Embed Size (px)
DESCRIPTION
Abordagem criativa sobre o ecossistema hadoop No atual mundo captalista, M Bison, dono do maior e-commerce mundial chamado Shadaloo, decide analisar o perfil de todos os seus clientes; não apenas mostrando os dados comuns do BI, mas analisar também: - Dados de TODOS os sistemas Legados - Dados de Navegação - SAC e Midias Sociais. Dessa forma ele poderia: - Criar mecanismo de ofertas personalizadas - Retenção de clientes que realizam reclamações no SAC - Identificar relação de entre reclamações no SAC e mídias sociais. - Analisar fluxo de navegação e proporcionar navegação personalizada por tipo de clientes
Citation preview

1 Tel : +55.11.34.68.01.03 www.octo.com
Hadoop: Mãos à massa!!!
2014

2
Thiago Santiago
Arquiteto de software, formado em engenharia de software pela USP.
Trabalha atualmente na OCTO Technology liderando projetos em web performance e Big Data.
Apresentação:
\thiagosantiago25

3
Agenda
IntroduçãoHistórico Arquitetura da plataforma HDP 2.0SandBoxStingerScripts Hive/PigFerramentas de visualização de dados

4
A história de Ryu,
o Analista de Dados

5
No atual mundo captalista, M Bison, dono do maior e-commerce mundial chamado Shadaloo, decide analisar o perfil de todos os seus clientes; não apenas mostrando os dados comuns do BI, mas analisar também: - Dados de TODOS os sistemas Legados- Dados de Navegação- SAC e Midias Sociais.
Dessa forma ele poderia:• Criar mecanismo de ofertas personalizadas• Retenção de clientes que realizam reclamações no SAC• Identificar relação de entre reclamações no SAC e
mídias sociais.• Analisar fluxo de navegação e proporcionar navegação
personalizada por tipo de clientes

6
Pode deixar chefe!
Ryu, Você será o escolhido para
essa tarefa!

7
… então depois de muito apanhar tentando achar uma solução ao problema, decidiu pedir ajuda ao Mestre Dhalsin.
Mestre, como posso processar esse
volume gigante de dados em pouco
tempo?
Dá Hadoop Ryu!!!

8
Não será tão fácil assim, meu
jovem...

9
O que é Apache Hadoop?
O Hadoop é um framework open source desenvolvido em Java, para rodar aplicações, que manipulem uma grande quantidade de dados, em ambientes “clusterizados”.
Inspirado originalmente pelo GFS e MapReduce da Google
E assim começou a batalha de Ryu… sabendo da força que o hadoop tem, ele decidiu estudar a fundo essa nova técnica…
…E descobriu que:
10
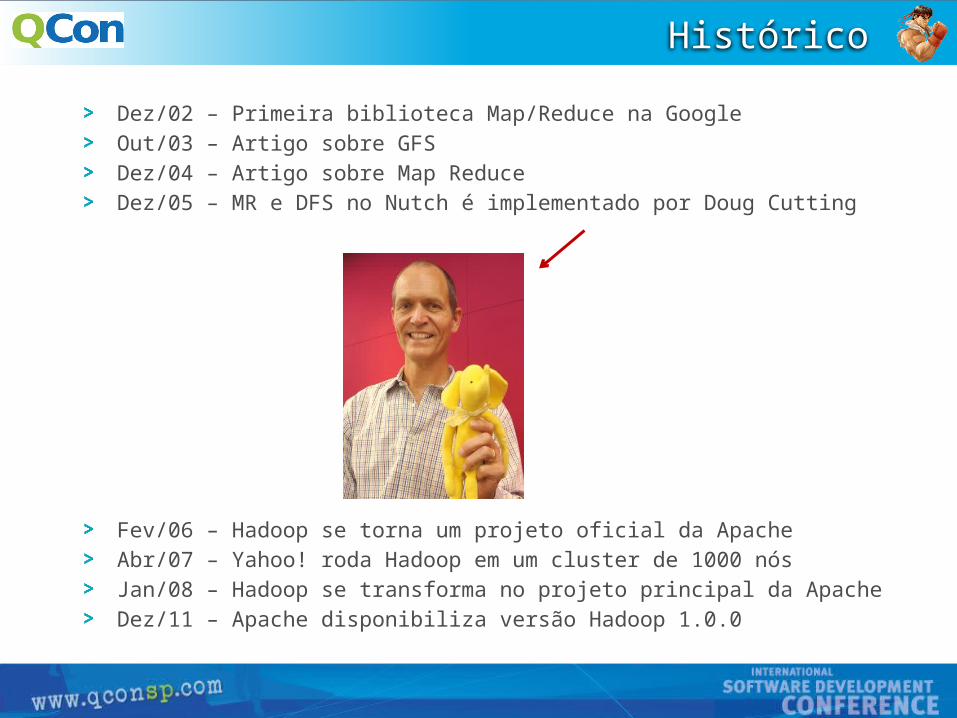
Histórico
Dez/02 – Primeira biblioteca Map/Reduce na Google
Out/03 – Artigo sobre GFS
Dez/04 – Artigo sobre Map Reduce
Dez/05 – MR e DFS no Nutch é implementado por Doug Cutting
Fev/06 – Hadoop se torna um projeto oficial da Apache
Abr/07 – Yahoo! roda Hadoop em um cluster de 1000 nós
Jan/08 – Hadoop se transforma no projeto principal da Apache
Dez/11 – Apache disponibiliza versão Hadoop 1.0.0

11
Principais Características do Hadoop
Escalável: ele pode armazenar e processar petabytes sem problemas;
Econômico: o Hadoop distribui os dados e o
processamento através dos clusters. Estes clusters
podem ter milhares de nós (máquinas);
Eficiente: Por distribuir os dados, o Hadoop pode
processar eles em paralelo por meio dos nós, onde os dados
estão alocados.
Confiável: ele automaticamente mantém múltiplas copias dos dados e remaneja as tarefas em caso de falhas.

