
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULESCOLA DE ENGENHARIA
DEPARTAMENTO DE ENGENHARIA ELÉTRICA
Fernando Sacilotto Crivellaro
Implementação de Código Reed-Solomon para Correção de Erros
Porto Alegre2012

UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULESCOLA DE ENGENHARIA
DEPARTAMENTO DE ENGENHARIA ELÉTRICA
Fernando Sacilotto Crivellaro
Implementação de Código Reed-Solomon para Correção de Erros
Trabalho de Conclusão de Curso apresentado aoDepartamento de Engenharia Elétrica da Uni-versidade Federal do Rio Grande do Sul, comorequisito parcial à obtenção do título de Bacharelem Engenharia Elétrica.
Orientador: Prof. Dr. Marcelo Götz
Porto Alegre2012

UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULESCOLA DE ENGENHARIA
DEPARTAMENTO DE ENGENHARIA ELÉTRICA
Fernando Sacilotto Crivellaro
Implementação de Código Reed-Solomon para Correção de Erros
Este Trabalho de Conclusão de Curso foi analisadoe julgado adequado para a obtenção do título de ba-charel em Engenharia Elétrica pela Universidade Fe-deral do Rio Grande do Sul e aprovado em sua formafinal pelo Orientador e pela Banca Examinadora.
Orientador: Prof. Dr. Marcelo Götz, UFRGSDoutor pela Universität Paderborn - Paderborn, Alemanha
Data
Banca Examinadora:
Prof. Dr. Marcelo Götz, UFRGSDoutor pela Universität Paderborn - Paderborn, Alemanha
Prof. Dr. Gilson Inácio Wirth, UFRGSDoutor pela Universität Dortmund - Dortmund, Alemanha
Eng. Luca Bochi Saldanha, Digitel S/A Indústria EletrônicaEngenheiro pela Universidade Federal do Rio Grande do Sul

RESUMO
O presente relatório refere-se ao trabalho realizado durante a disciplina Projeto de Diplomação,do curso de Engenharia Elétrica da Universidade Federal do Rio Grande do Sul. A sua aborda-gem está relacionada ao controle de erros em um canal sem memória, através de redundânciaestruturada, utilizando linguagem de descrição de hardware. A codificação linear em blocos,não binária e cíclica, escolhida para o desempenho desta tarefa é do tipo Reed-Solomon, umaimportante subclasse dos códigos Bose-Chaudhuri e Hocquenghem. Após um breve históricosobre codificação de canal e um estudo matemático necessário para o entendimento dos algorit-mos, apresenta-se os tipos de código que definem a estrutura básica do próprio Reed-Solomon.Enfim, com o desenvolvimento do codificador e decodificador RS(255, 239), os resultados ob-tidos através de simulações são mostrados, os quais ilustram a atuação deste tipo de código nacorreção de erros e os recursos necessários para a sua implementação em hardware programável.
Palavras-chave: Linguagem de descrição de hardware. Reed-Solomon. Hardware programável.

ABSTRACT
The present report refers to the work performed along the Graduation Project discipline of theElectrical Engineering course from Universidade Federal do Rio Grande do Sul. The approachis related to error control in a channel without memory through structured redundancy, usinghardware description language. The choosen linear block, non-binary and cyclic codification todo this is the Reed-Solomon, one important Bose-Chaudhuri and Hocquenghem codes subclass.After a brief history about channel codification and a necessary mathematic study to understandthe algorithms, is presented the code types that define the own Reed-Solomon basic structure.At the end, with the RS(255, 239) encoder and decoder development, simulation results thatillustrate the code performance in error correction and the resources to implementation in pro-grammable hardware are presented.
Keywords: Hardware Description Language. Reed-Solomon. Programmable Hardware.

LISTA DE FIGURAS
Figura 1 – Sistema de comunicação digital simplificado . . . . . . . . . . . . . . . 13Figura 2 – LFSR de tamanho L . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44Figura 3 – Célula Multiplicadora . . . . . . . . . . . . . . . . . . . . . . . . . . . 48Figura 4 – Conjunto de Células para multiplicação dos polinômios a(X) e b(X) . . 49Figura 5 – Simulação de uma operação do conjunto de células . . . . . . . . . . . 49Figura 6 – Codificador RS(255, 239) . . . . . . . . . . . . . . . . . . . . . . . . . 50Figura 7 – Codificação de dados gerados pseudo-aleatoriamente: início . . . . . . . 51Figura 8 – Codificação de dados gerados pseudo-aleatoriamente: fim . . . . . . . . 51Figura 9 – Decodificador RS em blocos . . . . . . . . . . . . . . . . . . . . . . . 51Figura 10 – Unidade de cálculo de síndrome . . . . . . . . . . . . . . . . . . . . . . 52Figura 11 – Bloco de cálculo de síndrome RS(255, 239) . . . . . . . . . . . . . . . 53Figura 12 – Simulação do bloco de síndrome, S(X) = 0 . . . . . . . . . . . . . . . . 53Figura 13 – Simulação do bloco de síndrome, S(X) 6= 0 . . . . . . . . . . . . . . . . 54Figura 14 – Diagrama de blocos do algoritmo de Berlekamp-Massey . . . . . . . . . 55Figura 15 – Deslocamento do polinômio de síndromes para dentro do registrador S . 56Figura 16 – Evolução do polinômio de conexão ao longo das 16 iterações . . . . . . 56Figura 17 – Aplicação da equação chave . . . . . . . . . . . . . . . . . . . . . . . . 57Figura 18 – Saídas do bloco de Berlekamp-Massey . . . . . . . . . . . . . . . . . . 57Figura 19 – Diagrama de blocos do algoritmo de Chien para σσσ(X) . . . . . . . . . . 58Figura 20 – Simulação do bloco Chien Localizador para o RS(255, 239) . . . . . . . 59Figura 21 – Diagrama de blocos do algoritmo de Chien para ΩΩΩ(X) . . . . . . . . . . 59Figura 22 – Simulação do bloco Chien Avaliador para o RS(255, 239) . . . . . . . . 60Figura 23 – Diagrama de blocos do algoritmo de Forney . . . . . . . . . . . . . . . 60Figura 24 – Simulação do bloco de Forney do RS(255, 239) . . . . . . . . . . . . . 60Figura 25 – Sistema para simulação do RS(255, 239) . . . . . . . . . . . . . . . . . 61Figura 26 – Visão geral da simulação do RS(255, 239) . . . . . . . . . . . . . . . . 61Figura 27 – Saída codificada do encoder RS(255, 239) . . . . . . . . . . . . . . . . 62Figura 28 – Entrada corrompida com erros contínuos, decodificador RS(255, 239) . 62Figura 29 – Saída decodificada do RS(255, 239), erros contínuos corrigidos . . . . . 62Figura 30 – Erros nos símbolos de paridade, decodificador RS(255, 239) . . . . . . 63Figura 31 – Correção de erros nos símbolos de paridade, decodificador RS(255, 239) 63Figura 32 – Simulação do RS(255, 239) para erros peudo-aleatórios . . . . . . . . . 64

LISTA DE TABELAS
Tabela 1 – Adição em módulo-2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Tabela 2 – Multiplicação em módulo-2 . . . . . . . . . . . . . . . . . . . . . . . . 16Tabela 3 – Alguns polinômios primitivos . . . . . . . . . . . . . . . . . . . . . . . 17Tabela 4 – Possíveis representações de campos finitos . . . . . . . . . . . . . . . . 20Tabela 5 – Adição sobre GF(23) com f(X) = 1+X +X3 . . . . . . . . . . . . . . . 20Tabela 6 – Multiplicação sobre GF(23) com f(X) = 1+X +X3 . . . . . . . . . . . 21Tabela 7 – Relação entre palavras de código e mensagens para um código (6,3) . . . 23Tabela 8 – Resultado da sintetização do codificador RS(255, 239) . . . . . . . . . . 65Tabela 9 – Resultado da sintetização do decodificador RS(255, 239) . . . . . . . . 65

LISTA DE ABREVIATURAS
A/D Analógico para DigitalBCH Bose, Chaudhuri e HocquenghemBSC Binary Symmetric ChannelD/A Digital para AnalógicoFEC Forward Error CorrectionFPGA Field-Programmable Gate ArrayGF Galois FieldJSIAM Journal of the Society for Industrial and Applied MathematicsLFSR Linear Feedback Shift RegisterLSB Least Significant BitMMC Mínimo Múltiplo ComumMSB Most Significant BitOTN Optical Transport NetworkRS Reed-SolomonVHDL VHSIC Description LanguageVHSIC Very High Speed Integrated Circuits

SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.1 MOTIVAÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.2 OBJETIVOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3 ESTRUTURA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112 CODIFICAÇÃO DE CANAL . . . . . . . . . . . . . . . . . . . . . . . . . . 132.1 SISTEMA DE COMUNICAÇÃO SIMPLIFICADO . . . . . . . . . . . . . . . 132.2 FORMAS DE CONTROLE DE ERROS . . . . . . . . . . . . . . . . . . . . . 142.3 BREVE HISTÓRICO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153 CAMPOS FINITOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.1 DEFINIÇÕES BÁSICAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.2 CONSTRUÇÃO DO CAMPO . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.2.1 Polinômios Primitivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.3 OPERAÇÕES EM CAMPOS ESTENDIDOS . . . . . . . . . . . . . . . . . . . 183.4 PROPRIEDADES BÁSICAS DOS CAMPOS DE GALOIS . . . . . . . . . . . 214 CÓDIGOS LINEARES EM BLOCO . . . . . . . . . . . . . . . . . . . . . . 234.1 ASPECTOS ESTRUTURAIS . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.1.1 Linearidade e Matriz Geradora . . . . . . . . . . . . . . . . . . . . . . . . . 244.1.2 Códigos Sistemáticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.1.3 Matriz de Verificação de Paridade . . . . . . . . . . . . . . . . . . . . . . . . 254.1.4 Síndrome . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.1.5 Distância Mínima de um Código em Bloco . . . . . . . . . . . . . . . . . . . 274.1.6 Arranjo Padrão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285 CÓDIGOS CÍCLICOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305.1 ESTRUTURA ALGÉBRICA . . . . . . . . . . . . . . . . . . . . . . . . . . . 305.1.1 Polinômio Gerador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305.1.2 Codificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.1.3 Matrizes Geradora e de Verificação de Paridade . . . . . . . . . . . . . . . . 325.1.4 Síndrome de Códigos Cíclicos . . . . . . . . . . . . . . . . . . . . . . . . . . 336 CÓDIGOS BCH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 356.1 ESTRUTURA ALGÉBRICA . . . . . . . . . . . . . . . . . . . . . . . . . . . 356.1.1 Polinômio Gerador e Codificação . . . . . . . . . . . . . . . . . . . . . . . . 356.1.2 Matriz de Verificação de Paridade . . . . . . . . . . . . . . . . . . . . . . . . 36

9
6.2 DECODIFICAÇÃO DE CÓDIGOS BCH . . . . . . . . . . . . . . . . . . . . . 377 CÓDIGOS REED-SOLOMON . . . . . . . . . . . . . . . . . . . . . . . . . 397.1 CÓDIGOS LINEARES EM BLOCO CÍCLICOS NÃO BINÁRIOS . . . . . . . 397.2 DEFINIÇÃO ALGÉBRICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 397.2.1 Polinômio Gerador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407.3 CODIFICAÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407.4 DECODIFICAÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418 ARQUITETURA DESENVOLVIDA . . . . . . . . . . . . . . . . . . . . . . 478.1 CÉLULA MULTIPLICADORA . . . . . . . . . . . . . . . . . . . . . . . . . . 478.2 CODIFICADOR RS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 498.3 DECODIFICADOR RS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 518.3.1 Cálculo da Síndrome . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 528.3.2 Berlekamp-Massey . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 548.3.3 Chien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578.3.4 Forney . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 609 RESULTADOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 619.1 SIMULAÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 619.1.1 Erros Contínuos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 629.1.2 Erros nos Símbolos de Paridade . . . . . . . . . . . . . . . . . . . . . . . . . 639.1.3 Erros Pseudo-Aleatórios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 639.2 SINTETIZAÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 649.2.1 Codificador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 649.2.2 Decodificador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6510 CONCLUSÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6610.1 TRABALHOS FUTUROS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68ANEXO A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69

10
1 INTRODUÇÃO
O volume de dados produzidos pela população está sempre em crescimento, com isso gera-se um fluxo de informação cada vez mais denso e geralmente sob exigências de grandes velo-cidades, portanto, altas taxas de dados. Com a globalização mais dinâmica do que nunca, asdistâncias entre os enlaces de comunicação se tornam maiores, exigindo, consequentemente, oavanço tecnológico do sistema de comunicação inteiro para atender a demanda.
No entanto, a base de qualquer tecnologia desenvolvida é a teoria que a fundamenta. Devidoà complexidade de um sistema de comunicação, no caso digital, este trabalho possui seu focoimposto sobre apenas uma parte do mesmo, a relacionada com codificação de canal. Busca-se,então, o aprofundamento teórico necessário para realizar na prática o controle de erros em umatransmissão de dados, aumentando a sua robustez.
Um tipo de sistema de comunicação com capacidade para atender os requisitos da demandade dados atuais é o que utiliza fibras ópticas. Assim, especificou-se mais ainda o assunto dotrabalho à operação neste sistema, de acordo com a recomendação G.709/Y.1331, criada pelaInternational Telecommunication Union (ITU), que trata de aspectos relacionados à transmis-sões digitais com altas taxas de dados em redes de transporte óptico, ou Optical Transport
Network (OTN). Em relação à codificação de canal, esta recomendação especifica a utilizaçãodo código RS(255, 239) para o controle de erros, como mostrado no ANEXO A. Portanto,optou-se pelo estudo e desenvolvimento deste código no trabalho.
Em relação à linguagem, os códigos RS podem ser desenvolvidos em diversas delas. Noentanto, a aplicação em que o código será utilizado direciona a implementação para algumalinguagem mais apropriada. Por exemplo, para a transmissão de dados em altas taxas, a lingua-gem de descrição de hardware, VHDL, é bastante apropriada, pois permite descrever operaçõesrápidas em nível de circuitos eletrônicos como portas lógicas e paralelamente. Da prática, sabe-se que um sistema operando em redes de transporte óptico utiliza uma frequência próxima a200 MHz. Assim, o código RS(255, 239) será desenvolvido através da linguagem VHDL.
1.1 MOTIVAÇÃO
A ideia deste trabalho motiva-se pela busca de aprimoramento teórico nas concepções ma-temáticas relacionadas aos códigos algébricos e algoritmos para detecção e correção de erros.Tal intenção ocorre conjuntamente com a de projeto prático, proveniente da necessidade de taisconhecimentos para o desenvolvimento de produtos durante período de estágio em empresas daárea.
Complementa-se as razões comentadas, a crescente elevação das taxas de transmissão dedados, requerendo tratamentos de erros cada vez mais sofisticados e complexos. Entre eles,nota-se a utilização do RS em conjunto com outros códigos, como os convolucionais, aumen-tando consideravelmente a capacidade de controle de erros.

11
Do ponto de vista empresarial, a motivação acontece a partir da importância do domínioda tecnologia que começa a ser ressaltada na medida em que ocorre a necessidade deste co-nhecimento para o desenvolvimento de produtos, afetando inclusive o balanço econômico entremanter a longo prazo uma licença de uso e o investimento em uma parceria público-privadacom a universidade, por exemplo, de forma que beneficie ambas.
1.2 OBJETIVOS
Este trabalho possui um objetivo principal, a fim de nortear os demais. Então, acimade tudo, busca-se desenvolver, através de linguagem de descrição de hardware, a codificaçãoRS(255, 239) especificada pela recomendação ITU-T G.709/Y.1331 (2009).
Consequentemente, procura-se expôr o aprofundamento dos conceitos matemáticos envol-vidos e ainda, as estruturas dos códigos que permitiram o surgimento do Reed-Solomon. Comisso, ocorre também a intenção de estimular, dentro da universidade, discussões a respeito dateoria relacionada à codificação de canal, ressaltando a sua importância.
Por fim, deseja-se traduzir para a linguagem VHDL as operações desenvolvidas pelos al-goritmos matemáticos utilizados neste código, exibindo a complexidade dessa relação teórico-prática, mesmo para algumas operações matemáticas aparentemente simples, como a multipli-cação ou até cálculo das raízes de polinômios.
1.3 ESTRUTURA
O desenvolvimento do trabalho foi estruturado de maneira a permitir o avanço gradual noentendimento de seu conteúdo, pois, a cada passo na direção dos códigos Reed-Solomon (quesão lineares em bloco, cíclicos e não binários), ocorre a necessidade de familiarização com ateoria que o precede.
No Capítulo 2, realiza-se uma contextualização da codificação de canal dentro de um sis-tema de comunicação genérico, apresentando uma ideia básica do que o compõe. Também sãoabordadas duas maneiras de se realizar controle de erros, discernindo qual delas é a utilizadaneste trabalho. Posteriormente, há uma visão histórica a respeito da teoria de codificação decanal, com o intuito de se obter uma ideia do que já foi desenvolvido e quando. Além disso,é possível perceber que o surgimento dos códigos e suas diferentes características avançamde acordo com o desenvolvimento teórico da época, então, torna-se interessante conhecer umpouco da história para prever o conteúdo que deve ser estudado, a fim de alcançar os objetivostraçados.
Inicia-se no Capítulo 3 a teoria. O primeiro assunto desenvolvido está relacionado aoscampos finitos, ou de Galois. Este assunto serve de base para todos os códigos apresentados aolongo deste trabalho, principalmente para o RS.

