.1: Arquitectura do C2FS.
3.1.2 Modelo do Sistema
Antes de descrevermos o servico de armazenamento do C2FS em detalhe, explicamosas hipoteses que o sistema requer para um correcto funcionamento.

Capıtulo 3. Armazenamento de Dados do C2FS 27
Em primeiro lugar o C2FS tolera um numero ilimitado de clientes assumindo quecada um destes tem um identificador unico, e assume que a media do tamanho maximopor ficheiro e de 50MBs para garantir bom desempenhos.
Em segundo lugar, o modelo de sistema do C2FS herda as propriedades dos modelosde sistema do DepSky e do DepSpace uma vez que o servico de armazenamento do C2FSrecorre ao DepSky para armazenar os dados na nuvem composta por uma cloud-of-cloudsenquanto que os servicos de directorias e locks utilizam o DepSpace para armazenar osmetadados.
Cada cloud utilizada pelo DepSky representa um servidor passivo ou seja, que nao ecapaz de executar codigo nenhum da aplicacao, fornecendo so uma interface para pro-ceder a operacoes de escrita ou leitura de dados. Estas operacoes tem uma semantica deconsistencia regular onde uma operacao de leitura que seja executada concorrentementecom uma operacao de escrita ira retornar ou os dados que ja la estavam, ou os dados resul-tante da escrita em processo. Embora, como referido acima, o C2FS tenha a preocupacaode nao permitir mais que um escritor para o mesmo ficheiro no mesmo instante, o sistemanao considera escritores maliciosos, pois estes ao terem acesso aos ficheiros, poderiam es-crever dados sem sentido do ponto de vista da aplicacao. A comunicacao existente entreo DepSky e as clouds e efectuada via o modelo classico de chamada remota a procedi-mentos (RPC). Cada operacao continua a ser invocada ate obter uma resposta da cloud ouate ser cancelada.
Ja a comunicacao existente entre os servico de directorias e locks com os servidoresDepSpace e efectuada atraves de canais fiaveis autenticados ponto-a-ponto atraves do usode sockets TCP e codigos de autenticacao de mensagens (MAC) com chaves de sessaosobre a assuncao que a rede pode perder, corromper ou atrasar mensagens, mas nao opode fazer infinitamente entre processos correctos. Para garantir que todas os servidoresexecutam as mesmas operacoes por ordem, e usada uma primitiva de multicast com ordemtotal, baseada no protocolo de consenso Paxos Bizantino [42]. Tal protocolo requer ummodelo de sistema eventualmente sıncrono.
Tanto as clouds que sao os servidores de armazenamento, como os servidores doDepSpace que mantem os metadados online, toleram faltas bizantinas [30] utilizando sis-temas de quoruns bizantinos onde sao requeridos n ≥ 3f + 1 para suportar f servidoresfaltosos. Contudo, o sistema tolera um numero ilimitado de clientes faltosos.
3.2 FUSE
O FUSE (File system in USEr space) [7] e um modulo para Linux que permite aconstrucao de sistemas de ficheiros no espaco do utilizador, eliminando assim a neces-sidade de efectuar modificacoes a nıvel do kernel. Isto significa que com a utilizacaodeste modulo, o sistema de ficheiros nao necessita ser executado no kernel pois e ex-

Capıtulo 3. Armazenamento de Dados do C2FS 28
ecutado a nıvel do utilizador. Outra vantagem inerente a utilizacao deste modulo para aimplementacao do sistemas de ficheiros e a interface ao estilo POSIX [13] que e oferecidaaos clientes, facilitando assim a gerencia de ficheiros na cloud-of-clouds.
A figura 3.2 ilustra como o FUSE interage com a arquitectura dos sistemas de ficheirosUnix. Quando o VFS (Virtual File System) intercepta uma chamada de sistema a um re-curso pertencente ao sistema de ficheiros C2FS, automaticamente chama o modulo FUSE(FUSE). Este modulo e instalado no Kernel aquando da instalacao do FUSE. Este porsua vez, envia a chamada para a biblioteca do FUSE (libfuse) atraves de um descritorde ficheiro especial. Por fim, o processo que concretiza o sistema de ficheiros recebe achamada, processa-a, e envia a resposta pelo caminho inverso.
Figura 3.2: Caminho percorrido por cada chamada ao sistema.
Contudo, o FUSE e implementado em C enquanto que os sistemas a integrar no C2FS,o DepSky e o DepSpace, sao implementados em Java, o que dificulta tal integracao. Eusado entao uma concretizacao do FUSE em Java chamado FUSE-J [8] para facilitar aintegracao dos sistemas existentes. Este fornece uma API Java que usa ligacoes JNI (JavaNative Interface) para comunicar com a biblioteca do FUSE. O FUSE-J fornece umainterface para implementar as operacoes de sistema de ficheiros chamada FileSystem3.
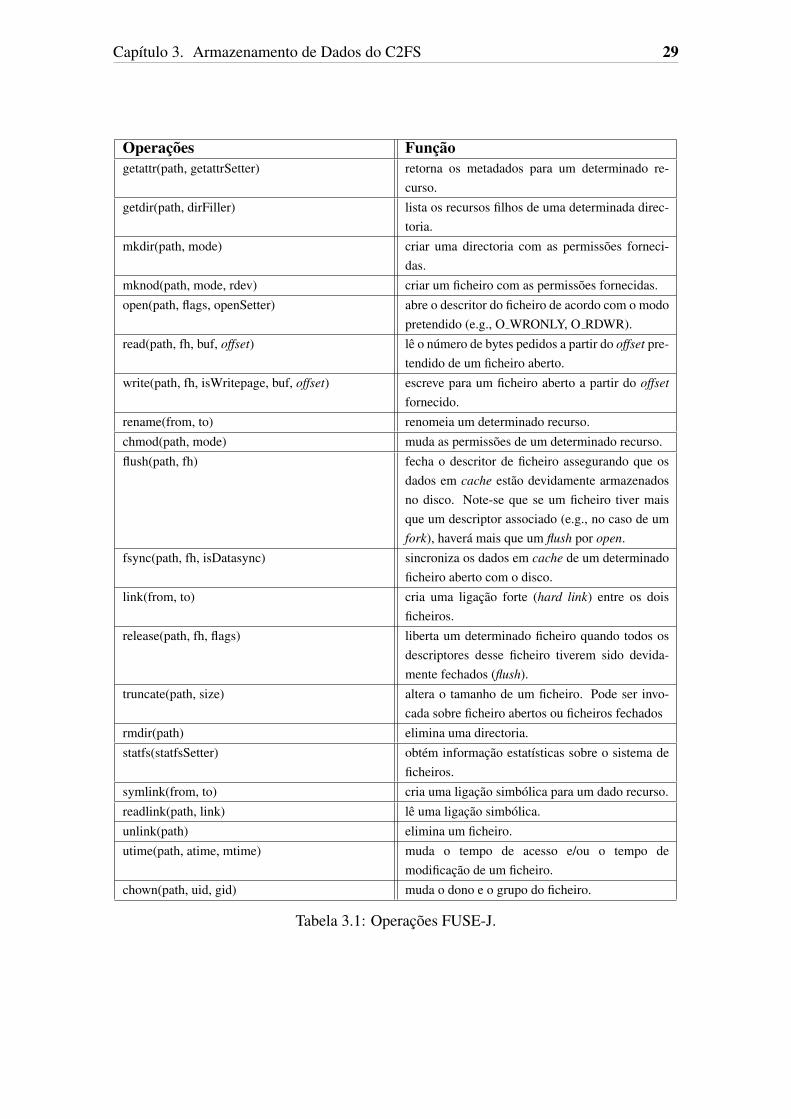
A tabela 3.1 apresenta a lista das operacoes que esta interface permite implementar ea funcao de cada uma delas no sistemas de ficheiros FUSE-J.
3.3 DepSky
Nesta seccao sao apresentadas as alteracoes que foram feitas no DepSky de modo aeste responder de uma melhor forma as necessidades do C2FS. Em sumario foram feitasduas melhorias significativas, sendo elas a adicao de um novo protocolo de uso e a adicaode uma nova operacao que permite ler versoes antigas de uma determinada Data Unit.Em baixo sao descritas estas duas alteracoes no DepSky.
Capıtulo 3. Armazenamento de Dados do C2FS 29
Operacoes Funcaogetattr(path, getattrSetter) retorna os metadados para um determinado re-
curso.getdir(path, dirFiller) lista os recursos filhos de uma determinada direc-
toria.mkdir(path, mode) criar uma directoria com as permissoes forneci-
das.mknod(path, mode, rdev) criar um ficheiro com as permissoes fornecidas.open(path, flags, openSetter) abre o descritor do ficheiro de acordo com o modo
pretendido (e.g., O WRONLY, O RDWR).read(path, fh, buf, offset) le o numero de bytes pedidos a partir do offset pre-
tendido de um ficheiro aberto.write(path, fh, isWritepage, buf, offset) escreve para um ficheiro aberto a partir do offset
fornecido.rename(from, to) renomeia um determinado recurso.chmod(path, mode) muda as permissoes de um determinado recurso.flush(path, fh) fecha o descritor de ficheiro assegurando que os
dados em cache estao devidamente armazenadosno disco. Note-se que se um ficheiro tiver maisque um descriptor associado (e.g., no caso de umfork), havera mais que um flush por open.
fsync(path, fh, isDatasync) sincroniza os dados em cache de um determinadoficheiro aberto com o disco.
link(from, to) cria uma ligacao forte (hard link) entre os doisficheiros.
release(path, fh, flags) liberta um determinado ficheiro quando todos osdescriptores desse ficheiro tiverem sido devida-mente fechados (flush).
truncate(path, size) altera o tamanho de um ficheiro. Pode ser invo-cada sobre ficheiro abertos ou ficheiros fechados
rmdir(path) elimina uma directoria.statfs(statfsSetter) obtem informacao estatısticas sobre o sistema de
ficheiros.symlink(from, to) cria uma ligacao simbolica para um dado recurso.readlink(path, link) le uma ligacao simbolica.unlink(path) elimina um ficheiro.utime(path, atime, mtime) muda o tempo de acesso e/ou o tempo de
modificacao de um ficheiro.chown(path, uid, gid) muda o dono e o grupo do ficheiro.
Tabela 3.1: Operacoes FUSE-J.

Capıtulo 3. Armazenamento de Dados do C2FS 30
Modificacao 1. Por motivos relacionados com o controlo de acesso sobre ficheirospartilhados, o servico de armazenamento (um componente do C2FS descrito na seccaoseguinte) cifra os dados antes de os guardar nas clouds (usando o DepSky), sendo a chavesimetrica usada para cifrar/decifrar os dados armazenada no servico de directorias. As-sim, os dados irao ser armazenados no DepSky ja previamente cifrados. Como ja descritoanteriormente, o DepSky fornece dois protocolos distintos para os clientes gerirem osseus dados na cloud-of-clouds: o DepSky-A e o DepSky-CA [19]. Contudo, nenhumdestes protocolos responde devidamente a necessidade do C2FS. O DepSky-A nao nose util porque, apesar de garantirmos a confidencialidade dos dados devido a sua cifracaono servico de armazenamento, se um bloco de dados de tamanho T for replicado em n
clouds, ira ser consumido n×T espaco de armazenamento e os custos irao ser, em media,n vezes maiores do que se for usado so uma cloud. O DepSky-CA tambem nao se revelaoptimo para o C2FS porque, embora solucione o problema descrito anteriormente atravesdo uso de codigos de apagamento, cifra tambem os dados e usa partilha de segredo paragarantir confidencialidade das chaves, o que penaliza a performance uma vez que os dadossao encriptados duas vezes, uma a nıvel do C2FS, e outra no DepSky.
Foi concretizado entao um novo protocolo que nao e mais que uma variante do DepSky-CA. A diferenca e que nao faz uso de tecnicas criptograficas nem de partilha de segredos,mas mantem a disponibilidade e integridade dos dados ao mesmo tempo que reduz oscustos monetarios de armazenamento devido a utilizacao de codigos de apagamento nareplicacao dos dados. Assim, em cada operacao de escrita, e armazenado em cada cloudum fragmento codificado (sao gerados tantos fragmentos quanto o numero de clouds uti-lizado). Na operacao de leitura sao necessarios f + 1 fragmentos (em que f e o numerode provedores que podem ser faltosos) para obter o bloco de dados inicial1. Note-se quemesmo na eventualidade de alguem escutar a rede e obter f+1 fragmentos (isto e, o blocoinicial), nao conseguira obter os dados em claro pois estes sao previamente cifrados peloservico de armazenamento do C2FS.
Modificacao 2. O DepSky mantem todas as versoes de todas as escritas efectuadas emcada cloud. Neste cenario foi concretizada uma operacao de leitura que permite ler umaversao antiga de uma unidade de dados do DepSky. A esta nova operacao demos o nomereadMatching(Du, h), onde o primeiro argumento e a unidades de dados do DepSky e osegundo e um resumo criptografico. Assim o objectivo e ler a primeira versao em que oseu resumo e igual ao resumo fornecido.
Para a concretizacao desta operacao foram necessarias algumas alteracoes na operacaode escrita do Depsky. Primeiro tem que ser armazenados todos os metadados referentes acada versao escrita, ao inves de armazenar somente os metadados da ultima versao. Estaalteracao foi efectuada de modo a garantirmos a integridade de todos os blocos de dados
1Contudo sao esperadas n− f respostas devido ao protocolo bizantino utilizado.

