Embed Size (px)
Citation preview

Maria de Fátima Monteiro Ferreira
Arvores de Regressão e generalizações - Aplicações -
Faculdade de Ciências da Universidade do Porto Departamento de Matemática Aplicada
Julho de 1999

Maria de Fát ima Monteiro Ferreira
Arvores de Regressão e generalizações - Aplicações -
Tese submetida à Faculdade de Ciências da Universidade do Porto
para obtenção do grau de Mestre em Matemática Aplicada
Faculdade de Ciências da Universidade do Porto Departamento de Matemática Aplicada
Julho de 1999

Gostaria de agradecer:
* Ao meu orientador, professor Doutor Joaquim Fernando Pinto da Costa, pelo apoio,
disponibilidade e compreensão manifestados ao longo destes meses, assim como por
todos os reparos críticos feitos a este trabalho.
* Ao professor Doutor Torres Pereira, reitor da Universidade de Trás-os-Montes e Alto
Douro, pela ajuda económica e por me ter proporcionado a frequência do mestrado.
* A professora Doutora Emília Giraldes e ao professor Doutor Fernandes de Carvalho,
todo o apoio e interesse manifestados, que constituíram um forte incentivo para a reali
zação deste trabalho.
* Ao professor Doutor José Basto, pela acessibilidade, compreensão e conselhos dados.
* A Dra Gabriela Direito, pelas facilidades concedidas nos horários Durante o tempo de
frequência do mestrado.
* Aos meus pais e irmã, que sempre acreditaram em mim e cuja força me deu coragem
para continuar.
* Ao Doutor Garcia e à Dra Gabriela, pelo apoio e amizade demonstrados.
* Ao PRODEP, pela atribuição de uma bolsa que facilitou a frequência deste mestrado.
Um agradecimento muito especial à minha mãe e a um leque de
amigos que me incentivaram a continuar e sem os quais este
trabalho não teria sido realizado.

Indice
Introdução 3
1. Arvores binárias de regressão e o m é t o d o C A R T 5
1.1 Construção inicial de uma árvore de regressão 6
1.2 Regra de Bayes ou do risco mínimo 9
1.3 Estimadores do risco mínimo 12
1.4 A divisão dos nós 13
1.4.1 Conjunto das questões binárias inerentes ao método CART e que
determinam as divisões admitidas em cada nó 13
1.4.2 Redução da complexidade do algoritmo de determinação da partição
óptima de uma variável nominal na regressão LSD 15
1.5 Quando parar o processo de segmentação dos nós. O método da poda 16
1.5.1 A árvore T m a x 17
1.5.2 A sequência de sub-árvores podadas 18
1.6 A melhor sub-árvore podada: um problema de estimação 22
1.6.1 Estimadores de amostra independente 23
1.6.2 Estimadores de validação cruzada 25
1.6.3 A escolha da árvore final: utilização da regra 1 SE 27
2. O m é t o d o M A R S 29
2.1 Uma outra apresentação do método CART 29
2.2 O método MARS como produto de generalizações do CART 32
2.2.1 Continuidade 32
2.2.2 Novas generalizações 33
2.2.3 O algoritmo do MARS 35
2.2.4 O processo de poda 36
2.4 Decomposição ANOVA 37
1

2.5 O critério LOF: estimador da ineficiência da função aproxiroante 38
2.6 O modelo final: contínuo e com primeira derivada contínua 40
3. Apl icações 42
3.1 Dados simulados 45
3.1.1 Aproximação de uma função com estrutura não linear 45
3.1.2 Aproximação de uma função linear 48
3.2 Dados reais 50
3.2.1 Previsão da idade do abalone 51
3.2.2 Previsão dos preços médios das casas em Boston 54
A n e x o A 57
Al Algoritmo que gerou o Io conjunto de dados simulados 57
A2 Resultados dos métodos LR, CART e MARS no Io
conjunto de dados simulados 58
A n e x o B 22
Resultados dos métodos LR, CART e MARS no 2o
conjunto de dados simulados 71
Referências 85
2

Introdução
Os métodos de regressão CART ("Classification and Regression Trees") e MARS ("Multi
variate Adaptive Regression Splines") que apresentaremos neste trabalho são filhos da era dos
computadores. Com efeito, ao contrário de alguns métodos que passaram do papel e lápis para as
calculadoras e posteriormente para os computadores, estes eram impensáveis antes da existência
dos computadores. Eles fornecem novas formas de explorar os dados. Não pretendemos neste
trabalho dar a ideia de que qualquer um destes métodos seja sempre o melhor. A potenciali
dade de cada método está directamente ligada à estrutura dos dados em estudo. Nenhum deles
deve portanto ser usado em exclusividade, pondo de lado os outros métodos existentes. Estes
métodos devem ser encarados como novas ferramentas, flexíveis e não paramétricas, do arsenal
de métodos de que o analista deve dispor ao estudar um conjunto de dados.
A utilização de técnicas de segmentação ou de aproximação com recurso a árvores foi mo
tivada pela necessidade de lidar com problemas complexos (envolvendo por exemplo dados
de dimensão elevada e/ou variável). Esta técnica teve início nas ciências sociais nos traba
lhos de [Morgan k Sonquist, 63] e [Sonquist k Morgan, 64]. Mais tarde [Hunt & Stone, 66],
[Messenger k Mandell, 72] e [Morgan k Messenger, 73] desenvolveram esta técnica para proble
mas de classificação. Contudo, foram as modificações introduzidas por Quinlan em 1979, 1983 e
1986 ([Quinlan, 86]) e os trabalhos de [Breiman k ai., 84] que mais contribuíram para a grande
popularidade da utilização de árvores binárias em problemas de classificação. A utilização de
árvores em problemas de regressão iniciou-se nos trabalhos de [Morgan k Sonquist, 63] com o
seu programa AID ("Automatic Interaction Detection"). Generalizações do mesmo são descritas
em [Sonquist k Morgan, 64], [Sonquist, 70], [Sonquist, Baker k Morgan, 73], [Fielding, 77] e
em [Van Eck, 80]. [Breiman k ai., 84] extenderam ainda mais estas técnicas dando origem ao
programa CART. As principais diferenças entre o AID e o CART encontram-se no processo de
poda e de estimação, ou seja no processo de crescimento de uma árvore "honesta". O CART não
coloca restrições ao número de valores que uma variável pode tomar e contém algumas ferra
mentas adicionais (combinações lineares das variáveis, tratamento de dados "omissos", acesso
à importância relativa das variáveis, e t c . ) . Por outro lado, o CART não contém algumas das
opções disponíveis no AID, como por exemplo a possibilidade de um "look ahead" limitado.
As árvores são muito utilizadas em problemas de botânica, biologia, medicina, etc....
Elas apresentam, para além do seu poder preditivo, um forte poder descritivo, o qual permite
3

compreender quais as variáveis que originam o fenómeno em estudo, e o modo como estão
relacionadas nesse fenómeno. Ao contrário das outras técnicas, as árvores não necessitam de
conhecer à priori todos os atributos. Este facto é especialmente vantajoso em problemas nos
quais os valores dos atributos são difíceis de medir ou cuja medição acarreta custos elevados. Para
prever o valor resposta de um caso temos apenas de recolher um a um os valores dos atributos
que aparecem no seu percurso de descida na árvore. A utilização e interpretação simples de
certas árvores são outros dos atractivos da utilização das mesmas.
As árvores binárias, são construídas de acordo com regras de divisão baseadas nas variáveis
preditivas do domínio em estudo. O domínio é particionado recursivamente de forma binária, por
forma a aumentar a homogeneidade dentro dos nós, a qual é determinada pela variável resposta
do problema. Quando o processo de partição termina, cada um dos nós obtidos é declarado
terminal e a cada um deles é associada uma classe nos problemas de classificação, ou um valor
constante real nos problemas de regressão. Assim, os ingredientes principais da construção de
uma árvore resumem-se aos seguintes pontos:
1. determinação de todas as divisões possíveis de um nó para cada variável do espaço de
predição (usualmente as divisões são determinadas por questões binárias);
2. selecção da "melhor" divisão de todas;
3. determinar quando se deve considerar um nó como terminal;
4. atribuição de um valor resposta a cada nó terminal.
No capítulo 1, explicitaremos o processo de construção de arvores de regressão, dando prin
cipal relevo ás técnicas utilizadas por [Breiman & ai., 84] no programa CART. Este programa,
implementa um dos métodos não paramétricos que melhor se adapta à aproximação de funções
multivariadas. Contudo, o método CART revela-se extremamente ineficiente ao aproximar
funções contínuas, ou funções nas quais as interações existentes envolvem um pequeno número
de variáveis (por exemplo funções lineares). No capítulo 2, apresentamos uma série de modi
ficações introduzidas por Friedman no programa CART, as quais vieram permitir a obtenção de
funções aproximantes contínuas com primeira derivada contínua. Estas modificações originaram
o método MARS ("Multivariate Adaptive Regression Splines"). Este método partilha das pro
priedades atractivas do método CART, sendo no entanto mais potente e flexível na modelação
de funções contínuas ou de funções cuja interação entre as variáveis envolva um número reduzido
de variáveis.
Por último, no capítulo 4, alertamos para os problemas inerentes à comparação global dos
métodos e apresentamos os resultados da aplicação dos mesmos a conjuntos de dados reais e
simulados.
4

Capítulo 1
Arvores binárias de regressão e o método CART
No problema clássico de regressão múltipla pretendemos determinar um modo sistemático de
prever o valor de uma variável real de resposta (também dita dependente) a partir da observação
prévia de um conjunto de medidas que, supostamente, descrevem o objecto em estudo e cujos
valores influenciam o valor tomado pela variável resposta.
Formalizando a ideia anterior, considere-se o vector das medidas observadas para o referido
objecto e seja x um espaço mensurável M-dimensional contendo todos os valores possíveis desse
vector; defina-se uma variável aleatória X = (X\, X2,..., XM), com valores em x e denote-se por
Y a variável de resposta associada a X.
Pretende-se determinar a função f{x)=y,ye R, de tal modo que y é o verdadeiro valor de Y
quando X toma o valor x. Razões práticas, como por exemplo a existência de erros de observação
e a impossibilidade do vector X conter todos os factores que influenciam o comportamento de
Y, inviabilizam a determinação da referida função. Inevitavelmente, limitamo-nos na prática
a procurar, com os dados disponíveis, uma função aproximante de / . A função aproximante,
que designaremos de função de predição e denotaremos por / , é uma função definida em \ e
com valores em JR, tal que a resposta / (x) é dada quando x é um valor observado da variável
aleatória X
f- x —* R x —> f(x)
O nosso objectivo resume-se à procura da função aproximante, / , minimizadora do custo dos
possíveis erros associados às respostas dadas.
Seja L (y, f (x)J o custo originado pela resposta / (2) quando y é o verdadeiro valor de Y
para o caso x em estudo.
Dada uma função de predição / (X), o valor esperado do custo da sua utilização na de-
5

terminação do valor de resposta, denota-se por R* (f(X)), e representa o risco asssociado à
utilização de / (X) para prever o verdadeiro valor de Y;
R*(Î(X))=E(L(YJ(X))).
Na regressão dos menores desvios absolutos (LAD) o valor do risco da função de predição
/ (X) é dado pelo erro absoluto médio
R*(f(X))=E(\Y-f(X)\)
e na regressão dos menores desvios quadrados (LSD) pelo erro quadrático médio
R*(f(X))=E^Y-f(X)j
(para uma revisão de métodos de regressão linear de menor desvio absoluto veja-se [Narula e
Wellington, 82]).
Neste capítulo apresentaremos a técnica de regressão por arvores binárias de regressão. Em
particular descreveremos alguma da metodologia utilizada no programa CART ("Classification
and Regression Trees"), desenvolvido em 1984 por Breiman, Friedman, Olshen e Stone [Breiman
k al., 84].
1.1 Construção inicial de u m a árvore de regressão
A uma árvore binária de regressão associa-se uma função de predição correspondente a uma
partição T de x, isto é, uma função de predição que a cada elemento t € T ( logo í c x ) associa
uma constante real t? (t).
A construção de uma árvore de regressão binária efectua-se de modo recursivo determinando
uma sequência de divisões binárias de subconjuntos de x (a iniciar-se pela divisão do próprio
X em 2 subconjuntos descendentes). As sucessivas divisões processam-se por forma a obter a
partição T do espaço x Toaais adequada ao nosso problema. Posteriormente é atribuído um valor
real de resposta a cada elemento dessa partição.
Na figura 1.1, que se segue, representamos uma possível árvore de regressão T. Os conjuntos
Xi e X2 são disjuntos com x = Xi U X2'-> analogamente xs e X4 são disjuntos com xi = Xz U X4>
e assim sucessivamente. O conjunto x designa-se por nó raiz de T e os seus subconjuntos,
determinados pelas sucessivas divisões, por nós de T. Os nós de T que não sofrem divisões,
neste caso X4> X5> X7> X8> X9 e Xio> designam-se por nós terminais e formam a partição T
de x determinada pela árvore. Sob cada nó terminal encontramos o correspondente valor de
resposta.Assim, uma árvore de regressão T determina uma função de partição associada a T,
6

isto é, uma função T \ \-*T onde r (x) = t se e somente se x G t, à qual fica associada uma
função de predição / (r (a;)) = tf (í) , i9 (í) G J? para cada valor x de X.
s(x7) ô(x8) »(x9) »(x10)
Fig 1.1: Arvore binária de regressão
Na prática, para construir uma árvore binária dispomos apenas de uma amostra aleatória do
vector (X,Y), ou seja, dispomos de um conjunto de valores observados de X para os quais se
sabe o valor exacto da variável resposta, e é com base nestes dados que se efectuam as referidas
divisões. Em cada passo, a ideia fundamental por detrás da divisão de um nó, consiste em
determinar, de entre todos os elementos do conjunto S (conjunto de todas as divisões binárias
admissíveis de um nó), aquele que origine os dois nós descendentes com dados mais "puros"; isto
é, aquele que conduza a uma diminuição máxima da "impureza" entre um nó de partida, t, e os
seus descendentes, Í£ e ÍR.
A "impureza" de um nó t é quantificada pelo risco pesado
R* (t) =E(L (Y, tf (í)) /Xet)P{t)=r(t)P (í)
onde P (t) = P (X € t ) > 0 e r (í) representa o custo esperado de se tomar no nó t a resposta
1? (t) G M.
Deste modo, uma divisão s G S de um nó t em Í£ e £R origina um decréscimo de impureza
dado por AiT (s, t) = R* (í) - R* (tL) - R* (tR).
O processo descrito acima, da escolha do elemento s G S que maximiza o decréscimo de
impureza, consiste em seleccionar a divisão binária s* G S, efectuada em í, tal que
AR* (s*,t) =max AR" (s, t).
Um conjunto de sucessivas divisões binárias conjuntamente com a ordem pela qual são
efectuadas formam uma árvore binária T e a partição de x P o r e l e s determinada constitui o
conjunto T dos seus nós terminais (ou nós folhas).
7

A impureza de uma árvore T, que denotaremos por R* (T), é dada pela soma das impurezas
de cada uma das suas folhas. Assim,
ir(r)=£iT(í)=5>(í)p(í), tef tef
ondeP( í ) > 0 , V t e T .
Cada divisão de um nó t G T em £& e tR origina uma nova árvore T' de folhas
f = (f-{t})u{tL,tR}
Em cada passo, procuramos escolher a divisão s* G S do nó t E T que minimize a impureza
da árvore T7 criada.
De facto, como
AR*(s,t) = R* (t) - R* (tL) - R* (tR)
= 53 i2* (Í) - ^ R* (t) , pois f' = (f- {t}) U {tL, tR} tef t<=f
= R*(T)-R*(T'),
a divisão s*que maximiza AR* (s,t), maximiza R* (T) — R*(T'), o que equivale a minimizar
R*Çf).
Observando que
AR*(s,t) = R*(t) - R*(tL) - R*(tR) = [r(t) - PLr{t£) - PRr(tR)]P(t),
onde
pL = P(XetL/Xet) = ^ - e PR = P(X€tR/X€t) = ^ - ,
e que P(t) > 0 é constante, maximizar AR* (s, t) consiste em maximizar
AR*(s/t) = r(t) - PLr(tL) - PRr(tR),
onde PL > 0 e PR > 0 representam a probabilidade dos elementos de t serem enviados pela
divisão para o nó ti, e tR, respectivamente (figura 1.2).
Fig 1.2
8

A construção de uma árvore binária de regressão inicia-se com um processo iterativo que em
cada passo visa a maximização de AR*(s /t); terminado o processo de crescimento da árvore,
a cada nó terminal t fica associada a resposta $(i) que será produzida pela árvore sempre que
um caso "atinja" esse nó. Fica assim definida uma função de predição, a qual confere à árvore
binária a estrutura de árvore binária de regressão.
1.2 Regra de Bayes ou do risco mínimo
Considere-se de novo o vector aleatório X com valores em x e a variável real de resposta Y.
Uma qualquer regra optimal fg (X), minimizadora do risco da sua utilização para prever o valor
de Y, diz-se uma regra de Bayes. Assim, fB (X) é uma regra de Bayes se e só se
V/ (função de predição), R* (fB (X)) < R* ( / (X)) .
Considerando que fx representa a densidade de X temos
R*(f(x)) = E[E(L(YJ(X))/X)]
= J E(L (Y, f (*)) /X = x)fx (x) dx. x
Assim sendo, a regra fB é uma regra de Bayes se
Vx G x E(L (Y, h (*)) /X = x) =min E (l (Y, f (»)) /X = x)
e o seu risco é dado por
R* (fB (X)) = / m i n E (L (Y, f (x)) fX = x) fx (x) dx. x
No problema de regressão LAD, a função de predição /g núoimizadora de
R*(f(X))=E(\Y-f(X)\),
é dada por um qualquer valor da mediana da distribuição de Y condicionada por X = x, ou
seja, fB(x) = v(Y/X = x),
onde
P (Y > v (Y/X = x)/X = x)>0.5 e P (Y < v (Y/X = x)/X = x)> 0.5.
Quanto ao problema de regressão LSD, a função de predição fg que nmiimiza
R*(f(X))=E(Y-f(X))2,
9

é dada pela função de regressão de Y em X, isto é,
fB(x)=E(Y/X = x).
Definimos de modo análogo a regra de Bayes correspondente a uma partição. O risco de uma
função de predição ff correspondente a uma partição T é dado por
R* (ff) = R* (T) = £ E(L(Y,*(t)) /X € t)P(t) = £ r (í)P(í) (1.1)
onde P (t) = P (X € *) e -õ (t) = / (x),V x€t.
A função / g , minimizadora de (1.1), diz-se uma regra de Bayes. Assim / g é a regra de Bayes
correspondente à partição T se
SB (X) =0(T (X)) onde Vi G f, a = 1? (í) minimiza £ (L (Y, a) /Xet).
Considerando na regressão LAD
v(t) = v(Y/Xet),
a regra de Bayes é dada por um qualquer valor da mediana da variável resposta no nó " atingido"
por X, isto é,
fB(X) = v(r(X)),
e o seu risco é dado por
K*(fB(X)) = X>(|y-t>(í)|/XGt).P(í)
= £>(Í)P(Í).
No que respeita à regressão LSD, fazendo
l*(t)=E(Y/Xet),
a regra de Bayes é dada pela média da variável resposta no nó "atingido" por X, ou seja,
fB(X) = /,(r(X)),
sendo o seu risco calculado pela expressão
R*(h(X)) = ^ £ ( ( y - M ( í ) f / l € í ) P ( í ) t€T
= ^ C 7 2 ( Í ) P ( Í ) .
Considere-se em ambos os problemas de regressão que
10

V t e í , o = i9(t) minimiza £ ( L (Y, a) /Xet).
Neste caso, o risco da regra de Bayes é dado por
R* ( / B ) = R* (T) = £ R* (t) = £ r (í) P (í) , ter tef
com
r ( í ) = £ ( L ( y , t f ( í ) ) / X € í ) .
Teorema 1.1: Seja t um nó de uma árvore T e J w uma colecção de nós que formam uma
partição de t. Então
R*(t)>Y, R*(s), sefW
ocorrendo a igualdade, se e só se a resposta óptima dada no nó t, i9 (t), for também óptima para cada nó s da partição de t, isto é, se e só se
r(s) = E (L (F,*(*)) /X£s) , Vs G f(t).
Teorema 1.2: Sejam T e T duas partições de x iois que a partição T refina a partição T.
Então R* (T) > R* ( V ) ,
ocorrendo a igualdade, se e só se,
r(s) — E (L (Y, T? (í)) / X G s) para todos os pares t ET, s G T tais que s C t.
Os teoremas anteriores, provados em [Breiman &; ai., 84], pág. 271, garantem-nos que o risco
de Bayes de uma árvore não aumenta com as segmentações dos nós; na pior das hipóteses uma
segmentação manterá inalterado o valor do risco. S e i G T for segmentado em ti, e ÍR dando
origem à árvore T', então o risco de Bayes de T1 será estritamente inferior ao risco de Bayes de
T, exceptuando se a acção óptima i? (í), tomada em t, for também óptima para ti, e ÍR (caso
em que a redução do risco é nula). Assim, AR*(s /t) > 0, ocorrendo a igualdade se e só se
r{tL)=E{L(X,ti(t)) IX G t£) er(tR)=E(L(Y,#(t)) jX G tR).
Embora óptima e garantindo que AR*(s/t) = r(t) — PL r(ti) — PRr(tn) > 0, a
utilização directa da regra de Bayes na escolha da divisão s* que maximiza AR* (s /1) pressupõe o
conhecimento prévio da distribuição conjunta de (X,Y). No entanto, na prática não dispomos
geralmente da distribuição de (X, Y), pelo que os valores reais de P(t), P{t£), P(tR), r(í) , r{ti)
e r(tji) têm de ser estimados a partir da amostra disponível.
11

1.3 Est imadores do risco m í n i m o
Seja {(Xn,Yn)}n=1 uma amostra aleatória de (X,Y) da qual dispomos da realização
{(xn,yn)}n=i, e, dado um nó t, considerem-se ra^(í) = {n G {1, ..., N} : xn € t} e
N(t) = |njv(í)|- Os valores de P(t), P(t£), P{tR), são estimados pelas proporções de elementos
da amostra em cada um dos nós:
onde N(t), N(tj_) e N(tn) representam o número de elementos da amostra que pertencem a t,
ÍL e ÍR, respectivamente.
Assim PL e PR são estimados pela proporção de dados de í que são enviados para Í£ e ÍR,
respectivamente: PL = W e **=
w Na regressão dos menores desvios absolutos os valores de d(t), d(ti) e <a(i#) são estimados
pelos respectivos desvios médios amostrais em relação à mediana amostrai do respectivo nó:
ã® = m £ i
y»-*(*)i. (
L2)
*■ ' nenN(t)
onde í)(t) representa a mediana amostrai do nó t; d[ti) e C2(ÍR) calculam-se de modo análogo
substituindo em (1.2) t por Í£ e ÍR, respectivamente.
Deste modo um estimador de
AR*(s/t) = d(t) - PLd(tL) - PR d(tR)
é dado por AR(s J t) = d(t) - pL d(tL) - PR d(tR).
Neste caso, a melhor divisão de t será a minimizadora da soma pesada dos desvios médios
dos nós descendentes relativos à sua mediana amostrai
PLd(tL)+pRd{tR). (1.3)
Na regressão dos menores desvios quadrados
AR*(s/t) = a2(í) - PL a\tL) - PR a2(tR), (1.4)
sendo os valores de <x2(í), <T2(ÍL) ecr2(í^) estimados pelas respectivas variâncias amostrais:
v ' n€nN(t) com
S2® = m) S (Yn-Y(t))
2, (1.5)
?W = ] 4 £ fti (1-6) nenjv(í)
12