12
Atualmente, Hortonworks, Cloudera e MapR são os principais distribuidores Hadoop (MapReduce, Hive, Sqoop, pig, etc) de forma mais integrada de acordo com a arquitetura de cada distribuição.
A amazon possui sua própria implementação Hadoop Chamada Elastic MapReduce (EMR)
Distribuições Hadoop

13
Composição do Apache Hadoop
Núcleo Hadoop:• Hadoop Common• HDFS• MapReduce

14
Composição do Apache Hadoop
1) Hadoop Common
Hadoop Common oculta o que os usuários comuns não precisam saber! Paralelização automática
Balanceamento de carga
Otimização nas transferências de disco e rede
Tratamento de falhas
Robustez
Escalabilidade

15
2) HDFS: Hadoop Distributed File System
Sistema de arquivos distribuídoGrande ordem de 10k nósMilhões de arquivos
Projetado para hardware de baixo custoRedundância por replicaçãoTolerância a falhas e recuperação
Otimizado para processamento em loteLocalização dos dados expostaGrande largura de banda associada
Coerência dos dadosModelo “write-once-ready-many”Arquivos existentes sofrem apenas operações de “append”
Arquivos quebrados em pedaços (blocos)Variam de 64mb (padrão) a 256mbBlocos distribuídos pelos nós (um arquivo é dividido em N blocos e armazenado em M nós)Blocos são replicados e as replicações distribuídas

16
3) MapReduce
O modelo inicial proposto pelo Google apresentou alguns conceitos para facilitar alguns problemas
Paralelização da computação em um aglomerado de máquinas comuns
Centenas/Milhares de CPUs
Paralelização e distribuição automática da computação deveria ser o mais simples possível
O sistema de execução se encarrega de:
Particionar e distribuir os dados de entrada
Escalonar as execuções em um conjunto de máquinas
Tratar as falhas
Comunicação entre as máquinas

17
MapReduce no Hadoop
A função Map atua sobre um conjunto de entrada com chaves e valores, produzindo uma lista de chaves e valores
A função Reduce atua sobre os valores intermediários produzidos pelo Map para, normalmente, agrupar os valores e produzir a saída

18
MapReduce - Arquitetura
Name Node
• Data Location
21
Client MapReduce
ResourceManager
ApplicationManager
Data node3
4
5
Data node
Data node
Reduce
Output
Reduce Reduce
Map MapMap
Shuffle & sort
ApplicationMaster
Task TaskTask
6

19
Storage API
Distributed FSGlusterFS
HDFSS3
IsilonMapRFS
Local FS
NoSQL basedCassandraDynamoDB
CephRing
Openstack Swift
MapReduce/TezYARN
Spark Streaming
TransacionalConsultas Analíticas
ETLComputação Científica Indexação
Interativo Batch
HBase Cassandra
Spark Impala Presto Hawg Drill
Cascading Pig Hive Talend Solr
Giraph HAMA Mahout Python R
sklearn nltk panda RHadoop
SAS
Uso
sF
erra
men
tas
Com
umS
iste
mas
de
Arm
azen
amen
to
Import/exportCLI
SqoopFlumeStorm
ETL (Talend, Pentaho)
Oozie
ElasticSearch
Ecossistema Hadoop
API MR Java
Upload
HCatalog
Dis
trib
uiçã
o

20
Hadoop na nuvem

21
Sandbox é um projeto Hortonworks, que torna o Hadoop portátil, permitindo rodar o hadoop em seu computador pessoal de forma simples e ágil.
Sandbox possui fins educacionais, facilitando a curva de aprendizagem no Hortonworks Hadoop.
Pré-requisitos: Ambiente de virtualização (Preferencialmente VirtualBox)
Hortonworks Sandbox
22
HDP 2.0
Hortonworks Data Platform 2.0 leva Hadoop de uma plataforma de dados de processamento em lote, para uma plataforma multi-uso que permite processamentos em lote, interativo, online e por fluxo.

