Embed Size (px)
Citation preview

Algoritmos para Codificação de Voz
Eriko C. M. Porto
Engenharia de Telecomunicações – Universidade Federal Fluminense (UFF) R. Passo da Pátria, 156 - São Domingos – Niterói – RJ – Brasil
Departamento de Engenharia de Telecomunicações (TET) [email protected]
Resumo. O objetivo deste trabalho é apresentar os principais conceitos relacionados à digitalização e compressão de voz, particularmente em relação às técnicas utilizadas pelo padrão MPEG-4, denominadas CELP e HVXC. Inicialmente conceituamos as classes de algoritmos de compressão de voz e comparamos as funcionalidades de cada tipo. A seguir descrevemos os principais conceitos e técnicas relacionados aos codificadores baseados na forma da onda do sinal de entrada, codificadores baseados na fonte com modelagem de sinais de voz por predição linear e também dos codificadores híbridos. Com base nestes conceitos apresentados estaremos descrevendo as técnicas de compressão utilizadas pelo padrão MPEG-4. O trabalho finaliza com uma comparação entra as técnicas de compressão apresentadas.
1. Introdução O campo de codificação de voz para transmissão engloba mais do que apenas a digitalização de sinais analógicos de voz. O foco da pesquisa atual consiste em desenvolver codificadores de áudio que proporcionem melhor qualidade de voz com a menor taxa de bits possível, atraso mínimo e baixa complexidade na implementação.
O algoritmo juntamente com o dispositivo associado é normalmente denominado codec na literatura, proveniente da fusão das palavras encoder e decoder. A função do codificador é digitalizar e processar um sinal em uma forma mais eficiente para transmissão ou armazenamento, enquanto que a função do decodificador é restaurar o sinal original. Em geral, os codecs de baixa taxa de bits produzem perdas, o que significa que a qualidade do sinal é reduzida por sucessivos ciclos de codificação.
Os codificadores de voz podem ser classificados da seguinte forma [1]:
• Baseados na forma do sinal (waveform codecs)
• Baseados na fonte do sinal (source codecs)
• Híbridos (hybrid codecs)
A Figura 1 mostra os requisitos de banda em relação à qualidade de áudio para os diferentes tipos de codificadores de voz [1].
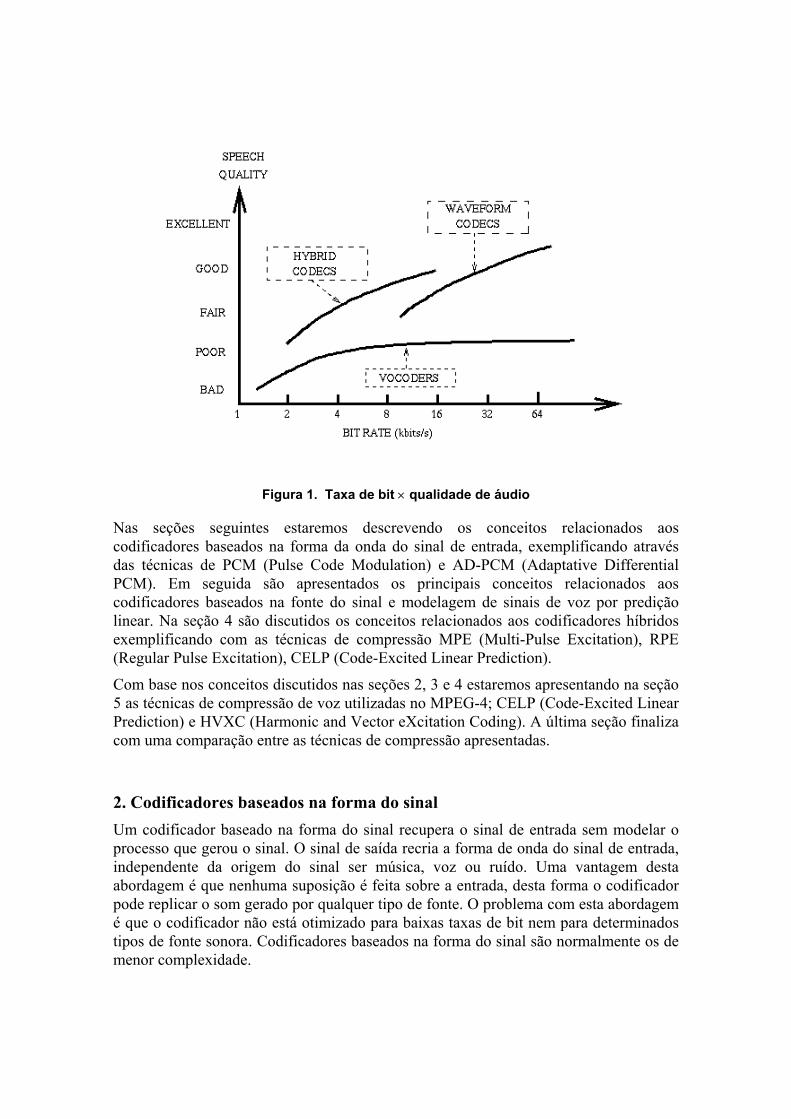
Figura 1. Taxa de bit × qualidade de áudio
Nas seções seguintes estaremos descrevendo os conceitos relacionados aos codificadores baseados na forma da onda do sinal de entrada, exemplificando através das técnicas de PCM (Pulse Code Modulation) e AD-PCM (Adaptative Differential PCM). Em seguida são apresentados os principais conceitos relacionados aos codificadores baseados na fonte do sinal e modelagem de sinais de voz por predição linear. Na seção 4 são discutidos os conceitos relacionados aos codificadores híbridos exemplificando com as técnicas de compressão MPE (Multi-Pulse Excitation), RPE (Regular Pulse Excitation), CELP (Code-Excited Linear Prediction).
Com base nos conceitos discutidos nas seções 2, 3 e 4 estaremos apresentando na seção 5 as técnicas de compressão de voz utilizadas no MPEG-4; CELP (Code-Excited Linear Prediction) e HVXC (Harmonic and Vector eXcitation Coding). A última seção finaliza com uma comparação entre as técnicas de compressão apresentadas.
2. Codificadores baseados na forma do sinal Um codificador baseado na forma do sinal recupera o sinal de entrada sem modelar o processo que gerou o sinal. O sinal de saída recria a forma de onda do sinal de entrada, independente da origem do sinal ser música, voz ou ruído. Uma vantagem desta abordagem é que nenhuma suposição é feita sobre a entrada, desta forma o codificador pode replicar o som gerado por qualquer tipo de fonte. O problema com esta abordagem é que o codificador não está otimizado para baixas taxas de bit nem para determinados tipos de fonte sonora. Codificadores baseados na forma do sinal são normalmente os de menor complexidade.

