Embed Size (px)
Citation preview

UNIVERSIDADE ESTADUAL DE CAMPINASFACULDADE DE ENGENHARIA ELÉTRICA E DE COMPUTAÇÃO
DEPARTAMENTO DE COMUNICAÇÕES
Algoritmos Heurísticos em Separação Cega de Fontes
AutorTiago Macedo Dias
OrientadorProf. Dr. João Marcos Travassos Romano
Co-orientadorProf. Dr. Romis Ribeiro de Faissol Attux
Banca Examinadora:Prof. Dr. João Marcos Travassos Romano (FEEC/UNICAMP)Prof. Dr. Christiano Lyra Filho (FEEC/UNICAMP)Prof. Dr. Luiz Cláudius Coradine (IC/UFAL)
Dissertação apresentada à Faculdade de Engenharia Elétrica e de Computação daUniversidade Estadual de Campinas como parte dos requisitos para a obtenção do títulode Mestre em Engenharia Elétrica.
Campinas, 16 de Dezembro de 2008

FICHA CATALOGRÁFICA ELABORADA PELABIBLIOTECA DA ÁREA DE ENGENHARIA - BAE - UNICAMP
Dias, Tiago MacedoD543a Algoritmos Heurísticos em Separação Cega de Fontes
/Tiago Macedo Dias. – Campinas, SP: [s.n.], 2008.
Orientadores: João Marcos Travassos Romano,Romis Ribeiro de Faissol Attux.Dissertação de Mestrado - Universidade Estadual de
Campinas, Faculdade de Engenharia Elétrica e deComputação.
1. Sistemas de telecomunicação. 2. Sistemas não-lineares. 3. Algoritmos genéticos. 4. Teoria dainformação. I. Romano, João Marcos Travassos. II.Attux, Romis Ribeiro de Faissol. III. UniversidadeEstadual de Campinas. Faculdade de Engenharia Elétricae de Computação. IV. Título
Título em Inglês: Heuristic Algorithms Applied to Blind Source SeparationPalavras-chave em Inglês: Telecommunication systems, Blind Source Separation,
Nonlinear Blind Source Separation, Bioinspired Algorithms,Metaheuristics
Área de concentração: Telecomunicações e TelemáticaTitulação: Mestre em Engenharia ElétricaBanca Examinadora: Christiano Lyra Filho, Luis Cláudius CoradineData da defesa: 16/12/2008Programa de Pós Graduação: Engenharia Elétrica
ii


Resumo
Esta dissertação se propõe a estudar um novo método para separação cega de fontesbaseado no modelo Post-Nonlinear, que une uma ferramenta de busca global baseada emcomputação bioinspirada a uma etapa de busca local conduzida pelo algoritmo FastICA.A idéia subjacente à proposta é procurar obter soluções precisas e eficientes usandode maneira parcimoniosa os recursos computacionais disponíveis. A nova proposta foitestada em diferentes cenários, e, em todos os casos, estabeleceram-se comparações comuma abordagem alternativa, cujo passo de otimização não inclui o estágio de busca local(ou “memética”). Os resultados obtidos por meio de simulações indicam que um bomcompromisso entre desempenho e custo computacional foi, de fato, atingido.
Palavras-chave: Post-Nonlinear, algoritmos bioinspirados, separação cega de fontes,algoritmos meméticos.
Abstract
This work deals with a new method for source separation of Post-Nonlinear mixturesthat brings together an evolutionary-based global search and a local search step basedon the FastICA algorithm. The rationale of the proposal is to attempt to obtain efficientand precise solutions using with parsimony the available computational resources. Thenew proposal was tested in different scenarios and, in all cases, we attempted to establishgrounds for comparison with an alternative approach whose optimization step does notinclude the local (memetic) search stage. Simulation results indicate that a good tradeoffbetween performance and computational cost was indeed reached.
Keywords: Post-Nonlinear, bioinspired algorithms, blind source separation, memeticalgorithms.

Agradecimentos
Ao meu orientador Prof. João Marcos Travassos Romano e co-orientador Prof. RomisRibeiro de Faissol Attux, sou grato pela orientação.
Agradeço em especial ao Ricardo Suyama pela orientação informal.
A todo pessoal do DSPCom pela colaboração, orientação e amizade.
Aos demais colegas de pós-graduação, pelas críticas e sugestões.
A minha família pelo apoio durante essa jornada.
A minha namorada pela compreensão e apoio.
vii

viii
Aos meus pais, irmãos, avós e tios.Em especial a minhas avós Maria Hipólito Macedo e Rosária Dias.

Sumário
Lista de Figuras xiii
Lista de Tabelas xv
Abreviaturas xvii
Lista de Símbolos xvii
Trabalhos Publicados Pelo Autor xix
1 Introdução 11.1 Organização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Separação Cega de Fontes 32.1 Descrição do problema . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Aplicações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Separação de sinais de áudio - O cocktail party-problem . . . . . 52.2.2 Processamento de sinais biomédicos . . . . . . . . . . . . . . . . 62.2.3 Telecomunicações - BSS e equalização cega de canais . . . . . . 72.2.4 Exploração Geofísica - Remote Sensing . . . . . . . . . . . . . . 92.2.5 Extração de imagens . . . . . . . . . . . . . . . . . . . . . . . . 102.2.6 Outras Aplicações . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Formalização matemática . . . . . . . . . . . . . . . . . . . . . . . . . . 122.3.1 Sistemas Lineares e Não-Lineares . . . . . . . . . . . . . . . . . 132.3.2 Sistemas Instantâneos e com Memória . . . . . . . . . . . . . . . 132.3.3 Com Relação ao Número de Fontes e de Sensores . . . . . . . . . 13
2.4 Análise por Componentes Independentes . . . . . . . . . . . . . . . . . . 142.4.1 Independência x Descorrelação Estatística . . . . . . . . . . . . . 152.4.2 Separabilidade . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5 Estratégias para ICA (Independent Component Analysis . . . . . . . . . 18
ix

x SUMÁRIO
2.5.1 Entropia e Informação Mútua . . . . . . . . . . . . . . . . . . . 182.5.1.1 Divergência de Kullback-Leibler . . . . . . . . . . . . 192.5.1.2 Contrastes . . . . . . . . . . . . . . . . . . . . . . . . 192.5.1.3 MaxEnt e InfoMax . . . . . . . . . . . . . . . . . . . 20
2.5.2 Critérios Baseados em Não-Gaussianidade - Negentropia,Curtose e FastICA . . . . . . . . . . . . . . . . . . . . . . . . . 222.5.2.1 Negentropia . . . . . . . . . . . . . . . . . . . . . . . 222.5.2.2 Curtose . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.3 FastICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.5.4 Estimação por máxima verossimilhança . . . . . . . . . . . . . . 252.5.5 Análise por componentes principais (PCA), Braqueamento e
PCA não-linear (NPCA) . . . . . . . . . . . . . . . . . . . . . . 272.6 Separação de misturas não-lineares . . . . . . . . . . . . . . . . . . . . . 30
2.6.1 ICA não-linear . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.6.2 Modelo Post-NonLinear (PNL) . . . . . . . . . . . . . . . . . . 342.6.3 Recuperação da independência estatística . . . . . . . . . . . . . 35
2.7 Métodos para Separação de Misturas PNL . . . . . . . . . . . . . . . . . 362.7.1 O algoritmo de Taleb-Jutten . . . . . . . . . . . . . . . . . . . . 362.7.2 Gaussianização de variáveis . . . . . . . . . . . . . . . . . . . . 38
2.8 Comentários Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3 Algoritmos Heurísticos e Metaheurísticas 413.1 Aplicações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.2 Algoritmos de busca local . . . . . . . . . . . . . . . . . . . . . . . . . 443.3 Metaheurísticas de análise de vizinhança . . . . . . . . . . . . . . . . . . 45
3.3.1 Busca Tabu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.3.2 Colônia de Formigas . . . . . . . . . . . . . . . . . . . . . . . . 463.3.3 Simulated Annealing . . . . . . . . . . . . . . . . . . . . . . . . 48
3.4 Algoritmos Bioinspirados . . . . . . . . . . . . . . . . . . . . . . . . . . 493.4.1 Algoritmos Genéticos . . . . . . . . . . . . . . . . . . . . . . . 49
3.4.1.1 A Técnica . . . . . . . . . . . . . . . . . . . . . . . . 513.4.1.2 Codificação . . . . . . . . . . . . . . . . . . . . . . . 523.4.1.3 Função de Avaliação - Fitness . . . . . . . . . . . . . . 533.4.1.4 Operadores genéticos . . . . . . . . . . . . . . . . . . 533.4.1.5 Convergência . . . . . . . . . . . . . . . . . . . . . . 583.4.1.6 Parâmetros . . . . . . . . . . . . . . . . . . . . . . . . 593.4.1.7 Aplicando a técnica . . . . . . . . . . . . . . . . . . . 60
3.4.2 Sistema Imunológico Artificial (Algoritmo opt-aiNet) . . . . . . . 613.4.2.1 Propriedades . . . . . . . . . . . . . . . . . . . . . . . 613.4.2.2 Definições . . . . . . . . . . . . . . . . . . . . . . . . 623.4.2.3 Funcionamento do sistema imunológico . . . . . . . . 62

SUMÁRIO xi
3.4.2.4 Sistema Imune Adaptativo . . . . . . . . . . . . . . . . 633.4.2.5 Características de Sistemas Imunológicos . . . . . . . . 663.4.2.6 O Algoritmo opt-aiNet . . . . . . . . . . . . . . . . . 67
3.5 Algoritmos Meméticos ou híbridos . . . . . . . . . . . . . . . . . . . . . 693.5.1 Pseudocódigo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.6 Comentários Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS 734.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando
a Informação Mútua . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 744.1.1 Estimação de entropia usando Estatísticas de ordem . . . . . . . . 754.1.2 Aplicação de Algoritmos Bioinspirados . . . . . . . . . . . . . . 77
4.1.2.1 Aplicação de Algoritmos Genéticos . . . . . . . . . . . 774.1.2.2 Aplicação de Algoritmo opt-aiNet . . . . . . . . . . . 79
4.1.3 Interpretação dos Resultados . . . . . . . . . . . . . . . . . . . . 804.1.3.1 Primeiro cenário . . . . . . . . . . . . . . . . . . . . . 804.1.3.2 Segundo cenário . . . . . . . . . . . . . . . . . . . . . 85
4.2 Aplicação de Técnicas de Gaussianização . . . . . . . . . . . . . . . . . 874.2.1 Minimização da Negentropia como medida de Gaussianização . . 884.2.2 Aplicabilidade ao problema PNL . . . . . . . . . . . . . . . . . . 89
4.2.2.1 Aplicação de Algoritmos Genéticos . . . . . . . . . . . 894.2.2.2 Aplicação de Algoritmo opt-aiNet . . . . . . . . . . . 90
4.2.3 O conceito de Gaussianização estendida . . . . . . . . . . . . . . 914.2.4 Interpretação dos Resultados . . . . . . . . . . . . . . . . . . . . 92
4.2.4.1 Primeiro cenário . . . . . . . . . . . . . . . . . . . . . 924.2.4.2 Segundo cenário . . . . . . . . . . . . . . . . . . . . . 98
4.3 Comentários Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
5 Conclusões, Sugestões e Perspectivas 103

Lista de Figuras
2.1 O Cocktail-party Problem . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 O Esquema de Equalização . . . . . . . . . . . . . . . . . . . . . . . . . 82.3 Imagens Iniciais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.4 Imagens Misturadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.5 Estimativas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.6 Modelo do sistema de misturas do problema de BSS. . . . . . . . . . . . 122.7 Sistema Separador para o caso Linear . . . . . . . . . . . . . . . . . . . 142.8 Sistema Separador x Sistema Misturador . . . . . . . . . . . . . . . . . . 152.9 Fontes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.10 Misturas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.11 Estrutura do sistema separador no critério InfoMax . . . . . . . . . . . . 212.12 Tratamento da BSS considerando estatística de segunda ordem. . . . . . . 302.13 Modelo PNL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.14 Modelo PNL - Gaussianização . . . . . . . . . . . . . . . . . . . . . . . 38
3.1 Gráfico de uma função objetivo com uma variável. . . . . . . . . . . . . 453.2 Codificação Binária, Inteira e Real . . . . . . . . . . . . . . . . . . . . . 533.3 Método da roleta. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 543.4 Método do torneio. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.5 Método da roleta com melhor indivíduo distante dos restantes sob a ótica
do fitness. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.6 Método do rank para o mesmo problema da figura 3.5, com mapeamento
ζ(·) da função de fitness. . . . . . . . . . . . . . . . . . . . . . . . . . . 563.7 Exemplo de cross-over multiponto. . . . . . . . . . . . . . . . . . . . . . 563.8 Ilustração da técnica de algoritmo genético. . . . . . . . . . . . . . . . . 613.9 Funcionamento do sistema imunológico. Fonte: [de Castro & Zuben
(2000)]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.10 O linfócito e o antígeno. Fonte: [de Castro & Zuben (2000)]. . . . . . . . 64
xiii

xiv LISTA DE FIGURAS
3.11 Recombinação para geração de anticorpos. Fonte: [de Castro & Zuben(2000)]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.12 Maturação de Afinidade. Fonte: [de Castro & Zuben (2000)]. . . . . . . . 66
4.1 O modelo Post-NonLinear (PNL). . . . . . . . . . . . . . . . . . . . . . 754.2 Estimação da entropia de uma variável aleatória uniforme [Duarte (2006)]. 784.3 Sinais observados e estimados para o primeiro cenário utilizando método
memético com opt-aiNet. . . . . . . . . . . . . . . . . . . . . . . . . . . 814.4 Sinais observados e estimados para o primeiro cenário utilizando método
memético com GA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.5 Gráficos de performance para o primeiro cenário (IM). . . . . . . . . . . 824.6 Gráficos comparativos do Erro Quadrático Médio para o primeiro cenário
(IM). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.7 Gráficos de performance para o segundo cenário (IM). . . . . . . . . . . 864.8 Gráficos comparativos do Erro Quadrático Médio para o segundo cenário
(IM). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 864.9 Modelo PNL - Gaussianização . . . . . . . . . . . . . . . . . . . . . . . 874.10 Estratégia de transformação gaussiana de uma variável aleatória . . . . . 884.11 Técnica de gaussianização estendida . . . . . . . . . . . . . . . . . . . . 924.12 Gaussianização estendida no problema PNL . . . . . . . . . . . . . . . . 924.13 Gráficos de performance para o primeiro cenário (Gauss.). . . . . . . . . 944.14 Gráficos comparativos do Erro Quadrático Médio para o primeiro cenário
(Gauss.). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 954.15 Gráficos de performance para o primeiro cenário (Gauss. Est.). . . . . . . 954.16 Gráficos comparativos do Erro Quadrático Médio para o primeiro cenário
(Gauss. Est.). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 964.17 Soma da Densidade de n sinais uniformemente distribuídos. . . . . . . . 974.18 Gráficos de performance para o segundo cenário (Gauss.). . . . . . . . . 994.19 Gráficos comparativos do Erro Quadrático Médio para o segundo cenário
(Gauss.). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 994.20 Gráficos de performance para o segundo cenário (Gauss. Est.). . . . . . . 1004.21 Gráficos comparativos do Erro Quadrático Médio para o segundo cenário
(Gauss. Est.). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100

Lista de Tabelas
2.1 Algoritmo FastICA com ortogonalização simétrica. . . . . . . . . . . . . 252.2 Algoritmo de Taleb e Jutten. . . . . . . . . . . . . . . . . . . . . . . . . 37
4.1 Resultados relacionados à convergência e tempo de simulação para o primeiro cenário
(IM). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 814.2 Média de resultados MSE para o primeiro cenário (IM). . . . . . . . . . . 814.3 Resultados relacionados à convergência e tempo de simulação para o segundo cenário
(IM). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 854.4 Média de resultados MSE para o segundo cenário (IM). . . . . . . . . . . 854.5 Resultados relacionados à convergência e tempo de simulação para o primeiro cenário
(Gauss.). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 934.6 Resultados relacionados à convergência e tempo de simulação para o primeiro cenário
(Gauss.) - continuação. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 944.7 Média de resultados MSE para o primeiro cenário (Gauss.). . . . . . . . . 944.8 Resultados relacionados à convergência e tempo de simulação para o segundo cenário
(Gauss.). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 984.9 Resultados relacionados à convergência e tempo de simulação para o segundo cenário
(Gauss.) - continuação. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 984.10 Média de resultados MSE para o segundo cenário (Gauss.). . . . . . . . . 98
xv

Abreviaturas
AG: Algoritmos GenéticosAGH: Algoritmos Genéticos Híbridos
AM: Algoritmos MeméticosARB: Artificial Recognition Ball
BS: Bell-SejnowskiBSS: Blind Source Separation – Separação Cega de FontesECG: EletrocardiogramaEEG: EletroencefalogramaMSE: Erro Quadrático MédiofMRI: Functional Magnetic Resonance Imaging – Ressonância Magnética FuncionalHOS: Higher Order Statistics – Estatísticas (ou Momentos) de Ordem Elevada
IM: Informação MútuaKLD: Kullback Leibler Divergence – Divergênciad e Kullback LieblerMEG: Magnetoencefalograma
MMSE: Minimum Mean Square Error – Erro Quadrático Médio MínimoNAT: Network Affinity Threshold
NBSS: Nonlinear Blind Source Separation – Separação Cega de Fontes Não-linearNICA: Nonlinear Independent Component Analysis – Análise de Componentes
Independentes Não-linearNPCA: Nonlinear Principal Component Analysis – Análise de Componentes
Principais Não-linearICA: Independent Component Analysis – Análise de Componentes Independentes
Infomax: Information MaximizationPCA: Principal Component Analysis – Análise de Componentes PrincipaisPNL: Post-NonlinearSNR: Signal-to-Noise Ratio – Relação Sinal-Ruído
xvii

Trabalhos Publicados Pelo Autor
1. T.M. Dias, R. Suyama, L.T. Duarte, R.R.F. Attux, J.M.T. Romano. “Blind Source
Separation using Evolutionary Computation and a Local Search Procedure”. Sociedade
Brasileira de Telecomunicações (SBrT’2007). 2007
2. R.R.F. Attux, A. Neves, L.T. Duarte, R. Suyama, C.C.M. Junqueira, L.E.P. Rangel, T. M.
Dias, J.M.T. Romano. “On the Relationships between Blind Equalization and Blind Source
Separation - Part I”. Aceito pelo Journal of the Brazilian Telecommunications Society. 2007
3. R.R.F. Attux, A. Neves, L.T. Duarte, R. Suyama, C.C.M. Junqueira, L.E.P. Rangel,
T. M. Dias, J.M.T. Romano. “On the Relationships between Blind Equalization and
Blind Source Separation - Part II: Relationships”. Aceito pelo Journal of the Brazilian
Telecommunications Society. 2007
4. T.M. Dias, R.R.F. Attux, R. Suyama, J.M.T. Romano. “Blind Source Separation of Post-
Nonlinear Mixtures Using Evolutionary Computation and Gaussianization”. Aceito pelo
8th International Conference on ICA and BSS. 2009
xix

Capıtulo 1Introdução
No campo de estudos de processamento de sinais, um dos problemas de maiorimportância é a recuperação de sinais através da observação de misturas. Nas estratégiasclássicas, esse processo é realizado através da análise de informações sobre os sinaisoriginais ou sobre o processo de mistura. Tal metodologia é referenciada comosupervisionada, já que pressupõe o conhecimento de informações prévias sobre as fontes.A necessidade desse conhecimento torna-se uma limitação dessa estratégia, já que existemproblemas em que não é possível obter tais informações. Além disso, há ainda, nessemodelo, hipóteses sobre os sinais e as misturas, que também restringe o seu espaço deaplicação.
É nesse contexto, que se buscam criar estratégias que necessitem tão poucainformação quanto possível na recuperação dos sinais. Dessa metodologia não-supervisionada ou cega, se origina o problema de BSS (Separação Cega de Fontes,do inglês Blind Source Separation). Desde 1980 esse problema vem sendo estudadopor muitos pesquisadores, devido à sua extensa aplicação nas mais diversas áreas deconhecimento: telecomunicações, tratamento de sinais de áudio, processamento de sinaisbiométicos e sensores. Fato é que, em alguns dos problemas analisados observou-se umacaracterística não-linear das misturas, o que levou à definição de uma metodologia deestudo denominada NBSS (Separação Não-linear Cega de Fontes, do inglês Nonlinear
Blind Source Separation). Da análise desses problemas sugiram alguns modelos não-lineares, dentre os quais destaca-se o modelo Post-Nonlinear, principal objeto de estudodesse trabalho. Com a construção desses modelos, as metodologias para análise eresolução do problema concentram-se em sua característica multimodal, que torna maiscomplexo o processo de busca por uma solução, sugerindo a utilização de técnicas deotimização mais robustas, tais como os algoritmos bioinspirados.
Desta forma, o principal objetivo deste trabalho é estudar o modelo Post-Nonlinear
1

2 Introdução
em NBSS, apresentando e discutindo os algoritmos meméticos: uma combinaçãode algoritmos heurísticos (bioinspirados e de análise de vizinhança) com técnicas deotimização baseadas em busca local (FastICA).
1.1 Organização
Essa dissertação está organizada em cinco capítulos, com os seguintes conteúdos eobjetivos:
• Capítulo (2): A teoria de separação de fontes a ser aplicada nesse trabalho éapresentada neste capítulo, mostrando suas principais estratégias. Após apresentaros conceitos relacionados ao problema de separação de fontes e suas aplicações, ocapítulo analisa o método ICA (Independent Component Analysis), suas estratégiase algoritmos associados. O estudo de técnicas para tratamento de problemas commistura não-linear também é parte deste texto, reforçando o modelo Post-Nonlinear,ponto central do estudo desse trabalho.
• Capítulo (3): Este capítulo versa sobre as estratégias de algoritmos heurísticosbioinspirados e aqueles baseados em análise de vizinhança. O objetivo é fornecer aoleitor conceitos relacionados a estratégias de otimização, mostrar sua aplicabilidadee construir a base teórica, para posterior aplicação em problemas de separação cegade fontes. Justificar e comparar conceitualmente algumas das técnicas é tambémum dos objetivos deste capítulo.
• Capítulo (4): Este capítulo mostra as metodologias empregadas nesse trabalhoe os resultados obtidos. Foram estudadas aplicações de algoritmos heurísticos(bioinspirados) em problemas de separação cega de fontes não-linear (NBSS).Mais especificamente, relata-se o modelo Post-Nonlinear (PNL) e algoritmosbioinspirados e meméticos guiados por estratégias de otimização baseadas emconceitos relacionados à BSS.
• Capítulo (5): As conclusões mostram um resumo das estratégias discutidase analisadas no decorrer do trabalho. Os modelos, resultados e análisessão sumarizados, permitindo tecer comentários finais e avaliar possibilidades esugestões para trabalhos futuros nessa área.

Capıtulo 2Separação Cega de Fontes
Este capítulo propõe-se a discutir teoricamente e analisar propostas relacionadasao problema de Separação Cega de Fontes (BSS, do inglês Blind Source Separation).Inicialmente, apresenta-se o problema sob sua ótica histórica. A segunda parte do capítulomostra algumas aplicações nas quais podem ser utilizados conceitos de Separação Cegade Fontes. Posteriormente analisam-se o modelo matemático e as técnicas e algoritmosutilizados para tratar este tipo de problema nas suas formas linear e não-linear.
2.1 Descrição do problema
As primeiras pesquisas sobre separação cega (ou autodidata) de fontes (BSS) datamdo início dos anos 80. Christian Jutten, da Universidade de Grenoble, iniciou nessaépoca alguns trabalhos para processamento de sinais neurofisiológicos em um modelosimplificado de codificação do movimento muscular que deu origem ao trabalho conjuntocom Hérault e Ans [Hérault et al. (1985)]. A idéia foi estudar o processo demovimentação dos músculos coordenado pelo cérebro para alcançar um determinadoobjeto. Os sinais coletados dos nervos musculares dependiam da distância do objetoe da velocidade de movimentação (no caso, deslocamento e velocidade angular domovimento). Para simplificação, Jutten e Hérault mediram o sinal incidente no nervomuscular e consideraram esse sinal como sendo uma combinação linear dos estímulosprovenientes do cérebro usados para movimentar o músculo em direção a um objeto, ouseja, uma combinação linear de dois sinais: um deles representando o descolamento e ooutro a velocidade angular. Dessa forma, os autores propuseram um método baseadoem uma estrutura de redes neurais artificiais capaz de separar os sinais linearmente
3

4 Separação Cega de Fontes
misturados1, o clássico algoritmo Hérault-Jutten [Hérault & Jutten (1994)].
No final da década de 80, com o trabalho dos franceses Pierre Comon e Jean-FrançoisCardoso, o problema de separação cega de fontes foi formalizado matematicamente.Utilizando os trabalhos iniciais de Jutten, a teoria da informação de Claude Shannon eos trabalhos de Darmois da década de 1950, Comon elaborou um modelo matemáticomais completo para o problema de BSS. O pesquisador formalizou a idéia da ICA(análise por componentes independentes, do inglês Independent Component Analysis) emostrou como a independência estatística se insere no problema de separação de fontes[Comon (1994)]. Já Cardoso contribuiu com os estudos sobre o estimador de máximaverossimilhaça em BSS [Cardoso (1998)], introduziu métodos tensoriais [Cardoso &Souloumiac (1993)] e também desenvolveu a técnica de gradiente relativo [Cardoso &Laheld (1996)], posteriormente muito difundido em BSS. Nessa mesma época, o trabalhode Bell e Sejnowski [Bell & Sejnowski (1995)] ajudou a popularizar a BSS. Ao aliarconceitos de codificação neural e ICA, as técnicas propostas nesse estudo possibilitaramseparar tipos diferentes de fontes, com o uso de algoritmos aplicáveis e relativamentesimples de implementar.
Posteriormente, destacam-se os trabalhos de três pesquisadores finlandeses,Karhunen, Oja e Hyvärinen, que concentraram seus estudos na técnica ICA. Karhunen eOja [Karhunen et al. (1998)] analisaram a ICA como uma extensão não-linear da técnicade Análise de Componentes Principais (PCA, do inglês Principal Component Analysis –vide seção 2.5.5). O grupo também observou que uma das dificuldades da técnica ICA éa necessidade de estimar a função densidade de probabilidade dos sinais das fontes. Talestimativa era muito complexa e praticamente infactível com os recursos computacionaise técnicas disponíveis até então. Sua grande contribuição veio da proposição de um novoalgoritmo ao qual se deu o nome de FastICA. O novo algoritmo simplificou a maneiracomo se obtém as estimativas das fontes [Hyvarinen & Oja (2000), Hyvarinen et al.
(2000)] e permitiu a maior popularização e disseminação de técnicas para resolução deproblemas em BSS.
Atualmente, diversos pesquisadores têm buscado analisar mais profundamente oproblema de separação cega de fontes através da utilização de novas técnicas alternativasà ICA. Ramificações das linhas de pesquisa produziram abordagens diferentes para oproblema de BSS, aumentando a riqueza de técnicas e trazendo maior flexibilidade emsua resolução. As atenções voltaram-se para a extensão dos resultados previamente
1Um Rede Neural Artificial (do inglês, Artificial Neural Network-ANN) é um modelo matemáticoou computacional baseado em redes neurais biológicas. Ele consiste em um grupo de neurôniosinterconectados que se adaptam através do processamento de informações internas e externas [Gurney(1997)].

2.2 Aplicações 5
obtidos a casos mais complexos de sistemas misturadores, como, por exemplo, modelosnão-lineares, convolutivos e sub-determinados. Ainda nos dias atuais, essas vertentescorrespondem aos principais temas de estudo em BSS, devido à sua importância e àsua complexidade. A capacidade de estender o problema para lidar com praticamentequaisquer tipos de misturas aumenta consideravelmente o espectro de atuação da BSSe permite utilizá-la em uma ampla gama de problemas práticos. É nesse sentido queeste trabalho busca analisar estratégias para separação de fontes, dando maior foco aproblemas em que a mistura apresenta características não-lineares.
2.2 Aplicações
Um problema tem sua importância reforçada quando se analisa, sobretudo, a suaaplicabilidade em situações práticas. Observa-se que o problema de BSS possui umagama de aplicações bastante variada e pode ser muito flexível para se adaptar a inúmerostipos de cenários. Esta seção busca descrever algumas das mais importantes aplicaçõesdessa técnica.
2.2.1 Separação de sinais de áudio - O cocktail party-problem
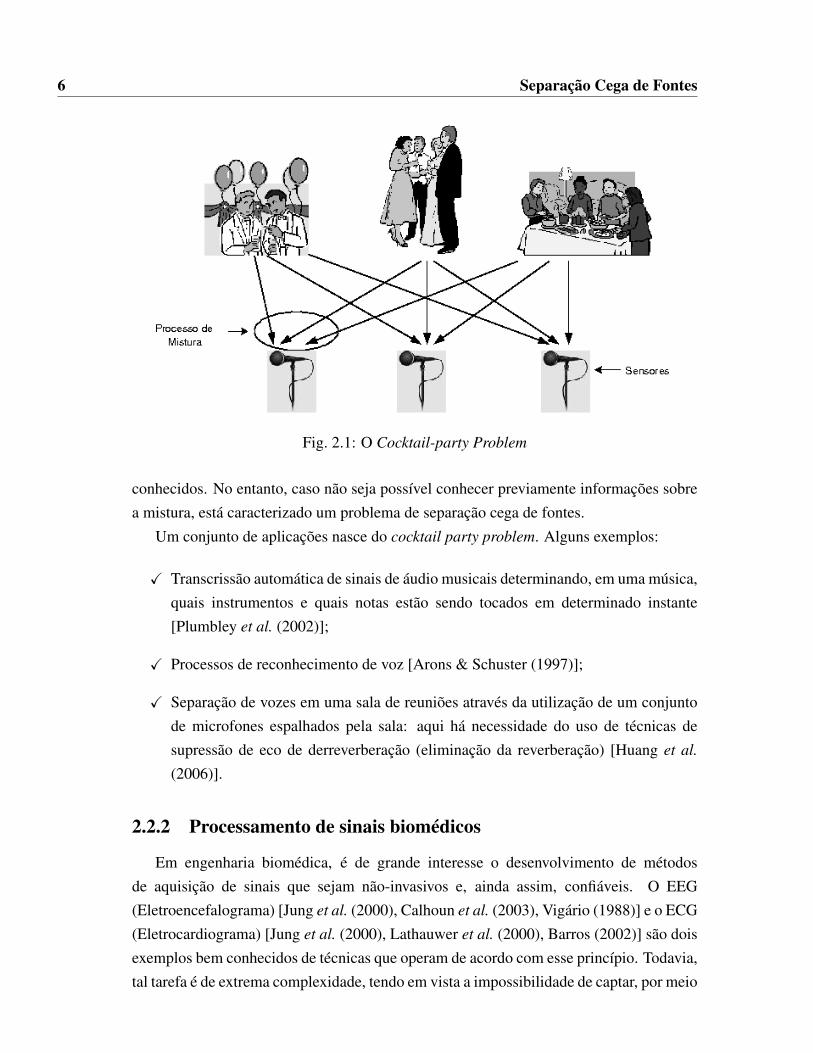
Se uma pessoa estiver numa sala ouvindo duas outras falarem simultaneamente, elaserá capaz de isolar uma das falas que mais lhe interessar. Constantemente o cérebrohumano repete esse processo e, para coordená-lo, basta que uma pessoa se concentrenaquilo que quer escutar. A esse processo dá se o nome de cocktail-party effect [Arons(1992)]. Mas, se o cérebro humano é capaz de realizar essa separação, deve ser possívelestudar esse sistema e inspirar modelos artificiais para solucionar problemas similaresem separação cega de fontes. Essa observação motivou a pesquisa sobre o problemaatualmente conhecido como o cocktail party problem, conforme ilustrado na Figura 2.1.
Um problema de separação de áudio normalmente é caracterizado por um ambiente ouuma sala, na qual existem pessoas conversando, e as vozes dessas pessoas são capturadaspor um conjunto de microfones. Para simplificar, suponha que há em tal sala duas pessoasfalando simultaneamente e que o som está sendo capturado por dois microfones (doiscanais). Se nesse sistema é possível conhecer as condições de transmissão dos sinaisdesde sua fonte (a boca da pessoa que está falando) até o sensor (microfone), em algunscasos (sistemas não convolutivos e/ou não subparametrizados), através de cálculos não tãocomplexos, é possível recuperar as falas de cada uma das pessoas separadamente. Esseprocesso caracteriza uma separação não-cega de fontes, pois os princípios de mistura são
6 Separação Cega de Fontes
Fig. 2.1: O Cocktail-party Problem
conhecidos. No entanto, caso não seja possível conhecer previamente informações sobrea mistura, está caracterizado um problema de separação cega de fontes.
Um conjunto de aplicações nasce do cocktail party problem. Alguns exemplos:
X Transcrissão automática de sinais de áudio musicais determinando, em uma música,quais instrumentos e quais notas estão sendo tocados em determinado instante[Plumbley et al. (2002)];
X Processos de reconhecimento de voz [Arons & Schuster (1997)];
X Separação de vozes em uma sala de reuniões através da utilização de um conjuntode microfones espalhados pela sala: aqui há necessidade do uso de técnicas desupressão de eco de derreverberação (eliminação da reverberação) [Huang et al.
(2006)].
2.2.2 Processamento de sinais biomédicos
Em engenharia biomédica, é de grande interesse o desenvolvimento de métodosde aquisição de sinais que sejam não-invasivos e, ainda assim, confiáveis. O EEG(Eletroencefalograma) [Jung et al. (2000), Calhoun et al. (2003), Vigário (1988)] e o ECG(Eletrocardiograma) [Jung et al. (2000), Lathauwer et al. (2000), Barros (2002)] são doisexemplos bem conhecidos de técnicas que operam de acordo com esse princípio. Todavia,tal tarefa é de extrema complexidade, tendo em vista a impossibilidade de captar, por meio