S ^ Í L ) e S^(ifl) calculam-se de modo análogo substituindo em (1.5) e (1.6) t por í& e tR, respectivamente.
Assim um estimador de AR*(s /t) é dado por
AR(s/t) = S2(t) -pL S2(tL) -pR £?(tR),
sendo a melhor divisão de t determinada por forma a minimizar a soma pesada das variâncias
amostrais dos nós descendentes pLS2(tL)+pRS2(tR). (1.7)
Como n(t)=PLix(tL) + PRn{tR)
e
a2(t) = E[(Y - n{t)?/X 6 t] = PLE[(Y - »(t))2/X € tL) + PR E[(Y - ^{t)f /X e tR],
podemos dar à expressão (1.4) a forma
AR*(s/t) = PLH2(tL) + PRli2(tR)-i?(t) (1.8)
= P L P R ( M ^ ) - M * Í Í ) ) 2 ,
a qual, quando não dispomos da distribuição de (X, Y), ê estimada por
AE(s/t) = ^M{Y(t,)-Y(tR)f. (1.9)
No programa CART, [Breiman &; ai., 84], em problemas de regressão nos quais não dispomos
da distribuição de (X, Y), a regra utilizada na divisão de cada nó consiste em escolher, de entre
as divisões possíveis desse nó, aquela que minimiza (1.3) ou (1.7), consoante o problema de
regressão. Na regressão LSD minimizar (1.7) é equivalente a maximizar (1.9). Mais à frente
explicamos qual o método escolhido para terminar o crescimento da árvore e como a escolha da
árvore final é feita recorrendo a uma amostra independente ou à vaJidação-cruzada, para podar
a arvore.
1.4 A divisão dos nós
1.4-1 Conjunto das questões binárias inerentes ao método CART e que determinam as divisões admitidas em cada nó
Os dados que neste trabalho nos propusemos estudar possuem estrutura standard, ou seja, os
vectores i e ^ , descritores dos casos em estudo tem dimensão fixa. O programa CART incorpora
para este tipo de situação (que ocorre na maioria dos problemas existentes) um conjunto standard
13

de questões binárias da forma x E Al que determina o conjunto das divisões standard permitidas
em cada nó. A questão x G A? associada a um qualquer nó t determina de modo unívoco a
divisão do conjunto t em dois subconjuntos disjuntos Í£ e ÍR, com Í£, U ÍR = í tais que,
tL = tDA e tR = tn(x-A),
assim, o nó descendente esquerdo, t^, será constituído pelos elementos de t que originam uma
resposta afirmativa à questão x e Al, sendo o nó descendente direito, ÍR, formado pelos restantes
elementos de t.
Considerando que cada vector observado é constituído pelos valores { x m } ^ _ x , tomados pelas
M variáveis {Xm}m=l, o conjunto das questões standard é dado por:
Q = {{xm < c?) ) c € IR , Xm variável numérica} U
{(xm € Bi?) , Bi C B ,Xm variável nominal com modalidades em B} .
Notemos que embora # Q possa ser infinito, o número de divisões binárias distintas origi
nadas por um conjunto de dados (#5 ) é sempre finito. De facto, sendo a amostra finita, uma
variável numérica, digamos Xm, tomará no máximo N valores distintos. Sejam xmi, xm2,..., xmN
esses valores que, sem perda de generalidade, consideraremos ordenados. As questões standard
associadas a tal variável conduzirão, no máximo, a J V - 1 divisões binárias distintas de um nó,
as quais coincidem com as divisões geradas pelas questões xm < Ci ?, com xmi < Cj < xmi+1,
i = 1,..., N — 1. Por sua vez, as questões associadas a uma variável nominal com L modalidades
conduzem à obtenção de 2L~l — 1 divisões binárias distintas de um nó.
As divisões geradas por questões standard dependem apenas do valor tomado por uma única
variável (numérica ou nominal). Sob um ponto de vista geométrico, no caso das variáveis serem
todas numéricas, o processo de construção de uma árvore de regressão binária recorrendo a
divisões standard, consiste em particionar recursivamente o espaço em rectângulos multidimen-
sionais, de lados perpendiculares aos eixos determinados pelas variáveis, nos quais a população
é cada vez mais homogénea (figura 1.3).
A h *
Fig 1.3
14

Situações há de problemas nos quais dados homogéneos se separam de um modo natural
por hiperplanos não perpendiculares aos eixos. O tratamento deste tipo de problemas torna-se
complexo e origina árvores de grandes dimensões se as divisões possíveis em cada nó se basearem
apenas em questões standard. Para tratar mais eficazmente dados que apresentam estrutura
linear, o conjunto das questões permitidas em cada nó foi extendido, possibilitando que a procura
da melhor divisão em cada nó se efectue também ao longo das combinações lineares das variáveis
ordenadas. Reuniu-se então ao conjunto das questões standard o conjunto de todas as questões K
da forma Yl °fcxfc < c ?, onde K representa o número de variáveis numéricas, c um qualquer fc=i
número real e os coeficientes a\, ..., a # (associados ás variáveis numéricas com o mesmo índice) K
números reais tais que £) a I — !• No entanto a introdução de questões permitindo combinações fc=i
lineares das variáveis numéricas não trás só benefícios; se por um lado ela permite que se descubra
e utilize possíveis estruturas lineares dos dados, gerando árvores menos complexas (com menos
nós terminais), por outro lado tais árvores não têm a interpretação fácil, característica daquelas
produzidas apenas com questões standard.
1.4.2 R e d u ç ã o da complex idade do algoritmo de determinação d a partição ó p t i m a de u m a variável nominal na regressão LSD
Seja Xm uma variável nominal do vector X com modalidades em B = {61, ..., &£,}. Considere-
se a divisão de um nó t em Í£, e i# efectuada em Xm dividindo B em Bi = {b^, ...} C B e
Bi = B—Bi e originando os nós descendentes Í£ = {x € t : Xm € Bi} e ÍR = {x € t : Xm € -62}-
Suponhamos que a divisão óptima de um nó t é aquela que origina a bipartição Bi, Bi de
B, minimizadora de Pz,(j) (/li (íz,)) + PR(J> ( /U(ÍR)), onde (f> é uma função côncava num intervalo
contendo /J,(.) (ver por exemplo (1.7)). Denomine-se esta partição por bipartição óptima de
B. Como o número de divisões possíveis de um nó, baseadas numa variável nominal, aumenta
exponencialmente com o número de modalidades (2L~l — 1 divisões binárias distintas de um
nó para uma variável nominal com L modalidades), a complexidade do algoritmo de escolha da
bipartição óptima que testa exaustivamente todas as possíveis bipartições torna-se insustentável
para variáveis nominais com um elevado número de modalidades. Na procura da bipartição
óptima de B pressupomos que
P(Xet,Xm = b)>0,\/b<EB
e que
E(Y J X Et, Xm = b) não é constante para b e B,
caso contrário todas as bipartições seriam óptimas.
15

O teorema que se segue, é demonstrado em [Breiman & ai., 84], págs. 275-278 (com simpli
ficação devida a P. Feigin). No caso particular da regressão LSD, no qual <j> (y) = —y2 (veja-se
(1.8)), o resultado deve-se a [Fisher, 58]. Este resultado é a base teórica do algoritmo de pesquisa
utilizado no programa CART [Breiman & ai., 84] na regressão LSD e que reduz a complexidade.
Teorema 1.3: Existe uma partição óptima de B em Bi e B^. Essa partição é tal que
E(Y/Xet,Xm = bl)<E(Y/X£t,Xm = b2)
para b\ 6 Bi e b2 G Bi.
Assim ordenando os valores de E(Y / X et, Xm = h), h G B:
E(Y/Xe t,Xm = bh) <E{Y/Xet,Xm = bh) < ... <E(Y/Xe t,Xm = blL),
o teorema 1.3 garante que a bipartição óptima de B estará entre as L — 1 bipartições de B em
Bl = {bh, ...,blh} e B2 = {blh+1, ...,blL) ,h=l, ..., L-l.
Quando a distribuição de (X, Y) é desconhecida temos de estimar os valores das médias a
partir dos valores da amostra aleatória {(Xn,Yn)}^=l. Seja então y{b{) o valor da média de
todos os yn tais que a m-ésima coordenada de xm é fy. Se ordenarmos esses valores:
y(bh)<y(bh)<...<y(blL)
temos a certeza de que a melhor divisão s* em Xm no nó t é uma das L — l divisões que originam
tL = {xet:XmeBi} e tR = {x G t : Xm G B2} com Bi = {bh, ...,kh} e
-S2 = {fy.+i' — ,hL\, h = 1, ..., L — 1. Assim, em vez de procurar Bi de entre 2L~l — 1
subconjuntos de B basta procurá-lo entre os L — 1 subconjuntos de B descritos acima. Este
resultado reduz drasticamente a complexidade do algoritmo de procura da bipartição óptima
baseada numa variável nominal aumentando consideravelmente a eficiência computacional.
1.5 Quando parar o processo d e segmentação dos nós. O m é t o d o d a p o d a
[Breiman & ai., 84] revolucionaram de certo modo o processo de criação de árvores de regressão
ao abordarem o problema da determinação da árvore de regressão final sob um ponto de vista
completamente diferente dos adoptados até à data. Os métodos de construção de árvores de
regressão existentes até então, e mesmo o método CART [Breiman & ai., 84] numa fase inicial,
utilizavam uma regra heurística de paragem da segmentação dos nós para terminar o processo
de crescimento da árvore e declará-la como árvore final. Esta regra consistia em declarar um
nó como terminal quando este não admitisse nenhuma divisão que conduzisse a um decréscimo
16

significativo da impureza, ou seja, se fixada à priori uma quantidade /3 > 0, max AR (s, t) < (3.
Tal regra produzia geralmente resultados insatisfatórios; tornava-se impossível fixar um /? que
fosse eficaz para todos os nós. Um j3 "pequeno" tinha o inconveniente de conduzir a árvores
"excessivamente grandes", no entanto, um aumento de f3 levava normalmente a declarar como
terminais certos nós nos quais o decréscimo de impureza era ínfimo mas cujos descendentes
possuíam divisões que originavam grandes decréscimos de impureza. Assim, aumentando /3, as
árvores tornavam-se "demasiado pequenas", na medida em que, alguns nós com elevado poder
predictivo (e portanto desejáveis) não chegavam a ser criados.
Depois de inventarem e testarem algumas variantes desta regra, que se revelaram de igual
modo insatisfatórias, [Breiman & ai., 84] propuseram um novo método de procura da árvore
final. Em vez de utilizarem critérios de paragem resolveram deixar crescer a árvore inicial
até obter uma árvore, Tmax, de grandes dimensões, a qual é posteriormente submetida a um
adequado processo de poda ascendente (que explicitaremos mais adiante) por forma a produzir
uma sequência de sub-árvores
Tmax, Ti , T2, —, {h} , com ti = Taiz(Tmax),
de complexidade decrescente. A árvore de regressão final será então escolhida desta sequência
como sendo aquela que minimiza a estimativa do risco da sua utilização como função de predição.
A escolha é feita através de uma amostra teste independente no caso de a amostra ter grandes
dimensões, ou através de um processo de validação cruzada no caso contrário.
1.5.1 A á r v o r e Tm a a .
Sob um ponto de vista teórico a construção da árvore inicial Tmax de [Breiman & ai., 84],
consistia num processo sequencial de divisão dos nós por forma a maximizar o decréscimo de
impureza, processo este que finalizaria apenas quando todos os nós folhas fossem conjuntos
singulares. No entanto, em diversos problemas, a criação de tal árvore acarretava custos com
putacionais elevados e pressupunha a disponibilidade de tempo computacional ilimitado o que
inviabilizava a sua utilização directa. Assim, uma vez que o tempo e custo computacionais dis
pendidos são factores de extrema importância e limitados, na prática, ao criar a árvore Tmax,
termina-se o processo de segmentação de um nó se este for puro (isto é, se o valor da variável
de resposta for o mesmo para todos os seus casos), ou for formado por um número pequeno
(geralmente entre 1 e 5) de casos.
As árvores Tmax assim obtidas são menores; no entanto, o tamanho exacto da árvore Tmax
de partida não é importante, desde que seja "suficientemente grande", uma vez que não tem
influência na determinação da árvore final. Como veremos, a partir de dada altura, a sequência
17

de subárvores originadas pelo processo de poda aplicado à maior árvore Tmax será coincidente
com a sequência obtida pelo mesmo processo quando este é aplicado a uma árvore de tamanho
inferior. Para uma árvore inferior mas "suficientemente grande" as sequências poderão ser
totalmente coincidentes, conduzindo à escolha da mesma árvore final.
Como nota final, referiremos apenas que, comparativamente, as árvores iniciais dos problemas
de regressão têm geralmente dimensões muito maiores do que as dos problemas de classificação.
1.5.2 A sequência de sub-árvores podadas
Numa fase inicial de trabalhos, [Breiman k, ai., 84] sugeriram construir a sequência de sub
árvores podadas de Tmax,
Tmax, T\,T2,..., {ti} ,
do seguinte modo:
considerese para cada H, 1 < H < \fmax\ (onde \Tmax\ representa a complexidade, isto é,
o número de nós terminais da árvore Tmax) a classe TH de todas as subárvores de Tmax com
complexidade \Tmax\ — He escolhase a árvore TH da classe TH tal que
R(TH) = min R(T), Tern
para tomar parte da sequência.
Este procedimento origina com efeito uma sequência de subárvores de Tm a x de complexidade
decrescente, cada uma delas a melhor para o seu tamanho, no sentido de minimização do custo;
no entanto tem o inconveniente de que nós previamente podados podem reaparecer mais à frente
na sequência. Para evitar este problema [Breiman & ai., 84] impuseram a seguinte restrição:
"a sequência de sub-árvores podadas de Tmax deverá ser constituída por árvores encaixadas"
Tmax ^Ti^T2y ... >- {h} .
Para posterior determinação desta sequência definiram previamente uma medida de
custocomplexidade de uma árvore, acrescentando ao custo global da mesma uma penalização a
(geralmente > 0) por cada nó terminal.
A medida de custocomplexidade de uma árvore T, que denotaremos por Ra(T), é dada por
RciT) = R(T) + a\f\ = £ (*(*) + «) = E «■(*). tef tef
onde a representa o parâmetro de complexidade e ilQ(í) = R(t) + a a medida de
custocomplexidade de um nó t.
Definiram ainda a menor subárvore optimamente podada de T com respeito a a como sendo
a subárvore T(a) de T verificando as seguintes condições:
18

(i) Ra(T(a)) = min Ra{ï) ;
(H) se J R Q ^ ) = Ra(T(a)) então T(a) ^ T \
Assim, T(a) é a menor subárvore de T que minimiza o custocomplexidade com respeito a
a, sendo a sua existência e unicidade garantida pelo teorema 1.4 ([Breiman & al., 84], pág. 285).
Nota: Um ramo Tt de T com raiz t ET consiste no nó t e todos os seus descendentes em T;
TL = Tt1L e TR = Tt1R representam os ramos primários de uma árvore T com raiz t\. Podar um
ramo Tt de uma árvore T consiste em remover de T todos os descendentes de t.
Teorema 1.4: Toda a árvore T tem uma única menor sub-árvore optimamente podada com
respeito a a. Seja T uma árvore não trivial com raiz ti e ramos primários TL e TR. Então,
Ra(T(a)) = m i n ^ f r ) , Ra(TL(a)) + Ra(TR(a))] ;
Temos T(a) = {h} se Ra(h) < Ra(TL(a)) + Ra(TR(a)) e T(a) = {ti} U TL(a) U TR(a) no
caso contrário.
A quantidade a (a > 0) influencia directamente o tamanho de T(a): se a é pequeno a
penalização da subárvore por ter um grande número de nós terminais é pequena e T(a) será
grande; um aumento de a traduzse em fortes penalizações para subárvores mais complexas
e na consequente obtenção de menores subárvores T(a); por último, para um valor de a
significativamente elevado, a subárvore T(a) reduzirseá apenas à raiz de T.
O teorema que se segue vem fundamentar as observações anteriores.
Teorema 1.5: Se aç > a i então T(ct2) •< T{a{).
Da transitividade de ■< segue que
seT(a ) <f di T então T(a) = T> (a). (1.10)
Se T < Tmax, a partir de um dado a teremos Tmax(a) ■< T1, logo T'(a) = Tmax(o;). Isto
significa que se começarmos o processo de poda com uma subárvore T1 de Tmax, a partir de um
certo a a sequência de subárvores obtida coincide com a que se obteria partindo de Tmax. Se a
subárvore "t for "suficientemente grande" o primeiro valor de a para o qual Tmax{a) ^ T" será
pequeno e as referidas sequências serão praticamente idênticas.
Seja N(T) o número de subárvores podadas de uma árvore T. Se T é trivial teremos
N(T) = 1 caso contrário N(T) = N(TL) x N(TR) + 1 onde TL e TR representam os ramos
primários de T. Em particular, consideremse as árvores T™, nas quais todos os caminhos desde
19

a raiz até aos nós terminais têm exactamente n + 1 nós. Temos f"1 = 2n e N(Trn+1) =
(N(Tn))2 + 1. Assim, para n = 4 teremos 677 sub-árvores, para n = 5, 458330 sub-árvores e,
para n = 6, 210066388900 sub-árvores. Daqui se depreende que o número de sub-árvores de
uma dada árvore aumenta vertiginosamente com o número de nós, pelo que, um processo de
pesquisa directo sobre todas as sub-árvores de T para determinar a sub-árvore T(a) se torna
computacionalmente dispendioso podendo até ser inviável em árvores de grandes dimensões.
O teorema 1.5, juntamente com os dois que se seguem, provados em [Breiman & ai., 84], págs.
286-288, permitem mostrar como é possível determinar a cadeia de sub-árvores encaixadas por
um processo iterativo simples.
Seja
Ra{Tt) = R{Tt) + a
a medida de custo-complexidade de um ramo Tt de raiz t.
Teorema 1.6: Se Ra(t) > Ra(Tt), VteT-T então Ra(T(a)) = Ra(T) e
T(a) = {t e T : Ra(s) > Ra(Ts)para todos os antepassados s G Tde t}.
Assim, a determinação de T(a) em árvores onde Vi G T — T ,Ra(t) > Ra(Tt) consiste em
podar de T todos os ramos Tt para os quais Ra(t) = Ra(Tt).
Dada uma árvore não trivial T, a condição necessária de aplicabilidade do teorema anterior
ocorre se e só se
Ra(t) > Ra{Tt) <* R(t) + a> R(Tt) + aft& g(t, T) = Ã ^ _ ~ R(T*> > a vt G T - f. Tt - 1
Temos então,
Teorema 1.7: Dada uma árvore não trivial T, seja a\ = min g(t,T). Então T é a única teT-f
sub-árvore optimamente podada de si própria com respeito a a para a < a\; T é uma sub-árvore optimamente podada de si própria com respeito a a i , mas não a menor; e T não é uma sub-árvore optimamente podada de si própria com respeito a a para a > ot\.
T\ = T(ai) = {t G T : g(s,T) > ampara todos os antepassados s G Tde t}.
SeteTi-fi então g(t,T{) > g(t,T) se Tu <Tt e g(t,T{) = g(t,T) no caso contário.
Com base nos teoremas anteriores determina-se de forma recursiva uma sequência de perâmetros
de complexidade
20

—OO < aX < OC < ... < OiK < + ° °
e uma sequência de sub-árvores
Tmax yTi^T2y ... ^TK = {*!> ,
onde cada sub-árvore Tfc+i, k=û,...,K-i, é a menor sub-árvore optimamente podada de Tmax com
respeito a afc+i e é obtida da sub-árvore anterior Tfc removendo desta um ou mais dos seus
ramos.
Considere-se a árvore Tmax referida anteriormente. Seja
a i = min_ g(t,TmaX) cfc-í max -* max
e
Ti = {t € Tmax '■ 9(s, Tmax) > <*i para todos os antepassados s € Tmax de í} .
Obviamente Tmax >- 2\ e pelo teorema 1.7 temos
Tmax{<x) = Tmax se a < a i e Tm a x(a) = T\ se a = a i .
Se Ti = {íi} temos, pelo teorema 1.5, Trnaa;(a) = Ti para todo o a > a i e o processo termina.
Caso contrário tome-se
a2 = min. g(t,Ti) teTi-Ti
e
T% = {t € Ti : p(s, Ti) > a2 para todos os antepassados s G Ti de í} .
Temos Ti >~ T2 e pelo teorema 1.7
Ti (a) = Ti se a < a2 e Ti (a) = T2 se a = a2.
Como a2 > a i , decorre do teorema 1.5, que Tmaxi^) ^ Tmax(ai) = Ti ■< Tmax logo por (1.10)
Tmaxfa) = Ti(a2) = T2. Por outro lado se a i < a < a 2 então T ^ a ) X Tmax(ai) = Ti -<
Tmax pelo que, por (1.10), Tmax(a) = Ti{a) = Tx.
Caso T2 = {ti}, pelo teorema 1.5, Tm a x(a) = T2 para todo o a > a2 e o processo termina.
Senão o processo prossegue de modo análogo: no passo, fc + 1, definimos
afc+i = min_ g(t,Tk)
e
Tfc+i = {t € Tfc : g(s,Tk) > ctk+i para todos os antepassados s G Tk de t}.
Temos Tk >■ Tk+i e pelo teorema 1.7
Tk(a) = Tfc se a < afc+i e Tfc(a) = Tfc+i se a = a f c+i.
21

