Embed Size (px)
Citation preview

Capítulo 12
EVEREVIS: Sistema de Navegação em Vídeos
Bruno do Nascimento Teixeira∗, Júlia Epischina Engrácia de Oliveira,Tiago de Oliveira Cunha, Fillipe Dias Moreira de Souza, Lucas Gonçalves,
Christiane Okamoto Mendoça, Vinícius de Oliveira Silva,Arnaldo de Albuquerque Araújo
Resumo: Este capıtulo relata um sistema desenvolvido para a na-vegacao de vıdeo baseado na analise multimodal. A abordagemmultimodal proposta realiza a transcricao de audio para categori-zacao de cenas (esportes, clima, polıtica e economia) combinandoinformacoes de audio e de vıdeo. Suas principais caracterısticas in-cluem resumos estaticos e dinamicos, segmentacao usando deteccaode face, classificacao em cenas internas e externas e transcricao deaudio para a busca de palavras-chave do tema. Palavras-chave saoselecionadas para representar os vıdeos. Uma serie de experimentosforam conduzidos para avaliar a eficacia da categorizacao usando asinformacoes de transcricao de audio.
Palavras-chave: Processamento de imagens, Analise multimodal,Classificacao e Sumarizacao.
Abstract: This chapter reports a system developed for video brow-sing based on multimodal analysis. The proposed multimodal ap-proach performs audio transcription for shot categorization (sports,weather, politics and economy) combining audio and visual infor-mation for theme categorization. Its main features include staticand dynamic summaries, segmentation using face detection, clas-sification into indoor and outdoor scenes based on Support VectorMachine (SVM) and audio transcription for theme keyword search.Keywords are selected to represent the subjects, followed by a simpletext search. A set of experiments was conducted for evaluating theeffectiveness of the shot subject categorization using audio trans-cription information.
Keywords: Image processing, Multimodal analysis, Classificationand summarization.
∗Autor para contato: [email protected]
Neves et al. (Eds.), Avanços em Visão Computacional (2012) DOI: 10.7436/2012.avc.12 ISBN 978-85-64619-09-8

220 Teixeira et al.
1. Introdução
O crescimento da demanda por informacoes visuais de vıdeos leva a necessi-dade de se criar formas adequadas de representacao, modelagem, indexacaoe recuperacao de dados multimıdias. A localizacao de um segmento de in-teresse em uma grande colecao de arquivos de vıdeo e ineficiente quantoao consumo de tempo, uma vez que e necessario assistir cada segmento devıdeo a partir do inıcio e usar os recursos de avanco e recuo para selecionaro segmento desejado. A segmentacao automatica de vıdeo oferece uma so-lucao eficiente e e o primeiro passo crucial em direcao a uma representacaoconcisa e abrangente do vıdeo baseada em conteudo.
No que diz respeito a visualizacao dos resultados do processamentode vıdeo, um desafio e fornecer uma ferramenta efetiva e eficiente para otratamento e exibicao dos dados gerados pelos algoritmos disponıveis, poisesta ferramenta deve oferecer um alto grau de interatividade, permitindoque os usuario limitem-se aos seus interesses e descartem o que nao forrelevante.
Este trabalho apresenta um sistema interativo de analise de vıdeo ba-seado no conteudo e que contem algoritmos especıficos capazes de facilitara navegacao no vıdeo de notıcias. Especificamente, estes algoritmos deprocessamento de vıdeo visam auxiliar a navegacao entre cenas internas eexternas no vıdeo, fornecer uma sumarizacao estatica e dinamica do vıdeo,navegar no vıdeo atraves da deteccao de faces, e reconhecer eventos espe-cıficos nos vıdeos. Alem disto, esta plataforma executa uma abordagemmultimodal, atraves do fornecimento da transcricao do audio para a cate-gorizacao de tomadas (esportes, tempo, polıtica e economia), combinandoinformacoes visuais e auditivas para esta categorizacao.
Alguns trabalhos lidam com o problema de tornar mais facil a interacaoentre os usuarios e o acesso ao conteudo de um vıdeo. Por exemplo, Forlines(2008) descreve um prototipo de sistema para exibicao de vıdeo que levaem conta o conteudo do vıdeo. O prototipo proposto renderiza os quadrosde um vıdeo em varias regioes da tela, de acordo com a estrutura de seusconteudos. Esta abordagem permite manter a continuidade da estoria, aopasso que melhora o processo de visualizacao do vıdeo.
Com respeito a busca de vıdeos, Su et al. (2010) apresentam um me-todo para busca de vıdeos por conteudo que utiliza indexacao baseada empadroes e tecnicas de combinacao. O problema da alta dimensionalidadedos vetores de caracterısticas e resolvido com a indexacao baseada em pa-droes, que tambem se mostra um metodo eficiente para encontrar os vıdeosdesejados entre uma quantidade grande de dados variados.
O problema de indexacao e recuperacao eficientes em base de dadosde vıdeos e abordado por Morand et al. (2010). Em seu trabalho, ummetodo para recuperacao de objetos escalaveis em vıdeos de alta resolucao

