Embed Size (px)
Citation preview

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
1
Aula 13 TFD: Transformada de Fourier Discreta Bibliografia
� OPPENHEIM, A. V.; SCHAFER, R W.; BUCK, J. R. Discrete-time signal processing, 3rd ed., Prentice-Hall,
2010. ISBN 9780131988422. Páginas 642-646.
� CARLSON, G. E. Signal and linear system analysis, 2nd ed., John Wiley, 1998, ISBN 0471124656. Páginas
644-661.
4.2. TFD: Transformada de Fourier Discreta
� A esta altura, você já conhece as seguintes representações de Fourier para sinais:
Figura 1 – Sinais e Transformadas de Fourier (HAYKIN; VAN VEEN, 2001).

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
2
� Repare que quando temos um sinal de tempo discreto não periódico, a represen-
tação de Fourier é de tempo contínuo a (TFTD) o que dificulta sua representa-
ção computacional.
� Por isso, define-se a TFD que é muito mais fácil de implementar computacio-
nalmente.
4.2.1. Definição
� Dada uma sequência aperiódica [ ]nx , 10 −≤≤ Nn , define-se a TFD como o par:
[ ] [ ]kXnx ↔ , formado da seguinte maneira:
I. Define-se uma sequência periódica construída a partir da sequência [ ]nx dada
com período N :
[ ] [ ] [ ] [ ][ ]Nr
nxNnxrNnxnx =≡+= ∑∞
−∞=
módulo ~
II. Para [ ]nx~ periódico, já definimos a SFD como:
[ ] [ ] ( )∞∞−∈=∑−
=
−,,~~ 1
0
2
kenxkXN
n
nkN
jπ
e sua inversa
[ ] [ ] ( )∞∞−∈= ∑−
=
,,~1~
1
0
2
nekXN
nxN
k
knN
jπ
III. Define-se a TFD [ ]{ }nx como:
[ ] [ ] [ ]kRkXkX N
~= , [ ] [ ] [ ]nRnxnx N~=

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
3
em que:
[ ] −≤≤
=contrário caso ,0
10 ,1 NkkRN (janela retangular),
ou seja, define-se o par TFD como:
[ ] [ ]
−≤≤
= ∑−
=
−
contrário caso ,0
10 ,1
0
2
NkenxkX
N
n
nkN
jπ
[ ] [ ]
−≤≤
= ∑−
=
contrário caso ,0
10 ,1 1
0
2
NnekXNnx
N
k
knN
jπ
Exercícios
1. Calcule a TFD da sequência impulso unitário para 10=N .
2. Dada a sequência retângulo
[ ] −≤≤
=contrário caso 0
10 para ,1 LnnrectL
Calcule a TFD de [ ] [ ]nrectnx 5= para 10=N .
3. (OPPENHEIM et al., 1999, p. 601) Calcule a TFD de comprimento N ( N
par) para:
(a) [ ] [ ]nnx δ=

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
4
(b) [ ] [ ]0nnnx −= δ , 10 0 −≤≤ Nn
(c) [ ]
−≤≤−≤≤
=10 ímpar, ,0
10 par, ,1
Nnn
Nnnnx
(d) [ ] −≤≤
=contrário caso ,0
10 , Nnanx
n
L6 – Processamento digital de áudio e voz
L.6.1 Exemplo simples de processamento digital de áudio
Atividades
1. Um filtro que programa um eco acústico é dado por:
[ ] [ ] [ ] [ ]25,017,0 −+−+= nxnxnxny .
(a) Desenhe um diagrama de blocos que represente este sistema.
(b) Determine sua resposta impulsiva (resposta quando [ ] [ ]nnx δ= ).
Resolução:
2. Um filtro FIR pode ser utilizado para obtermos um efeito de eco acústico. Se o sinal é amos-
trado a 8kHz, por exemplo, o seguinte filtro gera um eco de 0,5s.
[ ] [ ] [ ]40007,0 −+= nxnxny .
Este filtro pode ser utilizando o comando filter. Obtenha e ouça o resultado da aplicação
deste filtro ao sinal teste.wav . Para lê-lo no Matlab, use o comando:
>> [x, fs] = wavread(‘teste.wav’);