Como ak > afc+1) temos pelo teorema 1.5 Tmax{ak+i) < Tmax(ak) = Tk< Tmax logo por (1.10)
TmaX(ak+i) = Tk(ak+i) = Tk+i. Por outro lado para ak < a < ak+i vem, pelo teorema 1.5,
Tmax(a) 1 Tm^iak) = Tk± Tmax logo por (1.10) Tmaxia) = Tfc(a) = Tk.
Se Tk+i = {ti} então, pelo teorema 1.5, Tmax(a) = Tk+i para todo o a > ak+i e o processo
termina. Caso contrário o processo segue até se obter uma subárvore trivial.
Terminado o processo obtemos uma sequência de K parâmetros de complexidade
—00 < « i < Oi2 < ■■■ < OLK < +oo
e uma sequência de subárvores da forma
Tmax >-nyT2y ... ^ TK = {h},
tais que
Tmax{oc) — <
Tmax , a <a\
Tk , l<k<Keak<a< ak+i
TK -, Oi>aK
Notese que a sequência de subárvores determinada desta forma é uma subsequência da
sequência de subárvores referida no início (na qual cada uma das subárvores é a minimizadora
do custo na classe das árvores com a sua complexidade).
Com efeito, se considerarmos uma árvore TTnax(a) desta sequência então não existe uma outra
subárvore T de Tmax com a mesma complexidade e menor custo, caso contrário teríamos
Ra(T) = R{T) + a\f\= R(T) + a \fmax{a)\ < R(Tmax{a)) + a \fmax(<x)\ = RaiTmaxia)),
o que é absurdo por definição de Tm o x(a) .
1.6 A melhor sub-árvore podada: u m problema de est imação
O método de poda descrito na secção anterior resulta numa sequência de subárvores
Tmax =T0>-Tl^T2^ ... >- TK = {íx} ,
de complexidade decrescente de entre as quais se deverá escolher a subárvore de tamanho
óptimo. Para o efeito, a cada árvore Tk, k = 0,1,...,if, é asssociada uma estimativa R(Tk)
do custo real R* (Tk) de utilização dessa subárvore como função de predição. A subárvore de
tamanho óptimo é definida como sendo a núnimizadora de R (Tk);
Topt = Tk:R (Tfc) = min R (Tk). 0<k<K
22

Tendo sido as divisões de Tmax determinadas a partir da amostra £ por forma a mini
mizar a impureza estimada da árvore, torna-se óbvio que a utilização da estimativa R (Tk) de
R* (Tk), calculada com base na mesma amostra, levaria inevitavelmente à escolha de Tmax para
árvore óptima e dar-nos-ia um panorama optimista e enviesado do erro. A estimativa R(Tk)
diminui à medida que Tk aumenta, porque em cada divisão de um nó t em Í£ e tu se tem
R(t) > R(t£) + R(tR). Sendo assim, a estimativa R(Tk) de R* (Tk) é tanto mais optimista
quanto maior for a árvore.
Uma forma óbvia de curar a tendência optimista da estimativa R (Tk) é basear o seu cálculo
num novo conjunto de dados distintos dos de £, não intervenientes na criação da árvore. Contudo,
usualmente apenas dispomos da amostra de dados £, havendo poucas hipóteses de se obter um
novo conjunto de dados. Deste modo a amostra £ tem de ser utilizada simultaneamente para
gerar a árvore e para calcular estimativas credíveis do seu erro. A este tipo de estimativas
chamamos estimativas internas de £. Em [Toussaint, 74] encontrará um resumo e referência a
alguma bibliografia acerca das mesmas.
Apresentamos a seguir dois métodos de estimação frequentemente utilizados: o método de
amostra independente e o método de validação cruzada. A escolha de cada um deles depende
geralmente da dimensão de £: o método de amostra independente é preferível em amostras de
grandes dimensões uma vez que é computacionalmente mais eficiente; em amostras pequenas,
o método de validação cruzada, embora computacionalmente mais dispendioso é o preferido
porque faz uma utilização exaustiva dos dados tanto na criação da árvore como na estimação do
seu erro.
1.6.1 E s t i m a d o r e s d e amostra i n d e p e n d e n t e
Considere-se de novo uma amostra aleatória £ de (X, Y) de dimensão N. A utilização de
estimadores de amostra independente pressupõe uma divisão aleatória prévia da amostra £ em
duas amostras independentes £1 e £2, com Ni e N2 elementos, respectivamente. Frequentemente
toma-se Ni = | iV e JVjj = ^JV, embora não exista justificação teórica para esta divisão.
A árvore Tmax = TQ e a sequência de sub-árvores podadas To y Ti y ... >- TK = {ti} são
construídas apenas com os dados da amostra £1 (sem terem acesso aos dados de £2).
Recorde-se que cada árvore Tk, 0 < k < K, determina uma função de partição Tk, correspon
dente a Tk, que a cada x de x £az corresponder um nó t de Tk ao qual fica associada a resposta
real fk (x) — tf (rfc (x)) = i9 (í). Seja fk a função de predição determinada por Tk-
A amostra £2 é posteriormente utilizada para estimar o erro, R*(Tk), de cada sub-árvore Tk,
23

sendo essa estimativa dada por
2 (x„,y„)e&
com
na regressão LAD e
£ í *n> /fc (Xn)) = in ~ À (Xn)
L(YnJk(Xnj) = (Yn-fk(Xn))
na regressão L5.D.
Notando que os L \Yn,fk (Xn)j são variáveis aleatórias independentes e identicamente distribuídas, por serem funções contínuas de variáveis aleatórias independentes e identicamente distribuídas, é fácil ver que
Var (Rts(Tk)) = ±- | E [L (Yn, fk (Xn))2] ~E[L (rn , fk (Xn))]2} .
Utilizando as estimativas dos momentos amostrais, a estimativa do desvio padrão de Rts(Tk) é dada por
i £ [i(^,/fc(Xn))-i?ÍS(T,)]2
. 2 (x„,y„)6& J
= / —
As estimativas do desvio padrão na regressão LAD dependem apenas dos momentos absolutos
amostrais de primeira e segunda ordem, pelo que são menos variáveis do que as correspondentes
estimativas na regressão LSD (que dependem dos momentos amostrais de segunda e quarta
ordem) e portanto mais credíveis.
Para eliminar a dependência do valor de R*(Tk) relativamente à escala de medida da variável
de resposta, determina-se o erro relativo, RE*(Tk), que é uma medida de erro normalizada e
dada por:
onde ip — v (1") (mediana de Y) na regressão LAD e <p = E (Y) na regressão LSD.
Na regressão LSD o erro relativo determina a precisão de uma árvore de regressão Tk com
parando o seu erro quadrático médio com o erro quadrático médio do predictor constante que a
24

cada valor associa E (Y); na regressão LAD comparando o desvio absoluto médio de Tk com o
desvio absoluto médio do predictor constante que a cada valor associa a mediana de Y. Assim
o estimador i£E*s(Tfc) de RE*(Tk) é dado por
Rts(Tk) REts(Tk) = &>{$)
onde ip = v (mediana amostrai de Y) na regresssão LAD e tp = Y (media amostrai de Y) na
regressão LSD.
Por razões que dizem respeito à eficiência computacional, a medida de erro classicamente
utilizada em regressão é o erro quadrático médio. Neste caso, um estimador do erro padrão
assintótico ([Breiman & ai., 84], págs. 305 e 306) é dado por:
I" i / tí2 o o rfM1/2
SE (itE*s(Tfc)J = RE*5^ S? 2Si2 S% N2 \ i? s (r f c ) 2 ^(Tfc)^2 s\
onde S2 representa a variância amostrai de Y,
Sl = (w E {Yn-fk(Xn))4)-RtS(Tkf,
V 2 (x„,yn)eí2 /
e
512 = ( ~ E fr - A (Xn))2 (Yn ~ Y)2) - R^S* V 2 (^n,yn)SÍ2 /
1.6.2 Es t imadores de validação cruzada
Se a amostra de dados é pequena, a sua divisão em duas amostras independentes conduz
geralmente à construção de árvores "fracas". Por um lado, porque existem poucos dados para
basear a sua construção; por outro lado, porque obtemos estimativas imprecisas da precisão da
árvore criada, uma vez que a amostra disponível para estimar o erro tem também um número
muito reduzido de elementos. Neste caso, é preferível utilizar por exemplo o método de estimação
de validação cruzada, que cria a árvore com todos os dados disponíveis e permite obter bons
estimadores do erro real da mesma, usando igualmente todos os dados disponíveis.
Seja £ uma amostra de (X, Y) de dimensão N. Divida-se a amostra £ em V subconjuntos
disjuntos £„, v = 1,2,..., V com aproximadamente o mesmo número de elementos. A partir da
amostra £ e das V amostras complementares £ ^ de £„ em £ ( £(*) = £ — £„ ), construam-se V +1
árvores maximais
25

rp rp\ rpV
Pelo processo de poda já descrito obtenha-se a sequência de sub-árvores encaixadas de Tmax
Tmax >- Ti >- T2 y ... ^TK = {ti}
bem como os correspondentes valores dos parâmetros de complexidade
0 < « 1 < OL-Í < ... < OLK-
Relembre-se que
Tk = Tmax{ot) , Va G [cxk,otk+i[ com k — 1,2,...,K - 1
e
{*i} = Tmax{a) para a > aK.
Para um valor de V suficientemente grande as amostras £W têm a maior parte dos elementos
de £, pelo que podemos supor que as árvores Tmax e Tmax ,v = 1,2,..., V, não são muito dife
rentes. Assim sendo, uma estimação credível de R*(Tk) pode ser obtida testando as observações
de £„, que não foram consideradas na criação de 7 ^ . , na sub-árvore optimalmente podada de
Tmax c o m respeito a a'k, Tmàx{aík), onde a'k € [afc, ak+i[ para fc = 1,2,..., K.
[Breiman & ai., 84] sugerem utilizar para ak a média geométrica de ak e ak+i,
Qifc = y/atkak+l para fc = 1,2,..., í í - 1 e a'K = +oo,
sendo Tmàx (+oo) = {íi}.
Designando por / ^ a função de predição correspondente à árvore Tmàx(a'k), o estimador de
validação cruzada do custo real da árvore Tk é definido por
v N
onde
«"PM = ^ E E ^n,jf(Xn))
= è E ^ / S * 0 (*»)), (x„,y„)€í
/íl)(Xn) se (Xn,Yn)eh f{
kVn) (Xn) = \
fiV)(Xn) se (Xn,Yn)e£v
O estimador de validação cruzada RE^iTk) de RE*(Tk) é dado por
26

onde ip = v (mediana amostrai de Y) na regressão LAD e ip — Y (média amostrai de Y) na
regressão LSD.
Não é claro como se poderão obter estimadores do desvio padrão de iîcu(Tfc) e de RE^iTk)
porque as variáveis L \Yn, f^' (Xn)j não são independentes. [Breiman k, ai., 84] sugerem que na
prática se utilizem regras heurísticas que ignorem a falta de independência entre essas variáveis.
As fórmulas heurísticas assim obtidas são semelhantes ás obtidas no método de amostra inde
pendente. Temos,
SE(R™(Tk)) = M,
com 52 = ̂ E^(^^n)(^))-^N: n = l
e, na regressão dos menores desvios quadrados,
sendo S2 a variância amostrai de Y,
Sf 2S\2 st N2 {R^in)2 R^iT^S2 ' S4 +
1/2
% = (w E {Yn-ft](Xn)y)-R™(Tk)2, \ 2 (*«,yn)€& /
S2 = £ (Yn-Y)4)-S* (x„,yn)€í2
\ 2 (x„,Yn)eç2 " /
O grande problema da validação cruzada é o tempo de cálculo, que é função crescente de V.
[Breiman & ai., 84] sugerem a utilização de V = 10, podendo no entanto outros valores de V
serem mais adequados em certos conjuntos de dados.
1.6.3 A esco lha d a á r v o r e final: u t i l i zação d a r e g r a 1 S E
Estimativas de amostra independente ou de validação cruzada podem ser usadas para se
leccionar a árvore óptima de entre as candidatas To >- Ti y T2 y ... y TK- De entre estas
sub-árvores a de tamanho óptimo pode ser definida como sendo a árvore T^ minimizadora da
estimativa R (Tk) utilizada (Rts(Tk) ou jR^ÇT*)), ou seja, T^ é tal que
R(Tka)= min R(Tk). V K°' 0<k<K v ; (1.11)
27
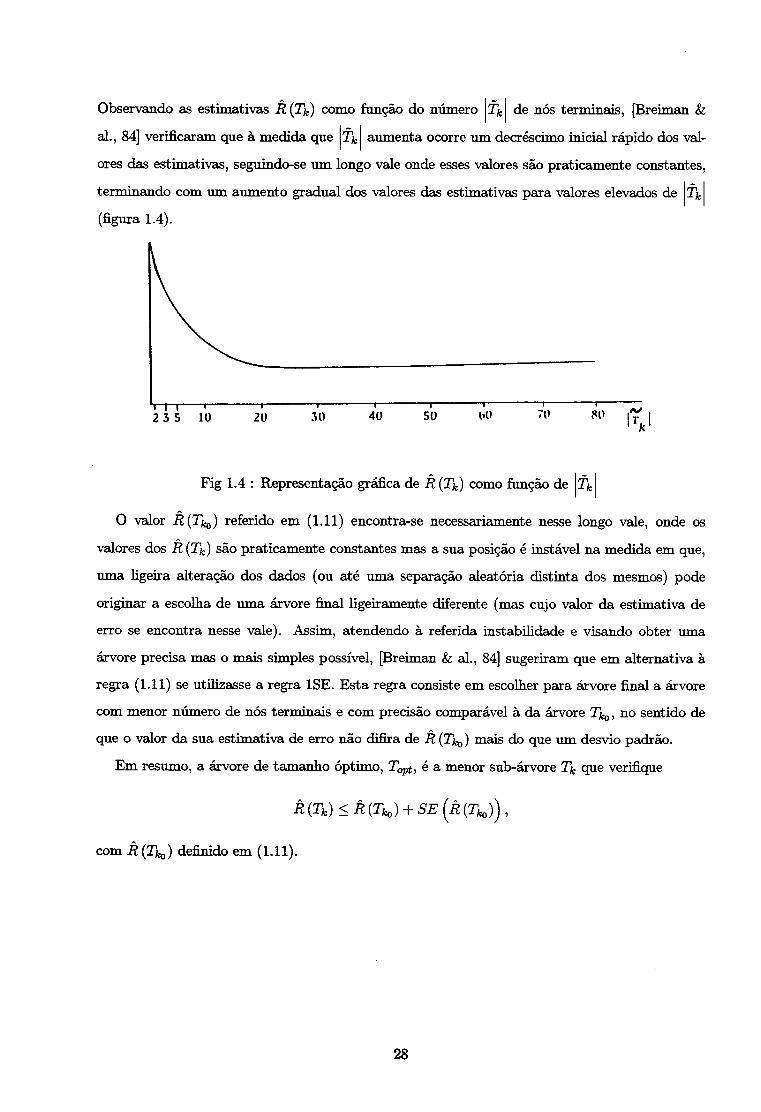
Observando as estimativas R (Tk) como função do número Tk de nós terminais, [Breiman &
ai., 84] verificaram que à medida que Tk aumenta ocorre um decréscimo inicial rápido dos val
ores das estimativas, seguindo-se um longo vale onde esses valores são praticamente constantes,
terminando com um aumento gradual dos valores das estimativas para valores elevados de Tk
(figura 1.4).
— i — 30
— i — 40 50
— i — 00 80 iV
Fig 1.4 : Representação gráfica de R (Tk) como função de Tk
O valor R(Tko) referido em (1.11) encontra-se necessariamente nesse longo vale, onde os
valores dos R (Tk) são praticamente constantes mas a sua posição é instável na medida em que,
uma ligeira alteração dos dados (ou até uma separação aleatória distinta dos mesmos) pode
originar a escolha de uma árvore final ligeiramente diferente (mas cujo valor da estimativa de
erro se encontra nesse vale). Assim, atendendo à referida instabilidade e visando obter uma
árvore precisa mas o mais simples possível, [Breiman h al., 84] sugeriram que em alternativa à
regra (1.11) se utilizasse a regra 1SE. Esta regra consiste em escolher para árvore final a árvore
com menor número de nós terminais e com precisão comparável à da árvore Tfc„, no sentido de
que o valor da sua estimativa de erro não difira de R (T^) mais do que um desvio padrão.
Em resumo, a árvore de tamanho óptimo, Topt, é a menor sub-árvore Tk que verifique
R(Tk) <R(Tko) + SE(£(Z*o)),
com R(Tko) definido em (1.11).
28

Capítulo 2
O método MARS
Embora sendo um dos métodos não paramétricos que melhor se adapta à aproximação de
funções gerais multivariadas, o método CART de [Breiman & ai., 84] apresenta certas restrições
que limitam fortemente a sua eficiência. A utilização da metodologia de atribuir à função apro-
ximante valores constantes nas sub-regiões do espaço de predição determinadas pelas divisões,
conduz inevitavelmente à obtensão de funções aproximantes fortemente descontínuas nas fron
teiras dessas sub-regiões e é uma das causas principais da ineficiência deste método quando
aplicado a situações em que a função a aproximar é contínua. Outro problema do método
CART é a extrema dificuldade que ele tem em aproximar funções lineares ou aditivas com mais
do que uma variável; de um modo geral, este método aproxima com dificuldade funções nas
quais as interações existentes envolvem um pequeno número de variáveis. A necessidade de
colmatar estas (e outras) limitações motivou o desenvolvimento de novas metodologias. Neste
capítulo descreveremos de forma sucinta o método MARS ("Multivariate Adaptive Regression
Splines"), desenvolvido por Friedman, em 1991, apresentando-o como uma série de genera
lizações do método CART que ultrapassam algumas das limitações referidas anteriormente. Este
método permite obter funções aproximantes, / , contínuas com primeira derivada contínua e é
mais potente e flexível na modelação de funções aditivas ou de funções cuja interação entre as
variáveis envolva um número reduzido de variáveis.
2.1 Uma outra apresentação do método CART
Os valores de resposta originados por uma árvore de regressão obtida através do método
CART podem ser expressos formalmente pela função aproximante
M f(X)=T,<hnBm(X),
7 7 1 = 1
29

onde os {Bm (.)}£f=1 representam as funções base
1 se X e Km
0 se X^Rm Bm (X) = <
os {Rm}m=i as sub-regiões nas quais a árvore particionou o espaço de predição e os {am}m = = 1
os coeficientes estimados por forma a melhor aproximar os dados (o que neste caso equivale à
estimativa da função de regressão da variável resposta na respectiva função base).
Seja H (rj) a função definida por
1 se 77 > 0 H(rj) = { (2.1)
0 se 77 < 0
e LOF (g) a função que estima, com base na amostra de dados, a ineficiência da função g como
função aproximante da função real. Então o procedimento de regressão passo a passo apresentado
no algoritmo 1 (que se segue) é equivalente ao do método CART aquando da criação da árvore
J-max-
A primeira linha do algoritmo 1 equivale no método CART a tomar para região inicial todo
o espaço de predição; o primeiro ciclo "for" gere as sucessivas divisões das regiões, permitindo
um número máximo, Mm a x , de sub-regiões (funções base) finais; nos três ciclos "for" interiores
procede-se à escolha da função base Bm*, da variável xv* e do ponto de divisão t* que originam
a melhor função aproximante g (minimizadora de LOF(g)), de entre todas as funções base
existentes até então. A função base Bm* é posteriormente substituída pelo seu produto por
H [— (x„* — **)] e uma nova função base, produto de Bm* (x) por H [+ (xv* —£*)], é introduzida
no modelo. Este processo equivale no método CART a escolher em cada iteração, de entre todas
as regiões existentes, a região Rm que proporcione a melhor divisão, sendo esta divisão efectuada
sob a variável xv* no ponto t*.
Algoritmo 1
Bi (z) «- 1;
For M = 2 to Mmax do:
l0f* +- +OO;
For m = 1 to M — 1 do:
For v = 1 to n do:
For t G {xvj : Bm {XJ) > 0} do:
g <- £ OiBi (x) + OmBm (x) H {+ (xv -1)] + aMBm (x) H [- {xv -1)] ;
30

lof*- min LOF (g); 01,... ,OM
if lof < lof* then:
lof* <— lof; m* <—m;v*<^- v; t* <— t;
end if
end for
end for
end for
BM (x) <- Bm. (x) H [- (xv. -1*)] ;
B m . (x) «- Bm- (x) H [+ (x„. -1*)] ;
end for
As funções resultantes da aplicação do algoritmo 1 são da forma
Km r / M Bm (x) =Y[ H \Skm (x„(fc,m) - ífcmj
fc=l
(2.2)
onde a quantidade ífm representa o número de divisões que dão origem a Bm, os s km tomam
os valores ±1 e indicam o sentido (dir./esq.) imposto pela função H que lhes corresponde, os
v (k, m) indicam as variáveis de predição intervenientes na função base Bm e os £fcm os valores
dessas variáveis nos quais se processa a divisão.
A figura 2.1, que se segue, representa em forma de árvore binária uma possível solução do
algoritmo 1. Aos nós intermédios da árvore estão associadas funções H, com os respectivos
parâmetros. Aos nós terminais da árvore estão associadas as funções base (2.2), produto das
funções H encontradas percorrendo o único caminho descendente desde a raiz até ao nó folha
correspondente. Assim,
Bi = H[-(xVa - ta)]H[-(xVb - tb)], B2 = H[-(xVa - ta)]H[+(xVb - tb)]H[-(xVc - tc)],
B3 = H [-(xVa - ta)]H [+{xVb - tb)]H [+(xVc - tc)] eB4 = H [+{xVa - ta)}.
Fig 2.1: Árvore binária de regressão com as funções base associadas
31

Terminado o algoritmo 1 efectua-se um processo adequado de poda ascendente. O procedi
mento de podar uma das funções base de cada vez não é conveniente porque origina "buracos"
no espaço de predição a cujos elementos o algoritmo 1 atribui indesejavelmente o valor zero.
Analogamente ao que foi visto no capítulo 1, o processo adequado de poda ascendente remove,
em cada iteração, duas regiões complementares substituindo-as pela região pai (que no processo
descendente lhes deu origem).
2.2 O m é t o d o M A R S c o m o produto de generalizações do C A R T
2.2.1 Cont inuidade
Referimos anteriormente que a eficiência do método CART (ou equivalentemente do algoritmo
1) na aproximação de funções contínuas é severamente limitada pela descontinuidade das funções
aproximantes produzidas. Verifica-se contudo que tal limitação é facilmente ultrapassável. Como
a utilização da função H (ri) (2.1) no algoritmo 1, é o único factor que introduz descontinuidade
no modelo, a simples substituição desta função por uma função contínua do mesmo argumento,
conduz à obtensão de um algoritmo com funções aproximantes contínuas.
Para fundamentar a escolha da função contínua substituta de H (77) (2.1) considere-se a base
bilateral de potências truncadas
1, {•%*. {(± OS-^KL (onde a notação a+ representa o valor zero para valores negativos de a e os {ífc}fc=1 representam
a localização dos "knots") geradora do espaço das funções "spline" univariadas de grau q. Para
q > 0, as aproximações de funções univariadas dadas por estas funções são contínuas e têm
q - 1 derivadas contínuas (veja-se [de Boor, 78] para uma revisão geral de funções "spline"). Na
aproximação de funções multivariadas por funções "spline" a correspondente base é dada pelo
produto tensorial sobre todas as funções base associadas a cada variável.
Como as funções H (2.1) do algoritmo 1 são funções de potências truncadas de grau 0
H(±(x-t)) = {±(x-tk))°+,
ocorre de modo natural substitui-las pelas funções de potências truncadas de grau q > 0,
6f = (± (x - tk))%,
de modo a originar um modelo contínuo com q — l derivadas contínuas.
As funções base obtidas com a referida substituição são da forma
B$ (*) = I Ï [s>™ {***•*) - fcm)]l • <2-3) fc=l
32