EVEREVIS: sistema de navegação em vídeos 221
e proposto, com a utilizacao de descritores do vıdeo obtidos atraves dedistribuicoes estatısticas de coeficientes da transformada wavelet.
Motivado pela funcao de uma tabela de conteudo em livro, Rui et al.(1998) propos uma tecnica de construcao da tabela de conteudo em vıdeosbaseada em clusterizacao nao supervisionada, facilitando o acesso ao vıdeo.O metodo proposto e dividido em quatro modulos: deteccao de cortese quadros chaves, extracao de caracterısticas, agrupamento adaptativo econstrucao da estrutura de cenas. Diferente da TV convencional, a TVinterativa permite ao usuario navegar para frente ou para tras no tempo.
Em Kim et al. (2006) sao propostas formas de navegacao baseadas naindexacao de episodios (EIT - Episodic Indexing Theory). Para validacaodos metodos e teste de sua eficiencia na navegacao temporal, foi usadosimulador de TV interativa. Na indexacao de cenas, pode-se usar faces,sons, cores e movimentos, como na interface web de busca de vıdeos doprojeto Open Video Project (Geisler et al., 2002), facilitando o acesso atrechos do vıdeo.
Mais recentemente, Bouaziz et al. (2010) investigam a localizacao detexto nos vıdeos para contribuir nesta area de indexacao dos conteudos dosvıdeos. E mudando um pouco o contexto em que os sistemas de recuperacaode vıdeos vem sendo desenvolvidos, Kim et al. (2011) propoem um sistemade navegacao em vıdeos musicais, de forma que os usuarios busquem vıdeosatraves de temas ou emocoes, como por exemplo, a busca por um vıdeomusical calmo de natureza.
As proximas secoes apresentam, respectivamente, a metodologia utili-zada para o desenvolvimento dos algoritmos integrados ao sistema intera-tivo de analise do vıdeo baseado em conteudo, o resultado do sistema econsideracoes finais.
2. Sumarização de Vídeos
Um resumo de vıdeo compreende a sıntese do conteudo do vıdeo, pre-servando suas sequencias mais importantes ou mais representativas, for-necendo uma versao concisa da mensagem do vıdeo original. Resumos devıdeo podem ser classificados em duas categorias: estaticos (uma sequenciade quadros-chave) ou dinamicos (uma sequencia de segmentos de vıdeo).Em geral, este ultimo e considerado mais atrativo por incorporar elemen-tos de movimentacao e audio. Com um resumo em maos, o usuario podetomar decisoes sobre a relevancia do vıdeo para tarefa desejada sem terque ve-lo inteiramente, economizando tempo e esforco.
Neste trabalho, para a sumarizacao estatica do vıdeo foi utilizado o me-todo proposto em de Avila et al. (2008). Este metodo foi concebido paraser simples e eficiente. Histogramas de cor e perfis de linha sao utilizadospara representar as imagens do vıdeo. Apos a extracao das caracterıs-ticas visuais, as imagens sao agrupadas pelo algoritmo k-means. Entao,