23
Passo 1 : baixar Sandbox for VirtualBoxhttp://hortonworks.com/products/hortonworks-sandbox/#install
Sandbox: Instalação
24
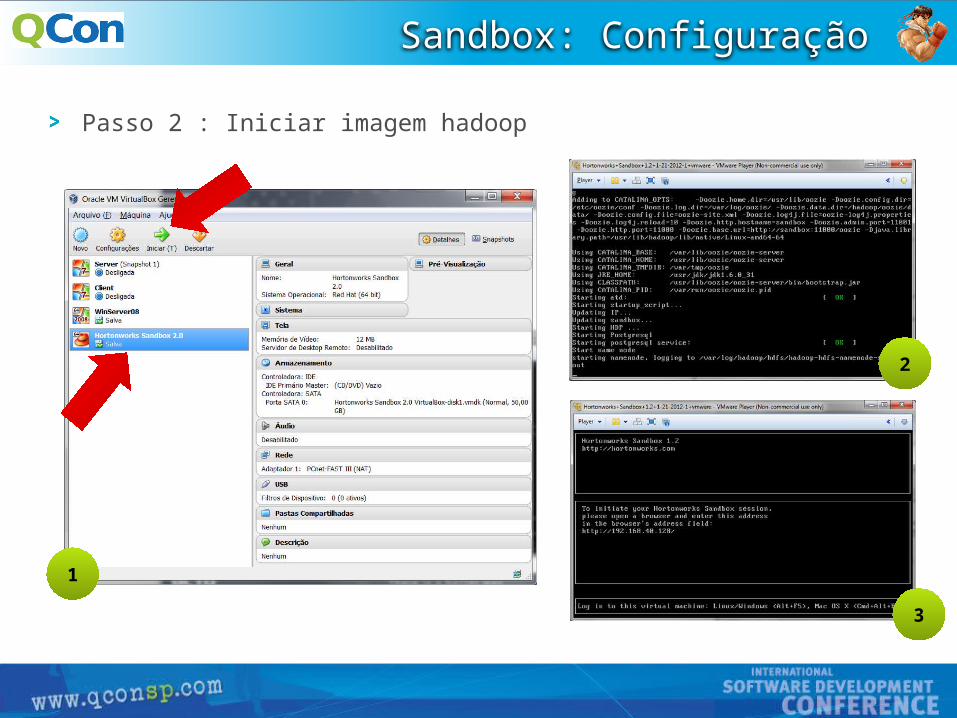
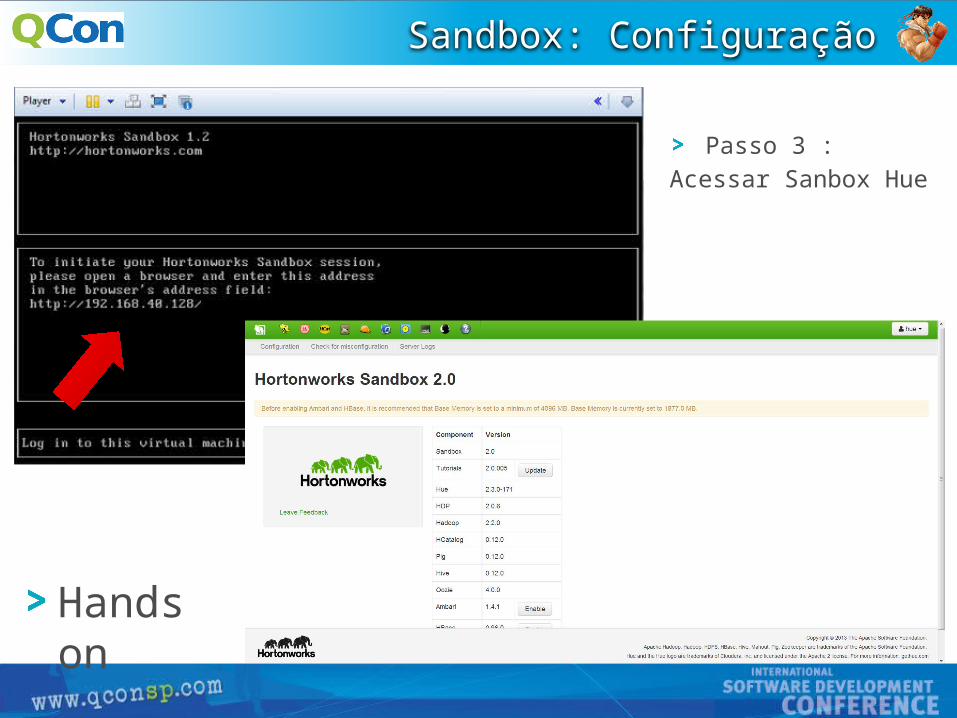
Passo 2 : Iniciar imagem hadoop
Sandbox: Configuração
1
2
3
25
Passo 3 : Acessar Sanbox Hue
Sandbox: Configuração
Hands on
26
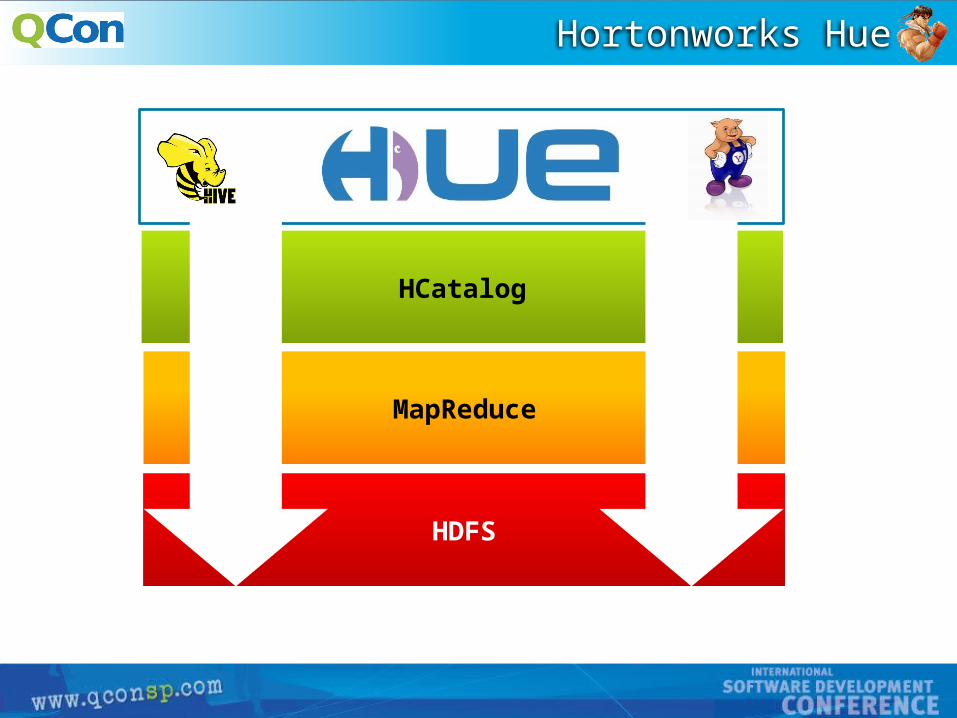
Hortonworks Hue
HCatalog
HDFS
MapReduce
27
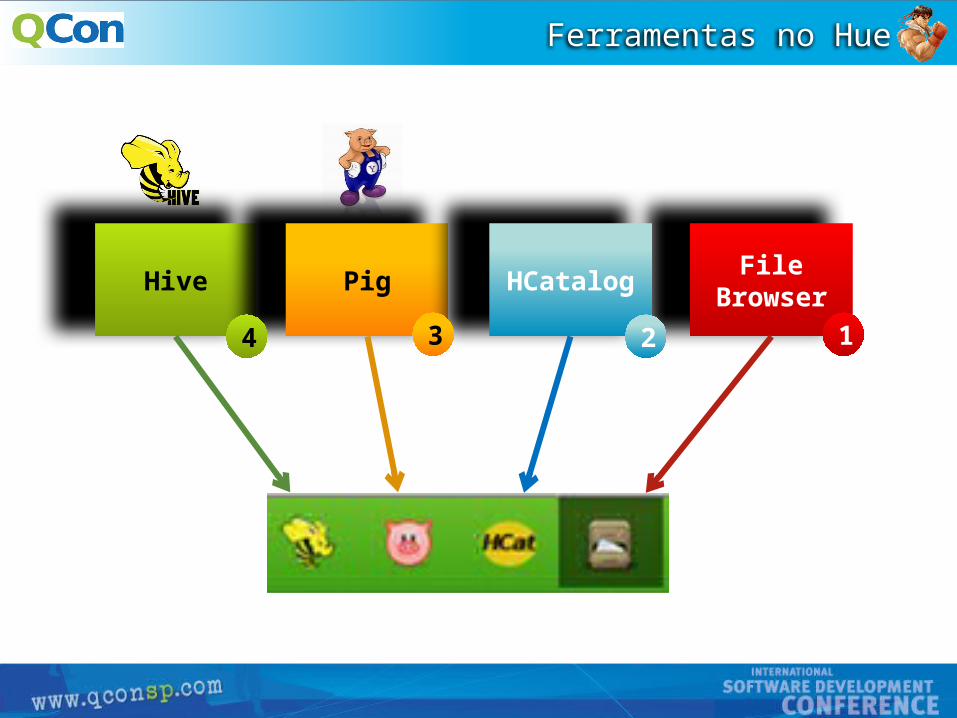
Ferramentas no Hue
Hive PigFile
BrowserHCatalog
1234
28
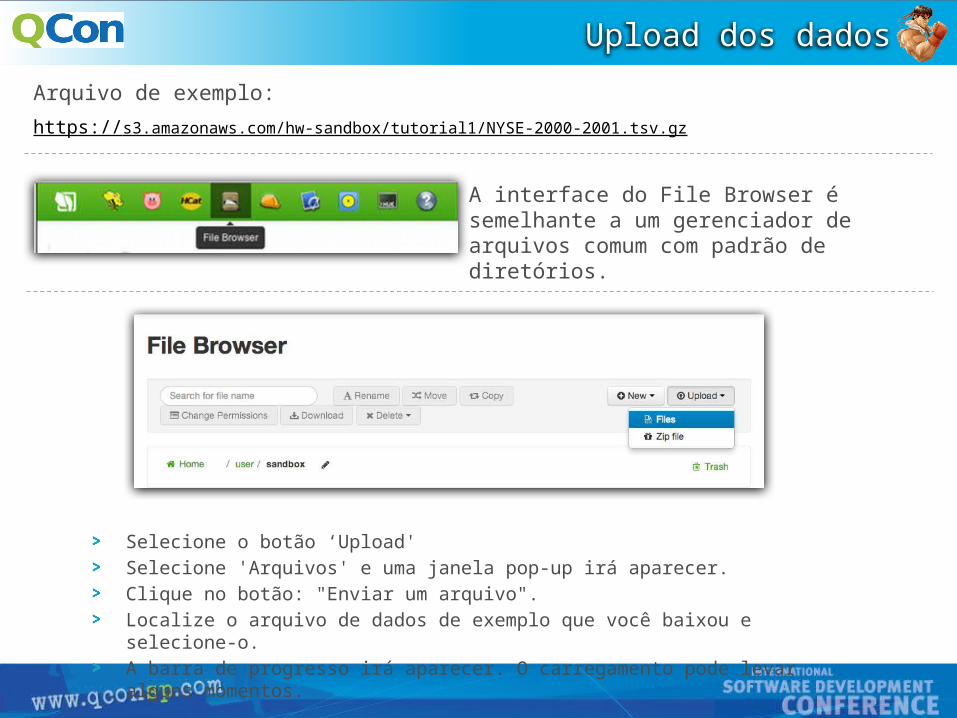
Upload dos dados
https://s3.amazonaws.com/hw-sandbox/tutorial1/NYSE-2000-2001.tsv.gz
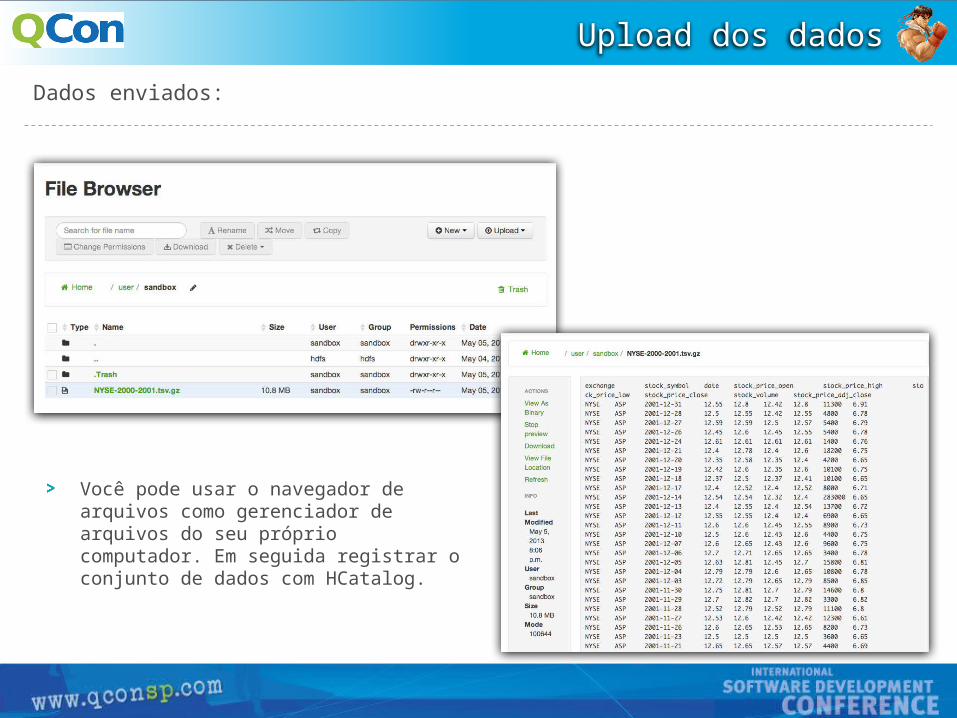
A interface do File Browser é semelhante a um gerenciador de arquivos comum com padrão de diretórios.