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
5
L.6.2 Fundamentos de sinais de voz
Fisicamente, a voz é produzida quando o ar dos pulmões excita o sistema de trato vocal mos-
trado na Figura 1.
O trato vocal se comporta como uma cavidade ressonante de forma que o sinal que emana
pela boca é uma soma ponderada de versões atrasadas do sinal vocal original mais as excita-
ções. O modelo em tubos do trato vocal é mostrado nas Figuras 2 e 3.
Os diferentes tipos de sons da voz podem ser divididos de forma simplificada em dois grupos:
os sons vocálicos e os sons fricativos ou não vocálicos.
Sons vocálicos: são produzidos usando uma sequência de impulsos como entrada; o período
fundamental desta sequência determina a tonalidade (“pitch”). Por exemplo, vogais são sons
vocálicos; quando se diz “a”, pode-se sentir a vibração das cordas vocais.
Figura 1 – Detalhes do trato vocal. (SENDA, 2005).
Sons não vocálicos: são produzidos usando ruído branco como entrada. Estes sons geralmente
são gerados por um fluxo turbulento de ar pela boca, por exemplo, quando se pronuncia “sh”.
Assim, o modelo em tempo discreto da produção de voz é mostrado na Figura 4.
L.6.3 Modelagem de voz em tempo discreto

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
6
Um modelo em equações de diferenças para o trato vocal pode ser desenvolvido como se
segue.
Como cada amostra de sinal de voz é muito relacionada com as anteriores, o valor da amostra
atual de voz pode ser estimado como uma combinação linear das anteriores.
Figura 2 – Modelo do trato vocal. (SENDA, 2005).

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
7
Figura 3 – Modelo em tubos do trato vocal. (McLELLAN et al., 1997).
Figura 4 – Modelo em diagrama de blocos da geração da fala humana (McLELLAN et al., 1997).
[ ] [ ]∑=
−=p
ii insns
1
ˆ α (1)
O sinal [ ]ns é a estimação do sinal de voz [ ]ns para a n -ésima amostra. O erro entre o sinal
original e o estimado é:
[ ] [ ] [ ]nsnsne ˆ−= (2)

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
8
L.6.4 Modelo de predição
A combinação das duas equações acima leva a um modelo por equações de diferenças da
predição do processo de fala:
[ ] [ ] [ ]∑=
=−−p
ii neinsns
1
α (3)
Este modelo de predição é usado em telecomunicações para aumentar o número de sinais de
voz que podem ser transmitidos por um canal.
Se os coeficientes iα são conhecidos pelo transmissor e pelo receptor, então apenas o erro
precisa ser transmitido e o sinal de voz pode ser reconstruído no receptor utilizando a equa-
ção de diferenças acima.
No transmissor [ ]ns é a entrada do filtro de predição e [ ]ne é a saída. No receptor a situação é
a inversa.
A transmissão do sinal de erro resulta em economia substancial da banda de transmissão.
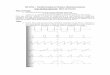
A Figura 5 mostra um exemplo de sinal predito, o erro e a reconstrução para um sinal de voz
[ ]ns .

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
9
0 1 2 3 4 5 6 7 8
x 104
-1
0
1or
igin
al
0 1 2 3 4 5 6 7 8
x 104
-1
0
1
Pre
dica
o
0 1 2 3 4 5 6 7 8
x 104
-1
0
1
Err
o de
pre
dica
o
0 1 2 3 4 5 6 7 8
x 104
-1
0
1
Rec
onst
ruid
o
Figura 5 – Exemplo de predição e reconstrução de um sinal de voz.
L.6.5 Modelo de síntese
Pode-se modificar o mesmo modelo básico de predição de voz para usar em síntese de voz.
Se o objetivo for criar um sinal [ ]ns~ que imita o sinal de voz original, podemos substituir o
erro [ ]ne por um sinal de entrada [ ]nx multiplicado por um ganho G .
Usando a mesma forma da equação de diferenças do modelo de predição, Eq. (3), resulta o
seguinte modelo de síntese:
[ ] [ ] [ ]∑=
=−−p
ii nGxinsns
1
~~ α. (4)
Tipicamente, os coeficientes iα mudam a cada 10-20ms conforme o trato vocal muda para
produzir sons diferentes. Veja a Figura 6.

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
10
Figura 6 – Segmentação do sinal de voz (STONICK; BRADLEY, 1996).
Na síntese aplica-se uma sequência de excitação conveniente para que naquele intervalo de
tempo seja gerada uma sequência de sons adequada.
L6.6 Transmissão de voz
Uma linha telefônica normal opera simplesmente amostrando a voz de uma pessoa, digitali-
zando as amostras com 8 bits e transmitindo estes bits para o receptor, onde novamente é
convertido em voz.
Um método alternativo é realizar a análise e predição como resumido anteriormente, digitali-
zar o sinal de erro e transmitir o sinal de erro digital resultante e coeficientes da predição line-
ar.
Por que fazer isso?
Voz normal necessita de 8 bits x 8 kHz = 64000 bits por segundo para ser transmitido.
Suponha que o sinal de erro possa ser quantizado com 4 bits ao invés de 8 e que cada coefici-
ente seja representado com 16 bits.
Então, para transmitir a mesma quantidade de informação é necessário 4bits x 8kHz + 16 x 10
coeficientes x 100 blocos de dez milissegundos por segundo = 48000 bits por segundo – 75%
da taxa anterior.
Se for utilizado apenas 1 bit de quantização para o sinal de erro, 24000 bits por segundo são
necessários – 37,5% da taxa anterior.

