Embed Size (px)
Citation preview

Algoritmo Genético para a Tomada de Decisão de Particionamento de Processos Lógicos em
Simulação Distribuída
S. M. Bruschi e R. F. D. Mello
Resumo — Este artigo descreve um método para
particionamento de modelos em processos lógicos no contexto de simulação distribuída. O método proposto utiliza algoritmos genéticos para decidir sobre a viabilidade e a técnica de particionamento mais indicada. Os parâmetros de entrada do algoritmo genético são informações referentes ao modelo (número de elementos, comunicação e taxas de chegada e serviço) e à arquitetura onde a simulação é executada. Como resultado, tem-se o número de processos lógicos a serem utilizados e também o mapeamento desses processos na arquitetura. Dois modelos ilustram a validade do método proposto.
Palavras-chave — simulação distribuída, otimização, algoritmos genéticos.
I. INTRODUÇÃO O conceito de Simulação Distribuída foi desenvolvido
visando a redução do tempo de execução de simulações. Fujimoto [11] distingue duas áreas: simulação analítica e ambientes virtuais. A simulação analítica é utilizada quando se deseja avaliar o desempenho de sistemas. Nesse caso, as seguintes métricas são adotadas: tempo médio de resposta, número médio de clientes no sistema, número médio de clientes em espera por serviços, tempo médio de fila, etc. De maneira inversa, os ambientes virtuais são voltados à interação com usuários, visando a análise de comportamento do sistema através de ações e reações. Nesse tipo de simulação, duas abordagens podem ser utilizadas: SRIP (Single Replication in Parallel) e MRIP (Multiple Replication in Parallel). A abordagem SRIP é baseada na decomposição do modelo de simulação em processos lógicos, os quais são executados em diferentes processadores. Esses processos comunicam-se através de trocas de mensagens. Um problema que ocorre na abordagem SRIP é a sincronização de vários processos. Os protocolos que têm sido desenvolvidos podem ser agrupados em três categorias: conservadores, otimistas e mistos [11].
A principal característica dos protocolos conservadores é que um evento será executado somente quando for seguro, isto
Manuscript received September 11, 2006; revised May 02, 2007. Os autores agradecem o suporte da Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – CAPES – processo número 032506-6. S. M. Bruschi e R. F. de Mello são professores do Instituto de Ciências Matemáticas e de Computação da Universidade de São Paulo, São Carlos, SP, Brasil – e-mail: {sarita,mello}@icmc.usp.br
é, não existe a possibilidade de ocorrência de erros de causa e efeito. Enquanto essa condição não é satisfeita, o processo permanece bloqueado, tornando possível a ocorrência de deadlock e perda de desempenho. As implementações dos protocolos conservadores diferem pela maneira pela qual eles tratam os deadlocks. Alguns protocolos previnem sua ocorrência e outros promovem uma recuperação após a mesma. O protocolo CMB (Chandy, Misra and Bryant) [7], [6] previne o deadlock através de mensagens nulas.
Os protocolos otimistas não impedem erros de causa e efeito, permitindo que todos os eventos sejam processados. Mecanismos de detecção e recuperação são implementados para evitar possíveis erros no fluxo de execução da simulação, mantendo um estado consistente. Esse protocolo tem a vantagem de explorar todo o paralelismo implícito no modelo, onde os protocolos conservadores são impedidos de progredir [11]. O protocolo Time Warp é a implementação mais tradicional dos protocolos otimistas e é baseado no paradigma de tempo virtual, proposto por Jefferson [15].
As duas classes de protocolos têm suas vantagens e desvantagens. A escolha entre elas não é simples e depende das características das aplicações e da arquitetura a ser utilizada para a realização da simulação.
Na abordagem MRIP, o modelo não é decomposto. Várias instâncias independentes do mesmo programa de simulação seqüencial são replicadas em paralelo e diferentes sementes de geração de números aleatórios são utilizadas nas replicações. Cada instância envia seus resultados parciais para um analisador global, obedecendo a um nível de confiança estatístico definido pelo usuário. O analisador global avalia as soluções e, quando a precisão exigida pelo usuário é atingida, a simulação é encerrada [9]. Ao contrário da abordagem SRIP, a abordagem MRIP pode ser facilmente utilizada, independente da existência de paralelismo no modelo. Entretanto, existem algumas situações nas quais a abordagem MRIP é inapropriada, tais como: uma única instância não pode ser executada em um único processador e quando os resultados são quase determinísticos [12].
Apesar de esse método parecer simples, alguns cuidados devem ser tomados com relação ao número de processadores (número de replicações), ao tamanho de cada instância e ao tamanho do período de warmup, no qual algumas observações devem ser eliminadas [12]. As abordagens SRIP e MRIP não são mutuamente exclusivas, isto é, é possível tê-las no mesmo
IEEE LATIN AMERICA TRANSACTIONS, VOL. 6, NO. 1, MARCH 2008 97

programa de simulação. Bruschi et al. [4] propuseram um ambiente automático para
simulação distribuída denominado ASDA (Ambiente de Simulação Distribuída Automático), com o objetivo de auxiliar usuários a modelar e simular sistemas. Esse ambiente utiliza a teoria de rede de filas na fase de modelagem e permite a geração de programas que utilizem uma das abordagens descritas anteriormente. Uma característica desse ambiente é o auxílio à tomada de decisões que envolve o processo de desenvolvimento de uma simulação, como, por exemplo, decidir entre a utilização das abordagens SRIP ou MRIP.