Arquivo de exemplo:
Selecione o botão ‘Upload'Selecione 'Arquivos' e uma janela pop-up irá aparecer.Clique no botão: "Enviar um arquivo".Localize o arquivo de dados de exemplo que você baixou e selecione-o.A barra de progresso irá aparecer. O carregamento pode levar alguns momentos.
29
Upload dos dados
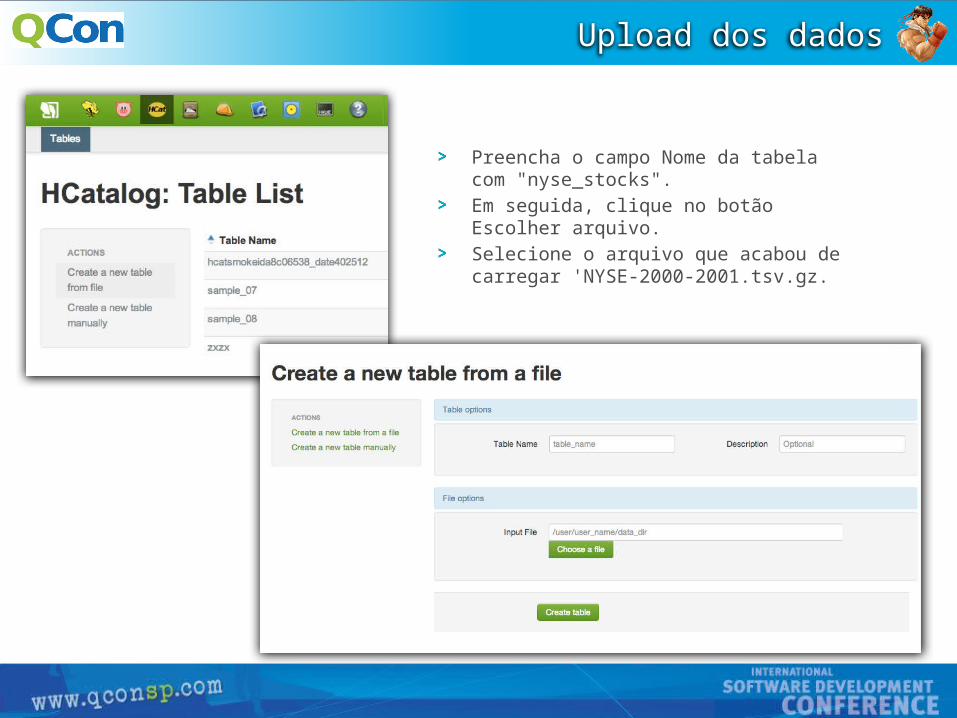
Dados enviados:
Você pode usar o navegador de arquivos como gerenciador de arquivos do seu próprio computador. Em seguida registrar o conjunto de dados com HCatalog.
30
Upload dos dados
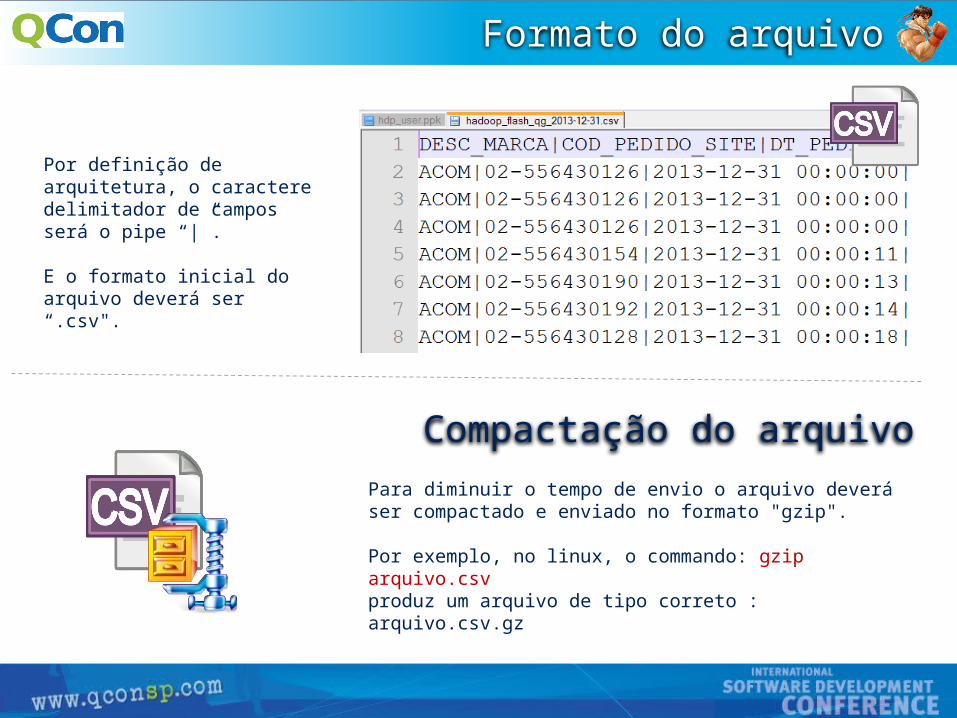
Preencha o campo Nome da tabela com "nyse_stocks". Em seguida, clique no botão Escolher arquivo. Selecione o arquivo que acabou de carregar 'NYSE-2000-2001.tsv.gz.