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
11
L.6.7 Atividades
1. Assuma que você tem um sinal de voz digitalizado com uma amostragem de 8kHz. Se este
sinal for quebrado em segmentos de 20ms, quantas amostras NS existem por bloco?
2. Se 1 segundo deste sinal estiver num vetor Matlab, quantos blocos de 20ms NBLKS podem
ser obtidos?
3. Suponha que se deseje usar como entrada para seu modelo de voz sintética um trem de impul-
sos unitários igualmente espaçados e que gostaríamos que o pitch fosse 200Hz. Se a voz foi
amostrada a 8kHz, quantas amostras devem ser colocadas por período, ou seja, quanto vale
N em:
[ ] [ ]∑∞
=
−=0i
iNnnx δ , NSn <≤0 .
4. Como devem ser definidos os vetores a e b usados como entrada do filter em termos de
iα e G para criar equações de diferenças que realizem as seguintes operações:
(a) fornecer [ ]ns como saída quando [ ]ns é a entrada. (predição)
(b) fornecer [ ]ne como saída quando [ ]ns é a entrada. (erro de predição)
(c) fornecer [ ]ns~ como saída quando [ ]ne é a entrada. (síntese)

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
12
5. A função sintetizavoz2 gera uma voz sintética a partir dos coeficientes iα e um trem
de impulsos com frequência fundamental dada por pitch ou um ruído branco gaussiano.
Seu formato é:
%[SYNTHimp, SYNTHnoise] = sintetizavoz2(nomarq,NS, pitch, NP);
% Sintetiza voz com sequencia de impulsos e ruído g aussiano
% nomarq - nome do arquivo .wav (entre aspas simple s)
% NS - numero de amostras por bloco
% pitch - frequência fundamental da sequencia de im pulsos
% NP - numero de coeficientes utilizados na prediçã o
% SYNTHimp - voz sintetizada com impulsos
% SYNTHnoise - voz sintetizada com ruído
Teste este programa utilizando o arquivo aula5.wav . Utilize NS=160, NP = 10 e um pitch
de 50Hz. Verifique o que ocorre ao se mudar estes parâmetros.
Em seguida, repita para o arquivo teste.wav . Tente encontrar um valor de pitch mais adequa-
do para este sinal. Repita para os arquivos show.wav e chinelo.wav que possuem muitos
fricativos.
Grave um sinal de voz e tente gerar uma voz sintética com o pitch mais adequando para a sua
voz.
6. O programa predivozquant simula a quantização do sinal de erro que é enviado ao recep-
tor.
% [RECON] = predivozquant(nomarq,NS,NP, Nbits);
% nomarq - nome do arquivo .wav (entre aspas simple s)
% NS - numero de amostras por bloco
% NP - numero de coeficientes utilizados na prediçã o
% Nbits - numero de bits utilizados na quantização do erro
% RECON - Sinal reconstruído no receptor

Processamento Digital de Sinais – Aula 13 – Professor Marcio Eisencraft – março 2012
13
Utilizando novamente o arquivo aula5.wav e as mesmas configurações da Atividade 5, verifi-
que qual a menor quantidade de bits que devem ser utilizados na quantização do erro de predição
de forma que o sinal possa ser recuperado de forma integral no receptor. Calcule, neste caso, a
taxa necessária de transmissão.
7. Deseja-se adicionar um efeito de eco a uma música gravada a uma taxa de 44,1kHz (qualida-
de de CD). Deseja-se que o eco esteja atrasado de 1 segundo e atenuado de 0,5 em relação ao
som principal.
(a) Escreva uma equação de diferenças que represente um filtro que implemente este efeito;
(b) Supondo que as amostras do sinal musical tenham sido lidas e guardadas no vetor x , escreva
comandos que permitam implementar o efeito de eco descrito e tocar o som resultante nos alto-
falantes do PC.

![ApresentaINPE [Modo de Compatibilidade]professor.ufabc.edu.br/marcio.eisencraft/Artigos/ApresentaINPE2009.pdf• Diagrama em blocos de um sistema SS básico 5.1 Princípios Básicos](https://img.document.onl/doc/110x75/6031d8b94979bf50cb343942/apresentainpe-modo-de-compatibilidade-a-diagrama-em-blocos-de-um-sistema-ss.jpg)



















![n [n] = H - professor.ufabc.edu.brprofessor.ufabc.edu.br/marcio.eisencraft/pds/EN2610-Aula19.pdf · Fatorando, obtemos: ( ) ( ) ∏( )](https://img.document.onl/doc/110x75/5c608c1509d3f22a6a8ba408/n-n-h-fatorando-obtemos-.jpg)