Capıtulo 3. Armazenamento de Dados do C2FS 31
escritos em cada cloud. Outra alteracao feita foi a introducao de um novo campo nosmetadados chamado datahash. Este campo armazena um resumo criptografico efectuadopelo DepSky sobre cada bloco de dados completo a ser escrito (i.e., antes de passar porqualquer processo de codificacao ou cifracao). Por fim, a operacao de escrita do DepSkypassa a retornar ao cliente este resumo.
O algoritmo desta nova alteracao e bastante simples.
• Primeiro e obtido o ficheiro de metadados referente a unidade de dados fornecidaDu. Neste caso basta obter o ficheiro de metadados de n − f cloud (uma vez queneste conjunto de clouds existe pelo menos uma com a versao do campo datahashmais actual).
• Depois sao comparados os resumos presentes nos campos datahash com o resumofornecido h, iniciando a procura na versao mais recente, ate a mais antiga.
• Quando encontrado um resumo igual ao resumo h, e lida das clouds a versao refer-ente a esse resumo encontrado. Esta leitura e realizada seguindo o protocolo normalde leitura, ou seja, e efectuada num quorum de n− f clouds. Caso nenhum resumopresente no ficheiro de metadados seja igual ao resumo fornecido, e retornado errona operacao.
Esta operacao foi introduzida para satisfazer um mecanismo explicado na tese [32],que tem por finalidade minimizar uma importante limitacao presente na maioria dasclouds, que e a consistencia eventual, fornecendo assim uma consistencia regular fortepara os ficheiros armazenados no C2FS.
3.4 Servico de Armazenamento
Nesta seccao e apresentado o servico de armazenamento concretizado para o C2FS.Como ja referido anteriormente, este servico utiliza o DepSky modificado descrito naprimeira modificacao da seccao 3.3 que mantem a integridade e a disponibilidade dosdados armazenados na cloud-of-clouds. A confidencialidade e fornecidada pelo proprioservico de armazenamento que cifra os dados antes do seu envio para as clouds. Cadaficheiro neste servico esta directamente relacionado com uma unidade de dados do Dep-Sky (Data Unit).
Este servico dispoe de uma cache local que aumenta o desempenho do sistema deficheiros e diminui os custos monetarios associados a downloads que, desta forma, saoevitados. Note-se que apesar de este servico armazenar os dados nas clouds atraves doDepSky, e importante referir que so opera em dados que estejam em cache, sendo sonecessario fazer o download dos dados das clouds caso exista uma versao mais recentedestes nas clouds. Isto acontece se o ficheiro for partilhado por diferentes utilizadores

Capıtulo 3. Armazenamento de Dados do C2FS 32
ou se o mesmo utilizador mantiver o C2FS em diferentes estacoes de trabalho. Paradados que nao sejam partilhados nunca e necessario efectuar uma leitura das clouds (anao ser que o mesmo utilizador monte o mesmo o sistema numa maquina diferente ondea cache nao esta actualizada), servindo estas so para backup. Isto e muito importantepois conseguimos poupar dinheiro uma vez que a transferencia de dados para dentro damaioria das clouds nao tem nenhum, ou quase nenhum preco associado, sendo apenas asoperacoes de transferencia de dados para fora cobradas.
Por omissao, a cache dos dados e feita no disco local, mas, os utilizadores desteservico podem tambem manter a cache dos dados em memoria volatil de forma a diminuiro tempo de resposta para cada operacao de leitura ou escrita. Este servico disponibilizatambem duas formas de enviar os dados para as clouds, sıncrona e assıncrona, em quena sıncrona os clientes esperam pela confirmacao de que os dados estao devidamentearmazenados, e na assıncrona o envio dos dados e feito em background.
Assim, este servico permite ao C2FS ser configurado de varios formas:
• O nıvel de cache a utilizar (so em memoria fısica ou tambem em memoria volatil).
• A forma do envio-o dos dados para as clouds (sıncrona ou assıncrona).
• Escolher se a operacao fsync do agente C2FS sincroniza os dados no disco local ouna cloud-of-clouds.
Note-se que consoante os parametros de configuracao escolhidos diferentes nıveis deconsistencia e durabilidade sao fornecidos. De seguida serao descritos os algoritmos paraas operacoes deste servico, a sua integracao no agente C2FS, e os diferentes nıveis deconsistencia consoante os parametros de configuracao.
3.4.1 Visao Geral da Gestao do Armazenamento
Conforme ja mencionado, o servico de armazenamento concretizado para o C2FS fazum uso intensivo de cache. Logicamente esta cache ocupa muito espaco no disco local(que pode vir a ser o disco todo). Poderıamos evitar isto concretizando um servico de ar-mazenamento que operasse directamente nos ficheiros armazenados nas clouds sem fazercache dos dados. Mas com isto terıamos muitos mais problemas do que benefıcios no quediz respeito ao desempenho do sistema e aos custos associados as transferencias de dadospara as clouds. Note-se que, por exemplo, para uma operacao de escrita com offset maiorque zero ocorrer com sucesso, iria ser necessario uma leitura no DepSky (que realmentesao duas leituras, uma para os metadados e outra para os dados [19]) para obter os dados,e depois de o blocos de dados final ser obtido (i.e., com a escrita ja efectuada no offsetcorrecto) iria ser necessario uma escrita no DepSky (que na verdade efectua uma leiturados metadados, e duas escritas, uma para os dados, e outras para ou metadados) para ar-mazenar o ficheiro ja actualizado. Assim para uma operacao de escrita no C2FS terıamos

Capıtulo 3. Armazenamento de Dados do C2FS 33
cinco acessos a cloud-of-clouds. Ora, sobre um ficheiro, desde o momento que e aberto(open) ate ao momento que e fechado (close), podem ocorrer inumeras operacoes de es-crita com offsets diferentes, o que provocaria um desempenho completamente inaceitavelconjugado com precos proibitivos. Assim, a cache que o servico de armazenamento fazsobre os ficheiros e um dos pontos cruciais para o bom desempenho do C2FS.
Os ficheiros podem ser mantido em tres diferentes localizacoes: em memoria, emdisco, e na cloud-of-clouds. A figura 3.3 ilustra o fluxo que os dados fazem enquanto saotransferidos entre as diferentes localizacoes. As setas contınuas representam as escritas,enquanto que as setas a tracejado representam as leituras. Como podemos verificar, osclientes so efectuam leituras e escritas na memoria volatil (se esta for utilizada). Damemoria os dados sao escritos para o disco, e posteriormente, do disco sao escritos paraas clouds. Como mostra a figura, nao e permitido que os dados sejam escritos directa-mente da memoria para as clouds. Isto nao e permitido para no caso de ocorrer um falhadurante o envio dos dados, estes poderem ser recuperados. Da mesma forma, quando obti-dos os dados das clouds, estes sao primeiro armazenados em disco, e so posteriormenteem memoria. As operacoes disponibilizadas para os clientes gerirem os dados nestasdiferentes localizacoes sao descritas em baixo.
Figura 3.3: Fluxo dos dados.
Tanto a cache em disco como a cache em memoria aplicam politicas LRU (LeastRecently Used) para a substituicao de ficheiros quando nao existe espaco suficiente paraarmazenar novos ficheiros. Basicamente quando e necessario espaco, sao eliminados osficheiros que ha mais tempo nao sao acedidos. O tamanho maximo da cache em discoe exactamente o espaco do disco local, ja o tamanho maximo da cache em memoria econfigurado pelo cliente. Note-se que antes da eliminacao de ficheiros da memoria, estessao armazenados devidamente em disco de forma a nao se perder a versao mais actual. Osclientes podem manter os dados na cache em memoria durante o tempo que desejarem.Isto significa que todas as alteracoes feitas sobre um ficheiro que esta em memoria naoserao armazenadas em memoria estavel (disco local ou clouds-of-clouds) ate o cliente oindicar ou ate que seja necessaria a sua substituicao.

Capıtulo 3. Armazenamento de Dados do C2FS 34
3.4.2 Algoritmos de Gestao de Armazenamento
Nesta seccao sao apresentadas as caracterısticas fundamentais do servico de armazena-mento como as variaveis utilizadaz e os algortimos concretizados.
Para a validacao da cache, o servico de armazenamento mantem armazenados os re-sumos criptograficos retornados em cada escrita no DepSky (modificacao 2 descrita naseccao 3.3). Este resumo e fornecido ao servico de directorias de forma a ser armazenadojuntamente com os outros metadados do ficheiro. Assim o resumo presente no servicode directorias e sempre o mais actual. A validacao de cada ficheiro em cache e entaoefectuada comparando o resumo fornecido pelo servico de directorias com o resumo ar-mazenado neste servico. Estes resumos criptograficos sao mantidos e tambem frequente-mente actualizados no disco local para evitar transferencias das clouds depois do sistemaser desligado e ligado novamente. Este servico mantem tambem a indicacao de quaisos ficheiros que foram alterados e que ainda nao foram enviados para as clouds, de for-mar a efectuar envios desnecessarios. Para possibilitar a recuperacao apos uma falha, ouseja, para sincronizar ficheiros que foram alterados e nao chegaram a ser enviados para asclouds, esta informacao e tambem mantida no disco local. Por ultimo, e tambem mantidoo tamanho dos dados de cada ficheiro. Estas informacoes sao carregadas para memoriasempre que o C2FS e montado.
Este servico foi concretizado tambem, tendo em conta que um dos objectivos do C2FSe fornecer um registo em que sao aceites um cliente escritor e multiplos clientes leitorespara o mesmo ficheiro para cada instante. Para o servico de armazenamento, este mod-elo obriga que a cada operacao de leitura sobre um determinado ficheiro seja verificadose existe uma nova versao disponıvel nas clouds, pois a qualquer momento da leitura,um cliente escritor pode actualiza-los. Ja na operacao de escrita nao e necessaria estaverificacao pois o servico de locks [32] garante que enquanto um cliente escritor efectuauma escrita, mais nenhum outro o pode fazer.
Em baixo sao apresentadas as operacoes que este servico disponibiliza para os clientesgerirem os dados nas tres diferentes localizacoes(memoria, disco e cloud-of-clouds) e quala funcionalidade de cada uma delas. Note-se que estas operacoes foram concretizadastendo em conta a interface de sistemas de ficheiros que o agente C2FS implementa e omomento em que cada operacao deste servico e invocada e determinante para o seu bomfuncionamento.
Nos algoritmos em baixo, os resumos criptograficos estao representados na variavelhashs, a informacao referente ao ficheiros alterados em cache e armazenado na variavelvalueToSend e o tamanho dos dados na variavel sizes. As variaveis cacheMemory ecacheDisk representam os acessos a memoria e ao disco respectivamente. Por sua vez, avariavel depsky representa os acessos efectuados ao DepSky.

Capıtulo 3. Armazenamento de Dados do C2FS 35
Operacao Update Cache. Esta operacao e responsavel por ler os dados da cloud-of-clouds utilizando o DepSky. Como podemos verificar no algoritmo 1, os dados sao lidosdas clouds por dois motivos: ou os dados nao se encontram em cache, ou os dados emcache estao desactualizados (linha 2). Os dados em cache nao se encontram actualizadosse o resumo fornecido pelo cliente do servico for diferente do resumo mantido no servicode armazenamento. Os dados sao entao lidos do DepSky usando a operacao readMatch-ing (modificacao 2 da seccao 3.3) como mostra a linha 5, que recebe como argumentos aunidade de dados referente ao ficheiro requerido (linha 3) e o resumo criptografico refer-ente a versao a obter. Como podemos ver no algoritmo, caso os dados nao consigam serobtidos das clouds, isto e, se nao houver nenhuma versao nas clouds que diga respeito aoresumo fornecido, esta operacao volta a tentar obter os dados mais tres vezes, de cincoem cinco segundos (linhas 4-8). Isto acontece porque como referido anteriormente, oresumo fornecido pelo cliente, no caso o agente C2FS, e sempre o mais actual, e porconseguinte, isto significa que os dados referentes a este resumo ja foram escritos paraas clouds (operacao Sync W Clouds). Os dados podem nao estar logo visıveis apos a suaescrita nas clouds devido a consistencia fraca fornecida por estes2. Devido a isto, a sualeitura e tentada tres vezes. Note-se que caso os dados nao sejam obtidos em nenhumadas tentativas e retornado erro ao cliente (linhas 9-10). Caso os dados sejam obtidos, saoentao decifrados utilizando a chave simetrica fornecida pelo cliente (linha 11) e a cache erevalidada, isto e, os dados obtidos sao colocados em cache a partir do offset 0, e e escritoem disco o novo resumo, a informacao de que o ficheiro neste momento esta actualizado eo tamanho dos dados lidos (linhas 12-16). Posteriormente, caso o cliente esteja a usufruirda memoria volatil, os dados sao adicionados a esta (linhas 17-20). Note que no caso denao ter sido necessario efectuar a leitura das clouds, para escrever os dados em memoria,estes tem que ser obtidos do disco (neste caso a partir do offset 0 e indicando que se querler o ficheiro todo). Esta operacao e responsavel por esta accao para garantirmos quesempre que um cliente desejar adicionar um ficheiro a este nıvel de memoria, adiciona aversao mais actual do ficheiro.
Esta operacao e chamada pelo agente C2FS na operacao open ao contrario do que seriasuposto. Embora a operacao open seja considerada uma operacao de metadados, a leiturados dados das clouds e feita nesta operacao para que todas as operacoes efectuadas sobreum ficheiro aberto (write, read, fsync e flush) sejam feitas sobre um ficheiro actualizado.
Operacao Write Data. Esta operacao tem a funcao de escrever os dados para o disco lo-cal ou para a memoria. O algoritmo 2 mostra-nos como a operacao e concretizada. Comopodemos ver, caso o servico de armazenamento esteja a usufruir da cache em memoriavolatil (linha 2), a referencia dos dados e obtida desta (linha 3). De seguida e verificado
2Note-se que no caso da Amazon S3, os dados estao visıveis num tempo aproximado a cinco segundos[4].