Um método para auxiliar nessa decisão, utilizando algoritmos genéticos, é proposto neste artigo. Este método mapeia o modelo do sistema (como, por exemplo, centros de serviço, conexões e comunicações entre eles) em computadores nos quais a simulação distribuída será executada, considerando suas capacidades de processamento e comunicação. Utilizando algoritmos genéticos, pode-se prover soluções para o particionamento e distribuição dos centros de serviço (representados por processos lógicos) nos computadores.
Este artigo contém as seguintes seções: II) trabalhos relacionados; III) algoritmos genéticos; IV) uma visão geral do ASDA; V) algoritmo genético proposto para o particionamento; VI) experimentos e VII) conclusões.
II. TRABALHOS RELACIONADOS As pesquisas direcionadas à etapa de particionamento de
modelos objetivam principalmente reduzir o tempo de execução de simulações, uma vez que um particionamento não realizado de maneira correta pode fazer com que a simulação demore muito tempo para ser executada [16], [3], [18], [2], [20].
Nandy e Loucks [16] apresentam uma solução orientada a simulações que utilizam protocolos conservadores. Esse trabalho é baseado na aplicação de heurísicas, definidas em [10], à simulação distribuída com protocolo CMB. O objetivo principal é minimizar o overhead de comunicação e otimizar a distribuição da carga de trabalho sobre elementos de processamento.
Uma representação por grafos é utilizada para fazer o particionamento. No primeiro estágio de execução, uma partição aleatória é gerada, a qual é continuamente refinada até que seja atingido o balanceamento de carga. Os autores obtiveram uma redução no tempo de simulação de 25%, apesar de serem necessárias execuções preliminares para coletar informações sobre o padrão de comunicação entre os processos. Essa técnica é limitada pelo tamanho do modelo. Quanto maior o modelo, mais alto é o tempo consumido para definir o padrão de comunicação.
Boukerche e Tropper [3] apresentam outra solução utilizando simulated annealing. Essa técnica introduz uma alta energia ao sistema (qualquer problema a ser otimizado) e a diminui gradativamente até atingir uma solução que satisfaça uma condição prévia. Nesse caso, a condição é o
balanceamento de carga e a diminuição da comunicação. Os autores obtiveram uma redução no tempo de simulação de 35%.
Boukerche e Das [2] propõem um algoritmo de balanceamento de carga que faz migração de processos em simulações distribuídas que utilizam protocolo conservador. Esse trabalho visa reduzir o delay de comunicação e o tempo de execução de simulações e avaliar o desempenho do algoritmo considerando diferentes cargas de trabalho em sistemas com memória distribuída compartilhada. Os autores detectaram um gargalo nas operações para obter informações de processos, o que motivou um algoritmo de balanceamento com dois níveis.
Subramaniam et al. [18] apresentam uma solução para simulações que utilizam o protocolo otimista baseado no Time Warp. Esse trabalho visa balancear a carga, maximizar a concorrência e reduzir a comunicação entre os processos em projetos VHDL. A solução executa em tempo linear um conjunto de heurísticas de particionamento. As heurísticas dividem o circuito lógico (representado como um grafo) em subgrafos, de acordo com a comunicação entre os nós. Após isso, tenta-se balancear a carga, distribuindo igualmente os nós e preservando a concorrência.
Xu e Ammar [20] propuseram um framework e uma metodologia para particionamento de simulação de redes de computadores. Os autores propuseram um benchmark para coletar informações sobre a topologia da rede e o desempenho dos recursos disponíveis a fim de otimizar o balanceamento de carga e minimizar a comunicação imposta pelos modelos. A metodologia utiliza essas informações para criar um grafo no qual são aplicados pesos e técnicas de particionamento. Os autores comparam a solução com outros trabalhos e concluem que houve uma melhora no tempo.
III. ALGORITMOS GENÉTICOS Algoritmos genéticos (AG) têm sido aplicados como
métodos de busca e otimização em vários domínios [17]. Esses algoritmos são baseados nos mecanismos de seleção natural visando a sobrevivência do indivíduo mais apto. Algoritmos genéticos não garantem a obtenção da melhor solução possível, contudo, permitem obter boas soluções para problemas NP-completos.
A resolução de problemas por meio de AG envolve dois aspectos: codificação da solução em cromossomos e uma função de aptidão (fitness). Cada cromossomo representa uma tentativa de solução, no espaço de soluções possíveis.
Nessa tentativa de solucionar problemas, técnicas de codificação podem usar cadeias de bits, base binária, números reais, etc. A função de aptidão é responsável por avaliar as possíveis soluções para o problema. Essa função toma como entrada um cromossomo e devolve um número real, informando a qualidade da solução obtida.
Os cromossomos (indivíduos) mais aptos são identificados e armazenados durante o processo de evolução. Os mais fracos, por outro lado, são excluídos. Vários métodos podem ser aplicados nessa escolha, entre eles, a seleção proporcional,
98 IEEE LATIN AMERICA TRANSACTIONS, VOL. 6, NO. 1, MARCH 2008

a seleção por ranking e a seleção por torneio [1]. Na seleção proporcional, indivíduos são transladados para
a próxima geração de acordo com probabilidades proporcionais ao seu valor de função de aptidão. Uma maneira de implementar tal método é através de uma roleta, a qual é dividida em N partes, N correspondendo ao número de indivíduos da população. O tamanho de cada uma das partes é proporcional à função de aptidão do indivíduo. A roleta é então girada N vezes, a cada giro o indivíduo indicado pelo ponteiro é selecionado e inserido na nova população.