2.1. PCM
O codificador PCM (Pulse Code Modulation), especificado na Recomendação ITU-T G.711 [3], é um codificador baseado na forma do sinal. O sinal analógico de voz é filtrado para remover componentes de alta e baixa freqüência, e amostrado a uma taxa de 8000 vezes por segundo. O valor amostrado é quantizado em um de 256 valores representados em uma palavra de 8 bits. A taxa de bit resultante do codificador G.711 é uma taxa de 64 kbps (kilobits por segundo), o que determina a banda de um canal DS-0 (Digital Signal – Level 0) básico da telefonia. O valor de cada amostra é codificado utilizando uma de duas leis possíveis: lei-µ ou lei-A. Estas leis se referem à distribuição dos níveis de quantização. Cada um dos sistemas trabalha com níveis de quantização que incrementam mediante uma escala logarítmica em função do nível do sinal. Desta forma, os níveis de quantização estão mais próximos na região silenciosa do sinal. Ambas as leis enfatizam a qualidade do sinal nas regiões de menor amplitude, de forma a compensar o erro de quantização relativo à amplitude do sinal. Mais detalhes podem ser encontrados em [2].
A lei-µ é utilizada nos Estados Unidos enquanto que a lei-A é utilizada na Europa e em outros países (inclusive no Brasil). A lei-µ é ligeiramente mais sensível às diferenças na região mais silenciosa do sinal (menores amplitudes) do que a lei-A, pois provê uma quantidade maior de níveis de quantização nesta região.
2.2. AD-PCM
O codificador AD-PCM (Adaptative Differential – Pulse Code Modulation), especificado na Recomendação ITU-T G.726 [4], é um codificador mais elaborado também baseado na forma do sinal. Ao invés de transmitir o valor real do nível PCM do sinal, este codificador transmite um sinal de erro que é a diferença entre o nível da amostra atual e uma entrada estimada. Se a entrada estimada está razoavelmente perto do valor atual de entrada, o sinal de erro terá uma magnitude pequena em relação à entrada original. Desta forma o AD-PCM consegue uma qualidade razoável utilizando baixas taxas de bit. A seguinte equação descreve o processo executado pelo codificador:
(entrada_original) – (entrada_estimada) = (erro_do_sinal)
Onde a entrada estimada é uma função das sucessivas amostras de erro do sinal. O codificador utiliza valores sucessivos de sua própria saída para estimar a entrada correta. O decodificador também utiliza esta informação para realizar uma estimativa idêntica da entrada corrente. Devido a esta mudança na função de estimativa, baseada nas características do sinal de entrada, é que o PCM diferencial é denominado AD-PCM (adaptativo). Rearrumando os termos da equação anterior, temos:
(erro_do_sinal) + (entrada_estimada) = (entrada_original)
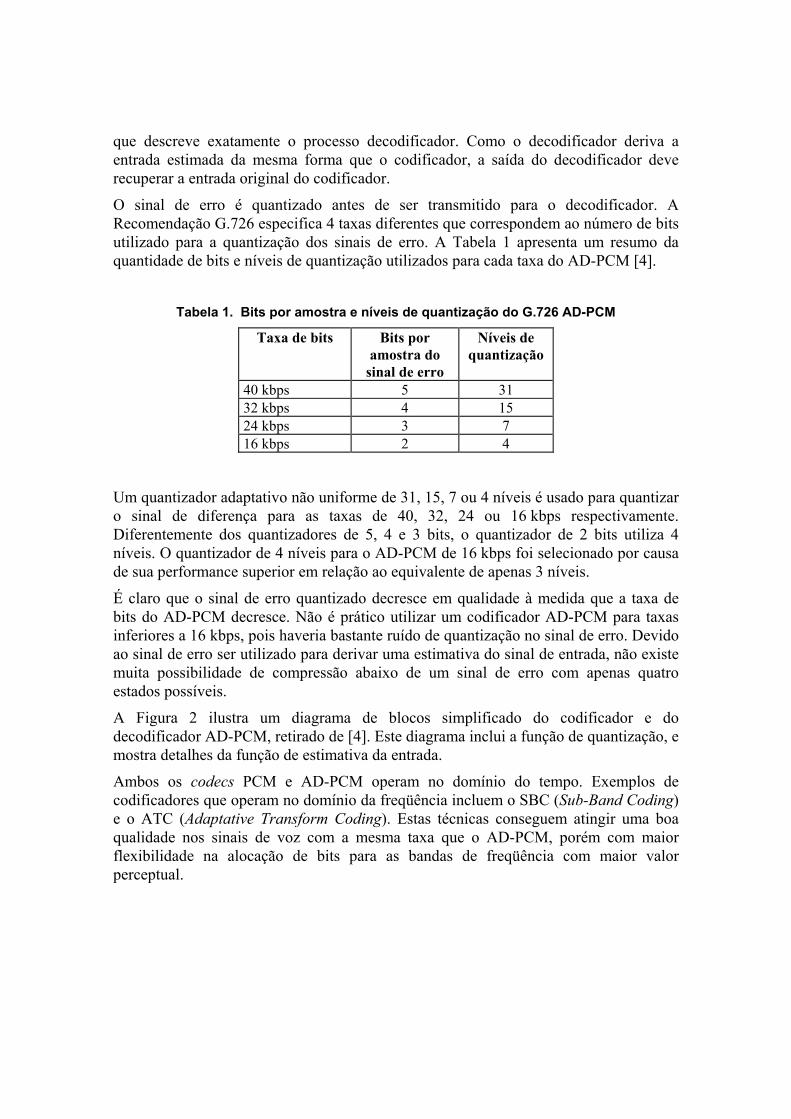
que descreve exatamente o processo decodificador. Como o decodificador deriva a entrada estimada da mesma forma que o codificador, a saída do decodificador deve recuperar a entrada original do codificador.
O sinal de erro é quantizado antes de ser transmitido para o decodificador. A Recomendação G.726 especifica 4 taxas diferentes que correspondem ao número de bits utilizado para a quantização dos sinais de erro. A Tabela 1 apresenta um resumo da quantidade de bits e níveis de quantização utilizados para cada taxa do AD-PCM [4].
Tabela 1. Bits por amostra e níveis de quantização do G.726 AD-PCM
Taxa de bits Bits por amostra do
sinal de erro
Níveis de quantização
40 kbps 5 31 32 kbps 4 15 24 kbps 3 7 16 kbps 2 4
Um quantizador adaptativo não uniforme de 31, 15, 7 ou 4 níveis é usado para quantizar o sinal de diferença para as taxas de 40, 32, 24 ou 16 kbps respectivamente. Diferentemente dos quantizadores de 5, 4 e 3 bits, o quantizador de 2 bits utiliza 4 níveis. O quantizador de 4 níveis para o AD-PCM de 16 kbps foi selecionado por causa de sua performance superior em relação ao equivalente de apenas 3 níveis.
É claro que o sinal de erro quantizado decresce em qualidade à medida que a taxa de bits do AD-PCM decresce. Não é prático utilizar um codificador AD-PCM para taxas inferiores a 16 kbps, pois haveria bastante ruído de quantização no sinal de erro. Devido ao sinal de erro ser utilizado para derivar uma estimativa do sinal de entrada, não existe muita possibilidade de compressão abaixo de um sinal de erro com apenas quatro estados possíveis.
A Figura 2 ilustra um diagrama de blocos simplificado do codificador e do decodificador AD-PCM, retirado de [4]. Este diagrama inclui a função de quantização, e mostra detalhes da função de estimativa da entrada.
Ambos os codecs PCM e AD-PCM operam no domínio do tempo. Exemplos de codificadores que operam no domínio da freqüência incluem o SBC (Sub-Band Coding) e o ATC (Adaptative Transform Coding). Estas técnicas conseguem atingir uma boa qualidade nos sinais de voz com a mesma taxa que o AD-PCM, porém com maior flexibilidade na alocação de bits para as bandas de freqüência com maior valor perceptual.