Embora as funções base (2.2) resultantes da aplicação do algoritmo 1 constituam um subconjunto
do produto tensorial completo de funções "spline" de grau q = 0 com "knots" em todos os valores
distintos dos dados, o mesmo não ocorre com as funções base (2.3) produzidas pela generalização
contínua (com q - 1 derivadas contínuas) do mesmo algoritmo. Na realidade, o algoritmo 1
permite divisões múltiplas na mesma variável, pelo que, a sua generalização contínua origina
funções base que podem conter vários factores de grau q > 0 envolvendo a mesma variável (não
sendo portanto um produto tensorial).
Seria desejável que a generalização contínua do algoritmo 1 produzi-se funções base "spline"
multivariadas, utilizadas na aproximação de funções multivariadas, porque estas têm muitas
propriedades interessantes [de Boor, 78]. Estas funções "spline" são produtos tensoriais de
funções "spline" univariadas. No entanto, não podemos simplesmente proibir divisões múltiplas
da mesma variável, de modo a obter produtos tensoriais de funções "spline" univariadas.
2.2.2 Novas generalizações
Outro problema inerente às funções base (2.2) produzidas pelo algoritmo 1 (ou às produzi
das pela sua generalização contínua (2.3)) surge com o aumento de uma unidade no nível de
interacção entre as variáveis sempre que ocorre uma divisão (uma vez que a função base Bm* (z)
é removida e substituída por duas funções fruto do seu produto por duas funções univariadas
reflexas). À medida que as divisões prosseguem as funções base finais têm tendência a envolver
um número significativo de variáveis envolvendo elevada interacção. Estes factores incapacitam
o método CART e a referida generalização contínua de aproximar convenientemente funções
nas quais não existe interacção entre as variáveis ou cujas interacções existentes envolvam um
pequeno número de variáveis (funções lineares e aditivas encontram-se nesta classe de funções).
Novas alterações no algoritmo 1 permitirão resolver este problema e obter funções base
"spline" multivariadas. O problema central reside na substituição da função base pelos seus
produtos por uma função "spline" univariada e pela sua reflexa da base bilateral de potências
truncadas, causando sucessivos aumentos de interacção. A solução proposta para o mesmo con
siste em simplesmente não remover a função base pai mas, em vez disso, acrescentar ao modelo
as duas funções suas "descendentes". Procedendo deste modo, o número de funções base au
menta duas unidades por iteração, sendo todas as funções base (pais e filhos) possíveis eleitas
para futuras divisões. Assim, funções envolvendo uma só variável obtêm-se escolhendo para pai
a função base Bi (x) = 1, funções de duas variáveis escolhendo para pai a função base univari
ada adequada, e assim sucessivamente. Uma vez que neste novo modelo não se fazem restrições
quanto à escolha da função pai, ele é capaz de produzir funções envolvendo tanto fortes como
33

fracas interacções entre as variáveis (até mesmo com ambas as situações). Modelos aditivos puros
obtêm-se escolhendo sempre como pai a função Bi (x) = 1. Esta estratégia de não remover a
função pai e possibilitar a escolha de qualquer função base para nova divisão torna redundante
a existência de múltiplos factores envolvendo uma mesma variável numa função base. Para
efectuar múltiplas divisões na mesma variável basta escolher várias vezes a mesma função pai
(correspondente a essa variável), aumentando o número de termos mas não a profundidade da di
visão. Modificando novamente o algoritmo por forma a não permitir funções base com múltiplos
factores envolvendo a mesma variável não alteramos o modelo e fazemos com que as funções
base obtidas sejam elementos do produto tensorial completo de funções "spline" univariadas
com "knots" em todos os valores distintos dos dados.
As várias generalizações apresentadas requerem que se efectue no algoritmo 1 três modi
ficações:
(i) substituir a função H (± (x — t)) pela função polinomial truncada (± (x — ífc))+;
(ii) não remover a função base pai Bm* {x) depois da sua divisão (de modo a que tanto ela
como as duas funções descendentes sejam candidatas a novas divisões);
(iii) obrigar o produto associado a cada função base a envolver factores com variáveis
distintas;
e conduzem à obtenção de uma função aproximante contínua, com q — l derivadas contínuas,
apresentando-se essa função em forma de expansão de produtos tensoriais de funções "spline"
de grau q.
Como o nosso objectivo é produzir uma boa função aproximante da função real (e não das suas
derivadas) em geral pouco se ganha e muito se pode perder impondo, para além da continuidade
da função aproximante, a continuidade das suas derivadas, especialmente em espaços de predição
de elevadas dimensões. A dificuldade associada à utilização de funções "spline" de ordem elevada
deve-se aos chamados "end effects". A maior contribuição para o erro estimado da função
aproximante 1 N , 2
— V* (yi — f (XÍ) J ( estimativa do erro quadrático médio) i= l
é dada pelos valores dos dados próximos da fronteira do domínio. Este fenómeno torna-se
ainda mais evidente em dimensões elevadas porque a proporção de dados próximos da fron
teira aumenta vertiginosamente com o aumento da dimensão do espaço de predição (os dados
encontram-se muito mais dispersos relativamente à média). Nestas regiões, a aproximação da
função real recorrendo a polinómios de grau elevado (determinados por funções base "spline" de
grau elevado), conduz a grande variância da função aproximante.
34

Para resolver este problema, [Stone & Koo, 85] sugeriram modificar as funções base "spline"
convertendo-as de modo diferenciável em funções lineares perto das fronteiras do intervalo de
dados de cada variável.
A forma computacional mais simples de assegurar aproximações lineares perto das fronteiras
é aproximar linearmente (por bocados) a função real sobre todo o espaço de predição. Para o
efeito basta utilizar produtos tensoriais de funções base "spline" de grau q — l.
Seguindo as sugestões de [Stone & Koo, 85] o programa MARS implementa, numa fase
inicial, as generalizações referidas em parágrafos anteriores utilizando q — 1, obtendo um modelo
aproximante contínuo com boas condições de fronteira. Posteriormente o conjunto de funções
base finais é modificado por forma a obter um modelo com primeira derivada contínua mas
mantendo condições favoráveis de fronteira.
2.2 .3 O algori tmo do M A R S
O algoritmo 2, que se segue, implementa esta fase do programa MARS.
Algoritmo 2
Bi (x) <- 1; M <- 2;
Loop until M > Mmax:
lof* *— oo;
For m = 1 to M - 1 do:
For v g {v (k, m) : 1 < k < Km} do:
For t G {xvj : Bm (XJ) > 0}: M—1
g^Yl ciiBi (x) + aMBm (x) [+ {xv -1)]+ + aM+iBm {x) [- (xv -1)]+ ;
lof +- min LOF (g); ai,...,ajvf
if lof < lof* then:
lof* <— lof; m* <— m; v* *- v; t* <— i;
end if
end for
end for
end for
BM (x) «- Bm. (x) [+ {xv. - i*)]+ ;
BM+i (X) «- Bm. (x) [+ (av - i*)]+ ;
M *- M + 2;
end loop
35

Este algoritmo produz Mmax funções base, produtos de funções "spline"de grau q = 1, que
são elementos da base bilateral de polinómios truncados representada pelo produto tensorial
completo sobre todas as funções base univariadas com "knots" em todos os valores distintos dos
dados. Como no método CART, este conjunto de funções é posteriormente sujeito a um processo
de poda que determina o conjunto de funções base final intervenientes na função aproximante
contínua.
As localizações dos "knots" associados a esta aproximação são então utilizadas para determi
nar funções cúbicas truncadas que permitem obter o modelo final do método MARS, contínuo e
com primeira derivada contínua.
2.2.4 O processo de p o d a
Ao contrário do que ocorre no algoritmo 1, as funções base do algoritmo 2 não correspondem a
sub-regiões disjuntas do espaço de predição mas sim a sub-regiões sobrepostas. É assim possível
podar uma a uma essas funções sem o inconveniente de originar os referidos "buracos" no espaço
de predição, desde que a função base Bi (x) = 1 (espaço total) nunca seja removida.
O algoritmo 3 implementa o referido método de poda. Na primeira linha J* representa o
conjunto das funções base produzidas pelo algoritmo 2; em cada iteração o algoritmo escolhe
a função base que removida nesse passo minimiza as perdas causadas e remove-a. A restrição
imposta de não remover B\ (x) = 1 é salvaguardada na linha 5 uma vez que m nunca assume o
valor 1. O algoritmo 3 constrói uma sequência de Mmax — 1 modelos, cada um com menos uma
função base que o anterior, e retorna em J* as funções base que constituem o modelo óptimo.
Algoritmo 3
J* = {l,2,...,Mmax};K*+-J*;
lof* *- min LOF l £ a-jBj (x) ) ; {dj-.-.jeJ*} \j€J* )
For M = Mmax to 2 do:
b <- oo; L «- K*;
For m = 2 to M do:
K «- L - {m} ;
lof ^r min LOF [ £ akBk (x) ) ; {ak:k£K} \k€K )
if lof < b then
b 4- lof; K* <- K;
end if
if lof < lof* then
36

lof* «- lof; J* <- K;
end if
end for
end for
2.3 D e c o m p o s i ç ã o A N O V A
O modelo MARS resultante da aplicação dos algoritmos 2 e 3 toma a forma
M Km r ( M / (x) = Oo+ X^ ° m I I [Skm \XHk,m) - tkm) > (2-4)
m—\ k=\
onde ao é o coeficiente da função base B\ = 1, e a soma é feita sobre as funções base Bm
((2.3), com o = 1) produzidas pelo algoritmo 2 que não foram podadas pelo algoritmo 3. A
interpretação deste modelo é facilitada pela sua representação numa outra forma que realça as
relações existentes entre as variáveis de predição e a variável de resposta: f{x)=ao+ J2 /<(**) + £ fij(xi,xj)+ J2 fijk(xi,xj,xk) + ... (2.5)
onde a primeira soma se processa sobre todas as funções base que envolvem apenas uma variável,
a segunda sobre todas as funções base que envolvem duas variáveis (salientando as variáveis com
interação de nível dois), e assim sucessivamente.
Pela sua semelhança com a decomposição utilizada na análise de variância em tabelas de
contingência, denominamos a representação (2.5) por decomposição ANOVA do modelo MARS.
Seja V (m) = {v ( f c ,™)}^ o conjunto das variáveis associadas à m-ésima função base Bm
(2.4).
Escrevemos cada função da primeira soma de (2.5) na forma
fi{xi)= Yl a>mBm(xi), (2.6) Km=l
soma de todas as funções base envolvendo apenas a variável Xi. Do mesmo modo escreve-se cada
função de duas variáveis da segunda soma de (2.5) na forma
fij(xi,xj)= ] T amBm(xi,Xj), (2.7) ■Km =2
(ij)€V(m)
que representa a soma de t o d a s as funções base envolvendo exac tamente as variáveis Xi e Xj.
A contr ibuição p a r a o modelo de duas variáveis específicas, digamos Xi e Xj, p o d e ser avaliada
representando graficamente a função
fifai, Xj) = fi (Xi) + fjiXj) + fij(Xi, Xj).
37

Termos envolvendo mais variáveis são associados e representados de modo análogo. A con
tribuição para o modelo de três ou mais variáveis específicas é usualmente avaliada representando
a correspondente função / * nos vários pares de variáveis para valores fixos das outras variáveis.
A representação de (2.4) na decomposição ANOVA (2.5) permitenos identificar facilmente
as variáveis intervenientes no modelo, averiguar se são puramente aditivas ou estão envolvidas
em interacções com outras variáveis e identificar o nível das interacções existentes.
2.4 O critério LOF: est imador da ineficiência d a função aproximante
A função LOF{}M) fornece, com base nos dados, um estimador do erro de futuras previsões
obtidas a partir da função aproximante / M NO decorrer do programa são determinados os
parâmetros do procedimento que minimizam esta função.
Como em [Friedman, 88] e [Friedman k Silverman, 89] utilizamos uma forma modificada do
critério generalizado de validação cruzada (GCV) originalmente proposto por [Craven k Wahba,
7 9 , : £ E Í V Í / M M ] 2
IX>F (/„) = GCV (M) = \ ^ ■ <2'8>
O critério GCV representa o erro quadrático médio com que a função aproximante apro
xima os dados (numerador) multiplicado por um factor (inverso do denominador) que penaliza
o aumento da variância associado ao aumento da complexidade do modelo (número de funções
base).
Se os valores dos parâmetros das funções base (o número de factores Km, as variáveis v (k, m),
a localização dos "knots" tkm e os sinais Skm), associados ao programa MARS, fossem de
terminados independentemente dos valores de resposta dos dados, (yi,...,2/jv), então apenas
os coeficientes (ao, a1? ..., aM) teriam de ser ajustados aos dados. Neste caso a função de
custocomplexidade seria dada por
C (M) = tr ÍB (BTB) ~l BA+1, (2.9)
sendo B a matriz M x JV dos valores tomados pelas funções base em cada elemento dos dados
(Bij = Bi(xj)), [Friedman, 91]. Este valor representa o número de funções base linearmente
independentes em (2.4) e portanto o número de coeficientes a determinar. As expressões (2.8) e
(2.9) definem o critério GCV de [Craven k Wahba, 79].
No entanto, tal como no programa CART, o programa MARS utiliza exaustivamente os
valores resposta dos dados para determinar o conjunto de funções base (sendo a sua eficácia e
flexibilidade devida, em grande parte, a esta utilização).
38

Embora a utilização dos valores de resposta dos dados, na determinação das funções base,
conduza geralmente a diminuições drásticas do viés do modelo ela origina simultaneamente um
aumento da variância, porque novos parâmetros (os das funções base) têm de ser ajustados.
A redução do viés diminui acentuadamente o valor estimado do erro (numerador de (3.8)).
Contudo, o inverso do denominador (2.8), com C (M) definido por (2.9), reflecte apenas a
variância associada à determinação dos coeficientes (ao, ai, ..., CLM), não reflectindo portanto o
aumento da variância devido ao número adicional de parâmetros a ajustar.
[Friedman & Silverman, 89] sugeriram a utilização de (2.8) para estimar a ineficiência de
função aproximante mas com uma função de custo-complexidade modificada. A nova função
de custo-complexidade, tem em conta, tanto os coeficientes (ao, ai , ..., ajií) como os parâmetros
adicionais das funções base a ajustar, e é dada por:
C{M) = C(M)+dM. (2.10)
Nesta expressão C (M) é determinado por (2.9) e M é o número de funções base não cons
tantes produzidas pelo método MARS ( número este proporcional ao número de parâmetros
dessas funções). A quantidade d representa um custo associado à optimização de cada função
base. Valores elevados de d conduzem à utilização de menos "knots" e portanto a um modelo
mais "suave". Um método de escolha do valor de d consiste em interpertar este valor como um
parâmetro do procedimento utilizado para controlar o grau de "suavidade" imposto à solução.
Estudos efectuados em variados conjuntos de dados simulados conduziram aos seguintes re
sultados:
1. o melhor valor de d é praticamente independente dos valores de M, N, n e das
distribuições das variáveis do espaço de predição;
2. em todas as situações estudadas o melhor valor de d pertence ao intervalo [2,4];
3. a aproximação (2.10), com d = 3, é geralmente eficiente;
4. o valor de GCV para o modelo final do método MARS depende moderadamente do valor
escolhido para d;
5. a eficiência real do modelo é praticamente insensível à escolha do valor de d neste
intervalo.
Uma consequência de 4 e 5 é que, embora a eficiência real do modelo produzido pelo método
MARS não dependa do valor de d, a eficiência que pensamos estar a produzir (baseados no
critério GCV modificado) depende desse valor. Em [Friedman k Silverman, 89] são dados
argumentos para a escolha de d = 2 no caso de modelos aditivos. Nos restantes casos toma-se,
em geral, d = 3.
39

2.5 O m o d e l o final: cont ínuo e c o m primeira derivada cont ínua
O modelo produzido pelos algoritmos 2 e 3 envolvem somas de produtos de funções da forma
b (x/s, t) = [s(x-1)]+ , com s = ± 1 . (2.11)
Motivados por [Stone e Koo, 85], com o objectivo de produzir um modelo com primeira
derivada contínua mas mantendo as propriedades óptimas de fronteira do modelo produzido
pelos algoritmos 2 e 3, substituímos cada factor (2.11) de cada função base do mesmo pela
correspondente função cúbica truncada da forma
C(x/s = +l,t-,t,t+) = <
0
p+ (x - í_)2 + r+ (x - í_) ;
x — t
X<t-
t-<t<t+ ,
x>t+
(2.12)
C(x/s = -l, <_, t, t+) = i
X<t-
t- <t<t+ ,
X>t+
-(x-t)
p- (x - t+)2 + r_ (x - í+)3
0
onde í_ < t < t+.
Fazendo p+ = (2í+ + 1 - - 3í) / (t+ - í_)2 , r+ = (2í - t+ - Í-) / (t+ - í - ) 3 ,
p_ = (3í - 2í_ -1+) I (t- - t+)2 e r_ = (í_ +1+ - 2í) / (í_ - í + ) 3 ,
obtemos uma função "spline" aproximante contínua com primeira derivada contínua e segunda
derivada descontínua nos pontos x = t±.
Na figura 2.2 apresentamos duas funções truncadas de potências de grau q = 1 com "knot"
t = 0.5 e as correspondentes funções cúbicas truncadas com "knot" central í = 0.5 e "knots"
laterais t_ = 0.2 e í + = 0.7.
0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0
0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0
Fig 2.2: funções "spline" de grau 1 e as correspondentes funções cúbicas truncadas
40

A localização do "knot" central t de cada função cúbica truncada (2.12) coincide com a do
"knot" da função linear truncada (2.11) que lhe está associada.
A cada função base m de (2.4) está associado um conjunto de "knots" {tkm}k=v A decom
posição ANOVA junta todas as funções base correspondentes a um mesmo conjunto de variáveis
{v (k, m)}%=v Deste modo, o conjunto de "knots" associado a cada função ANOVA (2.6), (2.7)
pode ver-se como um conjunto de pontos de um mesmo espaço ifm-dimensional. As projecções
desses pontos em cada um dos Km eixos, v (k, m), dão-nos a localização dos "knots" dos factores
correspondentes a essa variável que, como referimos, será a localização dos "knots" centrais das
funções cúbicas truncadas. Para "knots" laterais, i±, de cada função cúbica truncada, escolhem-
se os pontos médios entre o seu "knot" central e os dois "knots" centrais adjacentes na mesma
projecção.
Na figura 2.3 ilustra-se este procedimento para uma função ANOVA unidimensional com
três funções base e para uma função ANOVA bidimensional com duas funções base.
Fig 2.3
O modelo final obtido é contínuo e tem primeira (mas não segunda) derivada contínua. Como
a aproximação gerada por cada nova função base em pontos "afastados" do seu "knot" central
coincide com a originada pela correspondente função linear truncada, este modelo, embora com
derivada contínua, tem tendência a possuir as mesmas propriedades (óptimas) de fronteira que
o modelo de aproximação linear (por bocados) produzido pelos algoritmos 2 e 3.
41

Capítulo 3
Aplicações
Iniciamos este capítulo alertando os leitores de que a comparação global de vários métodos
é um problema complexo que envolve inúmeras questões estatísticas. A árvore taxonómica de
questões estatísticas que se segue permitirá compreender melhor a referida complexidade.
um único domínio vários domínios
análise de funções análise de de predição algoritmos
precisão de uma escolher entre precisão de escolher entre func. de pred. func. de pred. um algoritmo algoritmos
Fig 3.1: árvore taxonómica de questões estatísticas
O primeiro ponto consiste em considerar se estamos a estudar a "performance" dos métodos
quando aplicados a um único domínio ou a múltiplos domínios. Embora um objectivo funda
mental de pesquisa consista em encontrar métodos flexíveis que produzam bons resultados em
vários domínios, na maior parte das pesquisas temos apenas um domínio de dados de interesse,
para o qual procuramos a melhor função de predição ou o melhor algoritmo de aprendizagem
(uma função de predição, no nosso caso, é uma função que dado um exemplo de "imput" produz
uma resposta real; um algoritmo de aprendizagem é um algoritmo que constrói uma função de
predição com base num conjunto de exemplos e nos seus valores resposta).
Se nos restringirmos ao estudo de um único domínio temos ainda de considerar separadamente
a análise das funções de predição e a análise dos algoritmos de aprendizagem. Em cada uma
destas situações surge ainda a questão da estimação da precisão de um algoritmo específico
(ou função de predição) e o problema da escolha de um dos vários algoritmos (ou funções de
predição). O tamanho da amostra de dados disponível é ainda um factor a ter em conta na
análise uma vez que, se amostras grandes permitem utilizar técnicas envolvendo amostras teste
42

independentes, o mesmo não ocorre em amostras com poucos elementos.
Salientamos ainda que, os métodos em estudo estão sujeitos a várias fontes de variação, as
quais dificultam a análise.
Uma das fontes de variação é proveniente da escolha aleatória do conjunto de teste utilizado
na avaliação dos algoritmos. Para um conjunto teste uma função de predição pode originar
melhores resultados do que outra e, no entanto, se considerarmos a população total, ambas terem
"performances" idênticas, ou a outra ser a melhor. Este problema evidencia-se principalmente
em amostras com poucos elementos.
Uma outra fonte de variação deve-se à escolha aleatoridade na escolha da amostra treino.
Para uma amostra de treino específica um algoritmo de aprendizagem pode originar uma melhor
função de predição do que outro e, no entanto, se considerarmos varieis amostras de treino os
dois algoritmos podem ter, em média, a mesma "performance", ou o outro ser o melhor. Uma
pequena modificação do conjunto de treino pode originar significativas modificações na função
de predição produzida por um mesmo algoritmo. Em [Breiman, 94] e [Breiman, 96] designa-se
este comportamento por "instabilidade" e mostra-se que este é um problema sério inerente ao
CART.
Uma terceira fonte de variação é devida a factores aleatórios internos que ocorrem nalguns
algoritmos.
Um bom teste estatístico não deve ser "enganado" por estas fontes de variação. Para ter em
conta a variação dos dados da amostra teste e a possível aleatoridade do erro por ela determinado,
o procedimento de pesquisa, deve considerar o tamanho do conjunto de teste e as consequências
das modificações deste conjunto. Para ter em conta a variação dos dados da amostra de treino
e aleatoridade interna do algoritmo, o procedimento de pesquisa deve executar múltiplas vezes
o algoritmo e medir a variação da precisão das funções de predição resultantes.
Enumeros testes são sugeridos na literatura para responder a questões específicas ( veja-se
por exemplo [Snedecor k Cochran, 89], [Efron k Tibshirani, 93], [Kohavi,95], [Hinton& ai, 95],
[Rasmussen, 96], entre outros). No entanto todos eles apresentam problemas [Dietterich, 97].
Neste capítulo não pretendemos fazer uma comparação global dos algoritmos de regressão
CART e MARS. Limitamo-nos a apresentar os resultados da aplicação destes métodos a dois
conjuntos de dados simulados e a dois conjuntos de dados reais. O nosso objectivo é familiarizar-
nos com o "output" de cada programa e compreender em que situações deveremos esperar melhor
"performance" de cada um deles neste tipo de dados. Para além de compararmos entre si os
resultados obtidos com estes dois métodos (em cada conjunto específico de dados) comparamo-los
43

ainda com o resultado do tradicional método de regressão linear.
No que respeita aos programas CART e MARS utilizamos a versão 1.309 e a versão 3.6 para
UNIX, respectivamente. O CART e o MARS são programas comerciais (http://www.salford-
systems.com). Para produzir os modelos do método de regressão linear utilizamos a versão 4.0
para UNIX do programa RT [Luis Torgo, 99]. Refira-se contudo que a regressão linear é ape
nas um dos vários métodos de regressão implementados neste programa. O RT4.0 implementa
ainda, entre outras técnicas, a técnica de regressão por árvore, utilizando alguma da metodolo
gia do CART. O RT4.0 não é comercial mas poderão obter informações acerca do mesmo em
http://www.ncc.up.pt/~ltorgo/RT ou contactando o autor [email protected].
Nos exemplos do CART com amostras treino com menos de 1000 elementos, para escolher a
árvore óptima, utilizamos o método de validação cruzada associado à regra 1SE; nos restantes
casos utilizamos o método de amostra independente associado à regra 1SE. Nos exemplos do
MARS atribuímos o valor 3 ao parâmetro d (o software transforma-o automaticamente no valor
2 no caso de modelos aditivos) e os valor 15 ou 30 a Mm a x . Em todos os exemplos estudados,
os erros associados a cada modelo (MSE e MAD) foram calculados a partir de um conjunto
independente de dados.
Para comparar a precisão das funções de predição obtidas, com uma mesma amostra de
treino, por dois métodos, digamos A e B, fixada a amostra de teste, procedemos a um teste
de amostras emparelhadas. Para o efeito começamos por determinar o erro quadrático de cada
valor resposta, em cada um desses métodos; ou seja, determinamos para a realização disponível,
{(xi,yi)}i=v d* amostra teste {(X^Yi)}^ os valores das variáveis
SEAi = (YÍ - fA{Xi)f e SEBi = (YÍ - fB{Xijf ,
onde /A(XÍ) e /B(XÍ) representam, respectivamente, a resposta que o método A e o método B
associam ao elemento Xi.
Posteriormente calculamos os valores das variáveis
DABÍ = SE AÍ - SEBÍ,
obtendo a realização {dABi}iLi da amostra {DABÍ}ÍLI da variável DAB = SEA - SEB-
Testamos então Ho : HDAB = 0 contra H\ : \IDAB # 0.
Pelo teorema do limite central a variável DAB segue aproximadamente uma lei normal de
média HDAB e variância ^cr|j .
44