Capıtulo 3. Armazenamento de Dados do C2FS 36
Algorithm 1: Update CacheMap 〈 String, byte[] 〉 hashs;Map 〈 String, boolean 〉 valueToSend;Map 〈 String, int 〉 sizes;CacheOnDiskManager cacheDisk;CacheOnMemoryManager cacheMemory;DepSky depSky;
Entrada: name - identificador do ficheiro, key - chave para desencriptar os dados,hash - resumo criptografico para verificar se os dados esta em cacheestao actualizados
Saıda: nenhumainıcio1
se (name /∈ cacheDisk || hash 6= hashs.get(name)) entao2
dataUnit←− DataUnit(name);3
para (0 ≤ i ≤ 3) faca4
cipherdata←− depsky.readMatching(dataUnit, hash);5
se (cipherdata 6= null) entao6
sai do ciclo;7
senaosleep(5000ms);8
se (cipherdata = null) entao9
retorna false;10
data←− decryptData(cipherdata, key);11
cacheDisk.writeData(name, data, 0);12
sizes.add(name, data.length);13
valueToSend.add(name, false);14
hashs.add(name, hash);15
write to disk(name, hash, false, data.length);16
se (cacheMemory 6= null) entao17
se (data = null) entao18
data←− cacheDisk.getData(name, 0, sizes.get(name));19
cacheMemory.writeData(name, data, 0);20
retorna true;fim
se e necessario redimensionar o tamanho do buffer. Isto acontece se a soma do tamanhodo bloco a escrever com a posicao a iniciar a escrita for superior ao tamanho do buffer emcache (linha 4-5). O buffer e sempre redimensionado para o dobro do tamanho de formaa nao ser necessario redimensionar o buffer e todas as operacoes de escrita. Por fim oficheiro e marcado como alterado (linha 6) e os dados a escrever sao colocado no buffera partir no offset correcto. No caso de a escrita ser efectuada para disco, o ficheiro e mar-cado como alterado e esta informacao e armazenado em disco (linhas 8-9) no momento

Capıtulo 3. Armazenamento de Dados do C2FS 37
antes de se proceder a escrita dos dados (linha 10). Esta ordem de operacoes permite quetodos os ficheiros alterados sejam enviados para as clouds, mesmo na presenca de umafalha apos a sua escrita. Por fim e verificado se a escrita (quer em memoria ou em disco)alterou o tamanho dos dados, e caso tenha alterado, e armazenado o novo tamanho (linhas11-14). O tamanho do ficheiro e entao retornado ao cliente.
Logicamente esta operacao e chamada pelo agente C2FS aquando de uma chamadaao sistema write. Esta operacao ira escrever sempre sobre a versao mais actual dos dados,pois a chamada ao sistema write e so invocada sobre ficheiros abertos (isto e, depois deum open).
Algorithm 2: Write DataMap 〈 String, boolean 〉 valueToSend;Map 〈 String, int 〉 sizes;CacheOnDiskManager cacheDisk;CacheOnMemoryManager cacheMemory;
Entrada: name - identificador do ficheiro, value - dados a escrever, offset -posicao de onde iniciar a escrita
Saıda: tamanho final dos dadosinıcio1
se (cacheMemory 6= null) entao2
data←− cacheMemory.readData(name);3
se (value.length+ offset > data.length) entao4
resizeBuffer(data);5
valueToSend.add(name, true);6
memcopy(data, offset, value, 0, value.length);7
senaovalueToSend.add(name, true);8
write to disk(name, true);9
cacheDisk.writeData(name, value, offset);10
se (value.length+ offset > sizes.get(name)) entao11
size←− value.length+ offset;12
sizes.add(name, size);13
write to disk(name, size);14
retorna sizes.get(name);15
fim
Operacao Read Data. Esta operacao e usada para ler um determinado ficheiro. Comopodemos ver no algoritmo 3, a primeira preocupacao da operacao e verificar se os dadosem cache para o ficheiro em questao estao actualizados atraves da chamada a operacaoja descrita em cima Update Cache (linha 2). Esta verificacao em cada leitura vem aoencontro do modelo de operacao requerido pelo C2FS referido em cima (um escritor e

Capıtulo 3. Armazenamento de Dados do C2FS 38
multiplos leitores). Se nao for possıvel obter os dados actualizados e retornado erro aocliente. Apos ter a garantia que os dados em cache estao devidamente actualizados, osdados sao lidos atraves da memoria volatil se esta estiver a ser utilizada e se o ficheiroestiver presente neste nıvel, ou caso contrario sao obtidos do disco (linhas 3-5). Por fim,os dados sao requeridos sao retornados ao cliente.
Esta operacao e invocada pelo agente C2FS na operacao read.
Algorithm 3: Read DataMap 〈 String, byte[] 〉 hashs;CacheOnDiskManager cacheDisk;CacheOnMemoryManager cacheMemory;
Entrada: name - identificador do ficheiro, key - chave para desencriptar os dados,hash - resumo criptografico para verificar se os dados esta em cacheestao actualizados, offset - posicao para iniciar a leitura, capacity -numero de bytes a ler
Saıda: valor do ficheiro lidoinıcio1
se (Update Cache(name, key, hash)) entao2
se (cacheMemory 6= null && cacheMemory.contains(name)) entao3
data←− cacheMemory.readData(name, offset, capacity);4
senaodata←− cacheDisk.readData(name, offset, capacity);5
retorna data;6
retorna null;7
fim
Operacao Trunc Data. Esta operacao tem o objectivo de alterar o tamanho de um de-terminado ficheiro. No algoritmo 4 podemos ver como a operacao foi implementada. Aprimeira preocupacao a ter e conta e a de ler os dados da cloud se os dados em cache naoestiverem actualizados (linha 2). Caso a operacao retorne erro, e tambem retornado erroao cliente (linha 3). De seguida, os dados sao truncados tanto em disco como em memoria,caso esta esteja a ser utilizada (linhas 4-6). Posteriormente o ficheiro e armazenado tantoem memoria como em disco o novo tamanho do ficheiro e a informacao de que o ficheirofoi alterado. Por ultimo, caso o cliente do servico o obrigue, o ficheiro e enviado para asclouds (linhas 10-11).
Esta operacao e invocada na operacao truncate do agente C2FS. Esta operacao apre-senta uma semantica diferente das operacoes anteriores (Write Data e Read Data) devidoa especificacao que o FUSE-J da para esta chamada de sistema: a operacao truncate podeser invocada sobre um ficheiro fechado. Isto significa que os dados em cache podemnao estar actualizados aquando da sua chamada e que pode nao vir a ser invocada nen-

Capıtulo 3. Armazenamento de Dados do C2FS 39
huma operacao de sincronizacao (fsync ou flush) apos a alteracao do tamanho do ficheiro.Dai a necessidade de garantirmos que a alteracao e feita em todas as localizacoes ondeo ficheiro se encontra. Note-se ainda que esta operacao nao e mais que uma escrita, eportanto o ficheiro deve ser bloqueado para escrita caso ainda nao esteja (no caso doficheiro estar fechado). Assim, o cliente do servico, neste caso o agente C2FS, tem queter a preocupacao extra de verificar se o ficheiro ja esta bloqueado para escrita, e casonao esteja deve bloquea-lo. Se o ficheiro nao estiver bloqueado para escrita deve tambemobrigar a operacao Trunc-Data a sincronizar os dados com as clouds especificando-o noargumento da operacao toSyncWithClouds.
Algorithm 4: Trunc DataMap 〈 String, byte[] 〉 hashs;Map 〈 String, boolean 〉 valueToSend;Map 〈 String, int 〉 sizes;CacheOnDiskManager cacheDisk;CacheOnMemoryManager cacheMemory;
Entrada: name - identificador do ficheiro, key - chave para desencriptar os dados,hash - resumo criptografico para verificar se os dados esta em cacheestao actualizados, size - novo tamanho do ficheiro,toSyncWithClouds - variavel que diz a operacao se e necessariosincronizar os dados com as clouds ou nao
Saıda: nenhumainıcio1
se (Update Cache(name, key, hash)) entao2
retorna false;3
cacheDisk.truncateData(name, size);4
se (cacheMemory 6= null && cacheMemory.contains(name)) entao5
cacheMemory.truncateData(name, size);6
sizes.add(name, size);7
valueToSend.add(name, true);8
write to disk(name, true, size);9
se (toSyncWithClouds = true) entao10
Sync W Clouds(name, key);11
retorna true;12
fim
Operacao Sync W Disk. Esta operacao tem a funcao de armazenar um determinadoficheiro presente na memoria volatil no disco local. Como mostra o algoritmo 5 o ficheiroso e armazenado em disco se sofreu alguma alteracao desde o momento que foi car-regado para memoria (linha 2). Caso se verifique isso, o ficheiro e obtido da memoria(linha 3), depois e escrito em disco (linha 4), e por fim, e armazenado tambem em

Capıtulo 3. Armazenamento de Dados do C2FS 40
disco a informacao de que o ficheiro em disco sofreu alteracoes de forma a possibilitar arecuperacao apos um falha.
Esta operacao e invocada pelo agente C2FS na operacao fsync se o utilizador do C2FSapenas de desejar que a sincronizacao dos dados seja feita no disco local. Sincronizaros dados apenas no disco nesta chamada ao sistema pode significar um grande aumentoda performance se, durante a abertura e o fecho de um ficheiro, a operacao fsync forinvocada muitas vezes. Note-se que se o cliente configurar o sistema para a operacaofsync sincronizar os dados no disco e nao estiver a utilizar a memoria volatil, os dados jaestarao previamente sincronizados, nao sendo assim necessario nenhum acesso ao disco.
Algorithm 5: Sync W DiskMap 〈 String, int 〉 sizes;CacheOnDiskManager cacheDisk;CacheOnMemoryManager cacheMemory;
Entrada: name - identificador do ficheiroSaıda: nenhumainıcio1
se (cacheMemory 6= null && cacheMemory.contains(name) &&2
valueToSend.get(name) = true) entaodata←− cacheMemory.readData(name, 0, sizes.get(name));3
cacheDisk.writeData(name, data, 0);4
write to disk(valueToSend);5
fim
Operacao Sync W Clouds. Esta operacao e utilizada para sincronizar os dados com acloud-of-clouds. O algoritmo 6 comeca por efectuar uma chamada a operacao Sync W Diskpara garantir que os dados que irao ser armazenados nas clouds estao previamente ar-mazenados no disco local (linha 2). Os dados so sao entao enviados para as clouds sesofrerem alguma alteracao em cache (linha 6). Se nao sofrerem qualquer alteracao sig-nifica que estao iguais ao ultimo download ou envio efectuado, ou seja, nao e necessarioenvia-los para as clouds. Antes de serem enviados, os dados sao lidos do disco (linha 7) edepois sao cifrados com a chave simetrica (linha 8) fornecida pelo cliente. Os dados saoentao enviados consoante o modelo utilizado (sıncrono ou assıncrono). Estes diferentesmodelos sao explicados em detalhe na seccao 3.4.3. Em qualquer dos modelos, assimque o envio de dados para as clouds terminar e obtido o novo resumo criptografico dosdados enviados (linha 6) retornado na operacao de escrita do DepSky. O servico de di-rectorias e entao notificado com este novo resumo e com o tamanho dos dados (linha 7).E necessario esta sincronizacao entre o servico de directorias e o servico de armazena-mento para garantir que os metadados so serao actualizados depois dos dados o serem,de forma a que nunca nenhum cliente leia os metadados de um ficheiro que ainda nao