Figura 2. Diagrama de blocos simplificado do codec ITU-T G.726 AD-PCM
3. Codificadores baseados na fonte do sinal Os codificadores de fonte (source codecs) são projetados segundo uma filosofia que é fundamentalmente diferente dos codificadores de forma de onda. Estes tipos de codificadores são projetados para operar sobre um tipo específico de sinal de entrada (por exemplo, a voz humana), e utilizam este tipo de entrada presumida para modelar o sinal da fonte. Codificadores de fonte para voz tentam replicar o processo físico da criação do som vocálico.
3.1. Acústica da voz humana
Durante um discurso vocálico, um sinal excitado oriundo dos pulmões e cordas vocais é filtrado pelo trato vocal (garganta, língua, cavidade nasal e lábios). Para sinais não vocálicos, o ar em turbulência partindo dos pulmões produz um som sibilar que é moldado pelo trato vocal. As cordas vocais não são utilizadas durante a geração de um som não-vocálico. Um sinal sonoro não-vocálico é similar ao ruído branco, com energia em várias bandas de freqüência. Para a geração de sons vocálicos, as cordas vocais abrem e fecham em diferentes freqüências que modulam o ar passando através do trato vocal. Este sinal modulado tem uma forma de onda triangular que produz um som semelhante a um zumbido. Esta forma de onda é também composta por diversos componentes de freqüência, de forma que existe ampla quantidade de material permitindo ao trato vocal a geração de palavras e discursos. A Figura 3 mostra um esquema do trato vocal humano [8].

Figura 3. Os órgãos vocais humanos. (1) cavidade nasal, (2) Palato duro, (3)
Cume Alveoral, (4) Palato mole (Velum), (5) Ponta da língua (Ápice), (6) Dorsum, (7) Úvula, (8) Radical, (9) Faringe, (10) Epiglote, (11) Cordas vocais falsas, (12)
Cordas vocais, (13) Laringe, (14) Esôfago e (15) Traquéia
A fala contínua corresponde a um conjunto de sinais de áudio complicado que torna a tarefa de produzi-los artificialmente bastante complexa. Os sinais de fala são normalmente considerados como vocálicos ou não-vocálicos, mas em alguns casos eles se situam entre estas duas formas. Os sons vocálicos consistem em uma freqüência fundamental (f0) e seus componentes harmônicos produzidos pelas cordas vocais (dobras vocais). O trato vocal modifica esta excitação gerando freqüências formantes (pólo) e às vezes antiformantes (zero) [8]. Cada freqüência formante tem também uma amplitude e largura de banda e pode ser às vezes difícil definir alguns destes parâmetros corretamente. A freqüência fundamental e as freqüências formantes são provavelmente os conceitos mais importantes em síntese da fala e também em processamento da fala em geral.
Com sons puramente não-vocálicos, não existe nenhuma freqüência fundamental no sinal de excitação e portanto nenhuma estrutura harmônica e, neste caso, a excitação pode ser considerada como ruído branco. Uma corrente de ar é forçada por uma constrição do trato vocal que pode acontecer em vários lugares entre a glote e boca. Alguns sons são produzidos com uma obstrução completa de corrente de ar seguida por uma liberação súbita, produzindo uma excitação turbulenta impulsiva freqüentemente seguida por uma excitação turbulenta mais demorada. Os sons não-vocálicos também são normalmente mais silenciosos e menos estáveis que os vocálicos. Sussurrar é um caso especial da fala. Quando um som vocálico é sussurrado não existe nenhuma freqüência fundamental na excitação e as primeiras freqüências formantes produzidas pelo trato vocal são percebidas.

Os sinais de fala das três vogais (/a/ /i/ /u/) são apresentados nos domínios do tempo e da freqüência na Figura 4. A freqüência fundamental é mais ou menos 100 Hz em todos os casos e as freqüências formantes f1, f2 e f3 da vogal /a/ são aproximadamente 600 Hz, 1000 Hz, e 2500 Hz respectivamente. Com a vogal /i/, os primeiros três formantes são 200 Hz, 2300 Hz e 3000 Hz, e com a vogal /u/, 300 Hz, 600 Hz e 2300 Hz. A estrutura harmônica da excitação também é fácil de perceber na representação no domínio da freqüência.
Figura 4. A representação no domínio do tempo e da freqüência das vogais /a/, /i/, e /u/
A correlação a curto prazo de amostras de voz sucessivas tem algumas conseqüências para os envelopes espectrais. Estes envelopes espectrais têm alguns máximos locais, que são os formantes, correspondendo às freqüências de ressonância do trato vocal humano. A fala consiste em uma sucessão de sons, denominados fonemas. Durante um discurso de fala a configuração do trato vocal é continuamente modificada a fim de produzir diferentes freqüências de ressonância (formantes) e portanto diferentes sons.
Esta correlação de curto prazo pode ser usada para estimar a amostra de voz corrente em função das amostras passadas. Esta estimativa é chamada “predição”. Como a predição é determinada através de uma combinação linear de amostras (passadas) de voz, esta é denominada “predição linear” (Linear Predictive Coding – LPC). A diferença entre o sinal original e o estimado é denominada “sinal de erro da predição” (LPC residual). Idealmente, toda a correlação é removida pelo processo, isto é o sinal de erro é na verdade ruído branco. Somente o sinal de erro é enviado para o receptor pois possui menor redundância, e portanto cada bit transporta mais informações.