2.2 Aplicações 7
de sensores posicionados em uma determinada região do corpo humano, apenas os sinaisde interesse para um determinado exame, principalmente devido à interferência de sinaisgerados pelos mais diversos tipos de atividade fisiológica. Em suma, esses procedimentossão, geralmente, caracterizados por uma baixa relação sinal-ruído (SNR, Signal-to-Noise
Ratio) ou sinal-interferente.
Uma estratégia frequentemente utilizada para diminuir a intensidade do ruído nasamostras obtidas fundamenta-se na repetição de diversas realizações do exame, de modoque seja possível levantar um comportamento médio dos dados de interesse. A despeitodos bons resultados atingidos, esse tipo de abordagem exige a execução de um elevadonúmero de repetições, o que, em alguns casos, pode não ser um procedimento desejável,ou mesmo viável. Além disso, tal conduta pode causar fadiga nos indivíduos examinados,o que, por sua vez, acarreta alterações artificiais dos padrões obtidos, principalmente nomonitoramento de sinais cerebrais.
O emprego de técnicas de BSS oferece uma alternativa eficiente a essa abordagem,posto que, nesse caso, a recuperação dos sinais de interesse se dá através de estágiossofisticados de processamento conduzidos posteriormente à captação dos dados, o querequer a realização de apenas um experimento. Além disso, a ausência de modeloscapazes de determinar quais sinais fisiológicos interferentes são captados e, ademais,como eles se misturam, posiciona esse tipo de problema em uma condição favorávelà aplicação dos métodos de BSS. Uma boa evidência dessa aplicabilidade pode sercomprovada pela expressiva quantidade de trabalhos de separação de sinais biomédicos,a tal ponto que pode-se dizer que, atualmente, essa área corresponde a um dos principaisdomínios de aplicações técnicas de BSS [Hyvarinen et al. (2000)].
2.2.3 Telecomunicações - BSS e equalização cega de canais
A aplicação da BSS em telecomunicações está fortemente relacionada a um temade expressiva relevância em comunicações digitais: a equalização de canais. A idéiaessencial de um sistema de comunicação é fazer com que a informação enviada porum transmissor possa ser obtida de maneira tão fiel ao original quanto possível por umreceptor. Assim sendo, é primordial que o desenvolvimento de sistemas de comunicaçãoleve em conta estratégias capazes de mitigar as distorções introduzidas pelo canal,elemento presente entre o transmissor e o receptor, na informação transmitida. Em umadas estratégias mais empregadas, a equalização de canal, utiliza-se um filtro (equalizador)no receptor de modo que este seja capaz de inverter a ação do canal. O esquema básicoda equalização é apresentado na Figura 2.2. No caso, os sinais s(n), x(n) e y(n)

8 Separação Cega de Fontes
correspondem, respectivamente, ao sinal transmitido, ao sinal recebido e à estimativa dosinal transmitido.
Fig. 2.2: O Esquema de Equalização
Em essência, o desenvolvimento de técnicas de equalização está intimamenterelacionado à concepção de critérios que guiem o ajuste dos parâmetros livres doequalizador, de modo que se obtenha uma boa estimativa do sinal transmitido. Porexemplo, no caso do paradigma de Wiener, adota-se como critério a minimização doerro quadrático médio entre a saída do equalizador e o sinal desejado, no caso, o sinaltransmitido [Haykin (1996)].
No caso supracitado, chama a atenção o fato de que o critério adotado se apóia noconhecimento tanto do sinal recebido quanto de amostras do sinal transmitido. Essanecessidade caracteriza o paradigma de equalização supervisionada [Haykin (1996)].Em contrapartida, os critérios presentes na equalização não-supervisionada (ou cega)utilizam, além dos sinais recebidos, apenas algumas informações estatísticas dossinais transmitidos. Uma vantagem dessa estratégia em relação à supervisionada é apossibilidade de realizar o ajuste dos parâmetros concomitantemente com a transmissãodos dados. Por outro lado, a etapa de ajuste dos parâmetros no caso cego ésignificativamente mais complexa [Haykin (1994)].
Percebe-se então que a equalização cega busca recuperar o sinal transmitido, atravésde um filtro no receptor, valendo-se apenas de amostras da saída do canal. Observa-seque a equalização e a estratégia de BSS são muito similares. A diferença básica é que,originalmente, a equalização é definida em um cenário SISO (Single-Input Single-Output)e se baseia em filtragem temporal, ao passo que a BSS aborda sistemas MIMO (Multiple-Input Multiple-Output) e se fundamenta em filtragem espacial ou espaço-temporal. Aindaassim, é possível formular o problema de equalização cega de canais SISO como umatarefa de BSS [Hyvarinen et al. (2000), Attux et al. (2006)].
No que tange o problema de equalização cega de canais MIMO, pode-se afirmar que,em um âmbito teórico, essa situação praticamente se confunde com a formulação da BSS.Nesse contexto, merece destaque o trabalho de Cavalcante [Cavalcante (2004)], que tratouum tópico relacionado à equalização MIMO, a detecção multiusuário, a partir de umaabordagem fundamentada em BSS. A particularidade nessa situação é que se trata de umcanal de múltiplo acesso, ou seja, a transmissão das informações enviadas por diferentes

2.2 Aplicações 9
usuários se dá num mesmo canal. Esse compartilhamento de recursos é possível devidoà implantação de um esquema de múltiplo acesso como, por exemplo, as conhecidasestratégias FDMA, TDMA e CDMA.
2.2.4 Exploração Geofísica - Remote Sensing
Remote sensing é um processo de aquisição de informações sobre um objeto oufenômeno através da gravação ou uso de sensores em tempo real que não estão emcontato próximo com esse objeto. Dentre alguns exemplos de sensores é possívelcitar: instrumentos de observação da Terra, satélites de coleta de dados meteorológicos,plataformas para observação atmosférica e oceanográfica.
São definidos dois tipos de sensores remotos [Levada (2006)]:
1. Sensores passivos que detectam energia natural (radiação) emitida ou refletida porum objeto ou área em observação. Luz solar refletida é uma das fontes mais comunsde radiação medida por sensores passivos. Alguns exemplos desse tipo de sensorsão: fotografia com filme, infra-vermelho, radiômetros.
2. Sensores de coleta ativos que emitem energia para escanear objetos e áreas nasquais um sensor passivo é usado para detectar e medir a rediação refletida. ORADAR é um exemplo de sensor ativo cujo princípio básico é medir o tempo entrea emissão e o retorno do sinal estabelecendo a localização, tamanho e direção deum objeto.
Sensores remotos são comumente usados para monitorar desmatamento em áreascomo a floresta Amazônica; monitorar os efeitos da mudança climática em áreas glaciais,regiões árticas ou antárticas; medir a profundidade de oceanos e costas. Pode-se citaralguns exemplos de sistemas sensoriais (não traduzidos para manter o significado):Landsat Thematic Mapper, Seasat, Heat Capacity Mapping Mission, Space Shuttle
Imaging Radar, Large Format Camera, Advanced Very High Resolution Radiometer,
Coastal Zone Scanner, and Thermal Infrared Multispectral Scanner.Os sinais coletados através dos sensores descritos acima apresentam informações
misturadas de várias fontes ou até mesmo interferências do mesmo sinal no tempo. Astécnicas de separação cega de fontes podem então ser aplicadas diretamente nesses tiposde problemas, como, por exemplo, no uso de sensores hiperespectrais [Borges & Marçal(2007)]. Um dos principais problemas da aplicação desses sensores está relacionado aonúmero grande de dimensões, fato que aumenta muito a complexidade computacionale justifica a aplicação de técnicas de BSS. Tais técnicas são usadas com dois objetivos:

10 Separação Cega de Fontes
redução da dimensão do sistema e, posteriormente, reconhecimento das imagens obtidas.A idéia é preservar o maior conjunto de informações possível do conjunto de dadosoriginal para, em seguida, aplicar técnicas de classificação de imagens.
2.2.5 Extração de imagens
A extração de imagens não conhecidas a priori em ambientes contaminados porinterferência é mais um problema de destaque na área de BSS. Pode-se citar, entreoutras aplicações, os casos de ultrassonografia, recuperação de imagens deterioradas etratamento de imagens em astronomia.
Para ilustrar esse tópico, pode-se analisar, por exemplo, imagens que são combinadaspixel a pixel através de uma matriz de mistura obtida de forma aleatória. Na Figura 2.3,pode-se visualizar as duas fontes que são empregadas para a simulação. As duas imagenssão conhecidas no campo de reconhecimento de imagens (ao lado esquerdo Lenna eao lado direto Peppy). As misturas obtidas nos sensores são ilustradas na Figura 2.4.Com o conhecimento prévio das duas imagens originais, pode-se observar claramenteque as imagens em cada um dos sensores apresentam características das duas fontes. Noentanto, essa inferência não pode ser feita pelo receptor, que observa somente os sinais dossensores, sem conhecimento prévio das fontes. As estimativas dos sinais após a separaçãopodem ser visualizadas na Figura 2.5. Uma importante informação a ser destacada éque a existência de duas estimativas para cada sinal original é usual em problemas dessetipo. Isto ocorre pois as estruturas de separação apresentam pontos de equilíbrio para ossinais originais e para os sinais duais, ou seja, aqueles com os pixels com tons de cinzainvertidos.

2.2 Aplicações 11
Fig. 2.3: Imagens Iniciais
Fig. 2.4: Imagens Misturadas
Fig. 2.5: Estimativas
2.2.6 Outras Aplicações
Além das aplicações descritas, há ainda outros problemas de BSS provenientes dasmais diversas áreas como, por exemplo, arranjos de sensores químicos [Bermejo et al.

12 Separação Cega de Fontes
(2006)] e cancelamento de reflexões [Hyvarinen et al. (2000)]. O leitor interessado emoutras aplicações pode consultar as referências [Hyvarinen et al. (2000), Cichocki &Amari (2002), Puntonet & Prieto (2004); Rosca et al. (2006)].
2.3 Formalização matemática
Sabe-se que num problema de separação cega existem as fontes, a mistura e os sinaismisturados (vide Figura 2.6). Matematicamente, representam-se os sinais de entrada por:s(n) = [s1(n) s2(n) . . . sN(n)]T . Esses sinais são misturados através de uma sistemamisturador F . Os sinais na saída, ou seja, os sinais misturados, são representados por:x(n) = [x1(n) x2(n) · · ·xM(n)]T .
Fig. 2.6: Modelo do sistema de misturas do problema de BSS.
Pode-se então escrever:
x(n) = F(s(n), s(n− 1) . . . s(n− L), r(n)), (2.1)
onde:
• F(·) representa a ação do sistema misturador
• L corresponde ao número de amostras passadas levadas em conta no processo demistura
• r(n) é um vetor que denota o ruído associado às próprias fontes (ruído de fonte)e/ou aos sensores (ruído de sensor)
Devido a limitações nas técnicas de análises e de síntese, os problemas de BSSgeralmente não consideram todos os componentes do modelo descrito acima. Na prática,o modelo deve ser simplificado para que seja possível estudar o seu comportamento.Uma das simplificações é excluir o ruído associado às fontes e aos sensores, reduzindo omodelo a:

2.3 Formalização matemática 13
x(n) = F(s(n), s(n− 1) . . . s(n− L)), (2.2)
Sabendo como se dá o modelamento do problema geral é possível classificar umsistema de separação cega de fontes de acordo com as seguintes propriedades: linearidade,memória e número de fontes/sensores, como mostram as seções seguintes.
2.3.1 Sistemas Lineares e Não-Lineares
Um sistema misturador pode ser classificado como linear se o mapeamento F atendeao princípio da superposição, ou seja, quando:
F(a1s1(n) + a2s2(n)) = a1F(s1(n)) + b2F(s2(n)), (2.3)
Essa expressão deve ser válida para quaisquer constantes a1 e a2 e vetores s1(n) e s2(n).Caso contrário, o sistema misturador é dito não-linear.
2.3.2 Sistemas Instantâneos e com Memória
Quando o sistema misturador considera não só amostras instantâneas do sinal comotambém amostras passadas, chama-se o sistema de convolutivo ou com memória. Nessecaso, L > 0 e é necessário considerar não só a mistura dada pela composição dos sinaisde entrada no instante n, mas também nos instantes passados n−1, n−2 até n−L, comomostra a equação (2.2).
Caso o sistema não tenha memória, diz-se que ele é instantâneo. Nesse caso, L = 0
e os sinais na saída do sistema misturador dependem somente dos sinais de entrada noinstante da medição:
x(n) = F(s(n)) (2.4)
2.3.3 Com Relação ao Número de Fontes e de Sensores
Um sensor é um dispositivo usado para capturar os sinais das fontes. Por exemplo,num sistema em que se deseja captar os sinais de cinco pessoas falando e para o qual temosquatro microfones, tem-se cinco fontes e quatro sensores. Pode ser que um determinadoproblema possua mais fontes do que sensores ou vice-versa. Quando o número desensores é maior que o número de fontes, diz-se que há um problema de BSS sobre-determinado. Caso contrário, se o número de sensores é menor que o de fontes, tem-se o

14 Separação Cega de Fontes
caso sub-determinado.
O caso mais simples e mais estudado de problema de BSS é o caso em que se temum sistema linear, instantâneo e que possui o mesmo número de fontes e sensores, semruído. Nesse caso, pode-se modelar o sistema misturador por uma matriz A e o modelomatemático fica:
x(n) = As(n), (2.5)
onde:
• A é uma matriz N ×N chamada matriz de mistura.
• s(n) são os sinais instantâneos das fontes.
• x(n) são os sinais misturados.
2.4 Análise por Componentes Independentes
A Análise por Componentes Independentes (do inglês ICA, Independent Component
Analysis) é uma das principais ferramentas utilizadas no problema de BSS. A ICA deum vetor aleatório x = [x1 x2 · · ·xM ]T consiste na determinação de uma transformaçãolinear y = Wx de tal maneira que os elementos do vetor aleatório y = [y1 y2 · · · yN ]T
sejam tão estatisticamente independentes quanto possível, no sentido de otimizar umafunção custo Ψ(y), denominada função contraste (vide seção 2.4.2). Tal definição dáorigem ao sistema separador exibido na Figura 2.7. Nesse sistema, pode-se observar ossinais estimados y = [y1 y2 · · · yN ]T e o sistema separador que é modelado pela matriz deseparação W.
Fig. 2.7: Sistema Separador para o caso Linear
Aplicando-se o sistema separador da Figura 2.7 ao sistema misturador da Figura 2.6 e,utilizando a técnica de ICA, é possível obter estimativas das fontes, como mostra a Figura2.8.

2.4 Análise por Componentes Independentes 15
Fig. 2.8: Sistema Separador x Sistema Misturador
Para aplicação de técnicas baseadas em ICA, há uma restrição importante quantoà função densidade de probabilidade das fontes: no máximo uma delas pode sergaussiana [Kofidis (2001), Hyvarinen et al. (2000)]. Essa restrição é importante porque,num cenário no qual todas as fontes são gaussianas, a soma dos sinais também serágaussiana, impossibilitando inferir qualquer informação sobre as fontes somente atravésda observação do sinal nos receptores (vide seção 2.4.1).
Os trabalhos de Pierre Comon [Comon (1994)] e de Hyvärinen e Eriksson [Hyvarinenet al. (2000), Eriksson & Koivunen (2004), Hyvärinen (1999)] apresentam detalhessobre os conceitos e a metodologia da ICA. Conceitos como independência estatística,descorrelação estatística, contraste e representação de sinais são alguns dos pontosimportantes no estudo da ICA. Explorar estes conceitos é objetivo das próximas seções.
2.4.1 Independência x Descorrelação Estatística
Independência estatística é um dos conceitos fundamentais na teoria da probabilidade.Quando diz-se que um vetor de sinais x(·) tem componentes independentes,matematicamente, isto significa que a função densidade de probabilidade conjunta dessevetor é igual ao produto das funções densidade de probabilidade marginais de suascomponentes:
px1,x2,...xN (x1, x2, . . . xN) = px1(x1)px2(x2) . . . pxN (xN) ,k∏i=1
pxi(xi) (2.6)
onde:
px1,x2,...xN (x1, x2, . . . xN) corresponde à função densidade de probabilidadeconjunta das variáveis envolvidas.
pxi(xi) representa a função densidade de probabilidade marginal de xi.
Conhecendo o conceito de independência estatística, é também importante introduzir

16 Separação Cega de Fontes
o conceito de descorrelação estatística. A descorrelação estatística é menos restritiva quea independência. Matematicamente, diz-se que um conjunto K-dimensional de variáveisaleatórias (v.a.) é formado de variáveis descorrelacionadas se a sua covariância é zero:
E{x1 · x2 . . . xK} − E{x1} · E{x2} . . .E{xK} = 0 (2.7)
ou seja, se a esperança do produto das componentes de x é dada pela multiplicação daesperança de cada componente do vetor x.
Sabe-se que, se as variáveis são independentes, elas são descorrelacionadas: noentanto, o fato de serem descorrelacionadas não implica que elas sejam independentes.A única classe de variáveis aleatórias em que vale o intercâmbio entre descorrelação eindependência são as váriaveis gaussianas [Haykin (1994)]. No entanto, trabalhar comvariáveis aleatórias gaussianas não traz resultados satisfatórios para separação de misturasutilizando a técnica ICA.
Pode-se ilustrar essa limitação da ICA observando as Figuras 2.9.(a) e 2.9.(b),que ilustram fontes gaussianas e fontes uniformes misturadas através de uma matrizortogonal. As Figuras 2.10.(a) e 2.10.(b) permitem visualizar as respectivas misturaslineares produzidas a partir das fontes gaussianas e das fontes uniformes. Fica clara asimetria geométrica entre a mistura e as fontes para o caso gaussiano (não há rotação),e a presença de direções preferenciais caso as fontes tenham distribuição uniforme.Graficamente, verifica-se que a mistura de fontes gaussianas gera uma densidade conjuntagaussiana similar às anteriores. Fica impossível distinguir os sinais das fontes em meio aessa mistura.
(a) Distribuição conjuntade fontes gaussianas
(b) Distribuição conjuntade fontes uniformes
Fig. 2.9: Fontes

2.4 Análise por Componentes Independentes 17
(a) Mistura de fontesgaussianas
(b) Mistura de fontesuniformes
Fig. 2.10: Misturas
2.4.2 Separabilidade
A definição de separabilidade em um modelo ICA recai novamente na análise daequação que define um sistema BSS linear, reescrita a seguir 2:
x = As (2.8)
Nesse sistema, a estimativa das fontes é dada por:
y = Wx (2.9)
Como mostrado nas seções acima, a matriz W é a matriz de separação. Caso sejapossível tornar os elementos do vetor y estatisticamente independentes, pode-se dizerque o sistema é separável. Nesse caso, a matriz W ·A pode ser reescrita como o produtode uma matriz diagonal Λ e de uma matriz de permutação P. Reescrevendo a equação deseparação, tem-se:
y = PΛs (2.10)
Caso o modelo seja separável, a solução encontrada pela ICA corresponderá à equação(2.10), na qual as matrizes P e Λ mostram que as fontes podem não ser recuperadas namesma ordem e que há efeitos de ganho de escala. No entanto, como uma permutação eum fator de escala não alteram a condição de independência entre os sinais, as estimativasencontradas podem ser consideradas soluções satisfatórias para o problema.
Formalmente, a definição de separação em ICA é [Comon (1994)]:
2As notações seguintes suprimem o índice n, para maior simplicidade.

18 Separação Cega de Fontes
Definição 2.4.1 (Separação em ICA) O modelo x = As é separável se e somente se a
matriz A possuir posto completo e, no máximo, um dos elementos do vetor aleatório s for
gaussiano.
2.5 Estratégias para ICA (Independent ComponentAnalysis
Esta seção tem como objetivo estudar os conceitos e principais estratégias utilizadasem Análise por Componentes Independentes. São analisados os conceitos de entropia,informação mútua e gaussianização; o algoritmo FastICA; técnicas de estimação pormáxima verossimilhança; e estratégias de PCA, NPCA e branqueamento.
2.5.1 Entropia e Informação Mútua
Segundo a teoria de Shannon [Shannon (1948)], a entropia é uma medida da incertezade uma variável aleatória. Matematicamente, pode-se definir, para um vetor de v.a.contínuas x, sua entropia diferencialH(x) como:
H(x) , −E{ln[px(x)]} = −∫ ∞−∞
px(x) · ln(px(x))dx (2.11)
Outra definição importante é a da entropia condicional, que mede a incerteza do vetorde variáveis aleatórias x condicionada a um outro vetor y. A incerteza remanescente emx após observar y é dada por:
H(x|y) , −E{ln[px|y(x|y)]} = −∫ ∞−∞
px|y(x|y) · ln(px|y(x|y))dxdy (2.12)
em que:
px,y(x,y) = px|y(x|y)py(y) (2.13)
é a função densidade de probabilidade conjunta de x e y.Então, é válida a seguinte relação [Cover & Thomas (1991)]:
I(x,y) = H(x)−H(x|y) (2.14)
e tem-se a definição de informação mútua, que é a diferença entre as entropias do vetor dev. a. x e a incerteza que se tem após a observação de x por y. Em resumo, essa grandeza é

2.5 Estratégias para ICA (Independent Component Analysis 19
capaz de medir a informação adquirida sobre x através da observação de y. A informaçãomútua assume valor zero se e somente se x e y são independentes. Isto significa quepode-se usar a informação mútua como uma medida da independência estatística.
A informação mútua pode também ser definida entre componentes de um único vetorde variáveis aleatórias y [Haykin (1998)]:
I(y) = −H(y) +K∑
i=1
H(yi) (2.15)
Essa expressão mostra que minimizar a informação mútua entre os componentes do vetory é, como esperado, tornar a entropia de y o mais próximo possível da soma de suasentropias marginais.
2.5.1.1 Divergência de Kullback-Leibler
Outra forma de definir a informação mútua é através da Divergência de Kullback-Leibler (KLD, do inglês Kullback-Leibler Divergence), que permite mensurar asimilaridade entre funções estritamente positivas [Kullback & Leibler (1951)]. Esse tipode medida é usualmente empregado para a comparação entre duas funções densidade deprobabilidade.
Matematicamente:
D(px(x)||gx(x)) ,∫ ∞−∞
px(x) · ln[px(x)
gx(x)]dx (2.16)
onde
p(x) e g(x) são duas funções densidade de probabilidade estritamente positivas.
D(·||·) é a divergência de Kullback-Leibler.
Usando a KLD, pode-se escrever a informação mútua como:
I(x,y) =
∫ ∞−∞
px,y(x,y) · ln[px,y(x,y)
px(x)py(y)]dxdy = D(px,y(x,y)||px(x)py(y)) (2.17)
2.5.1.2 Contrastes
Uma ferramenta importante num sistema separável analisado sob a técnica ICA éa função contraste ou simplesmente contraste. Uma função é definida como contraste(representada por Ψ(·)), se atender aos seguintes requisitos [Comon (1994); Kofidis(2001)]:

20 Separação Cega de Fontes
1. Ψ(y) deve ser invariante às permutações dos elementos de y: Ψ(y) = Ψ(P · y)
para qualquer matriz de permutação P;
2. Ψ(y) deve ser invariante à mudanças de escala: Ψ(y) = Ψ(Λ · y), para qualquermatriz diagonal Λ;
3. Quando y possuir elementos independentes entre si, é necessário que, para qualquermatriz inversível A:
Ψ(y) ≥ Ψ(A · y) - considerando que a maximização do contraste resultou emfontes independentes.
Ψ(y) ≤ Ψ(A · y) - considerando que a minimização do contraste resultou emfontes independentes.
4. A igualdade nas expressões acima só deve ser respeitada se A = P · Λ onde P éuma matriz de permutação e Λ é uma matriz diagonal inversível.
Assumindo um sistema de separação de fontes linear, é possível construir, a partir dainformação mútua, o seguinte contraste: [Papoulis (1993); Picinbono (1993); Cavalcante(2004)]
ΨICA(W) = −I(y) = −H(x) + ln[|det(W)|] + E{ln[K∏i=1
pyi(yi)]} (2.18)
Como a matriz W não depende da entropia de x, tem-se como expressão a serotimizada:
ln[|det(W)|] + E{ln[K∏i=1
pyi(yi)]} (2.19)
Quando os sinais são pré-branqueados (vide seção 2.5.5), W é ortogonal e o primeirotermo da equação (2.18) torna-se zero. Então, a maximização da função contrasteΨICA(W) corresponde à minimização da soma de entropias das componentes de y.
2.5.1.3 MaxEnt e InfoMax
O conceito Infomax (Information Maximization), inicialmente proposto por Linsker[Linsker (1988)], foi relacionado, em 1994, a um caso não-linear com o princípio daredução de redundância de Barlow [Nadal & Parga (1994)], que está diretamente ligadoà ICA. O trabalho de Bell e Sejnowski [Bell & Sejnowski (1995)], além de mostrar

2.5 Estratégias para ICA (Independent Component Analysis 21
essa relação, propôs também uma técnica para resolver o problema de BSS utilizandoo InfoMax.
Fig. 2.11: Estrutura do sistema separador no critério InfoMax
A Figura 2.11 mostra o modelo adotado por Bell e Sejnowski. O modelo é compostopor dois estágios: o primeiro é o linear representado pela matriz W, e o segundo é o não-linear, caracterizado pelo vetor de funções g(·) = [g1(·) . . . gN(·)]. Matematicamente,essa estrutura pode ser representada por:
z = g(y) = g(Wx) = [ g1(w1x) . . . gN(wNx) ]T . (2.20)
A partir da definição da Informação Mútua (vide seção 2.5.1), e levando em contasomente a matriz W como a variável a ser otimizada, a aplicação do critério InfoMax naestrutura descrita em (2.20) resulta no seguinte problema de otimização:
maxW
I(z,x) = H(z)−H(z|x), (2.21)
onde I(z,x) corresponde à informação mútua entre z e x.Como o mapeamento entrada-saída da estrutura mostrada em (2.20) é determinístico,
observa-se que a entropia condicional H(z|x) não depende de W, e, portanto, nessasituação, o critério Infomax é equivalente à maximização da entropia conjunta das saídasdessa rede. Dessa forma pode-se escrever:
maxW
I(z,x) = H(z), (2.22)
É possível ainda mostrar que a entropia conjunta das saídas pode ser expressa por [Duarte(2006)]:
H(z) = H(x) + E{N∑i=1
log(g′
i(wix))}+ log(| det(W)|), (2.23)
onde g′i(·) representa a derivada primeira da função gi(·).Nota-se que apenas os dois últimos termos dependem de W, e, portanto, o problema
de otimização pode ser descrito por:

22 Separação Cega de Fontes
maxWH(z) , max
WE{
N∑i=1
log(g′
i(wix))}+ log(| det(W)|). (2.24)
A nova formulação do critério Infomax proposta pela equação (2.24) em BSSmostra que há uma correspondência entre essa abordagem e a estimação por máximaverossimilhança (vide seção 2.5.4). A equivalência entre essas duas abordagens foidemonstrada por Cardoso [Cardoso (1997)].
2.5.2 Critérios Baseados em Não-Gaussianidade - Negentropia,Curtose e FastICA
As medidas de não-gaussianidade permitem quantificar a proximidade de umavariável aleatória qualquer em relação a uma variável aleatória gaussiana. Estas medidassão utilizadas, por exemplo, no algoritmo FastICA, descrito na seção 2.5.3.
2.5.2.1 Negentropia
A Negentropia é uma medida de gaussianidade de uma variável aleatória. Paradefini-la, considera-se uma variável aleatória y e uma variável aleatória yGaussiano
com distribuição gaussiana e com média e matriz covariância iguais às do vetor y.Matematicamente, a negentropia é então dada por:
NG(y) , H(yGaussiano)−H(y) (2.25)
Como a entropia de uma variável gaussiana é maior que a de qualquer outra variável[Picinbono & Barret (1990)], pode-se dizer que a negentropia é uma medida sempre não-negativa.
Reescrevendo (2.25) com o auxílio da divergência de Kullback-Leibler, tem-se:
NG(y) , D(py(y)||pyGaussiano(yGaussiano)) (2.26)
Esse é um estimador ótimo cuja finalidade é medir a não-gaussianidade dos sinais[Picinbono & Barret (1990)]. Nesse caso, o objetivo é maximizar a Negentropia paraque os sinais estimados não sejam gaussianos.
Na prática, há uma certa dificuldade na utilização da negentropia ao problema de BSSdevido à necessidade de estimação de entropia como mostrado na equação (2.25). Poresse motivo, geralmente, faz-se necessária a utilização de uma aproximação baseada noschamados momentos polinomiais [Hyvarinen (1999)], dada por:

2.5 Estratégias para ICA (Independent Component Analysis 23
NG(y) = α(E{G(y)} − E{G(yGaussiano)})2 (2.27)
onde:
• G(·) é uma função não-linear não-quadrática;
• α é uma constante;
• yGaussiano é uma variável aleatória gaussiana de média zero e variância unitária.
2.5.2.2 Curtose
A curtose é o cumulante de quarta ordem de uma variável aleatória [Papoulis (1993);Picinbono (1993)]. Matematicamente, para uma variável x, a curtose é dada por:
K{x} , E{x4} − 3 · (E{x2})2 (2.28)
A curtose permite classificar uma função densidade de probabilidade em relação àuma função densidade de probabilidade gaussiana:
. Distribuição gaussiana: K{x} = 0
. Distribuição sub-gaussiana: K{x} < 0
. Distribuição super-gaussiana: K{x} > 0
Conclui-se então que, ao maximizar o módulo da curtose num problema de separaçãode fontes, o sistema está, na realidade, diminuindo a gaussianidade dos sinais estimados.Há uma série de trabalhos que mostram a aplicabilidade dessa idéia em BSS [Zarzoso& Nandi (1998), Matsuoka et al. (2000), Papadias (1993), Papadias (2000), Sharma &Paliwala (2006)].
2.5.3 FastICA
Para entender o desenvolvimento do algoritmo FastICA, primeiramente, é importanteobservar que ele é baseado em técnicas de maximização da não-gaussianidade. Umresultado importante nesse sentido é o teorema central do limite, que, em termos simples,mostra que a soma de variáveis aleatórias independentes tende assintoticamente a umavariável aleatória gaussiana. Com esse conceito em mente, é natural tentar estimar asfontes buscando obter sinais que tenham pouca ou nenhuma característica gaussiana,

24 Separação Cega de Fontes
pois, em teoria, isso reverteria o processo de mistura das fontes e traria uma estimativasatisfatória.
Com o objetivo de analisar a técnica FastICA matematicamente, considera-se arecuperação de uma das fontes yi. Ou seja, considerando o caso linear, para encontrara estimativa yi, determina-se a linha da matriz W, dada por wT
i de forma que yi = wTi x.
A expressão (2.27) mostra a Negentropia aproximada. Ao maximizar a Negentropia emtermos de wT
i , tem-se:
wi = arg maxwi
(E{G(yi)} − E{G(yiGaussiano)})2 (2.29)
sujeita a E{yi} = E{wTi x} = 1
Observando a expressão (2.29), verifica-se que o termo E{G(yiGaussiano)} é constante.
Dessa forma, basta otimizar o primeiro termo da equação para encontrar o valor ótimo dewTi . De acordo com as condições de Kuhn-Tucker [Luenberger (1969)], esse ótimo é
obtido nos pontos onde [Hyvarinen & Oja (2000)]:
E{xG′(wTi x)}+ λwi = 0 (2.30)
onde λ é uma constante (multiplicador de Lagrange).
A partir dessa condição de otimalidade, define-se o algoritmo FastICA. Tomandocomo premissa que os sinais que compõe a mistura são descorrelacionados, têm médiazero e variância unitária, pode-se utilizar um método de Newton aproximado para resolvera equação (2.30), obtendo a regra de atualização dada por [Hyvarinen & Oja (2000)]:
wi ←− E{xG′(wTi x)} − E{G′′(wT
i x)}wi
wi ←− wi/ ‖ wi ‖(2.31)
A restrição imposta em (2.29), que exige variância unitária, é cumprida através dapremissa de que os sinais são descorrelacionados. Uma função não-linear normalmenteempregada para G(·) é a tangente hiperbólica (tanh).
A partir da expressão (2.31), é possível determinar as N fontes. Para isso bastaexecutar a otimização para os N vetores wi. No entanto, é necessário controlar asdiferentes execuções do algoritmo para que não seja estimada sempre a mesma fonte.Uma maneira de evitar encontrar a mesma solução mais de uma vez é utilizar a informaçãode que o sistema separador pode ser representado por uma matriz ortogonal, já que houveos sinais são descorrelacionados. Ou seja, inserir no algoritmo alguma restrição quegaranta a ortogonalidade da matriz W é suficiente para evitar essa repetição.
O algoritmo FastICA é descrito pela tabela 2.1.