Capıtulo 3. Armazenamento de Dados do C2FS 41
existe. Embora assim um cliente possa obter metadados de uma versao mais antiga aosdados que estao nas clouds, e muito menos provavel que o contrario descrito em cima,pois uma escrita nos servidores de metadados [32] e muito mais rapida que uma escritanos servidores de armazenamento. Por fim o novo resumo criptografico e armazenadosubstituindo o antigo, o ficheiro e transferido do estado de alterado para actualizado, e asestas informacoes sao armazenadas em disco (linhas 8-11).
Esta operacao e invocada pelo agente C2FS na operacao flush garantindo assim que nofecho de qualquer ficheiro os dados serao actualizados na cloud-of-clouds. Esta operacaopode tambem ser invocada pelo agente C2FS na operacao fsync se o utilizador do C2FSassim o quiser. Note-se que desde que o ficheiro e aberto ate ser fechado, pode ser re-querida muitas vezes a sua sincronizacao (atraves de chamada ao sistema fsync). Assim,sincronizar os dados na cloud-of-clouds com a operacao fsync, embora ofereca garantiasmais seguras (por exemplo, tolerar a falha do disco), significa uma diminuicao na perfor-mance do C2FS.
Algorithm 6: Sync W CloudsMap 〈 String, byte[] 〉 hashs;Map 〈 String, boolean 〉 valueToSend;Map 〈 String, int 〉 sizes;CacheOnDiskManager cacheDisk;
Entrada: name - identificador do ficheiro, key - chave para encriptar os dadosSaıda: nenhumainıcio1
se (valueToSend.get(name) = true) entao2
Sync W Disk(name);3
data←− cacheDisk.getData(name, 0, sizes.get(name));4
cipherData←− encryptData(key, data);5
newHash←− Send By Model(name, cipherData);6
notifyDirectoryService(name, newHash, data.length);7
hashs.add(name, newHash);8
valueToSend.add(name, false);9
write to disk(name, newHash, false);10
fim
Operacao Delete Data. Esta operacao serve para eliminar um ficheiro do disco local.Os ficheiros nao sao eliminados das clouds durante esta operacao para evitar a diminuicaodo desempenho do sistema, uma vez que para um determinado ficheiro nao ficar visıvelaos clientes apos a sua eliminacao basta eliminar os metadados a ele referentes. Outromotivo para nao se proceder a eliminacao dos dados nas clouds nesta operacao deve-seao facto da necessidade de concretizar um colector de lixo que elimine as versoes antigas

Capıtulo 3. Armazenamento de Dados do C2FS 42
de ficheiros ainda nao eliminados. Assim, faz sentido proceder a eliminacao de dados nasclouds, quer seja de versoes antigas ou mesmo de todas as versoes de um ficheiro (se jativer sido eliminado), no mesmo protocolo (seccao 3.4.5). Alem de eliminar o ficheirodo disco, elimina tambem todas as entradas em todas as estruturas mantidas pelo servicode armazenamento referentes a ele, incluindo a estrutura de resumos criptograficos, aestrutura que mantem os ficheiros que tem que ser enviados para as clouds, a estruturaque mantem o tamanho dos ficheiros e, se o modelo de envio de dados por assıncrono, dafila de envio (seccao 3.4.3).
Esta operacao e integrada no agente C2FS na operacao unlink.
Operacao Release Data. Esta operacao tem o objectivo de libertar o ficheiro. Primeiroo ficheiro deve ser eliminado da memoria volatil se esta o contiver. Depois, o lock efec-tuado sobre o ficheiro deve ser libertado atraves do servico de locks [32]. No caso domodelo de envio ser sıncrono, o ficheiro e libertado no instante, pois este nao esta a serenviado. Ja no caso de o modelo ser assıncrono, se o ficheiro estiver a ser enviado ouainda estiver na fila de envio, o ficheiro so e libertado quando o seu envio em backgroundterminar.
Esta operacao e invocada pelo agente C2FS na operacao release de forma a libertaro ficheiro apos todos os descriptores associados a este serem fechados. Como ja descritoanteriormente na tabela 3.1, sobre um ficheiro aberto podem existir varios descriptores sepor exemplo a aplicacao fizer uso da funcao fork, e sobre cada um destes descriptores,que apontam para o mesmo ficheiro, e invocada a operacao flush. Ja a operacao release einvocada so quando o ultimo descriptor for fechado.
Ilustracao do Funcionamento. A fig 3.4 mostra, de uma forma resumida, uma possıvelsequencia de chamadas ao sistema que uma qualquer aplicacao pode exercer, e o que elasdesencadeiam no agente C2FS e, por sua vez, no servico de armazenamento aquandodo uso da cache em memoria. Note-se que nesta imagem esta escondida a interaccaoexistente com os servicos de directorias e locks [32].
A cache em memoria permite assim melhorar o desempenho do C2FS (principalmentequando se opera em ficheiros grandes) aquando de sucessivas operacoes de escrita ou deleitura num mesmo conjunto de ficheiros. Isto porque quando um ficheiro e aberto (open),a operacao Update Cache e chamada e o ficheiro e carregado para memoria. Depois todasas escritas e/ou leituras que sao efectuadas sobre um ficheiro aberto sao efectuadas sobrea memoria volatil. Quando o ficheiro e fechado, e chamada a operacao Sync W Cloudsque armazena devidamente as actualizacoes nas clouds e posteriormente a operacao Re-lease Data que liberta o ficheiro da memoria.

Capıtulo 3. Armazenamento de Dados do C2FS 43
Figura 3.4: Desencadeamento das chamadas ao sistema no servico de armazenamento.
3.4.3 Modelo de Envio de Dados
Como ja mencionado nas seccoes anteriores, o servico de armazenamento pode serconfigurado para efectuar escritas sıncronas ou assıncronas de ficheiros para a cloud-of-clouds, tendo esta escolha influencia nas garantias de consistencia dos dados em cachefornecidas pelo servico. Nos pontos seguinte sao descritos estes dois modelos.
• No caso de as escritas serem sıncronas, o retorno da operacao Sync W Cloudsgarante que os ficheiros ja estao devidamente armazenados na cloud-of-clouds. Estagarantia deve-se ao facto do cliente ser obrigado a esperar a confirmacao da es-crita do ficheiro nas clouds, tendo a garantia que, apos a conclusao da operacao, oficheiro esta correctamente armazenado. Assim a utilizacao deste tipo de escritasfornece tolerancia a faltas do disco local uma vez que o cliente tem a garantia queapos o retorno da operacao, o disco pode falhar pois os dados podem ser recupera-dos das clouds.
• No caso de serem utilizadas escritas assıncronas, tal nao se verifica, pois o clientenao tem garantias do momento em que o ficheiro ira chegar as clouds. Emboraexista uma diminuicao das garantias de consistencia da cache, a utilizacao destetipo de escritas representa um significativo aumento do desempenho do sistema. Aconcretizacao deste modelo de envio envolve um sistema de filas onde existe prior-idade de envio para os primeiros ficheiros que forem adicionados a esta. O sistema

Capıtulo 3. Armazenamento de Dados do C2FS 44
mantem assim tarefas em background a enviar dados de ficheiros diferentes em si-multaneo de modo a maximizar o desempenho. O numero de tarefas a desempenhareste trabalho e configurado pelo cliente. Sempre que uma das tarefas terminar o en-vio de um ficheiro, e iniciado outro envio caso existam ficheiros na fila. Note-seque se nao houvesse este sistema de filas e que se sempre que se quisesse enviar umficheiro assincronamente para as clouds fosse iniciada uma tarefa em background,a maquina onde o C2FS estaria a correr ficaria sobrelotada caso estivessem a serenviados centenas de ficheiros em simultaneo. Se for adicionado um ficheiro a filae este ja la existir, os dados que estavam para enviar sao substituıdos pelos novosevitando assim o envio de uma versao que ja nao e a mais actual. Como ja descritona operacao Delete Data se um determinado ficheiro for eliminado enquanto estana fila, e tambem eliminado da fila, evitando assim o seu envio. Tanto a substituicaode dados na fila como a sua eliminacao representam uma diminuicao nos custo rela-cionados com a transferencia de dados para as clouds.
3.4.4 Durabilidade dos Dados
A tabela 3.2 apresenta os diferentes nıveis em que os dados sao mantidos pelo servicode armazenamento. O primeiro nıvel diz respeito aos dados em memoria volatil. Comopodemos ver, e o nıvel em que se verifica o melhor desempenho de sistema, pois cadaoperacao de escrita ou de leitura e efectuada com uma latencia na ordem dos microsse-gundos. Contudo nao fornece nenhuma garantia no que diz respeito a tolerancia de faltas.No segundo nıvel, que e quando os dados atingem memoria estavel no disco local, oservico de armazenamento suporta a falha da estacao de trabalho onde o C2FS esta acorrer, podendo recuperar os dados depois do sistema ser reiniciado. No ultimo nıvelos dados sao mantidos na cloud-of-clouds permitindo assim a partilha de ficheiros entrediferentes clientes. Como podemos ver na tabela, a partir do momento em que os da-dos estao armazenados na cloud-of-clouds o sistema suporta tanto a falha do disco local,como a falha de f clouds num sistema em que sao utilizadas n − f [19]. Este e tambemo nıvel em que a latencia para as operacoes de escrita e leitura apresenta valor mais ele-vados. Este modelo de durabilidade, ou seja, as diferentes localizacoes em que os dadosse encontram aliado a integracao das operacao que gerem os dados nestas localizacoes noC2FS, permite a este garantir um nıvel de consistencia forte (consistencia ao fechar [26]).
Localizacao dos Dados Latencia Tolerancia a Faltas Partilhamemoria nao estavel microssegundos nenhuma naodisco local milissegundos crash naocloud-of-clouds segundos falha do disco e do provedor sim
Tabela 3.2: Durabilidade dos dados.

Capıtulo 3. Armazenamento de Dados do C2FS 45
3.4.5 Colector de Lixo
Conforme ja mencionado anteriormente, cada escrita no DepSky representa uma versaonova nas clouds. Assim uma preocupacao que este servico tem que ter e a de eliminarversoes antigas de ficheiros que ainda nao tenham sido eliminados. Juntamente com o pro-cedimento de eliminar versoes antigas de ficheiro, sao tambem eliminados das clouds osficheiros que ja foram eliminados do sistema de ficheiros mas que ainda estao armazena-dos nas clouds (operacao Delete Data). Para a eliminacao de versoes antigas, o clientedo servico e responsavel por fornecer o numero de versoes que devem ser mantidas nasclouds (na continuacao da descricao deste protocolo, este numero e representado por v).Em ambos os casos, o objectivo principal, alem de o de deixar mais espaco disponıvel, eo de nao obrigar os utilizadores do C2FS a pagar demasiado por dados obsoletos que naosejam mais necessarios. Em baixo e explicado como se procede a eliminacao de versoese a eliminacao de ficheiros por completo:
• Para a eliminacao de versoes que nao sejam mais necessarias, o servico de ar-mazenamento utiliza o protocolo para colectar lixo disponibilizado pelo DepSKy(garbageColector(unidade de dados, numero de versoes a manter)). Este proto-colo elimina todas as versoes excepto as que o cliente especificar que quer manter.Por exemplo, se uma determinada unidade de dados do DepSky (que referencia umficheiro no C2FS) contiver dez versoes (sendo a primeira a mais recente) e este pro-tocolo for invocado fornecendo como argumento a unidade de dados e o numerode versoes a manter (por exemplo se v tomar valor tres), serao eliminadas todas asversoes desde a quarta ate a decima.
• Para a eliminacao de ficheiros e utilizada a operacao deleteContainer(unidade dedados) disponibilizada pelo DepSky, que dado uma unidade de dados do DepSkyelimina toda a informacao a ela referente. Isto significa que em cada cloud saoeliminadas todas as versoes referentes a este ficheiro.
Assim, o servico de armazenamento do C2FS implementa um colector de lixo quequando activado, e responsavel por estas duas accoes. A complexidade da formulacaodeste protocolo e escolher o momento optimo para activa-lo, pois para escolher este mo-mento terıamos que saber exactamente a carga de trabalho que seria exercida sobre osistema. E excluıda a hipotese de se concretizar este protocolo como um servico externoao C2FS onde darıamos a responsabilidade ao cliente de o executar quando o bem enten-desse.
Uma das formas mais logicas para activar o colector de lixo seria a cada t unidadesde tempo. Contudo, este modelo poderia levantar alguns problemas. Primeiro, se ovalor t tomasse valores pequenos, o cliente poderia ser obrigado a ter custos adicionais