3.2. Modelo matemático
O modelo apresentado na Figura 5 é denominado o Modelo LPC (Linear Predictive Coding). O modelo representa um sinal de voz digitalizado através da saída de um filtro digital (denominado filtro LPC) cuja entrada é, ou um trem de pulsos, ou uma seqüência de ruído branco, dependendo se o sinal de saída é vocálico ou não vocálico [2].
Figura 5. Modelo matemático do LPC
A relação entre os elementos do modelo matemático e as variáveis físicas está apresentado na Tabela 2.
Tabela 2. Elementos do modelo LPC
Modelo Componente
H(z) trato vocal (filtro LPC)
u(n) sinal de entrada
V/UV voiced/unvoiced
T período de vibração das cordas vocais (pitch period)
G volume de ar (gain)
O filtro LPC é dado por:
1010
22
111
1)(−−− ⋅++⋅+⋅+
=zazaza
zHL

Que é equivalente à dizer que a relação entre a saída e a entrada do filtro é dada pela seguinte equação diferencial linear:
∑=
=−⋅+10
1)()()(
ii nuinsans
O modelo LPC pode ser representado na forma de um vetor como a seguir:
{ }TUVUGaaaaaaaaaaA ,,,,,,,,,,,, 10987654321=
O vetor A muda a cada 20 ms em geral, a uma taxa de amostragem de 8000 amostras/segundo, ou seja, 20 ms é equivalente a 160 amostras. O sinal de voz digital é dividido em quadros com 20 ms de tamanho, gerando 50 quadros/segundo.
O modelo afirma que o vetor A é equivalente a S, onde S é dado por:
{ })159(,),2(),1(),0( ssssS K=
Deste modo os 160 valores de S estão representados de forma compactada pelos 13 valores do vetor A. A síntese LPC consiste em dado A, gerar S (isto é feito através de técnicas usuais de aplicação de filtros). A análise LPC consiste inversamente em dado S, obter o vetor A que melhor aproxima S.
O processo de análise LPC é denominado autocorrelação pois consiste em resolver uma matriz de 10 equações lineares com 10 incógnitas que são os coeficientes a1 a a10 do filtro H(z). Os detalhes da demonstração matemática podem ser encontrados em [2].
Os coeficientes LPC são normalmente representados como Line Spectral Pairs (LSP). Parâmetros LSP são equivalentes um-a-um aos parâmetros LPC, sendo que os parâmetros LSP são mais adequados para quantização.
Os parâmetros LSP são calculados da seguinte forma:
( ) ( ) ( )( ) ( ) ( ) 1110
1102
921
101
1110110
292
1101
1)(
1)(−−−−
−−−−
+⋅+++⋅++⋅++=
−⋅−++⋅−+⋅−+=
zzaazaazaazQ
zzaazaazaazP
L
L

Fatorando as equações acima, temos:
( ) (( ) (∏
∏=
−−−
=−−−
+⋅−⋅+=
+⋅−⋅−=
9,3,1211
10,4,2211
cos211)(
cos211)(
K
K
k k
k k
zzzzQ
zzzzP
ω
ω ))
Os fatores { } são denominados parâmetros LSP. Estes parâmetros obtidos com esta transformação têm a vantagem de estarem ordenados e limitados (0<ω
101=kkω
1<ω2<…<ω10<π), possuindo também uma correlação maior de um quadro para o quadro seguinte, o que possibilita uma maior eficiência na representação quantizada [2].
3.3. Codificadores LPC
Codificadores de fonte para voz emulam a função do sinal de excitação e o filtro do trato vocal. As amostras de áudio do codificador são agrupadas em quadros, e cada quadro é analisado para determinar o tipo do sinal de excitação e a forma da filtragem. A forma do sinal de excitação é usualmente codificada em um único bit, indicando sinais de excitação vocálicos ou não-vocálicos. Para sinais não-vocálicos, o codificador pode usar um gerador de ruído branco para o sinal de excitação. Para sinais vocálicos, o codificador precisa determinar a freqüência de modulação das cordas vocais.
O filtro do trato vocal é uma função algébrica da freqüência do sinal. Algumas freqüências são enfatizadas por esta função, enquanto que outras são suprimidas, dependendo dos valores dos coeficientes algébricos da equação. Para cada grupo de amostras analisadas, um conjunto de coeficientes é determinado em função da melhor aproximação possível para o filtro do trato vocal. A maior parte dos modelos de filtros utiliza pelo menos equações lineares de ordem 10 (daí o termo predição linear). Os coeficientes da equação linear são atualizados para cada quadro, desta forma o modelo de filtro do trato vocal muda entre cada 5 a 30 ms. O tamanho do quadro pode variar dependendo do codificador utilizado. Os coeficientes da equação linear, um bit para o tipo de excitação produzida, e possivelmente a freqüência (pitch) do sinal de excitação de voz, são transmitidos em cada quadro. A Figura 6 resume as funções de um codificador de fonte.

Figura 6. Diagrama esquemático de um codificador e um decodificador de fonte
Um conceito importante introduzido pelos codificadores de fonte é o agrupamento de amostras em quadros para análise e codificação. O decodificador reconstrói o sinal original quadro-a-quadro passando o sinal de excitação pelo filtro do quadro. O codificador determina o valor das variáveis do filtro para cada quadro examinando as amostras do quadro em questão. O codificador também examina as amostras dos quadros anterior e posterior de forma a melhorar a qualidade dos valores das variáveis do filtro calculadas para o quadro corrente. A janela de amostras que ocorrem depois do quadro corrente é denominada look-ahead. A especificação de um codec é formada por diversas variáveis, incluindo o tamanho do quadro e do look-ahead. Estas variáveis são importantes pois elas introduzem um atraso algorítmico ao sistema em que o codificador será utilizado.
4. Codificadores híbridos Codificadores híbridos provêm uma melhor qualidade no sinal do que os codificadores de fonte puros, e com uma taxa de bits inferior a dos codificadores de forma de onda. Para atingir este desempenho, os codificadores híbridos utilizam uma combinação de análise da forma do sinal e modelagem da fonte. Os algoritmos em geral tendem a ser bastante complexos.
Codificadores híbridos tentam preencher a lacuna existente entre os codificadores baseados na fonte e os baseados na forma de onda. Codificadores baseados na forma do sinal são capazes de prover boa qualidade de voz para taxas de bit em torno de 16 kbps, mas são de uso limitado para taxas inferiores. Codificadores de fonte (vocoders) por outro lado podem prover voz inteligível a 2.4 kbps ou menos, mas com baixa qualidade em qualquer taxa de transferência. Embora existam outros tipos de codificadores híbridos, os mais bem sucedidos e comumente usados operam no domínio do tempo usando técnicas denominadas LPAS (Linear Prediction Analysis-by-Synthesis). Estes codificadores usam o mesmo modelo de filtro de predição linear do trato vocal dos codificadores de fonte LPC. Porém em vez de aplicar um entre dois estados, voiced/unvoiced, para identificar o modelo de entrada adequado para este filtro, o sinal de excitação é determinado tentando encontrar um sinal de fala reconstruído tão próximo quanto possível do sinal de fala original. Codificadores LPAS foram primeiramente introduzidos em 1982 por Atal e Remde [1] através do modelo conhecido como codificador MPE (Multi-Pulse Excitation). Posteriormente os