222 Teixeira et al.
um quadro-chave de cada grupo e identificado, e por fim as imagens saodispostas em ordem cronologica, produzindo o resumo estatico do vıdeo.
2.1 Sumarização dinâmicaUm metodo que tem como objetivo de tirar proveito de caracterısticas debaixo nıvel e de alto nıvel foi desenvolvido para a sumarizacao dinamica, oqual e baseado em caracterısticas espaciais e espaco-temporais representa-das por uma abordagem de histogramas de palavras visuais (Bags of VisualFeatures) (BoVF). BoVF e um tipo de representacao inspirada no saco daspalavras, uma abordagem comumente usada na recuperacao de informacaopara representar colecoes de texto (de Campos et al., 2011). No entanto,em vez de palavras, BoVF usa caracterısticas visuais, onde cada caracte-rıstica visual e representa por uma regiao de interesse na imagem, gerada apartir de descritores extraıdos dos segmentos. BoVF tenta reduzir a dife-renca semantica entre caracterısticas de baixo nıvel e o conteudo visual dovıdeo, e tem sido utilizado na literatura em varios cenarios de deteccao depadroes e classificacao, alcancando bons resultados devido a sua robustez auma serie de transformacoes na imagem e oclusao. No entanto, de acordocom a literatura pesquisada, esta tecnica nao foi empregada na area desumarizacao automatica de vıdeo.
Alem de representar os segmentos utilizando caracterıstica de alto nıvelgeradas a partir de caracterısticas de baixo nıvel, o metodo proposto tam-bem emprega uma estrategia inspirada em aprendizado multivisao (multi-view learning). O aprendizado multivisao utiliza diferentes representacoes(chamadas de visoes) extraıdas de um mesmo objeto (segmento) e aprendea partir deles independentemente (Muslea et al., 2002). Neste trabalho,sao utilizadas tres visoes, representadas pelos descritores SIFT, Hue-SIFTe STIP. Cada descritor e utilizado para gerar um BoVF e o processo deaprendizado corresponde a encontrar os segmentos mais similares (repre-sentados por BoVFs gerados a partir dos descritores) utilizando um algo-ritmo de agrupamento para cada visao separadamente.
Apos agrupar os segmentos, o mais representativo de cada grupo eextraıdo, e o resumo e gerado modelando a tarefa de sumarizacao com umproblema de otimizacao. Isto e feito com o objetivo de que os resumostenham uma duracao maxima pre-definida. No entanto, esta restricao detempo tem que ser obedecida enquanto preservam-se os segmentos de vıdeomais importantes. A importancia de um segmento e medida de acordo comas suposicoes que dizem que quanto maior o movimento no segmento, maiore a informacao contida (Pan et al., 2007; Laganiere et al., 2008). Assim, ageracao do resumo final e modelada como o problema da mochila, com aduracao do resumo sendo equivalente ao peso da mochila e a quantidadede movimento ao benefıcio de um item. Finalmente, depois dos resumosde cada visao (descritor) terem sido criados, eles sao unidos para formarum sumario unico e final, usando a mesma abordagem descrita acima. A
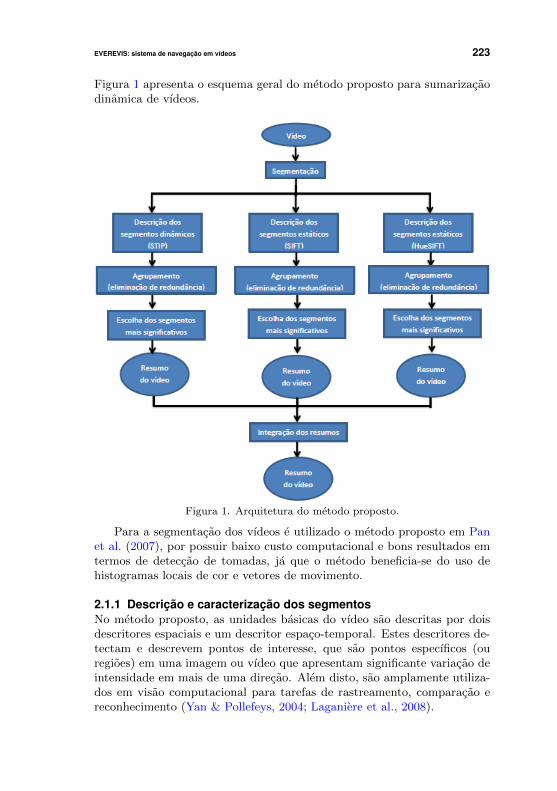
EVEREVIS: sistema de navegação em vídeos 223
Figura 1 apresenta o esquema geral do metodo proposto para sumarizacaodinamica de vıdeos.
Figura 1. Arquitetura do metodo proposto.
Para a segmentacao dos vıdeos e utilizado o metodo proposto em Panet al. (2007), por possuir baixo custo computacional e bons resultados emtermos de deteccao de tomadas, ja que o metodo beneficia-se do uso dehistogramas locais de cor e vetores de movimento.
2.1.1 Descrição e caracterização dos segmentosNo metodo proposto, as unidades basicas do vıdeo sao descritas por doisdescritores espaciais e um descritor espaco-temporal. Estes descritores de-tectam e descrevem pontos de interesse, que sao pontos especıficos (ouregioes) em uma imagem ou vıdeo que apresentam significante variacao deintensidade em mais de uma direcao. Alem disto, sao amplamente utiliza-dos em visao computacional para tarefas de rastreamento, comparacao ereconhecimento (Yan & Pollefeys, 2004; Laganiere et al., 2008).

224 Teixeira et al.
Para representar os segmentos previamente definidos, foi utilizada aabordagem de BoVF. BoVF (Csurka et al., 2004) e uma representacao ro-busta para imagens, onde cada imagem e vista como um conjunto de regioesou pontos e apenas as informacoes visuais sao levadas em consideracao semser necessaria a informacao sobre a localizacao do ponto na imagem. Estespontos sao chamados de palavras visuais.
O metodo BoVF e executado em algumas etapas. Primeiro, um metodopara detectar e descrever os pontos da imagem e aplicado. Os descritoresextraıdos da imagem precisam ser invariantes a mudancas que sao irrelevan-tes para a tarefa de categorizacao (transformacoes de imagem, variacoes deiluminacao e oclusoes), mas ricos o suficiente para discriminar categorias.Os segmentos de vıdeo sao descritos usando os descritores STIP (Laptev,2005), SIFT (Lowe, 2004) e Hue-SIFT (van de Sande et al., 2010a), quetem as caracterısticas mencionadas anteriormente.
Em uma segunda etapa, um vocabulario e definido. Esta definicaoe baseada na escolha de um conjunto de pontos interessantes (palavrasvisuais), que e feita aleatoriamente a partir de todos os pontos disponıveis.
O terceiro passo e associar cada descritor para um visual da palavrano vocabulario. Esta associacao e feita atraves do calculo da distanciaEuclidiana entre os pontos da imagem e do vocabulario. O mais proximovisual da palavra no vocabulario a um ponto de imagem e armazenado deforma a gerar um histograma de ocorrencia de palavras visual.
BoVF fornece uma representacao mais informativa em termos de carac-terısticas de baixo nıvel, e e esperado que as caracterısticas que compoem oshistogramas sejam realmente padroes representativos capazes de descrevero conteudo da imagem.
2.2 Eliminação de redundânciaPara a remocao de redundancia entre os segmentos do vıdeo e aplicado umalgoritmo de agrupamento. A ideia e que apos o processo de agrupamento,os histogramas de palavras visuais que representam segmentos semelhantesfacam parte dos mesmos grupos, e que de cada grupo seja escolhido somenteum unico segmento como representante.
Para a escolha do segmento mais representativo por grupo, e calculadaa proximidade dos histogramas pertencentes a um grupo em relacao ao seucentroide, e como resultado o histograma de maior proximidade e escolhidocomo o representante do grupo. Para o calculo da proximidade foi utilizadaa distancia Euclidiana. Na Figura 2 e visto o processo de agrupamento eescolha do segmento mais representativo por grupo.
3. Seleção dos Segmentos mais Informativos
De maneira a gerar o sumario dinamico, e necessario fazer uma selecaodos segmentos mais significativos. Parte-se da suposicao de que quanto