31
Upload dos dados
Na visualização da tabela você pode definir todos os campos e tipos de dados para a tabela.
Quando tudo estiver concluído, clique no botão "Create Table" na parte inferior.
Hands on
32
Formato do arquivo
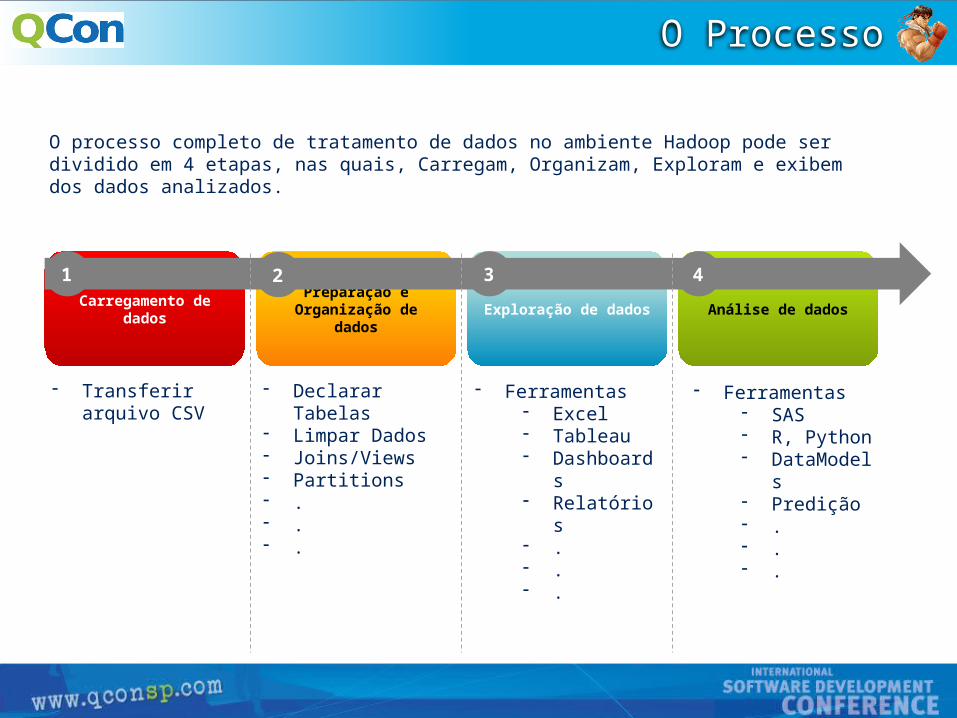
Para diminuir o tempo de envio o arquivo deverá ser compactado e enviado no formato "gzip".
Por exemplo, no linux, o commando: gzip arquivo.csv produz um arquivo de tipo correto : arquivo.csv.gz
Por definição de arquitetura, o caractere delimitador de campos será o pipe “|”.
E o formato inicial do arquivo deverá ser “.csv".
Compactação do arquivo
33
O Processo
Carregamento de dadosPreparação e
Organização de dadosExploração de dados Análise de dados
O processo completo de tratamento de dados no ambiente Hadoop pode ser dividido em 4 etapas, nas quais, Carregam, Organizam, Exploram e exibem dos dados analizados.
- Transferir arquivo CSV
- Declarar Tabelas- Limpar Dados- Joins/Views- Partitions- .- .- .
- Ferramentas- Excel- Tableau- Dashboards- Relatórios- .- .- .
- Ferramentas- SAS- R, Python- DataModels- Predição - .- .- .
1 2 3 4