codificadores RPE (Regular Pulse Excitation) e CELP (Code-Excited Linear Prediction) foram introduzidos.
O que distingue os diferentes tipos de codificadores LPAS é como o sinal de excitação para o filtro de síntese é determinado. Conceitualmente cada forma de onda possível é passada através do filtro para verificar qual sinal de voz reconstruído é produzido por cada sinal de excitação específico. O sinal de excitação que produz um sinal de erro entre o sinal original e o reconstruído com menor densidade de energia é escolhido pelo codificador e será utilizado no decodificador para modular o filtro de síntese LPC. Esta determinação do sinal de excitação em loop fechado permite aos codificadores LPAS produzir uma excelente qualidade de voz com taxa reduzida. Contudo a complexidade envolvida em passar todos os sinais de excitação possíveis pelo filtro é alta. Usualmente algum meio de reduzir esta complexidade, sem comprometer o desempenho do codificador, deve ser utilizado.
4.1. Multi-Pulse Excitation
O modelo MPE codifica o sinal de excitação como uma série de pulsos (diferentes de zero) que podem variar na posição temporal e na amplitude. Normalmente, este sinal de excitação é determinado para cada subquadro, ao invés de todo o quadro. A Figura 7 exemplifica o processo.
Figura 7. O MPE permite que cada pulso varie na posição e amplitude
O algoritmo do codificador determina a quantidade de pulsos que pode variar dentro do subquadro, que usualmente tem duração de 5 ms. Freqüentemente o subquadro é dividido em intervalos de tempo menores, e um único pulso está contido em cada um destes intervalos de tempo. O último intervalo de tempo é geralmente maior que os outros. Neste cenário, o codificador calcula separadamente a posição e a amplitude otimizadas para cada pulso. Em teoria seria possível achar o melhor valor possível para todas as posições de pulso e amplitudes, mas isto não é prático devido à excessiva complexidade requerida. Na prática algum método quase ótimo de achar as posições de pulso e amplitudes deve ser usado. Tipicamente existem de 4 a 5 pulsos dentro de cada

amostra de 5 ms, levando a uma boa qualidade na reconstrução da fala a uma taxa de bit em torno de 10 kbps. A saída do codificador inclui a posição e a amplitude de cada um dos pulsos no sinal de excitação.
A Recomendação G.723.1 do ITU-T [5] possibilita duas taxas de operação: 5.3 kbps e 6.3 kbps [5]. O codificador de 6.3 kbps utiliza uma versão do algoritmo MPE denominada Multi-Pulse Maximum Likelihood Quantization (MP-MLQ).
4.2. Regular Pulse Excitation
Assim como o MPE, o RPE representa a excitação do sinal como uma série de pulsos, só que ao invés de representar a posição e a amplitude de cada pulso, somente a amplitude é representada. Uma pequena porção da informação codifica o deslocamento (offset) do primeiro pulso em relação ao subquadro, e cada um dos pulsos subseqüente segue a intervalos de tempo regulares. Comparado com a técnica MPE, o RPE reduz o total de bits requeridos para representar uma dada quantidade de pulsos. O RPE realoca os bits economizados de maneira a prover uma maior quantidade de pulsos dentro do subquadro do sinal de excitação. Um codificador RPE típico utiliza de 10 a 12 pulsos por subquadro. A Figura 8 ilustra o método de codificação do sinal de excitação utilizado pelo MPE.
Figura 8. O codificador RPE operando a 13 kbps é atualmente utilizado na
telefonia sem fio
4.3. Code-Excited Linear Prediction
Os codificadores MPE e RPE transmitem as características de cada pulso como pedaços independentes de informação. A técnica de CELP utiliza uma abordagem diferente para a codificação dos pulsos. Um livro de códigos identifica diferentes tipos de combinação entre amplitudes de pulso e posição dentro do subquadro, e cada uma destas combinações é representada por um índice no livro de códigos. Tanto o codificador quanto o decodificador fazem referência ao mesmo livro de códigos. Para cada subquadro, o codificador CELP transmite o código binário do índice correspondente ao

sinal de excitação que mais se aproxima do sinal original. O decodificador utiliza este índice para identificar a excitação a partir de sua própria cópia do livro de códigos. A Figura 9 mostra o diagrama esquemático simplificado do codificador e do decodificador LD-CELP (Low-Delay CELP) conforme especificado na Recomendação G.728 [6].
Figura 9. Diagrama de blocos do codificador (a) e decodificador (b) CELP
A estratégia do livro de códigos permite que uma grande quantidade de informação seja transmitida utilizando-se poucos bits de dados. Uma desvantagem desta técnica é que identificar o melhor índice de aproximação no livro de códigos para cada subquadro exige muito processamento e requer muito tempo.
O desempenho de um codificador CELP está diretamente relacionado com a quantidade de entradas existentes na tabela de códigos e com a eficiência do algoritmo de procura na tabela. De maneira a simplificar a procura no livro de códigos, alguns livros de códigos possuem entradas apenas para a posição do pulso. A amplitude do pulso deve ser determinada separadamente. Algumas implementações do CELP utilizam livros de códigos simplificados sem informação de amplitude e com somente alguns poucos tipos de pulso, necessitando empregar técnicas algébricas para simplificar a procura no livro de códigos. Estas técnicas são denominadas ACELP (Algebraic CELP).
Vários tipos diferentes de codificadores pertencem à classe CELP, incluindo as Recomendações do ITU-T G.728 LD-CELP de 16 kbps [6], e G.729 CS-ACELP (Conjugate-Structure ACELP) de 8 kbps [7]. O G.729 Annex A utiliza o CS-ACELP