12
Prosseguindo ao Capítulo 4, os códigos lineares em bloco formam o primeiro tipo de códigotratado, pois sobre suas definições e estruturas genéricas, se apoiam os restantes. Mas, por nãoser eficiente a sua decodificação na prática para a época, surgem os códigos cíclicos, comentadosno Capítulo 5. Estes, apresentam, além das características explicitadas no tipo anterior, aspectosinstrínsecos que permitem uma maior praticidade na sua operação.
Ainda antes do código RS, aborda-se no Capítulo 6 os códigos de Bose, Chaudhuri e Hoc-quenghem. Estes, mais eficientes que os códigos anteriores, possuem diversos métodos paradecodificá-los, permitindo então sua disceminação prática.
Classificado como uma subclasse dos códigos BCH não binários, enfim chega-se ao RS noCapítulo 7. Sua estrutura é semelhante ao tipo comentado anteriormente, diferindo apenas emdetalhes. Aborda-se teoricamente o método de decodificação de Berlekamp-Massey, o qual foiutilizado no desenvolvimento prático, como será visto adiante. Além disso, finaliza-se nesteponto o tratamento teórico deste trabalho.
Assim, dá-se início às descrições das arquiteturas dos blocos que compõe o RS(255, 239)no Capítulo 8. São apresentadas figuras e trechos de simulações para expressarem as tarefasdesenvolvidas tanto pelo codificador quanto pelo decodificador. Estes, descritos através delinguagem de descrição de hardware, ou VHDL.
Dedica-se ainda o Capítulo 9 para exibição dos resultados obtidos nas simulações. A ideiaé mostrar os pontos importantes e de maior interesse para uma aplicação prática, inclusivefornecendo informações do uso de hardware e frequência máxima de operação.
Enfim, no Capítulo 10 conclui-se a respeito dos desafios encontrados ao longo do desen-volvimento do trabalho, dos resultados atingidos e de possíveis melhorias ou continuidades deestudo.

13
2 CODIFICAÇÃO DE CANAL
O código RS é considerado um tipo de codificação de canal. Ou seja, sua ação está relacio-nada ao controle de erros que podem ocorrer ao longo de um canal de comunicação. Assim, parainiciar o desenvolvimento do trabalho, apresenta-se a seguir uma ideia básica de um sistema decomunicação.
2.1 SISTEMA DE COMUNICAÇÃO SIMPLIFICADO
Um sistema de comunicação digital é composto por diversos componentes e cada um delespode ser tratado separadamente visando clareza no entendimento de suas funções. Através daFigura 1 é possível identificar em vermelho, dentro desse sistema simplificado, a localizaçãodos blocos de codificação e decodificação de canal, os quais são o foco do presente trabalho:
Figura 1 – Sistema de comunicação digital simplificado
A fonte de informação pode ser a fala de uma pessoa ou dados de um computador, porexemplo. A informação gerada pela fonte é encaminhada para o codificador da fonte, o quale responsável pela adaptação da informação ao tipo de sistema, podendo ser um transdutor emconjunto com um conversor A/D, ou um algum tipo de compressão de dados digitais, de formaque o número de bits representantes da informação por unidade de tempo seja, idealmente,o menor possível, e a saída não seja ambígua. Ou seja, o codificador da fonte transforma ainformação gerada em dígitos binários, formando uma sequência de símbolos, denotada, porexemplo, por u.
Prosseguindo no esquema acima, o codificador de canal recebe a sequência de informaçãou e gera, a partir dela, uma sequência codificada v denominada palavra código. Esta, possuimais símbolos do que a sequência de informação e esses símbolos adicionais são utilizadospara recuperação da mensagem, caso ela seja corrompida ao longo do canal.

14
Adiante, sendo o canal um meio físico, torna-se necessária a operação do modulador paratransformar o sinal discreto, proveniente do codificador de canal, em formas de onda analógicasvoltadas para a transmissão.
O canal é o meio pelo qual o sistema de comunicação interliga o transmissor e o receptor,podendo ser de diveros tipos, como por exemplo, o ar, cabos coaxias, as fibras óticas e outros.As ondas emitidas pelo transmissor podem ser corrompidas de diversas formas ao longo do seupercurso pelo canal, resultando em diferentes tipos de erros, como por exemplo, contínuos ounão.
O destino do sinal ao fim do canal é o receptor, mais precisamente o bloco de demodulação,que processa cada forma de onda recebida e fornece em sua saída um sinal discreto ou contí-nuo, dependendo dos blocos posteriores, chamado de sequência recebida r. Essa sequência éentão repassada para o bloco de decodificação do canal, o qual através de algoritmos especí-ficos, baseados na codificação do canal, é capaz de corrigir uma quantidade limitada de erros,fornecendo em sua saída uma estimativa da sequência de símbolos transmitida, u.
Por fim, a partir de u o decodificador da fonte fornece em sua saída a estimativa da infor-mação, sendo em alguns casos necessária uma conversão D/A, por exemplo.
2.2 FORMAS DE CONTROLE DE ERROS
Duas maneiras distintas de controle de erros, utilizando redundância, podem ser utilizadas.Uma delas é a detecção de erros e retransmissão, que utiliza símbolos de paridade (símbolosredundantes adicionados aos dados) para detectar a ocorrência de algum erro. O terminal re-ceptor, então, não corrige os erros, apenas os detecta e realiza o pedido de uma retransmissãodos dados.
Outra forma de controle de erros é a chamada Forward Error Correction (FEC), a qualutiliza os símbolos de paridade tanto para a detecção, quanto para correção dos erros. Nãosão todos os padrões de erros que podem ser corrigidos, como será visto posteriormente, eos códigos corretores de erros são classificados de acordo com suas capacidades de correção(SKLAR, 2001).
A maior vantagem do decodificador que utiliza retransmissão, em relação à correção ante-cipada de erros, é a simplicidade de implementação requerida. Além disso, a primeira forma éadaptativa, no sentido de que a informação somente será retransmitida quando ocorrerem erros.Por outro lado, há situações em que a FEC é necessária como, por exemplo, quando um canalreverso não é disponibilizado, quando o atraso devido à retransmissão é excessivo, ou o númerode erros é demasiado, necessitando de muitas retransmissões. Como exemplo de sistemas queutilizam FEC, pode ser citado o armazenamento digital, no qual a informação gravada podeser reproduzida semanas ou até meses depois. A maioria dos sistemas codificados atualmenteemprega alguma forma de FEC (LIN; COSTELLO, 2004).

15
2.3 BREVE HISTÓRICO
Em 1948, Claude Shannon demonstrou que há, associado com qualquer canal de comuni-cação ou de armazenamento, um número C (medido em bits por segundo) chamado de capa-cidade do canal. Isso significa que, sendo a taxa de transmissão de informação requerida porum sistema de comunicação ou armazenamento menor do que C, é possível desenvolver umacodificação do canal que permite uma probabilidade de erro de saída tão pequena quanto dese-jada. No entanto, Shannon não demonstrou como encontrar tais códigos, sua contribuição foiapenas provar que eles existem e definir suas funções (BLAHUT, 2003). Mas essa afirmaçãofoi suficiente para chamar a atenção, na época, para o desenvolvimento mais intenso da teoriade codificação.
A teoria dos códigos Reed-Solomon está intimamente ligada à história da codificação emblocos e, mais particularmente, algébrica. Com a introdução de estruturas matemáticas cres-centemente complexas, diversas classes de codificação em blocos surgiram, juntamente comsignificados algébricos de decodificação. No início da década de 50, Richard Hamming já ha-via produzido o primeiro código binário de uso prático, utilizando técnicas de álgebra linear, edefinindo a classe dos códigos de correção em blocos com capacidade de corrigir um erro. Namesma época, Marcel Golay desenvolveu o código de correção trípla de erros. Em 1954, DavidMuller inventou uma classe de códigos de correção múltipla de erros, na qual Irving Reed reco-nheceu uma estrutura algébrica específica, resultando em um algoritmo de decodificação paraa mesma, que tornou-se atualmente a classe de códigos Reed-Muller. Com o trabalho de NealZierler, Solomon Golomb e Eugene Prange, estes códigos foram logo gerados por registradoresde deslocamento linear, ou LFSR, com paridade adicionada, dotando-os de estrutura cíclica.
No final da década de 50, Reed estava fortemente interessado na teoria de Galois, refletindosobre a utilização de símbolos não binários de campos finitos em operações no nível de bytes,em oposição ao foco tradicional de algoritmos orientados a bits. Nesta época, Reed tambémestava introduzindo Gustave Solomon, especialista em álgebra, ao mundo da teoria de codifica-ção, e tal parceria foi responsável pelo descobrimento de uma nova classe de códigos, utilizandouma definição algébrica que introduziu somas simétricas como síndromes para um algoritmode decodificação (WICKER; BHARGAVA, 1994).
Assim, em 1960, ocorreu a primeira aparição pública dos códigos Reed-Solomon, ou tam-bém RS, no artigo intitulado Polynomial Codes over Certain Finite Fields, publicado no Journal
of the Society for Industrial and Applied Mathematics, JSIAM. Nas décadas posteriores ao seudescobrimento, os códigos RS já estavam presentes em diversas aplicações, desde aparelhos deCompact Disc até veículos espaciais.
Atualmente, a importância e a utilização deste tipo de código ainda prevalece, como no casode sistemas ópticos e também devido à atuação em conjunto com outros códigos, visando maiorpoder de correção e controle de erros. São os chamado códigos concatenados.

16
3 CAMPOS FINITOS
A teoria de campos finitos, ou de Galois é fundamental para os códigos não binários Reed-Solomon. Todas as operações desenvolvidas, tanto na codificação quanto na decodificação,utilizam-na. Dessa maneira, a própria mensagem transmitida é considerada como formada porelementos do campo em que se está trabalhando.
Então, este capítulo dedica-se à abordagem teórica de campos finitos, ou de Galois, servindocomo base para o restante da teoria e prática deste trabalho.
3.1 DEFINIÇÕES BÁSICAS
Um campo é o conjunto de elementos no qual é possível realizar operações de adição, sub-tração, multiplicação e divisão sem deixar o conjunto. As operações de adição e multiplicaçãodevem satisfazer as leis comutativa (a · b = b · a), associativa [(a+ b)+ c = a+(b+ c)] e dis-tributiva (a · (b+ c) = a ·b+a · c) (LIN; COSTELLO, 2004). Como exemplo, cita-se o campobinário denotado por GF(2) que realiza as seguintes operações:
Tabela 1 – Adição em módulo-2+ 0 10 0 11 1 0
Tabela 2 – Multiplicação em módulo-2· 0 10 0 01 0 1
O número de elementos pertencentes ao conjunto é chamado de ordem, e um campo comnúmero finito de membros denomina-se campo finito (ou de Galois). Por exemplo, um campofinito constituído por q elementos é indicado por GF(q), sendo q um número primo. É possívelestender GF(q) para um campo de q = pm elementos, chamando-o de campo estendido deGF(q) e denotando-o por GF(pm), neste caso, p é primo e m é inteiro positivo não nulo. Noscódigos de controle de erros, o campo estendido GF(2m) é de extrema importância, como serávisto ao longo do texto, e por isso terá mais ênfase em sua abordagem.
3.2 CONSTRUÇÃO DO CAMPO
A composição de GF(2m) é dada por, além de 0 e 1, elementos adicionais únicos represen-tados a partir do símbolo α e suas potências (SKLAR, 2001).
0,1,α,α2, · · · ,α j, · · ·
=
0,α0,α1,α2, · · · ,α j, · · ·
α2 = α ·α
α3 = α ·α ·α
...

17
Assim, percebe-se que há uma propriedade importante dos campos de Galois: sempre ha-verá um elemento, o qual suas potências formam todos os membros não nulos do campo. Talcomponente é denominado elemento primitivo.
Além disso, a definição de campos finitos também recai sobre os campos estendidos, ouseja, GF(2m) deve ser finito, possuir somente 2m elementos, e ser fechado sobre multiplicação.Portanto, as potências de α não podem ser todas distintas infinitamente, ou seja, em algumponto na sequência deve ocorrer uma repetição.
3.2.1 Polinômios Primitivos
Com o intuito de avançar no entendimento dos campos, torna-se necessária a introdução daclasse de polinômios primitivos, a qual define os campos finitos estendidos GF(2m) de extensouso nos códigos RS. Para um polinômio ser enquadrado nesta classe, ele deve ser irredutível.Entende-se por irredutível o polinômio que não pode ser fatorado em polinômios de ordensmenores.
Segundo SKLAR (2001), um polinômio irredutível, ϕϕϕ(X), de grau m é dito primitivo se omenor inteiro positivo n, para o qual ϕϕϕ(X) divide Xn + 1, for n = 2m− 1. Embora, teorica-mente, um polinômio irredutível e não primitivo também possa definir um campo estendido, émais conveniente utilizar um polinômio primitivo para essa definição, pois sua raiz é elementoprimitivo do campo. Esses polinômios já estão disponíveis em livros através de tabelas, como amostrada a seguir, por isso serão utilizados sem a demonstração de serem primitivos, assumindoque tal tarefa já foi desempenhada pelas fontes consultadas.
Tabela 3 – Alguns polinômios primitivos
m Polinômio Primitivo m Polinômio Primitivo
3 1+X +X3 9 1+X4 +X9
4 1+X +X4 10 1+X3 +X105 1+X2 +X5 11 1+X2 +X116 1+X +X6 12 1+X +X4 +X6 +X127 1+X3 +X7 13 1+X +X3 +X4 +X138 1+X2 +X3 +X4 +X8 14 1+X +X6 +X10+X14
Fonte: SKLAR(2001).
Suponha que ϕϕϕ(X) é um polinômio primitivo de grau m sobre GF(2). Ao considerar α
como raiz de ϕϕϕ(X) e sabendo que, por definição, ϕϕϕ(X) divide X2m−1 +1, tem-se, sendo q(X) oquociente da divisão:
X2m−1 +1 = q(X)ϕϕϕ(X)
α2m−1 +1 = q(α)ϕϕϕ(α)
α2m−1 +1 = q(α) ·0

18
então, utilizando operações em módulo-2, obtém-se:
α2m−1 = 1 = α
0. (3.1)
Utilizando (3.1) é possível delimitar a sequência
S =
0,1,α,α2, · · · ,α2m−2,α2m−1,α2m, · · ·
emS =
0,α0,α1,α2, · · · ,α2m−2,α0,α1
(3.2)
e assim, definir os elementos do campo estendido GF(2m):
GF(2m) =
0,α0,α1,α2, · · · ,α2m−2
(3.3)
Analisando (3.2) e (3.3), conclui-se que o grupo definido por GF(2m) é cíclico. Além disso,observa-se que todos os elementos não nulos podem ser representados como potências de ummesmo α , logo α é o elemento primitivo do campo. Portanto, um campo estendido de Galoispode ser completamente construído sobre seu elemento primitivo.
A forma de exibição em (3.3) é chamada representação de GF(2m) por potência, outrarepresentação é a polinomial, em que cada um dos 2m elementos é representado através depolinômios distintos de grau m−1 ou menos.
Sendo i = 0,1,2, · · · ,2m−2, divide-se o polinômio X i pelo primitivo ϕϕϕ(X):
X i = qi(X)ϕϕϕ(X)+ai(X) (3.4)
onde qi(X) é o quociente e ai(X) é o resto (polinômio de grau m−1 ou menor):
ai(X) = ai,0 +ai,1X1 +ai,2X2 + · · ·+ai,m−1Xm−1 (3.5)
Pelo fato de que X i e ϕϕϕ(X) são primos relativos, isto é, eles não possuem fatores em co-mum, exceto o número 1, X i não é divisível por ϕϕϕ(X). Dessa forma, para qualquer i ≥ 0,ai(X) 6= 0 (LIN; COSTELLO, 2004). Substituindo X = α em (3.5), se obtém a expressão paraos elementos não nulos:
αi = ai,0 +ai,1α
1 +ai,2α2 + · · ·+ai,m−1α
m−1
3.3 OPERAÇÕES EM CAMPOS ESTENDIDOS
Avançando no entendimento dos campos estendidos, é importante a abordagem das opera-ções aritméticas realizadas entre os seus elementos.
Para o campo binário GF(2), a adição é desenvolvida em módulo-2, ou também OU-