Capıtulo 3. Armazenamento de Dados do C2FS 46
desnecessarios, uma vez que teriam que ser listadas3 frequentemente todas as versoes detodos os ficheiros, que poderiam ate nao ter nada para eliminar (se tivessem menos versoesque aquelas a manter). Por outro lado, se o valor t tomasse valores grandes e o sistemasofresse de uma carga de trabalho com muitas escritas, o cliente iria pagar demasiado poruma grande quantidade de dados.
Para activar o colector de lixo de uma forma o mais perto do optimo possıvel, o servicode armazenamento oferece uma solucao que tem em conta a quantidade total de bytes eo numero total de versoes que existem para eliminar, conseguindo assim nao ter a neces-sidade de estudar a carga de trabalho a cada instante. A atencao prestada a totalidade debytes transferidos permite accionar o protocolo num perıodo de tempo razoavel na even-tualidade do utilizador do C2FS manter ficheiros grandes no sistema. Contudo, assim oprotocolo pode levar muito tempo a ser activado se o utilizador do C2FS mantiver muitasversoes pequenas no sistema. De forma a evitar isso e tambem dada atencao ao numerode versoes que estao para eliminar nas clouds.
Assim, o colector de lixo e activado quando se verificar algum dos seguintes acontec-imentos:
• Se o numero total de bytes a eliminar transferidos para as clouds for superior a X .
• Se o numero total de versoes a eliminar presentes nas clouds for superior a Y .
Para X foi escolhido o valor de 1,5 GB (1610612736 bytes). Como mencionadoanteriormente o tamanho maximo por ficheiro para garantir uma boa performance doC2FS e de 50 MB. Este valor de X permite assim, no pior caso (assumindo 50 MB porficheiro), limpar as clouds quando existem aproximadamente 31 versoes. Ja para Y foiescolhido o valor de 1500 versoes. Note-se que se o valor de X nao for atingido, temosaproximadamente cerca de 1 MB por cada uma desta 400 versoes. Estes valores forampensados para que o protocolo nao demore muito tempo aquando da sua execucao paranao penalizar o desempenho do sistema. Contudo, estes valores podem nao ser optimos.Para encontrarmos os valores optimos para X e Y terıamos que efectuar um estudo maisaprofundado. Note-se que estes valores podem ser facilmente reconfigurados pelo cliente.
Computando X e Y. O servico de armazenamento faz a contagem do numero de versoese da quantidade de bytes transferidos para as clouds por cada ficheiro. A contagem dasversoes e feita da seguinte forma: enquanto um determinado ficheiro estiver no seu tempode vida (ainda nao foi eliminado) sao contadas todas as vezes que este foi transferidopara as clouds. Esta contagem e so iniciada apos v transferencia (uma vez que enquantonao for eliminado, queremos la manter nunca menos que v versoes); quando o ficheirofor eliminado, o numero de transferencias para este e incrementado em v (uma vez que
3Note-se que para a listagem de versoes nas clouds esta associado um preco, dependendo este preco doprovedor.

Capıtulo 3. Armazenamento de Dados do C2FS 47
na proxima execucao do colector de lixo tem que ser eliminadas todas as versoes deste).Assim, a cada instante, o numero total de versoes que existem para eliminar sao a somade todas estas contagens para todos os ficheiros mantidos em cache. Para a contagem donumero de bytes, assim como na contagem de versoes, sao somados para cada ficheiro osbytes transferidos em cada transferencia. No caso de ficheiros ja eliminados sao contadosos bytes transferidos em todas as escritas efectuadas, ja no caso de ficheiros ainda noactivo sao contados os bytes transferidos para todas as escritas efectuadas com a excepcaodas ultimas v escritas, pois estas nao necessitam ser eliminadas4.
Para possibilitar a soma correcta do numero de todas as versoes a eliminar e do numerototal de bytes transferidos a cada instante, mesmo apos o sistema ser reiniciado, sao man-tidas em disco local as estruturas que armazenam os numeros de versoes e o numero debytes transferidos para cada ficheiro. Estas estruturas sao actualizadas durante a execucaodo protocolo (depois de um ficheiro ser limpo, sao eliminadas as entradas a ele referentes),para permitir a sua recuperacao depois de uma falha. Note-se que nao conseguimos con-tabilizar a totalidade de numero de versoes e o numero de bytes presentes nas clouds paraficheiros partilhados, uma vez que os outros clientes tambem podem efectuar escritasnestes ficheiros. Contudo, assume-se que mais tarde ou mais cedo algum dos clientes iralimpar o ficheiro, uma vez que cada instancia do C2FS executa um protocolo colector delixo.
Este colector de dados nao funciona correctamente, no que diz respeito a ficheirosque ja foram eliminados do sistema mas que ainda nao foram eliminados das clouds, seo utilizador do C2FS mudar de estacao de trabalho, pois perde-se os dados armazenadono disco local que referenciam esses mesmos ficheiros. Contudo, esta falha poderia serfacilmente corrigida se as estruturas fossem mantidas nas clouds. Mas devido as muitasactualizacoes que estas estruturas sofrem, o custo para o utilizador do C2FS seria muitoexcessivo, pois todas as actualizacao referidas anteriormente feitas no disco teriam queser feitas nas clouds.
3.5 Consideracoes Finais
Neste capıtulo foi primeiro apresentada a visao geral do C2FS, um sistema de ficheirospara cloud-of-clouds que ao mesmo tempo que fornece disponibilidade, integridade e con-fidencialidade dos dados armazenado, permite tambem a partilha de ficheiros. Posterior-mente foi descrito o modulo FUSE, que permite a implementacao e execucao do C2FSa nıvel do utilizador. Foram tambem introduzidas as alteracoes feitas a nıvel do DepSkyde forma a este responder melhor as necessidades do DepSky. Por fim foi apresentado o
4No entanto sao armazenados em disco o numero de bytes referentes a escritas recentes para poder-mos adicionar ao total de bytes transferidos o terceiro valor mais antigo quando uma nova transferencia eefectuada.

Capıtulo 3. Armazenamento de Dados do C2FS 48
servico de armazenamento do C2FS. Nesta seccao foram descritas as operacoes que per-mitem gerir os dados nas tres diferentes localizacoes que estes se podem encontrar sendoelas a memoria, o disco, e a cloud-of-clouds. Por ultimo foi explicado o colector de lixoque permite a limpeza de dados obsoletos nas clouds.
No proximo capıtulo sao apresentados os detalhes de concretizacao presentes no servicode armazenamento

Capıtulo 4
Concretizacao do Servico deArmazenamento
Neste capıtulo sao apresentados os aspectos relevantes da concretizacao do servico dearmazenamento do C2FS. Primeiro e apresentado o modelo de classes, e posteriormentealguns diagramas de sequencia que mostram a interaccao entre estas classes aquando dainvocacao das diferentes operacoes disponibilizadas.
Como ja mencionado na seccao 3.2, tanto o DepSky [19] como o DepSpace [20] saoconcretizados na linguagem Java. Razao essa que levou a utilizacao do modulo FUSE-J[8] para a implementacao do sistema de ficheiros. O servico de armazenamento, sendo ocomponente com a funcao de gerir os dados do sistema de ficheiros no DepSky, tambeme concretizado na linguagem Java, facilitando a sua integracao.
Em relacao a cifra dos dados efectuada por este servico, e utilizada a tecnica AESatraves das classes do pacote javax.crypto da plataforma Java. Em relacao ao resumocriptografico computado a nıvel do DepSky, este e computado atraves do algortimo SHA-1 utilizando a classe fornecida pela API do Java java.security.MessageDigest.
De seguida e primeiramente apresentado o modelo de classes do sistema e posterior-mente os diagramas de sequencia para as operacao de obtencao dos dados das clouds, daescrita do dados na cache e da escrita dos dados nas clouds.
4.1 Diagrama de Classes
A figura 4.1 apresenta o diagrama de classes do servico de armazenamento concretizado.O C2FSAgent e a classe que implementa o agente C2FS, ou seja, e a classe que in-
tegra o servico de armazenamento, assim como os restantes servicos [32], na interfacede sistema de ficheiros (seccao 3.2). Esta classe mantem uma instancia do objecto Stor-ageService, objecto este que implementa a interface IStorageService. Esta interface foipensada para responder da melhor forma possıvel aos objectivos do C2FS.
O objecto StorageService permite ao agente C2FS gerir os dados nas tres diferenteslocalizacoes: memoria, disco e cloud-of-clouds. Quando iniciado, este recebe parametros
49

Capıtulo 4. Concretizacao do Servico de Armazenamento 50
de configuracao, e consoante estes parametros, assim sao as instancias que este cria paragerir os dados.
Por omissao, o objecto do tipo StorageService mantem uma instancia do objectocacheDiskManager. Este objecto e responsavel por efectuar todos os acessos ao disco, ede aplicar politicas LRU para a substituicao de objectos em cache quando necessario. Paraaceder ao disco, e utilizada a classe RandomAccessFile que permite aceder ao ficheiro emoffsets diferentes. Este objecto mantem uma instancia do StorageService para no caso danecessidade de substituir ficheiros em cache, serem invocadas as operacoes syncWClouds,para armazenar o ficheiro nas clouds caso seja necessario, e deleteData(containerId), parase proceder a limpeza de todas as entradas em todas as estruturas referentes ao ficheiroem cache a substituir .
Contudo, consoante a configuracao indicada pelo C2FSAgent, tambem este pode man-ter uma instancia do objecto CacheMemoryManager. Assim como a classe descrita emcima, este objecto permite aceder a todos os ficheiros mantidos em memoria atraves dasoperacoes genericas de acesso a cache (ICacheManager). Este mantem uma instancia doobjecto CacheDiskManager de forma a garantir que um determinado ficheiro e devida-mente armazenado em memoria estavel aquando da aplicacao de politicas LRU.
O objecto StorageService mantem tambem uma instancia da classe DepSkyAcessor.Esta e a classe que opera directamente com o DepSky, e e tambem responsavel por cifraro ficheiro antes da sua escrita nas clouds, bem como por decifrar aquando da sua leitura.Se o C2FSAgent configurar o sistema para escrever assincronamente para as clouds, oobjecto StorageService mantem tambem um objecto do tipo SendingQueue. Esta classepermite a adicao e remocao de ficheiros na fila de envio. O objecto que e mantido na fila eo ObjectInQueue que armazena a informacao necessaria para o envio. O envio neste casoe feito atraves do objecto DataSync que representa uma thread possibilitando assim oenvio dos dados em background. Neste caso, cada thread de envio mantem uma instanciadiferente do DepSkyAcessor para o envio de diferentes ficheiros ser feito em paralelo.
A classe DataStatsManager mantem uma Map de objectos do tipo DataStats. Cadaobjecto destes guarda as informacoes que sao necessarias manter em disco sobre cadaficheiro em cache. A classe e assim responsavel por efectuar todas as actualizacoes nosobjectos DataStats e armazenar estas actualizacoes em disco. Esta classe tem tambem umobjecto do tipo GarbageCollectorService onde sao armazenadas as informacoes necessariaspara a activacao do colector de lixo (Garbagecollector).
A tabela 4.1 mostra as linhas de codigo para cada componente do sistema.
4.2 Diagramas de Sequencia
Nesta seccao sao apresentados tres diagramas de sequencia diferentes presentes nasfiguras 4.2, 4.3 e 4.4. O primeiro representa o fluxo de operacoes existente no servico

Capıtulo 4. Concretizacao do Servico de Armazenamento 51
Figura 4.1: Modelo de classes do sistema.

Capıtulo 4. Concretizacao do Servico de Armazenamento 52
Classe Numero de Linhas de CodigoC2FSAgent 988StorageService 322DiskCacheManager 85MemoryCacheManager 70DepSkyAcessor 75DataStats 40DataStatsManager 250SendingQueue 85DataSync 80GarbageCollector 150GarbageCollectorService 40
Tabela 4.1: Linhas de codigo das classes do servico de armazenamento
de armazenamento aquando da operacao de actualizacao da cache. O segundo diagramae referente a operacao de escrita na cache. Por fim, o terceiro, representa a operacaode sincronizacao dos dados na cloud-of-clouds. No primeiro e no ultimo diagrama eescondido o retorno da operacao (erro ou ok) de forma a simplifica-los.
Leitura das clouds. A figura 4.2 mostra o fluxo presente na operacao de actualizacaoda cache. Em primeiro lugar e obtido o objecto representante do fileId fornecido. Nocaso de o ficheiro nao existir em cache, e criado um novo objecto DataStats para estenovo ficheiro e este e adicionado a Map que guarda os objectos deste tipo.
Apos obtido o hash referente a versao em cache (atraves do objecto DataStats), enecessario verificar se este e igual ao hash fornecido pelo agente C2FS, pois se for igualsignifica que os dados em cache sao os mesmos que os dados presentes nas clouds, naosendo assim necessario efectuar o download.
Como podemos ver no diagrama, caso o download seja necessario, o objecto Stor-ageService tenta obter no maximo 4 vezes o ficheiro das clouds atraves do objecto Dep-SkyAcessor. Este objecto, por sua vez le os dados usando o DepSky DepSky atravesda operacao readMatching(Du, hash) e, caso consiga obter os dados correspondentes aohash fornecido, decifra-os e retorna os dados em claro, caso contrario retorna null. Nocaso de nao se conseguir obter os dados em nenhuma das quatro tentativas e retornadoerro ao C2FSAgent.
Se os dados conseguirem ser obtidos, sao entao colocado na cache em disco atravesdo objecto DiskCacheManager. Depois o objecto presente na Map de objectos do tipoDataStats referente a este ficheiro e actualizado com o novo estado (actualizado), com onovo tamanho e com o novo resumo criptografico (referente aos dados lidos). Note-seque o objecto e escrito para disco pelo objecto DataStatsManager so quando o hash eactualizado.