EVEREVIS: sistema de navegação em vídeos 225
Figura 2. Processo de agrupamento.
maior o nıvel de atividade no segmento, maior e a quantidade de infor-macao fornecida. Neste trabalho, assim como nos trabalhos de Pan et al.(2007), Laganiere et al. (2008) e Putpuek et al. (2008), utiliza-se medidasde movimentacao para o calculo do nıvel de atividade, em que a media dasmagnitudes dos vetores de movimentacao entre os quadros de um segmentoe utilizada como medida de informacao.
Para garantir que todos os resumos estejam de acordo com um tama-nho maximo predefinido, o problema foi modelado como o amplamenteconhecido problema da mochila binaria (Cormen et al., 2001). Dados umconjunto de n objetos e uma mochila com:
• cj = benefıcio do objeto j.
• wj = peso do objeto j.
• b = capacidade da mochila.
Deseja-se determinar quais objetos devem ser colocados na mochilapara maximizar o benefıcio total de tal forma que o peso da mochila naoultrapasse sua capacidade. Formalmente, o objetivo e:maximizar z =
∑nj=1 cjsj
Sujeita a∑n
j=1 wjsj ≤ b
sj ∈ {0, 1}
Os resumos serao formados pela uniao dos segmentos que possuem omaior valor de movimentacao de maneira que esta uniao ainda esteja de

226 Teixeira et al.
acordo com o tamanho maximo preestabelecido para o resumo. Assim, foidefinido que o numero de quadros do resumo seria correspondente ao pesoda mochila e o valor de movimentacao correspondente ao benefıcio. Coma resolucao do problema da mochila obtem-se os segmentos que unidosobedecem a um limite de tempo predefinido, ao mesmo tempo em quepossuem o valor maximo de movimentacao. Para a resolucao do problemada mochila foi utilizado o algoritmo baseado em programacao dinamica.
4. Classificação em Cenas Internas e Externas
Uma caracterıstica da aplicacao e o reconhecimento automatico de cenasinteriores e exteriores em vıdeos de notıcias. O objetivo desta tarefa ea de facilitar a busca pelo conteudo de interesse nas bases de dados devıdeo volumosos. Separar cenas internas de cenas de cenas externas podeser visto como uma etapa de pre-processamento de um sistema de buscabaseado em hierarquia. Para ilustrar, podemos assumir que e mais facilencontrar clips de destaques dos jogos da Copa do Mundo de Futebol, seconsiderar apenas a pesquisa no conjunto de cenas externas do que quandoutilizando o conjunto de dados inteiro. Ou seja, basta trabalhar com apenascom um subconjunto dos dados disponıveis.
Como cenas externas sao separadas, um conjunto de imagens estaticasque representam estas cenas do vıdeo de notıcias e exibida em uma guiaindependente do sistema. Este guia se destina a fornecer aos usuariosum meio alternativo para facilmente procurar o conteudo de interesse. Ousuario seria capaz de verificar visualmente se algum tema de interesse estapresente neste vıdeo particular.
4.1 DescritoresCenas internas podem ser definidas como cenas em que o ancora le a no-tıcia dentro do estudio, enquanto as cenas externas sao aqueles onde asentrevistas e as apresentacoes sao realizadas em um ambiente externo. Na-turalmente, a cor parece ser uma caracterıstica bem a divergir interior deambientes externos, embora a descricao forma ainda desempenhe o seu pa-pel. Por esta razao, recomenda-se utilizar uma representacao baseada emcor, forma de caracterizar as cenas de vıdeo. van de Sande et al. (2010b)propuseram descritores baseados em cores, que temum desempenho muitobom para categorizacao de objetos e cenas, sendo um deles o HueSIFT. Hu-eSIFT e uma combinacao do detector de caracterısticas locais SIFT (paraimagens estaticas) com histogramas matiz. Neste caso, a vizinhanca decada caracterıstica local e descrito em termos de matiz (a partir do es-paco de cores HSI) e seu histograma e concatenado com histogramas degradientes orientados (descricao da forma).