A seleção por ranking pode ser dividida em duas etapas. Na primeira, as soluções são ordenadas de acordo com seus valores da função de aptidão. Uma vez ordenada a lista, cada indivíduo recebe um novo valor da função de aptidão equivalente à sua posição no ranking. Na segunda, aplica-se um procedimento que selecciona os indivíduos de acordo com sua posição no ranking, ou seja, quanto melhor a posição, maior a chance de ser selecionado.
A seleção por torneio não atribui explicitamente probabilidades aos indivíduos. Estipula-se um tamanho (k) para o torneio, onde k ≥ 2 indivíduos. Os k indivíduos são escolhidos aleatoriamente a partir da população atual, e suas funções de aptidão, comparadas. O indivíduo com maior valor de aptidão é selecionado para reprodução. O valor de k é definido pelo usuário. Quanto maior o valor de k, maior a pressão seletiva, ou seja, maior a velocidade com que os indivíduos mais fortes dominam a população, causando a extinção dos mais fracos.
Uma vez selecionados os indivíduos para reprodução, necessita-se de técnicas para modificação das características genéticas dos seus descendentes. Tais técnicas são conhecidas como operadores genéticos e os dois mais utilizados são o crossover e a mutação.
O operador de crossover permite a troca de material genético entre dois indivíduos denominados pais, combinando informações de maneira que exista uma probabilidade razoável de os novos indivíduos serem melhores que seus pais [14].
O operador de crossover de um ponto é o mais utilizado. Para a aplicação desse operador, são selecionados dois indivíduos (pais) e a partir de seus cromossomos são gerados dois novos indivíduos (filhos). Para gerar os filhos, seleciona-se um mesmo ponto de corte aleatoriamente nos cromossomos dos pais, e os segmentos de cromossomo criados a partir do ponto de corte são combinados.
A mutação tem como objetivo substituir o valor de um gene por outro aleatório. No caso de o indivíduo ser representado por uma cadeia de bits, ela consiste em escolher, aleatoriamente, um gene do cromossomo e inverter seu valor de 1 para 0 ou vice-versa. O propósito da mutação é manter a diversidade da população e assegurar que o cromossomo sempre cobrirá uma parte suficientemente grande do espaço de busca [14]. Ela é normalmente aplicada em baixas freqüências, pois freqüências muito altas implicariam busca aleatória.
IV. ASDA O ASDA (Ambiente de Simulação Distribuída Automático)
tem por objetivo auxiliar usuários a transcrever modelos em programas de simulação distribuída, tornando disponível um ambiente automático onde as simulações possam ser desenvolvidas de uma maneira fácil e rápida. Detalhes de simulação, tais como comunicação e sincronização, são escondidos dos usuários [5]. Usuários que utilizam esse tipo de ambiente podem ter vários níveis de conhecimento, incluindo dois extremos: conhecimentos avançados e superficiais de simulação e computação paralela. O ASDA satisfaz os seguintes requisitos:
1) Oferecer ao usuário um ambiente de fácil aprendizagem e utilização;
2) Possibilitar a geração completa de um problema de simulação para um usuário menos experiente;
3) Oferecer flexibilidade necessária para que um usuário mais experiente possa modificar os programas gerados;
4) Possibilitar a utilização de simulações seqüenciais previamente desenvolvidas;
5) Oferecer diretrizes para que o usuário possa escolher entre diferentes abordagens para simulação distribuída. Se o usuário preferir, o ambiente deve ser capaz de selecionar a abordagem mais adequada;
6) Facilitar a obtenção de dados confiáveis através da avaliação estatística de resultados gerados pela simulação;
7) Minimizar o tempo de execução da simulação, oferecendo um escalonamento eficiente de processos.
O ASDA [5] é composto por sete módulos: Interface com o Usuário, Gerador, Interface de Software, Avaliador, Replicador, Executor e Escalonador, como pode ser observado na Fig. 1. Com o objetivo de manter a flexibilidade para os usuários mais experientes e ainda oferecer facilidades para os menos experientes, o ASDA apresenta, através do módulo de Interface com o Usuário, uma interface amigável, na qual se pode especificar um novo modelo, utilizar um programa de simulação desenvolvido ou definir variáveis de ambiente.
Se a opção do usuário for pela definição de um novo modelo, será necessário especificá-lo através do submódulo Especificação Gráfica. Quando a especificação gráfica estiver pronta, o código do programa de simulação poderá ser gerado através do módulo Girador e as replicações poderão ser submetidas ao módulo Replicador (caso a opção seja pela abordagem MRIP) ou para o módulo Executor (caso a opção seja pela abordagem SRIP). Essas possibilidades atendem os requisitos 1, 2 e 3 apresentados anteriormente. Se a opção escolhida for a utilização de um programa de simulação existente, o módulo de Interface de Software será ativado, inserindo no código funções necessárias para replicar o programa, utilizando a abordagem MRIP. Todos os programas são iniciados através do módulo Executor, o qual é responsável pela comunicação com o módulo Escalonador. Essas características atendem os requisitos 4 e 7. O módulo Avaliador tem uma função importante auxiliando o usuário em todo o processo de desenvolvimento da simulação, atendendo
MAZZINI BRUSCHI AND FERNANDES DE MELLO : LOGICAL PROCESS PARTITIONING 99

o requisito 5.