com alguns atalhos no algoritmo de processamento de forma a melhorar o desempenho. O G.723.1 utiliza ACELP para a taxa de 5.3 kbps [5]. Detalhes sobre os algoritmos podem ser encontrados em [3 a 7].
5. Codificação de áudio no MPEG-4 No contexto de evolução atual dos aplicativos multimídia – como radiodifusão digital, armazenamento de conteúdo multimídia, comunicação em tempo real, e jogos na Internet, surgem novas demandas por representação eficiente e flexível de conteúdo audiovisual. Além da alta eficiência exigida na codificação para lidar com a largura de banda limitada da Internet ou na comunicação móvel, novas funcionalidades também são desejadas como acesso flexível a dados codificados e manipulação pelo receptor. Para endereçar estes requisitos e desenvolver soluções de interoperabilidade, o ISO/IEC começou as atividades de padronização do MPEG-4 para codificação de objetos audiovisuais.
A primeira versão do padrão MPEG-4 para áudio foi finalizada em 1998 e contém ferramentas para codificação de objetos de áudio naturais e sintetizados, bem como composição de tais objetos em uma “cena de áudio” [11]. Objetos de áudio natural (como voz por exemplo) podem ser codificados em taxas de bits variando de 2 kbps até 64 kbps usando Codificação de Voz Paramétrica, codificação de voz baseada em CELP ou Codificação de Áudio Geral baseada em transformação. Os objetos de áudio sintetizados podem ser representados usando uma Interface de Sintetizador de Texto-para-Voz ou as ferramentas de síntese de Áudio Estruturado. Estas ferramentas também são usadas para adicionar efeitos, como eco, e misturar objetos de áudio diferentes para compor a “cena de áudio” final que é apresentado para o ouvinte.
Devido ao curto prazo para a publicação da primeira versão do padrão, algumas ferramentas ainda não estavam completamente maduras para serem incluídas nesta versão, e portanto os trabalhos continuaram até a extensão do padrão na segunda versão. Na área de áudio, novas ferramentas foram adicionadas ao MPEG-4 Versão 2 para prover as seguintes novas funcionalidades:
• Resiliência a erros – ferramentas de recuperação de erro com melhor desempenho em canais de transmissão propensos a erro.
• Codificação rápida de áudio – ferramentas de codificação com baixas taxas de bit para suportar a transmissão de sinais de áudio gerais em aplicativos exigindo um baixo atraso de codificação, como por exemplo comunicação bidirecional em tempo real.
• Escalabilidade – ferramentas para possibilitar codificação escalável com granularidade bem fina, permitindo a escolha da taxa de bits desejada sobre uma extensa escala de valores variando em pequenos degraus.
• Codificação de áudio paramétrica – ferramentas que combinam taxas de bit muito baixas na codificação de sinais de áudio gerais com a possibilidade de modificar a velocidade ou a freqüência (pitch) durante a decodificação sem a necessidade de uma unidade de processamento de efeitos externa ao codificador.

• Espacialização ambiental – permite a composição de uma “cena de áudio” com uma origem de som mais natural e modelagem de ambiente de som melhores que na Versão 1.
5.1. Padrão MPEG-4 de Áudio – Versão 1
Na codificação de áudio, uma variedade de modelos de fonte podem ser utilizados em combinação com modelos apropriados da percepção humana para reduzir a redundância e irrelevância contida no sinal de áudio. A Figura 10 ilustra o diagrama de blocos geral de um codificador e um decodificador de áudio a partir destas considerações [10].
Figura 10. Diagrama de blocos do codificador (a) e decodificador (b) baseados
na fonte do sinal
Como o Padrão MPEG-4 para Codificação de Áudio permite a codificação de sinais de áudio sobre uma extensa escala de valores de taxas de bit, é vantajoso utilizar diferentes modelos presumidos para diferentes taxas de bit de forma a obter um desempenho ótimo na codificação para cada taxa de bit. Inclusive as características do material de áudio sendo codificado devem ser consideradas, como por exemplo em codificadores especializados para voz, que oferecem melhor desempenho para sinais de voz em uma dada taxa de bit do que codificadores projetados para uso geral. Devido a estas considerações, o MPEG-4 Áudio inclui técnicas de codificação de voz e técnicas de codificação de áudio geral que são integradas em um framework comum.
5.2. Codificação de voz no MPEG-4
A codificação de voz a taxas de bit entre 2 e 24 kbps é suportada utilizando HVXC (Harmonic Vector eXcitation Coding) para uma taxa de bit de 2 a 4 kbps, e codificação CELP (Code -Excited Linear Prediction) para uma taxa de bit de 4 a 24 kbps. Em adição, o HVXC pode operar com uma taxa média em torno de 1.2 kbps em seu modo de taxa variável. Na codificação CELP, duas taxas de amostragem, 8 e 16 KHz, são utilizadas para suportar banda estreita e voz em banda larga. Ambas as codificações de voz HVXC e CELP possibilitam escalabilidade nas taxas de bit. Como o HVXC é um codificador de voz paramétrico, este possui a funcionalidade de modificação da velocidade e da freqüência (pitch) no próprio decodificador.

5.3. MPEG-4 HVXC
Redução na taxa de bits em aplicações de voz implica normalmente baixa qualidade. Codificação típica utilizando CELP apresenta baixa inteligibilidade abaixo de 4 kbps. A maior causa da degradação de qualidade do CELP é devido à ineficiência da representação harmônica. Codificadores HVXC utilizam princípios dos codificadores CELP e de codificadores paramétricos [9 e 10].
Modelagem paramétrica provê uma representação eficiente de sinais de áudio gerais e é utilizada em codificação de áudio com taxas muito baixas. Esta técnica é baseada na decomposição de um sinal áudio em componentes que são descritos por modelos de fonte apropriados e representados por parâmetros do modelo. Modelos de áudio perceptuais são utilizados para a decomposição do sinal e codificação dos parâmetros do sinal de origem. A Figura 11 apresenta a idéia básica de um codificador paramétrico [9].
Figura 11. Diagrama de blocos de um codificador paramétrico
O codificador HVXC classifica o sinal de entrada em quatro classes: a) não vocálico; b) misto com baixo nível de vocalização, c) misto com alto nível de vocalização d) vocálico. Se o sinal de entrada é classificado como não vocálico, uma procura em um livro de códigos é realizada como no CELP. Caso o sinal possua algum grau de vocalização é realizada uma quantização do envelope espectral. O esquema de codificação do HVXC está ilustrado na Figura 12 [12]. A operação de cada um dos blocos está descrita a seguir.

Figura 12. Diagrama esquemático de um codificador HVXC
O bloco de análise LPC e quantização LSP executa a determinação dos parâmetros LPC de ordem 10 sobre o quadro amostrado atual. Estes parâmetros são convertidos em parâmetros LSP e quantizados vetorialmente em um esquema com múltiplos estágios utilizando predição parcial.
A estimativa da freqüência (pitch) em loop aberto é baseada nos valores de pico da autocorrelação dos sinais residuais do LPC (computados independentemente pelo filtro LPC inverso). De forma a melhorar a confiabilidade do valor estimado para a freqüência e melhorar a continuidade do envelope espectral, são usados os valores de freqüência atual e anterior pelo bloco Fine Pitch Search. A decisão U/UV do quadro anterior é também utilizada para melhorar a confiabilidade da operação de determinação da freqüência (pitch) correta para o caso de sons vocálicos.
A seção unvoiced (em loop fechado) é um codificador CELP regular que utiliza apenas um livro de códigos estocástico. O módulo de decisão V/UV para os parâmetros obtidos pelos blocos voiced e unvoiced classifica o quadro corrente de 20 ms em uma das quatro classes possíveis. A decisão é baseada na autocorrelação máxima obtida a partir do sinal LPC residual
No decodificador, um componente sintetizador é utilizado para os sons não-vocálicos, enquanto que para sons com algum grau de vocalização é utilizado um sintetizador misto que utiliza ruído com componentes vocálicos. Desta forma, uma representação granular das transições entre sons vocálicos para não vocálicos e vice-versa pode ser obtida. O esquema do decodificador HVXC está apresentado na Figura 13 [12]. O