EVEREVIS: sistema de navegação em vídeos 227
4.2 Representação bag-of-visual-wordsDado um clip de vıdeo, uma representacao de alto nıvel para o conjunto decaracterısticas locais podem ser fornecidos pela abordagem bag-of-feature.Nesta abordagem, visual codebook e construıdo usando um algoritmo deagrupamento como o k-means (MacQueen, 1967), sobre uma amostra doconjunto de dados de treinamento. Caracterısticas locais de uma imagemsao atribuıdos a palavra mais proxima visual (pode-se usar como metricade distancia funcao de distancia Euclidiana). Como resultado, um his-tograma de palavras visual e construıdo para representar o conjunto decaracterısticas locais descrevendo o conteudo da imagem.
Foi usado aprendizado supervisionado com Support Vector Machines(SVM) Vapnik (1995) para classificar os vıdeos. Uma vez que e um pro-blema binario, e recomendado usar kernels lineares, uma vez que demons-traram bons resultados em problemas envolvendo apenas 2 classes comopor exemplo cenas internas e externas.
Na validacao do metodo de classificacao, pode-se testar o desempenhoatraves de uma abordagem de validacao cruzada. Neste esquema, umaamostra de quadros e extraıda de cada cena do vıdeo de ambos os tipos. Oconjunto e uniformemente dividido em cinco grupos de tal forma que cadagrupo e ponderado em termos da classe considerada. Desta forma, cadaconjunto e testado com a uniao dos grupos restantes, isto e, se fold0 e oconjunto de teste, entao o conjunto de treinamento e a concatenacao defold1, fold2, fold3 e fold4. Todos os quadros sao rotulados e correspondema entrada para treinar os classificadores. Para cada quadro dos conjuntose atribuıdo um rotulo (interna ou externa) e um esquema de votacao pormaioria e aplicado, determinando a classe da cena. A Tabela 1 mostra aavaliacao de desempenho em termos de shots.
Tabela 1. Performance da classificacao. As colunas #inshot e #outshotcorrespondem ao numero de cenas indoor e outdoor, respectivamente. Ascolunas Inclass e outclass correspondem a classificacao dos conjuntos de
shots indoor e outdoor, respectivamente.
fold #inshot #outshot inclass outclass
fold0 46 40 86,96% 92,50%fold1 46 40 97,83% 92,50%fold2 46 40 89,13% 87,50%fold3 46 40 91,30% 90,00%fold4 45 40 73,33% 90,00%
A perfomace geral e mostrada na tabela de matriz de confusao (Tabela2), o que demonstra que o metodo empregado e poderoso para o contextode aplicacao pretendida.

228 Teixeira et al.
Tabela 2. Matriz de confusao.
outdoor indoor
outdoor 90,00% 10,00%indoor 11,11% 88,89%
5. Detecção de Faces
Os algoritmos para a deteccao de faces possuem como tarefa encontrar oslocais e tamanhos de um numero conhecido de rostos quase que frequente-mente na posicao frontal.
O algoritmo deste trabalho utiliza o metodo de Viola & Jones (2001),que e implementado na biblioteca OpenCV (Open Source Computer Vi-sion1) (Bradsky & Kaehler, 2008). Este metodo de deteccao de objetosem imagens e baseado em quatro conceitos: caracterısticas simples e re-tangulares chamadas Haar features, uma imagem integral para rapida de-teccao de caracterısticas, o metodo Adaboost (Freund & Schapire, 1995)de aprendizado de maquina, e um classificador em cascata para combinareficientemente as caracterısticas.
Uma pequena janela e verificada atraves de toda a imagem e um clas-sificador e aplicado a cada janela, retornando ou nao uma face em cadalocalidade, e isto e repetido em multiplas escalas. O metodo Viola-Jonescombina classificadores fracos como se fossem uma cadeia de filtros, o quee especialmente eficiente para a classificacao de regioes em uma imagem.
6. Transcrição de Áudio
Para categorizar as cenas, a transcricao de audio gera uma descricao decada cena segmentada que representa os assuntos apresentados em vıdeo(fala). Em vıdeos de notıcias, e muito comum que informacoes de audiodescreve a informacao visual. Esta observacao sugere para converter au-dio em informacoes de texto usando Julius (Open-Source Large VocabularyCSR Engine Julius) (Kawahara et al., 2000), motor de reconhecimento devoz para transcricao de audio que usa modelos de gramatica e acustico. Umconjunto de cinco palavras-chave e definido para representar quatro temas:esportes, polıtica, economia e tempo. A taxa de segmentos classificadose de aproximadamente 5%. Com um vıdeo com 300 segmentos usandocaracterısticas visuais, apenas 15 serao classificados, e 9 segmentos foramclassificados corretamente. O tempo de processamento e de aproximada-mente 5 horas para todos os algoritmos. A Figura 3 mostra o princıpiode funcionamento do reconhecimento de fala baseado na interface entremodelos acusticos e de linguagem. Modelos ocultos de Markov (Hidden
1 Disponıvel em: http://opencv.org/

EVEREVIS: sistema de navegação em vídeos 229
Markov Model – HMM), base dos modelos acusticos, podem ser usados emaplicacoes de reconhecimento de padroes.
Figura 3. Plataforma LVCSR.
O reconhecimento de fala realiza uma pesquisa de dois passos (parafrente e para tras) usando modelos 2-gram e 3-gram. Modelos n-gramsao modelos probabilısticos para a previsao do proximo termo em umasequencia. Alguns modelos de linguagem construıdo a partir de n-gramssao modelos de Markov de ordem (n−1). Um n-gram e a sequencia contınuade n termos para uma da sequencia de texto ou fala. A primeira passagemgera uma“ındice de palavras”que consiste em um conjunto nos de palavras-finais por quadro, com suas pontuacoes. Ele sera usado eficientementepara procurar palavras candidatas no segundo passo. A segunda passagemrealiza outra pontuacao Viterbi permitindo superar a perda de precisaopor aproximacoes. No segundo passo, modelo de linguagem e dependenciade contexto e aplicado para re-pontuacao. A busca e realizada no sentidoinverso, e precisa ser dependente da sentenca.
Na fala espontanea, como palestras e reunioes, o segmento de entradae incerto e longo. Decodificacoes sucessivas sao realizadas usando pausa decurta-segmentacao, que consiste em automaticamente dividir a entrada eusar o reconhecimento por pequenas pausas. Quando uma pequena pausae detectada, ela finaliza a pesquisa atual neste ponto e, em seguida, reiniciao reconhecimento.