Capıtulo 4. Concretizacao do Servico de Armazenamento 53
Esta operacao escreve ainda os dados em memoria atraves do objecto MemoryCache-Manager, quer tenha sido necessario efectuar a leitura das clouds ou nao.
Escrita na cache. O diagrama presente na figura 4.3 mostra o fluxo de mensagens efec-tuado na operacao de escrita em cache. Quando o objecto StorageService recebe umaoperacao de escrita em cache, este encaminha o pedido de escrita para o local pretendido.Ou seja, para o objecto MemorycacheManager caso o StorageService esteja configuradopara a utilizacao de cache em memoria, ou para o disco caso contrario. Note-se queantes de efectuar a escrita, o estado do objecto e alterado para true, definindo assim queeste ficheiro sofreu alteracoes e necessita ser armazenado em memoria estavel. No casode a escrita ser efectuada para o objecto DiskcacheManager, esta alteracao e tambemarmazenada em disco atraves do objecto DataStatsManager explicitando-o no terceiroargumento da operacao setState, de forma a possibilitar a recuperacao na ocorrencia deuma falha antes do seu envio para as clouds. Por fim, e verificado se a escrita alterouo tamanho do ficheiro. Caso tenha alterado, o novo tamanho e armazenado no objectoDataStats referente ao ficheiro escrito e este novo tamanho e retornado ao agente C2FS.Caso contrario, retorna o tamanho que ja existente no objecto DataStats.
Escrita nas clouds. A figura 4.4 apresenta o diagrama de sequencia da operacao queescreve os dados presentes em cache na cloud-of-clouds. A primeira preocupacao daoperacao e a de chamar a operacao syncDisk(containerId) de modo que os dados actu-alizados em memoria fiquem armazenados em disco de forma a garantir a coerencia dacache em memoria estavel com os dados presentes nas clouds.
O proximo passo e obter o estado do ficheiro atraves do objecto DataStatsManagerque gere a Map de objectos do tipo DataStats. Se o estado estiver a false significa que naohouve alteracoes no ficheiro (provavelmente ocorreram so operacoes de leitura) e portantonao e necessario envia-lo para as clouds. Caso contrario, este tem que ser enviado. Nestecaso os dados sao entao obtidos da cache atraves do objecto DiskCacheManager.
Se o C2FSAgent utilizar escritas assıncronas, os dados sao adicionados ao objectoSendingQueue que gere a fila de envio. O fluxo da operacao presente aquando da adicaode um novo objecto na fila nao esta presente de forma a simplificar o diagrama. Ja seo envio for sıncrono, o StorageService chama a operacao de escrita para o DepSky pre-sente no objecto DepSkyAcessor. Este, antes de escrever no DepSky, cifra os dados coma chave fornecida. Apos a escrita, o objecto DataStats referente ao ficheiro enviado eactualizado com o estado a false, de forma a nao serem enviados os mesmos dados paraas clouds, e o hash que resulta da escrita no DepSky substitui o hash antigo. Aquandoda actualizacao do hash, o objecto DataStats e armazenado em disco. De seguida o ob-jecto DataStatsManager e tambem notificado com o numero de bytes transferidos paraa cloud. Este por sua vez actualiza esta informacao no objecto GarbageCollectorService
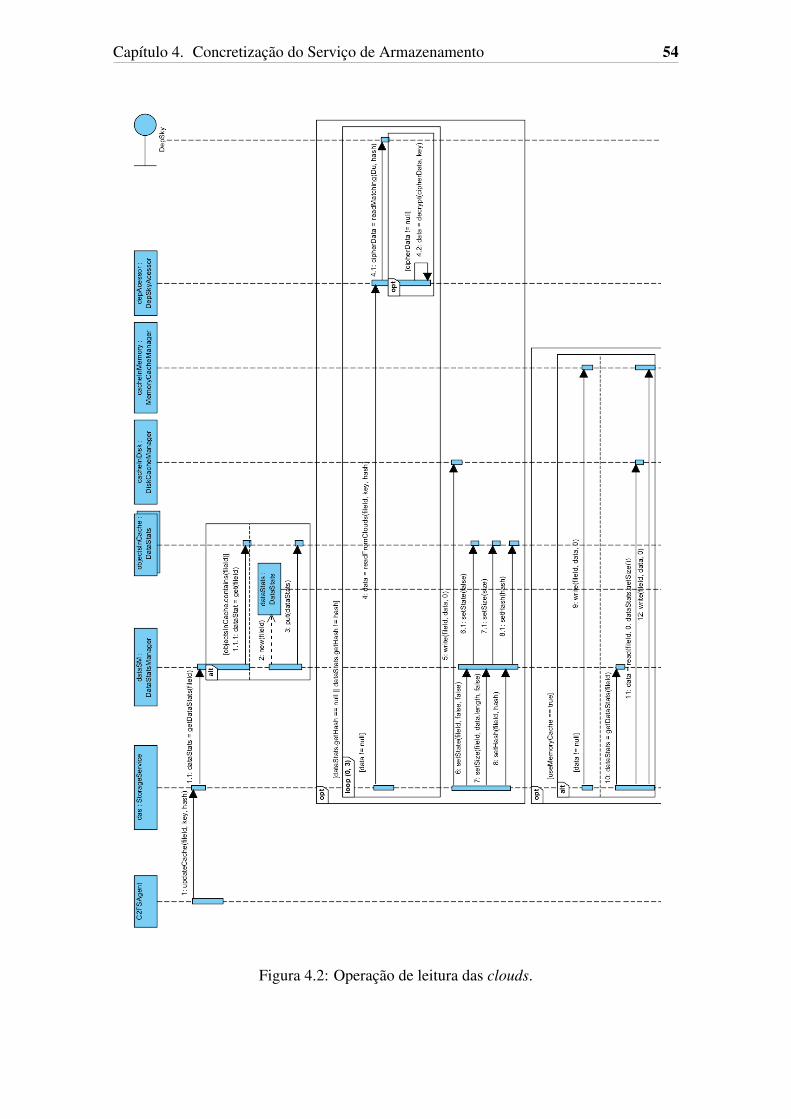
Capıtulo 4. Concretizacao do Servico de Armazenamento 54
Figura 4.2: Operacao de leitura das clouds.

Capıtulo 4. Concretizacao do Servico de Armazenamento 55
Figura 4.3: Operacao de escrita em cache.
para permitir a activacao do colector de lixo. Por fim o DirectoryService e notificado como novo hash e como o tamanho dos dados escritos e posteriormente e chamada a operacaocommitLocalMetadata para proceder ao envio dos metadados para os servidores.
4.3 Agente C2FS
Como ja mencionado varias vezes anteriormente, o agente C2FS e o componente queimplementa as operacoes do sistema de ficheiros e que integra os tres diferentes servicos(armazenamento, directorias e locks) onde, consoante a semantica de cada operacao, as-sim as operacoes dos diferentes servicos a invocar. Assim como o servico de armazena-mento, este por sua vez tambem e configuravel. Em baixo sao listadas os parametros deconfiguracao que os clientes podem utilizar aquando da montagem do sistema de ficheirosno Linux:
• -use memory cache - indica que o sistema ira usar o servico de armazenamentocom cache em memoria volatil (por omissao so e utilizada cache em disco);
• -assync model - indica que o sistema ira usar o servico de armazenamento comescritas assıncronas (por omissao utiliza escritas sıncronas);
• -max memory size=size - indica o tamanho maximo da cache em memoria no servicode armazenamento (por omissao size = 1 GB);
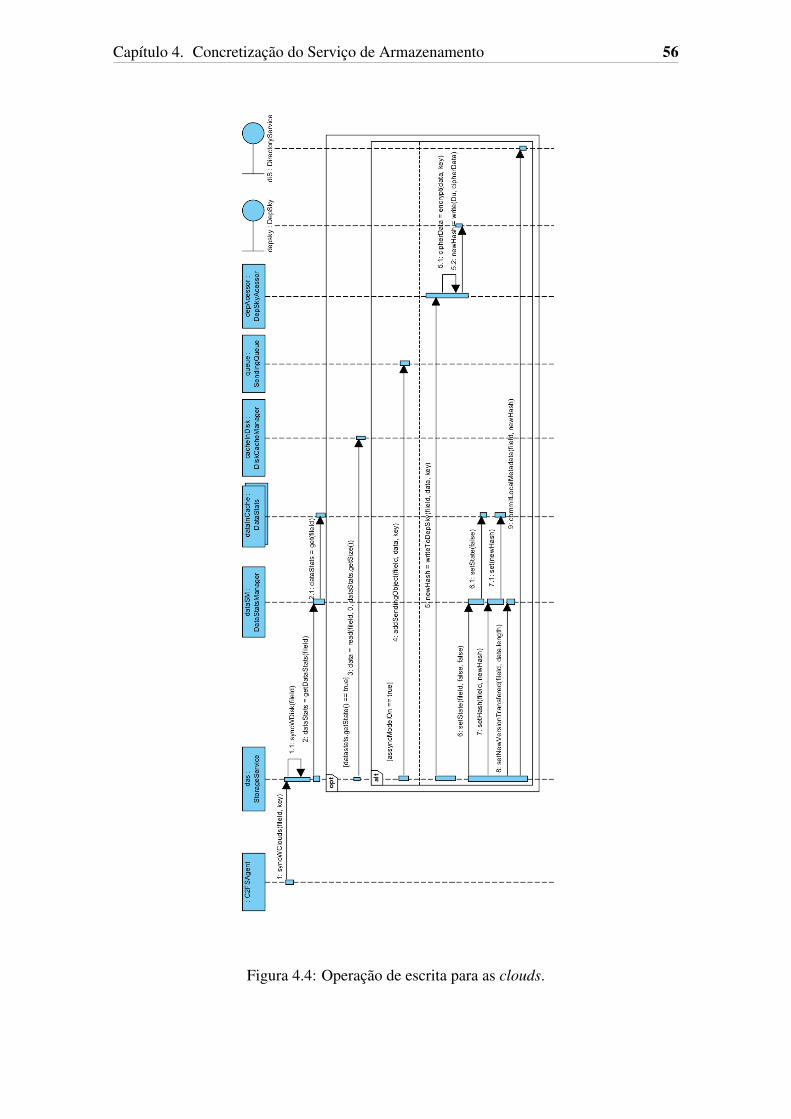
Capıtulo 4. Concretizacao do Servico de Armazenamento 56
Figura 4.4: Operacao de escrita para as clouds.

Capıtulo 4. Concretizacao do Servico de Armazenamento 57
• -num threads=num - indica o numero de threads a enviar dados em background(por omissao num = 4);
• -mantain old version=num - indica o numero de versoes a manter para cada ficheiroaquando da execucao do colector de lixo (por omissao num = 3).
• -fsync to clouds - indica que a operacao fsync envias os dados para as clouds (poromissao escreve-os na cache em disco);
• -use non sharing DS - indica que o sistema ira usar o servico de directorias sempartilha de ficheiros (por omissao utiliza a partilha de ficheiros);
• -delta=time - indica o tempo de validade dos metadados em cache (por omissaotime = 0).
4.4 Consideracoes Finais
Neste capıtulo foram apresentado alguns detalhes de implementacao do servico de ar-mazenamento. Primeiro foi descrito o modelo de classes e como os diferentes compo-nentes interagem entre si. Posteriormente foram ilustrados os modelos de sequencia paraas operacoes de actualizacao da cache atraves da leitura dos dados das clouds, de es-crita na cache (tanto em memoria como em disco) e de escrita dos dados actualizados nacloud-of-clouds.
No proximo capıtulo e apresentada uma avaliacao experimental do desempenho desteservico e do C2FS.