2.5 Estratégias para ICA (Independent Component Analysis 25
1. Descorrelacionar e normalizar os dados para que tenham média nula e variânciaunitária.
2. Definir os valores iniciais de wi (colunas de W). Ortogonalizar W de acordo como passo 4.
3. Para todo i, executar a regra de ajuste da equação (2.31).
4. Realizar a ortogonalização simétrica de W, que pode ser feita do seguinte modo
W←(WWT
)−1/2W.
5. Caso não convirja, voltar ao passo 3.
Tab. 2.1: Algoritmo FastICA com ortogonalização simétrica.
2.5.4 Estimação por máxima verossimilhança
A técnica de máxima verossimilhança [Cardoso (1997)] é uma abordagem clássicada teoria de estimação e é uma das estratégias que podem ser aplicadas ao problema deseparação linear. Ela representa uma alternativa à aplicação de estratégias ligadas maisdiretamente à ideía de ICA, como aquelas baseadas em informação mútua.
Primeiramente, é interessante recapitular o conceito de estimação por máximaverossimilhança. Para isso, toma-se primeiro o conceito de estimação de parâmetros,ou seja, de determinar um estimador para os parâmetros θ= [θ1, . . . , θp] a partir de umconjunto de amostras e = [e(1), . . . , e(J)]. Numa estratégia de máxima verossimilhança,as estimativas de θ, denotadas por θ, podem ser obtidas através da maximização da funçãode verossimilhança L(θ). Matematicamente, tem-se:
θ = arg maxθL(θ) = arg max
θpe(e | θ), (2.32)
Considerando e = [e(1), . . . , e(J)] estatisticamente independentes entre si a funçãode verossimilhança é dada por:
L(θ) = pe(e | θ) =J∏j=1
pe(e(j)|θ). (2.33)
Em um problema de BSS linear, as informações que se possui são as amostras dasmisturas dadas por x = [x(1), . . . , x(J)], e se quer determinar os valores dos elementosda matriz de separação W. Observando a equação (2.33) é possível escrever:

26 Separação Cega de Fontes
L(W) =J∏j=1
px(x(j)|W). (2.34)
Sabendo que [Papoulis (1993)]:
px(x) =ps(A
−1x)
| det(A)|= ps(Wx)| det(W)|, (2.35)
onde A é a matriz do sistema misturador, e que as fontes podem ser consideradasindependentes, tem-se:
L(W) =J∏j=1
N∏n=1
psn(wnx(j))| det(W)| (2.36)
onde wn denota a n-ésima linha da matriz W.
É possível fazer mais duas considerações para simplificar a expressão. Uma delaspermite transformar os produtórios em somatórios utilizando a função de máximaverossimilhança logarítmica. A outra utiliza as leis dos grandes números para obter umavariante probabilística.
Através da aplicação da primeira idéia de simplificação tem-se:
1
Jlog(L(W)) =
1
J
J∑j=1
N∑n=1
log(psn(wnx(j))) + log(| det(W)|). (2.37)
Considerando a lei dos grandes números:
1
Jlog(L(W)) = E{
N∑n=1
log(psn(wnx(j)))}+ log(| det(W)|). (2.38)
A divergência de Kullback-Leibler permite ainda escrever [Kofidis (2001)]:
W = arg maxW
(L(W)) , arg minW
(D(py(y|W))) | ps(y)). (2.39)
Essa expressão pode ser considerada um contraste, pois satisfaz todos os critériosapontados na seção 2.4.2. Assim, conclui-se que a máxima verossimilhança é obtidaatravés da escolha de uma matriz W que minimize a divergência de Kullback-Leiblerentre as funções densidade de probabilidade das misturas s e as funções densidade deprobabilidade de suas estimativas x. No entanto, é importante observar que essa estratégiaexige, a rigor, o conhecimento das funções densidade de probabilidade das fontes e, emgeral, essa informação não está disponível em sistemas de separação cega.

2.5 Estratégias para ICA (Independent Component Analysis 27
2.5.5 Análise por componentes principais (PCA), Braqueamento ePCA não-linear (NPCA)
A PCA (Análise por Componentes Indepedente, do inglês Principal Component
Analysis)[Hyvarinen et al. (2000)], também chamada de transformada discreta deKarhunen-Loève, é geralmente usada em aplicações de compressão de dados e extraçãode características. A PCA utiliza a medida de correlação para quantificar a redundânciaentre componentes de um sinal, em contraste com a ICA, que utiliza uma medida deindependência.
Matematicamente, uma das interpretações da PCA é considerá-la como uma estratégiaque busca comprimir um vetor x = [x1 · · ·xM ]T que, por construção, apresenta umacerta redundância, através de um vetor y = [y1 · · · yN ]T tal que N < M e comelementos descorrelacionados entre si. Para isso, a tarefa da PCA é encontrar umatransformação linear que permita mapear x em y. Aos elementos do vetor y dá-se onome de componentes principais.
Para encontrar as componentes principais, é necessário buscar um vetor w1 =
[w11 · · ·wM1]T de norma euclidiana unitária que garanta a máxima variância da expressão
para a primeira componente principal de y, y1:
y1 = wT1 x. (2.40)
As outras componentes principais y2 . . . yM são determinadas de maneira semelhante:
y2 = wT2 x, (2.41)
Deve-se ter o cuidado de selecionar uma componente principal y2 cuja correlaçãocom y1 seja nula. Sendo assim, em um sistema de duas dimensões, deve-se determinar oscomponentes de y usando as equações transcritas abaixo:
y1 = wT1 x
y2 = wT2 x
E{y1 · y2} − E{y1} · E{y2} = 0
(2.42)
onde wT1 x e wT
2 x são determinados de forma a garantir a máxima variância dascomponentes de y.
De forma generalizada, tem-se:
yi = wTi x, (2.43)

28 Separação Cega de Fontes
onde wTi wj = δij , onde δij corresponde à função delta de Kronecker.
Uma outra maneira de visualizar a análise por componentes principais é utilizar aminimização do erro quadrático médio mínimo (MMSE, Minimum Mean Square Error)entre o sinal e a sua estimativa (erro de compressão) para obter os vetores wi:
JPCA = E{‖x−N∑i=1
(wTi x)wi‖2}, (2.44)
onde deve-se impor que wTi wj = δij . Uma observação interessante é que, quanto maior
for o número de componentes principais considerados na compressão, menor será o errode compressão.
Mas e se N = M? Nesse caso, o objetivo não é a compressão dos dados, massim encontrar uma transformação linear sobre x que resulte em um vetor aleatóriodescorrelacionado y: essa é a definição de branqueamento espacial. É importante lembrarque descorrelação não significa independência entre as variáveis aleatórias, ou seja, a PCAnão garante que as componentes de y sejam independentes.
O desenvolvimento a seguir mostra que, assumindo um vetor x de média nula, asolução do problema de otimização descrito pela expressão (2.44) está relacionada aosautovetores da matriz de correlação Rx = E{xxT}. Para iniciar, observa-se que nomodelo ICA a matriz de correlação entre as misturas é dada por:
Rx = E{xxT} = ARsAT = AAT , (2.45)
onde Rs é a matriz de correlação das fontes.A seguir, assumindo um sistema linear, a correlação das estimativas das fontes é dada
por:
Ry = WRxWT , (2.46)
Para branquear as saídas, é necessário determinar W tal que:
Ry = I→WRxWT = I, (2.47)
Uma solução dessa expressão pode ser dada por:
Rx = EDET (2.48)
onde:
E é uma matriz ortogonal cuja coluna são os autovetores de Rx

2.5 Estratégias para ICA (Independent Component Analysis 29
D é uma matriz diagonal contendo os autovalores de Rx
Usando essa relação, chega-se a expressão abaixo que permite obter a matriz W:
W = ED−1/2ET . (2.49)
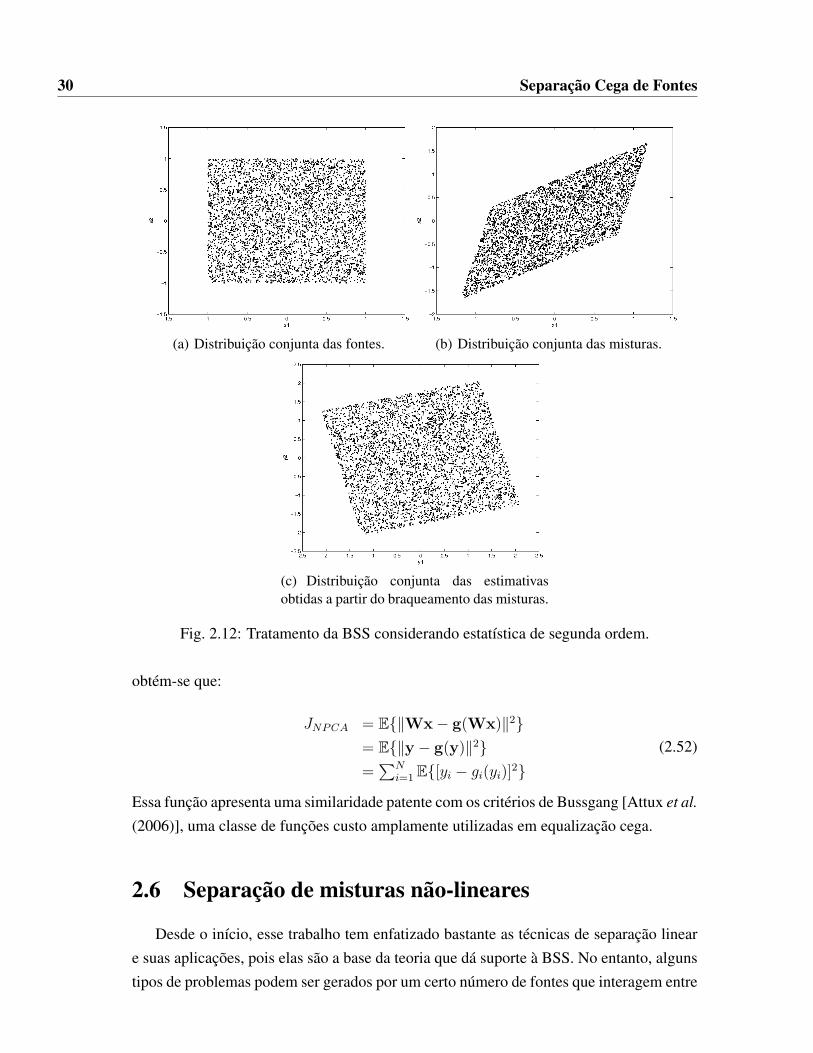
Note que a matriz W apenas garante que as estimativas y serão descorrelacionadas enão independentes, e, portanto, a separação dos sinais só será efetuada com uma matrizcomplementar de rotação, conforme ilustrado na Figura 2.12. A Figura 2.12(a) mostraas fontes, a Figura 2.12(b) mostra as misturas e a Figura 2.12(c) mostra as estimativasobtidas através do branqueamento.
Como se assume que o sistema misturador é linear, as misturas são geradas a partirde escalonamentos e rotações das fontes. Apesar de a recuperação via braqueamentopossibilitar a recuperação das escalas das fontes, ela não consegue recuperar a rotação,como mostra a Figura 2.12(c).
Embora não garanta a solução ótima para o problema, a estratégia de branqueamentopode ser usada como ponto de partida para algoritmos de otimização que permitamencontrar tal solução. A complexidade dos algoritmos de ICA pode ser reduzidasignificativamente, já que o problema restante se resume em determinar uma matriz derotação complementar.
A limitação da técnica PCA linear em recuperar a rotação das fontes pode sercontornada através da introdução de componentes não-lineares. Com isso define-se aNPCA (do inglês, Nonlinear Principal Component Analysis), que prevê a modificação daequação (2.44) incluindo componentes não-lineares:
JNPCA = E{‖x−N∑i=1
(gi(wTi x))wi‖2}, (2.50)
onde gi é uma função necessariamente não-linear.
Simplificando, pode-se ainda escrever:
JNPCA = E{‖x−WTg(Wx)‖2}, (2.51)
Essa não é a única maneira de transformar a estratégia de PCA em NPCA. A não-linearidade pode ser posicionada em outros pontos da equação [Hyvarinen et al. (2000)].Na abordagem via NPCA, é comum fazer com que as misturas passem por um estágio debranqueamento, que, como já apresentado, pode ser conduzido pela aplicação da PCA.Nesse caso, a matriz W a ser determinada é ortogonal, ou seja, WWT = I. Aplicandoessa condição na descrição matricial do problema, e, após um breve desenvolvimento,
30 Separação Cega de Fontes
(a) Distribuição conjunta das fontes. (b) Distribuição conjunta das misturas.
(c) Distribuição conjunta das estimativasobtidas a partir do braqueamento das misturas.
Fig. 2.12: Tratamento da BSS considerando estatística de segunda ordem.
obtém-se que:
JNPCA = E{‖Wx− g(Wx)‖2}= E{‖y − g(y)‖2}=∑N
i=1 E{[yi − gi(yi)]2}(2.52)
Essa função apresenta uma similaridade patente com os critérios de Bussgang [Attux et al.
(2006)], uma classe de funções custo amplamente utilizadas em equalização cega.
2.6 Separação de misturas não-lineares
Desde o início, esse trabalho tem enfatizado bastante as técnicas de separação lineare suas aplicações, pois elas são a base da teoria que dá suporte à BSS. No entanto, algunstipos de problemas podem ser gerados por um certo número de fontes que interagem entre

2.6 Separação de misturas não-lineares 31
si através de misturas não-lineares. Dentre muitos exemplos de sistemas dessa natureza,podem ser citados os sensores químicos [Bermejo et al. (2006)] e os amplificadores emsaturação. Encontrar uma solução adequada para um sistema não-linear constitui umatarefa mais complexa que os estudos lineares já analisados. É objetivo desta seção abordarestratégias não-lineares para que o leitor seja capaz de situar adequadamente os resultadosobtidos neste trabalho.
2.6.1 ICA não-linear
Os problemas de separação cega não-linear apresentam uma dificuldade inerentemuito maior que o caso linear. Encontrar a solução ótima, ou seja, determinar o sistemaseparador que permita estimar as fontes pode ser um trabalho árduo ou, muitas vezes,impossível de realizar. Normalmente, estratégias para tratar NBSS usam algoritmosaproximados para encontrar estimativas, mesmo que com algum grau de erro.
A primeira idéia no tratamento de problemas de NBSS é usar técnicas de sucesso jáaplicadas ao problema de BSS. A principal delas é a estratégia ICA (vide seção 2.4), que,adaptada para o caso não-linear, denomina-se NICA (do inglês Nonlinear Independent
Component Analysis). Tal como na ICA, dado um vetor aleatório x, a NICA buscaencontrar um mapeamento não-linear G(·) de modo que os elementos do vetor querepresenta os sinais estimados y = G(x) sejam tão estatisticamente independentes quantopossível.
Para o caso linear, a técnica ICA garante a recuperação das fontes, sob as hipótesespreviamente expostas. No entanto, quando se aplica a mesma técnica (NICA) em umproblema de NBSS, tal garantia não pode ser mais considerada. Para analisar melhor omotivo dessa dissociação, introduz-se o conceito de mapeamento trivial.
Um mapeamento M(·) = [M1(·), · · · ,Mn(·)] é considerado trivial se permitetransformar um vetor (original) r = [r1, · · · , rn], com elementos estatisticamenteindependentes, em um outro vetor (resultante) cujos elementos também são independentesentre si. Nesse sentido, um mapeamentoM(·) pode ser considerado trivial se, e somentese, a seguinte condição for satisfeita [Jutten & Karhunen (2003)]:
Mi(r1, · · · , rn) = mi(rρ(i)), i = 1, · · · , n (2.53)
onde:
r1, · · · , rn são as componentes do vetor original.
mi(·) são funções arbitrárias.

32 Separação Cega de Fontes
ρ é um operador de permutação sobre o conjunto {1, 2, · · · , n}.
mi(rρ(i)) é a componente i do vetor resultante.
Portanto, um mapeamento é considerado trivial se, e somente se, cada elemento dovetor resultante for uma função exclusiva de um dos elementos ri. Em outras palavras, ascomponentes do vetor resultante não podem ser combinações das componentes do vetororiginal. Num mapeamento trivial tanto as componentes do vetor resultante, como as dovetor original, são independentes entre si.
Considerando os mapeamentos G e W representando respectivamente a estruturade separação e o sistema misturador em um problema de NBSS, é possível escrever aseguinte relação para as estimativas das fontes:
y = G(W(s)) = (G ◦W)(s) (2.54)
Uma solução para o problema de separação cega de fontes não-linear expressana equação (2.54) pode ser obtida considerando que a composição G ◦ W seja ummapeamento trivial.
Como estudado na seção 2.4, para o caso linear, não é possível garantir que arecuperação das fontes ocorre na mesma ordem com que elas são recebidas pelos sensores,ou seja, pode ocorrer uma permutação da ordem. Para o caso não-linear pode ocorrerainda a presença de distorção residual não-linear [Hyvärinen & Pajunen (1999)]. Mesmocom algum erro de estimação é possível estimar as fontes, se o mapeamento G ◦ Wfor trivial. Fato é que a estratégia NICA não consegue garantir que sempre haverá ummapeamento trivial para representar o sistema separador. Com essa limitação, a aplicaçãoda NICA ao problema de NBSS não pode garantir a recuperação das fontes.
Para ilustrar esse conceito, normalmente estuda-se um exemplo retirado de [Jutten &Karhunen (2003)]. Nesse exemplo, tem-se duas fontes, s1 e s2, com suas distribuiçõesdadas por:
ps1(s1) = s1 exp(−s21/2): Distribuição de Rayleigh
ps2(s2) = 2/π quando s2 ∈ [0, π/2): Distribuição Uniforme
Como as fontes são estatisticamente independentes, a densidade de probabilidadeconjunta é:
ps1s2(s1, s2) =
{2πs1 exp
(−s212
), s2 ∈ [0, π/2);
0, s2 ∈ (−∞, 0) ou s2 ∈ [π/2,+∞).(2.55)

2.6 Separação de misturas não-lineares 33
O mapeamento proposto no trabalho é:[y1
y2
]=M(s) =
[s1 cos(s2)
s1 sin(s2)
]. (2.56)
Observa-se que os elementos de y são misturas dos elementos de s, já que o jacobianodessa transformação não é diagonal.
Isto posto, o próximo passo é verificar a densidade de probabilidade conjunta do vetory dada por [Papoulis (1993)]:
py1y2(y1, y2) =ps1s2(s1, s2)
| det JM(y)|, (2.57)
onde JM(y) é o jacobiano do mapeamentoM(·).
Assim:
| det JM(y)| =
∣∣∣∣∣det
([cos(s2) sin(s2)
s1 sin(s2) −s1 cos(s2)
])∣∣∣∣∣ =
= | − s1(cos2(s2) + sin2(s2))| = |s1|. (2.58)
Substituindo (2.55) e (2.58) em (2.57), e levando-se em conta que s21 = y2
1 +y22 , tem-se
py1y2(y1, y2) =2
πexp(−(y2
1 + y22)
2) = (
√2
πexp(−y2
1
2))(
√2
πexp(−y2
2
2)). (2.59)
A expressão (2.59) mostra um fato muito curioso em separação cega de fontes não-linear. Os elementos do vetor y, dados por y1 e y2, são estatisticamente independentes,mas não são solução do problema, pois ainda são misturas das fontes dadas pelo vetor s.Conclui-se então que existem mapeamentos não triviais que podem permitir a obtenção deestimativas independentes, mas que, devido à característica não-linear do sistema, podemainda ser misturas das fontes, não constituindo uma solução para o problema [Taleb &Jutten (1999)]. Essa é a essência da dificuldade de se utilizar a técnica NICA para estimaras fontes em um sistema NBSS.
Esse fato motiva estudos que permitam complementar o modelo considerandoinformações adicionais sobre o sistema, numa tentativa de eliminar as soluções que,apesar de terem componentes independentes, são misturas das fontes, como mostra oexemplo. No entanto, essa consideração pode exigir certo conhecimento sobre as fontes,e, sendo assim, o problema de separação cega de fontes fica descaracterizado, tornando-se

34 Separação Cega de Fontes
um problema de separação “semi-cego”.
Uma série de trabalhos tiveram sua motivação centrada na resolução desse problemabuscando uma mapeamento que permitisse recuperar as fontes sabendo que somenteo critério de independência não seria suficiente [Taleb & Jutten (1999), Taleb (2002),Hyvärinen & Pajunen (1999), Eriksson & Koivunen (2002), Babaie-Zadeh (2002)]. Emparticular, o trabalho de Taleb [Taleb & Jutten (1999)] restringe a solução a um conjuntode mapeamentos não-lineares denominados PNL, Post-NonLinear, para os quais o critériode independência é suficiente. Essa estratégia é o principal objeto de estudo destetrabalho.
2.6.2 Modelo Post-NonLinear (PNL)
O modelo Post-NonLinear (PNL), apresentado na Figura 2.13, é caracterizado poruma parte linear e outra não-linear, tanto na estrutura de mistura como na de separação.Estudos utilizando esse modelo têm como objetivo facilitar a obtenção das estimativasdas fontes através da divisão do problema geral em suas partes linear e não-linear. Dessaforma, ele pode ser compreendido como a combinação de dois sistemas separados quesão interrelacionados. Outra característica importante desse modelo é que as técnicas deseparação através de análise por componentes independentes (ICA) são válidas, já queo critério de independência é suficiente para obter uma estimativa satisfatória das fontes[Taleb & Jutten (1999)].
Fig. 2.13: Modelo PNL
Matematicamente, sabe-se que as misturas são dadas por x = f(As), onde f(·) =
[f1(·), f2(·), . . . , fn(·)]T são as não-linearidades aplicadas a cada saída do estágio linear.Em contraste com o modelo linear, o modelo PNL pode ajudar a descrever situações emque os sensores estão trabalhando em regiões saturadas nas quais o comportamento linearé seguido de um comportamento não-linear. Essa capacidade do modelo permite aplicá-lo a alguns problemas interessantes. Por exemplo, o modelo PNL pode ser utilizado paradescrever sistemas de comunicação MIMO com estágios de amplificação não-lineares

2.6 Separação de misturas não-lineares 35
[Taleb & Jutten (1999)] e em arranjos de sensores inteligentes de substâncias químicas ede gases [Bermejo et al. (2006)].
A separação de misturas PNL não-lineares pode ser obtida considerando um sistemaseparador generalizado do tipo y = Wg(x) [Taleb & Jutten (1999)], onde g(·) =
[g1(·), g2(·), . . . , gn(·)]T é um conjunto de funções não-lineares que precisam ser ajustadasde forma precisa para reverter os efeitos das não-linearidades da mistura f(·).
2.6.3 Recuperação da independência estatística
Diferentemente do caso linear de BSS, no qual é necessário apenas obter a matriz W,no modelo PNL é necessário também determinar cada uma das funções não-lineares dosistema separador dado por: y = Wg(f(As)). A idéia é encontrar estimativas das fontesque sejam estatisticamente independentes entre si. Para isso, a composição g ◦ f devecorresponder a um vetor de funções lineares. Em outras palavras, a concatenação da não-linearidade do sistema misturador f com a não-linearidade do sistema separador g devegerar um sistema linear em que vale a relação WA = ΛP, sendo Λ uma matriz diagonale P uma matriz de permutação. Dessa forma, é possível recuperar as fontes através daestimação de W, exceto por um ganho de escala dado por Λ e por uma permutação naordem das fontes dada por P. Em resumo, no caso do modelo PNL, é necessário que asestimativas y sejam estatisticamente independentes e que, mesmo havendo componenteslineares e não-lineares, seja possível obter resultados satisfatórios, exceto por ganhos deescala e/ou permutações das fontes.
O seguinte teorema fornece as condições necessárias para que haja separabilidade nomodelo PNL [Taleb & Jutten (1999), Babaie-Zadeh (2002), Achard & Jutten (2005)]:
Definição 2.6.1 (Separabilidade do Modelo PNL) Considere as seguintes hipóteses:
1. A matriz A é inversível;
2. As funções f(·) e g(·) são monotônicas e, consequentemente, h = g ◦ f também
deve ser um vetor de funções desse tipo;
3. Há, no máximo, uma fonte gaussiana;
4. A função densidade de probabilidade conjunta das fontes é diferenciável e sua
derivada é contínua em todo o seu suporte.
Nessas condições, se os elementos de y forem estatisticamente independentes, então
todos os elementos do vetor h(·) corresponderão a funções lineares e WA = ΛP.

36 Separação Cega de Fontes
2.7 Métodos para Separação de Misturas PNL
Como estudado nesse capítulo, nos problemas de separação cega lineares, utilizam-sealgoritmos baseados sobretudo na independência estatística dos sinais estimados. Noentanto, quando se trabalha com sistemas não-lineares, tentou-se utilizar os mesmosalgoritmos ou variantes deles sem muito sucesso, porque se percebeu que somentea independência dos sinais não é suficiente para garantir que a solução obtida sejasatisfatória para o problema em questão. O modelo PNL é um modelo de NBSS no qualo critério de independência estatística é válido, mas faz-se necessário o uso de estratégiasque possibilitem analisar também as não-linearidades do problema.
2.7.1 O algoritmo de Taleb-Jutten
Um dos critérios bastante difundidos na literatura para separação cega não-linear é oda minimização da informação mútua das estimativas das fontes. Num sistema PNL, ainformação mútua das estimativas das fontes y é dada por (vide Figura 2.13):
I(y) =N∑i=1
H(yi)−H(x)− log |det W| − E
{log
N∏i=1
|g′i(xi)|
}. (2.60)
Nessa expressão, os últimos dois termos são de fácil determinação e o termo H(x) éconstante, já que não depende de W ou g(·). No entanto, o primeiro termo correpondeao somatório das entropias marginais das estimativas das fontes, que dependem dasdistribuições de probabilidade das fontes. O Algoritmo de Taleb-Jutten busca abordara otimização dessa expressão utilizando o algoritmo de gradiente descendente. Para isso,divide-se a expressão em sua parte linear e não-linear aplicando o algoritmo a cada umade suas partes.
Para a parte linear, tem-se:
∂I(y)
∂W= −E{Ψ(y)zT} − (WT )−1, (2.61)
onde:
Ψ(y) = [ψy1(y1), . . . , ψyN (yN)], com ψyi(yi) = (pyi(yi)′/pyi(yi)) e
z representa os sinais na saída do estágio não-linear do sistema separador.
Considerando a parte não-linear do modelo, chega-se a:

2.7 Métodos para Separação de Misturas PNL 37
∂I(y)
∂Θi
= −E{∂ log |g′i(Θi, xi)|
∂Θi
}− E
{( N∑k=1
ψyk(yk)wki
)∂gi(Θi, xi)
∂Θi
}(2.62)
onde:
wki corresponde ao elemento (k, i) da matriz W.
gi(Θi, xi), i = 1, . . . , N são as funções não-lineares paramétricas do sistemaseparador
Θi é o vetor de parâmetros das funções não-lineares.
Para a estimativa de Ψ(y), Taleb e Jutten propuseram a utilização de duas estratégias:expansão de Gram-Charlier e estimação direta da densidade de probabilidade. Essa últimaproposta utiliza estimativas de erro quadrático médio e modelos não-lineares [Taleb &Jutten (1999)].
A dinâmica do algoritmo prevê que, numa dada interação, atualize-se a seção não-linear e os novos valores já são utilizados para a nova estimativa da seção linear.Algoritmicamente, o modelo pode ser representado pela tabela 2.2.
1. Defina os valores de (µl) e (µn), que são, respecitivamente, os passos referentes àspartes linear e não-linear do modelo.
2. Adapte a parte não-linear utilizando a expressão (2.62).
Θi ← Θi + µn∂I(y)
∂Θi
. (2.63)
3. Calcule a nova estimativa da parte não-linear: z = g(Θ,x).
4. Adapte a parte linear usando a expressão (2.61).
W←W + µl∂I(y)
∂W. (2.64)
5. Calcule a nova estimativa das fontes: y = Wz.
6. Voltar ao passo 2 até a convergência.
Tab. 2.2: Algoritmo de Taleb e Jutten.

38 Separação Cega de Fontes
2.7.2 Gaussianização de variáveis
A gaussianização de variáveis aleatórias para o modelo PNL foi proposta por Casalse Zhang [Solé-Casals et al. (2003), Zhang & Chan (2005)]. Ela é inspirada na estratégiade maximização da não-gaussianidade em problemas de BSS. Tal como essa estratégia,o princípio de análise da gaussianização de Casals e Zhang é baseada no teorema centraldo limite. Tendo como base esse teorema, pode-se inferir que, quanto maior o número defontes do sistema, mais a saída do estágio linear do sistema misturador do modelo PNLse aproxima de uma gaussiana. Sendo assim, a saída do sistema não-linear deve ser não-gaussiana, uma vez que uma transformação não-linear aplicada a uma variável gaussianatende a produzir uma variável não-gaussiana.
Assim, no sistema separador, tem-se como entrada do seu estágio de separação não-linear uma variável não gaussiana. Se for possível encontrar uma maneira de gaussianizaro sinal de modo a ter na saída do estágio não-linear do sistema separador uma variávelgaussiana, o problema reduz-se ao estágio linear de separação para o qual podemos aplicaras técnicas lineares de separação cega já conhecidas. A Figura 2.14 ilustra melhor oprocesso. Nela, é possível perceber que os valores obtidos para g(·) permitem inverter osefeitos de f(·).
Fig. 2.14: Modelo PNL - Gaussianização
Matematicamente, a gaussianização de uma variável aleatória zi = gi(xi) é definidapor:
gi(xi) = Φ−1(Fxi(xi)), (2.65)
onde:

2.8 Comentários Gerais 39
xi é uma mistura
Fxi(xi) é a distribuição cumulativa de xi
Φ−1 é a inversa da função cumulativa de uma variável aleatória gaussiananormalizada
Tipicamente a estimativa de Fxi(xi) é feita através de métodos de Kernel. A funçãoΦ−1 pode ser avaliada através de métodos numéricos, ou estimada pela aproximação deAbramowitz e Stegun [Abramowitz & Stegun (1968)].
É importante observar que a premissa básica desse processo é que a saída do estágiolinear do sistema misturador seja o mais próximo possível de uma gaussiana e, por isso,quanto maior o número de fontes, mais preciso é o resultado final. Caso essa premissanão seja realizável, o método pode apresentar distorções e as estimativas podem nãocorresponder a uma solução satisfatória.
2.8 Comentários Gerais
Os principais conceitos, estratégias, metodologias e aplicações de problemas deseparação cega de fontes foram estudados nesse capítulo. O objetivo geral é conhecer osproblemas BSS e o NBSS e as principais metodologias, técnicas e algoritmos empregadosna busca por uma estimativa das fontes. Percebe-se, no decurso do texto, que astécnicas utilizadas para o caso linear já estão bastante amadurecidas. Estender essastécnicas aos problemas não-lineares é uma das maneiras de buscar uma solução para essesproblemas mais complexos. Seguindo na análise de problemas não-lineares, chega-se aoprincipal objeto de estudo desse trabalho que é analisar o modelo PNL (Post-NonLinear)e as técnicas associadas ao tratamento deste tipo de abordagem. No próximo capítulosão abordadas metodologias baseadas em algoritmos heurísticos como ferramentas pararesolução de problemas baseados no modelo PNL.