230 Teixeira et al.
7. Interface
A interface do sistema web de vıdeos consiste em tres areas principais:navegacao, exibicao e montagem (Figuras 6, 7 e 8). A area de navegacao eo primeiro ponto focal do usuario e apresenta os resultados dos algoritmos.Cada algoritmo possui uma aba separada e em seu interior, imagens querepresentam seus segmentos. Estas imagens sao clicaveis para exibicao noplayer e arrastaveis ate a area de montagem.
Figura 4. Interface web com as ferramentas para navegacao e visualizacaode vıdeos de noticiarios. A barra de navegacao apresenta os algoritmos
usados na segmentacao e caracterizacao das cenas do vıdeo.
A area de exibicao apresenta um player com comandos simples de repro-ducao e pode ser redimensionado sem alterar a razao de aspecto do vıdeo.Por fim, a area de montagem apresenta uma linha do tempo inicialmentevazia que pode ser preenchida arrastando-se os segmentos disponıveis daarea de navegacao. Atraves do botao de exibicao, os segmentos sao exibi-dos sequencialmente e sem intervalos. Tambem, os segmentos podem serreordenados facilmente na linha temporal, formando uma nova edicao parao vıdeo. A tela home do sistema apresenta o resumo dinamico dos vıdeos,onde o usuario escolhe o vıdeo desejado (Figura 5). Alem destas areas,ha um menu na parte superior da tela no qual o usuario pode se regis-trar, escolher um vıdeo disponıvel para visualizacao ou enviar um vıdeopara o processamento dos algoritmos. A interface e uma camada comple-tamente isolada do modulo de processamento de vıdeos. A comunicacaoentre ambos ocorre somente por meio de um banco de dados.
8. Considerações Finais
Foi apresentada neste capıtulo uma interface visual para melhorar a efe-tividade do acesso a informacao em vıdeos. O sistema de navegacao nainterface e composto por sumarizacao estatica e dinamica, deteccao de fa-

EVEREVIS: sistema de navegação em vídeos 231
Figura 5. Tela home do sistema de navegacao em vıdeos com os vıdeos eos resumos dinamicos.
ces, classificacao em cenas internas e externas, e transcricao de audio paraa classificacao das cenas em temas.
A sumarizacao estatica utilizou um metodo simples que forneceu asimagens mais representativas do vıdeo, ao passo que a sumarizacao dina-mica apresentou um vıdeo curto como resumo. Ambos sumarios forneceramrapidamente a informacao concisa do vıdeo, permitindo ao usuario ter umaideia do conteudo dos vıdeos disponıveis na plataforma sem a necessidadede assisti-los inteiramente. Outra forma disponibilizada para a navegacaonos vıdeos de notıcias foi atraves das faces presentes. A deteccao de facese um dos passos do modelo computacional para o reconhecimento da face,cujo objetivo e identificar ou verificar pessoas no vıdeo e e um dos traba-lhos futuros a ser realizado. A classificacao em cenas internas e externasbaseada em aprendizagem supervisionada com SVM demonstrou ser umaferramenta poderosa para o contexto desta aplicacao, ou seja, vıdeos denotıcias. O algoritmo utilizou HueSIFT como detector das caracterısticaslocais, principalmente devido ao padrao azul observado nas cenas internas.Um trabalho futuro inclui expandir a caracterizacao das cenas atraves deoutros atributos, testando tambem outros kernels do SVM. Finalmente, atranscricao de audio forneceu uma taxa baixa de classificacao devido aouso de poucas palavras-chave para a descricao do tema e a segmentacaobaseada em caracterısticas visuais. Esta taxa pode ser aumentada usandoa segmentacao semantica de texto e audio.
Alem do aperfeicoamento dos algoritmos ja existentes, algumas direcoesde pesquisa sao a inclusao de outros tipos de vıdeos e a combinacao de audioe recursos visuais utilizando grafos para a busca vıdeo-vıdeo.

232 Teixeira et al.
(a)
(b)Figura 6. (a) Navegacao por cenas e classificacao das cenas em internas (b)
usando o metodo proposto com kernel linear.
Agradecimentos
Os autores agradecem ao CNPq, CAPES, FAPEMIG pelo suporte finan-ceiro do projeto.
Referências
de Avila, S.E.F.; da Luz, A.; de Albuquerque Araujo, A. & Cord, M.,VSUMM: An Approach for Automatic Video Summarization and