Desenvolvimentode uma nova
simulação
Utilizar umprograma desimulação já
pronto
EspecificaçãoGráfica
MRIP
Gerenciadorreplicações
Escalonamento
Interface como usuário
Geração docódigo
SRIP
MóduloGerador
Módulode Interface
com o usuário
Interfaces desoftware
Módulode Interfacede software
MóduloEscalonamento
MóduloReplicador
Nível 1
Nível 2
Nível 3
MóduloAvaliador
Definição dasvariáveis do
ambiente
ASDA - Ambiente de Simulação Distribuída Automático
TW CMB
1
2
Gerenciadorexecuções
MóduloExecutor
CMB ⇒TW
Fig. 1. Diagrama Modular do ASDA.
A. Módulo Avaliador O módulo do ASDA abordado neste artigo é o Avaliador
responsável por auxiliar usuários em duas etapas: na especificação do modelo e na escolha da abordagem de simulação distribuída a ser utilizada. Esse módulo é dividido em três níveis: 1) valida a especificação do modelo definido pelo usuário; 2) ajuda usuários a decidirem entre as abordagens SRIP, MRIP ou SRIP/MRIP; e 3) se a escolha foi pela abordagem SRIP, esse nível auxilia na escolha pelo protocolo de sincronização mais adequado.
Para realizar essas três tarefas, o módulo Avaliador utiliza diversos parâmetros que permitem decidir sobre a abordagem que poderá resultar no melhor desempenho para a simulação distribuída, isto é, a abordagem que resultará no menor tempo de execução do programa. Este artigo considera o segundo nível e adota os seguintes parâmetros (baseado no trabalho de [13]): plataforma paralela/distribuída onde a simulação será executada, número de processadores e granulosidade do modelo.
Antes da análise do terceiro nível, é importante decompor o modelo em processos lógicos. Para esse estágio, pode-se aplicar o método proposto na próxima seção, baseado na representação por grafos utilizada pelo ASDA.
V. PARTICIONAMENTO DE MODELO PARA SIMULAÇÃO DISTRIBUÍDA
O ASDA utiliza a teoria de rede de filas para representação de modelos. Esses modelos são convertidos em grafos, sendo que cada grafo contém informações sobre os centros de serviço (tais como tempo médio de serviço e chegada) e a probabilidade de comunicação com outros centros. Essas informações são utilizadas para construir um arquivo de configuração para o módulo avaliador. Esse arquivo é
composto por 4 blocos: a taxa de chegada, detalhes sobre os centros de serviço, comunicação entre eles e características dos computadores nos quais a simulação será executada (capacidade de processamento e latência de comunicação). A Fig. 2 apresenta uma representação de um modelo, sua representação por grafo e um arquivo de configuração.
Fig. 2. Modelo do sistema, grafo e arquivo de configuração.
Um algoritmo genético foi desenvolvido para avaliar as
escolhas de particionamento dos centros de serviço em processos lógicos. Centros de serviço alocados em um mesmo computador compõem um processo lógico. Para obter a solução, o algoritmo genético considera indivíduos
}g,...,g,g{ 110 −= nc compostos por n genes. Cada índice dos genes representa um centro de serviço e seu valor, o computador em que este será alocado. Após avaliação, o AG realiza crossover e mutações nos indivíduos, os quais irão compor uma nova população a ser avaliada. Esse processo se repete por um número de gerações especificado pelo usuário. A função de fitness pode ser observada na equação 1.
c
c
i i Lc
xxcf +
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
−
−=
−
=∑1
12
1)(
)( (1)
A latência da comunicação entre os centros de serviço alocados de acordo com o indivíduo c é definida pela equação 2, onde: é o valor de um gene individual de índice k, que representa onde (em qual computador) o centro de serviço será alocado; e é o custo de comunicação de um gene i para
j. Se os genes têm o mesmo valor, eles são alocados no mesmo computador, portanto, o custo de comunicação é nulo, caso contrário, esse é calculado segundo a equação 3, onde
é o número médio de mensagens transmitidas por
segundo do centro de serviço f para t; é a matriz que
contém a porcentagem de comunicação entre os centros de serviço; é o tamanho médio da mensagem; é o tamanho canônico da mensagem; e é o custo de
transmissão entre computadores nos quais os centros de serviço f e t serão executados.