Capıtulo 3Algoritmos Heurísticos e Metaheurísticas
Em princípio, os métodos que resolvem problemas relacionados à otimização podemser divididos em 2 grandes grupos: exatos e aproximados. Um método exato sempre buscaa solução de valor ótimo. No entanto, em muitos casos encontrar a solução ótima paraum problema pode ser muito difícil ou mesmo impossível e, por isso, buscar uma soluçãosubótima aproximada pode trazer uma relação custo/benefício mais interessante. Alémdisso, para uma vasta gama de problemas não existem procedimentos exatos eficientes,especialmente para instâncias de grande porte [Glover & Laguna (1995)]. Na ausênciadestes, uma alternativa é recorrer a heurísticas, técnicas capazes de encontrar soluçõesviáveis, mas para as quais, em geral, não é possível dar garantia a priori do afastamentomáximo em relação ao valor ótimo. Uma estratégia de otimização mais ampla pode serconstruída com a combinação de heurísticas, à qual dá-se o nome de Metaheurística.Metaheurísticas são usadas na resolução de problemas complexos de otimização que estãopresentes em muitas áreas, tais como, negócios, comércio, engenharia e produção. Elaspodem ser definidas formalmente como [Osman & Kelly (1997)]:
Definição 3.0.1 (Metaheurística) Uma metaheurística é um processo iterativo que guia
um grupo de heurísticas subordinadas, através da combinação de conceitos que permitem
explorar o espaço de soluções, usando estratégias de análise “inteligentes”, na busca por
soluções próximas às ótimas.
Em outras palavras, uma metaheurística é uma metodologia que busca guiar uma oumais heurísticas subordinadas a ela, usando conceitos “inteligentes”, que, nessa definição,significam conceitos derivados de inteligência artificial, biologia, matemática, ciênciafísica e natural. O objetivo final é melhorar o desempenho geral conjunto em relaçãoà aplicação de heurísticas isoladas. O nome vem da combinação do prefixo grego meta
que nesse contexto tem o sentido de além de, de alto nível e a palavra heurística que
41

42 Algoritmos Heurísticos e Metaheurísticas
vem de encontrar. Geralmente tal método produz boas soluções, ou permite resolver umproblema mais simples, que contém ou se intersecciona com a solução de um problemamais complexo.
Existe uma classe de métodos que é constituída por metaheurísticas baseadas emanálise de vizinhança, como mostra a seção 3.3. Métodos de busca tabu e colônia deformigas são algumas dessas metodologias, que são boas alternativas para a resoluçãode problemas de otimização. Outra classe de métodos é baseada na teoria da evolução,contando com técnicas classificadas como metaheurísticas bioinspiradas. Os algoritmosgenéticos e os sistemas imunológicos artificiais são parte desse conjunto. A seção3.4 descreve estas técnicas, que também se mostram muito eficientes na resolução deproblemas de otimização.
3.1 Aplicações
Há diversos problemas práticos que podem ser encarados como problemas deotimização e, para os quais, é possível utilizar as técnicas descritas neste capítulo. Aseguir uma lista com alguns dos principais problemas já estudados:
Roteamento de Veículos: Dado um conjunto de clientes que precisam recebermercadorias, uma fábrica tem que decidir a quantidade de carga a ser colocada emcada caminhão e quais caminhões irão atender quais clientes [Dantzig & Ramser(1959)].
Biologia Molecular: Um ramo da biologia chamado Biologia MolecularComputacional busca desenvolver novos métodos e algoritmos para soluçãodos desafios encontrados pelos pesquisadores nessa área [Parsons et al. (1995),Morohashi & Kitano (1999)].
Escalonamento em Escolas e Universidades (Timetabling): Todas as instituiçõesde ensino necessitam organizar suas aulas através da construção de horários para asdiversas turmas, considerando as disponibilidades de professores e alunos, alocaçãode salas e outras restrições relacionadas às disciplinas que oferecem [Burke &Newall (1999), Abramson (1992), Burke et al. (1996)].
Escalonamento de Trabalho Humano: Nos problemas de escalonamento depessoal, em geral, o que se pretende é obter uma escala de funcionários que respeiteum conjunto de restrições que podem ser trabalhistas ou relacionadas ao modo deoperação de uma empresa [Aickelin & Dowsland (2004), Dias et al. (2001)].

3.1 Aplicações 43
Escalonamento de Tarefas em Máquinas: Em certas fábricas, um produto finalé criado a partir da execução de pequenas tarefas. Essas tarefas possuem regras deprecedência entre si e particularidades que exigem um ou outro tipo de máquinapara sua execução. Com isso, dado um conjunto de itens a produzir, deseja-se descobrir, para cada máquina da fábrica, a ordem em que as tarefas devemser processadas de forma a minimizar o tempo de produção [Stallings (2004);Blazewicz et al. (2001)].
Corte de Materiais: Todas as empresas que possuem placas, rolos ou blocosprecisam cortar as peças em pedaços menores para vendê-las. O processo deotimização dos cortes busca reduzir as sobras, diminuindo os custos de fabricação.Esse problema é estudado com destaque na literatura e hoje já se encontraimplementado em algumas indústrias [Salto et al. (2006)].
Empacotamento: Nesse tipo de problema, é necessário encontrar a melhor maneirapara agrupar um conjunto de itens minimizando o espaço total necessário paraguardá-los [Falkenauer (1996), Lewisa et al. (2005)].
Localização de Facilidades: Nesse problema, há um conjunto de clientes queprecisam ser supridos com um determinado produto. O objetivo é escolher osmelhores locais para instalação das fábricas, de modo a suprir os clientes a umcusto mínimo de transporte [Kado (1995)].
Planejamento de Produção: Sabendo a demanda por produtos, é importantedecidir qual o volume de produção por mês para atender toda a demanda previstaminimizando os custos de produção e estocagem [Toso & Morabito (2005)].
Projeto de Circuitos Integrados: Em um projeto de circuitos integrados, alocalização dos chips em uma placa deve obdecer regras que considerem a topologiado circuito, o tamanho dos componentes, o próprio tamanho da placa e suascamadas. Otimizando a localização dos componentes na placa, é possível diminuiros gastos com ligações, diminuir a distância entre componentes que se comunicamcom mais frequência e, por fim, diminuir o tamanho do circuito como um todo[Lengauer (1990)].
Projeto de Redes com Restrições de Conectividade: Uma rede de dados oude voz precisa ser dimensionada considerando restrições críticas à operação. Oscomputadores importantes, por exemplo, devem ficar em posições que facilitema sua acessibilidade pelos outros componentes da rede. O mesmo ocorre com o

44 Algoritmos Heurísticos e Metaheurísticas
PABX, que deve ficar estrategicamente posicionado para conectar os ramais dosfuncionários. É necessário também definir qual será a disponibilidade da rede e osparâmetros de latência, jitter e perda de pacotes [Calegari et al. (1997)].
Problema do Caminho Mínimo: Na teoria de grafos, esse problema consiste naminimização do custo de travessia de um grafo entre dois nós (ou vértices). O custoé dado pela soma dos pesos de cada aresta percorrida [Goldberg (1989)].
Sistema de condução veicular: Essa pesquisa consiste em elaborar um sistema decondução de um veículo automóvel a partir da imagem recolhida por uma câmerade vídeo [Pomerleau & Jochem (1996)].
3.2 Algoritmos de busca local
Antes de analisar as metaheurísticas, é importante conhecer a técnica clássica de buscalocal. Em geral, um algoritmo desse tipo pode ser resumido pelos seguintes passos:
Passo 1 Inicializar com uma solução viável qualquer.
Passo 2 Enquanto o critério de parada não for satisfeito faça:
Passo 2.1 Escolher uma solução vizinha da solução corrente;
Passo 2.2 Definir a solução escolhida como corrente para o problema;
Passo 3 Retornar a melhor solução visitada no Passo 2.
Para caracterizar um algoritmo nesse esquema, é preciso definir bem qual o critério de
parada, o que caracteriza a vizinhança de uma solução (Passo 2.1) e o método de escolhada solução para a qual será feito o movimento (Passo 2.2).
Numa busca local clássica, o critério de parada do Passo 2 é atingido quando asolução corrente é tal que nenhum movimento pode ser realizado sem que se cheguea uma solução vizinha de custo pior ou igual ao da solução corrente. Diz-se que essasolução é um ótimo local. A Figura 3.1 descreve o comportamento da função objetivo deum problema de otimização com minimização de uma única variável. Considerando que avizinhança está restrita a um intervalo pequeno da reta real, nota-se que se o algoritmo debusca local chegar ao ponto de mínimo local indicado, o critério de parada será atingidoe, portanto, não mais será possível atingir o ótimo global da função objetivo.

3.3 Metaheurísticas de análise de vizinhança 45
3.3 Metaheurísticas de análise de vizinhança
Tomando como inspiração o procedimento de busca local e técnicas de observaçãoda vizinhança num problema de otimização, foram desenvolvidas metaheurísticas cujosalgoritmos têm como objetivo evitar ótimos locais e convergir para um ótimo global,como ilustra a figura 3.1. As metaheurísticas baseadas em análise de vizinhança buscam,dada uma solução, observar as soluções vizinhas e, utilizando técnicas próprias, avançarna busca de uma solução melhor. A técnica usada para observar a vizinhança é o quediferencia uma metodologia de outra.
Fig. 3.1: Gráfico de uma função objetivo com uma variável.
Alguns exemplos de metaheurísticas de análise de vizinhança são:Busca Tabu: utiliza mecanismos de memória e diversificação das soluções como
recursos para encontrar a solução ótima [Glover & Laguna (1995)];Colônia de Formigas: são algoritmos baseados no comportamento das formigas para
encontrar alimento [Caro et al. (1999)];Simulated Annealing: baseada originalmente em conceitos de Mecânica Estatística,
considerando a analogia entre o processo físico de resfriamento de sólidos e a resoluçãode problemas de otimização [Rojas et al. (2004)].
3.3.1 Busca Tabu
A idéia da técnica de Busca Tabu é permitir que haja movimento para soluçõesvizinhas mesmo que essas eventualmente deteriorem a função objetivo [Glover & Laguna(1995)]. Tipicamente, o movimento é feito de modo que se chegue à solução vizinha queapresente o melhor custo dentre todas as soluções vizinhas analisadas, mesmo que elaseja pior do que a solução corrente. Contudo, no caso de piora no custo, haveria um riscode que o movimento inverso levasse o algoritmo de volta à solução corrente da iteração

46 Algoritmos Heurísticos e Metaheurísticas
anterior. A maneira encontrada para impedir esse comportamento cíclico na Busca Tabufoi criar uma lista de movimentos que permanecem proibidos ou tabu durante um certonúmero de iterações. O número de iterações em que um movimento permanece na lista
tabu é denominado de prazo tabu. O critério de parada usualmente adotado restringe-sea um simples limite sobre o número total de iterações ou então sobre o número total deiterações sem que o custo da melhor solução visitada tenha sido alterado. Portanto, ospassos básicos de um algoritmo de busca Tabu são:
1. Iniciar uma lista Tabu vazia.
2. Obter um solução inicial S.
3. Inicializar S∗ fazendo S∗ = S.
4. Enquanto o critério de parada não for satisfeito faça
(a) Encontrar o conjunto Q(S) das soluções vizinhas de S que podem seratingidas por movimentos que não são Tabu.
(b) Escolher S ′ como sendo a solução de melhor custo em Q(S).
(c) Adicionar o movimento m(S, S ′) que leva de S a S ′ à lista Tabu.
(d) Atualizar S com S ′, ou seja, mover de S para S ′.
(e) Se a solução S ′ é melhor que S∗ então S∗ = S ′.
5. Retornar a melhor solução encontrada.
A partir desses passos é possível perceber que o algoritmo de Busca Tabu possuialguns parâmetros que precisam ser fixados, como, por exemplo, o número de iteraçõesque definem o critério de parada e o tamanho da lista Tabu. O ajuste desses parâmetros éuma tarefa essencial para o bom desempenho do algoritmo.
Finalmente, pode-se dizer que a Busca Tabu, por ser uma heurística, não oferecequalquer garantia de que irá produzir uma solução ótima. Mas, em geral, as soluçõesgeradas são bem superiores àquelas retornadas pelas heurísticas clássicas de busca local[Glover et al. (2003), Dias et al. (2002)].
3.3.2 Colônia de Formigas
A metaheurística da colônia de formigas foi proposta por Dorigo e Caro em 1999[Caro et al. (1999)] com base em um trabalho anterior do mesmo autor que definiu oconceito de sistema de formigas [Dorigo (1992)].

3.3 Metaheurísticas de análise de vizinhança 47
Para entender como funciona a metodologia, o ideal primeiro é analisar um sistemade colônia de formigas tal como se apresenta na natureza. As formigas são insetos sociaisque possuem um sistema complexo de organização e divisão de tarefas, cuja principalfunção é garantir a sobrevivência do formigueiro. Em uma colônia, cada formiga temuma função específica e um dos principais objetivos é encontrar alimento e carregá-lo atéo formigueiro para estocagem. A metaheurística da colônia de formigas foi inspirada naobservação dessas colônias de formigas reais, em particular, em como elas encontram omenor caminho entre a fonte de alimentos e o formigueiro.
Inspirando-se nessas idéias, Dorigo e Caro [Caro et al. (1999)] criaram ametaheurística da colônia de formigas. Uma das aplicações clássicas do algoritmo é noproblema do caixeiro viajante. Nesse problema, cada “formiga” constrói uma soluçãopara o problema a partir de um dos nós da rede. A formiga se move por uma sequênciade locais vizinhos de acordo com uma distribuição de probabilidade dada por:
pijk =
[τij ][ηij ]
β∑l∈Jk
i[τij ][ηij ]β
se j ∈ Jki0 caso contrário
(3.1)
onde:
pijk = probabilidade da formiga k, que se encontra em i, escolher o nó j comopróximo nó a ser visitado;
τij = quantidade de feromônio1 existente no arco (i, j). Inicialmente, adota-se ummesmo valor τ0 para todos os arcos da rede;
ηij = função heurística que representa a atratividade do arco (i, j).
Jki = conjunto de pontos que ainda não foram visitados pela formiga k, que seencontra atualmente no ponto i;
β = valor heuristicamente escolhido, que pondera a importância da quantidade deferomônio existente no arco em relação à distância entre os nós i e j.
Segundo essa função de probabilidade a preferência da formiga por determinadocaminho é maior para os caminhos com mais feromônio e com menor distância. Sendoassim, após um certo número N de formigas terem finalizado suas rotas, a quantidade deferomônio é atualizada em cada arco de modo a reforçar o caminho obtido pela melhorformiga. O procedimento se repete até que um número máximo de iterações tenha sidoalcançado ou caso não se verifiquem melhorias significativas nas soluções obtidas.
1O Feromônio é uma substância química expelida pela formiga ao percorrer um determinado caminho.Essa substância pode ser facilmente percebida por outras formigas.

48 Algoritmos Heurísticos e Metaheurísticas
3.3.3 Simulated Annealing
Simulated Annealing é uma técnica de otimização inspirada na observação de algunsprincípios da termodinâmica [Rojas et al. (2004)]. Um algoritmo de Simulated Annealingse utiliza de procedimentos similares ao arrefecimento ou resfriamento de metais aosubstituir uma solução encontrada por uma solução vizinha no espaço de soluçõesfactíveis. A solução vizinha é escolhida com base em uma função objetivo e uma variávelT , numa analogia com a temperatura. Quanto maior o valor de T , maior o espaço debusca. À medida em que o algoritmo avança, o valor de T diminui, num processochamado resfriamento, até que ocorra a convergência.
A busca se inicia a partir de uma solução inicial qualquer. A cada iteração é geradoum único vizinho s′ a partir da solução corrente s. Considerando a solução inicial e essenovo vizinho calcula-se o δ correspondente da função objetivo. Esse valor é dado por:δ = f(s′)− f(s), onde f(·) representa a função objetivo. De acordo com o valor de δ épossível obter as seguintes conclusões:
δ < 0: Há uma redução de energia, o que quer dizer que a nova solução é melhorque a anterior. O método aceita a solução e s′ passa a ser a nova solução corrente.
δ = 0: Caso de estabilidade, não havendo redução de energia. Na verdade, situaçãopouco provável de acontecer na prática. A aceitação da solução é, portanto,indiferente.
δ > 0: Houve um aumento do estado de energia. A aceitação desse tipo desolução é mais provável a altas temperaturas e bastante improvável a temperaturasreduzidas. Para calcular a probabilidade de se aceitar a nova solução usa-se umafunção conhecida por fator de Boltzmann dada por e−δ/T , onde T é um parâmetrodo método, que, conforme explicado acima, é uma analogia à Temperatura. Quantomaior o valor de T maiores as chances de essa solução ser escolhida.
Inicialmente, a temperatura T assume um valor elevado, T0. Após um número fixode iterações, a temperatura é gradativamente diminuída por uma razão de resfriamentor, tal que Tn = r ∗ Tn−1, sendo 0 < r < 1. À medida que o algoritmo evolui e ovalor de T diminui, ele se aproxima da convergência para um mínimo/máximo, pois aprobabilidade de aceitar movimentos que possam piorar a solução diminui. O sistemafica estável quando a temperatura está em um valor próximo de zero e nenhuma soluçãovizinha pior que a corrente é aceita. A estabilidade marca também o fim do processo ea solução encontrada é um mínimo local. Variações nas taxas de resfriamento durante o

3.4 Algoritmos Bioinspirados 49
curso do algoritmo ou até mesmo reaquecimento (aumento de T ) são técnicas geralmenteusadas para permitir a exploração de novas soluções.
3.4 Algoritmos Bioinspirados
As metaheurísticas de análise da vizinhança apresentam uma classe de metodologiasrelativamente simples e bastante robustas na solução de problemas com múltiplos ótimos.Explorando o espaço de soluções vizinhas de maneira eficiente, tais técnicas tem comoobjetivo escapar de ótimos locais, em direção ao ótimo global. Uma outra classe demetaheurísticas também importante na busca de soluções para problemas desse tipo sãoos algoritmos bioinspirados [Goldberg (1989), Glover et al. (2003)]. Neste trabalho, estesalgoritmos são utilizados preferencialmente em relação às metaheurísticas de análise devizinhança, devido ao conhecimento prévio adquirido sobre o assunto [Duarte (2006),Dias et al. (2001)]. Apesar de não ser objetivo desta pesquisa, as metaheurísticas deanálise de vizinhança podem também ser aplicadas nestes problemas, e constituem umespaço de estudo futuro válido neste contexto.
Os algoritmos bioinspirados são um subconjunto de métodos com base heurística e,por esse motivo, não conseguem garantir matematicamente que a solução encontrada apósum determinado número de iterações é uma solução ótima. No entanto, na prática, namaioria das vezes esses algoritmos são muito úteis para encontrar soluções próximas dasótimas para problemas até então sem nenhuma solução viável ou adequada.
Este trabalho apresenta duas estratégias baseadas em algoritmos bioinspirados:Algoritmos Genéticos e Sistemas Imunológicos Artificiais.
3.4.1 Algoritmos Genéticos
Evolução (do latim, evolvere = evoluir, desenvolver, expandir, progredir) pode serdefinida como um processo que provoca mudanças hereditárias em uma população atravésdas gerações. A evolução é sujeita a três condições principais:
1 A existência de indivíduos capazes de se reproduzir através de processos derecombinação;
2 A possibilidade de ocorrer mudanças aleatórias ou mutações diferenciando umindíviduo de outro e criando maior diversidade na população;
3 A sobrevivência dos indivíduos mais bem adaptados através da seleção natural;

50 Algoritmos Heurísticos e Metaheurísticas
No século XIX, mais especificamente em 1858, Charles Darwin concluiu seus longosanos de observações e experimentos apresentando sua teoria de evolução através daseleção natural. Tal teoria foi apresentada em 1858 num artigo escrito por CharlesDarwin e Alfred Russel Wallace [Darwin & Wallace (1858)] e popularizada no livro deDarwin “Origem das Espécies” (1859) [Darwin (1859)]. De acordo com essas idéias, aevolução é baseada no conceito de seleção natural, na qual indivíduos mais bem adaptadostêm maior probabilidade de sobreviverem e se reproduzirem. No século XX, surgiu amoderna teoria da evolução, combinando os conceitos de seleção natural estudados porDarwin e Wallace com a teoria genética criando, assim, o princípio básico da genéticapopulacional: a variabilidade entre indivíduos em uma população de organismos quese reproduzem sexualmente é produzida pela mutação e pela recombinação genética.Segundo essa teoria, uma combinação de genes dá origem a um cromossomo, que,sozinho ou combinado com outros cromossomos, constitui um indivíduo. O conjuntode indivíduos, denominado população, evolui privilegiando os mais aptos, que tendem asobreviver até a geração seguinte. Os indivíduos de uma população geralmente competementre si por recursos como comida, água e abrigo. Em uma mesma espécie, animaismais bem adaptados tendem a se sobressair em relação aos outros e, consequentemente,deixar mais descendentes. Ou seja, os genes que garantem a melhor adapção têm maioreschances de serem transmitidos para a próxima geração. Os mecanismos de alteração degenes de um cromossomo, como o crossover (recombinação) e a mutação, são as fontespara criação de espécies mais bem adaptadas.
Nos anos 1950 e 1960, muitos biólogos iniciaram o desenvolvimento de simulaçõescomputacionais de sistemas genéticos com o objetivo de analisar e buscar maioresdetalhes sobre o funcionamento do processo de evolução. John Holland foi um dospesquisadores que se dedicaram ao estudo e à pesquisa no tema. Após organizar suasidéias, ele escreveu um livro em 1975 denominado: “Adaptation in Natural and ArtificialSystems” [Holland (1975)]. Esse livro ainda hoje é um dos mais importantes sobreAlgoritmos Genéticos (AGs).
Os AGs são métodos de busca e otimização que simulam os processos naturais deevolução, aplicando a idéia darwiniana de seleção e conceitos da genética. É certamenteo algoritmo bioinspirado mais difundido e aplicado pela comunidade científica. Nessametodologia, cada indivíduo é representado por um cromossomo, que é definido comouma possível solução para um dado problema. A cada indivíduo se atribui uma pontuaçãode adaptação (função de fitness) que depende da qualidade da solução que ele apresentapara o problema em questão. Os mais adaptados, ou seja, aqueles que têm uma pontuaçãomaior, têm maior probabilidade de se reproduzir através de cruzamento com outros

3.4 Algoritmos Bioinspirados 51
indivíduos da população. Tem-se então um processo de recombinação criando a próximageração de indivíduos, que será uma mistura das características dos indivíduos melhoradaptados. Durante o processo evolutivo também podem ocorrer mutações, que permitemaos indivíduos modificar algumas de suas caraterísticas, criando soluções que podem serbastante diferentes das originais. Com isso, as gerações evoluem até que seja encontradauma solução satisfatória para o problema analisado [Goldberg (1989)].
Um algoritmo genético pode explorar o amplo espaço de soluções factíveis e,algumas vezes, caminhar por soluções infactíveis até encontrar uma solução consideradasatisfatória para o problema. Alguns componentes importantes de uma estrutura deotimização através de algoritmos genéticos são: o espaço de busca a ser considerado,que inclui todas as possibilidades de soluções para um determinado problema; a funçãode avaliação (fitness) e a composição de um indivíduo ou cromossomo.
3.4.1.1 A Técnica
A técnica para confecção de um algoritmo genético geralmente prevê que inicialmenteseja gerada uma população formada por um conjunto aleatório de indivíduos, que formama primeira solução para o problema. Eles são avaliados através de uma função de fitness
que estabelece uma classificação, permitindo mensurar e distinguir os indivíduos melhoradaptados, ou seja, os indíviduos que, no grupo, representam as melhores soluções parao problema. Esses indivíduos então passam por operações baseadas em recombinação,mutação e seleção. A metodologia prevê que uma parte dos indivíduos seja mantida napróxima geração e a restante seja exterminada. Os membros mantidos podem novamentese reproduzir através de recombinação ou sofrer mutações criando novos indivíduos quepodem estar mais bem adaptados ou menos adaptados que os anteriores. O algoritmoevolui através das gerações até que se atinja um critério de parada. O pseudo-código deum algoritmo genético pode ser descrito pelos passos a seguir:
1. Inicialize a população usando um Método de Inicialização;
2. Para cada geração faça até a condição de parada ser atingida:
a. Avalie a função de fitness da população;
b. Faça recombinações de pares de indivíduos que fazem parte da população,até que o número de recombinações geradas seja igual ao parâmetro definido comotaxa de recombinação:
c. Faça mutações nos indivíduos, até que o número de mutações geradas sejaigual ao parâmetro definido como taxa de mutação:

52 Algoritmos Heurísticos e Metaheurísticas
d. Avalie o fitness dos novos indivíduos da população;
e. Use um método de seleção para escolher quais indivíduos da populaçãopermanecerão e quais serão eliminados;
f. Com base nos indivíduos escolhidos, constitua a população para a próximageração;
3. Fim.
3.4.1.2 Codificação
A codificação é uma maneira de representar uma solução para o problema real.Essa representação se dá através de um cromossomo composto por um conjunto degenes, que definem o genótipo. A partir da avaliação desse cromossomo é possívelclassificá-lo em relação aos outros. Os cromossomos mais bem adaptados (com o melhorfenótipo) são aqueles com a melhor função de avaliação. É importante ressaltar que oprocesso de codificação é um dos pontos críticos de um algoritmo genético, pois definiráa complexidade e a maneira como os dados serão tratados no decorrer da aplicação dastécnicas evolutivas.
A técnica usada para codificar as soluções depende do problema e da construção doalgoritmo genético [Hajela & Lin (2000)]. A codificação clássica, usada no trabalhode Holland, consiste em usar strings de bits. No entanto, quando essa codificação éaplicada em problemas que possuem variáveis contínuas e cujas soluções requeridasnecessitam boa precisão numérica, os cromossomos tornam-se longos. Esse é um dosmotivos que levam a utilizar codificação inteira ou real. Na codificação inteira, um geneé representado por uma variável numérica inteira, limitada pela base numérica escolhida.Já na codificação real, um gene é representado por um valor real como mostrado na figura3.2. Um cromossomo pode ser composto por múltiplos genes quando o problema a serresolvido envolve duas ou mais variáveis [Herrera et al. (1998), Lucasius & Kateman(1989)]. As codificações inteira e real vêm ganhando espaço na literatura, pois podem serutilizadas em um conjunto maior de aplicações.

3.4 Algoritmos Bioinspirados 53
Fig. 3.2: Codificação Binária, Inteira e Real
3.4.1.3 Função de Avaliação - Fitness
A função de fitness (avaliação) é uma maneira de avaliar cada cromossomo quanto àsua adaptação. De acordo com o fitness cada cromossomo recebe uma nota que permiteordená-los em um ranking. Nesse ranking são listados todos os indivíduos, desde oindivíduo mais bem adaptado até o menos adaptado, ou seja, desde a melhor soluçãoencontrada para o problema até a pior solução existente naquela geração.
Deve-se analisar bem o problema para adotar uma função de fitness que consideretodas as suas características. Ela não pode ser parcial, pois, se o for, pode trazer umaanálise inadequada da população, selecionando soluções erradas e, em alguns casos, nãopermitindo encontrar uma solução satisfatória para o problema. Além disso, a função defitness deve ser calculada de forma rápida, pois será aplicada para cada indivíduo de cadapopulação e das sucessivas gerações. Experiências práticas mostram que grande partedo tempo gasto por um algoritmo genético é na avaliação da função de fitness [Crosby(1973), Kjellstrom (1991), Koza (1992), Duarte (2006)].
3.4.1.4 Operadores genéticos
Os operadores genéticos transformam a população através de sucessivas gerações,estendendo a busca até que um determinado critério de parada seja atingido. Eles sãouma característica importante dos algoritmos genéticos, pois possibilitam a evolução dasgerações em busca de uma solução adequada para um problema.
Os operadores genéticos básicos são três: seleção, mutação e recombinação.
3.4.1.4.1 Seleção Um dos propósitos do operador seleção é selecionar pares deindivíduos para recombinação (crossover), com o objetivo de aumentar a probabilidade

54 Algoritmos Heurísticos e Metaheurísticas
de reproduzir membros da população que estejam bem adaptados. Esse operador tambémpode ser usado em outras etapas do algoritmo genético, como, por exemplo, num eventualmomento em que seja necessário reduzir o tamanho da população e preservar os melhoresindivíduos ou durante um processo de elitismo.
Existem três maneiras clássicas de selecionar os indivíduos:(1) Método da roletaNesse método, a probabilidade de um indivíduo ser escolhido é proporcional ao valor
da sua função de fitness. Didaticamente, pode-se pensar num sorteio baseado num roletaformada por um círculo dividido em várias fatias com áreas proporcionais aos valoresda função de fitness associados aos individuos. Dessa forma, a maior fatia fica com oindivíduo melhor adaptado, a fatia seguinte com o próximo indivíduo e assim por dianteaté o último indivíduo (vide Figura 3.3). Imaginando que há uma agulha no centro daroleta, ela irá girar e assim selecionar um dos indivíduos [Holland (1992)].
Esse método permite selecionar os melhores indivíduos, mas, em contrapartida, podegerar perda da diversidade das soluções rapidamente.
Fig. 3.3: Método da roleta.
(2) Método do torneioNo torneio é utilizado o conceito de disputa entre um conjunto de indivíduos. Para
selecionar K indivíduos, podem ser realizadas K disputas. Uma disputa consiste naescolha de n indivíduos ao acaso na população, e o indivíduo cuja função de fitness seja amelhor no subconjunto é o vencedor. O método do torneio tem parâmetros ajustáveis quepermitem um controle da pressão seletiva [Goldberg (1989)].

3.4 Algoritmos Bioinspirados 55
Fig. 3.4: Método do torneio.
(3) Método do RankNesse método, a probabilidade de escolha de um indivíduo é definida de acordo com
uma função ζ(·) que depende da classificação do indivíduo segundo a função de fitness
(rank), frente aos demais membros da população [Baker (1985),Joines & Houck (1994)].As Figuras 3.5 e 3.6 trazem uma comparação desse método com o método da roleta.Pela figura observa-se que, no método da roleta, a área de cada fatia é dada diretamentepelo valor da função de fitness, enquanto, no método do rank, a área é definida pelafunção ζ(rank) correspondente a um mapeamento da função de fitness de acordo com afunção ζ(·). Esse método é util quando o valor da função de fitness difere muito de umcromossomo para outro. Quando o valor da função de fitness do melhor indivíduo é muitomelhor que a dos outros, a sua fatia do círculo na figura 3.5 pode ser muito grande. Ouseja, a probabilidade desse indivíduo ser selecionado é muito alta. No método de rank,a distribuição no círculo é mais uniforme, porque a fatia do círculo não é diretamenteproporcional ao valor da função de fitness e sim dada pela função de rank ζ(·), comomostra a figura 3.6. Portanto, o método de rank tende a ter uma pressão seletiva menorque a associada ao método da roleta.
Fig. 3.5: Método da roleta com melhor indivíduo distante dos restantes sob a ótica dofitness.

56 Algoritmos Heurísticos e Metaheurísticas
Fig. 3.6: Método do rank para o mesmo problema da figura 3.5, com mapeamento ζ(·) dafunção de fitness.
3.4.1.4.2 Recombinação Os cromossomos a serem recombinados são tipicamenteescolhidos através do operador de seleção. No caso binário, dentre as maneiras derecombinar indivíduos, descrevem-se três [Goldberg (1989)]:
(1) Crossover de um pontoSelecionam-se dois cromossomos que são repartidos em um determinado ponto dando
origem a dois segmentos em cada cromossomo. Os segmentos posteriores são trocados edá-se origem a dois novos cromossomos filhos:
Exemplo: Supondo dois pais:
Pai 1: 010110100
Pai 2: 110010010
Se aleatoriamente o ponto 3 fosse selecionado então os filhos ficam com as seguintesconfigurações:
Filho 1: 010 010010
Filho 2: 110 110100
(2) Crossover multi-pontoNesse caso, muitos pontos de cruzamento podem ser utilizados, como mostra a Figura
3.7, na qual são considerados dois pontos de corte em cada cromossomo;
Fig. 3.7: Exemplo de cross-over multiponto.