Sob a hipótese Ho e porque a amostra é grande podemos assumir que
z = DAB
segue aproximadamente uma lei normal centrada e reduzida.
Regeitamos Ho com significância a se
dABi
VNSDAB ^ za )
onde za é tal que P (Z < za) = 1 - §.
Na comparação simultânea dos resultados dos 3 métodos, efectuamos múltiplos testes de
hipótese deste tipo. Contudo, se os múltiplos testes forem efectuados a um nível de significância
a, o nível global de significância obtido (probabilidade de efectuarmos pelo menos uma rejeição
incorrecta) será superior a a. Para garantir um nível global de significância não superior a 5%,
quando efectuamos k testes, procedemos à correcção de Bonferroni para comparações múltiplas,
efectuando cada teste a um nível de significância de (5/k)%.
3.1 Dados simulados
3.1.1 Aproximação de uma função com estrutura não linear
Para averiguar o comportamento dos três métodos (LR, CART e MARS) na aproximação de
uma função com estrutura não linear geramos um conjunto de dados artificiais do modo seguinte:
1. geramos 10 variáveis, X\, X2,..., -X"io, correlacionadas (descrição detalhada no anexo
Al);
2. a variável resposta Y associada ao vector X = {X\,..., -X"io), e que pretendemos prever,
foi obtida pela equação Y - 10sin(7rXi X2) + 20(X3 - 0.5)2 + 10X4 + 5X5 + e, onde e
representa uma perturbação Gaussiana de média nula e variância unitária.
[Friedman,1991], págs. 37-41, e [Breiman, 96], pag. 193, estudaram esta mesma equação mas
para variáveis X\, X2,..., X10 independentes e uniformemente distribuídas no intervalo [0,1].
Geramos dois conjuntos de treino com 100 e 5000 elementos, respectivamente, e um conjunto
de teste com 10000 elementos. Para cada conjunto de treino construímos os modelos em estudo
e, para obter as estimativas dos erros, recorremos ao conjunto de teste.
Tendo a função a prever uma estrutura fortemente não linear é de esperar que o método de
regressão linear multivariada não aproxime adequadamente a função. Vejamos como se compor
tam nesta situação o método CART e o método MARS. No anexo A2 encontram-se os resultados
detalhados obtidos em cada programa.
45
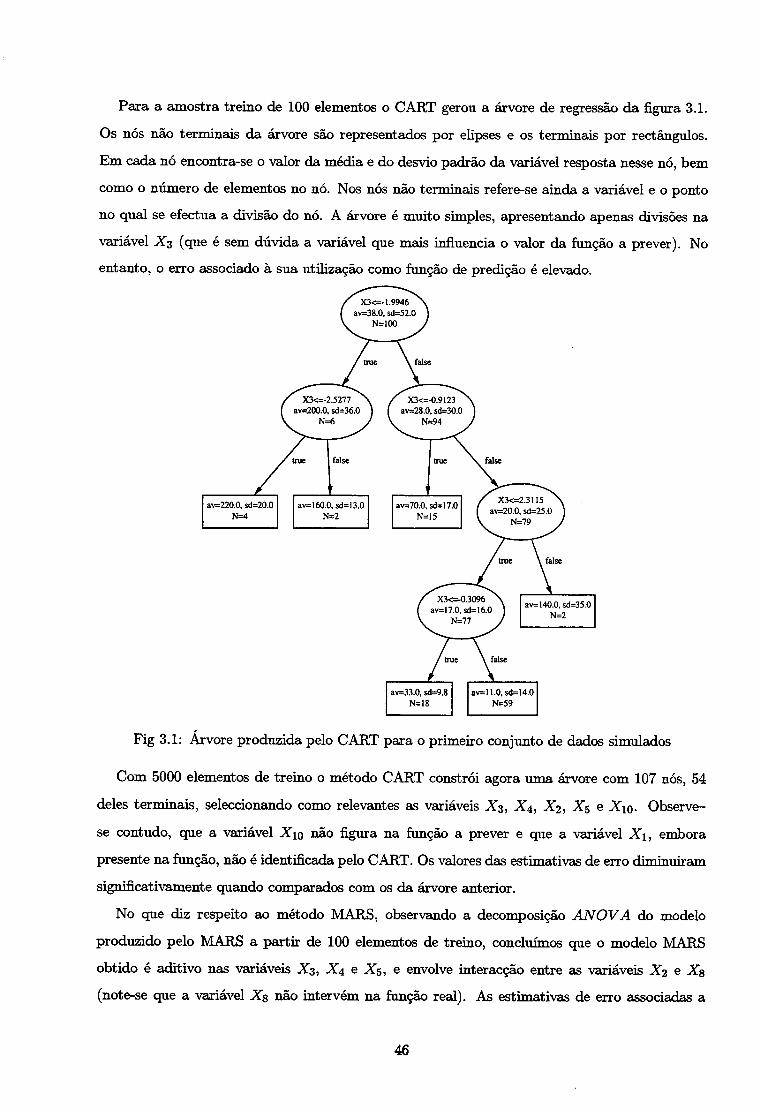
Paxá a amostra treino de 100 elementos o CART gerou a árvore de regressão da figura 3.1.
Os nós não terminais da árvore são representados por elipses e os terminais por rectângulos.
Em cada nó encontra-se o valor da média e do desvio padrão da variável resposta nesse nó, bem
como o número de elementos no nó. Nos nós não terminais refere-se ainda a variável e o ponto
no qual se efectua a divisão do nó. A arvore é muito simples, apresentando apenas divisões na
variável X3 (que é sem dúvida a variável que mais influencia o valor da função a prever). No
entanto, o erro associado à sua utilização como função de predição é elevado.
av=220.0, sd=20.0 N=4
av=140.0, sd=35.0 N=2
av=33.0, sd=9.8 N=18
av=11.0,sd=!4.0 N=59
Fig 3.1: Arvore produzida pelo CART para o primeiro conjunto de dados simulados
Com 5000 elementos de treino o método CART constrói agora uma árvore com 107 nós, 54
deles terminais, seleccionando como relevantes as variáveis Xz, X4, X2, X& e X10. Observe-
se contudo, que a variável X10 não figura na função a prever e que a variável X\, embora
presente na função, não é identificada pelo CART. Os valores das estimativas de erro diminuiram
significativamente quando comparados com os da árvore anterior.
No que diz respeito ao método MARS, observando a decomposição ANOVA do modelo
produzido pelo MARS a partir de 100 elementos de treino, concluímos que o modelo MARS
obtido é aditivo nas variáveis X3, X4 e X5, e envolve interacção entre as variáveis X2 e Xs
(note-se que a variável X$ não intervém na função real). As estimativas de erro associadas a
46

este modelo são bastante elevadas. O modelo produzido a partir de 5000 elementos de treino e
permitindo no máximo 15 funções base apresenta estimativas de erro significativamente menores
e, por observação da decomposição ANOVA do mesmo, concluímos que o modelo obtido é
aditivo nas variáveis X$, X4 e X5, e envolve interacção entre as variáveis X\ e X%. Este modelo
está de acordo com a função real. Permitindo um número máximo de 30 funções base no modelo
construído a partir de 5000 elementos, obtivemos erros muito menores. A decomposição ANOVA
confirma a construção de um modelo aditivo nas variáveis Xz, X4 e X5, envolvendo interacção
entre as variáveis Xi e Xi- A mesma decomposição revela interação entre as variáveis X3 e Xf
(que não faz parte da função real). Atendendo a que, a remoção da 7a função ANOVA conduz
a um pequeno desvio da função aproximante (na ordem de 1.612, vejase anexo A2), e a que a
variável X7 tem pouca importância para o modelo, podemos considerar que a 7o função ANOVA
é desnecessária, podendo ser removida do modelo. Notese que todos os modelos MARS relativos
a esta função seleccionam as variáveis X3, X4, X5, X2 e Xi como variáveis relevantes no modelo
(por esta ordem de importância). A variável X3 é sem dúvida a que mais influencia os valores
de resposta.
Na tabela seguinte apresentamos os erros associados aos modelos produzidos.
Dim. Amostra treino 100 5000
Tipo de erro MSE MAD MSE MAD LR (RT4.0) 920.493 22.950 747.206 18.501
CART 273.972 11.820 65.580 6.188
MARS (15 bf) 51.454 5.359 11.647 2.642
MARS (30 bf) 3.302 1.327
Para averiguar se devemos considerar significativas as diferenças dos resultados obtidos nos
3 métodos efectuamos os seguintes testes (cada um com significância de (5/3)%): Ho : VDLRCART = 0 contra Hx : VDLRCART # 0;
H0 '■ VDLR MARS-30 = 0 contra H[ : \IDLR MARS_30 ^ 0;
#0 : PDCART MARS-30 = ° contra Hx : ^DCART MARS-SO ¥" 0.
Tendo em conta que, para cada teste za ~ 2.395, obtivemos os seguintes resultados:
Dim. 100 5000
Sob
Ho
Ho'
Valor de z Conclusão
32.404 Reg. H0
38.079 Reg. IÏ0
31.447 Reg. HQ'
Valor de z Conclusão
25.282 Rej. H0
27.013 Rej. HQ
42.150 Rej. HQ'
47

Deste modo concluímos, com um nível global de significância não superior a 5%, que os resul
tados obtidos nos 3 métodos são significativamente diferentes. Por observação das estimativas
dos erros podemos agora afirmar que o método de regressão linear não é adequado para tratar
este problema (o que era de esperar) e que, embora neste problema o método CART seja muito
melhor do que a regressão linear, é o método MARS aquele que produz as melhores aproximações.
3.1.2 Aproximação de uma função linear
Para averiguar o comportamento dos três métodos (LR, CART e MARS) na aproximação de
uma função linear, geramos um conjunto de dados simulados, da forma que se segue:
1. geramos 10 variáveis, X\, -X2,..., .X10, independentes e uniformemente distribuídas no
intervalo [0,1];
2. a variável resposta Y, associada ao vector X = (X\,..., -X10), e que pretendemos prever,
foi obtida pela equação Y = 2X\ — 4X2+20( X3 — 0.5) + IO.X4 + 5X5 + e, onde e representa
uma perturbação Gaussiana de média nula e variância unitária.
Deste modo geramos dois conjuntos de treino com 100 e 5000 elementos, respectivamente, e
um conjunto de teste com 10000 elementos. Como no exemplo anterior, para cada conjunto de
treino construímos os modelos em estudo, e obtivemos as estimativas dos erros recorrendo ao
conjunto de teste.
Tendo a função a prever uma estrutura fortemente linear é de esperar que, dos três métodos,
o mais adequado para aproximar esta função seja o método de regressão linear multivariada.
Vejamos que de facto isto acontece e que, embora nesta situação o método CART não aproxime
adequadamente a função, o método MARS produz resultados competitivos comparativamente
aos obtidos na regressão linear. No anexo B encontram-se os resultados detalhados obtidos em
cada programa.
Para a amostra treino com 100 elementos o CART (utilizando apenas as questões standard)
produziu a árvore de regressão da figura 3.2. As variáveis X3, X4, X$ e XQ foram seleccionadas
como relevantes e obtivemos um MSE = 9.871.
Com 5000 elementos de treino, o MSE reduziu para 3.910, no entanto, a árvore obtida é
muitíssimo mais complexa (122 nós terminais). A elevada complexidade desta árvore não é de
estranhar. Como o método CART que utiliza apenas as questões standard aproxima a função
particionando o espaço em rectângulos de lados perpendiculares aos eixos determinados pelas
variáveis, ele tem de efectuar enumeras divisões nas variáveis seleccionadas para aproximar uma
estrutura linear. Neste último conjunto de dados, o CART identificou como relevantes para o
48
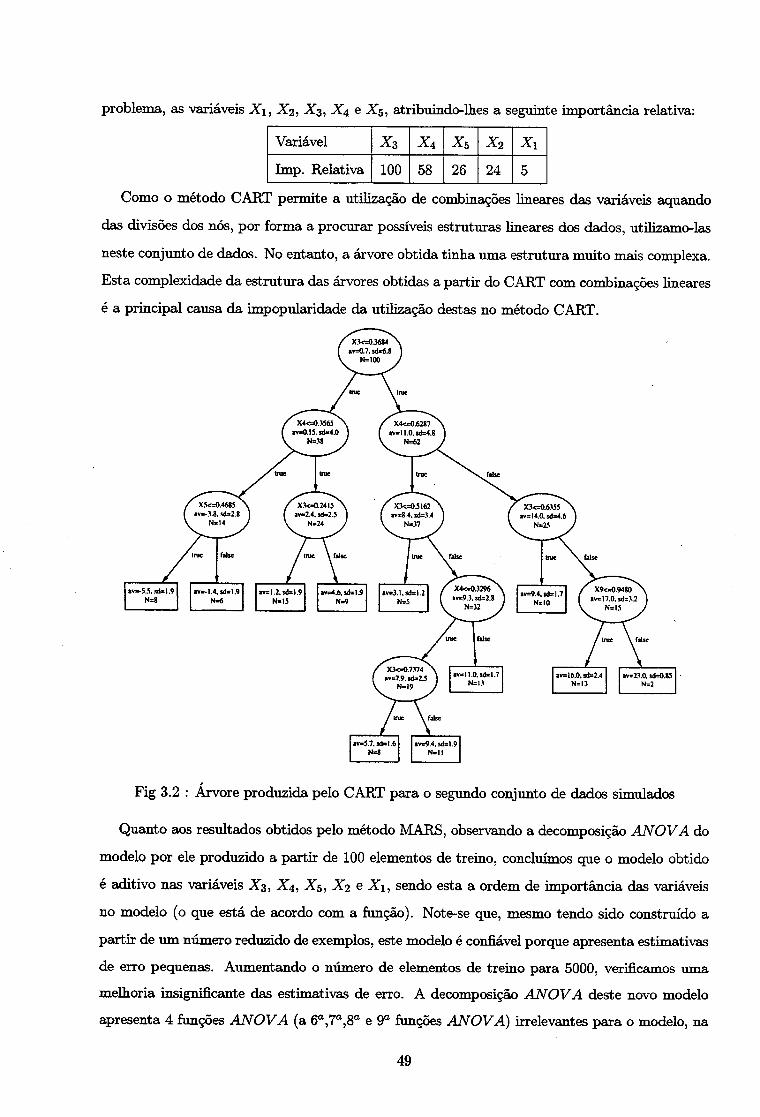
problema, as variáveis X\, X2, X3, X4 e X5, atribuindo-lhes a seguinte importância relativa:
Variável Xz x4 Xs x2 Xi
Imp. Relativa 100 58 26 24 5
Como o método CART permite a utilização de combinações lineares das variáveis aquando
das divisões dos nós, por forma a procurar possíveis estruturas lineares dos dados, utilizamo-las
neste conjunto de dados. No entanto, a árvore obtida tinha uma estrutura muito mais complexa.
Esta complexidade da estrutura das árvores obtidas a partir do CART com combinações lineares
é a principal causa da impopularidade da utilização destas no método CART.
/ X3<-0.7374 \ [ «v»7.9.«fa2J ) V N*" J
av=l 1.0. «1=1.7 av=16.0.5d=2.4 N=IJ
av=y.O. sd=0.85 N=2
/live \ false
av.5.7.!d*l.6 •v=9.4.sd=1.9 N.1I
Fig 3.2 : Arvore produzida pelo CART para o segundo conjunto de dados simulados
Quanto aos resultados obtidos pelo método MARS, observando a decomposição ANOVA do
modelo por ele produzido a partir de 100 elementos de treino, concluímos que o modelo obtido
é aditivo nas variáveis X3, X4, X5, X2 e X\, sendo esta a ordem de importância das variáveis
no modelo (o que está de acordo com a função). Note-se que, mesmo tendo sido construído a
partir de um número reduzido de exemplos, este modelo é confiável porque apresenta estimativas
de erro pequenas. Aumentando o número de elementos de treino para 5000, verificamos uma
melhoria insignificante das estimativas de erro. A decomposição ANOVA deste novo modelo
apresenta 4 funções ANOVA (a 6a,7°,8° e 9a funções ANOVA) irrelevantes para o modelo, na
49

medida em que, a remoção de cada uma delas produz desvios mínimos no modelo aproximante.
Removendo estas funções o modelo obtido é um modelo aditivo nas variáveis X3, X4, X$, X2 e
X\. A variável X3 é aquela que mais influencia os valores de resposta, seguindolhe as variáveis
X4, Xe,, X2 e X\.
Na tabela seguinte apresentamos os erros associados aos modelos produzidos.
Dim. Amostra treino 100 5000
Tipo de erro
LR (RT4.0)
CART
MARS (15 bf)
MSE MAD
1.014 0.807
9.871 2.523
0.996 0.799
MSE MAD
0.981 0.794
3.912 1.583
0.984 0.795
Para averiguar se podemos considerar significativas as diferenças dos resultados obtidos nos
3 métodos, efectuamos os seguintes testes:
Ho : PDLR CART = 0 c o n t r a Hi : HDLR CART # 0;
H'o ■ VDLRMARS=0 contra H[ : fiDcR MARS # 0;
HQ ■ VDMARS CART = ° contra Hx : HDMARS CART 7e 0.
Como anteriormente cada um dos testes foi realizado para uma significância de (5/3)% sendo
portanto za ~ 2.395. Os resultados dos testes encontramse resumidos na tabela que se segue:
Dim. 100 5000
Sob Valor de z Conclusão Valor de z Conclusão
Ho 66.492 Rej. H0 56.429 Rej. Ho
Ho 5.867 Rej. FÏ0 1.996 Não rej. HQ
H'ó 66.648 Rej. HQ' 56.371 Rej. H0
Neste conjunto de dados, a um nível global de significância não superior a 5%, concluímos
que os resultados da regressão linear são significativamente diferentes dos do método CART, não
sendo no entanto significativamente diferentes dos do método MARS quando a amostra treino
tem um número "razoável" de elementos. Por observação das estimativas de erro verificamos
então que o método CART é, de entre os três métodos, o que origina piores aproximações e
o método de regressão linear o que melhor aproxima a função. O método MARS aproxima
adequadamente a função, obtendo resultados comparáveis aos da regressão linear.
3.2 Dados reais
Em domínios com variáveis nominais não podemos aplicar o método de regressão linear e
o método MARS. O CART é então, dos 3 métodos que temos vindo a referir, o único que
50

permite gerar um modelo aproximante. Nestas situações, se o método CART por si só não
produz uma aproximação com estimativas de erro "satisfatórias" ele pode ainda ser utilizado
como um instrumento de selecção das variáveis relevantes do problema, permitindo averiguar
se as variáveis nominais têm ou não um papel importante na estrutura da função a prever.
Se as variáveis nominais não forem relevantes, a aplicação posterior do método MARS e/ou
da regressão linear nas variáveis numéricas, ou nas variáveis numéricas escolhidas pelo CART,
conduz, em certos domínios, à obtensão de melhores aproximações. O conjunto de dados que se
segue ilustra esta situação.
3.2.1 Previsão da idade do abalone
O abalone é um molusco gastrópode comestível, de concha auriforme de uma só peça, vulgar
mente denominado por orelha-do-mar. A idade do abalone é determinada cortando, em forma
de cone, a concha e contando o número de anéis da mesma com recurso a um microscópio. Este
processo é moroso e demorado. Outras medidas físicas, mais simples de obter, são determinadas
e utilizadas na previsão do número de anéis da concha, permitindo assim prever a idade do
abalone (número de anéis + 1.5).
O conjunto de dados que utilizamos para obter o modelo de predição da idade do abalone
é proveniente de um estudo levado a cabo por [Warwick Nash & ai., 94]. Embora o programa
CART permita trabalhar com valores "omissos" das variáveis, removemos dos dados originais
todos os exemplos nesta situação. O conjunto de dados resultante consiste em 4177 observações
de 9 variáveis (uma nominal e oito contínuas), entre elas a variável de previsão. De seguida,
apresentamos o nome, a unidade de medida e uma descrição sumária de cada variável.
Nome Medida Descrição
Sex M, F e I (infantil)
Lenght m m Comprimento máximo da concha
Diameter m m Diâmetro da concha
Height m m Altura do abalone incluindo a concha
Whole gr Peso do abalone incluindo a concha
Shucked gr Peso do abalone sem concha
Viscera gr Peso da tripa após sangramento
SheU gr Peso da concha depois de seca
Rings + 1.5 dá-nos a idade do abalone
A este domínio aplicamos apenas o método CART uma vez que a existência de uma variável
nominal (Sex) impossibilita a utilização da regressão linear e do método MARS. O CART gerou
51