19
exclusivo (XOR). Além disso, a subtração é exatamente igual à adição,
u− v = u+ v = u⊕ v (3.6)
onde u e v ∈ GF(2).Qualquer elemento de GF(2m) pode ser representado como um polinômio com seus coe-
ficientes retirados de GF(2) (JIANG, 2010). Assim, adição e subtração são realizadas comosegue,
u(X)+v(X) = (u0⊕ v0)+(u1⊕ v1)X + · · ·+(um−1⊕ vm−1)Xm−1 (3.7)
sendo as operações (ui⊕ vi) realizadas em módulo-2.No caso da multiplicação de elementos representados na forma de potência, a operação de
multiplicação resume-se à soma dos expoentes de cada componente. No entanto, o resultado éajustado para o campo, como observado a seguir:
αa ·αb = α
(a+b)mod(2m−1).
Quando a operação de multiplicação é realizada com elementos representados por polinô-mios, ela assume a forma ordinária, ou comum. No entanto, em módulo sobre o polinômioprimitivo sobre o qual GF(2m) é construído,
w(α) = u(X)v(X)modϕϕϕ(X)|x=α .
Para valores relativamente altos de m, por exemplo m > 3, a construção do campo para finsde entendimento do mesmo torna-se massante e desnecessária. Em função disso, será utilizadocomo exemplificação o campo estendido GF(23) que possui como polinômio primitivo ϕϕϕ(X) =
f(X) = 1+X +X3 e, assumindo que α é raiz de ϕϕϕ(X), a seguinte relação pode ser obtida,
f(α) = 1+α +α3 = 0
α3 = 1+α (3.8)
assim, os demais elementos são derivados de (3.8):
α4 = α ·α3 = α(1+α) = α +α
2
α5 = α
2 ·α3 = α2(1+α) = α
2 +α3 = 1+α +α
2
α6 = α
3 ·α3 = (1+α)(1+α) = 1+α +α +α2 = 1+α
2
α7 = α
3 ·α4 = (1+α)(α +α2) = α +α
2 +α2 +α
3 = α +1+α = 1 = α0
...
Com isso, é possível montar uma tabela com três tipos diferentes de representação de um campo,
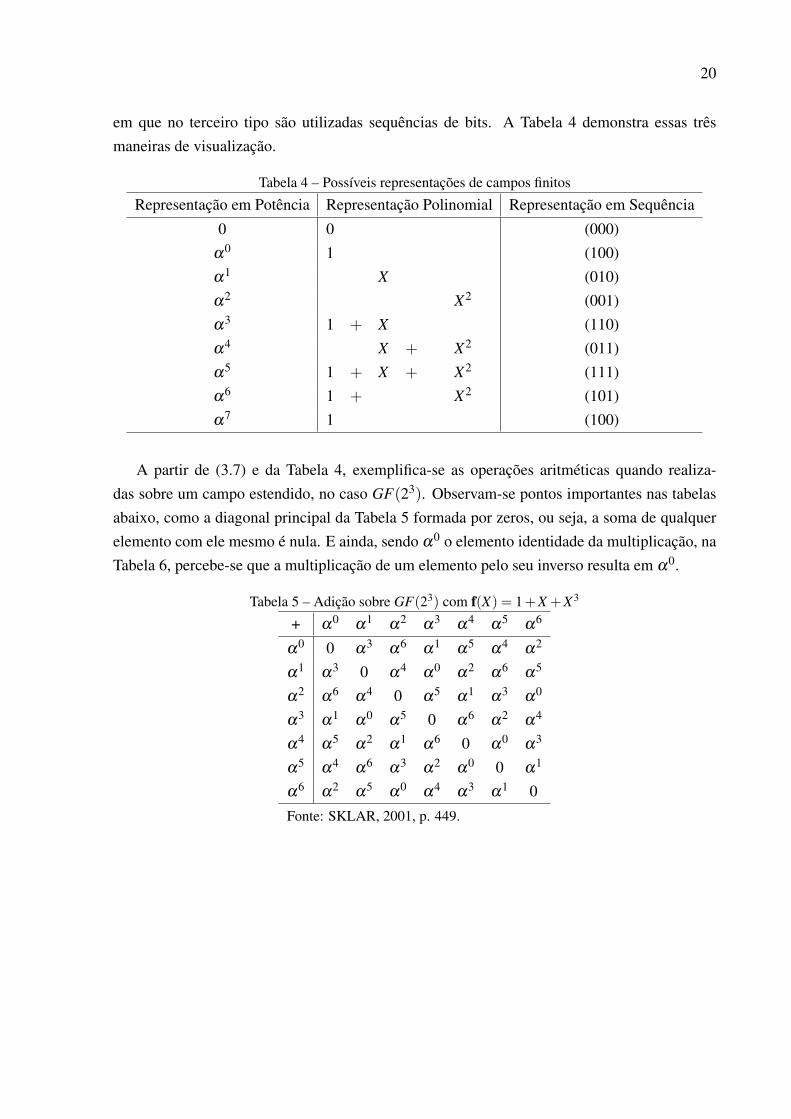
20
em que no terceiro tipo são utilizadas sequências de bits. A Tabela 4 demonstra essas trêsmaneiras de visualização.
Tabela 4 – Possíveis representações de campos finitos
Representação em Potência Representação Polinomial Representação em Sequência
0 0 (000)α0 1 (100)α1 X (010)α2 X2 (001)α3 1 + X (110)α4 X + X2 (011)α5 1 + X + X2 (111)α6 1 + X2 (101)α7 1 (100)
A partir de (3.7) e da Tabela 4, exemplifica-se as operações aritméticas quando realiza-das sobre um campo estendido, no caso GF(23). Observam-se pontos importantes nas tabelasabaixo, como a diagonal principal da Tabela 5 formada por zeros, ou seja, a soma de qualquerelemento com ele mesmo é nula. E ainda, sendo α0 o elemento identidade da multiplicação, naTabela 6, percebe-se que a multiplicação de um elemento pelo seu inverso resulta em α0.
Tabela 5 – Adição sobre GF(23) com f(X) = 1+X +X3
+ α0 α1 α2 α3 α4 α5 α6
α0 0 α3 α6 α1 α5 α4 α2
α1 α3 0 α4 α0 α2 α6 α5
α2 α6 α4 0 α5 α1 α3 α0
α3 α1 α0 α5 0 α6 α2 α4
α4 α5 α2 α1 α6 0 α0 α3
α5 α4 α6 α3 α2 α0 0 α1
α6 α2 α5 α0 α4 α3 α1 0
Fonte: SKLAR, 2001, p. 449.

21
Tabela 6 – Multiplicação sobre GF(23) com f(X) = 1+X +X3
· α0 α1 α2 α3 α4 α5 α6
α0 α0 α1 α2 α3 α4 α5 α6
α1 α1 α2 α3 α4 α5 α6 α0
α2 α2 α3 α4 α5 α6 α0 α1
α3 α3 α4 α5 α6 α0 α1 α2
α4 α4 α5 α6 α0 α1 α2 α3
α5 α5 α6 α0 α1 α2 α3 α4
α6 α6 α0 α1 α2 α3 α4 α5
Fonte: SKLAR, 2001, p. 449.
3.4 PROPRIEDADES BÁSICAS DOS CAMPOS DE GALOIS
Assim como ocorre na álgebra ordinária, polinômios com coeficientes reais podem ter raízescomplexas (sendo o real um subcampo do complexo), polinômios, na álgebra abstrata, com co-eficientes provenientes de GF(2) podem possuir raízes do seu campo estendido GF(2m) (LIN;COSTELLO, 2004).
Além disso, sendo f(X) um polinômio com coeficientes de GF(2) e β proveniente deGF(2m). Se β for uma raiz de f(X), então, para qualquer l ≥ 0, β 2l
é também uma raiz def(X). Essa propriedade pode ser entendida a partir do desenvolvimento abaixo:
f2(X) = f(X2) (3.9)
f2(X) = ( f0 + f1X + f2X2 + · · ·+ fnXn)2
= [ f0 +( f1X + f2X2 + · · ·+ fnXn)]2
= f 20 +2 f0( f1X + f2X + · · ·+ fnXn)+( f1X + f2X2 + · · ·+ fnXn)2
f 20 +( f1X + f2X2 + · · ·+ fnXn)2
aplicando repetitivamente o procedimento acima, tem-se:
f2(X) = f 20 +( f1X)2 +( f2X2)2 + · · ·+( fnXn)2
considerando que fi = 0 ou 1, então f 2i = fi:
f2(X) = f0 + f1(X2)1 + f2(X2)2 + · · ·+ fn(X2)n = f(X2)
Essa propriedade permanece verdadeira, sendo l ≥ 0, para
f2l(X) = f(X2l
) (3.10)

22
portanto,[f(β )]2
l= f(β 2l
) = 0
e β 2lé também raiz de f(X).
O elemento β 2lé chamado conjugado de β . De acordo com a propriedade demonstrada,
se β , um elemento de GF(2m) for raiz de um polinômio f(X) sobre GF(2), então todos osdiferentes conjugados de β , também elementos em GF(2m), são raízes de f(X).
Por exemplo, considerando α , pertencente o campo GF(23), como raiz do polinômio binário1+X +X3, observa-se que α2,α4, · · · , são também raízes deste mesmo polinômio e pertencema GF(23).

23
4 CÓDIGOS LINEARES EM BLOCO
Para implementação dos algoritmos de codificação de canal, utiliza-se códigos com carac-terísticas e estruturas específicas que permitem manipulações estratégicas da mensagem como,por exemplo, os códigos lineares em bloco.
A definição e a descrição dos códigos lineares em bloco ocorrem em termos das matrizeschamadas geradora e de verificação de paridade. Estas estão relacionadas com, além da estru-tura do código, o conceito de síndrome, o qual tem papel importante na detecção e correção doserros.
4.1 ASPECTOS ESTRUTURAIS
Esta família de códigos em blocos possui como principal característica dividir a sequên-cia de informação em um conjunto de k símbolos, u = u1,u2, · · · ,uk, e mapeá-los em umasequência maior, chamada palavra código ou vetor de código, de tamanho n, v = v1,v2, · · · ,vn. Um exemplo dessa transformação pode ser visto na Tabela 7. O número expresso por k
também é conhecido como dimensão do código, como será visto posteriormente.Portanto, existem 2k diferentes palavras código correspondentes às 2k mensagens. Denota-
se esse conjunto de palavras e associações como um código em bloco (n, k), com taxa decodificação dada por R= k/n, a qual pode ser interpretada como o número de símbolos entrandono codificador de canal, para cada símbolo que é transmitido por ele.
A taxa de codificação máxima é 1, ou seja, quando não há nenhum símbolo de redundânciaadicionado (a mensagem não é codificada). Por outro lado, observa-se que quanto mais redun-dância estruturada é adicionada, a capacidade de correção de erro é maior, ao custo da reduçãoda taxa de codificação. Portanto, a qualidade do código é maior para aquele que maximiza acapacidade de correção de erros, mantendo a taxa de codificação o mais próximo da unidade.
Tabela 7 – Relação entre palavras de código e mensagens para um código (6,3)
Mensagem Palavra de Código
000 000000100 110100010 011010110 101110001 101001101 011101011 110011111 000111
Esses blocos de informação, chamados de mensagem, são independentes entre si (poisassume-se um canal sem memória). Consequentemente, as operações realizadas não possuem

24
memória e podem ser implementadas através de lógica combinacional (JIANG, 2010).O conjunto de todas as sequências de n simbolos é chamado de espaço vetorial Vn sobre o
campo GF(q), com q = 2 neste caso, cujas operações de adição e multiplicação estão definidasnas tabelas 1 e 2, respectivamente. Os elementos de Vn são chamados de vetores, enquanto oselementos do campo são ditos escalares.
Adiante será necessária a definição de um subespaço, então, o mesmo é caracterizado comoum subconjunto S de Vn, devendo satisfazer duas condições:• O vetor com todos os elementos nulos pertence à S;• A soma de quaisquer dois vetores em S também está contida em S.
4.1.1 Linearidade e Matriz Geradora
Um conjunto de 2k sequências de n bits só é chamado de código linear em bloco (n, k) sefor um subespaço k-dimensional do vetor de espaços Vn. Ou seja, qualquer combinação lineardos vetores deste subespaço k (incluindo o vetor nulo) também será uma palavra código.
Com isso, pode-se verificar que há um conjunto de palavras código, o qual com númerode elementos menor que 2k, capaz de gerar todas as 2k palavras código do subespaço. Ouseja, sendo C um código linear (n, k), é possível encontrar k palavras código, linearmenteindependentes, g1,g2, · · · ,gk em C, de forma que qualquer vetor de código v é resultado deuma combinação linear dessas k palavras código geradoras. Isto é,
v = u1g1 +u2g2 + · · ·+ukgk
Agrupando essas palavras código, obtém-se a chamada matriz geradora, G, apresentada a se-guir:
G =
g1
g2
...
gk
=
g11 g12 g13 · · · g1,n
g21 g22 g23 · · · g2,n
......
......
gk,1 gk,2 gk,3 · · · gk,n
Sendo a mensagem a ser codificada expressa por u = u1,u2, · · · ,uk, a palavra de código
correspondente é obtida por:v = u ·G
A utilização de códigos lineares resulta na redução da memória utilizada na implementaçãoda codificação. Pois ao invés de utilizar tabelas com todas as 2k possibilidades de relação entremensagem e palavra código, gera-se apenas a palavra código correspondente a cada mensagemrecebida, através de somente k palavras de códigos.
A matriz G é chamada de geradora, pois como dito anteriormente, gera todos os 2k vetoresdo subespaço. O menor conjunto linearmente independente capaz de gerar o subespaço é dito

25
base do subespaço e o número de vetores na base define a dimensão deste. Neste caso, adimensão é k.
4.1.2 Códigos Sistemáticos
Sendo n > k, uma palavra código completa contém, além dos k símbolos da mensagem,(n− k) símbolos de redundância estruturada ou paridade, os quais quando estão implícitos nassequências de símbolos do código, caracterizam-no como não sistemático. Por outro lado,quando a redundância e a mensagem aparecem de maneira explícita na palavra código, o mesmoé então classificado como sistemático.
Para se obter estrutura sistemática em um código, parte da matriz geradora deve ser a matrizidentidade de dimensões k× k. Enquanto a outra porção é composta por símbolos de paridade,os quais são somas lineares dos símbolos de informação, formando a chamada matriz paridade.
G = [P | Ik]
G =
p11 p12 · · · p1,(n−k) 1 0 · · · 0
p21 p22 · · · p2,(n−k) 0 1 · · · 0...
...
pk1 pk2 · · · pk,(n−k) 0 0 · · · 1
Supondo v uma palavra código gerada pela matriz G, então, devido à estrutura sistemática,observa-se que
v = p1 p2 · · · pn−k︸ ︷︷ ︸paridade
m1 m2 · · · mk︸ ︷︷ ︸mensagem
4.1.3 Matriz de Verificação de Paridade
Existe uma matriz associada à qualquer código linear chamada matriz de verificação deparidade, denotada por H. Sua principal característica é o fato de que suas linhas geram oespaço nulo do subespaço definido pelas linhas de G. Isso significa que o produto interno entreos vetores de G e de H será sempre sempre nulo.
Essa matriz H possui dimensão (n− k)× n, sendo as (n− k) linhas linearmente indepen-dentes e de forma que qualquer vetor do subespaço das linhas de G seja ortogonal às linhas deH. Ou ainda, qualquer vetor que seja ortogonal às linhas de H está contido no subespaço daslinhas de G (LIN; COSTELLO, 2004).
A composição da matriz H é dada por,
H = [In−k | PT]

26
H =
1 0 · · · 0 p11 p21 · · · pk,1
0 1 · · · 0 p12 p22 · · · pk,2
......
0 0 · · · 1 p1,(n−k) p2,(n−k) · · · pk,(n−k)
sendo PT a matriz de paridade transposta.
Portanto, analisando o produto interno de uma linha i da matriz G com uma linha j da matrizH, tem-se
gi ·h j = pi j + pi j = 0.
Fazendo isso para 0 ≤ i ≤ k e 0 ≤ j ≤ n− k, obtém-se então G ·HT = 0. Dessa maneira, umasequência de símbolos n será uma palavra código v, gerada através da matriz G, somente sev ·HT = 0.
4.1.4 Síndrome
Um código (n, k) linear em bloco e sistemático transmite uma palavra código v= v1,v2, · · · ,vnatravés de um canal ruidoso e recebe um vetor r = r1,r2, · · · ,rn. Supondo a ocorrência dealgum tipo de erro durante a transmissão, o vetor recebido será
r = v+ e (4.1)
sendo e = e1,e2, · · · ,en o padrão de erro introduzido pelo canal. Então, ao receber o vetorr multiplica-se o mesmo pela matriz de verificação de paridade transposta, com o objetivo deverificar se r é uma palavra código. O resultado dessa operação é chamado de síndrome:
S = r ·HT (4.2)
se r for uma palavra código válida, então S = 0. Caso contrário, S 6= 0, significa a ocorrênciade erro e portanto, r 6= v.
No caso de um sistema de requisição de repetição, o receptor entra em contato com o trans-missor pedindo o reenvio da mensagem corrompida. Já no caso de correção antecipada, oreceptor realiza, se possível, a correção da mensagem utilizando os dados da síndrome.
Através das Equações (4.1) e (4.2) observa-se,
S = (v+ e) ·HT (4.3)
sendo v uma palavra de código, a Equação (4.3) fica
S = e ·HT = s1,s2, · · · ,sn−k. (4.4)

27
Observa-se que pode ocorrer um padrão de erro igual a uma palavra código. Assim, a somada palavra código transmitida v com o padrão de erro inserido pelo canal irá resultar em outrapalavra código, inclusive obtendo S = 0. Estes casos são considerados como não detectáveis,ou seja, o decodificador não irá corrigir o erro.
Portanto, é possível identificar duas importantes propriedades da matriz de verificação deparidade, requeridas para ser possível a identificação dos erros:• Nenhuma coluna de H pode ser formada somente por elementos nulos, pois, do contrário,
a ocorrência de erros não iria afetar o valor da síndrome e não seria possível corrigí-los;• As colunas de H devem ser únicas. Se duas colunas forem idênticas, os erros nas palavras
códigos correspondentes à essas colunas serão indistinguíveis.
4.1.5 Distância Mínima de um Código em Bloco
A capacidade de detecção e correção de um código em bloco está diretamente ligada àsua estrutura. Supondo uma palavra código v = v1,v2, · · · ,vn, o peso de Hamming, um dosparâmetros que fornece informações a respeito das características do código, é definido comosendo o número de componentes não nulas do vetor código, sendo denotado por w(v).
Outra definição utilizada para caracterização dos códigos em bloco é a chamada distânciade Hamming, a qual, dadas duas palavras de código u e v, é determinada como sendo o númerode locais em que as componentes dos vetores código diferem, denotada por d(u, v).
Há uma propriedade envolvendo tanto o peso, quanto a distância de Hamming, definindoque a distância entre duas palavras código é igual ao peso da soma das mesmas. Ou seja,
d(u, v) = w(u+v) (4.5)
Para a determinação da capacidade de detecção e correção de erros aleatórios de um códigoutiliza-se a chamada distância mínima do código, dmin. Esse parâmetro é a menor distânciade Hamming entre todas as palavras código. Mas como os códigos lineares em bloco devemsatisfazer a condição de que a soma de quaisquer duas palavras código deve ser outra palavracódigo, então é possível se obter a seguinte relação:
d(u, v) = w(u+v) = w(z) (4.6)
Com isso, é possível encontrar a distância mínima através apenas da análise dos pesos daspalavras código, excluindo a totalmente composta por elementos nulos, de forma que o pesomínimo encontrado será igual à distância mínima do código.
A fim de identificar a relação da distância mínima com a capacidade do código, supõe-se atransmissão de uma palavra código v através de uma canal ruidoso e a recepção de um vetor r.Calcula-se a distância entre os vetores, d(v, r) = l. Caso l seja igual à distância mínima dmin,então o vetor recebido r poderá ser identificado pelo decodificador como outra palavra código