34
Edge Node
Mapa - Fluxo de dados
SFTP
Remoção de cabeçalhoCompactação de dados
-Orc/SeqFile-Gzip/Snappy
PartitionsBuckets/Sampling
script
External Table
HDFS
Managed Table
Data
35
O que o Stinger?http://hortonworks.com/labs/stinger/
A Iniciativa Stinger é um projeto opensource para conduzir o futuro do Apache Hive, entregando 100x mais desempenho em escala, com execução Hive sobre o Apache Tez e semântica de SQL like.

36
O Hive e o PIG oferecem linguagens de processamento de dados de alto nível com suporte para tipos de dados complexos para a operação em conjuntos de dados grandes.
A linguagem do Hive é uma variante do SQL e, portanto, é mais acessível para pessoas já familiarizadas com SQL e bancos de dados relacionais.
O Hive tem suporte para tabelas particionadas que permitem que os fluxos de trabalho extraiam somente a partição da tabela relevante para a consulta sendo executada, em vez de realizar uma digitalização completa da tabela.
Hive X Pig
Em uma análise, a escolha pelo uso do Hive ou PIG dependerá dos requisitos exatos do domínio do aplicativo e das preferências dos implementadores e daqueles que gravam consultas.

37
Scripts Hive X Pig
SELECT * FROM Tabela WHERE Campo = “ABC”;
SELECT a.* FROM a JOIN b
ON (a.id = b.id)
SELECT MARCA, sum(vl_pedido) Valor_PedidosFROM `default.tb_orders`Group by MARCAORDER by Valor_Pedidos DESC
A = LOAD 'tabela' USING org.apache.hcatalog.pig.HCatLoader();B = LIMIT A 100; C = FILTER B BY campo1 == 'Teste';D = FOREACH C GENERATE symbol, date, close; E = DISTINCT D;F = GROUP E BY (campo1, campo2);G = ORDER F BY (campo1, campo2);H = JOIN G BY campo1, F BY campo1;DUMP C;
A = LOAD 'default.tb_orders' USING org.apache.hcatalog.pig.HCatLoader();B = GROUP A BY marca;X = FOREACH B GENERATE group, SUM(A.vl_pedido);DUMP X;
38
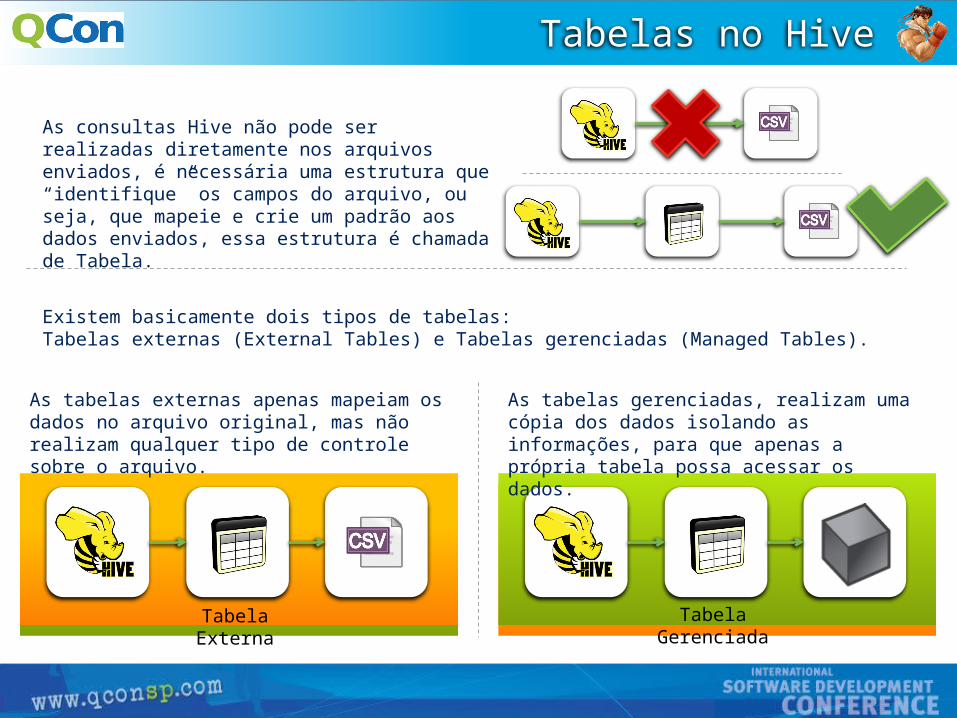
Tabelas no Hive
As consultas Hive não pode ser realizadas diretamente nos arquivos enviados, é necessária uma estrutura que “identifique” os campos do arquivo, ou seja, que mapeie e crie um padrão aos dados enviados, essa estrutura é chamada de Tabela.
Existem basicamente dois tipos de tabelas: Tabelas externas (External Tables) e Tabelas gerenciadas (Managed Tables).
Tabela GerenciadaTabela Externa
As tabelas externas apenas mapeiam os dados no arquivo original, mas não realizam qualquer tipo de controle sobre o arquivo.
As tabelas gerenciadas, realizam uma cópia dos dados isolando as informações, para que apenas a própria tabela possa acessar os dados.