a árvore de regressão da figura 3.3.
av=4.9.sd=:l.2 N=126
av=ll.0,sd=2.7 N=I24
av=l2.0.sd=2.6 N=66
av=l5.0. sd=3.6 N=I6
av=l3.0.sd=3.4 N=225
av=l6.0,sd=.1.6 N=27
Fig 3.3 : Arvore produzida pelo CART para os dados do abalone
Nesta árvore intervêm apenas as variáveis Whole, Shucked e Shell. O método considera que,
por si só, o peso total do abalone, o peso do abalone sem concha e o peso da concha seca são
factores que permitem prever a idade do abalone. Como o valor da variável nominal (Sex) não
é considerado relevante na previsão da idade do abalone, removemos essa variável e aplicamos
ao novo domínio a regressão linear e o método MARS. Aplicamos ainda estes dois métodos ao
espaço de predição constituído apenas pelas variáveis seleccionadas no método CART.
Observando a decomposição ANOVA do modelo produzido pelo MARS a partir de 8 variáveis
concluímos que o modelo é aditivo na variável "Whole" e envolve interacção entre as variáveis
"Viscera" e "Shell", "Shucked" e "Viscera", "Lenght" e "Shucked" e "Lenght", "Height" e
"Shucked". O modelo MARS gerado a partir das variáveis seleccionadas pelo método CART
apresenta interação entre as variáveis " Shucked" e " Shell" e entre as variáveis "Whole", " Shucked"
e "Shell". Este modelo para além de ter estimativas de erro inferiores, tem a vantagem de ser
52

menos complexo.
Nas tabela que se seguem estão os erros associados aos modelos produzidos.
Domínio
Tipo de erro
CART
9 var.
MSE MAD
5.582 1.768
Domínio 8 var. 4 var
Tipo de erro MSE MAD MSE MAD
LR 4.624 1.624 5.010 1.682
MARS 4.232 1.533 4.360 1.569
Para averiguar se podemos considerar significativas as diferenças dos resultados obtidos,
efectuamos os testes:
H'o
Aí
PDCAXT LR = ° C O I l t r a Hl '• VDCART LR = Q 7a 0 ;
VDCART MARS = ° c o n t r a Hx : nDcART MARS # 0 ;
V-Di* MARS = ° c o n t r a H'i ■■ VDLR MARS ^ 0 ;
considerando, separadamente, os casos de LR/MARS com 8 variáveis ou 4 variáveis. Cada teste
foi efectuado a uma significância de (5/3)%, sendo za ~ 2.395. Os resultados dos testes estão
resumidos na tabela que se segue:
Dim. LR/MARS com 8var. LR/MARS com 4 var.
Sob Valor de z Conclusão Valor de z Conclusão
Ho 4.917 Rej. Ho 2.954 Rej. HQ
H'o 6.857 Rej. H'Q 6.607 Rej. HQ
H'o 2.849 Rej. HQ 5.448 Rej. H'Q
Efectuamos ainda os testes:
Ho : VDLR(s w ) LR{4 ^ = 0 contra Hx : HDLR{8 W ) LR(4 W ) # 0 ;
HQ '■ PDMARS(S var) MARS(4 var) = ^ COntra H± l ^DMARS(8 vtx) MARS(_4 var) ^ ^ !
tendo obtido os seguintes resultados:
Sob. Valor de z Conclusão
< 4.775 Rej. H'Q"
K 1.767 Não rej. H'o"
Neste conjunto de dados, com um nível global de significância não superior a 5%, concluímos
que os resultados do CART diferem significativamente dos da regressão linear e dos do método
MARS e que, em cada domínio, os resultados da LR e do MARS também diferem significativa
mente. As estimativas de erro permitemnos então concluir que o método CART é o que produz
53

o pior modelo aproximante e que o melhor modelo é obtido com a aplicação do método MARS
nas 8 variáveis contínuas. Contudo, a utilização conjunta do CART e do MARS, cria um modelo
bem mais simples e cuja precisão não difere significativamente da do anterior. A regressão linear
nas 8 variáveis contínuas gera uma função aproximante "competitiva" com a do MARS e tem
uma estrutura menos complexa.
3.2.2 Previsão dos preços médios das casas em Boston
Os dados que estudaremos a seguir, foram recolhidos por [Harrison & Rubinfeld, 78], para
prever o preço médio das casas numa determinada área de Boston. Para o efeito [Harrison h
Rubinfeld, 78] efectuaram 506 censos na área de boston, registando os valores de 14 variáveis
contínuas (entre elas a variável de previsão) que descrevemos de seguida. Estes dados foram
utilizados por [Belsley, Kuh & Welsch, 80] em estudos de regressão.
Nome Descrição
CRIM Taxa criminal
ZN percentagem de terrenos divididos em lotes
INDUS percentagem de negócios de terrenos não retalhados
CHAS 1 se a casa é em Charles River, 0 caso contrário
NOX Concentração de oxido nítrico (partes por cada 10 milhões)
RM Número médio de quartos
AGE Percentagem de casas construídas antes de 1940
DIS Distância pesada a 5 centros de trabalho de Boston
RAD índice de acessibilidade a estradas nacionais
TAX Taxa de impostos
PTRATIO Taxa professor/aluno
B Proporção de negros
LSTAT Proporção de população de baixa posição social
MV Valor médio das casas em milhares de dollars
Aplicamos a regressão linear, o CART e o MARS a este domínio e estudamos ainda como se
comportam a regressão linear e o MARS quando aplicados apenas ás variáveis seleccionadas pelo
CART. Em todas as situações, utilizamos 405 elementos para treino e 101 elementos estimar
os erros. O método CART seleccionou como relevantes para prever o preço médio das casa em
Boston as variáveis CRIM, RM, DIS e LSTAT. A árvore de regressão obtida encontra-se na
figura 3.4 da página que se segue.
Quanto aos modelos obtidos com o método MARS, observando a decomposição ANOVA
54

do modelo produzido a partir das 14 variáveis e permitindo um número máximo de 15 funções
base, verificamos que o modelo envolve interacção entre as variáveis "RM" e "RAD", "TAX" e
"LSTAT", "DIS" e "B", "RM" e "TAX" e "LSTAT" e "TAX"; o modelo MARS gerado a partir
das variáveis seleccionadas pelo método CART e permitindo um número máximo de 15 funções
base, apresenta interação entre as variáveis "CRIM" e "RM',"DIS" e "LSTAT" e "CRIM" e
"LSTAT". Os modelos obtidos quando se permitem até 30 funções base têm uma estrurura
bastante mais complexa, envolvendo variadas interações entre duas e três variáveis.
av=50.0. sd=0.0 N=3
av=45.0. sd=6.1 N=30
av=13.0, sd=l.9 N=3
av=31.0,sd=3.9 N=66
av=47.0, sd=4.1 N=3
Fig 3.4: Arvore produzida pelo CART para os dados relativos ás casas de Boston
Na tabela seguinte encontram-se os erros associados aos modelos produzidos.
Domínio
Tipo de erro
CART
LR
MARS (15 bf)
MARS (30 bf)
14 var.
MSE MAD
69.354 5.001
31.871 4.640
41.515 5.405
22.839 3.656
5 var
MSE MAD
34.115 4.857
24.614 3.672
81.692 5.769
55

Para averiguar se podemos considerar significativas as diferenças dos resultados obtidos, efec
tuamos os testes:
H0 : HDcAKT LR=0 C O n t r a Hl : VDcART LR = 0 7a 0 !
#0 : VDCART MARS = 0 contra H'[ : (J.DCART MARS # 0; H'ó '■ VDLR MARS = 0 contra H[ : (J.DLR MARS ^ 0;
considerando, separadamente, os casos de 14 variáveis ou 5 variáveis. No caso de 14 variáveis
As comparações utilizaram os resultados do MARS com 30 funções base e no de 5 variáveis os
do MARS de 15 funções base. Cada teste foi efectuado a uma significância de (5/3)%, sendo
za ~ 2.395. Os resultados dos testes estão resumidos na tabela que se segue:
Dim. LR/MARS » com 14var. LR/MARS com 5 var.
Sob Valor de z Conclusão Valor de z Conclusão
Ho 1.834 Não rej. HQ 1.736 Não rej. Ho
Ho 2.123 Não rej. H0 2.206 Não rej. HQ
HZ 1.728 Não rej. H'0' 1.841 Não rej. HQ'
Efectuamos ainda os testes:
H o ^
DLR(\i var) LR(5 var)
U contra H, PD LR(14 var) LR{h var) 7^0;
H, r
l-C
,AíARS(14 var, 30bf) MARS(B var, 15bf)
tendo obtido os seguintes resultados:
0 contra Hx : fio MARS(14 var, 30bf) MARS{5 var, lBbf) 7^0;
Sob. Valor de z Conclusão
Ho" 1.133 Não rej. HQ"
H0 0.493 Não rej. HQ"'
A um nível global de significância não superior a 5%, concluímos que os resultados dos
vários métodos não diferem significativamente. Assim sendo, parecenos preferível a utilização
de árvore de regressão como função de predição, uma vez que, para além do seu poder descritivo,
ela permite que os valores das variáveis sejam tomados consoante "vamos descendo" na árvore,
evitando a necessidade de recolher os valores das 4 variáveis.
56

Anexo A
4.1 A l - C r i a ç ã o das variáveis d o espaço de predição e da variável a prever
attrpficontinuous,[ (_,unif_r(0,l)] ).
attr(X2 continuous, [ ( [Xx > 0.5], uiiifj:(0,l),-),(_,unifj:(-l,l),0.4),(_,unif_r(0,2),0.6)] ).
attr(X3,continuous,[ ( [Xx > 0.5,X2 = < 0.5],unif_r(0,l)],_),(_,norm(0,l),_)] ).
attr(X4,continuous,[ (_,unif_r(0,l)],0.6),(_,nornur(0,l),0.4)] ).
attr(X5,continuous,[ ( [X4 > 0.5],unif_r(0,l)],.),( [X3 > 0.5],norm(0,l),_),(_,norm_r(0,l),_)] ).
attr(X6,continuous,[ ( [Xx > 0.7],unif_r(-l,l)],_),( [X5 < 0.3],unif_r(0,l),_),
(-,norm(0,l),0.3),(.,nornu:(l,2),0.7)]).
attr(X7,continuous,[ (_,X3unif-r(0,l)-X6,-)] ).
attr(Xg,continuous,[ (_,unif_r(0,l),_)] ).
attr (^cont inuous , [ ( [X8 > 0.5],X8+unifjr(0,l),.),(_,X7norm_r(0,l),.)] ).
attr(Xio,continuous,[ (_,Xi+unif_r(0,l)-X5,_)] ).
attr(y,continuous,[ (^lOsin^Xx X2) + 20(X3 - 0.5)2 + 10Xt + 5X5+norm(0,!),_)] ).
57

A2-Resultados dos vários programas
**************************************************************** RT version 4.0, a Regression Tree Inductive System **************************************************************** (c) Copyright Luis Torgo, All Rights Reserved.
12-May-99 Information on 11 attributes was loaded. 100 examples were loaded.
# TESTING on file sfri.test
VAR. COEF. SE(COEF) Tvalue 1 constant' 23.45 xl 15.55 20.0554 0.7755 X2 11.63 6.0959 1.9086 x3 -22.75 8.8844 -2.5606 x4 14.34 5.7206 2.5061 x5 -22.58 16.2648 -1.3885 x6 -9.02 14.9772 -0.6023 x7 -9.286 13.5435 -0.6856 x8 19.53 14.8169 1.3178 x9 0.6096 3.4135 0.1786 xlO -17.66 15.4940 -1.1399 Critical t (0.025,89) = 1.987 R2 = 0.4285 Fvalue = 5.9987 Fcritical(0.050,10,89) = 1.9388 Regr SSD = 152174.0217 Using Linear Model :
Y = 23.4 + 15.6*xl + 11.6*x2 - 22.7*x3 + 14.3*x4 22.6*x5 9.02*x6
9.29*x7 + 19.5*x8 + 0.61*x9 - 17.7*xl0 Prediction Statistics based on 10000 test cases MEAN SQUARED ERROR (MSE) MEAN ABSOLUTE DEVIATION (MAD) RELATIVE MEAN SQUARED ERROR (RMSE)
902.493 = 22.950
0.633
USED SETTINGS: # Learning Mode :
Model obtained using all training data # Regression Model :
Least squares multiple linear regression
58

Script for runing CART vl.3 (c) California Statistical Software (c) 1998, Luis Torgo
Learning... WELCOME TO CART (TM) Version 1.309 October 29,
1993
Copyright (C) 1984, 1992 by California Statistical Software, Inc. 961 Yorkshire Ct. Lafayette, California
94549 (510) 283-3392 All rights
reserved
TREE SEQUENCE Terminal Cross -Validated Resubstitution
ree Nodes Relat ive ] Error Relative Error 1 37 0.15 +/- 0.044 0.02 2 36 0.15 +/- 0.044 0.02 3 35 0.15 +/- 0.044 0.02 4 34 0.15 +/- 0.044 0.02 5 33 0.15 +/- 0.044 0.02 6 32 0.15 +/- 0.044 0.02 7 31 0.15 +/- 0.044 0.02 8 30 0.15 +/- 0.044 0.02 9 29 0.15 +/- 0.044 0.02
10 28 0.15 +/- 0.044 0.02 11 27 0.15 +/- 0.044 0.02 12 26 0.15 +/- 0.044 0.02 13 25 0.15 +/- 0.044 0.02 14 24 0.15 +/- 0.044 0.02 15 23 0.15 +/- 0.044 0.02 16 22 0.15 +/- 0.044 0.02 17 21 0.15 +/- 0.044 0.02 18 20 0.15 +/- 0.044 0.02 19 19 0.14 +/- 0.043 0.02 20 18 0.14 +/- 0.043 0.03 21 17 0.15 +/- 0.043 0.03 22 16 0.15 +/- 0.044 0.03 23 15 0.15 +/- 0.044 0.03 24 14 0.15 +/- 0.044 0.03 25 13 0.15 +/- 0.043 0.03 26 12 0.15 +/- 0.043 0.04 27 11 0.15 +/- 0.043 0.04 28 10 0.15 +/- 0.044 0.04 29 9 0.15 +/- 0.044 0.05 30 8 0.17 +/- 0.047 0.05 31 7 0.18 +/- 0.049 0.06 32* 6 0.18 +/- 0.050 0.08 33 5 0.20 +/- 0.053 0.10 34 4 0.29 +/- 0.099 0.13 35 3 0.40 +/- 0.119 0.24 36 2 0.41 +/- 0.114 0.36 37 1 1.00 +/- 0.002 1.00
Complexity Parameter 0.00 2.34 11.4 17.6 21.3 24.2 25.6 39.1 50.7 65.5 77.1 108. 119. 129. 141. 145. 154. 169. 190. 219. 244. 275. 323. 489. 517. 643. 751. 965.
0.141E+04 0.200E+04 0.253E+04 0.461E+04 0.591E+04 0.671E+04 0.289E+05 0.319E+05 0.171E+06
Initial mean = 38.1 Initial variance = 0.266E+04 Number of cases in the learning sample = 100
NODE INFORMATION
* * Node 1 was split on variable x3 * A case goes left if variable x3 .le. -1.9946e+00
59

Dev.
* * * l * * * * * * *
Improve. *
02 *
* * Improve.
* * 02 * 2 *
02 02 02 01
94 *
Improvement = = 1.7e+03 (C. T. = 1.7e+05) Node Cases Average Standard
1 100 38. 52. 2 e 0.20E+03 36. 3 94 28. 30.
Surrogate Split Assoc. 1 x7 s -■3.4805e+00 0 33 6.5<
* * * Competitor Split
1 X7 -3.4805e+00 2 x2 1.0031e+00 3 X4 9.7909e-01 4 xlO 1.4012e+00 5 x9 1.0543e+00
6.5e+ 1.5e+ 1.2e+ 1.2e+ 9. 0e+
2 * *
Node 2 was split on variable x3 A case goes left if variable x3 .le. -2.5277e+00
= 5.9e+03) Improvement = 5.9e+01 Node Cases
Dev. * * *
* * * 4
Improve. *
01
01 I I
01 I I
01 I 1 I
00 Improve. 01 01 01 01 01
*
2 -1 -2
Surrogate 1 x8 2 x2 3 x5 4 x6 5 x7
Competitor 1 x8 2 x9 3 xl 4 x2 5 X5
6 4 2
(C. T. Average 0.20E+03 0.22E+03 0.16E+03
Split r 3.7687e-01 r -3.2746e-01 r -1.2711e+00 r -8.8542e-01 s -2.0414e+00
Split 3.7687e-01 2.1942e-02 6.0951e-01 -3.2746e-01 -1.7074e-01
Standard 36. 20. 13.
Assoc. 1.00 0.50 0.50 0.50 0.50
5.9e+
3.9e+
l . l e +
l . l e +
7 .8e+
5 .9e+
4 . 7 e +
4 . 7 e +
3 .9e+
3 .9e+
60

Node 3 was split on variable x3 A case goes left if variable x3 .le. Improvement = 3.1e+02 (C. T.
Node
3 -3 4
Cases 94 15 79
Average
28. 70. 20.
Surrogate Split
1 x 7 s -3.0101e+00
2 x9 s -3.5941e+00
3 x5 r 1.0737e+00
4 xlO s -5.7266e-01
-9.1235e-01 = 3.1e+04)
Standard
30. 17. 25.
Assoc
0.13 2 le+
0.13 2 le+
0.06 3 7e+
0.06 1 3e+
Competitor Split
1 x2 5.6850e-01
2 x9 -2.0057e+00
3 xl 8.5878e-01
4 x4 -2.0025e-01
5 x7 -1.8623e+00
9.6e+
5.4e+
4 . 4e+
3.9e+
3.9e+
Node 4 was split on variable x3 A case goes left if variable x3.1e. 2.3115e+00 Improvement = 2.9e+02 (C. T. = 2.9e+04)
Node Cases Average
4 79 20. 5 77 17. -6 2 0.14E+03
Competitor Split
1 x4 4.4593e-01
2 x2 5.3896e-01
3 x8 8.9692e-01
4 x7 3.8896e-01
5 xlO 2.4436e+00
Standard
25. 16. 35.
1.0e+
7.5e+
6.2e+
2.1e+
1.9e+
Node 5 was split on variable x3 A case goes left if variable x3 .le. -3.0962e-01 Improvement = 6.7e+01 (C. T. = 6.7e+03)
61

Dev.
* 5 * * * * * *
* * *
18 Improve. * 00
00 01 00
I 4 00 Improve. 01 01 01 01 01
59 *
Node 5 -4 -5
Cases 77 18 59
Average 17. 33. 11.
Standard
Surrogate Split 1 x 7 s -2.5930e+00 2 x8 s 7.5714e-02 3 x2 r 1.9717e+00 4 x6 s -2.2398e+00 5 x9 s -3.2795e+00
Competitor 1 x4 2 x2 3 x7 4 x8 5 x5
Split 4.2308e-01 5.0234e-01 2.1237e+00 9.7177e-01 -2.2666e-01
16. 9.8 14.
Assoc 0.16 6 0e+ 0.11 3 4e+ 0.05 9 4e-0.05 8 2e+
0.05 8 2e+
6 .4e+
4 . 1 e +
2 . 5 e +
1.7e+
1.6e+
Node Cases Average TERMINAL NODE INFORMATION
SD 1 4 224. 20. 2 2 158. 13. 3 15 70.0 17. 4 18 33.5 9.8 5 59 11.4 14. 6 2 138. 35.
Missing Code
( 3) x3 ( 7) x7 ( 9) x9 ( 8) x8 ( 10) xlO ( 5) x5 ( 2) x2 ( 6) x6 ( 4) x4 ( D xl
Construction Rule Estimation Method Tree Selection
VARIABLE IMPORTANCE Relative Number Of Minimum Importance Categories Category V.
100. numerical none 28. numerical none 3. numerical none 3. numerical none 2. numerical none 2. numerical none 2. numerical none 1. numerical none 0. numerical none 0. numerical none
MARY OPTION SETTINGS Least Squares 10 -fold cross-validation 1. 0 se rule
62

Variables Used See variable importance list above. Response is variable y
Linear Combinations No SECONDARY OPTION SETTINGS
1 Initial value of the complexity parameter = 0.000 2 Minimum size below which node will not be split = 5 3 Node size above which sub-sampling will be used = 101 4 Maximum number of surrogates used for missing values = 9 5 Number of surrogate splits printed = 5 6 Number of competing splits printed = 5 7 Maximum number of trees printed in the tree sequence = 100 8 Max. number of cases allowed in the learning sample = 20000 9 Maximum number of cases allowed in the test sample = 20000
10 Maximum number of nodes in the largest tree grown = 10000 (Actual number of nodes in largest tree grown = 38)
11 Max. no. of categorical splits including surrogates = 1 12 Max. number of linear combination splits in a tree = 0
(Actual number cat. + linear combination splits = 0) 13 Maximum depth of largest tree grown = 100
(Actual maximum depth of largest tree grown = 15) (Depth of final tree = 4)
Dimension of CART internal memory array = 7300000 (Memory used by this run = 375585)
Testing... Test Set results : MSE = 273.971692 MAD = 11.819893
63

MARS modeling, version 3.6 (3/25/93) input parameters (see doc.)
n p nk ms mi df il fv ic 100 10 15 0 8 3.000 0 0.000 0
here are 10 ordinal predictor variables. var min n/4 n/2 3n/4 max 1 0.1225E-01 0.2531 0.5804 0.7527 0.9999 2 -0.9554 0.1593 0.6272 1.042 1.988 3 -3.016 -0.6985 -0.4314E-01 0.5705 3.312 4 -1.971 0.9987E--01 0.4238 0.7928 1.647 5 -2.188 -0.7104 -0.2276 0.3196 1.960 6 -2.706 -0.5554E--01 0.6104 1.266 2.803 7 -4.072 -1.514 -0.6186 0.2014 2.420 8 0.7260E-02 0.2395 0.4391 0.7563 0.9965 9 -4.732 -0.6713 -0.1908E-01 0.3857 3.144
10 ■ -0.6750 0.6152 1.242 1.688 3.633
forward stepwise knot placement :
gcv #indbsfns #efprms basfn(s parent
0 2 1
0. 4 3
0. 6 5
0. 7
0. 9 8
0. 11 10
0. 13 12
8. 15 14
0.
2717. 345.1 245.7 118.7 73.63 58.16 53.45 51.04 50.71
0.0 2.0
3.0 4.0 5.0 7.0 9.0
11.0 12.0
1.0 6.0
10.0 14.0 18.0 23.0 28.0 33.0 37.0
variable knot
3. 0.1075
3. -1.396
3. 1.225
4. -1.971
2. 0.9371
5. 0.8723
8. 0.3294
3. -0.4613
final model after backward stepwise elimination: bsfn: 5 coef :
68.42 bsfn: 11 coef : 0.000 bsfn: coef:
0 -105.7
6 0.000
12 -38.41
1 -58.11
7 7.703
13 -58.24
2 107.8
8 0.000
14 0.000
3 63.28
9 -6.524
15 0.000
4 0.000
10 15.82
(piecewise linear) gcv = 48.06 #efprms = 28.0 anova decomposition on 9 basis functions: fun. std. dev. -gcv #bsfns #efprms variable(s) 1 50.86 3496. 4 12.0 3 2 5.756 98.76 1 3.0 4 3 3.430 61.16 1 3.0 2 4 2.407 53.88 1 3.0 5 5 4.654 68.79 2 6.0 2 8
piecewise cubic fit on 9 basis functions, gcv = 39.77
64