Capıtulo 4. Concretizacao do Servico de Armazenamento 58

Capıtulo 5
Avaliacao
Neste capıtulo e apresentada uma avaliacao do servico de armazenamento para oC2FS. Em primeiro lugar serao apresentadas as latencias inerentes ao envio de dados paraas clouds para diferentes tamanhos de ficheiros. De seguida serao mostradas medicoes dedesempenho efectuadas ao C2FS com diferentes configuracoes.
Por fim, sera comparado o desempenho do C2FS ao desempenho de outros dois sis-temas de ficheiros para clouds, nomeadamente o S3FS [16] e o S3QL [17].
5.1 Metodologia
As medicoes apresentadas neste capıtulo foram obtidas executando tres diferentesbenchmarks, sendo eles o Iozone [10], o PostMark [27] e o Filebench [6]. O Iozoneexercita operacoes de escrita e leitura sequenciais e aleatorias sobre um ficheiro. OPostMark, embora apresente um comportamento mais adequado para testar a gestao demetadados (criacao e destruicao de ficheiros pequenos), pode ser configurado para criarficheiros com um tamanho consideravel, podendo assim testar o comportamento do servicode armazenamento aquando de operacoes de escritas e leituras em diferentes ficheiros aomesmo tempo. Por fim, o Filebench permite testar diferentes tipos de workloads. Nestecaso foi utilizado o workload randomrw que permite exercitar operacoes de escrita eleitura aleatorias sobre o mesmo ficheiro.
Os diferentes benchmarks foram configurados da seguinte forma:
• Iozone - Este foi configurado para testar operacoes de escrita e leitura sequenciaise nao sequenciais para ficheiros com 512 KB, 1, 2, 4, 8, 16 e 32 Mb.
• PostMark - Este, por sua vez, foi configurado para criar e operar sobre 764 ficheirocom tamanhos aleatorios entre 512 Kb e 2 Mb.
• Worload randomrw - Por fim, este foi configurado para exercer carga de trabalho noC2FS atraves de 6 threads diferentes (3 para leituras e 3 para escritas) num unicoficheiro de 50MB.
59

Capıtulo 5. Avaliacao 60
Nestes tres benchmarks podemos avaliar o comportamento do servico de armazena-mento para algumas das propriedades descritas no trabalho apresentado em [25] para osworkloads das aplicacoes de hoje em dia, nomeadamente o acesso a muitos ficheirosem simultaneo, escritas e leituras aleatorias e acessos efectuados a partir de diferentesthreads.
Todas as medicoes foram efectuadas num computador com aproximadamente 2 anos,localizado em Lisboa. Este computador tem como caracterısticas principais um pro-cessador 2.4 GHz Intel Core 2 Duo, e uma memoria de 4GB DDR3. Para efectuar asmedicoes foi utilizado um servico de internet com ligacao de 23.67 Mbps de downloade 5.06 Mbps de upload. O DepSky [19] foi configurado para replicar os dados por 4diferentes provedores de armazenamento, sendo eles Amazon S3 [4], RackSpace [15],Windows Azure [11] e Google Storage [9]. O driver de acesso esta ultima cloud foi de-senvolvido de raiz para estes experimentos ja que o DepSky original nao suportava esteservico [19]. E importante referir ainda que os servidores utilizados para a Amazon S3,RackSpace e Windows Azure estao localizados na Europa, enquanto que o servidor uti-lizado para armazenar os dados na Google Storage situa-se no Estados Unidos. O servicode directorias utilizado para esta avaliacao foi uma versao sem partilha de ficheiros, naqual os metadados nao sao armazenado no DepSpace [32]. Esta escolha justifica-se como objectivo de minimizar a influencia deste servico nos resultados obtidos.
5.2 Latencia das Escritas e Leituras de Dados
Na figura 5.1 sao apresentadas as latencias experienciadas aquando da escrita e daleitura de dados para as clouds atraves do DepSky. Estes valores foram obtidos atravesda execucao do benchmark Iozone. Foram medidas as latencias para escritas e leituras dedados com seis distintos tamanhos, sendo eles 512KB, 1, 2, 4, 8, 16 e 32MB. Para cadaum dos tamanhos dos blocos de dados testados foram executas 100 operacoes.
Como podemos observar no grafico 5.1(a), as latencias obtidas para as escritas sofremuma perda de desempenho mais ou menos proporcional ao tamanho dos dados escritos.Este aumento proporcional da latencia deve-se ao facto de alguns dos provedores dearmazenamento utilizados sofrerem desta propriedade, como e descrito em [37]. Nografico 5.1(b) podemos observar que as latencias obtidas para as leituras apresentam umcomportamento semelhante ao anterior, com a excepcao de que os valores medidos paraos mesmos tamanhos dos dados sao muito mais baixos. Os tempos de latencia apresen-tados na figura sao superiores aos tempos apresentados no projecto atras referido. Istodeve-se ao facto de os testes apresentados em [37] terem sido efectuados na rede do De-partamento de Informatica, sendo o desempenho desta rede muito superior ao da ligacoesda internet utilizada.
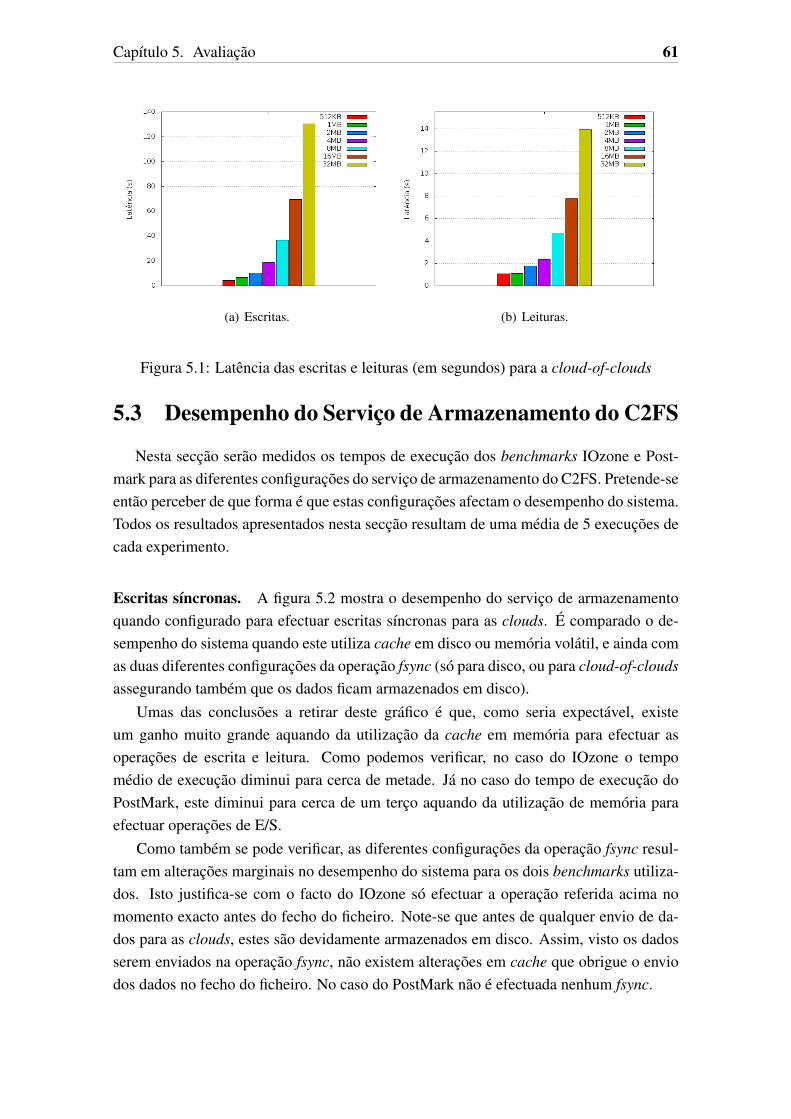
Capıtulo 5. Avaliacao 61
(a) Escritas. (b) Leituras.
Figura 5.1: Latencia das escritas e leituras (em segundos) para a cloud-of-clouds
5.3 Desempenho do Servico de Armazenamento do C2FS
Nesta seccao serao medidos os tempos de execucao dos benchmarks IOzone e Post-mark para as diferentes configuracoes do servico de armazenamento do C2FS. Pretende-seentao perceber de que forma e que estas configuracoes afectam o desempenho do sistema.Todos os resultados apresentados nesta seccao resultam de uma media de 5 execucoes decada experimento.
Escritas sıncronas. A figura 5.2 mostra o desempenho do servico de armazenamentoquando configurado para efectuar escritas sıncronas para as clouds. E comparado o de-sempenho do sistema quando este utiliza cache em disco ou memoria volatil, e ainda comas duas diferentes configuracoes da operacao fsync (so para disco, ou para cloud-of-cloudsassegurando tambem que os dados ficam armazenados em disco).
Umas das conclusoes a retirar deste grafico e que, como seria expectavel, existeum ganho muito grande aquando da utilizacao da cache em memoria para efectuar asoperacoes de escrita e leitura. Como podemos verificar, no caso do IOzone o tempomedio de execucao diminui para cerca de metade. Ja no caso do tempo de execucao doPostMark, este diminui para cerca de um terco aquando da utilizacao de memoria paraefectuar operacoes de E/S.
Como tambem se pode verificar, as diferentes configuracoes da operacao fsync resul-tam em alteracoes marginais no desempenho do sistema para os dois benchmarks utiliza-dos. Isto justifica-se com o facto do IOzone so efectuar a operacao referida acima nomomento exacto antes do fecho do ficheiro. Note-se que antes de qualquer envio de da-dos para as clouds, estes sao devidamente armazenados em disco. Assim, visto os dadosserem enviados na operacao fsync, nao existem alteracoes em cache que obrigue o enviodos dados no fecho do ficheiro. No caso do PostMark nao e efectuada nenhum fsync.

Capıtulo 5. Avaliacao 62
Figura 5.2: Tempo de execucao (em segundos) do IOzone e PostMark para escritassıncronas.
Escritas assıncronas. A figura 5.3 mostra o desempenho do C2FS quando utiliza es-critas assıncronas para as clouds. Assim como na avaliacao efectuada acima, e tambemavaliado neste caso o desempenho do sistema quando utiliza a cache em disco e emmemoria, assim como com as duas configuracoes da operacao fsync.
Figura 5.3: Tempo de execucao (em segundos) do IOzone e PostMark para escritasassıncronas.
Tal como anteriormente referido, tambem aqui podemos verificar o grande aumento

Capıtulo 5. Avaliacao 63
de desempenho quando o servico de armazenamento utiliza a cache em memoria. Nestacaso em concreto, podemos verificar a especial utilidade deste nıvel de cache quando seopera sobre ficheiros relativamente grandes. Esta conclusao pode retirar-se da figura, naqual existe um ganho muito significante no caso do IOzone (que opera sobre ficheiros ate32MB), ao contrario do observado no PostMark, que devido a utilizacao de ficheiros de(no maximo) 2MB, tem um ganho de desempenho mais modesto.
Pelas mesmas razoes apontadas anteriormente, a alteracao da forma de funcionamentoda operacao fsync nao representa alteracoes relevantes nos tempos de execucao dos bench-marks.
5.4 Comparacao do C2FS com outros Sistemas de Ficheirospara Cloud
Nesta seccao sera comparado o desempenho do C2FS com o S3FS e com o S3QL.Nos varios experimentos apresentados nesta seccao, tanto o S3FS como o S3QL foramconfigurados para armazenarem os seus dados na zona de disponibilidade da “Europa” doAmazon S3 [4].
Debito e Latencia das Operacoes. A figura 5.4 apresenta a latencia e debito das operacoesde escrita e leitura dos varios sistemas. Os valores apresentados foram obtidos atraves daexecucao do workload randomrw do Filebench, resultando estes da media de 5 execucoesdistintas deste experimento. Visto o workload so ter em conta as operacoes de escrita eleitura, a unica configuracao do servico de armazenamento relevantes para este experi-mento e o nıvel de cache a utilizar.
(a) Latencia. (b) Debito.
Figura 5.4: Latencia e throughput das operacoes de escrita e leitura nao sequenciais.Valores medidos atraves da execucao do workload randomrw do Filebench

Capıtulo 5. Avaliacao 64
Como podemos constatar na figura 5.4(a), o unico experimento que apresenta umalatencia superior a 1 ms por operacao de leitura e o C2FS quando opera sobre os dadosem disco. No entanto, nas escritas, podemos verificar que esta configuracao do C2FSapresenta melhor desempenho que o S3FS. Podemos ainda observar que o experimentocom melhor desempenho para as escritas e o C2FS quando utiliza a cache em memoriaprincipal.
Assim, na figura 5.4(b) e facil perceber que o C2FS com leituras feitas na cache emdisco apresenta novamente os piores resultados, tendo no entando um desempenho com-paravel ao S3FS no que diz respeito as operacoes de escrita. Podemos ainda verificarque o C2FS quando configurado para operar sobre os dados em memoria apresenta piordebito de leituras, apresentando no entanto o melhor debito de escritas de todos os sis-temas avaliados.
A unica explicacao encontrada para o C2FS ter um menor debito de leituras que oS3FS e que o S3QL esta relacionada com o uso do FUSE-J, uma vez que na pratica, umaleitura no servico de armazenamento do C2FS requer apenas copias de bytes de memoriaprincipal para memoria principal.
Tempos de Execucao. Nas tabelas abaixo sao comparados os tempos de execucao doIOzone e do PostMark obtidos pelo S3FS, S3QL e C2FS. Na tabela 5.1 e comparado odesempenho do C2FS quando configurado para efectuar escritas bloqueantes, e quandoopera tanto na cache em disco como na cache em memoria. Esta comparacao faz sentidopois o S3FS efectua todas as escritas para a Amazon S3 sincronamente aquando do fechodo ficheiro.
S3FS Block + Disk + SyncD Block + Memory + SyncDIOzone 2520.67 3770.6 1836.5PostMark 7737.5 8632.25 2725.5
Tabela 5.1: Comparacao dos tempos de execucao (em segundos) com o S3FS.
Como podemos verificar na tabela 5.1, o desempenho do C2FS com cache em disco einferior ao desempenho do S3FS em ambos os benchmarks. Contudo, quando e utilizadaa cache em memoria para efectuar as operacoes de escrita e leitura, o C2FS apresentaum desempenho muito mais satisfatorio que o S3FS, ao mesmo tempo que fornece maisgarantias no que diz respeito a disponibilidade dos dados, pois estes, ao contrario doS3FS, sao armazenados na cloud-of-clouds.
Por sua vez, na tabela 5.2 sao comparados os tempos de execucao, para os mesmobenchmarks, do S3QL e do C2FS quando efectua escritas assıncronas para as clouds.Esta comparacao e efectuada pois o S3QL envia tambem todos os dados para a cloudassincronamente.