3.4 Algoritmos Bioinspirados 57
(3) UniformeNão se utilizam pontos de cruzamento, mas define-se um parâmetro global (função
probabilidade) que informa qual a probabilidade de cada parte do cromossomo (gene) sertrocada entre os pais.
Caso a codificação dos cromossomos seja real, podem-se definir os cromossomos:c1 = (c11, c
21, . . . , c
N1 ) e c2 = (c12, c
22, . . . , c
N2 ) e o cromossomo recombinado por: r =
(r1, r2, . . . , rN). Alguns tipos mais difundidos de recombinação real são [Michalewicz(1996)]:
(1) Crossover de médiaNesse caso, o cromossomo recombinado é dado por: r = (c1+c2)
2.
(2) Crossover aritméticoO crossover aritmético admite que sejam gerados dois novos cromossomos dados por:
r1 = βc1 + (1− β)c2
r2 = (1− β)c1 + βc2
O parâmetro β é usualmente uma variável aleatória com distribuição uniforme entre 0e 1: β = U(0, 1)
(3) Crossover heurísticoEsse crossover utiliza os valores das funções de fitness dos pais, calculando um
“gradiente” de evolução ao qual é atribuído um peso ρ.
r = c1 + ρ(c1 − c2) (3.2)
onde ρ = U(0, 1) e c1 representa uma solução com melhor valor de fitness que c2.
Caso a solução gerada r seja infactível, um novo valor para ρ é escolhido.
3.4.1.4.3 Mutação O operador de mutação simplesmente modifica o valor de um genepara um novo valor escolhido de forma aleatória. A mutação aumenta a diversidade dapopulação, pois introduz novo material no repertório genético.
No caso binário, a mutação consiste em substituir com certa probabilidade (taxa demutação) o valor de um bit. Existem basicamente duas maneiras de implementá-la. Aprimeira maneira é trocar um bit escolhido aleatoriamente no cromossomo. A segunda égerar um bit, que pode ser 0 ou 1, e escolher a posição que será sobrescrita com o valor dobit gerado. Nesse último caso, pode ser que não haja nenhuma troca, já que um bit 0 pode

58 Algoritmos Heurísticos e Metaheurísticas
ser substituído por um outro bit 0, por exemplo. Para os casos de codificação não-binária,as possibilidades de mutação aumentam de acordo com a base numérica escolhida.
No caso de uma mutação real, as estratégias mais usadas são as seguintes [Davis &Mitchell (1991)]:
(1) Mutação uniformeAssim como na mutação binária, escolhe-se aleatoriamente um componente k ∈
[1, 2, . . . , N ] do cromossomo c = [c1, . . . , ck, . . . , cN ] e gera-se um novo indivíduo r =
[c1, . . . , rk, . . . , cN ], onde rk é um número aleatório com distribuição de probabilidadeuniforme no intervalo válido para a operação [ai, bi], dado pelo limite superior bi e pelolimite inferior ai.
(2) Mutação não uniformeUm dos genes é substituído por um valor aleatório dado por uma distribuição não
uniforme. Matematicamente, definindo o gene j do cromossomo como o gene escolhido,tem-se:
ri =
ci + (bi − ci)γ(G) , se α < 0, 5 e i = j
ci − (ci − ai)γ(G) , se α ≥ 0, 5 e i = j
ci , caso contrario
(3.3)
onde:
• [ai, bi] representa o intervalo válido para essa operação;
• γ(G) = (β(1 − GGmax
))b, onde Gmax é a quantidade máxima de gerações e G é onúmero da geração;
• α e β são variáveis aleatórias uniformes U(0, 1).
(3) Mutação gaussianaEssa estratégia busca provocar uma pequena perturbação nos genes adicionando um
vetor de variáveis aleatórias gaussianas independentes, com média zero e variância σ:
r = c + N(0, σ) (3.4)
3.4.1.5 Convergência
Um algoritmo genético deve ser continuamente monitorado quanto à suaconvergência. Devem-se incluir maneiras de se observar o algoritmo no decorrer dasiterações, para avaliar se a população está evoluindo significativamente no sentido demelhorar a função de fitness. Se a evolução permitir melhorar a função de fitness

3.4 Algoritmos Bioinspirados 59
de maneira consistente e contínua, há uma grande chance de encontrar uma soluçãosatisfatória para o problema analisado. Se o algoritmo não convergir, é necessárioreavaliar os parâmetros, função de fitness e até mesmo promover ajustes no processo decodificação [Bäck (1991)].
Convergência prematuraOs Algoritmos Genéticos são comumente utilizados em problemas que possuem
ótimos locais, devido à sua capacidade de evitar esses ótimos. No entanto, em algunscasos, pode ser que a solução final encontrada não seja um ótimo global. Quando oalgoritmo converge para um ótimo local, pode ter ocorrido uma convergência prematura.Nesse caso, faz-se necessário primeiro calcular a função de fitness para avaliar a qualidadeda solução encontrada. Caso essa qualidade não seja satisfatória, é importante reavaliar osprincipais pontos da implementação do algoritmo. A convergência prematura geralmenteestá associada a uma alta pressão seletiva. O uso de operadores de seleção inadequadospara o problema, por exemplo, pode ser um dos fatores que levam a isso. A escolha demétodos de recombinação e mutação também tem influencia direta na pressão seletiva e,como consequência, tem participação importante para evitar a diminuição da diversidadepopulacional.
3.4.1.6 Parâmetros
É importante analisar de que maneira alguns parâmetros influem no comportamentodos Algoritmos Genéticos, para que se possa estabelecê-los conforme as necessidades doproblema e dos recursos disponíveis. Alguns desses parâmetros são [Davis & Mitchell(1991):
(1) Tamanho da PopulaçãoUma população pequena oferece uma pequena cobertura do espaço de busca,
podendo levar à convergência prematura. Uma grande população fornece uma melhorcobertura do domínio do problema e pode ajudar a evitar a convergência prematura parasoluções locais. Entretanto, com uma grande população, tornam-se necessários recursoscomputacionais maiores ou um tempo maior de processamento.
(2) Taxa de CruzamentoQuanto maior for essa taxa, mais rapidamente novos indivíduos serão introduzidos
na população. Entretanto, isto pode gerar um efeito indesejado, pois a maior parteda população será substituída, podendo ocorrer perda de indivíduos bem adaptados oupromissores. Com um valor baixo, o algoritmo pode se tornar muito lento.
(3) Taxa de MutaçãoUma baixa taxa de mutação faz com que o algoritmo fique estagnado em um conjunto

60 Algoritmos Heurísticos e Metaheurísticas
de soluções. Uma taxa razoável permite explorar outros pontos do espaço de busca. Jácom uma taxa muito alta a busca se torna essencialmente aleatória.
Os parâmetros podem ser fixados no início do algoritmo, sem alterações durante asua execução, ou podem ser alterados dinamicamente, em tempo de execução. Técnicaspara ajuste dinãmico de parâmetros constituem um campo de estudo importante naimplementação de metaheurísticas [Golden et al. (1998), Grefenstette (1986), P. et al.
(2001)].
3.4.1.7 Aplicando a técnica
Em geral, quando é necessário elaborar um algoritmo genético, devem-se analisaralguns pontos importantes:
1 Escolher uma codificação adequada para o problema;
2 Eleger uma maneira de criar a população inicial;
3 Construir uma função de fitness que permita ordenar os cromossomos de acordocom a função objetivo;
4 Analisar os operadores genéticos que permitam alterar a composição dos novoscromossomos gerados pelos pais durante a reprodução;
5 Estabelecer os valores dos parâmetros que o algoritmo genético usa (tamanho dapopulação, probabilidades associadas com a aplicação dos operadores genéticos,etc.).
Finalmente, a Figura 3.8 mostra uma representação esquemática da operação de umalgoritmo genético.

3.4 Algoritmos Bioinspirados 61
Fig. 3.8: Ilustração da técnica de algoritmo genético.
3.4.2 Sistema Imunológico Artificial (Algoritmo opt-aiNet)
O algoritmo bioinspirado denominado opt-aiNet (Optimization Version of an ArtificialImmune Network) foi concebido a partir da teoria moderna sobre o sistema imunológico.Trata-se de uma combinação de seleção clonal, maturação de afinidade e do conceitode redes imunológicas [de Castro & Timmis (2002)]. Em [Attux (2005)], realizou-se um trabalho sobre a aplicabilidade dos algoritmos bioinspirados, particularmente doalgoritmo opt-aiNet, a alguns problemas típicos de processamento de sinais. Um dosresultados do trabalho foi a constatação da capacidade do algoritmo de evitar mínimoslocais, permitindo obter melhorias significativas em cenários de otimização multimodais,o que nos motivou a adotá-lo nesse trabalho.
As seções a seguir têm o objetivo de descrever em maiores detalhes esta técnica deotimização.
3.4.2.1 Propriedades
Essa técnica destaca-se por sua escalabilidade, robustez e flexibilidade. Ele se inspiranas seguintes propriedades do sistema imunológico [do Amaral (2006)]:
1. Unicidade: cada ser vivo possui um sistema imunológico com característicasespecíficas. Cada um deles possui capacidades e vulnerabilidades particulares;

62 Algoritmos Heurísticos e Metaheurísticas
2. Reconhecimento de padrões internos e externos ao sistema: o objetivo principaldo sistema é reconhecer e controlar os organismos que pertencem ou não ao sistema,preservando os internos e eliminando os agentes externos;
3. Detecção de anomalia: O sistema imunológico é capaz de detectar agentespatogênicos (causadores de anomalias) e neutralizá-los, mesmo que seja a primeiravez que esses agentes tenham entrado no organismo;
4. Detecção imperfeita: para melhorar o processo de defesa, o sistema pode reagirantes mesmo que seja feito o reconhecimento completo de um elemento causadorpatógeno. Ou seja, mesmo que a identificação do agente patógeno esteja em seusestágios iniciais, o organismo pode já demonstrar alguma reação;
5. Aprendizagem por reforço: se o sistema encontrar o mesmo agente patógeno emoutro momento no futuro sua metodologia de ataque será aprimorada;
6. Memória: o sistema imunológico possui memória, armazenando as informaçõessobre os agentes que entraram no organismo para melhorar a resposta futura, casohaja nova infecção.
3.4.2.2 Definições
Sob o conceito de seleção clonal e maturação de afinidade, o sistema imunológicopode ser entendido como uma composição de células (imuno-células) que carregamreceptores para combater determinados antígenos (agentes causadores de doenças). Naprática, quando esses receptores reconhecem um dado antígeno, eles são estimulados aproliferar, tal como acontece quando um grupo de células defensoras em nosso organismoencontra um vírus ou uma bactéria. No decorrer do processo, as células passam pormutações controladas na tentativa de produzir receptores capazes de se adequar cadavez mais aos antígenos invasores. A teoria de redes imunológicas também estabeleceque é possível que estas imuno-células interajam entre si gerando o que se chama de“eigenbehavior” (comportamento próprio) mesmo se não houver presença de organismosestranhos (antígenos). Isto significa que as células imunes podem evoluir mesmo sem apresença de invasores [de Castro & Timmis (2002)].
3.4.2.3 Funcionamento do sistema imunológico
Num organismo há uma série de camadas de defesas que buscam bloquear de formaefetiva os ataques externos. A figura 3.9 mostra estas camadas, descritas em maioresdetalhes a seguir [do Amaral (2006)]:

3.4 Algoritmos Bioinspirados 63
Pele: é a primeira barreira contra ataques externos isolando o organismo do contatodireto com o meio.
Barreiras Químicas: constituem barreiras fisiológicas onde condições detemperatura e pH são impróprias para sobrevivência de organismos estranhos.
Sistema Imune Inato: constitui a primeira linha de defesa do organismo. Ela ageenquanto o organismo procura detectar os invasores e criar defesa contra eles. Ascélulas denominadas fagocitárias, como macrófagos e neutrófilos, são as principaisatuantes nesse momento. Elas desempenham um papel crucial na iniciação eposterior direcionamento das respostas imunes adaptativas, enquanto o sistemaimunológico constrói as respostas adaptativas aos agentes patógenos.
Sistema Imune Adaptativo: as mais especializadas células de defesa doorganismos são os linfócitos produzidos na medula óssea e no timo. Os linfócitossão criados com uma programação que os permite atacar um antígeno (agentepatógeno) específico. Somente os linfócitos cujos receptores se combinem comantígenos presentes no organismo são multiplicados em larga escala. Após a ligaçãodo anticorpo de superfície ao antígeno, a célula é ativada para proliferar e produziruma série de células semelhantes, conhecidas como clones. Essas células secretamanticorpos com uma especificidade idêntica à da célula original.
Fig. 3.9: Funcionamento do sistema imunológico. Fonte: [de Castro & Zuben (2000)].
3.4.2.4 Sistema Imune Adaptativo
O sistema imune adaptativo é o foco desse estudo. Como visto, os linfócitos sãoas principais células do organismo, e se unem aos agentes patógenos (antígenos) com

64 Algoritmos Heurísticos e Metaheurísticas
o objetivo de neutralizá-los. Os linfócitos são formados por um ou mais receptores (osanticorpos) e os antígenos são formados por epítopos. Tipicamente, um antígeno contémvários epítopos e um linfócito contém cerca de 100.000 anticorpos do mesmo tipo. AFigura 3.10 mostra a ligação entre um anticorpo e um epítopo. Podem ser necessáriosvários linfócitos para neutralizar um antígeno [de Castro & Zuben (2000)].
Fig. 3.10: O linfócito e o antígeno. Fonte: [de Castro & Zuben (2000)].
3.4.2.4.1 Afinidade A afinidade entre o linfócito e o antígeno é dada pela quantidadede ligações estabelecidas entre seus receptores e os epítopos de um antígeno. A detecçãode um antígeno é, na maioria das vezes, aproximada, porque é muito difícil evoluirestruturas que sejam exatamente complementares a epítopos que o organismo nunca tenhaencontrado antes. Se houvesse necessidade de construir um linfócito capaz de neutralizartodos os epítopos de um antígeno, a probabilidade destas duas estruturas se encontraremno organismo seria muito pequena. Essa propriedade dá aos linfócitos a capacidade dedetectar e atuar em um subconjunto de epítopos. Isso significa que um número menorde linfócitos é necessário para fornecer proteção contra uma grande variedade de agentespatogênicos.
3.4.2.4.2 Diversidade Para atuar de forma efetiva contra os antígenos, é necessárioque o sistema imunológico possua uma diversidade grande de receptores, para garantirque pelo menos alguns linfócitos sejam ligados a um determinado agente patogênico. Ocorpo humano fabrica cerca de 106 proteínas diferentes. Essas proteínas podem ser usadaspara construir receptores que reconheçam cerca de 1016 proteínas diferentes [Bairochet al. (2005)]. Os receptores são contruídos a partir da recombinação aleatória de genes deantecessores como mostra a Figura 3.11. O número de combinações possíveis é bastantealto gerando uma diversidade muito grande na estrutura dos receptores.

3.4 Algoritmos Bioinspirados 65
Fig. 3.11: Recombinação para geração de anticorpos. Fonte: [de Castro & Zuben (2000)].
3.4.2.4.3 Maturação de Afinidade Para criar defesa contra todos os padrões dosantígenos, é necessário construir uma grande diversidade de receptores com limiares deafinidade baixos. Essa estratégia é importante para garantir ao sistema imunológico poderpara detectar qualquer agente patógeno vivo. No entanto, até que todos os epítopos deum antígeno sejam ligados aos anticorpos dos linfócitos, é necessário um tempo paraconstrução e produção de todos os anticorpos necessários. A produção de linfócitos éguiada pelo nível de afinidade entre eles e os antígenos presentes no organismo naquelemomento. Quanto maior o nível de afinidade de um linfócito, maior é a sua produção:esse processo é conhecido como maturação da afinidade. Como mostra a Figura 3.12, esseprocesso se utiliza de um tipo especial de linfócito, conhecido como célula B, produzidona medula óssea. Uma célula B é ativada através da união com agentes patogênicos. Apartir desse momento, a célula expele uma forma solúvel de seus receptores capaz de seunir aos agentes patógenos. Se a afinidade dessas células com os antígenos for alta, elassão clonadas, sofrendo uma alta taxa de mutações (hipermutação somática). As novascélulas geradas também podem se ligar aos agentes patógenos. Aquelas que tiveremmaior afinidade com os antígenos serão ativadas e clonadas. Quanto maior a afinidadede uma célula B com um antígeno, maior a probabilidade de que ela seja clonada. Aopassar por esse processo de maturação, as células B ficam mais eficientes para detectar eneutralizar a ameaça [Weinand (1990), Kelsey & Timmis (2003)].

66 Algoritmos Heurísticos e Metaheurísticas
Fig. 3.12: Maturação de Afinidade. Fonte: [de Castro & Zuben (2000)].
3.4.2.4.4 Memória Imunológica Quando um antígeno adentra o organismo, há umaploriferação de células B que tenham alta afinidade com o invasor. Ao final doprocesso, quando o agente patógeno for finalmente eliminado, é normal que as células Bdesapareçam. O sistema imunológico guarda uma memória das informações codificadasnas células B, caso o mesmo antígeno invada o sistema novamente. Nesse caso, o tempode resposta será muito menor. Na primeira vez que um antígeno penetra no organismo,há uma resposta primária baseada no processo de maturação da afinidade. Se esse mesmoantígeno invadir novamente o organismo, a subpopulação de células B ainda presentesé reativada. A resposta secundária é mais rápida em relação à resposta inicial, porcausa da memória imunológica pré-existente. Uma característica interessante do sistemaimunológico é que as células B adaptadas a um tipo de patógeno podem fornecer umaresposta secundária não só a esse antígeno, como também a um outro agente patógenoque seja estruturalmente semelhante ao primeiro [Kim (2002)].
3.4.2.5 Características de Sistemas Imunológicos
As técnicas de otimização para implementar Sistemas Imunológicos Artificiais sãobaseadas em características dos sistemas imunológicos dos seres vivos. As principaiscaracterísticas usadas nessa analogia são: seleção negativa, rede imunológica e seleçãoclonal [Köster et al. (2003)].
3.4.2.5.1 Seleção Negativa O sistema imunológico é capaz de produzir uma série detipos de linfócitos, como as células T, geradas no Timo. Essas células, por terem sua basealeatória, podem ser programadas para atacar um conjunto de proteínas que pertecem aopróprio organismo. Através do mecanismo de seleção negativa, o sistema imunológico

3.4 Algoritmos Bioinspirados 67
é capaz de destruir as células T que reagem às proteínas do corpo. Assim, somente ascélulas T que não se conectam às proteínas do corpo são disponibilizadas ao organismopara protegê-lo contra a ação de invasores [Kim & Bentley (1999)].
3.4.2.5.2 Rede Imunológica É comum analisar o sistema imunológico sob a ótica deum linfócito ou anticorpo combatendo um ou mais antígenos. No entanto, sabe-se que ascélulas B também possuem mecanismos de interação entre si. As células B funcionamestimulando-se ou inibindo-se umas as outras durante o processo de ataque aos antígenos.Essa comunicação permite estabilizar a rede imunológica. Define-se então uma medidade afinidade também entre células B [Castro & Zuben (1999)].
3.4.2.5.3 Seleção Clonal A seleção clonal é um processo pelo qual as células quereconhecem um antígeno são selecionadas para proliferar. Os pontos principais dessaseleção são [do Amaral (2006)]:
1 As células geradas pelo processo são cópias dos pais e passam por um processo demutação bastante severo (hipermutação somática);
2 Eliminação das células filhas que possuem receptores capazes de reagir comproteínas do organismo;
3 Disseminação de células mais adaptadas (com maior afinidade aos antígenos).
3.4.2.6 O Algoritmo opt-aiNet
Tomando como inspiração os conceitos apresentados na seção 3.4.2.4 e ascaracterísticas descritas na seção 3.4.2.5, apresenta-se a ferramenta que será utilizadanesse trabalho: o algoritmo opt-aiNet [Galeano et al. (2005)]. Na implementação dessatécnica, tipicamente devem-se avaliar os seguintes pontos:
- Representação dos Dados: Codificação das células da rede;
- Definição dos limites da rede;
- Inicialização da rede imunológica;
- Cálculo do nível de estimulação e sua influência no desenvolvimento da rede;
- Determinação dos parâmetros de clonagem e de controle da população;
- Algoritmo de mutação;

68 Algoritmos Heurísticos e Metaheurísticas
- Interpretação das soluções obtidas;
- Processo de treinamento da rede: algoritmo utilizado e ajuste dos parâmetros.
Esses itens devem ser avaliados em conjunto para que o algoritmo opt-aiNetimplementado seja capaz de produzir resultados satisfatórios. O ajuste de cada parâmetroe a escolha de métodos de clonagem e mutação adequados são importantes para construiruma técnica robusta e eficiente. Além disso, é importante considerar também que[de Castro & Zuben (2000)]:
1 A função que está sendo otimizada é, de fato, uma medida da afinidade entre oanticorpo e o antígeno;
2 Cada solução corresponde à informação contida em um dado receptor (célula darede);
3 A afinidade entre as células é medida pela distância Euclidiana.
A seguir o pseudo-código de um algoritmo opt-aiNet.
1. Inicialização: células da rede são criadas aleatoriamente;
2. Enquanto o critério de parada não for alcançado faça:
(a) Expansão Clonal: para cada célula da rede, determine o valor do fitness (afunção a ser otimizada). Gere um conjunto de Nc anticorpos, chamadosclones, que são cópias exatas das células pais.
(b) Maturação de afinidade: faça uma mutação em cada clone com uma taxainversamente proporcional a função de fitness do anticorpo pai. O anticorpopai é mantido sem mutação. A mutação segue a regra:
c′ = c+ αN(0, 1), com α = β−1 exp (−f ∗) (3.5)
onde:
c′ e c representam o indivíduo que sofreu mutação e o indivíduo original,respectivamente.
β é um parâmetro livre que controla o decaimento da função exponecialinversa e f ∗ é o fitness individual.
(c) Iterações de Rede: determine a similaridade entre cada par de anticorpos darede;

3.5 Algoritmos Meméticos ou híbridos 69
(d) Supressão: os clones gerados podem ser agrupados de acordo com suasimilaridade ou afinidade. Se a distância entre dois clones for menor que umdeterminado limiar σs, significa que eles são similares e há pouca diferençaentre os valores da função de fitness associada a cada um. Nos gruposformados de acordo com esse critério, é mantido apenas o clone com o maiorfitness. A seguir determina-se o número de células remanescentes na rede;
(e) Diversidade: introduza um número de células geradas aleatoriamente na rede.
3. Fim
No algoritmo apresentado acima, no passo 1 ocorre a inicialização. O passo 2 aplicaum algorimo de expansão clonal (2.a) e maturação de afinidade (2.b), baseado em umamutação dependente do fitness. Em seguida, agrupam-se os anticorpos de acordo com suaafinidade com as demais células da rede, selecionando, em cada grupo, o anticorpo como maior fitness (2.c e 2.d). Por fim, aumenta-se a diversidade da rede, na medida em quesão inseridas novas células construídas aleatoriamente (2.e).
3.5 Algoritmos Meméticos ou híbridos
Como visto na seção 3.4.1, os Algoritmos Genéticos (AG) tiveram projeção a partirde meados dos anos 70, depois da publicação do trabalho de John Holland. Desdeentão, os AGs se popularizaram, e, nos anos 80, uma nova classe primeiramentereferida como Algoritmos Genéticos Híbridos (AGH) começou a aparecer na literaturada área. Reconhecendo importantes diferenças e similaridades com outras abordagenspopulacionais, alguns desses AGHs foram categorizados como Algoritmos Meméticos em1989 [Moscato (1989)]. Em alguns casos, os Algoritmos Meméticos (AM) são associadosà combinação de Algoritmos Genéticos e algoritmos de busca local. Entretanto, nogeral, Algoritmos Meméticos tem um significado mais abrangente que esse, como seráexplorado no decorrer desta seção.
Os Algoritmos Meméticos podem ser definidos como algoritmos que unem apotencialidade de diversificação dos Algoritmos Bioinspirados a métodos que produzamintensificação da busca em determinadas partes do espaço de solução, tais como asmetaheurísticas de análise de vizinhança (Busca Tabu, Colônia de formigas ou SimulatedAnnealing) ou estratégias mais simples baseadas em busca local [Moscato (1989)].
Algoritmos Meméticos utilizam o conceito de “evolução cultural”, segundo o quala adaptabilidade de um indivíduo pode ser modificada no decorrer de sua existênciadentro da população. Segundo esse conceito, um indivíduo pode ser geneticamente pouco

70 Algoritmos Heurísticos e Metaheurísticas
favorecido ao nascer, mas devido às condições em que vive, por trocas de informaçãocom outros indivíduos, experiências pessoais, entre outros aspectos, pode se tornar maisadaptado, e mais do que isso, transmitir essa experiência aos seus descendentes (evoluçãocultural) [Ong & Keane (2004)]. Para entender essa idéia é importante analisar a teoriamemética. A unidade da teoria memética é o meme, definido por Richard Dawkins emseu livro O Gene Egoísta [Dawkins (1989)]. Trata-se de uma analogia entre o geneda genética e o meme da memória. O meme é uma unidade de informação que semultiplica de cérebro em cérebro, ou entre locais onde a informação é armazenada, comolivros, por exemplo. Funcionalmente, o meme é uma unidade de evolução cultural quepode de alguma forma se autopropagar. Os memes podem ser idéias, línguas, sons,desenhos, capacidades, valores estéticos e morais, ou qualquer outra informação quepossa ser aprendida e transmitida. Ao estudo de modelos evolutivos para transferênciadessa informação dá-se o nome de memética.
Na evolução genética, qualquer alteração que ocorre em um indivíduo no decorrerde sua vida não é propagada para os outros. A informação no DNA do seu genótipopermanece a mesma, e, quando houver reprodução, as características adquiridas nãopassam para os descendentes. Já na teoria memética, o fenótipo coincide com o genótipoe, dessa forma, as mudanças são transmitidas para os descendentes. A memética prevê queas culturas possam evoluir de maneira similar ao mecanismo de evolução das populaçõesde indivíduos. Entre as gerações são transmitidas idéias que podem modificar a chancede sobrevivência dos indivíduos. Do mesmo modo que a seleção natural dos genes, háum mecanismo que realiza a seleção das idéias que serão repassadas às gerações futuras.Uma característica similar entre os memes e os genes é o fato de ambos sobreviverementre gerações. Um gene bem sucedido pode conservar-se sem mutações no conjunto degenes de uma população por muito tempo. Da mesma forma, um meme bem sucedidopode se propagar de geração para geração.
3.5.1 Pseudocódigo
Na literatura, já se encontram algumas aplicações de algoritmos meméticos quemostram resultados melhores que aqueles em que utilizam-se algoritmos bioinspiradospuros [França & Mendes (2000)], [Buriol et al. (1999)]. Para analisar proceduralmenteum algoritmo memético, apresenta-se um de seus possíveis pseudocódigos, seguido deuma explicação sobre os componentes desse algoritmo.
1. Inicialize a população usando um Método de Inicialização;

3.5 Algoritmos Meméticos ou híbridos 71
2. Para cada indivíduo x da população inicial, aplique uma Busca Local, tal que xrecebe a solução encontrada pela busca local;
3. Para cada indivíduo x faça até a condição de parada ser atingida:
a. Avalie a função de fitness de x;
b. Faça até que o número de recombinações geradas seja igual ao parâmetrodefinido como taxa de recombinação:
b.1. A recombinação de um par de indivíduos que fazem parte da populaçãoprincipal;
b.2. Avalie a função de fitness de cada novo indíviduo criado;
b.3. Adicione o novo indivíduo à uma população intermediária;
c. Faça até que o número de mutações geradas seja igual ao parâmetro definidocomo taxa de mutação:
c.1. Escolha um indivíduo da população intermediária;
c.2. Aplique uma mutação nesse indivíduo;
c.3. Avalie a função de fitness de cada novo indíviduo criado;
c.4. Adicione o novo indivíduo à população intermediária;
d. Para cada indíviduo da população intermediária faça uma busca local. Oresultado da busca local substituirá o indíviduo na população intermediária;
e. Avalie o novo fitness dos indivíduos da população intermediária;
f. Use um método de seleção para escolher quais indivíduos da população atuale da população intermediária vão permanecer na população principal;
g. Com base nos indivíduos escolhidos, constitua a nova população principal;
h. Apague a população intermediária;
4. Fim.
Como já se observou na seção 3.4.1, o algoritmo memético é muito parecido como algoritmo genético. O pseudocódigo acima é composto de 4 partes principais, sendo:inicialização, laços de recombinação e mutação, a otimização e a atualização. A principalnovidade está no uso de algoritmos de busca local em duas partes do código acima. Talcomo nos algoritmos bioinspirados, a população pode ser inicializada de forma aleatória,ou seja, os indivíduos iniciais são escolhidos ao acaso. Após a inicialização, aplica-se um

72 Algoritmos Heurísticos e Metaheurísticas
algoritmo de busca local em todas as soluções iniciais. Desde que haja convergência, talprocedimento leva a população inicial a ser composta por mínimos locais. Posteriormentesão implementados laços para recombinação e mutação. Nesse ponto, são importantesos valores das taxas de recombinação e mutação para definir quantas operações destetipo serão realizadas. Os indivíduos recém-concebidos são adicionados à uma populaçãointermediária. Ao final, a população intermediária é avaliada e, através de um método deseleção (vide seção 3.4.1), são escolhidos quais indivíduos da população principal serãosubstituídos por indivíduos da população intermediária. Essa população intermediária é,então, apagada e o laço principal recomeça. O processo continua até que um critério deparada seja atingido.
É importante perceber que não só os algoritmos combinados nesse pseudocódigo,mas também outras estratégias de otimização podem ser combinadas para constituir umAlgoritmo Mémetico.
3.6 Comentários Gerais
Nesse trabalho, utilizam-se técnicas de algoritmos bioinspirados, como o Algoritmoopt-aiNet e os Algoritmos Genéticos aplicadas à teoria descrita no capítulo 2. Oobjetivo de construir Algoritmos Meméticos é buscar soluções para problemas complexosde separação cega não-linear (NBSS). Mais especificamente este trabalho busca tratarproblemas que possam ser concebidos através de modelos Post-NonLinear, conformedescrito na seção 2.6.2. Modelando o problema dessa forma, é possível analisar os efeitoslinear e não-linear da mistura separadamente, construindo um sistema separador formadopor duas partes. A aplicação de algoritmos híbridos (ou meméticos), como analisadonessa seção, tem como característica a combinação de técnicas de otimização baseadasem busca local com algoritmos bioinspirados. O objetivo então é estudar a aplicação detais técnicas de otimização mais clássicas à parte linear do sistema separador do modeloPNL, e algoritmos bioinspirados à sua parte não-linear. O próximo capítulo mostra comoaliar os conceitos desenvolvidos neste trabalho para separação cega das partes linear enão-linear em um problema PNL, buscando uma nova maneira de resolvê-lo.