-gcv removing each variable: 1
4 8 , . 0 6
7 4 8 . . 06
2 68 . 9 3
8 6 8 . . 7 9
98 . 7 6
10 4 8 . . 0 6
3 4 5 6 3496. 98.76 53.88 48.06
9 48.06
relative variable importance: 1 2 3 4 5 6
0.000 7.781 100.0 12.13 4.110 0.000 7 8 9 10
0-000 7.754 0.000 0.000
Test Set Evaluation : MSE = 51.453949 MAD = 5.358525
65

**************************************************************** RT version 4.0, a Regression Tree Inductive System **************************************************************** (c) Copyright Luis Torgo, All Rights Reserved.
12-May-99 Information on 11 attributes was loaded. 5000 examples were loaded.
# TESTING on file fri.test ...
VAR. COEF. SE(COEF) Tvalue 1 constant' 24.18 xl -5.385 2.0251 -2.6591 x2 5.985 0.5751 10.4055 x3 -23.05 0.8353 -27.5909 x4 10.47 0.6313 16.5918 x5 2.329 1.5115 1.5410 x6 -1.62 1.4873 -1.0893 x7 -2.105 1.4247 -1.4775 x8 0.995 1.4184 0.7016 x9 -0.55 0.3213 -1.7116 xlO 0.02141 1.4350 0.0149 Critical t (0.025,4989) = 1.960 R2 = 0.4255 Fvalue = 368.7992 Fcritical (0.050,10,4989) = 1.8326 Regr SSD = 4207371.8199 Using Linear Model : Y = 24.2 - 5.39*xl + 5.98*x2 - 23*x3 + 10.5*x4 + 2.33*x5
- 1.62*x6 - 2.11*x7 + 0.995*x8 - 0.55*x9 + 0.0214*xl0 Making predictions...
Prediction Statistics based on 10000 test cases : MEAN SQUARED ERROR (MSE) = 747.206 MEAN ABSOLUTE DEVIATION (MAD) = 18.501 RELATIVE MEAN SQUARED ERROR (RMSE) = 0.548
USED SETTINGS: # Learning Mode :
Model obtained using all training data # Regression Model :
Least squares multiple linear regression
66

MARS modeling, version 3.6 (3/25/93) input parameters (see doc.)
n p nk ms mi df il fv ic 5000 10 15 0 8 3.000 0 0.000 0
here are 10 ordinal predictor variables. var min n/4 n/2 3n/4 max 1 0.1300E-03 0.2547 0.5039 0.7605 0.9999 2 -0.9988 0.1774 0.6294 1.151 1.998 3 -3.723 -0.6750 -0.9984E-02 0.5797 4.327 4 -2.883 0.1237 0.4270 0.7342 3.445 5 -3.692 -0.8096 -0.1885 0.3571 3.618 6 -3.031 0.7022E--01 0.6561 1.413 4.796 7 -6.216 -1.498 -0.7008 0.2256E-■01 3.364 8 0.4870E-03 0.2524 0.4992 0.7566 0.9998 9 -10.19 -0.5118 0.4750E-03 0.5047 13.18
10 -2.214 0.5901 1.204 1.855 5.418
forward stepwise knot placement : basfn(s) gcv
parent 0 1465.
2 1 208.0 0.
4 3 162.2 0.
6 5 107.3 0.
7 67.90 0.
9 8 47.55 0.
11 10 29.73 0.
13 12 19.58 10.
15 14 16.55 0.
#indbsfns #efprms 0. .0 1. .0 2: .0 6. .0
3. .0 10. .0
4. .0 14. .0
5, .0 18, .0
7. ,0 23. ,0
9. .0 28. .0
11. .0 33. .0
12. .0 37. .0
variable knot
3. -0.7954E-01
3. 1.368
3. -1.422
4. -2.883
5. 2.349
2. 0.6995
1. 0.2954
3. 0.6500
final model after backward stepwise elimination: bsfn: 5 coef:
62.00
0 1 2 3 4 bsfn: 5 coef:
62.00 -88.66 -66.18 109.0 48.26 0.000
bsfn: 11 coef :
10.96
6
0.000
7
9.920
8
14.71
9
-5.049
10
2.912
bsfn: coef :
12 -34.75
13 -39.56
14 19.39
15 0.000
(piecewise linear) gcv 16.55 #efprms = 37.0 anova decomposition on 12 basis functions : fun. std. dev. -gcv #bsfns #efprms variable(s)
1 3 6 . 7 0 1372 . 5 1 5 . 0 3 2 6 .467 5 8 . 7 7 1 3 . 0 4 3 4 . 5 4 0 3 6 . 3 1 2 6 . 0 5 4 5 . 4 6 1 3 8 . 3 6 2 6 . 0 2 5 4 . 9 1 2 2 6 . 7 2 2 6 . 0 1 2
piecewise cubic fit on 12 basis functions, gcv 13.10
67

-gcv removing each variable: 1 2 3 4 5 6
2 6 . 7 2 4 4 . 1 4 1372 . 5 8 . 7 7 3 6 . 3 1 1 6 . 5 5
7 8 9 10 16.55 16.55 16.55 16.55
relative variable importance:
1 8 .660
2 1 4 . 2 7
7 0 .000
8 0 .000
3 4 5 6 100.0 17.65 12.07 0.000
9 10 0.000 0.000
Test Set Evaluation : MSE = 11.673832 MAD = 2.642224
68

MARS modeling, version 3.6 (3/25/93) input parameters (see d o c ) :
n P nk ms mi 5000 10 30 0 8
df 3.000
il fv 0 0.000
1C 0
there are 10 ordinal predictor variables. var min n/4 1 0.1300E-03 0.2547
0.9988 0.1774 -3.723 -0.6750 -2.883 0.1237 -3.692 -0.8096
2 3 4 5 6 7 8 9
10
n/2 3n/4 0.5039 0.7605 0.6294 1.151
-0.9984E-02 0.5797 0.4270 0.7342
-0.1885 0.3571 -3.031 0.7022E-01 0.6561 1 413 -6.216 -1.498 -0.7008 0.2256E-0.4870E-03 0.2524 0.4992 0.7566 -10.19 -0.5118 0.4750E-03 0.5047
01
-2.214 0.5901 1.204 forward stepwise knot placement:
1.855
basfn(s) parent
0 2 1
0. 4 3
0. 6 5
0. 7
0. 9 8
0. 11 10
0. 13 12
10. 15 14
0. 17 16
0. 19 18
0. 21 20
0. 23 22
0. 25 24
23. 27 26
22. 29 28
22. 30
16.
gcv #indbsfns #efprms variable 1465. 208.0
162.2 107.3 67.90 47.55 29.73 19.58 16.55 13.38 10.80 8.709 7.419 4.672 4.112 3.646 3.569
0.0 2.0 3.0 4.0 5.0 7.0 9.0
11.0 12.0 13.0 14.0 15.0 17.0 19.0 21.0 22.0 23.0
1.0 6.0
10.0 14.0 18.0 23.0 28.0 33.0 37.0 41.0 45.0 49.0 54.0 59.0 64.0 68.0 72.0
3. 3. 3. 4. 5. 2. 1. 3. 3. 3. 3. 1. 2. 2. 2. 7.
final model after backward stepwise elimination: bsfn: coef : bsfn: coef: bsfn: coef: bsfn:
0 -147.8
6 0.000
12 -47.87
18
1 -108.6
7 9.950
13 -27.10
19
2 133.3
8 9.139
14 29.52
20
3 30.80
9 -4.974
15 0.000
21
max 0.9999 1.998 4.327 3.445 3.618 4.796 3.364
0.9998 13.18 5.418
knot
-0.7954E-01 1.368
-1.422 -2.883 2.349
0.6995 0.2954 0.6500 2.349
-0.6187 -2.299 0.5039 0.6729 1.559
•0.6328 -6.216
4 0.000
5 34.25
10 2.015
11 -15.36
16 88.05
17 0.000
22 69

23 2Coef: 25.48 0.000 39.61 0.000 -188.8
2 £ S f n : 2 4 25 26 27 28 QCoef: 13.49 30.80 -14.31 84.77 87.67
bsfn: 30 coef: -4.999
(piecewise linear) gcv = 3.569 #efprms= 72.0 anova decomposition on 23 basis functions-
fT' S??"o?eV- "gCV # b s f n s #efprms variable (s) 1 3 7 . 2 2 1 3 3 2 . 8 24 7 3 2 6 . 4 8 6 4 6 . 5 9 1 3'x 4 3 4 . 4 5 7 2 2 . 8 4 2 6 2 5 4 7 . 1 6 9 1 6 . 7 7 2 6*2 2 5 2 8 . 4 8 6 . 7 5 7 2 6*2 1 6 2 8 . 2 5 1 6 . 8 4 7 2 1 . ' 6 1 2 7 1 . 6 1 2 3 . 6 4 9 1 3 - 1 37
piecewise cubic fit on 23 basis functions, gcv = 3.470 -gcv removing each variable:
1 18.55
2 34.10
3 1382.
4 46.59 22
5 .84
7 3.649 8
3.570 9
3.570 10
3.570 ilative variable importance:
1 10.42
2 14.88
3 100.0
4 17.67 11.
5 82
7 0.7571
8 0.000
9 0.000
10 0.000
======= == t Set Evaluation : MSE = 3.302452 MAD = 1. .326679
70

Anexo B **************************************************************** RT version 4.0, a Regression Tree Inductive System **************************************************************** (c) Copyright Luis Torgo, All Rights Reserved.
12-May-99 Information on 11 attributes was loaded. 100 examples were loaded.
# TESTING on file slin.test ...
VAR. COEF. SE(COEF) Tvalue 'constant' -10.01 Xl 2.236 0.3869 5.7788 x2 -3.707 0.3530 -10.5025 x3 19.82 0.3786 52.3448 x4 9.969 0.3674 27.1362 x5 4.84 0.3524 13.7327 x6 -0.3027 0.3476 -0.8709 x7 0.03478 0.3624 0.0960 X8 0.3189 0.3725 0.8560 x9 -0.1041 0.4068 -0.2559 XlO -0.2003 0.3945 -0.5078 Critical t (0.025,89) = 1.987 R2 = 0.9805 Fvalue = 401.3650 Fcritical(0.050,10,89) = 1.9388 Regr SSD = 90.6650 Using Linear Model : Y = -10 + 2.24*xl - 3.71*x2 + 19.8*x3 + 9.97*x4 + 4.84*x5
- 0.303*x6 + 0.0348*x7 + 0.319*x8 - 0.104*x9 - 0.2*xl0 Making predictions...
Prediction Statistics based on 10000 test cases : MEAN SQUARED ERROR (MSE) = 1.014 MEAN ABSOLUTE DEVIATION (MAD) = 0.807 RELATIVE MEAN SQUARED ERROR (RMSE) = 0.022
USED SETTINGS: # Learning Mode :
Model obtained using all training data # Regression Model :
Least squares multiple linear regression
71
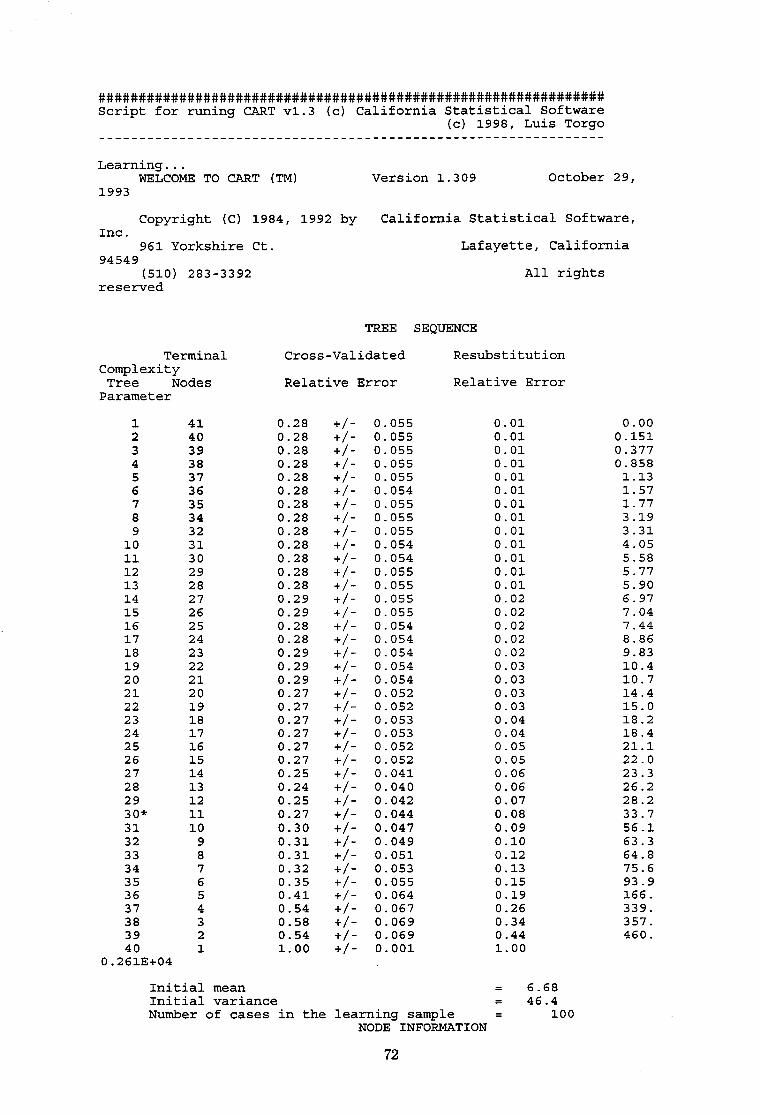
############################################################### Script for runing CART vi.3 (c) California Statistical Software
(c) 1998, Luis Torgo
Learning... WELCOME TO CART (TM)
1993 Version 1.309 October 29,
Copyright (C) 1984, 1992 by California Statistical Software, Inc.
961 Yorkshire Ct. 94549
(510) 283-3392 reserved
Lafayette, California
All rights
Terminal Complexity Tree Nodes Parameter
1 41 2 40 3 39 4 38 5 37 6 36 7 35 8 34 9 32
10 31 11 30 12 29 13 28 14 27 15 26 16 25 17 24 18 23 19 22 20 21 21 20 22 19 23 18 24 17 25 16 26 15 27 14 28 13 29 12 30* 11 31 10 32 9 33 8 34 7 35 6 36 5 37 4 38 3 39 2 40 1
0.261E+04
TREE SEQUENCE
Cross-Validated Resubstitution
Relative Error Relative Error
0.01 0.01 0.01
0. .28 +/- 0. .055 0. ,28 +/- 0. .055 0. ,28 +/- 0. .055 0. ,28 +/- 0. .055 0. .28 +/- 0. .055 0. .28 + /- 0. .054 0. .28 + /- 0. .055 0. .28 +/- 0. .055 0. ,28 + /- 0, ,055 0. .28 + /- 0. ,054 0. .28 + /- 0. .054 0. .28 + /- 0. ,055 0. .28 +/- 0. ,055 0. .29 + /- 0. ,055 0. .29 + /- 0. ,055 0. .28 +/- 0. .054 0. .28 +/- 0. .054 0. .29 +/- 0. .054 0. .29 + /- 0, .054 0 .29 +/- 0. .054 0, .27 +/- 0. .052 0. .27 + /- 0, .052 0. .27 +/- 0, .053 0, .27 + /- 0. .053 0. .27 +/- 0, .052 0. .27 +/- 0. .052 0. .25 +/- 0. .041 0. .24 +/- 0. .040 0. .25 +/- 0. .042 0 .27 +/- 0. .044 0. .30 +/- 0. .047 0 .31 +/- 0. .049 0 .31 +/- 0 .051 0 .32 +/- 0 .053 0 .35 +/- 0 .055 0 .41 + /- 0 .064 0 .54 +/- 0 .067 0 .58 + /- 0 .069 0 .54 +/- 0 .069 1 .00 +/- 0 .001
01 01 01
0.01 0.01 0.01 0.01 0.01 0.01 0.01
02 02 02 02
0.02 0.03 0.03 0.03 0.03 0.04 0.04 0.05 0.05
06 06 07 08 09 10
0.12 0.13
15 19
0.26 0.34 0.44 1.00
0 .00 0 . 1 5 1 0 .377 0 .858
1.13 57 77 19 31 05 58 77 90 97 04 44
8.86 9.83 10. 10. 14, 15. 18, 18. 21. 22, 23, 26. 28. 33. 56. 63. 64.8 75.6 93.9 166. 339. 357. 460.
,4 7 .4 .0 .2 .4 .1 .0 .3 .2 .2 ,7 ,1 ,3
Initial mean = 6.68 Initial variance = 46.4 Number of cases in the learning sample = 100
NODE INFORMATION
72

Dev.
* * *
* * * l *
* * *
* *
Node 1 was split on variable x3 A case goes left if variable x3 .le. Improvement = 2.6e+01
Node Cases
l 2 5
100 38 62
(C. T.
Average
6.7 0.15 11.
3.6839e-01 2.6e+03)
Standard
* 38 62
* Improve.
* 00
01 * *
00 00 *
01 2 * 5 *
* * * *
Improve. *
00
00
00
00
00
* * * *
Surrogate
1 x2 r
2 x4 r
3 x6 s
4 x8 r
5 xl r
Competitor
1 x4
2 x5
3 x9
4 x2
5 xl
Split
6.5483e-01
9.5590e-01
1.3922e-01
9.4710e-01
8.1626e-01
Split
2.7576e-01
6.0453e-01
9.8014e-01
7.2490e-01
9.9154e-01
6 4 4
.8
.0
.8
A£
0.
5SOC
.13 3. , 6e+
0. .13 5. . le-
0. .10 1. .3e+
0, .10 1. . 6e+
0. .07 7 . 5e-
Dev.
* * * * ' 2 *
* * *
* *
Node 2 was split on variable x4 A case goes left if variable x4 .le. Improvement = 3.3e+00
Node Cases
2 3 4
38 14 24
(C. T.
Average
0.15 -3.8 2.4
7.6e+
5.6e+
5.3e+
4 . 6e+
3.8e+
3.5650e-01 3.3e+02)
Standard
* 14 24
* Improve.
* 01
* 02
02 •*
01 *
01 3 *
* * * *
Improve. *
00
00
00
* * * *
Surrogate
1 xl s
2 x2 s
3 x6 r
4 xlO s
5 x7 r
Competitor
1 x2
2 xl
3 x3
Split
2.8075e-01
2.6711e-02
5.8742e-01
6.0313e-02
9.4078e-01
Split
7.4468e-01
9.4963e-01
2.6377e-01
4 .0 2 .8 2 .5
Assoc 0.14 6. 3e
0.14 4. ,5e
0.14 5. . 9e
0.14 1. . 3e
0.07 2. .le
l.le+
1.0e+
1.0e+
73

4 X5 5 x6
9.3086e-01 3.2698e-01
4.9e-3.7e-
Node 3 was split on variable x5 A case goes left if variable x5 .le. Improvement = 5.6e-01 (C. T.
Node 3 -1 -2
Cases 14 8 6
Average -3.8 -5.5 -1.4
Surrogate Split 1 x 2 r 2.1144e-01 2 x6 s 8.6273e-01 3 x8 r 4.2887e-01 4 x3 s 2.5970e-01 5 x 7 r 2.3368e-01
Competitor Split 1 x3 1.7342e-01 2 xl 9.9417e-01 3 x2 2.1144e-01 4 x7 8.1157e-01 5 x8 4.0160e-01
4.6853e-01 5.6e+01) Standard
2 1 1 .8 .9 .9
Assoc 0.50 2.9e 0.50 2.0e 0.50 1.9e 0.33 2.6e 0.33 7.5e
4.3e-3.5e-2.9e-2.9e-2.6e-
Node 4 was split on variable x3 A case goes left if variable x3 .le Improvement = 6.4e-01 (C. T.
Node 4 -3 -4
Cases 24 15 9
Average 2.4 1.2 4.5
Surrogate Split 1 x 7 s 8.6326e-01 2 xl s 7.1275e-01 3 x8 s 8.4365e-01 4 x2 r 2.8283e-01 5 x4 r 3.7163e-01
Competitor Split 1 x2 3.6868e-01
2.4151e-01 = 6.4e+01)
Standard 2 .5 1 .9 1 .9
Assoc. 0.44 2.7e 0.22 3.2e 0.22 1.7e 0.11 2. le 0.11 5.0e
3.4e-
74

01 01 01 01 01
2 Xl 3 x7 4 x4 5 x5
7.1275e-01 8.6326e-01 8.2313e-01 9.3086e-01
3.2e-2.7e-2.5e-2.2e-
Dev.
* * *
* * * 5 * * * * * *
* *
37 Improve. * 01 00
* * 01
* * 01 * 6 *
00 * * * *
Improve. *
00 00 00 00 00
25 *
Node 5 was split on variable x4 A case goes left if variable x4 .le. 6.2869e-01 Improvement = 4.6e+00 (C. T.
Node Cases Average
5 62 11. 6 37 8.4 9 25 14.
Surrogate Split 1 xl S 5.7013e-01 2 x2 r 8.3518e-02
* 3 x6 s 8.9300e-01 * 4 x9 s 6.6081e-01
9 * 5 xlO s 5.5442e-01 *
* Competitor Split 1 x3 6.6054e-01 2 x9 9.5979e-01 3 x2 8.3518e-02 4 x5 5.1766e-01 5 xlO 5.6016e-01
= 4. 6e-(-02) Standard
4 .8 3 .4 4 .6
Assoc . 0.32 1.6e-0.16 2.7e+ 0.16 1.0e-0.16 8.9e-0.16 1.2e+
4 . 4e+
3.0e+
2.7e+
2.2e+
1.4e+
Dev.
* * *
* * * 6 *
* * * * *
32 * Improve. * 01 01
I I 01 01
Node 6 was split on variable x3 A case goes left if variable x3 .le. 5.1619e-01 Improvement = 1.6e+00 (C. T. = 1.6e+02)
Node Cases 6 -5 7
37 5
32
Average 8.4 3.1 9.3
Standard
Surrogate Split 1x5 s 2.8152e-02 2 x6 r 9.0514e-01 3 x7 r 9.3985e-01 4 x9 s 2.8628e-02
3 1 2 .4 .2 .8
Assoc 0.20 5. . le-0.20 1. ,4e-0.20 3. ,9e-0.20 3. , 9e-
75