processo de decodificação é baseado em três etapas: recuperação dos parâmetros quantizados, sintetização do sinal de excitação vocálico ou não-vocálico e sintetização LPC.
Figura 13. Diagrama esquemático de um decodificador HVXC
5.4. MPEG-4 CELP
O decodificador CELP consiste principalmente em uma fonte de excitação e um filtro sintetizador. Normalmente os decodificadores CELP também incluem um filtro posterior. A fonte do sinal de excitação possui tanto componentes periódicos, oriundos do livro de códigos adaptável, quanto componentes aleatórios oriundos de um ou mais livros de códigos fixos. No decodificador, a excitação do sinal é reconstruída usando os índices dos livros de códigos (a freqüência é obtida do livro de códigos adaptável e o índice da forma a partir do livro de códigos fixo) e índices de ganho (ganhos dos livros de códigos adaptável e fixo). Esta excitação do sinal é então passada através do filtro LPC (LP synthesis filter). Este filtro é obtido através da interpolação dos coeficientes LPC de sucessivos quadros analisados, onde os coeficientes LPC são reconstruídos usando os índices LPC. Finalmente, um filtro posterior é aplicado a fim de realçar a qualidade da voz [13].
O que faz MPEG-4 CELP diferente do CELP convencional é a flexibilidade que este oferece. Convencionalmente, o CELP oferece somente funcionalidade de compressão em uma taxa de bit única dado um aplicativo particular. Dentro do padrão MPEG-4, compressão de alta qualidade é só uma das muitas características, sendo necessário portanto um esquema de codificação básico que atenda vários aplicativos diferentes. A possibilidade para gerar taxas de bit arbitrárias, taxa de transferência escalável em passos de 2 kbps (para sinais amostrados à 8 kHz) e escalabilidade na complexidade do decodificador são algumas das características inovativas que o codificador MPEG-4

CELP provê. A idéia básica por trás do codificador MPEG-4 CELP é suprir estas múltiplas funcionalidades.
A Figura 14 ilustra o diagrama de bloco de um decodificador MPEG-4 CELP [13].
Figura 14. Diagrama esquemático de um decodificador MPEG-4 CELP
6. Comparação entre codificadores selecionados A Figura 15, reproduzida de [1], mostra a qualidade da voz e a taxa de bit requerida para diferentes tipos de codificadores.
Como ponto de referência familiar para qualidade de voz subjetiva, foi incluído o padrão GSM utilizado na telefonia celular que codifica voz com grau 3.5 MOS (Mean Opinion Score). O MOS é uma medida subjetiva de qualidade de voz muito utilizada. Esta técnica determina empiricamente a medida da qualidade de voz de um sistema ou codificador através de testes realizados com pessoas, e é baseada em avaliações estatísticas sobre a resposta de um grupo de usuários com respeito a diversas amostras de áudio utilizando os sistemas em teste. A escala MOS varia de 1 a 5, com 1 representando qualidade ruim (sem possibilidade de entender o significado do discurso com qualquer que seja o esforço aplicado) e 5 representando qualidade excelente (nenhum esforço necessário para entender o discurso).
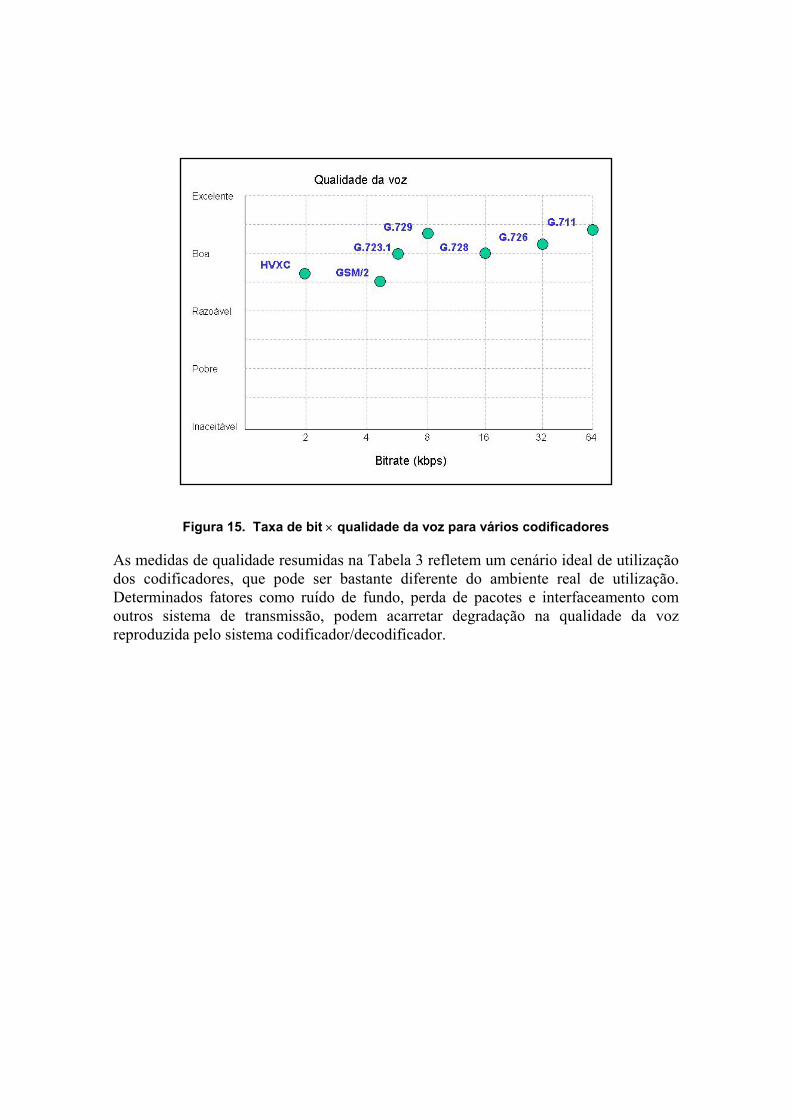
Figura 15. Taxa de bit × qualidade da voz para vários codificadores
As medidas de qualidade resumidas na Tabela 3 refletem um cenário ideal de utilização dos codificadores, que pode ser bastante diferente do ambiente real de utilização. Determinados fatores como ruído de fundo, perda de pacotes e interfaceamento com outros sistema de transmissão, podem acarretar degradação na qualidade da voz reproduzida pelo sistema codificador/decodificador.
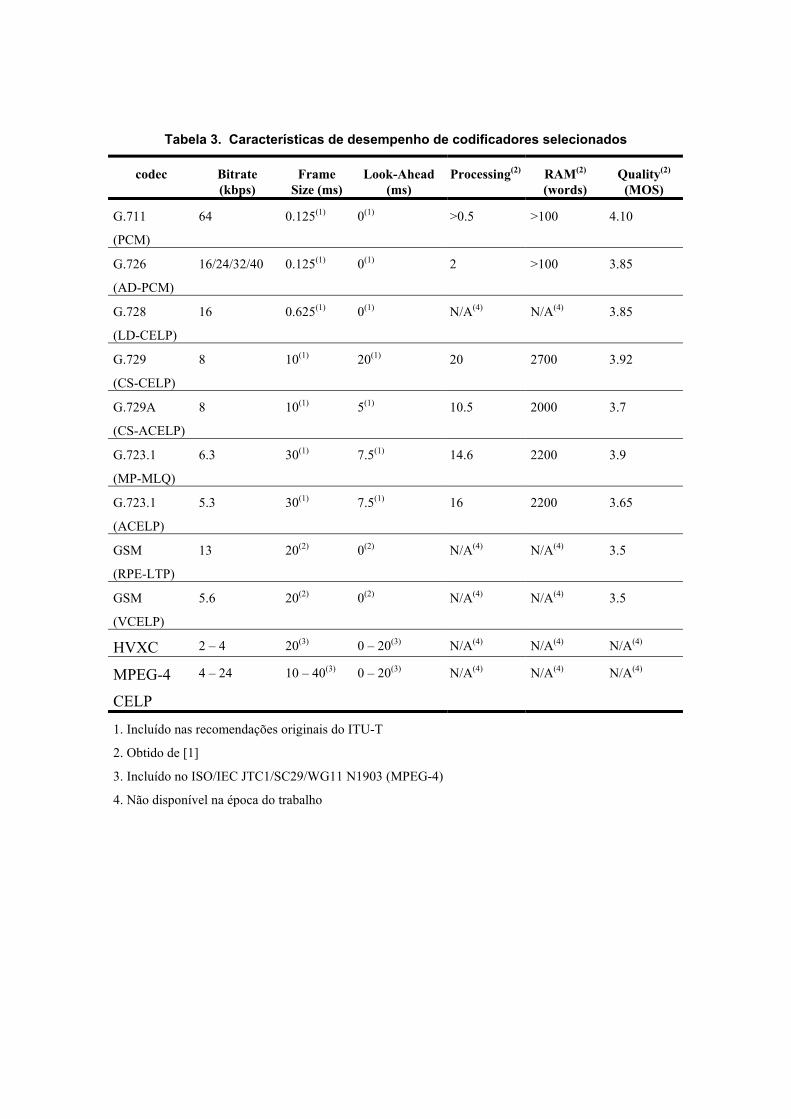
Tabela 3. Características de desempenho de codificadores selecionados
codec Bitrate (kbps)
Frame Size (ms)
Look-Ahead (ms)
Processing(2) RAM(2) (words)
Quality(2) (MOS)
G.711
(PCM)
64 0.125(1) 0(1) >0.5 >100 4.10
G.726
(AD-PCM)
16/24/32/40 0.125(1) 0(1) 2 >100 3.85
G.728
(LD-CELP)
16 0.625(1) 0(1) N/A(4) N/A(4) 3.85
G.729
(CS-CELP)
8 10(1) 20(1) 20 2700 3.92
G.729A
(CS-ACELP)
8 10(1) 5(1) 10.5 2000 3.7
G.723.1
(MP-MLQ)
6.3 30(1) 7.5(1) 14.6 2200 3.9
G.723.1
(ACELP)
5.3 30(1) 7.5(1) 16 2200 3.65
GSM
(RPE-LTP)
13 20(2) 0(2) N/A(4) N/A(4) 3.5
GSM
(VCELP)
5.6 20(2) 0(2) N/A(4) N/A(4) 3.5
HVXC 2 – 4 20(3) 0 – 20(3) N/A(4) N/A(4) N/A(4)
MPEG-4
CELP
4 – 24 10 – 40(3) 0 – 20(3) N/A(4) N/A(4) N/A(4)
1. Incluído nas recomendações originais do ITU-T
2. Obtido de [1]
3. Incluído no ISO/IEC JTC1/SC29/WG11 N1903 (MPEG-4)
4. Não disponível na época do trabalho