EVEREVIS: sistema de navegação em vídeos 233
(a)
(b)Figura 7. (a) Classificacao das cenas em internas e indexacao de cenas
usando deteccao de face (b) usando o metodo de Viola-Jones.
Quantitative Evaluation. In: Proceedings of XXI Brazilian Sympo-sium on Computer Graphics and Image Processing. p. 103–110, 2008.
Bouaziz, B.; Mahdi, W.; Zlitni, T. & ben Hamadou, A., Content-basedvideo browsing by text region localization and classification. Inter-national Journal of Video & Image Processing and Network Security,10(1):40–50, 2010.
Bradsky, G.R. & Kaehler, A., Learning OpenCV: Computer Vision withthe OpenCV Library. 1a edicao. Sebastopol, USA: O’Reilly Media,2008.
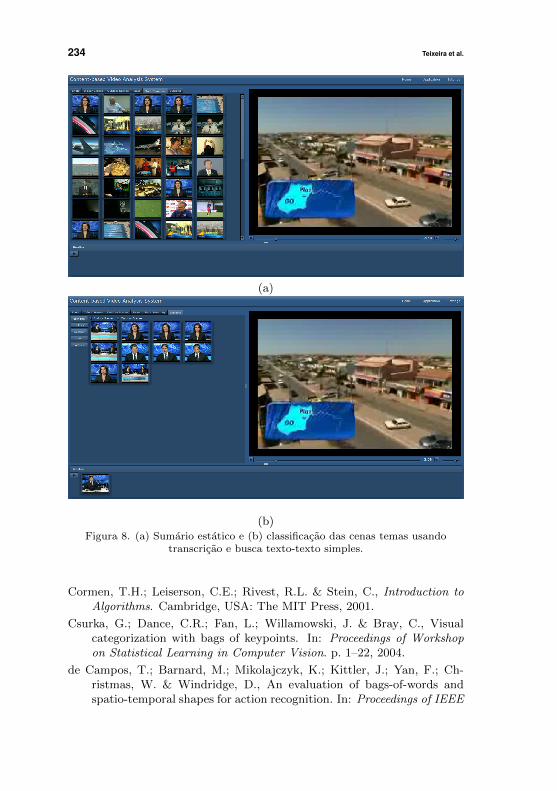
234 Teixeira et al.
(a)
(b)Figura 8. (a) Sumario estatico e (b) classificacao das cenas temas usando
transcricao e busca texto-texto simples.
Cormen, T.H.; Leiserson, C.E.; Rivest, R.L. & Stein, C., Introduction toAlgorithms. Cambridge, USA: The MIT Press, 2001.
Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J. & Bray, C., Visualcategorization with bags of keypoints. In: Proceedings of Workshopon Statistical Learning in Computer Vision. p. 1–22, 2004.
de Campos, T.; Barnard, M.; Mikolajczyk, K.; Kittler, J.; Yan, F.; Ch-ristmas, W. & Windridge, D., An evaluation of bags-of-words andspatio-temporal shapes for action recognition. In: Proceedings of IEEE

EVEREVIS: sistema de navegação em vídeos 235
Workshop on Applications of Computer Vision. Washington, USA:IEEE Computer Society, p. 344–351, 2011.
Forlines, C., Content aware video presentation on high-resolution displays.In: Proceedings of the Working Conference on Advanced Visual Inter-faces. New York, USA: ACM Press, p. 57–64, 2008.
Freund, Y. & Schapire, R.E., A decision-theoretic generalization of on-line learning and an application to boosting. In: Proceedings of theSecond European Conference on Computational Learning Theory. Lon-don, UK: Springer-Verlag, p. 23–37, 1995.
Geisler, G.; Marchionini, G.; Wildemuth, B.M.; Hughes, A.; Yang, M.;Wilkens, T. & Spinks, R., Video browsing interfaces for the OpenVideo Project. In: Proceedings of ACM SIGCHI Conference on HumanFactors in Computing Systems. p. 514–515, 2002.
Kawahara, T.; Lee, A.; Kobayashi, T.; Takeda, K.; Minematsu, N.; Sa-gayama, S.; Itou, K.; Ito, A.; Yamamoto, M.; Yamada, A.; Utsuro,T. & Shikano, K., Free software toolkit for japanese large vocabularycontinuous speech recognition. In: Proceedings of Sixth Annual Con-ference Spoken Language Processing. ISCA, v. 4, p. 476–479, 2000.
Kim, H.G.; Kim, J.Y. & Baek, J.G., An integrated music video browsingsystem for personalized television. Expert Systems with Applications,38:776–784, 2011.
Kim, J.; Kim, H. & Park, K., Towards optimal navigation through videocontent on interactive tv. Interactive Computing, 18:723–746, 2006.
Laganiere, R.; Bacco, R.; Hocevar, A.; Lambert, P.; Paıs, G. & Ionescu,B.E., Video summarization from spatio-temporal features. In: Pro-ceedings of the 2nd ACM TRECVid Video Summarization Workshop.New York, USA: ACM Press, p. 144–148, 2008.
Laptev, I., On space-time interest points. International Journal of Com-puter Vision, 64:107–123, 2005.
Lowe, D.G., Distinctive image features from scale-invariant keypoints. In-ternational Journal of Computer Vision, 60:91–110, 2004.
MacQueen, J.B., Some methods for classification and analysis of multivari-ate observations. In: Le Cam and J. Neyman, L.M. (Ed.), Proceedingsof the Fifth Berkeley Symposium on Mathematical Statistics and Pro-bability. University of California Press, v. 1, p. 281–297, 1967.
Morand, C.; Benois-Pineau, J.; Domenger, J.P.; Zepeda, J.; Kijak, E.& Guillemot, C., Scalable object-based video retrieval in hd videodatabases. Signal Processing: Image Communication, 25(6):450–465,2010.