* 7 * * *
Improve. I I
00 01 01 01 01
Competitor 1 x5 2 x4 3 x9 4 x8 5 xlO
Split 5.1766e01 3.2997e01 3.0754e01 8.5795e01 7.7339e01
l.le+ 9.9e
8.6e
8.0e
5.9e
* * *
* * * 7 *
Dev.
* 19
Improve. *
01 *
01 01
i
01 * 02
8 *
* * * *
Improve. *
01 01 01 01 01
13 *
Node 7 was split on variable x4 A case goes left if variable x4 .le. Improvement = 9.4e01 (C. T.
Node Cases Average 7 32 9.3 8 19 7.9
8 13 11.
Surrogate Split
1 x8 s 8.5795e01
2 xlO s 6.7983e01
3 xl s 9.4063e01
4 x2 r 1.1810e01
5 X9 s 6.7877e01
Competitor Split
1 x5 5.1766e01
2 x3 8.9139e01
3 x2 1.5641e01
4 x7 6.2982e02
5 x8 8.5795e01
3.2964e01 9.4e+01) Standard
2 2 1
.8
.5
.7
Assoc
0.30 4 6e
0.30 3 3e
0.23 1 le
0.23 1 9e
0.23 5 9e
7.Dé
fi.6e
5.2e
4.8e
4.6e
Dev.
* * *
* 8 *
* * *
* * * * 8 11
Improve. *
01 01
Node 8 was split on variable x3 A case goes left if variable x3 .le. 7.3737e01 Improvement = S.3e01 (C. T. = 6.3e+01)
Node Cases 8 ■6 7
19 8
11
Average 7.9 5.7 9.4
Standard
Surrogate Split 1 x 4 r 1.6397e01 2 xl r 6.0022e01
2 5 1 6 1 .9
Assoc
0.62 1 6e
0.50 3 9e
76

3 x9 s 3.2136e-01 0 50 1.4e-01
1 1 1 4 x2 s 5.2071e-01 0 25 6.0e-02 1 6 1 1 7 5 x5 s 9.6066e-02 0 25 9.3e-
02 Competitor Split
Improve. 1 x5 5.1766e-01 5.3e-
01 1 x5 5.1766e-01 5.3e-2 xl 6.0022e-01 3.9e-
01 3 x9 5.4691e-01 2.9e-
01 4 x7 6.6161e-02 2.5e-
01 5 x2 1.4298e-01 2.1e-
01
* Node 9 was spl It < Dn variable x3 * * A case goes left if variable x3 .le 6.3547e-01
* * Improvement = 3 .5e+00 (C. T. = 3 5e+02) * 9 * * * Node Cases Average Standard
Dev. * * 9 25 14. 4.6 * -9 10 9.4 1.7
* * 10 15 17. 3.2 * *
10 15 * * Surrogate Split Assoc.
Improve. * * 1 xl r 6.8303e-01 0 20 6.8e-
01 * * 2 x2 r 7.7270e-01 0 20 1.0e+
00 j I * * 3 x7 s 1.2063e-01 0 20 5.1e-
01 J j * * 4 x8 r 5.9891e-01 0 20 5.5e-
03 | 9 | * 10 * 5 X10 s 9.9610e-02 0 20 4.7e-
01 * * * * Competitor Split
Improve. __ _ * 1 x9 9.5979e-01 1.6e+
00 2 x2 7.7270e-01 1.0e+
00 3 x4 8.1153e-01 1.0e+
00 4 x5 4.2368e-01 1.0e+
00 5 xl 3.0350e-01 8.2e-
01
* Node 10 was split on variable x9 * * A case goes left if variable x9 .le 9.4804e-01
* * Improvement = 7 . 5e -01 (C. T. = 7 5e+01) * 10 * * * Node Cases Average Standard
Dev. * * 10 15 17. 3.2 * -10 13 16. 2.4
* * -11 2 23. 0.85 * *
: ,3 2
77
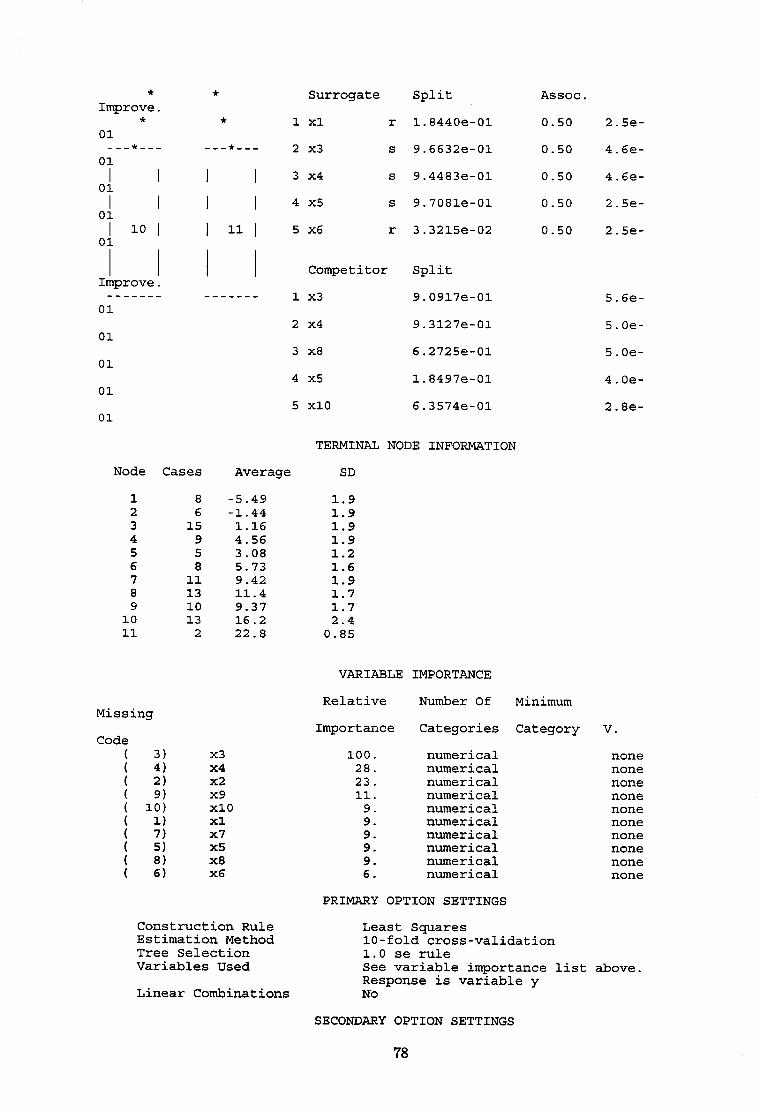
Improve. * 01 01 I I 01
I I 01 01
10
Improve. 01 01 01 01 01
I 1 1
Surrogate Split 1 xl r 1.8440e-01 2 x3 s 9.6632e-01 3 x4 s 9.4483e-01 4 x5 s 9.7081e-01 5 x6 r 3.3215e-02
Competitor Split 1 x3 9.0917e-01 2 x4 9.3127e-01 3 x8 6.2725e-01 4 x5 1.8497e-01 5 xlO 6.3574e-01
TERMINAL NODE INFORMATION Node Cases Average SD
1 8 -5.49 1.9 2 S -1.44 1.9 3 15 1.16 1.9 4 9 4.56 1.9 5 5 3.08 1.2 6 8 5.73 1.6 7 11 9.42 1.9 8 13 11.4 1.7 9 10 9.37 1.7
10 13 16.2 2.4 11 2 22.8 0.85
Assoc. 0.50 2 5e 0.50 4 6e 0.50 4 6e 0.50 2 5e 0.50 2 5e
5.6e-5.0e-5.0e-4.0e-2.8e-
Missing Code
( 3) x3 ( 4) x4 ( 2) x2 ( 9) x9 ( 10) xlO ( D xl ( 7) x7 ( 5) x5 ( 8) x8 ( 6) x6
Construction Rule Estimation Method Tree Selection Variables Used
Linear Combinations
VARIABLE IMPORTANCE Relative Number Of Minimum Importance Categories Category
100. 28. 23. 11. 9. 9. 9. 9. 9. 6.
numerical numerical numerical numerical numerical numerical numerical numerical numerical numerical
V.
none none none none none none none none none none
PRIMARY OPTION SETTINGS Least Squares 10-fold cross-validation 1.0 se rule See variable importance list above. Response is variable y No
SECONDARY OPTION SETTINGS
78

1 Initial value of the complexity parameter = 0.000 2 Minimum size below which node will not be split = 5 3 Node size above which sub-sampling will be used = 101 4 Maximum number of surrogates used for missing values = 9 5 Number of surrogate splits printed = 5 6 Number of competing splits printed = 5 7 Maximum number of trees printed in the tree sequence = 100 8 Max. number of cases allowed in the learning sample = 20000 9 Maximum number of cases allowed in the test sample = 20000 10 Maximum number of nodes in the largest tree grown = 10000
(Actual number of nodes in largest tree grown = 42) 11 Max. no. of categorical splits including surrogates = l 12 Max. number of linear combination splits in a tree = 0
(Actual number cat. + linear combination splits = 0) 13 Maximum depth of largest tree grown = loo
(Actual maximum depth of largest tree grown = 10) (Depth of final tree = 5)
Dimension of CART internal memory array = 7300000 (Memory used by this run = 375737)
Testing... Test Set results : MSE = 9.871293 MAD = 2.523043
79

MARS modeling, version 3.6 (3/25/93) input parameters (see d o c ) :
n P nk ms mi 100 10 15 0 8
df 3.000
il 0
fv 0.000
there are 10 ordinal predictor variables var min n/4 1 0.7500E-02 0.2866 2 0.7778E-02 0.1747 3 0.1361E-01 0.2544 4 0.2022E-02 0.1970 5 0.8600E-03 0.2290 6 0.2440E-02 0.2088 7 0.1988E-01 0.2570 8 0.1867E-01 0.2643 9 0.1845E-01 0.2306
10 0.9280E-03 0.1600
n/2 0.4750 0.4228 0.5179 0.4794 0.4868 0.4213 0.4906 0.4953 0.5203 0.4247
forward stepwise knot placement:
gcv #indbsfns #efprms basfn(s parent
0 1 2 3 4 5
6 8
10 12 14
0 0 0. 0. 0. 5. 5. 0.
13 11.
15 1.
7 9
11
47.34 16.14 5.584 3.513 1.927 1.483 1.585 1.719 1.905 2.118 2.356
0.0 1.0 2.0 3.0 4.0 5.0 7.0 9.0
11.0 13.0 15.0
1.0 5.0 9.0
13.0 17.0 21.0 26.0 31.0 36.0 41.0 46.0
3n/4 0.7896 0.6568 0.7505 0.7629 0.7479 0.6929 0.7524 0.7662 0.6952 0.6185
variable
3. 4. 5. 2. 1.
10. 5. 9. 2. 7.
final model after backward stepwise elimination: bsfn:
5 coef:
2.256 bsfn:
11 coef: 0.000 bsfn: coef:
0 -9.748
6 0.000
12 0.000
1 19.70
7 0.000
13 0.000
2 9.894
8 0.000
14 0.000
3 4.861
9 0.000
15 0.000
1C 0
max 0.9968 0.9909 0.9825 0.9957 0.9732 0.9968 0.9798 0.9937 0.9986 0.9961
knot
0.1361E-01 0.2022E-02 0.8600E-03 0.7778E-02 0.7500E-02 0.5696 0.7889 0.8471 0.8606 0.2466
4 -3.706
10 0.000
(piecewise linear) gcv = 1.311 #efprms = 16.0 anova decomposition on 5 basis functions-
T' SRd;«?eV- „;9r #bsfns #efP™* variable(s) 1 5 . 7 8 1 4 3 . 0 0 1 3 0 3 2 2 . 9 8 5 1 2 . 3 6 1 3 ' 0 4 3 1 .417 3 . 8 5 1 1 3 o 5 4 1 .102 2 . 7 9 3 1 3 " o 2 5 0 .6614 1.754 1 3 0 1
80

piecewise cubic fit on 5 basis functions, gcv = 1.311 -gcv removing each variable:
1 1.754
2 2.793
3 43.00
4 12.36
5 3.851
6 1.311
7 1.311
8 1.311
9 1.311
10 1.311
.ative variable importance: 1
10.30 2
18.85 3
100.0 4
51.48 5
24.68 6
0.000 7
0.000 8
0.000 9
0.000 10
0.000
Test Set Evaluation : MSE = 0.995668 MAD = 0.799360
81

**************************************************************** RT version 4.0, a Regression Tree Inductive System **************************************************************** (c) Copyright Luis Torgo, All Rights Reserved. 12-May-99
Information on 11 attributes was loaded. 5000 examples were loaded. # TESTING on file lin.test ...
COEF. SE(COEF) Tvalue VAR. 'constant' -10.05 xl x2 x3 x4 x5
1 923 0.0483 39.7908 -3 95 0.0487 -81.1198 20.01 0.0488 410.0006 10.1 0.0483 208.8693 4 973 0.0482 103.2687
x6 -0.02824 0.0493 -0^.S12B Xl x8 x9 xlO
-0.03401 0.0483 -0.7048 0.03043 0.0486 0.6268 0.08641 0.0488 1.7706 0.02391 0.0489 0.4890
Critical t (0.025,4989) = 1.960 R2 = 0.9792 Fvalue = 23421.1641 Fcritical(0.050,10,4989) = 1.8326 Regr SSD = 4892.1336 Using Linear Model : Y = -10.1 + 1.92*xl - 3.95*x2 + 20*x3 + 10.I*x4 + 4.97*x5 - 0.0282*x6 - 0.034*x7 + 0.0304*x8 + 0.0864*x9 + 0.0239*xl0
Making predictions... Prediction Statistics based on 10000 test cases : MEAN SQUARED ERROR (MSE) = 0.981 MEAN ABSOLUTE DEVIATION (MAD) = 0.794 RELATIVE MEAN SQUARED ERROR (RMSE) = 0.022
USED SETTINGS : # Learning Mode :
Model obtained using all training data # Regression Model :
Least squares multiple linear regression
82

MARS modeling, version 3.6 (3/25/93) input parameters (see doc.):
n p nk ms mi 5000 10 15 0 8
var min n/4 1 0. .1440E•03 0. ,2404 2 0. .7080E•03 0. ,2439 3 0. .4880E•03 0. ,2631 4 0, •2980E•03 0. ,2393 5 0. .4200E•04 0. .2428 6 0. .1307E•02 0. .2580 7 0 .2100E■04 0, .2358 8 0 .5180E■03 0. .2633 9 0 .2800E■03 0 .2414
10 0 .1790E•03 0 .2484
df il fv ic 3.000 0 0.000 0
r variables n/2 3n/4
0.4945 0.7483 0.4927 0.7386 0.5119 0.7587 0.4985 0.7514 0.4992 0.7541 0.5085 0.7485 0.4872 0.7421 0.5136 0.7560 0.4966 0.7374 0.5000 0.7429
max 0.9999 1.0000 0.9998 0.9998 1.0000 0.9994 0.9997 0.9999 1.0000 0.9997
forward stepwise knot placement : #indbsfns #efprms basfn(s) gcv
0 47.01 1 13.45 2 4.642 3 2.637 4 1.299
6 5 0.9870 8 7 0.9865
10 9 0.9859 12 11 0.9856 14 L3 0.9858
15 0.9859
0. ,0 1, ,0 1. ,0 5. ,0 2. ,0 9. ,0 3, ,0 13. .0 4, .0 17, .0 6. .0 22, .0 8. .0 27. .0
10, .0 32 .0 12, .0 37 .0 14 .0 42 .0 15 .0 46 .0
variable knot p are! 3. 0.4880E03 0 4. 0.2980E03 0 5. 0.4205E04 0 2. 0.7080E03 0 1. 0.5134 0 5. 0.2766 5 8. 0.1590 8 4. 0.6598E01 8 6. 0.9916 5 2. 0.7080E03 8
final model after backward stepwise elimination:
bsfn: 0 1 2 3 4 5 coef : 8.987 20.00 IC 1.10 5. ,061 3.979 1.544
bsfn: 6 7 8 9 10 11 coef: 2.139 0.000 0. 000 0 .000 89.14 0.000
bsfn: 12 13 14 15 coef: 401.8 915.6 0. .000 4 .842
(piecewise 1 inear) gcv s 0.9813 #efprms 31.0
anova decompôs lition on 10 basis functions : fun. std. dev gcv #bsfns #efprms variable(s) 1 5.756 34.40 1 3. ,0 3 2 2.930 9.571 1 3. ,0 4 3 1.474 2.878 1 3. ,0 5 4 1.146 2.262 1 3. .0 2 5 0.5401 1.247 2 6, .0 1 6 0.4166E 01 0.9818 1 3. ,0 1 6 7 0.5499E 01 0.9828 1 3, .0 1 5 8 8 0.4415E 01 0.9820 1 3. .0 1 4 5 9 0.4471E 01 0.9815 1 3 .0 1 2 5
piecewise cubic fit on 10 basis functions, gcv = 0.9855 gcv removing each variable :
1 1.297
7 0.9813
2 2.286
8 0.9828
3 34.40
9 0.9813
4 9.608
10 0.9813
5 3.095
6 0.9818
83

relative variable importance: 1 2 3 4 5 6
9 .716 1 9 . 7 6 1 0 0 . 0 5 0 . 8 1 2 5 . 1 5 0 .4079
7 8 9 10 0.000 0.6763 0.000 0.000
Test Set Evaluation : MSE = 0.983829 MAD = 0.795482
84

Referências
[Belsley, Kuh & Welsch, 80] D.A. Belsley, E. Kuh and R. E. Welsch, 1980. Regression
Diagnostics. New York: Wiley.
[Breiman & al., 84] Leo Breiman,Jerome H. Friedman, Richard A. Oslhen & Charles J. Stone,
1984. Classification and Regression Trees. Belmont, Wadsworth.
[Breiman, 94] Leo Breiman, 1994. Heuristics of Instability and Stabilization in Model Selec
tion. Tech. rep. 416, Department of Statistics, University of California, Berkeley, CA.
[Breiman, 96] Leo Breiman, 1996. Bagging Predictors. Machine Learning, 24(2), 123-140.
[Craven k Wahba, 79] P. Craven and G. Wahba, 1979. Smoothing and Noisy Data with
Spline Functions. Estimating the Correct Degree of Smoothing by the Method of Generalized
Cross-Validation. Numer. Math., 31: 317-403.
[de Boor, 78] C.de Boor, 1978. A Practical Guide to Splines. Springer, New York.
[Dietterich, 97] Thomas G. Dietterich, 1997. Approximate Statistical Tests for Comparing
Supervised Classification Learning Algorithms. Département of Computer Science, Oregon State
University, Corvallis, OR 97331.
[Efron & Tibshirani, 93] B. Efron and R. J. Tibshirani, 1993. An Introduction to the Boot
strap. Chapman and Hall, New York, NY.
[Fielding, 77] A. Fielding, 1977. Binary Segmentation: the Automatic Interaction Detector
and Related Techniques for Exploring Data Structure. In the Analysis of Survey Data, vol I,
ed. C. A. O'Muircheartaigh and C. Payne. Chichester: Wiley.
[Fisher, 58] W. D. Fisher, 1958. On Grouping for Maximum Homogeneity. J. Amer. Statist.
Assoc, 53: 789-798.
[Friedman, 88] Jerome H. Friedman, 1988. Fitting Functions to Noisy Data in High Dimen
sions. In Computing Science and Statistics: Proc. Twentieth Symp. on the Interface (E. J.
Wegman, D. T. Gantz and J. J. Miller, eds.) 13-43. Amer. Statist. Asso., Alexandria, Va.
[Friedman, 91] Jerome H. Friedman, 1991. Multivariate Adaptive Regression Splines (with
85

discussion). The Annals of Statistics 1991, vol. 19: 1-141.
[Friedman k Silverman, 89] Jerome H. Friedman and B. W. Silverman, 1989. Flexible Par
simonious Smoothing and Additive Modeling. Technometrics, 31: 3-39.
[Harrison k Rubinfeld, 78] D.Harrison and D. L.Rubinfeld, 1978. Hedonic prices and the
demand for clean air. J. Environ. Economics and Management, vol. 5: 81-102.
[Hinton k al, 95] G. E.Hinton, R. M. Neal, R Tibshirani and DELVE team members, 1995.
Assessing Learning Procedures Using DELVE. Tech. rep., University of Toronto, Département
of Computer Science.
[Hunt & Stone, 66] E. B. Hunt, J. Marin and P. J. Stone, 1966. Experiments in Induction.
NeW York: Academic Press.
[Kohavi, 95] R. Kohavi, 1995.Wrappers for Performance Enhancement and Decision Graphs.
Ph.D. tesis, Stanford University.
[Messenger k Mandell, 72] R. C.Messenger and M. L. Mandell, 1972. A model Search Tech
nique for Predictive Nominal Scale Multivariate Analysis. J. Amer. Statist. Assoc, 67: 768-772.
[Morgan k Messenger, 73] J. N. Morgan and R. C.Messenger, 1973. THAID: a Sequential
Search Program for the Analysis of Nominal Scale Dependent Variables. Ann Arbor: Institute
for Social Rechearch, University of Michigan.
[Morgan k Sonquist, 63] J.N. Morgan and J. A.Sonquist, 1963. Problems in the Analysis of
Survey Data and a Proposal. J. Amer. Statist. Assoc, 58: 415-434.
[Quinlan, 86] J. R Quinlan, 1986. Induction of Decision Trees. Machine Learning, 81-106.
[Rasmussen, 96] C. E. Rasmussen, 1996. Evaluation of Gaussian Processes and other Methods
for Non-Linear Regression. Ph.D. thesis, University of Toronto, Département of Computer
Science, Toronto, Canada.
[Snedecor k Cochran, 89] G. W. Snedecor and W. G. Cochran, 1989. Statistical Methods.
Iowa State University Press, Ames, IA. Eighth Edition.
[Sonquist, 70] J. A.Sonquist,1970. Multivariate Model Building: the Validation of a Search
Strategy. Ann Arbor: Institute for Social Research, University of Michigan.
[Sonquist k Morgan, 64] J. A.Sonquist and J.N. Morgan, 1964. The Detection of Interaction
86

Effects. Ann. Arbor: Institute for Social Research, University of Michigan.
[Sonquist, Baker & Morgan, 73] J. A.Sonquist, E. L. Baker and J.N. Morgan, 1973. Searching
for Structure. Rev. ed. Ann Arbor: Institute for Social Research, University of Michigan.
[Stone & Koo, 85] Charles J. Stone and C. Y. Koo, 1985. Additive Splines in Statistics. Proc.
Ann. Meeting Amer. Statist. Assoc. Statist. Comp. Section, 45-48.
[Van Eck, 80] A. N. Van Eck, 1980. Statistical Analysis and Data Management Highlights of
OSIRIS IV Amer. Statist., 34: 119-121.
[Warwick Nash & al., 94] Warwick Nash,TracySellers,Simon Talbot, Andrew Cawthorn k
Wes Ford, 1994. The Population Biology of Abalone (Haliotis Species) in Tasmania. I. Blacklip
Abalone (H. Rubra) from the North Coast and Islands of Bass Strait.Fisheries Division, technical
Report no 48 (ISSN 1034-3288).
87





