28
que não v, levando-o a cometer um erro. No entanto, se l for igual ou menor a dmin−1, r nãoserá igual à nenhuma palavra código e o erro será identificado. Portanto, um código em blococom dmin é capaz de detectar todos os padrões de dmin−1 ou menos erros.
Em relação à capacidade de correção, este código é capaz de corrigir até t erros,
t =⌊
dmin−12
⌋(4.7)
onde bxc significa o maior inteiro que não excede x.
4.1.6 Arranjo Padrão
Na transmissão através de um canal ruidoso, por mais que a palavra código seja distorcidapelo canal, ela continuará sendo um vetor pertencente ao espaço vetorial Vn. No entanto, caso amesma não pertença ao subespaço k, será obtida uma síndrome diferente de zero. Quando issoacontece é possível relacionar o padrão de erro ocorrido, com o valor da síndrome calculada eportanto o código poderá ser corrigido. Ao conjunto dessas relações (incluindo a síndrome devalor zero, com o padrão de erro nulo), dá-se o nome de arranjo padrão.
Baseando-se na estrutura linear do código, o arranjo padrão segue as seguintes regras deconstrução. Todas as 2k palavras códigos são distribuídas na primeira linha, formando k colunas,com o vetor nulo na primeira posição. Para as restantes 2n−2k, escolhe-se as primeiras colunasde cada linha como sendo o padrão de erro mais provável que possa acontecer, e o restante éformado pela soma do padrão de erro à palavra código da primeira coluna. Ainda como regrade construção, cada vetor do espaço Vn aparece somente uma vez no arranjo. Um exemplo dearranjo padrão é mostrado a seguir:
v1 v2 · · · vi · · · v2k
e2 e2 +v2 · · · e2 +vi · · · e2 +v2k
e3 e3 +v2 · · · e3 +vi · · · e3 +v2k
......
......
e j e j +v2 · · · e j +vi · · · e j +v2k
......
......
e2n−k e2n−k +v2 · · · e2n−k +vi · · · e2n−k +v2k
Observe que cada linha é formada por vetores que possuem uma importante característica emcomum, todos possuem o mesmo padrão de erro. Isso leva à outra propriedade importante:todos os vetores de cada linha terão a mesma síndrome, como pode ser visto na Equação (4.4).
O erro somente será corrigido se o padrão de erro estiver presente na primeira coluna, por-tanto, um código linear em bloco (n, k) é capaz de corrigir até 2n−k padrões de erro. Como

29
exemplo, em um canal binário simétrico (BSC), padrões de erro com menor peso são mais pro-váveis, então, na formação de um arranjo padrão para este caso, estes serão os escolhidos paracompor a primeira coluna.
A decodificação baseada na pesquisa no arranjo padrão, para códigos menores, resulta ematrasos pequenos. No entanto, para códigos maiores ela torna-se impraticável, tanto pela quan-tidade grande de informações que deverão ser armazenadas, quanto pela complexidade do cir-cuitos de lógica combinacional necessários.
Mesmo sendo inviável para codigos maiores, o arranjo padrão pode ser visto como umaferramenta organizacional, que permite a visualização de questões importantes, como limites dacapacidade de correção de erros. Um desses limites é o chamado limite de Hamming, descritoabaixo como
Símbolos de paridade: n− k ≥ log2
[1+(
n1
)+
(n2
)+ · · ·+
(nt
)](4.8a)
Padrões de erro: 2n−k ≥[
1+(
n1
)+
(n2
)+ · · ·+
(nt
)], (4.8b)
onde(
nj
)representa o número de maneiras em que os j símbolos podem gerar erros nos n com-
ponentes da palavra código. Observa-se que a soma dos termos de dentro dos colchetes forneceo número mínimo de linhas necessárias no arranjo padrão para corrigir todas as combinaçõesde erros de até t símbolos. As inequações (4.8) limitam inferiormente o número de símbolosde paridade, em função da capacidade de correção t do código. Ou então, elas podem expres-sar um limite superior para o número de erros que o código pode corrigir, t, de acordo com onúmero de símbolos de paridade. Assim, para qualquer código linear em bloco (n, k) provera capacidade de correção de t símbolos, é necessário que o limite de Hamming seja satisfeito(SKLAR, 2001).

30
5 CÓDIGOS CÍCLICOS
Os códigos cíclicos formam uma importante subclasse dos códigos lineares em bloco. Suaimportância se deve ao fato de que sua codificação e cálculo da síndrome podem ser feitos atra-vés de registradores de deslocamento linear com conexões de realimentação (LFSR), e tambémporque este tipo de código possui características estruturais algébricas instrínsecas que permi-tem diversas maneiras práticas de decodificação.
5.1 ESTRUTURA ALGÉBRICA
Os códigos cíclicos possuem uma importante característica, envolvendo as palavras código,que se refere ao deslocamento dos seus componentes. Ou seja, supondo uma palavra códigov = v0,v1, · · · ,vn−1, deslocando seus componentes uma vez para a direita, obtém-se outrapalavra código, a qual é chamada de deslocamento cíclico unitário de v,
v(1) = vn−1,v0, · · · ,vn−2
assim, um código linear (n, k) é dito cíclico se cada deslocamento como este, de uma palavracódigo, resultar em outra palavra código.
Pode-se expressar as palavras códigos de maneira polinomial. Através desse tipo de repre-sentação será explicitada a característica cíclica do código. Supondo então, v(X) = v0 + v1X +
v2X2 + · · ·+ vn−1Xn−1 um vetor código representado dessa forma, com grau (n−1). Então, aodividirmos X iv(X) por Xn + 1, o resto da divisão inteira será uma palavra código v(i)(X), ouseja,
X iv(X)
Xn +1= q(X)+
v(i)(X)
Xn +1(5.1a)
X iv(X) = q(X)(Xn +1)+v(i)(X) (5.1b)
Denota-se essa operação como,
v(i)(X) = X iv(X)mod(Xn +1)
5.1.1 Polinômio Gerador
Uma das característica que leva os códigos cíclicos a serem implementados de maneirasimples é o fato de que a palavra código relacionada ao polinômio de menor grau é única.Ou seja, existe somente um polinômio de menor grau no código. A partir disso, define-seque em um código cíclico (n, k) os seus polinômios consituintes são combinações lineares dopolinômio mínimo, isto é, sendo g(X) = 1+g1X + · · ·+gp−1X p−1+X p o polinômio de menor

31
grau do código, então um polinômio de grau (n−1) ou menos pertence ao código somente sefor múltiplo de g(X).
O polinômio g(X) é chamado de polinômio gerador, portanto, cada palavra código polino-mial do subespaço k é da forma v(X)=m(X)g(X), em que v(X) é um polinômio de grau (n−1)ou menos, enquanto que m(X) é de grau k− 1. A partir disso, define-se o grau do polinômiogerador como sendo p = n− k. Assim, em um código (n, k), existe apenas um polinômio degrau (n− k) e para este ser um polinômio gerador deve ser ainda um fator de Xn +1.
A medida que n cresce, Xn +1 vai possuindo mais fatores, alguns desses polinômios gerambons códigos, outros não. Como selecionar polinômios geradores para produzir bons códigoscíclicos é um problema muito difícil e bastante estudado por teóricos em códigos (LIN; COS-TELLO, 2004).
5.1.2 Codificação
Com a definição do polinômio gerador, codifica-se a mensagem através de v(X)=m(X)g(X).Essa operação é facilmente desenvolvida através de registradores de deslocamento, em que a re-alimentação é definida pelo polinômio g(X). São os chamados Linear Feedback Shift Registers
(LFSR).Os códigos cíclicos também podem ser codificados na forma sistemática para redução da
complexidade. Neste caso, os símbolos da mensagem,
m(X) = m0 +m1X +m2X2 + · · ·+mk−1Xk−1 (5.2)
são utilizados como parte do polinômio código (polinômio relacionado com determinada pala-vra código), mais especificamente nas k ordens mais altas do mesmo. Para realizar essa mani-pulação, desloca-se a mensagem (n− k) posições para a direita através de multiplicação,
Xn−km(X) = m0Xn−k +m1Xn−k+1 +m2Xn−k+2 + · · ·+mk−1Xn−1 (5.3)
A partir disso, gera-se os símbolos de paridade correspondentes ao restante do polinômiocódigo, dividindo o polinômio de (5.3) pelo polinômio gerador g(X) e obtendo o resto dessadivisão,
Xn−km(X) = q(X)g(X)+p(X) (5.4)
Através de operações aritméticas, obtém-se,
p(X)+Xn−km(X) = q(X)g(X) = v(X) (5.5)

32
Como g(X) possui grau (n− k), o grau de p(X) deve ser (n− k−1) ou menos. Então,
p(X)+Xn−km(X) = p0 + p1X + · · ·+ pn−k−1Xn−k−1
+m0Xn−k +m1Xn−k+1 + · · ·+mk−1Xn−1
correspondendo à palavra código v = p0 p1 · · · pn−k−1︸ ︷︷ ︸paridade
m0 m1 · · · mk−1︸ ︷︷ ︸mensagem
.
O circuito de codificação sistemática utiliza também LFSR, no entanto, são necessários maisalguns detalhes para produzir a palavra código da maneira descrita. Esses detalhes serão vistosposteriormente.
5.1.3 Matrizes Geradora e de Verificação de Paridade
Todos os polinômios códigos do subespaço k são múltiplos do polinômio gerador g(X) =
g0 + g1X + · · ·+ gn−kXn−k. Portanto, a matriz geradora deste código possui k polinômios,g(X),Xg(X), · · · ,Xn−kg(X), formando suas k linhas da seguinte maneira,
G =
g0 g1 g2 · · · gn−k 0 0 0 · · · 0
0 g0 g1 g2 · · · gn−k 0 0 · · · 0
0 0 g0 g1 g2 · · · gn−k 0 · · · 0... . . . . . . . . . ...
0 0 · · · 0 g0 g1 g2 · · · gn−k
Entretanto, a matriz G não está na forma sistemática. Para isto, bastaria realizar algumas ope-rações nas suas linhas.
Dado que o polinômio g(X) é um fator de Xn +1, tem-se,
Xn +1 = g(X)h(X) (5.6)
sendo h(X) um polinômio de grau k chamado de polinômio de verificação de paridade. Comoas palavras código são exatamente múltiplas de g(X), verifica-se, utilizando a teoria definida nocapítulo sobre campos de Galois, que
v(X)h(X) = m(X)g(X)h(X) = m(X)(Xn +1)≡ 0 (5.7)
assim, para verificar se um polinômio pertence ao conjunto das k palavras código, basta multiplicá-lo por h(X). Somente se o resultado for nulo o polinômio pertence ao código (MOON, 2005).
Da Equação (5.7), observa-se que as potências Xk,Xk+1, · · · ,Xn−1 não existem em m(X)(Xn+
1), já que m(X) tem grau (k− 1) ou menos. Com isso, os coeficientes Xk,Xk+1, · · · ,Xn−1 da

33
multiplicação v(X)h(X) devem ser nulos. Dessa maneira, obtem-se as seguintes (n− k) igual-dades (LIN; COSTELLO, 2004),
k
∑i=0
hivn−i− j = 0 for 1≤ j ≤ n− k (5.8)
Assim, define-se o polinômio recíproco de h(X) como sendo
Xkh(X−1), hk +hk−1X +hk−2X2 + · · ·+h0Xk (5.9)
o qual é utilizado para formar a matriz de verificação de paridade, H, do código gerado porg(X):
H =
hk hk−1 hk−2 · · · h0 0 0 0 · · · 0
0 hk hk−1 hk−2 · · · h0 0 0 · · · 0
0 0 hk hk−1 hk−2 · · · h0 0 · · · 0... . . . . . . . . . ...
0 0 · · · 0 h0 hk−1 hk−2 · · · h0
A partir das igualdades de (5.8), observa-se que qualquer vetor do código (n, k) será orto-
gonal a cada linha da matriz H, pois elas formam o código (n, n− k) que constitui o espaçonulo do subespaço definido por (n, k). Ou seja, G ·HT = 0.
5.1.4 Síndrome de Códigos Cíclicos
Sendo um vetor recebido r(X)= r0+r1X+r2X2+ · · ·+rn−1Xn−1, para verificar se o mesmopertence ao código, realiza-se sua divisão pelo polinômio gerador, resultando em
r(X) = q(X)g(X)+ s(X) (5.10)
onde s(X) é o polinômio relacionado à síndrome.A Equação (5.10) também pode ser analisada de outra maneira, relacionando o padrão de
erro ocorrido e(X) com a síndrome. Assumindo que foi transmitida a palavra código v(X) =
m(X)g(X) e o vetor recebido foi corrompido, r(X) = v(X)+ e(X), então verifica-se que
e(X) = [m(X)+q(X)]g(X)+ s(X) (5.11)
ou seja, a síndrome é obtida através da Equação (5.10) e então pode ser relacionada ao padrãode erro de acordo com arranjo padrão, como nos códigos lineares em bloco.
Por causa da estrutura cíclica do código, sendo s(X) a síndrome do vetor recebido r(X),

34
então s(1)(X) será a síndrome de r(1)(X). Essa propriedade é útil para a decodificação, poispermite realizá-la serialmente. O decodificador de Meggitt aplica este princípio na sua opera-ção, buscando um padrão de erro que se manifeste no bit da posição de mais alta ordem, Xn−1.Para isso, utiliza um circuito combinacional de forma que sua saída é 1 quando a síndromecorresponde ao padrão de erro corrigível nesta posição.

35
6 CÓDIGOS BCH
Os códigos BCH formam uma classe eficiente de códigos cíclicos de correção de erros.A partir do BCH binário, generalizou-se para códigos em qm, sendo q primo, ampliando aabrangência e utilização deste tipo de código. Com isso, vários algoritmos para decodificaçãoforam concebidos e melhorados com o passar do tempo. Os BCH são considerados os códigoscíclicos mais importantes e os melhores códigos de tamanho moderado, pois permitem métodoseficientes de decodificação devido a sua estrutura algébrica específica (JIANG, 2010).
Neste capítulo, será abordada, resumidamente, apenas a subclasse dos códigos BCH biná-rios. A dos BCH não binários será tratada no capítulo sobre os códigos Reed-Solomon.
6.1 ESTRUTURA ALGÉBRICA
Para quaisquer inteiros positivos m (m ≥ 3) e t (t < 2m−1) existe um código BCH bináriocom os seguintes parâmetros:• Tamanho do bloco: n = 2m−1;• Número de dígitos de paridade: n− k ≤ mt;• Distância mínima: dmin ≥ 2t +1.
Este tipo de código é capaz de corrigir qualquer combinação de t erros ou menos, por bloco.
6.1.1 Polinômio Gerador e Codificação
Por ser cíclico, o código possui um polinômio gerador, o qual é especificado em termosde suas raízes provenientes do campo de Galois GF(2m). Sendo α um elemento primitivo emGF(2m), o polinômio gerador g(X) é o de menor grau sobre o campo GF(2), que possui
α, α2, α
3, · · · , α2t (6.1)
como suas raízes, ou seja, g(α i) = 0 para 1≤ i≤ 2t (LIN; COSTELLO, 2004).Observa-se que dois campos estão envolvidos na construção de códigos BCH. O campo
GF(2), onde o polinômio gerador possui seus coeficientes e os elementos da palavra códigoestão presentes. E o campo estendido, GF(2m), onde o polinômio gerador possui suas raízes.
Assim, como já comentado no capítulo sobre os campos de Galois, os conjugados dasraízes de g(X) também são suas raízes. Portanto, define-se φφφ i(X) como o polinômio mí-nimo de α i. Então, o polinômio gerador deve ser o Mínimo Múltiplo Comum, MMC, deφφφ 1(X), φφφ 2(X), · · · , φφφ 2t(X),
g(X) = MMCφφφ 1(X), φφφ 2(X), · · · , φφφ 2t(X) (6.2)

36
Devido ao fato de que os elementos e seus conjugados possuem o mesmo polinômio mí-nimo, cada potência par de α , na sequência (6.1), possue o mesmo polinômio mínimo da po-tência ímpar que a precede. Portanto, o polinômio gerador pode ser reduzido para,
g(X) = MMCφφφ 1(X), φφφ 3(X), · · · , φφφ 2t−1(X) (6.3)
Como o grau de cada polinômio mínimo é m ou menos, pois as raízes pertencem ao GF(2m),g(X) terá grau de no máximo mt, ou seja, o número de símbolos de verificação de paridade docódigo, n− k, é no máximo igual a mt.
Para codificar as sequências de mensagem utiliza-se o polinômio gerador. Dessa maneira,obtem-se a palavra código na forma v(X) = m(X)g(X). O principal elo de ligação entre ocodificador e o decodificador são as raízes do polinômio gerador no primeiro, as quais sãoutilizadas no cálculo da síndrome no segundo.
Em relação ao circuito de codificação, utiliza-se também registradores de deslocamento comrealimentação, como no caso dos códigos cíclicos.
6.1.2 Matriz de Verificação de Paridade
Como as raízes do polinômio gerador estão definidas em (6.1) e sendo v(X) = m(X)g(X)
uma palavra código, então
v(α i) = m(α i)g(α i) = m(α i)0 = 0
isso equivale a
v(α1) = v0 + v1(α1)1 + v2(α
1)2 + · · ·+ vn−1(α1)n−1 = 0
v(α2) = v0 + v1(α2)1 + v2(α
2)2 + · · ·+ vn−1(α2)n−1 = 0 (6.4)
...
v(α2t) = v0 + v1(α2t)1 + v2(α
2t)2 + · · ·+ vn−1(α2t)n−1 = 0
ou então na forma matricial,
(v0, v1, · · · , vn−1) ·
1 1 · · · 1
(α1)1 (α2)1 · · · (α2t)1
(α1)2 (α2)2 · · · (α2t)2
...
(α1)n−1 (α2)n−1 · · · (α2t)n−1
= 0

37
Sabendo que a matriz de verificação de paridade deve satisfazer
v ·HT = 0 (6.5)
então, obtém-se a matriz de verificação de paridade para o código BCH descrito:
H =
1 1 · · · 1
(α1)1 (α2)1 · · · (α2t)1
(α1)2 (α2)2 · · · (α2t)2
...
(α1)n−1 (α2)n−1 · · · (α2t)n−1
T
=
1 (α1)1 (α1)2 · · · (α1)n−1
1 (α2)1 (α2)2 · · · (α2)n−1
1 (α3)1 (α3)2 · · · (α3)n−1
...
1 (α2t)1 (α2t)2 · · · (α2t)n−1
De acordo com a definição de projeto dos códigos BCH, a distância mínima é dmin ≥ 2t +1.
Com isso, o código possui capacidade de correção de b(dmin−1)/2c= t erros.Prova-se isso chegando-se a uma inconsistência. Como os códigos BCH são lineares e
em bloco, sua distância mínima é igual ao peso mínimo das palavras códigos não nulas. Su-pondo que existe uma palavra código v não nula de peso wmin(v) ≤ 2t, então, v j1 = 1, v j2 =
1, · · · , v jw = 1 são os elementos não nulos de v. Portanto, a partir de (6.5), verifica-se,
v ·HT = 0⇒ (v j1, v j2, · · · , v jw) ·
(α1) j1 (α2) j1 · · · (α2t) j1
(α1) j2 (α2) j2 · · · (α2t) j2
...
(α1) jw (α2) jw · · · (α2t) jw
= 0 (6.6)
⇒ (1, 1, · · · , 1) ·
(α j1)1 (α j1)2 · · · (α j1)2t
(α j2)1 (α j2)2 · · · (α j2)2t
...
(α jw)1 (α jw)2 · · · (α jw)2t
= 0 (6.7)
a relação (6.7) implica que cada coluna na matriz w× 2t deve possuir soma zero. Entretanto,qualquer submatriz quadrática w×w desta matriz é chamada matriz de Vandermonde, na qualnenhuma coluna possui soma zero (JIANG, 2010). Portanto, é inválida a suposição feita de quedmin ≤ 2t e então a distância do código excede 2t, ou seja, dmin ≥ 2t +1. Esse limitante inferiorda distância mínima é chamado de limite de BCH.
6.2 DECODIFICAÇÃO DE CÓDIGOS BCH
Similar ao mostrado nos códigos cíclicos, o cálculo da síndrome é feito através da divisão

38
do vetor recebido r(X) pelo polinômio mínimo gerador, obtendo um valor de síndrome paracada uma das raízes de g(X), como demontrado a seguir,
r(X) = qi(X)φφφ i(X)+bi(X) (6.8)
sendo bi(X) o resto da divisão, com grau menor que φφφ i(X). Como φφφ i(αi) = 0, tem-se
Si = r(α i) = b(α i) (6.9)
mas como r(X) = v(X)+ e(X), e de (6.4) observa-se que v(α i) = 0, então,
Si = e(α i) (6.10)
isso significa que a síndrome calculada depende somente do padrão de erro recebido.Como o decodificador não conhece o padrão de erro recebido, a busca deste é feita através
do calculo da síndrome. No entanto, nos códigos BCH a relação síndrome-padrão de erro nãoé procurada explicitamente em um arranjo padrão, como nos casos anteriores, e sim através dealgoritmos específicos que tornam a decodificação mais eficiente.
Então, supondo que ocorra um padrão de erro com v erros nas posições indicadas porX j1, X j2, · · · , X jv, representado polinomialmente através de
e(X) = X j1 +X j2 + · · ·+X jv (6.11)
utilizando (6.10) e (6.11) obtém-se, para as 2t raízes de g(X) definidas em (6.1), o seguinteconjunto de equações:
S1 = (α j1)1 +(α j2)1 + · · ·+(α jv)1
S2 = (α j1)2 +(α j2)2 + · · ·+(α jv)2 (6.12)...
S2t = (α j1)2t +(α j2)2t + · · ·+(α jv)2t
as incógnitas, neste caso, são as posições indicadas por α j1, α j2, ··· , α jv. Esse é o passo mais
complexo da decodificação, pois nota-se que esse conjunto de equações é não linear e possuimuitas soluções, (2k). Dessa maneira, devem ser utilizados métodos específicos apropriadospara encontrá-las, um deles será detalhado no capítulo sobre Reed-Solomon, que também utilizaessa metodologia de decodificação.