39
Tabelas no Hive
Tabela GerenciadaTabela Externa
40
Tabelas externas
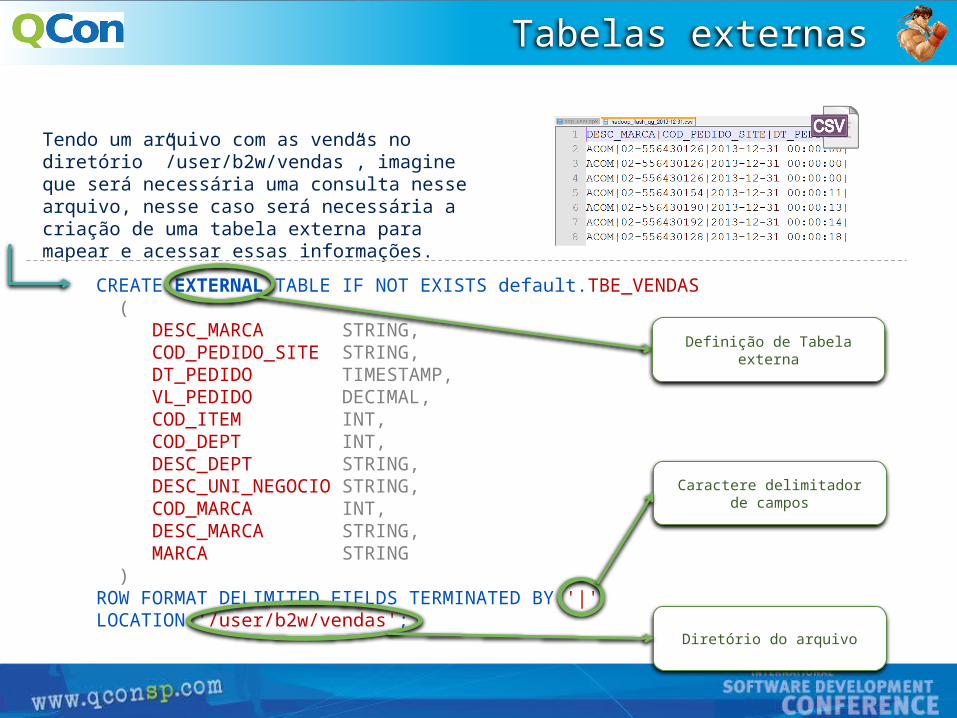
CREATE EXTERNAL TABLE IF NOT EXISTS default.TBE_VENDAS ( DESC_MARCA STRING, COD_PEDIDO_SITE STRING, DT_PEDIDO TIMESTAMP, VL_PEDIDO DECIMAL, COD_ITEM INT, COD_DEPT INT, DESC_DEPT STRING, DESC_UNI_NEGOCIO STRING, COD_MARCA INT, DESC_MARCA STRING, MARCA STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'LOCATION '/user/b2w/vendas';
Tendo um arquivo com as vendas no diretório ”/user/b2w/vendas”, imagine que será necessária uma consulta nesse arquivo, nesse caso será necessária a criação de uma tabela externa para mapear e acessar essas informações.
Definição de Tabela externa
Diretório do arquivo
Caractere delimitador de campos
41
Tabelas Gerenciadas
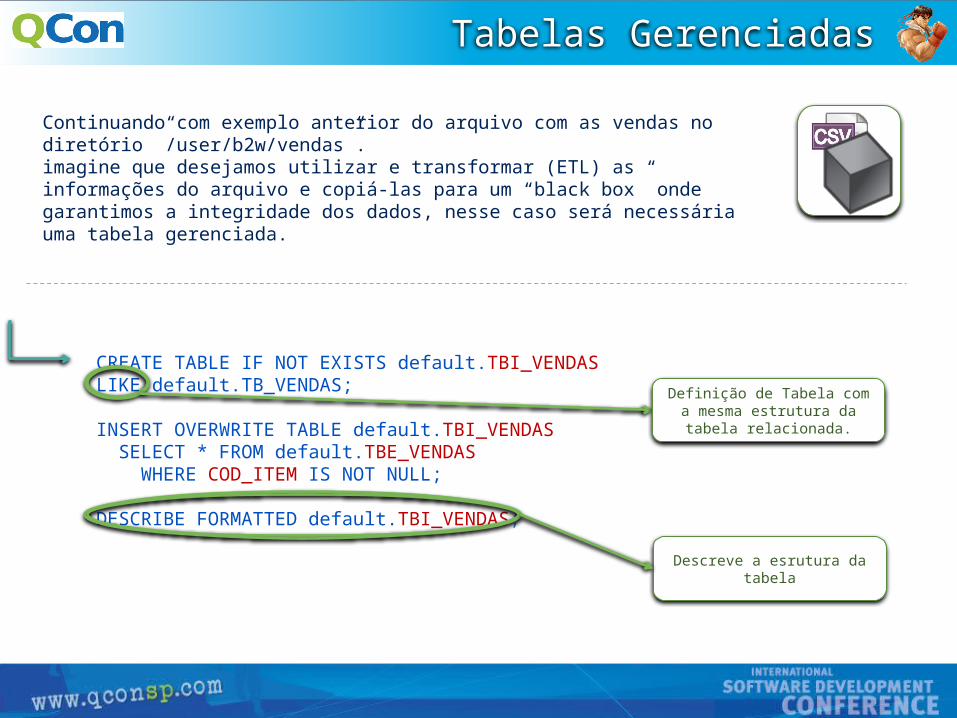
CREATE TABLE IF NOT EXISTS default.TBI_VENDAS LIKE default.TB_VENDAS;
INSERT OVERWRITE TABLE default.TBI_VENDAS SELECT * FROM default.TBE_VENDAS WHERE COD_ITEM IS NOT NULL;
DESCRIBE FORMATTED default.TBI_VENDAS;
Continuando com exemplo anterior do arquivo com as vendas no diretório ”/user/b2w/vendas”.imagine que desejamos utilizar e transformar (ETL) as informações do arquivo e copiá-las para um “black box” onde garantimos a integridade dos dados, nesse caso será necessária uma tabela gerenciada.
Definição de Tabela com a mesma estrutura da tabela
relacionada.
Descreve a esrutura da tabela
42
Hands on
Hands on
43
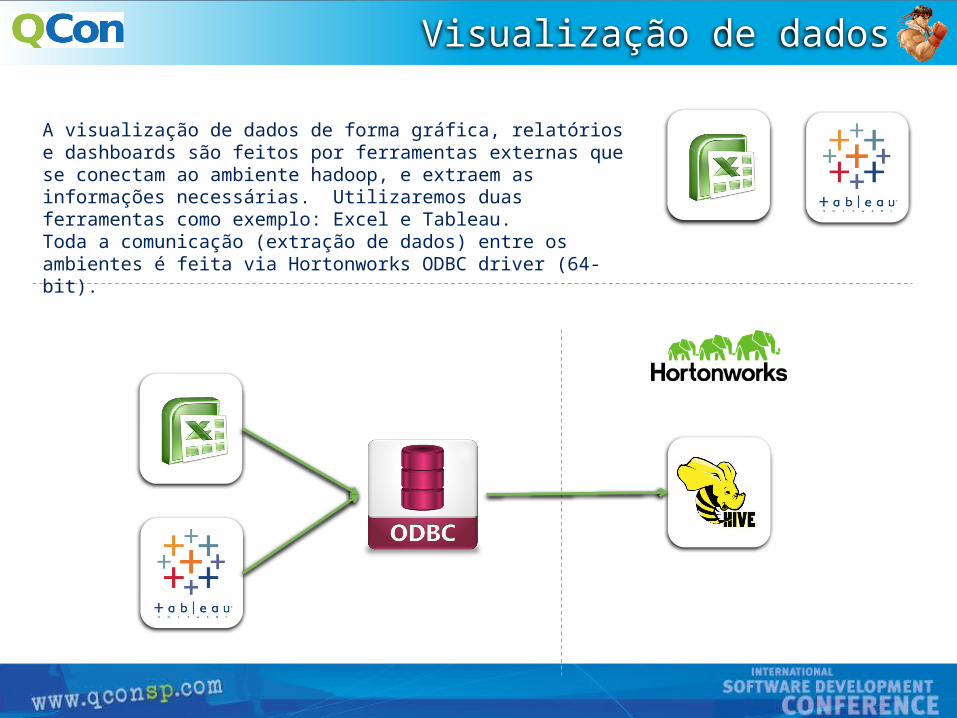
Visualização de dados
A visualização de dados de forma gráfica, relatórios e dashboards são feitos por ferramentas externas que se conectam ao ambiente hadoop, e extraem as informações necessárias. Utilizaremos duas ferramentas como exemplo: Excel e Tableau.Toda a comunicação (extração de dados) entre os ambientes é feita via Hortonworks ODBC driver (64-bit).
44
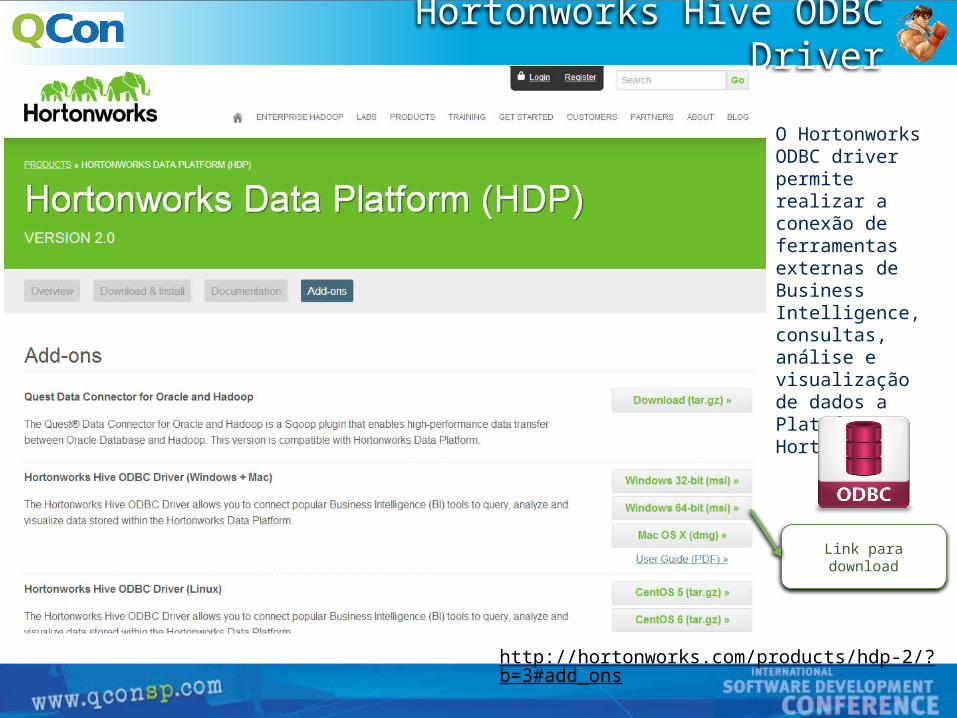
Hortonworks Hive ODBC Driver
http://hortonworks.com/products/hdp-2/?b=3#add_ons
O Hortonworks ODBC driver permite realizar a conexão de ferramentas externas de Business Intelligence, consultas, análise e visualização de dados a Plataforma Hortonworks.
Link para download
45
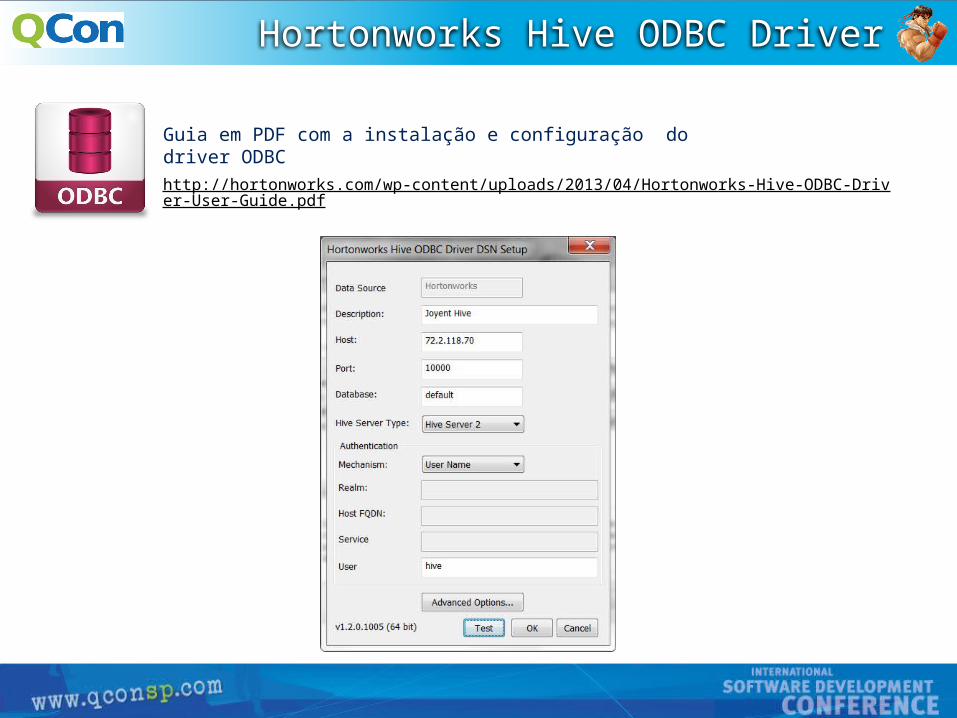
Hortonworks Hive ODBC Driver
Guia em PDF com a instalação e configuração do driver ODBC
http://hortonworks.com/wp-content/uploads/2013/04/Hortonworks-Hive-ODBC-Driver-User-Guide.pdf