Capıtulo 5. Avaliacao 65
S3QL NonBlock + Disk + SyncD NonBlock + Memory + SyncDIOzone 19.59 2391.74 30.27PostMark 3024.5 208.8 153.25
Tabela 5.2: Comparacao dos tempos de execucao (em segundos) com o S3QL.
No caso da tabela 5.2 podemos verificar que quando testados o S3QL e o C2FS com oIOzone, o S3QL apresenta o melhor resultado. Contudo, embora no caso do C2FS utilizarcache em disco obter resultado bastante inferiores ao S3QL, quando configurado para op-erar com cache em memoria, este obtem um resultado comparavel. Surpreendentemente,no que diz respeito aos tempos de execucao obtidos atraves do PostMark, o S3QL apre-senta um resultado bastante negativo quando comparado quer com o C2FS com cache emdisco, como com cache em memoria. Isto pode dever-se ao facto do S3QL ser lento alidar com o metadados.
5.5 Consideracoes Finais
Neste capıtulo foi apresentada uma avaliacao experimental do desempenho do servicode armazenamento do C2FS. Primeiramente foram mostradas as latencias observadas noenvio de dados para as clouds aquando da execucao dos testes ao sistema. Foi mostradotambem que com a diminuicao do nıvel de tolerancia a faltas e consistencia, o desempenhoaumenta drasticamente. Por fim foi mostrado que o C2FS, mesmo armazenando os dadosna cloud-of-clouds, consegue em alguns casos obter desempenhos superiores aos sistemasde ficheiros para clouds comparados na execucao de alguns benchmarks populares.
No proximo capıtulo, para finalizar este relatorio, serao apresentadas a conclusao e otrabalho futuro a realizar.

Capıtulo 5. Avaliacao 66

Capıtulo 6
Conclusao
Com o crescimento do armazenamento de dados em clouds, veio a necessidade deestudar tecnicas que possam melhorar tanto a fiabilidade dos dados armazenados, comoda forma de os armazenar. A fiabilidade dos dados torna-se um ponto essencial no ar-mazenamento em clouds no sentido em que estes tem o total controlo sobre os mesmos.A forma disponibilizada para armazenar os dados tambem se revela um ponto importantepois tanto os utilizadores comuns como os programadores precisam de um acesso facil aestes provedores de armazenamento.
O C2FS, um sistema de ficheiros seguro e fiavel para cloud-of-clouds, vem respondera estas necessidades, pois ao mesmo tempo que mantem os dados disponıveis e confiden-cias, disponibiliza uma interface do estilo POSIX facilitando assim o acesso a estes.
Neste trabalho foi apresentado o servico de armazenamento desenvolvido para o C2FS,que armazena os dados na cloud-of-clouds recorrendo ao DepSky [19], tirando assim par-tido das propriedades que este oferece, sendo elas disponibilidade, integridade e confiden-cialidade dos dados. Este servico mostra-se configuravel, pois sao disponibilizados doisnıveis distintos de cache e dois modelos de envio de dados para as clouds. Isto e muitobenefico pois os clientes podem tirar partido do sistema consoante as suas necessidades.
Na avaliacao experimental efectuada mostrou-se que o desempenho do C2FS com-paravel aos sistemas de ficheiros para clouds testados ao mesmo tempo que fornece garan-tias mais fortes de fiabilidade. Mostrou-se tambem que, como seria expectavel, a medidaque relaxamos o nıvel de coerencia da cache e a tolerancia a faltas, o desempenho aumentade uma forma muito satisfatoria.
6.1 Trabalho Futuro
Para alem do trabalho apresentado neste documento, existem ainda algumas tarefasem aberto que podem melhorar o C2FS como um todo. Um dos trabalhos futuros passapor estudar se, ao inves de armazenar em cache os dados de um ficheiro num unico bloco,armazena-lo dividindo-o em blocos mais pequenos, ira aumentar o desempenho do C2FS.
67

Capıtulo 6. Conclusao 68
Uma outra tarefa a executar no futuro consiste em alterar o DepSky. O C2FS, emborapermita a partilha de ficheiros [32], so o permite se os diferentes utilizadores partilharema mesma conta. Para tal nao ser necessario, e preciso evoluir o DepSky de forma a estefornecer listas de controlo de acesso aos contentores de dados armazenados nas clouds.Uma outra optimizacao futura e estudar uma tecnica que permita esconder a latencia iner-ente ao envio de muitos ficheiros pequenos em separado. O que se pretende neste pontoe descobrir quais as melhores formas de agrupar ficheiros pequenos num unico bloco dedados para enviar para as clouds. Por fim, e necessario tambem avaliar o comportamentoe desempenho do sistema com workloads de aplicacoes desktop da actualidade [25].

Bibliografia
[1] Amazon elastic block store. http://aws.amazon.com/ebs/.
[2] Amazon elastic compute cloud. http://aws.amazon.com/ec2/.
[3] Amazon elasticache. http://aws.amazon.com/elasticache/.
[4] Amazon simple storage service. http://aws.amazon.com/s3/.
[5] Apple icloud. http://www.apple.com/icloud/.
[6] Filebench. http://sourceforge.net/apps/mediawiki/filebench.
[7] Fuse. http://fuse.sourceforge.net/.
[8] Fuse-j. http://fuse-j.sourceforge.net/.
[9] Google cloud storage. https://developers.google.com/storage/.
[10] IOzone Filesystem Benchmark. http://www.iozone.org/.
[11] Microsoft Windows Azure. http://www.windowsazure.com/.
[12] Openstack storage. http://www.openstack.org/software/openstack-storage/.
[13] Posix. http://en.wikipedia.org/wiki/POSIX.
[14] Project TCLOUDS - trustworthy clouds - privacy and resilience for internet-scalecritical infrastructure. http://www.tclouds-project.eu/.
[15] Rackspace Cloud Hosting. http://www.rackspace.co.uk/.
[16] S3fs - fuse-based file system backed by amazon s3. http://code.google.com/p/s3fs/.
[17] S3ql - a full-featured file system for online data storage.http://code.google.com/p/s3ql/.
69

Bibliografia 70
[18] M. Abd-El-Malek, W. Courtright II, C. Cranor, G. Ganger, J. Hendricks, A. Kloster-man, M. Mesnier, Prasad M, B. Salmon, R. Sambasivan, S. Sinnamohideen,J. Strunk, Eno Thereska, M. Wachs, and J. Wylie. Ursa minor: versatile cluster-based sotrage. In Proceedings of the 4th USENIX Conf. on File and Storage Techon-ogy (FAST’05), December 2005.
[19] Alysson Bessani, Miguel Correia, Bruno Quaresma, Fernando Andre, and PauloSousa. DepSky: Dependable and Secure Storage in cloud-of-clouds. In Proc. of the3rd ACM European Systems Conference – EuroSys’11, April 2011.
[20] Alysson N. Bessani, Eduardo P. Alchieri, Miguel Correia, and Joni S. Fraga.DepSpace: a Byzantine fault-tolerant coordination service. In Proc. of the 3rd ACMEuropean Systems Conference – EuroSys’08, pages 163–176, April 2008.
[21] Miguel Castro and Barbara Liskov. Practical Byzantine fault-tolerance and proactiverecovery. ACM Transactions Computer Systems, 20(4):398–461, November 2002.
[22] George Coulouris, Jean Dollimore, and Tim Kindberg. Distributed Systems - Con-cepts and Designs, chapter Distributed File Systems, pages 323–364. 2005.
[23] Abu-Libdeh et al. RACS. Redundant array of cloud storage. In ACM SOCC 2010.
[24] Garth Gibson, David Nagle, Khalil Amiri, Jeff Butler, Fay Chang, Howard Gobioff,Charles Hardin, Erik Riedel, David Rochberg, and Jim Zelenka. A cost-effective,high-bandwidth storage architecture. In Proc. of the 8th Int. Conference on Archi-tectural Support for Programming Languages and Operating Systems - ASPLOS’98,pages 92–103, 1998.
[25] Tyler Harter, Chris Dragga, Michael Vaughn, Andrea C. Arpaci-Dusseau, andRemzi H. Arpaci-Dusseau. A File is Not a File: Understanding the I/O Behav-ior of apple desktop applications. In Proceedings of the 23rd ACM Symposium onOperating Systems Principles – SOSP’11, October 2011.
[26] J. H. Howard, M. L. Kazar, Menees S. G., D. N. Nichols, M. Satyanarayanan, R. N.Sidebotham, and M. J. West. Scale and performance in a distributed file system. InACM Trans. Comput. Syst. vol. 6, no. I, February 1988.
[27] Jeffrey Katcher. PostMark: A New File System Benchmark. Technical report,August 1997.
[28] J. Kubiatowicz, D. Bindel, Yan Chen, S. Czerwinski, P. Eaton, D. Geels, R. Gum-madi, S. Rhea, H. Weatherspoon, W. Weimer, C. Wells, and Ben Zhao. Oceanstore:An architecture for global-scale persistent storage. In Proceedings of the 9th Intl.

Bibliografia 71
Conf. on Architectural Support for Programming Langauges and Operating Sys-tems, November 2000.
[29] Edward L. Lee and Chandramohan A. Thekkath. Petal: Distributed virtual disks.In Proceedings of the 7th Intl. Conf. on Architectural Support for ProgrammingLangauges and Operating Systems. pages 84-92, October 1996.
[30] Barbara Liskov. From viewstamped replication to byzantine fault tolerance. InReplication, LNCS 5959, pages 121-149, 2010.
[31] N. Megiddo and D. Modha. Arc: A self tuning, low overhead replacement cache.In Proceedings of USENIX Conference on (FAST) File and Storage Technologies,2003.
[32] R. Mendes. Substrato de coordenacao para sistemas de ficheiros para cloud-of-clouds. Relatorio do Projecto de Engenharia Informatica. DI/FCUL, September2012.
[33] Ricardo Mendes, Tiago Oliveira, Alysson Bessani, and Marcelo Pasin. C2FS: umSistema de Ficheiros Seguro e Fiavel para Cloud-of-clouds. In INForum12, Septem-ber 2012.
[34] David A. Patterson, Garth Gibson, and Randy H. Katz. A case for redundant ar-rays of inexpensive disks (raid). In Proc. of the 1988 ACM SIGMOD InternationalConference on Management of Data, pages 109–116, 1988.
[35] C. Plaxton, R. Rajaraman, and A. Aggarwal. Accessing nearby copies of replicatedobjects in a distributed environment. In Proceedings of ACM SPAA, pages 311-320,Newport, Rhode Island, June 1999.
[36] Krishna P. N. Puttaswamy, Thyaga Nandagopal, and Murali Kodialam. Frugal Stor-age for Cloud File Systems. In Proc. of the 3rd ACM European Systems Conference– EuroSys’12, April 2012.
[37] B. Quaresma. Depsky: Sistema de Armazenamento em Clouds Tolerante a In-trusoes. Relatorio do Projecto de Engenharia Informatica. DI/FCUL, Setembro2010.
[38] R. L. Rivest. International conference on distributed computing systems. In IEEEComputer Society Press, 1989.
[39] R. L. Rivest. The md5 message-digest algorithm, rfc-1321. In Network WorkingGroup, IETF, April 1992.

Bibliografia 72
[40] M. Satyanarayanan, J. H. Howard, D. N. Nichols, R. N. Sidebotham, A. Z. Spector,and M. J. West. The ITC distributed file system: principles and design. In Proceed-ings of the 10th ACM Symposium Oper. Syst. Principles. Orcas Island, December1985.
[41] M. Satyanarayanan, P. Kumar, M. Okasaki, E. Siegel, and D. Steere. Coda: A highlyavailable file system for a distributed workstation environment. In IEEE Trans. onComp. 4. 39 (Apr 1990), 447-459.
[42] J. Sousa and A. Bessani. From byzantine consensus to bft state machine replication:A latency-optimal transformation. In In the Proc. of the 9th European DependableComputing Conference, 2012.
[43] C. Thekkath and E. L. T. Mann. Frangipani: A scalable distributed file system. InIn the Proceedings of the 16th SOSP.
[44] Michael Vrable, Stefan Savage, and Geoffrey M. Voelker. Cumulus: Filesystembackup to the cloud. volume 5, pages 1–28, 2009.
[45] Michael Vrable, Stefan Savage, and Geoffrey M. Voelker. BlueSky: A cloud-backedfile system for the enterprise. In Proc. of the 10th USENIX Conference on File andStorage Technologies – FAST’12, 2012.
[46] S. A. Weil, S. A. Brandt, E. L. Miller, and C. Maltzahn. CRUSH: Controlled,scalable, decentralized placement of replicated data. In Proceedings of the 2006ACM/IEEE Conference on Supercomputing (SC ’06). Tampa, FL, Nov, 2006, ACM.
[47] Sage A. Weil, Scott A. Brandt, Ethan L. Miller, Darrell D. E. Long, and CarlosMaltzahn. Ceph: A scalable, high-performance distributed file system. In Proc. ofthe 7th USENIX Symposium on Operating Systems Design and Implementation –OSDI 2006, pages 307–320, 2006.





