39
7 CÓDIGOS REED-SOLOMON
Os códigos RS pertencem à classe dos BCH não binários, isto é, os elementos da palavracódigo são provenientes do campo GF(q), sendo q > 2. Na prática, os códigos RS utilizamq= 2m. Dessa maneira, para realizar a decodificação, é necessário encontrar, além das posições,os valores dos erros ocorridos.
Os códigos Reed-Solomon são efetivos tanto para a correção de erros aleatórios, quanto paraerros contínuos. Sendo uma subclasse dos BCH, são considerados códigos lineares em bloco ecom estrutura cíclica.
7.1 CÓDIGOS LINEARES EM BLOCO CÍCLICOS NÃO BINÁRIOS
Os conceitos e propriedades descritos nos capítulos anteriores estavam atrelados à símbolosbinários, entretanto, é possível generalizá-los para aplicação em códigos não binários, ou q-ários, através de determinadas definições.
Considerando o espaço vetorial de todas as qn sequências de n símbolos sobre GF(q), esendo v = v0, v1, · · · , vn−1 e u = u0, u1, · · · , un−1 dois vetores deste espaço, o vetor soma édefinido como
(u0, u1, · · · , un−1)+(v0, v1, · · · , vn−1), (u0 + v0, u1 + v1, · · · , un−1 + vn−1) (7.1)
com a soma ui + vi realizada sobre o campo GF(q). Assim como a soma, a multiplicação érealizada, por definição, entre os termos de mesma ordem e sobre GF(q).
Assim, um código linear em bloco q-ário é especificado tanto por uma matriz geradora,quanto pela de verificação de paridade. A codificação e decodificação procedem da mesmaforma do que nos códigos binários, entretanto, as operações são desenvolvidas sobre o campoGF(q), com q > 2.
Um código q-ário (n, k) cíclico é gerado por um polinômio de grau (n− k) sobre GF(q),
g(X) = g0 +g1X + · · ·+gn−k−1Xn−k−1 +Xn−k (7.2)
definindo como pertencentes ao código aqueles polinômios que são divisíveis por g(X). Observa-se que os coeficientes do polinômio gerador pertencem ao campo GF(q).
7.2 DEFINIÇÃO ALGÉBRICA
Um código RS(n, k) corretor de t erros, com símbolos provenientes de GF(q), possui osseguintes parâmetros:• Tamanho do bloco: n = q−1;• Número de dígitos de paridade: n− k = 2t;

40
• Dimensão: k = q−1−2t
• Distância mínima: dmin = 2t +1.
7.2.1 Polinômio Gerador
Assim como nos códigos BCH binários, o polinômio gerador g(X) de um código RS sobreGF(q), que corrige t erros, possui 2t raízes consecutivas. Entretanto, neste caso, as raízespertencem a GF(q). Assim, como tanto os coeficientes, quanto as raízes de g(X) pertencemao mesmo campo, GF(q), o polinômio mínimo φφφ i(X) é simplesmente (X − α i). Portanto,assumindo que as raízes sejam, por exemplo, α0, α1, · · · , α2t−1, então,
g(X) = (X−α0)(X−α
1) · · ·(X−α2t−1) (7.3)
= g0 +g1X +g2X2 + · · ·+g2t−1X2t−1 +X2t
ou equivalentemente,
g(X) =2t−1
∏i=0
(X−αi) (7.4)
A partir da definição do grau 2t de g(X) e do tamanho do código ser um elemento a menosdo que o alfabeto que o define, observa-se que g(X) gera um código cíclico q-ário de tamanhon = q−1, com exatamente 2t símbolos de paridade.
Do limitante BCH comentado no capítulo anterior, dmin ≥ 2t + 1. Para não ir contra omesmo, nenhum coeficiente de g(X) deve ser nulo, pois do contrário poderia haver algumapalavra código com peso menor do que 2t + 1. Assim, o polinômio g(X) corresponde a umapalavra de tamanho 2t +1, implicando no fato de que a distância mínima do código RS geradopor g(X) é exatamente 2t +1.
7.3 CODIFICAÇÃO
A codificação dos códigos RS(n, k) é semelhante à dos BCH, ou seja, também baseia-se namultiplicação dos blocos de mensagem pelo polinômio gerador do código. No entanto, a grandediferença, neste caso, são as raízes utilizadas, as quais possuem as particularidades já comenta-das acima. Com isso, realiza-se o mapeamento dos blocos de mensagem com k símbolos paraas palavras código de n símbolos. Para o caso de codificação sistemática, procede-se da mesmaforma descrita no capítulo sobre códigos cíclicos.
A arquitetura desenvolvida para a codificação utiliza registradores de deslocamento do tipoLFSR, pois os códigos RS também são cíclicos. Sua função é calcular, a partir da mensagem, os2t símbolos de paridade, transmitindo-os no final da sequência de tamanho n. Posteriormente,esta arquitetura será ilustrada e analisada com mais detalhes.

41
7.4 DECODIFICAÇÃO
Baseando-se no conceito de síndrome introduzido pelos códigos lineares em bloco, na inser-ção do ponto de vista polinomial dos códigos com estrutura cíclica e da decodificação através desistemas de equações não lineares abordada nos códigos BCH cíclicos, o processo desenvolvidono decodificador RS(n, k) inicia-se no cálculo da síndrome. A partir do resultado desta etapa,inicia-se a busca da relação correta entre o padrão de erro ocorrido e a síndrome obtida.
Portanto, supondo o vetor recebido r(X) = r0 + r1X + · · ·+ rn−2Xn−1 + rn−1Xn−1, comr0, r1, · · · , rn−2, rn−1 pertencentes ao campo de Galois GF(q), dada a transmissão do ve-tor v(X), cujos elementos também pertencem a GF(q), através de um canal ruidoso, entãoconsidera-se, sendo e(X) o padrão de erro introduzido,
r(X) = v(X)+ e(X) (7.5)
Então, calcula-se o polinômio das síndromes, o qual é constituido pelos resultados obtidosquando substituídas as raízes do polinômio gerador no vetor recebido, ou seja,
S(X) = S1 +S2X +S3X2 + · · ·+S2t−1X2t−2 +S2tX2t−1 (7.6)
ondeSi = r(X)|X=α i para 1≤ i < 2t (7.7)
que é equivalente a,Si = e(X)|X=α i para 1≤ i < 2t (7.8)
Nos códigos RS, é necessário encontrar, além das posições de ocorrência dos erros, osvalores dos mesmos. Dessa maneira, o padrão de erro é definido como,
e(X) = e j1X j1 + e j2X j2 + · · ·+ e jvX jv (7.9)
onde e j1, e j2, · · · , e jv são os valores dos erros e X j1, X j2, · · · , X jv são as posições onde oserros ocorreram, sendo 0≤ j1 < j2 < · · ·< jv≤ n−1.
A partir de (7.8) e (7.9), é possível formar um conjunto de equações relacionando as locali-zações e os valores dos erros, com as síndromes calculadas a partir do vetor recebido.
S1 = e j1(αj1)1 + e j2(α
j2)1 + · · ·+ e jv(αjv)1
S2 = e j1(αj1)2 + e j2(α
j2)2 + · · ·+ e jv(αjv)2 (7.10)
...
S2t = e j1(αj1)2t + e j2(α
j2)2t + · · ·+ e jv(αjv)2t

42
por conveniência, para 1≤ i≤ v, define-se,
βi , αji e δi , e ji (7.11)
que simplificam a visualização, permitindo observar que essas 2t equações são funções simétri-cas em β1, β2, · · · , βv, mais conhecidas como funções simétricas soma de potências,
S1 = δ1β1 +δ2β2 + · · ·+δvβv
S2 = δ1β21 +δ2β
22 + · · ·+δvβ
2v (7.12)
...
S2t = δ1β2t1 +δ2β
2t2 + · · ·+δvβ
2tv
ou então,
Si =v
∑j=1
δ jβij para i = 1, 2, 3, · · · (7.13)
que devem solucionar as t posições e as t magnitudes dos erros, para que seja possível corrigí-los. Além disso, a solução está ligada ao padrão de erro com o menor número de erros, o queestará relacionado com o polinômio localizador de erros de menor grau, definido abaixo (LIN;COSTELLO, 2004).
Utilizando a série geométrica
11−β jX
= 1+β jX +β2j X2 + · · · (7.14)
é possível multiplicá-la por δ jβbj e somar, obtendo
v
∑j=1
δ jβbj
1−β jX= Sb +Sb+1X +Sb+2X2 + · · · (7.15)
sendo a parte esquerda da igualdade a expansão em frações parciais de ΩΩΩ(X)/σσσ(X), onde
σσσ(X) =v
∏j=1
(1−β jX) (7.16)
é o chamado polinômio localizador de erros e
ΩΩΩ(X) =v
∑j=1
δ jβbj
v
∏k=1k 6= j
(1−βkX) (7.17)
é o chamado polinômio avaliador de erros.

43
Dessa maneira, é possível escrever
ΩΩΩ(X)
σσσ(X)= Sb +Sb+1X +Sb+2X2 + · · · (7.18)
ou até mesmoσσσ(X)SSS(X) =ΩΩΩ(X)mod(X2t) (7.19)
mais conhecida como equação chave, definida por Berlekamp.A partir de (7.16), pode-se escrever,
σσσ(X) = (1−β1X)(1−β2X) · · ·(1−βvX)
= σ0 +σ1X +σ2X2 + · · ·+σvXv (7.20)
onde σ0 = 1. É possível relacionar as Equações (7.12) e (7.20), obtendo
Sv+1 +σ1Sv +σ2Sv−1 + · · ·+σvS1 = 0
Sv+2 +σ1Sv+1 +σ2Sv + · · ·+σvS2 = 0 (7.21)...
S2t +σ1S2t−1 +σ2S2t−2 + · · ·+σvS2t−v = 0
Essas equações são conhecidas como identidades de Newton generalizadas. O objetivo é en-contrar o polinômio mínimo, σσσ(X), do qual os coeficientes satisfazem estas identidades (LIN;COSTELLO, 2004).
O algoritmo de Berlekamp-Massey encontra, iterativamente, o polinômio σσσ(X) de menorgrau através das síndromes e depois o substitui na equação chave para encontrar ΩΩΩ(X).
Existem outros métodos para isso, como o Euclidiano, ou em frequência. No entanto,decidiu-se apresentar somente o método de Berlekamp-Massey, porque este é o que foi maiscomentado nas bibliografias consultadas como tendo uma boa relação entre efetividade e com-plexidade, e, por isso, desenvolvido na parte prática do trabalho.
O processo de encontrar o polinômio localizador de erros através do método de Berlekamp-Massey não é trivial e para entendê-lo são necessárias algumas observações relacionadas àspropriedades dos registradores do tipo LFSR apresentadas a seguir.
Primeiramente, um LFSR consiste de L estágios, os quais provêem uma combinação linearque serve de entrada para o primeiro registrador, como mostrado na Figura 2. A saída é obtidaa partir do último estágio, de forma que o conteúdo inicial do LFSR coincide com os primeirosL símbolos de saída e o restante é obtido com a relação:
s j =L
∑i=1
cis j−i para j = L, L+1, L+2, · · · (7.22)

44
onde os símbolos de saída e os coeficientes de realimentação pertencem ao campo GF(q).
Figura 2 – LFSR de tamanho L
Considera-se que o LFSR gera uma sequência finita s0, s1, · · · , sN−1, quando esta coincidecom os primeiros N símbolos de saída para uma inicialização específica. Se L≥ N, a sequênciaé sempre gerada. No entanto, para L < N, o LFSR a gera somente se
s j +L
∑i=1
cis j−i = 0 para j = L, L+1, · · · , N−1 (7.23)
Com isso, define-se LN(s) como sendo o tamanho mínimo do LFSR que gera a sequências0, s1, · · · , sN−1, de forma que LN(s)≤ N. No caso deste mesmo LFSR não gerar s0, s1, · · · ,sN−1, sN , então, o tamanho deve ser alterado da seguinte maneira,
LN+1(s) = máx[LN(s), N +1−LN(s)] (7.24)
Para provar a igualdade acima, Massey (1969) utiliza um algoritmo recursivo que encontraum LFSR de tamanho LN(s), o qual gera a sequência s dada por s0, s1, · · · , sN−1 para N =
1, 2, 3, · · · . Os coeficientes de realimentação formam o chamado polinômio de conexão, quepossui grau máximo LN(s) e é expresso como
c(N)(X) = 1+ c(N)1 X + c(N)
2 X2 + · · ·+ c(N)LN(s)
XLN(s) (7.25)
Então, supondo que tenham sido encontrados alguns LN(s) e c(N)(X) para N = 1, 2, · · · , n
através da igualdade (7.24), para N = 1, 2, · · · , n− 1. Agora, busca-se Ln+1(s), c(n+1)(X) emostrar que a mesma igualdade se mantém-se para N = n.
A partir de (7.23), encontra-se
s j +Ln(s)
∑i=1
c(n)i s j−i =
0, j = Ln(s), · · · , n−1
dn, j = n(7.26)
onde dn, chamada de próxima discrepância, é a diferença entre sn e o (n+ 1)-ésimo símbologerado pelo LFSR mínimo encontrado para gerar os primeiros n símbolos da sequência s. Casodn = 0, então este LFSR também gera os n+ 1 símbolos de s. Portanto, Ln+1(s) = Ln(s) ec(n+1)(X) = c(n)(X).

45
Mas se dn 6= 0, então deve ser encontrado um novo LFSR. Para isso, considere m comosendo o comprimento da sequência gerada antes da última alteração de tamanho do LFSR, ouseja,
Lm(s)< Ln(s) (7.27a)
Lm+1(s) = Ln(s) (7.27b)
Como a mudança de tamanho foi necessária, Lm(s) e c(m)(X) não são capazes de gerar asequência s0, s1, · · · , sm−1, sm. Então, de acordo com (7.23),
s j +Lm(s)
∑i=1
c(m)i s j−i =
0, j = Lm(s), · · · , m−1
dm 6= 0, j = m(7.28)
Seguindo (7.24) para N = m, tem-se
Lm+1(s) = Ln(s) = máx[Lm(s), m+1−Lm(s)]
e considerando (7.27a), entãoLn(s) = m+1−Lm(s) (7.29)
Utilizando essas definições, forma-se uma nova escolha para o polinômio de conexão,
c(n+1)(X) = c(n)−dnd−1m Xn−mc(m)(X) (7.30)
ou seja, o grau c(n+1)(X) é, no máximo,
máx[Ln(s), n−m+Lm(s)] = máx[Ln(s), n+1−Ln(s)] (7.31)
em que a igualdade é obtida considerando (7.29). Com isso, c(n+1)(X) é um polinômio deconexão válido para o LFSR de tamanho
Ln+1(s) = máx[Ln(s), n+1−Ln(s)] (7.32)
Além disso, a partir das Equações (7.26), (7.28) e da estrutura da (7.30), observa-se,
s j +Ln+1(s)
∑i=1
c(n+1)i s j−i = s j +
Ln(s)
∑i=1
c(n)i s j−i−dnd−1m ·
[s j +
Lm(s)
∑i=1
c(m)i s j−i
]
=
0, j = Ln+1(s), · · · , n−1
dn−dnd−1m dm = 0, j = n
provando a igualdade definida em (7.24).