cL
kc
jiCC ,
tfMPS →
tfCM ,
MS CStfRTT ,
∑ ∑= ≠≠=
=c
i
c
ccjijjic
ji
CCL1 ,,1
, (2)
100 IEEE LATIN AMERICA TRANSACTIONS, VOL. 6, NO. 1, MARCH 2008
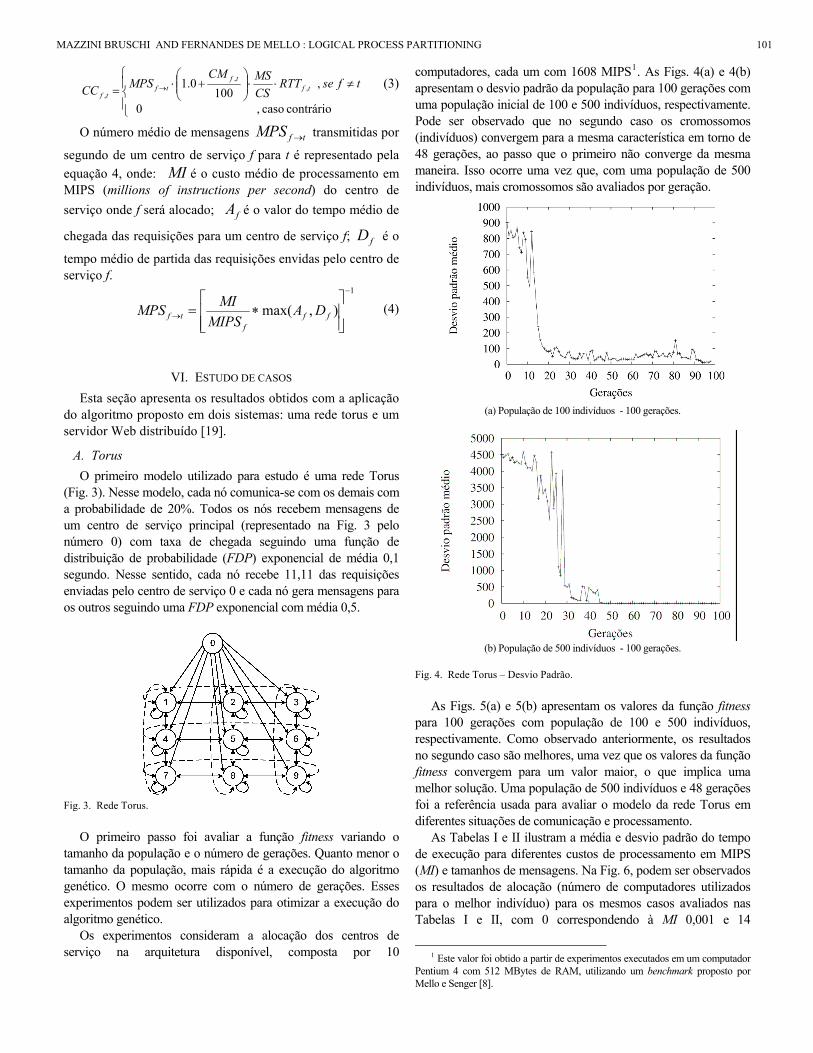
⎪⎩
⎪⎨⎧
≠⋅⋅⎟⎟⎠
⎞⎜⎜⎝
⎛+⋅= →
contrário caso , 0
, 100
0.1 ,,
,tfseRTT
CSMSCM
MPSCC tftf
tftf
(3)
O número médio de mensagens transmitidas por
segundo de um centro de serviço f para t é representado pela equação 4, onde:
tfMPS →
MI é o custo médio de processamento em MIPS (millions of instructions per second) do centro de serviço onde f será alocado; é o valor do tempo médio de
chegada das requisições para um centro de serviço f; é o
tempo médio de partida das requisições envidas pelo centro de serviço f.
fA
fD
1
),max(−
→⎥⎥⎦
⎤
⎢⎢⎣
⎡∗= ff
ftf DA
MIPSMIMPS (4)
VI. ESTUDO DE CASOS Esta seção apresenta os resultados obtidos com a aplicação
do algoritmo proposto em dois sistemas: uma rede torus e um servidor Web distribuído [19].
A. Torus O primeiro modelo utilizado para estudo é uma rede Torus
(Fig. 3). Nesse modelo, cada nó comunica-se com os demais com a probabilidade de 20%. Todos os nós recebem mensagens de um centro de serviço principal (representado na Fig. 3 pelo número 0) com taxa de chegada seguindo uma função de distribuição de probabilidade (FDP) exponencial de média 0,1 segundo. Nesse sentido, cada nó recebe 11,11 das requisições enviadas pelo centro de serviço 0 e cada nó gera mensagens para os outros seguindo uma FDP exponencial com média 0,5.
Fig. 3. Rede Torus.
O primeiro passo foi avaliar a função fitness variando o
tamanho da população e o número de gerações. Quanto menor o tamanho da população, mais rápida é a execução do algoritmo genético. O mesmo ocorre com o número de gerações. Esses experimentos podem ser utilizados para otimizar a execução do algoritmo genético.
Os experimentos consideram a alocação dos centros de serviço na arquitetura disponível, composta por 10
computadores, cada um com 1608 MIPS1. As Figs. 4(a) e 4(b) apresentam o desvio padrão da população para 100 gerações com uma população inicial de 100 e 500 indivíduos, respectivamente. Pode ser observado que no segundo caso os cromossomos (indivíduos) convergem para a mesma característica em torno de 48 gerações, ao passo que o primeiro não converge da mesma maneira. Isso ocorre uma vez que, com uma população de 500 indivíduos, mais cromossomos são avaliados por geração.
(a) População de 100 indivíduos - 100 gerações.
(b) População de 500 indivíduos - 100 gerações.
Fig. 4. Rede Torus – Desvio Padrão.
As Figs. 5(a) e 5(b) apresentam os valores da função fitness
para 100 gerações com população de 100 e 500 indivíduos, respectivamente. Como observado anteriormente, os resultados no segundo caso são melhores, uma vez que os valores da função fitness convergem para um valor maior, o que implica uma melhor solução. Uma população de 500 indivíduos e 48 gerações foi a referência usada para avaliar o modelo da rede Torus em diferentes situações de comunicação e processamento.
As Tabelas I e II ilustram a média e desvio padrão do tempo de execução para diferentes custos de processamento em MIPS (MI) e tamanhos de mensagens. Na Fig. 6, podem ser observados os resultados de alocação (número de computadores utilizados para o melhor indivíduo) para os mesmos casos avaliados nas Tabelas I e II, com 0 correspondendo à MI 0,001 e 14
1 Este valor foi obtido a partir de experimentos executados em um computador
Pentium 4 com 512 MBytes de RAM, utilizando um benchmark proposto por Mello e Senger [8].