Capıtulo 4Análise de Técnicas de OtimizaçãoBioinspiradas e Meméticas em NBSS
Este capítulo tem como objetivo analisar a aplicação prática de técnicas de otimizaçãobaseadas em algoritmos meméticos a uma instância de separação cega não-linearrepresentada pelo modelo Post-NonLinear (PNL).
A existência de técnicas eficientes como a ICA e sua variante computacional FastICAmostra que o grau de maturidade no tratamento de problemas de BSS linear está emum estágio bastante avançado. Por outro lado, a extensão dessas idéias para o contextonão-linear deve ser considerada com mais cuidado, uma vez que não há garantia de queserá sempre possível encontrar soluções baseadas somente no critério de independênciamútua das fontes, que é a essência da ICA. Felizmente, como se estudou nesse trabalho,mesmo com algumas limitações, as técnicas ICA podem ser aplicadas a algumas classesde problemas não-lineares [Taleb & Jutten (1999)]. Tipicamente, em problemas dessetipo há algumas dificuldades associadas, tais como, a presença de mínimos locais noespaço de soluções disponíveis e restrições quanto à aplicação de métodos de gradiente,devido à característica multimodal das expressões utilizadas na otimização (InformaçãoMútua e Negentropia). Esses fatores nos remetem ao uso de técnicas mais robustas nabusca por uma solução em NBSS como, por exemplo, as metaheurísticas, que permitemimplementar os critérios de otimização de maneira mais simples, evitando a necessidadede encontrar derivadas de expressões como Informação Mútua e Negentropia. É comesses objetivos que estratégias baseadas em algoritmos bioinspirados podem ser aplicadasem problemas não-lineares, como, por exemplo, aqueles decorrentes da estrutura PNL.Aliar a eficiência de algoritmos como o FastICA para modelar problemas lineares aalgoritmos bioinspirados como algoritmos genéticos e imunológicos (opt-aiNet) sugere
73

74 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
uma abordagem nova e interessante em sistemas de separação cega não-lineares.
Este trabalho busca, então, analisar a aplicabilidade de sistemas híbridos, aliandoconceitos clássicos de otimização de estruturas lineares em BSS a métodos mais robustose complexos de otimização bioinspirada em problemas NBSS. Avaliando o modeloPNL, que permite, por construção, separar as partes linear e não-linear em um sistemaseparador, e usando estratégias de minimização da informação mútua e gaussianizaçãocomo critérios de otimização, os algoritmos bioinspirados são a base para estimação dasnão-linearidades em NBSS. Nesse mesmo contexto, as técnicas clássicas como o ICApodem ser usadas para estimar a parte linear do sistema separador.
4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a Informação Mútua
Na seção 2.6.2, explicou-se o modelo Post-Nonlinear para separação cega de fontesno caso não-linear (NBSS). Os problemas PNL são caracterizados por possuírem umaparte linear e outra não-linear, como mostra a Figura 4.1. Geralmente, é um sistema semmemória (ou instantâneo – vide seção 2.3.2) que distorce, de maneira não-linear, sinaismisturados linearmente. A seção 2.7.1 mostrou um algoritmo desenvolvido por Taleb eJutten para reverter a ação de misturas lineares e não-lineares, num modelo PNL, atravésda minimização da informação mútua entre as estimativas das fontes. No entanto, naprática, existem dois problemas que dificultam sua aplicação. O primeiro vem do fatode que a obtenção da informação mútua demanda a estimação das entropias marginais,que é uma tarefa bastante difícil e complexa. O segundo está relacionado à presença demínimos locais na função de custo dada pela expressão de minimização da informaçãomútua [Puntonet & Prieto (2004)], o que traz dificuldade no uso de técnicas baseadas nogradiente para adaptação do sistema separador. Dessa forma, uma das maneiras de seresolver problemas cujo modelo empregado é PNL é utilizar mecanismos que evitem aconvergência para mínimos locais e também algoritmos eficientes para estimar a funçãode custo. Na análise da informação mútua, para estimar as entropias marginais, utiliza-seo método de estatísticas de ordem (do inglês order statistics). Já para construir um métodode busca, combinam-se o poder de exploração do espaço de soluções dos algoritmosbioinspirados com o potencial consolidado das estratégias de busca local derivadas doalgoritmo FastICA.
A expressão da informação mútua é dada pela equação (2.60), analisada na seção 2.6.2e repetida a seguir:

4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a InformaçãoMútua 75
Fig. 4.1: O modelo Post-NonLinear (PNL).
I(y) =∑
iH(yi)−H(x)− log |det W| − E
{log∏
i|g′i(xi)|
}, (4.1)
com g′i(·) como a primeira derivada de gi(·), que deve ser uma função inversível. A idéiapara encontrar a informação mútua é estimar da forma mais precisa possível os valoresde H(yi), pois sabe-se que H(x) é constante e, portanto, não influencia no processo deotimização.
Conclui-se então que há dois pontos principais a serem considerados: determinaçãoda informação mútua através da estimação das entropias marginais de cada saída yi eutilização de técnicas capazes de evitar a convergência para mínimos locais. O algoritmoFastICA será então aplicado para adaptar o estágio linear do modelo e construir a matrizde separação linear W. Em seguida são utilizados algoritmos bioinspirados para adaptaros parâmetros das não-linearidades gi(·).
A função não-linear g(·) é, idealmente, a inversa de f(·). Nesse trabalho, ela émodelada como um polinômio de grau 5 com potências ímpares: gi(xi) = ci1x
5i +
ci2x3i + ci3xi. O objetivo é, então, encontrar os coeficientes desse polinômio para cada
um dos componentes da mistura x. Sabe-se que um dos requerimentos do modelo PNL éque cada função seja monotônica, por isso os coeficientes de cada polinômio devem serestritamente positivos ou estritamente negativos.
4.1.1 Estimação de entropia usando Estatísticas de ordem
As aplicações de estatísticas de ordem em problemas BSS [Solé-Casals et al. (2003)]ilustram como esse método é atrativo, devido à sua baixa complexidade computacional,quando comparado com métodos que usam estimação da densidade de probabilidade, porexemplo.
Revisando o conceito de estatísticas de ordem, consideram-se T amostras de umaváriavel aleatória y ordenadas da forma:
y(1:T ) ≤ y(2:T ) ≤ · · · ≤ y(T :T ). (4.2)

76 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Aqui, a estatística de ordem k, dada por y(k:T ), é o k-ésimo valor, em ordem ascendente,dentre as T amostras disponíveis.
Para entender a aplicabilidade de estatísticas de ordem ao problema de estimação deentropia, reescreve-se a entropia como uma variável aleatória y em termos de sua funçãoquantil QY (u), que é, na verdade, o complemento da função de distribuição cumulativaFY (y) = P (Y ≤ y). Usando essa definição, é possível mostrar que:
H (y) =
∫ ∞−∞
fY (τ) logQ′
Y [FY (τ)] dτ =
∫ 1
0
logQ′Y (u)du, (4.3)
onde:
fY (y) são as funções densidade de probabilidade de y
Q′Y (y) é derivada da função quantil de Y
Na prática, para calcular a entropia de um dado sinal yi, é necessário obter a formadiscreta de (4.3), dada por:
H (yi) ≈L∑k=2
log
[QYi (uk)−QYi (uk−1)
uk − uk−1
]uk − uk−1
uL − u1
(4.4)
onde {u1, u2, . . . , uL} é um conjunto de números crescentes no intervalo [0, 1].
A ligação entre a estimação de entropia e as estatísticas de ordem está na relaçãoentre essa última e a função quantil. De fato, a estimativa do valor de QY ( k
T+1), chamada
de função quantil empírica, é dada pela estatística de ordem k: y(k:T ). Dessa forma, épossível aproximar o valor de QY (·) na equação (4.4) por QYi (u) ≈ y(k:T ), para k tal quek
T+1é dado pelo ponto mais próximo de u. Essa simplificação permite obter um algoritmo
mais eficiente para estimação da entropia, fato que é extremamente importante, dado queessa função é calculada a cada iteração do problema.
Comparativamente a outros métodos, a estimação da entropia através de estatísticasde ordem apresenta vantagens relacionadas à complexidade computacional e precisão dosresultados obtidos. Na literatura encontram-se outros métodos usados para estimação daentropia. Desses, os mais difundidos são:
Métodos de Kernel [Silverman (1986)]: Essa técnica é capaz de fornecer resultadosconsideravelmente precisos, mas requer um denso processamento computacional.Há também dificuldades em determinar os parâmetros dos kernels utilizados. Ométodo de Kernel é geralmente usado para estimar uma função densidade deprobabilidade. Considerando x1, x2, . . . , xN variáveis aleatórias independentes e

4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a InformaçãoMútua 77
identicamente distribuídas como amostras de uma variável aleatória ξ, a função densidadede probabilidade estimada através de kernel é dada por:
fh(x) =1
Nh
N∑i=1
K(x− xih
) (4.5)
onde K é um Kernel e h é o fator de dispersão. Geralmente K é dado por uma funçãogaussiana com média zero e variância unitária:
K(x) =1√2π
exp(−1
2x2) (4.6)
Métodos de Gram-Charlier [Comon (1994)]: Um outro método de estimaçãode entropia fundamenta-se na expansão em séries de Gram-Charlier de uma variávelaleatória. Nesse caso, a estimativa depende apenas dos momentos de terceira e quartaordens, o que torna esse processo extremamente rápido. Todavia, essa simplificaçãoprática surge às custas de uma perda de precisão no processo de estimação.
A Figura 4.2 mostra as estimativas da entropia de uma variável aleatória uniformeno intervalo [−
√3,√
3] para os métodos apresentados aqui. Na estimação via métodosde kernel, são considerados kernels gaussianos com desvio padrão representado porσ. Observa-se que o número de amostras requerido está intimamente relacionado àpolarização da estimativa e à escolha do desvio padrão. Para as séries de Gram-Charlier,a estimativa obtida apresenta uma significativa polarização. Dada a melhor precisão ebaixa complexidade computacional dentre os métodos avaliados, optou-se por utilizarestatísticas de ordem para estimativa da entropia no cálculo da função custo.
4.1.2 Aplicação de Algoritmos Bioinspirados
Nesse trabalho, conforme analisado no capítulo 3, optou-se pelo uso das seguintestécnicas de algoritmos bioinspirados: algoritmos genéticos e algoritmos opt-aiNet. Aimplementação de tais métodos é descrita nas seções seguintes.
4.1.2.1 Aplicação de Algoritmos Genéticos
Um dos algoritmos bioinspirados estudado nesse trabalho é o algoritmo genético.Conforme observado na seção 3.4.1 do capítulo 3, o algoritmo trabalha a partir de umasolução formada por um conjunto aleatório de indivíduos que constituem a primeirasolução para o problema. Os indivíduos são avaliados por uma função de fitness paramensurar e permitir escolher os que serão mantidos e aqueles que serão eliminados na
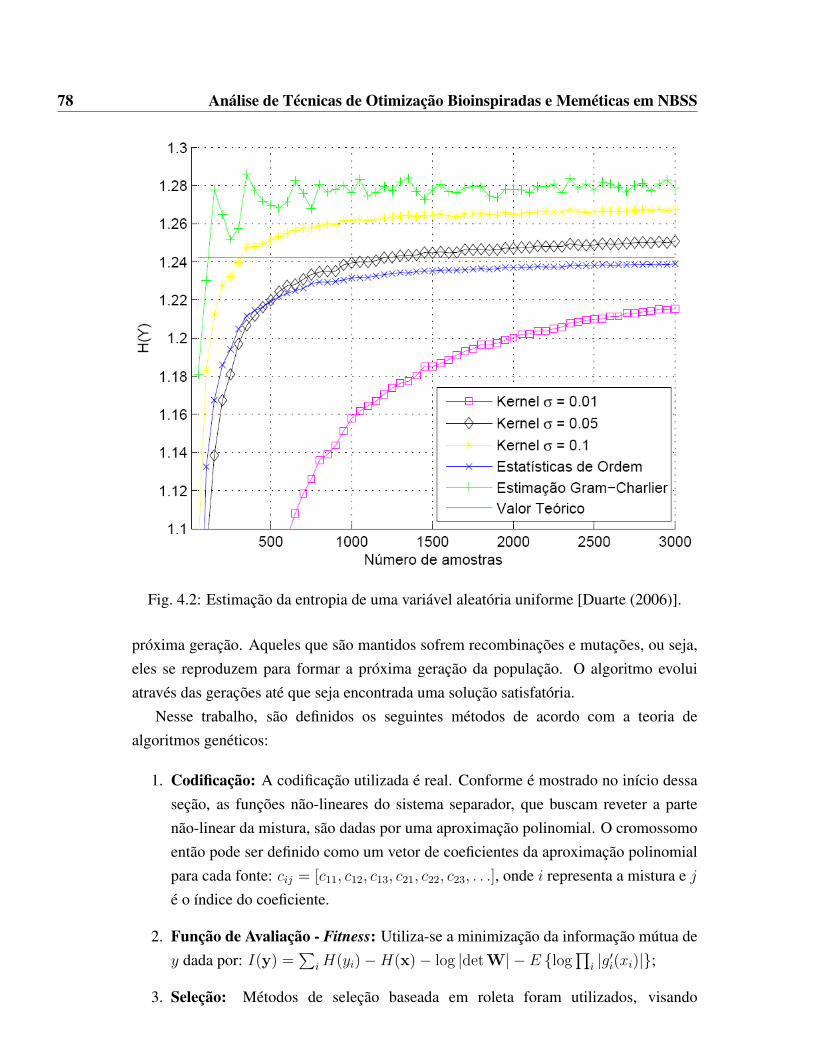
78 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Fig. 4.2: Estimação da entropia de uma variável aleatória uniforme [Duarte (2006)].
próxima geração. Aqueles que são mantidos sofrem recombinações e mutações, ou seja,eles se reproduzem para formar a próxima geração da população. O algoritmo evoluiatravés das gerações até que seja encontrada uma solução satisfatória.
Nesse trabalho, são definidos os seguintes métodos de acordo com a teoria dealgoritmos genéticos:
1. Codificação: A codificação utilizada é real. Conforme é mostrado no início dessaseção, as funções não-lineares do sistema separador, que buscam reveter a partenão-linear da mistura, são dadas por uma aproximação polinomial. O cromossomoentão pode ser definido como um vetor de coeficientes da aproximação polinomialpara cada fonte: cij = [c11, c12, c13, c21, c22, c23, . . .], onde i representa a mistura e jé o índice do coeficiente.
2. Função de Avaliação - Fitness: Utiliza-se a minimização da informação mútua dey dada por: I(y) =
∑iH(yi)−H(x)− log |det W| − E {log
∏i |g′i(xi)|};
3. Seleção: Métodos de seleção baseada em roleta foram utilizados, visando

4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a InformaçãoMútua 79
aumentar a performance do algoritmo através da diminuição do tempo deexecução. Conforme mostrado na seção 3.4.1, esse método exige menor esforçocomputacional, pois não necessita aplicar funções de mapeamento, como nométodo do rank, ou ordenar os indivíduos, como no método do torneio. Noentato, sua desvantagem é a dificuldade inerente em controlar o aumento da pressãoseletiva, que deve ser observada durante a execução do algoritmo;
4. Crossover: O crossover aritmético foi utilizado nessa implementação, devido a suasimplicidade e aos bons resultados obtidos em trabalhos prévios [Duarte (2006)].
5. Mutação: Aleatoriamente um dos componentes do vetor de coeficientes é alterado,de acordo com uma mutação uniforme. Aqui é necessário um grau de atenção, poisos coeficientes codificados devem ser positivos para que a solução seja factível.
6. Critério de parada: Quando se atinge 120% do número corrente de iterações, semque haja melhora de mais de 10% no fitness em comparação com a melhor soluçãoobtida até o momento, o algoritmo é finalizado.
Outros parâmatros como taxa de crossover, taxa de mutação, número de indivíduosna população inicial e tamanho da população são definidos de acordo com o cenárioestudado.
4.1.2.2 Aplicação de Algoritmo opt-aiNet
Como estudado na seção 3.4.2 do capítulo 3, o algoritmo opt-aiNet é construído apartir de uma combinação de noções de seleção clonal, maturação de afinidade e redeimunológica. Neste trabalho, para modelagem através de algoritmos meméticos, foramusadas as seguintes definições para o algoritmo opt-aiNet:
1. Codificação: Uma solução é dada pela informação contida em um receptor (célulada rede), e a codificação é formada por uma aproximação polinomial. A célula darede é então definida como um vetor de coeficientes da aproximação polinomialcij = [c11, c12, c13, c21, c22, c23, . . .], onde i representa a mistura e j é o índice docoeficiente. Esses coeficientes definem os valores das funções gi(·), a qual se desejaestimar;
2. Função de fitness: é a expressão para minimização da informação mútua de y dadapor: I(y) =
∑iH(yi)−H(x)− log |det W| − E {log
∏i |g′i(xi)|};

80 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
3. Afinidade: a medida de afinidade entre células é dada pela distância euclidianaentre elas.
4. Critério de parada: Quando se atinge 120% do número corrente de iterações, semque haja melhora de mais de 10% no fitness em comparação com a melhor soluçãoobtida até o momento, o algoritmo é finalizado.
Os parâmetros relacionados com este algoritmo são normalmente definidosempiricamente para cada cenário. São eles:
1. Número de indivíduos na população inicial N0;
2. Número de clones Nc;
3. Limiar de supressão σs;
4. Taxa de mutação β.
4.1.3 Interpretação dos Resultados
Como a principal novidade nesse trabalho é a introdução de um algoritmo de buscalocal específico do problema de BSS no processo de otimização, sob o conceito dealgoritmo memético, os resultados serão comparados com aqueles obtidos através deum método baseado somente em algoritmos bioinspirados, em que cada indivíduo écodificado como uma parte linear e outra não-linear. Este método será denominado“método padrão”, que, no caso de algoritmos genéticos será o “método padrão GA”, e, nocaso de algoritmos imunológicos, será o “método padrão opt-aiNet”[Duarte (2006)].
Para analisar a estratégia proposta pelas metodologias acima, esta seção descreve osresultados das simulações de dois cenários com 2 e 3 fontes, respectivamente.
4.1.3.1 Primeiro cenário
O primeiro cenário baseado em um modelo PNL é composto de duas fontesdistribuídas uniformemente entre [−1, 1] misturadas de acordo com o seguinte modelo:
A =
[1 0.6
0.5 1
]e
f1(e1) = tanh(2e1)
f2(e2) = 2 5√e2
. (4.7)
Os testes com os métodos padrão foram feitos com 10 experimentos e os seguintesparâmetros: N0 = 5, Nc = 5, β = 50, σs = 3. Esses parâmetros foram definidos combase em resultados obtidos em trabalhos anteriores. Considerando que o espaço de busca
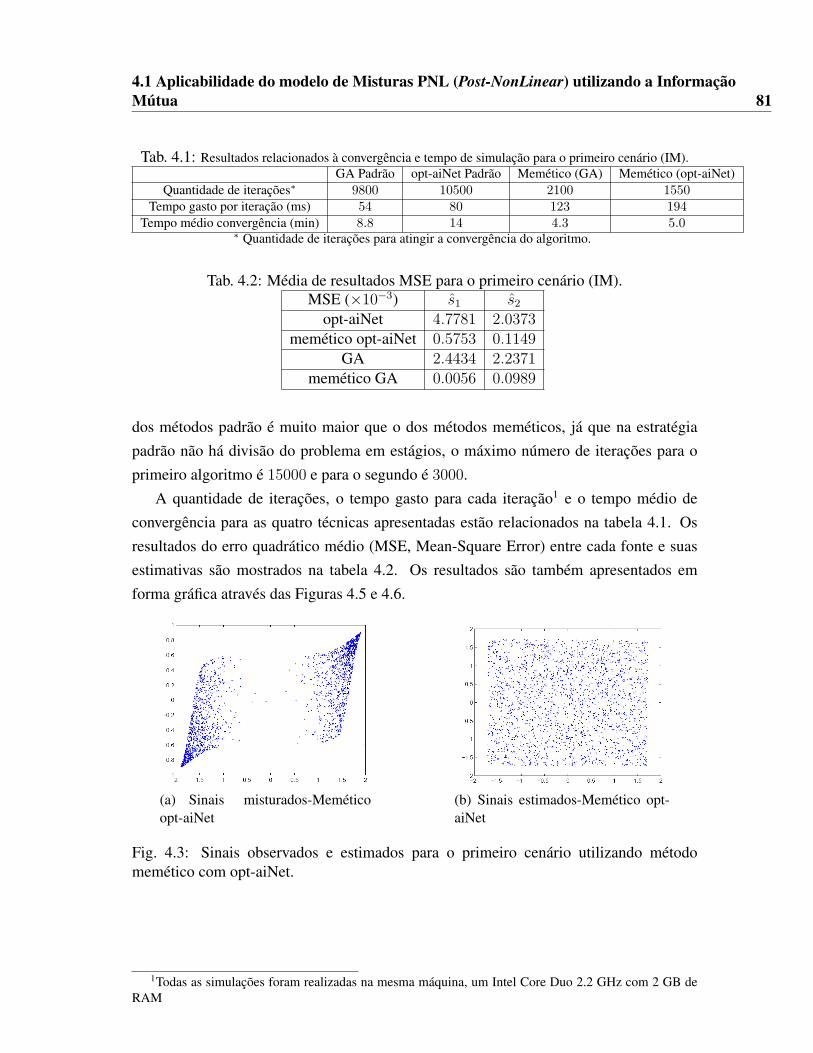
4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a InformaçãoMútua 81
Tab. 4.1: Resultados relacionados à convergência e tempo de simulação para o primeiro cenário (IM).GA Padrão opt-aiNet Padrão Memético (GA) Memético (opt-aiNet)
Quantidade de iterações∗ 9800 10500 2100 1550Tempo gasto por iteração (ms) 54 80 123 194
Tempo médio convergência (min) 8.8 14 4.3 5.0∗ Quantidade de iterações para atingir a convergência do algoritmo.
Tab. 4.2: Média de resultados MSE para o primeiro cenário (IM).MSE (×10−3) s1 s2
opt-aiNet 4.7781 2.0373memético opt-aiNet 0.5753 0.1149
GA 2.4434 2.2371memético GA 0.0056 0.0989
dos métodos padrão é muito maior que o dos métodos meméticos, já que na estratégiapadrão não há divisão do problema em estágios, o máximo número de iterações para oprimeiro algoritmo é 15000 e para o segundo é 3000.
A quantidade de iterações, o tempo gasto para cada iteração1 e o tempo médio deconvergência para as quatro técnicas apresentadas estão relacionados na tabela 4.1. Osresultados do erro quadrático médio (MSE, Mean-Square Error) entre cada fonte e suasestimativas são mostrados na tabela 4.2. Os resultados são também apresentados emforma gráfica através das Figuras 4.5 e 4.6.
(a) Sinais misturados-Meméticoopt-aiNet
(b) Sinais estimados-Memético opt-aiNet
Fig. 4.3: Sinais observados e estimados para o primeiro cenário utilizando métodomemético com opt-aiNet.
1Todas as simulações foram realizadas na mesma máquina, um Intel Core Duo 2.2 GHz com 2 GB deRAM
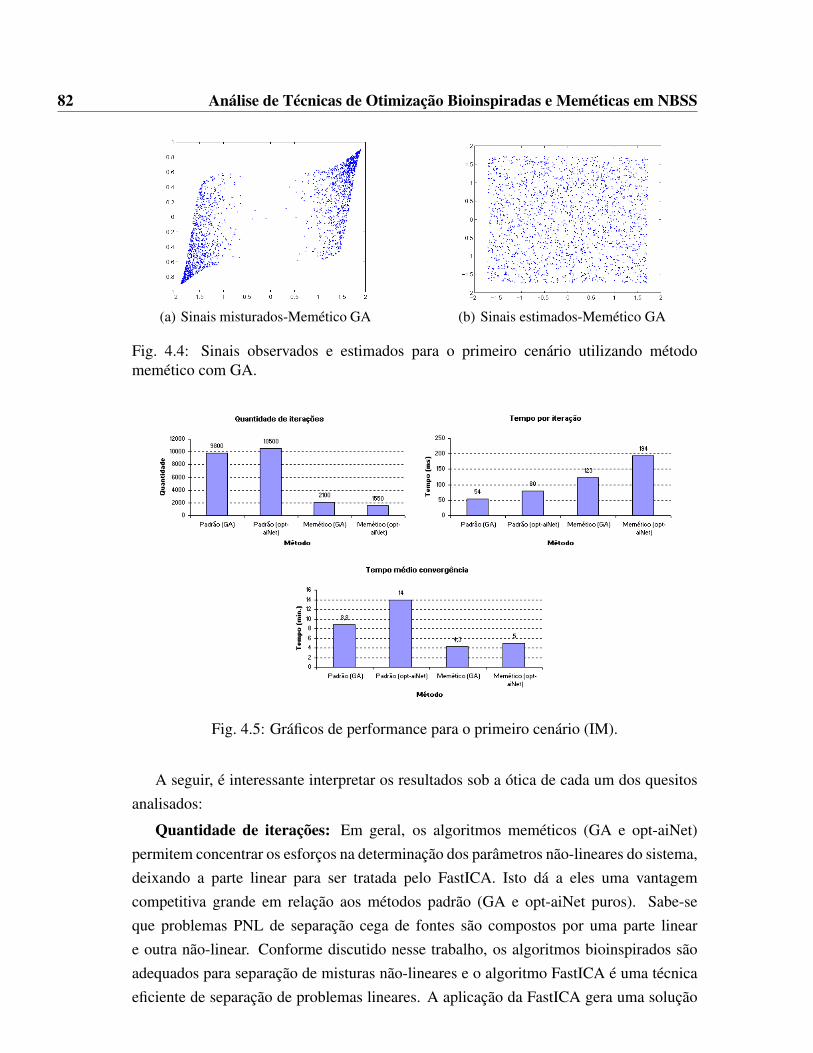
82 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
(a) Sinais misturados-Memético GA (b) Sinais estimados-Memético GA
Fig. 4.4: Sinais observados e estimados para o primeiro cenário utilizando métodomemético com GA.
Fig. 4.5: Gráficos de performance para o primeiro cenário (IM).
A seguir, é interessante interpretar os resultados sob a ótica de cada um dos quesitosanalisados:
Quantidade de iterações: Em geral, os algoritmos meméticos (GA e opt-aiNet)permitem concentrar os esforços na determinação dos parâmetros não-lineares do sistema,deixando a parte linear para ser tratada pelo FastICA. Isto dá a eles uma vantagemcompetitiva grande em relação aos métodos padrão (GA e opt-aiNet puros). Sabe-seque problemas PNL de separação cega de fontes são compostos por uma parte lineare outra não-linear. Conforme discutido nesse trabalho, os algoritmos bioinspirados sãoadequados para separação de misturas não-lineares e o algoritmo FastICA é uma técnicaeficiente de separação de problemas lineares. A aplicação da FastICA gera uma solução
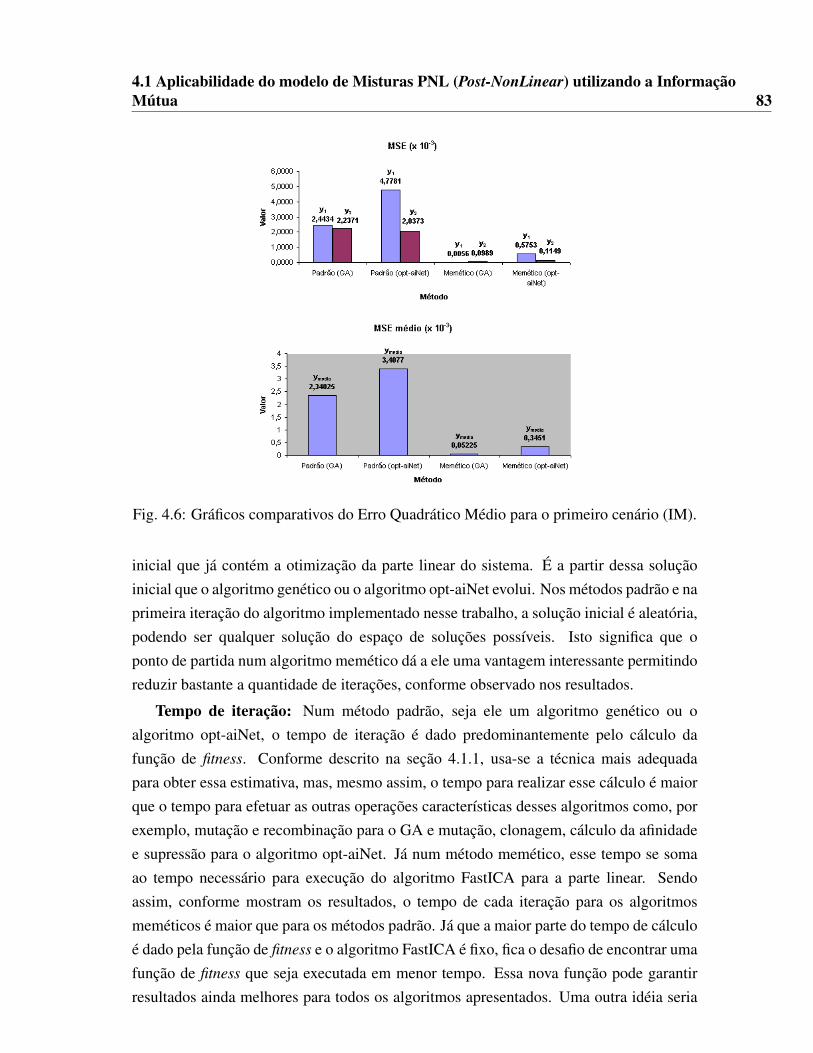
4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a InformaçãoMútua 83
Fig. 4.6: Gráficos comparativos do Erro Quadrático Médio para o primeiro cenário (IM).
inicial que já contém a otimização da parte linear do sistema. É a partir dessa soluçãoinicial que o algoritmo genético ou o algoritmo opt-aiNet evolui. Nos métodos padrão e naprimeira iteração do algoritmo implementado nesse trabalho, a solução inicial é aleatória,podendo ser qualquer solução do espaço de soluções possíveis. Isto significa que oponto de partida num algoritmo memético dá a ele uma vantagem interessante permitindoreduzir bastante a quantidade de iterações, conforme observado nos resultados.
Tempo de iteração: Num método padrão, seja ele um algoritmo genético ou oalgoritmo opt-aiNet, o tempo de iteração é dado predominantemente pelo cálculo dafunção de fitness. Conforme descrito na seção 4.1.1, usa-se a técnica mais adequadapara obter essa estimativa, mas, mesmo assim, o tempo para realizar esse cálculo é maiorque o tempo para efetuar as outras operações características desses algoritmos como, porexemplo, mutação e recombinação para o GA e mutação, clonagem, cálculo da afinidadee supressão para o algoritmo opt-aiNet. Já num método memético, esse tempo se somaao tempo necessário para execução do algoritmo FastICA para a parte linear. Sendoassim, conforme mostram os resultados, o tempo de cada iteração para os algoritmosmeméticos é maior que para os métodos padrão. Já que a maior parte do tempo de cálculoé dado pela função de fitness e o algoritmo FastICA é fixo, fica o desafio de encontrar umafunção de fitness que seja executada em menor tempo. Essa nova função pode garantirresultados ainda melhores para todos os algoritmos apresentados. Uma outra idéia seria

84 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
capturar informações sobre a mistura durante o processo de execução da FastICA, para,em seguida, organizar estas informações e promover uma maneira de utilizá-las durante oprocesso de otimização bioinspirado, com o objetivo de aumentar sua eficiência.
Erro de estimação: Pode-se dizer que os métodos meméticos são modelados para se“ajustar” melhor ao problema PNL que os métodos puros. Eles utilizam a natureza doproblema a seu favor, analisando com maior eficiência cada uma de suas partes. Esseajuste fino, aliado ao uso da técnica FastICA, dá aos métodos meméticos resultadosmelhores que aqueles apresentados pelos métodos puros. Devido à implementação daFastICA, os novos métodos são capazes de refinar a solução obtida com os métodospadrão. Esse resultado reflete o conceito de um algoritmo memético, que é o de utilizarinformações baseadas em busca local (FastICA) em conjunto com técnicas bioinspiradas(parte não-linear do PNL). As Figuras 4.3 e 4.4 mostram as misturas e os sinaisrecuperados usando a estratégia memética, para uma realização típica. Observando asfiguras, fica claro que o sistema separador foi capaz de estimar satisfatoriamente as fontesde distribuição uniforme nesse cenário.
Em geral, pode-se inferir que os métodos meméticos baseados em algoritmosgenéticos e aquele baseados em algoritmos opt-aiNet apresentam resultados similares.Devido à pequena diferença entre esses resultados não se pode afirmar que um algoritmoé melhor que o outro para essa instância.
Pode-se perceber também que, claramente, o uso do algoritmo FastICA comoferramenta de busca local aprimorou bastante os resultados obtidos em relação aosmétodos padrão (GA e opt-aiNet). Pode-se notar que o algoritmo memético foi capazde reduzir o número de iterações para convergência, mas, em contrapartida, o tempo daiteração aumentou, por causa do uso do algoritmo FastICA. Usando o algoritmo meméticobaseado em algoritmo genético o tempo de convergência é 4 vezes menor para o novométodo. Já para o algoritmo opt-aiNet, esse tempo de convergência é cerca de 3.5 vezesmenor. Sob a ótica do erro de estimação, pode-se verificar que os métodos meméticosmelhoram significativamente a qualidade dos resultados obtidos. Numa comparaçãoentre os dois métodos meméticos, observa-se uma melhora ligeiramente maior quandose implementa o algoritmo genético. No entanto, não se pode afirmar, também sob essaótica, qual é o melhor método, dada a pequena diferença entre os dois.

4.1 Aplicabilidade do modelo de Misturas PNL (Post-NonLinear) utilizando a InformaçãoMútua 85
4.1.3.2 Segundo cenário
Nesse cenário, a matriz de separação e as não-linearidades analisadas são:
A =
1 0.6 0.5
0.5 1 0.4
0.4 0.6 1
ef1(e1) = 2 3
√e1
f2(e2) = 2 3√e2
f3(e3) = 2 3√e3
.
Usando o mesmo método de análise do primeiro cenário, os parâmetros dos algoritmosbioinspirados foram configurados para: N0 = 10, Nc = 5, β = 50, σs = 3. Como nocaso anterior, o número máximo de iterações para os algoritmos padrão foi 15000 e paraos algoritmos meméticos foi 3000. O mesmo critério de parada e a mesma quantidade derealizações foram utilizadas nesse cenário.
Novamente, pode-se observar, através da tabela 4.3 e dos gráficos da Figura 4.7, que astécnicas meméticas permitiram melhorar o tempo de convergência, mostrando que o usode uma ferramenta de busca local é realmente eficiente. Nesse caso, a redução do tempode convergência é ainda mais expressiva quando comparada ao primeiro cenário. A tabela4.4 e a Figura 4.8 mostram o erro quadrático médio obtido com os quatro métodos.
Tab. 4.3: Resultados relacionados à convergência e tempo de simulação para o segundo cenário (IM).GA Padrão opt-aiNet Padrão Memético (GA) Memético (opt-aiNet)
Quantidade de iterações∗ 14550 13750 820 950Tempo gasto por iteração (ms) 102 164 260 380
Tempo médio convergência (min) 24.7 59.6 3.6 6.0∗ Quantidade de iterações para atingir a convergência do algoritmo.
Tab. 4.4: Média de resultados MSE para o segundo cenário (IM).MSE (×10−3) s1 s2 s3
opt-aiNet 7.8529 0.4387 0.2187memético opt-aiNet 1.0332 0.3466 4.0278
GA 4.5083 2.3009 1.4945memético GA 0.8867 1.5631 0.9843
Os resultados apresentados nas tabelas confirmam os pontos levantados no estudoanterior de duas fontes. Comparativamente ao estudo anterior, observa-se que, emgeral, o tempo de convergência aumentou dada a adição de mais uma dimensão aoproblema, o que aumenta a sua complexidade. Mantendo a estrutura e o número deindivíduos da população, os erros de estimação também se mostram maiores, indicandoque o aumento da dimensão do espaço de busca não foi totalmente compensado pelosparâmetros utilizados. O cenário não se modifica substancialmente para outras matrizes enão linearidades, conforme observado em outros ensaios.
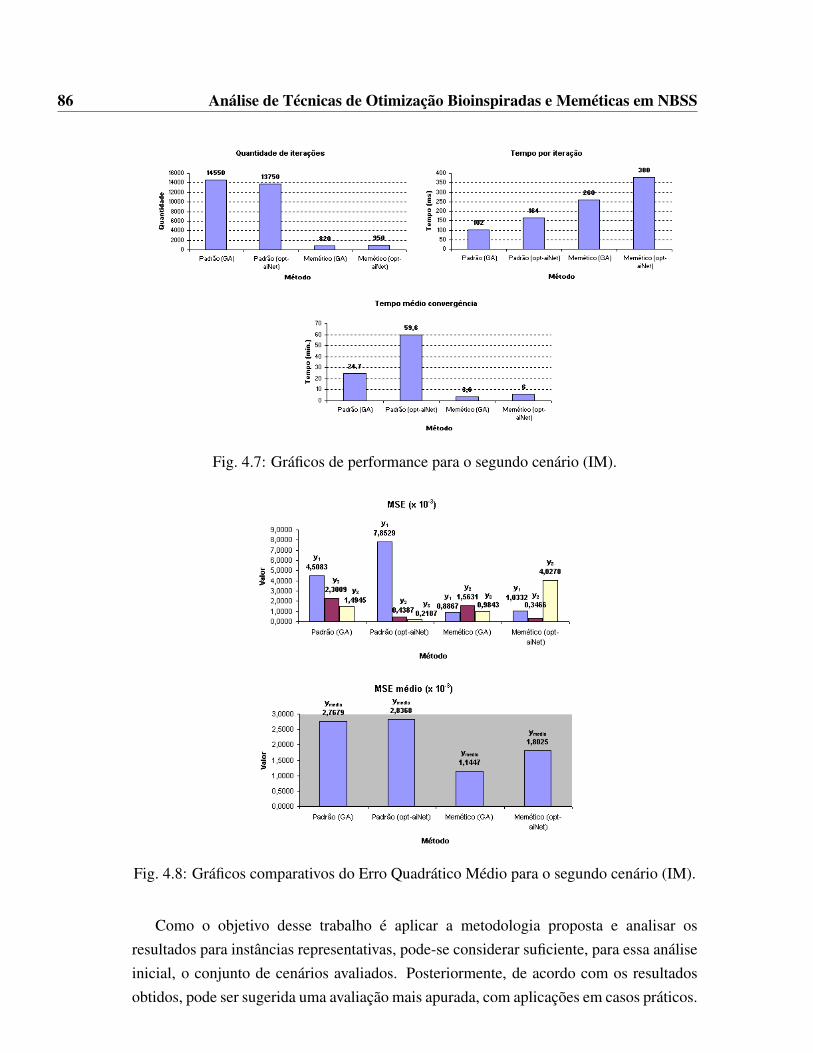
86 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Fig. 4.7: Gráficos de performance para o segundo cenário (IM).
Fig. 4.8: Gráficos comparativos do Erro Quadrático Médio para o segundo cenário (IM).
Como o objetivo desse trabalho é aplicar a metodologia proposta e analisar osresultados para instâncias representativas, pode-se considerar suficiente, para essa análiseinicial, o conjunto de cenários avaliados. Posteriormente, de acordo com os resultadosobtidos, pode ser sugerida uma avaliação mais apurada, com aplicações em casos práticos.