236 Teixeira et al.
Muslea, I.; Minton, S. & Knoblock, C.A., Active + semi-supervised lear-ning = robust multi-view learning. In: Proceedings of the NineteenthInternational Conference on Machine Learning. San Francisco, USA:Morgan Kaufmann, p. 435–442, 2002.
Pan, C.M.; Chuang, Y.Y. & Hsu, W.H., NTU TRECVID-2007 fast rushessummarization system. In: Proceedings of the International Workshopon TRECVID Video Summarization. New York, USA: ACM Press, p.74–78, 2007.
Putpuek, N.; Le, D.D.; Cooharojananone, N.; Satoh, S. & Lursinsap, C.,Rushes summarization using different redundancy elimination approa-ches. In: Proceedings of the 2nd ACM TRECVid Video SummarizationWorkshop. New York, USA: ACM, p. 100–104, 2008.
Rui, Y.; Huang, T.S. & Mehrotra, S., Constructing table-of-content forvideos. Multimedia Systems, 7(5):359–368, 1998.
van de Sande, K.E.A.; Gevers, T. & Snoek, C.G.M., Evaluating color des-criptors for object and scene recognition. IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 32(9):1582–1596, 2010a.
van de Sande, K.E.A.; Gevers, T. & Snoek, C.G.M., Evaluating color des-criptors for object and scene recognition. IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 32(9):1582 –1596, 2010b.
Su, J.H.; Huang, Y.T.; Yeh, H.H. & Tseng, V.S., Effective content-basedvideo retrieval using pattern-indexing and matching techniques. ExpertSystems with Applications, 37(7):5068–5085, 2010.
Vapnik, V.N., The nature of statistical learning theory. New York, USA:Springer-Verlag, 1995.
Viola, P. & Jones, M., Rapid object detection using a boosted cascade ofsimple features. In: Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Piscataway, USA: IEEE Press, p. 511–518, 2001.
Yan, J. & Pollefeys, M., Video synchronization via space-time interest pointdistribution. In: Proceedings of Advanced Concepts for Intelligent Vi-sion Systems. p. 1–5, 2004.

EVEREVIS: sistema de navegação em vídeos 237
Notas BiográficasBruno do Nascimento Teixeira e graduado em Engenharia de Controlee Automacao (Universidade Federal de Minas Gerais – UFMG, 2006) comestagio em Technion - Israel Institute of Technology, mestre em EngenhariaEletrica (UFMG, 2009) com estagio em University of British Columbia (UBC).Atualmente e doutorando em Ciencias da Computacao (UFMG, 2010).
Julia Epischina Engracia de Oliveira e graduada emEngenharia Eletrica(Universidade Presbiteriana Mackenzie, 2001), mestre em Fısica aplicada aMedicina e Biologia (Universidade de Sao Paulo, 2005) e doutor em Bioinforma-tica pela (UFMG, 2009). Fez um doutorado-sanduıche em Aachen, Alemanhana Universidade RWTH (2007). Concluiu um pos-doutorado em Ciencia daComputacao (UFMG, 2011). Atualmente, trabalha em um projeto de pesquisaem imagens mamograficas no Centro de Desenvolvimento da Tecnologia Nuclear(CDTN).
Fillipe Dias Moreira de Souza e bacharel e mestre em Ciencia da Computacao(Universidade Estadual de Santa Cruz, 2009 e UFMG, 2011, respectivamente).Participou do programa de formacao de Analistas de Teste de Software pro-movido pela Universidade Federal de Pernambuco em parceria com a MotorolaLtda (2008). Participou do programa de treinamento em projeto de circuitosintegrados digitais, CI-Brasil, promovido pela Universidade Federal do RioGrande do Sul em parceria com o governo brasileiro e Cadence Ltda, obtendoo tıtulo de projetista de circuitos integrados digitais (2009). Atualmente edoutorando em Ciencia da Computacao (University of South Florida, EUA).
Tiago de Oliveira Cunha e graduado e mestre em Ciencia da Computacao(pela Universidade Estadual de Santa Cruz, 2008 e UFMG, 2011, respectiva-mente). Possui experiencia na area de Ciencia da Computacao, com enfase emprocessamento digital de imagens e algoritmos evolucionarios, atuando princi-palmente nos seguintes temas: compressao de imagens digitais e sumarizacaoautomatica de vıdeos.
Lucas Figueiredo Goncalves e bacharel em Ciencia da Computacao (Pontifı-cia Universidade Catolica de Minas Gerais, 2011).
Christiane Okamoto Mendoca e graduanda em Ciencia da Computacao(UFMG).
Vinıcius de Oliveira Silva e graduando em Engenharia Eletrica (UFMG).
Arnaldo de Albuquerque Araujo e graduado, mestre e doutor em EngenhariaEletrica (Universidade Federal da Paraıba – UFPB – em Campina Grande,1978, 1981, 1987, respectivamente). Tem pos-graduacao em Processamento deImagens (Rheinisch-Westfaelische Technische Hochschule Aachen, 1981-1985) epos-doutorado em Processamento de Imagens (ESIEE Paris, 1994-1995; ENSEACergy-Pontoise, 2005; e UPMC Paris 6, 2008-2009). Foi professor adjuntoda UFPB, departamento de Engenharia Eletrica (1978-1989) e atualmente eprofessor associado da UFMG, Departamento de Ciencia da Computacao (desde1990).

238 Teixeira et al.
.





