MAZZINI BRUSCHI AND FERNANDES DE MELLO : LOGICAL PROCESS PARTITIONING 101
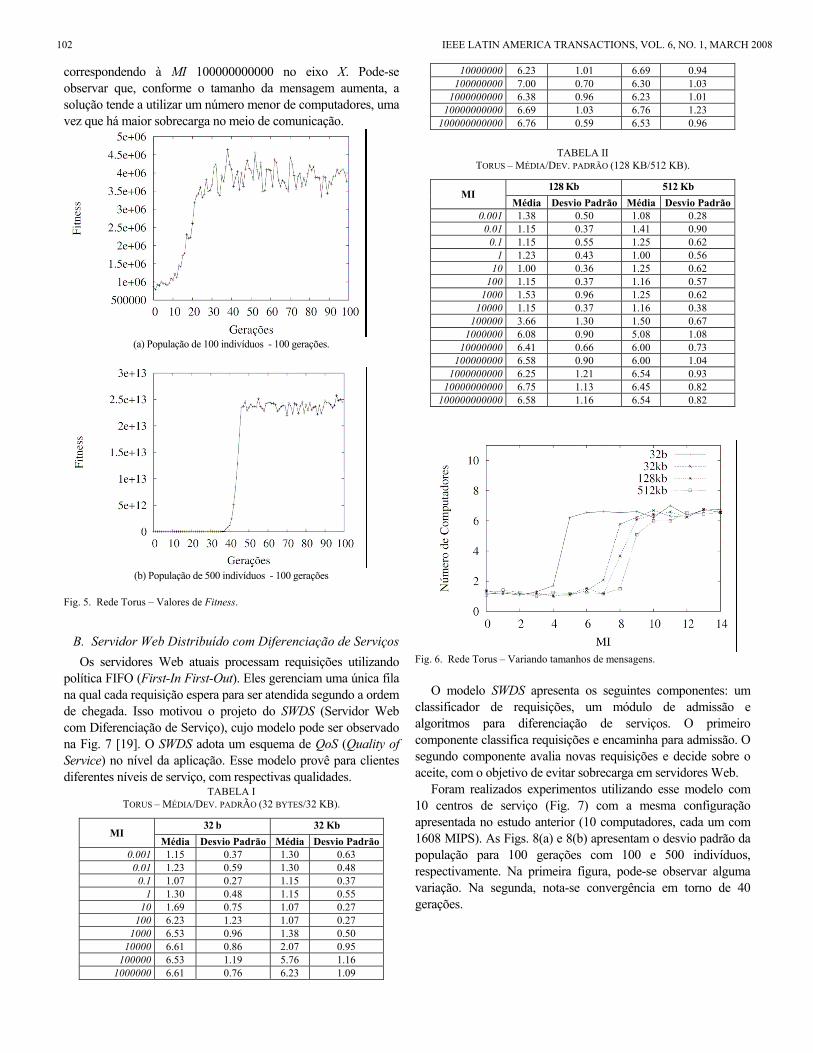
correspondendo à MI 100000000000 no eixo X. Pode-se observar que, conforme o tamanho da mensagem aumenta, a solução tende a utilizar um número menor de computadores, uma vez que há maior sobrecarga no meio de comunicação.
(a) População de 100 indivíduos - 100 gerações.
(b) População de 500 indivíduos - 100 gerações
Fig. 5. Rede Torus – Valores de Fitness.
B. Servidor Web Distribuído com Diferenciação de Serviços Os servidores Web atuais processam requisições utilizando
política FIFO (First-In First-Out). Eles gerenciam uma única fila na qual cada requisição espera para ser atendida segundo a ordem de chegada. Isso motivou o projeto do SWDS (Servidor Web com Diferenciação de Serviço), cujo modelo pode ser observado na Fig. 7 [19]. O SWDS adota um esquema de QoS (Quality of Service) no nível da aplicação. Esse modelo provê para clientes diferentes níveis de serviço, com respectivas qualidades.
TABELA I TORUS – MÉDIA/DEV. PADRÃO (32 BYTES/32 KB).
32 b 32 Kb MI
Média Desvio Padrão Média Desvio Padrão0.001 1.15 0.37 1.30 0.63
0.01 1.23 0.59 1.30 0.48 0.1 1.07 0.27 1.15 0.37
1 1.30 0.48 1.15 0.55 10 1.69 0.75 1.07 0.27
100 6.23 1.23 1.07 0.27 1000 6.53 0.96 1.38 0.50
10000 6.61 0.86 2.07 0.95 100000 6.53 1.19 5.76 1.16
1000000 6.61 0.76 6.23 1.09
10000000 6.23 1.01 6.69 0.94 100000000 7.00 0.70 6.30 1.03
1000000000 6.38 0.96 6.23 1.01 10000000000 6.69 1.03 6.76 1.23
100000000000 6.76 0.59 6.53 0.96
TABELA II TORUS – MÉDIA/DEV. PADRÃO (128 KB/512 KB).
128 Kb 512 Kb MI
Média Desvio Padrão Média Desvio Padrão0.001 1.38 0.50 1.08 0.28
0.01 1.15 0.37 1.41 0.90 0.1 1.15 0.55 1.25 0.62
1 1.23 0.43 1.00 0.56 10 1.00 0.36 1.25 0.62
100 1.15 0.37 1.16 0.57 1000 1.53 0.96 1.25 0.62
10000 1.15 0.37 1.16 0.38 100000 3.66 1.30 1.50 0.67
1000000 6.08 0.90 5.08 1.08 10000000 6.41 0.66 6.00 0.73
100000000 6.58 0.90 6.00 1.04 1000000000 6.25 1.21 6.54 0.93
10000000000 6.75 1.13 6.45 0.82 100000000000 6.58 1.16 6.54 0.82
Fig. 6. Rede Torus – Variando tamanhos de mensagens.