4.2 Aplicação de Técnicas de Gaussianização 87
4.2 Aplicação de Técnicas de Gaussianização
As técnicas baseadas em informação mútua, estudadas na seção anterior, mostramresultados melhores quando aplicadas em conjunto com algoritmos meméticos. Manterestes algoritmos e substituir a técnica de minimização da informação mútua por outrastécnicas permite analisar e entender melhor os benefícios da aplicação de algoritmoshíbridos. Desta forma, o objetivo desta seção é implementar estratégias baseadasem gaussianização de variáveis aleatórias, usando os mesmos conceitos de algoritmosmeméticos. Em um segundo momento, também será avaliada a aplicação conjunta detécnicas de minimização de informação mútua e gaussianização.
Fig. 4.9: Modelo PNL - Gaussianização
Como observado na seção 2.7.2, a gaussianização é uma técnica que transformavariáveis aleatórias gerais em variáveis aleatórias cuja distribuição é gaussiana [Chen &Gopinath (2001)]. Isto significa que, formalmente, dado um vetor aleatório x com funçãodensidade de probabilidade px(x), existem funções g : Rn → Rn, tal que z = g(x) ondez é gaussiana. Ou seja, há uma transformação g(·) que leva uma variável aleatória x atornar-se uma variável aleatória gaussiana z [Chen & Gopinath (2000)].
Tomando-se z como uma variável aleatória gaussiana, de variância unitária e médianula, sabe-se que a distribuição cumulativa de uma de suas componentes é dada por:
G(zi) =
∫ zi
−∞
1√2πe−α
2/2dα (4.8)
Dessa forma, a transformação gaussiana de xi pode então ser escrita como: zi =
gi(xi) = G−1(vi) = G−1(Pi(xi)). Assim, para encontrar as funções gi que tornamxi gaussianas é necessário estimar a distribuição cumulativa Pi(xi) e a função inversada distribuição cumulativa G(·). A Figura 4.10 ilustra a transformação dos sinais.Primeiramente, calcula-se a distribuição cumulativa do sinal não gaussiano xi, dada porPi(xi), que gera uma variável aleatória vi de distribuição uniforme. Em seguida, aplica-sea transformada inversa da distribuição cumulativa da variável gaussiana zi, dada por G−1.Ao aplicar essa transformação o resultado final, mostrado na figura, é a variável aleatória

88 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
zi, que é gaussiana.
Fig. 4.10: Estratégia de transformação gaussiana de uma variável aleatória
Na prática, para estimar a distribuição cumulativa de xi, podem ser utilizados métodosde Kernel. Já a função G−1 pode ser aproximada por métodos numéricos, ou através daforma analítica de Abramowitz e Stegun [Abramowitz & Stegun (1968)], que versa quepara 0.5 ≤ p < 1, G−1(p) pode ser aproximado por:
z = G−1(p) ∼= u− c0 + c1u+ c2u
1 + d1u+ d2u+ d3u3(0.5 ≤ p < 1) (4.9)
onde:
u =√
(ln[1/(1− p)2])
c0 = 2.515517, c1 = 0.802853, c2 = 0.010328
d1 = 1.432788, d2 = 0.189269, d3 = 0.001308
É importante observar que um dos pontos fortes da técnica de gaussianização é oaumento da precisão quanto maior o número de fontes. Essa característica se dá pois,quanto maior a quantidade de fontes, mais gaussiana é a soma delas.
4.2.1 Minimização da Negentropia como medida de Gaussianização
Uma outra maneira de encontrar a transformação gaussiana de uma variável é atravésda Negentropia. Nesse trabalho, optou-se por utilizar essa técnica ao invés de calcular asaproximações descritas no início dessa seção.

4.2 Aplicação de Técnicas de Gaussianização 89
Seja Υ = (Υ1, . . . ,Υ2) uma variável aleatória qualquer. O objetivo é encontrar atransformada φ : RD → RD tal que φ(Υ) tenha distribuição gaussiana. Sabe-se que, paravariáveis aleatórias gaussianas, a negentropia é nula [ Lee et al. (2000)]:
NG(φ(Υ)) = 0 (4.10)
Dessa forma, ao minimizar a expressão da Negentropia é possível encontrar atransformada φ que torne Υ uma variável gaussiana. Matematicamente, transportandoesse conceito para o modelo PNL representado na Figura 4.9, toma-se um vetor devariáveis aleatórias x ∈ RD, tal que tem-se e = As e x = f(e) = f(As). Conformemostra a seção 4.2, o objetivo é encontrar a transformação inversa da função não-linear f ,dada por g : Rn → Rn, tal que z = g(x):
NG(z) = NG(g(x)) = 0 (4.11)
Dessa forma, a função custo em um problema de otimização busca encontrar as não-linearidades g(·) que minimizem a expressão da negentropia:
mingNG(g(x)) (4.12)
Uma das maneiras de implementar algoritmicamente a expressão acima é decompora função g(·) em um polinôminio, assim como foi feito na seção 4.1: gi(xi) =
ci1x5i + ci2x
3i + ci3xi. Neste trabalho, a negentropia é estimada através da utilização de
métodos polinomiais, conforme mostra a equação (2.27): NG(g(x)) = α(E{G(g(x))} −E{G(x)})2, com a função não-linear G(·) dada pela função tangente hiberbólica tanh.
4.2.2 Aplicabilidade ao problema PNL
Esta seção tem como objetivo detalhar quais foram os parâmetros utilizados nastécnicas opt-aiNet e algoritmos genéticos para otimizar a parte não-linear do modelo PNL,através do conceito de gaussianização das variáveis aleatórias.
4.2.2.1 Aplicação de Algoritmos Genéticos
O algoritmo genético pode ser modificado para trabalhar com técnicas degaussianização, em vez de minimizar a informação mútua. Nesse caso, a novaconfiguração dos parâmetros fica:
1. Codificação: A codificação também será dada por uma aproximação polinomial

90 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
baseada em codificação real. O cromossomo é definido como um vetor decoeficientes da aproximação polinomial: cij = [c11, c12, c13, c21, c22, c23, . . .], ondei representa a mistura e j é o índice do coeficiente.
2. Função de Avaliação - Fitness: Será utilizada a minimização da negentropia, dadapor: NG(g(x));
3. Seleção: A seleção é baseada em roleta, por ser um método de menor custocomparativo de implementação. Caso os resultados apresentados não sejamsatisfatórios e o algoritmo apresente pressão seletiva alta, o uso desse método podeser revisto;
4. Crossover: Aqui também foi utilizado o crossover aritmético.
5. Mutação: Aleatoriamente um dos componentes do vetor de coeficientes é alterado,segundo o conceito de mutação uniforme.
6. Critério de parada: Quando se atinge 120% do número corrente de iterações, semque haja melhora de mais de 10% no fitness em comparação com a melhor soluçãoobtida até o momento, o algoritmo é finalizado.
Outros parâmatros como taxa de crossover, taxa de mutação, número de indivíduosna população inicial e tamanho da população são definidos de acordo com o cenárioestudado.
4.2.2.2 Aplicação de Algoritmo opt-aiNet
Utilizando o novo conceito de gaussianização, pode-se alterar também o algoritmoopt-aiNet correspondente:
1. Codificação: Continua sendo dada pela informação contida em um receptor (célulada rede). A célula da rede é definida como um vetor de coeficientes da aproximaçãopolinomial: cij = [c11, c12, c13, c21, c22, c23, . . .], onde i representa a mistura e j é oíndice do coeficiente.
2. Função de fitness: É a medida de gaussianização, na qual os parâmetros sãoobtidos através da minimização da negentropia, dada por: NG(g(x));
3. Afinidade: Aqui também a medida de afinidade entre células é dada pela distânciaeucliadiana entre elas.

4.2 Aplicação de Técnicas de Gaussianização 91
4. Critério de parada: Quando se atinge 120% do número corrente de iterações, semque haja melhora de mais de 10% no fitness em comparação com a melhor soluçãoobtida até o momento, o algoritmo é finalizado.
Os parâmetros relacionados ao algoritmo são os mesmos, sendo definidosempiricamente para cada cenário:
1. Número de indivíduos na população inicial N0;
2. Número de clones Nc;
3. Limiar de supressão σs;
4. Taxa de mutação β.
4.2.3 O conceito de Gaussianização estendida
A gaussianização estendida [Chen & Gopinath (2000)] é uma estratégia interessanteque permite aliar os conceitos de gaussianização aos conceitos de minimização deinformação mútua. Um dos objetivos dessa técnica é utilizar os resultados obtidos coma gaussianização como solução inicial do método que tem como critério a minimizaçãoda informação mútua. Com isso, espera-se que a velocidade e o tempo de convergênciadesse último estágio sejam aprimorados. Outra característica que pode ser observadanesse método é a capacidade do algoritmo de informação mútua de corrigir distorções,quando o número de fontes é relativamente pequeno, e o sinal na saída do sistema lineardo modelo PNL não pode ser considerado tão próximo do gaussiano. Na Figura 4.9, essesinal é ilustrado pela variável aleatória ei.
Na aplicação da gaussianização estendida, a função g(·), a qual se deseja obter, podeser dividida em duas outras, g(1)(·) e g(2)(·), conforme mostra a Figura 4.11. A primeira éconstruída utilizando-se técnicas de gaussianização e a segunda pode ser construída pelaminimização da informação mútua.
Nessa técnica, a não-linearidade é dividida em duas partes. Na primeira parte avariável aleatória v = (v1, v2, . . . , vn)T obtida tem distribuição gaussiana:
vi = g(1)i (xi) = G(−1)(P (xi)) (4.13)
Uma outra não-linearidade é aplicada ao sistema para obter a estimativa z tal que:gi = g
(2)i ◦ g
(1)i . Assim:
zi = g(2)(i) ◦ vi = (g(2)i ◦ g
(1)i ) ◦ xi (4.14)

92 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Fig. 4.11: Técnica de gaussianização estendida
No estudo do problema de separação cega de sistemas PNL, utiliza-se o conceito degaussianização para estimar g(1) e a minimização da informação mútua para encontrarg(2). A Figura 4.12 mostra como se dá o processo de estimação das fontes usando essatécnica híbrida.
Fig. 4.12: Gaussianização estendida no problema PNL
4.2.4 Interpretação dos Resultados
Esta seção tem como objetivo comparar os resultados obtidos na seção 4.1.3 com osresultados da aplicação de técnicas de gaussianização e gaussianização estendida.
4.2.4.1 Primeiro cenário
Utiliza-se o mesmo cenário composto de duas fontes distribuídas uniformemente entre[−1, 1]:

4.2 Aplicação de Técnicas de Gaussianização 93
A =
[1 0.6
0.5 1
]e
f1(e1) = tanh(2e1)
f2(e2) = 2 5√e2
. (4.15)
Com o objetivo de comparar os resultados obtidos com a minimização da informaçãomútua e a técnica de gaussianização, esta seção apresenta os resultados obtidos nesseprimeiro cenário repetindo os resultados obtidos na seção 4.1.3.1. Os testes foram feitoscom 10 experimentos e os seguintes parâmetros: N0 = 5, Nc = 5, β = 50, σs = 3. Omáximo número de iterações foi fixado em 15000.
As tabelas 4.5 e 4.6 mostram os resultados organizados da seguinte forma:
IM (GA): Método da minimização da informação mútua através de algoritmosgenéticos.
IM (opt-aiNet): Método da minimização da informação mútua através dealgoritmos opt-aiNet.
Gauss. (GA): Técnica de gaussianização utilizando algoritmos genéticos.
Gauss. (opt-aiNet): Técnica de gaussianização utilizando o algoritmo opt-aiNet.
G. Est. (GA): Técnica de gaussianização estendida utilizando algoritmos genéticos.
G. Est. (opt-aiNet): Técnica de gaussianização estendida utilizando o algoritmoopt-aiNet.
A quantidade de iterações, o tempo gasto para cada iteração2 e o tempo médio deconvergência para as quatro técnicas apresentadas estão relacionados nas tabelas 4.5 e 4.6.Os resultados do erro quadrático médio entre cada fonte e sua estimativa são mostradosna tabela 4.7.
Tab. 4.5: Resultados relacionados à convergência e tempo de simulação para o primeiro cenário (Gauss.).IM (GA) IM (opt-aiNet) Gauss. (GA) Gauss. (opt-aiNet)
Quantidade de iterações∗ 2100 1550 2650 1750Tempo gasto por iteração (ms) 123 194 144 222
Tempo médio convergência (min) 4.3 5.0 6.4 6.5∗ Quantidade de iterações para atingir a convergência do algoritmo.
2Todas as simulações foram realizadas na mesma máquina, um Intel Core Duo 2.2 GHz com 2GB deRAM
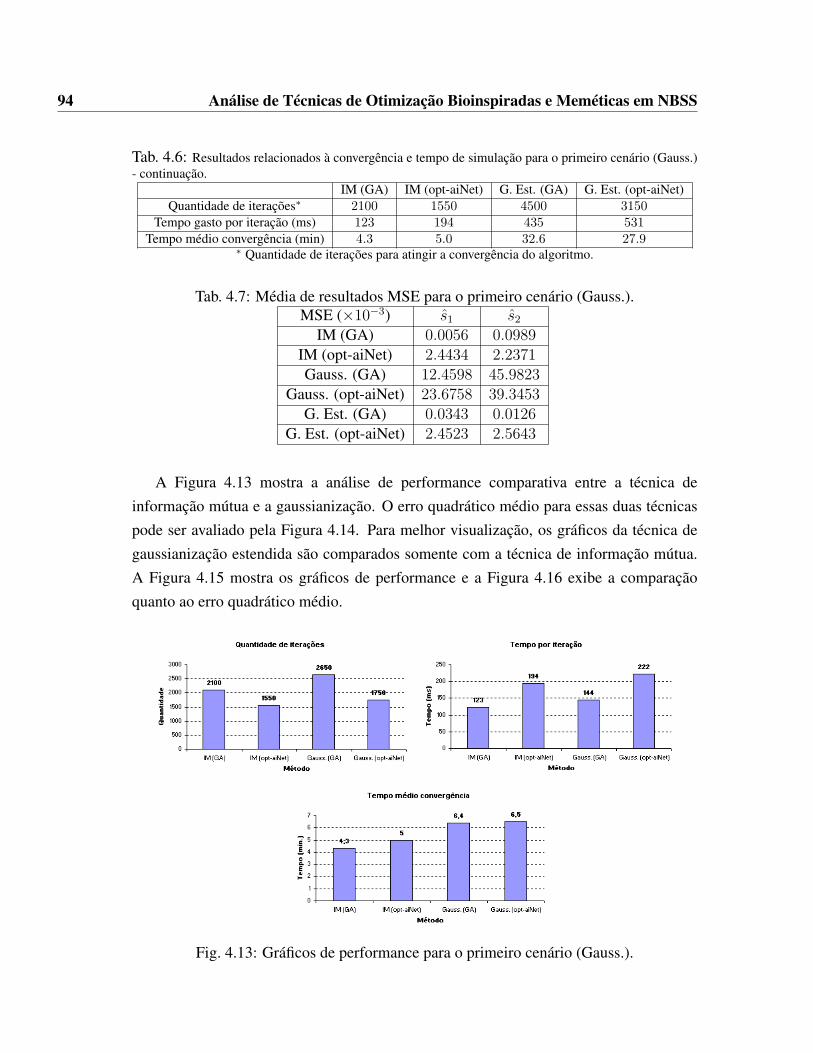
94 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Tab. 4.6: Resultados relacionados à convergência e tempo de simulação para o primeiro cenário (Gauss.)- continuação.
IM (GA) IM (opt-aiNet) G. Est. (GA) G. Est. (opt-aiNet)Quantidade de iterações∗ 2100 1550 4500 3150
Tempo gasto por iteração (ms) 123 194 435 531Tempo médio convergência (min) 4.3 5.0 32.6 27.9
∗ Quantidade de iterações para atingir a convergência do algoritmo.
Tab. 4.7: Média de resultados MSE para o primeiro cenário (Gauss.).MSE (×10−3) s1 s2
IM (GA) 0.0056 0.0989IM (opt-aiNet) 2.4434 2.2371Gauss. (GA) 12.4598 45.9823
Gauss. (opt-aiNet) 23.6758 39.3453G. Est. (GA) 0.0343 0.0126
G. Est. (opt-aiNet) 2.4523 2.5643
A Figura 4.13 mostra a análise de performance comparativa entre a técnica deinformação mútua e a gaussianização. O erro quadrático médio para essas duas técnicaspode ser avaliado pela Figura 4.14. Para melhor visualização, os gráficos da técnica degaussianização estendida são comparados somente com a técnica de informação mútua.A Figura 4.15 mostra os gráficos de performance e a Figura 4.16 exibe a comparaçãoquanto ao erro quadrático médio.
Fig. 4.13: Gráficos de performance para o primeiro cenário (Gauss.).
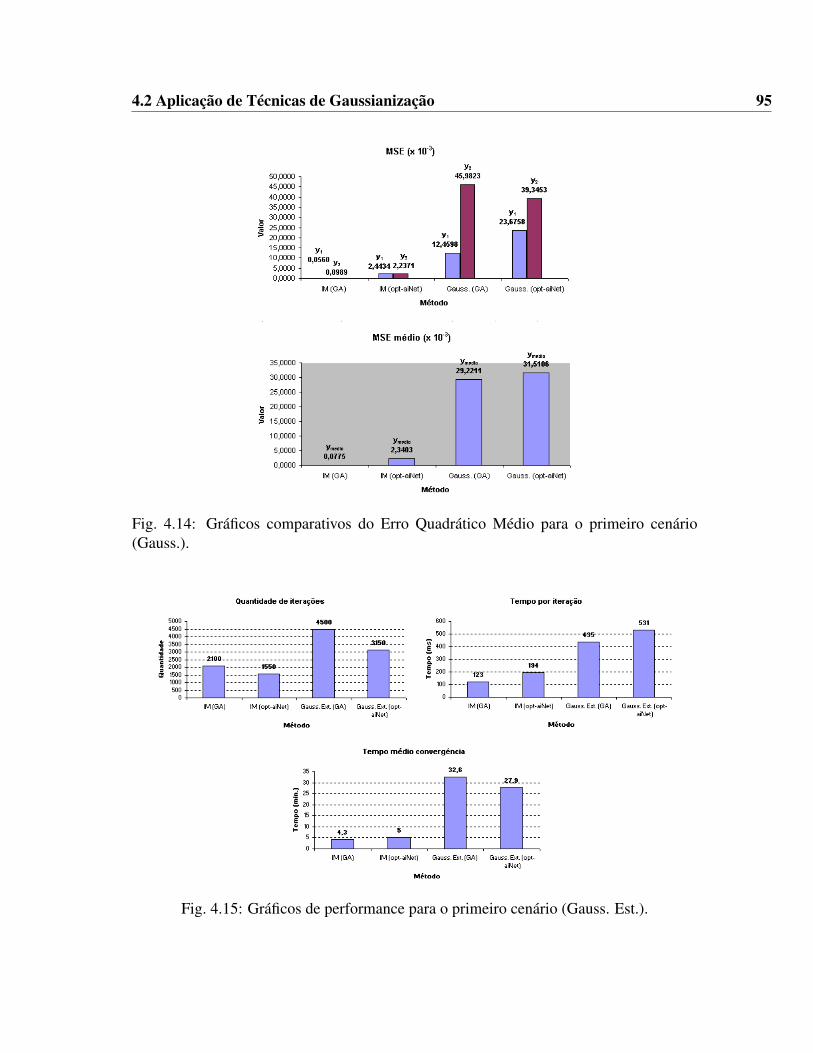
4.2 Aplicação de Técnicas de Gaussianização 95
Fig. 4.14: Gráficos comparativos do Erro Quadrático Médio para o primeiro cenário(Gauss.).
Fig. 4.15: Gráficos de performance para o primeiro cenário (Gauss. Est.).

96 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Fig. 4.16: Gráficos comparativos do Erro Quadrático Médio para o primeiro cenário(Gauss. Est.).
Comparando cada um dos quesitos de performance chega-se a:
Quantidade de iterações: As técnicas de gaussianização têm como premissa oteorema central do limite. Segundo esse teorema, a soma de um conjunto de variáveisaleatórias produz uma variável gaussiana. Essa aproximação é tão mais válida quantomaior for a quantidade de parcelas na soma, ou seja, quanto maior for a quantidadede fontes em um sistema, como ilustrado na Figura 4.17. O cenário em análise aquipossui duas fontes com distribuição uniforme e, portanto, assumir que a soma dasfontes é uma gaussiana pode não corresponder à realidade. Isto explica a quantidadede iterações necessárias ser maior que a técnica baseada em minimização da informaçãomútua. Análise semelhante vale para a técnica de gaussianização estendida, na qualo número de iterações é dado quase que pela soma do número de iterações das duastécnicas (informação mútua e gaussianização). Tal resultado mostra que a técnica degaussianização estendida não foi eficiente em prover uma solução inicial satisfatória parafacilitar a otimização do estágio de minimização da informação mútua.
Tempo de iteração: Tal como na seção anterior, aqui também o tempo de iteração écomposto quase que exclusivamente pelas avaliações da função de fitness. Isto ocorreporque essa função é obtida através do cálculo da informação mútua, que envolve aestimativa da entropia das fontes; ou através do cálculo da negentropia, que utiliza
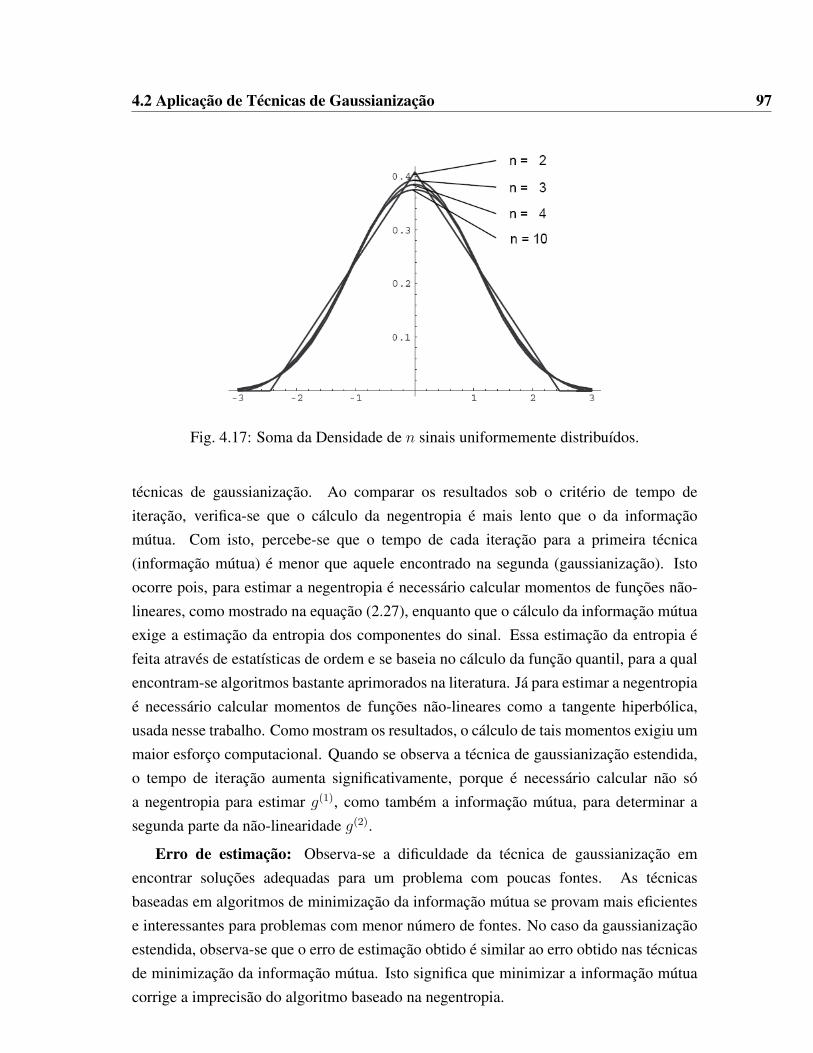
4.2 Aplicação de Técnicas de Gaussianização 97
Fig. 4.17: Soma da Densidade de n sinais uniformemente distribuídos.
técnicas de gaussianização. Ao comparar os resultados sob o critério de tempo deiteração, verifica-se que o cálculo da negentropia é mais lento que o da informaçãomútua. Com isto, percebe-se que o tempo de cada iteração para a primeira técnica(informação mútua) é menor que aquele encontrado na segunda (gaussianização). Istoocorre pois, para estimar a negentropia é necessário calcular momentos de funções não-lineares, como mostrado na equação (2.27), enquanto que o cálculo da informação mútuaexige a estimação da entropia dos componentes do sinal. Essa estimação da entropia éfeita através de estatísticas de ordem e se baseia no cálculo da função quantil, para a qualencontram-se algoritmos bastante aprimorados na literatura. Já para estimar a negentropiaé necessário calcular momentos de funções não-lineares como a tangente hiperbólica,usada nesse trabalho. Como mostram os resultados, o cálculo de tais momentos exigiu ummaior esforço computacional. Quando se observa a técnica de gaussianização estendida,o tempo de iteração aumenta significativamente, porque é necessário calcular não sóa negentropia para estimar g(1), como também a informação mútua, para determinar asegunda parte da não-linearidade g(2).
Erro de estimação: Observa-se a dificuldade da técnica de gaussianização emencontrar soluções adequadas para um problema com poucas fontes. As técnicasbaseadas em algoritmos de minimização da informação mútua se provam mais eficientese interessantes para problemas com menor número de fontes. No caso da gaussianizaçãoestendida, observa-se que o erro de estimação obtido é similar ao erro obtido nas técnicasde minimização da informação mútua. Isto significa que minimizar a informação mútuacorrige a imprecisão do algoritmo baseado na negentropia.

98 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
4.2.4.2 Segundo cenário
Nesse cenário a matriz de separação e as não-linearidades analisadas são:
A =
1 0.6 0.5
0.5 1 0.4
0.4 0.6 1
ef1(e1) = 2 3
√e1
f2(e2) = 2 3√e2
f3(e3) = 2 3√e3
.
Os parâmetros dos algoritmos foram configurados da mesma forma para as duastécnicas: N0 = 10, Nc = 5, β = 50, σs = 3. O número máximo de iterações paratodos os algoritmos foi 15000.
As tabelas 4.8 e 4.9 e as Figuras 4.18 (gaussianização) e 4.20 (gaussianizaçãoestendida) comparam a performance dos resultados obtidos. A tabela 4.10 e as Figuras4.19 e 4.21 mostram o erro de estimação para cada um dos métodos.
Tab. 4.8: Resultados relacionados à convergência e tempo de simulação para o segundo cenário (Gauss.).IM (GA) IM (opt-aiNet) Gauss. (GA) Gauss. (opt-aiNet)
Quantidade de iterações∗ 820 950 1050 1350Tempo gasto por iteração (ms) 260 380 311 430
Tempo médio convergência (min) 3.6 6.0 5.4 9.7∗ Quantidade de iterações para atingir a convergência do algoritmo.
Tab. 4.9: Resultados relacionados à convergência e tempo de simulação para o segundo cenário (Gauss.)- continuação.
IM (GA) IM (opt-aiNet) G. Est. (GA) G. Est. (opt-aiNet)Quantidade de iterações∗ 820 950 1600 2000
Tempo gasto por iteração (ms) 260 380 601 724Tempo médio convergência (min) 3.6 6.0 16.0 24.1
∗ Quantidade de iterações para atingir a convergência do algoritmo.
Tab. 4.10: Média de resultados MSE para o segundo cenário (Gauss.).MSE (×10−3) s1 s2 s3
IM (opt-aiNet) 1.0332 0.3466 4.0278IM (GA) 0.8867 1.5631 0.9843
Gauss. (GA) 11.4512 37.6565 67.3456Gauss. (opt-aiNet) 25.2899 41.9756 89.0077
G. Est. (GA) 1.1243 3.5310 2.3333G. Est. (opt-aiNet) 1.0865 0.0456 0.4512
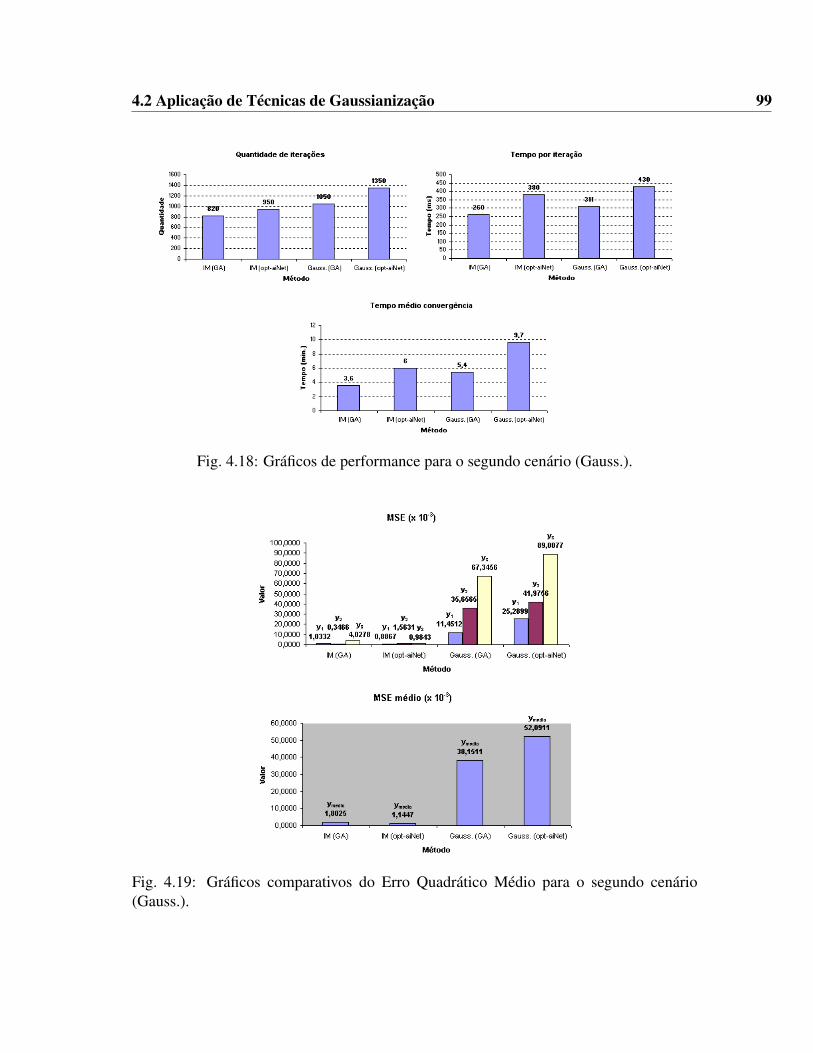
4.2 Aplicação de Técnicas de Gaussianização 99
Fig. 4.18: Gráficos de performance para o segundo cenário (Gauss.).
Fig. 4.19: Gráficos comparativos do Erro Quadrático Médio para o segundo cenário(Gauss.).
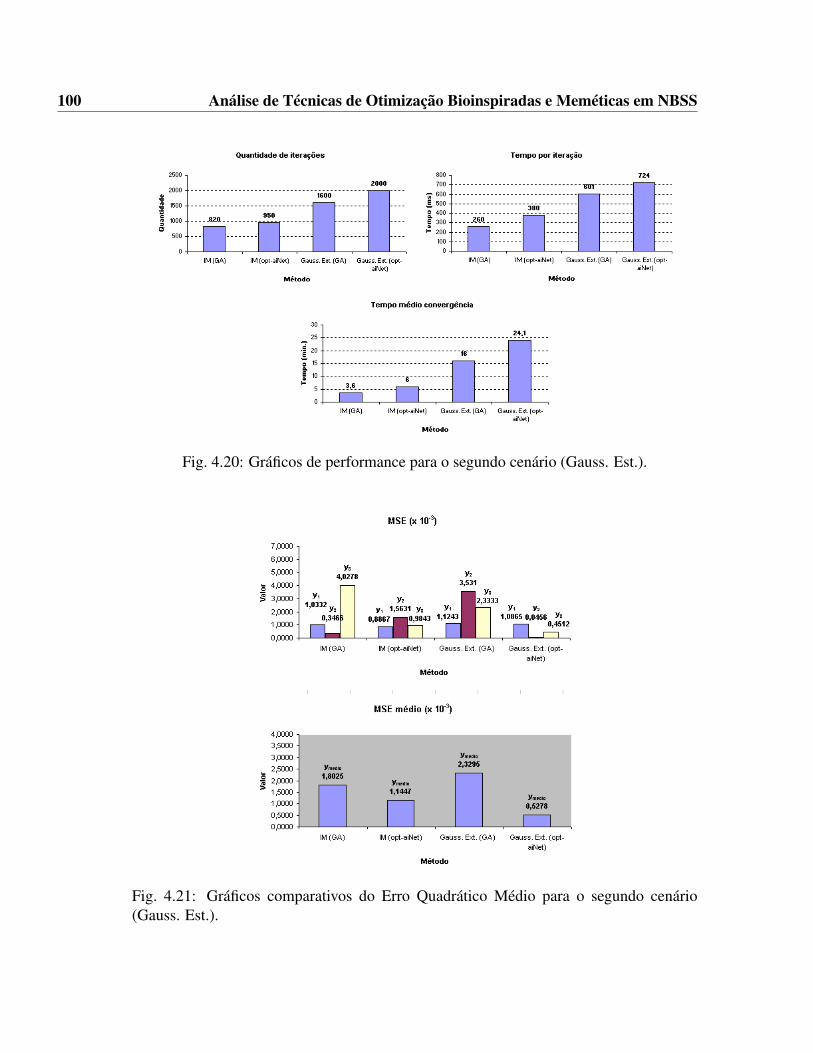
100 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
Fig. 4.20: Gráficos de performance para o segundo cenário (Gauss. Est.).
Fig. 4.21: Gráficos comparativos do Erro Quadrático Médio para o segundo cenário(Gauss. Est.).