46
O polinômio de conexão comentado é na verdade o polinômio localizador de erros, ou seja,
c(N)(X) =σσσ(X) (7.33)
enquanto que a sequência finita pré-definida s é o conjunto de síndromes calculadas em (7.7).Ainda pode ser percebida a equivalência entre as identidades de Newton, definidas em (7.21), econdição imposta em (7.23). Isso mostra que o problema de sintetização do LFSR na verdade éuma interpretação física da solução da equação chave.
Com essas definições, é possível encontrar os polinômios localizador e avaliador de erros.No entanto, suas raízes ainda são desconhecidas. O algoritmo de Chien realiza a busca destasraízes, para ambos os polinômios, fornecendo as informações necessárias para o algoritmo deForney, finalmente, encontrar os valores dos erros.
Observa-se, da definição do polinômio localizador em (7.16), que as raízes deste são inver-sas às posições dos erros. Assim, o procedimento realizado pelo algoritmo de Chien é calcularo valor dos polinômios para os elementos do campo, buscando o resultado nulo, o qual é cor-respondente a uma das raízes, β
−1l , e a uma posição específica βl , consequentemente.
Paralelamente, o mesmo algoritmo de Chien calcula o valor do polinômio avaliador nestaposição, substituindo a raiz encontrada, β
−1l , na Equação (7.17) e obtendo,
ΩΩΩ(β−1l ) =
v
∑j=1
δ jβbj
v
∏k=1k 6= j
(1−βkβ−1l )
= δlβl
v
∏k=1k 6=l
(1−βkβ−1l ) (7.34)
E ainda, derivando σσσ(X) em (7.16),
σσσ′(X) =
ddX
v
∏j=1
(1−β jX) =−v
∑j=1
β j
v
∏k=1k 6= j
(1−βkX) (7.35)
e substituindo o valor da raiz, observa-se
σσσ′(β−1
l ) =−βl
v
∏k=1k 6=l
(1−βkβ−1l ). (7.36)
Utilizando (7.34) e (7.36), a expressão para o valor do erro, δl , na posição βl é dada por,
δl =−ΩΩΩ(β−1
l )
σσσ ′(β−1l )
(7.37)
Descoberta por Forney, com ela finaliza-se o processo de decodificação.

47
8 ARQUITETURA DESENVOLVIDA
Após a abordagem das teorias, matemática e de códificação de canal, específicas para odesenvolvimento dos algoritmos utilizados nos códigos RS, volta-se agora a atenção para aparte prática, ou seja, para a descrição em VHDL da arquitetura dos blocos necessários para ofuncionamento do codificador e decodificador RS.
O código escolhido para implementação foi o RS(255, 239), de acordo com especificaçãoda norma G.709/Y1331 (12/2009) da ITU-T, que define a operação em símbolos não-binários,ou seja, bytes e codificação sistemática. Com isso, observa-se que o campo de operação será oGF(28) = GF(256), definido pelo polinômio primitivo
f(X) = 1+X2 +X3 +X4 +X8 (8.1)
A distância de Hamming mínima deste código é dmin = 17, portanto, a capacidade de cor-reção é de até t = 8 bytes. Logo, há 2t = 16 símbolos de paridade adicionados a cada bloco de239 bytes de informação.
A estrutura deste capítulo será a seguinte: primeiramente, será exposto um bloco comum avárias partes tanto do codificador, quanto do decodificador, chamado de célula multiplicadora,depois dar-se-á sequência aos blocos do codificador RS, que se resume praticamente apenas aum LFSR e, por fim, serão apresentados os blocos do decodificador RS que são o cálculo dasíndrome, algoritmo de Berlekamp, de Chien e de Forney.
8.1 CÉLULA MULTIPLICADORA
Como comentando no capítulo sobre Campos de Galois, as operações aritméticas destespossuem algumas particularidades. Além disso, são bastante utilizadas no desenvolvimento doscódigos RS, como no caso da realimentação nos LFSR e em todos os algoritmos de decodifica-ção, merecendo então atenção específica prévia ao restante dos blocos.
Utilizando a notação polinomial da Tabela 4 para representação dos elementos do campoGF(23), deseja-se realizar a multiplicação entre dois elementos, a(X) = a0 + a1X + a2X2 eb(X) = b0+b1X +b2X2. Para isso, devem ser levadas em conta a multiplicação termo a termo,a soma dos termos de mesmo grau e ainda a verificação de que todos os resultados pertencemao campo. Isso é realizado pela célula multiplicadora apresentada na Figura 3.
Observando a porta lógica AND1, nota-se que ela é responsável pela multiplicação termo atermo. Já a AND2 refere-se à realimentação de um possível resultado calculado previamente,de grau superior, que é considerado de acordo com o polinômio primitivo do campo, f(X), nocálculo atual, ou seja, é o que mantém os resultados como elementos pertencentes ao campo. Aporta XOR1 soma a saída da AND2 com algum possível resultado de mesmo grau já calculado.Por fim, a porta XOR2 soma todos estes casos, fornecendo a saída final da célula.

48
Figura 3 – Célula Multiplicadora
Utilizar somente uma célula para multiplicação dos polinômios a(X) e b(X) acarretá ematrasos desnecessários. Assim, podem ser utilizadas várias células em paralelo formando umcircuito combinacional que consome menos tempo para realizar as operações.
A Figura 4 ilustra esse conjunto de células que realizam as operações da Equação (8.2).
a(X) ·b(X) = (a2X2 +a1X +a0) · (b2X2 +b1X +b0)
= (a2 ·b2)X4 +(a1 ·b2)X3 +(a0 ·b2)X2
+(a2 ·b1)X3 +(a1 ·b1)X2 +(a0 ·b1)X
+(a2 ·b0)X2 +(a1 ·b0)X +(a0 ·b0)
(8.2)
mas como, neste caso, as operações são realizadas sobre o campo GF(23), o qual é definidopelo polinômio primitivo f(X) = 1+X +X3, os termos de ordem maior do que 3 são reduzidospara ordens menores através da divisão por f(X). Foi escolhido um campo de Galois pequenopara que fosse possível a visualização e o entendimento das operações realizadas. Na Figura 4observa-se que o resultado c(X) = a(X) ·b(X) aparece na saída do conjunto, na parte de baixo,neste caso, indicado pelos coeficientes c0, c1 e c2.
O bloco que realiza esse agrupamento das células é parametrizável, portanto, a expansão doconjunto para outros campos é direta.
Como os elementos de GF(256) são bytes, são necessárias 8× 8 células. O resultado doconjunto de células, mesmo para GF(256), possui um atraso resultante apenas das portas lógi-cas envolvidas, pois não há necessidade da utilização de registradores neste bloco.
A Figura 5 mostra a simulação, utilizando a ferramenta ModelSim, de uma multiplicação re-alizada pelo conjunto de células para este campo, entre os elementos 175−(MSB 10101111 LSB)
e 232− (11101000), tendo como resultado o valor 208− (11010000). A validação desta e deoutras operações foram feitas através do programa MATLAB, utilizando a função gf(x,m), quecria vetores pertencentes ao campo de Galois GF(2m). Após sua criação, basta multiplicá-losnormalmente e verificar o resultado.
Observa-se que o polinômio primitivo gerador do campo é explicitado através da porta f_i,

49
Figura 4 – Conjunto de Células para multiplicação dos polinômios a(X) e b(X)
enquanto aqueles que serão multiplicados utilizam a_i e b_i.
Figura 5 – Simulação de uma operação do conjunto de células
8.2 CODIFICADOR RS
A codificação implementada baseia-se, como comentado na abordagem teórica, em regis-tradores de deslocamento chamados LFSR. Esse tipo de registrador utiliza realimentação pa-rametrizada de acordo com o polinômio gerador do código, g(X), para realizar a divisão damensagem já deslocada (códificação sistemática) e obter os símbolos de paridade.

50
As raízes de g(X) utilizadas também estão definidas na norma G.709 e são as seguintes:
g(X) =15
∏i=0
(X−αi) (8.3)
com α i pertencente a GF(256). Portanto, os coeficientes de g(X) são,
g(X) =α120 +α
225X +α194X2 +α
182X3 +α169X4 +α
147X5+
α191X6 +α
91X7 +α3X8 +α
76X9 +α161X10 +α
102X11+ (8.4)
α109X12 +α
107X13 +α104X14 +α
120X15 +α0X16
esses coeficientes é que realizam a multiplicação da realimentação do LFSR, como mostradona Figura 6.
Além disso, como a codificação é sistemática, a mensagem deve aparecer explicitamentena palavra código. Assim, inicialmente a chave 1 está fechada e a chave 2 está para baixo, naposição que permite a saída da mensagem diretamente. Após a passagem de todos os símbolosreferentes à mensagem, a chave 1 é aberta e a 2 é alterada para cima, de forma que os símbolosde paridade sejam disponibilizados na saída.
No caso do RS(255, 239), passam 239 bytes de mensagem e posteriormente são liberados16 bytes de paridade, formando ao final um bloco com um total de 255 símbolos.
Figura 6 – Codificador RS(255, 239)
Observa-se que os círculos indicando multiplicação são, na verdade, vários conjuntos decélulas similares aquele da Figura 4. Já os círculos sinalizando soma são implementados atra-vés de operações de ou-exclusivo, XOR, como na Equação (7.1). Os quadrados contendoL1, L2, · · · ,L2t são os registradores que fornecem em suas saídas as entradas do ciclo de relógioanterior.
As Figuras 7 e 8 apresentam a simulação da codificação RS(255, 239) para símbolos de in-formação gerados de forma pseudo-aleatória. Ainda na Figura 8, são apontados os 16 símbolosde paridade gerados a partir dos 239 símbolos de dados.
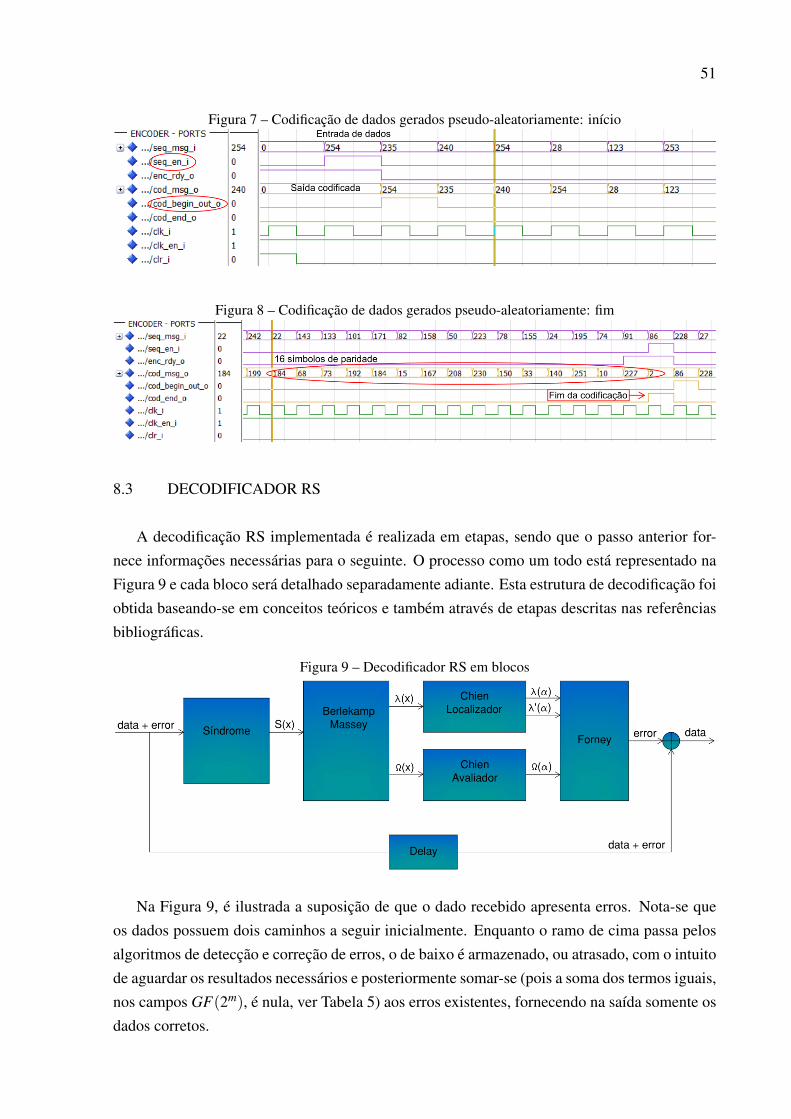
51
Figura 7 – Codificação de dados gerados pseudo-aleatoriamente: início
Figura 8 – Codificação de dados gerados pseudo-aleatoriamente: fim
8.3 DECODIFICADOR RS
A decodificação RS implementada é realizada em etapas, sendo que o passo anterior for-nece informações necessárias para o seguinte. O processo como um todo está representado naFigura 9 e cada bloco será detalhado separadamente adiante. Esta estrutura de decodificação foiobtida baseando-se em conceitos teóricos e também através de etapas descritas nas referênciasbibliográficas.
Figura 9 – Decodificador RS em blocos
Na Figura 9, é ilustrada a suposição de que o dado recebido apresenta erros. Nota-se queos dados possuem dois caminhos a seguir inicialmente. Enquanto o ramo de cima passa pelosalgoritmos de detecção e correção de erros, o de baixo é armazenado, ou atrasado, com o intuitode aguardar os resultados necessários e posteriormente somar-se (pois a soma dos termos iguais,nos campos GF(2m), é nula, ver Tabela 5) aos erros existentes, fornecendo na saída somente osdados corretos.

52
8.3.1 Cálculo da Síndrome
A partir da Figura 9, o primeiro bloco a receber dados é o da síndrome. Da teoria, tem-seque a síndrome é o resultado do cálculo do polinômio recebido nos pontos definidos pelas raízesdo polinômio gerador do código, ou seja, sendo
r(X) = r0 + r1X + r2X2 + · · ·+ r252X252 + r253X253 + r254X254 (8.5)
entãoSi = r(X)|X=α i para 0≤ i < 15 (8.6)
que pode ser implementado através de unidades lógicas, como ilustrado na Figura 10,
Figura 10 – Unidade de cálculo de síndrome
Essa unidade realiza a operação detalhada abaixo,
Si =r254
r254(αi)+ r253
r254(αi)2 + r253(α
i)+ r252
... (8.7)
r254(αi)254 + r253(α
i)253 + r252(αi)252 + · · ·+ r2(α
i)2 + r1(αi)+ r0
No entanto, o cálculo desenvolvido por ela considera apenas uma raiz e é concluído somenteapós a passagem de todos os dados. Assim, utilizando outras unidades em paralelo, Figura 11,é possível determinar os valores referentes a cada raíz de g(X) e obter todos os resultados nomesmo instante. Dessa maneira, forma-se o polinômio de síndromes, S(X) que é repassado aobloco seguinte de Berlekamp-Massey,
S(X) = S0 +S1X +S2X2 + · · ·+S14X14 +S15X15 (8.8)
Lembrando que somente no caso do vetor recebido r(X) ser uma palavra código, a síndromeserá nula.
Na Figura 12, apresenta-se a simulação deste bloco para o caso em que não há ocorrência deerros. Portanto, ao fim do cálculo, o polinômio de síndromes é nulo, como é possível perceberatravés do sinal s_o.
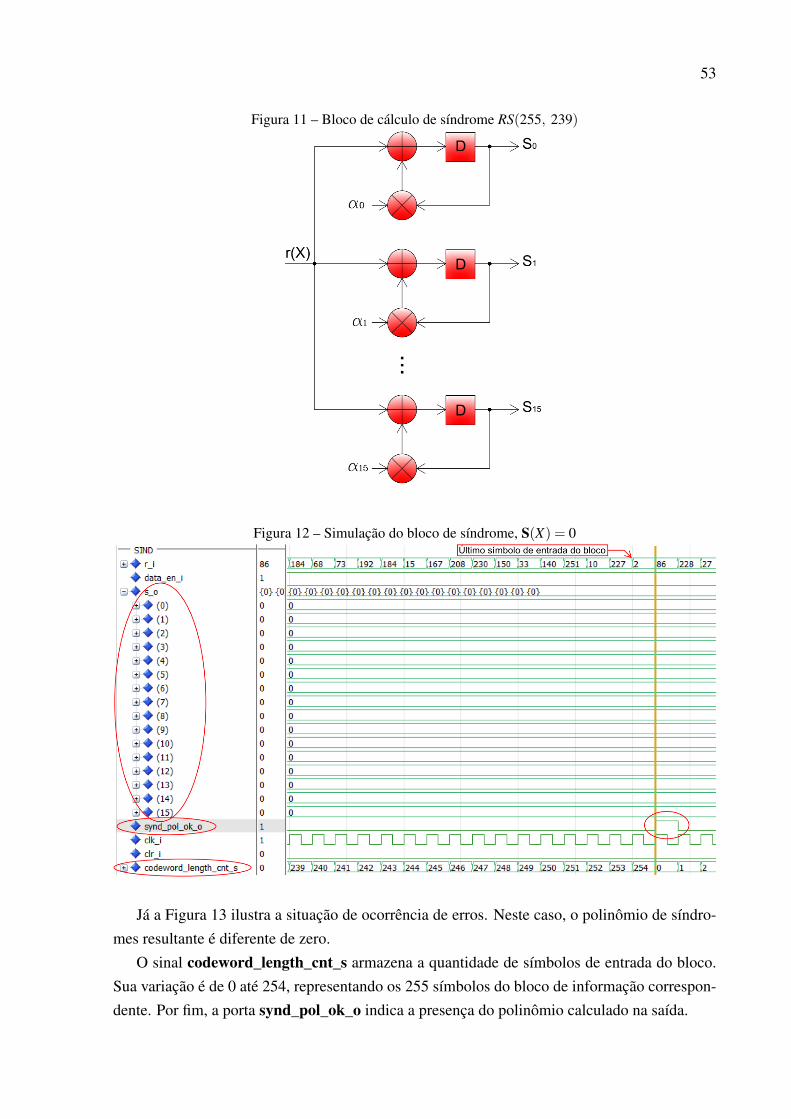
53
Figura 11 – Bloco de cálculo de síndrome RS(255, 239)
Figura 12 – Simulação do bloco de síndrome, S(X) = 0
Já a Figura 13 ilustra a situação de ocorrência de erros. Neste caso, o polinômio de síndro-mes resultante é diferente de zero.
O sinal codeword_length_cnt_s armazena a quantidade de símbolos de entrada do bloco.Sua variação é de 0 até 254, representando os 255 símbolos do bloco de informação correspon-dente. Por fim, a porta synd_pol_ok_o indica a presença do polinômio calculado na saída.