O modelo SWDS apresenta os seguintes componentes: um
classificador de requisições, um módulo de admissão e algoritmos para diferenciação de serviços. O primeiro componente classifica requisições e encaminha para admissão. O segundo componente avalia novas requisições e decide sobre o aceite, com o objetivo de evitar sobrecarga em servidores Web.
Foram realizados experimentos utilizando esse modelo com 10 centros de serviço (Fig. 7) com a mesma configuração apresentada no estudo anterior (10 computadores, cada um com 1608 MIPS). As Figs. 8(a) e 8(b) apresentam o desvio padrão da população para 100 gerações com 100 e 500 indivíduos, respectivamente. Na primeira figura, pode-se observar alguma variação. Na segunda, nota-se convergência em torno de 40 gerações.
102 IEEE LATIN AMERICA TRANSACTIONS, VOL. 6, NO. 1, MARCH 2008

Fig. 7. Modelo SWDS.
(a) População de 100 indivíduos - 100 gerações.
(b) População de 500 indivíduos - 100 gerações.
Fig. 8. Modelo SWDS – Desvio Padrão.
As Figs. 9(a) e 9(b) apresentam os valores de fitness obtidos
para 100 gerações com um tamanho de população de 100 e 500 indivíduos, respectivamente. Os resultados do segundo experimento foram melhores, pois o fitness convergiu para o valor mais alto. O tamanho de população de 500 indivíduos por 40 gerações foi adotado para avaliar o modelo SWDS sob diferentes condições de carga e comunicação. As Tabelas III e IV apresentam médias e desvios padrão do tempo de execução para diferentes custos de processamento em MIPS (MI) e tamanhos de mensagem. A Fig. 10 apresenta os resultados de alocação (número de computadores utilizados pelo melhor indivíduo) para os mesmos valores apresentados nas Tabelas III e IV. Como observado no experimento anterior da rede Torus, quando o tamanho de mensagem aumenta, a solução tende a usar um menor número de computadores, pois a sobrecarga na rede minimiza os benefícios do balanceamento de carga.
VII. CONCLUSÕES Este artigo apresentou um método para o particionamento
de modelos de simulação com o objetivo de distribuir e minimizar a comunicação entre processos lógicos.
A solução produzida pelo método indica o número e quais computadores devem ser utilizados para simulação distribuída.
Para isso, é adotada a capacidade de processamento e latência de comunicação. Caso a solução produzida não recomende nenhum particionamento, deve-se considerar a abordagem MRIP, caso contrário, SRIP. MRIP é indicado quando o tamanho e o custo de processamento do modelo forem muito pequenos.
(a) População de 100 indivíduos - 100 gerações.
(b) População de 500 indivíduos - 100 gerações.
Fig. 9. Modelo SWDS – Valores de Fitness.
TABELA III
SWDS – MÉDIA/DEV. PADRÃO (32 BYTES/32 KB).
32 b 32 Kb MI
Média Desvio Padrão Média Desvio Padrão0.001 1.54 0.68 1.72 1.00
0.01 1.54 0.68 1.45 0.52 0.1 1.63 0.50 1.45 0.68
1 1.81 0.98 1.45 0.68 10 2.63 1.36 1.18 0.40
100 5.45 0.82 1.54 0.52 1000 5.90 0.94 1.72 0.78
MAZZINI BRUSCHI AND FERNANDES DE MELLO : LOGICAL PROCESS PARTITIONING 103

10000 6.27 0.90 2.90 0.94 100000 6.63 0.90 6.00 1.00
1000000 6.45 1.03 6.18 0.75 10000000 6.36 1.28 6.36 0.92
100000000 6.27 0.90 6.45 0.93 1000000000 6.90 0.70 6.00 1.09
10000000000 6.72 0.90 6.27 0.90 100000000000 6.63 0.80 6.72 1.19
TABELA IV
SWDS– MÉDIA/DEV. PADRÃO (128 KB/512 KB).
128 Kb 512 Kb MI
Média Desvio Padrão Média Desvio Padrão0.001 1.45 0.93 1.40 0.51
0.01 1.54 0.82 1.20 0.42 0.1 1.09 0.30 1.60 0.69
1 2.00 1.09 1.70 0.82 10 1.45 0.52 1.30 0.67
100 1.63 0.50 1.60 0.51 1000 1.72 0.90 1.60 0.84
10000 1.81 0.75 1.20 0.42 100000 4.09 1.13 2.40 0.96
1000000 6.00 0.89 5.20 0.91 10000000 6.45 1.21 5.90 1.19
100000000 6.18 0.60 5.60 0.84 1000000000 6.63 0.92 6.40 0.96
10000000000 6.72 0.78 6.70 1.05 100000000000 6.54 0.82 6.70 0.67
Fig. 10. Modelo SWDS – Variando tamanhos de mensagens.
REFERÊNCIAS [1] Thomas Back, David B. Fogel, and Zbigniew Michalewicz, editors.
Advanced Algorithms and Operators. IOP Publishing Ltd., Bristol, UK, 1999.
[2] Azzedine Boukerche and Sajal K. Das. Reducing null messages overhead through load balancing in conservative distributed simulation systems. J. Parallel Distributed Computer, 64(3):330–344, 2004.
[3] Azzedine Boukerche and Carl Tropper. A static partitioning and mapping algorithm for conservative parallel simulations. In PADS ’94: Proceedings of the eighth workshop on Parallel and distributed simulation, pages 164–172, New York, NY, USA, 1994. ACM Press.