7. Referências Com relação às referências utilizadas neste trabalho, Purnhagen [9] e Sashia [10] apresentam uma visão detalhada e entendimento da técnica de codificação de áudio HVXC. Para uma visão abrangente do MPEG-4, é recomendada a leitura de Koenen [11] e para detalhes dos codificadores de voz [12] e [13] . A parte de descrição e comparação das técnicas básicas de codificação de voz foram retiradas de Keagy [1] e estendidas através da consulta às recomendações do ITU-T [3 a 7]. O conteúdo relativo à ciência da fala humana está contido parcialmente em Buford [2] e Lemmetty [8].
Referências [1] Keagy, Scott – Integrating Voice and Data Networks – Cisco Press, 2000.
[2] Buford, John F. Koegel – Multimedia Systems – Addison-Wesley, 1994.
[3] ITU-T Recommendation G.711 – Pulse code modulation (PCM) of voice frequencies.
[4] ITU-T Recommendation G.726 – 40, 32, 24, 16 kbit/s adaptive differential pulse code modulation (ADPCM).
[5] ITU-T Recommendation G.723.1 – Dual rate speech coder for multimedia Communications transmitting at 5.3 and 6.3 kbit/s.
[6] ITU-T Recommendation G.728 – Coding of speech at 16 kbit/s using low-delay code excited linear prediction.
[7] ITU-T Recommendation G.729 – Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear-prediction.
[8] Lemmetty, Sami – Review of Speech Synthesis Technology – Helsinki University of Technology – Master's Thesis 1999.
http://www.acoustics.hut.fi/~slemmett/dippa/contents.html
[9] Purnhagen, Heiko – Advances in Parametric Audio Coding – University of Hannover – 1999 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics.
http://citeseer.ist.psu.edu/purnhagen99advances.html
[10] Sashia, Alessandro Maso et al. – Real Time Implementation of the HVXC MPEG-4 Speech Coder – University of Padova – 5th Int. Conference on Digital Audio Effects, 2002.
http://citeseer.ist.psu.edu/560330.html
[11] Koenen, R. – Overview of the MPEG-4 Standard – ISO/IEC JTC1/SC29/WG11 N2725, 1999.
http://www.itu.int/ITU-D/tech/digital-broadcasting/kiev/References/mpeg-4.html
[12] MPEG-4 1 – ISO/IEC 14496-3 Subpart 2 – Parametric Coding, 1997.
[13] MPEG-4 1 – ISO/IEC 14496-3 Subpart 3 – CELP, 1997.





