54
Figura 13 – Simulação do bloco de síndrome, S(X) 6= 0
A latência total do bloco de síndromes é de 255 ciclos de relógio.
8.3.2 Berlekamp-Massey
O bloco de Berlekamp-Massey possui como entrada o polinômio das síndromes, S(X), apartir do qual se encontram os polinômios localizador, σσσ(X), e avaliador de erros, ΩΩΩ(X), deacordo com a equação chave definida em (7.19) e com o método detalhado de busca do LFSRde tamanho mínimo.
Assim, a base deste bloco é o algoritmo de Berlekamp tratado da maneira vista por Massey,da mesma forma como foi desenvolvida a abordagem teórica deste ponto da decodificação. En-tão, a arquitetura utilizada, presente na Figura 14 é a sugerida pelo artigo de Massey intituladoShift-Register Synthesis and BCH Decoding, citado nas referências do trabalho.
O polinômio de síndromes é deslocado, a cada ciclo, para dentro do registrador S mostradona Figura 14. Dessa maneira, é possível obter um valor para a discrepância indicada por d.A partir deste valor, da discrepância de um cálculo passado (indicada por b), e do polinômiode conexão relacionado com ela, implementa-se, através da lógica superior indicada na figura,a Equação (7.30). Então, novos valores são adicionados ao registrador C. Assim, ocorrem asiterações até todo o polinômio de síndromes estiver se deslocado para dentro do registrador S.
Algumas regras de operação devem ser observadas. Para isso, implementa-se uma máquinade estados descrita nos passos abaixo:
1) Os valores são inicializados, c(X)← α0; B(X)← α0; S(X)← 0; b← α0; L← 0; N← 0.Então, aguarda-se a confirmação de que o polinômio de síndromes esteja pronto. Quandoa confirmação chega, as síndromes são amostradas e passa-se para o passo seguinte;

55
Figura 14 – Diagrama de blocos do algoritmo de Berlekamp-Massey
2) O valor de N é incrementado de uma unidade. Além disso, o registrador S é deslocadopara a direita e um novo valor de síndrome é inserido na posição inicial do mesmo. Aindaneste estado, busca-se, em uma memória de valores inversos, o valor correspondente aoinverso de b. Por fim, desloca-se o registrador B para a direita, preparando-o para umpossível cálculo do novo polinômio de conexão e segue-se para o próximo passo;
3) Realiza-se o cálculo da discrepância, prosseguindo para o próximo estado;4) Testa-se o valor da discrepância. Se d = 0, passa-se para o estado 7; Se d 6= 0, calcula-se
um novo polinômio de conexão temporário, T(X), e, caso 2L > N−1 prossegue-se parao estado 5, senão para 6;
5) Apenas atualiza o valor do polinômio de conexão, c(X)← T (X) e passa-se para 7;6) Atualiza os valores, B(X)← c(X); c(X)← T (X); L← N−L; b← d. Prossegue-se para
o estado 7;7) Verifica se N = 16. Em caso afirmativo, prossegue-se para o estado final 8. Do contrário,
volta-se para o estado 2;8) Último estado, atribui o polinômio de conexão à saída referente ao polinômio de localiza-
ção, sinalizando o fim do cálculo deste e zera os registradores utilizados. Por fim, volta-seao estado 1, aguardando um novo polinômio de síndromes ficar pronto.
Observa-se que, quando d = 0 não há alteração no polinômio de conexão. No entanto,quando d 6= 0 a diferenciação entre os passos 5 e 6 é feita para se obter o LFSR mínimo único(MASSEY, 1969).

56
Ao fim, o polinômio c(X) deve possuir grau máximo 8 (referente às 8 raízes relacionadasaos 8 erros que o decodificador é capaz de corrigir), pois c(X) =σσσ(X).
O deslocamento do polinômio de síndromes é mostrado na Figura 15, enquanto a evoluçãodo polinômio de conexão é apresentada na Figura 16.
Figura 15 – Deslocamento do polinômio de síndromes para dentro do registrador S
Figura 16 – Evolução do polinômio de conexão ao longo das 16 iterações
Então, com σσσ(X) definido, encontra-se o polinômio avaliador de erros, ΩΩΩ(X), através docircuito da Figura 17. Este, realiza a multiplicação das síndromes, que vão sendo deslocadaspara dentro do registrador S, pelo polinômio localizador, como expresso na equação chave:σσσ(X)S(X) =ΩΩΩ(X) mod X16.
Esses dois blocos são englobados por um topo, o qual controla ambos também através deuma máquina de estados simples, que apenas aguarda a finalização do polinômio localizador,amostra-o, encaminha-o ao registrador A e desloca, a cada ciclo de relógio, a síndrome para den-tro do registrador S. Para cada nova síndrome deslocada obtém-se um coeficiente do polinômioavaliador.
Enfim, obtém-se ambos os polinômios, σσσ(X) e ΩΩΩ(X). O grau de ambos estará relacionadocom o número de erros do padrão de erro recebido.
A latência total do bloco de Berlekamp-Massey corresponde a 109 ciclos de relógio.
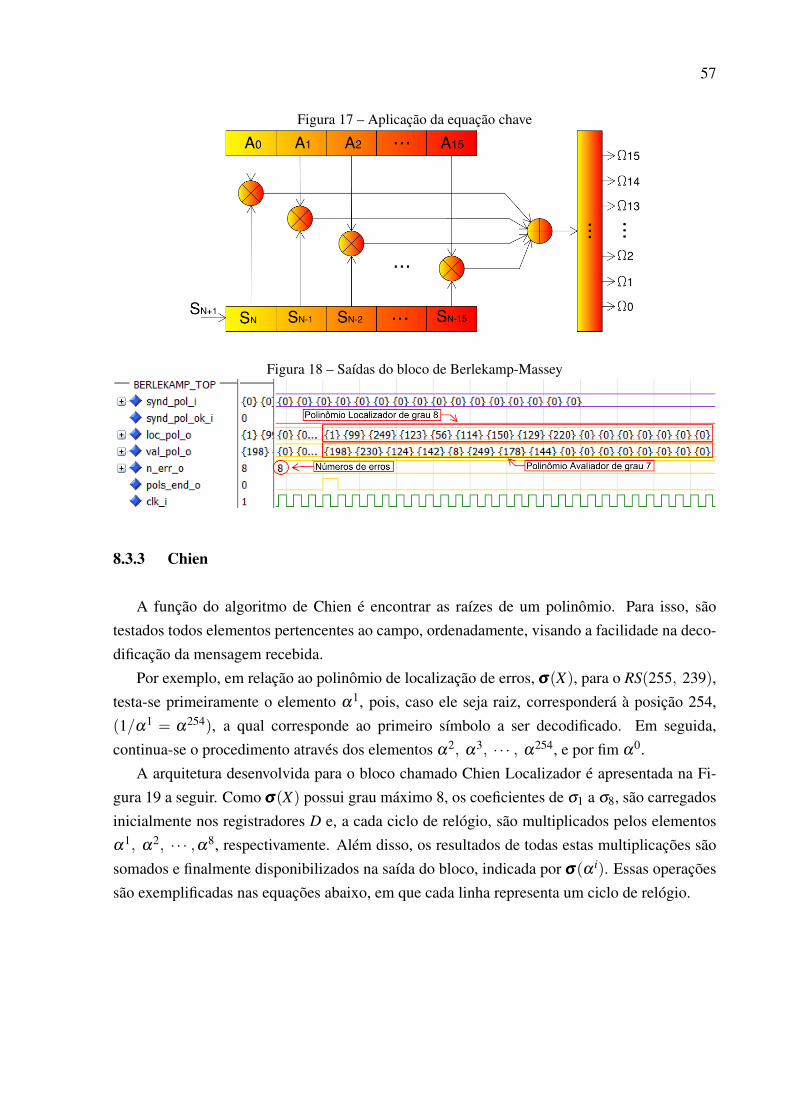
57
Figura 17 – Aplicação da equação chave
Figura 18 – Saídas do bloco de Berlekamp-Massey
8.3.3 Chien
A função do algoritmo de Chien é encontrar as raízes de um polinômio. Para isso, sãotestados todos elementos pertencentes ao campo, ordenadamente, visando a facilidade na deco-dificação da mensagem recebida.
Por exemplo, em relação ao polinômio de localização de erros, σσσ(X), para o RS(255, 239),testa-se primeiramente o elemento α1, pois, caso ele seja raiz, corresponderá à posição 254,(1/α1 = α254), a qual corresponde ao primeiro símbolo a ser decodificado. Em seguida,continua-se o procedimento através dos elementos α2, α3, · · · , α254, e por fim α0.
A arquitetura desenvolvida para o bloco chamado Chien Localizador é apresentada na Fi-gura 19 a seguir. Como σσσ(X) possui grau máximo 8, os coeficientes de σ1 a σ8, são carregadosinicialmente nos registradores D e, a cada ciclo de relógio, são multiplicados pelos elementosα1, α2, · · · ,α8, respectivamente. Além disso, os resultados de todas estas multiplicações sãosomados e finalmente disponibilizados na saída do bloco, indicada por σσσ(α i). Essas operaçõessão exemplificadas nas equações abaixo, em que cada linha representa um ciclo de relógio.
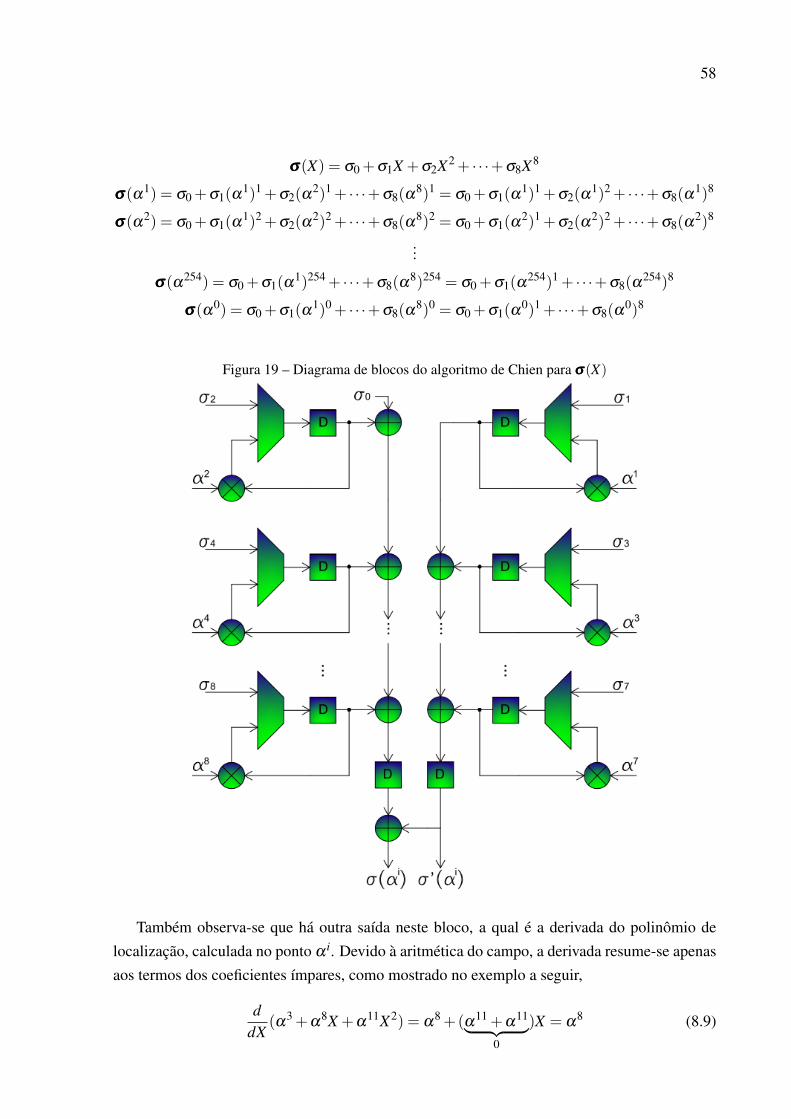
58
σσσ(X) = σ0 +σ1X +σ2X2 + · · ·+σ8X8
σσσ(α1) = σ0 +σ1(α1)1 +σ2(α
2)1 + · · ·+σ8(α8)1 = σ0 +σ1(α
1)1 +σ2(α1)2 + · · ·+σ8(α
1)8
σσσ(α2) = σ0 +σ1(α1)2 +σ2(α
2)2 + · · ·+σ8(α8)2 = σ0 +σ1(α
2)1 +σ2(α2)2 + · · ·+σ8(α
2)8
...
σσσ(α254) = σ0 +σ1(α1)254 + · · ·+σ8(α
8)254 = σ0 +σ1(α254)1 + · · ·+σ8(α
254)8
σσσ(α0) = σ0 +σ1(α1)0 + · · ·+σ8(α
8)0 = σ0 +σ1(α0)1 + · · ·+σ8(α
0)8
Figura 19 – Diagrama de blocos do algoritmo de Chien para σσσ(X)
Também observa-se que há outra saída neste bloco, a qual é a derivada do polinômio delocalização, calculada no ponto α i. Devido à aritmética do campo, a derivada resume-se apenasaos termos dos coeficientes ímpares, como mostrado no exemplo a seguir,
ddX
(α3 +α8X +α
11X2) = α8 +(α11 +α
11︸ ︷︷ ︸0
)X = α8 (8.9)
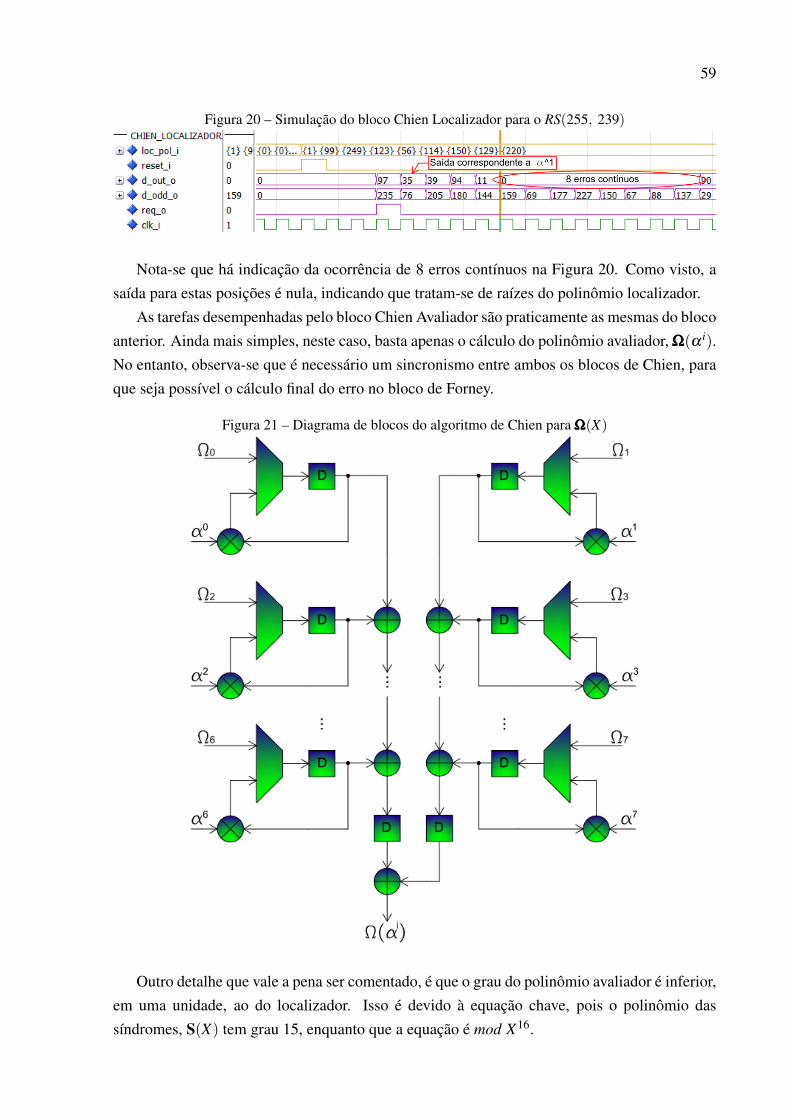
59
Figura 20 – Simulação do bloco Chien Localizador para o RS(255, 239)
Nota-se que há indicação da ocorrência de 8 erros contínuos na Figura 20. Como visto, asaída para estas posições é nula, indicando que tratam-se de raízes do polinômio localizador.
As tarefas desempenhadas pelo bloco Chien Avaliador são praticamente as mesmas do blocoanterior. Ainda mais simples, neste caso, basta apenas o cálculo do polinômio avaliador, ΩΩΩ(α i).No entanto, observa-se que é necessário um sincronismo entre ambos os blocos de Chien, paraque seja possível o cálculo final do erro no bloco de Forney.
Figura 21 – Diagrama de blocos do algoritmo de Chien para ΩΩΩ(X)
Outro detalhe que vale a pena ser comentado, é que o grau do polinômio avaliador é inferior,em uma unidade, ao do localizador. Isso é devido à equação chave, pois o polinômio dassíndromes, S(X) tem grau 15, enquanto que a equação é mod X16.
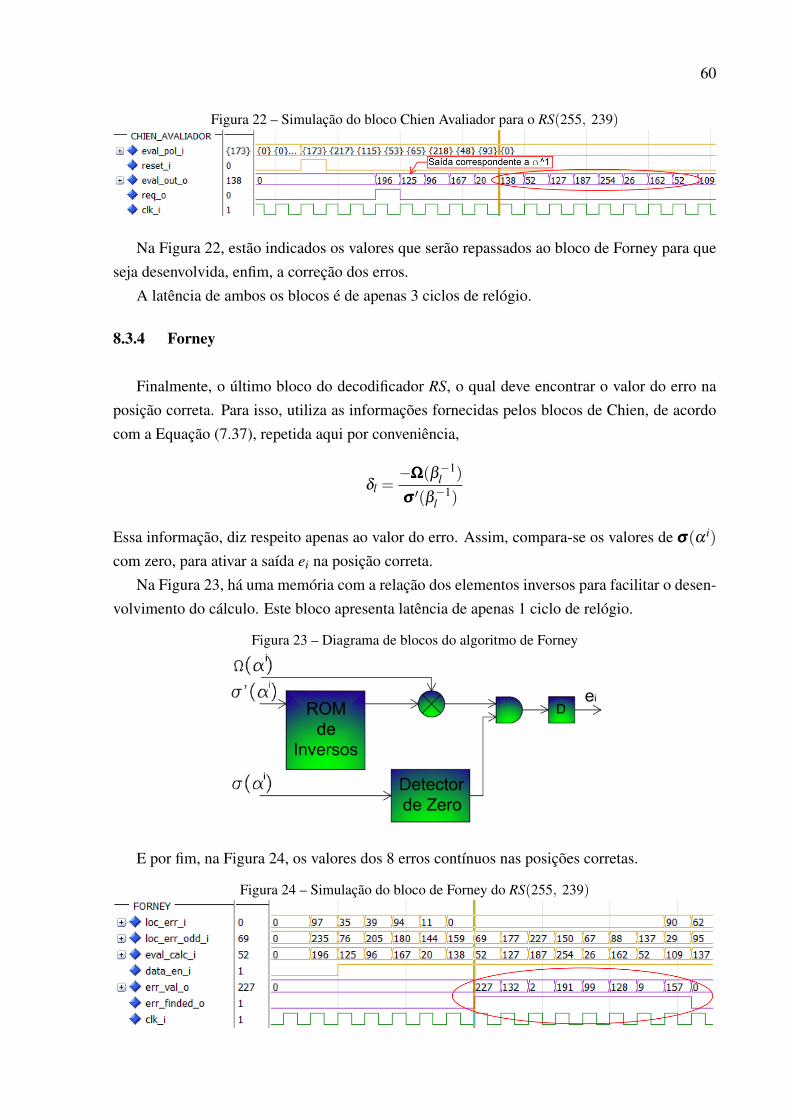
60
Figura 22 – Simulação do bloco Chien Avaliador para o RS(255, 239)
Na Figura 22, estão indicados os valores que serão repassados ao bloco de Forney para queseja desenvolvida, enfim, a correção dos erros.
A latência de ambos os blocos é de apenas 3 ciclos de relógio.
8.3.4 Forney
Finalmente, o último bloco do decodificador RS, o qual deve encontrar o valor do erro naposição correta. Para isso, utiliza as informações fornecidas pelos blocos de Chien, de acordocom a Equação (7.37), repetida aqui por conveniência,
δl =−ΩΩΩ(β−1
l )
σσσ ′(β−1l )
Essa informação, diz respeito apenas ao valor do erro. Assim, compara-se os valores de σσσ(α i)
com zero, para ativar a saída ei na posição correta.Na Figura 23, há uma memória com a relação dos elementos inversos para facilitar o desen-
volvimento do cálculo. Este bloco apresenta latência de apenas 1 ciclo de relógio.
Figura 23 – Diagrama de blocos do algoritmo de Forney
E por fim, na Figura 24, os valores dos 8 erros contínuos nas posições corretas.
Figura 24 – Simulação do bloco de Forney do RS(255, 239)