[4] S. M. Bruschi, R. H. C. Santana, M. J. Santana, and T. S. Aiza. Asda. In Proceedings of Winter Simulation Conference (WSC04), pages 378–385. Washington - DC, December 2004.
[5] Sarita M. Bruschi. Um Ambiente de Simulação Distribuída Automático. PhD thesis, Instituto de Ciências Matemáticas e Computação, São Carlos - SP, 2002.
[6] R. E. Bryant. Simulation of packet communication architecture computer systems. Technical report, Massachusetts Institute of Technology, Cambridge, MA, USA, 1977.
[7] K. M. Chandy and J. Misra. Distributed simulation. IEEE Transactions on Software Engineering, 5(5):440–452, 1979.
[8] R. F. de Mello and L. J. Senger. Model for simulation of heterogeneous high-performance computing environments. In 7th International Meeting High Performance Computing for Computational Science – VECPAR 2006, pages 1–13, July 2006.
[9] G. C. Ewing, D. McNickle, and L. Pawlikowski. Multiple replications in parallel: Distributed generation of data for speeding up quantitative stochastic simulation. In Proceedings of the 15th Congress of Int. Association for Mathemathics and Computer in Simulation, pages 397–402, 1997. Wissenschaft und Technik Verlag, Berlin.
[10] C. M. Fiduccia and R. M. Mattheyses. A linear-time heuristic for improving network partitions. In Proceedings of 19th Design Automation Conference, pages 175–181, Las Vegas, 1982. ACM/IEEE.
[11] Richard M. Fujimoto. Parallel and Distributed Simulation Systems. John Wiley Computer, 2000.
[12] P. W. Glynn and P. Heidelberger. Analysis of initial transient deletion for parallel steady-state simulations. SIAM J. Sci. Stat. Comput, 13(4):904– 922, 1992.
[13] P. Heidelberger. Statistical analysis of parallel simulations. In Proceeding of 1986 Winter Simulation Conference, pages 290–295, 1986. California – USA.
[14] Robert Hinterding. Representation, mutation and crossover issues in evolutionary computation. In Proc. of the 2000 Congress on Evolutionary Computation, pages 916–923, Piscataway, NJ, 2000. IEEE Service Center.
[15] D. R. Jefferson. Virtual time. ACM Transactions on Programming Languages and Systems, 7(3):404–425, 1985.
[16] Biswajit Nandy and Wayne M. Loucks. On a parallel partitioning technique for use with conservative parallel simulation. In PADS ’93: Proceedings of the seventh workshop on Parallel and distributed simulation, pages 43–51, New York, NY, USA, 1993. ACM Press.
[17] Mikhail A. Semenov and Dmitri A. Terkel. Analysis of convergence of an evolutionary algorithm with self-adaptation using a stochastic lyapunov function. Evol. Comput., 11(4):363–379, 2003.
[18] Swaminathan Subramanian, Dhananjai M. Rao, and Philip A. Wilsey. Study of a multilevel approach to partitioning for parallel logic simulation. In IPDPS: Proceedings of the 14th International Symposium on Parallel and Distributed Processing, page 833, Washington, DC, USA, 2000. IEEE Computer Society.
[19] Mário Antonio Meirelles Teixeira, Marcos José Santana, and Regina Helena Carlucci Santana. Using adaptive priority scheduling for service differentiation in QoS-aware web servers. In Proceedings of the IEEE International Performance, Computing and Communications Conference. Workshop on End-to-End Service Differentiation (IPCCC - EESD), Phoenix, Arizona, 2004. IEEE Computer Society.
[20] Donghua Xu and Mostafa Ammar. Benchmap: Benchmark-based, hardware and model-aware partitioning for parallel and distributed network simulation. 12th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunications Systems (MASCOTS’04), pages pp. 455–463, 2004.
Sarita Mazzini Bruschi possui graduação em Bacharelado em Ciência da Computação pela Universidade Estadual Paulista Júlio de Mesquita Filho (1994), mestrado (1997) e doutorado em Ciência da Computação pela Universidade de São Paulo (2002). Atualmente, é professora do Instituto de Ciências Matemáticas e de Computação da Universidade de São Paulo. Seus interesses de pesquisa compreendem simulação distribuída e avaliação de desempenho.
Rodrigo Fernandes de Mello possui graduação em Tecnologia em Processamento de Dados pela Universidade Estadual Paulista Júlio de Mesquita Filho (1997), mestrado em Ciência da Computação pela Universidade Federal de São Carlos (1999) e doutorado em Engenharia Elétrica pela Universidade de São Paulo (2003). Atualmente, é professor da Universidade de São Paulo. Também fez parte de dezenas de comitês de programa e é revisor de periódicos, tais como Atmospheric Environment, Journal of Parallel and Distributed
104 IEEE LATIN AMERICA TRANSACTIONS, VOL. 6, NO. 1, MARCH 2008

Computing, International Journal for Computers and Their Applications e do International Journal of Computational Intelligence. Seus interesses de pesquisa compreendem balanceamento de carga, computação de alto desempenho, avaliação de desempenho e simulação.
MAZZINI BRUSCHI AND FERNANDES DE MELLO : LOGICAL PROCESS PARTITIONING 105

![Regulacao Genica [Modo de Compatibilidade] · Material genético Genes e cromossomas ... DNA extranuclear em mitocôndriase cloroplastos. Material genético . Material genético](https://img.document.onl/doc/110x75/5bec822d09d3f22d248cdfaf/regulacao-genica-modo-de-compatibilidade-material-genetico-genes-e-cromossomas.jpg)



