46
Visualização de dados Excel
Uma vez que o Seu driver ODBC esteja configurado, Pode-se utilizar o Excel para acessar dados no Hive:
http://hortonworks.com/hadoop-tutorial/how-to-use-excel-2013-to-access-hadoop-data/http://hortonworks.com/hadoop-tutorial/how-use-excel-2013-to-analyze-hadoop-data/
12
3
4
47
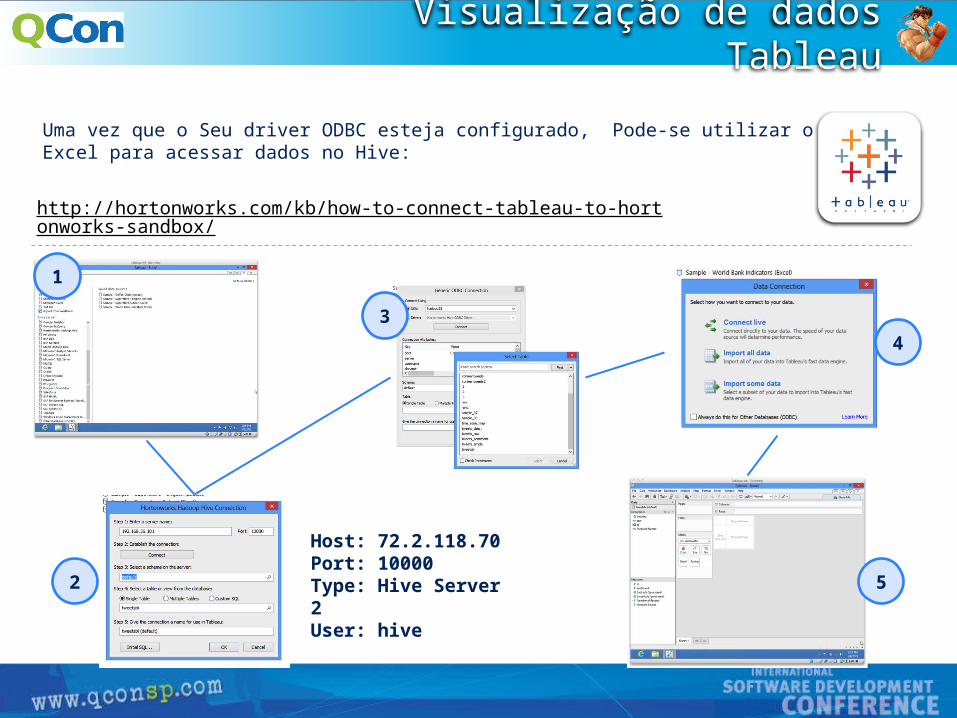
Visualização de dados Tableau
Uma vez que o Seu driver ODBC esteja configurado, Pode-se utilizar o Excel para acessar dados no Hive:
http://hortonworks.com/kb/how-to-connect-tableau-to-hortonworks-sandbox/
1
2
3
4
5
Host: 72.2.118.70Port: 10000Type: Hive Server 2User: hive

48
Ferramentas de visualização
49
You Win... Perfect!
Chefe, estamos prontos para iniciar
nossas análises usando Hadoop 2.0
Parabéns Ryu, You Win!

50
There is a way…