61
9 RESULTADOS
Após as abordagens teórica e prática, torna-se necessária a avaliação geral dos resultadosobtidos com o RS(255, 239) desenvolvido. Quanto as ferramentas, para a simulação utilizou-seo ModelSim, enquanto que para a síntese o ISE da Xilinx. Os dados de entrada são gerados demaneira pseudo-randômica e as situações simuladas são a ocorrência de erros contínuos, nossímbolos de paridade e também em posições pseudo-aleatórias. Além disso, é mostrado que osistema opera continuamente, apresentando apenas uma latência inicial, o que é de grande valiapara a integração com outros blocos externos. Por fim, são apresentados os dados referentes àquantidade de hardware utilizado e à frequência máxima de operação de cada bloco.
9.1 SIMULAÇÃO
As simulações são realizadas supondo um sistema como o da Figura 25, em que os dadosde entrada e saída são gravados em um arquivo de texto e posteriormente comparados. Assim,verifica-se a atuação do código RS através da análise do número de erros que a comparaçãoencontra. Caso este valor seja diferente de zero, o número de erros inseridos foi maior do que acapacidade do código.
Figura 25 – Sistema para simulação do RS(255, 239)
A Figura 26 apresenta as formas de onda desse sistema.
Figura 26 – Visão geral da simulação do RS(255, 239)

62
Analisando-se a Figura 26, percebe-se uma latência saliente entre a entrada de dados nodecodificador e sua correspondente saída. Especificamente, esse atraso inicial equivale à 371ciclos de relógio e não é considerado um problema, por causa, principalmente, da latência dobloco das síndromes.
9.1.1 Erros Contínuos
O primeiro teste consiste na inserção contínua de 8 símbolos errados. Para facilitar a vi-sualização optou-se pelo mesmo valor de erro, 255 na notação decimal. Portanto, a Figura 27apresenta a saída do codificador, indicando quais os símbolos que posteriormente serão corrom-pidos.
Figura 27 – Saída codificada do encoder RS(255, 239)
Então, no caminho entre o codificador e o decodificador, são inseridos os erros contínuos.A Figura 28 ilustra a entrada dos dados codificados, com os símbolos alterados em destaque.
Figura 28 – Entrada corrompida com erros contínuos, decodificador RS(255, 239)
Após todo o processo desenvolvido pelo decodificador, todos os erros são corrigidos e mos-trados na Figura 29. Pode-se, inclusive, realizar uma comparação visual entre as Figuras 27 e29, verificando-se que os valores nas posições correspondentes à ocorrência dos erros são osmesmos.
Figura 29 – Saída decodificada do RS(255, 239), erros contínuos corrigidos

63
A saída err_cnt_o apresenta o número de erros identificados pelo decodificador. Até 8 errossão corrigidos.
9.1.2 Erros nos Símbolos de Paridade
O próximo teste é semelhante ao anterior, no entanto, os erros são propositalmente inseridosno local definido pelos símbolos de paridade. Com este teste, é possível verificar que os errospodem ocorrer em qualquer posição do bloco. A Figura 30 mostra a entrada do decodificador.
Figura 30 – Erros nos símbolos de paridade, decodificador RS(255, 239)
Os erros nos símbolos de paridade são identificados e não afetam os demais. Além disso,como na saída do decodificador só há interesse nos símbolos referentes aos dados, não há ne-cessidade de realizar a correção dos bytes de paridade errados. Observa-se que os dados sãoindicados na saída do decodificador através do sinal data_en_o.
Figura 31 – Correção de erros nos símbolos de paridade, decodificador RS(255, 239)
Os valores indicados por right_data_cnt_s e error_data_cnt_s foram obtidos ao final dacomparação dos dados de entrada do codificador, com os de saída do decodificador. Eles for-necem as informações sobre a quantidade de dados corretos e incorretos, respectivamente, queforam transmitidos através sistema ao longo de toda simulação. Estes mesmos sinais são utili-zados nas figuras seguintes.
9.1.3 Erros Pseudo-Aleatórios
O terceiro teste verifica a questão de erros em posições pseudo-aleatórias. Então, assimcomo os dados, a posição e os valores de 8 erros serão gerados pseudo-randômicamente. Dessamaneira, a Figura 32 apresenta as formas de onda obtidas na simulação, as posições onde ocor-reram os erros e os valores dos mesmos.

64
Figura 32 – Simulação do RS(255, 239) para erros peudo-aleatórios
Observa-se que os 8 erros foram corrigidos, inclusive quando ocorrem nos símbolos de pari-dade.
9.2 SINTETIZAÇÃO
Outro tipo de resultado importante está ligado ao hardware, ou seja, à quantidade de ele-mentos físicos necessária para a implementação dos blocos desenvolvidos e em qual frequênciaeles podem ser operados.
Como o foco deste trabalho é no código RS(255, 239), de maneira que possa ser posteri-ormente integrado a um sistema de operação em redes de transporte ótico, o FPGA utilizadopara estimar a utilização de hardware deve ter grande capacidade lógica, como por exemplo,o XC6VHX565T da família Virtex-6 da Xilinx, com mais de 550000 células lógicas, utilizadona placa de desenvolvimento para OTN chamada ML630. Assim, foi realizada a sintetizaçãoconsiderando este hardware. Os resultados obtidos, referentes às Look-Up Tables, registradorese frequência máxima, são apresentados a seguir.
9.2.1 Codificador
O bloco do codificador é único. Portanto, seus resultados estão presentes na Tabela 8 abaixo.

65
Tabela 8 – Resultado da sintetização do codificador RS(255, 239)
Bloco LUTs Registradores Fmáx (MHz)
Codificador 187 147 346
Percebe-se que, por não possuir operações complexas e trabalhosas, o codificador não utilizauma grande quantidade de hardware. Além disso, a frequência máxima alcançada é bastante su-perior aos 200 MHz supostos, de acordo com o relógio global da placa ML630, para a aplicaçãoem redes de transporte óptico.
9.2.2 Decodificador
O decodificador é formado por diversos blocos. O resultado de cada um deles é apresentadoseparadamente, dessa maneira, é possível avaliá-los, verificando, por exemplo, onde ocorrealguma limitação de frequência.
Tabela 9 – Resultado da sintetização do decodificador RS(255, 239)
Bloco LUTs Registradores Fmáx (MHz)
Síndrome 331 266 494Berlekamp-Massey 2580 1553 258
Chien 434 318 593Forney 75 – 272
Decodificador 3539 2188 258
Analisando a Tabela 9, nota-se que o bloco de Berlekamp-Massey é o que utiliza a maiorquantidade de elementos lógicos. Ainda, sua frequência máxima é a limitante de todo o de-codificador. Isto já era esperado, pois este é o bloco mais complexo. No entanto, 258 MHz éo suficiente para a aplicação que requer 200 MHz. Dessa maneira, se alguma otimização fornecessária, o bloco de Berlekamp-Massey é o mais indicado para fazê-la.

66
10 CONCLUSÃO
Chegando-se ao fim deste trabalho, percebe-se a imensa importância do estudo da teoriamatemática que sustenta esta e outras aplicações da engenharia. Tendo-se a consciência de queos fundamentos teóricos apresentados representam apenas uma iniciação da teoria relacionadaà codificação de canal atualmente desenvolvida.
Em relação à linguagem VHDL, nota-se a necessidade de desenvolver os códigos semprepensando no hardware que será sintetizado a partir deles. Dessa maneira, é possível obter otimi-zações importantes para as limitações de projeto. Os blocos apresentados no capítulo referenteà arquitetura, são capazes de ilustrar os códigos desenvolvidos e representam a matemática ex-posta no capítulo que aborda à teoria do RS. Nota-se ainda que existem aspectos que podem sermelhorados, como será colocado mais adiante.
O código RS foi descrito de acordo com a recomendação G.709, obtendo resultados satisfa-tórios, em relação ao hardware utilizado e também à frequência, que permitem a sua integraçãoa um possível sistema de redes de transporte óptico, operando em uma placa similar à ML630,por exemplo.
Em relaçao às dificuldades encontradas, podem ser citadas a carência de referências bibli-ográficas sobre o tema do trabalho, a abordagem limitada do assunto ao longo da graduação eainda, a complexidade matemática dos algoritmos. Assim, a grande maioria dos tópicos tiveramque ser investigados pelo aluno autor deste trabalho, enriquecendo o seu conhecimento, além doadquirido ao longo do curso. Outro ponto, agora relacionado à prática, refere-se à arquiteturadesenvolvida que não é capaz de detectar mais do que 8 erros. Acredita-se que para se ter essacapacidade, o bloco de Berlekamp-Massey deveria ser alterado para somente realizar detecçõesde erro, sem fornecer informações para a correção. Outra alternativa seria a utilização de umsegundo bloco de síndromes ao final da decodificação, que forneceria resultados nulos, para aocorrência de até 8 erros, ou não, para mais.
No entanto, a arquitetura atual desempenha a sua tarefa principal que é detectar e corrigiraté 8 símbolos errados. Como no caso do código RS(255, 239) cada símbolo corresponde a umbyte, chega-se uma capacidade de correção de até 64 bits de erros contínuos.
Além de todas essas percepções, observou-se a importância da análise dos resultados inter-mediários para o desenvolvimento de projetos, evitando a abordagem por tentativa e erro queé, na maioria dos casos, ineficaz. As simulações permitem a verificação dos resultados passoa passo, assim, tendo-se o funcionamento correto do sistema desenvolvido ao longo das mes-mas e ainda dos resultados da sintetizações, é possível afirmar, também, o bom desempenho docódigo quando implementado em hardware.
10.1 TRABALHOS FUTUROS
Analisando o próprio desenvolvimento, uma das possíveis melhorias é, principalmente, no

67
decodificador. Existem várias proposições de otimização do algoritmo de Berlekamp-Massey,como, por exemplo, a de cálculo do polinômio avaliador simultaneamente ao do localizador,reduzindo a latência do bloco. Além disso, há diversos outros algoritmos propostos para subs-tituir este, que podem ser avaliados para verificar se são mais efetivos ou adequados à algumaoutra aplicação específica que se deseje.
Agora, voltando-se para a continuidade do trabalho, observando os requisitos da recomen-dação G.709, percebe-se que é necessário replicar o código desenvolvido de acordo com aestrutura do bloco OTN e integrá-lo a um sistema. Assim, as questões de hardware utilizadotornam-se primordiais, juntamente coma frequência de operação máxima.
E por fim, os códigos devem ser implementados e testados em hardware, em conjunto como restante do sistema de aplicação em redes de transporte óptico. Dessa maneira, será possívelverificar a robustez do sistema com e sem a adição do controle de erros através de FEC.

68
REFERÊNCIAS
BLAHUT, R. E. Algebraic Codes for Data Transmission. Cambridge: Cambridge UniversityPress, 2003.
INTERNATIONAL TELECOMMUNICATION UNION. ITU-T G.709/Y.1331: transmissionsystems and media, digital systems and networks. Geneva, 2009.
JIANG, Y. A Pratical Guide to Error-Control Coding Using MATLAB R©. Norwood: ArtechHouse, 2010.
LAWS, B.; RUSHFORTH, K. A Cellular-Array Multiplier for GF(2m). IEEE Transactionson Computers, Vol. C-20, No 12, 1971.
LIN, S.; COSTELLO, D. J. Error Control Coding: Fundamentals and Applications. NewJersey: Pearson Prentice-Hall, 2004.
MASSEY, J.L. Shift-Register Synthesis and BCH Decoding. IEEE Transactions on Informa-tion Theory, Vol. IT-15, No 1, 1969.
MOON, K.T. Error Correction Coding: Mathematical Methods and Algorithms. New Jer-sey: John Wiley & Sons, 2005.
SKLAR, B. Digital Communications: Fundamentals and Applications. 2nd ed. New Jersey:Pearson Prentice-Hall, 2001.
WAI, K. C.; YANG, S. J. Field Programmable Gate Array Implementation of Reed-SolomonCode, RS(255,239).
WICKER, S. B.; BHARGAVA, V. K. Reed-Solomon Codes and their Applications. NewYork: IEEE Press, 1994.
XILINX, Inc. Virtex-6 HXT FPGA ML630 Evaluation Kit for OTN. Disponível em:<http://www.xilinx.com/products/boards-and-kits/EK-V6-ML630-G.htm>. Acesso em: 19 dez.2012.

69
ANEXO A
Rec. ITU-T G.709/Y.1331 (12/2009) 153
Annex A
Forward error correction using 16-byte interleaved RS(255,239) codecs
(This annex forms an integral part of this Recommendation)
The forward error correction for the OTU-k uses 16-byte interleaved codecs using a Reed-Solomon RS(255,239) code. The RS(255,239) code is a non-binary code (the FEC algorithm operates on byte symbols) and belongs to the family of systematic linear cyclic block codes.
For the FEC processing a OTU row is separated into 16 sub-rows using byte-interleaving as shown in Figure A.1. Each FEC encoder/decoder processes one of these sub-rows. The FEC parity check bytes are calculated over the information bytes 1 to 239 of each sub-row and transmitted in bytes 240 to 255 of the same sub-row.
G.709/Y.1331_FA.1
Information bytes
Information bytes OTU row
Information bytes
Information bytes Parity check bytes FEC sub-row #16
Parity check bytes FEC sub-row #2
Parity check bytes FEC sub-row #1
Parity check bytes
... 1 2 1 6
3 8 2 5
3 8 2 6
3 8 4 0
3 8 2 4
4 0 8 0
239
1 240
239
1 240
2 3 9
1 2 4 0
...
255
255
25
5
Figure A.1 − FEC sub-rows
The bytes in an OTU row belonging to FEC sub-row X are defined by: X + 16 × (i − 1) (for i = 1...255).
The generator polynomial of the code is given by:
15
0i
i )z(G(z)=
α−=
where α is a root of the binary primitive polynomial 12348 ++++ xxxx .
The FEC code word (see Figure A.2) consists of information bytes and parity bytes (FEC redundancy) and is represented by the polynomial:
R(z)I(z)C(z) +=

70
154 Rec. ITU-T G.709/Y.1331 (12/2009)
G.709/Y.1331_FA.2
FEC sub-row
Transmission order within FEC code word
D254
1 2 3 4 238 239 240 254 255
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8
D253 D252 D251 Dj D17 D16 R15 Rj R1 R0
d7j d6j d5j d4j d3j d2j d1j d0j r7j r6j r5j r4j r3j r2j r1j r0j
241
R14
Figure A.2 − FEC code word
Information bytes are represented by:
1616
253253
254254 .... . .)( zDzDzDzI +++=
Where Dj (j = 16 to 254) is the information byte represented by an element out of GF(256) and:
jjjjj ddddD 01
16
67
7 ... +α⋅++α⋅+α⋅=
Bit jd7 is the MSB and jd0 the LSB of the information byte.
254D corresponds to the byte 1 in the FEC sub-row and 16D to byte 239.
Parity bytes are represented by:
01
114
1415
15 ...)( RzRzRzRzR +⋅++⋅+⋅=
Where Rj (j = 0 to 15) is the parity byte represented by an element out of GF(256) and:
jjjjj rrrrR 01
16
67
7 ... +α⋅++α⋅+α⋅=
Bit jr7 is the MSB and jr0 the LSB of the parity byte.
15R corresponds to the byte 240 in the FEC sub-row and R0 to byte 255.
R(z) is calculated by:
( ) ( )mod ( )R z I z G z=
where "mod" is the modulo calculation over the code generator polynomial G(z) with elements out of the GF(256). Each element in GF(256) is defined by the binary primitive polynomial
12348 ++++ xxxx .
The Hamming distance of the RS(255,239) code is dmin = 17. The code can correct up to 8 symbol errors in the FEC code word when it is used for error correction. The FEC can detect up to 16 symbol errors in the FEC code word when it is used for error detection capability only.
Recommended

