4.3 Comentários Gerais 101
A seguir avaliam-se as observações segundo cada critério apresentado na tabela:
Quantidade de iterações: Novamente, percebe-se que a soma de um conjuntode variáveis aleatórias, mesmo para o cenário com três fontes, não se aproximaadequadamente de uma variável gaussiana. Tal como no cenário com duas fontes,observa-se uma quantidade de iterações necessárias maior que a técnica baseada emminimização da informação mútua. Essa análise também é válida para a técnica degaussianização estendida, que mostrou-se não muito eficiente em gerar uma soluçãoinicial adequada para o próximo estágio baseado na minimização da informação mútua.
Tempo de iteração: Tal como no cenário com duas fontes, a função de fitness écalculada através da informação mútua e da negentropia, de acordo com o critério usadona otimização. A função de minimização da negentropia também mostrou-se mais lentapara o cenário com três fontes. Isto significa que, assim como no resultado anterior,o cálculo da expressão da negentropia é mais complexo e exige mais esforço e tempocomputacional que o cálculo da informação mútua.
Erro de estimação: Mais uma vez, verifica-se que técnica de gaussianizaçãoobtém solução de pior qualidade que a técnica baseada na informação mútua. Para agaussianização estendida vale observar que o erro de estimação é similar ao erro geradocom a técnica de minimização da informação mútua. Novamente, observa-se o estágio deminimização da informação mútua corrigindo a imprecisão do algoritmo que tem comobase a minimização da negentropia.
Conclui-se que as técnicas de gaussianização para cenários com poucas fontes sãomais lentas que as técnicas de minimização da informação mútua, e os resultadosapresentados pela técnica são inferiores, devido à pequena quantidade de fontes presentesno cenário. Para melhorar os resultados usando técnicas de gaussianização, seriainteressante analisar problemas cujo número de fontes seja maior.
4.3 Comentários Gerais
Esse capítulo teve como objetivo principal apresentar propostas originais desolução do problema de NBSS, a partir dos conceitos expostos nos capítulos 2 e3. O desenvolvimento desse estudo permitiu a comparação entre métodos puramentemetaheurísticos com métodos híbridos, ou meméticos. Além disso, buscou-se utilizartécnicas diferenciadas na tentativa de criar novos modelos de otimização com objetivosdiferentes. Com isso, foram implementadas as estratégias já conhecidas, relacionadasà minimização da informação mútua, mas também métodos relacionados à análise degaussianização dos sinais e minimização da negentropia. A combinação desses dois

102 Análise de Técnicas de Otimização Bioinspiradas e Meméticas em NBSS
métodos (informação mútua e gaussianização) constituiu o ponto final do estudo dessecapítulo. O capítulo seguinte traz a conclusão desta tese, resumindo os pontos maisimportantes e apresentando ao leitor sugestões para projetos futuros.

Capıtulo 5Conclusões, Sugestões e Perspectivas
Esse trabalho buscou analisar problemas de separação cega de fontes não-lineares(NBSS), através da aplicação de métodos heurísticos combinados com estratégiasclássicas de busca local em BSS. Tipicamente, nesse tipo de problema pesquisadoresencontram dois desafios: 1) evitar convergência para mínimos locais e 2) encontrar ummétodo eficiente para determinar a função de fitness.
No capítulo 2 apresenta-se o problema de BSS e os principais modelos e metodologiaspara sua resolução. O capítulo 3 explora metaheurísticas baseadas em análise devizinhança e bioinspiradas para que, no capítulo 4, sejam analisados problemas deNBSS através da aplicação de algoritmos meméticos em modelos Post-Nonlinear. Nessesentido, as principais contribuições desse trabalho vêm da análise de modelos PNL,através da aplicação de algoritmos bioinspirados: algoritmos genéticos e algoritmos opt-aiNet, em conjunto com o clássico algoritmo FastICA. Dois critérios são utilizados paraguiar a otimização dos algoritmos bioinspirados: minimização da informação mútua eminimização da negentropia (gaussianização).
Os resultados mostram duas situações. Na primeira, avaliada sob o critérioda minimização da informação mútua, observa-se uma melhora significativa dosresultados através da utilização de algoritmos meméticos em comparação comalgoritmos bioinspirados puros. A segunda situação mostra a aplicação de técnicas degaussianização, que apresentaram resultados satisfatórios, mas inferiores àqueles obtidosna primeira estratégia. Em ambas as situações, conclui-se que a idéia de aliar ferramentasde busca local consagradas como o FastICA, com estratégias de algoritmos bioinspirados,produz bons resultados para os problemas de separação cega de fontes não-linear (NBSS)analisados nesse trabalho.
Como sugestão para trabalhos futuros fica a idéia de analisar outros tipos decombinações possíveis para trabalhar o problema NBSS usando o modelo PNL. Poderia-
103

104 Conclusões, Sugestões e Perspectivas
se estender esse conceito aplicando outros tipos de metaheurísticas como, por exemplo,aquelas baseadas em análise da vizinhança. Outra sugestão complementar ao trabalho éa busca por algoritmos que permitam realizar separações com tempo de convergênciamenor que a apresentada, que é da ordem de alguns minutos. Algoritmos com essacaracterística são importantes para alguns tipos de problemas de separação de fontes, nasquais há necessidade de extrair informações em tempo real. Além disso, essa abordagempermitiria estudar problemas com um maior número de fontes, possibilitando analisarmais fielmente as técnicas de gaussianização e gaussianização estendida. Como estudofuturo pode-se sugerir também a análise prática da aplicação das técnicas de separação nosproblemas de BSS apresentados nesse trabalho, permitindo não só verificar os resultadoscomputacionais simulados, mas também pesquisar novas estratégias para solução deproblemas nessa área.

Referências Bibliográficas
ABRAMOWITZ, M., & STEGUN, I. A. 1968. Handbook of mathematical functions.General Publishing Company.
ABRAMSON, D. 1992. A parallel genetic algorithm for solving the school time tablingproblem. Australian Computer Science Conference, 15.
ACHARD, S., & JUTTEN, C. 2005. Identifiability of Post Nonlinear Mixtures. IEEESignal Processing Letters, 12(5), 423–426.
AICKELIN, U., & DOWSLAND, K. A. 2004. An indirect genetic algorithm for a nurse-scheduling problem. Computers and Operations Research, 31, 761–778.
ARONS, B. 1992. A Review of the Cocktail Party Effect. Journal of the American Voice
IO Society, 12, 35–50.
ARONS, F., & SCHUSTER, H. G. 1997. Blind Separation of Convolutive Mixturesand an Application in Automatic Speech Recognition in Noisy Environment. IEEETransactions on Signal Processing, 45(10), 2608–2619.
ATTUX, R., NEVES, A., DUARTE, L. T., SUYAMA, R., JUNQUEIRA, C. C. M.,RANGEL, L. E. P., DIAS, T. M., & ROMANO, J. M. T. 2006. On the Relationshipsbetween Blind Equalization and Blind Source Separation - Part II: Relationships. Aceito
pelo Journal of the Brazilian Telecommunications Society.
ATTUX, R. R. 2005 (abril). Novos Paradigmas para Equalização e Identificação
de Canais Baseados em Estruturas Não-lineares e Algoritmos Evolutivos. Tese deDoutorado, Universidade Estadual de Campinas (Brasil).
105

106 REFERÊNCIAS BIBLIOGRÁFICAS
BABAIE-ZADEH, M. 2002 (setembro). On Blind Source Separation in Convolutive and
Nonlinear Mixtures. Tese de Doutorado, Institut National Polytechnique de Grenoble(França).
BAIROCH, A., APWEILER, R., & MAGRANE, M. 2005. The Universal Protein Resource(UniProt). Nucleic Acids Res., 33, 154–159.
BAKER, J. 1985. Adaptive selection methods for genetic algorithms. Proceeding of an
International Conference on Genetic Algorithms and Their Applications.
BARROS, A. K. 2002. Extracting the Fetal Heart Rate Variability using a FrequencyTracking Algorithm. Neurocomputing, 49, 279–288.
BÄCK, T. 1991. Optimization by means of genetic algorithms. Pages 163–169 of:
KÖHLER, E. (ed), 36th International Scientific Colloquium. Technical University of
Ilmenau.
BELL, A. J., & SEJNOWSKI, T. J. 1995. An Information Maximisation Approach toBlind Separation and Blind Deconvolution. Neural Computation, 7(6), 1129–1159.
BERMEJO, S., JUTTEN, C., & CABESTANY, J. 2006. ISFET Source Separation:Foundations and Techniques. Sensors and Actuators B - Chemical, 13, 222–233.
BLAZEWICZ, J., BURKE, E. K., & PESCH, E. 2001. Scheduling Computer and
Manufacturing Processes. Publisher Springer Berlin / Heidelberg.
BORGES, J. S., & MARÇAL, A. R. 2007. Evaluation of feature extraction and reductionmethods for hyperspectral image. New Developments and Challenges in Remote
Sensing, Z. Bochenek (ed.), 265–274.
BURIOL, L. S., FRANÇA, P. M., & MOSCATO, P. 1999. A New Memetic Algorithm forthe Asymmetric Traveling Salesman Problem. Journal of Heuristics, 10(5), 483–506.
BURKE, E. K., & NEWALL, J. P. 1999. A multistage evolutionary algorithm for thetimetable problem. IEEE Transactions on Evolutionary Computation, 1(2), 63–74.
BURKE, E. K., NEWALL, J. P., & WEARE, R. F. 1996. A memetic algorithm for
university exam timetabling. Vol. 1153-1996. Publisher Springer Berlin-Heidelberg.
CALEGARI, P., GUIDEC, F., & KUONEN, P. 1997. Globally Convergent BlindSource Separation Based on a Multiuser Kurtosis Maximization Criterion. IEEE 47th
Vehicular Technology Conference.

REFERÊNCIAS BIBLIOGRÁFICAS 107
CALHOUN, V. D., ADALI, T., HANSEN, L. K., LARSEN, J., & PEKAR, J. J. 2003.ICA of Functional MRI Data: An Overview. Pages 281–288 of: Proceedings of the
Fourth International Workshop on Independent Component Analysis and Blind Signal
Separation.
CARDOSO, J. F. 1997. Infomax and Maximum Likelihood of Blind Source Separation.IEEE Signal Processing Letters, 4(4), 112–114.
CARDOSO, J. F. 1998. Blind Signal Separation: Statistical Principles. Proceedings of
the IEEE, 86(10), 2009–2025.
CARDOSO, J. F., & LAHELD, B. H. 1996. Equivariant Adaptive Source Separation.IEEE Transactions on Signal Processing, 44(12), 3017–3030.
CARDOSO, J. F., & SOULOUMIAC, A. 1993. Blind Beamforming for non-GaussianSignals. IEEE Proceedings Radar and Signal Processing, 140(6), 362–370.
CARO, G. DI, DORIGO, M., & GAMBARDELLA, L. M. 1999. Ant Algorithms forDiscrete Optimization. Artificial Life, 5(2), 137–172.
CASTRO, L. N., & ZUBEN, F. V. 1999. Artificial Immune Systems - Part I: Basic Theory
and Applications. Tech. rept. Department of Computer Engineering and IndustrialAutomation, School of Electrical and Computer Engineering, State University ofCampinas, Brazil.
CAVALCANTE, C. C. 2004 (abril). Sobre Separação Cega de Fontes: Proposicões
e Análise de Estratégias para Processamento Multi-Usuário. Tese de Doutorado,Universidade Estadual de Campinas (Brasil).
CHEN, S. S., & GOPINATH, R. A. 2000. Gaussianization. Tech. rept. IBM T. J. WatsonResearch Center.
CHEN, S. S., & GOPINATH, R. A. 2001. Gaussianization. Advances in neural
information processing systems. Vol. 13. Cambridge: MIT Press.
CICHOCKI, A., & AMARI, S.I. 2002. Adaptive Blind Signal and Image Processing:
Learning Algorithms and Applications. John Wiley and Sons.
COMON, P. 1994. Independent Component Analysis, a New Concept? Signal Processing,36(6), 287–314.

108 REFERÊNCIAS BIBLIOGRÁFICAS
COVER, T. M., & THOMAS, J. A. 1991. Elements of Information Theory. 2 edn. JohnWiley and Sons, Inc.
CROSBY, J. L. 1973. Computer Simulation in Genetics. 2 edn. John Wiley and Sons.
DANTZIG, G. B., & RAMSER, J. H. 1959. The Truck Dispatching Problem.Management Science, 6(1), 80–91.
DARWIN, C. 1859. On The Origin of Species by Means of Natural Selection, or the
Preservation of Favoured Races in the Struggle for Life. 1st edn. John Murray.
DARWIN, C. R., & WALLACE, A. R. 1858. On the Tendency of Species to formVarieties; and on the Perpetuation of Varieties and Species by Natural Means ofSelection. Journal of the Proc. of the Linnean Society (Zoology), 3, 53–62.
DAVIS, L. D., & MITCHELL, M. 1991. Handbook of Genetic Algorithms. Van NostrandReinhold.
DAWKINS, R. 1989. The Selfish Gene. 2 edn. Oxford University Press.
DE CASTRO, L. N., & TIMMIS, J. I. 2002. Artificial immune systems: A newcomputational intelligence approach. Springer-Verlag.
DE CASTRO, L. N., & ZUBEN, F. J. VON. 2000 (Fevereiro). Artificial Immune Systems:
Part II - A Survey Of Applications. Tech. rept. DCA-RT 02/00. Department ofComputer Engineering and Industrial Automation, School of Electrical and ComputerEngineering, State University of Campinas, SP, Brazil.
DIAS, T. M., FERBER, D. F., MOURA, A. V., & DE SOUZA, C. C. 2001. Busca tabue Algoritmos Genéticos Aplicados a Problemas de Escalonamento. XXXIII Simpósio
Brasileiro de Pesquisa Operacional (SOBRAPO 2001), 1624–1632.
DIAS, T. M., FERBER, D. F., MOURA, A. V., & DE SOUZA, C. C. 2002. Problemas deEscalonamento de Pessoal em Enfermarias Hospitalares. Relatório Técnico IC-02-02.
DO AMARAL, J. L. M. 2006. Sistemas Imunológicos Artificiais Aplicados à Detecção de
Falhas. Tese de Doutorado, Departamento de Engenharia Elétrica PUC-RJ.
DORIGO, M. 1992. Optimization, learning and natural algorithms. PhD Dissertation,Dipartimento di Elettronica e Informazione, Politecnico di Milano, Italy.

REFERÊNCIAS BIBLIOGRÁFICAS 109
DUARTE, L. T. 2006. Um Estudo sobre Separação Cega de Fontes e Contribuições
ao Caso de Misturas Não-lineares. Tese de Mestrado, Universidade Estadual deCampinas, Departamento de Comunicações.
ERIKSSON, J., & KOIVUNEN, V. 2002 (setembro). Blind identifiability of class ofnonlinear instantaneous ICA models. Pages 7–10 of: Proceedings of the XI European
Signal Processing Conference (EUSIPCO 2002), vol. 2.
ERIKSSON, J., & KOIVUNEN, V. 2004. Identifiability, Separability, and Uniqueness ofLinear ICA Models. IEEE Signal Processing Letters, 11(7), 601–604.
FALKENAUER, E. 1996. A hybrid grouping genetic algorithm for bin packing.International Transactions in Operational Research, 2, 5–30.
FRANÇA, P. M., & MENDES, A. S. 2000. Metaheuristic Approaches for the PureFlowshop Manufacturing Cell Problem. 7th International Workshop On Project
Management and Scheduling.
GALEANO, J. C., VELOZA-SUAN, A., & GONZÁLEZ, F. A. 2005. A comparativeanalysis of artificial immune network models. Pages 361–368 of: Proceedings of the
2005 conference on Genetic and evolutionary computation (GECCO’05).
GLOVER, F., & LAGUNA, M. 1995. Tabu Search. McGraw Hill.
GLOVER, F., LAGUNA, M., & MARTÍ, R. 2003. Advances in evolutionary computing:
theory and applications. 2 edn. Springer–Verlag New York, Inc.
GOLDBERG, D. E. 1989. Genetic algorithms in search, optimization, and machine
learning. Addison-Wesley.
GOLDEN, B., PEPPER, J., & VOSSEN, T. 1998. Using genetic algorithms for settingparameter values in heuristic search. Intelligent Engineering Systems Through Artificial
Neural Networks, 8, 239–245.
GREFENSTETTE, J. J. 1986. Optimization of Control Parameters for Genetic Algorithms.Man and Cybernetics, 1, 122–128.
GURNEY, K. 1997. An Introduction to Neural Networks. London: Routledge.
HAJELA, P., & LIN, C. Y. 2000. Real versus binary coding in genetic algorithms: acomparative study. Computational engineering using metaphors from nature, 77–83.

110 REFERÊNCIAS BIBLIOGRÁFICAS
HAYKIN, S. 1994. Blind Deconvolution. Prentice-Hall.
HAYKIN, S. 1996. Adaptive Filter Theory. 3 edn. Prentice-Hall.
HAYKIN, S. (ed). 1998. Neural Networks: A Comprehensive Foundation. 2nd edn.Prentice Hall.
HÉRAULT, J., JUTTEN, C., & ANS, B. 1985. Détection de grandeurs primitives dansun message composite par une architecture de calcul neuromimétique en apprentissagenon supervisé. Pages 1017–1022 of: Actes du Xème Colloque GRETSI.
HERRERA, F., LOZANO, M., & VERDEGAY, J. L. 1998. Tackling real-coded geneticalgorithms: operators and tools for behavioural analysis. Journal of the Proc. of the
Linnean Society (Zoology), 12, 265–319.
HOLLAND, J. 1975. Adaptation in Natural and Artificial Systems. 1st edn. University ofMichigan Press.
HOLLAND, J. 1992. Adaptation in Natural and Artificial Systems. San Francisco,California: MIT Press.
HÉRAULT, J., & JUTTEN, C. 1994. Réseaux Neuronaux et Traitement du Signal.HERMES.
HUANG, Y., BENESTY, J., & CHEN, J. 2006. Speech Acquisition and Enhancementin a Reverberant, Cocktail-Party-Like Environment. Acoustics, Speech and Signal
Processing, 2006. ICASSP 2006 Proceedings, 5, 14–19.
HYVARINEN, A. 1999. Fast and Robust Fixed-Point Algorithms for IndependentComponent Analysis. IEEE Transactions on Neural Networks, 10(3), 626–634.
HYVÄRINEN, A. 1999. Survey on Independent Component Analysis. Neural Computing
Surveys, 2, 94–128.
HYVARINEN, A., & OJA, E. 2000. Independent Component Analysis: Algorithms andApplications. Neural Networks, 13(4-5), 411–430.
HYVÄRINEN, A., & PAJUNEN, P. 1999. Nonlinear Independent Component Analysis:Existence and Uniqueness Results. Neural Networks, 3, 429–439.
HYVARINEN, A., OJA, E., & KARHUNEN, J. 2000. Independent Component Analysis.John Wiley and Sons.

REFERÊNCIAS BIBLIOGRÁFICAS 111
JOINES, J. A., & HOUCK, C. R. 1994. On the use of non-stationary penalty functions tosolve cosntrained optimization problemas with genetic algorithms. IEEE International
Symposium on Evolutionary Computation, 579–584.
JUNG, T. P., MAKEIG, S., LEE, T. W., MCKEOWN, M., BROWN, G., BELL, A. J.,& SEJNOWSKI, T. J. 2000. Independent Component Analysis of Biomedical Signals.Pages 633–644 of: Proceedings of the Second International Workshop on Independent
Component Analysis and Blind Signal Separation, ICA 2000.
JUTTEN, C., & KARHUNEN, J. 2003. Advances in Nonlinear Blind Source Separation.In: Proceedings of the Fourth International Workshop on Independent Component
Analysis and Blind Signal Separation, ICA 2003.
KADO, K. 1995. An Investigation of Genetic Algorithms for Facility Layout Problems.PhD thesis, Department of Artificial Intelligence, The University of Edinburgh,Edinburgh, UK.
KARHUNEN, J., PAJUNEN, P., & OJA, E. 1998. The Nonlinear PCA Criterion in BlindSource Separation: Relations with Other Approaches. Neurocomputing, 22, 5–20.
KELSEY, J., & TIMMIS, J. 2003. Immune Inspired Somatic Contiguous Hypermutationfor Function Optimisation. Pages 207–218 of: Proceedings, Part I Genetic and
Evolutionary Computation Conference (GECCO 2003).
KIM, J. 2002. Immune memory in the dynamic clonal selection algorithm. Pages 59–
67 of: Proceedings of the First International Conference on Artificial Immune Systems
ICARIS .
KIM, J., & BENTLEY, P. J. 1999. Negative Selection and Niching by an ArtificialImmune System for Network Intrusion Detection. In: A late-breaking paper, Genetic
and Evolutionary Computation Conference (GECCO ’99).
KJELLSTROM, G. 1991. On the Efficiency of Gaussian Adaptation. Journal of
Optimization Theory and Applications, 71(3), 589 a 597.
KOFIDIS, E. 2001. Blind Source Separation: Fundamentals and Recent Advances. Tech.rept. Mini-curso no XIX Simpósio Brasileiro de Telecomunicações (SBrT2001).
KOZA, J. R. 1992. Genetic Programming: On the Programming of Computers by Means
of Natural Selection. The MIT Press.

112 REFERÊNCIAS BIBLIOGRÁFICAS
KÖSTER, M., GRAUEL, A., KLENE, G., & CONVEY, H. 2003. A New Paradigm
of Optimisation by Using Artificial Immune Reactions, part of: Knowledge-Based
Intelligent Information and Engineering Systems. 2 edn. Vol. 2773–2003. SpringerBerlin – Heidelberg.
KULLBACK, S., & LEIBLER, R. A. 1951. On Information and Sufficiency. Pages 79–86
of: Annals of Mathematical Statistics, vol. 22.
LATHAUWER, L. DE, MOOR, B. DE, & VANDEWALLE, J. 2000. FetalElectrocardiogram Extraction by Blind Source Subspace Separation. IEEETransactions on Biomedical Engineering, 47(5), 567–572.
LEE, T. W., GIROLAMI, M., BELL, A. J., & SEJNOWSKI, T. J. 2000. A UnifyingInformation-Theoretic Framework for Independent Component Analysis. Computers
and Mathematics with Applications, 39(11), 1–21.
LENGAUER, T. 1990. Combinatorial algorithms for integrated circuit layout. 2 edn. JohnWiley and Sons.
LEVADA, A. M. 2006. Extração de Atributos Em Imagens de Sensoriamento Remoto
Utilizando Independent Component Abalysis e Combinação de Métodos Lineares. Tesede Mestrado, Universidade Federal de São Carlos.
LEWISA, J. E., RAGADEA, R. K., & BILES, A. K. 2005. A distributed chromosomegenetic algorithm for bin-packing. 14th International Conference on Flexible
Automation and Intelligent Manufacturing, 21(4–5), 486–495.
LINSKER, R. 1988. Self-Organization in a Perceptual Network. IEEE Computer, 21(3),105–117.
LUCASIUS, C. B., & KATEMAN, G. 1989. Applications of Genetic Algorithms inChemometrics. Pages 170–176 of: Proceedings of the 3rd International Conference
on Genetic Algorithms.
LUENBERGER, D. G. 1969. Optimization by vector space methods. New York: Wileyand Sons.
MATSUOKA, K., OHATA, M., & TOKUNARI, T. 2000. A kurtosis-based blind separationof sources using the Cayleytransform. IEEE Adaptive Systems for Signal Processing,
Communications, and Control Symposium 2000, 369–374.

REFERÊNCIAS BIBLIOGRÁFICAS 113
MICHALEWICZ, Z. 1996. Genetic algorithms + data structures = evolution programs.Springer-Verlag.
MOROHASHI, M., & KITANO, H. 1999. Identifying Gene Regulatory Networks fromTime Series Expression Data by in silico Sampling and Screening. In: Proceedings of
the 5th European Conference on Artificial Life (ECAL’99).
MOSCATO, P. 1989. On Evolution, Search, Optimization, Genetic Algorithms and
Martial Arts: Towards Memetic Algorithms. Tech. rept. Caltech ConcurrentComputation Program (report 826).
NADAL, J. P., & PARGA, N. 1994. Nonlinear Neurons in the Low-noise Limit: aFactorial Code Maximises Information Transfer. Network: Computation in Neural
Systems, 5(4), 565–581.
ONG, Y. S., & KEANE, A. J. 2004. Meta-Lamarckian learning in memetic algorithms.IEEE Transactions on Evolutionary Computation, 8, 99–110.
OSMAN, I. H., & KELLY, J. P. 1997. Meta-Heuristics: Theory and Applications. Journal
of the Operational Research Society, 48(6), 571–587.
P., S. P. COY S., GOLDEN, B. L., RUNGER, G.C., & WASIL, E. A. 2001. ExperimentalDesign to Find Effective Parameter Settings for Heuristics. Journal of Heuristics, 7,77–97.
PAPADIAS, C. B. 1993. Blind Separation of Independent Sources Based on Multiuser
Kurtosis Optimization Criteria In Unsupervised Adaptive Filtering. Vol. 2. John-Wileyand Sons.
PAPADIAS, C. B. 2000. Globally Convergent Blind Source Separation Based on aMultiuser Kurtosis Maximization Criterion. IEEE Transactions on Signal Processing,48(12), 3508–3519.
PAPOULIS, A. 1993. Probability, Random Variables, and Stochastic Processes. 3 edn.McGraw Hill.
PARSONS, R. J., FORREST, S., & BURKS, C. 1995. Genetic algorithms, operators, andDNA fragment assembly. Journal Machine Learning, 21(1–2), 11–33.
PICINBONO, B. 1993. Random Signals and Systems. Prentice Hall International Editions.

114 REFERÊNCIAS BIBLIOGRÁFICAS
PICINBONO, B., & BARRET, M. 1990. Nouvelle Présentation de la Méthode duMaximum d’Entropie. Traitement du Signal, 7(2), 153–158.
PLUMBLEY, M. D., ABDALLAH, S. A., BELLO, J. P., DAVIES, M. E., MONTI, G., &SANDLER, M. B. 2002. Automatic Music Transcription and Audio Source Separation.Cybernetics and Systems, 33(6), 603–627.
POMERLEAU, D., & JOCHEM, T. 1996. Rapidly Adapting Machine Vision forAutomated Vehicle Steering. IEEE Expert: Special Issue on Intelligent System and
their Applications, 11(2), 19–27.
PUNTONET, C. G., & PRIETO, A. (eds). 2004. Independent Component Analysis and
Blind Signal Separation Fifth International Conference, ICA 2004. Springer LectureNotes in Computer Science.
ROJAS, F., PUNTONET, C. G., RODRÍGUEZ-ÁLVAREZ, M., ROJAS, I., & MARTÍN-CLEMENTE, R. 2004. Blind Source Separation in Post-Nonlinear Mixtures UsingCompetitive Learning, Simulated Annealing, and a Genetic Algorithm. IEEETransactions on Systems, Man and Cybernetics - Part C: Applications and Reviews,34(4), 407–416.
ROSCA, J., ERDOGMUS, D., PRINCIPE, J. C., & HAYKIN, S. (eds). 2006. Independent
Component Analysis and Blind Signal Separation Sixth International Conference, ICA
2006. Springer Lecture Notes in Computer Science.
SALTO, C., ALBA, E., & MOLINA, J. M. 2006. Analysis of distributed geneticalgorithms for solving cutting problems. International Transactions in Operational
Research, 13, 403–423.
SHANNON, C. E. 1948. A Mathematical Theory of Communication. Bell Systems
Technical Journal, 27, 379–423; 623–656.
SHARMA, A., & PALIWALA, K. K. 2006. Subspace independent component analysisusing vector kurtosis. Pattern Recognition Society Published by Elsevier B.V., 39,2227–2232.
SILVERMAN, B.W. 1986. Density Estimation for Statistics and Data Analysis. Chapmanand Hall/CRCs.
SOLÉ-CASALS, J., BABAIE-ZADEH, M., JUTTEN, C., & PHAM, D.T. 2003. ImprovingAlgorithm Speed in PNL Mixture Separation and Wiener System Inversion. In:

REFERÊNCIAS BIBLIOGRÁFICAS 115
Proceedings of the Fourth International Workshop on Independent Component Analysis
and Blind Signal Separation, ICA 2003.
STALLINGS, W. 2004. Operating Systems Internals and Design Principles. 5th edn.Publisher Springer Berlin - Heidelberg.
TALEB, A. 2002. A Generic Framework for Blind Source Separation in StructuredNonlinear Models. IEEE Transactions on Signal Processing, 50(8), 1819–1930.
TALEB, A., & JUTTEN, C. 1999. Source Separation in Post-Nonlinear Mixtures. IEEETransactions on Signal Processing, 47(10), 2807–2820.
TOSO, E. V., & MORABITO, R. 2005. Otimização no dimensionamento eseqüenciamento de lotes de produção: estudo de caso numa fábrica de rações. Gestão
e Produção, 12(2).
VIGÁRIO, R. 1988. Independent Component Analysis for Identification of Artifacts in
Magnetoencephalographic Recordings in M. Jordan et al. (eds) Advances in Neural
Information Processing Systems. Vol. 10–233. MIT Press.
WEINAND, R. G. 1990. Somatic mutation, affinity maturation and the antibodyrepertoire: a computer model. Journal of Theoretical Biology, 143, 343–382.
ZARZOSO, V., & NANDI, A.K. 1998. Modelling signals of arbitrary kurtosis for testingBSS methods. IEEE Electronics Letters, 34(1), 29–30.
ZHANG, K., & CHAN, L.W. 2005. Extended Gaussianization Method for BlindSeparation of Post-Nonlinear Mixtures. Neural Computation, 17(2), 425–452.












![Brennan Manning ● Confiança Cega [algumas páginas]](https://img.document.onl/doc/110x75/57906cf31a28ab68748dcc73/brennan-manning-confianca-cega-algumas-paginas.jpg)
















